
Combining statistical and structural approaches for handwritten character description
11
Combining statistical and structural approaches for handwritten character description Pasquale Foggia, Carlo Sansone, Francesco Tortorella, Mario Vento * Dipartimento di Informatica e Sistemistica, Universita ` degli Studi di Napoli “Federico II”, via Claudio 21, I-80125 Naples, Italy Received 20 February 1998; received in revised form 2 June 1998; accepted 10 June 1998 Abstract In this paper a new character description method, based on the combination of structural and statistical approaches, is presented. Characters are preliminarily decomposed in terms of structural primitives (circular arcs) and successively described in terms of statistical features (geometric moments). The obtained description is much more stable and yields significant improvements in classification perfor- mance: its effectiveness has been demonstrated by comparing the recognition results obtained by applying the geometric moments directly on the character bit maps and, as proposed, on the character decomposition in circular arcs. Absolute and relative performance is significant especially for particularly critical cases. Novel recurrent formulae for evaluating in a closed form the moments of objects represented in terms of circular arcs are also introduced; experimental results reveal a significant reduction of the time needed for evaluating the moments. q 1999 Elsevier Science B.V. All rights reserved. Keywords: Optical character recognition; Geometric moments; Hybrid description methods 1. Introduction In typical pattern recognition problems the description phase plays a fundamental role, since it defines the set of properties which are considered essential for characterizing the pattern and salient for taking a classification decision, whichever approach to the classification is adopted. In the statistical approach, the input pattern is character- ized by a set of N features (e.g. a set of measurements performed on the raw data) and its description is achieved by means of a feature vector belonging to an N-dimensional space. If the features are properly chosen, feature vectors coming from objects of the same class will be close to each other in terms of geometric distance, while feature vectors belonging to different classes will be located in different regions of the feature space. In this way, recognition implies the partition of the feature space into regions, each pertain- ing to a single class. In this approach greater emphasis is given to the classification rather than to the description phase (in fact, the statistical approach is also referred to as decision-theoretic approach). Typically, the classification stage is reconducted to a problem of statistical decision theory and consequently a large variety of well documented and assessed algorithms can be employed. However, effec- tive and established methods for finding a priori a set of good features (i.e. features able to maximize the discrimina- tion degree among the classes to be recognized), are gener- ally not available. Usually, a large number of features is initially considered in order to capture all the discriminant information. The task of eliminating possible redundancies within the provisional set of features is performed by means of a feature selection process which generally employs statistical methods such as discriminant analysis [1]. In synthesis, the key problem of the statistical approach is the lack of a descriptive model for the patterns to be recog- nized which does not allow one to determine and control the information given by each feature, so as to choose the most suitable ones. An exhaustive review of feature extraction methods, especially devised for character recognition can be found elsewhere [2]. On the other hand, in the structural approach it is assumed that the pattern to be recognized can be decom- posed into simpler components (called primitives), possibly in a recursive way, and then described in terms of simple appropriate attributes of the primitives and of their topolo- gical relations. In this way, the effectiveness of the description in discriminating among different classes can be perceptively appraised, to some extent. However, the obtained descriptions do not have fixed length and frequently it is not possible to establish an a priori order Image and Vision Computing 17 (1999) 701–711 0262-8856/99/$ - see front matter q 1999 Elsevier Science B.V. All rights reserved. PII: S0262-8856(98)00146-2 * Corresponding author. Tel.: 1 39-081-768-3606; fax: 1 39-081-768- 3186. E-mail address: [email protected] (M. Vento)
Transcript of Combining statistical and structural approaches for handwritten character description

Combining statistical and structural approaches for handwrittencharacter description
Pasquale Foggia, Carlo Sansone, Francesco Tortorella, Mario Vento*
Dipartimento di Informatica e Sistemistica, Universita` degli Studi di Napoli “Federico II”, via Claudio 21, I-80125 Naples, Italy
Received 20 February 1998; received in revised form 2 June 1998; accepted 10 June 1998
Abstract
In this paper a new character description method, based on the combination of structural and statistical approaches, is presented.Characters are preliminarily decomposed in terms of structural primitives (circular arcs) and successively described in terms of statisticalfeatures (geometric moments). The obtained description is much more stable and yields significant improvements in classification perfor-mance: its effectiveness has been demonstrated by comparing the recognition results obtained by applying the geometric moments directly onthe character bit maps and, as proposed, on the character decomposition in circular arcs. Absolute and relative performance is significantespecially for particularly critical cases. Novel recurrent formulae for evaluating in a closed form the moments of objects represented in termsof circular arcs are also introduced; experimental results reveal a significant reduction of the time needed for evaluating the moments.q 1999Elsevier Science B.V. All rights reserved.
Keywords:Optical character recognition; Geometric moments; Hybrid description methods
1. Introduction
In typical pattern recognition problems the descriptionphase plays a fundamental role, since it defines the set ofproperties which are considered essential for characterizingthe pattern and salient for taking a classification decision,whichever approach to the classification is adopted.
