
Identification of Masses in Mammograms by Image Sub-segmentation
10
Identification of Masses in Mammograms by Image Sub-segmentation Benjam´ ın Ojeda-Maga˜ na, Rub´ en Ruelas, Joel Quintanilla-Dom´ ınguez, Mar´ ıa Adriana Corona-Nakamura, and Diego Andina Abstract Mass detection in mammography is a complex and challenge problem for digital image processing. Partitional clustering algorithms are a good alternative for automatic detection of such elements, but have the disadvantage of having to segment an image into a number of regions, the number of which is unknown in ad- vance, in addition to discrete approximations of the regions of interest. In this work we use a method of image sub-segmentation to identify possible masses in mam- mography. The advantage of this method is that the number of regions to segment the image is a known value so the algorithm is applied only once. Additionally, there is a parameter α that can change between 1 and 0 in a continuous way, offering the possibility of a continuous and more accurate approximation of the region of inter- est. Finally, since the identification of masses is based on the internal similarity of a group data, this method offers the possibility to identify such objects even from a small number of pixels in digital images. This paper presents an illustrative exam- ple using the traditional segmentation of images and the sub-segmentation method, which highlights the potential of the alternative we propose for such problems. 1 Introduction Breast cancer is one of the leading causes of death among women worldwide. How- ever, early detection has great potential to heal and reduce the loss of many lives. Currently one of the most effective methods for early detection and detection of Benjam´ ın Ojeda-Maga˜ na, Rub´ en Ruelas, Mar´ ıa Adriana Corona-Nakamura Departamento de Ingeniera de Proyectos CUCEI, Universidad de Guadalajara, Jos´ e Guadalupe Zuno, 48, C.P. 45101, Zapopan, Jalisco, M´ exico. e-mail: [email protected]; rru- [email protected], [email protected] Joel Quintanilla-Dom´ ınguez and Diego Andina E.T.S.I. de Telecomunicaci´ on, Universidad Polit´ ecnica de Madrid, Avda. Complutense 30, Madrid 28040, Spain. e-mail: [email protected], [email protected] 1
Transcript of Identification of Masses in Mammograms by Image Sub-segmentation

Identification of Masses in Mammograms byImage Sub-segmentation
Benjamın Ojeda-Magana, Ruben Ruelas, Joel Quintanilla-Domınguez, MarıaAdriana Corona-Nakamura, and Diego Andina
Abstract Mass detection in mammography is a complex and challenge problemfor digital image processing. Partitional clustering algorithms are a good alternativefor automatic detection of such elements, but have the disadvantage of having tosegment an image into a number of regions, the number of which is unknown in ad-vance, in addition to discrete approximations of the regions of interest. In this workwe use a method of image sub-segmentation to identify possible masses in mam-mography. The advantage of this method is that the number of regions to segmentthe image is a known value so the algorithm is applied only once. Additionally, thereis a parameterα that can change between 1 and 0 in a continuous way, offering thepossibility of a continuous and more accurate approximation of the region of inter-est. Finally, since the identification of masses is based on the internal similarity ofa group data, this method offers the possibility to identify such objects even from asmall number of pixels in digital images. This paper presents an illustrative exam-ple using the traditional segmentation of images and the sub-segmentation method,which highlights the potential of the alternative we propose for such problems.
1 Introduction
Breast cancer is one of the leading causes of death among women worldwide. How-ever, early detection has great potential to heal and reduce the loss of many lives.Currently one of the most effective methods for early detection and detection of
Benjamın Ojeda-Magana, Ruben Ruelas, Marıa Adriana Corona-NakamuraDepartamento de Ingeniera de Proyectos CUCEI, Universidad de Guadalajara, Jose GuadalupeZuno, 48, C.P. 45101, Zapopan, Jalisco, Mexico. e-mail: [email protected]; [email protected], [email protected]
Joel Quintanilla-Domınguez and Diego AndinaE.T.S.I. de Telecomunicacion, Universidad Politecnica de Madrid, Avda. Complutense 30, Madrid28040, Spain. e-mail: [email protected], [email protected]
1

2 Benjamın Ojeda-Maganaet al.
breast cancers is mammography, although achieving this early cancer detection isnot an easy task. The most accurate medical detection method available is biopsy,but it is an aggressive and invasive procedure that involves some risks, patient’sdiscomfort and high cost [1].
