webMethods Optimize User's Guide - Software AG Documentation
Upload
independentCategory
view
0download
0
Evolutionary approach to optimize the assignment of cells to switches
in personal communication networks
Alejandro Quintero*, Samuel Pierre
Mobile Computing and Networking Research Laboratory (LARIM), Department of Computer Engineering, Ecole Polytechnique de Montreal,
C.P. 6079, succ. Centre-Ville, Montreal, Que., Canada H3C 3A7
Received 14 February 2002; revised 17 September 2002; accepted 10 October 2002
Abstract
This paper proposes an evolutionary approach to solve the problem of assigning cells to switches in the planning phase of mobile cellular
networks. Well-known in the literature as an NP-hard combinatorial optimization problem, this problem requires the recourse to heuristic
methods, which can practically lead to good feasible solutions, not necessarily optimal, the objective being rather to reduce the convergence
time toward these solutions. Computational results obtained from extensive tests confirm the effectiveness of this approach to provide good
solutions to problems of a certain size. This approach can be used to solve NP-hard problems, like designing and planning, in the next
generation networking systems.
q 2002 Elsevier Science B.V. All rights reserved.
Keywords: Cellular networks; Cell assignment; Memetic algorithms; Genetic algorithms; Tabu search; Simulated annealing; Migration; Multi-population
algorithm
1. Introduction
A Personal Communication Network (PCN) is a wireless
communication network, which integrates various services
such as voice, video, electronic mail, accessible from a
single mobile terminal and for which the subscriber obtains
a single invoicing. These various services are offered in an
area called cover zone, which is divided, into cells. The cell
is the basic unit of a cellular system (Fig. 1). In each cell is
installed a base station which manages all the communi-
cations within the cell. In the cover zone, cells are connected
to special units called switches, which are located in mobile
switching centers (MSC). When a user in communication
goes from a cell to another, the base station of the new cell
has the responsibility to relay this communication by
allotting a new radio channel to the user. Supporting the
transfer of the communication from a base station to another
is called handoff. This mechanism, which primarily involves
the switches, occurs when the level of signal received by the
user reaches a certain threshold. We distinguish two types of
handoffs. In the case of Fig. 1 for example, when a user
moves from cell B to cell A, it refers to soft handoff because
these two cells are connected to the same switch.The MSC,
which supervises the two cells, remains the same and the
induced cost is weak. On the other hand, when the user
moves from cell B to cell C, there is a complex handoff. The
induced cost is high because both switches 1 and 2 remain
active during the procedure of handoff and the database
containing information on subscribers must be updated.
The total operating cost of a cellular network includes
two components: the cost of the links between the cells
(base station) and the switches to which they are joined, and
the cost generated by the handoffs between cells. It appears
therefore intuitively more discriminating to join cells B and
C to the same switch if the frequency of the handoffs
between them is high. The problem of assigning cells to
switches essentially consists of finding the configuration that
minimizes the total operating cost of the network. Assigning
cells to switches in cellular mobile networks being an NP-
hard problem, enumerative search methods are practically
inappropriate to solve large-sized instances of this problem
[2,18]. Because they exhaustively examine the entire search
space in order to find the optimal solution, they are only
efficient for small search spaces corresponding to small-
sized instances of the problem. For example, for a network
0140-3664/03/$ - see front matter q 2002 Elsevier Science B.V. All rights reserved.
PII: S0 14 0 -3 66 4 (0 2) 00 2 38 -4
Computer Communications 26 (2003) 927–938
www.elsevier.com/locate/comcom
* Corresponding author. Address: Department of Computer Engineering,
Ecole Polytechnique de Montreal, HPO Box 6079, Station, Centre-Ville
Montreal, Canada H3T1J4. Tel.: þ514-340-4711x5077; fax: þ514-340-
3240.
E-mail address: [email protected] (A. Quintero).

with m switches and n cells, m n solutions should be
examined. With 200 cells and 5 switches, that means 5200
possible solutions to examine. Obviously, it is unrealistic to
adopt such a brute-force approach. Thus, heuristic
approaches, like Tabu search, simulated annealing and
genetic algorithms have been developed for this kind of
problem [1,18,32].
Memetic algorithms (MA) are population-based heuristic
search approaches for combinatorial optimization problems
based on cultural evolution [27,28]. MAs are inspired by
Dawkins’ notion of a meme defined as a unit of information
that reproduces itself while people exchange ideas. In
contrast to genes, the people who transmit them before they
are passed on to the next generation typically adapt memes.
While genetic algorithms have been inspired in trying to
emulate biological evolution. Memetic algorithms would try
to mimic cultural evolution. Memetic algorithm is a
marriage between a population based global search and
the heuristic local search made by each of the individuals
[27]. They are in some respects similar to genetic algorithms
(GA), which simulate the process of biological evolution.
While in nature genes are usually not modified during an
individual’s lifetime, memes are modified [23].
The general idea behind memetic algorithms is to
combine the advantages of evolutionary operators that
determine interesting regions of the search space with local
neighborhood search that quickly finds good solutions in a
small region of the search space. Memetic algorithms have
been applied with success to several other combinatorial
optimization problems [23–25].
The paper is organized as follows. Section 2 presents
background and related work. Section 3 first describes the
evolutionary approach, and then presents some adaptation
and implementations details. Section 4 presents and analyses
results. Finally, Section 5 summarizes the main results.
2. Background and related work
This assignment problem consists of determining a cell
assignment pattern, which minimizes a certain cost
function, while respecting certain constraints, especially
those related to limited switch’s capacity. An assignment
of cells can be carried out according to a single or a
double cell’s homing. A single homing of cells corre-
sponds to the situation where a cell can only be assigned
to a single switch. When a cell is related to two switches
that refers to a double homing. For a double homing, the
call and handoff patterns do not remain the same during
the day. We have, for example, two patterns for the
daytime: one for the morning and another for the
afternoon. The two problems, related to each part of
the day, are not separated and cannot be solved
independently. Optimization should not be performed
separately for each pattern but simultaneously for both
patterns, in a way that minimizes the total cost,
particularly the link cost. In this paper, only single
homing is considered.
Let n be the number of cells to be assigned to m switches.
The location of cells and switches is fixed and known. Let
Hij be the cost per unit of time for a simple handoff between
cells i and j involving only one switch, and H0ij the cost per
time unit for a complex handoff between cells i and j
(I; j ¼ 1; …,n with i – j) involving two different switches.
Hij and H0ij are proportional to the handoff frequency
between cells i and j. Let cik be the amortization cost of the
link between cell i and switch kði ¼ 1;…; n; k ¼ 1;…;mÞ:
Let consider
xik ¼1 if cell i is related to switch k
0 if not
(
The assignment of cells to switches is subject to a
number of constraints. Actually, each cell must be
assigned to only one switch, which can be expressed
by the following formula:
Xmk¼1
xik ¼ 1 for i ¼ 1;…; n: ð1Þ
Let zijk and yij be defined as:
zijk ¼ xikxjk for i; j ¼ 1;…; n and k ¼ 1;…; m; with i – j:
yij ¼Xmk¼1
zijk for i; j ¼ 1;…; n; and i – j:
zijk is equal to 1 if cells i and j, with i – j; are both
connected to the same switch k, otherwise zijk is equal to
0. Thus yij takes the value 1 if cells i and j are both
connected to the same switches and the value 0 if cells i
and j are connected to different switches.