In thestatistical approach, the input pattern is character-ized by a set ofN features(e.g. a set of measurementsperformed on the raw data) and its description is achievedby means of a feature vector belonging to anN-dimensionalspace. If the features are properly chosen, feature vectorscoming from objects of the same class will be close to eachother in terms of geometric distance, while feature vectorsbelonging to different classes will be located in differentregions of the feature space. In this way, recognition impliesthe partition of the feature space into regions, each pertain-ing to a single class. In this approach greater emphasis isgiven to the classification rather than to the descriptionphase (in fact, the statistical approach is also referred to asdecision-theoreticapproach). Typically, the classificationstage is reconducted to a problem of statistical decisiontheory and consequently a large variety of well documented
and assessed algorithms can be employed. However, effec-tive and established methods for finding a priori a set ofgood features (i.e. features able to maximize the discrimina-tion degree among the classes to be recognized), are gener-ally not available. Usually, a large number of features isinitially considered in order to capture all the discriminantinformation. The task of eliminating possible redundancieswithin the provisional set of features is performed by meansof a feature selectionprocess which generally employsstatistical methods such as discriminant analysis [1]. Insynthesis, the key problem of the statistical approach isthe lack of a descriptive model for the patterns to be recog-nized which does not allow one to determine and control theinformation given by each feature, so as to choose the mostsuitable ones. An exhaustive review of feature extractionmethods, especially devised for character recognition canbe found elsewhere [2].
On the other hand, in thestructural approach it isassumed that the pattern to be recognized can be decom-posed into simpler components (calledprimitives), possiblyin a recursive way, and then described in terms of simpleappropriate attributes of the primitives and of their topolo-gical relations. In this way, the effectiveness of thedescription in discriminating among different classes canbe perceptively appraised, to some extent. However, theobtained descriptions do not have fixed length andfrequently it is not possible to establish an a priori order
Image and Vision Computing 17 (1999) 701–711
0262-8856/99/$ - see front matterq 1999 Elsevier Science B.V. All rights reserved.PII: S0262-8856(98)00146-2
* Corresponding author. Tel.:1 39-081-768-3606; fax:1 39-081-768-3186.
E-mail address:[email protected] (M. Vento)

for arranging the extracted primitives in the description.This characteristic strongly affects the choice of the datastructure for storing the description and makes critical theclassification phase. A technique for tackling such difficul-ties is to represent the patterns of a class as sentencesbelonging to a language, defined by means of a grammar.The most significant advantage of this approach, referred toassyntactic pattern recognition[3], is that most of the wellknown methodology of formal languages and parsing tech-niques can be simply reused; on the other hand, many diffi-culties may arise when defining the grammar, whosestructure can be very complex and hard to infer from asample set of patterns. Another way to represent structuraldescription is given by more complex data structures such astheattributed relational graphs(ARGs) [4,5], whose nodesand branches respectively characterize, by means of a set ofattributes, the primitives and their relations. ARGs havebeen widely adopted in structural pattern recognition,even if their description power is often paid in theclassification stage with a high computational cost. Infact, the noise and the shape variations occurring in realapplications generate distortions both in the structure ofthe graph and in its node and branch attributes, makingnecessary the use of complex algorithms for the inexactgraph matching.
In summary, both approaches present, together with somedrawbacks, appealing and complementary properties, whosecombination could lead to a more effective descriptionmethod for most pattern recognition applications.
In past years, possible ways of introducing statisticalrecognition techniques into the structural method havebeen identified, particularly with reference to the classifica-tion phase (see, for example, Goldfarb and Chan [6] whosuggest employing a nearest neighbor classifier with struc-tural prototypes, or Tsai [7] for a review of the stochasticgrammars in the syntactic approach). Moreover, much efforthas been made to include into the structural descriptionssome statistically modeled information about variations ofthe primitives and/or the relations due to the noise or distor-tions, so as to make the recognition process more robust. Atypical example is given by the random graphs [8], whichhave graph structure with randomly varying node and arcattribute values; more recently, Nishida [9] has proposed astructural description scheme which includes a model ofthe deformations affecting the patterns as geometric andstatistical transformations. In any case, the wholeapproach is essentially structural: the classification isstill performed through structural matching algorithms,even though it appears to be more robust with respect toinstabilities occurring during the extraction of theprimitives.
On the contrary, much less attention has been devoted todefine a way for including a structural description approachinto a statistical framework, so as to employ model-basedfeatures for classification; thus, very few proposals of thiskind are present in the literature. In the approach described
by Baird [10], characters are initially decomposed in termsof structural primitives, each described by some numericalparameters. The final feature vector has binary componentscorresponding to regions of the parameter space, which areidentified in a previous clustering phase: the value of thecomponent is set to 1 if there is at least one primitive fallingin the associated region, to 0 otherwise. It is worth notingthat the preliminary clustering is heavily domain dependentand thus its results can be quite dissimilar for differentdomains, giving rise to not homogeneous descriptions.Moreover, its computational cost is generally notnegligible.
In a paper by Taxt et al. [11], the description methodpresented produces a feature vector made of curvaturemeasurements taken from the outer boundary of a symbol.The boundary is initially approximated by means ofB-spline curves, but this is done only for removing noise:no hypothesis is made about the structure of the symbol tobe recognized and thus the type and the order of the approxi-mating spline are determined without taking into accountthe structural characteristics of the shape.
The character description method we propose combinesthe desirable properties of statistical and structuralapproaches. The pattern to be recognized is described bymeans of a feature vector, so allowing the use of suitablestatistical techniques in the classification phase: the relevantand original point is that the features (geometric moments)are extracted on a representation of the character comingfrom a suitable decomposition in terms of structural primi-tives (circular arcs). To this end, a preprocessing isperformed which, starting from the original bit map of thepattern, leads to its structural representation in terms ofcircular arcs. The use of such primitives allows the compu-tation of the geometric moments by means of closed recur-rent formulae: numerical evaluations of the moments, whichmay imply a high computational cost and some degree ofapproximation error, are thus avoided.
