
Evidence for an ancient chromosomal duplication in Arabidopsis thaliana by sequencing and analyzing...
9
Evidence for an ancient chromosomal duplication in Arabidopsis thaliana by sequencing and analyzing a 400-kb contig at the APETALA2 locus on chromosome 4 Nancy Terryn a , Leo Heijnen b , Annick De Keyser a , Martien Van Asseldonck 1;b , Rebecca De Clercq a , Henk Verbakel b , Jan Gielen a , Marc Zabeau b , Raimundo Villarroel a , Taco Jesse b , Pia Neyt a , Rene L Hogers b , Hilde Van Den Daele a , Wilson Ardiles a , Christine Schueller c , Klaus Mayer c , Patrice De Lhais a , Stephane Rombauts a , Marc Van Montagu a , Pierre Rouze L a;d; *, Pieter Vos b a Laboratorium voor Genetica, Departement Genetica, Vlaams Interuniversitair Instituut voor Biotechnologie (VIB), Universiteit Gent, K.L. Ledeganckstraat 35, B-9000 Ghent, Belgium b Keygene N.V., Postbus 216, AgroBusiness Park 90, Keyenbergseweg 6, NL-6700 AE Wageningen, The Netherlands c Munich Information Center for Protein Sequence, Max-Planck-Institut fu ºr Biochemie, D-82152 Martinsried, Germany d Laboratoire Associe L de l’Institut National de la Recherche Agronomique (France), Universiteit Gent, B-9000 Ghent, Belgium Received 9 January 1999 Abstract As part of the European Scientists Sequencing Arabidopsis program, a contiguous region (396 607 bp) located on chromosome 4 around the APETALA2 gene was sequenced. Analysis of the sequence and comparison to public databases predicts 103 genes in this area, which represents a gene density of one gene per 3.85 kb. Almost half of the genes show no significant homology to known database entries. In addition, the first 45 kb of the contig, which covers 11 genes, is similar to a region on chromosome 2, as far as coding sequences are concerned. This observation indicates that ancient duplications of large pieces of DNA have occurred in Arabidopsis. z 1999 Federation of European Biochemical Societies. Key words : Arabidopsis thaliana ; APETALA2 ; Genome; Sequencing 1. Introduction In plant molecular biology and genetics, Arabidopsis thali- ana has long been recognized as a model organism [1]. By the end of 1993, a project designated European Scientists Se- quencing Arabidopsis (ESSA) was initiated with the aim of sequencing large fragments of the A. thaliana genome. Cur- rently, a whole international team is working on the comple- tion of that genome [2]. Within the ESSA program, most e¡ort was concentrated initially on chromosome 4 around the FCA locus [3] and the APETALA2 (AP2) locus. The ap2 mutant had been described, mapped, and cloned before [4^6]. On the most recent map of Dean and Lister [7], AP2 was found between the markers m214 and g2486 at 93.2 cM (the whole chromosome 4 being 116 cM). Results of the sequencing and analysis of this latter region, as the result of cooperation between two laboratories, will be discussed here. This region represents the second largest con- tig of Arabidopsis being analyzed in detail, preceded by the 2 Mb FCA contig [3]. 2. Materials and methods 2.1. Isolation and subcloning of an AP2-containing yeast arti¢cial chromosome (YAC) The CIC YAC clone 7A10, size 420 kb (from the CIC A. thaliana (L.) Heynh. ecotype Columbia library) was isolated by using AFLP (¢led by Keygene N.V.) markers [8,9] derived from sequences of the AP2 gene and subcloned in the cosmid vector pCLD04541 [10], using a partial Sau3AI digest. To isolate YAC-speci¢c cosmids, a total number of 16 000 Escherichia coli clones were hybridized to gel-puri- ¢ed YAC DNA. Approximately 450 YAC-speci¢c clones were iden- ti¢ed. AFLP ¢ngerprinting [9] was used to build a cosmid contig. This approach resulted in a cosmid contig of approximately 260 kb. 2.2. Isolation of bacterial arti¢cal chromosome (BAC) clones extending the cosmid contig The BAC clones were isolated through hybridization of the BAC library with a probe containing the inserts of all cosmids of the 260-kb contig, followed by contig building by AFLP. All AFLP markers present in the cosmid contig were also present in the BAC contig, indirectly proving colinearity of the cosmid contig with the genomic sequence. TAMU 8H13 and TAMU 10C14, which overlapped with the cosmid contig, were selected for further sequencing (Fig. 1). 2.3. Construction of cosmid and BAC subclones DNA from cosmids and BAC clones was sheared either by sonica- tion (Misonix Inc., Farmingdale, NY; type XL2020) or by nebulizing (Lifecare Hospital Supplies, Harborough, UK). A 1.8^2.2-kb end-re- paired fraction was isolated and ligated in pUC18/SmaI/BAP (Phar- macia, Uppsala, Sweden) or a modi¢ed pUC19 vector (BamHI/SalI fragment replaced by a StuI-, SpeI-, and SalI-containing fragment). Individual colonies of the transformation were grown in 96- or 384- well microtiter plates. 0014-5793/99/$19.00 ß 1999 Federation of European Biochemical Societies. All rights reserved. PII:S0014-5793(99)00097-6 *Corresponding author. Fax: (32) (9) 264 5349. E-mail: [email protected] 1 Present address: University Hospital Nijmegen, Department of Human Genetics, Geert Grootteplein 24, NL-6500 HB Nijmegen, The Netherlands. Abbreviations : AFLP, amplified fragment length polymorphism (is a trademark in the Benelux); BAC, bacterial artificial chromosome; EST, expressed sequence tag; YAC, yeast artificial chromosome The genomic sequence of the contig has been submitted to the GenBank under accession numbers Z99707 and Z99708 (with 8361-bp overlap). Cognate cDNAs have accession numbers AJ002596, AJ002597, and AJ002598. FEBS 21569 FEBS Letters 445 (1999) 237^245
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Evidence for an ancient chromosomal duplication in Arabidopsis thaliana by sequencing and analyzing...

Evidence for an ancient chromosomal duplication in Arabidopsis thalianaby sequencing and analyzing a 400-kb contig at the APETALA2 locus on
chromosome 4
Nancy Terryna, Leo Heijnenb, Annick De Keysera, Martien Van Asseldonck1;b,Rebecca De Clercqa, Henk Verbakelb, Jan Gielena, Marc Zabeaub, Raimundo Villarroela,
Taco Jesseb, Pia Neyta, Reneè Hogersb, Hilde Van Den Daelea, Wilson Ardilesa,Christine Schuellerc, Klaus Mayerc, Patrice Deèhaisa, Stephane Rombautsa,
Marc Van Montagua, Pierre Rouzeèa;d;*, Pieter Vosb
aLaboratorium voor Genetica, Departement Genetica, Vlaams Interuniversitair Instituut voor Biotechnologie (VIB), Universiteit Gent,K.L. Ledeganckstraat 35, B-9000 Ghent, Belgium
bKeygene N.V., Postbus 216, AgroBusiness Park 90, Keyenbergseweg 6, NL-6700 AE Wageningen, The NetherlandscMunich Information Center for Protein Sequence, Max-Planck-Institut fuër Biochemie, D-82152 Martinsried, Germany
dLaboratoire Associeè de l'Institut National de la Recherche Agronomique (France), Universiteit Gent, B-9000 Ghent, Belgium
Received 9 January 1999
Abstract As part of the European Scientists SequencingArabidopsis program, a contiguous region (396 607 bp) locatedon chromosome 4 around the APETALA2 gene was sequenced.Analysis of the sequence and comparison to public databasespredicts 103 genes in this area, which represents a gene density ofone gene per 3.85 kb. Almost half of the genes show nosignificant homology to known database entries. In addition, thefirst 45 kb of the contig, which covers 11 genes, is similar to aregion on chromosome 2, as far as coding sequences areconcerned. This observation indicates that ancient duplicationsof large pieces of DNA have occurred in Arabidopsis.z 1999 Federation of European Biochemical Societies.
