Agrupamiento en datos cuantitativos y cualitativos - Ignacio Benítez - 2006
52
Universidad Polit´ ecnica de Valencia Departamento de Ingenier´ ıa de Sistemas y Autom´ atica Trabajo de Investigaci ´ on T ´ ecnicas de Agrupamiento para el An ´ alisis de Datos Cuantitativos y Cualitativos Ignacio Javier Ben´ ıtez S´ anchez Profesor responsable: Jos´ e Luis D´ ıez Ruano Valencia, Septiembre 2005
Transcript of Agrupamiento en datos cuantitativos y cualitativos - Ignacio Benítez - 2006

Universidad Politecnica de ValenciaDepartamento de Ingenierıa de Sistemas y Automatica
Trabajo de Investigacion
Tecnicas de Agrupamiento parael Analisis de Datos
Cuantitativos y Cualitativos
Ignacio Javier Benıtez Sanchez
Profesor responsable: Jose Luis Dıez Ruano
Valencia, Septiembre 2005

En este trabajo de investigacion se presenta un estudio de las tecnicas de reconocimiento depatrones en conjuntos de objetos multidimensionales (i.e., de multiples dimensiones, atributos ocualidades) y, en concreto, de las tecnicas que se usan para agrupar objetos definidos por da-tos cuantitativos (valores numericos) y datos cualitativos (valores nominales). Para ello, tras unadefinicion de los conceptos a tratar, se comienza con una introduccion al campo donde estas tec-nicas son mas usadas, que es el del llamado descubrimiento de informacion en bases de datos oKnowledge Discovery in Databases (KDD), uno de cuyos procesos principales es la extraccion deinformacion y relaciones de similitud entre los datos, busqueda de patrones o agrupamiento dedatos aparentemente inconexos, tecnicas que reciben el nombre comun de minerıa de datos o DataMining.
A continuacion, se procede a una revision del estado del arte en materia de los ultimos avancesy artıculos publicados en tecnicas, algoritmos y metodologıas para reconocimiento de patrones yagrupamiento de datos, centrandose principalmente en aquellos que buscan similitudes en objetoscon caracterısticas cuantitativas y cualitativas.
Tras la revision, se propone una metodologıa propia de procedimiento para reconocer patronesy agrupar objetos con atributos de naturaleza cuantitativa y cualitativa, analizando los resultadoscon un ejemplo.

Indice general
1 Introduccion y objetivos 1
2 Introduccion a la Minerıa de Datos y el KDD 32.1 Definiciones y tipos de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Los inicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.3 Knowledge Discovery in Databases (KDD) . . . . . . . . . . . . . . . . . . . . . . . 52.4 Minerıa de datos (Data Mining) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4.1 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4.2 Metodologıas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.4.3 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Tecnicas de agrupamiento o reconocimiento de patrones (clustering) 113.1 Medidas de distancia entre objetos . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1.1 Distancia Minkowski . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.1.2 Distancia de Mahalanobis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.1.3 Coeficiente de correlacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.1.4 Matching coefficients . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.1.5 Entropıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.1.6 distancia de Kullback-Leibler . . . . . . . . . . . . . . . . . . . . . . . . . . 143.1.7 Distancia de Gowda y Diday . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Clasificaciones de los algoritmos de agrupamiento . . . . . . . . . . . . . . . . . . . 153.2.1 Algoritmos particionales vs. algoritmos jerarquicos . . . . . . . . . . . . . . 153.2.2 Algoritmos de pertenencia exclusiva a clusters vs. pertenencia no exclusiva 153.2.3 Otras clasificaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3 Algoritmos de clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.3.1 Algoritmos de clustering particional . . . . . . . . . . . . . . . . . . . . . . 163.3.2 Algoritmos de clustering jerarquico . . . . . . . . . . . . . . . . . . . . . . . 183.3.3 Algoritmos de clustering borroso . . . . . . . . . . . . . . . . . . . . . . . . 193.3.4 Algoritmos de clustering basados en la densidad . . . . . . . . . . . . . . . 213.3.5 Algoritmos de clustering Grid-based . . . . . . . . . . . . . . . . . . . . . . 223.3.6 Algoritmos de clustering basado en modelos . . . . . . . . . . . . . . . . . . 223.3.7 Algoritmos de clustering geografico o espacial . . . . . . . . . . . . . . . . . 233.3.8 Algoritmos de clustering en datos distribuidos . . . . . . . . . . . . . . . . . 23
3.4 Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4 Tecnicas de agrupamiento para datos cuantitativos y cualitativos 254.1 Algoritmo K-modes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2 Algoritmo ROCK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.3 STIRR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264.4 CACTUS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.5 COOLCAT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.6 LIMBO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.7 KEROUAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.8 CLICKS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314.9 Mixed-type variable fuzzy c-means (MVFCM) . . . . . . . . . . . . . . . . . . . . . 31
4.9.1 Datos cuantitativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
iii

4.9.2 Datos cualitativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.9.3 Datos borrosos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.10 Fusion de datos cuantitativos y cualitativos en tecnicas distintas del agrupamiento 334.11 Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Propuesta de metodologıa para reconocimiento de patrones en entidades dedatos heterogeneos mediante tecnicas de clustering borroso 355.1 Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.1.1 Preprocesado de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.1.2 Clustering de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Ejemplo de aplicacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.2.1 Base de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.2.2 Analisis y resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405.2.3 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
6 Conclusiones y trabajo futuro 43

Capıtulo 1
Introduccion y objetivos
Los datos que se recogen de cualquier encuesta contienen normalmente muchos campos donde sepide informacion de distinta naturaleza: numerica, seleccion de categorıas, intervalos, etc.
De igual modo, existen actualmente grandes bases de datos, muchas de ellas distribuidas envarios nodos de una red, cuyas tablas pueden tener muchos campos o variables, cada una deellas de distinta naturaleza, con rangos acotados de posibles valores. Seguramente muchas de lascaracterısticas son superfluas, o no aportan el mismo grado de informacion que otras, representandouna informacion extra o de refinamiento o concrecion. En muchas ocasiones tambien se encuentrancampos en blanco o con datos erroneos, que son una fuente de ruido para los posteriores analisis.
Tambien es analoga la situacion en sistemas distribuidos, en donde todas las terminales informande su situacion incluyendo el valor del estado, y tambien alguna informacion adicional, como puedaser el apagado o encendido de un interruptor (ON / OFF), o sistemas de deteccion de fallos, queinforman con variables numericas y de estado.
Los datos se guardan con informacion numerica (cuantitativa) y simbolica o categorica (cuali-tativa). La informacion esta disponible, y hay una necesidad de extraer un conocimiento util de tanvasta cantidad de datos almacenados en tablas, un conocimiento que permita establecer relacionesentre campos o conjuntos de datos, clasificacion de los datos en tipos o clases, o agrupamiento detodos los datos en conjuntos segun similitud, una similitud que en ocasiones puede quedar ocultaa simple vista si no se aplicaran estas tecnicas.
Consideramos, pues, que existe motivo suficiente para realizar una revision de todas las tecnicasempleadas, y ademas para centrarse en los metodos que buscan relaciones y patrones de semejanzaen objetos con varias caracterısticas, unas de naturaleza numerica, y otras de naturaleza nominal.
Ademas de las motivaciones ya expuestas, los conocimientos adquiridos en el desarrollo deeste trabajo de investigacion son de gran interes para su aplicacion en el proyecto Profesion@l,un proyecto de la iniciativa comunitaria EQUAL, subvencionado por el Fondo Social Europeo,cuyo objetivo ultimo es el de analizar y aplicar las medidas estudiadas con el fin de erradicar ladesigualdad y los estereotipos de genero, que sobre las distintas carreras o perfiles profesionales setienen desde todos los niveles de la formacion en el sistema educativo, partiendo desde la ensenanzasecundaria obligatoria (ESO), hasta los ultimos anos de estudios en la Universidad. A tal fin,uno de los objetivos del proyecto es el de implementar una herramienta software de analisis querecibe datos sobre los alumnos de distintos centros y niveles, recogidos mediante encuestas, paragenerar un modelo basado en agentes que realiza un seguimiento dinamico de la evolucion de losdistintos grupos y sus indicadores de percepcion de estereotipos. Mediante el empleo de algoritmosde agrupamiento se identifican los distintos grupos o corrientes de opinion en una misma aula ocentro, junto con los prototipos o pensamientos representativos de cada grupo. Se pretende observary modelar como se modifican los comportamientos de los grupos de forma global cuando se ejercenacciones de sensibilizacion sobre estos, de forma que se puedan simular efectos y configuracionesdiferentes, basadas en el entrenamiento previo del comportamiento de estos modelos basados enagentes. Los datos que rellenan las personas encuestadas son principalmente de valoracion de variaspreguntas relacionadas con la percepcion de estereotipos y las distintas motivaciones para estudiaruna cosa u otra, por tanto se trata de respuestas cualitativas que precisan un analisis especıficopara este tipo de datos.
Los objetivos de este trabajo de investigacion son tres: por una parte, se pretende ofrecer unavision global sobre las tecnicas de agrupamiento de datos y reconocimiento de patrones, explicando
1

1. Introduccion y objetivos
los distintos tipos y configuraciones que se encuentran actualmente para este tipo de algoritmos.A continuacion, se pretende detallar el estado del arte en materia de algoritmos de agrupamientopara objetos con caracterısticas cuantitativas y cualitativas. Por ultimo, se presenta una propuestanueva para el manejo de esta clase de objetos, que incluyen variables con datos numericos y otrascon datos nominales, discretos o con categorıas.
Este trabajo esta estructurado de la siguiente manera: primero se ofrece una seccion de de-finiciones de conceptos y nombres que van a ser usados y mencionados en el presente trabajo.A continuacion, se presenta una definicion general de la principal rama o disciplina en donde seinvestigan y aplican las tecnicas del agrupamiento o clustering, que es la minerıa de datos (DataMining), como conjunto de tecnicas englobadas dentro del proceso del KDD o Knowledge Discoveryin Databases. El siguiente capıtulo es una descripcion de las tecnicas de agrupamiento de datos oclustering : definicion, clasificacion, tipos, filosofıa y ejemplos.
El capıtulo 4 esta dedicado a detallar los algoritmos mas significativos que se encuentran en laliteratura actualmente, para el agrupamiento de objetos con caracterısticas de naturaleza cuanti-tativa y cualitativa, o solo cualitativa. Tambien se mencionan tecnicas o metodos que no tienenpor objetivo el agrupamiento de objetos segun similitud, pero que sı tratan con la fusion de datoscon caracterısticas de distinta naturaleza.
Se incluye por ultimo una propuesta nueva para el manejo de esta clase de datos en tareas deagrupamiento o reconocimiento de patrones.
El trabajo acaba con una seccion de conclusiones y trabajo futuro, mas la bibliografıa consul-tada.
2 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

Capıtulo 2
Introduccion a la Minerıa de Datos yel KDD
Se presentan a continuacion unas cuantas definiciones que se ha considerado necesario detallar,con el fin de clarificar conceptos, que luego se van a usar o mencionar a lo largo del trabajo. Acontinuacion se describen brevemente los inicios y las necesidades de tratamiento de datos quellevaron al desarrollo del procedimiento del KDD y la minerıa de datos. En la ultima seccion sedescriben los distintos objetivos y metodologıas, junto con las tecnicas empleadas, en los procesosde minerıa de datos, uno de los cuales es el agrupamiento o clustering.
2.1 Definiciones y tipos de datos
Un objeto es un elemento representado por un conjunto de atributos, dimensiones o caracte-rısticas. Normalmente las caracterısticas del objeto se expresan en forma vectorial, como se puedever en (2.1), en donde cada elemento del vector es una caracterıstica o dimension distinta, desde 1hasta d.
x = [x1x2 . . . xd] (2.1)
Las bases de datos contienen no uno, sino muchos objetos, cada uno con sus atributos. Estosobjetos se manejan agrupados en forma matricial, como en (2.2), en donde cada fila de la matrizrepresenta un objeto distinto de la base de datos, y cada columna es una caracterıstica distin-ta. Esta configuracion implica que todos los objetos tienen el mismo numero de dimensiones ocaracterısticas, si bien alguna de estas puede estar incompleta o con un dato erroneo en algunaocasion.
X = [x1x2 . . . xn]T =
x11 x12 . . . x1d
x21 x22 . . . x2d
......
......
xn1 xn2 . . . xnd
(2.2)
Los datos son una serie de hechos u objetos que forman un conjunto F [50]. Un patron(pattern) es una expresion E mostrada en un lenguaje L, que describe los hechos de un subconjuntoFE de F , de tal forma que E sea mas sencillo de describir que la simple enumeracion de todos loshechos del subconjunto FE .
Segun la descripcion dada por Jain y Dubes [36], la clasificacion de datos se realiza en tipos y enescalas. El tipo de datos se refiere a su grado de cuantificacion, es decir, que rango de valores puedenabarcar y si estos son continuos o discretos. Una caracterıstica es continua si existen infinito numerode valores posibles entre dos valores cualesquiera que pueda tomar la caracterıstica. Por ejemplo,mediciones de sensores o el volumen de un objeto son variables consideradas continuas. Por elcontrario, una caracterıstica es discreta si todos los elementos del dominio al que pertenece puedenenumerarse en una correspondencia de un subconjunto finito de enteros positivos. Por ejemplo, laedad, el numero de hijos, o los numeros ordinales se consideran caracterısticas discretas. Un casoespecial de atributos discretos son aquellos que solo pueden tomar dos valores, como por ejemplo,
3

2. Introduccion a la Minerıa de Datos y el KDD
Figura 2.1: Ejemplo con dos clusters o grupos de datos y sus respectivos centroides
las respuestas con solo dos posibilidades (Sı – No, 1 – 0). Estas caracterısticas reciben el nombrede caracterısticas binarias.
La escala de datos indica la significancia de los posibles valores que pueden tomar estos datos.Define el tipo de relacion que hay entre ellos. Los datos se clasifican en cuantitativos y cualitati-vos. Se entiende que los datos cualitativos expresan significado solo cuando se expresan en relaciona otros datos cualitativos, mientras que los datos cuantitativos expresan un significado absolutopor sı mismos. Por ejemplo, los numeros ordinales solo tienen significado en relacion con otrosnumeros ordinales. Por tanto, son datos cualitativos. Los numeros o palabras usados como catego-rıas en escalas nominales, como los colores, o la asignacion de numeros a selecciones multiples derespuestas, tambien son datos cualitativos. La edad, la altura, el volumen, etc., son consideradospor el contrario datos cuantitativos, pues expresan un significado por sı solos.
En este trabajo de investigacion se aplica la clasificacion segun escala, es decir, se dividen losdatos en cuantitativos y cualitativos. Los datos cuantitativos suelen recibir el nombre de datosnumericos, mientras que los datos cualitativos se les llama datos simbolicos o categoricos.
Los clusters, grupos, o clases, son conjuntos de datos agrupados segun algun criterio de simi-litud. Los objetos que representan al conjunto de objetos de un mismo cluster, o que son los masrepresentativos del patron que sigue, son los llamados centros o centroides de los clusters. Porejemplo, en la figura 2.1 se muestran dos conjuntos de objetos con unicamente dos caracterısticas,que son sus coordenadas espaciales, x e y. Los centroides de ambos conjuntos se corresponden conel objeto mas representativo de cada conjunto, que en este caso serıa su centro de gravedad.
2.2 Los inicios
Los primeros avances en exploracion de bases de datos tratan de extraccion de reglas en textoscientıficos. A finales de los anos 70, algunos artıculos detallan algoritmos para consultas especiali-zadas, que incluyen rangos de valores en multiples campos [8] [11]. En estos artıculos ya se planteala existencia de enormes bases de datos disponibles, como censos poblacionales o artıculos de me-dicina, los cuales contienen campos numericos, como la edad o el salario percibido, y cualitativos,como el sexo, la situacion familiar, etc. Ademas se menciona que muchas veces hay campos vacıos,y otros que son redundantes, y que se precisa un preprocesado de los datos.
Ası pues, fue surgiendo una necesidad de desarrollar una metodologıa de extraccion de infor-macion util, y que ademas fuera comprensible. Actualmente se conoce este proceso por las siglas
4 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

2.3. Knowledge Discovery in Databases (KDD)
Figura 2.2: Procedimiento de extraccion de conocimiento en bases de datos
KDD [50], o Knowledge Discovey in Databases (Descubrimiento de Conocimiento en Bases deDatos). La minerıa de datos o Data Mining es un paso mas (o el principal) de este proceso dedescubrimiento o extraccion de informacion util.
Los metodos de KDD estan en constante evolucion y mejora, recibiendo aportaciones de otrasdisciplinas y areas de investigacion, como son la inteligencia artificial, el machine learning, recono-cimiento de patrones, la computacion neuronal, la estadıstica o los sistemas expertos.
A continuacion se presenta una descripcion del proceso del KDD, sus objetivos y metodologıas,y se detalla una de las principales componentes de este, que es la minerıa de datos. La informacionde las restantes secciones de este capıtulo esta extraıda de [18] [23] [48] y [50].
2.3 Knowledge Discovery in Databases (KDD)
El objetivo del KDD es el de hacer comprensible la informacion extraıda de los datos. Para ellose define un completo procedimiento de analisis, con unos pasos detallados que se comentan acontinuacion.
Primero, se precisa un tratamiento y conservacion adecuada de los datos, denominado DataWarehousing (almacenamiento de datos) [13]. Comprende la seleccion de los datos relevantes y delos atributos o dimensiones que se van a analizar, el preprocesado de los datos, que incluye eliminardatos erroneos que son fuente de “ruido”, y solucionar los problemas de perdida de informacion,como son datos con campos incompletos o sin rellenar, espacios vacıos, distintas escalas y formatos,normalizacion o problemas de compatibilidad cuando se usan bases de datos de distinta procedencia.
A continuacion se procede a la extraccion de informacion util, como patrones, modelos deprediccion, asociaciones, o los modelos de asociaciones entre los datos que se quieran buscar. Estees el proceso de minerıa de datos. Primero se debe decidir cual es el objetivo, que se quiere conseguir;sabiendo el objetivo, se puede elegir el metodo mas adecuado para conseguirlo. Los objetivos mascomunes y la metodologıa disponible estan detallados en la siguiente seccion.
Por ultimo, el paso que culmina el proceso del KDD es el de la evaluacion e interpretacion dela informacion obtenida, que permitira la aplicacion del conocimiento adquirido, para mejorar elrendimiento, seleccionar acciones, etc.
La figura 2.2 representa todo el proceso del KDD, incluyendo los metodos mas habituales paraminerıa de datos.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 5

