
EKONOMETRIKA DENGAN APLIKASI SPSS PANDUAN … · memilih adalah dengan mengklik sel di bawah kolom...
85
Ekonometrika dengan Aplikasi SPSS 0 EKONOMETRIKA DENGAN APLIKASI SPSS PANDUAN PRAKTIKUM Oleh: IR. ANWAR, MP JURUSAN SOSIAL EKONOMI PERTANIAN PROGRAM STUDI AGRIBISNIS FAKULTAS PERTANIAN UNIVERSITAS MATARAM OKTOBER 2018
Transcript of EKONOMETRIKA DENGAN APLIKASI SPSS PANDUAN … · memilih adalah dengan mengklik sel di bawah kolom...

Ekonometrika dengan Aplikasi SPSS 0
EKONOMETRIKA DENGAN APLIKASI SPSSPANDUAN PRAKTIKUM
Oleh:
IR. ANWAR, MP
JURUSAN SOSIAL EKONOMI PERTANIANPROGRAM STUDI AGRIBISNIS
FAKULTAS PERTANIANUNIVERSITAS MATARAM
OKTOBER 2018

Ekonometrika dengan Aplikasi SPSS 1
PENGENALAN SPSS
Sekilas tentang SPSS
SPSS merupakan software aplikasi statistik yang pada awalnya digunakan untuk
riset di bidang sosial (SPSS saat itu singkatan dari Statistical Package for the Social
Science). Sejalan dengan perkembangan SPSS digunakan untuk melayani berbagai jenis
user sehingga sekarang SPSS singkatan dari Statistical Product and Service Solutions.
Stastistical Package for the Social Science atau Product and Service Solutions
(SPSS) merupakan salah satu dari sekian banyak software aplikasi statistika yang telah
dikenal luas di kalangan penggunanya, atau aplikasi statistika yang sangat populer baik
bagi praktisi untuk melakukan riset maupun mahasiswa untuk menyelesaikan tugas
akhirnya. Disamping masih banyak lagi software statistika lainnya seperti Micro-TSP,
Eviews, Minitab, STATA, AMOS dan masih banyak lagi. SPSS adalah suatu software
yang berfungsi untuk menganalisis data, melakukan perhitungan statistik baik statistika
parametrik dan statistika non-parametrik dengan basis windows. Saat system operasi
komputer windows mulai populer, SPSS yang dahulunya under DOS dan bernama
SPSS PC, juga berubah menjadi under windows dan populer di Indonesia dengan SPSS
versi 6, kemudian versi 7.5, versi 9, versi 10, versi 11.5, versi 12, versi 13, versi 14,
versi 16, versi 17 dan terakhir saat ini adalah versi 25. SPSS sebagai sebuah tools
mempunyai banyak kelebihan, terutama untuk aplikasi di bidang ilmu sosial.
Buku panduan praktikum ini menggunakan SPSS versi 17, meski pengguna versi
sebelumnya juga dapat menggunakan modul ini sebagai panduan. Tidak ada perbedaan
yang mencolok dalam melakukan analisis bila dibandingkan versi sebelumnya.

Ekonometrika dengan Aplikasi SPSS 2
MENU BAR
Untuk mengaktifkan SPSS 17 dengan melakukan klik Start ===> All Programs ===>
SPSS Inc ===> SPSS Statistics 17.0 atau klik langsung icon SPSS Statistics 17.0
sehingga muncul kotak dialog SPSS 17 berikut.
SPSS Environment
VARIABLE VIEWDATA VIEW
TOOLBAR

Ekonometrika dengan Aplikasi SPSS 3
MENU BAR : Kumpulan perintah-perintah dasar untuk mengoperasikan
SPSS.
Pada Variable View tampak judul di kolom-kolom sebagai berikut :
Name. Pada kolom name dituliskan nama dari variabel. Untuk memasukkan
nama variabelnya pada sel dengan cara doube klik kemudian dituliskan nama
variabelnya.
Type. Pada kolom type untuk mengisikan tipe dari data untuk variabel tersebut.
Type data yang ada dalam SPSS adalah String, Numeric, Date, dan lain-lain. Cara
memilih adalah dengan mengklik sel di bawah kolom type, kemudian akan
muncul pilihan type data, klik type yang dipilih.
Width. Pada kolom width untuk mengisikan panjang dari data untuk variabel
tersebut. Panjang yang diijinkan dari 1 sampai 255 digit.
Decimals. Pada kolom decimals untuk mengisikan jumlah angka desimal untuk
data variabel tersebut.
Label. Pada kolom label untuk mengisikan keterangan dari variabel.
Value. Pada kolom value untuk mengisikan nilai dari variabel.
Missing. Pada kolom missing untuk mengisikan nilai yang hilang.
Column. Hampir sama fungsinya dengan width.
Align. Pada kolom align untuk menentukan posisi data
Measure.
Data View, merupakan tempat untuk memasukan datanya tiap variabel.
Menu yang terdapat pada SPSS adalah menu File, Edit, View, Data, Transform,
Analyze, Graphs, Utilities, Add-ons, Windows, dan Help. Secara rinci fungsi dari
masing-masing menu diuraikan berikut.

Ekonometrika dengan Aplikasi SPSS 4
1. FILE
Untuk operasi file dokumen SPSS yang telah dibuat, baik untuk perbaikan
pencetakan dan sebagainya. Ada 5 macam data yang digunakan dalam SPSS, yaitu :
1. Data : dokumen SPSS berupa data
2. Syntax : dokumen berisi file syntax SPSS
3. Output : dokumen yang berisi hasil running output SPSS
4. Script : dokumen yang berisi running output SPSS
5. Database
♠ NEW : membuat lembar kerja baru SPSS
♠ OPEN : membuka dokumen SPSS yang telah ada
Secara umum ada tiga macam ekstensi dalam lembar kerja SPSS, yaitu :
1. *.sav : file data yang dihasilkan pada lembar data editor
2. *.spo : file text/obyek yang dihasilkan oleh lembar output
3. *.cht : file obyek gambar/chart yang dihasilkan oleh chart window
♠ Read Text Data : membuka dokumen dari file text (yang berekstensi txt),
yang bisa dimasukkan/dikonversi dalam lembar data
SPSS
♠ Save : menyimpan dokumen/hasil kerja yang telah dibuat.
♠ Save As : menyimpan ulang dokumen dengan nama/tempat/type
dokumen yang berbeda
♠ Page Setup : mengatur halaman kerja SPSS
♠ Print : mencetak hasil output/data/syntaq lembar SPSS

Ekonometrika dengan Aplikasi SPSS 5
Ada 2 option/pilihan cara mencetak, yaitu :
- All visible output : mencetak lembar kerja secara keseluruhan
- Selection : mencetak sesuai keinginan yang kita sorot/blok
♠ Print Preview : melihat contoh hasil cetakan yang nantinya diperoleh
♠ Recently used data: berisi list file data yang pernah dibuka sebelumnya
♠ Recently used file : berisi list file secara keseluruhan yang pernah dikerjakan
2. EDIT
Untuk melakukan pengeditan pada operasi SPSS baik data, serta
pengaturan/option untuk konfigurasi SPSS secara keseluruhan.
♠ Undo : pembatalan perintah yang dilakukan sebelumnya
♠ Redo : perintah pembatalan perintah redo yang dilakukan
sebelumnya
♠ Cut : penghapusan sebual sel/text/obyek, bisa dicopy untuk
keperluan tertentu dengan perintah dari menu paste
♠ Paste : mempilkan sebua sel/text/obyek hasil dari perintah copy
atau cut
♠ Paste after : mengulangi perintah paste sebelumya
♠ Paste spesial : perintah paste spesial, yaitu bisa konvesri ke gambar,
word, dan lain-lain
♠ Clear : menghapusan sebuah sel/text/obyek
♠ Find : mencari suatu text
♠ Options : mengatur konfigurasi tampilan lembar SPSS secara umum

Ekonometrika dengan Aplikasi SPSS 6
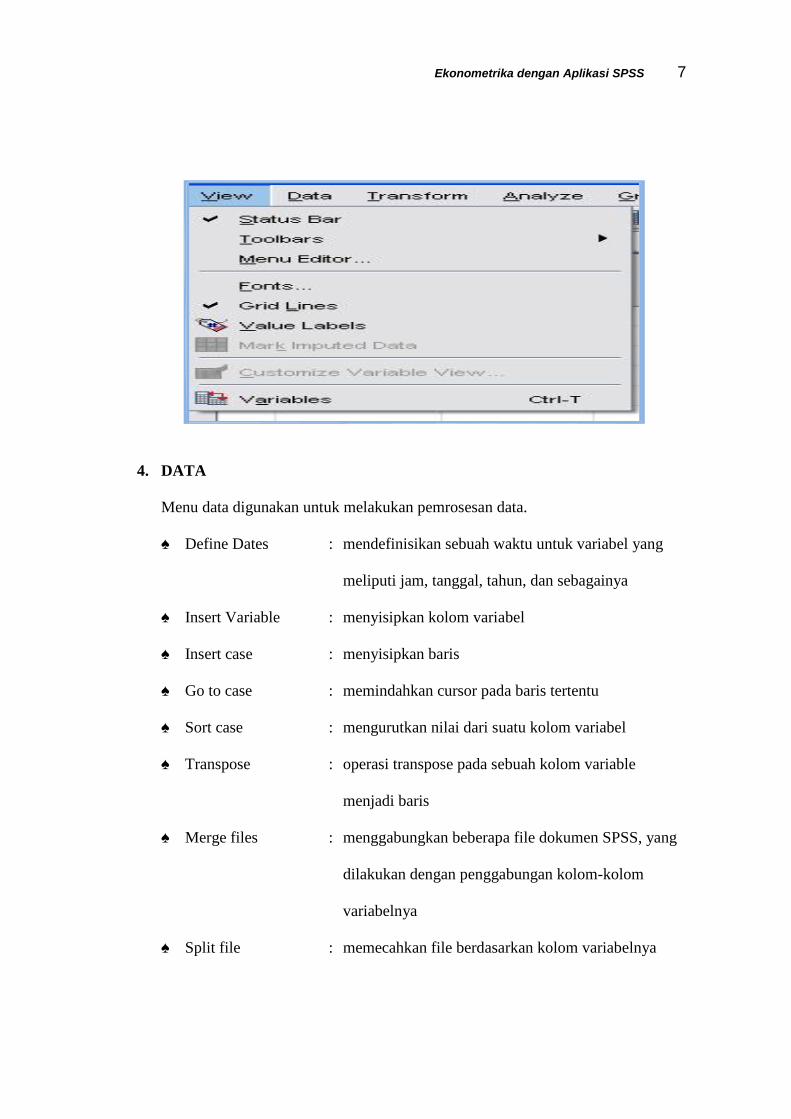
3. VIEW
Untuk pengaturan tambilan di layar kerja SPSS, serta mengetahu proses-prose
yang sedang terjadi pada operasi SPSS.
♠ Status Bar : mengetahui proses yang sedang berlangsung
♠ Toolbar : mengatur tampilan toolbar
♠ Fonts : untuk mengatur jenis, ukuran font pada data editor
SPSS
- Outline size : ukuran font lembar output SPSS
- Outline font : jenis font lembar output SPSS
♠ Gridlines : mengatur garis sel pada editor SPSS
♠ Value labels : mengatur tampilan pada editor untuk mengetahui
value label
Ekonometrika dengan Aplikasi SPSS 7
4. DATA
Menu data digunakan untuk melakukan pemrosesan data.
♠ Define Dates : mendefinisikan sebuah waktu untuk variabel yang
meliputi jam, tanggal, tahun, dan sebagainya
♠ Insert Variable : menyisipkan kolom variabel
♠ Insert case : menyisipkan baris
♠ Go to case : memindahkan cursor pada baris tertentu
♠ Sort case : mengurutkan nilai dari suatu kolom variabel
♠ Transpose : operasi transpose pada sebuah kolom variable
menjadi baris
♠ Merge files : menggabungkan beberapa file dokumen SPSS, yang
dilakukan dengan penggabungan kolom-kolom
variabelnya
♠ Split file : memecahkan file berdasarkan kolom variabelnya

Ekonometrika dengan Aplikasi SPSS 8
♠ Select case : mengatur sebuah variabel berdasarkan sebuah
persyaratan tertentu
5. TRANSFORM
Menu transform dipergunakan untuk melakukan perubahan-perubahan atau
penambahan data.
♠ Compute : operasi aritmatika dan logika untuk manipulasi
♠ Count : untuk mengetahui jumlah sebuah ukuran data tertentu
pada suatu baris tertentu
♠ Recode : untuk mengganti nilai pada kolom variabel tertentu,
sifatnya menggantikan (into same variable) atau
merubah (into different variable) pada variabel baru
♠ Categorize variable : merubah angka rasional menjadi diskrit
♠ Rank case : mengurutkan nilai data sebuah variabel
Ekonometrika dengan Aplikasi SPSS 9
6. ANALYZE
Menu analyze digunakan untuk melakukan analisis data yang telah kita masukkan
ke dalam komputer. Menu ini merupakan menu yang terpenting karena semua
pemrosesan dan analisis data dilakukan dengan menggunakan menu compare
mens, correlate, regression, dan lain-lain.
7. GRAPH
Menu graph digunakan untuk membuat grafik, diantaranya ialah bar, line, pie,
dan lain-lain.
8. UTILITIES
Menu utilities dipergunakan untuk mengetahui informasi variabel, informasi file,
dan lain-lain.

Ekonometrika dengan Aplikasi SPSS 10
9. ADD-ONS
Menu add-ons digunakan untuk memberikan perintah kepada SPSS jika ingin
menggunakan aplikasi tambahan, misalnya menggunakan aplikasi AMOS, SPSS
data entry, text analysis, dan sebagainya.
10. WINDOWS
Menu windows digunakan untuk melakukan perpindahan (switch) dari satu file ke
file lainnya.
11. HELP
Menu help digunakan untuk membantu pengguna dalam memahami perintah-
perintah SPSS jika menemui kesulitan.
TOOL BAR : Kumpulan perintah-perintah yang sering digunakan dalam
bentuk gambar.
POINTER : Kursor yang menunjukkan posisi cell yang sedang aktif/
dipilih.