Key words: Arabidopsis thaliana ; APETALA2 ; Genome;Sequencing
1. Introduction
In plant molecular biology and genetics, Arabidopsis thali-ana has long been recognized as a model organism [1]. By theend of 1993, a project designated European Scientists Se-quencing Arabidopsis (ESSA) was initiated with the aim ofsequencing large fragments of the A. thaliana genome. Cur-rently, a whole international team is working on the comple-tion of that genome [2].
Within the ESSA program, most e¡ort was concentratedinitially on chromosome 4 around the FCA locus [3] and theAPETALA2 (AP2) locus. The ap2 mutant had been described,mapped, and cloned before [4^6]. On the most recent map ofDean and Lister [7], AP2 was found between the markersm214 and g2486 at 93.2 cM (the whole chromosome 4 being116 cM).
Results of the sequencing and analysis of this latter region,as the result of cooperation between two laboratories, will bediscussed here. This region represents the second largest con-tig of Arabidopsis being analyzed in detail, preceded by the2 Mb FCA contig [3].
2. Materials and methods
2.1. Isolation and subcloning of an AP2-containing yeast arti¢cialchromosome (YAC)
The CIC YAC clone 7A10, size 420 kb (from the CIC A. thaliana(L.) Heynh. ecotype Columbia library) was isolated by using AFLP(¢led by Keygene N.V.) markers [8,9] derived from sequences of theAP2 gene and subcloned in the cosmid vector pCLD04541 [10], usinga partial Sau3AI digest. To isolate YAC-speci¢c cosmids, a totalnumber of 16 000 Escherichia coli clones were hybridized to gel-puri-¢ed YAC DNA. Approximately 450 YAC-speci¢c clones were iden-ti¢ed. AFLP ¢ngerprinting [9] was used to build a cosmid contig. Thisapproach resulted in a cosmid contig of approximately 260 kb.
2.2. Isolation of bacterial arti¢cal chromosome (BAC) clonesextending the cosmid contig
The BAC clones were isolated through hybridization of the BAClibrary with a probe containing the inserts of all cosmids of the 260-kbcontig, followed by contig building by AFLP. All AFLP markerspresent in the cosmid contig were also present in the BAC contig,indirectly proving colinearity of the cosmid contig with the genomicsequence. TAMU 8H13 and TAMU 10C14, which overlapped withthe cosmid contig, were selected for further sequencing (Fig. 1).
2.3. Construction of cosmid and BAC subclonesDNA from cosmids and BAC clones was sheared either by sonica-
tion (Misonix Inc., Farmingdale, NY; type XL2020) or by nebulizing(Lifecare Hospital Supplies, Harborough, UK). A 1.8^2.2-kb end-re-paired fraction was isolated and ligated in pUC18/SmaI/BAP (Phar-macia, Uppsala, Sweden) or a modi¢ed pUC19 vector (BamHI/SalIfragment replaced by a StuI-, SpeI-, and SalI-containing fragment).Individual colonies of the transformation were grown in 96- or 384-well microtiter plates.
FEBS 21569 2-3-99
0014-5793/99/$19.00 ß 1999 Federation of European Biochemical Societies. All rights reserved.PII: S 0 0 1 4 - 5 7 9 3 ( 9 9 ) 0 0 0 9 7 - 6
*Corresponding author. Fax: (32) (9) 264 5349.E-mail: [email protected]
1Present address : University Hospital Nijmegen, Department ofHuman Genetics, Geert Grootteplein 24, NL-6500 HB Nijmegen,The Netherlands.
Abbreviations: AFLP, amplified fragment length polymorphism (is atrademark in the Benelux); BAC, bacterial artificial chromosome;EST, expressed sequence tag; YAC, yeast artificial chromosome
The genomic sequence of the contig has been submitted to theGenBank under accession numbers Z99707 and Z99708 (with 8361-bpoverlap). Cognate cDNAs have accession numbers AJ002596,AJ002597, and AJ002598.
FEBS 21569 FEBS Letters 445 (1999) 237^245

2.4. Sequencing strategyThe sequence of the partially overlapping cosmids 3A6, 4B6, 4E12,
5C9, 2H2, 5E2, 2F3, 2H7, and BAC TAMU 10C14 was determined ina non-random approach by sequencing the cosmid or BAC ends, aswell as a few random subclones. Primers were designed to isolateprimer-speci¢c clones from pools of subclones. A random sequencingapproach was taken for cosmids 2C7, 3A6, 4F4, 3F11, 6B5, 5E3,4G12, 4E3, and BAC TAMU 13H8. The ABI PRISM dye terminatorcycle sequencing ready reaction kit was used mostly (Perkin-Elmer,Foster City, CA). The reaction products were analyzed on an ABIPrism 377. The sequence with the corresponding electropherogramswere assembled into contigs using a home-made computer programcalled Sequence Assembly Facility Environment (SAFE; [11]) or the1994 version of the Staden sequence analysis program [12]. The meanredundancy of the assembled sequence is 5.
2.5. Sequence comparisonsSequence analysis was done initially by the Martinsried Institute for
Protein Sequences (MIPS) center (Martinsried, Germany) and re¢nedby the bioinformatics team of the Laboratory of Genetics (Ghent,Belgium). To this end, the sequence was cut into pieces of 7000 bpwith 1000-bp overlaps. Each piece was submitted to a BLASTX/non-redundant protein and BLASTN/non-redundant DNA search as wellas a BLASTN/EST search (mostly on the Beauty BCM server). Fromthe resulting ¢les, the homologues with the highest score and a reliableannotation were looked for.
When a homologue was found with a high score (P(N)6E3100)and with homology over its whole length, its protein sequence wasfollowed to check whether the transcript did not show any frameshiftsor stop codons and whether the intron borders were correct. Whenany doubt arose, NetGene2 predictions were used [13,14].
For genes with weak homologies, di¡erent prediction programswere used according to the speci¢c problems: NetStart when the startcodon was not obvious, GeneMark [15] together with GenScan [16]for exon predictions, GeneMark for exon frame predictions, GenScanto check that small exons were not missed, and NetGene2 for intronborder prediction. When an expressed sequence tag (EST) was foundthrough BLASTN/EST (most of the time for the 5P or 3P parts of thegenes), the EST was used to complement the information obtained byBLASTX.
