
Structural Basis of Lysine-Acetylated HIV1 Tat Recognition by PCAF Bromodomain
Upload
independentCategory
view
5download
0
Plant Molecular Biology 22: 227-237, 1993. © 1993 Kluwer Academic Publishers. Printed in Belgium. 227
Isolation and characterization of wheat triticin cDNA revealing a unique iysine-rich repetitive domain
Nagendra K. Singh h2, 3, , Greg R. Donovan 2'4, Helen C. Carpenter 2, John H. Skerritt 2 and Peter Langridge 1
Centre for Cereal Biotechnology, Waite Agricultural Research Institute, Glen Osmond, SA 5064, Australia," 2 C.S.I.R.O. Division of Plant Industry, Grain Quality Research Laboratory, North Ryde, NSW 2113, Australia;present address: 3Molecular Biology Unit, Central Food Technological Research Institute, Mysore-570013, India (* author for correspondence); 4 Kolling Institute of Medical Research, Royal North Shore Hospital, St Leonard, NSW 2065, Australia
Received 30 July 1992; accepted in revised form 18 February 1993
Key words: mRNA accumulation, lysine-rich domain, triticin cDNA, wheat storage protein
Abstract
Polyclonal antibodies were raised against a purified 22 kDa triticin polypeptide (b) and were used to screen a wheat seed cDNA library in the Escherichia coli expression vector 2gtl 1. The isolated cDNA clones were grouped into three families based on their cross-hybridization reactions in DNA dot-blot studies. Southern blots of genomic DNAs extracted from ditelocentric and nullisomic-tetrasomic lines of Chinese Spring wheat, probed with the excised cDNA inserts, indicated that one of the three fami- lies (9 clones) had triticin clones. This was finally confirmed by comparing the predicted amino acid sequences of two of these clones (2Tri-12,),Tri-25) with the published tryptic peptide sequences of triticin. The Southern blots also showed that there is at least one triticin gene located on the short arm of each of the homoeologous group 1 chromosomes (1A, 1B, 1D), although till now no triticin protein product has been identified for the chromosome lB. The nucleotide sequence of the largest triticin cDNA clone 2Tri-25 (1567 bp) is presented here, and its predicted amino acid sequence shows strong homology with the legumin-like proteins of oats (12S globulin), rice (glutelin) and legume seeds. A unique feature of the triticin sequence is that it contains a lysine-rich repetitive domain, inserted in the hypervariable region of the typical legumin-like genes. Northern blotting of total RNA extracted from different stages of the developing wheat seed revealed that the triticin gene expression is switched on 5-10 days after anthesis (DAA). There was a steady increase in the level of triticin mRNA until 20 DAA, after which it started decreasing. The maximum mRNA accumulation occurred between 17 and 20 DAA. These observations conform closely with the published data on triticin protein accumulation during grain de- velopment.
Introduction
Legumin-like proteins (11-12 S globulins) are one of the most widely occurring classes of storage proteins accumulated in the seeds of angiosperms
[3]. However, their proportion in the total seed storage protein varies considerably, ranging from almost 100~o in some pumpkin seeds to an ap- parent absence from barley and rye seeds [6, 7]. In general, these proteins are much more preva-

228
lent in the legume seeds than in cereals, and re- present one of the two most abundant classes of seed storage proteins in the dicotyledonous plants [7], the other being vicilin-like proteins (7S glob- ulins). However, it is now well established that the rice glutelins and oat 12S globulins, which make up more than 80~o of the seed proteins in these cereals, also belong to the legumin family [29, 32].
There were some conflicting early reports on whether such proteins occurred in the wheat seed [4, 6, 20], but recently we have confirmed their presence in the wheat endosperm by amino acid sequence analysis of purified triticin polypeptides [23, 25]. Wheat triticin polypeptides are synthe- sized specifically during seed development 8 to 21 days after anthesis, and are deposited in the endosperm protein bodies [24]. From the nutri- tional quality point of view, wheat triticins have a very good balance of essential amino acids but they make up only about 5 ~o of the total seed proteins [26]. A recent immunocytolocalization study has revealed that triticins are heavily con- centrated in the electron-dense inclusions of the protein bodies, whereas the major prolamins are in the matrix of these protein bodies [2]. It has been suggested that triticin may play an important role in determining the functionality of wheat flour doughs by participating in thiol disulphide inter- change reactions [22].
In this paper, we describe the nucleotide se- quence of a triticin cDNA clone which was iso- lated using polyclonal antibodies raised against a purified triticin polypeptide. This triticin sequence is compared with those of other legumin-like pro- teins from diverse species, and the conserved and unique features of the triticin gene are highlighted. Data on the expression of triticin genes during grain development are also presented.
Materials and methods
Purification of triticin and production of polyclonal antibodies
A detailed procedure for the preparation of a triticin-rich fraction from the flour of wheat vari-
ety Chinese Spring and the purification of one of its small-basic polypeptides (b) has been de- scribed elsewhere [26]. Polyclonal antibodies against triticin were produced in New Zealand White rabbits raised on a gluten-free diet, by three subcutaneous injections of the purified b polypep- tide. The b polypeptide (1 mg/rabbit) was dis- solved in 4 M urea with 1 ~o (v/v) 2-mercaptoet- hanoi and the solution was mixed with an equal volume of Freund's complete adjuvant for the first injection. Half as much protein was injected at two subsequent monthly intervals using the above solvent, but with Freund's incomplete ad- juvant. A week after the last immunization, blood samples were collected and antiserum was pre- pared according to standard procedures [ 16] and stored at -20 °C with 0.1 ~o sodium azide.