The cost per time unit f of the assignment is expressed as
follows:
f ¼Xn
i¼1
Xmk¼1
cikxikþXn
i¼1
Xn
j¼1;j–i
H 0ijð12yijÞþ
Xn
i¼1
Xn
j¼1;j–1
Hijyij ð2Þ
The first term of the equation represents the link or
cabling cost. The second term takes into account
Fig. 1. Geographic division in a cellular network.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938928

the complex handoffs cost and the third, the cost of
simple handoffs. We should keep in mind that the cost
function is quadratic in xik, because yij is a quadratic
function of xik. Let us mention that an eventual
weighting could be taken into account directly in the
link and handoff costs definitions.
The capacity of a switch k is denoted Mk.If li denotes the
number of calls per unit of time destined to i, the limited
capacity of switches imposes the following constraint:Xn
i¼1
lixik # Mk for k ¼ 1;…;m ð3Þ
accordingtowhich the total loadofall cellswhichareassigned
to the switch k is less than the capacity Mk of the switch.
Finally, the constraints of the problem are completed by:
xik ¼ 0 or 1 for i ¼ 1;…; n and k ¼ 1;…;m: ð4Þ
zijk ¼ xijxik and i; j ¼ 1;…; n and k ¼ 1;…;m: ð5Þ
yij ¼Xmk¼1
zijk for i; j ¼ 1;…; n ð6Þ
Eqs. (1), (3) and (4) are constraints of transport problems. In
fact, each cell i could be assimilated to a factory which
produces a call volumeli. The switches are then considered as
warehouses of capacity Mk where the cells production could
be stored. Therefore, the problem is to minimize Eq. (2) under
Eq. (1), and Eqs. (3)–(6). When the problem is formulated in
this way, it could not be solved with a standard method such as
linear programming because constraint (5) is not linear.
Merchant and Sengupta [21,22] replaced it by the following
equivalent set of constraints:
zijk # xik ð7Þ
zijk # xjk ð8Þ
zijk $ xik þ xjk 2 1 ð9Þ
zijk $ 0 ð10Þ
Thus, the problem could be reformulated as follows:
minimizing Eq. (2) under constraints (1), (3) and (4) , and
Eqs. (6)–(10). We can further simplify the problem by
defining:
hij ¼ H 0ij 2 Hij:
hij refers to the reduced cost per time unit of a complex handoff
between cells i and j. Relation Eq. (2) is then re-written as
follows:
f ¼Xn
i¼1
Xmk¼1
cikxik þXn
i¼1
Xn
j¼1; j–1
hijð1 2 yijÞ þXn
i¼1
Xn
j¼1;j–1
Hij|fflfflfflffl{zfflfflfflffl}constant
The assignment problem takes then the following form:Minimize:
f ¼Xn
i¼1
Xmk¼1
cikxik þXn
i¼1
Xn
j¼1; j–1
hijð1 2 yijÞ ð11Þ
subject to: Eqs. (1), (3), (4) and (7)–(10). In this form, the
assignment problem could be solved by usual programming
methods.
The total cost includes two types of cost, namely cost of
handoff between two adjacent cells, and cost of cabling
between cells and switches. The design is to be optimized
subject to the constraint that the call volume of each switch
must not exceed its call handling capacity. This kind of
problem is NP-hard, so enumerative searches are practically
inappropriate for moderate- and large-sized cellular mobile
networks [18,21].
The geographical relationships between cells and
switches are considered in the value of the cost of cabling,
so that the base station of a cell is generally assigned to a
neighbouring switch and not to far switches [37]. In Ref.
[31], an engineering cost model has been proposed to
estimate the cost of providing personal communications
services in a new residential development. The cost model
estimated the costs of building and operating a new PCS
using existing infrastructure such the telephone, cable
television and cellular networks. In Ref. [11], economic
aspects of configuring cellular networks are presented.
Major components of costs and revenues and the major
stakeholders were identified and a model was developed to
determine the system configuration (e.g. cell size, number of
channels, etc.). For example, in a large cellular network, it is
impossible for a cell located in east America to be assigned
to a switch located in west America. In this case, the
variable cost is 1.
3. Evolutionary approach
Evolutionary thought, however, extends beyond the
study of life. Evolution is an optimization process that can
be simulated using a computer or other device and put to
good engineering purpose. The interest in such simu-
lations has increased dramatically in recent years as
applications of this technology have been developed to
supplant conventional technologies in power systems,
pattern recognition, control systems, factory scheduling,
pharmaceutical design, and diverse other areas [8,9].
Evolutionary algorithms have been applied successfully in
various domains of search, optimization, and artificial
intelligence [16,29,33,34,36]. In the field of combinatorial
optimization, it has been shown that combine evolutionary
algorithms with problem-specific heuristics can lead to
highly effective approaches. These hybrid evolutionary
algorithms combine the advantages of efficient heuristics
incorporating domain knowledge and population-based
search approaches.
3.1. Basic principles of classical genetic algorithms
The process used by genetic algorithms to solve
optimization problems is analogous to the natural
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938 929

process of evolution by natural selection [17,35]. Genetic
algorithms apply the natural evolutionary processes of
evaluation and selection to string representations of the
arguments of the function being optimized. Structures
(individuals in natural systems) are encoded into one or
more strings (chromosomes). The chromosome represents
individuals or solutions. At each generation, the individuals
reproduced and fit persist, yielding improved results. The
structure is analogous to the phenotype in natural systems
and corresponds to a candidate solution to the optimization
problem. The string encoding is analogous to the genotype
[10].
The initial search space of a GA usually consists of a
population of randomly generated solutions. A diversified
initial population is a prerequisite to good solutions. The
execution of a genetic algorithm can be viewed as a two-
stage process, which starts with a current population to
which selection operations are applied to create an
intermediate population. The selection scheme determines
which individuals are chosen for reproduction. For a
selection, two essential ingredients are required: (1)
inheritance: offspring must retain at least some of the
features that made their parents fitter than average; (2)
variability: at any given time, individuals of varying
fitness must coexist in the population. Then recombina-
tion (crossover) and mutation are applied to the
intermediate population to create a new population
[14]. In genetic algorithms, evolution from generation
to generation is simulated both by preserving the genetic
information contained in the chromosome and by altering
this information by means of random genetic changes.
Genetic operators affect both these goals. The goal
of preserving the genetic information of fit individuals is
achieved through crossover, one of the genetic
operators used to recombine the population’s genetic
material. Fig. 2 shows the flow chart of the genetic
process.
Crossover is the process by which two chosen string
genes arc interchanged. To execute the crossover, strings of
the mating pool are coupled at random. The crossover of a
string pair of length l is performed as follows: a position i is
chosen uniformly between 1 and (1 2 1 ), then two new
strings are created by exchanging all characters between
positions (i þ l) and l of each string of the pair considered.
The new strings can be totally different from their parents.
