
BAB 4 PERANCANGAN
46
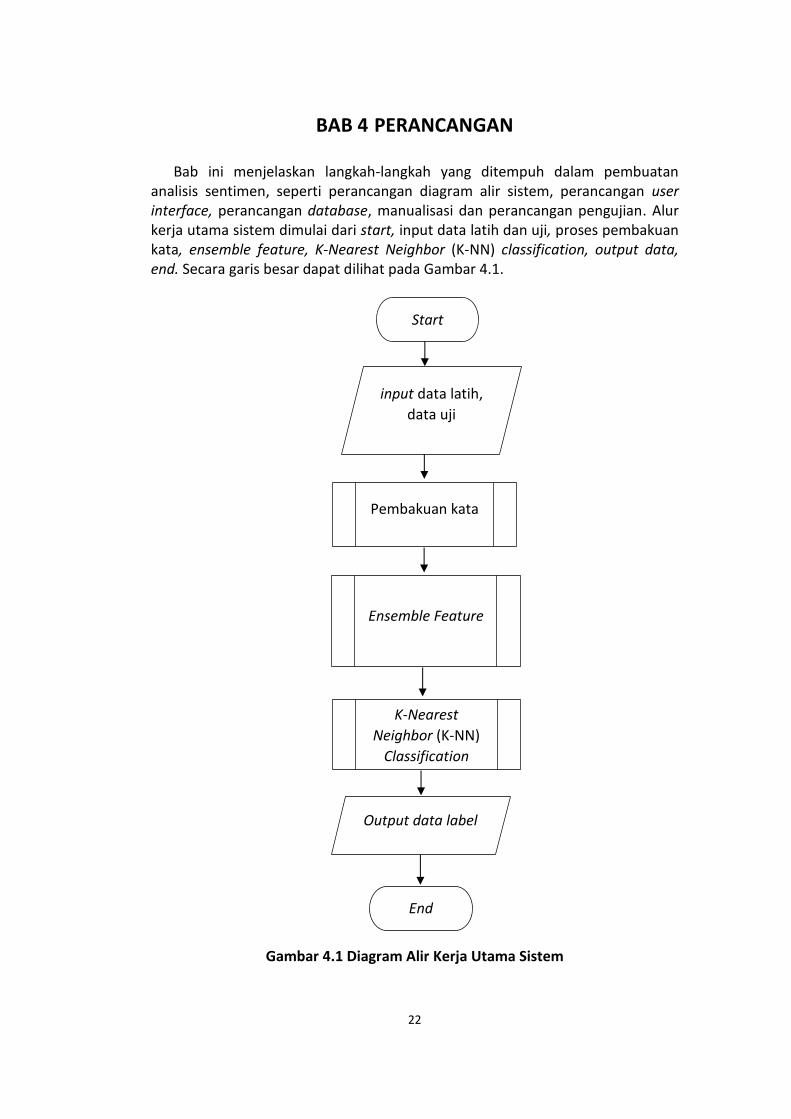
22 BAB 4 PERANCANGAN Bab ini menjelaskan langkah-langkah yang ditempuh dalam pembuatan analisis sentimen, seperti perancangan diagram alir sistem, perancangan user interface, perancangan database, manualisasi dan perancangan pengujian. Alur kerja utama sistem dimulai dari start, input data latih dan uji, proses pembakuan kata, ensemble feature, K-Nearest Neighbor (K-NN) classification, output data, end. Secara garis besar dapat dilihat pada Gambar 4.1. Gambar 4.1 Diagram Alir Kerja Utama Sistem Start input data latih, data uji Ensemble Feature K-Nearest Neighbor (K-NN) Classification Output data label End Pembakuan kata
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of BAB 4 PERANCANGAN
22
BAB 4 PERANCANGAN
Bab ini menjelaskan langkah-langkah yang ditempuh dalam pembuatan analisis sentimen, seperti perancangan diagram alir sistem, perancangan user interface, perancangan database, manualisasi dan perancangan pengujian. Alur kerja utama sistem dimulai dari start, input data latih dan uji, proses pembakuan kata, ensemble feature, K-Nearest Neighbor (K-NN) classification, output data, end. Secara garis besar dapat dilihat pada Gambar 4.1.
Gambar 4.1 Diagram Alir Kerja Utama Sistem
Start
input data latih,
data uji
Ensemble Feature
K-Nearest
Neighbor (K-NN)
Classification
Output data label
End
Pembakuan kata

23
4.1 Diagram Alir Sistem (Flowchart)
Diagram alir sistem (flowchart) merupakan gambaran dari urutan langkah-langkah yang ditempuh untuk menyelesaikan masalah. Analisis sentimen dalam penelitian kali ini dimulai dari tahap penginputan data latih dan data uji kemudian berlanjut ke proses pembakuan kata, lalu pengambilan nilai fitur dengan menggunakan ensemble feature yang terdiri dari 5 proses utama yaitu twitter specific, textual feature, Part of Speech (PoS) features, lexicon based features dan Bag of Words (BoW) features. Pada bagian Bag of Words (BoW) features dilakukan preprocessing terlebih dahulu agar dapat menuju proses berikutnya. Setelah itu barulah dapat menuju proses pengklasifikasian. Secara lebih rinci, diagram alir dari berbagai proses-proses tersebut dapat dilihat mulai dari Gambar 4.2 hingga Gambar 4.19.
4.1.1 Proses Pembakuan Kata
Pada tahapan ini, dilakukan proses untuk mengganti kata yang tidak baku menjadi kata Indonesia yang baku dengan menggunakan bantuan kamus. Diagram alir proses pembakuan kata dapat dilihat pada Gambar 4.2.
Gambar 4.2 Diagram Alir Proses Pembakuan Kata
Pembakuan kata
Start
Cek apakah kata baku ?
Return
Kata = kata baku
Yes
No
Output kata baku
Input data latih, data uji

24
4.1.2 Proses pada Ensemble Feature
Pada tahapan ini, dilakukan proses pengambilan nilai fitur menggunakan ensemble feature, mulai dari fitur F1 hingga fitur F38, terdapat 5 bagian proses utama, yaitu bagian twitter specific, textual features, Part of Speech (PoS) features, lexicon based features dan Bag of Words (BoW). Diagram alir proses pengambilan nilai fitur dapat dilihat pada Gambar 4.3.
Gambar 4.3 Diagram Alir Proses pada Ensemble Feature
Ensemble Feature Start
Return
Twitter Specific
Textual Features
Part of Speech (PoS) Features
Lexicon Based Features
Bag of Words (BoW) Features
Preprocessing

25
4.1.2.1 Twitter Specific
Pada tahapan ini, proses pengambilan nilai fitur dilakukan berdasarkan spesifikasi tertentu yang dimiliki suatu tweet, terdapat Fitur F1 – F4 dalam kategori ini meliputi pengecekan apakah pada tweet terdapat hastag (F1), retweet (F2), username (F3) atau URL (F4) sehingga diagram alir proses twitter specific dapat dilihat pada Gambar 4.4.
Gambar 4.4 Diagram Alir Proses Twitter Specific
Start
Input data latih, data uji
Return
Twitter Specific
Output feature value F1 – F4
Value = 0 Value =1
Apakah terdapat hastag (F1), retweet (F2),
username (F3), URL (F4) ? Yes
No

26
4.1.2.2 Textual Features
Tahapan ini merupakan proses pengambilan nilai fitur dilakukan berdasarkan informasi eksplisit yang terdapat dalam suatu tweet, terdapat fitur F5 – F12 dalam kategori ini meliputi menghitung panjang kata (F5), average word length (F6), jumlah tanda tanya (F7), jumlah tanda seru (F8), jumlah quotes (F9), jumlah kata yang diawali uppercase (F10), apakah mengandung emoticon positif (F11) atau negatif (F12) sehingga diagram alir proses secara keseluruhan dapat dilihat pada Gambar 4.5.
Start
Input data latih, data uji
Textual Features
Word length (F5)
Average word length (F6)
Jumlah tanda tanya (F7)
Jumlah quotes (F9)
Jumlah kata diawali uppercase (F10)
Jumlah tanda seru (F8)
A

27
Gambar 4.5 Diagram Alir Proses Textual Features
4.1.2.3 Part of Speech (PoS) Features
Tahapan ini merupakan proses pengambilan nilai fitur dilakukan berdasarkan informasi penanda kata/PoS tagging dari tweet, digunakan bantuan lexicon PoS tagging pada tahap ekstraksi fitur kali ini. Terdapat fitur F13 – F22 dalam kategori ini meliputi jumlah POS sebagai noun (F13) , jumlah PoS sebagai adjective (F14), jumlah POS sebagai verb (F15), jumlah PoS sebagai adverb (F16), jumlah PoS sebagai interjection (F17), persentase PoS sebagai noun (F18), persentase PoS sebagai adjective (F19), persentase PoS sebagai verb (F20), persentase PoS sebagai adverb (F21), persentase PoS sebagai interjection (F22) sehingga diagram alir proses secara keseluruhan dapat dilihat pada Gambar 4.6.
Return
Output feature value F5 – F12
Value = 0
Emoticon positif (F11) atau negatif
(F12) ?
Value =1
Start
Input data latih, data uji
Part of Speech (PoS) Features
Jumlah PoS sebagai noun (F13)
Jumlah PoS sebagai adjective (F14)
A
Yes No
A

