Seminar Paper: Use of Hough Forests for Object Detection, Tracking and Action Recognition
A Competitive Neural Network for Multiple Object Tracking in Video Sequence Analysis
25
Neural Processing Letters A competitive neural network for multiple object tracking in video sequence analysis --Manuscript Draft-- Manuscript Number: Full Title: A competitive neural network for multiple object tracking in video sequence analysis Article Type: SI: Iwann 2011 Keywords: growing competitive neural networks; feature weigthing; multiple object tracking Corresponding Author: Rafael Marcos Luque-Baena, Ph.D. University of Malaga Malaga, SPAIN Corresponding Author Secondary Information: Corresponding Author's Institution: University of Malaga Corresponding Author's Secondary Institution: First Author: Rafael Marcos Luque-Baena, Ph.D. First Author Secondary Information: Order of Authors: Rafael Marcos Luque-Baena, Ph.D. Juan Miguel Ortiz-de-Lazcano-Lobato, Dr. Ezequiel López-Rubio, Dr. Enrique Domínguez, Dr. Esteban José Palomo, Ph.D. Order of Authors Secondary Information: Abstract: Tracking of moving objects in real situation is a challenging research issue, due to dynamic changes in objects or background appearance, illumination, shape and occlusions. In this paper, we address with these difficulties by incorporating an adaptive feature weighting mechanism to the proposed growing competitive neural network for multiple objects tracking. The neural network takes the advantage of the most relevant object features (information provided by the proposed adaptive feature weighting mechanism) in order to estimate the trajectories of the moving objects. The feature selection mechanism is based on a genetic algorithm, and the tracking algorithm is based on a growing competitive neural network where each unit is associated to each object in the scene. The proposed methods (object tracking and feature selection mechanism) are applied to detect the trajectories of moving vehicles in roads. Experimental results show the performance of the proposed system compared to the standard Kalman filter. Powered by Editorial Manager® and Preprint Manager® from Aries Systems Corporation
Transcript of A Competitive Neural Network for Multiple Object Tracking in Video Sequence Analysis

Neural Processing Letters
A competitive neural network for multiple object tracking in video sequence analysis--Manuscript Draft--
Manuscript Number:
Full Title: A competitive neural network for multiple object tracking in video sequence analysis
Article Type: SI: Iwann 2011
Keywords: growing competitive neural networks; feature weigthing; multiple object tracking
Corresponding Author: Rafael Marcos Luque-Baena, Ph.D.University of MalagaMalaga, SPAIN
Corresponding Author SecondaryInformation:
Corresponding Author's Institution: University of Malaga
Corresponding Author's SecondaryInstitution:
First Author: Rafael Marcos Luque-Baena, Ph.D.
First Author Secondary Information:
Order of Authors: Rafael Marcos Luque-Baena, Ph.D.
Juan Miguel Ortiz-de-Lazcano-Lobato, Dr.
Ezequiel López-Rubio, Dr.
Enrique Domínguez, Dr.
Esteban José Palomo, Ph.D.
Order of Authors Secondary Information:
Abstract: Tracking of moving objects in real situation is a challenging research issue, due todynamic changes in objects or background appearance, illumination, shape andocclusions. In this paper, we address with these difficulties by incorporating anadaptive feature weighting mechanism to the proposed growing competitive neuralnetwork for multiple objects tracking. The neural network takes the advantage of themost relevant object features (information provided by the proposed adaptive featureweighting mechanism) in order to estimate the trajectories of the moving objects. Thefeature selection mechanism is based on a genetic algorithm, and the trackingalgorithm is based on a growing competitive neural network where each unit isassociated to each object in the scene. The proposed methods (object tracking andfeature selection mechanism) are applied to detect the trajectories of moving vehiclesin roads. Experimental results show the performance of the proposed systemcompared to the standard Kalman filter.
Powered by Editorial Manager® and Preprint Manager® from Aries Systems Corporation

Neural Processing Letters manuscript No.(will be inserted by the editor)
A competitive neural network for multiple object
tracking in video sequence analysis
Rafael M. Luque-Baena · Juan M.
Ortiz-de-Lazcano-Lobato · Ezequiel
Lopez-Rubio · Enrique Domınguez ·
Esteban J. Palomo
Received: date / Accepted: date
Abstract Tracking of moving objects in real situation is a challenging re-search issue, due to dynamic changes in objects or background appearance,illumination, shape and occlusions. In this paper, we address with these dif-ficulties by incorporating an adaptive feature weighting mechanism to theproposed growing competitive neural network for multiple objects tracking.The neural network takes the advantage of the most relevant object features(information provided by the proposed adaptive feature weighting mechanism)in order to estimate the trajectories of the moving objects. The feature selec-tion mechanism is based on a genetic algorithm, and the tracking algorithmis based on a growing competitive neural network where each unit is associ-ated to each object in the scene. The proposed methods (object tracking andfeature selection mechanism) are applied to detect the trajectories of movingvehicles in roads. Experimental results show the performance of the proposedsystem compared to the standard Kalman filter.
1 Introduction
Object tracking is a fundamental problem in computer vision and serves alot of attention because its performance is key to achieving a correct inter-pretation of the observed scene [1,7,15,21]. This is of paramount importancein many applications such as video surveillance, human-computer interaction,smart rooms and medical imaging. Tracking algorithms are developed to faith-fully determine the movement of objects in each video frame that matcheswith the given targets. The matching function should consider the object and
Rafael M. Luque-Baena · Juan M. Ortiz-de-Lazcano-Lobato · Ezequiel Lopez-Rubio · En-rique Domınguez · Esteban J. PalomoDepartment of Computer Languages and Computer ScienceBulevar Louis Pasteur, 35. 29071 Malaga. Spain.University of Malagarmluque,jmortiz,ezeqlr,enriqued,[email protected]
ManuscriptClick here to download Manuscript: main.tex Click here to view linked References

2
background dynamics in order to identify the targets effectively in each videoframe. In general, developing a robust tracker is a challenging problem due tochanges in appearance, dynamic changes in background, significant illumina-tion variations, occlusions and scale changes. Fast and robust color segmen-tation algorithms have been developed to detect and track objects in thesescenarios [11,5,19,12]. Tracking mechanism needs the motion analysis of thetarget behavior and is one of the most important but problematic features ofmotion analysis and understanding. In real scenarios, the target objects andits local surroundings in the video sequences change significantly, which affectsthe success of any tracking algorithm. Also, the absence of prior knowledge ofthe object or background dynamics further increases the complexity. Hence,developing robust tracker to handle the aforementioned issues has been thefocus of most recent object tracking research.
A number of the proposed approaches are based on the traditional Kalmanfilter to predict the positions of the target objects [3,4]. These approaches onprediction and tracking assume that the behavior of a moving target could becharacterized by a predefined model. However, in real situations these modelsfail to characterize the motion of moving targets accurately when there areocclusions caused by other objects or sudden changes in the trajectory of themotion [8]. Traditional feature-based methods, such as those based on color[6,16] or motion blobs [24], perform tracking by maintaining a simple model ofthe target and adapting that model over time. Many features can be added tothe color of the regions in order to improve the reliability of these algorithms.However, it is difficult for a human to manually determine which features arethe most significant in order to ensure a proper tracking of the moving objectsin complex environments.
In this paper, we propose a principled method to obtain a good weighting ofthe object features by means of a genetic algorithm. This allows us to designan appropriate scaling of the feature space, so that unsupervised learningapproaches can operate efficiently. In addition to this, a growing competitiveneural network (GCNN) is presented, which works in combination with thefeature weighting mechanism. Each unit of the network represents a potentialobject in the scene, and unit creation and destruction rules are described, soas to cope with entering and exiting objects.
The structure of this paper is as follows. First the proposed growing com-petitive neural network (GCNN) is presented in section 2. In the next section,a detailed feature analysis for object tracking is discussed. Then, an adaptivefeature selection using genetic algorithms is described in section 4 for improv-ing the performance of the GCNN proposal. Experimental results comparingthe proposed feature weighting mechanisms are provided in section 5. Finally,the conclusions of this work are outlined in Section 6.