Extraction of proteins and immunoblot analysis
SDS-PAGE (sodium dodecyl sulphate polyacry- lamide gel electrophoresis) and immunoblotting were performed according to the methods de- scribed earlier [26, 27], with some modifications. The total flour proteins were extracted using 4~o SDS in 60mM Tris-Cl, pH6.8, with 2~o 2-mercaptoethanol. The SDS-PAGE was per- formed in 1.5 mm thick slab gels with 15.8~o total acrylamide (T) and 0.8~o cross-linker (C). The gels were electroblotted for 6 h at 36 V to a 0.1 #m nitrocellulose membrane (Schleicher and Schuell, Dassel, Germany) using 20 mM Tris, 150mM glycine, 20~o methanol and 0.01 ~o SDS in a Gra- dipore electroblotting apparatus (Pyrmont, NSW, Australia). The membranes were then blocked for 16 h at 37 °C with 3~o bovine serum albumin (BSA) in 50mM sodium phosphate buffer pH 7.2, 150 mM NaC1 (PBS). The antiserum, di- luted in the blocking solution (1:20 000), was in- cubated with 7 mm wide strips cut from the immunoblots, for 90 rain at 20 °C with gentle rocking. After four 5 min washes in PBS with 0.05 ~o Tween-20, the strips were incubated with a 1:7000 dilution of anti-rabbit IgG alkaline phos- phatase conjugate (Promega, Madison, WI) in 2~o BSA in TBST (10mM Tris-C1 pH 8.0,

150 mM NaC1, 0.05Yo Tween-20) for 60 rain at 20 ° C. Finally, after four 5 min washes in TB ST the substrate was added and the binding of anti- bodies was revealed by the appearance of purple bands within 10 min.
Preparation and screening of a cDNA library in )~gt l l
The cDNA library in 2gtl l was made from a 2gtl0 library prepared from poly(A) + mRNA of membrane-bound polyribosomes isolated from the developing wheat seeds (Triticum aestivum cv. Timgalen) as described earlier [8]. Prior to screening, the primary antibody solution (1:20 000 dilution in TBST) was pre-absorbed by incuba- tion with nitrocellulose membrane discs soaked in E. coli extract. The screening was carried out with a Protoblot Immunoscreening System (Promega) using the anti-rabbit IgG alkaline phosphatase conjugate as second antibody (dilu- tion 1:7000)to detect the 2gtl 1 clones expressing /~-galactosidase-triticin fusion proteins. Immuno- positive clones were purified by re-plating at low plaque density until all plaques on the plate pro- duced a positive signal (two to three cycles). The isolated clones were amplified by single-plate confluent lysis, the phage were purified by poly- ethylene glycol precipitation followed by ultracen- trifugation in a CsC1 gradient [13]. The phase DNA was isolated from the CsC1 phage stocks using the formamide method [13]. The cDNA inserts were excised by Eco RI digestion of the recombinant phage DNAs, and size fractionated by electrophoresis in 1~o agarose gels.
Southern blotting and DNA dot blotting
For Southern blot analysis, the high-molecular- weight (HMW) genomic DNAs were isolated from fresh young leaves of Chinese Spring wheat and its ditelocentric and nullisomic-tetrasomic lines [21]. Ca. 20/~g of genomic DNA was di- gested with one of the three restriction endonu- cleases (Eco RI, Bam HI and Hind III) and frac-
229
tionated in 0.7~o agarose gels in TBE (Tris- borate-EDTA) buffer at 1.25 V/cm for 16 h. After a 15 min depurination with 0.25 M HC1 at 25 °C, and 45 min denaturation with 0.5 M NaOH, 1.5 M NaCI, the DNA was transferred overnight to a Hybond N (Amersham, UK) membrane using 0.25 M NaOH with 1.5 M NaC1. The mem- brane was rinsed with 5 × SSC, blot-dried and then DNA was UV-fixed (302 nm) for 5 min. Pre- hybridization (5 h) and hybridization (overnight) were carried out at 42 °C with 50~o formamide, 5 x SSPE, 5 x Denhardt's solution, 0 .3~ SDS, 20ktg/ml salmon sperm DNA and 10#g/ml poly(A). The probes were 32p-labelled to a spe- cific radioactivity of 108 CPM//~g of DNA by nick translation.
For DNA dot blot analysis, about 500 ng of purified phage DNA (or equivalent amount of CsC1 phage stock) in 0.1 ml volume was dena- tured by adding 2 #1 of 10 M NaOH at 20 °C for 15 min. After cooling on ice, the DNA was neu- tralized by adding 2 #1 of 10 M HCI and 5/~1 of 1 M Tris-Cl pH 8.0, and then 47 ktl of 20 x SSC was added. Fifteen microlitres of these denatured DNAs (ca. 50 ng) were spotted on a Hybond N membrane pre-wetted with 6x SSC. Several control prolamin DNAs, viz. HMW glutenin sub- unit genomic 1By 9 [10] and cDNA pTag 1290 [30], HMW secalin (pSc-512) and co-secalin (pSc-566) cDNAs [Martin Kreis, unpublished], and e/fl gliadin genomic pW 8233 [ 18], were also blotted on these membranes in the same way. The probing of membrane was done as described above for the Southern blotting.
DNA sequencing and sequence comparisons
Two of the triticin cDNA clones (2Tri-12 and 2Tri-25) were sub-cloned into the plasmid vector pTZ 18U in both orientations. Unidirectional de- letions of ca. 250 bp were created in the cDNA inserts using a Pharmacia-LKB Nested Deletion Kit. Overlapping cDNA fragments were se- quenced by double stranded DNA sequencing procedure, using a Multiwell DNA Sequencing System (Amersham)with M 13 universal sequenc-

230
ing primer, [35S]dATP~S label and T7 DNA polymerase enzyme. Both the strands were com- pletely sequenced. Analyses of the DNA and pre- dicted amino acid sequences were performed using DNA Inspector lie and PCGENE com- puter packages. An online FASTA computer search [17] was conducted to compare the 2Tri-25 sequence with a total of 44 353 sequences stored in the data bank.
