ictech--ivandari-23-1-ivan
4
Peningkatan Performa Algoritma Klasifikasi K-Nearest Neighbour pada Data Berdimensi Tinggi Ivandari Program Studi Teknik Informatika STMIK Widya Pratama Jl. Patriot 25 Pekalongan Telp (0285) 427816 Email: [email protected] Abstrak Klasifikasi merupakan salah satu tugas utama data mining. Salah satu algoritma klasifikasi yang banyak dipakai dan dikembangkan oleh peneliti adalah k-Nearest Neighbour. Penelitian ini merupakan sebuah klasifikasi untuk mengetahui kemungkinan heregistrasi mahasiswa dengan menggunakan data PMB STMIK Widya Pratama Pekalongan tahun 2011. Percobaan dilakukan dengan menggunakan jumlah atribut yang berbeda. K-NN menunjukkan performa yang lebih baik dengan menggunakan atribut berdimensi tinggi. Dengan 4 atribut akurasi k-NN hanya 62,10% dan dengan menambahkan 4 atribut menjadi 8 akurasinya naik drastis menjadi 81,38%. Sedangkan dengan menggunakan 12 atribut akurasinya kembali naik menjadi 83,79%. Dan dengan 16 atribut akurasi k-NN meningkat menjadi 94,30%. Hal ini menguatkan teori bahwa performa k-NN akan naik ketika data yang digunakan berdimensi tinggi. Kata kunci: K-NN, Atribut data, Akurasi 1 Pendahuluan 1.1 Latar Belakang Klasifikasi merupakan salah satu tugas utama data mining. Dalam klasifikasi terdapat berbagai macam algoritma dengan karakteristik serta kemampuan masing-masing [1] [2]. Salah satu algoritma klasifikasi yang banyak dipakai dan dikembangkan oleh peneliti adalah k-Nearest Neighbour [4]. K- Nearest Neighbour (k-NN) merupakan sebuah metode untuk mencari kedekatan kasus baru dengan kasus lama yang sudah tercatat [5]. Banyak penelitian yang dilakukan untuk meningkatkan performa algoritma k-NN. Salah satu yang paling menarik adalah dalam proses pemilihan atribut yang digunakan dalam proses perhitungan klasifikasi serta pembobotan atribut dalam data. STMIK Widya Pratama merupakan salah satu perguruan tinggi swasta yang ada di Kota Pekalongan. Setiap tahun STMIK Widya Pratama melakukan penerimaan mahasiswa baru dengan dibantu tim marketing beserta panitia PMB. Untuk sebuah perguruan tinggi swasta jumlah mahasiswa sangatlah mempengaruhi pendapatan akademik. Penelitian mengenai prediksi heregistrasi mahasiswa banyak dilakukan oleh peneliti. Ragab (2014) dalam penelitiannya membandingkan beberapa algoritma klasifikasi data mining [6]. Kemudian Sugianti (2012) melakukan prediksi heregistrasi calon mahasiswa STMIK Widya Pratama dengan menggunakan algoritma Bayesian classification [7]. Dalam penelitian tersebut algoritma bayessian classification memperoleh akurasi sebesar 78% dengan menggunakan data PMB Stmik Widya Pratama tahun 2011. Atribut yang digunakan dalam penelitian tersebut antara lain: kota asal, program studi, status pendaftaran serta gelombang untuk memprediksi atribut label yaitu registrasi. Dalam penelitian ini akan digunakan data yang sama yaitu data PMB STMIK Widya Pratama Pekalongan tahun 2011. Atribut yang digunakan dalam penelitian ini adalah atribut yang dianggap dapat mempengaruhi heregistrasi calon mahasiswa. Seleksi fitur dalam penelitian ini dilakukan dengan cara manual dan belum menggunakan algoritma seleksi fitur. Berikutnya akan dilakukan pembuktian apakah dengan banyaknya atribut
description
ivan
Transcript of ictech--ivandari-23-1-ivan
-
Peningkatan Performa Algoritma Klasifikasi K-Nearest Neighbour pada
Data Berdimensi Tinggi
Ivandari
Program Studi Teknik Informatika
STMIK Widya Pratama
Jl. Patriot 25 Pekalongan
Telp (0285) 427816
Email: [email protected]
Abstrak
Klasifikasi merupakan salah satu tugas utama data mining. Salah satu algoritma klasifikasi yang
banyak dipakai dan dikembangkan oleh peneliti adalah k-Nearest Neighbour. Penelitian ini merupakan
sebuah klasifikasi untuk mengetahui kemungkinan heregistrasi mahasiswa dengan menggunakan data
PMB STMIK Widya Pratama Pekalongan tahun 2011. Percobaan dilakukan dengan menggunakan
jumlah atribut yang berbeda. K-NN menunjukkan performa yang lebih baik dengan menggunakan
atribut berdimensi tinggi. Dengan 4 atribut akurasi k-NN hanya 62,10% dan dengan menambahkan 4
atribut menjadi 8 akurasinya naik drastis menjadi 81,38%. Sedangkan dengan menggunakan 12 atribut
akurasinya kembali naik menjadi 83,79%. Dan dengan 16 atribut akurasi k-NN meningkat menjadi
94,30%. Hal ini menguatkan teori bahwa performa k-NN akan naik ketika data yang digunakan
berdimensi tinggi.
