
2.1 Proses Pengolahan Citra - Repository UIN SUSKA
31
II-1 II. BAB II LANDASAN TEORI 2.1 Proses Pengolahan Citra Pengolahan citra adalah suatu metode atau teknik dalam memperbaiki citra agar citra lebih mudah dimengerti oleh manusia maupun komputer. Pada proses pengolahan citra, diharapkan citra inputan akan mengalami peningkatan kualitas citra sehingga informasi yang terdapat didalam citra tersebut dapat dikenali dan dipahami dengan baik oleh manusia maupun komputer. Adapun proses pengolahan citra yang dilakukan pada penelitian ini dapat dilihat pada gambar 2.1 berikut. Segmentasi Fuzzy Threshold Preprocessing Akuisisi Citra Ciri Warna: HSV Ciri Tekstur: GLCM Ekstraksi Ciri LVQ Klasifikasi Gambar 2.1 Proses Pengolahan Citra Berdasarkan gambar 2.1 diatas, dapat dilihat bahwa proses pengolahan citra terdiri dari akuisisi citra, prepocessing, ekstraksi ciri dan klasifikasi citra. 2.1.1 Pembentukan Citra (Akuisisi Citra) Secara umum ada empat komponen dalam proses pembentukan citra, yaitu (Gonzales, 2008 dikutip Cahyana, 2015): digitizer, komputer digital, piranti tampilan, dan media penyimpanan. Digitizer berungsi untuk menangkap citra digital yang akan di representasikan secara numerik sebagai inputan bagi komputer. Contoh dari digitizer adalah kamera digital. Komputer digital yang digunakan pada pengolahan citra digital merupakan seperangkat alat berupa perangkat keras maupun perangkat
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of 2.1 Proses Pengolahan Citra - Repository UIN SUSKA

II-1
II. BAB II
LANDASAN TEORI
2.1 Proses Pengolahan Citra
Pengolahan citra adalah suatu metode atau teknik dalam memperbaiki citra
agar citra lebih mudah dimengerti oleh manusia maupun komputer. Pada proses
pengolahan citra, diharapkan citra inputan akan mengalami peningkatan kualitas
citra sehingga informasi yang terdapat didalam citra tersebut dapat dikenali dan
dipahami dengan baik oleh manusia maupun komputer.
Adapun proses pengolahan citra yang dilakukan pada penelitian ini dapat
dilihat pada gambar 2.1 berikut.
Segmentasi Fuzzy Threshold
PreprocessingAkuisisi Citra
Ciri Warna: HSVCiri Tekstur: GLCM
Ekstraksi Ciri
LVQ
Klasifikasi
Gambar 2.1 Proses Pengolahan Citra
Berdasarkan gambar 2.1 diatas, dapat dilihat bahwa proses pengolahan citra
terdiri dari akuisisi citra, prepocessing, ekstraksi ciri dan klasifikasi citra.
2.1.1 Pembentukan Citra (Akuisisi Citra)
Secara umum ada empat komponen dalam proses pembentukan citra, yaitu
(Gonzales, 2008 dikutip Cahyana, 2015): digitizer, komputer digital, piranti
tampilan, dan media penyimpanan.
Digitizer berungsi untuk menangkap citra digital yang akan di
representasikan secara numerik sebagai inputan bagi komputer. Contoh dari
digitizer adalah kamera digital. Komputer digital yang digunakan pada pengolahan
citra digital merupakan seperangkat alat berupa perangkat keras maupun perangkat

II-2
lunak yang mampu melakukan pengolahan secara digital. Piranti tampilan berguna
untuk merepresentasikan citra yang telah diolah dengan komputer digital.
Sedangkan media penyimpanan adalah perangkat dengan memori yang berguna
untuk menyimpan citra – citra digital untuk jangka waktu yang bersifat sementara
maupun dalam jangka waktu yang lama.
2.1.2 Preprocessing
Pada umumnya, operasi – operasi pada pengolahan citra diterapkan pada
citra bila (Munir, 2004):
1. Perbaikan atau memodifikasi citra perlu dilakukan untuk meningkatkan
kualitas penampakan atau menonjolkan beberapa aspek informasi yang
terkandung di dalam citra
2. Elemen di dalam citra perlu dikelompokkan, dicocokkan, atau diukur
3. Sebagian citra perlu digabung dengan bagian citra yang lain.
Secara umum, operasi pengolahan citra dapat diklasifikasikan dalam
beberapa jenis sebagai berikut:
1. Perbaikan kualitas citra (image enhancement), Operasi ini bertujuan
untuk memerbaiki kualitas citra dengan cara memanipulasi parameter –
parameter citra. Seperti perbaikan kontras gelap atau terang, perbaikan tepian
objek (Edge Enhancement), penajaman (sharpening), pemberian warna semu
(pseudocoloring) serta penapisan derau (noisefiltering).
2. Pemugaran citra (image restoration), Operasi ini bertujuan untuk
menghilangkan atau meminimumkan cacat pada citra. Seperti penghilangan
kesamaran (deblurring) dan penghilangan derau (noise).
3. Kompresi citra (image compression), Operasi ini bertujuan untuk
merepresentasikan citra ke dalam bentuk yang lebih kompak sehingga
memerlukan memori yang lebih sedikit. Pada kompresi citra, kualitas citra
yang telah dikompresi harus tetap mempunyai kualitas citra yang bagus.

II-3
4. Segmentasi Citra (image Segmentation), Operasi ini bertujuan untuk
memecah suatu citra ke dalam beberapa segmen dengan suatu kriteria tertentu.
Operasi ini berkaitan erat dengan pengenalan pola.
5. Analisis citra (image analysis), Operasi ini bertujuan untuk menghitung
besaran kuantitatif dari citra untuk menghasilkan deskripsinya. Analisis citra
diperlukan untuk melokalisasi objek yang diinginkan dari sekelilingnya.
Seperti pendeteksian tepi (edge detection), ekstraksi batas (boundary) dan
representasi daerah (region).
6. Rekonstruksi citra (image reconstruction), Operasi ini bertujuan untuk
membentuk ulang objek dari beberapa citra hasil proyeksi. Rekonstruksi citra
banyak digunakan pada bidang medis. Salah satunya yaitu foto rontgen dengan
sinar X digunakan untuk membentuk ulang gambar organ tubuh.
2.1.2.1 Segmentasi Citra
Segmentasi citra adalah proses pengolahan citra yang bertujuan untuk
memisahkan wilayah objek pada citra dengan wilayah background pada citra agar
operasi ekstraksi ciri pada wilayah objek di tahap selanjutnya dapat dihitung dengan
lebih mudah. Terdapat dua pendekatan utama dalam segmentasi citra yaitu
didasarkan pada tepi (edge-based) dandidasarkan pada wilayah (region-based).
Segmentasi didasarkan pada tepi membagi citra berdasarkan diskontinuitas di
antara sub-wilayah (sub-region), sedangkan segmentasi yang didasarkan pada
wilayah bekerja berdasarkan keseragaman yang ada pada sub-wilayah tersebut.
Hasil dari segmentasi citra adalah sekumpulan wilayah yang melingkupi citra
tersebut, atau sekumpulan kontur yang diekstrak dari citra (pada deteksi tepi)
(Murinto & Harjoko, 2009).
1. Segmentasi Fuzzy Threshold
Threshold adalah suatu teknik yang digunakan untuk segmentasi citra.
Teknik threshold ini digunakan untuk memisahkan antara objek dan
backgroundnya. Proses threshold sering disebut dengan proses binerisasi.
Pada beberapa aplikasi pengolahan citra, terlebih dahulu dilakukan
threshold terhadap citra grayscale untuk dapat menjadi citra biner (citra yang