Ekonometrika dengan Aplikasi SPSS 11
PEMBUATAN FILE DATA SPSS
Menu File merupakan menu pertama dari Data Editor yang dibuka oleh para
pengguna SPSS. Dimana Data Editor pada SPSS mempunyai dua bagian utama :
1. Kolom, dengan ciri adanya kata var dalam setiap kolomnya. Kolom dalam SPSS
akan diisi oleh variabel.
2. Baris, dengan ciri adanya angka 1, 2, 3 dan seterusnya. Baris dalam SPSS akan diisi
oleh data.
Contoh : Berikut ini data barang di gudang, 10 barang diambil secara acak(angka dalam rupiah)
No Barang Harga Pokok/Unit Stock di Gudang
1. Buku Tulis 3000 5240
2. Tas Punggung 80000 40000
3. Dompet 45000 22000
4. Jam Tangan 70000 2500
5. Spidol 7000 7800
6. Kertas File 30000 25000
7. Gunting 70000 7800
8. Tempat CD 45000 5200
9. Pensil Zebra 17000 22000
10. Penggaris 5000 10500
Langkah-langkah Input Data :
1. Membuat Variabel
Klik variable view pada pojok kiri bawah, kemudian isikan :
● Nama Variabel beserta keterangan yang diinginkan tentang variabel tersebut.
Misal : Barang, Harga, Stock

Ekonometrika dengan Aplikasi SPSS 12
Hal yang perlu diperhatikan saat mengisi nama variabel adalah :
- Nama variabel harus diawali huruf dan tidak boleh diakhiri dengan tanda titik.
- Panjang maksimal 8 karakter.
- Tidak boleh ada yang sama, dengan tidak membedakan huruf kecil atau besar.
● Type, Width dan Decimal Variabel
- Default dari type setiap variabel baru adalah numeric, lebar 8 karakter sesuai
dengan desimal sebanyak 2 digit.
- Untuk mengubah tipe variabel dilakukan dengan cara mengklik tombol pilihan
pada kolom Type.
- Ada 8 tipe variabel, yaitu :
a. Numeric : angka, tanda (+) atau (-) didepan angka, indicator desimal
b. Comma : angka, tanda (+) atau (-) didepan angka, indicator desimal,
tanda koma sebagai pemisah bilangan ribuan
c. Dot : angka, tanda (+) atau (-) didepan angka, indicator desimal,
tanda titik sebagai pemisah bilangan ribuan
d. Scientific notation : sama dengan tipe numeric, tetapi menggunakan
symbol E untuk kelipatan 10 (misal 120000 = 1.20E+5)
e. Date : menampilkan data format tanggal atau waktu
f. Dollar : memberi tanda dollar ($), tanda koma sebagai pemisah
bilangan ribuan dan tanda titik sebagai desimal
g. Custom currency : untuk format mata uang
h. String : biasanya huruf atau karakter lainnya

Ekonometrika dengan Aplikasi SPSS 13
2. Mengisi Data
Memasukkan data pada Data Editor dilakukan dengan cara mengetik data yang
akan dianalisa pada sel-sel (case) di bawah judul (heading) kolom nama variabel.
3. Menyimpan Data
Setelah data dimasukkan, maka data perlu disimpan untuk kepeluan analisa
selanjutnya. Langkah penyimpanan data adalah sebagai berikut :
Klik Menu File ===> Save As ===> (Pilih folder penyimpanan), ketik Nama File
===> Klik OK.

Ekonometrika dengan Aplikasi SPSS 14
Membuka File Data SPSS
Data yang telah Anda buat dan simpan sewaktu-waktu dapat Anda buka untuk
analisis lebih lanjut. Berikut cara membuka data :
Klik File ===> Open ===> Data sehingga kotak dialog Open File akan muncul.
Cari folder file data pada daftar drop down Look in.
Klik ganda file data pada kotak atau klik file data kemudian klik Open sehingga
data yang telah Anda simpan akan muncul.
Mengimpor File Data Excel ke SPSS
Langkah-langkah transfer file data Excel ke SPSS mirip dengan saat Anda membuka file
data format SPSS (*.sav) :
Klik File ===> Open ===> Data sehingga kotak dialog Open File akan muncul.
Cari folder file data Anda pada daftar drop down Look in.
Klik Files of type di combo box sehingga muncul daftar berikut :

Ekonometrika dengan Aplikasi SPSS 15
Pilih format yang sesuai, misal Excel (*.xls).
Cari folder file data Excel Anda pada daftar drop down Look in.
Klik ganda file data pada kotak atau klik file data kemudian klik Open sehingga
kotak dialog Opening Excel Data Source muncul.

Ekonometrika dengan Aplikasi SPSS 16
Tanda cek akan aktif secara default. Tanda cek Read variable names from the
first row of data aktif dimaksudkan supaya nama variabel yang terdapat pada
baris pertama file data Excel tidak dianggap sebagai data, namun sebagai
variabel.
Klik OK.

Ekonometrika dengan Aplikasi SPSS 17
MODEL REGRESI LINIER SEDERHANA
Model regresi liner merupakan suatu model yang parameternya linier (bisa
saja fungsinya tidak berbentuk garus lurus), dan secara kuantitatif dapat digunakan
untuk menganalisis pengaruh suatu variabel terhadap variabel lainnya. Analisis
regresi menyangkut studi tentang hubungan antara satu variabel Y yang disebut
variabel tak bebas atau variabel yang dijelaskan (dependend variable) dan satu atau
lebih variabel X1, X2, …., Xk, yang disebut variabel bebas atau variabel penjelas
(independent variable).
Persamaan regresi yang hanya terdiri dari satu variabel bebas, maka model
tersebut dikenal dengan sebutan regresi linier sederhana (simple regression).
Sedangkan jika dalam persamaan regresi terdapat lebih dari satu variabel bebas, maka
model yang diperoleh disebut dengan regresi linier berganda (multiple regression).
Perhatian utama regresi pada dasarnya adalah menjelaskan dan mengevaluasi
hubungan antara suatu variabel dependen dengan satu atau lebih variabel independen.
Kita akan memberi ilustrasi tentang regresi sederhana yang terdiri dari satu variabel
independen. Sebagai contoh, diberikan ilustrasi sebagai berikut: menurut model
pendekatan tradisional (traditional approach) yang dikemukakan oleh Dornbusch
(2000), bahwa perubahan harga saham dipengaruhi oleh nilai tukar. Misalkan jika
nilai tukar rupiah terhadap dollar Amerika Serikat mengalami apresiasi (dollar AS
depresiasi) maka harga saham di Bursa Efek Indonesia mengalami penguatan, dan
seblaiknya jika nilai tukar rupiah terhadap dollar AS mengalami depresiasi (dollar AS
apresiasi) maka harga saham di Bursa Efek Indonesia mengalami penurunan dengan
asumsi variabel selain harga tetap.

Ekonometrika dengan Aplikasi SPSS 18
Kita asumsikan terdapat hubungan yang linier antara harga saham dan nilai
tukar. Hubungan keduannya tidak harus linier, namun untuk penyederhanaan kita
asumsikan linier. Hubungan linier kedua dapat kita tulis dalam persamaan regresi
berikut :
Yi = a + b Xi + ei
Dalam persamaan tersebut variabel Y yaitu jumlah permintaan barang
(harga saham) disebut variabel dependen (dependent variable) sedangkan variabel X
yaitu harga barang (nilai tukar) disebut sebagai variabel independen (independent
variable). Jumlah permintaan barang aktual tidak harus sama dengan nilai harapannya.
Ada banyak faktor yang mempengaruhi jumlah permintaan barang selain harga.
Dimana ei adalah variabel gangguan (disturbance/errors terms) yang nilainya bisa
positif atau negatif.
Variabel gangguan ini muncul karena hubungan variabel ekonomi adalah
hubungan yang acak atau random tidak seperti hubungan variabel dalam matematika
yang bersifat deterministik. Pada tingkat harga yang sama, jumlah barang yang dibeli
konsumen akan berbeda. Hal ini terjadi karena ada faktor selain harga yang juga bisa
mempengaruhi permintaan barang, misalnya selera konsumen. Dengan demikian,
variabel gangguan mencerminkan faktor-faktor selain harga (nilai tukar) yang
mempengaruhi jumlah permintaan konsumen tetapi tidak dimasukan dalam persamaan.
Oleh karen itu, variabel dependen Y adalah variabel random (random
variable) atau stokastik (stochastic variable) yang besar kecilnya tergantung dari
variabel independen X. Variabel independen X adalah variabel tetap atau non-
stochastic, sedangkan variabel ei adalah variabel random atau stokastik.

Ekonometrika dengan Aplikasi SPSS 19
Pendugaan Parameter (bo) dan (b1)
Untuk menduga nilai parameter 0 dan 1 terdapat bermacam-macam metode,
misalnya metode kuadrat terkecil (least square method), metode kemungkinan
maksimum (maximum likelihood method), metode kuadrat terkecil terboboti (weighted
least square method), dan sebagainya.
Contoh :
Data tentang hubungan antara nilai penjualan produk (Y) dengan biaya promosi (X)
sebagai berikut.
B_Promosi N_Sales23 10024 12034 13536 20034 25037 25538 26039 26845 27048 30049 34050 37060 38080 39086 40089 40590 46995 50096 55498 55698 576
Langkah-langkah untuk melakukan Analisis Regresi
a. Buka lembar kerja baru, dengan meng-klik menu File lalu pilih New kemudian klik
Data akan muncul tampilan layar Data Editor.

Ekonometrika dengan Aplikasi SPSS 20
b. Definisikan variabel yang akan digunakan di tab sheet Variable View yang ada di
bagian kiri bawah, dengan cara klik Variable View kemudian isi nama variabelnya,
ketik B_Promosi lalu tekan ENTER dan ketik N_Sales lalu tekan ENTER.
c. Selanjutnya klik Data View pada pojok kiri bawah dan masukkan data contoh di atas
pada kolom variabel masing-masing data. Hasilnya seperti pada tampilan berikut.
d. Simpan data Anda dengan cara meng-klik menu File lalu pilih Save As dan tulis
nama filenya, misalnya regresi sederhana.
e. Lakukan analisis regresi linier sederhana dengan cara, klik menu Analyze ===>
pilih submenu Regression ===> lalu klik Linear, pada layar akan muncul tampilan
berikut.

Ekonometrika dengan Aplikasi SPSS 21
f. Masukkan variabel N_Sales pada kotak sebelah kiri ke kotak Dependent, dan
variabel B_Promosi ke kotak Independent(s) dengan mengklik tombol tanda
panah, seperti tampak pada tampilan berikut.
g. Kemudian klik OK, hasilnya seperti pada tampilan berikut.

Ekonometrika dengan Aplikasi SPSS 22
h. Hasil output SPSS sebagai berikut.
Koefisien Determinasi (r2)
Model Summary
,943 a ,889 ,883 48,609Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), B_Promosia.
Berdasarkan tampilan output SPSS model summary besarnya R2 adalah 0,889
artinya 88,9% perubahan/variasi nilai variabel dependen (N_Sales) dapat
dijelaskan oleh variasi dari variabel independen (B_Promosi), dan sisanya
(100% - 88,9% = 11,1%) dijelaskan oleh sebab-sebab yang lain di luar model.

Ekonometrika dengan Aplikasi SPSS 23
Uji Signifikansi Serentak (Uji-F)
ANOVAb
359270,2 1 359270,247 152,051 ,000a
44893,753 19 2362,829404164,0 20
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), B_Promosia.
Dependent Variable: N_Salesb.
Berdasarkan uji ANOVA atau F-test didapat nilai F-hitung sebesar 152,051
dengan probabilitas 0,000; karena probabilitas jauh lebih kecil dari α = 0,05 maka
model regresi dapat digunakan untuk memprediksi nilai penjualan (N_Sales).
Uji Signifikansi Parsial (Uji-t)
Untuk menginterpretasikan koefisien variabel bebas (independen) dapat
menggunakan unstandardized coefficients maupun standardized coefficients.
Coefficientsa
45,528 25,983 1,752 ,0964,917 ,399 ,943 12,331 ,000
(Constant)B_Promosi
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: N_Salesa.
Hipotesis Uji
Ho : koefisien regresi tidak signifikan (β = 0)
H1 : koefisien regresi signifikan (β ≠ 0)
Ekonometrika dengan Aplikasi SPSS 24
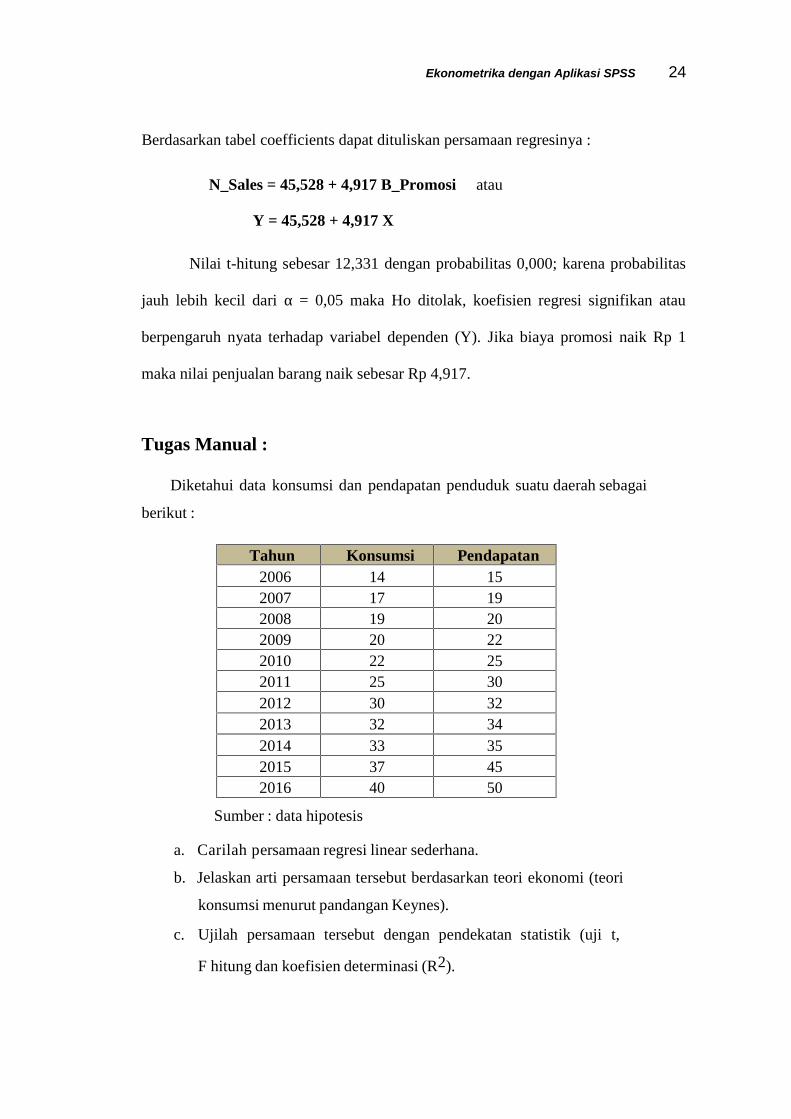
Berdasarkan tabel coefficients dapat dituliskan persamaan regresinya :
N_Sales = 45,528 + 4,917 B_Promosi atau
Y = 45,528 + 4,917 X
Nilai t-hitung sebesar 12,331 dengan probabilitas 0,000; karena probabilitas
jauh lebih kecil dari α = 0,05 maka Ho ditolak, koefisien regresi signifikan atau
berpengaruh nyata terhadap variabel dependen (Y). Jika biaya promosi naik Rp 1
maka nilai penjualan barang naik sebesar Rp 4,917.
Tugas Manual :
Diketahui data konsumsi dan pendapatan penduduk suatu daerah sebagai
berikut :
Tahun Konsumsi Pendapatan2006 14 152007 17 192008 19 202009 20 222010 22 252011 25 302012 30 322013 32 342014 33 352015 37 452016 40 50
Sumber : data hipotesis
a. Carilah persamaan regresi linear sederhana.
b. Jelaskan arti persamaan tersebut berdasarkan teori ekonomi (teori
konsumsi menurut pandangan Keynes).
c. Ujilah persamaan tersebut dengan pendekatan statistik (uji t,
F hitung dan koefisien determinasi (R2).

