
Hypermedia Databases: A Specification and Formal Language
11
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Hypermedia Databases: A Specification and Formal Language

Hypermedia Databases: A Speci�cation
and Formal Language
Yoshinori Hara
1
and Rodrigo A. Botafogo
2
1
C&C Research Labs
2
Media Technology Research Labs
NEC Corporation, 4{1{1, Miyazaki, Miyamae-ku, Kawasaki, Kanagawa 216, Japan
Abstract. Improving authoring and browsing techniques is fundamen-
tal if large hypermedia applications are to be authored and browsed
e�ciently. This paper presents a new, two step approach, for the de-
velopment of hypermedia systems. First data modeling is done using
standard database techniques. Second, a selected part of the database is
\projected" onto the \hypertext world." Using this approach, hypertext
and database technologies are integrated forming a powerful symbiosis:
hypermedia databases.
Advantages of this new approach are: (a) applications can be developed
using structured design, (b) nodes and links can be automatically gener-
ated, (c) it becomes much easier to author and update the application,
(d) query mechanisms are improved, (e) the same data can be reused
for di�erent applications, (f) reduction of redundancies and inconsisten-
cies, data sharing, improved security, etc., are obtained by having the
hypertext build on top of a database management system.
Introdction
Once upon a time, a 200 line program was considered a feat of intellectual
power, but with new compiling techniques, structured and object oriented pro-
gramming, a 200 line program can now be written in an afternoon. 200 nodes and
a couple of hundred links, and hypertext developers start talking about medium
size hypertext. Make it a thousand nodes and a couple of thousand links and
we are talking very large hypertext. It is now great time to start developing
hypertext with thousands of nodes and some hundred thousand links. If such
hypertext sizes are ever to be reached, we need to start thinking about more
automatic authoring (just think how much time it would take to add 100,000
links manually).
However, in the hypertext community, when one talks about automatic au-
thoring, immediately the image of low quality hypertext, not properly tailored
for its purpose is conveyed. This is clearly not our goal. We want high quality
hypertext, well planned and clearly structured. It should be clear that only by
improving authoring techniques can one move towards this goal. Instead of say-
ing: \add a link from node 250 to node 1273," authors should say: \create an
index of all french painters sorted by their date of birth and add links from this
index to the appropriate painter node."

A �rst step for the improvement of authoring, browsing and search is the
development of stronger hypermedia models that escape or extend the node and
link paradigm. Only in the last European Hypertext conference, ECHT'92, three
such models are presented [3, 9, 15]. Although having composite nodes, typed
links, etc., is a requirement for future generations of hypertext systems, one is
still at lost when having to decide which nodes to aggregate, or what type of
links to use.
On the other hand, database technology has been concerned exactly with
the issues stated above. Through schema organization, declarative access, views,
and also aggregation and generalization or more recently with Object Oriented
Database Systems, a strong theory about data structuring and retrieval has
been developed. Database systems, however, lack some features that make the
strength of hypertext: author's structuring, navigational access, history, brows-
ing, etc.
This paper proposes new theoretical concepts, and practical formal language
operations that provide a natural integration of both hypermedia and database
technologies. Some e�ort has already been done in that direction [11, 12], but
basically the database is used to implement the underlying hypertext data model
and not for its strong data modeling capabilities. In this paper we propose a
two step authoring approach: �rst we model our data using a standard database
modeling approach such as the E-R model, the relational model, etc. On a second
step we \project" the database into the hypermedia space.
DesignPhilosophforHpermediaDatabase
Hypermedia technology has now matured to the point that authors are start-
ing to write large applications, such as engeneering manuals [8], electronic li-
braries [4], and large scale CSCW's [13]. However, writing a large application is
still a very complex process. Authors have to manage hundreds of nodes and
thousands of links manually and there is still the famous \disorientation" prob-
lem.
In order to develop large applications in a more e�ortless and less error-
prone fashion one needs to abandon add-hoc development techniques and move
to a structured design approach based on well de�ned design methodologies [14].