II-4
memiliki nilai level keabuan 0 atau 255). Citra grayscale didapatkan dengan
melakukan konversi dari citra RGB. Untuk melakukan konversi citra RGB menjadi
citra grayscale, dapat menggunakan persamaan 2.1 berikut:
𝑔𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 0.3 ∗ 𝑅 + 0.5 ∗ 𝐵 + 0.2 ∗ 𝐵 (2.1)
Dengan R merupakan nilai Red (merah) suatu piksel pada citra, G
merupakan nilai Green (hijau) suatu piksel pada citra sedangkan B merupakan nilai
Blue (biru) suatu piksel pada citra.
Sebuah citra hasil proses threshold dapat disajikan dalam histogram citra
untuk mengetahui penyebaran nilai-nilai intensitas piksel pada suatu citra / bagian
tertentu dalam citra sehingga untuk citra bimodal, histogram dapat dipartisi dengan
baik (segmentasi objek dengan background) dan dapat ditentukan nilai threshold-
nya (Fauzi & Tjandrasa, 2010).
Menurut (Aja-Fernández et al, 2015) metode segmentasi fuzzy threshold
merupakan metode yang sangat baik digunakan untuk citra yang memiliki noise
jika dibandingkan dengan beberapa metode threshold lainnya.
Berikut adalah tahapan yang harus dilakukan untuk melakukan segmentasi
berdasarkan fuzzy threshold untuk suatu citra:
Citra Asli
Pre-processing Citra
Ekstraksi Centroid
Mendefinisikan fungsi keanggotaan
fuzzy[Nilai Parameter]
Menetapkan keanggotaan
Agregasi lokal
Segmentasi citra
Citra Threshold
Aturan Lokal
Gambar 2.2 Alur proses segmentasi fuzzy threshold
(Aja-Fernández et al, 2015)
Pada gambar 2.2 diatas dapat dijelaskan bahwa tahapan pertama dalam
melakukan segmentasi fuzzy threshold adalah dengan melakukan:
1. Ekstraksi sentroid, Area yang berbeda dimana gambar akan tersegmentasi
didefinisikan menggunkaan L sentroid. Dengan ketentuan L < N1. Jumlah
sentroid dapat diatur terlebih dulu untuk pencarian jumlah daerah yang
optimum.

II-5
2. Mendefinisikan fungsi keanggotaan fuzzy, fungsi keanggotaannya
adalahµ1(x), dengan I=1,…,L yang berhubungan dengan setiap kelas pada
sentroid yang telah ditetapkan sebelumnya. Ada dua cara untuk menentukan
fungsi keanggotaan:
a. Dari histogram gambar, metode ini mengikuti pendekatan klasik untuk
multiregion thresholding dimana tingkat utama dalam gambar yang diambil dari
histogram h(I), sebesar L didistribusikan ke dalam h(I):
h(I) ≈ ∑ 𝜔1. 𝑝1(𝑥; 𝜃1)𝐿𝐼=1 (2.2)
Dengan 𝑝1(𝑥; 𝜃1) adalah fungsi probabilititas density yang didefinisikan
oleh parameter 𝜃1, dan 𝜔1 adalah bobot yang memnuhi ∑ 𝜔1𝐼 = 1.
Untuk itu, fungsi keanggotaan fuzzy yang dipilih adalah dengan fungsi
keanggotaan trapesium. Seperti yang digambarkan pada gambar 2.3 berikut:
Wilayah1Wilayah2
0
1
a b 255
Gambar 2.3 Fungsi keanggotaan trapesium
b. Dari sentroid, jika fungsi keanggotaan yang dipilih adalah fungsi keanggotaan
trapesium, semua informasi dari histogram dapat diabaikan. Karena nilai – nilai
pada gambar 2.3 didapatkan secara langsung dari nilai ekstraksi sentroid pada
tahap sebelumnya. Keluaran pada tahap ini adalah fungsi keanggotaan yang
menggambarkan setiap set keluaran, µ1(x),1=1,…,L
Berdasarkan grafik fungsi keanggotaan trapezium pada gambar 2.3, dapat
ditentukan derajat keanggotaan suatu piksel didalam keanggotaan fuzzy
berdasarkan setiap wilayahnya seperti pada persamaan 2.3 dan 2.4 berikut:

II-6
𝜇𝑤𝑖𝑙𝑎𝑦𝑎ℎ1(𝑥) = {
1 𝑥 ≤ 𝑎𝑏−𝑥
𝑏−𝑎 𝐽𝑖𝑘𝑎 𝑎 < 𝑥 ≤ 𝑏
0 𝑏 < 𝑥 ≤ 255
} (2.3)
𝜇𝑤𝑖𝑙𝑎𝑦𝑎ℎ2(𝑥) = {
0 𝑥 ≤ 𝑎𝑥−𝑎
𝑏−𝑎 𝐽𝑖𝑘𝑎 𝑎 < 𝑥 ≤ 𝑏
1 𝑏 < 𝑥 ≤ 255
} (2.4)
Dimana x merupakan nilai grayscale pada suatu piksel yang akan ditentukan
keanggotaannya.
3. Menetapkan keanggotaan
Keanggotaan piksel r di dalam citra l(r) di dalam l kelas diberikan oleh,
µ1(l(r)). Dengan menggunakan fungsi keanggotaan trapesium yang telah
didefinisikan sebelumnya, diketahui bahwa:
∑𝜇𝐼(𝐼(𝑟))
𝐿
𝐼=1
= 1
Pada point ini, threshold pertama pada citra sudah bisa dilakukan:
𝑀(𝑟) = 𝑚𝑎𝑥𝐼{𝜇𝐼(𝐼(𝒓))} (2.5)
Dimana M(r) adalah hasil citra threshold. Pada tahap ini memiliki keluaran
pada setiap piksel, akan menjadi vektor keanggotaan :
𝜇(𝐼(𝑟)) = [𝜇1(𝐼(𝑟)) 𝜇2(𝐼(𝑟))… 𝜇𝐿(𝐼(𝑟))]
Jika fungsi keanggotaan yang dipilih berbentuk trapesium, maka hanya
ada 2 dari masing – masing elemen yang bernilai selain 0.
4. Agregasi lokal, pada langkah ini, informasi spasial akan dihitung sebelum
tahap akhir segmentasi. Nilai dari agrerasi lokal adalah:
𝜇𝑆(𝐼(𝑟)) = 𝑎𝑔𝑔𝑆∈ 𝜂(𝑟)
{𝜇(𝐼(𝑆))} (2.6)
Dimana agg adalah agregasi fuzzy ketetanggaan.
Berikut adalah beberapa agregasi untuk tujuan umum citra threshold.
a. Agregasi Median (MedAg): keanggotaan setiap piksel di dalam 𝜂(𝑟)
dikumpulkan menggunakan operator median
𝜇 𝑆𝐼(𝐼(𝑟)) = 𝑚𝑒𝑑𝑖𝑎𝑛
𝑆 ∈ 𝜂(𝑟){𝜇𝐼(𝐼(𝑆))} (2.7)