2. Introduccion a la Minerıa de Datos y el KDD
2.4 Minerıa de datos (Data Mining)
Los algoritmos para minerıa de datos llevan a cabo tareas descriptivas, como el descubrimiento derelaciones o el reconocimiento de patrones, o tareas predictivas, como la clasificacion o el ajuste demodelos que permiten predecir el comportamiento.
Los algoritmos para minerıa de datos se componen normalmente de: un modelo que hay queajustar para el conjunto especıfico de datos a analizar, un criterio de seleccion del modelo a usar, yun criterio de satisfaccion, o funcion de coste a optimizar para la obtencion del modelo. Todas estascomponentes se aunan en un algoritmo de busqueda, cuyo primer paso suele ser el de la instanciaciono iniciacion de todos los parametros del modelo a valores de estado inicial, normalmente aleatorios,para a continuacion ajustar iterativamente el modelo segun el criterio de satisfaccion.
2.4.1 Objetivos
Los objetivos de la minerıa de datos, no son siempre los de agrupar los datos segun similitud. Estosobjetivos pueden ser:
Analisis de secuencias Tratamiento de secuencias de datos, con el fin de determinar patronesy pautas de comportamiento [1] [70], como el analisis de secuencias temporales (time seriesanalysis), o analisis y comparacion de valores caracterısticos en secuencias de datos, comolos valores medios, medianas, desviacion tıpica, varianza, etc.
Clasificacion Consiste en clasificar los objetos, entre un rango de categorıas. Un ejemplo son losllamados Mapas Asociativos de Memoria o Mapas Auto-organizados, entre los que se encuen-tran las redes de Kohonen [41], redes neuronales que clasifican objetos mediante aprendizajepor refuerzo. Dentro de este apartado tambien se encuentran los algoritmos que generanreglas de clasificacion para los objetos [72].
Clustering Los algoritmos de clustering agrupan los objetos segun similitud de caracterısticas,formando conjuntos o clases. La diferencia con la clasificacion es que en el caso del clusteringno hay una division previa del espacio en categorıas o clases; otra diferencia es tambien quelos algoritmos de clasificacion no agrupan los datos, sino que los clasifican uno a uno. Hayvarios tipos de clustering, segun la metodologıa empleada, y muchos algoritmos de cada tipo[5] [15] [36]. Estos algoritmos y sus funcionalidades estan tratados con detenimiento en elcapıtulo 3.
Asociacion El objetivo es el de descubrir relaciones ocultas entre los objetos, o incluso entrelos propios atributos de los objetos, de los cuales se puede extraer una base de reglas, conestructura condicional (Si A es B y C es D, Entonces E es F ) [4] [12].
Dependency modeling Describen relaciones significativas de dependencia entre variables. Seestablecen dos tipos de dependencias: la estructural y la cuantitativa. La dependencia estruc-tural especifica las variables que son localmente dependientes. La dependencia cuantitativada una medida numerica de como de fuertes son las dependencias.
Prediccion Obtencion (o entrenamiento) de modelos de prediccion, con el fin de validar hipotesisde comportamiento preconcebidas.
Regresion A partir de muestras de datos, se pretende estimar una funcion o modelo que puedaestablecer una relacion de dependencia de ciertas variables respecto de otras, con el fin depoder predecir valores a partir de nuevos datos [66].
Summarization Tiene como objetivo generar descripciones globales de conjuntos de datos. Enalgunos casos estas descripciones son cualitativas. Se usa, por ejemplo, para la extraccion deinformacion en textos [31].
Visualizacion del modelo Consiste en adecuar y reinterpretar los datos para que sean visual-mente entendibles y se puedan extraer conclusiones de un vistazo. Comprende todo tipo degraficos, como histogramas, graficos en coordenadas (2D o 3D) o evolucion en el tiempo.
6 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

2.4. Minerıa de datos (Data Mining)
Analisis exploratorio de datos Es similar al clustering en su objetivo y a las tecnicas de vi-sualizacion del modelo en su metodo. Dado un conjunto de datos del cual se desconocensus posibles interdependencias y relaciones de similitud, estas tecnicas tratan de identificarpatrones de forma visual y sin ninguna estructura de busqueda o semejanza preconcebida [2].
2.4.2 Metodologıas
Cada objetivo de todos los posibles de los que se ocupa la minerıa de datos puede ser llevado acabo mediante distintos metodos. Cada metodo tiene sus propias ventajas y desventajas. Muchasveces se usan combinaciones de varios metodos para alcanzar un solo objetivo, con la intencion deobtener un mayor refinamiento y un mejor resultado.
A continuacion se muestra una posible clasificacion de casi todos los metodos que han sidousados en la minerıa de datos.
Arboles de decision Los decision trees son estructuras de busqueda consistentes en nodos yramificaciones: cada vez que se alcanza un nodo, se produce una decision que genera dos omas alternativas o ramas a seguir. De esta forma se consigue una estructuracion jerarquizadade los datos, en donde se pueden analizar las similitudes en todos los niveles, subiendo elnivel de abstraccion conforme se avanza por el arbol de decision hacia niveles superiores,hasta alcanzar la rama principal, de la cual se parte con todos los datos sin clasificar. Unavez el arbol esta construido, la clasificacion de datos consiste en partir de la rama principale ir decidiendo en cada nodo a que rama tiene una mayor pertenencia el objeto o dato encuestion [57]. En algunas aplicaciones se le anade logica borrosa, logrando algoritmos debusqueda segun grados de pertenencia en nodos.
Case-Based reasoning Literalmente, razonamiento basado en casos. Son metodos que tratande resolver un problema haciendo uso de experiencias y resultados anteriores y conocidos.Todos los casos de distintos problemas planteados (y la forma de resolverlos) son descritosy almacenados; cuando un nuevo problema se plantea, se buscan situaciones similares quepudieran estar ya guardadas en la base de casos. Si se encuentra un problema similar, seaplica la solucion y toda la descripcion de problema y solucion se anade a la base de casospara futuras referencias.
Metodos estadısticos Historicamente, los primeros analisis sobre bases de datos consistıan enobtener y mostrar visualmente los valores de variables estadısticas, como la media, media-na, desviacion tıpica, representaciones en histogramas, graficos de tarta, etc. Estos analisisprincipalmente se usan para validar una hipotesis previa o para asociar un modelo de com-portamiento a los datos analizados. Es necesario, pues, que un experto formule y ajuste estashipotesis o modelos que luego se verifican.
Graph-based theory La teorıa basada en grafos tambien se usa en la minerıa de datos. Elobjetivo principal es el de descubrir relaciones topologicas ocultas entre los datos. Matemati-camente, un grafo es un objeto G formado por unos vertices (V ), un conjunto de segmentosque conectan pares de vertices (E), y una funcion de mapeado f [65].
Redes neuronales Las redes neuronales estan basadas en el modelo de computacion paraleladel cerebro. Una neurona biologica se comunica con otras mediante sinapsis, en donde lasdendritas son los canales de entrada que reciben las senales electroquımicas de las neuronasvecinas, produciendo una senal de salida por el axon, cuyo valor depende de la combinacionde valores en las entradas. En la figura 2.3 se puede observar el modelo matematico pararepresentar la unidad neuronal de transmision de informacion. Se puede ver que el valorde salida depende de una funcion matematica que toma como valor de entrada la sumaponderada de todas las entradas. Se usan tipos distintos de funciones segun el objetivo quese quiere conseguir, como funciones de suma, producto, o exponenciales. Unas de las masusadas son las funciones de activacion, que son funciones cuyo valor de salida varıa entredos estados (apagado o encendido) en funcion de si la combinacion de los valores de entradasobrepasa cierto lımite. La transicion entre estos dos estados, que puede ser suave o brusca,caracteriza los distintos tipos de funciones de activacion, habiendo funciones, por ejemplo,de perceptron, sigmoidales o de tangente hiperbolica.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 7

2. Introduccion a la Minerıa de Datos y el KDD
Figura 2.3: Interpretacion matematica del proceso de sinapsis neuronal
La union de neuronas para construir estructuras especıficas provee a las redes neuronalesde una gran capacidad de representacion. Las redes neuronales se usan, por ejemplo, comoaproximadores para emular el comportamiento de sistemas complejos multivariables, o comoclasificadores de objetos, como el reconocimiento de formas [20]. Mediante el ajuste de lospesos de cada entrada a todas las neuronas y la adecuada eleccion de la funcion de disparo, seconsiguen entrenar redes neuronales que reconocen y clasifican patrones de datos. Las redesneuronales son muy utiles para entrenar modelos de regresion, mapas de memoria [41] oclasificadores, modelos de aprendizaje, la generacion y evaluacion de reglas, y combinacionescon logica borrosa (modelos neuro-fuzzy), muy utiles en tareas de clasificacion o generacione inferencia de reglas. Las redes se pueden entrenar para aprender ajustando los pesos de susconexiones mediante algoritmos de aprendizaje, siendo el mas conocido y usado de todos elalgoritmo de backpropagation. Ejemplos de configuraciones de redes son las redes multicapa,las RBF o Radial Basis Function, o las redes de Kohonen [41].
El entrenamiento de redes neuronales tambien presenta desventajas y factores principalesa tener en cuenta, como son el problema de la aproximacion a mınimos locales durante elaprendizaje, y la propia saturacion de las neuronas, que implica prestar especial atencion ala correcta normalizacion de los datos.
Induccion de reglas Son metodos que descubren relaciones entre los datos, produciendo comoresultado una base de reglas antecedente-consecuente. La logica borrosa se usa mucho en estosmetodos, consiguiendo reglas que son mas comprensibles. La induccion de reglas sirve en losobjetivos de asociacion y clasificacion. Tambien se usan combinaciones con redes neuronalespara extraccion de reglas y validacion.
Redes de Bayes Llamadas tambien redes de confianza (Belief Networks), consisten en represen-taciones graficas de distribuciones de probabilidad, en donde los nodos son los atributos odimensiones de los objetos, junto a posibles dependencias entre ellas, y a cada nodo se leasocia una funcion de probabilidad, condicional o confianza, que relaciona los nodos con susantecesores y predecesores. Estas redes de confianza se usan por los expertos para estimar sus
8 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

2.4. Minerıa de datos (Data Mining)
propias deducciones sobre las relaciones y dependencias entre los objetos y entre sus carac-terısticas. Partiendo de valores y datos conocidos, se pueden observar todas las posibilidadesde expansion y analisis, mediante los valores de probabilidad de suceso en cada nodo.
Algoritmos geneticos / Evolutionary programming Son algoritmos que imitan los mecanis-mos de seleccion natural para una mejor adaptacion al entorno. Partiendo de una solucionque se ha de encontrar, unas relaciones que se han de establecer, o un modelo que se hade ajustar, se generan aleatoriamente posibles soluciones y se computa su eficacia en laresolucion del problema. Las mejores respuestas son seleccionadas y se combinan entre sı(reproduccion) para obtener nuevas combinaciones, que mejoraran los resultados anteriores.El proceso continua hasta que ya no se detectan mejoras o hasta que se cumple cierto valorumbral de eficacia (minimizacion de un ındice de coste por debajo de un valor establecido),intercalando recombinaciones y mutaciones aleatorias para evitar estancamientos. De estaforma se consigue una mejor evolucion y especializacion con cada nueva iteracion. Esta clasede algoritmos se usan sobretodo en modelos de regresion y en asociacion de reglas.
Fuzzy Sets La logica borrosa es una poderosa herramienta de interpretacion con datos que muchasveces son imprecisos, intervalares, no exactos o con incertidumbre, y que sin embargo aportanmayor cantidad de informacion de una forma intuitiva. En vez de tener que acotar y traducira rangos y valores numericos, la logica borrosa permite trabajar con conceptos tal como losconocemos, en afinidad, por tanto, con la representacion humana del conocimiento.
En las bases de datos hay muchas fuentes de incertidumbre: datos imprecisos, no numericos,vagos. La logica borrosa traduce estos datos a un conjunto de pertenencias borrosas, en dondecada dato pertenece a todas las areas o rangos de pertenencia definidos en diferentes porcen-tajes. La logica borrosa se usa en algoritmos de clustering [16], en objetivos de Asociaciono inferencia de dependencias funcionales entre variables, para generar reglas que interpretanfacilmente incertidumbres, grados de pertenencia, categorıas y conceptos, para clasificacionborrosa de objetos, asignando distintos grados de pertenencia a las clases. Se usa tambien enel proceso de summarization de datos, para asignar una descripcion conceptual a un conjuntode datos.
Rough Sets Son otro metodo empleado para tratar con conceptos, categorıas e incertidumbres,descrito por Zdzislaw Pawlak al comienzo de los anos 80 [54]. Un Rough Set se define porel lımite superior e inferior de una serie. Se pueden considerar como conjuntos borrosos contres funciones de pertenencia predefinidas: ‘Sı’, ‘No’ y ‘Quizas’. Al igual que con la logicaborrosa, los Rough Sets son usados normalmente en combinacion con otras tecnicas, como laclasificacion o los algoritmos de clustering.
La informacion en un Rough Set se facilita en forma de tablas de decision, en donde a cadaconcepto X se le asocian dos variables que representan respectivamente la maxima y mınimadefinicion posible del concepto. Los elementos que no pertenecen a la representacion mınimade X, pero sı pueden pertenecer a la representacion maxima, se dice que son componentes dela region lımite de X. Una de las principales aplicaciones de los Rough Sets es la induccionde reglas condicionales a partir de las tablas de decision. Las reglas inducidas a partir deelementos que pertenecen a la mınima (segura) representacion, se dice que son relacionesciertas; las reglas inducidas en regiones lımite no son ciertas, sino posibles.
Busqueda por similitud Esta es una tecnica empleada en los algoritmos de clustering, en dondelos objetos se agrupan merced a una medida de similitud o semejanza entre ellos. Normal-mente esta medida es la distancia de proximidad entre pares de objetos dada por la distanciaeuclıdea [36], aunque hay otros tipos de distancias y de medidas de similitud entre variables[6]. Normalmente, un objeto pertenece a un grupo o cluster concreto, si la distancia de esteobjeto al centroide del cluster no supera cierto valor lımite.
Wavelets Los wavelets, nombre derivado de small wave [25] [42], son funciones que cortan y divi-den series de datos segun sus componentes en frecuencias, para estudiarlos con una resolucionapropiada a su escala. El procedimiento es similar a la descomposicion en terminos de Fourier,aunque los wavelets ofrecen otras ventajas.
Al parecer, su uso en la minerıa de datos es bastante reciente, pero ya esta muy presenteen casi todos los objetivos que plantea, gracias a sus propiedades. Los wavelets se utilizan
Departamento de Ingenierıa de Sistemas y Automatica. UPV 9

2. Introduccion a la Minerıa de Datos y el KDD
actualmente para ‘limpieza’ y preparacion de los datos, reduccion de dimensionalidad deestos, obtencion de modelos de regresion, algoritmos de clustering [60], tareas de clasificacion,minerıa de datos distribuidos o DDM (Distributed Data Mining), y visualizacion del modelo.
Optimized Set Reduction Metodologıa que busca reducir los datos a subgrupos que contenganla mejor caracterizacion o representacion del conjunto entero de datos. El conjunto originalse divide sucesivamente en subconjuntos, segun semejanza de los objetos en el valor de algunatributo o caracterıstica seleccionada, continuando el proceso hasta alcanzar algun criteriode finalizacion. Entonces se realiza la prediccion o clasificacion acorde con la estructuraresultante de la subdivision.
Esta metodologıa puede parecer similar a los arboles de decision, aunque en este caso latecnica que se emplea permite mayores opciones de subdivision, combinando valores de variosatributos.
2.4.3 Conclusiones
Como se puede percibir, existen muchas tecnicas que persiguen un amplio abanico de distintosobjetivos de extraccion de informacion de los datos. Muchas de las tecnicas mostradas se combinanpara generar modelos hıbridos, a la busqueda de perfeccionar o mejorar la eficacia de los algoritmosconocidos.
El objetivo que interesa para este trabajo de investigacion es el del agrupamiento de los ob-jetos segun similitud y el reconocimiento de patrones que pueden estar ocultos en el conjunto delos datos. Por ello, una vez se ha revisado el area de conocimiento de aplicacion de este tipo dealgoritmos, en los siguientes capıtulos se procede a una descripcion mas detallada de la metodo-logıa de clustering en general, y de los algoritmos de agrupamiento de datos con caracterısticascuantitativas y cualitativas en particular.
10 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

Capıtulo 3
Tecnicas de agrupamiento o recono-cimiento de patrones (clustering)
En este capıtulo se realiza una descripcion de los algoritmos de clustering, como funcionan, y lasdistintas clasificaciones que se aplican, explicando varios de los algoritmos mas conocidos.
Los algoritmos de clustering no se usan solo en minerıa de datos. Aunque su principal funciones la de agrupar objetos segun semejanza, Dıez en su tesis [15], por ejemplo, usa los algoritmosde clustering para identificacion y generacion de modelos Entrada/Salida, a partir de muestras dedatos.
El funcionamiento de los algoritmos de clustering esta basado en la optimizacion de una funcionobjetivo, que normalmente es la suma ponderada de las distancias a los centros, aunque estasfunciones pueden variar, y muchas veces los distintos algoritmos de reconocimiento de patrones sedistinguen principalmente en la definicion de sus funciones objetivo a optimizar.
Uno de los pasos en los algoritmos de agrupamiento es el de asignar a cada objeto una medidade semejanza al patron o centroide de cada cluster, con el fin de determinar a cual de los gruposdetectados pertenece el objeto en cuestion. Esta medida de semejanza entre objetos de un conjuntode datos se basa normalmente en el calculo de una funcion de distancia. Seguidamente se exponenlas mas comunes, tanto para datos cuantitativos como cualitativos.
A continuacion se detallan las clasificaciones tıpicas que se aplican en los algoritmos de agru-pamiento, para a continuacion explicar, por secciones, los algoritmos de clustering mas conocidos,a que tipo pertenecen y como funcionan.
3.1 Medidas de distancia entre objetos
La informacion en esta seccion esta extraıda principalmente de [6] y [36]. En estos trabajos sepuede leer que hay dos tipos de ındices de proximidad: los que miden la cercanıa entre los objetos osimilitud (similarity) o los que miden la distancia entre los objetos o la disimilitud (dissimilarity).Ambos ındices son complementarios, lo cual quiere decir que cuanto mayor sea el ındice de similitudentre dos objetos, menor sera su ındice de disimilitud.
Los ındices de proximidad se denotan con la expresion d(i, k) y deben cumplir una serie decondiciones, mostradas en (3.1), (3.2) y (3.3).
d(i, i){
= 0,∀ i (disimilitud)≥ maxkd(i, k),∀ i (similitud) (3.1)
d(i, k) = d(k, i), ∀ (i, k) (3.2)d(i, k) ≥ 0, ∀ (i, k) (3.3)
A continuacion se detallan los ındices de proximidad. Algunos son aplicables a datos cuantita-tivos y otros a datos cualitativos. Son medidas de semejanza entre objetos, aunque no por ello sonexclusivos de los algoritmos de agrupamiento, sino que se usan tambien en otras tecnicas y conotros objetivos.
11

