
Magician Simulator: From Simulation to Robot Teaming
17
Magician Simulator: From Simulation to Robot Teaming 1 Adham Atyabi, 1 Tom F. Anderson, 1 Kenneth Treharne, 1 Richard Leibbrandt, 1,2 David M. W. Powers, 1, School of Computer Science, Engineering and Mathematics, Flinders University of South Australia, Adelaide, Australia, {Adham.Atyabi,Tom.Anderson,Kenneth.Treharne,Richard.Libbrandt}@flinders.edu.au 2 Beijing Municipal Lab for Multimedia & Intelligent Software, Beijing University of Technology, Beijing, China, [email protected] Abstract This paper reports ongoing development of a realistic robot friendly simulator called Magician, addressing multiple problems in robot teaming, networking and communications, strategy development and operator training. The software package includes i) an environment simulator that provides multi phases of virtual urban environment, ii) simulated robots, for addressing the behavior of robots individually and as teams, iii) a strategy overlord unit that provides automated strategy selection for robots or teams of robots that best suits the situation in the dynamically changing field, and iv) a Human Machine Interface (HMI), used for visualizing the undergoing actions in the simulated field in addition to addressing robot-operator and operator-robot interactions. The focus of the paper is on the proposed strategies for robot teaming and the achieved experimental results. Keywords: Robot Teaming, Swarm robotics, Simulation, Human Computer Interface, Networking 1. Introduction After a series of evaluations in late 2010 and mid-2011, a consortium of UWA and Flinders robotic teams, called Magician, was named one of top 5 finalists in the world in the first Multi-Autonomous Ground-robotic International Challenge (MAGIC). The competition was co-sponsored by the Australian Defense Science and Technology Organization and the U.S. Department of Defense. In short, the competition focused on swarms of robots involved in counter terrorist scenarios in which i) safety of non-combatant personals was to be guaranteed, ii) objects of interest were to be identified, iii) moving enemy were to be neutralized, and iv) static hostile objects (e.g., mines) were to be neutralized. The competition addressed various degrees of complexity including i) the possibility of controlling a heterogeneous swarm of robots distributed over a tactical environment following teams-based or individual-based formations using only two human operators, ii) defining strategies with guarantees on performance considering networking complications, and iii) the autonomy of robots. The Magician Simulator (named after the Flinders team) is a 2D interface simulator, designed to examine the feasibility of various strategies for the competition. The simulator generates randomity based scenarios targeting a vast variety of situations, and it provides performance measurements for the suggested strategies. In addition, the Magician simulator is connected to a higher level human control interface (HCI_Unit) for operator interactions. The rules of the competition dictate penalties for operator-robot-interaction based on the length of time that humans spend on robot control, which motivates us to minimize the interactions by training the operators to maximize their perception from the HCI unit and only interact with the competition when it is absolutely necessary. This paper introduces the Magician simulator and provides some details about its structure and comprising packages, in addition to presenting some of the implemented strategies and achieved results. The outline of the paper is as follows: in Section 2, the basis of Robotic Swarms is introduced and some simulated based studies in the field are presented. In Section 3, other simulators, developed to study aspects of robot teaming, are introduced. The rules of Magic 2010 competition for which the Magician simulator was designed and developed are explained in Section 4. Structural details of the Magician simulator are presented in Sections 5and 6. The designated computer-based strategy dictator and the Human Machine Interface (HMI) are discussed in Sections 7 and 8 respectively. Some of the
-
Upload
washington -
Category
Documents
-
view
3 -
download
0
Transcript of Magician Simulator: From Simulation to Robot Teaming

Magician Simulator: From Simulation to Robot Teaming
1Adham Atyabi,
1 Tom F. Anderson,
1Kenneth Treharne,
1Richard Leibbrandt,
1,2David M. W.
Powers, 1,
School of Computer Science, Engineering and Mathematics, Flinders University of South
Australia, Adelaide, Australia,
{Adham.Atyabi,Tom.Anderson,Kenneth.Treharne,Richard.Libbrandt}@flinders.edu.au 2 Beijing Municipal Lab for Multimedia & Intelligent Software, Beijing University of
Technology, Beijing, China, [email protected]
Abstract This paper reports ongoing development of a realistic robot friendly simulator called Magician,
addressing multiple problems in robot teaming, networking and communications, strategy development
and operator training. The software package includes i) an environment simulator that provides multi
phases of virtual urban environment, ii) simulated robots, for addressing the behavior of robots
individually and as teams, iii) a strategy overlord unit that provides automated strategy selection for
robots or teams of robots that best suits the situation in the dynamically changing field, and iv) a
Human Machine Interface (HMI), used for visualizing the undergoing actions in the simulated field in
addition to addressing robot-operator and operator-robot interactions. The focus of the paper is on the
proposed strategies for robot teaming and the achieved experimental results.
Keywords: Robot Teaming, Swarm robotics, Simulation, Human Computer Interface, Networking
1. Introduction
After a series of evaluations in late 2010 and mid-2011, a consortium of UWA and Flinders robotic
teams, called Magician, was named one of top 5 finalists in the world in the first Multi-Autonomous
Ground-robotic International Challenge (MAGIC). The competition was co-sponsored by the
Australian Defense Science and Technology Organization and the U.S. Department of Defense. In
short, the competition focused on swarms of robots involved in counter terrorist scenarios in which i)
safety of non-combatant personals was to be guaranteed, ii) objects of interest were to be identified, iii)
moving enemy were to be neutralized, and iv) static hostile objects (e.g., mines) were to be neutralized.
The competition addressed various degrees of complexity including i) the possibility of controlling a
heterogeneous swarm of robots distributed over a tactical environment following teams-based or
individual-based formations using only two human operators, ii) defining strategies with guarantees on
performance considering networking complications, and iii) the autonomy of robots.
The Magician Simulator (named after the Flinders team) is a 2D interface simulator, designed to
examine the feasibility of various strategies for the competition. The simulator generates randomity
based scenarios targeting a vast variety of situations, and it provides performance measurements for the
suggested strategies. In addition, the Magician simulator is connected to a higher level human control
interface (HCI_Unit) for operator interactions. The rules of the competition dictate penalties for
operator-robot-interaction based on the length of time that humans spend on robot control, which
motivates us to minimize the interactions by training the operators to maximize their perception from
the HCI unit and only interact with the competition when it is absolutely necessary.
This paper introduces the Magician simulator and provides some details about its structure and
comprising packages, in addition to presenting some of the implemented strategies and achieved
results. The outline of the paper is as follows: in Section 2, the basis of Robotic Swarms is introduced
and some simulated based studies in the field are presented. In Section 3, other simulators, developed
to study aspects of robot teaming, are introduced. The rules of Magic 2010 competition for which the
Magician simulator was designed and developed are explained in Section 4. Structural details of the
Magician simulator are presented in Sections 5and 6. The designated computer-based strategy dictator
and the Human Machine Interface (HMI) are discussed in Sections 7 and 8 respectively. Some of the

implemented strategies are presented in Section 9, and the achieved performances are illustrated in
Section 10. In conclusion in Section 11 we will summarize the effectiveness of the approach and the
avenues that remain to explore.
2. Related Work in Simulated Robotic Swarms
A robotic swarm refers to a population of logical or physical robots. The effectiveness of
participation by a particular robot in such a swarm in complex problem solving tasks is by virtue due to
the collaboration and cooperation abilities of the robots. Robot teams are widely used in military-based
applications as bomb or threat detectors [13], for moving products in big warehouses [14, 17], and as
search and rescue teams [14]. Research efforts have focused on methods, based on the use of robots in
hazard scenarios, in which central control is weak or even impossible (due to large distances, lack of
communication, lack of information, and so forth). In such scenarios, the use of single intelligent
robots is costly (due to the time consuming nature of development, the level of intelligence necessary,
and the level of physical structure).
The principle idea behind a robotic swarm is to use the local behavior of each robot to collectively
and cooperatively solve a problem. As suggested by Yang and Simon [15], a robotic swarm can be
seen as a form of distributed artificial intelligence, due to the coordination and cooperation of
aggregated cohesiveness agents who make decisions. Hence, robotic swarms have been used in diverse
areas of studies, including cooperative learning [22], problem solving [21], and path planning [20].
