
The Blessing of Transformers in Translating Prose to Persian ...
16
Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry REZA KHANMOHAMMADI ∗ , University of Guilan, Iran MITRA SADAT MIRSHAFIEE ∗ , Alzahra University, Iran YAZDAN REZAEE JOURYABI, Shahid Beheshti University, Iran SEYED ABOLGHASEM MIRROSHANDEL, University of Guilan, Iran Persian Poetry has consistently expressed its philosophy, wisdom, speech, and rationale based on its couplets, making it an enigmatic language on its own to both native and non-native speakers. Nevertheless, the noticeable gap between Persian prose and poem has left the two pieces of literature medium-less. Having curated a parallel corpus of prose and their equivalent poems, we introduce a novel Neural Machine Translation (NMT) approach to translate prose to ancient Persian poetry using Transformer-based Language Models in an exceptionally low-resource setting. More specifically, we trained a Transformer model from scratch to obtain initial translations and pretrained different variations of BERT to obtain final translations. To address the challenge of using masked language modeling under poeticness criteria, we heuristically joined the two models and generated valid poems in terms of automatic and human assessments. Final results demonstrate the eligibility and creativity of our novel heuristically aided approach among Literature professionals and non-professionals in generating novel Persian poems. CCS Concepts: • Social and professional topics → Assistive technologies. Additional Key Words and Phrases: Machine Translation, Transformers, Persian Poetry, Low-resource Language ACM Reference Format: Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel. 2021. Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry. 1, 1 (November 2021), 16 pages. https://doi.org/XXX 1 INTRODUCTION The dawn of Persian Poetry dates back to almost 12 centuries ago when Rudaki, the founder of classical Persian/Farsi language and poetry, inaugurated a new literary pathway. As one of the most poetic languages globally, Persian has since witnessed chronological poets each contribute to its literature in their distinctive literary style, even though poems are generally written in a specific set of possible formats. According to Charles Baudelaire, a French poet, poetry serves as a bridge between the language of the universe and the universe of language. Historical events, emotions, reflections, objections, hopes, and dreams have been among different aspects involved in the cultural identities of ∗ Both authors contributed equally to the paper Authors’ addresses: Reza Khanmohammadi, [email protected], University of Guilan, Iran; Mitra Sadat Mirshafiee, mitra.mirshafi[email protected], Alzahra University, Iran; Yazdan Rezaee Jouryabi, [email protected], Shahid Beheshti University, Iran; Seyed Abolghasem Mirroshandel, [email protected], University of Guilan, Iran. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected]. © 2021 Association for Computing Machinery. Manuscript submitted to ACM Manuscript submitted to ACM 1 arXiv:2109.14934v3 [cs.CL] 27 Nov 2021
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of The Blessing of Transformers in Translating Prose to Persian ...

Prose2Poem: The Blessing of Transformers in Translating Prose to PersianPoetry
REZA KHANMOHAMMADI∗, University of Guilan, Iran
MITRA SADAT MIRSHAFIEE∗, Alzahra University, Iran
YAZDAN REZAEE JOURYABI, Shahid Beheshti University, Iran
SEYED ABOLGHASEM MIRROSHANDEL, University of Guilan, Iran
Persian Poetry has consistently expressed its philosophy, wisdom, speech, and rationale based on its couplets, making it an enigmaticlanguage on its own to both native and non-native speakers. Nevertheless, the noticeable gap between Persian prose and poem hasleft the two pieces of literature medium-less. Having curated a parallel corpus of prose and their equivalent poems, we introduce anovel Neural Machine Translation (NMT) approach to translate prose to ancient Persian poetry using Transformer-based LanguageModels in an exceptionally low-resource setting. More specifically, we trained a Transformer model from scratch to obtain initialtranslations and pretrained different variations of BERT to obtain final translations. To address the challenge of using masked languagemodeling under poeticness criteria, we heuristically joined the two models and generated valid poems in terms of automatic andhuman assessments. Final results demonstrate the eligibility and creativity of our novel heuristically aided approach among Literatureprofessionals and non-professionals in generating novel Persian poems.
CCS Concepts: • Social and professional topics → Assistive technologies.
Additional Key Words and Phrases: Machine Translation, Transformers, Persian Poetry, Low-resource Language
ACM Reference Format:Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel. 2021. Prose2Poem: TheBlessing of Transformers in Translating Prose to Persian Poetry. 1, 1 (November 2021), 16 pages. https://doi.org/XXX
1 INTRODUCTION
The dawn of Persian Poetry dates back to almost 12 centuries ago when Rudaki, the founder of classical Persian/Farsilanguage and poetry, inaugurated a new literary pathway. As one of the most poetic languages globally, Persian hassince witnessed chronological poets each contribute to its literature in their distinctive literary style, even thoughpoems are generally written in a specific set of possible formats. According to Charles Baudelaire, a French poet, poetryserves as a bridge between the language of the universe and the universe of language. Historical events, emotions,reflections, objections, hopes, and dreams have been among different aspects involved in the cultural identities of
∗Both authors contributed equally to the paper
Authors’ addresses: Reza Khanmohammadi, [email protected], University of Guilan, Iran; Mitra Sadat Mirshafiee, [email protected],Alzahra University, Iran; Yazdan Rezaee Jouryabi, [email protected], Shahid Beheshti University, Iran; Seyed Abolghasem Mirroshandel,[email protected], University of Guilan, Iran.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are notmade or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for componentsof this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or toredistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].© 2021 Association for Computing Machinery.Manuscript submitted to ACM
Manuscript submitted to ACM 1
arX
iv:2
109.
1493
4v3
[cs
.CL
] 2
7 N
ov 2
021

2 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
Persian poems. Hence, they are expected to convey rich and heavy loads of information by living up to LinguisticAesthetics’ expectations.
Nevertheless, Persian poetry cannot be easily comprehended. Besides its heavy literature, Figures of Speech such asMetaphor, Simile, Paradox, and Hyperbole are among the salient features that exert pressure on what can be bewilderingliterature even for native speakers and professionals [29, 39]. Additionally, factors affecting text generation can beindividually nonidentical since each poet has his/her own personal rhetoric style. In an analogy to Persian prose,wherein grammar is structurally defined, and the language is straightforward, poems are generally trying to describe aconcept using a creative language wherein sanely used irregular and anomalous speech is acceptable. The more literaryrules it wisely breaks, the more impressive it is.
Undeniably, the validity of poems is hard to assess and their generation can be no straightforward task. As ex-pected, relatively fewer studies have addressed the Poetry Generation task in Persian, whereas various Recurrent andTransformer-based approaches and baselines have been introduced in English [11, 23, 41]. Fortunately, pretrainedLanguage Models have recently step foot in Persian Natural Language Processing [10], and some initial work has solelyinvestigated the generative aspect of Persian Poetry [17]. In this work, we take a step forward by introducing a MachineTranslation approach called Prose2Poem to tackle the problem of generating Persian poems from prosaic text using anovel parallel corpus in a low-resource setting. Since translating such data will eventually output ancient poems, it isworth mentioning that our work is twofold, where one aspect is to translate and the other to generate valid poems.Building upon an Encoder-Decoder network, we overcome the first and design a heuristically aided Masked LanguageModel (MLM), which generates poems using a Beam Search decoder to face the latter. Additionally, we designed ourheuristic model to be adaptable to generate translated poems in six different formats of ancient Persian poetry, amongwhich the difference lies in where they locate rhymes in the hemistichs of a couplet. Namely, these formats are: Robaei,Ghazal, Ghasideh, Masnavi, Ghet’e, and Dobeiti.
Concisely, our contributions are as follows:
(1) We establish a firm baseline for the problem of Persian Prose to Poem translation.(2) We introduce two novel datasets to train and test our models.(3) A new method of low-resource NMT capable of better handling the unique nature of Persian poetry is developed.(4) We make both curated datasets and all implementation publicly available1 to aid further studies.
The rest of this paper is organized as follows: First, in section 2, we discuss the previous literature of Persian poetryand the bottlenecks of processing this natural language. Next, we break down our proposed method of NMT in section 3,including various subsections to delineate how we developed our approach. In section 4, we evaluate the results of ourexperimentation and provide several examples illustrating how our method can be applied to real-world circumstances.Finally, we conclude the paper in section 5.
