
Hydrogen-peroxide-induced oxidative stress responses in Desulfovibrio vulgaris Hildenborough
Upload
independentCategory
view
2download
0
PLEASE SCROLL DOWN FOR ARTICLE
This article was downloaded by: [B-on Consortium - 2007]On: 20 October 2008Access details: Access Details: [subscription number 778384750]Publisher Informa HealthcareInforma Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House,37-41 Mortimer Street, London W1T 3JH, UK
Mitochondrial DNAPublication details, including instructions for authors and subscription information:http://www.informaworld.com/smpp/title~content=t713640135
Characterisation of the 11 Kb DNA region adjacent to the gene encodingDesulfovibrio gigas flavoredoxinManuela Broco a; Ana Marques a; Solange Oliveira ab; Claudina Rodrigues-Pousada a
a Instituto de Tecnologia Química e Biológica, Universidade Nova de Lisboa, Oeiras, Portugal b Departamentode Biologia, Universidade de Évora, Évora, Portugal
Online Publication Date: 01 June 2005
To cite this Article Broco, Manuela, Marques, Ana, Oliveira, Solange and Rodrigues-Pousada, Claudina(2005)'Characterisation of the11 Kb DNA region adjacent to the gene encoding Desulfovibrio gigas flavoredoxin',Mitochondrial DNA,16:3,207 — 216
To link to this Article: DOI: 10.1080/10425170500088296
URL: http://dx.doi.org/10.1080/10425170500088296
Full terms and conditions of use: http://www.informaworld.com/terms-and-conditions-of-access.pdf
This article may be used for research, teaching and private study purposes. Any substantial orsystematic reproduction, re-distribution, re-selling, loan or sub-licensing, systematic supply ordistribution in any form to anyone is expressly forbidden.
The publisher does not give any warranty express or implied or make any representation that the contentswill be complete or accurate or up to date. The accuracy of any instructions, formulae and drug dosesshould be independently verified with primary sources. The publisher shall not be liable for any loss,actions, claims, proceedings, demand or costs or damages whatsoever or howsoever caused arising directlyor indirectly in connection with or arising out of the use of this material.

FULL LENGTH RESEARCH PAPER
Characterisation of the 11 Kb DNA region adjacent to the gene encodingDesulfovibrio gigas flavoredoxin
MANUELA BROCO1, ANA MARQUES1, SOLANGE OLIVEIRA1,2, &
CLAUDINA RODRIGUES-POUSADA1
1Instituto de Tecnologia Quımica e Biologica, Universidade Nova de Lisboa, Avenida Republica (EAN), Oeiras 2784-505,
Portugal, and 2Departamento de Biologia, Universidade de Evora, Apartado 94, Evora 7002-554, Portugal
(Received 3 December 2004)
AbstractFlavoredoxin is an FMN binding protein that functions as an electron carrier in the sulphate metabolism of Desulfovibrio gigas.The neighbouring DNA regions of the gene encoding flavoredoxin were sequenced and characterised. Transcript analysis ofthe flavoredoxin gene resulted in a positive band corresponding to the size of the coding region, suggesting that flavoredoxin isencoded by a monocystronic unit, as previously suggested by sequence analysis.
Analysis of the adjacent DNA regions revealed several interesting genes. The sequenced DNA regions contain nine openreading frames (ORFs) organised in two polycystronic and two monocystronic units. These genes encode proteins involved indifferent metabolic pathways, namely in DNA methylation, tRNA and rRNA modification, mRNA metabolism, cell division,CoA synthesis and lipoprotein transport across the membrane.
Keywords: Desulfovibrio gigas, flavoredoxin, monocystronic, flanking regions
Genebank accession No. AY702971
Introduction
Sulphate reducing bacteria (SRB) are anaerobicbacteria that have as common feature the ability touse sulphate as terminal electron acceptor (Postgate1984). These bacteria are widespread in terrestrialand aquatic environments, but they can also be foundin animal and human gastrointestinal tract (Barton1995). They have particular metabolic properties,which allow them to be involved in the sulphur cycle,via their ability to reduce sulphate (Postgate 1984); inthe nitrogen cycle, due to their capacity to perform thenon symbiotic fixation of nitrogen (Kent et al. 1989);and in the carbon cycle, associated with the importantrole they play in the mineralisation process of organicmatter (Peck 1984). SRB are involved in importantenvironmental processes like biocorrosion, due to the
high amounts of H2S produced during respiration.
Nevertheless, they can also be very important in
anaerobic biotransformation of environmental con-
taminants (Barton 1995), making these bacteria very
interesting ones from a biotechnological point of view.
Among the SRB, the Desulfovibrio genus is by far the
best known. Desulfovibrio has been considered a major
problem for industry and for the environment and some
of its proteins can be used for technological applications
(Barton 1995).These bacteria are metabolicallydiverse,
being able to use a wide range of electron donors and
acceptors to conserve energy. They are rich in redox-
proteins with a great variety of prosthetic groups and
many novel metal centres have been described in the last
years (Barton 1995). Several biochemical studies have
been made in order to characterise the proteins involved
ISSN 1042-5179 print/ISSN 1029-2365 online q 2005 Taylor & Francis Group Ltd
DOI: 10.1080/10425170500088296
Correspondence: C. Rodrigues-Pousada, Instituto de Tecnologia Quımica e Biologica, 2780 Oeiras, Portugal. Tel: 351 1 4469879.Fax: 351 1 4428766. E-mail: [email protected]
DNA Sequence, June 2005; 16(3): 207–216
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

in the energy conservation. However, the metabolism of
these bacteria is still poorly understood. Genomic
characterisation of these bacteria will largely contribute
to a better understanding of their complex metabolism,
namely by comparative analysis of the amino acid
sequence of redox proteins, which may allow the
identification of the prosthetic groups binding sites of
these proteins. The knowledge of the gene organisation
into operons will help to understand the biochemical
function of the proteins from the identified genes.
Several genes encoding important proteins have already
been isolated and characterised.