Bogatyreva and Shillerov [16] suggested a hybrid method, using hierarchical and stochastic
approaches in a distributed swarm robotic system. In their study, the issue was to prevent chaos and
perturbation in a path planning scenario. The study was done on logical robots (a simulation-based
application). They also suggested the possibility of adopting their proposed algorithm to a real world
problem by using a modular system of basic robots that is able to build temporary structures (bridges,
shelters) by self-assembling principles with respect to environmental construction [14]. Werfel et al.
[17] studied a simulation-based robotic swarm scenario based on goal locating. In this context, the goal
refers to a building block. After locating the goals, robots were to push them to another location for
assembly. This is an example of simple, identical, autonomous, decentralized robots participating in
structure-building scenario. The idea was to implement a single robot with simple skills that has the
ability to build simple structures with a low level of fault tolerance. They suggested the expansion of
their model to a multi-agent based system in which more than one robot is participating in the structure
building task. Towards such an aim, they introduced a lock factor on blocks to prevent the violation of
geometric constraints in which more than one block is nominated to be attached in a similar place of
the structure.
Mondada et al. [14] used a team of simulated robots in a problem based on exploration, navigation
and transportation of heavy objects on rough terrain. In their approach, robots are able to connect to
each other and change their shape. Such a connection will provide a chain of robots which helps to
cope with the problem of climbing obstacles or surf passing holes. The authors used a distributed
adaptive control architecture inspired by ACO.
3. Other Simulators
In related simulation work, we have been investigating human factors issues in the control of
groups of simulated vehicles. In particular, we studied the effects on human operators of being in a
supervisory role over unreliable technology. We have developed a simulation of the vehicle
supervision scenario, in which experimental subjects play the role of a vehicle supervisor who has to
guide a team of vehicles from one location to another in a grid of city streets. All vehicles other than
the lead vehicle are “robotic”, in the sense that they automatically follow the vehicle directly ahead of
them. The simulation requires subjects to perform a challenging navigation task, guiding vehicles
through a route in an urban terrain and correlating a route displayed on an on-screen map in one
interface panel with an adjacent display of the vehicle convoy as viewed from above, shown in the

context of the street grid. A third, higher-resolution view allows the supervisor to monitor whether
individual vehicles, which under normal circumstances follow each other, are veering away from the
path followed by the other vehicles in the convoy. A stream of audio messages simulates radio
communications to which operators are required to respond. Operators are required to perform three
concurrent tasks of: navigation, checking whether vehicles are still in convoy or have started veering,
and responding to communications messages. The simulation aims to recreate a high-workload
situation such as might be experienced by military personnel supervising hypothetical robotic vehicle
convoys in an urban combat situation. The secondary task of vehicle monitoring is difficult to perform,
as it (by design) requires operators to switch between two mutually exclusive views. In order to assist
operators in performing the secondary task, the simulation also features a warning system that alerts
operators when vehicle veering occurs. The warning system itself is often in error and manipulation of
the error type and error rate allows us to investigate the effect of errors on operators’ trust in the
warning technology, and on the level of workload they experience.
Another previously conducted series of studies focused on increasing swarm diversity through
cooperative learning in a 500 × 500(m) simulated environment in which swarm of robots were ordered
to search for survivors [27-33]. Particle Swarm Optimization (PSO) was used to model the decision
making of robots. The studies focused on robot heterogeneity by assuming various expertise among
robots and defining different care requisite for survivors. Communication constraints and
environmental noise (random and complex aggregated noise called illusion) were addressed, in
addition to highlighting the impact of knowledge transfer and transfer learning in improving the overall
efficiency of the swarm of robots.
4. Magic 2010 Competition: Rules & Tasks
The Multi Autonomous Ground-robotic International Challenge (MAGIC) was sponsored and
organized by the defense departments of Australia and the United States. The challenge targeted
autonomy in robotic teams involved in counter terrorism scenarios in urban environments. Three
phases were designed within a 500×500 meters arena with growing degrees of complexities influenced
from the used infrastructures, type of enemies, and the tasks to be performed. Phase I contained Static
Hostile Objects (SHOs) and the task was to map the environment, identify objects of interests (trees,
fences, holes, etc.) and neutralize SHOs. Phase II contained Moving Hostile Objects (MHOs) in
addition to Non-Combatant Objects (NCOs). The environment contained accessible buildings in
addition to cubicles and sand terrain. The task was to map the environment (indoor and outdoor),
neutralize both MHOs and SHOs and prevent NCOs from interfering with neutralization operation.
Phase III was similar to Phase II with the addition of having grassy ground and a sniper that targeted
robots. A cumulative maximum of 3.5 hours were permitted for completion of the three phases. Robots
were terminated due to loss of communication with operators for more than 3s or for entering the
lethality distance of MHOs and SHOs. Operators were positioned in Ground Control Station (GCS)
roughly in the center and out of the actual battle field and were provided a UAV feed indicating the
moving objects in the arena and their rough locations with no indication of their types. Penalties were
given to teams for intervention of operators with robots operator.
Robots were asked to map the arena and report locations of Objects Of Interests (OOIs) (MHOS,
SHOs, NCOs, trees, fences, buildings, etc.) within 0.5 meters accuracy. The required time for
neutralizing a MHO or SHO was set to 15 and 30 seconds respectively, during which time robots were
meant to maintain the hostile object in their line of sight for the entire duration of neutralization.
Penalties were given for attempted neutralizations of NCOs. Heterogeneity was forced through
defining two types of Sensor and Disruptor robots with different functionalities with no
intercommunication capabilities, i.e. Disruptors were not allowed to communicate with Sensors, and
their information were only reported to operators through networks. while Sensor robots were capable
of inter communications in addition to robot-operator/operator-robot connections. The ratio of at least
two sensor robots for a disruptor with minimum of three disruptors in the swarm was expected. Two
Sensor robots were required for neutralization of a MHO while individual Disruptors were capable of
handling the task for SHOs. To simulate neutralization, robots maintained the MHOs/SHOs on their
line of sight for specific periods.

Figure 1. An example of simulator captured view from three phases of the Magic 2010 competition.
Small dots with different colors represent robots and their role in the team while bigger red circles
indicate non-neutralized SHOs and their lethality ranges. The pink circle represents a neutralized SHO.
The green circles represent the points to be held and protected by robots in holding ground strategy
(see section 10). Grey, purple, and blue colored rectangles represent locked, open, and cubical
buildings respectively. Dark green and yellow colored areas represent grassy area and service zones,
respectively. Each phase of the competition is isolated by red lines.
5. Magician Simulator
To meet the complexities inherent within the Magic 2010 challenge, it was decided to produce a
realistic robot simulator that could be used for aspects such as:
• Future education of students in the field of swarm robotics.
• Pre-event training of human operators.
• Assessing possible robot teaming strategies
The package that is implemented includes three main applications that are capable to be running
individually or in any combinations simultaneously. These applications include i) a robot teaming
simulator, ii) a Human Machine Interface (HMI), and iii) Strategy OverLord (SOL).
The simulator was primarily designed to investigate the feasibility of strategies and robot teaming
configurations with respect to the existing complexities in the environment. In addition, it provided
simulated live feedback from robots and the environment to operators, to be used for the training of the
operators through the HMI system. The following issues were considered and addressed in the design
of the simulator.
5.1 Environment
The current version of the simulator can handle up to three different environments (referred to as
Phase I, II, and III) with increasing complexities. The environments can contain structures (buildings)
with different shapes and properties including maze, cubicles, open access buildings, and closed door
buildings. In addition, it is capable of taking the ground floor material and the elevation level of the
terrain into account (e.g. sandy field, grassy field, ramps, and so on). Various types of static obstacles,
including trees, fences, holes, and trenches, are considered, and their impact on the networking and
robot maneuvering is recorded.
