
Computing context-dependent temporal diagnosis in complex domains
Upload
independentCategory
view
2download
0
IEEE TRANSACTIONS ON COMPUTERS, VOL. c-33, NO. 3, MARCH 1984
A Diagnosis Algorithm for Distributed Computing
Systems with Dynamic Failure and Repair
S. H. HOSSEINI, JON G. KUHL, AND SUDHAKAR M. REDDY, MEMBER, IEEE
Abstract- The problem of designing distributed fault-tolerantcomputing systems is considered. A model in which the networknodes are assumed to possess the ability to "test'" certain othernetwork facilities for the presence of failures is employed. Usingthis model, a distributed algorithm is 'presented which allows allthe network nodes to correctly reach independent diagnoses of thecondition (faulty or fault-free) of all the network nodes and inter-node communication facilities, provided the total number of fail-ures does not exceed a given bound. The proposed algorithmallows for the reentry of repaired or replaced faulty facilities backinto the network, and it also has provisions for adding new nodesto the system. Sufficient conditions are obtained for designing adistributed fault-tolerant system by employing the given algo-rithm. The algorithm has the interesting property that it lets asmany as all of the nodes and internode communication facilitiesfail, but upon repair or replacement of faulty facilities, the systemcan converge to normal operation if no more than a certain num-ber of facilities remain faulty.
Index Terms- Computer networks, distributed systems, fault-tolerance, self-diagnosable systems, testing.
I. INTRODUCTION
A S the applications of distributed computing systems con-tinue to expand, issues relating to the reliability of
such systems are gaining increased attention. A number ofrecent papers have attempted to extend traditional notionsof "fault-tolerant computing" [16], to deal with the problem offailures affecting the facilities of distributed systems andcomputer networks [17], [20]. This work has generallyviewed the problem as consisting of four ordered steps:1) error detection, 2) diagnosis (location) of the source offailure, 3) system reconfiguration to remove the faulty facili-ties or repair/replacement of such facilities, and 4) recoveryof the system state [ 17].
For many truly distributed systems, however, it may not berealistic to view the detection, diagnosis, repair, and recov-ery actions in a time-ordered fashion. In a large fully distrib-uted system, such as the very large distributed networks ofmicroprocessors proposed by several authors [9]-[12], theremight not be any central facility available for the coordi-nating of failure handling activities. Rather, any mechanismsfor the detection of failures would likely need to be distrib-uted throughout the network, and any diagnosis of the sourceof network failures would also need to be accomplished in a
Manuscript received August 28, 1982. This work was supported in part byAir Force Office of Scientific Research Grant AFOSR-78-3582 and NationalScience Foundation Grant ECS-8205188.
S. H. Hosseini is with the Department of Electrical Engineering and Com-puter Science, University of Wisconsin, Milwaukee, WI 53201.
J. G. Kuhl arnd S. M. Reddy are with the Department of Electrical andComputer Engineering, University of Iowa, Iowa City, IA 52242.
distributed fashion. Since distribution of diagnostic re-sponsibility involves the flow of diagnostic informationthrough the network, and since the faulty facilities them-selves may participate in this flow and perhaps alter, destroy,or generate erroneous diagnostic information in the process,the diagnostic procedure itself may become complex. Thisproblem was discussed in [1].
Furthermore, in some truly distributed environments,hardware reconfiguration in response to diagnosed failuresmay not be possible (or desirable). This, again, stems fromthe lack of any central authority in the network capable ofperforming such activities. For very large networks (severalauthors have proposed distributed computing networks con-sisting of many thousands of nodes [9]-[12]) a central facilityin charge of diagnosis of failures and network recon-figuration in response to diagnosed failures might be in-feasible due to the high workload such a facility would haveto bear. Even if a central facility for this purpose were pos-sible, the facility could pose a reliability bottleneck for theentire network since failure, or incorrect operation, of thecentral facility could allow faulty facilities to operate un-checked in the system or could exclude healthy resourcesfrom the network by erroneously diagnosing them as faulty.
Note that distribution of unilateral authority to undertakehardware reconfiguration does not lessen this problem be-cause failures of any of the mechanisms involved in the diag-nosis or reconfiguration could cause unreliable facilities tolurk in the system. This includes schemes in which nodes aredesigned to test themselves and to remove themselves fromthe network following a detected failure [21], as well ashardware reconfiguration mechanisms operating in responseto "voted" inputs.An alternative to hardware reconfiguration is an approach
proposed in [1]-[3], called "distributed fault-tolerance." Inthis approach the constituent nodes of a distributed com-puting network attempt to produce independent diagnoses ofthe condition of network facilities. The information used bya node in producing its diagnosis is the result of tests whichthe node performs upon certain neighboring facilities alongwith information passed to the node concerning the results oftests performed by other network nodes. Since faulty networkfacilities may be involved in the performance of testingactivities and in the dissemination of diagnostic messages,the information reaching a network node may not be entirelycorrect or reliable. This problem was discussed in [1]-[3],[8] where several algorithms were presented via which allfault-free nodes of a distributed computing network can pro-duce correct diagnoses of the condition of all network fa-cilities. Once a correctly functioning node has diagnosed a
0018-9340/84/0300-0223$01.00 C 1984 IEEE
223

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-33, NO. 3, MARCH 1984
failure in a network facility, the node can refrain fromfurther dealings with that facility. If all fault-free nodes act inthis fashion, then the faulty network facilities are effectivelylogically isolated from the sysiem. If this "distributed fault-tolerance" can be achieved, then a fault-tolerant distributedsystem which is completely free of "hard-core," or circuitrywith critical reliability requirements, may be possible.
In this paper, we present a distributed diagnosis algorithmfor fully distributed computing networks. In the next sectionan abstract model of a distributed computing network isgiven. In this model, network modes are assumed to possess
the ability to "test" certain other network facilities for thepresence of failures. In Section III a distributed algorithm isintroduced for the model of Section II. This algorithm allowsall network nodes to correctly diagnose the condition (faultyor fault-free) of all other network nodes and internode com-
munication paths, provided the total number of failures doesnot exceed a given bound. This work is of the flavor of thatgiven in [2], [3], but extends the earlier work considerably inthat it allows repaired or replaced facilities back into thenetwork, and also it allows the entry of new nodes and com-
munication links into the network. Section IV defines a diag-nosability measure and gives a set of sufficient conditionsunder which the algorithm is guaranteed to provide a givenlevel of diagnosability. Section V discusses some extensionsto the work presented in this paper, and the final sectionprovides conclusions.