This approach was taken in database systems with the development of schemas
and schema languages. In the hypertext �eld, Garzotto et al. proposed this very
same idea; however claiming that, since hypertexts have di�erent characteristics
from databases new models needed to be developed. HDM{Hypertext Design
Model [5]{is the result of their e�orts.
We believe, however, that database models can and should be used in the
development of hypertext applications. In order to address the di�erent char-
acteristics of hypertexts, we propose a two step development approach. First,
information is modeled using standard database techniques. At this step hyper-
text is not considered at all. On a second step, we \project" selected parts of
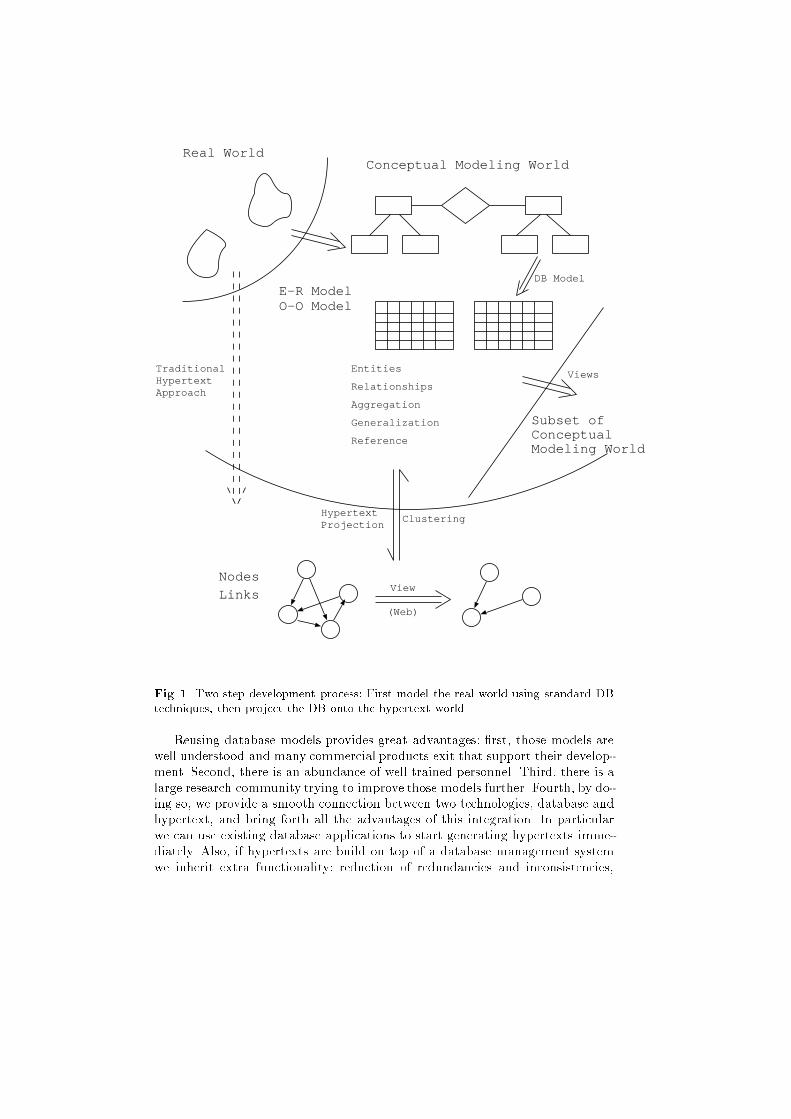
the database onto the hypertext world (see Fig. 1).
Real World
E-R ModelO-O Model
Conceptual Modeling World
Entities
Relationships
Aggregation
Generalization
Reference
Views
Subset of ConceptualModeling World
Hypertext Projection
TraditionalHypertextApproach
DB Model
Nodes
Links
Clustering
View
(Web)
Fig. 1. Two step development process: First model the real world using standard DB
techniques, then project the DB onto the hypertext world.