3
Algorithm 1: Main steps of the tracking algorithm.
Input: Time instant t and the features of the segmented objects xi(t)Output: Labelling of the segmented objectsforeach Segmented object xi(t) do
Compute winner neuron by means of Eq. (6);if Eq. (8) is satisfied then
Create a new neuron. Initialize it;else
Update the network using equation Eq. (7);end
end
Refresh the counter values belonging to the neurons which win a competition;Decrement the counters of all neurons by one;Check out neuron counters and destroy neurons whose counter value is zero;
2 Growing Competitive Neural Network
The start point of any tracking approach requires the extracted data fromobject detection algorithms, which is achieved by applying some methods [21,14,13]. These extracted features represent each object in each frame and arethe inputs of the tracking module, whose aim is to track the detected objectsalong the sequence. In this paper, the tracking stage is based on a growingcompetitive neural network (GCNN), which follows an online training processbased on a prediction-correction scheme.
The number of neurons of the network is not fixed, and it is related to theamount of objects which must be tracked by the system in each time instant.Every object appearing in the video frame is assigned to a neuron, which isthe responsible for identifying and representing that object exclusively. Newneurons are created when not previously detected objects appear in the image,whereas some neurons are destroyed when the objects associated to them leavethe scene.
It is also desirable that most of the pitfalls related to the object trackingstage can be tackled and solved by the network. Some of these problems arethose produced by object occlusion, and those due to some deficiencies in thesegmentation phase, such as the appearance of spurious objects in the middleof the video frame and the sudden disappearance of objects which shouldremain in the scene several frames later.
In algorithm 1 the main steps of the algorithm are shown. Each step isdescribed more thoroughly in the following sections.
2.1 Prediction-Correction Scheme
The proposed neural network is designed to follow a prediction-correctionscheme during the training process. In the competition step every neuron pre-dict the new state of the object that it is assigned to it. That is, where theobject it is supposed to be in the current frame and how it is to be like, in

4
terms of shape and colour. Each feature vector corresponding to objects thatappear in the current frame is compared with the estimated feature vectorsof the neurons. The neuron with the most accurate prediction is eligible asthe winner. In the update step the winner neuron is the only neuron able touse the object feature vector to correct the knowledge it has learnt, as it isexplained later.
In order to calculate the object prediction the memory capacity of theneurons has been augmented. Each neuron, j, stores a log, Hj , which containsK entries with the known information about the object assigned to the neuronin some previous video frames. Every time an object is detected the currentfeature vector that represents it, Hw
j , and the frame in which the detection
happens, Hfj , are kept in the log of the neuron Hj =
(
Hwj , H
fj
)
.
The estimated pattern xj(t) is obtained by summing the current objectpattern, stored in the weight vector of the neuron, and an estimated changevector. This vector depends on the difference between the current frame t andthe last frame in which the neuron was updated, and also on the averagedchange observed in that pattern and computed for the last P ≤ K entries inthe log,
xj(t) = wj(t− 1) +(
t−Hwj (K)
)
K−1∑
i=K−P+1
Hwj (i+ 1)−Hw
j (i)
Hfj (i+ 1)−H
fj (i)
(1)
with Hwj (i) the object feature vector which was written down in the log of
the j-th neuron in the frame Hfj (i). P is a user parameter which determines
the number of log entries that are used for the object prediction and allows toadapt the prediction to the requirements of the specific application. Besides,low values of P allow to speed up the computation of the prediction.
Notice that the frame which appears in the last entry of the log is the lastframe in which the neuron was updated and, consequently, its weight vectorwas modified.
2.2 Competition Step
Object tracking is a task which must be solved in real time. Therefore, thetracking system must be able to run in an online way. In a time instant t thesystem is provided M D-dimensional training patterns xi(t), i ∈ 1 . . .Mcorresponding to M objects which were detected in the video frame sampledin time instant t. Those feature vectors are managed in sequence and for eachone a competition arises.
In the competition step, every time an input pattern xi(t) is provided tothe network a competition process among the neurons starts. Each neuronpredicts a feature vector for the object it represents. This predicted featurevector represents the expected state of the object in the current frame t. The

5
neuron whose predicted vector xj(t) is the nearest in the input space to theinput pattern is declared the winner:
c(t) = arg min1≤j≤N
‖xi(t)− xj(t)‖2 (2)
with xj(t) computed by means of equation (1)The proposed neural model also tries to detect which components of an
object feature vector are more reliable when we want to identify it. For thatpurpose the inverse of the standard deviation of the time difference of the datastored in the log is used
rjz(t) =1
var(
Hwjz(t)−Hw
jz(t− 1))1/2
(3)
where Hwjz(t) is the z-th component of the feature vector Hw
j (t). The varianceis estimated as follows:
var(
Hwjz(t)−Hw
jz(t− 1))
= E[
(
(Hwjz(t)−Hw
jz(t− 1))−mjz(t))2]
(4)
=1
K
K∑
h=1
((Hwjz(t− h)−Hw
jz(t− h− 1))−mjz(t))2
where mjz(t) is the expectation of the difference
mjz(t) = E[
Hwjz(t)−Hw
jz(t− 1)]
=1
K
K∑
h=1
(Hwjz(t− h)−Hw
jz(t− h− 1)) (5)
These measures for each component of an object feature vector xj(t) are joinedto form a vector of reliabilities rj(t).
A mask vector m ∈ [0, 1]D, with D dimension of the input space, has beenadded in order to let the users choose a weight for the object componentsbased on their expert knowledge. A justified discussion about the integrationof this mask into a competitive neural network is provided in subsection 2.5.
Finally the resulting competition rule obtained when m and rj(t) are in-cluded is
c(t) = arg min1≤j≤N
‖m rj(t) (x(t)− xj(t))‖2 (6)
where stands for the componentwise product, also called Hadamard product.
2.3 Update Step
The neuron c(x(t)) which wins the competition for x(t) is the only one whichupdates its weight vector to include the knowledge extracted from x(t)
wi(t) =
wi(t− 1) +α (xt −wj(t− 1)) if i = c(x(t))wi(t− 1) otherwise
(7)

