
jets with a time-periodic supply velocity: a numerical analysis
Upload
independentCategory
view
2download
0
Clustering (Agrupamiento)
Dr. Elmer A. FernándezUniversidad Católica de CórdobaFac. Ingeniería

Clustering: Se basa en intentar responder como es que ciertos Objetos (casos) pertenecen o “caen” naturalmente en cierto número de clases o grupos, de tal manera que estos objetos comparten ciertas características.Esta definición asume que los objetos pueden dividirse , rasonablemente, en grupos que contienen objetos similares. Si tal división existe, ésta puede estar oculta y debe ser descubierta.Este es el objetivo principal de las técnicas o estudios de clustering
Definición

Objetos (Datos) y Variables Un Objeto es un dato, el cual esta formado por un conjunto finito de variables.
Variables: Numéricas: son números reales en general Nominales : Son variables discretas pero que no tienen un orden especificado (color de ojos)
Ordinales: Son variables discretas con una relación de orden (temp. Alta, Media, baja)
Binarias: solo pueden tomar dos estados posibles (dicotómicas)

Medidas de Disimilaridad (Similaridad)Asocian un número (dij) a un par de Objetos/Datos (i,j) , donde: (Sea S el subespacio de objetos a clasificar)dij 0 para todo i, j Sdij = 0 para todo i==j Sdij = dji para todo i, j Sdij diz + dzj

Distancias
p
kjkikkij xxWd
1
2
p
kjkikkij xxWd
1
0 1
p
kjkikkij xxWd
City-Block
Euclídea
Minkowski

Distancias
p
l
p
k
p
kjkik
ij
jlikxx
xxd
1
2
1
2
1
p
ljjl
p
kiik
p
kjjkiik
ij
xxxx
xxxxd
1
2
1
2
1
?
?

Problemas frecuentesIncompatibilidad en las Unidades de Medida
Variables de distinto tipo (Numericas, Nominales,etc..)
Variables faltantes (Missing Values)

Tipos de ClusteringJerárquico (Hierarchical) : dendrogramas, Grafos (Arboles)
De partición: División en grupos (SOM, LVQ, etc.)

Clustering Jerárquico Dendrogramas1. El primer paso es calcular las distancias
entre todos los pares de objetos. Esto es lo mismo que asumir que cada objeto constituye un cluster: {C1, ...,CN}.
2. Se buscan los dos clusters más cercanos (Ci, Cj), éstos se juntan y constituyen uno solo Cij.
3. Se repite el paso 2 hasta que no quedan pares de comparación.
En general se representan como árboles binarios.

