
Prediksi KNN
14
Dian Nuswantoro University 2014 ALGORITMA K-NEAREST NEIGHBOR BERBASIS CHI-SQUARED UNTUK PREDIKSI NASABAH ASURANSI Jatmiko Indriyanto, Purwanto, Catur Supriyanto Pascasarjana Teknik Informatika Universitas Dian Nuswantoro ABSTRACT The more people who take insurance, but do not think whether such insurance is appropriate and able to follow it. Therefore, the prediction needs to be done, to determine whether or not the insurance problem. COIL 2000 dataset dataset is a dataset with large data dimensions and are Class Imbalance. K-nearest Neighbor algorithm is known to solve the problem of data-dimensional datasets with large data and the results of only 89.26% accuracy. Chi-Square method is used to reduce the dimensions of large datasets and can help improve the accuracy of outcome prediction nearest K-Neighbor. K-nearest Neighbor Algorithm with Chi-Square as a feature selection proved to be accurate and effective in predicting the outcome of insurance with 94.90% accuracy and the value of Roc Curve 0.864 are included in the category of "Roc Curve good". Keywords: Prediction, insurance, K-nearest Neighbor, Chi-Square, Feature Selection. 1. PENDAHULUAN a. Latar Belakang Definisi asuransi menurut Pasal 246 Kitab Undang-undang Hukum Dagang (KUHD) Republik Indonesia : "Asuransi atau pertanggungan adalah suatu perjanjian, dengan mana seorang penanggung mengikatkan diri pada tertanggung dengan menerima suatu premi, untuk memberikan penggantian kepadanya karena suatu kerugian, kerusakan atau kehilangan keuntungan yang diharapkan, yang mungkin akan dideritanya karena suatu peristiwa yang tak tertentu. Sebelum perusahaan asuransi menyetujui asuransi yang diajukan calon nasabah asuransi, perusahaan melakukan analisa ke calon nasabah asuransi, apakah asuransi disetujui atau tidak disetujui. Analisa asuransi adalah penyelidikan faktor-faktor yang berpengaruh pada lancar atau tidak lancarnya proses pembayaran premi. Masyarakat menyoroti, penjualan produk asuransi tidak sesuai, baik dari segi pemasaran dan ilustrasi yang dilakukan oleh agen asuransi. Informasi yang disampaikan kepada calon klien asuransi tidak lengkap, pada saat klien sudah masuk asuransi, masa polis berakhir, untuk meminta uang pertanggungan sering kesulitan.
Transcript of Prediksi KNN

Dian Nuswantoro University 2014
ALGORITMA K-NEAREST NEIGHBOR BERBASIS CHI-SQUARED UNTUK PREDIKSI NASABAH ASURANSI
Jatmiko Indriyanto, Purwanto, Catur Supriyanto
Pascasarjana Teknik Informatika Universitas Dian Nuswantoro
ABSTRACT The more people who take insurance, but do not think whether such insurance is appropriate and able to follow it. Therefore, the prediction needs to be done, to determine whether or not the insurance problem. COIL 2000 dataset dataset is a dataset with large data dimensions and are Class Imbalance. K-nearest Neighbor algorithm is known to solve the problem of data-dimensional datasets with large data and the results of only 89.26% accuracy. Chi-Square method is used to reduce the dimensions of large datasets and can help improve the accuracy of outcome prediction nearest K-Neighbor. K-nearest Neighbor Algorithm with Chi-Square as a feature selection proved to be accurate and effective in predicting the outcome of insurance with 94.90% accuracy and the value of Roc Curve 0.864 are included in the category of "Roc Curve good". Keywords: Prediction, insurance, K-nearest Neighbor, Chi-Square, Feature Selection. 1. PENDAHULUAN a. Latar Belakang
Definisi asuransi menurut Pasal 246 Kitab Undang-undang Hukum Dagang (KUHD) Republik Indonesia : "Asuransi atau pertanggungan adalah suatu perjanjian, dengan mana seorang penanggung mengikatkan diri pada tertanggung dengan menerima suatu premi, untuk memberikan penggantian kepadanya karena suatu kerugian, kerusakan atau kehilangan keuntungan yang diharapkan, yang mungkin akan dideritanya karena suatu peristiwa yang tak tertentu.
Sebelum perusahaan asuransi menyetujui asuransi yang diajukan calon nasabah asuransi, perusahaan melakukan analisa ke calon nasabah asuransi, apakah asuransi disetujui atau tidak disetujui. Analisa asuransi adalah penyelidikan faktor-faktor yang berpengaruh pada lancar atau tidak lancarnya proses pembayaran premi. Masyarakat menyoroti, penjualan produk asuransi tidak sesuai, baik dari segi pemasaran dan ilustrasi yang dilakukan oleh agen asuransi. Informasi yang disampaikan kepada calon klien asuransi tidak lengkap, pada saat klien sudah masuk asuransi, masa polis berakhir, untuk meminta uang pertanggungan sering kesulitan.

Dian Nuswantoro University 2014
Dilihat dari grafik diatas terlihat banyaknya asuransi bermasalah, dikarenakan perusahaan asuransi
kurang dalam menganalisa data nasabah calon asuransi. Banyak penelitian prediksi dengan teknik klasifikasi datamining yang berhubungan dengan asuransi, adalah yang dilakukan oleh Osama Hanafy Mahmoud pada tahun 2008 yang melakukan prediksi efisiensi finansial untuk properti dan liability perusahaan asuransi menggunakan fuzzy clustering.