Reusing database models provides great advantages: �rst, those models are
well understood and many commercial products exit that support their develop-
ment. Second, there is an abundance of well trained personnel. Third, there is a
large research community trying to improve those models further. Fourth, by do-
ing so, we provide a smooth connection between two technologies, database and
hypertext, and bring forth all the advantages of this integration. In particular
we can use existing database applications to start generating hypertexts imme-
diately. Also, if hypertexts are build on top of a database management system
we inherit extra functionality: reduction of redundancies and inconsistencies,

improved security and integrity maintenance, etc. Other advantages are:
Consistent Node Layout: Nodes are obtained from records by de�ning tem-
plates. The use of templates ensure that every node of a same type will
have a consistent layout. Furthermore, if the database allows hierarchies of
objects, layouts can also be inherited.
Automatic Link Generation: Relationships in a database are implicit, based
on record content. Using link de�nitions, i.e., by making relationships explicit
through some language constructs, links can be automatically generated,
greatly reducing the risk of mistakes such as forgotten or dangling links.
Easy to Author/Update: Since nodes are created through the use of tem-
plates, changing them will a�ect whole families of nodes consistently. Also,
since links are automatically generated based on link de�nitions, which are
easily added or removed, authors can experiment at will.
Many Applications/Same Data: Two main activities need to be performed
when trying to transmit information: collecting the data, and presenting it in
an interesting way for the reader. Those two activities, although interelated,
are quite di�erent. When you buy a book, you are not only buying the facts,
you are also buying the authors view of those facts. Dynamic hypertexts
(those in which links are created on the y) only give you the facts; static
hypertexts (structured beforehand by the author) give the facts and the view,
but there is no way to separate one from the other. This is very unfortunate,
as having the facts stored in electronic form should also permit you to easily
change its presentation.
Reconciling the Literalists and the Virtualists: For the literalists links are
created and represented explicitly and navigation is done by traversing those
links. The virtualists, on the other hand, say that any structure is implicit
in the form or content of the nodes, and links are computed over the nodes.
It is clear that each vision brings advantages and disadvantages.
We reconcile the two views in our two way authoring approach, by having
an author at \compile" time create link de�nitions, e.g., \Add links between
all 17th century painters sorted by date of birth," or \Add link between
politicians and the events in which they were participants." Those author
de�ned links are then browsed in a static way, but readers can issue their
own queries in the same query language obtaining dynamic links. In short,
static links are dynamic links (queries) issued by a knowledgeable author
prior to the application delivery.
FormalSpecificationsforHpermediaDatabase
A hypermedia database is a system that integrates database models and hyper-
text structures and in which it is possible to smoothly translate from one model
to the other. For the bulk of this paper, we will work with the relational model
and a minor extension to the node and link model. Although we concentrate
our analysis to the E-R model, a similar approach could be taken for any other
database model.
