
L'anonimato in rete
43
18 luglio 2012 L’ANONIMATO IN RETE ANDREA BRASCHI Indice 1. Introduzione 3 Introduzione 3 1.1. Il problema dell’anonimato 3 1.2. Motivi per essere anonimi 4 1.3. Panoramica sui metodi per risalire all’identit`a 4 1.4. Il nostro modello teorico 5 2. Le informazioni che trasmettiamo involontariamente 6 Le informazioni che trasmettiamo involontariamente 6 2.1. Correlazione di pacchetti e identificazione di una comunicazione avvenuta tra due macchine 6 2.2. Informazioni scambiate negli headers del protocollo http 6 3. I dati che possono venirci richiesti dal Server 9 I dati che possono venirci richiesti dal Server 9 3.1. Operazioni di Fingerprinting 9 3.2. Cookies e sessions 9 3.3. history detection 10 3.4. Script per l’identificazione della macchina 11 3.5. “No Script”: Mozzilla e la disabilitazione dei JavaScript 12 3.6. Script per la geolocalizazzione (javascript e google API) 13 3.7. Alcune considerazioni 13 4. Risalire all’identit` a anagrafica 16 Risalire all’identit` a anagrafica 16 4.1. Simulazione vs pseudonimo 16 4.2. La “raccolta di bit” 16 5. La rete TOR 18 La rete TOR 18 5.1. Una overlay network 18 5.2. Elementi base del circuito 19 5.3. Elementi base della comunicazione 19 6. Instaurazione del circuito 20 6.1. Comunicazione 22 6.2. Privoxy 22 6.3. Analisi critica degli attacchi precedentemente illustrati 23 6.4. Possibili attacchi e controindicazioni 27 6.5. Timing-attack 27 7. Conclusioni 29 1
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of L'anonimato in rete

18 luglio 2012
L’ANONIMATO IN RETE
ANDREA BRASCHI
Indice
1. Introduzione 3
Introduzione 3
1.1. Il problema dell’anonimato 3
1.2. Motivi per essere anonimi 4
1.3. Panoramica sui metodi per risalire all’identita 4
1.4. Il nostro modello teorico 5
2. Le informazioni che trasmettiamo involontariamente 6
Le informazioni che trasmettiamo involontariamente 6
2.1. Correlazione di pacchetti e identificazione di una comunicazione avvenuta tra
due macchine 6
2.2. Informazioni scambiate negli headers del protocollo http 6
3. I dati che possono venirci richiesti dal Server 9
I dati che possono venirci richiesti dal Server 9
3.1. Operazioni di Fingerprinting 9
3.2. Cookies e sessions 9
3.3. history detection 10
3.4. Script per l’identificazione della macchina 11
3.5. “No Script”: Mozzilla e la disabilitazione dei JavaScript 12
3.6. Script per la geolocalizazzione (javascript e google API) 13
3.7. Alcune considerazioni 13
4. Risalire all’identita anagrafica 16
Risalire all’identita anagrafica 16
4.1. Simulazione vs pseudonimo 16
4.2. La “raccolta di bit” 16
5. La rete TOR 18
La rete TOR 18
5.1. Una overlay network 18
5.2. Elementi base del circuito 19
5.3. Elementi base della comunicazione 19
6. Instaurazione del circuito 20
6.1. Comunicazione 22
6.2. Privoxy 22
6.3. Analisi critica degli attacchi precedentemente illustrati 23
6.4. Possibili attacchi e controindicazioni 27
6.5. Timing-attack 27
7. Conclusioni 291

2 ANDREA BRASCHI
Conclusioni 29
7.1. I rischi che si corrono in rete 29
8. Definizionie del modello sperimentale 32
Definizionie del modello sperimentale 32
8.1. Esperimenti 33
Riferimenti bibliografici 39
9. Appendici 40
Appendici 40
.1. Le macchine virtuali 40
.2. L’entropia nella teoria dell’informazione 43

L’ANONIMATO IN RETE 3
1. Introduzione
1.1. Il problema dell’anonimato. Esistono diversi motivi che spingono un utente della
rete a voler restare anonimo, cosı come esistono diversi modi per non essere identificabili;
per contro esistono diversi interessi a risalire all’identita di un utente di un certo servizio
o di una certa comunicazione e quindi anche diversi metodi per farlo.
Innanzi tutto a seconda del tipo di informazioni che si vogliono reperire si possono
distinguere quattro livelli di profondita nell’identificazione:
• stabilire che tra una determinata macchina e un determinato server e avvenuta o
sta avvenendo una comunicazione.
• riconoscere un’utente che ritorna al server e quindi correlare le sue vecchie navi-
gazioni a quelle precedenti, questa operazione a sua volta puo essere effettuata in
diversi modi:
- tramite l’utilizzo di cookies e sessions.
- risalire all’identita fisica della macchina (MAC, NIC e caratteristiche fisiche).
- riconoscendo le abitudini dell’utente( history detection, informazioni nella
cache etc.)
• geolocalizzare l’utente e la macchina client.
• risalire proprio all’identita anagrafica dell’utente della macchina client.
Figura 1. Schema riepilogativo dei livelli di identificazione
Risulta evidente che piu si scende nell’albero dei gradi di identificazione piu il riuscire
in tale intento risulta tecnologicamente complesso.
Obbiettivo di questa tesi e stata l’analisi di alcuni attacchi all’identita del client (nei
livelli di discrezione sopra citati) e dei principali metodi di identificazione. Successiva-
mente e stata analizzata ed introdotta una rete di anonimizzazione (TOR [3]) e gli stessi
metodi sono stati utilizzate per condurre un’analisi critica di tale rete, anche tramite la
realizzazione di uno di questi attacchi (timing-attack [7]).

4 ANDREA BRASCHI
1.2. Motivi per essere anonimi. Una persona che utilizza la rete puo essere interessata
a non rivelare la propria identita per non essere tracciata negli acquisti che compie su
internet e per non essere schedata nei propri interessi e quindi non essere sommersa da
pubblicita mirate dalle quali potrebbe essere piu facilmente raggirata.
In altri casi delle aziende possono essere interessate a non rendere facilmente rivelabili
le conversazioni con i propri operatori, per ragioni di brevetto, oppure studi medici o
legali devono garantire, per legge, che venga mantenuta la riservatezza delle informazioni
da loro trattate.
Ancora, la magistratura o le forze dell’ordine in alcuni casi debbono essere sicuri che
dalle loro conversazioni non si riesca a capire la posizione dei propri agenti e che quindi
un’osservatore esterno che intercetti le comunicazioni non riesca a risalire ai reali desti-
natari e/o ai contenuti. Lo stesso discorso puo esser valido per dissidenti, informatori,
giornalisti o chiunque possa essere messo in pericolo dalle informazioni che trasmette (o
dal semplice fatto di trasmetterle).
In altri casi non e sufficiente nascondere il contenuto, ma e importante che venga nasco-
sta l’avvenuta comunicazione tra due macchine (si pensi al caso di un sito con contenuti
illeciti, non interessano i contenuti passati basta saper che il tale utente ha cercato di
visualizzare una qualunque pagina del sito).
Piu semplicemente si puo pensare che un’utente della rete possa non voler essere traccia-
to e riconosciuto quando effettua delle ricerche perche spesso i motori di ricerca profilano
gli utenti per capire le aree dei loro interessi e quindi essere in grado di fornire risposte alle
loro ricerche molto piu mirate, questo pero spesso, alla lunga, porta alla visualizzazione
delle stesse pagine e soprattutto certe volte i risultati visualizzati ne tralasciano alcuni
importanti; quindi durante alcune ricerche puo essere utile connettersi allo stesso motore
di ricerca, ma senza farsi riconoscere come lo stesso utente di una navigazione precedente.
Il problema puo anche essere analizzato dal lato opposto, infatti puo essere interessante
cercare di capire quali sono dei metodi sicuri per risalire all’identita di chi usa la rete
per compiere determinate operazioni che possono essere collegate, direttamente o indi-
rettamente, a crimini e quindi fornire alle forze dell’ordine efficaci strumenti che possano
condurre all’identita di persone che si avvalgono della rete per compiere reati.
1.3. Panoramica sui metodi per risalire all’identita. In base, quindi, alle necessita
esistono diversi metodi per riconoscere l’utente alle spalle della conversazione.
Per accertare l’esistenza di una comunicazione tra due macchine e necessario inter-
cettare e analizzare il traffico di rete, oppure osservare il traffico in ingresso e in uscita
a determinate macchine ed eseguire correlazioni sul traffico. Una ulteriore possibilita e
quella di generare un determinato pattern di dati in uscita da un server che si controlla
e vedere se viene rilevato un traffico simile all’ingresso di qualche client per individuare
l’avvenuta comunicazione, analogamente usando script lato client si puo far emettere al
client stesso un particolare pattern. Questi tipi di attacchi sono detti timing-attack[7][9]
e talvolta riescono anche a danni di reti anonime a bassa latenza (TOR[3]).
Per riconoscere un returning-client, invece, puo essere sufficiente l’utilizzo di cookies o
sessions, ma in certi casi non e detto che basti e quindi bisogna ricorrere a metodi piu
artificiosi e all’utilizzo di appositi script lato server e lato client. Ad esempio si puo risalire

L’ANONIMATO IN RETE 5
all’identita della macchina, in quanto e un servizio fornito dalla gran parte dei linguaggi
di scripting web, perche puo essere anche semplicemente usato per fornire al client i
dati con impaginazione piu consona ad essere visualizzati sulla propria macchina. Inoltre
esistono piu sofisticate tecniche di scripting che si basano sull’analisi dei tempi impiegati
da una macchina per svolgere determinati algoritmi che rappresentano una caratteristica
fortemente correlata al modello di computer usato e alla sua configurazione[8][4]. E ancora
si possono usare tecniche di profilazione dell’utente come history detection etc.[6] etc.
Per risalire, invece, alla vera e propria identita anagrafica dell’utente che naviga in rete,
puo essere necessario far ricorso a piu informazioni e quindi ricorrere ad analisi incrociate
a partire dall IP e, ad esempio dagli access-point visti dalla NIC (metodo usato per
geolocalizzare un utente, anche con ottima precisione).
Obiettivo di questa tesi e stato anche capire quante informazioni si e in grado di re-
cuperare con i pacchetti in entrata/uscita dal server o dal client (analizzati dall’uno per
risalire all’altro).
Figura 2. schema logico della comunicazione in rete
1.4. Il nostro modello teorico. Scopo di questa tesi non e stato quello di analizzare
la mole di informazioni carpibili attraverso l’uso di exploit o bachi presenti all’interno del
sistema, ma quello di analizzare i dati reperibili in un’analisi entro le specifiche, quindi
ogni sistema qui presentato verra analizzato e utilizzato secondo le proprie specifiche senza
esser forzato a comportamenti inusuali.
Sorprendentemente si e dimostrato che nel web esistono una serie di comportamenti e
standard [6] che in realta rappresentano una minaccia per la privacy degli utenti della
rete e che, quindi, e utile correre ai ripari o per lo meno divenire piu consapevoli dei rischi
ai quali si va incontro muovendosi nel web.