5.2 Enemy
Two types of static and dynamic enemies are considered. The static and dynamic enemies are
referred to as Static Hostile Objects (SHOs) and Moving Hostile Objects (MHOs), with various
properties such as lethality range (see Fig. 5), required neutralization time, required neutralization
expertise, and the number of robots required to be involved in a neutralization. For MHOs, also under
consideration are movement speed and movement patterns (random movements or circulating around
10 strategic or non-strategic points). Furthermore, a dynamic object with lethality range of 0 with no
neutralization requisite is considered, referred to as a Non-Combatant Object (NCO).
5.3 Robots
The robots are designed to have hardware complexities (i.e., cameras configurations, properties
(zoom, resolution) and characteristics, battery life, networking equipment and communication ranges
and networking capabilities, motor power and speed, sensor equipment, and so on) in addition to the
robots’ roles in the team (i.e., disruptor, boundary rangers, rangers, alpha team leader, beta team leader,
protector, gamma and kappa robots) with respect to their defined expertise taken into account. The
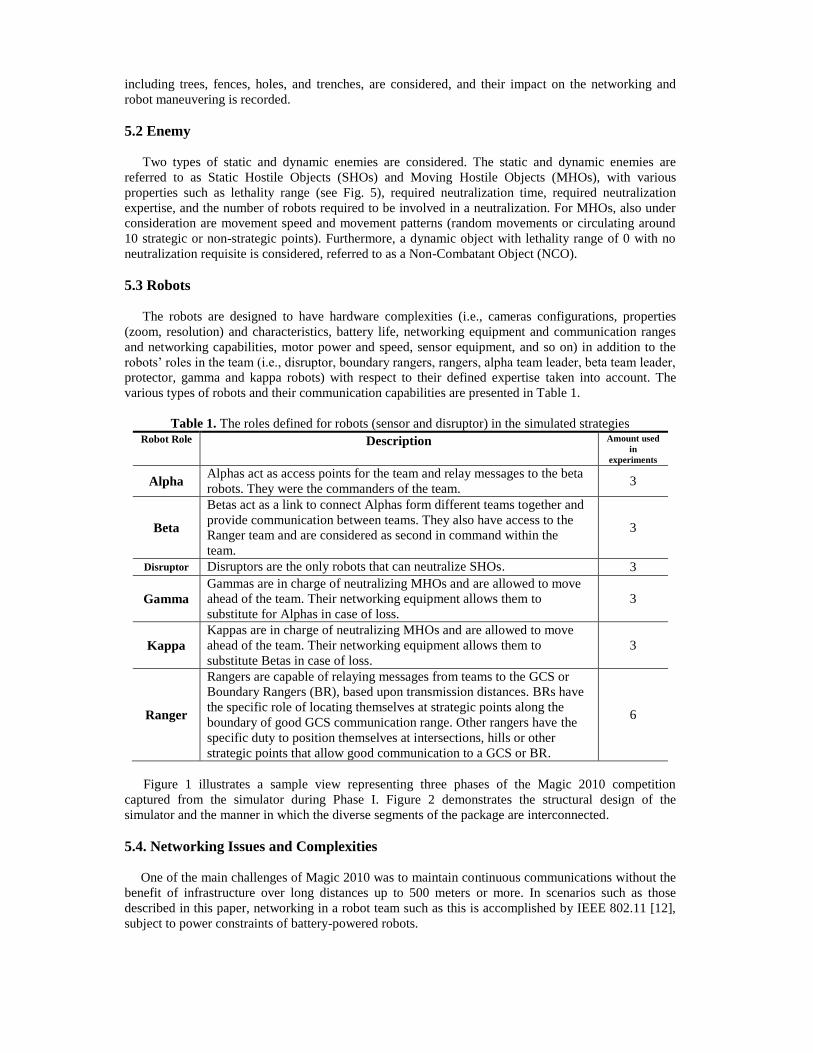
various types of robots and their communication capabilities are presented in Table 1.
Table 1. The roles defined for robots (sensor and disruptor) in the simulated strategies Robot Role Description Amount used
in
experiments
Alpha Alphas act as access points for the team and relay messages to the beta
robots. They were the commanders of the team. 3
Beta
Betas act as a link to connect Alphas form different teams together and
provide communication between teams. They also have access to the
Ranger team and are considered as second in command within the
team.
3
Disruptor Disruptors are the only robots that can neutralize SHOs. 3
Gamma
Gammas are in charge of neutralizing MHOs and are allowed to move
ahead of the team. Their networking equipment allows them to
substitute for Alphas in case of loss.
3
Kappa
Kappas are in charge of neutralizing MHOs and are allowed to move
ahead of the team. Their networking equipment allows them to
substitute Betas in case of loss.
3
Ranger
Rangers are capable of relaying messages from teams to the GCS or
Boundary Rangers (BR), based upon transmission distances. BRs have
the specific role of locating themselves at strategic points along the
boundary of good GCS communication range. Other rangers have the
specific duty to position themselves at intersections, hills or other
strategic points that allow good communication to a GCS or BR.
6
Figure 1 illustrates a sample view representing three phases of the Magic 2010 competition
captured from the simulator during Phase I. Figure 2 demonstrates the structural design of the
simulator and the manner in which the diverse segments of the package are interconnected.
5.4. Networking Issues and Complexities
One of the main challenges of Magic 2010 was to maintain continuous communications without the
benefit of infrastructure over long distances up to 500 meters or more. In scenarios such as those
described in this paper, networking in a robot team such as this is accomplished by IEEE 802.11 [12],
subject to power constraints of battery-powered robots.

Unique to the Magic competition, the ten-second rule dictates that any robot out of communication
with the GCS for ten seconds is to freeze and can no longer participate. With a maximum of one Mbps
bandwidth to be shared among the team of 21 robots, ensuring that each robot can communicate at all
times is a paramount concern. To avoid collisions (and subsequent retransmissions) after random back-
off, which occur in wireless networks for simultaneous transmissions, each robot is assigned a time slot
based on the number of robots attached to each access point. When a new robot enters the access point,
it is assigned to a new time slot.
By nature of the hardware available for our robots, maximum single-hop communication distances
for high bandwidth routes (HBR - designed to provide at least 1Mbps per robot downstream) are
limited to between 50 to 100 meters, depending on frequency (2.4 GHz or 5GHz 802.11n) and
interference such as reflections and obstructions to line of sight. The GCS has more capacity for larger
antennas (but must operate at reduced power due to regulatory limitations), so can provide greater
coverage and more sensitive reception; however, network black holes could still arise. To reduce the
chance of violations of the ten-second rule, a small number of low bandwidth routes (LBR) via
900MHz devices (or alternately, where available, via commercial 3G wireless), are distributed
among robot teams. Additionally, ad hoc 802.11b can also be used for low bandwidth fallback.
The robots use a number of different robot bases. The Alpha, Beta and Delta (Disruptor) use large
but lightweight (less than ten kg including payload) ⅛-scale "rock crawlers" capable of climbing steps
or gutters and operating a 2.4GHz and/or 5GHz Access Point (D-Link DIR825 on Alpha, DIR1522 on
Beta) and 3 FIT-PCs (each with 2.4GHz 802.11bg, one with 2.4/5GHz 802.11n), managing 6
webcams; while the Kappa and Gamma use smaller faster 'disposable' Lynxmotion robots (<5kg inc.
payload) with 2 FIT-PC CPUs (each with 2.4GHz 802.11bg, one with 2.4/5GHz 802.11n), managing
two pantilt cameras as well as an AP (D-Link DIR1522) capable of operating at 2.4GHz or 5GHz. The
crawlers are designed to work both onroad and offroad, and inside and outside buildings (and an Alpha
can sit in doorways to relay between interior and exterior). The lynxes are designed for scouting along
roads and paths, and in particular for peering around corners where there might be an enemy or
mine. These robots were developed by the South Australian (SA) part of the MAGICIAN team, and
did not include LIDAR but instead depend on vision and IR sensors for navigation and mapping.
