
A nested iterated local search algorithm for scheduling a flowline manufacturing cell with sequence...
6
A Nested Iterated Local Search Algorithm for Scheduling a Flowline Manufacturing Cell with Sequence Dependent Family Setup Times Radhouan Bouabda FSEGS, route de l’a´ eroport km 4, Sfax 3018 Tunisie Email: [email protected] Bassem jarboui Institut Supe´ rieur de Commerce et de Comptabilit´ e de Bizerte, Zarzouna,7021 Bizerte,Tunisie Email: bassem [email protected] Abdelwaheb Reba¨ ı FSEGS, route de l’a´ eroport km 4, Sfax 3018 Tunisie Email: [email protected] Abstract—This paper addresses the permutation flowline man- ufacturing cell with sequence dependent family setup times problem with the objective to minimize the makespan criterion. We propose a new way of hybridizing iterated local search. It consists in using Branch and Bound algorithm as the embedded local search algorithm inside an iterated local search algorithm. Moreover, the application of the branch and bound algorithm is based upon the decomposition of the problem into subproblems. The performance of the proposed method is tested by numerical experiments on a large number of representative problems. keywords—Branch and bound; Iterated local search algorithm; Flowline manufacturing cell; Setup times; Makespan. I. I NTRODUCTION Cellular Manufacturing (CM) systems can be defined as a manufacturing philosophy in which similar parts are identified and grouped into part families and machines are grouped into machine cells to take advantage of their similarities in manufacturing and design [1]. Jeon and Leep[2] have presented the design of CM as a tool for developing the production environment of machining centring by grouping the part families according to a number of similarities. Scheduling in a manufacturing cell is classified into two groups: jobshop environment and flowshop environment. In jobshop cell, we have low part similarity where materials follow irregular pattern, this environment is more flexible. In flowshop cell, usually, we have more simplified product flows due to the higher part similarity [3], in this case materials follow linear pattern. Allahverdi et al. [4] have presented an extensive review of the scheduling literature on models with setup times. In Cellular Manufacturing systems, switching between jobs within a part family requires negligible or no setup time and for this reason it can be included in the processing times of each job. Nevertheless, switching from a job in one part family to a job in another family requires a major setup and hence requires an explicit treatment of setup times. Scheduling flowline CM involving setup times can be classified into two classes; the first class is sequence-independent ([5],[6],[7] and[8]) and the second class is sequence-dependent setup times ([9],[10],[11] and[12]). This paper deals with sequencing part families and sequence dependent family setup times. This problem is NP-hard in the strong sense even for a two-machine case [11]. The structure of the paper is as follows. Section 2 introduces a formal problem definition. Section 3 illustrates the strategy of our optimization approach. A series of comparative experi- ments are conducted in section 4 to evaluate the performance of the proposed algorithm. Finally, some concluding remarks are given. II. PROBLEM STATEMENT The focus of this research is to schedule a permutation flowline manufacturing cell with sequence dependent family setup times where it is desired to minimize the makespan. For a formal definition of the problem consider the following notations: M : Number of machines. K: Number of families. m: Index for machines (m =1, 2, ..., M ). f : Index for families (f =1, 2, ..., K). N f : Number of jobs in family f . j : Index for Jobs (j =1, 2, ..., N f ). J f : Set of jobs in family f . S m rf : Setup time for family f processed immediately after family r at machine m. S m 0[1] : Setup time for the first family processed on machine m. P fjm : Processing time of job j in family f on machine m. π = {π [1] ,π [2] , ..., π [K] } is a set of sequence where π [f ] is the job sequence within the family sequenced in position f of π. δ f [j] : The job sequenced in position j of the job sequence for family f . C(δ [f ][j] ,m): The completion time on machine m of the job sequenced in position j of the job sequence for the family sequenced in position f of π. C(δ [f ][j] , 0) = 0 for (j =1, 2, ..., N [f ] ) and (f =1, 2, ..., K) C(0,m)=0 for (m =1, 2, ..., M ) 978-1-61284-4577-0324-9/11/$26.00 ©2011 IEEE 526
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of A nested iterated local search algorithm for scheduling a flowline manufacturing cell with sequence...

A Nested Iterated Local Search Algorithm forScheduling a Flowline Manufacturing Cell with
Sequence Dependent Family Setup TimesRadhouan Bouabda
FSEGS, route de l’aeroportkm 4, Sfax 3018 Tunisie
Email: [email protected]
Bassem jarbouiInstitut Superieur de Commerce et
de Comptabilite de Bizerte,Zarzouna,7021 Bizerte,Tunisie
Email: bassem [email protected]
Abdelwaheb RebaıFSEGS, route de l’aeroport
km 4, Sfax 3018 TunisieEmail: [email protected]
Abstract—This paper addresses the permutation flowline man-ufacturing cell with sequence dependent family setup timesproblem with the objective to minimize the makespan criterion.We propose a new way of hybridizing iterated local search. Itconsists in using Branch and Bound algorithm as the embeddedlocal search algorithm inside an iterated local search algorithm.Moreover, the application of the branch and bound algorithm isbased upon the decomposition of the problem into subproblems.The performance of the proposed method is tested by numericalexperiments on a large number of representative problems.
keywords—Branch and bound; Iterated local search algorithm;Flowline manufacturing cell; Setup times; Makespan.
