
Online Urdu Handwritten Character Recognition System ...
163
Online Urdu Handwritten Character Recognition System Quara-tul-Ain Safdar 2019 Department of Electrical Engineering Pakistan Institute of Engineering and Applied Sciences Nilore, Islamabad 45650, Pakistan
-
Upload
khangminh22 -
Category
Documents
-
view
3 -
download
0
Transcript of Online Urdu Handwritten Character Recognition System ...

Online Urdu Handwritten
Character Recognition System
Quara-tul-Ain Safdar
2019
Department of Electrical Engineering
Pakistan Institute of Engineering and Applied Sciences
Nilore, Islamabad 45650, Pakistan

to R. Sultana, S. M. Malik, and K. U. Khan
who think nobly and act sincerely.

Reviewers and Examiners
Reviewers and Examiners Name, Designation & Address
Foreign Reviewer 1
Dr. Jian Yang,ProfessorDeptt. of Electronic Engineering, Tsinghua University,Bejing, 100084, China
Foreign Reviewer 2
Dr. Choon Ki Ahn,ProfessorRoom 506, Engineering Building, School of ElectricalEngineering, Korea University,Seoul, Korea
Foreign Reviewer 3
Dr. Liangrui Peng,Associate ProfessorDeptt. of Electronic Engineering, Tsinghua University,Beijing, 100084, China
Internal Examiner 1
Dr. Abdul JalilProfessorDeptt. of Electrical Engineering, International IslamicUniversity,Islamabad, Pakistan
Internal Examiner 2
Dr. Mutawarra HussainProfessorDepartment of Computer and Information Sciences,Pakistan Institute of Engineering and Applied Sciences,Islamabad, Pakistan
Internal Examiner 3
Dr. Ijaz Mansoor QuereshiProfessorDeptt. of Electrical Engineering, Air University,Sector E-9, Islamabad
Head of the Department (Name):
Signature with Date:

Certificate of Approval
This is to certify that research work presented in this thesis titled Online Urdu
Handwritten Character Recognition System was conducted by Ms. Quara-
tul-Ain Safdar under the supervision of Dr. Kamran Ullah Khan.
No part of this thesis has been submitted anywhere else for any other degree. This
thesis is submitted to PhD in partial fulfillment of the requirements for the degree
of Doctor of Philosophy in the field of Electrical Engineering.
Student Name: Quara-tul-Ain Safdar Signature:
Examination Committee:
Examiners Name, Designation & Address Signature
Internal Examiner 1Dr. Abdul JalilProfessorDEE, IIU, Islamabad
Internal Examiner 2Dr. Mutawarra HussainProfessorDCIS, PIEAS, Islamabad
Internal Examiner 3Dr. Ijaz Mansoor QuereshiProfessorDEE, Air University, Islamabad
Supervisor Dr. Kamran Ullah KhanPE, DEE, PIEAS, Islamabad
Department Head Dr. Muhammad ArifDCE, DEE PIEAS, Islamabad
Dean Research PIEASDr. Naeem IqbalDCE, DEE PIEAS, Islamabad

Thesis Submission Approval
This is to certify that the work contained in this thesis entitled Online Urdu
Handwritten Character Recognition System was carried out by Quara-tul-
Ain Safdar under my supervision and that in my opinion, it is fully adequate,
in scope and quality, for the degree of PhD Electrical Engineering from Pakistan
Institute of Engineering and Applied Sciences (PIEAS).
Supervisor:
Name: Dr. Kamran Ullah Khan
Date: February 14, 2019
Place: PIEAS, Islamabad
Head, Department of Electrical:
Name: Dr. Muhammad Arif
Date: February 14, 2019
Place: PIEAS, Islamabad

Online Urdu Handwritten
Character Recognition System
Quara-tul-Ain Safdar
Submitted in partial fulfillment of the requirements
for the degree of Ph.D.
2019
Department ofElectrical Engineering
Pakistan Institute of Engineering and Applied Sciences
Nilore, Islamabad 45650, Pakistan

Acknowledgements
At last, I have traveled the (pro)long(ed) thoroughfare of writing PhD thesis. It
seems like walking on a never ending road. It looks like wandering from room to
room hunting for the diamond necklace that is already around the neck but you
are unaware of its presence. However, the whole endeavoring led to a beautiful
destination.
It started from PIEAS, in Nilore. Well, right before the beginning began,
the Higher Education Commission of Pakistan advertised the Indigenous Scholar-
ship, I applied, got selected, my parents encouraged and made me reach at PIEAS.
Let me take you there for a stroll.
Clear blue sky, picturesque hills, wild greenery, twittering birds, and tran-
quillity.... it is PIEAS! (There are jackals, oxen and pigs too, but do not look at
them). ‘Pleasant’, ‘Cooperative’, ‘Nice’, ‘very Nice’... three persons, four words!
they made the long lasting impression.
In the beginning, I was afraid of the ‘Giants of knowledge’ in the depart-
ment of Electrical Engineering, and my PhD supervisor is one of them. Fortu-
nately, they were kind enough to teach me the skills they learnt through out their
lives. And they were sensible enough to make me realize the difficulties coming
along the journey. You know, the most benevolent Allah favored me with a high
quality man as PhD supervisor. With very clear concepts and deep knowledge, my
PhD supervisor polished my learning skills and illuminated my research-avenue
with his intellectual proficiency. He never refused to answer my questions. As
a human being, giving respect to my space, he guided me deciding between ‘ap-
propriate and inappropriate’, and ‘right and wrong’. Like my parents, he always
made me decide independently. It is him who made me how to acknowledge the
things worth to be acknowledged.
Along the way, there were many faces; some turned into well-wishers, some
into friends, and a few into family. There were (uncountable) helping hands as
well and shoulders to whom I could rest on. I may not forget the ‘Golden Girls’ of
session 2009-2011 who filled the blanks with valuable moments. I will remember
ii

the ‘Caring Agglomerates’ of session 2012-2014 for the respect I was endowed with.
And then there were especial ones! The days we had walking, talking, laughing and
laughing, and once again laughing with hurting jaws. The messages of “bhookun
laggiun veryun shadeedun” (I am very very hungry) for lunch and dinners. The
prathas we literally made together and that birthday cake too. The arguments,
counter-arguments, counter counter-arguments, and never seconded each other’s
opinion yet still sang (screamed is a true word for our singing) the songs together.
This is all the love I am holding on forever.
The road was getting longer than usual and time was getting harder on me
because I had got stuck somewhere on the track of publishing my research work.
Mornings met up with the evenings, the evenings transformed into nights, and
the given time was getting over. But the ‘courage’ did not lost me because of the
prayers. The prayers and true support of my family, friends and well-wishers, my
diamonds!, never left me in the darkness of disappointment. Rather my home-
trips always made me fresh and more energetic to carry on the journey in forward.
I owe them all.
From the starting block to the finish line many ups and downs has been
passed. At this moment, I am thankful for the nights that turned into morn-
ings; I am thankful for the friends who turned into family; I am thankful for the
family who turned into absolute prayers and never-ending source of courage and
determination; and I am thankful for the dreams that turned into reality.
The people who deserve to be thanked in the most are the tax-payers of my
country. Because these are them who paved the way for an ordinary girl to take
the course of her dreams. These are them who helped me finding the diamonds of
my necklace. Thanks, sir/madam; all the rest is mute.
I am thankful to the Higher Education Commission of Pakistan (HEC) for
providing scholarship under the Indigenous PhD 5000 Fellowship Program (Phase-
V) for my PhD studies.
iii

Author’s Declaration
I, Quara-tul-Ain Safdar hereby declare that my PhD Thesis Titled Online
Urdu Handwritten Character Recognition System is my own work and
has not been submitted previously by me or anybody else for taking any degree
from Pakistan Institute of Engineering and Applied Sciences (PIEAS) or any other
university / institute in the country / world. At any time if my statement is found
to be incorrect (even after my graduation), the university has the right to withdraw
my PhD degree.
(Quara-tul-Ain Safdar)
February 14, 2019
PIEAS, Islamabad.
iv

Plagiarism Undertaking
I, Quara-tul-Ain Safdar solemnly declare that research work presented in the
thesis titled Online Urdu Handwritten Character Recognition System is
solely my research work with no significant contribution from any other person.
Small contribution / help wherever taken has been duly acknowledged or referred
and that complete thesis has been written by me.
I understand the zero tolerance policy of the HEC and Pakistan Institute of En-
gineering and Applied Sciences (PIEAS) towards plagiarism. Therefore, I as an
author of the thesis titled above declare that no portion of my thesis has been
plagiarized and any material used as reference is properly referred / cited.
I undertake that if I am found guilty of any formal plagiarism in the thesis titled
above even after the award of my PhD degree, PIEAS reserves the rights to with-
draw / revoke my PhD degree and that HEC and PIEAS has the right to publish
my name on the HEC / PIEAS Website on which name of students are placed
who submitted plagiarized thesis.
(Quara-tul-Ain Safdar)
February 14, 2019
PIEAS, Islamabad.
v

Copyright Statement
The entire contents of this thesis entitled Online Urdu Handwritten Char-
acter Recognition System was carried out by Quara-tul-Ain Safdar are an
intellectual property of Pakistan Institute of Engineering and Applied Sciences
(PIEAS). No portion of the thesis should be reproduced without obtaining ex-
plicit permission from PIEAS.
vi

Contents
Acknowledgements ii
Author’s Declaration iv
Copyright Statement vi
Contents vii
List of Figures xi
List of Tables xv
Abstract xxi
List of Publications and Patents xxii
List of Abbreviations and Symbols xxiii
1 Introduction 1
1.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Place of Handwriting in Digital Age . . . . . . . . . . . . . . . . . . 4
1.3 Word Processing Software . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Integrating Handwriting with Technology . . . . . . . . . . . . . . . 6
1.5 Difficulties Involved in Handwriting Recognition . . . . . . . . . . . 7
1.6 Online and Offline Handwriting Recognition . . . . . . . . . . . . . 9
1.6.1 Dynamic Information acquired through Online Hardware . . 10
1.6.2 Advantages of Online Handwriting Recognition over the Of-
fline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.6.3 Available Handwriting Recognition Software . . . . . . . . . 12
1.7 Problem Statement: Online Handwritten Urdu Character Recognition 14
vii

1.8 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.9 Literature Review . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.10 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.11 Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 Urdu 22
2.1 Urdu Character-Set . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.1.1 Urdu Diacritics . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.1.2 Single and Multi-Stroke Characters in Urdu . . . . . . . . . 24
2.1.3 Word-Breakdown Structure in Urdu . . . . . . . . . . . . . . 24
2.1.4 Half-Forms of Urdu Alphabets . . . . . . . . . . . . . . . . . 25
2.2 Urdu Fonts: Where do these Half-Forms come from? . . . . . . . . 27
2.2.1 The Nastalique Font . . . . . . . . . . . . . . . . . . . . . . 28
2.2.1.1 Characteristics of Nastalique Font . . . . . . . . . . 31
2.3 Idiosyncrasies of Urdu-Writing . . . . . . . . . . . . . . . . . . . . . 33
3 System Description 38
3.1 Data Acquisition . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.1.1 GUI: Writing Canvas . . . . . . . . . . . . . . . . . . . . . . 38
3.1.2 Information in Handwritten Character-Signal . . . . . . . . 39
3.1.3 About the Data . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.1.4 Instructions for writing . . . . . . . . . . . . . . . . . . . . . 42
3.2 Character Database . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.2.1 Handwritten Samples . . . . . . . . . . . . . . . . . . . . . . 44
3.3 Preprocessing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.3.1 Re-Sampling . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.3.2 Smoothing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4 Pre-Classification 50
4.1 Pre-Classification of Half-Forms . . . . . . . . . . . . . . . . . . . . 50
4.2 Results of Pre-Classification . . . . . . . . . . . . . . . . . . . . . . 52
4.3 Further Reflections of Pre-Classification . . . . . . . . . . . . . . . . 56
5 Features Extraction 58
viii

5.1 Wavelet Transform . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.1.1 Daubechies Wavelets . . . . . . . . . . . . . . . . . . . . . . 63
5.1.2 Discrimination Power of Wavelets . . . . . . . . . . . . . . . 63
5.1.3 Biorthogonal Wavelets . . . . . . . . . . . . . . . . . . . . . 65
5.1.4 Discrete Meyer Wavelets . . . . . . . . . . . . . . . . . . . . 65
5.2 Structural Features . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.3 Sensory Input Values . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6 Final Classification 72
6.1 Final Classifiers with Pre-Classification . . . . . . . . . . . . . . . . 72
6.2 Final Classifiers without Pre-Classification . . . . . . . . . . . . . . 74
6.3 Artificial Neural Networks . . . . . . . . . . . . . . . . . . . . . . . 74
6.4 Support Vector Machines (SVMs) . . . . . . . . . . . . . . . . . . . 75
6.5 Recurrent Neural Networks: Long Short-Term Memory . . . . . . . 77
6.6 Deep Belief Network . . . . . . . . . . . . . . . . . . . . . . . . . . 79
6.7 AutoEncoders . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.8 Results and Discussions . . . . . . . . . . . . . . . . . . . . . . . . 82
6.9 Results with Pre-Classification . . . . . . . . . . . . . . . . . . . . . 82
6.10 Results without Pre-Classification . . . . . . . . . . . . . . . . . . . 82
6.11 Maximum Recognition Rate . . . . . . . . . . . . . . . . . . . . . . 85
6.11.1 Overall Accuracy . . . . . . . . . . . . . . . . . . . . . . . . 86
6.11.2 Polling or Subset-wise Accuracy . . . . . . . . . . . . . . . . 87
6.11.3 Character-wise Accuracy . . . . . . . . . . . . . . . . . . . . 87
6.12 Error Analysis using Confusion Matrices . . . . . . . . . . . . . . . 87
6.12.1 Confusing Characters . . . . . . . . . . . . . . . . . . . . . . 91
7 Conclusion 95
7.1 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
Appendices 98
Appendix A Confusion Matrices 99
A.1 Confusion Matrices of Support Vector Classifier with db2 -Wavelet-
Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
ix

A.2 Confusion Matrices of Support Vector Classifier with Sensory Input
Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
Appendix B Handwritten Urdu Character Samples 115
References 122
x

List of Figures
Figure 1.1 Ancient symbols for alphabets [7] . . . . . . . . . . . . . . . 2
Figure 2.1 Urdu alphabets (fundamental) . . . . . . . . . . . . . . . . . 23
Figure 2.2 Alphabets added to fundamental Urdu alphabets to cope
with phonetic peculiarities . . . . . . . . . . . . . . . . . . . 23
Figure 2.3 Examples of Urdu (fundamental) alphabets with major and
(none, one-, two-, or three-) minor strokes . . . . . . . . . . 25
Figure 2.4 Constructing the Urdu-words . . . . . . . . . . . . . . . . . 26
Figure 2.5 All Urdu characters in all half-forms. . . . . . . . . . . . . . 26
Figure 2.6 Single- and multi-strokes half-forms of Urdu Characters . . . 28
Figure 2.7 Examples of words composed of half-form characters. . . . . 29
Figure 2.8 Examples of words composed from (segmented) handwritten
half-form characters . . . . . . . . . . . . . . . . . . . . . . 29
Figure 2.9 Different Urdu fonts . . . . . . . . . . . . . . . . . . . . . . 30
Figure 2.10 Context dependency . . . . . . . . . . . . . . . . . . . . . . 33
Figure 2.11 Distinct features of Nastalique font . . . . . . . . . . . . . . 34
Figure 2.12 Idiosyncrasies of Urdu writing emphasizing ligature overlap,
writing directions, and placement of diacritics . . . . . . . . 35
Figure 2.13 Idiosyncrasies of Urdu writing emphasizing presence and
characteristics of loops in different writing styles . . . . . . 36
Figure 2.14 Idiosyncrasies of Urdu writing emphasizing presence or ab-
sence of loop in the same character penned by different hands 36
Figure 3.1 Block diagram of the proposed Online Urdu character recog-
nition system: from data acquisition to preprocessing to pre-
classification to feature extraction to final classification. . . . 39
Figure 3.2 Writing interface for digitizing tablet . . . . . . . . . . . . . 40
xi

Figure 3.3 An Urdu word is written on the canvas with the help of a
stylus and tablet . . . . . . . . . . . . . . . . . . . . . . . . 41
Figure 3.4 Examples of handwritten character using stylus and digitiz-
ing tablet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
Figure 3.5 Examples of handwritten character using stylus and digitiz-
ing tablet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
Figure 3.6 Examples of handwritten character using stylus and digitiz-
ing tablet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Figure 3.7 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet . . 46
Figure 3.8 Re-sampling and Down-sampling of characters . . . . . . . . 48
Figure 3.9 Smoothing of Urdu Handwritten Samples . . . . . . . . . . . 49
Figure 4.1 Pre-classification of initial half-forms on the basis of stroke
count, position and shape of diacritics . . . . . . . . . . . . . 51
Figure 4.2 Pre-classification of medial half-forms on the basis of stroke
count, position and shape of diacritics . . . . . . . . . . . . . 52
Figure 4.3 Pre-classification of terminal half-forms on the basis of
stroke count, position and shape of diacritics . . . . . . . . . 53
Figure 5.1 Wavelet coefficients for ‘sheen’ and ‘zwad’ . . . . . . . . . . 59
Figure 5.2 Wavelet coefficients for different Urdu characters in their
half-forms. Top row shows the character, and x(t) and y(t)
of its major stroke. Second and third rows show level-2
db2 wavelet approximation, and level-4 db2 wavelet detail
coefficients of x(t) and y(t) respectively . . . . . . . . . . . . 61
Figure 5.3 Wavelet coefficients for ‘Tay’ . . . . . . . . . . . . . . . . . . 62
Figure 5.4 Wavelet coefficients for ‘kaafI’ . . . . . . . . . . . . . . . . . 64
Figure 5.5 Wavelet coefficients for ‘hamza’ . . . . . . . . . . . . . . . . 66
Figure 5.6 Wavelet coefficients for ‘ghain’ and ‘fay’ . . . . . . . . . . . . 68
Figure 5.7 Wavelet coefficients for ‘daal’ and ‘wao’. Due to flow of
writing by the users ‘daal’ has included a loop which makes
its wavelets transform similar to ‘wao’ . . . . . . . . . . . . . 69
xii

Figure 5.8 Wavelet coefficients for three different handwritten samples
of ‘meem’ in initial form. Top row shows the character
‘meem’ in initial form written differently by different users,
and x(t) and y(t) of its major stroke. Second and third
rows show level-2 db2 wavelet approximation, and level-4
db2 wavelet detail coefficients of x(t) and y(t) respectively . 70
Figure 5.9 Wavelet coefficients for Urdu character ‘hay ’ in their half-
forms. Top row shows character ‘hay ’, and x(t) and y(t)
of its major stroke. Second and third rows show level-2
db2 wavelet approximation, and level-4 db2 wavelet detail
coefficients of x(t) and y(t) respectively . . . . . . . . . . . . 71
Figure 6.1 Multi-layer perceptron neural network . . . . . . . . . . . . 75
Figure 6.2 Bidirectional multi-layer recurrent neural network . . . . . . 77
Figure 6.3 A simple recurrent neural network. Along solid edges acti-
vation is passed as in feed-forward network. Along dashed
edges a source node at each time t is connected to a target
node at each following time t+1 . . . . . . . . . . . . . . . . 78
Figure 6.4 Confusing pair of ‘fay ’ and ‘ghain’ in medial forms . . . . . 93
Figure 6.5 Confusing pair of ‘Tay ’ and ‘hamza’ in medial forms . . . . 94
Figure 6.6 Confusing pair of ‘ain’ and ‘swad ’ in medial forms . . . . . . 94
Figure 6.7 Confusing pair of ‘meem’ and ‘swad ’ in initial forms . . . . . 94
Figure 6.8 Confusing pair of ‘daal ’ and ‘wao’ in terminal forms . . . . . 94
Figure B.1 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
Figure B.2 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Figure B.3 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
xiii

Figure B.4 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
Figure B.5 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
Figure B.6 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
Figure B.7 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
Figure B.8 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
Figure B.9 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-9 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
Figure B.10 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
Figure B.11 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-11 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
Figure B.12 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-12 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
Figure B.13 A handwritten ensemble of all Urdu characters written on
the canvas with the help of a stylus and digitizing tablet by
writer-13 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
xiv

List of Tables
Table 1.1 Comparison of the proposed online Urdu handwritten char-
acter recognition method with Arabic work . . . . . . . . . . 18
Table 1.2 Comparison of the proposed online Urdu handwritten char-
acter recognition method with Persian work . . . . . . . . . . 18
Table 1.3 Comparison of online Urdu handwritten character recognition 19
Table 4.1 Pre-classification of Urdu character-set. The encircled num-
bers indicate the cardinality of final stage subsets that could
be obtained with the help of the proposed pre-classifier . . . . 54
Table 4.2 Characters recognized at pre-classification stage and don’t
require any further classification . . . . . . . . . . . . . . . . 55
Table 6.1 Features-classifier Summary . . . . . . . . . . . . . . . . . . . 73
Table 6.2 ANN configurations (trained using wavelet db2 approxima-
tion and detailed coefficients). . . . . . . . . . . . . . . . . . 76
Table 6.3 RNN configurations (trained using sensory input values). . . . 80
Table 6.4 DBN configurations (trained using wavelet dmey approxima-
tion and detailed coefficients). . . . . . . . . . . . . . . . . . 81
Table 6.5 Recognition rates for each subset of handwritten half-form
Urdu characters obtained from the pre-classifier. Results ob-
tained with using ANNs, and SVMs using different features
are presented for comparison. . . . . . . . . . . . . . . . . . . 83
Table 6.6 Recognition rates for each subset of handwritten Urdu char-
acters obtained from the pre-classifier. Results obtained with
DBN, AE-DBN, AE-SVM and RNN using different features
are presented for comparison. . . . . . . . . . . . . . . . . . . 84
xv

Table 6.7 Recognition rates for half-form Urdu characters without go-
ing through pre-classification. Results are obtained using
SVMs, DBN, AE-DBN, AE-SVM and RNN using different
features. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Table 6.8 Characters accuracy chart . . . . . . . . . . . . . . . . . . . . 88
Table 6.9 Confusion matrix for 4-stroke characters (initial half-form)
with dot diacritic above the major stroke . . . . . . . . . . . 89
Table 6.10 Confusion matrix for initial half-forms 2-stroke characters
with other-than-dot diacritic above the major stroke. Overall
accuracy for this subset is 91.9% . . . . . . . . . . . . . . . . 90
Table 6.11 Confusion matrix for medial half-form 2-stroke characters
with dot diacritic above the major stroke. Overall accuracy
for this subset is 93.6% . . . . . . . . . . . . . . . . . . . . . 90
Table 6.15 Confusion matrix for medial half-forms 2-stroke characters
with other-than-dot diacritic above the major stroke. Overall
accuracy for this subset is 93.3% . . . . . . . . . . . . . . . . 92
Table 6.16 Confusion matrix for terminal half-forms 2-stroke characters
with dot diacritic above the major stroke. Overall accuracy
for this subset is 96.7% . . . . . . . . . . . . . . . . . . . . . 92
Table 6.17 Confusion matrix for terminal half-forms 4-stroke characters
with dot diacritic above the major stroke. Overall accuracy
for this subset is 99.6% . . . . . . . . . . . . . . . . . . . . . 93
Table A.1 Confusion matrix for single-stroke characters (initial half-
form). It contains 7 characters. Overall accuracy: 94.7% . . . 99
Table A.2 Confusion matrix for 2-stroke characters (initial half-form)
with dot diacritic above the major stroke. It contains 6 char-
acters. Overall accuracy: 99.1% . . . . . . . . . . . . . . . . . 100
Table A.3 Confusion matrix for 2-stroke characters (initial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 6 characters. Overall accuracy: 91.9% . . . . . . . . . . 100
xvi

Table A.4 Confusion matrix for 2-stroke characters (initial half-form)
with dot diacritic below the major stroke. It contains 3 char-
acters. Overall accuracy: 97.2% . . . . . . . . . . . . . . . . . 100
Table A.5 Confusion matrix for 2-stroke characters (initial half-form)
with other-than-dot diacritic below the major stroke. It con-
tains 2 characters. Overall accuracy: 98.3% . . . . . . . . . . 101
Table A.6 Confusion matrix for 3-stroke characters (initial half-form)
with dot diacritic above the major stroke. It contains 3 char-
acters. Overall accuracy: 94.4% . . . . . . . . . . . . . . . . . 101
Table A.7 Confusion matrix for 3-stroke characters (initial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 2 characters. Overall accuracy: 100% . . . . . . . . . . 101
Table A.8 Confusion matrix for 4-stroke characters (initial half-form)
with dot diacritic above the major stroke. It contains 3 char-
acters. Overall accuracy: 88.8% . . . . . . . . . . . . . . . . . 101
Table A.9 Confusion matrix for 4-stroke characters (initial half-form)
with dot diacritic below the major stroke. It contains 3 char-
acters. Overall accuracy: 92.7% . . . . . . . . . . . . . . . . . 102
Table A.10 Confusion matrix for single-stroke characters (medial half-
form). It contains 8 characters. Overall accuracy: 89.1% . . . 102
Table A.11 Confusion matrix for 2-stroke characters (medial half-form)
with dot diacritic above the major stroke. It contains 8 char-
acters. Overall accuracy: 93.6% . . . . . . . . . . . . . . . . . 102
Table A.12 Confusion matrix for 2-stroke characters (medial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 4 characters. Overall accuracy: 93.3% . . . . . . . . . . 103
Table A.13 Confusion matrix for 2-stroke characters (medial half-form)
with dot diacritic below the major stroke. It contains 2 char-
acters. Overall accuracy: 98.3% . . . . . . . . . . . . . . . . . 103
Table A.14 Confusion matrix for 3-stroke characters (medial half-form)
with dot diacritic above the major stroke. It contains 2 char-
acters. Overall accuracy: 95.0% . . . . . . . . . . . . . . . . . 103
xvii

Table A.15 Confusion matrix for 3-stroke characters (medial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 2 characters. Overall accuracy: 95.8% . . . . . . . . . . 103
Table A.16 Confusion matrix for 4-stroke characters (medial half-form)
with dot diacritic above the major stroke. It contains 2 char-
acters. Overall accuracy: 95.8% . . . . . . . . . . . . . . . . . 104
Table A.17 Confusion matrix for 4-stroke characters (medial half-form)
with dot diacritic below the major stroke. It contains 2 char-
acters. Overall accuracy: 100% . . . . . . . . . . . . . . . . . 104
Table A.18 Confusion matrix for single-stroke characters (terminal half-
form). It contains 16 characters. Overall accuracy: 94.7% . . 104
Table A.19 Confusion matrix for 2-stroke characters (terminal half-form)
with dot diacritic above the major stroke. It contains 9 char-
acters. Overall accuracy: 96.7% . . . . . . . . . . . . . . . . . 105
Table A.20 Confusion matrix for 2-stroke characters (terminal half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 7 characters. Overall accuracy: 99.0% . . . . . . . . . . 105
Table A.21 Confusion matrix for 3-stroke characters (terminal half-form)
with dot diacritic above the major stroke. It contains 3 char-
acters. Overall accuracy: 99.4%. . . . . . . . . . . . . . . . . 105
Table A.22 Confusion matrix for 4-stroke characters (terminal half-
forms) with dot diacritic above the major stroke. It contains
4 characters. Overall accuracy: 99.6% . . . . . . . . . . . . . 106
Table A.23 Confusion matrix for single-stroke characters (initial half-
form). It contains 7 characters. Overall accuracy: 95.4% . . . 107
Table A.24 Confusion matrix for 2-stroke characters (initial half-form)
with dot diacritic above the major stroke. It contains 6 char-
acters. Overall accuracy: 99.0% . . . . . . . . . . . . . . . . . 107
Table A.25 Confusion matrix for 2-stroke characters (initial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 6 characters. Overall accuracy: 89.3% . . . . . . . . . . 108
xviii