The obtained description is much more stable and yieldssignificant improvements in classification performance. Onone hand, in fact, the data on which feature vectors areextracted do not show the variability typical of the bitmaps and so the relative distributions in the feature spaceare more compact and easy to model. On the other hand,possible instabilities in the character decomposition due tothe noise and/or pattern distortions produce variations in thefinal descriptions which are not critical to be statisticallymodeled: such situations can thus be profitably tackled inthe classification phase, without involving the problemsarising in a pure structural approach.
In the following sections the whole method is presented.In Section 2 the description process and the employed clas-sification technique are outlined. The experimentsperformed on a standard database of handwritten charactersand the relative results are described in Section 3, with adiscussion in Section 4. Finally, in Section 5, some conclu-sions and guidelines for future work are drawn.
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711702

2. The handwritten character description method
We have applied our method to the recognition of hand-written characters. This is a severe test-bed for a descriptionmethod, since characters come from different writers whoexhibit greatly varying drawing styles. This gives rise to ahigh variability within each class which is very difficult tomodel if a pure statistical approach is adopted. Typicalstatistical (quantitative) features (such as geometricmoments, Fourier descriptors, etc.), directly extractedfrom the bit maps, are revealed to be effective for the recog-nition of printed characters (for which the drawing processis very stable), but generally they do not achieve very satis-factory results when applied to the recognition of handwrit-ten characters.
This is a challenging problem also for a pure structuralapproach. In fact, the decomposition in primitives providesan undoubtedly more stable representation of the characterwithout any loss of information useful for the recognition,but frequently it does not completely eliminate the intrinsicvariability of the original raw data and gives rise to a certaininstability in the descriptions difficult to handle in the clas-sification phase.
A key point of our description method is the extraction, ina first phase, of a representation of the characters based onan effective structural decomposition. It is assumed thatcharacter images can be considered as ribbons evolving,joining and intersecting in a 2-D space (see Fig. 1(a)). Inthis case, the most convenient initial representation is a thinline centered within the stroke, since stroke thickness doesnot seem to be significant for recognition, with the exceptionof very special cases. The final structural representation is
made up of circular arcs approximating the obtained strokes:such a representation reabsorbs insignificant shape variabil-ity, without loosing morphological and/or topological infor-mation important for the recognition. Besides theirdescriptive power, these primitives are particularly usefulbecause it is possible, as we will show below, to evaluateefficiently the geometrical moments on the structural repre-sentation of the character by means of closed formulae.
The final step, which computes the geometrical momentsfrom the structural representation of the whole character,provides a pattern description which can be fed into a statis-tical classifier (a neural network in our case) since it has afixed length. Other kinds of descriptions simply derivedfrom the obtained circular arcs separately considered(such as the values of coordinates, angles and radii of theindividual arcs) would give rise to a variable length featurevector not suitable for a statistical classifier. Another impor-tant advantage of this description is that it is not substan-tially affected by variations in the structural representationdue to instabilities in the decomposition phase. In fact, sincethe moments are an integral measure, their values do notdiffer significantly if a single stroke is decomposed into twoor more pieces, nor do they depend on changes of the pointson the stroke chosen as the ends of each single component,as long as the set of components is a faithful approximationof the original stroke.
The assumptions underlying our approach are quitegeneral. They do not depend on the particular class ofobjects to be recognized: in fact, the same assumptionshold for other applications (such as recognizing symbolson topographic maps or components on electric circuits)for which the hypothesis of ribbon-like shapes is valid.
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711 703
Fig. 1. (a) Bit maps of some characters; (b) output of the thinning transformation; (c) polygonal approximations; (d) decompositions in circular arcs.

2.1. Handwritten character decomposition
Character images can be considered as ribbons evolving,joining and intersecting in a 2-D space (see Fig. 1(a)).According to the semantic information held by the ribbonshape, a suitable character representation could be achievedby applying to them a thinning (skeletonizing) transforma-tion (see Fig. 1(b)). Under certain hypotheses, the transfor-mation achieves the goal of compressing informationwithout loss, but its use for recognition purposes is notstraightforward. It is known, in fact, that skeletonizationtechniques may give place to distorted representations ofthe shape of the ribbons one would describe. The mostimportant shape distortions introduced by thinning techni-ques arise at the junction and crossing of ribbons represent-ing character strokes and mainly consist of spuriousskeleton branches, not corresponding to actual ribbons, orof spurious inflections of the skeleton lines whose relevancedepends on the relative thickness and on the angle formedby the joining strokes. However, it has been shown [12] thatit is possible to correct the distortions after thinning oncondition that skeleton pixels are labeled with their distancefrom the background. By using this information, togetherwith information about direction of skeleton lines, thementioned shape distortions can be reliably corrected inthe large majority of cases, avoiding side effects and at acontained computational cost. To obtain this, a medial axistransformation algorithm [13,14] followed by polygonalapproximation of the obtained skeleton is first applied tothe character bit map; the correction procedure is thenapplied to the attained polygonal (see Fig. 1(c)).
To cope with character variability and to single out thefeatures most characteristic and invariant for members of arecognition class, circular arcs have been assumed as primi-tives for the structural desription (see Fig. 1(d)). In fact, forLatin handwritten characters, the circular arcs seem to haveenough descriptive power to substitute curves of differentshape, but having the same contextual value, withoutdestroying really discriminant features. According to theseassumptions, we use an algorithm [15,16] which decom-poses the polygonal lines representing a character into circu-lar arcs of different radii of curvature, considering straightsegments as the limit case of an arc.