Ekonometrika dengan Aplikasi SPSS 25
MODEL REGRESI LINIER BERGANDA
Regresi linear ganda adalah persamaan regresi yang menggambarkan hubungan
antara lebih dari satu peubah bebas (X) dan satu peubah tak bebas (Y). Hubungan
peubah-peubah tersebut dapat dituliskan dalam bentuk persamaan:
Yi = βo + β1Xi1 + β2Xi2 + .... ...... + βkXik + i
Y = Peubah tak bebas, X = Peubah bebas, 0 = intersep/perpotongan dengan sumbu
tegak, 1, 2, ...., k = parameter model regresi, i saling bebas dan menyebar normal
N(0,2), dimana i = 1, 2, …, n
Persamaan regresi dugaannya adalah :
^Yi = bo + b1Xi1 + b2Xi2 + ………… + bkXik
Hipotesis yang harus diuji dalam analisis regresi ganda adalah
H0 : 1 = 2 = … = k = 0
H1 : Tidak semua i (i = 1, 2, …, k) sama dengan nol
Untuk melakukan pendugaan parameter model regresi ganda dan menguji
signifikansinya dapat dilakukan dengan program SPSS 17.
Contoh :
Data hipotetis tentang pengaruh pendapatan konsumen (X1), harga barang itu
sendiri (X2), dan harga barang substitusi (X3) terhadap permintaan suatu barang (Y) sbb:

Ekonometrika dengan Aplikasi SPSS 26
No Y X1 X2 X3
1 6,90 2,35 2,20 3,84
2 14,40 3,07 2,31 4,03
3 7,40 2,12 2,17 4,00
4 8,50 3,65 3,16 3,18
5 8,00 2,18 2,10 4,08
6 2,80 2,35 2,67 4,13
7 5,00 2,85 2,74 3,81
8 12,20 2,05 1,90 5,08
9 10,00 2,67 2,36 3,22
10 15,20 3,00 2,20 3,84
11 26,80 3,67 2,31 4,03
12 14,00 3,51 2,84 3,22
13 14,70 3,70 3,16 3,18
14 16,40 2,75 2,67 4,13
15 17,60 3,65 2,74 3,81
16 22,30 2,75 1,90 4,13
17 24,80 3,60 2,36 3,81
18 26,00 3,65 2,30 5,08
19 34,90 3,95 2,31 3,22
20 18,20 2,72 2,17 3,84
Langkah-langkah untuk melakukan Analisis Regresi
a. Buka lembar kerja baru, dengan meng-klik menu File lalu pilih New kemudian klik
Data akan muncul tampilan layar Data Editor.
b. Definisikan variabel yang akan digunakan di tab sheet Variable View yang ada di
bagian kiri bawah, dengan cara klik Variable View kemudian isi nama variabelnya,
ketik Y lalu tekan ENTER, ketik X1 lalu tekan ENTER, ketik X2 lalu tekan
ENTER, dan ketik X3 lalu tekan ENTER.
c. Selanjutnya klik Data View dan masukkan data contoh di atas pada kolom variabel
masing-masing data. Hasilnya seperti pada tampilan berikut.
Ekonometrika dengan Aplikasi SPSS 27
d. Simpan data Anda dengan cara meng-klik menu File lalu pilih Save As dan tulis
nama filenya, misalnya regresi berganda.
e. Lakukan analisis regresi linier berganda dengan cara, klik menu Analyze ===> pilih
submenu Regression ===> lalu klik Linear.
f. Masukkan variabel Y pada kotak sebelah kiri ke kotak Dependent, dan variabel
X1, X2, X3 ke kotak Independent(s) dengan mengklik tombol tanda panah,
hasilnya seperti tampak pada tampilan berikut.

Ekonometrika dengan Aplikasi SPSS 28
g. Kemudian klik OK, hasil outputnya seperti pada tampilan berikut.
h. Hasil output SPSS sebagai berikut.
Koefisien Determinasi (R2)
Model Summary
,931a ,866 ,841 3,3227Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), X3, X1, X2a.
Berdasarkan tampilan output SPSS model summary besarnya R2 adalah 0,866
artinya 86,6% perubahan/variasi nilai variabel dependen (Y) dapat dijelaskan
oleh variasi dari semua variabel independen (X1, X2, dan X3), dan sisanya
(100% - 86,6% = 13,4%) dijelaskan oleh sebab-sebab yang lain di luar model.

Ekonometrika dengan Aplikasi SPSS 29
Uji Signifikansi Serentak (Uji-F)
ANOVAb
1143,821 3 381,274 34,534 ,000a
176,649 16 11,0411320,470 19
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), X3, X1, X2a.
Dependent Variable: Yb.
Berdasarkan uji ANOVA atau F-test didapat nilai F-hitung sebesar 34,534
dengan probabilitas 0,000; karena probabilitas jauh lebih kecil dari α = 0,05 maka
Ho ditolak. Artinya secara bersama-sama (serentak) semua variabel bebas (X1, X2,
dan X3) yang dimasukan dalam model berpengaruh nyata terhadap jumlah
permintaan barang (Y).
Uji Signifikansi Parsial (Uji-t)
Untuk menginterpretasikan koefisien variabel bebas (independen) dapat
menggunakan unstandardized coefficients maupun standardized coefficients.
Coefficientsa
9,591 11,816 ,812 ,42914,270 1,453 1,058 9,824 ,000
-16,733 2,743 -,731 -6,100 ,000,867 1,749 ,056 ,496 ,627
(Constant)X1X2X3
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: Ya.
Berdasarkan tabel coefficients diketahui nilai t-hitung untuk X1 sebesar
9,824 dengan probabilitas 0,000; karena probabilitas jauh lebih kecil dari α = 0,05
maka Ho ditolak, artinya koefisien regresi X1 signifikan atau berpengaruh nyata

Ekonometrika dengan Aplikasi SPSS 30
terhadap variabel dependen (Y). Nilai t-hitung untuk X2 sebesar -6,100 dengan
probabilitas 0,000; karena probabilitas jauh lebih kecil dari α = 0,05 maka Ho
ditolak, artinya koefisien regresi X2 signifikan atau berpengaruh nyata (negatif)
terhadap variabel dependen (Y). Nilai t-hitung untuk X3 sebesar 0,496 dengan
probabilitas 0,627; karena probabilitas jauh lebih besar dari α = 0,05 maka Ho
diterima, artinya koefisien regresi X3 tidak signifikan atau tidak berpengaruh nyata
terhadap variabel dependen (Y).
Berdasarkan tabel coefficients dapat dituliskan persamaan regresinya :
Y = 9,591 + 14,270 X1 – 16,733 X2 + 0,867 X3
Konstanta sebesar 9,591 menyatakan bahwa jika semua variabel independen
dianggap konstan (tetap), maka rata-rata jumlah permintaan barang sebesar
9,591 unit.
Koefisien regresi X1 sebesar 14,270 menyatakan bahwa jika variabel X1
(pendapatan konsumen) naik satu unit dan variabel lain dianggap konstan
(tetap), maka jumlah permintaan barang naik sebesar 14,270 unit.
Koefisien regresi X2 sebesar -16,733 menyatakan bahwa jika variabel X2 (harga
barang itu sendiri) naik satu unit dan variabel lain dianggap konstan (tetap),
maka jumlah permintaan barang turun sebesar 16,733 unit.
Koefisien regresi X3 sebesar 0,867 menyatakan bahwa jika variabel X3 (harga
barang substitusi) naik satu unit dan variabel lain dianggap konstan (tetap),
maka jumlah permintaan barang naik sebesar 0,867 unit.
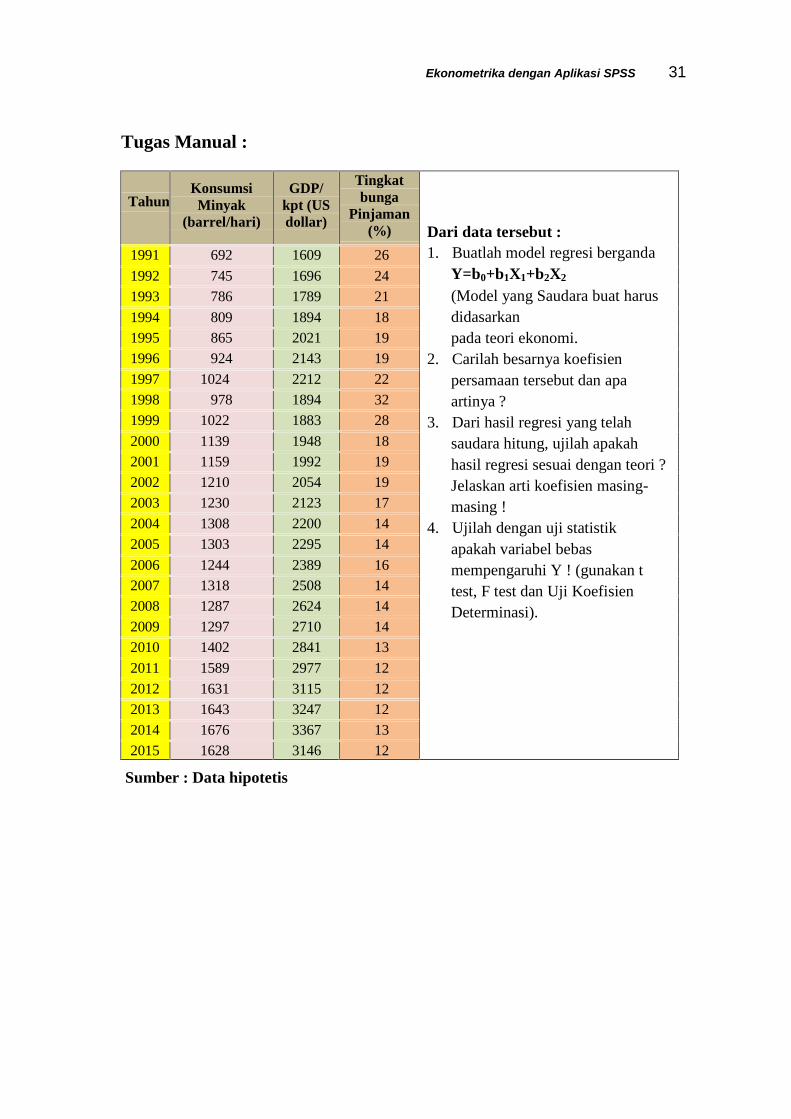
Ekonometrika dengan Aplikasi SPSS 31
Tugas Manual :
TahunKonsumsiMinyak
(barrel/hari)
GDP/kpt (USdollar)
Tingkatbunga
Pinjaman(%)(%)
Dari data tersebut :1. Buatlah model regresi berganda
Y=b0+b1X1+b2X2
(Model yang Saudara buat harusdidasarkanpada teori ekonomi.
2. Carilah besarnya koefisienpersamaan tersebut dan apaartinya ?
3. Dari hasil regresi yang telahsaudara hitung, ujilah apakahhasil regresi sesuai dengan teori ?Jelaskan arti koefisien masing-masing !
4. Ujilah dengan uji statistikapakah variabel bebasmempengaruhi Y ! (gunakan ttest, F test dan Uji KoefisienDeterminasi).
1991 692 1609 26
1992 745 1696 24
1993 786 1789 21
1994 809 1894 181995 865 2021 19
1996 924 2143 19
1997 1024 2212 22
1998 978 1894 32
1999 1022 1883 28
2000 1139 1948 182001 1159 1992 19
2002 1210 2054 19
2003 1230 2123 17
2004 1308 2200 14
2005 1303 2295 14
2006 1244 2389 162007 1318 2508 14
2008 1287 2624 14
2009 1297 2710 14
2010 1402 2841 13
2011 1589 2977 12
2012 1631 3115 12
2013 1643 3247 12
2014 1676 3367 13
2015 1628 3146 12
Sumber : Data hipotetis

Ekonometrika dengan Aplikasi SPSS 32
UJI ASUMSI KLASIK DALAM REGRESI
Model regresi linier berganda (multiple regression) dapat disebut sebagai model
yang baik jika model tersebut memenuhi kriteria BLUE (Best Linear Unbiased
Estimator). BLUE dapat dicapai bila memenuhi Asumsi Klasik. Sedikitnya terdapat
empat uji asumsi yang harus dilakukan terhadap suatu model regresi tersebut,
yaitu: Uji Normalitas, Uji Multikolinieritas, Uji Autokorelasi, dan Uji Heteroske-
dastisitas.
1. DATA
Data hipotetis tentang permintaan ayam ras (Y) di Kota Mataram selama periode
tahun 1991 – 2013 sebagai berikut.
Tahun Y X1 X2 X3 X41991 27.8 397.5 42.2 50.7 78.31992 29.9 413.3 38.1 52.0 79.21993 29.8 439.2 40.3 54.0 79.21994 30.8 459.7 39.5 55.3 79.21995 31.2 492.9 37.3 54.7 77.41996 33.3 528.6 38.1 63.7 80.21997 35.6 560.3 39.3 69.8 80.41998 36.4 624.6 37.8 65.9 83.91999 36.7 666.4 38.4 64.5 85.52000 38.4 717.8 40.1 70.0 93.72001 40.4 768.2 38.6 73.2 106.12002 40.3 843.3 39.8 67.8 104.82003 41.8 911.6 39.7 79.1 114.02004 40.4 931.1 52.1 95.4 124.12005 40.7 1021.5 48.9 94.2 127.62006 40.1 1165.9 58.3 123.5 142.92007 42.7 1349.6 57.9 129.9 143.62008 44.1 1449.4 56.5 117.6 139.2

Ekonometrika dengan Aplikasi SPSS 33
2009 46.7 1575.5 63.7 130.9 165.52010 50.6 1759.1 61.6 129.8 203.32011 50.1 1994.2 58.9 128.0 219.62012 51.7 2258.1 66.4 141.0 221.62013 52.9 2478.7 70.4 168.2 232.6
Keterangan : Y = konsumsi ayam ras per kapita
X1= pendapatan riil per kapita
X2 = harga ayam ras eceran riil per unit
X3 = harga kambing eceran riil per unit
X4 = harga sapi eceran riil per unit
Teori ekonomi mikro mengajarkan bahwa permintaan akan suatu barang
dipengaruhi oleh pendapatan konsumen, harga barang itu sendiri, harga barang
substitusi, dan harga barang komplementer.
2. UJI NORMALITAS
Salah satu asumsi model regresi adalah residual mempunyai distribusi normal.
Apa konsekuensinya jika model tidak mempunyai residual yang berdistribusi normal ?
Uji t dan F untuk melihat signifikansi variabel independen terhadap variabel dependen
tidak bisa diaplikasikan jika residual tidak mempunyai distribusi normal. Jadi, kalau
asumsi ini dilanggar maka uji statistik menjadi tidak valid untuk jumlah sampel kecil.
Uji normalitas hanya digunakan jika jumlah observasi kurang dari 30, untuk
mengetahui apakah residual (error term) mendekati distribusi normal. Jika jumlah
observasi lebih dari 30, maka tidak perlu dilakukan uji normalitas, sebab distribusi
sampling error term telah mendekati normal.
Cara yang sering digunakan dalam menentukan apakah suatu model
berdistribusi normal atau tidak hanya dengan melihat pada histogram residual apakah
memiliki bentuk seperti “lonceng” atau tidak. Cara ini menjadi fatal karena

Ekonometrika dengan Aplikasi SPSS 34
pengambilan keputusan data berdistribusi normal atau tidak hanya berpatokan pada
pengamatan gambar saja. Selain cara grafik, ada cara lain untuk menentukan data
berdistribusi normal atau tidak dengan menggunakan rasio skewness dan rasio kurtosis,
serta uji Kolmogorov-Smirnov.
Rasio skewness dan rasio kurtosis dapat dijadikan petunjuk apakah suatu data
berdistribusi normal atau tidak. Rasio skewness adalah nilai skewnes dibagi dengan
standard error skewness; sedang rasio kurtosis adalah nilai kurtosis dibagi dengan
standard error kurtosis. Sebagai pedoman, bila rasio kurtosis dan skewness berada di
antara –2 hingga +2, maka distribusi data adalah normal.
Langkah analisis dalam SPSS :
a. Ketik data permintaan ayam ras di atas pada lembar kerja Data Editor SPSS dan
simpan dengan nama Asumsi Klasik.
b. Lakukan regresi berganda dengan pilih Analyze ===> pilih submenu Regression
===> pilih Linear, akan muncul tampilan berikut.

