
Multi-Criteria Decision-Making Model to Support Landfill ...
Upload
independentCategory
view
1download
0
E L S E V I E R Decision Support Systems 17 (1996) 119-140
Doe; n 8up rt sysmm
Derived data for decision support systems
R i c h a : r d G . R a m i r e z a,*, U d a y R . K u l k a r n i b, K a t h l e e n A . M o s e r a
a College of Business, Iowa State University, Ames IA 50011-2063, USA b Decision and Information Systems, Arizona State University, TempeAZ 85287-4206, USA
Abstract
In decision-making situations requiring "what-if" analysis, in statistical databases, and in distributed databases, it is desirable to explicitly store derived data without losing consistency with the original data. We introduce independently-updated views (IUVs) for storage and use of derived data for decision-support systems. IUVs support multiple versions, provide derivation transparency, maintain data consistency, and afford control over time of derivation. The notion of data consistency is extended to allow for multiple versions so that versions are consistent with the actively updated database on which they are defined. Implementation issues are discussed and the cost of retrieving IUVs representing different types of derived data is estimated.
Keywords: What-if analysis; Derived data; Relational databases; Versions; Views; View updates
I. Introduct ion
Business databm,;es are typically designed un- der the philosophy of "storing a fact once and only once" to avoid redundancy and potential inconsistencies. However, user queries, particu- larly those needed for managerial decision mak- ing, cannot be satisfied with data as it is stored and require the de:rivation of data. Derived data may include simple computations on a record (balance = previous - charges + credits), data combined from several files, or summary data such as sums, averages, and totals. Different users require different derived data from the same stored data.
Decision-support: systems (DSS) can benefit from increased automatic support for derived
* Corresponding author. Email: [email protected]. Fax: (515) 294-6060.
data. Such support would address needs that are specific to decision-making and facilitate related tasks that presently require the intervention of a programmer. A decision-maker would then be free to concentrate on the decision rather than on the implementation. An obvious candidate for support of derived data is multiple scenarios for "what-if" analysis. Derived data in what-if analy- sis often takes the form of "versions." Consider a grocery store chain that has profiles of the prod- ucts bought together by customers ("product bas- kets"). The chain wishes to observe the impact of reducing the prices of some products (to attract customers) while simultaneously increasing the prices of others. The alternatives are studied by building what-if scenarios; each scenario is a copy of the complete price list that is modified for a few prices and processed to obtain the product baskets. In most database management systems (DBMSs) available today, such as DB2 and ORA- CLE, each copy must be individually created and
0167-9236/96/$15.00 ~ 1996 Elsevier Science B.V. All rights reserved SSDI 0167-9236(95)00008-9

120 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
stored as a new table. The burden of managing these copies falls on the decision-maker since the DBMS has no knowledge that these new tables are derived from other tables and that they, in fact, differ only on a few items. An alternative would be to mark each copy as a "vers ion" of the original table. A better alternative, as proposed in [38], would be to store only the differences to avoid duplication of data and update anomalies.
Another candidate for automatic support is data derived by aggregate functions in statistical and summary databases for managerial decision- making. If an operational database contains in- formation about every customer order, the sum- mary database may contain tables that store only total sales per store by month. As with what-if analysis, currently these databases must be indi- vidually created and managed as if their data were independent of the original database.
Data must often be derived as a consequence of database design. For example, to display an invoice, two files are usually joined: PROD- UCTS, containing product number, description, and unit price, and ORDERS, containing the product number and quantity ordered. Database normalization typically results in multiple tables that must be joined for any given query.
In this paper, we propose Independently-Up- dated Views (IUVs) that explicitly address ma- nipulation of derived data. IUVs present the fol- lowing features: 1. Derivation transparency: Data may be treated
identically regardless of whether it is derived or not. Derived data may be updated if the application so requires.
2. Support for multiple versions and what-if sce- narios: Versions are explicitly defined and no duplication of data is necessary.
3. Database consistency: For versions defined on a dynamic database (i.e., a database constantly being updated), it is possible to detect database updates that would contradict the data in a version, and process those according to prede- fined policies.
4. Control over derivation: IUVs allow the user to specify whether derived data is stored to facilitate retrievals, or recomputed when needed.
The remainder of the paper is as follows. Sec- tion 2 introduces IUVs, presents a comprehensive example, and discusses retrievals and updates to IUVs. IUVs on dynamic databases and the main- tenance of consistency are discussed. Section 3 discusses the performance of IUVs. We derive analytical cost expressions for retrieving IUVs and provide results of experiments with different types of derived data. Section 4 shows how IUVs provide support for the four different features listed above and compares IUVs with other mechanisms in the research literature on derived data. Section 5 concludes the paper.
2. Independently-updated views
We present Independent ly-Updated Views in top-down fashion. 2.1 gives an overview and in- troduces concepts and terminology. In 2.2 we provide details on the structures of the various tables involved. In 2.3 we discuss forming and querying IUVs. Updates to IUVs and their rela- tionship to the underlying database are discussed in 2.4. In 2.5 and 2.6, we introduce the notion of "overlapping updates" and the maintenance of consistency in dynamic databases. The section concludes with a review of previous research.
2.1. Overview of IUVs
In introducing IUVs, we follow the common relational terminology. A base table is a relation defined independently from other tables in the sense that no base table is completely derivable from any other table or tables [7]. A view is a table that is derived from one or more base tables [12]. Views that are not physically stored are virtual relations while views that are physically stored are snapshots or materialized views [2]. A differential table stores changes made to a "source" table [18,36]; these changes are incorpo- rated into the source table when it is retrieved.
An independently-updated view, or IUV, is a virtual relation formed by making changes to a table called the parent table (PT) of the IUV. These changes are stored in a differential table (DT) and do not physically modify base tables;

R.G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 121
they are only used to form the IUV. Being virtual relations, IUVs are not physically stored, only their DTs are physically stored. Conceptually, an I U V is formed by retrieving its PT and incorpo- rating into it the changes stored in the DT. Fig. 1 shows the conceptual retrieval of an IUV. Physi- cally, "query modification" [37] translates a query on an IUV into a query on physically-stored tables.
The PT contains data used as the basis for decision making. PT is either a base table, a view, or another IUV. W:ithout loss of generality, we assume that PT is defined by a query definition. An I U V is an updated version of its PT. Updates (insertions, deletion,;, modifications) to an IUV are stored in its D T as differences between PT and the desired status of the IUV. D T contains one row for each PT row that appears changed (modified or deleted) in the IUV plus any rows added to the IUV not already in PT. DT has the columns of the PT and an additional column called A C T I O N th~tt specifies the operat ion to be performed when the IUV is retrieved. If A C - T I O N = ins, the D T row is inserted in the IUV. If A C T I O N = mod, the D T row replaces the corre- sponding PT row in the IUV. If A C T I O N = del, the corresponding PT row is deleted in the IUV. PT rows that are not changed in the IUV have no matching rows in DT.
Fig. 2 shows an IUV D E P T - M G R based on the PT DM and the D T DIFF-DM. Dept. No. is the primary key for all tables. TS (t imestamp) is a system column that is automatically added and
I B3
~ l b a s e t a b l e
... ~ 1 I Bn =)1
Iuvl PT + updates
Fig. 1. Independently-updated views.
Parent Table DM
Dept No D1 D2 D4
Dept No Dept. Name Manager Budget TS D1 Sales-Corporate John Smith 410 567 D2 Sales - Retail Jane Adams 320 573 D3 Production Sally Kiefer 330 801
Differential Table DIFF-DM
Dept. Name Manager Budget ACTION TS Sales-Corporate John Smith 520 rood 901
del 903 Design Henry Field 600 ins 907
IUV DEPT-MGR
Dept No Dept. Name Manage r Budget TS D1 Sales-Corporate John Smith 520 901 D3 Production Sally Kiefer 330 801 D4 Design Henry Field 600 907
Fig. 2. Sample IUV.
updated by the DBMS. The purpose of TS is described in 2.2. The IUV is obtained by outer- joining PT and D T on the primary key and then selecting columns and rows according to the AC- T I O N code. The details of this operat ion are in 2.3. The rows in PT that have a matching row in DT (departments D1 and D2) are changed ac- cording to the value of the A C T I O N code. Thus, in the IUV, the expense budget of depar tment D1 is modi f i ed to "520" (or $520,000) and the row for D2 is dele ted (i.e., it does not appear in the IUV). Non-matching rows in PT (depar tment D3) are incorporated in the IUV without change. Non-matching rows in D T (depar tment D4) are insert ions into the IUV. Note that Fig. 2 does not make any assumption about the PT DM; DM can be a base table, any type of view (such as select /project , join, aggregate), or another IUV.
An IUV is a version of its parent table. Multi- ple versions of a PT are created by simply defin- ing multiple IUVs with the same PT. Only their DTs are physically-stored. "Versions of versions" are created when the parent table of an IUV is another IUV. In general, "version hierarchies" are created when multiple IUVs are defined on the same parent table and each IUV is used as the parent table for other IUVs.
If the database is not read-only (i.e., is updat- able), there are two sources of changes to an IUV: I U V updates and PT updates. A P T update to an IUV v is a database update to a table other than v that nonetheless causes a change to v. In