When no homologues were found through BLASTX, and no ESTswere available, we relied upon prediction programs, namely GenScanand GeneMark together to locate potential exons, NetGene2 for the
intron borders, and NetStart [17] for the position of the start codon.In all cases, the coding sequence (CDS) was reconstructed, translated,and submitted to BLASTP, for a last homology search and check forgaps.
Updated FASTA searches done at MIPS on the genes in this contigcan be found at http://speedy.mips.biochem.mpg.de/arbi/data/ap2_contig.html. Full annotations as well as various genomic featurescan also be found at the Ghent site (http://spider.rug.ac.be/public/seq/ap-2.html).
3. Results and discussion
3.1. General overview of the contigFig. 1 gives an overview of the clones used for the sequenc-
ing program. Initially cosmid clones were used, but during theproject BAC clones became available and these were used tocontinue the contig sequencing (see Section 2).
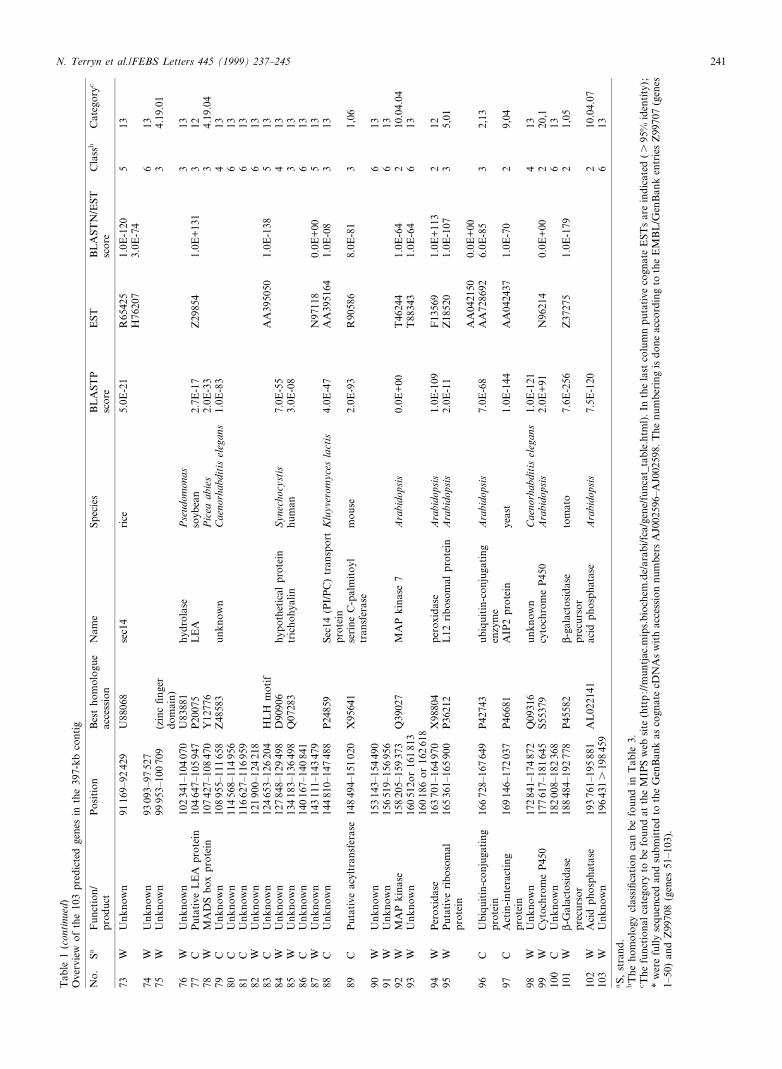
The 103 predicted genes that are present in this region aresummarized in Tables 1 and 2 and in Fig. 2. Table 1 providesinformation on their putative function, highest related entry inthe public databases as well as EST sequences that correspondto the putative genes whereas in Table 2 the genes are classi-¢ed based on their homology.
In conclusion, the putative role of approximately half of thegenes could be established by sequence similarity to knowngenes. These genes have been classi¢ed into 15 classes accord-ing to their putative cellular role that will be used to describegenes identi¢ed in the genome program [3]. This list ispreliminary and new categories and subcategories will beadded as more of the genome is sequenced (updated versionavailable at http://muntjac.mips.biochem.de/arabi/fca/gene/funcat_table.html).
3.2. Annotation and re-annotation processAfter the ¢rst MIPS automatic annotation, manual re-an-
notation showed discrepancies on about four genes out of
FEBS 21569 2-3-99
Fig. 1. Chromosomal location of the AP2 gene. Overview of the cosmids and BACs used for sequencing. The upper line represents the chromo-somal region (approximately 10 cM) with some known markers in the region. The sequenced cosmids and BAC clone are indicated as well asthe region covered by the two database submissions covering this region (Z99707 and Z99708). The sequence Z99707 (206 440 bp) contains 50genes (1^50) with an 8361-bp overlap with Z99708 (198 555 bp) that contains 53 genes (51^103).
N. Terryn et al./FEBS Letters 445 (1999) 237^245238

FEBS 21569 2-3-99
Tab
le1
Ove
rvie
wof
the
103
pred
icte
dge
nes
inth
e39
7-kb
cont
ig
No.
SaF
unct
ion/
prod
uct
Pos
itio
nB
est
hom
olog
ueac
cess
ion
Nam
eSp
ecie
sB
LA
STP
scor
eE
STB
LA
STN
/EST
scor
eC
lass
bC
ateg
oryc
1W
Cyt
ochr
ome
P45
06
1^56
0P
2446
5cy
toch
rom
eP
450
avoc
ado
1.6E
-25
H76
015
2.1E
-76
312
2W
Cyt
ochr
ome
P45
097
8^27
31P
2446
5cy
toch
rom
eP
450
avoc
ado
7.6E
-60
H76
015
3.6E
-65
212
3W
Cyt
ochr
ome
P45
031
15^5
137
P24
465
cyto
chro
me
P45
0av
ocad
o1.
5E-6
7A
A39
5149
1.3E
-149
212
4W
Cyt
ochr
ome
P45
059
94^7
943
P24
465
cyto
chro
me
P45
0av
ocad
o1.
6E-2
1T
4364
05.
9E-4
73
125
WC
ytoc
hrom
eP
450
8851
^11
532
P24
465
cyto
chro
me
P45
0av
ocad
o1.
0E-6
8F
1357
36.
4E-1
042
126
CU
nkno
wn
1218
6^12
879
N38
505
9.9E
-131
513
7W
Unk
now
n17
504^
1775
5A
C00
2391
unkn
own
Ara
bido
psis
413
8W
Unk
now
n18
322^
2093
6D
1542
1R
ICE
5.7E
-22
613
9W
Cat
ion-
tran
spor
ting
AT
P-a
se21
332^
2569
7P
3033
6C
u-tr
ansp
orti
ngA
TP
ase
mou
se3.
3E-1
4Z
3373
12.
0E-1
043
7,22
10C
Myb
-rel
ated
2612
0^27
082
Z54
136
Myb
-rel
ated
Ara
bido
psis
4.2E
-69
T43
211
5.5E
-35
24.