II-7
Ketetanggaan 𝜂(𝑟) dapat berorientasi untuk menemukan struktur pada
arah tertentu.
b. Agregasi Average (AvAg):Mendefinisikan rata – rata setiap fungsi
keanggotaan sebagai
𝜇 𝑆𝐼(𝐼(𝑟)) = ∑ 𝜔𝑖. 𝜇𝐼(𝐼(𝑟𝑖))𝑟𝑖 ∈ 𝜂(𝑟) (2.8)
Dengan 𝜔𝑖 merupakan bobot dari piksel yang bersangkutan.
c. Agregasi iterarif average (IterAg): Untuk menemukan struktur yang
lebih baik, dapat didefinisikan prosedur iteratif pada ruang
keanggotaan. Average yang kecil dapat didefinisikan sebagai:
ℎ = 1
3
0 0.5 00.5 1 0.50 0.5 0
Dan agregasi didefinisikan sebagai:
[𝜇𝐼(𝐼(𝑟))]𝑡+1 = [𝜇𝐼(𝐼(𝑟))]𝑡 ∗ ℎ (2.9)
Dengan * merupakan konvolusi spasial dan t = 0,….,T adalah jumlah
iterasi. Sehingga
𝜇𝐼𝑆(𝐼(𝑟)) = [𝜇1 (𝐼(𝑟))]𝑇
d. Absolut Maksimum (AbMax): Keanggotaan setiap piksel pada 𝜂(𝑟)
adalah agregasi yang menggunakan operator maksimum:
𝜇𝐼𝑆(𝐼(𝑟)) = 𝑚𝑎𝑥
𝑆 ∈ 𝜂(𝑟)(𝜇𝐼(𝐼(𝑆))) (2.10)
5. Segmentasi citra
Langkah terakhir adalah menghitung segmentasi citra akhir dari fungsi
keanggotaan yang telah dimodifikasi. Dengan menggunakan operator
maksimum:
𝑀(𝑟) = arg𝑚𝑎𝑥𝐼{𝜇𝐼
𝑆(𝐼(𝑟))} (2.11)
Meskipun defuzzifikasi yang lain dan perhitungan sentroid yang lain bisa
digunakan.

II-8
2.1.2.2 Cropping Citra
Cropping adalah proses pemotongan citra pada koordinat tertentu pada area
citra. Untuk memotong bagian dari citra digunakan dua koordinat, yaitu koordinat
awal yang merupakan awal koordinat bagi citra hasil pemotongan dan koordinat
akhir yang merupakan titik koordinat akhir dari citra hasil pemotongan. Sehingga
akan membentuk citra segi empat yang setiap pikselnya ada pada area koordinat
tertentu yang akan disimpan dalam citra yang baru.
Adapun proses pengolahan citra dapat terlihat seperti gambar 2.4 berikut.
2,2 2,3 2,4
3,2 3,3 3,4
4,2 4,3 4,4
5,2
1,1
2,1
3,1
4,1
5,1
1,2
5,3 5,4
1,3 1,4 1,5
2,5
3,5
4,5
5,5
2,2 2,3
3,2 3,3
1,1
2,1
3,1
1,2 1,3
Gambar 2.4 Cropping citra
Berdasarkan gambar 2.4 diatas, dapat diketahui bahwa terjadi cropping
terhadap citra berukuran 5x5 piksel menjadi citra 3x3 piksel dengan melakukan
pemotongan pada koordinat awal (2,2) dan koordinat akhir (4,4). Citra yang baru
ini memiliki nilai piksel dari koordinat citra awal yaitu (2,2) sampai koordinat (4,4).
Untuk melakukan cropping pada citra tersebut, dilakukan dengan
persamaan (2.10) dan (2.11) berikut.
𝑥′ = 𝑥 − 𝑥𝐿 𝑢𝑛𝑡𝑢𝑘 𝑥 = 𝑥𝐿 𝑠𝑎𝑚𝑝𝑎𝑖 𝑥𝑅 (2.12)
𝑦 = 𝑦 − 𝑦𝑇 𝑢𝑛𝑡𝑢𝑘 𝑦 = 𝑦𝑇 𝑠𝑎𝑚𝑝𝑎𝑖 𝑦𝐵 (2.13)

II-9
Dimana (𝑥𝐿, 𝑦𝑇) dan (𝑥𝑅, 𝑦𝐵) adalah koordinat titik pojok kiri atas dan
pojok kanan bawah citra yang akan di-crop.
2.1.3 Ekstraksi Ciri
Ekstraksi ciri merupakan proses pengindeksan suatu database citra dengan
isinya. Secara matematik, setiap ekstraksi ciri merupakan encode dari vektor n
dimensi yang disebut dengan vektor ciri. Komponen vektor ciri dihitung dengan
pemrosesan citra dan teknik analisis serta digunakan untuk membandingkan citra
yang satu dengan citra yang lain (Kusumaningsih, 2009). Beberapa Informasi atau
ciri yang dapat digunakan untuk merepresentasikan citra adalah ciri warna, ciri
tekstur, ciri berdasarkan wilayah citra serta ciri berdasarkan informasi semantik
yang terdapat pada citra.
Pada penelitian ini, identifikasi citra daging babi dan citra daging sapi
terlihat jelas pada warna dan serat yang terdapat pada daging tersebut. Oleh karena
itu, ekstraksi ciri yang digunakan pada penelitian ini adalah ekstraksi ciri warna
untuk mengidentifikasi perbedaan warna daging babi dan daging sapi serta
ekstraksi ciri tekstur untuk mengidentifikasi perbedaan serat daging yang terdapat
pada daging babi dan daging sapi.
2.1.3.1 Ekstraksi ciri warna
Pada setiap citra, memiliki piksel – piksel yang berbeda gradasi warnanya.
Pada setiap pikselnya, sebuah citra berwarna dapat mempunyai kombinasi warna
sebanyak 28.28.28=224=16 juta lebih (Rakhmawati, 2013). Dari banyaknya
kombinasi warna yang bisa muncul inilah dilakukan ekstraksi ciri warna terhadap
suatu citra agar suatu citra dapat dibedakan dengan citra yang lainnya.
Untuk melakukan ekstraksi ciri warna tersebut, ada beberapa model warna
yang digunakan. Antara lain, Hue Saturation Intencity (HSI), HSL dan Hue
Saturation Value (HSV). Persamaan antara ketiga model warna tersebut adalah
ketiganya menggunakan citra berwarna. Citra berwarna adalah citra yang setiap
pikselnya mewakili warna yang merupakan kombinasi dari tiga warna dasar yaitu
merah, hijau dan biru atau biasa disebut dengan kombinasi RGB (Red, Green,

II-10
Blue). Setiap warna dasar ini menggunakan penyimpanan 8 bit atau 1 byte, yang
berarti setiap warna mempunyai gradasi warna sebanyak 256 warna.
Pada model warna HSI, komponen warna RGB terlebih dahulu dikonversi
kedalam model warna HSI yang mengandung hue, saturation dan intencity
(Kiswanto, 2012). Hue menyatakan warna sebenarnya seperti merah, violet dan
kuning. Hue digunakan untuk membedakan warna – warna dan menentukan
kemerahan (redness), kehijauan (greenness) dan sebagainya. Saturation
menyatakan tingkat kemurnian warna cahaya, yaitu mengindikasikan seberapa
banyak warna putih diberikan pada warna. Intencity adalah atribut yang
menyatakan banyaknya cahaya yang diterima oleh mata tanpa memperdulikan
warna. Kisaran nilainya adalah antara gelap (hitam) hingga terang (putih).
Pada model warna HSV, komponen warna RGB terlebih dahulu dikonversi
kedalam model warna HSV yang mengandung hue, saturation dan value. Sama hal
nya dengan model warna HSI, pada model warna HSV, hue dan saturation
memiliki fungsi yang sama. SedangkanValue adalah atribut yang menyatakan
banyaknya cahaya yang diterima oleh mata tanpa memperdulikan warna.
Dari beberapa model warna yang telah disebutkan diatas, pada penelitian ini
menggunakan model warna HSV dalam mengekstraksi ciri warna. Karena menurut
(Gonzalez et al, 2010 dikutip oleh Cahyana, 2015) model HSV adalah pengenalan
ciri warna yang terbaik.
1. Model Warna HSV
Pada model warna HSV, nilai hue berkisar antara 0 sampai 1 yang berarti
warna antara merah lalu memutar nilai – nilai spektrum warna tersebut hingga
kembali ke warna merah. Nilai saturation berkisar antara 0 sampai 1 yang berarti
tidak tersaturasi (keabuan) sampai tersaturasi (tidak putih). Nilai value atau
kecerahan berkisar antara 0 sampai 1 yang berarti warna semakin cerah
(Rakhmawati, 2013). Untuk menjelaskan hubungan antara Hue, Saturation dan
Value dapat dilihat pada gambar 2.5 berikut.