122 R.G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
the example, adding a new row to DM with department D5 will result in that row also ap- pearing in D E P T - M G R . A P T update is automat- ically propagated to the IUV. In 2.6, we discuss update propagation in detail and introduce the problem of "overlapping updates" caused by PT updates to rows already modified in the IUV. The resolution of overlapping updates requires the modification ("refreshing") of DT to reflect the desired outcome.
2.2. The structure of lUV, PT, and DT
We now describe the structure of the tables involved in an IUV. Consider first the PT. As mentioned earlier, PT can be either a base table, a view, or another IUV. In our example, the PT DM in Fig. 2 is a view derived from the base tables in Fig. 3. DM is obtained using the follow- ing SQL statement. The system column TS is automatically added by the DBMS.
C R E A T E VIEW dm (deptno, deptName, manager, budget)
AS SELECT d.deptno, d.deptName, e .empName, d.budget
F R O M depts d, emps e W H E R E d.mgrno = e.empno AND region = 1.
If the PT is a view, it may be a virtual relation or a materialized view. If the PT is a materialized view, we assume its currency is maintained by a refresh procedure such as those in [2,6,16]. Since all these procedures are semantically equivalent, they can all be applied to the maintenance of a materialized PT.
Following conventional semantics of the rela- tional model, we assume that every relation has a primary key [11] including views [8], and therefore PT has a primary key. The primary key serves to guarantee that each row represents an object about which information is stored in the database and that is uniquely and explicitly identified [8].
Tables in a database also contain system columns. System columns are not visible to the user (unless explicitly requested). They are added and manipulated automatically by the DBMS.
Dept No Region D1 1 D2 1 D3 1
Dl l 2 D12 2
Base Table DEPTS
Dept. Name Mgr No Budget TS Sales - Corporate El00 410 567
Sales - Retail E230 320 428 , Production E367 330 780
Sales - Midwest E175 40 689 Warehouse E412 150 483
Emp No El00 E150 E175 E200 E230 E310 E367 E390 E412
Base Table EMPS
Emp Name Dept No John Smith D1 Mary Jones D 1 Beth Helms Dl l Tom Myers D2 Jane Adams D2 Kim Burton D3 Sally Kiefer D3 Henry Field D3 Tim Falk D12
Salary TS 50,000 345 30,000 602 67,000 783 45,000 574 60,000 573 25,000 605 55,000 801 45,000 893 48,000 515
Fig. 3. Base tables for sample IUV.
We assume that all tables have a system column TS showing the t imestamp when the row was last inserted or modified (see [17] for a discussion of t imestamps in DSS databases). Timestamps are used to detect overlapping updates. For derived tables, the t imestamp of a row PPT in PT is the latest t imestamp of the rows used to form PT. The first row of DM in Fig. 2 is obtained from the row for depar tment D1 in DEPTS and the row for employee El00 in EMPS in Fig. 3. The t imestamp is 567 since the row for depar tment D1 has a later t imestamp (TS = 567) than the row for the employee (TS = 345). For the second row in DM, the t imestamp is taken from the EMPS row rather than from the DEPTS row since em- ployee E230 has a later t imestamp. For derived tables formed using aggregate functions such as SUM, the t imestamp is the latest in the row subset used to compute an aggregate value.
D T is a physically-stored table that has the same columns as PT, including the timestamp, plus an additional system column ACTION. DT also has the same primary key as PT. A DT row represents the net effect of all updates made to an IUV row. At any time, there is at most one row in a DT for each row of its PT. For example, if an I U V row is modified and then deleted, only one row with del action appears in the DT. DT rows are modified as a result of: (a) user updates to the IUV and (b) the resolution of overlapping updates (discussed in 2.5).

R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 123
An I U V is a virtual relation that has the same columns and the same primary key as its PT. For each IUV there is ~ corresponding DT. Multiple IUVs (and therefore DTs) can be defined on a single PT. The key is used to form the IUV by outer-joining the parent and differential tables, as explained in 2.3. The key also allows the DBMS to check for entity integrity (nulls, duplicates) at the time the IUV is formed. The key of an IUV must be explicitly given at the time of definition since the key of the PT may not be known to the DBMS. We note that most DBMSs and SQL implementations do not require key specifications on base tables. In cases where the key of the PT is known to the DBMS or it may be automatically determined, a check is made to detect conflicting definitions. This is lhe case with PTs that are: (a) base tables with DBMS-known primary keys, (b) updatable views on a base table with a DBMS- known primary key, (c) views obtained using ag- gregates (the grouping attributes form the key), or (d) IUVs.
2.3. Forming the I U V
The IUV is formed by: (1) obtaining the outer join of PT and DT, and (2) forming rows in the IUV based on the result of the outer join. These actions are perforraed together since the outer join brings to main memory all the necessary information. Additional processing to resolve overlapping updates, described in 2.6, is neces- sary when the underlying database is updatable.
The first action is straightforward. Conceptu- ally, PT is retrieved and full outer joined with DT on the primary key. Fig. 4 shows the outer join of DM and D I F F - D M used to produce the IUV D E P T - M G R . A full outer join is performed be-
cause a "normal" (or inner) join would include only those rows from PT that match rows in DT; the full outer join includes non-matching rows in PT (rows not updated in the IUV) as well as non-matching rows in D T (rows inserted in the IUV). Note that physically PT may never be formed due to the DBMS query optimization. More specifically, "query modification" [37] translates the outer join and the query that de- fines PT to an equivalent algebraic expression on physically-stored tables.
The outer join produces rows that contain all the columns in both D T and PT. Then, forming the IUV involves choosing from the outer join the columns that will appear in the IUV. For non- matching rows of PT, i.e., rows not modified in DT (e.g. depar tment D3), the columns from PT are used. For non-matching rows of DT, i.e., IUV insertions (e.g., depar tment D4), the columns from DT are used. For matching rows, if the A C T I O N value is rood (e.g., depar tment D1) the columns of D T are used; if the A C T I O N value is del (e.g., depar tment D2), the corresponding row is not included in the IUV.
We conclude this subsection by commenting on primary key updates. Consider a row ppTEPT and a row PDTEDT, both with the same key value and representing the same real world entity. The outer join correctly generates a single row com- bining PPT and POT" Modifying the key in either PPT (a PT update) or Pmx (an IUV update) incor- rectly causes two rows to be formed by the outer join. The problem of updates to keys is well documented in the literature [20,22]. It is a natu- ral consequence of having user-defined keys as the main approach to object-identity in the rela- tional model. This causes key updates to be se- mantically different from updates to non-key at-
Dept]
D1 D2 D3
columns from DM I i
Dept Name Manager I nudgetl ~ I DeP t I
Sales - Corporate John Smith 410 567 D1 Sales - Retail Jane Adams 320 573 D2 Production Sally Kiefer 330 801 ---
--- D4
columns from DIFF-DM DeptName Manager [Budget[Action[ TS
Sales - Corporate John Smith 520 rood 901
--- del 903
Design Henry Field 600 /ns 907
Fig. 4. Outer join of DM and DIFF-DM.

124 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 1 1 9 -1 4 0
tributes. Since the key identifies the object or event described by the non-key attributes, a key update has the interpretation of " the non-key attributes here actually describe another real- world object or event" when in fact the intention may be " to correct a social security number that was entered incorrectly." In his R M / T revision to the relational model, Codd [7] proposed the use of surrogates as a solution. The similar idea of object-identifiers is well established in object- oriented databases [1,22]. An alternative ap- proach in SQL-92 uses primary and foreign key specifications to automatically propagate changes to a key throughout the database [27]. As these approaches affect only the mechanics of IUVs and not their semantics, we defer their detailed presentation to the appendix. Briefly, one can use an additional column(s) in DT for the key as it appears in the PT. This column is used in the outer join and is kept consistent with the database using key update propagations or triggers.
Another problem related to keys is the viola- tion of the "entity integrity" rule [12]. This occurs when a null value is assigned to the primary key of any row or when two rows have the same primary key value. Entity integrity is typically assumed in relational databases. However, in most DBMSs a key specification is not required for base tables and therefore it is possible to en- counter invalid rows. For this reason, we establish
the following semantics for entity integrity viola- tions: (1) any row whose primary key has a null value is ignored and does not appear in the IUV, and (2) whenever two or more rows have the same primary key value, the row with the latest timestamp is used and the other is ignored.
2.4. Updating IUVs
For updating, users treat an IUV just like a base table. Updating (modifying, inserting, delet- ing) an IUV row means that, on retrieval, the row will appear updated (modified, inserted, deleted) as intended. As the name "independently up- dated view" indicates, IUV updates are indepen- dent of the base tables from which the 1UV is derived. The express purpose of updating an IUV is to change only that IUV and not to affect the underlying base tables. This is different from the traditional view updating where a view is updated with the purpose of making changes to the under- lying database.
Before an IUV is updated, it is identical to its PT and its DT is empty. Updates to an IUV are translated into changes to its DT so that when the IUV is retrieved it reflects the updates. When an IUV row is updated (inserted, modified, deleted), a check is made for the existence of a DT row with the same key value. Table 1 shows
Table 1 Process ing of I U V upda t e s
I U V u p d a t e and its effect on D T
A C T I O N code Inse r t ion Modi f i ca t ion De le t ion in the D T row
no D T row Inser t a new D T row wi th Inser t a new row with
A C T I O N = ins if no row A C T I O N = mod.
with tha t key exists in PT. Rejec t o therwise .
Reject . Row wi th same key a l ready exists in the IUV.
rood
/ns
del
Reject . Row wi th same key a l ready exists in the IUV.
Rep l ace D T row wi th a new row wi th A C T I O N = mod.
Rep lace D T row with a new row wi th A C T I O N = mod.
Replace D T row wi th a new row wi th A C T I O N = ins.
Reject . Row wi th this key does not exist in IUV.
Inse r t a new row wi th A C T I O N = delete.
R e p l a c e D T row wi th a new row wi th A C T I O N = del.
Rep lace D T row wi th a new row wi th A C T I O N = del.
Reject . Row with this key does not exist in IUV.

