
EKONOMETRIKA PENGANTAR (DILENGKAPI PENGGUNAAN … · tentang pengertian regresi, ... Bab 1 Konsep...
203
Transcript of EKONOMETRIKA PENGANTAR (DILENGKAPI PENGGUNAAN … · tentang pengertian regresi, ... Bab 1 Konsep...



EKONOMETRIKA PENGANTAR
(DILENGKAPI PENGGUNAAN EVIEWS)
AGUS TRI BASUKI

EKONOMETRIKA PENGANTAR
(DILENGKAPI PENGGUNAAN EVIEWS)
Katalog Dalam Terbitan (KDT) Agus Tri Basuki. : EKONOMETRIKA PENGANTAR (DILENGKAPI PENGGUNAAN EVIEWS) - Yogyakarta : 2018 195 hal.; 17,5 X 24,5 cm Edisi Pertama, Cetakan Pertama, 2018 ISBN : 978-623-7054-00-9 Hak Cipta 2018 pada Penulis © Hak Cipta Dilindungi oleh Undang-Undang Dilarang memperbanyak atau memindahkan sebagian atau seluruh isi buku ini dalam bentuk apapun, secara elektronis maupun mekanis, termasuk memfotokopi, merekam, atau dengan teknik perekaman lainnya, tanpa izin tertulis dari penerbit
Penerbit : Danisa Media Banyumeneng, V/15 Banyuraden, Gamping, Sleman Telp. (0274) 7447007 Email : [email protected]

“Wahai orang-orang yang beriman, apabila dikatakan kepadamu, berilah
kelapangan di dalam majelis-majelis, maka lapangkanlah. Niscaya Allah Swt.
akan memberi kelapangan untukmu. Apabila dikatakan, berdirilah kamu,
maka berdirilah. Niscaya Allah Swt. akan mengangkat (derajat) orang-orang
yang beriman di antaramu dan orang-orang yang diberi ilmu beberapa
derajat. Allah Swt. Mahateliti apa yang kamu kerjakan.” (Surah al-
Mujadalah/58: 11)
Untuk istri dan anak-anaku : Sri, Nanda, Pandu dan Dinda


KATA PENGANTAR
Segala puji bagi Allah yang telah memberikan kami kemudahan sehingga dapat
menyelesaikan buku EKONOMETRIKA PENGANTAR (Dilengkapi Penggunaan
Eviews). Tanpa pertolongan-Nya penulis tidak akan sanggup menyelesaikan
buku ini dengan baik. Shalawat dan salam semoga terlimpahkan kepada baginda
tercinta Nabi Muhammad SAW.
Salah satu ciri penelitian kuantitatif adalah menggunakan statistik. Analisis
regresi dalam statistika adalah salah satu metode untuk menentukan hubungan
sebab-akibat antara satu variabel dengan variabel yang lain. Buku ini membahas
tentang pengertian regresi, penghitungan regresi secara manual, regresi dengan
menggunakan Eviews, pengujian asumsi klasik, perbaikan pelanggaran asumsi
klasik, serta contoh penelitian dengan regresi.
Buku ini kami tujukan untuk para mahasiswa yang sedang mengambil mata
kuliah Ekonometri, baik program S1 dan S2 bidang ekonomi. Untuk itu, dalam
buku ini kami menjelaskan berbagai materi tentang konsep dasar regresi, serta
pengujian asumsi klasik dan cara perbaikan pelanggaran asumisi klasik.
Sehingga dengan demikian buku ini akan membantu mereka untuk mendapatkan
kemampuan dalam menganalisis data dengan alat analisis regresi linear.
Semoga buku ini dapat memberikan pengetahuan yang lebih luas kepada
pembaca. Walaupun buku ini memiliki banyak kekurangan. Penulis
membutuhkan kritik dan saran dari pembaca yang membangun. Terima kasih.
Yogyakarta, 15 November 2018
Penulis


DAFTAR ISI
Halaman Judul
Kata Pengantar
Daftar Isi
Bab 1 Konsep Dasar Ekonometrika 1
Bab 2 Regresi Sederhana 7
Bab 3 Regresi Berganda 43
Bab 4 Variabel Dummy Dalam Regresi 65
Bab 5 Uji Asumsi Klasik 71
Bab 6 Perbaikan Pelanggaran Asumsi Klasik 97
Bab 7 Analisis Regresi dengan EViews 133
Bab 8 Interpolasi Data 139
Bab 9 Menyamakan Tahun Dasar 151
Bab 10 Aplikasi Ekonometri Dalam Penelitian 157
Daftar Pustaka


KONSEP DASAR EKONOMETRIKA
1.1. Konsep Dasar Ekonometrik Ekonometrika adalah penggunaan analisis komputer serta teknik
pembuatan model untuk menjelaskan hubungan antara kekuatan-
kekuatan ekonomi utama seperti ketenagakerjaan, modal, suku bunga, dan
kebijakan pemerintah dalam pengertian matematis, kemudian menguji
pengaruh dari perubahan dalam skenario ekonomi. Syahrul (2000:150)
Koutsoyiannis A. (1977). Econometrics is a combination of economic theory,
mathematical economics, and statistics, but it is completely distinct from
each one of these three branches of science.
"The application of mathematical statistics to economic data to lend empirical support to models constructed by mathematical economics and to obtain numerical estimates” (Samuelson et al., Econometrica, 1954)
Berdasarkan beberapa pengertian di atas, maka dapat disimpulkan bahwa
ekonometrika merupakan cabang dari ilmu ekonomi dengan
menggunakan dan menerapkan matematika dan statistika untuk
memecahkan masalah-masalah ekonomi yang dibuat dalam suatu model
BAB
1

ekonometrik yang kemudian diestimasi hasilnya dan diuji lagi
kesesuaiannya dengan teori ekonomi yang sudah ada.
Metode kuantitatif dalam ilmu ekonomi sebenarnya telah lama
dikembangkan sejak abad ke-18. Vilfredo Pareto (Paris, 15 Juli 1848 -
Jenewa, 19 Agustus 1923) berkontribusi dalam menjelaskan distribusi
pendapatan dan pilihan individu melalui pendekatan matematis yang
berdasarkan atas teori ekonomi. Selain Pareto, Marie-Esprit-Léon Walras
dari Perancis pada abad ke-18 mengembangkan teori keseimbangan
umum yang menjelaskan mengenai aliran barang dan jasa dalam
perekonomian. Pada awal tahun 1950-an ekonometri dikembangkan
sebagai satu cabang sendiri dari ilmu ekonomi. Jan Tinbergen dari Belanda,
yang kini namanya diabadikan sebagai salah satu institusi akademik besar
di Eropa (Tinbergen Institute), merupakan salah tokoh utama yang
mengembangkan ilmu ini.
Berdasarkan sedikit penjelasan diatas dapat kita lihat bahwa, konsep
dasar dari ilmu ekonometrik adalah mengkaji beberapa teori ekonomi
sebelumnya dengan melakukan suatu analisis yang dapat
dipertanggungjawabkan melalui matematika dan statistika. Sehingga, kita
dapat mengetahui apakah teori ekonomi yang ada benar-benar dapat
diaplikasikan pada suatu kasus tertentu atau pada suatu wilayah tertentu.
Hasil dari analisis ekonomi ini bisa mendukung teori sehingga kita dapat
melakukan forecasting (peramalan) selain itu hasilnya bisa menolak teori
sehingga perlu adanya perbaikan teori.
1.2. Metodologi ekonometrika
Penelitian ekonometri biasanya mengikuti prosedur sbb:
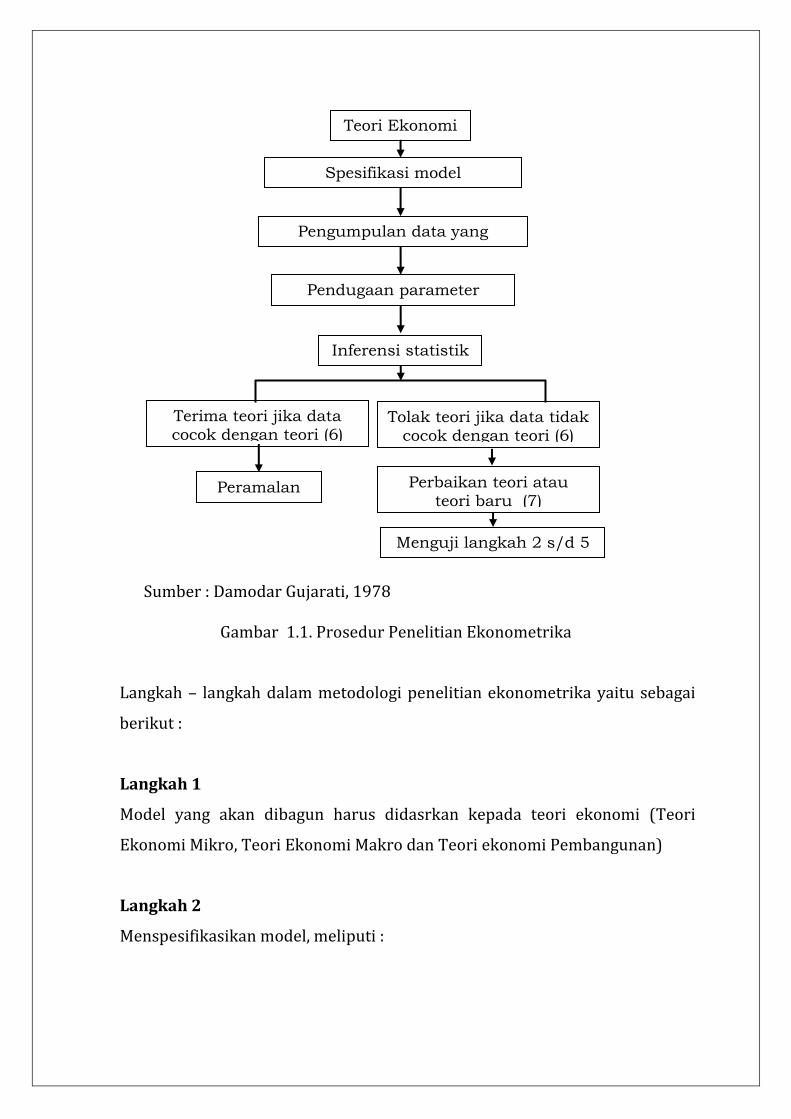
Sumber : Damodar Gujarati, 1978
Gambar 1.1. Prosedur Penelitian Ekonometrika
Langkah – langkah dalam metodologi penelitian ekonometrika yaitu sebagai
berikut :
Langkah 1
Model yang akan dibagun harus didasrkan kepada teori ekonomi (Teori
Ekonomi Mikro, Teori Ekonomi Makro dan Teori ekonomi Pembangunan)
Langkah 2
Menspesifikasikan model, meliputi :
Teori Ekonomi
(1)
Spesifikasi model ekonometrika (2)
Pengumpulan data yang relevan (3)
Pendugaan parameter model (4)
Inferensi statistik
(5)
Terima teori jika data cocok dengan teori (6)
Peramalan (7))
Menguji langkah 2 s/d 5
(8)
Tolak teori jika data tidak cocok dengan teori (6)
Perbaikan teori atau teori baru (7)

a. Variable bebas atau variable penjelas maupun variable terikat yang akan
dimasukkan ke dalam model.
b. Asumsi – asumsi a priori mengenai nilai dan tanda parameter dari model.
c. Bentuk matematik dari model.
Langkah 3
Penaksiran model dengan metode ekonometrika yang tepat, meliputi :
a. Pengumpulan data.
b. Menyelidiki ada tidaknya pelanggaran asumsi klasik.
c. Menyelidiki syarat identifikasi jika modelnya mengandung lebih dari satu
persamaan.
d. Memilih teknik ekonometrika yang tepat untuk penaksiran model.
Langkah 4
Evaluasi atau pengujian untuk memutuskan apakah taksiran – taksiran
terhadap parameter sudah bermakna secara teoritis dan nyata secara
statistic, meliputi :
a. Kriteria a priori ekonomi
b. Kriteria statistic
c. Kriteria ekonometri
Langkah 5
Menguji kekuatan peramalan model.
Langkah 6
Inferensi Statistik
Apakah hasil uji statistic dan ekonometrik mendukung teori, jika tidak
mendukung ulangi cek data kembali serta beri alas an pendukung mengapai
hasil tidak sesuai dengan teori.

1.3. Membedakan konsep regresi, kausalitas dan korelasi
Ekonometrik disini tidak terlepas dari ilmu statistika dan matematika.
statistika yang lazim digunakan juga akan masuk dalam ekonometrik.
berikut ada beberapa tehnik analisis yang akan sering digunakan dalam
analisis ekonometrik:
1. Regresi
2. Korelasi
3. Kausalitas
4. forecasting
Regresi menunjukkan hubungan pengaruh satu arah yaitu variabel
independen ke variabel dependen, sedangkan kausalitas menunjukkan
hubungan dua arah. Dan Analisis korelasi bertujuan untuk mengukur
kuatnya tingkat hubungan linear antara dua variabel.
selain tehnik analisis, data merupakan suatu hal yang akan sangat
mempengaruhi analsis yang akan digunakan dalam ekonometrik. karena
data akan mempengaruhi seberapa besar tingkat presisi dari analisis
tersebut. ada 3 jenis data:
Cross sectional
artinya itu data yang dikumpulkan dalam satu waktu.
Contoh : data PDRB provinsi di Indonesia tahun 2013
Time series
artinya data yang dikumpulkan dalam satu series waktu.
Contoh: data PDRB DIY tahun 1990-2013
Panel
merupakan data gabungan cross sectional dan time series.
Contoh: data PDRB provinsi di seluruh Indonesia tahun 1997-2012

Ilmu Ekonometri juga memiliki kelebihan dan kelemahan. Kelebihan
menggunakan model ekonometri dalam penelitian seringkali membuka
perpesktif dan temuan-temuan baru namun untuk mendapatkan hal
tersebut membutuhkan keahlian khusus pada berbagai bidang ilmu
sehingga membutuhkan banyak waktu. Kelemahan membutuhkan keahlian
khusus pada berbagai bidang ilmu sehingga membutuhkan waktu untuk
mempelajarinya.
1.4. PENGGOLONGAN EKONOMETRIKA
Ekonometrika digolongkan menjadi 2 yaitu sebagai berikut :
1. Ekonometrika Teoritik
Berkaitan dengan pengembangan metode-metode yang cocok untuk
mengukur hubungan-hubungan ekonomi yang ditetapkan dalam model
ekonometrika.
2. Ekonometrika Terapan
Membahas penggunaan atau penerapan metode ekonomi yang telah
dikembangkan dalam ekonometrik terapan.

REGRESI SEDERHANA 2.1. Regresi
Istilah regresi dikemukakan untuk pertama kali oleh seorang antropolog
dan ahli meteorology Francis Galton dalam artikelnya “Family Likeness in
Stature” pada tahun 1886. Ada juga sumber lain yang menyatakan istilah
regresi pertama kali mucul dalam pidato Francis Galton didepan Section H
of The British Association di Aberdeen, 1855, yang dimuat di majalah
Nature September 1855 dan dalam sebuah makalah “Regression towards
mediocrity in hereditary stature”, yang dimuat dalam Journal of The
Antrhopological Institute (Draper and Smith, 1992).
Studinya ini menghasilkan apa yang dikenal dengan hukum regresi
universal tentang tingginya anggota suatu masyarakat. Hukum tersebut
menyatakan bahwa distribusi tinggi suatu masyarakat tidak mengalami
perubahan yang besar sekali antar generasi. Hal ini dijelaskan Galton
berdasarkan fakta yang memperlihatkan adanya kecenderungan
mundurnya (regress) tinggi rata-rata anak dari orang tua dengan tinggi
tertentu menuju tinggi rata-rata seluruh anggota masyarakat. Ini berarti
terjadi penyusutan ke arah keadaan sekarang. Tetapi sekarang istilah
regresi telah diberikan makna yang jauh berbeda dari yang dimaksudkan
oleh Galton. Secara luas analisis regresi diartikan sebagai suatu analisis
BAB
2

tentang ketergantungan suatu variabel kepada variabel lain yaitu variabel
bebas dalam rangka membuat estimasi atau prediksi dari nilai rata-rata
variabel tergantung dengan diketahuinya nilai variabel bebas.
2.2. Konsep Dasar
Model regresi merupakan suatu cara formal untuk mengekspresikan dua
unsur penting suatu hubungan statistik :
1. Suatu kecenderungan berubahnya peubah tidak bebas Y secara
sistematis sejalan dengan berubahnya peubah besar X.
2. Perpencaran titik-titik di ser kurva hubungan statistik itu.
Kedua ciri ini disatukan dalam suatu model regresi dengan cara
mempostulatkan bahwa :
1. Ada suatu rencana peluang peubah Y untuk setiap taraf (level) peubah
X.
2. Rataan sebaran-sebaran peluang berubah secara sistematis sejalan
dengan berubahnya nilai peubah X.
Misalkanlah Y menyatakan konsumsi dan X menyatakan pendapatan
konsumen. Dalam hal ini di dalam model regresi peubah X diperlakukan
sebagai suatu peubah acak. Untuk setiap skore pendapatan, ada sebaran
peluang bagi X. Gambar 2.1. menunjukkan sebaran peluang demikian ini
untuk X = 30, yaitu konsumsi sebesar 27,87. Tabel 2.1. Nilai amatan X yang
sesungguhnya (30 dalam contoh ini) dengan demikian dipandang sebagai
suatu amatan acak dari sebaran peluang ini.
Tabel 2.1.
No Y X No Y X No Y X 1 10 11 11 38 42 21 70 74
2 12 14 12 40 45 22 74 79 3 15 17 13 45 49 23 77 85

No Y X No Y X No Y X 4 19 22 14 49 52 24 80 88 5 22 24 15 52 55 25 84 90 6 25 28 16 55 57 26 90 95 7 27 30 17 57 60 27 92 97
8 29 31 18 60 65 28 95 99 9 33 35 19 64 67 29 98 110
10 35 40 20 67 71 30 100 120
Gambar 2.1.
Representasi Gambar bagi Model Regresi Linear
Gambar 2.1. juga menunjukkan sebaran peluang Y untuk ukuran lot X = 60
dan X = 90. Perhatikan bahwa rataan sebaran-sebaran peluang ini
mempunyai hubungan yang sistematis dengan taraf-taraf peubah X.
Hubungan sistematis ini dinamakan fungsi regresi X terhadap Y. Grafik
fungsi regresi ini dinamakan kurva regresi. Perhatikan bahwa fungsi
regresi dalam Gambar 2.1. adalah linear. Ini berimplikasi untuk contoh
bahwa pendapatan bervariasi secara linear dengan konsumsi. Tentu saja
tidak ada alasan apriori mengapa pendapatan mempunyai hubungan
linear dengan konsumsi.
Pendapatan
X
90
60
30
0
Konsumsi
Distribusi Peluang bagi Y
Garis Regresi

Dua model regresi mungkin saja berbeda dalam hal bentuk fungsi
regresinya, dalam hal bentuk sebaran peluang bagi peubah X, atau dalam
hal lainnya lagi. Apapun perbedaannya, konsep sebaran peluang bagi X
untuk Y yang diketahui merupakan pasangan formal bagi diagram pencar
dalam suatu relasi statistik. Begitu pula, kurva regresi, yang menjelaskan
hubungan antara rataan sebaran-sebaran peluang bagi X dengan Y,
merupakan pasangan formal bagi kecenderungan umum bervariasinya X
secara sistematis terhadap Y dalam suatu hubungan statistik.
Ungkapan “peubah bebas” atau “peubah peramal” bagi X dan “peubah tak
bebas” atau “peubah respons” bagi Y dalam suatu model regresi adalah
kebiasaan saja. Tidak ada implikasi bahwa Y bergantung secara kausal
pada X. Betapa pun kuatnya suatu hubungan statistik, ini tidak
berimplikasi adanya hubungan sebab-akibat. Dalam kenyataannya, suatu
peubah bebas mungkin saja sesungguhnya bergantung secara kausal pada
peubah responsnya, seperti bila menduga suhu (respons) dari tinggi air
raksa (peubah bebas) dalam suatu termometer.
2.3. Bentuk Fungsional Hubungan Regresi
Pemilihan bentuk fungsional hubungan regresi terkait dengan pemilihan
peubah bebasnya. Ada kalanya, teori bilang ilmu bersangkutan bisa
menunjukkan bentuk fungsional yang cocok. Teori belajar, misalnya,
mungkin mengindikasikan bahwa fungsi regresi yang menghubungkan
biaya produksi dengan berapa kali suatu item tertentu telah pernah
muncul harus memiliki bentuk tertentu dengan sifat-sifat asimtotik
tertentu pula.
Yang lebih sering dijumpai adalah bahwa bentuk fungsional
hubungan regresi tersebut tidak diketahui sebelumnya, sehingga harus
ditetapkan setelah datanya diperoleh dan dianalisis. Oleh karenanya,
fungsi regresi linier atau kuadratik sering digunakan sebagai suatu model

yang cukup memuaskan bagi fungsi regresi yang tidak diketahui
bentuknya. Bahkan, kedua jenis fungsi regresi yang sederhana itu masih
juga sering digunakan meskipun teori yang mendasarinya menunjukkan
bentuk fungsionalnya, terutama bila bentuk fungsional yang ditunjukkan
oleh teori terlalu rumit namun secara logis bisa dihampiri oleh suatu
fungsi linier atau kuadratik.
2.4. Kegunaan Analisis Regresi
Analisis regresi setidak-tidaknya memiliki 3 kegunaan, yaitu :
1. untuk tujuan deskripsi dari fenomena data atau kasus yang sedang
diteliti, regresi mampu mendeskripsikan fenomena data melalui
terbentuknya suatu model hubungan yang bersifat numerik
2. untuk tujuan control, regresi juga dapat digunakan untuk melakukan
pengendalian (kontrol) terhadap suatu kasus atau hal-hal yang sedang
diamati melalui penggunaan model regresi yang diperoleh, serta
3. sebagai prediksi. model regresi juga dapat dimanfaatkan untuk
melakukan prediksi variabel terikat
2.5. Model Regresi Linear Sederhana dengan sebaran Suku-suku Galat
Tidak Diketahui
2.5.1. Model
Bentuk umum fungsi regresinya linear dapat dituliskan sebagai
berikut:
Yi = 0 + 1Xi + i (2.1)
Dalam hal ini :
Yi adalah nilai perubahan respons dalam amatan ke-i
0 dan 1 adalah parameter

Xi adalah konstanta yang diketahui, yaitu nilai peubah bebas dari
amatan ke-i
1 adalah suku galat yang bersifat acak dengan rataan E{i} = 0 dan
ragam 2{i} = 2; i dan j tidak berkorelasi sehingga peragam
(covariance) {I, j} = 0 untuk semua i, j; i j
i = 1, 2, . . . ., n
Model regresi (2.1) dikatakan sederhana, linear dalam parameter, dan
linier dalam peubah bebas. Dikatakan “sederhana” karena hanya ada
satu peubah bebas, “linear dalam parameter” karena tidak ada
parameter yang muncul sebagai salah satu eksponen atau dikalikan
atau dibagi oleh parameter lain, dan “linear dalam peubah bebas” sebab
peubah ini di dalam model berpangkat satu. Model yang linear dalam
parameter dan linear dalam peubah bebas juga dinamakan model ordo-
pertama.
2.5.2. Ciri-Ciri Penting Model Regresi
1. Nilai Yi teramati pada amatan ke-i merupakan jumlah dua
komponen yaitu :
a. suku konstan 0 + 1Xi dan
b. suku galat i. Jadi Yi adalah suatu peubah acak.
2. Karena E{i} = 0, maka peroleh :
E{Yi} = E{0 + 1Xi + i} = 0 + 1Xi + E{i} = 0 + 1Xi
0 + 1Xi memainkan peranan sebagai konstanta. Jadi, respons Yi
bila nilai X pada amatan ke-i adalah Xi berasal dari suatu sebaran
peluang yang rataannya adalah :

E{Yi} = 0 + 1Xi (2.2)
oleh karena itu peroleh fungsi regresi bagi model (2.1), yaitu :
E{Y} = 0 + 1X (2.3)
Karena fungsi regresi menghubungkan rataan sebaran peluang bagi
Y untuk X tertentu dengan nilai X itu sendiri.
3. Nilai teramati Y pada amatan ke-i lebih besar atau lebih kecil
daripada nilai fungsi regresi dengan selisih sebesar i.
4. Setiap suku galat i diasumsikan mempunyai ragam yang sama 2.
oleh karenanya, respons Yi mempunyai ragam yang sama pula :
2 {Yi} = 2 (2.4)
Karena, berdasarkan sifat variansi, memperoleh :
2{0 + 1Xi + i} = 2 {i) = 2
Jadi, model regresi (2.4) mengasumsikan bahwa sebaran peluang
bagi Y mempunyai ragam yang sama 2, tidak tergantung pada nilai
peubah bebas X.
5. Suku-suku galat diasumsikan tidak berkorelasi. Oleh karenanya,
hasil dari setiap amatan manapun yang mempengaruhi galat dari
amatan lain yang manapun baik posotof atau negatif, kecil atau
besar. Karena galat, i dan j tidak berkorelasi, maka begitu juga
dengan respons Yi dengan Yj.
6. Ringkasan model regresi mengimplementasikan bahwa peubah
respons Yi bersal dari sebaran peluang dengan rataan E{Yi) = 0 +
1Xi dan ragam 2 yang sama untuk semua nilai X. lebih lanjut, dua
amatan sembarang Yi dan dan Yj tidak berkorelasi.
Misalkan bahwa model regresi (2.1) dapat diterapkan pada contoh
hubungan pendapatan dengan konsumsi dan model itu sebagai
berikut : (lihat data 2.1.)

Yi = 0,484499 + 0,9199Xi + i
Pada Gambar 1.1 dapat dilihat fungsi regresi :
E{Y} = 0,484499 + 0,9199Xi
Gambar 2.2.
Misalnya bahwa suatu pendapatan Xi = 60 dan ternyata konsumsi yang
teramati ialah Y1 = 57. maka galatnya ialah I = +1,74, karena
E{Y1) = 0,48 + 0,92(60) = 55.26
dan
Yi = 57 = 55,26+1,74
Gambar 2.2 memperlihatkan sebaran peluang bagi Y untuk X= 60, dan
memperlihatkan dari mana di dalam sebaran ini amatan Y1 = 62 beasal.
Perhatikan sekali lagi bahwa suku galat I tidak lain adalah simpangan
Yi dari nilai rataannya E(Yi).
Gambar 2.2 juga memperhatikan sebaran peluang bagi Y bila X = 90.
Perhatikan bahwa sebaran ini mempunyai ragam yang sama seperti
sebaran peluang bagi Y untuk X = 90, sesuai dengan persyaratan model
regresi (2.1).
Y1 = 62
(Y1) = 2.8
E(Y1) = 59.2
E(Y) =0,48+0,92X
2
0
40 X
Pendapatan

2.5.3. Makna Parameter Regresi
Kedua parameter 0 dan 1 dalam model regresi (2.1) dinamakan
koefisien regresi. 1 adalah kemiringan (slope) garis regresi. Kemiringan
menunjukkan perubahan rataan sebaran peluang bagi Y untuk stiap
kenaikan X satu satuan. Parameter 0 adalah nilai intersep Y garis
regresi tersebut. Bila cakupan model tidak mencakup X = 0, maka 0
mempunyai makna sebagai rerata.
Gambar 2.3. memperlihatkan fungsi regresi :
E(Y) = 0,484499 + 0,9199 Xi
bagi contoh hubungan pendapatan dengan konsumsi. Kemiringan
1=0,9199 menunjukkan bahwa kenaikan pendapatan satu satuan
akan menaikkan rataan sebaran peluang bagi Y sebesar 0,9199 satuan.
Gambar 2.3. Fungsi regresi E(Y) = 0,484499 + 0,9199 Xi Intersep 0 = 0,4845 menunjukkan nilai fungsi pada X = 0. karena
model regresi linear ini diformulasikan untuk diterapkan pada
pendapatan yang berkisar antara 11 sampai 120, maka dalam hal ini 0
mempunyai makna rata-rata konsumsi pada waktu X sama dengan nol
adalah sebesar 0,4845.
50
Y
0 10 20 30 40 x
E(Y) = 0,48 + 0,92 X
1 = 0,92
Kemirinagn X
0 = 0,4845
Pendapatan
Konsumsi

2.5.4. Metode Kuadrat Terkecil
Tujuan metode kuadrat terkecil adalah menemukan nilai dugaan b0
dan b1 yang menghasilkan jumlah kesalahan kuadrat minimum. Dalam
pengertian tertentu, yang segera akan bahas, nilai dugaan itu akan
menghasilkan fungsi regresi linier yang “baik”.
Penduga Kuadrat Terkecil.
Penduga b0 dan b1 yang memenuhi kriterium kuadrat terkecil dapat
ditemukan dalam dua cara berikut :
Pendekatan Pertama, digunakan suatu prosedur pencarian numerik.
Prosedur ini untuk berbagai nilai dugaan b0 dan b1 yang berbeda
sampai diperoleh nilai dugaan yang meminimumkan.
Pendekatan kedua adalah menemukan nilai-nilai b0 dan b1 secara
analitis yang meminimumkan Jumlah Kesalahan Kuadrat (∑e2) .
Pendekatan analitis mungkin dilakukan bila model regresinya secara
sistematis tidak terlalu rumit, seperti halnya di sini. Dapat
diperlihatkan nilai-nilai b0 dan b1 yang meminimumkan (∑e2) untuk
data sampel yang dimiliki diberikan oleh sistem persamaan linear
berikut :
ii Xbnby 10 (2.5a)
2
101 iii XbXbYX (2.5b)
Persamaan (2.5a) dan (2.5b) dinamakan persamaan normal; b0 dan b1
dinamakan penduga titik (point estimator) bagi 0 dan 1.
Besaran-besaran Yi, Xi, dan seterusnya di dalam (2.5)
dihitung dari amatan-amatan sampel(Xi, Yi). Dengan demikian, kedua

persamaan itu bisa diselesaikan. Untuk memperoleh b0 dan b1 bisa
dihitung secara langsung menggunakan rumus :
1 2 2
2
i ii i
i i
i ii
X YX Y X X Y Ynb
X X XX
n
(2.6a)
0 1
1i i ib Y b X Y b X
n (2.6b)
dalam hal ini X dan Y berturut-turut adalah rataan Xi dan rataan Yi.
Persamaan normal (2.5) dapat diturunkan secara kalkulus. Untuk suatu
data amatan (Xi, Yi), besaran ∑e2 dalam (2.1) merupakan suatu fungsi
0 dan 1 yang meminimumkan ∑e2 dapat diturunkan dengan cara
mendiferensialkan:
∑e2 = ∑(Yi - 0 - 1Xi)2 terhadap 0 dan 1 . peroleh:
0 1
0
2 ( )i i
QY X
(2.7)
0 1
1
2 ( )i i i
QX Y X
(2.8)
Selanjutnya kedua turunan parsial ini disamakan dengan nol, dan
dengan menggunakan 0b dan 1b untuk menyatakan 0 dan 1 yang
meminimumkan (∑e2), maka:
0 1( ) 0i iY X (2.9)
0 1( ) 0i i iX Y X (2.10)

Sistem persamaan ini dinamakan persamaan normal. Dengan
menyelesaikan persamaan-persamaan normal ini diperoleh:
1 2 2
( )( )
( )
i i i i
i i
n X Y X Yb
n X X
(2.11)
0 1b Y b X (2.12)
Rumus terakhir ini merupakan versi lain dari rumusan yang telah
disajikan di depan, namun akan menghjasilkan nilai yang sama
(pembaca dapat membuktikannya).
Penduga kuadrat terkecil ini ialah penduga tak bias dan merupakan
fungsi linear dari iY , yaitu:
a. 0 0( )E b dan 1 1( )E b (jadi merupakan penduga tak bias).
b. 1 2 2
( )( )
( )
i i i i
i i
n X Y X Yb
n X X
2
( )
( )
i i
i i
i
X X Yk Y
X X
dimana:
2
( )
( )
i
i
i
X Xk
X X
(2.13)
0
1i i i i ib Y X k Y bY
n
(2.14)
dimana:

1
( )i ib Xkn
(2.15)
(jadi baik 1b maupun 0b merupakan kombinasi linear atau fungsi
linear dari iY ).
2.6. Asumsi-Asumsi Metode Kuadrat Terkecil
Metode OLS yang dikenal sebagai metode Gaussian merupakan
landasan utama di dalam teori ekonometrika. Metode OLS ini dibangun
dengan menggunakan asumsi-asumsi tertentu. Misalkan mempunyai
model regresi populasi sederhana sbb:
iii eXY 10 (2.16)
Asumsi yang berkaitan dengan model garis regresi linier dua variabel
tersebut adalah sbb:
Asumsi 1
Hubungan antara Y (variabel dependen) dan X (variabel independen)
adalah linier dalam parameter. Model regresi yang linier dalam parameter
dapat dilihat dalam persamaan (2.16). Dalam hal ini 1 berhubungan linier
terhadap Y.
Asumsi 2
Variabel X adalah variabel tidak stokastik yang nilainya tetap. Nilai X
adalah tetap untuk berbagai observasi yang berulang-ulang. Kembali
dalam kasus hubungan jumlah permintaan barang dengan tingkat
harganya, untuk mengetahui tingkat variasi jumlah permintaan barang
maka melakukan berbagai observasi pada tingkat harga tertentu. Jadi
dengan sampel yang berulang-ulang nilai variabel independen (X) adalah

tetap atau dengan kata lain variabel independen (X) adalah variabel yang
dikontrol.
Asumsi 3
Nila harapan (expected value) atau rata-rata dari variabel gangguan ei
adalah nol atau dapat dinyatakan sbb:
0 ii Xe (2.17)
Karena mengasumsikan bahwa nilai harapan dari Y hanya dipengaruhi
oleh variabel independen yang ada atau dapat dinyatakan sbb:
iXY 10 (2.18)
Asumsi 4
Varian dari variabel gangguan ei adalah sama (homoskedastisitas) atau
dapat dinyatakan sbb:
2iiiii XeeXeVar (2.19)
ii Xe2 karena asumsi 3
2
Asumsi 5
Tidak ada serial korelasi antara gangguan ei atau gangguan ei tidak saling
berhubungan dengan ej yang lain atau dapat dinyatakan sbb:
jjjiiijiji XeEeXeeXXeeCov )()(,, (2.20)
jjii XeXe
0
Asumsi 6
Variabel gangguan ei berdistribusi normal
e ~ N(0, 2) (2.21)

