
KLASIFIKASI SUARA BERDASARKAN GENDER (JENIS KELAMIN) DENGAN METODE K-NEAREST NEIGHBOR (KNN
9
1 KLASIFIKASI SUARA BERDASARKAN GENDER (JENIS KELAMIN) DENGAN METODE K-NEAREST NEIGHBOR (KNN) Riska Yessivirna 1 , Marji 2 , Dian Eka Ratnawati 3 Jurusan Ilmu Komputer, Fakultas Program Teknologi Informasi dan Ilmu Komputer, Universitas Brawijaya Malang Jalan Veteran No. 8, Malang 65145, indonesia Email 1 : [email protected] ABSTRAK Klasifikasi suara berdasarkan gender dibuat dengan tujuan agar komputer mampu mengenali suara laki-laki dan perempuan. Dengan kemampuan komputer yang mampu membedakan suara laki-laki dan perempuan akan memperkuat tingkat suatu sistem keamanan yang menggunakan password dengan suara. Pencocokan password tidak hanya berdasarkan kata saja, namun ditambah dengan pencocokan karakteristik suara sehingga akan lebih aman. Pengenalan suara berdasarkan gender dilakukan dengan teknik ekstraksi ciri sinyal audio pada domain frekuensi yaitu spectral centroid dan spectral flux untuk mendapatkan data numerik yang kemudian dilanjutkan dengan klasifikasi. K-Nearest Neighbor (KNN) diimplementasikan untuk klasifikasi suara berdasarkan gender dengan menggunakan 2 parameter fitur suara, yaitu Spectral centroid dan Spectral flux. Dalam penelitian ini digunakan teknik klasifikasi KNN dengan menggunakan dua kriteria, laki-laki dan perempuan. Uji coba dilakukan dengan 3 skenario yang berbeda. Pada skenario pertama parameter yang diubah adalah frame width, pada skenario kedua parameter yang diubah adalah frame shift, sedangkan untuk skenario ketiga parameter yang diubah adalah nilai alpha. Pada uji coba 3 skenario diperoleh hasil bahwa nilai frame width yang paling baik digunakan adalah 1024, prosentase frame shift yang baik digunakan adalah 31.25%, dan nilai alpha yang baik digunakan adalah 0.97. Pada uji coba pengaruh nilai k dihasilkan semakin tinggi nilai k maka semakin tinggi nilai akurasinya dan semakin mendekati titik kestabilannya, dengan rata-rata akurasi terendah sebesar 71,5% dan tertinggi sebesar 76,2%. Kata kunci: suara, ekstraksi ciri, spectral centroid, spectral flux, klasifikasi, k – Nearest Neighbor (KNN) ABSTRACT Voice classification based on gender was made in order for the computer to recognize the voice of male and female. By the computer skills who is able to recognize the voice of male and female will strengthen the security level of a system that uses a password with voice. Matching password not only based on words but coupled with matching characteristics of voice so that it will be safer. Voice recognition based on gender is done with feature extraction technique of the audio signal in the frequency domain spectral centroid and spectral flux to obtain numerical data which is then followed by classification. K-Nearest Neighbor (KNN) is implemented to voice classification based on gender with 2 parameters, spectral centroid and spectral flux. In this research, the KNN classification techniques using 2 ccriteria, male and female. The test is done by 3 different scenarios. In the first scenario, parameters are changed in a frame width, the second scenario is frame shift, while in the third scenario is alpha. The result from 3 scenarious are the value of frame width used is 1024, the good procentage of frame shift used is 31.25%, and the best value of alpha used is 0.97. At the test of the effect of k shows that the higher value of k produced the higher accuracy and getting closer to the point of stability, with the lowest accuracy of 71.5% and the highest accuracy of 76.2%. Keywords: voice, feature extraction, spectral centroid, spectral flux, classification, k – Nearest Neighbor (KNN). 1. PENDAHULUAN 1.1. Latar Belakang Tuhan menggolongkan manusia berdasarkan jenis kelaminnya, yaitu pria dan wanita. Setiap manusia dengan manusia yang lain memiliki perbedaan karakteristik, salah satunya dapat dilihat dari suaranya. Bila didengarkan dengan seksama, suara wanita cenderung lebih tinggi daripada suara pria. Di antara perbedaan-perbedaan masih terdapat kemiripan antara suara pria satu dengan pria lain dan antara suara wanita satu dengan wanita lain [1]. Berdasarkan penelitian Setiawan (2011) suara dapat digolongkan berdasarkan jenis kelamin dengan menggunakan metode ekstraksi ciri sinyal. Data sampel
-
Upload
independent -
Category
Documents
-
view
3 -
download
0
Transcript of KLASIFIKASI SUARA BERDASARKAN GENDER (JENIS KELAMIN) DENGAN METODE K-NEAREST NEIGHBOR (KNN

1
KLASIFIKASI SUARA BERDASARKAN GENDER (JENIS KELAMIN) DENGAN METODE
K-NEAREST NEIGHBOR (KNN)
Riska Yessivirna 1, Marji2, Dian Eka Ratnawati3
Jurusan Ilmu Komputer, Fakultas Program Teknologi Informasi dan Ilmu Komputer,
Universitas Brawijaya Malang
Jalan Veteran No. 8, Malang 65145, indonesia
Email1: [email protected]
ABSTRAK
Klasifikasi suara berdasarkan gender dibuat dengan tujuan agar komputer mampu mengenali suara laki-laki dan
perempuan. Dengan kemampuan komputer yang mampu membedakan suara laki-laki dan perempuan akan
memperkuat tingkat suatu sistem keamanan yang menggunakan password dengan suara. Pencocokan password tidak
hanya berdasarkan kata saja, namun ditambah dengan pencocokan karakteristik suara sehingga akan lebih aman.
Pengenalan suara berdasarkan gender dilakukan dengan teknik ekstraksi ciri sinyal audio pada domain frekuensi
yaitu spectral centroid dan spectral flux untuk mendapatkan data numerik yang kemudian dilanjutkan dengan
klasifikasi. K-Nearest Neighbor (KNN) diimplementasikan untuk klasifikasi suara berdasarkan gender dengan
menggunakan 2 parameter fitur suara, yaitu Spectral centroid dan Spectral flux. Dalam penelitian ini digunakan teknik
klasifikasi KNN dengan menggunakan dua kriteria, laki-laki dan perempuan.