28
Gambar 4.6 Diagram Alir Proses Part of Speech (PoS) Features
4.1.2.4 Lexicon Based Features
Tahapan ini merupakan proses pengambilan nilai fitur dilakukan dengan menggunakan bantuan kamus kata atau lexicon. Terdapat fitur F23 – F37 dalam kategori ini, yaitu meliputi jumlah PoS sebagai jumlah kata positif (F23) dan negatif (F24) di dalam tweet, jumlah kata adjective positif (F25) dan negatif (F26), jumlah kata verb positif (F27) dan negatif (F28), jumlah kata adverb positif (F29) dan negatif (F30), persentase kata adjective positif (F31) dan negatif (F32), persentase kata verb positif (F33) dan negatif (F34), persentase kata adverb positif (F35) dan negatif (F36), jumlah kata penguat (intensifier word) (F37), sehingga diagram alir proses secara keseluruhan dapat dilihat pada Gambar 4.7.
Jumlah PoS sebagai adverb (F16)
Jumlah PoS sebagai interjection (F17)
Persentase PoS sebagai noun (F18)
Persentase PoS sebagai adjective (F19)
Persentase PoS sebagai adverb (F21)
Persentase PoS sebagai interjection (F22)
Return
Output feature value F13 – F22
Persentase PoS sebagai verb (F20)
A
Jumlah PoS sebagai verb (F15)

29
Gambar 4.7 Diagram Alir Proses Lexicon Based Features
Start
Input data latih, data uji
Lexicon Based Features
Jumlah PoS sebagai jumlah kata positif (F23) dan negatif (F24)
Jumlah kata adjective positif (F25) dan negatif (F26)
Jumlah kata verb positif (F27) dan negatif (F28)
Jumlah kata adverb positif (F29) dan negatif (F30)
Persentase kata adjective positif (F31) dan negatif (F32)
Persentase kata verb positif (F33) dan negatif (F34)
Persentase kata adverb positif (F35) dan negatif (F36)
Jumlah intensifier word dalam tweet(F37)
Return
Output feature value F23 – F37

30
4.1.2.5 Preprocessing
Preprocessing adalah proses untuk membersihkan data mentah agar siap diolah ke pengolahan lebih lanjut. Tahapan ini melakukan analisis semantik dan sintaktik. Opersasi yang dilakukan dalam tahapan ini meliputi tokenization, filtering, stemming dan term weighting. Diagarm alir preprocessing dapat dilihat pada Gambar 4.8.
Gambar 4.8 Proses Preprocessing
a. Tokenization
Proses ini mengubah string dari huruf kapital menjadi huruf kecil (case folding) setelah proses case folding akan dilanjutkan dengan penghilangan tanda hitung, tanda baca, simbol-simbol atau angka-angka. Diagram alir proses tokenization dilihat pada Gambar 4.9.
Start
input data latih, data uji
Tokenization
Output hasil preprocessing
Return
Preprocessing
Filtering
Stemming
Start
Input data latih, data uji
Tokenization
huruf kapital ke huruf kecil
Hilangkan tanda baca, hitung, simbol dan angka
A

31
Gambar 4.9 Proses Tokenization
b. Filtering
Proses ini menghilangkan kata-kata tidak penting, kata yang dianggap tidak mempresentasikan isi dari suatu dokumen. Kata tersebut seperti kata stopword atau kata yang berfungsi sebagai kata hubung dan kata ganti. Contoh beberapa kata hubung seperti dan, yang, ke, di, dalam, terhadap, kemudian beberapa contoh kata ganti seperti aku, kamu, kita, mereka, dia. Semua kata tersebut akan diproses untuk dihilangkan dari dokumen. Diagram alir proses filtering dapat dilihat pada Gambar 4.10.
Gambar 4.10 Proses Filtering
Return
Output berupa term list
Start
Input term list
Term ada pada stopword list ?
Output berupa term list filtering
Return
Filtering
Hapus term
Yes
No
A

32
c. Stemming
Proses ini menghilangkan imbuhan pada termlist untuk mendapatkan kata dasar setelah dilakukannya proses filtering. Proses menghilangkan imbuhan menggunakan stemming library sastrawi. Stemming Sastrawi ini merupakan metode stemming pengembangan dari Nazief dan Adriani yang ditingkatkan dengan metode Confix Stripping, yang kemudian ditingkatkan lagi dengan metode Enhanced Confix Stripping, lalu ditingkatkan lagi dengan metode Modified Enhanced Confix Stripping (Suharno, Fauzi and Perdana, 2017). Diagram alir library Sastrawi dapat dilihat pada Gambar 4.11 hingga Gambar 4.14.
Gambar 4.11 Proses Stemming Library Sastrawi
Start
Input term list
filtering
Stemming
Kata Jamak
Output hasil
stemming
Return
Stemming
Kata Jamak ?
Stemming
Kata Tunggal
Yes No
Start
Ada pola “*-*” ?
Stemming
Kata Jamak
B A
Yes
No

33
Gambar 4.12 Proses Stemming Kata Jamak
Return
Pisahkan akhiran
dengan “-”
Ada akhiran ku, mu, nya ?
Stemming
kata tunggal
Tidak ada di dalam kamus dan hasil
stemming == kata ?
Tambahkan
awalan “me”
Stem1 == Stem2 ?
Hasil = hasilStem Hasil = kataAwal
B A
Yes No
Start Stemming
Kata Tunggal
A

34
Kata ada di dalam kamus ?
Kata <= 3
Hapus awalan
dengan 56 aturan
ambiguitas sastrawi
Ada pola be-lah, be-an, me-i, pe-i, ter-i ?
Hapus akhiran Confix
Stripping
Hapus akhiran lah, kah,
tah, pun, ku, mu, nya, i,
kan, an
Hapus awalan di,
ke, se
Kata ada di dalam kamus ?
A
A B C
Yes
No
Yes
No
Yes
No
No
Yes

35
Gambar 4.13 Proses Stemming Kata Tunggal
Return
Kata ada di dalam kamus ?
Hapus awalan
Kata ada di dalam kamus ?
Kembalikan akhiran
ke kata semula
Kata ada di dalam kamus ?
HasilStem = kataAsli
A B C
Yes
No
No
Yes
Yes
No
Start Confix
Stripping
Hapus awalan
Kata ada di dalam kamus ?
A B
Yes
No

36
Gambar 4.14 Proses Confix Stripping pada Stemming
4.1.2.6 Bag of Words (BoW) Features
Pada tahapan ini, proses pengambilan nilai fitur menggunakan kumpulan kata atau kumpulan term yang bisa disebut sebagai Bag of Word (BoW), pada pengambilan nilai fitur ini memerlukan preprocessing terlebih dahulu pada tweet, setelah itu baru akan dilakukan proses perhitungan nilai bobot kata dari setiap tweet, sehingga diagram alir proses secara keseluruhan dapat dilihat pada Gambar 4.15.
Gambar 4.15 Proses Pada Bag of Words (BoW) Features
Hapus akhiran
Kata ada di dalam kamus ?
Kata = kataSekarang
Return
A B
Yes
No
Bag of Words Features
Term Weighting
Start
Input hasil preprocessing
Return
Output nilai fitur (bobot kata)

37
a. Term Weighting
Proses ini melakukan pembobotan pada term-term yang telah didapatkan. Proses pembobotan dilakukan dengan menggunakan perhitungan Wft,d x idft. Diagram alir proses term weighting dapat dilihat pada Gambar 4.16.
Gambar 4.16 Proses Term Weighting
Start
Input Kata Dasar
for (t=0;t<banyaknya term)
Hitung Term Frequency (tft,d)
for (d=0;d<banyaknya dokumen)
d++
Wf-idft,d = Wft,d x idft
Hasil Pembobotan Term
Return
Hitung wft,d = 1 + log10 (tft,d)
idft = log 𝑁
𝑑𝑓𝑡
t++
Term Weighting
Hitung dft

38
4.1.3 Klasifikasi K-Nearest Neighbor (K-NN)
Pada tahapan ini, dilakukan proses pengklasifikasian dengan menggunakan metode K-Nearest Neighbor (K-NN), diagram alir proses pengklasifikasian dapat dilihat pada Gambar 4.17.
Gambar 4.17 Proses K-Nearest Neighbor (K-NN) Classification
Start
Input data latih, uji
Hitung Kemiripan
Output Class
Return
K-Nearest Neighbor (K-NN)
Classification
Sorted data
Voting k class

39
4.1.3.1 Hitung Kemiripan
Bagian ini merupakan proses untuk menghitung nilai kemiripan atau similarity data uji terhadap data latih, perhitungan kemiripan menggunakan cosine similarity. Diagram alir proses perhitungan kemiripan dapat dilihat pada Gambar 4.18.
Gambar 4.18 Proses Perhitungan Kemiripan
Hitung Kemiripan
Start
D = bobot dokumen latih Q = bobot dokumen uji
for (i=0;i<banyaknya data latih)
for (j=0;j<banyaknya fitur/term)
SumQD += Q[j] * D[j,i]
SumQ += Q[j] * Q[j]
SumD[i] += D[j,[i] * D[j,i]
j++
Similarity[i] = SumQD / sqrt (SumQ * SumD[i])
i++
Hasil similarity
Return