The Rangers were originally designed to use the crawler base too, but by the addition of a FIT-PC
and 2.4/5GHz 802.11n, the AP could be based on an alternate platform. In particular, after the initial
SA design, we merged with the West Australian (WA) group, which was developing robots using the
Pioneer AT3 base, with 802.11b comms, a Sphere pan-tilt camera and a number of different LIDAR
configurations. These are suitable for the Ranger role, as they have capabilities for detailed external
mapping using LIDAR. The Disruptor was also easily configured on the pioneers - this required
reduced communication functionality (not being allowed to transmit sensor/mapping information) and
the addition of laser targeting capabilities. The SA team provided this capability by replacing the LED
in pan-tilt Logitech Sphere cameras with a laser pointer; two of these cameras were used on each of the
SA robots, one on the WA robots [34].
Due to the size of the area to be explored being much greater than the individual communication
distances of each robot, the main approach taken for the networking is multi-hop, redundant paths,
such that at every time, any given robot maintains communication distance to support direct
networking with two or more other robots; likewise, at least two robots (Rangers) are in direct
communication with the GCS. Network coverage estimates for the entire environment are maintained
by the SOL system, and robots navigate through the environment via pathways that maximize coverage
and maintain connectivity. As shown in Figure 3, two Rangers (orange) relay information to and from
the GCS (blue). Movements of the Alpha robot (green) are restricted to only areas that are within the
communication of two or more Rangers. Broadcast ranges are shown as shaded circles. In this
arrangement, if the Alpha was to move in another direction, such as North, communications with the
Rangers could be compromised and the ten-second rule could be triggered. Note that Disruptors are
permitted to use the network for transmitting their messages; however, Disruptor messages can only be
forwarded to the GCS without eavesdropping by other robot types.

Robot/Robot
Simulator
Figure 2. Structural design of Magician Package
The basic mechanism of communication is for each robot to rebroadcast all new communications
along every available path, packaging the latest "heartbeat+telemetry" information for each robot into a
single compact message. Each communication is defined with an origin time-stamp and originator ID.
Each robot maintains a table of the most recent messages as indicated by origin time-stamps and
originator IDs. When a message is received that is newer than the one on the table, the data is included
in the scheduled broadcasts over every available interface. When a sending robot re-receives the data, it
knows that the data was received by the receiving robot and that the receiving robot had not received
that data by any other route.
A main consideration in this type of network is the time-stamp mechanism. We assume that the
clock on each robot may have drift in comparison with other clocks. Therefore, it is essential to provide
a mechanism for clock synchronisation. Upon receiving a reply message from a downstream robot, the
sender can update its clock using comparison between the send and receive time of the original
message and the reply. Such updates are performed incrementally with sub-integer precision to smooth
any minor inconsistencies in time. This synchronisation mechanism was demonstrated to provide time-
stamping accuracy to milliseconds, sufficient for the marking of new messages and calculation of time
slots.
6. Strategy OverLord
The Strategy OverLord (SOL) system takes advantage of a behaviour based structure that fuses
perceived information from robots and the observed changes in the dynamically changing environment
and proposes actions to operators after matching the action taken by robots, observed changes in the
environment, current status (environment, enemy, robots), and possible future threats.
The SOL system proposes various solutions/actions for a possible current or near future problems,
taking into account restrictions originating in heterogeneous capabilities of individual robots and
environmental complexities. These solutions are prioritized based on appropriateness and consider
factors such as i) risk factors, ii) network coverage, iii) resources required, iv) time required to resolve
current actions, and v) any combination of previous factors.
Figure 3. Depiction of communication
distances and permissible steps for robot
navigation.
Environment
Updater
Team
Strategy
Indicator
Robot Role
Updater
Robot
Decision
Maker
SOL System
HMI
Interface
Operators

For instance, if the SOL system realizes that a robot is soon to be out of battery, it proposes to
change that robot’s task to manual battery change and furthermore suggests possible paths to be taken
from the robot’s current position toward the designated service zone1 for that battery change based on:
1. The path with the minimum risk of enemy engagement.
2. The shortest path to the destination.
3. The path with the maximum network coverage.
4. A combination of 1 and 2.
5. A combination of 1, 2, and 3 (highest priority).
It should be noted that the system does not dictate to robots how to move and act but rather, it
provides a series of goals from current location toward the destination. As any given time in battery
shortage example, only points in the environment are provided for the robot, and it is asked to change
its status on the basis of that information and its own understanding of the environment. The robot is
still responsible to choose the best maneuver to reach to the designated points.
The system considers two types of risk of enemy engagements. I) Immediate risk, which indicates
that the enemy is positioned somewhere along the way of the designated path and encounter is
inevitable. II) Non-immediate risk, which indicates that the enemy is in nearby locations and there are
possibility of engagement with respect to the taken path by the enemy.
The SOL system is designed to oversee moment-to-moment operations of the system and to
propose required changes to robots and operators, subject to the approval of operators. It is likely that
the system would have a high impact on the performance of operators and overall achievements of
robots due to capabilities such as:
• Announcing vital information that might be missed by operators as a result of the large quantity of
information presented by robots and ongoing changes in the environment.
1 The grid/matrix representation of the environment used in the SOL system is inspired by the cell
decomposition approach and ongoing refreshing of this representation allows the system to compensate
for dynamically changing constraints of the environment. The path proposed by the SOL contains a
sequence of centring position of the selected cells between current location of the robot and the
destination.
a)
Figure 4. A color coded view captured from initial state of Phase I from simulated Magic 2010
competition provided by SOL system. The darkening of the regions represents the percentage of free
space in the regions for robots’ maneuvering. The red circles represent SHOs and green dots are robots
in the designated starting location. SR and DR represent the risk of having SHOs and MHOs in the
region and AR indicate the possible nearby MHOs that might visit the region. O, N, and U represent
the existence of objects of interests, network coverage and other robots in the region, respectively. The
colors Green, Blue, and Red represent different states for these values in [0, 2]. Sub-figure b is a
rescaled version of sub-figure a generated to provide better view.
b)

• Reducing workload on operators by providing possible solutions/actions for the announced problem
(subject to operator trust in the SOL’s solutions and near future prediction capabilities).
• Dynamically readjusting the robots or the teams of robots’ strategy based on the current or near
future status of the environment (assuming that operators allow the actions to be passed to the robots).
The system uses a regional representation, or matrix, for the environment, inspired by the Cell
Decomposition approach, in which the information streams including things perceived by robots,
observed changes in the environment and UAV feeds are fused together and a ratio for free space, in
addition to network coverage (subject to environmental constraints and relaying architecture), and risk
factors are computed for each region (in the current stage the regions are defined to be 20*20 meters).
The system is capable of providing a simplified view of the environment subject to the request of
operators. An example of such a view is illustrated in Fig. 4.
The SOL can focus more attention on all individual robots than can human operators, who can only
observe selective information as presented by the interface. Although the system takes advantage of a
simple structure for assessing the situation, given that it has higher information resolution (the entire
environment and the ongoing changes) compared to robots (only a couple of steps around their
locations), it is likely to have a better judgment than individual robots or operators (assuming that the
system is fine-tuned and the solutions prioritization is optimized).
7. Human Machine Interface (HMI)
Situation Awareness is knowing what is going on around you and is one component within a whole
system of dynamic human-decision making [3]. In Endsley’s model, situation awareness happens in
three stages: perception of cues, comprehension and interpretation of cues and projection of future
state. Despite its vital contribution under optimal conditions, perfect situation awareness does not
guarantee perfect decision-making. The decision maker may make poor decisions due to personal
characteristics such as impulsiveness or riskiness or due to a lack of training to readily and optimally
deal with foreseen situations.
Based on Endley’s model, in planning and designing the human-robot interface for the competition,
one should not expect an optimally functional system by solving the information representation
problem or by minimising cognitive load alone. Primarily, a system must be fully capable i.e. in our
case the HMI system must be able to send commands to the robot and the robot should comply
reliably. Next, a user must have an adequate grasp of the goals and objectives of the context of use; i.e.
in our case the rules and specifications of the competition. Furthermore, an operator should have
adequate training and experience with the HMI system to read the situation, make decisions and
execute appropriate actions.
