
A Simulated Annealing Approach to Understanding which Regions Matter for Explaining MNC Location

IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 34, NO. 4, NOVEMBER 2004 407
Blind Source Separation in Post-Nonlinear MixturesUsing Competitive Learning, Simulated Annealing,
and a Genetic AlgorithmFernando Rojas, Carlos G. Puntonet, Manuel Rodríguez-Álvarez, Ignacio Rojas, and
Rubén Martín-Clemente, Member, IEEE
Abstract—This paper presents a new adaptive procedure forthe linear and nonlinear separation of signals with nonuniform,symmetrical probability distributions, based on both simulatedannealing and competitive learning methods by means of a neuralnetwork, considering the properties of the vectorial spaces ofsources and mixtures, and using a multiple linearization in themixture space. Moreover, the paper proposes the fusion of twoimportant paradigms–genetic algorithms and the blind separationof sources in nonlinear mixtures. In nonlinear mixtures, opti-mization of the system parameters and, especially, the search forinvertible functions is very difficult due to the existence of manylocal minima. The main characteristics of the methods are theirsimplicity and the rapid convergence experimentally validatedby the separation of many kinds of signals, such as speech orbiomedical data.
Index Terms—Independent component analysis, nonlinear blindseparation of sources, signal processing.
I. INTRODUCTION
B LIND SOURCE separation (BSS) consists in recoveringunobserved signals from a known set of mixtures. The
separation of independent sources from mixed observed data isa fundamental and challenging signal-processing problem [2],[8], [17]. In many practical situations, one or more desired sig-nals needs to be recovered from the mixtures. A typical exampleis a set of speech recordings made in an acoustic environmentin the presence of background noise and/or competing speakers.This general case is known as the cocktail party effect, in ref-erence to a human’s brain ability to focus on one single voiceand ignoring other voices/sounds, which are produced simulta-neously with similar amplitude in a noisy environment. Spatialdifferences between the sources greatly increase this capability.
Manuscript received January 31, 2003; revised April 27, 2004. This work wassupported in part by the Spanish Interministerial Commission for Science andTechnology Spanish (CICYT) under Project TIC2001-2845 “PROBIOCOM”(Procedures for Biomedical and Communications Source Separation), ProjectTIC2000-1348, and Project DPI2001-3219. A preliminary version of this workwas presented at Advances in Multimedia Communications, Information Pro-cessing and Education (Learning 2002), Madrid, Spain, in 2002. This paperwas recommended by Guest Editors J. L. Fernández and A. Artés.
F. Rojas, C. G. Puntonet, M. Rodríguez-Álvarez, and I. Rojas are withthe Departamento de Arquitectura y Tecnología de Computadores (Com-puter Architecture and Technology Department), University of Granada,Granada 18071, Spain (e-mail: [email protected]; [email protected]; [email protected]; [email protected]).
R. Martín-Clemente is with the Department of Electronic Engineering, Uni-versity of Seville, Seville 41092, Spain (e-mail: [email protected]).
Digital Object Identifier 10.1109/TSMCC.2004.833297
The source separation problem has been successfully studiedfor linear instantaneous mixtures [1], [4], [14], [17], and morerecently, since 1990, for linear convolutive mixtures [12], [22],[24].
A. Independent Component Analysis (ICA)
The blind separation of sources problem can be approachedfrom a wider point of view by using ICA [7]. ICA appearedas a generalization of the popular statistical technique principalcomponent analysis (PCA).
The goal of ICA is to find a linear transformation given by amatrix , so that the random variables , of
are as independent as possible in
(1)
B. Nonlinear BSS
Nevertheless, the linear mixing model may not be appropriatefor some real environment. Even though the nonlinear mixingmodel is more realistic and practical, most existing algorithmsfor the BSS problem were developed for the linear model. How-ever, for nonlinear mixing models, many difficulties occur andboth the linear ICA and the existing linear demixing method-ologies are no longer applicable because of the complexity ofnonlinear parameters.
Therefore, researchers have recently started addressing algo-rithms for the BSS problem with nonlinear mixing models [10],[19], [20], [23]. In [11] and [15], the nonlinear componentsare extracted by a model-free method, which used Kohonen’sself-organizing-feature-map (SOFM), but suffers from the ex-ponential growth of network complexity and from interpolationerrors in recovering continuous sources. Burel [3] proposed anonlinear mixing model applying a two-layer perceptron to theblind source separation problem, which is trained by the clas-sical gradient descent method to minimize the mutual informa-tion.
In [10], a new set of learning rules for the nonlinear mixingmodels based on the information maximization criterion is pro-posed. The mixing model is divided into a linear mixing partand a nonlinear transfer channel, in which the nonlinear func-tions are approximated by parametric sigmoidal or by higherorder polynomials.