There are a large number of different types of mammographic abnormality [2].In the majority of cases, however, the abnormalities are either microcalcifications ormasses. Microcalcifications usually form clusters and individual microcalcificationscan range from twenty to several hundred microns in diameter. On the other hand, abreast mass is a generic term to indicate a localized swelling, protuberance, or lumpin the breast. Masses can be caused by different processes: from natural changes inthe breast to cancerous processes. Masses are characterised by their location, size,shape, margin, and associated findings (i.e. architectural distortion, contrast) [3].
In this paper we focus only on the identification of masses, a problem which isgenerally more difficult than the identification of microcalcifications. The difficultyis caused by the great variation in size and shape of the masses that occur in amammogram, and mainly because the masses are confused with normal tissue dueto poor contrast between them [4].
The purpose of this work is to use a method of image sub-segmentation [5] toidentify possible masses in mammography. This method is based on a hybridc-Means clustering model for determining membership and typicality values makingit possible to identify the masses. In this paper we use the PFCM [6] clusteringalgorithm in order to detect small homogeneous regions in mammograms.
Partitional clustering algorithms, especially the Fuzzy c-Means (FCM) clusteringalgorithm [7] have been used for mass detection and/or segmentation of suspiciousareas in digital mammography. The problem of identification is the low contrast be-tween malignant masses and normal breast tissue, increasing the number of regionsor clusters that have to be identified until one of them corresponds to the area ofinterest (i.e., the masses). They appear as small groups of pixels of high graylevelintensity and they usually occupy a very small range of values, hence they are hardto detect. The drawback of this approach is the computational cost, because everytime the number of regions or clusters to identify is increased, it is necessary tore-run the algorithm.
Unlike the traditional application of partitional clustering algorithms, a hybridalgorithm for sub-segmentation of images is applied only once and, based on typ-icality values, each region or cluster can be divided in typical and atypical values.Thus, if the image is divided into two regions: the breast (S1) and the background(S2), it is possible to further divide the pixels of each of these regions into:S1=S−typical1, S−atypical3 andS2= S−typical2, S−atypical4, resulting in four sub-regions. Thus, the sub-segmentation is achieved using a threshold valueα ∈[0,1] forthe values of typicality. As a consequence, the masses, even though they do not showa large contrast with the normal tissue, tend to differ from it and the pixels are shownto be outliers or atypical. The threshold valueα depends on the application. In par-ticular, when there is a low contrast the threshold valueα should be high, while ahigh contrast requires a low threshold valueα. The results show that the procedureis different from traditional methods, and that the masses are properly identified.

Identification of Masses in Mammograms by Image Sub-segmentation 3
Therefore, the proposal of this work may be considered an interesting alternativefor the identification of such objects.
This article is organized as follows: Section 2 presents the main features of par-titional clustering algorithms, as well as the sub-segmentation of images. Section3 presents the results of mass detection with a traditional segmentation method, asthe FCM, and the results by sub-segmentation. This section concludes with a com-parative analysis of results. Finally, Section 4 presents the main conclusions of thiswork.
2 Presence of masses in mammographies and methods foridentification
The masses in a breast can have different causes, such as the age of the person ora cancerous process. Under these conditions, the tissue that forms the masses hasdeveloped differently compared to healthy tissue, although this development doesnot lead to a very marked difference in contrast between them. In addition, shapesand sizes vary widely from case to case, making it difficult to standardize the searchfor such elements. However, it is possible to identify areas that may be associatedwith masses through the characteristics of the pixels.