RNA extraction and northern blotting
Developing seeds at different stages after anthe- sis were collected and ground to a coarse powder under liquid nitrogen. RNA was extracted into a buffer containing 100 mM Tris-C1 pH 8.5, 30 mM KC1 10 mM MgC12, 10 mM Na2EDTA and 1 ~o (w/v) iodoacetic acid. This produced an icy slurry which was vigorously mixed with an equal volume of phenol/chloroform. The phases were separated by centrifugation and the upper aqueous layer was extracted a further two times with phenol/ chloroform. The RNA was then recovered by eth- anol precipitation. For the Northern blotting, RNA was denatured with formamide (50 ~o) and formaldehyde (7 ~o) and electrophoresed in form- aldehyde agarose gels as described earlier [15]. The blots were probed with 32p-labelled triticin cDNA (Tri-25) as described above for the South- ern blotting.
the purification and characterization of triticin polypeptides are described elsewhere [26], how- ever, a SDS-PAGE of representative samples is shown in Fig. 1, where the total protein extracts from Chinese Spring wheat endosperm can be compared with the triticin-rich fraction prepared from the flour of Chinese Spring ditelocentric 1AL. The triticin-rich preparation showed a high concentration of the triticin large-acidic polypep- tide D and small-basic polypeptide 6, controlled by chromosome 1D (Fig. lb). This triticin-rich fraction was used to isolate the pure b (Fig. lc) by electroelution [26], which was injected into rab- bits for the production of triticin antibodies.
Immunoblots using these anti-b antibodies to probe the total protein extract from Chinese Spring wheat endosperm, showed that they bound strongly to the two homologous triticin polypep- tides ~ and b (Fig. 2). Although weak cross- reactions were observed with some of the slow- moving protein bands, the majority of seed proteins did not show any cross-reaction with these antibodies, indicating their high specificity. The triticin specificity of these antibodies was also checked by indirect ELISA (enzyme-linked im- munosorbent assay), and the titre to triticin was at least twenty-fold higher than those for glutenin and gliadin (data not shown).
Results and discussion
Production and characterization of triticin anti- bodies
The hetero-tetrameric oligomers of triticin are de- tected as triplet bands in non-reducing SDS- PAGE gels [23]. Upon reduction of disulphide bonds, the triplet bands are broken down into their four constituent polypeptides D (58 kDa), A (52 kDa), a (23 kDa) and b (22 kDa). Although difficult to distinguish in total seed protein ex- tracts, these polypeptides can be easily visualized in the triticin-enriched fractions. Detailed data on
Fig. 1. SDS-PAGE analysis of enriched and purified triticin: a, total seed protein extract from Chinese Spring (CS) wheat; b, triticin-rich preparation from CS ditelocentric 1AL, lacking polypeptides A and ~; c, b polypeptide purified by electroe- lution from the triticin-rich fraction in lane b. Large-acidic (D) and small-basic (b) polypeptides of triticin are indicated.

Isolation of cDNA clones and their analysis by DNA dot blots and Southern blots
The polyclonal antibodies were used to screen a cDNA library expressed in 2gtl l . A total of 42 antibody-positive clones (designated 2Tri-1 to 2Tri-42) were identified from amongst ca. 400 000 plaques screened. Electrophoretic analysis of the Eco RI digests of the phage DNAs isolated from these clones revealed that 35 of these had single cDNA inserts ranging in size from 410 to 2450 bp; six had double inserts (650-1480 bp) and one showed no detectable insert (may be a false- positive or with a very small insert). The phage DNAs from all the 42 antibody-positive clones were dot-blotted on to nylon membrane and probed with 32P-labelled cDNA inserts of 12 ran- domly selected clones (2Tri-3, 4, 8, 9, 10, 12, 15, 17, 18, 23, 33 and 39). Based on the DNA dot- blot results, these cDNA clones were divided into three distinct groups (group I, 20 clones; group II, 12 clones; group III, 9 clones), though some of the clones showed very weak cross-reaction be- tween groups. In addition, these dot blots were also probed with known cDNA and genomic clones representing the major prolamin storage proteins of wheat and rye, namely HMW glute- nin subunits (1By 9 and pTag 1290), e//~-gliadin (pW 8233), HMW secalin (pSc 512) and co-seca- lin (pSc 566). The clones in the largest of the three cDNA groups described above (group I) hybrid- ized strongly to the probes 1By 9 and pTag 1290, suggesting that these may represent HMW glute- nin subunits, though this was not anticipated based on the immunoblots (Fig. 2) where the an- tibodies did not show any cross-reaction with the HMW subunits.
Southern blots ofgenomic DNAs isolated from the ditelocentric and nullisomic-tetrasomic lines of Chinese Spring wheat probed with the cDNA inserts of group I clones, showed that the genes for these cDNAs were located on the long arms of wheat chromosomes 1A, 1B and 1D (data not shown), as expected for the HMW glutenin sub- units. Furthermore, the RFLP (restriction frag- ment length polymorphism) patterns observed with the Eco RI-, Hind III- and Barn HI-digested
231
Fig. 2. SDS-PAGE and immunoblot analysis of total seed protein extract from Chinese Spring wheat: a, Coomassie Blue-stained gel; b, immunoblot probed with the anti-b poly- clonal antibodies. Mixed proteins include: gliadins, LMW glu- tenin subunits, triticin large polypeptides and HMW albu- mins.
genomic DNAs matched with the published RFLP patterns for HMW subunits [ 11 ]. Hence, it was concluded that the 20 group I clones rep- resented cDNAs for the HMW subunits of glu- tenin and were selected by the anti-triticin anti- bodies probably because of some common epitopes on these proteins. The discrepancy be- tween the immunoblotting results where antibod- ies recognised mainly triticin polypeptides (Fig. 2) and the immunoscreening which also selected HMW glutenin cDNA clones, may be due to use of SDS in the former procedure, and/or the ex- tended period of incubation (overnight) with the anti-triticin antibodies in the case of immuno- screening, which could enhance the cross-reac- tions.