Table A.26 Confusion matrix for 2-stroke characters (initial half-form)
with dot diacritic below the major stroke. It contains 3 char-
acters. Overall accuracy: 98.6% . . . . . . . . . . . . . . . . . 108
Table A.27 Confusion matrix for 2-stroke characters (initial half-form)
with other-than-dot diacritic below the major stroke. It con-
tains 2 characters. Overall accuracy: 96.0% . . . . . . . . . . 108
Table A.28 Confusion matrix for 3-stroke characters (initial half-form)
with dot diacritic above the major stroke. It contains 3 char-
acters. Overall accuracy: 94.6% . . . . . . . . . . . . . . . . . 109
Table A.29 Confusion matrix for 3-stroke characters (initial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 2 characters. Overall accuracy: 100% . . . . . . . . . . 109
Table A.30 Confusion matrix for 4-stroke characters (initial half-form)
with dot diacritic above the major stroke. It contains 3 char-
acters. Overall accuracy: 86.6% . . . . . . . . . . . . . . . . . 109
Table A.31 Confusion matrix for 4-stroke characters (initial half-form)
with dot diacritic below the major stroke. It contains 3 char-
acters. Overall accuracy: 94.0% . . . . . . . . . . . . . . . . . 109
Table A.32 Confusion matrix for single-stroke characters (medial half-
form). It contains 8 characters. Overall accuracy: 93.7% . . . 110
Table A.33 Confusion matrix for 2-stroke characters (medial half-form)
with dot diacritic above the major stroke. It contains 8 char-
acters. Overall accuracy: 90.0% . . . . . . . . . . . . . . . . . 110
Table A.34 Confusion matrix for 2-stroke characters (medial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 4 characters. Overall accuracy: 93.0% . . . . . . . . . . 110
Table A.35 Confusion matrix for 2-stroke characters (medial half-form)
with dot diacritic below the major stroke. It contains 2 char-
acters. Overall accuracy: 100% . . . . . . . . . . . . . . . . . 111
Table A.36 Confusion matrix for 3-stroke characters (medial half-form)
with dot diacritic above the major stroke. It contains 2 char-
acters. Overall accuracy: 97.0% . . . . . . . . . . . . . . . . . 111
xix

Table A.37 Confusion matrix for 3-stroke characters (medial half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 2 characters. Overall accuracy: 98.0% . . . . . . . . . . 111
Table A.38 Confusion matrix for 4-stroke characters (medial half-form)
with dot diacritic above the major stroke. It contains 2 char-
acters. Overall accuracy: 96.0% . . . . . . . . . . . . . . . . . 111
Table A.39 Confusion matrix for 4-stroke characters (medial half-form)
with dot diacritic below the major stroke. It contains 2 char-
acters. Overall accuracy: 100% . . . . . . . . . . . . . . . . . 112
Table A.40 Confusion matrix for single-stroke characters (terminal half-
form). It contains 16 characters. Overall accuracy: 96.3% . . 112
Table A.41 Confusion matrix for 2-stroke characters (terminal half-form)
with dot diacritic above the major stroke. It contains 9 char-
acters. Overall accuracy: 91.5% . . . . . . . . . . . . . . . . . 113
Table A.42 Confusion matrix for 2-stroke characters (terminal half-form)
with other-than-dot diacritic above the major stroke. It con-
tains 7 characters. Overall accuracy: 99.4% . . . . . . . . . . 113
Table A.43 Confusion matrix for 3-stroke characters (terminal half-form)
with dot diacritic above the major stroke. It contains 3 char-
acters. Overall accuracy: 100%. . . . . . . . . . . . . . . . . . 113
Table A.44 Confusion matrix for 4-stroke characters (terminal half-
forms) with dot diacritic above the major stroke. It contains
4 characters. Overall accuracy: 98.5% . . . . . . . . . . . . . 114
xx

Abstract
This thesis presents an online handwritten character recognition system for Urdu
handwriting. The main target is to recognize handwritten script inputted on the
touch screen of a mobile device in particular, and other touch input devices in
general. Urdu alphabets are difficult to recognize because of inherent complexities
of the script. In a script, Urdu alphabets appear in full as well as in half-forms:
initials, medials, and terminals. Ligatures are formed by combining two or more
half-form characters. The character-set in half-forms has 108 elements. The whole
character-set of 108 elements is too difficult to be classified accurately by a single
classifier.
In this work, a framework for development of online Urdu handwriting
recognition system for smartphones has been presented. A pre-classifier is de-
signed to segregate the large Urdu character-set into 28 smaller subsets, based on
the number of strokes in a character and the position and shape of the diacrtics.
This pre-classification allows to cope with the demand of robust and accurate
recognition on processors having relatively low computational power and limited
memory available to mobile devices, through banks of computationally less com-
plex classifiers. Based on the decision of the pre-classifier, the appropriate classi-
fier from the bank of classifiers is loaded to the memory to achieve the recognition
task. A comparison of different classifier-feature combinations is presented in this
study to exhibit the features’ discrimination capability and classifiers’ recognition
ability. The subsets are recognized with different machine learning algorithms
such as artificial neural networks, support vector machines, deep belief networks,
long short-term memory recurrent neural networks, autoencoders-support vector
machines, and autoencoders-deep belief networks. These classifiers are trained
with wavelet transform features, structural features, and with sensory input val-
ues. Maximum overall classification accuracy of 97.2% has been achieved. A large
database of handwritten Urdu characters is developed and employed in this study.
This database contains 10800 samples of the 108 Urdu half-form characters (100
samples of each character) acquired from 100 writers.
xxi

List of Publications and Patents
Journal Publication:
• Safdar, Quara tul Ain, Khan, Kamran Ullah, and Peng, Lianguri, “A Novel
Similar Character Discrimination Method for Online Handwritten Urdu
Character Recognition in Half Forms”, Scientia Iranica, vol. , pp. , 2018.
ISSN=“1026-3098”, DOI=“10.24200/sci.2018.20826”
Conference Publication:
• Q. Safdar and K. U. Khan, “Online Urdu Handwritten Character Recog-
nition: Initial Half Form Single Stroke Characters”, in 12th International
Conference on Frontiers of Information Technology, Dec 2014, pp. 292–297.
xxii

List of Abbreviations and
Symbols
AE AutoEncodersANN Artificial Neural NetworkBPNN Back Propagation Neural Network
BRNN Bidirectional Recurrent Neural NetworkDBN Deep Belief Network
GUI Graphical User Interface
IHF Initial Half-FormLSTM Long Short-Term Memory
MHF Medial Half-FormMLP Multi-Layer Perceptron
NLPD National Language Promotion Department
OCR Optical Character Recognition
OS Operating System
PDA Personal Digital Assistant
POS Point of SaleRBF Radial Basis FunctionRBM Restricted Boltzmann MachineRNN Recurrent Neural NetworkSC Stroke CountSVC Support Vector Classifier
SVM Support Vector Machine
THF Terminal Half-FormUK United Kingdom
USA United Staes of America
xxiii

Chapter 1
Introduction
Online handwritten character recognition is a process in which data-stream for
handwritten characters is collected, recognized and converted to editable text as
the writer writes on a digital surface [1], [2]. The digital surface may be a tablet or
any hand-held device (like personal digital assistant, smartphone etc.) that allows
handwriting on its surface either by an electronic pen/stylus or with a finger-tip.
1.1 Background
Writing by hand, an illustration of a synchronization of mind and body, is one of
the most mesmerizing and influential inventions of human beings. It is seeded in
artistic depictions engraved on rocks, etched in sand, and marked on walls that at
last morphed into alphabets [3] (see Figure 1.1), ligatures, graphemes, and words.
Each hand-drawn shape, each handwritten word is not mere a scribbling expres-
sion but the most natural way of information exchange. It reminds us that we
are still conducting the ancient act of using hands to transcribe what rests in our
minds. Reading and writing play a vital role to develop a civilized society. Since
its early days thereabouts 5000 years ago in Mesopotamia and Egypt different
symbols (alphabets) were coined [4] in order to save thoughts and facts. Symbols
were imprinted or scratched in clay, or drawn on parchment, wax tablets, and
papyrus with the help of quill pens and reed pens. They also made use of thin
metal sticks called stylus (pl. styluses or styli) for writing in wax tablets and for
palm-leaf manuscripts. With the passage of time, interaction among individuals
1

Introduction
and tribes increased. Kingdoms expanded with which keeping track of historical
and environmental events became the calendrical and political necessity to survive
and rule. The complexity of administrative actions and trade transactions out-
grew human memory. It required the administrators and traders to keep record
of administrative affairs and transactions in some permanent form [5]. The obser-
vance of this substantial requirement helped writing to evolve as a more reliable
method for registering and presenting the matters and events, deals and deeds,
actions and transactions, and many other goings-on. Earlier the implements or
instruments used to write something were quills, reeds, and metallic sticks. To
speedup the writing process the writing implements were gradually complemented
by letterpress, stamps, chalks, split-nib pens, dip pens, graphite pencils etc. [6].
With the development of pen and paper handwriting became prevailing mode for
documentation. Afterwards, the handwriting turned to be the part of literacy
culture, qualified as a rudiment of academics and considered imperative to pro-
fessional life. Nowadays, the mode of writing is going through a dramatic change.
Early
Semitic
1800
Phoenician
1100 1100 900Greek
800 700Roman
100 CE
Ox
House
Throwing
Stick
Egyptian
2000 BCE
Early
Semitic
1800
Phoenician
1100
Roman
100 CE
Greek
600
Egyptian
2000
Sumerian
4000 BCE
Early
Semitic
1800
Phoenician
1100
Roman
100 CE
Greek
600
Early
Latin
300
Early
Hebrew
1000
Egyptian
2000 BCE
Figure 1.1: Ancient symbols for alphabets [7]
With the emergence of smart IT equipment and digital writing devices it is be-
ing observed that writing by hand is getting less and less in our daily lives [8].
These days it is just to use a keypad or a touch-sensitive screen to do number
of jobs with a single keypress or tap, like operating machines, withdrawing cash,
2

Introduction
filling forms, searching a book or an article in an online repository, posting mes-
sages, uploading images, adding animations and much more. As we type merrily
on keypads or signal to touch-screens, handwriting certainly seems like a dying
form. In this scenario one of the two questions should be addressed; whether this
withering away of handwriting is really a setback or it is inexorable evolution of
language-forms unfolded over the centuries from oral to written to printed, and
now in the form of electronic-ink [9]. Sometimes, at some places it’s just signing
naively on a credit-card-pay-screen using mere a finger or scribbling a signature
with an electronic-pen at the grocery store which tells us that handwriting needs
not fold up and die. Moreover, the desire to coalesce/fuse the convenience of
handwriting with the need to use, maintain, and communicate digital information
requires the digital industry to embed handwritten-input into hand-held devices,
smart boards and smartphones, tablet PCs, personal digital assistants (PDAs),
and other ubiquitous computing devices. From mainframes to ubiquitous devices,
shaping of personal computers and miniature devices have taken an intellectual
leap. Undoubtedly, invention of transistors and ICs revolutionized the technologi-
cal means, however mere the availability of instruments and devices cannot ensure
the breakthroughs. Computing for portable devices and smart environments en-
hanced the human-machine interaction and becomes the key turning point in the
modern world. Looking back, we see that primarily the mainframes were the ma-
chines shared by lots of people. Afterwards, in personal computers era people were
put into a computer generated virtual reality while the user and machine were star-
ing at each other across the desktop. In the current time, the mobile computing
made the machines to live out here in the physical world with the users. Mo-
bile devices which simply started as portable telephones evolved into smartphones
and smart computing devices. Undoubtedly, this evolution of portable computing
devices reshaped the world of personal computers. An important change that hap-
pened with this development is the change in mode of input to portable devices.
Soft(ware)-keyboard-replicas replaced the hard keyboarding which led the atten-
tion towards non-keyboard-based interfaces. An interface which interacts with
the device by taking input either through a pen or a finger-tip(s) is said to be a
non-keyboard-based interface. Input through a pen moving on a tablet or through
3

Introduction
a finger-tip tapping on a touch-screen swayed the research communities to design
and develop the interfaces that could realize the handwritten inputs efficiently.
1.2 Place of Handwriting in Digital Age
Handwriting represents a person’s identity and forms a unique part of a civiliza-
tion. It is less restrictive, more functional, and creative as compared to keyboard-
ing which is a digital counterpart of handwriting. Handwriting of an individual
and handwritten scripts of a society show evolution of text not only for a per-
son but more importantly for a civilization. Written languages either made up of
letters like Latin, English, German, Devanagari, Arabic, Urdu etc. or consist of
characters like Mandarin, Japanese etc. are the examples for evolution of text.
One can see through handwritten documents what went before. Writing by hand
is an integral part of not only our daily life but also a learning tool in any edu-
cational system. It is developed as a functional skill because of majority of our
academic examinations are still handwritten. Even a good handwriting can serve
as a benefit in scholastics. Usually the students who can write legible gets an ad-
vantage over those who cannot. Although technological means are becoming part
of our class rooms yet students’ ability to write clearly is still the center of atten-
tion. We all know that writing by hand is less restrictive. It gives the writer a free
hand to write things and thoughts in any style, draw any kind of shapes, connect
different sections together, scribble side notes, encircle important information and
much more wherever and whenever it makes sense. Besides retaining creative flow
use of pen also comes up with cognitive benefits. Writing and rewriting notes and
information by hand makes it more likely to remember it.
1.3 Word Processing Software
On the other hand, with the development of word processing software, creation,
updating and maintenance of documents can be viewed on a different level. Doc-
ument is typed up, saved with a single click, gone through editing as many times
as necessary. Pictures, shapes and diagrams are allowed to add although graphics
made in word processing softwares are often not as sophisticated as those created
4

Introduction
with specialized programs. Spelling and grammatical mistakes can be corrected
using in-built spell and grammar checking option. Text formatting, margin ad-
justments, and page layout settings are available to make the document look more
appealing, easy to read, and above all in a standard format. Generating multiple
copies and keeping older to newer versions of a document becomes an easy task
with the help of word processors. Converting the document from soft-form to
hard-form, that is to say, taking a printout is nothing but mere a story of a click
(if a printer is already installed). Moreover, the availability of the document files
on various platforms, and their synchronization across multiple devices have made
the documents handling somewhat an easier job.
However, the other side of the picture narrates that typing up in a lan-
guage which uses alphabets different from English (Latin script) is not a trivial
exercise. In fact, there are a number of languages which do not follow Latin
script and therefore have different character-sets. For example, Bulgarian, Be-
larusian, Russian, Ukrainian, Macedonian, Serbian, Old Church Slavonic, Church
Slavonic use Cyrillic alphabets. Bengali, Devanagari, Gurmukhi, Gujarati, and
Tibetan belong to Brahmic family of scripts. Urdu follows Arabic and Persian
like scripts. Chinese, Japanese, Korean, Hebrew, Greek, Armenian, Georgian,
each has its own set of alphabets/characters not matching with Latin alphabets
normally found on a standard keyboard. Moreover, Latin characters with diacritic
(circumflex or umlaut), part of some Latin script based languages (e.g. German,
French, Swedish, Finnish, Spanish, Italian etc.) are not easily accessible on a key-
board. Similarly taking the example of Japanese language used in daily life, there
are more than 3000 Kanji and Kana (Chinese ideographs (Kanji) and Japanese
syllabaries (Kana) where each of the syllabaries appears for one consonant-vowel
pair) characters and digits. Even though designating a nominal subset from larger
character-set (of 3000 characters), there would be at least 100 characters in the
subset. This subset is even too large to input through a keyboard for an ordinary
user [10]. Furthermore, incorporating complex mathematical symbols and equa-
tions in a document is not that much straight forward as that of typing a simple
English sentence. It is quite easier to hand write an equation (on a hard copy of
the document) than using some equation typing software.
5

Introduction
1.4 Integrating Handwriting with Technology
From a technology user’s point of view, such machines are receiving a warm wel-
come in which ease of human-machine interaction is well focused. Input through
handwriting is one such example of convenience that is being tried to provide in
smart machines. So what if we merge the convenience of handwriting with the
smartness of machines?
Earlier, personal computers and machines were provided with keyboards
and keypads. On a keyboard there are two ways to type, either by using two fingers
(Hunt and Peck Method, also called Eagle Finger Typing) or using both hands
where the fingers are set down on A, S, D, F and J, K, L keys and thumbs are used
to access the space bar (Touch-Typing or Touch-Keyboarding). In touch-typing, a
string of keys is typed pressing the keys one finger down at a time without looking
at the keyboard. A typed sentence is obtained through a series of coordinated and
automatized movements of fingers. However in touch-typing, to press the right
key with the right finger requires some beginner’s knowledge. Moreover, typing
rehearsal becomes necessary so that brain can learn coordination of fingers and
intricate movements of fingers could be executed easily at first and at last speedily.
Touch-keyboarding has already been replaced by touch-sensitive screens, panels
and interfaces in writing pads, smartphones, tablets, phablets and many other
portable and functional common electronics, and even in non-portable machines.
A touch-sensitive screen is a device which acts not only as an input device but also
as an output device. Displayed options on a touchscreen (output) can be chosen by
touching the screen (input) with the help of finger(s) or a special stylus (however,
for most modern touch-screens stylus has become an optional choice). The use of
touch-screens is established in various fields like heavy industry, medical, commu-
nication etc.; especially in those areas where keyboard and mouse may not permit
a suitably intuitive, instantaneous, or precise and accurate interaction between
the user and displayed content like kiosks, ATMs, point of sale (POS) systems,
electronic voting machines etc. Varying from machine to machine either a menu
driven interface or ‘app-icons’ are provided with touch-screens to access different
options or applications. Certainly, the technology with embedded touch screens
and intuitive user interfaces has brought great convenience to human-machine in-
6

Introduction
teraction. However, well effective interfacing is not an easy task. Moreover, there
are scenarios, like note taking, drawing/painting or electronic document annota-
tion, where a significant amount of data is taken as input, for which mere touch
interaction is not enough. To make these tasks easier and more natural there
should be other input methods. Today, for natural writing, note taking and draw-
ing, a pen or an active stylus can be viewed as the most potential device among
all input devices. Being precise and more intuitive, a stylus/pen can brush up
the user’s experience of touch-devices. Styluses/Pens are portable and have ex-
tendable functions of pressure sensitivity measurement and auxiliary customizable
buttons for different tasks. Instead of going through menus via touch or click it
is easier to write using a stylus and the required activity will be done. However,
‘from handwritten-command to task-done’ requires logically rich and an efficient
interfacing.
1.5 Difficulties Involved in Handwriting Recognition
As stated above, developing an interface that could recognize and respond effi-
ciently to handwritten input(s) is a non-trivial job. The task of efficient interfacing
is difficult mainly because of two reasons. At first, ‘handwriting’ by itself and at
second ‘hardware’ resources for processing in portable devices. Writing by hand
either by using a simple led-pencil on a paper or with the help of a pen/stylus on
a smart-screen inherits complications from versatile nature of handwriting(s). It
also owes complexities of the language in which the input command has been writ-
ten. Each writable language follows a particular script and each script has its own
alphabets and writing standards. Some scripts allow cursive style of writing, gen-
erally intended for making handwriting faster while some others are non-cursive,
in which writing style follows a ‘printscript’ where letters of a word are not con-
nected to each other. Certainly, the very nature of the language script propounds
difficulties to the interface development.
Nature of the script and versatility in writing by hand are not the only
challenges that make the handwriting recognizable interfacing a tough job. There
are other factors also to which developers would have to deal with. Speed of
writing is one such factor. Humans write things more quickly than they type up
7

Introduction
on a touch-keyboard or on a touch-screen. It requires that the technology used for
integrating handwriting should have fast response-rate so that it could reproduce
the shapes drawn in accordance to the speed of the writer. The technology should
also has to respond according to various delicate aspects of handwriting like the
force with which writing instrument has been used, the tilt of the nib at varying
angles, the quick or might be a slow rotation of the pen at various degrees. While
writing humans are habitual of resting their palm/wrist on writing surface or even
fingers other than used for holding the pen/stylus might touch the writing surface.
If this habit continues to go on a pen-tablet or on a stylus-touchscreen then the
display must be smart enough to distinguish between writing (stylus) function
and touch function. Another important aspect of handwriting is the first-touch-
latency or touch lag. A real pen does not leave a time gap (first-touch-latency or
touch lag) between inking and writing. A touch-latency for touch surfaces is how
fast a touch is registered on the surface. In other words, there is a delay between
actual physical input occurrence and that input being processed electronically
and displayed on an output device. For any interaction, according to Robert B.
Miller [11], the minimum just noticeable time difference related to the response
time of the system is 100 milliseconds. Humans are quicker and can respond even
in few milliseconds. Therefore, to replicate the function of handwriting, there is a
need to devise such devices which could catch up with human response.
Digging further into technology means and measures, we see that there are
limitations in capability of hardware resources available for portable devices. Two
main limitations, in respect of hardware resources, are coherent to smartphones,
tablets and other portable devices. On one side, for processing purposes, relatively
less speedy processors are available in smart devices. While on the other side ran-
dom access memory and auxiliary storage space available for or attached to these
devices cannot be enhanced to more than a certain limit. These lacks in resource-
fulness does not allow the developer to opt for some quick but resource consuming
techniques but that may open the new horizons of logics for the developer in which
these challenges could be coped efficiently.
8

Introduction
1.6 Online and Offline Handwriting Recognition
All of the above discussion is regarding online handwriting recognition. The terms
dynamic, and real time handwriting recognition are also used in place of online
handwriting recognition. It is a system in which handwriting is converted to text
as it is registered on special digitizer, smartphone, PDAs, or any other appro-
priate hand-held device(s). In simple words, the machine recognizes the writing
while the writing process is in progress [12]. In this type of recognition system,
a transducer (e.g. PDAs, smartphones, etc.) records pen-tip movements and
pen-up/pen-down events. The data generated against pen-tip movements and
pen-up/pen-down events is known as digital ink. This is nothing but digital rep-
resentation of handwriting. The elements of online handwriting recognition system
include a stylus/pen, a touch sensitive surface either embedded in, or attached to
some output display and a software that could translate pen movements across
the touch surface into writing strokes and digital text. The input through pen
is dynamic and stated as a function of time and order of the pen-stroke. The
digital representation of the input (pen movements actually) is a time dependent
sequential data based on pen trajectory. It gives not only the two dimensional in-
formation about position, velocity, and acceleration but also recounts the pressure
values, number of strokes, stroke order, and stroke direction.
Offline handwriting recognition or optical character recognition (OCR), in
contrast to online handwriting recognition, is conducted after the writing activity
is completed. In offline handwriting recognition, a raster image of the typed,
printed, or handwritten text is taken from an optical scanner or any other digital
input source (e.g. digital camera). The text might be typed, printed, or written
by hand on a document, on a sign board, on a billboard etc. It might be a
caption superimposed on some picture, photograph, figure etc. It may also be
subtitles embedded into a video or movie. The digital devices like optical scanners
or digital cameras yield the bit pattern of the image of the typed, printed or
handwritten text. After the handwriting is made available in the form of an
image, the recognition task can be performed at some later time, for example,
days, months, or even after years. The image obtained for offline recognition is
converted to a binary or colored image. Binary image is an image in which image
9

Introduction
pixels are either 0 or 1. To acquire a binary version of an image threshold technique
is used. The technique is applicable to both colored and gray scale images.
1.6.1 Dynamic Information acquired through Online Hardware
Today, with the technological development, we are able to get real time informa-
tion for a given process. One such example of this ascent can be seen for online
handwriting devices. Online handwriting hardware has risen up to that matu-
rity level that first hand information can be obtained instantaneously. It is not
just that but also this first hand information proves to be helpful to extract and
compute further information very easily. Instantaneously acquired information
include:
• Precise loci of the pen as a function of time. This also includes retraces of
the stroke made by the writer
• Pen inclination as a function of time. It reflects the trend of the pen/stylus
movement
• Pen pressure value for each pen locus
• A portrait of the full -stroke. It comprehends pen-down and pen-up events
listing all intermediary points between each pen-down and pen-up event
• Temporal connection between major and minor strokes to from a character
Above information can further be processed to yield the following:
• Velocity and acceleration with which a stroke is penned down
• Direction of the pen stroke
• Number of strokes with which a character is drawn
• Order of the strokes to form a character
• Variations at beginnings and endings of the strokes
• Variations in stroke length and width
10

Introduction
All the dynamic information associated to how a character has been written is lost
for scanned version of that handwritten character. That is why offline images of
handwritten scripts are referred to as static images. It is hard to acquire dynamic
features from static images. However, with today’s available online hardware,
dynamic attributes can be obtained and drawn with quite reasonable accuracy.
1.6.2 Advantages of Online Handwriting Recognition over the Offline
Handwriting input is natural and appealing style of input. That is why it is more
acceptable over keyboarding. As the information is immediately available and
processed for online handwriting signal therefore the work-flow is improved. The
main difference between online and offline is handwriting data capturing method.
In online recognition systems, machine/handwritten data is captured at the instant
the person writes on a writing surface. In offline recognition, data is captured at
some later time after the writing is created. The advantage of online data recording
is that online devices also capture temporal information of handwritten stroke
which is not available in offline images. Temporal information helps to keep track
of stroke order and direction. Such information may not seem much beneficial
for languages, like English, where stroke order does not matter. However, the
languages, like Chinese, Arabic, Urdu etc., in which writing a character is stroke-
order dependent, temporal information becomes more favorable to recognition
process. Temporal difference of writing can be used to identify and discard the
overlapping of strokes in a written character.
Another advantage of online system over offline is that online system ren-
ders interactivity between the writer and the device at the time of writing. This
interaction also allows the user to edit and/or rectify the mistakes immediately
which let the recognition errors be corrected at the spot. On the other hand, in of-
fline systems, writer-machine interaction does not occur when the writing activity
is in process. In fact, as stated above, in offline recognition system the interaction
with machine/device happens only after the writing is materialized. The result
of this script-machine interaction is a scanned or digital image which is further
dispensed to some recognition process.
11

Introduction
Adaptation is another advantage of online recognition system. Two possi-
bilities of adaptation can be observed for online recognition systems. One is writer
to machine adaptation and the other is machine to writer adaptation. Writer to
machine adaptation brings advantage where the writer sees that some of the writ-
ten characters are not correctly recognized he may modify his drawings to improve
the recognition. Machine to writer adaptation benefits when the recognizer has
the ability of adapting to the writer. Such recognizers have capability of storing
writer’s samples of handwritten stroke for subsequent recognition process.
On the other hand, to produce more respectable results, offline character
recognition systems are subject to some constraints. For example, the scanned or
digital image fed to recognition engine should have clear contrast between image
colours with even lighting exposure. For a good chance of recognition, specific
image resolution is another important factor. For example, for text recognition in
a document with Google’s OCR software built into Google Drive, the resolution
of the document in height should be at least 10 pixels to increase recognition
probability. Good recognition results might also be font dependent. With Google’s
OCR for best results the document should be prepared in Arial or Times New
Roman font (English script). Offline recognition engines also put a constraint on
file format (jpg, tiff, png, pdf etc.), text layout (single/multicolumn), skewness,
brightness and other layouts of the scanned image/document. For example, earlier
versions of Tesseract engine, originally developed by Hewlett Packard Labs, were
not able to process images for text in two columns and other than TIFF format.
1.6.3 Available Handwriting Recognition Software
There are many application softwares available for offline character recognition.
Following are a few to mention in this regard:
• Tesseract OCR, a free software for character recognition, supported by
Google since 2006 [13]. Initially developed for English language text but
now it can recognize text in more than 100 languages [14] in printed font. In
terms of character recognition accuracy, Tesseract OCR has been considered
one of the most accurate OCR engine [15], [16], [17]. The output format is
text, hOCR, pdf and others with different APIs.
12