Uji coba dilakukan dengan 3 skenario yang berbeda. Pada skenario pertama parameter yang diubah adalah frame
width, pada skenario kedua parameter yang diubah adalah frame shift, sedangkan untuk skenario ketiga parameter yang
diubah adalah nilai alpha. Pada uji coba 3 skenario diperoleh hasil bahwa nilai frame width yang paling baik digunakan
adalah 1024, prosentase frame shift yang baik digunakan adalah 31.25%, dan nilai alpha yang baik digunakan adalah 0.97.
Pada uji coba pengaruh nilai k dihasilkan semakin tinggi nilai k maka semakin tinggi nilai akurasinya dan semakin
mendekati titik kestabilannya, dengan rata-rata akurasi terendah sebesar 71,5% dan tertinggi sebesar 76,2%.
Kata kunci: suara, ekstraksi ciri, spectral centroid, spectral flux, klasifikasi, k – Nearest Neighbor (KNN)
ABSTRACT
Voice classification based on gender was made in order for the computer to recognize the voice of male and female. By the
computer skills who is able to recognize the voice of male and female will strengthen the security level of a system that uses a
password with voice. Matching password not only based on words but coupled with matching characteristics of voice so that it will
be safer.
Voice recognition based on gender is done with feature extraction technique of the audio signal in the frequency domain
spectral centroid and spectral flux to obtain numerical data which is then followed by classification. K-Nearest Neighbor (KNN) is
implemented to voice classification based on gender with 2 parameters, spectral centroid and spectral flux. In this research, the KNN
classification techniques using 2 ccriteria, male and female.
The test is done by 3 different scenarios. In the first scenario, parameters are changed in a frame width, the second scenario
is frame shift, while in the third scenario is alpha. The result from 3 scenarious are the value of frame width used is 1024, the good
procentage of frame shift used is 31.25%, and the best value of alpha used is 0.97. At the test of the effect of k shows that the higher
value of k produced the higher accuracy and getting closer to the point of stability, with the lowest accuracy of 71.5% and the highest
accuracy of 76.2%.
Keywords: voice, feature extraction, spectral centroid, spectral flux, classification, k – Nearest Neighbor (KNN).
1. PENDAHULUAN
1.1. Latar Belakang
Tuhan menggolongkan manusia berdasarkan
jenis kelaminnya, yaitu pria dan wanita. Setiap manusia
dengan manusia yang lain memiliki perbedaan
karakteristik, salah satunya dapat dilihat dari suaranya.
Bila didengarkan dengan seksama, suara wanita
cenderung lebih tinggi daripada suara pria. Di antara
perbedaan-perbedaan masih terdapat kemiripan antara
suara pria satu dengan pria lain dan antara suara
wanita satu dengan wanita lain [1].
Berdasarkan penelitian Setiawan (2011) suara
dapat digolongkan berdasarkan jenis kelamin dengan
menggunakan metode ekstraksi ciri sinyal. Data sampel

2
sejumlah 10 file suara berfomat (.wav) terdiri dari 2
suara wanita dan 8 suara pria. Dari data sample
dilakukan ekstraksi ciri berupa fitur-fitur pada domain
waktu yaitu Sort Time Energy dan Zero Crossing Rate,
dan fitur-fitur pada domain frekuensi yaitu Spectral
Centroid dan Spectral Flux. Hasil perhitungan ekstraksi
ciri yang diperoleh, direkam dalam file “pola.txt”, di
mana data yang disimpan merupakan rata-rata dari
masing-masing ciri. Data pada file “pola.txt” diolah
untuk proses klasterisasi dengan menggunakan metode
K-Means. K-Means merupakan teknik klastering
sederhana yang umum digunakan. Teknik ini
menggunakan ukuran jarak untuk mengelompokkan
objek. Dari hasil penelitian yang dilakukan 2 suara
masuk ke dalam klaster 1 dan 8 suara masuk ke dalam
klaster 2, sehingga dapat disimpulkan bahwa metode
K-Means mampu mengelompokkan suara berdasarkan
jenis kelamin [2].
Selain dengan metode K-Means,
pengelompokkan juga dapat dilakukan dengan
menggunakan metode k-Nearest Neighbour (KNN).
Berbeda dengan metode K-Means yang mempartisi
data ke dalam satu atau lebih kelompok sehingga data
yang memilik karakteristik yang sama akan
dikelompokkan menjadi satu cluster, KNN merupakan
metode klasifikasi yang didasarkan pada pembelajaran
data yang sudah terklasifikasi sebelumnya.
KNN termasuk dalam golongan supervised,
dimana hasil query instance yang baru diklasifikasi
berdasarkan mayoritas kedekatan jarak dari kategori
yang ada. Beberapa keunggulan pada metode KNN
adalah tangguh terhadap data training yang memiliki
banyak noise dan keefektifan apabila data training besar.
Selain itu proses klasifikasi mudah direpresentasikan
dibandingkan dengan metode klasifikasi lain [3].
Oleh karena itu pada penelitian ini, klasifikasi
suara berdasarkan jenis kelamin akan dilakukan
dengan mengimplementasikan metode KNN dan fitur
yang digunakan mengacu pada penelitian Setiawan
(2011) berupa fitur dari domain frekuensi yaitu Spectral
Centroid dan Spectral Flux. Dengan menggunakan
metode ini, diharapkan komputer mampu mengenali
suara berdasarkan gender (jenis kelamin) dengan
tingkat akurasi yang tinggi.
Berdasarkan latar belakang yang telah
dikemukakan, maka dilakukanlah penelitian dengan
judul “Klasifikasi Suara Berdasarkan Gender (Jenis
Kelamin) Dengan Metode K-Nearest Neighbour
(KNN)”.