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
Figura 3.1: Distancias de Minkowski
3.1.1 Distancia Minkowski
Es una medida de disimilitud apropiada para valores cuantitativos. Se define como en (3.4).
d(i, k) =
d∑
j=1
|xij − xkj |r
1r
, donde r ≥ 1 (3.4)
Asignando distintos valores a r, se obtienen las distancias de Minkowski mas comunes y usadas,que son tres, y se detallan a continuacion. En la figura 3.1 se muestran graficamente con un ejemplo.
Distancia Manhattan o taxicab
Cuando r = 1, la expresion resultante queda como en (3.5)
d(i, k) =d∑
j=1
|xij − xkj | (3.5)
Se le llama distancia taxicab por semejanza a un taxi recorriendo las calles cuadriculadas deManhattan. Si todas las dimensiones son binarias, se tiene una forma especial de distancia Manhat-tan que tiene su nombre propio, la distancia Hamming, que es una medida directa del numerode atributos en que difieren dos objetos binarios. Ademas de para tecnicas de clustering [46], elcodigo Hamming se usa mucho en codificacion y transmision de datos.
Distancia Euclıdea
Cuando r = 2, la expresion resultante queda como en (3.6)
d(i, k) =
d∑
j=1
|xij − xkj |2
12
=√
(xi − xk)T (xi − xk) = ‖xi − xk‖ (3.6)
Es la distancia mas corta entre objetos, y la mas usada en las tecnicas de clustering.
Distancia del supremo
Cuando r tiende a infinito (r →∞), la expresion resultante queda como en (3.7).
d(i, k) = max1≤j≤d|xij − xkj | (3.7)
Es la distancia del supremo o, dicho de otra manera, la distancia mas grande entre todas lasdimensiones o coordenadas de los objetos.
12 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

3.1. Medidas de distancia entre objetos
3.1.2 Distancia de Mahalanobis
Otra medida de distancia apropiada para datos cuantitativos. Su expresion es como en (3.8)
d(i, k) = (xi − xk)T ϕ−1(xi − xk) (3.8)
en donde ϕ toma el valor de la matriz de covarianza (3.9). Ası se consigue incorporar la corre-lacion entre caracterısticas y estandarizarlas a media cero y varianza unitaria.
ϕ =1N
N∑
k=1
(xk − x)(xk − x)T (3.9)
Cuando ϕ−1 adquiere el valor de la matriz identidad, el resultado es la distancia euclıdea elevadaal cuadrado (‖xi − xk‖2).
3.1.3 Coeficiente de correlacion
El sample correlation coefficient es un ımdice de similitud para datos cuantitativos, usado fre-cuentemente para medir la dependencia lineal entre dos caracterıstcas o dimensiones. Su expresionfigura en (3.10).
d(j, r) =∣∣∣∣(1/n)
∑ni=1(xij −mj)(xir −mr)
sjsr
∣∣∣∣ (3.10)
En donde mj y s2j representan media y varianza para la caracterıstica j, respectivamente. Si
d(j, r) = 0, significa que la caracterıstica j y la caracterıstica r son linealmente independientes. Si,por el contrario, el valor de d(j, r) esta proximo a 1, hay una fuerte dependencia entre caracterıs-ticas, permitiendo que una de las dos sea descartada.
3.1.4 Matching coefficients
Son ındices de proximidad para datos cualitativos. Se basan en el conteo de igualdades y desigual-dades entre valores de las caracterısticas de los objetos. Por ejemplo, asumiendo que dos objetos (xi
y xk) tienen caracterısticas binarias, es decir, cada una de sus caracterısticas solo puede adquirirdos valores cualitativos, 0 o 1, se cuenta entonces la cantidad de caracterısticas que cumple con lasrelaciones descritas en la tabla 3.1.
Si se suman los valores de las cuatro variables, se obtiene el valor d, que es el numero decaracterısticas o dimensiones de los objetos. Al haber solo dos posibles respuestas (binario), y dosobjetos, el numero de combinaciones posibles para el conteo es 22 = 4 combinaciones. Si todas lascaracterısticas pudieran tomar n posibles valores, se tendrıan que computar 2n combinaciones.
La distancia d(i, k) se resuelve a partir de los valores que dan estos coeficientes de correspon-dencia (matching coefficients). Los tipos de distancia que se usan se detallan a continuacion.
Simple matching coefficient
Dada por la expresion en (3.11).
d(i, k) =a00 + a11
a00 + a11 + a01 + a10=
a00 + a11
d(3.11)
Implica igual importancia al numero de 0 en las mismas caracterısticas y tambien al numerode 1.
Distancia Jaccard
Dada por la expresion en (3.12).
d(i, k) =a11
a11 + a01 + a10=
a11
d− a00(3.12)
La distancia Jaccard no tiene en cuenta el numero de 0 en las mismas caracterısticas de ambosobjetos, asumiendo que el valor 0 en la caracterıstica implica que no es importante para el analisis.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 13

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
Tabla 3.1: Combinaciones totales para dos caracterısticas binarias
a11 Numero de caracterısticas que tienen valor 1 en ambos objetosa10 Numero de caracterısticas que tienen valor 1 en xi y valor 0 en xk
a01 Numero de caracterısticas que tienen valor 0 en xi y valor 1 en xk
a00 Numero de caracterısticas que tienen valor 0 en ambos objetos
Proximidad unica
Esta funcion de distancia, tambien llamada overlap metric, es una de las variantes mas sencillas.Apta para datos cualitativos. Su expresion es como en (3.13).
d(i, k) =∑d
j=1 δxij ,xkj
en donde δxij ,xkj=
{0 si xij = xkj
1 si xij 6= xkj
(3.13)
Solo se contabilizan aquellas caracterısticas cuyos valores no coincidan. Es una medida dedisimilitud.
3.1.5 Entropıa
La entropıa se define como la medida de la informacion e incertidumbre de una variable aleatoria[59]. Formalmente, dada una variable aleatoria X, su rango de posibles valores S(X), y su funcionde probabilidad p(x), su entropıa E(X) se define con la expresion formulada en (3.14).
E(X) = −∑
x∈S(X)
p(x)log(p(x)) (3.14)
La entropıa se usa en los algoritmos de clustering como medida de la diversidad o heterogeneidadde un conjunto de objetos, con el fin de agrupar estos en clusters de objetos que sean semejantesu homogeneos [7].
3.1.6 distancia de Kullback-Leibler
la distancia de Kullback-Leibler o entropıa relativa, es una medida de la divergencia entre dosdistribuciones de probabilidad [6]. Dadas dos distribuciones p y q en una serie T , se define laentropıa relativa con la formula mostrada en (3.15).
DKL[p‖q] =∑
t∈T
p(t)logp(t)q(t)
(3.15)
La distancia de Kullback-Leibler se usa, por ejemplo, en [47], como medida de la ganancia endivergencia que se producirıa al fundir dos clusters en uno.
3.1.7 Distancia de Gowda y Diday
Esta medida de la disimilitud, propuesta en [24], define tres medidas distintas para dos variablesAk y Bk: position, span y content. La distancia resultante es la suma de las tres. Sean las siguientesdefiniciones:
al = lımite inferior de Ak
bl =lımite inferior de Bk
aµ = lımite superior de Ak
bµ = lımite superior de Bk
inters = longitud de la interseccion entre Ak y Bk
ls = span = |max(aµ, bµ)−min(al, bl)|Uk = diferencia entre el mayor y menor valor de la caracterıstica kth para todos los objetosla = |aµ− al|lb = |bµ− bl|
14 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

3.2. Clasificaciones de los algoritmos de agrupamiento
Las distancias definidas para position (dp), span (ds) y content (dc) tienen los valores mostradosen las expresiones (3.16), (3.17) y (3.18).
Dp(Ak, Bk) =|al − bl|
Uk(3.16)
Ds(Ak, Bk) =|la − lb|
ls(3.17)
Dc(Ak, Bk) =|la + lb − 2inters|
ls(3.18)
3.2 Clasificaciones de los algoritmos de agrupamiento
A partir de la bibliografıa recogida sobre tipos de algoritmos de agrupamiento [6][15][36], se es-tablecen dos principales divisiones o clasificaciones, que son: algoritmos particionales/jerarquicos,algoritmos de pertenencia exclusiva/no exclusiva.
3.2.1 Algoritmos particionales vs. algoritmos jerarquicos
Los algoritmos particionales funcionan particionando el espacio en conjuntos o clusters de datos,tratando de optimizar un ındice de coste. Los mas usados son el K-means [45], el PAM [40] o elCLARA(Clustering LARge Applications) [40].
Los algoritmos de clustering jerarquicos realizan una descomposicion jerarquica de los objetos.Hay dos tipos: los que comienzan considerando todos los objetos como un unico conjunto o clusterque se va ramificando en clusters mas pequenos, llamados divisive o top-down, y los algoritmosque empiezan desde abajo, es decir, considerando a todos los objetos como clusters separados, yfundiendolos en clusters mas grandes segun una medida de distancia. Estos algoritmos se llamanagglomerative o bottom-up.
Loa arboles que se generan, con nodos y ramificaciones, al acabar el proceso del agrupamiento,reciben el nombre de dendogramas. Ejemplos de clustering jerarquico son los algoritmos BIRCH[71] o CURE [26].
3.2.2 Algoritmos de pertenencia exclusiva a clusters vs. pertenencia no ex-clusiva
Esta clasificacion atiende a si los objetos pertenecen en exclusiva a un unico grupo o cluster, o sipertenecen a mas de uno a la vez. Los algoritmos de pertenencia no exclusiva mas caracterısticos sonlos algoritmos de agrupamiento borroso (fuzzy clustering) [9], en donde cada objeto tiene asignadoun grado de pertenencia a todos los grupos detectados; el grado de pertenencia es mayor cuantomas similar sea el objeto al patron del cluster al que se refiere.
A continuacion se explicaran algunos de los algoritmos mas usados, como el algoritmo fuzzy c-means o FCM [16], que es la extension borrosa del clasico algoritmo de K-means [45], o el algoritmode GK o Gustafson-Kesel [28].
3.2.3 Otras clasificaciones
Aparte de estas clasificaciones, que se podrıan denominar clasicas, existen otros algoritmos declustering basados en tecnicas distintas a las expuestas. Estos algoritmos son:
Density-Based Clustering Algoritmos de clustering que agrupan objetos segun un criterio dedensidad mas que de proximidad. Ejemplos son DBSCAN (Density-Based Spatial Clusteringof Applications with Noise) [37], GDBSCAN (Generalized Density Based Spatial Clusteringof Applications with Noise) [17], o DENCLUE (DENsity-based CLUstEring) [30].
Grid-Based Clustering Particionan el espacio y buscan los objetos que pertenecen a cada cel-da resultante de la particion. Ejemplos de Grid-based clustering son los algoritmos STING(STatistical INformation Grid) [64], WaveCluster [60] y CLIQUE (CLustering In QUEst)[3].
Departamento de Ingenierıa de Sistemas y Automatica. UPV 15

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
Model-Based Clustering Algoritmos que seleccionan un modelo matematico para los datos ybuscan valores para los parametros que mejor representan el comportamiento. Un ejemplo esel algoritmo de Expectation-Maximization [10].
Categorical Data Clustering Son algoritmos especializados en el agrupamiento de datos cuali-tativos. Los algoritmos existentes y su funcionamiento estan detallados en el siguiente capı-tulo.
Spatial Clustering Agrupamiento por semblanza geografica [49]. Los algoritmos de clusteringgeografico o espacial buscan agrupar los objetos en formas geometricas, y detectar las rela-ciones espaciales entre estos grupos o formas, como la distancia que separa sus centros, lasareas de cada grupo o sus respectivas densidades. Por ello muchos de los tipos de algoritmospreviamente descritos son tambien de tipo geografico o espacial, en las condiciones adecua-das. Ejemplos de ello son el GDBSCAN (Generalized Density Based Spatial Clustering ofApplications with Noise) [17], GRAVIclust [34] o los metodos Grid-based [3] [60] [64].
Distributed Data Clustering Una de las soluciones a la extraccion y obtencion de datos ensistemas distribuidos es el clustering de datos, en concreto el llamado DDM (DistributedData Mining). Tal como se afirma en [14], las tecnicas de reconocimiento de patrones yagrupamiento de objetos por similitud en los valores de sus variables caracterısticas, sonutiles en redes para reconocimiento o diagnostico de fallos, o para recibir informacion de laevolucion de los estados o puntos de funcionamiento. El conocimiento global captado poruna unidad central de procesado de los datos se basa en la informacion y el conocimientocolectivo, reunido de forma particular e incompleta por diferentes agentes en diferentes puntosde la red. Los algoritmos de busqueda y reconocimiento de patrones en sistemas distribuidosse clasifican en los que requieren multiples barridos y rondas de envıo de la informacionentre agentes, requiriendo por tanto una alta sincronizacion, y los que construyen los clustersen areas locales y luego transmiten esta informacion a una unidad central que procesa yreestructura la informacion llegada de todas las zonas o sectores analizados. Algunos de estosalgoritmos incluyen metodos de encriptacion y/o seleccion de la informacion a agrupar, pormotivos evidentes, sobretodo en el campo de desarrollo de minerıa de datos y transmision deinformacion en redes inseguras donde la privacidad es un factor a tener en cuenta, como enla red Internet.
A continuacion, se describen unos cuantos de los algoritmos de clustering mas usados y cono-cidos, con una breve explicacion de a que tipo pertenecen y como funcionan. Se han clasificadoatendiendo a su principal caracterıstica, ya que muchos de ellos podrıan clasificarse como pertene-cientes a mas de una clase.
El siguiente capıtulo (capıtulo 4) esta dedicado especialmente a detallar los algoritmos de clus-tering de datos cualitativos, que son el objeto de este trabajo de investigacion.
3.3 Algoritmos de clustering
3.3.1 Algoritmos de clustering particional
Algoritmo de las distancias encadenadas o chain-map
El algoritmo chain-map [15] [53], es uno de los algoritmos de agrupamiento mas sencillos. Dado elconjunto de objetos, en forma de vectores, en donde cada elemento es el valor de una caracterıstica,el algoritmo comienza seleccionando un objeto cualquiera de los disponibles. A continuacion seordenan todos los demas objetos formando una cadena segun proximidad, como se puede ver en(3.19), en donde el subındice i indica que se ha seleccionado al objeto i como al primero de lacadena.
zi(0), zi(1), . . . , zi(N − 1) (3.19)
El procedimiento consiste en calcular todas las distancias euclıdeas entre el objeto k y el in-mediatamente anterior (k− 1), y disponerlas en la cadena por el orden establecido. Las distanciaseuclıdeas pequenas indican que los objetos pertenecen a una misma clase, mientras que un gransalto en el valor de la distancia euclıdea, significa una transicion de un grupo a otro. De esta
16 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

3.3. Algoritmos de clustering
forma se obtiene una agrupacion de todos los objetos en grupos, sin necesidad de definir previa-mente el numero de estos. Sı que es preciso determinar, sin embargo, a partir de que valor de saltocuantitativo de la distancia euclıdea se considera que se ha saltado de un cluster a otro.
Este algoritmo chain-map, aunque no es el optimo en algunos casos, sı es muy recomendable entodos como un paso previo para la iniciacion de otros algoritmos de clustering, y para la estimacioninicial del numero de grupos a buscar.
Max-min
El algoritmo Max-min [15] tampoco necesita predefinir el numero inicial de grupos o clusters abuscar. El procedimiento que sigue es el siguiente:
• Se selecciona uno de los objetos al azar, quedando asignado como patron del grupo A1.
• Se calculan todas las distancias euclıdeas de todos los objetos restantes con respecto al objetopatron del grupo A1. El objeto con la distancia euclıdea mas grande (el mas alejado de A1),queda seleccionado como patron de un segundo grupo A2.
• A continuacion se calculan todas las distancias euclıdeas de todos los objetos restantes conrespecto al objeto patron del nuevo grupo A2. De las dos distancias obtenidas para cadaobjeto, se selecciona la mas pequena. De todo el conjunto de distancias ası formado, seselecciona la mayor, y si esta es mayor que la distancia, ponderada por un factor f , entre lospatrones de los grupos A1 y A2, entonces se crea un nuevo grupo, A3 (ver 3.20).
• El mismo procedimiento se repite, creando nuevos grupos hasta que la respectiva distanciamaxima ya no sea mayor que el valor medio de todas las distancias entre patrones de todoslos grupos creados.
• Se recalculan por ultima vez todas las distancias euclıdeas de los objetos restantes a todos losrespectivos patrones de todos los grupos creados, asignando cada objeto como pertenecienteal cluster que tenga mas cercano (menor distancia euclıdea).
dmax > f d(z1, z2), 0 < f < 1 (3.20)El inconveniente de este algoritmo es la apropiada eleccion del factor de ponderacion f , ya que
interviene directamente en la creacion de un mayor o menor numero de grupos o clases distintas.
K-means
El algoritmo de K-medias o K-means [15] [45] es muy conocido y muy usado, por su eficacia yrobustez. Su nombre hace referencia al numero K de clases o grupos a buscar, que debe definirsecon antelacion. El procedimiento del algoritmo es el siguiente:
• Se comienza seleccionando K objetos al azar del conjunto total y asignandolos como patroneso centroides de las K clases que se van a buscar.
• A continuacion, se calculan todas las distancias euclıdeas de todos los objetos restantes atodos los K centroides, y se asigna la pertenencia a cada objeto al cluster que tenga mascercano.
• Entonces se recalcula el centroide de cada cluster, como la media de todos los objetos quelo componen, buscando minimizar el valor de una funcion de coste, que es un sumatorio detodos los sumatorios de las distancias euclıdeas de los objetos de cada clase al centroide desu respectiva clase, como se puede ver en (3.21).
• Los dos pasos anteriores se repiten sucesivamente hasta que los centros de todos los grupospermanezcan constantes, o hasta que se cumpla alguna otra condicion de parada.
J =k∑
i=1
∑
j,zj∈Ai
‖zj − ci‖ (3.21)
La eficacia del algoritmo K-means depende de la idoneidad del parametro K. Si este es mayoro menor que el numero real de grupos, se crean grupos ficticios o se agrupan objetos que deberıanpertenecer a clusters distintos.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 17