Clones in the cDNA groups II and III did not cross-hybridize to any of the prolamin probes tested here. The identity and chromosomal loca- tion of genes controlling group II cDNAs could not be determined. However, probing of the Southern blots of EcoRI-digested genomic

232
Fig. 3. Southern blot analysis ofEco RI-digested leafgenomic DNAs from the euploid and homoeologous group 1 aneuploid lines of Chinese Spring, probed with 32P-labelled insert of cDNA clone 2Tri-12 (one of the group III clones). Chromo- somal location of the hybridizing DNA fragments is shown on the right (e.g. 1AS = short arm of chromosome 1A), and the size of 2-Hind III markers is on the left. In the ditelocentric (Dt) 1AL the short arm of chromosome 1A is missing, whereas in the nullisomic-tetrasomic (NT) 1A-IB the entire chromo- some 1A is missing and its loss is compensated by extra doses of chromosome 1B, and so on.
DNAs with the group III cDNA clones (Fig. 3, probe 2Tri-12), showed that their genes are lo- cated on the short arms ofhomoeologous group 1 chromosomes, as expected for the triticin [23]. The Southern blots revealed that there is at least one triticin gene located on each of the homoeol- ogous chromosome arms 1AS, 1BS and 1DS, the size of the Eco RI fragments being 4.2, 3.4 and 3.1 kb, respectively (Fig. 3). Furthermore, the in- tensity of the bands in euploid wheat was similar for all the three chromosomes, suggesting an equal number of genes on each chromosome. An in- crease in the band intensity due to four doses of specific chromosomes (instead of the normal two) in the nullisomic-tetrasomic lines was clearly seen: the 1AS-controlled fragment was darker in the NT 1B-1A and NT 1D-1A lines and so on (Fig. 3). To date, a 1B-encoded triticin protein has not been detected [23, 26], and hence this chromosome may carry a pseudogene for triticin.
Sequence analysis of triticin cDNA
The largest of the putative triticin cDNA clones (2Tri-25, 1567 bp) was selected for sequencing. Its nucleotide and deduced amino acid sequences are shown in Fig. 4. The cDNA 2Tri-25 has a single long open reading frame of 502 amino acids starting at the nucleotide position 60. However, the protein sequence did not terminate in this cDNA, suggesting that a part of the C-terminus is missing. This is unusual because normally the synthesis of oligo-dT-primed cDNAs starts at the m R N A poly(A) tall, which is situated further downstream to the stop codon. Therefore most cDNAs tend to be incomplete towards the N-termini of the proteins. Hence, another smaller cDNA clone of this family (2Tri-12, 980 bp) was sequenced (data not shown), but it also termi- nated at an identical position to the 2Tri-25, pos- sibly due to an internal Eco RI restriction site within the coding sequence of the triticin gene. The C-terminal end of the cDNAs may have been missing because this restriction site was not pro- tected during the preparation of 2gt 11 library from the precursor 2gtl0 library. We are currently screening a wheat genomic library to isolate com- plete triticin genes along with the flanking regu- latory sequences for further studies.
One interesting feature of the Tri-25 sequence is that its untranslated 5' leader sequence has an in-frame translation initiator codon ATG (nucle- otides 21-23) and a stop codon TGA (nucle- otides 33-35), situated upstream to the proposed initiation site at nucleotide 60 (Fig. 4). Although both the initiator codons conform to the consen- sus translation start site for eukaryotic genes (A/ GXXATGG) proposed by Kozak [14], there were two reasons for choosing the second site in Fig. 4: (i) the first initiation site would lead to a termination of the polypeptide chain after only four amino acid residues, and (ii) the second site matches strongly with the start site of the closely related 12S oat globulin sequence (see Fig. 6). Further studies are required to understand the significance of the in-frame start and stop codons in the 5' leader sequence.
A comparison of the amino acid sequence de-

233
M A A T R 5 TCCTT~TTTATG~CAC~T~ACCTTTGTTGATATCTCTCTCCTCCTC~CAGTTATG~AGCTACTAGT 74
F A L L S F Y L C I L L L C H S S M A O Q L F G M S 3 0 ~C~TTCGC~TCTTTTTACTTCTGCATTTTGCTCTTGTGCCATA~TCCATGGCAC~CTGTTT~A~A~ 149
F N P W Q S S H Q G G F R E C T F N R L Q A S T P 55 TTT~CCCATGGC~GCTCTCACC~G~TTTCAGAGAGTGTACATTC~TAGGCTAC~GCATCTACACCA 224
V R Q V R S Q A G L T E Y F D E E N E Q F R C T G 80 C~CGTC~GTGA~TCAC~AGGCCTGACCGAGTATT~GATGAGGA~TG~C~TTTCGTTGTACTGGT 299
V F A I R R V I E P R G Y L L P R Y H N T H G L V I 0 5 GTA~CATCCG~GTGT~TCG~CCTCGT~ATTTGTTACC~GATACCAC~CACTCAT~A~AGTC374
Y I I Q G S G F A G L S F P G C P E T F Q F Q F Q I 3 0 TACATCATCC~C~GTGGTTTCGCC~ACTGTCTTTTCCTGGATGCCCAGAGACATTCCAG~CAGTTTC~ 449