I. INTRODUCTION
Cellular Manufacturing (CM) systems can be defined as amanufacturing philosophy in which similar parts are identifiedand grouped into part families and machines are groupedinto machine cells to take advantage of their similaritiesin manufacturing and design [1]. Jeon and Leep[2] havepresented the design of CM as a tool for developing theproduction environment of machining centring by groupingthe part families according to a number of similarities.Scheduling in a manufacturing cell is classified into twogroups: jobshop environment and flowshop environment. Injobshop cell, we have low part similarity where materialsfollow irregular pattern, this environment is more flexible. Inflowshop cell, usually, we have more simplified product flowsdue to the higher part similarity [3], in this case materialsfollow linear pattern. Allahverdi et al. [4] have presented anextensive review of the scheduling literature on models withsetup times. In Cellular Manufacturing systems, switchingbetween jobs within a part family requires negligible orno setup time and for this reason it can be included in theprocessing times of each job. Nevertheless, switching froma job in one part family to a job in another family requiresa major setup and hence requires an explicit treatmentof setup times. Scheduling flowline CM involving setuptimes can be classified into two classes; the first class issequence-independent ([5],[6],[7] and[8]) and the second classis sequence-dependent setup times ([9],[10],[11] and[12]).
This paper deals with sequencing part families and sequencedependent family setup times. This problem is NP-hard inthe strong sense even for a two-machine case [11].
The structure of the paper is as follows. Section 2 introducesa formal problem definition. Section 3 illustrates the strategyof our optimization approach. A series of comparative experi-ments are conducted in section 4 to evaluate the performanceof the proposed algorithm. Finally, some concluding remarksare given.
II. PROBLEM STATEMENT
The focus of this research is to schedule a permutationflowline manufacturing cell with sequence dependent familysetup times where it is desired to minimize the makespan.For a formal definition of the problem consider the followingnotations:M : Number of machines.K: Number of families.m: Index for machines (m = 1, 2, ...,M).f : Index for families (f = 1, 2, ...,K).Nf : Number of jobs in family f .j: Index for Jobs (j = 1, 2, ..., Nf ).Jf : Set of jobs in family f .Sm
rf : Setup time for family f processed immediately afterfamily r at machine m.Sm
0[1]: Setup time for the first family processed on machinem.Pfjm: Processing time of job j in family f on machine m.π = {π[1], π[2], ..., π[K]} is a set of sequence where π[f ] is thejob sequence within the family sequenced in position f of π.δf [j]: The job sequenced in position j of the job sequence forfamily f .C(δ[f ][j],m): The completion time on machine m of the jobsequenced in position j of the job sequence for the familysequenced in position f of π.C(δ[f ][j], 0) = 0 for (j = 1, 2, ..., N[f ]) and (f = 1, 2, ...,K)C(0,m) = 0 for (m = 1, 2, ...,M)
978-1-61284-4577-0324-9/11/$26.00 ©2011 IEEE 526

C(δ[1][1],m) = max{C(δ[1][1],m − 1), Sm0[1]} + P[1][1]m for
(m = 1, 2, ...,M)C(δ[f ][1],m) = max{C(δ[f ][1],m− 1), C(δ[f−1][N[f−1]],m) +Sm
[f−1][f ]}+ P[f ][1]m for (f = 2, 3, ...,K)C(δ[f ][j],m) = max{C(δ[f ][j],m − 1), C(δ[f ][j−1],m)} +P[f ][j]m for (j = 2, 3, ..., N[f ]) and (f = 1, 2, ...,K)The objective of the problem is to find the sequence π thatresults in the minimum C(δ[K][N[K]],M)A solution of our problem requires two aspects sequencingvarious families and sequencing jobs within each family. Sinceour framework is permutation flowline, both the sequence offamilies and the parts within each family are the same on allmachines. The solution π of our problem takes the followingstructure π = {π[1], π[2], ..., π[f−1], π[f ], π[f+1], ..., π[K]}where π[f ] = {δ[f ][1], δ[f ][2], ..., δ[f ][N[f]]} is the sequence ofjob within the family sequenced in the position f of π(Figure.1).