6
where α ∈ [0, 1]D is named the learning rate vector and determines how im-portant is the information extracted from the current input sample is withrespect to the background information that the neuron already known fromprevious training steps.
The proposed solution considers that each neuron represents an object inthe frame and tracks this object through the input space frame by frame. Thelearning rate α should be fixed to a large value, for example 0.9. Otherwise,the network cannot adequately detect changes in the object, and thus, theobject may not be identified. Hence, the cluster defined by each neuron notonly encloses different object patterns in the frame, but also possible variationsof the object pattern.
2.4 Neurons Birth and Death
The size of the neural network layer should not be fixed a priori because thenumber of objects which are present in the scene varies from one frame toanother. Hence, the proposed network is formed by n(t) neurons in a timeinstant t, and a mechanism to add new neurons to the network and to removethe useless neurons is needed.
When an unknown object appears in the scene, none of the existing neuronsis able to represent it accurately and the quantisation error is expected to reacha high value, compared with the error obtained for correctly identified objects.Thus, a new neuron should be created in order to track that new object. A user-defined parameter δ ∈ [0, 1] has been utilised. It is related to the maximumrelative error permitted in the quantisation process. The parameter δ managesthe neurons birth by means of the check
∀j ∈ 1 . . . n(t)‖x(t)− xj(t)‖
‖x(t)‖> δ (8)
with xj(t) computed by equation (1).Notice that if δ is assigned a low value, then (8) ensures that the neurons
are updated only if the input pattern x(t) is very close to wj(t) in the inputspace. That is, when x(t) and wj(t) are patterns representing the same objectin different frames.
Once the neuron is created, its memory structures are initialised. The inputpattern responsible for the birth of the neuron is assigned to the weight vectorof the neuron and to the first entry in the neuron log.
wj(t) = x(t) ; Hj(1) = x(t) (9)
On the other hand, if an object leaves the scene then the neuron whichrepresents it should be destroyed. For this purpose, each neuron has a counterCdie which stands for the time to live of the neuron, measured in number oftraining steps, i.e., frames. Each training step, the counter value is decreasedby one and, if the value reaches zero then the corresponding neuron is removed.Every time a neuron wins a competition its counter value is changed to the

7
initial value. Therefore, only neurons associated to objects which are no longerin the scene are destroyed, since it is very unlikely for these neurons to win acompetition.
2.5 Component Weighting
The introduction of a mask as a way to select the relative weights of eachcomponent of the input samples of the proposed competitive neural networkcan be justified as follows. The energy function of our competitive neuralnetwork can be written as
E =1
2T
N∑
i=1
T∑
t=1
uit ‖m (wi − x (t))‖2 (10)
wherem ∈ [0, 1]Dis the vector which controls the relative weight of each of the
D components of the input samples x (t), and uit ∈ 0, 1 are binary variableswhich indicate whether unit i is the winner for input vector x (t):
uit = 1 iff i = arg mink∈1,..,N
m (wk − x (t)) (11)
The learning rule can be obtained by considering the derivative of E withrespect to the prototype vector wi and then using gradient descent:
∂E
∂wi=
1
T
N∑
i=1
T∑
t=1
uitm m (wi − x (t)) (12)
wi (t+ 1) = wi (t) +α (x (t)−wi (t)) (13)
where the vector learning rate α is controlled by the relative weight vector m:
α = α0uitm m (14)
If we take the derivative of the energy function E with respect to eachcomponent of the relative weight vector m we get:
∂E
∂mj=
1
T
N∑
i=1
T∑
t=1
uitmj (wij − xj (t))2
(15)
The above equation reveals that the variation of the energy function whenwe change the relative weight mj is directly proportional to the squared dif-ferences of values in the j-th coordinate among the input samples and theprototype vectors. That is, mj is related to the j-th coordinate of the inputsamples in the energy function E which the proposed competitive neural net-work tries to minimize. Hence, the selection of m made manually or by anyother type of computational technique deeply influences the behavior of thecompetitive neural network.

8
3 Feature Analysis
The centroid or center of mass of the object has been the most used featureto track objects in the scene. Thus, it is rather intuitive to determine theidentity of an object frame by frame, by analysing its position in the sceneand comparing it with the previous one. Statistical models as the Kalmanfilter take into account only this information to predict the position where theobject will be in the next frame t + 1. After extracting the features of theobjects detected in the new frame, a search over a narrow window centered inthe object centroid is performed, in order to find the previous tracked object.If it is found, its trajectory in the Kalman model is corrected by using the newretrieved centroid.
This simple and general technique could have difficulties when it faces withocclusions between various objects or intersections in their trajectories. It ispossible that two people in movement in a scene meet, begin a dialogue andafter a few seconds in a fixed position, keep walking or change their initialtrajectories. Note that the Kalman model computes the next position of theobject using only information from the previous frame, so that after a waitingperiod in a specific place, the identification of the objects can easily fail. Thesame case occurs in a traffic sequence where two adjacent vehicles stop at atraffic light. Therefore, the information of the object centroid is consideredinsufficient to determine the identity of the objects at the critical moments ofcross or overlap.
In this approach, a initial set of features which could be considered usefulin the tracking process is extracted for each segmented object. The aim is tofind features which satisfy:
– To be stable and robust over time, either due to they are constant or whichvary according to a known model (linear or non-linear).
– To provide the maximum difference between two objects of the scene, i.e.to be discriminant.
It should be noted that there are features that can be very stable but itsvalue is equal or very similar for all objects in the scene. It is important that,to some extent, both requirements fulfill.
Seven features have been selected to incorporate in our GCNN approach:the median centroid CL1 of the object, its median color m and its dimensionsd. Let Oj be the object or blob in movement which consists of N pixels whereOj = pi | i ∈ N. Each pixel is defined as pi = (xi, ci), with xi as theposition of the i− th pixel in the image, and ci its color.
Let CL1 be the coordinates of the L1-median centroid:
CL1 = argminx
∑
y∈blob
‖x− y‖ (16)
where x ∈ R2 and y = (x, y) are the coordinates in the image. We use the
L1-median as the centroid of each object because the mean, which is themost usual choice, is not robust. Hence, when spurious pixels appear in the

9
segmentation of the objects, the mean is heavily affected by this error, whilethe L1-median remains in the middle of the object. This effect is more acutewhen the spurious pixels appear only in one part of the object, that is, whenthey are not evenly distributed over the contour.
Since the Euclidean distance used in the RGB color space does not corre-spond to the differences in color which are actually perceived, a transformationof the object pixels to the Lab color space is performed. This color space is con-sidered as a perceptually uniform space [17]. This statement implies that theEuclidean distance between two colors in this new space is strongly correlatedwith the human visual perception. The color median m for each extractedblob in the scene, is defined as follow:
∀j ∈ L, a, b,mj = mediancij | i ∈ blob (17)
m = (mL,ma,mb) (18)
where ci is the color of the i− th pixel and mL, ma, mb are the object medianfor each component of the Lab color space.
The dimensions d represent the width and height of an object, and areobtained by:
dw = maxxi | i ∈ blob −minxi | i ∈ blob (19)
dh = maxyi | i ∈ blob −minyi | i ∈ blob (20)
where the origin of coordinates is in the upper left corner of the image. Sincethe inputs of the GCNN model should be in the range [0 . . . 1], both the L1-median centroid as the dimensions are normalized using the image size of thescene.
The main difficulty is to measure how important the selected features arein order to track objects. An analysis of this issue is visualized in Figures 1and 2. Four traffic sequences have been utilized to show the evolution of thechosen features along time over several selected vehicles.
The first row of both figures shows the trajectory of each object drawnon the background of the scene. Note that although the objects really do notappear in the sequence at the same time, we have made to coincide theirtrajectories to measure in a fair way the discrimination power of each featurein the process of identifying objects. It is observable that the segmentationmask generated by the object detection algorithm is not perfect. It is visuallyclear that the silhouette of an object varies from a frame to another despite thefact that we are dealing with rigid objects. Thus, these irregularities affect themeasures for each feature, as it can be observed in the color and dimensionssigns (third and fourth rows). Nevertheless, the centroid is rather robust tothis noise, getting a cleaner signal and without significant alterations for eachobject. With regard to the object discrimination, note that the Y coordinate(rows of the image) has a minor variation than the X coordinate (columns ofthe image) in Figure 1 (second row), which suggest that the importance of thefirst one is higher than the second in the tracking process. This situation is the