Asumsi 1 sampai 5 dikenal dengan model regresi linier klasik (Classical
Linear Regression Model).
Dengan asumsi-asumsi di atas pada model regresi linier klasik,
model kuadrat terkecil (OLS) memiliki sifat ideal dikenal dengan teorema
Gauss-Markov (Gauss-Markov Theorem). Metode kuadrat terkecil akan
menghasilkan estimator yang mempunyai sifat tidak bias, linier dan
mempunyai varian yang minimum (best linear unbiased estimators =
BLUE). Penjelasan detil tentang estimator yang BLUE bisa dilihat dalam
Lampiran 1.2. Suatu estimator 1 dikatakan mempunyai sifat yang BLUE
jika memenuhi kriteria sbb:
1. Estimator 1 adalah linier (linear), yaitu linier terhadap variabel
stokastik Y sebagai variabel dependen
2. Estimator 1 tidak bias, yaitu nilai rata rata atau nilai harapan
)ˆ( 1E sama dengan nilai 1 yang sebenarnya.
3. Estimator 1 mempunyai varian yang minimum. Estimator yang
tidak bias dengan varian minimum disebut estimator yang efisien
(efficient estimator).
Dengan demikian jika persamaan (2.16) memenuhi asumsi-asumsi
tersebut di atas maka nilai koefisien 1 dalam persamaan tersebut dapat
diartikan sebagai nilai harapan (expected value) atau rata-rata dari nilai Y
pada nilai tertentu variabel independen X. Catatan penting dalam teorema
Gauss-Markov adalah bahwa teorema ini hanya berlaku untuk regresi
linear dan tidak berlaku untuk non linear.
2.7. Standard Error dari OLS
Regresi sampel yang lakukan merupakan cara untuk mengestimasi
regresi populasi. Karena itu, estimator 0 dan 1 yang diperoleh dari

metode OLS adalah variabel yang sifatnya acak atau random yaitu nilainya
berubah dari satu sampel ke sampel yang lain. Adanya variabilitas
estimator ini maka membutuhkan ketepatan dari estimator 0 dan 1 . Di
dalam statistika untuk mengetahui ketepatan estimator OLS ini diukur
dengan menggunakan kesalahan standar (Standard error). Dengan kata
lain standard error mengukur ketepatan estimasi dari estimator 0 dan 1 .
Formula standard error bagi 0 dan 1 dapat ditulis sbb :
2
2
2
0 )ˆ( i
i
xn
XVar
(2.22)
2
2
2
00 )ˆ()ˆ( i
i
xn
XVarSe
(2.23)
2
2
1)ˆ(ix
Var
(2.24)
2
2
11 )ˆ()ˆ(ix
VarSe
(2.25)
Dimana var adalah varian, se adalah standard error dan 2 adalah
varian yang konstan (homoskedastik). Penurunan formula varian
estimator i secara detil bisa dilihat dalam Lampiran 1.2.
Semua variabel dalam perhitungan standard error di atas dapat
diestimasi dari data yang ada kecuali 2 . Nilai estimasi dari 2 dapat
dihitung dengan formula sbb:
kn
ei
22 ˆ
(2.26)
dimana: XXx ii
n = jumlah observasi
k = jumlah parameter estimasi yaitu 0 dan 1 .
2ˆie adalah jumlah residual kuadrat (residual sum of squares =RSS).
n-k dikenal dengan jumlah derajat kebebasan (number of degree of

freedom) disingkat sebagai df. df ini berarti jumlah observasi (n) dikurangi
dengan jumlah paremeter estimasi. Semakin kecil standard error dari
estimator maka semakin kecil variabilitas dari angka estimator dan berarti
semakin dipercaya nilai estimator yang didapat. Bagaimana varian dan
standard error dari estimator mampu membuat keputusan tentang
kebenaran dari estimator akan dijelaskan dalam bab berikutnya.
2.8. Koefisien Determinasi (R2)
Jika semua data terletak pada garis regresi atau dengan kata lain semua
nilai residual adalah nol maka mempunyai garis regresi yang sempurna.
Tetapi garis regresi yang sempurna ini jarang jumpai. Pada umumnya
yang terjadi adalah ie bisa positif maupun negatif. Jika ini terjadi berarti
merupakan garis regresi yang tidak seratus persen sempurna. Namun
yang harapkan adalah bahwa mencoba mendapatkan garis regresi yang
menyebabkan ie sekecil mungkin. Dalam mengukur seberapa baik garis
regresi cocok dengan datanya atau mengukur persentase total variasi Y
yang dijelaskan oleh garis regresi digunakan konsep koefisien determinasi
(R2).
Konsep koefisein determinasi dapat jelaskan melalui persamaan
sebelumnya sbb:
iii eYY ˆˆ (2.27 )
Kedua sisi persamaan (2.27) kemudian dikurangi dengan nilai rata-rata Y
)(Y sehingga akan dapatkan persamaan sbb:
YeYYY iii ˆˆ (2.28)
Persamaan (2.28) kemudian dapat ditulis kembali menjadi persamaan
sbb:
iii eYYYY ˆ)ˆ()(

)ˆ()ˆ()( iiii YYYYYY (2.29)
)( YYi adalah variasi di dalam Y dari nilai rata-ratanya dan total dari
penjumlahan kuadrat nilai ini disebut total sum of squares (TSS).
)ˆ( YYi adalah variasi prediksi Y )ˆ( iY terhadap nilai rata ratanya atau
variasi garis regresi dari nilai rata-ratanya dan total dari penjumlahan
kuadrat nilai ini disebut explained sum of squares (ESS). )ˆ( ii YY atau
residual e adalah variasi dari Y yang tidak dijelaskan oleh garis regresi
atau variasi Y yang dijelaskan oleh variabel residual dan nilai total dari
penjumlahan kuadratnya disebut residual sum of squares (RSS). Dengan
demikian maka persamaan (2.28) dapat ditulis kembali menjadi
persamaan sbb:
222 )ˆ()ˆ()( iiii YYYYYY (2.30)
atau dapat dinyatakan sebagai:
TSS = ESS + RSS (2.31)
Persamaan (2.31) ini menunjukkan bahwa total variasi dari Y dari
nilai rata-ratanya dijelaskan oleh dua bagian, bagian pertama terkait
dengan garis regresi dan satu bagian lainya oleh variabel residual yang
random karena tidak semua data Y terletak pada garis regresi. Penjelasan
ketiga konsep dapat dilihat pada gambar 2.5.

Y
ie = variasi karena residual
variasi total )( YY
Ŷ
)ˆ( YY = variasi karena regresi
Y
ii XY 10ˆˆˆ
Xi X Gambar 2.5.
Variasi nilai Y yang dijelaskan oleh Y dan residual ie
Jika garis regresi menjelaskan data dengan baik maka ESS akan
lebih besar dari RSS. Pada kasus ekstrim bila semua garis regresi cocok
dengan datanya maka ESS sama dengan TSS dan RSS sama dengan nol. Di
lain pihak jika garis regresi kurang baik menjelaskan datanya RSS akan
lebih besar dari ESS. Pada kasus ekstrim jika garis regresi tidak
menjelaskan semua variasi nilai Y maka ESS sama dengan nol dan RSS
sama dengan TSS. Oleh karena itu jika nilai ESS lebih besar dari RSS maka
garis regresi menjelaskan dengan proporsi yang besar dari variasi Y
sedangkan jika RSS lebih besar dari ESS maka garis regresi hanya
menjelaskan bagian kecil dari variasi Y.
Dari penjelasan ini dapat didefinisikan bahwa R2 sebagai rasio
antara ESS dibagi dengan TSS. Formula R2 dengan demikian dapat ditulis
sbb:
TSS
ESSR 2 (2.32)
2
2
)(
)ˆ(
YY
YY
i
i
Karena TSS = ESS + RSS, maka sebagai alternatifnya:

TSS
ESSR 2 (2.33)
TSS
RSSTSS
TSS
RSS 1
2
2
)(
ˆ1
YY
e
i
i
Dari formula persamaan (2.30) tersebut dengan demikian R2 dapat
didefiniskan sebagai proporsi atau persentase dari total variasi variabel
dependen Y yang dijelaskan oleh garis regresi (variabel independen X).
Jika garis regresi tepat pada semua data Y maka ESS sama dengan TSS
sehingga R2 = 1, sedangkan jika garis regresi tepat pada rata-rata nilai Y
maka ESS=0 sehingga R2 sama dengan nol. Dengan demikian, nilai
koefisien determinasi ini terletak antara 0 dan 1.
0 R2 1 (2.34)
Semakin angkanya mendekati 1 maka semakin baik garis regresi karena
mampu menjelaskan data aktualnya. Semakin mendekati angka nol maka
mempunyai garis regresi yang kurang baik. Misalnya, jika R2 = 0,9889,
artinya bahwa garis regresi menjelaskan sebesar 98,89% fakta sedangkan
sisanya sebesar 1,11% dijelaskan oleh variabel residual yaitu variabel
diluar model yang tidak dimasukkan dalam model.
Koefisien determinasi hanyalah konsep statistik. mengatakan
bahwa sebuah garis regresi adalah baik jika nilai R2 tinggi dan sebaliknya
bila nilai R2 adalah rendah maka mempunyai garis regresi yang kurang
baik. Namun demikian, harus memahami bahwa rendahnya nilai R2 dapat
terjadi karena beberapa alasan. Dalam kasus khusus variabel independen
(X) mungkin bukan variabel yang menjelaskan dengan baik terhadap
variabel dependen (Y) walaupun percaya bahwa X mampu menjelaskan Y.
Akan tetapi, dalam regresi runtut waktu (time series) seringkali

mendapatkan nilai R2 yang tinggi. Hal ini terjadi hanya karena setiap
variabel yang berkembang dalam runtut waktu mampu menjelaskan
dengan baik variasi variabel lain yang juga berkembang dalam waktu yang
sama. Dengan kata lain data runtut waktu diduga mengandung unsur
trend yakni bergerak dalam arah yang sama. Di lain pihak, dalam data
antar tempat atau antar ruang (cross section) akan menghasilkan nilai R2
yang rendah. Hal ini terjadi karena adanya variasi yang besar antara
variabel yang diteliti pada periode waktu yang sama.
2.9. Koefisien Korelasi (r)
Konsep yang sangat erat kaitannya dengan koefisien determinasi
(R2) adalah koefisien korelasi (r). R2 adalah koefisien yang menjelaskan
hubungan antara variabel dependen (Y) dengan variabel independen (Y)
dalam suatu model. Sedangkan koefisien korelasi (r) mengukur derajat
keeratan antara dua variabel. Koefisien korelasi (r) antara X dan Y dapat
didefinisikan sbb:
)()var(
),cov(
ii
ii
YVarX
YXr
(2.35)
dimana:
1
))((
),cov( 1
n
YYXX
YX
n
n
ii
ii (2.36)
1
)(
)var( 1
2
n
XX
X
n
n
i
i (2.37)
1
)(
)var( 1
2
n
YY
Y
n
n
i
i (2.38)
sehingga dapat menulis formula untuk koefisien korelasi sbb:

n
n
n
n
ii
n
n
ii
YYXX
YYXX
r
1 1
22
1
)()(
))((
(2.39)
Contoh perhitungan regresi linear sederhana
Dari tabel 2.1 diketahui data konsumsi dan pendapatan penduduk suatu
daerah sebagai berikut :
Tahun Konsumsi Pendapatan
2006 14 15 2007 17 19 2008 19 20 2009 20 22 2010 22 25 2011 25 30
2012 30 32 2013 32 34
2014 33 35 2015 37 45 2016 40 50
Sumber : data hipotesis
Dari data diatas maka dapat kita analisis sbb :
a. Persamaan regresi linear
b. Jelaskan arti persamaan tersebut berdasarkan teori ekonomi (teori
konsumsi menurut pandangan Keynes)
c. Ujilah persamaan tersebut dengan pendekatan statistic (uji t, F
hitung dan koefisien determinasi (R2)

Untuk bisa menjawab pertanyaan diatas maka saudara harus buat tabel isian sebagai berikut :
SUMMARY OUTPUT
Regression Statistics Multiple R …………….........
R Square …………….....… Adj R Square ……………....… Stand Error 1.706706
Observations ……………....…
ANOVA df SS MS F Sign F
Regression ………….......…. ……………… …………. ………… 7.587E-08 Residual ………….......…. ………………. ….………
Total …………......…. ………………
Coefficients Stand Error t Stat P-value Intercept ………….......… …………..…. …...….….. 0.060917
Pendapatan …………......… ……………… …...…….. 7.59E-08
Jawab: Missal Y = konsumsi X = pendapatan Maka persamaan regresi Y = b0 + b1X Persamaan tersebut dapat dicari dengan bantuan table sebagai berikut :
Tahun Y X YX X2
2006 14 15 210 225 2007 17 19 323 361 2008 19 20 380 400 2009 20 22 440 484 2010 22 25 550 625 2011 25 30 750 900
2012 30 32 960 1024 2013 32 34 1088 1156
2014 33 35 1155 1225 2015 37 45 1665 2025 2016 40 50 2000 2500
Σ 289 327 9521 10925

Sehingga dari bantuan table dapat disusun persamaan :
Σ Y = n b0 + b1ΣX
Σ YX = b0 ΣX + b1ΣX2
289 = 11 b0 + 327 b1 kalikan 327
9521 = 327 b0 + 10925 b1
11
94503 = 3597 b0 + 106929 b1
104731 = 3597 b0 + 120175 b1 kurangkan
-10228 = -13246 b1
b1 = 0.772
Setelah b1 diketahui maka dapat kita cari b0 melalui :
289 = 11 bo + 327 b1 masukan b1 = 0,772 diperoleh b0 = 3,318
Ujilah dengan persamaan lainnya
9521 = 327 b0 + 10925 b1 masukan b1 = 0,772 diperoleh b0 = 3,318
Dari hasil diatas dapat disusun persamaan regresi sebagai berikut :
C = 3,318 + 0,772 Y
Artinya :
Konstatnta = b0 =
3,318
jika factor lain tidak berubah maka rata-rata konsumsi
sebesar 3,318 satuan
Koefisien b1=0,772 jika factor lain tetap maka kenaikan pendapatan sebesar
1000 satuan akan meningkatkan konsumsi sebesar 0,772
x 1000 atau sebesar 772 satuan.

Hasil persamaan regresi dapat kita tuliskan ke dalam table berikut ini
Coefficients Stand Error t Stat P-value
Intercept 3,318 ………………….. ……………... 0.060917 Pendapatan 0,772 …………………... ……………… 7.59E-08
Untuk menguji hipotesis apakah adan pengaruh secara individu antara
pendapatan terhadap konsumsi maka kita harus mencari Standar Deviasi dari
masing-masing koefisien.
Untuk mencarai standar deviasi kita bias menggunakan formula sebagai berikut :
sehingga
sehingga
Dimana dan atau
Ingat : dan
Sehingga dapat kita cari dengan bantuan table sebagai berikut :

Tahun Y X YX X^2 y x y^2 x^2 Y' u u^2
2006 14 15 210 225 -12.2727 -14.7273 150.6198 216.8926 14.90095 -0.90095 0.811713
2007 17 19 323 361 -9.27273 -10.7273 85.98347 115.0744 17.98958 -0.98958 0.979272
2008 19 20 380 400 -7.27273 -9.72727 52.89256 94.61983 18.76174 0.238261 0.056768
2009 20 22 440 484 -6.27273 -7.72727 39.34711 59.71074 20.30605 -0.30605 0.093669
2010 22 25 550 625 -4.27273 -4.72727 18.2562 22.34711 22.62253 -0.62253 0.387541
2011 25 30 750 900 -1.27273 0.272727 1.619835 0.07438 26.48332 -1.48332 2.200226
2012 30 32 960 1024 3.727273 2.272727 13.89256 5.165289 28.02763 1.972369 3.89024
2013 32 34 1088 1156 5.727273 4.272727 32.80165 18.2562 29.57195 2.428054 5.895445
2014 33 35 1155 1225 6.727273 5.272727 45.2562 27.80165 30.3441 2.655896 7.053784
2015 37 45 1665 2025 10.72727 15.27273 115.0744 233.2562 38.06568 -1.06568 1.135674
2016 40 50 2000 2500 13.72727 20.27273 188.438 410.9835 41.92647 -1.92647 3.71128
Σ 289 327 9521 10925 0 0 744.1818 1204.182 289 0 26.21561
= 26,21561

Sehingga = 26,21561/(11-2) = 2.912846
Sehingga = 2,912846/1204,182=0.002419
= (0,002419)0,5 = 0.049183
Dan = = 2.402449
= 1.549984
Sehingga dapat disusun :
Hasil persamaan regresi dapat kita tuliskan ke dalam table berikut ini
Coefficients Standard Error t Stat P-value
Intercept 3,318 1.549984 2,141046 0.060917
Pendapatan 0,772 0.049183 15.69977 7.59E-08
2.141046 = 3.318 / 1.549984
15.69977 = 0.772/0.04918
Dari hasil analisis uji t diperoleh hasil sbb :
Bahwa pendapatan mempengaruhi konsumsi secara signifikan hal ini di buktikan
dengan dengan nilai t hitung lebih besar t table atau nilai α = 0,05 > p. value =
0,0000000759
Sedangkan uji secara keseluruhan bisa dicari dengan ANOVA
ANOVA dapat dicari dengan mengisi table di bawah ini :

SUMMARY OUTPUT
Regression Statistics Multiple R 0.98228
R Square 0.96477 Adjusted R Square ……………… Standard Error 1.706706
Observations ………………...
ANOVA df SS MS F Significance F
Regression …………….….. …………………..……. ……………… ……………… 7.58751E-08
Residual …………….….. 26.21561 ….………….. Total …………….…..
Tahun Y X y x yx y^2 x^2 Y' y' u u^2
2006 14 15 -12.273 -14.727 180.744 150.620 216.893 14.901 -11.372 -0.901 0.812
2007 17 19 -9.273 -10.727 99.471 85.983 115.074 17.990 -8.283 -0.990 0.979
2008 19 20 -7.273 -9.727 70.744 52.893 94.620 18.762 -7.511 0.238 0.057
2009 20 22 -6.273 -7.727 48.471 39.347 59.711 20.306 -5.967 -0.306 0.094
2010 22 25 -4.273 -4.727 20.198 18.256 22.347 22.623 -3.650 -0.623 0.388
2011 25 30 -1.273 0.273 -0.347 1.620 0.074 26.483 0.211 -1.483 2.200
2012 30 32 3.727 2.273 8.471 13.893 5.165 28.028 1.755 1.972 3.890
2013 32 34 5.727 4.273 24.471 32.802 18.256 29.572 3.299 2.428 5.895
2014 33 35 6.727 5.273 35.471 45.256 27.802 30.344 4.071 2.656 7.054
2015 37 45 10.727 15.273 163.835 115.074 233.256 38.066 11.793 -1.066 1.136
2016 40 50 13.727 20.273 278.289 188.438 410.983 41.926 15.654 -1.926 3.711
Σ 289 327 0 0 929.8182 744.1818 1204.182 289 0 0 26.21561
= =
Sehingga r2 = 0.96477

Setelah r diketahui maka anova dapat kita susus sebagai berikut :
Regression Statistics Multiple R 0.98228
R Square 0.96477 1-R2=0.035 Adj R Square 0.96085
Stand Error 1.706706
Observations 11
ANOVA df SS MS F Sign F
Regression (k-1) =1 717.9118382 717.91 82.15 7.59E-08 Residual (n-k) =3 ∑u2 = 26.21561 8.73
Total
(k-1)+(n-k) = 4 ∑y2 = 744.1274482
R2 = 717.9118382 / 744.1274482 = 0.96477
Nilai R2 = 0,96477 merupakan nilai koefisien determinasi yang mengartikan
bahwa variable bebas dapat menjelaskan variable terikat sebesar 96,4 persen, dan
sisanya 0.03523 persen dijelaskan oleh variable lain.
2.10. Uji Hipotesis
Hipotesis merupakan pernyataan tentang sifat populasi sedangkan uji hipotesis
adalah suatu prosedur untuk pembuktian kebenaran sifat populasi berdasarkan
data sampel.
Seseorang yang melakukan penelitian akan lebih banyak menggunakan data sampel
daripada data populasi. Dari sampel yang diambil kemudian dapat jadikan sebagai
alat untuk verifikasi kebenaran populasi. Di dalam melakukan penelitian
berdasarkan sampel, seorang peneliti dengan demikian harus menyatakan secara

jelas hipotesis penelitian yang dilakukan untuk dibuktikan kebenarannya melalui
penelitian dari data sampel.
Dalam statistika, hipotesis yang ingin uji kebenarannya tersebut biasanya
bandingkan dengan hipotesis yang salah yang nantinya akan tolak. Hipotesis yang
salah dinyatakan sebagai hipotesis nol (null hypothesis) disimbolkan H0 dan
hipotesis yang benar dinyatakan sebagai hipotesis alternatif (alternative hypothesis)
dengan simbol Ha. Dalam menguji kebenaran hipotesis dari data sampel, statistika
telah mengembangkan uji t. Uji t merupakan suatu prosedur yang mana hasil sampel
dapat digunakan untuk verifikasi kebenaran atau kesalahan hipotesis nol (H0).
Keputusan untuk menerima atau menolak H0 dibuat berdasarkan nilai uji statistik
yang diperoleh dari data.
Hal yang penting dalam hipotesis penelitian yang menggunakan data sampel dengan
menggunakan uji t adalah masalah pemilihan apakah menggunakan dua sisi atau
satu sisi. Uji hipotesis dua sisi dipilih jika tidak punya dugaan kuat atau dasar teori
yang kuat dalam penelitian, sebaliknya memilih satu sisi jika peneliti mempunyai
landasan teori atau dugaan yang kuat.
Misalnya menguji hubungan antara pendapatan terhadap konsumsi pada hitungan
sebelumnya. Karena mempunyai landasan teori atau dugaan yang kuat bahwa
terdapat hubungan yang positif antara jumlah pendapatan terhadap konsumsi maka
menggunakan uji satu sisi. Adapan hipotesis nol dan hipotesis alternatif dapat
dinyatakan sbb:
H0 : 1 ≤ 0 (2.45)
Ha : 1 > 0
Hipotesis nol atau hipotesis salah yakni menyatakan bahwa pendapatan tidak
berpengaruh dan atau berpengaruh negatif terhadap konsumsi yang ditunjukkan
oleh koefiesin 1 0. Sedangkan hipotesis alternatif menyatakan bahwa pendapatan
berpengaruh positif terhadap konsumsi yang ditunjukkan oleh 1 > 0.

Namun misalnya hubungan antara dua variabel dalam persamaan regresi bisa
positif maupun negatif maka prosedur uji hipotesis harus dilakukan dengan uji dua
sisi. Dalam kasus hubungan antara jumlah pendapatan terhadap konsumsi. Jumlah
pendapatan dan konsumsi bisa berhubungan positif atau negatif tergantung dari
jenis barangnya. Jika barang kualitas rendah (inferior) maka hubungan antara
jumlah konsumsi barang dan pendapatan akan negatif yakni semakin tinggi
pendapatan seseorang maka jumlah konsumsi barang inferior akan semakin kecil.
Sedangkan jika barang adalah normal atau barang mewah maka hubungannya akan
positif karena semakin tinggi pendapatan seseorang maka semakin besar jumlah
konsumsi kedua jenis barang ini. Hipotesis dua sisi ini dapat dinyatakan sbb:
H0 : 1 = 0 (2.46)
Ha : 1 0
Dalam hipotesis alternatif disini dinyatakan bahwa pendapatan bisa mempunyai
hubungan positif atau negatif tergantung jenis barangnya dilihat dari koefisien
pendapatan yang nilainya tidak sama dengan nol yakni 1 0. Sedangkan hipotesis
nolnya adalah pendapatan tidak berpengaruh terhadap jumlah konsumsin barang
ditunjukkan oleh nilai koefisien 1 = 0.
Misalkan dalam kasus hubungan antara jumlah pendapatan dan tingkat
konsumsi, kita akan menguji dari data yang pilih dari tahun 2006 sampai dengan
2016. Pertanyaannya, apakah memang terhadap hubungan yang positif antara
pendapatan dan tingkat konsumsi melalui uji t? Karena pendapatan mempunyai
pengaruh yang positif terhadap konsumsi maka uji yang digunakan adalah uji satu
sisi bukan uji dua sisi. Adapun prosedur uji t dengan uji satu sisi adalah sbb:
1. Membuat hipotesis melalui uji satu sisi
Uji hipotesis negatif satu sisi
H0 : 1 ≤ 0 (2.47)
Ha : 1 > 0

2. Menghitung nilai satisitik t ( t hitung) dan mencari nilai t kritis dari tabel
distribusi t pada dan degree of freedom tertentu. Adapun nilai t hitung dapat
dicari dengan formula sbb:
)ˆ(
ˆ
1
11
set
(2.48)
Dimana
1 merupakan nilai pada hipotesis nol
3. Membandingkan nilai t hitung dengan t kritisnya. Keputusan menolak atau
menerima H0 sbb:
jika nilai t hitung > nilai t kritis maka H0 ditolak atau menerima Ha
jika nilai t hitung < nilai t kritis maka H0 diterima atau menolak Ha
Jika menolak hipotesis nol H0 atau menerima hipotesisi alternatif Ha berarti
secara statistik variabel independen signifikan mempengaruhi variabel
dependen dan sebaliknya jika menerima H0 dan menolak H1 berarti secara
statistik variabel independen tidak signifikan mempengaruhi variabel dependen.
f(t) menolak H0 menerima H0 menolak H0 menerima Ha menolak Ha menerima Ha
/2 1- /2
- tc 0 tc t
Gambar 2.6.
Daerah penolakan (penerimaan) H0: 1=0 dan Ha: 1 0

Keputusan menolak hipotesis nol (H0) atau menerima hipotesis alternatif Ha
dapat juga dijelaskan melalui distribusi probabilitas t seperti terlihat dalam gambar
2.6. Nilai tc diperoleh dari nilai t kritis dari distribusi tabel t dengan dan degree of
freedom tertentu. Pada gambar 2.6. menjelaskan keputusan menolak hipotesis nol
atau tidak berdasarkan uji dua sisi, gambar 1.6. menjelaskan keputusan menolak
hipotesis nol dengan hipotesis alternatif positif dan gambar 2.6. menjelaskan
keputusan menolak hipotesis nol jika hipotesis alternatifnya adalah negatif.
Uji Hipotesis Pengaruh Pendapatan Terhadap Konsumsi
Ambil contoh kembali hubungan antara konsumsi dengan pendapatan. Hasil
regresinya tampilkan kembali disini sbb:
ii XC 772,0318,3 (2.49)
se (1,549) (0,049)
R2 = 0,964
Dengan menggunakan = 5% tentukanlah apakah pendapatan berpengaruh positif
terhadap jumlah konsumsi. Misalkan hipotesis nol H0 = 0. Langkah uji hipotesisnya
sebagai berikut:
1. uji satu sisi
H0 : 1 ≤ 0 (2.50)
Ha : 1 > 0
2. Menghitung t hitung dan mencari nilai t kritis dari tabel dengan = 5% dan df
sebesar 9 yakni 11-2. Besarnya t hitung sbb:
69,15049,0
772,0t (2.51)
Dimana nilai 0 merupakan nilai 1 dalam hipotesis nol. Sedangkan nilai t kritis
diperoleh dari t tabel yakni sebesar 1,8331 dengan = 5% dan df 9.

3. Keputusannya karena t hitung lebih besar dari nilai t kritis maka menolak H0
atau menerima Ha, lihat juga melalui gambar 2.6. Artinya, pendapatan
berpengaruh positif terhadap jumlah konsumsi. Dengan nilai 1 = -225 berarti
jika pendapatan naik satu juta rupiah, maka jumlah konsumsi akan
bertambah sebesar 772 ribu rupiah.

Latihan Soal
Diketahui data permintaan barang Q dan harga barang Q di suatu daerah sebagai
berikut :
Tahun Permintaan Harga
2006 14 20 2007 17 19 2008 19 19 2009 20 17 2010 22 16 2011 25 15
2012 30 15 2013 32 16 2014 33 18 2015 34 17 2016 37 17
Sumber : data hipotesis
Dari data diatas maka dapat kita analisis sbb :
a. Persamaan regresi linear
b. Jelaskan arti persamaan tersebut berdasarkan teori ekonomi (teori permintaan
akan suatu baran)
c. Ujilah persamaan tersebut dengan pendekatan statistic (uji t, F hitung dan
koefisien determinasi (R2)


REGRESI BERGANDA
Dalam praktek sebetulnya banyak sekali faktor yang mempengaruhi suatu variabel
terikat (dependent Variable), tidak hanya satu variabel. Contoh yang paling nyata
adalah permintaan akan barang X. Permintaan akan barang X oleh konsumen tidak
hanya dipengaruhi oleh faktor harga, tetapi juga bisa dipengaruhi oleh faktor harga
barang lain, pendapatan konsumen dan sebagainya. Untuk membuat analisis
pengaruh berbagai macam faktor independen terhadap variabel dependen bisa
menggunakan analisis regresi berganda.
3.1. Analisis Regresi Berganda
Ada beberapa asumsi OLS yang digunakan dalam regresi berganda. Selain
enam asumsi pada regresi sederhana, perlu menambah satu asumsi lagi di
dalamnya. Adapun asumsinya sbb:
1. Hubungan antara Y (variabel dependen) dan X (variabel independen)
adalah linier dalam parameter.
2. Nilai X nilainya tetap untuk obervasi yang berulang-ulang (non-stocastic).
Karena variabel independennya lebih dari satu maka ditambah asumsi tidak
BAB
3

ada hubungan linier antara variabel independen atau tidak ada
multikolinieritas antara X1 dan X2 dalam persamaan.
3. Nila harapan (expected value) atau rata-rata dari variabel gangguan ei
adalah nol.
0 iXe (3.1)
4. Varian dari variabel gangguan ei adalah sama (homoskedastisitas).
2iiiii XeeXeVar (3.2)
ii Xe2 karena asumsi 3
2
5. Tidak ada serial korelasi antara variabel gangguan ei atau variabel
gangguan ei tidak saling berhubungan dengan variabel gangguan ej yang
lain.
jjjiiijiji XeeXeeXXeeCov )()(,, (3.3)
jjii XeXe
0
6. Variabel gangguan ei berdistribusi normal
e ~ N(0, 2)
Jika regresi berganda memenuhi 6 asumsi diatas maka persamaan
(3.3) dapat diartikan sbb:
iiiiii eXXXXY 2211021 ),( (3.4)

Arti persamaan (3.4) tersebut adalah nilai harapan (expected value) atau rata-
rata dari Y pada nilai tertentu variabel independen X1 dan X2.
Dalam hal ini mengartikan 1 dan 2 agak sedikit berbeda dari regresi
sederhana sebelumnya. 1 adalah mengukur perubahan rata-rata Y atau nilai
harapan E (YX1, X2), terhadap perubahan per unit X1 dengan asumsi variabel
X2 tetap. Begitu pula 2 adalah mengukur perubahan rata-rata Y atau nilai
harapan E (YX1, X2), terhadap perubahan per unit X2 dengan asumsi variabel
X1 tetap
3.2. Estimasi OLS Terhadap Koefisien Regresi Berganda
Bagaimana caranya agar mendapatkan garis regresi yang sedekat
mungkin dengan datanya bila mempunyai model regresi berganda. Apakah
caranya sama dengan regresi sederhana sebelumnya dengan metode OLS. Jika
keenam asumsi yang bangun pada subbab 3.1 terpenuhi maka metode OLS
akan tetap mampu mendapatkan 10ˆ,ˆ dan 2 yang BLUE sehingga
menyebabkan garis regresi sedekat mungkin pada data aktualnya.
Prosedurnya sama sebagaimana regresi sederhana sebelumnya pada subbab
3.2.
Misalkan mempunyai model regresi sampel sbb:
iiii eXXY ˆˆˆˆˆ22110 (3.5)
Residual model tersebut dapat dinyatakan dalam persamaan sbb:
iii YYe ˆˆ
iiii XXYe 2210ˆˆˆˆ (3.6)