II. PRELIMINARIES
This paper will employ a model for a distributed com-
puting network which is similar to that given in [ 1]-[3] . Thatis to say, the network will be abstracted as a set of nodes andcommunication paths between nodes. A node is assumed tobe capable of "testing" certain of its neighboring nodes (i.e.,nodes with which it shares a direct communication path) forcorrect operation. While fault-free nodes are assumed to al-ways perform tests correctly and always to reach correctdecisions regarding the condition of-nodes which they test,faulty nodes may perform tests incorrectly and may reachinvalid conclusions. Diagnostic messages. which contain in-formation concerning test results are allowed to flow betweennodes and such messages may reach nonneighboring nodesb.y passing through one or more intermediate nodes. A mes-
sage passing through a faulty node may be altered or de-stroyed and a faulty node may issue erroneous messages.This model is in contrast to that commonly used in studyingnetwork fault-tolerance capabilities (e.g., [13], [14]) whichassumes that a faulty node will simply cease to function. Therationale for choosing this more general fault-model is two-fold. First, among the wide range of failures which can affecta node, many of these failures can clearly cause anomalousbehavior other than total loss of the node. As discussedearlier, even systems employing hardware facilities tophysically switch a faulty node out of the network may bevulnerable to failure of those facilities. Experience withreal networks has indicated that anomalous node behaviorshort of total loss of the node can lead to trouble. A well-known example is found in an incident which occurred inthe early operation of the ARPANET packet-switching
network [15]. The ARPANET is designed to provide multipleroutes between any two network nodes, so that loss of a nodecannot disconnect the remaining network. The routing ofpackets in the network is controlled by a distributed algo-rithm. This algorithm operates by maintaining at each nodea table of information to help determine the best way to routepackets to their respective destinations. At one point, a fail-ure affected the routing algorithm of a particular ARPANETnode in such a manner that the node essentially declared itselfto be on the optimal route to every node in the network. Aspacket traffic quickly converged on this node, the ability ofthe node to handle the traffic was exceeded and a systemfailure ensued. Thus, although the routing algorithm wouldhave reacted to the complete loss of the faulty node ina relatively graceful fashion, its failure in a particularmalicious manner led to serious system-wide problems.A second reason for choosing the fault-model to be used
herein lies in its generality. The abstract nature of the net-work model leaves the precise meanings of the words "fault"and "test" open to specification at lower levels of abstraction.Thus, it may be possible to apply the results obtained fromthis model over a wide range of interpretations of the actualmeanings of faults and tests. For instance, the model mightfind potential application in the realm of network security,wherein a fault would constitute a nodal action constituting abreach or potential breach of network security and a testwould be a mechanism for externally verifying the integrityof a node. (The question of how a network might be designedsuch that such mechanisms could be implemented is a chal-lenging problem which is outside of the scope of thispresentation.) In such a situation, deliberate malicious ac-tivities by a node wishing to subvert network intentionswould certainly need to be considered. The generality of theproposed fault model covers this situation.The fault model also allows for failures among the facili-
ties used for internode communication. It is assumed thatsuch facilities are basically passive in nature and that thecommonly used communication practices (e.g., encodingmessages with error-detecting codes) are sufficient to allowdetection of the failures affecting these facilities. Thus, it isassumed that any fault in an internode communication pathwill manifest itself in a manner detectable by the nodes mak-ing use of the path. Of course, a node experiencing difficultyin communicating with a neighbor may be unable to deter-mine whether it is the neighboring node or the commu-nication path which is the source of the difficulty. Since thephysical characteristics of the communication facilities usedfor internode communication may vary widely between vari-ous distributed computing networks, e.g., multiple sharedbuses in [11], discrete dedicated links in [9], the model mustbe general enough to cover a wide range of actual inter-connection architectures.The model is formally defined as follows.Definition 1: The system graph S of a distributed com-
puting network is an undirected graph with vertices V(S)corresponding to the nodes of the network and with edgesE(S) = {(P,- Pi)I there is a direct communication path be-tween Pi and Pj in the network}.
Definition 2: The testing graph Ts of a distributed com-puting network with system graph S is a directed graph with
224
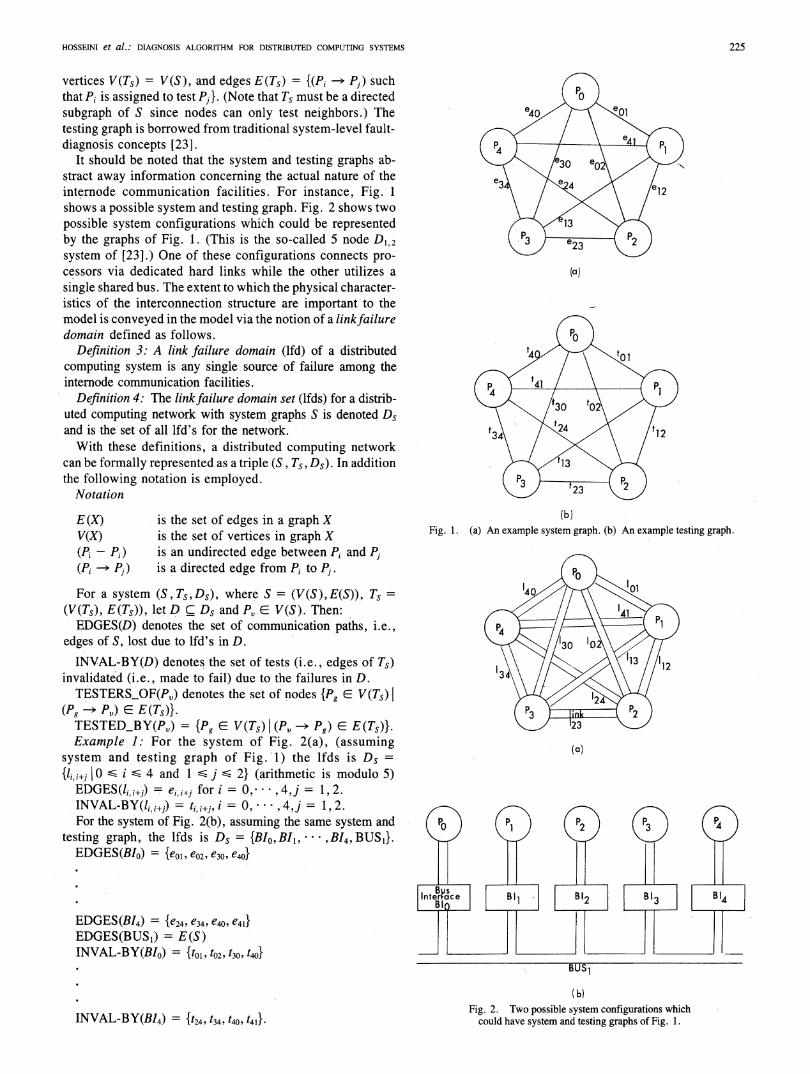
HOSSEINI et al.: DIAGNOSIS ALGORITHM FOR DISTRIBUTED COMPUTING SYSTEMS 225
vertices V(Ts) = V(S), and edges E(Ts) = {(Pi -> Pj) suchthat Pi is assigned to test Pi. (Note that Ts must be a directedsubgraph of S since nodes can only test neighbors.) The e4 /testing graph is borrowed from traditional system-level fault-diagnosis concepts [23].
It should be noted that the system and testing graphs ab- 0 e0stract away information concerning the actual nature of theinternode communication facilities. For instance, Fig. 1 12shows a possible system and testing graph. Fig. 2 shows twopossible system configurations whi&h could be representedby the graphs of Fig. 1. (This is the so-called 5 node D12 )system of [23].) One of these configurations connects pro-cessors via dedicated hard links while the other utilizes a (a)single shared bus. The extent to which the physical character-istics of the interconnection structure are important to themodel is conveyed in the model via the notion of a linkffailuredomain defined as follows.
Definition 3: A link failure domain (lfd) of a distributed t t
computing system is any single source of failure among theinternode communication facilities. 41
Definition 4: The linkfailure domain set (lfds) for a distrib- tuted computing network with system graphs S is denoted Ds
3\
and is the set of all lfd's for the network. 2
With these definitions, a distributed computing networkcan be formally represented as a triple (S, Ts, Ds). In addition 13the following notation is employed.
Notation
E(X) is the set of edges in a graph X (b)V(X) is the set of vertices in graph X Fig. 1. (a) An example system graph. (b) An example testing graph.(Pi - Pi) is an undirected edge between Pi and Pj(Pi -* 1) is a directed edge from Pi to Pj.For a system (S,Ts,Ds), where S = (V(S),E(S)), Ts =
(V(Ts), E(Ts)), let D C Ds and P, E V(S). Then:EDGES(D) denotes the set of communication paths, i.e.,
edges of S, lost due to lfd's in D.