2 PREVIOUS WORK
The applicability of Natural Language Processing (NLP)-related advancements in Poetry has long been a matter of debate.Since the essence of poetry is multifaceted, it makes our problem a laborious task to be computationally processed.Poems can be extremely rich in context [21] and very confusing for the machine to represent them [31]. Predictably,a vast majority of initial studies had to first analyze poetry’s core values such as Rhyme [18, 19], Meter [36], WordSimilarities [45], and Stresses [1] to gradually push the field towards better Poetic Machine Intelligence. Additionally,
1https://github.com/mitramir55/Prose2Poem
Manuscript submitted to ACM

Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 3
the generative aspect of poetry has also dedicated a substantial amount of literature to itself, and various approacheshave been introduced over the years [2, 4, 8, 11, 23, 41, 44] in which statistical, LSTM, Variational Autoencoders, andTransformer-based models were utilized. However, as many other NLP-related tasks have witnessed, the revolutionof Attention-based pretrained Language Models has also paved the way for further developments in this field. It isworth mentioning that a couple of studies have addressed the challenges of Poetry Generation in different settings.For instance, while Liu et al. [25] and Xu et al. [43] each introduced an approach of generating poems based on visualpoetic clues in English and Chinese, [26] developed the same but intended to better satisfied rhythmical expectations.
In terms of multilingualism, other languages with rich poetry literature such as Persian [3, 28], Spanish [12], Chinese[38, 42], Japanese [40], and Arabic [35] have also contributed to the field. More specifically, in Persian language, Asgariand Chappelier [3] were among the preliminary contributors of topic modeling in Persian Poetry. Years later, Moghadamand Panahbehagh [28] developed a method by which they extract patterns and arrange characters as seeds that willfurther be passed to an LSTM model. It is worth noting that pretrained Language Models have recently found their wayin Persian. Currently, there are different variations of BERT and GPT-2 model available in Persian; However, none hasserved as a Translation Model and have only had Poetry Generation use-cases.
3 PROPOSED METHOD
Machine Translation tasks are heavily dependent on parallel datasets, and because no such Persian datasets are available,we found this a great opportunity to curate a parallel set of prose and poems for tackling the problem. Generally, validpoetry-related sources are extremely rare; nevertheless, among available resources, didarejan2 is a parallel source thathappens to have matched simple Persian prose to semantically similar Ghazal poems written by ancient Persian poets,such as Hafez, Saadi, and Molana (Rumi). Curating this dataset is the first step to developing a Machine Translationmodel.
We break down our translation task into three stages. First, we generate an Initial translation of the input proseusing conventional NMT approaches. Then, to cover up the generated text’s poetic flaws and shortcomings, we add twoadditional stages to address the problem using MLM. To do this, we designed a heuristic in stage 2 to map an initialtranslation to a set of masked sequences with which our pretrained MLMs will generate a Final Translation in stagethree.
3.1 Initial Translation
In terms of standard architectures used in Translation Models (TMs), Encoder/Decoder models are among the oldest con-tributing architectures for sequence-to-sequence (Seq2Seq) problems. Besides, when based on the attention mechanism,such models can also overcome the challenge of decoding long input sequences and vanishing gradients. Furthermore,by applying the mechanism multiple times as one of the most significant parts of a Transformer Architecture, oneallows for wider ranges of attention span. That said, we initially tackle our domain-specific translation task by traininga Recurrent model, an Attention-based Encoder-Decoder model, and a Transformer-based Encoder-Decoder model onour parallel corpus. Given set 𝑋1:𝑎 = {𝑥1, ..., 𝑥𝑎} as input prose with 𝑎 length of words, we have defined our Seq2Seqmodels as functions that map 𝑋1:𝑎 input words to 𝐼1:𝑚 target words as an initial translation (Equation 1).
𝑓 : 𝑋1:𝑎 → 𝐼1:𝑚 (1)
2https://didarejan.com/
Manuscript submitted to ACM
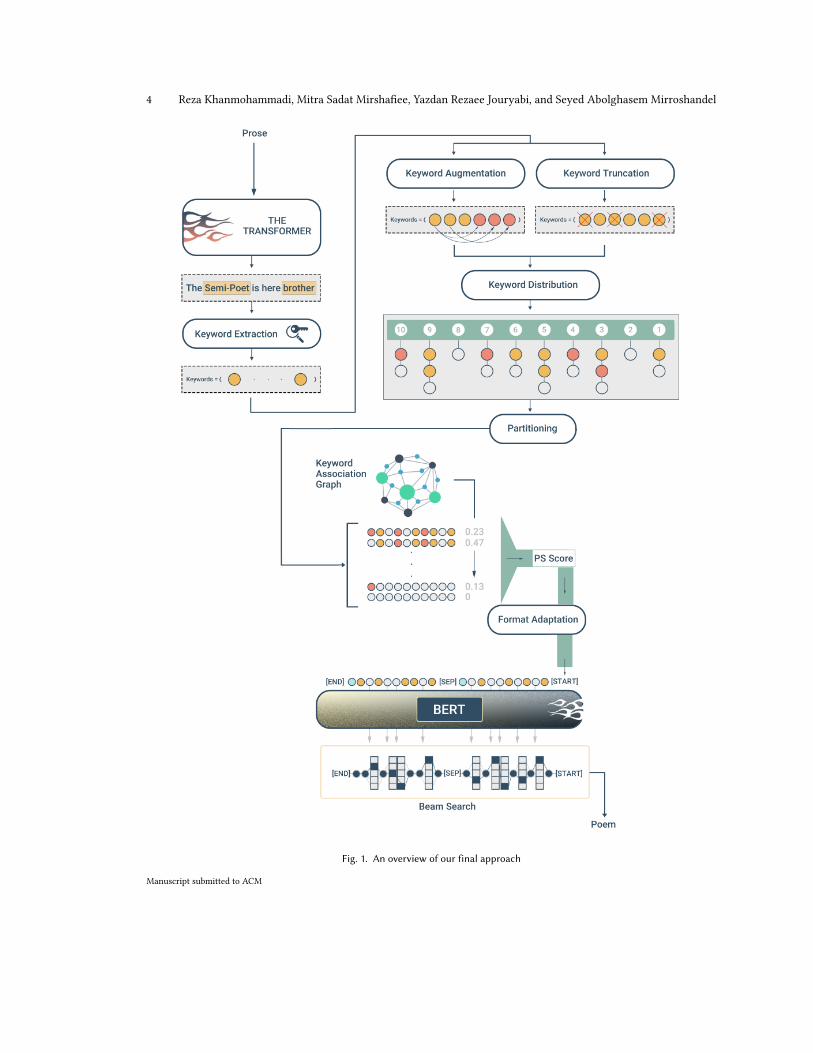
4 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
Fig. 1. An overview of our final approach
Manuscript submitted to ACM

Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 5
The single most marked observation of these models is that they perform reasonably well in transforming contextualinformation of input prose to poems. Meaning that generated poems bear a close resemblance to both ground truthprose and their relative poem in terms of their domain-of-speak. Additionally, these models learn to generate poemswith fair lengths and acceptable poetic meters. However, they suffer from a lack of poeticness, which means there areparticular prerequisites that their literature does not fulfil as eligible Persian poetry. Below is a list of their shortcomings.
• Very few generated samples in set 𝐼1:𝑚 seem to have formed rhythmic literature.• Even though an acceptable level of context transformation is seen among sets 𝑋1:𝑎 and 𝐼1:𝑚 , seq2Seq modelsseem to be unable to narrate that information and get to a specific point.
• Set 𝐼1:𝑚 forms irrational associations of words.
Hence, such architectures as the only source of translation account for incoherent and unintelligible results with weakhuman evaluation scores.
A serious objection to small corpora in Machine Translation tasks is that they constrain even the robust architecturesnot to generalize and overfit the data. In our setting, which is extremely low-resource, the model fails to contem-poraneously learn from such limited data to map input features to output features and to generate a well-writtenPersian poem which is alone an arduous task. Previous studies have proposed different solutions based on TransferLearning [30, 46], Multilingual NMT [14], and Zero-shot setting [20, 22] that mitigate the problem of scarce paralleldata. Furthermore, a particular group of studies such as Cold Fusion [34], Shallow Fusion [13], and Deep Fusion [13]have engaged Monolingual Language Models with NMT architectures to enhance translation quality and avoid pitfalls.Alongside our trained NMT models, we employed two available pretrained GPT2 [33] models from Bolbolzaban [6] andHooshvareTeam [17] that were previously trained on the Ganjoor Dataset to test these ideas on our task. Still, theseapproaches either failed to converge and stuck in local minima or produced low-quality poems.