6 ANDREA BRASCHI
2. Le informazioni che trasmettiamo involontariamente
E’ fondamentale in primo luogo capire quali sono i dati che noi stessi (il nostro browser)
forniamo inconsapevolmente ad un server presso il quale ci connettiamo, o ad un osser-
vatore esterno della nostra rete che tramite un packet-sniffer come WireShark cattura i
pacchetti che emettiamo.
2.1. Correlazione di pacchetti e identificazione di una comunicazione avvenuta
tra due macchine. Nel caso in cui una macchina client, normalmente, si sia connessa ad
un server usando un browser e trasferisca dei dati con un protocollo, come l’ http, senza
usare particolari proxy o reti di anonimizzazione, non risulta assolutamente difficile risalire
all’avvenuta comunicazione tra le due macchine. Infatti se la connessione e gia avvenuta
basta controllare i file di log del server, mentre se la connessione e in atto e sufficiente
con uno sniffer di rete porsi in mezzo al canale di comunicazione delle due macchine per
riuscire a capire se queste si stanno, o meno, scambiando informazioni a partire anche
solo dagli header dei pacchetti sniffati, come si mostra negli esempi.
Figura 3. un esempio di cattura con WireShark
2.2. Informazioni scambiate negli headers del protocollo http. Gli headers dei
pacchetti trasmessi sono facilmente accessibili a tutti (server ed osservatori della rete) a
qualsiasi livello. Dagli header del protocollo TCP e possibile ricavare mittente e destinata-
rio (indirizzo ip) del messaggio, ma ben piu importanti sono le informazioni che ci vengono
fornite dagli header http; essi infatti contengono informazioni sullo user-agent connesso
(un browser o un server?), la lingua accettata, e quindi, indirettamente, la nazionalita
di provenienza del messaggio; inoltre, nel caso in cui lo user-agent sia un server abbiamo
anche time-stamp e versione del server.
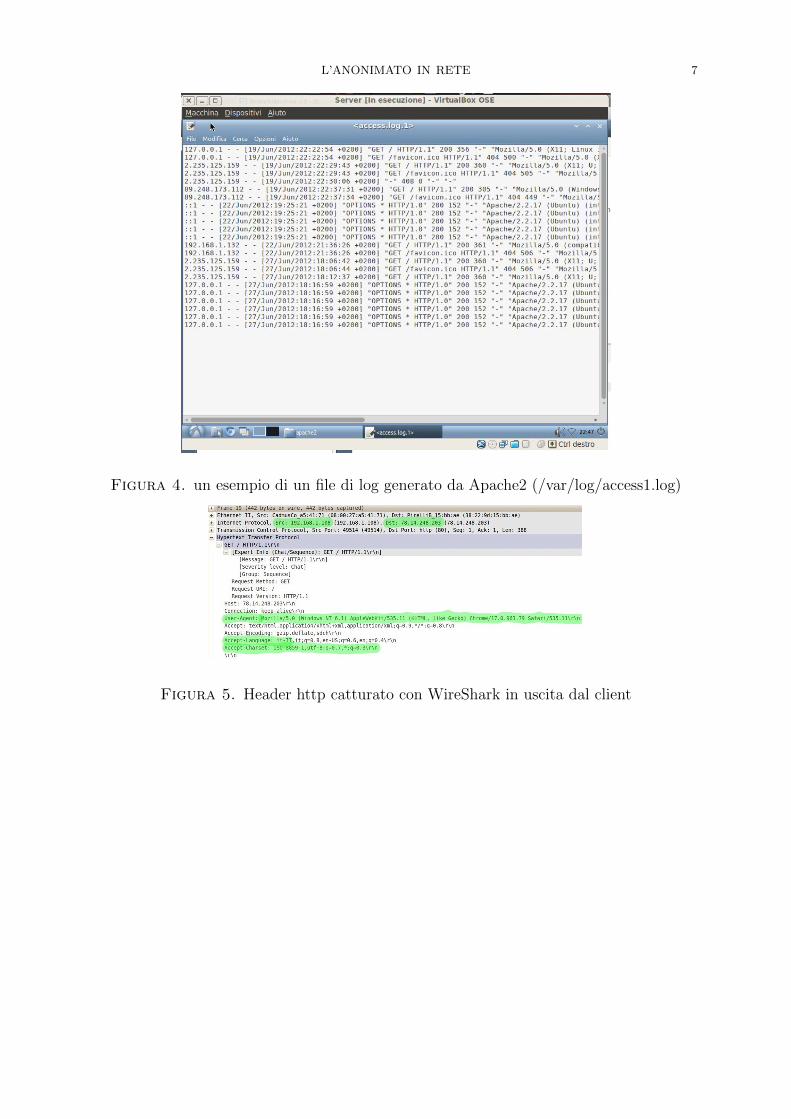
L’ANONIMATO IN RETE 7
Figura 4. un esempio di un file di log generato da Apache2 (/var/log/access1.log)
Figura 5. Header http catturato con WireShark in uscita dal client

8 ANDREA BRASCHI
Figura 6. Header http catturato con WireShark in uscita dal server

L’ANONIMATO IN RETE 9
3. I dati che possono venirci richiesti dal Server
In seconda istanza e importante capire quali sono le informazioni che ci possono venir
chieste da un server che cerchi, in modo attivo, di acquisire informazioni per risalire alla
nostra identita o per lo meno tracciarci nelle nostre navigazioni. Tale operazione e detta
fingerprinting in quanto l’attaccante cerca con tutti i mezzi a lui possibili di costruirsi
un’impronta, un segno univoco che possa distinguere il nostro device nelle richieste che
effettua al server e tracciare le navigazioni.
3.1. Operazioni di Fingerprinting. In questo capitolo vengono trattati in dettaglio i
piu comuni strumenti usati per riconoscere un returning client, partendo dai piu semplici
cookies e sessions, per concludere illustrando alcuni metodi piu complessi ma sorprenden-
temente piu efficaci e precisi.
Ogni utente e ogni macchina lascia dietro di se un’ impronta praticamente univoca
(e molto improbabile trovare due utenti con le stesse caratteristiche). Quest’impronta
e data dall’insieme delle caratteristiche fisiche della macchina: il tipo di browser e la
sua configurazione, il sistema operativo, l’architettura del processore, alcune caratteristi-
che dello schermo etc. A questi dati sono da aggiungersi informazioni riguardanti i siti
precedentemente visitati dall’utente della macchina e presenti nella history del browser.
E interessante poter analizzare quest’insieme di dati perche sono uno strumento potente
di identificazione dell’utente e da un lato agevolano la sicurezza dei sistemi informativi, in
quanto forniscono un metodo in piu da affiancare all’utilizzo delle credenziali per garantire
maggiore sicurezza, ma dall’altro sono un potente mezzo per tracciare gli utenti del web.
In seguito sono stati trattati alcuni dei principali metodi.
3.2. Cookies e sessions. Essendo il protocollo http stateless, fin da subito si e evi-
denziata la necessita di trovare un metodo che potesse servire per fornire un servizio di
riconoscimento degli utenti e che quindi sopperisse a questa mancanza dell’http. Per que-
sto si e ricorsi all’adozione dei cookies e piu recentemente delle sessions, che altro non sono
che file salvati sul client e contenenti identificatori univoci; tali file vengono ritrasmessi al
server all’atto del download di nuove pagine, permettendo cosı di riconoscere il client. Il
funzionamento dei cookies e delle sessions e analogo, cambiano solo le modalita di imple-
mentazione, ma analogamente corrispondono a delle variabili che possono essere salvate
dal server sul client ed essere richieste qualora si voglia dal server. In ogni cookie inoltre
puo essere impostato un tempo di vita, scaduto il quale il cookie non e piu considerato
valido, viene eliminato e deve essere rigenerato.
E’, quindi, evidente come l’uso dei cookies comporti un vantaggio proprio per l’utente
del web il quale non deve, in questo modo, autenticarsi in ogni pagina e puo piu como-
damente usufrire di informazioni e contenuti a lui riservati in maniera semplice, avendo
comunque le garanzie che le sue informazioni riservate rimangano tali. E pero facilmente
intuibile quali controindicazioni possa avere l’utilizzo di tali strumenti, infatti, non solo
all’interno dello stesso sito si puo tener traccia dei percorsi seguiti dall’utente e quindi
dei suoi gusti o preferenze, ma anche all’interno di piu siti, i quali semplicemente siano in
accordo sul formato (semplicemente i nomi delle variabili) del cookie e al limite abbiano
un database comune da cui si possa tracciare la navigazione di un utente in una rete di

10 ANDREA BRASCHI
contenuti piu vasta. Google gia fornisce un servizio del genere con opportune API sia per
generare pubblicita ad-hoc per l’utente sia per capire quali sono gli utilizzi che vengono
fatti di determinate piattaforme per poterne migliorare l’usabilita (in questo campo Google
Analytics rappresenta una potente dashboard [5]).Altro caso importante da evidenziare e
l’esistenza di mezzi come evercookie [10]( detti supercookies) che rappresentano l’essenza
della possibilita di un utilizzo malevolo di questi strumenti, infatti attraverso particolari
tecniche, analizzate in seguito, il suddetto supercookie viene salvato sul pc in modo che
sia veramente difficile elimanarlo.
3.2.1. evercookie never forget. Esiste, quindi, una categoria di cookies chiamata supercoo-
kies che non vengono salvati dal browser in maniera ordinaria, ma tramite API JavaScript
o Flash, le quali installano il cookies sul nostro computer in maniera piu persistente, tal-
volta nascosta e comunque sicuramente piu difficile da eliminare; un esempio di questo
tipo di supercookie e Evercookie[10], ma ne esistono veramente tanti e non e difficile
pensare a metodi alternativi per inventarne di ulteriori.
Evercookie [10] e un’ API JavaScript realizzata da Samy Kamkar, la quale ha come
obbiettivo quello di salvare sul client un cookie in maniera persistente. L’idea alla base di
evercookie e quella di salvare i dati usando tanti modi diversi messi a disposizione dall’
html, il JavaScript e Flash. Inoltre ad ogni rilettura Evercookie controlla anche che nessun
tipo di cookies usato per essere salvato sul pc sia stato cancellato dall’utente altrimenti lo
ricrea. I metodi che Evercookie usa sono i seguenti 13 ma l’autore nella documentazione
presente sul sito ne promette altri nelle successive release:
• Standard HTTP Cookies
• Local Shared Object(Flash Cookies)
• Silverlight Isolated Storage
• Salvare i cookies nei valori RGB di un’immagine PNG generata in automatico e
salvata forzatamente nella cache usando poi il tag Canvas di HTML5 per rileggere
i pixels (cookies)
• Salvare i cookies nella History del Browser
• Salvare i cookies negli ETags HTTP
• Salvare i cookies nella Cache
• window.name caching
• Internet Explorer userData storage
• HTML5 Session Storage
• HTML5 Local Storage
• HTML5 Global Storage
• HTML5 Database Storage via SQLite
3.3. history detection. Un attacco importante all’anonimato e alla privacy di un utente
del web e la history detection, che consiste nel tentare di risalire alla cronologia del
browser del client connesso. Tali informazioni sono molto piu discriminanti di quanto
possa sembrare, infatti possono sia dare molti indizi riguardo ai gusti dell’utente sia
possono, rapidamente e con bassi costi d’implementazione, rivelare che l’utente ha di
recente compilato form, frequentato social networks o letto feed rss di news site etc. etc.

