
Polydioptric Cameras: New Eyes for Structure from Motion
8
Polydioptric Cameras: New Eyes for Structure from Motion Jan Neumann, Cornelia Ferm ¨ uller and Yiannis Aloimonos Center for Automation Research University of Maryland College Park, MD 20742-3275, USA {jneumann, fer, yiannis}@cfar.umd.edu Abstract. We examine the influence of camera design on the estimation of the motion and structure of a scene from video data. Every camera captures a subset of the light rays passing though some volume in space. By relating the differential structure of the time varying space of light rays to different known and new cam- era designs, we can establish a hierarchy of cameras. This hierarchy is based upon the stability and complexity of the computations necessary to estimate structure and motion. At the low end of this hierarchy is the standard planar pinhole cam- era for which the structure from motion problem is non-linear and ill-posed. At the high end is a camera, which we call the full field of view polydioptric camera, for which the problem is linear and stable. We develop design suggestions for the polydioptric camera, and based upon this new design we propose a linear algo- rithm for structure-from-motion estimation, which combines differential motion estimation with differential stereo. 1 Introduction When we think about vision, we usually think of interpreting the images taken by (two) eyes, such as our own, that is images acquired by planar eyes. These are the so-called camera-type eyes based on the pinhole principle on which commercially available cam- eras are founded. But these are clearly not the only eyes that exist; the biological world reveals a large variety of designs. It has been estimated that eyes have evolved no fewer than forty times, independently, in diverse parts of the animal kingdom. The developed designs range from primitive eyes such as the nautilus’ pinhole eye or the marine snail eye to the different types of compound eyes of insects, camera-like eyes of land verte- brates and fish eyes that are all highly evolved. Evolutionary considerations tell us that the design of a system’s eye is related to the visual tasks the system has to solve. The way images are acquired determines how difficult it is to perform a task and since systems have to cope with limited resources, their eyes should be designed to optimize subsequent image processing as it relates to particular tasks. As such a task we chose the recovery of descriptions of space-time models from image sequences—a large and significant part of the vision problem itself. By “space-time models” we mean descriptions of shape and descriptions of actions (Action is defined as the change of shape over time). More specifically, we want to determine how we ought to collect images of a (dynamic) scene to best recover the scene’s shapes and actions from video sequences or in other words: ”What camera
Transcript of Polydioptric Cameras: New Eyes for Structure from Motion

Polydioptric Cameras: New Eyes for Structure fromMotion
Jan Neumann, Cornelia Fermuller and Yiannis Aloimonos
Center for Automation ResearchUniversity of Maryland
College Park, MD 20742-3275, USA{jneumann, fer, yiannis}@cfar.umd.edu
Abstract. We examine the influence of camera design on the estimation of themotion and structure of a scene from video data. Every camera captures a subsetof the light rays passing though some volume in space. By relating the differentialstructure of the time varying space of light rays to different known and new cam-era designs, we can establish a hierarchy of cameras. This hierarchy is based uponthe stability and complexity of the computations necessary to estimate structureand motion. At the low end of this hierarchy is the standard planar pinhole cam-era for which the structure from motion problem is non-linear and ill-posed. Atthe high end is a camera, which we call thefull field of view polydioptriccamera,for which the problem is linear and stable. We develop design suggestions for thepolydioptric camera, and based upon this new design we propose a linear algo-rithm for structure-from-motion estimation, which combines differential motionestimation with differential stereo.
1 Introduction
When we think about vision, we usually think of interpreting the images taken by (two)eyes, such as our own, that is images acquired by planar eyes. These are the so-calledcamera-type eyes based on the pinhole principle on which commercially available cam-eras are founded. But these are clearly not the only eyes that exist; the biological worldreveals a large variety of designs. It has been estimated that eyes have evolved no fewerthan forty times, independently, in diverse parts of the animal kingdom. The developeddesigns range from primitive eyes such as the nautilus’ pinhole eye or the marine snaileye to the different types of compound eyes of insects, camera-like eyes of land verte-brates and fish eyes that are all highly evolved.