1094-6977/04$20.00 © 2004 IEEE

408 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 34, NO. 4, NOVEMBER 2004
More recently, Yang et al. [23] developed an informationbackpropagation algorithm for Burel’s model by a natural gra-dient method, using special nonlinear mixtures in which thenonlinearity could be approximated by a two-layer perceptron.Other important work in source separation in post-nonlinearmixture is presented in [19]. In this methodology, the estima-tion of nonlinear functions and score functions is made using amultilayer perceptron with sigmoidal units trained by unsuper-vised learning.
In addition, an extension of ICA to the separation sources innonlinear mixture is to employ a nonlinear function to transformthe mixture such that the new outputs become statistically inde-pendent after the transformation. However, this transformationis not unique and, if it is not limited for demixing transforms,this extension may give statistically independent output sourcesthat are completely different from the original unknown sources.Although, to the best of our knowledge, there currently existmany difficulties in this transform and several nonlinear ICAalgorithms have been proposed and developed.
Nevertheless, one of the greatest problems encounteredwith nonlinear mixing models is that the approximation ofthe nonlinear function by the various techniques (perceptron,sigmoidal, radial basis functions networks (RBF), etc.) runsinto a serious difficulty: there are many local minima in thesearch space of the parameter solutions for adapting nonlinearfunctions. The output surface of a performance index, basedon the mutual information when the parameters of the non-linear function are modified, presents multiple and severe localminima. Therefore, algorithms that are based on a gradient de-scent for the adaptation of these nonlinear-function parametersmay become trapped within one such local minimum.
C. Outline of the Proposed Methods
This paper presents a new adaptive procedure for the linearand nonlinear separation of signals with nonuniform, sym-metrical probability distributions, based on both simulatedannealing (SA) and competitive learning (CL) methods bymeans of a neural network, considering the properties of thevectorial spaces of sources and mixtures, and using a multiplelinearization in the mixture space.
Also proposed in this work is a new algorithm for the non-linear mixing problem using flexible nonlinearities. This non-linear function may be approximated by th order odd polyno-mials. An algorithm that makes use of the synergy between ge-netic algorithms and the blind separation of sources (GABSS)was developed for the optimization of the parameters that de-fine the nonlinear functions. Simultaneously, a natural gradientdescent method is applied to obtain the linear demixing ma-trix. Unlike many classical optimization techniques, GAs donot rely on computing local first- or second-order derivativesto guide the search algorithm; GAs are a more general and flex-ible method that is capable of searching wide solution spacesand avoiding local minima (i.e., it provides more possibilities offinding an optimal or near-optimal solution). GAs deal simulta-neously with multiple solutions, not a single solution, and alsoinclude random elements, which help to avoid getting trappedin suboptimal solutions.
Fig. 1. Post-nonlinear mixing and demixing models for blind sourceseparation.
The paper is organized as follows: in the next section, thenonlinear mixture model and demixing system are illustrated(Section II). Section III depicts the proposed method usingcompetitive learning (Section III-A), simulated annealing (Sec-tion III-B) and both techniques simultaneously (Section III-C).In Section IV, a genetic algorithm (GA) approach is presentedin order to overcome entrapment within local minima, showingpromising experimental performance (Section IV-D). The twoproposed methods were compared in Section V. Finally, theconclusions and future work are summarized in Section VI.
II. NONLINEAR MIXTURE MODEL AND DEMIXING SYSTEM
The task of blind signal separation (BSS) is that of recoveringunknown source signals from sensor signals described by
(2)
where is an availablesensor vector, is an unknownsource vector having stochastic independent and zero-meannon-Gaussian elements , is an unknown full-rankand nonsingular mixing matrix, andare the set of invertible nonlinear transfer functions. The BSSproblem consists of recovering the source vector using onlythe observed data , the assumption of statistical indepen-dence between the entries of the input vector , and possiblysome a priori information about the probability distribution ofthe inputs. If all of the functions are linear, (2) reduces to thelinear mixing model. Even though the dimensions of andgenerally need not be equal, we make this assumption here forsimplicity.
Fig. 1 shows that the mixing system (known as a post-non-linear mixture) is divided into two different phases, as proposedin [19]. First, a linear mixing and then, for each channel , a non-linear transfer part. Reversely, for the separating system, first weneed to approximate , which is the inverse of the nonlinearfunction in each channel, and then separate the linear mixing byapplying to the output of the nonlinear function
(3)
In different approaches, the inverse function is approximatedby a sigmoidal transfer function, but because of certain situa-tions in which the human expert is not given the a priori knowl-

ROJAS et al.: BSS IN POST-NONLINEAR MIXTURES USING COMPETITIVE LEARNING 409
Fig. 2. Array of symmetrically distributed neurons in concentric p-spheres.
edge about the mixing model, a more flexible nonlinear transferfunction based on an th order odd polynomial is used
(4)
where is a parameter vector to be deter-mined. In this way, the output sources are calculated as
(5)
Nevertheless, computation of the parameter vectors is noteasy, as it presents a problem with numerous local minima whenthe usual BSS cost functions are applied. Thus, we require analgorithm that is capable of avoiding entrapment in such a min-imum. As a solution, we propose in this paper one algorithm em-ploying simulated annealing and competitive learning togetherand another algorithm applying GAs. We have used new meta-heuristics as simulated annealing and GAs for the linear case[5], [16], [18], [20], but in this paper, we will focus on a moredifficult problem, namely the nonlinear BSS.
