OBJECT TRACKING AND RECOGNITION FOR REAL TIME VIDEOS USING NAIVE – BAYES CLASSIFICATION
Video Object Segmentation and Tracking: A Survey - arXiv
39
1 Video Object Segmentation and Tracking: A Survey RUI YAO, China University of Mining and Technology GUOSHENG LIN, Nanyang Technological University SHIXIONG XIA, JIAQI ZHAO, and YONG ZHOU, China University of Mining and Technology Object segmentation and object tracking are fundamental research area in the computer vision community. These two topics are dicult to handle some common challenges, such as occlusion, deformation, motion blur, and scale variation. The former contains heterogeneous object, interacting object, edge ambiguity, and shape complexity. And the latter suers from diculties in handling fast motion, out-of-view, and real-time processing. Combining the two problems of video object segmentation and tracking (VOST) can overcome their respective diculties and improve their performance. VOST can be widely applied to many practical applications such as video summarization, high denition video compression, human computer interaction, and autonomous vehicles. This article aims to provide a comprehensive review of the state-of-the- art tracking methods, and classify these methods into dierent categories, and identify new trends. First, we provide a hierarchical categorization existing approaches, including unsupervised VOS, semi-supervised VOS, interactive VOS, weakly supervised VOS, and segmentation-based tracking methods. Second, we provide a detailed discussion and overview of the technical characteristics of the dierent methods. Third, we summarize the characteristics of the related video dataset, and provide a variety of evaluation metrics. Finally, we point out a set of interesting future works and draw our own conclusions. Additional Key Words and Phrases: Video object segmentation, object tracking, unsupervised methods, semi-supervised methods, interactive methods, weakly supervised methods ACM Reference format: Rui Yao, Guosheng Lin, Shixiong Xia, Jiaqi Zhao, and Yong Zhou. 2019. Video Object Segmentation and Tracking: A Survey. 1, 1, Article 1 (January 2019), 39 pages. DOI: 0000001.0000001 1 INTRODUCTION The rapid development of intelligent mobile terminals and the Internet has led to an exponential increase in video data. In order to eectively analyze and use video big data, it is very urgent to automatically segment and track the objects of interest in the video. Video object segmentation and tracking are two basic tasks in eld of computer vision. Object segmentation divides the pixels in the video frame into two subsets of the foreground target and the background region, and generates the object segmentation mask, which is the core problem of behavior recognition and video retrieval. Object tracking is used to determine the exact location of the target in the video Author’s addresses: R. Yao, S. Xia, J. Zhao, and Y. Zhou, School of Computer Science and Technology, China University of Mining and Technology, Xuzhou, 221116, China; emails: {ruiyao, xiasx, jiaqizhao, yzhou}cumt.edu.cn; G. Lin, School of Computer Science and Engineering, Nanyang Technological University; email: [email protected]. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specic permission and/or a fee. Request permissions from [email protected]. © 2019 ACM. XXXX-XXXX/2019/1-ART1 $15.00 DOI: 0000001.0000001 , Vol. 1, No. 1, Article 1. Publication date: January 2019. arXiv:1904.09172v3 [cs.CV] 26 Apr 2019
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Video Object Segmentation and Tracking: A Survey - arXiv

1
Video Object Segmentation and Tracking: A Survey
RUI YAO, China University of Mining and TechnologyGUOSHENG LIN, Nanyang Technological UniversitySHIXIONG XIA, JIAQI ZHAO, and YONG ZHOU, China University of Mining and Technology
Object segmentation and object tracking are fundamental research area in the computer vision community.These two topics are di�cult to handle some common challenges, such as occlusion, deformation, motionblur, and scale variation. The former contains heterogeneous object, interacting object, edge ambiguity,and shape complexity. And the latter su�ers from di�culties in handling fast motion, out-of-view, andreal-time processing. Combining the two problems of video object segmentation and tracking (VOST) canovercome their respective di�culties and improve their performance. VOST can be widely applied to manypractical applications such as video summarization, high de�nition video compression, human computerinteraction, and autonomous vehicles. This article aims to provide a comprehensive review of the state-of-the-art tracking methods, and classify these methods into di�erent categories, and identify new trends. First, weprovide a hierarchical categorization existing approaches, including unsupervised VOS, semi-supervised VOS,interactive VOS, weakly supervised VOS, and segmentation-based tracking methods. Second, we provide adetailed discussion and overview of the technical characteristics of the di�erent methods. Third, we summarizethe characteristics of the related video dataset, and provide a variety of evaluation metrics. Finally, we pointout a set of interesting future works and draw our own conclusions.
Additional Key Words and Phrases: Video object segmentation, object tracking, unsupervised methods,semi-supervised methods, interactive methods, weakly supervised methods
ACM Reference format:Rui Yao, Guosheng Lin, Shixiong Xia, Jiaqi Zhao, and Yong Zhou. 2019. Video Object Segmentation andTracking: A Survey. 1, 1, Article 1 (January 2019), 39 pages.DOI: 0000001.0000001
1 INTRODUCTIONThe rapid development of intelligent mobile terminals and the Internet has led to an exponentialincrease in video data. In order to e�ectively analyze and use video big data, it is very urgent toautomatically segment and track the objects of interest in the video. Video object segmentationand tracking are two basic tasks in �eld of computer vision. Object segmentation divides thepixels in the video frame into two subsets of the foreground target and the background region, andgenerates the object segmentation mask, which is the core problem of behavior recognition andvideo retrieval. Object tracking is used to determine the exact location of the target in the video
Author’s addresses: R. Yao, S. Xia, J. Zhao, and Y. Zhou, School of Computer Science and Technology, China University ofMining and Technology, Xuzhou, 221116, China; emails: {ruiyao, xiasx, jiaqizhao, yzhou}cumt.edu.cn; G. Lin, School ofComputer Science and Engineering, Nanyang Technological University; email: [email protected] to make digital or hard copies of all or part of this work for personal or classroom use is granted without feeprovided that copies are not made or distributed for pro�t or commercial advantage and that copies bear this notice andthe full citation on the �rst page. Copyrights for components of this work owned by others than ACM must be honored.Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requiresprior speci�c permission and/or a fee. Request permissions from [email protected].© 2019 ACM. XXXX-XXXX/2019/1-ART1 $15.00DOI: 0000001.0000001
, Vol. 1, No. 1, Article 1. Publication date: January 2019.
arX
iv:1
904.
0917
2v3
[cs
.CV
] 2
6 A
pr 2
019

1:2 R. Yao et al.
image and generate the object bounding box, which is a necessary step for intelligent monitoring,big data video analysis and so on.
The segmentation and tracking problems of video objects seem to be independent, but theyare actually inseparable. That is to say, the solution to one of the problems usually involvessolving another problem implicitly or explicitly. Obviously, by solving the object segmentationproblem, it is easy to get a solution to the object tracking problem. On the one hand, accuratesegmentation results provide reliable object observations for tracking, which can solve problemssuch as occlusion, deformation, scaling, etc., and fundamentally avoid tracking failures. Althoughnot so obvious, the same is true for object tracking problems, which must provide at least a coarsesolution to the problem of object segmentation. On the other hand, accurate object tracking resultscan also guide the segmentation algorithm to determine the object position, which reduces theimpact of object fast movement, complex background, similar objects, etc., and improves objectsegmentation performance. A lot of research work has noticed that the simultaneous processing ofthe object segmentation and tracking problems, which can overcome their respective di�cultiesand improve their performance. The related problems can be divided into two major tasks: videoobject segmentation (VOS) and video object tracking (VOT).
The goal of video object segmentation is to segment a particular object instance in the entirevideo sequence of the object mask on a manual or automatic �rst frame, causing great concern inthe computer vision community. Recent VOS algorithms can be organized by their annotations.The unsupervised and interactive VOS methods denote the two extremes of the degree of userinteraction with the method: at one extreme, the former can produce a coherent space-timeregion through the bottom-up process without any user input, that is, without any video-speci�ctags [17, 48, 58, 75, 95, 101]. In contrast, the latter uses a strongly supervised interaction methodthat requires pixel-level precise segmentation of the �rst frame (human provisioning is very timeconsuming), but also the human needs to loop error correction system [13, 23, 104, 114, 176]. Thereare semi-supervised VOS approaches between the two extremes, which requires manual annotationto de�ne what is the foreground object and then automatically segment to the rest frames of thesequence [22, 77, 125, 135, 162]. In addition, because of the convenience of collecting video-levellabels, another way to supervise VOS is to produce masks of objects given the [155, 206] or naturallanguage expressions [84]. However, as mentioned above, the VOS algorithm implicitly handles theprocess of tracking. That is, the bottom-up approach uses a spatio-temporal motion and appearancesimilarity to segment the video in a fully automated manner. These methods read multiple orall image frames at once to take full advantage of the context of multiple frames, and segmentthe precise object mask. The datasets evaluated by these methods are dominated by short-termvideos. Moreover, because these methods iteratively optimize energy functions or �ne-turns a deepnetwork, so it can be slow.
In contrast to VOS, given a sequence of input images, the video object tracking method utilizes aclass-speci�c detector to robustly predict the motion state (location, size, or orientation, etc.) ofthe object in each frame. In general, most of VOT methods are especially suitable for processinglong-term sequences. Since these methods only need to output the location, orientation or size ofthe object, the VOT method uses the online manner for fast processing. For example, tracking-by-detection methods utilize generative [139] and/or discriminative [63, 200] appearance models toaccurate estimate object state. The impressive results of these methods prove accurate and fasttracking. However, most algorithms are limited to generating bounding boxes or ellipses for theiroutput, so that when non-rigid and articulated motions are involved in the object, they are oftensubject to visual drift problems. To address this problem, part-based tracking methods [201, 202]have been presented, but they still use part of the bounding box for object localization. In order to
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:3
leverage the precision object masks and fast object location, segmentation-based tracking methodshave been developed which combine video object segmentation and tracking [3, 14, 174, 184, 203].Most of methods estimate the object results (i.e. bounding boxes of the object or/and object masks)by a combination of bottom-up and top-down algorithms. The contours of deformable objects orarticulated motions can be propagated using these methods e�ciently.
In the past decade, a large number of video object segmentation and tracking (VOST) studieshave been published in the literature. The �eld of VOST has a wide range of practical applications,including video summarization, high de�nition (HD) video compression, gesture control and humaninteraction. For instance, VOST methods are widely applied to video summarization that exploitsvisual object across multiple videos [36], and provide a useful tool that assists video retrieval or webbrowsing [138]. In the �led of video compression, VOST is used in video-coding standards MPEG-4to implement content-based features and high coding e�ciency [85]. In particular, the VOSTcan encode the video shot as a still background mosaic obtained after compensating the movingobject by utilizing the content-based representation provided by MPEG-4 [37]. Moreover, VOSTcan estimate the non-rigid target to achieve accurate tracking positioning and mask description,which can identify its motion instructions [183]. They can replace simple human body language,especially various gesture controls.
1.1 Challenges and issuesMany problems in video object segmentation and tracking are very challenging. In general, VOSand VOT have some common challenges, such as background clutter, low resolution, occlusion,deformation, motion blur, scale variation, etc. But there are some speci�c characteristics determinedby the objectives and tasks, for example, objects in the VOT can be complex due to fast motion, out-of-view, and real-time processing. In addition, segmenting and tracking the e�ects of heterogeneousobject, interacting object, edge ambiguity, shape complexity, etc. A more detailed description isgiven in [126, 187].
To address these problems, tremendous progress has been made in the development of video objectsegmentation and tracking algorithms. These are mainly di�erent from each other based on howthey handle the following issues in visual segmentation and tracking: (i) which application scenariois suitable for VOST? (ii) Which object representation (i.e. point, superpixel, patch, and object) isadapted to VOS? (iii) Which image features are appropriate for VOST? (iv) How to model the motionof an object in VOST? (v) How to per-process and post-process CNN-based VOS methods? (vi)Which datasets are suitable for the evaluation VOST, and what are their characteristics? A numberof VOST methods have been proposed that attempt to answer these issues for various scenarios.Motivated by the objective, this survey divides the video object segmentation and tracking methodsinto broad categories and provides a comprehensive review of some representative approaches. Wehope to help readers gain valuable VOST knowledge and choose the most appropriate applicationfor their speci�c VOST tasks. In addition, we will discuss video object segmentation and trackingnew trends in the community, and hope to provide several interesting ideas to new methods.
1.2 Organization and contributions of this surveyAs shown in Fig. 1, we summarize our organization in this survey. To investigate a suitableapplication scenario for VOST, we group these methods into �ve main categories: unsupervisedVOS, semi-supervised VOS, interactive VOS, weakly supervised VOS, and segmentation-basedtracking methods.
The unsupervised VOS algorithm typically relies on certain restrictive assumptions about theapplication scenario, so it does not have to be manually annotated in the �rst frame. According
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:4 R. Yao et al.
VOST methods
Unsupervised VOS methods
Semi-supervised VOS methods
Interactive VOSmethods
Weakly supervised VOS methods
Segmentation-based Tracking methods
Background subtraction
Point trajectory
Over-segmentation
CNN based
“Object-like”segments
Spatio-temporal graphs
CNN based
Graph partitioning
CNN based
Bottom-up based
Joint-based
Fig. 1. Taxonomy of video object segmentation and tracking.
to discover primary objects using appearance and motion cues, in Sec. 2.1, we categorize them asbackground subtraction, point trajectory, over-segmentation, “object-like” segments, and convolu-tional neural networks based methods. In Tab. 1, we also summarize some object representation,for example, pixel, superpixel, supervoxel, and patch, and image features. In Sec. 2.2, we describethe semi-supervised VOS methods for modeling the appearance representations and temporalconnections, and performing segmentation and tracking jointly. In Tab. 3, we discuss variousof per-process and post-process CNN-based VOS methods. In Sec. 2.3, interactive VOS methodsare summarized by the way of user interaction and motion cues. In Sec. 2.4, we discuss variousweakly supervised information for video object segmentation. In Sec. 2.5, we group and describethe segmentation-based tracking methods, and explain the advantages or disadvantages of di�erentbottom-up and joint-based frameworks, as shown in Tab. 5 and Tab. 6. In addition, we investigate anumber of video datasets for video object segmentation and tracking, and explain the metrics ofpixel-wise mask and bounding box based techniques. Finally, we present several interesting issuesfor the future research in Sec. 4, and help researchers in other related �elds to explore the possiblebene�ts of VOST techniques.
Although there are surveys on VOS [47, 126] and VOT [103, 188, 204], they are not directlyapplicable to joint video object segmentation and tracking, unlike our surveys. First, Perazzi etal. [126] present a dataset and evaluation metrics for VOS methods, Erdem et al. [47] measure toevaluate quantitatively the performance of VOST methods in 2004. In comparison, we focuses onthe summary of methods of video object segmentation, but also object tracking. Second, Yilmaz etal. [204] and Li et al. [103] discuss generic object tracking algorithms, and Wu et la. [188] evaluatethe performance of single object tracking, therefore, they are di�erent from our segmentation-basedtracking discussion.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:5
In this survey, we provide a comprehensive review of video object segmentation and tracking,and summarize our contributions as follows: (i) As shown in Fig. 1, a hierarchical categorizationexisting approaches is provided in video object segmentation and tracking. We roughly classifymethods into �ve categories. Then, for each category, di�erent methods are further categorized.(ii) We provide a detailed discussion and overview of the technical characteristics of the di�erentmethods in unsupervised VOS, semi-supervised VOS, interactive VOS, and segmentation-basedtracking. (iii) We summarize the characteristics of the related video dataset, and provide a varietyof evaluation metrics.
2 MAJOR METHODSIn the section, video object segmentation and tracking methods are grouped into �ve categories:unsupervised video object segmentation methods, semi-supervised video object segmentation meth-ods, interactive video object segmentation methods, weakly supervised video object segmentationmethods, and segmentation-based tracking methods.
2.1 Unsupervised video object segmentationThe unsupervised VOS algorithm does not require any user input, it can automatically �nd objects.In general, they assume that the objects to be segmented and tracked have di�erent motions orappear frequently in the sequence of images. Following we will review and discuss �ve groups ofthe unsupervised methods.
2.1.1 Background subtraction. Early video segmentation methods were primarily geometricbased and limited to speci�c motion backgrounds. The classic background subtraction methodsimulates the background appearance of each pixel and treats rapidly changing pixels as foreground.Any signi�cant change in the image and background model represents a moving object. The pixelsthat make up the changed region are marked for further processing. A connected componentalgorithm is used to estimate the connected region corresponding to the object. Therefore, the aboveprocess is called background subtraction. Video object segmentation is achieved by constructinga representation of the scene called the background model and then �nding deviations from themodel for each input frame.
According to the dimension of the used motion, background subtraction methods can be dividedinto stationary backgrounds [44, 61, 151], backgrounds undergoing 2D parametric motion [11, 38,76, 136], and backgrounding undergoing 3D motions [19, 75, 161].
2.1.1.1 Stationary backgrounds. Background subtraction became popular following the workof Wren et al. [185]. They use a multiclass statistical model of color pixel, I (x ,y), of a stationarybackground with a single 3D (Y ,U , and V color space) Gaussian, I (x ,y) ∼ N (µ(x ,y), Σ(x ,y)). Themodel parameters (the mean µ(x ,y) and the covariance Σ(x ,y)) are learned from the color observa-tions in several consecutive frames. For each pixel (x ,y) in the input video frame, after the model ofthe background is derived, they calculate the likelihood that their color is from N (µ(x ,y), Σ(x ,y)),and the deviation from the pixel. The foreground model is marked as a foreground pixel. However,Gao et al. [54] show that a single Gaussian would be insu�cient to model the pixel value whileaccounting for acquisition noise. Therefore, some work begin to improve the performance ofbackground modeling by using a multimodal statistical model to describe the background color perpixel. For example, Stau�er and Grimson [151] build models each pixel as a mixture of Gaussians(MoG) and uses an on-line approximation to update the model. Rather than explicitly modeling thevalues of all the pixels as one particular type of distribution, they model the values of a particularpixel as a mixture of Gaussians. In [44], Elgammal and Davis use nonparametric kernel density
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:6 R. Yao et al.