The procedure to find the arc approximating a piece ofpolygonal line involves a transformation that changes apolygonal line in the (x,y) plane into a set of horizontalsegments (a staircase function) in a (l,a ) plane, wherel isthe distance of the generic point along the polygonal from areference point (curvilinear abscissa), anda is the anglebetween each segment of the polygonal and a startingsegment. This transformation reduces the problem of fittinga circular arc to a polygonal line to that of approximating astaircase function with a straight line. In order to find thestraight line that better approximates a staircase in (l,a ), weminimize the value of a suitably defined error parameter, byusing the least square method.
2.2. The description through geometric moments
Geometric moments have been extensively employed inpattern recognition as image descriptors [17]. Severalauthors have proposed combinations of geometric momentsthat are invariant with respect to rotation [18]; other kinds ofmoments, based on orthonormal polynomials, have beenalso investigated [19,20].
In this paper we focus our attention on central geometricmoments, although the method we propose could beextended to other kinds of moments.
For a continuous image functionf(x,y), the geometricmoment of order (r,s) is defined as
Mrs �ZZ
xrysf �x; y� dxdy �1�
The quantityr 1 s is also referred to as the order of themoment. If the image is represented by a discrete function,integrals are replaced by summations, yielding
Mrs �X
i
Xj
xri y
sj f �xi ; yj� �2�
Moments defined by Eq. (2) are not independent of transla-tion. To obtain translation invariance, central moments areused
mrs �X
i
Xj
xi 2 �xÿ �r yi 2 �y
ÿ �sf �xi ; yj� �3�
where
�x� M10
M00and �y� M01
M00�4�
are the coordinates of the centroid of the image. Scale invar-iance can be obtained dividingmrs by M00
ÿ �l withl � ��r 1 s�=2�1 1.
In the case of bilevel images given in terms of a setSofcircular arcs, Eq. (1) can be rewritten as
Mrs �Xg[S
Zg
xrg�l�ys
g�l� dl �5�
where each circular arcg is described by means of thefunctions xg and yg , that express the coordinates of eachpoint in terms of the curvilinear abscissal. For circulararcs described by their centers, angles and radii, Eq. (5)becomes
Mrs �XNi�1
M�i�rs where
M�i�rs �Zbi
ai
Ricosq 1 xi
ÿ �r Risinq 1 yi
ÿ �sRi dq
�6�
whereN is the number of arcs,a i andb i are the start and endangles of theith arc, Ri is the radius and (xi ; yi) are thecoordinates of the arc center. Eq. (6) is not valid for anarc degenerating into a straight line segment; in this case
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711704

the corresponding term of the summation can be replaced by
M�i�rs �ZLi =2
2 Li =2lcosqi 1 xi
ÿ �r lsinqi 1 yi
ÿ �s dl �7�
whereLi is the length of the segment,q i is the angle formedby the segment with thex axis and xi ; yi
ÿ �are the coordinates
of the midpoint of the segment. Simple modifications ofEqs. (6) and (7) give the formulae to compute the centralmomentsmrs.
The evaluation of the momentM�i�rs can be performed byusing the moments~M�i�pq computed assuming the arc centeras origin of the coordinate system and withp andq varyingin the range 0…r and 0…s, respectively. In fact, taking intoaccount the well known identity
a 1 b� �n�Xnj�0
n
j
!ajbn2j
the moment of orderr 1 son the generic arc can be writtenas
Mrs �Zb
aRcosq 1 x� �r Rsinq 1 y
ÿ �sR dq
�Zb
a
Xr
p�0
r
p
!Rcosq� �pxr2p
24 35
�Xs
q�0
s
q
!Rsinq� �qys2q
24 35R dq
�Xr
p�0
Xs
q�0
r
p
!s
q
!xr2pys2q
Zb
aRcosq� �p Rsinq� �qR dq
�Xr
p�0
Xs
q�0
r
p
!s
q
!xr2pys2q ~Mpq �8�
For computing ~Mpq, a recurrence relation can be establishedby means of the application of the following formula [21]:Z
cosq� �p sinq� �q dq
� cosq� �p21 sinq� �q21
p 1 qsinq� �22
p 2 1p 1 q 2 2
� �
1p 2 1ÿ �
q 2 1ÿ �
p 1 qÿ �
p 1 q 2 2ÿ � Z cosq� �p22 sinq� �q22 dq
As a consequence, the definition of the moment~Mpq in Eq.(8) becomes:
~Mpq � Rp1q11 Fpq�b�2 Fpq�a�h
�
1 R4 p 2 1ÿ �
q 2 1ÿ �
p 1 qÿ �
p 1 q 2 2ÿ � ~Mp22;q22 �9�
where
Fpq q� � � cosq� �p21 sinq� �q21
p 1 qsinq� �22
p 2 1p 1 q 2 2
� �It is worth noting that Eq. (9) is applicable whenp $ 2 andq $ 2. The expressions giving the moments~Mp1 and ~M1q areeasily obtained
~Mp1 � Rp12
p 1 1cosa� �p112 cosb
ÿ �p11h i
�10�
~M1q � Rq12
q 1 1sinbÿ �q112 sina� �q11h i
�11�
For ~Mp0 and ~M0q the following formulae [21] can be used:Zsinq� �p dq � 2
sinq� �p21cosqp
1p 2 1
p
Zsinq� �p22 dq
Zcosq� �q dq � cosq� �q21sinq
q1
q 2 1q
Zcosq� �q22 dq
In these cases, the obtained expressions are, respectively:
~Mp0 � Rp11 Vp0 bÿ �
2 Vp0 a� �h i
1 R2 p 2 1p
~Mp22;0 �12�
~M0q � Rq11 V0q a� �2 V0q bÿ �h i
1 R2 q 2 1q
~M0;q22 �13�
where
Vp0 q� � � cosq� �p21sinqp
and
V0q q� � � sinq� �q21cosqq
As an example, in Table 1 the expressions relative to themoments up to the fourth order are given.
