
Velocity-adaptation of spatio-temporal receptive ... - CiteSeerX
6
Velocity-adaptation of spatio-temporal receptive fields for direct recognition of activities: An experimental study I. Laptev and T. Lindeberg Computational Vision and Active Perception Laboratory (CVAP) Department of Numerical Analysis and Computer Science KTH, SE-100 44 Stockholm, Sweden Abstract This article presents an experimental study of the influence of velocity adaptation when recognizing spatio-temporal patterns using a histogram-based statistical framework. The basic idea consists of adapting the shapes of the filter kernels to the local direction of motion, so as to allow the computation of image descriptors that are invariant to the relative motion in the image plane between the camera and the objects or events that are studied. Based on a frame- work of recursive spatio-temporal scale-space, we first out- line how a straightforward mechanism for local velocity adaptation can be expressed. Then, for a test problem of recognizing activities, we present an experimental evalua- tion, which shows the advantages of using velocity-adapted spatio-temporal receptive fields, compared to directional derivatives or regular partial derivatives for which the filter kernels have not been adapted to the local image motion. 1 Introduction A recent approach for recognition consists of computing statistical descriptors of receptive field responses. In par- ticular, histogram based schemes of derivative operators have emerged as an interesting alternative for formulating recognition schemes for static [25, 23, 4, 10, 24] as well as time-dependent [5, 27] image data. When representing spatio-temporal image data for such recognition tasks, as well as other tasks in video processing, surveillance and active vision, one observation that can be made is that temporal events can be characterized by their extents over time in a similar manner as spatial structures in still im- ages have their characteristic spatial scales. This motivates and emphasizes the need for analysing spatio-temporal data at different scales, both with respect to time and space [12, 13, 14, 19, 8, 15, 18]. The temporal domain, however, also has a number of specific properties, which differ from spatial data, and which must be taken into account explicitly. A basic con- straint on real-time processing is that the time direction is causal, and real-time algorithms may only access informa- tion from the past [13, 19]. Another difference concerns the classes of characteristic transformations that influence the data. Whereas perspective transformations have a high in- fluence on the image data in the spatial image domain, one of the most important sources of changes in the temporal dimension is due to motion between the observer and the patterns that are studied. When interpreting image data, it is important to base the analysis on image representations that are invariant to the external imaging conditions. Hence, it is important to con- struct representations of spatio-temporal patterns that are independent of the relative motion between the patterns and the observer. Previous work has addressed this problem by first stabilizing patterns of interest in the field of view, and then computing spatio-temporal descriptors using a fixed set of filters [27]. Camera stabilization, however, cannot al- ways be expected to be available, for example, in situations with multiple moving objects, moving backgrounds or in cases where initial segmentation of the patterns of interest cannot be done without (preliminary) recognition. A main aim of this work is thus to define and compute spatio-temporal descriptors that compensate for the relative motion between the pattern and the observer and do not rely on external camera stabilization. This is performed by local velocity adaptation of receptive fields. By integration with a histogram-based statistical framework, we then consider a test problem of recognising activities and show how ve- locity adaptation results in a considerable increase in recog- nition performance compared to two other receptive field representations not involving velocity adaptation. 1.1 Related work Velocity adaptation of spatio-temporal receptive fields fol- lows the idea of shape adaptation in the spatial domain, which has previously been considered by [20, 3, 7, 26, 2, 22]. In the spatio-temporal domain, adaptive spatio- temporal filters have been studied by [15, 21, 18]. Whereas Nagel et. al. [21] proposed an adaptation scheme close to ours, they used it for robust estimation of optic flow. With regard to recognition, this work relates to
-
Upload
khangminh22 -
Category
Documents
-
view
10 -
download
0
Transcript of Velocity-adaptation of spatio-temporal receptive ... - CiteSeerX

Velocity-adaptation of spatio-temporal receptive fields fordirect recognition of activities: An experimental study
I. Laptev and T. LindebergComputational Vision and Active Perception Laboratory (CVAP)
Department of Numerical Analysis and Computer ScienceKTH, SE-100 44 Stockholm, Sweden
AbstractThis article presents an experimental study of the influenceof velocity adaptation when recognizing spatio-temporalpatterns using a histogram-based statistical framework.The basic idea consists of adapting the shapes of the filterkernels to the local direction of motion, so as to allow thecomputation of image descriptors that are invariant to therelative motion in the image plane between the camera andthe objects or events that are studied. Based on a frame-work of recursive spatio-temporal scale-space, we first out-line how a straightforward mechanism for local velocityadaptation can be expressed. Then, for a test problem ofrecognizing activities, we present an experimental evalua-tion, which shows the advantages of using velocity-adaptedspatio-temporal receptive fields, compared to directionalderivatives or regular partial derivatives for which the filterkernels have not been adapted to the local image motion.
