
TEMA TEMA 2: 2: TEMA TEMA 2: 2: TÉCNICAS DE ANÁLISIS TÉCNICAS DE ANÁLISIS MULTIVARIANTE PARA...
73
TEMA TEMA 2: 2: TEMA TEMA 2: 2: TÉCNICAS DE ANÁLISIS TÉCNICAS DE ANÁLISIS MULTIVARIANTE PARA MULTIVARIANTE PARA MULTIVARIANTE PARA MULTIVARIANTE PARA AGRUPACIÓN AGRUPACIÓN Métodos Métodos cluster cluster é i d ió é i d ió Técnicas de segmentación Técnicas de segmentación Clasificación no supervisada Clasificación no supervisada Ana Ana Justel Justel Ana Ana Justel Justel 1
-
Upload
independent -
Category
Documents
-
view
5 -
download
0
Transcript of TEMA TEMA 2: 2: TEMA TEMA 2: 2: TÉCNICAS DE ANÁLISIS TÉCNICAS DE ANÁLISIS MULTIVARIANTE PARA...

TEMA TEMA 2:2:TEMA TEMA 2:2:TÉCNICAS DE ANÁLISIS TÉCNICAS DE ANÁLISIS MULTIVARIANTE PARA MULTIVARIANTE PARA MULTIVARIANTE PARA MULTIVARIANTE PARA
AGRUPACIÓNAGRUPACIÓN
Métodos Métodos clusterclusteré i d ióé i d ióTécnicas de segmentaciónTécnicas de segmentación
Clasificación no supervisadaClasificación no supervisada
Ana Ana JustelJustelAna Ana JustelJustel1

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
Clasificación con métodos jerárquicos
Dendrograma
Distancias/disimilitud entre individuos/
Criterios de proximidad entre grupos
Determinación del número de grupos
2

El problema de clasificación/asignación/agrupación
Se trata de clasificar en dos o más grupos a individuos en los queh b d i i bl
El problema de clasificación/asignación/agrupación
hemos observado varias variables.
CLASIFICACIÓNCLASIFICACIÓN NONO SUPERVISADASUPERVISADA: Identificar grupos de
CLASIFICACIÓN CLASIFICACIÓN
individuos con características comunes a partir de la observaciónde varias variables en cada uno de ellos
UtilizaremosMétodos basados en particiones
CLASIFICACIÓN CLASIFICACIÓN SUPERVISADASUPERVISADA: identificar grupos de individuos con p
Métodos jerárquicos características comunes a partir de la observación de varias variables en cada uno de ellos y con
Todos son métodos exploratorios de datos,Para cada conjunto de datos podemos tener diferentes agrupaciones dependiendo del método la información de
una muestra de entrenamiento
diferentes agrupaciones, dependiendo del método. Lo importante es identificar una solución que nos enseñe cosas relevantes de los datos.
3

Ejemplo: Ejemplo: Sostenibilidad municipal
Disponemos de datos de consumo per cápita en 103 municipios de la pComunidad de Madrid durante 20 años
Nos interesa identificar si hay grupos de municipios con una tendencia similar en el consumo de agua para identificar buenas prácticas para
la sostenibilidad y zonas problemáticas por alto consumo
4
y p p

EjemploEjemplo: : Mamíferos
Queremos agrupar 25 especies de mamíferos en clusters, en los que las especies tengan en común una cierta homogeneidad en las
ícaracterísticas de su leche
5

Las técnicas de análisis cluster han sido tradicionalmenteutilizadas en muchas disciplinas, por ejemploutilizadas en muchas disciplinas, por ejemplo
Astronomía.Astronomía. Cluster = galaxias, super galaxias, etc.
Marketing.Marketing. Segmentación de mercados.
BiologíaBiología.. Taxonomía. Microarrays.
Ciencias AmbientalesCiencias Ambientales. . Clasificación de ríos para establecer tipologías según la calidad de las aguas (directiva marco calidad de las aguas (directiva marco europea)
6

Un CLUSTERCLUSTER es un grupo de individuos que cuando la dimensión
¿QUÉ es un CLUSTER?¿QUÉ es un CLUSTER?
Un CLUSTERCLUSTER es un grupo de individuos que, cuando la dimensiónlo permite, el ojo humano identifica como homogéneos entre sí yseparados de los individuos de los otros clusters.p
7

I l d di i i tá l á t
¿QUÉ es un CLUSTER?¿QUÉ es un CLUSTER?
Incluso en dos dimensiones no siempre está claro cuántoscluster hay y cómo se agrupan los individuos.
8

Ejemplo: Ejemplo: Lirios (iris.txt)
En un estudio del estadístico y genetista Sir Ronald A. Fisher se utilizaron cuatro características de los sépalos y pétalos para identificar 150 lirios de las especies iris setosa iris versicolor e iris virginicaespecies iris setosa, iris versicolor e iris virginica.
9

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
10

Técnicas para encontrar clusters
Cuando conocemos cuántos grupos hay:Cuando conocemos cuántos grupos hay:CLUSTERCLUSTER PORPOR PARTICIONESPARTICIONES.. Producen una partición delos objetos en un número especificado de grupos siguiendolos objetos en un número especificado de grupos siguiendoun criterio de optimización
CLUSTERCLUSTER JERÁRQUICOJERÁRQUICO.. Producen una secuencia deCuando no conocemos cuántos grupos hay:
particiones, juntando o separando clusters. En cada paso sejuntan o separan dos clusters siguiendo algún criterioespecificado
11
especificado

Ejemplo:Ejemplo: Agrupación jerárquica y por particiones de un conjunto de Ejemplo: Ejemplo: Agrupación jerárquica y por particiones de un conjunto de datos
No jerárquicaJerárquica
12
j qq