10
Trajectories
23
91
67
Trajectories
71
82
81
0 10 20 30 40 50 600
100
200
300
400
500
600
700Centroid signals
Time
Pos
ition
X23
Y23
X91
Y91
X67
Y67
0 5 10 15 20 25 30 35 400
100
200
300
400
500
600
700Centroid signals
Time
Pos
ition
X71
Y71
X82
Y82
X81
Y81
0 10 20 30 40 50 60
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
0.65Normalized Color Signals
Time
Gre
y to
ne
L23
a23
b23
L91
a91
b91
L67
a67
b67
0 5 10 15 20 25 30 35 400.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75Normalized Color Signals
Time
Gre
y to
ne
L71
a71
b71
L82
a82
b82
L81
a81
b81
0 10 20 30 40 50 600
0.2
0.4
0.6
0.8
1
Dimension Signals
Time
Siz
e
X23
Y23
X91
Y91
X67
Y67
0 5 10 15 20 25 30 35 400
0.2
0.4
0.6
0.8
1
Dimension Signals
Time
Siz
e
X71
Y71
X82
Y82
X81
Y81
Fig. 1 Feature analysis over a set of motion objects along traffic sequences. The first rowshows the lankershim and US-101 highways with the trajectories of several vehicles. Thecentroid, normalized color and dimensions signals can be found in the following rows (second,third and fourth, respectively) It is evident the amount of noise of color and dimensionssignals whereas it should be noted the stability and robustness of the centroid measures.

11
Trajectories
61
32Trajectories
60 44 21
0 20 40 60 80 1000
50
100
150
200
250
300
350
400
450
500Centroid signals
Time
Pos
ition
X61
Y61
X32
Y32
0 20 40 60 80 100 1200
100
200
300
400
500
600
700Centroid signals
Time
Pos
ition
X60
Y60
X44
Y44
X21
Y21
0 20 40 60 80 1000.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8Normalized Color Signals
Time
Gre
y to
ne
L61
a61
b61
L32
a32
b32
0 20 40 60 80 100 1200
0.1
0.2
0.3
0.4
0.5
0.6
0.7Normalized Color Signals
Time
Gre
y to
ne
L60
a60
b60
L44
a44
b44
L21
a21
b21
0 20 40 60 80 1000
0.2
0.4
0.6
0.8
1
Dimension Signals
Time
Siz
e
X61
Y61
X32
Y32
0 20 40 60 80 100 1200
0.2
0.4
0.6
0.8
1
Dimension Signals
Time
Siz
e
X60
Y60
X44
Y44
X21
Y21
Fig. 2 Feature analysis over another traffic scene recorded with the camera in differentpositions and angles. The first row shows the peachtree highway using different recordingpositions with several vehicles moving along it. The second, third and fourth rows are asso-ciated to the centroid, normalized color and dimensions signals. Note that the dimensionsfeatures have little capacity of object discrimination according to the displayed signals.

12
opposite in the case of Figure 2, where the scene of the first column shows howthe variation in the X coordinate is less abrupt, providing more informationin the identification process.
Apart from the noise, the dimension signal seems to be quite similar for allthe analyzed objects, mainly in Figure 1 (last row), and it could be consideredunhelpful as discriminant feature. This conclusion is logical because we aretracking objects that have, in the case of the studied scenes, similar sizes, whichindicates that the use of the dimensions is implausible for the identificationprocess. The color signal has a different behavior for the displayed objects,whose variation is significant from some objects to others (third row of Figure2). However its stability is quite poor, and it can be seen these signs intersectin multiple frames due to the noise and the segmentation, which is not perfect.
Therefore, it can be deduced that the most important feature is the cen-troid, because of its stability along the time and its ability of discrimination.However, it is possible that the color information can also be useful on oc-casions where the centroids of the object are very close or their trajectoriescross. As we have observed, the importance of characteristics varies dependingon each scene. Consequently, a fixed or default value may not be sufficientlyappropriate for a correct tracking process. The use of genetic algorithms de-scribed in Section 4 allow to discover a feature weighting mask adapted tothe scene, improving the performance of the GCNN proposal. In the experi-mental results (Section 5) a comparison of the tracking method using fair orpredefined masks with those generated by the genetic algorithm is performed.
4 Feature Weighting Mechanism using Genetic Algorithms
The use of a set of features to represent an object can help to reinforce andimprove the object tracking. However, the influence which a specific featurehas in the tracking depends on several factors such as the sequence quality, thebehaviour of the objects in the scene and the results in the object segmentationstage. Thus, an equitable weighting mask with the same importance of all thefeatures in the tracking process is not always suitable. In fact, this task is moreand more critical when the number of features gets increase.
Genetic algorithms (GAs) are applied to achieve automatically a suitableweighting of the features in the tracking process. This technique has beenwidely used as parameter selection and tuning in combination with neuralnetworks [10]. Although this can be a time-consuming technique, the GA isapplied at the first frames of the sequence, with the aim of getting a weightingmask for the input features of the GCNN approach. The generation of thisoptimum mask is perform in parallel together with the normal execution ofthe GCNN tracking. While the genetic algorithm is working, the GCNN modelapplies a equally mask to weight the input features. When the GA is complete,the initial mask is replaced by the mask adapted to the scene. This reducesresources and time complexity, getting better tracking rates in the following

13
frames of the sequence. This process is repeated from time to time in order tothe weighting mask can adjust to any changes occurring in the scene.
4.1 Evolutionary Strategy
Genetic algorithms [18,20,23] are a class of optimisation procedures inspiredby the biological mechanisms of reproduction. In this kind of optimisationproblems, a fitness function f(x) should be maximised or minimised over agiven space X of arbitrary dimension. In this case, the fitness function tryto discover the best weighting of features, in order to provide a suitable andreliable object tracking. Since the variables are real numbers associated tothe relevance of object features such as dimensions, bounding box or color,an exhaustive search in X is unfeasible due to the great amount of possiblecombinations to evaluate.
Three basic genetic operators guide this search from an initial popula-tion: selection, crossover, and mutation. The genetic search process is iterative:evaluating, selecting, and recombining strings in the population during each( generation) until reaching some termination condition. Two stopping criteriaare considered. The first one is the maximum number of generations, whereasthe second one is the number of generations in which no improvement is ob-tained. In this approach, the first number is assigned to 300 and the secondto 50. In most cases, the GA converges in less than 300 generations.
4.1.1 Encoding and Initial Population
A simple encoding scheme to represent as much as possible the search spaceis employed, in which the chromosome is a double vector whose length is de-termined by the number of features extracted. Each variable i is associatedwith one position in the vector which represents its relevance, Ri ∈ (0, 1), withregard to the whole set of features. A lower value for the ith feature impliesthat its importance is relatively low in the tracking process. Each chromosomerepresents a different feature subset to evaluate. As initial population the rel-evance of the features for each chromosome is randomly generated with therequirement of
N∑
i=1
Ri = 1 (21)
where N is the total number of features. In all of our experiments, we used apopulation size of 50 individuals.
4.1.2 Selection
The selection function chooses parents for the next generation by favouringfitter candidates over weaker ones. A strategy based on roulette wheel anduniform sampling was applied [2], which involves mapping the individuals in