Mutation is the process by which a randomly chosen
bit in a chromosome is permuted. It is employed to
introduce new information into the population and also to
prevent the population from becoming saturated with
similar chromosomes (premature convergence). Large
mutation rates increase the probability that
good schemata be destroyed, but increase population
diversity.
Diversity is the term used to describe the relative
uniqueness of each individual in the population. However,
crossover and mutation generate new solutions, but with
certain limitations. Crossing nearly identical strings yields
offspring similar to the parent string. Consequently,
crossover cannot reintroduce diversity. Mutation, on the
other hand, can generate the full space, but may take
excessively long time to yield a desirable solution.
3.2. Basic principles of memetic algorithms
In problems characterized by many local optima,
traditional optimization techniques fail to find high-quality
solutions. In these cases, standard genetic algorithm
(SGA) can be considered as an efficient and interesting
option. However, SGA can suffer from excessively slow
convergence before finding an accurate solution because
of their characteristics of using a priori minimal knowl-
edge and failure to exploit local information [6,29,30,34].
This may prevent them from being really of practical
interest for a lot of large-scale constrained applications.
Genetic algorithms promise convergence but not optim-
ality. This implies that the choice of when to stop a
genetic algorithm is not well defined. Since there is no
guarantee of optimality, successive runs of the GA will
provide different chromosomes with varying fitness
measures. If we run an SGA several times, it will
converge each time, possibly at different optimal
chromosomes.
Memetic algorithms (MA) are population-based heuristic
search approaches for combinatorial optimization problems
based on cultural evolution [27,28]. They are inspired by
Dawkins’ notion of a meme defined as a unit of information
that reproduces itself while people exchange ideas. The
person usually modifies a meme before he or she passes it on
to the next generation. Memetic algorithm is a marriage
between a population-based global search and the heuristic
local search made by each of the individuals [27].
A brief description of memetic algorithm could be:
Given a representation of an optimization problem, a certain
number of individuals are created. The state of these
individuals can be randomly chosen or according to a
certain initialization procedure. A heuristic can be chosen to
initialize the population. After that, each individual makes
local search. The mechanism to do local search can be to
reach a local optima or to improve (regarding the objectiveFig. 2. Genetic process flow chart.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938930

cost function) up to a predetermined level. After that, when
the individual has reached a certain development, it interacts
with the other members of the population. The interaction
can be cooperative; it can be similar to the selection
processes of SGA. The cooperative behavior can be
understood as the mechanisms of crossover in SGA or
other types of breeding that result in the creation of a new
individual. More generally, we must understand cooperation
as an interchange of information. The local search and
cooperation (mating, interchange of information) or com-
petition (selection of better individuals) are repeated until a
stopping criterion is satisfied [27]. Fig. 3 shows the flow
chart of the memetic process.
In the context of evolutionary computation, a hybrid
evolutionary algorithm is called memetic if the individuals
representing solutions to a given problem are improved by a
local search or another improvement technique [26]. Kado
et al. [19] compare different implementations of hybrid
genetic algorithms.
In this paper, we propose memetic algorithms with local
refinement strategies to combine the strengths of both by
providing global and local exploitation aspects to the
problem of assigning cells to switches in cellular mobile
networks. The local refinement strategies used with
memetic algorithms are tabu search and simulated
annealing.
A tabu search method is an adaptive technique used in
combinatorial optimization to solve difficult problems [13,
18,21,22]. It is considered as a meta-heuristic method
because it can be applied to different instances of problems
to provide good solutions. The tabu search method is an
improvement to the general descent algorithm, because it
attempts to avoid the trap of local minima. For this purpose,
it is necessary to accept, from time to time, solutions, which
do not improve the objective function, with the hope to
reach better solutions later. However, accepting solutions
that are not necessary, the best introduces a cycle risk,
i.e. return to solutions that had already considered, hence the
idea of keeping a tabu list T of solutions that had already
considered. Thus, during the generation of the set V of
neighbour candidates, the candidates present in the tabu list
are removed.
The simulated annealing (SA) starts from an initial
solution, which they attempt to improve through a series of
greedy moves, while avoiding to be stranded in a local
minimum. The moves used to escape a local minimum
explore only a very limited set of options. They depend on
the initial solution and do not necessarily lead to a good final
solution.
SA can be applied to a large variety of technological
domains and in particular to telecommunications. It is a
heuristic optimization method, which consists of a local
search by perturbations. This process gives the possibility of
going away, from time to time, from a local minimum to
allow an extension of the field of research of the best
solution.
According to SA, the current topology considered for
a moment as the better one is constantly compared with
the other topologies, which are very ‘close’ to it, i.e. that
can be obtained by carrying out a small perturbation. If a
perturbation results in a topology better than the current
solution, then this topology is saved as current one.
However, it happens that, further to a disturbance, the
obtained nearby topology is kept as current solution,
even if it is not better than the current one, provided that
it respects a certain probability of acceptance. The fact of
accepting from time to time an empirical solution allows
to avoid being trapped too early into a local optimum.
On the other hand, the probability of acceptance should
be weak enough, so that the algorithm can approach as
good as possible the global optimum. Finally, the
algorithm ends when the stopping criterion is reached.
In this stage, the local search should have ended in a
local minimum or in a global optimum. It follows that
the ideal solution found is, either locally optimal,
considering the high number of local optima, or globally
optimal in the best of the cases.
It is customary, for simulated annealing practitioners, to
use the word temperature to denote the parameter u that
controls the probability of accepting a worsening pertur-
bation over time. At the beginning of the process, u is set to
a relatively high value. Then, it is reduced by a
multiplication by a factor a (0 , a , 1), called the cooling
rate or the annealing factor. This reduction of u takes place
every L iterations or trials.
3.3. Multi-population approach
Classical genetic and memetic algorithms are powerful
and perform well on a broad class of problems. However,
part of the biological and cultural analogies used to motivate
a genetic or memetic algorithm search are inherently
parallels.Fig. 3. Memetic process flow chart.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938 931

There exist different ways of exploiting parallelism in
genetic algorithms, and it could be classified into fine-
gained parallel genetic algorithms (also called diffusion or
neighbourhood model) and coarse-gained parallel genetic
algorithms (also called migration model). In the fine-grained
model, one individual resides at each processor. The
individuals have only local interactions and neighbourhood.
In coarse-grained models, the isolated subpopulations help
maintain genetic diversity. Individuals in a subpopulation or
deme (a separately evolving subset of the whole population)
are relatively isolated from individuals on another sub-
population. Therefore, the subpopulation of each island is
exploring a different part of the search space. Every
subpopulation evolves isolate for a few generations before
one or more individuals are exchanged between the sub-
populations. This exchange of individuals is called
migration [12]. Jens [21] indicates that parallel genetic
algorithms in isolated evolving subpopulations with
migrations may offer advantages over sequential
approaches.
The migration model divides the population into multiple
subpopulations, which evolve independently from each
other for a certain number of generations (isolation time).
After the isolation time, some individuals are distributed
between the subpopulations (migration).
By introducing migration, the island model is able to
exploit genetic and cultural differences in the various
subpopulations: this variation in fact represents a source of
genetic and memetic diversities. Each subpopulation is an
island, and there is some designated way in which genetic
and memetic material are moved from one island to another.