Kata kunci: K-NN, Atribut data, Akurasi
1 Pendahuluan
1.1 Latar Belakang
Klasifikasi merupakan salah satu tugas utama
data mining. Dalam klasifikasi terdapat
berbagai macam algoritma dengan
karakteristik serta kemampuan masing-masing
[1] [2]. Salah satu algoritma klasifikasi yang
banyak dipakai dan dikembangkan oleh
peneliti adalah k-Nearest Neighbour [4]. K-
Nearest Neighbour (k-NN) merupakan sebuah
metode untuk mencari kedekatan kasus baru
dengan kasus lama yang sudah tercatat [5].
Banyak penelitian yang dilakukan untuk
meningkatkan performa algoritma k-NN. Salah
satu yang paling menarik adalah dalam proses
pemilihan atribut yang digunakan dalam proses
perhitungan klasifikasi serta pembobotan
atribut dalam data.
STMIK Widya Pratama merupakan salah satu
perguruan tinggi swasta yang ada di Kota
Pekalongan. Setiap tahun STMIK Widya
Pratama melakukan penerimaan mahasiswa
baru dengan dibantu tim marketing beserta
panitia PMB. Untuk sebuah perguruan tinggi
swasta jumlah mahasiswa sangatlah
mempengaruhi pendapatan akademik.
Penelitian mengenai prediksi heregistrasi
mahasiswa banyak dilakukan oleh peneliti.
Ragab (2014) dalam penelitiannya
membandingkan beberapa algoritma klasifikasi
data mining [6]. Kemudian Sugianti (2012)
melakukan prediksi heregistrasi calon
mahasiswa STMIK Widya Pratama dengan
menggunakan algoritma Bayesian
classification [7]. Dalam penelitian tersebut
algoritma bayessian classification memperoleh
akurasi sebesar 78% dengan menggunakan
data PMB Stmik Widya Pratama tahun 2011.
Atribut yang digunakan dalam penelitian
tersebut antara lain: kota asal, program studi,
status pendaftaran serta gelombang untuk
memprediksi atribut label yaitu registrasi.
Dalam penelitian ini akan digunakan data yang
sama yaitu data PMB STMIK Widya Pratama
Pekalongan tahun 2011. Atribut yang
digunakan dalam penelitian ini adalah atribut
yang dianggap dapat mempengaruhi
heregistrasi calon mahasiswa. Seleksi fitur
dalam penelitian ini dilakukan dengan cara
manual dan belum menggunakan algoritma
seleksi fitur. Berikutnya akan dilakukan
pembuktian apakah dengan banyaknya atribut
-
dapat mempengaruhi performa dari algoritma
k-NN.
1.2 Landasan Teori
1.2.1 Klasifikasi
Klasifikasi merupakan supervised learning dan
telah menjadi salah satu peran utama data
mining. Supervised learning atau pembelajaran
dengan menggunakan guru adalah sebuah
proses data mining dengan menggunakan data
lampau. Dalam hal ini dapat juga diartikan
pembelajaran dengan menggunakan guru.
Dalam klasifikasi data lampau yang ada
sebelumnya dianalisa untuk mendapatkan pola
dari data. Selain pola proses klasifikasi juga
dapat mencari aturan ataupun sebuah pohon
keputusan. Salah satu atribut data dalam
sebuah klasifikasi dijadikan sebagai label atau
atribut tujuan. Kemudian jika ada record data
baru yang belum diketahui labelnya maka akan
dihitung dengan menggunakan algoritma
tersebut dan dapat diketahui kemungkinan
labelnya.
1.2.2 K-Nearest Neighbour
K-Nearest Neighbour (k-NN) [5] adalah
pendekatan untuk mencari kasus dengan
menghitung kedekatan antara kasus baru
dengan kasus lama, yaitu berdasarkan pada
pencocokan bobot dari sejumlah fitur yang ada
[12]. K didalam k-NN merupakan jumlah
tetangga yang akan diambil untuk menentukan
keputusan.