1 Introduction
A recent approach for recognition consists of computingstatistical descriptors of receptive field responses. In par-ticular, histogram based schemes of derivative operatorshave emerged as an interesting alternative for formulatingrecognition schemes for static [25, 23, 4, 10, 24] as wellas time-dependent [5, 27] image data. When representingspatio-temporal image data for such recognition tasks, aswell as other tasks in video processing, surveillance andactive vision, one observation that can be made is thattemporal events can be characterized by their extents overtime in a similar manner as spatial structures in still im-ages have their characteristic spatial scales. This motivatesand emphasizes the need for analysing spatio-temporal dataat different scales, both with respect to time and space[12, 13, 14, 19, 8, 15, 18].
The temporal domain, however, also has a number ofspecific properties, which differ from spatial data, andwhich must be taken into account explicitly. A basic con-straint on real-time processing is that the time direction iscausal, and real-time algorithms may only access informa-
tion from the past [13, 19]. Another difference concerns theclasses of characteristic transformations that influence thedata. Whereas perspective transformations have a high in-fluence on the image data in the spatial image domain, oneof the most important sources of changes in the temporaldimension is due to motion between the observer and thepatterns that are studied.
When interpreting image data, it is important to base theanalysis on image representations that are invariant to theexternal imaging conditions. Hence, it is important to con-struct representations of spatio-temporal patterns that areindependent of the relative motion between the patterns andthe observer. Previous work has addressed this problem byfirst stabilizing patterns of interest in the field of view, andthen computing spatio-temporal descriptors using a fixed setof filters [27]. Camera stabilization, however, cannot al-ways be expected to be available, for example, in situationswith multiple moving objects, moving backgrounds or incases where initial segmentation of the patterns of interestcannot be done without (preliminary) recognition.
A main aim of this work is thus to define and computespatio-temporal descriptors that compensate for the relativemotion between the pattern and the observer and do not relyon external camera stabilization. This is performed by localvelocity adaptation of receptive fields. By integration witha histogram-based statistical framework, we then considera test problem of recognising activities and show how ve-locity adaptation results in a considerable increase in recog-nition performance compared to two other receptive fieldrepresentations not involving velocity adaptation.
1.1 Related work
Velocity adaptation of spatio-temporal receptive fields fol-lows the idea of shape adaptation in the spatial domain,which has previously been considered by [20, 3, 7, 26,2, 22]. In the spatio-temporal domain, adaptive spatio-temporal filters have been studied by [15, 21, 18]. WhereasNagel et. al. [21] proposed an adaptation scheme close toours, they used it for robust estimation of optic flow.
With regard to recognition, this work relates to

histogram-based methods first proposed in the spatial do-main by [25] using color histograms computed from singlepixel responses. Extensions to receptive field histogramswere later presented by [23, 4, 10, 24]. Specifically, com-binations of automatic scale selection in the spatial do-main [17] with histogram based recognition schemes havebeen presented by [4, 10]. In the spatio-temporal domain,histogram-based approaches have been used for the recog-nition of activities by [5, 27]. Here, we build upon this workand show how the performance of spatio-temporal recogni-tion schemes can be increased by velocity adaptation.
2 Spatio-temporal scale-spaceThe image data we analyse is a spatio-temporal image se-quence f : Z2 � Z ! R from which a separable spatio-temporal signal L is computed by separable convolutionwith a spatial smoothing kernel g(x; y; �2) with variance�2 and a temporal smoothing kernel h(t; �2) with vari-ance �2 [12, 14, 19, 8]. To describe this separable spatio-temporal scale-space concept, we will henceforth use a co-variance matrix of the form � = diag (�2; �2; �2).