The migration algorithm partitions a population of
designs into a set of subpopulations, at specified
intervals, and shares information between these subpopu-
lations. The parameters associated with the migration
algorithm are introduced in Refs. [3–5]: the migration
interval and the migration rate. The migration interval is
the number of generations between each migration, and
the migration rate is the number of individuals selected
for migration.
4. Implementation details
We submitted our memetic algorithms with local
refinement strategies to a series of tests in order to determine
its efficiency and sensitivity to different parameters. Thus,
we will present a few results, which we compare to those
provided by other known heuristics.
4.1. Local search strategies
This section presents the implementations details of the
local refinement strategies used to improve the individuals
representing solutions provided by genetic algorithms: tabu
search and simulated annealing.
Tabu search program was executed by supposing that the
cells are arranged on an hexagonal grid of almost equal
length and width. The antennas are located at the center of
cells and distributed evenly on the grid. However, when two
or several antennas are too close to each other, the antenna
arrangement is rejected and a new arrangement is chosen.
The maximum cell size for the service area is related to the
desired availability level. Principle factors affecting cell
radius and availability include the rain region, the antenna
and its height, foliage loss, modulation, Tx power, Rx
sensitivity, and sectorization. These effects are generally
related to the service area, such as dense urban, suburban,
and low-density. The cost of cabling between a cell and a
switch is proportional to the distance separating both. We
took a proportionality coefficient equal to the unit. The call
rate gi of a cell i follows a gamma law of average and
variance equal to the unit. The call duration inside the cells
are distributed according to an exponential law of parameter
equal to 1. This is justified by the fact that we are
considering a simple model. For more realistic call duration
distributions and models, the reader is referred to Ref. [7]. If
a cell j has k neighbours, the [0,1] interval is divided into
k þ 1 sub-intervals by choosing k random numbers
distributed evenly between 0 and 1. At the end of the
service period in cell j, the call could be either transferred to
the ith neighbour (i ¼ 1;…; k) with a handoff probability rij
equal to the length of ith interval, or ended with a
probability equal to the length of the k þ 1th interval. To
find the call volumes and the rates of coherent handoff, the
cells are considered as M/M/1 queues forming a Jackson
network [20]. The incoming rates ai in cells are obtained by
solving the following system:
ai 2Xn
j¼1
ajrji ¼ gi avec i ¼ 1;…; n
If the incoming rate ai is greater than the service rate, the
distribution is rejected and chosen again. The handoff rate
hij is defined by:
hij ¼ li·rij
All the switches have the same capacity M calculated as
follows:
M ¼1
mð1 þ
K
100ÞXn
i¼1
li
where K is uniformly chosen between 10 and 50, which
insures a global excess of 10–50% of the switches’ capacity
compared to the cells’ volume of call.
In simulated annealing, the parameters are the tempera-
ture u, the annealing factor að0 , a , 1Þ; the current
solution S1; the solution after perturbations S2; and the
stopping criterion. The steps in simulated annealing are:
Create the initial solution S1 (at random, each cell being
allocated to a switch in an unpredictable way, we create a
solution free from capacity constraints on the switches, but
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938932
respecting the constraint of unique assignment of cells to
switches), u is set to a relatively high value (the best solution
cost); Select a new solution S2 that can be obtained by
carrying out a small perturbation over S1;If the solution S2 is
better than S1, then this topology is saved as current one.
However, it happens that, further to a disturbance, the
obtained nearby topology is kept as current solution, even if
it is not better than the current one, provided that it respects
a certain probability of acceptance (the fact of accepting a
loss of quality or fitness allows to avoid being trapped too
early into a local optimum); u is reduced by a multiplication
by an annealing factor aðukþ1 ¼ uk*aÞ; where a ¼ 0:95; If
the stopping criterion will not have been reached, go to step
to select a new solution S2.
4.2. Memetic algorithm implementation
It is desirable that the encoding makes the representation
as robust as possible. This means that even if a piece of the
representation is randomly changed, it will still represent a
viable individual. We have introduced a simple notation to
represent cells and switches, and for encoding chromosomes
and genes. We opted for a non-binary representation of the
chromosomes [15]. In this representation, the genes
(squares) represent the cells, and the integers they contain
represent the switch to which the cell of row i (gene of the
ith position) is assigned. Our chromosomes have therefore a
length equal to the number of cells in the network n, and the
maximal value that a gene can take is equal to the maximal
number of switches m. A chromosome represents the set of
cells in the cellular mobile network, and the length is the
number of cells. A particular value of the string is called a
gene and the possible values are called alleles, taken from
the alphabet V ¼ {1; 2;…;m}: For example, the position 3
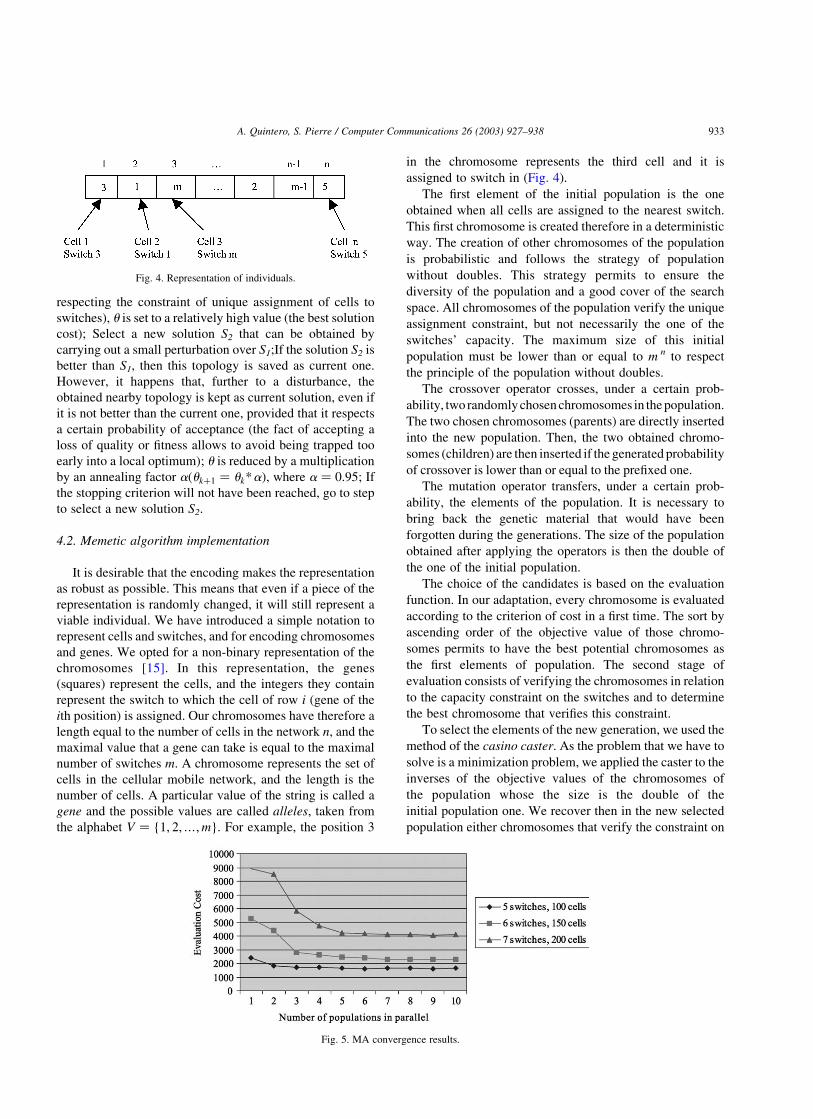
in the chromosome represents the third cell and it is
assigned to switch in (Fig. 4).