Evolutionary considerations tell us that the design of a system’s eye is related tothe visual tasks the system has to solve. The way images are acquired determines howdifficult it is to perform a task and since systems have to cope with limited resources,their eyes should be designed to optimize subsequent image processing as it relates toparticular tasks. As such a task we chose the recovery of descriptions of space-timemodels from image sequences—a large and significant part of the vision problem itself.By “space-time models” we mean descriptions of shape and descriptions of actions(Action is defined as the change of shape over time). More specifically, we want todetermine how we ought to collect images of a (dynamic) scene to best recover thescene’s shapes and actions from video sequences or in other words: ”What camera

should we use, for collecting video, so that we can subsequently facilitate the structurefrom motion problem in the best possible way?” This problem has wide implications
(a) Static World - Moving Cameras (b) Moving Object - Static Cameras
Fig. 1. Hierarchy of Cameras. We classify the different camera models according to the field ofview (FOV) and the number and proximity of the different viewpoints that are captured (DioptricAxis). This in turn determines if structure from motion estimation is a well-posed or an ill-posedproblem, and if the motion parameters are related linearly or non-linearly to the image mea-surements. The camera models are clockwise from the lower left: small FOV pinhole camera,spherical pinhole camera, spherical polydioptric camera, and small FOV polydioptric camera.
for a variety of applications not only in vision and recognition, but also in navigation,virtual reality, tele-immersion, and graphics.
To classify cameras, we will study the most complete visual representation of thescene, namely the plenoptic function as it changes differentially over time [1]. Anyimaging device captures a subset of the plenoptic function. We would like to knowhow, by considering different subsets of the plenoptic function, the problem of structurefrom motion becomes easier or harder. A theoretical model for a camera that capturesthe plenoptic function in some part of the space is a surfaceS that has at every pointa pinhole camera. We call this camera apolydioptriccamera1. With such a camera weobserve the scene in view from many different viewpoints (theoretically, from everypoint onS). A polydioptric camera can be obtained if we arrange ordinary camerasvery close to each other (Fig. 2). This camera has an additional property arising fromthe proximity of the individual cameras: it can form a very large number of orthographicimages, in addition to the perspective ones. Indeed, consider a directionr in space andthen consider in each individual camera the captured ray parallel tor. All these raystogether, one from each camera, form an image with rays that are parallel. Furthermore,
1 The term “plenoptic camera” had been proposed in [2], but since no physical device can cap-ture the true time-varying plenoptic function, we prefer the term ”polydioptric” to emphasizethe difference between the continuous concept and the discrete implementation.

Fig. 2. Design of a polydiop-tric camera
Fig. 3.capturing parallel rays Fig. 4. and capturing pencilsof rays.
for different directionsr a different orthographic image can be formed. For example,Fig. 3 shows that we can select one appropriate pixel in each camera to form an or-thographic image that looks to one side (blue rays) or another (red rays). Fig. 4 showsall the captured rays, thus illustrating that each individual camera collects conventionalpinhole images. In short, a polydioptric camera has the unique property that it captures,simultaneously, a large number of perspective and affine images (projections). We willdemonstrate later that this property also makes the structure from motion problem lin-ear. In contrast, standard single-pinhole cameras capture only one ray from each pointin space, and from this ray at different times the structure and motion must be estimated.This makes estimation of the viewing geometry a non-linear problem.
There is another factor that affects the estimation, namely the surfaceS on whichlight is captured. It has long been known that there is an ambiguity in the estimationof the motion parameters for small field of view cameras, but only recently has it beennoticed that this ambiguity disappears for a full field of view camera. For a planarcamera, which by construction has a limited field of view, the problem is nonlinear andill-posed. If, however, the field of view approaches360◦, that is, the pencil of light raysis cut by a sphere, then the problem becomes well-posed and stable [7], although stillnonlinear. The basic understanding of the influence of the field of view has attracted afew investigators over the years. In this paper we will not study this question in moredetail and only refer to the literature for more information [3, 6, 10].
Thus, in conclusion, there are two principles relating camera design to performancein structure from motion – the field of view and the linearity of the estimation. Theseprinciples are summarized in Fig. 1.
A polydioptric spherical camera is therefore the ultimate camera since it com-bines stability of full field of view motion estimation with a linear formulation of thestructure-from-motion problem.