Flavoredoxin (flr) is a flavoprotein from the Flavin
reductase family (Agostinho et al. 2000), which was
initially proposed to be involved in the sulphite
reduction as the direct electron donor to desulfoviridin
(Chen et al. 1993). However, recent in vivo studies have
suggested that this redox protein is in fact involved in the
thiosulphate reduction (Broco et al. submitted).
The present report presents the characterisation of the
DNAregions fromtheDesulfovibriogigasgenomeadjacent
to the gene encoding flavoredoxin (flr). These DNA
fragments contain several ORFs (open reading frames)
organised in monocystronic and polycystronic units,
encoding hypothetical proteins involved in different
metabolic pathways. The flr transcript characterisation
and that of the polycystronic units are also shown.
Materials and methods
Bacterial strains and growth conditions
D. gigas (ATCC 19364) was grown anaerobically as
previously described by Gomes et al. (1997).
Escherichia coli strains P2 392 and LE 392 were used
to screen a D. gigas genomic library (constructed in the
vector l-Dash II-Stratagene, La Jolla, CA, USA) and
in the purification of the recombinant positive phage.
E. coli strain XL1-blue (Stratagene) carrying the
plasmid pZErO-1e (Invitrogen, San Diego, CA,
USA) and pZErO-1e-derived vectors was grown as
described by the manufacturer. E. coli competent cells
were prepared according to standard protocols
(Sambrook et al. 1989).
DNA preparation
Genomic D. gigas DNA was purified as previously
described by Gomes et al. (1997). Phage DNA was
isolated using the Qiagen Lambda Maxi Kit (Qiagen,
Hilden, Germany). Plasmid DNA was prepared using
the Plasmid Purification kit (Sigma-Aldrich, St Louis,
USA).
Cloning and sequence analysis
The 11,000 bp genomic DNA fragment containing
the flr gene was isolated and cloned as described in
Agostinho et al. (2000). Sequencing of these DNA
fragment in both strands was performed using the
DYEnamic ET Terminator Cycle Sequencing Kit
(Amersham Biosciences, CPR, USA). Sequencing
reactions were analysed and organised with Gene-
Skipper software. The oligonucleotides necessary to
fill the gaps on the DNA sequence were purchased
(MWG Biotech, Ebersberg, Germany). Protein
identification and amino acid sequence analysis was
performed with BLAST 2.0 (Altschul et al. 1997) and
ExPASy server analysis tools (Gasteiger et al. 2003).
Hydropathy profiles were determined using the Kyte-
Doolittle method (Kyte & Doolittle 1982) and
TMpred (Hofmann & Stoffel 1993). The presence
of signal-peptide was analysed with SignalP V1.1
(Bendtsen et al. 2004). Amino acid sequence
alignments were performed with Clustal W (Higgins
et al. 1994) and BioEdit (http://www.mbio.ncsu.edu/
BioEdit/bioedit.html). Molecular Evolution Genetics
Analysis (MEGA version 2.1) (Kumar et al. 2001) was
used to obtain molecular phylogeny using the
Neighbour-Joining method (Saitou & Nei 1987).
Neighbour genes in other genomes were found using
Search Tool for the Retrieval of Interacting Genes/
Proteins (STRING) (Snel et al. 2000, von Mering
et al. 2003).
RNA isolation, northern blot and RT-PCR analysis
Total RNA was isolated from mid-log phase D. gigas
cells grown anaerobically in lactate/sulphate medium
(Malki et al. 1997) according to Ausubel et al. (1995).
RNA was separated on a 1.2% (wt/vol) agarose gel in
1X MOPS buffer and 6% (vol/vol) formaldehyde,
using the 0.24–9.5 Kb RNA Ladder (Invitrogen) as a
size marker. Northern blotting and membrane
hybridisation with a a32P-labelled probe for D. gigas
flr gene were performed as described by Ausubel et al.
(1995).
RT-PCR was carried out with Superscript First-
Strand Synthesis System Kit (Invitrogen). A negative
control was performed in which the RNA sample
was used as a template for PCR. Four oligonucleo-
tides were designed to perform RT-PCR, FlrPEch
(50CGCCCTGCCGCCGCCAC 30)/FlrP17 (50
CGGGAAGTCGCATACACCTG 30) and FlrP20
(50 GTCCAGGATCTCCGAGGCCT)/FlrP6 (50
CTCAGTCAGGGCAAGGCGTC 30) to amplify
the regions related to ORF1/ORF2 and ORF8/ORF9,
respectively.
Results and discussion
Flavoredoxin gene and its amino acid sequence were
already analysed by Agostinho et al. (2000). This
FMN binding protein contains 194 amino acid
residues and shows homology with proteins from the
flavin reductase family (Agostinho et al. 2000)
M. Broco et al.208
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

(Table I). Interestingly, the phylogenetic analysis
(see Figure 1A) of D. gigas flavoredoxin and
homologous proteins from other proteobacteria from
the d-subdivision shows that these proteins are more
closely related to members of Archaea than to proteins
from other bacteria, suggesting that a gene transfer
might have occurred.
