
Nuovi dati dal santuario umbro di Villa Fidelia. Fasi preromane e soluzioni architettoniche

Basi di Dati – Dispensa Didattica 2010/2011
Federico Giusfredi
Sommario Basi di Dati – Dispensa Didattica 2010/2011 ..................................................................................................... 1
1. Concetto di Banca Dati .............................................................................................................................. 3
2. Sistema gerarchico .................................................................................................................................... 3
3. Basi di Dati Relazionali ............................................................................................................................... 5
3.1 Distizione tra Token e Type ................................................................................................................. 5
3.2 Programmazione Object-Oriented ...................................................................................................... 6
3.3 Algebra Relazionale ............................................................................................................................. 6
3.4 Schema di una Banca Dati relazionale ................................................................................................. 8
3.5 Le forme normali ................................................................................................................................. 9
3.6 Tipi di join .......................................................................................................................................... 10
4. Cenni a SQL .............................................................................................................................................. 12
5. Cenni all’interazione di SQL con linguaggi di programmazione e scripting ............................................. 12
6. Esercizi ..................................................................................................................................................... 14

2
Alcune definizioni.
1. Banca dati: rappresentazione fisica dell’ordinamento concettuale di una porzione di
realtà
2. DBMS: database management system.
3. Struttura di una banca dati informatica: un insieme di tabelle.
4. Tabella: un insieme di attributi.
5. Attributo: campo di una tabella, può assumere diversi valori.
6. Dato: il contenuto di un campo di attributo.
7. Record: per record si intende la tupla dei dati contenuti in una riga di tabella.
8. Relazione: una relazione è qualsiasi legame tra tabelle, attributi o dati.
9. Superchiave: una superchiave è una tupla di colonne che identifica univocamente
un record.
10. Chiave candidata: è una superchiave di minima cardinalità in una tabella.
11. Chiave primaria: è una chiave candidata scelta come identificativo unario nella
progettazione della banca dati.
12. Query: una ricerca effettuata all’interno di una banca dati con una operazione di
selezione combinata, eventualmente, a forme di join.

3
1. Concetto di Banca Dati
Una banca dati è la rappresentazione fisica dell’ordinamento concettuale di una porzione di realtà. Il sito
dell’Università di Princeton definisce database come “an organized body of related information”. Sebbene
di norma si parli di banche dati solo in relazione all’informatica, è possibile pensare come banca dati
qualsiasi forma di archivio cartaceo o in altra forma.
L’organizzazione della banca dati si basa sui concetti di:
1. token e type
2. teoria degli insiemi
3. algebra relazionale
4. normalizzazione
Le banche dati, quando se ne dia definizione non strettamente informatica, sono sempre esistite. A
nascere nella seconda metà del XX secolo sono invece gli studi in merito alla loro architettura e, di
conseguenza, i primi sistemi informatici per la loro gestione. Prima di definire i termini citati nell’elenco
sovrastante, sarà utile qualche accenno alla storia di questi sistemi.
2. Sistema gerarchico
I primi sistemi di gestione di basi di dati (DBMS) nacquero negli anni 60, a partire dallo stesso gruppo di
ricerca che sviluppò il linguaggio di programmazione COBOL. Di fatto, i primi DBMS erano basati sul
concetto di navigazione (browsing) dei dati stessi, ed erano strutturalmente semplici.
Il primo DBMS propriamente inteso, definito cioè come un sistema per l’organizzazione e la ricerca dei dati
e non come una semplice collezione ordinata d’informazioni, fu il cosiddetto IMS (1968), un protocollo
gerarchico sviluppato da IBM. Ad esso seguì il protocollo di banca dati impiegato dal registro di sistema dei
sistemi operativi Windows. Questi tipi di banca dati sono tecnicamente definiti gerarchici.
La struttura di una banca dati gerarchica è essenzialmente verticale e lineare. Non permette alcun tipo di
relazione tra le sue parti che non siano relazioni di appartenenza in forma 1:N.
Corso di Informatica
Studenti Docenti
Nome Cognome Età Nome Cognome Età