2.1 Transformation properties under motionA limitation of using a separable scale-space for analysingmotion patterns originates from the fact that such a scale-space concept is not closed under 2-D motions in the imageplane. For a 2-D Galilean motion with (constant) velocity(vx; vy)
T , the covariance matrix of the smoothing kerneltransforms as [15, 18]
�0 =
0@
1 0 vx0 1 vy0 0 1
1A�
0@
1 0 00 1 0vx vy 1
1A (1)
and spatio-temporal derivatives transform according to
@x0 = @x; @y0 = @y; @t0 = @t + vx @x + vy @y: (2)
Hence, if we consider separable smoothing kernels only(corresponding to a diagonal covariance matrix), and if wedo not take the transformation property of spatio-temporalderivatives into account explicitly, it will not be possible toperfectly match the spatio-temporal scale-space representa-tions for different amounts of motion.
2.2 Scale-space with velocity adaptationA natural way of defining a scale-space that is closed un-der Galilean motion in the image plane, is by considering ascale-space representation that is parameterized by the fullfamily of (positive definite) covariance matrices [15, 8, 18].In terms of implementation, there are two basic ways ofcomputing such a scale-space — either by transforming the
@x�y�t L —
8<:
Galileantransformation
of receptive fields
9=;! @x0�y0�t0 L
0
" "
�g(x; y; t; �) �g0(x0; y0; t0; �0)
j j
f(x; y; t) —
8<:
Galileantransformationof space-time
9=; ! f 0(x0; y0; t0)
Figure 1: A pre-requisite for perfect matching of spatio-temporalreceptive field responses for different amounts of motion is that theimage representation is closed under motions in the image domain.The aim of velocity-adaptation is to allow for such closedness.
smoothing kernels themselves, or by transforming the inputimage prior to smoothing (see figure 1). In this work, thelatter approach is taken, and for reasons of simplicity andcomputational efficiency, we restrict the set of image veloc-ities to integer multiples of the pixel size. Thus, in combi-nation with spatial smoothing, a set of velocity-adapted re-cursive smoothing filtering steps is computed according to
L(k+1)(x; y; t)� L(k+1)(x � vx; y � vy; t� 1) =
=1
1 + �k(L(k)(x; y; t)�L(k+1)(x�vx; y�vy; t�1)):
(3)
Such recursive filters have mean �mk = �k and vari-ance ��2k = �2k + �k [18]. By coupling k such fil-ters in cascade, we obtain a filter with temporal meanmk =
Pk
i=1�mi =Pk
i=1 �i and temporal variance�2k =
Pki=1��2i =
Pki=1 �
2i + �i. The scale-space con-
cept we make use of, will hence be parameterized by a spa-tial scale �2, a temporal scale �2 and a set of discrete imagevelocities (vx; vy)T .
2.3 Mechanism for local velocity adaptation
When computing spatio-temporal derivatives of time-dependent image sequences, their responses will be stronglydependent on the relative motion between the camera andthe observed events. This is illustrated in figure 2 wherean image pattern with one spatial and one temporal dimen-sion (figure 2(a)) has been filtered with a separable spatio-temporal filter with v = 0 (figure 2(e)). As can be seen,space-time separable filtering enhances the stationary pat-tern while suppressing most of the moving pattern.
If we want to interpret events independently of their rel-ative motion to the camera, one approach is to adapt thereceptive fields globally with respect to the velocity of theevents in the field of view. This approach also correspondsto camera stabilization followed by non-adapted filtering.

time
(t)
space (x)
(a) (b) (c)
local velocity adaptation
(d)
v = �1
(e)
v = 0
(f)
v = 1
Figure 2: The effect of local vs. global velocity adaptation fora synthetic spatio-temporal pattern in (a). (b): results of filteringwith Laplacian spatio-temporal filters using local velocity adap-tation; (c) orientation of ellipses showing the chosen velocity ateach point; (d)-(f): filtering of (a) with Laplacian filters with ve-locity parameters v = �1; 0; 1, respectively. Note that filteringwith local velocity adaptation preserves the details of the patternwhile global velocity adaptation partially suppresses details.