Berbagai algoritma prediksi data mining telah diterapkan untuk membantu menmprediksi asuransi antara lain menggunakan: 1.Naive Bayes Kecepatan komputasi yang sangat tinggi, mampu menangani masalah data dataset yang berdimensi besar dan dataset yang bersifat Class Imbalance 2.Fuzzy Logic Hingga kini belum ada pengetahuan sistematik yang baku dan seragam tentang metodologi pemecahan problema kendali menggunakan pengendali fuzzy. fuzzy tidak bekerja dengan baik karena banyak data yang tidak terklasifikasi [4] [5]. 3.Artificial Neural Network Kelemahannya ANN hanya dapat menangani pola statis dan waktu komputasi yang lama [6]. 4.K-Nearest Neighbor Membutuhkan waktu yang cepat dalam training, dapat menjaga keamanan data yang besar [7]. 5.Support Vector Machine SVM banyak yang sudah menerapkan untuk prediksi asuransi,hasil yang memuaskan [8] tetapi SVM memiliki kekurangan,membutuhkan waktu komputasi yang lama dan dalam menangani dataset yang besar (record dan attribute banyak). 6.Case Based-Reasoning Case Based Reasoning (CBR) adalah suatu paradigma pemecahan masalah diselesaikan dengan membandingkan dengan kasus-kasus dimasa lalu yang serupa dan menggunakannya kembali kasus-kasus yang ada untuk menyelesaikan suatu masalah sekarang [9].
Feature Selection adalah salah satu cara untuk mereduksi dimensi dataset yang besar[46] dan meningkatkan keakuratan [10] [11]. Menurut Marcin Blachnik tentang Comparison of Various Feature Selection Methods in Application to Prototype Best Rules. Marcin Blachnik menjelaskan bahwa Feature Selection berperan memilih subset yang tepat dari set fitur asli, karena tidak semua fitur atau atribut relevan dengan masalah [12]. Bahkan beberapa dari fitur atau atribut tersebut mengganggu dan dapat
Gambar Asuransi Sunlife bermasalah (Sumber : [49] )

Dian Nuswantoro University 2014
mengurangi akurasi. Noisy Features atau fitur yang tidak terpakai tersebut harus dihapus untuk meningkatkan akurasi.
Algoritma k-nearest neighbor (k-NN atau KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut [13]. KNN memiliki beberapa kelebihan yaitu ketangguhan terhadap training data yang memiliki banyak noise dan efektif apabila training data-nya besar. K-NN merupakan algoritma yang algoritma yang menggunakan seluruh data latih untuk melakukan proses klasifikasi (complete storage). Hal ini mengakibatkan untuk data dalam jumlah yang sangat besar, proses prediksi menjadi sangat lama [13]. Menggunakan metode Chi-Square dapat mereduksi data yang besar [14], sehingga proses yang dibutuhkan menjadi cepat. Chi-square adalah salah satu supervised seleksi fitur yang mampu mengilangkan banyak fitur tanpa mengurangi tingkat akurasi [15].Chi-square banyak digunakan dan menghasilkan kinerja yang bagus dalam keakuratan [16].Untuk menyelesaikan permasalahan diatas, maka penulis menggunakan model k-nearest neighbors . Menggunakan K-Nearest Neighbors, karena berdasarkan penelitian Shibin Parameswaran dan Kilian Q. Weinberger, untuk memprediksi asuransi bisa menggunakan K-Nearest Neighbors [17]. Berdasarkan penelituan sebelumnya menggunakan KNN hanya menghasilkan akurasi 90% [18]. Model ini digunakan untuk memprediksi data asuransi. Sesuai penelitian yang dilakukan oleh faiza,K-NN cocok untuk mengklasifikasi data analisa asuransi, jika datanya akurat maka calon nasabah akan lancar membayar premi, jika data tidak akurat maka calon nasabah tidak lancar membayar premi.
b. Rumusan Masalah Berdasarkan latar belakang masalah yang telah diuraikan di atas, rumusan masalah pada penelitian ini adalah: Bagaimana K-Nearest Neigbor dapat meningkatkan hasil akurasi prediksi nasabah asuransi dan chi-squared dapat membantu mereduksi dimensi dataset asuransi yang besar c. Tujuan Tujuan penelitian ini adalah menerapkan K-Nearest Neigbor dapat meningkatkan hasil akurasi prediksi nasabah asuransi dan chi-squared dapat membantu mereduksi dimensi dataset asuransi yang besar. d. Manfaat Memberikan kontribusi keilmuan pada penelitan algoritma K-Nearest Neighbors untuk prediksi nasabah asuransi bermasalah, dan dapat dimanfaatkan oleh perusahaan asuransi sebagai pedoman untuk menentukan asuransi bermasalah. 2. TINJAUAN PUSTAKA
1). Penelitian Terkait
Peneliti Tahun Masalah Metode Kesimpulan V.Sree Hari Rao, Murthy V .Jonnalagedda
2012 prediksi nasabah asuransi kesehatan bermasalah, memiliki lebih dari 1 polis asuransi
K-d tree, K-NN
metode K-Nearest Neighbor dapat digunakan untuk memprediksi masalah nasabah asuransi dalam pembayaran premi
Mr.Ram Babu., Mr.A.Rama Satish
2013 kesulitan dalam credit scoring dipergunakan utk menentukan
K-NN K-NN dapat menentukan dalam credit scoring dipergunakan utk menentukan aplikasi

Dian Nuswantoro University 2014
aplikasi calon nasabah
calon nasabah
Xavier de luna, Per Johansson, Sara Sjostedt-de Luna
2010 Kesulitan dalam menyimpulkan polis asuransi social yang cocok
K-NN menggunakan KNN dapat menyimpulkan polis asuransi social yang cocok.