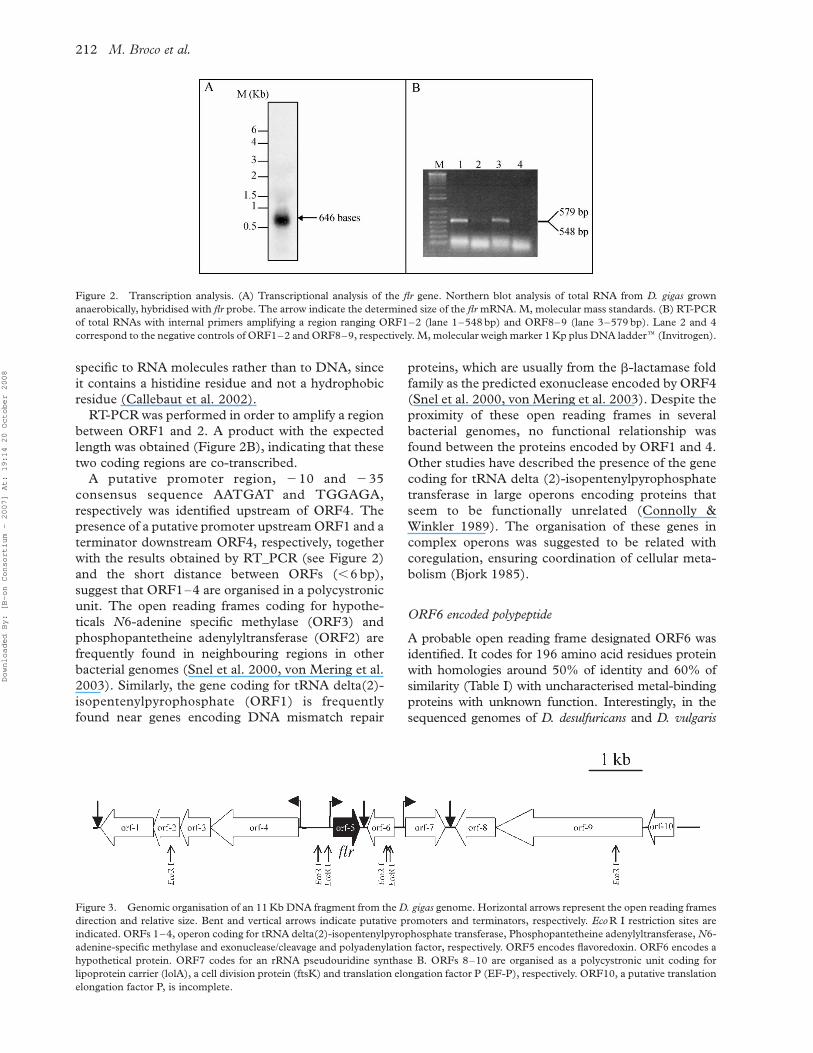
Northern blot analysis revealed that flr gene is
highly expressed in exponentially growing D. gigas
cells (Figure 2). The mRNA has about 670 bp,
showing that flavoredoxin is indeed encoded by a
monocystronic unit as predicted previously from the
nucleotide sequence analysis (Agostinho et al. 2000).
Sequence analysis reveals the presence of four ORFs
upstream and five ORFs downstream of flr. The first
region is organised as a polycystronic unit whereas the
second region is organised in two monocystronic and
one polycystronic units (Figure 3). ORF10 is
incomplete in the 50 region and except for ORFs 5
and 7, all ORFs are transcribed in the same direction.
ORF1–4 are organised in an operon
The predicted polypeptide encoded by ORF1 is a
35,023 Da protein with 315 amino acid residues and
revealed homologies with tRNA delta (2)-isopente-
nylpyrophosphate transferase from several prokar-
yotes (Table I). ORF1 seems to be the last of an
operon coding for ORF1–4 (see Figure 3) since a
hypothetical terminator was identified downstream of
this ORF. This terminator includes a hairpin that
probably also belongs to the terminator of the operon
encoding the membrane bound Ech [NiFe] hydro-
genase in opposite direction (Rodrigues et al. 2003).
The tRNA delta(2)-isopentenylpyrophosphate
transferase catalyses the first step in the biosynthesis
of 2-methylthio-N(6)-(delta(2)-isopentenyl)-adeno-
sine (ms2i6A), adjacent to the anticodon of tRNAs
whose codons start by uridine (Bartz et al. 1970).
Changes in the degree of tRNA modifications were
suggested to be involved in a regulatory mechanism
associated with environmental stress responses (Con-
nolly & Winkler 1989) and in the expression of
virulence genes (Gray et al. 1992, Durand et al. 1997,
Durand et al. 2000). The amino acid sequence of
ORF1 has a putative ATP binding site (VGPT-
GVGKT) in the N-terminus whose consensus
sequence is [AG]-x(4)-G-K-[ST]. Since this protein
is involved in the modification of an adenine residue
from a tRNA molecule, probably this motif is the
substrate recognition sequence.
The polypeptide chain of 19,950 Da encoded by
ORF2 shows high homologies with prokaryotic proteins
involved in the coenzyme-A metabolism, the phospho-
pantetheine adenylyltransferase (Table I). In bacteria,
phosphopantetheine adenylyltransferase was described
as a homohexamer (Geerlof et al. 1999) that catalyses
the penultimate step in coenzyme A (CoA) biosynthesis,
the reversible adenylation of 40phosphopantetheine
yielding 30dephospho-Coa (dPCoA) and pyropho-
sphate. In the amino acid sequence of ORF2, we could
identify the motif TXGH, proposed to make contact
with the adenylate group of dephospho-CoA and the
conserved amino acid residues, which create a positive
region proposed to bind b-phosphate (K51 and K142)
and g-phosphate (S137 and S138) of ATP (Izard &
Geerlof 1999).
The predicted 209 amino acid sequence encoded by
ORF3 revealed homologies with N6-adenine-specific
methylase from several prokaryotes (Table I). This
enzyme catalyses specifically the methylation of the
amino group of the C-6 position of adenines in DNA and
is usually associated with restriction-modification sys-
temsandDNAmismatch repair (Bickle&Kruger1993).
In the amino acid sequence predicted from ORF3,
eight from the nine motifs previously described in
DNA methylases (Malone et al. 1995) were identified
(see Figure 4). Motif VII was not found, but this
region was described as a low conserved motif
(Malone et al. 1995). Motifs I–III and X are
responsible for the binding of the methyl donor S-
adenosyl-L-methionine. Motifs IV–VIII form the
catalytic region of the protein (Malone et al. 1995).
Recent site-directed mutagenesis studies indicated
that the conserved aspartate residue from the DPPY
motif is involved in DNA binding (Szegedi &
Gumport 2000). According to the classification
suggested by Malone et al. (1995), D. gigas ORF3
seems to encode an N6-adenine-specific methylase
from class a.