The outline of this paper is as follows. We will use the framework of plenoptic videogeometry (Section 2) to show how a polydioptric camera makes structure from motionestimation a linear problem and how the image information captured by a polydioptriccamera relates to the image information of a conventional pinhole cameras. Based onthe insights gained, we propose a linear algorithm to accurately compute the structureand motion using all the plenoptic derivatives, and we conclude with suggestions aboutapplications of these new cameras and how to implement and construct polydioptriccameras.

2 Plenoptic Video Geometry: The Differential Structure of theSpace of Light Rays
At each locationx in free space the light intensity or color of the light ray coming froma given directionr at timet can be measured by the plenoptic functionE(x; r; t); E :R3 × S2 × R+ → Rd, whered = 1 for intensity,d = 3 for color images, andS2
is the unit sphere of directions inR3 [1]. Since a transparent medium such as airdoes not change the color of the light, we have a constant intensity or color along theview directionr: E(x; r; t) = E(x + λr; r; t) as long asλ ∈ R is chosen such that(x+λr) is in free space. Therefore, the plenoptic function in free space reduces to fivedimensions – the time-varying space of directed lines for which many representationshave been presented (for an overview see Camahort and Fussel [5]). We will choose thetwo-plane parameterization that was introduced by [8, 12] in computer graphics. All thelines passing through some space of interest can be parameterized by surrounding thisspace (that could contain either a camera or an object) with two nested cubes and thenrecording the intersection of the light rays entering the camera or leaving the objectwith the planar faces of the two cubes. We only describe the parameterization of therays passing through one side of the cube, the extension to the other sides is straightforward. Without loss of generality we choose both planes to be perpendicular to thez-axis and seperated by a distance off . We denote the inner plane asfocal planeΠf
indexed by coordinates(x, y) and the outer plane asimage planeΠi indexed by(u, v),where(u, v) is defined in a local coordinate sytem with respect to(x, y) (see Fig. 5a).Both (x, y) and(u, v) are aligned with the(X, Y )-axes of the world coordinates andΠf is at a distance ofZΠ from the origin of the world coordinate system.
This enables us now to parameterize the light rays that pass through both planesat any timet using the five tupels(x, y, u, v, t) and we can record their intensity inthe time-varying lightfieldL(x, y, u, v, t). For fixed location(x, y) in the focal plane,L(x, y, ·, ·, t) corresponds to the image captured by a perspective camera. If instead wefix the view direction(u, v), we capture an orthographic imageL(·, ·, u, v, t) of thescene.
A sensor element on the imaging surfaceS captures a light rayφ indexed by(x, y, u, v, t). If in the neighbourhood of the rayφ the radiance is varying continuously(e.g., smoothly varying reflectance and albedo, andφ is not tangent to a scene surface),then we can develop the lightfield in the neighborhood of rayφ, that isL(x, y, u, v, t),into a Taylor series
L(x + dx, y + dy, u + du, v + dv, t + dt) = L(x, y, u, v, t)+ (1)
Lxdx + Lydy + Ludu + Lvdv + Ltdt +O(‖dx, dy, du, dv, dt‖2)
whereLx = ∂L/∂x, . . . , Lt = ∂L/∂t are the partial derivatives of lightfield. Disre-garding the higher-order terms, we have a linear function which relates a local changein view ray position and direction to the differential brightness structure of the plenopticfunction at the sensor element.
The camera moves in a static world, therefore, we assume that the intensity of alight ray in the scene remains constant over consecutive time instants. This allows usto use the spatio-temporal brightness derivatives of the light rays captured by an imag-ing surface to constrain thelightfield flow [dx/dt, dy/dt, du/dt, dv/dt]T, that is the

difference between the index tupels that correspond to the same physical light ray atconsecutive time instants (dt = 1). We generalize the well-knownImage BrightnessConstancy Constraintto theLightfield Brightness Constancy Constraint:
d
dtL(x, y, u, v, t) = Lt + Lx
dx
dt+ Ly
dy
dt+ Lu
du
dt+ Lv
dv
dt= 0. (2)
It is to note, that this formalism can also be applied if we observe a rigidly movingobject with a set of static cameras (as seen in Fig. 1b). In this case, we attach the worldcoordinate system to the moving object and we can relate the relative motion of theimage sensors with respect to the object to the spatio-temporal derivatives of the lightrays that leave the object.