Shibin Parameswaran , Kilian Q. Weinberger
2010 Kesulitan metode SVM membagi dataset dalam membagi beberapa class
KNN Menggunakan KNN dapat membagi class dataset dan menghasilkan akurasi 89.26%. (Jurnal Acuan)
2). Landasan Teori a. Asuransi Definisi Asuransi menurut Kitab Undang-Undang Hukum Dagang (KUHD), tentang asuransi atau pertanggungan seumurnya, Bab 9, Pasal 246: [21]"Asuransi atau Pertanggungan adalah suatu perjanjian dengan mana seorang penanggung mengikatkan diri kepada seorang tertanggung, dengan menerima suatu premi, untuk memberikan penggantian kepadanya karena suatu kerugian, kerusakan atau kehilangan keuntungan yang diharapkan, yang mungkin akan dideritanya karena suatu peristiwa yang tak tertentu.” b. Data Mining Data mining atau sering disebut sebagai knowledge discovery in database (KDD) adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam data berukuran besar. Keluaran data mining ini bisa dipakai untuk membantu pengambilan keputusan di masa depan. Pengembangan KDD ini menyebabkan penggunaan pattern recognition semakin berkurang karena telah menjadi bagian data mining [8]. c. K-Nearest Neighbor K-Nearest Neighbor (K-NN) merupakan teknik klasifikasi yang melakukan prediksi secara tegas pada data uji berdasarkan perbandingan K tetangga terdekat. Parameter K pada K-Nearest Neigbor, K adalah jumlah tetangga terdekat yang dilibatkan dan mempunyai pengaruh dalam penentuan hasil prediksi [25] [26].K-nearest Neighbor merupakan metode klasifikasi instance-based, memilih satu objek latih yang memiliki sifat ketetanggaan (neighborhood) yang paling dekat. [27] Sifat ketetanggaan ini didapatkan dari perhitungan nilai kemiripan ataupun ketidakmiripan. KNN menggunakan metode perhitungan nilai ketidakmiripan ( Euclidian, Manhattan, Square Euclidian ,dll). Dekat atau jauhnya tetangga biasanya dihitung berdasarkan jarak ecludian. KNN akan memilih K tetangga terdekat untuk menentukan hasil klasifikasi dengan melihat jumlah kemunculan dari kelas dalam K-tetangga yang terpilih [28] Algoritma K - NN adalah mudah dilaksanakan , namun di sisi lain , termasuk metode klasifikasi ' malas ', hal tersebut bisa ditangani dengan menggunakan feature selection. Rumus Euclidian:

Dian Nuswantoro University 2014
Algoritma K-Nearest Neighbor: 1. Hitung jarak antara data training dengan data yang baru 2. Tentukan K terdekat, dengan melihat hasil perhitungan jarak yang pertama 3. Menetapkan label yang mendekati nilai k [8] e. Feature Selection Fitur seleksi adalah sebuah proses yang biasa digunakan pada Machine Learning dimana sekumpulan dari fitur yang dimiliki oleh data digunakan untuk pembelajaran algoritma. Feature selection menurut Oded Maimon [31] telah menjadi bidang penelitian aktif dalam pengenalan pola, statistik, dan Data Mining [14]. Seleksi fitur adalah salah satu faktor yang paling penting yang dapat mempengaruhi tingkat akurasi klasifikasi karena jika dataset berisi sejumlah fitur, dimensi dataset akan menjadi besar hal ini membuat rendahnya nilai akurasi klasifikasi. Masalah dalam seleksi fitur adalah pengurangan dimensi, dimana awalanya semua atribut diperlukan untuk memperoleh akurasi yang maksimal. Empat alasan utama untuk melakukan pengurangan dimensi menurut Maimon :
1. Decreasing the learning cost atau penurunan biaya pembelajaran. 2. Increasing the learning performance atau meningkatkan kinerja pembelajaran. 3. Reducing irrelevant dimensions atau mengurangi dimensi yang tidak relevan. 4. Reducing redundant dimensions atau mengurangi dimensi yang berlebihan. [12]
Keuntungan menggunakan fitur seleksi: 1. mengurangi biaya dan persyaratan penyimpanan komputasi 2. Berurusan dengan degradasi efisiensi klasifikasi karena ukuran terbatas pelatihan sampel set 3. mengurangi waktu pelatihan dan prediksi 4. memfasilitasi pemahaman data dan visualisasi [32]