Selanjutnya adalah mendapatkan nilai minimum jumlah residual kuadrat.
Adapun caranya minimumkan 2
22110
2 )ˆˆˆ(ˆiiii XXYe dengan
melakukan turunan parsial terhadap 10ˆ,ˆ dan 2 .
Sebagaimana metode OLS untuk regresi sederhana, tujuan metode OLS
untuk regresi berganda adalah agar dapat meminimumkan jumlah residual
kuadrat 2ˆie = 2)ˆ( ii YY dimana iii XXY 22110
ˆˆˆˆ . Nilai minimum jumlah
residual kuadrat dapat diperoleh dengan melakukan diferensiasi parsial
jumlah residual kuadrat tersebut terhadap 0 , 1 dan 2 dan kemudian
menyamakan nilainya sama dengan nol sehingga menghasilkan persamaan
(3.4), (3.5) dan (3.6). Adapun proses penurunannya sbb:
Meminimumkan 2
23120
2 )ˆˆˆ()ˆ( iiiiii XXYYY
)ˆˆˆ(2)ˆˆˆ(ˆ 22110
2
22110
0
iiiiiii XXYXXY
(3.7)
)ˆˆˆ(2)ˆˆˆ(ˆ 221101
2
22110
1
iiiiiiii XXYXXXY
(3.8)
)ˆˆˆ(2)ˆˆˆ(ˆ 221102
2
22110
2
iiiiiiii XXYXXXY
(3.9)
Menyamakan persamaan (3.7), (3.8) dan (3.9) dengan nol dan membaginya
dengan 2 maka akan menghasilkan
0)ˆˆˆ( 22110 iii XXY (3.10a)
0)ˆˆˆ( 221101 iiii XXYX (3.10b)
0)ˆˆˆ( 221102 iiii XXYX (3.10c)
Dengan memanipulasi persamaan (3.10a), (3.10b) dan (3.10c) tersebut maka
akan menghasilkan persamaan yang dikenal dengan persamaan normal
(normal equation) yakni:

iii XXnY 22110ˆˆˆ (3.10d)
iiiiii XXXXYX 212
2
21101ˆˆˆ (3.10e)
2
22211202ˆˆˆ
iiiiii XXXXYX (3.10f)
Dari persamaan (3.10d), (3.10e) dan (3.10f) tersebut kemudian bisa
dapatkan nilai untuk 0 , 1 dan 2 sbb:
ii XXY 22110ˆ (3.11)
2
21
2
2
2
1
212
2
211
)())((
))(())((ˆ
iiii
iiiiiii
xxxx
xxyxxyx
(3.12)
2
21
2
2
2
1
211
2
12
2)())((
))(())((ˆ
iiii
iiiiiii
xxxx
xxyxxyx
(3.13)
dimana:
XXx ii
YYy ii
Y dan X adalah rata-rata
Untuk mendapatkan nilai β0, β1dan β2 menggunakan perkalian matriks
dengan prediksi dua variabel independen, persamaan matriks yang
digunakan adalah sebagai berikut:
2
1
0
2
1
yx
yx
y
2
1
x
x
n
21
2
1
1
xx
x
x
2
2
21
2
x
xx
x
H = bA A
β = A-1.H dimana A- = A
A
det
det 11

dimana det A,
A =
2
1
x
x
n
21
2
1
1
xx
x
x
2
2
21
2
x
xx
x
Det A = n. Σx12 Σx22 + Σx1. Σx1x2 .Σx2 + Σx2. Σx1x2 .Σx1 - Σx2. Σx12 .Σx2 - Σx1x2 .
Σx1x2.n - Σx22. Σx1. Σx1
Det A1 = Σy Σx12Σx22 + Σx1. Σx1x2 .Σ2y + Σx2. Σx1x2 .Σx1y - Σx2y. Σx12 .Σx2 - Σx1x2 .
Σx1x2. Σy - Σx22. Σx1. Σx1y
Det A2 = n. Σx1y Σx22 + Σy. Σx1x2 .Σx2 + Σx2. Σx2y .Σx1 - Σx2. Σx1y .Σx2 – Σx2y .
Σx1x2.n - Σx22. Σy. Σx1
Det A3 = n Σx12. Σx2y + Σx1.Σx1y .Σx2 + Σy. Σx1x2 .Σx1 - Σx2. Σx12 .Σy – Σx1x2.
Σx1y.n - Σx2y. Σx1. Σx1
Dimana nilai a, b1, b2 bisa didapatkan dengan cara sebagai berikut:
β0 = A
A
det
det 1 β1 = A
A
det
det 2 β2 = A
A
det
det 3
Dalam mengestimasi koefisien regresi berganda dengan hanya dua variabel
independen di atas, masih mungkin bisa menghitung dengan manual. Namun
demi efisiensi waktu apalagi kalau mempunyai variabel independen lebih
dari dua maka harus menggunakan program komputer untuk olahan regresi

seperti Eviews, Sazam, Rats dsb untuk menghitung koefisien regresi
berganda.
Setelah mendapatkan estimator OLS berupa koefisien regresi parsial,
maka selanjutnya bisa mendapatkan varian dan standard error dari
koefisien regresi untuk mengetahui reliabilitas estimator tersebut. Formula
untuk menghitung varian dan standard error untuk 10ˆ,ˆ dan 2 sbb:
2
2
21
2
2
2
1
2121
2
1
2
2
2
2
2
10
)(
21)ˆ(
iiii
iiii
xxxx
xxXXxXxX
nVar (3.12)
)ˆ()ˆ( 00 Varse (3.13)
)1(
)ˆvar(2
12
2
1
2
1rx i
(3.14)
)ˆvar()ˆ( 11 Se (3.15)
)1()ˆvar(
2
12
2
2
2
2rx i
(3.16)
)ˆvar()ˆ( 22 Se (3.17)
dimana XXx ii dan r12 merupakan korelasi antara variabel independen X1
dan X2. Perhitungan korelasi X1 dan X2 sbb:
n
n
n
n
ii
n
n
ii
XXXX
XXXX
r
1 1
2
22
2
11
1
2211
)()(
))((
(3.18)
3.3. Interval Estimasi Koefisien Regresi Berganda
Sebagaimana pada regresi sederhana pada bab 2, koefisien regresi
yang dapatkan pada regresi berganda adalah estimasi titik. bisa mencari

interval estimasi koefisien regresi berganda didasarkan pada probabilitas
sebagaimana probabilitas pada regresi sederhana pada bab 2. Adapun
probabilitas untuk mencari interval estimasi dapat tulis kembali sbb:
1
)ˆ(
ˆ
c
k
kkc t
setP (3.22)
dimana tc adalah nilai kritis tabel distribusi t dengan derajat kebebasan
sebesar (n-k) sehingga 2/)( cttP . Penyusunan kembali persamaan
(3.22) akan menghasilkan interval estimasi untuk koefisien regresi sbb:
1)ˆ(ˆ)ˆ(ˆiciiick setsetP (3.23)
Persamaan (4.23) tersebut bisa sederhanakan sbb:
)ˆ(ˆ),ˆ(ˆiciici setset (3.24)
Dimana (1-) merupakan interval keyakinan untuk koefisien regersi . Jika
misalnya =5%, artinya 95% interval estimasi dari sampel mengandung
kebenaran 95% dari populasi.
3.4. Uji t koefisien Regresi Parsial
Pada regresi yang mempunyai lebih satu variabel independen, jika
asumsi 1-5 terpenuhi maka mempunai estimator i yang BLUE. Bila asumsi 6
juga terpenuhi yaitu variabel ei mempunyai distribusi normal maka variabel
dependen Y juga akan terdistribusi secara normal. Misalkan tulis kembali
regresi berganda sebagaimana persamaan (3.5) sbb:
ikikiii eXXXY ...22110 (3.28)
maka ei N(0, 2) dan Yi N(0, 2). Karena estimator i adalah fungsi
linier terhadap variabel dependen Y maka estimator i akan juga mempunyai
distribusi normal dengan rata-rata i dan varian sebesar var(i) sbb:

k )var(, kkN (3.29)
Jika mengurangi k dengan rata-ratanya kemudian dibagi dengan akar
variannya atau standard errornya, maka melakukan transformasi variabel
random k yang berdistribusi normal mejadi variabel Z yang mempunyai
standar normal sbb:
)var(
ˆ
k
kkZ
N(0,1) untuk k =1, 2, ..., k (3.30)
Jika mengganti )var( k dengan )ˆvar( k maka akan mendapatkan variabel
random t sbb:
)ˆvar(
ˆ
k
kkt
t(n-k) (3.31)
atau dapat ditulis menjadi:
)ˆ(
ˆ
k
kk
set
t(n-k) (3.32)
Perbedaan uji t regresi berganda dengan lebih dari satu variabel independen
dengan regresi sederhana dengan hanya satu variabel independen terletak
pada besarnya derajat degree of freedom (df) dimana untuk regresi sederhana
dfnya sebesar n-2 sedangkan regresi berganda tergantung dari jumlah
variabel independen ditambah dengan konstanta.
Prosedur uji t pada koefisien regresi parsial pada regresi berganda
sama dengan prosedur uji koefisien regresi sederhana. Untuk mengingat
kembali uji t koefisien regresi ini bisa dibaca kembali pada bab 2. akan
kembali membahas secara ringkas uji t tersebut. Misalnya mempunyai dua
variabel independen dengan estimator 1 dan 2, langkah uji t sbb:

1. Membuat hipotesis melalui uji satu sisi atau dua sisi
Uji hipotesis positif satu sisi
H0 : 1 0 (3.33)
Ha : 1 > 0
Uji hipotesis negatif satu sisi
H0 : 1 0 (3.34)
Ha : 1 < 0
Atau uji dua sisi
H0 : 1 = 0 (3.35)
Ha : 1 0
2. ulangi langkah pertama tersebut untuk 2
3. Menghitung nilai t hitung untuk 1 dan 2 dan mencari nilai nilai t kritis
dari tabel distribusi t. Nilai t hitung dicari dengan formula sbb:
)ˆ(
ˆ
1
11
set
(3.36)
Dimana 1* merupakan nilai pada hipotesis nol
4. Bandingkan nilai t hitung untuk masing-masing estimator dengan t
kritisnya dari tabel. Keputusan menolak atau menerima H0 sbb:
jika nilai t hitung > nilai t kritis maka H0 ditolak atau menerima Ha
jika nilai t hitung < nilai t kritis maka H0 diterima atau menolak Ha
3.5. Uji Hipotesis Koefisien Regresi Secara Menyeluruh: Uji F
perlu mengevaluasi pengaruh semua variabel independen terhadap
variabel dependen dengan uji F. Uji F ini bisa dijelaskan dengan

menggunakan analisis varian (analysis of variance = ANOVA). Misalkan
mempunyai model regresi berganda sbb:
iiii eXXY 22110 (3.40)
ingat kembali pada bab 2 sebelumnya bahwa
222 ˆˆiii eyy
2
2211
2 ˆˆˆiiiiii exyxyy (3.41)
Atau dapat ditulis menjadi:
TSS = ESS + RSS (3.42)
TSS mempunyai df= n-1, ESS mempunyai df sebesar k-1 sedangkan RSS
mempunyai df=n-k. Analisis varian adalah analisis dekomposisi komponenen
TSS. Analisis varian ini bisa ditampilkan dalam Tabel 3.1.
Tabel 3.1.
Analisys of Varian (ANOVA)
Sumber variasi
SS (sum of squares) df MSS (mean sum of squares)
ESS
RSS
2
2211ˆˆˆiiiii exyxy
2
ie
k-1
n-k
( 2
2211ˆˆˆiiiii exyxy )/k-1
22 ˆ/)( knei
TSS 2
iy n-1
Dengan hipotesis bahwa semua variabel independen tidak berpengaruh
terhadap variabel dependen yakni 1= 2 = . . . = k = 0 maka uji F dapat
diformulasikan sbb:
)/(
)1/(
knRSS
kESSF
(3.43)
Dimana n= jumlah observasi dan k = jumlah parameter estimasi termasuk
intersep atau konstanta.

Formula uji statistik F ini bisa dinyatakan dalam bentuk formula yang
lain dengan cara memanipulasi persamaan (3.43) tersebut yaitu:
)/()(
)1/(
knESSTSS
kESSF
)/()/(
)1/()/(
knTSSESSTSS
kTSSESSF
(3.44)
Karena ESS/TSS = R2 maka persamaan (4.44) tersebut dapat ditulis kembali
menjadi
)/(1
)1/(2
2
knR
kRF
(3.45)
Dari persamaan (2.45) tersebut jika hipotesis nol terbukti, maka
harapkan nilai dari ESS dan R2 akan sama dengan nol sehingga F akan juga
sama dengan nol. Dengan demikian, tingginya nilai F statistik akan menolak
hipotesis nol. Sedangkan rendahnya nilai F statistik akan menerima hipotesis
nol karena variabel independen hanya sedikit menjelaskan variasi variabel
dependen di ser rata-ratanya.
Walaupun uji F menunjukkan adanya penolakan hipotesis nol yang
menunjukkan bahwa secara bersama-sama semua variabel independen
mempengaruhi variabel dependen, namun hal ini bukan berarti secara
individual variabel independen mempengaruhi variabel dependen melalui uji
t. Keadaan ini terjadi karena kemungkinan adanya korelasi yang tinggi antar
variabel independen. Kondisi ini menyebabkan standard error sangat tinggi
dan rendahnya nilai t hitung meskipun model secara umum mampu
menjelaskan data dengan baik.
Misalnya mempunyai model regresi berganda dengan dua variabel
independen sebelumnya:

iiii eXXY 22110 (.46)
Untuk menguji apakah koefisien regresi (1dan 2) secara bersama-sama
atau secara menyeluruh berpengaruh terhadap variabel dependen, prosedur
uji F dapat dijelaskan sbb:
1. Membuat hipotesis nol (H0) dan hipotesis alternatif (Ha) sbb:
H0 : 1=2 = . . . = k = 0 (2.47)
Ha : 12 . . . k 0
2. Mencari nilai F hitung dengan formula seperti pada persamaan (2.45)
dan nilai F kritis dari tabel distribusi F. Nilai F kritsis berdasarkan
besarnya dan df dimana besarnya ditentukan oleh numerator (k-1)
dan df untuk denominator (n-k).
3. Keputusan menolak atau menerima H0 sbb:
Jika F hitung > F kritis, maka menolak H0 dan sebaliknya jika F hitung <
F kritis maka menerima H0
3.6. Koefisien Determinasi yang Disesuaikan
Pada pembahasan bab 1 tentang regresi sederhana dengan hanya satu
variabel independen menggunakan koefisien determinasi (R2) untuk
menjelaskan seberapa besar proporsi variasi variabel dependen dijelaskan
oleh variabel independen. Di dalam regresi berganda juga akan
menggunakan koefisien determinasi untuk mengukur seberapa baik garis
regresi yang punyai. Dalam hal ini mengukur seberapa besar proporsi
variasi variabel dependen dijelaskan oleh semua variabel independen.
Formula untuk menghitung koefisien determinasi (R2) regresi berganda sama
dengan regresi sederhana. Untuk itu kembali tampilkan rumusnya sbb:
TSS
RSSTSSESSR 1/2

)(
)ˆ(1
2
2
i
i
y
e
2
2
)(
)ˆ(1
YY
e
i
i
(3.48)
Dari rumus tersebut diatas tampak jelas bahwa koefisien determinasi tidak
pernah menurun terhadap jumlah variabel independen. Artinya koefisien
determinasi akan semakin besar jika terus menambah variabel independen
di dalam model. Hal ini terjadi karena 2)( YYi bukan merupakan fungsi dari
variabel independen X, sedangkan RSS yakni 2ˆie tergantung dari jumlah
variabel independen X di dalam model. Dengan demikian jika jumlah variabel
independen X bertambah maka 2ˆie akan menurun. Mengingat bahwa nilai
koefisien determinasi tidak pernah menurun maka harus berhati-hati
membandingkan dua regresi yang mempunyai variabel dependen Y sama
tetapi berbeda dalam jumlah variabel independen X. Kehati-hatian ini perlu
karena tujuan regresi metode OLS adalah mendapatkan nilai koefisien
determinasi yang tinggi.
Salah satu persoalan besar penggunaan koefisien determinasi R2
dengan demikian adalah nilai R2 selalu menaik ketika menambah variabel
independen X dalam model walaupun penambahan variabel independen X
belum tentu mempunyai justifikasi atau pembenaran dari teori ekonomi
ataupun logika ekonomi. Para ahli ekonometrika telah mengembangkan
alternatif lain agar nilai R2 tidak merupakan fungsi dari variabel independen.
Sebagai Alternatif digunakan R2 yang disesuaikan (adjusted R2) dengan rumus
sebagai berikut :
)1/()(
)/()ˆ(1
2
22
nYY
kneR
i
i (3.49)

dimana: k = jumlah parameter, termasuk intersep dan n = jumlah observasi
Terminologi koefisien determinasi yang disesuaikan ini karena disesuaikan
dengan derajat kebebasan (df) dimana 2ˆie mempunyai df sebesar n - k dan
2)( YYi dengan df sebesar n –1.
Untuk mengetahui lebih jelas berikut adalah contoh penerapan regresi
berganda. Seorang ekonom ingin mengetahui pengaruh pendapatan dan
harga barang terhadap permintaan dalam setahun selama 10 tahun. Data
yang dikumpulkan adalah sebagai berikut:
Tabel 3.2
Diketahui data permintaan akan suatu barang, harga barang dan pendapatan masyarakat sebagai berikut :
No Permintaan harga Pendapatan
1 10 8 20
2 11 9 25
3 11 7 27
4 13 6 30
5 16 7 33
6 17 6 36
7 18 5 40
8 20 6 44
9 23 7 45
10 25 5 50
Pertanyaan : (a) carilah persamaan regresi dan (b) ujilah secara statitik apakah harga dan pendapatan mempengaruhi permintaan secara signifikan, © serta berapa besarnya koefisien determinasinya dan apa artinya

Jawab
Y X1 X2 YX1 YX2 X1X2 X1^2 X22
10 8 20 80 200 160 64 400
11 9 25 99 275 225 81 625
11 7 27 77 297 189 49 729
13 6 30 78 390 180 36 900
16 7 33 112 528 231 49 1,089
17 6 36 102 612 216 36 1,296
18 5 40 90 720 200 25 1,600
20 6 44 120 880 264 36 1,936
23 7 45 161 1,035 315 49 2,025
25 5 50 125 1,250 250 25 2,500
164 66 350 1,044 6,187 2,230 450 13,100
buat persamaan ΣY = n b0 + b1ΣX1 + b2ΣX2
ΣYX1 = b0 ΣX1 + b1ΣX1^2 + b2ΣX1X2 ΣYX2 = b0 ΣX2 + b1ΣX1X2 + b2ΣX2^2
1) 164 = 10 b0 + 66 b1 + 350 b2 2) 1,044 = 66 b0 + 450 b1 + 2,230 b2 3) 6,187 = 350 b0 + 2,230 b1 + 13,100 b2
hilangkan b0 1) 164 = 10 b0 + 66 b1 + 350 b2 kali 66
2) 1,044 = 66 b0 + 450 b1 + 2,230 b2
10
10824 = 660 b0 + 4356 b1 + 23100 b2
10440 = 660 b0 + 4500 b1 + 22300 b2 kurangkan
4) 384 = 0 b0 + -144 b1 + 800 b2

hilangkan b0
2) 1,044 = 66 b0 + 450 b1 + 2,230 b2 kali 350
3) 6,187 = 350 b0 + 2,230 b1 + 13,100 b2
66
365400 = 23100 b0 + 157500 b1 + 780500 b2
408342 = 23100 b0 + 147180 b1 + 864600 b2 kurangkan
5) -42942 = 0 b0 + 10320 b1 + -84100 b2
Dari persamaan 4) dan 5) hilangkan b1
384 = 0 b0 + -144 b1 + 800 b2 kali 10320
-42942 = 0 b0 + 10320 b1 + -84100 b2
-144
3962880 = 0 b0 +
-1486080 b1 + 8256000 b2
6183648 = 0 b0 +
-1486080 b1 + 12110400 b2 kurangkan
-2220768 = 0 b0 + 0 b1 + -3854400 b2
b2 = 0.5762
b1 = 0.5342
b0 = -7.292

Y X1 X2 y x1 x2 x1x2 x12 X2
2 Y' u u2 y2
10 8 20 -6.4 1.4 -15 -21 1.96 225 8.5055 1 2.23359 40.96
11 9 25 -5.4 2.4 -10 -24 5.76 100 11.921 -1 0.84741 29.16
11 7 27 -5.4 0.4 -8 -3.2 0.16 64 12.004 -1 1.00879 29.16
13 6 30 -3.4 -0.6 -5 3 0.36 25 13.199 0 0.03945 11.56
16 7 33 -0.4 0.4 -2 -0.8 0.16 4 15.461 1 0.29012 0.16
17 6 36 0.6 -0.6 1 -0.6 0.36 1 16.656 0 0.11860 0.36
18 5 40 1.6 -1.6 5 -8 2.56 25 18.426 0 0.18150 2.56
20 6 44 3.6 -0.6 9 -5.4 0.36 81 21.265 -1 1.60005 12.96
23 7 45 6.6 0.4 10 4 0.16 100 22.375 1 0.39020 43.56
25 5 50 8.6 -1.6 15 -24 2.56 225 24.188 1 0.65988 73.96
164 66 350 0 0 0 -80 14 850 164 0 7.369589 244
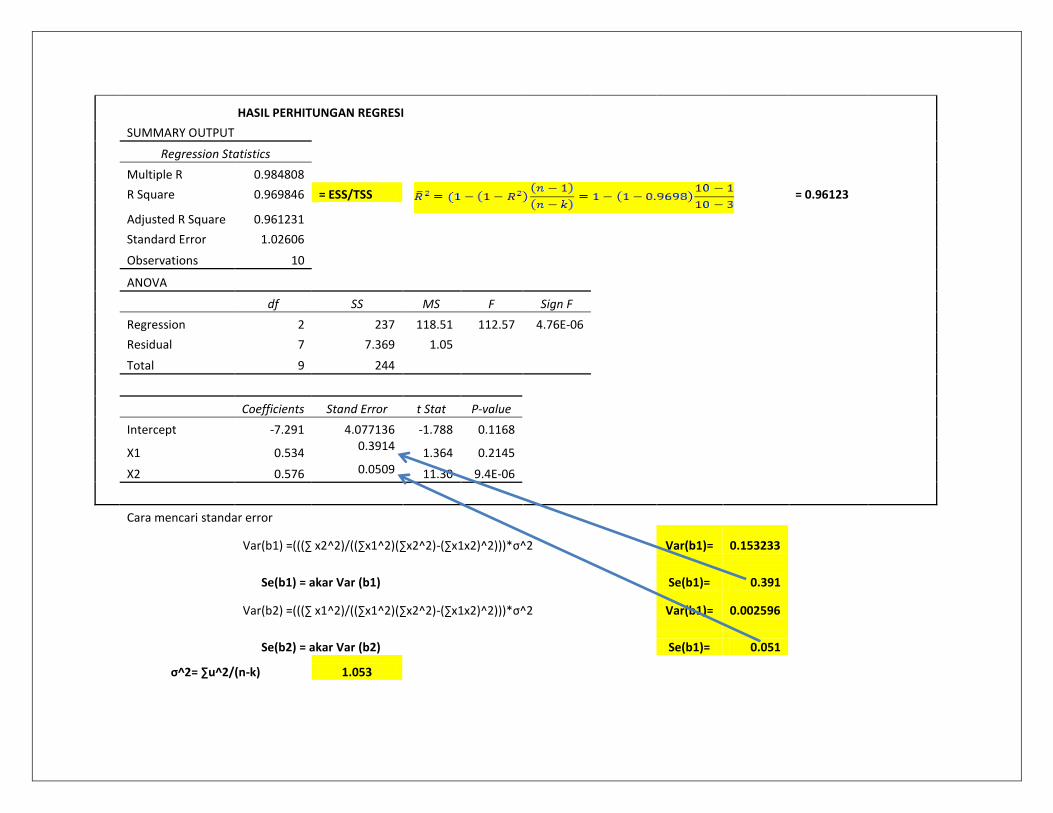
HASIL PERHITUNGAN REGRESI
SUMMARY OUTPUT
Regression Statistics
Multiple R 0.984808
R Square 0.969846 = ESS/TSS
= 0.96123
Adjusted R Square 0.961231
Standard Error 1.02606
Observations 10
ANOVA
df SS MS F Sign F
Regression 2 237 118.51 112.57 4.76E-06
Residual 7 7.369 1.05
Total 9 244
Coefficients Stand Error t Stat P-value
Intercept -7.291 4.077136 -1.788 0.1168
X1 0.534 0.3914
1.364 0.2145
X2 0.576 0.0509 11.30 9.4E-06
Cara mencari standar error
Var(b1) =(((∑ x2^2)/((∑x1^2)(∑x2^2)-(∑x1x2)^2)))*σ^2 Var(b1)= 0.153233
Se(b1) = akar Var (b1)
Se(b1)= 0.391
Var(b2) =(((∑ x1^2)/((∑x1^2)(∑x2^2)-(∑x1x2)^2)))*σ^2 Var(b1)= 0.002596
Se(b2) = akar Var (b2)
Se(b1)= 0.051
σ^2= ∑u^2/(n-k) 1.053

Hasil Regresi
Y = -7.292 + 0.53425 X1 + 0.576 X2
Se(b)
4.077
0.39145
0.051
t hitung
-1.788
1.36479
11.31
F hitung
112.6
R2
0.97
Berdasarkan print out hasil regresi, variable x1 tidak memiliki pengaruh terhadap Y (lihat t
hitung < t tabel) dan X2 memiliki pengaruh terhadap Y (lihat t hitung > t tabel). Dan R2
sebesar 0,97 artinya Variasi X1 dan X2 dapat menjelaskan 97 persen terhadap Y sedangan 1-
0,97 atau 3 persen dijelaskan oleh variable diluar model (misalnya X3, X4 dan X lainnya
diluar X1 dan X2).

LATIHAN SOAL
Tahun Konsumsi
Minyak (barrel/hari)
GDP/kpt (US
dollar)
Tingkat bunga
Pinjaman (%)
Dari data tersebut : 1. Buatlah model regresi berganda
Y=b0+b1X1+b2X2+e (Model yang Saudara buat harus didasarkan pada teori ekonomi) nilai 30%
2. Carilah besarnya koefisien persamaan tersebut dan apa artinya ? nilai 10 %
3. Dari hasil regresi yang telah saudara hitung, ujilah apakah hasil regresi sesuai dengan teori ? Jelaskan arti koefisien masing-masing ! nilai 30%
4. Ujilah dengan uji statistic apakah variable bebas mempengaruhi Y ! (gunakan t test, F test dan Uji Koefisien Determinasi) nilai 30%
Catatan : semua perhitungan didasarkan pada rumus atau formula yang tertera dalam buku ekonometri dan perhitungan menggunakan perhitungan manual.
1991 692 1609 26
1992 745 1696 24
1993 786 1789 21
1994 809 1894 18
1995 865 2021 19
1996 924 2143 19
1997 1024 2212 22
1998 978 1894 32
1999 1022 1883 28
2000 1139 1948 18
2001 1159 1992 19
2002 1210 2054 19
2003 1230 2123 17
2004 1308 2200 14
2005 1303 2295 14
2006 1244 2389 16
2007 1318 2508 14
2008 1287 2624 14
2009 1297 2710 14
2010 1402 2841 13
2011 1589 2977 12
2012 1631 3115 12
2013 1643 3247 12
2014 1676 3367 13
2015 1628 3146 12
Sumber : data hipotesis


VAIABEL DUMMY DALAM REGRESI
Nama lain Regresi Dummy adalah Regresi Kategori. Re-gresi ini menggunakan
prediktor kualitatif (yang bukan dummy dinamai prediktor kuantitatif).
Pembahasan pada regresi ini hanya untuk satu macam variabel dummy dan
dikhususkan pada penaksiran parameter dan kemaknaan pengaruh prediktor.
Pembahasan akan dilakukan dengan menggunakan berbagai contoh.
Di dalam metodologi penelitian dikenal ada sebuah variabel yang disebut dengan
dummy variable. Variabel ini bukan jenis lain dari variabel dependen-
independen, namun menunjukkan sebuah variabel yang nilainya telah
ditentukan oleh peneliti. Donald Cooper dan Pamela Schindler (2000)
mendefinisikan dummy variable sebagai sebuah variabel nominal yang
digunakan di dalam regresi berganda dan diberi kode 0 dan 1. Nilai 0 biasanya
menunjukkan kelompok yang tidak mendapat sebuah perlakuan dan 1
menunjukkan kelompok yang mendapat perlakuan. Dalam regresi berganda,
aplikasinya bisa berupa perbedaan jenis kelamin (1 = laki-laki, 0 = perempuan),
ras (1 = kulit putih, 0 = kulit berwarna), pendidikan (1 = sarjana, 0 = non-
sarjana).
Masalah di sini adalah bukan pada konsep variabel ini dan aplikasinya di dalam
riset, namun bagaimana dummy variable harus diterjemahkan atau
BAB
4

dialihbahasakan ke dalam bahasa Indonesia. Sepengetahuan saya, beberapa
orang membiarkannya tetap dummy dan menulisnya miring menjadi "variabel
dummy" (perhatikan bahwa ia diindonesiakan dengan membiarkan dummy
dalam bahasa aslinya). Sebagian orang lain menyerapnya ke dalam bahasa
Indonesia menggunakan azas bunyi sehingga menjadi "variabel dami". Sebagian
yang lain menyebutnya "variabel boneka" karena dummy di dalam bahasa Inggris
bisa berarti boneka.
Variabel dummy adalah variabel yang digunakan untuk mengkuantitatifkan
variabel yang bersifat kualitatif (misal: jenis kelamin, ras, agama, perubahan
kebijakan pemerintah, perbedaan situasi dan lain-lain).
Variabel dummy merupakan variabel yang bersifat kategorikal yang diduga
mempunyai pengaruh terhadap variabel yang bersifat kontinue.
Variabel dummy sering juga disebut variabel boneka, binary, kategorik atau
dikotom.
Variabel dummy hanya mempunyai 2 (dua) nilai yaitu 1 dan nilai 0, serta diberi
simbol D. Dummy memiliki nilai 1 (D=1) untuk salah satu kategori dan nol (D=0)
untuk kategori yang lain. D = 1 untuk suatu kategori (laki- laki, kulit putih,
sarjana dan sebagainya). D = 0 untuk kategori yang lain (perempuan, kulit
berwarna, non-sarjana dan sebagainya). Nilai 0 biasanya menunjukkan
kelompok yang tidak mendapat sebuah perlakuan dan 1 menunjukkan kelompok
yang mendapat perlakuan. Dalam regresi berganda, aplikasinya bisa berupa
perbedaan jenis kelamin (1 = laki-laki, 0 = perempuan), ras (1 = kulit putih, 0 =
kulit berwarna), pendidikan (1 = sarjana, 0 = non-sarjana).

4.1. Model Matematika Regresi Berganda dengan Dengan Variabel Dummy
Variabel dummy hanya mempunyai 2 (dua) nilai yaitu 1 dan nilai 0, serta
diberi simbol D. D = 1 untuk suatu kategori (wanita, Batak, Islam, damai
dan sebagainya). D = 0 untuk kategori yang lain (pria, Jawa, Kristen,
perang dan sebagainya). Variabel dummy digunakan sebagai upaya untuk
melihat bagaimana klasifikasi-klasifikasi dalam sampel berpengaruh
terhadap parameter pendugaan. Variabel dummy juga mencoba membuat
kuantifikasi dari variabel kualitatif. pertimbangkan model berikut ini:
I. Y = a + bX + c D1 (Model Dummy Intersep)
II. Y = a + bX + c (D1X) (Model Dummy Slope)
III. Y = a + bX + c (D1X) + d D1 (Kombinasi)
.

4.2. Pemanfaatan Regresi Berganda dengan Variabel Dummy
Tujuan menggunakan regresi berganda dummy adalah memprediksi
besarnya nilai variabel tergantung (dependent) atas dasar satu atau lebih
variabel bebas (independent), di mana satu atau lebih variabel bebas yang
digunakan bersifat dummy.
Variabel dummy adalah variabel yang digunakan untuk membuat kategori
data yang bersifat kualitatif (data kualitatif tidak memiliki satuan ukur),
agar data kualitatif dapat digunakan dalam analisa regresi maka harus
lebih dahulu di transformasikan ke dalam bentuk Kuantitatif. contoh data
kualitatif misal jenis kelamin adalah laki-laki dan perempuan, harus di
transform ke dalam bentuk Laki-laki = 1; Perempuan = 0. atau tingkat
pendidikan misal SMA dan Sarjana, maka diubah menjadi SMA = 0; Sarjana
= 1, skala yang terdiri dari dua yakni 0 dan 1 disebut kode Binary,
sedangkan persamaan model yang terdiri dari Variabel Dependentnya
Kuantitatif dan variabel Independentnya skala campuran : kualitatif dan
kuantitatif, maka persamaan tersebut disebut persamaan regresi berganda
Dummy. Dalam kegiatan penelitian, kadang variabel yang akan diukur
bersifat Kualitatif, sehingga muncul kendala dalam pengukuran, dengan
adanya variabel dummy tersebut, maka besaran atau nilai variabel yang
bersifat Kualitatif tersebut dapat di ukur dan diubah menjadi kuantitatif.
4.3. Contoh Kasus :
Diketahui data PDB (pendapatan domestik bruto), R (tingkat suku bunga)
dan d (dummy).
obs PDB R D obs PDB R D
1982 389786 9 1 1997 3141036 16.28 1
1983 455418 17.5 1 1998 4940692 21.84 0
1984 545832 18.7 1 1999 5421910 27.6 0
1985 581441 17.8 1 2000 6145065 16.15 0
obs PDB R D obs PDB R D
1986 575950 15.2 1 2001 6938205 14.23 0
1987 674074 16.99 1 2002 8645085 15.95 0
1988 829290 17.76 1 2003 9429500 12.64 0
1989 956817 18.12 1 2004 10506215 8.21 0 1990 1097812 18.12 1 2005 12450736 8.22 0
1991 1253970 22.49 1 2006 15028519 11.63 0
1992 1408656 18.62 1 2007 17509564 8.24 0
1993 1757969 13.46 1 2008 21666747 10.43 0
1994 2004550 11.87 1 2009 24261805 9.55 0
1995 2345879 15.04 1 2010 27028696 7.88 0
1996 2706042 16.69 1 2011 30795098 7.04 0
Dimana : D (dummy variabel) jika D = 1 sebelum terjadinya krisis ekonomi dan jika D = 0 setelah krisis ekonomi. Lakulan regresi LS Log(PDB) c r dummy Diperoleh hasil sebagai berikut : Dependent Variable: LOG(PDB) Method: Least Squares Date: 04/13/15 Time: 22:01 Sample: 1982 2011 Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob. C 17.10893 0.341276 50.13224 0.0000
R -0.062530 0.023664 -2.642416 0.0135 DUMMY -2.209288 0.230256 -9.594941 0.0000
R-squared 0.835735 Mean dependent var 15.00676
Adjusted R-squared 0.823567 S.D. dependent var 1.388631 S.E. of regression 0.583279 Akaike info criterion 1.854339 Sum squared resid 9.185804 Schwarz criterion 1.994459 Log likelihood -24.81508 Hannan-Quinn criter. 1.899164 F-statistic 68.68420 Durbin-Watson stat 0.452882 Prob(F-statistic) 0.000000
Dari hasil regresi diatas dapat disimpulkan sebagai berikut :

1. Variabel tingkat bunga memiliki hubungan negatif terhadap
pendapatan domestik bruto secara signifikan, artinya jika tingkat
bunga dinaikan sebesar 1 persen maka PDB akan turun sebesar 0,06
persen.
2. Variabel dummy memiliki hubungan negatif dan signifikan artinya
krisis ekonomi memiliki dampak terhadap PDB, sesudah krisis PDB
mengalami penurunan.

UJI ASUMSI KLASIK Model regresi linier klasik (OLS) berlkitaskan serangkaian asumsi. Tiga di antara
beberapa asumsi regresi klasik yang akan diketengahkan dalam penelitian ini
adalanh (lihat Maddala, 1992, hal. 229-269):
1. Non-autokorelasi.
Non-autokorelasi adalah keadaan dimana tidak terdapat hubungan antara
kesalahan-kesalahan (error) yang muncul pada data runtun waktu (time
series).
2. Homoskedastisitas.
Homoskedastisitas adalah keadaan dimana erros dalam persamaan regresi
memiliki varians konstan.
3. Non-multikolinearitas.
Non-multikolinearitas adalah keadaan dimana tidak ada hubungan antar
variabel-variabel penjelas dalam persamaan regresi.
Penyimpangan terhadap asumsi tersebut akan menghasilkan estimasi yang tidak
sahih. Deteksi yang biasa dilakukan terhadap ada tidaknya penyimpangan
asumsi klasik adalah uji autokorelasi, heteroskedastisitas, dan multikolinearitas.
MODEL DETEKSI / UJI PENGOBATAN
BAB
5

5.1. UJI MULTIKOLINEARITAS
Sebagaimana dikemukakan di atas, bahwa salah satu asumsi regresi
linier klasik adalah tidak adanya multikolinearitas sempurna (no perfect
multicolinearity) tidak adanya hubungan linier antara variabel penjelas
dalam suatu model regresi. Istilah ini multikoliniearitas itu sendiri
pertama kali diperkenalkan oleh Ragner Frisch tahun 1934. Menurut
Frisch, suatu model regresi dikatakan terkena multikoliniearitas bila
terjadi hubungan linier yang sempurna (perfect) atau pasti (exact) di
antara beberapa atau semua variabel bebas dari suatu model regresi.
Akibatnya akan kesulitan untuk dapat melihat pengaruh variabel penjelas
terhadap variabel yang dijelaskan (Maddala, 1992: 269-270).
Berkaitan dengan masalah multikoliniearitas, Sumodiningrat (1994:
281-182) mengemukakan bahwa ada 3 hal yang perlu dibahas terlebih
dahulu:
1. Multikoliniearitas pada hakekatnya adalah fenomena sampel.
Dalam model fungsi regresi populasi (Population Regression Function =
PRF) diasumsikan bahwa seluruh variabel bebas yang termasuk dalam
model mempunyai pengaruh secara individual terhadap variabel tak
bebas Y, tetapi mungkin terjadi bahwa dalam sampel tertentu.
2. Multikoliniearitas adalah persoalan derajat (degree) dan bukan
persoalan jenis (kind).
Artinya bahwa masalah Multikoliniearitas bukanlah masalah mengenai
apakah korelasi di antara variabel-variabel bebas negatif atau positif,
tetapi merupakan persoalan mengenai adanya korelasi di antara
variabel-variabel bebas.
3. Masalah Multikoliniearitas hanya berkaitan dengan adanya hubungan
linier di antara variabel-variabel bebas
Artinya bahwa masalah Multikoliniearitas tidak akan terjadi dalam
model regresi yang bentuk fungsinya berbentuk non-linier, tetapi

masalah Multikoliniearitas akan muncul dalam model regresi yang
bentuk fungsinya berbentuk linier di antara variabel-variabel bebas.
Multikonearitas adalah adanya hubungan eksak linier antar variabel
penjelas. Multikonearitas diduga terjadi bila nilai R2 tinggi, nilai t
semua variabel penjelas tidak signifikan, dan nilai F tinggi.
Konsekuensi multikonearitas:
1. Kesalahan stkitar cenderung semakin besar dengan meningkatnya
tingkat korelasi antar variabel.
2. Karena besarnya kesalahan stkitar, selang keyakinan untuk
parameter populasi yang relevan cenderung lebih besar.
3. Taksiran koefisian dan kesalahan stkitar regresi menjadi sangat
sensitif terhadap sedikit perubahan dalam data.
Konsekuensi multikearitas adalah invalidnya signifikansi variable
maupun besaran koefisien variable dan konstanta. Multikolinearitas
diduga terjadi apabila estimasi menghasilkan nilai R kuadrat yang tinggi
(lebih dari 0.8), nilai F tinggi, dan nilai t-statistik semua atau hampir
semua variabel penjelas tidak signifikan. (Gujarati, 2003)
Sebagai indikasi awal, perhatikan nilai R kuadrat, F-statistik, dan t-
statistik dari hasil regresi table III. Tabel III, dalam table ini merupakan
kasus baru yaitu kasus negara Kertagama, dimana defenden variabelnya
konsumsi dan indefenden variabelnya GNP, Subsidi dan PRM. Variabel
PRM merupakan variable antah berantah yang sengaja dimasukkan dalam
model dengan nilai hampir dua kali lipat dari nilai GNP untuk masing-
masing periode ( disengaja agar semakin memperjelas munculnya masalah
multikolinier). Tabel III, korelasi antar variable penjelas dan hasil analisis
dapat dilihat dibawah ini. Bagaimana penilaian saudara? Untuk lebih
pastinya, lakukan regresi antar variabel penjelas:

Kasus
Perhatikan nilai R kuadrat. Nilai R kuadrat jauh lebih rendah dibandingkan
dengan nilai R kuadrat regresi variabel dalam level (regresi awal). Namun
demikian, hal tersebut sama sekali tidak perlu dirisaukan. R kuadrat
regresi persamaan dalam difference jelas jauh lebih kecil daripada R
kuadrat regresi persamaan dalam level. R kuadrat kedua persamaan
berbada bentuk tersebut (difference versus level) sama sekali tidak dapat
dibandingkan (uncomparable).
Untuk membuktikan terobatinya multikolinearitas, lakukan regresi
antar variabel penjelas dalam perbedaan pertama. Jika nilai t-statistik
salah satu variabel independen masih signifikan, berarti masih terdapat
multikolinearitas pada persamaan tersebut. Hal sebaliknya terjadi jika
nilai t-statistik tidak signifikan. Dilihat dari t statistiknya memang terdapat
perbaikan dengan model regresi first difference, tetapi belum dapat
menyelesaikan masalah multikoliniernya.
Perintah untuk regresi antar variabel penjelas dalam perbedaan pertama:
pengobatan multikolinearitas melalui perbedaan pertama, akan
kehilangan informasi jangka panjang. Perbedaan pertama hanya
mengandung informasi jangka pendek. Hal ini riskan apabila kita
melakukan pengkajian empiris terhadap suatui teori karena teori
berkaitan dengan informasi jangka panjang. Bagaimana solusinya? Klein
mengajukan solusi yang kemudian disebut dengan Klein’s Rule of Thumb:
Multikolinearitas tidak usah dirisaukan apabila nilai R kuadrat regresi
model awal lebih besar daripada nilai R kuadrat regresi antar variabel
penjelas
Langkah berikutnya sebetulnya dengan menambah sample, tetapi dalam
kasus ini tidak dapat dilakukan sehingga terpaksa satu variabel yaitu PRM
atau GNP yang harus diamputasi dari model.