Clustering Jerárquico Dendrogramas La cuestión crítica de este
método es la forma de “juntar” los clusters entre sí, se utilizan básicamente tres formas:
Enlace simple Enlace promediado Enlace completo
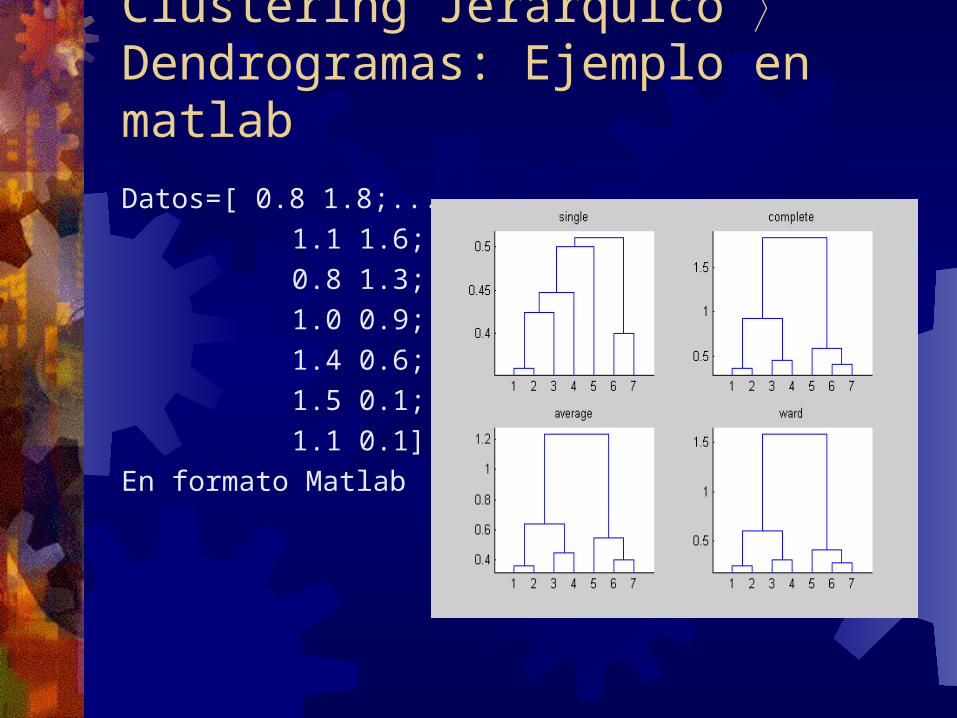
Clustering Jerárquico Dendrogramas: Ejemplo en matlabDatos=[ 0.8 1.8;... 1.1 1.6;... 0.8 1.3;... 1.0 0.9;... 1.4 0.6;... 1.5 0.1;... 1.1 0.1];En formato Matlab
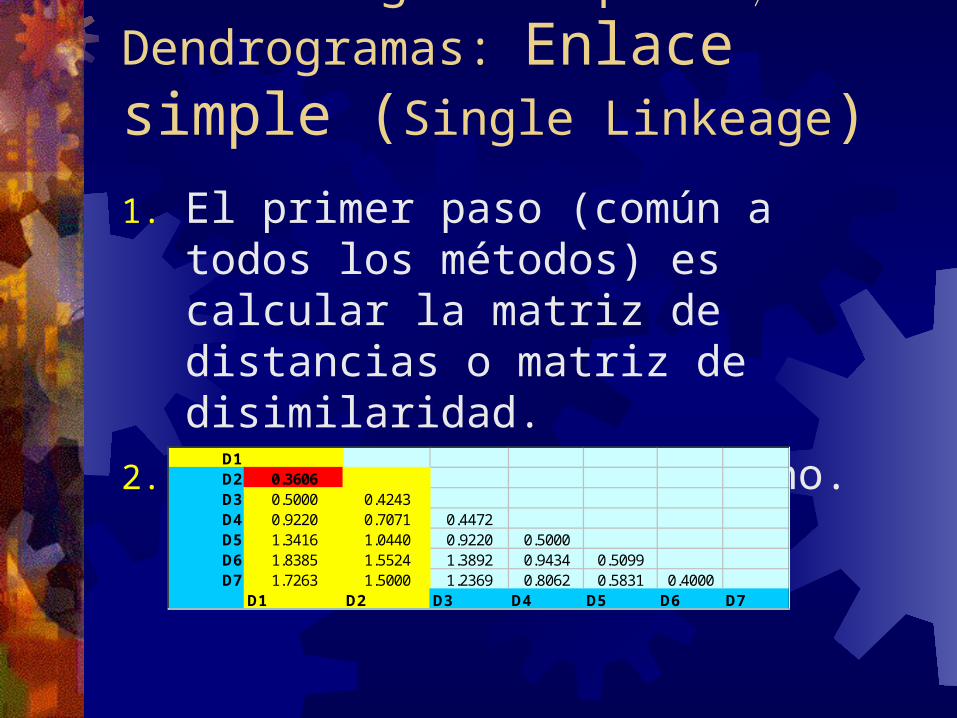
Clustering Jerárquico Dendrogramas: Enlace simple (Single Linkeage)1. El primer paso (común a
todos los métodos) es calcular la matriz de distancias o matriz de disimilaridad.
2. Buscar el par mas cercano.D1D2 0.3606D3 0.5000 0.4243D4 0.9220 0.7071 0.4472D5 1.3416 1.0440 0.9220 0.5000D6 1.8385 1.5524 1.3892 0.9434 0.5099D7 1.7263 1.5000 1.2369 0.8062 0.5831 0.4000
D1 D2 D3 D4 D5 D6 D7