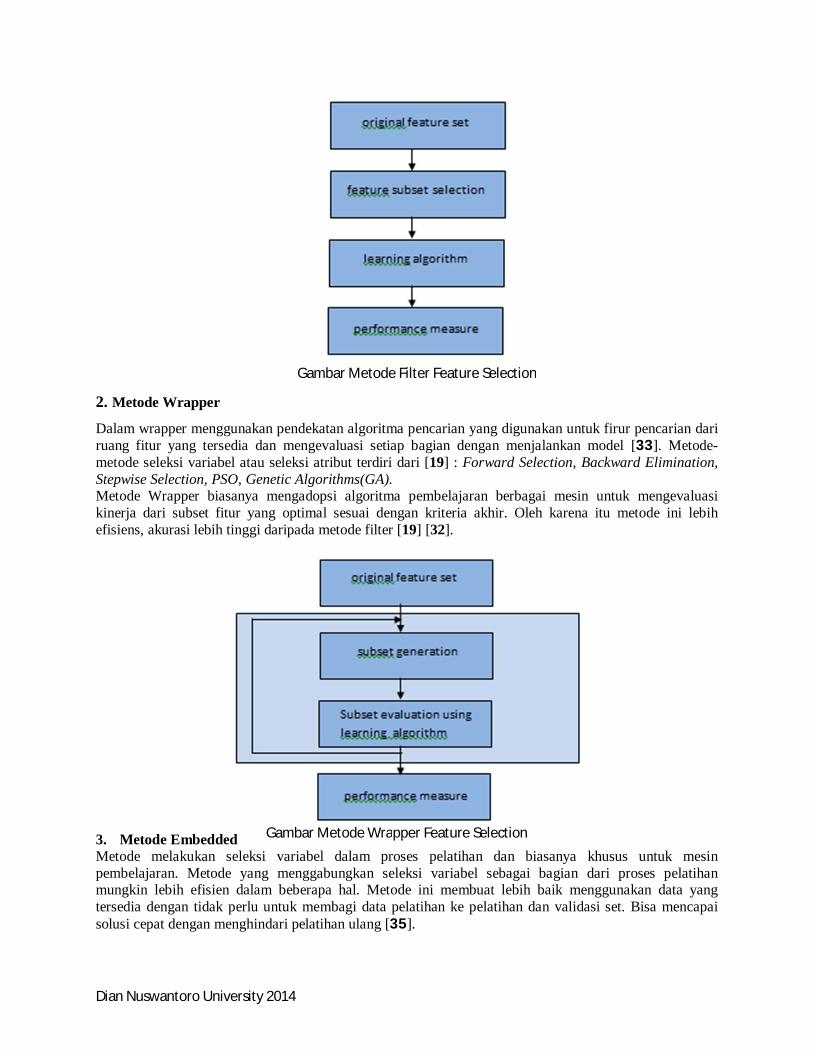
Selain itu dengan fitur atau atribut yang banyak akan memperlambat proses komputasi. Berikut gambar tahapan Feature Selection. Beberapa metode fitur selection: 1. Metode Filter Metode Filter adalah memilih atribut yang relevan sebelum pindah ke tahap pembelajaran berikutnya, atribut yang dianggap paling penting yang dipilih untuk pembelajaran, sedangkan sisanya dikecualikan. Metode Filter didasarkan pada kriteria peringkat tunggal. Akibatnya efisiensi seleksi begitu tinggi. Namun, akurasi yang rendah karena kriteria peringkatnya terlalu sederhana. Metode-metode seleksi variabel atau seleksi atribut terdiri dari : Chi-Squared, Markov Blanket Filtering, Genetic Algorithms(GA), PSO.
Dian Nuswantoro University 2014
2. Metode Wrapper
Dalam wrapper menggunakan pendekatan algoritma pencarian yang digunakan untuk firur pencarian dari ruang fitur yang tersedia dan mengevaluasi setiap bagian dengan menjalankan model [33]. Metode-metode seleksi variabel atau seleksi atribut terdiri dari [19] : Forward Selection, Backward Elimination, Stepwise Selection, PSO, Genetic Algorithms(GA). Metode Wrapper biasanya mengadopsi algoritma pembelajaran berbagai mesin untuk mengevaluasi kinerja dari subset fitur yang optimal sesuai dengan kriteria akhir. Oleh karena itu metode ini lebih efisiens, akurasi lebih tinggi daripada metode filter [19] [32].
3. Metode Embedded Metode melakukan seleksi variabel dalam proses pelatihan dan biasanya khusus untuk mesin pembelajaran. Metode yang menggabungkan seleksi variabel sebagai bagian dari proses pelatihan mungkin lebih efisien dalam beberapa hal. Metode ini membuat lebih baik menggunakan data yang tersedia dengan tidak perlu untuk membagi data pelatihan ke pelatihan dan validasi set. Bisa mencapai solusi cepat dengan menghindari pelatihan ulang [35].
Gambar Metode Filter Feature Selection
Gambar Metode Wrapper Feature Selection

Dian Nuswantoro University 2014
f. Chi-square Fitur seleksi menggunakan chi-square sangat umum digunakan, evaluasi atribut chi-square mengevaluasi nilai dari fitur berdasarkan perhitungan nilai statistik chi-square [36].Chi-Square disebut juga dengan Kai Kuadrat. Chi Square adalah salah satu jenis uji komparatif non parametris yang dilakukan pada dua variabel, di mana skala data kedua variabel adalah nominal. (Apabila dari 2 variabel, ada 1 variabel dengan skala nominal maka dilakukan uji chi square dengan merujuk bahwa harus digunakan uji pada derajat yang terendah). Uji chi-square merupakan uji non parametris yang paling banyak digunakan. Namun perlu diketahui syarat-syarat uji ini adalah: frekuensi responden atau sampel yang digunakan besar, sebab ada beberapa syarat di mana chi square dapat digunakan yaitu:
1. Tidak ada cell dengan nilai frekuensi kenyataan atau disebut juga Actual Count (F0) sebesar 0 (Nol). 2. Apabila bentuk tabel kontingensi 2 X 2, maka tidak boleh ada 1 cell saja yang memiliki frekuensi
harapan atau disebut juga expected count ("Fh") kurang dari 5. 3. Apabila bentuk tabel lebih dari 2 x 2, misak 2 x 3, maka jumlah cell dengan frekuensi harapan yang
kurang dari 5 tidak boleh lebih dari 20%. Chi-Square disebut juga dengan Kai Kuadrat. Chi Square adalah salah satu jenis uji komparatif non parametris yang dilakukan pada dua variabel, di mana skala data kedua variabel adalah nominal. (Apabila dari 2 variabel, ada 1 variabel dengan skala nominal maka dilakukan uji chi square dengan merujuk bahwa harus digunakan uji pada derajat yang terendah). Top p% adalah tingkatan reduksi dari dataset yang dikurangi dimensinya.