14
contiguous segments of a line, such that each individual segment is equal insize to its fitness value.
Furthermore, it is rather advisable to retain the chromosomes with thebest fitness values for the next generation. These individuals are called elitechildren. In these experiments, an elite count value of 5 is selected.
4.1.3 Crossover and Mutation
Different crossover strategies are used to generate variation in the chromosomeprogramming from one generation to other. In this case, a one-point crossoverstrategy is applied, in which we combine each of the parties obtained fromone parent, with the opposite associated with the other parent. We chose thisstrategy because the number of features extracted from objects is not toohigh. Otherwise, we could make use of variations of this strategy based ontwo, three, or N points. After the crossover process, it is necessary to weighthe new characteristics in order to satisfy the criteria described in the equation(21), because it is not possible to ensure that the sum of the importance of thevariables is one. Therefore, a normalization procedure is carried out for eachvariable Rj of the child chromosome:
R′j =Rj
∑Ni=1
Ri
(22)
After this process, we can assure that the sum of the Rj features is one.The probability of performing the crossover process in a population is fixed,whose value in our approach is 0.7.
As well as recombination, a mutation operator to alter one or more of thevariables of a chromosome is considered, with the aim of providing diversity inthe population. The mutation probability is assigned to one less the crossoverprobability. The proposed mutation strategy involves modifying one of thechromosome variables, chosen randomly among the whole set. This variableRi takes the random value λ ∈ (0, 1). Finally, it is necessary to weight thechromosome as we did in the equation (22), but in this case with the consid-eration of not modifying the value of the mutated variable. The new value ofeach variable Rk is:
R′k =Rk
∑Ni=1,i6=j Ri
(23)
where the Rk variable corresponds to any chromosome variable except for themutated variable Rj .
4.1.4 Fitness function
In this kind of optimisation problems, a fitness function F(m) should be max-imised or minimised over a given space X of arbitrary dimension. The fitnessfunction assesses each chromosome in the population so that it may be ranked

15
against all the other chromosomes. In this approach, the fitness function indi-cates how good the chosen feature weighting mask is. Because of the fact thatcorrect trajectories of the objects in the scene are not provided, it is necessaryto model a heuristic function which represents the committed error by thetracking algorithm. The objective of the GA is to minimise this function.
Let M be the incidence matrix of dimensions p× q, where p is the numberof tracked objects and q the number of detected objects by the segmentationphase. Each cell bij is a binary value which represents a matching between twoelements. The ideal incidence matrix matches all the tracked and segmentedobjects as a bijective function one by one. Thus, both the number of segmentedobjects not associated to any tracked objects or associated to more than one(M), and the number of tracked objects with no matching or more than one tothe segmented objects (N) are penalised in the fitness function. A mechanismto avoid penalising correctly predicted trajectories in the terms M and N isincluded. It should be noted that M and N are obtained over the completetraining set.
Let Li be the record of the centroid of an object i, defined as
Li = (xt, yt)|t ∈ 1 . . .K (24)
where K is the last occurrence of the object in the scene, xt and yt are thecoordinates of the centroid of the object i in the occurrence t. Let Di be thederivative of the previousHi function which represents the centroid differencesframe by frame
Di =δLi
δt(25)
Let Dm be the median of the differences Di, a trajectory swap (TS) happenswhen it is satisfied
|Di(K)−Dm| > T (26)
where T is a threshold to regulate the change variation. The value of TS willbe incremented every time the previous equation fulfils. Finally the fitnessfunction is defined as follows
F(m) = N +M + λTS (27)
where λ reflects the penalising value of the trajectory swap term. In our ap-proach, the T and λ constants are assigned to 40 and 25 respectively.
5 Experimental Results
In this section an analysis of the tracking results obtained by our approach isdone. In order to carry out the study, several sequences in which the objectsare considered as rigid objects are selected. Both real and hand-generated se-quences are taken into account. Thus, typical traffic sequences provided by avideo surveillance online repository are used, generated by the Federal High-way Administration (FHWA) under the Next Generation Simulation (NGSIM)
16
0 10 20 30 40 50 60 70 80 90 100
0
100
200
300
400
500
600
Frame
Err
or
GCNN−Eq.GCNN−AdHocGCNN−PCAGCNN−FAGCNN−GAKalman
(a)
1
2
3
4
5
6
7
(b)
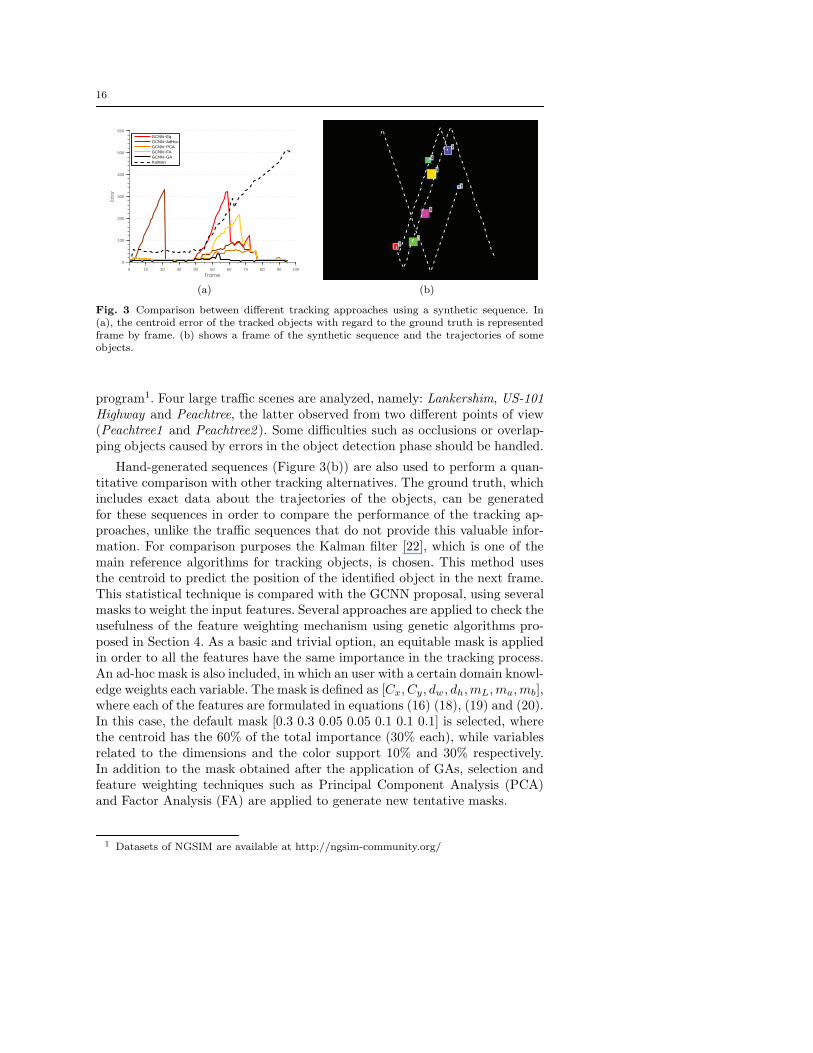
Fig. 3 Comparison between different tracking approaches using a synthetic sequence. In(a), the centroid error of the tracked objects with regard to the ground truth is representedframe by frame. (b) shows a frame of the synthetic sequence and the trajectories of someobjects.
program1. Four large traffic scenes are analyzed, namely: Lankershim, US-101Highway and Peachtree, the latter observed from two different points of view(Peachtree1 and Peachtree2 ). Some difficulties such as occlusions or overlap-ping objects caused by errors in the object detection phase should be handled.
Hand-generated sequences (Figure 3(b)) are also used to perform a quan-titative comparison with other tracking alternatives. The ground truth, whichincludes exact data about the trajectories of the objects, can be generatedfor these sequences in order to compare the performance of the tracking ap-proaches, unlike the traffic sequences that do not provide this valuable infor-mation. For comparison purposes the Kalman filter [22], which is one of themain reference algorithms for tracking objects, is chosen. This method usesthe centroid to predict the position of the identified object in the next frame.This statistical technique is compared with the GCNN proposal, using severalmasks to weight the input features. Several approaches are applied to check theusefulness of the feature weighting mechanism using genetic algorithms pro-posed in Section 4. As a basic and trivial option, an equitable mask is appliedin order to all the features have the same importance in the tracking process.An ad-hoc mask is also included, in which an user with a certain domain knowl-edge weights each variable. The mask is defined as [Cx, Cy, dw, dh,mL,ma,mb],where each of the features are formulated in equations (16) (18), (19) and (20).In this case, the default mask [0.3 0.3 0.05 0.05 0.1 0.1 0.1] is selected, wherethe centroid has the 60% of the total importance (30% each), while variablesrelated to the dimensions and the color support 10% and 30% respectively.In addition to the mask obtained after the application of GAs, selection andfeature weighting techniques such as Principal Component Analysis (PCA)and Factor Analysis (FA) are applied to generate new tentative masks.
1 Datasets of NGSIM are available at http://ngsim-community.org/

