
Modélisation économétrique du prix du riz sur le marché mondial »

UNIVERSITÉ DE LA MÉDITERRANÉEFACULTÉ DE MÉDECINE
ÉCOLE DOCTORALE MATHÉMATIQUES ET INFORMATIQUEE.D. 184
THÈSE
présentée pour obtenir le grade de
Docteur de l'Université de la Méditerranée �
Aix-Marseille II
Spécialité : Mathématiques
par
Jean GAUDART
sous la direction du Dr. Hervé CHAUDET et du Pr. JacquesDEMONGEOT
Titre :
Analyse spatio-temporelle et modélisationdes épidémies : application au paludisme à
P. falciparum
soutenue publiquement le 20 novembre 2007
Equipe d'accueil :Equipe Biomathématiques et Informatique Médicale
Laboratoire d'Informatique Fondamentale,UMR 6166 CNRS/Aix-Marseille Université,Faculté de Médecine, 27 Bd J. Moulin, 13005 Marseille, France
JURY
Dr. Hervé CHAUDET Univ. de la Méditerranée, Marseille Directeur
Pr. Jacques DEMONGEOT Univ. Joseph Fourier, Grenoble Directeur
Pr. Ogobara DOUMBO Univ. du Mali, Bamako Examinateur
Pr. Bruno FALISSARD Univ. Paris-Sud, Paris Rapporteur
Pr. Marius FIESCHI Univ. de la Méditerranée, Marseille Président
Pr. Antoine FLAHAULT Univ. Pierre et Marie Curie, Paris Rapporteur


Table des matières
Liste des tableaux 4Table des �gures 4
Avant Propos 3
Première partie : Analyse spatiale et spatio-temporelle 51. Détection de clusters spatiaux 61.1. Introduction 61.2. Qu'est-ce qu'un cluster spatial ? 71.3. Coe�cient de Moran 81.4. Statistique de Tango 101.5. Coe�cient local de Moran (Anselin) 121.6. Statistique de balayage 131.7. Arbres de régression oblique 151.8. Application 251.9. Discussion 311.10. Étude de la puissance de SpODT 362. Détection de clusters spatio-temporels 452.1. Introduction 452.2. Matériel 452.3. Méthodes 452.4. Résultats 462.5. Discussion 50
Deuxième partie : Modélisation déterministe 571. Introduction 581.1. Le cycle du paludisme 581.2. Les modèles du paludisme 592. Evolution temporelle du paludisme 612.1. Description de 2 modèles classiques 612.2. Modèle de Bancoumana et climat 713. Evolution spatio-temporelle du paludisme 863.1. Modèles de réaction-di�usion et paludisme 863.2. Le climat 863.3. Equations de réaction-di�usion 883.4. Résultats 914. Discussion 94
Conclusion Générale 101Références 105
Résumé 121

Liste des tableaux
1 Statistiques et inférences issues des di�érentes méthodesd'analyse spatiale. 32
2 Simulations circulaires. 43
3 Simulations en bande. 44
4 Clusters spatio-temporels de parasitémies à P. falciparum. 50
5 Clusters spatio-temporels de gamétocytémies à P. falciparum. 52
6 Clusters spatio-temporels de parasitémies à P. malariae. 52
7 Estimations des paramètres. 70
8 Estimation des paramètres avec dépendance climatique. 73
9 Matrice de transition estimée. 78
10 Validation externe : erreurs de prédiction desdi�érentes modèles MMC. 79
11 Modélisation du paludisme : erreurs de prédiction desdi�érentes modèles MMC. 79
12 Validation externe : erreurs de prédiction. 84
13 Modélisation du paludisme : erreurs de prédiction. 85
14 Paramètres utilisés pour les modèles de réaction-di�usion. 92
15 Résultats de SpODT appliqué aux simulations 93
16 Qualité du krigeage, erreurs en validation croisée 95
Table des figures
1 Construction de l'angle critique θij de la direction u 20
2 Transition via une direction critique u, d'un secteur 1à un secteur 2 21
3 Algorithme SpODT 23
4 Image satellite du village de Bancoumana -GoogleEarthr- 27
5 Image satellite du village de Bancoumana -GoogleEarthr- 27
6 Image satellite du village de Bancoumana -SPOTimager-10/11/2003 27
7 Evolution de la distribution de l'âge dans la cohortedynamique au cours du temps. 28
8 Cartographie du village de Bancoumana etreprésentation des clusters identi�és. 30
9 Risque pi en fonction de la distance di. 39
10 Risque pi en fonction de la distance di. 39
11 SpODT : simulation circulaire (τ = 0, 001 ; p = 0, 8). 40

12 Satscan : simulation circulaire (τ = 0, 001 ; p = 0, 8). 40
13 SpODT : simulation circulaire (τ = 0, 005 ; p = 0, 8). 40
14 Satscan : simulation circulaire (τ = 0, 005 ; p = 0, 8). 40
15 SpODT : simulation en bande (τ = 0, 001 ; p = 0, 8). 40
16 Satscan : simulation en bande (τ = 0, 001 ; p = 0, 8). 40
17 SpODT : simulation circulaire (τ = 0, 001 ; p = 0, 5). 41
18 Satscan : simulation circulaire (τ = 0, 001 ; p = 0, 5). 41
19 SpODT : simulation circulaire (τ = 0, 005 ; p = 0, 5). 41
20 Satscan : simulation circulaire (τ = 0, 005 ; p = 0, 5). 41
21 SpODT : simulation en bande (τ = 0, 001 ; p = 0, 5). 41
22 Satscan : simulation en bande (τ = 0, 001 ; p = 0, 5). 41
23 SpODT : simulation en bande (τ = 0, 005 ; p = 0, 5). 42
24 Satscan : simulation en bande (τ = 0, 005 ; p = 0, 5). 42
25 SpODT : simulation en bande (τ = 0, 005 ; p = 0, 8). 42
26 Satscan : simulation en bande (τ = 0, 005 ; p = 0, 8). 42
27 SpODT : simulation en bande �xe (p = 0, 8). 42
28 Satscan : simulation en bande �xe (p = 0, 8). 42
29 SpODT : simulation en bande �xe (p = 0, 5). 43
30 Résultats de Satscan pour une simulation en bande �xe (p = 0, 5). 43
31 Evolution de l'incidence de l'infection par les 3 espècesplasmodiales et par les gamétocytes de P. falciparum. 47
32 Modélisation de l'évolution de l'incidence de l'infectionà P. falciparum. 48
33 Modélisation de l'évolution de l'incidence de lagamétocytémie à P. falciparum. 48
34 Modélisation de l'évolution de l'incidence de l'infectionà P. malariae. 49
35 Localisations temporelles et spatiales des clusters decas. 51
36 Représentation simpli�ée du cycle de P. falciparum. 59
37 Modèle de Ross et McDonald. 62
38 Modèle de Dutertre. 64
39 Modèle de Bancoumana. 66
40 Modèle de Bancoumana : résolution numérique 67
41 Variations de la trajectoire Mi(t) = f(G(t)) en fonctiondes estimations des paramètres. 68
42 Modèle de Bancoumana : 1)gauche : mesure de préventionseule δ = 0, 004, 2)droite : mesure de prévention associée autraitement δ = 0, 004 et γ = 0, 1 69

43 Modélisation du paludisme : variable climatique exogène modélisée par la
distribution empirique de la pluviométrie. 74
44 Structure des modèles de chaîne de Markov cachée. 76
45 Modélisation du paludisme : variable climatiqueexogène modélisée par MMC 77
46 Probabilités d'émission estimées (pluviométrie enmm). 78
47 Modélisation du paludisme : variable climatiqueexogène modélisée par un modèle non-linéaire. 80
48 Modélisation du paludisme : variable climatiqueexogène modélisée par un modèle non-paramétrique. 83
49 Validation externe : pluviométrie décadaire 1981-1985 et prédictions. 85
50 Bancoumana : repérages des zones particulières. 1/ large collection du
sud-ouest (ht gche) ; 2/ briqueterie sud-ouest et son puit 3/ briqueterie
sud, 4/ large zone nord 88
51 Structure spatiale du modèle utilisé (logicielCOMSOL®) 91
52 Evolution temporelle : Incidences des Sujets susceptibles (S),infectés (I), à gamétocytémie (G) et résistants (R), en saison sèche (SS),
intermédiaire (SI) ou milieu de saison des pluies (SP), (incidence en
abscisse et temps en ordonnée). Les traits verticaux représentent les
instants où les distributions spatiales sont présentées aux �gures 53 et 57 93
53 Distribution spatiale de l'incidence des individusinfectés (I) : saison sèche (SS) à 90j, situation intermédiaire (SI) à
30j, et milieu de saison des pluies (SP) à 70j. Interpolation par krigeage
ordinaire. L'échelle des fonds de cartes est commune à toute les situations
(à gauche). Les échelles des isohyètes sont particulières à chaque situation
(à droite). 94
54 Distribution spatiale de l'incidence des individusinfectés (I), à t=0 : situation intermédiaire (SI), et milieu de saison
des pluies (SP) . Interpolation par krigeage ordinaire. L'échelle des fonds
de cartes est commune à toute les situations (à gauche). Les échelles des
isohyètes sont particulières à chaque situation (à droite). 95
55 Distribution spatiale de l'incidence des individusinfectés (I), à t= 6 mois : saison sèche (SS) , situation
intermédiaire (SI), et milieu de saison des pluies (SP). Interpolation par
krigeage ordinaire. L'échelle des fonds de cartes est commune à toute
les situations (à gauche). Les échelles des isohyètes sont particulières à
chaque situation (à droite). 96
56 Distribution spatiale observée de l'incidence desindividus infectés (I) : Juin 2000 (avant la saison des pluies) et

Octobre 2000 (�n de la saison des pluies) . Interpolation par krigeage
ordinaire. L'échelle des fonds de cartes est commune (à gauche). 97
57 Distribution spatiale des vecteurs (en pourcentage) :saison sèche (SS) à 90j, situation intermédiaire (SI) à 30j, et milieu de
saison des pluies (SP) à 70j. 98


Remerciements
Monsieur le Pr Jacques Demongeot, je vous remercie pour avoir suivi l'en-semble de ce travail, concrètement et régulièrement. Mes séjours à Grenoble m'ontpermi d'avancer et de me confronter à votre rigueur. Ce travail n'aurait pas puaboutir sans vous. J'ai beaucoup appris lors de ces courtes visites, et je les regrette-rai. Veuillez trouver ici l'expression de toute ma reconnaissance et de mon profondrespect.
Monsieur le Pr Marius Fieschi, depuis mon internat, vous m'avez fait con�ance.Votre présence ici en est une preuve, s'il en fallait encore. Je vous remercie, à nou-veau, pour votre soutient.
Messieurs les Pr Bruno Falissard et Pr Antoine Flahault, je vous remercied'avoir accepter de rapporter sur ce travail, j'en suis très honoré.
Monsieur le Pr Ogobara Doumbo, ce travail a béné�cier de vos travaux an-térieurs et de votre connaissance de la réalité de terrain, indispensable pour touteanalyse ou modélisation. Je vous remercie de votre aide, et de votre présence au-jourd'hui.
Monsieur le Pr Michel Roux, je vous remercie, à nouveau, pour votre accueil,dans votre laboratoire, et du soutient constant que vous m'avez accordé. Veuilleztrouver ici le témoignage de mon profond respect.
Monsieur le Docteur Hervé Chaudet, je vous remercie pour avoir acceptéd'encadrer cette thèse.
Je remercie tout les membres de l'équipe Biomathématiques et Informatiques Mé-dicale du LIF, spécialement Messieurs Bernard Fichet et Bernard Giusiano,pour leurs conseils, leur contribution et leur disponibilité, qui ont permis que ce tra-vail avance, ainsi que Loic Forest du laboratoire de mathématique (INSA Rouen).Je remercie tout les membres du LERTIM et du SSPIM, spécialement MessieursJoanny Gouvernet et Roch Giorgi.
Je remercie également lesProfesseurs Bruno Durand, Paul Sabatier et EtiennePardoux pour leur patience.
A ma famille, qui m'a supporté, en particulier Bérengère, Marion, Benoît,Lucile et Émilie.
A la mémoire d'Henri Laurent du LTHE (Grenoble).
Ce travail a été, en partie, supporté par le programme ACCIES-GICC du Mi-nistère de l'Ecologie et du Développement Durable, France.Les données cliniques et biologiques ont été obtenues par le Malaria Research andTraining Center (DEAP-MRTC), Bamako (Mali), dans le cadre du programmeMali-Tulane TMRC N° AI 95-002-P50 du NIH.
1


Avant Propos
L'étude de la distribution spatio-temporelle du paludisme et de sonévolution dans le temps et l'espace sont d'une importance relevée parl'OMS [186, 187, 188]. En e�et, l'élaboration de carte de risque, enparticulier sur le continent africain, et la mise en place de systèmesde surveillance sanitaire (systèmes d'information épidémiologique) per-mettent de guider les programmes de lutte contre cette maladie. Cesactions sont enrichies par la détection de zones à risque, nécessitantune méthodologie statistique et épidémiologique appropriée, et par laconnaissance des mécanismes de transmission. Suivant les 2 approchesde Ronald Ross [165], la première partie de ce travail propose uneapproche statistique de la distribution spatiale et temporelle du pa-ludisme. Nous avons présenté des outils statistiques classique de dé-tection de clusters spatiaux, et développé une approche fondée sur lesarbres de régressions obliques. La recherche de clusters spatio-temporelsd'infection palustre a été faite à l'échelle d'un village malien. La plu-part des résultats présentés dans cette première partie ont été publiés[87, 88, 96, 97, 98, 99]. Dans la deuxième partie, nous avons proposé unemodélisation déterministe de la transmission palustre, en tenant éga-lement compte de la pluviométrie. En�n, l'évolution spatio-temporelledu paludisme a été modélisée à l'aide d'équations de réaction-di�usion.
3


Première partie :
Analyse spatiale et spatio-temporelle
Avec ses quatre dromadaires
Don Pedro d'Alfaroubeira
Courut le monde et l'admira.
Il �t ce que je voudrais faire
Si j'avais quatre dromadaires.
Guillaume Appolinaire.Le Bestiaire : Le dromadaire

Part.I. 1. Détection de clusters spatiaux
1. Détection de clusters spatiaux
1.1. Introduction. La nécessité de systèmes d'alertes face aux risquessanitaires, en particulier environnementaux, amenant le développementde systèmes d'informations géographiques, a permis de construire descartes précises de nombreuses pathologies, et l'analyse des variationsspatiales d'indicateurs de santé [198, 112]. L'observation de ces va-riations spatiales dans le cadre d'études écologiques conduit à poserplusieurs questions : existe-t-il une structure (pattern) spatiale parti-culière ? Les cas se trouvent-ils à proximité d'autre cas ? Certaines zonesgéographiques ont-elles un nombre de cas excessif, ou encore existe-t-ilun (des)agrégat(s) de cas ?En d'autres termes, il s'agit de décrire l'hétérogénéité spatiale et derechercher les mécanismes qui l'ont générée.Di�érentes méthodes statistiques ont été développées pour l'identi�-cation de patterns spatiaux, en particulier d'agrégats spatiaux de cas(clusters), adaptées aux di�érentes situations [79, 144, 249]. Les di�é-rentes descriptions de l'hétérogénéité spatiale correspondent à autantd'hypothèses alternatives et à des méthodes di�érentes [120, 3, 247].Certains auteurs ont classé ces méthodes en 3 groupes, en fonction dela question posée [146, 25, 57, 48, 189] :
i: Les méthodes de détection locale d'agrégats de cas autour d'unesource potentielle [25, 227, 65, 48] ;
ii: Les méthodes de détection globale d'agrégats de cas, sans spé-ci�cation a priori d'une source potentielle, et dont les statis-tiques sont fondées, le plus souvent, sur les distances entre lescas [3, 228, 64, 107] ;
iii: Les méthodes de détection locale d'agrégats, sans spéci�ca-tion a priori d'une source. On retrouve dans cette catégorie desapproches fondées sur les distances entre les cas [7, 104] et desapproches portant sur le regroupement de données [144, 3, 97,230, 240].
Une condition inhérente à l'utilisation des méthodes du groupe i estla spéci�cation de la source potentielle, a�n de tester l'hypothèse d'unexcès de cas autour d'une source spéci�que [48]. Cependant une tellesource n'est pas toujours unique, ou même connue. En e�et, on peutêtre amené à rechercher des zones particulièrement à risque, notammentpour orienter les équipes d'épidémiologistes de terrain. Les méthodesdes groupes ii et iii, regroupées sous le terme de méthodes générales[249, 48], sont d'un intérêt particulier dans ces conditions, puisqu'ellespermettent de s'a�ranchir de la connaissance préalable d'une sourcespéci�que et de détecter des zones à risque de localisation quelconqueparmi toutes les zones considérées. Les méthodes générales dites de dé-tection globale (groupe ii) estiment une statistique sur l'ensemble de
6

Part.I. 1. Détection de clusters spatiaux
la zone géographique étudiée et testent ainsi un pattern spatial global,alors que les méthodes dites de détection locale estiment une statistiquesur chaque unité spatiale (u.s.). L'hétérogénéité spatiale peut être dé-crite par des u.s. particulières à haut risque. Ou bien, certaines u.s.peuvent être regroupées en une zone homogène en terme de risque. Ouencore, la région étudiée peut être découpée en zones où le risque est ho-mogène. Chacune de ces dé�nitions du pattern spatial correspond à unehypothèse alternative di�érente, et répond à une hypothèse nulle. L'hy-pothèse nulle la plus classiquement retenue est celle du risque constant,représentée par une distribution de Poisson hétérogène en espace. Unetelle hypothèse nulle modélise l'hétérogénéité spatiale sous l'hypothèsed'absence de clusters. La distribution du nombre attendu de cas dansl'u.s. i (d'e�ectif ni) est alors Ei P(λi = nip+) avec p+ = O+
n+, où O+
et n+ sont, respectivement, le nombre total de cas observés et l'e�ectiftotal de la population sur l'ensemble de la zone d'étude.A�n de comparer, de façon empirique, ces di�érentes méthodes, ditesgénérales, d'analyse de clusters, nous en avons sélectionné 5, deux parmiles méthodes du groupe ii et trois parmi celles du groupe iii, et les avonsappliquées sur des données d'incidence de parasitémie à Plasmodium
falciparum dans un village malien. Les deux méthodes globales étudiéessont le test du coe�cient de corrélation de Moran, classiquement uti-lisé, et le test de Tango, d'application plus récente. Les trois méthodesde détection locale étudiées sont le coe�cient local de Moran, introduitpar Anselin [7], la méthode de balayage du plan [144] et la méthodedes arbres de régression oblique [97]. Notre objectif est de présenter lesprincipes de ces cinq méthodes générales de détection de clusters et decomparer leurs résultats dans le cadre de la détection de zones à risquede paludisme dans un village du Mali.
1.2. Qu'est-ce qu'un cluster spatial ?Tout d'abord, un "pattern" spatial ("canevas", "motif") peut être dé-�ni comme une organisation spatiale de la variable étudiée. Elle peutêtre liée ou non à d'autres variables (facteurs de risque).Un cluster est une organisation spatiale (pattern) particulière, dé�niecomme un agrégat, une collection, un regroupement de cas proches lesuns des autres, la proximité étant dé�nie au sens d'une distance géo-graphique.En l'absence de cluster, les cas se répartissent aléatoirement sur l'en-semble de la zone géographique étudiée, sans organisation particulière.Cette répartition géographique des cas peut être uniforme (Complete
Spatial Randomness), mais dépend alors fortement de la distributionspatiale de la population à risque et de la distribution spatiale desu.s. étudiées. Comme nous l'avons vu précédemment, l'hétérogénéitéspatiale, en absence de cluster, est plus classiquement représentée par
7

Part.I. 1. Détection de clusters spatiaux
une répartition des cas suivant une loi de Poisson hétérogène, i.e. dé-pendant de la distribution de la population à risque (Constant RiskHypothesis) : Ei P(λi = nip+).
La présence d'un cluster sur une u.s. particulière c, hypothèse alter-native, peut être alors représentée par la distribution des cas suivante :Ec P(λc = ncpc), où pc > p+ représente le risque particulier à l'u.s.c.
1.3. Coe�cient de Moran.A�n de rechercher des patterns spatiaux inhabituels, la plupart desméthodes globales, dont celle issue de l'utilisation du coe�cient deMoran, reposent sur l'utilisation de distances entre les u.s. étudiéespour prendre en compte la proximité dans leur statistique. Plusieursdé�nitions de la proximité sont disponibles, pouvant amener à des résul-tats di�érents. La proximité est dé�nie en fonction de la distance entreles u.s., et les distances peuvent être euclidiennes ou calculées selond'autres métriques appropriées. Les méthodes fondées sur des statis-tiques globales peuvent être considérées comme des tests de tendanceà l'agrégation (clustering) et ne donnent qu'un seul degré de signi�-cation (p-value) testant l'organisation spatiale (pattern) observée surl'ensemble de la zone d'étude. La première méthode présentée utiliseune statistique d'autocorrélation spatiale classique, le coe�cient de cor-rélation de Moran [198, 50, 8, 154], pour tester la distribution spatialeobservée. La seconde méthode, la statistique de Tango, est fondée surune comparaison de distributions.L'autocorrélation spatiale rend compte à un niveau global de la ten-dance des régions proches à se ressembler ou à s'opposer. Le coe�cientde Moran est considéré assez unanimement comme un des meilleurschoix parce qu'il présente de bonnes propriétés locales [7, 150].Le coe�cient I de Moran peut être dé�ni comme un coe�cient de
corrélation pondéré utilisé pour détecter l'écart à la répartition spatialealéatoire, cet écart dé�nissant la présence d'un pattern spatial tel quedes clusters (agrégats). Une similarité des valeurs pour des u.s. voi-sines (autocorrélation spatiale signi�cative) peut s'observer sur la zonegéographique sous forme d'agrégats de valeurs soit plutôt faibles, soitplutôt fortes. La statistique de Moran recherche les u.s. qui possèdentun critère similaire. Ce critère, calculé pour chaque couple d'u.s., peuts'écrire :
(1.3.1) I =1
w+
×∑K
i,j wij(Yi − Y )(Yj − Y )PK
i=1(Yi−Y )2
K
avec K le nombre d'u.s. ; les wij sont les éléments de la matrice deproximité pour les u.s. i et j ; w+ =
∑Kij wij ; Yi = Oi
nicorrespond aux
8

Part.I. 1. Détection de clusters spatiaux
proportions de cas de chaque u.s. i (Oi est le nombre de cas observés
de l'u.s. i, et ni l'e�ectif de l'u.s. i) ; Y =PK
i=1 Yi
Kreprésente la moyenne
des proportions sur l'ensemble des K u.s..Au numérateur, on trouve un terme de covariance qui est localementcalculé entre la région i et les régions voisines, et pondéré par la mesurede proximité wij
w+[50, 8, 154].
La statistique de Moran I est donc une variable aléatoire dont ladistribution est déterminée par la distribution - et les similitudes spa-tiales - des Yi. La distribution de I est connue sous l'hypothèse nulle,assumant que le nombre de cas est une variable aléatoire suivant unedistribution normale, identique quelle que soit l'u.s., et, pour chaqueu.s., indépendante des unités voisines [8] (condition d'identité et d'indé-pendance de la distribution -i.i.d.-). Sous l'hypothèse nulle, l'espérancede I est connue, de même que sa variance (dépendant de la proximité),et sa distribution est asymptotiquement normale. Les hypothèses dutest peuvent s'écrirent :
H0 : I = 0, les cas dans chaque u.s. i sont spatialementdécorrélées (indépendantes dans le cas gaussien) ; hypo-thèse du risque constant ;H1 : I 6= 0, les cas dans chaque u.s. i ne sont pas spatia-lement indépendants ; la survenue de cas dans une u.s. idépend des u.s. voisines et de la distance entre les u.s..
Sous H0 et si I N (E(I), V ar(I)), on obtient asymptotiquementen K les estimateurs suivant
E(I) = −1K−1
;
V ar(I) =K2× 1
2
PKi,j 6=i(wij+wji)
2−K×PK
i=1(wi++w+i)2+3w2
+
(K−1)(K+1)w2+
− E(I)2(avec wi+ =
∑Kj=1wij et w+j =
∑Ki=1wij
)Alors,
Z = I−E(I)V ar(I)
N (0, 1)
Cependant, la condition de normalité n'est que rarement respectée,les distributions du nombre de cas sont assymétriques même pour degrands e�ectifs [227, 226], et l'hypothèse d'indépendance n'est pasraisonnable [198]. Le nombre d'u.s. K est en pratique souvent ré-duit et les u.s. ont le plus souvent un nombre di�érent de personnes-années exposées, ce qui altère également la distribution du coe�cientI [52]. L'inférence de Monte-Carlo permet de palier à ces problèmesen simulant des variables aléatoires sous l'hypothèse nulle appropriée[19]. Des adaptations de la statistique de Moran ont été proposées[8, 236, 130, 183, 248, 251] pour s'adapter à di�érents contextes.
9

Part.I. 1. Détection de clusters spatiaux
On peut remarquer que le coe�cient de Moran est très proche du coe�-cient de corrélation de Pearson, mesurant l'association entre K valeursde la variable aléatoire Y . Le I de Moran représente une forme spatialepondérée du coe�cient de Pearson. Mais contrairement à ce dernier,le coe�cient I n'est pas compris entre [−1,+1]. Cli� et Ord [50] ontdétaillé ces bornes [249].Le coe�cient de Moran mesure donc la similitude entre les u.s. voisines.Si les u.s. voisines sont similaires (i.e. existence d'un pattern sous formede clusters d'u.s.), le coe�cient I sera positif. Si les unités voisines sontdi�érentes (i.e. existence d'un pattern régulier), I sera négatif. S'il n'ya aucune corrélation entre les unités voisines, I sera en moyenne prochede son espérance (proche de zéro). Pour l'interpréter, on doit garderà l'esprit que le coe�cient de Moran ne permet pas d'identi�er l'e�etspéci�que exercé par une u.s. particulière, mais mesure globalementl'autocorrélation.
1.4. Statistique de Tango.Au lieu d'utiliser un coe�cient d'autocorrélation spatiale, certains au-teurs ont proposé des statistiques d'adéquation estimant l'écart entreles valeurs observées et les valeurs théoriques issues d'un modèle pro-babiliste (du plus simple -uniforme- au plus compliqué -processus dePoisson dépendant de covariables) [227, 251, 200].La statistique d'adéquation la plus connue est la statistique du χ2 dePearson, χ2 =
∑Ni=1
(Oi−Ei)2
Ei, où N est le nombre total de cellules, les
Oi sont les valeurs observées, les Ei sont les valeurs attendues sous l'hy-pothèse nulle (par exemple distribution Binomiale ou Multinomiale desvaleurs de chaque cellule).On peut appliquer le test du χ2 aux données spatiales en remplaçantl'hypothèse nulle habituelle par l'hypothèse du risque constant fon-dée sur une distribution de Poisson des valeurs de chaque cellule i,Ei = nip+. Sous H0, cette statistique suit une loi du χ2 à K−1 degrésde liberté (pour K u.s.).
Cependant, les tests fondés sur une statistique d'adéquation sup-posent l'indépendance des valeurs, sous l'hypothèse nulle mais aussisous l'hypothèse alternative. Cette supposition les distingue des testsfondés sur des indicateurs d'autocorrélation, où l'indépendance desdonnées n'est supposée que sous l'hypothèse nulle. Bien que l'hypo-thèse nulle du risque constant admette cette supposition, ce n'est pasle cas de l'alternative dé�nie par le regroupement de cas en clusters.De plus, cette approche ignore l'impact de la localisation des u.s.. Onpeut considérer que la statistique du χ2 fournit un test acceptable dedétection globale de clusters, bien qu'elle ne soit pas capable de repérerle caractère spatial des écarts au modèle théorique [200]. Par exemple,
10

Part.I. 1. Détection de clusters spatiaux
si plusieurs u.s. présentent un écart important au modèle théorique, lastatistique du χ2 reste inchangée, que ces u.s. soient contiguës (suggé-rant un cluster) ou non. On peut alors pondérer les écarts aux valeursthéoriques de façon à prendre en compte la structure spatiale du pro-blème.On voit ici que les statistiques d'adéquation et les indicateurs d'auto-corrélation quanti�ent la dépendance spatiale de façon di�érente. Onpeut adapter les hypothèses, mais les modi�cations de la statistique nepermettent pas de connaître formellement la distribution asymptotiqueet nécessitent d'utiliser l'inférence de Monte Carlo [249].Tango [227] a proposé une généralisation spatiale de la statistique
du χ2, pondérant l'écart par la proximité des u.s. :
(1.4.1) wik(Oi − Ei)(Ok − Ek)
Pour chaque u.s., on observe des proportions locales de cas,(O1
O+, . . . , Ok
O+
),
où O+ =∑K
i=1Oi représente le nombre total d'observations.Sous l'hypothèse nulle (hypothèse du risque constant), l'ensemble des
proportions locales d'observation suit une distribution Multinomiale.
L'ensemble des valeurs attendues sous H0 est donné par(n1
n+, . . . , nk
n+
)avec n+ =
∑Ki=1 ni. La statistique de Tango est donc dé�nie par
(1.4.2) T =K∑i,j
wij
(Oi
O+
− nin+
) (Oj
O+
− njn+
)Sous H0, la distribution de T est asymptotiquement Normale, mais
le nombre d'u.s. est rarement très élevé et la vitesse de convergence esten pratique souvent trop faible. Comme précédemment, on peut utiliserl'inférence de Monte-Carlo, en simulant, pour chaque u.s., des valeursattendues sous H0, conditionnellement au nombre total de cas. Tangoa proposé une approximation par la loi du χ2 de la statistiqueTg = T−E(T )√
V ar(T )
où T est l'indice de Tango, avec E(T ) et V ar(T ) connus et dépen-dants de la matrice des poids :E(T ) = 1
O+tr (WVp) et V ar(T ) = 1
O2+
tr[(WVp)
2]oùW est la matrice des poids wij, et Vp = diag(p)−pp′, avec le vecteurp =
(n1
n+, . . . , nK
n+
)Sous H0, ν + Tg
√2ν
a−→ χ2ν où le degré de liberté ν dépend de la
matrice des poids et des e�ectifs théoriques :
11

Part.I. 1. Détection de clusters spatiaux
ν = 8
(2√
2tr[(WVp)3]
(tr[(WVp)2])1,5
)−2
La statistique de Tango peut être décomposée en 2 parties [200], la pre-
mière représente l'écart au modèle théorique (avec i = j) et la seconde(i 6= j), dite produit croisé, représente la composante d'autocorrélationspatiale :
(1.4.3)
T =K∑i
wii
(Oi
O+
− nin+
)2
+K∑i,j 6=i
wij
(Oi
O+
− nin+
) (Oj
O+
− njn+
)avecwii = 1 ∀i ∈ {1, . . . , K}
Le choix des poids a un impact important sur la performance de cettestatistique : on peut choisir de renforcer l'importance de la composanted'autocorrélation spatiale ou de la faire disparaître (wij = 0, si dijinférieure à un seuil).
1.5. Coe�cient local de Moran (Anselin).Les méthodes de détection locale de clusters sont utilisées pour détectersi, dans chaque u.s. où se trouve un grand (ou petit) nombre de cas, onobserve un nombre similaire de cas dans les unités voisines. La premièreméthode présentée est l'application locale du coe�cient de Moran, laseconde balaye le plan avec une fenêtre variable à la recherche de re-groupements potentiels, la troisième découpe récursivement le plan enzones de risque homogène.Le coe�cient local de Moran, introduit par Anselin, appartient à lafamille des LISA, Local Indicators of Spatial Autocorrelation [7]. LesLISA sont des statistiques qui donnent des indications sur le regrou-pement spatial de valeurs similaires (ou contraires) dans le voisinagede chaque u.s.. De plus, ils doivent être (par dé�nition) proportion-nels à une statistique globale. Ces indices locaux d'association spatialepermettent de quanti�er la contribution individuelle de chaque u.s. àl'indice global. Le coe�cient local de Moran estime une mesure localede similarité entre les valeurs (nombre ou proportion de cas) de chaqueu.s. et les valeurs des unités voisines. Pour chaque u.s. i, un coe�cientlocal d'autocorrélation Ii est estimé par :
(1.5.1) Ii =1
w+
×(Yi − Y
) ∑Kj=1wij
(Yj − Y
)PK
i=1(Yi−Y )2
K
où les Yi = Oi
nisont les proportions de cas de chaque u.s. i.
Cette statistique est une version locale du coe�cient I de Moran. Bienque la somme des coe�cients locaux soit proportionnelle au coe�cientglobal (
∑Ki Ii = Iglobal pour la statistique présentée ici), les coe�cients
12

