
Effects of Classifier Structures and Training Regimes on Integrated Segmentation and Recognition of...
13
Effects of Classifier Structures and Training Regimes on Integrated Segmentation and Recognition of Handwritten Numeral Strings Cheng-Lin Liu, Senior Member, IEEE, Hiroshi Sako, Senior Member, IEEE, and Hiromichi Fujisawa, Fellow, IEEE Abstract—In integrated segmentation and recognition of character strings, the underlying classifier is trained to be resistant to noncharacters. We evaluate the performance of state-of-the-art pattern classifiers of this kind. First, we build a baseline numeral string recognition system with simple but effective presegmentation. The classification scores of the candidate patterns generated by presegmentation are combined to evaluate the segmentation paths and the optimal path is found using the beam search strategy. Three neural classifiers, two discriminative density models, and two support vector classifiers are evaluated. Each classifier has some variations depending on the training strategy: maximum likelihood, discriminative learning both with and without noncharacter samples. The string recognition performances are evaluated on the numeral string images of the NIST Special Database 19 and the zipcode images of the CEDAR CDROM-1. The results show that noncharacter training is crucial for neural classifiers and support vector classifiers, whereas, for the discriminative density models, the regularization of parameters is important. The string recognition results compare favorably to the best ones reported in the literature though we totally ignored the geometric context. The best results were obtained using a support vector classifier, but the neural classifiers and discriminative density models show better trade-off between accuracy and computational overhead. Index Terms—Numeral string recognition, integrated segmentation and recognition, noncharacter resistance, character classification, neural classifiers, discriminative density models, support vector classifiers. æ 1 INTRODUCTION H ANDWRITTEN character string recognition requires seg- menting the string image into constituent characters and classifying the segmented characters to predefined (target) classes. Due to the variability of character spacing and the presence of breaking or touching characters, reliable segmentation prior to classification is impossible. This problem is solved by integrated segmentation and recogni- tion with a hypothesis-and-test strategy [1], [2], also called recognition-based segmentation [3], classification-based segmentation [4], or internal segmentation, as opposed to external segmentation. A presegmentation module is used to oversegment the string image into primitive segments and generate candidate character patterns or, even more simply, images in sliding windows are taken as candidate patterns [5], [6]. Classification scores are assigned to the candidate patterns using an underlying character classifier and are combined to evaluate the segmentation paths. The optimal path, with the maximum score or minimum cost, gives the final segmentation. Since the presegmentation generates both character and noncharacter patterns, the underlying classifier must be resistant to noncharacters: When a noncharacter pattern is classified, all the target classes should be assigned low scores. Some classifiers like parametric statistical classifiers are inherently resistant to noncharacters because compact density models are assumed for the target classes. The quadratic discriminant function [7] and the modified quadratic discriminant function [8], both based on the Gaussian density assumption, have been successfully applied to numeral string recognition [4], [9]. Most neural network classifiers, on the other hand, are susceptible to noncharacters because they are trained to separate the in- class samples (the samples of target classes) disregarding the distribution in feature space. The noncharacter resis- tance of neural classifiers can be enhanced by training with noncharacter samples [3], [10], [11]. In character string recognition, many researchers have focused on the postprocessing of classification results using geometric context (character size/position and interchar- acter relationships) to reject noncharacters or on combining the geometric features with the classification scores to evaluate the segmentation paths [12], [13], [14], [15]. The geometric context remedies the insufficient noncharacter resistance of general classifiers and can further improve the recognition performance of classifiers that are already resistant to noncharacters. We evaluate state-of-the-art classifiers on handwritten numeral strings, where little linguistic context is available. To compare the classifiers in a common framework, we build a baseline numeral string recognition system using simple but effective presegmentation. Each classifier gives a string recognition result by combining the classification scores of candidate patterns into path scores and finding the optimal path. Since our focus is the effect of classifier structure and training on classification, we do not utilize IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004 1395 . The authors are with the Central Research Laboratory, Hitachi, Ltd., 1-280 Higashi-koigakubo, Kokubunji-shi, Tokyo 185-8601, Japan. E-mail: {liucl, sakou, fujisawa}@crl.hitachi.co.jp. Manuscript received 14 Dec. 2003; revised 5 Apr. 2004; accepted 3 May 2004. Recommended for acceptance by V. Govindaraju. For information on obtaining reprints of this article, please send e-mail to: [email protected], and reference IEEECS Log Number TPAMI-0426-1203. 0162-8828/04/$20.00 ß 2004 IEEE Published by the IEEE Computer Society
Transcript of Effects of Classifier Structures and Training Regimes on Integrated Segmentation and Recognition of...

Effects of Classifier Structures and TrainingRegimes on Integrated Segmentation andRecognition of Handwritten Numeral Strings
Cheng-Lin Liu, Senior Member, IEEE, Hiroshi Sako, Senior Member, IEEE, and
Hiromichi Fujisawa, Fellow, IEEE
Abstract—In integrated segmentation and recognition of character strings, the underlying classifier is trained to be resistant to
noncharacters. We evaluate the performance of state-of-the-art pattern classifiers of this kind. First, we build a baseline numeral string
recognition system with simple but effective presegmentation. The classification scores of the candidate patterns generated by
presegmentation are combined to evaluate the segmentation paths and the optimal path is found using the beam search strategy.
Three neural classifiers, two discriminative density models, and two support vector classifiers are evaluated. Each classifier has some
variations depending on the training strategy: maximum likelihood, discriminative learning both with and without noncharacter samples.
The string recognition performances are evaluated on the numeral string images of the NIST Special Database 19 and the zipcode
images of the CEDAR CDROM-1. The results show that noncharacter training is crucial for neural classifiers and support vector
classifiers, whereas, for the discriminative density models, the regularization of parameters is important. The string recognition results
compare favorably to the best ones reported in the literature though we totally ignored the geometric context. The best results were
obtained using a support vector classifier, but the neural classifiers and discriminative density models show better trade-off between
accuracy and computational overhead.
Index Terms—Numeral string recognition, integrated segmentation and recognition, noncharacter resistance, character classification,
neural classifiers, discriminative density models, support vector classifiers.
�
1 INTRODUCTION
HANDWRITTEN character string recognition requires seg-menting the string image into constituent characters
and classifying the segmented characters to predefined(target) classes. Due to the variability of character spacingand the presence of breaking or touching characters, reliablesegmentation prior to classification is impossible. Thisproblem is solved by integrated segmentation and recogni-tion with a hypothesis-and-test strategy [1], [2], also calledrecognition-based segmentation [3], classification-basedsegmentation [4], or internal segmentation, as opposed toexternal segmentation. A presegmentation module is usedto oversegment the string image into primitive segmentsand generate candidate character patterns or, even moresimply, images in sliding windows are taken as candidatepatterns [5], [6]. Classification scores are assigned to thecandidate patterns using an underlying character classifierand are combined to evaluate the segmentation paths. Theoptimal path, with the maximum score or minimum cost,gives the final segmentation.
Since the presegmentation generates both character andnoncharacter patterns, the underlying classifier must beresistant to noncharacters: When a noncharacter pattern isclassified, all the target classes should be assigned low
scores. Some classifiers like parametric statistical classifiersare inherently resistant to noncharacters because compactdensity models are assumed for the target classes. Thequadratic discriminant function [7] and the modifiedquadratic discriminant function [8], both based on theGaussian density assumption, have been successfullyapplied to numeral string recognition [4], [9]. Most neuralnetwork classifiers, on the other hand, are susceptible tononcharacters because they are trained to separate the in-class samples (the samples of target classes) disregardingthe distribution in feature space. The noncharacter resis-tance of neural classifiers can be enhanced by training withnoncharacter samples [3], [10], [11].
In character string recognition, many researchers havefocused on the postprocessing of classification results usinggeometric context (character size/position and interchar-acter relationships) to reject noncharacters or on combiningthe geometric features with the classification scores toevaluate the segmentation paths [12], [13], [14], [15]. Thegeometric context remedies the insufficient noncharacterresistance of general classifiers and can further improve therecognition performance of classifiers that are alreadyresistant to noncharacters.
We evaluate state-of-the-art classifiers on handwrittennumeral strings, where little linguistic context is available.To compare the classifiers in a common framework, webuild a baseline numeral string recognition system usingsimple but effective presegmentation. Each classifier gives astring recognition result by combining the classificationscores of candidate patterns into path scores and finding theoptimal path. Since our focus is the effect of classifierstructure and training on classification, we do not utilize
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004 1395
. The authors are with the Central Research Laboratory, Hitachi, Ltd., 1-280Higashi-koigakubo, Kokubunji-shi, Tokyo 185-8601, Japan.E-mail: {liucl, sakou, fujisawa}@crl.hitachi.co.jp.