INVAL-BY(D) denotes the set of tests (i.e., edges of Ts)invalidated (i.e., made to fail) due to the failures in D. 3TESTERStOF(PV) denotes the set of nodes {Pg E V(Ts)
(Pg P,) E E(Ts)}. inkTESTED_BY(P,) = {Pg E V(Ts) (P, Pg) E E(Ts)}. 23Example 1: For the system of Fig. 2(a), (assuming (a)
system and testing graph of Fig. l) the lfds is Ds ={Vi i+j °0< i - 4 and 1I j S 2} (arithmetic is modulo 5)EDGES(l, i+,) = ei, ij for i = 0, ,4, j = l,2.INVAL-BY(li,i+) = ti, i+j, i = 0, ,4,j = 1, 2.For the system of Fig. 2(b), assuming the same system and ()
testing graph, the lfds is Ds = {BIo,BI1, ,BI4,BUS1}.EDGES(BIo) = {e , eO2, e3O,e4oL
InterBrtace Bl | B12 B13 B14
EDGES(BI4) = {e24, e34, e4, e41}EDGES(BUS1) = E(S)INVAL-BY(BIo) = {tl, tO2,t30,t4}4 _ _ ____
BUS1
(b)Fig. 2. Two possible system configurations which
INVAL-BY(BI4) = {t24, t34, t40, t41}. could have system and testing graphs of Fig. 1.

226MEE TRANSACTIONS ON COMPUTERS, VOL. c-33, NO. 3, MARCH 1984
III. A DISTRIBUTED DIAGNOSIS ALGORITHM
In this section a diagnosis algorithm is given via whicheach fault-free node of a distributed computing network candiagnose the condition (faulty or fault-free) of all other net-work nodes. The algorithm also allows a node to diagnosefaulty communication paths between pairs of fault-free nodesin the network. The next section will discuss the conditionsnecessary for the algorithm to provide a correct diagnosis.The algorithm given here is a considerable extension of the
algorithms given in [1]-[3]. Specifically the algorithm al-lows diagnosis not only of failures, but also of the return offormerly faulty facilities which may have been repaired, re-placed, or which have otherwise recovered from earlier fail-ures. The algorithm allows the introduction of entirely newnodes and/or communication facilities to the system as well.As pointed'out in [1]-[3], a major problem in trying to
achieve a distributed diagnosis of failures in an environmentin which faulty facilities may act arbitrarily is that diagnosticmessages may be altered, destroyed, or erroneously issued bythe faulty facilities. Thus, a node cannot trust the diagnosticmessages reaching it to be complete or accurate. The algo-rithms in [1]-[3], as well as the algorithm given here, dealwith this problem by restricting the flow of information in away which ensures its reliability. Specifically, a node Pi willaccept a diagnostic message from a neighbor Pj only if Pi isa tester of Pj and is certain that Pj is fault-free. In this wayvalid diagnostic information flows "backward" along pathsin the testing graph. In the algorithm given here this is ac-complished via a simple mechanism which works as follows:when a node Pj E TESTED BY(Pi) sends a diagnostic mes-sage to Pi, Pi temporarily stores this message in a buffer,provided Pi has found Pj to be fault-free when it last testedPj. The next time that Pi tests Pj, if it finds P1 to still befault-free it will "checkmark" all messages received from P1in the interval between the two tests. These checkmarkedmessages may then be accepted by Pi as valid diagnosticmessages to be used in producing a diagnosis and to be passedon to other nodes. Of course, this strategy requires the as-sumption that a node Pj cannot fail in an undetected fashion,and recover from that failure, in the interval between twotests by Pi. This does not imply that a node cannot suffer atransient or temporary failure in the interval between testing.Rather, it requires only that such a failure be detectable bysubsequent'testing. This could be assured, for instance, byconstructing nodes in a self-testing [16] manner, with latchcircuitry for latching error indications. Then the testing pro-cess could include an interrogation of these latches. (Ofcourse, it might also be necessary to exercise these latchesduring testing since they would lie beyond the boundaries ofthe self-tested portion of the node.) The validity of this as-sumption is also enhanced by requiring that a node seekingreadmission to the network, after suffering a failure of whichit is aware, notify all of its testers of this fact.The possibility of reentry of previously faulty nodes and/or
communication facilities, or entry of new nodes and/or com-munication facilities, adds considerable complexity to thediagnostic process. This added complexity is due to the needto keep track of time ordering among certain diagnostic infor-
mation flowing in the network. For instance, suppose anode Pi fails and subsequently recovers from this failure.Diagnostic messages indicating this failure and recovery mayreach a distant node, say PJ, in various orders. If a messageindicating the recovery of Pi reaches Pj prior to a messageindicating the earlier failure, Pj must not mistakenly concludethat the failure occurred subsequent to the recovery. Similarlyif Pi fails once again, news of this failure may reach P1 beforenews of the earlier recovery and Pj must not interpret the latearriving recovery message as indicating recovery from thislatest failure. To deal with this problem, the algorithm provideseach node with a local clock or "time stamp." This mechanismis similar to that commonly used in distributed systems formessage sequencing and for maintaining consistency in distrib-uted databases [4], [5], but is complicated here by the fact thatfailure of a node may cause the node to lose its old clock value.
The algorithm maintains, at each node Pi, two arrays:ACCUSERSi and ENTRYi. The elements of both of thesearrays are sets of messages held by Pi for diagnostic pur-poses. The jth element of the arrays will always store mes-sages relative to node Pj. At any time, a fault-free node Piwill have in ACCUSERSi(j) a number of messages of theform [nil, Pk(tk), Pj] indicating that node Pk issued a messageat its local time tk indicating that Pj was faulty (this messagecould also have been issued by Pk due to a faulty commu-nication path between Pk and fj). In array ENTRYi (j) will bemessages indicating tests of Pj which have passed. Thesemessages may be of two types [Pp(tp),Pp(tp),Pj] or[Pp(tp), Pk(tk), Pj]. The total meanings of these messages willbe explained shortly, but both indicate that Pp tested Pj at itslocal time tp and found Pj to be fault-free.A node Pi tests a neighbor Pj E TESTED-BY(Pi) accord-
ing to some locally determined schedule. In addition to per-haps periodically scheduled tests,'Pi nmay test in response tosome suspicion concerning Pj (e.g., not having heard from Pjfor an abnormally long time) or in response to a request forentry from Pj which may be a new node added to the networkor may be a node repaired, replaced, or recovered from ear-lier failure. If Pi finds Pj to be faulty, then Pi composes amessage [nil,Pi(ti),Pj] and broadcasts it to all nodes inTESTERS OF(Pi).1 This is the initiation of the reliable dis-semination of the message throughout the network"backward" along paths in the testing graph, as mentionedearlier. th is the local clock of Pi at the time of the test. Aftereach test performance Pi increments ti. If Pi finds Pj to befault-free, then Pi will compose and broadcast a message[Pi(ti),Pi(ti),Pj]. In addition, if Pi currently has inACCUSERSi(j), any message of the form [nil, Pk(tk),P1](i.e., an indication that Pk found Pj to be faulty at its localtime tk), then Pi will compose and broadcast a message[Pi(ti), Pk(tk), PJ] to the testers of Pi. This message is essen-tially an announcement that Pj has recovered from thefailure which Pk detected at local time tk. When a node Pmhas received and validated (via the checkmarking pro-cedure described above) an entry message [Pi(ti), Pk(tk), Pj,
'Pi may transmit this message to all its neighbors, if it does not have theknowledge of its testers. However, only the TESTERS OF(P1) will utilizethis message.