Having mentioned Encoder-Decoder models’ inefficiencies in poem generation, the scarcity of our parallel data, theuniqueness of Persian poetry’s nature, and the availability of a relatively considerable number of monolingual data inthe target side, we introduce two additional stages that form our novel approach of prose to poem translation task.When leveraging Transformer-based pretrained Language Models’ robustness, conventional NMT approaches have agenerative point of view for which Generative Language Models (e.g. GPT2) seem to be a perfect fit. In contrast tosuch studies, we outline the efficiency of MLMs (e.g. BERT) in domain-specific generative tasks. This way, we exploit acontrollable generative setting where certain limitations and customizations can be applied to generate outputs thatbetter address poetic needs. In the following two subsections, we respectively map 𝐼1:𝑚 to a masked sequence and askMLMs to predict them.
3.2 Keyword Partitioning Heuristic
Principally, we want to investigate the utilization of the Transformer-based Encoder-Decoder model, the first stageleading TM, and its ability in context transformation. Using Keyword Extraction techniques as Context Informationextractors, we define heuristic ℎ in Equation 2 to map initial translations to 𝑃1:𝑐 = {𝑝1, ..., 𝑝𝑐 }, which is a set of partitionsof masked keyword sequences (MKSs) with length 𝑐 which will further be defined.
ℎ : 𝐼1:𝑚 → 𝑃1:𝑐 (2)
As shown in Figure 1, MKSs are inputs to an MLM (namely, BERT) to predict their masked tokens. We hold eachpartition with non-predicted MKSs as an infrastructure for further text generation and predicted MKSs as our approach’s
Manuscript submitted to ACM

6 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
final generated poems. Evidently, the quality of our final outcome is heavily dependent on the quality of our partitioning.When partitioning, below, we define a list of criteria that we expect ℎ to consider.
• Keywords Presence: Provided that a fair number of keywords have appeared in a partition, we may expectstage 3 MLM to generate a high-quality poem by mask predicting the partition.
• Keywords Adjacency: To encourage the generative aspect of our work, ℎ prefers a partition where keywordsare logically separated, and adjacency differentials are equally distributed.
• Keywords Association: Persian Poetry’s Literature is fulfilled with highly literary collocations. Hence, tounderstand and capture such a phenomenon, ℎ should avoid partitions in which keywords are nonliteraryassociated.
Henceforth, we step through different components of ℎ to partition 𝐼1:𝑚 while craving to meet the previously mentionedcriteria.
3.2.1 Keyword Extraction. Primarily, we extract keywords (key phrases) from the contextually rich 𝐼1:𝑚 set. We usedan unsupervised keyword extraction package called YAKE! [7] to automatically detect keywords in our text. Thisunbiased method is neither task nor language-specific, making it suitable for our work. The 𝐼1:𝑚 set, namely a couplet,consists of two hemistichs. First, we feed the entire set to YAKE! to capture a list of couplet-level keywords based on thebig-picture. Subsequently, we feed each hemistich individually to the model and extract a list of specific, hemistichs-levelkeywords. Finally, we combine the two lists and make a final set of both couplet-level and hemistichs-level keywords as𝐾1:𝑛 = {𝑘1, ..., 𝑘𝑛} and their frequencies of appearance in the two sets as 𝐹1:𝑛 = {𝑓1, ..., 𝑓𝑛}.
3.2.2 Keyword Distribution. To satisfy the quality of associated keywords, not only should a literary associationbe established among each MKS keywords, but we also need to make the heuristic aware of where to place eachkeyword in the MKS. As a specific order in which the keywords appear will later result in one particular contextualizedoutput in stage 3, we are making high-quality outcomes more probable while generation. Since more than 98% of allhemistichs available in the Ganjoor Dataset have a word count of less than or equal to 10, we dedicate a maximumlength of 10 tokens to each MKS to tackle this problem. Additionally, we calculate index-based frequency distributions𝐼𝐹1:10 = {𝑖 𝑓1, ..., 𝑖 𝑓10} using NLTK [5] to measure the presence of our vocabulary in each of the 1 to 10 indices.
To form logically ordered MKSs, we intend to distribute keywords among those indices where each keyword a) haspreviously been appeared in and b) is logically separated from the rest of the keywords. To do so, we repeat a processfor each 𝐾1:𝑛 during which all suggested positions are stored as 𝐴𝑃1:𝑛 = {𝑎𝑝1, ..., 𝑎𝑝𝑛}. At each iteration, we return themaximum argument of 𝐾𝑛 ’s scores in all indices (𝐴𝑆1:10) as 𝐾𝑛 ’s suggested position (Equation 3).
𝐴𝑆1:10 = {𝑖𝑠 (𝑖) |1 ≤ 𝑖 ≤ 10} (3)
𝐴𝑃𝑛 = 𝑎𝑟𝑔𝑚𝑎𝑥 (𝐴𝑆) (4)
To measure how likely it would be for 𝐾𝑛 to be appeared in index 𝑖 (Equation 4), we define the 𝑖𝑠 scoring function inEquation 5.
𝑖𝑠 (𝑋,𝑊 ,𝑍,𝑌, 𝐹,𝐺) =��𝑟𝑛𝑠 (𝑋,𝑊 ) − 𝑙𝑛𝑠 (𝑍,𝑌 )
��𝐺 + 1
× log10 (𝐹 ) (5)
Given 𝑛𝑟𝑛(𝑖) and 𝑛𝑙𝑛(𝑖) as two separate indices of the nearest right-side and left-side neighbours of index 𝑖 , we define𝑛𝑟𝑛𝑑 (𝑖) (X) and 𝑛𝑙𝑛𝑑 (𝑖) (Z) as the distance between index i and each of its two neighbour indices. 𝑛𝑟𝑛𝑎𝑔𝑔 (𝑖) (W) and𝑛𝑙𝑛𝑎𝑔𝑔 (𝑖) (Y) are also defined as the number of previously suggested keyword positions (𝐴𝑃1:𝑛) in 𝑛𝑟𝑛(𝑖) and 𝑛𝑙𝑛(𝑖)indices, respectively. Altogether, the 𝑖𝑠 scoring function deteriorates by the number of previously suggested positions atManuscript submitted to ACM

Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 7
index 𝑖 (𝑖𝑑𝑥𝑎𝑔𝑔) (G) and improves with two factors, where one is the frequency of 𝐾𝑛 in index 𝑖 (𝐼𝐹𝑖 (𝐾𝑛)) (F) and theother is the absolute difference between the right-side (𝑟𝑛𝑠) and the left-side (𝑙𝑛𝑠) neighbours scores. The intuition hereis that the less aggregated one neighbour-side of index 𝑖 is, the more appealing that index is for 𝐾𝑛 to be placed in.
𝑟𝑛𝑠 (𝑋,𝑊 ) = 𝑋 + 1(𝑛𝑟𝑙 (𝑖, 0, 𝐴𝑃 ) + 1) × (𝑊 + 1) (6)
𝑙𝑛𝑠 (𝑌,𝑍 ) = 𝑋 + 1(𝑛𝑟𝑙 (𝑖, 1, 𝐴𝑃 ) + 1) × (𝑌 + 1) (7)
To score each of the side-neighbours, we define 𝑟𝑛𝑠 (Equation 6) and 𝑙𝑛𝑠 (Equation 7), where both improve by thefurther their nearest neighbours (i.e. 𝑛𝑟𝑛 and 𝑛𝑙𝑛), and degrade by the more keyword aggregated their sides are. We use𝑛𝑟𝑙 (Equation 8) to measure total aggregation of keywords in both the right ( 𝑗 = 0) and the left ( 𝑗 = 1) side among all𝐴𝑃1:𝑛 elements.
𝑛𝑟𝑙 (𝑖, 𝑗, 𝐴𝑃) =
����{𝐴𝑃𝑖 |1 ≤ 𝑖 ≤ 10, 𝐴𝑃𝑖 < 𝑖}
���� 𝑗 = 0����{𝐴𝑃𝑖 |1 ≤ 𝑖 ≤ 10, 𝐴𝑃𝑖 > 𝑖}���� 𝑗 = 1
(8)
Having iterated through all 𝐾1:𝑛 elements, we obtain the full 𝐴𝑃1:𝑛 set, which contains detected indices of each 𝐾𝑛 .Lastly, we create the 𝐼𝐾1:10 = {𝑖𝑘1, ..., 𝑖𝑘10} set where it has a list of all suggested keywords for each of the 10 indices.The more uniformly distributed the keywords are among the indices, the more likely it is to form logically orderedassociated MKSs.
