
Cradle-loop barrels and the concept of metafolds in protein classification by natural descent
8
Available online at www.sciencedirect.com Cradle-loop barrels and the concept of metafolds in protein classification by natural descent Vikram Alva 1 , Kristin K Koretke 2 , Murray Coles 1 and Andrei N Lupas 1 Current classification systems for protein structure show many inconsistencies both within and between systems. The metafold concept was introduced to identify fold similarities by consensus and thus provide a more unified view of fold space. Using cradle-loop barrels as an example, we propose to use the metafold as the next hierarchical level above the fold, encompassing a group of topologically related folds for which a homologous relationship has been substantiated. We see this as an important step on the way to a classification of proteins by natural descent. Addresses 1 Department of Protein Evolution, Max-Planck-Institute for Developmental Biology, Spemannstr. 35, D-72076 Tu ¨ bingen, Germany 2 Computational Chemistry Group, GlaxoSmithKline, Collegeville, PA 19426-0989, USA Corresponding author: Lupas, Andrei N ([email protected]) Current Opinion in Structural Biology 2008, 18:358–365 This review comes from a themed issue on Sequence and Topology Edited by Nick Grishin and Sarah Teichmann Available online 3rd May 2008 0959-440X/$ – see front matter # 2008 Elsevier Ltd. All rights reserved. DOI 10.1016/j.sbi.2008.02.006 Introduction In most proteins, folding is indispensable for activity. The units of folding, that is the segments of a polypeptide chain capable of folding independently, are called domains. In most cases, folding occurs largely autonom- ously (with some assistance from cellular folding factors), but some domains will only fold if they receive an appropriate signal from an adjacent domain or if they encounter the correct scaffold, be this the membrane, another protein, or a nucleic acid. Because of the central importance of folding for the understanding the activity of proteins, systems for classifying protein structures have become an essential tool in molecular biology. These systems differ in the way they are generated: while the Dali Domain Dictionary is largely automated [1], relying on the popular structure comparison program DALI, CATH (Class-Architecture-Topology-Homology) com- bines automated and manual processes [2] and SCOP (Structural Classification of Proteins) is based mostly on manual assignments [3]. SCOP particularly has become a point of reference in the discussion of similarities and dissimilarities between proteins. Despite showing a con- siderable amount of agreement, each of these systems offers its own view of fold space, with many differences becoming apparent upon detailed, protein-by-protein comparison [4,5]. In this review, we will discuss the metafold concept as a method to achieve a more unified view of fold space and propose modifications to this concept, using cradle-loop barrels as an example. The metafold concept The most important source of disagreement between classification systems are differing domain definitions, but in a fair number of cases, disagreements also arise because the same domain is assigned to different folds. In order to understand these problems, it is useful to con- sider the definition of a fold as a conserved, topologically distinct arrangement of secondary structures in a domain, with extensions and insertions peripheral to the fold treated as decorations. A fold change occurs when one or more secondary structure elements within the fold alter their nature and/or their topology. Clearly a wide latitude in judgement is possible with respect to domain bound- aries, to what constitutes a decoration, and to the degree of topological change necessary to separate structures into different folds. To alleviate the discrepancies arising from subjective estimates of fold similarities and differences, Daggett and coworkers introduced the metafold concept as a consensus method designed to reveal fold similarities relatively independently of the methods used to compare protein domains [5]. In essence, domains are considered part of the same metafold if their topological similarity is recognized by multiple classification systems. Although the metafold concept is clearly helpful in obtaining a more unified view of fold space, we think that its usefulness is limited by the fact that it does not address a fundamental source of tension within and between classification systems, namely the coexistence of homologous and analogous classification criteria. Both SCOP and CATH explicitly use homology for classifi- cation, SCOP in the first two hierarchical levels (family and superfamily) and CATH in the first level. Clearly, what one percieves as homologous has a profound influ- ence on drawing domain boundaries and on labelling parts of the structure as decorations to a conserved core. These decisions, which have a substantial arbitrary com- ponent, by necessity shape the higher levels of the classifications. Furthermore, by placing homology at the base and topological considerations into the upper layers, both systems make the implicit assumption that homologous proteins always have the same fold. As has Current Opinion in Structural Biology 2008, 18:358–365 www.sciencedirect.com
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Cradle-loop barrels and the concept of metafolds in protein classification by natural descent

Available online at www.sciencedirect.com
Cradle-loop barrels and the concept of metafolds in proteinclassification by natural descentVikram Alva1, Kristin K Koretke2, Murray Coles1 and Andrei N Lupas1
Current classification systems for protein structure show many
inconsistencies both within and between systems. The
metafold concept was introduced to identify fold similarities by
consensus and thus provide a more unified view of fold space.
Using cradle-loop barrels as an example, we propose to use
the metafold as the next hierarchical level above the fold,
encompassing a group of topologically related folds for which a
homologous relationship has been substantiated. We see this
as an important step on the way to a classification of proteins
by natural descent.
Addresses1 Department of Protein Evolution, Max-Planck-Institute for
Developmental Biology, Spemannstr. 35, D-72076 Tubingen, Germany2 Computational Chemistry Group, GlaxoSmithKline, Collegeville, PA
19426-0989, USA
Corresponding author: Lupas, Andrei N
Current Opinion in Structural Biology 2008, 18:358–365
This review comes from a themed issue on
Sequence and Topology
Edited by Nick Grishin and Sarah Teichmann
Available online 3rd May 2008
0959-440X/$ – see front matter
# 2008 Elsevier Ltd. All rights reserved.
DOI 10.1016/j.sbi.2008.02.006
IntroductionIn most proteins, folding is indispensable for activity. The
units of folding, that is the segments of a polypeptide
chain capable of folding independently, are called
domains. In most cases, folding occurs largely autonom-
ously (with some assistance from cellular folding factors),
but some domains will only fold if they receive an
appropriate signal from an adjacent domain or if they
encounter the correct scaffold, be this the membrane,
another protein, or a nucleic acid. Because of the central
importance of folding for the understanding the activity
of proteins, systems for classifying protein structures have
become an essential tool in molecular biology. These
systems differ in the way they are generated: while the
Dali Domain Dictionary is largely automated [1], relying
on the popular structure comparison program DALI,
CATH (Class-Architecture-Topology-Homology) com-
bines automated and manual processes [2] and SCOP
(Structural Classification of Proteins) is based mostly on
manual assignments [3]. SCOP particularly has become a
point of reference in the discussion of similarities and
Current Opinion in Structural Biology 2008, 18:358–365
dissimilarities between proteins. Despite showing a con-
siderable amount of agreement, each of these systems
offers its own view of fold space, with many differences
becoming apparent upon detailed, protein-by-protein
comparison [4,5]. In this review, we will discuss the
metafold concept as a method to achieve a more unified
view of fold space and propose modifications to this
concept, using cradle-loop barrels as an example.