40
4.1.3.2 Voting
Voting adalah proses untuk mentukan kelas tweet uji. Tahapan ini melakukan perhitungan jumlah kelas positif dan negatif. Diagram alir proses voting dapat dilihat pada Gambar 4.19.
Gambar 4.19 Proses Voting k class
Voting k class Start
Inisialisasi k
for (k=0;k<banyaknya k)
k class Positif ?
Return
Positif++
Yes
No
Negatif++
Output = positif
k++
Positif > Negatif ?
Yes
No
Output = negatif

41
4.2 Perancangan User Interface
Perancangan User Interface atau desain antarmuka yang digunakan dalam penelitian kali ini meliputi perancangan halaman data latih, halaman data uji dan halaman hasil. Terdapat 3 tab utama untuk mewakili halaman tersebut secara umum. Perancangan user interface program secara umum dapat dilihat pada Gambar 4.20.
Gambar 4.20 Perancangan User Interface Program Secara Umum
Keterangan: 1 = Data Latih 2 = Data Uji 3 = Hasil 4 = View page
Bagian tab pertama adalah tab data latih yang ditunjukkan oleh nomor 1,
pada tab ini dapat digunakan oleh pengguna untuk melihat tabel data latih dan memasukkan data latih. Bagian tab kedua adalah tab data uji yang ditunjukkan oleh nomor 2, pada bagian tab ini pengguna dapat memasukkan data uji yang akan diproses ke dalam sistem dan bagian tab terakhir yang ditunjukkan oleh nomor 3 adalah tab hasil, pada tab ini pengguna dapat melihat hasil perhitungan yang telah dilakukan oleh program. Bagian view page digunakan sebagai penampil isi dari masing-masing halaman pada tab-tab tersebut.
1 2 3
4

42
4.2.1 Halaman Data Latih
Pada halaman ini berisi text input data latih dan view data latih, text input data latih digunakan untuk memasukkan data latih ke dalam database dan tabel data latih menampilkan data latih dalam bentuk tabel kepada pengguna. Berikut halaman data latih dapat dilihat pada Gambar 4.21.
Gambar 4.21 Halaman Data Latih
Data Latih Data Uji Hasil
Tabel Data Latih
Input Textfield
Input Pilihan kelas

43
4.2.2 Halaman Data Uji
Pada halaman ini berisi text input data uji, text input data uji digunakan untuk memasukkan data uji agar dapat diproses ke dalam sistem. Berikut halaman data uji dapat dilihat pada Gambar 4.22.
Gambar 4.22 Halaman Data Uji
4.2.3 Halaman Hasil
Pada halaman ini berisi hasil perhitungan yang telah dilakukan oleh sistem, hasil akan ditampilkan pada view hasil. Berikut halaman hasil dapat dilihat pada Gambar 4.23.
Gambar 4.23 Halaman Hasil
Data Latih Data Uji Hasil
Input textfield
input
Data Latih Data Uji Hasil
View Hasil

44
4.3 Perancangan Database
Perancangan database dalam penelitian ini memuat relasi dan rancangan berbagai tabel yang akan digunakan dalam analisis sentimen kurikulum 2013 menggunakan ensemble feature dan metode K-Nearest Neighbor (K-NN). Pada penelitian ini terdapat 13 tabel, yaitu tabel tweet, tabel twitter_specific, tabel textual_features, tabel pos_tag, tabel lexical_features, tabel ensemble_normalization, tabel positive_word, tabel negative_word, tabel intensifier_word, tabel tb_postag1, tabel tb_postag2, tabel tb_postag3 dan tabel kata_baku. Secara lebih rinci dapat dilihat pada Gambar 4.24.
Gambar 4.24 Perancangan Database
4.3.1 Tabel tweet
Tabel ini digunakan untuk menyimpan tweet yang dimasukkan oleh pengguna, setiap tweet memiliki id sebagai primary key dan kelas positif atau negatif, struktur tabel secara lengkap dapat dilihat pada Tabel 4.1.
Tabel 4.1 Struktur Tabel tweet
No Field Name Type Size
1 id varchar 20
2 class varchar 20
3 tweet varchar 255

45
4.3.2 Tabel twitter_specific
Tabel ini digunakan untuk menyimpan nilai fitur F1-F4, id digunakan sebagai foreign key, struktur tabel secara lengkap dapat dilihat pada Tabel 4.2.
Tabel 4.2 Struktur Tabel twitter_specific
No Field Name Type Size
1 id varchar 20
2 f1 int 1
3 f2 int 1
4 f3 int 1
5 f4 int 1
4.3.3 Tabel textual_features
Tabel ini digunakan untuk menyimpan nilai fitur F5-F12, id digunakan sebagai foreign key, struktur tabel secara lengkap dapat dilihat pada Tabel 4.3.
Tabel 4.3 Struktur Tabel twitter_specific
No Field Name Type Size
1 id varchar 20
2 f5 int 11
3 f6 double -
4 f7 int 11
5 f8 int 11
6 f9 int 11
7 f10 int 11
8 f11 int 1
9 f12 int 1
4.3.4 Tabel pos_tag
Tabel ini digunakan untuk menyimpan nilai fitur F12-F22, id digunakan sebagai foreign key, struktur tabel secara lengkap dapat dilihat pada Tabel 4.4.
Tabel 4.4 Struktur Tabel pos_tag
No Field Name Type Size
1 id varchar 20
2 f13 int 11
3 f14 int 11
4 f15 int 11
5 f16 int 11
6 f17 int 11
7 f18 double -
8 f19 double -

46
9 f20 double -
10 f21 double -
11 f22 double -
4.3.5 Tabel lexical_features
Tabel ini digunakan untuk menyimpan nilai fitur F23-F37, id digunakan sebagai foreign key, struktur tabel secara lengkap dapat dilihat pada Tabel 4.5.
Tabel 4.5 Struktur Tabel lexical_features
No Field Name Type Size
1 id varchar 20
2 f23 int 11
3 f24 int 11
4 f25 int 11
5 f26 int 11
6 f27 int 11
7 f28 int 11
8 f29 int 11
9 f30 double -
10 f31 double -
11 f32 double -
12 f33 double -
13 f34 double -
14 f35 double -
15 f36 double -
16 f37 double -
4.3.6 Tabel ensemble_normalization
Tabel ini digunakan untuk menyimpan nilai fitur F1-F37 yang telah dinormalisasi, id digunakan sebagai foreign key, struktur tabel secara lengkap dapat dilihat pada Tabel 4.6.
Tabel 4.6 Struktur Tabel ensemble_normalization
No Field Name Type Size
1 id varchar 20
2 f1 double -
3 f2 double -
4 f3 double -
5 f4 double -

47
6 f5 double -
7 f6 double -
8 f7 double -
9 f8 double -
10 f9 double -
11 f10 double -
12 f11 double -
13 f12 double -
14 f13 double -
15 f14 double -
16 f15 double -
17 f16 double -
18 f17 double -
19 f18 double -
20 f19 double -
21 f20 double -
22 f21 double -
23 f22 double -
24 f23 double -
25 f24 double -
26 f25 double -
27 f26 double -
28 f27 double -
29 f28 double -
30 f29 double -
31 f30 double -
32 f31 double -
33 f32 double -
34 f33 double -
35 f34 double -
36 f35 double -

48
37 f36 double -
38 f37 double -
4.3.7 Tabel positive_word
Tabel ini digunakan untuk menyimpan kata positif, primary key tabel adalah id, struktur tabel secara lengkap dapat dilihat pada Tabel 4.7.
Tabel 4.7 Struktur Tabel positive_word
No Field Name Type Size
1 id varchar 11
3 kata varchar 70
4.3.8 Tabel negative_word
Tabel ini digunakan untuk menyimpan kata negatif, primary key tabel adalah id, struktur tabel secara lengkap dapat dilihat pada Tabel 4.8.
Tabel 4.8 Struktur Tabel negative_word
No Field Name Type Size
1 id varchar 11
3 kata varchar 70
4.3.9 Tabel intensifier_word
Tabel ini digunakan untuk menyimpan nilai fitur, primary key tabel adalah id, struktur tabel secara lengkap dapat dilihat pada Tabel 4.9.
Tabel 4.9 Struktur Tabel intensifier_word
No Field Name Type Size
1 id varchar 11
3 kata varchar 70
4.3.10 Tabel tb_postag1
Tabel ini digunakan untuk menyimpan nilai tagging kata dasar, primary key tabel adalah id_katadasar, struktur tabel secara lengkap dapat dilihat pada Tabel 4.10.
Tabel 4.10 Struktur Tabel tb_postag1
No Field Name Type Size
1 id_katadasar varchar 11
2 katadasar varchar 70
3 tipe_katadasar varchar 25