F Y G Q S Q S V Q G Q S Q S Q K F K D E H Q K V H I 5 5 ~TATGG~AC~CGTAC&G~TC~C~CAAAAGTTT~GA~A~ACCAAAAAGTTCAC524
R F R Q G D V I A L P A G I V H W F Y N E G D A P I S 0 CG~AGAC~GATGTCATT~ATTACCG~A~TTGTACATTGGTTCTAC~C~T~CA599
I V A I Y V F D V N N Y A N Q L E P R H K E F L F 2 0 5 ATTG~CTATCTA~CGACGT~C~CTA2'GCT~TC~C~GAGCCTA~AT~TTT~ 674
A G N Y R S S Q L H S S Q N I F S G F D V R L L A 2 3 0 ~TG~CTATA~AGTTC~CTTCAC~TAGTCAAAACATATTCAGT~T~CGATG~GATT~T~T749
E A L G T S G K I A Q R L Q S Q N D D I I H V N H 2 5 5 ~CTT~GTAC~GTGGAAAAATA~CTTC~G~AAAAT~T~CAT~T~A~TG~TCAT824
T L K F L K P V F T Q Q R D A E S R T L N M R K G 2 8 0 ACCCTT~TTTCTG~GCCTGTT~ACAC~CAGCGAGACGCAG~TCCCGCACAC~TATGA~GGGC 899
N L R Q K T L R K S N L K W G S H R K S N L K W G 3 0 5 ~TC~AAAACAC~TCAG~CC~TGC~AGTCACAGG~CCTC~TC~974
S H R E S S L K W G S L R Q S T Q G E Q P Q M G W 3 3 0 AGTCACA~AGA~A~CTC~TGG~CAGTC TCA~GCACTCAG~AGAGC~CCTC~TGGGGT~ 1049
S Q A K H S Q G D Q P E E G Q G G Q S Q Q E Q ' S Q 3 5 5 ~TCA~ACTC~A~GAGACCA~CTG~C~AG~GG~TCTC~C~G~C~TCAGII24
A G P Y Q G C Q P H A G R S H A S Q S T Y G G W N 3 8 0 ~A~GCCATATCCG~TGTC~CCTCATGCA~GCGA~TCAT~A~AC~TC~C~ATGGTGGT~TII99
W G L E E N F C D H K L S V N I D D P S R A D I Y N 4 0 5 ~AGA~AG~CTTTTG~A~AT~GCT~GTGTG~CATCGAC~CCAGTCG~ACATATAC~TI274
P R A G T I T R L N S Q T F P I L N I V Q M S A T 4 3 0 CC~GTGCCGGTACGAT~CCCGTCTC~CTCCC~CGTTCCCCATCCTT~CATCGTGC~TGAGT~TACA 1349
R V H L Y Q N A I I S P L W N I N A H S V M Y M I 4 5 5 AGAGTACATCTCTACCAG~CGCCA~ATTTCACCA~ATC~CATT~TGCCCATAGTG~ATGTACATGATC 1424
Q G H I R V Q V V N D H G R N V F N D L I S P G Q 4 8 0 C~GGACATATCTGGG~CAGGTTGTC~.TGACCATGGTCG~TGTGTTC~TGACCTTATTAGTCCGG~C~ 1499
L L I I P Q N Y V V L K K A Q R D G S K Y I 502 CTATT~TCATACCACAG~CTATGTTG~CTG~G~AC~CGTGATGG~GTACATTGA 1567
~ . 4. The nucleotide ~ d deduced ~ i n o acid sequences of triticin cDNA '2Tri-25'. Proposed site ~r the co-tr~sl~ionN re- moval of signN peptide (Q), ~ d the highly conserved post-tr~slationN cleavage site between the l~ge ~ d smN1 polypeptides (m), ~e indicated. Lysine-contmning decapeptide repeats ~e underlined. Conse~ed cysteine residues linking l~ge ~ d smN1 polypeptides ~ e shown in bold letters ( ~ i n o acid positions 121 and 387).
duced from 2Tri-25 with the earlier published tryptic peptide sequences of purified triticin [25] confirmed that this is indeed a triticin clone. The N-terminal sequence (NH2-G-L-E-E-N-F-) of the purified b polypeptide [25] is located in the middle of this c D N A (Fig. 4), and the tryptic pep- tide sequences of both the large and small polypeptides of triticin [25] are located in this single cDNA. This is the first direct evidence to show that the large-acidic and small-basic
polypeptides of triticin are coded by a single gene and are produced by post-translational cleavage of a single protriticin molecule. Based on the 2Tri-25 sequence, the size of large-acidic polypep- tide is 40 .4kDa (356 amino acid residues), whereas our earlier estimates from the SDS- PAGE analysis were 52 and 58 kDa [23]. There are two possible reasons for this size anomaly. First, the molecular weights of the proteins may have been overestimated by S D S - P A G E as no-
234
ticed before with the glutenin HMW subunits [31]. Second, the triticin large polypeptide may be glycosylated, resulting in a larger size. There is a consensus glycosylation site [12] in this sequence (-N-H-T-, amino acid positions 254- 256 in Fig. 4). Although the legumin-like proteins are normally not glycosylated, we cannot rule out this possibility, especially since we have observed a positive PAS (periodic acid Schiff) staining re- action in our preliminary experiments.
Comparison of the 2Tri-25 sequence with those of oat 125 globulin [32], rice glutelin [28] and several other legumin-like proteins from dicotyle- donous species supports our earlier finding that triticin belongs to this protein class [25]. Among several conserved domains in these proteins [5, 28] which were also present in triticin (Figs. 4 and 5), the most noteworthy are: (i) a hydropho- bic N-terminal signal peptide which is involved in transport of the nascent polypeptide across the ER membrane, and is subsequently removed; (ii) a highly conserved post-translational proteolytic cleavage site between the large-acidic and small- basic polypeptides (between asparagine and gly- cine residues at positions 380 and 381, Fig. 4); (iii) two highly conserved cysteine residues at po- sitions 121 and 387 (Fig. 4), which are thought to link the large and small polypeptides by a disul-
+4--
H y d r o p h i l i c i t y Plot
ill +3-q . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
+2---
, . .