Introduction
• Google’s OCR is provided with Google Drive and can recognize 100+ lan-
guages with over 90% accuracy. It can take images (jpg, png) as well as
multipage pdf documents as input for recognition. For Urdu handwritten
text, the OCR has not been found very accurate.
• IRIS-Readiris for MAC and Windows operating systems (OS) implement
optical recognition technology and convert images and pdf files into editable
files. The converted file format may be of Word, Excel, PDF, HTML etc.
and can be chosen by the user. The software keeps the original layout intact.
IRISDocument Server is a server-based OCR solution which automatically
converts unlimited volumes of images into fully editable but structured for-
mats. It also offers hyper-compression of the converted documents for long
or short term archiving. It can deal with more than 100 languages for text
recognition [18].
• ABBYY FineReader OCR software converts the digital photographs and
scanned documents either in image form or pdf format into emendable for-
mats. The output document format may be any of the RTF, TXT, DOC,
DOCX, PDF, XLS, XLSX, HTML, PPTX, CSV, EPUB, DjVu, ODT, or
FB2 format as per user choice. The OCR can recognize 192 languages [19].
• CuneiForm, developed by Cognitive Technologies (a Russian software com-
pany), converts electronic copies of images and documents into editable for-
mats. The editable conversion of electronic copies is accomplished without
changing the fonts and structure of the document/image. It can recognize 28
languages in any printable font (including Russian-English bilingual, French,
German, and Turkish) saving the output in hOCR, HTML, TeX, RTF, or
TXT formats.
• OmniPage is another OCR software. With auto language detection feature,
it can recognize 120 different languages converting the scanned documents
into searchable and editable electronic versions. The output file matches
exactly to original input document in color, font, and layout. It is vended
by Nuance Communications [20].
13

Introduction
Above are a few OCR application softwares to mention. In fact, there is a long list
for offline character recognition softwares including OCR Using Microsoft OneNote
2007, Office Lens (an OCR application by Microsoft for mobile phones), OCR Us-
ing Microsoft Office Document Imaging, PDF Scanner (a document scanner soft-
ware with OCR technology, also available for Android users), ONLINE OCR [21]
(for personal computers an online facility for OCR/Free, Arabic/Persian/Urdu
languages are not supported), SimpleOCR (freeware) and SimpleOCR SDK for de-
velopers (royalty free). The list is to show that there is a lot of work done on offline
version of character recognition. However, for online character recognition there
is a lack of available softwares either commercial or non-commercial. MyScript-
Nebo is an application software for online handwriting recognition provided by
Vision Objects. It turns the natural handwriting recorded through a stylus, a dig-
ital pen or a finger into computer readable information. The software is available
for Linux, Microsoft Windows, Apple MAC OS, iOS, and Android as well. There
are many hand-held and smart devices that are supported by MyScript-Nebo such
as Samsung Galaxy Tab S3 with S-Pen, Samsung Galaxy Note 10.1′′, 2014 edi-
tion with S-Pen, Samsung Galaxy Note Pro 12.2′′ with S-Pen, iPad Pro and iPad
2018 with Apple Pencil, Microsoft Surface Pro 3 (Intel Core i3, i5, i7), Microsoft
Surface Pro 4 (Intel Core m3, i5, i7), Sony Vaio 13 (Core i5), Huawei Media Pad
2 10.1′′ with active pen and many more [22]. Recognizing 59 languages [23], the
software can convert handwritten notes, mathematical equations, and geometrical
shapes into editable and searchable digital text/ink. However, the software does
not support the most widespread right-to-left languages namely Hebrew, Arabic,
Persian, and Urdu [24].
1.7 Problem Statement: Online Handwritten Urdu Char-
acter Recognition
Character recognition has enjoyed a lot of research in the recent past. Good recog-
nition systems are available commercially for alphabetical languages based on Ro-
man characters and for symbolic languages like Chinese. But languages based on
Arabic alphabets like Urdu, Pashto, Sindhi etc. do not have such recognition sys-
14

Introduction
tems. The recognition systems generally have a scanner or a camera as the input
device for off-line recognition, or a stylus/tablet as input device for online recog-
nition. These systems are used in conjunction with the input peripheral devices
like keyboards and mice. With the recent developments in electronic tablets, pen
movements and pressure content can be captured more accurately. However, in
spite of these technological developments, we see there is no such application soft-
ware which could recognize Urdu characters written by hand using a pen-tablet or
on a smartphone with a stylus. Urdu language is based on Arabic alphabets with
a larger character-set as compared to Arabic (38 characters). Urdu, due to its
large character-set and limited number of strokes, is difficult to recognize. In this
work, we have focused on recognition of Urdu characters in half-forms. Half-form
characters appear in the start, mid, or end of a word while writing cursively. The
emphasis of this thesis is to propose a technique to recognize Urdu handwritten
characters using a pen-tablet.
1.8 Motivation
Absence of handwritten character recognition application for Urdu language is
the motivation behind this work. Such an application, in this digital age, is of
national interest. It can be used in mobile phones with styluses, in personal digital
assistants, and in any portable device with pen input. In Pakistan, there are
about 200 Million inhabitants and Urdu is a primary language of communication.
According to Pakistan Telecommunication Authority, there are about 130 Million
mobile phone users [25]. According to market estimates, based on current trends
in the e-commerce sector, there could be 40 million smartphones in Pakistan in
the coming year [26]. In that scenario, there is a need to carry out research
in the field of design and development of online Urdu handwriting recognition
systems for computing devices (like smartphones) to provide benefit to the large
Urdu speaking population of the world. It will also be helpful in Urdu data
entry for people not experienced with Urdu keyboard. Moreover, it can serve
the purpose of Urdu handwriting tutor-software for children and new learners.
The application can further be extended to touch systems as well. Online Urdu
handwriting recognition system can also extend its benefits to the users of other
15

Introduction
Arabic script based languages like Persian, Uyghur, Sindhi, Punjabi and Pushto
with minor modifications.
1.9 Literature Review
Urdu script comprises of a large character-set with cursively written and contextu-
ally dependent alphabets. Being context dependent, Urdu alphabets adjust their
shapes according to the preceding and succeeding characters. In this way, for
an Urdu alphabet there are one full- and at least three different half-forms with
few exceptions. Moreover, complexities for Urdu handwriting recognition arise
not only due to cursiveness and context dependency but also because of the very
nature of an alphabet-structure, word-formation in a particular font-style, and di-
acritics involved in alphabets. Overlapping ligatures, delicate joints of characters
in a word, atilt traces, neither fixed baseline nor standard slope (in Nastalique
font style), associated dots and other diacritic symbols which may be above, be-
low or within the character, displacement of dots with base stroke’s slope and
context [27–29] are a few to shed light on the complexities of Urdu script.
On the basis of recognition target-set, Urdu handwriting recognition (both
off-line and online) can be placed into three categories: isolated- or full-form char-
acter recognition [30–33], selecting ligatures for recognition or holistic approach
(also known as segmentation-free approach) [27, 34–39], and segmentation-based
or analytical approach [40–50]. Moreover, different researchers have tried to ad-
dress the recognition problem by focusing on different aspects. For example, the
authors in [51] worked out the baseline (an imaginary line on which characters are
combined to form the ligatures) of the character stroke, the work in [52] discussed
the diacritical marks associated with characters and ligatures, and the approach
in [53] emphasized the preprocessing operations.
Following the analytical approach along with dictionary based search to ob-
tain valid characters and words, Malik et al. [30] recognized 39 isolated characters
with an overall accuracy of 93% and 200 two-unattached-character ligatures with
an accuracy of 78%. Hussain et al. [36] preferred the holistic approach, proposed
spatial-temporal-artificial-neuron for the recognition, and reported an accuracy of
85% for 15 selected ligatures only. However, their data-set lacks the aspect of
16

Introduction
generality as it was acquired from only two different writers. Husain et al. [37]
investigated the recognition system for one-, two-, and three-character-ligatures
and obtained separate results of 93% and 98% for base and secondary strokes,
respectively. Shahzad et al. [31] studied the recognition of 38 isolated Urdu char-
acters using 9 geometric features for primary stroke and 4 for secondary stroke to
achieve the accuracy of 92.8% for the data obtained only from two native writers;
however, the recognition rate diminished to 31% when the characters were scrib-
bled by an untrained non-native writer. With data scribbled by trained non-native
writers, the recognition rate barely increased to 73%. Razzak et al. [38,39] inves-
tigated the recognition system for 1800 ligatures. By utilizing the features based
on fuzzy rules and hidden Morkov model, they secured 87.6% recognition rate for
Urdu Nastalique font and 74.1% for Naskh font. Most of the work available in
the online domain of Urdu character recognition deals with ligatures and full form
recognition. Segmentation-based approaches have been applied either to segment
the ligatures from each other present in a word or to dissociate the diacritics from
the base-character [29]. Here is to note that, to the best of authors’ knowledge,
no work is found there using wavelet analysis for recognition of Urdu characters.
However, studies have been reported for Arabic and Persian characters recogni-
tion using wavelets. Therefore on the basis of alike-script and wavelet analysis the
work presented in this paper is compared with Arabic and Persian work as well.
Table 1.1 and Table 1.2 account the comparison of proposed work with Arabic
and Persian recognition systems using wavelet analysis.
Inspired from [32,33,64] the authors propose in this work the online Urdu
character recognition problem for context-dependent shapes of Urdu characters,
that is, for half-forms. For the development of online cursive Urdu handwriting
recognition system, recognition of half form Urdu characters is a primary step be-
cause of the following four reasons: First, Urdu characters appear in half-forms in
a word. Although full form letters are also used within a word, yet the role of half-
forms is much more than that of full forms. Second, half-form characters are the
building blocks for ligatures and therefore segmentation-based systems eventually
attempt to recognize the constituent half-forms [40, 45, 49, 50]. Third, there are
a lot more ligatures in Urdu, which cannot be entirely enclosed within the scope
17
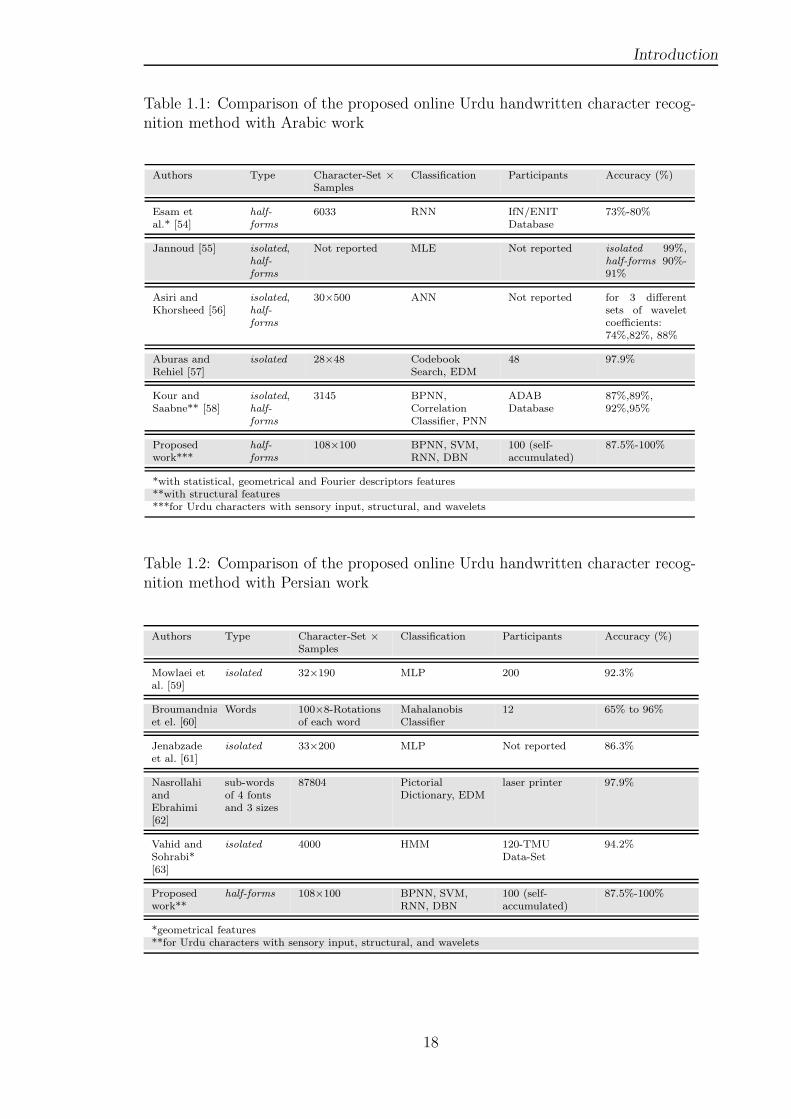
Introduction
Table 1.1: Comparison of the proposed online Urdu handwritten character recog-nition method with Arabic work
Authors Type Character-Set ×
SamplesClassification Participants Accuracy (%)
Esam etal.* [54]
half-
forms
6033 RNN IfN/ENITDatabase
73%-80%
Jannoud [55] isolated,half-
forms
Not reported MLE Not reported isolated 99%,half-forms 90%-91%
Asiri andKhorsheed [56]
isolated,half-
forms
30×500 ANN Not reported for 3 differentsets of waveletcoefficients:74%,82%, 88%
Aburas andRehiel [57]
isolated 28×48 CodebookSearch, EDM
48 97.9%
Kour andSaabne** [58]
isolated,half-
forms
3145 BPNN,CorrelationClassifier, PNN
ADABDatabase
87%,89%,92%,95%
Proposedwork***
half-
forms
108×100 BPNN, SVM,RNN, DBN
100 (self-accumulated)
87.5%-100%
*with statistical, geometrical and Fourier descriptors features**with structural features***for Urdu characters with sensory input, structural, and wavelets
Table 1.2: Comparison of the proposed online Urdu handwritten character recog-nition method with Persian work
Authors Type Character-Set ×
SamplesClassification Participants Accuracy (%)
Mowlaei etal. [59]
isolated 32×190 MLP 200 92.3%
Broumandniaet el. [60]
Words 100×8-Rotationsof each word
MahalanobisClassifier
12 65% to 96%
Jenabzadeet al. [61]
isolated 33×200 MLP Not reported 86.3%
NasrollahiandEbrahimi[62]
sub-wordsof 4 fontsand 3 sizes
87804 PictorialDictionary, EDM
laser printer 97.9%
Vahid andSohrabi*[63]
isolated 4000 HMM 120-TMUData-Set
94.2%
Proposedwork**
half-forms 108×100 BPNN, SVM,RNN, DBN
100 (self-accumulated)
87.5%-100%
*geometrical features**for Urdu characters with sensory input, structural, and wavelets
18

Introduction
Table 1.3: Comparison of online Urdu handwritten character recognition
Authors Type Data-Set Approach Features Classification Participants Accuracy(%)
Malik etal. [30]
isolated 39 Analytical Structural Tree baseddictionary search
Notreported
93%
Malik etal. [30]
2-characterligatures
200 Analytical Structural Tree baseddictionary search
Notreported
78%
Hussainet al. [36]
Ligatures 300 Holistic Primitives Spatio-temporalartificial neuronsearch
2 85%
S. A.Husain etal. [37]
Ligatures 250 baseligatureswith 6sec-ondarystrokes
Holistic Syntactical BPNN 2 93% forbasestroke,98%for sec-ondarystroke
Shahzadet al. [31]
Isolated 152 Analytical Structural Linear classifier 2 92.8%
isolated 76 Analytical Structural Linear classifier 1 untrainednon-native
31%
isolated 76 Analytical Structural Linear classifier 1 trainednon-native
92.8%
Razzaket al. [38]
Ligatures 1800 Holistic StatisticalandStruc-tural
Hidden MorkovModel and FuzzyLogic
Notreported
87.6% forNastalique& 74.1%for Naskh
K. U.Khan etal. [32,33]
Isolated 3145 Holistic Structural BPNN,CorrelationClassifier, PNN
85 87%,89%,92%, 95%
Proposedwork***
half-
forms
108×100 Analytical Sensoryinput,Struc-tural,andWavelets
BPNN, SVM,RNN, DBN
100 87.5%-100%
of a single study. That is why, researchers in their works have tried to recognize
selective number of ligatures through which many words can be composed, but
not all. Consequently, such systems have limited vocabulary available for process-
ing [29, 38, 53]. Furthermore, for acquiring a valid ligature or finding an optimum
word, dictionary based search becomes a necessary part of the work [37], however,
this is not the case with the half-forms. Last, targeting half-forms would mean
independence from dictionary. Even new words not present in the dictionary can
be recognized.
Preference for online recognition system over offline systems is because
there are less efforts for the development of online Urdu handwritten character
19

Introduction
recognition. There remains much to explore in this broad field. Moreover, unlike
the static images in case of offline recognition, the dynamic information of the pen
movement recorded for online recognition aids to develop better, easier and faster
recognition algorithms. Advantage of digital pen is that it immediately transforms
handwriting into digital representation that can be reused later without having
any risk of degradation. Furthermore, storage space complexity can be reduced
with significant reduction in memory required by the online data [65] as compared
to scanned images. In fact because of these characteristics of online data, some
researchers have tried to superimpose pseudo temporal information and retrieve
writing order information for offline static handwriting images [66–69]. Table 1.3
shows a comparison between available research work with this proposed work.
1.10 Contributions
The main contributions of this work are as follows:
1. A framework for development of online Urdu handwriting recognition for
smartphones has been presented.
2. Based on the number of strokes in a character and the position and shape of
diacrtics, segregation of larger character-set into smaller subsets is obtained
through the proposed pre-classification in contrast to the previous online
Urdu character recognition approaches like [30, 31, 36–39, 53].
3. To cope with the demand of robust and accurate recognition along with
relatively low computational power and limited memory available to mobile
devices, banks of computationally less complex classifiers are developed, from
which the appropriate classifier would be loaded to the memory to achieve
the recognition task.
4. A comparison of different classifier-feature combinations is presented in this
study to exhibit the features’ discrimination capability and classifiers’ recog-
nition ability.
20

Introduction
5. A comparison of feature-based classifiers (Artificial Neural Networks (ANN),
Support Vector Machines (SVM)) and end-to-end classifiers (Recurrent Neu-
ral Networks (RNN), Deep Belief Networks (DBN)) is presented.
6. Noting the small databases of existing Urdu character recognition works
[31,36,38,39], a large database of handwritten Urdu characters is developed
and employed in this study, which contains 10800 samples of all Urdu half-
form characters (100 samples of each character) acquired from 100 writers.
The database can be obtained from the authors for the research purposes.
1.11 Thesis Organization
The thesis is organized as follows:
Chapter 2: This chapter discusses about Urdu character-set, rules to be followed
for Urdu handwriting, complexities attached to the shape/drawing of Urdu char-
acters and much more.
Data acquisition phase is narrated in Chapter 3. This chapter also describes the
hardware used for Urdu handwriting, graphical user interface (GUI) implementa-
tion for collecting Urdu handwriting samples, and development of Urdu digital ink
database. Moreover, data preprocessing is also given along with down-sampling,
algorithm for removal of repeated data points, and smoothing of signals.
In Chapter pre-classification is explored and results of pre-classification in the
form of Urdu character-subsets are accounted.
Features extraction (structural, sensory input values, and wavelets transform) is
described in Chapter 5. In Chapter 6 final classification of Urdu character-set
using different state of the art classification techniques is presented and results
are discussed.
Summary and conclusion of the research work is furnished in Chapter 7 along with
future recommendations.
21

Chapter 2
Urdu
Urdu is classified as Indo-European, Indo-Iranian, Indo-Aryan, Hindustani, and
Western Hindi language [70]. It is intelligible with Hindi, however it borrows its
formal vocabulary from Arabic and persian languages [70]. It follows right to left
writing system based on Perso-Arabic chirography. It is the Statutory National
Language of Pakistan (1973, Constitution, Article 251(1)) [71]. It is also constitu-
tionally recognized in India [72] and has official status not only in national capital
territory of Delhi but also in six Indian states (Bihar, Uttar Pradesh, Jammu and
Kashmir, West Bengal, Telangana, Jharkhand). Urdu is also a registered language
of Nepal [73]. It is a primary communication language of Pakistan populated with
about 200 Million people (Pakistan’s 2017 national census July 2017 est.). There
are about 70 Million native Urdu speakers in India [74]. The language is also spo-
ken and used in Bangladesh, Fiji, the Middle East, USA and many other countries
around the globe, including UK (having about 400,000 native Urdu speakers). In
North America and Canada, Urdu is the first language of 30 percent of the immi-
grants [75].
2.1 Urdu Character-Set
Urdu has a larger alphabet-set (character-set) as compared to Arabic (26 al-
phabets) and Persian (32 alphabets). How many letters are there in the Urdu
alphabet-set? The answer is a controversy. Urdu is an Indo-Aryan (Indic) lan-
guage [76]. Although it follows Perso-Arabic script yet to conciliate the require-
22

Urdu
��������������������� ������������������������������������� �!�"�#
$�%�&Figure 2.1: Urdu alphabets (fundamental)
����
�
� ���� ��������������
������������
� �
Figure 2.2: Alphabets added to fundamental Urdu alphabets to cope with phoneticpeculiarities
ments of phonetic peculiarities especially aspiration, retroflexion and nasalization,
Urdu alphabet-set has been suitably modified. The 37 fundamental alphabets
are shown in Figure 2.1. The shapes of fundamental alphabets are said to be
isolated-forms or full-forms (half-forms of Urdu alphabets are discussed below in
section 2.1.4). The alphabets added to the fundamental set to meet the phonetic
peculiarities are given in Figure 2.2. National Language Promotion Deprtment
(NLPD) [77], the official authority responsible for taking measures to implement
Urdu as an official language in Pakistan, has declared that Urdu has exactly 58
letters including all letters denoting aspirant sounds. However, many may take
exception to this declaration. Moreover, there is a kind of tacit consensus on the
total number of letters in Urdu alphabet and it is generally believed that Urdu has
23

Urdu
36, 37, 38 or at the most 39 letters [29, 33]. The difference is due to the addition
of some alphabets to the basic Urdu alphabet-set as narrated above.
2.1.1 Urdu Diacritics
In linguistic, a mark which is added to a letter to indicate a special pronunciation
is called a diacritical mark or simply a diacritic. A diacritic is also known as a
minor stroke of a letter. In Urdu, there are five different types of diacritics or
minor strokes. These are:
• nuqta or dot ( � )
• towey ( ¢ )
• inverted hay ( � )
• hamza ( � )
• kash ( � )
An Urdu alphabet is shaped by drawing a major stroke with none, one-, two-, or
three- minor strokes. A few examples of Urdu alphabets with diacritics (minor
strokes) are shown in Figure 2.3.
2.1.2 Single and Multi-Stroke Characters in Urdu
Depending on the alphabet, a major stroke may have diacritic(s) above, below
or even inside the stroke. Number of diacritics with a given major stroke defines
an alphabet as a single-, or a multi-stroke character. A multi-stroke character
consists of two-, three- or four- strokes in total. See Figure 2.3.
2.1.3 Word-Breakdown Structure in Urdu
Word -breakdown structure in Urdu renders that words in Urdu are formed by
using one of the following ways:
• Two or more full-forms placed together, that is to say that no half-form is
used at all (Figure 2.4a).
24

Urdu
Major Stroke
One Minor Stroke
Two Minor Strokes
Three Minor Strokes
No Minor Stroke
������
�
�� �
��
�
Figure 2.3: Examples of Urdu (fundamental) alphabets with major and (none,one-, two-, or three-) minor strokes
• Two or more half-forms joined together to form ligatures and then these
ligatures are placed together to construct an Urdu-word. (Figure 2.4b). No
full-form is involved in such compositions. A word may have a single-ligature
or may be composed of multiple-ligatures.
• Full-forms placed with ligatures to form Urdu-words (Figure 2.4c). Full-
forms appearing in such type of words keep themselves detached with liga-
tures (Figure 2.4d).
2.1.4 Half-Forms of Urdu Alphabets
Figure 2.5 shows another set of Urdu characters. These are half-forms of fun-
damental Urdu alphabets. In other words, alphabets shown in Figure 2.1 are
full-forms of the alphabets given in Figure 2.5. These are 108 in number. There
are (mainly) three different types of half-forms as explained below:
• Initial Half-form : When a character occurs in the beginning of a
word/ligature it adopts its initial half-form. Not every character has an
25

Urdu
���������������������������� �������
(a) Urdu-words formed by using full-forms
�� � ���� �
��
2-letter Ligature
word composed of two
ligatures � � �
�
4-letter Ligature
single-ligature
� ��
2-letter
Ligature
(b) Urdu-words formed by using ligatures
�� � ��� � �� �Ligature formed with 4 letters
Isolated Character
��� �� ��
�
Ligature formed with 2 letters
Isolated Character
� � ��� �
(c) Urdu-words formed by using isolated-forms and ligatures
����
����������� ����������������������������������������������������� ������������������������������������������������������������� ��������������������������������� ������������������������������������������������������������������������������������������������������������������ ����������������������������������������������� ��
�������������������������������� �������������������������������������������������������������� ���������
� and � are joined together to form �
Isolated-forms/Detached letters
(d) Joined and detached letters in Urdu-words
Figure 2.4: Constructing the Urdu-words
’ ‘ — “ O N P M „ ƒ ‚ … K J I LBh • f c b a\ ZYˆ ‡ † W VU S R Q T| zyw v u sr q o n m ‹ l ™ j µ ´ ³± ° ¯ ¬ « © ¨ §¥ ¤ £ ñ ¡ ø
Å Ä Ã Á À ¿ ½ ¼ » { ô õ ò Œ ¸ º¹ ö · š ÓÎ Í � ˙ Ú × Ö é è ú É È ä ì Ì
Figure 2.5: All Urdu characters in all half-forms.
initial half-form and there are characters which have more than one initial
half-forms. Initial half-forms are 36 in number. (see Figure 2.6a)
26

Urdu
• Medial Half-form : When a character falls in between two characters to
compose a word/ligature it takes its medial half-form. Medial half-forms
are 30 in number (see Figure 2.6b). There are characters which do not have
medial half-forms. There are also characters that have more than one medial
half-forms.
• Terminal Half-form : When a character appears at the end of a
word/ligature it appears in its terminal half-form. Terminal half-forms are
very much similar in shape to the respective full-forms. There exists 42
terminal half-forms of different Urdu characters. Round-Hay is a character
which has two different terminal half-forms (‘É ’) and (‘ú ’). Figure 2.6c
shows terminal half-forms of Urdu characters.
Use of half-forms is shown in Figure 2.7. Figure 2.8 shows handwritten half-forms
combined together to form different words.
2.2 Urdu Fonts: Where do these Half-Forms come from?
Urdu fonts, like many other fonts are particular styles of typography with some
particular size and weights. In this era of digital typography, the word font is
similar to what the typeface is in metal-typesetting. Urdu follows Arabic and
Persian scripts (writing-styles). There existed and exists different writing-styles
for Arabic and Persian like Kofic, Andalusi-Maghribi, Muhaqqaq, Rayhani, Towqi,
Riqa’, Thuluth, Naskh, Ta’liq, Nastalique, Shikaste, Divani etc. Each script has its
own rules for writing and induces distinct visual characteristics. These writing-
styles were developed and used for different motives and needs. These were also
opted for Urdu writing.
Urdu-writing is an essential part of learning skills at primary level in native
population. The art of writing in different styles has highly been nourished by the
calligraphers. Figure 2.9 shows Urdu typographic transcribe in five different fonts,
that is, Nastalique, Naskh, Kasheeda, Thuluth, and Andalusi-Maghribi.
27