Ekonometrika dengan Aplikasi SPSS 35
c. Masukkan variabel Y pada kotak sebelah kiri ke kotak Dependent, dan variabel
X1, X2, X3 dan X4 ke kotak Independent(s) dengan mengklik tombol tanda
panah. Kemudian pilih Save dan muncul tampilan berikut.
d. Centang pilihan Unstandardized pada bagian Residuals, kemudian pilih Continue
dan pada tampilan awal pilih tombol OK, akan menghasilkan variabel baru
bernama Unstandardized Residual (RES_1). Selanjutnya Analyze ====> pilih
Descriptive Statistics ====> Descriptives akan muncul tampilan berikut.
Ekonometrika dengan Aplikasi SPSS 36
e. Masukkan variabel Unstandardized Residual (RES_1) ke kotak sebelah kiri,
selanjutnya pilih Options akan muncul tampilan berikut.

Ekonometrika dengan Aplikasi SPSS 37
f. Centang pilihan Kurtosis dan Skewness dan kemudian k l i k Continue dan
pada tampilan awal pilih OK. Hasilnya sebagai berikut (beberapa bagian dipotong
untuk menghemat tempat).
Descriptive Statistics
23 -3,26458 3,03053,00000001,766734 ,105 ,481 -1,002 ,93523
Unstandardized ResidualValid N (listwise)
Statistic Statistic Statistic Statistic Statistic Statistic Std. ErrorStatistic Std. ErrorN MinimumMaximum Mean Std.
DeviationSkewness Kurtosis
Berdasarkan tabel Descriptive Statistics dapat dihitung rasio skewness =
0,105/0,481 = 0,218; sedang rasio kurtosis = -1,002/0,935 = -1,071. Karena rasio
skewness dan rasio kurtosis berada di antara –2 hingga +2, maka dapat
disimpulkan bahwa distribusi data adalah normal.
Uji statistik lain yang dapat digunakan untuk menguji normalitas residual adalah uji
statistik non-parametrik Kolmogorov-Smirnov (K - S). Uji K - S dilakukan dengan
membuat hipotesis.
Ho : data residual berdistribusi normal
H1 : data residual tidak berdistribusi normal
Langkah Analisis :
a. Dari menu utama SPSS pilih menu Analyze, lalu pilih Nonparametrik Tests.
b. Kemudian pilih submenu 1-Sample K-S, di layar akan tampak tampilan windwos
One-sample Kolmogorov-Smirnov test.
Ekonometrika dengan Aplikasi SPSS 38
c. Pada kotak test variable list, isikan unstandardized residual (RES_1), dan aktifkan
test Distribution pada kotak Normal.
d. Pilih OK.
e. Output SPSS sebagai berikut.

Ekonometrika dengan Aplikasi SPSS 39
One-Sample Kolmogorov-Smirnov Test
23,0000000
1,76673414,163,163-,097,780,577
NMeanStd. Deviation
Normal Parametersa,b
AbsolutePositiveNegative
Most ExtremeDifferences
Kolmogorov-Smirnov ZAsymp. Sig. (2-tailed)
Unstandardized Residual
Test distribution is Normal.a.
Calculated from data.b.
Besarnya nilai Kolmogorov-Smirnov adalah 0,780 dan signifikan sebesar 0,577
lebih besar dari α = 0,05. Hal ini berarti Ho diterima yang berarti data residual
berdistribusi normal (hasilnya konsisten dengan uji sebelumnya).
3. MULTIKOLINIERITAS
Uji multikolinieritas bertujuan untuk menguji apakah model regresi ditemukan
adanya korelasi antar variabel bebas (independen). Model regresi yang baik seharusnya
tidak terjadi korelasi di antara variabel independen. Untuk mendeteksi ada atau tidaknya
multikolinieritas di dalam model regresi sebagai berikut :
a. Nilai R2 yang dihasilkan oleh suatu estimasi model regresi empiris sangat tinggi,
tetapi secara individual variabel independen banyak yang tidak signifikan
mempengaruhi variabel dependen.
b. Menganalisis matrik korelasi variabel-variabel independen. Jika antar variabel
independen ada korelasi yang cukup tinggi (umumnya > 0,70) maka hal ini
merupakan indikasi adanya multikolinieritas.

Ekonometrika dengan Aplikasi SPSS 40
c. Melihat nilai tolerance dan variance inflation factor (VIF). Kedua ukuran ini
menunjukkan setiap variabel independen manakah yang dijelaskan oleh variabel
independen lainnya. Tolerance mengukur variabilitas variabel independen yang
terpilih yang tidak dijelaskan oleh variabel independen lainnya. Jadi nilai tolerance
yang rendah sama dengan nilai VIF yang tinggi (karena VIF = 1/Tolerance). Jika
nilai tolerance < 0,10 atau sama dengan nilai VIF > 10 menunjukkan adanya gejala
multikolinieritas.
Berikut ini disajikan cara mendeteksi gejala multikolinieritas dengan menganalisis
matrik korelasi antar variabel independen dan perhitungan nilai tolerance dan VIF.
Langkah Analisis :
a. Buka file data Asumsi Klasik.sav
b. Dari menu utama SPSS, pilih menu Analyze, kemudian submenu Regression, lalu
pilih Linear.
c. Tampak di layar windows Linear Regression.
d. Pada kotak Dependent isikan variabel Y.
e. Pada kotak Independent isikan variabel X1, X2, X3, dan X4.
f. Pada kotak method, pilih Entar.
g. Untuk menampilkan matrik korelasi dan nilai Tolerance dan VIF, pilih Statistics di
layar akan muncul tampilan windows Linear Regression Statistics.
h. Aktifkan/centang pilihan Covariance matrix dan Collinierity Diagnostics.

Ekonometrika dengan Aplikasi SPSS 41
i. Tekan tombol Continue, abaikan yang lain dan tekan OK.
j. Tampilan output SPSS sebagai berikut.
Model Summary
,971a ,943 ,930 1,9532Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), X4, X2, X3, X1a.
ANOVAb
1127,259 4 281,815 73,871 ,000a
68,670 18 3,8151195,929 22
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), X4, X2, X3, X1a.
Dependent Variable: Yb.
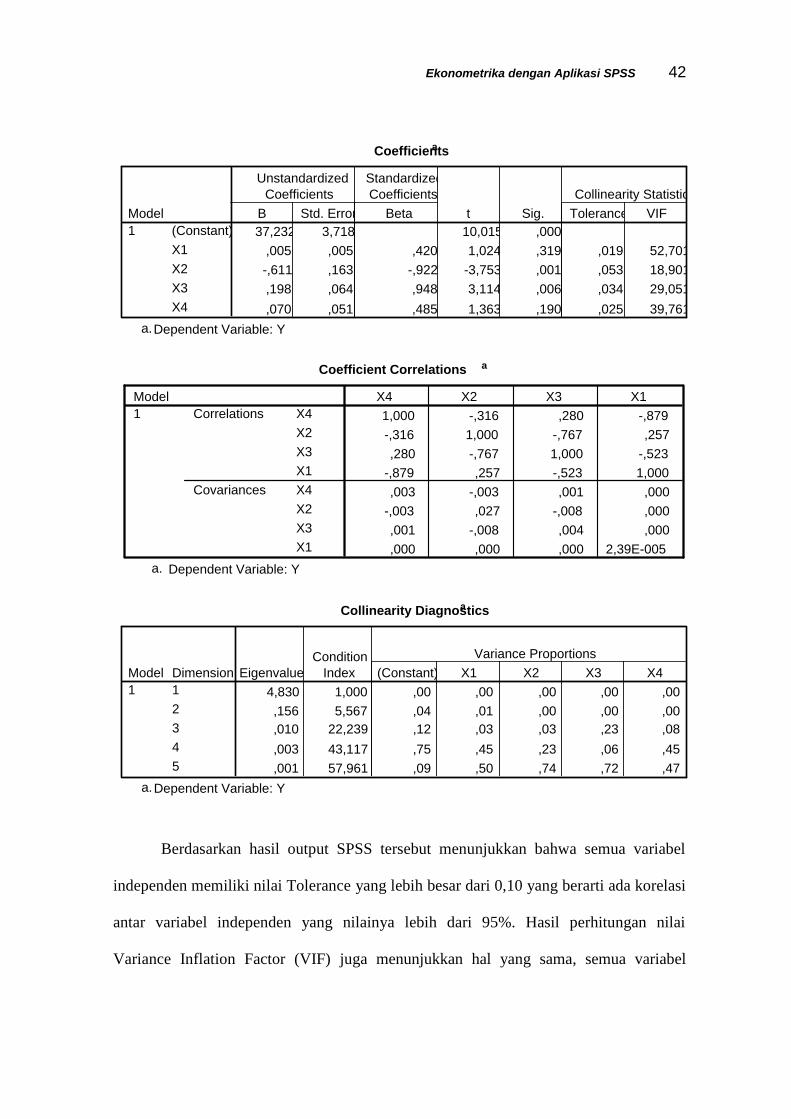
Ekonometrika dengan Aplikasi SPSS 42
Coefficientsa
37,232 3,718 10,015 ,000,005 ,005 ,420 1,024 ,319 ,019 52,701-,611 ,163 -,922 -3,753 ,001 ,053 18,901,198 ,064 ,948 3,114 ,006 ,034 29,051,070 ,051 ,485 1,363 ,190 ,025 39,761
(Constant)X1X2X3X4
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig. Tolerance VIFCollinearity Statistics
Dependent Variable: Ya.
Coefficient Correlations a
1,000 -,316 ,280 -,879-,316 1,000 -,767 ,257,280 -,767 1,000 -,523
-,879 ,257 -,523 1,000,003 -,003 ,001 ,000
-,003 ,027 -,008 ,000,001 -,008 ,004 ,000,000 ,000 ,000 2,39E-005
X4X2X3X1X4X2X3X1
Correlations
Covariances
Model1
X4 X2 X3 X1
Dependent Variable: Ya.
Collinearity Diagnosticsa
4,830 1,000 ,00 ,00 ,00 ,00 ,00,156 5,567 ,04 ,01 ,00 ,00 ,00,010 22,239 ,12 ,03 ,03 ,23 ,08,003 43,117 ,75 ,45 ,23 ,06 ,45,001 57,961 ,09 ,50 ,74 ,72 ,47
Dimension12345
Model1
EigenvalueCondition
Index (Constant) X1 X2 X3 X4Variance Proportions
Dependent Variable: Ya.
Berdasarkan hasil output SPSS tersebut menunjukkan bahwa semua variabel
independen memiliki nilai Tolerance yang lebih besar dari 0,10 yang berarti ada korelasi
antar variabel independen yang nilainya lebih dari 95%. Hasil perhitungan nilai
Variance Inflation Factor (VIF) juga menunjukkan hal yang sama, semua variabel

Ekonometrika dengan Aplikasi SPSS 43
independen memiliki nilai VIF lebih besar dari 10. Jadi dapat disimpulkan bahwa ada
gejala multikolinieritas antar variabel independen dalam model regresi.
Melihat hasil besaran korelasi antar variabel independen tampak bahwa variabel
X1 mempunyai korelasi sangat tinggi dengan variabel X4 sebesar -0,879, demikian juga
antara variabel X2 dengan X3 dengan korelasi -0,767 dimana kedua nilai korelasi ini
lebih besar dari 0,70. Jadi dapat disimpulkan bahwa terdapat gejala multikolinieritas yang
serius antar variabel independen dalam model regresi.
4. AUTOKORELASI
Uji autokorelasi bertujuan untuk menguji apakah dalam model regresi linier ada
korelasi antara kesalahan pengganggu pada periode t dengan kesalahan pengganggu
pada periode t-1 (sebelumnya). Jika terjadi korelasi, maka dinamakan terdapat problem
autokorelasi. Autokorelasi muncul karena observasi yang berurutan sepanjang waktu
berkaitan satu sama lainnya. Masalah ini timbul karena residual (kesalahan
pengganggu) tidak bebas dari satu observasi ke observasi lainnya. Hal ini sering
ditemukan pada data runtut waktu (time series) karena “gangguan” pada seseorang
individu/kelompok cenderung mempengaruhi “gangguan” pada individu/kelompok
yang sama pada periode berikutnya.
Pada data cross section (silang waktu), masalah autokorelasi relatif jarang
terjadi karena “gangguan” pada observasi yang berbeda berasal dari individu/kelompok
yang berbeda. Model regresi yang baik adalah regresi yang bebas dari autokorelasi.
Ada beberapa cara yang dapat digunakan untuk mendeteksi ada atau tidaknya
autokorelasi. Pertama, Uji Durbin-Watson (DW Test). Uji ini hanya digunakan untuk
autokorelasi tingkat satu (first order autocorrelation) dan mensyaratkan adanya

Ekonometrika dengan Aplikasi SPSS 44
intercept (konstanta) dalam model regresi dan tidak ada variabel lag di antara variabel
penjelas (independen).
Hipotesis yang diuji adalah:
Ho : p = 0 (tidak ada autokorelasi positif atau negatif)
H1 : p ≠ 0 (ada autokorelasi positif atau negatif)
Langkah Analisis :
a. Buka file data Asumsi Klasik.sav
b. Dari menu utama SPSS, pilih menu Analyze, kemudian submenu Regression, lalu
pilih Linear.
c. Tampak di layar windows Linear Regression.
d. Pada kotak Dependent isikan variabel Y.
e. Pada kotak Independent isikan variabel X1, X2, X3, dan X4.
f. Untuk menampilkan nilai Durbin-Watson, pilih Statistics di layar akan muncul
tampilan windows Linear Regression Statistics.
g. Aktifkan/centang pilihan Durbin-Watson.