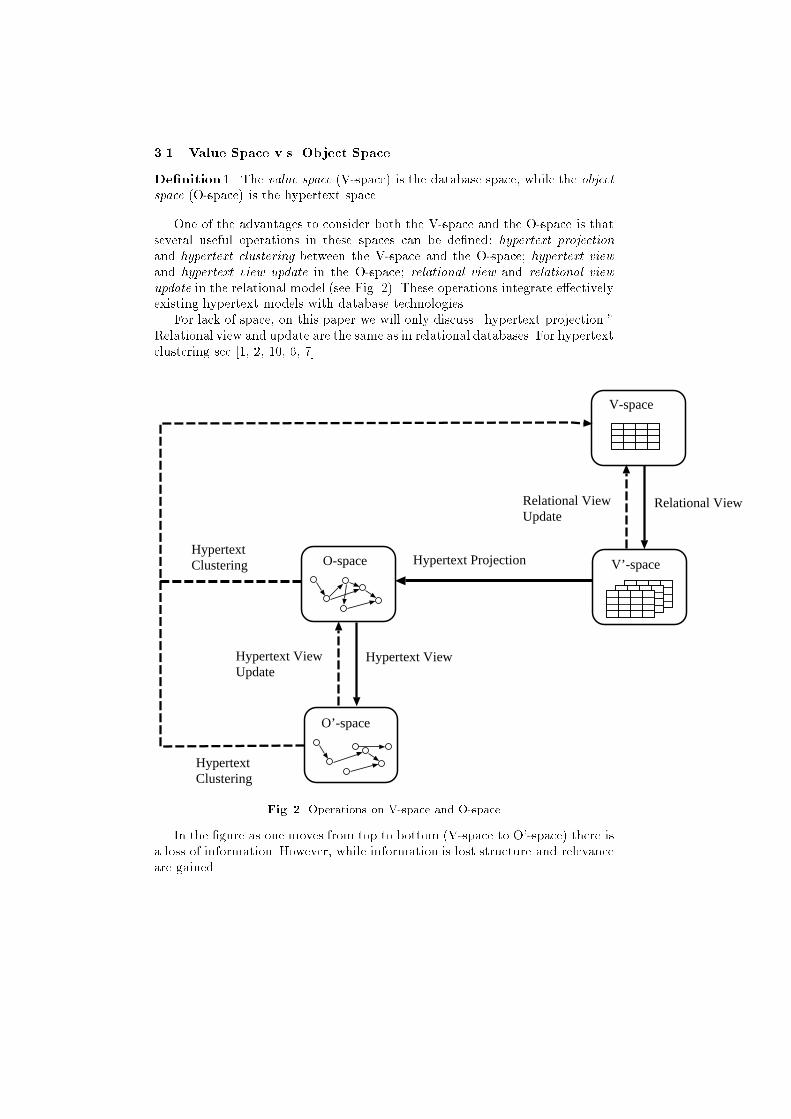
3.1 Value Space v.s. Object Space
De�nition1. The value space (V-space) is the database space, while the object
space (O-space) is the hypertext space.
One of the advantages to consider both the V-space and the O-space is that
several useful operations in these spaces can be de�ned: hypertext projection
and hypertext clustering between the V-space and the O-space; hypertext view
and hypertext view update in the O-space; relational view and relational view
update in the relational model (see Fig. 2). These operations integrate e�ectively
existing hypertext models with database technologies.
For lack of space, on this paper we will only discuss \hypertext projection."
Relational view and update are the same as in relational databases. For hypertext
clustering see [1, 2, 10, 6, 7]
HypertextClustering
Relational ViewRelational ViewUpdate
Hypertext ViewHypertext View Update
Hypertext Projection
HypertextClustering
V-space
O-space V’-space
O’-space
Fig. 2. Operations on V-space and O-space
In the �gure as one moves from top to bottom (V-space to O'-space) there is
a loss of information. However, while information is lost structure and relevance
are gained.

3.2 Hypertext Projection
Hypertext projection is an operation to translate relations in the V(V')-space
into a speci�c hypertext structure in the O-space. The basic procedure of hy-
pertext projection consists of the following three steps:
Forming Appropriate Relations: The �rst step is not really part of the pro-
jection, but it consists of forming, through relational operators (cartesian
product, projection, etc.), relations that are appropriate to be projected into
the O-Space. Which relations are appropriate depends, of course, on the ap-
plication being build. For instance, if one is constructing a hypermedia about
french painter of the 19
th
century, records containing painters from the 20
th
century might not be appropriate.
Creating nodes from tuples and relations: To create a node from a tuple
or a relation it is su�cient to specify a visualization for them. For tuples,
a visualization is a description of how and where each attribute should be
shown on the display. For a relation, the visualization describes a global
view of all its tuples. A node is, then, an explicit visualization of a tuple or a
relation. Note that the translation from an object in the V-space to a node
is one-to-one.
Creating links by specifying constraints: This step creates links between
related nodes. It consists of the following three sub-steps:
Specifying a set of source nodes, O
S
This step speci�es a set of nodes
to be used as source for the links.