49
4.3.11 Tabel tb_postag2
Tabel ini digunakan untuk menyimpan tagging kata yang memiliki imbuhan, primary key tabel adalah id_kata, struktur tabel secara lengkap dapat dilihat pada Tabel 4.11.
Tabel 4.11 Struktur Tabel tb_postag2
No Field Name Type Size
1 id_kata varchar 11
2 Kata varchar 70
3 tipe_kata varchar 25
4.3.12 Tabel tb_postag3
Tabel ini digunakan untuk menyimpan tagging kata khusus kata interjeksi, primary key tabel adalah id_kata, struktur tabel secara lengkap dapat dilihat pada Tabel 4.12.
Tabel 4.12 Struktur Tabel tb_postag3
No Field Name Type Size
1 id_kata varchar 11
2 kata varchar 70
3 tipe_kata varchar 25
4.3.13 Tabel kata_baku
Tabel ini digunakan untuk menyimpan koleksi kata baku dan tidak baku, primary key tabel adalah id, struktur tabel secara lengkap dapat dilihat pada Tabel 4.13.
Tabel 4.13 Struktur Tabel kata_baku
No Field Name Type Size
1 id varchar 11
2 tidak_baku varchar 25
3 baku varchar 25
4.4 Manualisasi
Bagian ini merupakan contoh perhitungan dari perancangan sistem yang telah dibuat dengan tujuan untuk mendapatkan hasil klasifikasi berupa opini positif atau opini negatif dengan menggunakan ensemble feature dan metode K-Nearest Neighbor (K-NN) dalam analisis sentimen.

50
4.4.1 Datasets
Datasets ini merupakan kumpulan data yang digunakan yaitu, terdapat data latih dan data uji. Pada contoh perhitungan kali ini, terdapat 10 data latih yang akan digunakan, contoh 10 data latih dapat dilihat pada Tabel 4.14 dan 1 data uji pada Tabel 4.15.
Tabel 4.14 Contoh 10 Data latih
ID Class Tweet
T1 Positif (+) Selamat hari pendidikan nasional. Semoga pelajaran melupakan dan mengikhlaskan seseorang masuk di mapel wajib kurikulum 2013 #hardiknas2017
T2 Positif (+) alhamdulillah berjalan lancar dan semoga kegiatan ini makin meningkatkan kualitas pendidikan di Purwakarta dan Indonesia #Kurikulum2013
T3 Positif (+) wish kuuh : semoga jd lebih baik,semoga kurikulum2013 dicopot,semoga UN engga20 paket, semoga bbm turun ,semoga kita bisa ketemu lg di thn 2016
T4 Positif (+) wish 2015 buat - Sukses kelas 8nya! Semangat pake kurikulum2013! Dahyaa http://ask.fm/a/bjg63gl7
T5 Positif (+) Baru kali ini gw lihat semangatnya siswa menggali informasi utk jadi bahan debat mengenai sejarah asal usul manusia :) #kurikulum2013
T6 Negatif (-) Terbebani dengan ujian yang berbelit-belit. Tapi mau gimana :( lagi #USBN #US #UNBK #2017 #Kurikulum2013
T7 Negatif (-) Kmrn katanya, #Kurikulum2013 UTS dihapus. Tapi sekolah saya masih memakai. Cuma diganti jadi UHB (Ulangan Harian Bersama). Pdhl sdh bahagia.
T8 Negatif (-) Ngajar nya gak lelah tapi lelah sama administrasi nyaa ;(
T9 Negatif (-) Jangan salahkan anak kalian jika nilai di raport nanti tidak sesuai yg diinginkan, kami pusing melayani kurikulum2013
T10 Negatif (-) gak tau deng, ane lupa,ane aja masih bingung sama nilai kurikulum2013"@vaniavalr: @inasakinahNH ada, lo ada 4 gak?kalau ada brapa?"
Tabel 4.15 Contoh 1 Data uji
ID Class Tweet
T11 Positif (+) Agenda hari ini: Memasukan nilai siswa dan membuat rapot #Kurikulum2013. Semangat!!!
51
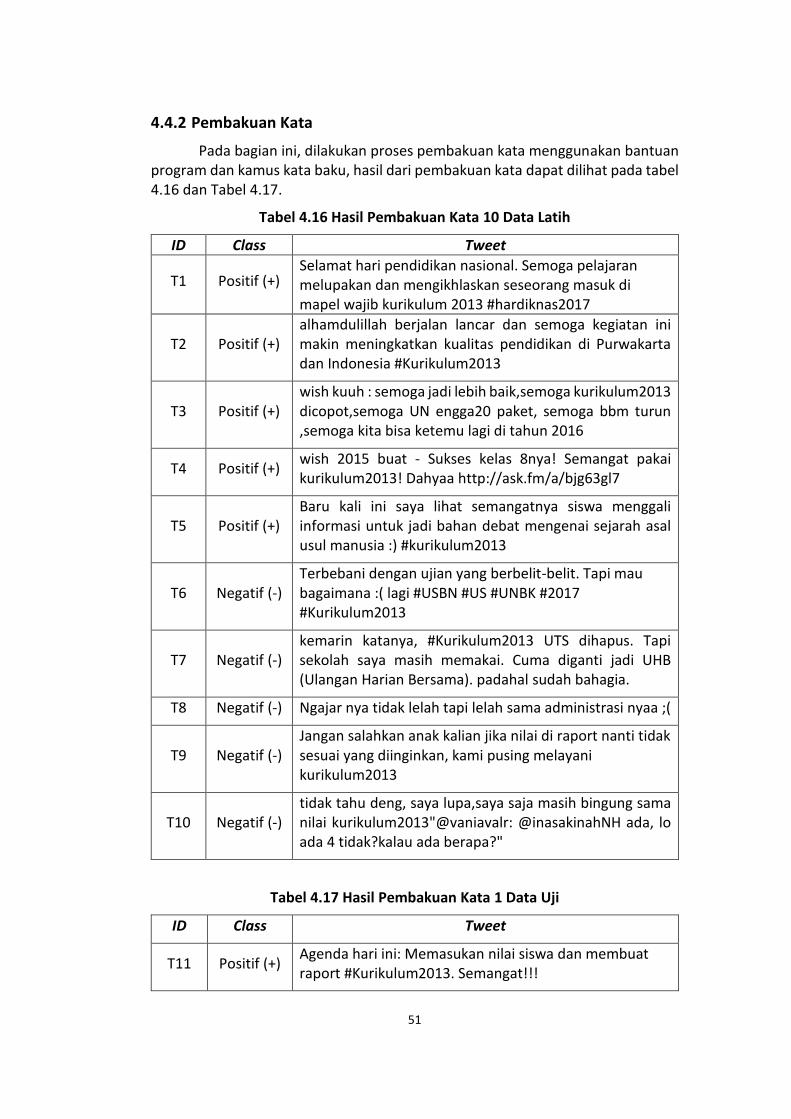
4.4.2 Pembakuan Kata
Pada bagian ini, dilakukan proses pembakuan kata menggunakan bantuan program dan kamus kata baku, hasil dari pembakuan kata dapat dilihat pada tabel 4.16 dan Tabel 4.17.
Tabel 4.16 Hasil Pembakuan Kata 10 Data Latih
ID Class Tweet
T1 Positif (+) Selamat hari pendidikan nasional. Semoga pelajaran melupakan dan mengikhlaskan seseorang masuk di mapel wajib kurikulum 2013 #hardiknas2017
T2 Positif (+) alhamdulillah berjalan lancar dan semoga kegiatan ini makin meningkatkan kualitas pendidikan di Purwakarta dan Indonesia #Kurikulum2013
T3 Positif (+) wish kuuh : semoga jadi lebih baik,semoga kurikulum2013 dicopot,semoga UN engga20 paket, semoga bbm turun ,semoga kita bisa ketemu lagi di tahun 2016
T4 Positif (+) wish 2015 buat - Sukses kelas 8nya! Semangat pakai kurikulum2013! Dahyaa http://ask.fm/a/bjg63gl7
T5 Positif (+) Baru kali ini saya lihat semangatnya siswa menggali informasi untuk jadi bahan debat mengenai sejarah asal usul manusia :) #kurikulum2013
T6 Negatif (-) Terbebani dengan ujian yang berbelit-belit. Tapi mau bagaimana :( lagi #USBN #US #UNBK #2017 #Kurikulum2013
T7 Negatif (-) kemarin katanya, #Kurikulum2013 UTS dihapus. Tapi sekolah saya masih memakai. Cuma diganti jadi UHB (Ulangan Harian Bersama). padahal sudah bahagia.
T8 Negatif (-) Ngajar nya tidak lelah tapi lelah sama administrasi nyaa ;(
T9 Negatif (-) Jangan salahkan anak kalian jika nilai di raport nanti tidak sesuai yang diinginkan, kami pusing melayani kurikulum2013
T10 Negatif (-) tidak tahu deng, saya lupa,saya saja masih bingung sama nilai kurikulum2013"@vaniavalr: @inasakinahNH ada, lo ada 4 tidak?kalau ada berapa?"
Tabel 4.17 Hasil Pembakuan Kata 1 Data Uji
ID Class Tweet
T11 Positif (+) Agenda hari ini: Memasukan nilai siswa dan membuat raport #Kurikulum2013. Semangat!!!