3.2.3 Keyword Augmentation/Truncation. To overcome the challenge of Keywords Presence, we initially augment the𝐾 set to highlight context information. We gathered a Synonyms-Antonyms Dataset for every word in the GanjoorDataset’s vocabulary using vajehyab3, which contains 4,756 words with an average synonym and antonym counts of7.12 and 2.34 per each. Given function 𝑆𝑦𝑛(𝐾𝑖 , 𝑗), which returns the 𝑗 th most frequent synonym of 𝐾𝑖 , we define thesynonyms set (𝑆) and the Final Keywords set (FK) as below.
𝑆 = {𝑆𝑦𝑛(𝐾𝑖 , 𝑗) |1 ≤ 𝑖 ≤ 𝑛, 1 ≤ 𝑗 ≤ 𝐹𝑖 } (9)
𝐹𝐾1:𝑘 ′ = 𝐾 ∪ 𝑆 (10)
Having defined the 𝐹𝐾 and 𝐴𝑃 sets, we introduce 𝐶 as the size/number of 𝑃1:𝑐 /couplets that we expect the heuris-tic/MLM to return/generate as below.
𝐶 =
⌈∑10𝑖=1
��𝐴𝑃𝑖 ��10
⌉(11)
Furthermore, we make the heuristic adaptable to the number of keywords it lies between masked tokens to form MKSs.Since MKSs are hemistich-based, we have control over the content load to indicate in either of the right- or left-sidehemistichs. Hence, we define 𝑟𝑠𝑣𝑘 and 𝑙𝑠𝑣𝑘 as the number of indicatable keywords in right-side and left-side hemistichMKSs. Given the two, the heuristic calculates the number of keywords it needs to form𝐶 × 2MKSs (𝑟𝑘𝑛) - each coupletcontains two hemistichs only- using Equation 12.
𝑟𝑘𝑛 = (𝐶 × 𝑟𝑠𝑣𝑘 ) + (𝐶 × 𝑙𝑠𝑣𝑘 ) (12)
Comparing the size of the 𝐹𝐾 set and the 𝑟𝑘𝑛 value, we choose to either re-augment or truncate the 𝐹𝐾 set when thetwo values differentiate. Given 𝐷 = |𝑟𝑘𝑛 − 𝑘′|, the former refers to a process during which we augment the D leastaggregated indices’ top frequent keywords using the 𝑆𝑦𝑛(𝐾𝑖 , 1) function (expanding the 𝐹𝐾 set). In contrast, the latter3https://www.vajehyab.com/
Manuscript submitted to ACM

8 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
points to a process during which we remove the D most aggregated indices’ least frequent keywords (shrinking the 𝐹𝐾set). At this step, the 𝐹𝐾 set contains 𝑟𝑘𝑛 keywords and is passed to Equation 8 to detect keyword indices to update𝐴𝑃1:𝑛 and 𝐼𝐾1:10 afterwards.
3.2.4 Word Associations Graph. To make the heuristic knowledgeable of poetic word associations, we seek to capturea pattern among available ones. However, associated words in Persian poetry cannot be easily extracted. Figures ofSpeech have long played prominent roles in the significance of Persian Poetry. Based on Aesthetic Values, they addnon-literary adjustments, which may, in certain scenarios, make the poem undergo meaning divergence. Hence, defininga meaningful association as "a set of contextually similar words" is inadequate. Instead, by modeling associationsindicated in our dataset’s poems, we capture an unbiased knowledge of them through constructing a graph. Thisway, the heuristic investigates both the spatial attitudes [9] and the context-of-agreement among words in associationssimultaneously.
To construct the graph using NetworkX [15] python package, we first construct an initial graph with 𝑉 (equal to thevocabulary size of the Ganjoor dataset) as the number of its vertices. Then we iterate over dataset couplets, extractunique combination sets with the length of two, and draw an edge between the two words at their earliest co-occurrence.Additionally, we define weight attribute sets (𝐶𝑆1:𝑢 = {𝑐𝑠1, ..., 𝑐𝑠𝑢 }) for each pair of vertices words where each 𝑐𝑠 scores(Equation 13) serves as a metric that rates a co-occurrence of the two word indices by their spatial distance.
𝐶𝑆 (𝑖, 𝑗, 𝑣𝑙 ) = 1 −��𝑖 − 𝑗
��𝑣𝑙
(13)
To partly encourage contextually similar and penalize contextually dissimilar associated pairs in the graph, we traina Word2Vec model [27] on the Ganjoor dataset with a window size of 5 to map words onto 64-dimensional spaces.Given 𝐶𝑆𝑚 as the mean of two indices’ 𝐶𝑆 set and 𝑠𝑖𝑚 as their word vectors’ cosine similarity, we define their edgeweight (𝑊 ) as the arithmetic mean of𝐶𝑆𝑚 and𝑊 . The graph will further be used to score word associations so that themore contextually similar and spatially close two words are, the more likely they are to be associated.
3.2.5 Partitioning. Excluding rhymes, which we will discuss in the final step, we build up the rest of each maskedsequence with a unique partitioning technique that prepares MKSs to further be fed to an MLM to generate final poems.Thus far, we have coped with Presence and Association-related challenges, which may have formed components of asubstandard poem. However, the adjacency of keywords in masked sequences effectively contributes to the quality offinal poems as well. This section will extract a set of hemistich-level MKSs with fairly distributed keywords in-betweenmasked tokens such that they A) adequate, B) are literary/contextually associated, and C) are logically separated amongmasked tokens. Having added a masked token to each 𝐼𝐾1:10 index-based keyword set, we score possible occurrencecombinations using Equation 14 to satisfy these criteria.
𝑃𝑆 (𝑑𝑠 , 𝑔𝑚) = 𝑠𝑖𝑔𝑚𝑜𝑖𝑑(log2 (𝑑𝑠 ) × 𝑔𝑚
)(14)
To score each candidate combination, we step through every two adjacent keywords (𝑤1, and𝑤2) and calculate pair-wise𝑑 and 𝑔(𝑤1,𝑤2) scores by their spatial difference and Association Graph edge weight. Given 𝑑𝑠 and 𝑔𝑚 as the sumof all pair-wise 𝑑 scores and the mean of all pair-wise association scores, 𝑃𝑆 (𝑑𝑠 , 𝑔𝑚) is calculated for every possiblecandidate. Finally, a total of 𝐶 × 2 top masked sequences with lengths of 𝑟𝑠𝑣𝑘 and 𝑙𝑠𝑣𝑘 are selected as final MKSs andzipped index-wise to form couple-level MKSs.
Manuscript submitted to ACM

Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 9
3.2.6 Poetry Format Adaptation. Persian Poems can be categorized into different styles such as Ghazal,Masnavi, Dobeiti,or Ghet’e where each has its uniquely synced set of ordered rhymes. We curate a list of words that rhyme togetherand adapt MKSs to a user-defined format using it. To select a set of rhymes as 𝑅1:𝑜 = {𝑟1, ..., 𝑟𝑜 } for a set of MKSs, wechoose an initial rhyme (𝑟1) and further explore other words that rhyme with it (𝑟2:𝑜 ). To select a final rhyme among aset of candidates, we choose the one with the highest mean of pair-wise 𝑔 scores among the candidate and each of theindicated keywords in an MKS. This will hold contextually related rhymes for MKS and take the final step towardsbetter represented 𝑃1:𝑐 set members.
3.3 Final Translation
After coming up with a set of MKSs with certain literary features, we define this section below.
𝑏 : 𝑃1:𝑐 → 𝑌1:𝑐 (15)
Given set 𝑃1:𝑐 , we define 𝑏 as a function that maps an MKS to 𝑌1:𝑐 by predicting masked tokens inside each 𝑃1:𝑐 setmember. To do so, we used BERT, an MLM, to predict masked tokens and build a full poetic couplet by filling in theblanks. As stated, instead of using an Encoder-Decoder model and let it become fully in charge of translating prose toPersian literary poems, we ask it to only serve as an extractor of prose features and let a heuristically aided controlledText Generator be in charge of poetry generation.
There are specific strategies for utilizing pretrained language models such as BERT to achieve our desired outcome.Since we have a relatively larger amount of unlabeled poems, we take the second step of pretraining the BERT modelon the Ganjoor Dataset to let it update its general knowledge of how "Persian Text" inputs should be distributed tohow "Persian Poems" naturally are in their closed domain. Whereas the MLM objective of pretraining BERT maskedonly 15% of the input text, we set BERT to randomly mask 40% to expect more of the model by giving it less. Wepretrained available Persian MLMs such as BERT, RoBERTa, ALBERT, and DistilBERT on the Ganjoor Dataset. In termsof length, we experimented with both hemistich-level and Couplet-level pretraining, among which the latter performedunderstandably better in predicting a contextually rich set of masked tokens.