Fig. 2. Illustration of video object segmentation based on point trajectory [128]. From le� to right: frame 1and 4: a shot of video, image 2 and 5: clustering of point, image 3 and 6: the results of segmentation.
estimation (KDE) to model the per-pixel background. They construct a statistical representationof the scene background that supports sensitive detection of moving objects in the scene. In [61],the authors propose a pixelwise background modeling and subtraction technique using multiplefeatures, where generative (kernel density approximation (KDA)) and discriminative (support vectormachine (SVM)) techniques are combined for classi�cation.
2.1.1.2 Backgrounds undergoing 2D parametric motion. Instead of modeling stationary back-grounds, another methods use backgrounds undergoing 2D parametric motion. For instance, Irani etal. [76] detect and track occluding and transparent moving objects, and use temporal integrationwithout assuming motion constancy. The temporal integration maintains sharpness of the trackedobject, while blurring objects that have other motions. Ren et al. [136] propose a backgroundsubtraction method based spatial distribution of Gaussians model for the foreground detection froma non-stationary background. Criminisi et al. [38] present segmentation of videos by probabilisticfusion of motion, color and contrast cues together with spatial and temporal priors. They build theautomatic layer separation and background substitution method. Barnich and Droogenbroeck [11]introduce a universal sample-based background subtraction algorithm, which include pixel modeland classi�cation process, background model initialization, and updating the background modelover time.
2.1.1.3 Backgrounding undergoing 3D motions. Irani and Anandan [75] describe a uni�ed ap-proach to handling moving-object detection in both 2D and 3D scenes. A two-dimensional algorithmapplied when a scene can be approximated by a plane and when the camera is only rotated andscaled. 3D algorithm that works only when there is a signi�cant depth change in the scene andthe camera is translating. This method bridges the two extremes of the strategy of the gap. Torrand Zisserman [161] present a Bayesian methods of motion segmentation using the constraintsenforced by rigid motion. Each motion model build 3D relations and 2D relations. In [19], Brutzer etal. evaluate the background subtraction method. They identify the main challenges of backgroundsubtraction, and then compare the performance of several background subtraction methods withpost-processing.Discussion. Due to the use of stationary backgrounds and 3D motions, these methods have
di�erent properties. Overall, the aforementioned methods must rely on the restrictive assumptionthat the camera is stable and slowly moving. That is, it is sensitive to model selection (2D or 3D)and cannot handle special backgrounds such as non-rigid object.
2.1.2 Point trajectory. The problem of video object segmentation can be solved by analyzingmotion information over longer period. Motion is a strong perceptual cue for segmenting a videointo separate objects [145]. Works of [17, 28, 51, 60, 66, 97, 119] approaches use long term motioninformation with point trajectories to take advantage of motion information available in multipleframes in recent years. Typically, these methods �rst generate point trajectories and then clusterthe trajectories by using their a�nity matrix. Finally, the clustering trajectory is used as the priorinformation to obtain the video object segmentation result. We divide point trajectory based VOS
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:7
methods into two subcategories based on the motion estimation used, namely, optical �ow andfeature tracking methods. Optical �ow estimates a dense motion �eld from one frame to the next,while feature tracking follows a sparse set of salient image points over many frames.
2.1.2.1 Optical �ow based methods. Many video object segmentation methods heavily rely onthe dense optical �ow estimation and motion tracking. Optical �ow is a dense �eld displacementvector used to determine the pixels of each region. And it is usually used to capture spatio-temporalmotion information of the objects of a video [67]. There are two basic assumptions:
• The brightness is constant. That is, when the same object moves between di�erent frames,its brightness does not change. This is the assumption of the basic optical �ow method forobtaining the basic equations of the optical �ow method.• Small movement. That is, the change of time does not cause a drastic change in the object
position, and the displacement between adjacent frames is relatively small.Classic point tracking method use Kanade-Lucas-Tomasi (KLT) [111] to generate sparse pointtrajectories. Brox and Malik [17] �rst perform point tracking to build sparse long-term trajectoriesand divide them into multiple clusters. Compared to the two-frame motion �eld, they argue thatanalyzing long-term point trajectories can better obtain temporally consistent clustering on manyframes. In order to calculate such a point trajectory, this work runs a tracker developed in [153]based on the large displacement optical �ow [18]. As shown in Fig. 2, Ochs et al. [128] propose touse a semi-dense point tracker based on optical �ow [17], which can generate reliable trajectoriesof hundreds of frames with only a small drift and maintain a wide coverage of the video lens. Chenet al. [28] employ both global and local information of point trajectories to cluster trajectories intogroups.
2.1.2.2 Feature tracking based methods. The above-mentioned methods �rst estimated the optical�ow and then processed the discontinuities. In general, optical �ow measurement is di�cult inareas with very small textures or movements. In order to solve this problem, these methodspropose to implement smoothing constraints in the �ow �eld for interpolation. However, onemust �rst know the segmentation to avoid the requirement of smooth motion discontinuity. Shiand Malik [145] de�ne a motion feature vector at each pixel called motion pro�le, and adoptthe normalized cuts [146] to divide a frame into motion segments. In [97], spatio-temporal videosegmentation algorithm is proposed to incorporate long-range motion cues from the past and futureframes in the form of clusters of point tracks with coherent motion. Later, based on [17], Ochsand Brox [119] introduce a variational method to obtain dense segmentations from such sparsetrajectory clusters. Their method employs the spectral clustering to group trajectories based on ahigher-order motion model. Fragkiadaki et al. [51] propose to detect discontinuities of embeddingdensity between spatially neighboring trajectories. In order to segment the non-rigid object, theycombine motion grouping cues to produce context-aware saliency maps. Moreover, a probabilistic3D segmentation method [66] is proposed to combine spatial, temporal, and semantic informationto make better-informed decisions.Discussion. For background subtraction based methods, they explore motion information in
short term and do not perform well when objects keep static in some frames. In contrast, pointtrajectories usually use long range trajectory motion similarity for video object segmentation.Objects captured by trajectory clusters have proven to have a long time frame. However, non-rigidobject or large motion lead to frequent pixel occlusions or dis-occlusions. Thus, in this case, pointtrajectories may be too short to be used. Additionally, these methods lack the appearance of theobject appearance, i.e. with only low-level bottom-up information.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:8 R. Yao et al.
Fig. 3. Illustration of hierarchy of over-segmentations [26]. From over-segmentation of a human contour(le�) to superpixel (right).
2.1.3 Over-segmentation. Several over-segmentation approaches group pixels based on color,brightness, optical �ow, or texture similarity and produce spatio-temporal segmentation maps [152,198]. These methods generate an over-segmentation of the video into space-time regions. Fig. 3shows the valid over-segmentations for a given human image. This example illustrates the di�erencebetween oversegmentations and superpixels. Although the terms “over-segmentation” and “super-pixel segmentation” are often used interchangeably, there are some di�erences between them. Asuperpixel segmentation is an over-segmentation that preserves most of the structure necessaryfor segmentation.
However, the number of over-segmentation makes optimization over sophisticated modelsintractable. Most current methods for unsupervised video object segmentation are graph-based [58,80, 96]. Graph-based approaches to pixel, superpixel, or supervoxel generation treat each pixel asa node in a graph, where the vertices D = {p,q, ...} of a graph G are partitioned into N disjointsubgraphs, Ai ,D = ∪Ni=1Ai ,Ai ∩ Aj = ∅, i , j, by pruning the weighted edges of the graph. Thetask is to assign a label l ∈ L to each p ∈ D, the vertices are created by minimizing a cost functionde�ned over the graph. Given a set of vertices D and a �nite set of labels L, an energy function is:
E(f ) =∑p∈D
Up (fp ) + λ∑
{p,q }∈Nwpд ·Vpд(fp , fq), (1)
where the unary termUp (fp ) express how likely is a label l for pixel p, the pairwise termVpд(fp , fq)represent how likely labels l1 and l2 are for neighboring pixels p and q, and N is a collection ofneighboring pixel pairs. The coe�cients wpд are the weights, and λ is the parameter.
2.1.3.1 Superpixel representation. Shi and Malik [146] propose the graph-based normalized cut toovercome the oversegmentation problem. The term superpixel is coined by Ren and Malik [134] intheir work on learning a binary classi�er that can segment natural images. They use the normalizedcut algorithm [146] for extracting the superpixels, with contour and texture cues incorporated.Levinshtein et al. [96] introduce the concept of spatio-temporal closure, and automatically recoverscoherent components in images and videos, corresponding to objects and object parts. Chang etal. [26] develop a graphical model for temporally consistent superpixels in video sequences, andpropose a set of novel metrics to quantify performance of a temporal superpixel representation:object segmentation consistency, 2D boundary accuracy, intra-frame spatial locality, inter-frametemporal extent, and inter-frame label consistency. Giordano et al. [55] generate a coarse fore-ground segmentation to provide predictions about motion regions by analyzing the superpixelsegmentation changes in consecutive frames, and re�ne the initial segmentation by optimizing anenergy function. In [196], appearance modeling technique with superpixel for automatic primaryvideo object segmentation in the Markov random �eld (MRF) framework is proposed. Jang et al. [80]introduce three foreground and background probability distributions: Markov, spatio-temporal,and antagonistic to minimize a hybrid of these energies to separate a primary object from its
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:9
Table 1. Summary of some major unsupervised VOS methods. #: number of objects, S: single, M: multiple.
References # Features Optical �ow MethodsBackground subtraction methods
Han [61] M RGB color, gra-dient, Haar-like
× Stationary backgrounds: generative (KDA) anddiscriminative(SVM) techniques
Stau�er [151] M RGB color × Stationary backgrounds: model each pixel as MoGand use on-line approximation to update
Criminisi [38] M YUV color × 2D motion: probabilistic fusion of motion, colorand contrast cues using CRF
Ren [136] M RGB color × 2D motion: estimate motion compensation usingGaussians model
Torr [161] M Corner features × 3D motion: a maximum likelihood and EM ap-proach to clustering
Irani [75] M RGB color × 3D motion: uni�ed approach to handling moving-object detection in both 2D and 3D scenes
Point trajectory methodsOchs [128] M RGB color
√Optical �ow: build spare long-term trajectoriesusing optical �ow
Fragkiadaki [51] M RGB color√
Optical �ow: combine motion grouping cues withcontext-aware saliency maps
Held [66] M Centroid, shape × Feature tracking: probabilistic framework to com-bine spatial, temporal, and semantic information
Lezama [97] M RGB color × Feature tracking: spatio-temporal graph-basedvideo segmentation with long-rang motion cues
Over-segmentation methodsGiordano [55] M RGB color × Superpixel: generate coarse segmentation with
superpixel and re�ne mask with energy functionsChang [26] M LAB color, im-
age axes
√Supervoxel: object parts in di�erent frames, model�ow between frames with a bilateral Gaussianprocess
Grundmann [58] M χ2 distance of thenormalized colorhistograms
× Supervoxel: graph-based method, iteratively pro-cess over multiple levels
Stein [152] M Brightness andcolor gradient
× Boundaries: graphical model, learn local classi�erand global inference
Convolutional neural network methodsTokmakov [159] S Deep features
√Build instance embedding network and link ob-jects in video
Jain [43] S Deep features√
Design a two-stream fully CNN to combine ap-pearance and motion information
Tokmakov [160] S Deep features√
Trains a two-stream network RGB and optical �ow,then feed into ConvGRU
Vijayanarasimha[166]
M Deep features√
Geometry-aware CNN to predict depth, segmen-tation, camera and rigid object motions
Tokmakov [159] S Deep features√
Encoder-decoder architecture, coarse representa-tion of the optical �ow, then re�nes it iterativelyto produce motion labels
Song [149] S Deep features × Pyramid dilated bidirectional ConvLSTM architec-ture, and CRF-based post-process
Continued on next page
, Vol. 1, No. 1, Article 1. Publication date: January 2019.
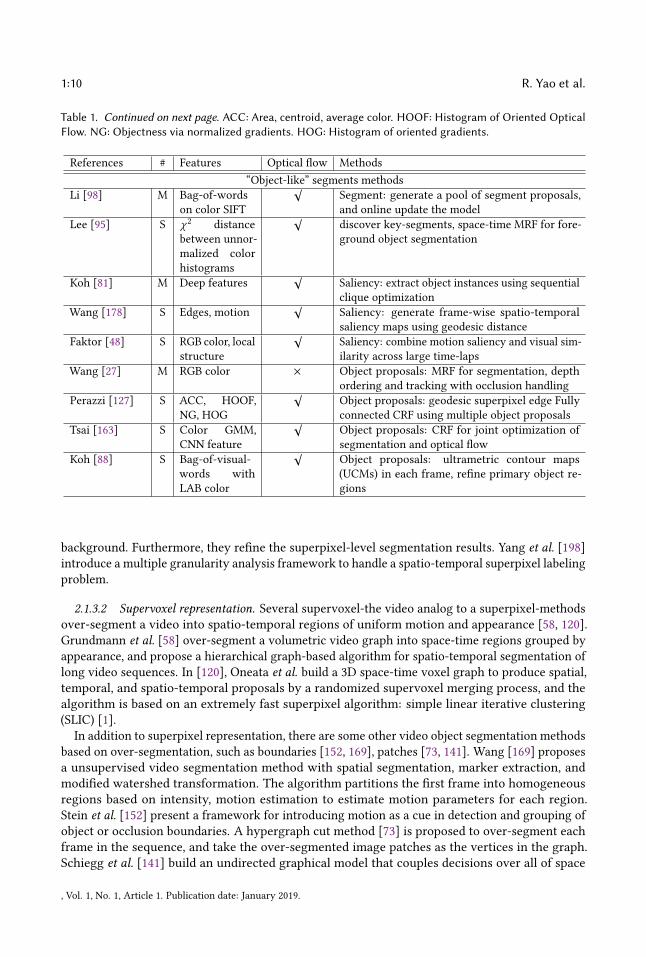
1:10 R. Yao et al.
Table 1. Continued on next page. ACC: Area, centroid, average color. HOOF: Histogram of Oriented OpticalFlow. NG: Objectness via normalized gradients. HOG: Histogram of oriented gradients.
References # Features Optical �ow Methods“Object-like” segments methods
Li [98] M Bag-of-wordson color SIFT
√Segment: generate a pool of segment proposals,and online update the model
Lee [95] S χ 2 distancebetween unnor-malized colorhistograms
√discover key-segments, space-time MRF for fore-ground object segmentation
Koh [81] M Deep features√
Saliency: extract object instances using sequentialclique optimization
Wang [178] S Edges, motion√
Saliency: generate frame-wise spatio-temporalsaliency maps using geodesic distance
Faktor [48] S RGB color, localstructure
√Saliency: combine motion saliency and visual sim-ilarity across large time-laps
Wang [27] M RGB color × Object proposals: MRF for segmentation, depthordering and tracking with occlusion handling
Perazzi [127] S ACC, HOOF,NG, HOG
√Object proposals: geodesic superpixel edge Fullyconnected CRF using multiple object proposals
Tsai [163] S Color GMM,CNN feature
√Object proposals: CRF for joint optimization ofsegmentation and optical �ow
Koh [88] S Bag-of-visual-words withLAB color
√Object proposals: ultrametric contour maps(UCMs) in each frame, re�ne primary object re-gions
background. Furthermore, they re�ne the superpixel-level segmentation results. Yang et al. [198]introduce a multiple granularity analysis framework to handle a spatio-temporal superpixel labelingproblem.
2.1.3.2 Supervoxel representation. Several supervoxel-the video analog to a superpixel-methodsover-segment a video into spatio-temporal regions of uniform motion and appearance [58, 120].Grundmann et al. [58] over-segment a volumetric video graph into space-time regions grouped byappearance, and propose a hierarchical graph-based algorithm for spatio-temporal segmentation oflong video sequences. In [120], Oneata et al. build a 3D space-time voxel graph to produce spatial,temporal, and spatio-temporal proposals by a randomized supervoxel merging process, and thealgorithm is based on an extremely fast superpixel algorithm: simple linear iterative clustering(SLIC) [1].
In addition to superpixel representation, there are some other video object segmentation methodsbased on over-segmentation, such as boundaries [152, 169], patches [73, 141]. Wang [169] proposesa unsupervised video segmentation method with spatial segmentation, marker extraction, andmodi�ed watershed transformation. The algorithm partitions the �rst frame into homogeneousregions based on intensity, motion estimation to estimate motion parameters for each region.Stein et al. [152] present a framework for introducing motion as a cue in detection and grouping ofobject or occlusion boundaries. A hypergraph cut method [73] is proposed to over-segment eachframe in the sequence, and take the over-segmented image patches as the vertices in the graph.Schiegg et al. [141] build an undirected graphical model that couples decisions over all of space
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:11
......
Fig. 4. Illustration of a set of key-segments to generate a foreground object segmentation of the video [95].Le�: video frames. Right: Foreground object segments.
and all of time, and joint segment and track a time-series of oversegmented images/volumes formultiple dividing cells.Discussion. In general, the over-segmentation approaches occupy the space between single
pixel matching and standard segmentation approaches. The algorithm reduce the computationalcomplexity, since disparities only need to be estimated per-segment rather than per-pixel. However,in more complex videos, the over-segmentation requires additional knowledge, and are sensitive toboundary strength �uctuations from frame to frame.
2.1.4 “Object-like” segments. Several recent approaches aim to upgrade the low-level groupingof pixels (such as pixel, superpixel, and supervoxel) to object-like segments [52, 121, 154]. Althoughthe details are di�erent, the main idea is to generate a foreground object hypothesis for each frameof the image using the learning model of the "object-like" regions (such as salient objects, and objectproposals from background).
2.1.4.1 Salient objects. In [71, 133, 178], these works introduce saliency information as priorknowledge to discover visually important objects in a video. A spatio-temporal video modeling andsegmentation method is proposed to partition the video sequence into homogeneous segments withselecting salient frames [150]. Fukuchi et al. [73] propose a automatic video object segmentationmethod based on visual saliency with the maximum a posteriori (MAP) estimation of the MRF withgraph cuts. Rahtu et al. [133] present a salient object segmentation method based on combininga saliency measure with a Conditional Random Field (CRF) model using local feature contrastin illumination, color, and motion information. Papazoglou and Ferrari [121] compute a motionsaliency map using optical �ow boundaries, and handle fast moving backgrounds and objectsexhibiting a wide range of appearance, motions and deformations. Faktor and Irani [48] performsaliency votes at each pixel, and iteratively correct those votes by consensus voting of re-occurringregions across the video sequence to separate a segment track from the background. In [178],Wang et al. produce saliency results via the geodesic distances to background regions in thesubsequent frames, and build global appearance models for foreground and background based thesaliency maps. Hu [71] propose a saliency estimation method and a neighborhood graph based onoptical �ow and edge cues for unsupervised video object segmentation. Koh et al. [81] generateobject instances in each frame and develop the sequential clique optimization algorithm to considerboth the saliency and similarity energies, then convert the tracks into video object segmentationresults.