Figure. 1. Solution Structure
III. THE PROPOSED APPROACH
In the literature, cooperative approach has attracted in thelast few years a great deal of research effort and a goodnumber of strategies have been developed to solve NP-hardcombinatorial optimization problems. Firstly, cooperationbetween metaheuristics is mainly proposed. Then cooperationbetween exact methods and metaheuristics is considered. Thislast kind of cooperation provides high-quality solutions sinceit takes advantage from both methods at once [13].In this context, we propose a cooperative approach (NestedIterated Local Search) to solve the manufacturing cellscheduling problem considered here, which consists tohybridize ILS with Branch-and-Bound algorithm. In fact,this is can be accomplished by using inside ILS algorithm alocal search procedure that is a Branch-and-Bound algorithm.The basic idea of the Nested Iterated Local Search is basedon the use of two neighborhood structure, knowing that theneighborhood structure defines for each current solution theset of possible solutions to which the local search algorithmcan move. The aim of using two neighborhood structures ina sequential way is to obtain neighborhoods of increasingcardinality allowing a progressive diversification of the searchprocess. NILS starts from the initial solution and at eachiteration a neighbour is selected in the neighborhood ofthe current solution. That neighbour is then submitted tobranch and bound algorithm that attempts to get better. Ifthe solution obtained is better than the current, update thecurrent and continue the search with the first neighborhood
structure. Otherwise, perturbe the current solution and itwill serve as an initial solution for the next call of the localsearch. This process iterates until a given stopping criterion.Our NILS algorithm terminates if we have reached themaximum number of iterations since the last improvement orthe maximum running time.
A. Iterated Local Search algorithm
Iterated local search (ILS) is a simple and generally applica-ble stochastic local search method that iteratively applies localsearch to perturbations of the current search point, leading toa randomized walk in the space of local optima [14]. To applyan ILS algorithm, four components have to be defined. Thefirst component ”Generate Initial Solution” generates an initialsolution. The second component ”Local Search” that providesan improved solution. The third component ”Perturbation” thatmodifies the current solution leading to some intermediatesolution. The last component ”Acceptance Criterion” thatdecides to which solution the next perturbation step is applied.
1) Generate Initial Solution: In our case, the initial solutionis randomly generated. A solution of our problem can berepresented merely by 1 + K vectors where K denotesthe number of families. The first vector corresponds to thepermutation order of part families processed on machines andthe last K vectors represent the permutation order of partswithin each part family.
2) Local Search: The next step is to refine this initialsolution. For this purpose we applied local search technique.Local search algorithm searches for an improved solutionwithin the neighborhood of the current solution. If an im-proving solution is found, it replaces the current solutionand the local search is continued. In fact, local search re-peatedly tries to improve a current solution by exploring itsneighborhood. One of the main components of a local searchalgorithm is the definition of the move set that creates a
527

neighborhood. In our nested iterated local search, we have usedtwo neighborhood structures. The first neighborhood structure(insertion moves) is assigned to reorder the sequence of partfamily, the second neighborhood structure (Branch and Boundalgorithm) is intended to reoptimize the sequence of jobswithin each part family. Firstly, a local search procedure basedin insertion moves is considered and is performed. Secondly,we applied local search procedure based on Branch and Boundalgorithm (Figure. 2). Whenever an improving solution isfound, the next iteration will return to the first neighborhoodstructure. Otherwise we apply a shake procedure based on theinterchange moves in order to leave the current local optimumand explore different solution spaces.
Figure. 2. Neighborhood structures
1) The first Neighborhood structure:The first neighborhood structure is based on insertionmoves which consist to remove a part family from oneposition in the sequence of part families and insert itat another position either before or after the originalposition.
2) The second neighborhood structure:
The solution π of our problem obtained by the firstneighborhood structure takes the following structureπ = {π[1], π[2], ..., π[f−1], π[f ], π[f+1], ..., π[K]} whereπ[f ] = {δ[f ][1], δ[f ][2], ..., δ[f ][N[f]]} is the sequence ofjobs within the family sequenced in the position f of π.In order to improve the solution obtained by the firstneighborhood structure we re-optimize the partial sched-ule within each family f ,π[f ], by the branch andbound algorithm. Therefore, the latter is based upondecomposition of the whole problem into subproblemsi.e. by considering one problem into each family. Insuch way, in each family, we consider the problem aspermutation flowshop scheduling problem with machineavailability constraint. In our study, the branch andbound algorithm can be considered as an intensificationoperator. We start by sequencing the jobs within thefamily sequenced in the first position then the jobswithin the family sequenced in the second position andso on. The branch and bound algorithm is used onlyfor the sequence of jobs of only one family and theremaining K− 1 sequences of jobs are already fixed bythe first neighborhood structure.