Specifying a set of destination nodes, O
D
This step speci�es a set of
nodes to be used as destination for the links.
Specifying the constraint between O
S
and O
D
This step is necessary
to produce meaningful hypertext links. Examples of such constraints are
select all, i.e., all nodes in O
S
are connected to all nodes in O
D
, select
one, i.e., a node in O
S
is connected to a speci�c node in O
D
, etc.
TranslatingLangage
In the previous section we presented a method for translating from the V-space to
the O-space. In this section we make things more concrete, by presenting an SQL-
like language for the translation. Two steps are necessary for this translation:
creating nodes from relations and tuples, and adding links between nodes.
We will show how those constructs are applied by giving some examples. All
our examples will be based on a hypothetical art database, with painters from
many countries, their works, etc.
The general syntax for creating nodes is:
CREATE NODE [<Relation>]
[SELF:
[NAME = <string>];
[TEMPLATE = <template-name>];

[ASSOCIATE <attribute-commalist>
<field-commalist>] ];
[CHILD:
[NAME = f<string> | attributeg];
[TEMPLATE = <template-name>];
[ASSOCIATE <attribute-commalist>
<field-commalist>] ];
Arguments inside square brackets ([]) are optional, those inside angle brackets
(<>) are to be substituted by the appropriate arguments, and only one argument
from those in braces (fg) separated by 'j' is to be selected. A \Relation" is a
relation of the database; \string" is any string of character; \template-name"
is the name of a template; \attribute" and \�eld" are respectively attributes in
the relation and �elds de�ned in the template. The \commalist" indicates that
a list of elements separated by commas can be used. In ASSOCIATE the size of
the attribute-commalist and �eld-commalist should be the same.
The above construct creates two types of nodes: a composite node generated
directly from the given \relation," and a set of nodes obtained from the tuples
of the relation. There is an implicit ordering of those nodes, following the same
ordering as the tuples in the relation. Also, nodes inherit all the attributes from
the relation, even if they are not seen through the template. The SELF part
gives information on how to create the composite node, while the CHILD part
indicates how to create nodes from tuples. If SELF.NAME is omitted, this name
will be the same as the \relation." If TEMPLATE is omitted, the node cannot
be seen/browsed, but still exists. Finally, if ASSOCIATE is omitted, there is an
implicit relationship between the \attributes" and the \�elds" based on their
names. An example will make things clear.
Assume that a painter relation has at least attributes: name, birth, death,
photo and biography. The next command will create composite node \Painter"
and child nodes obtained from the tuples in the relation \Painter." For example,
if relation \Painter" had 10 tuples, 11 nodes would be created: 1 composite node
called \Painter," and 10 nodes created from the painter's tuples. Note that each
node will also receive a name coming from attribute \Painter.name."
// Create node from relation Painter.
CREATE NODE Painter
SELF: // Composite node
TEMPLATE = ``index.temp''; // will be an index.
ASSOCIATE = (name, birth), (name, date);
CHILD: // Nodes from tuples.
NAME = name; TEMPLATE = ``painter.temp''
ASSOCIATE = // Rel. -> Temp.
(name, birth, death, photo, biography);
(name, born, died, picture, description)
Assume now that for the application being created the author wants to have
a composite node having only the french painters. In that case two steps are
necessary: �rst, de�ne a view over the database using its access language (in our
example SQL). Then create the nodes:

// Creates a view FPainters for the database. For convenience uses
// the same names as the painter template attributes
CREATE VIEW FPainters (name, born, died, picture, description)
As SELECT Painter.name, Painter.birth, Painter.death,
Painter.photo, Painter.biography;
FROM Painter; WHERE Painter.country = ``France''
// Create nodes from the view
CREATE NODE FPainters
SELF:
TEMPLATE = ``browser.temp''; // Graphical browser.