The deduced polypeptide of 546 amino acid
residues encoded by ORF4 shows homologies with
proteins with the b-lactamase fold involved in the
mRNA metabolism (Table I). A separate family of
enzymes with the metallo-b-lactamase fold, named
the b-CASP family, includes proteins acting on
nucleic acids, mainly involved in DNA repair and
RNA processing. These proteins can be found in the
three primary kingdoms (Eukarya, Bacteria and
Archaea), but the involvement of the bacterial proteins
in mRNA processing remains to be investigated
(Callebaut et al. 2002). Motifs I–III and V (Aravind
1999) belonging to the proteins with the b-lactamase
fold were identified (see Figure 5) using the
comparison of ORF4 predicted amino acid sequence
with its orthologues. This investigator has described
by in silico analysis that in the b-lactamase fold, the
Zn2þ ion is held in the active site coordinated by the
first two histidines from Motif II, the histidine from
Motif III and the negatively charged substrate, which
is stabilised by the histidine residue from Motif
V. Motif IV (f-f-f-D/E-T/S-T) (f is a hydrophobic
residue) and VI (a histidine residue between a
b-strand and an a-helix) are present only in proteins
that have nucleic acids as substrates. From the analysis
of Motif VI, it was possible to deduce that the ORF4 is
Characterisation of the flr flanking regions 209
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

Table I. Predicted polypeptides encoded by the ORFs present in an 11,000 bp DNA fragment from D. gigas and homologous proteins.
ORFs
Polypeptide molecular mass
(Da) Orthologous proteins Source Function
Similarity/Identity
(%)
ORF1 35,023 IPP transferase D. desulfuricans G20 tRNA modification 58.7/50.2
IPP transferase G. sulfurreducens 47.2/34.4
IPP transferase B. halodurans 44.3/30.5
IPP transferase C. hutchinsonii 47.6/28.6
ORF2 19,950 Phophopantetheine adenylyltransferase D. desulfuricans G20 Catalyses the rate limiting step in CoA biosynthesis 67.8/54.2
Phophopantetheine adenylyltransferase E. coli 55.7/43.2
Phophopantetheine adenylyltransferase T. tengcongensis 64.2/43.8
Phophopantetheine adenylyltransferase L. interrogans 61.4/40.3
ORF3 22,504 N6-adenine-specific methylase D. desulfuricans G20 DNA replication, recombination and repair 55/45
Putative methylase C. tepidum TLS 48.3/34.4
Conserved hypothetical protein S. pneumoniae R6 49.3/30.1
Putative methylase yhhF E. coli 42.7/28.6
ORF4 61,097 Predicted exonuclease of the b-lactamase fold D. desulfuricans Involved in RNA processing 73.8/61.2
Predicted exonuclease of the b-lactamase fold G. metallireducens 39.2/24.8
Putative mRNA 30-end processing factor A. fulgidus 26.5/18.2
Cleavage and polyadenylation specificity factor M. acetivorans 25/16.9
Cleavage and polyadenylation specificity factor 3 M. musculus 26.1/15.3
ORF5 21,053 Flavoredoxin homolog D. desulfuricans Flavoproteins involved in several biological processes 61.3/46.4
Flavoredoxin homolog M. barkeri 67.5/55.2
Actinorhodin polyketide dimerase ACTVB homologue S. roseofulvus 53.0/26.5
NADH-dependent FMN oxidoreductase R. erythropolis 44.2/19.0
Nitrilotriacetate monooxygenase component B C. heintzii 52.5/24.6
ORF6 22,142 MJ0455 M. jannaschii – 64.5/49.2
Uncharacterized metal-binding protein C. thermocellum 51.4/38.2
Uncharacterized metal-binding protein G. metallireducens 46.9/35
ORF7 27,765 16S rRNA uridine-516 pseudouridylate synthase D. desulfuricans rRNA uridine isomeration 57.1/44.9
16S rRNA uridine-516 pseudouridylate synthase T. tengcongensis 45.1/34
Ribosomal large subunit pseudouridine synthase B B. cererus 44.9/32.3
Ribosomal large subunit pseudouridine synthase B F. nucleatum 40.3/27.9
ORF8 24,929 Outer membrane lipoprotein-sorting protein D. desulfuricans Periplasmic lipoprotein carrier 48.1/34.3
Periplasmic chaperone LolA P. aeruginosa 37.1/21
Outer-membrane lipoproteins carrier protein LolA X. campestris 33/18.8
E. coli 29/16.1
ORF9 106,479 DNA segregation ATPase FtsK/SpoIIIE D. desulfuricans Cell division 43.5/35.1
DNA segregation ATPase FtsK/SpoIIIE G. metallireducens 34.2/26.1
DNA translocase ftsK C. perfringens 33.6/24.4
Cell division protein E. coli 31.9/23.5
ORF10 – – – – –
M.
Broco
etal.