226

HOSSEINI et al.: DIAGNOSIS ALGORITHM FOR DISTRIBUTED COMPUTING SYSTEMS
or [Pi(ti),Pi(ti),P], Pm checks to see if it has inACCUSERSm(j) any message of the form [nil, Pk(t*), Pj] or[nil, Pi(t'),Pj] with tk - tk, t' < ti. Any such messagesare indicative of failures which have been recovered fromand hence are removed. In addition the entry message ispassed on to neighbors in TESTERS-OF(Pm) to continue itsdissemination through the network. An entry messagemay arrive at a node prior to messages announcing theearlier failure of the nonrecovered node. Hence, entrymessages vis-a-vis a node Pj, reaching a node Pm, are storedin ENTRYm(j). The ENTRY array is used by the node inproducing its actual diagnosis, in a manner which willbe described later. When a failure message [nil, Pi(ti),Pj]reaches Pm, Pm checks to see if there is a message [Pg(tg),Pi (ti'), PjIor [Pi (ti'), Pi (td), Pj] with t,' > ti. If so, the failuremessage is no longer valid and is simply ignored. If not, Pmadds the message to ACCUSERSm(J) and also broadcasts itto the nodes in TESTERS_OF(Pm).
In order that the ACCUSERS and ENTRY arrays do notgrow in an unbounded fashion, messages are added tothese arrays only if the messages represent new and usefulinformation and any messages superceded by the new infor-mation are removed. For instance, when Pm receives a mes-sage [Pg(tg),Pi(ti),Pj] this message will be added toENTRYm(J) if 1) there is not a message [nil, Pi(t4), Pj] witht' > ti already in ACCUSERSm(j) (i.e., Pm has not receivedword from Pi of a failure of Pj occurring subsequent to localtime ti of Pi), and 2) there does not exist any message[Pg(tg), Pi(t), Pj] with t' > ti in ENTRYm(j) (i.e., Pm has notreceived an entry message from Pg indicating recovery ofnode Pj from a failure detected by Pi at some time subsequentto local time ti of Pi). A node uses the same criteria in deter-mining whether or not to broadcast a received message to itstesters, thus ensuring finite message lifetimes (i.e., a mes-sage will never pass through a node more than once).When a previously faulty node, or a new node, wishes to
join the network it issues an entry-request message to itstesters to trigger the entry process. The node also initializesall of its tables to empty, and its clock to zero. Note that thisrequires that in order to be returned into the network a nodemust be aware that it has failed. A recovered node is assumedto have lost its old clock value. Thus, until the node re-establishes a clock value higher than it had before it failed,diagnostic messages used by the node may be ignored sincemessages with higher numbers issued by the node prior to itsfailure may still exist in the network. A simple mechanism isused to quickly accomplish this clock update. Each time anode Pm receives any valid message [Pi(ti), Pk(tk), Pj] or[Pi(t), Pi(ti), Pj] or [nil, Pi(ti), Pj] it checks to see if its ownlocal clock has a value greater than the maximum of the clockvalues contained in the message. If not, it updates its ownclock to this value. In this way, clocks throughout the net-work tend to stay rather closely synchronized, and a recov-ering node will ultimately receive a diagnostic message witha clock value higher than the value the node had when itfailed, or at least higher than the clock value used by the nodein any messages still existing in the network. This is assuredsince any node accepting the message would have set its ownclock at least to a value as great as all clock values in the
message, and would propagate this higher value via sub-sequent diagnostic messages originating from the node.The actual diagnosis of which nodes are faulty and fault-
free is accomplished by examining the ENTRY array. Thepresence of a message [nil,Pk(tk),Pj] in ACCUSERSm(j)does not necessarily imply that Pj is faulty since this mayrepresent an old failure from which Pj has recovered but forwhich no entry message [Pg(tg), Pk(tk), Pj] will ever reach Pm.Under highly pathological circumstances this may occur[e.g., if Pk failed after issuing the message and due to somesequence of failures, the message never reached any nodes inTESTERS-OF(Pk)]. Also, the presence of a message[Pk(tk), PN(t), Pi] or [Pk(tk), Pk(tk), Pj] in ENTRYm(j) does notimply that Pj is fault-free since it is possible that Pk failed afterproducing this message, and that subsequent to this, Pj alsofailed. However, Pm can discover which nodes are fault-freeby performing a simple computation on the ENTRY array.First, Pm can directly certify the condition of the nodes it hastested. Then for any node Pj E TESTED_BY(Pm), which Pmhas found to be fault-free, if Pj has a message [Pj (tj), Pk(tk), Pg]or [Pi(t1), Pi(t1), Pg], then Pg must be fault-free. Then similarly,for any message [Pg(tg), Pr(tr), Pj] or [Pg(tg), Pg(tg), Pj, P, mustbe fault-free, etc. This diagnosis is accomplished via a simple"breadth-first-like" search of the ENTRY array, and, as will beproven later, will provide identification of all fault-free nodesin the steady state provided that the testing graph, minus faultyfacilities, remains connected.The procedure also allows for diagnosis of faulty commu-
nication paths (i.e., direct logical communication links),though, as mentioned earlier, the actual sources of failure(e.g., faulty lfd's) are not uniquely diagnosed. The de-tection of communication link failures takes place in one oftwo ways. First, if a test of a node Pj performed by a node Pifails, the test failure (assuming Pi is fault-free) may be due toa failure of P,, or to a failure of the communication pathbetween Pi and Pj, or both. Thus, the failure message[nil, P(ti), Pj] which Pi broadcasts must be interpreted bynodes receiving it as being possibly indicative of any of thesesituations. Secondly, a node Pi may have trouble accom-plishing normal, nontest-related communications with aneighbor Pj due to a faulty communication link. In such acase, the node can issue a message indicating this fact to thenetwork. Again, the trouble could be due to a faulty commu-nication facility or to a failure of Pj itself. If Pi is a tester ofPj, the message which Pi issues will look exactly like anyother failure message, i.e., will be of the form [nil, Pi(ti), Pj].If Pi is not a tester of Pj, the message it issues is of the form[link, Pi(ti), Pj]. Since we assume that any failure of a commu-nication facility incident on a fault-free node will disruptnormal communications in a manner detectable by the node,a failure message will always be issued for each such failure.A node Pm, receiving a failure message [nil, Pi(ti), Pj] initiallytreats the message as indicative of a failure of Pj, and adds itto ACCUSERSm(j). If, in fact, Pj is fault-free and the com-munication path from Pi to Pj is faulty, then Pm should even-tually receive an entry message, say [Pk(tk),PA(tO),PJ].(As described earlier, this message would be generated whenthe message [nil,Pi(t),Pj] reached Pk E TESTERS_OF(Pj).) Upon receiving this message Pm removes the fail-
227

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-33, NO. 3, MARCH 1984
ure message from ACCUSERSm(j) and adds it to arrayFAULTYLINKSm, indicating that the link between Pi and Pjis faulty.
In the event of repair of the faulty link, the message[link,Pj(tj),Pj] will be removed from FAULTY_LINKSmwhen a test of Pj by Pi passes; i.e., when Pm receives a validmessage of the form [Pi(t!), Pg(tg), Pj] with t' > ti. In the casewhere Pi is not a tester of Pj, when Pi certifies that it is nolonger having trouble communicating with Pj it sends amessage[link-up, Pi(t), Pj]. Note that this message is distinctfrom a normal entry message for Pj since Pi is not capable ofcertifying the correct operation of Pj but is only stating thatit is not having difficulties with Pj which could be attributableto a bad communication path. A message[link-up, P(t'), Pj]with t4 > ti, arriving at Pm causes message[link, Pi(ti), Pj] tobe removed from FAULTY_LINKSm. Of course, as discussedin the earlier discussion of diagnosing node failures, mes-sages indicative of failure of a link may arrive at a node laterthan messages indicating a subsequent recovery of that link.Hence, the most up-to-date link-up messages are stored in theENTRY array and before adding a message[link, Pi(t), Pj]to FAULTY-LINKSm, Pm first checks to see if a message[link-up, Pi(t!), Pj] or [P(t), Pi(t), Pj ] with t' > ti, alreadyexists in ENTRYm(j). If so, the arriving message is ignored.A precise description of the algorithm is given below.