It is possible to perform branch and bound algorithmseveral times to optimize the schedule of jobs within thesame family, until no improvement can be attained. Thisis done because the optimal solution given by the branchand bound algorithm for the sequence of jobs within agiven family is considered as a local optimum of thewhole problem, which takes into account the structureof the remaining families and their associated sequencesof jobs. So, after any modification in the sequence ofjobs of the remaining families, we can turn back byperforming another time the branch and bound algorithmaiming to improve the found solution. The proposedbranch and bound algorithm is used for finding optimaljob sequences within a family sequenced in position fof π, f = 1, 2, ...,K. The procedure is terminated whenthe number of nodes generated exceeded (ηmax).
a) Overall procedure:By considering the search tree for our algo-rithm, the root node φ corresponds to the nullschedule of jobs within the family sequencedin position f . Each of the other nodes corre-sponds to a partial schedule δ[f ] where δ[f ] ={δ[f ][1], δ[f ][2], ..., δ[f ][e]} is a subset of jobs to beplaced at the beginning of the sequence of jobswithin the family sequenced in the position f . Thejob δ[f ][j] occupies the jth position in the scheduleof family sequenced in position f , 1 ≤ e ≤ N[f ],N[f ] is the number of jobs in J[f ]. Let δ[f ] =J[f ]/δ[f ], by placing any unscheduled job q, q ∈δ[f ], in position e+1 of π[f ], we create a descendantnode δ[f ]q = {δ[f ][1], δ[f ][2], ..., δ[f ][e], q}.Our branch and bound algorithm employs an adap-tive depth-first plus backtracking search strategyand uses a lower bound to fathom nodes. Wecalculate the lower bound for each created nodessuch that the number of created nodes are alwaysless than or equal to N[f ]. The node to be branchedis selected among the recently created nodes whichhas the minimum lower bound. The nodes withlower bounds that are smaller to the current in-cumbent solution are interesting for further con-sideration such that the initial incumbent solutionis the solution obtained by our iterated local searchalgorithm.
b) Lower Bounding:
In this subsection, we develop a useful machine-based lower bound. To compute a lower boundof the makespan for each node of the searchtree, we suppose that only one machine m(m = 1, 2, ...,M), can process at most one job ata time and the remainder machines can handle atthe same time an infinite number of jobs. By thisrelaxation, the problem is transformed to sequencea set of jobs on a one machine with release
528

dates (heads) and delivery times (tails). Thus,we calculate a lower bound on the makespan bysolving a single-machine scheduling problem. Inorder to calculate a lower bound the main ideais that a job within a family f can be processedat a machine m only when both the job and themachine are ready.
Let:
C(q, k): The completion time of job q on machinek. With q is the last scheduled job within thefamily sequenced in position f .And
Zl,k =
min
j∈δ[f]/q
{∑k
i=lP[f ]ji
}for 1 ≤ l < k ≤ M
0 otherwise
Zl,k: is the minimum of sum of processing times, on the setof machines l, l + 1, ..., k, of jobs in δ[f ] after sequencing thejob q.Then,
lbkm = C(q, k)+Zk,m−1+
∑j∈δ[f]/q
P[f ]jm for k = 1, 2, ..., m.
Hence, a valid lower bound on the completiontime on machine m of the last sequenced jobswithin the family sequenced in position f of π:
lbm = max1≤k≤m
lbkm
We define by C ′(δ[f ][j],m) the lower bound valueof the completion time of the job in position jwithin the family sequenced in position f onmachine m.ThenC ′(δ[k][j], 0) = 0 for k = f + 1, f + 2, ...,KC ′(δ[f+1][1], 1) = lb1 + S1
[f ][f+1] + P[f+1][1]1
C ′(δ[f+1][1],m) = max{lbm +Sm
[f ][f+1], C′(δ[f+1][1],m − 1)} + P[f+1][1]m
for m = 2, 3, ...,MC ′(δ[k][1],m) = max{C ′(δ[k−1][N[k−1]],m) +Sm
[k−1][k], C′(δ[k][1],m − 1)} + P[k][1]m for
k = f + 2, f + 3, ...,K and m = 1, 2, ...,MC ′(δ[k][j],m) = max{C ′(δ[k][j],m −1), C ′(δ[k][j−1],m)} + P[k][j]m forj = 2, 3, ..., N[k], k = f + 1, f + 2, ...,Kand m = 1, 2, ...,MSo, the lower bound value of the completion timeof the last job in the last family on machine M isobtained by C ′(δ[K][N[K]],M).
3) Perturbation: Local search algorithm accept only im-proving moves and terminates in local optimum. The aim ofthe perturbation phase is to escape from these local optimaand to provide a good starting point for the local search.The perturbation carried out on a solution should be strong
enough to permit the local search to discover new regions inthe solution space, but also weak enough to produce a solutionthat maintains some good features of the current one and toprevent random restart. In our case, we use a simple shakeprocedure which consists of applying a number of randommoves both for the sequence of part families and the sequenceof jobs within each part family.