L’ANONIMATO IN RETE 11
dei quali puo essere noto che lascino cookies o comunque informazioni in cache che possono
facilmente ricondurre addirittura all’identita anagrafica dell’utente.
In [6] gli autori hanno compiuto un’importante analisi di uno dei principali metodi di
hostory detection: il css-based history detection.
E esperienza comune dell’utente internet che se in una pagina web sono presenti dei
link ad altri siti e questi sono gia stati visitati dall’utente stesso appariranno di un colore
diverso da quelli ancora non visitati, questa e una caratteristica molto importante nella
creazione di siti e servizi sul web ed essa e caldamente consigliata da tutti gli esperti
di usabilita non che dalla W3C. A tale proposito, quindi, sono stati attrezzati linguaggi
come il JavaScript e il CSS per favorirne l’implementazione. L’attacco css-based history
detection a partire da questo fatto, tramite l’opportuno uso di JavaScript, genera in
una pagina HTML una serie di collegamenti (〈a〉) e valuta il colore con cui vengono
rappresentati e inoltra al server tali dati raccolti.
L’articolo [6] presenta uno studio sulla fattibilita di tale attacco dimostrando la rea-
lizzazione di un algoritmo in grado di analizzare ben 30,000 links al secondo. Inoltre
nell’articolo e stato dimostrato che ben il 76% degli utenti sotto posti a tale test sono
risultati vulnerabili a tale attacco e che, tramite una successiva analisi dei dati richiesti
da alcuni siti, e stato possibile risalire perfino allo zip code US (codice postale) del 9,2%
degli utenti. Lo scopo dello studio non era quello di risalire alle informazioni private de-
gli utenti, ma solo di dimostrarne la fattibilita, si presume quindi che uno studio mirato
alla ricerca di tali informazioni basandosi su tale attacco possa tranquilamente ottenere
risultati migliori.
E quindi dimostrato che tale vulnerabilita nella CSS sia una minaccia reale ma pur-
troppo ancora ne i grandi browser ne la W3C sono stati in grado di risolvere il problema
in quanto ormai grande parte del web si basa su questo standard e quindi la questione
non e di facile risoluzione.
3.4. Script per l’identificazione della macchina. I JavaScript forniscono un poten-
tissimo strumento per l’identificazione sia dell’utente che della macchina da egli utilizzata.
Infatti la tecnologia JavaScript e in continua evoluzione e non e implementata allo stesso
modo su tutti i browser, questo fa si che una macchina impieghi tempi diversi nell’esecu-
zione di determinate operazioni e grazie proprio allo studio di queste tempistiche e stato
dimostrato che e possibile classificare i diversi tipi di browser, inoltre, sebbene con minor
precisione, e possibile anche raccoglier informazioni riguardanti il sistema operativo e ad-
dirittura l’architettura del processore[8]. Tutte queste informazioni sono da aggiungere a
quelle che si possono naturalmente ricavare riguardo la dimensione dello schermo, la sua
risoluzione e i suoi colori, caratteristiche che JavaScript riesce a recuperare senza grossi
probelmi, in quanto necessarie per poter fornire all’utente una migliore impaginazione.
Tutti questi dati vanno cosı a costituire un’arma a doppio taglio: da un lato il server avra
a disposizione maggiori elementi per effettuare autenticazoni, (e veramente difficile che
una persona che sia riuscita ad entrare in possesso di credenziali di un utente riesca anche a
ricreare le stesse condizioni software/hardware dell’utente originario) e si pensa che questo
strumento un domani possa anche essere usato dalle banche, o comunque, da tutti quei
servizi online particolarmente riservati che usufruiscono di chip per la generazione di chiavi

12 ANDREA BRASCHI
(generalmente numeri pseudocasuali) che rappresentano una vera e propria scomodita,
nonche un rischio (perdita del chip), per l’utente. Dall’altro lato facilitano il compito ad
un attaccante che volesse tracciare la navigazione di un utente attraverso diversi siti,
anche se quest’ultimo sta usando una rete anonima come TOR, in quanto comunque la
sua macchina lascerebbe una vera e propria “impronta digitale” del proprio passaggio.
Nel loro studio K. Mowery et al.[8] per dimostrare la fattibilita di tale operazione di
fingerprinting tramite JavaScript, utilizzando benchmark come SunSpider e V8 hanno
messo a punto ben 39 test basati ad esempio su cicli innestati, generazione di numeri
casuali e operazioni aritmetiche. Eseguendo questi test su oltre un migliaio di macchine
con le opportune messe a punto per migliorare la varianza dei dati raccolti, han dimostrato
esser possibile classificare le caratteristiche delle macchine in base al risultato dei test. Di
fatto ogni macchina ha restituito un vettore a 39 dimensioni (i 39 tempi dell’esecuzione
dei test) e dopo aver costruito un idoneo training-set sono stati in grado di classificare
macchine sconosciute solo tramite l’analisi di tale vettore, usando la semplice distanza
euclidea (nel caso di identificazione di browser e OS) o il metodo del 1-nearest-neighbour
(nel caso dell’architettura del processore). Quest’analisi ha dimostrato che tramite questo
tipo di fingerprinting e possibile ottenere un informazione riguardo la macchina utilizzato
con ben 18 bit di effettiva entropia1 [8].
3.5. “No Script”: Mozzilla e la disabilitazione dei JavaScript. Intuitivamente si
puo pensare che una possibile soluzione a tale problema dovuto alla ingente quantita
di informazioni passate da i JavaScript sia quella di disattivarli. La questione risulta
comunque piu complicata di quanto uno si possa aspettare. Si consideri ad esempio la
possibilita di usare un’apposito plug-in del browser che adempia a tale obbiettivo, come
ad esempio il diffuso “No Script” per Mozila; in realta l’utilizzo di questo plug-in, come
analizzato in [8],puo far trapelare molte piu informazioni di quante si possa immaginare.
Si consideri, ad esempio, lo specifico caso di “No script”, il suo funzionamento prevede che
tutti gli script vengano bloccati, addirittura nella fase di fetching. Risulta pero scomodo
avere tutti gli script bloccati in quanto in molti casi questi sono fondamentali alla corretta
visualizzazione di pagine web o all’esecuzione di piccoli giochi. Quindi e implementata
una, cosı detta, white-list nella quale l’utente aggiunge esclusivamente i siti trusted che e
solito frequentare e dei quali quindi e disposto ad eseguire gli script. I problemi cominciano
quando un sito malevolo riuscisse per un qualsiasi motivo ad entrare in questa lista, usando
piu o meno sofisticati metodi dell’ingegneria sociale (per esempio se nella pagina ci fosse
un gioco l’utente sarebbe obbligato a permettere l’esecuzione degli script per eseguire il
gioco), ed eseguire un suo script. In[8], infatti, e stato dimostrato che e possibile creare
uno script che riesce ad analizzare la white-list e capire cosı i gusti dell’utente e avere un
modo efficace per riuscire a distinguerlo in maniera univoca.
La realizzazione di tale script e relativamente semplice. Per determinare se un dominio
appartiene o meno alla white-list basta cercare all’interno di una pagina del dominio un
file .js che venga importato e analizzare se nello script vi e qualche variabile che viene
settata, quindi basta importare lo script nella nostra pagina di test e con un ulteriore
script controllare o meno l’esistenza di tale variabile: se la variabile esiste il dominio e
1cfr Appendice .2

L’ANONIMATO IN RETE 13
nella white-list, altrimenti no. In [8]si e mostrato come sia possibile generare in maniera
automatica una sofisticata pagina che compia un gran numero di queste analisi utilizzando
un web-spider e un tool per analizzare un gran numero di domini (nella fattispecie circa
700) in tempi ragionevoli.
3.6. Script per la geolocalizazzione (javascript e google API). Un’informazione
che porta con se molti bit di informazione e la nostra posizione geografica, se il dispositivo
da cui ci connettiamo ne e provvisto e possibile risalire a tale dato tramite GPS, oppure
con meno accuratezza si puo risalire alla posizione geografica tramite l’indirizzo IP, inoltre
esiste anche un’altro metodo chiamato wifi router-based geolocation che riesce ad effettuare
rilevamenti con una precisione notevole.
Forse a molti non e noto che tra le informazioni raccolte dalla Google-car, vi sono anche
tutte le posizioni e i BSSID degli access-point wifi. Tali dati sono l’elemento base della
wifi router-based geolocation tale metodo consente di ottenere informazioni sulla posizione
geografica il piu delle volte con un errore dell’ordine dei 50 metri.
L’algoritmo e semplice e consiste nel farsi inviare dal client i BSSID degli access-point
visti dalla NIC con le relative potenze del segnale; dalle potenze del segnale e quindi pos-
sibile ricavare la distanza dall’emettitore e quindi di conseguenza conoscendo la posizione
di almeno tre di questi access-point e possibile risalire alle coordinate del client.
Per fortuna il sistema di Google per poter effettuare una tale analisi ha bisogno del
nostro consenso, di contro pero fornisce un’API che dato un BSSID ci restituisce le coor-
dinate dell’access-point, quindi un qualsiasi attaccante scrivendo un JavaScript che gli
fornisca i dati della scheda di rete e poi in grado di risalire alle coordinate di un client a
lui connesso senza che questi ne sia a conoscenza.
3.7. Alcune considerazioni. Dagli articoli analizzati e emerso che le caratteristiche
delle nostre macchine, sia quelle fisiche (microprocessore, RAM etc) che quelle software
come il sistema operativo, il tipo di browser usato con relative cache e history ma anche
con plug-in che possiamo avere installato e le loro specifiche configurazioni possono fornire
a tutti gli effetti un impronta inequivocabile ed univoca di quella che e la nostra identita
nel web rendendoci facilmente tracciabili.
A tale scopo la Electronic frontier foundation ha iniziato un progetto, Panopticlick,
per dimostrare la potenzialita di questo tipo di informazioni, proprio in termini di bit
di entropia2. Qualsiasi utente puo sottoporsi a questa analisi contribuendo a fornire da-
ti significativi per le ricerche del gruppo sperimentale, nonche verificando il grado di
tracciabilita del proprio browser.
L’algoritmo di fingerprinting usato da [4] raccoglie una serie di dati usando gli strumenti
forniti da JavaScript e Flash, in particolare si e rivelata molto importante l’analisi svolta
sui tipi di fonts installati, che derivano dai plugins installati. Si e visto come l’ordine con
cui tali fonts vengono riportati dipenda dalla struttura del file system e quindi, di fatto
dall’ordine con cui vengono installati, diventando un caratteristica molto particolare e,
quindi, portatrice di un’alta entropia. Ancora, si e visto come sia possibile e utile ottenere
l’elenco dei plugins e dei MIME installati, in questo modo non solo si aumenta in maniera
2cfr Appendice .2