Algorithm NEW-SELF1) Every node Pk, at start up, should proceed as
follows:Procedure Initialization(Pk);BeginACCUSERSk := 4;FAULTYXLINKSk := 4;ENTRYk := 4;INPUT-BUFFERk := 4;FAULT_FREE_NODESk := 4;tk = +.
End2)
2.1)2.2)
2.2.1)
2.2.2)
2.3)
Each time a node Pi E TESTERS_OF(Pk) testsPk because of either- receiving an entry mes-
sage from Pk, malbehavior of Pk, its localschedule, etc., Pi should proceed as follows:
Procedure Performtesti(Pk, aik);Begin
ti := ti + 1;
if test passes
then beginaik 0= ;Checkmark every diagnostic message inINPUT-BUFFERi(k), which has notbeen checkmarked and was received be-fore test of Pk by Pi;Update and_broadcasti([Pi(ti), Pi(ti), Pk])for(every [nil, Pj(tj), P] in ACCUSERSi(j)doupdate._and_broadcast([PK(t4), Pj(tj), P,])
endelse/*test failed*/
begin
2.3.1)
2.3.2)
3)
3.1)
3.1.1)
3.1.2)3.1.3)
3.1.4)
3.1.5)
3.1.6)
3.2)3.2.1)
3.2.1.1)
3.2.1.2)3.2.1.3)
3.2.1.4)
3.2.1.5)
3.2.1.6)
3.2.1.7)
3.2. 1.7.1)
3.2. 1.7.2)
3.2. 1.7.3)
3.2.2)3.2.2.1)
3.2.2. 1. 1)3.2.2.1.2)
aik = 1;Discard every diagnostic message whichhas not been checkmarked and wasreceived before test of Pk by Pi;Update.and broadcasti([nil, Pi(t,), Pj])end
EndConsider the following procedure at every nodep.u
Procedure update and_broadcast, ([A, B, C]);Begin
if ([A, B, C] = [nil, P,(t,) Py])P,, Py EV(S) then begin/*update with failuremessage*/
if t, < t, then t, := t,; /*t, is local time-stamp of P,*/Add [nil, P,(t,), Py] to ACCUSERS,(y);Delete all [nil, P(t4), Py] from ACCUSERSV(y), for t' < t;
Delete all [link, P/(t), Py] from FAULTY_LINKSV, for t4 < t.;
Delete all [P,(t), P,(t'), Py from ENTRYV(y), fort' <tK P E V(S).
Broadcast [nil, Px(tx), Py] to all the testersof P,endelse
if [A, B, C] = [Pw(tw) Px(tx) Py] P,,Px, Py E V(S) then begin/* update withENTRY message*/.if tv < max(tw, tx) then t =max(t., tx);Add [Pw(tw), Px(tx), Py] to ENTRYJ(y);Delete all [nil,P,(t ),Py] fromACCUSERSV( y), for t' < tv,;
Delete all [link,Pw(t'),Py] fromFAULTY_LINKSv, for t' < tg;
Delete all [Pw(t'), Pw(tW), Py] fromENTRYV( y), for t' < tw;
Broadcast [Pw(tw), Px(tx), Py] to all thetesters of P,;
if PW # PX and there does not exist any[PX (tXt ), PZ(tZ! ), Py] E- ENTRYv y ),with t4 tx, Pz E V(S) then beginAdd [link,Px(tx),Py] to FAULTY_LINKS,;Delete all [nil,Px(tC),Py] fromACCUSERSV, for t< tx;Delete all [Pz(t,),P,(t'),Py] fromENTRYV( y), for t' < tx Pz E V(S)end
endelse
if ([A, B, C] = [link, Px(tx), Py]) thenbegin/* update with link failuremessage*/if t,< t, then t :=t=;Add [link, P,(tx), Py] to FAULTY_LINKS,;
228

229HOSSEINI et al.: DIAGNOSIS ALGORITHM FOR DISTRIBUTED COMPUTING SYSTEMS
Delete all [link,Px(t'),Py] fromFAULTY_LINKSV, for tx < tx;
Delete all [link-up,PX(t'), Py fromENTRYv( y), for t' < tx;
Broadcast [link, P,(t,), Py] to all thetesters of Pv.
endelse/* [A, B, C] = [link-up, P,(tx), Py*/
beginif tv < txthen tv =txAdd [link-up, Px(tx), Py] to ENTRYv (y);Delete all [link,Px(tX'),Py] fromFAULTY_LINKSv, for t' < tx;
Delete all [link-up,Pj(t'),Py] fromENTRYv (y), for t' < tx;
Broadcast [link-up, Px(tx), Py] to all thetesters of Pv
end
EndEach time a node P' wants to process a failuremessage [nil, Pj(tj), Pk] E INPUT_BUFFER,(s), such that [nil, Pj(tj), Pk] has been check-marked by Pi and Pi E TESTERS&OF(PS),then Pi should proceed as follows
Procedure Failure_message_process:Begin
if (there does not exist any [nil, Pj(tj), Pj EACCUSERS' (k), tj' - tj or does not existany [Pz(t,), Pj(tj7), Pk] E ENTRY' (k), tj' 3
tj, Pz E V(S)then if Pi E TESTERS&OF(Pk)
then beginPerformtesti(Pk; aik);if aik = 0 then update_and broadcasti( [Pi (ti), Pj (tj ), Pk] )
else update-and_broadcast([nil,Pj(tj), Pk])end
else update_and_broadcast([nil, Pj (tj),Pk]);
Delete [nil, Pj(tj), Pk] from INPUT-BUFFERi(s).