2.1.4.2 Object proposals. Recently, video object segmentation methods generate object proposalsin each frame, and then rank several object candidates to build object and background models [87,95, 98, 163, 191]. Typically, it contains three main categories: (i) �gure-ground segmentations basedobject regions; (ii) optical �ow based object proposals; (iii) bounding box based object proposals.
For (i), the proposals are obtained by multiple static �gure-ground segmentations similar to[25, 46]. Their works generate the generic foreground object using several image cues such ascolor, texture, and boundary. Brendel and Todorovic et al. [16] segment a set of regions by using
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:12 R. Yao et al.
any available low-level segmenter in each frame, and cluster the similar regions across the video.In [95], Lee et al. discover key-segments and group them to predict the foreground objects in avideo. As shown in Fig. 4, their works generate a diverse set of object proposals or key-segments ineach frame using the static region-ranking method of [46]. Later, Ma and Latercki produce a bag ofobject proposals in each frame using [46], and build a video object segmentation algorithm usingmaximum weight cliques with mutex constraints. Banica et al. [9] generate multiple �gure-groundsegmentations based on boundary and optical �ow cues, and construct multiple plausible partitionscorresponding to the static and the moving objects. Moreover, Li et al. [98] produce a pool ofsegment proposals using the �gure-ground segmentation algorithm, and present a new compositestatistical inference approach for re�ning the obtained segment tracks. To handle occlusion of themethod [98], Wu et al. [189] propose a video segment proposal approach start segments from anyframe and track them through complete occlusions. Koh and Kim [88] generate candidate regionsusing both color and motion edges, estimate initial primary object regions, and augment the initialregions with missing parts or reducing them. In addition, visual semantics [164], or context [171]cues are used to generate object proposals and infer the candidates for subsequent frames.
For (ii), instead of modeling the foreground regions of statics object proposals, video objectsegmentation methods were presented by optical �ow based object proposals [50, 205]. Lalos etal. [93] propose the object �ow to estimate both the displacement and the direction of an object-of-interest. However, their work does not solve the problem of �ow estimation and segmentation.Therefore, Fragkiadaki et al. [50] present a method to generate moving object proposals frommultiple segmentations on optical �ow boundaries, and extend the top ranked segments intospatio-temporal tubes using random walkers. Zhang et al. [205] present a optical �ow gradientmotion scoring function for selection of object proposals to discriminate between moving objectsand the background.
For (iii), several methods [87, 191] employ bounding box based spatio-temporal object proposalsto segment video object recently. Xiao and Lee [191] present a unsupervised algorithm to generate aset of spatio-temporal video object proposals boxes and pixel-wise segmentation. Koh and Kim [87]use object detector and tracker to generate multiple bounding box tracks for objects, transformeach bounding box into a pixel-wise segment, and re�ne the segment tracks.
In addition, many researchers have exploited the Gestalt principle of “common fate” [86] wheresimilarly moving points are perceived as coherent entities, and grouping based on motion pointedout occlusion/disocclusion phenomena. In [154], Sundberg et al. exploit motion cues and distin-guishes occlusion boundaries from internal boundaries based on optical �ow to detect and segmentforeground object. Taylor et al. [157] infer the long-term occlusion relations in video, and usedwithin a convex optimization framework to segment the image domain into regions. Furthermore,a video object segmentation method detect disocclusion in video of 3D scenes and to partition thedisoccluded regions in objects.Discussion. Object-like regions (such as salient objects and object proposals) have been very
popular as a preprocessing step for video object segmentation problems. Holistic object proposalscan often extract over entire objects with optical �ow, boundary, semantics, shape and other globalappearance features, lead to better video object segmentation accuracy. However, these methodsoften generate many false positives, such as background proposals, which reduces segmentationperformance. Moreover, these methods usually require heavy computational loads to generateobject proposals and associate thousands of segments.
2.1.5 Convolutional neural networks (CNN). Prior to the impressive of deep CNNs, some meth-ods segment video object to rely on hand-crafted feature and do not leverage a learned videorepresentation to build the appearance model and motion model.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:13
Recently, there have been attempts to build CNNs for video object segmentation. The earlyprimary video object segmentation method �rst generate salient objects using complementaryconvolutional neural network [100], then propagate the video objects and superpixel-based neigh-borhood reversible �ow in the video. Later, several video object segmentation methods employdeep convolutional neural networks in an end-to-end manner. In [43, 159, 160, 166], these methodsbuild a dual branch CNN to segment video object. MP-Net [159] takes the optical �ow �eld oftwo consecutive frames of a video sequence as input and produces per-pixel motion labels. Inorder to solve the limitations of appearance features of object of MP-Net framework, Tokmakov etal. [160] integrate one stream with appearance information and a visual memory module based onconvolutional Gated Recurrent Units (GRU) [193]. FSEG [43] also proposes a two-stream networkwith appearance and optical �ow motion to train with mined supplemental data. SfM-Net [166]combines two streams motion and structure to learn object masks and motion models withoutmask annotations by di�erentiable rending. Li et al. [101] transfer transferring the knowledgeencapsulated in image-based instance embedding networks, and adapt the instance networks tovideo object segmentation. In addition, they propose a motion-based bilateral network, then agraph cut model is build to propagate the pixel-wise labels. In [57], a deep reinforcement learningmethods is proposed to automatically detect moving objects with the relevant information foraction selection. Recently, Song et al. [149] present a video salient object detection method usingpyramid dilated bidirectional ConvLSTM architecture, and apply it to the unsupervised VOS. Then,based on the CNN-convLSTM architecture, Wang et al. [181] propose a visual attention-drivenunsupervised VOS model. Additional, they collect unsupervised VOS human attention data fromDAVIS [126], Youtube-Objects [131], and SegTrack v2 [98] dataset.
2.1.6 Discussion. Without any human annotation, unsupervised methods take the foregroundobject segmentation on an initial frame automatically. They do not require user interaction to specifyan object to segment. In other words, these methods exploit information of saliency, semantics,optical �ow, or motion to generate primary objects, and then propagate it to the remainder ofthe frames. However, these unsupervised methods are not able to segment a speci�c object dueto motion confusions between di�erent instances and dynamic background. Furthermore, theproblem with these unsupervised methods is that they are computationally expensive due to manyunrelated interference object-like proposals. A qualitative comparison of some major unsupervisedVOS methods are listed in Tab. 1.2.2 Semi-supervised video object segmentationSemi-supervised video object segmentation methods are given with an initial object mask in the �rstframe or key frames. Then, these methods segment the object in the remaining frames. Typically,it can be investigated in the following main two categories: spatio-temporal graph and CNN basedsemi-supervised VOS.
2.2.1 Spatio-temporal graphs. In recent years, early methods often solve some spatio-temporalgraph with hand-crafted feature representation including appearance, boundary, and optical �ows,and propagate the foreground region in the entire video. These methods typically rely on twoimportant cues: object representation of graph structure and spatio-temporal connections.
2.2.1.1 Object representation of graph structure. Typically, the task is formulated as a spatio-temporal label propagation problem, these methods tackle the problem by building up graphstructures over the object representation of (i) pixels, (ii) superpixels, or (iii) object patches to inferthe labels for subsequent frames.
For (i), the pixels can maintain very �ne boundaries, and are incorporated into the graph structurefor video object segmentation. Tsai et al. [162] perform MRF optimization using pixel appearance
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:14 R. Yao et al.
Table 2. Summary of spatio-temporal graphs of semi-supervised VOS methods. Object rep. denotes objectrepresentation.
References Object rep. Connections Appearance features Optical �owWang [180] Pixel Dense point clustering Spatial location, color, velocity
√
Märki [115] Pixel Spatio-temporal lattices Image axes, YUV color ×Tsai [163] Superpixel CRF RGB color, CNN
√
Jiang [79] Superpixel MRF LAB color ×Perazzi [127] Patch CRF HOG
√
Fan [49] Patch Nearest neighbor �elds SURF, RGB color√
Jain [77] Superpixel MRF Color histogram ×Ramakanth [4] Patch Nearest neighbor �elds Color histogram ×Ellis [45] Pixel Sparse point tracking RGB color ×Badrinarayanan[5]
Patch Mixture of tree Semantic texton forests feature ×
Budvytis [20] Superpixel Mixture of tree Semantic texton forests feature ×Tsai [162] Pixel MRF RGB color ×Ren [135] Superpixel CRF Local brightness, color and tex-
ture×
Wang [173] Superpixel Mean-shift Image axes, RGB color ×Patras [124] Patch Maximization of joint
probabilityImage axes, RGB color ×
similarity and motion coherence to separate a foreground object from the background. In [115],given some user input as a set of known foreground and background pixels, Märki et al. design aregularly sampled spatio-temporal bilateral grid, and minimize implicitly approximates long-range,spatio-temporal connections between pixels. Several methods build the dense [180] and sparsetrajectories [45] to segment the moving objects in video by using a probabilistic model.
For (ii), in order to su�er from high computational cost and noisy temporal links of pixel-basedgraphs, many methods extract superpixels at from the input frames, and construct the superpixelgraph. Each node in the graph represents a label. An edge is added between any two adjacentneighbors. Graph structures such as CRF [135, 163, 182], MRF [77], or mixture of trees [20] can beintegrated into the framework to further improve the accuracy. For instance, Ren and Malik [135]generate a sets of superpixels in the images, and build a CRF to segment �gure from backgroundin each frame. Then �gure/ground segmentation operates sequentially in each frame by utilizingboth static image cues and temporal coherence cues. Unlike using probabilistic graphical model tosegment images independently, other graphical models decompose each into spatial nodes, andseek the foreground-background label assignment that maximizes both appearance consistency andlabel smoothness in space and time. Jain and Grauman [77] present a higher order spatio-temporalsuperpixel label consistency potential for video object segmentation. In [20], a mixture of treesmodel is presented to link superpixels from the �rst to the last frame, and obtain super-pixel labelsand their con�dence. In addition, some methods use mean shift [173] and random walker [79]algorithm to separate the foreground from the background.
For (iii), to make video object segmentation more e�cient, researchers embed per-frame objectpatches and employ di�erent techniques to select to a set of temporally coherent segments byminimizing and energy function of spatio-temporal graph. For example, Ramakanth et al. [4] andFan et al. [49] employ approximate nearest neighbor algorithm to compute a mapping betweentwo framers or �elds, then predict the labels. Tasi et al. [163] utilize the CRF model to assign each
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:15
pixel with a foreground or background label. Perazzi et al. [127] formulate as a minimization of anovel energy function de�ned over a fully connected CRF of object proposals, and use maximum aposteriori to inference the foreground-background segmentation. Following in the work in [20],Badrinarayanan et al. [5] propose a patch-based temporal tree model to link patches betweenframes. Patras et al. [124] use watershed algorithm obtain the color-based segmentation in eachframe, and employ an iterative local joint probability search algorithm to generates a sequence oflabel.
2.2.1.2 Spatio-temporal connections. Another important cue is how to estimate temporal connec-tions between nodes by using spatio-temporal lattices [115], nearest neighbor �elds [4, 49], mixtureof trees [5, 20]. Some methods even build up long-range connections using appearance-based meth-ods [124, 127]. Besides the cue of the temporal connections, another important issue is selecting thesolution of optimization algorithm. Some algorithms use the local greedy strategy to infer labels byconsidering only two or more adjacent frames at a time [4, 45, 49, 115], while other algorithms try to�nd global optimal solutions considering all frames [127, 162]. The locally optimization strategiesperform segmentation on-the-�y allowing for applications where data arrives sequentially, whileglobally optimal solutions solve the limitation of short range interactions. A brief summary ofspatio-temporal graphs methods is shown in Tab. 2.
2.2.2 Convolutional neural networks. With the success of convolutional neural networks on staticimage segmentation [107, 110], CNN based methods show overwhelming power when introducedto video object segmentation. According to the used techniques for temporal motion information,they can be grouped into two types: motion-based and detection-based.
2.2.2.1 Motion-based methods. In general, the motion-based methods utilize the temporal coher-ence of the object motion, and formulate the problem of mask propagation starting from the �rstframe or a given annotated frame to the subsequent frames.
For (i), one class of methods are developed to train network to incorporate optical �ow [32, 69, 78,102]. Optical �ow is important in early stages of the video description. It is common to apply optical�ow to VOS to maintain motion consistency. And optical �ow represents how and where eachand every pixel in the image is going to move in the future pipeline. These VOS methods typicallyuse optical �ow as a cue to track pixels over time to establish temporal coherence. For instance,SegFlow [32], MoNet [192], PReMVOS [112], LucidTrack [83], and VS-ReID [102] methods consistof two branches: the color segmentation and the optical �ow branch using the FlowNet [41, 74]. Tolearn to exploit motion cues, these methods receive twice or triple inputs, including the target frameand two adjacent frames. Jampani et al. [78] present a temporal bilateral network to propagatevideo frames in an adaptive manner by using optical �ow as additional feature. With temporaldependencies established by optical �ow, Bao et al. [10] propose a VOS method via inference inCNN-based spatio-temporal MRF. Hu et al. [69] employ active contour on optical �ow to segmentmoving object.
To capture the temporal coherence, some methods employ a Recurrent Neural Network (RNN)for modeling mask propagation with optical �ow [70, 102]. RNN has been adopted by manysequence-to-sequence learning problems because it is capable to learn long-term dependency fromsequential data. MaskRNN [70] build a RNN approach which fuses in each frame the output of abinary segmentation net and a localization net with optical �ow. Li and Loy [102] combine temporalpropagation and re-identi�cation functionalities into a single framework.
For (ii), another direction is to use CNNs to learn mask re�nement of an object from currentframe to the next one. For instance, as shown in Fig. 5, MaskTrack [125] method trains a re�ne theprevious frame mask to create the current frame mask, and directly infer the results from optical
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:16 R. Yao et al.
Fig. 5. Illustration of mask prorogation to estimate the segmentation mask of the current frame from theprevious frame as a guidance [125].
�ow. Compared to their approach [125] that uses the exact foreground mask of the previous frame,Yang et al. [197] use a very coarse location prior with visual and spatial modulation. Oh et al. [190]use both the reference frame with annotation and the current frame with previous mask estimationto a deep network. A reinforcement cutting-agent learning framework is to obtain the object boxfrom the segmentation mask and propagates it to the next frame [62]. Some methods leveragetemporal information on the bounding boxes by tracking objects across frames [31, 94, 118, 144].Sharir et al. [144] present a temporal tracking method to enforce coherent segmentation throughoutthe video. Cheng et al. [31] utilize a part-based tracking method on the bounding boxes, andconstruct a region-of-interest segmentation network to generate part masks. Recently, somemethods [165, 195] introduce a combination of CNN and RNN for video object segmentation. Xu etal. [195] generate the initial states for our convolutional Long Short-Term Memory (LSTM), and usea feed-forward neural network to encode both the �rst image frame and the segmentation mask.
2.2.2.2 Detection-based methods. Without using temporal information, some methods learna appearance model to perform a pixel-level detection and segmentation of the object at eachframe. They rely on �ne-tuning a deep network using the �rst frame annotation of a giventest sequence [22, 167]. Caelles et al. [22] introduce an o�ine and online training process by afully convolutional neural network (FCN) on static image for one-shot video object segmentation(OSVOS), which �ne-tunes a pretrained convolutional neural network on the �rst frame of thetarget video. Furthermore, they extend the model of the object with explicit semantic information,and dramatically improve the results [113]. Later, an online adaptive video object segmentation isproposed [167], the network is �ne-turned online to adapt to the changes in appearance. Cheng etal. [30] propose a method to propagate a coarse segmentation mask spatially based on the pairwisesimilarities in each frame.
Other approaches formulate video object segmentation as a pixel-wise matching problem toestimate an object of interest with subsequence images until the end of a sequence. Yoon et al. [147]propose a pixel-level matching network to distinguish the object area from the background on thebasis of the pixel-level similarity between two object units. To solve computationally expensiveproblems, Chen et al. [29] formulate a pixel-wise retrieval problem in an embedding space forvideo object segmentation, and VideoMatch approach [72] learns to match extracted features to aprovided template without memorizing the appearance of the objects.
2.2.2.3 Discussion. As indicated, CNN-based semi-supervised VOS methods can be roughlyclassi�ed into: motion-based and detection-based ones. The classi�cation of these two methods isbased on temporal motion or non-motion. Temporal motion is an important feature cue in videoobject segmentation. As long as the appearance and position changes are smooth, the complex
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:17
Base Network
(pretrained on ImageNet)
Parent Network
(trained on DAVIS)
Test Network
(fine-tuned on the first frame)
Fig. 6. Illustration of the pipeline of one-shot video object segmentation [22]. The first step is to pertrain onlarge datasets (e.g. ImageNet [39] for image classification). The second step is to train parent network on thetraining set of DAVIS [126]. Then, during test time, it fine-tunes on the first frame.
deformation and movement of the target can be handled. However, these methods are susceptibleto temporal discontinuities such as occlusion and fast motion, and can su�er from drift once thepropagation becomes unreliable. On the other hand, since such methods rarely rely on temporalconsistency, they are robust to changes such as occlusion and rapid motion. However, since theyneed to estimate the appearance of the target, it is generally not possible to adapt to changes inappearance. It is di�cult to separate the appearance of similar object instances.
A qualitative comparison of CNN-based semi-supervised VOS methods can be obtained based onmotion-based or detection-based methods, requirement of optical �ow, requirement of �ne-tuningand computational speed, ability to handle post-processing, and requirement of data augmentation.In Tab. 3, we provide the qualitative comparison of the methods discussed in this section.