Técnicas para encontrar clustersEn general, se busca HOMOGENEIDAD dentro de los grupos yHETEROGENEIDAD entre grupos
Técnicas para encontrar clusters
Los criterios para identificar los clusters se basan siempre en
HETEROGENEIDAD entre grupos
MEDIDAS de SIMILITUD o de DISCREPANCIA entre todos lospares de datos. Algunos procedimientos cluster se puedenejecutar conociendo sólo la MATRIZ de DISCREPANCIASejecutar conociendo sólo la MATRIZ de DISCREPANCIAS
13

Decisiones que hay que tomar para hacer un cluster
1. Elegir el método cluster que se va a emplear
2. Decidir sobre si trabajar con los datos según se miden o estandarizados
3. Seleccionar la forma de medir la DISTANCIA/DISIMILITUD ENTRE INDIVIDUOS,,dependiendo de si los datos son cuantitativos o cualitativos
4 Clusters por particiones: Elegir un criterio de OPTIMALIDAD4. Clusters por particiones: Elegir un criterio de OPTIMALIDADClusters jerárquicos: Elegir un criterio para unir grupos, DISTANCIA ENTRE GRUPOS
5. Decidir el número de clusters
14

Estandarización de los datos
La mayoría de los métodos cluster son muy sensibles al hecho La mayoría de los métodos cluster son muy sensibles al hecho de que las variables no estén todas medidas en las mismas unidades y que la variabilidad sea muy diferente.
SOLUCIÓN: Si queremos que todas las variables tengan la misma importancia en el análisis, podemos estandarizar los misma importancia en el análisis, podemos estandarizar los datos variable por variable de varias maneras:
-- Puntuaciones Z: Puntuaciones Z: restar la media y dividir por la desviación típica.-- Rango Rango --1 a 1: 1 a 1: dividir por el rango.-- Rango 0 a 1: Rango 0 a 1: restar el mínimo y dividir por el rangoRango 0 a 1: Rango 0 a 1: restar el mínimo y dividir por el rango.-- Magnitud máxima de 1:Magnitud máxima de 1: dividir por el máximo valor.-- Media de 1: Media de 1: dividir por la media.
ó íó í ó í-- Desviación típica 1: Desviación típica 1: dividir por la desviación típica.
15

Estandarización de los datosPermite comparar las variables que vienen expresadas en distintas unidades o tienen diferentes magnitudes.
Las puntuaciones Z son las estandarizaciones habituales de Las puntuaciones Z son las estandarizaciones habituales de los datos los datos univariantesunivariantes
jijij s
xxz
La transformación se aplica a cada elemento de la matriz de datos, restando la media y dividiendo por la
js restando la media y dividiendo por la desviación típica, por variables (columnas)
Propiedades:• El vector de medias de los datos estandarizados es un vector de ceros.
L t i d i d l d t t d i d l t i d• La matriz de covarianzas de los datos estandarizados es la matriz de correlaciones de los datos.
16

Estandarización de los datos
Datos: Datos: xx P t i Z P t i Z
Ejemplo de puntuacionEjemplo de puntuaciones es Z:Z:
Datos: Datos: xx Puntuaciones Z: Puntuaciones Z: yy
17

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
18

ClustersClusters por particiones por particiones Existen distintos métodos que difieren en alguna característica
K MEDIAS Es el que se usa más habitualmente Fácil de
D i i h t h l t
K-MEDIAS.. Es el que se usa más habitualmente. Fácil deprogramar y da resultados razonables
Decisiones que hay que tomar para hacer un cluster
1. Elegir el método cluster que se va a emplear
2. Decidir sobre si trabajar con los datos según se miden o estandarizadosestandarizados
3. Seleccionar la forma de medir la DISTANCIA/DISIMILITUD ENTRE INDIVIDUOSDISTANCIA/DISIMILITUD ENTRE INDIVIDUOS,,dependiendo de si los datos son cuantitativos o cualitativos
4. Clusters por particiones: Elegir un criterio de OPTIMALIDAD
5 D idi l ú d l t5. Decidir el número de clusters19

Al it d k di (KMEDIAS KMEANS)
KMEDIASKMEDIAS tiene por objetivo separar las observaciones en k
Algoritmo de k-medias (KMEDIAS – KMEANS)
KMEDIASKMEDIAS tiene por objetivo separar las observaciones en kclusters, de manera que cada dato pertenezca a un grupo ysólo a uno
El algoritmo de K-MEDIAS busca con un método iterativo:- Los centroides (medias, medianas,…) de los k clusters.- Asignar cada individuo a un cluster.
C1 C2
El objetivo de OPTIMALIDAD
C3 C4
que se persigue es “maximizarla homogeneidad dentro de losgrupos”grupos
20

Algoritmo de k-medias
U f d tifi l it i d ti lid d
g(KMEDIAS – KMEANS)
Una forma de cuantificar el criterio de optimalidad es:
- Minimizar la media ponderada (por el tamaño del grupo) de las varianzas dentro de cada grupo para todas las variables
K p
SSW 2
O d h l b
k j
kjk snSSW1 1
2,
O dicho con otras palabras…
- Minimizar la suma de los cuadrados de las diferencias entre
K nk 2
cada dato y la media de su grupo
k i
kki
k
xxSSW1 1
2
21

P d l Al it d k di
Partiendo de un conjunto inicial de k centroides
Pasos del Algoritmo de k-medias
Partiendo de un conjunto inicial de k centroides,m1(1),…,mk(1), que se pueden elegir al azar para evitar sesgos opor cualquier otro procedimiento, el algoritmo va alternando losdos siguientes pasos:
PASO DE ASIGNACIÓN Cada observación se asigna alPASO DE ASIGNACIÓN. Cada observación se asigna alcluster con el centroide más próximo (siguiendo el criteriode optimalidad), con la distancia euclidea.
PASO DE CENTRALIZACIÓN. Para los clusters modificadosse calculan los nuevos centroides.se calculan los nuevos centroides.
El algoritmo se considera que ha alcanzado la convergenciacuando en una iteración no se produce ningún cambio, o secumple un criterio de parada.
22