Manuscript received 14 Dec. 2003; revised 5 Apr. 2004; accepted 3 May 2004.Recommended for acceptance by V. Govindaraju.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number TPAMI-0426-1203.
0162-8828/04/$20.00 � 2004 IEEE Published by the IEEE Computer Society

geometric context in postprocessing. We compare neuralclassifiers, support vector classifiers, and hybrid discrimi-native density models using a common feature representa-tion for candidate patterns. The experiments reveal theinfluences of the classifier structure, the learning algorithm,and the training data on string recognition.
The classifiers to compare are the Multilayer Perceptron(MLP), the Radial Basis Function (RBF) classifier [16], thePolynomial Classifier (PC) [17], [18], a Learning VectorQuantization (LVQ) classifier [19], a Discriminative Learn-ing Quadratic Discriminant Function (DLQDF) classifier[20], [21], and two support vector classifiers (with poly-nomial kernel and Gaussian kernel, respectively) [22], [23].The LVQ and DLQDF classifiers can be viewed as hybriddiscriminative density models because their parameterscharacterize pattern distributions and are adjusted bydiscriminative learning, wherein a regularization term isused to attract the parameters to the initial estimates fromMaximum Likelihood (ML). Each of the seven classifiershas at least two discriminative versions, depending onwhether noncharacter samples are used in training or not.
We evaluate the classifiers on the numeral string imagesof the NIST Special Database 19 (SD19) and on the zipcodeimages of the CEDAR CDROM-1. The results show thatclassification accuracy and noncharacter resistance are bothimportant to string recognition. The classifier structure,learning algorithm, and training samples are influential tothe classification accuracy and the noncharacter resistance.As a result of good feature representation and improvedtraining strategy, all the classifiers yield string recognitionaccuracies that compare favorably with the best onesreported in the literature.
We have introduced the baseline numeral string recogni-tion system and reported preliminary comparison results ina previous presentation [24]. Since then, we have modifiedthe string recognition algorithm and evaluated a larger setof classifiers. The rest of this article is organized as follows:Section 2 describes the numeral string recognition system.Section 3 describes the classifier structures and trainingmethods. Section 4 presents the experimental results onnumeral string recognition. Section 5 offers our conclusions.
We use many acronyms throughout the article, especiallyfor referring to classifier structures and learning algorithms.For the readers’ convenience, we list them in Table 1.
2 NUMERAL STRING RECOGNITION SYSTEM
A block diagram of our numeral string recognition systemis shown in Fig. 1. The preprocessing module detects andremoves underlines. An underline is detected when themaximum of the horizontal projection profile is comparableto the width of the string image. Upon detection, thecorresponding vertical stroke run in each column isremoved if it is short as compared to the estimatedthickness of the underline. The presegmentation modulehas two functions: Connected Component Analysis (CCA)and splitting of touching patterns. The string image isoversegmented into a sequence of primitive image seg-ments so that each segment can be expected to correspondto a character or to part of a character. Consecutivesegments are combined to generate candidate characterpatterns, which are represented in a segmentation candi-date lattice (Fig. 2). The segmentation paths are evaluatedby the classification scores of their constituent patterns. Theoptimal path, in the sense of maximum score or minimumcost, gives the segmentation-recognition result.
2.1 Presegmentation
After connected component labeling, the components thatheavily overlap horizontally are merged because they arelikely to compose the same character. The overlap of alpha-numeric characters is more severe than that of Chinesecharacters [25], so we compute the overlap degree in adifferent way and set a larger threshold to discouragemerging. The normalized overlap degree novlp is com-puted by
novlp ¼ ovlp
minðw1; w2Þ� dist
span; ð1Þ
where w1 and w2 are the widths of two neighboringcomponents, dist is the horizontal distance between theircenters, ovlp is the with of horizontal overlap, and span is thehorizontal span of the two components (Fig. 3a). The two
1396 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004
TABLE 1List of Acronyms
Fig. 1. Diagram of numeral string recognition system (CCA is Connected Component Analysis).

components are to be merged if novlp > 0:55. The thresholdis based on the value of 0.55 of novlp in two marginalsituations: 1) Both components have the same width andoverlap three quarters (Fig. 3b). 2) One component is 10 timesthe width of the other and overlaps the other at one end(Fig. 3c). Pairs of neighboring components are mergediteratively until no pair meets the threshold.
The height and the vertical center of the string image areestimated after merging connected components. The stringheight is estimated from the histogram of componentheights. In computing this histogram, pairs of neighboringcomponents are merged temporarily to overcome theunreliability of the height of individual components. Thestring height is the weighted average of the heights of thetemporarily merged components weighted by their width.The vertical center of the string is the weighted average ofthe vertical centers of the temporarily merged componentsweighted by their area. The estimated height and verticalposition of the string image are used later for judgingtouching patterns and generating candidate patterns.
After component merging, the components (not necessa-rily connected now) that are taller than half the string heightand wider than 0.8 times the string height or have anabnormally large width/height ratio (greater than 1.2) aretreated as potential touching patterns. To split a potentialtouching pattern, its upper and lower profile curves areanalyzed to generate candidate cuts. As shown in Fig. 4, thecorner points of the profile curves are detected using apolygonal approximation technique [26]. The concavecorners in the upper profile and the convex corners in thelower profile correspond to potential cut positions, calledupper cuts and lower cuts. If an upper cut and a lower cutare closer to each other horizontally than one eighth of thestring height, they are merged into a new cut.
The above thresholds were determined empirically suchthat few candidate cuts and primitive segments aregenerated while the parts of different characters are usuallyseparated. Changing the thresholds to increase the numberof cuts improves the separation rate, but it also generatesmore candidate patterns and increases the classificationoverhead. To save space, we omit the string recognitionresults for various separation thresholds.
After oversegmentation, the string image is representedas a sequence of primitive image segments (Fig. 5). Forstring recognition, consecutive segments are combined togenerate candidate character patterns subject to someconstraints of character size and vertical position. In ourexperiments, the maximum number of segments in acandidate pattern was set to four. The height of thecandidate pattern must be at least one-third of the stringheight, its width not more than 2.4 times the string height,and its width/height ratio not more than 3. Each candidatepattern is also required to cross the vertical center line of thestring image. These constraints are loose enough to avoidexcluding true characters.
2.2 Path Scoring and Search
A segmentation path is composed of a sequence ofcandidate patterns. Classification associates each candidatepattern with a character class or with several alternativeclasses and with the corresponding class scores. When aconstituent pattern is associated with multiple classes, thesegmentation path is split into multiple segmentation-recognition paths. For brevity, we will refer to a segmenta-tion-recognition path, which is a sequence of pattern-classpairs, as a segmentation path or, simply, a path. Denotingthe constituent patterns in a path by xj, j ¼ 1; . . . ; n, and thecorresponding class labels by Cij , j ¼ 1; . . . ; n, the a poster-iori probability of the path is computed by Bayes’ rule:
P ðCi1 . . .Cin jx1 . . .xnÞ ¼pðx1 . . .xnjCi1 . . .CinÞP ðCi1 . . .CinÞ
pðx1 . . .xnÞ:
ð2Þ
The mixture probability pðx1 . . .xnÞ is independent of thestring class Ci1 . . .Cin . The a priori probability P ðCi1 . . .CinÞrepresents the linguistic context. Though the linguisticcontext of numeral strings can be modeled in specialapplications like zipcode recognition [27], it is ignoredin our study since we aim to evaluate the classifierperformance and do not specify an application. Therefore,the a priori probabilities are assumed equal and thesegmentation path can be scored by the conditionalprobability pðx1 . . .xnjCi1 . . .CinÞ. The path of maximumconditional probability (i.e., maximum likelihood) gives theoptimal result of segmentation-recognition. Assuming
LIU ET AL.: EFFECTS OF CLASSIFIER STRUCTURES AND TRAINING REGIMES ON INTEGRATED SEGMENTATION AND RECOGNITION OF... 1397
Fig. 2. Segmentation candidate lattice of a character string image. Eachnode represents a separation point and each edge represents acandidate pattern. The path corresponding to the most plausiblesegmentation is denoted by a thick line.
Fig. 3. Definition of normalized overlap (a) and two situations with normalized overlap 0.55 (b) and (c).