Since MLMs predict a probability distribution over each word to predict a mask, we need a strategy to decode thelikelihoods of a set of most probable words into a final sequence. We approach this by using a Beam Search decoderwith a customised heuristic.
𝑆𝐹 (𝑓 , 𝑡, 𝑏) = (4 × 𝑓 ) + (3 × 𝑡) + (2 × 𝑏)10
(16)
Given 𝑓 , 𝑡 , and 𝑏 as the 4-gram, 3-gram, and 2-gram of each candidate word and its 𝑛 − 1 number of previouslymentioned words, the Beam Search decoder constantly ranks the d (Beam Depth) most probable sequences usingEquation 16. Final decoded sequences are also named 𝑌1:𝑐 , which is the final set of poems generated by our approach.
4 EXPERIMENTS & RESULTS
Our curated parallel corpus contains 5,191 pairs of prose and poems. First we leave 1,720 pairs for evaluating andincreased the remaining up to 28,820 pairs using Word Substitution techniques on our textual data for training purposesusing our pretrained MLMs. The Monolingual pretraining phase of MLMs was carried out for 5 epochs using 321,581extracted couplets from the Ganjoor Dataset4 (train=289,422 test=32,159). To augment keywords in the heuristic, wecollected a list of synonyms and antonyms for each word in our vocabulary. Lastly, we gathered a dataset of 1,319
4www.ganjoor.net
Manuscript submitted to ACM
10 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
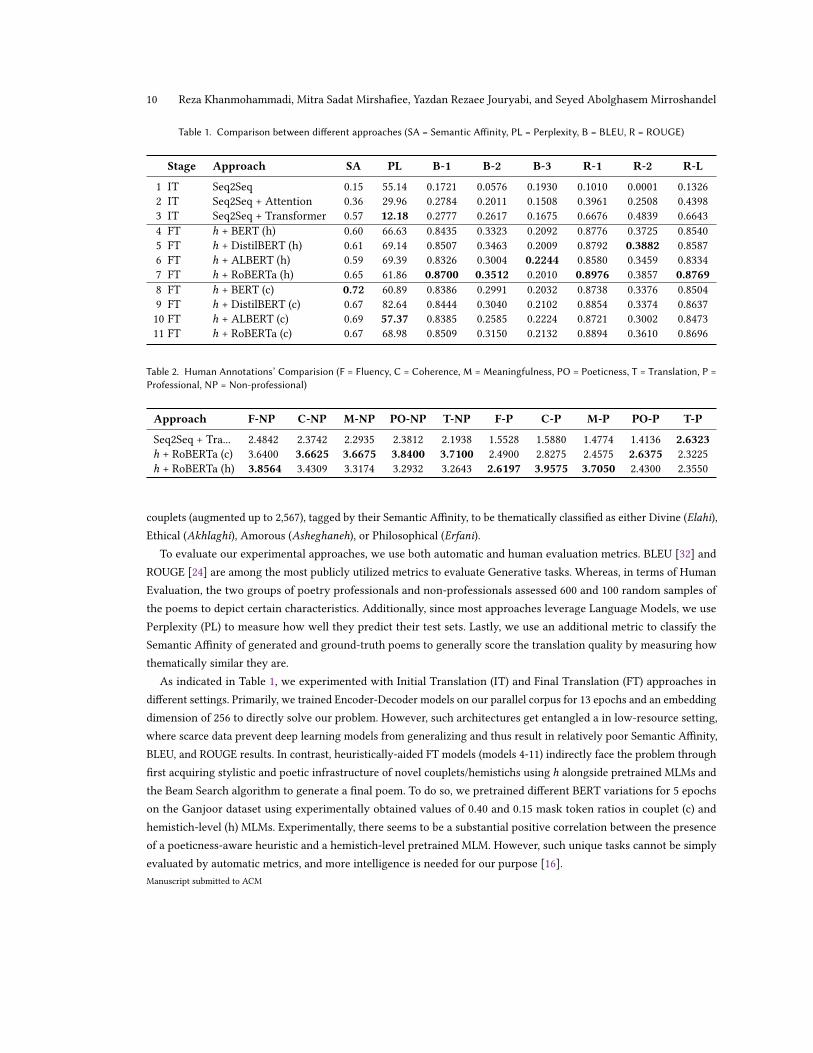
Table 1. Comparison between different approaches (SA = Semantic Affinity, PL = Perplexity, B = BLEU, R = ROUGE)
Stage Approach SA PL B-1 B-2 B-3 R-1 R-2 R-L
1 IT Seq2Seq 0.15 55.14 0.1721 0.0576 0.1930 0.1010 0.0001 0.13262 IT Seq2Seq + Attention 0.36 29.96 0.2784 0.2011 0.1508 0.3961 0.2508 0.43983 IT Seq2Seq + Transformer 0.57 12.18 0.2777 0.2617 0.1675 0.6676 0.4839 0.66434 FT ℎ + BERT (h) 0.60 66.63 0.8435 0.3323 0.2092 0.8776 0.3725 0.85405 FT ℎ + DistilBERT (h) 0.61 69.14 0.8507 0.3463 0.2009 0.8792 0.3882 0.85876 FT ℎ + ALBERT (h) 0.59 69.39 0.8326 0.3004 0.2244 0.8580 0.3459 0.83347 FT ℎ + RoBERTa (h) 0.65 61.86 0.8700 0.3512 0.2010 0.8976 0.3857 0.87698 FT ℎ + BERT (c) 0.72 60.89 0.8386 0.2991 0.2032 0.8738 0.3376 0.85049 FT ℎ + DistilBERT (c) 0.67 82.64 0.8444 0.3040 0.2102 0.8854 0.3374 0.863710 FT ℎ + ALBERT (c) 0.69 57.37 0.8385 0.2585 0.2224 0.8721 0.3002 0.847311 FT ℎ + RoBERTa (c) 0.67 68.98 0.8509 0.3150 0.2132 0.8894 0.3610 0.8696
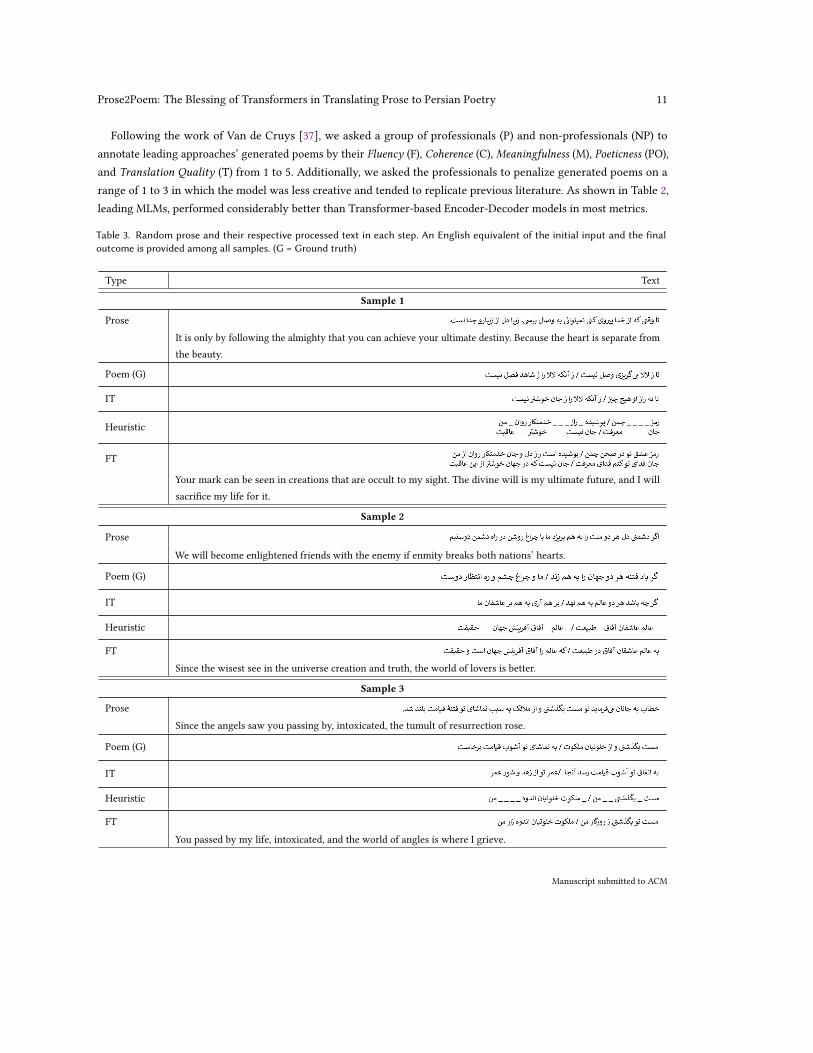
Table 2. Human Annotations’ Comparision (F = Fluency, C = Coherence, M = Meaningfulness, PO = Poeticness, T = Translation, P =Professional, NP = Non-professional)
Approach F-NP C-NP M-NP PO-NP T-NP F-P C-P M-P PO-P T-P
Seq2Seq + Tra... 2.4842 2.3742 2.2935 2.3812 2.1938 1.5528 1.5880 1.4774 1.4136 2.6323ℎ + RoBERTa (c) 3.6400 3.6625 3.6675 3.8400 3.7100 2.4900 2.8275 2.4575 2.6375 2.3225ℎ + RoBERTa (h) 3.8564 3.4309 3.3174 3.2932 3.2643 2.6197 3.9575 3.7050 2.4300 2.3550
couplets (augmented up to 2,567), tagged by their Semantic Affinity, to be thematically classified as either Divine (Elahi),Ethical (Akhlaghi), Amorous (Asheghaneh), or Philosophical (Erfani).