Part.I. 1. Détection de clusters spatiaux
locaux peuvent mettre en évidence des situations locales en contradic-tion avec la valeur de l'indice global. Ces statistiques permettent detester, pour chaque u.s., le comportement de ses unités voisines. SousH0 (Ii = 0), et à condition que la distribution des cas dans chaque u.s.soit Normale et indépendante des unités voisines (i.i.d.), Ii suit une loinormale connue. Mais, comme précédemment, la condition de norma-lité est rarement respectée. Les propriétés formelles de la distributiondes Ii restent alors inconnues en dehors de la distribution gaussienne[236]. Les simulations de Monte-Carlo sont donc souvent utilisées pouradapter le test à l'hypothèse nulle de risque constant.Il faut noter, également, que les coe�cients Ii sont corrélés. Vouloir lestester conduit donc à des comparaisons multiples non indépendantespour lesquelles il conviendra d'adapter le risque nominal de premièreespèce en utilisant par exemple la correction de Bonferroni αi = α
nv,
ou de Sidak αi = 1− nv√
1− α , nv étant le nombre de voisins. Cepen-dant, la multiplicité des tests faits sur de petits échantillons, l'absencede connaissance des propriétés analytiques des coe�cients locaux (endehors du cas Gaussien), la corrélation des statistiques estimées surles u.s., rendent les inférences très instables [236]. Pour permettre unecomparaison empirique des u.s. étudiées entre elles, les pondérationssont souvent standardisées par le nombre d'u.s. voisines wij =
f(dij)
nv, tel
que∑K
i=1wij = 1 (standardisation en ligne).Le coe�cient local de Moran, indicateur d'associations locales, peutêtre interprété soit comme indicateur d'un groupe d'u.s. similaires for-mant un ou plusieurs clusters locaux, soit comme indicateur d'une seuleu.s. particulière dans le pattern global ("outlier"). Dans le premier cas,on pourra observer de grandes valeurs de la statistique (Ii � 0), indi-quant une similitude importante entre l'u.s. étudiée et les unités voi-sines, i.e. un même nombre ou une même proportion de cas, que cesvaleurs soit grandes ou petites. Dans le second cas, on observera desvaleurs négatives du coe�cient local de Moran (Ii � 0), suggérant uneu.s. très di�érente de ses voisines. Cependant, l'observation d'u.s. voi-sines, non indépendantes, ayant des risques similaires entre elles mais,également, similaires au risque estimé sur l'ensemble de la zone d'étude,peut conduire à l'estimation d'un coe�cient local faible et non signi�-catif, malgré l'absence d'indépendance entre ces unités.
1.6. Statistique de balayage.Cette approche cherche à regrouper les di�érentes u.s. voisines en clus-ters potentiels à l'aide d'une fenêtre se déplaçant sur le plan géogra-phique [144, 148]. Proposée par Openshaw, l'algorithme "GeographicalAnalysis Machine" (GAM) a béné�cié de nombreuses adaptations etextensions. Sur une grille régulière de points recouvrant la zone d'étude,
13

Part.I. 1. Détection de clusters spatiaux
l'algorithme GAM génère des fenêtres circulaires chevauchantes cen-trées en chaque point de la grille et de rayon constant, dépendant del'espacement de la grille. La procédure est répétée pour di�érentes va-leurs prédéterminées du rayon regroupant les di�érentes u.s. voisinesen clusters, de façon à dé�nir un ensemble de clusters potentiels. Unealternative utilise des fenêtres circulaires centrées sur les u.s. observées[240] et balaye la zone d'étude sur la grille irrégulière ainsi constituée.L'utilisation de fenêtres rectangulaires a également été proposée [3],pouvant donner des résultats di�érents. Les di�érentes fenêtres circu-laires ainsi construites (de centre et de rayon variants) déterminentl'ensemble des clusters potentiels.Plusieurs statistiques et tests ont été proposés avec, en particulier, desadaptations face à la multiplicité des tests non indépendants. Faisantsuite aux travaux d'Openshaw et Turnbull [240, 148], la méthode pro-posée par Kulldor� est une des plus utilisée [212, 146, 121]. Une sta-tistique Tk, fondée sur le rapport de vraisemblance, a été dé�nie parKulldor� [144, 148], sans hypothèse concernant la forme ou la tailledes fenêtres de balayage. Cependant, l'implémentation demande de dé-�nir au préalable un type de fenêtrage. L'algorithme Satscan [145] im-pose un fenêtrage circulaire balayant la zone géographique étudiée àl'aide d'une grille régulière (comme l'algorithme GAM) ou irrégulière(dont les sommets sont dé�nis par les localisations géographiques).Pour chaque centre ainsi dé�ni, le rayon varie continuement de zéroà une limite supérieure pré-déterminée, en général égale au rayon dudisque possédant 50% du nombre d'u.s.. Chaque fenêtre, dé�nie parun centre et un rayon, est un candidat possible pour contenir un re-groupement de cas, i.e. un cluster potentiel, et l'ensemble des clusterspotentiels est ainsi déterminé.La statistique Tk proposée par Kulldor� [144] est estimée pour chaquecluster potentiel par :
(1.6.1) Tk ∝ maxnf
(Oint
Eint
)Oint(Oext
Eext
)Oext
où Oint et Eint représentent respectivement les e�ectifs observés etattendus dans la fenêtre, Oext et Eext représentant respectivement lese�ectifs observés et attendus à l'extérieur de la fenêtre ; nf est le nombretotal de fenêtres.Les e�ectifs attendus sont estimés selon l'hypothèse nulle du risqueconstant, i.e. correspondent au produit du risque global par l'e�ectiflocal Ei = nip+. La distribution de la statistique de Kulldor� n'étantpas connue, l'inférence de Monte-Carlo permet de tester l'hypothèsenulle. Comme précédemment, il s'agit de simuler, suivant l'hypothèsenulle, des cas dans chaque u.s., ce qui permet de construire la distri-bution empirique de la statistique de Kulldor� sous H0. Le degré de
14

Part.I. 1. Détection de clusters spatiaux
signi�cation ainsi obtenu correspond à la probabilité d'observer unestatistique au moins aussi extrême, sur la zone géographique d'étude.Même si pour chaque simulation les rapports entre observés et atten-dus ne sont pas indépendants (d'un cluster potentiel à l'autre), lesstatistiques (représentant des maxima) restent indépendantes entre lesdi�érentes distributions simulées. Cette particularité de l'approche deKulldor� permet d'éviter les adaptations de type Bonferroni. Un clus-ter est identi�é si un excès de cas est observé dans une fenêtre donnée.De plus le rapport Oi
Eipeut être interprété comme un risque relatif ou
un rapport d'incidence en fonction du protocole de l'étude. Par contre,son intervalle de con�ance ne peut être calculé de façon classique [241],en particulier à cause de l'absence de connaissance formelle de la dis-tribution de la statistique et du recouvrement des fenêtres de balayage.Il faut noter que l'utilisation de di�érentes formes de fenêtres ou dedi�érentes grilles peut conduire à des résultats di�érents. Gangnon etClayton ont introduit une approche bayesienne [95], a�n d'éviter de pré-déterminer la forme et le centre du fenêtrage, mais cette approche de-mande la spéci�cation de distributions a priori des formes et des taillesdes clusters. De plus, Gangnon et Clayton limitent le nombre de mo-dèles considérés pour approcher les distributions a posteriori. Pour ceproblème de fenêtrage pré-déterminé, Patil et Taillie [191] ont proposéde constituer les clusters potentiels en regroupant les u.s. ayant unemême incidence de cas et étant connectées géographiquement. Chaqueniveau d'incidence détermine un cluster potentiel. Cependant, ces ni-veaux d'incidence, pré-déterminés, dépendent des observations et ilsdoivent de plus être en nombre limité sous peine d'obtenir un ensemblede clusters potentiels inexploitable. D'autres procédures utilisent desalgorithmes stochastiques pour réduire l'ensemble des clusters poten-tiels [73], mais toutes ces méthodes restent non optimales d'un pointde vue classi�cation.
1.7. Arbres de régression oblique.Cette méthode, issue de la méthode CART (Classi�cation And Re-
gression Tree) [30, 56], consiste à découper progressivement le plan,déterminé par les coordonnées géographiques, selon un critère d'homo-généité. L'algorithme recherche, parmi les variables explicatives (numé-riques dans le cas qui nous intéresse), une variable et une bi-partitionde celle-ci (en deux parties connexes) qui maximise la variance inter-classes de la variable numérique à expliquer. Appliquée récursivement,cette procédure conduit à un arbre hiérarchique binaire, appelé arbrede régression, dont la racine comporte l'ensemble des données, et dontles partitions successives forment les n÷uds descendants. Les n÷udsterminaux représentent la partition de l'espace dé�ni par les variablesexplicatives, faite par des hyperplans. Appliqués pour la recherche de
15

Part.I. 1. Détection de clusters spatiaux
patterns spatiaux, les arbres de régression estiment les lignes de chan-gement d'une fonction constante par partie sur R2 [105], interprétablescomme des frontières entre des zones à risques di�érents. Il faut no-ter, d'une part, que les modèles CART ne fournissent que des patternsrectangulaires. D'autre part, les algorithmes recherchant une partitionoblique (conduisant à un "arbre de décision oblique") font appel à desprocédures stochastiques [33, 38, 175, 119] ou heuristiques [30], qui nesont ni robustes ni optimales. Cependant, nous avons récemment mon-tré que l'on peut obtenir une solution optimale dans le plan pour larecherche de patterns spatiaux (algorithme SpODT : Spatial ObliqueDecision Tree) [97, 87]. Dans ce cadre, la variable à expliquer peut êtrele nombre ou le pourcentage de cas (plus adapté au cas de popula-tions hétérogènes). Le nombre de partitions obliques possibles est �ni,correspondant à l'ensemble des perpendiculaires à toutes les droites dé-terminées par les couples de points du plan (u.s.). Des règles d'arrêtde l'algorithme doivent être prédé�nies, et nous en avons choisi quatre,parmi les plus classiques, reposant sur : i) l'e�ectif minimal d'un n÷udpère en dessous duquel aucune coupure n'est faite, ii) l'e�ectif minimald'un n÷ud �ls, en dessous duquel la coupure amenant au n÷ud �lsest refusée, iii) le pourcentage de variance expliquée pour une coupure,en dessous duquel la coupure est refusée, car n'améliorant pas assez lemodèle, et iv) le nombre maximal de niveaux de l'arbre de régression.Un fois l'arbre et donc la partition du plan obtenus, la principale carac-téristique de ce modèle est le pourcentage de variance expliquée global,noté R2, dé�ni comme le rapport entre la somme des carrés des écartsinterclasses (issue du modèle) et la somme des carrés des écarts totaux.L'inférence de Monte-Carlo, simulant un grand nombre d'arbres sousl'hypothèse nulle et conditionnellement aux localisations et aux e�ectifslocaux, permet d'obtenir la distribution empirique des R2 et ainsi dela tester. Cet arbre de régression, dé�ni comme une méthode généralede détection de clusters spatiaux, peut être interprété soit comme uneanalyse globale, soit comme une analyse locale. En e�et, bien que lastatistique testée soit globale (seul le pattern global est testé), l'arbrede régression a l'avantage de détecter des clusters locaux potentiels.
1.7.1. CART et modèles ODT.
Les modèles en arbres comme CART [30] sont des alternatives non li-néaires et non paramétriques, utilisables pour des problèmes de régres-sion ou de classi�cation (par exemple : régression linéaire, régressionlogistique, analyse discriminante, modèle de Cox. . . ). Les modélisationsCART consistent en des partitions binaires récursives de l'espace (mul-tidimensionnel) des covariables Xn, dans lequel l'échantillon observéest successivement découpé en des sous-ensembles de plus en plus ho-mogènes, jusqu'à ce qu'un critère d'arrêt soit satisfait.Pour la première partition, l'algorithme CART recherche (pour toute
16

Part.I. 1. Détection de clusters spatiaux
les covariables) la meilleure partition binaire de la covariable (parmitoutes les partitions binaires) et dé�nit 2 sous-espaces qui maximisentla séparation (i.e. la variance interclasse de la variable à expliquer Z).Chacun des sous-espaces ainsi obtenus sera à son tour partitionné defaçon indépendante. A chaque étape, la covariable utilisée pour la par-tition est donc sélectionnée dans l'ensemble des variables explicativesXn pour obtenir une partition optimale, compte tenu des actions pré-cédentes.La séquence des partitions peut-être résumée par un arbre binaire.Le n÷ud racine de cet arbre correspond à l'espace des observationstotales. Les partitions de cet espace sont représentées par les descen-dants du n÷ud racine. Les feuilles de l'arbre, ou n÷uds terminaux,correspondent aux sous-espaces qui ne peuvent plus être découpés. Lastabilité du processus peut-être étudiée en utilisant des méthodes clas-siques de ré-échantillonnage.
Ordinairement utilisés comme techniques exploratoires, les modèlesCART sont encore peu utilisés dans un but prédictif. Ces arbres de-mandent généralement moins d'hypothèses que les méthodes statis-tiques classiques, et peuvent être utilisés dans de nombreux cas. Deplus, les arbres de régression sont d'utilisation et d'interprétation simples.CART a été utilisé dans des applications médicales variées [30, 207],comme l'analyse de survie [254, 153, 206], l'analyse de données longi-tudinales, des évaluations diagnostiques ou pronostiques ou encore desessais cliniques [256, 56, 94, 164].
Une application particulière concerne le domaine de l'analyse du si-gnal [105], où le problème consiste en la détection de plusieurs pointsde changement de la moyenne. La procédure CART est alors utiliséepour estimer les points de changement et les moyennes, ajustant unefonction f(t) constante par parties. Notons mi la moyenne pour chaquepartie i = 1 . . . K et ti les points de changement. On a alors :yt = f(t) + εtavec f(t) =
∑Ki=1mi1[ti,ti+1]
Si nous étendons ce point de vue à l'espace des covariables dé�ni parles coordonnées géographiques, CART peut estimer les "lignes de chan-gement" (à la place des points de changement) d'une fonction constantepar parties sur R2. En d'autres termes, les arbres de régression peuventdéterminer des patterns spatiaux.
Une des limitations de CART est que cette procédure ne détermineque des partitions de l'espace des covariables perpendiculaires aux axes,i.e. que des patterns rectangulaires si nous l'appliquons à l'espace géo-graphique. Les arbres de décisions obliques (ODT : Oblique decision
17

Part.I. 1. Détection de clusters spatiaux
trees) ont été étudiés pour fournir des partitions obliques (et donc po-lygonales) de l'espace des covariables. Cependant, les ODT sont peuutilisés, car, d'une part, les partitions sont di�cilement interprétables,et d'autre part, ils requièrent des algorithmes d'une grande complexité.Trouver le meilleur arbre oblique dans l'espace des covariables a étémontré comme NP-di�cile [119]. Les algorithmes existant utilisentdes procédures déterministes heuristiques ou des algorithmes stochas-tiques (par exemple le système OC1 [175]) pour trouver les meilleurshyperplans partitionnant l'espace des covariables [30, 119, 175, 38]. Descomparaisons des di�érents algorithmes ont été étudiées par Murthy[175], Cantu-Paz [38] et Brodley [33].Malgré cette di�culté dansRN , nous avons cherché une partition obliquedans le cas particulier de l'espace dé�ni par les coordonnées géogra-phiques, i.e. dans R2. Les algorithmes stochastiques et heuristiques nesont pas robustes et peuvent être a�ectés par des minima locaux [175].Ainsi, ce ne sont pas des procédures optimales dans R2. L'algorithmeSpODT (Spatial Oblique Decision Tree) que nous avons développé estune procédure optimale pour obtenir la solution optimale sans utiliserdes procédures heuristiques ou stochastiques.
1.7.2. Algorithme SpODT.
L'objectif général de l'ensemble de la procédure est de trouver plusieurspartitions du plan (espace des covariables dé�ni par les coordonnéesgéographiques). Nous présentons la première étape, qui a pour but detrouver la meilleure partition oblique du plan.Ce sous-chapitre est organisé de la façon suivante :
i: Premièrement, nous introduirons la façon dont le plan est dé-coupé en 2 partitions adjacentes, en regard de la variance inter-classe.
ii: Deuxièmement, nous présenterons comment est déterminé l'en-semble �ni des droites obliques, i.e. l'ensemble des partitionspossibles.
iii: Troisièmement, nous proposerons une optimisation de cettepremière étape de l'algorithme.
L'ensemble des trois points présentés ici font partie de la premièreétape de l'algorithme, aboutissant au premier découpage du plan en 2partitions adjacentes. En poursuivant de façon récursive cette étape,l'algorithme partitionnera le plan en plusieurs partitions, jusqu'à at-teindre un critère spéci�que.
i. Procédure de partition.Soit, dans l'espace des covariables représenté par le plan de base or-thogonale correspondant aux coordonnées x et y, d'origine �xée O, npoints M de coordonnées {x, y}. Ces coordonnées peuvent représenter
18

Part.I. 1. Détection de clusters spatiaux
les coordonnées géographiques (déterminées par GPS) d'une localisa-tion.A chaque point Mi est associée une variable aléatoire continue Zi (ap-pelée variable à expliquer ou prédite), dont l'observation est notée zi.La procédure CART découpe le plan selon une droite perpendiculaire
à l'axe représentant la covariable découpée, en maximisant la varianceinterclasse de Zi entre les 2 partitions. Notre procédure découpe leplan selon une droite oblique D maximisant de la même façon la va-riance interclasse de Zi. Pour trouver cette droite oblique suivant ladirection D, nous dé�nissons la direction perpendiculaire u et l'angle(−→Ox,
−→Ou) = θ ∈ [0, π[
D'une façon générale, pour une direction �xée D, la procédure doit :� Projeter les points Mi orthogonalement sur l'axe O~u, dé�nissantainsi la coordonnée ui ;
� Considérer tout les ui comme des seuils potentiels pour le décou-page du plan dans la direction D perpendiculaire à l'axe O~u etpassant par ui ;
� Trouver le découpage optimal en 2 classes adjacentes (parmi l'en-semble des découpages possibles), maximisant la variance inter-classe de Zi, selon les projections précédentes.
ii. Ensemble des partitions possibles.
La première étape comprend la détermination des di�érentes direc-tions D de découpage possibles, i.e. la spéci�cation des angles θ quidoivent être analysés. Une solution globale consisterait en un balayagede toutes les directions obliques D, i.e. de tous les θ ∈ [0, π[. De façonheuristique, on pourrait également discrétiser cet intervalle a�n d'ob-tenir un ensemble �ni d'angles θ. Cependant, ces 2 procédures ne sontpas optimales, alors que l'algorithme optimal pour une solution opti-male est assez simple, comme nous allons le montrer.En e�et, il est clair que 2 points Mi(xi, yi) et Mj(xj, yj) possèdent lesmêmes coordonnées en projection sur l'axe O~u si et seulement siMiMj
est perpendiculaire à l'axe O~u [�g.1].Le nombre de directions critiques, dé�nies par les angles θij, existe
donc et est un nombre �ni.Pour chaque direction D passant par 2 points Mi et Mj, il existe unangle ϕij entre la droite MiMj et l'axe O~x. Alors :ϕij = arctan (aij) ∈
[−π
2; π
2
[avec aij =
yj−yi
xj−xi
Comme dé�ni précédemment, θ est l'angle entre l'axe O~x et l'axe O~uperpendiculaire à la droite MiMj. Alors, pour chaque couple (Mi,Mj),on a θij = ϕij + π
2
19

Part.I. 1. Détection de clusters spatiaux
Fig. 1. Construction de l'angle critique θij de ladirection u
� L'espace des covariables est représenté par le plan avec une baseorthogonale correspondant aux coordonnées x et y et une origine�xée O ;
� u est la direction perpendiculaire à la direction de découpage D ;� Mi et Mj sont 2 localisations ponctuelles dans le plan, déterminéespar leurs coordonnées géographiques.
Chaque angle critique θij permet également de dé�nir un secteur an-gulaire à l'intérieur duquel l'ordre des coordonnées ui en projection surl'axe O~u ne dépend pas de cette direction. Pour les points Mi et Mj,la di�érence de leurs coordonnées projetées (uj − ui) véri�e :
(1.7.1) (uj − ui) cos(ϕij) = (xj − xi) sin(θ − θij)
avec : xj = xi ⇐⇒ ϕij = −π2
et (uj − ui) = (yj − yi) sin(θ)Ainsi, (uj −ui) dépend de θ de façon continue. Le signe de cette dif-
férence ne peut donc pas changer à l'intérieur d'un secteur angulaire,puisque (uj − ui) = 0, si et seulement si θ = θij.
Il s'ensuit qu'à l'intérieur d'un secteur angulaire, la variance inter-classe (et même l'ensemble de la procédure) n'est pas modi�ée.Comme conséquence directe de l'équation 1.7.1, la transition d'un
secteur angulaire au suivant, via un angle critique θij, induit un ordredes coordonnées projetées inchangé, à l'exception de la permutation de2 éléments adjacents de coordonnées ui et uj [�g.2].Il faut noter que, pour des points alignés Mi, Mj et Mk, l'algo-
rithme doit permuter l'ensemble des éléments adjacents (ui, uj, uk) →(uk, uj, ui). De même, pour des directions parallèles, MiMj ‖ MkMl,
20

Part.I. 1. Détection de clusters spatiaux
Fig. 2. Transition via une direction critique u,d'un secteur 1 à un secteur 2
� u est la direction perpendiculaire à la direction de découpage D ;� Mi et Mj sont 2 localisations ponctuelles dans le plan, déterminéespar leurs coordonnées géographiques ;
� u′ et u′′ sont les directions d'angles intermédiaires (non critiques),appartenant respectivement au secteur 1 et 2 ;
� u′i, u′j, u
′′i et u
′′j sont les coordonnées des pointsMi etMj en projection
orthogonales sur les directions u′ et u′′. On notera que u′i > u′j etu′′i < u′′j ;
l'algorithme doit permuter en même temps les couples d'éléments ad-jacents (ui, uj) et (uk, ul) → (uj, ui) et (ul, uk).
On peut remarquer que tous les secteurs angulaires dé�nissent au-tant de covariables. On peut alors revenir à une procédure CART ha-bituelle. Cependant, le nombre d'angles critiques di�érents est donnépar N ≤ n×(n−1)
2, et la disponibilité en temps et en espace est souvent
insu�sante pour utiliser CART de cette façon. A titre d'exemple, dansnotre application, le nombre de localisations était de n = 150 et lenombre de secteurs angulaires di�érents était de N = 11170.
iii. Optimisation de l'algorithme.
L'algorithme le plus e�cace consiste en une analyse pas à pas dessecteurs angulaires, ordonnés selon les θij observés. A chaque étape,l'algorithme utilise les résultats précédants. En e�et, il su�t de calculerune seule variance interclasse, puisque seulement 2 éléments ont étépermutés, correspondant à un seul découpage (ou bien un petit nombrede variances interclasses, dans le cas de la permutation d'un grouped'éléments ou de plusieurs couples). La procédure hérite donc du calculdes variances interclasses fait pour le secteur angulaire précédant, à
21

Part.I. 1. Détection de clusters spatiaux
l'exception de la variance interclasse correspondant à la permutation.Ainsi, la complexité de l'algorithme est en O (n2 lnn) en temps et enO(n) en espace pour une seule partition, et en O (n3 lnn) en tempspour l'ensemble de la procédure. Finalement, l'algorithme découpe leplan en 2 partitions adjacentes de la façon suivante :� ordonner les xi ;� calculer et ordonner les θij via les aij ;� calculer
∑ni=1 zi ;
� pour chaque découpage potentiel du premier secteur (correspon-dant à l'axe des x), i.e. pour chaque valeur de xi :� calculer les
∑zi pour chaque classe (de part et d'autre du
seuil xi) et la variance interclasse en utilisant les résultatsprécédants ;
� si la variance interclasse est plus grande que la précédante,conserver les résultats ;
� pour le secteur suivant� permuter les xi, xj correspondants (ou le groupe d'éléments) ;� calculer les
∑zi seulement pour les classes générées par le
découpage entre xj et xi (ou les quelques découpages dans ungroupe d'éléments permutés) ;
� si la variance interclasse ainsi calculée est plus grande quel'optimum précédant, conserver les résultats ;
� jusqu'à ce que tous les secteurs angulaires soient balayés.L'algorithme poursuit la partition de façon récursive jusqu'à at-
teindre un critère d'arrêt.
L'algorithme complet est présenté dans le �gure 3.
Dans notre programme, nous avons utilisé 4 règles d'arrêt intrin-sèques classiquement utilisées :� le pourcentage de variance expliquée en dessous duquel le décou-page du noeud est rejeté
� l'e�ectif minimal d'un noeud �ls, en dessous duquel le découpagedu noeud père correspondant est rejeté ;
� l'e�ectif minimal d'un noeud père, en dessous duquel il n'est pasdécoupé ;
� le nombre maximal de niveaux.D'autres règles d'arrêt, ainsi que des règles d'élagage, sont discutéesailleurs dans le cadre de la méthode CART [30, 105].
Remarque 1.Les arbres de régression peuvent être considérés comme des régressionsnon-paramétriques [105], dont la forme fonctionnelle peut s'écrire :
22

Part.I. 1. Détection de clusters spatiaux
Fig. 3. Algorithme SpODT
23

Part.I. 1. Détection de clusters spatiaux
zi = f(xi) + εi, où (xi) est le vecteur des coordonnées du point Mi. Lafonction f(.) peut être dé�nie comme suit :
f(xi) =P∑j=1
zi1{Mi(xi)∈j}
autrement dit, pour chaque point Mi, de coordonnées (xi), apparte-nant à la classe j, la valeur prédite sera zi = zj, à εi près. Le principalproblème est de déterminer l'ensemble P des classes j ∈ P . Les fonc-tions sj(xi) sont des fonctions linéaires des xi, (axi + byi + c = 0 dansR2), correspondant aux frontières entre les classes. Ces frontières, sj, oudroites de partition, sont déterminées de façon récursive pour chaqueensemble de points ξ, encore appelé noeud, correspondant soit à l'en-semble initial des points du plan étudié, soit à une classe issue d'undécoupage précédant. Cet ensemble ξ est coupé (en 2 classes �lles) parla droite de partition sj. Si sj(xi) < 0 alors le point Mi de coordonnées(xi) appartiendra à la classe �lle jl, sinon (i.e. sj(xi) > 0), Mi appar-tiendra à la classe �lle jr.Pour l'ensemble ξ de pointsMi, on cherche parmi l'essemble S de toutesles fonctions linéaires des xi la fonction sj(.) tel que :
SCEinter(sj, ξ) = maxs∈S
SCEinter(s, ξ)
Comme nous l'avons écrit plus haut, l'ensemble S est �ni, et le nombrede classes P �nales est déterminé par les noeuds terminaux de l'arbrede régression, en particulier par les règles d'arrêt. Ici, un noeud ξ estdéclaré terminal si :
(1) SCEinter(sj, ξ) ≤ R2c × SCEtot
n(ξ)−1, i.e. R2 < R2
c , R2c étant une va-
leur seuil choisie, n(ξ) est l'e�ectif du noeud ξ. Autrement dit,la nouvelle partition n'explique pas assez de variance supplé-mentaire.
(2) n(ξ) ≤ nc1, où le critère prédéterminé nci est l'e�ectif minimaldu noeud ξ en dessous duquel le noeud ne sera pas découpé.
(3) n(jl) ≤ nc2 ∨ n(jr) ≤ nc2, jl et jr étant les 2 classes �lles issuesde la partition du noeud ξ, et le critère prédéterminé nc2 estl'e�ectif minimal des classes �lles en dessous duquel la partitionest rejetée.
(4) Le nombre maximal de niveaux.
24

Part.I. 1. Détection de clusters spatiaux
Remarque 2.L'algorithme SpODT ne tient pas compte de l'e�ectif du noeud �ls,sauf en terme de règle d'arrêt, ni de la dispersion des unités statis-tiques dans une classe (dispersion dans l'espace des covariables). Dansle cadre d'applications géographiques, cette dispersion spatiale dansune classe donnée doit être prise en compte, pour pondérer le critèrede découpage utilisé. Comme nous l'avons vu, le critère utilisé est lavariance interclasse de Zi, variable à expliquer, selon les classes de Xi
(variables explicatives, i.e. coordonnées géographiques). Plus la variabi-lité spatiale à l'intérieure d'une classe (i.e. la dispersion géographique)est grande, moins l'intérêt pour une telle classe est grand, d'autant plusque l'e�ectif est faible.Nous proposons une pondération du critère de la variance interclassepar l'e�ectif de la classe et la matrice de variance-covariance V desvariables explicatives (i.e. coordonnées géographiques).On dé�nit, pour une partition donnée en 2 classes 1 et 2,
la somme des carrés des écarts inter-classe :SCEic =
∑2i=1 ni(Zi − Z)2
et la somme des carrés des écarts pondérés :SCEicα =
∑2i=1 αini(Zi − Z)2
La pondération αi doit tenir compte de l'e�ectif ni de la classe i ∈ 1, 2et de la dispersion géographique notée δi. αi doit être une fonctioncontinue croissante bornée de ni et de δi, par exemple une fonctionlogistique de ni
δi.
Cependant, nous devons traiter le cas où δi = 0. En e�et, si δi = tr(V)ou δi = det(V), il est possible d'avoir δi = 0, en particulier pour ni = 1ou ni = 2. Nous proposons donc que la pondération soit une fonction deni
ni+δi, où ni est l'e�ectif de la classe i et δi = det(Vi), avec Vi la matrice
de variance-covariance pour la classe i des 2 variables explicatives (i.e.les coordonnées géographiques). La pondération peut donc s'écrire :
(1.7.2) αi =exp { ni
ni+δi}
1 + exp { ni
ni+δi}
Remarque 3.En plus des règles d'arrêt utilisées ici, d'autres règles extrinsèques d'ar-rêt peuvent être envisagées. En particulier la réa�ectation de chaquepoint à la classe la plus proche, en terme de distance euclidienne parexemple, permet de véri�er si le nombre de réa�ectations est stable etsi la classi�cation est en cohérence avec une réalité de terrain.
1.8. Application.
25

Part.I. 1. Détection de clusters spatiaux
1.8.1. Matériel.
La base de données utilisée pour cette application est issue d'uneinvestigation du risque palustre dont l'objectif était d'étudier de nom-breux facteurs de risques palustres (environnementaux, immunologiques,génétiques, entomologiques... ).
Lieu d'étude.Cette étude a eu lieu sur l'ensemble d'un village, Bancoumana, cerclede Kati, à 60 km au sud-ouest de Bamako (capitale du Mali) [�g.4].Le village, situé en savanne soudanaise, recouvre une surface d'environ2,5 km2, avec une population d'environ 8000 habitants [238]. Les prin-cipales activités sont la riziculture et le maraîchage sur les bords du�euve Niger.Bancoumana est en zone d'hyperendémie palustre à transmission sai-sonnière [238, 66]. En saison des pluies, de juin à octobre, avec destempératures comprises entre 25 et 40°C, la transmission est très éle-vée. Cette transmission décroît ensuite graduellement pour atteindreun minimum au milieu de la saison sèche (autour de février).Trois espèces plasmodiales sont présentes : P. falciparum, P. ovale et P.malariae. P. falciparum représente environ 95% des parasites présents(O. Doumbo, communication personnelle).
Population et protocole de l'étude.Une cohorte dynamique a été constituée en juin 1996 et suivie jusqu'enjuin 2001. Cette étude comprenait 173 des 340 maisons (concessions)sélectionnées selon un échantillonnage aléatoire strati�é sur les 4 quar-tiers. Dans chaque concession, tous les enfants âges de 0 à 12 ans ontété suivis, constituant ainsi la cohorte dynamique (avec en moyenne1356,68 enfants par évaluation 95%CI[1298,98-1414,39]), avec 1101 en-fants lors de la première évaluation (juin 1996) et 1491 enfants pourla dernière évaluation (juin 2001). Il y avait en moyenne 9,12 enfantspar concession et par évaluation (95% CI [8,01-10,2]). Peu d'enfants ontquitté le village et certains sont nés au cours de l'étude. La distributionde l'âge n'a pas été modi�ée au cours du temps et la cohorte dynamiqueest restée représentative de la population d'enfants du village [�g.7].Les évaluations (22) ont été faites au rythme d'environ 1 évaluation
tout les 2 mois durant la saison des pluies et tous les 3 mois en saisonsèche. Ce rythme a été dé�ni sur la base d'études précédentes concer-nant la saison de transmission [238, 66].
Le consentement communautaire a d'abord été obtenu, avant d'obtenirle consentement éclairé oral des parents ou des responsables des enfants
26