Urdu
Single-Stroke
à ö · « ¯ £ y a U
å Ö ì ä
³ M PÍ õ Œ
T ‚ …q † Q
u m Y¿ » § ø
2-Strokes
— “ I L
3-Strokes
4-Strokes
(a) Initial Half-Forms
bV ‘ J
´ N
R ƒ
¡ v n Zè À ¼ ¨
° ¬ ¤zÈ Ä ¹ º
Î ô ò
r ‡
Single-Stroke
2-Strokes
3-Strokes
4-Strokes
×(b) Medial Half-Forms
Single-Stroke
2-Strokes
3-Strokes
4-Strokes
š Óé ú
jf \ B© ñ woÉ Ì Á ½
c W ’ Kl ™ h •
± ¥| ˛ Ú Å ¸
Ł
−
�
µ O � {
S „s ‹ ˆ
(c) Terminal Half-Forms
Figure 2.6: Single- and multi-strokes half-forms of Urdu Characters
2.2.1 The Nastalique Font
The Nastalique writing-style is accustomed among Urdu natives. Primitively it
was devised for Persian script, that is why it is also known as farsi font in Arab
28

Urdu
��� �
«
I
� ��
† õ
�³
(a) Use of initial half-forms
���������������
¤
NÈ
r
V
°(b) Use of medial half-forms
������ �� � ��� � �� �
ú ¸
j Á
Å
O
(c) Use of terminal half-forms
Figure 2.7: Examples of words composed of half-form characters.
Figure 2.8: Examples of words composed from (segmented) handwritten half-formcharacters
world. Besides Persian, Nastalique is also used for writing Sindhi, and Punjabi,
two regional languages of Pakistan and India. It is a hybrid of Naskh and Ta’liq
fonts. The Naskh font is the most common font in printed Arabic because of high
legibility. It is also used to write Pashto script (Pashto is a language of about
40-60 million people around the world [78]). The Ta’liq font gives a visual effect
of letters hanging together or suspended from a line while the descending strokes
are shaped as loops. Taking the legibility and grace of both Naskh and Ta’liq,
Nastalique font is visually beautiful, eminently precise, and inherently intricate
font. Mainly, it characterises the presence of diacritic(s) and superposed marks.
Due to beauty and gracefulness of the trace, it has been used for writing royal
messages, letters, albums of calligraphic illustrations, and poetry etc. Since its
birth and introduction it has widely been used for literary works in Iran and sub-
29

Urdu
�����������
�سخ(Naskh)
����������
پتی پتی آنگن سارا دن ایک کہ تھا یقین اسے ہوئے سنبھالتے تبرکا
تھی۔ جانتی مفہوم کا تبرک وه گا؛ اٹھے مہک
� � �� �� �� �� � � � �� �� ��� �� !� "# �$ %� � &' () *+
:
:
:
���
�,�-.-/���� ��� ��� �� ����� ���� ��� ���� ��� � ��� �� ���� �� ! �"# ��$� %�& '( )� � *�"+# �� �, -���
ايک هک اھت يقين ےاس ےوئه ےالتھسنب تبرکا پتی پتی
۔یھت جانتی ومهمف کا تبرک هو گا؛ ٹھےا کهم آنگن سارا دن
�. / �- �234# �01�.-�234��/�51
:
:
� � ��� �� �� �� � � � ��� �� �� !" # $� %& '( )� � *+ ,- ./
�
Figure 2.9: Different Urdu fonts
continent. The font stood the test of time, acknowledged the necessity of time
and responded well to the needs of people in a widespread. Although difficult to
execute yet the font was opted for use in routine Urdu writings by public at large.
Nastalique font is used to teach writing skills at early stages of education. And
now, it will be no wrong to say that Nastalique font is not only the preferred choice
of writing but has actually been ingrained in native Urdu knowers. For printed
Urdu, a computerized version of the font was created by Mirza Ahmed Jameel
in 1980, naming it as Noori Nastalique [79]. It is a less elaborated adaptation of
Nastalique writing-style, however it completely follows the basic characteristics of
the style [28]. For Urdu writing, the difference between Naskh and Nastalique is
significant as shown in Figure 2.9. In Nastalique, ligatures are oblique whereas in
Naskh ligatures are linearly placed. Analyzing the shapes of letters, for Nastalique
we observe that the variations in shapes of Urdu characters according to their
position in a ligature or a word. Although variations in shapes of Urdu letters
can be seen in other writing-styles too (such as in Naskh) yet these are more pro-
nounced in Nastalique. Moulding of a letter/character into a shape different from
fundamental shape (or full-form) is called context dependency of Urdu characters.
30

Urdu
Half-forms are actually these moulded shapes, born because of writing-styles and
further elaborated by Nastalique.
2.2.1.1 Characteristics ofNastalique Font
In the this section, some characteristics of Nastlique writing-style are narrated.
Context Dependency: In Nastlique font, each character modifies its fundamen-
tal shape as per context in which it has been written. For a given character
there are three possible contexts; the context of beginning, the context of
middle, and the context of final. When a character has to be written in
the beginning of a ligature or word, generally, it will take initial half-form.
When a character is required to be placed in between two letters, that is
in the context of middle, it will be penned in its medial half-form. When a
character appears at the end of a ligature or word, that is in the context of
final, it is shaped in terminal half-form. Pictorially context dependency is
shown in Figure 2.10a for Urdu character ‘� ’ and in Figure 2.10b for Urdu
character ‘ � ’. As stated in subsection 2.1.4, a character may have more
than one half-forms. Now which half-form a given character would opt for
depends upon the preceding and subsequent characters to which the given
character has to be connected [80]. For example see Figure 2.10c. However,
for some characters exceptions lie in general contextual dependent behavior.
It is described as an Assertion as follows:
Assertion-1: Alif (‘��’), Dal (‘�’), Ddal (‘�’), Zal (‘�’), Ray (‘�’), Aday
(‘�’), Zay (‘ ��’), Zhay (‘�’), and Wao (‘�’) are such characters in
Urdu character-set when written in the context of beginning keep
their isolated- (fundamental- or full-) form intact and do not attach
themselves to the subsequent character.
Implication-1: The above mentioned Assertion-1 implies that whenever
the characters mentioned in Assertion-1 will occur at the terminal of
a ligature of a word, the subsequent character will either be in its full-
form if it is the last character of the word, or will be in initial half-form
if it is not the last character of the word. See Figure 2.10d.
31

Urdu
Baseline: In every script, there is a horizontal line which serves as a baseline for
drawing characters. A baseline is a horizontal line to which all the characters
in a word and all the words in a sentence touch at some point. Naskh font
gives very good example of this concept see Figure 2.11a. However, this is
not the case with Nastlique font. In other words, while following Nastlique
font, there is no horizontal or vertical physical line which could cut all the
characters in a word at some point [29], [37]. The reason for the absence of
such a line is the tilting factor induced by Nastlique writing-style in Urdu
characters.
Atilt Half-forms and Ligatures: In Nastlique font, usually half-forms and
ligatures commence from some top-right location and finally rests on some
bottom-left point with few exceptions. This kind of writing comes up with a
tilt in ligatures. Characters place themselves along a diagonal and therefore
drawing a baseline that could touch all the characters in a word at some point
is not possible for this font. This arrangement along the diagonal also brings
forth varying heights and widths of ligatures. Moreover, the allowed tilting
does not mind stacking any number of characters in a ligature. Character
by character stacking just increases the slope of some ligatures as compared
to the ones which have less number of adjoined characters [81]. See Figure
2.11b.
Cursiveness: Urdu writing-style is actually cursive in its very nature. Cursive-
ness is further flourished with the evolvement of Nastalique font. It is the
property of rapid writing in which successive letters within a ligature or word
are connected together without lifting the pen from the writing surface. It
fosters the flow in writing.
Character Thickness: Characters written in Nastlique style vary in their thick-
ness as well. In a single character, variations in the stroke-thickness are
clearly observable in Figure 2.11c. Variation in the thickness can be wit-
nessed only when a flat tipped pen is used for writing. With a round tipped
pen this is not present.
32

Urdu
�� � �� �� � � � ��
�
Context of Beginning:
Initial half-form
IK
J
Context of Final:
Terminal half-form
Context of Middle:
Medial half-formFull-form
(a) Varying shapes of Urdu character ‘� ’
� � ��� �� � � �
ä
È
ú Context of Beginning:
Initial half-form
Context of Final:
Terminal half-form
Context of Middle:
Medial half-form
(b) Varying shapes of Urdu character ‘ � ’
Two different initial half-forms of � connected to two different letters � and �
Two different medial half-forms of � connected to two different letters � ��� �
� ����� (c) Two different initial/medial half-formsof ‘� ’
���������� �������� �� �� ��� �� �� ��� �� �� ��� �� ��� �� �� ��� ��� � �
�� ��
�� �t the terminal of ligature ���
next ligature � � begins with
initial form of �
� � �t the middle of word ���� the
ligature � begins with initial
form of �
� � �t the beginning of ligature �� the ligature � begins with
initial form of �
�� �� ��� �� ��� �� �� ��� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� ���� �� �� �� �� � �� � at the terminal of ligature �� the last letter � of the word is in
full form
(d) Assertion-1
Figure 2.10: Context dependency
Stroke Analysis: Along the horizontal axis, generally, strokes in Nastalique are
broad and sweeping while along vertical direction the strokes are shorter.
An example is shown in Figure 2.11d.
Visual Impression: Nastalique prevails an impression of expeditious flow in
writing. Characters seem to be floating or hanging across the page, es-
pecially when the text is arranged diagonally.
2.3 Idiosyncrasies of Urdu-Writing
Regardless of the font used or style adopted, Urdu writing has a mode of behaviour
that is peculiar in different aspects as given below:
Course of writing/Direction of Text: In Urdu, the direction/course of writ-
ing (and reading too) depends on whether the piece of text is alphabetic
or alphanumeric. Alphabetic text is written from right to left direction. In
alphanumeric text, digits also follow the course from right to left direction.
33

Urdu
Nastalique:
Naskh:
������������������
دل و نگاه مسلماں نہیں تو کچھ بھی نہیں
(a) Baseline
���� ����������� ����� ������� ����� ���
Increase in tilting for Nastalique
(b) Atilt ligatures
Á Thick Part
Thin Part
Thick Part
(c) Thickness variation in an Urdu strokewritten in Nastalique font
K
Drawn horizontally
(from right to left)
�� »Drawn vertically
(from up to down)
(d) An Urdu ligature with horizontallybroad and vertically short character
Figure 2.11: Distinct features of Nastalique font
However, the numbers appearing in an alphanumeric text are penned from
left to right [46]. See Figure 2.12a.
Course of the Stroke: Mostly, the strokes of Urdu characters do not go just
along a single direction [29]. For a particular character, for example ‘�’ the
stroke starts from the left, comes up, turns right, then coming down to left,
makes a curve while going towards right, or for ‘�’ the stroke starts from
the top right, comes down, goes upward while making a curve. See Figure
2.12b.
Ligatures Overlap: There occurs two types of overlapping in Urdu ligatures [28]
whether the ligatures are of the same word or belong to consecutive words
of the same sentence. First is intra-ligature overlapping in which characters
of the same ligature extend over each other so as to cover some portions
of the neighboring character. The second is inter-ligature overlapping in
which terminating character of preceding ligature partly covers the beginning
character of the subsequent ligature or vice versa. The inter-ligature overlap
also occurs between adjacent ligatures of two different words, that is actually
inter-word overlap. See Figure 2.12a. Overlapping is practised to obviate
the unnecessary white-spaces, however the characters do not make contact
with each other [29].
34

Urdu
Position and Count of Diacritics: In Urdu alphabets, there are 5 different di-
acritics (see subsection 2.1.1). The diacritic towey, (‘¢’), hamza, (‘�’), and
kash, (‘�’) always take a place above the major stroke. Diacritic inverted hay,
(‘�’) always occupies a place below the major stroke. The nuqta or dot, (‘�’)
may be found above, below, or inside the major stroke depending upon the
alphabet. Besides the position taken, the count of the diacritics also varies
from alphabet to alphabet. For a multi-stroke character, towey, (‘¢’), hamza,
(‘�’) and inverted hay, (‘�’) only occur in two-stroke alphabets. Diacritic kash,
(‘�’) is used to form ‘one two-stroke’ and ‘one three-stroke’ alphabets. In case
of three-stroke alphabets two kashes, (‘ ’) are used. The count for nuqta or
dot, (‘�’) is 1 for two-stroke alphabets, 2 (‘��’) for three-stroke characters, and
3 (‘��� ’) for four-stroke characters.
��������� ��� ���� �����������
��������� ����� � �!��"�#$�%�&��'
(��������)*%�+,�-.� -/0�����1�
(13)(14)(47)
inter-ligature
intra-ligature
Overlap
inter-word
overlap
(a) Alternating course of writing, and liga-tures overlapping
� ���(b) Stroke directions for Urdu charactersand words
° l W V I
r ˆ T ‚ Î ´ M
· “
Dots or Nuqtas: Above/Below/
Inside the major stroke
È × {
Diacritic other than dots:
Above/Below the major
stroke
(c) Urdu diacritics
��
��
� � �
��
(d) Above and below placement of nuqtasfor Urdu words
Figure 2.12: Idiosyncrasies of Urdu writing emphasizing ligature overlap, writingdirections, and placement of diacritics
Knottiness of Dots or nuqtas: As narrated previously that the minor stroke
dot or nuqta can occupy a place above, below or inside the major stroke. But
35

Urdu
Unfilled loop for �Filled loop for �
(a) Handwritten �
Unfilled loops
(b) Loops in in handwritten version
��� ������������� ����
������������
Filled loop Filled loopUnfilled loops
Filled loop
(c) Loops in typographic version
Figure 2.13: Idiosyncrasies of Urdu writing emphasizing presence and character-istics of loops in different writing styles
�������������� � � �������� ����
����
Initial half-form Y with a loop without a loop
(a) Loop: to be or not to be
False loop
Initial half-form Y
handwritten version
Recommended
(b) Occurrence of false loop
Figure 2.14: Idiosyncrasies of Urdu writing emphasizing presence or absence ofloop in the same character penned by different hands
36

Urdu
will this placement be exactly above/below/inside, or above/below/inside-
right, or above/below/inside-left of the major stroke as shown in Figures
2.12c and 2.12d? The answer to this question depends on how much the
ligature has gone diagonal and how the writer thinks to place the nuqtas.
Moreover, in case of multi-dots (two, or three nuqtas), the dots may or may
not adjoin each other. It is again the writing-hand’s choice how to draw the
nuqtas.
Small Loops: Some of Urdu characters have small circular or oval shaped loops
in their strokes. Mostly these are hollow for handwritten characters with
some exception as shown in Figure 2.13a and 2.13b, but may or may not
be filled for typographic scripts for example see Figure 2.13c. Sometimes
in handwritten characters there occurs some delusive loops. Such loops do
not lie in the standard stroke but happen to occur due to the writing-hand
writing the character. See Figure 2.14.
37

Chapter 3
System Description
Proposed online handwritten Urdu character recognition system begins from data
acquisition, goes through some pre-processing algorithms to get prepared for some
pre-classification and features extraction phase. It ends up with characters’ final
classification. The block diagram of the whole system is shown in Figure 3.1.
Data acquisition and preprocessing are described in the following while the rest is
accounted in upcoming chapters.
3.1 Data Acquisition
Handwriting data can be acquired using a pen-tablet device connected to a com-
puter. Data may also be acquired by writing on the touch sensitive screen of a
smartphone. In our study, 100 native Urdu writers of different age groups have
provided their handwriting samples using a stylus and digitizing tablet.
3.1.1 GUI: Writing Canvas
A Wacom tablet is used to collect handwritten samples for Urdu characters in
their half-forms. For this purpose, a graphical user interface (GUI) is developed
in Visual C# programming language using wintab.dll. The interface connects to
the Wacom tablet and provides an on-screen writing canvas. Respective half-form
(initial, medial, or terminal) is selected from a dropdown menu and with the help
of stylus the character is drawn on the writing canvas. To visually aid the writer,
upon selection of the half-form the actual shape of the character and an exemplary
38

System Description
Preprocessed Data
Extracted
Features
Input Data
Character subsets
Yes
No
Sole member
of the subset,
therefore no
need to feed to
the classifier
Output
Writing on
Tablet SurfaceInterface
Urdu
Half Form
Database
Feature Extraction
Subset I Subset II Subset n…………Subset III
Pre-Classification
(No. of Strokes, Minor Stroke Position, Minor Stroke Shape)
Down Sampling Smoothing
Cardinality
> 1
Recognized Half Form
Characters
Decision of Pre-
Classifier for selection
from Classifier Bank
Classifier
I
Classifier
II
Classifier
n....
Classifiers Bank
Or Or
Preprocessing
Data Acquisition
Figure 3.1: Block diagram of the proposed Online Urdu character recognitionsystem: from data acquisition to preprocessing to pre-classification to featureextraction to final classification.
word which uses respective half-form character also appear on right side of the
canvas. The canvas is depicted in Figure 3.2. Figure 3.3 shows an Urdu word
written on the canvas.
3.1.2 Information in Handwritten Character-Signal
Online handwritten character-signals contain the information of the digitized coor-
dinates (x(t), y(t)), the pressure values and time-stamps for each point (x(t), y(t)).
39

System Description
Connect to the
tabletDropdown Menus
Enable the
writing area
Writing AreaUse of selected
character
Shape of selected
character
Figure 3.2: Writing interface for digitizing tablet
During the data acquisition, the following attributes of character strokes were ac-
quired:
1. Number of times the pen gets up or down.
2. Number of strokes used to draw a character.
3. Starting/ending index of each stroke.
4. Temporal order of each sample of (x(t), y(t)) coordinates.
40

System Description
Figure 3.3: An Urdu word is written on the canvas with the help of a stylus andtablet
5. Pressure value at (x(t), y(t)). Note: pressure value are utilized in this work
only for detecting pen up/down events.
3.1.3 About the Data
The data obtained from the writers is in segmented form. Figure 2.8 (from Chapter
2) shows few examples of full Urdu words and ligatures composed from the seg-
mented characters obtained from the participating writers, and demonstrates that
the words composed from these segmented characters do resemble the words as if
written continuously. To use a recognition system based on our proposed method
in its current form, it is required to draw the characters in their segmented forms.
If the visual feeling of continuous word is required then the segmented characters
should be drawn at appropriate positions as shown in Figure 2.8 (Chapter 2). We
are also working on segmentation of characters from ligatures and will be reported
in future. A related work on segmentation of handwritten Arabic text can be
found at [82] that presents an efficient skeleton-based grapheme segmentation al-
41

System Description
gorithm. With some modifications, this segmentation algorithm along with our
proposed methodology may serve as a full system for online Urdu handwriting
recognition. Segmentation of printed Urdu script can be found in [40, 49, 50].
3.1.4 Instructions for writing
For non-native audience, here we present some instructions that should be followed
while writing Urdu characters. These instructions are implicitly followed by native
Urdu writers.
• There should be no pen-up event while drawing the major stroke i.e. the
major stroke should be drawn continuously without raising the pen,
• In case of multi-stroke characters, the major stroke should precede the minor
stroke(s), and
• Minor strokes should be penned one at a time, i.e. there must be pen up
events between two or three dots or between two ‘kashes ’. In some cases,
this instruction is violated by the native writers, but for this work, we stress
on following this instruction.
Two minor strokes drawn together (for example, two dots) can be separated using
the variation in pressure values.
3.2 Character Database
There is availability of Arabic handwritten words database (Arabic DAtaBase:
ADAB [83] ) but for Urdu there is a lack of standard handwritten character
database. Using the above GUI a large database of Urdu handwritten characters
(in half-forms) has also been accumulated during this study. For this purpose,
samples for Urdu characters have been hand written by 100 different persons (all
natives). The handwritten sample contributors, both males and females, belong
to different age groups and different literacy competence. Most of the contributors
used the stylus and digitizing tablet first time. Each of them wrote 108 characters
on the tablet. This created a database of 108x100 Urdu characters in their half-
42

System Description
forms where each character-signal is saved in a binary file format. The database
can be provided for research purposes.
(a) Example-1: An Urdu character in initial half-form is written onthe canvas with the help of a stylus and tablet
(b) Example-2: An Urdu character in initial half-form is written onthe canvas with the help of a stylus and tablet
Figure 3.4: Examples of handwritten character using stylus and digitizing tablet
43

System Description
(a) Example-3: An Urdu character in medial half-form is written onthe canvas with the help of a stylus and tablet
(b) Example-4: An Urdu character in terminal half-form is written onthe canvas with the help of a stylus and tablet
Figure 3.5: Examples of handwritten character using stylus and digitizing tablet
3.2.1 Handwritten Samples
In this subsection different samples of handwritten characters are given. These
samples are obtained from native Urdu writers of different age groups. Figure 3.4
44

System Description
Figure 3.6: Examples of handwritten character using stylus and digitizing tablet
to 3.6 show a few handwritten samples. Figure 3.7 shows all Urdu characters in
their half-forms written by a user with the help of stylus and digitizing tablet.
3.3 Preprocessing
The raw data obtained from the hardware contains artifacts like jitters, hooks in
start and end of a stroke, speed variations etc. To reduce the effect of artifacts,
the following preprocessing steps have been performed on the raw data.
3.3.1 Re-Sampling
Algorithm 1 has been implemented to remove repeated data-samples. Repeated
data-samples are points which occur consecutively in temporal order. Actually,
due to varying handwriting speed of the writers, the acquired spatial sampling rate
does not remain constant. Since there is a constant temporal data rate for a tablet,
45

System Description
Figure 3.7: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet
a large number of samples are generated in the regions where the writing speed is
slow. It usually occurs at the beginning of a stroke and around the corners as well.
These large number of data-samples at the specific locales can produce several
samples at the same (x, y) location and may steer towards erroneous values in the
course of features extraction. To eliminate such multiple samples, repeated data-
samples are taken away from the signal recorded for each character. Afterwards
a down-sampled version of this signal is obtained by keeping every second data-
sample starting with the first. Few samples of down-sampled data are shown in
Figure 3.8.
3.3.2 Smoothing
Drawing on a tablet by inexperienced users, or roughness of pen tip or writing
surface may result in jitters and trembles in writing [53]. To mitigate jittering
effects the character data is smoothed using a 5-point moving average filter given
46

System Description
by the following difference equation:
ys(i) =1
2N + 1(y(i+N) + y(i+N − 1) + ... + y(i−N)) (3.1)
where ys(i) is smoothed value for the ith data point, N is the number of neigh-
boring data points on either side of ys(i) (in this case N=2), and 2N + 1 is the
span. The results of smoothing function are shown in Figure. 3.9.
Algorithm 1 Repeated elements removed
1: procedure RemoveRepeatedDataPoints(S)
⊲ S(M × 2) contains X and Y coordinates of a given stroke
2: initialize k ← 1
3: initialize Sr(k)← S(1)
4: for i = 2 to M do
5: if ||(S(i− 1)− S(i)||2 = 0 then
6: Sr(k)← S(i)
7: else
8: k ← k + 1
9: Sr(k)← S(i)
10: end if
11: end for
12: return Sr
13: end procedure
47

System Description
Original DataDown−Sampled Data
(a) Down-sampling of character ‘q’
Original DataDown−Sampled Data
(b) Down-sampling of character ‘«’
Original DataDown−Sampled Data
(c) Down-sampling of character ‘· ’
Original DataDown−Sampled Data
(d) Down-sampling of character ‘|’
Original DataDown−Sampled Data
(e) Down-sampling of character ‘‘’
Original DataDown−Sampled Data
(f) Down-sampling of character ‘W’
Figure 3.8: Re-sampling and Down-sampling of characters
48

System Description
Original DataSmoothed Data
(a) Smoothing of character ‘…’
Original DataSmoothed Data
(b) Smoothing of character ‘†’
Original DataSmoothed Data
(c) Smoothing of character ‘Œ ’
Original DataSmoothed Data
(d) Smoothing of character ‘ ì ’
Original DataSmoothed Data
(e) Smoothing of character ‘q’
Original DataSmoothed Data
(f) Smoothing of character ‘Q’
Figure 3.9: Smoothing of Urdu Handwritten Samples
49

Chapter 4
Pre-Classification
Urdu characters can be grouped into subsets based on the similar major stroke
and differ from each other due to their minor strokes. These similar characters
pose difficulty in classification. To reduce the difficulty level in classification, a
novel concept of pre-classification is presented here. The pre-classifier classifies the
characters into small subgroups. The classification criterion is derived from the
properties of Urdu characters presented in Chapter 2. For online data acquisition,
information about the character becomes available to us as soon as it is written
on the tablet surface. This fact is exploited to pre-classify the Urdu character-set.
4.1 Pre-Classification of Half-Forms
The pre-classification for initial half-forms is explained here, whereas the pre-
classification of medial and terminal half-forms is similar.
Phase-I: In the first phase of pre-classification, the character-set is divided into
different groups on the basis of number of pen-up events. The number of
pen-up events actually represents the number of strokes in a character. On
the basis of stroke-count (SC) following four subsets are yielded (see Figure
4.1).
• The subset of single-stroke characters. It contains 7 characters
• The subset of two-stroke characters. It contains 17 characters
50

Pre-Classification
Urdu Initial Half Form Characters
Single Stroke
Two Strokes
Four Strokes
ThreeStrokes
³P M Œ õ
q T Q †… ‚
U L I
U L I ä ì£ y a
à ¯ «
ö “— å Ö ·
Œ õ ³P M Í
Œ õ³P M
u Y
¿ » § ø m
Q … ‚
q †T Í· ö ¯ «
“ — L I £ y a U
ì ä Ãå Ö
« £ y a“ — å Ö Ã · ö ¯
ì ä
Figure 4.1: Pre-classification of initial half-forms on the basis of stroke count,position and shape of diacritics
• The subset of three-stroke characters. It contains 6 characters
• The subset of four-stroke characters. It contains 6 characters
Phase-II: In the second phase of pre-classification, on the basis of position of
the diacritic(s), every multi-stroke subset obtained in the Phase-I is further
segregated into two sub-subsets. In initial- andmedial half-forms the position
of the diacritic(s) for multi-stroke Urdu characters is either above, or below
the major stroke. For terminal half-forms the position of the diacritic(s) is
either above, below, or inside the major stroke. For this study, for the sake
of simplicity, diacritic placed inside the major stroke in terminal half-forms
is considered as the diacritic placed above the major stroke. At the end of
the Phase-II of pre-classification, we get 6 sub-subsets of multi-stroke initial
half-form characters.
Phase-III: For third phase, the shape of diacritics helps for further segregation
of sub-subsets obtained in Phase-II. For Urdu characters, the diacritics can
be divided mainly into two genres on the basis of their shapes.
51

Pre-Classification
Urdu Medial Half Form Characters
Single Stroke
Two Strokes
Four Strokes
R ƒ
ThreeStrokes
´ N
È V J
È
Î
b V ‘ J° ¬ ¤ zÄ º¹ × È
º¹ ° ¬ × Ä
¤ z b ‘
ô ò Î
´ N ô ò
´ N ô ò
r ‡
r R ‡ ƒ
º¹ × ‘ ¤ zb
Ä ° ¬
V J
n Z ¨ ¡ v è À ¼
Figure 4.2: Pre-classification of medial half-forms on the basis of stroke count,position and shape of diacritics
• nuqta or dot, (‘�’) diacritic.
• Other-than-dot diacritics. These are towey, (‘¢’), inverted hay, (‘�’),
hamza, (‘�’), and kash, (‘�’)
The simplest way to to differentiate between the dot diacritic and other-
than-dot diacritics is the length of the shape. On inherent basis, the length
of the dot is found shorter in length than any other-than-dot diacritic. This
fact helped for further classification. The sub-subsets obtained in second
phase are further divided, where possible, to produce 10 sub-sub-subsets of
characters in initial half-forms. These final sub-sub-subsets are the terminal
leaves of the pre-classification trees shown for initial-, medial-, and terminal
half-forms in Figures 4.1, 4.2, and 4.3 respectively.
4.2 Results of Pre-Classification
As a result of pre-classification, finally we get 10, 10, and 8 subsets for initial-,
medial-, and terminal half-form characters respectively. These are:
52

