
Multiclassification: reject criteria for the Bayesian combiner
13
* Corresponding author. Tel.: 00 39 081 768 3606; Fax: 00 39 081 768 3186; E-mail: vento@unina.it Pattern Recognition 32 (1999) 1435}1447 Multiclassi"cation: reject criteria for the Bayesian combiner P. Foggia!, C. Sansone!, F. Tortorella", M. Vento!,* !Dipartimento di Informatica e Sistemistica, Universita+ di Napoli **Federico II++, Via Claudio 21, I-80125 Napoli, Italy "Dipartimento di Automazione, Elettromagnetismo, Ingegnesia dell+Informazione e Matematica Industriale, Universita ` degli Studi diCassino, via G. di Biasio 43, I-03043, Cassino, Italy Received 19 June 1998; received in revised form 19 October 1998; accepted 19 October 1998 Abstract In the present paper we propose a method for determining the best trade-o! between error rate and reject rate for a multi-expert system (MES) using the Bayesian combining rule. The method is based on the estimation of the reliability of each classi"cation act and on the evaluation of the convenience of rejecting the input sample when the reliability is under a threshold, evaluated on the basis of the requirements of the application domain. The adaptability to the given domain represents an original feature since, till now, the problem of de"ning a reject rule for an MES has not been systematically introduced, and the few existing proposals seldom take into account the requirements of the domain. The method has been widely tested with reference to the recognition of handwritten characters coming from a standard database. The results are also compared with those provided by employing the well-known Chow's rule. ( 1999 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved. Keywords : Multi-expert systems; Bayesian combination; Classi"cation; Reliability; Error/reject trade-o!; Chow's rule 1. Introduction In pattern recognition problems, the idea of combining various experts with the aim of compensating the weak- ness of each single expert, preserving its own strength [1], has been recently widely investigated. The rationale lies in the assumption that, by suitably combining the results of a set of experts according to a rule (combining rule), the obtained performance can result better than that of any single expert. The successful implementation of a multiple expert system (MES) implies the use of as much as possible complementary experts, and the de"nition of a combining rule for determining the most likely class a sample should be attributed to, on the basis of the class to which it is attributed by each single expert. Preliminary experimental results encouraged this approach and vari- ous research groups concentrated the attention on di!er- ent aspects of the problem [2}4]. The main problem is that the combining rule should be able to solve the con#icts, i.e. to take the right classi"ca- tion decision when the experts disagree; in these cases, the "nal decision of the combiner cannot be considered al- ways reliable. Very crucial situations for the combiner are the ones in which two or more classes are estimated to have a comparable likeness, or when no class can be considered su$ciently certain. In these conditions it would be desirable to take a decision about the advant- age of rejecting a sample (i.e. not assigning it to a class), instead of running the risk of misclassifying it. In practice, this advantage can only be evaluated by taking into account the requirements of the speci"c application 0031-3203/99/$20.00 ( 1999 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved. PII: S 0 0 3 1 - 3 2 0 3 ( 9 8 ) 0 0 1 6 9 - 1
Transcript of Multiclassification: reject criteria for the Bayesian combiner

*Corresponding author. Tel.: 00 39 081 768 3606; Fax: 00 39081 768 3186; E-mail: [email protected]
Pattern Recognition 32 (1999) 1435}1447
Multiclassi"cation: reject criteria for the Bayesian combiner
P. Foggia!, C. Sansone!, F. Tortorella", M. Vento!,*
!Dipartimento di Informatica e Sistemistica, Universita+ di Napoli **Federico II++, Via Claudio 21, I-80125 Napoli, Italy"Dipartimento di Automazione, Elettromagnetismo, Ingegnesia dell+Informazione e Matematica Industriale, Universita degli Studi
diCassino, via G. di Biasio 43, I-03043, Cassino, Italy
Received 19 June 1998; received in revised form 19 October 1998; accepted 19 October 1998
Abstract
In the present paper we propose a method for determining the best trade-o! between error rate and reject rate for amulti-expert system (MES) using the Bayesian combining rule. The method is based on the estimation of the reliability ofeach classi"cation act and on the evaluation of the convenience of rejecting the input sample when the reliability is undera threshold, evaluated on the basis of the requirements of the application domain. The adaptability to the given domainrepresents an original feature since, till now, the problem of de"ning a reject rule for an MES has not been systematicallyintroduced, and the few existing proposals seldom take into account the requirements of the domain. The method hasbeen widely tested with reference to the recognition of handwritten characters coming from a standard database. Theresults are also compared with those provided by employing the well-known Chow's rule. ( 1999 Pattern RecognitionSociety. Published by Elsevier Science Ltd. All rights reserved.
Keywords: Multi-expert systems; Bayesian combination; Classi"cation; Reliability; Error/reject trade-o!; Chow's rule
1. Introduction
In pattern recognition problems, the idea of combiningvarious experts with the aim of compensating the weak-ness of each single expert, preserving its own strength [1],has been recently widely investigated. The rationale liesin the assumption that, by suitably combining the resultsof a set of experts according to a rule (combining rule),the obtained performance can result better than that ofany single expert. The successful implementation of amultiple expert system (MES) implies the use of as muchas possible complementary experts, and the de"nition of acombining rule for determining the most likely class a
sample should be attributed to, on the basis of the class towhich it is attributed by each single expert. Preliminaryexperimental results encouraged this approach and vari-ous research groups concentrated the attention on di!er-ent aspects of the problem [2}4].
The main problem is that the combining rule should beable to solve the con#icts, i.e. to take the right classi"ca-tion decision when the experts disagree; in these cases, the"nal decision of the combiner cannot be considered al-ways reliable. Very crucial situations for the combinerare the ones in which two or more classes are estimatedto have a comparable likeness, or when no class can beconsidered su$ciently certain. In these conditions itwould be desirable to take a decision about the advant-age of rejecting a sample (i.e. not assigning it to a class),instead of running the risk of misclassifying it. In practice,this advantage can only be evaluated by taking intoaccount the requirements of the speci"c application
0031-3203/99/$20.00 ( 1999 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved.PII: S 0 0 3 1 - 3 2 0 3 ( 9 8 ) 0 0 1 6 9 - 1

domain. In fact, there are applications for which the cost ofa misclassi"cation is very expensive, so that a high rejectrate is acceptable provided that the misclassi"cation rateis kept as low as possible; a typical example could be theclassi"cation of medical images in the framework ofa pre-screening for early cancer detection. In other ap-plications, it may be desirable to assign every sample toa class even at the risk of a higher misclassi"cation rate.Let us consider, for instance, the case of applications inwhich the output of the system has to be subjected tosubsequent extensive revision by man. Between theseextremes, a number of applications can be characterizedby intermediate requirements. A wise choice of the rejectrule thus allows the system behavior to be tuned to thegiven application. This is a more general topic that tillnow has concerned mainly single classi"ers. With regardsto this case, the problem of de"ning an optimal rejectoption has been tackled by Chow [5,6]. The Chow's ruleis optimal since it minimizes the Bayesian risk, but itassumes that the classi"er provides the a posteriori prob-ability for each class. In many real application, however,it is very di$cult to achieve a good estimate of suchprobabilities.