19.0
411
WK
inas
e-lik
ere
cept
or37
499^
3989
5P
3354
3re
cept
orki
nase
TM
K1
Ara
bido
psis
4.5E
-50
H76
836
1.4E
-135
310
,01
12C
Unk
now
n42
632^
4306
6H
7666
34.
6E-3
45
1313
CP
seud
o-ge
ne50
097^
5130
0S0
4132
phot
osys
tem
IIox
ygen
-evo
lvin
gco
mpl
ex
pea
D49
160
RIC
E8.
2E-2
23
2,2
14C
Col
dac
clim
atio
npr
otei
n51
715^
5257
8U
7321
6co
ldac
clim
atio
nT
riti
cum
aest
ivum
4.4E
-56
AA
6506
471.
3E-3
52
11,0
5
15C
Put
ativ
ehi
ston
ebi
ndin
g53
662^
5530
8A
2568
0nu
clea
rhi
ston
ebi
ndin
gA
fric
ancl
awed
frog
3.3E
-07
313
16W
Thi
ored
oxin
5645
4^57
848
P73
920
thio
disu
l¢de
inte
r-ch
ange
prot
ein
Syn
echo
cyst
is4.
4E-2
3A
A39
4562
1.9E
-150
32,
2
17C
Put
ativ
ece
lldi
visi
onre
gula
tor
5817
2^60
529
U80
043
mis
ato
gene
Dro
soph
ilam
elan
o-ga
ster
3.5E
-15
R64
911
5.4E
-110
33,
22
18C
Unk
now
n61
577^
6233
5or
6300
96
13
19W
Glu
-t-R
NA
6682
1^66
868
K00
193
Glu
-tR
NA
Dro
soph
ilam
elan
o-ga
ster
34,
19
20W
Unk
now
n67
029^
6910
4F
1544
22.
1E-3
06
1321
WP
ecti
nest
eras
e70
560^
7286
4Z
9405
8pe
ctin
este
rase
tom
ato
1.6E
-123
H76
007
1.3E
-106
21,
059,
0122
WH
ydro
xyni
trile
lyas
e73
627^
7469
9Z
3427
1pi
r7a
rice
3.3E
-39
AA
6514
822.
5E-2
62
11,0
223
WP
seud
o-ge
nehy
drox
ynit
rile
lyas
e74
956^
7556
9Z
3427
1pi
r7b
rice
2.5E
-27
R30
024
9.5E
-20
311
,02
24C
Unk
now
n75
724^
7811
7U
6383
9nu
cleo
pori
nra
t2.
3E-0
2A
A23
1701
6.9E
-18
613
25C
Unk
now
n78
561^
8076
1A
C00
1229
unkn
own
Cae
norh
abdi
tis
eleg
ans
0.0E
+00
AA
3949
562.
9E-1
174
1326
WU
nkno
wn
8148
7^83
341
AA
6513
306.
3E-0
16
1327
WU
nkno
wn
8582
1^88
511
Z69
793
unkn
own
Cae
norh
abdi
tis
eleg
ans
1.2E
-08
T21
702
7.3E
-19
413
28C
Unk
now
n89
125^
9034
66
1329
CU
nkno
wn
9347
6^90
968
613
30*
WP
atat
inho
mol
ogue
100
626^
102
768
P15
478
pata
tin
toba
cco
9.2E
-57
H35
955
2.3E
-128
26,
231
WP
atat
inho
mol
ogue
103
950^
106
111
AJ0
0259
6pa
tati
nto
bacc
o4.
7E-2
28H
3595
62.
6E-1
063
6,2
32W
Pat
atin
hom
olog
ue10
804
2^11
042
3A
J002
596
pata
tin
toba
cco
1.1E
-153
H35
957
7.5E
-29
36,
233
CM
ethi
onyl
-am
ino-
pept
idas
e-lik
e11
059
9^11
250
9A
L00
8883
met
hion
ylam
ino-
pept
idas
eye
ast
8.8E
-70
AA
3946
716.
1E-2
32
6,07
34C
Unk
now
n11
333
7^11
553
46
1335
CU
nkno
wn
120
506^
121
725
AA
3947
792.
0E-1
545
1336
CC
altr
acti
n-lik
e12
230
4^12
326
3P
4121
0ca
ltra
ctin
Atr
iple
xnu
mm
ular
ia2.
0E-5
8A
A39
5741
6.5E
-136
29,
043,
25
N. Terryn et al./FEBS Letters 445 (1999) 237^245 239

FEBS 21569 2-3-99
Tab
le1
(con
tinu
ed)
Ove
rvie
wof
the
103
pred
icte
dge
nes
inth
e39
7-kb
cont
ig
No.
SaF
unct
ion/
prod
uct
Pos
itio
nB
est
hom
olog
ueac
cess
ion
Nam
eSp
ecie
sB
LA
STP
scor
eE
STB
LA
STN
/EST
scor
eC
lass
bC
ateg
oryc
37C
Unk
now
n12
392
2^12
505
76
1338
CH
eat
shoc
kfa
ctor
125
978^
127
024
U68
017
HS
fact
orH
SF4
Ara
bido
psis
2.2E
-188
R90
161
0.0E
+00
111
,05
4.19
.04
39W
Unk
now
n13
067
2^13
399
86
1340
WU
nkno
wn
136
224^
137
857
613
41C
Rib
onuc
leop
rote
in13
824
3^14
033
3S4
0774
ribo
nucl
eopr
otei
nX
enop
us7.
8E-2
2T
4334
31.
6E-0
53
4,22
42W
Kin
ase
143
838^
147
989
AB
0007
98pr
otei
nki
nase
sim
ilar
toN
PK
1A
rabi
dops
is1.
3E-2
3Z
2666
08.
9E-3
23
10.0
4.04
43C
Put
ativ
eni
coti
nate
phos
phor
ibos
yl-
tran
sfer
ase
148
171^
150
743
Z99
120
nico
tina
teph
osph
o-ri
bosy
ltra
nsfe
rase
Bac
illus
subt
ilis
5.3E
-47
N65
739
3.2E
-93
313
44C
Unk
now
n15
129
9^15
351
4A
C00
2330
2.9E
-07
C21
906
3.1E
-08
613
45C
AP
216
454
1^16
668
3U
1254
6ap
etal
a2A
rabi
dops
is1.
6E-2
831
4.19
.04
46W
Unk
now
n17
446
3^17
666
5D
6399
9de
hydr
ogen
ase
Syn
echo
cyst
is1.
8E-1
263
1347
*C
TIN
Y-l
ike
178
076^
178
665
AJ0
0259
8T
INY
Ara
bido
psis
2.6E
-182
AA
4048
104.
0E-1
152
4.19
.04
48W
Unk
now
n18
586
8^18
805
0Z
4642
94.
7E-7
65
1349
WC
yste
ine
prot
eina
se19
150
1^19
298
9P
2525
1cy
stei
nepr
otei
nase
rape
7.8E
-198
R84
153
4.3E
-81
26,
1350
CP
utat
ive
hom
eoti
cpr
otei
n19
395
8^19
825
6A
5763
2B
EL
1A
rabi
dops
is6.