III. HYBRIDIZING COMPETITIVE LEARNING AND
SIMULATED ANNEALING
We propose an original method for independent componentanalysis and blind separation of sources that combines adaptiveprocessing with a simulated annealing technique, and which isapplied by normalizing the observed space in a set of con-centric -spheres in order to adaptively compute the slopes cor-responding to the independent axes of the mixture distributionsby means of an array of symmetrically distributed neurons ineach dimension (Fig. 2).
A preprocessing stage to normalize the observed space is fol-lowed by the processing or learning of the neurons, which esti-mate the high density regions in a way similar, but not identicalto that of self-organizing maps. A simulated annealing optimiza-tion method provides a fast initial movement of the weights to-ward the independent components by generating random valuesof the weights and minimizing an energy function; this being a
way of improving the performance by speeding up the conver-gence of the algorithm. In order to work with well-conditionedsignals, the observed signals are preprocessed or adaptivelyset to zero mean and unity variance as follows:
(6)
In general, for blind separation and taking into account thepossible presence of nonlinear mixtures, the observation space
is subsequently quantized into spheres of di-mension ( -spheres), circles if , each with a radius
covering the points as follows:
(7)
The integer number of -spheres, , ensures accuracy in theestimation of the independent components, and it can be ad-justed depending on the extreme values of the mixtures ineach real problem. Obviously, the value of each radius de-pends on the number of -spheres, . From now on, we shalluse to denote the vector that verifies the inequality
. If, in some applications, the mixtureprocess is known to be linear, then the number of -spheresis set to 1, and a normalization of the space is obtained with
. Although the quantization given in (7) allows a piece-wise linearization of the observed space for the case of nonlinearand post-nonlinear mixtures, it is also useful with the assump-tion of linear media since it allows us to detect unexpected non-linearities in some real applications [16].
A. Competitive Learning
The above-described preprocessing is used to apply a com-petitive learning technique by means of a neural network whoseweights are initially located on the Cartesian edges of the
-dimensional space such that the network has neurons,with each neuron being identified with scalar weights
per -sphere. For instance, for mixtures oftwo sources and , thenand the network has four neurons (i.e., the neuron is repre-sented by ), and the neuron is representedby the weights both neurons initially locatedon the edge; the neuron is represented by the weights
, and the neuron is represented by theweights both neurons initially located on the
edge. The Euclidean distance between a point andthe neurons existing in the -dimensional space (Fig. 2) is
(8)
A neuron, labeled , in a p-sphere is at a minimum distancefrom the -dimensional point and verifies
(9)
The main process for competitive learning when a neuron ap-proaches the density region, in a sphere at time , is given by
(10)

410 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 34, NO. 4, NOVEMBER 2004
with being a decreasing learning rate. Note that a varietyof suitable functions, and can be used. In particular, alearning procedure that activates all of the neurons at once isenabled by means of a factor that modulates competitivelearning as in self-organizing systems, that is
(11)
Here is a neighborhood decreasing parameter, and isnow geometry-dependent and proportional to , as follows:
(12)where and modify the value of the learning rate de-pending on the correlation of the points in the observation spaceand on the number of -spheres in order to equalize the angularvelocity of the outer and inner weights. Note that the weightupdating is carried out using the sign function, in contrast tothe usual way [6]. As is well known, the term modulatesthe learning -sphere of jurisdiction depending on the valueof . After the learning process, the weights are maintainedin their respective -spheres, , by means of the followingnormalization:
(13)After converging, at the end of the competitive process, the
weights in (13) are located at the center of the projections ofthe maximum density points, or independent components, ineach -sphere. It is easy to corroborate that the total number ofscalar weights is . For the purpose of the separation ofsources, a matrix similar to and verifying expression(3) is needed, and a recursive neural network similar to the Her-ault–Jutten [9] network uses, as weights, a continuous functionof the scalar weights per sphere, as shown in Section III-A,(16) for the general case of sources. Once the neural networkhas estimated the maximum density subspaces by means of anadaptive (11), and due to the piecewise linearization of the ob-servation space with a number n of -spheres, a set of matricescan be defined as follows:
(14)
where, for dimensions, the matrices have the fol-lowing form:
(15)For linear systems or “symmetric” nonlinear mixtures, the ele-ments of this matrix obtained using competitive learningare considered to be the symmetric slopes in the segment of
-sphere radius between two consecutive weights initially
located on the same axis for each dimension , and finally, com-puted in (11) if the following transformation is carried out undergeometric considerations:
(16)
The superscript indicates that the separation matrix has beencomputed using competitive learning, which will be usefulin Section III-C. Note that (16) works only with even-labeledweights and can be simplified for linear media if and
; for instance, when , it is practical tooperate with only two neurons and in the circle . If
, the use of several -spheres is useful for nonlinearitydetection since in different matrices, in (15) are obtainedfor successive values of . The total number of coefficients
is since the value of the diagonal elementsin (16) is 1.