The metafold conceptThe most important source of disagreement between
classification systems are differing domain definitions,
but in a fair number of cases, disagreements also arise
because the same domain is assigned to different folds. In
order to understand these problems, it is useful to con-
sider the definition of a fold as a conserved, topologically
distinct arrangement of secondary structures in a domain,
with extensions and insertions peripheral to the fold
treated as decorations. A fold change occurs when one
or more secondary structure elements within the fold alter
their nature and/or their topology. Clearly a wide latitude
in judgement is possible with respect to domain bound-
aries, to what constitutes a decoration, and to the degree
of topological change necessary to separate structures into
different folds. To alleviate the discrepancies arising from
subjective estimates of fold similarities and differences,
Daggett and coworkers introduced the metafold concept
as a consensus method designed to reveal fold similarities
relatively independently of the methods used to compare
protein domains [5]. In essence, domains are considered
part of the same metafold if their topological similarity is
recognized by multiple classification systems.
Although the metafold concept is clearly helpful in
obtaining a more unified view of fold space, we think
that its usefulness is limited by the fact that it does not
address a fundamental source of tension within and
between classification systems, namely the coexistence
of homologous and analogous classification criteria. Both
SCOP and CATH explicitly use homology for classifi-
cation, SCOP in the first two hierarchical levels (family
and superfamily) and CATH in the first level. Clearly,
what one percieves as homologous has a profound influ-
ence on drawing domain boundaries and on labelling
parts of the structure as decorations to a conserved core.
These decisions, which have a substantial arbitrary com-
ponent, by necessity shape the higher levels of the
classifications. Furthermore, by placing homology at
the base and topological considerations into the upper
layers, both systems make the implicit assumption that
homologous proteins always have the same fold. As has
www.sciencedirect.com

The cradle-loop barrel metafold Alva et al. 359
become increasingly clear in recent years, this is not the
case and multiple events have been described that can
lead to fold change in evolution: point mutations, indels,
topological substitutions, circular permutations, strand
swaps, strand and hairpin invasions, 3D domain swaps,
and chimeric fusions [6,7,8�,9�,10]. In such cases,
homology typically trumps topological dissimilarity,
leading to the grouping of homologous proteins into
the same fold, even when they have undergone changes
that would cause analogous proteins to be classified into
separate folds.
In order to address the tensions arising in classification
systems from fold changes between homologous proteins,
we think that the metafold would more usefully be viewed
as the next hierarchical level above the fold, bringing
together groups of topologically similar folds for whom a
homologous relationship has been substantiated in at least
one case. This core group of member folds could be
usefully expanded by a periphery of candidate folds, which
are related to the core members by a topological change
known to occur between homologous proteins, albeit with-
out homology having been substantiated in that particular
case. Proteins known to be analogous to members of the
core group should be excluded from the metafold. Thus,
topologically similar proteins may end up in different
metafolds, based on evidence of their descent. In such
cases, these proteins will also need to be assigned to
different folds. Although this may seem to subvert the
concept of fold, we note that this concept has always had a
large arbitrary component and that some larger folds are
currently subdivided without easily recognizable reasons.
The goal of our proposal is to ultimately eliminate all
analogous criteria from protein classifications (more on this
subject at the end of this paper).
Although more complicated and also fuzzier than the
definition of Daggett and coworkers, our metafold defi-
nition offers several advantages: it addresses the
homology–analogy problem directly, it has considerably
greater explanatory power with regard to the fold space it
maps, it acknowledges explicitly that the classification is
more robust and better supported in some cases (the core
groups) than in others (the peripheries), and it provides a
first step toward a comprehensive classification of proteins
by descent.
In the following, we would like to explain our ideas on
metafolds using the example of cradle-loop barrels, which
we have studied in detail for almost a decade.
The cradle-loop barrel core groupOur interest in the cradle-loop barrels began with the
structure determination of VatN, the substrate recog-
nition domain of the AAA protein VAT [11]. The N-
terminal part of this domain (VatN-N) forms one of the
most topologically complex folds known, consisting of
www.sciencedirect.com
duplicated bbab units that are completely interdigi-
tated to form a six-stranded barrel. The b1–b2 loops of
each unit cross over the symmetry-related b20 strand,
giving the fold an unusual, knotted appearance
(Figure 1) and its name: the double-psi b-barrel [12].
In each bbab unit, the helix is connected to the last
strand by a conspicuous Gly-Asp motif, which we named
the GD box (Figure 2).
In order to understand how such a complex fold could
have evolved, we undertook an extensive bioinformatics
and structural study with the aim of identifying possible
precursors with simpler topologies. We focussed on sev-
eral groups of proteins that showed sequence similarity to
VatN-N. Of particular interest were dimeric bacterial
transcription factors, typified by Bacillus subtilis AbrB,
whose N-domains carried a single GD box and were
elaborated by an additional C-terminal b-strand. They
thus appeared to represent a homodimeric precursor to
the double-psi barrel, with a permuted fold that would
resolve the topological complexities of the latter. This led
us to propose this topology as the ancestral form [11]. Our
hypothesis was contradicted by the published structure of
AbrB-N (1EKT), which, instead of a barrel, showed a
side-by-side dimer of two three-stranded b-meanders
with two equatorial helices.