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
PAM
PAM (Partitioning Around Medoids) [5] [40] es una extension del algoritmo K-means, en donde cadagrupo o cluster esta representado por un medoide en vez de un centroide. El medoide es el elementomas centrico posible del cluster al que pertenece; similar al centroide, pero no necesariamente, yaque el centroide representa el valor patron o medio del conjunto, que no siempre coincide con elmas centrico.
El procedimiento para el agrupamiento es similar al del K-means.
CLARA
El algoritmo CLARA (Clustering Large Applications) [5] [40] divide la base de datos original enmuestras de tamano s, aplicando el algoritmo PAM sobre cada una de ellas, seleccionando la mejorclasificacion de las resultantes. Este algoritmo esta indicado para bases de datos con gran cantidadde objetos, y su principal motivacion es la de minimizar la carga computacional, en detrimento deuna agrupacion optima y precisa.
3.3.2 Algoritmos de clustering jerarquico
BIRCH
BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) [5] [71], almacena paracada cluster un triplete de datos que contiene el numero de objetos que pertenecen a ese grupo, elvalor de la suma de todos los valores de los atributos de todos los objetos pertenecientes al grupo,y la suma de los cuadrados de los atributos de los objetos que pertenecen al cluster. Con estainformacion construye un arbol de grupos llamado CF-tree (Cluster Features tree). En cada nodose indica el numero de grupos que pertenecen a esa ramificacion y cuales son sus caracterısticas.El procedimiento del algoritmo BIRCH es el siguiente:
• Generar un CF-tree inicial, leyendo los datos y asignandolos a una rama o a otra. Si ladistancia entre un objeto nuevo y los anteriores se hace mayor que cierto parametro T , secrea una rama nueva.
• Revisar el arbol creado para ver si es demasiado grande, y moldearlo modificando el valordel parametro T . Si el valor de este parametro se aumenta, las ramas del arbol se juntan alno haber distincion de grupos.
• Aplicar algun procedimiento de clustering, como el K-means, sobre la informacion contenidaen los nodos de cada nivel.
• Redistribuir los datos segun los centroides descubiertos en el paso anterior, logrando un mayorrefinamiento en el agrupamiento.
Las principales desventajas del algoritmo BIRCH son su secuencialidad, lo cual puede provocarasignacion a distintos clusters de objetos replicados, colocados en distintos lugares de la secuencia,y la fuerte dependencia del parametro T , de forma que una mala eleccion de este valor puedegenerar la creacion de falsas agrupaciones, o ramificaciones duplicadas, o la asignacion de objetosa un mismo nodo, cuando deberıan estar en nodos distintos.
CURE
CURE (Clustering Using REpresentatives) [5] [26] es un algoritmo de clustering jerarquico, que sebasa en la seleccion de mas de un elemento representativo de cada cluster. Como resultado, CUREes capaz de detectar grupos con multiples formas y tamanos.
Es un algoritmo de tipo aglomerativo, que comienza considerando todos los objetos como gruposindependientes, y a partir de ahı combina sucesivamente los objetos, agrupandolos en clusters. Decada uno de estos grupos, almacena los objetos extremos, desplazandolos hacia el centro del clustermediante un factor de acercamiento que es el valor medio de todos los elementos que componen elgrupo.
18 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

3.3. Algoritmos de clustering
3.3.3 Algoritmos de clustering borroso
Los algoritmos de clustering borroso se basan todos en una particion no-exclusiva de las pertenen-cias de los objetos a los distintos clusters. En una particion clasica (exclusiva) todos los objetos delconjunto son asignados (pertenecen) a un unico cluster y solo uno, cumpliendo los grupos formadoslas propiedades que se muestran en las expresiones (3.22), (3.23) y (3.24).
Ai
⋂Aj = ∅, 1 ≤ i 6= j ≤ c (3.22)
∅ ⊂ Ai ⊂ Z, 1 ≤ i ≤ c (3.23)c⋃
i=1
Ai = Z (3.24)
La expresion (3.22) indica que la interseccion de los elementos de dos clusters distintos debegenerar como resultado el conjunto vacıo (c es el numero de grupos). Las expresiones (3.23) y (3.24)indican que ningun grupo es el conjunto vacıo, y que la union de todos los elementos de todos losgrupos da como resultado el conjunto total de objetos (Z). Si se genera una matriz de pertenenciasU = [µik] de dimensiones c x N (c numero de clusters, N numero de objetos), se define un espaciode particiones clasicas como el conjunto de la expresion (3.25).
Mhc =
{U ∈ RcxN |µik ∈ {0, 1}, ∀i, k;
c∑
i=1
µik = 1, ∀k; 0 <
N∑
k=1
µik < N,∀i}
(3.25)
En una particion clasica, los valores de todo µik solo pueden ser o 0 o 1. Sin embargo, enuna particion borrosa [9] [15], los elementos µik de la matriz de pertenencias U , pueden tomarcualquier valor entre cero y uno. La particion borrosa se define segun la expresion (3.26), que tienelas mismas propiedades que la particion clasica (3.25), pero incorporando la posibilidad de que laspertenencias puedan adquirir valores dentro del rango [0, 1].
Mfc =
{U ∈ RcxN |µik ∈ [0, 1], ∀i, k;
c∑
i=1
µik = 1,∀k; 0 <
N∑
k=1
µik < N, ∀i}
(3.26)
En ambas particiones se requiere que la suma de todas las pertenencias de un unico objetoa todos los clusters ha de sumar uno. Este es un requerimiento no-posibilista. Aunque no es tanusada, tambien existe la variante posibilista de particion, en donde no se exige que la suma depertenencias para cada objeto sea exactamente igual a uno, sino que al menos la pertenencia dealgun objeto a un determinado cluster sea mayor de cero.
En los algoritmos que se detallan a continuacion se usa la particion borrosa no-posibilista (sumade pertenencias en cada objeto ha de ser igual a uno).
Algoritmo de las c-medias o fuzzy c-means
El algoritmo FCM o Fuzzy c-means [15] [16], esta basado en la minimizacion de la funcion objetivodefinida en (3.27), que es una medida ponderada del error cuadratico que se comete al definir loselementos ci como centroides de los c clusters.
J(Z; U,C) =c∑
i=1
N∑
k=1
(µik)m‖zk − ci‖2B (3.27)
Los elementos implicados en esta funcion son: Z, que es el numero de objetos; la matriz depertenencias U , cuyos elementos µik aparecen elevados a un factor de ‘borrosidad’ m, que puedetomar cualquier valor mayor de uno; y la matriz C de centroides de los clusters. La expresion‖zk − ci‖2B es una medida de la distancia, como se puede ver en (3.28).
‖zk − ci‖2B = (zk − ci)T B(zk − ci) = D2ikB (3.28)
Cuando a B se le da de valor la matriz identidad, se tiene cmo resultado la distancia euclıdeaelevada al cuadrado. Si B se sustituye por la inversa de la matriz de covarianzas, el resultado es ladistancia de Mahalanobis.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 19

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
El resultado de minimizar esta funcion objetivo, mediante igualacion a cero de las respectivasderivadas parciales, produce dos expresiones para obtener los valores de los centroides y de laspertenencias, mostrados en las expresiones (3.29) y (3.30).
µik =1
∑cj=1
(D2
ikB
D2jkB
) 2m−1
, 1 ≤ i ≤ c, 1 ≤ k ≤ N (3.29)
ci =∑N
k=1(µik)mzk∑Nk=1(µik)m
, 1 ≤ i ≤ c (3.30)
Partiendo de estas expresiones, el algoritmo FCM sigue los siguientes pasos:
• Inicializar la matriz de pertenencias U con valores aleatorios, pero que cumplan con losrequisitos definidos en (3.26).
• Calcular los centros de los clusters segun la expresion (3.30).
• Hallar todas las distancias de los objetos a los respectivos centros de sus grupos (3.28).
• Recalcular toda la matriz de particiones U aplicando la expresion (3.29) cuando D2ikB para
todo i, k, y aplicando la solucion expuesta en (3.31) para cualquier otro caso.
• Verificar si se cumple la condicion de parada. Si no se cumple, volver a empezar desde elsegundo paso del algoritmo. La condicion de parada es que la variacion en la matriz depertenencias de la nueva iteracion respecto a la calculada en la iteracion anterior este pordebajo de un valor umbral ε, tal y como se indica en (3.32). El parametro ε suele tener unvalor pequeno, normalmente 0.001 o menor, indicando que la nueva matriz de pertenenciasdebe ser muy similar a la anterior para que se pare el algoritmo.
µik = 0, si DikB > 0µik ∈ [0, 1], con
∑ci=1 µik = 1 para el resto (3.31)
‖U(k) − U(k−1)‖ < ε (3.32)
Algoritmo de Gustafson-Kessel o GK
El algoritmo GK es una variante del algoritmo FCM, propuesta por Gustafson y Kessel en 1979[15] [28]. Esta consiste en asignar distintas clases de normas B a los distintos grupos o clases, conlo cual se obtienen agrupaciones con distintas formas.
Ası pues, se define un vector B que contiene c normas, y se modifica la funcion objetivo aminimizar de forma que quede como en (3.33).
J(Z; U,C, B) =c∑
i=1
N∑
k=1
(µik)m‖zk − ci‖2Bi(3.33)
Para obtener una solucion viable, el rango de posibles valores de los elementos Bi se limitaestableciendo un valor fijo para su determinante, como se puede ver en (3.34).
|Bi| = ρi, ρ > 0 (3.34)
El resultado de minimizar la funcion objetivo resulta en una nueva expresion para el calculo delas normas (3.35), en donde la variable Fi representa la matriz de covarianzas de la clase i, y sepuede obtener usando la expresion (3.36). La formula para el calculo de los centroides se mantienecomo en el FCM (3.30), y la nueva expresion para calcular las pertenencias a las clases es como laanterior (3.29), pero incorporando el hecho de que hay una norma distinta para cada grupo, comose puede ver en (3.37).
20 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

3.3. Algoritmos de clustering
Bi = [ρidet(Fi)]1n F−1
i (3.35)
Fi =∑N
k=1(µik)m(zk − ci)(zk − ci)T
∑Nk=1(µik)m
(3.36)
µik =1
∑cj=1
(D2
ikBi
D2jkBi
) 2m−1
, 1 ≤ i ≤ c, 1 ≤ k ≤ N (3.37)
Los pasos que sigue el algoritmo son, pues, los siguientes:
• Inicializar la matriz de pertenencias U con valores aleatorios.
• Calcular los centros de los grupos, segun la expresion (3.30).
• Calcular la matriz de covarianzas de cada clase (3.36).
• Calcular todas las distancias, aplicando la norma correspondiente en cada caso, segun (3.35)y (3.28).
• Hallar todos los nuevos valores de la matriz de pertenencia, siguiendo el mismo procedimientodescrito para el FCM, y teniendo en cuenta que hay una norma distinta para cada cluster(3.37).
• Verificar la condicion de parada, que es la misma que en el caso del FCM (3.32). Si no secumple, volver al paso 2 del algoritmo.
Algoritmo de estimacion de la maxima probabilidad o FMLE
El algoritmo FMLE (Fuzzy Maximum Likelihood) [15] [21] es otra variante del FCM que incluyeuna norma con un termino exponencial, que se calcula mediante el uso de las expresiones (3.38),(3.39) y (3.40).
D2ikGi
=
√det(Gi)Pi
exp
[12(zk − ci)T G−1
i (zk − ci)]
(3.38)
Gi =∑N
k=1 µik(zk − ci)(zk − ci)T
∑Nk=1 µik
(3.39)
Pi =1N
N∑
k=1
µik (3.40)
Al igual que el algoritmo GK, cada grupo o clase tiene su propia norma asociada, que se calculade la forma que se ha mostrado. El resto del procedimiento es similar a la secuencia de pasos delalgoritmo GK.
3.3.4 Algoritmos de clustering basados en la densidad
GDBSCAN
El algoritmo GDBSCAN (Generalized Density Based Spatial Clustering of Applications with Noise)[17] esta basado en la densidad de los grupos formados. Al buscar formas densas que pueden ocuparzonas geograficas, este es tambien un algoritmo clasificado como de clustering geografico.
El principio en que se basa es que para que se reconozca un cluster en una zona, esta deberebasar cierto lımite o threshold de densidad. Este valor de densidad es una relacion entre el numerode objetos y el area que ocupan en el conjunto considerado como perteneciente a un unico cluster.
Los grupos detectados (o inicializados) son considerados como objetos o cuerpos geometricos,con sus propias caracterısticas, como son el centro de gravedad, el area total, la densidad, etc. Todoslos objetos pueden compararse entre sı para establecer relaciones de distancia entre los centros delos clusters, o si hay un solapamiento entre regiones, con lo cual se puede plantear la fusion oreorganizacion de los distintos grupos.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 21

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
Normalmente se realiza un proceso iterativo, en el que a cada objeto de la base de datos sele calcula si pertenece o no a alguno de los clusters reconocidos, y a que distancia se encuentrade todos ellos. Si este objeto no se asigna como perteneciente a ningun grupo, se considera comoruido y se pasa al siguiente elemento, hasta completar un barrido de todos los objetos. Finalizadoel proceso, si la condicion de parada no se satisface, se vuelve a empezar variando las condicionesiniciales.
El resultado final es un mapa geografico de densidades, en donde las zonas con mayor densidadde objetos se agrupan para formar clusters geometricos, con sus propios valores definiendo suforma, densidad y situacion en el espacio de coordenadas.
DENCLUE
DENCLUE (DENsity-based CLUstEring) [30] usa el concepto de las funciones de influencia paracatalogar la influencia que cada objeto ejerce sobre los elementos cercanos. Estas funciones deinfluencia son similares a las funciones de activacion usadas para redes neuronales: superado ciertovalor umbral de distancia entre objetos (distancia euclıdea), la salida cambia de un estado a otro,normalmente entre un estado inactivo (0) y otro activo (1). El valor umbral viene definido porfunciones de activacion, como la gaussiana o la sigmoidal.
La densidad se computa como la suma de todas las funciones de influencia de todos los objetos.Los clusters se determinan mediante la deteccion de los atractores, o maximos locales de densidad.Se consigue ası un algoritmo de agrupamiento robusto, capaz de manejar datos ruidosos o erroneos.
3.3.5 Algoritmos de clustering Grid-based
STING
STING (STatistical INformation Grid) [5] [64] particiona el espacio segun niveles, en un numerofinito de celdas con una estructura jerarquica rectangular. De cada celda extrae la informacion delos objetos que allı encuentra, que es: media, varianza, mınimo y maximo de los valores y tipode distribucion de los objetos encontrados. Con cada nivel se vuelven a particionar las celdas,construyendo un arbol jerarquico a semejanza del algoritmo BIRCH [71]. Acabada la particion delespacio hasta el nivel de detalle deseado, los clusters se forman asociando celdas con informacionsimilar mediante consultas especializadas.
CLIQUE
CLIQUE (CLustering In QUEst) [3] [5] tambien realiza particiones del espacio segun niveles, peroen esta ocasion cada nivel nuevo es una dimension mas, hasta alcanzar la n dimensiones o caracterıs-ticas de los objetos. La estructura de particion es en forma de hiper-rectangulos. El funcionamientoes el siguiente: comienza con una unica dimension, y la divide en secciones, buscando las mas den-sas, o aquellas donde se encuentran mas objetos. A continuacion incluye la segunda dimension en elanalisis, particionando el espacio en rectangulos, y buscando los mas densos. Luego sigue con cubosen tres dimensiones, y ası sucesivamente. Cuando acaba con todas las caracterısticas o dimensionesde los objetos, se definen los clusters y las relaciones entre ellos mediante semejanza de densidadesy otra informacion extraıda, en todos los niveles o dimensiones.
3.3.6 Algoritmos de clustering basado en modelos
Expectation-Maximization
el algoritmo de Expectation-Maximization [5] [10] o EM, asigna cada objeto a un cluster predefinido,segun la probabilidad de pertenencia del objeto a ese grupo concreto. Como modelo se usa unafuncion de distribucion gaussiana, siendo el objetivo el ajuste de sus parametros, segun como losdistintos objetos del conjunto se ajustan a la distribucion en cada cluster. El algoritmo de EMpuede identificar grupos o clases de distintas formas geometricas, si bien implica un alto costecomputacional, para conseguir un buen ajuste de los parametros de los modelos.
22 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

3.4. Resumen
3.3.7 Algoritmos de clustering geografico o espacial
GRAVIclust
El GRAVIclust es un algoritmo de clustering geografico, propuesto en [34], que busca conjuntosgeograficos definidos por el area, el centro y el radio del area localizada (con lo cual los grupostienen una forma mas o menos circular), y la densidad de cada grupo, es decir, las zonas masconcurridas son las que mas probabilidad tienen de formar un cluster de datos. Como medida desimilitud se usa la distancia euclıdea, siendo la funcion objetivo a optimizar la mostrada en laexpresion (3.41)
J =k∑
i=1
∑
p∈Ci
d(p, Li) (3.41)
en donde k es el numero de clusters a buscar, p es un objeto perteneciente al cluster Ci, y des la distancia del objeto p al centro de gravedad de la agrupacion Ci, llamado Li. El objeto ppertenece unicamente al conjunto cuya distancia al centro de gravedad Li sea menor.
La busqueda se perfecciona en sucesivas iteraciones, buscando los centros de los clusters for-mados mediante el calculo del centro de masas (o centro de gravedad) de todos los objetos quecomponen el cluster correspondiente.
3.3.8 Algoritmos de clustering en datos distribuidos
Collective Principal Component Analysis
En [39] se propone un algoritmo para el agrupamiento de objetos cuyas caracterısticas se encuen-tran distribuidas entre varios nodos de una red, lo que se conoce como datos heterogeneamentedistribuidos. Para ello se basa en la tecnica del PCA (Principal Components Analysis) [35], lacual busca una representacion reducida de los datos que contenga la informacion mas relevantepara permitir la agrupacion (los Principal Components).
El nombre resultante es el de CPCA (Collective Principal Components Analysis). Cada nodolocal realiza el agrupamiento sobre sus caracterısticas, y envıa la informacion con los datos masrepresentativos obtenidos a una unidad central. Allı se vuelve a aplicar el procedimiento de cluste-ring sobre los datos recibidos; los resultados son enviados de vuelta a todos los nodos, que vuelvena aplicar la tarea de agrupacion tomando como patrones los datos recibidos. Los clusters localesresultantes son vueltos a enviar a la unidad central.
RACHET
RACHET (Recursive Agglomeration of Clustering Hierarchies by Encircling Tactic) [58] es unalgoritmo de clustering jerarquico disenado para conjuntos de objetos distribuidos homogeneamente(con todas sus caracterısticas o dimensiones) en distintos nodos en una red.
Cada nodo genera primero un dendograma (arbol jerarquico de agrupamiento) local, segun losobjetos contenidos en el. A continuacion todos los dendogramas locales son enviados a una unidadcentral, pero para reducir costes de comunicacion, lo que se envıa es una aproximacion de losresultados en forma de resumenes estadısticos de ciertos indicadores, como el numero de objetosen cada grupo o la distancia euclıdea media de todos los datos al centroide del grupo.
El nodo central procesa toda la informacion de los dendogramas locales para crear un den-dograma global, con el agrupamiento de todos los objetos contenidos en la red distribuida. Paraello va anadiendo los dendogramas locales como si fueran ramificaciones del dendograma global, ycombina agrupaciones cuando se cumplen ciertas condiciones.
3.4 Resumen
En la figura 3.2 se muestra el esquema con los distintos tipos de algoritmos de agrupamiento quehan sido mencionados en esta seccion. Todos ellos fueron en principio disenados para conjuntos deobjetos con multiples caracterısticas o dimensiones numericas. En el siguiente capıtulo se describenlos algoritmos encontrados en la literatura, que han sido disenados especıficamente para tratar condatos cualitativos o con caracterısticas que no son solo numericas, sino de otro tipo, como nominales,borrosas o intervalares.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 23