14 ANDREA BRASCHI
Figura 7. Risultato del Test di Panopticlick
consistente l’entropia delle informazioni raccolte, ma si mostra come gli stessi pluggins
anti-tracking, col solo fatto di essere installati, forniscano un importante informazione
soprattutto se sono globalmente poco diffusi. Un altro inconveniente dovuto all’utilizzo di
pluggin anonimizzanti e il fatto che spesso rispondono occultando alcune caratteristiche
nell’enumerazione, oppure simulando header di differenti user-agent ma poi testati su
alcuni tempi di risposta si comportano diversamente dalle aspettative creando ancora

L’ANONIMATO IN RETE 15
una volta una combinazione di informazioni singolare e quindi con un’alta entropia.
Inoltre gli autori di [4] pongono un notevole dilemma sulla debuggability dei browser
o dei pluggin, infatti gli sviluppatori tendono a far sı che un server possa facilmente
ottenere informazioni riguardo alla versione (e micro versione) dei plugin per agevolare
la segnalazione di problemi e bug, queste informazioni pero ancora una volta sono una
combinazione ad alta entropia e permettono di ottenere dati fondamentali per tracciare
gli utenti del web. E quindi importante che gli sviluppatori giungano in fretta ad un buon
compromesso per poter garantire la debuggability e al contempo la non tracciabilita.
Un ultimo punto trattato dall’EFF e la questione dell’evoluzione tecnologica; si e visto
come, anche se gli strumenti che si interfacciano col web sono in continua evoluzione e,
quindi con essi mutano anche i fingerprint, le mutazioni non siano cosı radicali e in realta
possano essere benissimo seguite da un semplice algoritmo euristico permettendo cosı una
tracciabilita prolungata nel tempo.
3.7.1. code injection. E rilevante notare che tali informazioni non possono essere carpite
solamente da un server malevolo, ma e sufficiente che l’attaccante abbia anche solo l’acceso
alla rete del server, in modo da poter catturare il traffico entrante e uscente da tale nodo,
infatti tramite attacchi del tipo man in the middle (ad es l’arp poisoning) e possibile
contraffarre I pacchetti sniffati e aggiungervi il codice malevolo per ottenere le informazioni
desiderate. Nel codice in questione bastera poi aver la cura di trasmettere I dati di nostro
interesse nelle query delle pagine successive nella navigazione del nostro utente in modo
cosı di poterle recuperare o dai log del server o ancora una volta sniffando I pacchetti in
entrata senza assolutamente essere invasivi.
3.7.2. come fare per non essere tracciati. Un buon modo per non essere tracciati e rinco-
nosciuti risulta, quindi, quello di impedire al sever di memorizzare informazioni sul nostro
dispositivo, disabilitando ogni possibile cookie o session. Tale azione comporta, d’altro
canto, che non potremo usufrire di una rete a stati e di tutti i servizi relativi a tale funzio-
ne. Questa operazione e, poi, resa piu ardua dall’esistenza di innumerevoli supercookies,
quindi l’utente che non volesse farsi tracciare dovrebbe anche bene informarsi su tali stru-
menti e prevenirne la memorizzazione. Inoltre bisogna anche difendersi dagli altri possibili
modi che un server puo avere per tracciare un utente. A tali scopi e necessario impedire
l’esecuzione di qualsiasi programma lato client (JavaScript, Flash etc.), ancora una volta
a scapito dell’usabilita del web.
Ma anche rinunciando a tutto non si puo stare tranquilli, in quanto, proprio, questa
configurazione molto particolare del browser potrebbe fornire una nostra impronta univoca
e quindi renderci molto facilmente tracciabili.
Una possibile soluzione potrebbe consistere nell’uso di un proxy a livello di rete e a
livello applicativo e una volta identificati i dati che vengono richiesti come fingerprint
modificarli ad ogni richiesta cercando sempre di usare combinazioni differenti, di modo
da avere un’impronta diversa ad ogni pagina che si scarica, inoltre se si conoscono i
meccanismi di fingerprinting usati dal determinato server sul quale si vuole agire non
tracciati risulta facile automatizzare tale operazione, in questo caso come vedremo in
seguito puo anche essere efficace l’utilizzo di proxy rete come Privoxy e reti anonime
come TOR.

16 ANDREA BRASCHI
4. Risalire all’identita anagrafica
Figura 8. parte dello schema di comunicazione che interessa il passaggio
di informazioni personali rigurdanti l’utente
Come risulta dallo schema iniziale, l’ultimo step, nonche il piu difficoltoso e il riuscire
a risalire, tramite le informazioni della navigazione, all’identita anagrafica della persona
fisica che, in un determinato momento, sta usando la macchina.
Tale accuratezza, e difficilmente ottenibile senza il consenso dell’utente, il quale di sua
spontanea volonta ceda questi suoi dati personali.
Nell’ambito di questa tesi, come gia precedentemente detto nella definizione del modello
teorico, si e presupposto il perfetto rispetto delle regole da parte di tutti gli elementi e gli
individui in gioco; percio non sono stati trattati i casi in cui un utente sia stato interessato
a falsificare i propri dati personali ma, al limite, si e considerato il caso in cui tale individuo
abbia avuto l’interesse di non rivelarli. Allo stesso modo non si sono analizzati i casi in
cui il server, o un piu generico attaccante, abbiano cercato in maniera attiva di ottenere
dati personali e identificativi dell’utente attraverso forzature dei sistemi.
Si sono trattati, invece i casi, in cui tutte le operazioni si sono svolte in maniera legale;
quindi si sono brevemente introdotti i principali punti riguardanti la trattazione di dati
esposti in [2].
4.1. Simulazione vs pseudonimo. Per prima cosa e importante evidenziare come la
legge permetta ad una persona fisica utente del web di non rivelare la propria identita su
internet e quindi di poter usare un pseudonimo. Tale affermazione e vera entro certi limiti,
infatti tale operazione diventa reato di simulazione nel momento in cui chi la compie ne
riceve in ingiusto guadagno o e causa di un altrui danno.
4.2. La “raccolta di bit”. Secondo il decreto [2] una persona fisica, una persona giuridi-
ca, la pubblica amministrazione e qualsiasi altro ente, associazione od organismo possono
richiedere, per un determinato trattamento, i dati personali degli utenti dei loro servi-
zi, dovendo pero garantire agli utenti il rispetto di determinate regole e vincoli, i quali
ad esempio impongono che non vengano rivelati dati personali sensibili etc.(per una piu
dettagliata trattazione si rimanda proprio al decreto [2]).
Un server puo quindi o richiedere all’utente dei dati personali identificativi al fine di,
appunto, identificarlo, oppure puo raccogliere, tramite le suddette operazioni di finger-
printing, sufficienti dati da riuscire a definire inequivocabilmente e risalire all’identita
anagrafica dell’utente.
Sulla Terra ci sono, circa, 6 miliardi di persone; quindi come si puo ben vedere, par-
tendo dalle definizioni fornite precedentemente, una serie di informazioni con un entropia

L’ANONIMATO IN RETE 17
effettiva di 33 bit e in grado di definire in maniera univoca un essere umano. Quindi qua-
lora un sistema fosse in grado di ottenere tale numero di informazioni sarebbe in grado di
tracciare univocamente un utente del web, ma soprattutto potrebbe risalire alla persona
fisica che sta utilizzando la macchina client.E importante notare subito come tutte queste
informazioni, non debbano e non possano riferirsi soltanto alla macchina ma anche all’u-
tente, questione che rende ancora piu difficile la raccolta (soprattutto se l’utente non li
vuole fornire o li falsifica) di un’ingentissima quantita di dati. Quest’operazione utopica e,
pero, resa molto piu realizzabile di quanto si possa pensare, se si utilizzano informazioni
come la geolocalizzazione e dati relativi alle abitudini sul web (history detection).

18 ANDREA BRASCHI
5. La rete TOR
A questo punto risulta interessante introdurre uno dei piu diffusi metodi di anonimiz-
zazione e valutarne l’effetto sugli attacchi all’anonimato precedentemente illustrati, so-
prendentemente diverra evidente che ancora si riescono a reperire una notevole quantita
di informazioni.
Figura 9. schema logico del posizionamento della rete TOR all’interno
dello schema di comunicazione precedentemente visto
TOR( the onion router )[3] e un progetto open source, che si pone l’obbiettivo di offrire
una rete anonima. A differenza di altri precedenti servizi la rete TOR offre un servizio a
bassa latenza, per cui riesce a supportare la grande maggioranza dei servizi di maling e chat
del web, in quanto benche la comunicazione sia rallentata e pero di gran lunga piu veloce
di quella fornita da servizi ad alta latenza, per via dell’utilizzo di algoritmi di controllo
della congestione e una struttura a leaky pipe. Questa rete e circuit based per cui ogni
client TOR instaura periodicamente un circuito, negoziando con ogni singolo hop (nodo
della rete) una session key, per cui garantisce che la comunicazione avvenga in maniera
sicura, e soprattuto che nessun’osservatore analizzando il traffico in uscita e in entrata
da un nodo sia in grado di correlarlo e ricostruire effettivamente il percorso. A differenza
delle precedenti versioni, l’ultima release di TOR usa un’unico circuito per piu flussi
TCP, questo per garantire migliori prestazioni in quanto la creazione dei circuiti costa
molto tempo, comunque per garantire l’anonimato e necessario periodicamente cambiare
il circuito e quindi distruggere quello vecchio. Ogni nodo all’interno del circuito conosce
solo i nodi a lui adiacenti, ma non le loro chiavi che sono note solo all’Onion proxy che
sta usando rete per comunicare, al momento della distruzione del circuito tutti questi dati
vanno persi. Un nodo puo essere attraversato da piu circuiti e un circuito puo portare piu
stream di dati.
Per favorine l’usabilita i proxy TOR forniscono un’interfaccia di Proxy SOCKS per cui
e garantito il supporto alla stragrande maggioranza delle possibili applicazioni, al costo,
pero, di una maggiore lentezza dovuta al fatto di incapsulare il TCP sul TCP stesso.
In sintesi la rete TOR garantisce: una bassa latenza e quindi non viene alterato l’ordine
di invio e ricezione dei paccheti, una perfect forward secrecy cioe un’osservatore locale
non puo conoscere o alterare il contenuto dei pacchetti inviati quand’anche riuscisse a
catturarli (comunicazione tramite Transport Layer Security a chiavi effimere), ma non
garantisce anonimato e sicurezza nei confronti di un nemico globale, che quindi riesca a
osservare completamente la rete e monitorarne i volumi del traffico [9], come vedremo
queste caratteristiche sono alla base degli attachi che vengono effettuati ai danni della
rete TOR.
5.1. Una overlay network. TOR si definisce[3] una distributed overlay network, cio
significa che sopra la rete IP tramite nodi che comunicano, a livello applicativo, con un
protocollo TLS con chiavi effimere, si crea un’altra rete virtuale a livello di trasporto(