further that the constituent patterns in the path areindependent in shape (i.e., ignoring the geometric context),the path-conditional probability can be decomposed intothe product of the pattern class-conditional probabilities:
pðx1 . . .xnjCi1 ; . . . ; CinÞ ¼Ynj¼1
pðxjjCijÞ: ð3Þ
Many classifiers output a similarity or dissimilaritymeasure instead of a probability for each defined class. Inparametric classification, assuming Gaussian densities forthe defined classes, the Linear Discriminant Function (LDF)or Quadratic Discriminant Function (QDF) corresponds tothe log-likelihood, while square Euclidean distance andMahalanobis distance correspond to the negative log-like-lihood [7]. We generalize this notion to neural networks,support vector classifiers, and dissimilarity-based classifiers.Denoting the output score of class Ck of neural networks orsupport vector classifiers by yk, the output score is assumed,by analogy with the LDF, to be proportional to the logarithmof the class-conditional probability:
ykðxÞ / log pðxjCkÞ: ð4Þ
On the other hand, the distance measures given bydissimilarity-based classifiers are related to the class-conditional probability by analogy with the square Eu-clidean distance or Mahalanobis distance:
dðx; CkÞ / � log pðxjCkÞ: ð5Þ
Similarity and dissimilarity measures can be unified bytreating ykðxÞ ¼ �dðx;CkÞ, hence the output scores of allclassifiers can be related to class-conditional probabilities asin (5). The cost of the segmentation path can therefore beformulated as
Dðx1 . . .xn; Ci1 . . .CinÞ ¼Xnj¼1
dðxj; CijÞ; ð6Þ
and the task of string recognition is to find the path ofminimum cost.
When the string length is unknown, the path score as theproduct of probabilities or the sum of distances is biasedtoward short strings (those with few characters). This can beovercome by normalizing the path score with respect to thestring length [28]. Accordingly, the normalized cost is theaverage of pattern distances:
NDðx1; . . . ;xn; Ci1 ; . . . ; CinÞ ¼1
n
Xnj¼1
dðxj; CijÞ: ð7Þ
If the segmentation path is scored by the accumulatedcost (6), the optimal path of minimum cost can be easilyfound by dynamic programming. Under the normalizedcost criterion (7), dynamic programming does not guaranteefinding the optimal path, but still performs satisfactorily[24]. We have, nevertheless, switched to beam search to findpaths of even smaller normalized cost. Among the partialpaths ending at an intermediate node in the candidatelattice, beam search retains multiple partial paths with highscores (low costs) for extension, unlike dynamic program-ming which retains solely the optimal partial path. All theretained partial paths of the parent nodes are extended toeach child, where several high-score partial paths are againretained. At the terminal node, the retained paths corre-spond to multiple segmentation-recognition results. We calla complete segmentation path together with its string classlabel a result string. The availability of multiple result stringsis useful for rejection, as will be addressed later. In ourimplementation of beam search, the maximum number ofretained partial paths at a node was set to 10.
To obtain multiple alternative result strings, we shouldassign multiple classes to each candidate pattern since theresult strings may correspond to the same segmentationpath and differ only in the class labels of a constituentpattern. Specifically, we assign the two classes of maximumscores to each candidate pattern and finally obtain tworesult strings on path search.
2.3 Rejection Strategy
The string recognition result is considered correct if thestring class label corresponding to the minimum cost path isidentical to the ground truth. The error rate can be reducedby rejecting unreliable result strings according to the pathscore or the class scores of constituent patterns. Promisingresults of rejection have been reported using pattern classscores [24]. However, a more effective strategy is to baserejection on the difference between the two highest stringscores. The optimal result string and the most competingstring differ either in the segmentation path or in the classlabels of constituent patterns.
Denoting the optimal result string and the competingone by S1 ¼ Ci1 � � �Cin and S2 ¼ Cj1 � � �Cjm and their normal-ized costs by NDðS1Þ and NDðS2Þ, the optimal result stringis rejected if
1398 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004
Fig. 5. Primitive image segments after oversegmentation. Each segmentis enclosed with a rectangular box.
Fig. 4. Touching pattern splitting by profile curve analysis. Filled boxesindicate candidate cuts.

NDðS2Þ �NDðS1Þ < T; ð8Þ
where T is a tunable threshold that controls the overallrejection rate. When the two result strings differ only in theclass label of a constituent pattern, the difference ofaccumulated cost does not depend on the string length.To set a rejection threshold appropriate for variable stringlengths, we hence restore the accumulated cost after pathsearch based on the normalized cost. The top two stringscores are multiplied by a same number (the estimate ofstring length) to prevent swapping their ranks. The stringlength (which is unknown a priori) is estimated as theaverage of the two result strings: sl ¼ ðnþmÞ=2 and therecognition result is rejected if
sl � ½NDðS2Þ �NDðS1Þ� < T: ð9Þ
3 CLASSIFICATION METHODS
The input to every classifier is a d-dimensional featurerepresentation x of a candidate pattern. The task ofclassification is to assign similarity/dissimilarity scores toM defined classes fC1; . . . ; CMg and to sort the classesaccording to maximum similarity or minimum dissimilarity.
3.1 Classifier Structures
The classifiers that we evaluate are three neural classifiers,two hybrid discriminative density models, and two supportvector classifiers.
3.1.1 Neural Classifiers
The Multi-Layer Perceptron (MLP) that we use has onehidden layer. The score for class Ck is computed by
ykðxÞ ¼ sXNh
j¼1
wkj � sðvTj xþ vj0Þ þ wk0
" #
¼ sXNh
j¼1
wkj � hj þ wk0
" #;
ð10Þ
where Nh denotes the number of hidden units, wkj and vjidenote the connecting weights of the output layer and the
hidden layer, respectively. sð�Þ is the sigmoid function:
sðaÞ ¼ 1
1þ e�a: ð11Þ
The Radial Basis Function (RBF) classifier has one hiddenlayer with each hidden unit being a Gaussian kernel:
hjðxÞ ¼ exp �kx� �jk2
2�2j
!: ð12Þ
Each output is a linear combination of the Gaussian kernelswith sigmoid nonlinearity:
ykðxÞ ¼ sXNh
j¼1
wkjhjðxÞ þ wk0
" #: ð13Þ
The Polynomial Classifier (PC) is a single-layer network
with the polynomials of feature measurements as inputs.
We use a PC with the binomial terms of the principal
components [18]. Denoting the principal components in the
m-dimensional (m < d) subspace by z, the score for class Ck
is computed by
ykðxÞ ¼ sXmi¼1
Xmj¼i
wð2ÞkijziðxÞzjðxÞ
"
þXmi¼1
wð1Þki ziðxÞ þ wr
krðxÞ þ wk0
#;
ð14Þ
where zjðxÞ is the projection of x onto the jth principal axis
of the subspace, and rðxÞ is the residual of projection. The
residual helps reject noncharacters because the subspace is
estimated only from character samples. Both the projected
features and the residual are rescaled to a moderate range.Specifically, the residual is divided by the largest eigenva-
lue of the feature space, and the projections are divided by
the square root of the largest eigenvalue.The sigmoid function (11) of neural classifiers is only
used in training. In numeral string recognition, the linear
outputs are taken as the class scores of candidate patterns.