EndEach time a node Pi wants to process anentry message, [Pz(tz), Pj(tj), Pk] E INPUT_BUFFERi(s) such that [Pz(tz),Pj(tj),Pk]has been checkmarked by Pi, and Pi ETESTERS-OF(Ps), then Pi should proceedas follows:
Procedure entry_message_process;Begin
if (there does not exist any [nil, Pj(tj'), Pk] EACCUSERSi(k), with tj' > tj, or there doesnot exist any [P(t'P),P1(t'), PJ E ENTRY,
5.2)
6)
6.1)6.2)
7)
7.1)
7.2)
8)
8.1)8.2)
9)
9.1)
9.2)
10)
(k), with tj' , tj, Pz E V(S)then update-and&broadcasti([P,(t,), Pj (tj),Pk]);
Delete [PZ(tZ),Pj(tj),Pk] from INPUT_BUFFERi(s)
EndEach time a node Pj that is not a tester of an-other node Pk has difficulty in communicat-ing with Pk, then Pj will periodically proceedas follows:
Procedure Link_failure_message;Begin
tj := tj + 1;Update.and&broadcastj([link, Pj (tj), Pk])
EndEach time a node Pi wants to process a mes-sage, [link, Pj(tj), PkI E INPUT_BUFFERi(s), such that it has been checkmarked by Piand Pi E TESTERS_OF(PS), then Pi shouldproceed as follows
Procedure Link_failure_messagesprocess;Begin
if.(there does not exist any [link,Pj(tj'),Pk4E FAULTY_LINKSi with tj' ¢ tj, or theredoes not exist any [link-up,Pj(tj7),Pk] EENTRYi(k), tj )tj)
then update and_broadcasti([link,Pj(tj),Pk]);Delete [link,Pj(tj),PkI from INPUT_BUFFERi(s)
EndWhen a node Pj is not having difficulty com-municating with a neighbor Pk and neither ofthem tests the other one, Pj should periodi-cally proceed as follows:
Procedure linkup-message;Begin
tj := tj + 1;update-and_broadcastj[link-up, Pj(tj), Pk]
EndEach time a node Pi wants to processa message, [link-up, Pj(tj), Pk] EINPUT_BUFFERi(s), such that it has beencheckmarked by Pi and Pi E TESTERS_OF(Ps), then Pi should proceed as follows:
Procedure link-up_message_process;Begin
if (there does not exist any [link, Pj(tj),PJ] E FAULTY-LINKSi, with t!1' tj,or there does not exist any [link-up,Pj (tj),pk E ENTRYi(k), with tj' : tjthen update and_broadcasti([link-up,Pj(tj), Pk]);Delete [link-up, Pj(tj), Pk] from INPUT_BUFFERi(s)
EndEach time a node Pk wants to enter the network(either a new node or a node which was faultyand has been repaired), then it should proceedas follows:Procedure Node-entry;Begin
3.2.2.1.3)
3.2.2.1.4)
3.2.2.1.5)
3.2.2.2)
3.2.2.2.1)3.2.2.2.2)3.2.2.2.3)
3.2.2.2.4)
3.2.2.2.5)
4)
4.1)
4.1.1)
4.1.1.1)4.1.1.2)
4.1.1.3)
4.1.2)
4.2)
5)
5.1)

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-33, NO. 3, MARCH 1984
10.1)10.2)
10.3)
11)
11.1)
11.1.1)11.1.1.1)
11.1.1.1.1)11.1.1.1.2)11. 1. 1.1.3)
11.211.311.4
Initialization(Pk);for every Pj E TESTERS-OF(Pk) dobroadcast an ENTRY-REQUEST(Pk)message to Pj;
for every Pm E TESTED-BY(Pk) doperformjtestk(Pm, akm)
EndEach time a node Pi wants to diagnose the sta-tus of the nodes in the network, then it shouldproceed as follows:Procedure Decisionmaking(Pi)/ *all entry messages are picked up just fromENTRYi*/Procedure search (Pr);Beginfor every node Pk E TESTED BY(PX) dofor all [PX(tx),Pj(tj),Pk] E ENTRYi,Pj E V(S), such that Pk has not beenlabeled 'VISITED' do
beginAdd Pk to FAULT-FREE-NODESi;Label Pk 'VISITED';Search(PO)
endEnd (search)BeginFAULT_FREE_NODES := 4Mark all nodes "UNVISITED";Search(Pi)
End (Decisionmaking)
IV. PERFORMANCE OF THE ALGORTM
In order to determine the conditions under which the algo-rithm of the previous section can be guaranteed to providecorrect diagnosis in the network, it is necessary to establisha diagnosability measure. Earlier work [1]-[3] used a mea-
sure called t-fault self-diagnosability. A network was deemedto be t-fault self-diagnosable if the network was always guar-
anteed to be in a state in which all fault-free nodes wouldconverge to a correct diagnosis of all failures, provided thatnot more than t failures had occurred. When it is allowed thatfaulty facilities may recover and reenter the system, thisdefinition becomes inadequate because the meaning of"provided no more than t-failures have occurred" becomesimprecise. It could be taken to mean that no more than a totalof t failures have occurred since the initial start up of thenetwork. But this seems restrictive since the diagnosability ofthe network should not be dependent on past failures whichare no longer present. Thus, we adopt the following diagnos-ability measure for this work.Definition 5: A distributed computing network (S, Ts, Ds)
is said to be q-fault-survivable, t-fault self-diagnosable, q 3 t,if the following two conditions are satisfied.
1) The system is always in a self-diagnosable state pro-
vided that t or fewer nodes in V(S) and lfd's in Ds are
simultaneously faulty.2) Whenever a total of z, t < z S q, failures are simulta-
neously present, the network is guaranteed to be in statesuch that, if z-t or more of the faulty facilities are restoredto fault-free operation, the system will return to at-diagnosable state.The following theorem demonstrates that a distributed
computing network employing algorithm NEW_SELF cansurvive the failure of up to all of its nodes, and also givessufficient conditions for t-fault-self-diagnosability.
Definition 6: The node-lfd connectivity of a testing graph Tsin a system (S, Ts, Ds), denoted by Kn, (7(T'), is the minimuminteger, say k, for which there exist sets V' C V(Ts)and D' C Ds with IV'I + ID'I = k such that the graphTs= (V(TS) - V', E(Ts)- INVAL-BY (D')) is either notstrongly connected or is a graph with one node.Theorem 1: An n-node system (S, Ts,Ds) employing
algorithm NEW_SELF is n-fault survivable, t-fault-self-diagnosable if Knl,(Ts) > t.
Proof: (sketch) Consider the system at any point in timewhen less than or equal to t failures are currently present. Letq be the largest time stamp present in any diagnostic messageheld by any fault-free node, say Pi. Then ti (the local timestamp of Pi) must be at least as large as q since a node sets itslocal time stamp to be at least as large as the time stamps inany message it receives. Since the system has node-lfdconnectivity ¢ t, there is a path of fault-free nodes and linksin Ts, from each fault-free node to Pi. Thus, if the systemremains in steady state, each fault-free node in Ts will even-tually receive diagnostic messages from Pi with time stampgreater than t. Hence, all fault-free nodes must eventuallyupdate their local time stamps to a value greater than thelargest value used by the node prior to the system reachingsteady state. (This is important since for a node whichhas failed and recovered, there may still be old diagnosticmessages issued by the node prior to its failure present inthe system.)Now let Pi be a fault-free node, and consider any other
node Pj E V(T,).Case 1: Pj is fault-free. Then since Kns,(TS) > t,
there must be at least one path in Ts from Pi to Pj whichis composed entire-ly of fault-free nodes, and linkswhich are not in any faulty lfd. Denote this path by Pi =
Pk,-* Pk, > - **> P = Pj,m > 1. Then (if the systemremains in steady state) Pi will receive messages[P4(tkq),Pkq(tkq), Pk+,] for all 0 , q < m with time stamp tk higherthan any time stamp in any message from Pk previously heldby Pi. Thus, when Pi executes procedure decision making itwill find Pj and all Pkr, 1 - r < m, fault-free.
Case 2: Pj is faulty. Then consider any path in Ts from Pi toa tester of Pj, say Ps, which does not include any faultynodes or any links which are in faulty lfd' s. (Note P, may beequal to Pi.) Then Pi will eventually receive [nil, P,(t,), Pj]with time stamp ts superceding all previous messagesfrom Ps concerning Pj (or if Ps = Pi, then Pi will directlydiagnose Pi as faulty). Reception of such a message willcause Pi to remove any messages[P (t'),Ps(t'),Pj] or[P'(t"),Ps(t,'), Pi], P, E V(S), which it might have inENTRYi. Hence, procedure decision making at Pi cannotfind P1 to be fault-free.