R.G. Ramirez et a l . / Decision Support Systems 17 (1996) 119-140 125
the processing of each type of IUV update given the ACTION code in the corresponding DT row.
Note that the classical view update problem of [4,14] does not arise in the case of IUVs. This problem occurs when view updates cannot be automatically mapped to the corresponding base tables. IUVs do not present the view update problem because the IUV is treated as a base table and updates are mapped to the DT and not to the underlying database. The difficulty of map- ping view updates to base tables is the reason that most DBMSs support updates only for views that are row or column subsets of a single base table [27,10]. However, some front-end systems allow definition of views based on joins. INGRES supports "JoinDefs" that define a join, typically those which join a primary key to a foreign key [33]. A JoinDef can be used with the forms-based front-end for updates but not directly with SQL or QUEL, the INGRES query languages. Mi- crosoft Access supports updating of some join queries ("dynasets") [26]. Other approaches to extending view updatability that have not been incorporated in commercial DBMSs include a "complementary view" [4,9], Keller's intelligent assistant that helps to define mappings at view definition time [19], and the capture of semantic information at both view definition and view up- date time [24]. Unlike IUVs, all these approaches are designed to update the database through views.
IUVs share the row disappearance problem with views. This problem arises when a row is changed in such a way that it "disappears" from
the view because it violates the view definition. Consider a view defined as a selection where sales > 10,000 and a view update that changes the sales amount in a row from 17,000 to 9,000. This row disappears from the view since it no longer satisfies the selection criterion. In SQL systems, the WITH CHECK OPTION [12,23,27] is used to prevent these view updates by rejecting any change that would violate the predicate in the W H E R E clause of the view definition. We assume a similar mechanism for IUVs.
2.5. IUVs on updatable databases
If an IUV is defined on a database that is not read-only, changes in the database are automati- cally propagated to the IUV. Database updates are either: (1) PT updates, i.e. those that affect the PT of an IUV, or (2) irrelevant updates, i.e., those that have no effect on the PT (see [6] for a discussion on irrelevant updates). In the case of the IUV DEPT-MGR, an update to a depart- ment in region 1 in the base table DEPTS is a PT update. Whereas any update to a department in region 5 is irrelevant since it has no effect on the state of PT. Irrelevant updates do not affect an IUV and are not discussed any further. Note that an update that changes a department from region 1 to region 5 is not irrelevant since it affects the PT. Its effect is to delete that department from PT.
The interaction of IUV and PT updates can lead to overlapping updates. Consider the row for department D1 in the PT DM of Fig. 2. The dept.
T i m e
to
t l
t2
EVENT EFFECT NOTES
An IUV is defined on DT is an empty table. IUV is identical to its PT. a PT. The IUV is updated. IUV is not the same as at t 0. IUV IUV is different from its No updates are made updates are stored in the DT which is no PT. Overlapping updates to the dat~,base, longer empty. PT is the same as at to. do not exist.
Database iis updated. Database updates may affect the PT. Some of the affected PT rows may have been updated in the IUV at t 1.
Fig. 5. A sequence of IUV and database updates.
IUV is different from its PT. Overlapping updates may exist.

126 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
budget "410" is modified in the IUV to "520." This update can be interpreted as "increase the dept. D1 expense budget from $410,000 to $520,000." If the PT is read-only, the original budget ("410") will never change and therefore this interpretation will always remain valid. How- ever, if PT is not read-only, it is possible for the value "410" in the PT DM to be updated to, say, "540." In that case, the IUV update now has the meaning "decrease the dept. D1 expense budget from $540,000 to $520,000." Since this may not be what the decision maker intended, a problem has been created.
Fig. 5 shows a sequence of I U V and PT up- dates leading to overlapping updates. At time t o , the IUV is identical to its PT. At time t I the IUV is updated; the database does not change. The IUV and its PT are no longer identical. At time t2, the database is updated. At this time, a PT update is: (i) an overlapping update if it changes a PT row already modified in the IUV or (ii) a non-overlapping update if it changes a PT row that has not been modified in the IUV.
More precisely, given an IUV and its PT and rows P l u v e l U V and ppxePT with the same key value, a PT update is an overlapping update if (1) at time t, an IUV update modifies or deletes p lUV, and at time t',t' > t, the PT update modi- fies or deletes PPT, or (2) at time t, an IUV update inserts Piuv such that n o p p T e P T exists with the same key value, and at time t',t' > t, the PT update inserts PPT with the same key value.
Overlapping updates cause inconsistencies be- tween an IUV and its PT, temporarily making the IUV invalid. Overlapping updates must be re- solved so that the IUV can be constructed as per the intended changes. We define the following policies to that effect; each policy reflects a dif- ferent intent.
Table 2 Detecting overlapping updates
• Policy 1: IUV updates prevail over PT updates; an overlapping update is not reflected in the IUV. A P T row is considered to be a basis or an assumption that is valid only as long as it is not changed by an IUV update. The user in- tends the change made to an IUV to be per- manent, only to be affected by further IUV updates. Subsequent PT updates should not affect the user 's intentional changes. Policy 2: PT updates prevail over IUV updates. An IUV update is valid only as long as the original information remains unchanged. Any update of a PT row subsequent to an IUV update of the same row is reflected in the IUV. Thus, updating a PT row that has been earlier modified in the IUV renders the IUV update ineffective. The policies do not differ on the t reatment of
both non-overlapping PT updates and IUV up- dates of rows not affected by later PT updates. Both types of updates are treated in the same manner under the two policies.
2.6. Detecting and resolving overlapping updates
An overlapping update is detected whenever an IUV row is accessed (either for update or retrieval) by comparing the PT and the DT. The procedure, shown in Table 2, uses the A C T I O N value in the DT row and the t imestamps d and p of matching D T and PT rows, respectively. The shaded ceils in Table 2 show the types of overlap- ping updates. Consider the inser t / inser t cell, i.e., an overlapping updated caused by the insertion of an IUV row followed by an insertion of a PT row with the same primary key value. The IUV insertion creates a D T row with t imestamp d and A C T I O N ins. The subsequent PT row insertion
DT ACTION value
Timestamps of matching DT and PT rowsd = DT timestamp, p = PT timestamp
No PT row p > d p < d
ins mod del
no overlapping update insert/insert modify / delete modify / modify delete / delete delete / modify
no overlapping update no overlapping update no overlapping update

R. G. Ramirez et aL / Decision Support Systems 17 (1996) 119-140 127
creates a PT row with timestamp p > d. The overlapping update is detected by the condition A C T I O N = ins and p > d. Similarly, the modify/dele te cell represents an IUV modifica- tion followed by a PT deletion that is detected by the condition A C T I O N = mod and "no PT row."
Once detected, a:a overlapping update is re- solved according to one of the two policies dis- cussed in 2.5. For each overlapping update, the DT is changed to reflect the resolution. Consider the insert/insert overlapping update. For Policy 1 IUVs, an IUV update prevails over a subse- quent PT update. Hence, the resolution results in keeping the inserted IUV row by changing the ACTION in DT frem ins to mod. In addition, the timestamp of the DT row is made current (d ~ t) to reflect that the conflict has been re- solved.
For Policy 1 IUVs, the actions to resolve the overlapping updates are: • for modify/delete overlapping update: Make
d ~- t. Change ACTION to insert. • for delete/delete overlapping update: Make d
~"- t .
• for insert/insert overlapping update: Make d t. Change ACTION to modify.
for modi fy /modi j~ overlapping update: Make d o t .
• for delete/modify overlapping update: Make d ~ t . For Policy 2 IUV~,;, PT updates prevail over the
IUV updates. Hence, an overlapping update is resolved by nullifying the effect of the IUV up- date. This is done by deleting the corresponding DT row.
Regardless of policy, overlapping updates are checked and detected only when the IUV row is accessed. A consequence of this is that multiple database updates affecting the same row in the PT between two ILIV accesses are treated as a single update. Therefore, the situations in Table 2 may occur as a result of one or more database updates. For example, the overlapping update " inser t / inser t " may be the result of one insertion of a row in the PT, or an insertion followed by a modification of the same row. Multiple database updates do not affect the tests for detecting over- lapping updates.
Note that IUVs require no overhead for database (e.g. PT) updates since it is not neces- sary to monitor, separately store, or propagate database updates as they occur. A processing cost occurs only when the IUV is accessed. Also note that the cost of processing the overlapping up- dates is minimal since the DT rows are already in main memory (for forming the IUV rows). The major cost is for writing back the refreshed DT and it therefore depends mainly on the size of the DT and the extent of overlap. In normal IUV applications, the DT is not expected to be very large because it stores only the difference be- tween the PT and the DT.
2. 7. Prior research
The notion of IUVs was introduced in [32] which focused only on the retrieval aspects and did not discuss IUVs on dynamic databases or multiple base tables (e.g. PTs defined using joins). The Oracle DBMS was used to evaluate retrieval times for IUVs defined using selection and aggre- gation of single base tables. [32] is most closely related to portions of Section 3 which generalizes [32] with implementation-independent analytical expressions and different file structures for IUVs based on selections, joins, and aggregates. The cost of refreshing the differential file is also stud- ied in Section 3 for the first time.
The propagation of PT updates to IUVs is similar to the refreshing of snapshots. Snapshots differ from IUVs in that they are read-only tables that cannot be updated; a snapshot is a read-only materialization of a view [2]. Snapshots avoid the cost of generating a view every time a query is made on the view. To maintain consistency with the original data, snapshots need to be "re- freshed" (i.e., regenerated) periodically to reflect updates made to the database [2,6,16,25]. The periodic regeneration of Adiba and Lindsay [2] does not require any modifications to the update mechanism to base tables. Thus, it can be easily be implemented on an existent DBMS. A variant by Segev and Park [35] uses a differential file to propagate updates to several materialized views. Unlike IUVs, the mechanism of [35] adds over- head to database updates by requiring every up-