For computing the coordinates of the centroid of theimage, we can apply Eqs. (4) and (8), thus obtaining
�x�
XNi�1
xi~M�i�00 1 ~M�i�10
� �XNi�1
~M�i�00
; �y�
XNi�1
yi~M�i�00 1 ~M�i�01
� �XNi�1
~M�i�00
�14�
At this point we can refer to Eq. (8) once again for evaluat-ing the central momentsmrs:
mrs �XNi�1
Xr
p�0
Xs
q�0
r
p
!s
q
!xi 2 �xÿ �r2p yi 2 �y
ÿ �s2q ~M�i�pq �15�
From the operative point of view, all the terms necessary forcomputingmrs are easily obtained by means of Eqs. (9)–(13), once the parameters (Ri,a i,b i) have been derived from
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711 705

each of theN arcs into which the image has been decom-posed.
Eq. (8) can also be used, with small changes, if the arcdegenerates into a straight line segment; in this casex andyare the coordinates of the center of the segment, and
~Mpq �ZL=2
2 L=2lcosq� �p dl � cosq� �p sinq� �q
ZL=2
2 L=2lp1q dl
� cosq� �p sinq� �qp 1 q 1 1
L2
� �p1q11
2 2L2
� �p1q11" #
� 2cosq� �p sinq� �q
p 1 q 1 1L2
� �p1q11
for p 1 q even
0 for p 1 q odd
8><>:�16�
2.3. The coding
Once the moments have been evaluated, to obtain afeature vector as much as possible unaffected by changes
in the scale and in the position of the character, a normal-ization is needed, according to the formulae presented in theprevious subsection which evaluate the coordinates of thecentroid and the normalization coefficient for the scaleinvariance. Since the formulae employ the values of thezero- and first-order moments, such values are no longerincluded in the feature vector. As a consequence, whilethe total number of the moments up to thenth order is
n 1 1� � n 1 2� �2
the components of the corresponding feature vector will be
n 1 1� � n 1 2� �2
2 3
Another point to take into account is that the magnitudeof the moments decreases as the order increases, since thecoordinates of the points on the arcs are normalized to therange [0,1]. This situation could cause a reduction of theperformance of some classifiers (such as the neural one usedin the experiments described in the next section), whichmight consider as less significant the components with asmaller magnitude, and loose in this way discriminant infor-mation contained in higher-order moments. To overcomethis problem, it should be advisable to scale each componentby the mean absolute value of that component over a train-ing set. This kind of normalization has been proved to bevery effective in a preliminary experimental phase.
3. Experimental results
The proposed method has been tested using a set of hand-written digits from the ETL Database [22]. In particular, weused a set of 1000 randomly selected characters for traininga neural network classifier, a set (training test set) of 1000characters to decide when the training phase had to bestopped in order to prevent the overtraining phenomenon[23], and a test set composed of 5000 characters, disjointfrom the former two sets, to evaluate the performance of themethod (see Fig. 2). The classifier adopted for testing the
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711706
Fig. 2. Some samples of the considered test set.
Table 1Expressions of the moments~Mpq evaluated up to the fourth order
p 1 q ~Mpq
0 ~M00 � R�b 2 a�1 ~M10 � R2�sinb 2 sina�
~M01 � R2�cosa 2 cosb�
2 ~M20 � R3
sin2b 2 sin2a
4
!1
R2
2~M00
~M11 � R3
2��sinb�22�sina�2�
~M02 � R3
sin2a 2 sin2b
4
!1
R2
2~M00
3 ~M30 � R4
"�cosb�2sinb 2 �cosa�2sina
3
#1
2R2
3~M10
~M21 � R4
3��cosa�32�cosb�3�
~M12 � R4
3��sinb�32�sina�3�
~M03 � R4
"�sina�2cosa 2 �sinb�2cosb
3
#1
2R2
3~M01
4 ~M40 � R5
"�cosb�3sinb 2 �cosa�3sina
4
#1
3R2
4~M20
~M31 � R5
4��cosa�42�cosb�4�
~M22 � R5
sin4a 2 sin4b
32
!1
R4
8~M00
~M13 � R5
4��sinb�42�sina�4�
~M04 � R5
"�sina�3cosa 2 �sinb�3cosb
4
#1
3R2
4~M02

proposed method is a multi-layer perceptron [24] using asigmoidal activation function. In particular, a three-layerfully connected network has been used, because it isknown that this number of layers allows one to build deci-sion regions of any shape (but not multiply connected) asrequired for facing the large majority of classificationproblems [25]. The output layer is obviously made of 10neurons, each representing one of the classes to be recog-nized. The number of hidden neurons was chosen equal to30. The network was trained with the standard back-propa-gation algorithm [24], using a constant learning rateh , fixedto 0.5.
Two classifiers based on the same neural architecturehave been used for evaluating the recognition performanceof the moments evaluated on the bit maps (hereinafterdenoted by BMM) and of the moments evaluated on thestructural decompositions (SDM from now on). To avoidany bias in the final results, we started the training with thesame initial weights in both cases.