230

HOSSEINI et al.: DIAGNOSIS ALGORITHM FOR DISTRIBUTED COMPUTING SYSTEMS
Case 3: Pj is fault-free but link between Pj and some fault-free P, is in a faulty lfd. In this case since Kn, (T7) > t, theremust be some Pq # Ps in TESTERS-OF(Pj). Now considertwo subcases.Subcase 3.1: P E£ TESTERS-OF(Pj) or Pj E
TESTERS OF(PS). Without loss of generality assume P, ETESTERS_OF(Pj). There must be a path in Ts from Pi to P,which does not pass through any faulty node or include anylink which is in a faulty lfd. Similarly, there must be suchfault-free paths from Pq to Ps and from Pi to Pq. Now PS willissue messages[nil,Ps(ts),Pj] with time stamps which willsupercede time stamps in all previous messages from Ps re-garding Pj. Such a message will reach Pi and Pq and when themessage reaches Pq, Pq will test Pj and find Pj to be fault-free.Then Pq will issue message[Pq(tq), PA(t), Pj ] which will reachPi. This will cause Pi to place a [link, Ps(ts), Pi] message inFAULTY_LINKSi indicating that link between Ps and Pj isfaulty. (Note this will happen independent of order or arrivalof messages.) Furthermore, via Case 1 above, Pj and Ps will bediagnosed as fault-free.Subcase 3.2: P5 E TESTERS_OF Pj, Pj E TESTERS_
OF(Ps). In this case, when P1 has trouble communicating withPs, it eventually will issue [link, Pj(tj), Ps] with high enoughsequence number such that upon reaching Pi via fault-freepath, it will be placed in FAULTY_LINKSi.
Case 4: There is a link Ps-P1 in E(S) such that Ps, P1 arefault-free and the link is not in any faulty lfd, but there is amessage[link, P,(t,), Pj] in faulty-links (i.e., link was faultybut has been repaired).
Subcase 4.1: Ps is tester of Pj. Then P. will find Pj (andhence link) to be fault-free and will eventually issue message[Ps(ts), P (ts), Pj] with ts > t' which will reach Pi via a fault-free path and will cause removal of [link,Ps(t,),Pj] fromFAULTY_LINKSi.
Subease 4.2: Ps is not a tester of Pj. Then Ps, when it findsit can communicate with P1, will send periodic messages ofthe form [link-up, Ps(ts), Pj]. Such a message will reach Piwith t, > ts and will cause [link, Ps(ts), Pj] to be removedfrom FAULTY-LINKSi.
These cases ensure that at any point when less than t nodesand lfd's are faulty, the system is in a state such that if nomore failures occur, all fault-free nodes will converge to acorrect diagnosis. Q.E.-D.
A. Adding New Nodes to the Network
The algorithm NEW_SELF allows entirely new nodes tobe dynamically added to the network. However, care mustbe taken in the way new nodes and associated communi-cation facilities are added to the system or the node-lfd con-nectivity of the system may be decreased, thus lessening theability of the system to meet the conditions of Theorem 1.The following lemma characterizes the necessary and suf-ficient conditions involved in adding a new node to a systemin a manner which does not reduce the node-lfd connectivity.Lemma 1: Let (S, Ts, Ds) be a system with node-lfd
connectivity K. Then a system (S', T.", D.) formed byadding a new node to the original system has node-lfdconnectivity B K if in (S', Ts, Ds):
1) ITESTERS-OF(P,ew)l 3 K,
ITESTED-BY(Pnew)l ¢ K
and2) There does not exist any set Q , Ds with IQI S K
such that
{(Pa > Pnew) (Pq E TESTERS-OF(Pnew)} C INVAL-BY(Q)
or
{(Pnew > Pq) Pq E TESTED-BY(Pnew)} C INVAL_BY(Q).
Proof: Necessity: It is easily seen that if either of theconditions 1) or 2) is violated then Ts cannot have node-lfdconnectivity : K.
Sufficiency: Suppose 1) and 2) are satisfied, but Ts hasnode-lfd connectivity of -K. Then since Ts has node-lfdconnectivity of K, any two nodes in Ts must be k-connected.Hence, it only remains to show that Pnew is k-connected to therest of Ts. Suppose that there exists V' C V(T) -{Pnew}and D' C D' such that |V'| + ID'I - K and the graphT' = (V(Ts) - V', E(Ts)-INVAL-BY(D')) contains either
a) no path from some Pj E V(Ts5) - V' to Pnewor
b) no path from Pnew to some Pm E V(TS) - V'.
But in case a) since IV'I < K, these must be least K - IV'Inodes in TESTERS-OF(Pnew) - V'. Furthermore, in Ts,there must be a path from PJ to every such node. Then,since in T' there is no path from Pj to Pnew it must bethe case that for each P, E TESTERS-OF(Pj) - V', thetest (Pr P,ew) E INVAL_BY(D'). But, then, sincefor every P, E V', there is at least one lfd d E Ds,such that P, E INVAL-BY(d), there must be a set D" C Ds,with |D"I - IV'I such that INVAL-BY(D") D {(PqPnew)IPq E TESTERS-OF(Pnew) - V'}. But then D' UD {(Pq Pnew) Pq E TESTERS-OF(Pnew)} and since
ID'I + ID"I S k, a contradiction is reached.For case b) above a similar contradiction is reached.Hence, Ts must have node-lfd connectivity of ¢ K.
Q.E.D.Though this theorem is slightly cumbersome, in certain
special cases it reduces to a very simple set of conditions. Forinstance, for link-oriented systems [2], [3] (i.e., those sys-tems in which nodes communicate via discrete commu-nication links, and lfd's correspond directly with edges of thecommunication graph) the lemma states simply that to main-tain the node-lfd connectivity k of the system, a new nodeneed only be tested by any k or more other nodes of the systemand must test any k or more nodes of the system. A moredetailed discussion of problems of adding new nodes to asystem is given in [7].The problem of unbounded time stamps: Time stamping
(sequence numbering) has been employed to differentiate theold diagnostic messages from the most up-to-date versions ofthem. But it should be noticed that the local clocks can notcount up to infinity. So, there must be some maximum upperbound considered for them, say z. Hence, modulo arithmetic
231

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-33, NO. 3, MARCH 1984
must be used. But then, a wrap-around problem arises. To seethis, suppose that a time stamp t1 was used for time stampingan old message, and that the local clock time has reached itsmaximum value z and is reset to zero. Now messages whichare time stamped with a time t2 such that t2 < t1 will appearolder than the preceding messages with time stamp tl. Thereare several approaches to solving this problem, for instanceas the one given in [5]. We suggest a procedure similar to thatproposed by Kaneko et al. [4] for synchronizing the localclock times of the nodes of a network. Because the nodes mayfail, and because it is assumed that the maximum delay in thenetwork for messages to reach their destinations is unknownand unbounded, it is not possible to have a system in whichall the local clocks have the same value. But we can force thelocal clock times to be as close to each other as possible. Thisis done in our algorithm (see update-and_broadcast proce-dure) by having every node, upon the reception of a message,check to see if the received message has a higher time stampvalue than its current clock time. If so, then it will set itsclock time equal to that time stamp number. Now if the clocktime of a node reaches its maximum value z, then it can resetits clock time to zero and can broadcast a RESET message toall the other nodes in the network to reset their local clock tozero also. Every node upon the reception of RESET messagewill reset its clock time to zero provided its clock time isgreater than z/2. Otherwise, the node simply ignores themessage, and does not pass it on. Hence (if z is chosen largeenough), the RESET message has enough time to reach everynode in the system and when all nodes have been reset, themessage dies.Now a node, in determining the relative age of the time
stamps, say t1 and t2 produced by a particular node, wheret2 > tl, would judge t2 older than t1 if t2 - t z/2 and t2younger than t1 if t2 - t1 > z/2. This scheme will work pro-vided time stamps of all nodes remain within z/2 of eachother and provided that no message from a node remains valid(i.e., is not superceded by a more recent message) for aninterval of more than z/2 ticks. A large enough choice of zshould make both of thes'e assumptions easy to satisfy. (Notethat this method of determining message age is not imple-mented in the algorithm as given in Section III.)