As illustrated in figure 2(d), the result of filtering with glob-ally adapted receptive fields with v = �1 indeed enhancesthe structure of the moving pattern. However, the stationarypattern is now suppressed and it follows that global velocityadaptation is not able to handle multiple motions. More-over, global velocity adaptation is likely to fail if the exter-nal velocity information is incorrect (figure 2(f)).
To address these problems, we propose to make use of lo-cal velocity adaptation of receptive fields. The main idea isto obtain information about motion in the local neighbour-hood and to use this information for velocity adaptation ofreceptive fields in the same neighbourhood.
Before proceeding to specific schemes for local veloc-ity adaptation in space-time, however, let us observe thatthere are two main approaches for handling multiple imagevelocities. One approach is to consider the entire ensem-ble of receptive fields over image motions as the represen-tation, while the other is to select receptive field outputscorresponding to a single motion estimate. From basic ar-guments, the first approach can be expected to be more ro-bust in critical situations (compare with biological visionsystems), while the second approach followed in this workcould be expected to be more accurate and also computa-tionally more efficient on a serial architecture.
The mechanism we will use for accomplishing local ve-locity adaptation is inspired by related work on automaticscale selection [17] extended to a multi-parameter scale-space [15] as well as by motion energy approaches for com-puting optic flow [1, 11]. Given a set of image velocities,the normalized Laplacian response is computed for each
image velocity in a motion compensated frame (3) in thespatio-temporal scale-space. Then, for each scale, a motionestimate is computed from the velocity (vx; vy)
T that max-imizes the normalized derivative response
(vx; vy)T (x; y; t)(k) =
= argmaxvx;vy
�r2
normL(k)(x; y; t; �2; vx; vy)
�2; (4)
wherer2norm = �2(@xx+@yy) is a scale-normalized Lapla-
cian operator in space. Figs. 2(b)–(c) show the result ofsuch local velocity adaptation for the spatio-temporal imagepattern in figure 2(a). From the results, shown as velocity-adapted receptive field outputs as well as ellipses displayingthe selected orientation in space-time, it is apparent that thevelocity-adaptation scheme enhances structures both on themoving object and in the static background.
2.4 Comparison with steerable filters
Velocity adaptation relates to steerable filters [9] for com-puting higher-order spatial derivatives in a rotationally in-variant way. A main difference, however, is that we in ad-dition to adapting the directional derivatives in space-time,also adapt the shapes of the underlying smoothing kernels.
To illustrate the importance of shape adaptation, we willhere compare the results of filtering using
� velocity-adaptation of both the smoothing kernels andthe directional derivatives according to (3) and (2);
� steering of only the directional derivatives according to(2) defined from a separable scale-space (this approachwill henceforth be referred to as steerable filtering);
Original signal
t
yx
(a)
Velocity-adapted filtering
t
yx
(b)
Velocity-steered filtering
t
yx
(c)
Non-adapted filtering
t
yx
(d)
Figure 3: (a): Prototype spatio-temporal blob signal with veloc-ity vx = 2. (b)-(d): Responses to the @xxt-derivative operatorwhen using (b): velocity-adapted filters; (c): velocity-steered fil-ters; (d): non-adapted filters. A correct shape of the filter responseis obtained only for the case of velocity-adapted filtering.

� no velocity adaptation of neither the smoothing opera-tion nor the derivatives.
Figure 3 presents filter responses for a moving spatio-temporal impulse. As can be seen, only the velocity-adapted filtering gives a correct shape of the derivative re-sponse (fig. 3(b)). Velocity-steered derivatives (fig. 3(c))and regular partial derivatives (fig. 3(d)) result in com-pletely different shapes (due to the fact that these filteringschemes are not closed under Galilean motion).
In the next section, we give a quantitative comparison ofthese methods and evaluate them on a recognition task.