Up to now, a systematic approach for de"ning a rejectoption speci"cally tailored for MES architectures has notbeen yet introduced. The main reason is that, in the caseof MES, the evaluation of the post probabilities is muchmore di$cult; in fact, even in the hypothesis that eachexpert participating to the combination provides a verygood estimate of the post probabilities, the evaluation ofthe post probabilities after the combination can be cor-rectly achieved only if the experts can be assumed inde-pendent or the dependencies among the experts can bestatistically characterized. In real cases, the experts arenot totally independent and their dependencies are veryhard to model, even for a small number of experts. As aconsequence, simply heuristic reject rules are introducedfor each known combination rule.
For example, one of the simplest combining rule,namely the &&Majority Voting'' [2,7], assigns the inputsample the class for which a relative or absolute majorityof experts agree, and rejects the sample in the case inwhich two or more classes receive the same number ofvotes. More sophisticated combining rules introducea measure of the reliability associated to the response ofeach expert. In the &&Weighted Voting'' rule [2,3], thevotes of all the experts are collected and the input sampleis assigned to the class for which the sum of the votes,each weighted by the estimated reliability of the corres-ponding expert, is the highest. Generally, weighted votingmethods do not introduce reject criteria; alternatively, assuggested in [4], the reject is obtained by "xing a thre-shold on the minimum value of the weighted vote and onthe minimum tolerable di!erence between the two high-est votes. In this case, however, the threshold is notassigned by considering the requirements of the domain,
and the behavior of the whole system could be inad-equate for the considered application.
A particular combining scheme with reject option isproposed in [8]. The aggregation of the outputs of theexperts and the "nal decision are performed by means ofa particular look-up table (the Behavior KnowledgeSpace, say BKS), which is constructed on the basis ofa training set. For each input sample, the method allowsto obtain the most likely class together with the asso-ciated post-probability; a threshold is evaluated to con-trol the reliability of the "nal decision so as to reject thesample if the related post-probability is not su$cientlyhigh. The computation of the threshold is performed insuch a way to make the classi"cation, error and rejectrates of the system as much as possible close to preassig-ned values. Since this is made by using the BKS, thisapproach cannot be easily extended to other MES archi-tectures.
In this paper, we propose a method for introducinga reject option in an MES architecture, which drops theassumption of knowing the exact values of the post-probabilities. A method similar, but limited to the case ofa single classi"er, was discussed in [9] with reference to aneural network, and in particular to a multi-layer per-ceptron trained with the back-propagation algorithm. Asuccessive generalization to other neural classi"cationparadigms was proposed in [10].
The reject option is presented with reference to anMES architecture based on the Bayesian combining rule(see Fig. 1). The reasons for this choice are twofold: "rst,it is a quite general rule which can be realized in sucha way that each expert should provide only the classassigned to the input sample (this information is obvious-ly provided by any kind of expert). Second, the Chow'srule can be directly applied to an MES architecture basedon the Bayesian rule, and thus it is possible to comparethe performance of our approach with the Chow's one.
The rationale of the method lies on the characteriza-tion of the situations which may lead to unreliableclassi"cations. In particular, the reliability of each classi-"cation act of the MES is evaluated on the basis of theoutput of the combiner and, if it is greater than a thre-shold p, the decision of the MES is considered acceptable,otherwise the input sample is rejected (see Fig. 1a). Theoptimal threshold value, denoted by p*, is determined bymeans of a training procedure which takes into accountthe speci"c recognition requirements through a functionP which measures the MES e!ectiveness in the con-sidered application domain (see Fig. 1b). Such a functionis de"ned on the basis of some costs attributed, for thespeci"c application, to misclassi"cations, rejects and cor-rect classi"cations. The threshold value is evaluated soas to maximize the e!ectiveness function P: in this way,the reject option allows to obtain the best error/rejecttrade-o! for the application at hand. It is worth pointingout that no a priori knowledge about the probability
1436 P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447

Fig. 1. The architecture of the method (a). Each of the considered experts provides, for the input sample x, the most likely class. The classattributed to x by the MES is obtained according to the Bayesian combining rule. The reliability t of the MES is evaluated starting fromthe values associated with the winner class and the second winner class. The reject option compares the value of t with the optimalthreshold value p* and rejects the input sample if its estimated reliability is less than p*. (b) p* is determined by means of a trainingprocedure which takes into account the speci"c recognition requirements through a functionP which measures the MES e!ectiveness inthe considered application domain.
distributions is needed, and the MES can be seen asa black box, no matter of its architecture.
The application chosen for testing the method hasbeen the recognition of handwritten characters. Severalexperts have been considered, combined to form multi-expert systems with varying number of experts. The e!ec-tiveness of the MES has been evaluated for several costvalues and a comparison has been made with the Chow'srule. As expected, our method performs better thanChow's, especially in those combinations with a highnumber of experts when the probability estimate is morelikely a!ected by errors.
The paper is organized in the following way: in Section2 a brief review of the Bayesian combining rule is re-ported, while in Section 3 the de"nition of a reliabilityparameter based on the same rule and the algorithm forevaluating the threshold are introduced. The experi-mental results together with some discussions are pre-sented in Section 4, while a comparison with the Chow'srule is eventually reported in Section 5.
2. Bayesian combining rule
Many ways to combine classi"er decisions, and thus toorganize an MES, have been proposed in the recent past.
Some of them are based on heuristic approaches, likevoting or ranking, while others are founded on moreformalized theoretical bases, like those based on theDempster}Shafer evidence theory or on statisticalmethods [2]. Among these, the Bayesian combining (BC)rule is very often used because it is based on a well-settledmathematical framework and is simply applicable toseveral MES architectures. It can be applied even in casethat each expert participating to the combination pro-vides only the class assigned to the input sample. This isobviously the minimal information supplied by a classi-"cation system. From an operative point of view, the BCrule estimates the a posteriori probability that the inputsample belongs to a generic class C and selects the classwith the highest post-probability. In the hypothesis ofindependence of the experts and that the a priori prob-ability is the same for all the classes, the output > of theMES with the BC rule is given by
>"arg maxi
M<k/1
plk, l)i)n, (1)
where plk
is the post-probability assigned to the classC
iby the kth expert, given the input sample x, M is the
number of the experts and n the number of the classes.Several classi"er paradigms provide outputs which
allow to simply estimate the post-probabilities pkl
(e.g.