In order to understand this contradiction, we investigated
a group of sequences that were intermediate between
VatN-N and AbrB. Proteins of this group, typified by
PhS018 from Pyrococcus horikoshii, either have internal
sequence symmetry and carry two copies of the GD
box or are homodimers with one copy per subunit.
PhS018 turned out to have yet a third fold, forming a
singly interdigitated, six-stranded barrel (Figure 1) [13�].We named this topology the RIFT barrel for its wide-
spread occurrence in ancient proteins, such as the ribo-
somal protein L3, the N-domain of the F1 ATPase, and
translation factors of the Ef-Tu family. This topology was
clearly related to that of double-psi barrels by a strand
swap of the symmetry-related b2/b20 strands, but was not
visibly related to the published AbrB fold, 1EKT. In
particular, the conserved GD boxes resembled closely
those of VatN-N (Figure 2), but had an entirely different
conformation from 1EKT.
Given this discrepancy, we decided to redetermine the
structure of AbrB-N, which turned out to neither
resemble the published structure (which was sub-
sequently retracted), nor a permuted form of the
double-psi barrel. Rather, additional C-terminal strands
were inserted into the RIFT barrel to form an eight-
stranded architecture with two pairs of interdigitated b-
hairpins (Figure 1), leading us to name this fold the
swapped–hairpin barrel [14]. Significantly, the GD-box
region now resembled the equivalent regions closely in
double-psi and RIFT barrels (Figure 2).
Current Opinion in Structural Biology 2008, 18:358–365
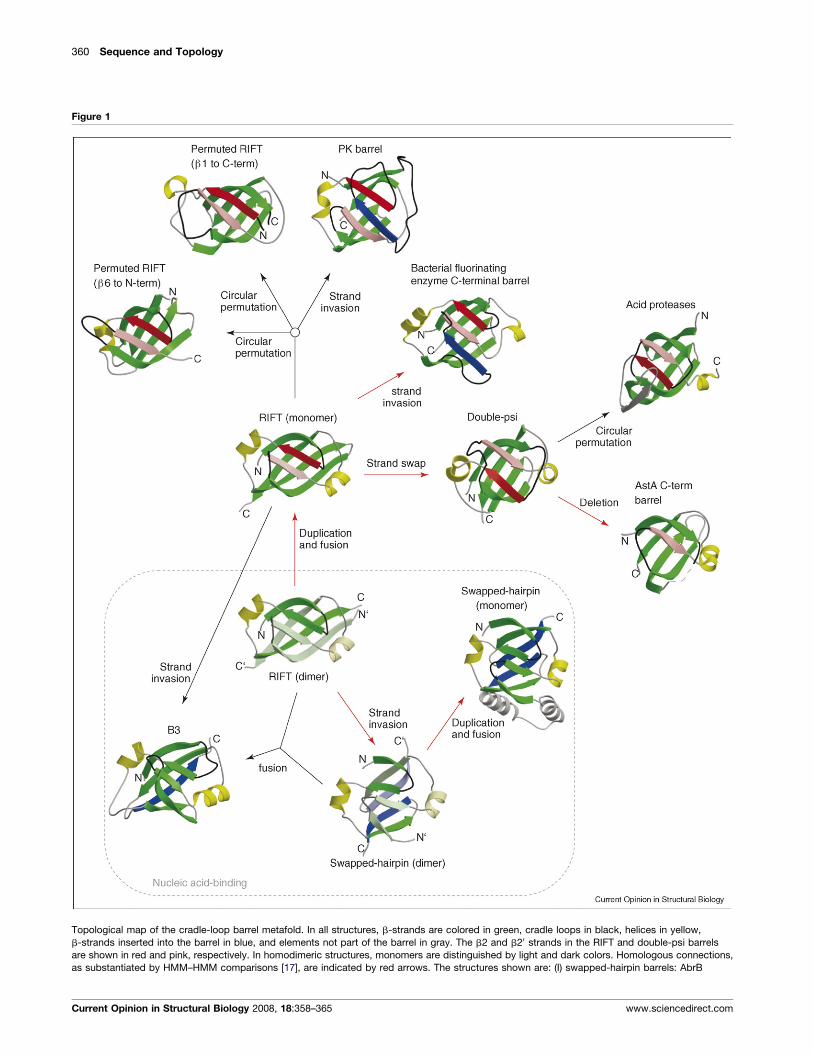
360 Sequence and Topology
Figure 1
Topological map of the cradle-loop barrel metafold. In all structures, b-strands are colored in green, cradle loops in black, helices in yellow,
b-strands inserted into the barrel in blue, and elements not part of the barrel in gray. The b2 and b20 strands in the RIFT and double-psi barrels
are shown in red and pink, respectively. In homodimeric structures, monomers are distinguished by light and dark colors. Homologous connections,
as substantiated by HMM–HMM comparisons [17], are indicated by red arrows. The structures shown are: (I) swapped-hairpin barrels: AbrB
Current Opinion in Structural Biology 2008, 18:358–365 www.sciencedirect.com
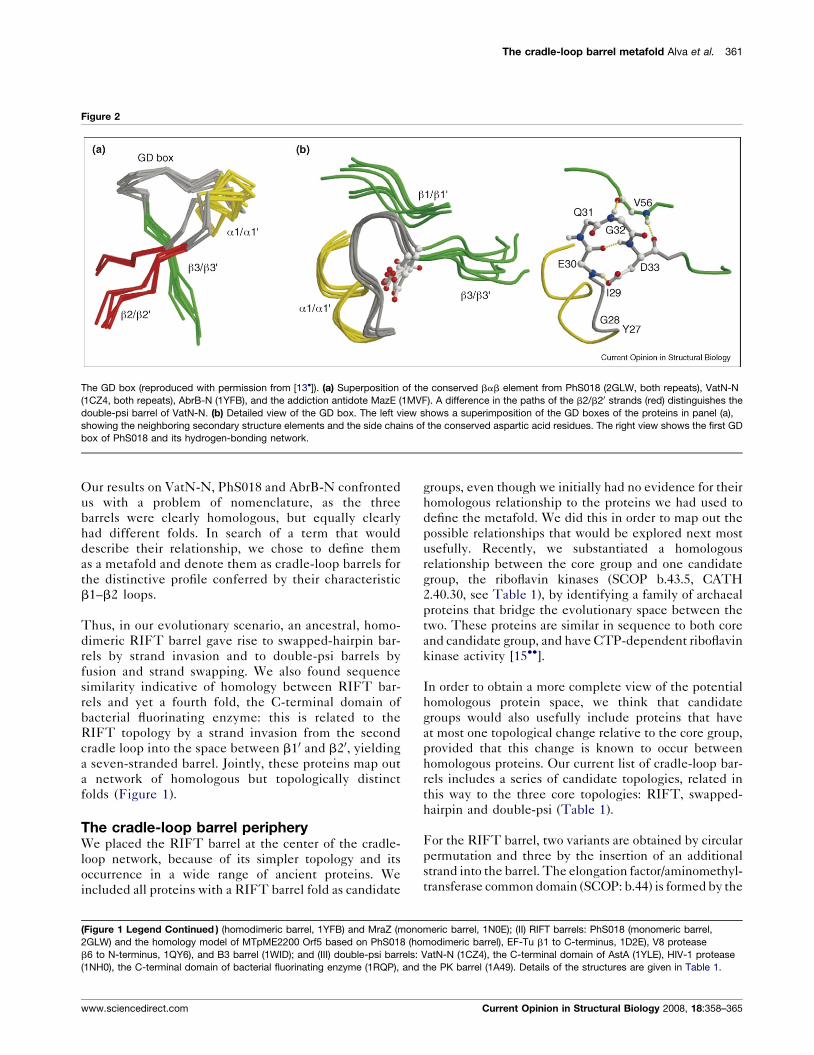
The cradle-loop barrel metafold Alva et al. 361
Figure 2
The GD box (reproduced with permission from [13�]). (a) Superposition of the conserved bab element from PhS018 (2GLW, both repeats), VatN-N
(1CZ4, both repeats), AbrB-N (1YFB), and the addiction antidote MazE (1MVF). A difference in the paths of the b2/b20 strands (red) distinguishes the
double-psi barrel of VatN-N. (b) Detailed view of the GD box. The left view shows a superimposition of the GD boxes of the proteins in panel (a),
showing the neighboring secondary structure elements and the side chains of the conserved aspartic acid residues. The right view shows the first GD
box of PhS018 and its hydrogen-bonding network.
Our results on VatN-N, PhS018 and AbrB-N confronted