3 Histogram based recognition
Following [23, 5, 4, 27], let us represent image patterns byhistograms of receptive field responses. For this purpose,we use mixed spatio-temporal derivative operators up to or-der four and collect histograms of these at different spa-tial and temporal scales. For simplicity, we restrict our-selves to 1-D histograms for each type of filter response. Toachieve independence with respect to the direction of mo-tion (left/right or up/down) and the sign of the spatial grey-level variations, we simplify the problem by only consid-ering the absolute values of the filter responses. Moreover,to emphasize the parts of the histograms that correspondto stronger spatio-temporal responses, we also weight theaccumulated histograms H(i) by a function f(i) = i2 re-sulting in h(i) = i2H(i).
3.1 Experimental setupAs a test problem we have chosen a data set with image se-quences containing people performing actions of type walk-ing W1:::W4 and exercise E1:::E4 as illustrated in figure 4.
W1 W2 W3 W4 E1 E2 E3 E4
Figure 4: Test sequences of people walking W1–W4 and peo-ple performing an exercise E1–E4. Whereas the sequencesW1,W4,E1,E3 were taken with a manually stabilized camera, theother four sequences were recorded using a stationary camera.
Some of the sequences were taken with a stationary camera,while the others were recorded with a manually stabilizedcamera. Each of these 4 sec. long sequences were subsam-pled to a spatio-temporal resolution of 80� 60� 50 pixelsand convolved with a set of spatio-temporal smoothing ker-nels for all combinations of seven velocities vx = �3:::3,five spatial scales �2 = f2; 4; 8; 16; 32g and five temporalscales �2 = f2; 4; 8; 12; 16g.
For each spatial scale �i, velocity adaptation was per-formed according to (4) at scale level �i+1. Since in ourexamples the relative camera motion was mostly horizontal,we maximized (4) over vx only. The result of this adapta-tion for the sequences W2 and E1 is illustrated in fig. 5.
(a)
(c)
(b)
(d)
Figure 5: Results of local velocity adaptation for image se-quences recorded with a manually stabilized camera (a), and witha stationary camera (b). Directions of cones in (c)-(d) correspondto the velocity chosen by the proposed adaptation algorithm. Thesize of the cones corresponds the value of the squared Laplacian�(@xx + @yy)L(x; y; t; �; �)
�2at the selected velocities.
To represent the patterns, we accumulated histogramsof derivative responses for each combination of scales andeach type of derivatives. For the purpose of evaluation,separate histograms were accumulated over (i) velocity-adapted derivative responses; (ii) velocity-steered direc-tional derivative responses and (iii) non-adapted partialderivative responses computed at velocity v = 0.
3.2 Discriminability of histograms