To evaluate our experimental approaches, we use both automatic and human evaluation metrics. BLEU [32] andROUGE [24] are among the most publicly utilized metrics to evaluate Generative tasks. Whereas, in terms of HumanEvaluation, the two groups of poetry professionals and non-professionals assessed 600 and 100 random samples ofthe poems to depict certain characteristics. Additionally, since most approaches leverage Language Models, we usePerplexity (PL) to measure how well they predict their test sets. Lastly, we use an additional metric to classify theSemantic Affinity of generated and ground-truth poems to generally score the translation quality by measuring howthematically similar they are.
As indicated in Table 1, we experimented with Initial Translation (IT) and Final Translation (FT) approaches indifferent settings. Primarily, we trained Encoder-Decoder models on our parallel corpus for 13 epochs and an embeddingdimension of 256 to directly solve our problem. However, such architectures get entangled a in low-resource setting,where scarce data prevent deep learning models from generalizing and thus result in relatively poor Semantic Affinity,BLEU, and ROUGE results. In contrast, heuristically-aided FT models (models 4-11) indirectly face the problem throughfirst acquiring stylistic and poetic infrastructure of novel couplets/hemistichs using ℎ alongside pretrained MLMs andthe Beam Search algorithm to generate a final poem. To do so, we pretrained different BERT variations for 5 epochson the Ganjoor dataset using experimentally obtained values of 0.40 and 0.15 mask token ratios in couplet (c) andhemistich-level (h) MLMs. Experimentally, there seems to be a substantial positive correlation between the presenceof a poeticness-aware heuristic and a hemistich-level pretrained MLM. However, such unique tasks cannot be simplyevaluated by automatic metrics, and more intelligence is needed for our purpose [16].Manuscript submitted to ACM
Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 11
Following the work of Van de Cruys [37], we asked a group of professionals (P) and non-professionals (NP) toannotate leading approaches’ generated poems by their Fluency (F), Coherence (C), Meaningfulness (M), Poeticness (PO),and Translation Quality (T) from 1 to 5. Additionally, we asked the professionals to penalize generated poems on arange of 1 to 3 in which the model was less creative and tended to replicate previous literature. As shown in Table 2,leading MLMs, performed considerably better than Transformer-based Encoder-Decoder models in most metrics.
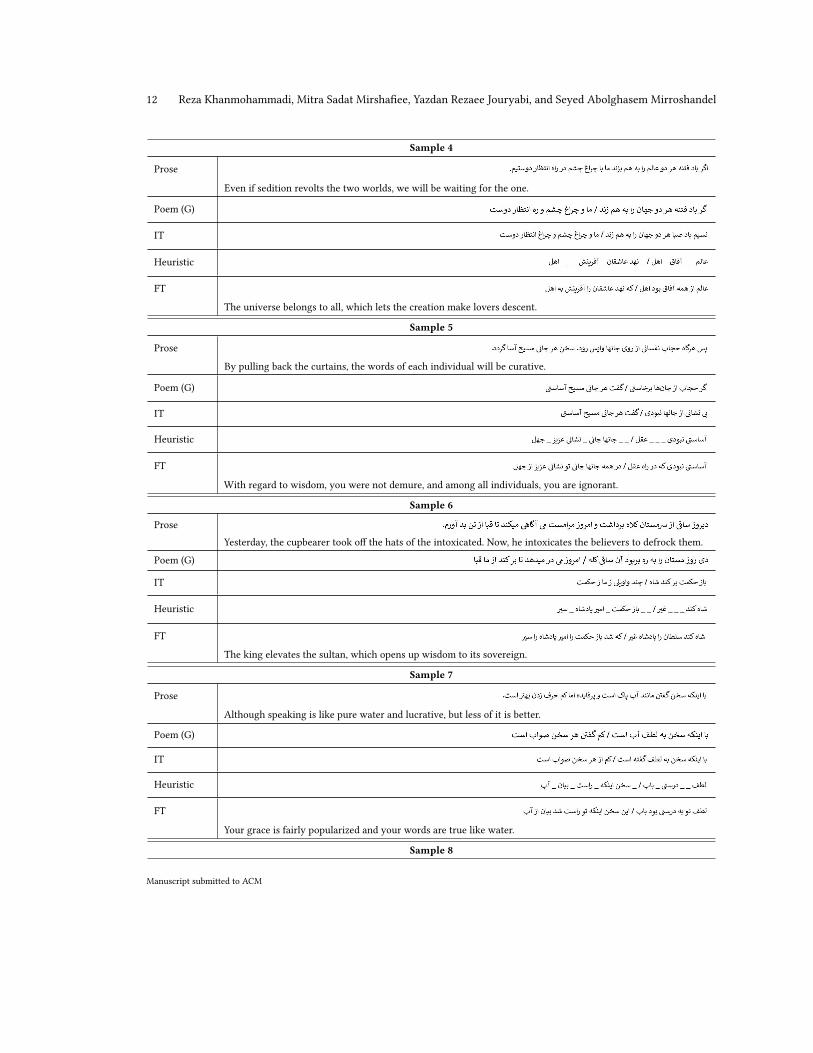
Table 3. Random prose and their respective processed text in each step. An English equivalent of the initial input and the finaloutcome is provided among all samples. (G = Ground truth)
Type Text
Sample 1
Prose
It is only by following the almighty that you can achieve your ultimate destiny. Because the heart is separate fromthe beauty.
Poem (G)
IT
Heuristic
FT
Your mark can be seen in creations that are occult to my sight. The divine will is my ultimate future, and I willsacrifice my life for it.
Sample 2
Prose
We will become enlightened friends with the enemy if enmity breaks both nations’ hearts.
Poem (G)
IT
Heuristic
FT
Since the wisest see in the universe creation and truth, the world of lovers is better.
Sample 3
Prose
Since the angels saw you passing by, intoxicated, the tumult of resurrection rose.
Poem (G)
IT
Heuristic
FT
You passed by my life, intoxicated, and the world of angles is where I grieve.
Manuscript submitted to ACM
12 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
Sample 4
Prose
Even if sedition revolts the two worlds, we will be waiting for the one.
Poem (G)
IT
Heuristic
FT
The universe belongs to all, which lets the creation make lovers descent.
Sample 5
Prose
By pulling back the curtains, the words of each individual will be curative.
Poem (G)
IT
Heuristic
FT
With regard to wisdom, you were not demure, and among all individuals, you are ignorant.
Sample 6
Prose
Yesterday, the cupbearer took off the hats of the intoxicated. Now, he intoxicates the believers to defrock them.
Poem (G)
IT
Heuristic
FT
The king elevates the sultan, which opens up wisdom to its sovereign.
Sample 7
Prose
Although speaking is like pure water and lucrative, but less of it is better.
Poem (G)
IT
Heuristic
FT
Your grace is fairly popularized and your words are true like water.