us with a problem of nomenclature, as the three
barrels were clearly homologous, but equally clearly
had different folds. In search of a term that would
describe their relationship, we chose to define them
as a metafold and denote them as cradle-loop barrels for
the distinctive profile conferred by their characteristic
b1–b2 loops.
Thus, in our evolutionary scenario, an ancestral, homo-
dimeric RIFT barrel gave rise to swapped-hairpin bar-
rels by strand invasion and to double-psi barrels by
fusion and strand swapping. We also found sequence
similarity indicative of homology between RIFT bar-
rels and yet a fourth fold, the C-terminal domain of
bacterial fluorinating enzyme: this is related to the
RIFT topology by a strand invasion from the second
cradle loop into the space between b10 and b20, yielding
a seven-stranded barrel. Jointly, these proteins map out
a network of homologous but topologically distinct
folds (Figure 1).
The cradle-loop barrel peripheryWe placed the RIFT barrel at the center of the cradle-
loop network, because of its simpler topology and its
occurrence in a wide range of ancient proteins. We
included all proteins with a RIFT barrel fold as candidate
(Figure 1 Legend Continued ) (homodimeric barrel, 1YFB) and MraZ (mono
2GLW) and the homology model of MTpME2200 Orf5 based on PhS018 (ho
b6 to N-terminus, 1QY6), and B3 barrel (1WID); and (III) double-psi barrels:
(1NH0), the C-terminal domain of bacterial fluorinating enzyme (1RQP), and
www.sciencedirect.com
groups, even though we initially had no evidence for their
homologous relationship to the proteins we had used to
define the metafold. We did this in order to map out the
possible relationships that would be explored next most
usefully. Recently, we substantiated a homologous
relationship between the core group and one candidate
group, the riboflavin kinases (SCOP b.43.5, CATH
2.40.30, see Table 1), by identifying a family of archaeal
proteins that bridge the evolutionary space between the
two. These proteins are similar in sequence to both core
and candidate group, and have CTP-dependent riboflavin
kinase activity [15��].
In order to obtain a more complete view of the potential
homologous protein space, we think that candidate
groups would also usefully include proteins that have
at most one topological change relative to the core group,
provided that this change is known to occur between
homologous proteins. Our current list of cradle-loop bar-
rels includes a series of candidate topologies, related in
this way to the three core topologies: RIFT, swapped-
hairpin and double-psi (Table 1).
For the RIFT barrel, two variants are obtained by circular
permutation and three by the insertion of an additional
strand into the barrel. The elongation factor/aminomethyl-
transferase common domain (SCOP: b.44) is formed by the
meric barrel, 1N0E); (II) RIFT barrels: PhS018 (monomeric barrel,
modimeric barrel), EF-Tu b1 to C-terminus, 1D2E), V8 protease
VatN-N (1CZ4), the C-terminal domain of AstA (1YLE), HIV-1 protease
the PK barrel (1A49). Details of the structures are given in Table 1.