• Fine-tuning. Most of CNN-based semi-supervised VOS methods share a similar two-stageparadigm (as shown in Fig. 6): �rst, train a general-purpose CNN to segment the foregroundobject; second, this network use online �ne-tuning using the �rst frame of the test video tomemorize target object appearance, leading to a boost in the performance [22, 125, 167].It has been shown that �ne-tuning on the �rst frame signi�cantly improves accuracy.However, since at test time some methods only use the �ne-tuned network, it is not ableto adapt to large changes in appearance, which might for example be caused by drasticchanges in viewpoint [10, 22, 69, 83, 113, 192]. And it becomes harder for the �ne-tunedmodel to generalize to new object appearances. To overcome this limitation, some methodsupdate the network online to changes in appearance using training examples [118, 167].• Computational speed. Despite the high accuracies achieved by these approaches, the
�ne-tuning process requires many iterations of optimization, the step on the video iscomputationally expensive, where it usually takes more than ten minutes to update a modeland is not suitable for online vision applications. Recently, several methods [29, 31, 72, 197]work without the need of the computationally expensive �ne-tuning in test time, andmake them much faster than comparable methods. For instance, Chen et al. [29] onlyperform a single forward through the embedding network and a nearest-neighbor searchto process each frame in test time. Yang et al. [197] use a single forward pass to adapt thesegmentation model to the appearance of a speci�c object. VideoMatch approach [72] builda soft matching layer, and does not require online �ne-tuning.• Post-processing. Besides the training of CNN-based segmentation, several methods lever-
age post-processing steps to achieve additional gains. Post-processing is often employed toimprove the contours, such as boundary snapping [22, 113], re�ne-aware �lter [30, 147], anddense MRF or CRF [91] in [10, 125]. For instance, OSVOS [22] perform boundary snappingto capture foreground masks to accurate contours. Yoon et al. [147] perform a weightedmedian �lter on the resulting segmentation mask. Li et al. [102] additionally considerpost-processing steps to link the tracklets. In addition, some VOS frameworks [10, 83, 192]
, Vol. 1, No. 1, Article 1. Publication date: January 2019.
1:18 R. Yao et al.
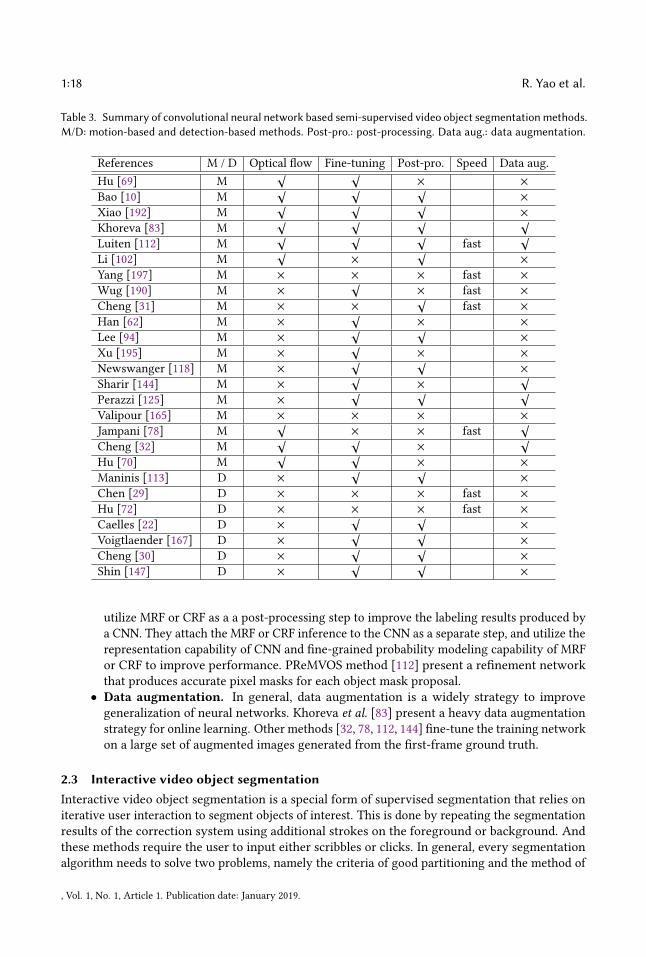
Table 3. Summary of convolutional neural network based semi-supervised video object segmentation methods.M/D: motion-based and detection-based methods. Post-pro.: post-processing. Data aug.: data augmentation.
References M / D Optical �ow Fine-tuning Post-pro. Speed Data aug.Hu [69] M
√ √ × ×Bao [10] M
√ √ √ ×Xiao [192] M
√ √ √ ×Khoreva [83] M
√ √ √ √
Luiten [112] M√ √ √
fast√
Li [102] M√ × √ ×
Yang [197] M × × × fast ×Wug [190] M × √ × fast ×Cheng [31] M × × √
fast ×Han [62] M × √ × ×Lee [94] M × √ √ ×Xu [195] M × √ × ×Newswanger [118] M × √ √ ×Sharir [144] M × √ × √
Perazzi [125] M × √ √ √
Valipour [165] M × × × ×Jampani [78] M
√ × × fast√
Cheng [32] M√ √ × √
Hu [70] M√ √ × ×
Maninis [113] D × √ √ ×Chen [29] D × × × fast ×Hu [72] D × × × fast ×Caelles [22] D × √ √ ×Voigtlaender [167] D × √ √ ×Cheng [30] D × √ √ ×Shin [147] D × √ √ ×
utilize MRF or CRF as a a post-processing step to improve the labeling results produced bya CNN. They attach the MRF or CRF inference to the CNN as a separate step, and utilize therepresentation capability of CNN and �ne-grained probability modeling capability of MRFor CRF to improve performance. PReMVOS method [112] present a re�nement networkthat produces accurate pixel masks for each object mask proposal.• Data augmentation. In general, data augmentation is a widely strategy to improve
generalization of neural networks. Khoreva et al. [83] present a heavy data augmentationstrategy for online learning. Other methods [32, 78, 112, 144] �ne-tune the training networkon a large set of augmented images generated from the �rst-frame ground truth.
2.3 Interactive video object segmentationInteractive video object segmentation is a special form of supervised segmentation that relies oniterative user interaction to segment objects of interest. This is done by repeating the segmentationresults of the correction system using additional strokes on the foreground or background. Andthese methods require the user to input either scribbles or clicks. In general, every segmentationalgorithm needs to solve two problems, namely the criteria of good partitioning and the method of
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:19
achieving e�ective partitioning [146]. Typically, interactive video object segmentation techniquescan be divided into one of the following three main branches: graph partitioning models, activecontours models, and convolutional neural network models.
2.3.1 Graph partitioning models. Most of image segmentation techniques of interactive videoobject segmentation methods are formulated as a graph partitioning problems, where the ver-tices D of a graph G are partitioned into disjoint N subgraphs. Examples of existing interactivesegmentation methods are graph-cuts, random walker, and geodesic based.
2.3.1.1 Graph-cuts based. Several works are based on the GrabCut algorithm [140], whichiteratively alternates between estimating appearance models (typically Gaussian Mixture Models)and re�ning the segmentation using graph cuts [15]. Wang et al.[172] were among the �rst authorsto address interactive video segmentation tasks. To improve the performance, they used two-stagehierarchical mean-shift clustering as a preprocessing step to reduce the computation of the min-cutproblem. In [104], Li et al. segment every tenth frame, and graph cut uses the global color modelfrom keyframes, gradients and coherence as its primary clue to calculate the choice between frames.The user can also manually indicate the area in which the local color model is applied. Price etal. [132] propose additional types of local classi�ers, namely LIVEcut. The user iteratively correctsthe propagated mask frame to frame and the algorithm learns from it. In [8], Bai et al. build aset of local classi�ers that each adaptively integrates multiple local image features. This methodre-trains the classi�er from the new mask by transforming the neighborhood regions accordingto the optical �ow, and then retrains the user correction through the classi�er. Later, the authorconstruct the foreground and background appearance models adaptively in the same group [7],and use the probability optical �ow to update the color space Gaussian of the individual pixel. Incontrast to pixel, Reso et al. [137] and Dondera et al. [40] adopt the graph-cut framework by usingsuperpixels on every video frame. In addition, Chien et al. [33] and Pont-Tuset et al. [129] usenormalized cut [146] based multiscale combinatorial grouping (MCG) algorithm to segment andgenerate accurate region proposals, and use point clicks on the boundary of the objects to �t objectproposals to them.
2.3.1.2 Random walker based. In [143], Nagaraja et al. use a few strokes to segment videos byusing optical �ow and point trajectories. Their method integrate into a user interface where theuser can draw scribbles in the �rst frame. When satis�ed, the user presses a button to run therandom walker.
2.3.1.3 Geodesic based. Bai and Sapiro [6] present a geodesics-based algorithm for interactivenatural image and video by using region color to compute a geodesic distance to each pixel toform a selection. This method exploits weights in the geodesic computation that depend on thepixel value distributions. In [179], Wang et al. combine geodesic distance-based dynamic modelswith pyramid histogram-based con�dence map to segment the image regions. Additionally, theirmethod determines the frame of the operator’s mark to improve segmentation performance.
2.3.2 Active contours models. In the active contour framework, object segmentation use an edgedetector to halt the evolution of the curve on the boundary of the desired object. Based on thisframework, the TouchCut approach [176] uses a single touch to segment the object using level-settechniques. They simplify the interaction to a single point in the �rst frame, and then propagatesthe results using optical �ow.
2.3.3 CNN models. Many recent works employ convolutional neural network models to ac-curately interactive segment the object in successive frames [13, 23, 29, 114]. Benard et al. [13]
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:20 R. Yao et al.
Table 4. Summary of interactive video object segmentation methods. #: number of objects, S: single, M:multiple.
References # Methods Way of labeling Optical �ow Over-segmentationManinis [114] M CNN models Clicks × PixelCaelles [23] M CNN models Scribbles × PixelChen [29] M CNN models Clicks × PixelBenard [13] S CNN models Clicks × PixelNagaraja [143] S Random walker Scribbles
√Pixel
Pont-Tuset[129] S Graph-cut Clicks√
SuperpixelChien [33] S Graph-cut Clicks × PixelWang [176] S Active contours Clicks
√Pixel
Donder [40] S Graph-cut Clicks√
SuperpixelReso [137] S Graph-cut Scribbles
√Superpixel
Bai [7] S Graph-cut Scribbles√
PixelBai [6] S Geodesic Scribbles
√Pixel
Bai [8] S Graph-cut Scribbles√
PixelPrice [132] S Graph-cut Scribbles × PixelLi [104] S Graph-cut Scribbles × PixelWang [172] S Graph-cut Scribbles
√Pixel
and Caelles et al. [23] propose the deep interactive image and video object segmentation methoduse OSVOS technique [22]. To improve localization, Benard et al. propose to re�ne the initialpredictions with a fully connected CRF. Caelles et al. [23] de�ne a baseline method (i.e. Scribble-OSVOS) to show the usefulness of the 2018 DAVIS challenge benchmark. Chen et al. [29] formulatevideo object segmentation as a pixel-wise retrieval problem. And their method allow for a fastuser interaction. iFCN [194] guides a CNN from positive and negative points acquired from theground-truth masks. In [114], Maninis et al. build on iFCN to improve the results by using fourpoints of an object as input to obtain precise object segmentation for images and videos.
2.3.4 Discussion. Given scribbles or a few clicks by the user, the interactive video object seg-mentation helps the system produce a full spatio-temporal segmentation of the object of interest.Interactive segmentation methods have been proposed in order to reduce annotation time. How-ever, on small touch screen devices, using a �nger to provide precise clicks or drawing scribblescan be cumbersome and inconvenient for the user. A qualitative comparison of interactive VOSmethods can be made based on their ability to segment single or multiple objects, label an objectwith clicks or scribbles, and type of over-segmentation (i.e. pixel or superpixel). A brief summaryof the qualitative comparison is shown in Tab. 4. Most of the conventional graph partitioningmodel based interactive VOS methods to seeded segmentation is the graph-cut algorithm. Recentmethods use the ideas in the pipeline of deep architectures, CNN models are utilized to improvethe interactive segmentation performance. In addition, several CNN models based methods canhandle multiple-object interactive video object segmentation.
2.4 Weakly supervised video object segmentationWeakly supervised VOS can provide a large amount of video for this method, where all videos areknown to contain the same foreground object or object class. Several weakly supervised learning-based approaches to generate semantic object proposals for training segment classi�ers [64, 155]
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:21
or performing label transfer [108], and then produce the target object in videos. For instance,Hartmann et al. [64] formulate pixel-level segmentations as multiple instance learning weaklysupervised classi�ers for a set of independent spatio-temporal segments. Tang et al. [155] estimatethe video in the positive sample with a large number of negative samples, and regard those segmentswith a distinct appearance as the foreground. Liu et al. [108] further advance the study to addressthis problem in multi-class criterion rather than traditional binary classi�cation. These methodsrely on training examples and may produce inaccurate segmentation results. To overcome thislimitation, Zhang et al. [206] propose to segment semantic object in weakly labeled video by usingobject detection without the need of training process. In contrast, Tsai et al. [164] does not requireobject proposal or video-level annotations. Their method link objects between di�erent video andconstruct a graph for optimization.
Recently, Wang et al. [170] combine the recognition and representation power of CNN with theintrinsic structure of unlabelled data in the target domain of weakly supervised semantic videoobject segmentation to improve inference performance. Unlike semantics-aware weakly-supervisedmethods, Khoreva et al. [84] employ natural language expressions to identify the target object invideo. Their method integrate textual descriptions of interest as foreground into convnet-basedtechniques.2.5 Segmentation-based TrackingIn the previous video object segmentation methods, they usually cues like motion and appearancesimilarity to segment videos, that is, these methods estimate the position of a target in a manualor automatic manner. The object representation consists of a binary segmentation mask whichindicates whether each pixel belongs to the target or not. For applications that require pixel-levelinformation, such as video editing and video compression, this detailed representation is moredesirable. Therefore, the estimating of all pixels requires a large amount of computational cost, andvideo object segmentation methods have been traditionally slow. In contrast, visual object trackingis to estimate the position of an object in the image plane as it moves around a scene. In general, theclassical object shape is represented by a rectangle, ellipse, etc. This simple object representationhelps reduce the cost of data annotation. Moreover, such methods can quickly detect and tracktargets, and the initialization of object is relatively simple. However, these methods still operatemore or less on the image regions described by the bounding box and are inherently di�cultto track objects that undergo large deformations. To overcome this problem, some approachesintegrate some form of segmentation into the tracking process. Segmentation-based trackingmethods provide an accurate shape description for these objects. The strategies of these methodscan be grouped into two main categories: bottom-up methods and joint-based methods. Figure 7presents the �owchart of two segmentation-based tracking frameworks.
2.5.1 Bo�om-up based methods. In the domain of bottom-up segmentation-based tracking, theobject is presented from a segmented area instead of a bounding box. The segmentation-basedtracking is a natural solution to handle non-rigid and deformable objects e�ectively. These methodsuse a low-level segmentation to extract regions in all frames, and then transitively match orpropagate the similar regions across the video. We divide bottom-up based methods into twocategories, namely contour matching and contour propagation. Contour matching approachessearch for the object region in the current frame. On the other hand, by using a state space model,contour propagation methods change the initial contour to a new position in the current frame. Aqualitative comparison of bottom-up segmentation-based tracking approaches is given in Tab. 5.
2.5.1.1 Contour matching. Contour matching searches the object silhouette and their associatedmodels in the current frame. One solution is to build an appearance model of the object shape and
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:22 R. Yao et al.
Input Image
Input Image
Segmentation
Segmentation
Object tracking
Object tracking
Box or/and Mask
Box or/and Mask
.........
...
(a) Bo�om-up based framework.
Input Image
Input Image
Segmentation
Segmentation
Object tracking
Object tracking
Box or/and Mask
Box or/and Mask
.........
...
(b) Joint-based framework.
Fig. 7. Segmentation-based tracking frameworks: (a) Bo�om-up based, (b) Joint-based.
match the best candidate image region to match the model, i.e., generative methods, for instance,integral histogram based models [2, 34], independent component analysis based models [90], sub-space learning based models [208], distance measures-based models [37, 68, 99], spatio-temporal�lter [89], spectral matching [24]. Some approaches measure similarity between patches by com-paring their gray-level or color histograms. Adam et al. [2] segment the target into a number offragments to preserve the spatial relationships of the pixels, and use the integral histogram. Later,Chockalingam et al. [34] choose fragment adaptively according to the video frame, by clusteringpixels with similar appearance, rather than using a �xed arrangement of rectangles. Yang et al. [90]propose a boosted color soft segmentation algorithm and incorporate independent componentanalysis with reference into the tracking framework. Zhou et al. [208] present a shifted subspacestracking to segment the motions and recover their trajectories. The authors use the Hausdor�distance [99] and Mahalanobis distance [37] to construct a correlation surface from which theminimum is selected as the new object position. Hsiao et al. [68] utilize trajectory estimationscheme for automatically deploying the growing seeds for tracking the object in further frames.Kompatsiaris et al. [89] take into account the intensity di�erences between consequent frames, andpresent a spatio-temporal �lter to separate the moving person from the static background. Cai etal. [24] build a dynamic graph to exploit the inner geometric structure information of the object byoversegmenting the target into several superpixels. And spectral clustering is used to solve thegraph matching.
Another approach is to model both the object and the background and then to distinguish theobject from the background by using a discriminative classi�er, such as boosting-based models [148],Hough-based models [42, 56], and so on. These methods maintain object appearances based onsmall local patches or object regions, and perform tracking by classifying the silhouette into theforeground or the background. And the �nal tracking result is given by the mask of the bestsample. Son et al. [148] employ an online gradient decision boosting tree to classify each patch,and construct segmentation masks. Godec et al. [56] propose a patch-based voting algorithm withHough forests [53]. By back-projecting the patches that voted for the object center, the authors
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:23
Table 5. Summary of bo�om-up segmentation-based tracking methods. #: number of objects, S: single, M:multiple. Box and Mask: the bounding box and mask of the object.