Sample 8
Manuscript submitted to ACM
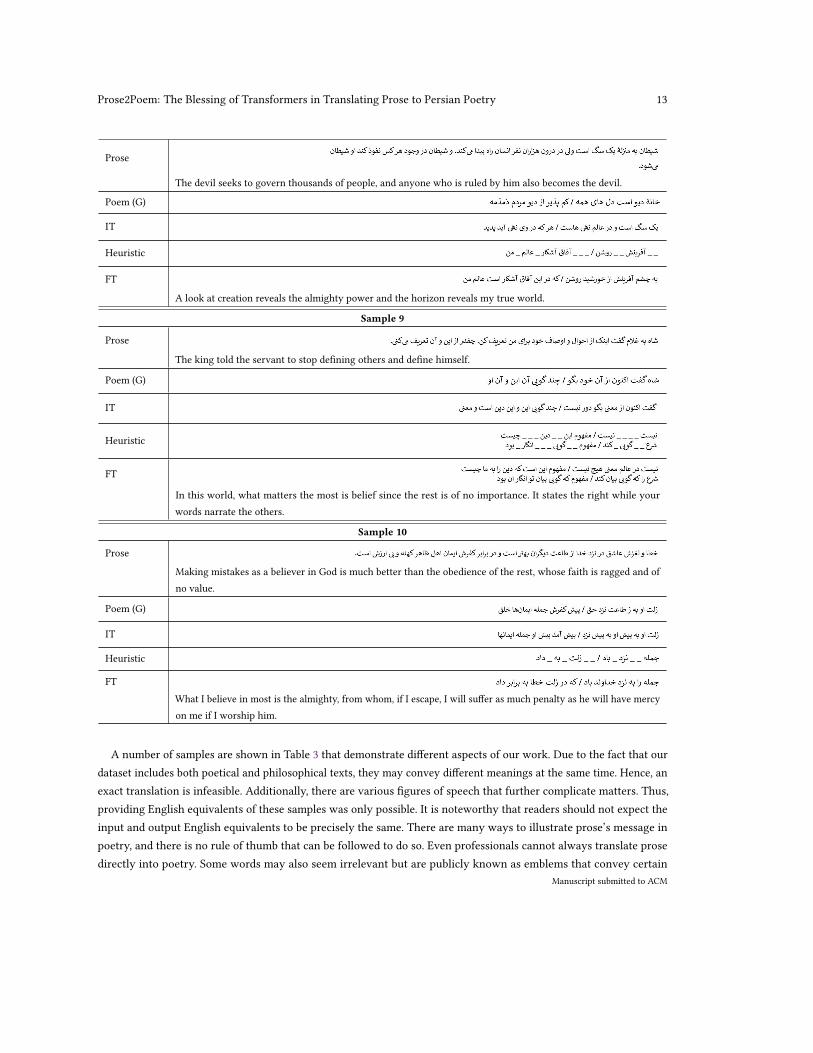
Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 13
Prose
The devil seeks to govern thousands of people, and anyone who is ruled by him also becomes the devil.
Poem (G)
IT
Heuristic
FT
A look at creation reveals the almighty power and the horizon reveals my true world.
Sample 9
Prose
The king told the servant to stop defining others and define himself.
Poem (G)
IT
Heuristic
FT
In this world, what matters the most is belief since the rest is of no importance. It states the right while yourwords narrate the others.
Sample 10
Prose
Making mistakes as a believer in God is much better than the obedience of the rest, whose faith is ragged and ofno value.
Poem (G)
IT
Heuristic
FT
What I believe in most is the almighty, from whom, if I escape, I will suffer as much penalty as he will have mercyon me if I worship him.
A number of samples are shown in Table 3 that demonstrate different aspects of our work. Due to the fact that ourdataset includes both poetical and philosophical texts, they may convey different meanings at the same time. Hence, anexact translation is infeasible. Additionally, there are various figures of speech that further complicate matters. Thus,providing English equivalents of these samples was only possible. It is noteworthy that readers should not expect theinput and output English equivalents to be precisely the same. There are many ways to illustrate prose’s message inpoetry, and there is no rule of thumb that can be followed to do so. Even professionals cannot always translate prosedirectly into poetry. Some words may also seem irrelevant but are publicly known as emblems that convey certain
Manuscript submitted to ACM

14 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
historical or cultural meanings. Hence, valid judgements of our method’s applicability can not be made from Englishequivalents which are basically indicated to aid non-native readers to gain insight into Persian prose/poems. Hereafter,we will discuss certain aspects of these examples.
Positively, Aesthetic Values can almost be seen among every FT outcome. For instance, in sample 1, (Lawn) and(covered) are contextually related. Additionally, (spirit), , and (soul) are also close in meaning. The
two words and can also be known as synonyms in Persian literature. Alliteration is another Figure of Speechwhich consists of words that are similarly written but may or may not differ in a phoneme. In sample 2, the FT consistsof the word (wise) and (world) as two words that are similarly written but differ when are pronounced. Thesame can also be seen in sample 4 where has been repeated but pronounced similarly, whereas one means docileand the other means inhabitant. Furthermore, a paradox can be seen in the generated poem of sample 5 where(intellect) and (foolishness) are antonyms. Phonotactics are known as another figure where a certain character isrepeated for several times. In this manner, in sample 6, (pronounced as /sh/) is repeated. These effects demonstratehow different aspects of this work have successfully contributed to poetical values. On the other hand, albeit minor,there are also evidences that depicts how some examples suffer from an increase of prepositions which results in thelack of coherency.
5 CONCLUSION
In this work, we took the initial steps of modeling Persian poetry as a translation task, for which we experimented withmajor MT models. Tried to capture centuries of advancements in Persian poetry, results showed that state-of-the-artTransformer models could benefit from a heuristic, knowledgeable of steps that need to be taken to generate poeticoutputs. We introduced an MLM approach that utilized such a heuristic, trained it using our parallel prose-poem dataset,and evaluated it using a Semantic Affinity dataset. Poems were assessed by official NLG metrics and human assessors,where they aided us in establishing a solid baseline for the prose to poem translation task. Empowered by pretrainedGLMs and MLMs, future work in Persian NLP is expected to better combine computational poetry with the requisitesof poeticness through enabling robust Language Models to better model poetry while less supervision and engineeringare applied.
REFERENCES[1] Manex Agirrezabal, Iñaki Alegria, and Mans Hulden. 2016. Machine Learning for Metrical Analysis of English Poetry. In Proceedings of COLING
2016, the 26th International Conference on Computational Linguistics: Technical Papers. The COLING 2016 Organizing Committee, Osaka, Japan,772–781. https://www.aclweb.org/anthology/C16-1074
[2] Manex Agirrezabal, Bertol Arrieta, Aitzol Astigarraga, and Mans Hulden. 2013. POS-Tag Based Poetry Generation with WordNet. In Proceedingsof the 14th European Workshop on Natural Language Generation. Association for Computational Linguistics, Sofia, Bulgaria, 162–166. https://www.aclweb.org/anthology/W13-2121
[3] Ehsaneddin Asgari and Jean-Cédric Chappelier. 2013. Linguistic Resources & Topic Models for the Analysis of Persian Poems.[4] Brendan Bena and Jugal Kalita. 2020. Introducing Aspects of Creativity in Automatic Poetry Generation. arXiv:2002.02511 [cs.CL][5] Steven Bird, Ewan Klein, and Edward Loper. 2009. Natural language processing with Python: analyzing text with the natural language toolkit. "
O’Reilly Media, Inc.".[6] Bolbolzaban. 2020. GPT2-Persian. http://bolbolzaban.com/.[7] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Jorge, Célia Nunes, and Adam Jatowt. 2020. YAKE! Keyword extraction from single
documents using multiple local features. Information Sciences 509 (2020), 257–289. https://doi.org/10.1016/j.ins.2019.09.013[8] Huimin Chen, Xiaoyuan Yi, M. Sun, Wenhao Li, Cheng Yang, and Z. Guo. 2019. Sentiment-Controllable Chinese Poetry Generation. In IJCAI.[9] Sean M. Conrey. 2007. A Canvas for Words: Spatial and Temporal Attitudes in the Writing of Poems. New Writing 4, 1 (2007), 79–90. https:
//doi.org/10.2167/new406.0 arXiv:https://doi.org/10.2167/new406.0
Manuscript submitted to ACM

Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry 15
[10] Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, and Mohammad Manthouri. 2020. ParsBERT: Transformer-based Model forPersian Language Understanding. arXiv:2005.12515 [cs.CL]
[11] Marjan Ghazvininejad, Xing Shi, Jay Priyadarshi, and Kevin Knight. 2017. Hafez: an Interactive Poetry Generation System. In Proceedings of ACL2017, System Demonstrations. Association for Computational Linguistics, Vancouver, Canada, 43–48. https://www.aclweb.org/anthology/P17-4008
[12] Hugo Gonçalo Oliveira. 2012. PoeTryMe: a versatile platform for poetry generation, Vol. 1, article 21.[13] Caglar Gulcehre, Orhan Firat, Kelvin Xu, Kyunghyun Cho, Loic Barrault, Huei-Chi Lin, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2015.