Pre-Classification
Urdu Terminal Half Form Characters
�������
����
w o j
� �
�����
���
�����
����
�����
KNo character
with secondary below the
primary stroke
f \ B
Óé
½ © ñ
ú
É Ì Á Ł ˛ Ú
c W ’ Kl ™ h • �
−� ¥|Å ¸ ±
• c W ’| l ™ h
Ł ˛ Ú Å¸ ±¥ −�
� {µ O S „
s ‹ ˆ
„s ‹ˆ S
� {µ O
µ O�
{
h c W|l−�
Å ±¥
™ • ’Ú ¸ Ł ˛
Figure 4.3: Pre-classification of terminal half-forms on the basis of stroke count,position and shape of diacritics
Initial Half-forms: All initial half-forms are pre-classified as follows:
1. Single-stroke characters (7 characters)
2. Two-stroke characters with dot diacritic above the major stroke (6 char-
acters)
3. Two-stroke characters with other-than-dot diacritic above the major
stroke (6 characters)
4. Two-stroke characters with dot diacritic below the major stroke (3 char-
acters)
5. Two-stroke characters with other-than-dot diacritic below the major
stroke (2 characters)
6. Three-stroke characters with dot diacritic above the major stroke (3
characters)
7. Three-stroke characters with other-than-dot diacritic above the major
stroke (2 characters)
53
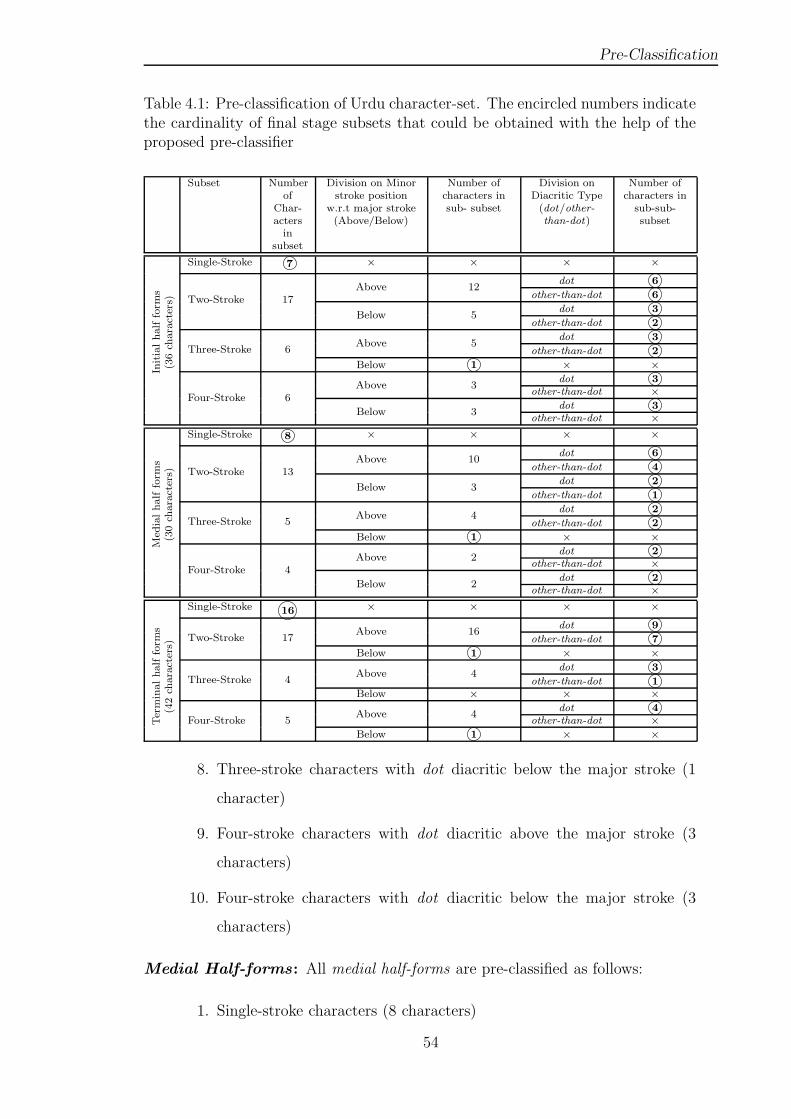
Pre-Classification
Table 4.1: Pre-classification of Urdu character-set. The encircled numbers indicatethe cardinality of final stage subsets that could be obtained with the help of theproposed pre-classifier
Subset Numberof
Char-actersin
subset
Division on Minorstroke position
w.r.t major stroke(Above/Below)
Number ofcharacters insub- subset
Division onDiacritic Type(dot/other-than-dot)
Number ofcharacters in
sub-sub-subset
Initialhalfform
s(36ch
aracters)
Single-Stroke 7 × × × ×
Two-Stroke 17Above 12
dot 6
other-than-dot 6
Below 5dot 3
other-than-dot 2
Three-Stroke 6Above 5
dot 3
other-than-dot 2
Below 1 × ×
Four-Stroke 6Above 3
dot 3
other-than-dot ×
Below 3dot 3
other-than-dot ×
Med
ialhalfform
s(30ch
aracters)
Single-Stroke 8 × × × ×
Two-Stroke 13Above 10
dot 6
other-than-dot 4
Below 3dot 2
other-than-dot 1
Three-Stroke 5Above 4
dot 2
other-than-dot 2
Below 1 × ×
Four-Stroke 4Above 2
dot 2
other-than-dot ×
Below 2dot 2
other-than-dot ×
Terminalhalfform
s(42ch
aracters)
Single-Stroke16
× × × ×
Two-Stroke 17Above 16
dot 9
other-than-dot 7
Below 1 × ×
Three-Stroke 4Above 4
dot 3
other-than-dot 1
Below × × ×
Four-Stroke 5Above 4
dot 4
other-than-dot ×
Below 1 × ×
8. Three-stroke characters with dot diacritic below the major stroke (1
character)
9. Four-stroke characters with dot diacritic above the major stroke (3
characters)
10. Four-stroke characters with dot diacritic below the major stroke (3
characters)
Medial Half-forms: All medial half-forms are pre-classified as follows:
1. Single-stroke characters (8 characters)
54

Pre-Classification
Table 4.2: Characters recognized at pre-classification stage and don’t require anyfurther classification
Half-Form Subset/sub-Subset Character Recognition Rate
Initial
Medial
Medial
Terminal
Terminal
Terminal
3-stroke dot below
2-stroke other than
dot below
3-stroke dot below
2-stroke dot below
3-stroke other than
dot above
4-stroke dot below
Í È Î K
{ „
100%
100%
100%
100%
100%
100%
2. Two-stroke characters with dot diacritic above the major stroke (6 char-
acters)
3. Two-stroke characters with other-than-dot diacritic above the major
stroke (4 characters)
4. Two-stroke characters with dot diacritic below the major stroke (2 char-
acters)
5. Two-stroke characters with other-than-dot diacritic below the major
stroke (1 characters)
6. Three-stroke characters with dot diacritic above the major stroke (2
characters)
7. Three-stroke characters with other-than-dot diacritic above the major
stroke (2 characters)
8. Three-stroke characters with dot diacritic below the major stroke (1
character)
9. Four-stroke characters with dot diacritic above the major stroke (2
characters)
55

Pre-Classification
10. Four-stroke characters with dot diacritic below the major stroke (2
characters)
Terminal Half-forms: All terminal half-forms are pre-classified as follows:
1. Single-stroke characters (16 characters)
2. Two-stroke characters with dot diacritic above the major stroke (9 char-
acters)
3. Two-stroke characters with other-than-dot diacritic above the major
stroke (7 characters)
4. Two-stroke characters with dot diacritic below the major stroke (1 char-
acters)
5. Three-stroke characters with dot diacritic above the major stroke (3
characters)
6. Three-stroke characters with other-than-dot diacritic above the major
stroke (1 characters)
7. Four-stroke characters with dot diacritic above the major stroke (4
characters)
8. Four-stroke characters with dot diacritic below the major stroke (1
characters)
Figures 4.1 to 4.3 show pictorial description of pre-classification of initial-, medial-
, and terminal half-form characters. Table 4.1 records the the pre-classification
results in tabular form.
4.3 Further Reflections of Pre-Classification
Classification of Urdu characters into subsets and sub-subsets through pre-
classification reflects that:
For 3-stroke characters there occur no such case where we could have a char-
acter with other-than-dot diacritic below the major stroke.
56

Pre-Classification
For 4-stroke characters there exist characters only with dot diacritic either
above or below the major stroke and no other-than-dot diacritic is present
for this case.
Uncontested characters are filtered out due to pre-classification. An uncon-
tested character is the one which stands alone in its respective subset or
sub-subset. For example, we see that character ‘Í’, in three-stroke charac-
ters group, stands alone in its subset having no competition for any further
classification. Uncontested characters from all half-forms are given in Table
4.2. These are fully recognized at pre-classification stage and do not require
any further recognition.
With the small subsets produced by the pre-classifier, it becomes possible to design
banks of simple artificial neural networks (ANN), support vector classifiers (SVCs),
deep belief networks, or recurrent neural networks for fine classification within the
subsets.
57

Chapter 5
Features Extraction
Selection of appropriate features for recognition tasks is necessary for achieving
high performance [84]. Computing suitable features, in every online system, helps
reducing the computational complexity of a pattern recognition problem [85].
However, selection and extraction of such features do not follow any specific tech-
nique. Variations involved in one kind of a problem manifests that a feature
set designated for a particular problem may not necessarily be satisfactory for a
similar problem. One can deduce the fact that no widely accepted feature set
contemporarily exists that can survive successfully for at least one kind of prob-
lems [86]. To reduce computational complexity prominent features are acquired
from preprocessed data. However, optimum size of feature vector to recognize a
handwritten character depends on the complexity involved.
For Arabic/Urdu handwritten characters recognition, different types of fea-
tures have been presented in literature, namely structural features, statistical fea-
tures, and global transformation features. Using structural features [30, 36, 37], a
model/standard template is designed for each class of letters that contains all the
significant information with which test classes are compared. Statistical approach
uses the information of the underlying statistical distribution of some measurable
events or phenomena of interest in the input data [32, 33]. Character recogni-
tion problem has also been addressed in transformed domains using Fourier trans-
form, discrete cosine transform, wavelet transform or Gabor, andWalsh-Hadamard
transform etc. [29, 87].
58

Features Extraction
0 0.5 10
0.5Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.1
0.2Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-5
0
5detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-5
0
5detail of Y
(a) Top row shows character ‘sheen’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
0 0.5 10
0.5Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-5
0
5detail of Y
(b) Top row shows character ‘zwad ’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
Figure 5.1: Wavelet coefficients for ‘sheen’ and ‘zwad’
59

Features Extraction
In this research work, the problem of online handwritten Urdu characters in
half-forms recognition have been addressed using three types of features separately.
These are:
1. Wavelet Transform
2. Structural Features
3. Sensory Input Values
5.1 Wavelet Transform
To discriminate characters from each other, a human reader looks for the exact
location of smooth regions, sharp turns, and cusps as the landmarks of interest.
With structural, statistical and global transformation features as used in [29, 30,
32, 33, 36, 37] it is not possible to find out these landmarks exactly. In proposed
study, wavelet transformation of handwritten stroke data enables us to accurately
pinpoint the mentioned landmarks and leads to attain better recognition rates.
Wavelet transformation is applied to a signal/image to determine and an-
alyze the localized features of a signal/image, i.e. a time-scale representation of
that signal/image. It is a multi-resolution technique that clips data into differ-
ent frequency components, and then analyzes each component with a resolution
matched to its scale [88]. Wavelet series expansion of a function f(x) is given in
Equation5.1.
f(x) =∑
k
cjo (k)ϕjo,k (x) +
∞∑
j=jo
∑
k
dj (k) Ψj,k (x) (5.1)
where cjo (k) are approximation (or scaling) coefficients, and dj (k) are detailed
(or wavelet) coefficients [89]. Details about the wavelets can be studied from [88]
however a brief review of wavelet properties can be studied from [90].
60

Features Extraction
-50 0 500
50Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5
1Y-coordinates
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(a) ‘alif ’ in terminal form and its waveletstransform
0 50 1000
20
40Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(b) ‘bari ye’ in terminal form and itswavelets transform
-50 0 50-10
0
10Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(c) ‘swad ’ in initial form and its waveletstransform
0 100 2000
50
100Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5
1Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(d) ‘two-eyed-hay ’ in terminal form and itswavelets transform
Figure 5.2: Wavelet coefficients for different Urdu characters in their half-forms.Top row shows the character, and x(t) and y(t) of its major stroke. Second andthird rows show level-2 db2 wavelet approximation, and level-4 db2 wavelet detailcoefficients of x(t) and y(t) respectively
In character recognition problems, wavelet transform has been used for lan-
guages like English, Chinese, Arabic, Persian, and different Indian languages as
well [57, 59, 61, 85, 91–93]. To verify the discriminating potential of wavelet fea-
tures for handwritten Urdu characters in half-forms, a multilevel one-dimensional
wavelet analysis is applied to the preprocessed data. For this purpose, differ-
ent wavelet-families are used in which approximation and detail coefficients are
obtained for the x(t) and y(t) coordinates of the handwritten strokes.
61

Features Extraction
0 0.5 10
0.5
1Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(a) Top row shows character ‘Tay ’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
0 0.5 10
0.5
1Handwritten minor stroke
0 10 200
0.5
1X-coordinates
0 10 200
0.5
1Y-coordinates
time0 5 10ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 5 10ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(b) Top row shows the minor stroke ‘towey ’ and its x(t) and y(t) coordinates.Second and third rows show the level-2 db2 wavelet approximation and level-2db2 wavelet detail coefficients of x(t) and y(t) of minor stroke respectively
Figure 5.3: Wavelet coefficients for ‘Tay’
62

Features Extraction
5.1.1 Daubechies Wavelets
Daubechies wavelets [94] are helpful to solve problems where self-similarity prop-
erties of a signal are prominent. Morever, Daubechies family is also useful to deal
with signal discontinuities. Both of these properties, self-similarity and disconti-
nuities, are inherent features of Urdu characters. Therefore, in order to obtain
better classification accuracy Daubechies db2 family is applied to Urdu character
signals under consideration. Both approximation and detailed coefficients are used
in the feature vector. In fact, keeping the feature vector as small as possible, it is
found after some trials that the level-2 approximation coefficients and level-4 de-
tail coefficients were providing the best classification accuracy. The feature vector
is
W =[
−−→cA2x
−−→cD4x
−−→cA2y
−−→cD4y
]T
∈ Rn (5.2)
where−−→cA2x and
−−→cA2y are the vectors of level-2 approximation coefficients, and
−−→cD4x and
−−→cD4y are the vectors of level-4 detail coefficients of the one dimensional
x(t) and y(t) signals of the stroke coordinates (x(t), y(t)). C++ or MATLAB
codes may be used to obtain the wavelet coefficients. In this study MATLAB is
used for wavelet transformations.
5.1.2 Discrimination Power of Wavelets
Figures 5.1 and 5.2, show different handwritten characters in half-forms along with
their wavelet profiles. Each of these figures show the handwritten stroke and x(t),
and y(t) signals of the major stroke in the top row, the second row shows the−−→cA2x
and−−→cA2y coefficients, while the third row shows the
−−→cD4x and
−−→cD4y coefficients.
From the figures it can easily be observed that the wavelet coefficients of different
characters are quite different from each other. Such dissimilarity provide the
promise of wavelet features to present good discrimination power. The results
have verified that using wavelet features, in the way presented above, provided
high recognition rates.
63

Features Extraction
0 0.5 10
0.5Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(a) Top row shows character ‘kaafI ’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
0 0.5 10
0.2
0.4Handwritten minor stroke
0 10 200
0.5
1X-coordinates
0 10 200
0.2
0.4Y-coordinates
time0 5 10ap
prox
coe
ffs
-1
0
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 5 10ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(b) Top row shows the minor stroke ‘kash’ and its x(t) and y(t) coordinates.Second and third rows show the level-2 db2 wavelet approximation and level-2db2 wavelet detail coefficients of x(t) and y(t) of minor stroke respectively
Figure 5.4: Wavelet coefficients for ‘kaafI’
64

Features Extraction
Figures 5.3 to 5.5 are representative of the case where other-than-dot minor
stroke is involved. In this case there are characters having similar major strokes
and were distinguishable from each other only on the basis of the shape of their
minor strokes. Since the minor stroke here is significantly long, the wavelet coef-
ficients of the minor stroke is also included along with the wavelet coefficients of
the major stroke to form the feature vector.
Sometimes, because of variability of hand movements and flow of writing
the minor difference(s) between the shapes are omitted. Therefore, one shape
might look like the other. Such scenarios give birth to confusions among different
characters. For example, the character ‘ghain’ seems similar to the character ‘fay ’,
both in medial half-forms as shown in Figure 5.6. Another example is shown in
Figure 5.7 in which x(t) and y(t) coordinates look alike for two different characters
‘daal ’ and ‘wao’ in terminal form. The implication behind these similarities is well
explained by handwritten samples for the said characters in Chapter 6. In another
example, the character ‘meem’ in Figure 5.8b is shaped by the user more alike the
character ‘hay ’ in initial form given in Figure 5.9b.
5.1.3 Biorthogonal Wavelets
Biorthogonal wavelets provide the symmetric extensions for finite length signals.
Using bior1.3 in MATLAB, level-2 approximation coefficients and level-4 detail
coefficients of Urdu character signals are employed as feature vectors.
5.1.4 Discrete Meyer Wavelets
Meyer wavelets are actually used for continuous analysis however discrete approx-
imation of Meyer wavelets (dmey) is used as feature vector for Urdu characters in
this study. Again, it is found after some trials that the level-2 approximation co-
efficients and level-4 detail coefficients provided the better classification accuracy.
65
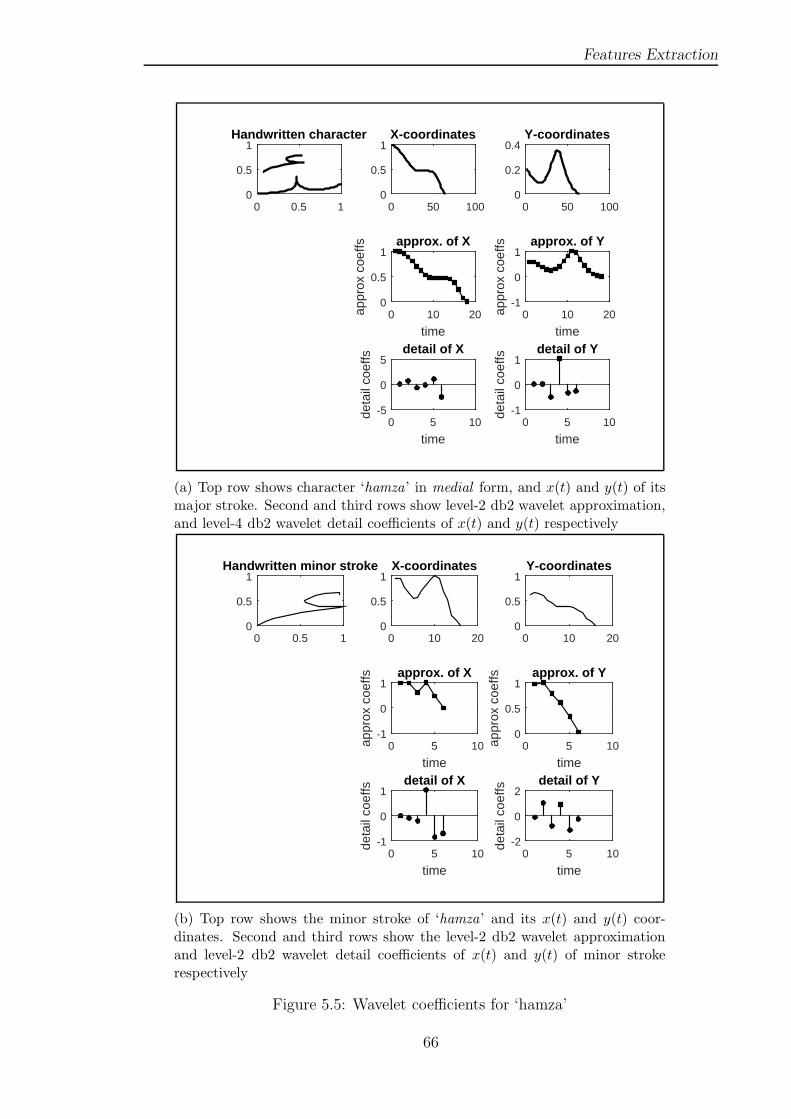
Features Extraction
0 0.5 10
0.5
1Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-5
0
5detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(a) Top row shows character ‘hamza’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
0 0.5 10
0.5
1Handwritten minor stroke
0 10 200
0.5
1X-coordinates
0 10 200
0.5
1Y-coordinates
time0 5 10appr
ox c
oeffs
-1
0
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 5 10ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(b) Top row shows the minor stroke of ‘hamza’ and its x(t) and y(t) coor-dinates. Second and third rows show the level-2 db2 wavelet approximationand level-2 db2 wavelet detail coefficients of x(t) and y(t) of minor strokerespectively
Figure 5.5: Wavelet coefficients for ‘hamza’
66

Features Extraction
5.2 Structural Features
In this study, for comparison purpose, in addition to wavelet based features, struc-
tural features proposed by Khan and Haider [32,33], have also been employed and
tested. The feature vector includes the following structural aspects of the charac-
ter:
Major Stroke Length
Initial x and y Trend (Major Stroke)
Final x and y Trend (Major Stroke)
Major to Minor Stroke Ratio
Half-Major-Stroke Box-Slope
Cusp in Major Stroke
Cusp in Minor Stroke
Pre-Cusp x and y Trend (Major Stroke)
Terminating Half Plane
Int. of Major Stroke Traj. with Centroid Axes
Is Start. Ord. the Highest Ord. of Major Stroke?
(5.3)
It is shown in the results (Chapter 6) that with wavelet features the recognition
accuracy is far better than that obtained with structural features.
5.3 Sensory Input Values
For a given character, sensory input values are x(t) and y(t) coordinates recorded
through a pen-tablet device. These are the raw data values, just passed through
preprocessing phase and then fed to the classifier as one dimensional array.
67

Features Extraction
0 0.5 10
0.5
1Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5
1Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(a) Top row shows character ‘ghain’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
0 0.5 10
0.5
1Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-5
0
5detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(b) Top row shows character ‘fay ’ in medial form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
Figure 5.6: Wavelet coefficients for ‘ghain’ and ‘fay’
68

Features Extraction
0 200 4000
50
100Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-5
0
5detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-5
0
5detail of Y
(a) Top row shows character ‘daal ’ in terminal form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
0 100 2000
50
100Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5
1Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(b) Top row shows character ‘wao’ in terminal form, and x(t) and y(t) of itsmajor stroke. Second and third rows show level-2 db2 wavelet approximation,and level-4 db2 wavelet detail coefficients of x(t) and y(t) respectively
Figure 5.7: Wavelet coefficients for ‘daal’ and ‘wao’. Due to flow of writing bythe users ‘daal’ has included a loop which makes its wavelets transform similar to‘wao’
69

Features Extraction
-50 0 50-10
0
10Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(a) ‘meem’ in initial form: version-1, and itswavelets transform
0 50 1000
20
40Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-5
0
5detail of Y
(b) ‘meem’ in initial form: version-2, andits wavelets transform
0 50 1000
10
20Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(c) ‘meem’ in initial form: version-3, and itswavelets transform
Figure 5.8: Wavelet coefficients for three different handwritten samples of ‘meem’in initial form. Top row shows the character ‘meem’ in initial form written dif-ferently by different users, and x(t) and y(t) of its major stroke. Second andthird rows show level-2 db2 wavelet approximation, and level-4 db2 wavelet detailcoefficients of x(t) and y(t) respectively
70

Features Extraction
0 50 1000
20
40Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-5
0
5detail of Y
(a) ‘hay ’ in initial form and its waveletstransform
0 50 1000
10
20Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.2
0.4Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-1
0
1detail of X
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(b) The same character ‘hay ’ in initial formwritten a bit more like ‘meem’ in fig 5.8b
0 500
20
40Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5
1Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-5
0
5detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-2
0
2detail of Y
(c) ‘hay ’ in medial form and its waveletstransform
0 50 1000
20
40Handwritten character
0 50 1000
0.5
1X-coordinates
0 50 1000
0.5
1Y-coordinates
time0 10 20ap
prox
coe
ffs
0
0.5
1approx. of X
time0 5 10
deta
il co
effs
-2
0
2detail of X
time0 10 20ap
prox
coe
ffs
-1
0
1approx. of Y
time0 5 10
deta
il co
effs
-1
0
1detail of Y
(d) ‘hay ’ in terminal form and its waveletstransform
Figure 5.9: Wavelet coefficients for Urdu character ‘hay ’ in their half-forms. Toprow shows character ‘hay ’, and x(t) and y(t) of its major stroke. Second andthird rows show level-2 db2 wavelet approximation, and level-4 db2 wavelet detailcoefficients of x(t) and y(t) respectively
The reason for employing different types of features is to find a better
recognition solution for handwritten Urdu characters. How much one kind of a
feature proved itself helpful is discussed in Chapter 6.
71

Chapter 6
Final Classification
For ‘fine and final ’ classification, different classifiers from traditional artificial neu-
ral networks to deep learning machines are employed. Support vector machines
(SVMs) have also been manoeuvred using different wavelet families. For final
classification two ways are adopted. On one way, it is achieved with proposed
pre-classification and on the other way it is accomplished without going through
proposed pre-classification. However, to reach the goal of fine classification, the
route of final classification through pre-classification proved to be far better than
the other one. Below are the classification techniques used in this research work.
6.1 Final Classifiers with Pre-Classification
Classifiers along with their input feature-types are listed below.
• Artificial neural networks with Daubechies (db2 ) wavelets and with struc-
tural features.
• Support vector machines with Daubechies (db2 ), with Biorthogonal
(bior1.3 ), and with Discrete Meyer (dmey) wavelets and with sensory
input, separately for each of mentioned input feature-type.
• Deep belief networks with Discrete Meyer (dmey) wavelets.
• Deep belief networks using AutoEncoders with Discrete Meyer (dmey)
wavelet features and with sensory input values.
72

Final Classification
Table 6.1: Features-classifier Summary
Pre-classification Features Classifier
with pre-classification
Daubechies wavelets ANN
Structural ANN
Daubechies wavelets SVM
Biorthogonal wavelets SVM
Discrete Meyer wavelets SVM
Sensory input values SVM
Discrete Meyer wavelets DBN
Sensory input values AutoEncoders-DBN
Discrete Meyer wavelets AutoEncoders-DBN
Discrete Meyer wavelets AutoEncoders-SVM
Sensory input values AutoEncoders-SVM
Sensory input values RNN
without pre-classification
Discrete Meyer wavelets SVM
Sensory input values SVM
Discrete Meyer wavelets DBN
Sensory input values DBN
Discrete Meyer wavelets AutoEncoders-DBN
Sensory input values AutoEncoders-DBN
Sensory input values AutoEncoders-SVM
Sensory input values RNN
• AutoEncoders-SVM classifier with sensory input values and with Discrete
Meyer (dmey) wavelet features.
• Recurrent neural networks using sensory input values.
For fine classification of each character within the subsets produced by the pre-
classifier, a dedicated classifier is designed for each of the subsets. In this work, the
responses of artificial neural networks (ANNs) and support vector machine (SVM)
classifiers along with different input features described in Chapter 5 have been
studied. Moreover, recurrent neural networks (RNNs) and deep belief networks
73