3 Plenoptic Motion Equations
Assuming that the imaging sensor undergoes a rigid motion with instantaneous transla-tion t and rotationω around the origin of the world coordinate system, then the motionof a point in the world in the coordinate frame of a camera located at position(x, y) onthe planeΠf is given byP = −ω×(P − [x, y, ZΠ ]T)−t. Using the well-known equa-tions relating the motion parameters to the motion flow in perspective and orthographicimages [9], we can define the lighfield ray flow for the ray indexed by(x, y, u, v, t) as([·; ·] denotes the vertical stacking of vectors):
dx/dtdy/dtdu/dtdv/dt
=
1 0 −u
f −uyf
uxf + ZΠ −y
0 1 − vf −(vy
f + ZΠ) vxf x
0 0 0 −uvf f + u2
f −v
0 0 0 −(f + v2
f ) uvf u
(
tω
)= M [t;ω]. (3)
Combining Eqs. 2 and 3 leads to thelightfield motion constraint
−Lt = [Lx, Ly Lu, Lv]M [t;ω] (4)
which is a linear constraint in the motion parameters and relates them to all the differ-ential image information that an imaging sensor can capture. Thus, by combining theconstraints across all the lightfield, we can form a highly over-determined linear systemand solve for the rigid motion parameters. To our knowledge, this is the first time thatthe temporal properties of the lightfield have been related to the structure from motionproblem. In previous work, only four-dimensional static lightfields have been studiedin the context of image-based rendering in computer graphics [8, 12].
It is important to realize that the lightfield derivativesLx, . . . Lt can be obtaineddirectly from the image information captured by a polydioptric camera. Recall that apolydioptric camera can be envisioned as a surface where every point corresponds to apinhole camera (see Fig. 4). To convert the image information captured by these pin-hole cameras into a lightfield, for each camera we simply have to intersect the rays fromits optical center through each pixel with the two planesΠf andΠi and set the corre-sponding lightfield value to the pixel intensity. Since our measurements are in generalscattered, we have to use appropriate interpolation schemes to compute a continuous
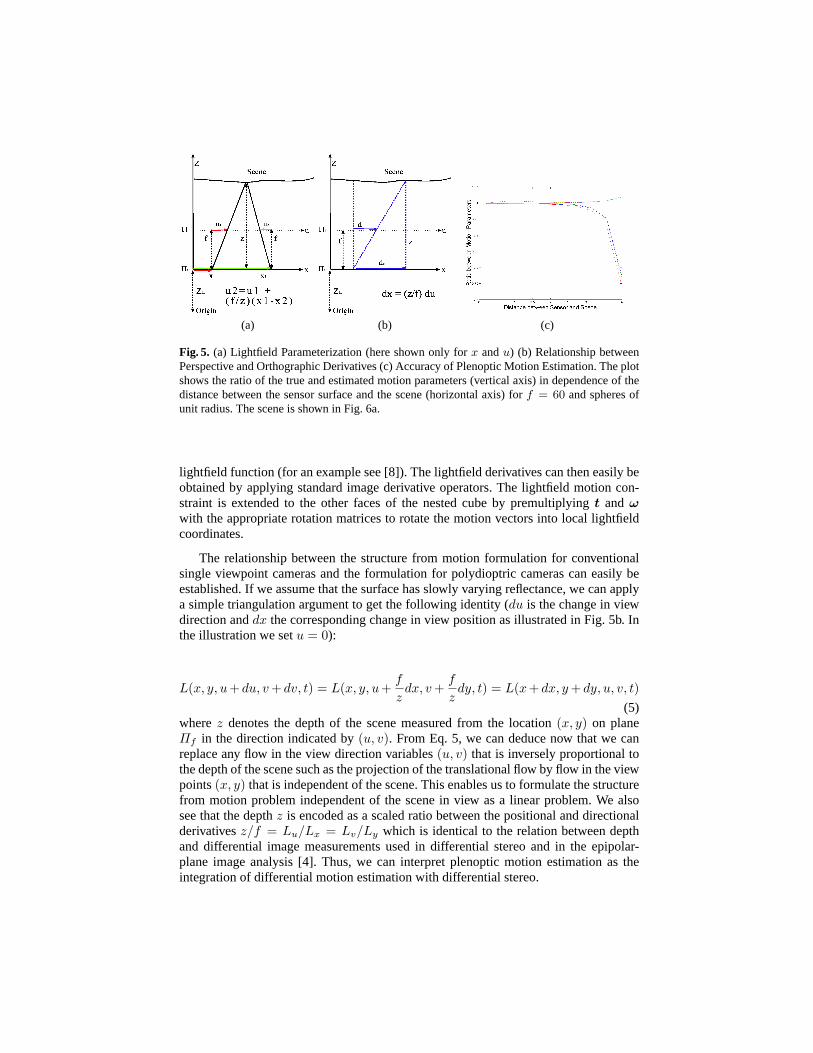
(a) (b) (c)
Fig. 5. (a) Lightfield Parameterization (here shown only forx andu) (b) Relationship betweenPerspective and Orthographic Derivatives (c) Accuracy of Plenoptic Motion Estimation. The plotshows the ratio of the true and estimated motion parameters (vertical axis) in dependence of thedistance between the sensor surface and the scene (horizontal axis) forf = 60 and spheres ofunit radius. The scene is shown in Fig. 6a.
lightfield function (for an example see [8]). The lightfield derivatives can then easily beobtained by applying standard image derivative operators. The lightfield motion con-straint is extended to the other faces of the nested cube by premultiplyingt and ωwith the appropriate rotation matrices to rotate the motion vectors into local lightfieldcoordinates.