L’ANONIMATO IN RETE 19
TCP ). Come gia accennato tale soluzione comporta che la latenza sia maggiore, pero e
il concetto chiave alla base delle garanzie di anonimato della rete TOR.
5.2. Elementi base del circuito.
• Onion proxy(OP): Il proxy e quel programma, che installato sul client, si occupa
di instaurare i circuiti e controllare il flusso, contratta con ogni nodo del circuito le
chiavi per la comunicazione, chiavi che usa per comunicare con i nodi o trasferire
dati end-to-end.
• Onion router(OR): I router rappresentano i nodi della rete TOR; sono in grado
di ricevere e inviare celle, decrittarle o criptarle con la propria chiave, come gia
detto non hanno una conoscenza globale del circuito di cui fanno parte e possono
far parte di piu circuiti.
I nodi comunicano tra di loro tramite connessioni TLS con chiavi effimere, assicu-
rando cosı una perfetta segretezze nella trasmissione(perfect forward secrecy) dei dati e
autenticazione di contenuti ed interlocutori.
5.3. Elementi base della comunicazione. Le celle sono l’elemento base della comu-
nicazione nella rete TOR e sono pacchetti da 512 bytes suddivisi in intestazione e dati.
Esistono due tipi di celle.
• Control cell : Una control cell e una cella usata per inviare ai nodi dei dati non diret-
tamente coinvolti nella comunicazione end-to-end, ma bensı per svolgere operazioni
di controllo e gestione degli anelli. Possono essere di cinque tipi:
- Padding : non ancora utilizzate, servono a prevenire timing-attack.
- Create: usate per creare o estendere un circuito, contiene i dati necessari per
contrattare le chiavi per la comunicazione.
- Created : usate per confermare l’avvenuta creazione del ciruito e trasmettere
le chiavi.
- Destroy : usate per distruggere circuiti inutilizzati.
• Relay cell : Le relay cell sono le celle usate per trasmettere messaggi end-to-end,
oppure per inviare delle control cell a nodi successivi al primo dell’anello. Esistono
diversi tipi di relay cell, quelle per contenere dati, quelle per instaurare connessioni
con i server esterni alla rete TOR, controllare la congestione etc. Gli header di
queste celle, oltre a contenere i vari dati per gestirne l’instradamento (CIRCID
et similia) contengono anche un checksum per controllare l’integrita della cella
una volta giunta a destinazione. Header e payload delle celle sono criptati con un
cifrario AES a 128-bit in modalita counter per garantirne la segretezza.
Figura 10. struttura delle celle [3]

20 ANDREA BRASCHI
6. Instaurazione del circuito
• Creazione ed espansione del circuito: Al momento di instaurare un anello l’OP
invia al primo OR del percorso una cella con il comando CREATE e nella parte
dei dati il codice concernente la prima parte dell’handshake di un protocollo di
Diffie Hellman per iniziare a contrattare la session key e il CIRCID del circuito
che vuole creare, a questa cella l’OR risponde con una cella CREATED e la chiave
per la sessione. La comunicazione e quindi instaurata, per estendere il circuito ora
basta che l’OP mandi al primo OR una cella relay EXTEND con l’handshake di
Diffie Hellman e l’indirizzo dell’ OR a cui estendere il circuito( OR2), a questo
punto l’OR1 procede analogamente a quanto detto precedentemente e estende il
circuito all’OR2, il quale invia la session key che viene direttamente inoltrata a
OP in una cella relay EXTENDED. La prossima volta che dovra essere esteso il
circuito OP invia una relay cell che pero sara criptata con la chiave di OR2 e
quindi non potra essere letta da OR1.
Figura 11. esempio del’istaurazione di un circuito nella rete TOR [3]
• La struttura a leaky pipe: Attraverso la stratificazione della crittografia l’OP decide
il destinatario del messaggio semplicemente fermandosi alla costruzione del suo
strato di crittografia. In questo modo l’OP puo anche decidere di cambiare exit
node all’interno dell’anello (magari per problemi di exit polices).
Come gia detto l’OP contratta con ogni OR del circuito le chiavi con cui criptare i
messaggi; l’OP, quindi, prima di inviare una cella la cripta con le diverse chiavi dei nodi
nei quali passera, nell’ordine inverso a quello con cui la cella incontrera i nodi, cosı facendo
aggiunge attorno alla cella degli strati (come una cipolla!!) di crittografia che mano a mano
verranno rimossi dai vari nodi, il nodo che riceve il messaggio ed e in grado di decifrarlo lo
interpreta e non lo inoltra piu a nessuno. E’ evidente che cosı facendo la cella non viaggia
mai in chiaro all’interno della rete TOR e da ogni nodo esce con una crittografia diversa ed
e quindi estremamente difficile tracciarla. E pero vero che il contenuto della comunicazione
viaggia in chiaro nel tragitto dall’ exit node al server con cui si sta comunicando, e quindi
necessario, per mantenere una maggior, sicurezza comunicare tramite protocolli sicuri,
come HTTPS o SSH.

L’ANONIMATO IN RETE 21
Risulta ancora evidente che, quando, l’OP vorra comunicare con un nodo all’interno del
circuito diverso dall’exit node gli bastera, semplicemente, fermarsi alla costruzione dello
strato corrispondente al nodo con cui vuole comunicare, in questo modo puo cambiare exit
node, oppure decidere di troncare il circuito o modificarlo per controllare la congestione.
Analogamente, in ricezione, il circuito della rete TOR riceve, nel suo ultimo nodo, il
pacchetto dati che incapsula nelle celle alle quali aggiunge il suo strato di crittografia, e
le inoltra al nodo a lui precedente, la cella percorre il circuito a ritroso e ogni OR che
attraversa le aggiunge il suo strato di crittografia, alla fine giunge all’OP al quale non
resta altro compito che “sbucciare la cipolla” e passare la cella a livello applicativo.
Figura 12. schema della comunicazione attraverso la rete TOR

22 ANDREA BRASCHI
6.1. Comunicazione. Per iniziare una comunicazione l’OP decide con quale nodo del
circuito comunicare col server ( ad eccezione di casi particolari e l’ultimo), quindi gli invia
una relay cell begin, il nodo instaura la connessione e risponde con una relay cell connected.
Come gia detto ogni cella contiene un campo di checksum nell’header, tale campo
e un digest SHA1 del campo dati esso viene controllato per verificare l’integrita della
trasmissione e anche per capire se la cella e da inoltrare oppure e destinata al nodo che ne
e in possesso, infatti se l’OR che riceve la cella dopo averla decrittata, riesce a leggere il
digest, significa che il messaggio era diretto a lui altrimenti significa che la cella deve essere
inoltrata al nodo successivo, se una volta giunta a destinazione la cella arriva corrotta il
circuito viene distrutto e la comunicazione viene effettuata su un altro circuito nuovo.
Inoltre se il pacchetto giunge a destinazione e il checksum non e ritenuto valido( non
coincide con quello calcolato al momento della ricezione) il pacchetto viene rifiutato, il
circuito viene chiuso e se ne crea un’altro( end-to-end integrity check ).
Grazie al design incrementale la rete Tor garantisce che nessun nodo malevolo o fasullo
possa intromettersi, ad esempio fingendosi un altro nodo o obbligando gli altri nodi a
fornirgli i pacchetti a loro destinati decrittati. Inoltre, grazie ai controlli sul checksum
e alla possibilita di rilevare congestioni e/o nodi che interrompono la comunicazione e,
quindi, potendo decidere di cambiare il circuito, viene garantito che il pacchetto giunga
sempre a destinazione in tempi relativamente brevi( perfect forward secrecy & low-latency
).
Per ora la possibilita di introdurre padding cell( cioe celle riempitive per evitare timing
attack ), e prevista ma non ancora messa in atto perche non si ritengono una reale mi-
naccia alla sicurezza del sistema gli attacchi basati sull’analisi del traffico; pero, qualora
si verificasse che tali attacchi rappresentino una vera minaccia, il sistema e pronto per
correre ai ripari.
Figura 13. schema logico del posizionamento di Privoxy all’interno dello
schema di comunicazione precedentemente visto
6.2. Privoxy. Privoxy[1] e un non-caching web proxy, e un progetto open source e ha lo
scopo di proteggere la privacy degli utenti della rete. Il proprio Browser puo essere configu-
rato, in modo che usi Privoxy come proxy per le connessioni http e https, in questo modo
Privoxy agisce fitrando le pagine prima che vengano visualizzate dal browser eliminando
le pubblicita, i pop-up e controllando gli accessi. Spesso viene usato concatenato alla rete
Tor per aggirare la censura su internet. Gli stessi sviluppatori di Tor consigliano[3] l’uso
di Privoxy per migliorare la sicurezza e i servizzi di anonimizzazione offerti dalla loro rete.

L’ANONIMATO IN RETE 23
6.3. Analisi critica degli attacchi precedentemente illustrati. Spesso vengono so-
pravvalutate le potenzialita della rete TOR, essa infatti garantisce anonimizzazione solo a
livello di rete, come si puo vedere dagli screenshot di wireshark, gli headers dei pacchetti
intercettati3 non forniscono piu informazioni interessanti sugli indirizzi IP come nell’esem-
pio precedente, e in uscita al client troviamo solo pacchetti TLS criptati dai quali non e
possibile dedurre il contenuto.
Figura 14. header http di richiesta GET catturato in ingresso al server
ottenuto connettendosi attraverso la rete TOR
Figura 15. header http catturato in uscita dal server verso la rete TOR
Cio che non e garantito dalla rete TOR e la difesa da tutti quegli attacchi che tracciano
l’utente nelle sue navigazioni 4in quanto tutte queste operazioni sono svolte a livello appli-
cativo. Come si vede, infatti le componenti http del pacchetto sono intatte; in particolare
si puo notare come, nonstante l’IP sorgente del pacchetto GET sia differente da quello
vero, le informazioni sullo user-agent e in particolare sulla lingua accettata siano le stesse
dell’esperimento effettuato precedentemente senza la rete TOR.
3Riproducendo la stessa situazione della sezione 2.4cfr. Sezione 3.

24 ANDREA BRASCHI
Figura 16. Risultato del Test di Panopticlick cancellando i dati di navigazione
Si e dimostrato, inoltre, che connettendosi a panopticlick con lo stesso browser (avendo
rimosso history e cookies tra una connessione e l’altra), prima tramite l’usuale rete internet
e successivamente attraverso la rete TOR o Privoxy l’entropia delle informazioni e ridotta
solamente di uno o due bit su 20, e il calo e sempre riscontrato nelle informazioni dovute
ai plugin installati, visto che pero questi particolari sono a livello applicativo e quindi
in realta non vengono cambiati da TOR e Privoxy un tale risultato sembra piu essere

L’ANONIMATO IN RETE 25
Figura 17. Risultato del Test di Panopticlick cancellando i dati di
navigazione e usando la rete TOR
dovuto ad una imprecisione nel programma di fingerprinting che effettivamente all’utilizzo
dei sopracitati programmi di anonimizzazione. Si noti anche come rispetto alla prima
connessione l’entropia non sia sostanzialmente cambiata in quanto non viene effettuato
alcun tipo di history detection informazione che aumenterebbe drasticamente l’entropia.