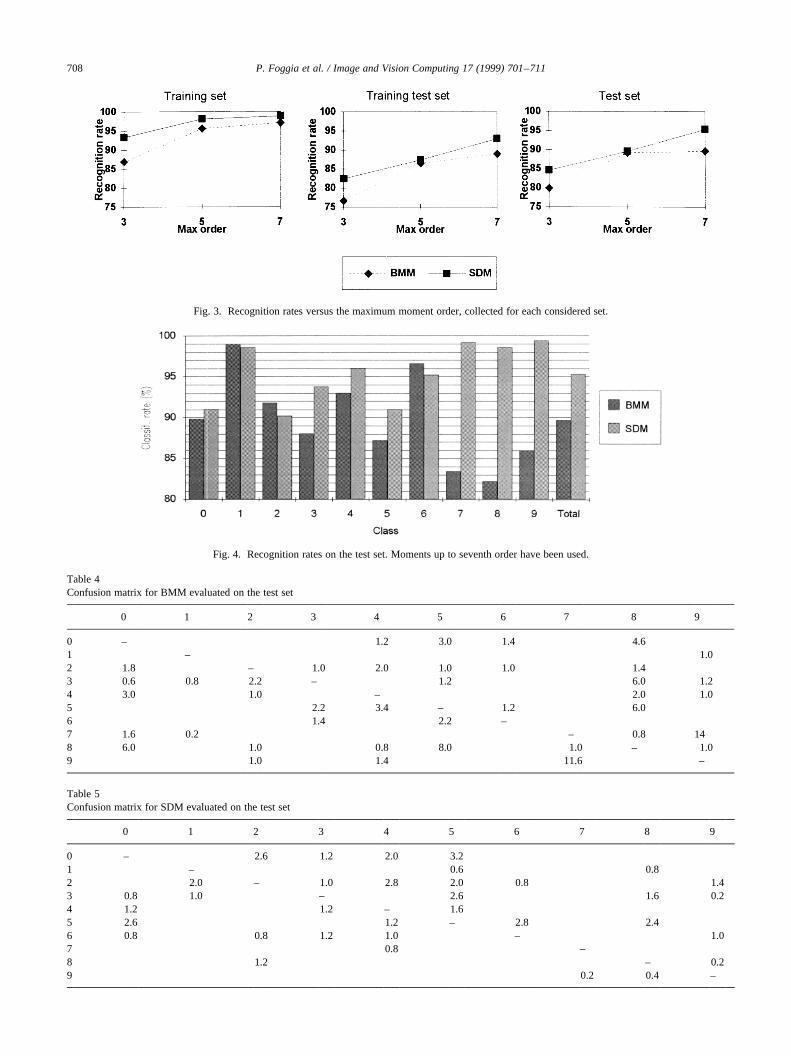
Tables 2 and 3 respectively report the recognition ratesobtained by using BMM and SDM, for different values ofthe maximum moment order. In particular we compare theresults for moments up to third, fifth and seventh order.Results obtained with higher-order moments are notreported, as they did not give a significant contribution tothe recognition rate.
It is worth noting that the obtained results are notoutstanding; on the other hand, they are neither low, consid-ering the quality of the characters in the database. Otherauthors have obtained better results [9] by employingsophisticated classification systems and training schemestailored to the particular application.
The primary goal of our experiments, instead, was not theachievement of the best classification performance on thechosen data set, but the assessment of the performanceimprovement due exclusively to the introduction of a struc-tural approach into a statistical framework for the characterclassification. For this reason, we have employed a simple,perhaps not optimal, classifier without an extensive tuningof the classifier parameters. Our only concern has been to
provide a fair comparison between the proposed hybriddescription scheme and the purely statistical one chosenas reference.
As evident from the tables and from the diagrams in Fig.3, the proposed method leads to a sensible improvement ofthe classification rate in all the considered tests. In particu-lar, for moments up to seventh order, which give the bestperformance in both approaches, the improvement in therecognition rate on the test set is about 6%. This behaviorconfirms our hypothesis that a description method basedon a combination of structural and statistical approachesleads to feature vectors more stable with respect to shapevariations.
Considering the recognition rate for each class can high-light further differences in performance of both methods.The results reported in Fig. 4 show that with SDM there isan overall improvement, which is very significant with somecharacters (‘7’, ‘8’, ‘9’): in these cases, because of the largevariability in character bit maps, the morphological differ-ences among samples of different classes become smaller.Global measurements, such as BMM, fail to catch thesedifferences, so causing a considerable decrease of the recog-nition rate. In these situations, structural decompositions arestill able to extract primitives in a stable way, so preservingmost of the discriminant information. There are three cases(‘1’, ‘2’, ‘6’), however, in which BMM works slightlybetter.
Other useful data are presented in Tables 4 and 5, whichshow the confusion matrices for the compared descriptionmethods, using moments up to seventh order. The elementtijof the table represents the percentage of samples belongingto the ith class which has been wrongly assigned to theclassj.
Such results further confirm that the combination ofstatistical and structural approaches effectively helps inimproving the classification performance. This is particu-larly evident when considering pairs of classes difficult todistinguish by means of a pure statistical method: see, forexample, the case of ‘7’ and ‘9’, which are stronglyconfused when using moments on bit maps, while there isvery little confusion with moments on circular arcs. Otherexamples of this type are given by the pairs (‘0’, ‘8’) and(‘5’, ‘8’).
Finally, Fig. 5 summarizes some overall differencesbetween the two methods. About 86% of the samples arecorrectly recognized by both methods and only a small part(about 1%) remains unrecognized.