Figure 6 illustrates the means and the variances of the his-tograms computed separately for both of the classes. Ascan be seen from figures 6(a)-(c), velocity-adaptation of re-ceptive fields results in discriminative class histograms andlow variation of histograms computed for the same class ofactivities. On the contrary, the high variations in the his-tograms in figures 6(d)-(f) and figures 6(g)-(i) clearly indi-cate that activities are much harder to recognise when usingvelocity-steered or non-adapted receptive fields.
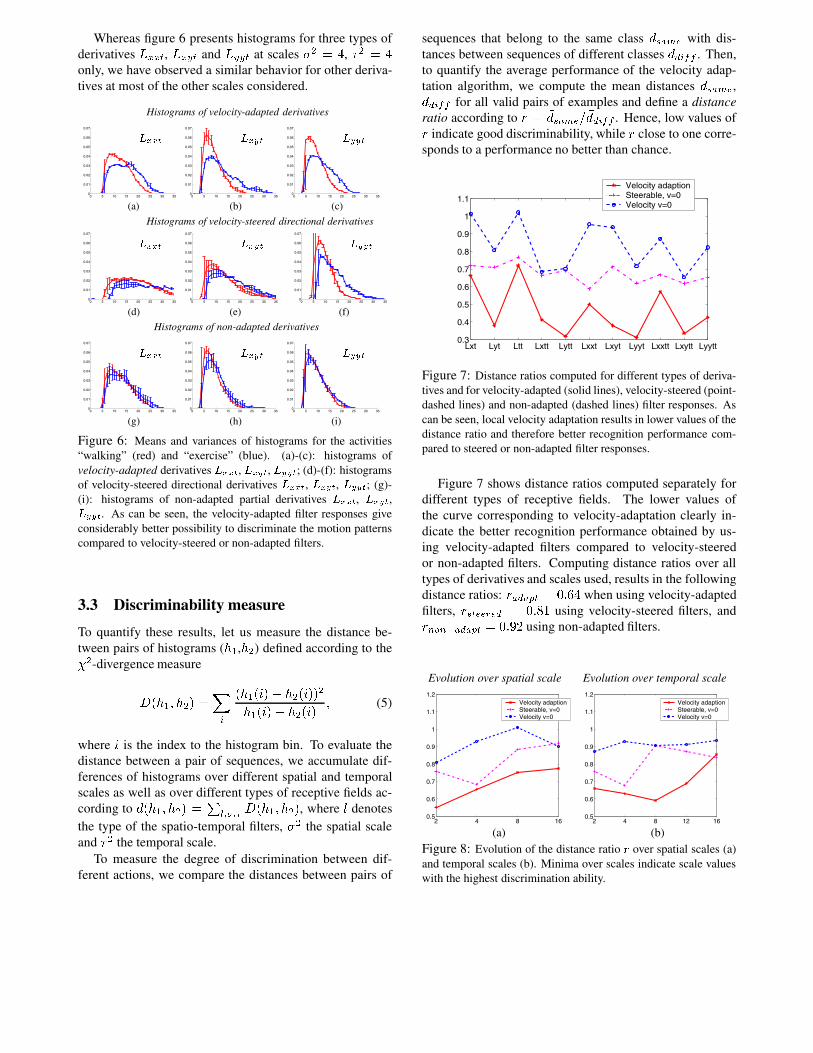
Whereas figure 6 presents histograms for three types ofderivatives Lxxt, Lxyt and Lyyt at scales �2 = 4, �2 = 4only, we have observed a similar behavior for other deriva-tives at most of the other scales considered.
Histograms of velocity-adapted derivatives
0 5 10 15 20 25 30 350
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lxxt
(a)0 5 10 15 20 25 30 35
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lxyt
(b)0 5 10 15 20 25 30 35
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lyyt
(c)
Histograms of velocity-steered directional derivatives
0 5 10 15 20 25 30 350
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lxxt
(d)0 5 10 15 20 25 30 35
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lxyt
(e)0 5 10 15 20 25 30 35
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lyyt
(f)
Histograms of non-adapted derivatives
0 5 10 15 20 25 30 350
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lxxt
(g)0 5 10 15 20 25 30 35
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lxyt
(h)0 5 10 15 20 25 30 35
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Lyyt
(i)
Figure 6: Means and variances of histograms for the activities“walking” (red) and “exercise” (blue). (a)-(c): histograms ofvelocity-adapted derivatives Lxxt, Lxyt, Lyyt; (d)-(f): histogramsof velocity-steered directional derivatives Lxxt, Lxyt, Lyyt; (g)-(i): histograms of non-adapted partial derivatives Lxxt, Lxyt,Lyyt. As can be seen, the velocity-adapted filter responses giveconsiderably better possibility to discriminate the motion patternscompared to velocity-steered or non-adapted filters.
3.3 Discriminability measure
To quantify these results, let us measure the distance be-tween pairs of histograms (h1,h2) defined according to the�2-divergence measure
D(h1; h2) =Xi
(h1(i)� h2(i))2
h1(i) + h2(i); (5)
where i is the index to the histogram bin. To evaluate thedistance between a pair of sequences, we accumulate dif-ferences of histograms over different spatial and temporalscales as well as over different types of receptive fields ac-cording to d(h1; h2) =
Pl;�;� D(h1; h2), where l denotes
the type of the spatio-temporal filters, �2 the spatial scaleand �2 the temporal scale.
To measure the degree of discrimination between dif-ferent actions, we compare the distances between pairs of
sequences that belong to the same class dsame with dis-tances between sequences of different classes ddiff . Then,to quantify the average performance of the velocity adap-tation algorithm, we compute the mean distances �dsame,�ddiff for all valid pairs of examples and define a distanceratio according to r = �dsame= �ddiff . Hence, low values ofr indicate good discriminability, while r close to one corre-sponds to a performance no better than chance.