P d l Al it d k diPasos del Algoritmo de k-medias
23

Ejemplo: Ejemplo: Proceso iterativo partiendo de centroides arbitrarios.
3Iteration 1
3Iteration 2
3Iteration 3
1.5
2
2.5
y
1.5
2
2.5
y
1.5
2
2.5
y
0
0.5
1
0
0.5
1
0
0.5
1
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
3Iteration 4
3Iteration 5
3Iteration 6
1.5
2
2.5
1.5
2
2.5
1.5
2
2.5
0
0.5
1
y
0
0.5
1
y
0
0.5
1
y
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
© Tan, Steinbach, Kumar. Introduction to Data Mining
24

P d l Al it d k diPasos del Algoritmo de k-medias
Reglas de parada del SPSS:Reglas de parada del SPSS:
C it i d i El l it d t d á i Criterio de convergencia: El algoritmo se detendrá si en una iteración completa ninguno de los centros se desplaza una distancia superior a un porcentaje previamente especificado porcentaje previamente especificado de la distancia más corta entre cualquiera de los centros iniciales.
Máximo numero de iteraciones: Para evitar que el algoritmo entre en un bucle infinito, se detendrá después de un número de número de iteraciones preiteraciones pre--determinadodeterminado aunque el criterio de convergencia iteraciones preiteraciones pre determinadodeterminado, aunque el criterio de convergencia no se cumpla.
25

Ejemplo: Ejemplo: Tortugas
Buscamos con KMEANS dos clusters (machos y hembras) en cuatro tortugas pintadas (trachemys scripta). En cada tortuga cuatro tortugas pintadas (trachemys scripta). En cada tortuga se midió la longitud, el ancho y la altura del caparazón.
Id Longitud Ancho AltoId. Longitud Ancho Altom1 120 89 40m2 119 93 41m2 119 93 41f1 159 118 63f2 155 115 63
1. Inicialmente, asignamos al azar la mitad de los datosa cada grupo y calculamos los dos centroides con lasmedias de los datos que hay en cada grupo.
En este caso ha salido m1 y f1 en el primer grupo y m2 yEn este caso ha salido m1 y f1 en el primer grupo y m2 yf2 en el segundo
26

Ejemplo: Ejemplo: Tortugas
Revisamos la asignación de cada dato y recalculamoslas medias de cada cluster cuando hay cambioslas medias de cada cluster cuando hay cambios
Id. Grupo inicial
Dist. amedia g1
Dist. a Media g2
Grupo final
Nueva media g1 Nueva media g2g g
m1 1 26,8 25,7 2 [159 118,0 63] [131,3 99 48,0]m2 2 52 15,4 2 [159 118,0 63] [131,3 99 48,0]f1 1 0 36,8 1 [159 118,0 63] [131,3 99 48,0]f2 2 5 32,3 1 [157 116,5 63] [119,5 91 40,5]
Repetimos hasta que no hay ningún cambio
Id. Grupo i i i l
Dist. adi 1
Dist. a M di 2
Grupo fi l
Nueva media 1
Nueva media g2inicial media g1 Media g2 final g1
m1 2 51,5 2,1 2 [157 116,5 63] [119,5 91 40,5]m2 2 49,8 2,1 2 [157 116,5 63] [119,5 91 40,5]m2 2 49,8 2,1 2 [157 116,5 63] [119,5 91 40,5]f1 1 2,5 52,9 1 [157 116,5 63] [119,5 91 40,5]f2 1 2,5 48,4 1 [157 116,5 63] [119,5 91 40,5]
27

Ejemplo: Ejemplo: Contaminación atmosférica en ciudades de USA
Los datos incluyen una variable de contaminación atmosférica, cuatro variables climáticas y dos indicadores de ecología humana en 41 ciudades de Estados Unidos.
SO2 contenido de SO2 en aire, en mg/m3 TEMP Temperatura media anual, en °FMANUF Número de empresas manufactureras con 20 empleados o másPOP Tamaño de la población, en miles WIND Velocidad media del viento, en millas por horaPRECI Precipitación media anual en pulgadas DAYS Número medio de días con precipitación al año
28
PRECI Precipitación media anual, en pulgadas DAYS Número medio de días con precipitación al año

Ejemplo: Ejemplo: Contaminación atmosférica en ciudades de USA
El objetivo del análisis cluster es agrupar optimamente las ciudades en cuatro cluster en función de las variables climáticas y ecológicas.
Se emplea el algoritmo de k medias con k igual a Localización espacial de los clusters k-medias, con k igual a cuatro.
Localización espacial de los clusters
Como las variables se miden en distintas unidades, los datos se estandarizan previamente para que tengan para que tengan desviación típica 1.
29

Ejemplo: Ejemplo: Contaminación atmosférica en ciudades de USAG1 (Sureste de USA) Clima húmedo: Abundante precipitación y altas temperaturas.G2 (N d t d USA) Cli
Localización espacial de los clusters
G2 (Nordeste de USA) Clima húmedo, frio y ventoso: Alto número de días con precipitación, baja tempe at a ientos f e tesbaja temperatura y vientos fuertes.G3 (Oeste de USA) Clima seco: Baja precipitación.G4 Densidad alta de población: G4 Densidad alta de población: Valores altos de los indicadores de ecología humana (Chicago, Filadelfia etc )
Medias de cada variable en cada grupoFiladelfia, etc.)
SO2 no se usa para hacer el cluster pero se incluye para validar el interés de las agrupaciones
Los clusters están relacionados con los niveles de SO2. Por tanto, las variables d l í h li b di t d l lid d d l i
30
de ecología humana y clima son buenos predictores de la calidad del aire.

Una limitación de KMEDIAS es que se espera que los grupos
Comentarios sobre el algoritmo de k-medias
Una limitación de KMEDIAS es que se espera que los grupos sean separables, con forma esférica y de tamaño similar.
Ej lEj l Li iEjemplo: Ejemplo: Lirios
KMEANS falla a menudo cuando trata de separar las tres especies. p pCon k = 2, se identifican los dos clusters visibles (uno conteniendo dos especies), mientras que con k = 3 uno de los dos clusters se divide en dos partes iguales
31
divide en dos partes iguales.