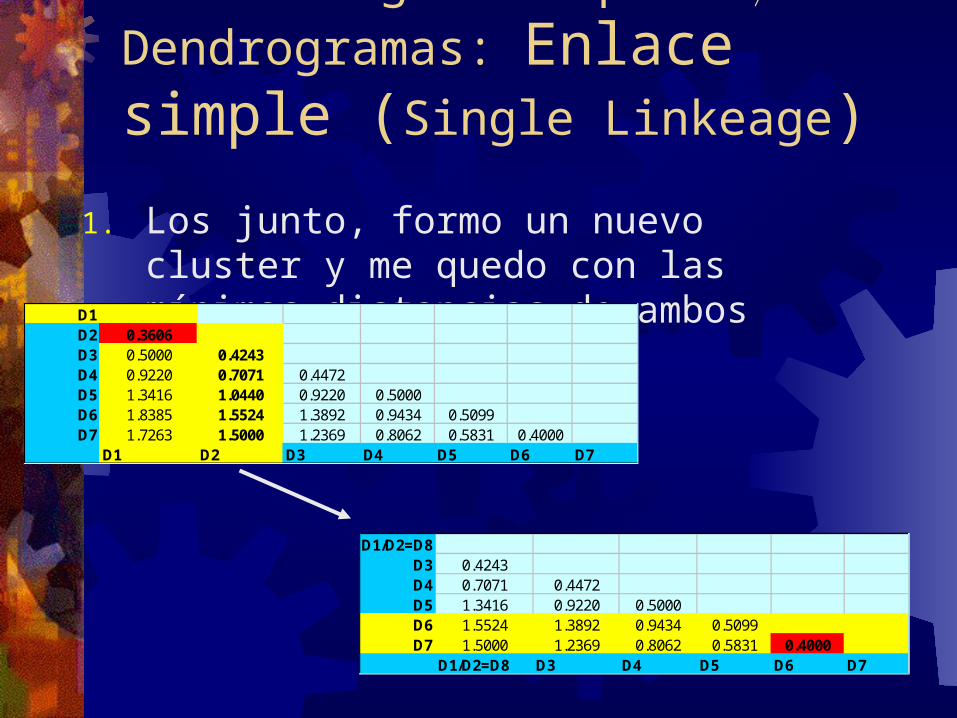
Clustering Jerárquico Dendrogramas: Enlace simple (Single Linkeage)
1. Los junto, formo un nuevo cluster y me quedo con las mínimas distancias de ambos clusters.
D1D2 0.3606D3 0.5000 0.4243D4 0.9220 0.7071 0.4472D5 1.3416 1.0440 0.9220 0.5000D6 1.8385 1.5524 1.3892 0.9434 0.5099D7 1.7263 1.5000 1.2369 0.8062 0.5831 0.4000
D1 D2 D3 D4 D5 D6 D7
D1/D2=D8D3 0.4243D4 0.7071 0.4472D5 1.3416 0.9220 0.5000D6 1.5524 1.3892 0.9434 0.5099D7 1.5000 1.2369 0.8062 0.5831 0.4000
D1/D2=D8 D3 D4 D5 D6 D7

Clustering Jerárquico Dendrogramas: Enlace simple (Single Linkeage)
D1/D2=D8D3 0.4243D4 0.7071 0.4472D5 1.3416 0.9220 0.5000D6 1.5524 1.3892 0.9434 0.5099D7 1.5000 1.2369 0.8062 0.5831 0.4000
D1/D2=D8 D3 D4 D5 D6 D7
D8D3 0.4243D4 0.7071 0.4472D5 1.3416 0.9220 0.5000
D6/D7=D9 1.5000 1.2369 0.8062 0.5831D8 D3 D4 D5 D6/D7=D9