P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447 1437

some classi"ers based on a neural network [11]), makingso the BC rule directly applicable by using Eq. (1). Thisfeature, however, is not shared by all the classi"er archi-tectures: in the most general case, the only informationprovided by an expert is the one specifying the mostprobable class an input sample belongs to. In this case, inorder to apply the BC rule, it is necessary to calculate theprobability P (x3C
iD>
k"o
k), i.e. the probability that the
sample x belongs to the class Cigiven that the output
>kof the kth expert is equal to o
k(the index specifying the
class). In this way, if both the hypotheses of conditionalindependence among classi"ers and of equiprobability ofthe classes hold, the output of the MES is given by
>"argmaxi
M<k/1
P (x3CiD>
k"o
k), 1)i)n. (2)
An e!ective estimate for P (x3CiD>
k"o
k) can be
obtained by considering the classi"cation results of theexpert on a training set of samples [4]. In particular, letus consider the classi"cation confusion matrix Ek for thekth expert, whose generic element ek
i, j(1)i, j)n) rep-
resents the percentage of samples of the training setwhich belong to the ith class and are assigned by the kthexpert to the jth class. It is possible to show [4] that
P (x 3CiD>
k"o
k):ek1,o
kNn+h/1
ekh,ok. (3)
By using Eq. (3), we can rewrite Eq. (2), thus obtaining
>"arg maxi
M<k/1Aeki,okN+
h
ekh,okB . (4)
It is worth noting that in this way, for each expert, onlythe information specifying the class assigned to the inputsample (winning class) is considered, and this is su$cientto establish the most likely winning class for the entireMES.
A more careful look at the distribution of the values ofthe post-probabilities of the other classes could provideadditional information useful to evaluate the classi"ca-tion reliability of the MES. This aspect is commonlydisregarded in the de"nition of a combining rule, while itcould signi"cantly improve the performance of the wholeclassi"cation system, especially in complex applicationdomains. In the next sections we will show how to usesuch information for de"ning some reliability parametersand employing them in an optimal reject rule for an MESusing the BC rule.
3. Classi5cation reliability and reject rule
Classi"cation reliability can be expressed by associat-ing a reliability parameter to every decision taken by theMES. Its quantitative evaluation requires the detectionof situations which can give rise to unreliable classi"ca-
tions. The low reliability of a classi"cation is generallydue to one of the following situations: (a) there is a dif-fused disagreement among the experts about the class towhich the sample should be assigned and thus there isno class whose value of the post-probability is su$cientto judge the classi"cation reliable; (b) the experts partinto groups, each agreeing on a di!erent class, but thevalues of the corresponding post-probabilities are sosimilar that there is not a clear overwhelming class.
It may be convenient to distinguish between classi"ca-tions which are unreliable because a sample is of type(a) or (b). To this end, let us de"ne two parameters, sayta
and tb, whose values vary in the range [0,1] and
quantify the reliability of a classi"cation from the twodi!erent points of view. Values near to 1 will characterizevery reliable classi"cations, while low parameter valueswill be associated with classi"cations unreliable becausethe considered sample is of type (a) or (b). For the opera-tive de"nitions of t
aand t
b(which will be referred to as
reliability parameters), let us denote by n1the value of the
post-probability associated to the winning class and withn2
the value of the second highest post-probability.A suitable de"nition for the reliability parameters is
ta"n
1, t
b"1!(n
2/n
1) . (5)
In this way, if the value of tais low, the corresponding
classi"cation is characterized by a weak post-probabilityand thus should be regarded as unreliable. Similar con-siderations hold for low t
bvalue: in this case, however,
there are more classes resulting equally probable andthus a reliable decision cannot be taken.
A parameter t providing a comprehensive measure ofthe reliability of a classi"cation can result from the com-bination of the values of t
aand t
b:
t"t (t!, t
b) . (6)
In this way, it is possible to judge about the reliabilityof the decision of the MES on the basis of a single value.There are several ways to combine the reliability para-meters. A review of combination operators can be foundin Bloch [12]. In the following some of the operatorsproposed in that paper will be used.
In classi"cation problems regarding real applications,"nding a reject rule which achieves the best trade-o!between error rate and reject rate is undoubtedly ofpractical interest. The reject rule we propose for a BC-based MES compares the classi"cation reliability t witha suitably determined threshold p. The classi"cation isconsidered acceptable if the reliability value is greaterthan p, otherwise the input sample is rejected. The rejectrule is optimal with reference to the environment inwhich the MES works: in fact, the threshold p is com-puted by maximizing a function P which measures theMES classi"cation e!ectiveness in the considered ap-plication domain.
1438 P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447
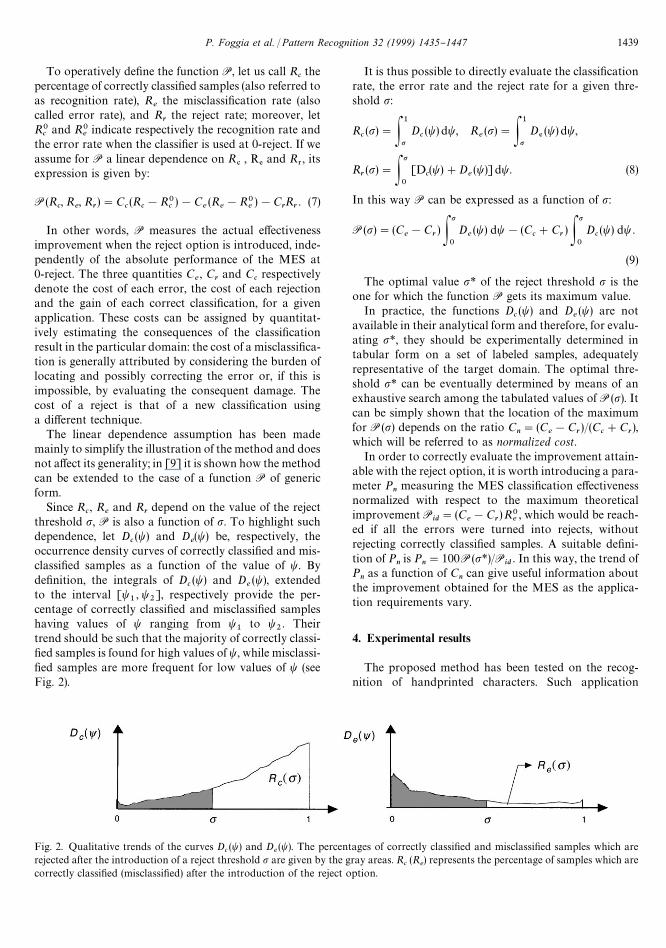
Fig. 2. Qualitative trends of the curves Dc(t) and D
e(t). The percentages of correctly classi"ed and misclassi"ed samples which are
rejected after the introduction of a reject threshold p are given by the gray areas. Rc(R
e) represents the percentage of samples which are
correctly classi"ed (misclassi"ed) after the introduction of the reject option.