3. Tecnicas de agrupamiento o reconocimiento de patrones (clustering)
Figura 3.2: Tipos de algoritmos de agrupamiento
24 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

Capıtulo 4
Tecnicas de agrupamiento para datoscuantitativos y cualitativos
En este capıtulo se detallan algoritmos de agrupamiento para datos exclusivamente cualitativos ocon caracterısticas cuantitativas y cualitativas. Estos algoritmos ofrecen alternativas a la opcion mascomun: la de asignar un numero a cada categorıa y aplicar directamente el calculo de la distanciaeuclıdea para realizar el proceso de clustering con cualquier algoritmo existente. Esta tecnica noes recomendable aunque pueda parecer que produce resultados acertados, como se explica en [6].Una de las razones es el posible desajuste entre las distancias entre categorıas cualitativas tomadascomo cuantitativas, y el rango de variables posibles, que puede ser mucho mayor o indefinido. Otrarazon es que los resultados de la agrupacion pueden unir en una misma clase objetos que no tienennada en comun. Se puede ver en el siguiente ejemplo, mostrado por Guha et al. en [27]. Dadoscuatro objetos, cada uno de seis dimensiones o caracterısticas cualitativas que, en este caso, sonbinarias, sus valores son los que se muestran en la expresion (4.1), haciendo hincapie en que elvalor 0 indica ausencia de elemento y, por tanto, el objetivo es el de agrupar los objetos segun lascaracterısticas que sean iguales a 1.
X =
1 1 1 0 1 00 1 1 1 1 01 0 0 1 0 00 0 0 0 0 1
(4.1)
Al proceder por orden de presentacion (desde el objeto en la fila 1 hasta el objeto en la fila4 de la matriz de datos X), a calcular las distancias euclıdeas entre los objetos, un algoritmo deagrupamiento como el K-means concluye que el mejor resultado de agrupacion es el de formarun cluster con los objetos 1 y 2, y otro con los objetos 3 y 4. El algoritmo procede ası porqueprimero calcula la distancia entre los objetos 1 y 2, obteniendo la mınima distancia de todas lascombinaciones posibles, y a continuacion prueba las combinaciones de distancias de los objetos3 y 4 con los demas datos y entre ellos mismos, obteniendo como mınima distancia la que hayentre ellos, que es sin embargo mas grande que la distancia entre los objetos 1 y 2. El primercluster formado sı que parece apropiado, pues ambos objetos (1 y 2) tienen tres dimensiones ocaracterısticas en comun. Sin embargo, los objetos 3 y 4 no tienen nada en comun ni compartenninguna caracterıstica, por tanto su agrupacion como resultado de la minimizacion de las distanciaseuclıdeas es inapropiada.
A continuacion se presentan algoritmos encontrados en la literatura, que tratan el analisis dedatos de distinta naturaleza con tecnicas distintas al uso de distancias euclıdeas.
4.1 Algoritmo K-modes
Es una extension del algoritmo particional k-means, y su descripcion se puede encontrar en [33].El algoritmo k-modes se diferencia del K-means en que:
• Usa una medida de la distancia distinta.
• Las medias son reemplazadas por modos.
25

4. Tecnicas de agrupamiento para datos cuantitativos y cualitativos
• Los modos se actualizan con un metodo basado en frecuencia.
La funcion de distancia empleada es la de proximidad unica (ver 3.1.4), en donde se contabilizael numero de no-concordancias entre atributos de los objetos.
El modo en una caracterıstica es el valor que mas aparece en esa caracterıstica. La funcionobjetivo del algoritmo k-modos es el sumatorio de todas las distancias de todos los objetos a todoslos modos, habiendo tantos modos como clusters.
El algoritmo k-modos esta disenado para datos cualitativos. Para objetos con atributos cua-litativos y cuantitativos, se define una extension del algoritmo k-modos, llamada algoritmo k-prototipos [52]. En este algoritmo las distancias entre atributos cuantitativos y atributos cua-litativos se computan por separado, siendo la medida de distancia total la suma ponderada dedistancias cuantitativas y cualitativas, segun se expresa en (4.2)
sT = snum + γscat (4.2)
en donde γ representa un factor de ponderacion para equilibrar la importancia de ambos tiposde caracterısticas.
k-modes y k-prototipos tienen su equivalente en fuzzy [52].
4.2 Algoritmo ROCK
ROCK (RObust Clustering using linKs) es un algoritmo de clustering jerarquico disenado paradatos cualitativos [5] [27]. Su funcionamiento esta basado en el concepto de los enlaces (links)entre objetos vecinos (neighbors). Se describe como vecinos a dos objetos si el valor de una funcionde similitud entre los dos objetos excede cierto valor de lımite θ (4.3).
sim(x, y) ≥ θ (4.3)
La funcion de similitud esta definida por el usuario y puede ser cualquiera de las medidasde distancia apropiadas para datos cualitativos, como por ejemplo los matching coefficients (verseccion 3.1.4). El valor umbral θ tambien esta definido por el usuario.
Se denomina enlace entre dos objetos x e y (link(x, y)), al numero de vecinos comunes a losobjetos x e y, o dicho de otra manera, el numero de objetos al que tanto x como y son similares.La funcion objetivo se define con la intencion de maximizar el sumatorio de todos los enlaces detodos los objetos pertenecientes a cada cluster, y minimizar el sumatorio de todos los enlaces entreobjetos pertenecientes a clusters distintos. La expresion para esta funcion objetivo se puede ver en(4.4), en donde Ci representa el cluster i de tamano ni.
J =k∑
i=1
ni
∑
x,y∈Ci
link(x, y)
n1+2f(θ)i
(4.4)
ROCK es un algoritmo jerarquico. Comienza interpretando todos los objetos como si fuerangrupos independientes, y con cada iteracion combina los clusters intentando mejorar el resultadode la funcion objetivo. Para ello realiza una medida de la bondad (goodness measure) entre paresde grupos. Los pares que tengan la bondad mas alta, son los que se combinan para formar un nuevocluster. Esta medida de bondad se muestra en la expresion (4.5), en donde link[Ci, Cj ] indica elnumero de enlaces entre todos los objetos del cluster Ci y todos los objetos del cluster Cj .
g(Ci, Cj) =link[Ci, Cj ]
(ni + nj)1+2f(θ) − n1+2f(θ)i − n
1+2f(θ)i
(4.5)
4.3 STIRR
STIRR (Sieving Through Iterated Relational Reinforcement) [5] [22] aplica la teorıa de grafospara transformar los objetos de la base de datos en graficos de co-ocurrencia de valores entrelos distintos atributos: los objetos similares son aquellos que tienen concurrencias de elementoscomunes. Para ello, cada posible valor de cada caracterıstica se representa graficamente como unnodo, estableciendose uniones entre nodos para representar los distintos objetos, como se puedever en el ejemplo la figura 4.1 para los objetos con tres caracterısticas, a, b y c, de la tabla 4.1.
26 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

4.4. CACTUS
Figura 4.1: Ejemplo de grafo mostrando las co-ocurrencias entre los objetos de la tabla 4.1
Tabla 4.1: Conjunto de objetos con tres caracterısticas
Object a b c1 A W 12 A X 13 B W 24 B X 25 C Y 36 C Z 3
Cada nodo lleva un peso asignado, que se inicializa en el paso inicial del algoritmo. El pesototal del objeto se calcula mediante un operador ⊕ que puede ser definido como un sumatorio o unproducto de los pesos de los nodos que forman el objeto. Una funcion de normalizacion previeneen cada iteracion que los pesos crezcan en exceso, aplicando el reescalado de los datos.
El agrupamiento se realiza definiendo una funcion f , que contiene un operador ⊕ y una funcionde normalizacion determinadas. Con cada nueva iteracion, se obtiene el valor global de f a partirde los computos de pesos , buscando una solucion convergente. Cuando f converge, se asume quelas distintas combinaciones de pesos, y por tanto la agrupacion de objetos segun co-ocurrencias, esoptima.
Las co-ocurrencias con un mayor peso resultante son las que mas destacan para formar agrupa-ciones, por tanto en el paso inicial del algoritmo se puede asignar un mayor peso a aquellos valoresque se consideran mas importantes, o que se quieren encontrar todas sus correspondencias.
Una de las desventajas del algoritmo STIRR es que no se ha logrado que identifique mas dedos clusters.
4.4 CACTUS
El algoritmo CACTUS (Clustering Categorical Data Using Summaries) [5] [19] se basa en la mismametodologıa que el STIRR, intentando mejorar este mediante el uso de sumarios o resumenes.Partiendo de la configuracion de los objetos en grafos de co-ocurrencia, como el de la figura 4.1,se establece que las zonas con mayor probabilidad de formar grupos o clusters son aquellas conmayor numero de co-ocurrencias o, dicho de otro modo, las mas “densas” en conexiones. Por tanto,los clusters en el algoritmo CACTUS son areas rectangulares que engloban series de nodos con lasmayores cantidades de co-ocurrencias, como se puede ver en el ejemplo de la figura 4.2.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 27

4. Tecnicas de agrupamiento para datos cuantitativos y cualitativos
Para formular la pertenencia de los objetos a las regiones o clusters, se introducen una serie dedefiniciones, que son las siguientes:
• Se denomina a S = S1xS2x . . . xSn region intervalo (interval region) si para todo i ∈[1, . . . , n], Si ⊆ Di, en donde Di es el dominio de todos los posibles valores cualitativosde la caracterıstica Ai. El soporte (support) σD(ai, aj) del par de valores de las caracterıs-ticas (ai, aj) con respecto a D se define como en la expresion (4.6). Dada una region S, elsoporte σD(S) indica el numero de objetos en D que pertenecen a S.
• Dados dos valores de dos caracterısticas distintas, (ai, aj) se dice que estan fuertementeconectados (strongly connected) con respecto a D, si σD(ai, aj) > α · |D|
|Di|·|Dj | , con α > 1. Lafuncion σ∗D(ai, aj) se define como en la expresion (4.7).
• Se define a C como un cluster si cumple las siguientes tres condiciones: (1) todos los objetosque lo componen estan fuertemente conectados, (2) no existe ningun objeto no pertenecienteal cluster que este fuertemente conectado con algun objeto perteneciente al grupo, y (3) elsoporte σD(C) de C es al menos α veces el soporte esperado de C bajo la asuncion de laindependencia de caracterısticas. El soporte esperado de C (Expected Support) se define enla expresion (4.8), en donde n es el numero de atributos o caracterısticas.
• La similitud o semejanza de dos valores distintos (a1, a2) de un mismo atributo i respectoa otra caracterıstica distinta Aj se define como en la expresion (4.9). La similitud establecerelaciones de semejanza entre distintos objetos con co-ocurrencias comunes.
• El sumario inter-atributos ΣIJ (ver (4.10)) y el sumario intra-atributos ΣII (ver (4.11))recogen toda la informacion (sumarios) de todas las relaciones fuertemente conectadas endonde cada par de valores son de diferentes caracterısticas, en el primer caso (inter-atributos),y de la misma caracterıstica en el segundo (intra-atributos).
σD(ai, aj) = |{t ∈ D : t.Ai = ai y t.Aj = aj}| (4.6)
σ∗D(ai, aj){
σD(ai, aj), si ai y aj estan fuertemente conectados0, en cualquier otro caso (4.7)
E[σ(C)] = |D| · |C1|x . . . x|Cn||D1|x . . . x|Dn| (4.8)
γj(a1, a2) = |{x ∈ Dj : σ∗(a1, x) > 0 y σ∗(a2, x) > 0}| (4.9)
ΣIJ = {Σij : i, j ∈ {1, . . . , n}, i 6= j}, dondeΣij = {(ai, aj , σ
∗D(ai, aj)) : ai ∈ Di, aj ∈ Dj , y σ∗D(ai, aj) > 0} (4.10)
ΣII = {Σjii : i, j ∈ {1, . . . , n} y i 6= j}, donde
Σjii = {(ai1, ai2, γ
j(ai1, ai2)) : ai1, ai2 ∈ Di y γj(ai1, ai2) > 0} (4.11)
El procedimiento del algoritmo CACTUS consta de tres pasos: uno de sumarizacion, otro deagrupamiento y otro de validacion. En el de sumarizacion se computa toda la informacion desumarios inter e intra-atributos de todo el conjunto de objetos. En la fase de agrupamiento se usala informacion de los sumarios para formar las agrupaciones candidatas, y en la fase de validacionse obtienen los clusters resultantes mediante refinamiento de las agrupaciones candidatas.
Una de las desventajas del algoritmo CACTUS es su alto coste computacional cuando losatributos o caracterısticas de los objetos tienen dominios grandes, con muchos distintos valores.
4.5 COOLCAT
COOLCAT [7] es un algoritmo de agrupamiento de datos cualitativos basado en la medida de laentropıa (ver seccion 3.1.5). El objetivo del algoritmo es lograr la agrupacion de todos los objetosen clusters de forma que se minimice la entropıa global. La funcion a optimizar es la mostrada en(4.12), que es un sumatorio de todas las medidas de entropıa de todos los clusters identificados, endonde D representa el conjunto total de objetos a agrupar.
28 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

4.6. LIMBO
Figura 4.2: Ejemplo de identificacion de clusters con CACTUS
E(C) =∑
k
( |Ck||D| E(Ck)
)(4.12)
El procedimiento del algoritmo es el mismo que el que se usa para el algoritmo Max-min (verseccion 3.3.1), pero aplicando la medida de la entropıa en vez de la distancia euclıdea, como medidade disimilitud entre los objetos: los dos mas dispares de todo el conjunto se eligen como centrosde los dos primeros clusters, y a continuacion se asignan las pertenencias del resto de objetos,secuencialmente, al grupo en el que la entropıa resultante sea la menor de todas las posibilidades(indicando la mayor homogeneidad o similitud de un objeto con todos los demas asignados a ununico cluster). Al contrario que en el algoritmo Max-min, en este caso el numero de grupos oclusters a identificar ya debe estar definido de antemano.
Una de las ventajas de COOLCAT es que la medida de la entropıa parece ser una de las masidoneas para tratar con datos cualitativos [43]. La mayor desventaja de este algoritmo, sin embargo,es que depende fuertemente del orden en que se analizan los objetos para asignarles la pertenenciaa un grupo. Los autores recomiendan una heurıstica o conocimiento previo de los objetos, pudiendoası establecer un orden determinado previo al agrupamiento.
4.6 LIMBO
LIMBO (scaLable InforMation BOttleneck) [6] es un algoritmo de clustering jerarquico basado en elmetodo del Information Bottleneck [62], en el que la informacion sobre una variable aleatoria Y estacontenida en otra variable aleatoria X, que se reinterpreta intentando compactarla lo mas posiblesin perder la informacion original sobre la variable Y . En este caso se trata de optimizar una funcionde “compactacion” del conjunto de objetos contenidos en una serie T , en una representacion C,que son los clusters. Para ello hace uso del algoritmo Agglomerative Information Bottleneck (AIB),propuesto en [61].
El algoritmo AIB trabaja con calculo de probabilidades. Dado un conjunto de n elementospertenecientes a la serie T , todos ellos con una serie de atributos o caracterısticas A, se define unagrupamiento C formado por grupos de clusters c. Asumiendo que todos los objetos tienen igualprobabilidad de darse (p(t) = 1
n ), las expresiones que relacionan T , A y C se muestran en lasexpresiones (4.13) y (4.14).
Departamento de Ingenierıa de Sistemas y Automatica. UPV 29

4. Tecnicas de agrupamiento para datos cuantitativos y cualitativos
p(c) =∑t∈c
p(t) =|c|n
(4.13)
p(a|c) =1
p(c)
∑t∈c
p(t)p(a|t) (4.14)
El algoritmo AIB comienza identificando todos los objetos como grupos independientes, quesucesivamente se iran combinando hasta formar una agrupacion optima. En cada iteracion seescogen dos clusters, ci y cj , que se combinan para formar un nuevo grupo c∗ de forma quese minimice una funcion de perdida de informacion, δI(ci, cj). La informacion del nuevo clusterc∗ = ci
⋃cj se calcula como se puede ver en las expresiones (4.15) y (4.16).
p(c∗) = p(ci) + p(cj) (4.15)
p(A|c∗) =p(ci)p(c∗)
p(A|ci) +p(cj)p(c∗)
p(A|cj) (4.16)
En cuanto a la funcion de perdida de informacion, esta se calcula con la formula mostrada enla expresion (4.17), en donde la variable DJS es la divergencia de Jensen-Shannon, una medidade similitud que se calcula a partir de la distancia de Kullback-Leibler (DKL) (ver seccion 3.1.6),como se muestra en la expresion (4.18).
δI(ci, cj) = [p(ci) + p(cj)]DJS [p(A|ci), p(A|cj)] (4.17)
pi = p(A|ci)pj = p(A|cj)
p = p(A|c∗) = p(ci)p(c∗)pi + p(cj)
p(c∗)pj
DJS [pi, pj ] = p(ci)p(c∗)DKL[pi‖p] + p(cj)
p(c∗)DKL[pj‖p]
(4.18)
El algoritmo AIB supone un coste computacional muy alto. El algoritmo LIMBO hace uso delAIB, pero englobandolo dentro de una estructura jerarquica, con el fin de disminuir significativa-mente este coste computacional. Para ello, el algoritmo LIMBO sigue tres pasos:
1. Todos los objetos son leıdos y convertidos en clusters independientes, guardando la informa-cion en forma de Distributional Cluster Features o DCF (a semejanza del algoritmo BIRCH(3.3.2) y sus arboles CF jerarquicos). La informacion en cada DCF son las dos probabilidadesvistas anteriormente, p(c) y p(A|c). Si hay muchos objetos se generan iterativamente nuevosniveles de agrupamiento, mediante la combinacion de clusters, en donde la informacion de lanueva clase c∗ se calcula de la forma que se ha explicado con anterioridad (expresiones (4.15)y (4.16)). La distancia entre los clusters ci y cj y, por tanto, la distancia entre los DCF deuno y otro o distancia entre ambos nodos, se define como la perdida de informacion δI(ci, cj)(4.17) que se produce al combinar los dos grupos. El valor de perdida de informacion que de elmınimo de todas las combinaciones posibles, define los maximos candidatos para combinarsey formar un nuevo cluster.
2. A continuacion, se procede a aplicar el algoritmo AIB sobre cada uno de los conjuntos deobjetos resultantes asignados a cada uno de todos los nodos del arbol jerarquico.
3. Por ultimo, se produce un refinamiento en los valores de los DCF en todos los nodos, con elfin de mejorar la representatividad del agrupamiento final.
4.7 KEROUAC
El algoritmo de agrupamiento KEROUAC [38] esta disenado para sistemas de datos distribuidoscuyas caracterısticas sean cualitativas. Se basa en un ındice de similitud llamado NCC (New Con-dorcet Criterion), que relaciona el numero de similitudes entre objetos de distintos clusters (la
30 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