References # Methods Segment Techniques Track Techniques ResultsSon [148] S Contour matching Graph-cut Boosting decision
treeBox, Mask
Cai [24] S Contour matching Graph-cut SVM BoxDu�ner [42] S Contour matching Probabilistic soft
segmentationHough voting Box
Wang [177] S Contour propagation Mean shift cluster-ing
Particle �lter Box
Zhou [208] M Contour matching Subspace learning Subspace learning MaskHeber [65] S Contour matching Graph-cut Blending-based
template, houghvoting, mean-shift
Mask
Chien [33] M Contour propagation Threshold decision Particle �lter BoxBelagiannis[12]
S Contour propagation Graph-cut Particle �lter Mask
Godec [56] S Contour matching Graph-cut Hough voting MaskWang [175] S Contour matching SLIC Particle �lter BoxChockalingam[35]
S Contour matching Spatially variant �-nite mixture models
Particle �lter Mask
Colombari [37] M Contour matching Region matching Blob matching andconnection
Mask
Hsiao [68] S Contour matching Region growing andmerging
Interframe di�er-ence
Mask
Kompatsiaris[89]
S Contour matching K-Means clustering Spatiotemporal �l-ter
Box, Mask
Gu [59] S Contour propagation Morphological wa-tershed
Temporal gradient Mask
initialize a graph-cut algorithm to segment foreground from background. However, the graph-cutsegmentation it is relatively slow, and the binary segmentation increases the risk of drift due towrongly segmented image regions. To address this problem, Du�ner and Garcia [42] present afast tracking algorithm using a detector based on the generalized Hough transform and pixel-wisedescriptors, then update the global segmentation model.
In addition, researchers propose hybrid generative-discriminative segmentation-based methodsto fuse the useful information from the generative and the discriminative models. For instance,Heber et al. [65] present a segmentation-based tracking method to fuse three target tracker, i.e.blending-based template tracker, Hough voting-based discriminative tracker, and feature histogram-based mean shift tracker. And the fusion process additionally provides a segmentation.
2.5.1.2 Contour propagation. Contour propagation of bottom-up based methods can be doneusing two di�erent approaches: sequential Monte Carlo (or particle �lter) based methods and directminimization based methods. Some approaches employ sequential Monte Carlo-based methodsto generate the state of the candidate of object contour [12, 33, 175, 177]. The state is de�ned interms of the shape and the motion parameters of the contour. Given all available observations ofobjectZ1:t = {Zt , . . . ,Zt } up to the t-th frame, the state variable yt is updated by the maximuma posteriori (MAP) estimation, i.e. yt =argmaxyt,i (yt,i |Z1:t ). The posterior probability p(yt,i |Z1:t )
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:24 R. Yao et al.
can be computed recursively as
p(yt |Z1:t ) ∝ p(Zt |yt )∫
p(yt |yt−1)p(yt−1 |Z1:t−1)dyt−1. (2)
Here, p(Zt |yt ) is the observation model, which is usually de�ned in terms of the distance ofthe contour from observed edges. And p(yt |yt−1) represents the dynamic motion model. Thedynamic motion model p(yt |yt−1) depicts the temporal correlation of state transition between twoconsecutive frames. The observation model p(Zt |yt ) describes the similarity between a candidateo�set and the best o�set of the tracked object. For instance, Wang et al. [175] use superpixelfor appearance modeling and incorporate particle �ltering to �nd the optimal target state, andtheir observation model is built as p(Zt |yt ) ∝ C(yt ), where C(yt ) represents the con�dence of anobservation at state yt . Belagiannis et al. [12] propose two particle sampling strategies based onsegmentation to handle the objectâĂŹs deformations, occlusions, orientation, scale and appearancechanges. Some methods use particle-based approximate inference algorithm over the DynamicBayesian Network (DBN) [177] and the Hidden Markov Model (HMM) [33] to estimate the contour.
Both segmentation and tracking methods can minimize functions through gradient descent. Inaddition, Gu et al. [59] combine supervised segmentation with unsupervised tracking. Speci�cally,the supervised segmentation method use mathematical morphology, and the unsupervised trackingmethod use computation of the partial derivatives.
2.5.2 Joint-based methods. In the above bottom-up based methods, the foreground region is�rst segmented from the input image, then some features are extracted from the foreground region,and �nally the object is tracked according to these features. The foreground segmentation andobject tracking are performed as two separate tasks, as shown in Fig. 7 (a). The biggest limitationof these methods is that the errors in the foreground segmentation inevitably propagate forward,causing errors in object tracking. Therefore, many researchers integrate foreground segmentationand object tracking into a joint framework. The result of foreground segmentation determinesthe accuracy of feature extraction, which further a�ects the performance of silhouette tracking.On the other hand, the tracking results can provide top-down cues for foreground segmentation.These methods make full use of the correlation between foreground segmentation and objecttracking, which greatly improve the performance of video segmentation and tracking, as shownin Fig. 7 (b). To utilize energy minimization techniques of the joint video object segmentationand tracking framework, we divide these methods into three categories, namely, graph-basedframework, probabilistic framework, and CNN framework. In Tab. 6, we provide the qualitativecomparison of these methods in this section.
2.5.2.1 Graph-based framework. The basic technique of joint-based methods is to constructa graph for the energy function to be minimized. The variations on graph-based frameworkare primarily built using a small set of core algorithms-graph cuts [21, 82, 184, 199], randomwalker [122], and shortest geodesics [123].
For instance, Bugeau and Pérez [21] formulate an objective functions that combine low-level pixel-wise measures and high-level observations. The minimization of these cost functions simultaneouslyallows tracking and segmentation of tracked objects. In [184], Wen et al. integrate the multi-parttracking and segmentation into a uni�ed energy minimization framework, which is optimizediteratively by a RANSAC-style approach. Yao et al. [199] present a joint framework to introducesemantics [106] into tracking procedure. Then, they propose to exploit semantics to localise objectaccurately via an energy-minimization-based segmentation. In [82], Keuper et al. present a graph-based segmentation and multiple object tracking framework. Speci�cally, they combine bottom-upmotion segmentation by grouping of point trajectories with top-down multiple object tracking by
, Vol. 1, No. 1, Article 1. Publication date: January 2019.
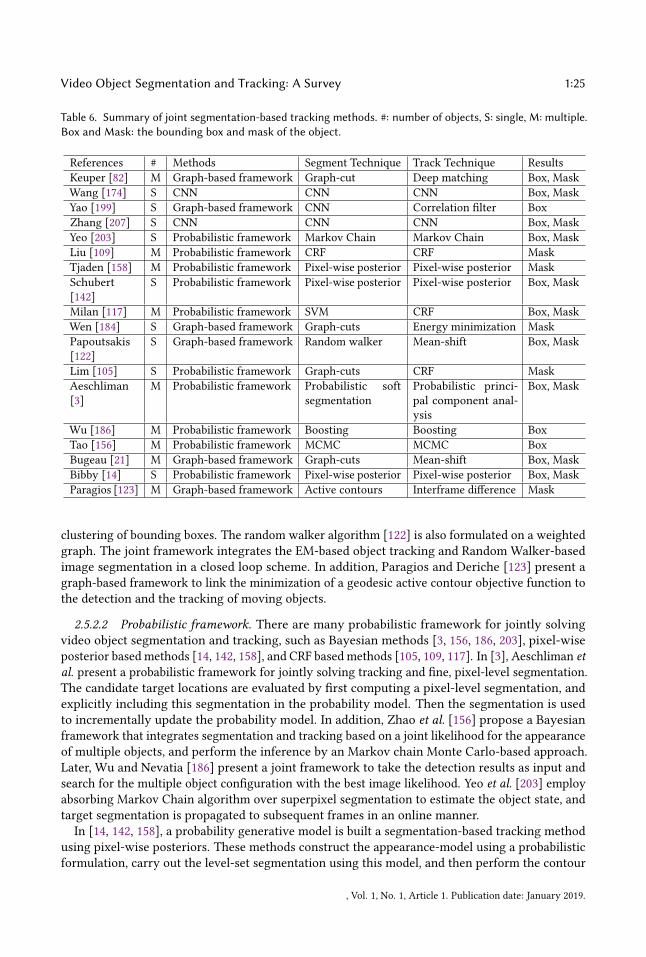
Video Object Segmentation and Tracking: A Survey 1:25
Table 6. Summary of joint segmentation-based tracking methods. #: number of objects, S: single, M: multiple.Box and Mask: the bounding box and mask of the object.
References # Methods Segment Technique Track Technique ResultsKeuper [82] M Graph-based framework Graph-cut Deep matching Box, MaskWang [174] S CNN CNN CNN Box, MaskYao [199] S Graph-based framework CNN Correlation �lter BoxZhang [207] S CNN CNN CNN Box, MaskYeo [203] S Probabilistic framework Markov Chain Markov Chain Box, MaskLiu [109] M Probabilistic framework CRF CRF MaskTjaden [158] M Probabilistic framework Pixel-wise posterior Pixel-wise posterior MaskSchubert[142]
S Probabilistic framework Pixel-wise posterior Pixel-wise posterior Box, Mask
Milan [117] M Probabilistic framework SVM CRF Box, MaskWen [184] S Graph-based framework Graph-cuts Energy minimization MaskPapoutsakis[122]
S Graph-based framework Random walker Mean-shift Box, Mask
Lim [105] S Probabilistic framework Graph-cuts CRF MaskAeschliman[3]
M Probabilistic framework Probabilistic softsegmentation
Probabilistic princi-pal component anal-ysis
Box, Mask
Wu [186] M Probabilistic framework Boosting Boosting BoxTao [156] M Probabilistic framework MCMC MCMC BoxBugeau [21] M Graph-based framework Graph-cuts Mean-shift Box, MaskBibby [14] S Probabilistic framework Pixel-wise posterior Pixel-wise posterior Box, MaskParagios [123] M Graph-based framework Active contours Interframe di�erence Mask
clustering of bounding boxes. The random walker algorithm [122] is also formulated on a weightedgraph. The joint framework integrates the EM-based object tracking and Random Walker-basedimage segmentation in a closed loop scheme. In addition, Paragios and Deriche [123] present agraph-based framework to link the minimization of a geodesic active contour objective function tothe detection and the tracking of moving objects.
2.5.2.2 Probabilistic framework. There are many probabilistic framework for jointly solvingvideo object segmentation and tracking, such as Bayesian methods [3, 156, 186, 203], pixel-wiseposterior based methods [14, 142, 158], and CRF based methods [105, 109, 117]. In [3], Aeschliman etal. present a probabilistic framework for jointly solving tracking and �ne, pixel-level segmentation.The candidate target locations are evaluated by �rst computing a pixel-level segmentation, andexplicitly including this segmentation in the probability model. Then the segmentation is usedto incrementally update the probability model. In addition, Zhao et al. [156] propose a Bayesianframework that integrates segmentation and tracking based on a joint likelihood for the appearanceof multiple objects, and perform the inference by an Markov chain Monte Carlo-based approach.Later, Wu and Nevatia [186] present a joint framework to take the detection results as input andsearch for the multiple object con�guration with the best image likelihood. Yeo et al. [203] employabsorbing Markov Chain algorithm over superpixel segmentation to estimate the object state, andtarget segmentation is propagated to subsequent frames in an online manner.
In [14, 142, 158], a probability generative model is built a segmentation-based tracking methodusing pixel-wise posteriors. These methods construct the appearance-model using a probabilisticformulation, carry out the level-set segmentation using this model, and then perform the contour
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:26 R. Yao et al.
propagation. The minimization of these algorithms are implemented by the gradient descent.Thereinto, Tjaden et al. [158] segment multiple 3D objects and track pose using pixel-wise second-order optimization approach.
Some methods utilize energy minimization techniques of CRF to perform �ne segmentationand target object. For instance, Milan et al. [117] propose a CRF model that exploits high-leveldetector responses and low-level superpixel information to jointly track and segment multipleobjects. Lim et al. [105] handle joint estimation to segment foreground object and track humanpose using a MAP solution. Liu et al. [109] present a uni�ed dynamic couple CRF model to jointtrack and segment moving objects in region level.
2.5.2.3 CNN framework. Recently, some researchers begin to pay attention to perform visualobject tracking and semi-supervised video object segmentation using convolutional neural networkframework [174, 207]. Wang et al. [174] present a a Siamese network to simultaneously estimatebinary segmentation mask, bounding box, and the corresponding object/background scores. Byonly inputting a bounding box in the �rst frame, Zhang et al. [207] build a two-branch network,i.e., appearance network and contour network. And tracking output and segmentation results helpre�ne each other mutually.
2.5.3 Discussion. In general, given a bounding box of a target in the �rst frame, the bottom-upbased methods estimate the location of the object in subsequent images, which is similar to thetracking-by-detection methods. Unlike traditional visual object tracking methods, the bottom-upbased methods use the foreground object contour as a special feature to solve the problem ofobject drift in non-rigid object tracking and segmentation. The purpose of these methods is to �ndthe location of the target, so only the bounding box or coarse mask of object is estimated. Somemethods simply use the result of the segmentation to estimate the scale problem in visual objecttracking. Compared to joint-based methods, the processing speed of these methods is faster.
On the other hand, joint-based methods unify the two tasks of segmentation and tracking intothe graph-based or probabilistic framework, and use energy minimization method to estimate theexact object mask. Speci�cally, these energy minimization methods are iterated many times toestimate accurate object poses, motions, occlusions, and so on. Many methods do not output thebounding box of the object, but only the object mask. Generally, iterative optimization inherentlylimits runtime speed. Recently, some researchers have used o�ine and online CNN-based methodsto simultaneously process segmentation and tracking, and the impressive results demonstrateaccurate and very fast tracking and segmentation.
3 DATASETS AND METRICSTo evaluate the performance of various video object segmentation and tracking methods, one needstest video dataset, the ground truth, and metrics of the competing approaches. In this section, wewill give brief introduced of datasets, evaluation protocols.
3.1 Video object segmentation and tracking datasetsA brief summary of video object segmentation and tracking datasets is shown in Table 7 . Thesedatasets are described and discussed in more detail next.
SegTrack [162] and SegTrack v2 [98] are introduced to evaluate tracking and video objectsegmentation algorithms. SegTrack contains 6 videos (monkeydog, girl, birdfall, parachute, cheetah,penguin) and pixel-level ground-truth for the single moving foreground object in every frame.These videos provide a variety of challenges, including non-rigid deformation, similar objectsand fast motion of the camera and target. SegTrack v2 contains 14 videos with instance-level
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:27
Table 7. Brief illustration of datasets that are used in the evaluation of the video object segmentation andtracking methods. V #: number of video. C #: number of categories. O #: number of objects. A #: annotatedframes. U, S, I, W, T: unsupervised VOS, semi-supervised VOS, interactive VOS, weakly supervised VOS, andsegmentation-based tracking methods. Object pro.: object property, T. of methods: type of methods.
V # C # O # A # Object pro. T. of methods Labels Publish yearSegTrack 6 6 6 244 Single U, S, I, W, T Mask 2012 [162]SegTrack v2 14 11 24 1475 Multiple U, S, I, W, T Mask 2014 [98]BMS-26 26 2 38 189 Multiple U Mask 2010 [17]FBMS-59 59 16 139 1,465 Multiple U, S Mask 2014 [128]YouTube-objects 126 10 96 2,153 Single U, S, I, W Mask 2014 [77, 131]YouTube-VOS 3252 78 6048 133,886 Multiple S Mask 2018 [195]JumpCut 22 14 22 6,331 Single U, S Mask 2015 [49]DAVIS 2016 50 – 50 3,440 Single U, S, I, W Mask 2016 [126]DAVIS 2017 150 – 384 10,474 Multiple U, S, I, W Mask 2017 [130]NR 11 – 11 1,200 Single S, T Box, Mask 2015 [148]MOT 2016 14 – – 11,000 Multiple U, T Box 2016 [116]VOT 2016 60 – 60 21,511 Single S, T Box, Mask 2016 [92, 168]OTB 2013 50 – 50 29,000 Single T Box 2013 [187]OTB 2015 100 – 100 58,000 Single T Box 2015 [188]
moving object annotations in all the frames. Other videos from SegTrack v2 also include clutteredbackgrounds and dynamic scenes caused by camera movement or moving background objects. Insome video sequences, the objects are visually very similar to the image background, that is, lowcontrast along object boundaries, such as the birdfall, frog and worm sequences in the SegTrack v2dataset. In contrast to SegTrack, many videos have more than one object of interest in SegTrack v2.
BMS-26 (Berkeley motion segmentation) [17] and FBMS-59 (Freiburg-Berkeley motion segmen-tation) [128] are widely used for unsupervised and semi-supervised VOS methods. BMS-26 datasetconsists 26 videos with a total of 189 annotated image frames, which shots from movie stories andthe 10 vehicles and 2 human sequences. The FBMS-59 dataset re�ects two major improvements inthe previous version of BMS-26. First, the updated version dataset adds 33 new sequences, therefore,the FBMS-59 dataset consists of 59 sequences. Second, these 33 new sequences incorporate chal-lenges of unconstrained videos such as fast motion, motion blur, occlusions, and object appearancechanges. The sequences are divided into 29 training and 30 test video sequences.
YouTube-objects [131] and YouTube-VOS (YouTube video object segmentation) [195] containa large amount of Internet videos. Jain et al. [77] adopt its subset that contains 126 videos with 10object categories and 20,977 frames. In these videos, 2,153 key-frames are sparsely sampled andmanually annotated in pixel-wise masks according to the video labels. YouTube-objects dataset isused for unsupervised, semi-supervised, interactive, and weakly supervised VOS approaches. In2018, Xu et al. [195] release a large-scale video object segmentation dataset called YouTube-VOS. Thedataset contains 3,252 YouTube video clips and 133,886 object annotations, of which 78 categoriescover 78 categories covering common animals, cars, accessories and human activities. At thesame time, the authors build a sequence-to-sequence semi-supervised video object segmentationalgorithm to verify this dataset and performance.
JumpCut dataset [49] consists of 22 video sequences with medium image resolution. It contains14 categories (6,331 annotation images in total) along with pixel level ground-truth annotations.Most image frames in the JumpCut dataset contain very fast object motion and signi�cant fore-ground deformations. Thus, the JumpCut dataset is considered a more challenging video sequences
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:28 R. Yao et al.
for unsupervised and semi-supervised VOS, and is widely used to evaluate modern unsupervisedand semi-supervised video segmentation techniques.