3.1.2 Discriminative Density Models
The Learning Vector Quantization (LVQ) classifier takes the
nearest neighbor rule for classification, but the prototypes
are designed discriminatively. The parameters of the LVQ
classifier include a set of prototype vectors for each class
fmijjj ¼ 1; . . . ; nig, i ¼ 1; . . . ;M. In classification, the dis-
criminant score of a class is the distance between the input
pattern and the closest prototype of this class:
dP ðx; CiÞ ¼ minj
dEðx;mijÞ; ð15Þ
where the distance metric is the square Euclidean distance
dEðx;mÞ ¼ kx�mk2.The Discriminative Learning Quadratic Discriminant
Function (DLQDF) is developed from the Modified Quad-
ratic Discriminant Function (MQDF2) of Kimura et al. [8],
which is a smoothed version of the quadratic discriminant
function under the Gaussian density assumption [7]. The
parametersofMQDF2areestimatedbymaximumlikelihood,
while the parameters of DLQDF are estimated discrimina-
tively. The DLQDF has the same form as the MQDF2:
dQðx; CiÞ ¼ g2ðx; CiÞ
¼Xkj¼1
1
�ij½�T
ijðx� �iÞ�2 þXdj¼kþ1
1
�i½�T
ijðx� �iÞ�2
þXkj¼1
log�ij þ ðd� kÞ log �i
¼Xkj¼1
1
�ij½�T
ijðx� �iÞ�2 þ1
�iriðxÞ
þXkj¼1
log�ij þ ðd� kÞ log �i;
ð16Þ
where �i denotes the mean vector of class Ci, and �ij and �ij
(j ¼ 1; . . . ; d) are the eigenvectors and eigenvalues of the
covariance matrix. The eigenvalues are sorted in descend-
ing order and the minor eigenvalues are replaced by a
LIU ET AL.: EFFECTS OF CLASSIFIER STRUCTURES AND TRAINING REGIMES ON INTEGRATED SEGMENTATION AND RECOGNITION OF... 1399

constant �i. k is the number of principal eigenvectors and
riðxÞ is the class-specific residual of subspace projection:
riðxÞ ¼ kx� �ik2 �Xkj¼1
½ðx� �iÞT�ij�2: ð17Þ
3.1.3 Support Vector Classifiers
For M-class classification, the support vector classifier
consists of M binary support vector machines with each
separating one class from the others. On an input pattern x,
the discriminant function of a binary classifier is
fðxÞ ¼X‘i¼1
yi�i � kðx;xiÞ þ b; ð18Þ
where ‘ is the number of learning patterns, yi is the target
value of learning pattern xi (þ1=� 1 for positive/negative
class), b is a bias, and kðx;xiÞ is a kernel function which
implicitly defines an expanded feature space (possibly of
infinite dimensionality):
kðx;xiÞ ¼ �ðxÞ � �ðxiÞ: ð19Þ
Two types of kernels, polynomial and Gaussian (RBF),
are frequently used. They are computed by
kðx;xi; pÞ ¼ ð1þ x � xiÞp ð20Þ
and
kðx;xi; �2Þ ¼ exp �kx� xik2
2�2
!; ð21Þ
respectively. In our implementation, the pattern vectors are
appropriately scaled for the polynomial kernel, with the
scaling factor estimated from the lengths of the sample
vectors. For the Gaussian kernel, the kernel width �2 is
estimated from the variance of the sample vectors. We call
the support vector classifier using the polynomial kernel
SVC-poly and the one using the Gaussian kernel SVC-rbf.The discriminant function (18) can be viewed as a
generalized linear discriminant function with weight vector
w ¼X‘i¼1
yi�i � �ðxiÞ: ð22Þ
3.2 Training Methods
On a sample set fðxn; cnÞjn ¼ 1; . . . ; Ng (cn is the class label
of xn), the neural classifiers are trained by minimizing the
Mean Square Error (MSE) [16], the discriminative density
models are trained by optimizing the Minimum Classifica-
tion Error (MCE) criterion [29], [30], and support vector
classifiers are trained to maximize the margin of classifica-
tion [22], [23].
3.2.1 Neural Network Training
The connecting weights of the neural classifiers as well as
the kernel center vectors of the RBF classifier are adjusted
by MSE training. On the sample set, the MSE criterion is
E ¼ 1
2N
XNn¼1
XMk¼1
�ykðxn;wÞ � tnk
�2 þ �Xw2W
w2
( ); ð23Þ
where � is a coefficient that controls the decay of connectingweights (excluding the biases); tnk is the target output ofclass Ck, with value 1 for the genuine class cn and 0,otherwise. The connecting weights are updated by stochas-tic gradient descent [31].
The MSE training of the MLP by gradient descent with amomentum for acceleration is known as back-propagation.The center vectors of the RBF classifier are initialized byclustering the sample data and then adjusted by MSEtraining.
The MSE training of neural classifiers is discriminative inthe sense that the fitting of target outputs leads to theseparation of samples of different classes. Nevertheless, thetrained classifier may misclassify noncharacters to targetclasses with high confidence because discriminative train-ing does not consider the boundary between in-classsamples and noncharacters. Adding noncharacter samplesto the training data set can greatly improve the nonchar-acter resistance. In MSE training, when the input pattern isa noncharacter, the target outputs of all classes are set to 0 inorder to guide the classifier to give low confidence to all thedefined classes.
3.2.2 Discriminative Density Learning
The prototype vectors of the LVQ classifier are initialized byk-means clustering on the sample data of each class andthen adjusted by MCE training. The cluster centers can beused directly as the prototypes for classification. This can beviewed as the Maximum Likelihood (ML) version of theLVQ classifier since clustering approximates the MLestimate of a Gaussian mixture with equal variances.
The parameters of the DLQDF classifier are initiallyinherited from the MQDF2 and then adjusted by MCEtraining. The parameters of the MQDF2 are estimated bymaximum likelihood under the multivariate Gaussiandensity assumption.
In MCE training [29], [30], the misclassification loss on atraining pattern is computed based on the difference ofdiscriminant score between the genuine class and compet-ing classes. We take the difference between the genuineclass and the closest competing class as the misclassificationmeasure and transform to soft (sigmoid) 0-1 loss lcðxÞ. Theempirical loss on the training sample set is
L1 ¼1
N
XNn¼1
½lcðxnÞ þ �dðxn; CcÞ�; ð24Þ
where we have added a regularization term proportional tothe within-class distances (Cc denotes the genuine class ofxn), which attracts the parameters to the ML estimate andhelps improve the generalized classification performanceand the noncharacter resistance. The parameters of LVQand DLQDF are updated by stochastic gradient descent tooptimize the MCE criterion (24). More details of DLQDF canbe found in [21].
The LVQ and DLQDF classifiers are inherently resistantto noncharacters because they represent compact densitymodels (Gaussian mixtures or multivariate Gaussians)
1400 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004

whose parameters are attracted to the ML estimate byregularization. We attempt to further improve their non-character resistance by noncharacter training. MCE trainingdoes not generalize to noncharacter samples as simply asMSE training because no target output is used. For rejectingnoncharacters, we apply a threshold T1 to the discriminantscores of LVQ and DLQDF classifiers. The threshold is theonly parameter of an additional “noncharacter” classmodel. Then, the parameters of the M þ 1 classes areupdated by optimizing the total MCE criterion. Aftertraining, the parameters of the M target classes are usedin classification.
3.2.3 Support Vector Learning
In training a binary support vector machine that separatesclass Ck from the others, the samples of class Ck are used aspositive samples and all the other samples (includingnoncharacters) are negative samples. The parameters(multipliers �i, i ¼ 1; . . . ; ‘) of each binary support vectormachine are determined on the learning patterns by solvingthe following optimization problem:
minimize �ðwÞ ¼ 12 kwk2
subject to yi � fðxiÞ � 1� i; i � 0; i ¼ 1; . . . ; ‘:ð25Þ
The objective is to maximize the margin of classificationsubject to constraints. This is a quadratic programmingproblem that can be converted to the following dualproblem:
maximize Wð�Þ ¼P‘
i¼1 �i � 12
P‘i;j¼1 �i�jyiyjkðxi;xjÞ
subject to 0 � �i � C; i ¼ 1; . . . ; ‘; andP‘
i¼1 �iyi ¼ 0;
ð26Þ
where C is a parameter that controls the tolerance toclassification errors in learning by setting an upper boundon the multipliers. We use the successive overrelaxationalgorithm of Mangasarian and Musicant [32] for solving thisproblem.
After optimization, only a portion of the learningpatterns have a nonzero multiplier �i. These patterns arecalled support vectors. For multiclass classification, theinput pattern is assigned to the class of the maximumdiscriminant score of theM binary support vector machines.
4 EXPERIMENTAL RESULTS
We evaluated the string recognition performances on thestring images of the NIST Special Database 19 (SD19) and thezipcode images of the CEDARCDROM-1. The parameters ofthe classifiers were estimated on isolated digits and onnoncharacter samples. The trained classifiers were thenapplied interchangeably to the numeral string recognitionsystem of Section 2 for classifying the candidate patterns.