1.2. Rumusan Masalah
Permasalahan yang ada pada skripsi ini
dapat dirumuskan sebagai berikut:
1. Bagaimana proses ekstraksi ciri yang dilakukan
sehingga dari data suara dapat dihasilkan data
numerik berupa fitur dari domain frekuensi
(Spectral Centroid dan Spectral Flux) yang nantinya
digunakan dalam proses pengklasifikasian.
2. Bagaimana cara mengklasifikasikan suara dengan
menggunakan KNN berdasarkan parameter yang
ada.
3. Bagaimana akurasi yang terbentuk jika metode
KNN diimplementasikan dalam
mengklasifikasikan suara berdasarkan jenis
kelamin.
1.3. Batasan Masalah
Masalah yang dibahas pada skripsi ini
dibatasi pada:
1. Data yang digunakan dalam penelitian ini adalah
file suara berformat (.wav).
2. Sampel suara yang digunakan adalah suara orang
dewasa yang melafalkan kata “Aku” secara
normal.
3. Proses akuisisi data numerik dilakukan dengan
ekstraksi ciri sinyal suara dengan domain
frekuensi (Spectral Centroid dan Spectral Flux).
4. Pengklasifikasian suara dilakukan dengan
menggunakan KNN weighted voting.
1.4. Tujuan
Penelitian ini dibuat dengan tujuan:
1. Melakukan ekstraksi ciri berupa Spectral Centroid
dan Spectral Flux pada sinyal suara
2. Melakukan klasifikasi suara berdasarkan gender
(jenis kelamin) dengan menggunakan metode
KNN
3. Menghitung akurasi dari hasil pengklasifikasian
suara.
1.5. Manfaat
Manfaat yang dapat diambil dari penelitian ini
adalah menghasilkan aplikasi yang dapat digunakan
untuk mengklasifikasikan suara berdasarkan gender
(jenis kelamin), sehingga dapat membuat komputer
mampu mengenali suara manusia berdasarkan jenis
kelamin.
2. Kajian Pustaka dan Dasar Teori
2.1. Suara dan Audio Digital
Bunyi atau suara adalah sesuatu yang
dihasilkan oleh getaran dari benda yang bergetar. Suara
yang dihasilkan oleh suatu sumber getar dapat sampai
ke telinga karena suara merambat sebagai gelombang.
Bunyi terjadi secara berkelanjutan dikarenakan adanya
gelombang analog. Untuk merubah gelombang analog
ke dalam komputer dilakukan dengan cara melakukan
digitalisasi gelombang analog tersebut [4].

3
2.2. Sampling
Sampling merupakan proses mengubah sinyal
analog menjadi sinyal digital dalam fungsi waktu. Teori
sampling Nyquist menyebutkan bahwa frekuensi
sampling (sampling rate) minimal harus dua kali lebih
tinggi dari frekuensi maksimum yang akan di-sampling,
dimana (𝑓𝑠) frekuensi sampling dan (𝑓ℎ ) frekuensi sinyal
analog tertinggi [5].
𝑓𝑠 ≥ 2𝑓ℎ (2-1)
2.3. Pre-emphasis
Dalam proses pengolahan sinyal suara, proses
pre-emphasis dilakukan setelah proses sampling. Tujuan
dari pre-emphasis adalah untuk mendapatkan bentuk
spectral frekuensi sinyal suara yang lebih halus.
Pre-emphasis didasari oleh hubungan
input/output dalam domain waktu yang dinyatakan
dalam persamaan 2-2
𝑦 𝑛 = 𝑥 𝑛 − 𝑎𝑥(𝑛 − 1) (2-2)
dimana α merupakan konstanta filter pre-emphasis yang
biasanya bernilai 0,9<α<1,0 [6].
2.4. Frame Blocking
Frame Blocking adalah pembagian sinyal audio
menjadi beberapa frame. Satu frame terdiri dari beberapa
sampel tergantung tiap berapa detik suara yang akan
di-sampling dan berapa besar frekuensi sampling-nya [7].
Pada tahap ini, output dari pre-emphasis diblok ke
dalam frame yang terdiri dari N sample data dan tiap
frame dipisahkan dengan M sampel data [8]. Sinyal
hasil dari framing adalah sinyal terpotong yang
diskontinu. Sinyal terpotong tersebut akan dilanjutkan
dalam proses windowing [9].
2.5. Windowing
Window penghalus pada setiap frame
digunakan untuk mereduksi puncak pada tiap segmen
(awal dan akhir suatu frame) [7]. Fungsi windowing yang
digunakan adalah hamming window karena fungsi ini
dapat membuat data pada awal frame dan akhir frame
mendekati nilai 0 dengan baik [9]. Jika didefinisikan
window yang digunakan sebagai w(n) maka output dari
proses window adalah:
𝑥𝑙 𝑛 = 𝑥𝑙 𝑛 𝑤(𝑛) (2-3)
dimana 0 < n < N-1, dan model window yang
digunakanadalah Hamming window [8] yaitu:
𝑤 𝑛 = 0.54 − 0.46 cos 2𝜋𝑛
𝑁−1 (2-4)
2.6. FFT
Proses FFT sinyal dibagi menjadi beberapa
bagian yang lebih kecil yang bertujuan untuk
memperoleh waktu proses yang lebih cepat.
Modifikasi DFT dilakukan dengan mengelompokkan
batas n ganjil dan batas n genap [5]. N-point dengan
urutan {x(n), n = 0, 1, …, N-1} dibagi menjadi urutan
genap
𝑥𝑒 𝑛 = 𝑥 2𝑚 ,𝑚 = 0, 1,… , 𝑁
2 − 1 (2-5)
dan urutan ganjil
𝑥𝑜 𝑛 = 𝑥 2𝑚 + 1 ,𝑚 = 0, 1,… , 𝑛
2 − 1 (2-6)
Oleh karena itu, panjang 𝑁 = 2𝑚 dimana m
adalah bilangan positif integer, maka persamaan DFT
dapat ditulis menjadi [10].