DAVIS 2016, 2017, and 2018 datasets are one of the most popular datasets for training andevaluating video object segmentation algorithms. DAVIS 2016 [126] dataset contains 50 full highquality video sequences with 3,455 annotated frames in total, and focuses on single-object videoobject segmentation, that is, there is only one foreground object per video. 30 training set and20 validation set in this dataset is divided. Later, DAVIS 2017 [130] complements DAVIS 2016dataset training and validation sets with 30 and 10 high quality videos, respectively. It alsoprovides an additional 30 development test sequences and 30 challenge test sequences. Also, theDAVIS 2017 dataset relabels multiple objects in all video sequences. These improvements makeit more challenging than the original DAVIS 2016 dataset. In addition, Each video is labeled withmultiple attributes such as occlusion, object deformation, fast motion, and scale change to provide acomprehensive analysis of model performance. Moreover, DAVIS 2018 dataset [23] adds 100 videoswith multiple objects per video to the original DAVIS 2016 dataset, and complements an interactivesegmentation teaser track.
NR (non-rigid object tracking) dataset [148] consists of 11 video sequences with 1,200 frameswhich contain deformable and articulated objects. First, the pixel-level annotations are performedmanually. The bounding box annotation is then generated by calculating the tightest rectangularbounding box that contains all of the object pixels. Each video is labeled with only one object. Ithas been to evaluate segmentation-based tracking and semi-supervised VOS algorithms.
MOT 2016 (multiple object tracking) dataset [116] consists of 14 sequences with 11,000 frameswhich contain crowded scenarios, di�erent viewpoints, camera and object motions and weatherconditions. The targets are annotated with axis-aligned minimum bounding boxes in each videosequence. The scale of datasets for MOT is relatively smaller than single object tracking, and currentdatasets focus on pedestrians. This dataset is used to evaluate multiple object of unsupervised VOSand segmentation-based tracking algorithms.
VOT 2016 (video object tracking) dataset [92] contains 60 high-quality video sequences targetedat single video tracking and segmentation tasks. It consists 21,511 frames in total. In [168], Vojir et al.provide pixel-level segmentation annotations for the VOT 2016 dataset, and construct a challengingsegmentation tracking and test dataset.
OTB (object tracking benchmark) is widely used to evaluate single segmentation-based videoobject tracking algorithms. OTB 2013 dataset [187] has 50 video sequences includes fully annotatedvideo sequences with bounding box. OTB 2015 dataset [188] consists of 100 video sequences and58,000 annotated frames of real-world moving objects.
3.2 MetricsTo order to evaluate the performance, this section focuses on the speci�c case of video objectsegmentation and tracking, where both the predicted results and the ground-truth are used forforeground-background partitioning. Measures can be focused on evaluating which pixels of theground truth are detected, or indicating the precision of the bounding box.
3.2.1 Evaluating of pixel-wise object segmentation techniques. For video object segmentation,the standard evaluation metric has three measurements [126], namely the spatial precision of thesegmentation, the consistency of contour similarity and the temporal stability.
• Region similarity J . The region similarity is the intersection over union (IoU) functionbetween the predicted object segmentation mask M and ground truth G. This quantitativemetric for measuring the number of misclassi�ed image pixels and measuring pixelsmatching segmentation algorithm. In this way, it is de�ned as J = M∩G
M∪G .
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:29
• Contour precision F . The segmented mask is treated as a set of closed contour regions,and the function of precision and recall is to calculate the contour-based F -measure. Thatis to say, the F -measure of the contour precision is based on the precision and recall of thecontour. This indicator is used to measure the precision of the segmentation boundary. Letsegmented mask M be interpreted as a set of closed contours c(M). Thus, we can achievethe contour-based precision Pc and recall Rc based on c(M) and c(G). Therefore, F -measureis de�ned as F = 2PcRc
Pc+Rc.
• Temporal stability T . Most of VOS methods also use time stability t to measure theturbulence and inaccuracy of the contours. The temporal stability of the video segmentationis measured by the dissimilarity of the target shape context descriptors that describe thepixels on the contour of the segmentation between two adjacent frames in the videosequences.
3.2.2 Evaluating of bounding box based object tracking techniques. For segmentation-basedtracking approaches, both the mask and the bounding box of object may be output. To evaluateobject tracking algorithms, therefore, we should account for two categories: single object andmultiple objects.
The evaluation protocol of OTB 2013 [187] and VOT 2016 [92] dataset is widely used in singleobject tracking algorithm. For OTB 2013 benchmark, four metrics with one-pass evaluation (OPE)are used to evaluate all the compared trackers: (i) bounding box overlap, which is measured byVOC overlap ratio (VOR); (ii) center location error (CLE), (iii) distance precision (DP), and (iv)overlap precision (OP). For VOT 2016 benchmark, there are three main measures for analyzing theperformance of short-term tracking: accuracy, robustness, and expected average overlap (EAO).The accuracy is the average overlap between the prediction during the successful tracking and thereal boundary box of the ground truth. The robustness measures the number of times a trackerloses a target (i.e., fails) during the tracking period. EAO estimates the accuracy of the estimatedbounding box after processing a certain number of frames since initialization.
Metrics for multiple targets tracking are divided into three classes by di�erent attributes: ac-curacy, precision, and completeness. Combining multiple target false positives, false positives,and mismatches into a single value becomes a multi-target tracking accuracy (MOTA) metric.The multiple object tracking accuracy (MOTP) metric describes the accuracy of measuring ob-jects by boundary box overlap and/or center location distance. The complete metrics indicate thecompleteness of tracking the ground truth trajectory.
4 FUTURE DIRECTIONSBased on signi�cant advances in video object segmentation and tracking, we suggest some futureresearch directions that would be interesting to pursue.Simultaneous prediction of VOS and VOT. In the traditional hand-crafted video object segmen-tation and tracking methods, there are many algorithms to simultaneously output the mask andbounding box of the object. Recently, researchers came up with end-to-end VOS and VOT methodsthat dealt with two problems in a deep framework, they simultaneously predict pixel-level objectmasks and object-level bounding boxes for impressive performance. This will lead to an importantproblem: speed and accuracy. On the one hand, accuracy is important in some applications, suchas �ne-tuning iterations to improve segmentation and tracking performance. It is computationallyexpensive and the speed is bound to be slow. On the other hand, if the processing speed is increasedwithout losing the performance of object segmentation and tracking, this will be a very interestingdirection.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:30 R. Yao et al.
Fine-grained video object segmentation and tracking. Segmentation and tracking of �ne-grained objects in the full HD video is challenging. Since such videos generally have a largebackground of various appearance and motion, small parts of �ne-grained objects in video cannotbe segmented and tracked with su�cient accuracy. On the one hand, in �ne-grained segmentationand recognition tasks, these small parts usually contain semantic information that is extremelyimportant for �ne-grained classi�cation. Moreover, object tracking is essentially a process ofcontinuous predicting the motion of a very small object between frames, if a method can notdistinguish good small di�erences, it may not be an optimal design choice. Therefore, how toaccurately segment and track �ne-grained objects, and then improve the performance of video andvideo recognition tasks plays an important role in many real-world applications.Generalization performance of VOST. Generalization has always been a di�culty in videosegmentation and tracking algorithms. Although VOST tasks can be solved after training, butit is di�cult to transfer the acquisition experience to new categories, or unconstrained videos,such as these videos are noisy, compressed, unstructured, and included by moving from multipleviews. End-to-end training in deep learning is currently used to improve generalization. Althoughthere are many datasets, such as DAVIS, YouTube-VOS, OTB, and VOT, these datasets have somelimitations and are somewhat di�erent from the actual environment. Not only the diversity of theappearance of the foreground object, but also the complexity of the object motion trajectory willdirectly a�ect the generalization ability of the object segmentation and tracking methods. Therefore,how to fast and accurate segment and track objects in these new categories or environments willbe the focus of research.Multi-camera video object segmentation and tracking. Performing video analysis and moni-toring in complex environments requires the use of multiple cameras. This problem has led to anincreasing interest in research on multi-camera collaborative video analysis. In multiple cameras,due to the fusion of di�erent visual information from di�erent viewpoints, the method synergisti-cally handles video object segmentation and tracking in the same scene monitored by di�erentcameras, thus it may improve the performance. However, it should be noted that the images used inmulti-camera surveillance are usually captured by cameras located at di�erent locations. Therefore,there is a great diversity in visual perspective, which should be considered separately in the videoobject segmentation and tracking techniques.3D video object segmentation and tracking. The analysis and processing of 3D object is acore problem in the computer vision community. There may be two directions of interest here.First, VOST is an important prerequisite for avoiding obstacles and pedestrians. Segmentationcombined with 3D images produces detailed object boundaries in 3D. The subsequent path planningalgorithm can then generate motion trajectories to avoid collisions. Autonomous robots usevideo object segmentation and tracking to locate, �nd and grab objects of interest. Second, inbuilding infrastructure modeling, you can create virtual 3D models of buildings that contain theirsemantic regions. This model can then be used to quickly calculate statistics in the video. The 3Dreconstruction system provides very detailed geometry. However, after scanning, cumbersomepost-processing steps are required to cut the object of interest. Video object segmentation andtracking helps automate this task.
5 CONCLUSIONIn this article, we provided a comprehensive survey of the video object segmentation and trackingliterature. We described challenges and potential application in the �eld, classi�ed and analyzedthe recent methods, and discussed di�erent algorithms. The presented survey uses an organizationof application scenarios to review �ve important categories of literature in VOST: unsupervised
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:31
VOS, semi-supervised VOS, interactive VOS, weakly supervised VOS, and segmentation-basedtracking methods. We provided a hierarchical categorization of the di�erent groups in existingworks, and summarized some object representation, image features, motion cues, etc. We alsodescribed various of per-process and post-process CNN-based VOS methods, and discussed theadvantages or disadvantages aspects of the methods. Moreover, we described the related videodatasets for video object segmentation and tracking, and the evaluation metrics of pixel-wise maskand bounding box based techniques. We believe this review will bene�t researchers in this �eldand provide useful insights into this important research topic. We hope to encourage more futurework to develop in this direction.
REFERENCES[1] Radhakrishna Achanta, Appu Shaji, Kevin Smith, Aurelien Lucchi, Pascal Fua, and Sabine Süsstrunk. 2012. SLIC
superpixels compared to state-of-the-art superpixel methods. IEEE transactions on pattern analysis and machineintelligence 34, 11 (2012), 2274–2282.
[2] A. Adam, E. Rivlin, and I. Shimshoni. 2006. Robust Fragments-based Tracking using the Integral Histogram. In 2006IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), Vol. 1. 798–805.
[3] Chad Aeschliman, Johnny Park, and Avinash C. Kak. 2010. A probabilistic framework for joint segmentation andtracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 1371–1378.
[4] S Avinash Ramakanth and R Venkatesh Babu. 2014. Seamseg: Video object segmentation using patch seams. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 376–383.
[5] Vijay Badrinarayanan, Ignas Budvytis, and Roberto Cipolla. 2013. Semi-supervised video segmentation using treestructured graphical models. IEEE transactions on pattern analysis and machine intelligence 35, 11 (2013), 2751–2764.
[6] Xue Bai and Guillermo Sapiro. 2009. Geodesic matting: A framework for fast interactive image and video segmentationand matting. International journal of computer vision 82, 2 (2009), 113–132.
[7] Xue Bai, Jue Wang, and Guillermo Sapiro. 2010. Dynamic color �ow: a motion-adaptive color model for objectsegmentation in video. In European Conference on Computer Vision. Springer, 617–630.
[8] Xue Bai, Jue Wang, David Simons, and Guillermo Sapiro. 2009. Video snapcut: robust video object cutout usinglocalized classi�ers. In ACM Transactions on Graphics (ToG), Vol. 28. ACM, 70.
[9] Dan Banica, Alexandru Agape, Adrian Ion, and Cristian Sminchisescu. 2013. Video object segmentation by salientsegment chain composition. In Proceedings of the IEEE International Conference on Computer VisionWorkshops. 283–290.
[10] L. Bao, B. Wu, and W. Liu. 2018. CNN in MRF: Video Object Segmentation via Inference in a CNN-Based Higher-OrderSpatio-Temporal MRF. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5977–5986.
[11] Olivier Barnich and Marc Van Droogenbroeck. 2011. ViBe: A universal background subtraction algorithm for videosequences. IEEE Transactions on Image processing 20, 6 (2011), 1709–1724.
[12] Vasileios Belagiannis, Falk Schubert, Nassir Navab, and Slobodan Ilic. 2012. Segmentation based particle �ltering forreal-time 2d object tracking. In European Conference on Computer Vision. Springer, 842–855.
[13] Arnaud Benard and Michael Gygli. 2017. Interactive video object segmentation in the wild. arXiv preprintarXiv:1801.00269 (2017).
[14] Charles Bibby and Ian Reid. 2008. Robust Real-Time Visual Tracking Using Pixel-Wise Posteriors. In Computer Vision –ECCV 2008, David Forsyth, Philip Torr, and Andrew Zisserman (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg,831–844.
[15] Yuri Y Boykov and M-P Jolly. 2001. Interactive graph cuts for optimal boundary & region segmentation of objects inND images. In Proceedings eighth IEEE international conference on computer vision. ICCV 2001, Vol. 1. IEEE, 105–112.
[16] William Brendel and Sinisa Todorovic. 2009. Video object segmentation by tracking regions. In Proceedings of the IEEEInternational Conference on Computer Vision. IEEE, 833–840.
[17] Thomas Brox and Jitendra Malik. 2010. Object Segmentation by Long Term Analysis of Point Trajectories. In ComputerVision – ECCV 2010, Kostas Daniilidis, Petros Maragos, and Nikos Paragios (Eds.). Springer Berlin Heidelberg, Berlin,Heidelberg, 282–295.
[18] Thomas Brox and Jitendra Malik. 2011. Large displacement optical �ow: descriptor matching in variational motionestimation. IEEE transactions on pattern analysis and machine intelligence 33, 3 (2011), 500–513.
[19] Sebastian Brutzer, Benjamin Höferlin, and Gunther Heidemann. 2011. Evaluation of background subtraction techniquesfor video surveillance. In CVPR 2011. IEEE, 1937–1944.
[20] Ignas Budvytis, Vijay Badrinarayanan, and Roberto Cipolla. 2012. MoT-Mixture of Trees Probabilistic Graphical Modelfor Video Segmentation.. In BMVC, Vol. 1. Citeseer, 7.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:32 R. Yao et al.
[21] Aurélie Bugeau and Patrick Pérez. 2008. Track and cut: Simultaneous tracking and segmentation of multiple objectswith graph cuts. Eurasip Journal on Image and Video Processing 2008, October (2008).
[22] S. Caelles, K. . Maninis, J. Pont-Tuset, L. Leal-TaixÃľ, D. Cremers, and L. V. Gool. 2017. One-Shot Video ObjectSegmentation. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5320–5329.
[23] Sergi Caelles, Alberto Montes, Kevis-Kokitsi Maninis, Yuhua Chen, Luc Van Gool, Federico Perazzi, and Jordi Pont-Tuset.2018. The 2018 davis challenge on video object segmentation. arXiv preprint arXiv:1803.00557 1, 2 (2018).
[24] Zhaowei Cai, Longyin Wen, Zhen Lei, Nuno Vasconcelos, and Stan Z Li. 2014. Robust deformable and occluded objecttracking with dynamic graph. IEEE Transactions on Image Processing 23, 12 (2014), 5497–5509.
[25] Joao Carreira and Cristian Sminchisescu. 2012. CPMC: Automatic object segmentation using constrained parametricmin-cuts. IEEE Transactions on Pattern Analysis and Machine Intelligence 34, 7 (2012), 1312–1328.
[26] Jason Chang, Donglai Wei, and John W Fisher. 2013. A video representation using temporal superpixels. In Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition. 2051–2058.
[27] Chaohui Wang, Martin de La Gorce, and Nikos Paragios. 2009. Segmentation, ordering and multi-object trackingusing graphical models. In 2009 IEEE 12th International Conference on Computer Vision. 747–754.
[28] Lin Chen, Jianbing Shen, Wenguan Wang, and Bingbing Ni. 2015. Video object segmentation via dense trajectories.IEEE Transactions on Multimedia 17, 12 (2015), 2225–2234.
[29] Yuhua Chen, Jordi Pont-Tuset, Alberto Montes, and Luc Van Gool. 2018. Blazingly fast video object segmentationwith pixel-wise metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.1189–1198.
[30] Jingchun Cheng, Sifei Liu, Yi-Hsuan Tsai, Wei-Chih Hung, Shalini De Mello, Jinwei Gu, Jan Kautz, Shengjin Wang, andMing-Hsuan Yang. 2017. Learning to segment instances in videos with spatial propagation network. arXiv preprintarXiv:1709.04609 (2017).
[31] Jingchun Cheng, Yi-Hsuan Tsai, Wei-Chih Hung, Shengjin Wang, and Ming-Hsuan Yang. 2018. Fast and AccurateOnline Video Object Segmentation via Tracking Parts. arXiv preprint arXiv:1806.02323 (2018).
[32] Jingchun Cheng, Yi-Hsuan Tsai, Shengjin Wang, and Ming-Hsuan Yang. 2017. Seg�ow: Joint learning for video objectsegmentation and optical �ow. In Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 686–695.
[33] S. Y. Chien, W. K. Chan, Y. H. Tseng, and H. Y. Chen. 2013. Video Object Segmentation and Tracking Framework WithImproved Threshold Decision and Di�usion Distance. IEEE Transactions on Circuits and Systems for Video Technology23, 6 (2013), 921–934.
[34] P. Chockalingam, N. Pradeep, and S. Birch�eld. 2009. Adaptive fragments-based tracking of non-rigid objects usinglevel sets. In 2009 IEEE 12th International Conference on Computer Vision. 1530–1537.
[35] Prakash Chockalingam, Nalin Pradeep, and Stan Birch�eld. 2009. Adaptive fragments-based tracking of non-rigidobjects using level sets. In 2009 IEEE 12th international conference on computer vision. IEEE, 1530–1537.
[36] Wen-Sheng Chu, Yale Song, and Alejandro Jaimes. 2015. Video co-summarization: Video summarization by visualco-occurrence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3584–3592.
[37] Andrea Colombari, Andrea Fusiello, and Vittorio Murino. 2007. Segmentation and tracking of multiple video objects.Pattern Recognition 40, 4 (2007), 1307–1317.
[38] Antonio Criminisi, Geo�rey Cross, Andrew Blake, and Vladimir Kolmogorov. 2006. Bilayer segmentation of live video.In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), Vol. 1. IEEE, 53–60.
[39] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical imagedatabase. In 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 248–255.