4.1 Implementation of Classifiers
We used a digit data set compiled from the NIST SD19 fortraining the classifiers and two test data sets (NIST andCEDAR) for evaluating the classification accuracies. As inour previous evaluation study [33], the training set wascomprised of the 66,214 digit patterns of 600 writers (writersnos. 0-399 and nos. 2100-2299) of the NIST SD19, and the
test set was comprised of the 45,398 digit patterns of
400 writers (nos. 500-699 and nos. 2400-2599). In addition,
we used a validation set comprised of 22,271 samples of
200 writers (nos. 400-499 and nos. 2300-2399) for determin-
ing the structures and hyper-parameters of the classifiers.While our previous experiments used synthesized
noncharacter samples [33], [24], we have turned to collect
real noncharacters from string images. From the page
images of 600 writers (nos. 0-399 and nos. 2100-2299) in the
NIST SD19, we extracted all the numeral fields of string
length 2-6 (field nos. 6-30). From each of the 2 and 3-digit
string images, our presegmentation module generated a set
of candidate patterns from which we eliminated all the true
digits and all the patterns similar to digits. We thus
obtained 17,338 noncharacter images such as those in Fig. 6.In training and recognition, each sample or candidate
pattern is represented by a feature vector of 100 blurred
chaincode feature measurements. The details of feature
extraction can be found in [33], [34].By trial training and validation, we determined the
classifier structures and hyperparameters that gave high
classification accuracies on the validation dataset. As a
result, the Multilayer Perceptron (MLP) and the Radial
Basis Function (RBF) classifier have 300 hidden units each;
the Polynomial Classifier (PC) uses 70 principal compo-
nents; the Learning Vector Quantization (LVQ) classifier
has 30 prototypes for each class; the Discriminative
Learning Quadratic Discriminant Function (DLQDF) uses
40 eigenvectors for each class, while the Modified Quadratic
Discriminant Function (MQDF2, the ML version of DLQDF)
uses 30 eigenvectors for each class. The coefficient of weight
decay was set to 0.05 in training the MLP, 0.02 for the RBF,
and 0.1 for the PC. The regularization coefficient of the LVQ
was set to � ¼ 0:05=var, where var is the average within-
class cluster variance. The regularization coefficient of the
DLQDF was set to � ¼ 0:1=DQ, where DQ is the average
within-class quadratic distance estimated on the initial
parameters (inherited from the MQDF2). The smoothed
minor eigenvalue of the MQDF2 was set to a class-
independent constant. The discriminative versions of the
LIU ET AL.: EFFECTS OF CLASSIFIER STRUCTURES AND TRAINING REGIMES ON INTEGRATED SEGMENTATION AND RECOGNITION OF... 1401
Fig. 6. Examples of noncharacter patterns.
LVQ and the DLQDF without regularization (� ¼ 0) werealso tested.
In training the support vector classifiers, the power of thepolynomial kernel was set to p ¼ 5 and the upper bounds ofthe multipliers of SVC-poly (polynomial kernel) andSVC-rbf (Gaussian kernel) were set to 1 and 10, respectively.After training, the SVC-poly and the SVC-rbf had 5,115 and8,176 distinct support vectors shared by 10 classes. Ontraining with noncharacter samples as well as digit samples,the numbers of distinct support vectors became 8,520 and12,197. The large number of support vectors implies thatsupport vector classifiers are extremely expensive in storageand computation.
Each of the neural classifiers (MLP, RBF, PC) and thesupport vector classifiers (SVC-poly, SVC-rbf) has twodiscriminative versions depending on whether they weretrained with noncharacters or not. Both the LVQ and theDLQDF have four versions: the ML version and threediscriminative versions. The ML version of the LVQ is themultiprototype classifier obtained by clustering the trainingdata, while the ML version of the DLQDF is actually theMQDF2. The three discriminative versions are those trainedwithout regularization, trained with regularization, andtrained with noncharacter samples. For each of the sevenclassifier structures, the discriminative version with non-character training is also called its enhanced version.
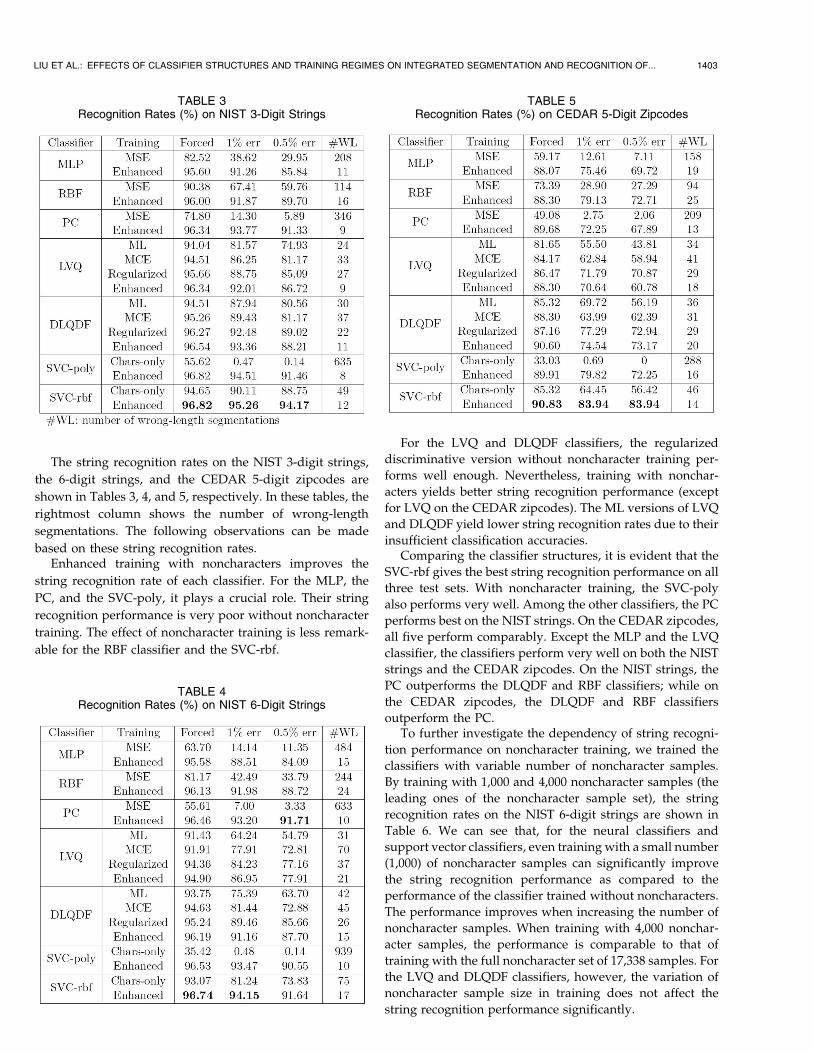
To investigate the correlation between individual digitclassification accuracy and string recognition accuracy, wereport the accuracies of isolated digit classification on thetest data sets of NIST and CEDAR (goodbs, 2,213 samples)in Table 2. In Table 2, the discriminative version withoutnoncharacter training is referred to as “MSE” for the neuralclassifiers and “MCE” for the discriminative density models(without regularization), according to the training criterion.Each classifier has an enhanced version that was trainedwith noncharacters. The support vector classifiers trainedwithout noncharacters are referred to as “Chars-only.”
From the results on the NIST test set, we can see thattraining with noncharacters does not influence the accura-cies of the discriminative versions. The accuracies of theML versions of the LVQ and DLQDF classifiers areapparently lower. The classifiers trained on the NIST dataset also give high accuracies on the CEDAR test set, thoughthe variance of their accuracies on this small set is large.Except the MLP and the LVQ classifier, the classifiers givehigh accuracies to both test sets.
4.2 Numeral String Recognition Results
Many researchers have tested their ideas on numeral stringrecognition on selected string images of the NIST SD19. Forexample, Ha et al. [35], Lee and Kim [6], and Kim et al. [36]tested on the numeral strings of writer nos. 1800-1899 andnos. 2000-2099, whereas Oliveira et al. [14] tested onselected samples of hsf-7 (writers nos. 3600-4099). Thespecific page and field numbers selected by [14] are notavailable, however.
In order to compare our results with those of [6], [35],[36] and test a greater number of samples, we extractednumeral string images of 300 writers, nos. 1800-2099. Fromthe 300 page images, we discarded four pages (nos. 1965,1977, 2027, and 2067) with faded ink and extracted the
numeral fields with string length 2-6. Since we aim tocompare many recognition methods, we report only ourrecognition results on 3 and 6-digit strings. From the 1,4803-digit strings and 1,480 6-digit strings, we further excludedsome samples that mismatch the ground-truth labels. Wekept 1,476 3-digit strings and 1,471 6-digit strings fortesting. Note that Ha et al. [35] and Kim et al. [36] alsoexcluded some samples from testing, but the indices ofthese excluded samples are unknown to us.
To compare with Ha et al. [35], we also tested ourmethods on the 5-digit zipcode images of the CEDARCDROM-1 in the BINZIP directory. The zipcode imageswere segmented from live mail images of the US PostalService (USPS) and contain an appreciable number oftouching patterns. The BINZIP directory contains 436 5-digitstrings and 59 9-digit strings. We did not experiment withthe 9-digit strings because our system does not deal with thehyphen in these strings.