𝑋 𝑘 = 𝑥 𝑛 𝑊𝑁𝑘𝑛𝑁−1
𝑛=0
= 𝑥 2𝑚 𝑊𝑁2𝑚𝑘 + 𝑥(2𝑚 + 1)𝑊𝑁
2𝑚+1 𝑘 𝑛
2 −1
𝑚=0
𝑛
2 −1
𝑚=0
(2-7)
2.7. Spectral Centroid
Spectroid Centroid didefinisikan sebagai titik
berat atau titik keseimbangan dari magnitude pada
spektrum domain frekuensi yang merepresentasikan
sinyal audio [11]. Berdasarkan penelitian Setiawan
(2011) spectral centroid dapat diperoleh dengan
persamaan 2-8
𝑆𝐶𝑡 = 𝑀𝑡 𝑛 .𝑛𝑁𝑛=1
𝑀𝑡[𝑛]𝑁𝑛=1
(2-8)
dimana N adalah jumlah pita frekuensi pada spectrum,
Mt[n] adalah magnitude dari spektrum pada frame
indeks t dan pita indeks n [2].
2.8. Spectral Flux
Spectral Flux menyatakan perbedaan antara pita
magnitude dari sejumlah frame pada spektrum domain
frekuensi yang merepresentasikan sebuah sinyal audio
dan dapat diperoleh dengan menggunakan persamaan
𝑆𝐹𝑡 = 𝑀𝑡 𝑛 − 𝑀𝑡−1[𝑛] 2
=1
𝑁 𝑀𝑡 𝑛 − 𝑀𝑡−1[𝑛] 2𝑁
𝑛=1 (2-9)
dimana N adalah jumlah pita frekuensi, Mt[n] adalah
magnitude dari spectrum pada frame indeks t dan pita
indeks n, dan Mt-1[n] adalah magnitude dari spekturm
pada frame indeks t-1 dan pita indeks n [11].
2.9. K – Nearest Neighbor (KNN)
Klasifikasi Nearest Neighbor didasarkan pada
pembelajaran (learning) dengan membandingkan

4
sebuah data uji dengan sejumlah data latih. Data latih
terdiri dari n atribut. Tiap data merepresentasikan titik
pada sebuah ruang berdimensi n, dengan begitu semua
data latih disimpan di dalam ruang pola berdimensi n.
Ketika diberikan sebuah data yang tidak diketahui
kelasnya, k-nearest neighbor akan mencari pola ruang
untuk data latih k yang terdekat. Data latih k ini
merupakan k “nearest neighbor” dari data yang tidak
diketahui tersebut [12].
2.9.1. Normalisasi
Normalisasi dilakukan untuk menghindari
beberapa atribut yang memiliki nilai besar
mempengaruhi atribut lain yang diukur pada skala
yang lebih kecil. Pada data kontinyu, normalisasi dapat
dilakukan dengan menggunakan Z-Score standardization
dengan persamaan 2-10 [13].
𝑋∗ =𝑋−𝑚𝑒𝑎𝑛 (𝑋)
𝑆𝐷(𝑋) (2-10)
2.9.2. Jarak Euclidean
Kedekatan didefinisikan dengan ukuran jarak
seperti Euclidean distance, di mana jarak dua data
𝑋1 = (𝑥11 , 𝑥12 ,… , 𝑥1𝑛) dan 𝑋2 = (𝑥21 , 𝑥22 ,… , 𝑥2𝑛)
dinyatakan dalam persamaan 2-11 [12][HAN-06].
𝑑𝑖𝑠𝑡 𝑋1,𝑋2 = (𝑥1𝑖 − 𝑥2𝑖)2𝑛
𝑖=1 (2-11)
2.9.3. Weighted Voting
Pada fungsi kombinasi dengan menggunakan
weighted voting diharapkan dapat memperkecil
kesalahan. Fungsi kombinasi ini merupakan kebalikan
proporsi jarak dari rekord baru dengan klasifikasi,
dimana vote dibobotkan dengan inverse square dari
nilai jarak [13].
2.10. Akurasi Sistem
Akurasi merupakan ukuran seberapa dekat
suatu angka hasil pengukuran terhadap angka
sebenarnya. Akurasi dapat diperoleh dari prosentase
kebenaran, yaitu perbandingan antara jumlah data
benar dengan keseluruhan data [14]. Akurasi
dinyatakan dengan persamaan
𝑎𝑘𝑢𝑟𝑎𝑠𝑖 =𝑗𝑢𝑚𝑙𝑎 ℎ 𝑑𝑎𝑡𝑎 𝑏𝑒𝑛𝑎𝑟
𝑗𝑢𝑚𝑙𝑎 ℎ 𝑑𝑎𝑡𝑎 × 100% (2-12)
3. Metodologi Penelitian dan Perancangan
3.1. Data Penelitian
Data yang digunakan adalah data suara yang
dikumpulkan secara langsung dengan melakukan
perekaman kepada sejumlah orang yang kemudian
disimpan dalam format (.wav). Perekaman dilakukan
dengan bantuan aplikasi Audacity dengan format PCM
8000Hz, 16 bit, 1 channel (mono). Dari data suara akan
dibuat sebuah dataset melalui proses ekstrasi fitur
dengan atribut id, filename, alpha, frame_width,
frame_shift, spectral_centroid dan spectral_flux, dan
kelas berupa jenis kelamin. Data suara terdiri dari 294
suara dengan 147 suara perempuan dan 147 suara laki-
laki.
3.2. Perancangan Sistem
Perancangan proses klasifikasi suara
berdasarkan gender ini terdiri dari tiga proses utama
yaitu ekstraksi fitur, pelatihan, dan pengujian. Proses
ekstraksi fitur bertujuan untuk memperoleh nilai fitur
spectral centroid dan spectral flux. Proses ekstraksi fitur
ditunjukkan pada gambar 3.1.
Ekstraksi Fitur
Mulai
Sinyal digital
tersampling
Pre-emphasis
Frame Blocking
Windowing
Transformasi Fourier
Hitung Spectral
Centroid
Selesai
Hitung Spectral Flux
Gambar 3.1 Proses Ekstraksi Fitur
Proses pelatihan sistem bertujuan untuk
menentuan klasifikasi suara pada sejumlah data uji dan
data latih dengan menggunakan metode KNN. Proses
pelatihan ditunjukkan oleh gambar 3.2.