4) Acceptance Criterion: The last important component isthe acceptance criterion. The acceptance criterion defines theconditions that must be satisfied so that the generated solutionreplaces the current solution. Different tecnics can be appliedfor acceptance of the solution obtained by the local searchtechnique. If the solution is accepted it will be perturbedand will serve as an initial solution for the next call of thelocal search techniques. In our experiments, we use the firstimprovement principle. In other words, the first better solutionfound, in terms of the objective function, in the neighbourhoodis accepted and used to replace the current solution.
IV. COMPUTATIONAL RESULTS
Nested iterated local search was coded using C++ languageand run on a PC with an Intel Pentium IV (3.2 GHz) CPUand 512Mb of RAM. In order to assess the performance ofour algorithm, we carried out several tests. We use the 900test problems developed by Schaller et al. [9] and testedby Schaller et al. [9], Franca et al. [10], Hendizadeh etal. [11] and Lin et al. [12] for the same problem. These900 benchmark problems are classified into three classes,according to the balance between the average processingtimes and the average setup times, called Small Setups (SSU),Medium Setups (MSU) and Large Setups (LSU). For eachclass 10 problem sets were generated, such that each of themcontains 30 problem instances. More detailed informationsabout these test problems are available in Schaller et al. [9].In order to evaluate the performance of our algorithm, we usethe following measures for each of the 30 problem sets:∆avg: the average relative percentage error rate of themakespan with respect to the lower bound values obtained bySchaller et al. [8].
∆avg =
∑30i=1(
Mij−LBi
LBi)
30× 100
where Mij is the makespan of instance i obtained by thealgorithm j. LBi is the lower bound value of the instance iobtained by Schaller et al. [8].
∆min = mini=1,2,...,30
(Mij − LBi
LBi)× 100
is the minimum relative percentage deviation from the lowerbound for each problem sets.
∆max = maxi=1,2,...,30
(Mij − LBi
LBi)× 100
is the maximum relative percentage deviation from the lowerbound for each problem sets.tavg is the average computational times of different algorithms
529

in seconds.The parameter settings were determined by preliminary testsas follows: The parameter ηmax is set to Nf × 50The number of random moves for the sequence of partfamilies is equal to the smallest integer greater than or equalto K
3 .The number of random moves for the sequence of jobs withineach part family is equal to the smallest integer greater thanor equal to Nf
4 .
We perform a comparison of the proposed cooperativeapproach (NILS) with the other proposed algorithms in theliterature and the results are displayed in Table I and Table II.
Table I provides results from evolutionary algorithms; thefirst column illustrates the results of the Memetic Algorithm(MA) of Franca et al. [10], the second column represents theresults of the genetic algorithm of Lin et al. [12]. Table IIillustrates the results obtained from local search algorithm thatis results of Tabu search algorithm (TS(2)) of Hendizadeh etal. [11] into the first column, results of Simulated Annealing(SA) and Tabu search algorithm (TS(1)) developed both byLin et al. [12] respectively into the second and third columnand in the last column results of our proposed algorithm.
By comparing our obtained results with other approaches,we find that, our algorithm can provide good results in termsof solution quality according to the employed performancemeasure. In overall, the performance of our algorithm is betterthan the previous proposed techniques with the exception ofthe SA which shows a slight superiority. About the CPU times,we cannot conclude much information because of the PCconfigurations used for the different approaches. However, thecomputational effort of our algorithm seems to be acceptable.
V. CONCLUSION
In this paper we presented a cooperative approach in which aBranch and Bound algorithm is integrated into an Iterated localsearch algorithm. The adressed problem is the permutationflowline manufacturing cell with sequence dependent familysetup times while minimizing the makespan criterion. TheBranch and Bound algorithm decomposes the whole problemby considering, in each family, the problem as permutationflowshop scheduling problem with machine availability con-straint. The experimental results, based on the used problemtests, show that our algorithm provided good results.
REFERENCES
[1] Prabhaharan G, Muruganandam A , Asokan P, Girish BS. Machinecell formation for cellular manufacturing systems using an ant colonysystem approach. The International Journal of Advanced ManufacturingTechnology. Int J Adv Manuf Technol 2005; 25: 1013-1019.
[2] Jeon G, Leep HR. Forming part families by using genetic algorithm anddesigning machine cells under demand change. Computers and OperationsResearch 2006; 33: 263-83.
[3] Billo RE. A design methodology for configuration of manufacturing cells.Computers and Industrial Engineering 1998; 34: 63-75.