Technik amputasinya dipilih variabel yang bukan variabel utama,
sedangkan jika dua variabel tersebut memiliki kedudukan sejajar maka
variabel yang nilai prob-valuenya yang besarlah yang diamputasi. Variabel
yang diregres jangan dibuang, jika memang masih dibutuhkan, dan
dijadikan regresi tunggal dengan defenden tetap variabel konsumsi.
5.2. UJI HETEROSKEDASTISITAS
Homoskedastisitas terjadi bila distribusi probabilitas tetap sama
dalam semua observasi x, dan varians setiap residual adalah sama untuk
semua nilai variabel penjelas:
Var (u) = E [ut – E(ut)]2
= E(ut)2 = s2u konstan
Penyimpangan terhadap asumsi diatas disebut heteroskedastisitas.
Pengujian heteroskedastisitas dilakukan denga uji Glesjer berikut ini:
|
|
|
| ie =β1Xi + vt
dimana β = nilai absolut residual persamaan yang diestimasi
Xi = variabel penjelas
Vt = Unsur gangguan
Apabila nilai t statistik signifikan, maka dapat disimpulkan bahwa
hipotesis adanya heteroskedastisitas tidak dapat ditolak.
a. Konsekuensi Adanya Heteroskedastisitas
Dalam kenyataan, asumsi bahwa varian dari disturbance term
adalah konstan mungkin sulit untuk bisa dipenuhi. Hal ini dapat
dipahami jika diperhitungkan atau melihat faktor-faktor yang menjadi

penyebab munculnya masalah heteroskedasitisitas dalam suatu model
regresi. Namun demikian, apabila seorang peneliti atau
econometrician melanggar asumsi homoskedastisitas atau dengan kata
lain model empiris yang diestimasi oleh seorang peneliti tersebut
adalah (Ramanathan, 1996: 417-418), Maddala, 1992: 209,
Koutsoyiannis, 1977: 184-185: Gujarati, 1995: 365-267 dan Gujarati,
1999: 348-349)
b. Cara Mendeteksi Masalah Heteroskedastisitas dalam Model
Empiris
Seperti halnya dalam masalah Multikoliniearitas salah satu
masalah yang sangat penting adalah bagaimana bisa mendeteksi ada-
tidaknya masalah heteroskedastistitas, tidak ada satu aturan yang
kuat dan ketat untuk mendeteksi heteroskedastisitas. Walaupun
demikian, para ahli ekonometrika menyarankan beberapa metode
untuk dapat mendeteksi ada-tidaknya masalah heteroskedastisitas
dalam model empiris, seperti dengan menggunakan uji Park tahun
1966, uji Glejscr 1969, Uji White (1980), uji Breusch-Pagan-Godfre
(Gujarati, 1995, 369-380), Sumodiningrat, 1994: 270-278,
Koutsoyiannis, 1977: 185-187, Ramanathan, 1996: 418-424, Thomas,
1997: 284-288, Breusch dan Pagan, 1979: 1287-1294 dan White 1980:
817-838).
Konsekuensi heteroskedastisitas:
1. Penaksir OLS tetap tak bias dan konsisten tetapi tidak lagi efisien
dalam sampel kecil dan besar.
2. Variansnya tidak lagi minimum.
Heteroskedastisitas adalah situasi tidak konstannya varians.
Konsekuensi heteroskedasitas adalah biasnya varians sehingga uji
signifikansi menjadi invalid. Salah satu cara mendeteksi

heteroskedastisitas adalah dengan melakukan uji Glesjer. Uji Glesjer
dilakukan dengan cara meregresi nilai absolut residual dari model
yang diestimasi terhadap variabel-variabel penjelas. Regresi model
awal setelah variable PRM dihilangkan:
5.3. UJI AUTOKORELASI
a. Penyebab Munculnya Otokorelasi
Berkaitan dengan asumsi regresi linier klasik, khususnya asumsi no
autocorrelation pertanyaan yang patut untuk diajukan adalah
(mengapa otokorelasi itu terjadi atau muncul?) Padahal dalam dunia
nyata, segala sesuatu tidak ada yang sifatnya tetap tetapi berubah terus
seiring waktu. Untuk menjawab pertanyaan di atas, di bawah ini akan
dikemukakan beberapa hal yang dapat mengakibatkan munculnya
otokorelasi (Gujarati, 1995: 402-406. Koutsoyiannis, 1977: 203-204,
Arief, 1993: 38-41):
1. Adanya Kelembaman (intertia)
Salah ciri yang menonjol dari sebagian data runtun waktu ekonomi
adalah kelembaman, seperti data pendapatan nasional, indeks
harga konsumen, data produksi, data kesempatan kerja, data
pengangguran-menunjukkan adanya pola konjuktur. Dalam situasi
seperti ini, data observasi pada periode sebelumnya dan periode
sekarang kemungkinan besar akan saling ketergantungan
(interdependence).
2. Bias Specification: Kasus variabel yang tidak dimasukkan
Hal itu terjadi karena disebabkan oleh tidak masukkan variabel
yang menurut teori ekonomi, variabel tersebut sangat penting
peranannya dalam menjelaskan variabel tak bebas. Bila hal ini
terjadi, maka unsur pengganggu (error term)μi akan merefleksikan
suatu pola yang sistematis di antara sesama unsur pengganggu,
sehingga terjadi situasi otokorelasi di antara unsur pengganggu.

3. Adanya fenomena sarang laba-laba (cobweb phenomenon)
Munculnya fenomena sarang laba-laba terutama terjadi pada
penawaran komoditi sektor pertanian. Di sektor pertanian, reaksi
penawaran terhadap perubahan harga terjadi setelah melalui suatu
tenggang waktu (gestation period). Misalnya, panen komoditi
permulaan tahun dipengaruhi oleh harga yang terjadi pada tahun
sebelumnya. Akibatnya, bila pada akhir tahun t, harga komoditi
pertanian ternyata lebih rendah daripada harga sebelumnya, maka
pada tahun berikutnya (t + 1) akan ada kecenderungan di sektor
pertanian untuk memproduksi komoditi ini lebih sedikit daripada
yang diproduksi pada tahun t. Akibatnya, μi tidak lagi bersifat acak
(random) tetapi mengikuti suatu pola yaitu sarang laba-laba.
b. Konsekuensi dari Munculnya Otokorelasi
Sebagaimana telah diuraikan, bila hasil suatu regresi dari suatu
model empiris memenuhi semua asumsi regresi linier klasik maka
berdasarkan teori yang dikemukakan oleh Gauss Markov, hasil regresi
dari model empiris tersebut akan Best Linier Unbiased Estimator (BLUE)
ini berarti bahwa dalam semua kelas, semua penaksir akan unbiased
linier dan penaksir OLS adalah yang terbaik, yaitu penafsir tersebut
mempunyai varian yang minimum. Singkatnya, penaksir OLS tadi
efisien.
Berangkat dari pemikiran di atas, bila semua asumsi regresi linier
klasik dipenuhi kecuali asumsi no autocorrelation, maka penafsir-
penafsir OLS akan mengalami hal-hal sebagai berikut (Arief, 1993: 41,
Sumodiningrat, 1994: 241-244, Ramanathan, 1996: 452-, Gujarati,
1995: 410-415 dan Gujarati, 1999: 381-382).

c. Cara Mendeteksi Ada-tidaknya Masalah Otokorelasi
Harus diakui bahwa tidak ada prosedur estimasi yang dapat menjamin
mampu mengeliminiasi masalah otokorelasi karena secara alamiah,
perilaku otokorelasi biasanya tidak diketahui. Oleh karen itu, dalam
beberapa kasus, orang atau penggunaan ekonometrika mungkin akan
merubah bentuk fungsi persamaan regresinya misalnya, dalam bentuk
log atau first difference. Hal ini menunjukkan bahwa pendeteksian
terhadap ada-tidaknya otokorelasi merupakan suatu hal yang sangat
diperlukan. Berkaitan dengan hal tersebut, di bawah ini akan
ditawarkan beberapa cara atau metode untuk mendeteksi ada-
tidaknya otokorelasi (Arief, 1993: 41-46, Sumodiningrat, 1994: 234-
240, Ramanthan, 1996: 452-458, Gujarati, 1995: 415-426 dan
Kautsoyiannis, 1977: 211-227, Thomas 1997: 302-307 Maddala, 1992:
229-268).
Autokorelasi terjadi bila nilai gangguan dalam periode tertentu
berhubungan dengan nilai gangguan sebelumnya. Asumsi non-
autokorelasi berimplikasi bahwa kovarians ui dan uj sama dengan no l:
cov (uiuj) = E([ui – E(ui)][uj – E(uj)]
= E(uiuj) = 0 untuk i+j
Uji d Durbin Waston ( Durbin-Waston d Test )
Model ini diperkenalkan oleh J. Durbin dan G.S Watson tahun 1951.
Deteksi autokorelasi dilakukan dengan membandingkan nilai statiatik
Durbin Watson hitung dengan Durbin Watson tabel. Mekanisme uji
Durbin Watson adalah sebagai berikut :
1. Lakukan regresi OLS dan dapatkan residualnya.
2. Hitung nilai d (Durbin Watson).
3. Dapatkan nilai kritis dL dan du.

4. Apabila hipotesis nol adalah bahwa tidak ada serial korelasi positif,
maka jika
d < dL, tolak Ho
d < du, terima Ho
dL= d = du, pengujian tidak menyakinkan
5. Apabila hipotesis nol adalah bahwa tidak ada serial korelasi baik
negatif, maka jika
d > 4-dL, tolak Ho
d < 4-du, terima Ho
4-du = d = 4-dL, pengujian tidak menyakinkan
6. Apabila Ho adalah dua ujung, yaitu bahwa tidak ada serial korelasi
baik positif maupun negatif, maka jika
d < dL, tolak Ho
d > 4-dL, tolak Ho
du < d < 4-du, terima Ho
dL = d = du, pengujian tidak menyakinkan
4-du = d = 4-dL, pengujian tidak menyakinkan
Pendeteksian ada tidaknya autokorelasi pada persamaan yang
mengandung variabel dependen kelambanan, misalnya pada model
penyesuaian parsial, dapat dilakukan uji Durbin LM seperti berikut ini:
ut = xt’d + T Yt-1 + Ut-1+ et
dimana ut = residual dari model yang diestimasi
xt = variabel-variabel penjelas
Yt-1 = variabel dependen kelambanan
Ut-1 = residual kelambanan
Apabila nilai t hitung dari residual kelambanan signifikan, maka dapat
disimpulkan bahwa hipotesis tidak adanya autokorelasi tidak dapat
ditolak.
Konsekuensi autokorelasi:
1. Penaksir tidak efisien, selang keyakinanya menjadi lebar secara tak
perlu dan pengujian signifikansinya kurang kuat.
2. Variasi residual menaksir terlalu rendah.
3. Pengujian arti t dan F tidak lagi sahih dan memberi kesimpulan
yang menyesatkan mengenai arti statistik dari koefisien regresi
yang ditaksir.
4. Penaksir memberi gambaran populasi yang menyimpang dari nilai
populasi yang sebenarnya.
Autokorelasi adalah adanya hubungan antar residual pada satu
pengamatan dengan pengamatan lain. Konsekuensi autokorelasi
adalah biasnya varians dengan nilai yang lebih kecil dari nilai
sebenarnya, sehingga nilai R kuadrat dan F-statistik yang dihasilkan
cenderung sangat berlebih (overestimated). Cara mendeteksi adanya
autokorelasi adalah d dengan membandingkan nilai Durbin Watson
statistik hitung dengan Durbin Watson (DW) statistik tabel:
Contoh Kasus
TAHUN INVESTASI INFLASI SUKU BUNGA KURS
1984 3750 8.76 18.7 1076
1985 3830 4.31 17.8 1125
1986 4126 8.83 15.2 1641
1987 11404 8.9 16.99 1650
1988 15681 5.47 17.76 1729
1989 19635 5.97 18.12 1795 1990 59878 9.53 18.12 1901
1991 41084 9.52 22.49 1992
1992 29315 4.94 18.62 2062
1993 40400 9.77 13.46 2110
1994 53289 9.24 11.87 2206
1995 69853 8.64 15.04 2308
1996 100715 6.47 16.69 2383
1997 50873 11.05 16.28 4650

TAHUN INVESTASI INFLASI SUKU BUNGA KURS
1998 60749 77.63 21.84 8025
1999 61500 2.01 27.6 7100
2000 93894 9.35 16.15 9595
2001 98816 12.55 14.23 10400 2002 125308 10.03 15.95 8940
2003 1484845 506 12.64 8447
2004 164528 6.4 8.21 9290
2005 146900 17.11 8.22 9830
2006 227000 6.6 11.63 9020
2007 215100 6.59 8.24 9419
2008 320600 11.06 10.43 10950
2009 227000 2.78 9.55 9400
2010 269900 6.96 7.88 8991 2011 279000 3.79 7.04 9068
2012 289800 4.3 5.75 9670
Uji serial korelasi Klik Quick Estimate Equation investasi c inflasi bunga kurs
Klik View Residual Diagnostics kemudian pilih Serial
Correlation LM test

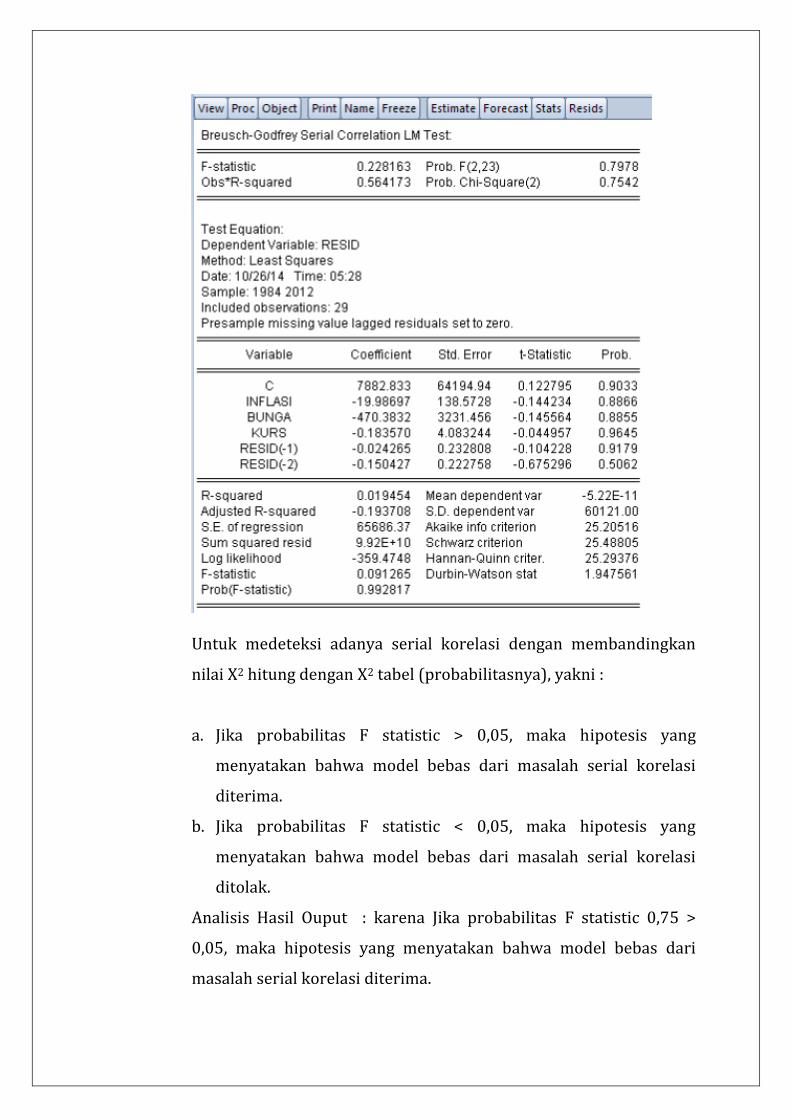
Untuk medeteksi adanya serial korelasi dengan membandingkan
nilai X2 hitung dengan X2 tabel (probabilitasnya), yakni :
a. Jika probabilitas F statistic > 0,05, maka hipotesis yang
menyatakan bahwa model bebas dari masalah serial korelasi
diterima.
b. Jika probabilitas F statistic < 0,05, maka hipotesis yang
menyatakan bahwa model bebas dari masalah serial korelasi
ditolak.
Analisis Hasil Ouput : karena Jika probabilitas F statistic 0,75 >
0,05, maka hipotesis yang menyatakan bahwa model bebas dari
masalah serial korelasi diterima.
5.4. Uji Normalitas
Klic View Residual diagnostics histogram – Normality Test
Klik OK
Untuk mendeteksi apakah residualnya berdistribusi normal atau tidak
dengan membandingkan jilai Jarque Bera (JB) dengan X2 tabel, yaitu :

a. Jika probabilitas Jarque Bera (JB)> 0,05, maka residualnya
berdistribusi normal
b. Jika probabilitas Jarque Bera (JB)< 0,05, maka residualnya
berdistribusi tidak normal
Hasil Analisis Output : probabilitas Jarque Bera (JB)0,289 > 0,05, maka
residualnya berdistribusi normal
5.5. Uji Linearitas
Klik view Stability Diagnostics Ramsey RESET Test, klik ok dan
abaikan jumlah fitted terms
Klik OK

Untuk medeteksi apakah model linear atau tidak dengan membandingkan
nilai F statistic dengan F table (atau dengan membandingkan
probabilitasnya), yaitu :
a. Jika probabilitas F statistic > 0,05, maka hipotesis yang menyatakan
bahwa model linear adalah diterima.
b. Jika probabilitas F statistic < 0,05, maka hipotesis yang menyatakan
bahwa model linear adalah ditolak.
Analisis Hasil Output karena Jika probabilitas F statistic 0,00 < 0,05, maka
hipotesis yang menyatakan bahwa model linear adalah ditolak.
Model dirubah menjadi double log, diperoleh hasil

Uji Linearitas
Analisis Hasil Output karena Jika probabilitas F statistic 0,13 > 0,05, maka
hipotesis yang menyatakan bahwa model linear adalah diterima.
Uji Multikolinearitas
Tahapan pengujian melalui program eviews dengan pendekatan korelasi
partial dengan tahapan sebagai berikut :
1. Lakukan regresi seperti contoh diatas :
Investasi = a0 + a1 Inflasi + a2 bunga + a3 kurs …………. (5.1)
(investasi c inflasi bunga kurs)
2. Kemudian lakukan estimasi regresi untuk :
Inflasi = b0 + b1 bunga + b2 kurs ……………………….……….. (5.2)
(inflasi c bunga kurs).
bunga = b0 + b1 inflasi + b2 kurs ……………………………..….. (5.3)
(bunga c inflasi kurs)
kurs = b0 + b1 infasi+ b2 bunga) …………………………......... (5.4)
(kurs c inflasi bunga)

Hasil Estimasi sebagai berikut :

Untuk persamaan (1) nilai R2 adalah sebesar 0,951 selanjutnya disebut
R21
Untuk persamaan (2) nilai R2 adalah sebesar 0,0276 selanjutnya disebut
R22

Untuk persamaan (3) nilai R2 adalah sebesar 0,296 selanjutnya disebut
R23
Untuk persamaan (4) nilai R2 adalah sebesar 0,312 selanjutnya disebut
R24
Hasil Analisis Output : menunjukan bahwa R21 > R22, R23, R24 maka dalam
model tidak ditemukan adanya multikolinearitas
Uji Heteroskedastisitas
Uji White
Lakukan estimasi persamaan regresi bergkita diatas, setelah itu klik view
residula diagnostics heteroskedastisitas Test
Pilih white, dan klik ok

Diperoleh hasil sebagai berikut :

Apabila nilai X2 hitung (nilai Obs* R squared) > nilai X2 tabel, misalnya
dengan derajat kepercayaan α = 5%, baik untuk cross terms maupun no
cross terms maka dapat disimpulkan model diatas tidak lolos uji
heteroskedasitisitas.
Hasil analisis output, berdasarkan table output diatas, tampak bahwa nilai
nilai Obs* R squared 27,11 , probabilitas X2 0,0013 < 0,05 maka tidak lolos
uji heteroskedastisitas.
Karena model tidak lolos Heteroskedastisitas maka model dibuat log

Kita uji dengan uji white kembali, diperoleh :

Hasil analisis output, berdasarkan table output diatas, tampak bahwa nilai
nilai Obs* R squared 10,04, probabilitas X2 > 0,05 maka Ho diterima atau
model tidak mengandung heteroskedastisitas.
Uji Autokorelasi
Dari hasil regresi Investasi = f(inflasi, bunga, kurs) dapat kita lihat nilai dw
yaitu sebesar 1,985. Nilai dw ini kemudian kita bandingkan dengan dw
table.
Karena nila dw diantara du < dw < 4-du, terima Ho, maka dapat disimpulkan bahwa H0 diterima artinya model tersebut tidak mengandung autokorelasi.


PERBAIKAN PELANGGARAN ASUMSI KLASIK
6.1. Multikolinearitas
Jika model kita mengandung multikolinieritas yang serius yakni
korelasi yang tinggi antar variabel independen, Ada dua pilihan yaitu kita
membiarkan model tetap mengandung multikolinieritas dan kita akan
memperbaiki model supaya terbebas dari masalah multikolinieritas.
Tanpa Ada Perbaikan
Multikolinieritas sebagaimana kita jelaskan sebelumnya tetap
menghasilkan estimator yang BLUE karena masalah estimator yang BLUE
tidak memerlukan asumsi tidak adanya korelasi antar variabel
independen. Multikolinieritas hanya menyebabkan kita kesulitan
memperoleh estimator dengan standard error yang kecil. Masalah
multikolinieritas biasanya juga timbul karena kita hanya mempunyai
jumlah observasi yang sedikit. Dalam kasus terakhir ini berarti kita tidak
punya pilihan selain tetap menggunakan model untuk analisis regresi
walaupun mengandung masalah multikolinieritas.
BAB
6

Dengan Perbaikan
a. Menghilangkan Variabel Independen
Ketika kita menghadapi persoalan serius tentang
multikolinieritas, salah satu metode sederhana yang bisa dilakukakan
adalah dengan menghilangkan salah satu variabel independen yang
mempunyai hubungan linier kuat. Misalnya dalam kasus hubungan
antara tabungan dengan pendapatan dan kekayaan, kita bisa
menghilangkan variabel independen kekayaan.
Akan tetapi menghilangkan variabel independen di dalam suatu
model akan menimbulkan bias spesifikasi model regresi. Masalah bias
spesifikasi ini timbul karena kita melakukan spesifikasi model yang
salah di dalam analisis. Ekonomi teori menyatakan bahwa pendapatan
dan kekayaan merupakan faktor yang mempengaruhi tabungan
sehingga kekayaan harus tetap dimasukkan di dalam model.
b. Transformasi Variabel
Misalnya kita menganalisis perilaku tabungan masyarakat
dengan pendapatan dan kekayaan sebagai variabel independen. Data
yang kita punyai adalah data time series. Dengan data time series ini
maka diduga akan terjadi multikolinieritas antara variabel independen
pendapatan dan kekayaan karena data keduanya dalam berjalannya
waktu memungkinkan terjadinya trend yakni bergerak dalam arah
yang sama. Ketika pendapatan naik maka kekayaan juga mempunyai
trend yang naik dan sebaliknya jika pendapatan menurun diduga
kekayaan juga menurun.
Dalam mengatasi masalah multikolinieritas tersebut, kita bisa
melakukan transformasi variabel. Misalnya kita mempunyai model
regresi time series sbb:

tttt eXXY 22110 (6.1)
dimana :
Y = tabungan;
X1 = pendapatan;
X2 = kekayaan
Pada persamaan (6.1) tersebut merupakan perilaku tabungan pada
periode t, sedangkan perilaku tabungan pada periode sebelumnya t-1
sbb:
112211101 tttt eXXY (6.2)
Jika kita mengurangi persamaan (6.1) dengan persamaan (6.2) akan
menghasilkan persamaan sbb:
)()()( 112222111111 tttttttt eeXXXXYY (6.3)
ttttttt vXXXXYY )()( 122211111 (6.4)
dimana vt = et – et-1
Persamaan (6.4) tersebut merupakan bentuk transformasi
variabel ke dalam bentuk diferensi pertama (first difference). Bentuk
diferensi pertama ini akan mengurangi masalah multikolinieritas
karena walalupun pada tingkat level X1 dan X2 terdapat
multikolinieritas namun tidak berarti pada tingkat diferensi pertama
masih terdapat korelasi yang tinggi antara keduanya.

Transformasi variabel dalam persamaan (6.4) akan tetapi
menimbulkan masalah berkaitan dengan masalah variabel gangguan.
Metode OLS mengasumsikan bahwa variabel gangguan tidak saling
berkorelasi. Namun transformasi variabel variabel gangguan vt = et –
et-1 diduga mengandung masalah autokorelasi. Walaupun variabel
gangguan et awalnya adalah independen, namun variabel gangguan vt
yang kita peroleh dari transformasi variabel dalam banyak kasus akan
saling berkorelasi sehingga melanggar asumsi variabel gangguan
metode OLS.
c. Penambahan Data
Masalah multikolinieritas pada dasarnya merupakan
persoalan sampel. Oleh karena itu, masalah multikolinieritas
seringkali bisa diatasi jika kita menambah jumlah data. Kita kembali ke
model perilaku tabungan sebelumnya pada contoh 6.5. dan kita tulis
kembali modelnya sbb:
iiii eXXY 22110 (6.5)
dimana:Y= tabungan; X1= pendapatan; X2 = kekayaan.
Varian untuk 1 sbb:
)1(
)ˆvar(2
12
2
1
2
1rx i
(6.6)
Ketika kita menambah jumlah data karena ada masalah
multikolinieritas antara X1 dan X2 maka 2
1ix akan menaik sehingga
menyebabkan varian dari 1 akan mengalami penurunan. Jika varian
mengalami penurunan maka otomatis standard error juga akan
mengalami penurunan sehingga kita akan mampu mengestimasi

1 lebih tepat. Dengan kata lain, jika multikolinieritas menyebabkan
variabel independen tidak signifikan mempengaruhi variabel
dependen melalui uji t maka dengan penambahan jumlah data maka
sekarang variabel independen menjadi signifikan mempengaruhi
variabel dependen.
Contoh Kasus 6.1:
Data perkembangan Ekspor, Konsumsi, impor, angkatan kerja dan
populasi di Negara ABC sebagai berikut :
Tabel 6.1.
Perkembangan Ekspor, Konsumsi, impor, angkatan kerja dan populasi
Tahun Ekspor konsumsi Impor Angkatan
Kerja Populasi
1990 468359 119802 95842 72574728 181436821 1991 556306 140805 112644 73845896 184614740
1992 632582 157484 125987 75104839 187762097
1993 671218 192959 154367 76349299 190873248 1994 737948 228119 182495 77575965 193939912
1995 794926 279876 223901 78783138 196957845
1996 855022 332094 265676 79970646 199926615
1997 921714 387171 309737 81141540 202853850
1998 1024791 647824 518259 82301397 205753493
1999 698856 813183 650547 83457632 208644079
2000 883948 856798 685439 84616171 211540428
2001 889649 1039655 831724 85779320 214448301
2002 878823 1231965 985572 86947635 217369087
2003 930554 1372078 1097662 88123124 220307809
2004 1056442 1532888 1226311 89307442 223268606
2005 1231826 1785596 1428477 90501881 226254703 2006 1347685 2092656 1674125 91705592 229263980
2007 1462818 2510504 2008403 111244331 232296830
2008 1602275 2999957 2399966 113031121 235360765
2009 1447012 3290996 2632797 115053936 238465165
2010 1667918 3858822 3087057 116495844 241613126
2011 1914268 4340605 3472484 118515710 244808254

Tahun Ekspor konsumsi Impor Angkatan
Kerja Populasi
2012 1945064 4858331 3886665 120426769 248037853
2013 2026120 5456626 2359212 122125092 251268276 2014 2046740 6035674 2580527 124061112 254454778
Lakukan regresi LS EKS C CONS IMP AK POP Kita peroleh hasil persamaan regresi sebagai berikut :
Dependent Variable: EKS Method: Least Squares Date: 01/09/17 Time: 04:26 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. C -892281.2 712567.2 -1.252206 0.2249
CONS 0.119704 0.049762 2.405542 0.0259 IMP 0.022910 0.064591 0.354693 0.7265 AK 0.007369 0.006623 1.112725 0.2790
POP 0.005041 0.003399 1.483299 0.1536 R-squared 0.959611 Mean dependent var 1147715.
Adjusted R-squared 0.951533 S.D. dependent var 488609.5 S.E. of regression 107567.9 Akaike info criterion 26.18649 Sum squared resid 2.31E+11 Schwarz criterion 26.43026 Log likelihood -322.3311 Hannan-Quinn criter. 26.25410 F-statistic 118.7968 Durbin-Watson stat 1.357171 Prob(F-statistic) 0.000000
Dari hasil output regresi diatas dapat kita susun persamaan sebagai berikut : EKS = - 892281 + 0.12*CONS + 0.023*IMP + 0.007*AK + 0.005*POP (0.0498) (0.0645) (0.0066) (0.0033) T hitung 2.4055*** 0.3546 1.1127 1.4832 R2 = 0.959 F hitung = 118.796
Konsekuensi multikearitas adalah invalidnya signifikansi variable
maupun besaran koefisien variable dan konstanta. Multikolinearitas

diduga terjadi apabila estimasi menghasilkan nilai R kuadrat yang tinggi
(lebih dari 0.8), nilai F tinggi, dan nilai t-statistik semua atau hampir
semua variabel penjelas tidak signifikan. (Gujarati, 2003)
Untuk medeteksi awal apakah dalam suatu model mengandung
multikolinearitas, maka tindakan awal dengan melihat estimasi nilai R2
yang tinggi (lebih dari 0.8), nilai F tinggi, dan nilai t-statistik semua atau
hampir semua variabel penjelas tidak signifikan. Dari hasil diatas dapat
kita lihat R2 tinggi, F tinggi namun sebagian besar tidak signifikan. Artinya
ada kemungkinan model diatas mengandung multikolinearitas yang
serius.
Uji selanjutnya, bandingkan R kuadrat regresi diatas dengan R
kuadrat regresi antar variable bebasnya.
Regres LS AK IMP CONS POP C Dependent Variable: AK Method: Least Squares Date: 01/09/17 Time: 04:49 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. IMP 5.078742 1.816942 2.795215 0.0108
CONS 4.832311 1.255603 3.848599 0.0009 POP 0.137917 0.107873 1.278517 0.2150
C 47839133 21030811 2.274716 0.0335 R-squared 0.964931 Mean dependent var 93561606
Adjusted R-squared 0.959922 S.D. dependent var 17704591 S.E. of regression 3544388. Akaike info criterion 33.14528 Sum squared resid 2.64E+14 Schwarz criterion 33.34030 Log likelihood -410.3159 Hannan-Quinn criter. 33.19937 F-statistic 192.6086 Durbin-Watson stat 1.277394 Prob(F-statistic) 0.000000

Jika kita bandingkan R12 regresi LS EKS C CONS IMP AK POP dengan R22
regresi LS AK IMP CONS POP C, maka R12 = 0.959611lebih kecil dari
R22 = 0.964931, sehingga dapat disimpulkan model diatas
mengandung multikolearitas.
Cara menghilangkan multikonearitas :
Dengan menghilangkan variable yang tidak signifikan Misal variable konsumsi kita hilangkan Regres LS EKS C IMP AK POP
Dependent Variable: EKS Method: Least Squares Date: 01/09/17 Time: 05:02 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. C -2058947. 578495.0 -3.559144 0.0019
IMP 0.010873 0.071359 0.152363 0.8804 AK 0.017615 0.005620 3.134436 0.0050
POP 0.007095 0.003646 1.946095 0.0651 R-squared 0.947925 Mean dependent var 1147715.
Adjusted R-squared 0.940486 S.D. dependent var 488609.5 S.E. of regression 119198.4 Akaike info criterion 26.36061 Sum squared resid 2.98E+11 Schwarz criterion 26.55563 Log likelihood -325.5077 Hannan-Quinn criter. 26.41470 F-statistic 127.4227 Durbin-Watson stat 1.280160 Prob(F-statistic) 0.000000
Hasil regresi diatas : R kuadrat yang tinggi (lebih dari 0.8), nilai F tinggi,
dan nilai t-statistik hampir semua variabel penjelas signifikan.