The use of automation in HMI systems is both advantageous and a potential threat to operator
workload. In one sense, using automated responses to deal with routine or predictable events frees an
operator’s workload to detect and respond to unforeseen or complex events. In another sense however,
the operator may be unaware of the level of automation occurring and can have ramifications for
perceptual and interpretative stages of Situation Awareness [2].
There are many levels of system automation. These range from completely dependent in which the
operator must perform all actions with little or no support from the interface right through to
completely autonomous in which the system will identify the situation and act on it accordingly
without interaction from the operator. Cook [2] proposes a list of automation strategies that support the
operator throughout the continuum of automation. Cook’s strategies consider the system’s action: to
respond automatically, to notify operator of event, or to propose solution and notify operator of event;
the response autonomy: to execute solution automatically, or to await user interaction, and the
conditions under which to act: when fully matching or partially matching threshold conditions. Cook
discusses the long-term risks of use of highly autonomous systems including complacency, skill-
erosion (i.e. not needing to learn tasks that the system carries out) and poor mental model development.
Cook suggests that a more complex system requires more training to increase the operator’s mental
model of the system but in doing so, benefits decision-making performance since greater knowledge of
the environment is necessary to weigh benefits and risks of the situation.
Whilst assumptions may be drawn about the capabilities, experience and training of operators
beforehand, careful consideration must be given to the design and implementation of a capable system.
Task-analysis should take place as an initial step in the planning phases (as opposed to ad-hoc
throughout the development process) to ensure that full system capability is realized. With knowledge
of the system capabilities in mind, principles of efficiency and cognitive load may then, and only then,
begin to guide the planning processes.
Cognitive load may be estimated through task-analysis and later verified through field-testing. In
either the design or testing phases, excessive cognitive load can be mitigated through interface re-
development, task automation and training [9].
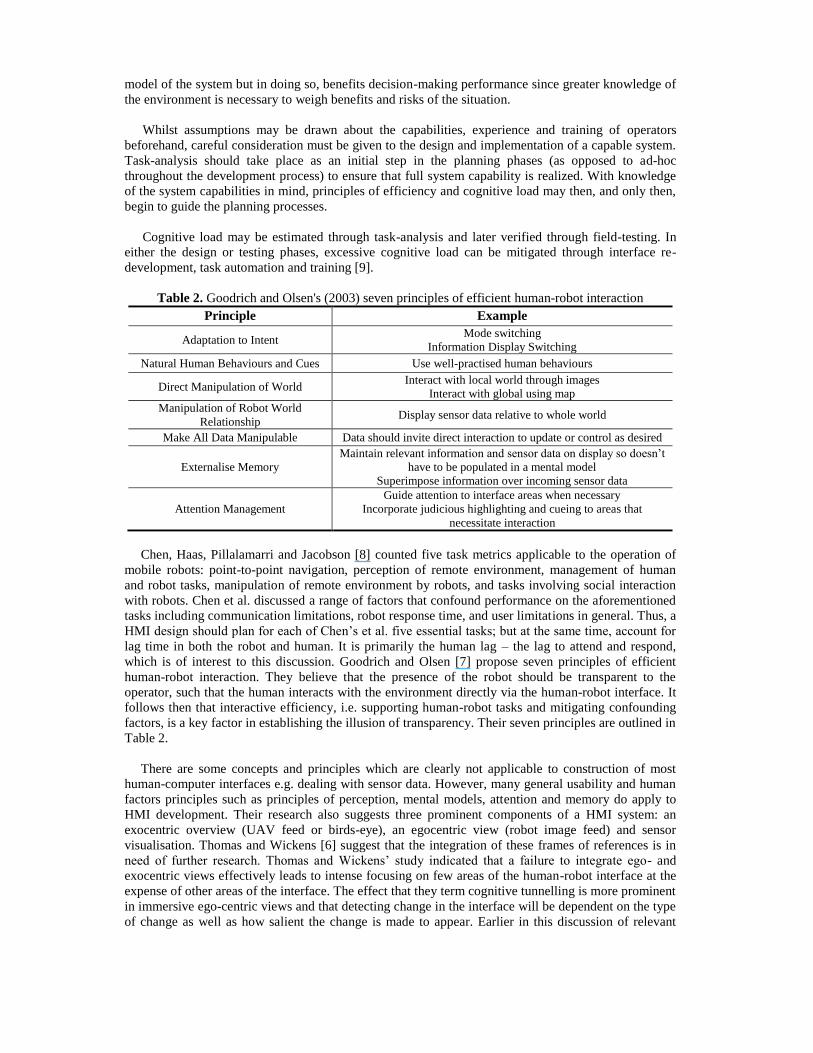
Table 2. Goodrich and Olsen's (2003) seven principles of efficient human-robot interaction
Principle Example
Adaptation to Intent Mode switching
Information Display Switching
Natural Human Behaviours and Cues Use well-practised human behaviours
Direct Manipulation of World Interact with local world through images
Interact with global using map
Manipulation of Robot World
Relationship Display sensor data relative to whole world
Make All Data Manipulable Data should invite direct interaction to update or control as desired
Externalise Memory
Maintain relevant information and sensor data on display so doesn’t
have to be populated in a mental model
Superimpose information over incoming sensor data
Attention Management
Guide attention to interface areas when necessary
Incorporate judicious highlighting and cueing to areas that
necessitate interaction
Chen, Haas, Pillalamarri and Jacobson [8] counted five task metrics applicable to the operation of
mobile robots: point-to-point navigation, perception of remote environment, management of human
and robot tasks, manipulation of remote environment by robots, and tasks involving social interaction
with robots. Chen et al. discussed a range of factors that confound performance on the aforementioned
tasks including communication limitations, robot response time, and user limitations in general. Thus, a
HMI design should plan for each of Chen’s et al. five essential tasks; but at the same time, account for
lag time in both the robot and human. It is primarily the human lag – the lag to attend and respond,
which is of interest to this discussion. Goodrich and Olsen [7] propose seven principles of efficient
human-robot interaction. They believe that the presence of the robot should be transparent to the
operator, such that the human interacts with the environment directly via the human-robot interface. It
follows then that interactive efficiency, i.e. supporting human-robot tasks and mitigating confounding
factors, is a key factor in establishing the illusion of transparency. Their seven principles are outlined in
Table 2.
There are some concepts and principles which are clearly not applicable to construction of most
human-computer interfaces e.g. dealing with sensor data. However, many general usability and human
factors principles such as principles of perception, mental models, attention and memory do apply to
HMI development. Their research also suggests three prominent components of a HMI system: an
exocentric overview (UAV feed or birds-eye), an egocentric view (robot image feed) and sensor
visualisation. Thomas and Wickens [6] suggest that the integration of these frames of references is in
need of further research. Thomas and Wickens’ study indicated that a failure to integrate ego- and
exocentric views effectively leads to intense focusing on few areas of the human-robot interface at the
expense of other areas of the interface. The effect that they term cognitive tunnelling is more prominent
in immersive ego-centric views and that detecting change in the interface will be dependent on the type
of change as well as how salient the change is made to appear. Earlier in this discussion of relevant

literature, it was claimed that one should not expect an optimally functional system by solving the
information representation problem or by minimising cognitive load alone. This claim is still valid.
A minimally functioning HMI system (for this competition) requires essential pragmatic
functionality including manual map labelling, task management (of OOI neutralisation), monitoring of
robot health, and manual strategic direction. But the competition explicitly forbids intervention with
robots. Thus autonomous navigation, autonomous detection, autonomous task execution and reliable
communications must be the default operating mode with controls in place for operators to manage
robotic systems before, during and after breakdown of this autonomy. Where these controls are not
available to the HMI system, cognitive load assessment is pointless, as the task becomes primarily an
observation task and the operator is powerless to execute their decision-making outcomes.
7.1 Human Robot Interface
The HMI system in Magician package is designed for two operators sitting side by side at a four
wide-screen monitor set up. Each operator has an exocentric view (see Fig. 8) of the environment and
egocentric view (see Fig. 9) from the perspective of the team of robots assigned to their control. Each
exocentric view consists of four main components: an event-log window, two embodied conversation
agents (representing robot team leaders), an OOI task management window, and a global overview.