The detection of abnormalities in digital mammograms is based on the fact thatpixels corresponding to the abnormalities (masses) have different features from therest of the pixels that are within the breast area. These features may be related tothe gray-level intensity, texture, morphological measurements, etc. Partitional clus-tering algorithms are one of the most common techniques for segmenting digitalimages and for mass detection. Suttonet al [8] use the FCM clustering algorithm todetect masses in, themdb001image from the MIAS database [10], using the pixelintensity level as the only feature.
However, it is necessary to provide these algorithms with the number of clustersto identify in an image, or within a database, and they group data according to adistance measure and to the criteria used. In this paper we use these two differentversions of these algorithms, one of them a traditional process which serves as abenchmark against which to compare the results obtained with the second method,which consists of sub-segmentation of the main regions.
2.1 Partitional clustering algorithms
Clustering algorithms are based on unsupervised learning, or learning where thenumber of regions present in the image is unknown. However, these algorithmsidentify groups of pixels from the similarity of their characteristics, such as gray-level intensity. Thus, these algorithms require the number of clusters to find to beprovided as a parameter.

4 Benjamın Ojeda-Maganaet al.
To determine the similarity between pixels the algorithms use prototypes, in or-der to identify the most representative elements of each of the cluster. From theseprototypes, and generally using the Euclidean distance, it is possible to determinethe most appropriate cluster for each pattern. Once all pixels have been identified,the pixels from each group are used to adjust the value of the prototype so that itremains the most representative element of the region. This iterative process contin-ues until an objective function is minimized or until a certain number of iterationshas been reached.
The clusters identified in this way can be binary clusters. For example, each pixelcan belong only to one cluster and nothing else. This creates a strict partition ofthe feature space, where the edge of each cluster defines the elements of each oneof them. There are also algorithms that allow null, partial or total membership toeach of the clusters for each pixel. In this case the result is a fuzzy partition of thefeature space, where each data point is associated with the cluster for which it hasthe maximum membership degree. This partition has a restriction, however, thatforces the total membership of a pixel to be distributed among all clusters, so thatthe partition is determined by the number of clusters and the relative distance amongthem.
Besides the strict and fuzzy partition methods, there is also a possibilistic par-tition where the data are divided in the feature space according to a measure ofsimilarity. The advantage is that pixels are grouped because they have similar char-acteristics, rather than being forced to necessarily belong to one of the clusters.
Partitional clustering algorithms are one of the most commonly used techniquesfor image segmentation and for mass detection. In this paper we use the FCM inorder to illustrate a classic procedure of image segmentation implementing parti-tional clustering algorithms, and a benchmarks for comparing the results obtainedby sub-segmentation.
Some of the disadvantages of the partitional clustering algorithms are that theyrequire the user to know,a priori, the number of regions in which the image will bedivided, and they do not use the spatial information inherent in the image. Recentlysome approaches, in which the objective function has been modified so that spatialinformation can be taken into account have been proposed [12], [13]. The traditionalpartitional clustering algorithm is thek-Means [9], which provides a strict partitionof the feature space. An extension of thek-Means is the FCM algorithm [7], whereeach pixel of the image has a partial membership to each class, and the total mem-bership is distributed among all classes. This algorithm performs a fuzzy partitionof the feature space.
2.2 Image sub-segmentation
The process of image sub-segmentation to find masses in mammographies is basedon the application of a hybrid partitional clustering algorithm, so that it providesmembership and typicality values of each pixel. These values translate, to a great ex-

Identification of Masses in Mammograms by Image Sub-segmentation 5
tent, an external dissimilarity and an internal similarity respectively. This facilitatesthe identification of different objects in an image, as the masses in a mammography,as we shall see in the following sections.
For the image sub-segmentation of mammography image, we propose using thehybrid clustering algorithm Posibilistic Fuzzyc-Means (PFCM) [6], which allowsfinding homogeneous groups of pixels in the feature space. This algorithm achievesboth a fuzzy partition and a possibilistic partition of the feature space [5].