Part.I. 1. Détection de clusters spatiaux
Fig. 4. Image satellite du village de Bancoumana-GoogleEarthr-
Fig. 5. Imagesatellite du villagede Bancoumana-GoogleEarthr-
Fig. 6. Imagesatellite du villagede Bancoumana-SPOTimager-10/11/2003
inclus, selon la procédure décrite par O. Doumbo [70]. Trois familles ontrefusé de participer. L'ensemble de l'étude, �nancée par le programmeMali-Tulane TMRC N° AI 95-002-P50 du NIH, a été approuvé par lecomité d'éthique de la Faculté de Médecine, Odontologie et Pharmacie
27

Part.I. 1. Détection de clusters spatiaux
Fig. 7. Evolution de la distribution de l'âge dansla cohorte dynamique au cours du temps.
de Bamako, Université du Mali.
Variables.A chaque évaluation, un échantillon de sang était prélevé sur chaqueenfant. Une équipe de biologistes expérimentés a étudié la parasitémieà P. falciparum, P. malariae, et P. ovale, et la gamétocytémie (P. fal-ciparum), sur frottis colorés au Giemsa. Pour contrôler la qualité de lalecture des frottis, à chaque évaluation 10% d'entre eux (randomisés)étaient lus par un biologiste senior. En cas de désaccord, l'ensemble desprélèvements était à nouveau analysé.L'infection était dé�nie par la présence de parasites à l'étude du frot-tis (parasitémie positive). L'équipe médicale recevait alors les enfantsinfectés, et administrait un traitement suivant les recommandationsdu programme national de lutte contre le paludisme (chloroquine enpremière intention, associée à une surveillance clinique et biologique).Ainsi, en tenant compte des intervalles entre les évaluations, un se-cond frottis sanguin positif lors d'une seconde évaluation était consi-déré comme une nouvelle infection et non comme une persistance del'infection première.L'équipe médicale était présente en permanence dans le village. Danstous les cas, des soins appropriés étaient donnés aux enfants, incluantl'hospitalisation à l'hôpital national de Bamako, si nécessaire.
Tous les enfants ont été géoréférencés selon leur concession, i.e. l'en-droit où ils dormaient. Le géoréférencement a été fait à l'aide du sys-tème GPS GeoExplorerII associé au système d'information géogra-phique ArcGIS8.3 (précision de 1 à 3m).
28

Part.I. 1. Détection de clusters spatiaux
Étude spatiale.Pour l'étude purement spatiale qui nous intéresse ici, comparant lesdi�érentes méthodes développées précédemment, nous avons étudié lapremière évaluation du mois d'août 1999, comprenant 1339 enfants.Parmi eux, 511 enfants avaient un prélèvement positif (38,16%,CI95%[35,56-40,76]).
1.8.2. Méthodes.
Nous avons utilisé le package Dcluster du logiciel gratuit R version 2.2.0(the R Foundation for Statistical Computing, 2005, http ://CRAN.R-project.org) pour les méthodes de Moran, Tango et LISA. La mêmematrice de proximité, d'éléments wij = e−dij , a été utilisée pour cesméthodes, a�n de pouvoir comparer leurs résultats. Pour la méthode debalayage de Kulldor�, nous avons utilisé SaTScanv5.1, téléchargeablegratuitement http ://www.satscan.org [145]. L'analyse purement spa-tiale a recherché des clusters à haut risque ou à risque faible, testantl'hypothèse de distribution de Poisson du risque. Pour l'arbre de régres-sion nous avons utilisé SpODTv1.2 (téléchargeable gratuitement surhttp ://mtcd.timone.univ-mrs.fr/mtcd2006/).En�n, pour l'ensemble des méthodes, l'hypothèse nulle utilisée étaitcelle des risques constants, testée à l'aide de simulations de Monte-Carlo, à l'aide de scripts ad hoc (logiciels R et SpODT) ou déjà im-plémentés (Satscan). Dans le premier cas, les simulations (999) ont étéfaites à l'aide du logiciel Matlab 7.0.1 (The Mathworks Inc. 2004).
1.8.3. Résultats.Toutes les méthodes utilisées ont mis en évidence une hétérogénéitéspatiale signi�cative, rejetant l'hypothèse des risques constants.Les méthodes globales (Tango et Moran) ont montré [tab.1] des corré-lations spatiales faibles, estimées par des statistiques très petites, res-pectivement I = 0, 1×10−3 (p = 0, 008) et T = 0, 2×10−6 (p = 0, 004).L'utilisation du coe�cient local de Moran (Anselin)a mis en évidence 5clusters signi�catifs (après ajustement de Bonferroni). Les valeurs néga-tives des coe�cients indiquaient que les valeurs au voisinage des conces-sions étudiées étaient di�érentes. Là encore, les coe�cients étaient, envaleur absolue, très faibles, indiquant une faible corrélation négative.Certaines de ces concessions avaient un risque plus faible que le voisi-nage, d'autres avaient un risque plus élevé. Nous n'avons pas observéde regroupement de ces concessions sur une partie du village.La méthode de Kulldor� a mis en évidence un seul cluster où le nombrede cas observé était supérieur au nombre de cas attendu sous l'hypo-thèse nulle, i.e. un excès de risque palustre (p = 0, 004). Le risquerelatif y était modéré (RR = 1, 279). Il comprenait 50 concessions, soitun rayon de 0,48 km, correspondant à 465 enfants. Cette zone, situéeà l'ouest du village [�g.8], correspondait à la localisation d'une mare
29

Part.I. 1. Détection de clusters spatiaux
Fig. 8. Cartographie du village de Bancoumanaet représentation des clusters identi�és.Chaque point représente une concession et l'échelle decouleur représente la proportion d'enfants positifs àP. falciparum. Les concessions encadrées de rouge sontcelles détectées par la méthode LISA. Le cerclereprésente le cluster à haut risque détecté par laméthode de balayage et le risque relatif correspondantest indiqué. Les droites représentent le découpageobtenu par l'arbre de régression. Les risques relatifs dechaque classe issue de l'arbre de régression sontindiqués.
temporaire (partie sud-ouest du cluster) et d'une briqueterie (partienord-ouest) pour laquelle l'excavation de terre était à l'origine de gîtesd'anophèles (vecteurs du paludisme). Cette particularité a été trouvéea posteriori par les épidémiologistes de terrain. Aucun autre clustern'était signi�catif, qu'il soit à risque accru ou à risque faible.L'arbre de régression a découpé la zone géographique en 6 zones. Cetteclassi�cation était signi�cative (p = 0, 047), bien que le pourcentage devariance expliquée soit faible (R2 = 0, 299). Les 2 zones les plus àl'ouest comprenaient le cluster issu de la méthode de Kulldor�. Nousavons observé dans la partie nord-ouest un risque plus élevé (63,11%).Une autre zone à risque élevé (52,38%) a pu être mise en évidence au
30

Part.I. 1. Détection de clusters spatiaux
nord-est du village, située elle aussi à proximité d'une mare tempo-raire. En�n une zone à risque faible a été détectée au nord du village(23,53%).
1.9. Discussion.Les di�érentes méthodes présentées ici permettent de décrire l'hétéro-généité spatiale, soit en analysant globalement les structures spatiales,soit en détectant localement des zones à risques. Nous avons utilisétrois approches fondées sur l'autocorrélation, deux globales, une locale,et deux approches portant sur le regroupement de données, l'une ba-layant la zone d'étude et utilisant une fenêtre à rayon variable, l'autrepartant de la zone globale et la découpant récursivement. Pour chaqueapproche, nous avons choisi une méthode, parmi les plus appropriées : lecoe�cient d'autocorrélation de Moran qui a des propriétés reconnues etla méthode de Tango qui ajoute la notion d'adéquation, le coe�cientlocal de Moran introduit par Anselin qui a également des propriétésreconnues, la méthode de balayage de Kulldor� qui est l'évolution deméthodes anciennes, et la méthode d'arbre de régression oblique, adap-tée de CART, qui est une approche nouvelle dans le cadre de l'épidé-miologie spatiale. Cette analyse de la structure spatiale a pour butd'orienter les épidémiologistes de terrain vers des sources potentielles.Les méthodes présentées répondent à des dé�nitions di�érentes de l'hé-térogénéité spatiale, et présentent toutes des avantages et des inconvé-nients.Le coe�cient global de Moran recherche si les u.s. voisines sont, globa-lement, similaires. Ce coe�cient d'autocorrélation spatiale est le plusutilisé [8]. Il rend compte à un niveau global de la tendance des lieuxproches à se ressembler (autocorrélation positive) ou au contraire às'opposer (autocorrélation négative). Il est considéré comme un desmeilleurs choix parce qu'il présente de bonnes propriétés et que le testd'indépendance est plus puissant que d'autres coe�cients d'autocorré-lation [154, 150, 252]. En particulier, le coe�cient de Moran (et le testassocié) est moins a�ecté que les autres par une mauvaise spéci�cationde la matrice de proximité [72]. Cependant, la valeur et l'interpréta-tion de I sont fortement dépendantes de la mesure de la proximité spa-tiale. De plus, le coe�cient de Moran ne permet pas d'identi�er l'e�etspéci�que exercé par une u.s. particulière. La mesure de l'autocorré-lation est a�ectée par le niveau d'agrégation i.e. par l'échelle utilisée.Ce problème est connu sous le nom de MAUP (Modi�able Areal Unit
Problem) [195]. Le coe�cient d'autocorrélation est également sensibleà la forme, la surface, la distribution et à la taille des e�ectifs desu.s. étudiées. Celles-ci sont souvent dé�nies administrativement, ce quipeut altérer la puissance des tests [250, 244, 149]. Certains auteurs re-commandent d'utiliser plusieurs échelles d'agrégation lorsque cela estpossible, et plusieurs méthodes. De plus, plusieurs études comparatives
31

Part.I. 1. Détection de clusters spatiaux
Tab. 1. Statistiques et inférences issues des di�érentesméthodes d'analyse spatiale.
Méthodes globalesStatistique p
Moran I = 0, 1 10−3 0,008
Tango T = 0, 2 10−6 0,004
Méthodes localesCoordonnéesa Statistique RRd (var) Nb
Conces-sions
p
obs.att.
e
x = −8, 26505 I1 = −4, 8 10−03 0 1 0,005
y = 12, 20436 00,76
x = −8, 26471 I2 = −1, 26 10−01 1, 22 (0, 21) 1 0,01
y = 12, 20232 75,72
Coe�cient x = −8, 26147 I3 = −4, 38 10−03 0 1 0,025
local y = 12, 20514 00,38
de Moran x = −8, 26824 I4 = −5, 12 10−03 0 1 0,035
(Anselin)b y = 12, 20453 00,38
x = −8, 26691 I5 = −7, 64 10−04 1, 75 (1, 53) 1 0,04
y = 12, 20497 21,15
Méthodede
x = −8, 27102 Tk = 10, 23 1, 28 (0, 007) 50 0,004
Kulldor� c y = 12, 20237 227177,46 rayon=0,48Km
x = −8, 26787 1, 03 (0, 004) 72
y = 12, 20267 274265,61
x = −8, 27038 1, 65 (0, 04) 11
y = 12, 20489 6539,31
Arbre de x = −8, 26409 R2 = 0, 299b 0, 85 (0, 03) 11 0,047
Régression y = 12, 20423 2428,24
Oblique x = −8, 26056 1, 36 (0, 14) 5
y = 12, 20993 139,54
x = −8, 26538 0, 99 (0, 01) 23
y = 12, 20598 8383,96
x = −8, 26443 0, 62 (0, 007) 37
y = 12, 20956 5284,34
a. coordonnées géographiques des concessions fournies par GPSb. correction de Bonferroni pour tenir compte de la multiplicité des tests corrélésc. détection d'un seul cluster signi�catifd. risque relatif de parasitémie positive à P. falciparum (variance). Estimé par lerapport obs./att.e. nombre de cas observés rapporté au nombre de cas attendus sous l'hypothèsenulle
f. pourcentage de variance expliqué.
32

Part.I. 1. Détection de clusters spatiaux
[250, 149, 53] ont permis de montrer que les tests globaux perdent enpuissance en présence d'un cluster unique. En�n, le coe�cient d'auto-corrélation de Moran dépend d'une part de la dé�nition de la proximité(qui augmente avec la taille de l'u.s. choisie), et, d'autre part, de la si-milarité entre unités voisines (en relation inverse avec la taille de l'u.s.choisie). On peut donc penser que pour notre étude, le coe�cient I deMoran est faible à cause, d'une part, du choix de la matrice de proxi-mité, et, d'autre part, de la faiblesse des distances géographiques.La statistique de Tango tient compte, non seulement de l'autocorréla-tion, mais permet également de tester l'adéquation. L'avantage de cetteméthode sur le coe�cient de Moran est que la statistique de Tangoprend en compte la distribution de la population à risque, i.e. l'hétéro-généité de peuplement. Plusieurs études de comparaisons sont en faveurdu test de Tango dans la détermination de clusters [120, 227]. Cepen-dant, à l'instar du coe�cient de Moran, la statistique de Tango restedépendante de la matrice de proximité, de l'échelle spatiale choisie etde la forme des u.s.. Les méthodes locales permettent d'appréhender lastructure spatiale de l'hétérogénéité en recherchant une u.s. particulièredi�érente de ses voisines. L'analyse vise à faire ressortir les particula-rités au niveau local pour mettre en évidence des données atypiques.Dans ce sens, les indices locaux sont plus adaptés à la recherche localede clusters.Le coe�cient local de Moran a de meilleures propriétés que les autresindicateurs de la famille LISA [154]. Parmi ses inconvénients, on re-trouvre le problème du choix de la matrice de proximité, de l'échelled'analyse et de la forme des u.s.. D'autres problèmes sont liés à lamultiplicité des tests non indépendants faits sur de petits échantillons,à l'absence de connaissance des propriétés analytiques des coe�cientsLISA (en dehors du cas Gaussien pour le coe�cient local de Moran),à la corrélation des statistiques estimées sur les u.s., rendant les in-férences peu puissantes [236, 131]. De plus, l'observation d'u.s. voi-sines, non indépendantes, ayant des risques similaires entre elles maisaussi similaires au risque estimé sur l'ensemble de la zone d'étude peutconduire à l'estimation d'un coe�cient local faible et non signi�catif,malgré l'absence d'indépendance entre ces u.s.. En�n, les coe�cientslocaux peuvent mettre en évidence des situations locales en contradic-tion avec la valeur de l'indice global. Mais bien que les méthodes localessoient plus puissantes pour détecter des anomalies locales, elles perdenten puissance pour des clusters très larges.L'approche par balayage recherche un cluster pouvant regrouper plu-sieurs u.s.. Elle permet de s'a�ranchir du problème du choix de la ma-trice de proximité. La taille et la forme des unités u.s. ont égalementmoins d'in�uence sur la statistique de Kulldor� que sur les statistiquesprécédentes, en particulier grâce au choix du fenêtrage et au balayage de
33

Part.I. 1. Détection de clusters spatiaux
la zone d'étude à l'aide d'une fenêtre de rayon variable. De plus, la sta-tistique de Kulldor�, fondée sur le rapport de vraisemblance, permet des'a�ranchir du problème de la multiplicité des tests non indépendants(à l'inverse des autres méthodes de balayage). Cependant, le choix dufenêtrage a priori, pour mettre en oeuvre la procédure, restreint l'hy-pothèse alternative à une forme particulière de cluster (classiquementcirculaire), et des e�ets de bords (cluster non circulaire) peuvent di-minuer la puissance du test [149, 74]. De plus, l'hypothèse alternativespéci�e qu'il existe un seul cluster sur l'ensemble de la zone d'étude. Cetest aura donc la meilleure puissance possible en présence d'un clusterréellement unique, et l'existence de plusieurs clusters isolés peut en-traîner une perte de puissance. En�n, la procédure de Kulldor� tendà détecter des clusters trop larges (manque de spéci�cité) par rapportà la réalité, en absorbant des u.s. proches mais où le risque n'est pasélevé [229].L'approche par arbre de régression oblique (ARO) tente de répondre àla question � peut-on découper la zone d'étude en classes (sous-zones)de risques di�érents, à l'intérieur desquelles le risque est homogène ? �.Les avantages sont qu'aucune matrice de proximité n'est à dé�nir, lataille et la forme des u.s. ont peu d'in�uence, et qu'il n'est pas néces-saire de dé�nir a priori la forme des classes (sous-zones) recherchées(contrairement à la statistique de balayage). Le découpage récursif desARO permet de regrouper certaines u.s. et ainsi reconstruire une struc-ture plus représentative des variations du risque. L'inconvénient majeurest le manque de stabilité des ARO, en particulier à cause du décou-page binaire et de la récursivité. La statistique utilisée (R2) peut êtreremplacée par d'autres, notamment la statistique de Kulldor� sur lesclasses dé�nies par l'ARO. Le choix a priori des critères d'arrêt peutégalement modi�er le résultat et son interprétation. Nous proposonsd'utiliser cette méthode dans un but descriptif, préalable à une analyseinférentielle.La dé�nition d'� absence de cluster �, l'hypothèse nulle, doit être éga-lement dé�nie avec précision. En e�et, la distribution spatiale uniformedes cas (Complete Spatial Randomness) parfois utilisée n'est pas satis-faisante, dépendant de la distribution des populations et de la localisa-tion des u.s.. L'hypothèse du risque constant (Constant Risk Hypothe-sis) est plus adaptée à la recherche de clusters. Elle correspond à desdistributions de Poisson conditionnellement aux e�ectifs et aux locali-sations des u.s. (encore appelées distributions hétérogènes de Poisson).Une telle hypothèse permet d'éviter l'écueil d'une distribution uniformeirréaliste, dans le sens où la probabilité d'observer un excès de cas estalors trop importante [198, 249, 17, 246].
De nombreuses statistiques (comme le coe�cient de Moran, la statis-tique de Tango, le coe�cient local de Moran) utilisent une dé�nition de
34

Part.I. 1. Détection de clusters spatiaux
la proximité fondée sur les distances entre les u.s.. Il s'agit d'une repré-sentation formelle de l'espace sous la forme d'une matrice de proximitéà construire à l'aide des informations liées au phénomène étudié et desobservations. Les distances dij sont, généralement, des distances eu-clidiennes, ou calculées selon d'autres métriques appropriées, entre lesu.s. ou leur centre de gravité. La proximité peut être dé�nie par unematrice de contiguïté, telle qu'elle a été utilisée initialement, caracté-risant de façon binaire les u.s. frontalières, i.e. wij = 1 si les u.s. i etj ont une frontière commune, 0 sinon. Ce choix suppose que la portéespatiale de la dépendance entre les u.s. est limitée aux unités connexes.Le choix peut, également, se porter sur une matrice de proximité dé�niecomme une fonction de la distance dij entre les u.s.. En particulier, onpeut caractériser de façon binaire des u.s. proches, i.e. dont la distanceest inférieure à un seuil �xé δ,
wij =
{1 si dij < δ0 sinon
,
créant ainsi des fenêtres circulaires dont le rayon correspond à δ. Làencore, la portée de la dépendance spatiale est limitée par le rayon δde la fenêtre de voisinage.On peut être amené à tenir compte des tailles des populations des dif-férentes u.s. adjacentes, les u.s. à grande population obtenant plus depoids. Les poids deviennent ainsi :
wij =
{nj si dij < δ0 sinon
où nj est l'e�ectif de l'u.s. voisine j 6= i, j ∈ {1 . . . K}.
L'utilisation de fonctions continues, en général monotones décrois-santes, est classique, en particulier pour les maladies transmissibles,avec des formes fonctionnelles du type wij = 1
dτijou wij = exp{−dij
τ}.
Le paramètre d'échelle τ est choisi en fonction de caractéristiques spé-ci�ées ou empiriques, liées à des contraintes caractérisant la vitesse dedécroissance. Par exemple la distance parcourue par une voiture peutêtre très di�érente de la distance à vol d'oiseau. Plus τ sera grand,plus le test sera sensible au larges clusters et inversement. La déter-mination optimale de la matrice de proximité est un des problèmesles plus débattus [7, 195, 6]. Une mauvaise spéci�cation de cette ma-trice peut modi�er les résultats et l'interprétation des tests statistiques,avec notamment une perte de puissance. Le choix doit être fondé surdes caractéristiques spéci�ques ou empiriques associées au phénomèneétudié [154]. Un des problèmes de la matrice de contiguïté est l'exclu-sion des u.s. n'ayant pas d'unité directement voisine (contiguë) [26].L'utilisation de matrice binaire n'est pas considérée comme la plus op-timale pour représenter la relation spatiale [154]. L'utilisation d'unemesure de proximité de forme exponentielle décroissante est classiquepour de nombreux auteurs [229], lorsque les distances sont disponibles,
35

Part.I. 1. Détection de clusters spatiaux
et, de plus, cette forme est robuste par rapport au choix du paramètred'échelle τ , permettant d'adapter la vitesse de la perte d'in�uence d'uneu.s. en fonction de la distance. En particulier, une décroissance rapidede l'in�uence d'une u.s. avec la distance est souvent préférée a�n dedonner plus d'importance à un e�et local qu'à un e�et à distance.Dans l'application précédante, nous avons choisi une telle pondération(τ = 1) pour donner une importance similaire aux deux composantes dela statistique de Tango (partie écart au modèle probabiliste et partie au-tocorrélation). D'autres fonctions (fonctions noyaux, splines, méthodesbayesiennes...) peuvent être utilisées pour les adapter au problème poséet aux données présentes.La recherche de clusters est très discutée, en particulier parce qu'elleprésente souvent des résultats faux positifs. La suspicion d'un excès derisque dans une zone amène souvent à trouver une cause apparente. Orl'évaluation statistique a posteriori d'une telle cause est biaisée [80].En particulier, les outils ne sont pas indiqués pour rechercher de nou-veaux facteurs de risque, inconnus ou mal connus, d'autant plus quel'association avec la maladie est faible. La sélection de la zone d'étude(trop petite ou trop grande), la sélection de la fenêtre temporelle, lefaible e�ectif de la population exposée, la rareté de la maladie, les hypo-thèses mal dé�nies (et donc une méthode inappropriée), de nombreuxfacteurs de risques non maîtrisés, tout ces problèmes peuvent biaiser lesrésultats statistiques et leur interprétation. Il est donc nécessaire, d'unepart, de suivre une méthodologie rigoureuse, et, d'autre part, d'inter-préter les résultats en fonction de la méthode choisie [80, 81, 253].La détection de clusters peut être utilisée comme étude préliminaireaux études épidémiologiques classiques, a�n de préciser certaines ques-tions, notamment concernant les particularités de la zone d'étude. Lesméthodes de détection de clusters sont aussi très utiles dans le cadrede la surveillance épidémiologique, où l'évolution temporelle est égale-ment étudiée. En particulier, l'OMS préconise depuis plusieurs années[186] des études permettant de connaître l'épidémiologie du paludismeà l'échelle locale. Dans ce cadre, et pour une maladie fréquente dont lesfacteurs de risque environnementaux sont bien connus, les outils quenous présentons ici permettent d'aller dans ce sens.
1.10. Étude de la puissance de SpODT.L'objectif du travail présenté dans cette section a été de comparer Sats-can et SpODT sur leur capacité à détecter des clusters de risque. Sats-can a été comparé à plusieurs autres méthodes [221, 53, 149], mettanten évidence sa grande capacité de détection. Cependant, la préspéci�-cation de son fenêtrage implique une baisse de cette capacité lorsquele cluster à risque n'est pas conforme à la fenêtre utilisée. L'intérêt deSpODT est justement l'absence de préspéci�cation, qui permet ainsi
36

Part.I. 1. Détection de clusters spatiaux
de détecter des clusters de formes inattendues.
1.10.1. Critères de comparaisons.
Pour les deux méthodes, nous avons étudié leur puissance à l'aide desimulations, pour un risque de première espèce à 5% et à 10%. Cepen-dant, la présence d'un test signi�catif n'indique pas si la localisationdu cluster signi�catif est conforme à la réalité. Pour cela, nous avonsestimé la sensibilité (probabilité de détecter une zone à risque, lorsquecelle-ci l'est réellement) et la spéci�cité (probabilité de ne pas détecterune zone à risque, lorsque celle-ci ne l'est réellement pas) de chacunedes méthodes, pour chacune des con�gurations simulées.
1.10.2. Simulations.
Nous avons simulé des hypothèses alternatives selon 8 con�gurations :� la source est circulaire ou en bande� le risque à la source est de p = 0, 8 ou p = 0, 5� la vitesse de décroissance du risque est élevée (τ = 0, 001) ou faible(τ = 0, 005)
Les observations, sous chaque hypothèse alternative, étaient simuléesde la façon suivante :
Oi P(Ei = nipwi)
avecni : e�ectif �xe de la concession i (issue de l'étude épidémiologique), lalocalisation des concessions étant également �xée ;p = 0, 8 ou p = 0, 5 : le pourcentage de cas �xé, au point source ;wi = exp
{−di
τ
}, la pondération liée à la distance à la source et à la dé-
croissance du risque, où di est la distance entre le point (la concession)i et le point source (dans le cas d'une simulation circulaire), ou entrele point i et la bande source (dans le cas d'une simulation en bande) ;le paramètre τ permet de simuler une décroissance du risque rapide(τ = 0, 001) ou lente (τ = 0, 005) [�g. 9, 10].Pour mettre en évidence des e�ets de bords, nous avons simulé unecon�guration supplémentaire représentée par une bande �xe (sans dé-croissance), de largeur �xée, avec, à l'intérieur de la bande, p = 0, 8 oup = 0, 5 et, à l'extérieur de la bande, p = 0, 1.Pour chaque con�guration, 500 �chiers ont été simulés.
Concernant l'hypothèse nulle, pour chaque con�guration, les obser-vations ont été simulées sous l'hypothèse du risque constant, de la façonsuivante :
37

Part.I. 1. Détection de clusters spatiaux
Ci P(Ei = O+
n+ni)
Où O+ =∑
iOi et n+ =∑
i ni, sur toutes les concessions i.Pour chaque con�guration et pour chaque �chier de simulations sous
H1, 999 �chiers ont été simulés sous H0.
Les règles d'arrêt utilisées pour SpODT :� R2 < 10−6
� e�ectif d'un noeud père <5� e�ectif d'un noeud �ls <3� nombre de niveaux <5
1.10.3. Résultats.
Concernant les simulations circulaires [�g. 11�14], Satscan présentedes puissances très élevées [tab. 2], autour de 98%, quel que soit lepourcentage au point source et la vitesse de décroissance, même pourα = 1%. Par contre, SpODT ne présente une bonne puissance que pourun pourcentage au point source élevé (p = 80%) quelle que soit la vi-tesse de décroissance, pour α = 5% (1 − β = 87% pour τ = 0, 001, et1 − β = 92% pour τ = 0, 005). La puissance chute rapidement pourles autres con�gurations. En terme de sensibilité, SpODT (100%) estmeilleure que Satscan, bien que celle-ci présente de très bonnes sensi-bilités (> 80%). Cependant, les spéci�cités de SpODT ne sont pas trèsélevées pour la plupart des con�gurations (entre 54 et 65%), sauf pourla con�guration p = 0.5, τ = 0.005, où la spéci�cité approche les 80%.En revanche, les spéci�cités de Satscan sont toutes supérieures à 87%.
Concernant les simulations en bandes décroissantes [�g.15, 16], les puis-sances de Satscan sont moins élevées, même pour α = 5% [tab.3], etce d'autant moins que le pourcentage à la source et la vitesse de dé-croissance sont faibles (passant d'environ 70% à 60% pour une dimi-nution du pourcentage à la source de 80% à 50%). Lorsque le risquede 1ère espèce est α = 1%, les puissances sont également plus faiblesque pour SpODT, et semblent plus in�uencées par la modi�cation dela vitesse de décroissance (passant de 66% à 57% pour un pourcentageà la source de 80% et de 63% à 46% pour un pourcentage à la source de50%, lorsque τ passe de 0,001 à 0,005). SpODT possède de meilleurespuissances lorsque le pourcentage à la source est élevé. Ces puissancesrestent supérieures à celles de Satscan dans les autres con�gurations(restant autour de 70% pour α = 5%), mais sont globalement faibles.En terme de sensibilité, SpODT est supérieure à Satscan, repérant,quelle que soit la con�guration, 100% des concessions simulées commeà risque, alors que Satscan n'en repère qu'entre 50% et 70%. Par contre,
38

Part.I. 1. Détection de clusters spatiaux
Fig. 9. Risque pi en fonction de la distance di.
Simulation circulaire à décroissance rapide ; p = 0, 8 ;τ = 0, 001.
Fig. 10. Risque pi en fonction de la distance di.
Simulation circulaire à décroissance lente ; p = 0, 8 ; τ =0, 005.
la spéci�cité de SpODT varie, allant de 97,2% pour la con�gurationp = 0, 8; τ = 0, 001 à 49,6% pour la con�guration p = 0, 5; τ = 0, 001.La spéci�cité de Satscan est excellente quelle que soit la con�guration,supérieure à 95% pour un pourcentage à la source de 80% et autour de80% pour un pourcentage à la source de 50%.
Concernant les simulations en bandes �xes, SpODT possède des valeursde puissance [tab.3], de sensibilité et de spéci�cité supérieures à 93%.Les puissances de Satscan sont également excellentes, mais Satscan nerepère pas toutes les concessions simulées comme à risque (sensibilitéautour de 70%), bien que sa spéci�cité soit bonne (91,2% et 79,5%).
39

Part.I. 1. Détection de clusters spatiaux
Fig. 11. SpODT :simulation circu-laire (τ = 0, 001 ;p = 0, 8).
Fig. 12. Satscan :simulation circu-laire (τ = 0, 001 ;p = 0, 8).
Fig. 13. SpODT :simulation circu-laire (τ = 0, 005 ;p = 0, 8).
Fig. 14. Satscan :simulation circu-laire (τ = 0, 005 ;p = 0, 8).
Fig. 15. SpODT :simulation enbande (τ = 0, 001 ;p = 0, 8).
Fig. 16. Satscan :simulation enbande (τ = 0, 001 ;p = 0, 8).
40
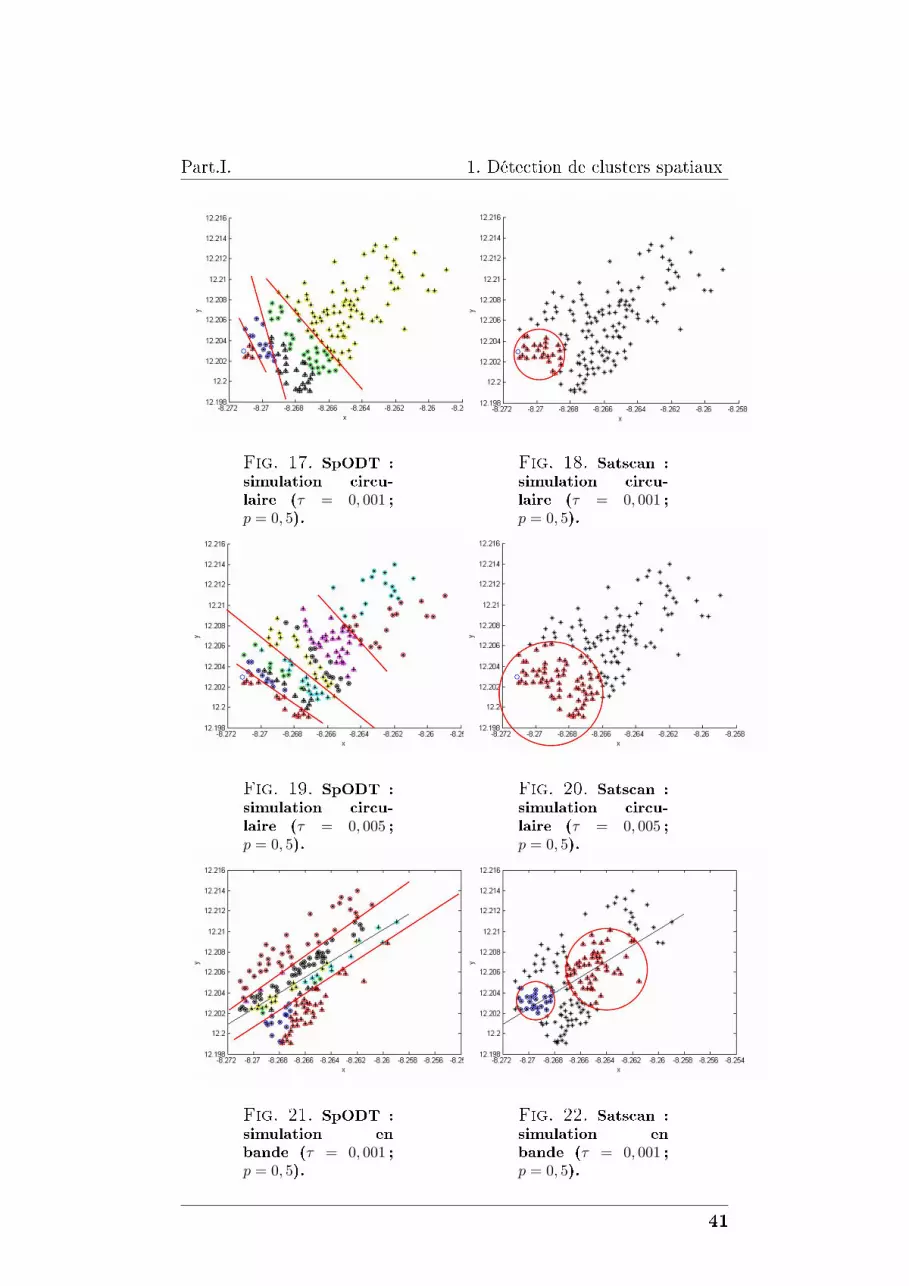
Part.I. 1. Détection de clusters spatiaux
Fig. 17. SpODT :simulation circu-laire (τ = 0, 001 ;p = 0, 5).
Fig. 18. Satscan :simulation circu-laire (τ = 0, 001 ;p = 0, 5).
Fig. 19. SpODT :simulation circu-laire (τ = 0, 005 ;p = 0, 5).
Fig. 20. Satscan :simulation circu-laire (τ = 0, 005 ;p = 0, 5).
Fig. 21. SpODT :simulation enbande (τ = 0, 001 ;p = 0, 5).
Fig. 22. Satscan :simulation enbande (τ = 0, 001 ;p = 0, 5).
41