26 ANDREA BRASCHI
Figura 18. Risultato del Test di Panopticlick cancellando i dati di
navigazione, usando la rete TOR e Privoxy
In aggiunta si consideri il fatto che, come constatato anche dall’autore di [4], il test-
set dell’esperimento e un gruppo di utenti che e interessato all’argomento e che quindi
spesso si connette al sito con strumenti come Privoxy e TOR per testarne l’efficacia (come
abbiamo fatto noi) e che quindi il valore dell’entropia delle informazioni usa TOR, usa
Privoxy e sicuramente sottovalutata in quanto e una caratteristica molto piu comune nel

L’ANONIMATO IN RETE 27
test-set di quanto lo sia nella realta.
Come gia detto la soluzione a questo tipo di problema (la tracciabilita) potrebbe essere
non tanto il non fornire informazioni su di se (che potrebbe risultare, paradossalmente,
una caratteristica unica e quindi in grado di identificarci) ma, bensı, fornire informazioni
realistiche ma sempre diverse (ad ogni richiesta http o pagina che si scarica).
6.4. Possibili attacchi e controindicazioni. Gli attacchi che possono avere un maggio-
re effetto per l’identificazione degli utenti della rete TOR, sono i cosı detti timing-attack,
i quali si basano sul correlare pacchetti catturati in uscita da alcuni client con quelli in
entrata su un determinato server, in alcuni casi possono essere inseriti all’interno dei dati
inviati dal server degli script appositi per emettere dati secondo determinati pattern di
volume e quindi riconoscere il client incriminato con maggiore facilita.
Un’altro problema notevole risiede nel fatto che spesso alcune applicazioni inviano pac-
chetti al loro DNS con l’indirizzo dell’host con cui stanno comunicando senza usare la rete
TOR e, quindi, di fatto emettono dei pacchetti con l’indirizzo del destinatario della comu-
nicazione in atto, facendo venir meno l’anonimato garantito da TOR. Al fine di evitare
un simile inconveniente e sempre buona cosa usare TOR concatenandolo con Privoxy.
6.5. Timing-attack. a rete TOR non garantisce anonimato nei confronti di un attac-
cante globale che, cioe, controlli e possa analizzare il traffico di tutta la rete, o per lo meno
di due end point. Tale situazione in realta e meno improbabile di quanto si possa pensare;
si immagini infatti, che in un ipotetico blog dell’Universita appaiano messaggi diffamatori
nei confronti di un individuo, mettiamo caso un docente, molto probabilmente il diffa-
matore stesso (che plausibilmente conosce la vittima e fa parte del suo ambiente) usa
la rete dell’Universita per connettersi alla rete TOR; in questo caso e evidente come nei
nodi di commutazione della rete interna dell’Ateneo saranno presenti dei dati dai quali e
possibile ricavare i volumi di traffico dei due end point della rete TOR e quindi correlando
il traffico in ingresso al suddetto blog con quello in uscita a uno dei nodi sospettati capire
chi stava effettivamente commettendo la diffamazione. Questo e quello che si chiama un
timing-attack; di seguito entreremo nel merito di un analisi piu formale per poi produrre
un’esperimento per dimostrarne l’effettiva fattibilita. E importante notare che questo tipo
di attacchi sono possibili per via della bassa latenza della rete, essa infatti fa in modo che
i volumi del traffico in realta non vengano molto cambiati dai nodi e che quindi sia facile
correlarli.

28 ANDREA BRASCHI
Figura 19. schema path rete a bassa latenza
6.5.1. Definizione formale. Il problema[7] si pone in questi termini: un client I comunica
con un server attraverso un path P I che e composto da un aserie di h nodi N I1 ,...,N I
h (nel
caso di TOR generalmente h vale o 2 o 3).
Nel nostro caso l’attaccante controlla il traffico in entrata a N I1 e quello in uscita a un
exit node NJ1 su due path P I e P J e ha l’obbiettivo di determinare se I = J .
Per fare questo l’attaccante puo semplicemente analizzare il traffico cosı com’e (attacco
passivo) oppure puo decidere di cancellare dei pacchetti per generare cosı dei ritardi che
facilitino la correlazione dei traffici (active dropping) ancora, se l’attaccante controlla il
server puo decidere di generare traffico secondo determinati pattern ed essere ancora una
volta facilitato nella correlazione.
Risulta evidente come in questo tipo di analisi il valore della correlazione della funzione
del volume dei pacchetti inviati nel tempo con quella del volume di pacchetti ricevuti dia
un indicazione di tipo probabilistico, cioe che probabilita c’e che i due nodi stiano effet-
tivamente comunicando, e che quindi e necessario considerare casi di falsi negativi e falsi
positivi e, ancora, riflettere sul fatto che, se la rete usa un traffico di copertura per rendere
omogeneo il volume in uscita da ogni nodo, e notevolmente incrementata la probabilita
di falsi positivi, mentre l’uso di tecniche come il defensive dropping [7] aumenta quella
dei falsi negativi; e ancora e utile considerare che nel caso di attacchi attivi tutte queste
probabilita sono decisamente decrementate. Per un’analisi piu rigorosa di tali fattori si
rimanda all’articolo [7] che tratta l’argomento in maniera dettagliata, precisa e formale.
Si nota inoltre che nell’articolo [9] e presentato un metodo che, mezzo alcune modifiche
ad un nodo TOR (tutte pero entro le specifiche), permette un’analisi dei volumi e un rico-
noscimento del path usato per la comunicazione, degradando TOR da rete anonimizzatrice
a semplice proxy, senza pero essere attaccanti globali.
Ai fini di dimostrarne la fattibilita, come ultimo esperimento si e realizzato un sempli-
ce timing-attack ai danni del sistema precedentemente analizzato (Privoxy+TOR), tale
esperimento e presentato e analizzato nel dettaglio alla fine della sezione 8. Da tale espe-
rimento e immediatamente emerso quanto sia piu facile trovare evidenti correlazioni, nei
volumi dei pacchetti relativi ai due end-point in questione, tanto piu sia ingente la quan-
tita di pacchetti trasmessa( e catturata).Infatti, trattandosi di analisi di segnali, risulta
chiaro che gli effetti del rumore sulla correlazione tra le due funzioni in questione siano
inversamente proporzionali all’ampiezza delle funzioni stesse.
In quanto l’argomento necessiterebbe di uno sviluppo eccessivo uscendo dai quelli che
sono gli obbiettivi di questa tesi, la trattazione di tale esperimento e stata svolta solo
in maniera qualitativa e non approfondita, l’esperimento mirava, infatti a dimostrare la
fattibilita di un simile attacco ai danni di un sistema cosı ben congegnato.

L’ANONIMATO IN RETE 29
7. Conclusioni
7.1. I rischi che si corrono in rete. Nel corso di questa tesi abbiamo introdotto la va-
rieta di attacchi alla privacy e all’identita che si possono incontrare in rete. Si e visto come
ne esistano veramente tanti tipi, e come spesso alcuni standard e abitudini degli utenti
della rete possano essere usate contro di loro per risalirne all’identita o per tracciarne le
navigazioni.
Partendo dai metodi piu semplici si e visto come sia gia di per se facile reperire infor-
mazioni utili dagli headers http e come sia semplice tracciare le navigazioni di un utente
tramite l’uso di cookies e sessions. Inoltre si e visto che esistono i supercookies che hanno
origini gia piu malevole e quindi di come grazie all’uso della tecnologia JavaScript e html5
si possano salvare su un pc dati che ne permettano il tracking in maniera che sia molto
piu difficile rimuoverli.
In seguito e stata effettuata un’analisi di alcuni dei principali metodi di fingerprintig,
cioe i metodi che permettono di ottenere delle informazioni sulle caratteristiche dell mac-
china connessa. E emerso come, grazie all’uso di JavaScript e Flash sia possibile ottenere
un gran numero di informazioni utili (oltre 20 bit di effettiva entropia). Analizzando vari
tipi di attacchi ci si e accorti di come alcuni standard siano una minaccia alla riservatezza
degli utenti della rete, in particolare la css-based history detection e proprio un esempio
di come uno standard, consigliato dalla W3C e da molte guide per l’usabilita dei siti,
abbia portato alla creazione di un potente strumento di fingerprinting degli utenti della
rete. In un altro caso nell’analisi dei risultati dell’esperimento di Panopticlick e emerso
come le informazioni precise sulle versioni dei plugins installati, utili per le operazioni di
debug, forniscano un’altra fonte ad alta entropia per tracciare gli utenti del web,e quindi
di come, con lo scopo di agevolare il lavoro degli sviluppatori, certe volte si vada incontro
a gravi rischi per la riservatezza degli utenti.
Lo studio di Panopticlick ha anche evidenziato come il fatto che l’elenco dei fonts non
venga riordinato nell’invio al server, ma dipenda fortemente dall’ordine con cui l’utente
ha installato i plugins, sia una, inutilmente gratuita, fonte di informazioni ad altissima
entropia. Quest’analisi dei dati derivanti dai plugins installati ha portato anche a conclu-
dere che in realta l’utilizzo di pluggins anti-traccking, se questi non sono sufficientemente
diffusi puo portare piu svantaggi che vantaggi.
A questo punto, nella tesi, sono stati introdotti i due principali metodi di anonimizza-
zione: la rete TOR e Privoxy, si e visto pero che entrambi lavorano a livello di rete e che
quindi di fatto difendono dalla diffusione di tutte quelle informazioni reperebili a livello
di rete ma che non possono nulla contro tutti i metodi di fingerprinting che lavorano a
livello applicativo.
Infine si sono analizzati i principali tipi di attacco alla rete TOR, in particolare i timing-
attacks, a dimostrazione del fatto che e vero che la rete TOR e sicura ma e altrettanto
vero che, in particolare nel caso di pochi sospettati, non e impossibile risalire, tramite
analisi dei volumi dei dati inviati, ai due end-point di una comunicazione tramite TOR.
7.1.1. Alcuni possibili modi per prevenirli. Nella tesi e percio emerso come, ai fini di una
miglior riservatezza sia necessario ma non sufficiente l’utilizzo congiunto di strumenti co-
me TOR e Privoxy; infatti essi sono uno strumento molto potente di difesa della propria