128 R.G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
date to a base table to create a new row in the differential file.
The notion of differential tables to support multiple versions of a relation has been used for hypothetical relations (HRs) [3,38-40] and de- rived relations with exceptions (DREs) [13,30]. Both HRs and DREs differ from IUVs in that they cannot be kept consistent when they are defined on non read-only tables. DREs allow versions to be defined on an arbitrary view [30,31] as IUVs do. However, HRs can only be defined on a single read-only base table; they do not allow versions to be created based on derived data, such as summary data or data derived from multiple base tables.
3. Processing costs
To evaluate the processing costs of IUVs, we derive generalized analytical cost expressions for their retrieval. These cost expressions can then be used to estimate the performance of IUVs under various operating conditions and hardware con- figurations. We consider commonly used views (select /project , join, and aggregate) that have been used in similar studies in the context of view materialization strategies [16,6].
To assess the performance of IUVs, we com- pare the cost of an IUV (IUV-cost) with the cost of retrieving just its parent table (PT-cost). This is a very conservative estimate s ince IUVs by definition involve more processing. However, as the results show, IUV costs are reasonably close to PT costs in most cases. We define %IUV-cost as 100 x (IUV-cost - PT-cost )/PT-cost.
We assume that a primary clustered B + tree index is available on the physical tables. Such indexes can be useful in retrieving both the view and the corresponding IUV, as well as for updat- ing the relations and the DT. Only complete retrievals of the IUV are considered. The follow- ing parameters are used in the cost expressions:
N/ Number of rows in relation R i P/ Number of blocks occupied by relation
R i (P i = [AT/ tsize/B]) where B = block size; tsize = row size
fpt View or PT predicate selectivity (Npt = fp,U/)
fat Fraction of PT changed by DT (Nat = fd, Npt)
fre£ Fraction of D T refreshed between every IUV retrieval due to overlapping updates
C~ Average Rotational Delay C z Average I / O cost to r ead /wr i t e a block
randomly To construct an IUV, its PT and D T are
retrieved and joined. In addition, DT is refreshed to resolve overlapping updates since the last ac- cess to the IUV. This involves modifying the relevant D T rows and writing them back. We assume that CPU operations (such as screening, comparing, computing) are carried out simultane- ously with the I / O operations because of double buffering. The cost to construct an I U V can be broken down into the following three compo- nents: IUV-cost = cost to retrieve PT (Hp) + cost to retrieve DT ( H d ) + cost to refresh D T (Hr).
3.1. Select/project IUVs
Parent tables of these IUVs are formed using a relational algebra selection and projection on a relation R v The selection applies a predicate with selectivity fpt to a subset of the attributes of R v Selected rows are projected according to the attributes in the view's definition. We assume that the primary key of R a is preserved by the projection.
To retrieve the parent table, the entire rela- tion R~ (P1 blocks) is read using a clustered scan, each block requiring one disk access. Rows are screened against the view predicate and projec- tion is carried out as they are read. Therefore, the estimated retrieval cost of the parent table is H p = C 2 P l.
The retrieval cost of DT, Hd, is the cost to read the Pat blocks of DT, also using a clustered scan. Hence, H d = C2Pat. Since both PT and DT are formed using a clustered scan, their rows are available in order by primary key and the join requires only a single pass over the two relations, without any additional I / O .
Hr, the cost to refresh the differential table, consists of the cost to update (modify or delete)

R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 129
frefNdt rows of Dr[ in place. In terms of the n u m b e r of blocks , this works ou t to Y(Ndt,Pdt,frefNdt), w h e r e the function y(n, m, k ) estimates the number of blocks touched when accessing k out of n records in a file occupying m blocks [41]. T h e r e f o r e , Hr = 2C 1 × Y(Ndt,edt,frefNdt) , where 2C l is the additional time for one complete rotation of the disk needed for writing back a block in its original location after it is read; no seek time is needed [34]. Thus, IUV-cost (select/project) = C z P 1 + CzPdt + 2C 1
× Y(Ndt,Pdt,frefgdt)
3.2. Join IUVs
These IUVs have parent tables formed using a natural join of two relations, R 1 and R 2. For generality, join views may also include selection and projection operations. We assume that the selection restricts R~ with selectivity fp, and that every row of R 1 joi:as to exactly one row of R 2. This is a very common join in practice, occurring when an attribute d is the primary key of R 2 and a foreign key in R~. We assume the simple hash join algorithm of [29] with R 2 read first. As R 2 is read, a hash index is formed in memory. R~ is read and joined with R 2 using the hash index. The join requires only one pass over R 1 and R 2 if the hash index can be fully accommodated in memory (in our study, R 1 had a size of 100,000 rows and R 2 a size of 2,000; much larger tables can be accommodated). Therefore, kip = C2P 1 + CaP z. The cost expressions for the other compo- nents of IUV-cost of these IUVs, Hd and Hr, are the same as those of select/project views. Hence, IUV-cost (join) = C 2 P 1 + C 2 P 2 + C2edt -]- 2 C 1 ×
Y(Ndt,edt, frefgat ).
Table 3 Performance results
3.3. Aggregate 1UVs
The PT of an aggregate IUV is formed using one or more aggregate functions such as SUM, AVG, or COUNT on a single relation R r A subset of the attributes of R~ serves as the aggre- gation attributes. The PT is formed by reading the entire relation R 1 and computing the aggre- gate in one pass over the N~ rows of R l. We assume that as each row is scanned, a hash index is built in memory and the values of the aggrega- tion attribute are computed simultaneously. Hence the cost of retrieving the aggregate view, Up = C2P 1. The hash index on the PT can also be used for joining the PT and the DT. Note that the primary key of an aggregate view is formed by the aggregation attributes. The remaining compo- nents of IUV-cost, the cost to retrieve DT, Hd, and the cost to refresh DT, Hr, have the same expressions as in the earlier cases. Therefore, IUV-cost (aggregate) = C z P 1 + C2Pat + 2C 1 ×
Y( Ndt,Pdt,frefNdt ).
3.4. Results
Table 3 summarizes the performance of IUVs for the three view types using the following pa- rameter values: N 1 = 100,000 tuples, N 2 = 200 tu- pies values, tsize = 100 bytes, B = 4000 bytes, C 1 = 8 ms, C 2 = 25 ms.
We considered three values of fpt (0.1, 0.2, and 0.3) representing views that are subsets of base tables (i.e., up to 30% of the size of the base tables). For the differential tables, we considered a range of values for fat" This range represents IUVs that differ by 20% to 40% from their par-
% I UV-cost
for = 0.1fat range 0.2-0.4 fpt = 0.2fat range 0.2-0.4 fm= 0"3fdt range 0.2-0.4
Selec t /projec t fref = 0.0 2.0%--4.1% 4.1%--8.1% 6.1%-11.8% fref = 0.5 3.4%--6.4% 6.4%--13.2% 10.0%-19.6%
Join fref = 0.0 2.0%--4.0% 4.0%--7.6% 6.0%-11.6%
fref = 0.5 3.3%--6.3% 6.3%--12.9% 9.6%--19.2% Aggregate fref = 0.0 2.0%--4.1% 4.1%--8.1% 6.1%-11.8%
fref = 0.5 3.4%--6.4% 6.4%--13.2% 10.0%-19.6%