52
4.4.3 Ensemble Feature
Langkah ini melakukan pengambilan nilai fitur dimulai dari twitter specific features, textual features, Parts of Speech (PoS) features, lexicon based features dan Bag of Words (BoW).
4.4.3.1 Twitter Specific Features
Proses pengambilan nilai fitur F1 – F4, nilai 1 menyatakan fitur tersebut terdapat pada tweet dan nilai 0 menyatakan fitur tersebut tidak terdapat pada tweet. F1 menyatakan apakah terdapat hastag (#) atau tidak pada tweet, F2 menyatakan apakah terdapat retweet (RT) atau tidak, F3 menyatakan apakah terdapat username (@) atau tidak dan F4 menyatakan apakah terdapat URL atau tidak pada tweet. Hasil twitter specific features dapat dilihat pada Tabel 4.18.
Tabel 4.18 Twitter Specific Table Features
ID F1 F2 F3 F4
T1 1 0 0 0
T2 1 0 0 0
T3 0 0 0 0
T4 0 0 0 1
T5 1 0 0 0
T6 1 0 0 0
T7 1 0 0 0
T8 0 0 0 0
T9 0 0 0 0
T10 0 0 1 0
T11 1 0 0 0
4.4.3.2 Textual Features
Proses pengambilan nilai fitur F5 – F12, pada langkah ini dilkaukan pengambilan nilai fitur dari sisi informasi eksplisit pada suatu tweet. F5 menyatakan nilai banyaknya kata dalam tweet, F6 menyatakan nilai rata-rata panjang karakter dari kata dalam tweet, F7 menyatakan banyaknya tanda tanya dalam tweet, F8 menyatakan banyaknya tanda seru dalam tweet, F9 menyatakan banyaknya tanda petik dalam tweet, F10 menyatakan banyaknya kata yang dimulai dengan huruf kapital, F11 menyatakan apakah terdapat emoticon positif dan F12 menyatakan apakah terdapat emoticon negatif dalam tweet. Hasil textual features dapat dilihat pada Tabel 4.19.

53
Tabel 4.19 Textual Features Table Features
ID F5 F6 F7 F8 F9 F10 F11 F12
T1 17 8,176 0 0 0 2 0 0
T2 16 8,438 0 0 0 3 0 0
T3 24 6,208 0 0 0 1 0 0
T4 15 6,467 0 2 0 3 0 0
T5 19 7,211 0 0 0 1 1 0
T6 15 7,133 0 0 0 6 0 1
T7 21 7,048 0 0 0 8 0 0
T8 10 5,9 0 0 0 1 0 1
T9 17 7 0 0 0 1 0 0
T10 23 6,087 2 0 2 0 0 0
T11 12 7,083 0 3 0 4 0 0
4.4.3.3 Parts of Speech (PoS) Features
Proses pengambilan nilai fitur F13 – F22, pada langkah ini dilakukan pengambilan nilai fitur dari sisi tagging kata, F13 menyatakan banyaknya noun dalam tweet, F14 menyatakan banyaknya adjective, F15 menyatakan banyaknya verb, F16 menyatakan adverb, F17 menyatakan banyaknya interjection dalam suatu tweet. Selanjutnya dilakukan perhitungan persentase dari setiap tag tersebut yaitu banyaknya tag kata yang dimaksud dibagi dengan banyaknya seluruh kata dalam tweet lalu dikalikan dengan 100. Fitur dimulai dari F18 menyatakan persentase noun dalam tweet, F19 menyatakan persentase adjective, F20 menyatakan persentase verb, F21 menyatakan persentase adverb dan F22 menyatakan persentase interjection dalam tweet. Hasil Parts of Speech (PoS) features dapat dilihat pada Tabel 4.20.
Tabel 4.20 Parts of Speech (PoS) Table Features
ID F13 F14 F15 F16 F17 F18 F19 F20 F21 F22
T1 2 2 2 0 1 11,765 11,765 11,765 0 5,882
T2 3 1 0 2 2 18,75 6,25 0 12,5 12,5
T3 2 2 4 2 5 8,333 8,333 16,667 8,333 20,833
T4 3 1 2 0 0 20 6,667 13,333 0 0
T5 9 1 2 0 0 47,368 5,263 10,526 0 0
T6 1 0 0 2 0 6,667 0 0 13,333 0
T7 3 0 1 4 0 14,286 0 4,762 19,048 0

54
T8 1 3 0 1 0 10 30 0 10 0
T9 3 0 1 2 0 17,647 0 5,882 11,765 0
T10 1 2 5 5 1 4,348 8,696 21,739 21,739 4,348
T11 5 0 0 0 0 41,667 0 0 0 0
4.4.3.4 Lexicon Based Features
Proses pengambilan nilai fitur F23 – F37, pada langkah ini dilakukan pengambilan nilai fitur menggunakan bantuan kamus atau lexicon, F23 menyatakan banyaknya kata positif dalam tweet, F24 menyatakan banyaknya kata negatif, F25 menyatakan banyaknya kata positif sebagai adjective, F26 menyatakan banyaknya kata negatif sebagai adjective, F27 menyatakan banyaknya kata positif sebagai verb, F28 menyatakan banyaknya kata negatif sebagai verb, F29 menyatakan banyaknya kata positif sebagai adverb, F30 menyatakan banyaknya kata negatif sebagai adverb dalam tweet. Kemudian dilakukan perhitungan persentase dari setiap banyaknya kata tersebut, yaitu banyaknya tag kata positif atau negatif yang dimaksud dibagi dengan banyaknya seluruh kata dalam tweet lalu dikalikan dengan 100. Fitur dimulai dari F31 menyatakan persentase kata positif sebagai adjective dalam tweet, F32 menyatakan persentase kata negatif sebagai adjective, F33 menyatakan persentase kata positif sebagai verb, F34 menyatakan persentase kata negatif sebagai verb, F35 menyatakan persentase kata positif sebagai adverb, F36 menyatakan persentase kata negatif sebagai adverb dalam tweet. Hasil lexicon based features dapat dilihat pada Tabel 4.21.
Tabel 4.21 Lexicon Based Table Features
ID F23 F24 F25 F26 F27 F28 F29 F30 F31 F32 F33 F34 F35 F36 F37
T1 2 0 2 0 0 0 0 0 11,76 0 0 0 0 0 0
T2 3 2 1 1 0 0 0 2 6,25 6,25 0 0 0 12,25 0
T3 3 0 4 0 0 0 2 0 16,67 0 0 0 8,33 0 1
T4 3 0 1 0 0 0 0 0 6,67 0 0 0 0 0 0
T5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
T6 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
T7 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
T8 0 3 0 2 0 0 0 1 0 20 0 0 0 10 0
T9 2 2 0 0 0 1 0 1 0 0 0 5,88 0 5,88 0
T10 0 5 0 2 0 1 0 2 0 8,7 0 4,35 0 8,7 0
T11 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
4.4.3.5 Bag of Words (BoW) Features
Pada langkah ini proses ekstraksi fitur dilakukan dengan mendapatkan nilai bobot kata dari suatu tweet. Nilai bobot didapatkan dari perhitungan term weighting dimulai dari term frequency menjadi wft,d, idft dan wft,d x idft. Untuk

55
mendapatkan bobot kata tersebut akan dilakukan preprocessing terlebih dahulu pada tweet. Preprocessing meliputi tokenization, filterization dan stemming. Contoh proses tokenization yang dilakukan pada salah satu tweet dapat dilihat pada Tabel 4.22.
Tabel 4.22 Contoh Hasil Proses Tokenization
Tokenization
Input Selamat hari pendidikan nasional. Semoga pelajaran melupakan dan mengikhlaskan seseorang masuk di mapel wajib kurikulum 2013 #hardiknas2017
Output selamat hari pendidikan nasional semoga pelajaran melupakan dan mengikhlaskan seseorang masuk di mapel wajib kurikulum hardiknas
Setelah dilakukannya proses tokenization kemudian berlanjut ke proses filterization. Contoh proses filterization dapat dilihat pada Tabel 4.23.
Tabel 4.23 Contoh Hasil Proses Filterization
Filterization
Input selamat hari pendidikan nasional semoga pelajaran melupakan dan mengikhlaskan seseorang masuk di mapel wajib kurikulum hardiknas
Output selamat pendidikan nasional semoga pelajaran melupakan mengikhlaskan masuk mapel wajib kurikulum hardiknas
Selanjutnya dilakukann proses stemming untuk mendapatkan bentuk kata dasar. Contoh proses filterization dapat dilihat pada Tabel 4.24.
Tabel 4.24 Contoh Hasil Proses Stemming
Stemming
Input selamat pendidikan nasional semoga pelajaran melupakan mengikhlaskan masuk mapel wajib kurikulum hardiknas
Output selamat didik nasional moga ajar lupa ikhlas masuk mapel wajib kurikulum hardiknas
Setelah dilakukan preprocessing diatas maka dapat dilakukan perhitungan berikutnya yaitu term frequency merupakan perhitungan frekuensi kemunculan kata pada setiap tweet. Contoh jika terdapat kata selamat muncul 1 kali pada dokumen tweet ke 1 maka nilai term frequency = 1. Untuk lebih lengkapnya dapat dilihat pada Tabel 4.25.