210
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008
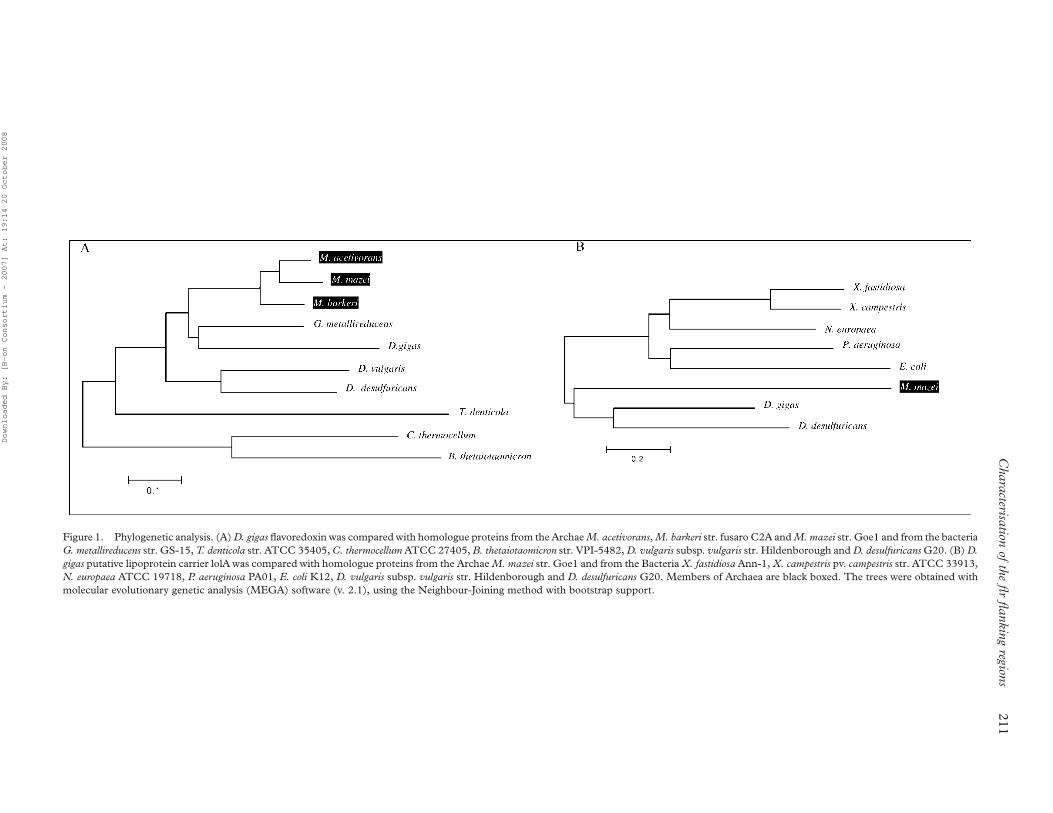
Figure 1. Phylogenetic analysis. (A) D. gigas flavoredoxin was compared with homologue proteins from the Archae M. acetivorans, M. barkeri str. fusaro C2A and M. mazei str. Goe1 and from the bacteria
G. metallireducens str. GS-15, T. denticola str. ATCC 35405, C. thermocellum ATCC 27405, B. thetaiotaomicron str. VPI-5482, D. vulgaris subsp. vulgaris str. Hildenborough and D. desulfuricans G20. (B) D.
gigas putative lipoprotein carrier lolA was compared with homologue proteins from the Archae M. mazei str. Goe1 and from the Bacteria X. fastidiosa Ann-1, X. campestris pv. campestris str. ATCC 33913,
N. europaea ATCC 19718, P. aeruginosa PA01, E. coli K12, D. vulgaris subsp. vulgaris str. Hildenborough and D. desulfuricans G20. Members of Archaea are black boxed. The trees were obtained with
molecular evolutionary genetic analysis (MEGA) software (v. 2.1), using the Neighbour-Joining method with bootstrap support.
Characterisation
ofth
efl
rfl
ankin
gregion
s211
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008
specific to RNA molecules rather than to DNA, since
it contains a histidine residue and not a hydrophobic
residue (Callebaut et al. 2002).
RT-PCR was performed in order to amplify a region
between ORF1 and 2. A product with the expected
length was obtained (Figure 2B), indicating that these
two coding regions are co-transcribed.
A putative promoter region, 210 and 235
consensus sequence AATGAT and TGGAGA,
respectively was identified upstream of ORF4. The
presence of a putative promoter upstream ORF1 and a
terminator downstream ORF4, respectively, together
with the results obtained by RT_PCR (see Figure 2)
and the short distance between ORFs (,6 bp),
suggest that ORF1–4 are organised in a polycystronic
unit. The open reading frames coding for hypothe-
ticals N6-adenine specific methylase (ORF3) and
phosphopantetheine adenylyltransferase (ORF2) are
frequently found in neighbouring regions in other
bacterial genomes (Snel et al. 2000, von Mering et al.
2003). Similarly, the gene coding for tRNA delta(2)-
isopentenylpyrophosphate (ORF1) is frequently
found near genes encoding DNA mismatch repair
proteins, which are usually from the b-lactamase fold
family as the predicted exonuclease encoded by ORF4
(Snel et al. 2000, von Mering et al. 2003). Despite the
proximity of these open reading frames in several
bacterial genomes, no functional relationship was
found between the proteins encoded by ORF1 and 4.
Other studies have described the presence of the gene
coding for tRNA delta (2)-isopentenylpyrophosphate
transferase in large operons encoding proteins that
seem to be functionally unrelated (Connolly &
Winkler 1989). The organisation of these genes in
complex operons was suggested to be related with
coregulation, ensuring coordination of cellular meta-
bolism (Bjork 1985).
ORF6 encoded polypeptide
A probable open reading frame designated ORF6 was
identified. It codes for 196 amino acid residues protein
with homologies around 50% of identity and 60% of
similarity (Table I) with uncharacterised metal-binding
proteins with unknown function. Interestingly, in the
sequenced genomes of D. desulfuricans and D. vulgaris
Figure 3. Genomic organisation of an 11 Kb DNA fragment from the D. gigas genome. Horizontal arrows represent the open reading frames
direction and relative size. Bent and vertical arrows indicate putative promoters and terminators, respectively. Eco R I restriction sites are
indicated. ORFs 1–4, operon coding for tRNA delta(2)-isopentenylpyrophosphate transferase, Phosphopantetheine adenylyltransferase, N6-
adenine-specific methylase and exonuclease/cleavage and polyadenylation factor, respectively. ORF5 encodes flavoredoxin. ORF6 encodes a
hypothetical protein. ORF7 codes for an rRNA pseudouridine synthase B. ORFs 8–10 are organised as a polycystronic unit coding for
lipoprotein carrier (lolA), a cell division protein (ftsK) and translation elongation factor P (EF-P), respectively. ORF10, a putative translation
elongation factor P, is incomplete.
Figure 2. Transcription analysis. (A) Transcriptional analysis of the flr gene. Northern blot analysis of total RNA from D. gigas grown
anaerobically, hybridised with flr probe. The arrow indicate the determined size of the flr mRNA. M, molecular mass standards. (B) RT-PCR
of total RNAs with internal primers amplifying a region ranging ORF1–2 (lane 1–548 bp) and ORF8–9 (lane 3–579 bp). Lane 2 and 4
correspond to the negative controls of ORF1–2 and ORF8–9, respectively. M, molecular weigh marker 1 Kp plus DNA laddere (Invitrogen).