130 R.G. Ramirez et al./Decision Support Systems 17 (1996) 119-140
ent tables. We believe that these parameter val- ues cover views that are typically used for sup- porting managerial decision-making. The fref value of 0.0 represents a read-only or a static database; there are no overlapping updates and hence there is no cost to maintain the DT. On the other hand, the fref value of 0.5 represents a extremely dynamic database where 50% of the DT tuples are affected by overlapping updates between every IUV access.
The results show that the %IUV-cost is less than 20% of the cost of retrieving the corre- sponding view for all the three types of views. Over a major portion of the range, the %IUV-cost is well below 10%. For smaller values of fpt, the %IUV-cost would be even lower. Thus, in most cases a user would feel no appreciable difference between running a query on a conventional view or on an IUV. For aggregate IUVs, where aggre- gate functions result in a parent table that is substantially smaller than the original tables, this is particularly true. We also found that the cost of processing overlapping updates tapers of as fref increases beyond a certain limit (f~ef = 0.5 repre- sents an extreme) because of the nature of the y(n, m, k) function [41].
4. Derived data in decision-support systems
This section discusses support for derived data in decision support systems using the summary requirements listed in Table 4. These require- ments are classified as: (1) derivation trans- parency, (2) the ability to build multiple versions or scenarios, (4) automatic maintenance of con- sistency, and (3) control over the time of deriva- tion. For each requirement, the support given by IUVs is described. The section concludes with a comparative summary of other mechanisms for derived data.
4.1. Derivation transparency
Ideally, a relational database system should allow users to treat all tables identically, regard- less of whether they are physically-stored or not. We refer to this capability as derivation trans-
parency. In practice, DBMSs significantly restrict the user 's ability to manipulate derived data, causing decision makers to manipulate the database in ways that are unnatural to the appli- cation.
Fig. 6 helps explain derivation transparency in relational databases. Fig. 6(a) shows a database that appears to programmers and end-users as a collection of views and base tables. If views V1 and V2 are updatable, the user schema for Fig. 6(a) consists of tables B1, V1, and V2. On the other hand, if V1 and V2 are not updatable, then the user schema must also include tables B2-B4 to support updates. Thus, the lack of derivation transparency forces users to manipulate tables that do not provide additional information. While in many cases, a decision maker may utilize views for retrieval and have a programmer write the routines for correct updating, this is an unneces- sary complication. Fig. 6(b), on the other hand, shows a database in which all tables in the user schema can be treated identically, regardless of whether they are derived or base tables.
We make a further distinction between data that is derived from the user point of view ("logi- cally-derived data") and data that is derived from the database point of view ("physically-derived" data). From a relational database viewpoint, data is either stored in base tables (base data) or it is physically-derived. Base data is obtained from the outside world through direct measurement or ob- servation such as names, product prices, and salaries. On the other hand, data is physically-de- rived because of choices in the database design. Data stored in two base tables (often as a result of normalization) but retrieved as one table for ease of use, is an example of physically-derived data. Another example of physically-derived data is the use of a copy of the table P R O D U C T placed in Houston to avoid the communication costs of accessing the original table in Hong-Kong.
From a user 's point of view, data is either primitive or logically-derived. Primitive data is data that is t reated by an application as if it were obtained directly from the outside world and not derived from any other data in the database. In actuality, primitive data may be base data or physically derived. By contrast, data is logically-
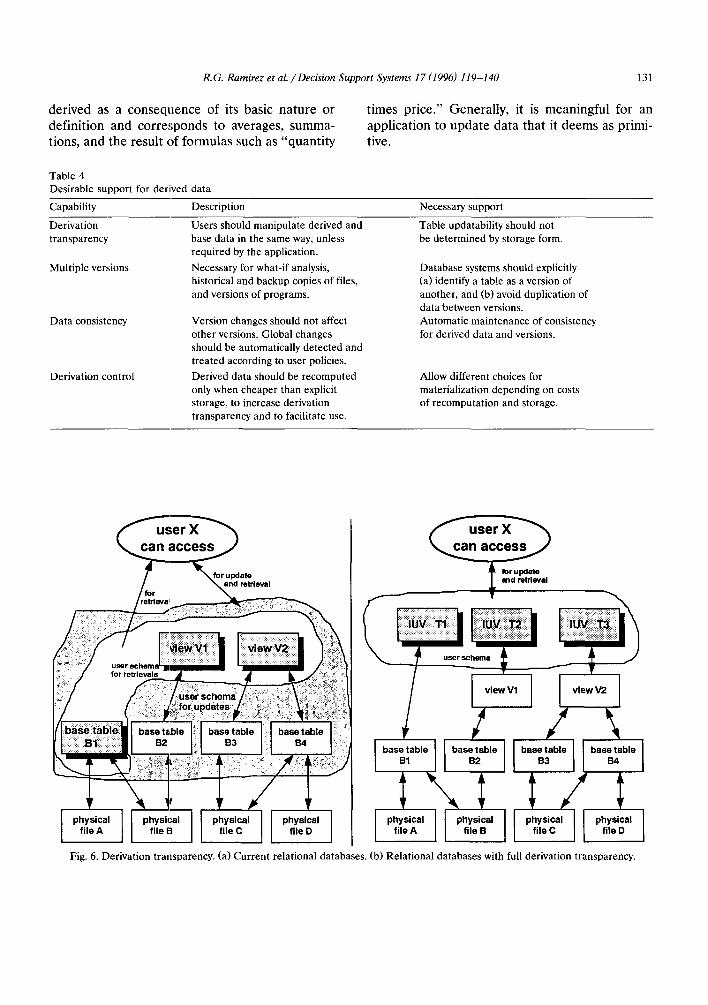
R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 131
derived as a consequence of its basic nature or definition and corre,;ponds to averages, summa- tions, and the result of formulas such as "quanti ty
times price." Generally, it is meaningful for an application to update data that it deems as primi- tive.
Table 4 Desirable support for derived data
Capability Description Necessary support
Derivation transparency
Multiple versions
Data consistency
Derivation control
Users should manipulate derived and base data in the same way, unless required by the application.
Necessary for what-if analysis, historical and backup copies of files, and versions of programs.
Version changes should not affect other versions. Global changes should be automatically detected and treated according to user policies.
Derived data should be recomputed only when cheaper than explicit storage, to increase derivation transparency and to facilitate use.
Table updatability should not be determined by storage form.
Database systems should explicitly (a) identify a table as a version of another, and (b) avoid duplication of data 'between versions. Automatic maintenance of consistency for derived data and versions.
Allow different choices for materialization depending on costs of recomputation and storage.
I 0-,.b,eB, "e'' ' '
I" I file A file B file C file D
Fig. 6. Derivation transparency. (a) Current relational databases. (b) Relational databases with full derivation transparency.

132 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
The distinction between primitive and logi- cally-derived data is application dependent, and not an absolute property of a data item. Consider two cases. (1) Different levels of aggregation: from a CEO's point of view, when budgeting for various divisions' expenses, each division's total salaries is a primitive item. However, a divisional application treats that division's total salaries as the aggregate of salaries of that division's person- nel, e.g. a logically-derived item. (2) Different uses of the data: product cost in a manufacturing company may be a logically derived item for production engineers (sum of part and labor costs). At the same time, it may be a primitive item for accounting personnel who manipulate the combined product cost as a single value for adjusting the value of inventory for inflation.
Since many classes of conventional views (especially aggregate views which are often used in managerial/strategic decision-making) cannot be updated, an application cannot modify data that it deems as primitive but is actually physi- cally-derived. The IUV mechanism, as opposed to conventional views, provides derivation trans- parency by allowing users to update primitive data (in the form of IUVs) regardless of its stor- age form (base or derived). When an IUV is accessed, its PT is retrieved, any derived fields are computed, and the IUV updates are applied regardless of whether the original values were physically stored or derived. For example, in a what-if analysis, given a derived table summariz- ing the number of employees per department, a manager may wish to change the number of em- ployees in a department from 11 to 10 without necessarily making the choice (at this point) of the particular employee to be dismissed. Retail sales provide another example. A store may give a discount on the total invoice amount rather than modifying the unit price of individual prod- ucts.
By providing derivation transparency, IUVs treat updatability correctly as a semantic issue rather than as a physical constraint. A data item is updatable if it is a primitive item for a particu- lar application. The same item can be treated as primitive and updatable for some applications, and as derived and non-updatable for others.
4.2. Multiple versions
Multiple versions are necessary to support what-if scenarios and different interpretations of the same data. Versions go beyond simply being different "windows" to the database, as views are. The difference lies primarily in the treatment of changes to the data. Updates made through one view (or "window") are mapped to the base tables and affect all other views on the same data. Updates to a version, on the other hand, affect only that particular version and are not visible in any other version.
Without explicit support for multiple versions, users are forced to make copies of the data, and then manipulate each copy independently. Multi- ple what-if scenarios result in multiple copies of mostly the same data. In many cases a version differs from the original data or from another version only on a few values. This not only results in waste of storage space, but requires additional effort from the decision-maker to manage the multiple copies. No indication exists in the system that the new tables are copies or versions of other tables.
Support for versions, according to Katz and Lehman [18], requires (a) minimum redundancy, with only changed records stored in the new version, (b) that all versions can be accessed, and (c) that all records in a version can be accessed. The existence of specific mechanisms to create and access ("reference") versions is emphasized in the IRIS System [5,15]. In ORION, version hierarchies can be defined, rather than simple linear versions of versions [21].
IUVs provide basic support for multiple ver- sions. As with IRIS, IUVs provide explicit sup- port for versions and establish the relationships between tables and their versions. All IUVs and all rows in an IUV are accessible to the user; however, access can be restricted following stan- dard SQL practice. Version hierarchies are cre- ated by defining IUVs whose PTs are also IUVs. Minimum redundancy is obtained by storing only changed rows in the DT.
IUVs also provide the ability to identify and separate versions from other information. Any implementation of IUVs will store information