It is worth noting that the percentage of samples correctlyclassified by only one of the two considered methods issignificantly higher in the case of SDM. Our method, infact, allows one to recognize 9.1% of samples missed byBMM. However, the actual overall gain is only 5.6%because SDM fails on 3.5% of characters recognized byBMM.
Such cases, already highlighted in the discussion regard-ing Fig. 4, are mainly generated by an intrinsic weakness of
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711 707
Table 2Recognition rate obtained with BMM
Training set Training test set Test set
Up to third order 86.9 76.7 79.9Up to fifth order 95.6 86.5 89.2Up to seventh order 97.1 89.0 89.7
Table 3Recognition rate obtained with SDM
Training set Training test set Test set
Up to third order 93.3 82.4 84.6Up to fifth order 98.1 87.4 89.6Up to seventh order 98.8 93.0 95.3
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711708
Fig. 3. Recognition rates versus the maximum moment order, collected for each considered set.
Fig. 4. Recognition rates on the test set. Moments up to seventh order have been used.
Table 4Confusion matrix for BMM evaluated on the test set
0 1 2 3 4 5 6 7 8 9
0 – 1.2 3.0 1.4 4.61 – 1.02 1.8 – 1.0 2.0 1.0 1.0 1.43 0.6 0.8 2.2 – 1.2 6.0 1.24 3.0 1.0 – 2.0 1.05 2.2 3.4 – 1.2 6.06 1.4 2.2 –7 1.6 0.2 – 0.8 148 6.0 1.0 0.8 8.0 1.0 – 1.09 1.0 1.4 11.6 –
Table 5Confusion matrix for SDM evaluated on the test set
0 1 2 3 4 5 6 7 8 9
0 – 2.6 1.2 2.0 3.21 – 0.6 0.82 2.0 – 1.0 2.8 2.0 0.8 1.43 0.8 1.0 – 2.6 1.6 0.24 1.2 1.2 – 1.65 2.6 1.2 – 2.8 2.46 0.8 0.8 1.2 1.0 – 1.07 0.8 –8 1.2 – 0.29 0.2 0.4 –

structural approaches. In fact, even though the use of astructural approach generally gives a great help in reabsorb-ing shape variability, the structural decomposition mayactually sharpen the shape deformations, so producing anunfaithful description, when the pattern does not satisfy thehypotheses of the structural method. In particular, charac-ters misclassified by SDM generally lie outside the hypoth-esis of the ribbon-like shape model (e.g. broken or too thickcharacters, characters with filled holes, etc.). In these cases,skeletons may exhibit distortions which cannot be simplyrecovered by successive processing.
4. Discussion
The hybrid structural/statistical shape description methodwe have presented is based on two assumptions: (1) it ispossible to model the shape to be described as a ribbon andthus its skeleton can be adopted as a faithful, compressedversion from which to start for obtaining the description;(2) circular arcs are primitives suitable for a significant
structural decomposition of the shape. The first hypothesisis not strictly necessary: the approach is applicable if adifferent characteristic such as the contour is used fordescribing the shape, provided that it is still possible toobtain a decomposition in terms of circular arcs. The choiceof these primitives has been made since there are manyapplicative contexts (besides handwritten character recogni-tion, other possible applications are the recognition ofsymbols on topographic maps, the recognition of compo-nents in electronic circuits, etc.) in which their descriptivepower is enough to substitute curves of different shape with-out loosing any morphological and/or topological informa-tion necessary for identifying the object.
The aim of our proposal was not to derive a fast methodfor the computation of geometric moments (there areseveral algorithms [26–30] which allow one to speed upthis task), and thus a precise and extended analysis of theperformance attainable is beyond the scope of this paper.Nevertheless, a rough comparison between the times neededto compute the two kinds of descriptions considered shows aclear improvement when using SDM. In Figs. 6 and 7 thetimes are plotted as a function of the number of pixels in thepattern: it is possible to see that in both cases the curves arequite linear, but with much higher values for the BMM.
It is worth noting that, for the SDM, the most part of thetime is spent for the preprocessing and that the evaluation ofthe moments by means of the recurrence relations is veryinexpensive and almost constant with respect to the numberof the pixels of the pattern (see Fig. 8).
Since the aim of the experiments was to verify the perfor-mances of our method in terms of description effectiveness,no great care has been taken in optimizing the speed of thepreprocessing steps. Therefore, for some of them fasteralgorithms could be used, thus attaining shorter times forthe whole description evaluation.
Finally, it is worth noting that, as is shown in Fig. 5, theset of characters which are not recognized using either of the
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711 709
Fig. 5. Percentages of characters recognized by each of the two consideredmethods, by both and by neither of them.
Fig. 6. Times (in ms) for computing the BMM descriptions versus the number of pixels of the character bit maps.

two description schemes amounts to just 1.2% of the wholetest set. This fact seems to suggest that a hypothetical recog-nition rate of 98.8% could be achieved if it were possible todecide, for each character, which of the two descriptions ismore suitable for its recognition. To this end a promisingapproach can be the adoption of a multi-expert system forthe classification phase.
5. Conclusions and future work
In this paper a description method based on the combina-tion of structural and statistical approaches is presented. Themethod describes a character by geometrical moments eval-uated on a structural representation of the character in termsof circular arc primitives. The results of the method havebeen compared with those obtained by evaluating the
geometrical moments directly on the character bit mapsand reveal a significant improvement in the recognition rate.
Future investigations will be oriented to generalize themethod to other kinds of moments, and to adopt a multi-expert system for exploiting the advantages of both thedescription schemes.
References
[1] K. Fukunaga, Introduction to Statistical Pattern Recognition, 2nd ed.,Academic Press, New York, 1990.