[40] Radu Dondera, Vlad Morariu, Yulu Wang, and Larry Davis. 2014. Interactive video segmentation using occlusionboundaries and temporally coherent superpixels. In IEEE Winter Conference on Applications of Computer Vision. IEEE,784–791.
[41] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt,Daniel Cremers, and Thomas Brox. 2015. Flownet: Learning optical �ow with convolutional networks. In Proceedingsof the IEEE international conference on computer vision. 2758–2766.
[42] Stefan Du�ner and Christophe Garcia. 2014. PixelTrack: A Fast Adaptive Algorithm for Tracking Non-rigid Objects.In IEEE International Conference on Computer Vision.
[43] Suyog Dutt Jain, Bo Xiong, and Kristen Grauman. 2017. FusionSeg: Learning to combine motion and appearance forfully automatic segmentation of generic objects in videos. In Proceedings of the IEEE conference on computer vision andpattern recognition. 3664–3673.
[44] Ahmed Elgammal, Ramani Duraiswami, David Harwood, and Larry S Davis. 2002. Background and foregroundmodeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 90, 7 (2002), 1151–1163.
[45] Liam Ellis and Vasileios Zografos. 2013. Online Learning for Fast Segmentation of Moving Objects. In Computer Vision– ACCV 2012, Kyoung Mu Lee, Yasuyuki Matsushita, James M. Rehg, and Zhanyi Hu (Eds.). Springer Berlin Heidelberg,Berlin, Heidelberg, 52–65.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:33
[46] Ian Endres and Derek Hoiem. 2010. Category independent object proposals. In European Conference on ComputerVision. Springer, 575–588.
[47] ÇiÇğdem EroÇğlu Erdem, Bülent Sankur, and A. Murat Tekalp. 2004. Performance measures for video objectsegmentation and tracking. IEEE Transactions on Image Processing 13, 7 (2004), 937–951.
[48] Alon Faktor and Michal Irani. 2014. Video Segmentation by Non-Local Consensus voting.. In BMVC, Vol. 2. 8.[49] Qingnan Fan, Fan Zhong, Dani Lischinski, Daniel Cohen-Or, and Baoquan Chen. 2015. JumpCut: non-successive mask
transfer and interpolation for video cutout. ACM Trans. Graph. 34, 6 (2015), 195–1.[50] Katerina Fragkiadaki, Pablo Arbelaez, Panna Felsen, and Jitendra Malik. 2015. Learning to segment moving objects in
videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4083–4090.[51] Katerina Fragkiadaki, Geng Zhang, and Jianbo Shi. 2012. Video segmentation by tracing discontinuities in a trajectory
embedding. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 1846–1853.[52] Ken Fukuchi, Kouji Miyazato, Akisato Kimura, Shigeru Takagi, and Junji Yamato. 2009. Saliency-based video segmen-
tation with graph cuts and sequentially updated priors. In 2009 IEEE International Conference on Multimedia and Expo.IEEE, 638–641.
[53] Juergen Gall, Angela Yao, Nima Razavi, Luc Van Gool, and Victor Lempitsky. 2011. Hough forests for object detection,tracking, and action recognition. IEEE transactions on pattern analysis and machine intelligence 33, 11 (2011), 2188–2202.
[54] Xiang Gao, Terrance E Boult, Frans Coetzee, and Visvanathan Ramesh. 2000. Error analysis of background adaption.In Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), Vol. 1. IEEE,503–510.
[55] Daniela Giordano, Francesca Murabito, Simone Palazzo, and Concetto Spampinato. 2015. Superpixel-based video objectsegmentation using perceptual organization and location prior. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. 4814–4822.
[56] Martin Godec, Peter M Roth, and Horst Bischof. 2013. Hough-based tracking of non-rigid objects. Computer Visionand Image Understanding 117, 10 (2013), 1245–1256.
[57] Vikash Goel, Jameson Weng, and Pascal Poupart. 2018. Unsupervised video object segmentation for deep reinforcementlearning. In Advances in Neural Information Processing Systems. 5688–5699.
[58] Matthias Grundmann, Vivek Kwatra, Mei Han, and Irfan Essa. 2010. E�cient hierarchical graph-based video segmen-tation. In 2010 ieee computer society conference on computer vision and pattern recognition. IEEE, 2141–2148.
[59] Chuang Gu and Ming-Chieh Lee. 1998. Semiautomatic segmentation and tracking of semantic video objects. IEEETransactions on Circuits and Systems for Video Technology 8, 5 (Sep. 1998), 572–584.
[60] Vitor Guizilini and Fabio Ramos. 2013. Online self-supervised segmentation of dynamic objects. In 2013 IEEE Interna-tional Conference on Robotics and Automation. IEEE, 4720–4727.
[61] Bohyung Han and Larry S Davis. 2012. Density-based multifeature background subtraction with support vectormachine. IEEE Transactions on Pattern Analysis and Machine Intelligence 34, 5 (2012), 1017–1023.
[62] Junwei Han, Le Yang, Dingwen Zhang, Xiaojun Chang, and Xiaodan Liang. 2018. Reinforcement Cutting-AgentLearning for Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 9080–9089.
[63] Sam Hare, Stuart Golodetz, Amir Sa�ari, Vibhav Vineet, Ming-Ming Cheng, Stephen L Hicks, and Philip HS Torr. 2016.Struck: Structured output tracking with kernels. IEEE transactions on pattern analysis and machine intelligence 38, 10(2016), 2096–2109.
[64] Glenn Hartmann, Matthias Grundmann, Judy Ho�man, David Tsai, Vivek Kwatra, Omid Madani, Sudheendra Vijaya-narasimhan, Irfan Essa, James Rehg, and Rahul Sukthankar. 2012. Weakly supervised learning of object segmentationsfrom web-scale video. In European Conference on Computer Vision. Springer, 198–208.
[65] Markus Heber, Martin Godec, Matthias RÃijther, Peter M. Roth, and Horst Bischof. 2013. Segmentation-based trackingby support fusion. Computer Vision and Image Understanding 117, 6 (2013), 573 – 586.
[66] David Held, Devin Guillory, Brice Rebsamen, Sebastian Thrun, and Silvio Savarese. 2016. A Probabilistic Frameworkfor Real-time 3D Segmentation using Spatial, Temporal, and Semantic Cues.. In Robotics: Science and Systems.
[67] Berthold KP Horn and Brian G Schunck. 1981. Determining optical �ow. Arti�cial intelligence 17, 1-3 (1981), 185–203.[68] Ying-Tung Hsiao, Cheng-Long Chuang, Yen-Ling Lu, and Joe-Air Jiang. 2006. Robust multiple objects tracking using
image segmentation and trajectory estimation scheme in video frames. Image and Vision Computing 24, 10 (2006),1123–1136.
[69] Ping Hu, Gang Wang, Xiangfei Kong, Jason Kuen, and Yap-Peng Tan. 2018. Motion-Guided Cascaded Re�nementNetwork for Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 1400–1409.
[70] Yuan-Ting Hu, Jia-Bin Huang, and Alexander Schwing. 2017. Maskrnn: Instance level video object segmentation. InAdvances in Neural Information Processing Systems. 325–334.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:34 R. Yao et al.
[71] Yuan-Ting Hu, Jia-Bin Huang, and Alexander G Schwing. 2018. Unsupervised video object segmentation using motionsaliency-guided spatio-temporal propagation. In Proceedings of the European Conference on Computer Vision (ECCV).786–802.
[72] Yuan-Ting Hu, Jia-Bin Huang, and Alexander G. Schwing. 2018. VideoMatch: Matching based Video Object Segmenta-tion. In The European Conference on Computer Vision (ECCV).
[73] Yuchi Huang, Qingshan Liu, and Dimitris Metaxas. 2009. ] Video object segmentation by hypergraph cut. In 2009 IEEEConference on Computer Vision and Pattern Recognition. IEEE, 1738–1745.
[74] Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, and Thomas Brox. 2017. FlowNet 2.0:Evolution of Optical Flow Estimation With Deep Networks. In The IEEE Conference on Computer Vision and PatternRecognition (CVPR).
[75] Michal Irani and P Anandan. 1998. A uni�ed approach to moving object detection in 2D and 3D scenes. IEEEtransactions on pattern analysis and machine intelligence 20, 6 (1998), 577–589.
[76] Michal Irani, Benny Rousso, and Shmuel Peleg. 1994. Computing occluding and transparent motions. InternationalJournal of Computer Vision 12, 1 (1994), 5–16.
[77] Suyog Dutt Jain and Kristen Grauman. 2014. Supervoxel-Consistent Foreground Propagation in Video. In ComputerVision – ECCV 2014, David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars (Eds.). Springer InternationalPublishing, Cham, 656–671.
[78] Varun Jampani, Raghudeep Gadde, and Peter V Gehler. 2017. Video propagation networks. In Proc. CVPR, Vol. 6. 7.[79] Won-Dong Jang and Chang-Su Kim. 2016. Semi-supervised Video Object Segmentation Using Multiple Random
Walkers.. In Proc. BMVC.[80] Won-Dong Jang, Chulwoo Lee, and Chang-Su Kim. 2016. Primary object segmentation in videos via alternate convex
optimization of foreground and background distributions. In Proceedings of the IEEE conference on computer vision andpattern recognition. 696–704.
[81] Yeong Jun Koh, Young-Yoon Lee, and Chang-Su Kim. 2018. Sequential Clique Optimization for Video Object Segmen-tation. In The European Conference on Computer Vision (ECCV).
[82] M. Keuper, S. Tang, B. Andres, T. Brox, and B. Schiele. 2018. Motion Segmentation and Multiple Object Tracking byCorrelation Co-Clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018), 1–1.
[83] A. Khoreva, R. Benenson, E. Ilg, T. Brox, and B. Schiele. 2017. Lucid Data Dreaming for Object Tracking. In The 2017DAVIS Challenge on Video Object Segmentation - CVPR Workshops.
[84] Anna Khoreva, Anna Rohrbach, and Bernt Schiele. 2018. Video object segmentation with language referring expressions.arXiv preprint arXiv:1803.08006 (2018).
[85] Changick Kim and Jenq-Neng Hwang. 2002. Fast and automatic video object segmentation and tracking for content-based applications. IEEE Transactions on Circuits and Systems for Video Technology 12, 2 (Feb 2002), 122–129.
[86] Kurt Ko�ka. 2013. Principles of Gestalt psychology. Routledge.[87] Yeong Jun Koh and Chang-Su Kim. 2017. CDTS: Collaborative Detection, Tracking, and Segmentation for Online
Multiple Object Segmentation in Videos. In 2017 IEEE International Conference on Computer Vision (ICCV). IEEE,3621–3629.
[88] Yeong Jun Koh and Chang-Su Kim. 2017. Primary object segmentation in videos based on region augmentation andreduction. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 7417–7425.
[89] I. Kompatsiaris and M. Gerassimos Strintz. 2000. Spatiotemporal segmentation and tracking of objects for visualizationof videoconference image sequences. IEEE Transactions on Circuits and Systems for Video Technology 10, 8 (Dec 2000),1388–1402.
[90] Hong Kong. 2010. ROBUST TRACKING BASED ON BOOSTED COLOR SOFT SEGMENTATION AND ICA-R Depart-ment of Electronic Engineering Dalian University of Technology Dalian , CHINA College of Information Science andEngineering Ritsumeikan University. In Icip. 3917–3920.
[91] Philipp Krähenbühl and Vladlen Koltun. 2011. E�cient inference in fully connected crfs with gaussian edge potentials.In Advances in neural information processing systems. 109–117.
[92] Matej Kristan, Aleš Leonardis, Jiři Matas, Michael Felsberg, Roman P�ugfelder, and Luka Čehovin. 2016. The VisualObject Tracking VOT2016 Challenge Results. In Computer Vision – ECCV 2016 Workshops, Gang Hua and Hervé Jégou(Eds.). Springer International Publishing, Cham, 777–823.
[93] Constantinos Lalos, Helmut Grabner, Luc Van Gool, and Theodora Varvarigou. 2010. Object �ow: Learning objectdisplacement. In Asian Conference on Computer Vision. Springer, 133–142.
[94] Hakjin Lee, Jongbin Ryu, and Jongwoo Lim. 2018. Joint Object Tracking and Segmentation with IndependentConvolutional Neural Networks. In Proceedings of the 1stWorkshop and Challenge on Comprehensive Video Understandingin the Wild. ACM, 7–13.
[95] Yong Jae Lee, Jaechul Kim, and Kristen Grauman. 2011. Key-segments for video object segmentation. In 2011International conference on computer vision. IEEE, 1995–2002.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:35
[96] Alex Levinshtein, Cristian Sminchisescu, and Sven Dickinson. 2012. Optimal image and video closure by superpixelgrouping. International journal of computer vision 100, 1 (2012), 99–119.
[97] J. Lezama, K. Alahari, J. Sivic, and I. Laptev. 2011. Track to the future: Spatio-temporal video segmentation withlong-range motion cues. In CVPR 2011. 3369–3376.
[98] Fuxin Li, Taeyoung Kim, Ahmad Humayun, David Tsai, and James M. Rehg. 2014. Video Segmentation by TrackingMany Figure-Ground Segments. In IEEE International Conference on Computer Vision.
[99] Hongliang Li and King N Ngan. 2007. Automatic video segmentation and tracking for content-based applications.IEEE Communications Magazine 45, 1 (2007), 27–33.
[100] Jia Li, Anlin Zheng, Xiaowu Chen, and Bin Zhou. 2017. Primary video object segmentation via complementary cnnsand neighborhood reversible �ow. In Proceedings of the IEEE International Conference on Computer Vision. 1417–1425.
[101] Siyang Li, Bryan Seybold, Alexey Vorobyov, Alireza Fathi, Qin Huang, and C-C Jay Kuo. 2018. Instance embeddingtransfer to unsupervised video object segmentation. In Proceedings of the IEEE Conference on Computer Vision andPattern Recognition. 6526–6535.
[102] Xiaoxiao Li and Chen Change Loy. 2018. Video object segmentation with joint re-identi�cation and attention-awaremask propagation. In Proceedings of the European Conference on Computer Vision (ECCV). 90–105.
[103] Xi Li, Weiming Hu, Chunhua Shen, Zhongfei Zhang, Anthony Dick, and Anton Van Den Hengel. 2013. A survey ofappearance models in visual object tracking. ACM transactions on Intelligent Systems and Technology (TIST) 4, 4 (2013),58.
[104] Yin Li, Jian Sun, and Heung-Yeung Shum. 2005. Video object cut and paste. In ACM Transactions on Graphics (ToG),Vol. 24. ACM, 595–600.
[105] T. Lim, S. Hong, B. Han, and J. H. Han. 2013. Joint Segmentation and Pose Tracking of Human in Natural Videos. In2013 IEEE International Conference on Computer Vision. 833–840.
[106] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian Reid. 2017. Re�nenet: Multi-path re�nement networks forhigh-resolution semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition.1925–1934.
[107] Guosheng Lin, Chunhua Shen, Anton Van Den Hengel, and Ian Reid. 2018. Exploring context with deep structuredmodels for semantic segmentation. IEEE transactions on pattern analysis and machine intelligence 40, 6 (2018), 1352–1366.
[108] Xiao Liu, Dacheng Tao, Mingli Song, Ying Ruan, Chun Chen, and Jiajun Bu. 2014. Weakly supervised multiclassvideo segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 57–64.
[109] Yuqiang Liu, Kunfeng Wang, and Dayong Shen. 2016. Visual tracking based on dynamic coupled conditional random�eld model. IEEE Transactions on Intelligent Transportation Systems 17, 3 (2016), 822–833.
[110] Jonathan Long, Evan Shelhamer, and Trevor Darrell. 2015. Fully convolutional networks for semantic segmentation.In Proceedings of the IEEE conference on computer vision and pattern recognition. 3431–3440.
[111] B LUCAS. 1981. An iterative image registration technique with an application to stereo vision. Proc. of 7th IJCAI,1981 (1981).
[112] Jonathon Luiten, Paul Voigtlaender, and Bastian Leibe. 2018. Premvos: Proposal-generation, re�nement and mergingfor the davis challenge on video object segmentation 2018. In The 2018 DAVIS Challenge on Video Object Segmentation-CVPR Workshops.
[113] K. Maninis, S. Caelles, Y. Chen, J. Pont-Tuset, L. Leal-TaixÃľ, D. Cremers, and L. Van Gool. 2018. Video ObjectSegmentation Without Temporal Information. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018),1–1.
[114] Kevis-Kokitsi Maninis, Sergi Caelles, Jordi Pont-Tuset, and Luc Van Gool. 2018. Deep extreme cut: From extremepoints to object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.616–625.
[115] Nicolas Märki, Federico Perazzi, Oliver Wang, and Alexander Sorkine-Hornung. 2016. Bilateral space video segmen-tation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 743–751.
[116] Anton Milan, Laura Leal-Taixé, Ian Reid, Stefan Roth, and Konrad Schindler. 2016. MOT16: A benchmark formulti-object tracking. arXiv preprint arXiv:1603.00831 (2016).
[117] Anton Milan, Laura Leal-Taixé, Konrad Schindler, and Ian Reid. 2015. Joint tracking and segmentation of multipletargets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5397–5406.
[118] Amos Newswanger and Chenliang Xu. 2017. One-shot video object segmentation with iterative online �ne-tuning.In CVPR Workshop, Vol. 1.
[119] Peter Ochs and Thomas Brox. 2012. Higher order motion models and spectral clustering. In 2012 IEEE Conference onComputer Vision and Pattern Recognition. IEEE, 614–621.
[120] Dan Oneata, Jérôme Revaud, Jakob Verbeek, and Cordelia Schmid. 2014. Spatio-temporal object detection proposals.In European conference on computer vision. Springer, 737–752.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:36 R. Yao et al.
[121] Anestis Papazoglou and Vittorio Ferrari. 2014. Fast Object Segmentation in Unconstrained Video. In IEEE InternationalConference on Computer Vision.
[122] Konstantinos Papoutsakis and Antonis Argyros. 2013. Integrating tracking with �ne object segmentation. Image andVision Computing 31 (10 2013), 771–785.
[123] Nikos Paragios and Rachid Deriche. 2000. Geodesic active contours and level sets for the detection and tracking ofmoving objects. IEEE Transactions on pattern analysis and machine intelligence 22, 3 (2000), 266–280.