4
Un sistema di tabelle nella banca dati in questione (esempio 1) gerarchica si presenterà in questo modo:
Banca Dati Corso di Informatica:
Tabella Docenti
Nome Cognome Età
Federico Giusfredi 28
Alfredo Rizza 35
Tabella Studenti
Nome Cognome Età
Mario Rossi 24
Maria Bianchi 23
Esempi più complessi di banche dati gerarchiche sono costituiti dai linguaggi di mark-up usati per la
costruzione di pagine web e per l’annotazione di testi tecnici e scientifici (SGML, HTML, XML, XHTML e
protocolli successivi). Può essere importante mostrare questo fatto attraverso un esempio, perché aiuta a
introdurre un concetto fondamentale per la comprensione dell’informatica: tutto quello che sta dentro un
computer è una banca dati.
Ecco un esempio di codice HTML (esempio 2):
<html>
<head>
<title>Sample</title>
<author>FG</author>
</head>
<body>
<h1>Titolo</h1>
<p>testo1</p></br>
<p>testo2</p></br>
</body>
</html>
HTML
HEAD BODY
TITLE AUTHOR H1 P

5
Il concetto di relazione 1:N fa parte della cosiddetta algebra relazionale. Per il momento, è sufficiente dire
che in questo tipo di relazione e in questo tipo di architetture è possibile associare a un elemento di ordine
superiore un numero indefinito di elementi di ordine inferiore, mentre a ciascun elemento di ordine
inferiore rimane associato uno e un solo elemento di ordine superiore.
In rappresentazione a tabelle, nell’esempio 1 alla tabella Studenti appartengono diversi elementi:
Studenti ∊ {nome, cognome, età}
Alla tabella Nome appartengono numerosi elementi, ma vi è una sola tabella T, in questo caso la tabella
Studenti, che la contiene.
Nome ∊ {mario, maria}
∃! T | Nome ∊ T
Per avere un esempio chiaro e lampante della struttura di una banca dati gerarchica, sarà dunque
sufficiente aprire il registro di Windows di un computer o aprire con un editor di testo la sorgente di un
testo taggato in HTML, XML o linguaggio affine.
3. Basi di Dati Relazionali
Le banche dati gerarchiche hanno una potenza piuttosto limitata. Qualora vi sia la necessità di creare
banche dati con una struttura molto complessa, si genererebbero difficoltà legate al peso informatico della
struttura e alla necessità di formulare query molto lunghe, ripetitive e poco duttili.
In una banca dati simile a quella dell’esempio 1, ma che raccolga i corsi di informatica di tutte le università
della Lombardia, con un numero elevatissimo di studenti, potremmo avere 300 persone che abbiano il
nome Mario. Ogni occorrenza del nome Mario, in sé e per sé, pesa 40 bit (5 byte). Il totale dei “Mario” nella
banca dati peserà quindi 1200 bit (240 byte). Se anche non si tratta di una cifra spaventosa, è evidente che
se fosse possibile evitare di ripetere il nome 300 volte, scrivendolo una volta sola e “collegando” tutti i
Mario della banca dati a quell’unica occorrenza del nome, risparmieremmo 235 byte.
In banche dati veramente grandi, ad esempio nell’Opac di sbn, che contiene tutti i libri editi in Italia e/o
posseduti da biblioteche italiane, questo spreco di spazio diviene un problema critico. I “Mario” contenuti
in tale banca dati sono – al 17 febbraio 2011, 140678. Più di mezzo Mb sprecato per un singolo nome di
battesimo.
La soluzione a questo problema è offerta dalle cosiddette banche dati relazionali, per spiegare le quali è
necessario introdurre alcuni concetti di base.
3.1 Distizione tra Token e Type
La distinzione tra type e token, introdotta da Willard Van Orman Quine nel 1987 (Quiddities), permette di
superare la necessità di un’organizzazione gerarchica delle informazioni. Di fatto, non è certo stato
necessario attenderne la teorizzazione, giacché si tratta di un concetto piuttosto intuitivo: la frase “I gatti
non mangiano i gatti” contiene 6 parole-token (i, gatti, non, mangiano, i, gatti), ma solo 4 parole-type (i,
gatti, non, mangiano). Si tratta, molto semplicemente, di distinguere tra i tipi – che sono meno – e le