CHILD:
NAME = name; TEMPLATE = ``painter.temp''
In the above speci�cation a set of nodes is created. Assuming that there are 5
french painters in the database, Fig. 3-(a) shows the painters' nodes create from
template \painter.temp," and Fig. 3-(b) shows the graphical browser created
from template \browser.temp." There is yet no way to browse through this set.
We now specify how to create links:
CREATE LINK [link-name]
SOURCE:
NAME = <node-name>;
IN fSELF | CHILDg;
[ANCHOR <field>];
DEST:
NAME = <node-name>;
IN fSELF | CHILDg;
[ANCHOR <field>];
DIRECTION fFORWARD | BACKWARD | BIDIRECTIONALg;
[WHERE <constraint-list>];
\link-name" speci�es the type of the link. SOURCE and DEST are respectively
the source and destination nodes of the links. If CHILD is speci�ed in the IN
clause, then links will be added to the children of the node; otherwise, the link
is added to the node itself. ANCHOR indicates to what �eld in the template
the link should be anchored. Note that DEST has also an ANCHOR. This is
necessary in case the DIRECTION of the link is either BACKWARD or BIDI-
RECTIONAL. WHERE speci�es constraints on the links. It is possible to use
in WHERE all attributes of nodes, e.g., SOURCE.name.
We now specify the in uence relationship form the \Impressionists" to the
\Post-impressionists." Links added are BIDIRECTIONAL so that both \in u-
enced" and \was in uenced by" traversals can be performed.
CREATE LINK Influenced
SOURCE:
NAME = FPainters; IN CHILD; ANCHOR ``Inf''
DEST:
NAME = FPainters; IN CHILD; ANCHOR = ``Inf By''

(a) French painters’ nodes arecreated.
Pictureof person
Descrip-tion
Name BornDead
Prev Next
Pictureof person
Descrip-tion
Name BornDead
Prev Next
Pictureof person
Descrip-tion
Name BornDead
Prev Next
Pictureof person
Descrip-tion
Name BornDead
Prev Next
Pictureof person
Descrip-tion
Name Born
Died
Next
(c) "Influence" relation added."Select all" constraint used.
Prev InfInf By
(b) No links between nodes yet.
French Painters
Graphical Browser
French Painters
Graphical Browser
NextPrev
NextPrev
French Painters
Graphical Browser
(d) "Next" added. "Select one"constraint used.
NextPrev
Fig. 3. Conversion from the V-space to the O-space.
DIRECTION BIDIRECTIONAL;
WHERE SOURCE.school = ``Impressionism'',
DEST.school = ``Postimpressionism''
Note that links do not need to be one-to-one (see Fig. 3-(c)). In this example it
is most likely that an one-to-many relationship exists. How to decide to which
node to jump when button \Inf" is clicked, is part of the user interface. One
possible solution, though, would be to show the list of all possible destination
nodes.
It is now possible to start browsing through the FPainter node, but it is not
necessarily true that all nodes are accessible. It would be interesting to have all

painters sorted by their date of birth and linked using a \next" button (see dotted
links in Fig. 3-(d))
3
. The sorting is done by de�ning a view on the database
(remember that there is an implicit ordering of the nodes which is identical to the
tuples' ordering), and the linking is similar as above. ANCHOR the link to the
\next" button, the DIRECTION is FORWARD, and the constraint \WHERE
SOURCE.next = DEST," where \next" is an implicitly de�ned attribute of the
node. Other attributes are: �rst, last, and a number, e.g., DEST.5.
Conclsion
In this paper we proposed a novel approach for authoring hypermedia applica-
tions: �rst, we model our data using standard database techniques, and then,
we project the database into the hypermedia space. This novel technique when
provided with four operations: hypertext projection, hypertext clustering, rela-
tional view, and hypertext view, e�ectively and smoothly integrates hypertext
and database technology creating what we call a hypermedia database.
With a formal framework to work with, it became possible to provide and
SQL-like language for the translation between the database world and the hy-
permedia world. This language not only provides this translation but can also be
used at run time to help retrieve information. Consequently, not only is author-
ing improved, as nodes and links can be created automatically, but also browsing
is enhanced. We believe, that this formal speci�cation and its declarative hyper-
media access language provides a useful perspectives for the next generation of
hypermedia systems.