Final Classification
(DBNs) have also been applied to compare the responses obtained through ANN
and SVM.
6.2 Final Classifiers without Pre-Classification
Classifiers used without pre-classification along with their input feature-types are
listed below.
• Support vector machines with Discrete Meyer (dmey) wavelets and with
sensory input.
• Deep belief networks with Discrete Meyer (dmey) wavelets and with sensory
input values.
• Deep belief networks using AutoEncoders with Discrete Meyer (dmey)
wavelet features and also with sensory input values.
• AutoEncoders-SVM classifier with sensory input values .
• Recurrent neural networks using sensory input values.
The classification results show that pre-classification of Urdu characters-set plays a
vital role in achieving greater recognition accuracy. Table 6.1 presents a summary
of classification techniques used in this study along with the features which are
used by a particular classifier.
6.3 Artificial Neural Networks
For pattern recognition problems, developing a multi-layer perceptron (MLP) neu-
ral network with backpropagation algorithm is very popular approach [95–99]. The
ANNs used in this work are single or multi-layer Back Propagation Neural Net-
works (BPNN). A sample structure of multi-layer perceptron neural network is
shown in Figure 6.1. For each of the 22 subsets (cardinality ≥ 2), an ANN is
configured, trained, and tested. In this way a bank of ANNs is obtained in which
each neural network serves to recognize a specific character subset. There are two
different banks of ANNs:
74

Final Classification
1. ANNs which are trained using structural features. All of these ANNs consist
of not more than 3-layers with a few number of neurons in each layer.
2. ANNs which are trained using wavelet db2 approximation and detailed co-
efficients. Table 6.2 presents configurations of these ANNs.
In MATLAB environment, from 10800 Urdu half-form samples, all ANNs are
trained on 40% (40 instances of each character) and tested for remaining 60%
(6480 samples) of the data-set.
x1
x2
x3
x4
xp
……
.
……
.
Inputs Layer 1
Layer 2
Output Layer
y
Figure 6.1: Multi-layer perceptron neural network
6.4 Support Vector Machines (SVMs)
SVMs are also widely used for pattern classification and recognition [99, 100].
Speciality of SVM is that the minimization of empirical classification error and
maximization of geometric margins occur simultaneously. Using SVM with pre-
classification, six separate banks are trained to classify the data-set. Three more
banks of SVM without any pre-classification are also trained and tested on the
data. See Table 6.1 for details.
SVMs are setup using LIBSVM (MATLAB) [101]. LIBSVM offers to select
different types of kernel functions (e.g. linear, polynomial, radial basis function
(RBF), sigmoid etc.) with various parameters of these kernels. For the proposed
75

Final Classification
Table 6.2: ANN configurations (trained using wavelet db2 approximation anddetailed coefficients).
Target Group No. of hidden layers Neurons in hiddenlayer-
1 2 3
ANN Configuration: Initial Half Forms
Single-stroke 3 9 9 5
2-stroke dot Above 2 9 6 -
2-stroke other- Above 2 9 6 -
2-stroke dot Below 1 1 - -
2-stroke other- Below 1 1 - -
3-stroke dot Above 2 2 3 -
3-stroke other- Above 2 2 3 -
4-stroke dot Above 2 6 3 -
4-stroke dot Below 2 4 3 -
ANN Configuration: Medial Half Forms
Single-stroke 3 8 6 8
2-stroke dot Above 2 9 9 -
2-stroke other- Above 2 8 6 -
2-stroke dot Below 1 1 0 -
3-stroke dot Above 2 3 3 -
3-stroke other- Above 1 2 - -
4-stroke dot Above 2 4 2 -
4-stroke dot Below 2 4 2 -
ANN Configuration: Terminal Half Forms
Single-stroke 3 8 8 16
2-stroke dot Above 2 7 9 -
2-stroke other- Above 2 7 7 -
3-stroke dot Above 1 2 - -
4-stroke dot Above 2 4 2 -
76

Final Classification
study, C-SVM (multi-class classification) with radial basis function is employed.
For the selection of good parameters, the training set is used with 5-fold cross
validation and optimized values are obtained (of cost of constraint violation C and
γ in radial basis function). All the SVM banks are then trained with randomly
selected 40% of sample data, while tested on 60% of the remaining data.
6.5 Recurrent Neural Networks: Long Short-Term Mem-
ory
Recurrent neural networks (RNNs) (Figure 6.2) introduce a notion of time to the
traditional feedforward artificial neural networks enabling the network to make
use of the temporal patterns present in the sequential data. In a sequential set of
data, the current output depends on previously computed values. RNNs are ele-
vated with the inclusion of edges that span the adjacent time steps. For sequence
learning, Long Short-Term Memory (LSTM) and Bidirectional Recurrent Neural
Networks (BRNN) are considered to be the most successful RNN architectures.
In LSTM RNNs traditional nodes in the hidden layer of a network are replaced
by a memory unit. The architecture of Bidirectional Recurrent Neural Networks
utilize the information from both the past and the future to compute the output
at any point in the sequence [102]. It helped the recurrent neural networks to be
applicable to cursively handwritten scripts more efficiently.
zt-2 zt-1 zt zt+1
Input Layer
Output Layer
Hid
den
Lay
ers
ot-2 ot-1 ot ot+1
Figure 6.2: Bidirectional multi-layer recurrent neural network
77

Final Classification
Input
Output
Hidden
Layer
Edge to Next
Time-Step
Figure 6.3: A simple recurrent neural network. Along solid edges activation ispassed as in feed-forward network. Along dashed edges a source node at eachtime t is connected to a target node at each following time t+1
For a simple recurrent neural network shown in Figure 6.3 the following
Equation 6.1 and Equation 6.2 express all calculations necessary for computation
at each time step on the forward pass [102]
h(t) = σ(W hXx(t) +W hhh(t−1) + bh) (6.1)
y(t) = softmax(W yhh(t) + by) (6.2)
where, WhX is conventional weight matrix between input-layer and the hidden-
layer, Whh is recurrent-weight matrix computed at adjacent time-steps between
the hidden-layer and itself, and bh and by are bias terms that allow each node to
learn an off-set.
In this work, using RNNLIB [103] with Python language, RNNs with LSTM
architecture, without any feature extraction (using only the preprocessed sensory
input) and with/without using the proposed pre-classification, are applied to the
handwritten data . With proposed pre-classification, each subset is presented to
a recurrent neural network which is specifically trained for that subset. Results of
RNN classifier without using the proposed pre-classifier have also been obtained to
78

Final Classification
check the end-to-end capability of the RNN classifier. Using the raw stroke data
saved in inkml file, each RNN is trained, validated, and tested on 30%, 20%, and
50% of randomly selected subsets of the data-set respectively. To recognize the
108 online handwritten Urdu characters altogether, that is without going through
pre-classification, it took more than 100 hours for recurrent neural network to
produce maximally accurate results. Table 6.3 shows configurations for RNNs
used for each subset.
6.6 Deep Belief Network
Deep belief networks (DBNs) were introduced by Hinton in 2006 [104] to explore
the dependencies between hidden and visible units [105]. To set up a DBN, a
bank of restricted Boltzmann machines (RBM) [106] are stacked on top of each
other and in that way a special type of Bayesian probabilistic generative model is
formed. The layers of RBM are connected in such a way that the visible layer of
each RBM is anchored to the hidden layer of the previous RBM. The connection
between the upper layer and the lower layer is set in a top-down manner [107].
Each nonlinear layer of the DBN learns gradually more complex structures of
data to solve pattern classification problems in a promising way [108]. Problems
successfully addressed by variants of deep generative models include visual object
recognition, speech recognition, natural language processing, information retrieval,
and regression analysis [109].
In this research work, deep belief networks are also implemented for recogni-
tion of online handwritten Urdu characters. The DBN classifiers are implemented
with pre-classification and without pre-classification. Using sensory input as well
as wavelet features, each DBN is trained, validated, and tested on 30%, 20%, and
50% of randomly selected subsets of the data-set respectively. For all chracter-
subsets, Table 6.4 shows number of RBMs stacked upon each other with number
of neurons in each RBM. Discrete Meyer wavelets have been used as input features
for this configuration.
79

Final Classification
Table 6.3: RNN configurations (trained using sensory input values).
Target Group No. oflayers
HiddenBlock
HiddenSize
HiddenType
RNN Configuration: Initial Half Forms
Single-stroke 8 1 100 LSTM
2-stroke dot Above 11 1 100, 200 LSTM
2-stroke other- Above 8 2 739 LSTM
2-stroke dot Below 11 1 32, 19 LSTM
2-stroke other- Below 8 2; 4 59 LSTM
3-stroke dot Above 8 2 100 LSTM
3-stroke other- Above 8 1 2 LSTM
4-stroke dot Above 8 5; 2 385 LSTM
4-stroke dot Below 13 2; 2 121, 7 LSTM
RNN Configuration: Medial Half Forms
Single-stroke 8 1 100 LSTM
2-stroke dot Above 8 1 100 LSTM
2-stroke other- Above 8 1 23 LSTM
2-stroke dot Below 8 3 10 LSTM
3-stroke dot Above 8 1 7 LSTM
3-stroke other- Above 8 3; 6 8, 8 LSTM
4-stroke dot Above 8 6; 5 262 LSTM
4-stroke dot Below 8 3 6 LSTM
RNN Configuration: Terminal Half Forms
Single-stroke 8 2 174 LSTM
2-stroke dot Above 8 1 71 LSTM
2-stroke other- Above 8 1 100 LSTM
3-stroke dot Above 8 1 3 LSTM
4-stroke dot Above 8 2 100 LSTM
6.7 AutoEncoders
AutoEncoders (AEs) [110,111] have a key role in deep structured architectures and
unsupervised learning. An AutoEncoder aims to learn salient features for a set of
80

Final Classification
Table 6.4: DBN configurations (trained using wavelet dmey approximation anddetailed coefficients).
DBN-RBMs
Target Set GenerativeRBM-I
PerformanceMethod:
Reconstruction
GenerativeRBM-II
PerformanceMethod:
Reconstruction
DiscriminativeRBM
PerformanceMethod:
Classification
VisibleNeurons
HiddenNeurons
VisibleNeurons
HiddenNeurons
VisibleNeurons
HiddenNeurons
Initial Half-Forms
Single-stroke 209 500 500 500 508 2000
2-stroke dot Above 209 500 500 500 507 2000
2-stroke other- Above 209 500 500 500 507 2000
2-stroke dot Below 209 500 500 500 504 2000
2-stroke other- Below 209 500 500 500 503 1200
3-stroke dot Above 209 500 500 500 504 2000
3-stroke other- Above 209 500 500 500 503 2000
4-stroke dot Above 209 500 500 300 304 2000
4-stroke dot Below 209 500 500 500 504 193
Medial Half-Forms
Single-stroke 209 500 500 500 509 2000
2-stroke dot Above 209 870 870 700 707 500
2-stroke other- Above 209 700 700 1000 1005 2000
2-stroke dot Below 209 500 500 500 503 1000
3-stroke dot Above 209 850 850 950 953 2020
3-stroke other- Above 209 950 950 850 853 2020
4-stroke dot Above 209 500 500 500 503 1000
4-stroke dot Below 209 50 50 50 53 500
Terminal Half-Forms
Single-stroke 209 500 500 750 767 200
2-stroke dot Above 209 413 413 600 610 717
2-stroke other- Above 209 700 700 830 838 700
3-stroke dot Above 209 400 400 500 504 800
4-stroke dot Above 209 300 300 453 458 700
input data, usually to reduce the dimensionality of the data. In recent years, the
AutoEncoders have been applied to learn generative models of data. Besides con-
tinuous features extraction AutoEncoder filters out the noisy element of the input.
A hidden-layer of an AutoEncoder can be encoded by another hidden-layer which
results in stacking of AutoEncoders. To produce additional structural properties
of input data many variants of AutoEncoder model have been proposed, for exam-
ple Denoising AutoEncoders, Sparse AutoEncoder etc. Moreover, AutoEncoders
81

Final Classification
can be combined with other machine learning algorithms like artificial neural net-
works, or SVMs for classification purposes [112].
AutoEncoders are implemented here for dimensionality reduction in case of
discrete Meyer wavelet features and also for sensory input values. The extracted
features from the AutoEncoder are then fed to SVMs to get comparable recognition
results. All the DBNs and AutoEncoders are implemented using Deep Belief
Network (DeeBNet) toolbox [113].
6.8 Results and Discussions
The recognition results of online Urdu handwritten characters using classification
techniques accounted previously, are given here. The results can be categorized
mainly in two types.
• Recognition results obtained after applying the proposed pre-classification,
and
• Recognition results obtained without applying proposed pre-classification.
6.9 Results with Pre-Classification
The pre-classifier produced a total of 28 subsets and sub-subsets from the set of
108 half-form characters (see Table 4.1 in chapter 4). Out of these 28 subsets
and sub-subsets there are 6 subsets containing only one character and do not
need any further classification (Chapter 4 Table 4.2). For different classifiers and
different types of features described earlier, the remaining 22 subsets are tried for
classification. A comparable range of recognition results can be seen in Tables 6.5
and 6.6.
6.10 Results without Pre-Classification
Urdu characters under consideration for this study have also been tried to recognize
without the proposed pre-classification. Support vector machines, Deep Belief
AutoEncoders and classifiers, and Recurrent neural networks are used to achieve
the recognition task. The results are reported in Table 6.7.
82

Final Classification
Table 6.5: Recognition rates for each subset of handwritten half-form Urdu char-acters obtained from the pre-classifier. Results obtained with using ANNs, andSVMs using different features are presented for comparison.
Character-Subset
Recognition Rate (%)ANN SVM
Structural db2 db2 bior-
1.3
dmey SensoryInput
Initial Half-FormsSingle-stroke 80.7 93.3 94.7 95.9 93.7 95.42-stroke dot Above 81.3 90.2 99.1 98.0 96.0 99.02-stroke other- Above 76.3 87.7 91.9 98.0 93.3 89.32-stroke dot Below 92.2 94.4 97.2 97.7 96.0 98.62-stroke other- Below 90.0 97.5 98.3 96.6 96.0 96.03-stroke dot Above 88.8 97.7 94.4 95.5 97.3 94.63-stroke other- Above 99.1 98.3 100 100 100 100
3-stroke dot Below ‘Í’ 1004-stroke dot Above 77.7 89.4 88.8 83.7 89.3 86.64-stroke dot Below 88.8 89 92.7 93.3 93.3 94.0
Medial Half-FormsSingle-stroke 62.7 83.7 89.1 90 92.0 93.72-stroke dot Above 58.0 81.6 93.6 91.3 92.0 90.02-stroke other- Above 80.4 91.6 93.3 94.1 94.0 93.02-stroke dot Below 99.0 99.1 98.3 100 99.0 100
2-stroke other- Below ‘È’ 100
3-stroke dot Above 95.0 98.3 95.0 98.3 95.0 97.03-stroke other- Above 94.1 97.5 95.8 97.5 97.0 98.03-stroke dot Below ‘Î’ 1004-stroke dot Above 87.5 97.5 95.8 95.8 97 96.04-stroke dot Below 97.5 100 100 100 100 100
Terminal Half-FormsSingle-stroke 78.4 81.7 94.7 94.2 96.7 96.32-stroke dot Above 66.6 93.3 96.7 97.2 90.4 91.52-stroke other- Above 82.6 95.7 99.0 99.2 99.1 99.42-stroke dot Below ‘K’ 1003-stroke dot Above 93.3 95.5 99.4 100 99.3 1003-stroke other- Above ‘{’ 1004-stroke dot Above 94.1 97.9 99.6 99.1 100 98.54-stroke dot Below ‘„’ 100Overall Accuracy (%) 80.9 91.0 95.5 95.3 95.4 95.4
83

Final Classification
Table 6.6: Recognition rates for each subset of handwritten Urdu characters ob-tained from the pre-classifier. Results obtained with DBN, AE-DBN, AE-SVMand RNN using different features are presented for comparison.
Character-Subset
Recognition Rate (%)DBN AE-DBN AE-SVM RNNdmey Sensory
Inputdmey dmey Sensory
InputSensoryInput
Initial Half-FormsSingle-stroke 95.0 94.8 92.5 93.7 96.0 75.42-stroke dot Above 94.0 94.6 96.3 95.3 99.3 84.62-stroke other- Above 89.6 87.6 90.6 91.3 86.0 73.32-stroke dot Below 97.3 96.6 98.0 96.6 98.6 94.02-stroke other- Below 96.0 99.0 98.0 94.0 97.0 90.03-stroke dot Above 96.6 96.6 95.3 91.3 98.6 91.33-stroke other- Above 98.0 100 97.0 100 100 97.0
3-stroke dot Below ‘Í’ 1004-stroke dot Above 84.0 85.3 84.6 84.0 90.6 85.34-stroke dot Below 93.3 94.6 93.3 93.3 92.6 88.6
Medial Half-FormsSingle-stroke 86.2 90.2 86.7 92 93.0 71.52-stroke dot Above 91.6 83.6 91.3 93.6 86.3 74.02-stroke other- Above 94.0 93.5 96.0 91.5 93.0 73.52-stroke dot Below 99.0 99.0 100 99.0 100 96.0
2-stroke other- Below ‘È’ 100
3-stroke dot Above 95.0 93.0 94.0 97.0 97.0 90.03-stroke other- Above 97.0 97.0 98.0 97.0 97.0 94.03-stroke dot Below ‘Î’ 1004-stroke dot Above 96.0 97.0 95.0 93.0 94.0 86.04-stroke dot Below 100 100 100 100 100 99.0
Terminal Half-FormsSingle-stroke 91.3 94.7 89.8 90.2 96.6 84.62-stroke dot Above 85.5 87.7 87.1 89.1 92.8 92.02-stroke other- Above 97.1 97.4 97.4 98.0 98.5 91.72-stroke dot Below ‘K’ 1003-stroke dot Above 99.3 100 99.3 98.6 100 99.33-stroke other- Above ‘{’ 1004-stroke dot Above 99.0 98.5 99.0 98.5 99.0 97.54-stroke dot Below ‘„’ 100Overall Accuracy (%) 93.2 93.7 93.2 93.7 95.3 85.9
84

Final Classification
Table 6.7: Recognition rates for half-form Urdu characters without going throughpre-classification. Results are obtained using SVMs, DBN, AE-DBN, AE-SVMand RNN using different features.
Classifier Recognition
Rate (%)
Features Type Number of Features
SVM 55.0 Sensory input values 224
SVM 42.2 Discrete Meyer wavelets 239
DBN 51.3 Sensory input values 224
DBN 46.3 Discrete Meyer wavelets 239
AE-SVM 51.2 Sensory input values 100
AE-DBN 45.0 Sensory input values 99
AE-DBN 35.5 Discrete Meyer wavelets 99
RNN 67.3 Sensory input values Variable stroke length
6.11 Maximum Recognition Rate
Accuracy of online Urdu handwritten character recognition can be viewed accord-
ing to following perspectives:
Overall Accuracy: Overall accuracy (subsection 6.11.1) describes the recogni-
tion rates delivered by different classifiers taking every thing into account.
With pre-classification in practice, for different classifier-feature combina-
tions the overall accuracy ranges between 85.9% to 95.5% whereas without
pre-classification, different classifier-feature combinations produce accura-
cies between 35.5% to 67.3%.
subset-wise Accuracy: It describes (subsection 6.11.2), from the bank of clas-
sifiers, how much a classifier is proved to be successful for the subsets. Ac-
curacies for all the subsets with different classifier-feature combinations is
presented in Tables 6.5 and 6.6 where values in boldface are the maximum
accuracy for the subset among different classifier-feature combinations.
Character-wise Accuracy: It is important to know how much accurately a
character is recognized by the classifiers with different features (subsection
85

Final Classification
6.11.3). In this study, 29% of the characters are recognized 100% accurately
while 58% of the characters achieved more than 90% recognition accuracy.
Rest of the characters successfully attained more than 80% recognition rate.
6.11.1 Overall Accuracy
with Pre-Classification: For various features-classifier combinations, maximum
overall recognition accuracy of 95.5% is occasioned by db2 -SVM com-
bination for all the subsets obtained through pre-classification. This max-
imum accuracy is computed with the inclusion of subsets in which char-
acters are recognized at pre-classification stage. (These subsets are given
in Table 4.2). Tables 6.5 and 6.6 show that support vector machines per-
formed the best among all the classifiers mentioned previously. In fact we
see that, all those combinations which involved SVMs, whether features-
classifier combination (db2 -SVM, biorthogonal -SVM, dmey-SVM, sensory
input values-SVM) or classifier-classifier combination (AutoEncoder-SVM)
showed up with the maximum range of accuracy, that is more than 95%.
ANN with db2 wavelet features provided somewhat lesser overall accuracy
of 91% as compared to SVM. For ANNs with structural features the overall
accuracy of 80.89% is significantly lower as compared to all other combi-
nations. Moreover, RNNs with multi LSTM hidden layers of varying sizes
delivered overall 85.9% accurate recognition results. Deep belief networks
whether used with discrete Meyer wavelets or with sensory input provided
about 93% accurate results. DBN and SVM resulted in overall accuracies of
93.7 and 95.3 respectively while using features extracted by AutoEncoders
from the sensory input.
without Pre-Classification: In this case, the maximum of 67.3% overall accu-
racy is delivered by recurrent neural network using sensory input values.
For other classifiers (like SVM, DBN, AE-DBN) the recognition accuracy
ranges between 35.5% to 55.0% as shown in Table 6.7. The huge difference
between the accuracies achieved through pre-classification and the accura-
cies obtained without pre-classification illustrates the effectiveness of the
proposed pre-classification.
86

Final Classification
6.11.2 Polling or Subset-wise Accuracy
In Tables 6.5 and 6.6, the results obtained through different classifier-feature com-
binations are presented in a subset-wise manner. Through polling, i.e. considering
the maximum recognition rate for the subsets among all the classifiers, it can be
observed that there are 11 (out of 28), 100% accurately recognized subsets. There
are 13 subsets for which the recognition accuracy is ≥ 96% whereas the remaining
4 subsets are recognized with more than 90% accurate results. With subset-wise
maximum recognition rates, the overall accuracy for the system becomes 97.2%.
This accuracy is greater than the accuracy yielded through SVM+db2 -wavelet-
features (i.e. 95.5%). It suggests to use a bank of classifiers for Urdu characters
recognition rather than relying on a single classifier.
6.11.3 Character-wise Accuracy
Recognition accuracy for each character is given in Character-wise Accuracy Chart
Table 6.8. There are 32 characters out of 108 (total target shapes) which are 100%
accurately recognized. There are 44 characters which showed up with more than
95% accuracy. The accuracy of 19 characters lied between 90% to 95% while the
accuracy of 12 characters are between 80% to 90%. The terminal half-form ‘f’
has the minimum accuracy of 73.3%.
6.12 Error Analysis using Confusion Matrices
Some confusion matrices are presented in this section for the best and worst cases
of the best classifier-feature combination i.e. SVM+db2 -wavelet-features. In each
confusion matrix, X is a representative mark for some unknown class. The con-
fusion matrices for all subsets can be seen in Appendix A.
Table 6.9 shows the confusion matrix of a subset that contains 3 characters.
The overall accuracy of this subset is 88.8%. It is among the lowest accuracies
obtained with the SVM+db2 -wavelet-features combination.
87

Final Classification
Table 6.8: Characters accuracy chart
Character
Accuracy%
L I JK
95 98.3 93.3 96.6 100
… ‚ ƒ „ P M N O
83.3 95.0 100 100 90.0 95.0 98.3 100
“ — ‘ ’ T Q R S
81.6 90.0 85 98.3 85.0 91.6 91.6 100
U V W † ‡ ˆ
100 100 98.3 100 100 100
Y Z \ a b c96.6 95.0 96.6 100 100 93.3
f • h j ™ l ‹73.3 98.3 96.6 96.6 100 100 100
m n o q r s
93.3 93.3 98.3 90.0 100 98.3
u v w y z |
93.3 85.0 90.0 98.3 98.3 98.3
ø ¡ ñ £ ¤ ¥98.3 86.6 96.6 100 98.3 96.6
§ ¨ © « ¬ −
95.0 80.0 96.6 100 85.0 90.0
¯ ° ± ³ ´ µ98.3 85.0 96.6 98.3 91.6 98.3
· ù ¹ º ¸
100 98.3 100 95.0 100
Œ õ ò ô {
100 100 98.3 93.3 100
88

Final Classification
Table 6.8 continued...
Character
Accuracy%
» ¼ ½ ¿ À Á100 96.6 98.3 86.6 83.3 98.3
Ã Ä Å Ì Û è é
98.3 95.0 100 90.0 98.3 93.3 98.3ì ä È É ú Ñ98.3 98.3 100 96.6 93.3 100
Ö å × š Ł95.0 86.6 93.3 100 100
Í Î Ó ˛
100 100 93.3 98.3
Table 6.9: Confusion matrix for 4-stroke characters (initial half-form) with dotdiacritic above the major stroke
T Q q X
T 51 7 2 0 60
Q 2 55 3 0 60
q 3 3 54 0 6056 65 59 0
Table 6.10 shows the confusion matrix of a subset containing 6 characters.
The recognition accuracy of 91.9% for this subset. The character å is 3 times
misclassified as Ö and 4 times misclassified as“. This should be expected because
of the shape similarity among these characters. Similarly“is 7 times misclassified
as — and 4 times misclassified aså for the same reason.
Table 6.11 shows the confusion matrix for another subset yielding low over-
all recognition accuracy (93.6%) with the SVM+db2-wavelet-features combina-
tion. The main culprits for the low accuracy in this subset are the characters
° and¬. Although ° and¬ have distinct major strokes in standard form with¬89

Final Classification
Table 6.10: Confusion matrix for initial half-forms 2-stroke characters with other-than-dot diacritic above the major stroke. Overall accuracy for this subset is91.9%
Ö å · ù “ — X
Ö 57 2 0 0 1 0 0 60
å 3 52 1 0 4 0 0 60
· 0 0 60 0 0 0 0 60
ù 0 0 1 59 0 0 0 60
“ 0 4 0 0 49 7 0 60
— 2 2 0 0 2 54 0 6062 60 62 59 56 61 0
Table 6.11: Confusion matrix for medial half-form 2-stroke characters with dotdiacritic above the major stroke. Overall accuracy for this subset is 93.6%
° ¬ b Ä ¤ z X
° 51 5 0 1 0 3 0 60
¬ 7 51 0 1 0 1 0 60
b 0 0 60 0 0 0 0 60
Ä 1 1 0 57 1 0 0 60
¤ 0 0 1 0 59 0 0 60
z 0 0 0 0 1 59 0 6059 57 61 59 61 63 0
having a cusp in its major stroke, many writers ignore this cusp while handwriting
¬ casually. The¬ then appears very much similar to °. This is confirmed by the
confusion matrix which shows that ¬ is 7 times misclassified as °. Removing ¬and ° from this subset results in 96.6% accuracy (Confusion matrix in table 6.12).
Removing only ° results in 96.3% accuracy, while removing only ¬ gives 96.6%
accuracy (Confusion matrices in Tables 6.13 and 6.14).
Confusion matrix of another subset yielding low overall accuracy of 93.3%
is presented in Table 6.15. Here × and ‘ are responsible for the low recognition
rate. Both characters have same major stroke but distinct minor strokes, so minor
stroke was also utilized for feature vector formation. But casual penning of minor
90