g. Cross Validation Cross Validation adalah teknik validasi dengan membagi data secara acak kedalam k bagian dan masing-masing bagian akan dilakukan proses klasifikasi [37]. Dengan menggunakan cross validation akan dilakukan percobaan sebanyak k. Data yang digunakan dalam percobaan ini adalah data training untuk mencari nilai error rate secara keseluruhan. Secara umum pengujian nilai k dilakukan sebanyak 10 kali untuk memperkirakan akurasi estimasi. Dalam penelitian ini nilai k yang digunakan berjumlah 10 atau 10-fold Cross Validation. Menggunakan cross-validation dapat memilih k dari k-nearest neighbor yang tepat [8]. Pada gambar terlihat bahwa tiap percobaan akan menggunakan satu data testing dan k-1 bagian akan menjadi data training, kemudian data testing itu akan ditukar dengan satu buah data training sehingga untuk tiap percobaan akan didapatkan data testing yang berbeda-beda. Data training adalah data yang akan dipakai dalam melakukan pembelajaran sedangkan data testing adalah data yang belum pernah dipakai sebagai pembelajaran dan akan berfungsi sebagai data pengujian kebenaran atau keakurasian hasil pembelajaran [38]

Dian Nuswantoro University 2014
h. Confusion Matrix Confusion matrix memberikan keputusan yang diperoleh dalam traning dan testing, confusion matrix memberikan penilaian performance klasifikasi berdasarkan objek dengan benar atau salah [37] [8]. Confusion matrix berisi informasi aktual (actual) dan prediksi (predicted) pada sistem klasifikasi. Confusion bisa untuk menilai kinerja prediksi [39] [40]. Confusion matrix terdiri dari: a. a adalah jumlah prediksi yang tepat bahwa instance bersifat negatif, b. b adalah jumlah prediksi yang salah bahwa instance bersifat positif, c. c adalah jumlah prediksi yang salah bahwa instance bersifat negatif, dan d. d adalah jumlah prediksi yang tepat bahwa instance bersifat positif. 3). Kerangka Pemikiran
3. METODE PENELITIAN Pada Penelitian kali ini menggunakan metode penelitian eksperimen. Penelitian eksperimen melibatkan penyelidikan perlakuan pada atribut parameter atau variabel tergantung dari penelitinya dan menggunakan tes yang dikendalikan oleh si peneliti itu sendiri. dengan metode penelitian sebagai berikut: 1. Pengumpulan data (Data Gathering) Pada tahap ini ditentukan data yang akan diproses. Mencari data yang tersedia, memperoleh data tambahan yang dibutuhkan, mengintegrasikan semua data kedalam dataset, termasuk variabel yang diperlukan dalam proses. 2. Pengolahan awal data (Data Pre-processing) Ditahap ini dilakukan penyeleksian data, data dibersihkan dan ditransformasikan kebentuk yang diinginkan sehingga dapat dilakukan persiapan dalam pembuatan model. Tahap pengolahan awal data dilakukan untuk mempersiapkan data yang benar-benar valid sebelum diproses pada tahap berikutnya. Menurut Gurunescu [29] pada tahap ini dilakukan cleansing, transformasi, reduksi dan seleksi fitur. Data

Dian Nuswantoro University 2014
50.00%
55.00%
60.00%
65.00%
70.00%
75.00%
80.00%
85.00%
90.00%
95.00%
100.00%
0.10% 0.20% 0.30% 0.40% 0.50% 0.60% 0.70% 0.80% 0.90%
KNN dengan Chi-square
Naïve B dengan Chi-square
SVM dengan Chi-square
ANN dengan Chi-square
yang didapat diolah untuk mendapatkan atribut yang relevan dan sesuai. Dalam penelitian ini, tidak dilakukan proses pengolahan awal data. 3. Metode yang diusulkan (Proposed Method) Pada tahap ini data dianalisis, dikelompokan variabel mana yang berhubungan dengan satu sama lainnya. Setelah data dianalisis lalu diterapkan model-model yang sesuai dengan jenis data. Pembagian data kedalam data latihan (training data) dan data uji (testing data) juga diperlukan untuk pembuatan model. 4. Eksperimen dan pengujian model (Model Testing and Experimen) Pada tahap ini model yang diusulkan akan diuji untuk melihat hasil berupa aturan yang akan dimanfaatkan dalam pengambilan keputusan. 5. Evaluasi dan validasi hasil (Result Evaluation) Pada tahap ini dilakukan evaluasi terhadap model yang ditetapkan untuk mengetahui tingkat keakurasian model. 4. HASIL PENELITIAN
Metode
KNN NAÏVE SVM ANN Dtree Akurasi 94.17% 93.45% 92.13% 92.36% 94.02%
Berdasarkan hasil eksperimen 4 metode, K-Neares Neighbor , Naïve Bayes, Support Vector Machine, Artificial neural network tanpa Chi-square, terbukti K-Neares Neighbor akurasinya paling tinggi dibandingkan metode yang lain. Untuk Nilai AUC(kurva ROC) metode paling tinggi adalah Naïve Bayes.