The first element of the initial population is the one
obtained when all cells are assigned to the nearest switch.
This first chromosome is created therefore in a deterministic
way. The creation of other chromosomes of the population
is probabilistic and follows the strategy of population
without doubles. This strategy permits to ensure the
diversity of the population and a good cover of the search
space. All chromosomes of the population verify the unique
assignment constraint, but not necessarily the one of the
switches’ capacity. The maximum size of this initial
population must be lower than or equal to m n to respect
the principle of the population without doubles.
The crossover operator crosses, under a certain prob-
ability, two randomly chosen chromosomes in the population.
The two chosen chromosomes (parents) are directly inserted
into the new population. Then, the two obtained chromo-
somes (children) are then inserted if the generated probability
of crossover is lower than or equal to the prefixed one.
The mutation operator transfers, under a certain prob-
ability, the elements of the population. It is necessary to
bring back the genetic material that would have been
forgotten during the generations. The size of the population
obtained after applying the operators is then the double of
the one of the initial population.
The choice of the candidates is based on the evaluation
function. In our adaptation, every chromosome is evaluated
according to the criterion of cost in a first time. The sort by
ascending order of the objective value of those chromo-
somes permits to have the best potential chromosomes as
the first elements of population. The second stage of
evaluation consists of verifying the chromosomes in relation
to the capacity constraint on the switches and to determine
the best chromosome that verifies this constraint.
To select the elements of the new generation, we used the
method of the casino caster. As the problem that we have to
solve is a minimization problem, we applied the caster to the
inverses of the objective values of the chromosomes of
the population whose the size is the double of the
initial population one. We recover then in the new selected
population either chromosomes that verify the constraint on
Fig. 4. Representation of individuals.
Fig. 5. MA convergence results.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938 933
the capacity of the switches or those that rape it. The number
of generations is fixed at the beginning of the execution. We
inserted into our adaptation the concept of cycle that permits
to run several successive genetic processes. At every cycle,
a new initial population is created.
Our multi-population memetic algorithm (MA) is con-
trolled by many parameters that affect their efficiency and
accuracy. Among other things, one must decide the number
and the size of the populations, the rate of the migration, and
the destination of the migrants.
For the migration algorithm used in this paper,
subpopulations are arranged in fully-meshed topology.
Here, individuals may migrate from any subpopulation to
another. For each subpopulation, a pool of potential
emigrants is constructed from the other subpopulations.
The migration interval is incorporated into the parallel
algorithm as a probability Pm; and the migration rate is
incorporated as a maximum value Sm: For each subpopu-
lation in the parallel algorithm, migration is achieved as
follows. At the end of a generation, a uniformly distributed
random number x is generated. If x , Pm then migration is
initialized. During migration, a uniform random number
determines the number of individual ns between 1 and Sm to
send. The selection of the individuals for migration is
a fitness-based process. The best ns individuals
in the subpopulation are sent to the other subpopulations.
Whether or not emigrants are sent to the other
subpopulations, each subpopulation then checks to see if
emigrants are arriving from its neighbour. If so, a uniform
random number pr determines the number of accepted
individuals, then the best pr individuals are received into the
subpopulation and replace the pr least fit individuals.
4.3. Some computational experiments
In the first step, we generate an initial population of size
200 chromosomes, then we choose at random the values,
which compose each chromosome: it is the first generation
of chromosomes. In the second step, we estimate each
chromosome by the objective function, what allows to
deduct its value of capacity. Finally, in the last step, the
cycle of generations of the populations begins then, each
new population replacing the previous one. The number of
400 generations is defined at first. In each generation, we
will apply the various genetic operators and the local search
to 200 chromosomes. After each generation, 200 newly
created chromosomes replace the previous generation. After
the ith generation, chromosomes will have evolved in such a
way that this last generation contains chromosomes better
than those in previous generations (i 2 1)th.
To determine the number of subpopulations in parallel,
MA was executed over a set of 600 test cases with 3 instances
of problem in series of 20 tests for each assignment pattern,
with a number of populations varying between 1 and 10. This
experience shows that MA converges to good solutions, close
the lower bound, with a number of populations varying
between 7 and 10, as shown in Fig. 5. An intuitive lower
bound for the problem is the link cost of the solution obtained
by assigning each cell ito the nearest switch k. This lower
bound does not take into account handoff cost. In fact, we
suppose that capacity constraint is being relaxed and that all
cells could be assigned to a single switch.
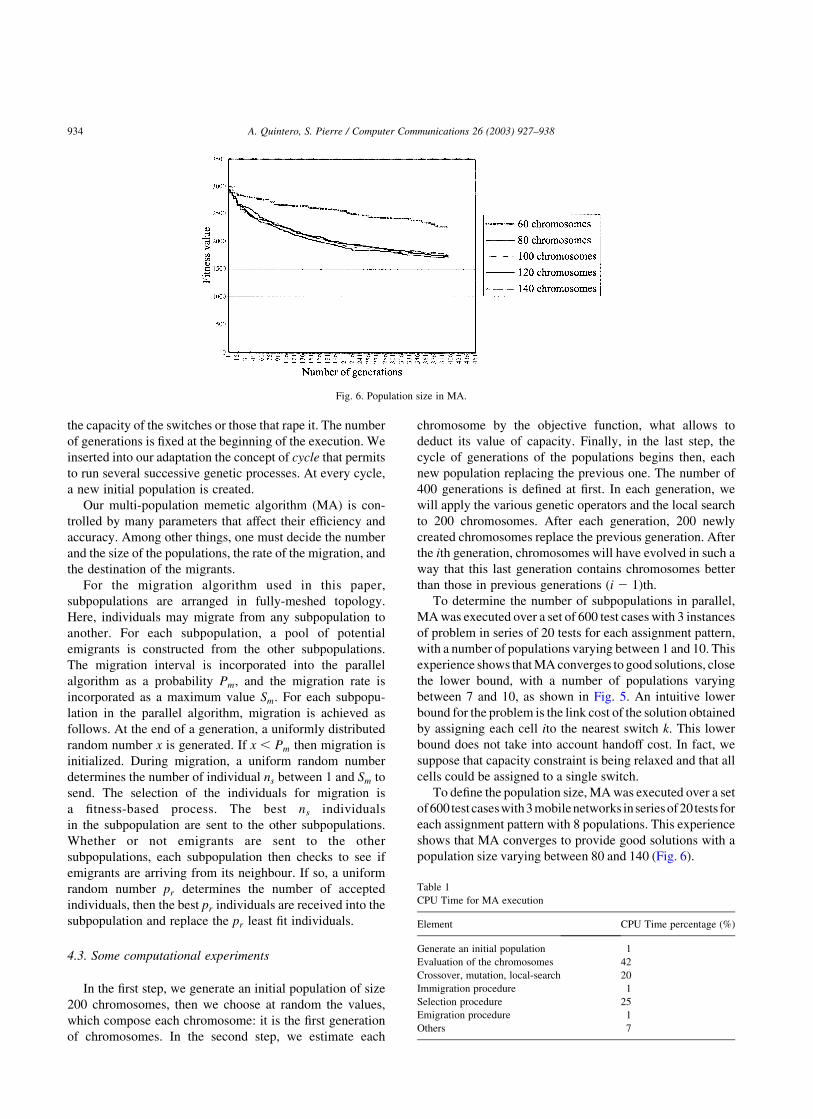
To define the population size, MA was executed over a set
of600 test caseswith3mobilenetworks inseriesof20 tests for
each assignment pattern with 8 populations. This experience
shows that MA converges to provide good solutions with a
population size varying between 80 and 140 (Fig. 6).