B. Simulated Annealing
Simulated annealing is a stochastic algorithm that representsa fast solution to some combinatorial optimization problems.As an alternative to the competitive learning method describedabove, we first propose hybridation with stochastic learning,such as simulated annealing, in order to find a fast convergenceof the weights around the maximum density points in the ob-servation space . This technique is effective if the chosenenergy or cost function for the global system is appropriate.It is first necessary to generate random values of the weightsand, second, to compute the associated energy of the system.This energy vanishes when the weights achieve a global min-imum, the method thus allowing escape from local minima. Forthe problem of blind separation of sources, we define an energy
related to the fourth-order statistics of the original p sources,due to the necessary hypothesis of statistical independence be-tween them as follows:
(17)
where is the 2 2 fourth-order cumulant ofand , that is
(18)
and represents the expectation of .
C. Competitive Learning With Simulated Annealing
Despite the fact that the technique presented in Section III-Bis fast, the greater accuracy achieved by means of the compet-itive learning shown in Section III-A led us to consider a newapproach. An alternative method for the adaptive computationof the matrix concerns the simultaneous use (or hybrida-tion) of the two methods described in Sections III-A and III-B
ROJAS et al.: BSS IN POST-NONLINEAR MIXTURES USING COMPETITIVE LEARNING 411
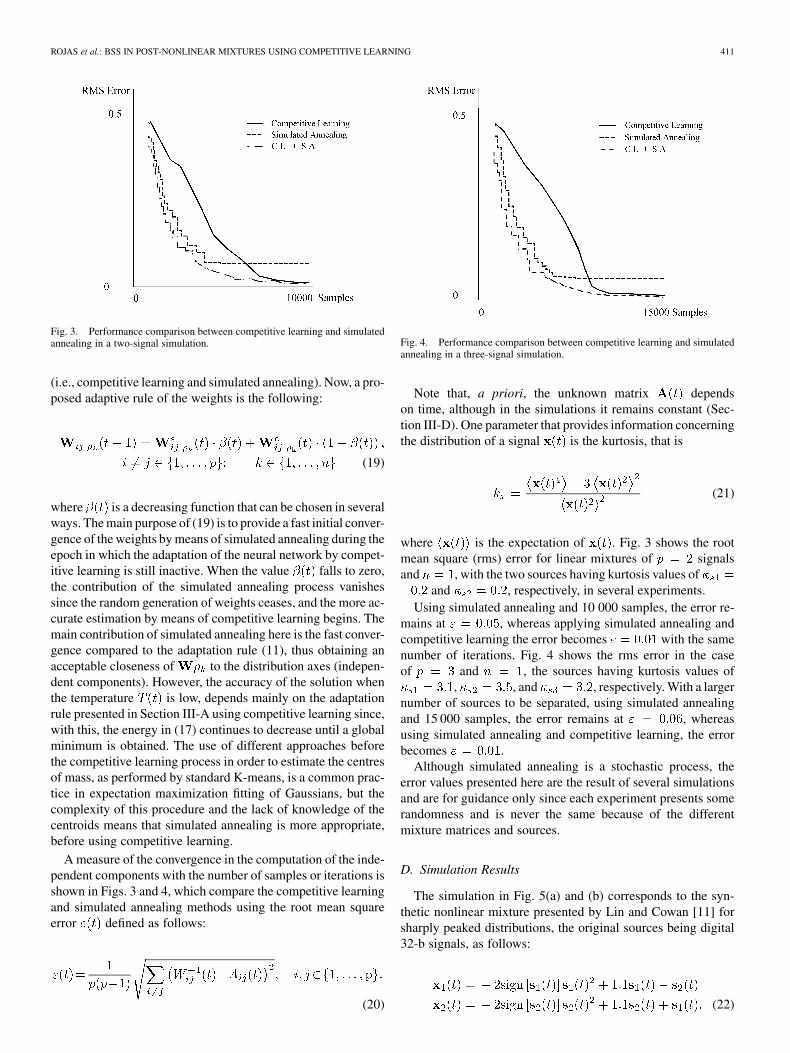
Fig. 3. Performance comparison between competitive learning and simulatedannealing in a two-signal simulation.