-~= I ~v~ I --SP t LAP t SBP
-3-- -- hydrophobi c
-4 ---I I [ I I 100 200 300 400 500
amino acid position
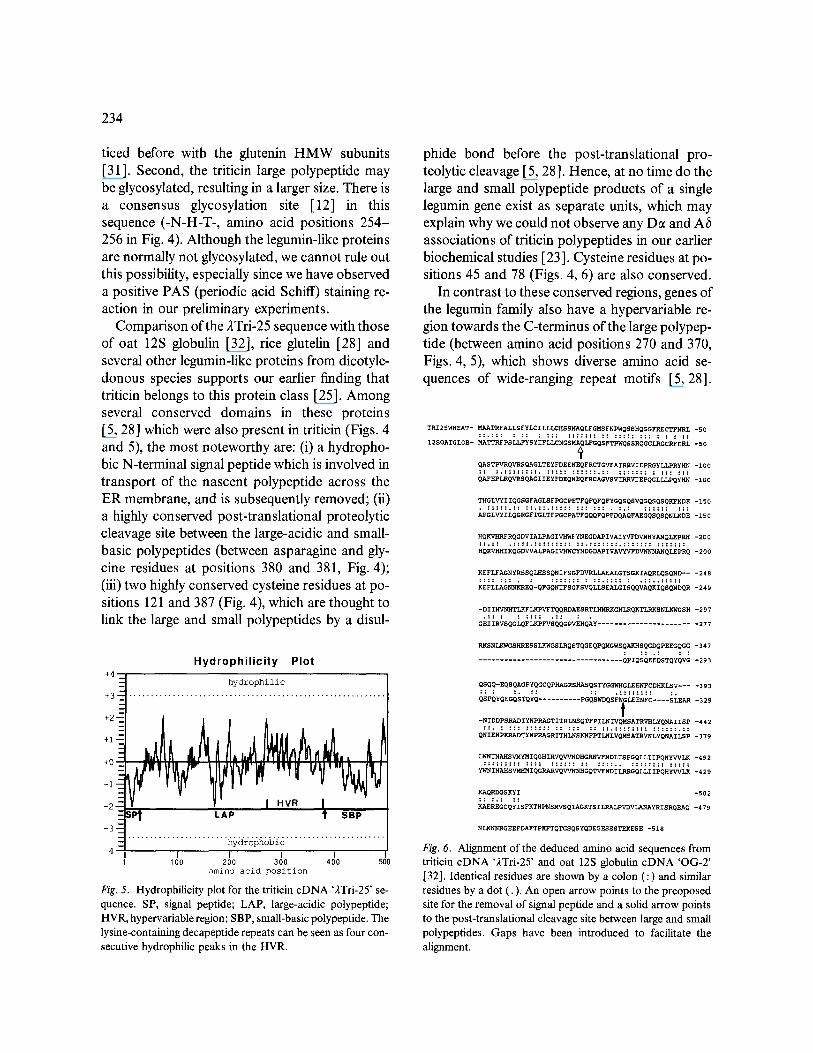
Fig. 5. Hydrophilicity plot for the triticin cDNA '2Tri-25' se- quence. SP, signal peptide; LAP, large-acidic polypeptide; HVR, hypervariable region; SBP, small-basic polypeptide. The lysine-containing decapeptide repeats can be seen as four con- secutive hydrophilic peaks in the HVR.
phide bond before the post-translational pro- teolytic cleavage [5, 28]. Hence, at no time do the large and small polypeptide products of a single legumin gene exist as separate units, which may explain why we could not observe any D~ and Ab associations of triticin polypeptides in our earlier biochemical studies [23 ]. Cysteine residues at po- sitions 45 and 78 (Figs. 4, 6) are also conserved.
In contrast to these conserved regions, genes of the legumin family also have a hypervariable re- gion towards the C-terminus of the large polypep- tide (between amino acid positions 270 and 370, Figs. 4, 5), which shows diverse amino acid se- quences of wide-ranging repeat motifs [5, 28].
TRI25WHEAT-
12SOATGLOB-
MAATRFALLSFYLCILLLCHSSMAQLFGMSFNPWQSSHQGGFP~ECTFNRL -50 ::.::: : :: : ::: ::::::: :: ::::: ::: : : : ::
MATTRFPSLLFYSYIFLLCNGSMAQLFGQSFTPWQSSRQGGLRGCRFDRL -50
QASTPVRQVRSQAGLTEYFDEENEQFRCTGVFAIRRVIEPRGYLLPRyH~ -I00 := :.::::::::. ::::: ::::::.:: ::::::: : ::: :::
QAFEPLRQVRSQAGIIEYFDEQNEQFRCAGVSVIRRVIEPQGLLLPQyHN -100
THGLVYIIQGSGFAGLSFPGCPETFQFQFQFYGQSQSVQGQSQSQKFKDE -150
HQK~RQGDVIALPAGIV~YNEGDA2IVAIYVFDVA~y~/~QLEpRH -200 ::.:: .::::.::::::::: ::.:::: .... : ............
HQRV~IKQGDWALPAGIV~q4CYNDGDAPiVA~;~N~Q~pIQ -200
KEFLFAGNYRSSQLHSSQNIFSGFDVRLLAEALGTSGKIAQRLQSQND-- -248 :::: ::: . : ::::::: : ::.:::: : .::..:::::
KEFLLAGNNKREQ-QFGQNIFSGFSVQLLSEALGISQQVAQKIQSQNDQR -249
- D I I HVNHT LKF LK PVFTQ QRDAE S RTI/qMRXGNI/~QKTLRKS N LKWGS H -297
GEIIRVSQGLQFLKPFVSQQGPVEHQAY ....................... 277
RKSNLKWGSH~SSLKWGSLRQSTQGEQPQMGWSQAKHSQGDQPEEGQGG -347
.................................. QPIQSQEEQSTQYQVG - 2 9 3
QSQQ-EQSQAGPYQGCQpHAGRSHA~QSTYGGWNGLEENFCDHKLSV .... 393 :: : :. :: . . . . . . . . . . .