Una limitación de KMEDIAS es que se espera que los grupos
Comentarios sobre el algoritmo de k-medias
Una limitación de KMEDIAS es que se espera que los grupos sean separables, con forma esférica y de tamaño similar.
á óNo está garantizado que KMEDIAS llegue siempre a la solución óptima debido a que el resultado final va a depender de los centroides iniciales.
32

Ejemplo: Ejemplo: Proceso iterativo partiendo de centroides arbitrarios.
3Iteration 1
3Iteration 2
1.5
2
2.5
y1.5
2
2.5
y
0
0.5
1
y
0
0.5
1
y
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
3Iteration 5
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
3Iteration 3
3Iteration 4
1.5
2
2.5
y
1.5
2
2.5
y
1.5
2
2.5
y
0
0.5
1
y
0
0.5
1
0
0.5
1
© Tan, Steinbach, Kumar. Introduction to Data Mining
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2x
33

Una limitación de KMEDIAS es que se espera que los grupos
Comentarios sobre el algoritmo de k-medias
Una limitación de KMEDIAS es que se espera que los grupos sean separables, con forma esférica y de tamaño similar.
á óNo está garantizado que KMEDIAS llegue siempre a la solución óptima debido a que el resultado final va a depender de los centroides iniciales.
Como el algoritmo suele ser muy rápido, se suele ejecutar varias veces con distintos centroides iniciales.varias veces con distintos centroides iniciales.
El número k de clusters es un input, por tanto, una elección inapropiada de k puede conducir a un mal resultado inapropiada de k puede conducir a un mal resultado.
Cuando usamos KMEDIAS es importante chequear distintas i d t i l ú d ibl l t opciones para determinar el número de posibles clusters que
hay en el conjunto de datos.
34

Decidir el número de clusters
1. Una regla empirica para seleccionar el número de clusters esintroducir un nuevo cluster (pasar de K a K+1) cuando
10)1()1()(
KSSWKSSWKSSWF
1)1(
KnKSSW
2 Chequear con herramientas como el ANOVA si los grupos son2. Chequear con herramientas como el ANOVA si los grupos sonsignificativamente distintos (¿cómo de validos son losgrupos?)g p )
35

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
Clasificación con métodos jerárquicos
Dendrograma
Distancias/disimilitud entre individuos/
Criterios de proximidad entre grupos
36

Clusters jerárquicos Clusters jerárquicos Los divisivos requieren muchos
cálculos, casi no se usan
MÉTODOS DIVISIVOS. Parten de un único cluster con todos losdatos que se va dividiendo paso a paso, hasta obtener tantosq p p ,clusters como datos.
MÉTODOS AGLOMERATIVOS Parten de tantos clusters comoMÉTODOS AGLOMERATIVOS.. Parten de tantos clusters comodatos tiene la muestra y en cada paso se van juntando dosclusters siguiendo algún criterio especificado hasta obtener unúnico cluster con todos los datos.
Cada método se diferencia por la estrategia de fusión en cada Cada método se diferencia por la estrategia de fusión en cada etapa. Y todos tienen en común que la primera unión es entre los individuos más similares.
La elección de la estrategia de fusión dependerá de los objetivos de la investigación.
37

Decisiones que hay que tomar para hacer un cluster
1. Elegir el método cluster que se va a emplear
2. Decidir sobre si trabajar con los datos según se miden o estandarizados
3. Seleccionar la forma de medir la DISTANCIA/DISIMILITUD ENTRE INDIVIDUOS,,/ ,,dependiendo de si los datos son cuantitativos o cualitativosMÉTODOS AGLOMERATIVOS.. Parten de tantos clusters como
4. Clusters jerárquicos: Elegir un criterio para unir grupos,
datos tiene la muestra y en cada paso se van juntando dos cluster.
j q g p g p ,DISTANCIA ENTRE GRUPOS
38

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
Clasificación con métodos jerárquicos
Dendrograma
39

DENDROGRAMADENDROGRAMAEs una representación gráfica en forma de árbol.
Los clusters están representados mediante trazos horizontales (verticales) y las etapas de fusión mediante trazos verticales (h l )(horizontales).
La separación entre las etapas de fusión es proporcional a la di t i l tá l f d tdistancia a la que están los grupos que se funden en esa etapa.
40
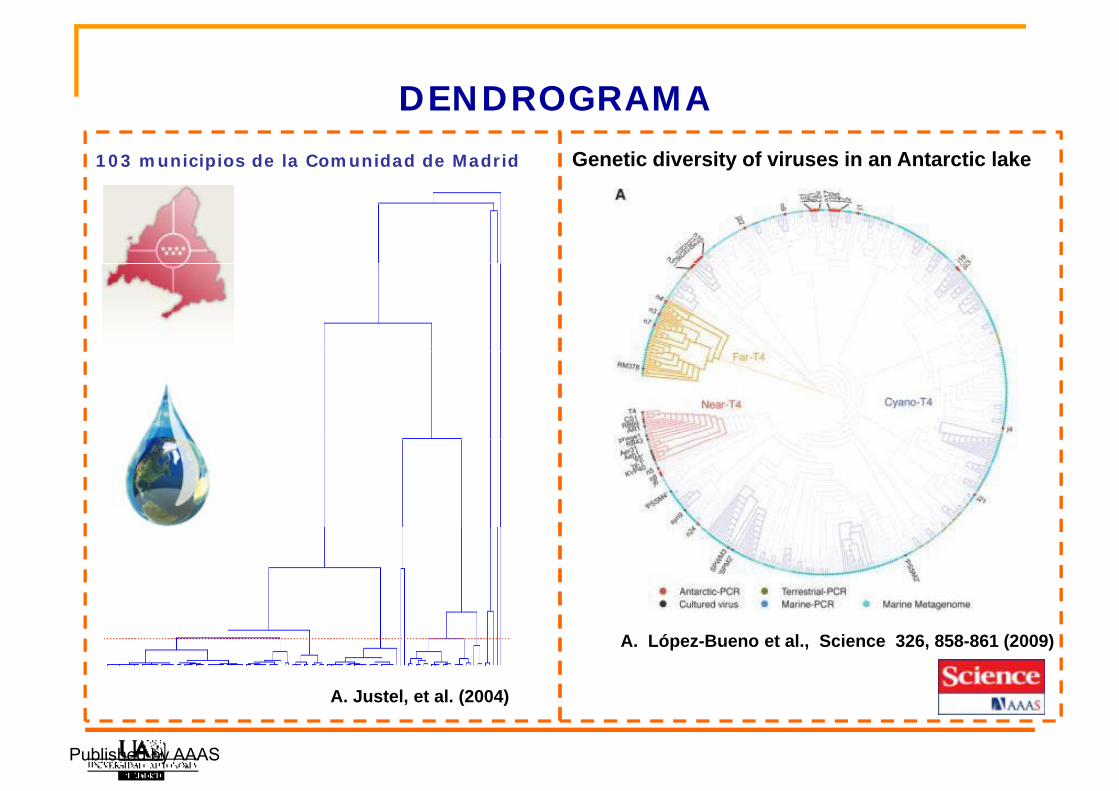
DENDROGRAMAGenetic diversity of viruses in an Antarctic lake103 municipios de la Comunidad de Madrid
DENDROGRAMA
A. López-Bueno et al., Science 326, 858-861 (2009)
A. Justel, et al. (2004)
Published by AAAS
, ( )