Fig. 6. Population size in MA.
Table 1
CPU Time for MA execution
Element CPU Time percentage (%)
Generate an initial population 1
Evaluation of the chromosomes 42
Crossover, mutation, local-search 20
Immigration procedure 1
Selection procedure 25
Emigration procedure 1
Others 7
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938934
The values used by MA and SGA are: the number of
generations is 200; the population size is 100; the number of
populations is 8 for MA and 1 for SGA; the crossover
probability is 0.9; the mutation probability is 0.08; the
migration interval (Pm) is0.1; themigration rate (Sm) is0.4and
the emigrants accepted (Pr) is 0.2. The number of exchanged
individuals (migration rate) determines the importance
of genetic and memetic diversities in the subpopulations.
Theexperiences showthat anumber ofexchanged individuals
between 40 and 80% of the subpopulation size provide good
solutions. In terms of evaluation fitness, a migration rate of
40% or 80% provides similar results.
Whereas the migration algorithm seeks to improve the
normalized cost and reliability of the SGA, it is important
also to ensure that unacceptable time overhead is not
introduced by migration (Table 1). In order to analyze the
performance of the memetic algorithm independent of
the migration algorithm, migration is turned off ðpm ¼ 0:0Þ:
Table 2
MA and SGA parameters
Number
of generations
Population
size
Number
of cycles
Number
of populations
Crossover
probability
Mutation
probability
SGA 100 100 40 1 0.9 0.08
MA1 (SMA-Simulated
annealing)
100 100 1 1 0.9 0.08
MA2 (SMA-tabu
search)
100 100 1 1 0.9 0.08
Fig. 7. Comparison between MA and SGA.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938 935
Turning off migration for analysis of the memetic algorithm
ensures that timing measurements indicate the effects of
parallel algorithm, rather than the effects of migration.
5. Performance evaluation and numerical results
In order to compare the performance of memetic
algorithm (MA) and genetic algorithm (SGA) with that of
the other heuristics, two types of experiments were
performed: a set of experiments to evaluate the quality of
the solutions in terms of their costs, and another set to
evaluate the performance of MA and SGA in terms of CPU
times. All the test runs described in this section were
performed in a networked workstation environment operat-
ing at 100 Mbps with 10 PCs (Pentium 500 MHz).
5.1. Comparison with standard genetic algorithm approach
In this section, we present the comparative results,
solution costs and CPU times, between memetic
algorithm (MA) and standard genetic algorithm (SGA).
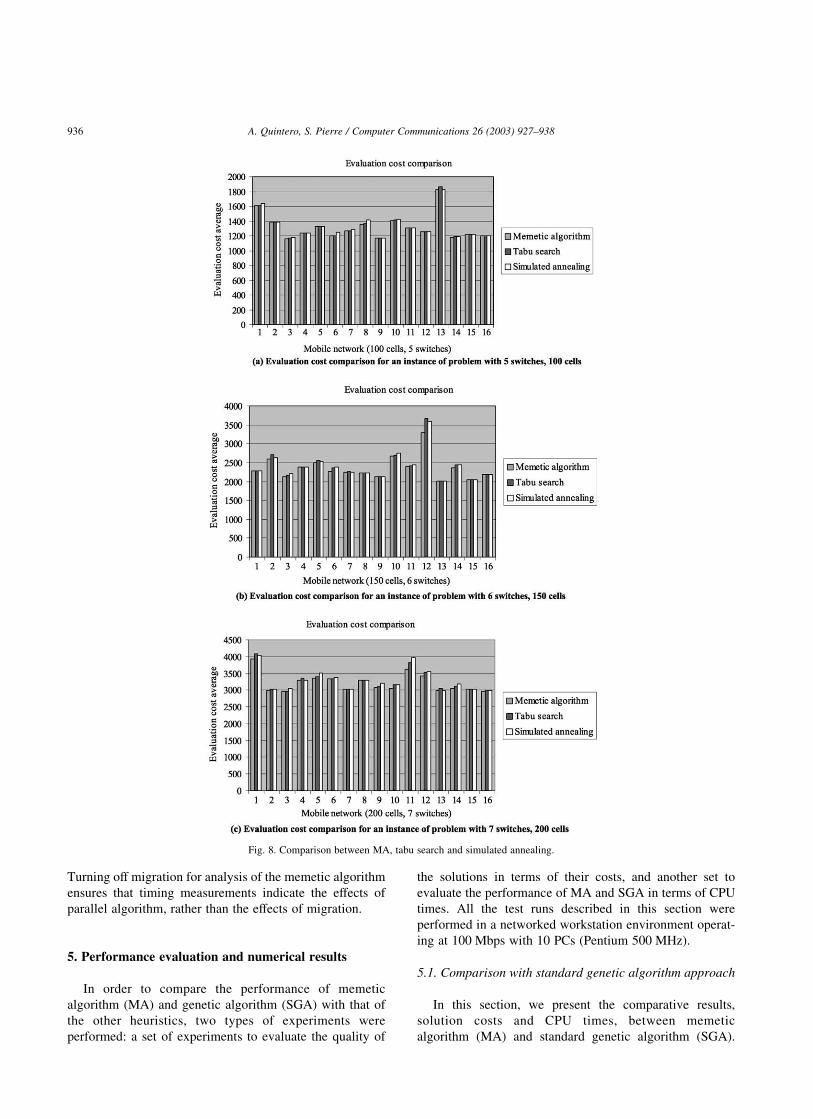
Fig. 8. Comparison between MA, tabu search and simulated annealing.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938936

For the experiments, MA and SGA are executed over a set
of 600 test cases with 3 topologies in series of 50 tests for
each assignment pattern. Table 2 shows the parameter
values used by MA and SGA.
We have tested two memetic algorithms (standard
genetic algorithm in combination with simulated annealing
and tabu search). For these experiments, SMA and MA are
executed over a set of 600 test cases with 3 instances of
problem in series of 50 tests for each assignment pattern.