To operatively de"ne the function P, let us call Rcthe
percentage of correctly classi"ed samples (also referred toas recognition rate), R
ethe misclassi"cation rate (also
called error rate), and Rr
the reject rate; moreover, letR0
cand R0
eindicate respectively the recognition rate and
the error rate when the classi"er is used at 0-reject. If weassume for P a linear dependence on R
#, R
%and R
3, its
expression is given by:
P (Rc, R
e, R
r)"C
c(R
c!R0
c)!C
e(R
e!R0
e)!C
rR
r. (7)
In other words, P measures the actual e!ectivenessimprovement when the reject option is introduced, inde-pendently of the absolute performance of the MES at0-reject. The three quantities C
e, C
rand C
crespectively
denote the cost of each error, the cost of each rejectionand the gain of each correct classi"cation, for a givenapplication. These costs can be assigned by quantitat-ively estimating the consequences of the classi"cationresult in the particular domain: the cost of a misclassi"ca-tion is generally attributed by considering the burden oflocating and possibly correcting the error or, if this isimpossible, by evaluating the consequent damage. Thecost of a reject is that of a new classi"cation usinga di!erent technique.
The linear dependence assumption has been mademainly to simplify the illustration of the method and doesnot a!ect its generality; in [9] it is shown how the methodcan be extended to the case of a function P of genericform.
Since Rc, R
eand R
rdepend on the value of the reject
threshold p, P is also a function of p. To highlight suchdependence, let D
c(t) and D
e(t) be, respectively, the
occurrence density curves of correctly classi"ed and mis-classi"ed samples as a function of the value of t. Byde"nition, the integrals of D
c(t) and D
e(t), extended
to the interval [t1, t
2], respectively provide the per-
centage of correctly classi"ed and misclassi"ed sampleshaving values of t ranging from t
1to t
2. Their
trend should be such that the majority of correctly classi-"ed samples is found for high values of t, while misclassi-"ed samples are more frequent for low values of t (seeFig. 2).
It is thus possible to directly evaluate the classi"cationrate, the error rate and the reject rate for a given thre-shold p:
Rc(p)"P
1
pD
c(t) dt, R
e(p)"P
1
pD
%(t) dt,
Rr(p)"P
p
0
[Dc(t)#D
e(t)] dt. (8)
In this way P can be expressed as a function of p:
P (p)"(Ce!C
r)P
p
0
De(t) dt!(C
c#C
r)P
p
0
Dc(t) dt .
(9)
The optimal value p* of the reject threshold p is theone for which the function P gets its maximum value.
In practice, the functions Dc(t) and D
e(t) are not
available in their analytical form and therefore, for evalu-ating p*, they should be experimentally determined intabular form on a set of labeled samples, adequatelyrepresentative of the target domain. The optimal thre-shold p* can be eventually determined by means of anexhaustive search among the tabulated values of P (p). Itcan be simply shown that the location of the maximumfor P (p) depends on the ratio C
n"(C
e!C
r)/(C
c#C
r),
which will be referred to as normalized cost.In order to correctly evaluate the improvement attain-
able with the reject option, it is worth introducing a para-meter P
nmeasuring the MES classi"cation e!ectiveness
normalized with respect to the maximum theoreticalimprovement P
id"(C
e!C
r)R0
e, which would be reach-
ed if all the errors were turned into rejects, withoutrejecting correctly classi"ed samples. A suitable de"ni-tion of P
nis P
n"100P (p*)/P
id. In this way, the trend of
Pnas a function of C
ncan give useful information about
the improvement obtained for the MES as the applica-tion requirements vary.
4. Experimental results
The proposed method has been tested on the recog-nition of handprinted characters. Such application
P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447 1439
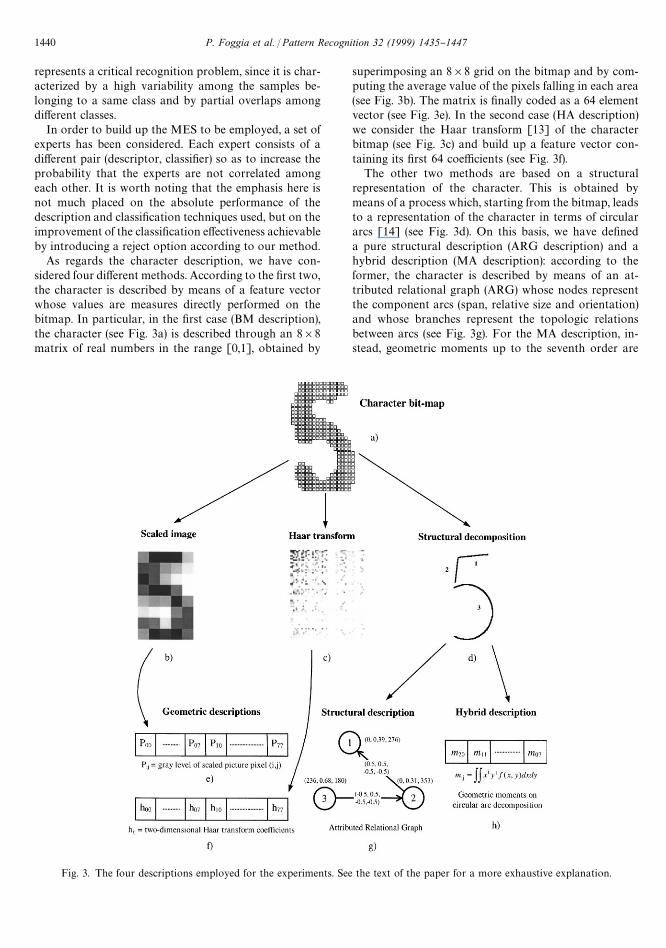
Fig. 3. The four descriptions employed for the experiments. See the text of the paper for a more exhaustive explanation.
represents a critical recognition problem, since it is char-acterized by a high variability among the samples be-longing to a same class and by partial overlaps amongdi!erent classes.
In order to build up the MES to be employed, a set ofexperts has been considered. Each expert consists of adi!erent pair (descriptor, classi"er) so as to increase theprobability that the experts are not correlated amongeach other. It is worth noting that the emphasis here isnot much placed on the absolute performance of thedescription and classi"cation techniques used, but on theimprovement of the classi"cation e!ectiveness achievableby introducing a reject option according to our method.
As regards the character description, we have con-sidered four di!erent methods. According to the "rst two,the character is described by means of a feature vectorwhose values are measures directly performed on thebitmap. In particular, in the "rst case (BM description),the character (see Fig. 3a) is described through an 8]8matrix of real numbers in the range [0,1], obtained by
superimposing an 8]8 grid on the bitmap and by com-puting the average value of the pixels falling in each area(see Fig. 3b). The matrix is "nally coded as a 64 elementvector (see Fig. 3e). In the second case (HA description)we consider the Haar transform [13] of the characterbitmap (see Fig. 3c) and build up a feature vector con-taining its "rst 64 coe$cients (see Fig. 3f).
The other two methods are based on a structuralrepresentation of the character. This is obtained bymeans of a process which, starting from the bitmap, leadsto a representation of the character in terms of circulararcs [14] (see Fig. 3d). On this basis, we have de"neda pure structural description (ARG description) and ahybrid description (MA description): according to theformer, the character is described by means of an at-tributed relational graph (ARG) whose nodes representthe component arcs (span, relative size and orientation)and whose branches represent the topologic relationsbetween arcs (see Fig. 3g). For the MA description, in-stead, geometric moments up to the seventh order are
1440 P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447

Fig. 4. Some characters of the considered test set (the set hsf}4 of the NIST Database 19).
computed on the circular arcs constituting the structuralrepresentation of the character [15]; since moments ofzero and "rst order have been used to make the remain-ing moments scale and translation invariant, the "naldescription is given by a 33-element vector (see Fig. 3h).