R.G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 133
about IUVs in the system catalog, explicitly iden- tifying IUVs as separate from base tables and views. For example, the system table SYSTA- BLES in DB2 [10] indicates whether the table is a base table or a view. Another system table would indicate the parent table of an I U V and other specifics of the IUVs.
Version hierarchies are formed by using an IUV as the parent table. Any version in the hierarchy can be accessed. In particular, versions in a sequence of versions can be accessed if the names of the versions are known or by tracing the hierarchy in the system catalog.
The basic capabilities of IUVs for version management can be enhanced to build ad hoc and more comprehensive support. For example, the "merging" of versions can be done by com- bining the differential tables. A version hierarchy may be "collapsed" by merging sequential ver- sions. The differential tables provide a record of the changes used to build a version.
4.3. Database consistency
Data consistency i:~ a critical issue in databases. It guarantees that all users receive the same information for the same real world entity. Con- sistency is equally significant when multiple ver- sions and derivation transparency are supported. However, a version is intended to be different from the original data. We use the notion of " intent" to define the concept of uersion consis- tency.
Conventionally, data are consistent if two data items representing tl~e same fact have exactly the same value. Thus, il! "Mary Doe" had January sales of $15,000 and there are database tables A and B with this information, both tables need to have exactly $15,00C, to be consistent. The two tables need not be base tables; table A may be a base table with one rows for each sales transac- tion, while table B may be a view with one row per salesperson. The value $15,000 appears as one data item in table B and as several in table A that together add up to $15,000.
The conventional :aotion does not help in deal- ing with versions and alternative what-if scenarios
which introduce differences by definition. There- fore we differentiate version differences from those that create inconsistencies. Before at tempt- ing a definition consider the following cases. First, a sales manager may create a what-if scenario where "Mary Doe" has sales of $17,000 while the actual sales are still $15,000. Since the sales man- ager is purposely introducing a difference to the actual sales, the version is deemed consistent. In other cases, a difference in the version is a true inconsistency. One case is when the user mistak- enly believes that the version represents actual data or is not aware of the intention behind the version. This occurs because of the user 's inter- pretation of the version. Another case is when the data on which the version is based changes as the database is updated. These database changes must be either reflected in the version or it should be recognized that these changes do not affect the version; in both cases the version "acknowl- edges" the changes in the database. If the version is incognizant of the changes to the data on which it is based, the version becomes inconsistent.
We define two conditions for version consis- tency: (1) there must exist at least two versions of the same data item, one of which is identified as the "original data" and the others as "versions," and (2) there must be a mapping from the origi- nal data to each version. Condition 1 eliminates the case of (possibly incorrect) database design where users are not aware that the same data item is stored independently in several locations. Condition 2 establishes the fact that differences created when versions are updated do not cause inconsistency; inconsistency may arise only when the original data is modified. This is so because the purpose of updates to a version is to modify data as it originally existed. An update to a ver- sion only re-establishes the mapping between the original data and the version; the version is still consistent. The user is (or should be) fully aware of the change. A version can become inconsistent if this mapping is destroyed. This can happen if the original data is updated and the mapping is not re-established. Our definition of version con- sistency subsumes data consistency, in that data are assumed to be consistent in the conventional sense.

134 R.G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
IUVs meet Condition 1 automatically since an IUV, by definition, is a view (a version) on some base tables, and it is explicitly labeled as a ver- sion. Condition 2 is met because the mapping between the original data and an IUV is main- tained at all times. A change in the original data that affects a previous IUV updates is detected as an overlapping update whenever the IUV is ac- cessed. The overlapping update is resolved by modifying the DT to reflect the new mapping. For Policy 1 IUVs, the DT modification has the effect of intentionally ignoring the database changes in the version. For Policy 2 IUVs, the effect is propagation of the changes to the ver- sion.
In practical terms, support for data consistency in IUVs means that a version or a what-if sce- nario can be defined on "live" databases in active use. It is not necessary to make a copy of the database at some point in time and use this copy as the basis for scenarios. For example, in plan- ning a payroll budget, a version can be defined based on the payroll data of May 1993. The different policies allow the budget planner to (a) treat the payroll data as "frozen" as of May 1993, thus ignoring for planning purposes all actual payroll changes after May, or (b) automatically detect changes occurring after May and incorpo- rate them to the new budget as they occur. Using "live" databases provides more realistic scenarios
and simplifies application development as copies and updates are automatically managed by the system.
The extended notion of consistency introduced here applies in other areas. Copies made for back-up purposes are one example. A month-old copy of the table PAYROLL (i.e., a snapshot) that does not include changes made in the cur- rent month is an inconsistent copy only if its users are unaware that no changes are included. In the earlier example of a retail store maintaining a local version of a global price list in a distributed database, the local version is prepared by inten- tionally modifying specific items' values in the current global price list. Changes to the global price list can cause the version to be inconsistent unless the changes are reflected in the version or are intentionally ignored.
4.4. C o n t r o l o v e r derit~ation
Derivation control is an efficiency concern as it mostly affects response time. An ideal system gives the database administrator the choice of storing derived data or recomputing it every time it is needed. Virtual relations are recomputed every time they are needed. A view may be mate- rialized if the cost of storage is lower than the cost of recomputation. In processing environ- ments that are heavily loaded with on-line up-
Table 5 Comparison of support for derived data
Derivation Multiple versions Data consistency Derivation control transparency
Virtual relations for retrieval only, not supported not for updates
Snapshots for retrieval only, not supported not for updates
Hypothetical no derived d a t a , supported only relations exact copy of a for single table
single base table DREs supported supported
IUVs supported supported
single copy of data accessed single copy of data, may be inconsistent until refreshed original data must be read-only
original data must be read-only original data can be modified
recompute whenever accessed store materialized copy and refresh periodically
recompute whenever accessed
recompute whenever accessed option of materialized copy or recompute whenever accessed

R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 135
dates, a materialized view is expensive to main- tain. On the other hand, if the database is read- only or seldom upd~lted, a materialized view may be cost-effective. Not only the time to form the view is eliminated, but indexes and clustering techniques can be applied to the materialized view to further improve the response time. Han- son [16] found that the choice of whether to materialize or not is highly application-depen- dent.
IUVs provide derivation control by allowing the PT to be a virtual relation or a materialized relation, and thus giving users the control over whether PT is recomputed each time it is needed, or computed once and stored for fast retrieval. To maintain the currency of the materialized PT, any of the mechanisms proposed in the literature can be used as noted in 2.7. An easy to imple- ment solution is a complete regeneration of the PT periodically or o:a demand, as suggested in [2]. Other solutions are more efficient, such as those that capture each database update and use it to refresh the materialized view [6,16] but require modifications to the DBMS.
4.5. Comparison with other proposals f o r derived data
We conclude this section with a brief compari- son between IUVs and other proposals for de- rived data in the literature. Table 5 compares IUVs, virtual relat:ions, snapshots, hypothetical relations (HR), and derived relations with excep- tions (DRE). IUVs can be regarded as a logical superset of those proposals. If the database is not updatable, then an IUV behaves like a DRE. If, in addition, the parent table is restricted to be a base table, the IUV behaves like an HR. In the case of HRs and DREs, since the database can- not be updated, the question of version consis- tency does not arise, but the use of versions becomes less flexible. Moreover, an H R is not a version of derived data but of a single base table. Hence, some very common applications involving aggregates, joins, and subsets of base tables can- not be supported. ]if there are no I U V updates (DT is empty), then an IUV becomes a snapshot or a conventional view, depending on whether the
parent table is materialized or not. Views and snapshots facilitate the use of derived data only for retrieval, hence derived data has to be treated differently than primitive data. Also, since a ver- sion cannot be updated, multiple versions cannot be created.
5. Summary and conclusions
We have presented Independent ly-Updated Views (IUVs), a new approach for derived data in decision-support systems. IUVs allow a decision maker the freedom to manipulate derived data according to the needs of the application by re- moving many of the limitations in current database systems. IUVs are particularly useful in decision-making situations requiring what-if anal- ysis, statistical databases, and local control of data in distributed databases. We showed how multiple versions of derived data can be created without substantially duplication of data. More- over, these capabilities are achieved without hav- ing to compromise on the operational value of the database, i.e., the normal database operations are not affected at all. IUVs offer update as well as retrieval derivation transparency, and can be defined on dynamic databases to reflect the changing conditions in the real world. Consis- tency between the IUVs and the underlying database is maintained at all times.
An advantage of IUVs is their simplicity of implementation; IUVs can be implemented using conventional DBMS facilities and data structures. A differential table stores the mapping between the database and a version. It is just another base table. A front-end processor, can translate queries and updates on IUVs to those on base tables. Alternatively, programmers may translate IUV queries directly into SQL queries as in [32]. For increased performance, the DBMS query proces- sor can be modified to take advantage of the characteristics and structure of IUVs.
To determine the performance of IUVs, we derived analytical cost expressions that generalize the experimental results obtained in [32] using the O R A C L E DBMS. For the views typically used in decision-making processes such as bud-