Clustering Jerárquico Dendrogramas: Enlace simple (Single Linkeage)
D8D3 0.4243D4 0.7071 0.4472D5 1.3416 0.9220 0.5000
D6/D7=D9 1.5000 1.2369 0.8062 0.5831D8 D3 D4 D5 D6/D7=D9
D3/D8=D10D4 0.4472D5 0.9220 0.5000D9 1.2369 0.8062 0.5831
D3/D8=D10 D4 D5 D9
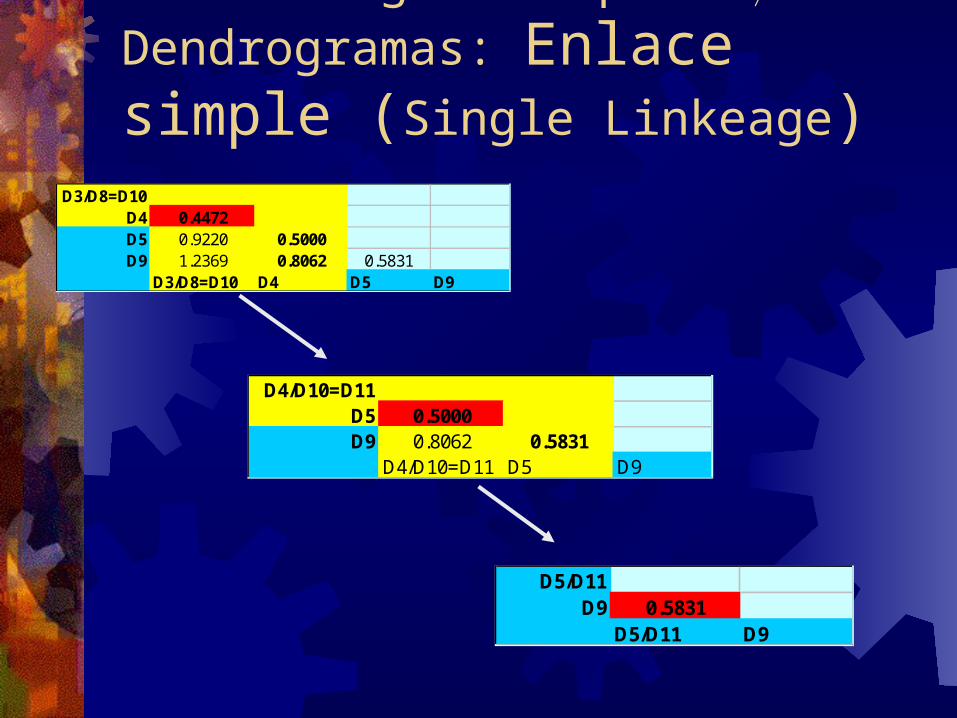
Clustering Jerárquico Dendrogramas: Enlace simple (Single Linkeage)
D3/D8=D10D4 0.4472D5 0.9220 0.5000D9 1.2369 0.8062 0.5831
D3/D8=D10 D4 D5 D9
D5/D11D9 0.5831
D5/D11 D9
D4/D10=D11D5 0.5000D9 0.8062 0.5831
D4/D10=D11 D5 D9
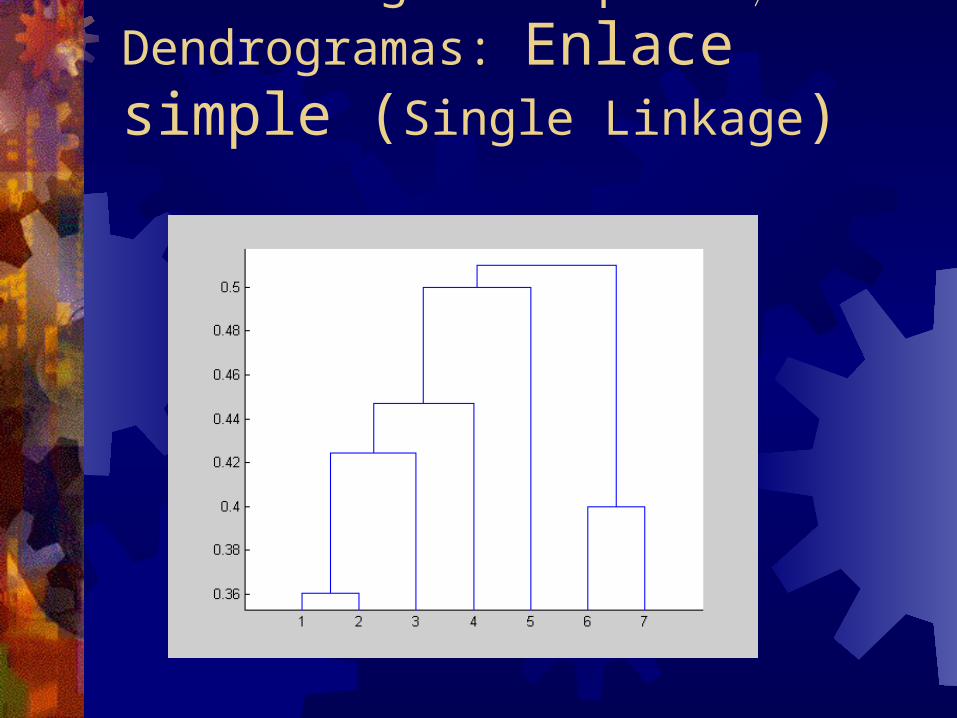
Clustering Jerárquico Dendrogramas: Enlace simple (Single Linkage)

Clustering de Partición
KMeansEl algoritmo de las K-medias es otro algoritmo de partición. Básicamente este algoritmo busca formar clusters (grupos) los cuales serán representados por K objetos. Cada uno de estos K objetos es el valor medio de los objetos que pertenecen a dicho grupo.