[4] Allahverdi A, Ng CT, Cheng TCE, Kovalyov MY. A survey of schedulingproblems with setup times or costs. European Journal of OperationalResearch 2008; 187(3): 985-1032.
TABLE ICOMPUTATIONAL RESULTS OF GENETIC AND MEMETIC ALGORITHMS
MA GA
instances ∆min ∆avg ∆max tavg ∆min ∆avg ∆max tavg
LSU33 0.00 0.07 1.12 3.1 0.00 0.08 1.12 2.56LSU34 0.00 0.32 2.43 10.1 0.00 0.33 2.38 2.69LSU44 0.00 0.20 1.09 10.1 0.00 0.20 1.09 5.29LSU55 0.00 0.28 1.86 12.1 0.00 0.28 1.83 8.01LSU56 0.00 0.51 2.42 21.1 0.00 0.50 2.37 8.21LSU65 0.00 0.31 2.42 15.1 0.00 0.32 2.37 10.97LSU66 0.00 0.19 1.36 15.3 0.00 0.21 1.35 12.90LSU88 0.00 0.58 1.86 24.7 0.00 0.58 1.83 24.59LSU108 0.00 0.47 1.19 29.8 0.00 0.43 1.12 39.59LSU1010 0.00 0.77 2.27 29.5 0.00 0.62 1.43 43.61
MSU33 0.00 0.37 3.37 7.1 0.00 0.35 3.26 2.54MSU34 0.00 0.56 2.29 13.1 0.00 0.56 2.25 2.69MSU44 0.00 0.50 2.32 19.1 0.00 0.50 2.27 5.33MSU55 0.00 0.45 2.09 15.1 0.00 0.46 2.05 7.58MSU56 0.00 0.87 3.12 24.1 0.00 0.89 3.03 8.23MSU65 0.00 0.36 1.22 16.2 0.00 0.37 1.21 10.79MSU66 0.00 0.50 1.63 22.7 0.00 0.50 1.61 12.78MSU88 0.00 0.99 2.98 27.3 0.00 0.99 2.89 23.83MSU108 0.00 0.86 1.80 30.1 0.00 0.82 2.24 39.66MSU1010 0.15 1.15 2.53 30.8 0.15 0.98 2.82 43.71
SSU33 0.00 0.31 2.47 7.1 0.00 0.31 2.42 2.55SSU34 0.00 0.83 2.94 15.1 0.00 0.82 2.86 2.71SSU44 0.00 0.57 2.90 15.0 0.00 0.62 2.82 5.32SSU55 0.00 0.92 2.34 26.0 0.00 0.93 2.29 7.57SSU56 0.00 1.56 3.08 27.4 0.00 1.55 3.00 8.25SSU65 0.00 0.99 3.44 24.0 0.00 1.00 3.33 10.86SSU66 0.00 1.28 2.72 29.1 0.00 1.31 2.65 12.82SSU88 0.28 1.85 3.31 30.3 0.29 1.88 3.34 23.82SSU108 0.72 1.77 2.9 30.7 0.72 1.51 2.83 39.65SSU1010 0.59 2.33 3.65 30.6 0.59 2.18 3.33 43.75
all 0.06 0.76 2.37 20.4 0.06 0.74 2.31 15.76
MA was run on a PC Pentium II 266 MHz processor and 128 Mb RAM. [10]GA was run on a PC Pentium IV 2.4 GHz processor and 512 Mb RAM. [12]
[5] Vakharia AJ, Chang YL. A simulated annealing approach to schedulinga manufacturing cell. Naval Research Logistics 1990; 37: 559-577.
[6] Skorin-Kapov J, Vakharia AJ. Scheduling a flow-line manufacturing cell:a tabu search approach. International Journal of Production Research 1993;31(7): 1721-1734.
[7] Schaller J. A comparison of heuristics for family and job scheduling in aflow-line manufacturing cell. International Journal of Production Research2000; 38(2): 287-308.
[8] Schaller J. A new lower bound for the flow shop group schedulingproblem. Computers and Industrial Engineering 2001; 41(2): 151-161.
[9] Schaller JE, Gupta JND, Vakharia AJ. Scheduling a flowline manufactur-ing cell with sequence dependent family setup times. European Journal ofOperational Research 2000; 125: 324-39.
[10] Franca PM, Gupta JND, Mendes AS, Moscato P, Veltink KJ. Evo-lutionary algorithms for scheduling a flowshop manufacturing cell withsequence dependent family setups. Computers and Industrial Engineering2005; 48(3): 491-506.
[11] Hendizadeh H, Faramarzi H, Mansouri SA, Gupta JND, ElmekkawyTY. Meta- heuristics for scheduling a flowshop manufacturing cell withsequence dependent family setup times. International Journal of ProductionEconomics 2008; 111: 593-605.