Part.I. 1. Détection de clusters spatiaux
Fig. 23. SpODT :simulation enbande (τ = 0, 005 ;p = 0, 5).
Fig. 24. Satscan :simulation enbande (τ = 0, 005 ;p = 0, 5).
Fig. 25. SpODT :simulation enbande (τ = 0, 005 ;p = 0, 8).
Fig. 26. Satscan :simulation enbande (τ = 0, 005 ;p = 0, 8).
Fig. 27. SpODT :simulation enbande �xe (p = 0, 8).
Fig. 28. Satscan :simulation enbande �xe (p = 0, 8).
42

Part.I. 1. Détection de clusters spatiaux
Fig. 29. SpODT :simulation enbande �xe (p = 0, 5).
Fig. 30. Résultatsde Satscan pourune simulation enbande �xe (p = 0, 5).
Tab. 2. Simulations circulaires.
SpODT Satscanpuissance puissance5% 1% Se Sp 5% 1% Se Sp
p = 0, 8τ = 0, 001 87 69,2 100 54,4 98,2 98,2 84,9 99,7τ = 0, 005 92 75,8 100 60,8 98,6 98,5 95,8 87,4
p = 0, 5τ = 0, 001 64 40,8 100 65,4 97,9 97,9 81,1 92,5τ = 0, 005 46,8 43,2 100 78,4 98,2 98,2 93,1 89,9
Les valeurs sont présentées en pourcentages (500 échantillons simulés par
con�guration).
1.10.4. Discussion.Comme cela a été décrit dans la littérature, la puissance de Satscanbaisse en présence d'e�ets de bords. C'est ce que montrent les simula-tions en bande. Dans ces con�gurations, Satscan ne peut pas repérertoutes les zones à risque et possède donc des sensibilités faibles. Cepen-dant, Satscan conserve des spéci�cités élevées quelle que soit la con�gu-ration. Lorsque les caractéristiques sont nettes (risque élevé, vitesse dedécroissance rapide), SpODT détecte correctement l'organisation spa-tiale et possède de bonnes sensibilités, quelle que soit la con�guration.Avant d'utiliser l'une où l'autre méthode, il faut donc avoir une idée dece que l'on cherche. Satscan est une méthode puissante pour détecterdes clusters, mais peut être in�uencée par des e�ets de bords. SpODTest plus adapté pour la détection de pattern. D'autres statistiques que
43

Part.I. 1. Détection de clusters spatiaux
Tab. 3. Simulations en bande.
SpODT Satscanpuissance puissance5% 1% Se Sp 5% 1% Se Sp
p = 0, 8τ = 0, 001 94,8 94 100 97,2 73,2 65,6 64,9 97,9τ = 0, 005 95,4 78,6 100 62,1 71,4 57,4 69,2 97,2�xe 100 100 100 98,4 100 100 71 91,2
p = 0, 5τ = 0, 001 76,2 66,8 100 49,6 67,3 63,3 61,3 84,4τ = 0, 005 68,5 53,4 100 54,9 59,6 45,9 52,9 79,3�xe 100 100 100 93,6 100 100 68,7 79,5
Les valeurs sont présentées en pourcentages (500 échantillons simulés par
con�guration).
R2 mise en ÷uvre ici pourraient être utilisées pour l'inférence. En par-ticulier, la statistique de Kulldor� peut être employée sur un ensemblede clusters potentiels déterminé par SpODT. Les statistiques de Tangoou de Moran peuvent également être utilisées sur un pattern constituépar SpODT, qui devient alors un outil descriptif préalable à l'inférence.
44

Part.I. 2. Détection de clusters spatio-temporels
2. Détection de clusters spatio-temporels
2.1. Introduction.Dans ce chapitre, nous analyserons l'évolution spatiale et temporelledu paludisme dans le village de Bancoumana. L'épidémiologie du pa-ludisme est fortement liée au climat. Pour cette raison, la recherche devariations locales doit être faite en tenant compte de l'évolution tempo-relle de la transmission, qui est, à Bancoumana, endémo-épidémique.La recherche de clusters spatio-temporels apporte donc des informa-tions importantes aux épidémiologistes de terrain, a�n de déterminerdes zones et des périodes à risque particulier.Malgré une importante littérature étudiant l'évolution spatiale et
temporelle du risque palustre, peu de travaux analysant ce risque à uneéchelle �ne (en dessous du district) ont été publiés [1, 28]. Les recherchessur la maladie et son contrôle, comme les essais vaccinaux, peuventbéné�cier d'une analyse épidémiologique �ne analysant les patterns entemps et en espace. Ces analyses facilitent l'élaboration de protocoles decontrôle et la précision des interventions. Dans cette étude, nous avonsévalué le risque palustre au niveau des concessions (résolution de 1 à 3m), ainsi que les variations de ce risque dans le temps et l'espace. Cetteétude avait pour objectif d'identi�er des clusters de risque élevé dans letemps et l'espace, a�n d'identi�er ensuite sur le terrain des facteurs derisque particuliers, de connaître précisément la population à risque, etde préparer des essais vaccinaux. En 2005, de tels essais vaccinaux ontété mis en place dans ce village (collaboration MVDB/NIAID/NIH etMRTC/DEAP/University of Bamako).
2.2. Matériel.Sur la base de la cohorte dynamique décrite précédemment, nous avonsétudié l'incidence de l'infection palustre, dé�nie comme la proportionde ré-infection (nouveaux frottis sanguins positifs), par concession etpar évaluation. Lors de la première évaluation en juin 1996, l'équipemédicale a véri�é que tous les enfants de la cohorte étaient négatifs (noninfectés ou traités). Cette première évaluation n'a donc pas été priseen compte dans l'analyse statistique. Certaines concessions possédaientdes toits de tôle, plus rarement de ciment, et, pour 47%, de chaume.La présence de vecteurs étant liée à la présence de toit de chaume,l'analyse spatio-temporelle a été ajustée sur cette covariable [238, 237].
2.3. Méthodes.Premièrement, une analyse temporelle globale a été faite à l'aide desmodèles classiques d'analyse de séries temporelles ARIMA [29, 71],après transformation logarithmique de l'incidence de l'infection danschaque concession. Ces modèles permettent une description des sériestemporelles et leur prédiction à l'aide de décompositions en compo-santes tendancielle, cyclique, saisonnière et accidentelle. L'analyse a
45

Part.I. 2. Détection de clusters spatio-temporels
été faite à l'aide du logiciel SPSS 11.5 (SPSS Inc., Chicago, IL). Lechoix du modèle a été fait suivant les critères d'Akaike (AIC) et deSchwarz (BIC).Deuxièmement, la recherche de clusters spatio-temporels a été faitepar la statistique de balayage de Kulldor� [144], à l'aide du logicielSatscanTM v5.1, Information Management Services Inc., Silver Spring,Maryland, 2004 (freeware available on http ://www.satscan.org). Lar-gement utilisé (voir par exemple [184, 181, 44, 173, 114]), le logicielSatscanTM de Kulldor� a l'avantage de mettre en ÷uvre une statistiquesimple repérant des cluster spatiaux ou spatio-temporels, basée sur lescoordonnées géographiques et pouvant être ajustée sur des covariables.Cette méthode balaye la carte et l'intervalle de temps à l'aide d'unefenêtre cylindrique avec une base géographique circulaire centrée surchaque unité spatiale (u.s.), la hauteur du cylindre correspondant autemps. La fenêtre balaye ainsi l'espace et le temps, et, pour chaque u.s.et chaque rayon, elle balaye chaque période de temps, construisant ainsil'ensemble de clusters potentiels. Comme nous l'avons décrit précédem-ment, la statistique de Kulldor� permettant la détection des clusters àhaut risque est fondée sur la statistique du rapport de vraisemblance.Pour la présente analyse spatio-temporelle, nous avons utilisé le mo-dèle spatio-temporel à permutation, ajusté sur la tendance temporelleet les variations saisonnières, et qui ne nécessite que la connaissancedes cas [147]. Le nombre de cas observés dans un cluster potentiel estcomparé au nombre de cas attendus si les localisations temporelles etspatiales de tous les cas étaient indépendantes les unes des autres. Lerisque relatif (RR) a été dé�ni comme le rapport entre le nombre de casobservés et le nombre de cas attendus. Le nombre de cas attendus a étéestimé suivant l'hypothèse du risque constant (distribution de Poissonhétérogène). Ainsi, on obtient un cluster dans une zone géographiquesi, durant une période déterminée, cette zone géographique à une pro-portion élevée de cas excédentaires. Le test d'hypothèse était fondésur le test du rapport de vraisemblance généralisé, utilisant l'inférencede Monte-Carlo. L'hypothèse nulle d'absence de cluster (constant riskhypothesis) était rejetée pour un degré de signi�cation p < 0.1. Pourl'inférence de Monte-Carlo, 999 échantillons ont été simulés sous l'hypo-thèse nulle conformément aux recommandations de Kulldor�. L'unitéd'espace était donnée par les coordonnées géographiques des conces-sions et l'unité temporelle était le mois. La taille maximale du clusterspatial était de 50% de la population à risque. La taille maximale de lafenêtre temporelle était de 50% de la période d'étude. Les intervalles decon�ance à 95% des proportions ont été calculés à l'aide de la méthodede Wilson [178].
2.4. Résultats.
46

Part.I. 2. Détection de clusters spatio-temporels
Fig. 31. Evolution de l'incidence de l'infection parles 3 espèces plasmodiales et par les gamétocytesde P. falciparum.
2.4.1. Série temporelle.
Sur les 5 années de l'étude, 22 enquêtes ont permis l'analyse d'un total31200 frottis sanguins. Pour P. falciparum, nous avons identi�é un totalde 13861 cas d'infection sur l'ensemble de l'étude, 1594 gamétocytémiespositives, 612 cas d'infection à P. malariae et 185 cas d'infection à P.
ovale.La Chloroquine est restée e�cace contre l'infection à P. falciparum du-rant toute la durée de l'étude. Le taux de bonne réponse clinique dutraitement (Good Clinical Therapeutic Responses) était de 86,7% en1996, 88,3% en 1997, 97,2% en 1998, 97.1% en 1999, 94,4% en 2000et 92,5% en 2001. La modélisation a montré clairement une évolu-tion saisonnière de l'incidence de l'infection à P. falciparum [�g.31].La décroissance annuelle constante était signi�cative (p=0,01), maisest restée faible (-0,107 après transformation logarithmique, écart typeSD=0,037) [�g.32]. Un modèle similaire a été obtenu pour l'incidencede la gamétocytémie à P. falciparum, avec une saisonnalité et une dé-croissance faible (constante cst.=-0,205, SD=0,096, p=0,05) [�g.33].L'analyse de l'évolution de l'incidence de l'infection à P. malariae a misen évidence une composante autorégressive (AR) d'ordre 1 signi�cative,avec une décroissance constante (AR1=0,782, SD=0,079, p<0,0001 ;cst.=-4,085, SD=0,272, p<0.0001) [�g.34], sans composante saisonnièresigni�cative.Les cas incidents d'infection à P. ovale était trop rares (pourcentageinférieur à 2,5%) pour pouvoir en dégager une structure évolutive.
47

Part.I. 2. Détection de clusters spatio-temporels
Fig. 32. Modélisation de l'évolution de l'incidencede l'infection à P. falciparum.
Fig. 33. Modélisation de l'évolution de l'incidencede la gamétocytémie à P. falciparum.
2.4.2. Analyse spatio-temporelle.
La recherche de clusters spatio-temporels d'infection à P. falciparum amis en évidence une hétérogénéité à la fois en temps et en espace. Ene�et, l'analyse a montré la présence de 6 clusters signi�catifs au risqueα = 10% [tab. 4]. Quatre d'entre eux se situaient autour de l'année2000, et deux clusters en 1996. Le cluster 2 dont le risque était le plusélevé, s'étendait de septembre à octobre 1996, avec un risque relatif
48
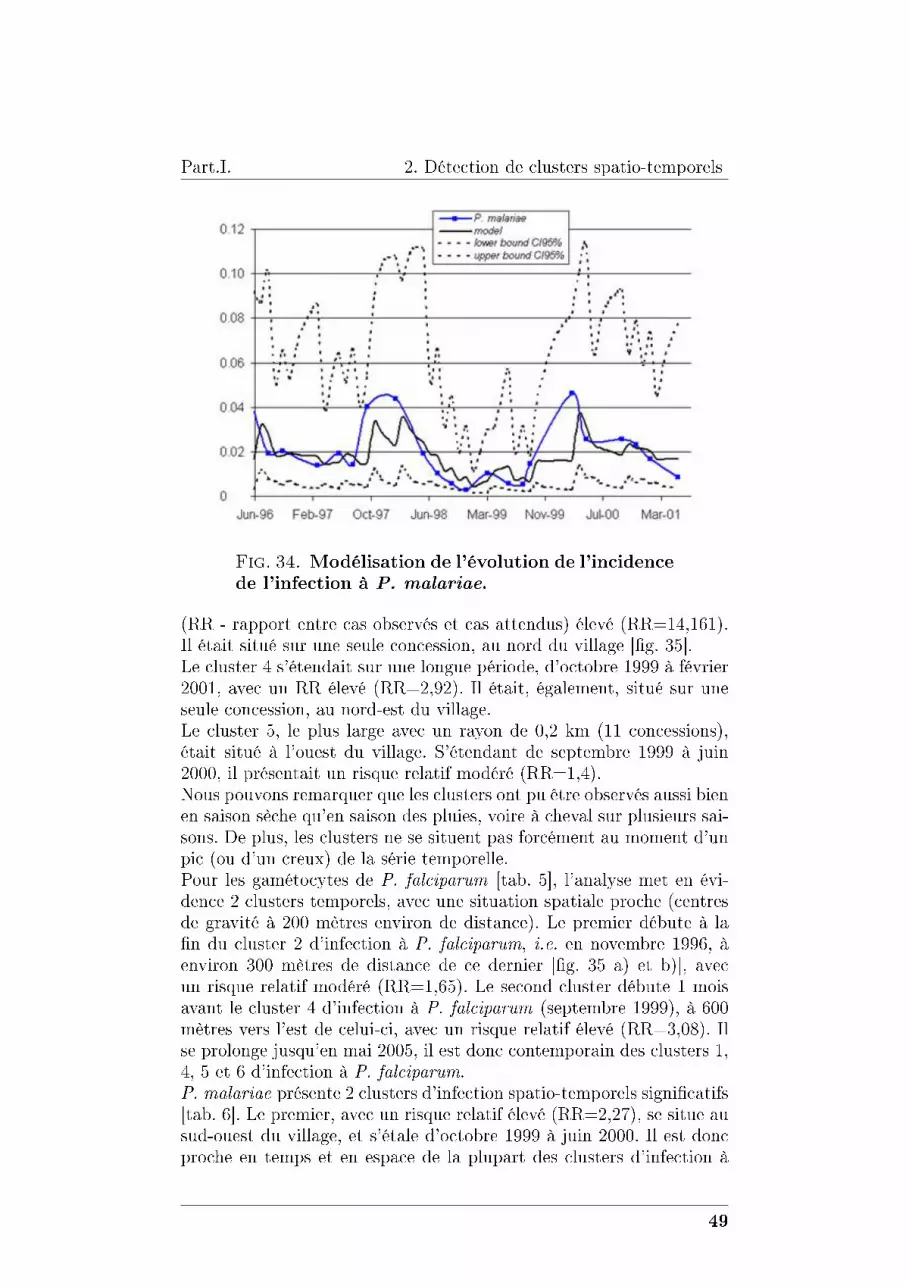
Part.I. 2. Détection de clusters spatio-temporels
Fig. 34. Modélisation de l'évolution de l'incidencede l'infection à P. malariae.
(RR - rapport entre cas observés et cas attendus) élevé (RR=14,161).Il était situé sur une seule concession, au nord du village [�g. 35].Le cluster 4 s'étendait sur une longue période, d'octobre 1999 à février2001, avec un RR élevé (RR=2,92). Il était, également, situé sur uneseule concession, au nord-est du village.Le cluster 5, le plus large avec un rayon de 0,2 km (11 concessions),était situé à l'ouest du village. S'étendant de septembre 1999 à juin2000, il présentait un risque relatif modéré (RR=1,4).Nous pouvons remarquer que les clusters ont pu être observés aussi bienen saison sèche qu'en saison des pluies, voire à cheval sur plusieurs sai-sons. De plus, les clusters ne se situent pas forcément au moment d'unpic (ou d'un creux) de la série temporelle.Pour les gamétocytes de P. falciparum [tab. 5], l'analyse met en évi-dence 2 clusters temporels, avec une situation spatiale proche (centresde gravité à 200 mètres environ de distance). Le premier débute à la�n du cluster 2 d'infection à P. falciparum, i.e. en novembre 1996, àenviron 300 mètres de distance de ce dernier [�g. 35 a) et b)], avecun risque relatif modéré (RR=1,65). Le second cluster débute 1 moisavant le cluster 4 d'infection à P. falciparum (septembre 1999), à 600mètres vers l'est de celui-ci, avec un risque relatif élevé (RR=3,08). Ilse prolonge jusqu'en mai 2005, il est donc contemporain des clusters 1,4, 5 et 6 d'infection à P. falciparum.P. malariae présente 2 clusters d'infection spatio-temporels signi�catifs[tab. 6]. Le premier, avec un risque relatif élevé (RR=2,27), se situe ausud-ouest du village, et s'étale d'octobre 1999 à juin 2000. Il est doncproche en temps et en espace de la plupart des clusters d'infection à
49

Part.I. 2. Détection de clusters spatio-temporels
Tab. 4. Clusters spatio-temporels de parasitémies à P. falciparum.
Cluster
Coordonneesa Rayon P eriode RRb Evald Loce pf
(km) (Obs./Att.)c
1 x = −8, 26398 0,18 2000/04 5,495 1 15 0,001y = 12, 206213 2000/05 (26/4,73)
2 x = −8, 26605 0 1996/09 14,161 1 1 0,001y = 12, 211784 1996/10 (8/0,56)
3 x = −8, 2667 0 1996/07 2,298 2 1 0,002y = 12, 207973 1996/10 (53/23,99)
4 x = −8, 2621 0,2 1999/10 2,924 5 1 0,004y = 12, 211801 2001/02 (30/10,26)
5 x = −8, 27033 0 1999/09 1,406 3 11 0,007y = 12, 206117 2000/06 (222/158,19)
6 x = −8, 26797 0,09 2000/04 3,891 1 7 0,08y = 12, 199266 2000/05 (15/3,85)
a. coordonnées GPS des centres de gravitéb. risque relatif de parasitémie positive à P. falciparum (variance). Estimé par lerapport obs./att.c. nombre de cas observés (obs.) rapporté au nombre de cas attendus (att.) sousl'hypothèse nulled. nombre d'évaluations pendant la périodee. nombre de concessions
f. degré de signi�cation
P. falciparum et de gamétocytes de P. falciparum. Le second clusterd'infection à P. malariae a un risque relatif très élevé (RR=8,82). Ilest isolé dans le temps, s'étendant de septembre 1998 à juin 1999. Il sesitue à l'est du village, dans une zone où se trouvent d'autres clustersà un temps di�érent (clusters d'infection par les gamétocytes 1 et 2,cluster 1 d'infection à P. falciparum).En�n, l'analyse des taux d'infection à P. ovale ne met pas en évidencede clusters spatio-temporels signi�catifs (valeurs non présentées).
2.5. Discussion.En repérant des zones à risques de paludisme, cette étude a permisune strati�cation temporelle et spatiale du risque local comme le re-commande l'OMS [186, 31]. Alors que la région est classée comme zoneà haut risque de paludisme (MARA prevalence estimation = 62,27% ;95%CI[56,37% ; 68,18%]) [158], les habitants savent que ce risque esthétérogène dans le village. Le repérage de clusters montre cette varia-bilité en temps et en espace du risque palustre. L'utilisation d'un SIGpermet l'analyse précise de ces variations à l'échelle des concessions
50

Part.I. 2. Détection de clusters spatio-temporels
Fig. 35. Localisations temporelles et spatiales desclusters de cas.
(a) octobre 1996, (b) octobre 1997, (c) décembre 1998, (d) mai 2000.P.f. : cluster de cas de parasitémie à P. falciparum,gam : cluster de cas de gamétocytémie à P. falciparum,P.m. : cluster de cas de parasitémie à P. malariae.Les 4 fenêtres temporelles ont été choisies de façon à ce que tous lesclusters soient représentés.
(résolution de 1-3m), a�n de mieux connaître et contrôler la maladie.La série chronologique de l'incidence de l'infection à P. falciparum in-dique une saisonnalité bien connue de l'infection (fortement liée à lasaison des pluies), avec une régularité très marquée. En e�et, les pics
51

Part.I. 2. Détection de clusters spatio-temporels
Tab. 5. Clusters spatio-temporels de gamétocytémies àP. falciparum.
Cluster
Coordonneesa Rayon P eriode RRb Evald Loce pf
(km) (Obs./Att.)c
1 x = −8, 26548 0,07 1996/11 1,65 7 5 0,068y = 12, 205422 1998/08 (76/46,05)
2 x = −8, 2651 0,1 1999/09 3,08 3 11 0,095y = 12, 207458 2000/05 (18/5,84)
a. coordonnées GPS des centres de gravitéb. risque relatif de parasitémie positive à P. falciparum (variance). Estimé par lerapport obs./att.c. nombre de cas observés (obs.) rapporté au nombre de cas attendus (att.) sousl'hypothèse nulled. nombre d'évaluations pendant la périodee. nombre de concessions
f. degré de signi�cation
Tab. 6. Clusters spatio-temporels de parasitémies à P. malariae.
Cluster
Coordonneesa Rayon P eriode RRb Evald Loce pf
(km) (Obs./Att.)c
1 x = −8, 26947 0,17 1999/10 2,27 3 24 0,066y = 12, 203629 2000/06 (30/13,21)
2 x = −8, 26205 0,24 1998/09 8,82 4 9 0,094y = 12, 207684 1999/06 (6/0,68)
a. coordonnées GPS des centres de gravitéb. risque relatif de parasitémie positive à P. falciparum (variance). Estimé par lerapport obs./att.c. nombre de cas observés (obs.) rapporté au nombre de cas attendus (att.) sousl'hypothèse nulled. nombre d'évaluations pendant la périodee. nombre de concessions
f. degré de signi�cation
d'infections se situent en octobre 1996, octobre 1997, octobre 1998, sep-tembre 1999 et octobre 2000. On peut remarquer la persistance d'uneincidence élevée au début de l'année 2000, en rapport avec des pluiesintercurrentes en janvier 2000. Au total, la ré-infection par P. falcipa-rum atteind un maximum de 70% (95%CI[68,1% ; 73,3%]) des enfantssuivis (Octobre 1996).
52

Part.I. 2. Détection de clusters spatio-temporels
En ce qui concerne l'incidence du portage de gamétocytes de P. falci-parum, l'évolution temporelle est beaucoup moins régulière, avec no-tamment un pic en février 1998 et un en décembre 1998. On remarqueque le pic d'août 1999 est très important et dépasse la borne supé-rieure de l'intervalle de con�ance à 95%. Cette évolution brutale n'apas d'équivalent dans l'évolution de l'incidence de P. falciparum. Onpeut supposer un lien entre ce pic de gamétocytémies et l'allongementobservé de la période épidémique en 1999.La tendance décroissante de l'incidence de P. falciparum a déjà étéobservée dans d'autres études sur le même site [238, 66]. Il est peu pro-bable que cette tendance soit due à l'évolution naturelle de la présencede P. falciparum dans la région (sauf, peut-être, en cas de changementsclimatiques). Il n'y a pas eu non plus d'évolution du village, en parti-culier la proportion de maisons à toit de chaume est restée constante(autour de 47%). De même, l'évolution de l'e�ectif de la cohorte dyna-mique n'est sans doute pas à l'origine de cette tendance décroissante,car, d'une part le nombre d'enfants inclus est déjà important initiale-ment et, d'autre part, l'infection est hyper-endémique dans cette région.Cette tendance décroissante de l'incidence de P. falciparum est pro-bablement liée à la présence de l'équipe médicale dans une populationdéjà sensibilisée au problème du paludisme et au traitement des enfantsinfectés. L'usage adéquat de la chloroquine comme traitement de pre-mière intention a réduit de façon signi�cative l'auto-médication dansle village de Bancoumana. En e�et, la proportion d'auto-médicationest passée de 6,5% en 1997 à 3,8% en 1998, 3,7% en 1999, et en�n0,8% en 2000 [193], ce qui a permi de limiter le développement de lachloroquino-résistance dans ce village.Par contre, on observe des évolutions plus erratiques des incidences deP. malariae et P. ovale, ne présentant pas d'argument en faveur d'unetransmission saisonnière.D'une façon globale, le taux d'infection à P. falciparum atteint un maxi-mum de près de 70% des enfants (octobre 1996). Ce chi�re, bien queproche d'autres valeurs dans d'autres localisations géographiques [1],ne rend pas compte de la grande hétérogénéité géographique, même àl'échelle �ne du village, dont la connaissance est précieuse pour la miseen place d'un programme de lutte. L'évolution temporelle moyenne del'ensemble du village est en fait plus complexe, si l'on regarde attenti-vement au niveau local. En e�et, la recherche de clusters de cas spatio-temporels met en évidence l'absence d'homogénéité de l'ensemble duvillage. Ainsi, on pourra identi�er des zones à risque élevé d'infection,malgré la tendance décroissante globale. De même, indépendammentde l'évolution globale saisonnière de l'infection, on retrouve des clus-ters de cas en saison sèche (avril mai 2000, juin 1996 novembre 1999à février 2001). Ces clusters rendent compte du risque d'infection à P.
falciparum de façon beaucoup plus précise. A l'échelle des concessions,
53

Part.I. 2. Détection de clusters spatio-temporels
on peut donc remettre en cause le pro�l global saisonnier de la trans-mission à tendance décroissante, ce pro�l global étant une moyenne surl'ensemble du village. La transmission de P. falciparum est liée à desfacteurs locaux que l'on doit pouvoir repérer et contrôler. Par exemple,le cluster 5 de cas d'infection à P. falciparum est situé à proximitéd'un site récent de fabrication de briques en banco. La terre y est pré-levée pour fabriquer artisanalement les briques et les excavations ré-sultantes sont des gîtes d'anophèles. On peut supposer que l'évolutionspatio-temporelle des clusters est liée à l'évolution spatio-temporelledes facteurs locaux, en particulier des marigots temporaires.On peut noter la proximité en temps et en espace des clusters de cas
d'infection à P. falciparum et de porteurs de gamétocytes : le cluster 3de cas d'infection à P. falciparum se termine �n octobre 1996 et le clus-ter 1 de cas de gamétocytémie débute début novembre 1996, à environ300 mètres de distance. Le cluster 2 de cas de gamétocytémie débute enseptembre 1999, à proximité, dans le temps et l'espace, d'autres clustersde cas de P. falciparum. Malgré cette proximité spatio-temporelle, il estdi�cile d'en déduire une relation causale. Par contre, cette observationdoit alerter les épidémiologistes de terrain sur cette zone particulière-ment à risque. De même, la grande proximité spatiale des 2 clustersde porteurs de gamétocytes de P. falciparum (200 mètres) est un signed'alerte. En ce qui concerne les 2 clusters de cas de P. malariae, lepremier est proche en temps et en espace des clusters de cas de P. fal-ciparum, alertant là encore sur la présence d'un facteur de risque localcommun. Le second, par contre, est éloigné. La présence de clustersspatio-temporels de cas de P. malariae est là encore une alerte supplé-mentaire. La détection de clusters à haut risque, étalés sur plusieurssaisons des pluies, suggère que, si un cluster avait été détecté dès son ap-parition, le risque aurait pu être contrôlé par une enquête de terrain à larecherche de facteurs de risque, conduisant à la mise en place d'actionsde contrôle ciblées sur cette zone géographique. Les relations entre les 3espèces plasmodiales sont complexes [218, 162, 194], d'autant plus queP. falciparum domine largement au Mali. Mais les facteurs de risquesenvironnementaux restent sensiblement les mêmes. La cartographie durisque d'infection à P. ovale ou P. malariae alerte donc aussi sur lerisque d'infection à P. falciparum. De même, l'analyse de la gamétocy-témie à P. falciparum rend compte de la variation spatio-temporelle dela transmission palustre, permettant d'orienter et de focaliser les ac-tions de prévention [208]. De plus, l'analyse spatio-temporelle conjointedes di�érentes espèces plasmodiales peut nous permettre de mieux ap-procher leurs relations.Dans la littérature, si certaines publications rapportent une analyseépidémiologique au niveau du district, peu analysent une échelle plus�ne [205, 141, 67, 196, 201, 32] et rares sont celles qui utilisent un mo-dèle statistique spatial ou spatio-temporel [101, 214, 217, 28].
54

Part.I. 2. Détection de clusters spatio-temporels
Le modèle de permutation de Kulldor� utilisé possède plusieurs avan-tages : il permet de n'utiliser que le nombre de cas et leur localisation,sans la nécessité de connaître la totalité de la population à risque ;il prend en compte d'éventuelles variables d'ajustement ; il n'y a pasde biais de pré-sélection, puisque les clusters sont recherchés sans pré-suppositions sur leur localisation, leur taille ou la période de tempscorrespondante. La statistique testée prend en compte la répétitiondes tests et ne donne qu'un seul degré de signi�cation [147]. Le modèlede permutation dépend de l'évolution de la distribution de la popula-tion, lorsque cette évolution est hétérogène. En e�et, si la populationcroît ou décroît plus rapidement dans une zone que dans une autre,cela peut introduire un biais dans l'analyse. Au niveau du village deBancoumana, la population n'a pas augmenté de façon importante surl'ensemble du village. De plus, à l'échelle du village, nous avons consi-déré que cette augmentation a été homogène. Ainsi, cette croissancede la population ne conduit pas à des résultats biaisés. Cependant, iln'est pas possible d'estimer les intervalles de con�ance pour les risquesrelatifs des clusters détectés, à cause de la procédure de balayage et dela multiplicité des fenêtres.
Les principaux facteurs de risque palustre dans ce village sont la pré-sence de toits de chaumes [237], l'âge, l'accès au traitement, la saisondes pluies et la présence d'Anopheles dans des gîtes particuliers va-riant dans le temps, même pendant une saison. Notre analyse a permisl'ajustement sur la présence de toits de chaumes. Elle était limitée auxenfants entre 0 et 12 ans. La présence de l'équipe médicale en per-mance sur le terrain a rendu l'accès au traitement identique pour tousles individus. La saisonnalité a été prise en compte par la modélisation,dont l'objectif �nal était de détecter des zones à haut risque dans letemps et l'espace, notamment à la recherche de gîtes particuliers, sanspré-spéci�cation des localisations.
Parmi les actions de lutte contre le paludisme, le contrôle de l'envi-ronnement préconisé par l'OMS [188] permet une lutte ciblée et sélec-tive. En particulier, une gestion spéci�que d'un environnement favo-rable à la pullulation de vecteurs entraîne une réduction importantede la transmission [138]. La priorisation et la spéci�cation des inter-ventions sont liées à la compréhension de l'hétérogénéité environne-mentale [139, 116, 43, 163] à une échelle su�samment �ne. De plus,devant la grande complexité de la transmission et de l'infection pa-lustre, les populations et l'environnement des lieux où sont conduitesdes études d'interventions, doivent être précisément connus avant ledémarrage de telles études [140]. Le développement des SIG a permis
55