Lxt Lyt Ltt Lxtt Lytt Lxxt Lxyt Lyyt Lxxtt Lxytt Lyytt0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
Velocity adaptionSteerable, v=0 Velocity v=0
Figure 7: Distance ratios computed for different types of deriva-tives and for velocity-adapted (solid lines), velocity-steered (point-dashed lines) and non-adapted (dashed lines) filter responses. Ascan be seen, local velocity adaptation results in lower values of thedistance ratio and therefore better recognition performance com-pared to steered or non-adapted filter responses.
Figure 7 shows distance ratios computed separately fordifferent types of receptive fields. The lower values ofthe curve corresponding to velocity-adaptation clearly in-dicate the better recognition performance obtained by us-ing velocity-adapted filters compared to velocity-steeredor non-adapted filters. Computing distance ratios over alltypes of derivatives and scales used, results in the followingdistance ratios: radapt = 0:64 when using velocity-adaptedfilters, rsteered = 0:81 using velocity-steered filters, andrnon�adapt = 0:92 using non-adapted filters.
2 4 8 160.5
0.6
0.7
0.8
0.9
1
1.1
1.2Velocity adaptionSteerable, v=0 Velocity v=0
Evolution over spatial scale
(a)2 4 8 12 16
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2Velocity adaptionSteerable, v=0 Velocity v=0
Evolution over temporal scale
(b)Figure 8: Evolution of the distance ratio r over spatial scales (a)and temporal scales (b). Minima over scales indicate scale valueswith the highest discrimination ability.

3.4 Dependency on scales
When analysing discrimination performance for differenttypes of derivatives and different scales, we have observedan interesting dependency of the distance ratio on the spa-tial and the temporal scales. Figures 8(a)-(b) show how thedistance ratio has a clear minimum over scales at �2 = 2,�2 = 8 indicating that these scales give rise to the best dis-crimination for patterns considered here. In particular, itcan be noted that �2 = 8 approximately corresponds to thetemporal extent of one gait cycle in our examples.
Computation of distance ratios for the selected scale val-ues results in radapt = 0:41 when using velocity-adaptedfilters, rsteered = 0:71 using velocity-steered filters andrnon�adapt = 0:79 using non-adapted filters. The existenceof such preferred scales motivates approaches for automaticselection of both spatial [17] and temporal [16] scales.
4 Summary and discussion
We have addressed the problem of representing and recog-nising events in video in situations where the relative mo-tion between the camera and the observed events is un-known. Experiments on a test problem of recognising activ-ities show that the use of a velocity adaptation scheme re-sults in a clear improvement in the recognition performancecompared to using either (steerable) directional derivativesor regular partial derivatives computed from a non-adaptedspatio-temporal filtering step. Whereas for the treated set ofexamples, recognition could also have been accomplishedby using a camera stabilisation approach, a major aim herehas been to consider a filtering scheme that can be extendedto recognition in complex scenes, where camera stabilisa-tion may not be available, i.e. scenes with complex non-static backgrounds or multiple events of interest that havenot been pre-segmented. Full-fledged recognition in suchsituations, however, requires more sophisticated statisticalmethods for recognition than the present histogram-basedscheme, and should be investigated in future work.
Less restricted to this specific visual task, the resultsof our investigation also indicate how, when dealing withfilter-based representations of spatio-temporal image data,velocity adaptation appears as an important complement tomore traditional approaches of using separable space-timefiltering. For the purpose of performing a clean experimen-tal investigation, we have in this work made use of an ex-plicit velocity-adapted spatio-temporal filtering for each im-age velocity. While such an implementation has interestingqualitative similarities to biological vision systems (wherethere are two main classes of receptive fields in space-time— separable filters and non-separable ones) [6], there is aneed for developing more sophisticated multi-velocity fil-tering schemes for efficient implementations in practice.
Finally, future work should also address the problem ofselecting appropriate scales in both the spatial and the tem-poral domains. The preliminary results in section 3.4 in-dicate the potential of performing joint scale selection inspace-time for increasing the recognition performance.