Current Opinion in Structural Biology 2008, 18:358–365
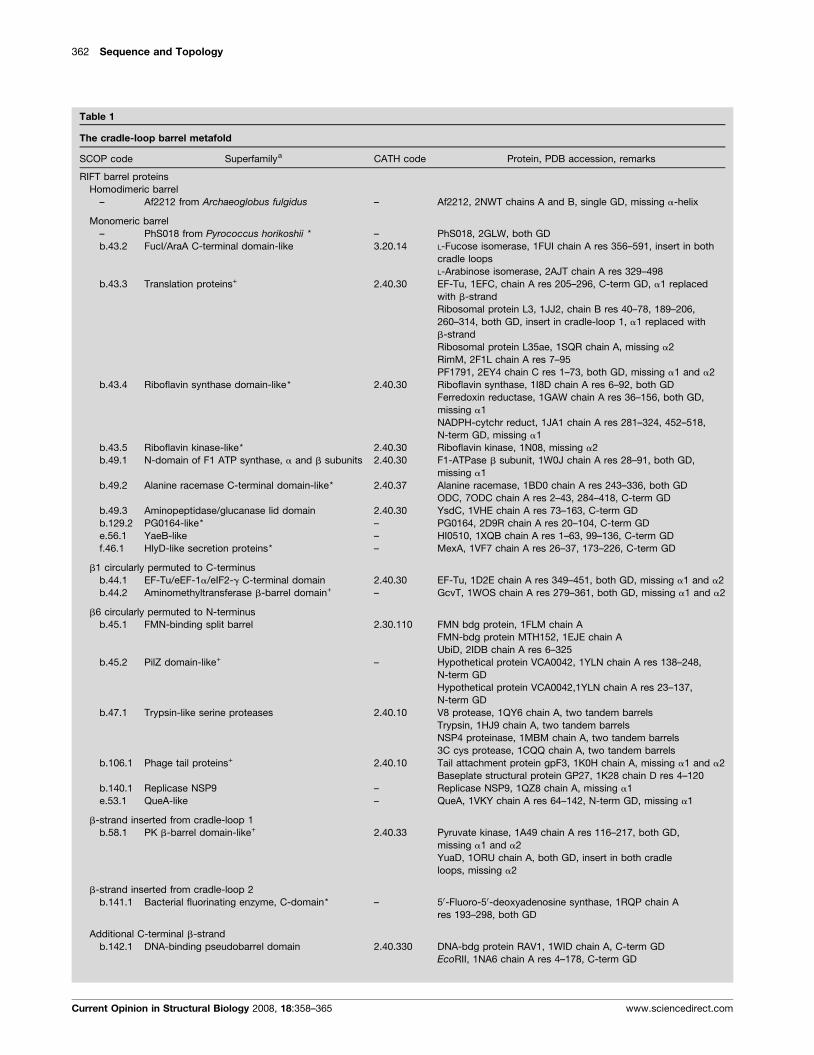
362 Sequence and Topology
Table 1
The cradle-loop barrel metafold
SCOP code Superfamilya CATH code Protein, PDB accession, remarks
RIFT barrel proteins
Homodimeric barrel
– Af2212 from Archaeoglobus fulgidus – Af2212, 2NWT chains A and B, single GD, missing a-helix
Monomeric barrel
– PhS018 from Pyrococcus horikoshii * – PhS018, 2GLW, both GD
b.43.2 FucI/AraA C-terminal domain-like 3.20.14 L-Fucose isomerase, 1FUI chain A res 356–591, insert in both
cradle loops
L-Arabinose isomerase, 2AJT chain A res 329–498
b.43.3 Translation proteins+ 2.40.30 EF-Tu, 1EFC, chain A res 205–296, C-term GD, a1 replaced
with b-strand
Ribosomal protein L3, 1JJ2, chain B res 40–78, 189–206,
260–314, both GD, insert in cradle-loop 1, a1 replaced with
b-strand
Ribosomal protein L35ae, 1SQR chain A, missing a2
RimM, 2F1L chain A res 7–95
PF1791, 2EY4 chain C res 1–73, both GD, missing a1 and a2
b.43.4 Riboflavin synthase domain-like* 2.40.30 Riboflavin synthase, 1I8D chain A res 6–92, both GD
Ferredoxin reductase, 1GAW chain A res 36–156, both GD,
missing a1
NADPH-cytchr reduct, 1JA1 chain A res 281–324, 452–518,
N-term GD, missing a1
b.43.5 Riboflavin kinase-like* 2.40.30 Riboflavin kinase, 1N08, missing a2
b.49.1 N-domain of F1 ATP synthase, a and b subunits 2.40.30 F1-ATPase b subunit, 1W0J chain A res 28–91, both GD,
missing a1
b.49.2 Alanine racemase C-terminal domain-like* 2.40.37 Alanine racemase, 1BD0 chain A res 243–336, both GD
ODC, 7ODC chain A res 2–43, 284–418, C-term GD
b.49.3 Aminopeptidase/glucanase lid domain 2.40.30 YsdC, 1VHE chain A res 73–163, C-term GD
b.129.2 PG0164-like* – PG0164, 2D9R chain A res 20–104, C-term GD
e.56.1 YaeB-like – HI0510, 1XQB chain A res 1–63, 99–136, C-term GD
f.46.1 HlyD-like secretion proteins* – MexA, 1VF7 chain A res 26–37, 173–226, C-term GD
b1 circularly permuted to C-terminus
b.44.1 EF-Tu/eEF-1a/eIF2-g C-terminal domain 2.40.30 EF-Tu, 1D2E chain A res 349–451, both GD, missing a1 and a2
b.44.2 Aminomethyltransferase b-barrel domain+ – GcvT, 1WOS chain A res 279–361, both GD, missing a1 and a2
b6 circularly permuted to N-terminus
b.45.1 FMN-binding split barrel 2.30.110 FMN bdg protein, 1FLM chain A
FMN-bdg protein MTH152, 1EJE chain A
UbiD, 2IDB chain A res 6–325
b.45.2 PilZ domain-like+ – Hypothetical protein VCA0042, 1YLN chain A res 138–248,
N-term GD
Hypothetical protein VCA0042,1YLN chain A res 23–137,
N-term GD
b.47.1 Trypsin-like serine proteases 2.40.10 V8 protease, 1QY6 chain A, two tandem barrels