30 ANDREA BRASCHI
identita a livello di rete, ma non difendono affatto da tutte quelle informazioni che posso-
no venirci richieste a livello applicativo. A tale fine, come gia discusso precedentemente,
non e nemmeno necessario l’utilizzo di plugins-anti-tracking in quanto, paradossalmente,
il fatto stesso di non dare informazioni puo essere un’informazione, soprattutto se e una
pratica poco diffusa. Una possibile soluzione, come gia accennato, potrebbe essere quella
di, tramite l’utilizzo di proxy a livello applicativo, falsificare le informazioni che vengono
trasmesse e usate come fingerprint dando ad ogni richiesta di pagina dati diversi essendo
cosı difficilmente tracciabili. Emerge subito, pero, che tale operazione e poco standardiz-
zabile e difficile da realizzare in quanto ogni sito e ogni sistema puo utilizzare un suo
proprio metodo di fingerprinting, quindi la soluzione e differente a seconda dell’applica-
zione web dalla quale non si vuole essere tracciati. Altro fattore da tener da conto e che i
dati fasulli forniti devono essere al contempo molto differenti tra di loro (tra una richiesta
e l’altra), ma devono essere per lo piu realistici, altrimenti ancora una volta fornirebbero
informazioni ad altissimo contenuto di entropia (l’uso di informazioni spooffate eviden-
temente fasulle e poco realistiche sarebbe utile solo nel caso in cui questa diventi una
pratica diffusa).
Lo studio per la realizzazione di un Proxy a livello applicativo che possa generare infor-
mazioni false e sempre diverse esula dagli scopi di questa tesi in quanto argomento troppo
vasto, perche, come si e visto, esistono moltissimi modi per tracciare gli utenti del web e
non e difficile immaginarne molti altri, anche solo derivanti dalle combinazioni di quelli
fin ora visti. Risulta, pero, opportuno trarre alcune considerazioni sulla reallizzabilita di
tale impresa e sui vantaggi e svantaggi a cui andrebbe incontro un utente di tale siste-
ma. Prima di tutto sarebbe necessario uno studio accurato dei metodi di fingerprinting
effettivamente in uso sui principali siti, successivamente, sicuramente, un primo passo
nell’implementazione del nostro proxy dev’essere la cattura di un notevole campione di
fingerprint da poter usare e ricombinare inviandoli a server che li richiedano. Osservando
che le soluzioni fin ora proposte sono poco elastiche in quanto si dovrebbero rifare ad un
chiuso numero di siti dei si e analizzato il sistema di tracking, si propongono anche delle
soluzioni piu generali emerse proprio dall’analisi dei risultati dello studio dell’articolo [4],
in primo luogo il proxy dovrebbe randomizzare le microversioni dei plugin, i fonts installati
e il loro ordine di presentazione e informazioni sulle dimensioni dello schermo( risoluzione,
colori etc) e tutti questi tipi di dati che vengono inviati dai javascript (all’interno di file
Json o XML), ancora si potrebbero rendere casuali i dati contenuti negli header http.
Bisogna pero notare come chi si avvalga di un tale sistema debba pero rendersi disponi-
bile ad incontrare problemi di presentazione delle pagine richieste (lingua, impaginazione
etc.).
Concludiamo quindi mostrando lo schema logico di tale sistema, evidenziando come
la soluzione proposta non vada a sostituire elementi come TOR e Privoxy ma anzi si
inserisca nella catena integrando il servizio da loro fornito (TOR anonimizza a livello
di rete e rende non tracciabile il nostro ip, Privoxy ci protegge dal rivelare tutte quelle
informazioni, sempre a livello di rete, che TOR si lascia sfuggire, come i pacchetti DNS,
mentre il nostro sistema ci rende non tracciabili a livello applicativo).
In attesa, che qualche sviluppatore di buona volonta decida di implementare un proxy
simile a quello descritto precedentemente, citiamo l’esistenza di proxy a livello applicativo

L’ANONIMATO IN RETE 31
Figura 20. schema logico del posizionamento dell’ipotetico proxy a livello
applicativo all’interno dello schema di comunicazione precedentemente visto
come WebScarab della OWASP il quale gia ci consente di fare, sebbene manualmente, un
lavoro simile a quello sopra descritto.

32 ANDREA BRASCHI
8. Definizionie del modello sperimentale
Gli esperimenti, che sono stati svolti nel corso della tesi, si basano sul modello di rete
seguente: un client che, connesso ad una rete, comunica con un server.
Figura 21. schema logico della comunicazione in rete
E stata assunta l’ipotesi che sia il client che la rete si comportino secondo le specifiche e
che quindi non vi sia alcun tipo di software malevolo che operi sfruttando exploit o errori
all’interno del browser, e nella rete non vi siano nodi fasulli che disattendano le specifiche.
Si assume invece che il SERVER non sia trusted, ma che, comunque, lavori all’interno di
quelle che sono le specifiche e gli standard accettati, cercando cioe di carpire il maggior
numero di informazioni dagli utenti senza pero avvalersi di metodi illeciti e exploit ai
danni di client e rete. L’apparato sperimentale e quindi cosı costituito:
Figura 22. schema dell’impianto sperimentale
Il CLIENT e una macchina virtuale con sistema operativo Windows 7 professional che
accede al server tramite il browser Google Chrome. Nel corso di tutte le sperimentazioni
i dati in uscita dal browser sono stati analizzati a partire dai dati ottenuti dal monitor
di rete Wireshark. A seconda degli esperimenti la RETE potra essere la normale rete
internet oppure la rete TOR, infine nell’ultimo esperimento il CLIENT non si e connesso
direttamente alla rete TOR ma passando attraverso il proxy di rete Privoxy. Sia al mo-
mento dell’instradamento dal client nella rete, che al momento della ricezione lato server,
i pacchetti sono stati catturati e analizzati dal monitor di rete Wireshark.
Il SERVER e una macchina virtuale con sistema operativo Lubuntu 11.10 e server Apa-
che2 con php5, nel corso delle sperimentazioni abbiamo analizzato lo scambio di informa-
zioni server/client a livello applicativo tramite l’analisi dei log di Apache e dei pacchetti
catturati dal monitor di rete WhireShark.
Le macchine virtuali sono create e gestite dal programma VirtualBOX OSE e sono
ospitate su una macchina con sistema operativo Ubuntu 10.04. Entrambe le macchine
virtuali sono connesse alla rete tramite scheda bridge (ognuna ha il suo indirizzo locale
nella rete NAT domestica) e quindi al router verra specificato di trasferire al server tutte
le richieste sulla porta 80,mentre il client si e sempre connesso specificando l’indirizzo del
modem.

L’ANONIMATO IN RETE 33
8.1. Esperimenti.
8.1.1. Semplice connessione. Nel primo esperimento e stata effettuata una connessione
al SERVER tramite il browser del CLIENT e tramite lo sniffer di rete installato sulla
macchina host si sono catturati i pacchetti emessi dalle due macchine. Di particolare
interesse sono stati i due pacchetti del protocolo http, il primo dei quali era una richiesta
della pagina index.php da parte del CLIENT, quindi un header di tipo GET mentre il
secondo era la risposta del SERVER, come presumibile, un 200 OK contenente il codice
html della pagina richiesta; questi pacchetti sono megli analizzati e discussi nella sezione
2. Per iniziare la cattura si e avviato Wireshark con i permessi d’amministratore e si
avviata la cattura sull’interfaccia di rete wlan1(utilizzata dalle due macchine virtuali).
Figura 23. la pagina di prova sul SERVER
8.1.2. Connessione attraverso la rete TOR. Successivamente si e voluto ripetere l’esperi-
mento precedente, connettendosi al SERVER tramite la rete TOR. Dopo aver scaricato il
pacchetto di TOR boundle, si e configurato il browser e il sistema Windows per usare come
rete TOR tramite impostazioni e pannello di controllo, quindi si e avviata la rete tramite
l’interfaccia Vidalia, del pacchetto suddetto, si e avviato il browser e, per assicurarci di
essere connessi alla rete TOR, ci siamo connessi alla pagina http://check.toproject.org di
test per il corretto funzionamento della rete TOR. Quindi si e avviato lo sniffer per la
cattura dei pacchetti e si e avviata la connesione al SERVER per scaricare index.php. Da
subito si nota che l’IP visualizzato dalla pagina e cambiato rispetto al primo esempio, per
effetto della rete TOR, inoltre in uscita al CLIENT non ci sono piu pacchetti http ma
solo TLSv1 che quindi sono criptati, mentre in ingresso e uscita dal SERVER sono sempre
presenti i pacchetti http che sono stati trattati e discussi nella sezione 5.
lo stesso esperimento e stato eseguito anche usando Privoxy concatenato alla rete TOR
ma gli header http non sono sostanzialmente cambiati quindi tale esperimento non e stato
approfondito nel corso della tesi.

34 ANDREA BRASCHI
Figura 24. screen-shot della pagina ottenuta connettendosi a
http://check.toproject.org in caso di configurazione corretta della rete TOR
Figura 25. la pagina di prova sul SERVER scaricata tramite la rete TOR
8.1.3. I test di Panopticlick. Come anticipato nella sezione 3 (dove sono anche presenti gli
screen-shot), per testare la quantita di informazione lasciata dal nostro browser ci si e av-
valsi di della sistema online messo a disposizione dalla Electronic Frontier Foundation al si-
to [4]. Dapprima5 ci si e connessi con il browser senza particolari configurazioni e attraverso
la rete domestica, successivamente6 attraverso la rete TOR e poi ancora inserendo Privoxy
tra il CLIENT e la rete TOR. Dopo aver installato e avviato Privoxy sono state decommen-
tate le opportune righe del file config per poterlo concatenare alla rete TOR, indi si e pro-
ceduto modificando le proprieta dell’icona di lancio per google chrome per far sı che emetta
i suoi pacchetti su Privoxy e non direttamente su TOR, a tale fine nelle proprieta si e mo-
dificato la stringa di lancio del programma da “c : \Users\ v \Application\chrome.exe”
5Sezione 36Sezione 5

L’ANONIMATO IN RETE 35
a \c : \Users\ v \Application\chrome.exe − −proxy − server = ”127.0.0.1 : 8118””,
dove 8118 e il numero della porta sulla quale e in ascolto privoxy.
Figura 26. screen-shot della pagina ottenuta connettendosi a
http://config.privoxy.org in caso di configurazione corretta di Privoxy
8.1.4. Un timing-attack. Come anticipato nella sezione 5, in ultima istanza si e voluto
dimostrare la fattibilita di un timing-attack ai danni del sistema Privoxy+TOR realiz-
zandone e analizzandone, solamente a livello qualitativo, un semplice esempio. Per fare
cio si e caricato nella cartella “/var/www/” del SERVER un file film.zip (originariamente
film.avi rinominato per renderlo scaricabile, di circa 700MByte) in seguito connettendosi
con la macchina CLIENT, configurata come precedentemente descritto si e scaricato il file,
contemporaneamente, sulla macchina HOST, si e avviata, con WireShark, una sessione
di cattura di pacchetti su interfaccia wlan1.
Figura 27. scaricamento di film.zip