Clustering de Partición
KMeans1. Inicialmente se seleccionan K
objetos del conjunto de entrada. Estos K Objetos serán los centroides iniciales de los K-grupos.
2. Se calculan las distancias de los objetos(datos) a cada uno de los centroides. Los Datos (Objetos) se asignan a aquellos grupos cuya distancia es mínima con respecto a todos los centroides.

Clustering de Partición
KMeans3. Se actualizan los centroides
como el valor medio de todos los objetos asignados a ese grupo.
4. Se repite el paso 2 y 3 hasta que se satisface algún criterio de convergencia.
KMdemo
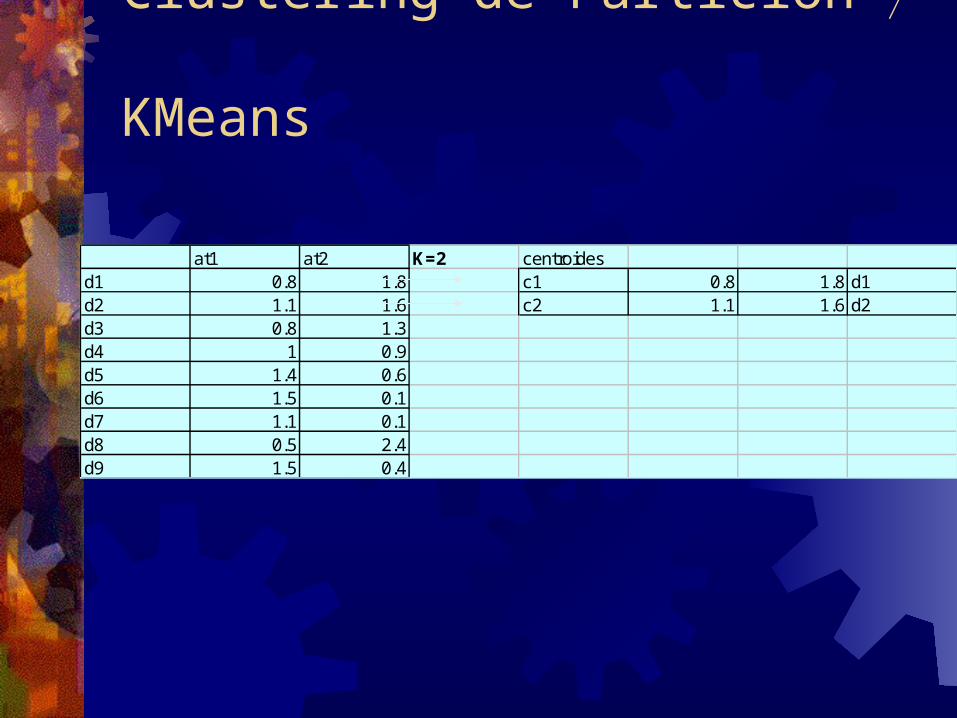
Clustering de Partición
KMeans
at1 at2 K=2 centroidesd1 0.8 1.8 c1 0.8 1.8 d1d2 1.1 1.6 c2 1.1 1.6 d2d3 0.8 1.3d4 1 0.9d5 1.4 0.6d6 1.5 0.1d7 1.1 0.1d8 0.5 2.4d9 1.5 0.4
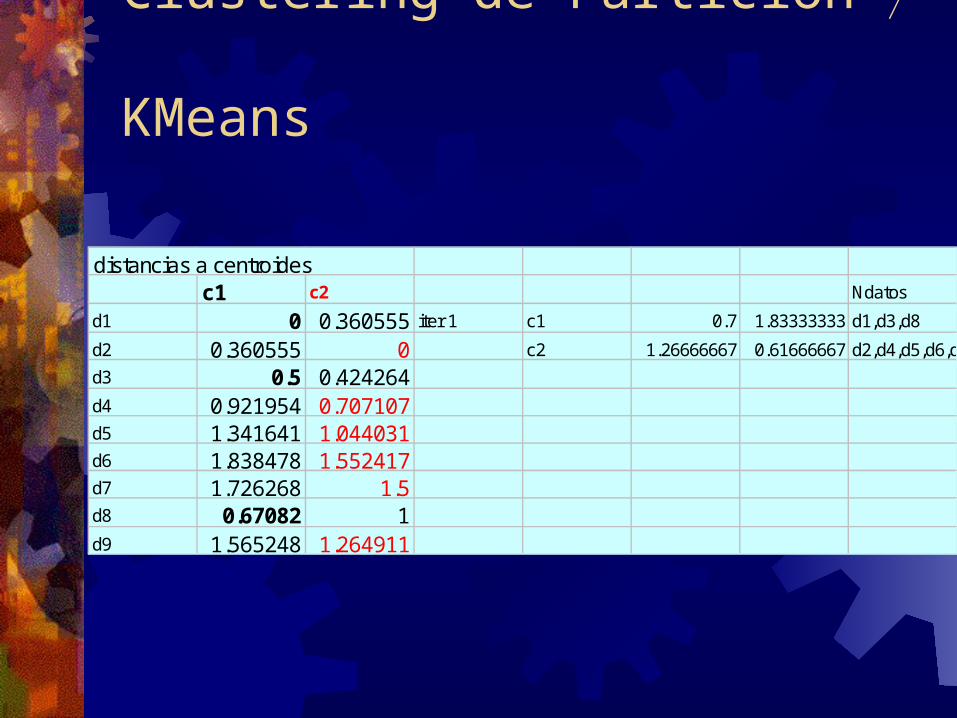
Clustering de Partición
KMeans
distancias a centroides c1 c2 Ndatosd1 0 0.360555 iter 1 c1 0.7 1.83333333 d1,d3,d8d2 0.360555 0 c2 1.26666667 0.61666667 d2,d4,d5,d6,d7,d9d3 0.5 0.424264d4 0.921954 0.707107d5 1.341641 1.044031d6 1.838478 1.552417d7 1.726268 1.5d8 0.67082 1d9 1.565248 1.264911
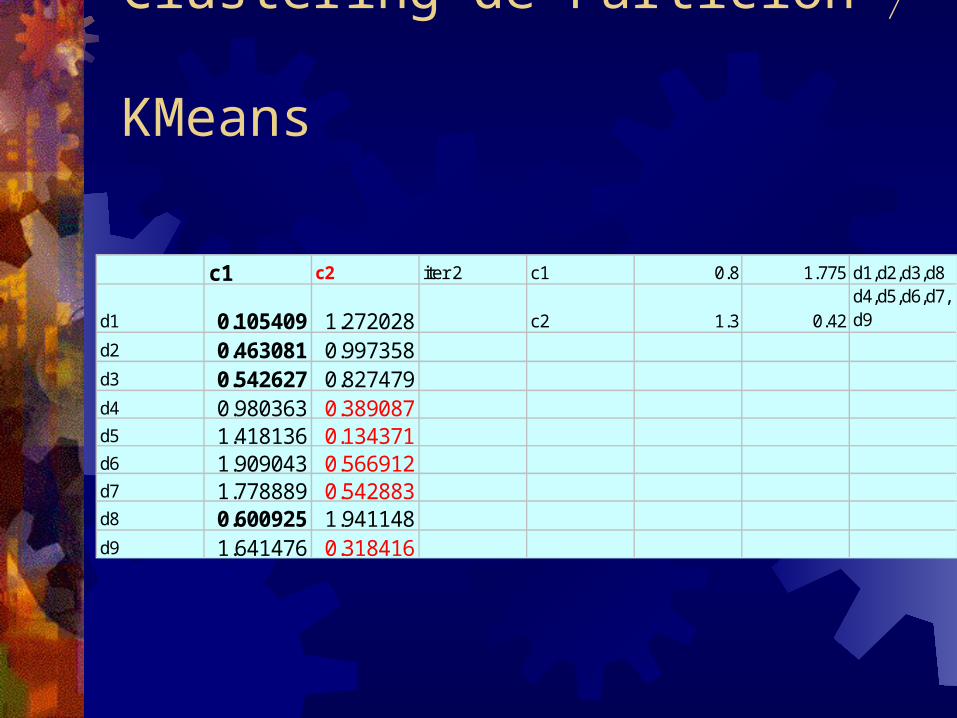
Clustering de Partición
KMeans
c1 c2 iter 2 c1 0.8 1.775 d1,d2,d3,d8
d1 0.105409 1.272028 c2 1.3 0.42d4,d5,d6,d7,d9
d2 0.463081 0.997358d3 0.542627 0.827479d4 0.980363 0.389087d5 1.418136 0.134371d6 1.909043 0.566912d7 1.778889 0.542883d8 0.600925 1.941148d9 1.641476 0.318416