3E-8
02
4.19
.04
51W
Unk
now
n83
63^1
104
9A
C00
3000
6.7E
-89
N65
197
2.4E
-124
513
52W
Unk
now
n13
796^
1620
2S5
7377
prob
able
mem
bran
epr
otei
nye
ast
4.4E
-13
H77
118
1.8E
-104
513
AA
6055
073.
9E-1
2053
CU
nkno
wn
1673
6^17
917
H77
079
7.2E
-11
613
54C
Unk
now
n19
236^
2010
5T
4588
19.
3E-1
475
1355
CU
nkno
wn
2162
2^22
727
U41
558
unkn
own
Cae
norh
abdi
tis
eleg
ans
7.5E
-11
L46
423
1.3E
-48
413
56C
Ger
anyl
gera
nyl-
pyro
-ph
osph
atas
esy
ntha
se24
988^
2610
3P
3480
2ge
rany
lger
anyl
-pyr
o-ph
osph
atas
esy
ntha
seA
rabi
dops
is1.
0E-1
79L
3747
71.
0E-0
81
20,2
57W
Ubi
quit
in-c
onju
gati
ngpr
otei
n27
468^
2837
8P
5249
1ub
iqui
tin-
conj
ugat
ing
prot
ein
yeas
t4.
0E-3
4T
4155
00.
0E+
003
6,07
58C
Unk
now
n31
311^
3325
5A
J001
694
mem
bran
epr
otei
nT
herm
otog
am
arit
ima
3.1E
-08
413
59W
Unk
now
n35
403^
3662
5R
6479
21.
0E-1
625
1360
WG
luco
sylt
rans
fera
se38
024^
3939
8Q
4028
7U
TP
-glu
cose
gluc
osyl
-tr
ansf
eras
eca
ssav
a9.
6E-1
062
1,05
61C
Am
inop
epid
ase
3963
6^42
894
AF
0385
91X
-pro
amin
opep
tida
sera
t5.
9E-1
35N
9600
83.
0E-6
82
6,13
62C
Phy
coer
ythr
in-l
ike
prot
ein
4340
1^44
974
D45
900
Led
i-3
Lit
hosp
ernu
mer
ythr
orhi
zon
1.50
E-4
9R
6494
91.
0E-1
582
12
63W
Put
ativ
eho
meo
tic
prot
ein
5330
3^54
968
X94
947
hom
eoti
cpr
otei
nto
mat
o2.
0E-2
33
4.19
.04
64W
G-b
oxbi
ndin
gG
BF
157
865^
5976
7X
6389
4G
-box
bind
ing
GB
F1
Ara
bido
psis
1.0E
-162
H37
673
3.0E
-43
14.
19.0
49,
165
CP
seud
o-ge
ne59
949^
6184
8Q
0076
5T
B2
hum
an2.
0E-2
03
1366
CSc
arec
row
hom
olog
ue62
097^
6355
7U
6279
8sc
arec
row
Ara
bido
psis
1.0E
-23
N65
163
1.0E
-175
34.
19.0
467
WP
utat
ive
stor
age
prot
ein
6928
0^71
174
Z54
364
vici
linM
atte
ucci
ast
ruth
iopt
eris
4.0E
-38
Z48
554
4.0E
-70
36,
268
WSp
licin
gfa
ctor
7200
8^75
478
S202
50sp
licin
gfa
ctor
hum
an8.
0E-7
0N
9670
41.
0E-1
123
4,22
69*
WP
utat
ive
salt
indu
cibl
e75
900^
7713
8A
J002
597
puta
tive
salt
indu
cibl
eA
rabi
dops
is0.
0E+
00R
6549
21.
0E-1
683
11,0
570
WT
rans
port
prot
ein
8013
4^81
937
Q10
286
suga
rtr
ansp
orte
rbe
etro
ot1.
6E-4
53
7,07
71W
Unk
now
n82
336^
8326
7H
3638
23.
0E-1
26
1372
WP
utat
ive
tran
scri
ptio
nin
itia
tion
fact
or84
089^
8633
3P
2905
3tr
ansc
ript
ion
init
iati
onfa
ctor
IIB
Afr
ican
claw
edfr
og5.
0E-2
63
4,19
N. Terryn et al./FEBS Letters 445 (1999) 237^245240
FEBS 21569 2-3-99
Tab
le1
(con
tinu
ed)
Ove
rvie
wof
the
103
pred
icte
dge
nes
inth
e39
7-kb
cont
ig
No.
SaF
unct
ion/
prod
uct
Pos
itio
nB
est
hom
olog
ueac
cess
ion
Nam
eSp
ecie
sB
LA
STP
scor
eE
STB
LA
STN
/EST
scor
eC
lass
bC
ateg
oryc
73W
Unk
now
n91
169^
9242
9U
8806
8se
c14
rice
5.0E
-21
R65
425
1.0E
-120
513
H76
207
3.0E
-74
74W
Unk
now
n93
093^
9752
76
1375
WU
nkno
wn
9995
3^10
070
9(z
inc
¢nge
rdo
mai
n)3
4.19
.01
76W
Unk
now
n10
234
1^10
407
0U
8388
1hy
drol
ase
Pse
udom
onas
313
77C
Put
ativ
eL
EA
prot
ein
104
647^
105
947
P20
075
LE
Aso
ybea
n2.
7E-1
7Z
2985
41.
0E+
131
312
78W
MA
DS
box
prot
ein
107
427^
108
470
Y12
776
Pic
eaab
ies
2.0E
-33
34.
19.0
479
CU
nkno
wn
108
955^
111
658
Z48
583
unkn
own
Cae
norh
abdi
tis
eleg
ans
1.0E
-83
413
80C
Unk
now
n11
456
8^11
495
66
1381
CU
nkno
wn
116
627^
116
959
613
82W
Unk
now
n12
190
0^12
421
86
1383
CU
nkno
wn
124
653^
126
204
HL
Hm
otif
AA
3950
501.
0E-1
385
1384
WU
nkno
wn
127
848^
129
498
D90
906
hypo
thet
ical
prot
ein
Syn
echo
cyst
is7.
0E-5
54
1385
WU
nkno
wn
134
183^
136
498
Q07
283
tric
hohy
alin
hum
an3.
0E-0
83
1386
CU
nkno
wn
140
167^
140
841
613
87W
Unk
now
n14
311
1^14
347
9N
9711
80.
0E+
005
1388
CU
nkno
wn
144
810^
147
488
P24
859
Sec1
4(P
I/P
C)
tran
spor
tpr
otei
nK
luyv
erom
yces
lact
is4.
0E-4
7A
A39
5164
1.0E
-08
313
89C
Put
ativ
eac
yltr
ansf
eras
e14
849
4^15
102
0X
9564
1se
rine
C-p
alm
itoy
ltr
ansf
eras
em
ouse
2.0E
-93
R90
586
8.0E
-81
31,
06
90W
Unk
now
n15
314
3^15
449
06
1391
WU
nkno
wn
156
519^
156
956
613
92W
MA
Pki
nase
158
205^
159
373
Q39
027
MA
Pki
nase
7A
rabi
dops
is0.
0E+
00T
4624
41.