Ekonometrika dengan Aplikasi SPSS 45
h. Tekan tombol Continue, abaikan yang lain dan tekan OK.
i. Tampilan output SPSS sebagai berikut, sebagian hasilnya dihilangkan.
Model Summaryb
,971a ,943 ,930 1,9532 1,065Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Durbin-Watson
Predictors: (Constant), X4, X2, X3, X1a.
Dependent Variable: Yb.
Nilai Durbin-Watson sebesar 1,065 dan nilai ini akan dibandingkan dengan nilai
DW tabel. Langkah selanjutnya adalah menetapkan nilai dl dan du, dengan cara
menggunakan α=5%, sampel (n) yang kita miliki sebanyak 23 observasi, dan variabel
independen sebanyak 4, maka didapatkan nilai dl = 1,078 dan du = 1,660. Jadi nilai DW
lebih kecil dari nilai dl (1,065 < 1,078) sehingga dapat disimpulkan bahwa model ini
memiliki gejala autokorelasi positif.
5. HETEROSKEDASTISITAS
Uji heteroskedastisitas bertujuan menguji apakah dalam model regresi terjadi
ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang lain. Jika
variance dari residual satu pengamatan ke pengamatan yang lain tetap, maka disebut

Ekonometrika dengan Aplikasi SPSS 46
homoskedastisitas dan jika berbeda disebut heteroskedastisitas. Model regresi yang baik
adalah yang homoskedastisitas atau tidak terjadi heteroskedastisitas. Kebanyakan data
cross section mengandung situasi heteroskedastisitas karena data ini menghimpun data
yang mewakili berbagai ukuran (kecil, sedang dan besar).
Banyak metoda statistik yang dapat digunakan untuk menentukan apakah suatu
model regresi terbebas dari masalah heteroskedastisitas atau tidak, seperti Uji White, Uji
Park, Uji Glejser, dan lain-lain. Modul ini akan memperkenalkan salah satu uji
heteroskedastisitas yang mudah dan dapat diaplikasikan dengan SPSS, yaitu Uji Glejser.
Uji Glejser dilakukan dengan cara meregresikan nilai absolut residual terhadap
variabel independen, dengan persamaan regresi sebagai berikut:
| ei | = bo + bi Xi + v
Dimana :
| ei | = nilai absolut dari residual yang dihasilkan oleh regresi model
Xi = Variabel independen
Jika variabel independen secara statistik signifikan mempengaruhi variabel
dependen (residual) maka ada indikasi dalam model terjadi masalah heteroskedastisitas.
Langkah Uji Glejser dengan SPSS
a. Buka file data Asumsi Klasik.sav
b. Lakukan regresi dari menu utama SPSS, pilih menu Analyze, kemudian submenu
Regression, lalu pilih Linear.
c. Tampak di layar windows Linear Regression.
d. Pada kotak Dependent isikan variabel Y.
e. Pada kotak Independent isikan variabel X1, X2, X3, dan X4.

Ekonometrika dengan Aplikasi SPSS 47
f. Dapatkan variabel residual (ei), pilih tombol Save pada tampilan windows Linear
Regression Statistics.
g. Aktifkan/centang pilihan Unstandardized residual.
h. Tekan tombol Continue, abaikan yang lain dan tekan OK.
i. Hasilnya, kita memiliki variabel baru Unstandardized Residual (RES_1).
j. Selanjutnya absolutkan nilai residual (RES_1) dengan menu Transform
dan Compute variable.
k. Pada kotak Target Variable ketik Abresid, pada kotak Function group pilih All
dan di bawahnya akan muncul beberapa pilihan fungsi, pilihlah Abs. Kemudian klik
pada tombol tanda panah arah ke atas, dan masukkan variabel Unstandardized
Residual (RES_1) ke dalam kotak Numeric Expression dengan klik tombol tanda
panah arah ke kanan dan tampilannya seperti berikut.

Ekonometrika dengan Aplikasi SPSS 48
l. Tekan tombol OK.
m. Lakukan regresi dari menu utama SPSS, pilih menu Analyze, kemudian submenu
Regression, lalu pilih Linear.
n. Regresikan variabel absolut residual (Abresid) dengan semua variabel independen.
o. Pada kotak Dependent isikan variabel Abresid.
p. Pada kotak Independent isikan variabel X1, X2, X3, dan X4, di layar tampak
tampilan berikut.
q. Tekan tombol OK, dan hasil output SPSS seperti berikut.

Ekonometrika dengan Aplikasi SPSS 49
Coefficientsa
-1,507 1,590 -,948 ,356-,002 ,002 -1,097 -,737 ,471,068 ,070 ,866 ,971 ,344-,001 ,027 -,060 -,055 ,957,012 ,022 ,713 ,552 ,588
(Constant)X1X2X3X4
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: Abresida.
Jika variabel independen secara statistik signifikan mempengaruhi variabel
dependen (residual) maka ada indikasi dalam model terjadi masalah heteroskedastisitas.
Hasil tampilan output SPSS dengan jelas menunjukkan bahwa tidak ada satupun
variabel independen yang signifikan secara statistik mempengaruhi variabel dependen
nilai absolut residual (Abresid). Hal ini terlihat dari probabilitas signifikansi tiap-tiap
variabel independen yang semuanya lebih besar dari α = 0,05; sehingga dapat
disimpulkan bahwa model regresi ini tidak mengandung adanya masalah
heteroskedastisitas atau bersifat homoskedastisitas.

Ekonometrika dengan Aplikasi SPSS 50
REGRESI DENGAN VARIABEL DUMMY
Variabel di dalam analisis regresi bisa debedakan menjadi dua yaitu variabel
kuantitatif dan variabel kualitatif. Model regresi pada bagian ini memfokuskan pada
regresi dengan variabel independen kualitatif. Harga, volume produksi, volume
penjualan, biaya promosi adalah beberapa contoh variabel yang datanya bersifat
kuantitatif. Namun, bila kita membicarakan masalah jenis kelamin, tingkat pendidikan,
status perkawinan, krisis ekonomi maupun kenaikan harga BBM berarti kita
membicarakan variabel bersifat kualitatif.
Variabel-variabel kualitatif tersebut sangat mempengaruhi perilaku agen-agen
ekonomi. Variabel kualitatif ini bisa terjadi pada dara cross section maupun data time
series. Misalnya dalam data cross section kita bisa memasukkan jenis kelamin di dalam
regresi dalam mempengaruhi volume penjualan handphone. Begitu pula data kualitatif
seperti kenaikan harga BBM bisa kita masukkan di dalam regresi dalam mempengaruhi
volume penjualan dalam data time series.
Contoh :
Menganalisis apakah masa kerja, tingkat pendidikan karyawan, dan jenis kelamin
mempengaruhi gaji karyawan. Pendidikan dikategorikan menjadi dua yaitu Diploma dan
Sarjana. Menggunakan data hipotetis sebanyak 20 karyawan suatu perusahaan.
Yi = βo + β1 Xi + β2 D1 + β3 D2 + ei
Dimana :
Yi = gaji karyawan
Xi = masa kerja karyawan (tahun)

Ekonometrika dengan Aplikasi SPSS 51
D1 = 1 jika sarjana dan 0 jika tidak (diploma)
D2 = 1 jika pria dan 0 bila wanita
Data 20 Karyawan di Perusahaan PT Maju Mundur
Gaji (juta) Masa_kerja Pendidikan Kelamin
2,700 11 0 0
3,400 3 1 1
3,900 18 0 1
3,400 14 0 1
4,800 9 1 1
2,200 3 0 1
6,400 15 1 1
6,230 17 1 0
4,200 20 0 1
2,065 2 0 0
3,510 4 1 0
2,500 5 0 1
2,800 8 0 1
2,975 14 0 0
5,890 15 1 0
3,105 15 0 0
3,200 2 1 1
3,365 19 0 0
3,850 5 1 0
6,910 20 1 0
Langkah-langkah Analisis Regresi
a. Buka lembar kerja baru, dengan meng-klik menu File lalu pilih New kemudian klik
Data akan muncul tampilan layar Data Editor.
b. Klik Variable View kemudian isi nama variabelnya, ketik Gaji lalu tekan ENTER,
ketik Masa_keja lalu tekan ENTER, ketik Pendidikan lalu tekan ENTER, dan ketik
Kelamin lalu tekan ENTER.

Ekonometrika dengan Aplikasi SPSS 52
c. Selanjutnya klik Data View dan masukkan data contoh di atas pada kolom variabel
masing-masing data.
d. Simpan data Anda dengan cara meng-klik menu File lalu pilih Save As dan tulis
nama filenya, misalnya dummy.
e. Lakukan analisis regresi linier berganda dengan cara, klik menu Analyze ===> pilih
submenu Regression ===> lalu klik Linear.
f. Masukkan variabel Gaji pada kotak sebelah kiri ke kotak Dependent, dan
variabel Masa_kerja, Pendidikan, Kelamin ke kotak Independent(s) dengan
mengklik tombol tanda panah, hasilnya seperti tampak pada tampilan berikut.
g. Kemudian klik OK, hasil output SPSS seperti pada tampilan berikut.
Model Summary
,958a ,917 ,901 ,45176Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), Kelamin, Pendidikan, Masa_kerja
a.
Nilai koefisien determinasi sebesar 0,917 artinya hasil regresi menunjukkan
bahwa variasi masa kerja, tingkat pendidikan karyawan dan jenis kelamin mampu
menjelaskan variasi gaji karyawan sebesar 91,7% dan sisanya sebesar 9,3% dijelaskan
oleh faktor lain di luar model.

Ekonometrika dengan Aplikasi SPSS 53
ANOVAb
36,101 3 12,034 58,964 ,000a
3,265 16 ,20439,367 19
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), Kelamin, Pendidikan, Masa_kerjaa.
Dependent Variable: Gajib.
Nilai F-hitung sebesar 58,964 dan nilai F-tabel pada α=5% dengan df (3,16)
sebesar 3,24 (cari dalam tabel F). Nilai F-hitung lebih besar dari nilai F-tabel sehingga
kita menolak Ho. Bisa juga melihat nilai signifikansi sebesar 0,000 < α = 0,05 maka Ho
ditolak (H1 diterima). Hasil regresi ini mengindikasikan bahwa secara serentak variabel
masa kerja, tingkat pendidikan karyawan dan jenis kelamin secara nyata mempengaruhi
gaji karyawan.
Coefficientsa
1,067 ,280 3,815 ,002,156 ,016 ,703 9,448 ,000
2,183 ,207 ,774 10,560 ,000,228 ,208 ,081 1,096 ,289
(Constant)Masa_kerjaPendidikanKelamin
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: Gajia.
Uji signifikansi variabel independen terhadap variabel dependen menunjukkan
bahwa nilai t-hitung variabel masa kerja sebesar 9,448; variabel dummy tingkat
pendidikan sebesar 10,560; dan variabel dummy jenis kelamin sebesar 1,096. Sementara
itu, nilai t-tabel uji dua sisi pada α=5% dengan df =16 sebesar 2,120 (cari dalam tabel t).
Dengan demikian variabel masa kerja dan dummy tingkat pendidikan signifikan pada
α=5% (nilai t-hitung > nilai t-tabel), sedangkan variabel dummy jenis kelamin tidak
berpengaruh nyata. Bisa juga membandingkan nilai Sig. (probabilitas atau p-value) jika

Ekonometrika dengan Aplikasi SPSS 54
lebih kecil dari alpha maka Ho ditolak, artinya variabel tersebut berpengaruh nyata
terhadap variabel dependen.
Hasil regresi mengindikasikan bahwa variabel kualitatif tingkat pendidikan
karyawan berpengaruh nyata terhadap gaji karyawan. Koefisien regresi variabel dummy
tingkat pendidikan sebesar 2,183 dapat diartikan gaji karyawan berpendidikan sarjana
lebih besar 2,183 juta dibandingkan dengan gaji karyawan berpendidikan tidak sarjana
dengan asumsi variabel lain tetap. Variabel dummy jenis kelamin tidak signifikan maka
dapat diartikan tidak ada perbedaan gaji antara karyawan pria dan wanita dengan asumsi
variabel lain tetap. Koefisien regresi variabel dummy jenis kelamin 0,228 artinya gaji
karyawan pria lebih tinggi 0,228 juta dibandingkan dengan gaji karyawan wanita tetapi
secara statistik perbedaan itu tidak berbeda nyata.
Karyawan Sarjana dan Pria :
E(Yi | D1=1; D2=1, Xi) = (βo + β2 + β3) + β1Xi
Karyawan Tidak Sarjana dan Pria :
E(Yi | D1=0; D2=1, Xi) = (βo + β3) + β1Xi
Karyawan Sarjana dan Wanita :
E(Yi | D1=1; D2=0, Xi) = (βo + β2) + β1Xi
Karyawan Tidak Sarjana dan Wanita :
E(Yi | D1=0; D2=0, Xi) = βo + β1Xi
Persamaan regresi Yi = 1,067 + 0,156 Xi + 2,183 D1 + 0,228 D2
Gaji karyawan berpendidikan sarjana dan pria :
Y’ = (1,067 +2,183 + 0,228) + 0,156 Xi ====> Y’ = 3,478 + 0,156 Xi
Gaji karyawan berpendidikan tidak sarjana dan pria :
Y’ = (1,067 + 0,228) + 0,156 Xi ===> Y’ = 1,295 + 0,156 Xi
Gaji karyawan berpendidikan sarjana dan wanita :
Y’ = (1,067 + 2,183) + 0,156 Xi ===> Y’ = 3,250 + 0,156 Xi
Gaji karyawan berpendidikan tidak sarjana dan wanita :
Y’ = 1,067 + 0,156 Xi

Ekonometrika dengan Aplikasi SPSS 55
Tugas Manual :
1. Suatu penelitian ingin menganalisis apakah masa kerja, tingkat pendidikan karyawan
dan jenis kelamin mempengaruhi gaji mereka. Pendidikan dikategorikan menjadi
dua yaitu pendidikan Diploma dan Sarjana. Hasil analisis data hipotesis sebanyak 20
karyawan sebagai berikut.
Y = 1,082 + 0,156 X + 2,174 D1 + 0,218 D2
Y = Gaji karyawan dalam (juta rupiah), X = masa kerja karyawan (tahun)D1 = 1 jika Sarjana dan D1 = 0 jika tidak (Diploma)D2 = 1 jika pria dan D2 = 0 jika wanita
a. Interpretasikan persamaan regresi tersebut.
b. Buatlah formula gaji karyawan pria dan berpendidikan Sarjana.
c. Buatlah formula gaji karyawan pria dan berpendidikan Diploma.
d. Buatlah formula gaji karyawan wanita dan berpendidikan Sarjjana.
e. Buatlah formula gaji karyawan wanita dan berpendidikan Diploma.
2. Suatu penelitian ingin menganalisis apakah masa kerja dan tingkat pendidikan
karyawan mempengaruhi gaji mereka. Pendidikan dikategorikan menjadi tiga yaitu
pendidikan SMA, Diploma dan Sarjana. Hasil analisis data hipotesis sebanyak 20
karyawan sebagai berikut.
Y = 0,973 + 0,107 X + 0,921 D1 + 2,466 D2
Y = Gaji karyawan dalam (juta rupiah), X = masa kerja karyawan (tahun)D1 = 1 jika Diploma dan D1 = 0 jika tidak (SMA)D2 = 1 jika Sarjana dan D2 = 0 jika tidak (SMA)
a. Interpretasikan persamaan regresi tersebut.
b. Buatlah formula gaji karyawan berpendidikan SMA.
c. Buatlah formula gaji karyawan berpendidikan Diploma.
d. Buatlah formula gaji karyawan berpendidikan Sarjana.