[2] Ø.D. Trier, A.K. Jain, T. Taxt, Feature extraction methods for char-acter recognition—a survey, Pattern Recognition 29 (1996) 641–662.
[3] K.S. Fu, Synthetic Methods in Pattern Recognition, Academic Press,New York, 1974.
[4] M.A. Eshera, K.S. Fu, An image understanding system using attrib-uted symbolic representation and inexact graph matching, IEEETrans. Pattern Anal. Mach. Intell. 8 (1986) 604–617.
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711710
Fig. 7. Times (in ms) for computing the SDM descriptions versus the number of pixels of the character bit maps.
Fig. 8. Times (in ms) for computing the SDM starting from the structural representations of the characters.

[5] L.G. Shapiro, R.M. Haralick, Structural description and inexactmatching, IEEE Trans. Pattern Anal. Mach. Intell. 3 (1981) 505–519.
[6] L. Goldfarb, T.Y.T. Chan, On a new unified approach to patternrecognition, Proc. 7th Int. Conf. on Pattern Recognition, Montreal,Canada, 1984, pp. 705–708.
[7] W.H. Tsai, Combining statistical and structural methods, in: H.Bunke, A. Sanfeliu (Eds.), Syntactic and Structural Pattern Recogni-tion—Theory and Applications, World Scientific, Singapore, 1990,pp. 349–366.
[8] A.K.C., Wong, J. Costant, M.L. You, Random graphs, in: H. Bunke,A. Sanfeliu (Eds.), Syntactic and Structural Pattern Recognition—Theory and Applications, World Scientific, Singapore, 1990, pp.197–236.
[9] H. Nishida, Shape recognition by integrating structural descriptionsand geometrical/statistical transforms, Computer Vision and ImageUnderstanding 64 (1996) 248–262.
[10] H.S. Baird, Feature identification for hybrid structural/statisticalpattern classification, Comput. Vision Graph. Image Process 42(1988) 318–333.
[11] T. Taxt, J.B. Olafsdottir, M. Dæhlen, Recognition of handwrittensymbols, Pattern Recognition 23 (1990) 1155–1166.
[12] G. Boccignone, A. Chianese, L.P. Cordella, A. Marcelli, Using skele-tons for OCR, in: V. Cantoni, L.P. Cordella, S. Levialdi, G. Sanniti diBaja (Eds.), Image Analysis and Processing, World Scientific, Singa-pore, 1990, pp. 275–282.
[13] C. Arcelli, G. Sanniti di Baja, A thinning algorithm based on promi-nence detection, Pattern Recognition 13 (1981) 225–235.
[14] C. Arcelli, L.P. Cordella, S. Levialdi, From local maxima toconnected skeleton, IEEE Trans. Pattern Anal. Mach. Intell. 3(1981) 134–143.
[15] A. Chianese, L.P. Cordella, M. De Santo, M. Vento, Decompositionof ribbon-like shapes, Proc. 6th Scandinavian Conf. on Image Analy-sis, Oulu, Finland, 1989, pp. 416–423.
[16] L. P. Cordella, F. Tortorella, M. Vento, Shape description through linedecomposition, in: C. Arcelli, L.P. Cordella, G. Sanniti di Baja (Eds.),
Aspects of Visual Form Processing, World Scientific, Singapore,1994, pp. 129–138.
[17] A. Rosenfeld, A.C. Kak, Digital Picture Processing, vol. 2, AcademicPress, New York, 1982.
[18] M. Hu, Visual pattern recognition by moment invariants, IRE Trans.Information Theory 8 (1962) 179–187.
[19] S.X. Liao, M. Pawlak, On image analysis by moments, IEEE Trans.Pattern Anal. Mach. Intell. 18 (1996) 254–266.
[20] C.H. Teh, R.T. Chin, On image analysis by the methods of moments,IEEE Trans. Pattern Anal. Mach. Intell. 10 (1988) 496–513.
[21] I.S. Gradshteyn, I.M. Ryzhik, Table of Integrals, Series and Products,4th ed., Academic Press, New York, 1965.
[22] ETL-1 character database, collected by the Technical Committee forOCR at the Japan Electronic Industry Development Association anddistributed by the Electroctechnical Laboratory.
[23] R. Hecht-Nielsen, Neurocomputing, Addison Wesley, Reading, MA,1990, Chap. 5.
[24] D.E. Rumelhart, J.L. McClelland, Parallel Distributed Processing—Explorations in the Microstructure of Cognition, vol. 1, MIT Press,Cambridge, MA, 1986.
[25] R.P. Lippmann, An introduction to computing with neural nets, IEEEASSP Magazine 4 (1987) 4–22.
[26] M. Dai, P. Baylou, M. Najim, An efficient algorithm for computationof shape moments from run-length codes or chain codes, PatternRecognition 25 (1992) 1119–1128.
[27] M. Hatamian, A real-time two dimensional moment generating algo-rithm and its single chip implementation, IEEE Trans. ASSP 34(1986) 546–553.
[28] B.C. Li, J. Shen, Fast computation of moment invariants, PatternRecognition 24 (1991) 807–813.
[29] W. Philips, A new fast algorithm for moment computation, PatternRecognition 26 (1993) 1619–1621.
[30] L. Yang, F. Albregsten, Fast and exact computation of cartesiangeometric moments using discrete Green’s theorem, Pattern Recogni-tion 29 (1996) 1061–1073.
P. Foggia et al. / Image and Vision Computing 17 (1999) 701–711 711




