II-11
Gambar 2.5 Model Warna HSV
(Rakhmawati, 2013)
Pada gambar 2.5 diatas, dapat dilihat hubungan antara hue, saturation dan
value seperti yang telah dijelaskan diatas.
2. Konversi Citra RGB menjadi citra HSV
Untuk melakukan konversi citra RGB menjadi citra HSV, perlu dilakukan
persamaan berikut untuk setiap nilai Hue, Saturation dan value pada setiap
pikselnya.
𝑯 = 𝒕𝒂𝒏 [𝟑(𝑮−𝑩)
(𝑹−𝑮)+(𝑹−𝑩)] ..................... (2. 14)
𝑺 = 𝟏 −𝐦𝐢𝐧(𝑹,𝑮,𝑩)
𝑽 .................. (2. 15)
𝑽 =𝑹+𝑮+𝑩
𝟑 .................. (2. 16)
Pada rumus diatas, dalam kondisi tertentu nilai H tidak dapat ditentukan.
Oleh karena itu, perlu dilakukan normalisasi terhadap nilai RGB pada citra. Adapun
persamaan untuk menormalisasikan nilai RGB adalah sebagai berikut.

II-12
𝑟 =𝑅
𝑅+𝐺+𝐵 ..................... (2. 17)
𝑔 =𝐺
𝑅+𝐺+𝐵 ..................... (2. 18)
𝑏 =𝐵
𝑅+𝐺+𝐵 ..................... (2. 19)
Pada ketiga persamaan diatas, nilai R, G dan B menyatakan nilai RGB yang
belum dinormalisasi. Sedangkan nilai r,g dan b menyatakan nilai RGB yang telah
dinormalisasi.
Setelah nilai RGB dinormalisasi, maka persamaan untuk mengkonversi nilai
RGB menjadi citra HSV berubah menjadi berikut.
𝑽 = 𝒎𝒂𝒙(𝒓, 𝒈, 𝒃) ..................... (2. 20)
𝑺 = {𝑽−
𝒎𝒊𝒏(𝒓,𝒈,𝒃)
𝑽
𝟎 ; 𝑱𝒊𝒌𝒂 𝑽>𝟎𝑱𝒊𝒌𝒂 𝑽=𝟎
............... (2. 21)
𝑯 =
{
𝟎 𝑱𝒊𝒌𝒂 𝑺 = 𝟎𝟔𝟎 𝒙 (𝒈−𝒃)
𝑺 𝒙 𝑽 𝑱𝒊𝒌𝒂 𝑽 = 𝒓
𝟔𝟎 𝒙 [𝟐 +(𝒃−𝒓)
𝑺 𝒙 𝑽] 𝑱𝒊𝒌𝒂 𝑽 = 𝒈
𝟔𝟎 𝒙 [𝟒 +(𝒓−𝒈)
𝑺 𝒙 𝑽] 𝑱𝒊𝒌𝒂 𝑽 = 𝒃
. (2. 22)
𝑯 = 𝑯+ 𝟑𝟔𝟎 𝑱𝒊𝒌𝒂 𝑯 < 𝟎 ............ (2. 23)
2.1.3.2 Ekstraksi Ciri Tekstur
Ekstraksi ciri tekstur biasanya dimanfaatkan sebagai proses antara untuk
melakukan klasifikasi dan interpretasi citra. Berdasarkan orde statistiknya,
ekstraksi ciri tekstur dapat dikategorikan menjadi 3, yaitu orde satu, orde dua dan
orde tiga (Adi putra, 2013).
Statistik Orde – kesatu, merupakan metode pengambilan ciri yang
didasarkan pada karakteristik histogram citra. Histogram menunjukkan
kemungkinan kemunculan nilai derajat keabuan piksel pada suatu citra, dengan
mengabaikan piksel tetangga. Statistik orde – kesatu lebih baik dalam
mengekstraksi tekstur citra dengan parameter seperti mean, skewness, variance,
kurtosis dan entropy.

II-13
Statistik Orde – kedua, merupakan metode pengambilan ciri yang
mempertimbangkan hubungan antara dua piksel (piksel yang bertetangga) pada
citra. Statistik orde kedua memerlukan bantuan matriks kookurensi (matrix co-
occurence) untuk citra keabuan. Statistik orde kedua lebih baik dalam
mengekstraksi tekstur citra dengan parameter seperti kontras, korelasi, variansi,
entropi dan energi.
Statistik Orde – ketiga dan yang lebih tinggi, merupakan metode
pengambilan ciri yang mempertimbangkan hubungan antara tiga atau lebih piksel.
Hal ini memungkinkan secara teoritis, akan tetapi belum bisa diterapkan.
Pada penelitian ini, akan dilakukan ekstraksi ciri tekstur dengan statistik
orde kedua dengan bantuan matriks kookurensi untuk citra keabuan atau yang biasa
disebut dengan Gray Level Co-Occurence Matrix (GLCM).
1. GLCM (Gray Level Co-Occurence Matrix)
Matriks kookurensi merupakan matriks berukuran L x L (L menyatakan
tingkat keabuan) dengan elemen P(x1, x2) yang merupakan distribusi probabilitas
bersama (join probability distribution) dari pasangan titik – titik dengan tingkat
keabuan x1 yang berlokasi pada koordinat (j,k) dengan x2yang berlokasi pada
koordinat (m,n). Koordinat pasangan titik – titik tersebut berjarak r dengan dengan
sudut𝜃. Histogram tingkat kedua P(x1, x2) dihitung dengan persamaan berikut (Adi
putra, 2013):
𝑃(𝑥1,𝑥2) = 𝑏𝑎𝑛𝑦𝑎𝑘𝑛𝑦𝑎 𝑝𝑎𝑠𝑎𝑛𝑔𝑎𝑛 𝑡𝑖𝑡𝑖𝑘−𝑡𝑖𝑡𝑖𝑘 𝑑𝑒𝑛𝑔𝑎𝑛 𝑡𝑖𝑛𝑔𝑘𝑎𝑡 𝑘𝑒𝑎𝑏𝑢𝑎𝑛 𝑥1 𝑑𝑎𝑛 𝑥2
𝑏𝑎𝑛𝑦𝑎𝑘𝑛𝑦𝑎 𝑡𝑖𝑡𝑖𝑘 𝑝𝑎𝑑𝑎 𝑑𝑎𝑒𝑟𝑎ℎ 𝑠𝑢𝑎𝑡𝑢 𝑐𝑖𝑡𝑟𝑎 (2.24)
GLCM adalah suatu matriks yang elemen – elemennya merupakan
pasangan piksel dengan tingkat kecerahan tertentu, dimana pasangan piksel itu
terpisah dengan jarak d dengan suatu sudut inklinasi 𝜃. Dengan kata lain, matriks
kookurensi adalah kemungkinan munculnya gray level i dan j dari dua piksel yang
terpisah jarak d dan sudut 𝜃.