M. Broco et al.212
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

the gene encoding this metal binding protein was not
found, suggesting diversity among the Desulfovibrio
genus.
ORF7 encodes a putative rRNA pseudouridine synthase B
The predicted 253 amino acid sequence codified by
ORF7 shows homologies with the rRNA pseudo-
uridine synthase B from several prokaryotes (Table I).
The amino acid predicted sequence presents two
domains, Rsu (14 residues) and S4 (59 residues). The
Rsu domain is very conserved, and its presence in
D. gigas suggests that this protein is involved in rRNA
small subunit isomeration like the Rsu protein in E. coli
(Conrad et al. 1999). In the Rsu domain there is a
conserved motif, GRLD, whose aspartate residue is
essential for the catalytic activity of the protein. The
S4 domain is not as conserved as the Rsu domain and
is involved in the RNA binding (Aravind & Koonin
1999). A hypothetical promoter and terminator were
found upstream and downstream ORF7, respectively,
suggesting that a monocystronic unit encodes this
protein in D. gigas. Pseudouridine synthases are a
family of enzymes that catalyse the synthesis of
pseudouridine, the C5-C10 isomer of uridine, in a
variety of RNAs.
ORF8–10 are organised as a polycystronic unit
ORF8 encodes a predicted 224 amino acid residues
sequence with homologies with the outer membrane
lipoprotein carrier lolA from several gram-negative
bacteria (Table I). LolA is involved in a mechanism
responsible for the sorting and localization of mature
lipoproteins in either the inner or in outer-membrane.
In fact, a 27 amino acid residues signal peptide was
found in the N-terminus of the predicted polypeptide
chain. The presence of a signal peptide suggests that
Figure 4. Amino acid sequences alignment containing part of D. gigas ORF3 and its homologous proteins from several prokaryotes, namely
D. desulfuricans G20, C. tepidum TLS, A. gambiae str. PEST, E. coli K12, G. sulfurreducens str. PCA. Motifs I–III and X are involved in the
binding of S-adenosyl-L-methionine molecule. Motifs IV–VIII constitute the catalytic region (Malone et al. 1995).
Figure 5. Amino acid sequences alignment of D. gigas ORF4 and homologous proteins from several bacteria, namely D. desulfuricans G20,
T. tengcongensis str. MB4, D. radiodurans str., C. hutchinsonii str. ATCC 33406 and G. metallireducens G5-15; from the Archae A. fulgidus str.
DSM 4304 and M. acetivorans C2A; and from the Eukarya D. melanogaster and M. musculus. Sequence comparison of Motifs I–VI of the
ORF4 encoded polypeptide with homologous proteins. E and H represent b-strand and a-helix, respectively. Consensus sequences of
the motifs are indicated above the motif line.
Characterisation of the flr flanking regions 213
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

this protein, after being synthesized is exported to the
periplasmic space. No conserved domains were
identified in this protein. From the phylogenetic
analysis (Figure 1B) we can see that the proteins from
D. gigas and D. desulfuricans are more closely related to
protein from the Archaea Methanosarcina than to the
proteins from their bacteria group. This suggests the
occurrence of gene transfer, such as it might have
happened for flavoredoxin and for the D. gigas Ech
operon (Rodrigues et al. 2003).
Upstream ORF8 is ORF9, which encodes a large
protein with 991 amino acid residues with homologies
with the membrane protein involved in the cell
division, ftsK. Similarly to what was already described
for E. coli ftsK (Begg et al. 1995), the deduced amino
acid sequence of putative ORF9 revealed a high
conserved C-terminus, a less conserved N-terminus
and a domain with repeats between these two regions.
The N-terminus is highly hydrophobic and contains
five membrane-spanning a-helices, indicating that as
in E. coli ftsK, the N-terminus of the predicted
polypeptide is integrated in the membrane. In the N-
terminus of E. coli ftsK it was described the presence
of the conserved motif HEXXH, characteristic of zinc
metalloproteases, important for the enzyme activity in
cell division (Dorazi & Dewar 2000). In D. gigas and
D. desulfuricans this motif is not complete, since the
second histidine residue is missing. The C-terminus of
the predicted amino acid sequence is hydrophilic
similarly to E. coli ftsK and contains the ATPases
Associated several cellular Activities (AAA) domain
with a conserved ATP/GTP binding site (GAT-
GAGKS). The domain between the N- and C-
terminal region has different characteristics among the
proteins homologous to ORF9. In E. coli, it is well
described the presence of the PQ rich region (Begg
et al. 1995), proposed to be responsible for the dif
recombination activity of the enzyme (Boyle et al.
2000). However, this repeated region is not conserved
among ftsK proteins and it has been suggested that
this region might have some specific and additional
function (Boyle et al. 2000). In D. gigas amino acid
sequence, the PQ rich region is not present as
described in E. coli but there are a proline and
proline/valine/alanine rich regions, containing seven
PVA repeats. Interestingly, a similar amino acid repeat
region is not observed in D. desulfuricans.
The predicted 34 amino acid sequence encoded by
the incomplete ORF10 shows homologies with the
C-terminus of the translation elongation factor P
(EF-P). According to the alignment with its ortho-
logues, the predicted amino acid sequence represents
about 19% of the complete sequence, but it contains
the EF-P elongation factor P signature (KPATLET-
GLQVQVPLFVNLG). The EF-P is a prokaryotic
protein required for efficient peptide bond biosyn-
thesis on 70S ribosomes from fMet-tRNAfMet (Aoki
et al. 1997). EF-P reveals homologies with eIF5A
from Archaea/Eukarya, indicating that the machinery
of translation initiation would be present in the
universal ancestor (Kent et al. 1989).