MA were executed with 8 parallel populations. The results
of this experiment show that the simulated annealing and
tabu search improved the individuals representing solutions
provided by sequential genetic algorithm and multi-
population algorithm. In the case of simulated annealing,
the average improvement rate for sequential algorithm is
39.69% and the average improvement rate for multi-
population algorithm is 22.34%. In the case of tabu search,
the average improvement rate for sequential algorithm is
40.24% and the average improvement rate for multi-
population algorithm is 16.5%.
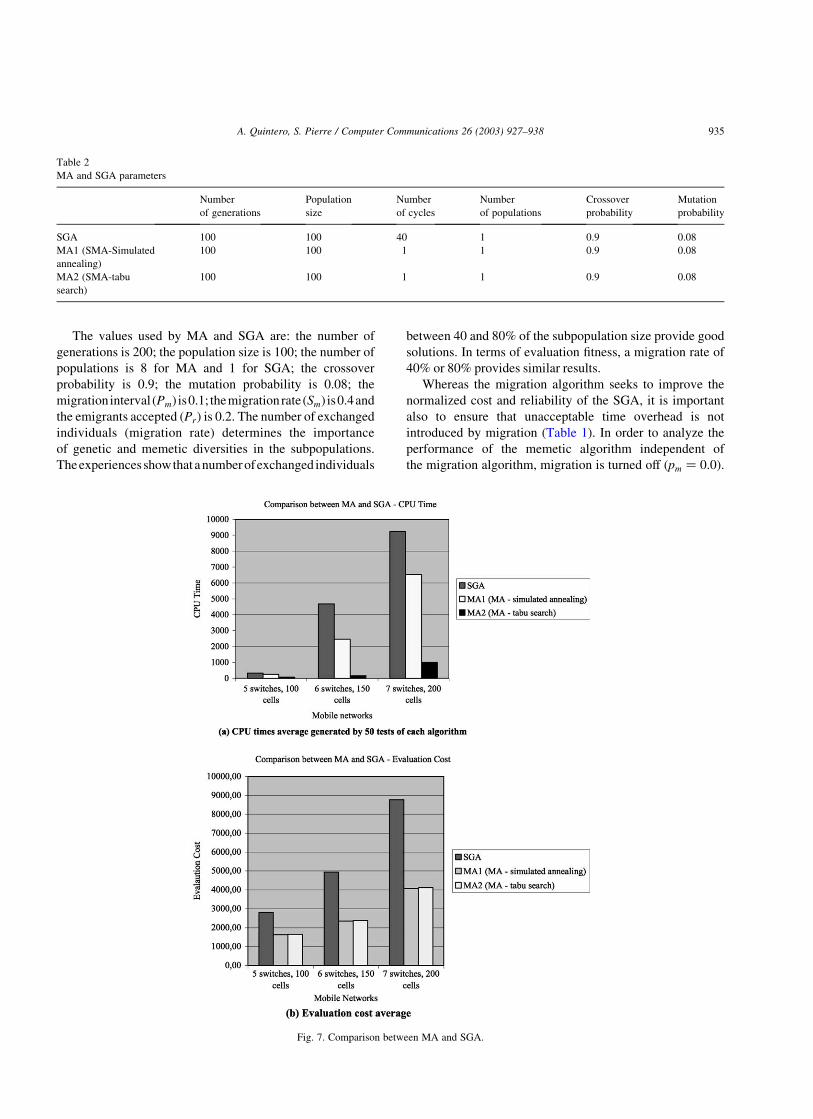
A comparison between MA and SGA is undertaken in
order to measure the evolution cost and the execution
time. In the first set of experiments, the results obtained
by SGA are compared directly with those provided by
MA. MA and SGA always find the feasible solutions. In
each of the three considered series of tests, MA yields an
improvement in terms of both CPU times and evaluation
cost, in comparison with SGA. In terms of CPU times,
MA2 is between 10 and 20 faster than MA1 and SGA to
find a feasible solution (Fig. 7a). In terms of costs, MA
provide always feasible solutions with a very similar
cost, with better results than sequential memetic
algorithm and standard genetic algorithm. Fig. 7b
shows the comparison between MA and SGA in which
each simulation represents the average over 50 tests of
each algorithm. In conclusion, experimental results from
solving different instances of assignment problem show
that MA approach provides better results than a standard
genetic algorithm.
5.2. Comparison with other heuristics
In this section, we compare tabu search method,
simulated annealing and memetic algorithm (MA) against.
For the experiments, memetic algorithm and the other
heuristics are executed over a set of 600 test cases with a
number of cells varying between 100 and 200, and a number
of switches varying between 5 and 7, that means the search
space size is between 5100 and 7200. We did not consider
problems with small search spaces, because in these cases it
is possible to use enumerative searches to solve them.
The three heuristics always find feasible solutions. In
each of the all considered series of tests, MA yields an
improvement in the cost function in comparison with the
other two heuristics. In terms of costs, MA provides better
results than tabu search and simulated annealing and
the average improvement rates are 1.6 and 4.5% (Fig. 8).
However, in terms of CPU MA is slower than simulated
annealing and tabu search.
6. Conclusions
In this paper, we proposed an evolutionary approach
(memetic algorithms) to solve the problem of assigning cells
to switches in cellular mobile networks. Experiments have
been conducted to measure the quality of solutions provided
by these algorithms. Experimental results from solving
different instances of assignment problem show that our
approach provides better results than a standard genetic
algorithm (SGA). In each of the series of tests considered,
memetic algorithms (MA) yield an improvement in CPU
times and in costs in comparison with SGA.
Finally, the results obtained have been compared with
the results provided by tabu search and simulated
annealing. MA, tabu search and simulated annealing
provide feasible solutions with a very similar cost. In
general, they results obtained with MA are better than
those generated by tabu search and simulated annealing.
The MA were tested with data supplied by a local
network operator and the obtained results were
also satisfying. However the best guarantee of the
efficiency of the algorithm is the large range of data
used in our tests. In summary, the numerical results have
shown that MA can adequately solve this NP-hard
problem and they provide good solutions for moderate-
and large-sized cellular networks (from 5 switches and
100 cells).
References
[1] P. Bhattacharjee, D. Saba, A. Mukherjee, Heuristics for assignment of
cells to switches in a pcsn: a comparative study, International
Conference on Personal Wireless Communications, Jaipur, India
(1999) 331–334.
[2] R. Beaubrun, S. Pierre, J. Conan, An efficient method for optimizing
the assignment of cells to MSCs in PCS networks, Proceedings 11th
International Conference on Wireless Comm., Wireless 99, Calgary
(AB) 1 (1999) 259–265.
[3] E. Cantu-Paz, On the effects of migration on the fitness distribution of
parallel evolutionary algorithms, Proceedings of Genetic and
Evolutionary Computational Conference Workshop Program, Las
Vegas, Nevada 8 (2000) 3.
[4] E. Cantu-Paz, D. Goldberg, in: J. Koza, K. Deb, M. Dorigo, D. Fogel,
M. Garzon, H. Iba, R. Riolo (Eds.), Genetic Programming,
Proceedings of the Second Annual Conference, San Francisco,
Morgan Kaufmann, Los Altos, CA, 1997, pp. 353–361.