Ekonometrika dengan Aplikasi SPSS 56
MODEL REGRESI LOGISTIK (LOGIT MODEL)
Banyak kasus di dalam analisis regresi dimana variabel dependennya bersifat
kualitatif. Keputusan seseorang membeli mobil atau tidak. Keputusan seorang konsumen
membeli televisi merk Sonny atau bukan Sonny. Dua contoh tersebut merupakan contoh
variabel dependen yang mempunyai dua kelas atau bersifat binari (binary). Tetapi sering
kali kita juga menemukan variabel dependen yang mempunyai lebih dari dua kelas
(multinomial). Misalnya kemampuan nasabah bank di dalam membayar kreditnya.
Kemampuan nasabah ini bisa dikategorikan menjadi tiga, yaitu mereka yang mampu
membayar tepat waktu (repay), mereka yang membayar terlambat (late repay) dan
mereka yang gagal membayar (default).
Kembali kepada kasus keputusan seseorang untuk membeli mobil, jawaban yang
kita peroleh adalah mereka yang membeli mobil atau mereka yang tidak membeli mobil.
Dengan kata lain respon setiap orang tersebut bersifat dikotomis (binari). Pada bahasan
variabel dummy, dalam model regresi dimana variabel independen bersifat kualitatif
maka kita harus mengkuantitatifkan variabel kualitatif ini agar regresi bisa dilakukan.
Namun, mengkuantitatifkan variabel kualitatif di dalam regresi juga berlaku untuk
variabel dependen bersifat kualitatif. Setiap variabel kualitatif di dalam regresi baik
variabel independen maupun dependen, kita akan mengambil nilai 1 jika variabel
mempunyai atribut dan nilai 0 jika tidak mengandung atribut. Dengan demikian, kita
akan memberi angka 1 untuk variabel dependen kualitatif yang mempunyai atribut dan
angka 0 untuk variabel dependen yang tidak mempunyai atribut. Metode ini sama dengan
metode regresi dengan menggunakan variabel independen kualitatif (regresi variabel
dummy).

Ekonometrika dengan Aplikasi SPSS 57
Contoh :
Mengaplikasikan model logit tentang keputusan seseorang untuk membeli mobil
atau tidak. Keputusan membeli mobil atau tidak dipengaruhi oleh dua variabel yaitu
jumlah pendapatan dan status pernikahan. Status pernikahan merupakan variabel
independen kualitatif.
Model Logit ===> ln (Pi / 1 – Pi) = Zi = βo + β1 X1 + β2 X2
dimana, P = probabilitas membeli mobil
X1 = jumlah pendapatan (juta per bulan)
X2 = status pernikahan (1 jika menikah dan 0 jika belum menikah)
Data hipotesis yang digunakan sebagai berikut.
No. Keptusan Pendptan S_nikah Lokasi Keluarga Penddkan
1 0 5,10 0 1 3 0
2 1 12,25 1 1 3 1
3 1 9,00 1 0 2 1
4 0 6,00 0 0 4 0
5 1 10,20 1 1 3 1
6 0 5,25 0 1 2 0
7 0 5,50 0 0 3 0
8 1 11,40 1 1 3 1
9 0 5,90 0 0 2 1
10 1 11,00 1 0 2 1
11 0 6,25 0 0 3 0
12 1 6,40 0 0 4 0
13 0 6,70 1 1 3 1
14 1 7,10 1 0 1 0
15 1 7,50 0 0 1 1
16 0 7,70 0 1 3 0

Ekonometrika dengan Aplikasi SPSS 58
17 0 8,00 0 0 6 0
18 1 8,20 1 1 2 1
19 0 8,50 0 0 2 0
20 1 8,60 1 1 3 1
21 0 8,80 0 1 5 0
22 0 5,80 1 0 2 0
23 1 9,40 1 1 3 1
24 1 9,75 1 1 2 1
25 1 9,90 1 1 3 1
26 1 10,60 1 1 2 1
27 1 10,80 1 1 3 1
28 0 6,95 0 1 2 0
29 1 11,80 1 1 2 1
30 1 12,00 1 1 3 1
Langkah-langkah Analisis :
a. Buka lembar kerja baru, dengan meng-klik menu File lalu pilih New kemudian klik
Data akan muncul tampilan layar Data Editor.
b. Klik Variable View kemudian isi nama variabelnya, ketik Keptusan lalu tekan
ENTER, ketik Pendptan lalu tekan ENTER, ketik S_nikah lalu tekan ENTER.
c. Selanjutnya klik Data View dan masukkan data contoh di atas pada kolom variabel
masing-masing data.
d. Simpan data Anda dengan cara meng-klik menu File lalu pilih Save As dan tulis
nama filenya, misalnya logit.
e. Lakukan analisis regresi linier berganda dengan cara, klik menu Analyze ===> pilih
submenu Regression ===> lalu klik Binary Logistic.
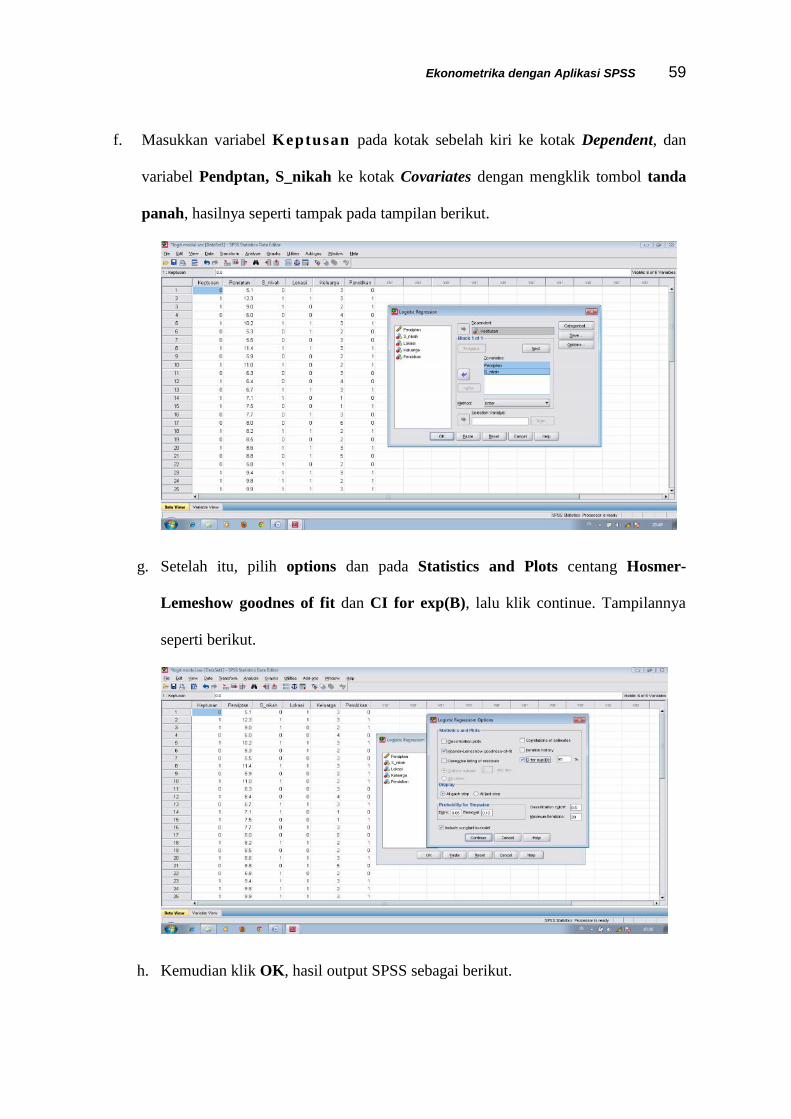
Ekonometrika dengan Aplikasi SPSS 59
f. Masukkan variabel Keptusan pada kotak sebelah kiri ke kotak Dependent, dan
variabel Pendptan, S_nikah ke kotak Covariates dengan mengklik tombol tanda
panah, hasilnya seperti tampak pada tampilan berikut.
g. Setelah itu, pilih options dan pada Statistics and Plots centang Hosmer-
Lemeshow goodnes of fit dan CI for exp(B), lalu klik continue. Tampilannya
seperti berikut.
h. Kemudian klik OK, hasil output SPSS sebagai berikut.

Ekonometrika dengan Aplikasi SPSS 60
Case Processing Summary
30 100,00 ,0
30 100,00 ,0
30 100,0
Unweighted Casesa
Included in AnalysisMissing CasesTotal
Selected Cases
Unselected CasesTotal
N Percent
If weight is in effect, see classification table for the totalnumber of cases.
a.
Dependent Variable Encoding
01
Original Value01
Internal Value
Block 0: Beginning Block
Classification Tablea,b
0 13 ,00 17 100,0
56,7
Observed01
Keptusan
Overall Percentage
Step 00 1
Keptusan PercentageCorrect
Predicted
Constant is included in the model.a.
The cut value is ,500b.
Variables in the Equation
,268 ,368 ,530 1 ,467 1,308ConstantStep 0B S.E. Wald df Sig. Exp(B)
Variables not in the Equation
15,325 1 ,00015,922 1 ,00018,706 2 ,000
PendptnS_nikah
Variables
Overall Statistics
Step0
Score df Sig.

Ekonometrika dengan Aplikasi SPSS 61
Tampilan output SPSS di atas memberi informasi jumlah kasus yang dianalisis
ada 30 kasus tidak ada yang terlewatkan (missing). Classification Table menyajikan
informasi tentang keakuratan prediksi. Dengan hanya menggunakan konstanta,
keakuratan prediksi sebesar 56,7%. Tampilan Variables in the equation menampilkan uji
wald. Dengan hanya konstanta tanpa variabel pendapatan (X1) dan status pernikahaan
(X2) tidak signifikan pada α=5% dalam mempengaruhi keputusan seseorang dalam
membeli mobil (Sig 0,467 > α=0,05). Dengan demikian ada varfiabel independen yang
mempengaruhi keputusan memberi mobil.
Block 1: Method = Enter
Uji Serentak
Omnibus Tests of Model Coefficients
23,944 2 ,00023,944 2 ,00023,944 2 ,000
StepBlockModel
Step 1Chi-square df Sig.
Tabel Omnibus Tests of Model Coefficients menyajikan uji serentak semua koefisien
variabel di dalam regresi logistik. Nilai Chi-square merupakan perbedaan -2LL model
dengan hanya konstanta dan model yang diestimasi. Nilai Chi-squares model sebesar
23,944 dengan df sebesar 2 (Chi-square tabel 5,991) maka signifikan (Sig 0,000 <
α=0,05) sehingga dapat disimpulkan bahwa pendapatan dan status pernikahan
mempengaruhi keputusan seseorang di dalam membeli mobil.
Uji Goodness of Fit
Model Summary
17,110 a ,550 ,738Step1
-2 Loglikelihood
Cox & SnellR Square
NagelkerkeR Square
Estimation terminated at iteration number 6 becauseparameter estimates changed by less than ,001.
a.

Ekonometrika dengan Aplikasi SPSS 62
Model summary menunjukkan nilai Cox & Snell R square sebesar 0,550 berarti
variabel pendapatan (X1) dan status pernikahan (X2) di dalam model logit mampu
menjelaskan perilaku seseorang dalam membeli mobil atau tidak sebesar 55%.
Sedangkan berdasarkan Nagelkerke R square sebesar 0,738 berarti variabel pendapatan
(X1) dan status pernikahan (X2) di dalam model logit mampu menjelaskan perilaku
seseorang dalam membeli mobil atau tidak sebesar 73,8%
Hosmer and Lemeshow Test
12,837 8 ,118Step1
Chi-square df Sig.
Contingency Table for Hosmer and Lemeshow Test
3 2,923 0 ,077 33 2,839 0 ,161 31 2,611 2 ,389 33 2,155 0 ,845 33 1,584 0 1,416 30 ,611 3 2,389 30 ,163 3 2,837 30 ,072 3 2,928 30 ,031 3 2,969 30 ,012 3 2,988 3
12345678910
Step1
Observed ExpectedKeptusan = 0
Observed ExpectedKeptusan = 1
Total
Classification Tablea
12 1 92,32 15 88,2
90,0
Observed01
Keptusan
Overall Percentage
Step 10 1
Keptusan PercentageCorrect
Predicted
The cut value is ,500a.

Ekonometrika dengan Aplikasi SPSS 63
Classification tables menunjukkan seberapa baik model mengelompokkan kasus
ke dalam dua kelompok baik yang tidak mempunyai mobil maupun yang mempunyai
mobil. Keakuratan prediksi secara menyeluruh sebesar 90%, hal ini lebih baik dari model
yang hanya dengan konstanta sebelumnya sebesar 56,7%. Sedangkan keakuratan prediksi
yang tidak mempunyai mobil sebesar 92,3% dan yang mempunyai mobil sebesar 88,2%.
Variables in the Equation
1,001 ,493 4,121 1 ,042 2,720 1,035 7,1462,443 1,242 3,869 1 ,049 11,511 1,009 131,369-8,932 3,852 5,377 1 ,020 ,000
PendptnS_nikahConstant
Step1a
B S.E. Wald df Sig. Exp(B) Lower Upper95,0% C.I.for EXP(B)
Variable(s) entered on step 1: Pendptn, S_nikah.a.
Uji signifikansi variabel independen secara individual dengan menggunakan uji
Wald. Hasil uji menunjukkan bahwa variabel pendapatan (X1) dan status pernikahan
(X2) berpengaruh nyata terhadap keputusan seseorang di dalam membeli mobil dengan
tingkat signifikansi 5% (sig < α=0,05).
Persamaan regresi logistik Zi = -8,932 + 1,001 X1 + 2,443 X2
Interpretasi persamaan logistik menggunakan odd ratio atau Exp(B), untuk pendapatan
(X1) odd ratio sebesar 2,720 dapat diartikan bahwa jika pendapatan naik 1 unit (1 juta)
maka rasio kemungkinan memiliki mobil dengan yang tidak memiliki mobil naik dengan
faktor 2,720 dengan asumsi variabel status pernikahan tetap. Sementara itu odd ratio
untuk status pernikahan (X2) sebesar 11,511 dapat diartikan bahwa rasio kemungkinan
membeli mobil dengan tidak membeli mobil untuk mereka yang menikah lebih tinggi

Ekonometrika dengan Aplikasi SPSS 64
daripada yang belum menikah sebesar 11,511 kali dengan asumsi variabel pendapatan
tetap.
Persamaan regresi logistik dapat juga digunakan untuk melakukan prediksi, misal
individu mempunyai pendapatan 10 juta dan status pernikahan sudah menikah (X2 =1)
maka probabilitas memiliki mobil dapat dihitung sebagai berikut.
Z = -8,932 + 1,001(10) + 2,443(1) = 3,521
Pi = (1 / 1 + e-Z) = (1 / 1 + 2,7182818^-3,521) = 0,97
Nilai prediksi probabilitas individu tersebut memiliki mobil sebesar 0,97 sedangkan
probabilitas tidak mempunyai mobil sebesar 1 – 0,97 = 0,03.