Final Classification
Table 6.12: Confusion matrix for medial half-form 2-stroke characters with dotdiacritic above the major stroke excluding both ° and¬. Overall accuracy for thissubset is 96.6%
b Ä ¤ z X
b 60 0 0 0 0 60
Ä 1 56 1 2 0 60
¤ 1 0 59 0 0 60
z 0 0 3 57 0 6062 56 63 59 0
strokes results in similar shapes of the minor strokes. Consequently ‘ is 9 times
misclassified as×.Table 6.16 and Table 6.17 present two subsets showing high overall recog-
nition accuracy.
6.12.1 Confusing Characters
In Urdu there are a few groups of characters in which the major stroke is common
to the group and the discrimination is made on the basis of minor strokes. This
similarity is inherent to Urdu and the similar characters were put into different
subsets by the pre-classifier. There is another kind of similarity between different
characters which arises from the careless writing by the user. This user imposed
similarity occurs inside the subsets produced by the pre-classifier and results in
confusing pairs of characters within a subset.
Table 6.13: Confusion matrix for medial half-form 2-stroke characters with dotdiacritic above the major stroke excluding °. Overall accuracy for this subset is96.3%
¬ b Ä ¤ z X
¬ 58 0 1 0 1 0 60
b 1 59 0 0 0 0 60
Ä 0 1 56 1 2 0 60
¤ 0 1 0 59 0 0 60
z 0 0 0 3 57 0 6059 61 57 63 60 0
91

Final Classification
Table 6.14: Confusion matrix for medial half-form 2-stroke characters with dotdiacritic above the major stroke excluding¬. Overall accuracy for this subset is96.6%
° b Ä ¤ z X
° 54 0 2 0 4 0 60
b 0 60 0 0 0 0 60
Ä 1 0 58 1 0 0 60
¤ 0 1 0 59 0 0 60
z 0 0 0 1 59 0 6055 61 60 61 63 0
Table 6.15: Confusion matrix for medial half-forms 2-stroke characters with other-than-dot diacritic above the major stroke. Overall accuracy for this subset is 93.3%
× ¹ º ‘ X
× 56 1 0 3 0 60
¹ 0 60 0 0 0 60
º 0 3 57 0 0 60
‘ 9 0 0 51 0 6065 64 57 54 0
Table 6.16: Confusion matrix for terminal half-forms 2-stroke characters with dotdiacritic above the major stroke. Overall accuracy for this subset is 96.7%
± −
W c Å h l ¥ | X
± 58 0 0 0 0 0 0 0 2 0 60
−
0 54 0 6 0 0 0 0 0 0 60W 0 1 59 0 0 0 0 0 0 0 60
c 0 4 0 56 0 0 0 0 0 0 60Å 0 0 0 0 60 0 0 0 0 0 60
h 0 0 0 0 0 58 2 0 0 0 60l 0 0 0 0 0 0 60 0 0 0 60
¥ 0 0 0 1 0 1 0 58 0 0 60| 1 0 0 0 0 0 0 0 59 0 60
59 59 59 63 60 59 62 58 61 0
Figure 6.4 shows few handwritten samples of two confusing characters °(Fay) and¬ (Ghain) present in the subset shown in the confusion matrix of Table
6.11. If drawn according to rules, the character¬ should have a well defined cusp
92

Final Classification
Table 6.17: Confusion matrix for terminal half-forms 4-stroke characters with dotdiacritic above the major stroke. Overall accuracy for this subset is 99.6%
ˆ S s ‹ X
ˆ 60 0 0 0 0 60S 0 60 0 0 0 60s 0 0 59 1 0 60
‹ 0 0 0 60 0 6060 60 59 61 0
Fay
Ghain
Fay
Ghain
Fay
Ghain
Fay
Ghain
Figure 6.4: Handwritten samples of ° (Fay) and¬ (Ghain). The¬ (Ghains) areconfusingly similar to the ° (Fays).
in its major stroke. Some users do not draw the cusp while writing casually or in
hurry. The¬ drawn in this way appears like ° to a human reader as well and can
be seen in Figure 6.4. The classifier also many times misclassified¬ as ° and vice
versa as shown in confusion matrix of Table 6.11.
Another pair of confusing characters is shown in Figure 6.5. These are the
characters × (hamza) and ‘ (Tay) in medial form. The major stroke for both
the characters is the same and the discrimination is made on the basis of minor
stroke. Many users casually draw the minor stroke of ‘ in a very much similar
way to the minor stroke of×. The confusion matrix in Table 6.15 for this subset
confirms this where it can be seen that‘ has been 9 times misclassified as×.In medial half-form a pair of¨and v when handwritten (Figure 6.6) causes
confusion due to the absence of tooth required to be drawn with v. Handwritten
samples shown in figures 6.7 and 6.8 also depict confusing resemblance between ¿
and u in initial half-forms andf and Ì in teminal half-forms.
93

Final Classification
hmza
Tay
hmza
Tay
hmza
Tay
hmza
Tay
Figure 6.5: Handwritten samples of × (hamza) and ‘ (Tay). The ‘ (Tays) are
confusingly similar to the× (hamzas).
Ain Ain Ain Ain
Suwad Suwad Suwad Suwad
Figure 6.6: Handwritten samples of ¨ (ain) and v (swad). The ¨ (ains) areconfusingly similar to the v (swads).
Meem Meem Meem Meem
Suwad Suwad Suwad Suwad
Figure 6.7: Handwritten samples of ¿ (meem) and u (swad). The ¿ (meems) areconfusingly similar to the u (swads).
Daal Daal Daal Daal
Wao Wao Wao Wao
Figure 6.8: Handwritten samples of f (daal) and Ì (wao). The f (daals) areconfusingly similar to the Ì (waos).
94

Chapter 7
Conclusion
In this study, a novel character recognition system for Urdu language online hand-
written characters is presented. All initial, medial, and terminal half form charac-
ters have been recognized. A large scale handwriting data set was acquired from
100 native Urdu writers of different age groups and educational qualifications. The
data was acquired using a digitizing tablet. Spatial coordinates in temporal or-
der with their respective pressure values, and pen up/down events were recorded.
The raw data was refined after its manipulation with different preprocessing oper-
ations. A novel pre-classifier was designed to pre-classify Urdu characters set into
smaller subsets. The pre-classifier yielded smaller subsets based on the number of
strokes to yield two-, three-, four-stroke subsets. The pre-classifier further divided
the subsets based on the position of the minor stroke with respect to the major
stroke, and also on the basis of whether the minor stroke is a dot or other-than-
dot. The pre-classifier helped in discriminating similar characters from each other
by putting them in different subsets. Three types of features, namely structural
features, wavelet transform features, and sensory input values were extracted.
Wavelet features were obtained using Daubechies db2, Biorthogonal bior1.3, and
discrete Meyer families. ANN, SVM, DBN, AE-DBN, AE-SVM and RNN clas-
sifiers were used for fine classification of the individual characters in the subsets
generated by the pre-classifier. The classifiers were also employed without going
through proposed pre-classification. Results of RNN (LSTM) classifier without
using the proposed pre-classifier and features were also obtained to check the
end-to-end capability of the RNN classifier. Since there is no sufficient previous
95

Conclusion
work for comparison, different combinations of features and classifiers were tried
to find the best recognition results. Thirteen (13) different features-classifier com-
binations were tried which resulted in overall accuracies of 80.9%, 91.0%, 95.5%,
95.3%, 95.4%, 95.4% with classical approaches and 93.2% , 95.7%, 93.2%, 93.7%,
95.3%, 85.9% with deep learning classifiers (DBN, AEDBN, AESVM, RNN). The
best overall recognition rate of 95.5% was found for SVM+db2 -wavelet-features
combination. For individual characters, recognition rates obtained were between
80% to 100% with an exception of one character that obtained the accuracy of
73.3%. Overall accuracy for different subsets was between 88.8% to 100% for
SVM+db2 -wavelet-features combination, and overall accuracy for all initials, me-
dials, and terminals were 95.1%, 93.9%, and 97.0% respectively. We have followed
the segmentation-based approach which requires extraction of half forms of char-
acters from the ligatures. The data was actually obtained in segmented form from
the users. Research on segmentation of ligatures into half-form characters is also
being carried out in parallel to this work. RNNs promise of end-to-end recognition
capability was also explored but was found to yield inferior results as compared
to the classical feature-based approaches of SVM and ANN, however, DBNs pro-
duced comparable results. The results with RNNs may be improved if more data
is added to the database.
7.1 Future Work
For future work the followings are of major concern:
• Focus on segmentation of ligatures into half forms and recognition of Urdu
handwritten words.
• Increase in the size of database of handwritten Urdu characters.
• Implementation on touch screens and android based smartphones.
• Classification using deep convolutional neural networks.
• Implementation of recognition system on digital signal processor
Another interesting idea for future recommendation is to capture and classify in
real time the character data while the writer is writing on a page.
96

Conclusion
In future, with the increased size of database, other deep learning methods
like deep belief networks and convolutional neural networks may be employed.
Other kinds of features may also be explored.
97

Appendices
98

Appendix A
Confusion Matrices
A.1 Confusion Matrices of Support Vector Classifier with
db2 -Wavelet-Features
Confusion matrices are presented in this section for all subsets of the best classifier-
feature combination i.e. SVM+db2 -wavelet-features. The overall accuracy for
this classifier-feature combination is 95.53%. In each confusion matrix, X is a
representative mark for some unknown class.
Table A.1: Confusion matrix for single-stroke characters (initial half-form). Itcontains 7 characters. Overall accuracy: 94.7%
§ Y » ¿ m u ø X
§ 57 0 0 0 0 0 3 0 60Y 0 58 0 2 0 0 0 0 60
» 0 0 60 0 0 0 0 0 60¿ 0 3 0 52 0 4 1 0 60m 0 0 1 3 56 0 0 0 60u 0 1 0 3 0 56 0 0 60
ø 1 0 0 0 0 0 59 0 6058 62 61 60 56 60 63 0
99

Confusion Matrices
Table A.2: Confusion matrix for 2-stroke characters (initial half-form) with dotdiacritic above the major stroke. It contains 6 characters. Overall accuracy: 99.1%
¯ « a à £ y X
¯ 59 1 0 0 0 0 0 60
« 0 60 0 0 0 0 0 60
a 0 0 60 0 0 0 0 60
à 0 1 0 59 0 0 0 60
£ 0 0 0 0 60 0 0 60
y 1 0 0 0 0 59 0 6060 62 60 59 60 59 0
Table A.3: Confusion matrix for 2-stroke characters (initial half-form) with other-than-dot diacritic above the major stroke. It contains 6 characters. Overall accu-racy: 91.9%
Ö å · ù “ — X
Ö 57 2 0 0 1 0 0 60
å 3 52 1 0 4 0 0 60
· 0 0 60 0 0 0 0 60
ù 0 0 1 59 0 0 0 60
“ 0 4 0 0 49 7 0 60
— 2 2 0 0 2 54 0 6062 60 62 59 56 61 0
Table A.4: Confusion matrix for 2-stroke characters (initial half-form) with dotdiacritic below the major stroke. It contains 3 characters. Overall accuracy: 97.2%
L I U XL
59 1 0 0 60I
4 56 0 0 60U 0 0 60 0 60
63 57 60 0
100

Confusion Matrices
Table A.5: Confusion matrix for 2-stroke characters (initial half-form) with other-than-dot diacritic below the major stroke. It contains 2 characters. Overall accu-racy: 98.3%
ì äXì
59 1 0 60ä1 59 0 6060 60 0
Table A.6: Confusion matrix for 3-stroke characters (initial half-form) with dotdiacritic above the major stroke. It contains 3 characters. Overall accuracy: 94.4%
³ P M X
³ 59 0 1 0 60P 0 54 6 0 60
M 1 2 57 0 6060 56 64 0
Table A.7: Confusion matrix for 3-stroke characters (initial half-form) with other-than-dot diacritic above the major stroke. It contains 2 characters. Overall accu-racy: 100%
Œ õ X
Œ 60 0 0 60õ 0 60 0 60
60 60 0
Table A.8: Confusion matrix for 4-stroke characters (initial half-form) with dotdiacritic above the major stroke. It contains 3 characters. Overall accuracy: 88.8%
T Q q X
T 51 7 2 0 60
Q 2 55 3 0 60
q 3 3 54 0 6056 65 59 0
101

Confusion Matrices
Table A.9: Confusion matrix for 4-stroke characters (initial half-form) with dotdiacritic below the major stroke. It contains 3 characters. Overall accuracy: 92.7%
† … ‚ X†
60 0 0 0 60… 0 50 10 0 60‚
0 3 57 0 6060 53 67 0
Table A.10: Confusion matrix for single-stroke characters (medial half-form). Itcontains 8 characters. Overall accuracy: 89.1%
¨ Z ¼ À n v ¡ è X
¨ 48 0 3 0 0 6 1 2 0 60Z 0 57 0 2 0 1 0 0 0 60¼ 0 0 58 0 1 1 0 0 0 60À 2 3 1 50 0 4 0 0 0 60n 0 0 0 2 56 2 0 0 0 60v 6 0 1 0 2 51 0 0 0 60¡ 2 2 2 0 0 1 52 1 0 60è 1 0 0 1 0 1 1 56 0 60
59 62 65 55 59 67 54 59 0
Table A.11: Confusion matrix for 2-stroke characters (medial half-form) with dotdiacritic above the major stroke. It contains 8 characters. Overall accuracy: 93.6%
° ¬ b Ä ¤ z X
° 51 5 0 1 0 3 0 60
¬ 7 51 0 1 0 1 0 60
b 0 0 60 0 0 0 0 60
Ä 1 1 0 57 1 0 0 60
¤ 0 0 1 0 59 0 0 60
z 0 0 0 0 1 59 0 6059 57 61 59 61 63 0
102

Confusion Matrices
Table A.12: Confusion matrix for 2-stroke characters (medial half-form) withother-than-dot diacritic above the major stroke. It contains 4 characters. Overallaccuracy: 93.3%
× ¹ º ‘ X
× 56 1 0 3 0 60
¹ 0 60 0 0 0 60
º 0 3 57 0 0 60
‘ 9 0 0 51 0 6065 64 57 54 0
Table A.13: Confusion matrix for 2-stroke characters (medial half-form) with dotdiacritic below the major stroke. It contains 2 characters. Overall accuracy: 98.3%
J V XJ
58 2 0 60V 0 60 0 60
58 62 0
Table A.14: Confusion matrix for 3-stroke characters (medial half-form) with dotdiacritic above the major stroke. It contains 2 characters. Overall accuracy: 95.0%
´ N X
´ 55 5 0 60N 1 59 0 60
56 64 0
Table A.15: Confusion matrix for 3-stroke characters (medial half-form) withother-than-dot diacritic above the major stroke. It contains 2 characters. Overallaccuracy: 95.8%
ò ô X
ò 59 1 0 60ô 4 56 0 60
63 57 0
103

Confusion Matrices
Table A.16: Confusion matrix for 4-stroke characters (medial half-form) with dotdiacritic above the major stroke. It contains 2 characters. Overall accuracy: 95.8%
R r X
R 55 5 0 60
r 0 60 0 6055 65 0
Table A.17: Confusion matrix for 4-stroke characters (medial half-form) with dotdiacritic below the major stroke. It contains 2 characters. Overall accuracy: 100%
‡ ƒX‡
60 0 0 60ƒ 0 60 0 6060 60 0
Table A.18: Confusion matrix for single-stroke characters (terminal half-form). Itcontains 16 characters. Overall accuracy: 94.7%
© š f \ ½ Ó Á j É ú o w ñ é Ì X© 58 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 60
0 57 0 0 0 0 0 0 0 1 0 0 0 2 0 0 0 60š 0 0 60 0 0 0 0 0 0 0 0 0 0 0 0 0 0 60
f 0 0 0 44 0 1 0 0 3 0 0 1 0 1 0 10 0 60\ 2 0 0 0 58 0 0 0 0 0 0 0 0 0 0 0 0 60½ 0 0 0 0 0 59 0 0 0 0 0 0 0 0 1 0 0 60Ó 0 0 0 0 0 1 56 0 0 0 0 3 0 0 0 0 0 60Á 0 0 0 0 0 0 0 59 0 0 1 0 0 0 0 0 0 60j 0 0 0 0 0 0 0 1 58 0 1 0 0 0 0 0 0 60É 1 0 0 0 1 0 0 0 0 58 0 0 0 0 0 0 0 60ú 0 0 0 0 0 0 0 1 3 0 56 0 0 0 0 0 0 60o 0 0 0 0 0 0 0 0 0 0 0 59 1 0 0 0 0 60w 0 0 0 0 0 2 0 0 0 0 0 2 54 0 1 1 0 60ñ 0 0 0 1 0 0 0 0 0 0 0 1 0 58 0 0 0 60é 0 0 0 0 0 0 0 0 0 0 0 0 0 1 59 0 0 60Ì 0 0 0 4 0 0 0 0 1 0 0 0 0 0 1 54 0 60
61 57 60 49 60 63 56 62 65 59 58 66 55 62 62 65 0
104

Confusion Matrices
Table A.19: Confusion matrix for 2-stroke characters (terminal half-form) withdot diacritic above the major stroke. It contains 9 characters. Overall accuracy:96.7%
± −
W c Å h l ¥ | X
± 58 0 0 0 0 0 0 0 2 0 60
−
0 54 0 6 0 0 0 0 0 0 60W 0 1 59 0 0 0 0 0 0 0 60
c 0 4 0 56 0 0 0 0 0 0 60Å 0 0 0 0 60 0 0 0 0 0 60
h 0 0 0 0 0 58 2 0 0 0 60l 0 0 0 0 0 0 60 0 0 0 60
¥ 0 0 0 1 0 1 0 58 0 0 60| 1 0 0 0 0 0 0 0 59 0 60
59 59 59 63 60 59 62 58 61 0
Table A.20: Confusion matrix for 2-stroke characters (terminal half-form) withother-than-dot diacritic above the major stroke. It contains 7 characters. Overallaccuracy: 99.0%
™ • ˛ Ł ¸ ’ Û X
™ 59 1 0 0 0 0 0 0 60
• 0 60 0 0 0 0 0 0 60˛ 0 0 59 0 1 0 0 0 60Ł 0 0 0 60 0 0 0 0 60¸ 0 0 0 0 60 0 0 0 60’ 1 0 0 0 0 59 0 0 60
Û 0 0 0 0 1 0 59 0 6060 61 59 60 62 59 59 0
Table A.21: Confusion matrix for 3-stroke characters (terminal half-form) withdot diacritic above the major stroke. It contains 3 characters. Overall accuracy:99.4%.
µ Ñ O Xµ 59 0 1 0 60
Ñ 0 60 0 0 60O 0 0 60 0 60
59 60 61 0
105

Confusion Matrices
Table A.22: Confusion matrix for 4-stroke characters (terminal half-forms) withdot diacritic above the major stroke. It contains 4 characters. Overall accuracy:99.6%
ˆ S s ‹ X
ˆ 60 0 0 0 0 60S 0 60 0 0 0 60s 0 0 59 1 0 60
‹ 0 0 0 60 0 6060 60 59 61 0
106

Confusion Matrices
A.2 Confusion Matrices of Support Vector Classifier with
Sensory Input Values
Confusion matrices are presented in this section for all subsets of the second best
classifier-feature combination i.e. SVM+ sensory input values. The overall accu-
racy for this classifier-feature combination is 95.45%. In each confusion matrix,
X is a representative mark for some unknown class.
Table A.23: Confusion matrix for single-stroke characters (initial half-form). Itcontains 7 characters. Overall accuracy: 95.4%
§ Y » ¿ m u ø X
§ 48 0 0 0 0 0 2 0 50Y 0 49 0 1 0 0 0 0 50
» 0 0 50 0 0 0 0 0 50¿ 1 4 0 42 0 3 0 0 50m 0 0 0 0 50 0 0 0 50u 0 0 0 3 1 46 0 0 50
ø 0 1 0 0 0 0 49 0 5049 54 50 46 51 49 51 0
Table A.24: Confusion matrix for 2-stroke characters (initial half-form) with dotdiacritic above the major stroke. It contains 6 characters. Overall accuracy: 99.0%
¯ « a à £ y X
¯ 48 1 0 0 0 1 0 50
« 0 50 0 0 0 0 0 50
a 0 0 50 0 0 0 0 50
à 0 0 0 50 0 0 0 50
£ 0 0 1 0 49 0 0 50
y 0 0 0 0 0 50 0 5048 51 51 50 49 51 0
107

Confusion Matrices
Table A.25: Confusion matrix for 2-stroke characters (initial half-form) with other-than-dot diacritic above the major stroke. It contains 6 characters. Overall accu-racy: 89.3%
Ö å · ù “ — X
Ö 45 1 0 0 0 4 0 50
å 4 35 0 0 10 1 0 50
· 0 0 50 0 0 0 0 50
ù 0 0 1 49 0 0 0 50
“ 0 4 0 0 42 4 0 50
— 2 0 0 0 1 47 0 5051 40 51 49 43 56 0
Table A.26: Confusion matrix for 2-stroke characters (initial half-form) with dotdiacritic below the major stroke. It contains 3 characters. Overall accuracy: 98.6%
L I U XL
48 2 0 0 50I
0 50 0 0 50U 0 0 50 0 50
48 52 50 0
Table A.27: Confusion matrix for 2-stroke characters (initial half-form) with other-than-dot diacritic below the major stroke. It contains 2 characters. Overall accu-racy: 96.0%
ì äXì
50 0 0 50ä4 46 0 5054 46 0
108

Confusion Matrices
Table A.28: Confusion matrix for 3-stroke characters (initial half-form) with dotdiacritic above the major stroke. It contains 3 characters. Overall accuracy: 94.6%
³ P M X
³ 50 0 0 0 50P 0 43 7 0 50
M 0 1 49 0 5050 44 56 0
Table A.29: Confusion matrix for 3-stroke characters (initial half-form) with other-than-dot diacritic above the major stroke. It contains 2 characters. Overall accu-racy: 100%
Œ õ X
Œ 50 0 0 50õ 0 50 0 50
50 50 0
Table A.30: Confusion matrix for 4-stroke characters (initial half-form) with dotdiacritic above the major stroke. It contains 3 characters. Overall accuracy: 86.6%
T Q q X
T 35 8 7 0 50
Q 1 48 1 0 50
q 2 1 47 0 5038 57 55 0
Table A.31: Confusion matrix for 4-stroke characters (initial half-form) with dotdiacritic below the major stroke. It contains 3 characters. Overall accuracy: 94.0%
† … ‚ X†
50 0 0 0 50… 0 43 7 0 50‚
0 2 48 0 5050 45 55 0
109

Confusion Matrices
Table A.32: Confusion matrix for single-stroke characters (medial half-form). Itcontains 8 characters. Overall accuracy: 93.7%
¨ Z ¼ À n v ¡ è X
¨ 41 0 2 0 0 4 1 2 0 50Z 0 48 0 2 0 0 0 0 0 50¼ 2 0 48 0 0 0 0 0 0 50À 0 0 0 49 1 0 0 0 0 50n 0 0 0 0 50 0 0 0 0 50v 0 0 3 0 0 47 0 0 0 50¡ 4 0 0 0 0 0 44 2 0 50è 1 0 0 0 0 1 0 48 0 50
48 48 52 51 51 52 45 52 0
Table A.33: Confusion matrix for 2-stroke characters (medial half-form) with dotdiacritic above the major stroke. It contains 8 characters. Overall accuracy: 90.0%
° ¬ b Ä ¤ z X
° 42 6 0 0 1 1 0 50
¬ 8 41 0 0 0 1 0 50
b 1 0 48 0 1 0 0 50
Ä 1 0 1 47 1 0 0 50
¤ 2 0 1 0 46 1 0 50
z 0 1 0 3 0 46 0 5054 48 50 50 49 49 0
Table A.34: Confusion matrix for 2-stroke characters (medial half-form) withother-than-dot diacritic above the major stroke. It contains 4 characters. Overallaccuracy: 93.0%
× ¹ º ‘ X
× 40 1 1 8 0 50
¹ 0 50 0 0 0 50
º 0 0 50 0 0 50
‘ 4 0 0 46 0 5044 51 51 54 0
110

Confusion Matrices
Table A.35: Confusion matrix for 2-stroke characters (medial half-form) with dotdiacritic below the major stroke. It contains 2 characters. Overall accuracy: 100%
J V XJ
50 0 0 50V 0 50 0 50
50 50 0
Table A.36: Confusion matrix for 3-stroke characters (medial half-form) with dotdiacritic above the major stroke. It contains 2 characters. Overall accuracy: 97.0%
´ N X
´ 47 3 0 50N 0 50 0 50
47 53 0
Table A.37: Confusion matrix for 3-stroke characters (medial half-form) withother-than-dot diacritic above the major stroke. It contains 2 characters. Overallaccuracy: 98.0%
ò ô X
ò 49 1 0 50ô 1 49 0 50
50 50 0
Table A.38: Confusion matrix for 4-stroke characters (medial half-form) with dotdiacritic above the major stroke. It contains 2 characters. Overall accuracy: 96.0%
R r X
R 48 2 0 50
r 2 48 0 5050 50 0
111

Confusion Matrices
Table A.39: Confusion matrix for 4-stroke characters (medial half-form) with dotdiacritic below the major stroke. It contains 2 characters. Overall accuracy: 100%
‡ ƒX‡
50 0 0 50ƒ 0 50 0 5050 50 0
Table A.40: Confusion matrix for single-stroke characters (terminal half-form). Itcontains 16 characters. Overall accuracy: 96.3%
© š f \ ½ Ó Á j É ú o w ñ é Ì X© 49 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 50
0 50 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 50š 0 0 50 0 0 0 0 0 0 0 0 0 0 0 0 0 0 50
f 0 0 0 43 0 0 0 0 2 0 0 0 0 0 0 5 0 50\ 1 0 0 0 49 0 0 0 0 0 0 0 0 0 0 0 0 50½ 0 0 0 0 0 50 0 0 0 0 0 0 0 0 0 0 0 50Ó 0 0 0 0 0 0 49 0 0 0 0 1 0 0 0 0 0 50Á 0 0 0 0 0 0 0 49 0 0 1 0 0 0 0 0 0 50j 0 0 0 0 0 0 0 1 49 0 0 0 0 0 0 0 0 50É 0 0 1 0 0 0 0 0 0 49 0 0 0 0 0 0 0 50ú 0 0 0 0 0 0 0 0 4 0 46 0 0 0 0 0 0 50o 0 0 0 0 0 0 0 0 0 0 0 50 0 0 0 0 0 50w 0 0 0 1 0 1 0 0 0 0 0 5 43 0 0 0 0 50ñ 0 0 0 1 0 0 0 0 0 1 0 0 0 48 0 0 0 50é 0 0 0 0 0 0 0 0 0 0 0 0 0 0 49 1 0 50Ì 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 48 0 50
50 50 51 46 50 51 49 50 56 50 47 56 43 48 49 54 0
112

Confusion Matrices
Table A.41: Confusion matrix for 2-stroke characters (terminal half-form) withdot diacritic above the major stroke. It contains 9 characters. Overall accuracy:91.5%
± −
W c Å h l ¥ | X
± 50 0 0 0 0 0 0 0 0 0 50
−
0 49 1 0 0 0 0 0 0 0 50W 0 1 31 18 0 0 0 0 0 0 50
c 0 1 12 37 0 0 0 0 0 0 50Å 0 0 0 0 49 0 0 0 1 0 50
h 1 0 0 0 0 47 1 1 0 0 50l 0 0 0 0 0 0 50 0 0 0 50
¥ 0 0 0 0 0 0 0 50 0 0 50| 1 0 0 0 0 0 0 0 49 0 50
52 51 44 55 49 47 51 51 50 0
Table A.42: Confusion matrix for 2-stroke characters (terminal half-form) withother-than-dot diacritic above the major stroke. It contains 7 characters. Overallaccuracy: 99.4%
™ • ˛ Ł ¸ ’ Û X
™ 49 1 0 0 0 0 0 0 50
• 0 49 0 0 0 1 0 0 50˛ 0 0 50 0 0 0 0 0 50Ł 0 0 0 50 0 0 0 0 50¸ 0 0 0 0 50 0 0 0 50’ 0 0 0 0 0 50 0 0 50
Û 0 0 0 0 0 0 50 0 5049 50 50 50 50 51 50 0
Table A.43: Confusion matrix for 3-stroke characters (terminal half-form) withdot diacritic above the major stroke. It contains 3 characters. Overall accuracy:100%.
µ Ñ O Xµ 50 0 0 0 50
Ñ 0 50 0 0 50O 0 0 50 0 50
50 50 50 0
113