Clustering de Partición Self-Organizing Maps Los Mapas Autoorganizativos o Self-Organizing Maps es un modelo de red neuronal desarrollado por Teuvo Kohonen en los 80s.
Básicamente este modelo procesa una base de datos, resultando en un mapa (usualmente bidimensional) donde casos similares se “mapean” en regiones cercanas.
De esta manera “vecindad” significa “similaridad”.

Clustering de Partición Self-Organizing MapsLa estructura de este modelo es una capa de nodos (uni, bi o tridimensional). La disposición de los nodos es sobre un espacio geométrico y no están conectados entre si.
Todos los nodos se conectan a las mismas entradas del modelo.
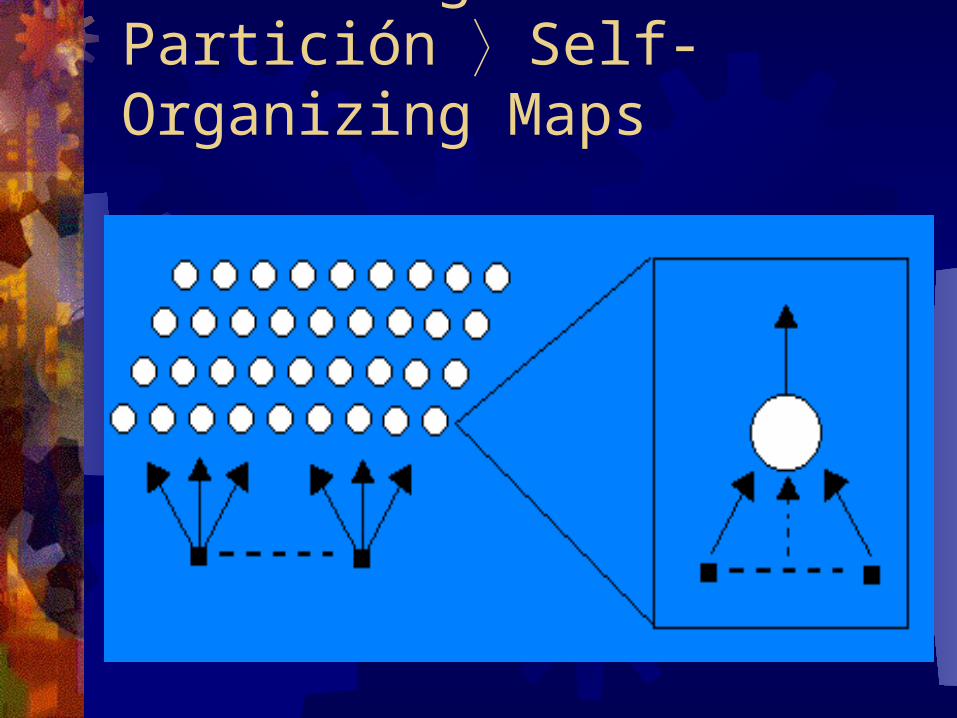
Clustering de Partición Self-Organizing Maps
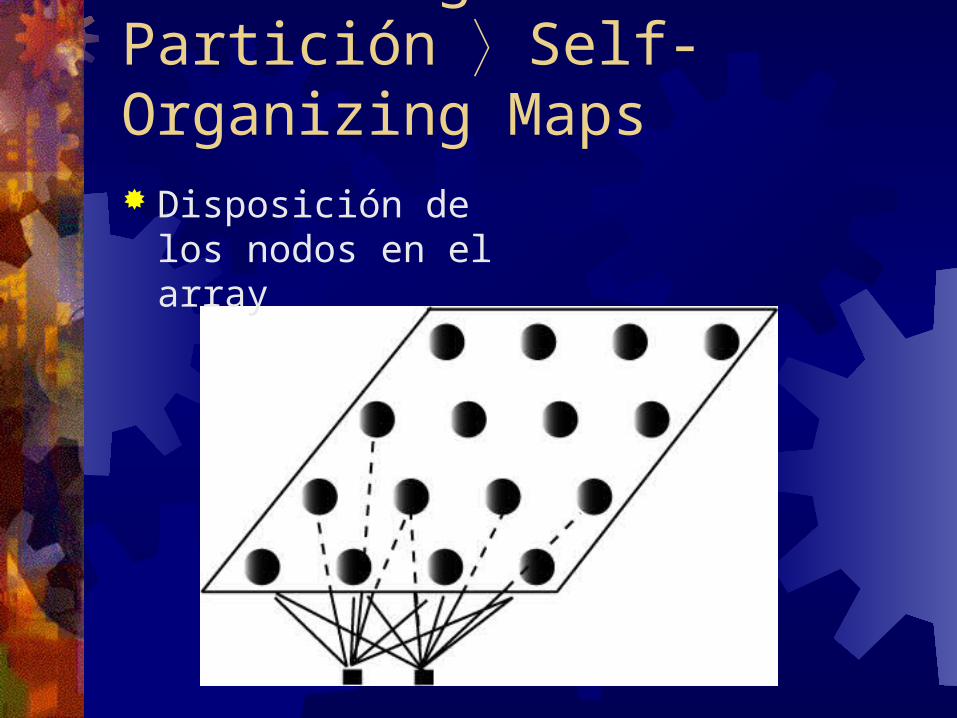
Clustering de Partición Self-Organizing Maps Disposición de los nodos en el array
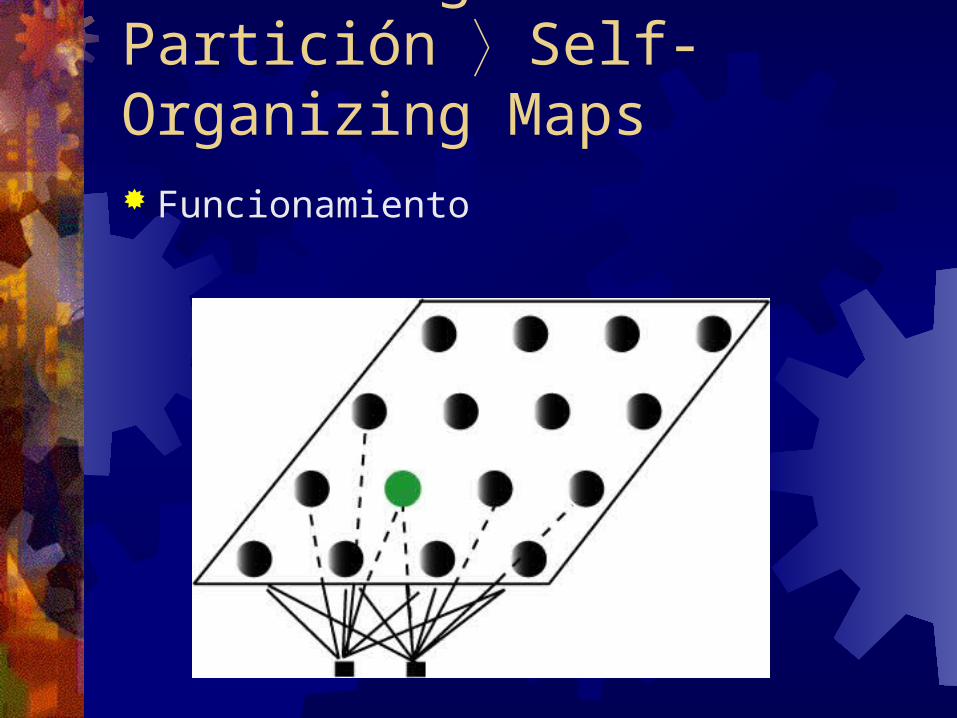
Clustering de Partición Self-Organizing Maps Funcionamiento

Clustering de Partición Self-Organizing Maps: Entrenamiento1. Se inicializan
los pesos de cada nodo (por ej. aleatoriamente.)
2. Se presenta una entrada a la red.
3. Se busca el nodo ganador
4. Se actualizan los pesos del nodo ganador y de sus vecinos.
5. Se vuelve al paso 2 hasta que se satisface el criterio de detención impuesto.