6
singole occorrenze di ciascun tipo. Per ulteriori dettagli, si veda la Stanford Encyclopedia of Philosophy:
http://plato.stanford.edu/entries/types-tokens/
Nel caso dell’esempio 1, ciascun “mario” è un token, o istanza, del type “mario”. Possiamo dunque
riformulare il problema della riduzione del peso informatico nei termini seguenti: vogliamo che ogni type
sia citato una sola volta, e che ciascun suo token punti ad esso.
3.2 Programmazione Object-Oriented
La programmazione orientata all’oggetto è la trasposizione informatica della teoria dei token e dei type. La
distinzione è fra classi (type) e istanze (token) di funzioni e comandi. I linguaggi di programmazione usati
per costruire banche dati sono linguaggi (generalmente del secondo ordine) orientati all’oggetto.
Non bisogna confondere le banche-dati relazionali costruite con linguaggi orientati all’oggetto con i
cosiddetti Object Oriented Relational Data Base Management Systems (OORDBMS), che sono invece
banche dati di classi e funzioni informatiche, usate in prevalenza in ambito tecnologico e ingegneristico.
3.3 Algebra Relazionale
L’algebra relazionale è un’algebra della logica del primo ordine e del linguaggio degli insiemi. Oggetti
dell’algebra relazionale sono le relazioni tra insiemi.
Essa prevede 6 operatori primari: unione, differenza, prodotto cartesiano, selezione, proiezione,
ridenominazione. Prevede inoltre tre operatori derivati: intersezione, join, divisione.
3.3.1 Unione
L’unione di due o più relazioni contiene le tuple che appartengono a una qualunque delle due relazioni:
R ∊ {a,b,c}
S ∊ {a, d, e}
R∪S ∊ {a,b,c,d,e}
3.3.2 Differenza
La differenza di due o più relazioni contiene le tuple che non appartengono ad entrambe le relazioni:
R ∊ {a,b,c}
S ∊ {a, d, e}
R-S ∊ {b,c,d,e}
3.3.3 Intersezione
L’intersezione di due o più relazioni contiene le tuple che appartengono ad entrambe le relazioni:
R ∊ {a,b,c}
S ∊ {a, d, e}
R∩S ∊ {a}

7
3.3.4 Ridenominazione
L’operatore unario o binario di ridenominazione modifica il nome di uno o più attributi in una relazione. Si
usa di solito per rendere omogenee le tuple di diverse relazioni.
3.3.5 Prodotto Cartesiano
L’operatore binario di prodotto cartesiano è identico all’omonimo operatore dell’algebra degli insiemi.
3.3.6 Selezione
L’operatore di selezione è definito su una o due relazioni R (e S) e una formula di relazione F, definita come
una procedura su un insieme di attributi mediata dagli operatori di uguaglianza e disuguaglianza (≥≤ <> =≠).
La selezione restituisce gli elementi di S che verificano F su R. Ad esempio:
R ∊ {5, 8, 3}
S ∊ {1, 2, 9}
(applicazione binaria) F(X,Y) = Xi ≤ Yi F(S,R) = {1, 2}
(applicazione unaria) G(X) = Xi > 5 G(R) = {8}
3.3.7 Proiezione
L’operatore unario di proiezione definisce un sottoinsieme di nomi di attributo all’interno di una relazione.
3.3.8 Divisione
L’operatore di divisione tra due relazioni R, S restituisce gli elementi di R che non sono presenti in S ma le
cui combinazioni con tuple in S sono presenti in R.
R ∊ {AB, AC, BC, BD}
S ∊ {B,C}
R÷S ∊ {A}
3.3.9 Join
L’operatore di join è di gran lunga il più complicato. In generale, si definisce condizione di join un
collegamento logico tra due relazioni. La condizione di join può essere vista come una formula di relazione
definita sugli attributi delle due relazioni: in tal senso, il join può è un’operazione di selezione il cui risultato
definisce una nuova relazione.
Un esempio elementare è il seguente.
R ∊ {a, b, c}
S ∊ {a, b, c, d, e}
F(Xi,Yi) = Xi=Yi
J = R⋈S
J = {a, b, c }