DENDROGRAMADENDROGRAMAEl SPSS representa las distancias entre grupos rescaladas, por tanto son difíciles de interpretar, nos fijaremos sólo en la forma.
Para más información nos fijamos en el Historial de l óconglomeración.
Cuando se combinan dos clusters, el SPSS asigna al nuevo cluster la etiqueta menor entre las que tienen los cluster que se combinan.
Los coeficientes son una medida de distancia/similitud l
42
entre clusters.

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
Clasificación con métodos jerárquicos
Dendrograma
Distancias/disimilitud entre individuos/
43

Distancias entre datos continuos (en SPSS)Distancia Distancia euclídeaeuclídea.. Raíz cuadrada de la suma de cuadrados de las diferencias entre los valores. Es la medida por defecto para datos
Distancias entre datos continuos (en SPSS)
p pde intervalo
Distancia Distancia euclídeaeuclídea al cuadrado.al cuadrado. Suma de cuadrados de las diferencias entre los valoresdiferencias entre los valores
Correlación de Correlación de PearsonPearson.. Correlación producto-momento entre dos vectores de valores
Coseno.Coseno. Coseno del ángulo entre dos vectores de valores
ChebychevChebychev.. Diferencia absoluta máxima entre los valoresyy
Bloque.Bloque. Suma de las diferencias absolutas entre los valores. También se conoce como distancia de Manhattan
MinkowskiMinkowski. Raíz p-ésima de la suma de las diferencias absolutas elevada a la potencia p-ésima entre los valores
PersonalizadaPersonalizada Raíz r ésima de la suma de las diferencias absolutas Personalizada.Personalizada. Raíz r-ésima de la suma de las diferencias absolutas elevada a la potencia p-ésima entre los valores de los elementos
MahalanobisMahalanobis distancedistance..
44
MahalanobisMahalanobis distancedistance..

Distancias entre datos continuos
DistanciaDistancia EuclídeaEuclídea
Distancias entre datos continuos
DistanciaDistancia EuclídeaEuclídea
Distancia Distancia EuclídeaEuclídea estandarizada, o estandarizada, o EuclídeaEuclídea entre datos entre datos estandarizadosestandarizadosestandarizadosestandarizados
Distancia de MahalanobisDistancia de Mahalanobis
45

Similitudes entre datos cualitativos binarios
Para calcular la similitud entre dos individuos para los que se observan p variables binarias tipo “presencia/ausencia” se calculan observan p variables binarias tipo presencia/ausencia se calculan todas las situaciones posibles
Individuo x1 x2 x3 … xpIndividuo x1 x2 x3 … xp
i 1 1 0 … 0
j 1 0 0 … 1
a: Número de veces en las p variables que ambas observaciones son 1
j
son 1.
b: Número de veces en las p variables que una observación es 1 y la otra 0la otra 0.
c: Número de veces en las p variables que una observación es 0 y la otra 1y la otra 1.
d: Número de veces en las p variables que ambas observaciones son 0son 0.
46

Similitudes entre datos cualitativos binarios
Individuo x1 x2 x3 … xp
i 1 1 0 … 0
j 1 0 0 … 1
Individuo iIndividuo i
du
o j 1 0 Total
1 a b a+b
Concordancia simpleConcordancia simple
Ind
ivid
1 a b a+b
0 c d c+d
Total a+c b+d p=a+b+c+d Coeficiente de JaccardCoeficiente de JaccardTotal a+c b+d p a+b+c+d
Coeficientes menos usados:Coeficientes menos usados:SokalSokal y y SneathSneath:: CzekanowskiCzekanowski y y SorensenSorensen::
Coeficientes menos usados:Coeficientes menos usados:
47

Ejemplo:Ejemplo: Presencia/ausencia de tres especies
Presencia (1) o ausencia (0) de tres especies (A, B, C) en 15 parcelas.
Ejemplo: Ejemplo: Presencia/ausencia de tres especies
Coeficiente de concordancia Coeficiente de concordancia simplesimple
Coeficiente de Coeficiente de JaccardJaccard
La ausencia no sabemos si es porque no existe la especie o porque no la hemos observado
48