As regards the classi"ers, we have employed a statist-ical classi"er, the Nearest Neighbor [16] (NN), and twoneural networks. The "rst neural classi"er is a multi-layerperceptron [17] (MLP) with a single hidden layer of 30neurons. Learning is performed with the standard back-propagation algorithm, with a constant learning rateequal to 0.5. The sigmoidal activation function waschosen for all the neurons. The second neural architec-ture is a learning vector quantization [18] (LVQ) with anumber of Kohonen neurons "xed to 7 for every class.The net was trained with a supervised version of theFSCL algorithm [19] to overcome the neuron under-utilization problem [20]. The learning rate was initiallyset equal to 0.5 and then decreased according to the rulesillustrated in [19].
By coupling a description method with a classi"erparadigm, we have built-up "ve di!erent experts: three ofthem employ the MLP classi"er with the BM, HA andMA descriptions (let us denote these experts with MLP-BM, MLP-HA and MLP-MA); the fourth is constitutedby the LVQ classi"er with the BM description (LVQ-BM), and the last expert is a nearest-neighbor classi"erwith the ARG description (NN-ARG). In this last case,we have used a metric de"ned in the ARG space [21].
All the tests were performed on the NIST database 19[22]. For the tests, only digits were considered. As sug-gested by NIST, we used the set hsf
}3 for training and the
hsf}4 for testing. In particular, the set hsf
}3 was split in
two sets: a training set (TR), composed of 34,644 samples,used for training the MLP-BM, MLP-HA, MLP-MAand LVQ-BM experts, and a so-called training-test set(TT) made of 29,252 samples. A subset of TR (8000samples) was assumed as reference set for the NN-ARGexpert. TT was used both to compute the confusionmatrices and to establish the number of cycles for stop-ping the learning phase of the experts based on neuralclassi"ers, in order to avoid the overtraining phenom-enon [20]. The set hsf
}4, adopted as test set (TS), is made
of 58,646 samples; in Fig. 4 some characters of this set areshown. The recognition rate of the MES made up of allthe "ve experts on TS was 93.82 at 0-reject.
As regards the cost coe$cients, we assumed Cc"1,
while for Ce
and Crthe pairs (4,9), (4,12), (4,15), (3,15),
(3,18), (3,21) were selected, corresponding to values of thenormalized cost C
nranging from 1.00 to 4.50 (see
Table 1).To combine the reliability parameters, the following
operators were considered:
t.*/
"min Mta, t
bN, t
.%$"
ta#t
b2
,
t.!9
"max Mta,t
bN, t
4:."
tatb
1!ta!t
b#2t
atb
.
P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447 1441
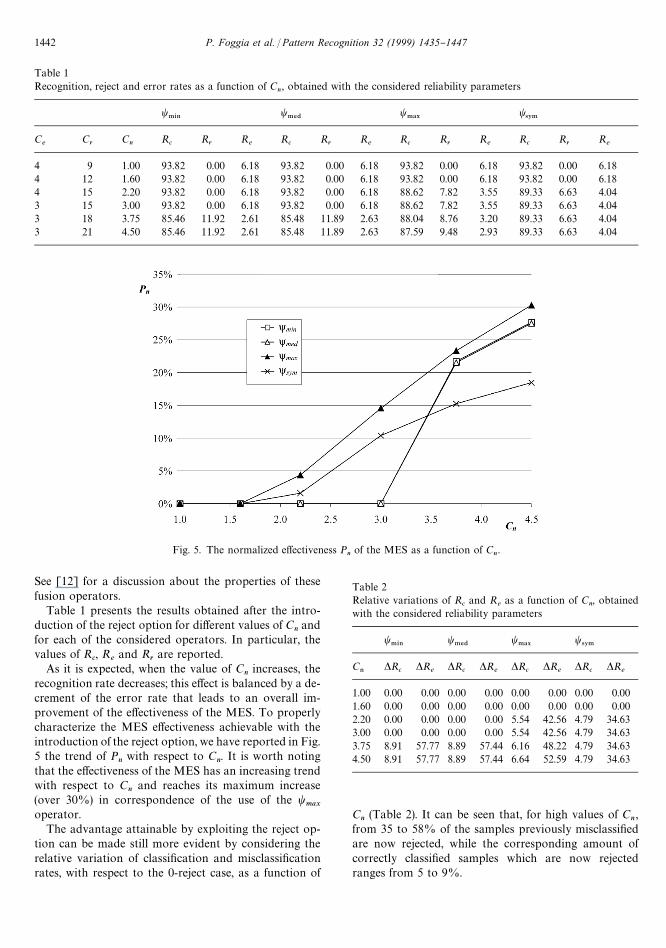
Table 1Recognition, reject and error rates as a function of C
n, obtained with the considered reliability parameters
t.*/
t.%$
t.!9
t4:.
Ce
Cr
Cn
Rc
Rr
Re
Rc
Rr
Re
Rc
Rr
Re
Rc
Rr
Re
4 9 1.00 93.82 0.00 6.18 93.82 0.00 6.18 93.82 0.00 6.18 93.82 0.00 6.184 12 1.60 93.82 0.00 6.18 93.82 0.00 6.18 93.82 0.00 6.18 93.82 0.00 6.184 15 2.20 93.82 0.00 6.18 93.82 0.00 6.18 88.62 7.82 3.55 89.33 6.63 4.043 15 3.00 93.82 0.00 6.18 93.82 0.00 6.18 88.62 7.82 3.55 89.33 6.63 4.043 18 3.75 85.46 11.92 2.61 85.48 11.89 2.63 88.04 8.76 3.20 89.33 6.63 4.043 21 4.50 85.46 11.92 2.61 85.48 11.89 2.63 87.59 9.48 2.93 89.33 6.63 4.04
Fig. 5. The normalized e!ectiveness Pnof the MES as a function of C
n.
Table 2Relative variations of R
cand R
eas a function of C
n, obtained
with the considered reliability parameters
t.*/
t.%$
t.!9
t4:.
C/
*Rc
*Re
*Rc
*Re
*Rc
*Re
*Rc
*Re
1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.001.60 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.002.20 0.00 0.00 0.00 0.00 5.54 42.56 4.79 34.633.00 0.00 0.00 0.00 0.00 5.54 42.56 4.79 34.633.75 8.91 57.77 8.89 57.44 6.16 48.22 4.79 34.634.50 8.91 57.77 8.89 57.44 6.64 52.59 4.79 34.63
See [12] for a discussion about the properties of thesefusion operators.
Table 1 presents the results obtained after the intro-duction of the reject option for di!erent values of C
nand
for each of the considered operators. In particular, thevalues of R
c, R
eand R
rare reported.