8
3.4 Schema di una Banca Dati relazionale
Diversamente delle banche dati gerarchiche, le banche dati relazionali sono organizzate in base a relazioni
che non sono limitate a uno schema 1:N. Prevedono invece tre tipi di relazione: 1:N, 1:1, N:N. Questi tre
livelli di relazione sono uno strumento molto potente, che, attraverso l’impiego di linguaggi orientati
all’oggetto, permette di creare architetture snelle e duttili, che ottimizzano lo spazio e le dinamiche di
organizzazione e di query.
Nei seguenti schemi, illustrerò alcune possibili parti di banche dati bibliografiche di tipo relazionale. Si noti
che ogni tabella contiene un campo id. Si tratta di un identificativo unario del record all’interno dea tabella,
che è definito, di norma, attraverso un numero intero.
Ecco un primo esempio di schema relazionale, basato su relazioni tra chiavi primarie:
1:1 1:1
1:1
In generale, una banca dati gerarchica per una bibliografia avrebbe necessità, come abbiamo visto, di
riscrivere il nome “mario” per ciascun libro scritto da un autore che si chiami Mario. Allo stesso modo,
dovremmo riscrivere l’anno 1952 per tutti i libri pubblicati nel 1952, e dovremmo riscrivere Ellroy per tutti i
libri scritti da un autore che di cognome si chiami Ellroy.
La tabella qui sopra mostra una possibile soluzione per risolvere questo problema, basata su relazioni 1:N:
lo stesso identificativo unario punta a istanze potenzialmente infinite di un’unica stringa. Il rapporto tra
questo genere di modello di dati e il concetto di token e type dovrebbe ora risultare evidente.
La relazione N:N è più complicata. Immaginiamo di voler ottimizzare i nomi e i cognomi degli autori in una
banca dati. A più cognomi corrispondono più nomi e viceversa (ad esempio Mario Rossi, Guido Bianchi,
Guido Rossi, Mario Bianchi).
Id.
Id Nome
Id Cognome
Titolo
Id Anno
Id anno
Anno
Id Nome
Nome
Id Cognome
Cognome
Nome Id.
Marco 1
Mario 2
Filippo 3
Mauro 4

9
N:1 1:N
1:N
Questo tipo di relazione permette di creare entries in cui un singolo numero id riporta una singola
associazione di nome e cognome.
3.5 Le forme normali
I metodi per la creazione di architetture dati ottimali sono riassunti da una famiglia di leggi comunemente
dette forme normali. Sono regole che – se seguite in fase di progettazione – permettono di creare basi di
datti leggere e funzionali, e di evitare bug nelle query e nell’inserimento dei dati.
3.5.1 Prima Forma Normale
Se una tabella contiene più campi dello stesso tipo, essi vanno eliminati e organizzati in una tabella
separata.
N:1
3.5.2 Seconda Forma Normale
Se una tabella contiene campi con valori ripetuti, è necessario organizzare il campo in una nuova tabella.
Inoltre, perché si consideri applicata la seconda forma normale, è necessario che sia applicata la prima.
N:1
Id.
Nome
Id.NomeCognome
Id. Nome
Id. Cognome
Id.
Cognome
Id.Libro
Id. NomeCognome
Titolo
Anno
Editore
Collana
Titolo
Autore1
Autore2
Id. Titolo
Id. Attore
Attore
Id. Titolo
Titolo
Titolo
Autore
Titolo
Id. Autore
Id.
Nome Autore