Part.I. 2. Détection de clusters spatio-temporels
d'améliorer cette connaissance "micro-épidémiologique" [34]. De plus,cette connaissance et cette gestion de l'environnement peuvent êtreappliquées dans les grandes villes africaines. Les villes sub-sahariennesont une croissance très rapide [138, 134, 34, 188, 132]. Associée à lapauvreté, cette urbanisation entraîne une augmentation des cas de pa-ludisme. En e�et, ces nouveaux quartiers sont caractérisés par l'absencede structure d'hygiène urbaine, la pauvreté des maisons, une forte pro-miscuité et l'absence de drainage des eaux de pluies entraînant l'émer-gence de nombreux gîtes de vecteurs. Ce terrain est très favorable à uneexplosion épidémique du paludisme. Il est donc urgent d'en faire unecartographie détaillée a�n de détecter les quartiers à haut risque pourguider les interventions ciblées. Au niveau des villes, l'élimination degîtes clefs peut avoir un grand impact sur l'épidémiologie du paludismeurbain [134, 34].
56

Deuxième partie :
Modélisation déterministe
Voici que le temps et l'espace
créent la distance favorable,
le mètre même et le verset de l'orgue.
Léopold Sédar Senghor.Élégies Majeures

Part.II. 1. Introduction
1. Introduction
1.1. Le cycle du paludisme.Nous débuterons par un rappel simple de cette maladie bien connue, ducycle et de la transmission de l'agent, indispensable pour la modélisa-tion. Le paludisme est une protozoose due à un hématozoaire du genreplasmodium. Quatre espèces de plasmodii sont agents du paludismehumain :� P. falciparum, le plus répandu dans les régions tropicales et inter-tropicales, dont la durée de vie est, en moyenne, inférieure à 2 mois(rarement une année) ; c'est à cette espèce, la plus dangereuse, quele présent travail s'adresse ;
� P. vivax, touchant des régions plus tempérées, dont la durée de viepeut atteindre 3 ans ;
� P. ovale, plus rare, d'une durée de vie moyenne également de 3ans ;
� P. malariae, localisé en foyers, dont la durée de vie peut atteindreplusieurs dizaines d'années.
La transmission du parasite est, dans les conditions naturelles, indi-recte. En e�et, l'hématozoaire est transmis, du sujet contagieux ausujet sain, par de nombreux moustiques du genre Anopheles. Une seulepiqûre d'anophèle infectante est su�sante. Seules les femelles piquentl'homme, le soir ou surtout la nuit, a�n d'assurer la maturation desoeufs et terminer ainsi leur cycle gonotrophique (la transmission trans-placentaire est également possible).On peut donc décrire 2 cycles, chez l'homme et chez l'anophèle [�g.36].Chez l'homme, le cycle asexué (intrinsèque ou schizogonique) comprend2 étapes. Après l'inoculation par piqûre, les sporozoïtes atteignent lescellules hépatiques en moins de 30 minutes, et s'y multiplient (phaseexo-érythrocytaire, 1 à 2 semaines). L'éclatement des hépatocytes pa-rasités libère les mérozoïtes dans la circulation. Au cours de la phaseérythrocytaire, les mérozoïtes atteignent les hématies où ils se trans-forment en trophozoïtes, puis, par multiplication, en schizontes. L'écla-tement des hématies libère les schizontes qui vont coloniser d'autreshématies. Le cycle érythrocytaire dure environ 48h (P. falciparum).Après plusieurs cycles érythrocytaires, des gamétocytes (mâles et fe-melles) apparaissent dans les hématies. Lors de sa piqûre, indispen-sable pour la maturation de ses oeufs, l'anophèle femelle ingère, entreautre, les gamétocytes. Après fécondation et maturation, des sporo-zoïtes apparaissent et gagnent les glandes salivaires de l'anophèle. Cecycle sexué (extrinsèque ou sporogonique) n'a lieu que chez l'anophèle.Sa durée est très dépendante du climat : elle est de 10 à 30 jours, avecdes températures minimales de 17°C et maximales de 40°C et une hy-drométrie supérieure à 60%. Les variables climatiques agissent sur laproduction de moustiques, leur survie, leur vitesse de reproduction, et,
58

Part.II. 1. Introduction
Fig. 36. Représentation simpli�ée du cycle de P. falciparum.
également, sur le cycle parasitaire lui-même [55, 54, 59, 76, 106, 115,118, 117, 123, 127, 137, 172, 219, 231, 232]. Cette relation avec desvariables climatiques et environnementales explique la répartition géo-graphique du paludisme à P. falciparum. Dans les régions tropicaleset inter-tropicales, la maladie est endémique ou endémo-épidémique(saisonnalité de l'incidence) comme c'est le cas dans le village de Ban-coumana. Elle peut être également épidémique lorsque les pluies sontplus rares.L'homme ne dispose d'aucune immunité naturelle, mais, soumis à
des réinfections, développe une immunité dite relative, réversible enl'absence de réinfection, limitant la pathogénicité du parasite. Les en-fants, qui n'ont pas encore développé cette immunité relative, sont doncparticulièrement à risque. Dans certaines régions, la transmission inter-mittente, liée aux facteurs climatiques, ne permet pas l'instauration decette immunité relative, par manque de réinfection régulière.
1.2. Les modèles du paludisme.La �n du 19ème siècle a été riche en découverte sur le paludisme [12]. Ene�et, Laveran décrit en 1880 la présence de parasites dans les globulesrouges humains. En 1894, Manson suggère l'importance de certainsmoustiques dans la transmission. En 1897 et 1898, Ronald Ross décritla présence de parasites chez le moustique, en particulier la présencede sporozoïtes dans les glandes salivaires, et établit le cycle complet du
59

Part.II. 1. Introduction
parasite chez l'oiseau, la même année que Grassi, Bignami et Bastia-nelli pour l'homme. Ross débute immédiatement la lutte anti-vectorielleau Sierra-Leone en 1899 (essentiellement larvicide, en attendant la dé-couverte du DDT en 1939). Les premiers traitements anti-parasitairesseront découverts plus tard (Pamaquine 1924, Mepacrine 1930, Chloro-quine 1934). Les premiers parasites chloroquino-résistants apparaitrontvers 1961 en Asie du Sud-Est, puis vers 1978 en Afrique de l'Est.Aidant à l'élaboration des mesures de contrôle, les modèles détermi-nistes ont été utilisés très tôt, en particulier par Ronald Ross dès 1909[4, 12]. Il montre qu'il n'est pas nécessaire d'éradiquer complètementle vecteur, mais qu'une réduction de la densité vectorielle su�t pouréliminer l'infection palustre (théorie du seuil). Les modèles de R. Rossutilisent 2 équations di�érentielles du premier ordre qui interagissent,l'une pour l'infection humaine et l'autre pour les moustiques [eq.2.1.1].Dans les années 1950, George McDonald reprend la modélisation deRoss et introduit plusieurs concepts supplémentaires, en particulier lanotion de sur-infection, dont la modélisation sera généralisée par Dietz,Molineaux et Thomas dans les années 1970 [63, 171]. D'autres auteursont étudié d'autres facteurs comme l'immunité (Hethcote 1974), en par-ticulier l'immunité relative (Dutertre 1976 [76], et Ngwa [179]), la dis-tribution spatiale de l'hôte et du vecteur (Radcli� 1976 ), la co-infectionP. falciparum et P. vivax [159]. D'autres travaux sur le paludisme ontproposé une modélisation stochastique (Bartlett 1964, Gri�ths 1972,Radcli� 1973, Bekessy 1976, Singer 1980 [213]). Les premiers modèlesdéterministes ont considéré le plasmodium comme un micro-parasiteà transmission indirecte [4, 12]. L'intérêt a, alors, porté sur les infec-tions secondaires et non sur le cycle du parasite lui-même. Ce n'est queplus tard (en particulier avec l'utilisation de modèles stochastiques)que les cycles intrinsèque et extrinsèque du parasite seront étudiés, enparticulier la dynamique intra-hôte du parasite [109, 202], sa diversitégénétique [167, 203], la production de gamétocytes [61], la résistance duparasite [5]. Di�érentes caractéristiques humaines ont, également, étéétudiées comme la migration [49] ou la diversité génétique (co-évolutionHomme-parasite) [86]. En�n, des modèles de réaction-di�usion ont ré-cemment été étudiés, en particulier pour la di�usion de la résistanceau traitement [11].
L'objectif de ce travail était de proposer, à partir des modèles clas-siques, un modèle plus adapté au terrain de Bancoumana, re�étantl'évolution temporelle du paludisme, en tenant compte de variablesclimatiques, puis l'évolution temporo-spatiale. Dans la section 2, nousavons présenté les 2 modèles classiques. Un modèle déterministe adaptéà Bancoumana est proposé, ainsi que 4 modélisations de la pluviomé-trie. La section 3 présente la modélisation spatio-temporelle par équa-tion de réaction-di�usion.
60

Part.II. 2. Evolution temporelle du paludisme
2. Evolution temporelle du paludisme
2.1. Description de 2 modèles classiques.Nous avons choisi de présenter 2 modèles classiques, avec des notationsidentiques : le modèle de Ross, repris par McDonald, et le modèle deDutertre que nous avons ensuite modi�é pour l'adapter à notre situa-tion.Notations ( not.2.1)Les variables :� S(t) : taux d'hommes susceptibles ;� I(t) : taux d'hommes infectés non contagieux, i.e. avec une para-sitémie positive, mais une gamétocytémie négative ;
� G(t) : taux d'hommes infectés contagieux, i.e. avec une gamétocy-témie positive (indice gamétocytique) ;
� R(t) : taux d'hommes résistants, i.e. suivant le cas, traités et enpériode de résistance à la maladie, immunisés, décédés, ou dépla-cés ;
� As(t) : taux d'anophèles susceptibles ;� Ag(t) : taux d'anophèles contaminées, non contagieux ;� Ai(t) : taux d'anophèles contagieux, noté également Mi(t) ;� N(t) : nombre total d'hommes ;� M(t) : nombre total d'anophèles ;� i(t) : force de l'infection chez les hommes, i.e. incidence de la ma-ladie ;
� im(t) : force de l'infection chez les anophèles, i.e. incidence de lacontagiosité des anophèles ;
� Pl(t) : variable exogène, représentant le climat.
Les paramètres :� δ : perte de la résistance chez l'homme, où 1
δest la durée moyenne
de l'e�et de la résistance (traitement, immunité, déplacement selonle cas) ;
� η1 : lié à l'apparition des gamétocytes chez l'homme, où 1η1
est ladurée moyenne entre l'infection et l'apparition des gamétocytes ;
� η2 : perte des gamétocytes, où 1η2
est la durée moyenne de la pertede gamétocytes ;
� γ : apparition de la résistance (traitement, immunité, déplacementselon le cas) ;
� µ : densité anophélienne, i.e. nombre d'anophèles par homme ;� α : nombre de piqûres par anophèle et par nuit. α = τ
ψ, où τ est le
taux d'anthropophilie, et ψ est la durée du cycle gonotrophique ;µα est donc l'agressivité ;
61

Part.II. 2. Evolution temporelle du paludisme
Fig. 37. Modèle de Ross et McDonald.
� β : coe�cient de contagiosité des hommes susceptibles par les ano-phèles contagieuses ;
� ξ : mortalité quotidienne des anophèles ;� ζ : coe�cient de contagiosité des anophèles susceptibles par leshommes contagieux ;
� ν : durée moyenne du cycle extrinsèque ;� ε : taux de guérison sans immunité ;� λ : taux de mortalité humaine ;� θ : paramètre retard ;� D : paramètre de di�usion (modèle de réaction-di�usion) ;� $ : paramètre correspondant à la production d'anophèles suscep-tibles (modèle de réaction-di�usion).
2.1.1. Les premiers modèles : Ross et McDonald.
Le premier modèle de Ross, repris par McDonald est fondé sur un mo-dèle à 2 dimensions, les hommes contagieux et les vecteurs contagieux[5, 4, 12, 49, 174]. Il s'agit d'un modèle de type SIS [�g.37], où le pas-sage de susceptible à infecté (le classique "taux de contact") n'est pasconstant, mais dépend des moustiques, i.e. de la densité anophélienne,de l'agressivité et de la capacité contagieuse. Ce modèle peut s'écrire :
(2.1.1)
dG(t)
dt= +i(t) (1−G(t))− γ G(t)
dAi(t)
dt= im(t) (1− Ai(t))− ξ Ai(t)
i(t) = µ α β Ai(t)
im(t) = α ζ G(t)
µα est donc l'agressivité, i.e. le nombre de piqûres par homme et parnuit (notations cf not.2.1).Il faut noter que, pour les hommes, le taux de guérison γ est plus grandque leur mortalité, au contraire des vecteurs, qui possèdent une morta-lité ξ élevée et un taux de guérison négligeable. Le modèle ne tient doncpas compte de la mortalité humaine ni de la guérison des moustiques.
62

Part.II. 2. Evolution temporelle du paludisme
Dans ce modèle, aucun des paramètres ne dépend de circonstances ex-térieures.En tenant compte de la durée du cycle extrinsèque et de la survie duvecteur, McDonald a modi�é l'équation :
(2.1.2)
dS(t)
dt= −i(t) S(t) + γ G(t)
dG(t)
dt= +i(t) S(t)− γ G(t)
dAi(t)
dt= im(t)
(e−ξν − Ai(t)
)− ξ Ai(t)
i(t) = µ α β Ai(t)
im(t) = α ζ G(t)
La décroissance de la population de vecteurs suit une exponentiellenégative f(t) = e−ξt. Après ν jours, la population de vecteurs aura di-minué de e−ξν . Si ν est la durée du cycle extrinsèque, il reste donc,après une piqûre infectante sur l'homme, e−ξν des vecteurs initiaux quipeuvent à nouveau transmettre la maladie. De cette façon, McDonaldprend en compte, sans avoir besoin de l'écrire, une catégorie de vecteursinfectés non contagieux.
A l'équilibre, il vient :
(2.1.3)
{dGdt
= µαβAi(1−G)− γG = 0dAi
dt= αζG
(e−ξν − Ai
)− ξAi = 0
⇔
{Ai = 0 ou Ai = αζGe−ξν
αζG+ξ
G = 0 ou G = µα2βζe−ξν−ξγµα2βζe−ξν+αζγ
Avec Mc Donald, on en déduit le nombre de reproductions z0 :
(2.1.4)si G > 0 alors µα2βζe−ξν − ξγ > 0
⇔ z0 =µα2βζe−ξν
ξγ> 1
Ce modèle simpli�é a permis de mieux comprendre les observationsde terrain et d'améliorer les actions de lutte contre le paludisme. Ce-pendant, ce modèle de base ne distingue ni les di�érentes catégoriesd'hommes, ni celles de vecteurs, infectés ou non, contagieux ou résis-tants. De nombreux auteurs ont retravaillé, modi�é et généralisé cemodèle de base. Par exemple, Bailey a ajouté une catégorie d'hommesinfectés non contagieux et une catégorie de vecteurs infectés mais noncontagieux. Dietz, Molineaux et Thomas [63] ont proposé des modi�-cations importantes.
63

Part.II. 2. Evolution temporelle du paludisme
Fig. 38. Modèle de Dutertre.
2.1.2. Le modèle de Dutertre.
Dutertre propose un modèle [76] où un Susceptible devient Gamétocy-tique (i.e. contagieux) après une piqûre infectante [�g.38], puis, peutsoit guérir et acquérir une immunité (γ), soit devenir Infecté Plasmo-dique (non contagieux) (η2). Un Plasmodique peut soit redevenir Ga-métocytique (η1), soit guérir et acquérir une immunité (γ), soit guérirsans immunité et ainsi redevenir susceptible (ε). En�n, un Résistant(immun) perd son immunité (δ). A chaque étape, Dutertre ajoute lapossibilité de mourir au taux λ, constant quelque soit le compartiment.En�n, Dutertre travaille sur 2 facteurs particuliers : la perte d'immu-nité d(t) qu'il fait dépendre des infections à répétition, et l'incidencei(t)S(t). La dynamique des proportions de chaque compartiment peuts'écrire selon le modèle suivant (notations cf not.2.1) :
(2.1.5)
dS(t)
dt= −i(t) S(t) + d(t) R(t)
dG(t)
dt= +i(t) S(t) + η1 I(t)− (η2 + γ) G(t)
dI(t)
dt= +η2 G(t)− (η1 + γ + ε) I(t)
dR(t)
dt= +γ (I(t) +G(t))− d(t) R(t)
dAi(t)
dt= im(t)
(e−ξν − Ai(t)
)− ξ Ai(t)
i(t) = µαβ Ai(t)
im(t) = αζ G(t)
Dutertre utilise numériquement d(t) = δ(1 − CA(t)) avec CA le risqueannuel d'être infecté, et l'équation aux di�érences :1− CA(t+ 1) = (1− CA(t))(1− i(t))(12/13)
64

Part.II. 2. Evolution temporelle du paludisme
i(t) peut être remplacé par i1(t) = 1−(1 + (µαβ
κAi(t)
)−κoù κ permet
de prendre en compte la distribution hétérogène de la sensibilité face àl'infection. Cette dernière version permet de tenir compte des inégalitésdes susceptibles face à la transmission (loi Binomiale négative).
2.1.3. Le modèle de Bancoumana.
A la di�érence du modèle de Dutertre, nous avons souhaité respecterl'ordre chronologique d'apparition des gamétocytes. En e�et, ceux-ciapparaissent, dans le sang des hommes contaminés, après l'apparitiondes formes asexuées du parasite. De plus, notre étude s'adresse à desenfants, et nous avons donc considéré que l'immunité relative n'étaitpas encore e�cace. En�n, les enfants infectés (contagieux ou non) étanttraités tous les 2 ou 3 mois, ils deviennent alors résistants pendantla durée de l'e�cacité du traitement, avant de redevenir susceptibles[�g.39]. Le modèle peut alors s'écrire :
(2.1.6)
dS(t)
dt= −i(t) S(t) + δ R(t) [a]
dI(t)
dt= +i(t) S(t)− (η1 + γ) I(t) + η2 G(t) [b]
dG(t)
dt= +η1 I(t)− (η2 + γ) G(t) [c]
dR(t)
dt= +γ (I(t) +G(t))− δ R(t) [d]
dAi(t)
dt= im(t)
(e−ξν − Ai(t)
)− ξ Ai(t) [e]
i(t) = µαβ Ai(t)
im(t) = αζ G(t)
Remarque : si on choisit de modéliser la densité anophélienneµ(t) = M(t)
N(t), il faut alors écrire les 2 premières équations :
dS(t)dt
= −i(t) S(t) N + δ R(t)
et dI(t)dt
= +i(t) S(t) N − (η1 + γ) I(t) + η2 G(t)
65

Part.II. 2. Evolution temporelle du paludisme
Fig. 39. Modèle de Bancoumana.
A l'équilibre, il vient :(2.1.7)δ R = µαβ Ai (1−G− I −R) d′apres [a],
δ R = γ (I +G) d′apres [d],
η1 I = (η2 + γ) G d′apres [c],
⇔ δ R = G γ
(η1 + η2 + γ
η1
)si k = 1 +
η2 + γ
η1
+γ
δ
(η1 + η2 + γ
η1
)alors S = 1− k G
⇔ δ R = µαβ Ai (1− k G)
⇔ Ai =G γ
(η1+η2+γ
η1
)µαβ (1− k G)
or αζ G (e−ξν − Ai)− ξ Ai = 0 d′apres [e],
⇔ αζ G e−ξν − αζ GG γ
(η1+η2+γ
η1
)µαβ(1− k G)
− ξG γ
(η1+η2+γ
η1
)µαβ(1− k G)
= 0
⇔ G = 0
ou
αζe−ξν − αζG γ
(η1+η2+γ
η1
)µαβ(1− k G)
− ξγ
(η1+η2+γ
η1
)µαβ(1− k G)
= 0
⇔ µα2βζe−ξν(1− k G)− αζ G γ
(η1 + η2 + γ
η1
)− ξγ
(η1 + η2 + γ
η1
)= 0
⇔ G =µα2βζe−ξν − ξγ
(η1+η2+γ
η1
)kµα2βζe−ξν + αζγ
(η1+η2+γ
η1
)66

Part.II. 2. Evolution temporelle du paludisme
On en déduit le nombre de reproductions z0 :
(2.1.8)
si G > 0 alors µα2βζe−ξν − ξγ
(η1 + η2 + γ
η1
)> 0
⇔ z0 =µα2βζe−ξν
ξγ(η1+η2+γ
η1
) > 1
qui est de la même forme que le nombre de reproductions proposé parMcDonald [eq.2.1.4].Ce nombre de reproductions prend en compte les taux de passages entreInfectés non contagieux et Gamétocytiques η1 et η2, le taux de guérisondes infectés contagieux ou non γ.
Résolution numérique :La résolution numérique de l'équation [eq.3.3.1] a été faite à l'aide
de solveurs classiques (Matlab)[�g.40]. Les solveurs ODE45, ODE23 etODE113 [27, 69, 209, 210] avaient des temps de calcul trop longs (plu-sieurs jours). Les solveurs ODE15s, ODE23s et ODE23t et ODE23tbont donné des résultats équivalents. Les paramètres utilisés sont, gé-néralement, issues de la littérature [tab.7 et 8], adaptés au modèle etaux données présentes. Une analyse de sensibilité a été faite à partirdes estimations de la littérature [�g.41]. Les conditions initiales ont étéestimées sur la base de l'étude de Bancoumana :� N=2000� S(t=0)=0,425� I(t=0)=0,5� G(t=0)=0,075� R(t=0)=0� Mi(t=0)=0
Fig. 40. Modèle de Bancoumana : résolution numérique
67

Part.II. 2. Evolution temporelle du paludisme
Fig. 41. Variations de la trajectoire Mi(t) =f(G(t)) en fonction des estimations des para-mètres.
68

Part.II. 2. Evolution temporelle du paludisme
Fig. 42. Modèle de Bancoumana : 1)gauche : me-sure de prévention seule δ = 0, 004, 2)droite : mesure deprévention associée au traitement δ = 0, 004 et γ = 0, 1
On remarque qu'il faut une stabilisation importante [�g.41, 42]dela résistance pour avoir un e�et sur la transmission. En e�et, en di-visant par 10 la perte de résistance, δ = 0, 004 (à l'occasion d'unemesure de prévention comme une vaccination par exemple), il persisteenviron 30% d'enfants infectés [�g.42]. Pour être e�cace, il faut asso-cier, à cette mesure de prévention, le traitement des enfants infectéset contagieux (par exemple γ = 0, 1). Les autres paramètres n'ont quepeu d'in�uence. Comme cela a été montré dans d'autres travaux [216],ce résultat indique l'e�et potentialisateur de di�érentes méthodes decontrôles.
69

Part.II. 2. Evolution temporelle du paludisme
Tab. 7. Estimations des paramètres.
Param.* EstimationsBk** Littérature
α 2,5 0,45 [76, 224] ; 0,5 [109] ; 0,56 [49] ; et [tab.8]β 0,5 0,02 [49] ; 0,08 [76] ; 0,5 [109]
8, 1 · 10−3 ± 7, 1 · 10−4 [12]0,06-0,27 [177] chez les enfants0,013 0,056 0,065 [63, 171]0.39 (0.26-0.91)§ [35]
γ 0,01 0,00047 [167] ; 0,00118 [224] ; 0,0023 [76, 224]0,003704 [49] ; 0,00735 [177] ; 0,9716 [123]0,0011-0,0085 [213] ; 0,0083-0,0125 [179]0,038(0,011-0,13) [176]0,005 ou 0,1 en cas de traitement [220]0,0015-0,005 [63, 171], chez les enfants0,0057 [63, 171], apparition des anticorps0.0049 (0.0005-0.057)§ [35]
δ 0,04 0,0143 [159] ; 0,0146 [179, 49]0,001 (0,0067-0,02) [166]0,0015-0,0323[213]1, 6710−5 [166] e�et d'un vaccin0.0043 (0.0034-0.056)§ [35]
ζ 1 0,15 [109] ; 0,5 [123] ; 0,47 [224] ; 0,83 [49]0,024 0,055 0,018 0,074 [137]0,38(0,24-0,51) ou 0,47(0,28-0,66) [176]
ξ 0,014 0,0417 [179] ; 0,1429 [49] ; 0,1997 [224] ; 0,5 [123]0,125 0,0694 0,088 0,1 (An. gambiae) [76]0,046-0,139 [166] ; 0,139-0,185 [63, 171]0.94 0.9 0.83 0.86 [137]
µ 12 12 [76]0,1 à 256 (en classes 0,1-4 4,1-16 16,1-64 64,1-256)[63, 171]
ν 13 2,4 [179] ; 10 [12, 109] [63, 171] ; et [tab.8]10,3 11,6 10,7 8,3 9,6 [137]
η1 0,05 0,04 [159] ; 0,0667 [109] ;0,083 [49]0,25 [76] ; 0,3 [167] ; 0,05-0,1 [166]
η2 0,75 0,5 [167] ; 0,0108 et 0,002 [224]0,0333 et 0,0465 [76]0.004-0.009 [177] ; 0,0333-0,1 [166]0.00099 (0.00068-0.0014) [176] ; 0.12 (0.0055-2)§ [35]
τ 0,61-0,91 An. gambiae [63, 171]µα 30 0,569 ± 0,048 An. gambiae [12] ; 0,125 [63, 171] ; et [tab.8]*Paramètres ; **Valeurs utilisées pour le modèle de Bancoumana� médiane(2,5 percentile - 97,5 percentile), estimation bayesienne de ladistribution du paramètre.
70

Part.II. 2. Evolution temporelle du paludisme
2.2. Modèle de Bancoumana et climat.
2.2.1. Variables climatiques.
De nombreuses variables climatiques et environnementales jouent unrôle dans l'épidémiologie du paludisme [54, 115, 157, 211]. L'in�uencede ces variables peut être sur le vecteur (gîtes de production, survie,cycle gonotrophique, gîtes de repos, nourriture, déplacement...), surl'hôte (déplacement) ou sur le parasite lui-même (cycles parasitaires).La température au sol est une des variables les mieux connues [231],jouant un rôle direct sur le vecteur, aussi bien dans sa forme adulteque dans les stades précédants. Elle joue également un rôle indirect, enin�uençant l'évapo-transpiration, le volume des points d'eau et la végé-tation. La pluie est également une variable indispensable, mais d'étudeplus délicate. Le vecteur pond sur des points d'eau (mares ou �aques),et les larves s'y développent. La pluie joue, également, un rôle indirect,in�uençant l'humidité relative, la température et la végétation. En de-hors de ces 2 principales variables, on retrouve des variables commel'humidité relative, in�uençant directement la survie et le déplacementdes vecteurs, le volume des points d'eau et leur dynamique (avec l'in-�ltration, l'évapo-transpiration, la capacité du sol en eau, l'expositionsolaire du point d'eau, le courant, la turbidité) agissant directementsur les stades larvaires, la végétation (indispensable pour le repos et lesrepas des vecteurs), la vitesse du vent et son orientation, et l'utilisa-tion du terrain (agriculture, barrages, habitations...). Il faut noter que,dans des régions où alternent une saison sèche et une saison humide (etoù la température est appropriée), la transmission du paludisme estsaisonnière, soit épidémique, soit endémo-épidémique comme à Ban-coumana. La pluie et la température sont les 2 variables qui ont étéles plus étudiées comme variables exogènes à la modélisation. Parmiles paramètres du modèle précédant, l'agressivité est très liée à cesvariables (augmentant avec la température notamment), soit par l'in-termédiaire de la densité anophélienne (µ), soit par la durée du cyclegonotrophique (ψ). La contagiosité β des anophèles est également liéeaux variables climatiques, de même que la mortalité anophélienne ξ etla durée du cycle gonotrophique ν qui diminuent avec la température(dans des limites établies). Les autres paramètres, γ, δ, ζ, η1 et η2,semblent n'être pas (ou peu) in�uencés par les variables climatiques[tab.8].
71

Part.II. 2. Evolution temporelle du paludisme
Pour tenir compte, dans notre modélisation, du climat, nous avonsintroduit une variable exogène dans notre modèle SIS. Pour la résolu-tion numérique de l'équation [eq.2.2.1], cette variable exogène, notéePl(t), a été simulée à partir de données de pluviométrie de Bancou-mana, à l'aide de plusieurs techniques.
Le modèle peut s'écrire (notations cf not.2.1) :(2.2.1)
dS(t)
dt= −i(t) S(t) + δ R(t) [a]
dI(t)
dt= +i(t) S(t)− (η1 + γ) I(t) + η2 G(t) [b]
dG(t)
dt= +η1 I(t)− (η2 + γ) G(t) [c]
dR(t)
dt= +γ (I(t) +G(t))− δ R(t) [d]
dAi(t)
dt= im(t)
(e(−
ξν1+Pl(t−θ)) − Ai(t)
)− ξ
1 + Pl(t− θ)Ai(t) [e]
i(t) = µαβ Ai(t) Pl(t− θ)
im(t) = αζ G(t) Pl(t− θ)
On en déduit le nombre de reproductions zp0 = µα2βζP l(t−θ)2e(− ξν
1+Pl(t−θ))
( ξ1+Pl(t−θ))γ
�η1+η2+γ
η1
�
Les équations [eq.2.2.1] rendent compte de l'in�uence positive de lavariable exogène Pl(t) sur l'agressivité, de son l'in�uence négative surla mortalité vectorielle et sur la durée du cycle gonotrophique. θ est unparamètre retard représentant le délai entre la variable exogène et lesconséquences sur la transmission palustre (les premières infections ontlieu quelques semaines après les premières pluies).
72

Part.II. 2. Evolution temporelle du paludisme
Tab. 8. Estimation des paramètres avec dépendance climatique.
Param.* EstimationsBk** revue de la littérature
α 2,5 4(17°C), 3,2(19°C), 2,67(21°C), 2,29(23°C), 2(25°C) [106]β 0,5 0,055 saison des pluies, 0,3 saison sèche [76]γ 0,01 indep.δ 0,04 indep.ζ 1 indep.ξ 0,014 0,93(17°C), 0,91(19°C), 0,9(21°C), 0,88(23°C), 0,87(25°C)
[106]µ 12 �ν 13 13(25°C), 11(24°C) [76]
111(17°C), 37(19°C), 22,2(21°C), 15,9(23°C), 12,3(25°C) [106]η1 0,05 indep.η2 0,75 indep.µα 30 de 0,11 à 3,3 avec un pic à 12 [76]
6,1-67,2 en saison des pluies, 0 en saison sèches pour An. gam-
biae [63, 171]2(17°C), 2,45(19°C), 2,83(21°C), 3,16(23°C), 3,46(25°C) [106]
indep. : paramètre considéré comme indépendant du climat.� : µ dépend du climat par l'intermédiaire du nombre total d'anophèles.*Paramètres ; **Valeurs utilisées pour le modèle de Bancoumana
2.2.2. Simulation de la variable exogène climatique.
Parmi les variables climatiques liées au paludisme, seules les obser-vations de la pluviométrie décadaire, de 1960 à 1985, étaient à notredisposition, ainsi que les cumuls mensuels de 1999 à 2004 (en mm). Apartir de ces observations, nous avons simulé la variable exogène, Pl(t)dans les équations précédantes, selon 4 modèles. Le premier utilise lesdistributions empiriques de la pluviométrie décadaire. Le deuxième mo-délise la pluviométrie à l'aide de chaînes de Markov cachées (MMC).Le troisième, un modèle non-linéaire, est fondé sur des fonctions tri-gonométriques. En�n, le quatrième modèle est fondé sur la prédictionnon-paramétrique. Chaque modèle a été estimé à l'aide des observa-tions de la pluviométrie décadaire de 1960 à 1980. Les observations de1981 à 1985 ont servi de validation externe, ainsi que les observationsmensuelles de 1999 à 2004. Lors de la validation externe, l'erreur qua-dratique moyenne (EQM) et l'erreur relative moyenne (ERM) ont étécalculées de la façon suivante :
(2.2.2)EQM =
∑ht=1(Xt −Xt)
2
h
ERM =
∑ht=1
|Xt−Xt|Xt+1
h
73