17
5.1 PCA and Factor Analysis
The PCA technique converts a set of observations of D possibly correlatedvariables xj into a set of values of Q ≤ D linearly uncorrelated variables zicalled principal components.
z1 = a11x1 + a12x2 + ...+ a1DxD
z2 = a21x1 + a22x2 + ...+ a2DxD
...
zQ = aQ1x1 + aQ2x2 + ...+ aQDxD
where each aij , i = 1, 2, ..., Q; j = 1, 2, ..., D is known as a component coeffi-cients or loadings.
The principal components are computed to be orthogonal to each other,and they are ordered so that the first few retain most of the variation presentin all of the original variables.
For a given component zithe absolute value of the loading aij correspondingto the xj variable can be seen as an estimation of the variable contribution tothe component [9]. In data sets of almost uncorrelated variables each factorloading for a particular component is near to 0, except for one of its loadingsthat has a value near to 1. Therefore the normalized vector comprising thefactor loadings for a principal components can be used as a feature weightingestimation.
miPCA =
ai
‖ai‖1
with ai = [ai1, ai2, ..., aiD]The more appropriate principal component to be used for that purpose is
the first one, because it preserves the greatest amount of variance of the wholedata set. Normally, this component explains the global relationship among theoriginal variables. Those variables that have loadings a1jwith greater absolute
Method Mean Error Max. Error No. spurious objs No. mixed trajs
Kalman 26.72 59.57 2 2
GCNN-Eq. 2.99 11.93 19 0
GCNN-AdHoc 3.88 32.31 10 0
GCNN-PCA 1.78 5.75 19 0
GCNN-FA 2.50 8.41 20 0
GCNN-GA 1.26 2.34 0 0
Table 1 Comparative analysis of the success rate among the studied methods for the se-quence observed in Figure 3(b).

18
Mask
Method Cx Cy dw dh mL ma mb
GCNN-Eq. 1
7
1
7
1
7
1
7
1
7
1
7
1
7
GCNN-AdHoc 0.3 0.3 0.05 0.05 0.1 0.1 0.1
GCNN-PCA 0.02 0.08 0.14 0.14 0.23 0.18 0.21
GCNN-FA 0.02 0.19 0.18 0.17 0.18 0.15 0.11
GCNN-GA 0.62 0.31 0.02 0.03 0.00 0.01 0.01
Table 2 Masks obtained by the different alternatives in order to be applied to the GCNNmodel. These masks are associated to the Figure 3(b). It should be noted the importanceof the centroid features in the best approach (GCNN-GA).
values are the most meaningful and can be used to discriminate. Thus, thefeature weighting vector mPCA = m1
PCAwas used in the experiments.On the other hand, FA attempts to express D original variables as a linear
function of Q < D variables called common factors.
x1 = λ11f1 + λ12f2 + ...+ λ1QfQ + e1
x2 = λ21f1 + λ22f2 + ...+ λ2QfQ + e2
...
xD = λD1f1 + λD2f2 + ...+ λDQfQ + eD
where λjk.j = 1, 2, ..., D; k = 1, 2, ..., Q are constants called the factor loadingsand ej , j = 1, 2, ..., D are error terms that captures the percentage of thevariance present in variable j that has not been explained by the factor model[9].
The proposed feature weighting mask provided by this method is based onthe error terms of the factor model. Meaningful variables are better explainedby the model and, thus, their corresponding error terms are low in relation toless important variables.
miFA =
λiFA
∥
∥λiFA
∥
∥
1
where i is the number of factors that has been selected for the underlyingmodel and λ
iFA = [1−e1, 1−e2, ..., 1−eD]. In the experiments, a factor model
with a dimensionality of 3 was choosen to obtain the mask vector mFA =m3
FAbecause models with less factors did not capture adequately the datastructure.
In Figure 3(a), the errors in the coordinates of the centroid obtained byseveral algorithms at each frame are shown. The closer to the x-coordinatethe curve, the better the tracking. In Table 1 the mean and maximum errorsof each trajectory are calculated for each algorithm. The last two columns

19
3
9
10
12
13
20
28
34
39
42
44
47
50
(a)
3
7
9
10
12
13
23
43
47
51
56
61
62
(b)
3
7
9
1217
32
53
65
68
70
79
80
81
(c)
1
3
9
10
12
13
17
18
19
20
21
23
24
(d)
Fig. 4 Analysis of different feature weighting mechanisms over the Lankershim scene inthe competitive approach. The tracking results are showed in: (a) using a mask to weightthe features equally; (b), (c) and (d) from the masks provided by the FA, PCA and GAtechniques respectively. Yellow and green boxes correspond to spurious and correctly trackedobjects, respectively. Some objects and their trajectories are showed in red.
0 100 200 300 400 500 600 700 800 900 1000
0
10
20
30
40
50
60
70
80
Frame
Fitn
ess
Eq.AdHocPCAFAGA
Fig. 5 Quantitative results after applying different feature weighting strategies in theGCNN approach, measured by an heuristic function. The analyzed sequence is Lankershim(Figure 4). The closer to zero, the better the tracking performance.