(i.e., competitive learning and simulated annealing). Now, a pro-posed adaptive rule of the weights is the following:
(19)
where is a decreasing function that can be chosen in severalways. The main purpose of (19) is to provide a fast initial conver-gence of the weights by means of simulated annealing during theepoch in which the adaptation of the neural network by compet-itive learning is still inactive. When the value falls to zero,the contribution of the simulated annealing process vanishessince the random generation of weights ceases, and the more ac-curate estimation by means of competitive learning begins. Themain contribution of simulated annealing here is the fast conver-gence compared to the adaptation rule (11), thus obtaining anacceptable closeness of to the distribution axes (indepen-dent components). However, the accuracy of the solution whenthe temperature is low, depends mainly on the adaptationrule presented in Section III-A using competitive learning since,with this, the energy in (17) continues to decrease until a globalminimum is obtained. The use of different approaches beforethe competitive learning process in order to estimate the centresof mass, as performed by standard K-means, is a common prac-tice in expectation maximization fitting of Gaussians, but thecomplexity of this procedure and the lack of knowledge of thecentroids means that simulated annealing is more appropriate,before using competitive learning.
A measure of the convergence in the computation of the inde-pendent components with the number of samples or iterations isshown in Figs. 3 and 4, which compare the competitive learningand simulated annealing methods using the root mean squareerror defined as follows:
(20)
Fig. 4. Performance comparison between competitive learning and simulatedannealing in a three-signal simulation.
Note that, a priori, the unknown matrix dependson time, although in the simulations it remains constant (Sec-tion III-D). One parameter that provides information concerningthe distribution of a signal is the kurtosis, that is
(21)
where is the expectation of . Fig. 3 shows the rootmean square (rms) error for linear mixtures of signalsand , with the two sources having kurtosis values of
and , respectively, in several experiments.Using simulated annealing and 10 000 samples, the error re-
mains at , whereas applying simulated annealing andcompetitive learning the error becomes with the samenumber of iterations. Fig. 4 shows the rms error in the caseof and , the sources having kurtosis values of
, , and , respectively. With a largernumber of sources to be separated, using simulated annealingand 15 000 samples, the error remains at , whereasusing simulated annealing and competitive learning, the errorbecomes .
Although simulated annealing is a stochastic process, theerror values presented here are the result of several simulationsand are for guidance only since each experiment presents somerandomness and is never the same because of the differentmixture matrices and sources.
D. Simulation Results
The simulation in Fig. 5(a) and (b) corresponds to the syn-thetic nonlinear mixture presented by Lin and Cowan [11] forsharply peaked distributions, the original sources being digital32-b signals, as follows:
(22)

412 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 34, NO. 4, NOVEMBER 2004
Fig. 5. (a) Joint distribution space of 32-b uniform sources. (b) Nonlinearmixture joint distribution.
Fig. 6. Neurons configuration adapting to Lin and Cowan nonlinearity.
The crosstalk parameter is used to verify the similaritybetween the original and separated signals with sam-ples, and is defined as
(23)As shown in Fig. 6, good estimation of the density distribution
is obtained with 20 000 samples, and using -spheres. For the purpose of the separation, the four equation
matrices obtained by means of (14), at the end of the competitivelearning process, were
(24)
The crosstalk parameters of the separated signals regardingthe original sources were on average of 100 simulations
dB dB
It has been verified that the greater the kurtosis of the sig-nals, the more accurate and faster is the estimation, except forthe case in which the signals are not well conditioned or are af-fected by noise, and this is so since a high density of points onthe independent components speeds up convergence when thecompetitive learning of (11) is used. Moreover, since the distri-bution estimation is made in the observation space and theseparation is blind, it is useful to take into account the kurtosisof the observed signals in order to test the time convergence andthe precision.
IV. GAs
Genetic algorithms (GAs) are nowadays one of the most pop-ular stochastic optimization techniques, being inspired by nat-ural genetics and biological evolutionary process. The GA eval-uates a population and generates a new one iteratively, with eachsuccessive population referred to as a generation. Given the cur-rent generation at iteration , , the GA generates a new gen-eration based on the previous generation, applying a setof genetic operations. The GA uses three basic operators to ma-nipulate the genetic composition of a population: reproduction,crossover, and mutation [5]. Reproduction consists of copyingchromosomes according to their objective function (strings withhigher evaluations will have more chances of surviving). Thecrossover operator mixes the genes of two chromosomes se-lected in the phase of reproduction, in order to combine the fea-tures, especially their positive ones. Mutation is occasional; withlow probability, it produces an alteration of some gene valuesin a chromosome (for example, in binary representation a 1 ischanged into a 0 or vice versa).
A. Evaluation Function Based on Mutual Information
In order to perform the GA, it is very important to define anappropriate fitness function (or contrast function in BSS con-text). This fitness function is constructed bearing in mind thatthe output sources must be independent of their nonlinear mix-tures. For this purpose, we must utilize a measure of indepen-dence between random variables. Here, the mutual informationis chosen as the measure of independence.