Proposed approach for detection of masses by sub-segmentation
I Get the vector of features through the mapping of the original image.II Assign a value to the parameters(a,b,m,η) as well as to the number of clusters,
in this casec = 2.III Run the PFCM algorithm to get:
• The membership matrixU .• The typicality matrixT.
IV Get the maximum typicality value for each pixel.
Tmax= maxi [tik], i = 1, . . . ,c. (1)
V Select a value for the thresholdα.VI With α and theTmaxmatrix, separate all the pixels into two sub-matrices(T1,T2),
with the first matrixT1 = Tmax≥ α (2)
containing the typical pixels (normal tissue), and the second matrix
T2 = Tmax< α (3)
containing the atypical pixels (possible masses).VII From the labelled pixelszk of theT1 sub-matrix the following sub-regions can be
generatedT1 = S− typical1, ...,S− typicalc, i = 1, . . . ,c. (4)
and from theT2 sub-matrix
T2 = S−atypical1+c, ...,S−atypical2c, i = 1, . . . ,c. (5)
such that each regionSi , i = 1, ...,c is defined by
Si = S− typicali and S−atypicali+c. (6)
VIII Select the sub-matrixT1 or T2 of interest for the corresponding analysis. In thecase of this work,T2 is the sub-matrix of interest.

6 Benjamın Ojeda-Maganaet al.
Among the advantages of this procedure is that the algorithm is applied onlyonce, then the threshold value is adjusted to separate the healthy tissue (typical pix-els) from the masses (atypical pixels). Moreover, the number of clusters identifiedin this case is well defined and is equal to two: the breast and the background of theimage.
The application of the sub-segmentation method is very appropriate here due tothe characteristics of the application, where depending on the stage of developmentof the masses that we are trying to detect, they can vary in size from fairly large tovery small, and this method does not require a large amount of pixels in order toidentify atypical pixels. Additionally, this type of problem is based on the premisethat in an initial time (that is, in a patient of), all the tissue has the same charac-teristics. However, due to maturity or health problems, tissues evolve and change.These changes can be related to problems such as cancer. This means that the char-acteristics of the tissue in certain areas begin to differ from healthy tissue, indicatedby atypical pixels, and it is precisely at this early stage that it is important to tryto identify such anomalies. This requires methods able to identify such pixels evenwhen they are available in small quantity. Some applications in soft computing tomedical problems can be seen in [14].
3 Detection of masses
In this paper we use three images from the MIAS database. The original images areshown in Fig. 1 (a), Fig. 3 (a) and Fig. 3 (c). In the first image it can be observedthat the mass has almost the same intensity (gray-level) as the breast tissue, whichmakes its detection difficult. This is the image which is used to perform a compar-ative evaluation of the results obtained with a partitional clustering algorithm, theFCM, and the method of sub-segmentation. The three images are in grayscale andin the case of this work the level of gray is the only feature that is used, that is,the spatial information is not taken into account. Furthermore, we use the completemammography image without any preprocessing.