II-14
Arah piksel tetangga untuk mewakili jarak dapat dipilih, misalnya 135˚, 90˚,
45˚ dan 0˚. Ilustrasi gambar piksel yang bertetanggaan dapat dilihat pada gambar 2.6
berikut.
(i-1, j-1) (i,j-1) (i+1, j-1)
(i-1, j) (i,j) (i+1, j)
(i-1, j+1) (i, j+1) (i+1, j+1)
0˚
45˚90˚
135˚
Gambar 2.6 Hubungan Ketetanggaan antar piksel
Setelah memperoleh matriks kookurensi tersebut, kemudian dapat
menghitung ciri statistik orde dua yang merepresentasikan citra yang diamati. Ciri
tekstur yang digunakan dalam penelitian ini menggunakan 6 ciri statik orde dua,
yaitu Angular Second Moment (ASM), contrast, correlation, variance, Inverse
Difference Moment (IDM) serta entropy (Putra dkk , 2012).
a. Angular Second Moment(ASM)
ASM atau energy menyatakan tingkat keseragaman piksel – piksel suatu
citra. Semakin tinggi nilai ASM, maka semakin seragam teksturnya. Untuk
menghitung ASM, dapat menggunakan persamaan (2.25) berikut.
𝐴𝑆𝑀 = ∑ 𝑝(𝑖, 𝑗)2𝑖,𝑗 (2.25)
b. Contrast
Contrast menyatakan kandungan variasi lokal pada citra. Semakin tinggi
nilai contrast, maka semakin tinggi tingkat kekontrasannya. Persamaan (2.26)
digunakan untuk menghitung contrast.
𝐶𝑂𝑁 = ∑ | 𝑖 − 𝑗 |2𝑖,𝑗 𝑃(𝑖, 𝑗) (2.26)

II-15
c. Correlation
Correlation menyatakan ukuran hubungan linear dari nilai gray level piksel
ketetanggaan. Persamaan (2.27) digunakan untuk menghitung Correlation.
𝐶𝑂𝑅 =∑ ∑ (𝑖𝑗).𝑝(𝑖,𝑗)−µ𝑖𝑗𝑖 𝜇𝑗
𝜎𝑖𝜎𝑗 (2.27)
Dimana nilai 𝜇𝑥, 𝜇𝑦, σxdan σy didapatkan dengan persamaan berikut.
𝜇𝑖 = ∑ ∑ 𝑖 𝑝(𝑖, 𝑗)𝑗𝑖 (2.28)
𝜇𝑗 = ∑ ∑ 𝑗 𝑝(𝑖, 𝑗)𝑗𝑖 (2.29)
σ𝑖 = ∑ ∑ 𝑝(𝑖, 𝑗)(𝑖 − 𝜇𝑖)2
𝑗𝑖 (2.30)
σ𝑗 = ∑ ∑ 𝑝(𝑖, 𝑗)(𝑗 − 𝜇𝑗)2
𝑗𝑖 (2.31)
d. Variance
Variance digunakan untuk menunjukkan variasi elemen – elemen matriks
kookurensi. Citra dengan transisi derajat keabuan kecil akan memiliki variansi yang
kecil pula. Persamaan (2.32) digunakan untuk menghitung variance.
𝑉𝐴𝑅 = ∑ (𝑖 − 𝜇𝑖)(𝑗 − 𝜇𝑗)𝑝(𝑖, 𝑗)𝑖,𝑗 (2.32)
e. Inverse Difference Moment (IDM)
IDM merupakan kebalikan dari contrast. Semakin tinggi nilai IDM maka
semakin rendah tingkat kekontrasannya. Nilai IDM bisa didapatkan dari persamaan
(2.33) berikut.
𝐼𝐷𝑀 = ∑1
1+(𝑖−𝑗)2𝑖,𝑗 𝑝(𝑖, 𝑗) (2.33)
f. Entropy
Entropy menyatakan tingkat keacakan piksel – piksel suatu citra. Semakin
tinggi nilai entropy, maka semakin acak teksturnya. Nilai Entropy bisa didapatkan
dari persamaan (2.34) berikut.
𝐸𝑁𝑇 = − ∑ 𝑃(𝑖, 𝑗) log(𝑃(𝑖, 𝑗))𝑖,𝑗 (2.34)
Keterangan:
𝑃(𝑖, 𝑗) = Elemen baris ke-i, kolom ke-j dari matriks kookurensi
𝜇𝑖 = nilai rata – rata baris ke-i pada matriks P

II-16
𝜇𝑗 = nilai rata – rata kolom ke-j pada matriks P
𝜎𝑖 = standard deviasi baris ke-I pada matriks P
𝜎𝑗 = standard deviasi kolom ke-j pada matriks P
2.1.4 Klasifikasi
Klasifikasi merupakan proses menemukan sekumpulan model yang
menggambarkan dan membedakan kelas – kelas data, dengan tujuan agar model
tersebut dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang
label kelasnya tidak diketahui. Klasifikasi terdiri atas duat tahap, yaitu pelatihan
dan pengujian. Pada tahap pelatihan, dibentuk sebuah model yang didapatkan dari
sekumpulan data yang telah diketahui labelnya. Sedangkan pada tahap pengujian
dilakukan prediksi terhadap model baru berdasarkan model yang telah diketahui
pada tahap pelatihan.
Pada pengklasifikasian menggunakana pembelajaran terarah, ada beberapa
metode klasifikasi yang digunakan. Diantaranya adalah backpropagation dan LVQ.
Backpropagation atau propagasi balik, merupakan metode klasifikasi
yang jaringannya terdiri dari banyak lapisan. Ketika jaringan diberikan pola
masukan sebagai pola pelatihan, maka pola tersebut akan menuju unit – unit lapisan
tersembunyi yang selanjutnya akan diteruskan kepada unit – unit lapisan keluaran.
Jika hasil keluaran tidak sesuai dengan hasil yang diharapkan, maka keluaran akan
disebarkan mundur (backward) pada lapisan tersembunyi kemudian pola tersebut
akan dikembalikan ke lapisan masukan sebagai hasil akhir (Putra dkk, 2012).
LVQ merupakan metode klasifikasi pola yang outputnya mewakili kelas
tertentu. Pada LVQ, arsitektur jaringannya terdiri dari lapisan input, lapisan
kompetitif serta lapisan output. Lapisan kompetitif akan belajar secara otomatis
untuk melakukan klasifikasi terhadap vektor input yang diberikan. Apabila vektor
input memiliki jarak yang sangat berdekatan, maka vektor input tersebut akan
dikelompokkan dalam kelas yang sama (Nasir & Syahroni, 2012).

II-17
Pada penelitian ini, dilakukan klasifikasi menggunakan metode LVQ karena
LVQ memiliki tingkat akurasi yang tinggi untuk pengenalan pola. Bahkan ada
penelitian yang menggunakan metode klasifikasi LVQ memiliki tingkat akurasi
mencapai 100% (Harjunowibowo, 2010).
2.1.4.1 Arsitektur LVQ (Learning Vector Quantization)
Adapun arsitektur LVQ yang akan digunakan pada penelitian ini dapat
dilihat pada gambar 2.7 berikut:
X1
| X – W1| F1
X2
X3
X4
X5
X6
X7
X8
X9
| X – W2| F2
Y_in1
Y_in2
Y1
Y2
Gambar 2.7 Arsitektur LVQ
Gambar 2.7 merupakan arsitektur LVQ yang akan digunakan dalam
penelitian ini. Nilai X1, X2,...,X9 menyatakan nilai masukan pada LVQ. Nilai ini
didapatkan dari nilai mean H, mean S, mean V, Angular Second Moment(ASM),
contrast, correlation, variance, Inverse Difference Moment (IDM) serta entropy
dari citra yang akan dilatih dan diuji. Sedangkan X- W1, X-W2 adalah proses untuk
menghitung jarak antara data uji dan data yang telah dilatih seblumnya. Y_in adalah
masukan ke dalam lapisan kompetitif untuk pencarian bobot baru. F adalah lapisan
kompetitif yang nilainya diperoleh dari proses pencarian bobot baru. W merupakan
vektor bobot yang menyatakan kelas untuk unit keluaran. Sedangkan Y adalah nilai