6.2. Heteroskedastisitas
Diketahui bahwa heteroskedastisitas tidak merusak sifat kebiasan dan
konsistensi dari penaksir OLS, tetapi penaksir tadi tidak lagi efisien yang
membuat prosedur pengujian hipotesis yang biasa nilainya diragukan.
Oleh karena itu diperlukan suatu tindakan perbaikan pada model regresi
untuk menghilangkan masalah heteroskedastisitas pada model regresi
tersebut. Tindakan perbaikan ini tergantung dari pengetahuan kita
tentang varian dari variabel gangguan. Ada dua pendekatan untuk
melakukan tindakan perbaikan, yaitu jika σ2i diketahui dan jika σ2i tidak
diketahui.
a. Varian Variabel gangguan Diketahui (i2 )
Jika kita mengetahui besarnya varian maka penyembuhan masalah
heteroskedastisitas bisa dilakukan melalui metode WLS yang
merupakan bentuk khusus dari metode Generalized Least Squares
(GLS). Dari metode WLS ini akhirnya kita bisa mendapatkan estimator
yang BLUE kembali. Untuk mengetahui bagaimana metode WLS ini
bekerja, misalkan kita mempunyai model regresi sederhana sbb:
iii eXY 10 (6.7)
Jika varian variabel gangguan 2
i diketahui maka persamaan (6.7)
dibagi i akan mendapatkan persamaan sbb:
i
i
i
i
ii
i eY
0 (6.8)
Atau dapat ditulis sbb:
ii
i
i eXY 10
1
(6.9)

Persamaan (6.9) merupakan transformasi dari persamaan (6.7). Dari
metode transformasi ini kita akan mendapatkan varian variabel
gangguan yang konstan.
2)()( ii eeVar (6.10)
2
i
ie
)(1 2
2 i
i
e
karena varian variabel gangguan 2
i diketahui dan 22 )( iie maka
)(1 2
2 i
i
1
Varian dari transformasi variabel gangguan
ie ini sekarang konstan.
Ketika kita mengaplikasikan metode OLS dalam persamaan
transformasi (6.9) maka kita akan mempunyai estimator yang BLUE.
Namun perlu diingat bahwa estimator pada persamaan awal yakni
persamaan (6.7) tetap tidak BLUE.
b. Ketika Varian Variabel gangguan Tidak Diketahui (I2 )
Dalam kenyataannya sulit kita mengetahui besarnya varian
variabel gangguan. Oleh karena itu dikembangkanlah metode
penyembuhan yang memberi informasi cukup untuk mendeteksi
varian yang sebenarnya. Ada beberapa metode yang dapat digunakan
untuk menyembuhkan masalah heteroskedastisitas.
Metode White
Jika kita tidak mengetahui besaranya varian variabel gangguan
maka kita tidak mungkin bisa menggunakan metode WLS. OLS
estimator sebenarnya menyediakan estimasi parameter yang

konsisten jika terjadi heteroskedastisitas tetapi standard errors OLS
yang biasa tidak tepat untuk membuat sebuah kesimpulan. White
kemudian menggembangkan perhitungan standard errors
heteroskedastisitas yang dikoreksi (heteroscedasticity-corrected
standard errors). Untuk menjelaskan metode White ini kita ambil
contoh regresi sederhana sbb:
iii eXY 10 (6.11)
Dimana 2)var( iie
Jika model mempunyai varian variabel gangguan yang tidak sama maka
varian estimator tidak lagi efisien. Varian estimator 1 menjadi:
22
22
1)(
)ˆvar(i
ii
x
x
(6.12)
Karena 2
i tidak bisa dicari secara langsung maka White mengambil
residual kuadrat 2ˆie dari persamaan (6.12) sebagai proksi dari 2
i .
Kemudian varian estimator 1 dapat ditulis sbb:
22
22
1)(
)ˆvar(i
ii
x
ex
(6.13)
Sebagaimana ditunjukkan oleh White, varian )ˆ( 1 dalam persamaan
(6.13) adalah estimator yang konsisten dari varian dalam persamaan
(6.12). Ketika sampel bertambah besar maka varian persamaan (6.13)
akan menjadi varian persamaan (6.12).

Prosedur metode White dilakukan dengan mengestimasi
persamaan (6.11) dengan metode OLS, dapatkan residualnya dan
menghitung varian berdasarkan persamaan (6.10). Bagi model regresi
lebih dari satu variabel independen maka kita harus mencari varian
setiap variabel independen. Untuk mengatasi masalah ini, beberapa
program komputer seperti Eviews menyediakan metode White ini.
Metode White tentang heteroscedasticity-corrected standard
errors didasarkan pada asumsi bahwa variabel gangguan et tidak saling
berhubungan atau tidak ada serial korelasinya. Untuk itu maka Newey,
Whitney dan Kennneth West menggembangkan metode dengan
memasukkan masalah unsur autokoralsi (6.13)
Mengetahui Pola Heteroskedastisitas
Kelemahan dari metode White adalah estimator yang didapatkan
mungkin tidak efisien. Metode lain yang bisa dilakukan adalah dengan
mengetahui pola heteroskedastisitas di dalam model. Pola ini bisa
diketahui melalui hubungan antara varian variabel gangguan dengan
variabel independen. Misalnya kita mempunyai model sbb:
iii eXY 10 (6.14)
Kita asumsikan bahwa pola varian variabel gangguan dari persamaan
(6.14) adalah proporsional dengan Xi sehingga:
)()(var 2
iii eEXe (6.15)
iX2
untuk menghilangkan masalah heteroskedastisitas jika variabel
gangguan proporsional dengan variabel independen Xi, kita dapat

melakukan transformasi persamaan (6.15) dengan membagi dengan
iX sehingga akan menghasilkan persamaan sbb:
i
i
i
i
ii X
e
X
X
XX
Y 1
0
ii
i
vXX
10
1 (6.16)
dimana i
ii
X
ev
Sekarang kita bisa membuktikan bahwa varian variabel gangguan dalam
persamaan (6.16) tidak lagi heteroskedastisitas tetapi
homoskedastisitas:
2
2 )(
i
ii
X
eEvE karena persamaan (6.16)
)(1 2
i
i
eX
(6.17)
i
i
XX
21
2 Karena persamaan (6.15)
Persamaan (6.17) tersebut berbeda dengan model persamaan regresi
awal. Sekarang kita tidak lagi mempunyai intersep sehingga kita bisa
melakukan regresi tanpa intersep untuk mengestimasi 0 dan 1. Kita
kemudian bisa mendapatkan regresi awal dengan cara mengalikan
persamaan (6.16) dengan iX .

Selain proporsional dengan variabel independen X, kita bisa
mengasumsikan bahwa pola varian variabel gangguan adalah
proporsional dengan 2
iX sehingga:
222 )( ii XeE (6.18)
Kemudian kita bisa melakukan transformasi persamaan (6.14) dengan
membagi Xi sehingga akan menghasilkan persamaan sbb:
i
i
iii
i
X
e
XXX
Y 10
i
i
vX
10
1 (6.19)
Kita dapat membuktikan bahwa varian variabel gangguan persamaan
(7.62) sekarang bersifat homoskedastisitas yaitu:
2
2 )(
i
ii
X
eEvE
)(1 2
2 i
i
eX
22
2
1i
i
XX
2 karena persamaan (6.18) (6.20)
Dalam transformasi persamaan di atas konstanta dan slope
persamaan awal menjadi variabel independen dan variabel intersep
baru.

Contoh Kasus 6.2:
Data perkembangan Ekspor, Konsumsi, impor, angkatan kerja dan
populasi di Negara DEF sebagai berikut :
Tabel 6.2. Perkembangan Ekspor, Konsumsi, impor,
angkatan kerja dan populasi
Tahun Ekspor Consumsi Import Angkatan Kerja Pop 1990 468359 119802 95842 54431046 181436821 1991 556306 140805 112644 55384422 184614740 1992 632582 157484 125987 56328629 187762097 1993 671218 192959 154367 57261974 190873248 1994 737948 228119 182495 58181974 193939912 1995 794926 279876 223901 59087354 196957845 1996 855022 332094 265676 59977985 199926615 1997 921714 387171 309737 60856155 202853850 1998 1024791 647824 518259 61726048 205753493 1999 698856 813183 650547 62593224 208644079 2000 883948 856798 685439 84616171 211540428 2001 889649 1039655 831724 85779320 214448301 2002 878823 1231965 985572 86947635 217369087 2003 930554 1372078 1097662 88123124 220307809 2004 1056442 1532888 1226311 89307442 223268606 2005 1231826 1785596 1428477 90501881 226254703 2006 1347685 2092656 1674125 91705592 229263980 2007 1462818 2510504 2259453 111244331 232296830 2008 1602275 2999957 2699961 113031121 235360765 2009 1447012 3290996 2961896 115053936 238465165 2010 1667918 3858822 3472940 116495844 241613126 2011 1914268 4340605 3906545 118515710 244808254 2012 1945064 4858331 3886665 120426769 248037853 2013 2026120 5456626 2359212 122125092 251268276 2014 2046740 6035674 2580527 124061112 254454778
Lakukan regresi LS IMP C CONS EKS AK POP
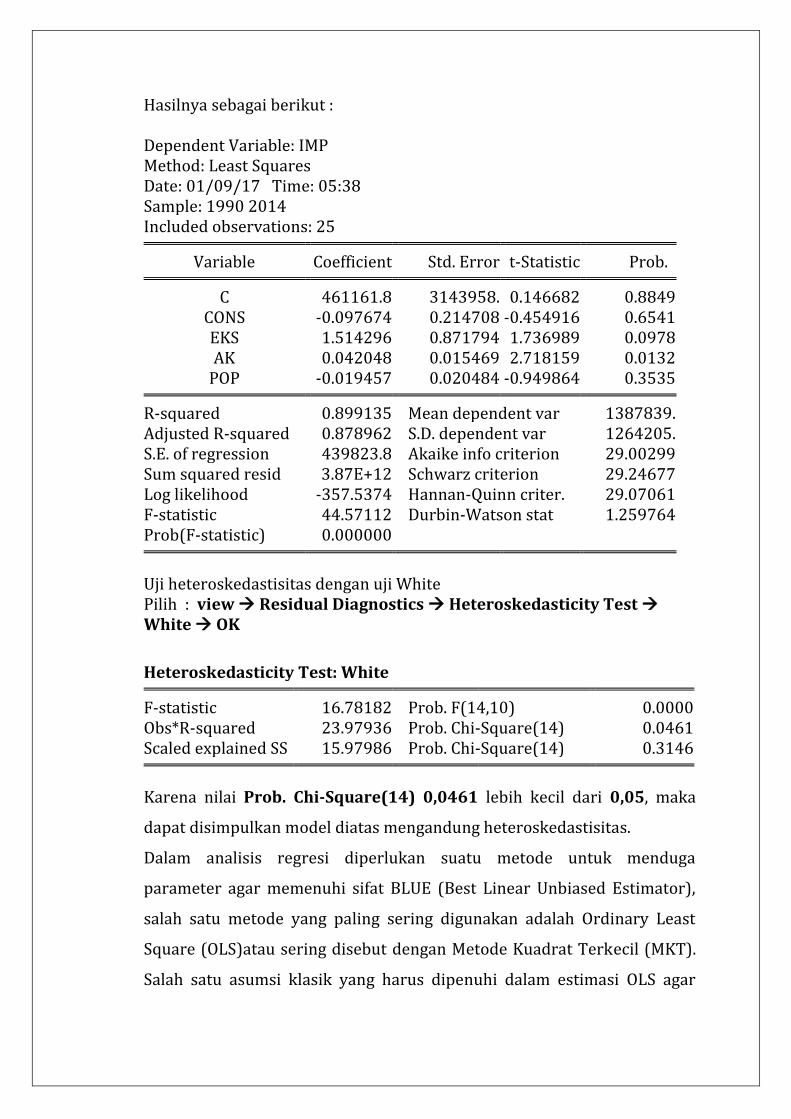
Hasilnya sebagai berikut : Dependent Variable: IMP Method: Least Squares Date: 01/09/17 Time: 05:38 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. C 461161.8 3143958. 0.146682 0.8849
CONS -0.097674 0.214708 -0.454916 0.6541 EKS 1.514296 0.871794 1.736989 0.0978 AK 0.042048 0.015469 2.718159 0.0132
POP -0.019457 0.020484 -0.949864 0.3535 R-squared 0.899135 Mean dependent var 1387839.
Adjusted R-squared 0.878962 S.D. dependent var 1264205. S.E. of regression 439823.8 Akaike info criterion 29.00299 Sum squared resid 3.87E+12 Schwarz criterion 29.24677 Log likelihood -357.5374 Hannan-Quinn criter. 29.07061 F-statistic 44.57112 Durbin-Watson stat 1.259764 Prob(F-statistic) 0.000000
Uji heteroskedastisitas dengan uji White Pilih : view Residual Diagnostics Heteroskedasticity Test White OK
Heteroskedasticity Test: White F-statistic 16.78182 Prob. F(14,10) 0.0000
Obs*R-squared 23.97936 Prob. Chi-Square(14) 0.0461 Scaled explained SS 15.97986 Prob. Chi-Square(14) 0.3146
Karena nilai Prob. Chi-Square(14) 0,0461 lebih kecil dari 0,05, maka
dapat disimpulkan model diatas mengandung heteroskedastisitas.
Dalam analisis regresi diperlukan suatu metode untuk menduga
parameter agar memenuhi sifat BLUE (Best Linear Unbiased Estimator),
salah satu metode yang paling sering digunakan adalah Ordinary Least
Square (OLS)atau sering disebut dengan Metode Kuadrat Terkecil (MKT).
Salah satu asumsi klasik yang harus dipenuhi dalam estimasi OLS agar

hasil estimasinya dapat diandalkan, yaitu ragam sisaan homogeny E(ui2) =
σ2 (homoskedastisitas). Pelanggaran terhadap asumsi homoskedastisitas
disebut heteroskedastisitas, yang artinya galat bersifat tidak konstan.
Konsekuensi dari terjadi heteroskedastisitas dapat mengakibatkan
penduga OLS yang diperoleh tetap memenuhi persyaratan tak bias, tetapi
varian yang diperoleh menjadi tidak efisien, artinya varian cenderung
membesar sehingga tidak lagi merupakan varian yang kecil. Dengan
demikian model perlu diperbaiki dulu agar pengaruh dari
heteroskedastisitas hilang (Gujarati, 2003)
.
Perbaikan heteroskedastisitas dapat dilakukan melalui :
a. Melalui Logaritma
Lakukan regresi LS LOG(IMP) C LOG(CONS) lOG(EKS) LOG(AK) LOG(POP)
Dependent Variable: LOG(IMP) Method: Least Squares Date: 01/09/17 Time: 05:51 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. C 284.8554 96.85826 2.940951 0.0081
LOG(CONS) 1.941547 0.351879 5.517657 0.0000 LOG(EKS) 0.635442 0.372278 1.706901 0.1033 LOG(AK) 0.700437 0.452365 1.548390 0.1372
LOG(POP) -16.65656 5.608760 -2.969740 0.0076 R-squared 0.985814 Mean dependent var 13.57581
Adjusted R-squared 0.982977 S.D. dependent var 1.221827 S.E. of regression 0.159415 Akaike info criterion -0.657761 Sum squared resid 0.508260 Schwarz criterion -0.413986 Log likelihood 13.22201 Hannan-Quinn criter. -0.590148 F-statistic 347.4638 Durbin-Watson stat 1.115773 Prob(F-statistic) 0.000000

Uji heteroskedastisitas dengan uji White Pilih : view Residual Diagnostics Heteroskedasticity Test White OK
Heteroskedasticity Test: White F-statistic 3.011030 Prob. F(9,15) 0.0288
Obs*R-squared 16.09248 Prob. Chi-Square(9) 0.0650 Scaled explained SS 15.04800 Prob. Chi-Square(9) 0.0896
Karena nilai Prob. Chi-Square(9) sebesar 0,065, lebih besar dari 0,05, maka dapat disimpulkan model diatas mengandung tidak heteroskedastisitas.
b. cara mengatasi heteroskedastisitas pada regresi dengan metode
Weighted Least Square .
Uji menguji ada tidaknya heteroskedastisitas dapatjuga digunakan Uji Breusch Pagan Godfrey (BPG). Hipotesis: H0: tidak ada heteroskedastisitas H1: ada heteroskedastisitas
Heteroskedasticity Test: Breusch-Pagan-Godfrey F-statistic 12.01533 Prob. F(4,20) 0.0000
Obs*R-squared 17.65368 Prob. Chi-Square(4) 0.0014 Scaled explained SS 11.76442 Prob. Chi-Square(4) 0.0192
Berdasarkan perhitungan dengan metode BPG diperoleh bahwa H0
ditolak yang artinya terdapat masalah Heteroskedastisitas dalam
model, sehingga diperlukan adanya perbaikan pada model agar tidak
menyesatkan kesimpulan.
Persoalan heteroskedastisitas dapat ditangani dengan melakukan
pembobotan suatu faktor yang tepat kemudian menggunakan metode
OLS terhadap data yang telah diboboti. Pemilihan terhadap suatu faktor

untuk pembobotan tergantung bagaimana sisaan berkorelasi dengan X
atau Y, jika sisaan proporsional terhadap Xi maka model akan dibagi
engan iX , jika sisaan adalah proporsional dengan sehingga model
akan dibagi dengan Xi2, selain proporsional dengan X1 dan Xi2 bisa juga
diasumsikan bahwa pola varian sisaan adalah proporsional dengan
[E(Yi)]2 sehingga dibagi dengan E(Yi) . Namun dalam prakteknya tidak
selalu dengan pembobotan iYEXX
1,
1,
1
11
dapat mengatasi
heteroskedastisitas karena sesungguhnya pembobot yang diberikan
bergantung pada pola sebaran sisaan terhadap variabel bebas maupun
variabel terikat. Oleh karena itu, dalam penelitian ini faktor pembobot
yang akan dianalisis adalah iYEXX
1,
1,
1
11
, dani
1 (dimana σ = residual
kuadrat).
Pembobotan yang digunakan untuk mengatasi adalah dengan
mengalikan semua variable dengan i
1 , sehingga diperoleh variable
baru sebagai berikut :

Tabel 6.3. Variabel baru setelah pembobotan
Tahun Eks2 Cons2 Imp2 AK2 Pop2 1990 2.621783 0.670628 0.536503 304.6944 1015.648 1991 6.463996 1.636083 1.308867 643.5391 2145.13 1992 89.52568 22.28782 17.83026 7971.872 26572.91 1993 396.505 113.9855 91.18837 33826.06 112753.5 1994 -15.7647 -4.8733 -3.89864 -1242.94 -4143.13 1995 -12.048 -4.24184 -3.39348 -895.536 -2985.12 1996 -9.52208 -3.69842 -2.95873 -667.954 -2226.51 1997 -7.59771 -3.19146 -2.55317 -501.639 -1672.13 1998 -43.457 -27.4715 -21.9772 -2617.54 -8725.13 1999 1.095045 1.274185 1.019348 98.07796 326.9265 2000 -1.87041 -1.81296 -1.45037 -179.046 -447.614 2001 -2.87528 -3.36009 -2.68807 -277.233 -693.082 2002 -7.79908 -10.933 -8.74642 -771.614 -1929.03 2003 -16.1859 -23.8656 -19.0925 -1532.8 -3831.99 2004 -11.0095 -15.9747 -12.7797 -930.698 -2326.74 2005 -9.71356 -14.0803 -11.2643 -713.652 -1784.13 2006 -72.1373 -112.013 -89.6106 -4908.71 -12271.8 2007 -4.44035 -7.62058 -6.85852 -337.68 -705.132 2008 -23.6262 -44.2356 -39.812 -1666.69 -3470.49 2009 3.341787 7.600355 6.84032 265.7101 550.7208 2010 2.50583 5.797379 5.217641 175.0199 362.9924 2011 2.550768 5.783871 5.205484 157.9226 326.2078 2012 2.712767 6.775881 5.420705 167.9584 345.9367 2013 -2.29378 -6.17747 -2.67087 -138.258 -284.462 2014 -3.1197 -9.19976 -3.93332 -189.098 -387.848
Lakukan regresi LS IMP2 C CONS2 EKS2 AK2 POP2

Method: Least Squares Date: 01/09/17 Time: 05:47 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. C 1.081297 0.055690 19.41639 0.0000
CONS2 -0.123846 0.033695 -3.675453 0.0015 EKS2 1.439465 0.054908 26.21585 0.0000 AK2 0.042008 0.001491 28.17096 0.0000
POP2 -0.016739 0.000594 -28.19219 0.0000 R-squared 0.999955 Mean dependent var -3.964814
Adjusted R-squared 0.999946 S.D. dependent var 28.37547 S.E. of regression 0.207613 Akaike info criterion -0.129424 Sum squared resid 0.862064 Schwarz criterion 0.114351 Log likelihood 6.617805 Hannan-Quinn criter. -0.061812 F-statistic 112074.9 Durbin-Watson stat 1.533574 Prob(F-statistic) 0.000000
Lakukan Uji heteroskedastisitas dengan uji White
Pilih : view Residual Diagnostics Heteroskedasticity Test
Breusch-Pagan-Godfrey OK
Heteroskedasticity Test: Breusch-Pagan-Godfrey F-statistic 1.084458 Prob. F(4,20) 0.3907
Obs*R-squared 4.455852 Prob. Chi-Square(4) 0.3478 Scaled explained SS 6.778892 Prob. Chi-Square(4) 0.1480
Berdasarkan perhitungan dengan metode BPG diperoleh bahwa H0
diterima yang artinya tidak terdapat masalah Heteroskedastisitas dalam
model (Prob. Chi-Square(4) = 0.34 lebih besar dari α = 0.05)
Dapat disimpulkan bahwa pembobot pada α taraf sebesar 0,05 dapat
mengatasi heteroskedastisitas .

6.3. Autokorelasi
Setelah kita ketahui konsekuensi masalah autokorelasi dimana estimator
dari metode OLS masih linier, tidak bias tetapi tidak mempunyai varian
yang minimum.
Penyembuhan masalah autokorelasi sangat tergantung dari sifat
hubungan antara residual. Atau dengan kata lain bagaimana bentuk
struktur autokorelasi.
Model regresi sederhana seperti dalam persamaan (6.21) sbb:
ttt eXY 10 (6.21)
Diasumsikan bahwa residual mengikuti model AR(1) sebagai berikut:
ttt vee 1 11 (6.22)
Penyembuhan masalah autokorelasi dalam model ini tergantung dua hal:
(1) jika atau koefisien model AR(1) diketahui;
(2) jika tidak diketahui tetapi bisa dicari melalui estimasi.
a. Ketika Struktur Autokorelasi Diketahui
Pada kasus ketika koefisien model AR(1) yakni struktur
autokorelasi diketahui, maka penyembuhan autokorelasi dapat
dilakukan dengan transformasi persamaan dikenal sebagai metode
Generalized difference equation. Pada bab 7 kita telah mengembangkan
metode GLS untuk mengatasi masalah heteroskedastisitas yakni ketika
varian residual tidak konstan. Dengan melakukan transformasi model
kita dapat menghilangkan masalah heteroskedastisitas sehingga kita

kemudian dapat mengestimasi model dengan menggunakan metode
OLS.
Untuk menjelaskan metode Generalized difference equation
dalam kasus adanya autokorelasi, misalkan kita mempunyai model
regresi sederhana dan residualnya (et) mengikuti pola autoregresif
tingkat pertama AR(1) sbb:
ttt eXY 10 (6.23)
ttt vee 1 11 (6.24)
Dimana residual vt memenuhi asumsi residual metode OLS yakni
E(vt)=0; Var(vt) = 2; dan Cov (vt,vt-1) =0.
Kelambanan (lag) satu persamaan (6.23) sbb:
11101 ttt eXY (6.25)
Jika kedua sisi dalam persamaan (6.25) dikalikan dengan maka akan
menghasilkan persamaan sbb:
11101 ttt eXY (6.26)
Kemudian persamaan (6.23) dikurangi persamaan (6.25) akan
menghasilkan persamaan diferensi tingkat pertama sbb:
1111001 tttttt eeXXYY
ttttt vXXYY 11101 )1(
ttt vXX )()1( 110 (6.27)

dimana 1 ttt eev dan memenuhi asumsi OLS seperti persamaan
(6.24)
Persamaan (6.27) tersebut dapat kita tulis menjadi:
tttt vXY 0 (6.28)
Dimana )(;);1();( 111001
tttttt XXXYYY
Residual vt dalam persamaan (6.28) sudah terbebas dari masalah
autokorelasi sehingga memenuhi asumsi OLS. Sekarang kita bisa
mengaplikasikan metode OLS terhadap transformasi variabel Y* dan X*
dan mendapatkan estimator yang menghasilkan karakteristik
estimator yang BLUE.
b. Ketika Struktur Autokorelasi Tidak Diketahui
Walaupun metode penyembuhan masalah autokorelasi
sangat mudah dilakukan dengan metode generalized difference
equation jika strukturnya diketahui, namun metode ini dalam
prakteknya sangat sulit dilakukan. Kesulitan ini muncul karena sulitnya
kita untuk mengetahui nilai . Oleh karena itu kita harus menemukan
cara yang paling tepat untuk mengestimasi . Ada beberapa metode
yang telah dikembangkan oleh para ahli ekonometrika untuk
mengestimasi nilai .
1) Metode Diferensi Tingkat Pertama
Nilai terletak antara -1 1. Jika nilai = 0 berarti tidak
ada korelasi residual tingkat pertama (AR 1). Namun jika nilai =
1 maka model mengandung autokorelasi baik positif maupun
negatif. Ketika nilai dari = +1, masalah autokorelasi dapat

disembuhkan dengan diferensi tingkat pertama metode generalized
difference equation. Misalkan kita mempunyai model sederhana
seperti persamaan (6.29) sebelumnya, metode diferensi tingkat
pertama (first difference) dapat dijelaskan sbb:
ttt eXY 10 (6.29)
Diferensi tingkat pertama persamaan (6.23) tersebut sebagaimana
dalam persamaan (6.30) sebelumnya sbb:
111101 )1( tttttt eeXXYY (6.30)
Jika = +1 maka persamaan tersebut dapat ditulis kembali menjadi
)()( 1111 tttttt eeXXYY (6.31)
Atau dapat ditulis menjadi persamaan sbb:
ttt vXY 1 (6.32)
dimana adalah diferensi dan 1 ttt eev
Residual vt dari persamaan (6.32) tersebut sekarang terbebas dari
masalah autokorelasi. Metode first difference ini bisa diaplikasikan
jika koefisien autokorelasi cukup tinggi atau jika nilai statistik
Durbin-Watson (d) sangat rendah. Sebagai rule of thumb jika R2 > d,
maka kita bisa menggunakan metode first difference. Dari
transformasi first difference ini sekarang kita tidak lagi mempunyai
intersep atau konstanta dalam model. Konstanta dalam model dapat

dicari dengan memasukkan variabel trend (T) di dalam model
aslinya. Misalkan model awalnya dengan trend sbb:
ttt eTXY 210 (6.33)
dimana T adalah trend, nilainya mulai satu pada awal periode dan
terus menaik sampai akhir periode. Residual et dalam persamaan
(6.24) tersebut mengikuti autoregresif tingkat pertama.
Transformasi persamaan (6.34) dengan metode first difference akan
menghasilkan persamaan sbb:
ttt vXY 211 (6.34)
dimana residual 1 ttt eev
Pada proses diferensi tingkat pertama persamaan (6.32)
menghasilkan persamaan (6.33) yang mempunyai konstanta
sedangkan diferensi pertama pada persamaan (6.34) tanpa
menghasilkan konstanta.
2) Estimasi Didasarkan Pada Berenblutt- Webb
Metode transformasi dengan first difference bisa digunakan
hanya jika nilai tinggi atau jika nilai d rendah. Dengan kata lain
metode ini hanya akan valid jika nilai = +1 yaitu jika terjadi
autokorelasi positif yang sempurna. Pertanyaannya bagaimana kita
bisa mengetahui asumsi bahwa = +1. Berenblutt-Webb telah
mengembangkan uji statistik untuk menguji hipotesis bahwa = +1.
Uji statistik dari Berenblutt-Webb ini dikenal dengan uji statistik g
(Gujarati, 2005). Rumus statistiknya dapat ditulis sbb:

nt
t
n
t
e
g
1
2
2
(6.34)
Dimana et adalah residual dari regresi model asli dan vt merupakan
residual dari regresi model first difference. Dalam menguji
signifikansi statistik g diasumsikan model asli mempunyai
konstanta. Kemudian kita dapat menggunakan tabel Durbin-Watson
dengan hipotesis nol = 1, tidak lagi dengan hipotesis nol = 0.
Keputusan bahwa = 1 ditentukan dengan membandingkan nilai
hitung g dengan nilai kritis statistik d. Jika g dibawah nilai batas
minimal dL maka tidak menerima hipotesis nol sehingga kita bisa
mengatakan bahwa = 1 atau ada korelasi positif antara residual.
3) Estimasi Didasarkan Pada Statistik d Durbin Watson
Kita hanya bisa mengaplikasikan metode transformasi first
difference jika nilai tinggi yakni mendekati satu. Metode ini tidak
bisa digunakan ketika rendah. Untuk kasus nilai rendah maka
kita bisa menggunakan statistik d dari Durbin Watson. Kita bisa
mengestimasi dengan cara sbb:
)ˆ1(2 d (6.35)
atau dapat dinyatakan dalam persamaan sbb:
21ˆ
d (6.36)
Sebagaimana pembahasan sebelumnya, kita bisa mencari nilai
dari estimasi statistik pada persamaan (6.36) di atas. Asumsi first

difference menyatakan bahwa 1ˆ hanya terjadi jika d=0 di dalam
persamaan (6.36). Begitu pula jika d = 2 maka 0ˆ dan bila d =4
maka 1ˆ . Persamaan tersebut hanya suatu pendekatan tetapi
kita bisa menggunakan nilai statistik d untuk mendapatkan nilai .
Di dalam sampel besar kita dapat mengestimasi dari persamaan
(6.36) dan menggunakan yang kita dapatkan untuk model
generalized difference equation dalam persamaan (6.13)
sebelumnya.
4) Estimasi Dengan Metode Dua Langkah Durbin
Untuk menjelaskan metode ini maka kita kembali ke model
generalized difference equation persamaan (6.37). Kita tulis kembali
persamaan tersebut sbb:
1111001 tttttt eeXXYY (6.37)
Atau dapat kita tulis kembali menjadi
ttttt vYXXY 111110 )1( (6.38)
Dimana )( 1 ttt eev
Setelah mendapatkan persamaan (6.38), Durbin menyarankan
untuk menggunakan prosedur dua langkah untuk mengestimasi
yaitu:
1. Lakukan regresi dalam persamaan (6.38) dan kemudian
perlakukan nilai koefisien Yt-1 sebagai nilai estimasi dari .

Walaupun ini bias, tetapi merupakan estimasi yang
konsisten
2. setelah mencapai pada langkah pertama, kemudian lakukan
transformasi variabel )( 1
ttt YYY dan )( 1
ttt XXX dan
kemudian lakukan regresi metode OLS pada transformasi
variabel persamaan (6.11.)
5) Estimasi Dengan Metode Cochrane-Orcutt
Uji ini merupakan uji alternatif untuk memperoleh nilai
yang tidak diketahui. Metode Cochrane-Orcutt sebagaimana metode
yang lain menggunakan nilai estimasi residual et untuk memperoleh
informasi tentang nilai (Pindyck, S and Daniel. L, 1998). Untuk
menjelaskan metode ini kita misalkan mempunyai model regresi
sederhana sbb:
ttt eXY 10 (6.39)
Diasumsikan bahwa residual (et) mengikuti pola autoregresif (AR1) sbb:
ttt vee 1 (6.40)
dimana residul vt memenuhi asumsi OLS
Metode yang kita bicarakan sebelumnya untuk mengetimasi hanya
merupakan estimasi tunggal terhadap . Oleh karena itu, Cochrane-Orcutt
merekomendasi untuk mengestimasi dengan regresi yang bersifat iterasi
sampai mendapatkan nilai yang menjamin tidak terdapat masalah
autokorelasi dalam model. Adapun metode iterasi dari Cochrane-Orcutt
dapat dijelaskan sbb:

1. Estimasi persamaan (6.39) dan kita dapatkan nilai residualnya te
2. Dengan residual yang kita dapatkan maka lakukan regresi
persamaan berikut ini:
ttt vee 1ˆˆˆ (6.41)
3. Dengan yang kita dapatkan pada langkah kedua dari persamaan
(6.41) kemudian kita regresi persamaan berikut ini:
1111001ˆˆˆˆ
tttttt eeXXYY (6.42)
ttttt vXXYY )ˆ()ˆ1(ˆ1101
atau dapat ditulis dalam bentuk yang lebih sederhana menjadi
persamaan
tt eXY 10 (6.43)
dimana: )ˆ1(00
4. Karena kita tidak mengetahui apakah nilai yang diperoleh dari
persamaan (6.41) adalah nilai estimasi yang terbaik, maka masukan
nilai )ˆ1(00 dan
1 yang diperoleh dalam persamaan (6.43)
ke dalam persamaan awal (6.39) dan kemudian dapatkan
residualnya
te sbb:
ttt XYe 10ˆˆˆ (6.44)
5. Kemudian estimasi regresi sbb:

ttt wee ˆˆˆ (6.45)
yang kita peroleh dari persamaan (6.45) ini merupakan langkah
kedua mengestimasi nilai
Karena kita tidak juga mengetahui apakah langkah kedua ini mampu
mengetimasi nilai yang terbaik maka kita dapat melanjutkan pada
langkah ketiga dan seterusnya. Pertanyaannya, sampai berapa langkah
kita harus berhenti melakukan proses iteratif untuk mendapatkan nilai .
Menurut Cochrane-Orcutt, estimasi nilai akan kita hentikan jika nilainya
sudah terlalu kecil.
Contoh Kasus :
Data perkembangan Ekspor, Konsumsi, Impor dan Jumlah penduduk di
Negara GHI sebagai berikut :

Tabel 6.4. Perkembangan Ekspor, Konsumsi, impor, dan populasi
Tahun Ekspor Consumsi Impor Populasi
1990 468359 119802 95842 181436821 1991 556306 140805 112644 184614740 1992 632582 157484 125987 187762097 1993 671218 192959 154367 190873248 1994 737948 228119 182495 193939912 1995 794926 279876 223901 196957845 1996 855022 332094 265676 199926615 1997 921714 387171 309737 202853850 1998 1024791 647824 518259 205753493 1999 698856 813183 650547 208644079 2000 883948 856798 685439 211540428 2001 889649 1039655 831724 214448301 2002 878823 1231965 985572 217369087 2003 930554 1372078 1097662 220307809 2004 1056442 1532888 1226311 223268606 2005 1231826 1785596 1428477 226254703 2006 1347685 2092656 1674125 229263980 2007 1462818 2510504 2259453 232296830 2008 1602275 2999957 2699961 235360765 2009 1447012 3290996 2961896 238465165 2010 1667918 3858822 3472940 241613126 2011 1914268 4340605 3906545 244808254 2012 1945064 4858331 3886665 248037853 2013 2026120 5456626 2359212 251268276 2014 2046740 6035674 2580527 254454778
Lakukan regresi LS Log(IMP) C Log(CONS) Log(EKS) Log(POP)
Hasilnya seperti di bawah ini :
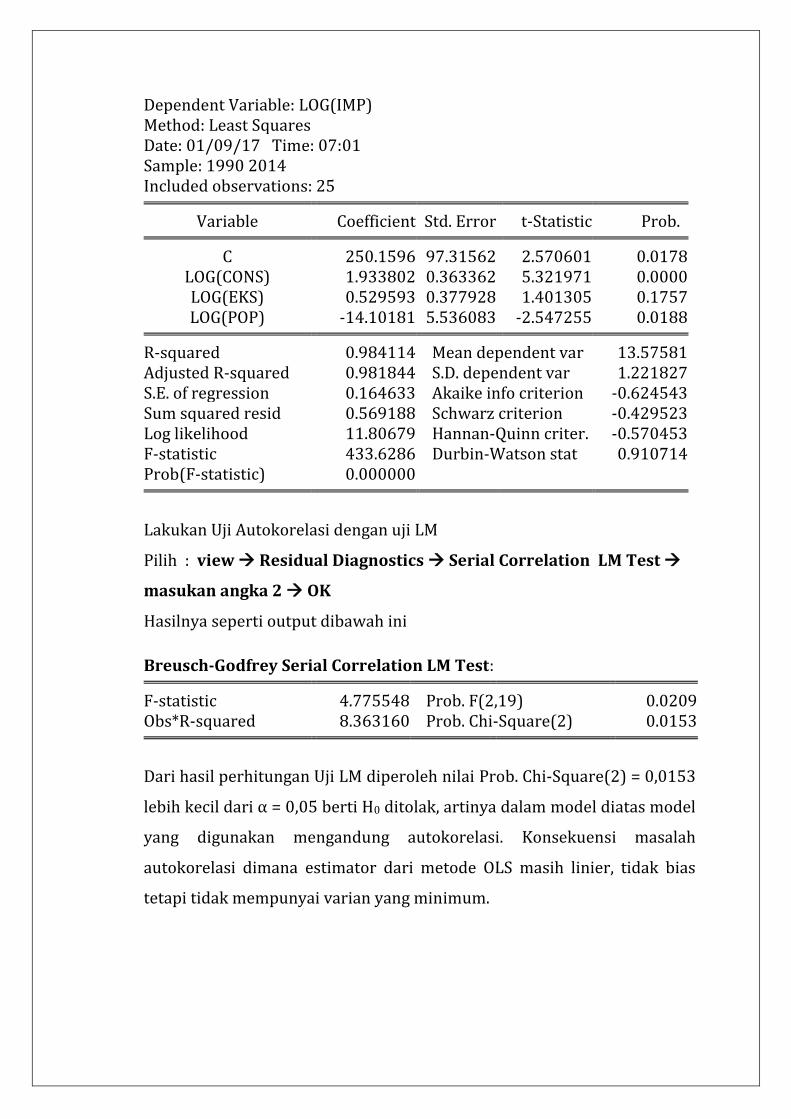
Dependent Variable: LOG(IMP) Method: Least Squares Date: 01/09/17 Time: 07:01 Sample: 1990 2014 Included observations: 25
Variable Coefficient Std. Error t-Statistic Prob. C 250.1596 97.31562 2.570601 0.0178
LOG(CONS) 1.933802 0.363362 5.321971 0.0000 LOG(EKS) 0.529593 0.377928 1.401305 0.1757 LOG(POP) -14.10181 5.536083 -2.547255 0.0188
R-squared 0.984114 Mean dependent var 13.57581
Adjusted R-squared 0.981844 S.D. dependent var 1.221827 S.E. of regression 0.164633 Akaike info criterion -0.624543 Sum squared resid 0.569188 Schwarz criterion -0.429523 Log likelihood 11.80679 Hannan-Quinn criter. -0.570453 F-statistic 433.6286 Durbin-Watson stat 0.910714 Prob(F-statistic) 0.000000
Lakukan Uji Autokorelasi dengan uji LM
Pilih : view Residual Diagnostics Serial Correlation LM Test
masukan angka 2 OK
Hasilnya seperti output dibawah ini
Breusch-Godfrey Serial Correlation LM Test: F-statistic 4.775548 Prob. F(2,19) 0.0209
Obs*R-squared 8.363160 Prob. Chi-Square(2) 0.0153
Dari hasil perhitungan Uji LM diperoleh nilai Prob. Chi-Square(2) = 0,0153
lebih kecil dari α = 0,05 berti H0 ditolak, artinya dalam model diatas model
yang digunakan mengandung autokorelasi. Konsekuensi masalah
autokorelasi dimana estimator dari metode OLS masih linier, tidak bias
tetapi tidak mempunyai varian yang minimum.