4.8. CLICKS
heterogeneidad), y las disimilitudes entre objetos pertenecientes a una misma clase (la homogenei-dad). El objetivo es el obtener un determinado agrupamiento Cα = {SO
1 . . . SOh } de los objetos, tal
que NCC(Cα) sea mınimo.Las formulas para calcular NCC(Cα) se muestran a continuacion, en las expresiones (4.19),
(4.20), (4.21) y (4.22). De ellas se deduce que el criterio NCC esta basado en la medida de distanciade la proximidad unica (ver seccion 3.1.4). El parametro gran denota un factor de granularidad,definido por el usuario, para dar mayor peso al conjunto de similitudes o al conjunto de disimili-tudes.
NCC(Cα) =∑
i=1...h,j=1...h,i>j
Sim(SOi , SO
j ) + gran
h∑
i=1
Dissim(SOi , SO
i ) (4.19)
Sim(SOi , SO
j ) =∑
oa∈SOi ,ob∈SO
i ,a>b
sim(oa, ob); sim(oa, ob) =p∑
i=1
δsim(oai , obi) (4.20)
Dissim(SOi , SO
j ) =∑
oa ∈ SOiα ,
ob ∈ SOiα ,
a > b
dissim(oa, ob); dissim(oa, ob) =p∑
i=1
(1− δdissim(oai, obi
)) (4.21)
δsim(oai , obi) = δdissim(oai , obi) ={
1 si oai = obi
0 si oai 6= obi
(4.22)
El procedimiento de agrupamiento se realiza en todos los nodos localmente, y luego se envıala informacion resultante a una unidad central. Una vez allı, con los datos de todos los clustersobtenidos en las areas o nodos locales, se construye una matriz con los datos relevantes, y secombinan los grupos segun el mismo criterio NCC.
4.8 CLICKS
CLICKS, nombre formado por el anagrama de Subspace CLustering of Categorical data via maximalK-partite cliques [69], es un algoritmo de busqueda de clusters en subespacios del conjunto de datos.La definicion de clusters planteada para CLICKS esta extraıda de los planteamientos y definicionespara el algoritmo CACTUS (ver seccion 4.4). En un paso inicial, el algoritmo CLICKS lee todoslos datos de los objetos y construye el llamado k-partite graph, que es un arbol de conjuntos densos,llamados cliques, que estan definidos aplicando las funciones de soporte y proximidad del algoritmoCACTUS. Concretamente, sea una serie D de objetos de caracterısticas cualitativas A1 . . . An, ysea V =
⋃ni=1 Di, un k-partite graph de D es ΓD = (V, E) donde (vi, vj) ∈ E ⇔ δα({vi}x{vj}) = 1.
Un subconjunto C ⊆ V es un k-partite clique en ΓD si y solo si todo par de vertices vi ∈ C⋂
Di yvj ∈ C
⋂Dj (con i 6= j) estan conectados por un lımite en ΓD. Por ultimo, se dice que un clique
es denso si δα(C) = 1.El algoritmo CLICKS realiza el procedimiento de clustering en tres pasos: primero, accede
a todos los objetos y computa la funcion soporte de todos los valores de todas las dimensiones.Entonces genera la particion o k-partite graph, resaltando aquellas uniones que son mas densas.Seguidamente procesa y enumera los cliques detectados, aplicando un algoritmo recursivo de op-timizacion del agrupamiento definido, y encontrando los cliques maximos, que son aquellos queaportan la maxima informacion sobre el grupo. En el ultimo paso, realiza un barrido de toda laestructura, decidiendo si los cliques mas densos y los maximos se consideran como clusters o no.En este paso aplica una tecnica de exploracion vertical de la estructura, que le reporta los cliquesmaximos mas densos (y, por tanto, los mas susceptibles de ser definidos como clusters).
4.9 Mixed-type variable fuzzy c-means (MVFCM)
El Fuzzy clustering de fuzzy data es una metodologıa que consiste en aplicar algoritmos de clusteringborroso a conjuntos de datos cuantitativos y cualitativos que han sido previamente borrosificados.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 31

4. Tecnicas de agrupamiento para datos cuantitativos y cualitativos
Normalmente se usan los algoritmos de fuzzy c-means (FCM) (ver seccion 3.3.3) o el de la maximaprobabilidad (FMLE) (ver seccion 3.3.3).
En [67] se define el MVFCM, una variante del algoritmo FCM, en donde se dividen los tiposde datos en borrosos y simbolicos, y se describe una medida de la disimilitud que es la suma detodas las medidas de disimilitud en todas las caracterısticas o atributos, segun de que tipo seanestos (4.23).
D(A,B) =d∑
k=1
αkD(Ak, Bk) (4.23)
El parametro α es un coeficiente para asignar mayor o menor peso a las caracterısticas segunla relevancia que tengan en el analisis. Segun las caracterısticas sean de naturaleza cuantitativa,cualitativa o borrosa, las distancias se obtienen de forma distinta. Con la suma final de todas lasdistancias, se aplica un algoritmo de FCM ligeramente modificado al sustituir la distancia euclıdeapor las otras medidas que se describen a continuacion.
4.9.1 Datos cuantitativos
Se definen tres medidas distintas: position, span y content, basadas en una modificacion de ladistancia de Gowda y Diday (ver seccion 3.1.7). La distancia resultante es la suma de las tres.Sean las siguientes definiciones:
al = lımite inferior de Ak
bl =lımite inferior de Bk
aµ = lımite superior de Ak
bµ = lımite superior de Bk
inters = longitud de la interseccion entre Ak y Bk
ls = span = |max(aµ, bµ)−min(al, bl)|Uk = diferencia entre el mayor y menor valor de la caracterıstica kth para todos los objetosla = |aµ− al|lb = |bµ− bl|
Las distancias definidas para position (dp), span (ds) y content (dc) tienen los valores mostradosen las expresiones (4.24), (4.25) y (4.26).
dp(Ak, Bk) =|(al + aµ)/2− (bl + bµ)/2|
Uk(4.24)
ds(Ak, Bk) =|la − lb|
Uk + la + lb − inters(4.25)
dc(Ak, Bk) =|la + lb − 2inters|
Uk + la + lb − inters(4.26)
4.9.2 Datos cualitativos
Se definen dos medidas de disimilitud, tambien basadas en la distancia de Gowda y Diday. Seanlas siguientes definiciones:
inters = numero de elementos en la interseccion entre Ak y Bk
ls = numero de elementos en la union entre Ak y Bk
la = numero de elementos en Ak
lb = numero de elementos en Bk
Las distancias definidas son las de span (Ds) y content (Dc), que se pueden ver en las expresiones(4.27) y (4.28).
Ds(Ak, Bk) =|la − lb|
ls(4.27)
Dc(Ak, Bk) =|la + lb − 2inters|
ls(4.28)
La distancia resultante es la suma de las dos.
32 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

4.10. Fusion de datos cuantitativos y cualitativos en tecnicas distintas del agrupamiento
Figura 4.3: Parametrizacion de funcion de pertenencia borrosa usando TFN
4.9.3 Datos borrosos
Se definen las funciones de pertenencia borrosas usando el modelo de los trapezoidal fuzzy numberso TFN, en donde cada funcion de pertenencia se representa con un conjunto de cuatro parametros,A = m(a1, a2, a3, a4): a1 es el centro de la funcion, a2 su diametro interno, a3 el ancho de lafuncion al decrecer por la izquierda y a4 el ancho de la funcion al decrecer por la derecha. De estamanera se pueden definir numeros, intervalos, funciones rectangulares, triangulares y trapezoidalesasimetricas, como se puede ver en la figura 4.3.
La distancia propuesta es la que se puede ver en las expresiones (4.29), (4.30) y (4.31).
d2f (A,B) =
14(g2− + g2
+ + (g− − (a3 − b3))2 + (g+ + (a4 − b4))2) (4.29)
g− = 2(a1 − b1)− (a2 − b2) (4.30)g+ = 2(a1 − b1) + (a2 − b2) (4.31)
4.10 Fusion de datos cuantitativos y cualitativos en tecnicas dis-tintas del agrupamiento
El tratamiento de datos cualitativos y cuantitativos tambien se trata en otras metodologıas queno persiguen a priori el agrupamiento de los datos, pero que igualmente proponen tecnicas parael manejo y la fusion de datos heterogeneos, y es interesante incluirlas en este trabajo.
Por ejemplo, en [55] plantean la combinacion de datos borrosos de distinta naturaleza (numeros,intervalos, funciones de pertenencia). Para ello, definen un modelo no-parametrico de datos borrososheterogeneos (Heterogeneous Fuzzy Data) mediante el uso de los llamados cognitive landmarks,conjuntos estandar de funciones de pertenencia que son una representacion del conocimiento y delas variables linguısticas. Cada atributo o caracterıstica se asocia con este conjunto de funciones.
Otra aproximacion consiste en el manejo de los datacubos, que se caracterizan mediante larepresentacion de formas n-dimensionales, creadas a partir de unir los n puntos de cada valorde cada atributo representado en una escala sobre un eje definido para cada caracterıstica. Esteprocedimiento se usa por ejemplo en tareas de clasificacion y regresion [44].
En [63] proponen tecnicas para cuantificar datos cualitativos mediante el mapeo de todaslas categorıas de una variable en un espacio numerico en dos dimensiones, de forma que cadacategorıa se pueda traducir en un par de valores numericos especıficos. Para ello obtienen primerouna representacion en dos dimensiones de todos los datos, y luego buscan patrones numericosque puedan corresponderse con las categorıas especıficas, sugiriendo el empleo de algoritmos declustering y la minimizacion de la entropıa global.
Los hedges [32] son operadores linguısticos para funciones de pertenencia borrosas. Transfor-man la forma de la funcion mediante operaciones matematicas asociadas a la variacion semanticade una variable (mucho, poco, extremadamente, bastante, etc.). Un ejemplo se puede ver en lafigura 4.4.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 33

4. Tecnicas de agrupamiento para datos cuantitativos y cualitativos
Figura 4.4: Ejemplo de aplicacion de los hedges “very” y “more or less” a una funcion de pertenencia
Clasificacion Funcion de similitud Tipo de datosK-modes Particional Overlap metric CualitativosK-prototypes Particional Overlap metric Cualitativos y cuantitati-
vosCOOLCAT Particional Entropıa CualitativosROCK Jerarquico Enlaces o vecinos comunes CualitativosLIMBO Jerarquico Dist. de Kullback-Leibler CualitativosSTIRR Basado en grafos Co-ocurrencias CualitativosCACTUS Basado en grafos Conexiones fuertes CualitativosCLICKS Basado en grafos Densidad CualitativosKEROUAC Datos distribuidos New Condorcet Criterion
(NCC)Cualitativos
MVFCM Borroso Dist. de Gowda y Didaymodificada, y dist. segunlos TFN
Cualitativos, cuanti-tativos y funciones depertenencia borrosas
Tabla 4.2: Algoritnos de clustering para datos cualitativos
El algoritmo PNC2 [29] es un procedimiento de clustering disenado para induccion de reglas enbases de datos. Puede trabajar con datos cualitativos y cuantitativos, usando funciones de distanciaque estan basadas en la proximidad unica (ver seccion 3.1.4).
Por ultimo, en [72] se presenta un diseno completo de redes neuronales combinadas conlogica borrosa para entrenar modelos de prediccion, asociacion, clasificacion y extraccion de reglasa partir de datos cuantitativos y cualitativos.
4.11 Resumen
Se han descrito las tecnicas encontradas en la literatura para realizar el agrupamiento y reconoci-miento de patrones en conjuntos de objetos con caracterısticas cualitativas y cuantitativas. En latabla 4.2 se exponen de forma resumida todos los algoritmos encontrados, junto con las principalescaracterısticas que los definen, que son: a que clase de algoritmos de clustering pertenecen, quetecnicas usan para medir la similitud o disimilitud entre los objetos para realizar el agrupamiento,y que tipo de datos pueden analizar.
Como se puede ver, hay variedad en cuanto a tipos de algoritmos y las medidas de similitudempleadas, con una mayor presencia de los matching coefficients y sus variantes. Casi todos losalgoritmos, sin embargo, estan disenados para tratar con datos cuantitativos o con datos cualitati-vos, pero en muy pocas ocasiones con grupos de datos cuantitativos y cualitativos (solo dos de losalgoritmos en la tabla).
A partir de este conocimiento y esta revision de todas las tecnicas actuales de agrupamiento,en el siguiente capıtulo se presenta una propuesta propia de metodologıa para el tratamiento deobjetos con multiples caracterısticas de distinta naturaleza, haciendo uso de tecnicas de logicaborrosa.
34 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

Capıtulo 5
Propuesta de metodologıa para reco-nocimiento de patrones en entidadesde datos heterogeneos mediante tec-nicas de clustering borroso
El objetivo es plantear una metodologıa que sea eficaz en el reconocimiento de patrones en con-juntos de objetos que contienen caracterısticas de naturaleza cuantitativa y cualitativa. A partirde la revision de las tecnicas actuales, esta propuesta se basa en aprovechar las propiedades de lalogica borrosa [68], por sus cualidades para manejar datos cualitativos o areas de incertidumbre,mas cercanos a como recibe la informacion la comprension humana que una secuencia de valoresnumericos.
Por tanto, se sugiere comenzar con la borrosificacion de todos los datos imprecisos y no nume-ricos, para trabajar con lo que se ha dado en llamar “datos borrosos heterogeneos” (heterogeneousfuzzy data) [55], en donde los datos son adaptados en variables borrosas, que son funciones sin-gleton para los datos numericos, funciones de pertenencia rectangulares para datos intervalares, yfunciones de pertenencia borrosa para datos cualitativos o imprecisos.
Para continuar, se sugiere emplear algoritmos de clustering borrosos sobre el conjunto de datosreinterpretados de manera borrosa, en lınea con la filosofıa de que la logica borrosa aporta unamayor comprension de la naturaleza de los datos, y ademas facilita mas posibilidades de analisis.
A continuacion se desarrolla esta metodologıa propuesta para el reconocimiento de patrones ygrupos en conjuntos de datos con caracterısticas cualitativas y cuantitativas.
5.1 Metodologıa
Se propone dividir el analisis en dos partes. Primero, un paso de preprocesado de datos, para ade-cuarlos al formato que se considera idoneo para el posterior analisis. Segundo, tras el preprocesadode los datos, se sugiere el uso de algoritmos de clustering borroso.
5.1.1 Preprocesado de datos
Se sugiere asignar un factor de peso o importancia a cada caracterıstica individualmente, tanto endatos cualitativos como cuantitativos [6]. Este procedimiento sirve para dar mayor importancia deforma subjetiva a ciertas caracterısticas de los datos que pueden ser de mayor relevancia para tomardecisiones o para minimizar la presencia de otras caracterısticas consideradas poco relevantes. Elfactor de peso se anade al calculo de la distancia, por ejemplo en la expresion (5.1) se puedeobservar como se anaden factores de peso wi al calculo de distancias euclıdeas entre variables.
d(x, y) =
√√√√m∑
i=1
(wi(xi − yi))2 (5.1)
35

5. Propuesta de metodologıa para reconocimiento de patrones en entidades de datos heterogeneos mediantetecnicas de clustering borroso
Figura 5.1: Configuracion de funciones de pertenencia e implicacion borrosa para datos cualitativos ydatos borrosos
Ademas se sugiere asignar un factor de peso en la funcion objetivo que pondere la importanciaque se le asigna a las caracterısticas cualitativas en comparacion con el conjunto de caracterısticascuantitativas [52], como se puede ver en la expresion (5.2). En ocasiones la informacion realmenteimportante es la nominal o cualitativa, y los datos numericos se incluyen para respaldar o matizarla informacion principal. Tambien se da el caso contrario, cuando es la informacion numerica laque cuenta, y los datos nominales refuerzan la significancia de los datos cuantitativos.
total = [peso · cuantitativos (1− peso) · cualitativos] , 0 ≤ peso ≤ 1 (5.2)
En los datos cuantitativos, el orden y configuracion de las funciones de pertenencia es importan-te, ası como el hecho de que sea un conjunto determinıstico (es decir, que la suma de pertenenciasde cada objeto a todos los grupos sea uno en todos los casos). En los datos cualitativos, sin em-bargo, lo que cuenta es la unidad de informacion aportada por el dato en sı mismo; no es unainformacion cuantificable en relacion a una sucesion numerica y, por tanto, la signacion de un valornumerico dentro de un rango es mas para asignarle un valor identificativo que un valor que se puedacuantificar. De hecho, asumir este valor como un numero e incluirlo en la cuantificacion junto conlos demas es un error que puede llevar a resultados indeseados, como se puede leer en [6].
Por tanto, la asignacion tiene como objetivo mostrar una region del espacio (el rango de da-tos), la cual debe quedar relacionada con cierto valor nominal o cualitativo de cierto atributo ocaracterıstica del objeto, en exclusiva.
Es importante resaltar que las regiones de pertenencia de los datos cualitativos no se debensolapar, a menos que esta informacion de solapamiento sea facilitada. El“Sı”no se puede solapar conel“No”. Si se presenta la opcion“Mas o menos”, esta debe estar claramente incluida como opcion, encuyo caso tendra su propia region del espacio asignada. Por tanto, estas “funciones de pertenencia”para datos cualitativos son de tipo hard, sin transicion ni solapamiento entre zonas de distintapertenencia. Si, por el contrario, la asignacion de categorıas esta disponible junto con la informacionde transicion, entonces se pueden traducir estas categorıas a funciones de pertenencia borrosas,siendo analizadas como conjuntos borrosos segun los procedimientos habituales de borrosificacion,como se puede ver en el ejemplo de la figura 5.1.
Ademas, dado que la informacion cualitativa no contiene valor de cuantificacion, las regiones delespacio relacionadas con cada posible valor nominal o cualitativo pueden ser asignadas en cualquierpunto del rango. Por equivalencia, se asume como rango el rango normalizado del espacio de datoscuantitativos. Por tanto, un paso previo en el preprocesado de datos es el de la normalizacion detodas las caracterısticas cuantitativas a un mismo rango.
El siguiente paso consiste en la asignacion de areas de pertenencia a los posibles valores cua-litativos. Normalmente, para cada caracterıstica se realiza una particion del espacio, habiendotantas zonas como posibles valores cualitativos para esa caracterıstica concreta. Segun [55], unrango optimo de categorıas para variables cualitativas, es entre cinco y siete areas de pertenencia.Esto, no obstante, puede acarrear problemas de identificacion, como la duplicidad de areas iguales
36 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