Ejemplo:Ejemplo: Presencia/ausencia de tres especies
Utilizando el coeficiente de concordancia simple, Briza media es más parecida a Cynosurus cristatus que a Agrostis tenuis
Ejemplo: Ejemplo: Presencia/ausencia de tres especies
parecida a Cynosurus cristatus que a Agrostis tenuis
CCoeficiente de concordancia simple
Caso 1 2 31: Agrostis tenuis 1,000 ,600 ,3332 B i di 600 1 000 733
Utilizando el coeficiente de Jaccard Agrostis tenuis es más parecida
2: Briza media ,600 1,000 ,7333: Cynosurus cristatus ,333 ,733 1,000
Utilizando el coeficiente de Jaccard, Agrostis tenuis es más parecida a Briza media que a Cynosurus cristatus.
C fi i t d J dCaso
Coeficiente de Jaccard1 2 3
1: Agrostis tenuis 1 000 500 1671: Agrostis tenuis 1,000 ,500 ,1672: Briza media ,500 1,000 ,3333: Cynosurus cristatus ,167 ,333 1,000
49

Similitudes entre datos categóricosg
Para variables cualitativas con más de dos categorías la medida de similitud más utilizada es una generalización del coeficiente de similitud más utilizada es una generalización del coeficiente de concordancia simple
a1: es el número de veces que ambas observaciones son 1.
a2: es el número de veces que ambas observaciones son 2.
⁞ ⁞ ⁞ ⁞ ⁞ ⁞⁞ ⁞ ⁞ ⁞ ⁞ ⁞
ak: es el número de veces que ambas observaciones son k.
d: es el número de veces que ambas observaciones son 0.
50

Ejemplo:Ejemplo: Presencia/ausencia de cinco especies
Presencia (1) o ausencia (0) de cinco especies en 15 parcelas
Ejemplo: Ejemplo: Presencia/ausencia de cinco especies
CasoCoeficiente de Jaccard
1 2 3 4 5Caso 1 2 3 4 51: Agrostis tenuis 1,000 ,500 ,167 ,600 ,8572: Briza media ,500 1,000 ,333 ,500 ,4292: Briza media ,500 1,000 ,333 ,500 ,4293: Cynosurus cristatus ,167 ,333 1,000 ,167 ,1434. Dactylis glomerata ,600 ,500 ,167 1,000 ,7335. Festuca rubra ,857 ,429 ,143 ,733 1,000
51

Ejemplo:Ejemplo: Presencia/ausencia de cinco especies
1. Empezamos con 5 clusters (cada individuo en uno) y buscamos los dos más similares en la matriz:
Ejemplo: Ejemplo: Presencia/ausencia de cinco especies
CasoCoeficiente de Jaccard
1 2 3 4 5
los dos más similares en la matriz:
1 2 3 4 5
1: Agrostis tenuis 1,000 ,500 ,167 ,600 ,857
2: Briza media ,500 1,000 ,333 ,500 ,429
3: Cynosurus cristatus ,167 ,333 1,000 ,167 ,143
4. Dactylis glomerata ,600 ,500 ,167 1,000 ,733
5 Festuca rubra 857 429 143 733 1 0005. Festuca rubra ,857 ,429 ,143 ,733 1,000
2. Creamos el nuevo cluster y actualizamos la matriz de similaridad.Coeficiente de Jaccard
CasoCoeficiente de Jaccard
1+5 2 3 4
1+5 1,000 ??? ??? ???
2: Briza media ??? 1,000 ,333 ,500
3: Cynosurus cristatus ??? ,333 1,000 ,167
4 Dactylis glomerata ??? 500 167 1 000
52
4. Dactylis glomerata ??? ,500 ,167 1,000

Decisiones que hay que tomar para hacer un cluster
1. Elegir el método cluster que se va a emplear
2. Decidir sobre si trabajar con los datos según se miden o estandarizados
3. Seleccionar la forma de medir la DISTANCIA/DISIMILITUD ENTRE INDIVIDUOS,,/ ,,dependiendo de si los datos son cuantitativos o cualitativosMÉTODOS AGLOMERATIVOS.. Parten de tantos clusters como
4. Clusters jerárquicos: Elegir un criterio para unir grupos,
datos tiene la muestra y en cada paso se van juntando dos cluster.
j q g p g p ,DISTANCIA ENTRE GRUPOS
53

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
Clasificación con métodos jerárquicos
Dendrograma
Distancias/disimilitud entre individuos/
Criterios de proximidad entre grupos
54

Criterios para unir grupos en métodos jerárquicosmétodos jerárquicosp g p j qj qLos métodos de enlace (linkage) utilizan la proximidad entre pares de individuos para “unir” grupos de individuos.
1.1. EnlaceEnlace sencillosencillo (SINGLE(SINGLE LINKAGE)LINKAGE): utiliza la mínimadistancia/disimilitud entre dos individuos de cada grupo (útil
p g p
distancia/disimilitud entre dos individuos de cada grupo (útilpara identificar atípicos)
22 EnlaceEnlace completocompleto (COMPLETE(COMPLETE LINKAGE)LINKAGE): utiliza la máxima2.2. EnlaceEnlace completocompleto (COMPLETE(COMPLETE LINKAGE)LINKAGE): utiliza la máximadistancia/disimilitud entre dos individuos de cada grupo.
3.3. EnlaceEnlace promediopromedio (AVERAGE(AVERAGE LINKAGE)LINKAGE): utiliza la media3.3. EnlaceEnlace promediopromedio (AVERAGE(AVERAGE LINKAGE)LINKAGE): utiliza la media(mediana) de las distancias/disimilitud entre todos losindividuos de los dos grupos.
4.4. EnlaceEnlace dede centroidescentroides (CENTROID(CENTROID LINKAGE)LINKAGE): utiliza ladistancia/disimilitud entre los “centros” de los grupos.
5.5. MétodoMétodo dede WardWard (WARD(WARD LINKAGE)LINKAGE): utiliza la suma de lasdistancias al cuadrado a los centros de los grupos.
55