Many forms of evaluation functions can be used in a GA, sub-ject to the minimal requirement that the function be able to mapthe population into a partially ordered set. As stated, the eval-uation function is independent of the GA (i.e., stochastic de-cision rules). Unfortunately, regarding the separation of a non-linear mixture, independence alone is not sufficient to performblind recovery of the original signals. Some knowledge of themoments of the sources, in addition to the independence, is re-quired. A similar index as proposed in [5] is used for the fitnessfunction that approximates mutual information
(25)Values near to zero of mutual information (25) between the
imply independence between those variables, being statisticallyindependent if .

ROJAS et al.: BSS IN POST-NONLINEAR MIXTURES USING COMPETITIVE LEARNING 413
In the above expression, the calculation of needs toapproximate each marginal probability density function (pdf)of the output source vector , which are unknown. One usefulmethod is the application of the Gram–Charlier expansion,which only needs some moments of as suggested by Amariet al. [1] to express each marginal pdf of as
(26)where and .
The approximation of entropy (26) is only valid for uncorre-lated random variables, being necessary to preprocess the mixedsignals (prewhitening) before estimating their mutual informa-tion. Whitening or sphering of a mixture of signals consists offiltering the signals so that their covariances are zero (uncorre-latedness), their means are zero, and their variances equal unity.
The evaluation function that we compute is the inverse ofmutual information in (25), so that the objective of the GA is tomaximize the following function in order to increase statisticalindependence between variables:
eval function (27)
B. Synergy Between GAs and Natural Gradient Descent
Given a combination of weights obtained by the GAs for thenonlinear functions expressed as , where theparameter vector that defines each function is expressed by
, it is necessary to learn the elements ofthe linear separating matrix to obtain the output sources
. For this task, we use the natural gradient descent method toderive the learning equation for as proposed in [20] and [23]
(28)
where
(29)
and denotes the Hadamard product of two vectors.
C. Genetic Operators
Typical crossover and mutation operators will be used for themanipulation of the current population in each iteration of theGA. The crossover operator is “Simple One-point Crossover.”The mutation operator is “Non-Uniform Mutation” [13]. Thisoperator presents the advantage, compared to the classical uni-form mutation operator, of making fewer significant changesto the genes of the chromosome as the number of genera-tions grows. This property makes the exploration-exploitation
Fig. 7. Original signals (s) corresponding to three persons saying the numbers1 to 10 in English, Japanese, and Spanish.
tradeoff more favorable to exploration in the early stages of thealgorithm, while exploitation becomes of greater importancewhen the solution given by the GA is closer to the optimalsolution.
D. Simulation Results
To provide an experimental demonstration of the validity ofGABSS, we will use a system of three sources. The signalsmatch up with three different persons saying the numbers one toten in English, Japanese, and Spanish, respectively. The numberof samples was 12 600. These signals were first linearly mixedwith a 3 3 mixture matrix
(30)
The nonlinear distortions were selected as
The goal of the simulation was to analyze the behavior of the GAand observe whether the fitness function thus achieved is opti-mized. With this aim, we studied the mixing matrix obtainedby the algorithm and the inverse function. When the number ofgenerations reached a maximum value, the best individual fromthe population was selected and the estimated signals wereextracted, using the mixing matrix , and the inverse func-tions . Figs. 7 and 8 represent the original and mixed signals,respectively.
Fig. 9 shows the separated signals obtained with the proposedalgorithm for one of the simulations. As can be seen, the signalsare very similar to the original ones, up to possible scaling fac-tors and permutations of the sources (e.g., estimated signal

414 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 34, NO. 4, NOVEMBER 2004
Fig. 8. Mixed signals (x) after a post-nonlinear mixture.
Fig. 9. Obtained signals (y) which approximate source signals in Fig. 7.
match up with source signal , but it changed also in amplitudeterms).
Fig. 10 compares the approximation of the polynomial func-tions to the inverse of . Finally, Fig. 11 shows the joint rep-resentation of the original, mixed, and obtained signals.
1) Parameters of the GA: In this practical application, thepopulation size was and the number of generationswas iterations . The crosstalk parameters of the separatedsignals regarding to the original voices were on average of100 simulations
dB
dB
and dB
Concerning genetic operator parameters, the crossover proba-bility per chromosome was and mutation probability
Fig. 10. Comparison of the unknown f and its approximation by p .
Fig. 11. Representation of the joint distribution of the original (s), mixed (x),and obtained (y) signals.
per gene was . These values were selected becauseof their better performance when compared with other combi-nations that were evaluated as well.
V. PERFORMANCE COMPARISON
After having presented both approaches, let us compare thetwo. At first glance, simulated annealing is the faster approach,although competitive learning gives better results in terms ofaccuracy. The GA approach, on the other hand, is slower butleads to better performance when there are many local minimadue to the tendency of other algorithms to get stuck in these localsolutions.
Although a thorough performance analysis should be carriedout in future studies, some conclusions can be drawn from theexperimental performance results shown in Table I. The parame-ters of the GA were the same as those described in Section IV-D.