5.1. Metodologıa
Figura 5.2: Ejemplos de duplicidad y ocultacion de areas de pertenencia para datos cualitativos
en caracterısticas distintas, o la ocultacion de valores por solapamiento con otras areas de otrascaracterısticas cualitativas. En la figura 5.2 se explican con ejemplos estas dos situaciones.
Por tanto, se sugiere que cada posible opcion o valor cualitativo ocupe una unica region delespacio exclusiva para esa asignacion concreta, para todo el conjunto de posibles valores de todoslos atributos de naturaleza cualitativa. En la figura 5.3 se muestra un ejemplo de particion delrango disponible.
De este modo, el proceso de preparacion de los datos es como el que se muestra en la figura5.4 para cada objeto: una vez construidos sus respectivos mapas de pertenencias cualitativas ycuantitativas, se extrae la informacion numerica significativa que servira para reescribir la identifi-cacion del objeto en un nuevo vector de caracterısticas con valores numericos, sobre el que aplicarcualquier algoritmo borroso de reconocimiento de patrones, basado en la distancia euclıdea entrelos objetos en el espacio n-dimensional.
Como se puede ver en la figura 5.4, se propone realizar una agregacion de todos los resultadosde las implicaciones borrosas, de caracterısticas cuantitativas y cualitativas por separado. De estaforma se consigue sumarizar en dos valores numericos, equiparables entre sı, toda la informacioncuantitativa y cualitativa del objeto.
5.1.2 Clustering de datos
Uno de los procedimientos mas comunes para la desborrosificacion, o convertir a informacion nume-rica el resultado de la implicacion y la agregacion borrosas, es el de obtener el centro de gravedad(realmente el centro de masas) de cada conjunto. Este es el punto geografico de equilibrio en el
Departamento de Ingenierıa de Sistemas y Automatica. UPV 37

5. Propuesta de metodologıa para reconocimiento de patrones en entidades de datos heterogeneos mediantetecnicas de clustering borroso
Figura 5.3: Ejemplo de particion del rango disponible en areas de pertenencia para todos los valoresposibles de todas las caracterısticas cualitativas
Figura 5.4: Ejemplo de preprocesado de datos. En este caso el objeto (xi) tiene tres caracterısticas cua-litativas (de la 1 a la 3), y tres cuantitativas (de la 4 a la 6)
38 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

5.2. Ejemplo de aplicacion
cual todas las fuerzas ejercidas por cada diferencial de masa se anulan. En el equivalente a la logicaborrosa, los puntos son todos los vertices de todas las formas resultantes de la implicacion borrosa,en concreto sus valores de proyeccion sobre el eje horizontal (el rango), y sus correspondientesvalores de pertenencia (equivalentes a las masas en fısica). El centro de masas se calcula como unsumatorio, tal como se puede ver en (5.3).
CG =∑
xiµi∑µi
(5.3)
El resultado es el equivalente numerico a la desborrosificacion del espacio de funciones de per-tenencia. De esta forma se tienen dos caracterısticas por cada objeto, una es el centro de gravedadde la implicacion borrosa de los datos cuantitativos borrosificados, y el otro es el equivalente a sin-tetizar la configuracion espacial de los datos cualitativos en un unico valor numerico equivalente,que sı tiene en este caso significado cuantitativo.
El nuevo objeto ya no esta constituido por caracterısticas cualitativas y cuantitativas, sino pordatos numericos ponderados segun importancia, que indican una region del espacio equivalentea toda la informacion contenida previamente. A partir de aquı, se propone el analisis mediantecualquiera de los algoritmos de clustering borroso conocidos, si bien se pueden considerar otrasvariantes, comentadas a continuacion.
Una variante consiste en considerar cada centro de masas de cada uno de los atributos numericospor separado, para no perder esa informacion numerica disponible para cada caracterıstica, yevitar una sumarizacion excesiva, que puede resultar en perdida de precision en el agrupamiento.De esta forma, junto con los datos borrosificados y desborrosificados de todas las caracterısticascuantitativas, se anadirıa el valor numerico de la resultante de la borrosificacion y desborrosificacionde todos los atributos cualitativos en su conjunto.
Otra opcion implica el uso de algoritmos de clustering geografico o espacial, (spatial clustering)[49], en vez de los clasicos algoritmos de clustering borroso. Estos algoritmos buscan similitudesgeograficas, con lo cual pueden resultar idoneos para, en vez de realizar una desborrosificacion a uncentro de gravedad numerico, usar las funciones de pertenencia como patrones geograficos en losque buscar semejanzas para la agrupacion. Uno de ellos es el basado en la densidad [17] GDBSCAN(Generalized Density Based Spatial Clustering of Applications with Noise).
A continuacion se explica un ejemplo de aplicacion de la metodologıa propuesta, y los resultadosobtenidos.
5.2 Ejemplo de aplicacion
Se incluye un ejemplo de aplicacion de esta metodologıa sobre una base de datos con caracterısticascualitativas y cuantitativas.
5.2.1 Base de datos
Se ha escogido para este primer ejemplo la base de datos de concesion de tarjetas de credito,disponible en el directorio de bases de datos del departamento de informacion y ciencias de lacomputacion de la Universidad de California (UCI Repository of machine learning databases) [51].Las fuentes de esta base de datos son confidenciales, si bien referencias a su uso pueden encontrarseen [56] y [57].
La base de datos consiste en 690 instancias de clientes de banco solicitando una aprobacion detarjeta de credito. Cada aplicacion consta de 14 campos o atributos, mostrados en la tabla 5.1.Seis son atributos numericos y ocho nominales (cualitativos). Ademas, el rango de valores de lascaracterısticas cualitativas no es el mismo en todos los casos: hay cuatro caracterısticas con solodos posibles valores, dos con tres posibles respuestas, una con 9 posibles valores, y una mas conhasta 14 posibles valores nominales. Se supone que teniendo en cuenta estos datos, los expertosen las entidades bancarias han hecho una seleccion de aplicaciones o instancias, clasificandolas enaceptadas o rechazadas.
Esta base de datos se considera especialmente apropiada porque combina datos cuantitativos ycualitativos en una buena proporcion (casi el 50 %). Por razones de confidencialidad, los posiblesvalores nominales de los atributos cualitativos reciben una asignacion generica, indicandose conletras o numeros.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 39

5. Propuesta de metodologıa para reconocimiento de patrones en entidades de datos heterogeneos mediantetecnicas de clustering borroso
Attribute Class ValuesA1 Qualitative 0 or 1A2 Quantitative ContinuousA3 Quantitative ContinuousA4 Qualitative 1, 2 or 3A5 Qualitative 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 or 14A6 Qualitative 1, 2, 3, 4, 5, 6, 7, 8 or 9A7 Quantitative ContinuousA8 Qualitative 0 or 1A9 Qualitative 0 or 1A10 Quantitative ContinuousA11 Qualitative 0 or 1A12 Qualitative 1, 2 or 3A13 Quantitative ContinuousA14 Quantitative Continuous
A15 (Output) Qualitative 1 or 2
Tabla 5.1: Atributos y clases para la base de datos de concesion de tarjetas de credito
Los resultados que debe conseguir el analisis son conocidos: el atributo numero 15 de la base dedatos (ver tabla 5.1) es en realidad el valor de salida para cada aplicacion. Solo hay dos clases, queson aquellas aplicaciones que fueron aprobadas (y la aplicacion de tarjeta de credito concedida) yaquellas que fueron rechazadas. El resultado total es de 383(55.5%) para la clase 1, y 307(44.5%)para la clase 2. En la figura 5.5 se han representado en forma de grafico tridimensional las tresprimeras caracterısticas numericas de todos los objetos o instancias, indicando mediante dos coloresla clase a la que pertenecen. Los valores de caracterısticas cuantitativas han sido todos normalizadosa un rango entre 0 y 10.
5.2.2 Analisis y resultados
Con el fin de evaluar la eficiencia se tienen en cuenta dos factores. Uno es el numero de objetosasignados a cada clase. Para ello, y dado que solo hay que buscar dos clases, se calcula el ratioo relacion entre el numero de objetos asignados a cada cluster. Este ratio se calcula obteniendolas respectivas cantidades de objetos asignados a cada cluster y dividiendo la menor cantidad porla mayor. El ratio del resultado conocido y, por tanto, al que debe aproximarse el resultado delanalisis, es el que se muestra en la expresion (5.4).
ratio =307383
= 0.8016 (5.4)
El otro factor es el porcentaje de aciertos. Ya que el resultado esta dado, con la asignacion acada uno de los dos grupos de todos los objetos indicada en la ultima caracterıstica (atributo 15,ver tabla 5.1), se puede calcular el numero de aciertos comparando la asignacion final de clases conlos resultados obtenidos del analisis, lo cual quiere decir asignar a cada objeto la pertenencia alcluster con el mayor ındice de pertenencia y comparar, mediante una operacion XOR por ejemplo,el numero de errores o asignaciones erroneas.
Con el fin de evaluar y comparar la tecnica propuesta con otros metodos, se han probadodistintos casos y variantes, cuyos resultados se muestran en la tabla 5.2, y que se detallan acontinuacion. Para todos los casos se ha usado el clasico algoritmo de clustering de fuzzy c-meanso FCM [9] [16].
Fuzzy clustering sobre todos los datos (cuantitativos y cualitativos) normalizados
Para empezar, se ha probado a hacer lo que se supone que no se debe hacer. El resultado esque se consigue la mejor tasa de aciertos de todas las pruebas realizadas, lo cual no deja de sersorprendente. Se han normalizado todos los valores de todas las caracterısticas a un rango entre 0y 10, y se le ha aplicado el algoritmo FCM. El ratio resultante es de 0.9885, como se puede ver enla tabla 5.2, y el porcentaje de aciertos es del 81.45 %.
40 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos
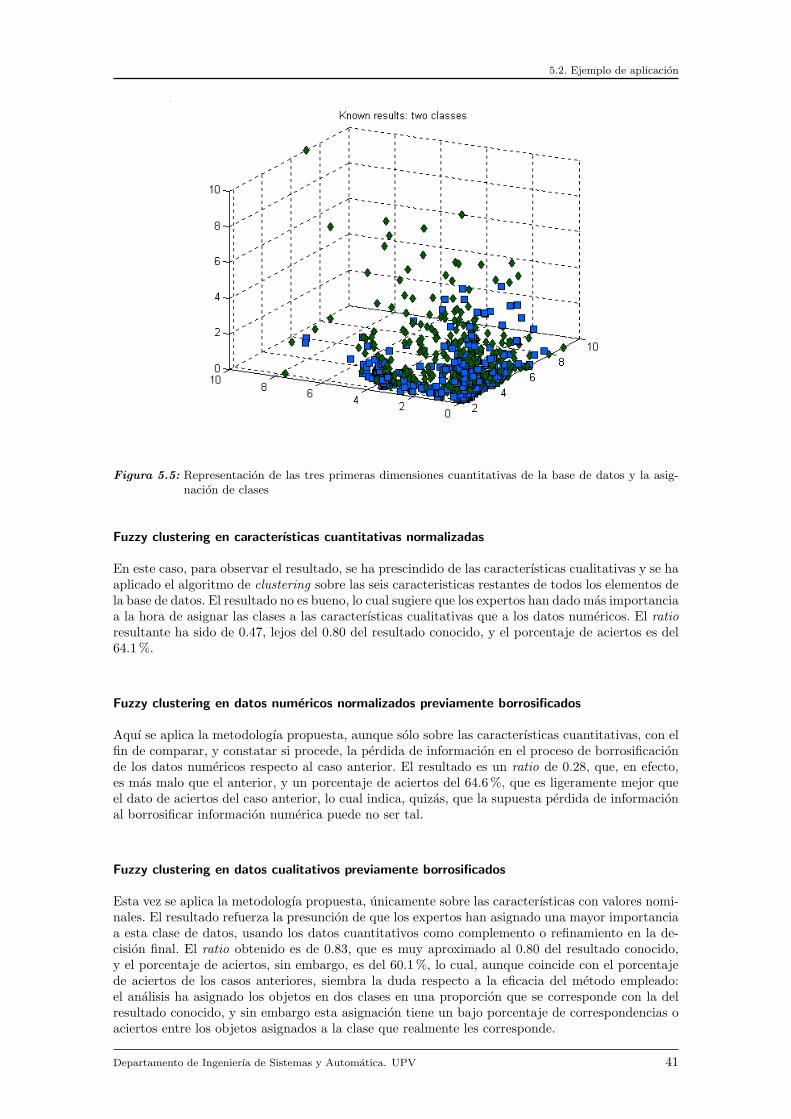
5.2. Ejemplo de aplicacion
Figura 5.5: Representacion de las tres primeras dimensiones cuantitativas de la base de datos y la asig-nacion de clases
Fuzzy clustering en caracterısticas cuantitativas normalizadas
En este caso, para observar el resultado, se ha prescindido de las caracterısticas cualitativas y se haaplicado el algoritmo de clustering sobre las seis caracteristicas restantes de todos los elementos dela base de datos. El resultado no es bueno, lo cual sugiere que los expertos han dado mas importanciaa la hora de asignar las clases a las caracterısticas cualitativas que a los datos numericos. El ratioresultante ha sido de 0.47, lejos del 0.80 del resultado conocido, y el porcentaje de aciertos es del64.1 %.
Fuzzy clustering en datos numericos normalizados previamente borrosificados
Aquı se aplica la metodologıa propuesta, aunque solo sobre las caracterısticas cuantitativas, con elfin de comparar, y constatar si procede, la perdida de informacion en el proceso de borrosificacionde los datos numericos respecto al caso anterior. El resultado es un ratio de 0.28, que, en efecto,es mas malo que el anterior, y un porcentaje de aciertos del 64.6 %, que es ligeramente mejor queel dato de aciertos del caso anterior, lo cual indica, quizas, que la supuesta perdida de informacional borrosificar informacion numerica puede no ser tal.
Fuzzy clustering en datos cualitativos previamente borrosificados
Esta vez se aplica la metodologıa propuesta, unicamente sobre las caracterısticas con valores nomi-nales. El resultado refuerza la presuncion de que los expertos han asignado una mayor importanciaa esta clase de datos, usando los datos cuantitativos como complemento o refinamiento en la de-cision final. El ratio obtenido es de 0.83, que es muy aproximado al 0.80 del resultado conocido,y el porcentaje de aciertos, sin embargo, es del 60.1 %, lo cual, aunque coincide con el porcentajede aciertos de los casos anteriores, siembra la duda respecto a la eficacia del metodo empleado:el analisis ha asignado los objetos en dos clases en una proporcion que se corresponde con la delresultado conocido, y sin embargo esta asignacion tiene un bajo porcentaje de correspondencias oaciertos entre los objetos asignados a la clase que realmente les corresponde.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 41
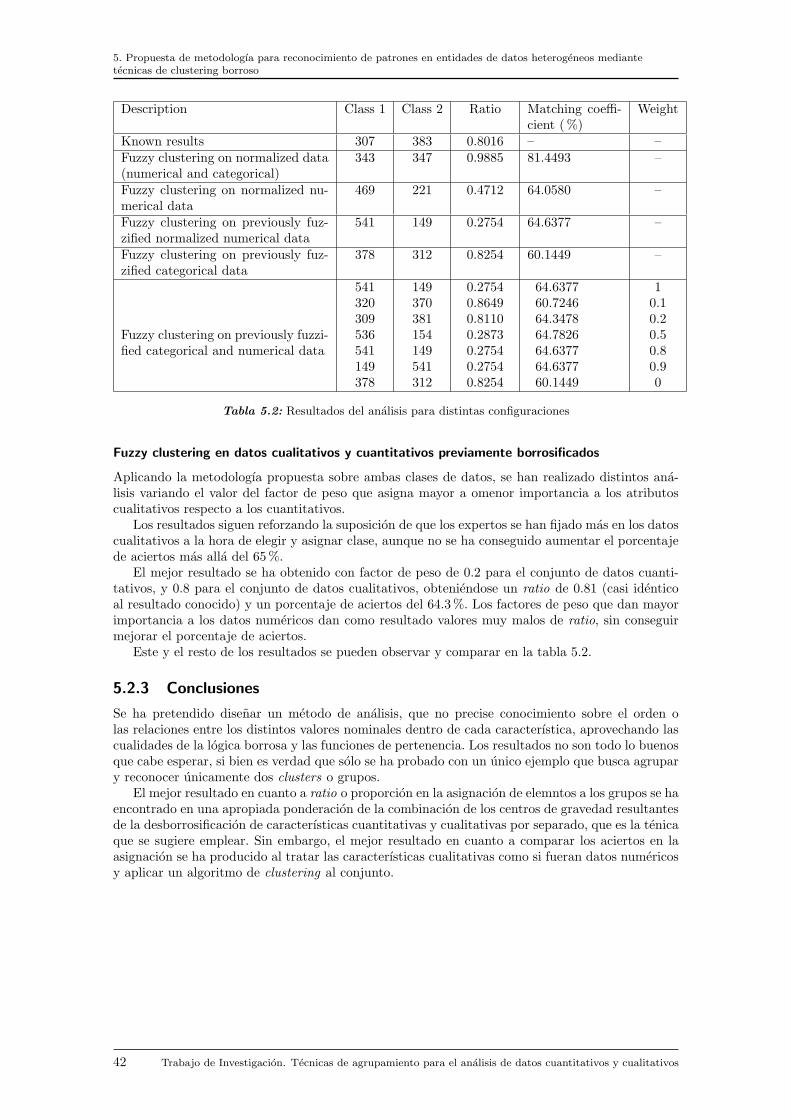
5. Propuesta de metodologıa para reconocimiento de patrones en entidades de datos heterogeneos mediantetecnicas de clustering borroso
Description Class 1 Class 2 Ratio Matching coeffi-cient (%)
Weight
Known results 307 383 0.8016 – –Fuzzy clustering on normalized data(numerical and categorical)
343 347 0.9885 81.4493 –
Fuzzy clustering on normalized nu-merical data
469 221 0.4712 64.0580 –
Fuzzy clustering on previously fuz-zified normalized numerical data
541 149 0.2754 64.6377 –
Fuzzy clustering on previously fuz-zified categorical data
378 312 0.8254 60.1449 –
Fuzzy clustering on previously fuzzi-fied categorical and numerical data
541320309536541149378
149370381154149541312
0.27540.86490.81100.28730.27540.27540.8254
64.637760.724664.347864.782664.637764.637760.1449
10.10.20.50.80.90
Tabla 5.2: Resultados del analisis para distintas configuraciones
Fuzzy clustering en datos cualitativos y cuantitativos previamente borrosificados
Aplicando la metodologıa propuesta sobre ambas clases de datos, se han realizado distintos ana-lisis variando el valor del factor de peso que asigna mayor a omenor importancia a los atributoscualitativos respecto a los cuantitativos.
Los resultados siguen reforzando la suposicion de que los expertos se han fijado mas en los datoscualitativos a la hora de elegir y asignar clase, aunque no se ha conseguido aumentar el porcentajede aciertos mas alla del 65 %.
El mejor resultado se ha obtenido con factor de peso de 0.2 para el conjunto de datos cuanti-tativos, y 0.8 para el conjunto de datos cualitativos, obteniendose un ratio de 0.81 (casi identicoal resultado conocido) y un porcentaje de aciertos del 64.3 %. Los factores de peso que dan mayorimportancia a los datos numericos dan como resultado valores muy malos de ratio, sin conseguirmejorar el porcentaje de aciertos.
Este y el resto de los resultados se pueden observar y comparar en la tabla 5.2.
5.2.3 Conclusiones
Se ha pretendido disenar un metodo de analisis, que no precise conocimiento sobre el orden olas relaciones entre los distintos valores nominales dentro de cada caracterıstica, aprovechando lascualidades de la logica borrosa y las funciones de pertenencia. Los resultados no son todo lo buenosque cabe esperar, si bien es verdad que solo se ha probado con un unico ejemplo que busca agrupary reconocer unicamente dos clusters o grupos.
El mejor resultado en cuanto a ratio o proporcion en la asignacion de elemntos a los grupos se haencontrado en una apropiada ponderacion de la combinacion de los centros de gravedad resultantesde la desborrosificacion de caracterısticas cuantitativas y cualitativas por separado, que es la tenicaque se sugiere emplear. Sin embargo, el mejor resultado en cuanto a comparar los aciertos en laasignacion se ha producido al tratar las caracterısticas cualitativas como si fueran datos numericosy aplicar un algoritmo de clustering al conjunto.
42 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