Misalkan data rumah sakit mencatat banyak
pasien dengan gejala penyakit tertentu dan
penanganan khusus untuk jenis deteksi
penyakit tertentu. Jika terdapat kasus baru
dengan gejala yang menyerupai beberapa
kasus dengan vonis penyakit yang berbeda
maka k-NN dapat digunakan sebagai alat bantu
untuk menentukan jarak kedekatan antara
pasien baru dengan semua pasien lama. Maka
kasus dengan jarak kedekatan yang terbesar
yang akan diambil solusi yang sama untuk
pasien baru tersebut. Contoh secara nyata
kedekatan kasus dalam k-NN dapat dilihat
pada gambar 2.10 berikut
.
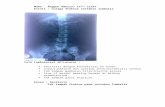
Gambar 1.1 Ilustrasi kedekatan pasien baru dengan kasus lama [12]
Seperti tampak pada gambar 2.11 terdapat tiga
pasien lama yaitu A, B, dan C. Ketika muncul
pasien baru, maka solusi yang akan diambil
adalah solusi dari pasien lama yang memiliki
kedekatan jarak paling dekat dengan pasien
baru. Tentunya pasien A menjadi pasien
terdekat yang nantinya dapat digunakan
sebagai solusi penanganan pasien baru
tersebut. Rumus dasar untuk menghitung
kedekatan antara dua kasus adalah sebagai
berikut:
Keterangan:
T : Kasus baru
S : Kasus yang ada dalam penyimpanan
n : Jumlah atribut dalam setiap kasus
i : Atribut individu antara 1 sampai dengan n
f : Fungsi similarity atribut i antara kasus T
dan kasus S
w : Bobot yang diberikan pada atribut ke i
Perhitungan algoritma k-NN menghitung
kedekatan data baru dengan keseluruhan data
A
Baru C
B
-
yang ada. Artinya jika data lampau adalah data
dengan record yang besar maka k-NN akan
membutuhkan waktu yang lama dan komputasi
yang mahal untuk menghitung kedekatan
keseluruhan record data lampau dengan data
baru.
2 Metode Penelitian
Penelitian ini dilakukan dengan menggunakan
metode eksperimen dan dengan alat bantu
yaitu rapid miner. Data yang digunakan adalah
data PMB STMIK Widya Pratama Pekalongan
tahun penerimaan 2011. Pengujian dilakukan
dengan menggunakan confusion matrix untuk
mengetahui tingkat akurasi dari algoritma K-
NN terhadap dataset yang disediakan.
2.1 Dataset
Dataset yang digunakan dalam penelitian ini
adalah data PMB STMIK Widya Pratama
Pekalongan tahun 2011. Percobaan dilakukan
beberapa kali dengan menggunakan jumlah
atribut yang berbeda. Percobaan pertama
dilakukan dengan menggunakan 4 atribut yang
sama seperti yang pernah dilakukan oleh
penelitian Sugianti (2012) sebelumnya.
Kemudian percobaan kedua dengan
menggunakan 8 atribut, percobaan ketiga
dengan menggunakan 12 atribut, serta
percobaan keempat dengan menggunakan 16
atribut data. Seluruh atribut yang digunakan
dalam keempat percobaan tersebut dapat
dilihat pada tabel 2.1 berikut.
Tabel 2.1 Atribut dalam percobaan
Percobaan 1
(4 Atribut)
Percobaan 2
(8 Atribut)
Percobaan 3
(12 Atribut)
Percobaan 4
(16 Atribut)
Atribut
yang
digunakan
Kota / kecamatan,
prodi,
status pendaftaran,
geelombang.
Kota / kecamatan,
prodi,
status pendaftaran,
geelombang,
agama,
status pekerjaan,
status sipil,
tahun lulus.
Kota / kecamatan,
prodi,
status pendaftaran,
geelombang,
agama,
status pekerjaan,
status sipil,
tahun lulus,
jenis kelamin,
jenjang,
shift kelas,
biaya kuliah.
Kota / kecamatan,
prodi,
status pendaftaran,
geelombang,
agama,
status pekerjaan,
status sipil,
tahun lulus,
jenis kelamin,
jenjang,
shift kelas,
biaya kuliah,
sesi pendaftaran,
kota sekolah asal,
gelombang grade,
kelas.
2.2 Pengujian
Pengujian dalam penelitian ini adalah
menggunakan cross validation. Dalam
pengujian cross validation sejumlah record
data dijadikan sebagai data uji (data testing)
serta sebagian besar yang lain digunakan
sebagai data pelatihan (data training).
Kemudian hasil klasifikasi dari data uji
tersebut dibandingkan dengan data sebenarnya
untuk mengetahui benar atau salah klasifikasi
yang dilakukan. Proses tersebut diulang
sampai keseluruhan record data mendapatkan
bagian sebagai data uji. Hasil dari semua
pengujian dihitung dan diambil rata-rata untuk
mendapatkan tingkat akurasi dari algoritma.