ROJAS et al.: BSS IN POST-NONLINEAR MIXTURES USING COMPETITIVE LEARNING 415
TABLE IPERFORMANCE COMPARISON OF THE TWO APPROACHES
To quantify the performance achieved, we calculate the compo-nent-wise crosstalk measure (23) and we ran each algorithm 100times for two and three nonlinear mixtures, measuring also thetime of convergence.
The two uniform signals simulation match with theLin–Cowan nonlinear mixture already presented in Sec-tion III-D. The simulation of two synthetic signals and avoice signal refers to a sinusoidal and a square signal, and atelephone ring recording, respectively. The three Laplaciansignals correspond to the ones shown in simulation describedin Section IV-D.
VI. CONCLUSION
We have shown a new powerful adaptive-geometric methodbased on competitive unsupervised learning and simulated an-nealing, which finds the distribution axes of the observed signalsor independent components by means of a piecewise lineariza-tion in the mixture space, the use of simulated annealing in theoptimization of a fourth-order statistical criterion being an ex-perimental advance.
This article also discusses an appropriate application of GAsto the complex problem of the blind separation of sources.It is widely believed that the specific potential of genetic orevolutionary algorithms originates from their parallel search bymeans of entire populations. In particular, the ability to escapefrom local optima is an ability very unlikely to be observed insteepest-descent methods. Although to date and to the best ofthe authors’ knowledge, there is little mention in the literatureof this synergy between GAs and BSS in nonlinear mixtures[20]; the article shows how GAs provide a tool that is perfectlyvalid as an approach to this problem.
We are currently studying the adaptation of the proposed GAtechnique to other types of nonlinear mixtures, such as timedependent and convolutive mixtures. Future work will include
a more meticulous performance comparison of the proposedmethods and their application to higher dimensionality prob-lems.
REFERENCES
[1] S.-I. Amari, A. Cichocki, and H. Yang, “A new learning algorithm forblind signal separation,” Adv. Neural Inform. Processing Syst., vol. 8,pp. 757–763, 1996.
[2] A. Bell and T. J. Sejnowski, “An information-maximization approachto blind separation and blind deconvolution,” Neural Comput., pp.1129–1159, 1995.
[3] G. Burel, “Blind separation of sources: a nonlinear neural algorithm,”Neural Netw., vol. 5, pp. 937–947, 1992.
[4] J. F. Cardoso, “Source separation using higher order moments,” in Proc.Int. Conf. Acoustics, Speech, Signal Processing, Glasgow, U.K., May1989, pp. 2109–2212.
[5] D. E. Goldberg, Genetic Algorithms in Search, Optimization and Ma-chine Learning. Reading, MA: Addison-Wesley, 1989.
[6] S. Haykin, Neural Networks. Englewood Cliffs, NJ: Prentice-Hall,1999.
[7] A. Hyvärinen, J. Karhunen, and E. Oja, Independent Component Anal-ysis. New York: Wiley, 2001.
[8] A. Hyvärinen and E. Oja, “A fast fixed-point algorithm for indepen-dent component analysis,” Neural Comput., vol. 9, no. 7, pp. 1483–1492,1997.
[9] C. Jutten and J. Herault, “Blind separation of sources, part I: An adaptivealgorithm based on neuromimetic structure,” Signal Processing, vol. 24,no. 1, pp. 1–10, 1991.
[10] T.-W. Lee, B. Koehler, and R. Orglmeister, “Blind separation of non-linear mixing models,” in Proc. IEEE Neural Networks for Signal Pro-cessing, 1997, pp. 406–415.
[11] J. K. Lin, D. G. Grier, and J. D. Cowan, “Source separation and densityestimation by faithful equivariant SOM,” in Advances in Neural Infor-mation Processing Systems. Cambridge, MA: MIT Press, 1997, vol. 9,pp. 536–542.
[12] A. Mansour, C. Jutten, and P. Loubaton, “Subspace method for blindseparation of sources in convolutive mixtures,” in Proc. Eur. Signal Pro-cessing Conf., Trieste, Italy, Sept. 1996, pp. 2081–2084.
[13] Z. Michalewicz, Genetic Algorithms + Data Structures = Evolution Pro-grams, 3rd ed. New York: Springer-Verlag, 1999.
[14] A. V. Oppenheim, E. Weinstein, K. C. Zangi, M. Feder, and D. Gauger,“Single-sensor active noise cancellation,” IEEE Trans. Speech AudioProcessing, vol. 2, pp. 285–290, Apr. 1994.
[15] P. Pajunen, A. Hyvarinen, and J. Karhunen, “Nonlinear blind source sep-aration by self-organizing maps,” in Proc. Progress in Neural Informa-tion Processing, vol. 2, New York, 1996, pp. 1207–1210.
[16] C. G. Puntonet, A. Mansour, C. Bauer, and E. Lang, “Separation ofsources using simulated annealing and competitive learning,” Neuro-computing, vol. 49, no. 1–4, pp. 39–60, 2002.