V. EXTENSIONS
The work reported here has been extended in several ways.An alternate form of the algorithm NEW_SELF has beendeveloped which treats communication facility failures dif-ferently. This modified algorithm does not result in any tem-porary misdiagnosis of a node as faulty, due to failure of acommunication facility incident on the node. In the modifiedalgorithm, diagnosis of communication link failures is doneonly by the nodes incident on the failed link, and there is nonetwork-wide dissemination of such information.The algorithm has also been extended to the case of non-
homogeneous networks [22] in which some nodes may beincapable of performing tests and in which the conditions ofTheorem 1 cannot be met.The details of these extensions can be found in [7]. This
reference also discusses application of the algorithm in im-plemeInting a distributed backword error recovery mecha-
nism, and in maintaining consistency and fault-tolerance in areplicated distributed database.
VI. CONCLUSIONS
This paper has considered diagnosis of failures in distrib-uted computing networks. A distributed algorithm was pro-posed, in which every fault-free node in the network cancorrectly diagnosc the conditions (faulty or fault-free) of theother nodes and/or internode communication facilities. Thisalgorithm allows that nodes and/or internode communicationfacilities may both fail and be repaired or replaced. Thealgorithm allows the introducing of new nodes into the sys-tem. A diagnosability measure was derived and sufficientconditions were given for a system employing the algorithmto achieve a given level of diagnosability under this measure.The algorithm was shown to be particularly robust, in thateven when the number of failures present exceeds thediagnosability of the system, the algorithm remains in astate such that, when sufficient facilities are returned totheir fault-free state to bring the number of failures withinthe diagnosability limit, the algorithm will converge to acorrect diagnosis.
REFERENCES
[1] J. G. Kuhl and S. M. Reddy, "Distributed fault-tolerance for large multi-processor systems," in Proc. 7th Annu. Symp. Comput. Arch., May1980, pp. 23-30.
[2] , "Fault-diagnosis in fully distributed systems," in Proc. 11th Int.Conf. Fault-Tolerant Computing, June 1981, pp. 100-105.
[3] J. G. Kuhl, "Fault diagnosis in computing networks," Dep. Elec.Comput. Eng., Univ. of Iowa, Tech. Rep., Aug. 1980.
[4] A. Kaneko, R. Nishira, K. Tsuruoka, and M. Hattori, "Logical clocksynchronization method for duplicated database control," in Proc. Int.Conf. Dist. Comput. Syst., Oct. 1979, pp. 601-611.
[5] R. S. Tominson, "Selecting sequence numbers," in Proc. ACMSIGCOMMISIGOPS Interprocess Commun. Workshop, 1975,pp. 11-23.
[6] S. Even, "An algorithm for determining whether the connectivity of agraph is at least K," SIAM J. Comput., vol. 4, no. 3, pp. 393-396,Sept. 1975.
[7] S. H. Hosseini, "Fault diagnosis and recovery in distributed systems,"Ph.D. dissertation, Dep. Elec. and Comput. Eng., Univ. of Iowa,Aug. 1982.
[8] C. Kime, C. Holt, J. McPherson, and J. Smith, "Fault diagnosis ofdistributed systems," in Proc. COMSAC 1980, pp. 355-364.
[9] H. Sullivan, T. Bashkov, -and D. Klappholz, "A large scale, homoge-nous, fully distributed parallel machine," in Proc. 4th Annu. Symp.Comput. Arch., Mar. 1977, pp. 105-124.
[10] A. Despain and D. Patterson, "X-tree: A tree structured multiprocessorcomputer architecture," in Proc. 5th Annu. Symp. Comput. Arch., Apr.1978, pp. 144-151.
[11] L. Wittie, "MICRONET: A Reconfigurable microcomputer network fordistributed systems research," Simulation, vol. 31, pp. 145-153,Nov. 1978.
[12] C. Reams and M. Liu, "Design and simulation of the distributed loopcomputer network," in Proc. 3rd Annu. Symp. Comput. Arch., Jan.1975, pp. 124-129.
[13] P. M. Merlin and A. Segall, "A failsafe distributed routing protocol,"IEEE Trans. Commun., vol. COM-27, pp. 1280-1287, Sept. 1979.
[14] A. Segall, "Advances in verifiable fail-safe routing procedures," IEEETrans. Commun., vol. COM-29, pp. 491-497, Apr. 1981.
[15] L. Kleinrock, Queueing Systems, Volume II: Computer Applica-tions. New York: Wiley, 1976.
[16] A. Avizienis, "Fault-tolerant systems," IEEE Trans. Comput.,vol. C-25, pp. 1304-1312, Dec. 1976.
[17] K. Kim, "Error detection, reconfiguration and testing in distributed pro-cessing systems," in Proc. 1stInt. Conf. Dist. Comput. Syst., Oct. 1979,pp. 284-295.
[18] P. Merlin and B. Randell, "State restoration in distributed systems," inProc. 8th Int. Symp. Fault-Tolerant Computing, June 1978,pp. 129-134.
232

14I._
oSSEII et al.: DIAGNOSIS AIGORTHM FOR DSTRIBLTED CO b'ETNO SYSTEMS
[19] W. Kohler, "A survey of techniques for synchronization and recovery indecentralized computer systems," Computing Surveys, vol. 13, no. 2,pp. 149-183, June 1981.
[20] C. Leung and J. Dennis, "Design of a fault-tolerant packet commu-nication computer architecture," in Proc. 10th Int. Symp. Fault-TolerantComputing, Oct. 1980, pp. 328-335.
[21] D. Powell et al., "RHEA: A system for reliable and survivable inter-connection of real-time processing elements," in Proc. 8th Int. Symp.Fault-Tolerant Computing, June 1978, pp. 117-122.
[22] C. -C. Liaw, S. Y. H. Su, and Y. K. Malaiya, "Self-diagnosis of non-homogeneous distributed systems," in Proc. 12th Int. Symp. Fault-Tolerant Computing, June 1982, p. 349.
[23] F. P. Preparata, G. Metze, and R. T. Chien, "On the connection assign-ment problem of diagnosable systems," IEEE Trans. Electron. Comput.,vol. EC-16, pp. 848-854, Dec. 1967.
S. H. Hosseini was born in Tehran, Iran. He re-ceived the B.Sc. degree in electrical engineering in1972 from Tehran Polytechnique University, Tehran,Iran, the M.E. degree in electrical engineering in1977 from Iowa State University, Ames, IA, and thePh.D. degree in electrical and computer engineeringin 1982 from the University of Iowa, Iowa City, IA.He was with the Iran Telecommunication Research
Center from 1973 to 1975. Since 1982 he has beenwith the Department of Electrical and Computer
233
Science, University of Wisconsin, Milwaukee, where he is currently anAssistant Professor. His research interests include fault-tolerant computingsystems, computer architecture, and computer networks.
Jon G. Kuhi was born in Creston, IA. He receivedthe B.S. degree in computer science in 1975, theM.S. degree in electrical and computer engineeringin 1977, and the Ph.D. degree in computer sciencein 1980, all from the University of Iowa, Iowa
0 City, IA.ISince graduation he has been with the Department
of Electrical and Computer Engineering, Universityof Iowa, where he is currently an Assistant Pro-fessor. His research interests include distributedcomputation, computer networks, fault-tolerance,and computer architecture.
Sudhakar M. Reddy (S'68-M'68) was born inGadwal, India. He received the B.S. degree(E.C.E.) in 1962 from Osmania University, theM.E. degree (E.C.E.) in 1963 from the Indian Insti-tute of Science, India, and the Ph.D. degree (E.E.)in 1968 from the University of Iowa, Iowa City, IA.He is a Professor and Chairman of the Department
of Electrical and Computer Engineering, Universityof Iowa. His research interests include fault-tolerantcomputing, computing networks, and coding theory.
Dr. Reddy is currently on the editorial board ofIEEE TkANSACTIONS ON COMPUTERS.
Copyright © 2022 FDOKUMEN




