3.1 Detection of masses by segmentation using partitionalclustering algorithms
When image data are processed using clustering algorithms, they try to find groupsof pixels with similar characteristics (intensity, texture, etc.), dividing the imageinto more or less homogeneous regions. Fig. 1 (a) shows the original imagemdb001from the MIAS database. This image is then partitioned into several regions. Fig.1 (b) shows the results of image segmentation with the FCM in 4 regions. Fig. 1(c) shows the results when the number of clusters is increased to 6, while Fig. 1 (d)shows the results when the number of clusters is equal to 8, while Fig. 1 (e) contains
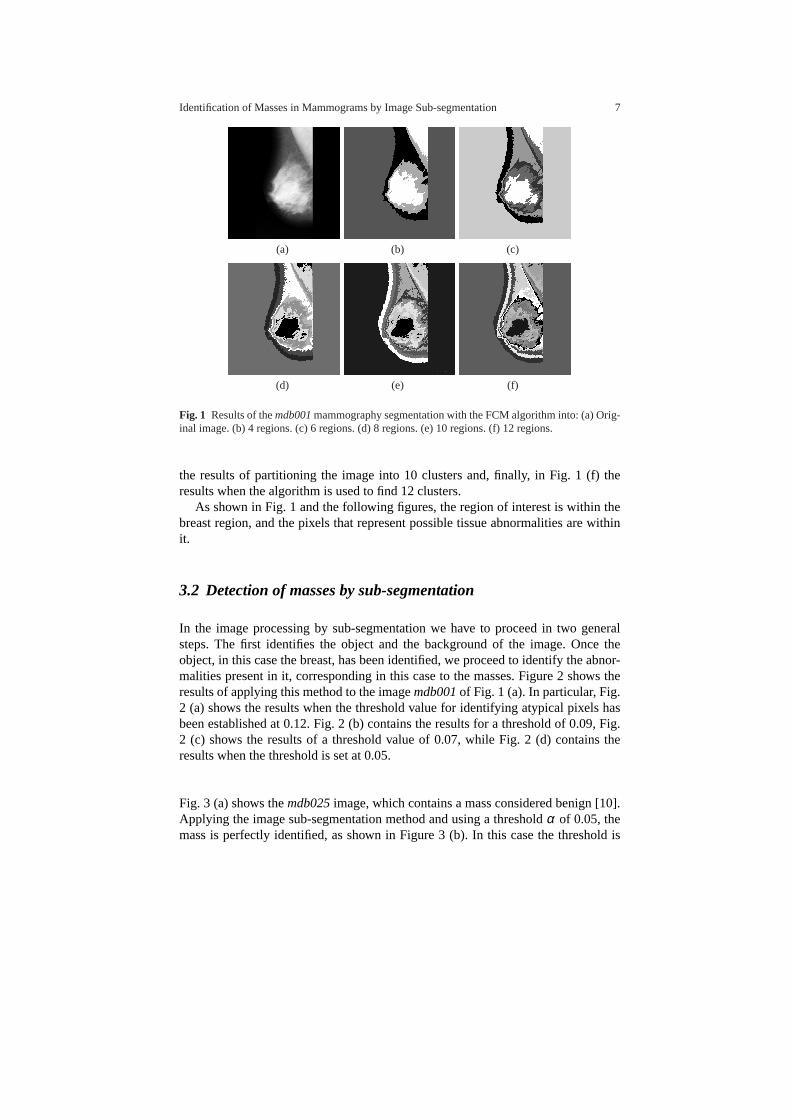
Identification of Masses in Mammograms by Image Sub-segmentation 7
(a) (b) (c)
(d) (e) (f)
Fig. 1 Results of themdb001mammography segmentation with the FCM algorithm into: (a) Orig-inal image. (b) 4 regions. (c) 6 regions. (d) 8 regions. (e) 10 regions. (f) 12 regions.
the results of partitioning the image into 10 clusters and, finally, in Fig. 1 (f) theresults when the algorithm is used to find 12 clusters.
As shown in Fig. 1 and the following figures, the region of interest is within thebreast region, and the pixels that represent possible tissue abnormalities are withinit.
3.2 Detection of masses by sub-segmentation
In the image processing by sub-segmentation we have to proceed in two generalsteps. The first identifies the object and the background of the image. Once theobject, in this case the breast, has been identified, we proceed to identify the abnor-malities present in it, corresponding in this case to the masses. Figure 2 shows theresults of applying this method to the imagemdb001of Fig. 1 (a). In particular, Fig.2 (a) shows the results when the threshold value for identifying atypical pixels hasbeen established at 0.12. Fig. 2 (b) contains the results for a threshold of 0.09, Fig.2 (c) shows the results of a threshold value of 0.07, while Fig. 2 (d) contains theresults when the threshold is set at 0.05.