10
3.5.3 Terza Forma Normale
Se la tabella contiene campi collegati in modo univoco fra loro, è necessario eliminarli includendoli in una
tabella a parte. Un buon esempio si può fornire considerando una banca dati di libri americani. Spesso, in
bibliografia, si citano la cassa editrice, la città di pubblicazione e – ad esempio negli USA – anche lo stato.
N:1
3.5.4 La Forma normale di Boyce-Codd, la quarta e la quinta forma normale
Le tre forme normali superiori alla terza non sono sempre richieste nella prassi, e sono, di fatto, delle forme
teoriche di ottimizzazione.
La forma normale di Boyce Codd è un potenziamento della terza forma normale, in cui ogni relazione
definita su coppie di attributi sia una superchiave o un sovrainsieme. Di fatto, quasi tutte le banche dati in
3NF sono già automaticamente in BCNF.
La quarta forma normale richiede che ogni relazione N:N sia una superchiave.
La quinta forma normale richiede che ogni relazione di dipendenza sia derivabile dalle chiavi candidate.
3.6 Tipi di join
I tipi di join che possono essere applicati ad una relazione tra tabelle sono fondamentalmente 3: cross join
(prodotto cartesiano), inner join, outer join (a sinistra o a destra).
3.6.1 Cross Join
Si tratta di un semplice prodotto cartesiano. Si consideri il seguente esempio:
Il cross join delle due tabelle è il banalmente seguente:
Casa Editrice
Città
Stato
Id. Casa Editrice Id.
Casa Editrice
Città
Stato
Libro Autore
IT St. King
L.A. Confidential J. Ellroy
Autore Età
St. King 62
J. Ellroy 63
Libro Autore Autore Età
IT St. King St. King 62
L.A. Confidential J. Ellroy J. Ellroy 63
IT St. King J. Ellroy 63
L.A. Confidential J. Ellroy St. King 62
11
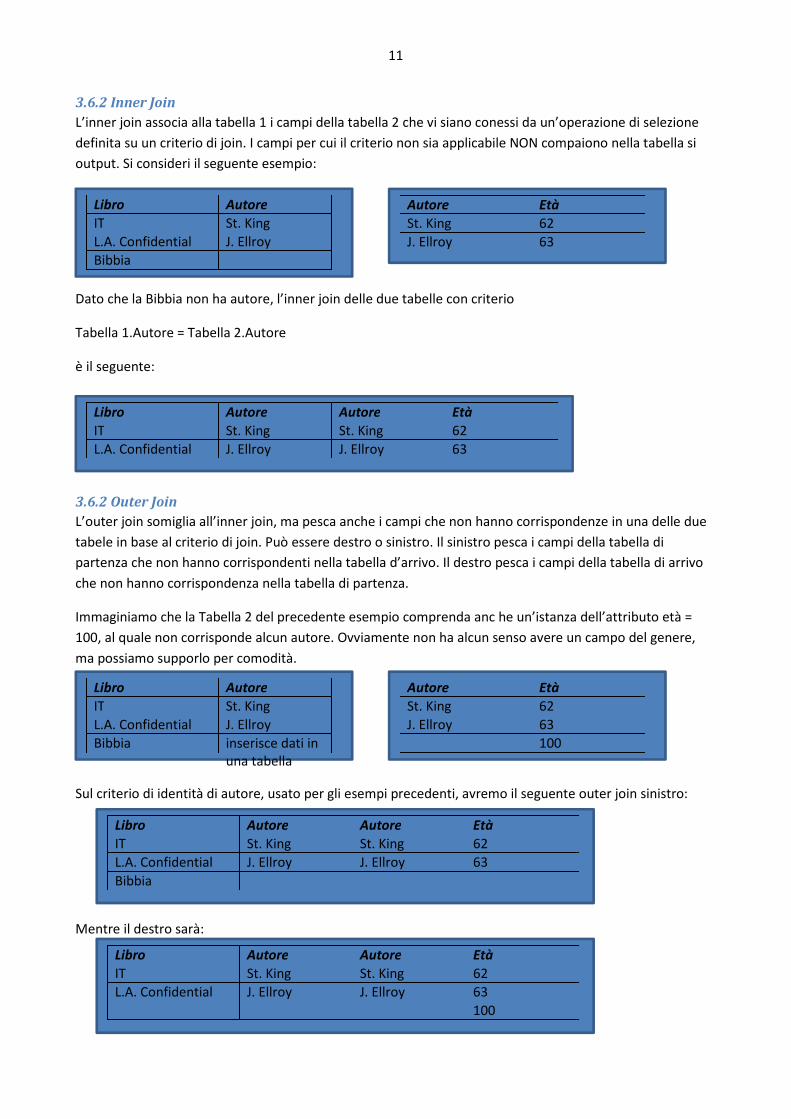
3.6.2 Inner Join
L’inner join associa alla tabella 1 i campi della tabella 2 che vi siano conessi da un’operazione di selezione
definita su un criterio di join. I campi per cui il criterio non sia applicabile NON compaiono nella tabella si
output. Si consideri il seguente esempio:
Dato che la Bibbia non ha autore, l’inner join delle due tabelle con criterio
Tabella 1.Autore = Tabella 2.Autore
è il seguente:
3.6.2 Outer Join
L’outer join somiglia all’inner join, ma pesca anche i campi che non hanno corrispondenze in una delle due
tabele in base al criterio di join. Può essere destro o sinistro. Il sinistro pesca i campi della tabella di
partenza che non hanno corrispondenti nella tabella d’arrivo. Il destro pesca i campi della tabella di arrivo
che non hanno corrispondenza nella tabella di partenza.
Immaginiamo che la Tabella 2 del precedente esempio comprenda anc he un’istanza dell’attributo età =
100, al quale non corrisponde alcun autore. Ovviamente non ha alcun senso avere un campo del genere,
ma possiamo supporlo per comodità.
Sul criterio di identità di autore, usato per gli esempi precedenti, avremo il seguente outer join sinistro:
Mentre il destro sarà:
Libro Autore
IT St. King
L.A. Confidential J. Ellroy
Bibbia
Autore Età
St. King 62
J. Ellroy 63
Libro Autore Autore Età
IT St. King St. King 62
L.A. Confidential J. Ellroy J. Ellroy 63
Libro Autore
IT St. King
L.A. Confidential J. Ellroy
Bibbia inserisce dati in
una tabella
Autore Età
St. King 62
J. Ellroy 63
100
Libro Autore Autore Età
IT St. King St. King 62
L.A. Confidential J. Ellroy J. Ellroy 63
Bibbia
Libro Autore Autore Età
IT St. King St. King 62
L.A. Confidential J. Ellroy J. Ellroy 63
100