Berdasarkan hasil eksperimen K-Neares Neigbor , Naïve Bayes, Support Vector Machine, dan Artificial Neural Network menggunakan Chi-square, dengan top p% 0.1%, 0.2%, 0.3%, 0.4%, 0.5%, 0.6%, 0.7%, 0.8%, 0.9%, terbukti K-Nearest Neigbor akurasinya meningkat dan lebih tinggi dibandingkan metode lainnya. Penelitian ini menguji keakuratan prediksi asuransi bermasalah dengan menggunakan algoritma K-Nearest Neighbor dengan Chi-Square sebagai fitur seleksi dari dataset yang diambil dari CoIL 2000
Tabel Hasil Eksperimen 4 metode tanpa Chi-Square
Grafik Komparasi Akurasi 5 metode

Dian Nuswantoro University 2014
dataset, yaitu dataset dari perusahaan asuransi yang memiliki 85 atribut dan 1 label, dengan data yang besar (memiliki 5823 record) serta bersifat Class Imbalance. Seperti diketahui sebelumnya bahwa K-Nearest Neighbor bisa memecahkan masalah data Class Imbalance dan fitur seleksi dari Chi-Square adalah salah satu cara untuk mereduksi dimensi dataset yang besar, Chi-Square berperan memilih subset yang tepat dari set fitur asli, karena tidak semua fitur/atribut relevan dengan masalah karena beberapa dari fitur atau atribut tersebut mengganggu dan dapat mengurangi akurasi. Data dianalisa dengan melakukan dua perbandingan yaitu menggunakan algoritma 4 metode tanpa Chi-Square dan algoritma 4 metode dengan Chi-Square sebagai fitur seleksi. Terbukti metode K-Nearest Neighbor hasil akurasinya stabil dan meningkat dibanding 4 metode yang lain. 5. KESIMPULAN DAN SARAN a. Algoritma K-Nearest Neighbor terbukti akurasi meningkat dalam memprediksi nasabah asuransi dari
dataset dengan dimensi data yang besar, dari akurasi penelitian sebelumnya 89.26%. Metode Chi-Square dapat mereduksi dimensi dataset yang besar dan dapat membantu meningkatkan hasil akurasi prediksi K-Nearest Neighbor. Dalam hal ini K-Nearest Neighbor memanfaatkan fungsi seleksi fitur dari Chi-Square untuk pemilihan atribut data dengan karakteristik data itu sendiri, dan meningkatkan keakuratan prediksi K-Nearest Neighbor. K-Nearest Neighbor berbasis Chi-Square lebih akurat dan efektif dalam memprediksi nasabah asuransi asuransi dari dataset dengan data yang besar dengan hasil akurasi 94,90% dan nilai AUC 0.864 termasuk dalam kategori “Roc Curve good”.
b. Metode Chi-Square berbasis K-Nearest Neighbor terbukti akurat dalam prediksi nasabah asuransi dari dataset dengan dimensi data yang besar, tetapi dalam penelitian ini terdapat beberapa saran dalam pengembangannya antara lain prosedur ini tidak selalu mengarahkan ke model pemilihan atribut yang terbaik. Chi-Square berbasis K-Nearest Neighbor hanya mempertimbangkan sebuah subset kecil dari semua model-model yang mungkin, sehingga resiko melewatkan atau kehilangan model terbaik akan bertambah, seiring dengan penambahan jumlah variabel be bas.Penelitian ini diharapkan dapat digunakan sebagai bahan pertimbangan untuk prediksi asuransi bagi siapa saja yang bekerja didalam bidang asuransi. Penelitian ini dapat dikembangkan dengan metode klasifikasi Data Mining lainnya, penggunaan metode fitur seleksi atau metode optimasi lainnya yang dapat mengatasi masalah dimensi data yang besar.
6. PENUTUP
Tesis ini juga tidak dapat selesai tanpa dukungan, bimbingan dan motivasi secara langsung dan tidak langsung dari semua pihak. Oleh karena itu saya ingin menyampaikan ucapan terima kasih kepada: 1. ALLAH S.W.T karena telah memberikan kesehatan dan kekuatan untuk menyelesaikan tesis. 2. Kedua orang tua tercinta untuk dukungan moril maupun spiritual. 3. Istriku tercinta Maya Indra Mulyani untuk dukungan moril maupun materil. 4. Dr. Ir. Edi Noersasongko, M.Kom selaku rektor Universitas Dian Nuswantoro. 5. Dr. Abdul Syukur, MM selaku Direktur Program Pascasarjana Universitas Dian Nuswantoro. 6. Purwanto, S.Si,. M.Kom,. Ph.D selaku dosen pembimbing yang telah memberikan pengetahuan, bimbingan dan dorongan semangat dalam penyusunan tesis ini. 7. Catur Supriyanto, M.C.S selaku dosen pembimbing yang telah memberikan pengetahuan, bimbingan dan dorongan semangat dalam penyusunan tesis ini. 8. Romi Satria Wahono, M.Eng yang telah memberikan dukungan dan bantuan. 9. Dr. Eng. Yuliman Purwanto, M.Eng yang telah memberikan dukungan dan bantuan. 10. Dosen penguji yang telah memberikan masukan berupa kritik dan saran yang membangun untuk perbaikan tesis ini. 11. Seluruh dosen dan staf tata usaha pada lingkungan Program Pascasarjana Magister Teknik Informatika di Universitas Dian Nuswantoro yang telah membantu selama proses studi.

Dian Nuswantoro University 2014
PERNYATAAN ORIGINALITAS “Saya menyatakan dan bertanggungjawab dengan sebenarnya bahwa artikel ini adalah hasil karya sendiri kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya” [Jatmiko Indriyanto – P31.2008.00448] 7. DAFTAR PUSTAKA
[1] Soeisno Djojosoedarso, Prinsip-prinsip manajemen risiko dan asuransi. Jakarta : Salemba Empat, 2003.