Part.II. 2. Evolution temporelle du paludisme
où Xt représente l'observation de la pluviométrie au temps t, Xt saprédiction, et h l'horizon de prédiction. L'ERM a été adaptée pour desvaleurs observées nulles.
Pluie 1. Distribution empirique de la pluviométrie.A partir de la série décadaire de la pluviométrie de 1960 à 1980, nousavons estimé les distributions empiriques décadaires de la pluviométrie.Les valeurs prédites ont été tirées d'une distribution de Gumble, dontla fonction de probabilité est donnée par :
f(x|µ, σ) = σ−1 exp
(x− µ
σ
)exp
[− exp
(x− µ
σ
)]Les paramètres, µ et σ, ont été estimés à partir des moyennes et desécart-types des distributions empiriques de la pluviométrie.
Fig. 43. Modélisation du paludisme : variable climatique exo-gène modélisée par la distribution empirique de la pluviométrie.
74

Part.II. 2. Evolution temporelle du paludisme
En utilisant les valeurs de la pluviométrie ainsi prédites, le modèledéterministe prédit une évolution endémo-épidémique du paludisme,correspondant à l'observation [�g.43]. En particulier, les évolutions destaux de parasitémies positives et de gamétocytémies positives sont bienrestituées, en dehors de la tendance décroissante, qui n'a pas été mo-délisée. De plus, l'aggressivité simulée des anophèles correspond à cequi est décrit dans la littérature.
Pluie 2. Modélisation à l'aide de chaînes de Markov cachées.Les modèles par chaînes de Markov cachés (MMC) ont été introduitsà la �n des années 60 par Baum et Petries [14, 15, 16]. Cette famillede modèles stochastiques a été trés développée, tant sur le plan théo-rique [22, 23, 75, 102, 155, 170, 242] que sur le plan des applications.Ces méthodes font l'hypothèse que les données observées sont géné-rées par un mélange �ni de distributions sous-jacentes, lui-même or-ganisé en une chaîne de Markov. Utilisés dans l'analyse de séquence,ils permettent de modéliser des motifs (ou classes) de séquences ob-servées. En e�et, la variable cachée peut être interprétée comme uneclasse de la variable observée correspondante. Ces modèles ont été uti-lisés, entre autres, en traitement du signal, notamment ECG [51, 233],EMG ou EEG [42, 182], analyse de séquences génomiques ou protéiques[77, 143, 255], analyse de texte, reconnaissance de la parole [197], mo-délisation de l'ouverture de canaux ioniques [135], reconnaissance deformes, l'analyse de marqueurs de l'infection par VIH [113], l'analysed'une maladie évolutive [2], avec erreurs de classi�cation [129], la sur-veillance épidémiologique [223], la surveillance écologique [18, 93, 122]etc.. On peut , également, noter ici une application particulière concer-nant l'hydraulogie, la climatologie, et, en particulier, l'étude de la plu-viométrie [234, 239, 257]. Di�érentes monographies présentent ces mo-dèles de façon plus complète [68, 82, 83, 111, 197].
Un modèle MMC {(Sk, Ok)} est constitué d'un ensemble �ni d'étatsSk, k ∈ {1, K} associés à une distribution de probabilité [�g.44]. Lestransitions entre états sont gouvernées, en temps discret, par des lois(probabilités) de transitions, et la séquence (suite) non-observée (St, t >0) est une chaîne de Markov homogène, d'ordre 1 :p(St+1|St, St−1, ..., S1) = p(St+1|St), ∀t.Pour un état donné, une observation Oi peut être générée (émise),en fonction de la distribution de probabilité associée à cet état (loi ouprobabilité d'émission p(Ot = o|St = k)). La séquence observée est doncune séquence de variables aléatoires conditionnellement indépendantes{Ok}, la distribution conditionnelle de la séquence d'observations nedépendant que de la variable cachée correspondante :p(Ot|St = k) = p(Ot|St, . . . , S1) .Un tel modèle est donc dé�ni par les paramètres suivants :
75

Part.II. 2. Evolution temporelle du paludisme
� p(S1 = k)k∈{1,...,K}, probabilités initiales,� p(St+1 = j|St = i)(i,j)∈{1,...,K}2 , éléments de la matrice de transitionP ,
� p(Ot = o|St = k)k∈{1,...,K}, probabilités d'émission.
Fig. 44. Structure des modèles de chaîne de Mar-kov cachée.
Les MMC peuvent être utilisées comme outils de classi�cation, à la re-cherche d'états cachés, interprétés comme des classes de la variable ob-servée. Les variables cachées trouvent alors une interprétation concrète :phonème dans la reconnaissance de la parole, zone codante ou non co-dante dans l'analyse du génome, signal ou bruit dans le traitement dusignal, etc.. Une autre utilisation concerne l'apprentissage. Les étatssont alors spéci�és, a�n d'estimer les probabilités de transition et d'émis-sion. Ainsi, le modèle peut reconstruire la séquence observée. L'estima-tion des paramètres est fondée sur la vraisemblance et requiert, en gé-néral, des algorithmes itératifs, par exemple l'algorithme Baum-Welch.Les di�érents algorithmes ont été discutés par di�érents auteurs (parexemple [68, 75, 170, 242]).
Dans cette approche, suivant l'exemple d'autres auteurs [126, 133,190, 199, 204, 234, 239, 257], nous avons simulé la pluviométrie à l'aided'une chaîne de Markov cachée, où les états cachés représentent lesmois. En e�et, l'objectif était d'estimer les probabilités d'émission etde transition, à l'aide de la séquence d'états cachés et de la séquenceobservée de la pluviométrie. Les estimateurs du maximum de vraisem-blance des paramètres nous ont ensuite permis de prédire la suite de
76

Part.II. 2. Evolution temporelle du paludisme
la séquence de pluie, pour la séquence d'états cachés donnée. Cetteapproche utilise les MMC comme modèle de la dynamique climatique.
Fig. 45. Modélisation du paludisme : variable cli-matique exogène modélisée par MMC
77

Part.II. 2. Evolution temporelle du paludisme
Tab. 9. Matrice de transition estimée.
1 2 3 4 5 6 7 8 9 10 11 121 0,667 0,333 0 0 0 0 0 0 0 0 0 02 0 0,667 0,333 0 0 0 0 0 0 0 0 03 0 0 0,667 0,333 0 0 0 0 0 0 0 04 0 0 0 0,667 0,333 0 0 0 0 0 0 05 0 0 0 0 0,667 0,333 0 0 0 0 0 06 0 0 0 0 0 0,667 0,333 0 0 0 0 07 0 0 0 0 0 0 0,667 0,333 0 0 0 08 0 0 0 0 0 0 0 0,667 0,333 0 0 09 0 0 0 0 0 0 0 0 0,667 0,333 0 010 0 0 0 0 0 0 0 0 0 0,667 0,333 011 0 0 0 0 0 0 0 0 0 0 0,667 0,33312 0,322 0 0 0 0 0 0 0 0 0 0 0,678
Fig. 46. Probabilités d'émission estimées (pluvio-métrie en mm).
Les probabilités de transition estimées (tab.9) rendent compte ducaractère saisonnier du phénomène. Les changements de régimes plu-viométriques sont ainsi modélisés, comme le montrent également les
78

Part.II. 2. Evolution temporelle du paludisme
Tab. 10. Validation externe : erreurs de prédic-tion des di�érentes modèles MMC.
1981-1985 1999-2004ERM EQM ERM EQM
Saisons 1,8151 681,53 0,6312 4827,32 mois 4,2640 994,08 1,5968 5025,2mois 0,8978 588,81 0,4317 5026,3
décades 0,7552 500,67 0,7327 5287,6
Tab. 11. Modélisation du paludisme : erreurs deprédiction des di�érentes modèles MMC.
Parasitémie GamétocytémieERM EQM ERM EQM
Saisons 0,0758 0,0282 0,0122 0, 422 10−3
2 mois 0,0724 0,0273 0,0114 0, 425 10−3
mois 0,0677 0,0243 0,0103 0, 379 10−3
décades 0,0689 0,0267 0,0104 0, 386 10−3
estimations des probabilités d'émission [�g.46]. En e�et, la probabilitéd'émission de quelques millimètres de pluies en janvier ou février estquasi-nulle. A contrario, la probabilité d'émission de 150 à 200 milli-mètres de pluies est plus importante, durant les mois de juillet, août etseptembre.Comme précédemment, le modèle déterministe prédit une évolutionendémo-épidémique du paludisme [�g.45], et les évolutions des taux deparasitémies positives et de gamétocytémies positives sont bien resti-tuées. L'aggressivité simulée des anophèles correspond également auxvaleurs décrites dans la littérature.
Remarque :Le choix de 12 états (correspondant aux 12 mois de l'année) a été faiten comparant les résultats des di�érentes erreurs [tab.10 et 11].L'utilisation des 3 saisons comme états cachés (de mars à mai : sai-
son sèche chaude, de juin à septembre : saison des pluies, d'octobreà février : saison sèche froide) permet une bonne prédiction pour lesannées 1999 à 2004, mais pas pour les années 1981-1985. A l'inverse,l'utilisation des décades (10 jours) permet une bonne prédiction immé-diate, mais pas à plus long terme. De plus, le nombre de paramètresestimés est important. L'états cachés représentant les mois sont, ici, lesplus adaptés, en regard des erreurs de prédiction de la pluviométrie etdu paludisme.
79

Part.II. 2. Evolution temporelle du paludisme
Pluie 3. Modèle non-linéaire.Nous avons choisi d'associer des fonctions sinus et cosinus, a�n de mo-déliser le caractère périodique de la pluviométrie. la fonction retenuepour modéliser la pluviométrie moyenne était :f(t) = a0 + a1cos(b1t+ c1) + a2sin(b2t+ c2)
Les paramètres a0, a1, a2, b1, b2, c1 et c2 ont été estimés par l'algo-rithme de Gauss-Newton. Les valeurs initiales étaient approchées partransformée de Fourier.La pluviométrie moyenne, ainsi simulée, correspondait à l'estimationde la moyenne d'une loi de Poisson. La pluviométrie décadaire a étémodélisée ainsi :Pl(t) P(f(t))
Fig. 47. Modélisation du paludisme : variable cli-matique exogène modélisée par un modèle non-linéaire.
80

Part.II. 2. Evolution temporelle du paludisme
Le caractère saisonnier, endémo-épidémique, du paludisme de Ban-coumana a été ainsi modélisé [�g.47]. Cependant, la pluviométrie simu-lée est, d'une part, décalée en certains points, et, d'autre part, l'agressi-vité des anophèles est moins importante, par rapport aux modélisationsprécédantes.
Pluie 4. Prévisions non-paramétrique.A cause du manque fréquent d'informations sur sa forme fonctionnelle,une mauvaise spéci�cation d'un modèle paramétrique est souvent inévi-table, entrainant un biais plus ou moins important, pouvant altérer laprédiction. L'approche non-paramétrique permet d'éviter ce problèmeen utilisant, à la place d'un ensemble restreint de fonctions préétablies,une forme fonctionnelle �exible, qui est, pour l'essentiel, déterminée parles observations [161]. Les méthodes non-paramétriques ne nécessitentdonc pas de modèle, ni un nombre restreint de paramètres [225]. Engénéral, elles s'adaptent bien localement aux données, sont robustes, etdonnent des résultats assez précis, sans cumuls d'erreurs (à l'inverse deméthodes plus classiques, SARIMA par exemple).
Au lieu de dé�nir l'estimateur de la fonction de lien à l'aide d'une loiconditionnelle théorique, l'estimateur est construit à partir de l'échan-tillon observé, i.e. de l'estimation de la loi conditionnelle. L'estimateurde Nadaraya-Watson que nous présentons ici, aussi appelé estimateurde la méthode du noyau, est un des plus classique [21, 39, 40, 161, 225].Soit (Xt)t∈Z stationnaire. A partir des observations X1,...XT , il s'agit
de prédire la valeur deX à l'horizon h,XT+h, avec h ∈ N∗. L'estimateurnaturel de XT+h est donné par
E(XT+h|XT , ..., X1)
Si on suppose, comme cela est classique dans de nombreuse modélisa-tions de séries temporelles, que le processus est k-markovien, alors
E(XT+h|XT , ..., X1) = E(XT+h|XT , ..., XT−k+1)
On régresse alors XT+h sur ce passé proche. La prédiction est consi-dérée comme raisonnable, même si le processus n'est pas markovien.Le coe�cient k ne doit pas être trop grand, car, sinon, la vitesse deconvergence est plus faible et le nombre d'observations nécessaire àl'estimation augmente. La convergence de l'estimateur du prédicteur ànoyau a été démontré [161].
L'espérance conditionnelle deXT+h peut être estimée par une moyennepondérée des observations passées, via un estimateur à noyau K, ap-plication mesurable sur Rk, à valeurs réelles :
XT+h,k =T−h∑t=k
φt,T,kXt+h
81

Part.II. 2. Evolution temporelle du paludisme
où φt,T,k =K
�Xk
T−Xkt
ω(T )
�
PT−ht=k K
�Xk
T−Xk
tω(T )
� Les poids aléatoires φt,T,k peuvent s'inter-
préter comme des indices de similarité entre les 2 vecteurs XkT et Xk
t .Plus les 2 vecteurs sont similaires ( a contrario dissemblables), plusle poids est grand (a contrario proche de zéro), le noyau Gaussien K,classiquement utilisé, donnant un poids plus important aux valeurs si-milaires.La prévision à l'horizon T + 1 se calcule en faisant les moyennes pon-dérées des Xt+1, en faisant varier t. De même, la prévision à l'horizonT +2 se calcule en faisant les moyennes pondérées des Xt+2. La fenêtreω(T ) détermine le degré de lissage de la prédiction. Une fenêtre étroitereproduit les observations (erreurs faibles), avec une grande variance,alors qu'une large fenêtre donne des erreurs plus importantes, mais unevariance moins grande. Lors de l'implémentation, sous Matlab, nousavons choisi ω(T ) = 2, et le paramètre k a été estimé empiriquement à5.
82

Part.II. 2. Evolution temporelle du paludisme
Fig. 48. Modélisation du paludisme : variable cli-matique exogène modélisée par un modèle non-paramétrique.
Ce dernier modèle permet, également, une bonne modélisation del'endémo-épidémie palustre et les évolutions des taux de parasitémiespositives et de gamétocytémies positives sont bien restituées [�g.48].L'aggressivité simulée des anophèles correspond également aux évolu-tions décrites dans la littérature.
Comparaison des résultats des di�érents modèles.Les di�érents modèles de variables climatiques exogènes sont satisfai-santes, aussi bien pour la prédiction de la pluviométrie [tab.12 et �g.49],que pour la modélisation du paludisme [tab.13].Les résultats montrent des valeurs élevées des EQM, en particulier lorsde la confrontation avec les observations de 1999 à 2004. Ce dernier cas
83

Part.II. 2. Evolution temporelle du paludisme
Tab. 12. Validation externe : erreurs de prédiction.
1981-1985 1999-2004ERM EQM ERM EQM
Distributions empiriques 0,5588 423,32 0,2932 3720,3MMC 0,8978 588,81 0,4317 5026,3
Non-linéaire 3,4033 693,47 1,4948 4964,6Non-paramétrique 1,7412 207,69 0,7697 2841,9
peut être expliqué par l'observation d'un changement de régime de plu-viométrique autour des années 2000. Globalement, on peut observer queles prédictions à l'aide des distributions empiriques ont des erreurs rela-tives les plus faibles, en moyenne (ERM). Le modèle non-paramétriqueprésente les erreurs quadratiques les plus faibles en moyenne. L'intérêtde l'utilisation des distributions empiriques et du MMC réside dans lamodélisation du phénomène lui-même. En e�et, ces deux approches mo-délisent, de façon explicative, l'alternance des saisons et son impact surla pluviométrie, alors que les modèles non-linéaire et non-paramétriquetraitent le signal sans tenter de modéliser le phénomène sous-jacent. Ce-pendant l'utilisation des distributions empiriques ne tient pas compte,de façon explicite, de la dépendance entre 2 décades. Les changementsde régimes ne sont pas explicitement modélisées. Utilisant les distri-butions décadaires empiriques, la dépendance est prise en compte parl'intermédiaire de la dépendance entre les distributions empiriques dé-cadaires. Par contre dans le modèle Markovien, cette dépendance estexplicitement modélisée, puisque les changements de régimes sont for-malisés en une chaîne de Markov, et, de plus, les résultats de ce modèlesont globalement satisfaisants.Dans le cadre de la modélisation du paludisme, les erreurs de prédic-tions sont faibles [tab.13], en moyenne, aussi bien pour la prédiction destaux de parasitémies positives que des taux de gamétocytémies posi-tives. L'utilisation d'un MMC pour modéliser la variable exogène donneles erreurs les plus faibles, sauf pour les erreurs quadratiques des tauxde gamétocytémies, où le meilleur modèle (EQM le plus faible) uti-lise les distributions empiriques. Il faut remarquer que, l'ensemble desrésultats présentés ici ne concerne, pour chaque modélisation, qu'uneprédiction. Cependant, les prédictions sont assez stables, notammentpour les modélisations dont les résultats théoriques sont connues.
84

Part.II. 2. Evolution temporelle du paludisme
Fig. 49. Validation externe : pluviométrie décadaire 1981-1985et prédictions.
Tab. 13. Modélisation du paludisme : erreurs de prédiction.
Parasitémie GamétocytémieERM EQM ERM EQM
Distributions empiriques 0,0742 0,0267 0,0104 0, 291 10−3
MMC 0,0677 0,0243 0,0103 0, 379 10−3
Non-linéaire 0,0725 0,0279 0,0104 0, 381 10−3
Non-paramétrique 0,0736 0,0297 0,0110 0, 419 10−3
85

Part.II. 3. Evolution spatio-temporelle du paludisme
3. Evolution spatio-temporelle du paludisme
3.1. Modèles de réaction-di�usion et paludisme.Les modèles dynamiques en temps, utilisés plus haut, font, d'une part,l'hypothèse d'une répartition homogène en espace des vecteurs et deshommes, et, d'autre part, l'hypothèse de naissances homogènes en es-pace des vecteurs. Cependant, ces 2 hypothèses simplistes ne corres-pondent pas à la réalité de terrain. Les individus ont une distributionnon-homogène en espace, interagissent avec l'environnement et avec lesautres individus voisins. De plus, l'environnement varie également dansl'espace. Les mécanismes intervenant dans la di�usion et la variabilitéspatiale des anophèles sont complexes, faisant intervenir de nombreuxparamètres, notamment climatiques. Récemment, de nombreux travauxont étudié la variation spatiale des anophèles [136]. Certains ont mis enévidence un gradient de densité anophélienne [36, 84] ou de cas cliniques[222, 185, 243], partant de gîtes potentiels (bords de rivière, marigots...)vers les concessions. D'autres ont mis en évidence la variation spatiale,ou spatio-temporelle, des gîtes larvaires ou des sites d'ovipositions, enrelation avec la densité larvaire [89], le cycle gonotrophique [110], et,in �ne, la transmission [169].Cependant, peu de travaux ont modélisé cette variabilité spatiale. N.Bacaër et C. Sokhna [11] ont étudié la propagation de la résistanceaux anti-paludéens à l'aide d'un système de réaction-di�usion. D'autresauteurs ont également utilisé de tels systèmes pour d'autres maladiesvectorielles [92, 91].Les premières équations de réaction-di�usion ont été introduites enscience de la vie par R. Fisher, en 1937 [90], à propos de l'évolutionspatiale de gènes, avantageux en terme de survie, dans une population.Plus tard, J. Skellam [215] montrera que l'échelle spatiale et les carac-téristiques de l'environnement in�uencent les interactions entre popu-lations, ainsi que leur survie. En dynamique de population, on peutdécrire 3 phénomènes principaux où les modèles de réaction-di�usionont été utilisés [37] :� la propagation de front d'onde [90, 62]� la formation de pattern dans un espace homogène,� l'existence de zones de taille minimale, su�sante pour permettrela survie de populations [215].
3.2. Le climat.Les variables climatiques in�uencent la production des anophèles etleur di�usion. Les gîtes larvaires peuvent beaucoup varier selon l'es-pèce et la zone géographique étudiée. On peut considérer qu'au Mali,en particulier à Bancoumana, les formes immatures d'An. gambiae s.l.(espèce la plus fréquente) se développent principalement dans de pe-tites collections d'eau chaude, peu profondes, sans végétation ni pol-lution organique. Il faut noter que ce comportement est �exible, et
86

Part.II. 3. Evolution spatio-temporelle du paludisme
les oeufs d'An. gambiae peuvent parfois se développer dans un sol hu-mide [124]. Cependant, à partir d'une température de l'eau de 40°C,la mortalité des oeufs dépend du temps. Les oeufs sont détruits au-delà de 45°C [125]. En ce qui concerne le développement des larves,la température optimale de l'eau est d'environ 28°C, avec un maxi-mum autour de 40°C [125]. De même, la qualité de l'eau joue un rôledans le développement larvaire [78]. En saison des pluies, ces petitescollections d'eau peuvent se trouver n'importe où dans la zone géogra-phique (micro-gîtes). Lorsque les mares sont profondes, leur périphérie(environ 1 mètre de largeur) sont des zones privilégiées. On y trouvedes traces de pas (en particulier d'animaux venant s'abreuver), gîteslarvaires classiques. De même, l'excavation de terre, au niveau des bri-queteries, est, classiquement, à l'origine de gîtes larvaires. En�n, ausud-ouest du village de Bancoumana se trouve une zone de stagnationd'eau, productrice d'anophèles sur toute sa surface. Cette zone est as-sez plane et la roche, peu profonde et a�eurant pas endroit, empêchel'in�ltration d'eau et, ainsi, participe à la formation de gîtes larvaires.Les formes immatures d'An. funestus acceptent des collections d'eau,moins chaude, plus importantes et comportant de la végétation. Il estclassique d'observer cette espèce plutôt en �n de saison des pluies,lorsque les micro-gîtes s'assèchent, ou lorsque la température refroidit.
En ce qui concerne notre travail, nous avons localisé, sur le terrain,5 zones particulières [�g.50]. Au sud-ouest, outre la zone décrite plushaut, se trouve une briqueterie. En saison sèche, le seul gîte connu estun puits situé dans cette dernière. Au sud du village, au-delà d'une zonede maraîchage, se trouve une grande briqueterie, avec 2 puits connuscomme gîtes en saison sèche. Au nord, une large collection d'eau, peuprofonde en saison des pluies (pendant laquelle elle sert de briqueterie)et à sec en saison sèche. En�n, une petite briqueterie est située à lasortie nord-est du village (route de Bamako).Dans cette première approche de la modélisation spatio-temporelle,
nous avons modélisé 3 situations (saison sèche -SS-, situation intermé-diaire -SI-, et milieu de la saison des pluies -SP-) a�n de prendre encompte, en partie, l'in�uence du climat. En plus des 5 zones particu-lières localisées sur le terrain, nous avons, uniquement pour les situa-tions SI et SP, imposé des micro-gîtes dans le village. La température,ainsi que les autres variables climatiques, comme l'humidité relativequi joue un rôle essentiel dans la di�usion des anophèles, ont été consi-dérées comme constantes dans l'espace, pour chacune des 3 situations.L'absence d'uniformité de la pluie dans le plan est plus di�cile à mo-déliser. En e�et, en fonction de l'avancée de la pluie, même à l'échelled'un village, le nombre et la localisation des micro-gîtes n'est pas uni-forme, dépendant, également, du terrain (surface, type de sol...). Danscette première approche, la localisation et le nombre de micro-gîtes ont
87

Part.II. 3. Evolution spatio-temporelle du paludisme
Fig. 50. Bancoumana : repérages des zones particulières. 1/large collection du sud-ouest (ht gche) ; 2/ briqueterie sud-ouestet son puit 3/ briqueterie sud, 4/ large zone nord
été déterminés de façon empirique.Outre la localisation spatiale, l'évolution temporelle des gîtes est éga-lement importante. En e�et, les marigots permanents ont une surface,un volume et, surtout, un périmètre qui �uctuent selon le climat etla nature du sol. De même, les marigots temporaires peuvent persisterplus ou moins longtemps en saison sèche, en fonction du climat et del'environnement. A ces �uctuations saisonnières s'ajoutent des �uctua-tions interannuelles.Dans le village de Bancoumana, nous avons localisé, sur le terrain, lesprincipaux macro-gîtes et les principaux gîtes permanents. En l'absencede modélisations hydraulogique et météorologique, notre approche en3 situations permet d'avoir une idée de l'évolution de la transmissionpalustre.
3.3. Equations de réaction-di�usion.Sur la base du modèle de réaction précédant, nous avons développé lapartie di�usion, seulement dans les équations concernant les anophèles.En e�et, nous avons fait l'hypothèse de l'absence de mobilité des in-dividus (absence de di�usion). Comme dans la première partie, celasuppose que les individus sont contaminés et contaminants chez eux(activité nocturne des anophèles et individus dormant toujours dans la
88

Part.II. 3. Evolution spatio-temporelle du paludisme
même concession).A�n de mieux modéliser l'hétérogénéité spatiale des sites de produc-tion d'anophèles, nous avons décomposé la population d'anophèles en3 parties : anophèles susceptibles As, anophèles contaminés, pendantla période d'incubation Ag, et anophèles contagieux ou infectants Ai[179].Les anophèles de ces 3 parties n'ont pas toujours des comportementsidentiques. En particulier, la di�usion des anophèles susceptibles Asest plus importante que les autres. De plus, ils apparaissent au niveaudes gîtes, alors que les anophèles contaminés Ag apparaissent unique-ment dans les concessions. Les anophèles infectants Ai le restent jusqu'àla �n de leur vie. Comme nous l'avons vu, la production d'anophèlessusceptibles est fonction de nombreux paramètres : volume du gîte,température, ensoleillement, végétation, turbidité, mais aussi densitélarvaire. Dans un premier temps, nous avons considéré le paramètredes naissances $ comme, d'une part, fonction de la surface du gîte, et,d'autre part, fonction du climat, représenté par les 3 situations clima-tiques simulées.Cela a permis de simuler une production d'anophèles même en saison
sèche où les gîtes sont parfois mal connus. Il faut noter qu'en saison despluies, seul le contour des macro-gîtes a été considéré comme produc-teur d'anophèles susceptibles (en plus des micro-gîtes), alors que dansles autres situations, la totalité des surfaces a été considérée commeproductrice.
Soit x le vecteur de coordonnées dans le plan géographique [x1, x2].Le modèle peut s'écrire ainsi :(3.3.1)
dS(t)
dt= −µαβ Ai(t) S(t) + δ R(t)
dI(t)
dt= +µαβ Ai(t) S(t)− (η1 + γ) I(t) + η2 G(t)
dG(t)
dt= +η1 I(t)− (η2 + γ) G(t)
dR(t)
dt= +γ (I(t) +G(t))− δ R(t)
∂As(x, t)
∂t= $ − αζ G(t) As(x, t)− ξ As(x, t) +Ds ∆As(x, t)
∂Ag(x, t)
∂t= +αζ G(t) As(x, t)− (ξ + ν) Ag(x, t) +Dg ∆Ag(x, t)
∂Ai(x, t)
∂t= ν Ag(x, t)− ξ Ai(x, t) +Di ∆Ai(x, t)
89

Part.II. 3. Evolution spatio-temporelle du paludisme
avec Dj, ∀j ∈ {s, g, i}, le paramètre de di�usion.Le laplacien de Aj, ∀j ∈ {s, g, i}, par rapport au plan déterminé par
les coordonnées géographiques s'écrit ∆Aj(x, t) =∂2Aj(x,t)
∂x21
+∂2Aj(x,t)
∂x22
.On peut, également, faire varier µ qui est la densité de moustiques
par habitant i.e. µ(t) = M(t)N(t)
Dans ce cas là, les 2 premières équations s'écrivent :
dS(t)dt
= −M(t)N(t)
αβ Ai(t) S(t) N(t) + δ R(t)dI(t)dt
= +M(t)N(t)
αβ Ai(t) S(t) N(t)− (η1 + γ) I(t) + η2 G(t)
Cependant, dans notre approche, nous avons considéré µ constantpour chacune des 3 situations simulées.
La résolution numérique a été faite à l'aide du logiciel COMSOL
Multiphysics® 3.2.Les 3 situations simulées sont les suivantes :� Saison Sèche (SS) : marigots temporaires asséchés, mares perma-nentes au niveau le plus bas, i.e. seuls 2 ou 3 points d'eau persistent(comme dans les briqueteries).
� Situation Intermédiaire (SI) : présence de micro-gîtes, marigotspermanents à un niveau intermédiaire, marigots temporaires desurface restreinte mais produisant sur toute leur surface.
� Pleine Saison des Pluies (SP) : marigots temporaires et permanentsremplis et présence de micro-gîtes. Seule la périphérie des macro-gîtes sert de production d'An. gambiae.
Pour chaque situation, les simulations étaient ré-initialisées, a�n queles conditions initiales correspondent aux données de terrain.La �gure 51 représente la structure spatiale du modèle utilisé. Les
habitations (en bleu foncé) sont situées selon leur référencement géo-graphique. Le contour du village a été tracé de façon à ce que lesvecteurs ne di�usent pas au-delà. En saison sèche, seuls persistent les3 micro-gîtes (en rouge), dans les zones b) et c), au sud du village. Dèsle début de la saison des pluies (situation intermédiaire), les briquete-ries du sud b) et c) deviennent des gîtes plus importants (en vert). Aunord apparaît également un nouveau gîte e) (en magenta). Ce derniergîte persistera tout au long de la saison des pluies. Dans les zones a)et d) apparaissent des zones d'humidité persistante, micro-gîtes d'An.gambiae. Dans cette situation intermédiaire, seuls quelques micro-gîtes(magenta) ont été simulés. Dans le reste du village, quelques micro-gîtesont été simulés (magenta) pour représenter l'importance des �aquesd'eau dans la production d'An. gambiae. Pour la troisième période, lemilieu de la saison des pluies, l'ensemble des micro-gîtes ponctuels aété utilisé (magenta et bleu clair) pour le village et pour les zones a)et d). La zone e) au nord du village n'a pas été modi�ée. Les zones b)et c), au sud, étant en eau, seul leur contour (en marron) sert de gîte
90

Part.II. 3. Evolution spatio-temporelle du paludisme
Fig. 51. Structure spatiale du modèle utilisé (lo-giciel COMSOL®)
de production d'An. gambiae.Nous avons également procédé aux simulations en l'absence de micro-gîtes dans le village, le reste de la structure restant identique à la struc-ture précédante pour les zones a), b), c), d) et e). Les paramètres mo-di�és (adaptés de la littérature) pour les modèles de réaction-di�usionsont donnés dans la table 14.
3.4. Résultats.Les résultats des simulations montrent une augmentation, dans letemps [Fig.52], des individus infectés, augmentation comparable auxmodèles non spatiaux. Seuls les résultats du modèle de saison sèchesont di�érents, mais correspondent à la réalité de terrain avec une en-démie de faible niveau. Trente jours après le début de la période in-termédiaire, la distribution spatiale correspond aux résultats attendus[Fig.53, Fig.56, 54, 55]. De même, 70 jours après le début de la saisondes pluies, les résultats sont conformes à ce qui peut être observé sur leterrain. L'analyse des 3 périodes à l'aide d'arbres de régression obliquedonne des résultats signi�catifs, avec des pourcentages de variance ex-pliquée supérieurs à 80% [Tab.15]. Le découpage obtenu correspond à cequi était attendu lors de la simulation. Les résultats de l'interpolation
91