Clustering de Partición Self-Organizing Maps: Entrenamiento Consideraciones Iniciales:
Selección de la dimensión de la red Selección de la cantidad de nodos Selección de una medida de
similaridad Inicialización aleatoria de pesos Selección del coeficiente de
aprendizaje Elección de una vecindad inicial.
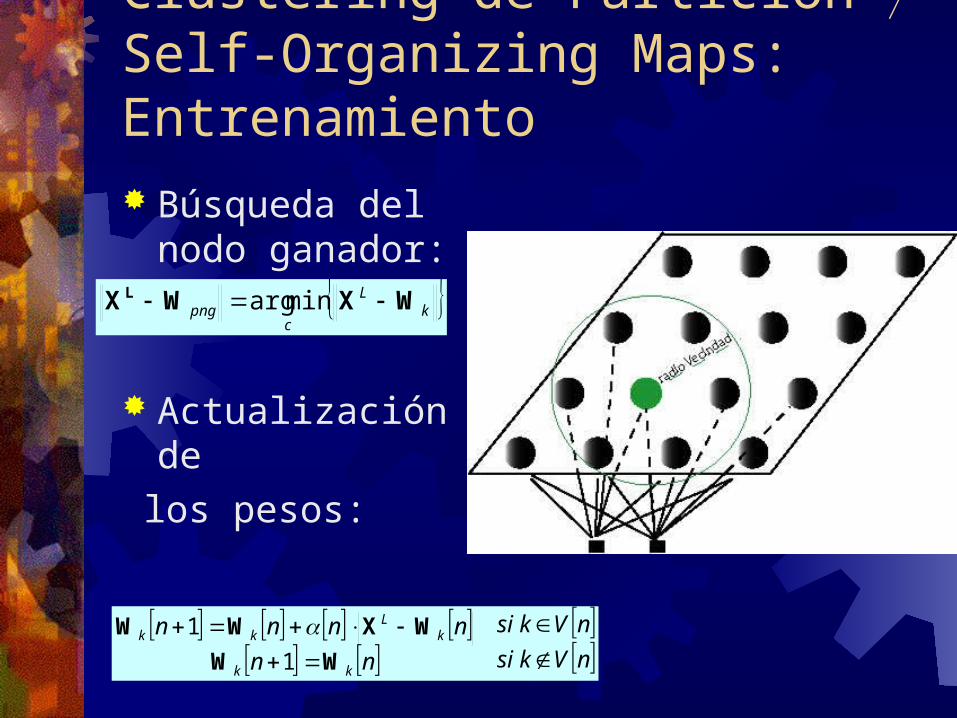
Clustering de Partición Self-Organizing Maps: Entrenamiento Búsqueda del nodo ganador:
Actualización de
los pesos:
kL
cpng WXWX L minarg
nVksinVksi
nnnnnn
kk
kL
kk
WWWXWW
11

Clustering de Partición Self-Organizing Maps: Entrenamiento
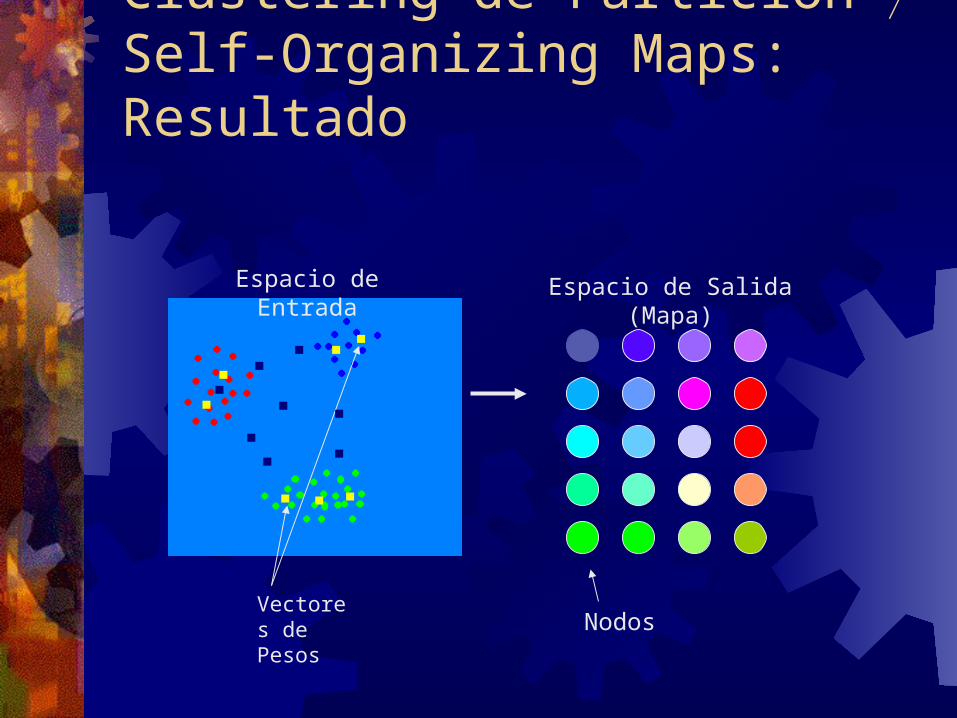
Clustering de Partición Self-Organizing Maps: Resultado
Vectores de Pesos
Espacio de Entrada
Espacio de Salida (Mapa)
Nodos
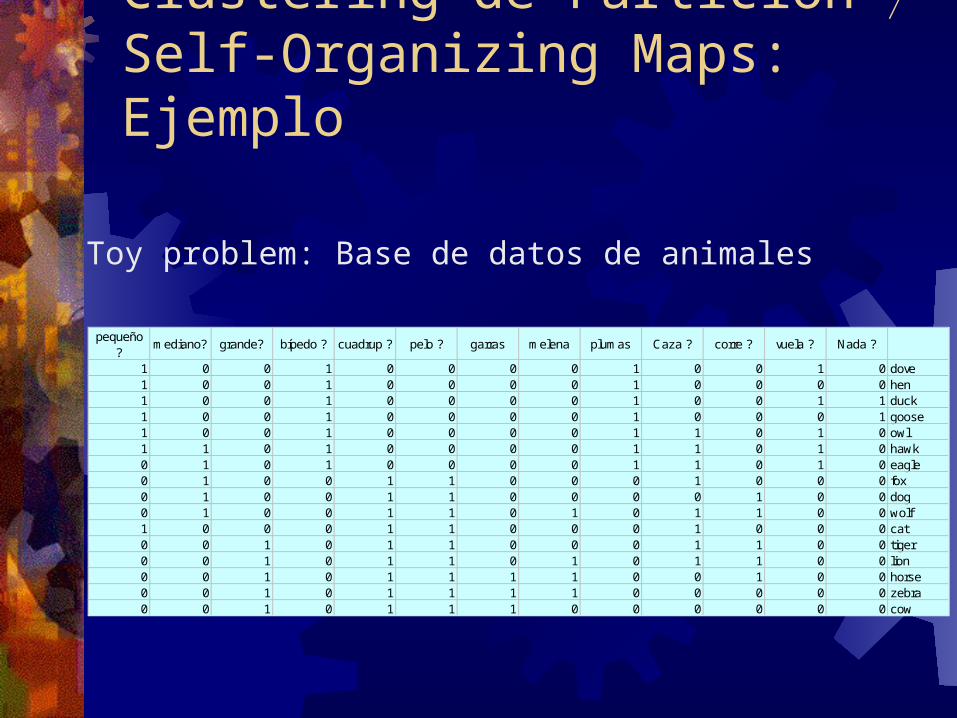
Clustering de Partición Self-Organizing Maps: Ejemplo
pequeño ? m ediano? grande? bípedo ? cuadrup ? pelo ? garras m elena plum as Caza ? corre ? vuela ? Nada ?
1 0 0 1 0 0 0 0 1 0 0 1 0 dove1 0 0 1 0 0 0 0 1 0 0 0 0 hen1 0 0 1 0 0 0 0 1 0 0 1 1 duck1 0 0 1 0 0 0 0 1 0 0 0 1 goose1 0 0 1 0 0 0 0 1 1 0 1 0 owl1 1 0 1 0 0 0 0 1 1 0 1 0 hawk0 1 0 1 0 0 0 0 1 1 0 1 0 eagle0 1 0 0 1 1 0 0 0 1 0 0 0 fox0 1 0 0 1 1 0 0 0 0 1 0 0 dog0 1 0 0 1 1 0 1 0 1 1 0 0 wolf1 0 0 0 1 1 0 0 0 1 0 0 0 cat0 0 1 0 1 1 0 0 0 1 1 0 0 tiger0 0 1 0 1 1 0 1 0 1 1 0 0 lion0 0 1 0 1 1 1 1 0 0 1 0 0 horse0 0 1 0 1 1 1 1 0 0 0 0 0 zebra0 0 1 0 1 1 1 0 0 0 0 0 0 cow
Toy problem: Base de datos de animales