The event log consists of a console type window in which messages of various types are displayed.
This design decision was influenced by human factors research [5] which found that a message event
window was a more effective tool in maintaining situation awareness than a map over view in a
policing context. Each message has an arbitrary importance weight associated with it that determines
how each message is styled causing important messages to pop-out to the operator. Filters allow the
operators to ignore messages from specific categories if deemed appropriate. This is specifically aimed
at controlling the amount/load versus relevance/memory tradeoffs represented by the Externalize
Memory criterion (Table 2).
The Thinking Head [11] is incorporated into the HMI system. Auditory modalities (with and
without Embodied Conversational Agents) in HCI systems have been extensively investigated in
human factors research as the auditory channel is multidimensional and can be interpreted without
needing to orient one’s body toward a particular output device as in the case of the visual modality.
Conveniently, much of the infrastructure laid down for the event display is transferrable to the
conversational agent’s message queuing system; for example, the weight and categorisation
information that accompanies event log messages can be used to prioritise spoken messages. It was
early on specified that one or two units from each robot team would have a personality of its own
consisting of a gender and nationality (with appropriate voice accent) in the spirit of NATO.
The OOI management panel contains a record for every identified object of interest. Metadata for
each OOI includes its system assigned ID, its location in UTM coordinate space, the most recent image
of the unit, controls to manage the neutralisation of that object, the robot assigned to neutralise the
object and the neutralisation status of the object of interest. Large icons provide interactive access to
the neutralisation protocol and are made large to maximise accuracy and minimise time to execute the
command. The status bar at the bottom of the interface display keeps track of the number of reported
SHO, MHO, OOI and fleet UGV. Mission time and current time also appear on the status bar. As does
an estimation of the time of the last user interface interaction and an estimation of total interface
interaction time. The global overview provides an exocentric overview of the environment (see Fig. 8).
The overview consists of several layers though the HMI system generally operates with the
environment view (the satellite image) and the object of interest layers. The additional layers are
currently under experimentation but will be discussed here for completeness and these include a
trajectory layer and communications layer.
The trajectory layer provides a visual record of the trajectories taken by robots and known targets in
the phase area. A basic trajectory representation is evident in Fig. 5, but only a few seconds into the
past. The same concept is used to indicate the planned path to a specified waypoint. Trajectories for

OOI targets are not reported when they are in line of sight. Prediction of where targets could end up
may be computationally expensive for little benefit. An alternative way of showing a predicted target
out of line of sight, but in the area would be to flag a region of doubt/uncertainty as a cue to operators
to relay to robots entering the area should use additional caution.
The communications layer (Fig. 5) is a predictive tool for operators to gauge the expected reliability
of communications links between robots based on a rough estimation of the communications hardware
operating characteristics [10]. The networking architecture incorporates number of different wireless
technologies to create a multi-hop wireless network to provide multiple layers of redundancy and
ensure that messages arrive to their destination. The predictive tool estimates the coverage of each
wireless technology based on the technology’s maximum operating characteristics and an estimation of
the environmental characteristics such as building type. Operators use this information to ensure robots
maintain a distance that does not put them out of communication range.
Fig. 6 provides a visualization of the safe, critical condition, and dangerous/dead conditions with
respect to the distance between a robot and an OOI with respect to the type of OOI.
Animated features were extensively investigated during the HMI implementation. However,
animation is primarily used to depict events such as different stages of neutralisation. An animated
countdown clock metaphor indicated the progress of a neutralisation as depicted in Fig. 8 by the cyan
object. A variation of the countdown animation can be found by looking at the cyan mobile hostile
object in Fig. 7. In addition, part b and c of Fig. 7 indicate that flashing is used to indicate that the robot
is currently performing a task. Pulsating and flashing are also considered for representing rate of
message flow (calculated at the HMI), whereby high frequency flashing of the robot decal would
indicate abnormal message sending (many reports of something). Flashing of influence zones is also
considered for the highlighting whether robots were approaching too closely to hostile trigger zones, or
if non hostile objects during the neutralisation process.
Figure 6. A visual depiction of robot and object
of interest interaction.
Figure 5. Reliable communications boundary
outlined in red. Within this boundary reliable
communications are assumed.
Figure 7. Count down animation during neutralization; the filling of the empty white influence zone
annulus indicates the progress of the neutralization in stages a) start, b) quarter finished; c) almost
finished d) finished. The blue robot in b and c has its central unit flashing to indicate it is
neutralizing a hostile target.

It is straightforward to say that we have many graphical devices available for information coding
but difficult to incorporate many of these graphical devices into a single icon which optimally encodes
data. In addition, use of coding must be perceptible; a multidimensional icon which encodes a
multitude of sensor and hardware data is useless when zoomed out so far that the different codes blend
into a hardly visible blob of color. On the other hand, encoding summative values into codes for the
sake of brevity comes at the cost of not being able to drill down into each data value at a glance (e.g.
using a summative data code for four battery status readings for instance).
8. Strategies
Four strategies were created for role assignment of robots and teams of robots, prioritizing i) finding
objects of interests (OOI) by random movements, ii) maximizing the percentage of the environment
under control and observation of robots (holding ground), and iii) maximizing the mapping by sweep
through the environment.
8.1 Random robot movements
Two random search strategies were implemented. In the first, robots do not move as a team, and
they search for OOIs individually through random destination selection, and in the second, robots
maintain their group formation as a team but the location to be searched is selected randomly by the
team leader (alpha robot).
8.2 Holding Ground Strategy
Although random search is a valuable method, especially in dynamic environments, given the
complexities that exist within the considered framework of Magic 2010, especially networking, the
need for a more advance search strategy is undeniable. The holding ground strategy is designed to
minimize the area under the control of the enemy by maximizing the percentage of the environment
that is captured while giving the highest priority to preventing repenetration by the enemy. This
strategy is implemented by defining various roles for teams such as:
• Protector (Alpha/Beta): prevents repenetration by MHOs through holding strategic points.
• Relay (Ranger): provides proper network coverage through positioning the relay robots on relay
points.
• Explorer (Gamma/Kappa): maps the environment and neutralize enemies.
The relay and strategic points are defined during initialization. The exploring team has a semi
random behavior while prioritizing the un-mapped locations. This strategy is depicted in Algorithm 1.
8.3 Sweep Strategy
Figure 8. Exocentric global view.
Figure 9. Egocentric view

Similar to the holding ground approach, the highest priority in the sweeping strategy is placed on
the prevention of MHOs from penetrating into the mapped regions. The main difference between the
sweep strategy and holding ground is the defined roles for teams of robots. While the holding ground
approach has strict rules about the tasks that each team should perform, the sweep strategy provides
more flexibility by allowing the teams to switch between roles based on environmental constraints.
9. Experimental Results of the Implemented Strategies
Given that the number of SHOs, MHOs, and NCOs in the environment (in each phase) can change
the complexity of the problem, three sets of experiments featuring various numbers of MHOs, NCOs,
and SHOs were conducted. 100 runs of experiments defined based on Magic 2010 competition
framework featuring various strategies were conducted. The experimental parameterization is
presented in Table 4. Various factors were considered for the evaluation of the results achieved by each
strategy. These factors include i) the number of lost robots either due to losing network coverage or
from an explosion caused by SHOs or MHOs, ii) the number of neutralized OOIs, and iii) the
percentage of the environment that was mapped. It should be noted that at the current stage the
experiments do not take into consideration the SOL and MHI systems and are only used for the
evaluation of the suggested strategies within various phases with different level of complexities.
The strategies were implemented and tested by Hodder and Attard as part of a research project [1].
The average results achieved by the implemented strategies over 100 runs are presented in Tables 5, 6,
and 7. Given the large number of conducted experiments, only a portion of the results are reported
here. The poor performance achieved in Phase III indicates the infeasibility of the designed strategies
for such a complex phase with such a compound infrastructure.