Part.II. 3. Evolution spatio-temporelle du paludisme
Tab. 14. Paramètres utilisés pour les modèles deréaction-di�usion.
Param.* ValeursSaison Sèche Situation In-
termédiaireSaison des Pluies
α 1,5 2,5 2β 0,7 0,5 0,05γ 0,01 0,01 0,01δ 0,04 0,04 0,04ζ 1 1 1ξ 0,9 0.1 0,014µ 4 12 30ν 8 13 14η1 0,05 0,05 0,05η2 0,75 0,75 0,75Ds 0,5 3 5Dg 0,25 0,5 0,75Di 0,25 0,5 0,75csp** 1,5 1,5 2$ 1 1 1S(t = 0) 0,7 0,65 0,59I(t = 0) 0,28 0,32 0,37G(t = 0) 0,02 0,03 0,04R(t = 0) 0 0 0As(t = 0) 1 1 1Ag(t = 0) 0 0 0Ai(t = 0) 0 0 0
indep. : paramètre considéré comme indépendant du climat.*Paramètres ; **csp : coe�cient de surface pour les gîtes ponctuels.
par krigeage ordinaire (avec modèle gaussien du semi-variogramme)sont donnés dans le tableau [Tab.16]. Les résultats des simulations sansmicro-gîtes ne sont pas très di�érents. Seule la progression est ralentiepar rapport aux simulations avec micro-gîtes [Fig.52 et 53].L'évolution spatiale des vecteurs est une bonne représentation de notreconnaissance de terrain [Fig.57]. Entre les situations avec micro-gîtes etsans micro-gîtes, la production d'anophèles susceptibles est identique,avec une production un peu plus importante dans la première situa-tion. La di�usion de ces anophèles est importante, puisqu'ils sont àla recherche d'hommes pour leur repas sanguin. On observe particu-lièrement bien la localisation des anophèles infectés (mais non encorecontagieux), localisés au niveau des concessions. La di�usion de cesanophèles est moins grande, puisqu'il existe une période de repos après
92

Part.II. 3. Evolution spatio-temporelle du paludisme
SS
avec micro-gîtes sans micro-gîtes
SI
SP
Fig. 52. Evolution temporelle : Incidences des Sujetssusceptibles (S), infectés (I), à gamétocytémie (G) et résistants(R), en saison sèche (SS), intermédiaire (SI) ou milieu de saison despluies (SP), (incidence en abscisse et temps en ordonnée). Les traitsverticaux représentent les instants où les distributions spatialessont présentées aux �gures 53 et 57
Tab. 15. Résultats de SpODT appliqué aux simulations
Avec micro-gîtes Sans micro-gîtesR2 p R2 p
SS 97,79% 0,001SI 87,08% 0,0012 95,09% 0,001SP 94,17% 0,00104 96,67% 0,001
SS : saison sèche, SI : situation intermédiaire, SP : milieu de la saison des pluies
le repas sanguin. En�n, la di�usion des anophèles infectants (conta-gieux) correspond aux observations de terrain, de très limitée en saisonsèche, à importante en saison des pluies. Dans les simulations sansmicro-gîtes, l'absence de ces gîtes ne fait que ralentir la di�usion desanophèles infectés non-contagieux et des anophèles infectants (conta-gieux).
93

Part.II. 4. Discussion
SS
avec micro-gîtes sans micro-gîtes
SI
SP
Fig. 53. Distribution spatiale de l'incidence desindividus infectés (I) : saison sèche (SS) à 90j, situationintermédiaire (SI) à 30j, et milieu de saison des pluies (SP) à 70j.Interpolation par krigeage ordinaire. L'échelle des fonds de cartesest commune à toute les situations (à gauche). Les échelles desisohyètes sont particulières à chaque situation (à droite).
4. Discussion
Comme nous l'avons vu, notre modélisation simple, à l'aide d'unsystème d'équations de réaction-di�usion, a permis de simuler les ob-servations de terrain. Les modèles de réaction-di�usion ont pour avan-tage de traiter l'espace de façon explicite. Cependant, ces modèles
94

Part.II. 4. Discussion
avec micro-gîtes sans micro-gîtes
SI
SP
Fig. 54. Distribution spatiale de l'incidence desindividus infectés (I), à t=0 : situation intermédiaire(SI), et milieu de saison des pluies (SP) . Interpolation par krigeageordinaire. L'échelle des fonds de cartes est commune à toute lessituations (à gauche). Les échelles des isohyètes sont particulièresà chaque situation (à droite).
Tab. 16. Qualité du krigeage, erreurs en validation croisée
Avec micro-gîtes Sans micro-gîtesMoyenne Variance Moyenne Variance
SS 1, 03 10−7 2, 58 10−12
SI −5, 43 10−4 1, 16 10−4 9,87 10-7 7, 13 10−6
SP −3, 75 10−3 2, 71 10−4 −9, 01 10−4 1, 11 10−4
SS : saison sèche, SI : situation intermédiaire, SP : milieu de la saison des pluies
prennent mal en compte les phénomènes nécessitant de longues dis-tances (grandes échelles). La modélisation de l'endémo-épidémie depaludisme sur un territoire plus grand nécessiterait d'autres modèles,comme, par exemple, les modèles "small-world" [41]. De plus, les mo-dèles de di�usion prédisent qu'une population, initialement concentréeen un point, se développera, au cours du temps, selon une distribution
95

Part.II. 4. Discussion
SS
avec micro-gîtes sans micro-gîtes
SI
SP
Fig. 55. Distribution spatiale de l'incidence desindividus infectés (I), à t= 6 mois : saison sèche (SS), situation intermédiaire (SI), et milieu de saison des pluies (SP).Interpolation par krigeage ordinaire. L'échelle des fonds de cartesest commune à toute les situations (à gauche). Les échelles desisohyètes sont particulières à chaque situation (à droite).
Normale en espace, ce qui n'est pas forcément le cas sur le terrain, oùune distribution de Poisson est souvent plus adaptée.Le modèle choisi, �xant la localisation a priori des micro-gîtes, ne tientpas compte de l'hydraulogie de terrain. En e�et, une averse est une
96

Part.II. 4. Discussion
Fig. 56. Distribution spatiale observée de l'inci-dence des individus infectés (I) : Juin 2000 (avant lasaison des pluies) et Octobre 2000 (�n de la saison des pluies) .Interpolation par krigeage ordinaire. L'échelle des fonds de cartesest commune (à gauche).
structure spatio-temporelle qui engendre un hyétogramme complexe.Aux �uctuations pluviométriques spatiales (distribution spatiale et in-tensité de l'averse), il faut ajouter les e�ets du ruissellement, réponsehydraulogique du terrain [85]. Il est clair que la pluviométrie n'est pasuniforme en temps et en espace (voir par exemple [45]). Certains au-teurs ont modélisé des champs de pluie à l'aide d'un processus de Pois-son [142], dépendant de la durée de vie d'un cluster de pluie, de savitesse, de l'intensité de pluie, du lieu et date de naissance du clus-ter. Cependant, il n'est pas certain qu'un processus de Poisson soitapplicable à une résolution spatiale �ne, et sur une durée de plusieursjours [47]. D'autres utilisent une loi de Gumble [235]. La durée desévènements et celle de la période inter-évènements sont également trèsvariables dans la région sahélienne [58]. La pluviométrie, caractériséepar un gradient nord-sud d'environ 1 mm/km, est variable non seule-ment d'une saison à l'autre, mais aussi d'une année sur l'autre (pourune présentation plus complète des évènements pluvieux sahéliens voir[13, 103, 128, 151, 152, 160, 235, 245]). Les états de surface (végétation,texture du sol, nature du terrain...) sont aussi importants. La texturedu sol peut entraîner la formation d'une croûte de battance, qui, di-minuant l'in�ltration de l'eau, permet la formation de �aques ou deruissellements. L'état de surface du sol varie très largement au coursde la saison des pluies [60, 100, 180, 192]. Par exemple, la végétationou le piétinement du bétail favorisent l'in�ltration en brisant la croûtede battance. La présence de végétation ralentit l'assèchement. De plus,les caractéristiques des sols sont souvent modi�ées par l'homme (agri-culture ou habitations) [9, 156]. Gerbaux et al. ont proposé un modèle
97

Part.II. 4. Discussion
SS
avec micro-gîtes
SI
SP
sans micro-gîtes
SI
SP
Fig. 57. Distribution spatiale des vecteurs (enpourcentage) : saison sèche (SS) à 90j, situation intermédiaire(SI) à 30j, et milieu de saison des pluies (SP) à 70j.
98

Part.II. 4. Discussion
du ruissellement en milieu sahélien, dépendant des précipitations et desparamètres du sol, comme sa perméabilité, son humidité, son utilisation[103]. Au cours d'un épisode pluvieux, les variations au sol, notammentdu vent, peuvent modi�er les conditions de vie et de di�usion des vec-teurs [10].Les gîtes (micro- et macro-gîtes) étant ainsi créés, la production d'ano-phèles n'est pas constante. En e�et, elle dépend du volume, de la sur-face, de la distance aux hommes, de la température, de la turbiditéde l'eau, de leur densité [110]. Les particularités d'Anopheles funestusdoivent également être modélisées. Lorsque l'anophèle adulte éclo, il vad'abord chercher son repas sanguin. Après un temps de repos, il cher-chera un site d'oviposition, puis repartira pour un repas sanguin. Cesaller-retours entre sites de piqûres et sites de pontes, dépendant de fac-teurs climatiques (température, humidité relative), jouent un rôle nonnégligeable dans la transmission [169]. Nos résultats vont dans le sensd'une faible importance des micro-gîtes. Ce point est important à préci-ser. En e�et, la gestion de l'environnement est un des outils de contrôlede la maladie qui a été relativement négligé en Afrique [46, 110].D'autres paramètres, liés à l'homme, doivent être également pris encompte pour améliorer la modélisation. Le premier, l'anthropophilie,conditionne la di�usion des anophèles. En e�et, ce comportement inclunon seulement la préférence trophique pour le repas sanguin mais éga-lement l'endophilie et une préférence pour l'environnement modi�é parl'homme [20]. Nos observations étant faites sur des enfants, notre mo-délisation ne tient pas compte de l'immunité acquise. Cependant, l'im-munité joue un rôle important dans la transmission, non négligeablechez les sujets adultes. De plus, l'hypothèse d'absence de mobilité deshommes doit également être adaptée [108, 243], et les variations spa-tiales et temporelles de la densité humaine [84] jouent également unrôle (pastoralisme). En�n, avec une modélisation plus complète de latransmission palustre, les mesures de contrôle pourront être mieux ex-périmentées in silico, en particulier l'impact des moustiquaires impré-gnées (en tenant compte de la résistance des anophèles), le traitementprophylactique ou curatif (avec la di�usion des parasites résistants), lesvaccinations (avec l'évolution spatio-temporelle des formes moins sen-sibles des parasites), ou encore l'assèchement des macro-gîtes prochesdes habitations.
99


Conclusion Générale

Conclusion générale.
La transmission du paludisme a une grande variabilité à traversl'Afrique [24, 36], non seulement d'un pays à l'autre mais aussi à uneéchelle plus �ne, comme nous l'avons montré dans la première partie.L'environnement et le climat sont les principaux facteurs à l'origine decette grande variabilité. En e�et, ces 2 facteurs se situent à l'intersec-tion entre le vecteur, le parasite et l'hôte. Ils facilitent non seulementla survie et la di�usion vectorielles mais aussi humaines.Fondée sur une connaissance de terrain, la recherche de zones parti-culièrement à risque permet de mieux cibler les actions de contrôle.La modélisation, notamment spatio-temporelle, a un rôle à jouer pourvéri�er les hypothèses et expérimenter in silico les mesures de contrôle[136]. Même si les modèles ne sont qu'une représentation plus -oumoins- réaliste [216], ils peuvent apporter des arguments supplémen-taires en faveur d'une hypothèse ou d'une autre : "Models are used to
approach questions too complex, inaccessible, numerous, diverse, mu-
table, unique, dangerous, expensive, big, small, slow or fast to approach
by other means" [165]. Ronald Ross (cité entre autre par McKenzie[165]) distingue 2 approches distinctes : l'approche a posteriori et l'ap-proche a priori. L'approche a posteriori est une approche statistiqued'observations passées (étude épidémiologique de terrain), dont l'ob-jectif est d'en déduire des facteurs de risque voire des arguments decausalité. L'approche a priori assume l'existence de mécanismes cau-sals, et en déduit, comme conséquence logique, les données qui auraientdû (ou devraient) être observées. Ces deux approches sont donc com-plémentaires [168], et doivent être conduites pour, d'une part, mieuxcomprendre les mécanismes des épidémies (ou endémo-épidémies), et,d'autre part, pour aider au choix d'une stratégie de contrôle. Suivantcette idée, notre travail, aussi bien dans la partie statistique que dansla partie modélisation déterministe, semble indiquer que, bien que par-ticipant à la distribution spatio-temporelle, les micro-gîtes sont moinsimportants, comparativement aux macro-gîtes. Cette piste doit être ap-profondi, en particulier en tenant compte de la densité et de la distribu-tion spatiale des micro-gîtes, car les implications, en terme de lutte, sontimportantes. La connaissance des interactions entre, d'une part, l'envi-ronnement et le climat, et, d'autre part, le vecteur, l'hôte et le parasite,permet de mieux comprendre les évolutions spatio-temporelle des épi-démies de paludisme. Dans le contexte du changement climatique, lesfaciès environnementaux vont être modi�és. Ainsi, ces connaissancespourront permettre de mieux appréhender l'impact du changement cli-matique sur la distribution spatio-temporelle du paludisme.
102

Conclusion générale.
Ko daminè do ga ko laban tè.
103


Références
Références
1. M.S. Alilio, A. Kitua, K. Njunwa, M. Medina, A.M. Rønn, J. Mhina, F. Msuya,J. Mahundi, J.M. Depinay, S. Whyte, A. Krasnik, and I.C. Bygbjerg, Mala-ria control at the district level in africa : the case of the muheza district innortheastern tanzania, Am J Trop Med Hyg 71(suppl 2) (2004), 205�13.
2. R.M. Altman and A.J. Petkau, Application of hidden markov models to mul-tiple sclerosis lesion count data, Statist Med 24 (2005), 2335�44.
3. N.H. Anderson and D.M. Titterington, Some methods for investigating spatialclustering, with epidemiological applications, J R Stat Soc [ser A] 160 (1997),87�105.
4. R.M. Anderson and R.M. May, Infectious diseases of humans : dynamics andcontrol, Oxford Science, Oxford, 1998.
5. S.J. Aneke, Mathematical modelling of drug resistant malaria parasites andvector populations, Math Meth Appl Sci 25 (2002), 335�46.
6. L. Anselin, Spatial economics : methods and model, Kluwer, Dordrecht, 1988.
7. , Local indicators of spatial association : Lisa, Geogr Anal 27 (1995),93�116.
8. R.M. Assunçao and E.A. Reis, A new proposal to adjust moran's i for popula-tion density, Statist Med 18 (1999), 2147�62.
9. B. Augeard, C. Kao, J. Ledun, C. Chaumont, and Y. Nédélec, Le ruissellem-ment sur sols drainés : identi�cation des mécanismes de génèse, Ingénieries43 (2005), 3�18.
10. D.E. Aylor and K.M. Ducharme, Wind �uctuations near the ground duringrain, Agric Forest Meteorol 76 (1995), 59�73.
11. N. Bacaër and C. Sokhna, A reaction-di�usion system modelling the spread ofresistance to antimalarial drug, Math Biosci Eng 2 (2005), 227�38.
12. N.T.J. Bailey, The biomathematics of malaria, C. Gri�n, London, 1982.
13. M. Balm, T. Vischel, T. Lebel, C. Peugeot, and S. Galle, Assessing the waterbalance in the sahel : Impact of small scale rainfall variability on runo�. part1 : Rainfall variability analysis, J Hydrol 331 (2006), 336�48.
14. L.E. Baum, An inequality and associated maximization technique in statisti-cal estimation for probabilistic functions of markov processes, Inequalities 3(1972), 1�8.
15. L.E. Baum and T. Petrie, Statistical inference for probabilistic functions of�nite state markov chains, Ann Math Stat 37 (1966), 1554�63.
16. L.E. Baum, T. Petrie, G. Soules, and N. Weiss, A maximization techniqueoccuring in the statistical analysis of probabilistic functions of markov chains,Ann Math Stat 41 (1970), 164�71.
17. S. Bellec, D. Hemon, and J. Clavel, Answering cluster investigation requests :the value of simple simulations and statistical tools, Eu J Epidemiol 20 (2005),663�71.
18. F. Le Ber, M. Benoît, C. Schott, J.F. Mari, and C. Mignolet, Studying cropsequences with carrotage, a hmm-based data mining software, Ecol Model 191(2006), 170�85.
19. J. Besag and J. Newell, The detection of clusters in rare diseases, J R StatSoc 154[SerA] (1991), 327�33.
105

Références
20. N.J. Besansky, C.A. Hill, and C. Costantini, No accounting for taste : hostpreference in malaria vectors, Trends Parasitol 20 (2004), 249�51.
21. P.C. Besse, H. Cardot, and D.B. Stephenson, Autoregressive forecasting ofsome functional climatic variations, Scan J Statist 27 (2000), 673�87.
22. P.J. Bickel, Y. Ritov, and T. Rydén, Asymptotic normality of the maximum-likelihood estimator for general hidden markov models, Ann Stat 26 (1998),1614�35.
23. , la vraisemblance des chaînes de markov cachées se comporte commecelle de variables i.i.d., Ann I H Poincaré 6 (2002), 825�46.
24. J.D. Bigoga, L. Manga, V.P. Titanji, M. Coetzee, and R.G. Leke, Malariavectors and transmission dynamics in coastal south-western cameroon, MalarJ 6 (2007), 5.
25. J.F. Bithell, The choice of test for detecting raised disease risk near a pointsource, Statist Med 14 (1995), 2309�22.
26. R.S. Bivand and A. Gebhardt, Implementing functions for spatial statisticalanalysis using the r language, J Geogr Syst 2 (2000), 307�17.
27. P. Bogacki and L.F. Shampine, A 3(2) pair of runge-kutta formulas, ApplMath Letters 2 (1989), 1�9.
28. M. Booman, D.N. Durrheim, K. La Grange, C. Martin, A.M. Mabuza, A. Zi-tha, F.M. Mbokazi, C. Fraser, and B.L. Sharp, Using a geographical informa-tion system to plan a malaria control programme in south africa, Bull WorldHealth Organ 78 (2000), 1438�44.
29. G.E.P. Box and G.M. Jenkins, Time series analysis : forecasting and control,Holden-Day, San Francisco, 1976.
30. L. Breiman, J.H. Friedman, R.A. Olshen, and C.J. Stone, Classi�cation andregression trees, Chapman and Hall, New York, 1993.
31. J.G. Breman, M.S. Alilio, and A. Mills, Conquering the intolerable burdenof malaria : what's new, what's needed : a summary, Am J Trop Med Hyg71(suppl 2) (2004), 1�15.
32. O.J.T. Briet, D.M. Gunawardena, W. Van der Hoek, and F.P. Amerasinghe,Sri lanka malaria maps, Malar J 2 (2003), 22.
33. C.E. Brodley and P.E. Utgo�, Multivatiate decision trees, COINS technicalreports 92-82, University of Massachusetts, 1992.
34. M. Caldas-De-Castro, Y. Yamagata, D. Mtasiwa, M. Tanner, J. Utzinger,J. Keiser, and B.H. Singer, Integrated urban malaria control : a case study indar es salaam, tanzania, Am J Trop Med Hyg 71(suppl 2) (2004), 103�17.
35. N. Cancré, A. Tall, C. Rogier, J. Faye, O. Sarr, J.F. Trape, A. Spiegel, andF. Bois, Bayesian analysis of an epidemiologic model of Plasmodium falcipa-rum malaria infection in ndiop, senegal, Am J Epidemiol 152 (2000), 760�70.
36. J. Cano, M.A. Descalzo, M. Moreno, Z. Chen, S. Nzambo, L. Bobuakasi, J.N.Buatiche, M. Ondo, F. Micha, and A. Benito, Spatial variability in the density,distribution and vectorial capacity of anopheline species in a high transmissionvillage (equatorial guinea), Malar J 5 (2006), 21.
37. R.S. Cantrell and C. Cosner, Spatial ecology via reaction-di�usion equations,Wiley, Chichester, UK, 2003.
38. E. Cantu-Paz and C. Kamath, Inducing oblique decision trees with evolutio-nary algorithms, IEEE Trans Evol Comput 7 (2003), 54�68.
106

Références
39. M. Carbon, Prédiction non paramétrique, In : Approche non paramétrique enrégression, Eds : J.J. Droesbeke, G. Saporta, 2006.
40. M. Carbon and M. Delecroix, Non parametric vs parametric forecasting intime series : a computational point of view, Appl Stoch Mod Data Anal 9(1993), 215�29.
41. F. Carrat, J. Luong, H. Lao, A.V. Sallé, C. Lajaunie, and H. Wackernagel, A'small-world-like' model for comparing interventions aimed at preventing andcontrolling in�uenza pandemics, BMC Medicine 4 (2006), 26.
42. M.J. Cassidy and P. Brown, Hidden markov based autoregressive analysis ofstationary and non-stationary electrophysiological signals for functional cou-pling studies, J Neurosci Methods 116 (2002), 35�53.
43. D.D. Chadee and U. Kitron, Spatial and temporal patterns of imported malariacases and local transmission in trinidad, Am J Trop Med Hyg 61 (1999), 513�7.
44. E.K. Chaput, J.I. Meek, and R. Heimer, Spatial analysis of human granulocyticehrlichiosis near lyme, connecticut, Emerg Infect Dis 8 (2002), 943�8.
45. I. Chaubey, C.T. Haan, S. Grunwald, and J.M. Salisbury, Uncertainty in themodel parameters due to spatial variability of rainfall, J. Hydrol 220 (1999),48�61.
46. H. Chen, A.K. Githeko, G. Zhou, J.I. Githure, and G. Yan, New records ofAnopheles arabiensis breeding on the mount kenya highlands indicate indige-nous malaria transmission, Malar J 5 (2006), 17.
47. P. Chevallier, Simulation de pluie sur deux bassins versants sahéliens, CahORSTOM [ser Hydrol] 19 (1982), 253�97.
48. E. Chirpaz, M. Colonna, and J.F. Viel, Cluster analysis in geographical epide-miology : the use of several statistical methods and comparison of their results,Rev Epidemiol Sante Publique 52 (2004), 139�49.
49. N. Chitnis, J.M. Cushing, and J.M. Hyman, Bifurcation analysis of a mathe-matical model for malaria transmission, LAUR-05-5077, 2005.
50. A.D. Cli� and J.K. Ord, Spatial autocorrelation, Pion, London, 1973.
51. D.A. Coast, G.G. Cano, and S.A. Briller, Use of hidden markov models foeelectrocardiographic signal analysis, J Electrocardiol 23 (1990), 184�91.
52. M. Colonna, J. Estève, and F. Ménégoz, Détection de l'autocorrélation spatialedu risque de cancer dans le cas où la densité de population est hétérogène, RevEpidemiol Sante Publique 41 (1993), 235�40.
53. M.A. Costa and R.M. Assunçao, A fair comparison between the spatial scanand the besag newell disease clustering tests, Environ Ecol Stat 12 (2005),301�19.
54. M.H. Craig, I. Kleinschmidt, J.B. Nawn, D. LeSueur, and B.L. Sharp, Explo-ring 30 years of malaria case data in kwazulu-natal, south africa : Part i. theimpact of climatic factors, Trop Med Int Health 9 (2004), 1247�57.
55. M.H. Craig, R.W. Snow, and D. LeSueur, A climate-based distribution modelof malaria transmission in sub-saharan africa, Parasitol Today 15 (1999),105�11.
56. N.J. Crichton, J.P. Hinde, and J. Marchini, Models for diagnosing chest pain :is cart helpful ?, Statist Med 16 (1997), 717�27.
57. J. Cuzick and R. Edwards, Spatial clustering for inhomogeneous populations,J R Stat Soc [Ser B] 52 (1990), 73�104.
107

Références
58. N. D'Amato and T. Lebel, On the characteristics of the rainfall events in thesahel with a view to the analysis of climatic variability, Int J Climatol 18(1998), 955�74.
59. J.M.O. Depinay, C.M. Mbogo, G. Killeen, B. Knols, J. Beier, J. Carlson, J. Du-sho�, P. Billingsley, H. Mwambi, J. Githure, A.M. Toure, and F.E. McKenzie,A simulation model of african Anopheles ecology and population dynamics forthe analysis of malaria transmission, Malar J 3 (2004), 29.
60. J.M. d'Herbès and C. Valentin, Land surface conditions of the niamey region :ecological and hydrological implications, J Hydrol 188 (1997), 18�42.
61. H. Diebner, M. Eichner, L. Molineaux, W.E. Collins, G.M. Je�ery, andK. Dietz, Modelling the transition of asexual blood stages of Plasmodium fal-ciparum to gametocytes, J Theor Biol 202 (2000), 113�127.
62. O. Diekmann and J.A.P. Heesterbeek,Mathematical epidemiology of infectiousdiseases, Wiley, Chichester, UK, 2000.
63. K. Dietz, L. Molineaux, and A. Thomas, A malaria model tested in the africansavannah, Bull World Health Organ 50 (1974), 347�57.
64. P.J. Diggle and A.G. Chetwynd, Second-order analysis of spatial clustering forinhomogeneous populations, Biometrics 47 (1991), 1155�63.
65. P.J. Diggle, S. Morris, P. Elliott, and G. Shaddick, Regression modelling ofdisease risk in relation to point sources, J R Stat Soc [ser A] 160 (1997),491�505.
66. A. Dolo, F. Camara, B. Poudiougou, A. Touré, B. Kouriba, M. Bagayoko,D. Sangaré, M. Diallo, A. Bosman, D. Modiano, Y.T. Touré, and O. Doumbo,Epidémiologie du paludisme dans un village de savane soudanienne du mali(bancoumana), Bull Soc Pathol Exot 96 (2003), 308�12.
67. O. Domarle, F. Migot-Nabias, H. Pilkington N. Elissa F.S. Toure, J. Mayombo,M. Cot, and P. Deloron, Family analysis of malaria infection in dienga, gabon,Am J Trop Med Hyg 66 (2002), 124�9.
68. I.L. Mc Donald andW. Zucchini,Hidden markov and other models for discrete-valued time series, Chapman and Hall, London, 1997.
69. J.R. Dormand and P.J. Prince, A family of embedded runge-kutta formulae, JComp Appl Math 6 (1980), 19�26.
70. O.K. Doumbo, It takes a village : medical research and ethics in mali, Science307 (2005), 679�81.
71. J.J. Droesbeke, B. Fichet, and P. Tassi, Séries chronologiques : théorie etpratique des modèles arima, Economica, Paris, 1989.
72. J.J. Droesbeke, M. Lejeune, and G. Saporta, Analyse statistique des donnéesspatiales, Technip, Paris, 2006.
73. L. Duczmal and R.M. Assunciao, A simulated annealing strategy for the de-tection of arbitrarily shaped spatial clusters, Comput Statist Data Anal 45(2004), 269�86.
74. L. Duczmal and D.L. Buckeridge, A work�ow spatial scan statistic, StatistMed 25 (2006), 743�54.
75. J.B. Durand, Modèles à structure cachée : inférence, sélection de modèles etapplications, Ph.D. thesis, Université Grenoble I, 2003.
76. J. Dutertre, Etude d'un modèle épidémiologique appliqué au paludisme, AnnSoc Belge Med Trop 56 (1976), 127�41.
77. S.R. Eddy, Hidden markov models, Curr Opin Struct Biol 6 (1996), 361�5.
108

Références
78. F.E. Edillo, F. Tripét, Y.T. Touré, G.C. Lanzaro, G. Dolo, and C.E. Taylor,Water quality and immatures of the m and s forms of Anopheles gambiae s.s.and An. arabiensis in a malian village, Malar J 5 (2006), 35.
79. P. Elliott, M. Martuzzi, and G. Shaddick, Spatial statistical methods in envi-ronmental epidemiology : a critique, Stat Methods Med Res 4 (1995), 137�59.
80. P. Elliott and J. Wake�eld, Disease clusters : should they be investigated, ifso, when and how ?, J R Stat Soc [Ser A] 164 (2001), 3�12.
81. P. Elliott and D. Wartenberg, Spatial epidemiology : current approaches andfuture challanges, Environ Health Perspect 112 (2004), 998�1006.
82. R.J. Elliott, L. Aggoun, and J.B. Moore, Hidden markov models, Springer,New York, 1997.
83. Y. Ephraim and N. Merhav, Hidden markov processes, IEEE Trans InformTheory 48 (2002), 1518�69.
84. K.C. Ernst, S.O. Adoka, D.O. Kowuor, M.L. Wilson, and C.C. John, Malariahotspot areas in a highland kenya site are consistent in epidemic and non-epidemic years and are associated with ecological factors, Malar J 5 (2006),78.
85. V. Estupina-Borrell, Vers une modélisation hydrologique adaptée à la prévisionopérationnelle des crues éclair, Ph.D. thesis, Institut National Polytechniquede Toulouse, 2003.
86. Z. Feng, D.L. Smith, F.E. McKenzie, and S.A. Levin, Coupling ecology andevolution : malaria and the s-gene across time scales, Math Biosci 189 (2004),1�19.
87. B. Fichet and J. Gaudart, Extension de cart dans le cas bivarié : partitionoptimale du plan, Proc XIIème congrès de la Société Francophone de Classi�-cation (Montréal, Québec), 2005.
88. B. Fichet, J. Gaudart, and B. Giusiano, Bivariate cart with oblique regressiontrees, International conference of Data Science and Classi�cation, InternationalFederation of Classi�cation Societies (Ljubljana, Slovenia), Juillet 2006.
89. U. Fillinger, G. Sonye, G.F. Killeen, B.G.J. Knols, and N. Becker, The practicalimportance of permanent and semi permanent habitats for controlling aquaticstages of Anopheles gambiae sensu lato mosquitoes : operational observationsfrom a rural town in western kenya, Trop Med Int Health 9 (2004), 1274�89.
90. R.A. Fisher, The wave of advance of advantageneous genes,Ann Eugen 7 (1937), 355�69, disponible sur : http ://digi-tal.library.adelaide.edu.au/coll/special/�sher/index.html.
91. W.E. Fitzgibbon, M. Langlais, F. Marpeaux, and J.J. Morgan, Modeling thecirculation of a disease between two host populations on non coincident spatialdomains, Biological Invasions 7 (2005), 863�75.
92. W.E. Fitzgibbon, M. Langlais, and J.J. Morgan, A mathematical model forindirectly transmitted diseases, Math Biosci 206 (2007), 233�48.
93. A. Franke, T. Caelli, G. Kuzyk, and R.J. Hudson, Prediction of wolf (Canislupus) kill-sites using hidden markov models, Ecol Model 197 (2006), 237�46.
94. C.Y. Fu, Combining loglinear model with classi�cation and regression tree(cart) : an application to birth data, Comput Statist Data Anal 45 (2004),865�74.
95. R.E. Gangnon and M.K. Clayton, Bayesian detection and modeling of spatialdisease clustering, Biometrics 56 (2000), 922�35.
109