[2] Herman Darmawi, MANAJEMEN ASURANSI.: Bumi Aksara, 2004. [3] HM. Adler, Financial Planner.: KOMPAS Penerbit Buku, 2008. [4] Sri Hartati, Agus Harjoko, Retantyo Wardoyo Sri Kusumadewi, Fuzzy Multi Atribut Decision
Making. Yogyakarta: Graha Ilmu, 2006. [5] Hsiao Tshung Wong Vincent C. S. Lee, "A multivariate neuro-fuzzy system for foreign currency
risk management decision making," vol. Volume 70 , no. Issue 4-6, 2007. [6] Sudjati Rachmat, "Metode jaringan syaraf tiruan untuk penentuan permeabilitas batuan reservoir dari
data logging," Kartika, vol. 62, April 2008. [7] C. Vercellis, Business Intelligent: Data Mining and Optimizzation for Decision Making. West
Sussex, United Kingdom: John Wiley & Sons Ltd, 2009. [8] Florin Gorunescu, Data Mining Concept,Models and Techniques, 12th ed., Prof. Lakhmi C. Jain
Prof. Janusz Kacprzyk, Ed. Craiova, Romania: Springer, 2011. [9] A. Aamodt, Case Based Reasoning :Foundational Issues, Methodological Variations, and System
Approaches. Norwegia: IOS Press, 1993. [10] Ye Xu and Dan Rockmore, "Feature Selection for Link Prediction," PIKM, vol. ACM 978-1-4503-
1719-1/12/11, p. 25, November 2012. [11] Xiaoyun Wu, Rohini Srihari Zhaohui Zheng, "Feature Selection For Text Categorization On
Imbalanced Data," Sigkdd Explorations, vol. 6, no. 1, p. 80, 2004. [12] Marcin Blachnik, "Comparison of Various Feature Selection Methods in Application to Prototype
Best Rules," Science Works, vol. III, February 2009. [13] Mohammad Zulkernine Liwei Kuang, "An Anomaly Intrusion Detection Method Using the CSI-
KNN Algorithm," 2008. [14] Narayanan K Bong Chih How, "An Empirical Study of Feature Selection for Text Categorization
based on Term Weightage," Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, vol. 0-7695-2100-2/04, p. 1, 2004.
[15] Affandy Catur Supriyanto, "Kombinasi teknik Chi square dan singular value decomposition Untuk reduksi fitur pada pengelompokan dokumen," Semantik, no. ISBN 979-26-0255-0, p. 4, Agustus 2011.
[16] Eduardo T. Ueda Routo Terada, "A new version of the RC6 algorithm, stronger against χ2 cryptanalysis," Proc. 7th Australasian Information Security Conference, vol. 98, 2009.
[17] Kilian Q. Weinberger Shibin Parameswaran, "Large Margin Multi-Task Metric Learning," 2010. [18] Per Johansson , Sara Sjostedt-de Luna Xavier de luna, "Bootstrap Inference for k-nearest neighbour
matching estimators," IFAU, no. ISSN 1651-1166, p. 5, November 2010. [19] Murthy V.Jonnalagedda V.Sree Hari Rao, "Insurance Dynamics – A Data Mining Approach for
Customer Retention in Health Care Insurance Industry," CYBERNETICS AND INFORMATION TECHNOLOGIES, vol. 12, p. 2, January 2012.

Dian Nuswantoro University 2014
[20] Mr.A.Rama Satish Mr.Ram Babu, "Improved of K-Nearest Neighbor Techniques in Credit Scoring," International Journal For Development of Computer Science & Technology, vol. 2, no. 1, p. 3, Feb-March 2013.
[21] Kitab Undang-Undang Hukum Dagang. Cetakan IV. Bandung: Citra Umbara, 2010. [22] Heru Susanto, Menjual Asuransi itu Gampang.: PT.Bhuana Ilmu Populer, 2008. [23] G, Ramesh, K, & Chinna Rao M Subbalakshmi, "Decision Support in Heart Disease Prediction
System using Naive Bayes," 2011. [24] Reza Allahyari Soeini and Keyvan Vahidy Rodpysh, "Applying Data Mining to Insurance Customer
Churn Management," vol. 30, 2012. [25] Shuo Wang and Xin Yao, "Using Class Imbalance Learning for Software Defect Prediction," IEEE
Transactions on Reliability, p. 434, June 2013. [26] Rr Ani Dijah Rahajoe,Arif Arizal Eko Prasetyo, "Perbandingan k-support vector nearest neighbor
Terhadap decision tree dan naive bayes," SANTIKA, vol. ISSN 2252-3081, pp. 57-60, Maret 2013. [27] Abdelmalek TOUMI, Ali KHENCHAF,Mounir DHIBI, M.S.BOUHLEL Imen JDEY, "Fuzzy
Fusion System for Radar Target Recognition," vol. I, no. Issue III, March 2012. [28] Eko Prasetyo, "Fuzzy k-nearest neighbor in every class Untuk klasifikasi data," 2012. [29] Moch Zen Samsono Hadi, Entin Martiana K Novi Anisyah1, "Aplikasi mobile untuk k-nearest
neighbor pada intrusion Detection system berbasis snort," 2011. [30] M. Bramer, Principles of Data Mining. London: Springer-Verlag, 2007. [31] Ferry Febrian, "Analisis Komparasi Algoritma Klasifikasi Data Mining pada Akseptasi Data
Fakultatif Reasuransi Jiwa," STMIK Eresha, Jakarta , MasterThesis 2011. [32] Lior Rokach Oded Maimon, data mining and knowledge discovery handbook.: Springer, 2010. [33] Shih-Chieh Chen, Wen-Jie Wu Shih-Wei Lin, "Parameter determination and feature selection for
back-propagation network by particle swarm optimization," Knowl Inf Syst, vol. 21, p. 250, 2009. [34] Santosh Kalamkar, Parag Kulkarni Yashodhara Haribhakta, "Feature Annotation for Text
Categorization," CUBE, vol. ACM 978-1-4503-1185-4/12/09, p. 309, September 2012. [35] Luan Van Tran Huong Thanh Le, "Automatic Feature Selection for Named Entity Recognition
Using Genetic Algorithm," SoICT, vol. ACM 978-1-4503-2454-0/13/12, p. 82, December 2013. [36] Andre Elisseeff Isabelle Guyon, "An Introduction to Variable and Feature Selection," Journal of
Machine Learning Research, vol. 1157-1182, p. 1166, March 2003. [37] Perica STRBAC, Dusan BULATOVIĆ Jasmina NOVAKOVIĆ, "Toward optimal feature selection
using ranking methods and classification algorithms," Yugoslav Journal of Operations Research, vol. 10.2298/YJOR1101119N, p. 123, March 2011.