Ekonometrika dengan Aplikasi SPSS 65
Tugas Mandiri :
Sebuah penelitian ingin mengetahui apakah faktor pendapatan dan lamanya pendidikan
pengusaha kecil berpengaruh terhadap pilihan pengusaha dalam bermitra dengan
perusahaan X atau tidak. Diambil 15 sampel (diasumsikan memenuhi) dari pengusaha
dan didapatkan hasil sebagai berikut.
Pengaruh Faktor Pendapatan dan Pengalaman terhadap Pilihan Bermitra
No Pilihan Pendapatan(Juta/bulan)
Pengalaman(tahun)
Y X1 X21 1 4 62 0 1 43 1 3 74 0 3 75 0 4 86 1 3 67 1 3 68 0 1 49 0 4 310 0 4 311 1 4 712 1 4 713 1 3 714 0 1 215 0 1 2
Keterangan :
Y = 1 jika bermitra , Y = 0 jika tidak bermitra
1. Lakukan analisis logit dengan menggunakan aplikasi SPSS.
2. Interpretasikan model yang diperoleh.

Ekonometrika dengan Aplikasi SPSS 66
REGRESI MULTINOMIAL LOGIT
Konsep regresi Multinomial Logit pada dasarnya sama dengan konsep regresi
logistik lainnya. Namun demikian yang membedakannya adalah bahwa dalam Model
Regesi Multinomial Logit terdapat multiple interpretation dari hasil analisis. (i) hasil
regresi dengan Multinomial Logit dapat digunakan untuk menunjukkan relationship
antara variabel independen dengan variabel dependen, hasil ini dapat dilihat dari
Likelihood ratio test. (ii) dengan menggunakan hasil pengujian parameter estimate, akan
diperoleh hasil kemampuan klasifikasi (classifiacation) terhadap variabel kategori
dependen yang sebelumnya telah dilakukan pengelompokkan.
Dalam metode Regresi Multinomial Logit, variabel dependen dalam bentuk non
metric, sementara itu variabel bebasnya (independent variables) dalam bentuk metric
atau dichotomous variabeles. Dengan demikian pengujiannya tidak menggunakan
distribusi t atau F, namun menggunakan distribusi chi-square (χ2). Dalam pengujian
Regresi Multinomial Logit nilai variabel kategori bersifat probabilistik, dimana terdapat
kemungkinan data variabel X tersebut mampu mengklasifikasikan variabel terikat
menjadi kategori pertama, kedua atau kemungkinan masuk klasifikasi kelompok ketiga.
Pengujian signifikansi model multinomial logit dilakukan dengan melihat hasil
pengujian model fitting information. Hasil ini menunjukkan overall test, kelayakan model
dapat dilihat dari nilai double likelihood (2LL). Suatu model dapat dikatakan layak
apabila nilai -2LL pada model final lebih kecil jika dibandingkan dengan nilai -2LL pada
model awal (interceipt only). Hal ini menunjukkan bahwa model multinomial logit
bermanfaat (a usefull model). Sementara itu kemampuan model dalam
mengklasifikasikan kategori variabel dependen apabila suatu subjek dimasukkan dapat
Kam (1990;307-308)

Ekonometrika dengan Aplikasi SPSS 67
dilihat dari hasil classification atau predicted dengan observed, kategori mana yang dapat
diprediksikan lebih baik, hasilnya dapat dilihat dari nilai persentase masing-masing
kategori.
Contoh :
Mengaplikasikan model multinomial logit tentang keputusan seseorang untuk
membeli mobil atau tidak. Keputusan seseorang terdiri dari tiga kemungkinan yaitu
membeli mobil dengan tunai (3), membeli mobil dengan kredit (2) dan tidak membeli
mobil (1). Ada dua variabel yang mempengaruhi keputusan tersebut yaitu jumlah
pendapatan dan status pernikahan. Status pernikahan merupakan variabel independen
kualitatif.
Model Multinomial Logit ===> ln (Pi / Pj) = Zi = βo + β1 X1 + β2 X2
dimana, P = probabilitas kategori ke i dan j
X1 = jumlah pendapatan (juta per bulan)
X2 = status pernikahan (1 jika menikah dan 0 jika belum menikah)
Data hipotesis yang digunakan sebagai berikut.
No. Keptusan Pendptan S_nikah
1 3 9,90 0
2 1 5,25 0
3 1 7,70 0
4 1 5,80 0
5 3 11,40 1
6 1 6,00 0
7 3 12,00 1
8 2 6,40 0
9 1 6,70 1
10 1 6,95 0

Ekonometrika dengan Aplikasi SPSS 68
11 3 10,20 1
12 3 7,50 0
13 1 5,50 0
14 1 8,00 0
15 2 8,20 1
16 1 8,50 0
17 2 8,60 1
18 1 8,80 0
19 2 9,00 1
20 3 9,40 1
21 3 9,75 1
22 1 5,90 0
23 2 7,10 1
24 3 10,60 1
25 2 10,80 1
26 3 11,00 1
27 1 6,25 0
28 3 11,80 1
29 1 5,10 0
30 3 12,25 1
Langkah-langkah Analisis :
a. Buka lembar kerja baru, dengan meng-klik menu File lalu pilih New kemudian klik
Data akan muncul tampilan layar Data Editor.
b. Klik Variable View kemudian isi nama variabelnya, ketik Keptusan lalu tekan
ENTER, ketik Pendptan lalu tekan ENTER, ketik S_nikah lalu tekan ENTER.
c. Selanjutnya klik Data View dan masukkan data contoh di atas pada kolom variabel
masing-masing data.

Ekonometrika dengan Aplikasi SPSS 69
d. Simpan data Anda dengan cara meng-klik menu File lalu pilih Save As dan tulis
nama filenya, misalnya multinomial logit.
e. Lakukan analisis regresi dengan cara, klik menu Analyze ===> pilih submenu
Regression ===> lalu klik Multinomial Logistic.
f. Masukkan variabel Keptusan pada kotak sebelah kiri ke kotak Dependent,
variabel S_nikah sebagai variabel independen yang kualitatif ke dalam kotak
Factor dan Pendptan sebagai variabel independen kuantitatif ke dalam kotak
Covariates dengan mengklik tombol tanda panah, hasilnya seperti tampak pada
tampilan berikut.
g. Kemudian pilih statistics sehingga akan muncul tampilan berikut.
h. Pada kotak case processing summary lalu pada model pilih atau centang Pseudo R
Squares, step summary, model fitting information, classification tables dan goodness
of fit.
i. Pada parameter pilih atau centang Estimates dan likelihood correlation.
j. Pada define subpopulation pilih atau centang covariate patterns defined by factors
and covariates. Kemudian klik continue, tampilannya seperti berikut.

Ekonometrika dengan Aplikasi SPSS 70
k. Setelah itu klik Reference Category sehingga muncul tampilan berikut. Pada
reference category pilih custom dan ketik nilai 1 (karena 1 merupakan pilihan
individu tidak membeli mobil. Pada Category order pilih Ascending kemudian klik
continue, dan klik OK. Kalau kita pilih pilihan individu membeli mobil dengan
kredit maka pilih custom dan ketik angka 2, dan bila pilihan individu membeli mobil
dengan tunai maka pilih custom dan ketik angka 3. Hasil output SPSS seperti
berikut.

Ekonometrika dengan Aplikasi SPSS 71
Case Processing Summary
13 43,3%6 20,0%
11 36,7%15 50,0%15 50,0%30 100,0%0
3030a
123
Keptusan
01
S_nikah
ValidMissingTotalSubpopulation
NMarginal
Percentage
The dependent variable has only one value observedin 30 (100,0%) subpopulations.
a.
Model Fitting Information
63,12829,659 33,470 4 ,000
ModelIntercept OnlyFinal
-2 LogLikelihood
ModelFittingCriteria
Chi-Square df Sig.
Likelihood Ratio Tests
Tabel Model Fitting Information merupakan uji signifikansi variabel independen
secara serentak melalui uji Chi-square (X2). Nilai Chi-squares model sebesar 33,470
dengan df sebesar 4 (Chi-square tabel 9,488) maka signifikan (Sig 0,000 < α=0,05)
sehingga dapat disimpulkan bahwa pendapatan dan status pernikahan secara bersama-
sama menentukan keputusan seseorang di dalam membeli mobil.
Goodness-of-Fit
43,870 54 ,83629,659 54 ,997
PearsonDeviance
Chi-Square df Sig.
Pseudo R-Square
,672,766,530
Cox and SnellNagelkerkeMcFadden
Tabel Goodness of Fit merupakan uji kecocokan model melalui Person Chi-
square dan Deviance Chi-square. Kedua uji ini secara statistik tidak signifikan sehingga

Ekonometrika dengan Aplikasi SPSS 72
hipotesis nol diterima, berarti model mampu menjelaskan data dengan baik. Sedangkan
Tabel Pseudo R-square yaitu mengukur proporsi variasi data yang dijelaskan oleh model.
Nilai Cox and Snell R-square sebesar 0,672; Nagelkerke R-square sebesar 0,766; dan
McFadden R-square sebesar 0,530 berarti variabel pendapatan (X1) dan status
pernikahan (X2) di dalam model multinominal logit mampu menjelaskan keputusan
seseorang dalam membeli mobil masing-masing sebesar 67,2%; 76,6% dan 53%.
Likelihood Ratio Tests
29,659 a ,000 0 .44,428 14,770 2 ,00136,016 6,357 2 ,042
EffectInterceptPendptanS_nikah
-2 LogLikelihood of
ReducedModel
Model FittingCriteria
Chi-Square df Sig.
Likelihood Ratio Tests
The chi-square statistic is the difference in -2 log-likelihoodsbetween the final model and a reduced model. The reducedmodel is formed by omitting an effect from the final model. Thenull hypothesis is that all parameters of that effect are 0.
This reduced model is equivalent to the final modelbecause omitting the effect does not increase thedegrees of freedom.
a.
Tabel Likelihood Ratio Tests memberikan informasi tentang uji secara individual
pengaruh masing-masing variabel independen terhadap variabel dependen. Hasil uji
menunjukkan variabel pendapatan (X1) dan status pernikahan (X2) signifikan
berpengaruh terhadap keputusan seseorang dalam membeli mobil (sig. < α=0,05).

Ekonometrika dengan Aplikasi SPSS 73
Referensi Pertama tidak Membeli Mobil
Parameter Estimates
-1,709 4,828 ,125 1 ,723,402 ,584 ,475 1 ,491 1,495 ,476 4,694
-3,524 1,636 4,637 1 ,031 ,029 ,001 ,7290b . . 0 . . . .
-14,431 6,684 4,661 1 ,0311,758 ,730 5,792 1 ,016 5,799 1,386 24,269-1,134 1,782 ,405 1 ,525 ,322 ,010 10,581
0b . . 0 . . . .
InterceptPendptan[S_nikah=0][S_nikah=1]InterceptPendptan[S_nikah=0][S_nikah=1]
Keptusana
2
3
B Std. Error Wald df Sig. Exp(B) Lower BoundUpper Bound
95% Confidence Interval forExp(B)
The reference category is: 1.a.
This parameter is set to zero because it is redundant.b.
Tabel Parameter Estimates menyajikan uji signifikansi variabel independen
melalui uji Wald. Pertama, sebagai reference category adalah pilihan pertama yaitu tidak
membeli mobil. Pada koefisien logit pertama variabel pendapatan tidak signifikan (sig. >
α=0,05). dan status pernikahan signifikan (sig. < α=0,05). Koefisien odds ratio pada
kolom Exp(B) untuk status pernikahan (X2) sebesar 0,029. Karena koefisien B bertanda
negatif dapat diartikan bahwa kemungkinan membeli mobil dengan kredit dibandingkan
dengan tidak membeli mobil bagi mereka yang menikah lebih rendah daripada yang
belum menikah sebesar 0,029 dengan asumsi variabel pendapatan tetap.
Pada koefisien logit kedua, variabel pendapatan signifikan dan status pernikahan
tidak signifikan. Koefisien odds ratio pada kolom Exp(B) untuk pendapatan (X1) sebesar
5,799. Karena koefisien B bertanda positif dapat diartikan bahwa rasio kemungkinan
membeli mobil dengan tunai dibandingkan dengan tidak membeli mobil naik dengan
faktor 5,799 kali jika pendapatan naik 1 juta dengan asumsi variabel status pernikahan
tetap.

Ekonometrika dengan Aplikasi SPSS 74
Referensi Kedua Membeli Mobil dengan Kredit
Parameter Estimates
1,709 4,828 ,125 1 ,723-,402 ,584 ,475 1 ,491 ,669 ,213 2,1003,524 1,636 4,637 1 ,031 33,908 1,372 837,730
0b . . 0 . . . .-12,722 5,964 4,550 1 ,033
1,355 ,610 4,942 1 ,026 3,878 1,174 12,8122,390 1,900 1,582 1 ,209 10,910 ,263 452,051
0b . . 0 . . . .
InterceptPendptan[S_nikah=0][S_nikah=1]InterceptPendptan[S_nikah=0][S_nikah=1]
Keptusana
1
3
B Std. Error Wald df Sig. Exp(B) Lower BoundUpper Bound
95% Confidence Interval forExp(B)
The reference category is: 2.a.
This parameter is set to zero because it is redundant.b.
Sebagai reference category adalah pilihan kedua yaitu membeli mobil dengan
kredit. Pada koefisien logit pertama variabel pendapatan tidak signifikan (sig. > α=0,05).
dan status pernikahan signifikan (sig. < α=0,05). Koefisien odds ratio pada kolom
Exp(B) untuk status pernikahan (X2) sebesar 33,908. Karena tanda koefisien B positif
dapat diartikan bahwa kemungkinan tidak membeli mobil dibandingkan dengan membeli
mobil dengan kredit bagi mereka yang menikah lebih tinggi daripada yang belum
menikah sebesar 33,908 kali dengan asumsi variabel pendapatan tetap.
Pada koefisien logit kedua, variabel pendapatan signifikan dan status pernikahan
tidak signifikan. Koefisien odds ratio pada kolom Exp(B) untuk pendapatan (X1) sebesar
3,878. Karena koefisien B bertanda positif dapat diartikan bahwa rasio kemungkinan
membeli mobil dengan tunai dibandingkan dengan membeli mobil dengan kredit naik
dengan faktor 3,878 kali jika pendapatan naik 1 juta dengan asumsi variabel status
pernikahan tetap.