Algorithm 1: Holding Ground Strategy
Initialization (mark strategic positions, set the teams, identify the roles)
While mapping task is not over
for each team T(i)
if the team has no task allocated to
find a random location that is not mapped
inform the relay team to provide network coverage
inform other teams to provide protection
change team's task to mapping/exploring
move toward destination while maintaining team's formation
if an SHO is found,
alert other teams
change the team's task to neutralization
protect the disruptor until the neutralization is over
if an MHO is found
alert other teams and ask for assistance
change the team's task to neutralization
maintain the distance and keep the HOOI in line-of sight until the
neutralization is over
if MHO penetrated the safe zone,
alert other teams and ask for assistance
if penetrated MHO is in-line of sight
change the team's task to neutralization
maintain the distance and keep the HOOI in line-of sight until the
neutralization is over
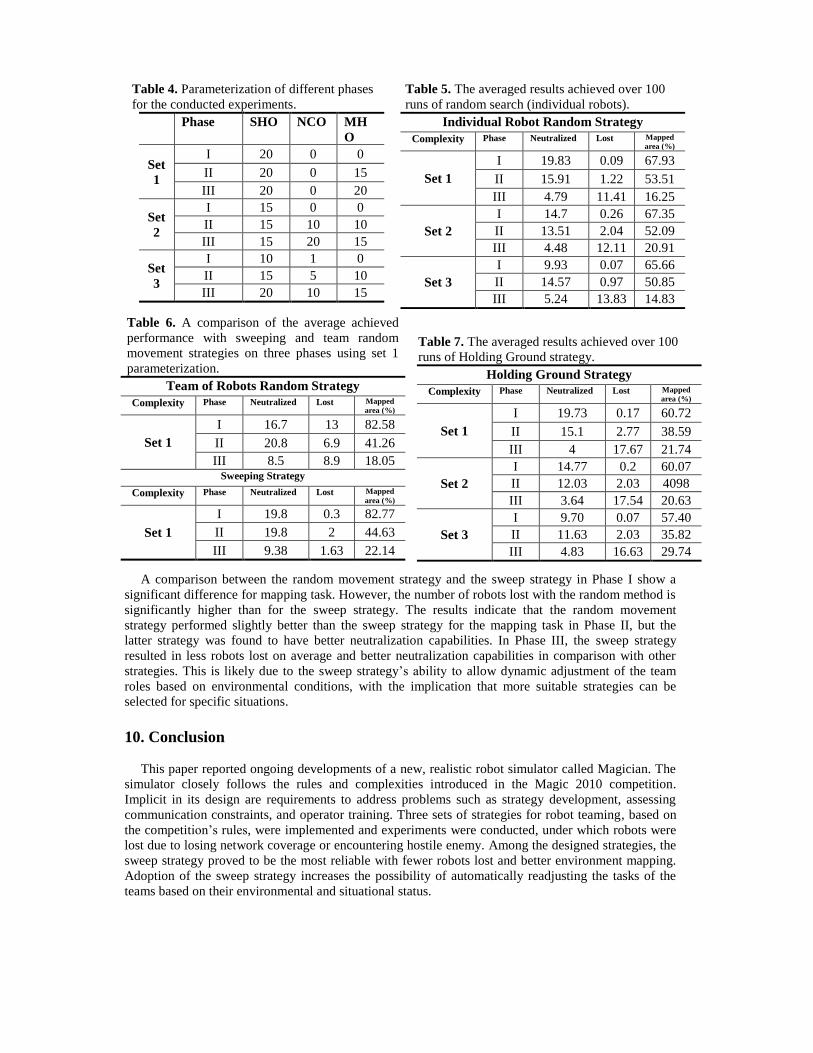
A comparison between the random movement strategy and the sweep strategy in Phase I show a
significant difference for mapping task. However, the number of robots lost with the random method is
significantly higher than for the sweep strategy. The results indicate that the random movement
strategy performed slightly better than the sweep strategy for the mapping task in Phase II, but the
latter strategy was found to have better neutralization capabilities. In Phase III, the sweep strategy
resulted in less robots lost on average and better neutralization capabilities in comparison with other
strategies. This is likely due to the sweep strategy’s ability to allow dynamic adjustment of the team
roles based on environmental conditions, with the implication that more suitable strategies can be
selected for specific situations.
10. Conclusion
This paper reported ongoing developments of a new, realistic robot simulator called Magician. The
simulator closely follows the rules and complexities introduced in the Magic 2010 competition.
Implicit in its design are requirements to address problems such as strategy development, assessing
communication constraints, and operator training. Three sets of strategies for robot teaming, based on
the competition’s rules, were implemented and experiments were conducted, under which robots were
lost due to losing network coverage or encountering hostile enemy. Among the designed strategies, the
sweep strategy proved to be the most reliable with fewer robots lost and better environment mapping.
Adoption of the sweep strategy increases the possibility of automatically readjusting the tasks of the
teams based on their environmental and situational status.
Table 4. Parameterization of different phases
for the conducted experiments.
Phase SHO NCO MH
O
Set
1
I 20 0 0
II 20 0 15
III 20 0 20
Set
2
I 15 0 0
II 15 10 10
III 15 20 15
Set
3
I 10 1 0
II 15 5 10
III 20 10 15
Table 5. The averaged results achieved over 100
runs of random search (individual robots).
Individual Robot Random Strategy
Complexity Phase Neutralized Lost Mapped
area (%)
Set 1
I 19.83 0.09 67.93
II 15.91 1.22 53.51
III 4.79 11.41 16.25
Set 2
I 14.7 0.26 67.35
II 13.51 2.04 52.09
III 4.48 12.11 20.91
Set 3
I 9.93 0.07 65.66
II 14.57 0.97 50.85
III 5.24 13.83 14.83
Table 6. A comparison of the average achieved
performance with sweeping and team random
movement strategies on three phases using set 1
parameterization.
Team of Robots Random Strategy
Complexity Phase Neutralized Lost Mapped
area (%)
Set 1
I 16.7 13 82.58
II 20.8 6.9 41.26
III 8.5 8.9 18.05 Sweeping Strategy
Complexity Phase Neutralized Lost Mapped
area (%)
Set 1
I 19.8 0.3 82.77
II 19.8 2 44.63
III 9.38 1.63 22.14
Table 7. The averaged results achieved over 100
runs of Holding Ground strategy.
Holding Ground Strategy
Complexity Phase Neutralized Lost Mapped
area (%)
Set 1
I 19.73 0.17 60.72
II 15.1 2.77 38.59
III 4 17.67 21.74
Set 2
I 14.77 0.2 60.07
II 12.03 2.03 4098
III 3.64 17.54 20.63
Set 3
I 9.70 0.07 57.40
II 11.63 2.03 35.82
III 4.83 16.63 29.74

Further experiments are required to investigate the feasibility of operators to work with the designed
HMI system in addition to evaluate the impact of SOL system on overall performance of the robots and
possible reduction of workload on operators.
11. Acknowledgments
This material is based on research sponsored by the Air Force Research Laboratory, under
agreement number FA2386-10-4024. The U.S. Government is authorized to reproduce and distribute
reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and
conclusions contained herein are those of the authors and should not be interpreted as necessarily
representing the official policies or endorsements, either expressed or implied, of the Air Force
Research Laboratory or the U.S. Government.
References
[1] Nathan Hodder, Jarred Attard, “Magic – Robot Teaming”. Honours Thesis, Flinders University,
Australia, 2010.
[2] James Cook Malcolm, Charles Cranmer, Corinne Adams, and Angus Carol, “Electronic Warfare
in the Fifth Dimension: Human Factors Automation Policies and Strategies for Enhanced Situation
Awareness and SEAD Performance”, RTO HFM Symposium on The Role of Humans in
Intelligence and Automated Systems, Warsaw, Poland, 2003.
[3] Mica R. Endsley, “Theoretical Underpinnings of Situation Awareness: A Critical Review”. In M.
Endsley, and D.J. Garland, (Eds.) Situation Awareness Analysis and Measurement. London:
Lawrence Erlbaum Associates, 2000.