36 ANDREA BRASCHI
Successivamente si e prodotta la seguente serie di grafici ( funzione IO Graphs di Wi-
reShark), come evidenziato nelle regole della didascalia da prima si sono confrontati pac-
chetti tcp inviati dal CLIENT con il volume di pacchetti ricevuti dal SERVER (in questo
caso per lo piu ACK della ricezione dei frammenti del file in download), a segurie si sono
confrontati i pacchetti tcp in uscita dal SERVER con quelli in ingresso al CLIENT (in
quantita naturalmente maggiore in quanto costituenti il file in download), in seguito si
sono confrontati tutti i pacchetti contenenti l’ip del SERVER con quelli contenenti l’ip del
CLIENT quindi una somma delle due precedenti funzioni, da ultimo si sono confrontati
tutti i pacchetti in emessi o destinati al CLIENT con tutti quelli destinati o emessi dal
SERVER.
Dai primi tre grafici risulta evidente la presenza di una correlazione trai due volumi,
correlazione che aumenta di evidenza con l’aumentare delle quantita di dati in gioco,
mentre nell’ultimo grafico si puo vedere come aumenta il rumore dovuto ai dati inviati
tramite altri protocolli per la gestione della connessione (soprattutto verso la fine dell’invio
del messaggio). E invece notevole come le due comunicazioni inizino e finiscano pressoche
nello stesso istante, questa e gia di per se un’utilissima informazione.
Figura 28. grafico di confronto tra i volumi dei pacchetti tcp in uscita al
CLIENT7e quelli in ingresso al SERVER8
7192.168.1.1376192.168.1.135

L’ANONIMATO IN RETE 37
Figura 29. grafico di confronto tra i volumi dei pacchetti tcp in uscita al
SERVER e quelli in ingresso al CLIENT
Figura 30. grafico di confronto tra i volumi dei pacchetti tcp contenenti
l’ip del SERVER e quelli con l’ip del CLIENT
Figura 31. grafico di confronto tra i volumi dei pacchetti contenenti l’ip
del SERVER e quelli con l’ip del CLIENT
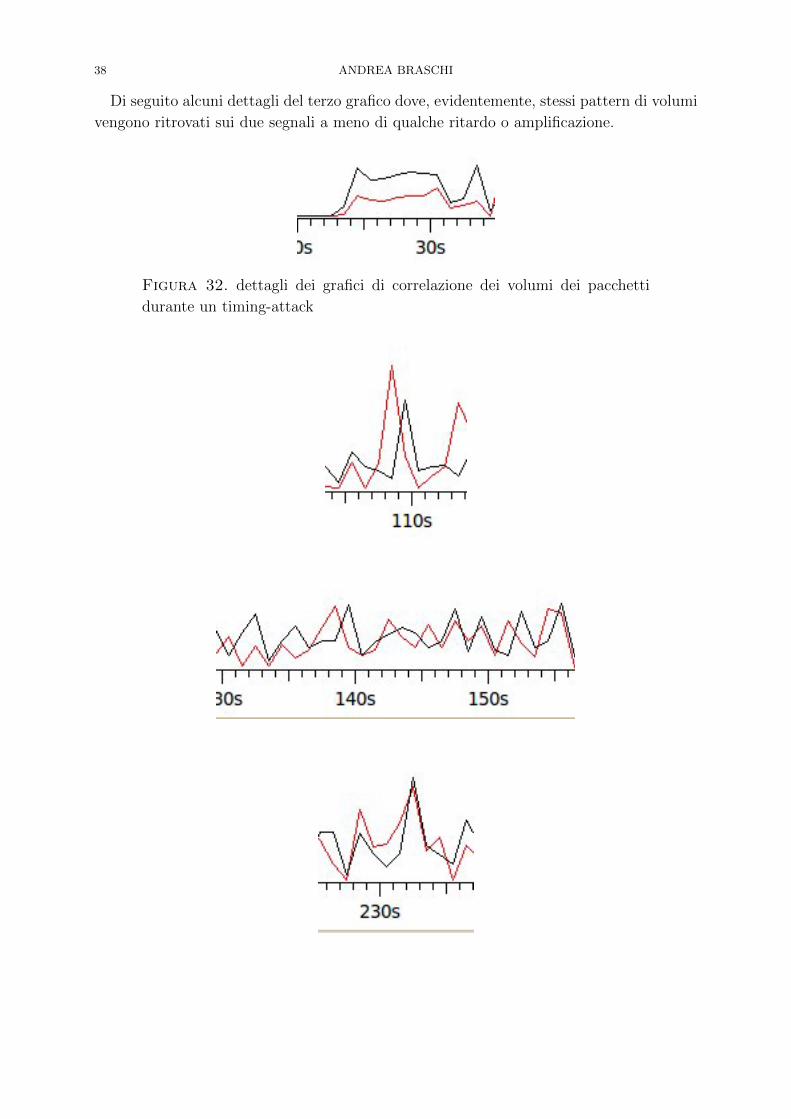
38 ANDREA BRASCHI
Di seguito alcuni dettagli del terzo grafico dove, evidentemente, stessi pattern di volumi
vengono ritrovati sui due segnali a meno di qualche ritardo o amplificazione.
Figura 32. dettagli dei grafici di correlazione dei volumi dei pacchetti
durante un timing-attack

L’ANONIMATO IN RETE 39
Riferimenti bibliografici
[1] Privoxy.
[2] Decreto legislativo 30 giugno 2003, n. 196, 2003.
[3] Roger Dingledine, Nick Mathewson, and Paul Syverson. Tor: The second-generation onion router.
In In Proceedings of the 13th USENIX Security Symposium, pages 303–320, 2004.
[4] Peter Eckersley. How unique is your web browser? Technical report, Electronig Frontier Foundation,
2009.
[5] Wei Fang. Using google analytics for improving library website content and design: A case study.
Library Philosophy and Practice 2007: Special Issue on Google and Libraries, 2007.
[6] Artur Janc and Lukasz Olejnik. Feasibility and real-world implications of web browser history
detection.
[7] Brian N. Levine, Michael K. Reiter, Chenxi Wang, and Matthew Wright. Timing attacks in low-
latency mix systems (extended abstract). In PROCEEDINGS OF THE 8TH INTERNATIONAL
FINANCIAL CRYPTOGRAPHY CONFERENCE (FC 2004), KEY WEST, FL, USA, FEBRUARY
2004, VOLUME 3110 OF LECTURE NOTES IN COMPUTER SCIENCE, pages 251–265. Springer,
2004.
[8] Keaton Mowery, Dillon Bogenreif, Scott Yilek, and Hovav Shacham. Fingerprinting information in
javascript implementations.
[9] Steven J. Murdoch and George Danezis. Low-cost traffic analysis of tor. In In Proceedings of the
2005 IEEE Symposium on Security and Privacy. IEEE CS, pages 183–195, 2005.
[10] samy kamkar samy kamkar. Evercookie never forget, 2010.

40 ANDREA BRASCHI
9. Appendici
Figura 33. screen-shot dei software usati per gli esperimenti
.1. Le macchine virtuali. Per la realizzazione delle macchine virtuali abbiamo usato il
programma di virtualizzazione VirtualBox OSE, col quale abbiamo creato due macchine
virtuali un client e un server.
.1.1. Client. Sulla macchina client sono installati Google Chrome, TOR, vidalia e Privoxy
ed e una macchina con le seguenti caratteristiche.
scheda CLIENT
Generale
Nome: Client
Sistema operativo: Windows 7
Sistema
Memoria di base: 1024 MB
Processore(i): 1
Ordine di avvio: Floppy, CD/DVD-ROM, Disco fisso
Schermo
Memoria video: 16 MB
Accelerazione 3D: Disabilitata
Accelerazione video 2D: Disabilitata
Archiviazione
Controller IDE
IDE master primario: Client.vdi (Normale, 20,00 GB)
IDE master secondario (CD/DVD): Lett. host OptiarcDVD RWAD-7561S(sr0)
Controller floppy
Dispositivo floppy 0: Vuoto
Audio
Driver del sistema host: PulseAudio
Controller: ICH AC97
Rete
Driver 1: Intel PRO/1000MT Desktop(bridge,wlan1)
Porte seriali
Disabilitate
Cartelle condivise: 1

L’ANONIMATO IN RETE 41
.1.2. Server. Sulla macchina server sono installati Apache2 e php5 ed e una macchina con
le seguenti caratteristiche.scheda SERVER
Generale
Nome: Server
Sistema operativo: Lubuntu 11.10
Sistema
Memoria di base: 1024 MB
Processore(i): 1
Ordine di avvio: Floppy,CD/DVD-ROM,Disco fisso
Schermo
Memoria video: 12 MB
Accelerazione 3D: Disabilitata
Accelerazione video 2D: Disabilitata
Archiviazione
Controller IDE
IDE master primario: Server.vdi (Normale, 8,00 GB)
IDE master secondario (CD/DVD): Vuoto
Controller floppy
Dispositivo floppy 0: Vuoto
Audio
Driver del sistema host: PulseAudio
Controller: ICH AC97
Rete
Driver 1: PCnet-FASTIII(Scheda con bridge, wlan1)
Porte seriali
Disabilitate
Cartelle condivise: 1
Sul server e presente la seguente pagina PHP (index.php) che semplicemente mostra al
client il suo IP.
<?php
$ip=$ SERVER [ ’REMOTE ADDR’ ] ;
echo ”<html><header><t i t l e >t e s t1−t e s i </ t i t l e ></header>” ;
echo ”<body>ip : $ ip ” ;
echo ”</body></html>” ;
?>
.1.3. La macchina host. La macchina host e un compaq presario CQ61 avente sistema
operativo Ubuntu 10.04 con installati WireShark e VirtualBox OSE.

42 ANDREA BRASCHI
Figura 34. WireShark in azione durante un timing-attack
.1.4. la rete e il modem. Tutto il sistema si interfaccia su un modem TISCALI con inter-
faccia di rete in modalita NAT e un virtual server configurato opportunamente di modo
da inoltrare a “Server” tutte le connessioni sulla porta 80.

L’ANONIMATO IN RETE 43
.2. L’entropia nella teoria dell’informazione. Nel 1948 Claude Shanon e il primo a
introdurre il concetto di entropia nella teoria dell’informazione nel suo lavoro “Una teoria
matematica della comunicazione”, come misura della quantita di informazione presente
in un segnale aleatorio.
L’entropia e definita come la media dell’autoinformazione di un segnale. Dato un se-
gnale x(t) aleatorio codificato con un alfabeto A = {A(1), A(2), ..., A(n)} quindi con n
caratteri e definendo come p(i) la probabilita di riscontrare il catattere A(i), si definisce
autoinformazione di A(i) il logaritmo in base 2 dell’inverso di p(i): I(xi) = log 1p(i)
. E,
quindi, evidente come un segnale piu probabile, di fatto, porti meno informazione (se p
tende a uno I tende a 0). Inoltre si consideri il caso della presenza di correlazioni tra x(t)
e x(t + 1), e evidente che se aumenta la probabilita p(x(t + 1) = A(j)|x(t) = A(i)) e
quindi l’informazione portata dalla combinazione A(i)A(j) e piu bassa rispetto ad altre
combinazioni meno probabili.
Concludendo l’entropia di un segnale e quindi definita come :
H(x) = E [I(x)] =∑n
i=1 p(i) ∗ log 1p(i)
si misura in bit e indica il minimo numero di bit con cui poter rappresentare le
informazioni del segnale in questione senza perdita di dati.
Nel corso della tesi e nelle analisi dei risultati esposti in [4] con bit di effettiva entropia
si intende quindi il logaritmo in base due del numero di campioni (di browser) nei quali il
fingerprinting trovato risulta essere unico (es.: 20 bit = il fingerprint risulta essere unico
in un set di 220 elementi).




