Ekonometrika dengan Aplikasi SPSS 75
Referensi Ketiga Membeli Mobil dengan Tunai
Sebagai reference category adalah pilihan ketiga yaitu membeli mobil dengan
tunai. Pada koefisien logit pertama variabel pendapatan signifikan (sig. < α=0,05) dan
status pernikahan tidak signifikan (sig. > α=0,05). Koefisien odds ratio pada kolom
Exp(B) untuk pendapatan (X1) sebesar 0,258. Karena koefisien B bertanda negatif
sehingga dapat diartikan bahwa kemungkinan membeli mobil dengan kredit
dibandingkan dengan membeli mobil dengan tunai turun dengan faktor sebesar 0,258
kali jika pendapatan naik 1 juta dengan asumsi variabel status pernikahan tetap (lihat
tampilan berikut).
Parameter Estimates
14,431 6,684 4,661 1 ,031-1,758 ,730 5,792 1 ,016 ,172 ,041 ,7221,134 1,782 ,405 1 ,525 3,108 ,095 102,203
0b . . 0 . . . .12,722 5,964 4,550 1 ,033-1,355 ,610 4,942 1 ,026 ,258 ,078 ,852-2,390 1,900 1,582 1 ,209 ,092 ,002 3,798
0b . . 0 . . . .
InterceptPendptan[S_nikah=0][S_nikah=1]InterceptPendptan[S_nikah=0][S_nikah=1]
Keptusana
1
2
B Std. Error Wald df Sig. Exp(B) Lower BoundUpper Bound
95% Confidence Interval forExp(B)
The reference category is: 3.a.
This parameter is set to zero because it is redundant.b.
Pada koefisien logit kedua, hanya variabel pendapatan signifikan (sig. < α=0,05)
dan status pernikahan tidak signifikan (sig. < α=0,05). Koefisien odds ratio pada kolom
Exp(B) untuk pendapatan (X1) sebesar 3,878. Karena koefisien B bertanda positif dapat
diartikan bahwa rasio kemungkinan membeli mobil dengan tunai dibandingkan dengan

Ekonometrika dengan Aplikasi SPSS 76
membeli mobil dengan kredit naik dengan faktor 3,878 kali jika pendapatan naik 1 juta
dengan asumsi variabel status pernikahan tetap.
Classification
12 1 0 92,3%1 4 1 66,7%1 0 10 90,9%
46,7% 16,7% 36,7% 86,7%
Observed123Overall Percentage
1 2 3PercentCorrect
Predicted
Pada classification table menunjukkan seberapa baik model mengelompokkan
kasus ke dalam tiga kelompok yaitu membeli mobil dengan tunai, membeli mobil dengan
kredit dan tidak membeli mobil. Keakuratan prediksi secara menyeluruh sebesar 86,7%.
Sedangkan keakuratan prediksi secara detail yaitu individu yang membeli mobil dengan
tunai sebesar 90,9%; membeli mobil dengan kredit sebesar 66,7% dan tidak membeli
mobil sebesar 92,3%.

Ekonometrika dengan Aplikasi SPSS 77
Tugas Mandiri :
Keputusan seseorang untuk membeli mobil atau tidak, ada tiga kemungkinan yaitu
membeli mobil dengan tunai (3), membeli mobil dengan kredit (2) dan tidak membeli
mobil (1). Ada dua variabel yang mempengaruhi keputusan tersebut yaitu jumlah
pendapatan (juta per bulan) dan status pernikahan. Status pernikahan merupakan variabel
independen kualitatif (1 jika menikah dan 0 jika belum menikah). Gunakan aplikasi
SPSS untuk analisis mulinomial logit dan interpretasikan output SPSS tersebut.
No. Keptusan Pendptan S_nikah1 3 10,90 02 1 8,25 03 1 9,70 04 1 5,80 05 3 11,40 16 1 7,00 07 3 12,00 18 2 8,40 09 1 9,70 110 1 6,95 011 3 10,20 112 3 7,50 013 1 6,50 014 1 8,00 015 2 8,20 116 1 8,50 017 2 8,60 118 1 9,80 019 2 9,00 120 3 9,40 121 3 9,75 022 1 5,90 023 2 7,10 124 3 11,60 125 2 10,80 026 3 11,00 127 1 6,25 028 3 11,80 129 1 7,10 030 3 10,25 1
Sumber : Data hipotetis

Ekonometrika dengan Aplikasi SPSS 78
MODEL PERSAMAAN SIMULTAN
Suatu himpunan persamaan dimana variabel dependen dalam satu atau lebih
persamaan juga merupakan variabel independen dalam beberapa persamaan yang lain.
Suatu model yang mempunyai hubungan sebab akibat antara variabel dependen dan
variabel independennya, sehingga suatu variabel dapat dinyatakan sebagai variabel
dependen maupun independen dalam persamaan yang lain.
Ada hubungan dua arah atau simultan antara X dan (beberapa dari) X, yang
membuat perbedaan antara variabel tak bebas dan variabel yang menjelaskan menjadi
meragukan. Ada lebih dari satu persamaan, satu untuk variabel tidak bebas atau bersifat
endogen atau gabungan atau bersama. Dalam model persamaan simultan orang mungkin
tidak menaksir parameter dari satu persamaan tunggal tanpa memperhitungkan informasi
yang diberikan oleh persamaan lain dalam sistem.
Persamaan simultan merupakan suatu sistem persamaan yang menggambarkan
saling ketergantungan antar variabel. Estimasi parameter suatu persamaan simultan tidak
dapat dilakukan tanpa mempertimbangkan informasi pada persamaan lainnya.
Dalam banyak situasi ekonomi, hubungan variabel ekonomi tidak hanya bersifat
satu arah namun bersifat saling mempengaruhi. Dalam bahasa ekonometrika satu variabel
independen (Xi) mempengaruhi variabel dependen (Y) dan selanjutnya variabel Y itu
sendiri mempengaruhi Xi, model yang demikian disebut sebagai model persamaan
simultan. Hubungan dua-arah atau simultan antar beberapa variabel
Y1i = 10 + 11Y2i + 12 Xi + 1i
Y2i = 20 + 21Y1i + 22 Xi + 2i

Ekonometrika dengan Aplikasi SPSS 79
Y1, Y2 = Variabel Endogen (saling terikat) – stochastic
X1 = Variabel eksogen ; 1i, 2i = Error - stochastic
Contoh :
Misalnya persamaan simultan pada model persamaan pendapatan dan persamaan
penawaran uang, yaitu :
Fungsi pendapatan Yt = 10 + 11Mt + 12 It + 13 Gt + 1i
Fungsi penawaran uang Mt = 20 + 21Yt + 22Yt-1 + 23Mt-1 + 2i
dimana : Y = pendapatan ; M = penawaran uang ; I = investasi ; G = pengeluaran
pemerintah ; Yt-1 = pendapatan periode sebelumnya ; Mt-1 = penawaran uang periode
sebelumnya.
Data hipotetis pendapatan pemerintah dan penawaran uang
Tahun Y G I M Y(-1) M(-1)
1980 3578,0 198,6 436,2 626,4
1981 3697,7 216,6 485,8 710,1 3578,0 626,4
1982 3998,4 240,0 543,0 802,1 3697,7 710,1
1983 4123,4 259,7 606,5 855,2 3998,4 802,1
1984 4099,0 291,2 561,7 901,9 4123,4 855,2
1985 4084,4 345,4 462,2 1015,9 4099,0 901,9
1986 4311,7 371,9 555,5 1151,7 4084,4 1015,9
1987 4511,8 405,0 639,4 1269,9 4311,7 1151,7
1988 4760,6 444,2 713,0 1365,5 4511,8 1269,9
1989 4912,1 489,6 735,4 1473,1 4760,6 1365,5
1990 4900,9 576,6 655,3 1599,1 4912,1 1473,1
1991 5021,0 659,3 715,6 1754,6 4900,9 1599,1
1992 4913,3 732,1 615,2 1909,5 5021,0 1754,6
1993 5132,3 797,8 673,7 2126,0 4913,3 1909,5
1994 5505,2 856,1 871,5 2309,7 5132,3 2126,0

Ekonometrika dengan Aplikasi SPSS 80
1995 5717,1 924,6 863,4 2495,4 5505,2 2309,7
1996 5912,4 978,5 857,7 2732,1 5717,1 2495,4
1997 6113,3 1018,4 879,3 2831,1 5912,4 2732,1
1998 6368,4 1066,2 902,8 2994,3 6113,3 2831,1
1999 6591,9 1140,3 936,5 3158,4 6368,4 2994,3
2000 6707,9 1228,7 907,3 3277,6 6591,9 3158,4
2001 6676,4 1287,6 829,5 3376,8 6707,9 3277,6
2002 6880,0 1418,9 899,8 3430,7 6676,4 3376,8
2003 7062,6 1471,5 977,9 3484,4 6880,0 3430,7
2004 7347,7 1506,0 1107,0 3499,0 7062,6 3484,4
2005 7343,8 1575,7 1140,6 3641,9 7347,7 3499,0
2006 7813,2 1635,9 1242,7 3813,3 7343,8 3641,9
2007 8159,5 1678,8 1393,3 4028,9 7813,2 3813,3
2008 8515,7 1705,0 1566,8 4380,6 8159,5 4028,9
2009 8875,8 1750,2 1669,7 4643,7 8515,7 4380,6
Selain metode Indirect Least Square (ILS), metode Two Stage Least Squares
(TSLS) adalah metode yang umum digunakan untuk mengestimasi persamaan simultan.
Langkah-langkah Analisis :
a. Buka lembar kerja baru, dengan meng-klik menu File lalu pilih New kemudian klik
Data akan muncul tampilan layar Data Editor.
b. Klik Variable View kemudian isi nama variabelnya, ketik Y lalu tekan ENTER,
ketik G lalu tekan ENTER, ketik I lalu tekan ENTER, ketik M lalu tekan ENTER,
ketik Y_1 lalu tekan ENTER, M_1 lalu tekan ENTER.
c. Selanjutnya klik Data View dan masukkan data contoh di atas pada kolom variabel
masing-masing data.
d. Simpan data Anda dengan cara meng-klik menu File lalu pilih Save As dan tulis
nama filenya, misalnya simultan.

Ekonometrika dengan Aplikasi SPSS 81
e. Lakukan analisis regresi dengan cara, klik menu Analyze ===> pilih submenu
Regression ===> lalu klik 2-Stage Least Squares.
f. Masukkan variabel Y pada kotak sebelah kiri ke kotak Dependent, variabel M, I,
G sebagai variabel independen ke dalam kotak Explanatory dan I, G, Y_1, M_1
sebagai variabel eksogen ke dalam kotak Instrumental dengan mengklik tombol
tanda panah, hasilnya seperti tampak pada tampilan berikut.
g. Kemudian klik OK. Hasil output SPSS untuk persamaan pendapatan pada tampilan
berikut.
Two-stage Least Squares AnalysisModel Description
Type of Variable
Equation 1 Y dependent
M predictor
I predictor & instrumental
G predictor & instrumental
Y_1 instrumental
M_1 instrumental

Ekonometrika dengan Aplikasi SPSS 82
Model Summary
Equation 1 Multiple R .998
R Square .996
Adjusted R Square .995
Std. Error of the Estimate 103.144
ANOVA
Sum ofSquares df Mean Square F Sig.
Equation 1 Regression 61121218.948 3 20373739.649 1915.059 .000
Residual 265967.513 25 10638.701
Total 61387186.461 28
Coefficients
Unstandardized Coefficients
Beta t Sig.B Std. Error
Equation 1 (Constant) 2511.908 70.409 35.676 .000
M .599 .144 .481 4.148 .000
I 1.445 .160 .300 9.009 .000
G .685 .313 .237 2.192 .038
Pada persamaan pendapatan, tanda koefisien variabel M, I, dan G positif sesuai
dengan hipotesis yang diharapkan dan secara statistik signifikan pada α=5% (sig < α).
Untuk persamaan penawaran uang, caranya dengan mengganti variabelnya (sesuai
variabel pada persamaannya).
h. Masukkan variabel M pada kotak sebelah kiri ke kotak Dependent, variabel Y,
Y_1, M_1 sebagai variabel independen ke dalam kotak Explanatory dan I, G, Y_1,
M_1 sebagai variabel eksogen ke dalam kotak Instrumental dengan mengklik
tombol tanda panah, hasilnya seperti tampak pada tampilan berikut.

Ekonometrika dengan Aplikasi SPSS 83
i. Kemudian klik OK. Hasil output SPSS untuk persamaan penawaran uang sebagai
berikut.
Two-stage Least Squares Analysis
Model Description
Type of Variable
Equation 1 M dependent
Y predictor
Y_1 predictor & instrumental
M_1 predictor & instrumentalI instrumental
G instrumental
Model Summary
Equation 1 Multiple R .999
R Square .997Adjusted R Square .997
Std. Error of the Estimate 66.878

Ekonometrika dengan Aplikasi SPSS 84
ANOVASum of
Squares df Mean Square F Sig.
Equation 1 Regression 39497810.543 3 13165936.848 2943.651 .000
Residual 111816.402 25 4472.656
Total 39609626.945 28
Coefficients
Unstandardized Coefficients
Beta t Sig.B Std. Error
Equation 1 (Constant) -230.285 182.410 -1.262 .218
Y .289 .115 .359 2.508 .019
Y_1 -.188 .125 -.224 -1.503 .145
M_1 .889 .077 .866 11.511 .000
Pada persamaan penawaran uang, tanda koefisien variabel Y dan kelambatan M
(M_1) positif dan secara statistik signifikan pada α=5% (sig < α), sedangkan untuk
kelambatan Y (Y_1) bertanda negatif dan secara statistik tidak signifikan pada α=5% (sig
> α).
DAFTAR PUSTAKA
Agus Widarjono, 2005. Ekonometrika, Teori dan Aplikasi untuk Ekonomi dan Bisnis.Penerbit Ekonisia, Fakultas Ekonomi UII, Yogyakarta.
Agus Widarjono, 2010. Analisis Statistika Multivariat Terapan. Penerbit UPP SekolahTinggi Ilmu Manajemen YKPN, Yogyakarta.
C. Trihendradi, 2008. Step by Step SPSS 16. Analisis Data Statistik. Penerbit ANDIYogyakarta. Yogyakarta.
Imam Ghozali, 2006. Aplikasi Analisis Multivariate dengan Program SPSS. BadanPenerbit Universitas Diponegoro, Semarang.
Nachrowi Djalal, 2005. Penggunaan Teknik Ekonometri. Penerbit PT RajaGrafindoPersada, Jakarta.




