12
4. Cenni a SQL
Per costruire banche dati relazionali è possibile utilizzare interfacce software più o meno duttili e
tendenzialmente user-friendly, oppure lavorare direttamente con un linguaggio di programmazione e
query. I linguaggi più usati appartengono alla famiglia di SQL: Structured Query Language.
Tali linguaggi sono di norma inglobato all’interno di software per la gestione e l’architettura, quali MS
Access, Openoffice Base, Oracle, MySQL.
Per una introduzione a SQL, si rimanda alla guida di S. Rubini, MySQL, Apogeo, 2004. In questa sede, mi
limiterò a fornire un esempio di serie di comandi per creare una semplice banca dati relazionale.
CREATE DATABASE Bibliografia; crea la banca dati vuota
USE Bibliografia; entra in Bibliografia per modificarlo/consultarlo
CREATE Titoli
(id INTEGER NOT NULL,
titolo VARCHAR,
id_autore INTEGER NOT NULL,
PRIMARY KEY id);
crea la tabella Titoli, con campi titolo (una stringa di
caratteri), id (un intero, chiave primaria), id_autore
(un intero).
CREATE Autori
(id INTEGER NOT NULL,
autore VARCHAR,
PRIMARY KEY id)
crea la tabella autori.
INSERT INTO Autori
SET id=’1’, autore=’Alessandro Manzoni’;
inserisce dati in una tabella
INSERT INTO Titoli
SET id=’1’, titolo=”I promessi sposi”, id_autore=’1’;
inserisce dati in una tabella
SELECT * from Autori; Restituisce la tabella autori con tutti i suoi campi.
SELECT Titoli.titolo, Autori.autore from Titoli INNER
JOIN Autori WHERE Titoli.autore_id =
Autori.autore_id SORT BY Autore.autori;
Restituisce l’esito di un inner join delle due tabelle,
limitandosi ai soli campi autore e titolo, ordinandoli
in ordine alfabetico in base al campo autore.
Questo semplice esempio rappresenta la resa in SQL della banca dati così formata:
N:1
In quasi tutti i software di gestione di banca dati, è possibile scegliere di operare in vista SQL invece che
sulla finestra del wizard.
5. Cenni all’interazione di SQL con linguaggi di programmazione e scripting
Le banche dati relazionali sono spesso chiamate a interagire con programmi in linguaggi diversi da SQL, ad
esempio, nella gestione di pagine web scritte con PHP, Python, Javascript o Java.
Si pensi a una pagina web che contenga un’area riservata. Sarà necessario salvare le coppie ordinate di
utenti e password dentro una tabella. Questa tabella è di norma inserita in una banca dati in MySQL che ha
per chiave primaria almeno la superchiave {utente, password}.
Titoli
id
titolo
id_autore
Autori
id
autore