On Using Monolingual Corpora in Neural Machine Translation. arXiv:1503.03535 [cs.CL][14] Thanh-Le Ha, Jan Niehues, and Alexander Waibel. 2016. Toward Multilingual Neural Machine Translation with Universal Encoder and Decoder.
arXiv:1611.04798 [cs.CL][15] Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart. 2008. Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings
of the 7th Python in Science Conference, Gaël Varoquaux, Travis Vaught, and Jarrod Millman (Eds.). Pasadena, CA USA, 11 – 15.[16] Lifeng Han. 2018. Machine Translation Evaluation Resources and Methods: A Survey. arXiv:1605.04515 [cs.CL][17] HooshvareTeam. 2021. ParsGPT2 the Persian version of GPT2. https://github.com/hooshvare/parsgpt.[18] Jack Hopkins and Douwe Kiela. 2017. Automatically Generating Rhythmic Verse with Neural Networks. In Proceedings of the 55th Annual Meeting
of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vancouver, Canada, 168–178.https://doi.org/10.18653/v1/P17-1016
[19] Harsh Jhamtani, Sanket Vaibhav Mehta, Jaime Carbonell, and Taylor Berg-Kirkpatrick. 2019. Learning Rhyming Constraints using StructuredAdversaries. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference onNatural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 6025–6031. https://doi.org/10.18653/v1/D19-1621
[20] Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, GregCorrado, Macduff Hughes, and Jeffrey Dean. 2017. Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation.arXiv:1611.04558 [cs.CL]
[21] Vaibhav Kesarwani, Diana Inkpen, Stan Szpakowicz, and Chris Tanasescu. 2017. Metaphor Detection in a Poetry Corpus. In Proceedings of the JointSIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature. Association for ComputationalLinguistics, Vancouver, Canada, 1–9. https://doi.org/10.18653/v1/W17-2201
[22] Surafel M. Lakew, Quintino F. Lotito, Matteo Negri, Marco Turchi, and Marcello Federico. 2018. Improving Zero-Shot Translation of Low-ResourceLanguages. arXiv:1811.01389 [cs.CL]
[23] Jey Han Lau, Trevor Cohn, Timothy Baldwin, Julian Brooke, and Adam Hammond. 2018. Deep-speare: A joint neural model of poetic language,meter and rhyme. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association forComputational Linguistics, Melbourne, Australia, 1948–1958. https://doi.org/10.18653/v1/P18-1181
[24] Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out. Association for ComputationalLinguistics, Barcelona, Spain, 74–81. https://www.aclweb.org/anthology/W04-1013
[25] Bei Liu, Jianlong Fu, Makoto P. Kato, and Masatoshi Yoshikawa. 2018. Beyond Narrative Description. Proceedings of the 26th ACM internationalconference on Multimedia (Oct 2018). https://doi.org/10.1145/3240508.3240587
[26] Malte Loller-Andersen and Björn Gambäck. 2018. Deep Learning-based Poetry Generation Given Visual Input. In ICCC.[27] TomasMikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation ofWord Representations in Vector Space. arXiv:1301.3781 [cs.CL][28] Mehdi Moghadam and Bardia Panahbehagh. 2018. Creating a New Persian Poet Based on Machine Learning.[29] Neda Moradi and Mohammad Jabbari. 2020. A Study of Rendering Metaphors in the Translation of the Titles of Persian Medical Articles. Budapest
International Research and Critics in Linguistics and Education (BirLE) Journal 3 (02 2020), 540–551. https://doi.org/10.33258/birle.v3i1.675[30] Toan Q. Nguyen and David Chiang. 2017. Transfer Learning across Low-Resource, Related Languages for Neural Machine Translation. In Proceedings
of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Asian Federation of Natural Language Processing,Taipei, Taiwan, 296–301. https://www.aclweb.org/anthology/I17-2050
[31] Marmik Pandya. 2016. NLP based Poetry Analysis and Generation. https://doi.org/10.13140/RG.2.2.35878.73285[32] Kishore Papineni, Salim Roukos, Todd Ward, and Wei Jing Zhu. 2002. BLEU: a Method for Automatic Evaluation of Machine Translation. (10 2002).
https://doi.org/10.3115/1073083.1073135[33] Alec Radford, Jeffrey Wu, R. Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners.[34] Anuroop Sriram, Heewoo Jun, Sanjeev Satheesh, and Adam Coates. 2017. Cold Fusion: Training Seq2Seq Models Together with Language Models.
arXiv:1708.06426 [cs.CL][35] Sameerah Talafha and Banafsheh Rekabdar. 2019. Arabic Poem Generation Incorporating Deep Learning and Phonetic CNNsubword Embedding
Models. International Journal of Robotic Computing (10 2019), 64–91. https://doi.org/10.35708/TAI1868-126246[36] Chris Tanasescu, Bryan Paget, and D. Inkpen. 2016. Automatic Classification of Poetry by Meter and Rhyme. In FLAIRS Conference.[37] TimVan de Cruys. 2020. Automatic Poetry Generation from Prosaic Text. In Proceedings of the 58th Annual Meeting of the Association for Computational
Linguistics. Association for Computational Linguistics, Online, 2471–2480. https://doi.org/10.18653/v1/2020.acl-main.223[38] Zhe Wang, Wei He, Hua Wu, Haiyang Wu, Wei Li, Haifeng Wang, and Enhong Chen. 2016. Chinese Poetry Generation with Planning based Neural
Network. (10 2016).
Manuscript submitted to ACM

16 Reza Khanmohammadi, Mitra Sadat Mirshafiee, Yazdan Rezaee Jouryabi, and Seyed Abolghasem Mirroshandel
[39] Leila Weitzel, Ronaldo Prati, and Raul Aguiar. 2016. The Comprehension of Figurative Language: What Is the Influence of Irony and Sarcasm on NLPTechniques? Vol. 639. https://doi.org/10.1007/978-3-319-30319-2_3
[40] Xiao-feng Wu, Naoko Tosa, and Ryohei Nakatsu. 2009. New Hitch Haiku: An Interactive Renku Poem Composition Supporting Tool Applied forSightseeing Navigation System, Vol. 5709. 191–196. https://doi.org/10.1007/978-3-642-04052-8_19
[41] S. Xie. 2017. Deep Poetry : Word-Level and Character-Level Language Models for Shakespearean Sonnet Generation.[42] Zhuohan Xie, Jey Han Lau, and Trevor Cohn. 2019. From Shakespeare to Li-Bai: Adapting a Sonnet Model to Chinese Poetry. In Proceedings of the
The 17th Annual Workshop of the Australasian Language Technology Association. Australasian Language Technology Association, Sydney, Australia,10–18. https://www.aclweb.org/anthology/U19-1002
[43] Linli Xu, Liang Jiang, Chuan Qin, Zhe Wang, and Dongfang Du. 2018. How Images Inspire Poems: Generating Classical Chinese Poetry from Imageswith Memory Networks. arXiv:1803.02994 [cs.CL]
[44] Xiaoyuan Yi, Maosong Sun, Ruoyu Li, and Wenhao Li. 2018. Automatic Poetry Generation with Mutual Reinforcement Learning. In Proceedings ofthe 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Brussels, Belgium, 3143–3153.https://doi.org/10.18653/v1/D18-1353
[45] Lingyi Zhang and Junhui Gao. 2017. A Comparative Study to Understanding about Poetics Based on Natural Language Processing. Open Journal ofModern Linguistics 07 (01 2017), 229–237. https://doi.org/10.4236/ojml.2017.75017
[46] Barret Zoph, Deniz Yuret, Jonathan May, and Kevin Knight. 2016. Transfer Learning for Low-Resource Neural Machine Translation. In Proceedingsof the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Austin, Texas, 1568–1575.https://doi.org/10.18653/v1/D16-1163
Manuscript submitted to ACM




