5
Proses Pelatihan
Mulai
Input dataset suara,
jml data testing, k-
tetangga terdekat
KNN
Output akurasi
Selesai
For i=0 to jml data testing
i
Hasil=benar? Benar=Benar+1
T
Y
Akurasi=Benar/jml data
testing
Proses pengujian bertujuan untuk menguji suatu
data suara yang dimasukkan oleh pengguna. Proses ini
menghasilkan klasifikasi suara berdasarkan jenis
kelaminnya. Perancangan proses pengujian
ditunjukkan oleh gambar 3.3.
Proses Pengujian
Mulai
Input file suara format
(.wav), k-tetangga
terdekat
Ekstraksi Fitur
KNN
Output hasil klasifikasi
Selesai
Gambar 3.3 Proses Pengujian
Pada proses pelatihan dan pengujian terdapat
proses pengklasifikasian dengan menggunakan metode
KNN. Proses KNN ditunjukkan pada gambar 3.4.
KNN
Mulai
Input data uji, k
tetangga terdekat
Perhitungan jarak
Weighted voting
Output hasil
klasifikasi
Selesai
Normalisasi
Sorting
Gambar 3.15 Proses KNN
4. Implementasi
Antarmuka aplikasi untuk klasifikasi suara
berdasarkan gender terdiri atas 3 bagian utama, yaitu:
1. Form Ekstraksi Fitur
Form ini bertujuan untuk melakukan ekstraksi
fitur spectral centroid dan spectral flux dari file suara yang
akan diekstraksi. Antarmuka dari form ekstraksi fitur
ditunjukkan pada Gambar 4.1.
Gambar 4.1 Form Ekstraksi Fitur
Gambar 3.2 Proses Pelatihan

6
2. Form Proses Pelatihan
Form pelatihan digunakan untuk mengetahui
hasil akurasi dari implementasi KNN. Antarmuka dari
form pelatihan ditunjukkan pada Gambar 4.2.
Gambar 4.2 Form Pelatihan
3. Form Proses Pengujian
Form pengujian digunakan untuk
mengklasifikasikan suara berdasarkan jenis kelamin.
Form pengujian akan ditunjukkan pada Gambar 4.3.
Gambar 4.3 Form Pengujian
5. Pengujian dan Analisis
Pengujian klasifikasi suara berdasarkan gender
(jenis kelamin) dengan metode KNN digunakan dataset
suara sebanyak 294 record. Data yang digunakan dalam
sistem terbagi menjadi 2 kelas, yaitu kelas “L” untuk
laki-laki, dan “P” untuk perempuan dengan fitur yang
digunakan adalah spectral centroid dan spectral flux.
Pada setiap uji coba digunakan prosentase data latih
sebesar 70% dan data uji sebesar 30%, serta
menggunakan 19 nilai k yang berbeda. Proses
pengujian, terdapat 3 skenario yang digunakan:
a. Skenario 1
Pada skenario 1 digunakan 4 nilai frame width
yang berbeda, yaitu 128, 256, 512, dan 1024. Nilai frame
shift yang digunakan berdasarkan penelitian Wardana
(2011) adalah 31,25% dengan nilai alpha 0,97. Akurasi
pengujian tiap nilai frame width yang digunakan
diperoleh dari hasil rata-rata akurasi tiap uji coba pada
nilai frame width yang sama.