II-18
dari vektor keluaran yang menyatakan kelas dari data yang diuji. Dalam penelitian
ini, kelas dinyatakan sebagai kelas daging babi dan kelas daging sapi. Daging
Oplosan diklasifikasikan sebagai daging babi.
1. Proses Pembelajaran LVQ
Proses pembelajaran pada LVQ bertujuan mencari nilai bobot yang sesuai
untuk mengelompokkan vektor – vektor input kedalam kelas yang sesuai dengan
inisialisasi bobot awal pada saat pembentukan jaringan. Adapun parameter –
parameter yang akan digunakan pada LVQ adalah sebagai berikut (Hidayati &
Warsito, 2010).
a. ∝ (Learning Rate), ∝ didefinisikan sebagai laju pembelajaran. Jika ∝ terlalu
besar, maka algoritma akan menjadi tidak stabil. Sebaliknya, jika ∝ terlalu
kecil, maka prosesnya akan terlalu lama. Nilai ∝ adalah 0 <∝< 1.
b. 𝐷𝑒𝑐 ∝ (Penurunan Learning Rate), 𝐷𝑒𝑐 ∝ adalah penurunan laju
pembelajaran. Didefinisikan sebagai (0.1 * ∝).
c. 𝑀𝑖𝑛 ∝ (Minimum Learning Rate), 𝑀𝑖𝑛 ∝ adalah nilai minimum laju
pembelajaran yang masih diperbolehkan.
d. 𝑀𝑎𝑥𝐸𝑝𝑜𝑐ℎ (Maksimum Epoch), 𝑀𝑎𝑥𝐸𝑝𝑜𝑐ℎ adalah jumlah epoch atau
iterasi maksimum yang boleh dilakukan selama pelatihan. Iterasi akan
berhenti jika nilai epoch mencapai epoch maksimum.
Adapun algoritma proses pembelajaran pada metode LVQ dijelaskan pada
gambar 2.8 berikut ini.
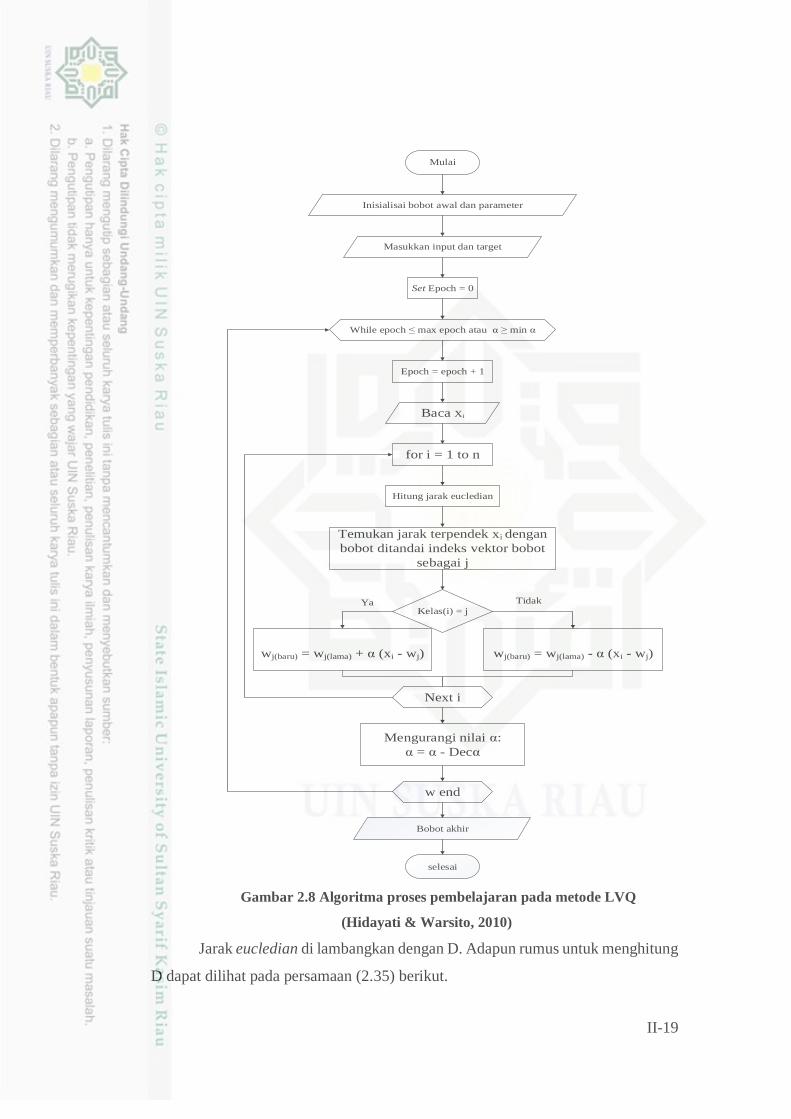
II-19
While epoch max epoch atau α min α
Kelas(i) = j
Mulai
Masukkan input dan target
Inisialisai bobot awal dan parameter
Set Epoch = 0
Epoch = epoch + 1
Baca Xi
for i = 1 to n
Hitung jarak eucledian
Temukan jarak terpendek xi dengan
bobot ditandai indeks vektor bobot
sebagai j
wj(baru) = wj(lama) + α (xi - wj)
Next i
Mengurangi nilai α:
α = α - Decα
w end
Bobot akhir
selesai
Ya Tidak
wj(baru) = wj(lama) - α (xi - wj)
Gambar 2.8 Algoritma proses pembelajaran pada metode LVQ
(Hidayati & Warsito, 2010)
Jarak eucledian di lambangkan dengan D. Adapun rumus untuk menghitung
D dapat dilihat pada persamaan (2.35) berikut.

II-20
𝐷 = √(𝑥1 −𝑤1)2+. . . . +(𝑥𝑛 −𝑤𝑛)2 (2.35)
Keterangan:
D adalah jarak eucledian antara data latih inputan dengan bobot kelas
x1, xn adalah nilai – nilai pada data latih inputan
w1, wn adalah bobot – bobot pada suatu kelas
Ketika jarak eucledian sudah didapatkan, maka akan dilakukan perbaikan
terhadap bobot kelas yang memiliki jarak eucledian paling kecil. Dengan ketentuan
sebagai berikut.
Jika kelas (i) = j, maka akan dilakukan perbaikan bobot seperti persamaan
(2.36) berikut.
𝑊𝑗(𝑏𝑎𝑟𝑢) = 𝑊𝑗(𝑙𝑎𝑚𝑎)+ ∝ (𝑥𝑖 −𝑊𝑗) (2.36)
Adapun jika kelas (i) ≠ j, maka akan dilakukan perbaikan bobot seperti persamaan
(2.37) berikut.
𝑊𝑗(𝑏𝑎𝑟𝑢) = 𝑊𝑗(𝑙𝑎𝑚𝑎)− ∝ (𝑥𝑖 −𝑊𝑗) (2.37)
2. Proses Pengujian LVQ
Setelah dilakukan proses pembelajaran pada LVQ, akan didapatkan bobot
akhir untuk setiap kelas. Bobot akhir inilah yang akan digunakan pada proses
pengujian. Adapun alur proses pengujian pada LVQ dapat dilihat pada gambar 2.9
berikut.
Mulai
Masukkan inputan data uji
dan bobot akhir
Hitung jarak eucledian
Pilih Kelas dengan jarak eucledian minimum
Kelas data uji
ditetapkan
selesai
Gambar 2.9 Algoritma proses pengujian pada metode LVQ
(Hidayati & Warsito, 2010)