56
Tabel 4.25 Contoh Hasil Perhitungan Term Frequency
Term T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11
administrasi 0 0 0 0 0 0 0 1 0 0 0
agenda 0 0 0 0 0 0 0 0 0 0 1
ajar 1 0 0 0 0 0 0 0 0 0 0
alhamdulillah 0 1 0 0 0 0 0 0 0 0 0
anak 0 0 0 0 0 0 0 0 1 0 0
bahagia 0 0 0 0 0 0 1 0 0 0 0
bahan 0 0 0 0 1 0 0 0 0 0 0
bbm 0 0 1 0 0 0 0 0 0 0 0
beban 0 0 0 0 0 1 0 0 0 0 0
belit 0 0 0 0 0 2 0 0 0 0 0
bingung 0 0 0 0 0 0 0 0 0 1 0
copot 0 0 1 0 0 0 0 0 0 0 0
dahyaa 0 0 0 1 0 0 0 0 0 0 0
debat 0 0 0 0 1 0 0 0 0 0 0
deng 0 0 0 0 0 0 0 0 0 1 0
didik 1 1 0 0 0 0 0 0 0 0 0
engga 0 0 1 0 0 0 0 0 0 0 0
gali 0 0 0 0 1 0 0 0 0 0 0
ganti 0 0 0 0 0 0 1 0 0 0 0
giat 0 1 0 0 0 0 0 0 0 0 0
hapus 0 0 0 0 0 0 1 0 0 0 0
hardiknas 1 0 0 0 0 0 0 0 0 0 0
hari 0 0 0 0 0 0 1 0 0 0 0
ikhlas 1 0 0 0 0 0 0 0 0 0 0
indonesia 0 1 0 0 0 0 0 0 0 0 0
informasi 0 0 0 0 1 0 0 0 0 0 0
jalan 0 1 0 0 0 0 0 0 0 0 0
kali 0 0 0 0 1 0 0 0 0 0 0
kelas 0 0 0 1 0 0 0 0 0 0 0
kemarin 0 0 0 0 0 0 1 0 0 0 0
ketemu 0 0 1 0 0 0 0 0 0 0 0
kualitas 0 1 0 0 0 0 0 0 0 0 0
kurikulum 1 1 1 1 1 1 1 0 1 1 1
kuuh 0 0 1 0 0 0 0 0 0 0 0
lancar 0 1 0 0 0 0 0 0 0 0 0
layan 0 0 0 0 0 0 0 0 1 0 0

57
lelah 0 0 0 0 0 0 0 2 0 0 0
lihat 0 0 0 0 1 0 0 0 0 0 0
lo 0 0 0 0 0 0 0 0 0 1 0
lupa 1 0 0 0 0 0 0 0 0 1 0
manusia 0 0 0 0 1 0 0 0 0 0 0
mapel 1 0 0 0 0 0 0 0 0 0 0
masuk 1 0 0 0 0 0 0 0 0 0 0
moga 1 1 5 0 0 0 0 0 0 0 0
nasional 1 0 0 0 0 0 0 0 0 0 0
ngajar 0 0 0 0 0 0 0 1 0 0 0
nilai 0 0 0 0 0 0 0 0 1 1 1
pakai 0 0 0 1 0 0 1 0 0 0 0
paket 0 0 1 0 0 0 0 0 0 0 0
pasu 0 0 0 0 0 0 0 0 0 0 1
purwakarta 0 1 0 0 0 0 0 0 0 0 0
pusing 0 0 0 0 0 0 0 0 1 0 0
raport 0 0 0 0 0 0 0 0 1 0 1
salah 0 0 0 0 0 0 0 0 1 0 0
sejarah 0 0 0 0 1 0 0 0 0 0 0
sekolah 0 0 0 0 0 0 1 0 0 0 0
selamat 1 0 0 0 0 0 0 0 0 0 0
semangat 0 0 0 1 1 0 0 0 0 0 1
sesuai 0 0 0 0 0 0 0 0 1 0 0
siswa 0 0 0 0 1 0 0 0 0 0 1
sukses 0 0 0 1 0 0 0 0 0 0 0
tingkat 0 1 0 0 0 0 0 0 0 0 0
turun 0 0 1 0 0 0 0 0 0 0 0
uhb 0 0 0 0 0 0 1 0 0 0 0
uji 0 0 0 0 0 1 0 0 0 0 0
ulang 0 0 0 0 0 0 1 0 0 0 0
un 0 0 1 0 0 0 0 0 0 0 0
unbk 0 0 0 0 0 1 0 0 0 0 0
us 0 0 0 0 0 1 0 0 0 0 0
usbn 0 0 0 0 0 1 0 0 0 0 0
usul 0 0 0 0 1 0 0 0 0 0 0
uts 0 0 0 0 0 0 1 0 0 0 0
wajib 1 0 0 0 0 0 0 0 0 0 0
wish 0 0 1 1 0 0 0 0 0 0 0

58
Langkah selanjutnya menghitung TF ke dalam bentuk log normalization yaitu menggunakan perhitungan 1+log(TF). Contoh perhitungan sebagai berikut:
tft,d = 5
wft,d = 1 + log10 (tft,d)
wft,d = 1 + log10 (5)
wft,d = 1,698
Tabel 4.26 Contoh Hasil Perhitungan Wft,d
Term T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11 dfi
administrasi 0 0 0 0 0 0 0 1 0 0 0 1
agenda 0 0 0 0 0 0 0 0 0 0 1 1
ajar 1 0 0 0 0 0 0 0 0 0 0 1
alhamdulillah 0 1 0 0 0 0 0 0 0 0 0 1
anak 0 0 0 0 0 0 0 0 1 0 0 1
bahagia 0 0 0 0 0 0 1 0 0 0 0 1
bahan 0 0 0 0 1 0 0 0 0 0 0 1
bbm 0 0 1 0 0 0 0 0 0 0 0 1
beban 0 0 0 0 0 1 0 0 0 0 0 1
belit 0 0 0 0 0 1,30103 0 0 0 0 0 1
bingung 0 0 0 0 0 0 0 0 0 1 0 1
copot 0 0 1 0 0 0 0 0 0 0 0 1
dahyaa 0 0 0 1 0 0 0 0 0 0 0 1
debat 0 0 0 0 1 0 0 0 0 0 0 1
deng 0 0 0 0 0 0 0 0 0 1 0 1
didik 1 1 0 0 0 0 0 0 0 0 0 2
engga 0 0 1 0 0 0 0 0 0 0 0 1
gali 0 0 0 0 1 0 0 0 0 0 0 1
ganti 0 0 0 0 0 0 1 0 0 0 0 1
giat 0 1 0 0 0 0 0 0 0 0 0 1
hapus 0 0 0 0 0 0 1 0 0 0 0 1
hardiknas 1 0 0 0 0 0 0 0 0 0 0 1
hari 0 0 0 0 0 0 1 0 0 0 0 1
ikhlas 1 0 0 0 0 0 0 0 0 0 0 1
indonesia 0 1 0 0 0 0 0 0 0 0 0 1
informasi 0 0 0 0 1 0 0 0 0 0 0 1
jalan 0 1 0 0 0 0 0 0 0 0 0 1
kali 0 0 0 0 1 0 0 0 0 0 0 1
kelas 0 0 0 1 0 0 0 0 0 0 0 1

59
kemarin 0 0 0 0 0 0 1 0 0 0 0 1
ketemu 0 0 1 0 0 0 0 0 0 0 0 1
kualitas 0 1 0 0 0 0 0 0 0 0 0 1
kurikulum 1 1 1 1 1 1 1 0 1 1 1 10
kuuh 0 0 1 0 0 0 0 0 0 0 0 1
lancar 0 1 0 0 0 0 0 0 0 0 0 1
layan 0 0 0 0 0 0 0 0 1 0 0 1
lelah 0 0 0 0 0 0 0 1,30103 0 0 0 1
lihat 0 0 0 0 1 0 0 0 0 0 0 1
lo 0 0 0 0 0 0 0 0 0 1 0 1
lupa 1 0 0 0 0 0 0 0 0 1 0 2
manusia 0 0 0 0 1 0 0 0 0 0 0 1
mapel 1 0 0 0 0 0 0 0 0 0 0 1
masuk 1 0 0 0 0 0 0 0 0 0 0 1
moga 1 1 1,69897 0 0 0 0 0 0 0 0 3
nasional 1 0 0 0 0 0 0 0 0 0 0 1
ngajar 0 0 0 0 0 0 0 1 0 0 0 1
nilai 0 0 0 0 0 0 0 0 1 1 1 3
pakai 0 0 0 1 0 0 1 0 0 0 0 2
paket 0 0 1 0 0 0 0 0 0 0 0 1
pasu 0 0 0 0 0 0 0 0 0 0 1 1
purwakarta 0 1 0 0 0 0 0 0 0 0 0 1
pusing 0 0 0 0 0 0 0 0 1 0 0 1
raport 0 0 0 0 0 0 0 0 1 0 1 2
salah 0 0 0 0 0 0 0 0 1 0 0 1
sejarah 0 0 0 0 1 0 0 0 0 0 0 1
sekolah 0 0 0 0 0 0 1 0 0 0 0 1
selamat 1 0 0 0 0 0 0 0 0 0 0 1
semangat 0 0 0 1 1 0 0 0 0 0 1 3
sesuai 0 0 0 0 0 0 0 0 1 0 0 1
siswa 0 0 0 0 1 0 0 0 0 0 1 2
sukses 0 0 0 1 0 0 0 0 0 0 0 1
tingkat 0 1 0 0 0 0 0 0 0 0 0 1
turun 0 0 1 0 0 0 0 0 0 0 0 1
uhb 0 0 0 0 0 0 1 0 0 0 0 1
uji 0 0 0 0 0 1 0 0 0 0 0 1
ulang 0 0 0 0 0 0 1 0 0 0 0 1
un 0 0 1 0 0 0 0 0 0 0 0 1