[124] Ioannis Patras, Emile A Hendriks, and Reginald L Lagendijk. 2003. Semi-automatic object-based video segmentationwith labeling of color segments. Signal Processing: Image Communication 18, 1 (2003), 51–65.
[125] Federico Perazzi, Anna Khoreva, Rodrigo Benenson, Bernt Schiele, and Alexander Sorkine-Hornung. 2017. Learningvideo object segmentation from static images. In Computer Vision and Pattern Recognition, Vol. 2.
[126] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung.2016. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition. 724–732.
[127] Federico Perazzi, Oliver Wang, Markus Gross, and Alexander Sorkine-Hornung. 2015. Fully connected objectproposals for video segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Vol. 2015Inter. 3227–3234.
[128] Ochs Peter, Malik Jitendra, and Brox Thomas. 2014. Segmentation of Moving Objects by Long Term Video Analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence 36, 6 (2014), 1187–1200.
[129] Jordi Pont-Tuset, Miquel A Farré, and Aljoscha Smolic. 2015. Semi-automatic video object segmentation by advancedmanipulation of segmentation hierarchies. In 2015 13th International Workshop on Content-Based Multimedia Indexing(CBMI). IEEE, 1–6.
[130] Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. 2017.The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017).
[131] Alessandro Prest, Christian Leistner, Javier Civera, Cordelia Schmid, and Vittorio Ferrari. 2012. Learning object classdetectors from weakly annotated video. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE,3282–3289.
[132] Brian L Price, Bryan S Morse, and Scott Cohen. 2009. Livecut: Learning-based interactive video segmentation byevaluation of multiple propagated cues. In 2009 IEEE 12th International Conference on Computer Vision. IEEE, 779–786.
[133] Esa Rahtu, Juho Kannala, Mikko Salo, and Janne Heikkilä. 2010. Segmenting salient objects from images and videos.In European conference on computer vision. Springer, 366–379.
[134] Xiaofeng Ren and Jitendra Malik. 2003. Learning a classi�cation model for segmentation. In null. IEEE, 10.[135] X. Ren and J. Malik. 2007. Tracking as Repeated Figure/Ground Segmentation. In 2007 IEEE Conference on Computer
Vision and Pattern Recognition. 1–8.[136] Ying Ren, Chin-Seng Chua, and Yeong-Khing Ho. 2003. Statistical background modeling for non-stationary camera.
Pattern Recognition Letters 24, 1-3 (2003), 183–196.[137] Matthias Reso, Björn Scheuermann, Jörn Jachalsky, Bodo Rosenhahn, and Jörn Ostermann. 2014. Interactive
segmentation of high-resolution video content using temporally coherent superpixels and graph cut. In InternationalSymposium on Visual Computing. Springer, 281–292.
[138] Mrigank Rochan, Linwei Ye, and Yang Wang. 2018. Video summarization using fully convolutional sequence networks.In Proceedings of the European Conference on Computer Vision (ECCV). 347–363.
[139] David A Ross, Jongwoo Lim, Ruei-Sung Lin, and Ming-Hsuan Yang. 2008. Incremental learning for robust visualtracking. International journal of computer vision 77, 1-3 (2008), 125–141.
[140] Carsten Rother, Vladimir Kolmogorov, and Andrew Blake. 2004. Grabcut: Interactive foreground extraction usingiterated graph cuts. In ACM transactions on graphics (TOG), Vol. 23. ACM, 309–314.
[141] Martin Schiegg, Philipp Hanslovsky, Carsten Haubold, Ullrich Koethe, Lars Hufnagel, and Fred A Hamprecht. 2014.Graphical model for joint segmentation and tracking of multiple dividing cells. Bioinformatics 31, 6 (2014), 948–956.
[142] Falk Schubert, Daniele Casaburo, Dirk Dickmanns, and Vasileios Belagiannis. 2015. Revisiting robust visual trackingusing pixel-wise posteriors. In International Conference on Computer Vision Systems. Springer, 275–288.
[143] Naveen Shankar Nagaraja, Frank R Schmidt, and Thomas Brox. 2015. Video segmentation with just a few strokes. InProceedings of the IEEE International Conference on Computer Vision. 3235–3243.
[144] Gilad Sharir, Eddie Smolyansky, and Itamar Friedman. 2017. Video object segmentation using tracked object proposals.arXiv preprint arXiv:1707.06545 (2017).
[145] Jianbo Shi and J. Malik. 1998. Motion segmentation and tracking using normalized cuts. In Sixth InternationalConference on Computer Vision (IEEE Cat. No.98CH36271). 1154–1160.
[146] Jianbo Shi and Jitendra Malik. 2000. Normalized Cuts and Image Segmentation. IEEE Transactions on Pattern Analysisand Machine Intelligence 8 (2000), 888–905.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:37
[147] Jae Shin Yoon, Francois Rameau, Junsik Kim, Seokju Lee, Seunghak Shin, and In So Kweon. 2017. Pixel-level matchingfor video object segmentation using convolutional neural networks. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. 2167–2176.
[148] Jeany Son, Ilchae Jung, Kayoung Park, and Bohyung Han. 2015. Tracking-by-segmentation with online gradientboosting decision tree. In Proceedings of the IEEE International Conference on Computer Vision. 3056–3064.
[149] Hongmei Song, Wenguan Wang, Sanyuan Zhao, Jianbing Shen, and Kin-Man Lam. 2018. Pyramid dilated deeperConvLSTM for video salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV).715–731.
[150] Xiaomu Song and Guoliang Fan. 2007. Selecting salient frames for spatiotemporal video modeling and segmentation.IEEE Transactions on Image Processing 16, 12 (2007), 3035–3046.
[151] Chris Stau�er and W. Eric L. Grimson. 2000. Learning patterns of activity using real-time tracking. IEEE Transactionson pattern analysis and machine intelligence 22, 8 (2000), 747–757.
[152] Andrew Stein, Derek Hoiem, and Martial Hebert. 2007. Learning to Find Object Boundaries Using Motion Cues. In2007 IEEE 11th International Conference on Computer Vision. IEEE, 1–8.
[153] Narayanan Sundaram, Thomas Brox, and Kurt Keutzer. 2010. Dense point trajectories by GPU-accelerated largedisplacement optical �ow. In European conference on computer vision. Springer, 438–451.
[154] Patrik Sundberg, Thomas Brox, Michael Maire, Pablo Arbeláez, and Jitendra Malik. 2011. Occlusion boundarydetection and �gure/ground assignment from optical �ow. In CVPR 2011. IEEE, 2233–2240.
[155] Kevin Tang, Rahul Sukthankar, Jay Yagnik, and Li Fei-Fei. 2013. Discriminative segment annotation in weakly labeledvideo. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2483–2490.
[156] Zhao Tao, Nevatia Ram, and Wu Bo. 2008. Segmentation and tracking of multiple humans in crowded environments.IEEE Transactions on Pattern Analysis and Machine Intelligence 30, 7 (2008), 1198–1211.
[157] Brian Taylor, Vasiliy Karasev, and Stefano Soatto. 2015. Causal video object segmentation from persistence ofocclusions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4268–4276.
[158] Henning Tjaden, Ulrich Schwanecke, and Elmar Schömer. 2016. Real-time monocular segmentation and pose trackingof multiple objects. In European conference on computer vision. Springer, 423–438.
[159] Pavel Tokmakov, Karteek Alahari, and Cordelia Schmid. 2017. Learning motion patterns in videos. In Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition. 3386–3394.
[160] Pavel Tokmakov, Karteek Alahari, and Cordelia Schmid. 2017. Learning video object segmentation with visualmemory. arXiv preprint arXiv:1704.05737 3 (2017).
[161] Philip HS Torr and Andrew Zisserman. 1998. Concerning Bayesian motion segmentation, model averaging, matchingand the trifocal tensor. In European Conference on Computer Vision. Springer, 511–527.
[162] David Tsai, Matthew Flagg, Atsushi Nakazawa, and James M. Rehg. 2012. Motion Coherent Tracking Using Multi-labelMRF Optimization. International Journal of Computer Vision 100, 2 (01 Nov 2012), 190–202.
[163] Yi-Hsuan Tsai, Ming-Hsuan Yang, and Michael J Black. 2016. Video segmentation via object �ow. In Proceedings ofthe IEEE conference on computer vision and pattern recognition. 3899–3908.
[164] Yi-Hsuan Tsai, Guangyu Zhong, and Ming-Hsuan Yang. 2016. Semantic co-segmentation in videos. In EuropeanConference on Computer Vision. Springer, 760–775.
[165] Sepehr Valipour, Mennatullah Siam, Martin Jagersand, and Nilanjan Ray. 2017. Recurrent fully convolutional networksfor video segmentation. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on. IEEE, 29–36.
[166] Sudheendra Vijayanarasimhan, Susanna Ricco, Cordelia Schmid, Rahul Sukthankar, and Katerina Fragkiadaki. 2017.Sfm-net: Learning of structure and motion from video. arXiv preprint arXiv:1704.07804 (2017).
[167] Paul Voigtlaender and Bastian Leibe. 2017. Online adaptation of convolutional neural networks for video objectsegmentation. In Proc. BMVC.
[168] Tomas Vojir and Jiri Matas. 2017. Pixel-wise object segmentations for the VOT 2016 dataset. Research ReportCTU-CMP-2017–01, Center for Machine Perception, Czech Technical University, Prague, Czech Republic (2017).
[169] Demin Wang. 1998. Unsupervised video segmentation based on watersheds and temporal tracking. IEEE Transactionson Circuits and Systems for video Technology 8, 5 (1998), 539–546.
[170] Huiling Wang, Tapani Raiko, Lasse Lensu, Tinghuai Wang, and Juha Karhunen. 2016. Semi-supervised domainadaptation for weakly labeled semantic video object segmentation. In Asian conference on computer vision. Springer,163–179.
[171] Huiling Wang and Tinghuai Wang. 2016. Primary object discovery and segmentation in videos via graph-basedtransductive inference. Computer Vision and Image Understanding 143 (2016), 159–172.
[172] Jue Wang, Pravin Bhat, R Alex Colburn, Maneesh Agrawala, and Michael F Cohen. 2005. Interactive video cutout. InACM Transactions on Graphics (ToG), Vol. 24. ACM, 585–594.
[173] Jue Wang, Yingqing Xu, Heung-Yeung Shum, and Michael F Cohen. 2004. Video tooning. In ACM Transactions onGraphics (ToG), Vol. 23. ACM, 574–583.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

1:38 R. Yao et al.
[174] Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, and Philip HS Torr. 2018. Fast Online Object Tracking andSegmentation: A Unifying Approach. arXiv preprint arXiv:1812.05050 (2018).
[175] Shu Wang, Huchuan Lu, Fan Yang, and Ming-Hsuan Yang. 2011. Superpixel tracking. In Proceedings of the 2011International Conference on Computer Vision. IEEE Computer Society, 1323–1330.
[176] Tinghuai Wang, Bo Han, and John Collomosse. 2014. Touchcut: Fast image and video segmentation using single-touchinteraction. Computer Vision and Image Understanding 120 (2014), 14–30.
[177] Weijun Wang and Ramakant Nevatia. 2013. Robust Object Tracking Using Constellation Model with Superpixel.In Proceedings of the 11th Asian Conference on Computer Vision - Volume Part III (ACCV’12). Springer-Verlag, Berlin,Heidelberg, 191–204.
[178] Wenguan Wang, Jianbing Shen, and Fatih Porikli. 2015. Saliency-aware geodesic video object segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition. 3395–3402.
[179] Wenguan Wang, Jianbing Shen, and Fatih Porikli. 2017. Selective video object cutout. IEEE Transactions on ImageProcessing 26, 12 (2017), 5645–5655.
[180] Wenguan Wang, Jianbing Shen, Jianwen Xie, and Fatih Porikli. 2017. Super-Trajectory for Video Segmentation. InComputer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 1680–1688.
[181] Wenguan Wang, Hongmei Song, Shuyang Zhao, Jianbing Shen, Sanyuan Zhao, Steven Chu Hong Hoi, and HaibinLing. 2019. Learning Unsupervised Video Object Segmentation through Visual Attention. In IEEE Conference onComputer Vision and Pattern Recognition (CVPR).
[182] Zhenhua Wang, Jiali Jin, Tong Liu, Sheng Liu, Jianhua Zhang, Shengyong Chen, Zhen Zhang, Dongyan Guo,and Zhanpeng Shao. Understanding human activities in videos: A joint action and interaction learning approach.Neurocomputing 321, 2019 (????), 216–226.
[183] Zhenhua Wang, Liu Sheng, Jianhua Zhang, Shengyong Chen, and Guan Qiu. 2017. A Spatio-temporal CRF for HumanInteraction Understanding. IEEE Transactions on Circuits and Systems for Video Technology 27, 8 (2017), 1647–1660.
[184] Longyin Wen, Dawei Du, Zhen Lei, Stan Z Li, and Ming-Hsuan Yang. 2015. Jots: Joint online tracking and segmentation.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2226–2234.
[185] Christopher Richard Wren, Ali Azarbayejani, Trevor Darrell, and Alex Paul Pentland. 1997. P�nder: Real-timetracking of the human body. IEEE Transactions on pattern analysis and machine intelligence 19, 7 (1997), 780–785.
[186] Bo Wu and Ram Nevatia. 2009. Detection and segmentation of multiple, partially occluded objects by grouping,merging, assigning part detection responses. International journal of computer vision 82, 2 (2009), 185–204.
[187] Yi Wu, Jongwoo Lim, and Ming-Hsuan Yang. 2013. Online object tracking: A benchmark. In Proceedings of the IEEEconference on computer vision and pattern recognition. 2411–2418.
[188] Yi Wu, Jongwoo Lim, and Ming Hsuan Yang. 2015. Object Tracking Benchmark. IEEE Transactions on Pattern Analysisand Machine Intelligence 37, 9 (2015), 1834–1848.
[189] Zhengyang Wu, Fuxin Li, Rahul Sukthankar, and James M Rehg. 2015. Robust video segment proposals with painlessocclusion handling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4194–4203.
[190] Seoung Wug Oh, Joon-Young Lee, Kalyan Sunkavalli, and Seon Joo Kim. 2018. Fast video object segmentation byreference-guided mask propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.7376–7385.
[191] Fanyi Xiao and Yong Jae Lee. 2016. Track and segment: An iterative unsupervised approach for video object proposals.In Proceedings of the IEEE conference on computer vision and pattern recognition. 933–942.
[192] Huaxin Xiao, Jiashi Feng, Guosheng Lin, Yu Liu, and Maojun Zhang. 2018. MoNet: Deep Motion Exploitationfor Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.1140–1148.
[193] SHI Xingjian, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. 2015. ConvolutionalLSTM network: A machine learning approach for precipitation nowcasting. InAdvances in neural information processingsystems. 802–810.
[194] Ning Xu, Brian Price, Scott Cohen, Jimei Yang, and Thomas S Huang. 2016. Deep interactive object selection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 373–381.
[195] Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, andThomas Huang. 2018. YouTube-VOS: Sequence-to-Sequence Video Object Segmentation. In The European Conferenceon Computer Vision (ECCV).
[196] Jiong Yang, Brian Price, Xiaohui Shen, Zhe Lin, and Junsong Yuan. 2016. Fast appearance modeling for automaticprimary video object segmentation. IEEE Transactions on Image Processing 25, 2 (2016), 503–515.
[197] Linjie Yang, Yanran Wang, Xuehan Xiong, Jianchao Yang, and Aggelos K Katsaggelos. 2018. E�cient video objectsegmentation via network modulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.6499–6507.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.

Video Object Segmentation and Tracking: A Survey 1:39
[198] Rui Yang, Bingbing Ni, Chao Ma, Yi Xu, and Xiaokang Yang. 2017. Video segmentation via multiple granularityanalysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3010–3019.
[199] Rui Yao, Guosheng Lin, Chunhua Shen, Yanning Zhang, and Qinfeng Shi. 2018. Semantics-Aware Visual ObjectTracking. IEEE Transactions on Circuits and Systems for Video Technology (2018), 1–1.
[200] Rui Yao, Qinfeng Shi, Chunhua Shen, Yanning Zhang, and Anton van den Hengel. 2012. Robust tracking withweighted online structured learning. In European Conference on Computer Vision. Springer, 158–172.
[201] Rui Yao, Qinfeng Shi, Chunhua Shen, Yanning Zhang, and Anton van den Hengel. 2017. Part-based robust trackingusing online latent structured learning. IEEE Transactions on Circuits and Systems for Video Technology 27, 6 (2017),1235–1248.
[202] Rui Yao, Shixiong Xia, Zhen Zhang, and Yanning Zhang. 2017. Real-time correlation �lter tracking by e�cient densebelief propagation with structure preserving. IEEE Transactions on Multimedia 19, 4 (2017), 772–784.
[203] Donghun Yeo, Jeany Son, Bohyung Han, and Joon Hee Han. 2017. Superpixel-based tracking-by-segmentation usingmarkov chains. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 511–520.
[204] Alper Yilmaz, Omar Javed, and Mubarak Shah. 2006. Object tracking: A survey. Acm computing surveys (CSUR) 38, 4(2006), 13.
[205] Dong Zhang, Omar Javed, and Mubarak Shah. 2013. Video object segmentation through spatially accurate andtemporally dense extraction of primary object regions. In Proceedings of the IEEE conference on computer vision andpattern recognition. 628–635.
[206] Yu Zhang, Xiaowu Chen, Jia Li, Chen Wang, and Changqun Xia. 2015. Semantic object segmentation via detection inweakly labeled video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3641–3649.
[207] Zongpu Zhang, Yang Hua, Tao Song, Zhengui Xue, Ruhui Ma, Neil Robertson, and Haibing Guan. 2018. Tracking-assisted Weakly Supervised Online Visual Object Segmentation in Unconstrained Videos. In 2018 ACM MultimediaConference on Multimedia Conference. ACM, 941–949.
[208] Tianyi Zhou and Dacheng Tao. 2013. Shifted subspaces tracking on sparse outlier for motion segmentation. InProceedings of the Twenty-Third international joint conference on Arti�cial Intelligence. AAAI Press, 1946–1952.
, Vol. 1, No. 1, Article 1. Publication date: January 2019.