136 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
geting, forecasting, and planning (aggregates, joins, and subsets of base tables), we found that the cost of IUVs is within 10% over the cost of simply retrieving the corresponding parent table.
We presented a comparison between IUV ca- pabilities and those of other alternatives pro- posed for derived data, namely, virtual relations, snapshots, hypothetical relations (HR), and de- rived relations with exceptions (DRE). In addi- tion to having many of the desirable capabilities for use of derived data in DSS, IUVs are a superset of those proposals for derived data.
Appendix A. Updates to keys
Our presentation of IUVs has followed the traditional semantics of the relational model where a user-defined primary key identifies a unique object in the real world [12]. The primary key is a subset of the object's attributes that captures its uniqueness. Therefore, two rows in different tables that refer to the same object would have the same key value.
User-defined keys are the main approach to object identity in relational databases. However, they suffer from several problems (see [20,22,7]). A classic example is the insertion of rows for persons without a social security number in pay- roll, student, and library databases. Not only is there a problem during insertion when a tempo- rary number must be given, but eventually when a social security number is obtained, all references to that person in the database must be changed to the new number. This may involve multiple tables. If the user or programmer making the changes is unaware or unauthorized to change all of them, dangling references are created. Codd [7], in his R M / T extension to the relational model, proposed the use of surrogates as a solu- tion. Tables reference each other based on the surrogate rather than the value of the key. The similar notion of "object identifiers" is well estab- lished in object-oriented databases [1,22]. In con- ventional relational systems, the newer imple- mentations of SQL provide mechanisms to auto- matically propagate changes to a key throughout the database.
This appendix presents a solution to the prob- lem caused by updating keys. First, we describe the problem in the context of IUVs. We then present a general solution followed by alternative implementations using triggers, declarative refer- ential integrity, or surrogates. In all the cases, the implementation can be made transparent to the user.
A.1. The key update problem
Consider an IUV SAMPLE with PT DEPT1, a view defined on a base table as follows.
CREATE VIEW dept l AS SELECT empno, name
FROM employees W H E R E deptno = 1;
CREA TE TABLE employees (empno deptno name position salary PRIMARY KEY (empno)).
I N T E G E R NOT NULL, INTEGER, CHAR(20), CHAR(10), DECIMAL(9,2),
We first illustrate the potential problem due to updates to the PT key. Assume that DEPT1 initially contains a single row with empno 100 and name "Jane Smith." The first update to the IUV SAMPLE changes the name from "Jane Smith" to "Jane Blake." This creates a row in the DT with empno 100, name "Jane Blake" and AC- TION mod. Next, an update to EMPLOYEES changes empno from 100 to 125. A subsequent access of the IUV SAMPLE will detect an over- lapping update of type modify/delete since there is no PT row with the same key value as the DT row. Following Section 2.6, the resolution of this overlapping update for Policy 1 results in two rows in the IUV: "100 Jane Blake" (from DT) and "125 Jane Smith" (from PT), an unintended result from the IUV user's point of view. A problem also occurs if the above PT update (from 100 to 125) is followed by a PT insertion of "100 Tom Sanders." If this insertion happens before the IUV is accessed, the previous IUV update

R.G. Ramirez et a l . / Decision Support Systems 17 (1996) 119-140 137
( f rom " J a n e A d a m s " to " J a n e B lake" ) is consid- e r ed as be ing f rom " T o m S a n d e r s " to " J a n e Blake . " F o r Policy 2, these key u p d a t e s do not p r e s en t a p r o b l e m because the I U V u p d a t e is cor rec t ly t r e a t e d (d i , ; regarded) in bo th s i tuat ions .
No te tha t not all key upda t e s to base tab les cause p rob lems . O f all P T u p d a t e s to a key, only those tha t resu l t in ove r l app ing u p d a t e s cause a p rob lem. Al so no te tha t some key upda t e s a re semant ica l ly invalid r ega rd les s of the type of table , such as changing an e m p l o y e e n u m b e r f rom 100 to 125 if 125 a l read~ exists in the table .
Cons ide r now the, p r o b l e m caused by u p d a t e s to the I U V key. A g a i n we s ta r t wi th the single PT row with e m p n o 1(10, and n a m e " J a n e Smith ." A s s u m e now tha t the I U V u p d a t e changes the row f rom "100 J ane Smi th" to "150 Jane Smi th ." A la te r PT u p d a t e changes the PT row to "125 Jane Smi th ." U n d e r Policy 1, t he re will be two rows in the IUV: "125 Jane Smi th" (from PT) and "150 Jane Smi th" ( f rom DT), an u n i n t e n d e d result . U n d e r Policy 2, the p r o b l e m does not exist s ince the I U V u p d a t e will be t r e a t ed as an I U V modi f i ca t ion fol lowed by a PT de le t ion and the re fo re correc t ly ignored .
A . 2 . A genera l so lu t i on
A genera l so lu t ion is to def ine D T with two key co lumns (or two sets of co lumns in case of a mul t i - a t t r ibu te key). The co lumn B A S E K E Y stores the va lue of the key as found in the PT and
the co lumn D I F F K E Y stores the va lue to ap- p e a r in the IUV. B-ASE K E Y is a system column (like the t i m e s t a m p and A C T I O N ) and t he r e fo re h idden to the user . Ordinar i ly , the va lues of bo th B A S E K E Y and D I F F K E Y are the same; the i r va lue s -d i f f e r only w h e n key upda t e s occur. To re t r ieve the IUV, the mechan i sm of 2.3 uses B A S E _ K E Y , ins tead of the D I F F _ K E Y , to ou te r jo in the D T and the PT. The va lue of B A S E K E Y never a p p e a r s in the IUV; it is used only for jo in ing D T and PT.
I f an I U V u p d a t e m o d i f i e s t h e key , B A S E K E Y will re ta in the previous value and D I F F - K E Y will have the mod i f i ed value. If a PT u p d a t e modif ies a key value, the change is p ropa - ga ted to the co r r e spond ing B A S E K E Y in the D T and the t imes t amps of bo th the PT and D T rows are m a d e equal . This ref lects the fact that the u p d a t e takes effect s imul taneous ly in bo th tables. To p r o p a g a t e (or c a s c a d e , in the S Q L te rminology) the PT change as it occurs, we dis- cuss in A.3 the app l i ca t ion of mechan i sms tha t are widely avai lable in S Q L implemen ta t ions .
W e i l lus t ra te the gene ra l so lu t ion in Tab le 6 for the five over l app ing upda tes . F o r the first four cases assume tha t there is a PT row with init ial va lues "100, JS, t" for empno , name , and the t imes t amp (TS), respect ively. F o r the last case the re is no PT row.
Cons ide r the first case ( m o d i f y ~ m o d i f y ) in Tab le 6. A t ime tO, a non-key I U V u p d a t e changes
Table 6 Detection and resolution of updates to keys
(1) (2) time t o (3) time t I (4) time t l Type of DT row PT row DT row after overlapping after key cascading key update update update
(5) time t 2 (6) time t 2 DT row after IUV row (result) resolving over- lapping update
base dif fkey n a m e act ion T S e m p n o n a m e T S base dif fkey n a m e act ion T S base dif fkey n a m e act ion T S e m p n o n a m e T S
modify / 100 100 JB modify t o 125 JS t 1 125 100 JB modify t 1 Policy 1 modify Policy 2 modify / 100 100 JB modify t o no PT row null 100 JB modify t I Policy 1 delete Policy 2 delete/ 100 100 JS delete t o 125 JS t 1 125 100 JS delete t 1 Policy 1 modify Policy 2 delete / 100 100 JS delete t o no PT row null 100 JS delete t 1 Policy 1 delete Policy 2 insert/ 200 200 AT insert t o 200 A K t 1 200 200 AT insert t o Policy 1 insert Policy 2
125 100 JB modify t 2 100 JB t 2
no DT row 125 JS t 1 null 100 JB insert t 2 100 JB t 2
no DT row no IUV row 125 100 JS delete t 2 no IUV row no DT row 125 JS t 1
null 100 JS delete t 2 n o IUV row no DT row no IUV row 200 200 AT insert t 2 200 AT t 2
no DT row 200 AK t x

138 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
the name from "JS" to " JB" (short for "Jane Smith" and "Jane Blake"). This creates the D T row with "JB" shown in column 2. BASE KEY and DIFF KEY are the same since the key was not modified. At time t~, a PT update changes the key empno from 100 to 125 as shown in column 3. Column 4 shows the DT row after the propagation of the new key value (BASE KEY is now 125). Then, at time t z, the IUV is accessed. Column 5 shows the DT row after resolving the overlapping update for both policies, and column 6 shows the resulting IUV row.
The other cases in Table 5 are mostly self-ex- planatory. The "no PT row" entry in column 3 for modify/delete and delete~delete denotes the deletion of the PT row at time t~. This results in cascading a null value to the BASE KEY in the DT row. The case inser t / inser t denotes the in- sertion of an IUV row with empno 200 and name " A T " at time t 0, followed by an insertion of a PT row with the same key value but a different name (column 3) at time t~.
A.3. Implementation of key updates
To implement the general solution, two widely available mechanisms in SQL systems are used: triggers and referential integrity constraints. Trig- gers are supported by many DBMSs, including DEC's RDB, the Sybase and Microsoft SQL Servers, S Q L / D S , INGRES, and Oracle 7. We illustrate the automatic cascading o f key updates to DT using the SQL Server syntax [28] for trig- gers. In this syntax, the logical table " inser ted" contains the values of the columns after the up- date. The trigger is automatically fired by the DBMS whenever the specified table is updated. The following example updates the DT DIFF- SAMPLE whenever EMPLOYEES is updated.
C R E A T E T R I G G E R cascadeKey ON employees
F O R U P D A T E AS U P D A T E SET
W H E R E
diffSample base_key = inserted.empno b a s e k e y = employees. empno.
An alternative to triggers is the declarative referential integrity of SQL-92 supported by most DBMSs. The differential table is created with an additional foreign key clause that references the primary key of a base table. This base table may or may not be the PT; all that is required is that it contains the current values for that key (i.e., it plays a role similar to the E-relations of [7]).
C R E A T E TABLE ( b a s e k e y d i f f k e y name salary P R I M A R Y KEY (d i f fkey) , F O R E I G N KEY ( b a s e k e y ) R E F E R E N C E S employees ON U P D A T E CASCADE ON D E L E T E SET NULL.
diff-sample2 I N T E G E R , I N T E G E R , CHAR(30), DECIMAL(9,2),
Using referential integrity constraints to imple- ment the general solution requires a special treat- ment for IUV insertions. By definition, IUV in- sertions violate the constraint since the key in the inserted DT row has no match in the PT. In systems that support the temporary deactivation of key constraints, such as S Q L / D S and Oracle 7, a simple solution is to deactivate the constraint whenever an IUV insertion is made. In systems that do not support temporary deactivation, in- sertions to the IUV must use a null value for BASE KEY and check for two IUV rows with the same key value when the IUV is accessed. The presence of two rows with the same key values indicates an overlapping update that is resolved by retaining only one of the two rows in the IUV, according to its policy.
A variation of the referential integrity ap- proach is to use surrogates. A surrogate is imple- mented using the row (or tuple) identifier (TID) of the PT row. TIDs are assigned when a base table row is first inserted and do not change throughout the existence of the row. In the DT, BASE KEY contains either the T ID of the matching PT row or a null value if there is no matching row. Base table updates that modify the value of the key do not modify the TID. Neither do the IUV updates. Surrogates replace the pri-