Criterios para unir grupos en métodos jerárquicosmétodos jerárquicosp g p j qj q
llEnlaceEnlacesencillosencillo
Enlace Enlace completocompleto
EnlaceEnlacemediomedio
Enlace Enlace centroidecentroide
C t id d t tit ti l di d i bl Centroide para datos cuantitativos: la media para cada variable de todos los individuos del grupo
Medioide para datos categóricos: el individuo con la menor disimilitud media con el resto de los miembros del grupo
56

Ejemplo:Ejemplo: Presencia/ausencia de cinco especies
Enlace simple: La similitud entre dos clusters es igual a la máxima similitud entre dos individuos de cada cluster (individuos más
Ejemplo: Ejemplo: Presencia/ausencia de cinco especies
CasoCoeficiente de Jaccard
similitud entre dos individuos de cada cluster (individuos más cercanos)
Caso 1 2 3 4 5
1: Agrostis tenuis 1,000 ,500 ,167 ,600 ,857
2: Briza media ,500 1,000 ,333 ,500 ,4292: Briza media ,500 1,000 ,333 ,500 ,429
3: Cynosurus cristatus ,167 ,333 1,000 ,167 ,143
4. Dactylis glomerata ,600 ,500 ,167 1,000 ,733
5. Festuca rubra ,857 ,429 ,143 ,733 1,000
La nueva matriz de similitudes es:
57

Ejemplo:Ejemplo: Presencia/ausencia de cinco especies
3. Repetir los pasos 1 y 2
Ejemplo: Ejemplo: Presencia/ausencia de cinco especies
CasoCoeficiente de Jaccard
1+5 2 3 4
1+5 1 000 500 167 7331+5 1,000 ,500 ,167 ,733
2: Briza media ,500 1,000 ,333 ,500
3: Cynosurus cristatus ,167 ,333 1,000 ,167
4. Dactylis glomerata ,733 ,500 ,167 1,000
Coeficiente de JaccardCaso
Coeficiente de Jaccard
1+5+4 2 3
1+5+4 1,000 ??? ???
2: Briza media ??? 1,000 ,333
3: Cynosurus cristatus ??? ,333 1,000
58
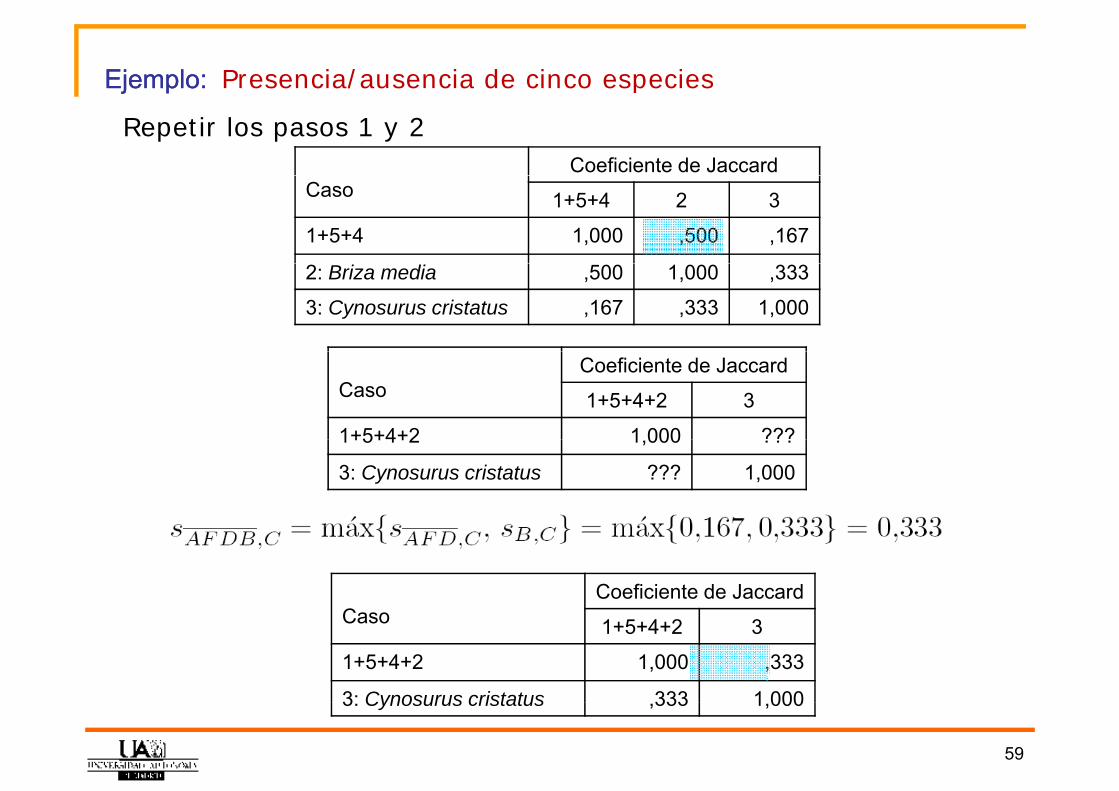
Ejemplo:Ejemplo: Presencia/ausencia de cinco especies
Coeficiente de Jaccard
Repetir los pasos 1 y 2
Ejemplo: Ejemplo: Presencia/ausencia de cinco especies
Caso 1+5+4 2 3
1+5+4 1,000 ,500 ,167
2: Briza media ,500 1,000 ,333
3: Cynosurus cristatus ,167 ,333 1,000
CasoCoeficiente de Jaccard
1+5+4+2 3
1+5+4+2 1 000 ???1+5+4+2 1,000 ???
3: Cynosurus cristatus ??? 1,000
CasoCoeficiente de Jaccard
Caso 1+5+4+2 3
1+5+4+2 1,000 ,333
3: Cynosurus cristatus 333 1 000
59
3: Cynosurus cristatus ,333 1,000