Trypsin, 1HJ9 chain A, two tandem barrels
NSP4 proteinase, 1MBM chain A, two tandem barrels
3C cys protease, 1CQQ chain A, two tandem barrels
b.106.1 Phage tail proteins+ 2.40.10 Tail attachment protein gpF3, 1K0H chain A, missing a1 and a2
Baseplate structural protein GP27, 1K28 chain D res 4–120
b.140.1 Replicase NSP9 – Replicase NSP9, 1QZ8 chain A, missing a1
e.53.1 QueA-like – QueA, 1VKY chain A res 64–142, N-term GD, missing a1
b-strand inserted from cradle-loop 1
b.58.1 PK b-barrel domain-like+ 2.40.33 Pyruvate kinase, 1A49 chain A res 116–217, both GD,
missing a1 and a2
YuaD, 1ORU chain A, both GD, insert in both cradle
loops, missing a2
b-strand inserted from cradle-loop 2
b.141.1 Bacterial fluorinating enzyme, C-domain* – 50-Fluoro-50-deoxyadenosine synthase, 1RQP chain A
res 193–298, both GD
Additional C-terminal b-strand
b.142.1 DNA-binding pseudobarrel domain 2.40.330 DNA-bdg protein RAV1, 1WID chain A, C-term GD
EcoRII, 1NA6 chain A res 4–178, C-term GD
Current Opinion in Structural Biology 2008, 18:358–365 www.sciencedirect.com
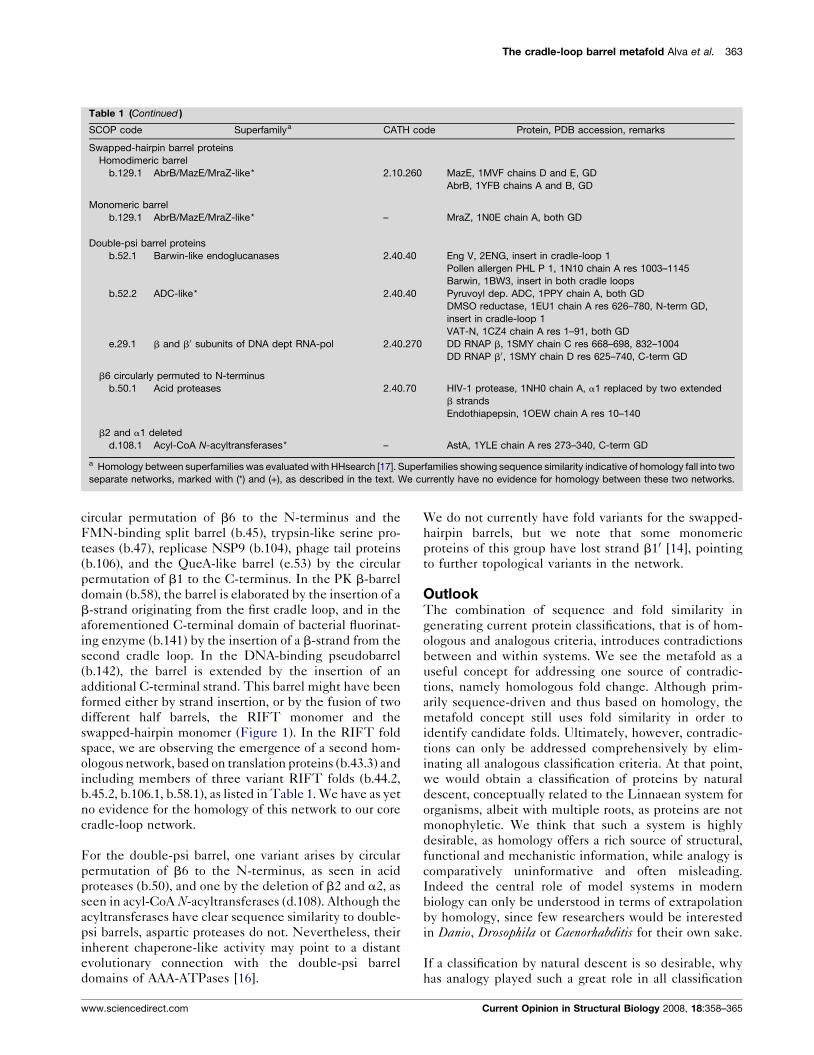
The cradle-loop barrel metafold Alva et al. 363
Table 1 (Continued )
SCOP code Superfamilya CATH code Protein, PDB accession, remarks
Swapped-hairpin barrel proteins
Homodimeric barrel
b.129.1 AbrB/MazE/MraZ-like* 2.10.260 MazE, 1MVF chains D and E, GD
AbrB, 1YFB chains A and B, GD
Monomeric barrel
b.129.1 AbrB/MazE/MraZ-like* – MraZ, 1N0E chain A, both GD
Double-psi barrel proteins
b.52.1 Barwin-like endoglucanases 2.40.40 Eng V, 2ENG, insert in cradle-loop 1
Pollen allergen PHL P 1, 1N10 chain A res 1003–1145
Barwin, 1BW3, insert in both cradle loops
b.52.2 ADC-like* 2.40.40 Pyruvoyl dep. ADC, 1PPY chain A, both GD
DMSO reductase, 1EU1 chain A res 626–780, N-term GD,
insert in cradle-loop 1
VAT-N, 1CZ4 chain A res 1–91, both GD
e.29.1 b and b0 subunits of DNA dept RNA-pol 2.40.270 DD RNAP b, 1SMY chain C res 668–698, 832–1004
DD RNAP b0, 1SMY chain D res 625–740, C-term GD
b6 circularly permuted to N-terminus
b.50.1 Acid proteases 2.40.70 HIV-1 protease, 1NH0 chain A, a1 replaced by two extended
b strands
Endothiapepsin, 1OEW chain A res 10–140
b2 and a1 deleted
d.108.1 Acyl-CoA N-acyltransferases* – AstA, 1YLE chain A res 273–340, C-term GD
a Homology between superfamilies was evaluated with HHsearch [17]. Superfamilies showing sequence similarity indicative of homology fall into two
separate networks, marked with (*) and (+), as described in the text. We currently have no evidence for homology between these two networks.