References[1] E.H. Adelson and J.R. Bergen. Spatiotemporal energy models for the
perception of motion. JOSA, A 2:284–299, 1985.[2] A. Almansa and T. Lindeberg. Fingerprint enhancement by shape
adaptation of scale-space operators with automatic scale-selection.IEEE Transactions on Image Processing, 9(12):2027–2042, 2000.
[3] C. Ballester and M. Gonzalez. Affine invariant texture segmentationand shape from texture by variational methods. J. Math. Im. Vis.,9:141–171, 1998.
[4] O. Chomat, V.C. de Verdiere, D. Hall, and J.L. Crowley. Local scaleselection for Gaussian based description techniques. Proc. ECCV’00,Springer LNCS 1842, I: 117–133, Dublin, Ireland, 2000.
[5] O. Chomat, J. Martin, and J.L. Crowley. A probabilistic sensorfor the perception and recognition of activities. Proc. ECCV’00,Springer LNCS 1842, I:487–503, Dublin, Ireland, 2000.
[6] G. C. DeAngelis, I. Ohzawa, R. D. Freeman. Receptive field dynam-ics in the central visual pathways, TINS, 18, 451–457, 1995.
[7] L. Florack, W. Niessen, M. Nielsen. The intrinsic structure of opticflow incorporating measurement duality. IJCV, 27, 263–286, 1998.
[8] L. M. J. Florack. Image Structure. Kluwer, Netherlands, 1997.[9] W. T. Freeman and E. H. Adelson. The design and use of steerable
filters. IEEE-PAMI, 13(9):891–906, 1991.[10] D. Hall, V.C. de Verdiere, and J.L. Crowley. Object recognition using
coloured receptive fields. Proc. ECCV’00, I: 164–177, 2000.[11] D. Heeger. Optical flow using spatiotemporal filters. IJCV, 1:279–
302, 1988.[12] J. J. Koenderink, The structure of images, Biol. Cyb. 50, 363–370.[13] J. J. Koenderink. Scale-time. Biol. Cyb., 58:159–162, 1988.[14] T. Lindeberg, Scale-Space Theory in Computer Vision, 1994.[15] T. Lindeberg. Linear spatio-temporal scale-space. In Proc. Scale-
Space’97, Springer LNCS 1252, 113–127, Utrecht, 1997.[16] T. Lindeberg. On automatic selection of temporal scales in time-
casual scale-space. In Proc. AFPAC’97, Springer LNCS 1315, 94–113, Kiel, Germany, 1997.
[17] T. Lindeberg. Feature detection with automatic scale selection. IJCV,30(2):77–116, 1998.
[18] T. Lindeberg. Time-recursive velocity-adapted spatio-temporalscale-space filters. Proc. ECCV’02, Copenhagen, 2002, in press.
[19] T. Lindeberg and D. Fagerstrom. Scale-space with causal time direc-tion. Proc. ECCV’96, Springer LNCS 1064, 229–240, 1996.
[20] T. Lindeberg, J. Garding. Shape-adapted smoothing in estimation of3-D depth cues from affine distortions of local 2-D structure. Proc.ECCV’94, Springer LNCS 800, A:389–400, Stockholm, 1994.
[21] H.H. Nagel and A. Gehrke. Spatiotemporal adaptive filtering forestimation and segmentation of optical flow fields. Proc. ECCV’98,Springer LNCS 1407, II:86–102, Freiburg, Germany, 1998.
[22] F. Schaffalitzky and A. Zisserman. Viewpoint invariant texturematching and wide baseline stereo. Proc. ICCV’01, 636–643, 2001.
[23] B. Schiele, J. L. Crowley. Recognition without correspondence usingmultidimensional receptive field histograms. IJCV, 36, 31–50, 2000.
[24] H. Schneiderman, T. Kanade. A statistical method for 3-D object de-tection applied to faces and cars. Proc. CVPR’00, I:746–751, 2000.
[25] M.J. Swain, D.H. Ballard. Color indexing. IJCV, 7(1):11–32, 1991.[26] J. Weickert. Anisotropic Diffusion in Image Processing. 1998.[27] L. Zelnik-Manor and M. Irani. Event-based analysis of video. Proc.
CVPR’01, Hawaii, II:123–130, 2001.




