On embedding each classifier in the numeral stringrecognition system, we report the rate of correct stringrecognition without rejection (forced recognition rate). Theerror rate of string recognition can be reduced by rejectionwith variable thresholds in (9). Like many researchers, wetuned the error rate to be lower than 1 and 0.5 percent.
The string recognition errors may be caused either by themissegmentation of string images or by the misclassificationof correctly segmented characters. The segmentation per-formance is largely dependent on the noncharacter resis-tance of the underlying classifier. To investigate the effectsof classifier training strategy on the string recognitionperformance, we wanted to count the number of mis-segmentations. However, missegmentation cannot bejudged automatically because the ground truth of characterboundaries is not available. Considering the fact thatmissegmentation usually gives the wrong string length,we instead count the number of wrong-length segmenta-tions (called “missegmentation” in our discussions).
1402 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004
TABLE 2Classification Accuracies (%) on Isolated Digits
The string recognition rates on the NIST 3-digit strings,
the 6-digit strings, and the CEDAR 5-digit zipcodes are
shown in Tables 3, 4, and 5, respectively. In these tables, the
rightmost column shows the number of wrong-length
segmentations. The following observations can be made
based on these string recognition rates.Enhanced training with noncharacters improves the
string recognition rate of each classifier. For the MLP, the
PC, and the SVC-poly, it plays a crucial role. Their string
recognition performance is very poor without noncharacter
training. The effect of noncharacter training is less remark-
able for the RBF classifier and the SVC-rbf.
For the LVQ and DLQDF classifiers, the regularized
discriminative version without noncharacter training per-
forms well enough. Nevertheless, training with nonchar-
acters yields better string recognition performance (except
for LVQ on the CEDAR zipcodes). The ML versions of LVQ
and DLQDF yield lower string recognition rates due to their
insufficient classification accuracies.Comparing the classifier structures, it is evident that the
SVC-rbf gives the best string recognition performance on all
three test sets. With noncharacter training, the SVC-poly
also performs very well. Among the other classifiers, the PC
performs best on the NIST strings. On the CEDAR zipcodes,
all five perform comparably. Except the MLP and the LVQ
classifier, the classifiers perform very well on both the NIST
strings and the CEDAR zipcodes. On the NIST strings, the
PC outperforms the DLQDF and RBF classifiers; while on
the CEDAR zipcodes, the DLQDF and RBF classifiers
outperform the PC.To further investigate the dependency of string recogni-
tion performance on noncharacter training, we trained the
classifiers with variable number of noncharacter samples.
By training with 1,000 and 4,000 noncharacter samples (the
leading ones of the noncharacter sample set), the string
recognition rates on the NIST 6-digit strings are shown in
Table 6. We can see that, for the neural classifiers and
support vector classifiers, even training with a small number
(1,000) of noncharacter samples can significantly improve
the string recognition performance as compared to the
performance of the classifier trained without noncharacters.
The performance improves when increasing the number of
noncharacter samples. When training with 4,000 nonchar-
acter samples, the performance is comparable to that of
training with the full noncharacter set of 17,338 samples. For
the LVQ and DLQDF classifiers, however, the variation of
noncharacter sample size in training does not affect the
string recognition performance significantly.
LIU ET AL.: EFFECTS OF CLASSIFIER STRUCTURES AND TRAINING REGIMES ON INTEGRATED SEGMENTATION AND RECOGNITION OF... 1403
TABLE 3Recognition Rates (%) on NIST 3-Digit Strings
TABLE 4Recognition Rates (%) on NIST 6-Digit Strings
TABLE 5Recognition Rates (%) on CEDAR 5-Digit Zipcodes

4.3 Discussions
Based on the results shown above, we herein discuss theeffects of classifier structure and training strategy on theperformance of numeral string recognition. The misrecog-nition of numeral strings has two major causes: themisclassification of correctly segmented characters andthe missegmentation of string images. The missegmenta-tion mostly appears as wrong-length segmentation. Fromthe results of the classifiers that give large numbers ofstring recognition errors in Tables 3, 4, and 5, especially theSVC-poly without noncharacter training, we can see thatthe wrong-length segmentations cover a majority of thesegmentation errors. The correct segmentation of stringimages relies on both the classification accuracy and thenoncharacter resistance of the classifier because theclassification scores of characters and noncharacters com-pete with each other in path search. Nevertheless, whentwo classifiers have comparable classification accuracies,the noncharacter resistance plays a decisive role in stringsegmentation.
Without noncharacter training, the MLP, the PC, and theSVC-poly give poor string recognition performance thoughtheir accuracies on isolated characters are very high. Theseclassifiers are not resistant to noncharacters because theclassifier structures do not assume density models for thedefined classes and give high class scores in the nonchar-acter region of the feature space. By noncharacter training,the classifier parameters are adjusted such that the non-character region in the feature space is assigned low scoresto target classes. In string recognition integrating segmenta-tion and classification, the noncharacter training results insignificant reduction of segmentation errors.
The string recognition performances of the RBF classifierand the SVC-rbf are not very poor when training withoutnoncharacters. This is because the hidden units or thesupport vectors represent local Gaussian densities thoughthe classifier does not assume parametric density modelsglobally. Noncharacters can still be falsely accepted due tothe presence of negative weights, but this risk is lower thanfor the MLP, the PC, and the SVC-poly, and can be reduced
by noncharacter training as well. The SVC-rbf enhanced by
noncharacter training yields the best string recognition
performance owing to both the high classification accuracy
and the resistance to noncharacters. For the neural classifiers
and the support vector classifiers, the effect of noncharacter
sample size is also reflected by the number of missegmenta-
tions (Table 6) in the sense that increasing the noncharacter
sample size reduces the number of missegmentations.As discriminative density models, the LVQ and DLQDF
classifiers perform very well in string recognition without
noncharacter training. They are inherently resistant to
noncharacters in the sense that noncharacters are assigned
low scores (large distances) to target classes because the
classifier parameters characterize compact density models
and are attracted by regularization to the ML estimate.
Comparing the string recognition results of the LVQ and
DLQDF with and without regularization, it is evident that
the regularization plays an important role. The MCE
versions of the LVQ and DLQDF give classification
accuracies comparable to their regularized versions, but
are inferior in string recognition. In contrast, the ML
versions of LVQ and DLQDF perform fairly well in string
recognition although their classification accuracies are
significantly lower than their MCE versions. The fact that
the ML version and the regularized discriminative version
of LVQ or DLQDF generate a comparable number of
missegmentations suggests that the inferior string recogni-
tion performance of the ML version can be attributed to its
low classification accuracy.We conclude that both the classification accuracy and the
noncharacter resistance of the embedded classifier signifi-
cantly affect the performance of integrated segmentation
and recognition of numeral strings. The noncharacter
resistance is affected by both the classifier structure (density
model) and the training strategy (regularization and
noncharacter training).For selecting a classifier structure for string recognition
applications, we must also evaluate its computational
overhead. On Pentium4-1.7GHz CPU, the preprocessing
of 1,471 6-digit string images takes 1.4s, i.e., 0.95ms per
string on average. The presegmentation generates
31,464 candidate patterns (21.4 per string on average), and
the feature extraction takes 11.5s or 0.37ms per pattern. The
search time is 0.10-0.17ms per string, depending on the
classification scores. The classification time is largely
dependent on the classifier structure, as shown in Table 7,
where we give the CPU times for each classifier with and
without noncharacter training. The two versions of the LVQ
classifier differ because of the dynamic search for the
nearest prototype, while the support vector classification
times depend on the number of support vectors. We can see
that the classification time of the neural classifiers and the
LVQ/DLQDF classifiers is comparable to the feature
extraction time 11.5s, while the support vector classifiers
are extremely expensive. The trade-off between the recogni-
tion performance and the computation cost favors the PC,
the DLQDF classifier, and the RBF classifier for practical
applications.
1404 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004
TABLE 6Recognition Rates (%) on NIST 6-Digit Strings:
Effects of Noncharacter Sample Size

4.4 Examples of String Recognition Errors
Figs. 7 and 8 show some examples of NIST 6-digit stringsand CEDAR zipcodes misrecognized by the enhancedversions of the PC, DLQDF, and SVC-rbf. In the figures,each string sample is misrecognized by at least one of thethree classifiers. The segmented patterns after optimal pathsearch are boxed. The resulting string label is given belowthe string image. When the three classifiers give the samesegmentation, the differing portion of string label isenclosed in parentheses.