13
Occorrerà dunque permettere agli utenti di effettuare il login. Nella sorgente delle pagine, scritte in HTML,
sarà inserito un breve script in un linguaggio capace di interagire con i browser, ad esempio PHP.
Innanzitutto, l’HTML creerà un form che dalla home page invii i dati alla pagina contenente lo script:
<form action=../gestione/check.php method=POST>
User: <input type="text" name="user">
Password: <input type="password" name="password">
<input type="Submit" value="Invia">
</form>
Poi la pagina check.php, che contiene il codice, effettuerà la query nella nostra banca dati:
<?php
session_start();
$_SESSION["user"] = $_POST["user"];
$_SESSION["password"] = $_POST["password"];
?>
<html>
<head></head>
<body>
<h3>Autenticazione dei Dati di Login:</h3><hr>
<?php
include("connector.php");
if(!empty($_POST["user"]) AND !empty($_POST["password"])) {
$db = new MysqlConnector("localhost", "fgiusfredi", "pwd");
$db->connect();
$db->selectDb("my_fgiusfredi");
$user = $_SESSION["user"];
$password = $_SESSION["password"];
$num = $db->queryNum("SELECT * FROM `utenti` WHERE nome='$user' AND password='$password'");
if($num!=1) {
print "Login Errato"; }
else {
print "<a href=sessione.php>Procedi</a>";
}
}
?>
</body>
</html>
La parte evidenziata è la query, scritta in linguaggio SQL e integrata con il resto dello script. Le funzioni PHP
che richiamano l’SQL sono in parte primitive, in parte possono essere sviluppate dal programmatore della
pagina. Per una completa panoramica su questo genere di procedure, è opportuno rifarsi alle guide dei
principali linguaggi impiegati per la scrittura di siti web dinamici:
www.php.net/ www.python.org/ www.javascript.com/
E ancora alle guide:
V. Vaswani, PHP: a beginner's guide, 2008.
M. Lutz, Learning Python, 2009.
D. Crockfors, Javascript: a beginner's guide, 2008.
14
6. Esercizi
6.1 Chiavi e superchiavi
Si individuino le superchiavi e le chiavi candidate della seguente tabella:
Nome Cognome Età Capelli Occhi
Marcella Bianchi 21 neri verdi
Pietro Rossi 23 neri neri
Giovanni Verdi 21 biondi neri
Marzia Ferrara 25 neri neri
Giovanni Boi 21 neri neri
Marzia Ferrara 27 neri neri
6.2 Operazioni su relazioni (1)
Si calcolino le seguenti operazioni relazionali tra le due tabelle
Nome Cognome Cognome Età
Marcella Bianchi Bianchi 24
Pietro Rossi Rossi 23
Giovanni Verdi Verdi 22
Giovanni Marchesi Marchesi
(Nomi) (Età)
6.2.1) SELECT * from Nomi INNER JOIN Età WHERE Nomi.Cognome = Età.Cognome;
6.2.2) SELECT * from Nomi LEFT OUTER JOIN Età WHERE Nomi.Cognome = Età.Cognome;
6.2.3) SELECT * from Nomi CROSS JOIN Età;
6.2.4) Nomi÷Età
6.2.5) Età÷Nomi
6.2.6) SELECT *from (Nomi÷Età) WHERE (Nomi÷Età).Nomi !=Pietro
6.3 SQL e normalizzazione
Si consideri il seguente file in SQL, relativo a una ipotetica banca dati archeologica:
CREATE DATABASE Ritrovamenti;
USE Ritrovamenti;
CREATE Item
(id INTEGER NOT NULL AUTO_INCREMENT,
tipologia VARCHAR,
strato VARCHAR,
epoca VARCHAR,
quadrante VARCHAR,
data VARCHAR,
fotografie oggetto VARCHAR,
PRIMARY KEY id);

15
Esso definisce una banca dati costituita da una sola tabella.
1) Si descriva tale tabella.
2) Si individuano i problemi di normalizzazione.
3) Si propongano soluzioni per la normalizzazione della tabella.
6.4 Cardinalità di Relazioni
Si consideri il seguente sistema di tabelle per una banca dati bibliografica
Id Id Id Id
Nome Titolo Id autore anno
Cognome Id anno Id titolo
(Autori) (Titoli) autori.titoli (Anno)
Si definisca la cardinalità delle relazioni in modo che la banca dati sia in 3NF.
6.5 Operazioni su relazioni (2)
Si dia rappresentazione insiemistica e si calcoli la cardinalità dei risultati delle seguenti operazioni sulle
relazioni. Infine, se ne calcolino i risultati:
A = {1,2,3,4,5,6,7,8,9}
B = {1,2,3,5,7,9}
C= {1,3,5,7}
6.5.1) A CROSS JOIN B
6.5.2) B LEFT OUTER JOIN C
6.5.3) A INNER JOIN C
6.5.4) A INNER JOIN (B÷C)
6.5.5) B INNER JOIN (C÷A)
Copyright © 2022 FDOKUMEN




