The relationship between the structure from motion formulation for conventionalsingle viewpoint cameras and the formulation for polydioptric cameras can easily beestablished. If we assume that the surface has slowly varying reflectance, we can applya simple triangulation argument to get the following identity (du is the change in viewdirection anddx the corresponding change in view position as illustrated in Fig. 5b. Inthe illustration we setu = 0):
L(x, y, u+ du, v + dv, t) = L(x, y, u+f
zdx, v +
f
zdy, t) = L(x+ dx, y + dy, u, v, t)
(5)wherez denotes the depth of the scene measured from the location(x, y) on planeΠf in the direction indicated by(u, v). From Eq. 5, we can deduce now that we canreplace any flow in the view direction variables(u, v) that is inversely proportional tothe depth of the scene such as the projection of the translational flow by flow in the viewpoints(x, y) that is independent of the scene. This enables us to formulate the structurefrom motion problem independent of the scene in view as a linear problem. We alsosee that the depthz is encoded as a scaled ratio between the positional and directionalderivativesz/f = Lu/Lx = Lv/Ly which is identical to the relation between depthand differential image measurements used in differential stereo and in the epipolar-plane image analysis [4]. Thus, we can interpret plenoptic motion estimation as theintegration of differential motion estimation with differential stereo.

4 Experiments
To examine the performance of an algorithm using the lightfield motion constraint, wedid experiments with synthetic data. We distributed spheres, textured with a smoothlyvarying pattern, randomly in the scene so that they filled the horizon of the camera (seeFig. 6a). We then computed the lightfields for all the faces of the nested cube surround-ing the camera through raytracing (Fig. 6b-6c), computed the derivatives, stacked thelinear equations (Eq. 4) to form a linear system, and solved for the motion parameters.Even using derivatives only at one scale, we find that the motion is recovered very ac-curately as seen in Fig. 5c. As long as the relative scales of the derivatives are similarenough (scene distance matches the filter widths of the derivative operators) the errorin the motion parameters varies between 1% and 3%. This accurate egomotion esti-mate could then be used to compute depth from differential measurements using thefollowing four formulas (Mi denotes theith row of the coefficient matrixM in Eq. 3):
z =Lu
fLx=
Lv
fLy= − [LuM1;LvM2][t;ω]
f(Lt + [LuM3;LvM4][t;ω])= −Lt + [LxM1, LyM2][t;ω]
f [LxM3, LyM4][t;ω]
These differential depth measurements can finally be refined using the large base-line stereo information from widely seperated views along the path of the camerato construct accurate three-dimensional descriptions or image-based representations(e.g. [11]) of the scene.