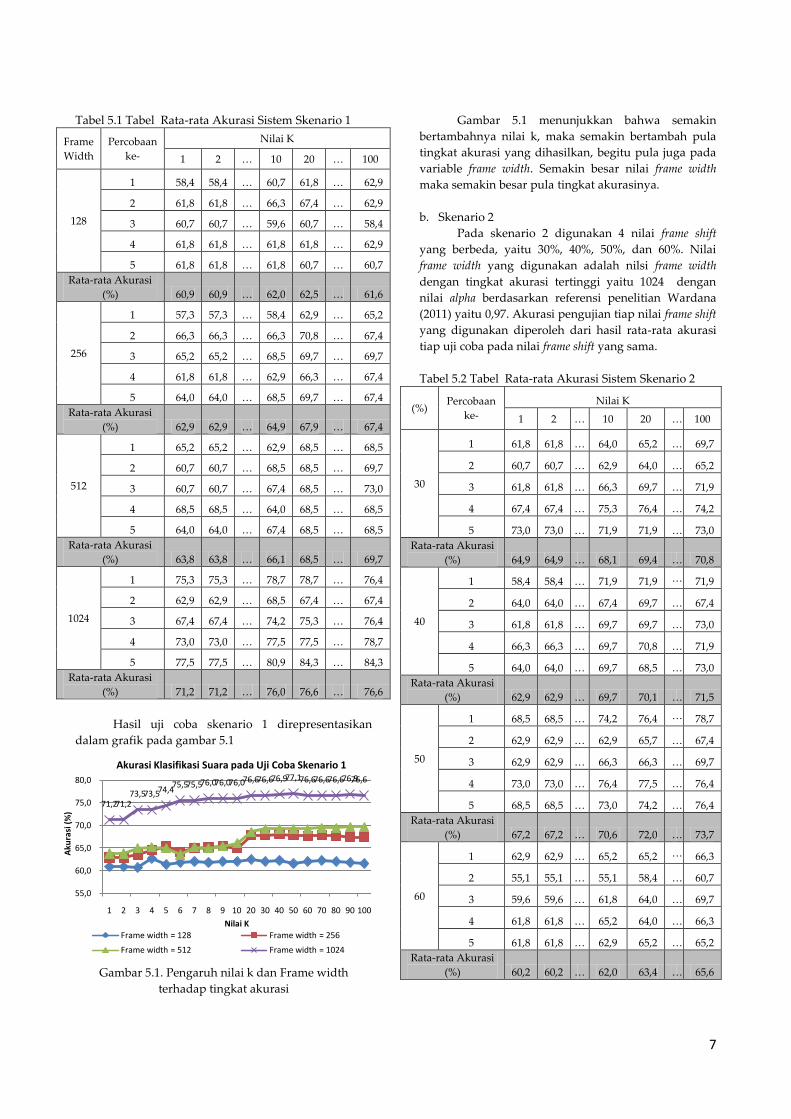
7
Tabel 5.1 Tabel Rata-rata Akurasi Sistem Skenario 1
Frame
Width
Percobaan
ke-
Nilai K
1 2 … 10 20 … 100
128
1 58,4 58,4 … 60,7 61,8 … 62,9
2 61,8 61,8 … 66,3 67,4 … 62,9
3 60,7 60,7 … 59,6 60,7 … 58,4
4 61,8 61,8 … 61,8 61,8 … 62,9
5 61,8 61,8 … 61,8 60,7 … 60,7
Rata-rata Akurasi
(%) 60,9 60,9 … 62,0 62,5 … 61,6
256
1 57,3 57,3 … 58,4 62,9 … 65,2
2 66,3 66,3 … 66,3 70,8 … 67,4
3 65,2 65,2 … 68,5 69,7 … 69,7
4 61,8 61,8 … 62,9 66,3 … 67,4
5 64,0 64,0 … 68,5 69,7 … 67,4
Rata-rata Akurasi
(%) 62,9 62,9 … 64,9 67,9 … 67,4
512
1 65,2 65,2 … 62,9 68,5 … 68,5
2 60,7 60,7 … 68,5 68,5 … 69,7
3 60,7 60,7 … 67,4 68,5 … 73,0
4 68,5 68,5 … 64,0 68,5 … 68,5
5 64,0 64,0 … 67,4 68,5 … 68,5
Rata-rata Akurasi
(%) 63,8 63,8 … 66,1 68,5 … 69,7
1024
1 75,3 75,3 … 78,7 78,7 … 76,4
2 62,9 62,9 … 68,5 67,4 … 67,4
3 67,4 67,4 … 74,2 75,3 … 76,4
4 73,0 73,0 … 77,5 77,5 … 78,7
5 77,5 77,5 … 80,9 84,3 … 84,3
Rata-rata Akurasi
(%) 71,2 71,2 … 76,0 76,6 … 76,6
Hasil uji coba skenario 1 direpresentasikan
dalam grafik pada gambar 5.1
Gambar 5.1. Pengaruh nilai k dan Frame width
terhadap tingkat akurasi
Gambar 5.1 menunjukkan bahwa semakin
bertambahnya nilai k, maka semakin bertambah pula
tingkat akurasi yang dihasilkan, begitu pula juga pada
variable frame width. Semakin besar nilai frame width
maka semakin besar pula tingkat akurasinya.
b. Skenario 2
Pada skenario 2 digunakan 4 nilai frame shift
yang berbeda, yaitu 30%, 40%, 50%, dan 60%. Nilai
frame width yang digunakan adalah nilsi frame width
dengan tingkat akurasi tertinggi yaitu 1024 dengan
nilai alpha berdasarkan referensi penelitian Wardana
(2011) yaitu 0,97. Akurasi pengujian tiap nilai frame shift
yang digunakan diperoleh dari hasil rata-rata akurasi
tiap uji coba pada nilai frame shift yang sama.
Tabel 5.2 Tabel Rata-rata Akurasi Sistem Skenario 2
(%) Percobaan
ke-
Nilai K
1 2 … 10 20 … 100
30
1 61,8 61,8 … 64,0 65,2 … 69,7
2 60,7 60,7 … 62,9 64,0 … 65,2
3 61,8 61,8 … 66,3 69,7 … 71,9
4 67,4 67,4 … 75,3 76,4 … 74,2
5 73,0 73,0 … 71,9 71,9 … 73,0
Rata-rata Akurasi
(%) 64,9 64,9 … 68,1 69,4 … 70,8
40
1 58,4 58,4 … 71,9 71,9 … 71,9
2 64,0 64,0 … 67,4 69,7 … 67,4
3 61,8 61,8 … 69,7 69,7 … 73,0
4 66,3 66,3 … 69,7 70,8 … 71,9
5 64,0 64,0 … 69,7 68,5 … 73,0
Rata-rata Akurasi
(%) 62,9 62,9 … 69,7 70,1 … 71,5
50
1 68,5 68,5 … 74,2 76,4 … 78,7
2 62,9 62,9 … 62,9 65,7 … 67,4
3 62,9 62,9 … 66,3 66,3 … 69,7
4 73,0 73,0 … 76,4 77,5 … 76,4
5 68,5 68,5 … 73,0 74,2 … 76,4
Rata-rata Akurasi
(%) 67,2 67,2 … 70,6 72,0 … 73,7
60