[12] Lin SW, Ying KC, Lee ZJ. Metaheuristics for scheduling a non-permutation flowline manufacturing cell with sequence dependent familysetup times. Computers and Operations Research 2009; 36: 1110-1121.
[13] Jourdan L, Basseur M, Talbi EG. Hybridizing exact methods andmetaheuristics: A taxonomy. European Journal of Operational Research2009; 199: 620-629.
[14] Lourenc HR, Martin O, Sttzle T. Iterated local search, in: Glover F,
530
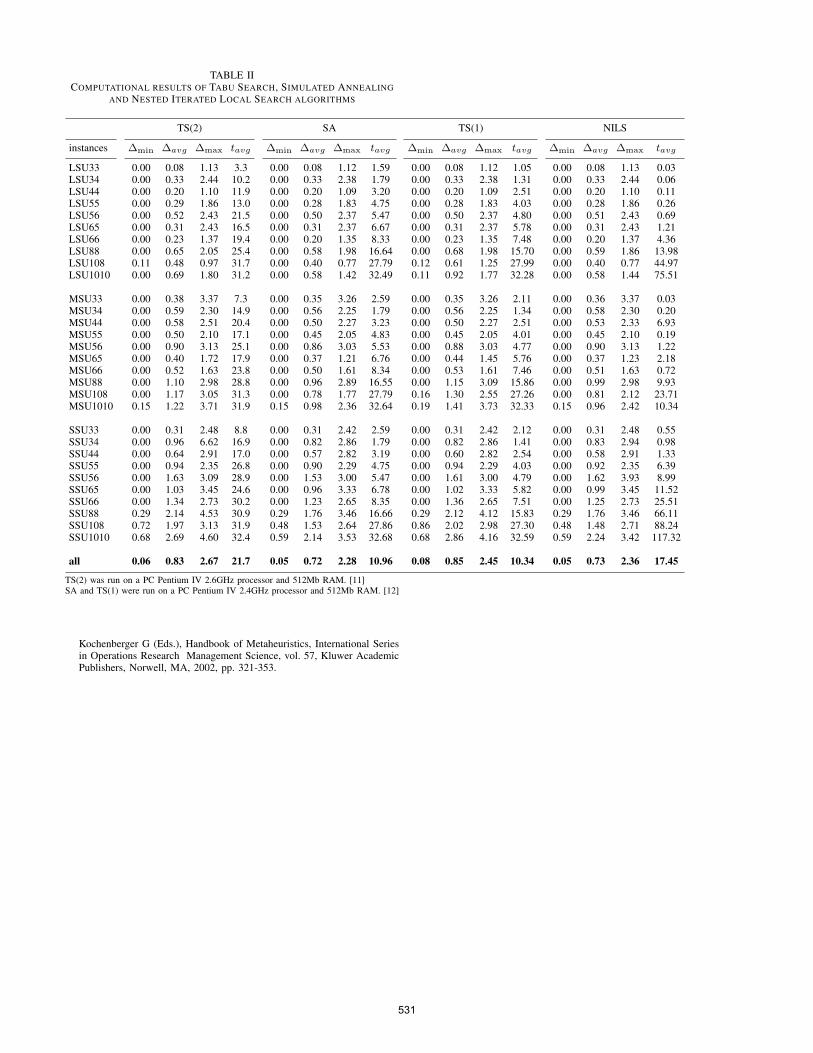
TABLE IICOMPUTATIONAL RESULTS OF TABU SEARCH, SIMULATED ANNEALING
AND NESTED ITERATED LOCAL SEARCH ALGORITHMS
TS(2) SA TS(1) NILS
instances ∆min ∆avg ∆max tavg ∆min ∆avg ∆max tavg ∆min ∆avg ∆max tavg ∆min ∆avg ∆max tavg
LSU33 0.00 0.08 1.13 3.3 0.00 0.08 1.12 1.59 0.00 0.08 1.12 1.05 0.00 0.08 1.13 0.03LSU34 0.00 0.33 2.44 10.2 0.00 0.33 2.38 1.79 0.00 0.33 2.38 1.31 0.00 0.33 2.44 0.06LSU44 0.00 0.20 1.10 11.9 0.00 0.20 1.09 3.20 0.00 0.20 1.09 2.51 0.00 0.20 1.10 0.11LSU55 0.00 0.29 1.86 13.0 0.00 0.28 1.83 4.75 0.00 0.28 1.83 4.03 0.00 0.28 1.86 0.26LSU56 0.00 0.52 2.43 21.5 0.00 0.50 2.37 5.47 0.00 0.50 2.37 4.80 0.00 0.51 2.43 0.69LSU65 0.00 0.31 2.43 16.5 0.00 0.31 2.37 6.67 0.00 0.31 2.37 5.78 0.00 0.31 2.43 1.21LSU66 0.00 0.23 1.37 19.4 0.00 0.20 1.35 8.33 0.00 0.23 1.35 7.48 0.00 0.20 1.37 4.36LSU88 0.00 0.65 2.05 25.4 0.00 0.58 1.98 16.64 0.00 0.68 1.98 15.70 0.00 0.59 1.86 13.98LSU108 0.11 0.48 0.97 31.7 0.00 0.40 0.77 27.79 0.12 0.61 1.25 27.99 0.00 0.40 0.77 44.97LSU1010 0.00 0.69 1.80 31.2 0.00 0.58 1.42 32.49 0.11 0.92 1.77 32.28 0.00 0.58 1.44 75.51
MSU33 0.00 0.38 3.37 7.3 0.00 0.35 3.26 2.59 0.00 0.35 3.26 2.11 0.00 0.36 3.37 0.03MSU34 0.00 0.59 2.30 14.9 0.00 0.56 2.25 1.79 0.00 0.56 2.25 1.34 0.00 0.58 2.30 0.20MSU44 0.00 0.58 2.51 20.4 0.00 0.50 2.27 3.23 0.00 0.50 2.27 2.51 0.00 0.53 2.33 6.93MSU55 0.00 0.50 2.10 17.1 0.00 0.45 2.05 4.83 0.00 