60
unbk 0 0 0 0 0 1 0 0 0 0 0 1
us 0 0 0 0 0 1 0 0 0 0 0 1
usbn 0 0 0 0 0 1 0 0 0 0 0 1
usul 0 0 0 0 1 0 0 0 0 0 0 1
uts 0 0 0 0 0 0 1 0 0 0 0 1
wajib 1 0 0 0 0 0 0 0 0 0 0 1
wish 0 0 1 1 0 0 0 0 0 0 0 2
Setelah didapatkan nilai dari Wft,d maka akan dilanjutkan dengan perhitungan idft, setelah perhitungan idft didapatkan barulah akan dilakukan perhitungan bobot term, yaitu Wf-idft,d = Wft,d x idft. Contoh perhitungan jika nilai Wft,d yang didapatkan adalah 1,69897 dengan nilai dfi adalah 3 dan nilai N (total dokumen) adalah 11 maka sebagai berikut:
idft = log 𝑁
𝑑𝑓𝑡
idft = log 11
2
idft = 0,56427 Sehingga:
Wf-idft,d = Wft,d x idft
Wf-idft,d = 1,69897 x 0,56427
Wf-idft,d = 0,95868
Tabel 4.27 Contoh Hasil Perhitungan Wf-idft,d
Term T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T11
administrasi 0 0 0 0 0 0 0 1,04 0 0 0
agenda 0 0 0 0 0 0 0 0 0 0 1,04
ajar 1,04 0 0 0 0 0 0 0 0 0 0
alhamdulillah 0 1,04 0 0 0 0 0 0 0 0 0
anak 0 0 0 0 0 0 0 0 1,04 0 0
bahagia 0 0 0 0 0 0 1,04 0 0 0 0
bahan 0 0 0 0 1,04 0 0 0 0 0 0
bbm 0 0 1,04 0 0 0 0 0 0 0 0
beban 0 0 0 0 0 1,04 0 0 0 0 0
belit 0 0 0 0 0 1,35 0 0 0 0 0
bingung 0 0 0 0 0 0 0 0 0 1,04 0
copot 0 0 1,04 0 0 0 0 0 0 0 0
dahyaa 0 0 0 1,04 0 0 0 0 0 0 0
debat 0 0 0 0 1,04 0 0 0 0 0 0

61
deng 0 0 0 0 0 0 0 0 0 1,04 0
didik 0,74 0,74 0 0 0 0 0 0 0 0 0
engga 0 0 1,04 0 0 0 0 0 0 0 0
gali 0 0 0 0 1,04 0 0 0 0 0 0
ganti 0 0 0 0 0 0 1,04 0 0 0 0
giat 0 1,04 0 0 0 0 0 0 0 0 0
hapus 0 0 0 0 0 0 1,04 0 0 0 0
hardiknas 1,04 0 0 0 0 0 0 0 0 0 0
hari 0 0 0 0 0 0 1,04 0 0 0 0
ikhlas 1,04 0 0 0 0 0 0 0 0 0 0
indonesia 0 1,04 0 0 0 0 0 0 0 0 0
informasi 0 0 0 0 1,04 0 0 0 0 0 0
jalan 0 1,04 0 0 0 0 0 0 0 0 0
kali 0 0 0 0 1,04 0 0 0 0 0 0
kelas 0 0 0 1,04 0 0 0 0 0 0 0
kemarin 0 0 0 0 0 0 1,04 0 0 0 0
ketemu 0 0 1,04 0 0 0 0 0 0 0 0
kualitas 0 1,04 0 0 0 0 0 0 0 0 0
kurikulum 0,04 0,04 0,04 0,04 0,04 0,04 0,04 0 0,04 0,04 0,04
kuuh 0 0 1,04 0 0 0 0 0 0 0 0
lancar 0 1,04 0 0 0 0 0 0 0 0 0
layan 0 0 0 0 0 0 0 0 1,04 0 0
lelah 0 0 0 0 0 0 0 1,35 0 0 0
lihat 0 0 0 0 1,04 0 0 0 0 0 0
lo 0 0 0 0 0 0 0 0 0 1,04 0
lupa 0,74 0 0 0 0 0 0 0 0 0,74 0
manusia 0 0 0 0 1,04 0 0 0 0 0 0
mapel 1,04 0 0 0 0 0 0 0 0 0 0
masuk 1,04 0 0 0 0 0 0 0 0 0 0
moga 0,56 0,56 0,96 0 0 0 0 0 0 0 0
nasional 1,04 0 0 0 0 0 0 0 0 0 0
ngajar 0 0 0 0 0 0 0 1,04 0 0 0
nilai 0 0 0 0 0 0 0 0 0,56 0,56 0,56
pakai 0 0 0 0,74 0 0 0,74 0 0 0 0
paket 0 0 1,04 0 0 0 0 0 0 0 0
pasu 0 0 0 0 0 0 0 0 0 0 1,04
purwakarta 0 1,04 0 0 0 0 0 0 0 0 0
pusing 0 0 0 0 0 0 0 0 1,04 0 0

62
raport 0 0 0 0 0 0 0 0 0,74 0 0,74
salah 0 0 0 0 0 0 0 0 1,04 0 0
sejarah 0 0 0 0 1,04 0 0 0 0 0 0
sekolah 0 0 0 0 0 0 1,04 0 0 0 0
selamat 1,04 0 0 0 0 0 0 0 0 0 0
semangat 0 0 0 0,56 0,56 0 0 0 0 0 0,56
sesuai 0 0 0 0 0 0 0 0 1,04 0 0
siswa 0 0 0 0 0,74 0 0 0 0 0 0,74
sukses 0 0 0 1,04 0 0 0 0 0 0 0
tingkat 0 1,04 0 0 0 0 0 0 0 0 0
turun 0 0 1,04 0 0 0 0 0 0 0 0
uhb 0 0 0 0 0 0 1,04 0 0 0 0
uji 0 0 0 0 0 1,04 0 0 0 0 0
ulang 0 0 0 0 0 0 1,04 0 0 0 0
un 0 0 1,04 0 0 0 0 0 0 0 0
unbk 0 0 0 0 0 1,04 0 0 0 0 0
us 0 0 0 0 0 1,04 0 0 0 0 0
usbn 0 0 0 0 0 1,04 0 0 0 0 0
usul 0 0 0 0 1,04 0 0 0 0 0 0
uts 0 0 0 0 0 0 1,04 0 0 0 0
wajib 1,04 0 0 0 0 0 0 0 0 0 0
wish 0 0 0,74 0,74 0 0 0 0 0 0 0
4.4.3.6 Normalization
Pada langkah ini akan dilakukan normalisasi nilai dari nilai fitur semantik, yaitu fitur F1-F37 yang meliputi twitter specific, textual features, Parts of Speech (PoS) Features dan lexicon based features. Berikut contoh hasil normalisasi fitur pada kategori twitter specific dapat dilihat pada Tabel 4.28, textual features pada Tabel 4.29, Parts of Speech (PoS) features pada Tabel 4.30, lexicon based features pada Tabel 4.31. Perhitungan menggunakan min-max normalization, sebagai contoh normalisasi pada fitur F5 data latih T1:
xM =𝑥 − 𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖𝑛
= 17 − 10
24 − 10
= 0,5

63
Tabel 4.28 Twitter Specific Normalization
ID F1 F2 F3 F4
T1 1 0 0 0
T2 1 0 0 0
T3 0 0 0 0
T4 0 0 0 1
T5 1 0 0 0
T6 1 0 0 0
T7 1 0 0 0
T8 0 0 0 0
T9 0 0 0 0
T10 0 0 1 0
T11 1 0 0 0
Tabel 4.29 Textual Features Normalization
ID F5 F6 F7 F8 F9 F10 F11 F12
T1 0,5 0,8971 0 0 0 0,25 0 0
T2 0,4286 1 0 0 0 0,375 0 0
T3 1 0,1215 0 0 0 0,125 0 0
T4 0,3571 0,2233 0 0,6667 0 0,375 0 1
T5 0,6429 0,5165 0 0 0 0,125 1 0
T6 0,3571 0,486 0 0 0 0,75 0 1
T7 0,7857 0,4523 0 0 0 1 0 0
T8 0 0 0 0 0 0,125 0 1
T9 0,5 0,4335 0 0 0 0,125 0 0
T10 0,9286 0,0737 1 0 1 0 0 0
T11 0,1429 0,4663 0 1 0 0,5 0 0
Tabel 4.30 Parts of Speech (PoS) Features Normalization
ID F13 F14 F15 F16 F17 F18 F19 F20 F21 F22
T1 0,125 0,6667 0,4 0 0,2 0,1724 0,3922 0,5412 0 0,2824
T2 0,25 0,3333 0 0,4 0,4 0,3348 0,2083 0 0,575 0,6