Clustering de Partición Self-Organizing Maps: Ejemplo
Toy problem: Mapa de animales

Clustering de Partición Self-Organizing Maps: Ejemplo
Toy problem: Mapa de animales (Distancias – Clusters)
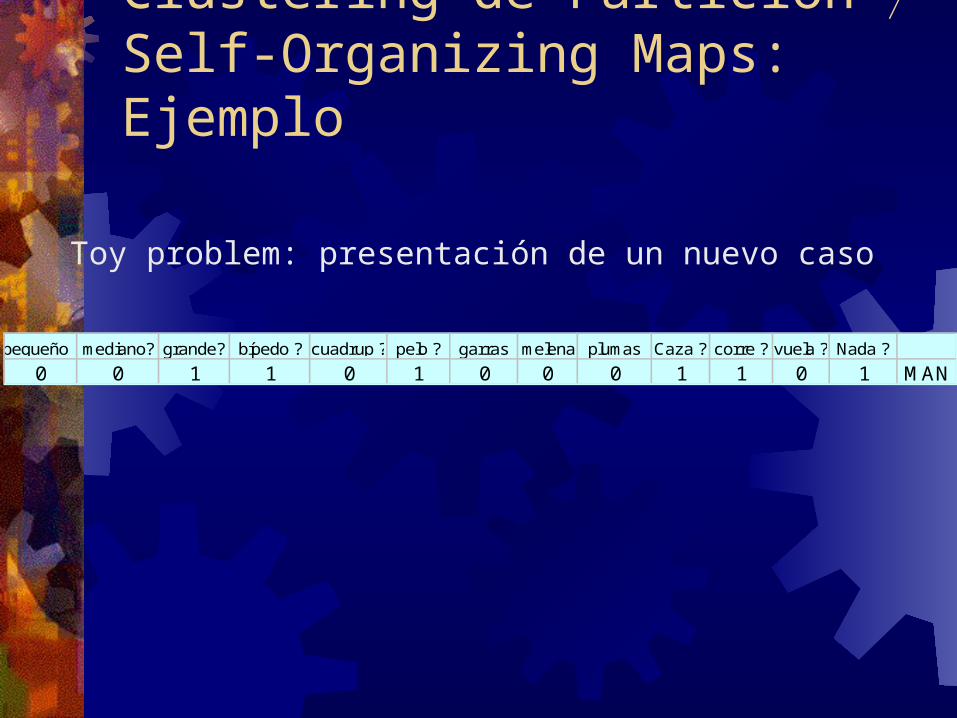
Clustering de Partición Self-Organizing Maps: Ejemplo
Toy problem: presentación de un nuevo caso
pequeño ?mediano? grande? bípedo ? cuadrup ? pelo ? garras melena plumas Caza ? corre ? vuela ? Nada ?0 0 1 1 0 1 0 0 0 1 1 0 1 M AN

Clustering de Partición Self-Organizing Maps: Ejemplo
Hijo’e tigre !!!
Copyright © 2022 FDOKUMEN




