Despite the apparently non-related functions of the
predicted proteins, some features suggest that these
ORFsareorganised asa polycystronicunit. Firstly, these
ORFs are separated by only few nucleotides. Secondly,
the analysis of genomes from other bacteria show that
the genes coding for putative lolA and ftsK are
frequently found in adjacent positions (Snel et al.
2000, von Mering et al. 2003), which suggests that these
proteins could be functionally related. Thirdly, RT-PCR
using oligonucleotides to amplify a region containing
parts of both ORF8 and 9 (Figure 2), resulted in a
product with the expected length, indicating that these
genes are co-transcribed in D. gigas.
It was found in the ORF9 (ftsK) N-terminus a lipid-
binding domain (MLGLGCLLLAC) usually present
in lipoproteins, not typical of ftsK. The presence of
this domain could suggest that the predicted ftsK
might have a different function in D. gigas somehow
related with the predicted lolA. However, the
D. desulfuricans homologous protein coding region
also seems to be co-transcribed with the lolA gene,
although the amino acid sequence does not contain
this lipoprotein lipid attachment site.
Conclusions
In the present report, it is shown that flavoredoxin is
transcribed by a monocystronic unit as previously
predicted from the DNA sequence analysis (Agostinho
et al. 2000). Additionally, it was also shown that the
genes identified in the adjacent regions of flr, encode
several hypothetical proteins whose function are not
related with the metabolic pathway in which flavo-
redoxin was recently proposed to be involved (Broco
et al. submitted). Concerning the recently published
D. vulgaris genome (Heidelberg et al. 2004) and the
sequenced DNA regions of the D. desulfuricans genome,
flr seems to be encoded also by a monocystronic unit in
these Desulfovibrio species. Comparing the genes present
in the DNA regions around flr in these species of
Desulfovibrio with the D. gigas genomic organisation
described in the present paper, apart from an ABC
transporter operon present only in D. vulgaris and
D. desulfuricans, there is no common genes around flr
among these species. This suggests that the genetic
organisation around flr does not give any additional
information on the metabolic pathway on which
flavoredoxin might be involved. Interestingly, six from
the nine ORFs present in these regions encode
hypothetical proteins involved in the nucleic acids
metabolism, mainly in pathways involving RNA
molecules. It would be interesting to complete the
sequence of the operon containing ORF8–10. This
operon can contain additional genes frequently found
adjacent to lolA and fts K genes, such as the gene
M. Broco et al.214
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

encoding an ATPase from the AAA family, related to the
helicase subunit of the Holliday junction resolvase.
Additionally, it would be also interesting to investigate if
the N-terminus lipid-binding domain found in the
amino acid sequence of D. gigas ftsK is recognized by the
lipoprotein carrier lolA.
Acknowledgements
We are gratefull to STAB-Vida for having determined
the nucleotide sequence fluorograms. We thank
Fundacao para a Ciencia e a Tecnologia (FCT) for
the fellowship PRAXIS XXI/BD/21527/99 to
Manuela Broco, for the financial support POC-
TI/BME/37480/2001 to Claudina Rodrigues-Pousada.
References
Agostinho M, Oliveira S, Broco M, Liu MY, LeGall J, Rodrigues-
Pousada C. 2000. Molecular cloning of the gene encoding
flavoredoxin, a flavoprotein from Desulfovibrio gigas. Biochem
Biophys Res Commun 272:653–656.
Altschul F, Stephen TL, Madden AA, Schaffer J, Zhang Z, Zhang W,
Miller DJ, Lipman. 1997. Gapped BLAST and PSI-BLAST:
A new generation of protein database search programs. Nucleic
Acids Res 25:3389–3402.
Aoki H, Adams SL, Turner MA, Ganoza MC. 1997. Molecular
characterization of the prokaryotic efp gene product involved in a
peptidyltransferase reaction. Biochimie 79:7–11.
Aravind L. 1999. An evolutionary classification of the metallo-beta-
lactamase fold proteins. In Silico Biol 1:69–91.
Aravind L, Koonin EV. 1999. Novel predicted RNA-binding
domains associated with the translation machinery. J Mol Evol
48:291–302.
Ausubel FM, Brent R, Kingston RE, Moore DD, Seidman JG, Smith
JA, Struhl K. 1995. Current protocols in molecular biology.
New York: Greene Publishing Associates and Wiley-Interscience.
Barton LL. 1995. Sulfate-reducing bacteria. Vol. 8. New York
London: Plenum Press.
Bartz JK, Kline LK, Soll D. 1970. N6-(Delta 2-isopentenyl)adeno-
sine: Biosynthesis in vitro in transfer RNA by an enzyme purified
from Escherichia coli. Biochem Biophys Res Commun
40:1481–1487.
Begg KJ, Dewar SJ, Donachie WD. 1995. A new Escherichia coli cell
division gene, fts K. J Bacteriol 177:6211–6222.
Bendtsen JD, Nielsen H, von Heijne G, Brunak S. 2004. Improved
prediction of signal peptides: SignalP 3.0. J Mol Biol 340:783–795.
Bickle TA, Kruger DH. 1993. Biology of DNA restriction.
Microbiol Rev 57:434–450.
Bjork GR. 1985. E. coli ribosomal protein operons: The case of the
misplaced genes. Cell 42:7–8.
Boyle DS, Grant D, Draper GC, Donachie WD. 2000. All major
regions of FtsK are required for resolution of chromosome
dimers. J Bacteriol 182:4124–4127.
Callebaut I, Moshous D, Mornon JP, de Villartay JP. 2002.
Metallo-beta-lactamase fold within nucleic acids processing
enzymes: The beta-CASP family. Nucleic Acids Res 30:
3592–3601.
Chen L, Liu MY, LeGall J. 1993. Isolation and characterization of
flavoredoxin, a new flavoprotein that permits in vitro reconstitu-
tion of an electron transfer chain from molecular hydrogen to
sulfite reduction in the bacterium Desulfovibrio gigas. Arch
Biochem Biophys 303:44–50.