Perbaikan Autokorelasi
Perbaikan Autokorelasi digunakan metode transformasi first difference
jika nilai tinggi yakni mendekati satu. 2
1ˆd
seperti dalam persaman
(6.36), sehingga ρ dapat di cari dengan formula dalam persamaan 6,36.
Karena hasil regresi dengan log(imp)=f(log(cons), log(eks), log(pop))
diperoleh dw =0.910714, maka ρ diperoleh ρ = 1-(0,910714/2) = 0.5446.
Tabel 6.5.
Pembentukan Variabel Baru Ekspor, Konsumsi, impor, dan populasi
Tahun log(Eks)* log(Cons)* log(Imp)* log(Pop)* 1991 2.656873 2.382668 2.33854 3.768209
1992 2.671972 2.393078 2.348949 3.771444
1993 2.667326 2.454826 2.410697 3.774582
1994 2.694465 2.479471 2.435342 3.777617
1995 2.704348 2.528681 2.484552 3.780553 1996 2.718406 2.554609 2.510481 3.783398
1997 2.733786 2.580786 2.536657 3.786172 1998 2.76206 2.768045 2.723916 3.788898
1999 2.570737 2.745019 2.700891 3.7916
2000 2.763322 2.713936 2.669807 3.794287 2001 2.710539 2.785588 2.74146 3.796955
2002 2.703701 2.813542 2.769413 3.799601
2003 2.731437 2.820177 2.776048 3.802233
2004 2.773012 2.84283 2.798701 3.804855
2005 2.809704 2.882888 2.83876 3.807467
2006 2.812413 2.915708 2.871579 3.810063
2007 2.826753 2.957237 2.964261 3.812645
2008 2.846909 2.99153 2.970694 3.815227
2009 2.781106 2.989612 2.968776 3.817819
2010 2.866917 3.036838 3.016002 3.820415
2011 2.893139 3.050284 3.029448 3.823018
2012 2.867485 3.071392 2.999403 3.825603
2013 2.881441 3.095176 2.7838 3.828122
2014 2.876182 3.111507 2.940825 3.830534

Dimana : Log(ekst)* = Log(ekst)-0.5446*Log(ekst-1) Log(const)* = Log(const)-0.5446*Log(const-1) Log(impt)* = Log(impt)-0.5446*Log(impt-1) Log(popt)* = Log(popt)-0.5446*Log(popt-1)
Lakukan regresi LS Log(IMP)* C Log(CONS)* Log(EKS)* Log(POP)*
Hasilnya seperti di bawah ini : Dependent Variable: LOG(IMP)* Method: Least Squares Date: 01/09/17 Time: 07:37 Sample (adjusted): 1991 2014 Included observations: 24 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 28.69959 16.89465 1.698738 0.1049
LOG(CONS)* 0.118989 0.301800 0.394264 0.6976 LOG(EKS)* 1.529882 0.351877 4.347779 0.0003 LOG(POP)* -8.041788 4.805893 -1.673318 0.1098
R-squared 0.937858 Mean dependent var 2.734542
Adjusted R-squared 0.928537 S.D. dependent var 0.222501 S.E. of regression 0.059480 Akaike info criterion -2.655333 Sum squared resid 0.070758 Schwarz criterion -2.458991 Log likelihood 35.86399 Hannan-Quinn criter. -2.603243 F-statistic 100.6150 Durbin-Watson stat 1.332800 Prob(F-statistic) 0.000000
Lakukan Uji Autokorelasi dengan uji LM Pilih : view Residual Diagnostics Serial Correlation LM Test masukan angka 2 OK
Breusch-Godfrey Serial Correlation LM Test: F-statistic 1.596644 Prob. F(2,18) 0.2300
Obs*R-squared 3.616187 Prob. Chi-Square(2) 0.1640

Dari hasil perhitungan Uji LM diperoleh nilai Prob. Chi-Square(2) = 0,1640 lebih besar dari α = 0,05 berti H0 diterima, artinya dalam model diatas model yang digunakan tidak mengandung autokorelasi.

ANALISIS REGRESI DENGAN EVIEWS
Model regresi sederhana dilakukan jika bermaksud meramalkan bagaimana
keadaan (naik turunnya) variabel dependen (kriterium), bila ada satu variabel
independen sebagai prediktor dimanipulasi (dinaik turunkan nilainya),
Persamaan yang diperoleh dari regresi sederhana adalah Y = β0 + β1 X + µ
Tiga model persamaan tunggal yang umum digunakan adalah OLS, ILS, dan 2SLS
(Gujarati dan Porter, 2009), Ordinary least square (OLS) merupakan metode
estimasi yang sering digunakan untuk mengestimasi fungsi regresi populasi dan
fungsi regresi sampel, Kriteria OLS adalah “line best fit” atau jumlah kuadrat dari
deviasi antara titik-titik observasi dengan garis regresi adalah minimum,
(penjelasan OLS, ILS dan 2SLS secara teknis dapat baca di Buku Gujarati dan
Porter, 2009, Dasar-dasar ekonometrika, Jakarta : Salemba Empat),
Tabel 7.1
Data Inflasi, GDP, Harga Minyak dan Tingkat Bunga riil Tahun 1990 sd 2012
Tahun Inflasi GDP Poil Bunga
1990 9,456366 840,2205 69,6 3,294167 1991 9,416131 705,0475 75,1 2,216667 1992 7,525736 752,318 79,8 4,430833 1993 9,687786 840,3758 80,2 6,039167 1994 8,518497 925,7217 106,8 5,226667
BAB
7
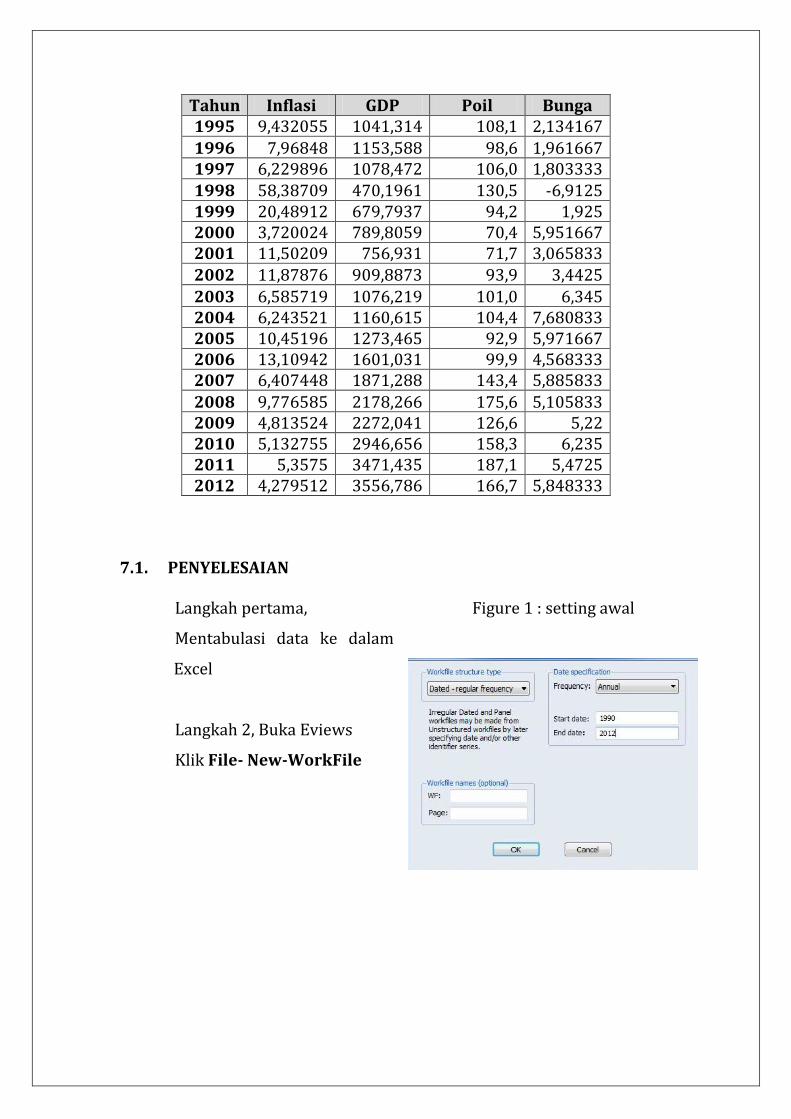
Tahun Inflasi GDP Poil Bunga 1995 9,432055 1041,314 108,1 2,134167
1996 7,96848 1153,588 98,6 1,961667 1997 6,229896 1078,472 106,0 1,803333
1998 58,38709 470,1961 130,5 -6,9125 1999 20,48912 679,7937 94,2 1,925 2000 3,720024 789,8059 70,4 5,951667 2001 11,50209 756,931 71,7 3,065833
2002 11,87876 909,8873 93,9 3,4425
2003 6,585719 1076,219 101,0 6,345 2004 6,243521 1160,615 104,4 7,680833 2005 10,45196 1273,465 92,9 5,971667 2006 13,10942 1601,031 99,9 4,568333 2007 6,407448 1871,288 143,4 5,885833
2008 9,776585 2178,266 175,6 5,105833 2009 4,813524 2272,041 126,6 5,22 2010 5,132755 2946,656 158,3 6,235 2011 5,3575 3471,435 187,1 5,4725 2012 4,279512 3556,786 166,7 5,848333
7.1. PENYELESAIAN
Langkah pertama,
Mentabulasi data ke dalam
Excel
Langkah 2, Buka Eviews
Klik File- New-WorkFile
Figure 1 : setting awal

Klik pada frekuensi pilih
“anual” atau tahunan
kemudian isi nilai 1990
pada Start Date dan 2012
pada “End Date”. Klik OK
maka akan terlihat tampilan
sebagai berikut :
Klik Quick empty groups edit, buka excel dan copy data dari
excel dan paste di eviews, lalu ganti nama untuk ser01, ser02, ser03
dan ser04 dengan Inflasi, GDP, Poil dan Bunga.
Langkah 3, Membuat Equation
Klik Quick – Estimate Equation, lalu setting data seperti ini :

Isilah Estimate Specification Inflasi c GDP Poil Bunga
Klik OK Hasil
Dependent Variable: INFLASI Method: Least Squares Date: 04/11/15 Time: 19:19 Sample: 1990 2012 Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob. C 13.15826 5.951899 2.210766 0.0395
GDP -0.005652 0.003241 -1.744046 0.0973 POIL 0.147798 0.076199 1.939625 0.0674
BUNGA -2.679244 0.520047 -5.151925 0.0001 R-squared 0.786231 Mean dependent var 10.71174
Adjusted R-squared 0.752478 S.D. dependent var 11.00843 S.E. of regression 5.476867 Akaike info criterion 6.395714 Sum squared resid 569.9254 Schwarz criterion 6.593192 Log likelihood -69.55072 Hannan-Quinn criter. 6.445379 F-statistic 23.29369 Durbin-Watson stat 1.489334 Prob(F-statistic) 0.000001

Interpretasi :
Dari persamaan regresi diatas maka dapat disimpulkan :
GDP dan tingkat BUNGA memiliki hubungan negatif signifikan dengan
inflasi, sedangkan POIL memiliki pengaruh positif signifikan terhadap
inflasi. 75,24 persen variable bebas dapat menjelaskan variable terikat,
sisanya 24,76 dijelaskan oleh variable diluar model.
Langkah 4, Uji Normalitas
Pada hasil uji yang berinama “eq01”, klik Views – Residual Diagnostics -
Histogram – Normality test

7.2. INTERPRETASI HASIL
Nilai probabilitas adalah 0,833 (> 0,05) sehingga dapat dikatakan
model ini adalah tidak signifikan, Sementara berdasarkan hasil uji
normalitas dapat dilihat dari nilai probabilitas dari Jargue-Bera (JB),
Jika probabilitas > 0,05, maka model dinyatakan normal, Berdasarkan
parameter ini diketahui bahwa besaran nilai probabilitas pada JB
adalah 0,833, lebih besar dibanding nilai 0,05, Dengan demikian dapat
disimpulkan bahwa model regresi memenuhi asumsi normalitas,
Langkah 5, Uji Serial Korelasi
klik Views – Residual Diagnostics – Serial Correlation LM Test
Kemudian akan muncul

Klik OK
Breusch-Godfrey Serial Correlation LM Test: F-statistic 1.053489 Prob. F(2,17) 0.3704
Obs*R-squared 2.536271 Prob. Chi-Square(2) 0.2814
Test Equation: Dependent Variable: RESID Method: Least Squares Date: 04/11/15 Time: 19:29 Sample: 1990 2012 Included observations: 23 Presample missing value lagged residuals set to zero.
Variable Coefficient Std. Error t-Statistic Prob. C 0.926749 6.091227 0.152145 0.8809
GDP 0.000511 0.003256 0.157069 0.8770 POIL -0.004432 0.076085 -0.058252 0.9542
BUNGA -0.279152 0.626121 -0.445844 0.6613 RESID(-1) 0.368969 0.275532 1.339112 0.1982 RESID(-2) -0.155183 0.256216 -0.605675 0.5527
R-squared 0.110273 Mean dependent var 2.88E-15
Adjusted R-squared -0.151412 S.D. dependent var 5.089764 S.E. of regression 5.461513 Akaike info criterion 6.452787 Sum squared resid 507.0782 Schwarz criterion 6.749003 Log likelihood -68.20705 Hannan-Quinn criter. 6.527285 F-statistic 0.421395 Durbin-Watson stat 1.968138 Prob(F-statistic) 0.827409
Hasil analisis output berdasarkan tabel diatas, tampak bahwa nilai Obs
probabilitas F-statistic 0,8274 > 0,05 maka dapat disimpulkan model
diatas bebas dari masalah serial korelasi diterima.

Langkah 6, Uji Heteroskedastisitas
klik Views – Residual Diagnostics – Heteroskedasticity Test
Pilih White
Tekan OK Heteroskedasticity Test: White
F-statistic 2.634672 Prob. F(9,13) 0.0551
Obs*R-squared 14.85553 Prob. Chi-Square(9) 0.0950 Scaled explained SS 10.50440 Prob. Chi-Square(9) 0.3112

Hasil analisis output berdasarkan tabel diatas, tampak bahwa nilai Obs*R
squared 0,095, probabilitas X2 > 0,05 maka dapat disimpulkan model
diatas tidak mengandung heteroskedastisitas.


INTERPOLASI DATA Buku Insukindro yang berjudul ekonomi uang dan bank yang didalamnya
terdapat cerita tentang interpolasi data. Interpolasi data merupakan metode
pemecahan data menjadi data triwulan atau bentuk kuartalan, dimana data
setahun dibagi menjadi empat data dalam bentuk kuartalan.
Berikut rumus interpolasi data:
Yt1=1/4{Yt-4,5/12(Yt-Yt-1)}
Yt2=1/4{Yt-1,5/12(Yt-Yt-1)}
Yt3=1/4{Yt+1,5/12(Yt-Yt-1)}
Yt4=1/4{Yt+4,5/12(Yt-Yt-1)}
Cara Melakukan Interpolasi Data dengan Eviews 7
Berikut ini adalah langkah-langkah melakukan interpolasi data:
1. Buka Eviews hingga muncul tampilan seperti di bawah ini :
Klik File New Workfile
Muncul tampilan seperti di bawah ini :
BAB
8

Jika kita ingin melakukan interpolasi data dari data tahunan ke data
kuartalan (misalnya) maka pada Frequency pilih Annual. Kemudian
isikan dengan tahun yang sesuai dengan data anda, misalnya:
Start date : 2000
End date : 2010
Klik OK, akan muncul tampilan seperti di bawah ini:
Klik Quick Empty Group (Edit Series)

Isikan data :
Tahun GDP
2000 213.634
2001 223.817
2002 232.749
2003 241.291
2004 259.578
2005 274.014
2006 287.921
2007 306.373
2008 324.768
2009 336.093
2010 357.201

Setelah mengisikan data anda, kembali ke Workfile dan pilih Store
Akan muncul kotak seperti ini:
Pada kolom Store GDP as berikan nama variabel anda (misalnya “gdp”)
Pada kolom Store in pilih Individual.DB? files
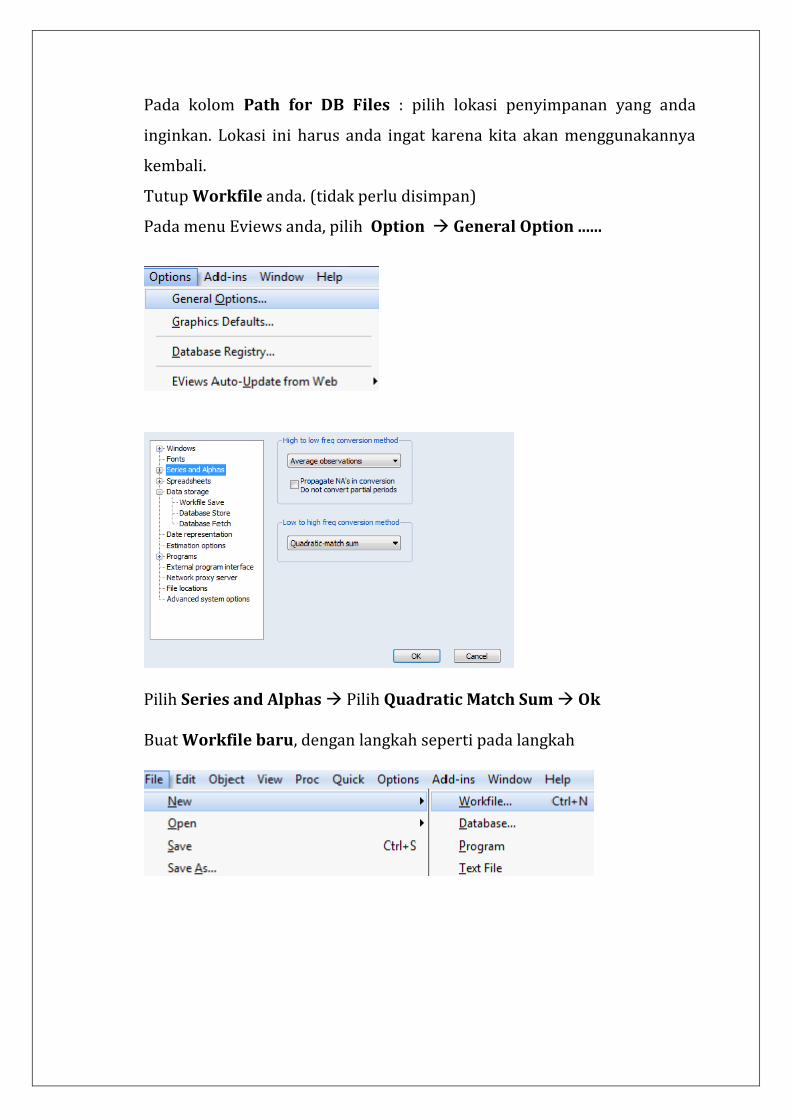
Pada kolom Path for DB Files : pilih lokasi penyimpanan yang anda
inginkan. Lokasi ini harus anda ingat karena kita akan menggunakannya
kembali.
Tutup Workfile anda. (tidak perlu disimpan)
Pada menu Eviews anda, pilih Option General Option ......
Pilih Series and Alphas Pilih Quadratic Match Sum Ok
Buat Workfile baru, dengan langkah seperti pada langkah

pada kolom Frequency, anda pilih Quarterly (jika interpolasi anda dari
data tahunan ke data kuartalan) atau Monthly (jika data yang anda
inginkan adalah dari data tahunan ke data bulanan)
Isikan Start date dan End date sesuai dengan data anda (misal Start date
2000 dan End date 2010)
Setelah muncul tampilan seperti di bawah ini, klik Fetch

Akan muncul tampilan seperti di bawah ini:
Pada Fetch from pilih Individual .DB? files
Pada path for DB Files pilih lokasi data tempat database yang anda
simpan tadi
Pada Objects to fecth tulis gdp
Kemudian klik OK
Pada Workfile anda akan muncul variabel yang sudah terinterpolasi.

Klik gdp, maka akan muncul :

MENYAMAKAN TAHUN DASAR
Misalkan kita ingin mencari data tentang PDB (Produks Domestik Bruto) suatu
Negara yang diambil dari buku statististik berbagai terbitan, dan kita telah
peroleh data PDRB sebagai berikut :
Tahun PDB riil 2003 123,456 2004 129,629 2005 136,110 2006 141,555 2007 150,048 2008 157,550 2009 163,852 2010 173,683 2011 267,548 2012 278,250 2013 286,597 2014 298,061 2015 312,964
Sumber : data hipotesis
Sekilas data diatas kelihatan benar, sehingga data tersebut siap diolah. Maka
agar kita tidak terjebak kepada data yang kurang valid maka perlu kita cek
pertumbuhan PDB nya terlebih dahulu sebagai berikut :
BAB
9
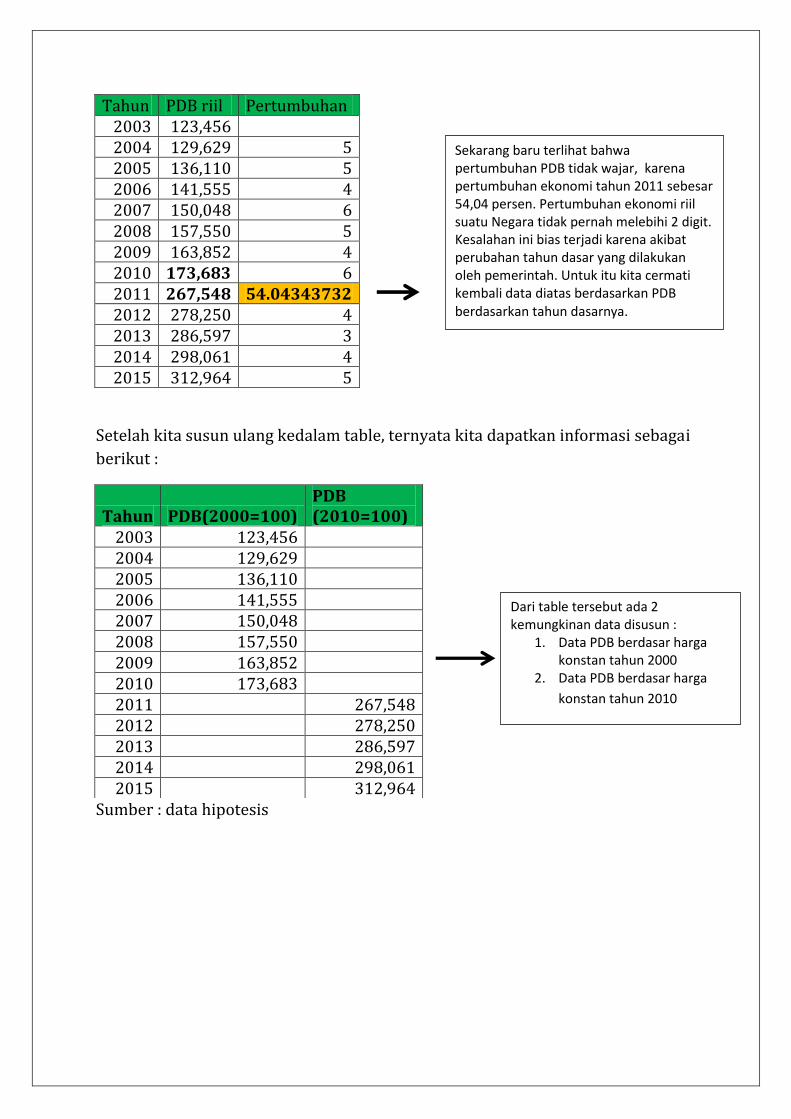
Setelah kita susun ulang kedalam table, ternyata kita dapatkan informasi sebagai
berikut :
Sumber : data hipotesis
Tahun PDB riil Pertumbuhan 2003 123,456 2004 129,629 5 2005 136,110 5 2006 141,555 4 2007 150,048 6 2008 157,550 5 2009 163,852 4 2010 173,683 6 2011 267,548 54.04343732 2012 278,250 4 2013 286,597 3 2014 298,061 4 2015 312,964 5
Tahun PDB(2000=100) PDB (2010=100)
2003 123,456 2004 129,629 2005 136,110 2006 141,555 2007 150,048 2008 157,550 2009 163,852 2010 173,683 2011 267,548 2012 278,250 2013 286,597 2014 298,061 2015 312,964
Sekarang baru terlihat bahwa pertumbuhan PDB tidak wajar, karena pertumbuhan ekonomi tahun 2011 sebesar 54,04 persen. Pertumbuhan ekonomi riil suatu Negara tidak pernah melebihi 2 digit. Kesalahan ini bias terjadi karena akibat perubahan tahun dasar yang dilakukan oleh pemerintah. Untuk itu kita cermati kembali data diatas berdasarkan PDB berdasarkan tahun dasarnya.
Dari table tersebut ada 2 kemungkinan data disusun :
1. Data PDB berdasar harga konstan tahun 2000
2. Data PDB berdasar harga
konstan tahun 2010
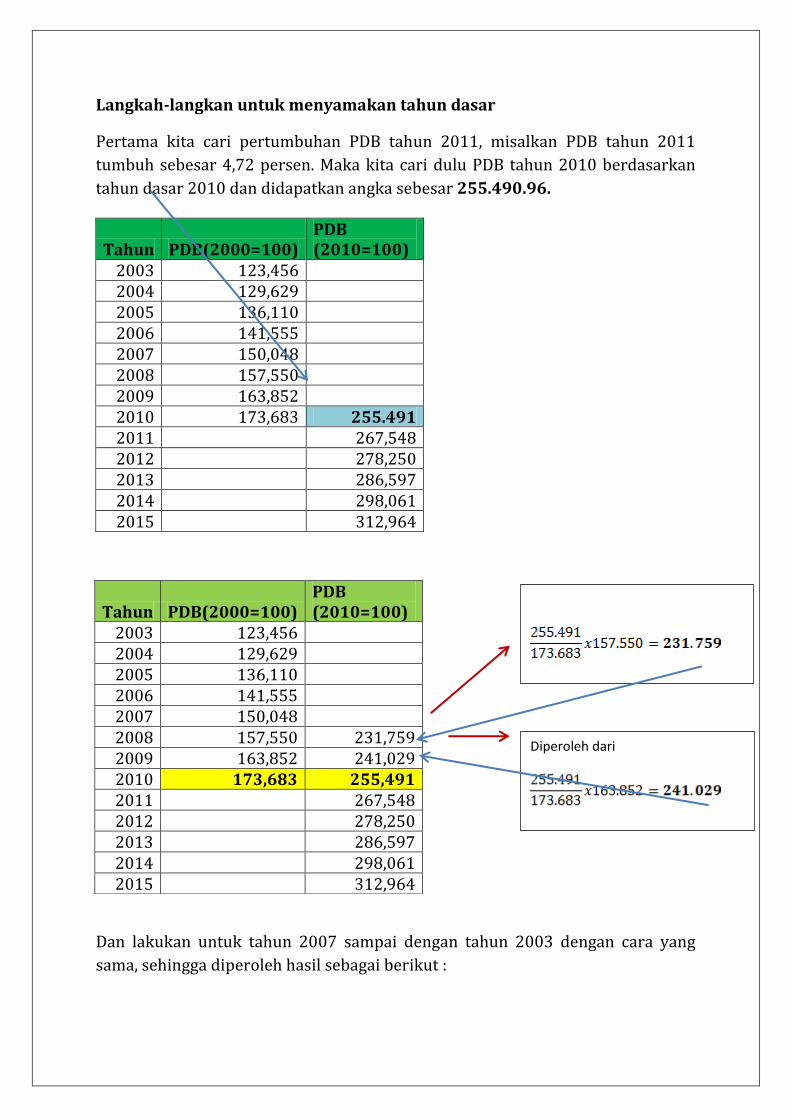
Langkah-langkan untuk menyamakan tahun dasar
Pertama kita cari pertumbuhan PDB tahun 2011, misalkan PDB tahun 2011
tumbuh sebesar 4,72 persen. Maka kita cari dulu PDB tahun 2010 berdasarkan
tahun dasar 2010 dan didapatkan angka sebesar 255.490.96.
Dan lakukan untuk tahun 2007 sampai dengan tahun 2003 dengan cara yang
sama, sehingga diperoleh hasil sebagai berikut :
Tahun PDB(2000=100) PDB (2010=100)
2003 123,456 2004 129,629 2005 136,110 2006 141,555 2007 150,048 2008 157,550 2009 163,852 2010 173,683 255.491 2011 267,548 2012 278,250 2013 286,597 2014 298,061 2015 312,964
Tahun PDB(2000=100) PDB (2010=100)
2003 123,456 2004 129,629 2005 136,110 2006 141,555 2007 150,048 2008 157,550 231,759 2009 163,852 241,029 2010 173,683 255,491 2011 267,548 2012 278,250 2013 286,597 2014 298,061 2015 312,964
Diperoleh dari
Diperoleh dari

Tahun PDB(2000=100) PDB (2010=100)
2003 123,456 181,606 2004 129,629 190,686 2005 136,110 200,220 2006 141,555 208,229 2007 150,048 220,723 2008 157,550 231,759 2009 163,852 241,029 2010 173,683 255,491 2011 181,880 267,548 2012 189,155 278,250 2013 194,830 286,597 2014 202,623 298,061 2015 212,754 312,964
Jika data yang kita inginkan adalah PDB tahun dasar 2000 maka caranya
adalah sebagai berikut :
Tahun PDB(2000=100) PDB (2010=100)
2003 123,456 181,606 2004 129,629 190,686 2005 136,110 200,220 2006 141,555 208,229 2007 150,048 220,723 2008 157,550 231,759 2009 163,852 241,029 2010 173,683 255,491 2011 181,880 267,548 2012 189,155 278,250 2013 286,597 2014 298,061 2015 312,964
Hasil perhitungan
PDB berdasar
tahun dasar 2010
Diperoleh dari
Diperoleh dari
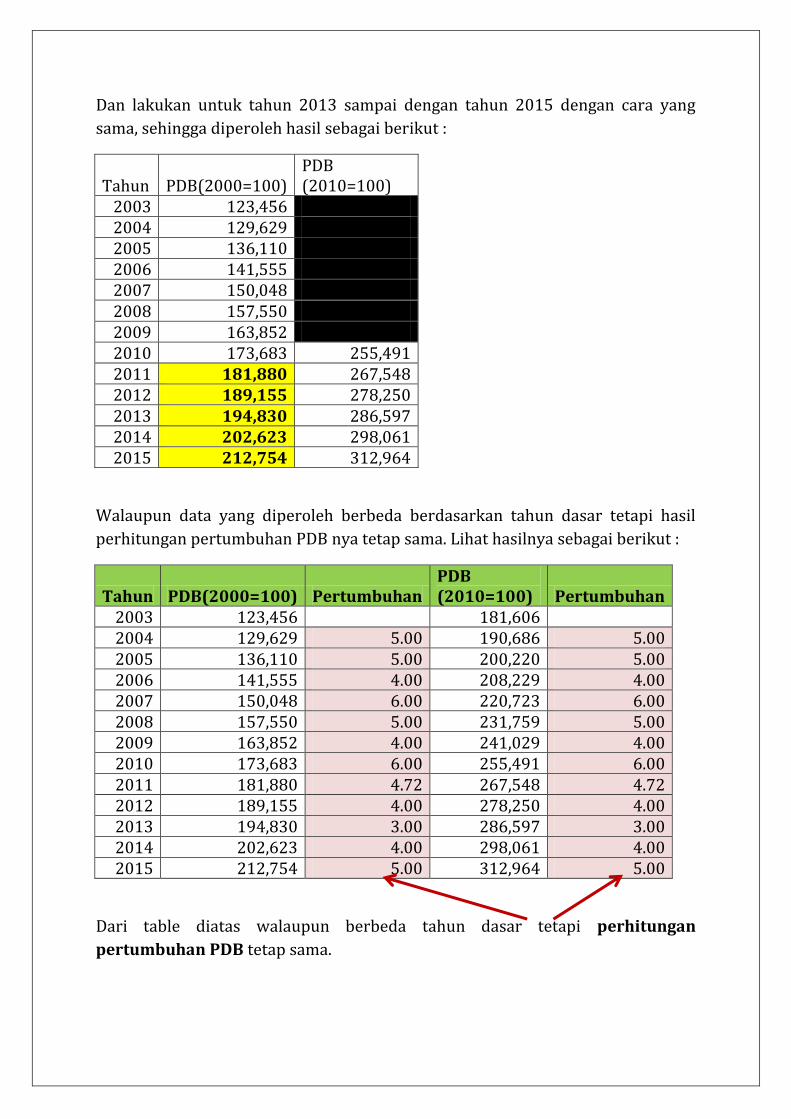
Dan lakukan untuk tahun 2013 sampai dengan tahun 2015 dengan cara yang
sama, sehingga diperoleh hasil sebagai berikut :
Tahun PDB(2000=100) PDB (2010=100)
2003 123,456 181,606 2004 129,629 190,686 2005 136,110 200,220 2006 141,555 208,229 2007 150,048 220,723 2008 157,550 231,759 2009 163,852 241,029 2010 173,683 255,491 2011 181,880 267,548 2012 189,155 278,250 2013 194,830 286,597 2014 202,623 298,061 2015 212,754 312,964
Walaupun data yang diperoleh berbeda berdasarkan tahun dasar tetapi hasil
perhitungan pertumbuhan PDB nya tetap sama. Lihat hasilnya sebagai berikut :
Tahun PDB(2000=100) Pertumbuhan PDB (2010=100) Pertumbuhan
2003 123,456 181,606 2004 129,629 5.00 190,686 5.00 2005 136,110 5.00 200,220 5.00 2006 141,555 4.00 208,229 4.00 2007 150,048 6.00 220,723 6.00 2008 157,550 5.00 231,759 5.00 2009 163,852 4.00 241,029 4.00 2010 173,683 6.00 255,491 6.00 2011 181,880 4.72 267,548 4.72 2012 189,155 4.00 278,250 4.00 2013 194,830 3.00 286,597 3.00 2014 202,623 4.00 298,061 4.00 2015 212,754 5.00 312,964 5.00
Dari table diatas walaupun berbeda tahun dasar tetapi perhitungan
pertumbuhan PDB tetap sama.