As it is expected, when the value of Cn
increases, therecognition rate decreases; this e!ect is balanced by a de-crement of the error rate that leads to an overall im-provement of the e!ectiveness of the MES. To properlycharacterize the MES e!ectiveness achievable with theintroduction of the reject option, we have reported in Fig.5 the trend of P
nwith respect to C
n. It is worth noting
that the e!ectiveness of the MES has an increasing trendwith respect to C
nand reaches its maximum increase
(over 30%) in correspondence of the use of the tmax
operator.The advantage attainable by exploiting the reject op-
tion can be made still more evident by considering therelative variation of classi"cation and misclassi"cationrates, with respect to the 0-reject case, as a function of
Cn
(Table 2). It can be seen that, for high values of Cn,
from 35 to 58% of the samples previously misclassi"edare now rejected, while the corresponding amount ofcorrectly classi"ed samples which are now rejectedranges from 5 to 9%.
1442 P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447
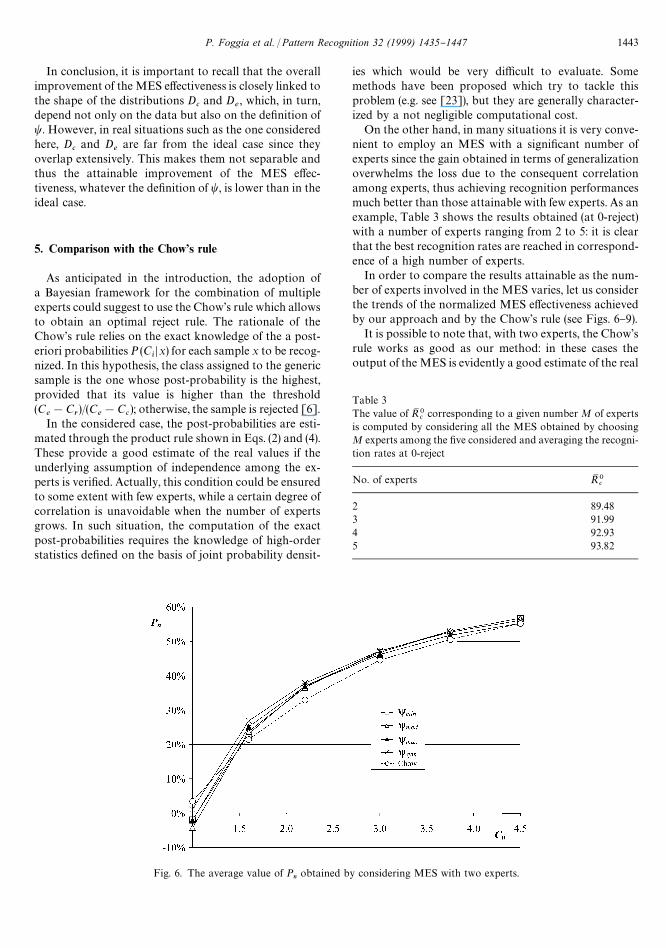
Fig. 6. The average value of Pn
obtained by considering MES with two experts.
Table 3The value of RM 0
ccorresponding to a given number M of experts
is computed by considering all the MES obtained by choosingM experts among the "ve considered and averaging the recogni-tion rates at 0-reject
No. of experts RM 0c
2 89.483 91.994 92.935 93.82
In conclusion, it is important to recall that the overallimprovement of the MES e!ectiveness is closely linked tothe shape of the distributions D
cand D
e, which, in turn,
depend not only on the data but also on the de"nition oft. However, in real situations such as the one consideredhere, D
cand D
eare far from the ideal case since they
overlap extensively. This makes them not separable andthus the attainable improvement of the MES e!ec-tiveness, whatever the de"nition of t, is lower than in theideal case.
5. Comparison with the Chow:s rule
As anticipated in the introduction, the adoption ofa Bayesian framework for the combination of multipleexperts could suggest to use the Chow's rule which allowsto obtain an optimal reject rule. The rationale of theChow's rule relies on the exact knowledge of the a post-eriori probabilities P (C
iDx) for each sample x to be recog-
nized. In this hypothesis, the class assigned to the genericsample is the one whose post-probability is the highest,provided that its value is higher than the threshold(C
e!C
r)/(C
e!C
c); otherwise, the sample is rejected [6].
In the considered case, the post-probabilities are esti-mated through the product rule shown in Eqs. (2) and (4).These provide a good estimate of the real values if theunderlying assumption of independence among the ex-perts is veri"ed. Actually, this condition could be ensuredto some extent with few experts, while a certain degree ofcorrelation is unavoidable when the number of expertsgrows. In such situation, the computation of the exactpost-probabilities requires the knowledge of high-orderstatistics de"ned on the basis of joint probability densit-
ies which would be very di$cult to evaluate. Somemethods have been proposed which try to tackle thisproblem (e.g. see [23]), but they are generally character-ized by a not negligible computational cost.
On the other hand, in many situations it is very conve-nient to employ an MES with a signi"cant number ofexperts since the gain obtained in terms of generalizationoverwhelms the loss due to the consequent correlationamong experts, thus achieving recognition performancesmuch better than those attainable with few experts. As anexample, Table 3 shows the results obtained (at 0-reject)with a number of experts ranging from 2 to 5: it is clearthat the best recognition rates are reached in correspond-ence of a high number of experts.
In order to compare the results attainable as the num-ber of experts involved in the MES varies, let us considerthe trends of the normalized MES e!ectiveness achievedby our approach and by the Chow's rule (see Figs. 6}9).
It is possible to note that, with two experts, the Chow'srule works as good as our method: in these cases theoutput of the MES is evidently a good estimate of the real
P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447 1443
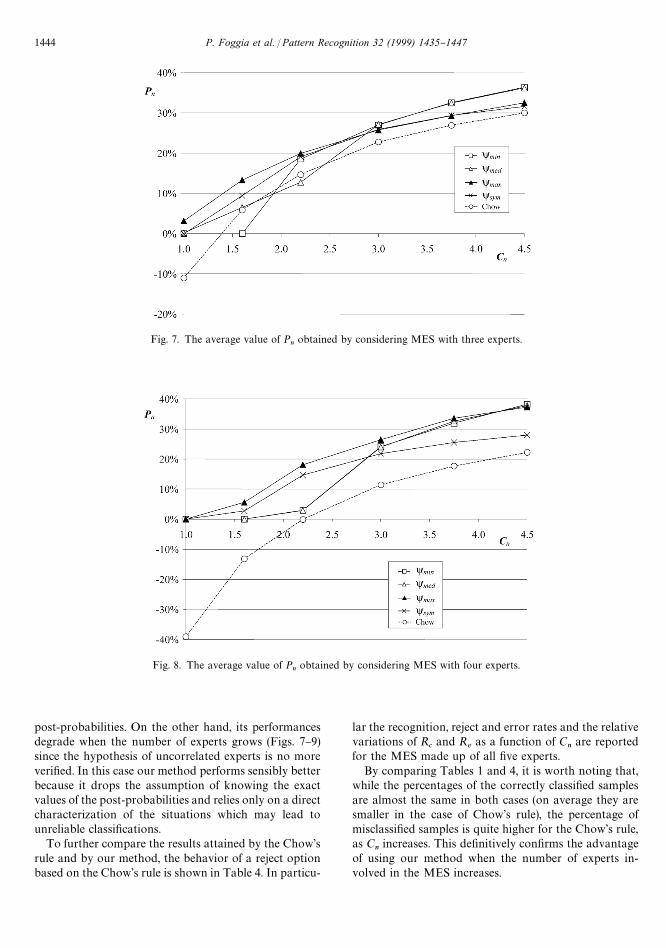
Fig. 7. The average value of Pn
obtained by considering MES with three experts.