Capıtulo 6
Conclusiones y trabajo futuro
Se ha planteado la revision de las tecnicas de agrupamiento y reconocimiento de patrones enobjetos de caracterısticas cuantitativas y cualitativas. Para ello, se ha comenzado con una extensadescripcion de uno de los principales motivos que respaldan el auge en la investigacion y mejorade esta clase de tecnicas: la busqueda de informacion en bases de datos, de todo tipo, extension yorigen.
Se ha visto que actualmente se encuentran en la literatura gran cantidad de tecnicas para lacombinacion de datos de naturaleza cuantitativa y cualitativa; desde los mas sencillos, hasta los mascomplicados modelos hıbridos, que combinan dos o mas metodos, casi todas las tecnicas propuestasparecen funcionar bien, con ciertas limitaciones.
Se ha propuesto una metodologıa propia de analisis, en base a unas suposiciones que tienen suorigen en la logica borrosa, y se ha visto que los resultados obtenidos son dispares, si bien solose ha aplicado sobre una base de datos. Se plantea, pues, la necesidad de hacer mas pruebas yde computar la eficiencia de la metodologıa propuesta mediante la implementacion de indicadoresconocidos. El trabajo inmediato es probar la metodologıa propuesta con mas ejemplos de bases dedatos reales, que tengan variedad de configuraciones para poder comparar los distintos casos y losresultados que se obtengan. Tambien se deben seleccionar unos cuantos de los algoritmos que sehan visto en la revision del estado del arte, e implementarlos, para poder compararlos y evaluar sueficacia. Se plantea por tanto, la necesidad de implementar indicadores de eficiencia como los quese detallan en [6] para comparar los resultados de los distintos algoritmos de clustering.
Teniendo en cuenta la posibilidad de modificacion de la metodologıa planteada, se consideracomo buen camino seguir trabajando en la lınea de los algoritmos de clustering de naturalezaborrosa, pues se entienden como los mas apropiados para simular el razonamiento y el analisishumano.
Por ultimo, se incluye en el plan de trabajo el indagar en las propiedades de los algoritmos declustering geograficos (spatial) y en como se les podrıa anadir la componente borrosa (comprobandosi esta adicion mejora los resultados).
43


Bibliografıa
[1] J. Abonyi, B. Feil, S.Nemeth, and P. Arva. Fuzzy clustering based time series segmentation.Lecture Notes in Computer Science, 2810:75–84, 2003.
[2] J. Abonyi, F. D. Tamas, and J. Tritthart. Explorarory data analysis of trace elements inclinker. Advances in Cement Research, 16(1):9–16, 2004.
[3] Rakesh Agrawal, Johannes Gehrke, Dimitrios Gunopulos, and Prabhakar Raghavan. Auto-matic subspace clustering of high dimensional data. Data Min. Knowl. Discov., 11(1):5–33,2005.
[4] Rakesh Agrawal, Tomasz Imieli, and Arun Swami. Mining association rules between sets ofitems in large databases. In SIGMOD ’93: Proceedings of the 1993 ACM SIGMOD interna-tional conference on Management of data, pages 207–216, New York, NY, USA, 1993. ACMPress.
[5] Periklis Andritsos. Data clustering techniques. Qualifying oral examination paper, Universityof Toronto, March 2002.
[6] Periklis Andritsos. Scalable Clustering of Categorical Data and Applications. PhD thesis,University of Toronto, 2004.
[7] Daniel Barbara, Yi Li, and Julia Couto. Coolcat: an entropy-based algorithm for categoricalclustering. In CIKM ’02: Proceedings of the eleventh international conference on Informationand knowledge management, pages 582–589, New York, NY, USA, 2002. ACM Press.
[8] Jon Louis Bentley and Jerome H. Friedman. Data structures for range searching. ACMComput. Surv., 11(4):397–409, 1979.
[9] J. C. Bezdek. Pattern Recognition with Fuzzy Objective Function Algorithms. Plenum Press,1981.
[10] Paul S. Bradley, Usama Fayyad, and Cory Reina. Scaling clustering algorithms to largedatabases. In Proceedings of the 4th International Conference on Knowledge Discovery andData Mining (KDD), pages 9–15, New York, NY, USA, 1998.
[11] Donald D. Chamberlin. Relational data-base management systems. ACM Comput. Surv.,8(1):43–66, 1976.
[12] Keith C. C. Chan and Wai-Ho Au. Mining fuzzy association rules. In CIKM ’97: Proceedings ofthe sixth international conference on Information and knowledge management, pages 209–215,New York, NY, USA, 1997. ACM Press.
[13] Surajit Chaudhuri and Umeshwar Dayal. An overview of data warehousing and olap techno-logy. SIGMOD Rec., 26(1):65–74, 1997.
[14] Josenildo da Silva, Chris Giannella, Ruchita Bhargava, Hillol Kargupta, and Matthias Klusch.Distributed data mining and agents. Engineering Applications of Artificial Intelligence,18:791–807, 2005.
[15] Jose Luis Dıez. Tecnicas de agrupamiento para identificacion y control por modelos locales.PhD thesis, Universidad Politecnica de Valencia, Julio 2003.
45

BIBLIOGRAFIA
[16] J. Dunn. A fuzzy relative of the isodata process and its use in detecting compact well-separatedclusters. Journal of Cybernetics, 3:32–57, 1974.
[17] Martin Ester, Hans-Peter Kriegel, and Jorg Sander. Geographic Data Mining and KnowledgeDiscovery, chapter Algorithms and Applications for Spatial Data Mining. Taylor & Francis,2001.
[18] Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. The kdd process for extrac-ting useful knowledge from volumes of data. Commun. ACM, 39(11):27–34, 1996.
[19] Venkatesh Ganti, Johannes Gehrke, and Raghu Ramakrishnan. Cactus - clustering categoricaldata using summaries. In KDD ’99: Proceedings of the fifth ACM SIGKDD internationalconference on Knowledge discovery and data mining, pages 73–83, New York, NY, USA, 1999.ACM Press.
[20] Gabriela Andreu Garcıa. Mapas de Caracterısticas Auto-organizados con Topologıa Toroidal.PhD thesis, Universidad Politecnica de Valencia, 1996.
[21] I. Gath and A.B. Geva. Unsupervised optimal fuzzy clustering. IEEE Transactions on PatternAnalysis and Machine Intelligence, 11:773–781, 1989.
[22] David Gibson, Jon M. Kleinberg, and Prabhakar Raghavan. Clustering categorical data: Anapproach based on dynamical systems. In VLDB ’98: Proceedings of the 24rd InternationalConference on Very Large Data Bases, pages 311–322, San Francisco, CA, USA, 1998. MorganKaufmann Publishers Inc.
[23] Michael Goebel and Le Gruenwald. A survey of data mining and knowledge discovery softwaretools. SIGKDD Explor. Newsl., 1(1):20–33, 1999.
[24] K. Chidananda Gowda and E. Diday. Symbolic clustering using a new dissimilarity measure.Pattern Recogn., 24(6):567–578, 1991.
[25] Amara Graps. An introduction to wavelets. IEEE Computational Science and Engineering,8(2), 1995.
[26] Sudipto Guha, Rajeev Rastogi, and Kyuseok Shim. Cure: an efficient clustering algorithmfor large databases. In SIGMOD ’98: Proceedings of the 1998 ACM SIGMOD internationalconference on Management of data, pages 73–84, New York, NY, USA, 1998. ACM Press.
[27] Sudipto Guha, Rajeev Rastogi, and Kyuseok Shim. Rock: A robust clustering algorithm forcategorical atributes. In Proceedings of the 15th International Confererence on Data Enginee-ring (ICDE), pages 512–521, Sydney, Australia, March 1999. IEEE Press.
[28] E. E. Gustafson and W. C. Kessel. Fuzzy clustering with a fuzzy covariance matrix. In Proc.of the IEEE Conference on Decision and Control, pages 761–766, San Diego, CA, 1979.
[29] Lars Haendel. Clusterverfahren zur datenbasierten Generierung interpretierbarer Regeln unterVerwendung lokaler Entscheidungskriterien. PhD thesis, University of Dortmund, 2003.
[30] A. Hinneburg and D. Keim. An efficient approach to clustering in large multimedia databaseswith noise. In Proceedings of the 1998 International Conference on Knowledge Discovery andData Mining, pages 58–65, 1998.
[31] Minqing Hu and Bing Liu. Mining and summarizing customer reviews. In KDD ’04: Procee-dings of the tenth ACM SIGKDD international conference on Knowledge discovery and datamining, pages 168–177, New York, NY, USA, 2004. ACM Press.
[32] Chun-Yueh Huang, Chuen-Yau Chen, and Bin-Da Liu. Current-mode fuzzy linguistic hedgecircuits. Analog Integr. Circuits Signal Process., 19(3):255–278, 1999.
[33] Zhexue Huang and Michael K. Ng. A fuzzy k-modes algorithm for clustering categorical data.IEEE Transactions on Fuzzy Systems, 7(4):446–452, August 1999.
[34] M. Indulska and M. E. Orlowska. Gravity based spatial clustering. In GIS ’02: Proceedingsof the 10th ACM international symposium on Advances in geographic information systems,pages 125–130, New York, NY, USA, 2002. ACM Press.
46 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos

BIBLIOGRAFIA
[35] J. Edward Jackson. A User’s Guide to Principal Components. Wiley, 2003.
[36] Anil K. Jain and Richard C. Dubes. Algorithms for clustering data. Prentice Hall, New Jersey,1988.
[37] Eshref Januzaj, Hans-Peter Kriegel, and Martin Pfeifle. Scalable density-based distributedclustering. In PKDD ’04: Proceedings of the 8th European Conference on Principles andPractice of Knowledge Discovery in Databases, pages 231–244, New York, NY, USA, 2004.Springer-Verlag New York, Inc.
[38] Pierre-Emmanuel Jouve and Nicolas Nicoloyannis. A new method for combining partitions,applications for distributed clustering. In Proceedings of the Workshop on Parallel and Distri-buted Computing for Machine Learning as part of the 14th European Conference on MachineLearning, 2003.
[39] Hillol Kargupta, Weiyun Huang, Krishnamoorthy Sivakumar, and Erik Johnson2. Distributedclustering using collective principal component analysis. Knowledge and Information Systems,3:422–448, 2001.
[40] Leonard Kaufman and Peter J. Rousseeuw. Finding Groups in Data: An Introduction toCluster Analysis. John Wiley & Sons, 1990.
[41] Teuvo Kohonen. Self-organization and associative memory. Springer-Verlag, Berlin, 1989.
[42] Tao Li, Qi Li, Shenghuo Zhu, and Mitsunori Ogihara. A survey on wavelet applications indata mining. SIGKDD Explor. Newsl., 4(2):49–68, 2002.
[43] Tao Li, Sheng Ma, and Mitsunori Ogihara. Entropy-based criterion in categorical clustering.In ICML ’04: Proceedings of the twenty-first international conference on Machine learning,page 68, New York, NY, USA, 2004. ACM Press.
[44] Patricia E.N. Lutu. An integrated approach for scaling up classification and prediction algo-rithms for data mining. In SAICSIT ’02: Proceedings of the 2002 annual research conference ofthe South African institute of computer scientists and information technologists on Enablementthrough technology, pages 110–117, , Republic of South Africa, 2002. South African Institutefor Computer Scientists and Information Technologists.
[45] J. B. MacQueen. Some methods for classification and analysis of multivariate observations.In Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability, pages281–297, Berkeley, CA, 1967. University of California.
[46] Nikos Mamoulis, David W. Cheung, and Wang Lian. Similarity search in sets and categoricaldata using the signature tree. In Proceedings of the 19th International Conference on DataEngineering (ICDE 03), pages 75–86. IEEE, 2003.
[47] Sally McClean, Bryan Scotney, Kieran Greer, and Ronan Pairceir. Conceptual clustering ofheterogeneous distributed databases. In Workshop on Distributed and Parallel KnowledgeDiscovery, 2000.
[48] Manoel Mendonca and Nancy L. Sunderhaft. Mining software engineering data: A survey.State-of-the-art report, DoD Data and Analysis Center for Software (DACS), 1999.
[49] Harvey J. Miller and Jiawei Han, editors. Geographic Data Mining and Knowledge Discovery.Taylor & Francis, 2001.
[50] Sushmita Mitra, Sankar K. Pal, and Pabitra Mitra. Data mining in soft computing framework:A survey. IEEE Transactions on Neural Networks, 13(1):3–14, January 2002.
[51] D.J. Newman, S. Hettich, C.L. Blake, and C.J. Merz. UCI repository of machine learningdatabases. http://www.ics.uci.edu/∼mlearn/MLRepository.html, 1998.
[52] Michael K. Ng and Joyce C. Wong. Clustering categorical data sets using tabu search techni-ques. Pattern Recognition, 35:2783–2790, 2002.
[53] E. A. Patrick. Fundamentals of Pattern Recognition. Prentice Hall, 1972.
Departamento de Ingenierıa de Sistemas y Automatica. UPV 47

BIBLIOGRAFIA
[54] Zdzislaw Pawlak, Jerzy Grzymala-Busse, Roman Slowinski, and Wojciech Ziarko. Rough sets.Commun. ACM, 38(11):88–95, 1995.
[55] Witold Pedrycz, James C. Bezdek, Richard J. Hathaway, and G. Wesley Rogers. Two nonpa-rametric models for fusing heterogeneous fuzzy data. IEEE Transactions on Fuzzy Systems,6(3):411–425, 1998.
[56] J. R. Quinlan. Simplifying decision trees. Int. J. Man-Mach. Stud., 27(3):221–234, 1987.
[57] Ross Quinlan and J.R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann,1992.
[58] Nagiza F. Samatova, George Ostrouchov, Al Geist, and Anatoli V. Melechko. Rachet: An effi-cient cover-based merging of clustering hierarchies from distributed datasets. Distrib. ParallelDatabases, 11(2):157–180, 2002.
[59] C.E. Shannon. A mathematical theory of communication. Bell System Technical Journal,pages 379–423, 1948.
[60] Gholamhosein Sheikholeslami, Surojit Chatterjee, and Aidong Zhang. Wavecluster: a wavelet-based clustering approach for spatial data in very large databases. The VLDB Journal, 8(3-4):289–304, 2000.
[61] N. Slonim and N. Tishby. Agglomerative information bottleneck. In NIPS, 1999.
[62] Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck met-hod. In Proceedings of the 37th Annual Allerton Conference on Communication, Control andComputing, pages 368–387, 1999.
[63] Eugene Tuv and George C. Runger. Scoring levels of categorical variables with heterogeneousdata. IEEE Intelligent Systems, 19(2):14–19, 2004.
[64] Wei Wang, Jiong Yang, and Richard R. Muntz. Sting:astatistical information grid approach tospatial data mining. In Proceedings of the 23rd International Conference onVery Large DataBases (VLDB), pages 186–195, Athens, Greece, 1997. Morgan Kaufmann Publishers.
[65] Takashi Washio and Hiroshi Motoda. State of the art of graph-based data mining. SIGKDDExplor. Newsl., 5(1):59–68, 2003.
[66] Kebin Xu, Zhenyuan Wang, and Kwong-Sak Leung. Using a new type of nonlinear integral formulti-regression: An application of evolutionary algorithms in data mining. In IEEE Inter-national Conference on Systems, Man and Cybernetics, volume 3, pages 2326–2331, October1998.
[67] Miin-Shen Yang, Pei-Yuan Hwang, and De-Hua Chen. Fuzzy clustering algorithms for mixedfeature variables. Fuzzy Sets and Systems, 141(2):301–317, 2004.
[68] L. Zadeh. Fuzzy sets. Journal of Information and Control, 8:338–353, 1965.
[69] Mohammed J. Zaki, Markus Peters, Ira Assent, and Thomas Seidl. Clicks: an effective al-gorithm for mining subspace clusters in categorical datasets. In KDD ’05: Proceeding of theeleventh ACM SIGKDD international conference on Knowledge discovery in data mining,pages 736–742, New York, NY, USA, 2005. ACM Press.
[70] He Zengyou, Xu Xiaofei, and Deng Shengchun. Clustering categorical data streams. In TheFirst China Doctoral Candidates’ Academic Forum, Beijing, China, 2003.
[71] Tian Zhang, Raghu Ramakrishnan, and Miron Livny. Birch: an efficient data clustering methodfor very large databases. In SIGMOD ’96: Proceedings of the 1996 ACM SIGMOD interna-tional conference on Management of data, pages 103–114, New York, NY, USA, 1996. ACMPress.
[72] Y. Q. Zhang, M. D. Fraser, R. A. Gagliano, and A. Kandel. Granular neural networks fornumerical-linguistic data fusion and knowledge discovery. IEEE Transactions on Neural Net-works, 11(3):658–667, May 2000.
48 Trabajo de Investigacion. Tecnicas de agrupamiento para el analisis de datos cuantitativos y cualitativos