[38] Micheline Kamber, Jian Pei Jiawei Han, Data mining Concepts and Techniques, 3rd ed., Elsevier, Ed. Waltham, United States of America: Morgan Kaufmann, 2012.
[39] H. I., Eibe, F., & Hall, A. M. Witten, Data Mining Machine Learning Tools and Techiques, 2nd ed., Jim Gray, Ed. San Fransisco, USA: Morgan Kaufmann, 2011.
[40] Prabowo Pudjo Widodo Yusuf Elmande, "Pemilihan criteria splitting dalam algoritma iterative dichotomiser 3 (id3) untuk penentuan kualitas beras : studi kasus ada perum bulog divre lampung," Jurnal Telematika MKOM, vol. Vol.4 No.1, p. 80, Maret 2012.
[41] Tracy Hall, David Gray David Bowes, "Comparing the performance of fault prediction models which report multiple performance measures:recomputing the confusion matrix," PROMISE, vol. 978-1-4503-1241-7/12/09, p. 110, September 2012.
[42] Carlo Vercellis, Business intelligence:data mining and optimization for decision making, 1st ed. Est susex, United Kingdom: Wiley, 2009.

Dian Nuswantoro University 2014
[43] Kadarsah, "Aplikasi ROC untuk uji kehandalan model hybmg," Jurnal Meteorologi dan Geofisika , vol. 11 , p. 34, Juni 2010.
[44] Ngakan Ketut Wira Suastika, "Akurasi diagnostik kombinasi total lymphocyte count (tlc) dan kadar hemoglobin untuk memprediksi imunodefisiensi berat pada penderita terinfeksi human immunodeficiency virus (hiv) pra terapi antiretroviral," Program Pasca Sarjana Universitas Udayana, Denpasar, Thesis Master 2013.
[45] Yu Cao, Cliff Chiung-Yu Lin Aditya Khosla, "An Integrated Machine Learning Approach to Stroke Prediction," ACM, vol. 978-1-4503-0055-1/10/07, p. 6, July 2010.
[46] Jörgen Hansson, Björn Olsson, and Björn Lundell Mikael Berndtsson, Thesis Projects A Guide for Students in Computer Science and Information Systems, 2nd ed. London: Springer, 2008.
[47] Christian W Dawson, Projects in Computing and Information Systems A Student’s Guide, 2nd ed. England: Pearson Education, 2009.
[48] CA Irvine. (2000) http://kdd.ics.uci.edu/databases/tic/tic.html. [49] Hui Zhang, Rui Liu, Weifeng Lv Deqing Wang, "Feature Selection Based on Term Frequency and
T-Test forText Categorization," CIKM, vol. 978-1-4503-1156-4/12/10, p. 1483, October–November 2012.
[50] Suk-Hoon Chung, Yong-Moo Suh Jin Oh Kang, "Prediction of Hospital Charges for the Cancer Patients with Data Mining Techniques," vol. 15, 2009.
[51] Hassan Najadat, Mohammed K. Ali Shatnawi Khalid Alkhatib, "Stock Price Prediction Using K-Nearest Neighbor Algorithm," International Journal of Business, Humanities and Technology, vol. Vol. 3 No. 3, p. 32, March 2013.
[52] PT.Sunlife, "Laporan Sunlife," Semarang, 2007. [53] M Maniroja P M Mhatre, "Offline Signature Verification Based on Statistical Features,"
International Conference and Workshop on Emerging Trends in Technology, vol. 978-1-4503-0449-8/11/02, p. 61, February 2011.
[54] Shawn Newsam, Chandrika Kamath Erick Cant´u-Paz, "Feature Selection in Scientific Applications," KDD’04, no. ACM 1-58113-888-1/04/0008, p. 789, August 2004.
[55] Qiang Shen Richard Jensen, computational Intelligence and feature selection rough and fuzzy approaches, Lajos Hanzo, Ed. New Jersey, USA: Wiley , 2008.

Dian Nuswantoro University 2014
JURNAL
ALGORITMA K-NEAREST NEIGHBOR BERBASIS CHI-SQUARED UNTUK PREDIKSI NASABAH ASURANSI
Oleh:
Jatmiko Indriyanto, Purwanto, S.Si,. M.Kom,. Ph.D, Catur Supriyanto, M.C.S
Pascasarjana Teknik Informatika Universitas Dian Nuswantoro
PROGRAM PASCASARJANA MAGISTER TEKNIK INFORMATIKA
UNIVERSITAS DIAN NUSWANTORO SEMARANG
2014




