APLIKASI EKONOMETRI DALAM PENELITIAN
Dalam bab ini akan dibahas tentang penerapan regresi berganda dalam
kasus ekonomi :
ANALISIS PENGARUH UTANG LUAR NEGERI DAN PENGELUARAN PEMERINTAH TERHADAP PERTUMBUHAN EKONOMI INDONESIA
Muhammad Paozan
Agus Tri Basuki
ABSTRAK
Penelitian ini bertujuan menganalisis pengaruh utang luar negeri dan pengeluaran pemerintah terhadap pertumbuhan ekonomi. Data yang digunakan dalam penelitian ini diambil dari BPS tahun 1985 sampai dengan 2014. Variabel dependen dalam penelitian ini adalah pertumbuhan ekonomi dengan menggunakan data PDB Indonesia, sedangkan variabel independennya adalah utang luar negeri dan pengeluaran pemerintah Indonesia. Untuk melihat pengaruh variabel independent dan variabel dependent, peneliti melakukan pengujian analisis regresi linier berganda juga melakukan uji asumsi klasik. Berdasarkan hasil penelitian yang diperoleh, dapat diketahui bahwa secara simultan utang luar negeri dan pengeluaran pemerintah berpengaruh signifikan terhadap pertumbuhan ekonomi Indonesia. Selanjutnya secara parsial, utang luar negeri berpengaruh positif dan signifikan terhadap pertumbuhan ekonomi, dan pengeluaran pemerintah juga berpengaruh positif dan signifikan terhadap terhadap pertumbuhan ekonomi Indonesia.
BAB
10

A. PENDAHULUAN
Pertumbuhan ekonomi adalah salah satu indikator yang sangat penting
dalam melakukan analisis tentang pembangunan ekonomi suatu negara.
Pertumbuhan ekonomi menunjukkan sejauh mana aktivitas perekonomian
akan menghasilkan tambahan pendapatan masyarakat pada suatu periode
tertentu. Karena pada dasarnya aktivitas perekonomian adalah suatu proses
penggunaan faktor-faktor produksi yang menghasilkan output, yang diukur
dengan menggunakan PDB.
Berdasarkan data dari Badan Pusat Statistik Indonesia, pertumbuhan
ekonomi Indonesia sejak tahun1986 sampai tahun 1989 terus mengalami
peningkatan, yakni masing-masing 5.9% di tahun1986, kemudian 6.9% di
tahun 1988 dan menjadi 7.5% di tahun 1989. Namun pada tahun 1990 dan
1991 pertumbuhan ekonomi Indonesia mencatat angka sebesar 7.0%,
kemudian tahun 1992, 1993, 1994, 1995, dan 1996, masing-masing tingkat
pertumbuhan ekonominya adalah sebesar 6.2%, 5.8%, 7.2%, 6.8%, dan 5.8%.
Angka inflasi yang stabil, jumlah pengangguran yang cukup rendah seiring
dengan kondusifnya iklim investasi yang ditandai dengan kesempatan kerja
yang terus meningkat, dan sebagainya. Namun pada satu titik tertentu,
perekonomian Indonesia akhirnya runtuh oleh krisis ekonomi yang melanda
secaraglobal pada tahun 1997-1998 yang ditandai dengan inflasi yang
meningkat tajam, nilai kurs Rupiah yang terus melemah, tingginya angka
pengangguran seiring dengan menurunnya kesempatan kerja, dan ditambah
lagi semakin besarnya jumlah utang luar negeri Indonesia akibat kurs rupiah
yang semakin melemah. Hal ini terjadi dikarenakan tidak adanya dukungan
mikro yang kuat, semakin meningkatnya praktek korupsi, kolusi, dan
nepotisme (KKN), sumber daya manusia yang kurang kompetitif, dan
sebagainya (Anggito Abimanyu, 2000).
Beberapa faktor yang mempengaruhi PDB diantaranya adalah ekspor,
jumlah utang luar negeri, penanaman modal asing, investasi, kurs dan lain-
lain. Hubungan utang luar negeri terhadap PDB adalah variabel yang bisa saja

mendorong perekonomian sekaligus menghambat pertumbuhan ekonomi.
Mendorong perekonomian maksudnya jika hutang-hutang tersebut
digunakan untuk membuka lapangan kerja dan investasi dibidang
pembangunan yang pada akhirnya dapat mendorong perekonomian,
sedangkan menghambat pertumbuhan apabila utang-utang tersebut tidak
dipergunakan secara maksimal karena masih kurangnya fungsi pengawasan
dan integritas atas penanggung jawab utang-utang itu sendiri. Hubungan
Pengeluaran Pemerintah dengan PDB tercermin dalam pernyataan Y = C + I +
G + ( X – M ). Yaitu ketika pengeluaran pemerintah naik maka akan menaikkan
Produk Domestik Bruto (PDB) dengan ketentuan bahwa belanja pemerintah
akan menaikkan konsumsi masyarakat melalu pemberian subsidi,
pembangunan infrastruktur, operasi pasar dan sebagainya yang akhirnya
akan mempermudah mobilitas sehingga menaikkan tingkat perekonomian
dan pertumbuhan ekonomi dan pendapatan negara naik.
Maka, berdasarkan permasalahan yang dikemukakan di atas, dimana
utang luar negeri mempunyai pengaruh terhadap pertumbuhan ekonomi.
Namun belakangan terdapat banyak kontradiksi dalam teori dan
penerapannya di Indonesia, maka yang akan diteliti dan dibahas dalam
tulisan ini adalah masalah utang luar negeri dan pengeluaran pemerintah
dalam kaitannya dengan pertumbuhan ekonomi dengan mengangkat judul
“Analisis Pengaruh Utang Luar Negeri dan Pengeluaran Pemerintah
terhadap Pertumbuhan Ekonomi Indonesia Periode 1985-2014”
B. Rumusan Masalah
Berdasarkan uraian latar belakang di atas, permasalah pokok yang
akan diteliti adalah sebagai berikut :
1. Seberapa besar pengaruh utang luar negeri terhadap pertumbuhan
ekonomi (PDB) periode 1985-2014?
2. Seberapa besar pengaruh pengeluaran pemerintah terhadap pertumbuhan
ekonomi (PDB) periode 1985-2014?

C. Batasan Masalah
Dalam penelitian ini peneliti membatasi variabel-variabel yang
ditelitinya sebagai berikut :
1. Untuk variabel dependen (Y) adalah pertumbuhan ekonomi menggunakan
indikator PDB
2. Untuk variabel independennya adalah utang luar negeri (X1), pengeluaran
pemerintah (X2)
D. Tujuan Penelitian
Sesuai dengan rumusan masalah di atas, maka tujuan yang ingin
dicapai dari penelitian ini adalah :
1. Untuk mengetahui seberapa besar pengaruh utang luar negeri terhadap
pertumbuhan ekonomi periode 1985-2014
2. Untuk mengetahui seberapa besar pengaruh pengeluaran pemerintah
terhadap pertumbuhan ekonomi periode 1985-2014
E. Manfaat Penelitian
Adapun manfaat dari penelitian ini adalah sebagai berikut :
1. Sebagai bahan informasi tambahan tentang faktor-faktor yang dapat
mempengaruhi pertumbuhan ekonomi di Indonesia 1985-2014
2. Dapat digunakan sebagai bahan masukan bagi peneliti lain yang akan
mengadakan penelitian ruang lingkup yang sama
3. Dapat menambah pengetahuan bagi pembaca yang lain
F. Kajian Pustaka
1. Landasan Teori
a. Pertumbuhan Ekonomi
Secara umum, pertumbuhan ekonomi didefinisikan sebagai
peningkatan kemampuan dari suatu perekonomian dalam memperoduksi
barang-barang dan jasa-jasa. Pertumbuhan ekonomi adalah salah satu

indicator yang amat penting dalam melakukan analisis tentang
pembangunan ekonomi yang terjadi pada suatu Negara. Pertumbuhan
ekonomi menunjukkan sejauh mana aktivitas perekonomian akan
menghasilkan tambahan pendapatan masyarakat pada suatu periode
tertentu. Karena pada dasarnya aktivitas perekonomian adalah suatu
proses penggunaan factor-faktor produksi untuk menghasilkan output,
maka proses ini pada dasarnya akan menghasilkan suatu aliran balas jasa
terhadao factor produksi yang dimiliki oleh masyarakat (Basri, 2002),
dengan adanya pertumbuhan ekonomi maka diharapkan pendapatan
masyarakat sebagai pemilik factor produksi juga akan meningkat.
Perekonomian dianggap mengalami pertumbuhan jika seluruh balas
jasa riil terhadap penggunaan factor produksi pada tahun tertentu lebih
besar dari pada tahun sebelumnya. Dengan kata lain perekonomian
dikatakan mengalami pertumbuhan jika pendapatan riil masyarakat pada
tahun tertentu lebih besar dari pada pendapatan riil masyarakat
sebelumnya (Basri, 2002).
Dengan perkataan lain bahwa pertumbuhan ekonomi lebih
menunjuk kepada perubahan yang bersifat kuantitatif (quantitative
change) dan biasanya diukur dengan menggunakan data Produk Domestik
Bruto (GDP) atau pendapatan atau nilai akhir pasar (total market value)
dari barang-barang akhir dan jasa-jasa (final goods and services) yang
dihasilkan dari suatu perekonomian selama kurun waktu tertentu
(biasanya satu tahun).
Kuznets dalam Hariyanto (2005) mendefinisikan pertumbuhan
ekonomi sebagai kenaikan jangka panjang dalam kemapuan suatu Negara
dalam menyediakan semakin banyak jenis barang-barang ekonomi kepada
penduduknya; kemampuan ini tumbuh sesuai dengan kemajuan teknologi,
dan penyesuaian kelembagaan dan ideologis yang diperlukannya.
b. Teori-teori Pertumbuhan Ekonomi
Teori-teori pertumbuhan ekonomi yang berkembang antara lain:

1) Teori Pertumbuhan Klasik
Teori ini dipelopori oleh Adam Smith, David Ricardo, Malthus,
dan Jhon Stuart Mill. Menurut teori ini pertumbuhan ekonomi
dipengaruhi oleh empat factor, yaitu jumlah penduduk, jumlah barang
modal, luan tanah dan kekayaan alam serta teknologi yang digunakan.
Mereka lebih memilih perhatianya pada pengaruh pertambahan
penduduk terhadap pertumbuhan ekonomi. Mereka asumsikan luas
tanah dan kekayaan alam serta teknologi tidak mengalami perubahan.
Teori yang menjelaskan keterkaitan antara pendapatan perkapita
dengan jumlah penduduk disebut dengan teori penduduk optimal.
Menurut teori ini, pada mulanya pertambahan penduduk akan
menyebabkan kenaikan pendapatan perkapita. Namun jika jumlah
penduduk terus bertambah maka hukum hasil lebih yang semakin
berkurang akan mempengaruhi fungsi produksi marginal akan
mengalami penurunan, dan akan membawa pada keadaan perkapita
sama dengan produksi marginal.
Pada keadaan ini pendapatan perkapita mencapai nilai yang
maksimal. Jumlah penduduk pada waktu itu dinamakan penduduk
optimal. Apabila jumlah penduduk terus meningkat melebihi titik
optimal maka pertumbuhan penduduk akan menyebabkan penurunan
nilai pertumbuhan ekonomi (Ricardo dalam Hariani, 2008).
2) Teori Pertumbuhan Harrod-Domar
Teori ini dikembangkan hampir pada waktu yang bersamaan
oleh Harrod (1984) di Inggris dan Domar (1957) di Amerika Serikat.
Diantara mereka menggunakan proses perhitungan yang berbeda
tetapi memberikan hasil yang sama, sehingga keduanya diangap
mengemukakan ide yang sama dan disebut teori Harrod-Domar. Teori
ini melengkapi teori Keynes, dimana Keynes melihatnya dalam jangka
pendek (kondisi statis), sedangkan Harrod-Domar melihatnya dalam

jangka panjang (kondisi dinamis). Teori Harrod-Domar didasarkan
pada asumsi:
1. Perekonomian bersifat tertutup
2. Hasrat menabung (MPS=s) adalah konstan
3. Proses produksi memiliki koefisien yang tetap (constant return to
scale)
4. Tingkat pertumbuhan angkatan kerja adalah konstan dan sama
dengan tingkat pertumbuhan penduduk.
Model ini menerangkan dengan asumsi supaya perekonomian
dapat mencapai pertumbuhan yang kuat (steady growth) dalam jangka
panjang. Asumsi yang dimaksud di sini adalah kondisi dimana barang
modal telah mencapai kapasitas penuh, tabungan memiliki
proporsional yang ideal dengan tingkat pendapatan nasional, rasio
antara mdal denga produksi (Capital Output Ratio / COR) tetap
perekonomian terdiri dari dua sektor (y=C+I).
Atas dasar asumsi-asumsi tersebut, Harrod-Domar membuat
analisis dan menyimpulkan bahwa pertumbuhan jangka panjang yang
mantap (seluruh kenaikan produksi dapat diserap oleh pasar) hanya
bisa tercapai apabila terpenuhi syarat-syarat keseimbangan sebagai
berikut :
g=K=n
dimana :
g : Growth (tingkat pertumbuhan output)
K : Capital (tingkat pertumbuhan modal)
n : Tingkat pertumbuhan angkatan kerja
Harrod-Domar dalam Hariani (2008) teorinya berdasarkan
mekanisme pasar tanpa campur tangan pemerintah. Akan tetapi
kesimpulannya menunjukkan bahwa pemerintah perlu merencanakan
besarnya investasi agar terdapat keseimbangan dalam sisi penawaran
dan sisi permintaan barang.

3) Teori Pertumbuhan Neo Klasik
Teori pertumbuhan neoklasik dikembangkan oleh Solow (1970)
dan Swan (1956). Model Solow-Swan menggunakan unsur
pertumbuhan penduduk, akumulasi capital, kemajuan teknologi, dan
besarnya output yang saling berinteraksi.
Perbedaan utama dengan model Harrod-Domar adalah
dimasukkannya unsur kemajuan teknologi dalam modelnya. Selain itu,
Solow, dan Swan menggunakan model fungsi produksi yang
memungkinkan adanya subtitusi antara capital (K) dan tenaga kerja
(L). dengan demikian, syarat-syarat adanya pertumbuhan ekonomi
yang baik dalam model Solow Swan kurang restriktif disebabkan
kemungkian subtitusi antara tenaga kerja dan modal. Hal ini berarti
ada fleksibilitas dalam rasio modal-output dan rasio modal-tenaga
kerja.
Solow-Swan dalam Hariani (2008) melihat bahwa dalam banyak
hal, mekanisme pasar dapat menciptakan keseimbangan, sehingga
pemerintah tidak perlu terlalu banyak mencampuri/mempengaruhi
pasar. Campur tangan pemerintah hanya sebatas kebijakan fiskal dan
kebijakan moneter. Tingkat pertumbuhan berasal dari tiga sumber,
yaitu akumulasi modal, bertambahnya penawaran tenaga kerja, dan
peningkatan teknologi. Teknologi ini terlihat dari peningkatan skill atau
kemajuan teknik, sehingga produktivitas capital meningkat. Dalam
model tersebut, masalah teknologi dianggap sebagai fungsi dari waktu.
Teori Neoklasik sebagai penerus dari teori klasik menganjurkan
agar kondisi selalu diarahkan untuk menuju pasar sempurna. Dalam
keadaan pasar sempurna, perekonomian bisa tumbuh maksimal. Sama
seperti dalam ekonomi model klasik, kebijakan yang perlu ditempuh
adalah meniadakan hambatan dalam perdagangan termasuk
perpindahan orang, barang, dan modal. Harus dijamin kelancaran arus

barang, modal, tenaga kerja, dan perlunya penyebarluasan informasi
pasar. Harus diusahakan, terciptanya prasarana perhubungan yang
baik dan terjaminnya keamanan, ketertiban, dan stabilitas politik. Hal
khusus yang perlu dicatat adalah bahwa model neoklasik
mengasumsikan I=S. Hal ini berarti kebiasaan masyarakat yang suka
memegang uang tunai dalam jumlah besar dapat menghambat
pertumbuhan ekonomi.
Analisis lanjutan dari paham neoklasik menunjukkan bahwa
untuk terciptanya suatu pertumbuhan yang mantap (steady growth),
diperlukan suatu tingkat saving yang tinggi dan seluruh keuntungan
pengusaha diinvestasikan kembali.
4) Teori Schumpeter
Teori ini menekankan pada inovasi yang dilakukan oleh para
pengusaha dan mengatakan bahwa kemajuan teknologi sangat
ditentukan oleh jiwa usaha (entrepreneurship) dalam masyarakat yang
mampu melihat peluang dan berani mengambil risiko membuka usaha
baru, maupun memperluas usaha yang telah ada. Dengan pembukaan
usaha baru dan perluasan usaha, tersedia lapangan kerja tambahan
untuk menyerap angkatan kerja yang bertambah setiap tahunnya.
Didorong oleh adanya keinginan untuk memperoleh keuntungan
dari inovasi tersebut maka para pengusaha akan meminjam modal dan
mengadakan investasi. Investasi ini akan mempertinggi kegiatan
ekonomi suatu negara. Kenaikan tersebut selanjutnya juga akan
mendorong pengusaha-pengusaha lain untuk menghasilkan lebih
banyak lagi sehingga produksi agregat akan bertambah.
Maka menurut Schumpeter dalam Hariani (2008) penanaman
modal atau investasi dapat dibedakan menjadi dua, yakni penanaman
modal otonomi (autonomous investment) yakni penanaman modal
untuk melakukan inovasi. Jenis investasi kedua yaitu penanaman

modal terpengaruh (induced investment) yakni penanaman modal
yang timbul sebagai akibat kegiatan ekonomi setelah munculnya
inovasi tersebut.
Selanjutnya Schumpeter menyatakan babwa jika tingkat
kemajuan suatu perekonomian semakin tinggi maka keinginan untuk
melakukan inovasi semakin berkurang, hal ini disebabkan oleh karena
masyarakat telah merasa mencukupi kebutuhannya. Dengan demikian
pertumbuhan ekonomi akan semakin lambat jalannya dan pada
akhirnya tercapai tingkat keadaan tidak berkembang (stationery state).
Namun keadaan tidak berkembang yang dimaksud di sini berbeda
dengan pandangan klasik. Dalam pandangan Schumpeter keadaan
tidak berkembang itu dicapai pada tingkat pertumbuhan ekonomi
tinggi. Sedangkan dalam pandangan klasik, keadaan tidak berkembang
terjadi pada waktu perekonomian berada pada kondisi tingkat
pendapatan masyarakat sangat rendah.
5) Tahap-Tahap Pertumbuhan Ekonomi
Teori ini dimunculkan oleh Rostow yang memberikan lima tahap
dalam pertumbuhan ekonomi. Analisis ini didasarkan pada keyakinan
bahwa pertumbuhan ekonomi akan tercapai sebagai akibat dan
timbulnya perubahan yang fundamental dalam corak kegiatan
ekonomi, juga dalam kehidupan politik dan hubungan sosial dalam
suatu masyarakat dan negara.
Rostow dalam Hariani (2008) menyebutkan tahapan tersebut yakni;
1. Tahap masyarakat tradisonil
2. Tahap peletakan dasar untuk tinggal landas
3. Tahap tinggal landas
4. Tahap gerak menuju kematangan
5. Tahap era konsumsi tinggi secara massa

c. Perhitungan Tingkat Pertumbuhan Ekonomi
Salah satu kegunaan penting dari data pendapatan nasional adalah
untuk menentukan tingkat pertumbuhan ekonomi yang dicapai satu
negara dari tahun ke tahun.
Dalam penghitungan pendapatan nasional didasarkan pada dua
sistem harga yakni harga berlaku dan harga tetap. Pendapatan nasional
berdasarkan harga berlaku adalah penghitungan pendapatan nasional
berdasarkan pada harga-harga yang berlaku pada tahun tersebut. Apabila
menggunakan harga berlaku maka nilai pendapatan nasional
menunjukkan kecenderungan yang semakin meningkat dari tahun ke
tahun. Perubahan tersebut dikarenakan oleh karena pertambahan barang
dan jasa dalam perekonomian serta adanya kenaikan harga-harga yang
berlaku dari waktu ke waktu.
Pendapatan nasional berdasarkan harga tetap yakni penghitungan
pendapatan nasional dengan menggunakan harga yang berlaku pada satu
tahun tertentu (tahun dasar) yang seterusnya digunakan untuk menilai
barang dan jasa yang dihasilkan pada tahun-tahun berikutnya. Nilai
pendapatan nasional yang diperoleh secara harga tetap ini dinamakan
Pendapatan Nasional Riil.
1. Pendekatan Pengeluaran
Pendekatan pengeluaran adalah pendekatan dimana produk
nasional atau produk domestik bruto diperoleh dengan eara
menjumlahkan nilai pasar dari seluruh permintaan akhir (final
demand) atas output yang dihasilkan di dalam perekonomian, diukur
pada harga pasar yang berlaku. Dengan perkataan lain, produk nasional
atau produk domestik bruto adalah penjumlahan nilai pasar dari
permintaan sektor rumah tangga untuk barang-barang konsumsi dan
jasa-jasa (C), permintaan sektor bisnis untuk barang-barang investasi

(I), pengeluaran pemerintah untuk barang-barang dan jasa-jasa (G),
dan pengeluaran sektor luar negeri untuk ekspor dan impor (X -M).
Secara matematis dapat dirumuskan sebagai berikut :
Y = C + I + G (X-M)
Dimana :
Y = Pendapatan nasional (GNP atau GDP)
C = Nilai pasar pengeluaran konsumsi barang-barang dan jasa-jasa
oleh rumah tangga
I = Nilai pasarpengeluaran investasi barang-barang modal
G = Nilai pasar pengeluaran pemerintah untuk barang-barang dan jasa-
jasa (pemerintah pusat, daerah tingkat I dan II)
X = Nilai pasar pengeluaran atas barang-barang dan jasa-jasa yang
diekspor
M = Nilai pasar pengeluaran untuk barang-barang dan jasa-jasa yang
diimpor
2. Pendekatan Pengeluaran
Pendekatan pendapatan (income approach) adalah suatu
pendekatan dimana pendapatan nasional diperoleh dengan eara
menjumlahkan pendapatan dari berbagai faktor produksi yang
menyumbang terhadap proses produksi yang dijumlahkan dari jenis-
jenis pendapatan ;
a. Kompensasi untuk pekerja, yang terdiri atas upah dan gaji plus
factor rent terhadap upah gaji, dan ini merupakan komponen
terbesar dari pendapatan nasional.
b. Keuntungan perusahaan yang merupakan kompensasi kepada
pemilik perusahaan, dimana sebagaian digunakan untuk
membayar pajak keuntungan perusahaan, sebagaian lagi
dibagikan pada pemegang saham sebagai deviden, dan sebagaian

lagi ditabung oleh perusahaan sebagai laba perusahaan yang
tidak dibagikan.
c. Pendapatan usaha perorangan, yang merupakan kompensasi
atas penggunaan tenaga kerja dan sumber-sumber dari
selfemployed persons, misalnya petani, Self-employed
professional, dan lain-lain.
d. Pendapatan sewa, yang merupakan kompensasi untuk para
pemiliki tanah, rental business dan residential properties.
Secara matematis pendapatan nasional berdasarkan pendekatan
pendapatan dapat dirumuskan sebagai berikut :
N1 = Yw + Yr + Yi + Ynr + Ynd
Dimana :
1. Yw menunjukkan pendapatan dari upah, gaji, dan pendapatan
lainnya setelah pajak,
2. Yr adalah pendapatan dari bunga
3. Ynr, Ynd adalah pendapatan dari keuntungan perusahaan dan
pendapatan lainnya sebelum pengenaan pajak.
3. Pendekatan Produksi
Dengan pendekatan produksi (production approach) produk
nasional atau produk domestik bruto diperoleh dengan menjumlahkan
nilai pasar dari seluruh barang dan jasa yang dihasilkan oleh berbagai
sektor di dalam perekonomian. Dengan demikian, GNP atau GDP
merupakan penjumlahan dari harga masing-masing barang dan jasa-
jasa dikalikan dengan jumlah atau kuantitas barang atau jasa yang
dihasilkan. Secara matematis dapat dinyatakan sebagai berikut :
Dimana:

Y = Produk nasional atau produk domestic bruto (GNP atau GDP)
P = Harga barang dari unit ke-J hingga jenis ke-n
Q = jumlah barang dari jenis ke-I hingga ke-n
Dengan perkataan lain, GNP atau GOP diperoleh dengan
menjumlahkan nila tambah (value added) yang dihasilkan oleh
berbagai sektor perekonomian. Dalam hal ini, GDP atau GNP
merupakan penjumlahan dari nilai tambah dan sektor pertanian,
ditambah nilai tambah di sektor pertambangan, ditambah nilai tambah
dari sektor manufaktur, dan seterusnya.
VA = nilai tambah (value added) sektor-sektor perekonomian (mulai
dari sektor ke-I sampai dengan sektor ke-n)
Untuk menghitung laju pertumbuhan ekonomi (rate of economic
growth) dapat dilakukan dengan menggunakan formula sebagai
berikut:
Dimana:
g : Pertumbuhan ekonomi
yt : Produk domestic bruto tahun sekarang
yt-1 : Produk domestic bruto tahun yang lalu
d. Faktor-Faktor Yang Mempengaruhi Pertumbuhan Ekonomi
Proses pertumbuhan ekonomi dipengaruhi oleh dua macam factor,
factor ekonomi dan factor non ekonomi. (Todaro, 2000)
1) Faktor Ekonomi
Para ahli ekonomi menganggap faktor produksi sebagai
kekuatan utama yang mempengaruhi pertumbuhan, jatuh atau

bangunnya perekonomian adalah konsekuensi dari perubahan yang
terjadi di dalam faktor produksi tersebut.
Faktor utama yang mempengaruhi perkembangan suatu
perekonomian adalah sumber daya alam atau tanah. Tanah
sebagaimana dipergunakan dalam ilmu ekonomi mencakup sumber
daya alam seperti kesuburan tanah, letak dan susunannya, kekayaan
hutan, mineral, iklim, sumber air, sumber lautan, dan sebagainya.
Dalam pertumbuhan ekonomi, tersedianya sumber daya alam secara
melimpah merupakan hal yang penting.
Modal berarti persediaan faktor produksi yang secara fisik
dapat direproduksi. Apabila stok modal naik dalam batas waktu
tertentu, hal ini disebut akumulasi modal atau pembentukan modal.
Pembentukan modal merupakan investasi dalam bentuk barang-
barang modal yang dapat menaikkan stok modal, output nasional dan
pendapatan nasional.
Organisasi merupakan bagian penting dari proses
pertumbuhan. Organisasi berkaitan dengan penggunaan faktor
produksi dalam kegiatan ekonomi. Organisasi bersifat melengkapi
(komplemen) modal, buruh dan membantu meningkatkan
produktifitasnya. Dalam ekonomi modern para wiraswastawan tampil
sebagai organisator dan pengambil resiko dalam ketidakpastian.
Perubahan teknologi dianggap sebagai sektor paling penting
dalam proses pertumbuhan ekonomi. Perubahan ini berkaitan dengan
perubahan dalam metode produksi yang telah menaikkan
produktivitas buruh, modal, dan sektor produksi lain.
Spesialisasi dan pembagian kerja menimbulkan peningkatan
produktivitas. Keduanya membawa prekonomian kearah ekonomi
skala besar yang selanjutnya membantu perkembangan industri.

2) Faktor Non Ekonomi
Faktor non ekonomi bersama sektor ekonomi saling
mempengaruhi kemajuan perekonomian. Faktor sosial dan budaya
juga mempengaruhi pertumbuhan ekonomi. Misalnya saja pendidikan
dan kebudayaan barat yang menanamkan semangat yang
menghasilkan berbagai penemuan baru, juga merubah cara pandang,
harapan, struktur, dan nilai nilai sosial.
Sumber daya manusia merupakan faktor terpenting dalam
pertumbuhan ekonomi, baik jumlah dan efisiensi mereka. Faktor
politik dan administratif yang kokoh juga membantu pertumbuhan
ekonomi modern.
a) Produk Domestik Bruto
Indicator yang digunakan untuk mengukur pertumbuhan
ekonomi adalah tingkat pertumbuhan Produk Domestik Bruto
(PDB), yang mengukur pendapatan total setiap orang dalam
perekonomian (Mankiw, 2000). Produk Domestik Bruto (PDB)
adalah pendapatan total dan pengeluaran total nasional atas output
barang dan jasa pada periode tertentu. PDB ini dapat mecerminkan
kinerja ekonomi, sehingga semakin tinggi PDB suatu Negara maka
dapat dikatakan bahwa semakin bagus pula kinerja ekonomi di
Negara tersebut. Sebenarnya banyak sekali faktor yang
mempengaruhi baik langsung maupun tidak langsung terhadap
PDB. Namun menurut teori Keynes, PDB terbentuk dari empat
faktor yang secara positif mempengaruhinya, keempat faktor
tersebut adalah konsumsi (C), investasi (I), pengeluara pemerintah
(G), dan ekspor neto(NX). Keempat faktor tersebut kembali
dipengaruhi oleh berbagai macam faktor antara lain dipengaruhi
oleh faktor-faktor seperti tingkat pendapatan, tingkat harga, suku
bunga, tingkat inflasi, money supply, nilai tukar dan sebagainya.