1 62,9 62,9 … 65,2 65,2 … 66,3
2 55,1 55,1 … 55,1 58,4 … 60,7
3 59,6 59,6 … 61,8 64,0 … 69,7
4 61,8 61,8 … 65,2 64,0 … 66,3
5 61,8 61,8 … 62,9 65,2 … 65,2
Rata-rata Akurasi
(%) 60,2 60,2 … 62,0 63,4 … 65,6
71,271,273,573,574,4
75,575,576,076,076,076,676,676,977,176,676,676,676,976,6
55,0
60,0
65,0
70,0
75,0
80,0
1 2 3 4 5 6 7 8 9 10 20 30 40 50 60 70 80 90 100
Aku
rasi
(%
)
Nilai K
Akurasi Klasifikasi Suara pada Uji Coba Skenario 1
Frame width = 128 Frame width = 256
Frame width = 512 Frame width = 1024
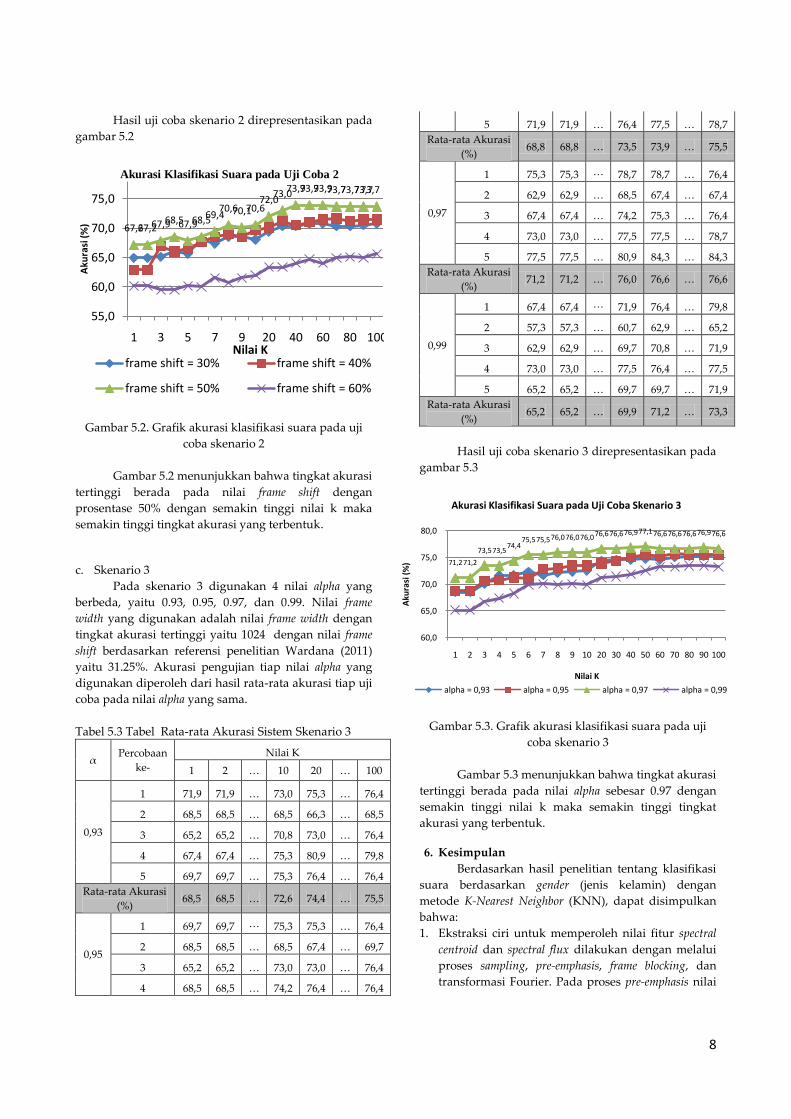
8
Hasil uji coba skenario 2 direpresentasikan pada
gambar 5.2
Gambar 5.2. Grafik akurasi klasifikasi suara pada uji
coba skenario 2
Gambar 5.2 menunjukkan bahwa tingkat akurasi
tertinggi berada pada nilai frame shift dengan
prosentase 50% dengan semakin tinggi nilai k maka
semakin tinggi tingkat akurasi yang terbentuk.
c. Skenario 3
Pada skenario 3 digunakan 4 nilai alpha yang
berbeda, yaitu 0.93, 0.95, 0.97, dan 0.99. Nilai frame
width yang digunakan adalah nilai frame width dengan
tingkat akurasi tertinggi yaitu 1024 dengan nilai frame
shift berdasarkan referensi penelitian Wardana (2011)
yaitu 31.25%. Akurasi pengujian tiap nilai alpha yang
digunakan diperoleh dari hasil rata-rata akurasi tiap uji
coba pada nilai alpha yang sama.
Tabel 5.3 Tabel Rata-rata Akurasi Sistem Skenario 3
α Percobaan
ke-
Nilai K
1 2 … 10 20 … 100
0,93
1 71,9 71,9 … 73,0 75,3 … 76,4
2 68,5 68,5 … 68,5 66,3 … 68,5
3 65,2 65,2 … 70,8 73,0 … 76,4
4 67,4 67,4 … 75,3 80,9 … 79,8
5 69,7 69,7 … 75,3 76,4 … 76,4
Rata-rata Akurasi
(%) 68,5 68,5 … 72,6 74,4 … 75,5
0,95
1 69,7 69,7 … 75,3 75,3 … 76,4
2 68,5 68,5 … 68,5 67,4 … 69,7
3 65,2 65,2 … 73,0 73,0 … 76,4
4 68,5 68,5 … 74,2 76,4 … 76,4
5 71,9 71,9 … 76,4 77,5 … 78,7
Rata-rata Akurasi
(%) 68,8 68,8 … 73,5 73,9 … 75,5
0,97
1 75,3 75,3 … 78,7 78,7 … 76,4
2 62,9 62,9 … 68,5 67,4 … 67,4
3 67,4 67,4 … 74,2 75,3 … 76,4
4 73,0 73,0 … 77,5 77,5 … 78,7
5 77,5 77,5 … 80,9 84,3 … 84,3
Rata-rata Akurasi
(%) 71,2 71,2 … 76,0 76,6 … 76,6
0,99
1 67,4 67,4 … 71,9 76,4 … 79,8
2 57,3 57,3 … 60,7 62,9 … 65,2
3 62,9 62,9 … 69,7 70,8 … 71,9
4 73,0 73,0 … 77,5 76,4 … 77,5
5 65,2 65,2 … 69,7 69,7 … 71,9
Rata-rata Akurasi
(%) 65,2 65,2 … 69,9 71,2 … 73,3
Hasil uji coba skenario 3 direpresentasikan pada
gambar 5.3
Gambar 5.3. Grafik akurasi klasifikasi suara pada uji
coba skenario 3
Gambar 5.3 menunjukkan bahwa tingkat akurasi
tertinggi berada pada nilai alpha sebesar 0.97 dengan
semakin tinggi nilai k maka semakin tinggi tingkat
akurasi yang terbentuk.