circular permutation of b6 to the N-terminus and the
FMN-binding split barrel (b.45), trypsin-like serine pro-
teases (b.47), replicase NSP9 (b.104), phage tail proteins
(b.106), and the QueA-like barrel (e.53) by the circular
permutation of b1 to the C-terminus. In the PK b-barrel
domain (b.58), the barrel is elaborated by the insertion of a
b-strand originating from the first cradle loop, and in the
aforementioned C-terminal domain of bacterial fluorinat-
ing enzyme (b.141) by the insertion of a b-strand from the
second cradle loop. In the DNA-binding pseudobarrel
(b.142), the barrel is extended by the insertion of an
additional C-terminal strand. This barrel might have been
formed either by strand insertion, or by the fusion of two
different half barrels, the RIFT monomer and the
swapped-hairpin monomer (Figure 1). In the RIFT fold
space, we are observing the emergence of a second hom-
ologous network, based on translation proteins (b.43.3) and
including members of three variant RIFT folds (b.44.2,
b.45.2, b.106.1, b.58.1), as listed in Table 1. We have as yet
no evidence for the homology of this network to our core
cradle-loop network.
For the double-psi barrel, one variant arises by circular
permutation of b6 to the N-terminus, as seen in acid
proteases (b.50), and one by the deletion of b2 and a2, as
seen in acyl-CoA N-acyltransferases (d.108). Although the
acyltransferases have clear sequence similarity to double-
psi barrels, aspartic proteases do not. Nevertheless, their
inherent chaperone-like activity may point to a distant
evolutionary connection with the double-psi barrel
domains of AAA-ATPases [16].
www.sciencedirect.com
We do not currently have fold variants for the swapped-
hairpin barrels, but we note that some monomeric
proteins of this group have lost strand b10 [14], pointing
to further topological variants in the network.
OutlookThe combination of sequence and fold similarity in
generating current protein classifications, that is of hom-
ologous and analogous criteria, introduces contradictions
between and within systems. We see the metafold as a
useful concept for addressing one source of contradic-
tions, namely homologous fold change. Although prim-
arily sequence-driven and thus based on homology, the
metafold concept still uses fold similarity in order to
identify candidate folds. Ultimately, however, contradic-
tions can only be addressed comprehensively by elim-
inating all analogous classification criteria. At that point,
we would obtain a classification of proteins by natural
descent, conceptually related to the Linnaean system for
organisms, albeit with multiple roots, as proteins are not
monophyletic. We think that such a system is highly
desirable, as homology offers a rich source of structural,
functional and mechanistic information, while analogy is
comparatively uninformative and often misleading.
Indeed the central role of model systems in modern
biology can only be understood in terms of extrapolation
by homology, since few researchers would be interested
in Danio, Drosophila or Caenorhabditis for their own sake.
If a classification by natural descent is so desirable, why
has analogy played such a great role in all classification
Current Opinion in Structural Biology 2008, 18:358–365

364 Sequence and Topology
efforts so far? We would argue that this was by default, as
homologous criteria were not available: sequence search
methods were not sufficiently developed to reveal remote
homology, sequence databases were too sparse to allow
for efficient connections in sequence space, and there
were too few structures to validate distant relationships.
Also, proteins are not monophyletic, so that — unlike in
the Linnaean system — analogy was the default assump-
tion for observed similarities.
This situation is changing. With the emergence of profile
search methods and, more recently, with methods based
on the comparison of profile Hidden Markov Models [17],
bioinformatic tools have reached considerable sensitivity.
Sequence databases have been growing fairly steadily by
about one order of magnitude every 5 years [18], and
currently contain about 5 � 106 proteins. Given a global
proteome of about one trillion proteins (�108 species with
�104 protein-coding genes each), at current rates we
might know the sequence of most proteins on Earth in
about a quarter century. Of possibly greater immediate
impact, there are now some 700 complete genomes from
all over the tree of life, also growing by about one order of
magnitude every 5 years [19]. In parallel, the number of
structures known to atomic resolution, currently at
5 � 104, has been growing steadily, if more slowly, by
about one order of magnitude every 9 years [20] (the
number of ‘non-redundant’ structures with at most 30%
pairwise sequence identity is about one-fifth this size).
Given that we currently recognize �105 protein families
[21] and this number is unlikely to rise by more than at
most one order of magnitude (if indeed it will rise at all), it
seems likely that most protein families will have at least
one member of known structure within the next 10–20
years [22�]. By targeting proteins from a wide range of
families that have remained unexplored, without regard
to the availability of functional information, structural
genomics initiatives are playing a key role in this effort
[23]. The wide availability of sequence and structure data
for most families is essential for substantiating remote
homology, since sequence similarity as a function of
structure similarity is a powerful discriminator between
homology and analogy (M Remmert et al., unpublished).
We therefore wish to argue that it has become possible to
start removing analogous criteria across protein classifi-
cations and move toward a system based on natural
descent.
In recent months, structural genomics initiatives have
been discussed critically in a string of papers appearing in
the main structural biology journals. One criticism has
been that their goal of covering fold space is not useful, as
fold space is structurally continuous in the sense that most
folds consist of recurring subdomain-sized fragments
[24,25] and attempts at structure classification are there-
fore ultimately futile [26]. We disagree with this argu-
ment because, while structure space may be
Current Opinion in Structural Biology 2008, 18:358–365
geometrically continuous, it is evolutionarily discontinu-
ous [10]. Natural descent therefore provides a robust basis
for protein classification. The primary goal of structural
genomics is not to chart hitherto unknown and in most
cases peripheral areas of fold space, it is to map structure
space onto sequence space, allowing us to merge the
currently separate sequence-based and structure-based
approaches into one comprehensive protein classification.
AcknowledgementThis work was supported by institutional funds from the Max PlanckSociety.
References and recommended readingPapers of particular interest, published within the annual period ofreview, have been highlighted as:
� of special interest�� of outstanding interest
1. Dietmann S, Park J, Notredame C, Heger A, Lappe M, Holm L: Afully automatic evolutionary classification of protein folds: DaliDomain Dictionary version 3. Nucleic Acids Res 2001, 29:55-57.