0E-6
42
10.0
4.04
93W
Unk
now
n16
051
2or
161
813
T88
343
1.0E
-64
613
160
186
or16
261
894
WP
erox
idas
e16
370
1^16
497
0X
9880
4pe
roxi
dase
Ara
bido
psis
1.0E
-109
F13
569
1.0E
+11
32
1295
WP
utat
ive
ribo
som
alpr
otei
n16
536
1^16
590
0P
3621
2L
12ri
boso
mal
prot
ein
Ara
bido
psis
2.0E
-11
Z18
520
1.0E
-107
35,
01
AA
0421
500.
0E+
0096
CU
biqu
itin
-con
juga
ting
prot
ein
166
728^
167
649
P42
743
ubiq
uiti
n-co
njug
atin
gen
zym
eA
rabi
dops
is7.
0E-6
8A
A72
8692
6.0E
-85
32,
13
97C
Act
in-i
nter
acti
ngpr
otei
n16
914
6^17
203
7P
4668
1A
IP2
prot
ein
yeas
t1.
0E-1
44A
A04
2437
1.0E
-70
29,
04
98W
Unk
now
n17
284
1^17
487
2Q
0931
6un
know
nC
aeno
rhab
diti
sel
egan
s1.
0E-1
214
1399
WC
ytoc
hrom
eP
450
177
617^
181
645
S553
79cy
toch
rom
eP
450
Ara
bido
psis
2.0E
+91
N96
214
0.0E
+00
220
,110
0C
Unk
now
n18
200
8^18
236
86
1310
1W
L-G
alac
tosi
dase
prec
urso
r18
848
4^19
277
8P
4558
2L
-gal
acto
sida
sepr
ecur
sor
tom
ato
7.6E
-256
Z37
275
1.0E
-179
21,
05
102
WA
cid
phos
phat
ase
193
761^
195
881
AL
0221
41ac
idph
osph
atas
eA
rabi
dops
is7.
5E-1
202
10.0
4.07
103
WU
nkno
wn
196
431s
198
459
613
aS,
stra
nd.
bT
heho
mol
ogy
clas
si¢c
atio
nca
nbe
foun
din
Tab
le3.
cT
hefu
ncti
onal
cate
gory
tobe
foun
dat
the
MIP
Sw
ebsi
te(h
ttp
://m
untj
ac.m
ips.
bioc
hem
.de/
arab
i/fca
/gen
e/fu
ncat
_tab
le.h
tml)
.In
the
last
colu
mn
puta
tive
cogn
ate
EST
sar
ein
dica
ted
(s95
%id
enti
ty);
*w
ere
fully
sequ
ence
dan
dsu
bmit
ted
toth
eG
enB
ank
asco
gnat
ecD
NA
sw
ith
acce
ssio
nnu
mbe
rsA
J002
596^
AJ0
0259
8.T
henu
mbe
ring
isdo
neac
cord
ing
toth
eE
MB
L/G
enB
ank
entr
ies
Z99
707
(gen
es1^
50)
and
Z99
708
(gen
es51
^103
).
N. Terryn et al./FEBS Letters 445 (1999) 237^245 241

¢ve. In addition, the re-annotation pointed to a few frame-shifts caused by sequence errors that have been corrected thisway. Similar issues have been raised for annotation of bacte-rial genomes [18], but to a lesser extent. As the task of anno-tation of a higher eukaryote genome is much more di¤cultbecause of the larger size of the genome, the lesser gene con-tent, the split gene structure, and less homologies to knowndatabase entries, such a result is not surprising. It is clearly awarning for caution when using the present-day annotations,and it indicates that complete re-annotation of the genomewill be needed.
3.3. Statistical analysis of the contigAs can be deduced from Table 1, 59 genes can be found on
the Watson and 44 on the Crick strand. Gene density is quitehigh (3.85 kb/gene) compared to that of the FCA region [3]
(4.8 kb/gene) and the mean density of 4.1 kb/gene reported for6.7 Mb sequenced on chromosome 5 [19]. Nevertheless, re-gions of 1.2 Mb on chromosome 5 have been reported witha similarly high gene density of 3.84 kb/gene [20]. In total,42% of the genes are highly similar to Arabidopsis EST se-quences (s 95% similarity).
Table 3 represents a statistical analysis done on bothstrands of the 400-kb contig in terms of occurrence and sizeof genes, introns, and exons. Intergenic regions cover approx-imately 53% of the contig, whereas introns represent 16% andcoding sequences 31%. As a mean, the ¢rst intron is longerthan the others and the ¢rst and last exons longer than themiddle ones. It is noteworthy that local as well as strandheterogeneities were observed. For example, genes in the ¢rsthalf of the sequence have smaller introns than those in thesecond half of the contig, whereas exons have a similar aver-
FEBS 21569 2-3-99
Fig. 2. Schematic overview of the exons of the 103 genes present in the 379-kb contig. Genes are marked by numbers; each number representsa new gene. Gene 13 is not indicated.
Table 2Classes of similarities to genes
Class BLAST E value Type of matching protein Number Predicted function
1 identical same protein 4 42 6 10350 known protein 23 233 between 10310 and 10350 known protein 33 284 6 10310 hypothetical protein 8 ^5 s 10310 none, but has cognate EST match 11 ^6 6 150 none, no cognate EST match 24 ^
Total 103 55
N. Terryn et al./FEBS Letters 445 (1999) 237^245242
age size (data not shown). In addition, both exons and intronson the Watson strand are larger than those on the Crickstrand.