[17] C. G. Puntonet and A. Prieto, “Neural net approach for blind separationof sources based on geometric properties,” Neurocomputing, vol. 18, no.3, pp. 141–164, 1998.
[18] F. Rojas, I. Rojas, R. M. Clemente, and C. G. Puntonet, “Nonlinear blindsource separation using genetic algorithms,” in Proc. 3rd Int. WorkshopIndependent Component Analysis Signal Separation, San Diego, CA,2001, pp. 400–405.
[19] A. Taleb and C. Jutten, “Source separation in post-nonlinear mixtures,”IEEE Trans. Signal Processing, vol. 47, no. 10, pp. 2807–2820, 1999.
[20] Y. Tan and J. Wang, “Nonlinear blind source separation using higherorder statistics and a genetic algorithm,” IEEE Trans. Evol. Comput.,vol. 5, pp. 600–612, Dec. 2001.
[21] Y. Tan, J. Wang, and J. M. Zurada, “Nonlinear blind source separationusing a radial basis function network,” IEEE Trans. Neural Networks,vol. 12, pp. 124–134, Jan. 2001.
[22] H. L. N. Thi and C. Jutten, “Blind source separation for convolutivemixtures,” Signal Processing, vol. 45, pp. 209–229, 1995.
[23] H. H. Yang, S. Amari, and A. Chichocki, “Information-theoretic ap-proach to blind separation of sources in nonlinear mixture,” Signal Pro-cessing, vol. 64, pp. 291–300, 1998.
[24] D. Yellin and E. Weinstein, “Multichannel signal separation: methodsand analysis,” IEEE Trans. Signal Processing, vol. 44, pp. 106–118, Jan.1996.

416 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 34, NO. 4, NOVEMBER 2004
Fernando Rojas received the B.Sc. degree in com-puter science and the Ph.D. degree in independentcomponent analysis and blind source separation fromthe Universty of Granada, Granada, Spain, in 2000and 2004, respectively.
Currently, he is an Associate Professor working inthe Department of Computer Architecture and Tech-nology, University of Granada. From 2000 to 2001,he was working under a local fellowship with the De-partment of Computer Science and Artificial Intelli-gence at the University of Granada. He was a Visiting
Researcher with the University of Regensburg, Regensburg, Germany, in 2002.His main research interests include signal processing, source separation, inde-pendent component analysis, and evolutionary computation.
Carlos G. Puntonet was born in Barcelona, Spain,on August 11, 1960. He received the B.Sc., M.Sc.,and Ph.D. degrees in electronics physics from theUniversity of Granada, Granada, Spain, in 1982,1986, and 1994, respectively.
Currently, he is an Associate Professor withthe Department of Architecture and ComputerTechnology, University of Granada. He has been aVisiting Researcher with the Laboratorie de Traite-ment d’Images et Reconnaissance de Formes (INPG)Grenoble, France; the Institute of Biophysics, Re-
gensburg, Germany; and at the Institute of Physical and Chemical Research(RIKEN) Nagoya, Japan. His research interests include the signal processing,independent component analysis and blind separation of sources, artificialneural networks, and optimization methods.
Manuel Rodríguez-Álvarez received the B.Sc.degree in electronic physics and the Ph.D. degree inphysics from the University of Granada, Granada,Spain, in 1986 and 2002, respectively.
Currently, he is Associate Professor at the Com-puter Architecture and Technology Department, Uni-versity of Granada. He was a Visiting Professor atthe National Polytechnic Institute, Grenoble, France,in 1994 and 1995 and at the University of Regens-burg, Regensburg, Germany, in 2002. He was Asso-ciate Professor at the Electronic Department, Univer-
sity of Granada. His research interests include blind source separation (BSS)and independent component analysis (ICA).
Ignacio Rojas received the M.S. degree in physicsand electronics and the Ph.D. degree in neuro-fuzzynetworks from the University of Granada, Granada,Spain, in 1992 and 1996, respectively.
Currently, he is a Teaching Assistant with the De-partment of Architecture and Computer Technology,University of Granada. In 1998, he was a VisitingProfessor of the Berkeley Institute in Soft Computing(BISC) at the University of California at Berkeley.His research interests are hybrid system and combi-nation of fuzzy logic, genetic algorithms and neural
networks, financial forecasting, and financial analysis.
Rubén Martín-Clemente (S’96–M’01) was born inCordoba, Spain, on August 9, 1973. He received theM.Eng. degree in telecommunications engineeringand the Ph.D. degree (Hons.) in telecommunicationsengineering from the University of Seville, Seville,Spain, in 1996 and 2000, respectively.
Currently, he is an Assistant Professor with theDepartment of Electronic Engineering, Universityof Seville. His research interests include blind signalseparation, higher order statistics, and statisticalsignal and array processing and their application to
biomedical problems and communications. He has coauthored many contribu-tions in international journal and conference papers.
Copyright © 2022 FDOKUMEN




