Fig. 8. The average value of Pn
obtained by considering MES with four experts.
post-probabilities. On the other hand, its performancesdegrade when the number of experts grows (Figs. 7}9)since the hypothesis of uncorrelated experts is no moreveri"ed. In this case our method performs sensibly betterbecause it drops the assumption of knowing the exactvalues of the post-probabilities and relies only on a directcharacterization of the situations which may lead tounreliable classi"cations.
To further compare the results attained by the Chow'srule and by our method, the behavior of a reject optionbased on the Chow's rule is shown in Table 4. In particu-
lar the recognition, reject and error rates and the relativevariations of R
cand R
eas a function of C
nare reported
for the MES made up of all "ve experts.By comparing Tables 1 and 4, it is worth noting that,
while the percentages of the correctly classi"ed samplesare almost the same in both cases (on average they aresmaller in the case of Chow's rule), the percentage ofmisclassi"ed samples is quite higher for the Chow's rule,as C
nincreases. This de"nitively con"rms the advantage
of using our method when the number of experts in-volved in the MES increases.
1444 P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447
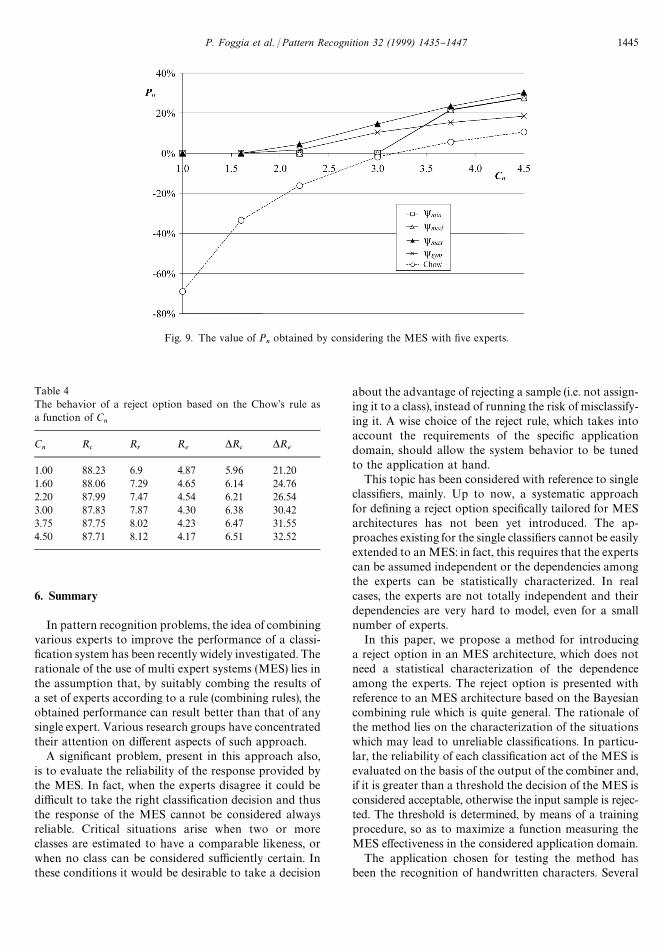
Fig. 9. The value of Pn
obtained by considering the MES with "ve experts.
Table 4The behavior of a reject option based on the Chow's rule asa function of C
n
Cn
Rc
Rr
Re
*Rc
*Re
1.00 88.23 6.9 4.87 5.96 21.201.60 88.06 7.29 4.65 6.14 24.762.20 87.99 7.47 4.54 6.21 26.543.00 87.83 7.87 4.30 6.38 30.423.75 87.75 8.02 4.23 6.47 31.554.50 87.71 8.12 4.17 6.51 32.52
6. Summary
In pattern recognition problems, the idea of combiningvarious experts to improve the performance of a classi-"cation system has been recently widely investigated. Therationale of the use of multi expert systems (MES) lies inthe assumption that, by suitably combing the results ofa set of experts according to a rule (combining rules), theobtained performance can result better than that of anysingle expert. Various research groups have concentratedtheir attention on di!erent aspects of such approach.
A signi"cant problem, present in this approach also,is to evaluate the reliability of the response provided bythe MES. In fact, when the experts disagree it could bedi$cult to take the right classi"cation decision and thusthe response of the MES cannot be considered alwaysreliable. Critical situations arise when two or moreclasses are estimated to have a comparable likeness, orwhen no class can be considered su$ciently certain. Inthese conditions it would be desirable to take a decision
about the advantage of rejecting a sample (i.e. not assign-ing it to a class), instead of running the risk of misclassify-ing it. A wise choice of the reject rule, which takes intoaccount the requirements of the speci"c applicationdomain, should allow the system behavior to be tunedto the application at hand.
This topic has been considered with reference to singleclassi"ers, mainly. Up to now, a systematic approachfor de"ning a reject option speci"cally tailored for MESarchitectures has not been yet introduced. The ap-proaches existing for the single classi"ers cannot be easilyextended to an MES: in fact, this requires that the expertscan be assumed independent or the dependencies amongthe experts can be statistically characterized. In realcases, the experts are not totally independent and theirdependencies are very hard to model, even for a smallnumber of experts.
In this paper, we propose a method for introducinga reject option in an MES architecture, which does notneed a statistical characterization of the dependenceamong the experts. The reject option is presented withreference to an MES architecture based on the Bayesiancombining rule which is quite general. The rationale ofthe method lies on the characterization of the situationswhich may lead to unreliable classi"cations. In particu-lar, the reliability of each classi"cation act of the MES isevaluated on the basis of the output of the combiner and,if it is greater than a threshold the decision of the MES isconsidered acceptable, otherwise the input sample is rejec-ted. The threshold is determined, by means of a trainingprocedure, so as to maximize a function measuring theMES e!ectiveness in the considered application domain.
The application chosen for testing the method hasbeen the recognition of handwritten characters. Several
P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447 1445

experts have been considered, combined to form MESarchitectures with varying number of experts. The e!ec-tiveness of the MES has been evaluated for several ap-plication requirements: the results obtained have beenalso compared with other approaches and proved to bevery encouraging.
References
[1] C.Y. Suen, C. Nadal, R. Legault, T.A. Mai, L. Lam, Com-puter recognition of unconstrained handwritten numeral,Proc. IEEE 80 (1992) 1162}1180.