6. Kesimpulan
Berdasarkan hasil penelitian tentang klasifikasi
suara berdasarkan gender (jenis kelamin) dengan
metode K-Nearest Neighbor (KNN), dapat disimpulkan
bahwa:
1. Ekstraksi ciri untuk memperoleh nilai fitur spectral
centroid dan spectral flux dilakukan dengan melalui
proses sampling, pre-emphasis, frame blocking, dan
transformasi Fourier. Pada proses pre-emphasis nilai
67,267,267,968,567,968,569,470,670,170,6
72,073,073,973,973,973,773,773,773,7
55,0
60,0
65,0
70,0
75,0
1 3 5 7 9 20 40 60 80 100
Aku
rasi
(%
)
Nilai K
Akurasi Klasifikasi Suara pada Uji Coba 2
frame shift = 30% frame shift = 40%
frame shift = 50% frame shift = 60%
71,271,2
73,573,574,4
75,575,576,076,076,076,676,676,977,176,676,676,676,976,6
60,0
65,0
70,0
75,0
80,0
1 2 3 4 5 6 7 8 9 10 20 30 40 50 60 70 80 90 100
Aku
rasi
(%
)
Nilai K
Akurasi Klasifikasi Suara pada Uji Coba Skenario 3
alpha = 0,93 alpha = 0,95 alpha = 0,97 alpha = 0,99

9
alpha yang baik digunakan adalah 0,97. Pada proses
frame blocking nilai frame width yang baik digunakan
adalah 1024 dan nilai frame shift yang baik
digunakan adalah 31,25%. Setelah meendapatkan
hasil transformasi Fourier, dihitung dan diperoleh
nilai fitur spectral centroid dan nilai fitur spectral flux.
2. Pengklasifikasian suara dengan menggunakan
metode KNN dilakukan dengan menggunakan fitur
spectral centroid dan spectral flux pada suara, dengan
2 kelas tujuan yaitu laki-laki dan perempuan.
Penggunaan nilai k mempengaruhi tingkat akurasi.
Semakin tinggi nilai k maka semakin tinggi tingkat
akurasi yang dihasilkan.
3. Akurasi pada klasifikasi suara berdasarkan gender
(jenis kelamin) dengan metode KNN cukup baik.
Akurasi terendah pada uji coba dengan nilai frame
width 1024, frame shift 31,25%, dan nilai alpha 0.97
adalah 71,2% dan akurasi tertinggi adalah 77,1% .
Nilai akurasi yang dihasilkan cukup baik, sehingga
disimpulkan bahwa metode KNN dapat diterapkan
pada klasifikasi suara berdasarkan gender (jenis
kelamin).
7. Daftar Pustaka
[1] Prasetya, Binyamin Widi. 2008. “Identifikasi Suara
Pria dan Wanita Berdasarkan Frekuensi Suara”.
Jurnal Informatika. Vol. 4, No. 1. hal. 10-17.
http://ti.ukdw.ac.id/ojs/index.php/informatika/arti
cle/download/13/15. [4 Februari 2013] [2] Setiawan, Arif dan Pratomo Setiaji. 2011.
Klasifikasi Suara Berdasarkan Gender dengan
Algoritma K-Means. Prosiding Seminar Nasional
Pengaplikasian Telematika 2011 (SINAPTIKA 2011).
Universitas Mercu Buana. Jakarta. Indonesia.
http://library.si.umk.ac.id/index.php?p=fstream-
pdf&fid=69&bid=136. [4 Februari 2013].
[3] Sikki, Muhammad Ilyas. 2009. “Pengenalan Wajah
Menggunakan K-Nearest Neighbour dengan
Praproses Transformasi Wavelet”. Jurnal
Paradigma. Vol. 10, No. 2. http://www.ejournal-
unisma.net/ojs/index.php/paradigma/article/down
load/198/185 [7 Februari 2013]. [4] Daryanto, Tri. 2008. “Sistem Multimedia
Pertemuan ke-2 Audio dan Suara”.
http://kk.mercubuana.ac.id/files/92052-2-
132860772042.pdf . [18 April 2013].
[5] Tanudjaja, Harlianto. 2007. “Pengolahan Sinyal
Digital dan Sistem Pemrosesan Sinyal”. Andi
Offset. Yogyakarta.
[6] Jayati, Ari Endang. 2009. “Proses Pemfilteran
Sinyal Suara”. Elektrika. Vol. 1. No. 2.Hal 107-116.
[7] Huda, Miftahul. 2011. “Konversi Nada-nada
Akustik Menjadi Chord Menggunakan Pitch Class
Profile”. http://repo.eepis-
its.edu/175/3/KONVERSI_NADA-
NADA_AKUSTIK_MENJADI_CHORD_.pdf. [24
April 2013].
[8] Thiang. 2007. “Implementasi Sistem Pengenalan
Kata pada Mikrokontroler Keluarga MCS51”.
http://fportfolio.petra.ac.id/user_files/97-
031/Pengenalan%20Kata-
Mikrokontroler%20%20MCS51.pdf. [24 April
2013]. [9] Basuki, Achmad dkk. 2006. “Aplikasi Pengolahan
Suara untuk Request Lagu”. http://lecturer.eepis-
its.edu/~huda/Dokumen/Karya/Request%20Lagu.
pdf. [24 April 2013].
[10] Kuo, Sen M dan Woon-Seng Gan. 2005. “Digital
Signal Processor Architectures, Implementations,
and Applications”. Pearson Prentice Hall. United
States of Amerika.
[11] Thoman, Chris. 2009. “Model-Based Classification
Of Speech Audio”.
http://books.google.co.id/books?id=48pycpKBqwk
C&printsec=frontcover&hl=id#v=onepage&q&f=fa
lse. [24 April 2013]. [12] Han, Jiawei. 2006. “Data Mining: Concept and
Techniques”. Second Edition. Elsevier Inc. [13] Larose, Daniel T. “Discovering Knowledge in
Data: An Introduction to Data Mining”. John
Wiley & Sons. United States of Amerika.
[14] Ludviani, Resti. 2011. “Pembangkitan Aturan
Fuzzy Menggunakan Fuzzy C-Means (FCM)
Clustering Untuk Diagnosa Risiko Penyakit
Jantung Koroner (PJK)”. Skripsi. Universitas
Brawijaya Malang.
[15] Wardana, Mohammad Mahendra Jaya. 2011.
“Pengenalan Suara Menggunakan Algoritma Fast
Fourier Transform (FFT) dengan Algoritma Mel
Frequency Cepstrum Coefficient (MFCC) Sebagai
Ekstraksi Ciri ”. Skripsi. Universitas Brawijaya
Malang.




