3 Hasil dan Pembahasan
Dari haasil penelitian diketahui bahwa
algoritma k-NN mengalami peningkatan
akurasi ketika data memiliki dimensi yang
tinggi. Dengan menggunakan 4 atribut k-NN
mendapat tingkat akurasi sebesar 62,10%.
Peningkatan yang cukup signifikan terjadi
ketika atribut yang digunakan berjumlah 8 dan
16. Dengan menggunakan 8 atribut k-NN
mendapat tingkat akurasi sebesar 81,38%.
Sedangkan dengan menggunakan jumlah
atribut 12 k-NN mendapat tingkat akurasi
83,79%, dan 94,30% untuk 16 atribut. Hasil
penelitian secara lebih jelas dapat dilihat pada
tabel 3.1 dibawah.
-
Tabel 3.1 Tingkat akurasi k-NN untuk data PMB STMIK Widya Pratama Pekalongan
Percobaan 1
(4 atribut)
Percobaan 2
(8 atribut)
Percobaan 3
(12 atribut)
Percobaan 4
(16 atribut)
Akurasi 62,10% 81,38% 83,79% 94,30%
Precission 37,60% 70,33% 71,15 91,43%
recall 54,12% 57,65% 70,59% 87,84%
4 Kesimpulan
Dari hasil penelitian yang telah dilakukan
sebelumnya maka dapat ditarik kesimpulan
bahwa algoritma k-NN akan lebih kuat jika
atribut dalam data yang dipakai berdimensi
tinggi. Terbukti dengan semakin naiknya
tingkat akurasi algoritma ketika atribut yang
digunakan ditambah sesuai dengan skala
tertentu. Semakin banyak atribut yang
mempengaruhi akan meningkatkan performa
k-NN secara keseluruhan [10].
5 Saran dan Penelitian berikutnya
Dalam penelitian ini setiap atributnya belum
diberikan pembobotan untuk membedakan
prioritas dan kepentingan satu atribut dengan
atribut lainnya. Penelitian berikutnya k-NN
dapat ditambahkan dengan pembobotan untuk
setiap atributnya. Serta dalam penelitian ini
atribut yang digunakan dipilih secara manual
dengan melihat pengaruh atribut tersebut
terhadap heregistrasi mahasiswa. Dalam
penelitian berikutnya juga dapat ditambahkan
algoritma seleksi fitur untuk melakukan
pemilihan atribut secara otomatis.
6 Daftar Pustaka
[1] I. H. Witten, E. Frank, and M. A. Hall,
Data Mining: Practical Machine
Learning Tools and Techniques 3rd
Edition. Elsevier, 2011.
[2] D. T. Larose, Discovering Knowledge
in Data: an Introduction to Data
Mining. John Wiley & Sons, 2005.
[3] J. Han and M. Kamber, Data Mining:
Concepts and Techniques Second
Edition. Elsevier, 2006.
[4] X. Wu, V. Kumar, J. R. Quinlan, J.
Ghosh, Q. Yang, H. Motoda, G. J.
Mclachlan, A. Ng, B. Liu, P. S. Yu, Z.
Z. Michael, S. David, and J. H. Dan,
Top 10 algorithms in data mining.
2007, pp. 137.
[5] T. M. Cover and P. E. Hart, Nearest Neighbor Pattern Classification, vol. I, 1967.
[6] A. H. M. Ragab, A. Y. Noaman, A. S.
Al-Ghamdi, and A. I. Madbouly, A Comparative Analysis of Classification
Algorithms for Students College
Enrollment Approval Using Data
Mining, 2014.
[7] D. Sugianti, Algoritma Bayesian Classification Untuk Memprediksi
Heregistrasi Mahasiswa Baru di
STMIK Widya Pratama, no. 2, pp. 15, 2012.
[8] Maimoon, Data Mining and Knowledge
Discovery Handbook. 2010.
[9] E. Alpaydin, Introduction to Machine
Learning Second Edition. 2010.
[10] D. R. Amancio, C. H. Comin, D.
Casanova, G. Travieso, O. M. Bruno, F.
A. Rodrigues, and L. da F. Costa, A Systematic Comparison of Supervised
Classifiers, 2013.
[11] A. Ashari, I. Paryudi, and A. M. Tjoa,
Performance Comparison between Nave Bayes , Decision Tree and k-
Nearest Neighbor in Searching
Alternative Design in an Energy
Simulation Tool, vol. 4, no. 11, pp. 3339, 2013.
[12] Kusrini and L. E. Taufiq, Algoritma
Data Mining. Yogyakarta: Andi Offset,
2009.