II-21
Pada tahap pengujian, data uji diuji dengan mencari jarak eucledian terdekat
antara data uji dengan bobot akhir setiap kelas. Kelas dengan jarak yang terdekatlah
yang menyatakan kelas data citra uji yang dimasukkan.
2.2 Daging
Daging merupakan salah satu bahan pangan yang memiliki susunan asam
amino yang lengkap. Asam amino ini merupakan salah satu komponen yang
memiliki zat – zat gizi protein yang sangat diperlukan oleh manusia. Menurut
(Nugraheni, 2013) daging dapat didefinisikan sebagai urat daging (otot) yang
melekat pada kerangka. Setelah mengalami proses pemotongan, otot – otot yang
melekat pada kerangka mengalami penghentian fungsi fisiologisnya sehingga
mengakibatnya terbentuknya daging. Daging ini tersusun atas jaringan ikat,
epitelial, jaringan – jaringan syaraf, pembuluh darah, dan lemak. Komponen –
komponen inilah yang membedakan antara otot dengan daging.
2.2.1 Daging Sapi
Di Indonesia, ternak sapi memiliki urutan teratas dari segi populasi serta
penyebaran daging. Hampir seluruh daerah di Indonesia memiliki peternakan
sapi. Baik dengan skala besar maupun dengan skala kecil. Secara umum, setiap
sapi dapat menghasilkan daging, namun berbeda mutunya antar satu jenis dengan
jenis lainnya. Secara garis besar, daging sapi di Indonesia dapat dibedakan
menjadi beberapa tipe, yaitu sapi lokal, sapi pedaging dan sapi perah. Selain itu,
juga terdapat jenis sapi peranakan hasil perkawinan silang antar jenis serta jenis
daging sapi impor. Hal inilah yang semakin menyebabkan banyaknya variasi jenis
daging sapi di Indonesia. Walaupun berbeda - beda variasi jenisnya, akan tetapi
bentuk daging dari bermacam jenis tersebut tetaplah sama.
Beberapa hal yang harus diperhatikan dalam membedakan daging sapi
dengan daging lainnya dapat dilakukan dengan mengamati warna, aroma, tekstur
(kasar halusnya serat daging), konsistensi dan lemak (Nugraheni, 2013). Pada
daging sapi, daging berwarna merah pucat, bau dan rasa aromatis, berserabut halus
dengan konsistensi liat, dan sedikit lemak.

II-22
2.2.2 Daging Babi
Babi merupakan ternak yang mempunyai daya pertumbuhan dan
perkembangan yang relatif pesat, selain itu babi merupakan sumber daging sangat
efisien sehingga arti ekonominya sebagai ternak potong sangat tinggi. Varietas babi
yang diketahui sebanyak 312 tetapi hanya 87 yang resmi diakui sebagai bangsa
babi. Beberapa varietas pada bangsa babi ini memiliki ciri khas dan menempati
daerah geografis tertentu (Nugraheni, 2013).
Adapun perbedaan antara daging babi dengan daging – daging ternak
lainnya adalah daging babi berwarna pucat hingga merah muda, otot punggung
yang mengandung lemak umumnya kelihatan kelabu putih, serabut halus,
konsistensi padat dan berbau spesifik. Pada umur tua, daging babi berwarna lebih
tua, sedikit lemak dan serabut kasar.
2.3 Mean Opinion Score (MOS)
Untuk melihat akurasi pada pengujian segmentasi, pada penelitian ini
menggunakan perhitungan nilai rata – rata Mean Opinion Score (MOS) untuk
pengujian kualitatif pada citra penelitian hasil segmentasi. Penilaian ini dilakukan
berdasarkan pengamatan mata manusia sehingga hasil dari pengujian ini bersifat
subjektif (Sa'adah dkk, 2009).
Pada penelitian ini, Penilaian pada citra hasil segmentasi dilakukan oleh
peneliti terhadap keseluruhan citra penelitian. Adapun kriteria penilaian pada MOS
yang digunakan pada penelitian ini adalah sebagai berikut:
1. Sangat baik, direpresentasikan dengan angka 6. Penilaian ini diberikan jika
citra hasil segmentasi memiliki kualitas yang sangat baik, yaitu dapat
membagi dengan tepat wilayah background dan wilayahobjek.
2. Baik, direpresentasikan dengan angka 5. Penilaian ini diberikan jika citra
hasil segmentasi memiliki kualitas yang baik, yaitu dapat membagi wilayah
background dan wilayah objek hampir tepat.

II-23
3. Cukup baik, direpresentasikan dengan angka 4. Penilaian ini diberikan jika
citra hasil segmentasi memiliki kualitas yang cukup baik, yaitu dapat
membagi wilayah background dan wilayah objek sedikit menyimpang.
4. Buruk, direpresentasikan dengan angka 3. Penilaian ini diberikan jika citra
hasil segmentasi memiliki kualitas yang buruk, yaitu dapat membagi
wilayah background dan wilayah objek menyimpang.
5. Sangat Buruk, direpresentasikan dengan angka 2. Penilaian ini diberikan
jika citra hasil segmentasi memiliki kualitas yang sangat buruk, yaitu dapat
membagi wilayah background dan wilayah objek dengan sangat
menyimpang.
6. Tidak tersegmentasi, direpresentasikan dengan angka 1. Penilaian ini
diberikan jika citra hasil segmentasi memiliki kualitas yang benar – benar
buruk, yaitu tidak dapat membagi antara wilayah background dan wilayah
objek.
2.4 Confussion Matrix
Untuk melihat akurasi pada pengujian klasifikasi, pada penelitian ini
menggunakan confussion matrix. Menurut (Gurunescu, 2011), Jika data yang akan
diuji memiliki class positif dan negatif, maka dapat dibuatkan tabel seperti tabel 2.1
berikut:
Tabel 2.1 Tabel Confussion matrix 2 class
Classification Predicted Class
Observed Class Class = Yes Class = No
Class = Yes (True Positive - TP) (False Negative -
FN)
Class = No (False Positive - FP) (True Negative - TN)
Keterangan:
True Positive – TP = Jumlah data kelas benaryang diklasifikasikan sebagai kelas
benar
True Negative – TN = Jumlah data kelas salah yang diklasifikasikan sebagai kelas
salah

II-24
False Positive – FP = Jumlah data kelas salah yang diklasifikasikan sebagai kelas
benar
False Negative – FN = Jumlah data kelas benar yang diklasifikasikan sebagai kelas
salah
Berdasarkan tabel 2.1 diatas, dapat dilakukan perhitungan akurasi seperti
persamaan 2.38 berikut:
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝐹𝑁+𝐹𝑃+𝑇𝑁× 100% (2.38)
2.5 Penelitian Terkait
Adapun penelitian – penelitian yang terkait dengan penelitian yang akan
dilakukan adalah sebagai berikut:
2.5.1 Metode Segmentasi Fuzzy Threshold
Adapun beberapa penelitian mengenai metode segmentasi Fuzzy Threshold
dapat dilihat pada tabel 2.2 berikut:
Tabel 2.2 Penelitian terkait segmentasi fuzzy threshold
No Nama Peneliti Judul Penelitian Tahun
Penelitian
Hasil yang
Didapatkan
1 Santiago Aja-
Fernandez et al
A local fuzzy
thresholding
methodology for
multiregion image
segmentation
2015 Pada penelitian ini
dilakukan
segmentasi
menggunakan fuzzy
threshold pada citra
noise dengan
membandingkan
hasil segmentasi
dengan beberapa
metode segmentasi.
II-25
No Nama Peneliti Judul Penelitian Tahun
Penelitian
Hasil yang
Didapatkan
2 Feng Zhao et al A multiobjective
spatial fuzzy
clustering
algorithm for
image
segmentation
2015 Pada penelitian ini
dilakuan segmentasi
citra yang noise dan
membandingkannya
dengan beberapa
metode fuzzy.
2.5.2 Metode Ekstraksi Ciri Warna HSV
Adapun beberapa penelitian mengenai metode ekstraksi ciri warna HSV
dapat dilihat pada tabel 2.3 berikut:
Tabel 2.3 Penelitian terkait ekstraksi ciri warna HSV
No Nama Peneliti Judul Penelitian Tahun
Penelitian
Hasil yang
Didapatkan
1 R.D Kusumanto,
dkk
Klasifikasi warna
menggunakan
pengolahan model
warna HSV
2011 Penelitian
dilakukan dengan
menggunakan 6
jenis warna.
Dengan tingkat
error yang paling
kecil sebesar 10%
pada warna coklat.
2 Jati Sasongko
Wibowo
Deteksi dan
klasifikasi citra
berdasarkan warna
kulit
2011 Penelitian
dilakukan untuk
mengklasifikasikan
sebuah citra
termasuk