(a) (b) (c)
Fig. 6. (a) Subset of an Example Scene, (b) the corresponding unfolded lightfield of size194 and(c) a detailed view of the upper left corner (u, v = 1, . . . , 19, x, y = 1, 2, 3).
5 Conclusion
According to ancient Greek mythology Argus, the hundred-eyed guardian of Hera, thegoddess of Olympus, alone defeated a whole army of Cyclopes, one-eyed giants. Themythological power of many eyes became real in this paper, which proposed a math-ematical analysis of new cameras. Using the two principles relating camera design tothe performance of structure from motion algorithms, the field of view, and the linearityof the estimation, we defined a hierarchy of camera designs. In this paper, based upon

the two design principles that we have formulated, we have introduced a new family ofcameras we called polydioptric cameras. Polydioptric cameras are constructed by plac-ing a large number of individual cameras very close to each other. Polydioptric camerascapture all the rays falling on a surface and allow estimation of the plenoptic ray flowof any light ray under any rigid movement. This provides polydioptric cameras withthe capability of solving for ego-motion and scene models in a linear manner, openingnew avenues for a variety of applications. For example, polydioptric domes open newavenues for 3D video development. This linear formulation is based upon the study ofthe plenoptic video geometry that is the relation between the local differential struc-ture of the time-varying lightfield and the rigid motion of an imaging sensor which wasintroduced in this paper.
Perhaps the biggest challenge in making a polydioptric camera is to make surethat neighboring cameras are at a distance that allows estimation of the “orthographic”derivatives of rays, i.e., the change in ray intensity when the ray is moved parallel toitself. By using special pixel readout from an array of tightly spaced cameras we canobtain a polydioptric camera. For scenes that are not too close to the cameras it is notnecessary to have the individual cameras very tightly packed; therefore, miniature cam-eras may be sufficient.
Currently, we are developing different physical implementations of polydioptriceyes as suggested, and we will evaluate the proposed plenoptic structure from motionalgorithm on a benchmark set of image sequences captured by these new cameras.
References
1. E. H. Adelson and J. R. Bergen. The plenoptic function and the elements of early vision. InM. Landy and J. A. Movshon, editors,Computational Models of Visual Processing, pages3–20. MIT Press, Cambridge, MA, 1991.
2. E. H. Adelson and J. Y. A. Wang. Single lens stereo with a plenoptic camera.IEEE Trans.PAMI, 14:99–106, 1992.
3. G. Adiv. Inherent ambiguities in recovering 3D motion and structure from a noisy flow field.In Proc. IEEE Conference on Computer Vision and Pattern Recognition, pages 70–77, 1985.
4. R. C. Bolles, H. H. Baker, and D. H. Marimont. Epipolar-plane image analysis: An approachto determining structure from motion.International Journal of Computer Vision, 1:7–55,1987.
5. E. Camahort and D. Fussell. A geometric study of light field representations. TechnicalReport TR99-35, Dept. of Computer Sciences, The University of Texas at Austin, 1999.
6. K. Daniilidis. On the Error Sensitivity in the Recovery of Object Descriptions. PhD thesis,Department of Informatics, University of Karlsruhe, Germany, 1992. In German.
7. C. Fermuller and Y. Aloimonos. Observability of 3D motion.International Journal ofComputer Vision, 37:43–63, 2000.
8. S. Gortler, R. Grzeszczuk, R. Szeliski, and M. Cohen. The lumigraph. InProc. of ACMSIGGRAPH, 1996.
9. B. K. P. Horn.Robot Vision. McGraw Hill, New York, 1986.10. A. D. Jepson and D. J. Heeger. Subspace methods for recovering rigid motion II: Theory.
Technical Report RBCV-TR-90-36, University of Toronto, 1990.11. R. Koch, M. Pollefeys, B. Heigl, L. VanGool, and H. Niemann. Calibration of hand-held
camera sequences for plenoptic modeling. InICCV99, pages 585–591, 1999.12. M. Levoy and P. Hanrahan. Light field rendering. InProc. of ACM SIGGRAPH, 1996.




