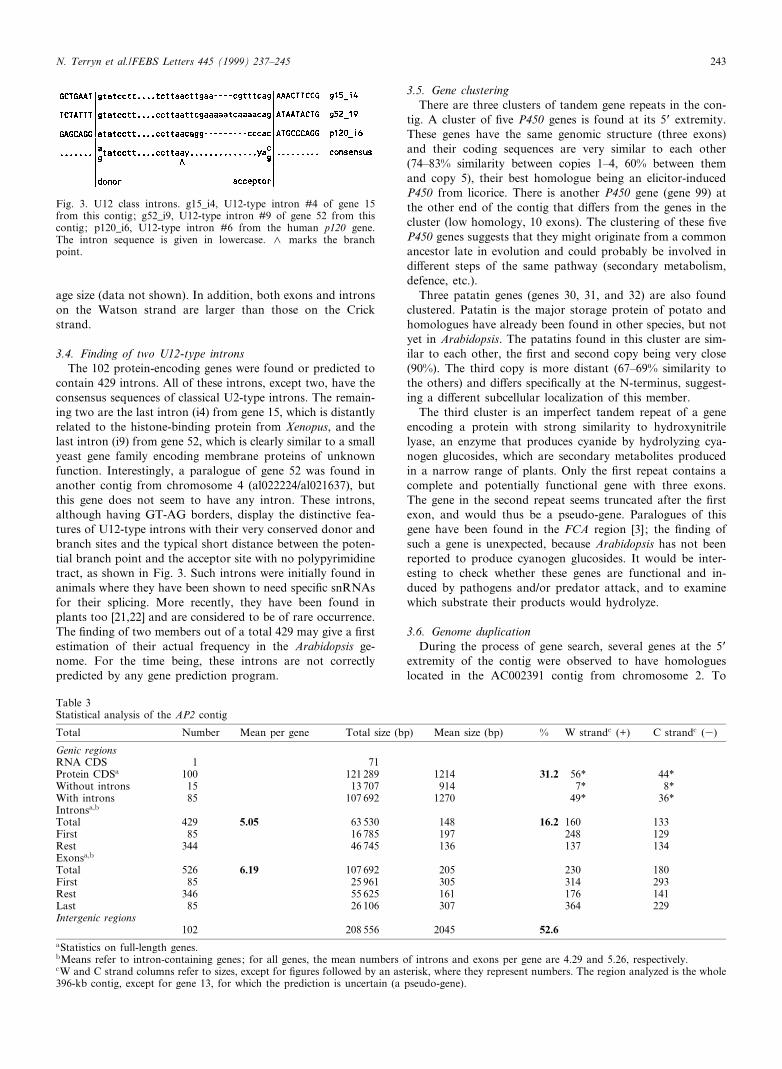
3.4. Finding of two U12-type intronsThe 102 protein-encoding genes were found or predicted to
contain 429 introns. All of these introns, except two, have theconsensus sequences of classical U2-type introns. The remain-ing two are the last intron (i4) from gene 15, which is distantlyrelated to the histone-binding protein from Xenopus, and thelast intron (i9) from gene 52, which is clearly similar to a smallyeast gene family encoding membrane proteins of unknownfunction. Interestingly, a paralogue of gene 52 was found inanother contig from chromosome 4 (al022224/al021637), butthis gene does not seem to have any intron. These introns,although having GT-AG borders, display the distinctive fea-tures of U12-type introns with their very conserved donor andbranch sites and the typical short distance between the poten-tial branch point and the acceptor site with no polypyrimidinetract, as shown in Fig. 3. Such introns were initially found inanimals where they have been shown to need speci¢c snRNAsfor their splicing. More recently, they have been found inplants too [21,22] and are considered to be of rare occurrence.The ¢nding of two members out of a total 429 may give a ¢rstestimation of their actual frequency in the Arabidopsis ge-nome. For the time being, these introns are not correctlypredicted by any gene prediction program.
3.5. Gene clusteringThere are three clusters of tandem gene repeats in the con-
tig. A cluster of ¢ve P450 genes is found at its 5P extremity.These genes have the same genomic structure (three exons)and their coding sequences are very similar to each other(74^83% similarity between copies 1^4, 60% between themand copy 5), their best homologue being an elicitor-inducedP450 from licorice. There is another P450 gene (gene 99) atthe other end of the contig that di¡ers from the genes in thecluster (low homology, 10 exons). The clustering of these ¢veP450 genes suggests that they might originate from a commonancestor late in evolution and could probably be involved indi¡erent steps of the same pathway (secondary metabolism,defence, etc.).
Three patatin genes (genes 30, 31, and 32) are also foundclustered. Patatin is the major storage protein of potato andhomologues have already been found in other species, but notyet in Arabidopsis. The patatins found in this cluster are sim-ilar to each other, the ¢rst and second copy being very close(90%). The third copy is more distant (67^69% similarity tothe others) and di¡ers speci¢cally at the N-terminus, suggest-ing a di¡erent subcellular localization of this member.
The third cluster is an imperfect tandem repeat of a geneencoding a protein with strong similarity to hydroxynitrilelyase, an enzyme that produces cyanide by hydrolyzing cya-nogen glucosides, which are secondary metabolites producedin a narrow range of plants. Only the ¢rst repeat contains acomplete and potentially functional gene with three exons.The gene in the second repeat seems truncated after the ¢rstexon, and would thus be a pseudo-gene. Paralogues of thisgene have been found in the FCA region [3] ; the ¢nding ofsuch a gene is unexpected, because Arabidopsis has not beenreported to produce cyanogen glucosides. It would be inter-esting to check whether these genes are functional and in-duced by pathogens and/or predator attack, and to examinewhich substrate their products would hydrolyze.
3.6. Genome duplicationDuring the process of gene search, several genes at the 5P
extremity of the contig were observed to have homologueslocated in the AC002391 contig from chromosome 2. To
FEBS 21569 2-3-99
Table 3Statistical analysis of the AP2 contig
Total Number Mean per gene Total size (bp) Mean size (bp) % W strandc (+) C strandc (3)
Genic regionsRNA CDS 1 71Protein CDSa 100 121 289 1214 31.2 56* 44*Without introns 15 13 707 914 7* 8*With introns 85 107 692 1270 49* 36*Intronsa;b
Total 429 5.05 63 530 148 16.2 160 133First 85 16 785 197 248 129Rest 344 46 745 136 137 134Exonsa;b
Total 526 6.19 107 692 205 230 180First 85 25 961 305 314 293Rest 346 55 625 161 176 141Last 85 26 106 307 364 229Intergenic regions
102 208 556 2045 52.6aStatistics on full-length genes.bMeans refer to intron-containing genes; for all genes, the mean numbers of introns and exons per gene are 4.29 and 5.26, respectively.cW and C strand columns refer to sizes, except for ¢gures followed by an asterisk, where they represent numbers. The region analyzed is the whole396-kb contig, except for gene 13, for which the prediction is uncertain (a pseudo-gene).
Fig. 3. U12 class introns. g15_i4, U12-type intron #4 of gene 15from this contig; g52_i9, U12-type intron #9 of gene 52 from thiscontig; p120_i6, U12-type intron #6 from the human p120 gene.The intron sequence is given in lowercase. L marks the branchpoint.
N. Terryn et al./FEBS Letters 445 (1999) 237^245 243

check the gene arrangement, a dot-plot comparison of bothcontigs was performed using the GCG compare/dot-plot andthe dotter [23] programs. As seen in Fig. 4, the ¢rst 45 kb(Watson strand) of the contig show similarities to a region ofcomparable size of the AC002391 contig (Crick strand,77 000^32 000). The extent of the duplication is perhaps larger,because no sequence is available yet on the 5P side of the AP2contig described here. The homology is patchy, being mostly
restricted to the coding sequence of the homologous genes.Among the 12 genes found in this region on the contig,nine have a counterpart in the chromosome 2 contig, theorder and the orientation of the genes being conserved. Thissituation strongly suggests an ancient duplication of this re-gion in the Arabidopsis genome. This duplication must indeedbe ancient, because most non-coding sequences (introns, inter-genic sequences) are not conserved and because the two copies
FEBS 21569 2-3-99
Fig. 4. Dot-plot comparison of a region on chromosome 2 (AC002391, bp 15 000^75 000) with the ¢rst 60 kb of the sequence described here(Z99707). Genes are numbered as in Table 1. Asterisks indicate non-homologous genes, the arrows inside the plot mark the regions of homolo-gous genes.