Connolly DM, Winkler ME. 1989. Genetic and physiological
relationships among the miaA gene, 2-methylthio-N6-(delta 2-
isopentenyl)-adenosine tRNA modification, and spontaneous
mutagenesis in Escherichia coli K-12. J Bacteriol 171:3233–3246.
Conrad J, Niu L, Rudd K, Lane BG, Ofengand J. 1999. 16S
ribosomal RNA pseudouridine synthase RsuA of Escherichia coli:
Deletion, mutation of the conserved Asp102 residue, and
sequence comparison among all other pseudouridine synthases.
RNA 5:751–763.
Dorazi R, Dewar SJ. 2000. Membrane topology of the N-terminus
of the Escherichia coli FtsK division protein. FEBS Lett 478:
13–18.
Durand JM, Bjork GR, Kuwae A, Yoshikawa M, Sasakawa C. 1997.
The modified nucleoside 2-methylthio-N6-isopentenyladeno-
sine in tRNA of Shigella flexneri is required for expression of
virulence genes. J Bacteriol 179:5777–5782.
Durand JM, Dagberg B, Uhlin BE, Bjork GR. 2000. Transfer RNA
modification, temperature and DNA superhelicity have a
common target in the regulatory network of the virulence of
Shigella flexneri: The expression of the vir F gene. Mol Microbiol
35:924–935.
Gasteiger E, Gattiker A, Hoogland C, Ivanyi I, Appel RD, Bairoch
A. 2003. ExPASy: The proteomics server for in-depth protein
knowledge and analysis. Nucleic Acids Res 31:3784–3788.
Geerlof A, Lewendon A, Shaw WV. 1999. Purification and
characterization of phosphopantetheine adenylyltransferase
from Escherichia coli. J Biol Chem 274:27105–27111.
Gomes CM, Silva G, Oliveira S, LeGall J, Liu MY, Xavier AV,
Rodrigues-Pousada C, Teixeira M. 1997. Studies on the redox
centers of the terminal oxidase from Desulfovibrio gigas and
evidence for its interaction with rubredoxin. J Biol Chem
272:22502–22508.
Gray J, Wang J, Gelvin SB. 1992. Mutation of the miaA gene of
Agrobacterium tumefaciens results in reduced vir gene expression.
J Bacteriol 174:1086–1098.
Heidelberg JF, Seshadri R, Haveman SA, Hemme CL, Paulsen IT,
Kolonay JF, Eisen JA, Ward N, Methe B, Brinkac LM, et al.
2004. The genome sequence of the anaerobic, sulfate-reducing
bacterium Desulfovibrio vulgaris Hildenborough. Nat Biotechnol
22:554–559.
Hofmann K, Stoffel W. 1993. TMbase—A database of membrane
spanning proteins segments. Biol Chem Hoppe-Seyler 374:166.
Izard T, Geerlof A. 1999. The crystal structure of a novel bacterial
adenylyltransferase reveals half of sites reactivity. EMBO J
18:2021–2030.
Kent HM, Buck M, Evans DJ. 1989. Cloning and sequencing of the
nifH gene of Desulfovibrio gigas. FEMS Microbiol Lett 61:73–78.
Kumar S, Tamura K, Jakobsen IB, Nei M. 2001. MEGA2:
Molecular evolutionary genetics analysis software. Bioinfor-
matics 17:1244–1245.
Kyte J, Doolittle RF. 1982. A simple method for displaying the
hydropathic character of a protein. J Mol Biol 157:105–132.
Malki S, De Luca G, Fardeau ML, Rousset M, Belaich JP,
Dermoun Z. 1997. Physiological characteristics and growth
behavior of single and double hydrogenase mutants of
Desulfovibrio fructosovorans. Arch Microbiol 167:38–45.
Malone T, Blumenthal RM, Cheng X. 1995. Structure-guided
analysis reveals nine sequence motifs conserved among DNA
amino-methyltransferases, and suggests a catalytic mechanism
for these enzymes. J Mol Biol 253:618–632.
von Mering C, Huynen M, Jaeggi D, Schmidt S, Bork P, Snel B.
2003. STRING: A database of predicted functional associations
between proteins. Nucleic Acids Res 31:258–261.
Peck HD. 1984. Physiological diversity of sulfate-reducing bacteria.
In: Tuovinen EOH, editor. Microbial chemoautothrophy.
Colombus: Ohio State University Press. p 309–335.
Postgate JR. 1984. The sulphate-reducing bacteria. 2nd ed.
Cambridge, England: Cambridge University Press.
Rodrigues R, Valente FM, Pereira IA, Oliveira S, Rodrigues-
Pousada C. 2003. A novel membrane-bound Ech [NiFe]
Characterisation of the flr flanking regions 215
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008

hydrogenase in Desulfovibrio gigas. Biochem Biophys Res
Commun 306:366–375.
Saitou M, Nei M. 1987. The neighbor-joining methods:A new method
for constructing phylogenetic trees. Mol Biol Evol 4:406–425.
Sambrook J, Fritsch EF, Maniatis T. 1989. Molecular cloning,
a laboratory manual. New York: Cold Spring Harbor.
Snel B, Lehmann G, Bork P, Huynen MA. 2000. STRING: A
web-server to retrieve and display the repeatedly occurring
neighbourhood of a gene. Nucleic Acids Res 28:3442–3444.
Szegedi SS, Gumport RI. 2000. DNA binding properties in vivo
and target recognition domain sequence alignment analyses of
wild-type and mutant Rsr I [N6-adenine] DNA methyltransfer-
ases. Nucleic Acids Res 28:3972–3981.
Thompson JD, Higgins DG, Gibson TJ. 1994. CLUSTAL W:
Improving the sensitivity of progressive multiple sequence
alignment through sequence weighting, position-specific gap
penalties and weight matrix choice. Nucleic Acids Res
22:4673–4680.
M. Broco et al.216
Downloaded By: [B-on Consortium - 2007] At: 19:14 20 October 2008
Copyright © 2022 FDOKUMEN




