0.45 2.05 4.01 0.00 0.45 2.10 0.19MSU56 0.00 0.90 3.13 25.1 0.00 0.86 3.03 5.53 0.00 0.88 3.03 4.77 0.00 0.90 3.13 1.22MSU65 0.00 0.40 1.72 17.9 0.00 0.37 1.21 6.76 0.00 0.44 1.45 5.76 0.00 0.37 1.23 2.18MSU66 0.00 0.52 1.63 23.8 0.00 0.50 1.61 8.34 0.00 0.53 1.61 7.46 0.00 0.51 1.63 0.72MSU88 0.00 1.10 2.98 28.8 0.00 0.96 2.89 16.55 0.00 1.15 3.09 15.86 0.00 0.99 2.98 9.93MSU108 0.00 1.17 3.05 31.3 0.00 0.78 1.77 27.79 0.16 1.30 2.55 27.26 0.00 0.81 2.12 23.71MSU1010 0.15 1.22 3.71 31.9 0.15 0.98 2.36 32.64 0.19 1.41 3.73 32.33 0.15 0.96 2.42 10.34
SSU33 0.00 0.31 2.48 8.8 0.00 0.31 2.42 2.59 0.00 0.31 2.42 2.12 0.00 0.31 2.48 0.55SSU34 0.00 0.96 6.62 16.9 0.00 0.82 2.86 1.79 0.00 0.82 2.86 1.41 0.00 0.83 2.94 0.98SSU44 0.00 0.64 2.91 17.0 0.00 0.57 2.82 3.19 0.00 0.60 2.82 2.54 0.00 0.58 2.91 1.33SSU55 0.00 0.94 2.35 26.8 0.00 0.90 2.29 4.75 0.00 0.94 2.29 4.03 0.00 0.92 2.35 6.39SSU56 0.00 1.63 3.09 28.9 0.00 1.53 3.00 5.47 0.00 1.61 3.00 4.79 0.00 1.62 3.93 8.99SSU65 0.00 1.03 3.45 24.6 0.00 0.96 3.33 6.78 0.00 1.02 3.33 5.82 0.00 0.99 3.45 11.52SSU66 0.00 1.34 2.73 30.2 0.00 1.23 2.65 8.35 0.00 1.36 2.65 7.51 0.00 1.25 2.73 25.51SSU88 0.29 2.14 4.53 30.9 0.29 1.76 3.46 16.66 0.29 2.12 4.12 15.83 0.29 1.76 3.46 66.11SSU108 0.72 1.97 3.13 31.9 0.48 1.53 2.64 27.86 0.86 2.02 2.98 27.30 0.48 1.48 2.71 88.24SSU1010 0.68 2.69 4.60 32.4 0.59 2.14 3.53 32.68 0.68 2.86 4.16 32.59 0.59 2.24 3.42 117.32
all 0.06 0.83 2.67 21.7 0.05 0.72 2.28 10.96 0.08 0.85 2.45 10.34 0.05 0.73 2.36 17.45
TS(2) was run on a PC Pentium IV 2.6GHz processor and 512Mb RAM. [11]SA and TS(1) were run on a PC Pentium IV 2.4GHz processor and 512Mb RAM. [12]
Kochenberger G (Eds.), Handbook of Metaheuristics, International Seriesin Operations Research Management Science, vol. 57, Kluwer AcademicPublishers, Norwell, MA, 2002, pp. 321-353.
531




