[2] B. Ackermann, H. Bunke, Combination of classi"ers onthe decision level for face recognition, Technical ReportIAM-96-002, Institut fuK r Informatik und angewandteMathematik, UniversitaK t Bern, 1996.
[3] T.K. Ho, J.J. Hull, S.N. Srihari, Decision combination inmultiple classi"er systems, IEEE Trans. Pattern Anal.Mach. Intell. 16 (1994) 66}75.
[4] L. Xu, A. Krzyzak, C.Y. Suen, Method of combining mul-tiple classi"ers and their application to handwritten nu-meral recognition, IEEE Trans. Systems Man Cybernet.22 (1992) 418}435.
[5] C.K. Chow, An optimum character recognition systemusing decision functions, IRE Trans. Electron. Comput.6 (1957) 247}254.
[6] C.K. Chow, On optimum recognition error and rejecttradeo!, IEEE Trans. Inform. Theory 10 (1970) 41}46.
[7] L. Lam, C.Y. Suen, Increasing experts for majority vote inOCR: theoretical considerations and strategies, Proc. 4thInt. Workshop on Frontiers in Handwriting Recognition,(1994) pp. 245}254.
[8] Y.S. Huang, C.Y. Suen, A method of combining multipleexperts for the recognition of unconstrained handwrittennumerals, IEEE Trans. Pattern Anal. Mach Intell. 17(1995) 90}94.
[9] L.P. Cordella, C. De Stefano, F. Tortorella, M. Vento,A method for improving classi"cation reliability of multi-layer perceptrons, IEEE Trans. Neural Networks 6 (1995)1140}1147.
[10] L.P. Cordella, C. De Stefano, C. Sansone, F. Tortorella,M. Vento, Neural network classi"cation reliability: prob-lems and applications, in: C.T. Leondes (Ed.), Neural Net-work Systems Techniques And Applications, 5: Image
Processing and Pattern Recognition, Academic Press,New York, 1997, pp. 161}199.
[11] M.D. Richard, R.P. Lippman, Neural network classi"ersestimates Bayesian a posteriori probabilities, Neural Com-put. 3 (1991) 461}483.
[12] I. Bloch, Information combination operators for datafusion: A comparative review with classi"cation, IEEETrans. Systems Man Cybernet. Part A 26 (1996) 52}76.
[13] W.K. Pratt, Digital Image Processing, Wiley-Interscience,New York, 1991.
[14] L.P. Cordella, C. De Stefano, M. Vento, A neural networkclassi"er for OCR using structural descriptions, Mach.Vision Appl. 8 (1995) 336}342.
[15] P. Foggia, C. Sansone, F. Tortorella, M. Vento, Characterrecognition by geometrical moments on structural de-compositions, Proc. 4th Int. Conf. on Document Analysisand Recognition, IEEE Computer Society Press, LosAlamitos, CA, 1997, pp. 6}10.
[16] T.M. Cover, P.E. Hart, Nearest neighbor patternclassi"cation, IEEE Trans. Inform. Theory 13 (1967)21}27.
[17] D.E. Rumelhart, J.L. Mc Clelland, Parallel DistributedProcessing } Explorations in the Microstructure of Cogni-tion, 1: Foundations, MIT Press, Cambridge, 1986.
[18] T. Kohonen, The self-organizing map, Proc. IEEE 78(1990) 1464}1480.
[19] C. De Stefano, C. Sansone, M. Vento, Comparing general-ization and recognition capability of learning vectorquantization and multi-layer perceptron architectures,Proc. 9th Scandinavian Conf. Image Analysis, 1995, pp.1123}1130.
[20] R. Hecth-Nielsen, Neurocomputing, Addison-Wesley,Reading, 1990.
[21] C. De Stefano, P. Foggia, F. Tortorella, M. Vento, A dis-tance measure for structural descriptions using circle arcsas primitives, Proc. 13th Int. Conf. on Pattern Recogni-tion, vol. II, IEEE Computer Society Press, Los Alamitos,CA, 1996, 290}294.
[22] P.J. Grother, NIST Special Database 19, Technical Re-port, National Institute of Standards and Technology,1995.
[23] H. Kang, J.H. Kim, A probabilistic framework for combin-ing multiple classi"ers at abstract level, Proc. 4th Int. Conf.on Document Analysis and Recognition, vol. 2, IEEEComputer Society Press, Los Alamitos, CA, 1997, pp.870}874.
About the Author=PASQUALE FOGGIA was born in Naples, Italy, in 1971. He received a Laurea degree with honors in ComputerEngineering from the University of Naples &&Federico II'' in 1995. He is currently a Ph.D. student at the Dipartimento di Informaticae Sistemistica of the University of Naples &&Federico II''. His research interests are in the "elds of classi"cation algorithms, opticalcharacter recognition, graph matching and inductive learning. Pasquale Foggia is a member of the International Association for PatternRecognition (IAPR).
About the Author=CARLO SANSONE was born in Naples, Italy, in 1969. He received a Laurea degree with honors in ElectronicEngineering in 1993 and a Ph.D. Degree in Electronic and Computer Engineering in 1997, both from the University of Naples &&FedericoII''. He has been Assistant Professor of Computer Sciences and Databases at the University of Naples &&Federico II'' and AssistantProfessor of Computer Science at the University of Cassino. His research interests are in the "elds of classi"cation algorithms, opticalcharacter recognition and neural networks theory and applications. Carlo Sansone is a member of the International Association forPattern Recognition (IAPR).
1446 P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447

About the Author=FRANCESCO TORTORELLA was born in Salerno, Italy, in 1963. He received a Laurea degree with honors inElectronic Engineering in 1991 and a Ph.D. Degree in Electronic and Computer Engineering in 1995, both from the University of Naples&&Federico II'', Italy. From 1995 to 1996 he was Assistant Professor of Computer Architectures at the University of Naples &&Federico II'';from 1997 to 1998 he was Assistant Professor of Computer Science at the University of Cassino. In September 1998 he joined theDipartimento di Automazione, Elettromagnetismo, Ingegneria dell'Informazione e Matematica Industriale, University of Cassino, asa researcher. His current research interests include: classi"cation algorithms, optical character recognition, map and documentprocessing, neural networks. Dr. Tortorella is a member of the International Association for Pattern Recognition (IAPR).
About the Author=MARIO VENTO was born in Naples, Italy, in 1960. In 1984 he received a Laurea degree with honors in ElectronicEngineering, and in 1988 a Ph.D. in Electronic and Computer Engineering, both from University of Naples &&Federico II'', Italy. Since1989, he has been a researcher associated with the Dipartimento di Informatica e Sistemistica at the above University. Currently he isAssociate Professor of Arti"cial Intelligence and Computer Science at the Faculty of Engineering of the University of Naples. Hispresent research interests are in the "eld of image analysis and recognition, image description and classi"cation techniques, softcomputing, machine learning and arti"cial intelligence. Mario Vento is a member of the International Association for PatternRecognition (IAPR).
P. Foggia et al. / Pattern Recognition 32 (1999) 1435}1447 1447




