II-26
No Nama Peneliti Judul Penelitian Tahun
Penelitian
Hasil yang
Didapatkan
menggunakan
HSV
pornografi atau
tidak dengan
segmentasi warna
kulit manusia.
3 Rizqa Puji
Rakhmawati
Sistem Deteksi
Jenis Bunga
Menggunakan
nilai HSV dari
Citra Mahkota
Bunga
2013 Penelitian
dilakukan untuk
mendeteksi citra
mahkota bunga
menggunakan
metode HSV
dengan gabungan
nilai HS sebesar
26.67%, nilai HV
sebesar 33.33%,
nilai SV sebesar
20% dan HSV
sebesar 13.33%
tidak terdeteksi
2.5.3 Metode Ekstraksi Ciri Tekstur GLCM
Adapun beberapa penelitian mengenai metode ekstraksi ciri tekstur GLCM
dapat dilihat pada tabel 2.4 berikut:
II-27
Tabel 2.4 Penelitian terkait ekstraksi ciri tekstur GLCM
No Nama
Peneliti
Judul Penelitian Tahun
Peneliti
an
Hasil yang Didapatkan
1 Idaliana
Kusumanings
ih
Ekstraksi ciri
warna, bentuk dan
tekstur untuk
temu kembali
citra hewan.
2009 Penelitian ini dilakukan
untuk temu kembali pada
citra hewan dengan
melakukan ekstraksi ciri
warna Fuzzy color
histogram, ekstraksi ciri
tekstur GLCM serta
ekstraksi ciri bentuk edge
direction histogram
dengan operator sobel.
2 Toni
Wijarnako
Adi Putra
Pengenalan
Wajah dengan
Matriks
Kookurensi Aras
Keabuan dan
Jaringan Syaraf
Tiruan
Probabilistik
2013 Penelitian ini dilakukan
untuk melakukan
pengenalan wajah
menggunakan
penggabungan antara
metode GLCM dengan
Probabilistik Neural
Network (PNN) dengan
tingkat keberhasilan
pengenalan wajah secara
langsung sebesar 92%
sedangkan keberhasilan
pengenalan wajah secara
tidak langsung sebesar
93.33%.
II-28
No Nama
Peneliti
Judul Penelitian Tahun
Peneliti
an
Hasil yang Didapatkan
3 Refta Listia &
Agus Harjoko
Klasifikasi Massa
Pada Citra
Mammogram
Berdasarkan Gray
Level
Cooccurence
Matrix (GLCM)
2014 Hasil penelitian
menunjukkan bahwa fitur
ekstraksi GLCM 4 arah
(0˚,45˚,90˚,135˚) dengan
jarak d = 1 memiliki
akurasi terbaik dalam
mengklasifikasi
mammogram sebesar
81.1% dan khusus pada 0˚
akurasi diperoleh sebesar
100%.
2.5.4 Metode Klasifikasi LVQ
Adapun beberapa penelitian mengenai metode klasifikasi LVQ dapat dilihat
pada tabel 2.5 berikut:
Tabel 2.5 Penelitian terkait klasifikasi LVQ
No Nama
Peneliti
Judul Penelitian Tahun
Penelitian
Hasil yang Didapatkan
1 Muhammad
Nasir &
Muhammad
Syahroni
Pengujian Kualitas
Citra Sidik Jari
Kotor
Menggunakan
Learning Vector
Quantization(LVQ)
2012 Penelitian dilakukan
untuk pengujian kualitas
citra sidik jari yang kotor
dengan metode LVQ
yang menhasilkan
peningkatan akurasi
menjadi 87%.
II-29
No Nama
Peneliti
Judul Penelitian Tahun
Penelitian
Hasil yang Didapatkan
2 Abdul
Fadlil &
Surya Yeki
Sistem Verifikasi
Wajah
Menggunakan
Jaringan Syaraf
Tiruan Learning
Vector
Quantization
2010 Penelitian dilakukan
untuk menjelaskan
perancangan dan
pembuatan sistem
verifikasi wajah manusia
menggunakan metode
ekstraksi SPCA (Simple
Principle Component
Analysis) dan teknik
klasifikasi jaringan syaraf
tiruan LVQ.
3 Nurul
Hidayati &
Budi
Warsito
Prediksi
Terjangkitnya
Penyakit Jantung
dengan Metode
Learning Vector
Quantization
2010 Penelitian dilakukan
untuk memprediksi
terjangkitnya penyakit
jantung dengan LVQ
menghasilkan akurasi
sebesar 66.79%.
2.5.5 Identifikasi Citra Daging babi dan daging sapi
Adapun beberapa penelitian mengenai identifikasi citra daging babi dan
daging sapi dapat dilihat pada tabel 2.6 berikut:

II-30
Tabel 2.6 Penelitian terkait identifikasi citra daging babi dan daging sapi
No Nama Peneliti Judul Penelitian Tahun
Penelitian
Hasil yang
Didapatkan
1 Meiky Surya
Cahyana
Jaringan Saraf
Tiruan LVQ
(Learning Vector
Quantization)
Dalam
Mengidentifikasi
Citra Daging Babi
Dan Daging Sapi
2015 Akurasi pada
penelitian ini sebesar
94.81% dalam
mengidentifikasi citra
daging babi dan
daging sapi dengan
menggunakan metode
klasifikasi LVQ.
2 Ahamd Farid
Hartono dkk
Implementasi
Jaringan Syaraf
Tiruan
Backpropagation
Sebagai Sistem
Pengenalan Citra
Daging Babi Dan
Citra Daging Sapi
2012 Penelitian ini
dilakukan sebagai
sistem pengenalan
citra daging babi dan
daging sapi dengan
metode klasifikasi
backpropagation
menghasilkan Tingkat
akurasi sebesar 88.3
%.
3 Kiswanto Identifikasi Citra
Untuk
Mengidentifikasi
Jenis Daging Sapi
Dengan
Menggunakan
Transformasi
Wavelet Haar
2012 Penelitian ini
dilakukan untuk
mengidentifikasi jenis
daging sapi. Tingkat
akurasi pada penelitian
ini sebesar 80% pada
daging sapi segar,
daging sapi segar
II-31
No Nama Peneliti Judul Penelitian Tahun
Penelitian
Hasil yang
Didapatkan
dibekukan, daging
sapi busuk, daging
sapi busuk
dikeringkan.
Sedangkan pada
daging sapi busuk
dibekukan nilai
akurasi adalah 0%.




