2. Greene LH, Lewis TE, Addou S, Cuff A, Dallman T, Dibley M,Redfern O, Pearl F, Nambudiry R, Reid A et al.: The CATH domainstructure database: new protocols and classification levelsgive a more comprehensive resource for exploring evolution.Nucleic Acids Res 2007, 35:D291-D297.
3. Andreeva A, Howorth D, Chandonia JM, Brenner SE, Hubbard TJ,Chothia C, Murzin AG: Data growth and its impact on the SCOPdatabase: new developments. Nucleic Acids Res 2008,36:D419-D425.
4. Hadley C, Jones DT: A systematic comparison of proteinstructure classifications: SCOP, CATH and FSSP. Structure1999, 7:1099-1112.
5. Day R, Beck DA, Armen RS, Daggett V: A consensus view of foldspace: combining SCOP, CATH, and the Dali DomainDictionary. Protein Sci 2003, 12:2150-2160.
6. Grishin NV: Fold change in evolution of protein structures.J Struct Biol 2001, 134:167-185.
7. Kinch LN, Grishin NV: Evolution of protein structures andfunctions. Curr Opin Struct Biol 2002, 12:400-408.
8.�
Andreeva A, Murzin AG: Evolution of protein fold in thepresence of functional constraints. Curr Opin Struct Biol 2006,16:399-408.
This article along with Ref. [9�] describe examples of homologous foldchange by a range of different mechanisms. The level of structural insightdisplayed in both papers is impressive.
9.�
Andreeva A, Prlic A, Hubbard TJ, Murzin AG: SISYPHUS —structural alignments for proteins with non-trivialrelationships. Nucleic Acids Res 2007, 35:D253-D259.
Like Ref. [8�], this article presents examples of homologous fold change.In addition, it introduces a database of manually curated structuralalignments, which allows users to explore the fold changes interactively.
10. Lupas AN, Koretke KK: Evolution of protein folds. InComputational Structural Biology. Edited by Peitsch M, SchwedeT. World Scientific Publishing Co.; 2008.
11. Coles M, Diercks T, Liermann J, Groger A, Rockel B,Baumeister W, Koretke KK, Lupas A, Peters J, Kessler H: Thesolution structure of VAT-N reveals a ’missing link’ in theevolution of complex enzymes from a simplebetaalphabetabeta element. Curr Biol 1999, 9:1158-1168.
12. Castillo RM, Mizuguchi K, Dhanaraj V, Albert A, Blundell TL,Murzin AG: A six-stranded double-psi beta barrel is shared byseveral protein superfamilies. Structure 1999, 7:227-236.
13.�
Coles M, Hulko M, Djuranovic S, Truffault V, Koretke K,Martin J, Lupas AN: Common evolutionary origin of
www.sciencedirect.com

The cradle-loop barrel metafold Alva et al. 365
swapped-hairpin and double-psi beta barrels. Structure 2006,14:1489-1498.
This paper establishes the homologous relationship between DNA-bind-ing swapped-hairpin barrels and double-psi barrels with chaperoneactivity via proteins with an intermediate topology, which are most likelyalso DNA binding.
14. Coles M, Djuranovic S, Soding J, Frickey T, Koretke K, Truffault V,Martin J, Lupas AN: AbrB-like transcription factors assume aswapped hairpin fold that is evolutionarily related to double-psi beta barrels. Structure 2005, 13:919-928.
15.��
Ammelburg M, Hartmann MD, Djuranovic S, Alva V, Koretke KK,Martin J, Sauer G, Truffault V, Zeth K, Lupas AN et al.: A CTP-dependent archaeal riboflavin kinase forms a bridge in theevolution of cradle-loop barrels. Structure 2007, 15:1577-1590.
This paper makes two important contributions. It provides the firstcharacterization of an archaeal riboflavin kinase and it shows thatarchaeal riboflavin kinases are intermediate in sequence betweenbasal, DNA-binding cradle-loop barrels and bacterial and eukaryoticriboflavin kinases, providing an evolutionary bridge. The paper makespredictions about the sequence of mutations necessary to transform aDNA-binding protein into an enzyme, first bringing about CTP bindingand subsequently conferring the ability to transfer the g-phosphate toriboflavin.
16. Hulko M, Lupas AN, Martin J: Inherent chaperone-like activity ofaspartic proteases reveals a distant evolutionary relation todouble-psi barrel domains of AAA-ATPases. Protein Sci 2007,16:644-653.
17. Soding J: Protein homology detection by HMM-HMMcomparison. Bioinformatics 2005, 21:951-960.
www.sciencedirect.com
18. The GenBank entry in Wikipedia. http://en.wikipedia.org/wiki/GenBank.
19. The Genomes OnLine Database v 2.0. http://www.genomesonline.org/gold_statistics.htm.
20. The PDB Statistics hyperlink on the Protein Data Bank home page.http://www.rcsb.org/pdb/statistics/contentGrowthChart.do?content=total&seqid=100.
21. The InterPro database. http://www.ebi.ac.uk/interpro/.
22.�
Marsden RL, Lewis TA, Orengo CA: Towards a comprehensivestructural coverage of completed genomes: a structuralgenomics viewpoint. BMC Bioinformatics 2007, 8:86.
Structural genomics approaches are essential for a comprehensivestructural characterization of proteins. This paper presents an excellentdescription of the current structural coverage of protein families anddiscusses further developments needed to bring this effort to a success-ful conclusion.
23. Burley SK, Bonanno JB: Structuring the universe of proteins.Annu Rev Genomics Hum Genet 2002, 3:243-262.
24. Taylor WR: Evolutionary transitions in protein fold space. CurrOpin Struct Biol 2007, 17:354-361.
25. Kolodny R, Petrey D, Honig B: Protein structure comparison:implications for the nature of ‘fold space’, and structure andfunction prediction. Curr Opin Struct Biol 2006, 16:393-398.
26. Honig B: Protein structure space is much more than the sum ofits folds. Nat Struct Mol Biol 2007, 14:458.
Current Opinion in Structural Biology 2008, 18:358–365




