R.G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140 139
mary key for the purpose of joining DT and PT. DT rows with null l'IDs are processed as indi- cated in the previous paragraph for systems that do not support temporary deactivation of foreign key constraints. TIDs have been used for hypo- thetical relations [40] and materialized views [35] and simplify dealing with long multi-attribute keys. A limitation of this approach is that TIDs can only be used when the PT preserves the primary key of a base table on which it is defined or is a row subset of a single base table.
References
[1] S. Abiteboul and P. Kanellakis, 1989, Object Identity as a Query Language Primitive, Proceedings of the ACM SIGMOD Conference Portland, Oregon, June 1989.
[2] M.E. Adiba and B G. Lindsay, 1980, Database Snap- shots, Proceedings of the International Conference on Very Large Data Bases (October 1980), pp. 86-91.
[3] R. Agrawal and D.J DeWitt, 1983, Updating Hypotheti- cal Data Bases, Information Processing Letters 16 (1983), pp. 145-146.
[4] F. Bancilhon and N. Spyratos, 1981, Update Semantics of Relational Views, ACM Transactions on Database Sys- tems 6, No. 4 (December), pp. 557-575.
[5] D. Beech and B. Mahbod, 1988, Generalized Version Control in an Object-Oriented Database Language, Pro- ceedings of the 1988 SIGMOD Conference, Chicago, I11. (June 1988), pp. 56-68.
[6] J.A. Blakeley, P. Larson and F.W. Tompa, 1986, Effi- ciently Updating Materialized Views, Proceedings of the 1986 ACM-SIGMOD Conference on Management of Data, Washington DC (May 1986), pp. 61-71.
[7] E.F. Codd, 1979, Extending the Relational Model to Capture More Meaning, ACM Transactions on Database Systems 4 (1979), No. 4, pp. 397-434.
[8] E.F. Codd, 1990, The Relational Model for Database Management: Version 2 (Addison-Wesley, Reading, Massachusetts, 1990).
[9] S. Cosmadakis and C. Papadimitriou, 1984, Updates on Relational Views, Jeurnal of ACM 31, No. 4, pp. 742-760.
[10] C.J. Date and C. White, 1989, A Guide to DB2, 3rd edition (Addison-Wesley Publishing Company, Reading, Massachusetts, 1989).
[11] C.J. Date, 1986, Why Every Relation Should Have Ex- actly One Prima~j Key, in: C.J. Date, Relational Database: Selected Writings, Addison-Wesley (1986), pp. 33-40.
[12] C.J. Date, 1990, /Ml Introduction to Database Systems, 5th edition (Addison-Wesley Publishing Company, Read- ing, Massachusetts, 1990).
[13] R. Dattero, R.G. Ramirez, and J. Choobineh, 1990, De- rived Relations with Exceptions: Decision Support Capa- bilities, Journal of Management Information Systems 6, No. 4 (Spring 1990), pp. 83-101.
[14] U. Dayal and P.A. Bernstein, 1980, On The Updatability of Relational Views, Proceedings of the Fourth Confer- ence on Very Large Databases, West Berlin (September 1980), pp. 368-374.
[15] D. Fishman et al, IRIS: An Object-Oriented Database Management System, ACM Transactions on Office Infor- mation Systems 5, No. 1 (1987), pp. 48-69.
[16] E.N. Hanson, 1987, A Performance Analysis of View Materialization Strategies, Proceedings of ACM SIG- MOD 1987, San Francisco, pp. 440-453.
[17] W.H. Inmon, 1990, Using Oracle to Build Decision Sup- port Systems (QED Information Sciences, Inc., 1990).
[18] R.H. Katz and T.J. Lehman, 1984, Database Support for Versions and Alternatives of Large Design Files, IEEE Transactions on Software Engineering SE-10, No. 2 (March 1984), pp. 191-200.
[19] A.M. Keller, 1986, Choosing Translator at View Defini- tion Time, Proceedings of the 12th VLDB Conference, Kyoto, Japan.
[20] W. Kent, 1979, Limitations of Record-Based Information Systems, ACM Transactions on Database Systems 4, No. 1, pp. 107-131.
[21] W. Kim, 1990, Introduction to Object-Oriented Databases (The MIT Press, Cambridge, MA, 1990).
[22] S. Khoshafian and George P. Copeland, 1990, Object Identity, in Readings in Object-Oriented Database Sys- tems, Stanley B. Zodnik and David Maier, Eds. (Morgan-Kaufmann Publishers, Inc., 1990). A previous version appears in Proceedings of OOPSLA 1986.
[23] S. Khoshafian, C. Arvola, A. Wong and H.K.T. Wong, 1991, A Guide to Developing Client/Server SQL Appli- cations (Morgan Kaufmann Publishers).
[24] J.A. Larson and A.P. Sheth, 1991, Updating Relational Views using Knowledge at View Definition and View Update Time, Information Systems 16, No. 2, pp. 145- 168.
[25] B. Lindsay, L. Haas, C. Mohan, H. Pirahesh and P. Wilms, 1986, A Snapshot Differential Refresh Algorithm, Proceedings of the 1986 ACM-SIGMOD Conference on Management of Data, Washington DC (May 1986), pp. 53-60.
[26] Microsoft, 1993, Microsoft Access - User's Guide (Mi- crosoft Corporation, 1993).
[27] J. Melton and A.R. Simon, 1993, Understanding the New SQL: A Complete Guide (Morgan Kaufmann Publishers, Inc.).
[28] Microsoft, 1993, Microsoft SQL Server Language Refer- ence (Microsoft Corporation).
[29] P. Mishra and E.M. Heich, Join Processing in Relational Databases, ACM Computing Surveys 24, No. 1 (March 1992), pp. 64-113.
[30] R.G. Ramirez, R. Danero and J. Choobineh, Represent- ing Generalization Rules and Exceptions in Expert

140 R. G. Ramirez et al. / Decision Support Systems 17 (1996) 119-140
Database Systems, Decision Support Systems 5 (1990), pp. 29-44.
[31] R.G. Ramirez, R. Dattero and J. Choobineh, 1990b, Extension of Relational Views to Derived Relations with Exceptions, Information Systems 15, No. 3 (1990).
[32] R.G. Ramirez, U. Kulkarni and K.A. Moser, 1992, Per- formance Analysis of "What-if" Databases Using Inde- pendently-Updated Views, Journal of Management In- formation Systems 9, No. 1 (Summer 1992), pp. 185-203.
[33] RTI, 1990, The INGRES Documentation Set (Relational Technology Inc.).
[34] B. Salzberg, File Structures (Prentice Hall, 1988). [35] A. Segev and J. Park, 1989, Updating Distributed Materi-
alized Views, IEEE Transactions on Knowledge and Data Engineering 1, No. 2 (June 1989).
[36] D. Severance and G. Lohman, 1976, Differential Files: Their Application to the Maintenance of Large Databases, ACM Transactions on Database Systems, June 1976.
[37] M. Stonebraker, 1975, Implementation of Integrity Con- straints and Views by Query Modification, Proceedings of the 1975 ACM-SIGMOD International Conference on Management of Data, San Jose, CA, June 1975.
[38] M. Stonebraker, 1980, Embedding Expert Knowledge and Hypothetical Data Bases into a Data Base System, Proceedings of the 1980 ACM-SIGMOD Conference on Management of Data, Santa Monica, CA., May 1980.
[39] M. Stonebraker, 1981, Hypothetical Data Bases as Views, Proceedings of the 1981 ACM-SIGMOD Conference on Management of Data, Ann Arbor.
[40] J. Woodfill and M. Stonebraker, 1983, An Implementa- tion of Hypothetical Relations, Proceedings of the Ninth International Very Large Data Base Conference Flo- rence, Italy, December 1983.
[41] S.B. Yao, 1977, Approximating Block Accesses in Database Organizations, Communications of the ACM 20, No. 4 (April 1977), pp. 260-261.
Richard G. Ramirez is an Assistant Professor of Information Systems at Iowa State University. A graduate of Texas A&M University, his research interests are object-oriented systems and the integration of mathematical programming and databases. Professor Ramirez has published research on rela- tional databases and decision support systems.
Uday R. Kulkarni is an Assistant Professor of Computer Information Systems at Arizona State University. He received his B. Tech. degree in electrical engineering from the Indian Institute of Technology, Bombay, in 1977, his MBA degree from the Indian Institute of Management, Calcutta, in 1979, and his Ph.D. in MIS from the University of Wisconsin, Milwaukee, in 1989. His research interests are centered on manipulation of relational views, materialized views in cen- tralized and distributed databases, and design of distributed databases.
Kathleen A. Moser is an Assistant Professor of Information Systems at Iowa State University. She received her Ph.D. in computer information systems from Arizona State Univer- sity. Her major research interests are gender issues in information systems, and strategic planning. Professor Moser is a member of AIS, the Soci- ety for Information Management (SIM), and the Association for Sys- tems Management (ASM).
Copyright © 2022 FDOKUMEN




