Fig. 3 (a) shows themdb025image, which contains a mass considered benign [10].Applying the image sub-segmentation method and using a thresholdα of 0.05, themass is perfectly identified, as shown in Figure 3 (b). In this case the threshold is

8 Benjamın Ojeda-Maganaet al.
(a) (b) (c) (d)
Fig. 2 Results ofmdb001mammography sub-segmentation with threshold: (a)α = 0.12. (b) α =0.09, (c) α = 0.07 (d) α = 0.05.
(a) (b) (c) (d)
Fig. 3 Results of sub-segmentation of two mammographies from the MIAS database. (a) Originalimagemdb025. (b) Results of sub-segmentation using a thresholdα of 0.05. (c) Original imagemdb028.(d) Results of sub-segmentation using a thresholdα of 0.05.
very low because there is a great contrast between the mass and normal breast tissue.The results show also another atypical region. However, as noted in the original im-age, this is a consequence of the illumination while the image was acquired. For thisreason this region is not of interest. The results for the imagemdb028are similar,and in this case the threshold valueα is also 0.05.
3.3 Comparative analysis
Fig. 1 (a) shows the original mammography image. It can be seen that the mass isalmost the same gray-level as the breast tissue, making it difficult to detect. Figures1 (b), (c), (d), (e) and (f) show the results when applying the FCM algorithm and thenumber of regions is increased to 2, 4, 6, 8 , 10 and 12, respectively. Here we canobserve how the number of clusters increases, the region of interest (the masses) isbetter defined. The drawback in this case is that we do not know the most appropriatenumber of regions to segment the image. So it is necessary to do a validation ofclusters in order to determine what number of cluster is the most appropriate inorder to segment the image [11]. If the image has little contrast between normaltissue and the masses, the number of clusters tends to be large. Otherwise, if thecontrast is high, the number of regions required tends to be more moderate.

Identification of Masses in Mammograms by Image Sub-segmentation 9
Figures 2 (a), (b), (c) and (d) shown the results of the sub-segmentation of theimagemdb001. In this case they only show the regions identified with the followingvalues of thresholdsα: 0.12, 0.09, 0.07 and 0.05, respectively. Here we can seethat, as the threshold value continuously approaches 0 (in this example, startingfrom 0.5), it better delimits the pixels that have the most marked differences tothe normal tissue. In this case, the background region (S2) of the image does notcontain atypical pixels as this is a very homogeneous region. However, the breasttissue region (S1) shows greater variation and is more heterogeneous, so here are alot of atypical pixels which correspond to the mass present in the breast. In the imagesub-segmentation we have more control over the region to identify as it depends ona parameter (α threshold) that changes continuously between 0 and 1, thus allowingbetter identification of the masses and a better definition of the edge.
In cases where the masses are represented by a large amount of data is rela-tively easy to locate them using either of the two methods discussed previously.However, when the masses are small and they are represented by a few quantity ofpixels, which may be the case during an early stage of these anomalies, clusteringalgorithms tend to have the disadvantage that, in order to correctly identify masses,many iterations are required, since otherwise the few atypical pixels that correspondto the masses are included in other groups. In this case the sub-segmentation hasadvantages since the identification of these data is based on similarity and not onthe quantity of pixels, which provides the ability to identify masses even with fewpixels.
4 Conclusions
In this study we have applied the method of image sub-segmentation for the task ofmass detection in mammographies. We have also implemented a partitional cluster-ing algorithm following a typical application of these algorithms to these problems.Among the main differences is that the sub-segmentation algorithm needs to beapplied only once, and it is possible to identify the masses from the results. Further-more, through a continuous adjustment of the thresholdα it is possible to make acontinuous approximation of the region corresponding to the masses. For the clus-tering algorithms, it is necessary to proceed iteratively in a bottom-up search of theoptimal number of groups in order to identify the masses. This involves re-applyingthe algorithm for each number of groups in order to identify changes. As a resultthere is a discrete approximation of the region from the masses, and the approxima-tion depends on several factors, which makes it difficult to control the size of theidentified region. This is an important aspect to consider especially if the masseshave little contrast with the rest of the breast if there is a gradual transition betweennormal tissue and the masses.