N. Terryn et al./FEBS Letters 445 (1999) 237^245244

di¡er by several insertions/deletions of various genes. Onesuch deletion is found in the chromosome 2 counterpart ofgene 9 for which homologies are found with several metal(Cu, Cd) transporters. On chromosome 4, gene 9 is predictedwith 13 exons, encoding a 819-amino acid protein. On chro-mosome 2, the corresponding gene is truncated on its 5P sideand is predicted to have three exons encoding a 221-aminoacid protein. The P450 cluster described above is the 5P-mostpart of the duplicated region. Whereas the chromosome 4copy contains ¢ve P450 members in tandem repeat, onlytwo P450 members are found in the chromosome 2 counter-part, separated by an insertion of two foreign genes and£anked by a P450 of di¡erent origin. The genetic distancesbetween the di¡erent P450 members suggests that the dupli-cation of the P450 genes on chromosome 2, and at least theduplications responsible for the four ¢rst copies on chromo-some 4, occurred after the duplication of the 45-kb regionitself. Although the Arabidopsis genome is of small size, du-plication of individual genes appears to be frequent. Duplica-tion on a larger scale has been suggested from mapping data[24], but, to our knowledge, this is the ¢rst demonstration of aduplication of a large region in Arabidopsis. The completionof the Arabidopsis genome sequence will tell us to which ex-tent these duplications occur. A comparative analysis of therepeats in various ecotypes and neighbor species will informus when this happened in the Arabidopsis evolutionary his-tory.
Acknowledgements: The authors wish to acknowledge the ABRCStock Center in Ohio for the distribution of ESTs, M. Bevan forcoordinating the ESSA program, H.W. Mewes, S. Klostermann,and N. Chalwatzis from MIPS for computer data analysis, PeterBreyne and Koen Goethals for critical reading of the manuscript,M. De Cock for help preparing it, and Rebecca Verbanck for the¢gures. This work was supported by the EU (Biotech ERBB102-CT93-0075 and ERBB104-CT96-0338) and by the Flemish govern-ment (VLAB-COT).
References
[1] Goodman, H.M., Ecker, J.R. and Dean, C. (1995) Proc. Natl.Acad. Sci. USA 92, 10831^10835.
[2] Arabidopsis Genome Initiative (1997) Plant Cell 9, 476^478.[3] Bevan, M., Bancroft, I., Bent, E., Love, K., Pi¡anelli, P., Good-
man, H., Dean, C., Bergkamp, R., Dirkse, W., Van Staveren, M.,Stiekema, W., Drost, L., Ridley, P., Hudson, S.-A., Patel, K.,Murphy, G., Wedler, H., Wedler, E., Wanbutt, R., Weitzenegger,T., Pohl, T., Terryn, N., Gielen, J., Villarroel, R., De Clercq, R.,Van Montagu, M., Lecharny, A., Kreis, M., Lao, N., Kavanagh,
T., Hempel, S., Kotter, P., Entian, K.-D., Rieger, M., Scholfer,M., Funk, N., Muller-Auer, S., Silvey, M., James, R., Montfort,A., Pons, A., Puigdomenech, P., Douka, A., Voukelatou, E.,Milioni, D., Hatzopoulos, P., Piravandi, E., Obermaier, B., Hil-bert, H., Duesterhoeft, A., Moores, T., Jones, J., Eneva, T.,Palme, K., Benes, V., Rechman, S., Ansorge, W., Cooke, R.,Berger, C., Delseny, M., Volckaert, G., Mewes, H.-W., Schueller,C. and Chalwatzis, N. (1998) Nature 391, 485^488.
[4] Koornneef, M., van Eden, J., Hanhart, C.J., Stam, P., Braaksma,F.J. and Feenstra, W.J. (1983) J. Hered. 74, 265^272.
[5] Bowman, J.L., Smyth, D.R. and Meyerowitz, E.M. (1989) PlantCell 1, 37^52.
[6] Jofuku, K.D., den Boer, B.G.W., Van Montagu, M. and Oka-muro, J.K. (1994) Plant Cell 6, 1211^1225.
[7] Dean, C. and Lister, C. (1996) in: Weeds World: The Interna-tional Electronic Arabidopsis Newsletter (Anderson, M., Ed.),Vol. 3 (iii), pp. 1^6, Nottingham Arabidopsis Stock Centre, Not-tingham.
[8] Zabeau, M. and Vos, P. (1993) European Patent Application EP534858A1.
[9] Vos, P., Hogers, R., Bleeker, M., Reijans, M., van de Lee, T.,Hornes, M., Frijters, A., Pot, J., Peleman, J., Kuiper, M. andZabeau, M. (1995) Nucleic Acids Res. 23, 4407^4414.
[10] Bancroft, I., Love, K., Bent, E., Sherson, S., Lister, C., Cobbett,C., Goodman, H.M. and Dean, C. (1997) in: Weeds World: TheInternational Electronic Arabidopsis Newsletter (Anderson, M.,ed.), Vol. 4 (ii), pp. 1^9, Nottingham Arabidopsis Stock Centre,Nottingham.
[11] Deèhais, P., Coppieters, J. and Van Montagu, M. (1996) Arch.Physiol. Biochem. 104, B38.
[12] Staden, R. (1996) Mol. Biotechnol. 5, 233^241.[13] Hebsgaard, S.M., Korning, P.G., Tolstrup, N., Engelbrecht, J.,
Rouzeè, P. and Brunak, S. (1996) Nucleic Acids Res. 24, 3439^3452.
[14] Tolstrup, N., Rouzeè, P. and Brunak, S. (1997) Nucleic Acids Res.25, 3159^3163.
[15] Borodovsky, M. and MacIninch, J.D. (1993) Comput. Chem. 17,123^133.
[16] Burge, C. and Karlin, S. (1997) J. Mol. Biol. 268, 78^94.[17] Pedersen, A.G. and Nielsen, H. (1997) in: Proceedings of the
Fifth International Conference on Intelligent Systems for Molec-ular Biology, (Gaasterland, T., Karp, P., Karplus, K., Ouzounis,C., Sander, C. and Valencia, A., Eds.), pp. 226^233, AmericanAssociation for Arti¢cial Intelligence Press, Menlo Park, CA.
[18] Galperin, M.Y. and Koonin, E.V. (1998) In Silico Biol. 1, 0007(http://www.bioinfo.de/isb/1998/01/0007/).
[19] Nakamura, Y., Sato, S., Kaneko, T., Kotani, H., Asamizu, E.,Miyajima, N. and Tabata, S. (1997) DNA Res. 4, 401^414.
[20] Kaneko, T., Kotani, H., Nakamura, Y., Sato, S., Asamizu, E.,Miyajima, N. and Tabata, S. (1998) DNA Res. 5, 131^145.
[21] Wu, H.-J., Gaubier-Comella, P., Delseny, M., Grellet, F., VanMontagu, M. and Rouzeè, P. (1996) Nature Genet. 14, 383^384.
[22] Sharp, P.A. and Burge, C.B. (1997) Cell 91, 875^879.[23] Sonnhammer, E.L.L. and Durbin, R. (1995) Gene 167, GC1^10.[24] Kowalski, S.P., Lan, T.-H., Feldmann, K.A. and Paterson, A.H.
(1994) Genetics 138, 499^510.
FEBS 21569 2-3-99
N. Terryn et al./FEBS Letters 445 (1999) 237^245 245




