Références
96. J. Gaudart, R. Giorgi, B. Poudiougou, O. Touré, S. Ranque, O.K. Doumbo,and J. Demongeot, Détection de clusters spatiaux sans point source prédé�ni :utilisation de cinq méthodes et comparaison de leurs résultats, Rev EpidemiolSanté Publique sous presse (2007).
97. J. Gaudart, B. Poudiougou, S. Ranque, and O.K. Doumbo, Oblique decisiontrees for spatial pattern detection : optimal algorithm and application to ma-laria risk, BMC Med Res Methodol 5 (2005), 22.
98. , Oblique decision trees for spatial pattern detection : optimal algorithmand application to malaria risk, BMC Med Res Methodol 5 (2005), 22.
99. J. Gaudart, N.O. Ramatriravo, and B. Giusiano, Evaluation de la puissancedes méthodes de balayage et d'arbres de régression pour la détection de patternsspatiaux, Congrès d'épidémiologie, ADELF et EPITER (Dijon, France), Aout2006.
100. S.R. Gaze, L.P. Simmonds, J. Brouwer, and J. Bouma,Measurement of surfaceredistribution of rainfall and modelling its e�ect on water balance calculationsfor a millet �eld on sandy soil in niger, J Hydrol 188 (1997), 267�84.
101. A. Gemperli, P. Vounatsou, I. Kleinschmidt, M. Bagayoko, C. Lengeler, andT. Smith, Spatial patterns of infant mortality in mali : the e�ect of malariaendemicity, Am J Epidemiol 159 (2004), 64�72.
102. V. Genon-Catalot and C. Laredo, Leroux's method for general hidden markovmodels, Stochastic Process Appl 116 (2006), 222�43.
103. M. Gerbaux, N.M.J. Hall, N. Dessay, and I. Zin, The sensitivity of sahelianruno� to climate change, Hydrol Sci J sous presse (2007).
104. A. Getis and J.K. Ord, The analysis of spatial association by distance statistics,Geogr Anal 24 (1992), 189�207.
105. S. Gey, Bornes de risque, détection de ruptures boosting : trois thèmes sta-tistiques autour de cart en régression, Ph.D. thesis, University of Paris XI,2002.
106. A.K. Githeko and W. Ndegwa, Predicting malaria epidemics in the kenyanhighlands using climate data : a tool for decision makers, Global Change Hu-man Health 2 (2001), 54�63.
107. V. Gomez-Rubio, J. Ferrandiz, and A. Lopez, Detecting clusters of diseaseswith r, Proc 3rd Int Workshop on Distributed Statistical Computing (Vienna,Austria) (K. Hornik, F. Leisch, and A. Zeileis, eds.), March 2003, Availableon : [http ://www.ci.tuwien.ac.at/Conferences/DSC-2003/].
108. E. GroverKopec, M. Kawano, R.W. Klaver, B. Blumenthal, P. Ceccato, andS.J. Connor, An online operational rainfall-monitoring resource for epidemicmalaria early warning systems in africa, Malar J 4 (2005), 6.
109. W. Gu, G.F. Killeen, C.M. Mbogo, J.L. Regens, J.I. Githure, and J.C. Beier,An individual-based model of Plasmodium falciparum malaria transmissionon the coast of kenya, Trans R Soc Trop Med Hyg 97 (2003), 43�50.
110. W. Gu, J.L. Regens, J.C. Beier, and R.J. Novak, Source reduction of mosquitolarval habitats has unexpected consequences on malaria transmission, ProcNatl Acad Sci USA 103 (2006), 17560�3.
111. Y. Guédon, Exploring the state sequence space for hidden markov and semi-markov chains, Computat Statist Data Analysis 51 (2007), 2379�409.
112. C. Guihenneuc-Jouyaux, Modélisation statistique des variations géogra-phiques : enjeu d'importance en épidémiologie et en statistique, Rev EpidemiolSante Publique 50 (2002), 409�12.
110

Références
113. C. Guihenneuc-Jouyaux, S. Richardson, and I.M. Longini, Modeling markersof disease progression by a hidden markov process : application to characteri-zing cd4 cell decline, Biometrics 56 (2000), 733�41.
114. H. Guis, S. Clerc, B. Hoen, and J.F. Viel, Clusters of autochthonous hepatitisa cases in a low endemicity area, Epidemiol Infect 134 (2006), 498�505.
115. H. Guthmann, A. Llanos-Cuentas, A. Palacios, and A.J. Hall, Environmentalfactors as determinants of malaria risk. a descriptive study on the northerncoast of peru, Trop Med Int Health 7 (2002), 518�25.
116. K. Hanson, Public and private roles in malaria control : the contributions ofeconomic analysis, Am J Trop Med Hyg 71(suppl 2) (2004), 168�73.
117. S.I. Hay, J. Cox, D.J. Rogers, S.E. Randolph, D.I. Stern, G.D. Shanks, M.F.Myers, and R.W. Snow, Climate change and the resurgence of malaria in theeast african ighlands, Nature 415 (2002), 905�9.
118. S.I. Hay, M.F. Myers, D.S. Burke, D.W. Vaughn, T. Endyi, N. Anandai, G.D.Shanksi, R.W. Snow, and D.J. Rogers, Etiology of interepidemic periods ofmosquito-borne disease, Proc Natl Acad Sci USA 97 (2000), 9335�9.
119. D. Heath, M. Kasif, and S. Salzberg, Induction of oblique decision trees, Proc13th Int Joint Conf on Arti�cial Intelligence (Chambery, France) (R. Bajcsy,ed.), Morgan Kaufmann, August 1993, pp. 1002�7.
120. E.G. Hill, L. Ding, and L.A. Waller, A comparison of three tests to detectgeneral clustering of a rare disease in santa clara county, california, StatistMed 19 (2000), 1363�78.
121. U. Hjalmars, M. Kulldor�, G. Gustafsson, and N. Nagarwall, Childhood leu-kemia in sweden : using gis and spatial scan statistic for cluster detection,Statist Med 15 (1996), 707�15.
122. H. Holzmann, A. Munk, M. Suster, and W. Zucchini, Hidden markov modelsfor circular and linear-circular time series, Environ Ecol Stat 13 (2006), 325�47.
123. M.B. Hoshen and A.P. Morse, A weather-driven model of malaria transmis-sion, Malar J 3 (2004), 32.
124. J. Huang, E.D. Walker, P.E. Otienoburu, F. Amimo, J. Vulule, and J.R. Miller,Laboratory tests of oviposition by the african malaria mosquito, Anophelesgambiae, on dark soil as in�uenced by presence or absence of vegetation, MalarJ 5 (2006), 88.
125. J. Huang, E.D. Walker, J. Vulule, and J.R. Miller, Daily temperature pro�lesin and around western kenyan larval habitats of anopheles gambiae as relatedto egg mortality, Malar J 5 (2006), 87.
126. J.P. Hughes, P. Guttorp, and S.P. Charles, A non-homogeneous hidden markovmodel for precipitation occurence, J R Stat Soc [ser C] 48 (1999), 15�30.
127. J.N. Ijumba, F.W. Mosha, and S.W. Lindsay, Malaria transmission risk va-riations derived from di�erent agricultural practices in an irrigated area onnorthern tanzania, Med Vet Entom 16 (2002), 28�38.
128. S. Islam, R.L. Bras, and K.A. Emanuel, Predictability of mesoscale rainfall inthe tropics, J Appl Meteor 32 (1993), 297�310.
129. C.H. Jackson and L.D. Sharples, Hidden markov models for the onset andprogression of bronchiolitis obliterans syndrome in lung transplant recipients,Statist Med 21 (2002), 113�28.
111

Références
130. H. Jacqmin-Gadda, D. Commenges, C. Nejjari, and J.F. Dartigues, Tests ofgeographical correlation with adjustment for explanatory variables : an appli-cation to dyspnoea in the elderly, Statist Med 16 (1997), 1283�97.
131. S. Kabos and F. Csillag, The analysis of spatial association on a regular lat-tice by join-count statistics without the assumption of �rst-order homogeneity,Comput Geosci 28 (2002), 901�10.
132. W. Kazadi, J.D. Sexton, M. Bigonsa, B. W'Okanga, and M. Way, Malariain primary school children and infants in kinshasa, democratic republic of thecongo : surveys from the 1980s and 2000, Am J Trop Med Hyg 71(suppl 2)(2004), 97�102.
133. A. Kehagias, A hidden markov model segmentation procedure for hydrologicaland environmental time series, Stoch Environ Res Risk Ass 18 (2004), 117�30.
134. J. Keiser, J. Utzinger, M. Caldas de Castro, T.A. Smith, M. Tanner, and B.H.Singer, Urbanization in sub-saharan africa and implication for malaria control,Am J Trop Med Hyg 71(suppl 2) (2004), 118�27.
135. R.N. Khan, B. Martinac, B.W. Madsen, R.K. Milne, G.F. Yeo, and R.O.Edeson, Hidden markov analysis of mechanosensitive ion channel gating, MathBiosci 193 (2005), 139�58.
136. G.F. Killeen, B.G.J. Knols, and W. Gu, Taking malaria transmission out ofthe bottle : implications of mosquito dispersal for vector control interventions,Lancet Inf Dis 3 (2003), 297�303.
137. G.F. Killeen, F.E. McKenzie, B.D. Foy, C. Schie�elin, P.F. Billingsley, andJ.C. beier, A simpli�ed model for predicting malaria entomologic inoculationrates based on entomologic and parasitologic parameters relevant to contol, AmJ Trop Med Hyg 62 (2000), 535�44.
138. G.F. Killeen, A. Seymoum, and B.G.J. Knols, Rationalizing historical suc-cesses of malaria control in africa in terms of mosquito resource availabiltymanagement, Am J Trop Med Hyg 71(S2) (2004), 87�93.
139. A.E. Kiszewski and A. Teklehaimanot, A review of the clinical and epidemio-logic burdens of epidemic malaria, Am J Trop Med Hyg 71(suppl 2) (2004),128�35.
140. A.Y. Kitua, Field trials of malaria vaccines, Indian J Med Res 106 (1997),95�108.
141. I. Kleinschmidt, B. Sharp, I. Mueller, and P. Vounatsou, Rise in malaria inci-dence rates in south africa : a small-area spatial analysis of variation in timetrends, Am J Epidemiol 155 (2002), 257�64.
142. W.F. Krajewski, R. Raghavan, and V. Chandrasekar, Physically based simu-lation of radar rainfall data using a space-time rainfall model, J Appl Meteor32 (1993), 268�83.
143. A. Krogh, M. Brown, I.S. Mian, K. Sjölander, and D. Haussler, Hidden markovmodels in computational biology : applications to protein modeling, J Mol Biol235 (1994), 1501�31.
144. M. Kulldor�, A spatial scan statistic, Commun Stat Theory and Methods 26(1997), 1481�96.
145. , Satscantm v5.1-software for the spatial and space-time scan statistics,Information Management Services Inc., Silver Spring, Maryland, 2004.
146. M. Kulldor�, E.J. Feuer, B.A. Miller, and L.S.Freeman, Breast cancer in nor-theastern united states : a geographical analysis, Am J Epidemiol 146 (1997),161�70.
112

Références
147. M. Kulldor�, R. He�ernan, J. Hartman, R. Assunçao, and F. Mostashari, Aspace-time permutation scan statistic for disease outbreak detection, PLoS Med2 (2005), e59.
148. M. Kulldor� and N. Nargawalla, Spatial disease clusters : detection and infe-rence, Statist Med 14 (1995), 799�810.
149. M. Kulldor�, T. Tango, and P.J. Park, Power comparisons for disease cluste-ring tests, Comput Stat Data Anal 42 (2003), 665�84.
150. S. Lallich, F. Muhlenbach, and D.A. Zighed, Test de structure pour la prédic-tion de variable numérique, Proc IXème congrès de la Société Francophone deClassi�cation, 2002.
151. T. Lebel and L. Le Barbé, Rainfall monitoring during hapex-sahel. 2. pointand areal estimation at the event and seasonal scales, J Hydrol 188 (1997),97�122.
152. T. Lebel, J.D. Taupin, and N. D'Amato, Rainfall monitoring during hapex-sahel. 1. general rainfall conditions and climatology, J Hydrol 188 (1997),74�96.
153. M. Leblanc and J. Crowley, Relative risk trees for censored survival data,Biometrics 48 (1992), 411�25.
154. J. Lee and D.W.S. Wong, Statistical analysis with arcview gis, Wiley, NewYork, 2001.
155. B. Leroux, Maximum-likelihood estimation for hidden markov models, StochProcess Applic 40 (1992), 127�43.
156. K.Y. Li, M.T. Coe, N. Ramankutty, and R. De Jong,Modeling the hydrologicalimpact of land-use change in west africa, J Hydrol, sous presse.
157. S.W. Lindsay, L. Parson, and C.J. Thomas, Mapping the ranges and relativeabundance of the rwo principal african malaria vectors, An. gambiae sensustricto and An. arabiensis, using climate data, Proc R Soc Lond [ser B] 265(1998), 847�54.
158. MARA/ARMA, version3.0.0 build5, South Africa Medical Research Council,2002.
159. D.P. Mason and F.E. McKenzie, Blood-stage dynamics and clinical implica-tions of mixed Plasmodium vivax - Plasmodium falciparum infections, Am JTrop Med Hyg 61 (1999), 367�74.
160. V. Mathon and H. Laurent, Life cycle of sahelian mesoscale convective cloudsystems, Q J R Meteor Soc 127 (2001), 377�406.
161. E. Matzner-Lober, A. Gannoun, and J.G. De Gooijer, Nonparametric forecas-ting : Comparison of three kernel-based methods, Com Statist Theor Methods27 (1998), 1593�617.
162. J. May, F.P. Mockenhaupt, O.G. Ademowo, A.G. Falusi, P.E. Olumese,U. Bienzle, and C.G. Meyer, High rate of mixed and subpatent malarial in-fections in southwest nigeria, Am J Trop Med Hyg 61 (1999), 339�43.
163. C.M. Mbogo, J.M. Mwangangi, J. Nzovu, W. Gu, G. Yan, J.T. Gunter,C. Swalm, J. Keating, J.L. Regens, J.I. Shililu, J.I. Githure, and J.C. Beier,Spatial and temporal heterogeneity of Anopheles mosquitoes and Plasmodiumfalciparum transmission along the kenyan coast, Am J Trop Med Hyg 68(2003), 734�42.
164. W.J.H. McBride, H. Mullner, R. Muller, J. Labrooy, and I. Wronski, Determi-nants of dengue 2 infection among residents of charters towers, queensland,australia, Am J Epidemiol 148 (1998), 1111�6.
113

Références
165. F.E. McKenzie, Why model malaria ?, Parasitol Today 16 (2000), 511�6.
166. F.E. McKenzie, J.K. Baird, J.C. Beier, A.A. Lal, and W.H. Bossert, A biologicbasis for integrated malaria control, Am J Trop Med Hyg 67 (2002), 571�7.
167. F.E. McKenzie and W.H. Bossert, An integrated model of Plasmodium falci-parum dynamics, J Theor Biol 232 (2005), 411�26.
168. F.E. McKenzie and E.M. Samba, The role pf mathematical modeling inevidence-based malaria control, Am J Trop Med Hyg 71(suppl. 2) (2004),94�6.
169. A. Le Menach, F.E. McKenzie, A. Flahault, and D.L. Smith, The unexpec-ted importance of mosquito oviposition behaviour for malaria : non-productivelarval habitats can be sources for malaria transmission, Malar J 4 (2005), 23.
170. L. Mevel, Statistique asymptotique pour les modèles de markov cachés, Ph.D.thesis, Université Rennes I, 1997.
171. L. Molineaux, K. Dietz, and A. Thomas, Further epidemiological evaluationof a malaria model, Bull World Health Organ 56 (1978), 565�71.
172. A.P. Morse, F.J. Doblas-Reyes, M.B. Hoshen, R. Hagedorn, and T.N. Pal-mer, A forecast quality assessment of an end-to-end probabilistic multi-modelseasonal forecast system using malaria model, Tellus 57A (2005), 464�75.
173. F. Mostashari, M. Kulldor�, J.J. Hartman, J.R. Miller, and V. Kulasekera,Dead bird clusters as an early warning system for west nile virus activity,Emerg Infect Dis 9 (2003), 641�6.
174. J.D. Murray, Mathematical biology, Springer, Berlin, 1993.
175. S.K. Murthy, M. Kasif, and S. Salzberg, A system for induction of obliquedecision trees, J Artif Intell Res 2 (1994), 1�32.
176. J. Nedelman, Inoculation and recovery rates in the malaria model of dietz,molineaux, and thomas, Math Biosci 69 (1984), 209�33.
177. , Introductory review some new thoughts about some old malaria mo-dels, Math Biosci 73 (1985), 159�82.
178. R.G. Newcombe, Two-sided con�dence intervals for the single proportion :comparison of seven methods, Statist Med 17 (1998), 857�72.
179. G.A. Ngwa and W.S. Shu, A mathematical model for endemic malaria withvariable human and mosquito populations, Math Comput Model 32 (2000),747�63.
180. S.E. Nicholson, J.A. Marengo, J. Kim, A.R. Lare, S. Galle, and Y.H. Kerr,A daily resolution evapoclimatonomy model applied to surface water balancecalculations at the hapex-sahel supersites, J Hydrol 188 (1997), 946�64.
181. E.T. Nkhoma, C.E. Hsu, V.I. Hunt, and A.M. Harris, Detecting spatiotemporalclusters of accidental poisoning mortality among texas counties, u.s., 1980-2001, Int J Health Geogr 3 (2004), 25.
182. B. Obermaier, C. Guger, and G. Pfurtscheller, Hidden markov models used forthe o�ine classi�cation of eeg data, Biomed Technik 44 (1999), 158�62.
183. N. Oden, Adjusting moran's i for population density, Statist Med 14 (1995),17�26.
184. A. Odoi, S.W. Martin, P. Michel, J. Holt, D. Middleton, and J. Wilson, Geo-graphical and temporal distribution of human giardiasis in ontario, canada,Int J Health Geogr 2 (2003), 5.
114

Références
185. M.J.A.M. Oesterholt, J.T. Bousema, O.K. Mwerinde, C. Harris, P. Lushino,A. Masokoto, H. Mwerinde, F.W. Mosha, and C.J. Drakeley, Spatial and tem-poral variation in malaria transmission in a low endemicity area in northerntanzania, Malar J 5 (2006), 98.
186. World Health Organization, Malaria control as part of primary health care,World Health Organ Tech Rep (1984), 712.
187. , Expert committee on malaria : 18th report, World Health Organ TechRep (1986), 735.
188. , Expert committee on malaria 20th report, World Health Organ TechRep (2000), 735.
189. K. Osnes, Iterative random aggregation of small units using regional measuresof spatial autocorrelation for cluster localization, Statist Med 18 (1999), 707�25.
190. J.P. Palutikof, C.M. Goodess, S.J. Watkins, and T. Holt, Generating rainfalland temperatures scenarios at multiple sites :..., J Clim 15 (2002), 3529�48.
191. G.P. Patil and C. Taillie, Upper level set scan statistic for detecting arbitrarilyshaped hotspots, Environ Ecol Stat 11 (2004), 183�97.
192. C. Peugeot, M. Esteves, S. Galle, J.L. Rajot, and J.P. Vandervaere, Runo�generation processes : results and analysis of �eld data collected at the eastcentral supersite of the hapex-sahel experiment, J Hydrol 188 (1997), 179�202.
193. B. Poudiougo, S. Diawara, M. Diakite, M. Diallo, A. Dicko, I. Sagara, O. Toure,A. Dolo, D. Krogstad, and O. Doumbo O, The impact of community-basedmalaria case management on the anti-malaria drugs resistance in south ofmali : Bancoumana, 3rd MIM Pan-African Conference on Malaria (ArushaTanzania), November 2002.
194. D. Prybylski, A. Khaliq, E. Fox, A.R. Sarwari, and T. Strickland, Parasitedensity and malaria morbidity in the pakistan punjab, Am J Trop Med Hyg61 (1999), 791�801.
195. Y. Qi and J. Wu, E�ects of changing spatial resolution on the results of land-scape pattern analysis using spatial autocorrelation indices, Landscape Ecol11 (1996), 39�49.
196. I.A. Quakyi, R.G.F. Leke, R. Be�di-Mengue, M. Tsafack, D. Bomba-Nkolo,L. Manga, V. Tchinda, E. Njeungue, S. Kouontchou, J. Fogako, P. Nyonglema,L. Thuita Harun, R. Djokam, G. Sama, A. Eno, R. Megnekou, S. Metenou,L. Ndoutse, A. Same-Ekobo, G. Alake, J. Meli, J. Ngu, F. Tietche, J. Lohoue,J.L. Mvondo, E. Wansi, R. Leke, A. Folefack, J. Bigoga, C. Bomba-Nkolo,V. Titanji, A. Walker-Abbey, M.A. Hickey, A.H. Johnson, and D.W. Tay-lor, The epidemiology of plasmodium falciparum malaria in two cameroonianvillages : Simbok and etoa, Am J Trop Med Hyg 63 (2000), 222�30.
197. L.R. Rabiner, A tutorial on hidden markov models and selected applicationsin speech recognition, Proc IEEE 77 (1989), 257�86.
198. S. Richardson, Modélisation statistique des variations géographiques en épidé-miologie, Rev Epidemiol Sante Publique 40 (1992), 33�45.
199. A.W. Robertson, S. Kirshner, and P. Smyth, Hidden markov models for mo-deling daily rainfall ocurrence over brazil, Tech. Report UCI-ICS 03-27, Infor-mation and computer science, Univ. of California, Irvine, 2003.
200. P.A. Rogerson, The detection of clusters using a spatial version of the chi-square goodness of �t statistic, Geogr Anal 31 (1999), 130�47.
115

Références
201. C. Rogier, A.B. Ly, A. Tall, and B. Cisse J.F. Trape, Plasmodium falciparumclinical malaria in dielmo, a holoendemic area in senegal : no in�uence ofacquired immunity on initial symptomatology and severity of malaria attacks,Am J Trop Med Hyg 60 (1999), 410�20.
202. I.M. Rouzine and F.E. McKenzie, Link between immune response and parasitesynchronization in malaria, Proc Natl Acad Sci USA 100 (2003), 3473�8.
203. W. Sama, S. Owusu-Agyei, I. Felger, P. Vounatsou, and T. Smith, Animmigration-death model to estimate the duration of malaria infection whendetectability of the parasite is imperfect, Statist Med 24 (2005), 3269�88.
204. J. Sansom, A hidden markov model for rainfall using breakpoint data, J Clim11 (1998), 42�53.
205. J.A. Schellenberg, J.N. Newell, R.W. Snow, V. Mungala, K. Marsh, P.G.Smith, and R.J. Hayes, An analysis of geographical distribution of severe ma-laria in children in kili� district, kenya, Int J Epidemiol 27 (1998), 323�9.
206. C. Schmoor, K. Ulm, and M. Schumacher, Comparison of the cox model andthe regression tree procedure in analyzing a randomized clinical trial, StatistMed 12 (1993), 2351�66.
207. M.R. Segal and I.B. Tager, Trees and tracking, Statist Med 12 (1993), 2153�68.
208. L. Von Seidlein, C. Drakeley, B. Greenwood, G. Walraven, and G. Targett,Risk factors for gametocyte carriage in gambian children, Am J Trop MedHyg 65 (2001), 523�7.
209. L.F. Shampine and M.W. Reichelt, The matlab ode suite, SIAM Journal onScienti�c Computing 18 (1997), 1�22.
210. L.F. Shampine, M.W. Reichelt, and J.A. Kierzenka, Solving index-1 daes inmatlab and simulink, SIAM Review 41 (1999), 538�52.
211. G.D. Shanks, S.I. Hay, D.I. Stern, K. Biomndo, and R.W. Snow, Meteorologicin�uences on P. falciparum malaria in the highland tea estates of kericho,western kenya, EID 8 (2002), 1404�8.
212. T.J. Sheehan, L.M. De Chello, M. Kulldor�, D.I. Gregorio, S. Gershman,and M. Mroszczyk, The geographic distribution of breast cancer incidence inmassachusetts 1988 to 1997, adjusted for covariates, Int J Health Geogr 3(2004), 17.
213. B. Singer and J.E. Cohen, Estimating malaria incidence and recovery ratesfrom panel survey, Math Biosci 49 (1980), 273�305.
214. N.G. Sipe and P. Dale, Challenges in using geographic information systems(gis) to understand and control malaria in indonesia, Malar J 2 (2003), 36.
215. J.G. Skellam, Random dispersal in theoretical populations, Biometrika 38(1951), 196�218, disponible sur : Bull Math Biol, 1991 ;53 :135-65.
216. D.L. Smith and F.E. McKenzie, Statics and dynamics of malaria infection inanopheles mosquitoes, Malar J 3 (2004), 13.
217. T. Smith, J.D. Charlwood, W. Takken, M. Tanner, and D.J. Spiegelhalter,Mapping the densities of malaria vectors within a single village, Acta Tropica59 (1995), 1�18.
218. T. Smith, G. Genton, K. Baea, N. Gibson, A. Narara, and M.P. Alpers, Pros-pective risk of morbidity in relation to malaria infection in an area of high en-demicity of multiple species of Plasmodium, Am J Trop Med Hyg 64 (2001),262�7.
116

Références
219. R.W. Snow, E. Gouws, J. Omumbol, B. Rapuoda, M.H. Craig, F.C. Tamers,D. LeSueur, and J.Ouma, Models to predict the intensity of Plasmodium fal-ciparum transmission : applications to the burden of disease in kenya, TransR Soc Trop Med Hyg 92 (1998), 601�6.
220. C.S. Sokhna, F.B.K. Faye, A. Spiegel, H. Dieng, and J.F. Trapé, Rapid reap-pearance of Plasmodium falciparum after drug treatment among senegaleseadults exposed to moderate seasonal transmission, Am J Trop Med Hyg 65(2001), 167�70.
221. C. Song and M. Kulldor�, Power evaluation of disease clustering tests, Int JHealth Geogr 2 (2003), 9.
222. S.G. Staedke, E.W. Nottingham, J. Cox, M.R. Kamya, P.J. Rosenthal, andG. Dorsey, Short report : proximity to mosquito breedings sites as a risk factorfor clinical malaria episodes in an urban cohort of ugandan children, Am JTrop Med Hyg 69 (2003), 244�6.
223. Y. Le Strat and F. Carrat, Monitoring epidemiologic surveillance data usinghidden markov models, Statist Med 18 (1999), 3463�78.
224. C.J. Struchiner, M.E. Halloran, and A. Spielman, Modeling malaria vaccinesi : new uses for old ideas, Math Biosci 94 (1989), 87�113.
225. K. Takezawa, Introduction to nonparametric regression, Wiley, Hoboken, NewJersey, 2006.
226. T. Tango, Assymptotic distribution of an index for disease clustering, Biome-trics 46 (1990), 351�7.
227. , A test for spatial disease clustering adjusted for multiple testing, Sta-tist Med 19 (2000), 191�204.
228. , Score tests for detecting excess risks around putative sources, StatistMed 21 (2002), 497�514.
229. , Score tests for detecting excess risks around putative sources, StatistMed 21 (2002), 497�514.
230. T. Tango and K. Takahashi, A �exibly shaped spatial scan statistic for detectingclusters, Int J Health Geogr 4 (2005), 11.
231. H.D. Teklehaimanot, M. Lipsitch, A. Teklehaimanot, and J. Schwartz,Weather-based prediction of Plasmodium falciparum malaria in epidemic-prone regions of ethiopia i. patterns of lagged weather e�ects re�ect biologicalmechanisms, Malar J 3 (2004), 41.
232. H.D. Teklehaimanot, J. Schwartz, A. Teklehaimanot, and M. Lipsitch,Weather-based prediction of Plasmodium falciparum malaria in epidemic-prone regions of ethiopia ii. weather-based prediction systems perform compa-rably to early detection systems in identifying times for interventions, MalarJ 3 (2004), 44.
233. L. Thoraval, Analyse statistique de signaux électrocardiographiques par modèlesde markov cachés, Ph.D. thesis, Université Rennes I, 1995.
234. M. Thyer and G. Kuczera, A hidden markov model for modelling long-termpersistence in multi-site rainfall time series. 2. real data analysis, J Hydrol275 (2003), 27�48.
235. A.G.B. Tie, B. Konan, Y.T. BROU, S. Issiaka, V. Fadika, and B. Srohourou,Estimation des pluies exceptionnelles journalières en zone tropicale : cas de lacôte d'ivoire par comparaison des lois lognormale et de gumbel, Hydrol Sci J52 (2007), 49�67.
117

Références
236. M. Tiefelsdorf, The saddlepoint approximation of moran's i and local moran's i's reference distribution and their numerical evaluation, Geogr Anal 34 (2002),187�206.
237. Y. Touré, The Anopheles gambiae genome : potential contribution to malariavector control, 3rd MIM Pan-African Conference on Malaria (Arusha Tanza-nia), November 2002.
238. Y.T. Touré, O. Doumbo, A. Toure, M. Bagayoko, M. Diallo, A. Dolo, K.D.Vernick, D.B. Keister, O. Muratova, and D.C. Kaslow, Gametocyte infectivityby direct mosquito feeds in an area of seasonal malaria transmission : impli-cations for bancoumana, mali, as a transmission-blocking vaccine site, Am JTrop Med Hyg 59 (1998), 481�6.
239. B.C. Tucker and M. Anand, On the use of stationary versus hidden markovmodels to detect simple versus complex ecological dynamics, Ecol Model 185(2005), 177�93.
240. B.W. Turnbull, E.J. Iwano, W.S. Burnett, H.L. Howe, and L.C. Clark, Mo-nitoring for clusters of disease : application to leukemia incidence in upstatenew york, Am J Epidemiol 132 (1990), S136�43.
241. K.A. Ulm, A simple method to calculate the con�dence interval of a standar-dized mortality ratio, Am J Epidemiol 131 (1990), 373�5.
242. P. Vandekerkhove, Identi�catuib de l'ordre des processus arma stables. contri-bution à l'étude statistique des chaînes de markov cachées, Ph.D. thesis, Uni-versité Montpellier II, 1997.
243. W. Vanderhoek, F. Konradsen, P.H. Amerasinghe, D. Perera, M.K. Piyaratne,and F.P. Amerasinghe, Towards a risk map of malaria for sri lanka : theimportance of house location relative to vector breeding sites, Int J Epidemiol32 (2003), 280�5.
244. J.F. Viel, N. Floret, and F. Mauny, Spatial and space-time scan statistics todetect low rate clusters of sex ratio, Environ Ecol Stat 12 (2005), 289�99.
245. T. Vischel and T. Lebel, Assessing the water balance in the sahel : Impact ofsmall scale rainfall variability on runo�. part 2 : Idealized modeling of runo�sensitivity, J Hydrol 333 (2007), 340�55.
246. J. Wake�eld and P. Elliott, Issues in the statistical analysis of small area healthdata, Statist Med 18 (1999), 2377�99.
247. J. Wake�eld, M. Quinn, and G. Rabb, Disease clusters and ecological studies,J R Stat Soc [Ser A] 164 (2001), 1�2.
248. T. Waldhör, The spatial autocorrelation coe�cient moran's i under heterosce-dasticity, Statist Med 15 (1996), 887�92.
249. L.A. Waller and C.A. Gotway, Applied spatial statistics for public health data,Wiley, Hoboken New Jersey, 2004.
250. L.A. Waller, E.G. Hill, and R.A. Rudd, The geography of power : statisticalperformance of tests of clusters and clustering in heterogeneous populations,Statist Med 25 (2006), 853�65.
251. L.A. Waller, D. Smith, J.E. Childs, and L.A. Real, Monte carlo assessmentsof goodness of �t for ecological simulation models, Ecol Modell 164 (2003),49�63.
252. S.D. Walter, The analysis of regional patterns in health data. ii. the power todetect environmental e�ects, Am J Epidemiol 136 (1992), 136�59.
253. D. Wartenberg, Investigating disease clusters : why, when and how ?, J R StatSoc [Ser A] 164 (2001), 13�22.
118

Références
254. R. Xu and S. Adak, Survival analysis with time-varying regression e�ects usinga tree-based approach, Biometrics 58 (2002), 305�15.
255. M.M. Yin and J.T.L. Wang, E�ective hidden markov models for detectingsplicing junction sites in dna sequences, Information Sciences 139 (2001), 139�63.
256. H. Zhang, T. Holford, and M.B. Bracken, A tree-based method of analysis forprospective studies, Statist Med 15 (1996), 37�49.
257. W. Zucchini and P. Guttorp, A hidden markov model for space-time precipi-tation, Water Resour Res 27 (1991), 1917�23.
119


Résumé
Introduction
L'étude de la distribution spatiotemporelle du paludisme permet l'élaboration de carte derisque. A l'instar de Ross, nous proposons une approche statistique et une modélisationdéterministe.
Analyse spatiale et spatiotemporelle
Parmi les méthodes décrivant l'hétérogénéité spatiale, nous développons une méthode pararbre de régression oblique (SpODT) découpant la région en zones de risques di�érents. 5méthodes générales de détection de clusters sont comparées et appliquées à la descriptiondu risque à Bancoumana, Mali. La recherche de clusters spatiotemporels met en évidenceles variations saisonnières et spatiales du risque palustre.
Modélisation déterministe
Nous proposons un modèle adapté à Bancoumana tenant compte de la pluviométrie si-mulée par 4 méthodes (distribution empirique, chaîne de Markov cachées, nonlinéaire,nonparamétrique). Un modèle de réaction-di�usion modélise la progression des anophèlesà partir de leurs gîtes et l'évolution spatiotemporelle du risque.
121
Copyright © 2022 FDOKUMEN




