20
168
272
280
290
293
301
302
308
322
329
332336
338
(a)
453
458
467
490
495
505
513
520
561
569
573
579
581
(b)
385
390
396
416
430
432
439
445
476
482487
489
490
(c)
6
17
37
44
48
65
80
81
83
8485
86
87
(d)
Fig. 6 The same analysis as in Figure 4 but on the sequence Peachtree2. The results afterapplying the mask obtained equally and by the FA, PCA and GA strategies, can be observedin (b), (c) and (d), respectively.
0 100 200 300 400 500 600 700 800 900 1000
0
5
10
15
20
25
30
35
Frame
Fitn
ess
EqAdHocPCAFAGA
Fig. 7 Quantitative results after analyzing the Peachtree2 sequence using different featureweighting strategies. The closer to zero, the better the tracking performance.

21
represent the number of the spurious objects that appear in the scene andthe number of mixed trajectories. It happens when two different objects swaptheir trajectories. This situation is undesirable, since the analysis of each tra-jectory will be done incorrectly. As we can observe, the greatest errors occurin the last frames of the Kalman curve because of the confusion between twotrajectories. The use of our GCNN approach solves the problem of the trajec-tory confusion, but generates a large number of spurious objects when simplemasks (equitable and ad-hoc) are applied, and even with those ones obtainedby PCA and FA. The feature weighting mechanism based on genetic algorithms(GCNN-GA) avoids the appearance of spurious objects, hereby improving con-siderably the results of the tracking process. In Table 2, the weighting masksfor each proposed alternative are showed. By analyzing the mask obtained bythe GCNN-GA proposal, it is noted that the importance of the centroid is sig-nificantly high in the analyzed synthetic scene, with more than the 90% of thetotal importance. The remaining masks differ largely in the weights assignedto the centroid features, which justify the large number of spurious objectsthat appear using these alternatives.
In Figures 4 and 6, a qualitative comparison of the GCNN algorithm withdifferent masks for the sequences Lankershim and Peachtree2 is outlined. Forthis purpose, it is graphically shown the result of the tracking process, whichis frozen until a specific frame. From left to right and from top to bottom, wehave used an equitable mask and several masks generated after applying FA,PCA and GA, respectively. Figures 4(a), 4(b) and 4(c) highlight the amountof spurious objects which appear in the scene (yellow boxes). Although thetracking is effective, its complexity could raise because of the increase of pro-cessed objects along the time. Unlike this approach, the GCNN-GA strategy(Figures 4(d) and 6(d)) succeeds in a better resource management, with fewspurious objects and longer trajectories. The object reduction is particularlyevident in the Peachtree2 sequence (Figure 6), since the vehicle numberingindicates that the GCNN-GA model needs a smaller number of objects toperform the tracking stage. Furthermore, some occlusions caused by trees inthe scene are well-solved by the GCNN-GA method, as it is showed in the cartrajectories with ID 1 and 19, respectively (Figure 4(d)). In order to evaluatequantitatively the performance of the methods over the test sequences, theheuristic defined in equation 27 is considered. The results can be analyzed inFigures 5 and 7, showing the heuristic values frame to frame. The closer tozero the value, the better the tracking process according to defined heuristics.It may be noted that the GCNN-GA proposal is which performs better in bothscenes.
The masks generated by GA techniques, PCA and FA for the previousfigures can be found in Table 3, in conjunction with the sequences those onesobtained for US-101 Highway and Peachtree1.
PCA and FA give more importance to the centroid coordinate correspond-ing to the movement direction. That is the coordinate that presents a greatervariance because the cars tend to remain in the same lane, and the othercoordinate is considered dispensable. Though that strategy is optimal for rep-
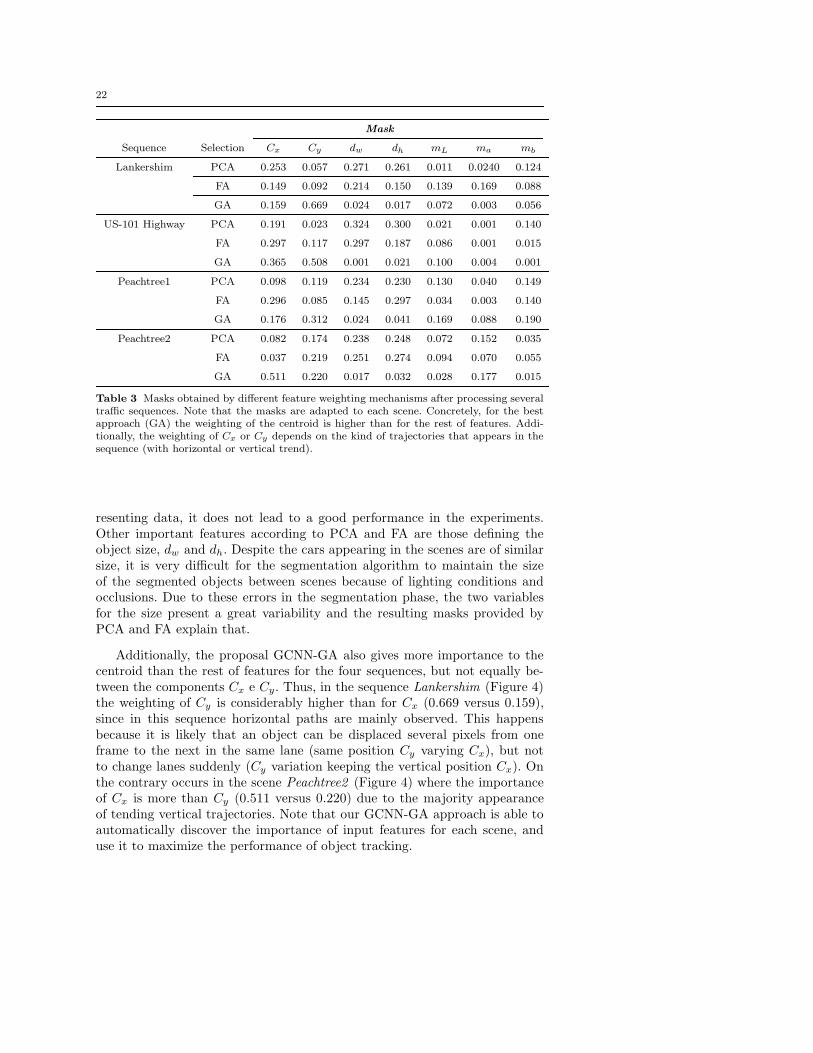
22
Mask
Sequence Selection Cx Cy dw dh mL ma mb
Lankershim PCA 0.253 0.057 0.271 0.261 0.011 0.0240 0.124
FA 0.149 0.092 0.214 0.150 0.139 0.169 0.088
GA 0.159 0.669 0.024 0.017 0.072 0.003 0.056
US-101 Highway PCA 0.191 0.023 0.324 0.300 0.021 0.001 0.140
FA 0.297 0.117 0.297 0.187 0.086 0.001 0.015
GA 0.365 0.508 0.001 0.021 0.100 0.004 0.001
Peachtree1 PCA 0.098 0.119 0.234 0.230 0.130 0.040 0.149
FA 0.296 0.085 0.145 0.297 0.034 0.003 0.140
GA 0.176 0.312 0.024 0.041 0.169 0.088 0.190
Peachtree2 PCA 0.082 0.174 0.238 0.248 0.072 0.152 0.035
FA 0.037 0.219 0.251 0.274 0.094 0.070 0.055
GA 0.511 0.220 0.017 0.032 0.028 0.177 0.015
Table 3 Masks obtained by different feature weighting mechanisms after processing severaltraffic sequences. Note that the masks are adapted to each scene. Concretely, for the bestapproach (GA) the weighting of the centroid is higher than for the rest of features. Addi-tionally, the weighting of Cx or Cy depends on the kind of trajectories that appears in thesequence (with horizontal or vertical trend).
resenting data, it does not lead to a good performance in the experiments.Other important features according to PCA and FA are those defining theobject size, dw and dh. Despite the cars appearing in the scenes are of similarsize, it is very difficult for the segmentation algorithm to maintain the sizeof the segmented objects between scenes because of lighting conditions andocclusions. Due to these errors in the segmentation phase, the two variablesfor the size present a great variability and the resulting masks provided byPCA and FA explain that.
Additionally, the proposal GCNN-GA also gives more importance to thecentroid than the rest of features for the four sequences, but not equally be-tween the components Cx e Cy. Thus, in the sequence Lankershim (Figure 4)the weighting of Cy is considerably higher than for Cx (0.669 versus 0.159),since in this sequence horizontal paths are mainly observed. This happensbecause it is likely that an object can be displaced several pixels from oneframe to the next in the same lane (same position Cy varying Cx), but notto change lanes suddenly (Cy variation keeping the vertical position Cx). Onthe contrary occurs in the scene Peachtree2 (Figure 4) where the importanceof Cx is more than Cy (0.511 versus 0.220) due to the majority appearanceof tending vertical trajectories. Note that our GCNN-GA approach is able toautomatically discover the importance of input features for each scene, anduse it to maximize the performance of object tracking.