QSPQYQEGQS~QYQ .......... ~I~QS~G~b~ .... ;~ -n9
-NIDDPSRADIYNPRAGTITRLNSQTFPILNIVQMSATRVHLYQNAIISP -442 ::. : ::: :::::: :: ::: :: ::.:::::::: ::::::.::
QNIENPKRADTYNPRAGRITHLNSKNFPTLNLVQMSATRVNLYQNAILSP -379
LW~INA/~SIq4~IQGHIRVQ~F4~DHGP/~NDLISpGQLLIIPQNYVVLK -492 ::::::::: :::: :::::: :: :::" : ............
YWNI NAHSV~ I QGRARVQV~GQT~NDI ~RGQ~I i p Q H ~ -429
KAQRDGSKYI -502 :: :.: ::
K~%EREGCQY I SFKTNPNSMVSQIAGKTS I IAWALPVDVI~AYRI SRQEAQ -479
NLKNNRGEEFDAFTPKFTQTGSQSYQDEGESSSTEKESE -518
Fig. 6. Alignment of the deduced amino acid sequences from triticin cDNA '2Tri-25' and oat 125 globulin cDNA 'OG-2' [32]. Identical residues are shown by a colon (:) and similar residues by a dot (.). An open arrow points to the preoposed site for the removal of signal peptide and a solid arrow points to the post-translational cleavage site between large and small polypeptides. Gaps have been introduced to facilitate the alignment.

The triticin sequence in this region has a unique decapeptide repeat motif containing two lysine residues (Fig. 4). The decapeptide is reiterated four times (Figs. 4 and 5), making this part of the sequence a lysine-rich domain. From our FASTA computer search of 44 353 sequences, it was con- cluded that this decapeptide motif is unique to wheat triticin. The computer search further re- vealed that, out of the top 25 sequences closest to triticin, the first 18 were either oat 12S globulin or rice glutelin. The remaining sequences were 12S globulins of cotton, broad bean, Arabidopsis, and soybean. The oat globulin sequence with a 57.7 ~o amino acid sequence identity was the closest to wheat triticin. An alignment of the wheat triticin and oat 12S globulin sequences is shown in Fig. 6. To facilitate the alignment, a large gap was intro- duced in the oat sequence to accommodate the lysine-rich triticin repeats. This suggests that the triticin repeats may have originated by an inser- tion of the decapeptide sequence in the hypervari- able region of the ancestral triticin gene followed by its reiteration.
From the nutritional point of view for humans and monogastric domestic animals, lysine is the first limiting amino acid in many cereal seeds, including wheat. It may be possible in future to increase the number of these decapeptide repeat units and/or to increase the proportion of triticin in wheat seeds to improve its nutritional quality. The hypervariable region, which is over 100 amino acids long and tolerates a wide range of sequences, can accommodate more than ten of these repeat units. Since this repeat motif is nat- urally present in the wheat triticin, it is unlikely to adversely affect the biological stability of triticin in the seeds, or the normal kernel development.
235
level peaking at 20 DAA (Fig. 7). Positive hybrid- ization signals were observed at 10 and 12 DAA also, but they were in the form of broad streaks of slightly higher electrophoretic mobility. The tri- ticin cDNA did not hybridize to RNAs isolated from leaves, or the developing grains at 5 DAA (Fig. 7), suggesting that the transcription of triti- cin genes is developmentally regulated in a man- ner similar to the major storage proteins of wheat and other species [1, 9]. The triticin genes are turned on between 5 to 10 DAA and are actively transcribed at least until 20 DAA, after which the m R N A level starts decreasing. The northern data correspond well with our published results show- ing accumulation of the triticin protein in the seeds between 10-21 DAA [24]. However, unlike the closely related rice glutelin mRNAs which are completely degraded at 24 DAA [ 19], there was still a large amount of triticin m R N A present at 25 DAA (Fig. 7). The pattern of triticin m R N A accumulation is quite similar to that of the other major storage proteins of wheat namely gliadin and glutenin [1 ], suggesting a coordinated regu-
Expression of triticin genes during grain develop- ment
Northern blot analysis was used to monitor the expression of triticin genes during grain develop- ment. The triticin cDNA probe hybridized to mRNAs of ca. 2 kb isolated from the grains at 15 to 25 days after anthesis (DAA), with the m R N A
Fig. 7. RNA gel blot (northern) analysis of the expression of triticin genes. Total RNAs isolated from the wheat leaves (L) or developing seeds collected at 5, 10, 12, 15, 17, 20 and 25 days after anthesis were probed with 32p-labelled triticin cDNA clone Tri-25. The positions of the 18S and 25S yeast ribosomal RNAs are indicated on the right.

236
lation of the transcription of these genes. The gliadin and glutenin mRNA levels also peak 15- 20 DAA, and there is a large concentration of mRNA present even at 30 DAA. However, the capacity of the mRNAs to direct in vitro protein synthesis was drastically reduced 20 DAA [ 1]. The lack of any significant increase in the accu- mulation of triticin beyond 21 DAA as reported earlier [24], may be due to a reduced translational capacity of the older triticin mRNAs, or a trans- lational regulation mechanism.
Acknowledgements
The senior author is grateful for financial support of a Queen Elizabeth II Fellowship from the Aus- tralian government, and for help and advice by Dr M. Batchlietner at the Waite Institute, during DNA sequencing. We thank Drs P. Shewry, M. Kreis, D. Soil and R. Flavell ,for their kind gifts of various prolamin genomic and cDNA probes.
References
1. Bartels D, Thompson RD: Synthesis of mRNAs coding for abundant endosperm proteins during wheat grain de- velopment. Plant Sci 46:117-125 (1986).
2. Bechtel DB, Wilson JD, Shewry PR: Immunocyto- chemical localization of wheat storage protein triticin in developing endosperm tissue. Cereal Chem 68:573-577 (1991).