Although for this paper we exempli�ed our approach using the E-R model
and an SQL-like language, the approach is general and could be applied for any
DB-model. What is requires is that the DB-model supports an access language
through which restructuring of the data is possible. In that case instead of an
SQL-like language, a language similar to the DB access language should be build.
References
1. R. A. Botafogo. Cluster analysis for hypertext systems. In 16th ACM SIGIR
International Conference on Research and Development in Information Retrieval,
pages 116{125, Pittsburgh, Pensylvania, June 1993.
2. R. A. Botafogo, E. Rivlin, and B. Shneiderman. Structural analysis of hypertexts:
Identifying hierarchies and useful metrics. ACM Transactions on Information Sys-
tems, 10(2):142{180, April 1992.
3. P. De Bra, G. Houben, and Y. Kornatzky. An extensible data model for hyperdoc-
uments. In Proceedings of the European Conference on Hypertext, pages 222{231,
Milano, Italy, 1992.
3
Do not confuse the \next" button in template \painter.tem" and the \next" button
in template \browser.temp." Specifying CHILD indicates that the links are to be
added to the painters.

4. D. E. Egan, M. E. Lesk, R. D. Ketchum, C. C. Lochbaum, J. R. Remde,
M. Littman, and T. K. Landauer. Hypertext for the electronic library? core sam-
ple results. In Proceedings of the Hypertext 91 Conference, pages 299{312, San
Antonio, Texas, December 1991.
5. F. Garzotto, P. Paolini, and D. Schwabe. HDM { A model based approach to
hypertext application design. ACM Transactions on Information Systems, 11(1):1{
26, January 1993.
6. Y. Hara, A. M. Keller, and G. Wiederhold. Implementing hypertext database re-
lationships through aggregation and exceptions. In Proceedings of the Hypertext
91 Conference, pages 75{90, San Antonio, Texas, December 1991.
7. Y. Hara, A. M. Keller, and G. Wiederhold. Relationship abstractions for an ef-
fective hypertext design: Augmentation and globalization. In DEXA'91, pages
270{274, 1991.
8. K. C. Malcolm and S. E. Poltrock. Industrial strength hypermedia: Requirements
for a large engineering enterprise. In Proceedings of the Hypertext 91 Conference,
pages 13{24, San Antonio, Texas, December 1991.
9. M. Marmann and G. Schlageter. Towards a better support for hypermedia struc-
turing: The hydesign model. In Proceedings of the European Conference on Hyper-
text, pages 232{241, Milano, Italy, 1992.
10. E. Rivlin, R. A. Botafogo, and B. Shneiderman. Navigating in hyperspace: De-
signing a structure-based toolbox. Communications of the ACM., 37(2):87{96,
February 1994.
11. J. L. Schnase, J. J. Leggett, and Szabo R. L. Semantic data modeling of hyperme-
dia associations. ACM Transactions on Information Systems, 11(1):27{50, January
1993.
12. H. A. Sch�utt and N. A. Streitz. Hyperbase: A hypermedia engine based on a rela-
tional database management system. In Proceedings of the European Conference
on Hypertext, pages 95{108, Paris, France, 1990.
13. K. Watabe, S. Sakata, K. Maeno, and H. Fukuoka. Distributed multiparty desktop
conferencing system: MERMAID. In Proceedings of the Conference on Computer-
Supported Cooperative Work, pages 27{38, Los Angeles, CA, October 1990.
14. G. Wiederhold. Database Design. McGraw-Hill, 1983.
15. Y. Zheng and M. Pong. Using statecharts to model hypertext. In Proceedings of
the European Conference on Hypertext, pages 242{250, Milano, Italy, 1992.
This article was processed using the L
A
T
E
X macro package with LLNCS style




