Confusion Matrices
Table A.44: Confusion matrix for 4-stroke characters (terminal half-forms) withdot diacritic above the major stroke. It contains 4 characters. Overall accuracy:98.5%
ˆ S s ‹ X
ˆ 50 0 0 0 0 50S 0 50 0 0 0 50s 0 1 49 0 0 50
‹ 0 0 2 48 0 5050 51 51 48 0
114

Appendix B
Handwritten Urdu Character
Samples
Figure B.1: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-1
115

Handwritten Urdu Character Samples
Figure B.2: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-2
Figure B.3: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-3
116

Handwritten Urdu Character Samples
Figure B.4: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-4
Figure B.5: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-5
117

Handwritten Urdu Character Samples
Figure B.6: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-6
Figure B.7: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-7
118

Handwritten Urdu Character Samples
Figure B.8: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-8
Figure B.9: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-9
119

Handwritten Urdu Character Samples
Figure B.10: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-10
Figure B.11: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-11
120

Handwritten Urdu Character Samples
Figure B.12: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-12
Figure B.13: A handwritten ensemble of all Urdu characters written on the canvaswith the help of a stylus and digitizing tablet by writer-13
121

References
[1] S. D. Connell and A. K. Jain, “Writer adaptation for online handwriting
recognition,” IEEE Transactions on Pattern Analysis and Machine Intelli-
gence, vol. 24, no. 3, pp. 329–346, March 2002.
[2] S. D. Connell and A. K. Jain, “Template based online character recognition,”
Pattern Recognition, The Journal of the Pattern Recognition Society, vol. 34,
pp. 1–14, 2001.
[3] O. Goldwasser, “How the alphabet was born from hieroglyphs, discussion
with anson rainey:,” Biblical Archaeology Review. Washington, DC: Biblical
Archaeology Society., vol. 36(1), pp. 40–53, March/April 2010. [Online].
Available: http://www.bib-arch.org/scholars-study/alphabet.asp
[4] L. Mitchell, “Earliest egyptian glyphs,” Archaeological Institute of
America, vol. 52, no. 2, March/April 1999. [Online]. Available:
archive.archaeology.org/9903/newsbriefs/egypt.html
[5] D. Crowley and P. Heyer, Communication in History: Technology, Culture,
Society. Boston: Allyn and Bacon/Pearson Education Inc., 2003.
[6] M. Kiefer and J.-L. Velay, “Writing in the digital age,” Trends in
Neuroscience and Education, vol. 5, no. 3, pp. 77–81, 2016, writing in
the digital age. [Online]. Available: http://www.sciencedirect.com/science/
article/pii/S2211949316300205
[7] C. B. Walker and W. V. Davies, Reading the Past: Ancient Writing from
Cuneiform to the Alphabet, J. T. Hooker, Ed. Berkeley: University of
California Press/British Museum, 1990.
122

REFERENCES
[8] A. Mangen and J.-L. Velay, Digitizing Literacy: Reflections on the
Haptics of Writing in Advances in Haptics, IntechOpen, M. H. Zadeh,
Ed., 2010. [Online]. Available: https://www.intechopen.com/books/
advances-in-haptics/digitizing-literacy-reflections-on-the-haptics-of-writing
[9] B. Bash, “The Simple Joy of Writing by Hand,” Mindful, taking
time for what matters, vol. April, 2016. [Online]. Available: https:
//www.mindful.org/the-simple-joy-of-writing-by-hand/
[10] K. Yoshida and H. Sakoe, “Online Handwritten Character Recognition for a
Personal Computer System,” IEEE Transactions on Consumer Electronics,
vol. CE-28, pp. 202 – 209, Aug. 1982.
[11] R. B. Miller, “Response Time in Man-computer Conversational Trans-
actions,” in Proceedings of the December 9-11, 1968, Fall Joint
Computer Conference, Part I, ser. AFIPS ’68 (Fall, part I). New
York, NY, USA: ACM, 1968, pp. 267–277. [Online]. Available:
http://doi.acm.org/10.1145/1476589.1476628
[12] M. F. Zafar, D. Mohamad, and R. Othman, “On-line handwritten character
recognition: An implementation of counterpropagation neural net,” World
Academy of Science, Engineering and Technology International Journal of
Computer and Information Engineering, vol. 1, no. 10, 2007.
[13] E. Case, L. Vincent, and U. T. Lead, “Announcing Tesseract
OCR,” 2006. [Online]. Available: http://googlecode.blogspot.com/2006/
08/announcing-tesseract-ocr.html
[14] “GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine
(main repository),” Retrieved: 2018-07-01. [Online]. Available: https:
//github.com/tesseract-ocr/tesseract#brief-history/
[15] S. V. Rice, F. R. Jenkins, and T. A. Nartker, “The
Fourth Annual Test of OCR Accuracy,” 1995. [Online]. Avail-
able: http://www.expervision.com/wp-content/uploads/2012/12/1995.
The Fourth Annual Test of OCR Accuracy.pdf
123

REFERENCES
[16] “OCR, Canonical Ltd.” 2011. [Online]. Available: https://help.ubuntu.
com/community/OCR
[17] N. Willis, “Google’s Tesseract OCR engine is a quantum leap
forward,” 2006. [Online]. Available: https://www.linux.com/news/
googles-tesseract-ocr-engine-quantum-leap-forward
[18] “Readiris 17, the PDF and OCR solution for Win-
dows.” [Online]. Available: http://www.irislink.com/EN-GB/c1462/
Readiris-16-for-Windows---OCR-Software.aspx
[19] “ABBYY FineReader 14 for Windows: Features,” Retrieved: 2018-07-01.
[Online]. Available: https://www.abbyy.com/en-eu/finereader/in-details/
[20] “OmniPage 18 Save Time and Money with Superior Ac-
curacy, Datasheet,” Retrieved: 2018-07-01. [Online]. Avail-
able: https://www.nuance.com/content/dam/nuance/en us/collateral/
imaging/data-sheet/ds-omnipage-standard-18-en-us.pdf
[21] “FREE ONLINE OCR SERVICE,” Retrieved: 2018-07-01. [Online].
Available: https://www.onlineocr.net/
[22] “MyScript App Support, The Devices Currently Sup-
ported by Nebo,” Retrieved: 2018-07-01. [Online]. Avail-
able: https://app-support.myscript.com/support/solutions/articles/
16000070607-what-are-the-devices-currently-supported-by-nebo-
[23] “MyScript: Nebo,” Retrieved: 2018-07-01. [Online]. Available: https:
//www.myscript.com/nebo
[24] “MyScript App Support, About Right-to-Left Languages,” Retrieved: 2018-
07-01. [Online]. Available: https://app-support.myscript.com/support/
solutions/articles/16000077562-what-about-right-to-left-languages-rtl-
[25] “Telecom indicators,” June 2016, [Online; accessed 14-June-2016]. [Online].
Available: http://www.pta.gov.pk/index.php?Itemid=599
124

REFERENCES
[26] F. Baloch, “Telecom sector: Pakistan to have 40 million smart-
phones by end of 2016,” September ”2015, [Online; accessed 18-
May-2016]. [Online]. Available: http://tribune.com.pk/story/953333/
telecom-sector-pakistan-to-have-40-million-smartphones-by-end-of-2016/
[27] S. T. Javed, S. Hussain, A. Maqbool, S. Asloob, S. Jamil, and M. H., “Seg-
mentation free Nastalique Urdu OCR,” World Academy of Science, Engi-
neering and Technology, vol. 4, 2010.
[28] D. A. Satti and K. Saleem, “Complexities and implementation challenges
in offline Urdu Nastaliq OCR,” in Proceedingds of the Conference on Lan-
guage & Technology 2012 (CLT12), University of Engineering & Technol-
ogy(UET), Lahore, Pakistan, 2012, pp. 85–91.
[29] S. Naz, K. Hayat, M. I. Razzak, M. W. Anwar, S. A. Madani, and S. U.
Khan, “The optical character recognition of Urdu-like cursive scripts,” Pat-
tern Recognition, Elsevier, vol. 47, pp. 1229–1248, 2014.
[30] S. Malik and S. A. Khan, “Urdu online handwriting recognition,” in IEEE
International Conference on Emerging Technologies, 2005.
[31] N. Shahzad, B. Paulson, and T. Hammond, “Urdu Qaeda: recognition sys-
tem for isolated Urdu characters,” in IUI Workshop on Sketch Recognition,
2009.
[32] I. Haider and K. U. Khan, “Online recognition of single stroke handwritten
Urdu characters,” in IEEE 13th International Multitopic Conference (IN-
MIC2009), 2009.
[33] K. U. Khan and I. Haider, “Online recognition of multi-stroke handwritten
Urdu characters,” in Image Analysis and Signal Processing (IASP), 2010.
[34] N. H. Khan, A. Adnan, and S. Basar, “Urdu ligature recognition using
multi-level agglomerative hierarchical clustering,” Cluster Computing, May
2017. [Online]. Available: https://doi.org/10.1007/s10586-017-0916-2
125

REFERENCES
[35] S. Shabbir and I. Siddiqi, “Optical Character Recognition System for Urdu
Words in Nastaliq Font,” International Journal of Advanced Computer Sci-
ence and Applications, vol. 7, no. 5, pp. 567–576, 2016.
[36] M. Hussain and M. N. Khan, “Online Urdu ligature recognition using spatial
temporal neural processing,” in IEEE International Multitopic Conference
(INMIC05), 2005.
[37] S. A. Husain, A. Sajjad, and F. Anwar, “Online Urdu character recognition
system,” in IAPR Machine Vision Applications (MVA2007), Conference on,
2007.
[38] M. I. Razzak, F. Anwar, S. A. Hussain, A. Belaid, and M. Sher, “HMM
and fuzzy logic: A hybrid approach for online Urdu script-based languages’
character recognition,” Knowledge-Based Systems, Elsevier, vol. 23, pp. 914–
923, 2010.
[39] M. I. Razzak, S. A. Hussain, A. M. Abdulrahman, and M. K. Khan, “Bio-
inspired multilayered and multilanguage Arabic script character recognition
system,” International Journal of Innovative Computing Information and
Control, vol. 8, no. 4, pp. 2681–2691, 2012.
[40] S. Naz, I. U. Arif, R. Ahmad, B. A. Saad, S. H. Shirazi, I. Siddiqi, and M. I.
Razzak, “Offline cursive Urdu-Nastaliq script recognition using multidimen-
sional recurrent neural networks,” Neurocomputing, vol. 177, pp. 228–241,
2016.
[41] S. Naz, A. I. Umar, R. Ahmed, M. I. Razzak, S. F. Rashid, and
F. Shafait, “Urdu Nasta’liq text recognition using implicit segmentation
based on multi-dimensional long short term memory neural networks,”
SpringerPlus, vol. 5, no. 1, p. 2010, Nov 2016. [Online]. Available:
https://doi.org/10.1186/s40064-016-3442-4
[42] S. Naz, A. Umar, R. Ahmad, S. Ahmed, S. Shirazi, and M. Razzak, “Urdu
Nasta’liq text recognition system based on multi-dimensional recurrent neu-
ral network and statistical features,” vol. 28, 09 2015.
126

REFERENCES
[43] S. Naz, A. I. Umar, R. Ahmad, I. Siddiqi, S. B. Ahmed, M. I. Razzak, and
F. Shafait, “Urdu Nastaliq recognition using convolutional-recursive deep
learning,” Neurocomputing, vol. 243, pp. 80–87, 2017. [Online]. Available:
http://www.sciencedirect.com/science/article/pii/S0925231217304654
[44] A. Ul-Hasan, S. B. Ahmed, F. Rashid, F. Shafait, and T. M. Breuel, “Offline
Printed Urdu Nastaleeq Script Recognition with Bidirectional LSTM Net-
works,” in 2013 12th International Conference on Document Analysis and
Recognition, Aug 2013, pp. 1061–1065.
[45] U. Pal and A. Sarkar, “Recognition of printed Urdu script,” in 7th Inter-
national Conference on Document Analysis and Recognition (ICDAR’03),
2003.
[46] Z. Ahmad, J. K. Orakzai, I. Shamsher, and A. Adnan, “Urdu Nastaleeq opti-
cal character recognition,” International Journal of Computer, Information,
Systems and Control Engineering, vol. 1(8), 2007.
[47] G. S. Lehal, “Choice of recognizable unit for Urdu OCR,” in Workshop on
Document Analysis and Recognition (DAR12), 2012.
[48] S. Zaman, W. Slany, and F. Saahito, “Recognition of segmented Ara-
bic/Urdu characters using pixel values as their features,” in ICCIT, 2012.
[49] S. T. Javed and S. Hussain, “Segmentation based Urdu Nastalique OCR,”
in 18th Iberoamerican Congress (CIARP2013), 2013, pp. 41–49.
[50] S. Naz, A. I. Umar, S. Bin Ahmed, S. H. Shirazi, M. I. Razzak, and
I. Siddiqi, “An OCR system for printed Nasta’liq script: A segmentation
based approach,” in IEEE 17th International, Multi-Topic Conference (IN-
MIC’2014), 2014, pp. 255–259.
[51] M. I. Razzak, M. Sher, and S. A. Hussain, “Locally baseline detection for
online Arabic script based languages character recognition,” International
Journal of the Physical Sciences, vol. 5, no. 7, pp. 955–959, 2010.
127

REFERENCES
[52] M. I. Razzak, S. A. Hussain, M. K. Khan, and S. Muhammad, “Handling Di-
acritical Marks for Online Arabic Script Based Languages Character Recog-
nition using Fuzzy c-mean Clustering and Relative Position,” Information-
an International Interdisciplinary Journal, vol. 14, no. 1, pp. 157–165, 2011.
[53] M. I. Razzak, S. A. Husain, A. A. Mirza, and A. Belaid, “Fuzzy based
preprocessing using fusion of online and offline trait for online Urdu script
based languages character recognition,” International Journal of Innovative
Computing, Information and Control, vol. 85(A), pp. 3149–3161, 2012.
[54] E. Qaralleh, G. Abandah, and F. Jamour, “Tuning Recurrent Neural Net-
works for Recognizing Handwritten Arabic Words,” Journal of Software En-
gineering and Applications, vol. 6, no. 10, pp. 533–542, May 2013.
[55] I. A. Jannoud, “Automatic Arabic handwritten text recognition system,”
American journal of applied sciences, vol. 4(11), pp. 857–864, 2007.
[56] A. Asiri and M. S. Khorsheed, “Automatic processing of handwritten Arabic
forms using neural networks,” in World academy of science, engineering and
technology, vol. 7, 2005.
[57] A. A. Aburas and S. M. A. Rehiel, “Off-line omni-style handwriting Arabic
character recognition system based on wavelet Compression,” vol. 3(4), pp.
123–135, 2007.
[58] G. Kour and R. Saabne, “Fast classification of handwritten on-line Arabic
characters,” in 2014 6th International Conference of Soft Computing and
Pattern Recognition (SoCPaR), Aug 2014, pp. 312–318.
[59] A. Mowlaei, K. Faez, and A. T. Haghighat, “Feature extraction with wavelet
transform for recognition of isolated handwritten Farsi/Arabic characters
and numerals,” in IEEE 13th Workshop on Neural Networks for Signal Pro-
cessing, NNSP’03, 2003, pp. 547–554.
[60] A. Broumandnia, J. Shanbehzadeh, and M. R. Varnoosfaderani, “Per-
sian/Arabic handwritten word recognition using M-band packet wavelet
transform,” Image Vision Computing, vol. 26(6), pp. 829–842, 2008.
128

REFERENCES
[61] M. R. Jenabzade, R. Azmi, P. B., and S. Shirazi, “Two methods for recogni-
tion of handwritten Farsi characters,” International Journal of Image Pro-
cessing (IJIP), vol. 5(4), 2011.
[62] S. Nasrollahi and A. Ebrahimi, “Printed Persian Subword Recognition
Using Wavelet Packet Descriptors,” Journal of Engineering, vol. 2013, 2013.
[Online]. Available: https://doi.org/10.1155/2013/465469
[63] V. Ghods and M. K. Sohrabi, “Online Farsi Handwritten Character Recogni-
tion Using Hidden Markov Model,” Journal of Computers, vol. 11(2), 2016.
[64] Q. Safdar and K. U. Khan, “Online Urdu Handwritten Character Recog-
nition: Initial Half Form Single Stroke Characters,” in 12th International
Conference on Frontiers of Information Technology, Dec 2014, pp. 292–297.
[65] K. C. Santosh and E. Iwata, Stroke-based cursive char-
acter recognition, Advances in Character Recognition,
P. X. Ding, Ed. InTech, 2012. [Online]. Available:
http://www.intechopen.com/books/advances-in-character-recognition/
stroke-based-cursive-character-recognition
[66] G. Boccignone, A. Chianese, L. Cordella, and A. Marcelli, “Recovering dy-
namic information from static handwriting,” Pattern Recognition, vol. 26,
pp. 409–418, 1993.
[67] G. C. Viard, L. M. Pierre, and S. Knerr, “Recognition directed recovering
of temporal information from handwritimg images,” Pattern Recognition
Letters, vol. 26, pp. 2537–2548, 2005.
[68] D. S. Doermann and A. Rosenfeld, “Recovery of temporal information from
static images of handwriting,” International Journal of Computer Vision,
vol. 15(1-2), pp. 143–164, 1995.
[69] Y. Qiao, M. Nishiara, and M. Yasuhara, “A framework toward restoration
of writing order from single-stroked handwriting image,” IEEE Transactions
on Pattern Analysis and Machine Intelligence, vol. 28(11), pp. 1724–1737,
2006.
129

REFERENCES
[70] “Ethnologue: Languages of the World,” https://www.ethnologue.com.
[71] “National Language, THE CONSTITUTION OF THE ISLAMIC REPUB-
LIC OF PAKIATAN,” http://na.gov.pk/uploads/documents/1333523681
951.pdf.
[72] “EIGHTH Schedule, Languages, THE CONSTITUTION OF
INDIA,” https://www.india.gov.in/sites/upload files/npi/files/
coi-eng-schedules 1-12.pdf.
[73] “Language of the Nation, Nepal’s Constitution of 2015,” https://www.
constituteproject.org/constitution/Nepal 2015.pdf.
[74] “PAKISTAN: THE WORLD FACTBOOK,” https://www.cia.gov/library/
publications/the-world-factbook/geos/pk.html.
[75] A. Mirza, “Urdu as a First Language: The Impact of Script on Reading in the
L1 and English as a Second Language,” Ph.D. dissertation, Wilfrid Laurier
University, 2014. [Online]. Available: http://scholars.wlu.ca/etd/1660
[76] G. Cardona and D. Jain, “The Indo-Aryan Languages,” Routledge, Routledge
Language Family Series, 2003.
[77] “National Language Promotion Department.” [Online]. Available: http:
//nlpd.gov.pk
[78] H. P. and I. Sloan, A Grammar of Pashto a Descriptive Study of the Dialect
of Kandahar, Afghanistan. Ishi Press International., 2009.
[79] S. Abdul Khair Kashfi, “Noori Nastaliq Revolution in Urdu Composing,”
2008.
[80] R. Safabakhsh and P. Adibi, “Nastaaligh handwritten word recognition us-
ing a continuous-density variable-duration HMM,” The Arabian Journal for
Science and Engineering, vol. 30(1B), 2005.
[81] A. Muaz, “Urdu Optical Character Recognition System,” Ph.D. dissertation,
National University of Computer & Emerging Sciences Lahore, Pakistan,
2010.
130

REFERENCES
[82] G. A. Abandah and F. T. Jamour., “Recognizing handwritten Arabic script
through efficient skeleton-based grapheme segmentation algorithm,” in 10th
International Conference on Intelligent Systems Design and Applications,
Nov 2010, pp. 977–982.
[83] H. E. Abed, V. Margner, M. Kherallah, and A. M. Alimi, “ICDAR 2009
Online Arabic Handwriting Recognition Competition,” in 2009 10th Inter-
national Conference on Document Analysis and Recognition, July 2009, pp.
1388–1392.
[84] A. Wahi, S. Sundaramurthy, and P. Poovizhi, “Recognition of handwritten
Tamil characters using wavelet,” International Journal of Computer Science
& Engineering Technology (IJCSET), vol. 5(4), 2014.
[85] P. Singh and S. Budhiraja, “Handwritten Gurmukhi character recognition
using wavelet transform,” vol. 2, no. 3, 2012.
[86] S. Jaeger, S. Manke, J. Reichert, and A. Waibel, “Online handwriting recog-
nition: the NPen++ Recognizer,” International Journal of Document Anal-
ysis and Recognition, IJDAR, 2001.
[87] M. D. Al-Hassani, “Optical character recognition system for multifont En-
glish texts using DCT and Wavelet Transform,” vol. 4(6), 2013.
[88] S. Mallat, A wavelet tour of signal processing, The Sparse Way,. Academic
Press Elsevier Inc. San Dieago, 2008.
[89] R. C. Gonzalez and R. E. Woods, Digital Image Processing (3rd Edition).
Upper Saddle River, NJ, USA: Prentice-Hall, Inc., 2006.
[90] C. B. Amar, M. Zaied, and A. Alimi, “Beta wavelets. synthesis
and application to lossy image compression,” Advances in Engineering
Software, vol. 36, no. 7, pp. 459 – 474, 2005, advanced Algorithms
and Architectures for Signal Processing. [Online]. Available: http:
//www.sciencedirect.com/science/article/pii/S0965997805000116
131

REFERENCES
[91] D. K. Patel, T. Som, S. K. Yadav, and M. K. Singh, “Handwritten character
recognition using multiresolution technique and euclidean distance metric,”
vol. 3, pp. 208–214, 2012.
[92] W. Wei, L. Ming, G. Weina, W. Dandan, and L. Jing, “A new mind of
wavelet transform for handwritten Chinese character recognition,” in Sec-
ond International Conference on Instrumentation, Measurement, Computer,
Communication and Control (IMCCC), 2012.
[93] K. P. Primekumar and S. M. Idiculla, “On-line Malayalam handwritten char-
acter recognition using wavelet transform and SFAM,” in 3rd International
Conference on Electronics Computer Technology (ICECT), vol. 1, 2011.
[94] I. Daubechies, Ten Lectures on Wavelets. Philadelphia, PA, USA: Society
for Industrial and Applied Mathematics, 1992.
[95] N. Murru and R. Rossini, “A Bayesian approach for initialization of weights
in backpropagation neural net with application to character recognition,”
Neurocomputing, vol. 193, pp. 92 – 105, 2016. [Online]. Available:
http://www.sciencedirect.com/science/article/pii/S0925231216001624
[96] A. Prieto, B. Prieto, E. M. Ortigosa, E. Ros, F. Pelayo, J. Ortega,
and I. Rojas, “Neural networks: An overview of early research, current
frameworks and new challenges,” Neurocomputing, vol. 214, pp. 242 – 268,
2016. [Online]. Available: http://www.sciencedirect.com/science/article/
pii/S0925231216305550
[97] I. Shamsher, Z. Ahmad, J. K. Orakzai, and A. Adnan, “OCR for printed
Urdu script using feed forward neural network,” World Academy of Science,
Engineering and Technology, vol. 1(10), 2007.
[98] W. A. Salameh and M. A. Otair, “Online handwritten character recogni-
tion using an optical backpropagation neural network,” Issues in Informing
Science and Information Technology, vol. 3, 2005.
[99] T. Sergios and K. Konstantinos, Pattern Recognition, Fourth Edition, 4th ed.
Academic Press, 2008.
132

REFERENCES
[100] J. Shawe-Taylor and N. Cristianini, Kernel Methods for Pattern Analysis.
Cambridge University Press, 2004.
[101] C.-C. Chang and C.-J. Lin, “LIBSVM: A library for support vector
machines,” ACM Transactions on Intelligent Systems and Technology,
vol. 2, pp. 27:1–27:27, 2011. [Online]. Available: http://www.csie.ntu.edu.
tw/∼cjlin/libsvm
[102] Z. C. Lipton, “A Critical Review of Recurrent Neural Networks for
Sequence Learning,” CoRR, vol. abs/1506.00019, 2015. [Online]. Available:
http://arxiv.org/abs/1506.00019
[103] A. Graves, “RNNLIB: A recurrent neural network library for sequence learn-
ing problems,” http://sourceforge.net/projects/rnnl/.
[104] G. E. Hinton, S. Osindero, and Y.-W. Teh, “A Fast Learning Algorithm
for Deep Belief Nets,” Neural Comput., vol. 18, no. 7, pp. 1527–1554, Jul.
2006. [Online]. Available: http://dx.doi.org/10.1162/neco.2006.18.7.1527
[105] W. Liu, Z. Wang, X. Liu, N. Zeng, Y. Liu, and F. E. Alsaadi, “A
survey of deep neural network architectures and their applications,”
Neurocomputing, vol. 234, pp. 11–26, 2017. [Online]. Available: http:
//www.sciencedirect.com/science/article/pii/S0925231216315533
[106] P. Smolensky, “Parallel Distributed Processing: Explorations in the
Microstructure of Cognition,” D. E. Rumelhart, J. L. McClelland,
and C. PDP Research Group, Eds. Cambridge, MA, USA: MIT
Press, 1986, vol. 1, ch. Information Processing in Dynamical Systems:
Foundations of Harmony Theory, pp. 194–281. [Online]. Available:
http://dl.acm.org/citation.cfm?id=104279.104290
[107] G. E. Dahl, D. Yu, L. Deng, and A. Acero, “Context-Dependent Pre-Trained
Deep Neural Networks for Large-Vocabulary Speech Recognition,” IEEE
Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp.
30–42, Jan 2012.
133

REFERENCES
[108] Y. Bengio, “Learning Deep Architectures for AI,” Found. Trends Mach.
Learn., vol. 2, no. 1, pp. 1–127, Jan. 2009. [Online]. Available:
http://dx.doi.org/10.1561/2200000006
[109] R. Salakhutdinov, “Learning Deep Generative Models,” Ph.D. dissertation,
Toronto, Ont., Canada, Canada, 2009, aAINR61080.
[110] P. Vincent, H. Larochelle, Y. Bengio, and P. A. Manzagol, “Extracting and
Composing Robust Features with Denoising Autoencoders,” in Proceedings
of the 25th International Conference on Machine Learning, ser. ICML ‘08.
New York, NY, USA: ACM, 2008, pp. 1096–1103. [Online]. Available:
http://doi.acm.org/10.1145/1390156.1390294
[111] C. Xing, L. Ma, and X. Yang, “Stacked Denoise Autoencoder Based Feature
Extraction and Classification for Hyperspectral Images,” pp. 1–10, 01 2016.
[112] Y. Ju, J. Guo, and S. Liu, “A Deep Learning Method Combined Sparse Au-
toencoder with SVM,” in 2015 International Conference on Cyber-Enabled
Distributed Computing and Knowledge Discovery, Sept 2015, pp. 257–260.
[113] M. Ali Keyvanrad and M. Homayoonpoor, “A brief survey on deep belief
networks and introducing a new object oriented MATLAB toolbox,” 08 2014,
arXiv:1408.3264.
134

About the Author
Quara-tul-Ain Safdar is a PhD scholar at PIEAS, Islamabad, IR Pakistan.
She has received her MS. degree in Computer Science from University of Central
Punjab, Lahore, IR, Pakistan in 2005. Her research interests include Pattern
recognition, and Urdu handwriting recognition.
135




