64
T3 0,125 0,6667 0,8 0,4 1 0,0926 0,2778 0,7667 0,3833 1
T4 0,25 0,3333 0,4 0 0 0,3638 0,2222 0,6133 0 0
T5 1 0,3333 0,4 0 0 1 0,1754 0,4842 0 0
T6 0 0 0 0,4 0 0,0539 0 0 0,6133 0
T7 0,25 0 0,2 0,8 0 0,231 0 0,219 0,8762 0
T8 0 1 0 0,2 0 0,1314 1 0 0,46 0
T9 0,25 0 0,2 0,4 0 0,3091 0 0,2706 0,5412 0
T10 0 0,6667 1 1 0,2 0 0,2899 1 1 0,2087
T11 0,5 0 0 0 0 0,8675 0 0 0 0
Tabel 4.31 Lexicon Based Features Normalization
ID F23 F24 F25 F26 F27 F28 F29 F30 F31 F32 F33 F34 F35 F36 F37
T1 0,6667 0 0,5 0 0 0 0 0 0,7059 0 0 0 0 0 0
T2 1 0,4 0,25 0,5 0 0 0 1 0,375 0,3125 0 0 0 1 0
T3 1 0 1 0 0 0 1 0 1 0 0 0 1 0 1
T4 1 0 0,25 0 0 0 0 0 0,4 0 0 0 0 0 0
T5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
T6 0,3333 0 0 0 0 0 0 0 0 0 0 0 0 0 0
T7 0,3333 0 0 0 0 0 0 0 0 0 0 0 0 0 0
T8 0 0,6 0 1 0 0 0 0,5 0 1 0 0 0 0,8 0
T9 0,6667 0,4 0 0 0 1 0 0,5 0 0 0 1 0 0,4706 0
T10 0 1 0 1 0 1 0 1 0 0,4348 0 0,7391 0 0,6957 0
T11 0,3333 0,2 0 0 0 0 0 0 0 0 0 0 0 0 0
4.4.4 K-Nearest Neighbor (K-NN) Classification
Pada langkah ini, akan dilakukan pengklasifikasian tweet menggunakan metode K-Nearest Neighbor (K-NN). Langkah-langkah pengklasifikasian terbagi menjadi 3 bagian utama yaitu, perhitungan kemiripan, sorting dan voting.
4.4.4.1 Perhitungan Kemiripan
Perhitungan kemiripan dilakukan dengan menggunakan cosine similarity. Tabel 4.32 menunjukan hasil perhitungan kemiripan data uji terhadap masing-masing data latih yang didapatkan menggunakan cosine similarity. Sebagai contoh, dokumen T11 sebagai data uji yang akan dihitung nilai kemiripannya dengan data latih T1 maka:
Similarity T1 = ∑ (𝑤𝑖𝑗
𝑡𝑖=1 . 𝑤𝑖𝑞)
√∑ 𝑊𝑖,𝑗2𝑛
𝑖=1 .√∑ 𝑊𝑖,𝑞2𝑛
𝑖=1

65
= (0,04∗0,04)+ (1∗1)+(0,5 ∗ 0,14)+(0,8 ∗ 0,4)+(0,25 ∗ 0,5)+(0,125∗0,5)+(0,17∗0,86)+(0,6∗0,3)
√1,042+0,742+1,042+1,042+0,042+0,742… ∗ √1,042+0,042+0,562+1,042+0,742+0,562…
= 2,7468
3,8234 ∗ 2,7468
=0,1953
Tabel 4.32 Hasil Perhitungan Cosine Similarity
ID Similarity
T1 0,1953
T2 0,2253
T3 0,0584
T4 0,2478
T5 0,3319
T6 0,2004
T7 0,2136
T8 0,0332
T9 0,2130
T10 0,0593
4.4.4.2 Sorting
Pada langkah ini akan dilakukan pengurutan nilai mulai dari yang terbesar hingga yang terkecil, nilai terbesar menunjukkan data uji yang memiliki nilai similarity paling tinggi hingga yang memiliki similarity yang paling rendah.
Tabel 4.33 Hasil Pengurutan Nilai Kemiripan
ID Similarity Class
T5 0,3319 Positif (+)
T4 0,2478 Positif (+)
T2 0,2253 Positif (+)
T7 0,2136 Negatif (-)
T9 0,2130 Negatif (-)
T6 0,2004 Negatif (-)
T1 0,1953 Positif (+)
T10 0,0593 Negatif (-)
T3 0,0584 Positif (+)
T8 0,0332 Negatif (-)

66
4.4.4.3 Voting
Langkah ini melakukan proses perhitungan jumlah kelas terbanyak yang dilihat dari tetangga yang paling terdekat sejumlah k tetangga. Pada contoh kali ini akan diambil k sebanyak 5, sehingga hasil perhitungan voting dapat dilihat pada Tabel 4.34.
Tabel 4.34 Hasil Voting Kelas Tweet Data Uji
ID Similarity Class
T5 0,3319 Positif (+)
T4 0,2478 Positif (+)
T2 0,2253 Positif (+)
T7 0,2136 Negatif (-)
T9 0,2130 Negatif (-)
Dapat dilihat pada tabel diatas jumlah kelas positif adalah sebanyak 3 kelas dan kelas negatifnya hanya 2 kelas, sehingga data tweet uji akan dimasukkan ke kelas tweet yang positif.
4.5 Perancangan Pengujian
Pada bagian ini dilakukan perancangan pengujian dengan tujuan untuk mendapatkan hasil klasifikasi berupa opini positif atau opini negatif dengan menggunakan ensemble feature dan metode K-Nearest Neighbor (K-NN) dalam analisis sentimen. Terdapat 4 skenario pengujian yang akan dilakukan yaitu:
Pengujian pertama adalah pengujian nilai k terhadap akurasi metode K-Nearest Neighbor (K-NN), pengujian ini dilakukan bertujuan untuk mendapatkan nilai k dengan akurasi terbaik, rancangan tabel pengujian nilai k dapat dilihat pada Tabel 4.35 . Setelah didapatkan nilai k dengan akurasi terbaik, maka nilai tersebut dapat digunakan untuk pengujian selanjutnya, yaitu pengujian variasi fitur.
Tabel 4.35 Rancangan Tabel Pengujian Nilai k
Pengujian ke Nilai k Akurasi (%)
Pengujian kedua adalah pengujian fitur Bag of Words (BoW) yaitu, fitur dari
sisi statistik kata, pengujian ini dilakukan bertujuan untuk mengetahui pengaruh fitur Bag of Words (BoW) ini terhadap akurasi metode K-Nearest Neighbor (K-NN) dalam menganalisis sentimen.

67
Pengujian ketiga adalah pengujian fitur ensemble (twitter specific features, textual features, Parts of Speech (PoS) features, lexicon based features) yaitu, fitur dari sisi semantik kata, pengujian ini dilakukan bertujuan untuk mengetahui pengaruh fitur ensemble ini tanpa Bag of Words terhadap akurasi metode K-Nearest Neighbor (K-NN) dalam menganalisis sentimen.
Pengujian keempat adalah pengujian fitur ensemble secara lengkap, yaitu penggabungan fitur dari sisi statistik yang menggunakan Bag of Words dan dari sisi semantik kata menggunakan ensemble (twitter specific features, textual features, Parts of Speech (PoS) features, lexicon based features), pengujian ini dilakukan bertujuan untuk mengetahui pengaruh fitur ensemble secara lengkap terhadap akurasi metode K-Nearest Neighbor (K-NN) dalam menganalisis sentimen.
Dari pengujian pertama hingga terakhhir perhitungan nilai akurasi didapatkan dari persentase data uji yang diklasfikasikan dengan benar. Pada pengujian variasi fitur yaitu, pengujian kedua hingga ke empat dilakukan perancangan tabel untuk menampilkan hasil klasifikasi positif/negatif dari pengujian fitur yang dilakukan dan perbedaan akurasi yang didapatkan. Berikut perancangan tabel hasil pengujian fitur dapat dilihat pada Tabel 4.36 dan tabel perbedaan akurasi penggunaan fitur pada Tabel 4.37.
Tabel 4.36 Rancangan Tabel Hasil Pengujian Fitur
Sistem
Positif Negatif
Pak
ar Positif
Negatif
Tabel 4.37 Rancangan Tabel Pengujian Perbedaan Akurasi Penggunaan Fitur
Fitur Akurasi (%)
Bag of Words (BoW)
Ensemble (twitter specific features, textual features, Parts of Speech (PoS) features, lexicon based features)
Bag of Wors + Ensemble (twitter specific features, textual features, Parts of Speech (PoS) features, lexicon based features)




