23
6 Conclusions
A new algorithm for tracking of rigid objects in video sequences is presented.This approach is able to take advantage of the feature set extracted fromthe object detection process to perform a more effective tracking. It consistsin growing competitive neural networks in which the importance of the eachinput is computed by a feature weighting mechanism, which is based on geneticalgorithms.
The combination of the two approaches is more accurate and reliable, thusdiminishing the number of spurious objects and improving the resource man-agement in terms of complexity. Both real and hand-generated sequences areused to show the viability of the system, by comparing to other alternativessuch as the Kalman filter and alternative feature weighting techniques, includ-ing PCA and FA.
Acknowledgements This work is partially supported by the Ministry of Economy andCompetitiveness of Spain under grant TIN2011-24141, project name Detection of anoma-lous activities in video sequences by self-organizing neural systems, and the AutonomousGovernment of Andalusia (Spain) under project P12-TIC-6213, project name Developmentof Self-Organizing Neural Networks for Information Technologies.
References
1. Amer, A., Dubois, E., Mitiche, A.: Real-time system for high-level video representation:Application to video surveillance. In: Proceedings of the SPIE International Symposiumon Electronic Imaging, pp. 530–541 (2003)
2. Baker, J.E.: Reducing bias and inefficiency in the selection algorithm. In: Proceedingsof the Second International Conference on Genetic Algorithms on Genetic algorithmsand their application, pp. 14–21. L. Erlbaum Associates Inc. (1987)
3. Comaniciu, D., Ramesh, V.: Mean shift and optimal prediction for efficient object track-ing. In: IEEE Int. Conf. Image Processing (ICIP’00), pp. 70 – 73 (2000)
4. Comaniciu, D., Ramesh, V., Meer, P.: Real-time tracking of non-rigid objects usingmean shift. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 142– 149 (2000)
5. Culibrk, Marques, Socek, Kalva, Furht: Neural network approach to background mod-eling for video object segmentation. Neural Networks, IEEE Transactions on 18(6),1614–1627 (2007)
6. Grest, D., Koch, R.: Realtime multi-camera person tracking for immersive environments.In: IEEE 6th Workshop on Multimedia Signal Processing, pp. 387 – 390 (2004)
7. Haritaoglu, I., Harwood, D., Davis, L.: w4: Real-time surveillance of people and theiractivities. IEEE Trans. Pattern Anal. Mach. Intell 22(8), 809 – 830 (2000)
8. Jang, D., Jang, S., Choi, H.: 2d human body tracking with structural kalman filter.Pattern recognition 35, 2041 – 2049 (2002)
9. Jolliffe, I.T.: Principal Component Analysis, second edn. Springer (2002)10. Leung, F., Lam, H., Ling, S., Tam, P.: Tuning of the structure and parameters of a
neural network using an improved genetic algorithm. IEEE Transactions on NeuralNetworks 14(1), 79 – 88 (2003)
11. Liyuan, L., Huang, W., Gu, I., Tian, Q.: Statistical modeling of complex backgroundsfor foreground object detection. Image Processing, IEEE Transactions on 13(11), 1459–1472 (2004)
12. Lopez-Rubio, E., Luque-Baena, R.M., Dominguez, E.: Foreground detection in videosequences with probabilistic self-organizing maps. International Journal of Neural Sys-tems 21(3), 225 – 246 (2011)

24
13. Lopez-Rubio, E., Luque-Baena, R.M.: Stochastic approximation for background mod-elling. Computer Vision and Image Understanding 115(6), 735 – 749 (2011)
14. Luque, R., Dominguez, E., Palomo, E., Munoz, J.: An art-type network approach forvideo object detection. In: European Symposium on Artificial Neural Networks, pp.423–428 (2010)
15. Lv, F., Kang, J., Nevatia, R., Cohen, I., Medioni, G.: Automatic tracking and labelingof human activities in a video sequence. In: Proceedings of the 6th IEEE InternationalWorkshop on Performance Evaluation of Tracking and Surveillance (2004)
16. Nummiaro, K., Koller-Meier, E., Van Gool, L.: An adaptive color-based particle filter.Image Vision Comput. 21, 99 – 110 (2003)
17. Rautiainen, M., Ojala, T., Kauniskangas, H.: Detecting perceptual color changes fromsequential images for scene surveillance. IEICE Transactions on Information and Sys-tems E84D(12), 1676–1683 (2001)
18. Raymer, M., Punch, W., Goodman, E., Kuhn, L., Jain, A.: Dimensionality reductionusing genetic algorithms. IEEE Transactions on Evolutionary Computation 4(2), 164–171 (2000)
19. R.M. Luque E. Domınguez, E.P., Munoz, J.: A neural network approach for video ob-ject segmentation in traffic surveillance. In: Springer (ed.) Lecture Notes in ComputerScience, vol. 5112, pp. 151 – 158 (2008)
20. Siedlecki, W., Sklansky, J.: A note on genetic algorithms for large-scale feature selection.Pattern Recognition Letters 10(5), 335 – 347 (1989)
21. Stauffer, C., Grimson, W.: Learning patterns of activity using real time tracking. IEEETrans. Pattern Anal. Mach. Intell. 22(8), 747 – 767 (2000)
22. Welch, G., Bishop, G.: An introduction to the kalman filter. Tech. rep., Chapel Hill,NC, USA (1995)
23. Yang, J., Honavar, V.: Feature subset selection using a genetic algorithm. IntelligentSystems and their Applications, IEEE 13(2), 44–49 (1998)
24. Zhao, T., Nevatia, R.: Tracking multiple humans in complex situations. IEEE Trans.Pattern Anal. Mach. Intell. 26(9), 1208 – 1221 (2004)




![KLV-30MR1 - Error: [object Object]](https://static.fdokumen.com/doc/165x107/631786651e5d335f8d0a6a63/klv-30mr1-error-object-object.jpg)