Beberapa ekonom berpendapat bahwa kecenderungan yang
terus meningkatterhadap output perkapita saja tidak cukup,
tetapi kenaikan output harus bersumber dariproses intern
perekonomian tersebut. Dengan kata lain pertumbuhan ekonomi
harus bersifatself generating, yang mengandung arti
menghasilkan kekuatan bagi timbulnya kelanjutanpertumbuhan
dalam jangka panjang (periode-periode selanjutnya).
b) Utang Luar Negeri
Terdapat beberapa pandangan yang menyatakan tentang
keterkaitan antara utang da pertumbuhan ekonomi. Pasaribu
(2003), menuliskan tentang pandangan ekonom mengena
hubungan antara utang dan pertumbuhan ekonomi dijelaskan
melalui 3 aliran, yaitu Klasik/Neo Klasik, Keynesian dan Ricardian.
Menurut Barsky, et. Al (1986) ekonom Klasik/Neo Klasi
mengindikasikan bahwa kenaikan utang luar negeri untuk
membiayai pengeluaran pemerinta hanya menaikkan
pertumbuhan ekonomi dalam jangka pendek, namun dalam jangka
panjang tidak akan mempunyai dampak yang signifikan akibat
adanya crowding-out, yaitu keadaan di mana terjadi overheated
dalam perekonomian yang menyebabkan investasi swasta
berkurang yang pada akhirnya akan menurunkan produk domestik
bruto. Kelompok Neo Klasik berpendapat bahwa setiap individu
mempunyai informasi yang cukup, sehingga mereka dapat
merencanakan tingkat konsumsi sepanjang waktu hidupnya. Defisit
anggaran pemerintah yang dibiayai oleh utang luar negeri akan
meningkatkan konsumsi individu. Sedangkan pembayaran pokok
utang dan cicilannya dalam jangka panjang akan membebankan
kenaikan pajak untuk generasi berikutnya. Dengan asumsi bahwa
seluruh sumber daya secara penuh dapat digunakan, maka

peningkatan konsumsi akan menurunkan tingkat tabungan dan
suku bunga akan meningkat. Peningkatan suku bunga akan
mendorong permintaan swasta menurun, sehingga kaum Neo
Klasik menyimpulkan bahwa dalam kondisi full employment,
defisit anggaran pemerintah yang permanen dan penyelesaiannya
dengan utang luar negeri akan menyebabkan investasi swasta
tergusur (Barsky, et al, 1986).
Sedangkan paham keynesian ditelaah oleh Eisner (1989) dan
Bernheim (1989). Pahamkeynesian melihat kebijakan peningkatan
anggaran belanja yang dibiayai oleh utang luar negeri akan
memiliki pengaruh yang signifikan terhadap pertumbuhan
ekonomi akibat naiknya permintaan agregat sebagai pengaruh
lanjut dari terjadinya akumulasi modal. Kelompok keynesian
memiliki pandangan bahwa defisit anggaran pemerintah yang
ditutup dengan utang luar negeri akan meningkatkan pendapatan
dan kesejahteraan sehingga kenaikan pendapatan akan
meningkatkan konsumsi. Hal ini mengakibatkan beban pajak pada
masa sekarang relatif menjadi lebih ringan, hal ini kemudian akan
menyebabkan peningkatan pendapatan yang siap dibelanjakan.
Peningkatan pendapatan nasional akan mendorong perekonomian.
Kesimpulannya, kebijakan menutup defisit anggaran dengan utang
luar negeri dalam jangka pendek akan menguntungkan
perekonomian dengan adanya pertumbuhan ekonomi.
Sedangkan pendapat berbeda lagi digagaskan oleh Ricardian.
Pemahaman Ricardianmenurut Barro (1974, 1989), Evans (1988)
menjelaskan bahwa kebijakan utang luar negeri untuk membiayai
defisit anggaran belanja pemerintah tidak akan mempengaruhi
pertumbuhan ekonomi. Hal ini terjadi karena efek pertumbuhan
pengeluaran pemerintah yang dibiayai dengan utang publik harus
dibayar oleh pemerintah pada masa yang akan datang dengan

kenaikan pajak. Oleh karena itu, masyarakat akan mengurangi
konsumsinya pada saat sekarang untuk memperbesar tabungan
yang selanjutnya digunakan untuk membayar kenaikan pajak pada
masa yang akan datang.
c) Pengeluaran Pemerintah
Teori ini dapat digolongkan menjadi dua bagian, diantaranya
yaitu Teori Makro yang terdiri dari : (Mangkoesoebroto, 2001)
(1) Rostow dan Mungrave, dimana mereka menghubungkan
pengeluaran pemerintahdengan tahap-tahap pembangunan
ekonomi. Pada tahap awal perkembanganekonomi, menurut
mereka rasio rasio pengeluaran pemerintah terhadap
pendapatannasional-relatif besar. Hal itu dikarenakan pada
tahap awal ini pemerintah harusmenyediakan berbagai sarana
dan prasarana. Pada tahap menengah pembangunanekonomi,
investasi pemerintah tetap diperlukan guna memacu
pertumbuhan agardapat lepas landas. Bersamaan dengan itu
posisi investasi pihak swasta jugameningkat. Tetapi besarnya
peranan pemerintah adalah karena pada tahap ini
banyakkegagalan pasar yang ditimbulkan perkembangan
ekonomi itu sendiri, yaitu kasuseksternalitas negatif, misalnya
pencemaran lingkungan.
Dalam suatu proses pembangunan, menurut
Musgrave rasio investasi total terhada pendapatan nasional
semakin besar, tetapi rasio investasi pemerintahterhadap
pendapatan nasional akan semakin mengecil. Sementara itu
Rostowberpendapat bahwa pada tahap lanjut pembangunan
terjadi peralihan aktivitaspemerintah, dari penyediaan
prasarana ekonomi ke pengeluaran-pengeluaran
untuklayanan sosial seperti kesehatan dan pendidikan. Teori

Rostow dan Musgrave adalahpandangan yang timbul dari
pengamatan atas pengalaman pembangunan ekonomiyang
dialami banyak negara, tetapi tidak didasari oleh suatu teori
tertentu. Selain itutidak jelas, apakah tahap pertumbuhan
ekonomi terjadi dalam tahap demi tahap, ataubeberapa tahap
dapat terjadi secara simultan.
(2) Hukum Wagner, Wagner melakukan pengamatan
terhadap negara-negara Eropa,Amerika Serikat dan Jepang
pada abad ke-19 yang menunjukkan bahwa
aktivitaspemerintah dalam perekonomian cenderung
semakin meningkat. Wagner mengukurdari perbandingan
pengeluaran pemerintah terhadap produk nasional.
Temuan oleh Richard Musgrave dinamakan hukum
pengeluaran pemerintah yang selalu meningkat (law of
growing public expenditures). Wagner sendiri menamakannya
hukum aktivitas pemerintah yang selalu meningkat (law of
ever increasing state activity).
Dimana :
Gpc = Pengeluaran pemerintah perkapita
YpC = Produk atau pendapatan nasional perkapita
T = Indeks waktu
Menurut Wagner ada lima hal yang menyebabkan
pengeluaran pemerintahselalu meningkat yaitu tuntutan
peningkatan perlindungan keamanan dan
pertahanan,kenaikan tingkat pendapatan masyarakat,
urbanisasi yang mengiringi pertumbuhanekonomi,
perkembangan demokrasi dan ketidakefisienan birokrasi
yang mengiringiperkembangan pemerintahan.

(3) Peacock dan Wiseman, mereka mengemukakan pendapat
lain dalam menerangkan perilaku perkembangan
pemerintah. Mereka mendasarkannya padasuatu analisis
"dialektika penerimaan-pengeluaran pemerintah".
Pemerintah selalu berusaha memperbesar pengeluarannya
dengan mengandalkan penerimaan dari pajak. Padahal
masyarakat tidak menyukai pembayaran pajak yang kian
besar.
Mengacu pada teori pemungutan suara (voting),
mereka berpendapat bahwamasyarakat mempunyai batas
toleransi pajak, yakni suatu tingkat dimana masyarakat dapat
memaham besarnya pungutan pajak yang dibutuhkan oleh
pemerintah untukmembiayai pengeluaran-pengeluarannya.
Tingkat toleransi pajak ini merupakankendala yang
membatasi pemerintah untuk menaikkan pungutan pajak
secara tidaksemena-mena atau sewenang-wenang.
Menurut Peacock-Wiseman, perkembangan ekonomi
menyebabkan pungutan pajak meningkat yang meskipun
tarif pajaknya mungkin tidak berubah, padagilirannya
mengakibatkan pengeluaran pemerintah meningkat pula.
Jadi dalam keadaan normal, kenaikan pendapatan
nasional menaikkan pula baik penerimaan maupun
pengeluaran pemerintah. Apabila keadaan normal
jaditerganggu, katakanlah karena perang atau ekstemalitas
lain, maka pemerintahterpaksa harus memperbesar
pengeluarannya untuk mengatasi gangguan dimaksud.
Konsekuensinya, timbul tuntutan untuk memperoleh
penerimaan pajak lebih besar.Pungutan pajak yang lebih
besar menyebabkan dana swasta untuk investasi danmodal
kerja menjadi berkurang. Efek ini disebut efek penggantian

(displacement effict). Postulat yang berkenaan dengan efek ini
menyatakan, gangguan sosial dalamperekonomian
menyebabkan aktivitas swasta digantikan oleh aktivitas
pemerintah. Pengatasan gangguan acap kali tidak cukup
dibiayai semata-mata dengan pajaksehingga pemerintah
mungkin harus juga meminjam dana dari luar negeri.
Setelahgangguan teratasi, muncul kewajiban melunasi utang
dan membayar bunga. Pengeluaran pemerintah pun kian
membengkak karena kewajiban baru tersebut.Akibat lebih
lanjut ialah pajak tidak turun kembali ke tingkat semula
meskipun gangguan telah usai.
Jika pada saat terjadinya gangguan sosial dalam
perekonomain timbul efek penggantian, maka sesudah
gangguan berakhir timbul pula sebuah efek lain yangdisebut
efek inspeksi (inspection effect). Postulat efek ini
menyatakan, gangguansosial menumbuhkan kesadaran
masyarakat akan adanya hal-hal yang perlu ditanganioleh
pemerintah sesudah redanya gangguan sosial tersebut.
Kesadaran semacam inimenggugah kesediaan masyarakat
untuk membayar pajak lebih besar, sehingga memungkinkan
pemerintah beroleh penerimaan yang lebih besar pula. Inilah
yangdimaksudkan dengan analisis dialektika penerimaan-
pengeluaran pemerintah.
Suatu hal yang perlu dicatat dari Teori Peacock dan
Wiseman adalah bahwa mereka mengemukakan adanya
toleransi pajak, yaitu suatu limit perpajakan, akantetapi
mereka tidak menyatakan pada tingkat berapakah toleransi
pajak tersebut. Clarke menyatakan bahwa limit perpajakan
sebesar 25% dari pendapatan nasional. Apabila limit tersebut

dilampaui maka akan terjadi inflasi dan gangguan social
lainnya.
G. Tinjauan Empiris
Penelitian tentang pengaruh Utang Luar Negeri dan Pengeluaran
Pemerintah telah banyak dilakukan di Indonesia. penelitian-penelitian
tersebut menggunakan variabel-variabel yang bervariatif. Variabel tersebut
diantaranya : pengeluaran pemerintah, utang luar negeri dan penanaman
modal asing,
Walaupun dasar teori yang digunakan relatif sama, namun sebagian
besar kesimpulan tidak menunjukkan hasil yang sama. Untuk lebih jelasnya
dapat dilihat pada tabel dibawah ini :
Tabel 1. Review Penelitian terdahulu (Theoritical Mapping)
Nama
Peneliti Tahun Judul
Variabel yang
digunakan Hasil yang diperoleh
Desi Dwi
Bastias
2010 Analisis Pengaruh
Pengeluaran
Pemerintah atas
Pendidikan,
Kesehatan dan
Infrastruktur
Terhadap
Pertumbuhan
Ekonomi
Indonesia Periode
1969-2009
Variabel
Dependen
Pertumbuhan
Ekonomi
Variabel
Independen
Pengeluaran
Pemerintah
Secara Simultan :
Pengeluaran
Pemerintah
berpengaruh
signifikan terhadap
pertumbuhan
ekonomi.
Secara Parsial :
Pengeluaran
Pemerintah
berpengaruh
signifikan terhadap
pertumbuhan
ekonomi.
Baguskoro
Bayu
Perdana
2009 Analisis Pengaruh
Pengeluaran
Pemerintah
terhadap
Variabel
Dependen
Pertumbuhan
Ekonomi
Secara Simultan :
Pengeluaran
pemerintah
berpengaruh

Nama
Peneliti Tahun Judul
Variabel yang
digunakan Hasil yang diperoleh
Pertumbuhan
Ekonomi
Variabel
Independen
Pengeluaran
Pemerintah
signifikan terhadap
pertumbuhan
ekonomi
Secara Parsial :
Pengeluaran
pemerintah
berpengaruh
signifikan terhadap
pertumbuhan
ekonomi.
Arwini
Fajriah
Anwar
2011 Analisis Pengaruh
Utang Luar Negeri
dan Penanaman
Modal Asing
Terhadap
Pertumbuhan
Ekonomi
Indonesia Periode
2000-2009
Variabel
dependen
Pertumbuhan
ekonomi
Variabel
independen
Utang luar negeri
dan penanaman
modal asing
Secara Simultan :
Utang luar negeri dan
penanaman modal
asing berpengaruh
signifikan terhadap
pertumbuhan
ekonomi.
Secara Parsial :
Utang luar negeri dan
penanaman modal
asing berpengaruh
signifikan terhadap
pertumbuhan
ekonomi.
Rosmawati
Sinuraya
2010 Analsis Pengaruh
Pengeluaran
Pemerintah
Tehadap
Pertumbuhan
Ekonomi
Kabupaten Karo
Variabel
dependen
Pertumbuhan
ekonomi
Variabel
independen
Pengeluaran
pemrintah.
Secara Simultan :
Pengeluaran
pemerintah
berpengaruh
signifikan terhadap
cadangan devisa
Secara Parsial :
Pengeluaran
pemerintah
berpengaruh
signifikan terhadap
pertumbuhan
ekonomi.

1. Kerangka Berpikir
Kerangka Konsep yang dapat dibentuk dari penelitian ini adalah :
Independen Dependen
Gambar 1 : Kerangka Berpikir
Berdasarkan kajian teori yang telah dijabarkan diatas, maka hipotesis yang
dapat dibuat untuk penelitian ini adalah utang luar negeri dan pengeluaran
pemerintah berpengaruh secara simultan maupun parsial terhadap cadangan
devisa Indonesia untuk periode 1985 sampai 2014.
H. METODE PENELITIAN
Penelitian ini adalah deskriftif kuantitatif. Populasi yang digunakan adalah
data PDB, utang luar negeri, dan pengeluaran pemerintah yang diperoleh dari
World Bank dan Badan Pusat Statistik periode 1985 sampai dengan 2014.
Tekhnik pengambilan sampel dengan menggunakan sampel jenuh. Sampel
jenuh merupakan sampel yang mewakili populasi, dimana biasanya hanya
digunakan jika populasi kurang dari 100. Sehingga pada akhirnya diperoleh
jumlah sampel sebanyak 30 data.
Metode analisis yang digunakan oleh penulis untuk menerangkan
kerangka dasar perhitungan hubungan antara variabel dependent dan
variabel indpendent didasarkan pada analisis regresi berganda dengan
pengolahan data menggunakan program E-views 7.0. Untuk
menyederhanakan perhitungan dengan metode ekonometrika, variabel
dependent merupakan pertumbuhan ekonomi dengan variabel (Y) dan
Utang Luar
Negerti (X1)
Pengeluaran
Pemerintah (X2)
Pertumbuhan
Ekonomi (Y)

variabel independent adalah utang luar negeri (X1) dan pengeluaran
pemerintah (X2). Selanjutnya akan dianalisa dengan cara sebagai berikut :
Fungsi persamaannya adalah : Y = f (X1, X2) ……………………………………………(1)
Dengan model persamaan sebagai berikut : Y = 𝛽0 + 𝛽1.𝑋1 + 𝛽2.𝑋2 + e ………(2)
Dimana :
𝛽0 = Konstanta
𝛽1 = Koefisien Utang Luar Negeri
𝛽2 = Koefisien Pengeluaran Pemerintah
Y = Pertumbuhan Ekonomi
X1 = Utang Luar Negeri
X2 = Pengeluaran Pemerintah
e = Error (Variabel Pengganggu)
Metode selanjutnya dilakukan pengujian Asumsi Klasik dan pengujian
Statistik.
I. Hasil dan Pembahasan
1. Analisis Regresi Linier Berganda
Untuk mendapatkan hasil regresi antara variabel dependen
pertumbuhan ekonomi (Y) dengan variabel independen utang luar negeri
(X1) dan pengeluaran pemerintah (X2) diolah denga bantuan program
Eviews 7.0, dengan menggunakan metode Ordinary Least Square (OLS),
yang ditampilkan pada tabel berikut :

Tabel 2. Hasil Regresi Linier Berganda
Dependent Variable: LOG(PDB)
Method: Least Squares
Date: 06/03/16 Time: 17:42
Sample: 1985 2014
Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob.
C 3.880759 0.243170 15.95905 0.0000
LOG(ULN) 0.354095 0.022934 15.43962 0.0000
LOG(GOV) 0.767301 0.015050 50.98435 0.0000
R-squared 0.996864 Mean dependent var 26.16087
Adjusted R-squared 0.996632 S.D. dependent var 0.795993
S.E. of regression 0.046198 Akaike info criterion -3.217102
Sum squared resid 0.057626 Schwarz criterion -3.076982
Log likelihood 51.25653 Hannan-Quinn criter. -3.172277
F-statistic 4291.088 Durbin-Watson stat 1.275188
Prob(F-statistic) 0.000000
Berdasarkan Tabel 2 di atas, maka persamaan regresi berganda
dapat dirumuskan sebagai berikut :
Pertumbuhan Ekonomi = 3,880759 + 0,354095*Log(Utang LN) +
0,767301 *Log (Pengeluaran Pemerintah) + e
β0 = 3,880759, artinya bahwa jika variabel utang luar negeri dan
pengeluaran pemerintah diasumsikan cateris paribus (variabel
independen dianggap konstan atau nol), maka nilai dari
pertumbuhan ekonomi (PDB) adalah sebesar 3.880759.
β1 = 0,354095, artinya bahwa setiap kenaikan utang luar negeri sebesar
100 satuan, maka pertumbuhan ekonomi (PDB) akan naik sebesar
35.4095 dengan asumsi variabel lain dianggap konstan.
β2 = 0,767301, artinya bahwa setiap kenaikan pengeluaran pemerintah
sebesar 100 satuan, maka pertumbuhan ekonomi (PDB) akan naik
sebesar 76,7301 dengan asumsi variabel lain dianggap konstan.

2. Uji Statistik
a) Koefisien Determinasi (R2)
Dari pengujian yang telah dilaksanakan menghasilkan nilai koefisien
determinasi (Adjusted R2) sebesar 0.996632, sehingga dapat dikatakan
bahwa hasil pengujian yang dilakukan memberikan hasil yang baik
(goodness of fit). Nilai koefisien determinasi bernilai positif, hal ini
menunjukkan bahwa 99,66% variasi dari pertumbuhan ekonomi dapat
dijelaskan oleh variabel utang luar negeri dan pengeluaran pemerintah.
Sedangkan sisanya 0,34% dijelaskan oleh variabel lain di luar model.
b) Uji-F
Uji-f digunakan untuk menguji signifikansi pengaruh variabel bebas
terhadap variabel terikat secar keseluruhan. Dari hasil analisis regresi
diperoleh nilai probabilitas signifikansi dari f-statistik yaitu 0.000000
(lihat tabel 2). Karena probabilitas signifikansi f-statistik < 0,05
(0,000000 < 0,05), maka H0 ditolak dan H1 diterima, artinya utang luar
negeri dan pengeluaran pemerintah secara simultan atau bersama-
sama berpengaruh signifikan terhadap pertumbuhan ekonomi.
c) Uji-t
Uji-t digunakan untuk menguji signifikansi dari pengaruh
veriabel bebas terhadap variabel terikat secara individual/parsial.
Untuk mengetahui pengaruh masing-masing veriabel terhadap veriabel
dependen dapat dijelaskan di bawah ini :
1. Pengaruh utang luar negeri terhadap pertumbuhan ekonomi
Berdasarkan hasil anailis data dapat diperoleh nilai probabilitas
variabel ekspor sebesar 0,0000 (lihat tabel 2). Karena nilai
probabilitas utang luar negeri < 0,05 maka H0 diterima dan H1
ditolak sehingga variabel utang luar negeri berpengaruh signifikan
terhadap pertumbuhan ekonomi.
2. Pengaruh pengeluaran pemerintah terhadap pertumbuhan ekonomi

Berdasarkan hasil analisis data dapat diperoleh nilai probabilitas
variabel pengeluaran pemerintah sebesar 0,0000 (lihat tabel 2).
Karena nilai probabilitas pengeluaran pemerintah < 0,05, maka H0
diterima dan H1 ditolak sehingga variabel pengeluaran pemerintah
berpengaruh siginifikan terhadap pertumbuhan ekonomi.
3. Uji Asumsi Klasik
(1) Uji Normalitas
Uji normalitas yang digunakan dalam penelitian ini adalah
mengunakan uji Jarque Bera denga melihat nilai probabilitasnya. Jika
nilai probabilitas lebih besar dari derajat kesalahan α =5% (0,05),
maka penelitian ini tidak ada terdapat permasalahan normalitas atau
dengan kata lain data tersebut adalah normal. Dan sebaliknya, bila
probabilitas < 0,05, maka dalam penelitian ini tidak terdistribusi
secara normal dan hasilnya sebagai berikut :
0
1
2
3
4
5
6
7
8
9
-0.100 -0.075 -0.050 -0.025 0.000 0.025 0.050 0.075 0.100
Series: ResidualsSample 1985 2014Observations 30
Mean 8.28e-16Median -0.000377Maximum 0.083137Minimum -0.089108Std. Dev. 0.044577Skewness -0.034888Kurtosis 2.318072
Jarque-Bera 0.587369Probability 0.745512
Berdasarkan gambar tersebut dapat terlihat hasil data yang diuji
terdistribusi secara normal. Dapat dilihat pada nilai probabilitas
Jarque Bera (JB) sebesar 0.745512 yang lebih besar dari derajat
kesalahan yaitu sebesar 0,05 (0.745512 > 0,05).

(2) Uji Heteroskedastisitas
Uji heteroskedastisitas ini dilakukan untuk mengetahui apakah
dalam model regresi terjadi ketidaksamaan variab dari residual satu
pengamatan ke pengamatan yang lain. Jika varian dari satu residual
satu pengamatan ke pengamatan yang lain tetap, maka disebut
homokedastisitas dan jika varian tidak konstan atau berubah-ubah
disebut dengan heteroskedastisitas. Model regresi yang baik adalah
yang homokedastisitas atau tidak terjadi heteroskedastisitas
(Gujarati, 2007). Untuk mengetahui ada tidaknya hetero-
skedastisitas dapat dilihat pada tabel berikut ini :
Tabel 3. Hasil Uji Heteroskedastisitas
Heteroskedasticity Test: White
F-statistic 1.023673 Prob. F(5,24) 0.4259
Obs*R-squared 5.273337 Prob. Chi-Square(5) 0.3834
Scaled explained SS 2.815008 Prob. Chi-Square(5) 0.7285
Dari tabel 3 di atas diketahui bahwa nilai Obs*R Squared adalah
0,3834 lebih dari α = 0,05. Maka dapat disimpulkan model ini tidak
mengandung Heteroskedastisitas.
(3) Uji Autokorelasi
Autokorelasi adalah suatu keadaan dimana terjadi korelasi
(hubungan) antara residual tahun ini dengan tingkat kesalahan tahun
sebelumnya. Untuk mengetahui ada atau tidaknya penyakit
autokorelasi dalam suatu model, dapat dilihat dari nilai statistik
durbin-watson. Selain dengan menggunakan uji Durbin-Watson,,
untuk melihat ada tidaknya masalah penyakit autokorelasi dapat juga
digunakan uji langrange multiple (LM Test) atau yang disebut dengan

uji Breusch-Godfrey dengan membandingkan nilai probabilitas Obs*R
Squared dengan α = 5% (0,05). Untuk mengetahui ada tidaknya
autokorelasi dapat dilihat pada tabel berikut ini :
Tabel 4. Hasil Uji Langrange Multiple Test
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 2.367450 Prob. F(2,25) 0.1144
Obs*R-squared 4.777114 Prob. Chi-Square(2) 0.0918
Berdasarkan tabel 4 di atas diketahui bahwa nilai Obs*R-squared
adalah 4.777114 dan nilai probabilitasnya adalah 0.0918 yang lebih
besar dari α = 5 % (0,05) sehingga dapat disimpulkan bahwa data
dalam penelitian ini tidak terdapat masalah autokorelasi.
(4) Uji Multikolinearitas
Uji multikolinearitas dilakukan untuk mengetahui ada tidaknya
hubungan (korelasi) yang signifikan di antara dua atau lebih variabel
independen dalam model regresi. Deteksi adanya multikolinieritas
dilakukan dengan menggunakan uji korelasi parsial antar variabel
independen, kemudian dapat diputuskan apakah data terkena
multikolinieritas atau tidak, yaitu dengan menguji koefisien korelasi
antar variabel independen. Suatu model regresi yang baik adalah tidak
terjadi multikolinieritas antar variabel independen dengan variabel
dependen (Gujarati, 2007:67). Setelah diolah menggunakan aplikasi
Eviews 7.0, maka terlihat hasil sebagai berikut :
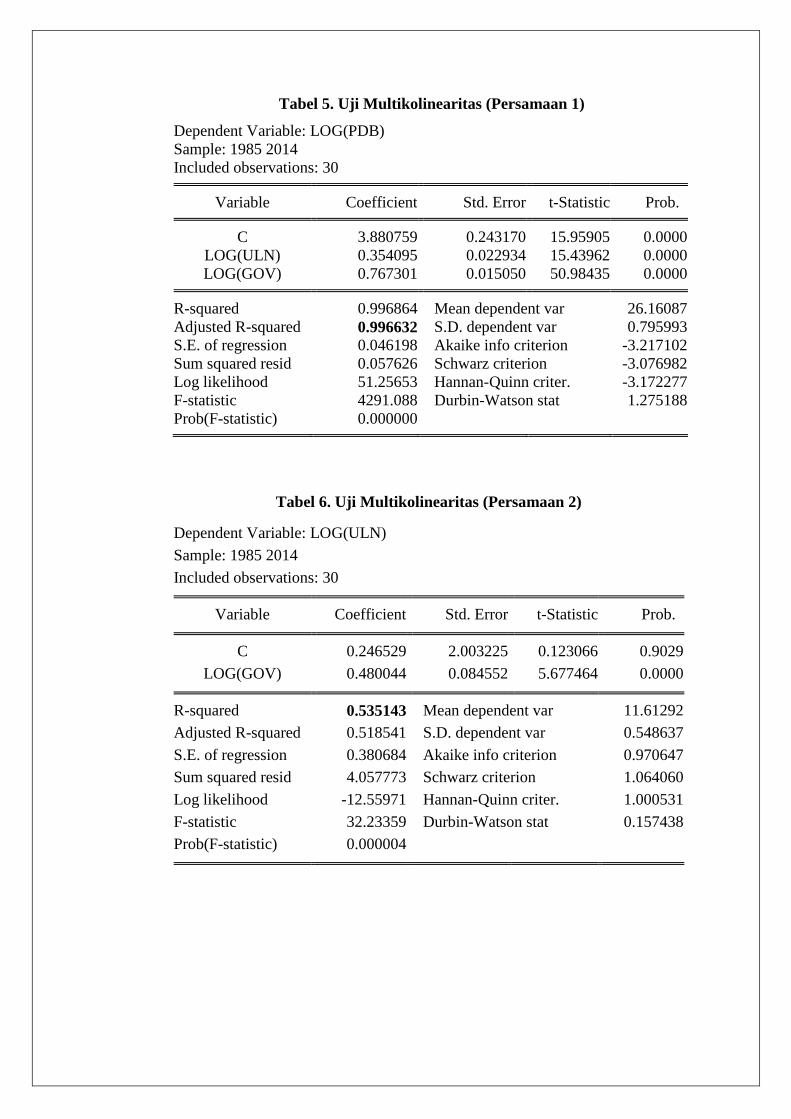
Tabel 5. Uji Multikolinearitas (Persamaan 1)
Dependent Variable: LOG(PDB)
Sample: 1985 2014
Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob.
C 3.880759 0.243170 15.95905 0.0000
LOG(ULN) 0.354095 0.022934 15.43962 0.0000
LOG(GOV) 0.767301 0.015050 50.98435 0.0000
R-squared 0.996864 Mean dependent var 26.16087
Adjusted R-squared 0.996632 S.D. dependent var 0.795993
S.E. of regression 0.046198 Akaike info criterion -3.217102
Sum squared resid 0.057626 Schwarz criterion -3.076982
Log likelihood 51.25653 Hannan-Quinn criter. -3.172277
F-statistic 4291.088 Durbin-Watson stat 1.275188
Prob(F-statistic) 0.000000
Tabel 6. Uji Multikolinearitas (Persamaan 2)
Dependent Variable: LOG(ULN)
Sample: 1985 2014
Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob.
C 0.246529 2.003225 0.123066 0.9029
LOG(GOV) 0.480044 0.084552 5.677464 0.0000
R-squared 0.535143 Mean dependent var 11.61292
Adjusted R-squared 0.518541 S.D. dependent var 0.548637
S.E. of regression 0.380684 Akaike info criterion 0.970647
Sum squared resid 4.057773 Schwarz criterion 1.064060
Log likelihood -12.55971 Hannan-Quinn criter. 1.000531
F-statistic 32.23359 Durbin-Watson stat 0.157438
Prob(F-statistic) 0.000004

Tabel 6. Uji Multikolinearitas (Persamaan 3)
Dependent Variable: LOG(GOV)
Method: Least Squares
Date: 06/03/16 Time: 17:49
Sample: 1985 2014
Included observations: 30
Variable Coefficient Std. Error t-Statistic Prob.
C 10.73198 2.282676 4.701488 0.0001
LOG(ULN) 1.114780 0.196352 5.677464 0.0000
R-squared 0.535143 Mean dependent var 23.67783
Adjusted R-squared 0.518541 S.D. dependent var 0.836064
S.E. of regression 0.580122 Akaike info criterion 1.813183
Sum squared resid 9.423154 Schwarz criterion 1.906596
Log likelihood -25.19774 Hannan-Quinn criter. 1.843067
F-statistic 32.23359 Durbin-Watson stat 0.219273
Prob(F-statistic) 0.000004
Untuk persamaan (1) nilai R² adalah sebesar 0.996632 selanjutnya
disebut R² 1
Untuk persamaan (2) nilai R² adalah sebesar 0.535143 selanjutnya
disebut R² 2
Untuk persamaan (3) nilai R² adalah sebesar 0.535143selanjutnya
disebut R² 3
Hasil analisis output : menunjukkan bahwa R² 1 > R² 3 > R² 2 maka
dalam model tidak ditemukan adanya multikolinearitas.
J. KESIMPULAN DAN SARAN
Berdasarkan hasil analisis data dan pembahasan yang telah
dikemukakan, maka kesimpulan yang dapat diambil dari penelitian ini adalah
sebagai berikut :
1. Utang luar negeri berpengaruh positif dan signifikan terhadap cadangan
devisa dengan nilai probabilitas t-statistik sebesar 0.0000.

2. Pengeluaran pemerintah berpengaruh positif dan signifikan terhadap
cadangan devisa dengan nilai probabilitas t-statistik sebesar 0.0000.
3. Nilai Adjusted R2 cukup tinggi yaitu 0.9966, yang berarti 99,66% variabel
independen (utang luar negeri dan pengeluaran pemerintah) dapat
menjelaskan variabel dependen, dan sisanya 0, 34% dijelaskan oleh
variabel diluar model.
DAFTAR PUSTAKA
Agus Widarjono, Ekonometrika Teori dan Aplikasi untuk Ekonomi dan Bisnis, Edisi Kedua, Cetakan Kesatu, Penerbit Ekonisia Fakultas Ekonomi UII Yogyakarta 2007.
Deprianto,Asrizal dan Jolianis., 2012, Pengaruh Konsumsi dan Investasi Terhadap Pertumbuhan Ekonomi di Kota Padang, Jurnal Mahasiswa Programstudi Pendidikan Ekonomi STKIP PGRI Sumatera Barat, STKIP PGRI Sumatera Barat, Sumatera Barat.
Gujarati, Damodar N. 2003. Basic Econometrics. Third Edition.Mc. Graw-Hill, Singapore.
Rachmadi, A.L., 2014, Analisis Pengaruh Utang Luar Negeri Terhadap Pertumbuhan Ekonomi Indonesia (2001-2011), Skripsi, Universitas Brawijaya, Malang.
Sinuraya, Rosmawati., 2010, Analisis Pengaruh Pengeluaran Pemrintah Terhadap pertumbuhan Ekonomi Kabupaten Karo, Skripsi, Universitas Sumatera Utara, Sumatera Utara.
Anwar, A.F., 2011 Analisis Pengaruh Utang Luar Negeri dan Penanaman Modal Asing Terhadap Produk Domestik Bruto Di Indonesia Periode 2000-2009, Skripsi, Universitas Hasanuddin, Makassar.

DAFTAR PUSTAKA
Agus Widarjono, Ekonometrika Teori dan Aplikasi untuk Ekonomi dan Bisnis, Edisi Kedua, Cetakan Kesatu, Penerbit Ekonisia Fakultas Ekonomi UII Yogyakarta 2007.
Baltagi, Bagi (2005). Econometric Analysis of Panel Data, Third Edition. John Wiley & Sons.
Budiyuwono, Nugroho, Pengantar Statistik Ekonomi & Perusahaan, Jilid 2, Edisi Pertama, UPP AMP YKPN, Yogyakarta, 1996.
Barrow, Mike. Statistics of Economics: Accounting and Business Studies. 3rd edition. Upper Saddle River, NJ: Prentice-Hall, 2001
Catur Sugiyanto. 1994. Ekonometrika Terapan. BPFE, Yogyakarta
Dajan, Anto. Pengantar Metode Statistik. Jakarta: Penerbit LP3ES, 1974
Daniel, Wayne W. Statistik Nonparametrik Terapan. Terjemahan Alex Tri Kantjono W. Jakarta: PT Gramedia
Gujarati, Damodar N. 2003. Basic Econometrics. Third Edition.Mc. Graw-Hill, Singapore.
Ghozali, Imam, Dr. M. Com, Akt, 2001, “Aplikasi Analisis Multivariate dengan Program SPSS”, Semarang, BP Undip.
Insukindro (1996), “Pendekatan Masa Depan Dalam Penyusunan Model Ekonometrika: Forward-Looking Model dan Pendekatan Kointegrasi”, Jurnal Ekonomi dan Industri, PAU Studi Ekonomi, UGM, Edisi Kedua, Maret 1-6
Insukindro (1998a), “Sindrum R2 Dalam Analisis Regresi Linier Runtun Waktu”, Jurnal Ekonomi dan Bisnis Indonesia, Vol. 13, No. 41 1-11.
Insukindro (1998b), “Pendekatan Stok Penyangga Permintaan Uang: Tinjauan Teoritik dan Sebuah Studi Empirik di Indonesia”, Ekonomi dan Keuangan Indonesia, Vol XLVI. No. 4: 451-471.
Insukindro (1999), “Pemilihan Model Ekonomi Empirik Dengan Pendekatan Koreksi Kesalahan”, Jurnal Ekonomi dan Bisnis Indonesia, Vol. 14, No. 1: 1-8.
Insukindro dan Aliman (1999), “Pemilihan dan Bentuk Fungsi Model Empiris: Studi Kasus Permintaan Uang Kartil Riil di Indonesia”, Jurnal Ekonomi dan Bisnis Indonesia. Vol. 13, No. 4: 49-61.
Johnston, J. and J. Dinardo (1997), Econometric Methods, McGrow-Hill

Koutsoyiannis, A (1977). Theory of Econometric An Introductory Exposition of Econometric Methods 2nd Edition, Macmillan Publishers LTD.
Maddala, G.S (1992). Introduction to Econometric, 2nd Edition, Mac-Millan Publishing Company, New York.
Nachrowi, D.N. dan H. Usman (2002). Penggunaan Teknik Ekonometrika. Jakarta: PT Raja Grafindo Persada.
Pindyck, S and Daniel. L. Rubinfeld,” Econometrics Model and Economic Forecast, 1998, Singapore: McGraw-Hill, pp. 163-164
Sritua Arif.1993. Metodologi Penelitian Ekonomi. BPFE, Yogyakarta.
Sumodiningrat, Gunawan. 2001. Ekonometrika Pengantar. Yogyakarta: PFE-Yogyakarta.
Supranto, J. 1984. Ekonometrika. Jakarta: Lembaga Penerbit Fakultas Ekonomi Universitas Indonesia.
Thomas, R.L. 1998. Modern Econometrics : An Intoduction. Addison-Wesley. Harlow, England.

AGUS TRI BASUKI adalah Dosen Fakultas Ekonomi di Universitas Muhammadiyah Yogyakarta sejak tahun 1994. Mengajar Mata Kuliah Statistik, Ekonometrik, Matematika Ekonomi dan Pengantar Ekonomi. S1 diselesaikan di Program Studi Ekonomi Pembangunan Universitas Gadjah Mada Yogyakarta tahun 1993, kemudian pada tahun 1997 melanjutkan Magister Sains di Pascasarjana Universitas Padjadjaran Bandung jurusan Ekonomi Pembangunan. Dan saat ini penulis sedang melanjutkan Program Doktor Ilmu Ekonomi di Universitas Sebelas Maret Surakarta. Penulis selain mengajar di Universitas Muhammadiyah Yogyakarta juga mengajar diberbagai Universitas di Yogyakarta. Selain sebagai dosen, penulis juga menjadi konsultan di berbagai daerah di Indonesia. Selain Buku Pengantar Ekonometrika, penulis juga menyusun Buku :
1. Pengantar Teori Ekonomi 2. Statistik Untuk Ekonomi dan Bisnis, 3. Electronic Data Processing 4. Analisis Regresi Dalam Penelitian Ekonomi dan Bisnis 5. Analisis Statistik dengan SPSS




