[5] E. Cantu-Paz, D. Goldberg, Predicting speedups of idealized bounding
cases of parallel genetic algorithms, in: T. Back (Ed.), Proceedings of
the Seventh International Conference on Genetic Algorithms, San
Francisco, Morgan Kaufmann, Los Altos, CA, 1997, pp. 113–121.
[6] W. Ching-Hung, H. Tzung-Pei, T. Shian-Shyong, Integrating fuzzy
knowledge by genetic algorithms, IEEE Transactions on Evolutionary
Computation 2 (4) (1998) 138–149.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938 937

[7] Y. Fang, I. Chlamtac, Y. Lin, P.C.S. Modeling, Networks under
general call holding time and cell residence time distributions, IEEE/
ACM Transactions on Networking 5 (6) (1997) 893–905.
[8] D. Fogel, in: L. Davis, K. De Jong, M. Vose, L.D. Whitley (Eds.), An
Overview of Evolutionary Programming, Evolutionary Algorithms,
IMA Volumes in Mathematics and its Applications, Springer, Berlin,
1999, pp. 89–109.
[9] D. Fogel, in: K. Miettinen, M.M. Makela, P. Neittaanmaki, J. Periaux
(Eds.), An introduction to evolutionary computation and some
applications, Evolutionary Algorithms in Engineering and Computer
Science, Wiley, Chichester, UK, 1999, pp. 23–41.
[10] D. Fogel, Evolutionary Computation, IEEE Press, Piscataway, NJ,
1995, pp. 38–43.
[11] B. Gavish, S. Sridhar, Economic aspects of configuring cellular
networks, Wireless Networks 1 (1) (1995) 115–128.
[12] M. Georges-Schleuter, Explicit Parallelism of Genetic Algorithms
Through Populations Structures, Parallel Problem Solving from
Nature, Springer, Berlin, 1991, pp. 150–159.
[13] F. Glover, E. Taillard, D. de Werra, A user’s guide to tabu search,
Annals of Operations Research 41 (3) (1993) 3–28.
[14] D.E. Goldberg, Genetic Algorithms in Search, Optimization and
Machines Learning, Addison-Wesley, Reading, MA, 1989.
[15] R.L.P. Gondim, Genetic algorithms and the location area partitioning
problem in cellular networks, Proceedings of the Vehicular Technol-
ogy Conference 96, Atlanta, VA, April 29–30, May 1 (1996)
1835–1838.
[16] L. He, N. Mort, Hybrid genetic algorithms for telecommunications
network back-up routing, BT Technology Journal 18 (4) (2000)
42–50.
[17] J. Holland, Adaptation in Natural and Artificial Systems, The
University of Michigan Press, Ann Arbor, 1975.
[18] F. Houeto, S. Pierre, A tabu search approach for assigning cells to
switches in cellular mobile networks, Computer Communications 25
(2002) 464–477.
[19] K. Kado, P. Ross, D. Come, in: L.J. Eshelman (Ed.), A Study of
Genetic Algorithms Hybrids for Facility Layout Problems, Proceed-
ings Sixth International Conference on Genetic Algorithms, Morgan
Kaufmann, San Mateo, CA, 1995, pp. 498–505.
[20] L. Kleinrock, Queuing Systems I: Theory, Wiley, New York, 1975.
[21] A. Merchant, B. Sengupta, Assignment of cells to switches in PCS
networks, IEEE/ACM Transactions on Networking 3 (5) (1995)
521–526.
[22] A. Merchant, B. Sengupta, Multiway graph partitioning with
applications to PCS networks, IEEE Infocom’94 2 (1994) 593–600.
[23] P. Merz, B. Freisleben, Genetic local search for the tsp: new results,
Proceedings IEEE International Conference on Evolutionary Com-
putation, Piscataway, NJ (1997) 159–164.
[24] P. Merz, B. Freisleben, in: A.-E. Eiben, T. Back, M. Schoenauer,
H.P. Schwefel (Eds.), Memetic Algorithms and the Fitness
Landscape of the Graph Bi-Partitioning Problem, Proceedings
of the Fifth International Conference on Parallel Problem
Solving from Nature PPSN V, Springer, Berlin, 1998, pp.
765–774.
[25] P. Mer-z, B. Freisleben, A comparison of memetic algorithms, tabu
Search, and Ant Colonies for the quadratic assignment problem,
Proceedings of the 1999 International Congress of Evolutionary
Computation (CEC’99), IEEE Press, New York, 1999, pp. 2063–
2070.
[26] P. Merz, B. Freislcben, Fitness landscape analysis and memetic
algorithms for the quadratic assignment problem, IEEE Transactions
on Evolutionary Computation 4 (4) (2000) 337–352.
[27] P. Moscato, On Evolution, Search, Optimization, Genetic Algorithms
and Martial Arts: Towards Memetic Algorithms, Caltech Concurrent
Computation Program, Technical Report. 826, California Institute of
Technology, Pasadena, California, USA, 1989.
[28] P. Moscato, M.G. Norman, in: M. Valero, E. Onate, M. Jane, J.L.
Larriba, B. Suarez (Eds.), Memetic Approach for the Travelling
Salesman Problem Implementation of a Computational Ecology for
Combinatorial Optimization on Message-Passing Systems, Parallel
Computing and Transputer Applications, IOS Press, Amsterdam,
1992, pp. 177–186.
[29] F. Olivier, An evolutionary strategy for global minimization and its
Markov chain analysis, IEEE Transactions on Evolutionary Compu-
tation 2 (3) (1998) 77–90.
[30] R. Rankin, R. Wilkerson, G. Harris, J. Spring, A hybrid genetic
algorithm for an NP-complete problem with an expensive evaluation
function, Proceedings of the 1993 ACM/SIGAPP Symposium on
Applied Computing: States of the Art and Practice, Indianapolis, USA
(1993) 251–256.
[31] D.P. Reed, The cost structure of personal communication services,
IEEE Communications Magazine (1993) 102–108.
[32] D. Saha, A. Mukherjee, P. Bhattacharjee, A simple heuristic for
assignment of cell to switches in a PCS network, Wireless Personal
Communication 12 (2000) 209–224.
[33] R. Salomon, Evolutionary algorithms and gradient search: similarities
and differences, IEEE Transactions on Evolutionary Computation 2
(2) (1998) 45–55.
[34] V. Schenecke, O. Vornberger, Hybrid genetic algorithms for
constrained placement problems, IEEE Transactions on Evolutionary
Computation 1 (4) (1997) 266–277.
[35] T. Shigeyoshi, G. Ashish, Genetic algorithms with a robust solution
searching scheme, IEEE Transactions on Evolutionary Computation 1
(3) (1997) 201–208.
[36] P. Turney, Cost-sensitive classification: empirical evaluation of a
hybrid genetic decision tree induction algorithm, Journal of Artificial
Intelligence Research 2 (1995) 369–409.
[37] C. Wheatly, Trading coverage for capacity in cellular systems: a
system perspective, Microwave Journal (1995) 62–79.
A. Quintero, S. Pierre / Computer Communications 26 (2003) 927–938938
Copyright © 2022 FDOKUMEN




