We can see from the misrecognition examples that thesolution of missegmentation also relies on the preciselocation of the candidate cuts and on the geometric contextof candidate patterns (size, position, interpattern relation-ships, etc.). Since we only generate vertical cuts, thecharacters that overlap and touch cannot be separated.Slant correction of string images could alleviate this, but wewould still need a sophisticated splitting technique. Somemissegmented patterns are accepted as characters althoughthey are incompatible with the geometric context becausethey resemble character shapes.
The misclassification of segmented characters is due toambiguous character shapes or image noises. Since thecharacters are classified individually, there are some casesof misclassification where similar shapes belonging to thesame class are classified to different classes in the samestring image, while distinctly different shapes are classifiedto the same class. This kind of misclassification can beresolved using the style consistency of isogenous fields [37].
4.5 Comparison with Previous Results
The results we obtained are competitive with the best onesreported in the literature even though we did not utilize alleffective strategies to optimize the string recognitionperformance. In experiments on NIST strings, Ha et al.[35], Kim et al. [36], and Oliveira et al. [14] have reportedhigh recognition rates as compared to other works. Theirrecognition rates on 3 and 6-digit strings are compared inTable 8 with our results using the enhanced versions of theRBF, PC, DLQDF, and SVC-rbf.
It is fair to compare our results with those of [35] and[36] because their string images were also extracted fromthe page images of writer nos. 1800-2099. Since both Ha etal. [35] and Kim et al. [36] tested on selected samples andthe indices of the selected test samples are unknown to us,in comparing the recognition rates, we can take intoaccount only the inclusion rate of samples. On 200 pageimages (with five samples of each string length of 2-6 on a
LIU ET AL.: EFFECTS OF CLASSIFIER STRUCTURES AND TRAINING REGIMES ON INTEGRATED SEGMENTATION AND RECOGNITION OF... 1405
TABLE 7Total Classification Time on 1,471 6-Digit Strings
Fig. 7. Examples of misrecognition of NIST 6-digit strings. “C” in
parentheses denotes correct recognition.
Fig. 8. Examples of misrecognition of CEDAR zipcodes. “C” in
parentheses denotes correct recognition.
page), the inclusion rates of [35] and [36] are ð986þ982Þ=ð10�200Þ¼0:984 and ð956þ 961Þ=ð10� 200Þ ¼ 0:9585,respectively. On 300 page images, our inclusion rate isð1; 476þ 1; 471Þ=ð10� 300Þ ¼ 0:9823. Hence, it is fair tocompare our results with those of [35], while the results of[36] are less confident. Overall, our results comparefavorably.
On the CEDAR zipcodes, Ha et al. [35] have reportedhigh recognition rates. Their results on 436 5-digit zipcodesare collected in Table 9, along with our results using theenhanced versions of four classifiers. Our results aresignificantly superior to those of Ha et al.
5 CONCLUSION
The performance of integrated segmentation and recogni-
tion of character strings relies on the classification accuracy
and the resistance to noncharacters of the underlying
classifier. We therefore evaluated various classifiers in the
context of handwritten numeral strings. We demonstrated
that superior string recognition performance can be
achieved with appropriately designed classifiers even with
simple presegmentation and without using geometric
context in postprocessing. Our string recognition results
compare favorably to the best ones reported in the literature.
Specifically, we obtained superior results on the numeral
strings of the NIST SD19 and the zipcodes of the CEDAR
CDROM-1. The performance can be further improved by
slant correction of string images, sophisticated splitting, and
incorporating geometric context in postprocessing.Our comparison results show that training with non-
character samples improves neural classifiers and supportvector classifiers. Noncharacter training is less useful forhybrid discriminative density models for which the reg-ularization of parameters in training is more important. Thesupport vector classifier with Gaussian kernel (SVC-rbf) hasyielded the best string recognition result but requiresextremely expensive computation. The Polynomial Classi-fier (PC), the DLQDF and RBF classifiers provide the mostpracticable trade-off between recognition accuracy and
computational overhead. Up to now, we have trained the
classifiers only with segmented digits and noncharacter
samples collected from string images. In the future, we will
be training classifiers on string image samples with the aim
of minimizing the string recognition error directly.
ACKNOWLEDGMENTS
The authors would like to thank Professor George Nagy of
Rensselaer Polytechnic Institute for helpful discussions and
proofreading the manuscript.
REFERENCES
[1] H. Fujisawa, Y. Nakano, and K. Kurino, “Segmentation Methodsfor Character Recognition: From Segmentation to DocumentStructure Analysis,” Proc. IEEE, vol. 80, no. 7, pp. 1079-1092, 1992.
[2] R.G. Casey and E. Lecolinet, “A Survey of Methods and Strategiesin Character Segmentation,” IEEE Trans. Pattern Analysis andMachine Intelligence, vol. 18, no. 7, pp. 690-706, July 1996.
[3] C.J.C. Burges, O. Matan, Y. LeCun, J.S. Denker, L.D. Jackel, C.E.Stenard, C.R. Nohl, and J.I. Ben, “Shortest Path Segmentation: AMethod for Training a Neural Network to Recognize CharacterStrings,” Proc. Int’l Joint Conf. Neural Networks, vol. 3, pp. 165-172,1992.
[4] Y. Saifullah and M.T. Manry, “Classification-Based Segmentationof ZIP Codes,” IEEE Trans. System, Man, and Cybernetics, vol. 23,no. 5, pp. 1437-1443, 1993.
[5] C.L. Martin, “Centered-Object Integrated Segmentation andRecognition of Overlapping Handprinted Characters,” NeuralComputation, vol. 5, pp. 419-429, 1993.
[6] S.-W. Lee and S.-Y. Kim, “Integrated Segmentation and Recogni-tion of Handwritten Numerals with Cascade Neural Network,”IEEE Trans. System, Man, and Cybernetics—Part C, vol. 29, no. 2,pp. 285-290, 1999.
[7] R.O. Duda, P.E. Hart, and D.G. Stork, Pattern Classification, seconded. Wiley Interscience, 2001.
[8] F. Kimura, K. Takashina, S. Tsuruoka, and Y. Miyake, “ModifiedQuadratic Discriminant Functions and the Application to ChineseCharacter Recognition,” IEEE Trans. Pattern Analysis and MachineIntelligence, vol. 9, no. 1, pp. 149-153, Jan. 1987.
[9] F. Kimura, Y. Miyake, and M. Sridhar, “Handwritten ZIP CodeRecognition Using Lexicon Free Word Recognition Algorithm,”Proc. Third Int’l Conf. Document Analysis and Recognition, pp. 906-910, 1995.
[10] J. Bromley and J.S. Denker, “Improving Rejection Performance onHandwritten Digits by Training with Rubbish,” Neural Computa-tion, vol. 5, pp. 367-370, 1993.
[11] J. Liu and P. Gader, “Neural Networks with Enhanced OutlierRejection Ability for Off-Line Handwritten Word Recognition,”Pattern Recognition, vol. 35, no. 1, pp. 2061-2071, 2002.
[12] P.D. Gader, M. Mohamed, and J.-H. Chiang, “Handwritten WordRecognition with Character and InterCharacter Neural Net-works,” IEEE Trans. System, Man, and Cybernetics—Part B, vol. 27,no. 1, pp. 158-164, 1997.
[13] J. Zhou, A. Krzyzak, and C.Y. Suen, “Verification—A Method ofEnhancing the Recognizers of Isolated and Touching Hand-written Numerals,” Pattern Recognition, vol. 35, no. 5, pp. 1179-1189, 2002.
1406 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004
TABLE 8Comparison of Correct Rates on NIST String Images
TABLE 9Comparison of Correct Rates on CEDAR Zipcodes

[14] L.S. Oliveira, R. Sabourin, F. Bortolozzi, and C.Y. Suen, “Auto-matic Recognition of Handwritten Numeral Strings: A Recogni-tion and Verification Strategy,” IEEE Trans. Pattern Analysis andMachine Intelligence, vol. 24, no. 11, pp. 1438-1454, Nov. 2002.
[15] H. Xue and V. Govindaraju, “Incorporating Contextual CharacterGeometry in Word Recognition,” Proc. Eighth Int’l WorkshopFrontiers in Handwriting Recognition, pp. 123-127, 2002.
[16] C.M. Bishop, Neural Networks for Pattern Recognition. Oxford:Claderon Press, 1995.
[17] J. Schurmann, Pattern Classification: A Unified View of Statistical andNeural Approaches. Wiley Interscience, 1996.