Another advantage of the sub-segmentation method is that allows the identifica-tion of masses from a small number of pixels, which allows the detection of suchobjects at early stages of development. This is extremely important, especially when

10 Benjamın Ojeda-Maganaet al.
the anomalies have their origin in cancerous processes. In these circumstances, thatis, when there are few pixels corresponding to the masses, clustering algorithms re-quire a significant increase in the number of clusters in order to identify them. Often,more than ten clusters are needed for a proper identification of the region of interest.
The results are interesting even though the images used in this work have not beenpreprocessed. As a future work, it will be important to use pre-processed images inorder to improve the contrast, and perform comparative analysis between the twomethods considered in this work using preprocessed data. Furthermore, it will beimportant to estimate the total computational cost of each one of the two alternativesin addition to comparing the results. Finally, it would be interesting to develop anautomatic procedure for determining the thresholdα used in the sub-segmentation,as this value is determined experimentally currently.
References
1. Quintanilla-Domınguez J, Cortina-Januch M G, Ojeda-Magana B, Vega- Corona A, and An-dina D (2010) Microcalcification detection applying artificial neural networks and mathemat-ical morphology in digital mammograms. Proceedings of the World Automation Congress
2. Kopans D B (1998). Breast Imaging, 2nd edn. Lippincott-Raven, Philadelphia, 19983. Oliver A, Freixenet J, Marti J, Perez E, Pont J, Denton R E, and Zwiggelaar R (2010) A re-
view of automatic mass detection and segmentation in mammographic image. Medical ImageAnalysis 12(2):87-110
4. Vyborny C J and Giger M L (1994) Computer vision and artificial intelligence in mammog-raphy. American Journal of Roentgenology, 162(3):699-708
5. Ojeda-Magana B, Quintanilla-Domınguez J, Ruelas R, Andina D (2009) Images sub-segmentation with the PFCM clustering algorithm. Proc 7th IEEE Int Conf Industrial In-formatics 499-503
6. Pal N R, Pal K, Keller J M, and Bezdek, J C (2005) A possibilitic fuzzy c-means clusteringalgorithm. IEEE T Fuzzy Syst 13(4):517-530
7. Bezdek J C, Keller J, Krishnapuram R, and Pal N R (1999) Fuzzy Models and Algorithms forPattern Recognition and Image Processing. Boston, London
8. Sutton M A, Bezdek J C and Cahoon T (2000) Handbook of medical imaging. AcademicPress, Inc. Orlando, FL, USA 87-106
9. MacQueen J B (1967) Some methods for classification and analysis of multivariate obser-vations. Proc 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley,University of California Press 281-297
10. University of South Florida (2001) Digital database for screening mammography.http://figment.csee.usf.edu/pub/ddsm/cases/
11. Hathaway R J and J. C Bezdek J C (2003) Visual cluster validity for prototype generatorclustering models. Pattern Recognition Letters 24:1563-1569
12. Chuang K S, Tzeng H L, Chen S W, Wu J, and Chen T J (2006) Fuzzy c-means clustering withspatial information for image segmentation. Computerized Medical Imaging and Graphics30(1):9-15
13. Kang J, Min L, Luan Q, Li X and Liu J (2009) Novel modifieed fuzzy c-means algorithmwith aplications. Digital Signal Processing 19(2):309-319
14. Vera V, Garcia A E, Suarez M J, Hernando B, Redondo R, Corchado E, Sanchez M A, GilA, Sedano J (2010) A bio-inspired computational high-precision dental milling system. Pro-ceedings of the World Congress on Nature and Biologiacally Inspired Computing. IEEE




