3. Boroto K, Dure III L: The globulin seed storage proteins of flowering plants are derived from two ancestral genes. Plant Mol Biol 8:113-131 (1987).
4. Burgess SR, Shewry PR: Identification of homologous globulins from embryos of wheat, barley, rye and oats. J Exp Bot 37:1863-1871 (1986).
5. Casey R, Domoney C, Ellis N: Legume storage proteins and their genes. Oxford Surv Plant Mol Cell Biol 3:1-95 (1986).
6. Danielsson CE: Seed globulins ofgramineae and legumi- noseae. Biochem J 44:387-400 (1949).
7. Derbyshire E, Wright DJ, Boulter D: Legumin and vicilin storage proteins of legume seeds. Phytochemistry 15:3-24 (1976).
8. Donovan GR, Skerritt JH, Castle SL: Monoclonal anti- bodies used to characterize cDNA clones expressing spe- cific wheat endosperm proteins. J Cereal Sci 9:97-111 (1989).
9. Goldberg RB, Barker SJ, Perez-Grau L: Regulation of gene expression during plant embryogenesis. Cell 56: 149-160 (1989).
10. Halford NG, Forde J, Anderson OD, Greene FC, Sh- ewry PR: The nucleotide and deduced amino acid se- quences of a HMW glutenin subunit gene from chromo- some 1B of bread wheat (Triticum aestivum L.) and comparison with those of genes from chromosomes 1A and 1D. Theor Appl Genet 75:117-126 (1987).
11. Harberd NP, Bartels D, Thompson RD: DNA restric- tion-fragment variation in the gene family encoding high molecular weight (HMW) glutenin subunits of wheat. Biochem Genet 24:579-596 (1986).
12. Hunt LT, DayhoffMO: The occurrence in proteins of the tripeptides Asn-X-Ser and Asn-X-Thr and of bound car- bohydrate. Biochem Biophys Res Commun 39:757-765 (1970).
13. Huynh TV, Young RA, Davis RW: Constructing and screening cDNA libraries in 2gtl0 and 2gtl 1. In: Glover DM (ed) DNA Cloning: A Practical Approach, vol 1. IRL Press, Oxford (1985).
14. Kozak M: Compilation and analysis of sequences up- stream from the translational start site in eukaryotic mRNAs. Nucl Acids Res 12:857-872 (1984).
15. Langridge P, Pintor-Toro JA, Feix G: Zein precursor mRNAs from maize endosperm. Mol Gen Genet 187: 432-438 (1982).
16. Mayer RJ, Walker JH: Polyclonal antiserum production, processing. In: Immunochemical Methods in Cell and Molecular Biology. Academic Press, London (1987).
17. Pearson WR, Lipman DJ: Improved tools for biological sequence comparison. Proc Natl Acad Sci USA 85: 2444-2448 (1988).
18. Rafalski JA, Scheets K, Metzler M, Peterson DM, Hedg- coth C, Soll DG: Developmentally regulated plant genes: the nucleotide sequence of a wheat gfiadin genomic clone. EMBO J 3:1409-1415 (1984).
19. Ramchandran C, Raghvan V: Intracellular localization of glutelin mRNA during grain development in rice. J Exp Bot 41:393-399 (1990).
20. Robert LS, Nozzolillo C, Altosaar I: Homology between legumin-like polypeptides from cereals and pea. Biochem J 226:847-852 (1985).
21. Sears ER: The aneuploids of common wheat. Res Bull Univ Missouri Agric Exp Stn 572:1-59 (1954).
22. Sievert C, Sapirstein HD, Bushuk W: Changes in elec- trophoretic patterns of acetic acid insoluble wheat flour proteins during dough mixing. J Cereal Sci 14:243-256 (1991).
23. Singh NK, Shepherd KW: The structure and genetic con- trol of a new class of disulphide-finked proteins in wheat endosperm. Theor Appl Genet 71:79-92 (1985).
24. Singh NK, Shepherd KW: Solubility behaviour, synthe- sis, degradation and subcellular location of a new class of disulphide-linked proteins in wheat endosperm. Aust J Plant Physiol 14:245-252 (1987).

25. Singh NK, Shepherd KW, Langridge P, Gruen LC, Sker- ritt JH, Wrigley CW: Identification of legumin-like pro- teins in wheat. Plant Mol Biol 11:633-639 (1988).
26. Singh NK, Shepherd KW, Langridge P, Gruen LC: Bio- chemical characterization of triticin, a legumin-like pro- tein in wheat endosperm. J Cereal Sci 13:207-219 (1991).
27. Skerritt JH, Robson LG: Wheat low molecular weight glutenin subunits-structural relationship to other gluten proteins analysed using specific antibodies. Cereal Chem 67:250-257 (1990).
28. Shotwell MA, Larkins BA: The biochemistry and molec- ular biology of seed storage proteins. In: Marcus A (ed) The Biochemistry of Plants, vol. 15. Academic Press, London (1989).
237
29. Takaiwa F, Kikuchi S, Oono K: A rice glutelin gene family - a major type of glutelin mRNAs can be divided into two classes. Mol Gen Genet 208:15-22 (1987).
30. Thompson RD, Bartels D, Harberd NP, Flavell RB: Characterization of the multigene family coding for HMW glutenin subunits in wheat using cDNA clones. Theor Appl Genet 67:87-96 (1983).
31. Shewry PR, Tatham AS, Forde J, Kreis M, Miflin BJ: The classification and nomenclature of wheat gluten pro- teins: a reassessment. J Cereal Sci 4:96-106 (1986).
32. Walburg G, Larkins BA: Isolation and characterization of cDNAs encoding oat 12 S globulin mRNAs. Plant Mol Biol 6:161-169 (1986).
Copyright © 2022 FDOKUMEN




