[18] U. Kreßel and J. Schurmann, “Pattern Classification TechniquesBased on Function Approximation,” Handbook of CharacterRecognition and Document Image Analysis, H. Bunke andP.S.P. Wang, eds., pp. 49-78, 1997.
[19] C.-L. Liu and M. Nakagawa, “Evaluation of Prototype LearningAlgorithms for Nearest Neighbor Classifier in Application toHandwritten Character Recognition,” Pattern Recognition, vol. 34,no. 3, pp. 601-615, 2001.
[20] C.-L. Liu, H. Sako, and H. Fujisawa, “Learning QuadraticDiscriminant Function for Handwritten Character Recognition,”Proc. 16th Int’l Conf. Pattern Recognition, vol. 4, pp. 44-47, 2002.
[21] C.-L. Liu, H. Sako, and H. Fujisawa, “Discriminative LearningQuadratic Discriminant Function for Handwriting Recognition,”IEEE Trans. Neural Networks, vol. 15, no. 2, pp. 430-444, 2004.
[22] V. Vapnik, The Nature of Statistical Learning Theory. Springer-Verlag, 1995.
[23] C.J.C. Burges, “A Tutorial on Support Vector Machines for PatternRecognition,” Knowledge Discovery and Data Mining, vol. 2, no. 2,pp. 1-43, 1998.
[24] C.-L. Liu, H. Sako, and H. Fujisawa, “Integrated Segmentation andRecognition of Handwritten Numerals: Comparison of Classifica-tion Algorithms,” Proc. Eighth Int’l Workshop Frontiers in Hand-writing Recognition, pp. 303-308, 2002.
[25] C.-L. Liu, M. Koga, and H. Fujisawa, “Lexicon-Driven Segmenta-tion and Recognition of Handwritten Character Strings forJapanese Address Reading,” IEEE Trans. Pattern Analysis andMachine Intelligence, vol. 24, no. 11, pp. 1425-1437, Nov. 2002.
[26] U. Ramer, “An Iterative Procedure for the Polygonal Approxima-tion of Plane Closed Curves,” Computer Graphics and ImageProcessing, vol. 1, pp. 244-256, 1972.
[27] D. Bouchaffra, V. Govindaraju, and S.N. Srihari, “Postprocessingof Recognized Strings Using Nonstationary Markovian Models,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 21, no. 10,pp. 990-999, Oct. 1999.
[28] S. Tulyakov and V. Govindaraju, “Probabilistic Model forSegmentation Based Word Recognition with Lexicon,” Proc. SixthInt’l Conf. Document Analysis and Recognition, pp. 164-167, 2001.
[29] B.-H. Juang and S. Katagiri, “Discriminative Learning forMinimum Error Classification,” IEEE Trans. Signal Processing,vol. 40, no. 12, pp. 3043-3054, 1992.
[30] B.-H. Juang, W. Chou, and C.-H. Lee, “Minimum ClassificationError Rate Methods for Speech Recognition,” IEEE Trans. Speechand Audio Processing, vol. 5, no. 3, pp. 257-265, 1997.
[31] H. Robbins and S. Monro, “A Stochastic Approximation Method,”Annals Math. Statistics, vol. 22, pp. 400-407, 1951.
[32] O.L. Mangasarian and D.R. Musicant, “Successive Overrelaxationfor Support VectorMachines,” IEEE Trans. Neural Networks, vol. 10,no. 5, pp. 1032-1037, 1999.
[33] C.-L. Liu, H. Sako, and H. Fujisawa, “Performance Evaluation ofPattern Classifiers for Handwritten Character Recognition,” Int’l J.Document Analysis and Recognition, vol. 4, no. 3, pp. 191-204, 2002.
[34] C.-L. Liu, Y-J. Liu, and R-W. Dai, “Preprocessing and Statistical/Structural Feature Extraction for Handwritten Numeral Recogni-tion,” Progress of Handwriting Recognition, A.C. Downton andS. Impedovo, eds., pp. 161-168, 1997.
[35] T.M. Ha, J. Zimmermann, and H. Bunke, “Off-Line HandwrittenNumeral String Recognition by Combining Segmentation-Basedand Segmentation-Free Methods,” Pattern Recognition, vol. 31,no. 3, pp. 257-272, 1998.
[36] K. Kim, Y. Chung, J. Kim, and C.Y. Suen, “Recognition ofUnconstrained Handwritten Numeral Strings Using DecisionValue Generator,” Proc. Sixth Int’l Conf. Document Analysis andRecognition, pp. 14-17, 2001.
[37] S. Veeramachaneni, H. Fujisawa, C.-L. Liu, and G. Nagy,“Classifying Isogenous Fields,” Proc. Eighth Int’l WorkshopFrontiers in Handwriting Recognition, pp. 41-46, 2002.
Cheng-Lin Liu received the BS degree inelectronic engineering from Wuhan University,Wuhan, China, the ME degree in electronicengineering from Beijing Polytechnic University,Beijing, China, and the PhD degree in patternrecognition and artificial intelligence from theInstitute of Automation, Chinese Academy ofSciences, Beijing, China, in 1989, 1992 and1995, respectively. From March 1996 to October1997, he was a postdoctoral fellow at the Korea
Advanced Institute of Science and Technology (KAIST), Taejon, Korea,and, from November 1997 to March 1999, at the Tokyo University ofAgriculture and Technology, Tokyo, Japan. Afterward, he became aresearch staff member at the Central Research Laboratory, Hitachi, Ltd.,Tokyo, Japan, where he is now a senior researcher. His researchinterests include pattern recognition, artificial intelligence, imageprocessing, neural networks, machine learning, and especially theapplications to character recognition and document processing. He is asenior member of the IEEE and the IEEE Computer Society.
Hiroshi Sako received the BE and ME degreesin mechanical engineering from Waseda Uni-versity, Tokyo, Japan, in 1975 and 1977,respectively, and the PhD degree in computerscience from the University of Tokyo, in 1992.From 1977 to 1991, he worked in the field ofindustrial machine vision at the Central Re-search Laboratory of Hitachi, Ltd., Tokyo, Japan(HCRL). From 1992 to 1995, he was a seniorresearch scientist at Hitachi Dublin Laboratory,
Ireland, where he did research in facial and hand gesture recognition.Since 1996, he has been with the HCRL where he directs researchgroups of character recognition and image recognition, and he iscurrently a chief researcher. Since 1998, he has also been a visitingprofessor at the Japan Advanced Institute of Science and Technology,Hokuriku Postgraduate University, and a visiting lecturer at HoseiUniversity, Tokyo, Japan, since 2003. He is a fellow of the InternationalAssociation for Pattern Recognition (IAPR), and a member of theInstitute of Electronics, Information, and Communication Engineers(IEICE) of Japan, the Japanese Society for Artificial Intelligence, theInformation Processing Society of Japan, and the Hitachi Henjin-kai. Hewas a recipient of the 1988 Best Paper Award from IEICE of Japan, andthe 1994 Industrial Paper Award from 12th IAPR InternationalConference on Pattern Recognition, Jerusalem, Israel. He is a seniormember of the IEEE and a member of the IEEE Computer Society.
Hiromichi Fujisawa received the BE, ME, andPhD degrees in electrical engineering fromWaseda University, Tokyo, Japan, in 1969,1971, and 1975, respectively. In 1974, he joinedCentral Research Laboratory, Hitachi, Ltd.,Tokyo, Japan, where he is currently a corporatechief scientist. At Central Research Laboratory,he has engaged in research and developmenton character recognition and document under-standing including mail-piece address recogni-
tion and forms processing, and document retrieval. From 1980 through1981, he was a visiting scientist at the Computer Science Department atCarnegie Mellon University, Pittsburgh, Pennsylvania. Besides workingat Hitachi, he has been a visiting lecturer at Waseda University from1985 to 1997, and at Kogakuin University, Tokyo, Japan, from 1998 tothe present. Dr. Fujisawa is a fellow of the International Association forPattern Recognition (IAPR), and the Institute for Electronics, Informationand Communication Engineers, Japan (IEICE), and a member of theACM, American Association for Artificial Intelligence (AAAI), andInformation Processing Society of Japan (IPSJ). He is a fellow ofthe IEEE.
. For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
LIU ET AL.: EFFECTS OF CLASSIFIER STRUCTURES AND TRAINING REGIMES ON INTEGRATED SEGMENTATION AND RECOGNITION OF... 1407




