[4] Lisa C. Thomas, Christopher D. Wickens, “Visual Displays and Cognitive Tunnelling: Frames of
Reference Effects on Spatial Judgments and Change Detection”, Proceedings of the Human
Factors and Ergonomics Society Annual Meeting, vol. 45, no. 4, pp. 336 - 340, 2000.
[5] Mancero Gabriela, Wong William, Loomes Martin, “Change blindness and Situation Awareness in
a Police C2 Environment”, European Conference on Cognitive Ergonomics: Designing beyond the
Produce – Understanding Activity and User Experience in Ubiquitous Environments, Article no. 5,
2009.
[6] Christopher D. Wickens, John D. Lee, Lui Yili, Gorden-Becker Sallie, “Introduction to Human
Factors Engineering” (2nd Ed.) Pearson Prentice Hall, 2003.
[7] Michael A. Goodrich, Dan R. Olsen, “Seven Principles of Efficient Human Robot Interaction”,
Proceedings of Systems, Man and Cybernetics, vol. 4, pp. 3942 - 3948, 2003.
[8] Jessie Y.C. Chen, Ellen C. Haas, Krishna Pillalamarri, and Catherine N. Jacobson, “Human-Robot
Interface: Issues in Operator Performance, Interface Design and Technologies”, Technical Report
ARL-TR-3834, Army Research Laboratory, Aberdeen Proving Ground, Maryland, USA, 2006.
[9] NASA, “Human Integration Design Handbook, Technical Report”, NASA/SP-2010-3407,
National Aeronautical and Space Administration, Washington, DC, USA. 2010.
[10] de Athaydes, R., “MAGIC HMI System”, Honours Thesis, Flinders University of South Australia,
2010.
[11] Damith C. Herath, Christian Kroos, Catherine J. Stevens, Prashan Premaratne, “Thinking Head:
Towards human centered robotics”, 11th International Conference on Control Automation
Robotics & Vision - ICARCV, pp.2042 - 2047, Singapore, 2010.
[12] David M.W. Powers, Adham Atyabi, Tom F. Anderson, “MAGIC Robots - resilient
Communications”. Spring World Congress on Engineering and Technology, 2012.
[13] Eric Martinson and Ronald C. Arkin, “Learning to role-switch in multi-robot systems”.
Proceedings IEEE International Conference on Robotics and Automation, ICRA '03. vol. 2, pp.
2727 - 2734, 2004.
[14] Francesco Mondada , Giovanni C. Pettinaro , Andre Guignard , Ivo W. Kwee , Dario Floreano ,
Jean-Louis Deneubourg , Stefano Nolfi, et al., “Swarm-bot: a new distributed robotic concept”.
Autonomous Robots, special Issue on Swarm Robotics, vol. 17, no. 2-3, pp. 193 - 221, 2004.
[15] Yang Chunming and Simon, Dan, “A new particle swarm optimization technique”. 18th
International Conference on Systems Engineering (ICSEng 2005), pp. 164 - 169, 2005.

[16] Olga Bogatyreva, Alexandr Shillerov, “Robot swarms in an uncertain world: controllable
adaptability”. International Journal of Advanced Robotic Systems. vol.2, no3, pp. 187 - 196, 2005.
[17] Justin Werfel, Yaneer Bar-Yam, and Radhika Nagpal, “Building patterned structures with robot
swarms”. In Proceedings of the 19th International Joint Conference on Artificial Intelligence
(IJCAI’05), pp. 1495 - 1502, 2005.
[18] Chang K., Jung-rae Hwang, Lee-Min Lee, and Kazadi Sanza, “The application of swarm
engineering technique to robust multi chain robot systems”. IEEE Conference on Systems,Man,
and Cybernetics, USA, vol. 2, pp. 1429 - 1434, 2005.
[19] William Agassounon, Alcherio Martinoli, and Kjerstin Easton, “Macroscopic modeling of
aggregation experiments using embodied agents in teams of constant and time-varying sizes”.
Autonomous Robots. Hingham, MA, USA, September 2004, vol. 17, pp. 163 - 192, 2004.
[20] Guillaume Beslon, Frédérique Biennier, and Béat Hirsbrunner, “Multi-robot path-planning based
on implicit cooperation in a robotic swarm”. Proceedings of the second international conference on
Autonomous agents, Minneapolis, Minnesota, United States, pp. 39 - 46, 1998.
[21] Alejandro Rodríguez, James A. Reggia, “Extending self-organizing particle systems to problem
solving”. MIT Press Artificial Life, vol. 10, no. 4, pp. 379 - 395, 2004.
[22] Ahmadabadi Majid Nili, Asadpour Masoud, Nakano Eiji, “Cooperative q-learning: the knowledge
sharing issue”. Advanced Robotics, vol. 15, no. 8, pp. 815 - 832, 2001.
[23] Jim Pugh, Alcherio Martinoli, “Inspiring and modeling multi-robot search with particle swarm
optimization”. Proceeding of the 2007 IEEE Swarm Intelligence Symposium (SIS 2007), pp. 332 -
339, 2007.
[24] Ling Li, Alcherio Martinoli, Yaser S. Abu-Mostafa, “Learning and measuring specialization in
collaborative swarm systems”. International Society for Adaptive Behavior. vol. 12, no. 3 -4, pp.
199 - 212, 2004.
[25] Kristina Lerman, Aram Galstyan , Alcherio Martinoli, “A macroscopic analytical model of
collaboration in distributed robotic systems”. Artificial Life, vol. 7, pp. 375 - 393, 2001.
[26] Sanza T. Kazadi, A. Abdul-Khaliq, Ron Goodman, “On the convergence of puck clustering
systems”, Robotics and Autonomous Systems, vol. 38, no. 2, pp. 93 - 117, 2002.
[27] Adham Atyabi, Somnuk Phon-Amnuaisuk, “Particle swarm optimization with area extension
(AEPSO)”. In: IEEE Congress on Evolutionary Computation (CEC), Singapore, pp. 1970 - 1976,
2007.
[28] Adham Atyabi, Somnuk Phon-Amnuaisuk, Chin Kuan Ho, “Effects of Communication Range,
Noise and Help Request Signal on Particle Swarm Optimization with Area Extension (AEPSO)”,
IEEE Computer Society, Washington DC, pp. 85 - 88, 2007.
[29] Adham Atyabi, Somnuk Phon-Amnuaisuk, Chin Kuan Ho, “Effectiveness of a cooperative
learning version of AEPSO in homogeneous and heterogeneous multi robot learning scenario”. In:
IEEE Congress on Evolutionary Computation (CEC 2008), Hong Kong, pp. 3889 - 3896, 2008.
[30] Adham Atyabi, Somnuk Phon-Amnuaisuk, Chin Kuan Ho, “Navigating agents in uncertain
environments using particle swarm optimization”. MSc thesis, Dept. Information Technology,
Univ Multimedia, Cyberjaya, Malaysia, 2009.
[31] Adham Atyabi, Somnuk Phon-Amnuaisuk, Chin Kuan Ho, “Navigating a robotic swarm in an
uncharted 2D landscape”, Applied Soft Computing 10, Elsevier, doi:10.1016/j.asoc.2009.06.017,
pp. 149 - 169, 2010.
[32] Adham Atyabi, Somnuk Phon-Amnuaisuk, Chin Kuan Ho, “Applying Area Extension PSO in
Robotic Swarm”, Journal of Intelligent and Robotic Systems, vol. 58, no. 3-4, pp. 253 - 285, 2010,
[33] Adham Atyabi, David M.W. Powers, “Cooperative Area Extension of PSO: Transfer Learning vs.
Uncertainty in a simulated Swarm Robotics”, IEEE, ACM, Springer Int'l Conf. on Informatics in
Control, Automation and Robotics, ICINCO’13, Island, accepted, 2013
[34] Adrian Boeing, Adrian Morgan, David M.W. Powers, Kevin Vinsen, and Thomas Bräunl,
“MAGICian”, Land Warfare Conference 2010 Brisbane, pp. 347 - 355, 2010.




