Ejemplo:Ejemplo: Presencia/ausencia de cinco especiesEjemplo: Ejemplo: Presencia/ausencia de cinco especies
Diferentes criterios dan lugar a diferentes agrupaciones
EnlaceEnlace sencillosencillo Enlace centroideEnlace centroideEnlaceEnlace sencillosencillo Enlace centroideEnlace centroide
60

Comentarios sobre el cluster jerárquico
Hacer las jerarquías en conjuntos de datos grandes es problemático ya que un árbol con más de 50 individuos es difícil de
Comentarios sobre el cluster jerárquico
problemático ya que un árbol con más de 50 individuos es difícil de representar e interpretar.
Una desventaja general es la imposibilidad de reasignar los individuos a los clusters en los casos en que la clasificación haya sido dudosa en las primeras etapas del análisis.
Debido a q e el análisis cl ste implica la elección ent e dife entes Debido a que el análisis cluster implica la elección entre diferentes medidas y procedimientos, con frecuencia es difícil juzgar la “veracidad” de los resultados. A veces, hacer cluster se considera más un arte que una ciencia. ¡Cuidado con los "abusos“!
Se recomienda comparar los resultados con diferentes métodos de hacer el cluster Soluciones similares generalmente indican de hacer el cluster. Soluciones similares generalmente indican la existencia de una estructura en los datos. Soluciones muy diferentes probablemente indican una estructura pobre.
En ultimo caso, la validez de los clusters se juzga mediante una interpretación cualitativa que puede ser subjetiva.
61

Técnicas de análisis multivariante para agrupación
Motivación
Métodos para construir clustersMétodos para construir clusters
Clasificación con el algoritmo de k-medias
Clasificación con métodos jerárquicos
Dendrograma
Distancias/disimilitud entre individuos/
Criterios de proximidad entre grupos
Determinación del número de grupos
62
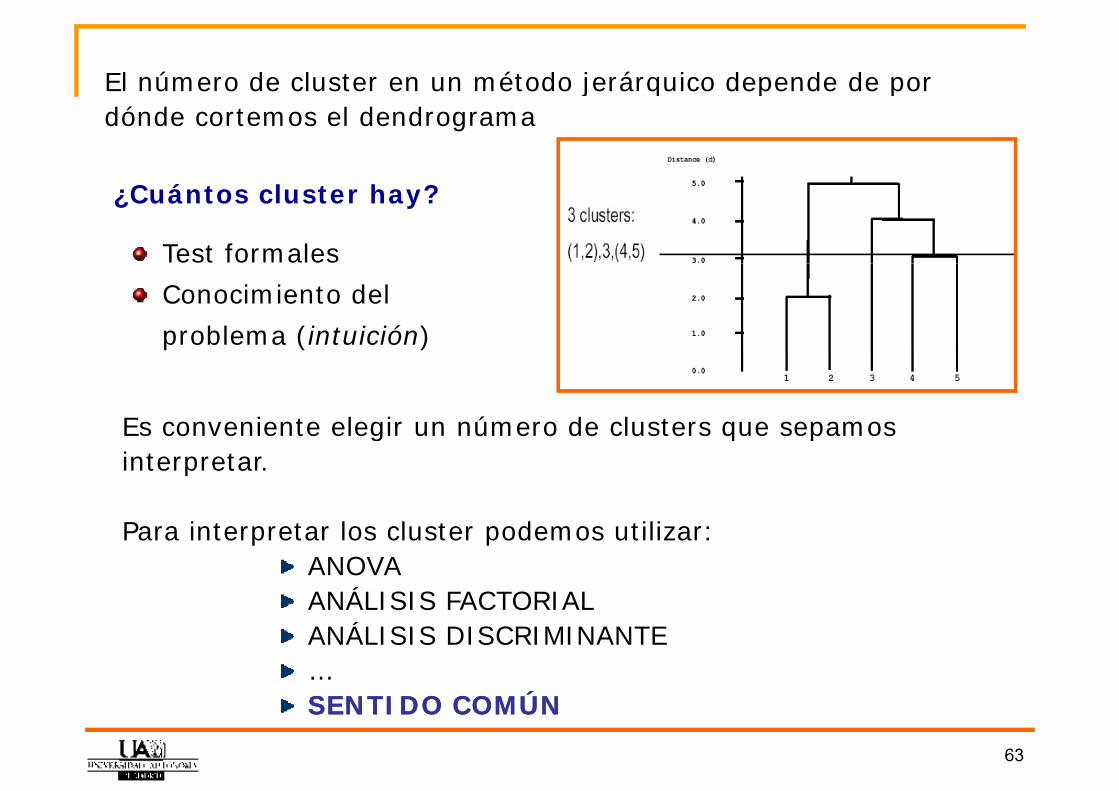
El número de cluster en un método jerárquico depende de por El número de cluster en un método jerárquico depende de por dónde cortemos el dendrograma
¿Cuántos cluster hay?
Test formalesConocimiento del problema (intuición)
Es conveniente elegir un número de clusters que sepamos g q pinterpretar.
Para interpretar los cluster podemos utilizar:Para interpretar los cluster podemos utilizar:ANOVAANÁLISIS FACTORIALANÁLISIS DISCRIMINANTE…SENTIDOSENTIDO COMÚNCOMÚNSENTIDOSENTIDO COMÚNCOMÚN
63

EjemploEjemplo: : Mamíferos
Queremos agrupar 25 especies de mamíferos en clusters, en los que las especies tengan en común una cierta homogeneidad en las
ícaracterísticas de su leche
64

EjemploEjemplo: : Mamíferos
G1 G1 -- Alto contenido en agua y Alto contenido en agua y lllactosalactosa
G2 G2 –– Niveles intermedios Niveles intermedios entre G1 y G3entre G1 y G3
G4 G4 Alto o te ido e Alto o te ido e
G3 G3 -- Similar al G4, menos grasa y más cenizaSimilar al G4, menos grasa y más ceniza
G4 G4 -- Alto contenido en grasasAlto contenido en grasas
Ficha Técnica: Variables estandarizadas desviación típica 1. Distancia euclídea. Enlace promedio
65
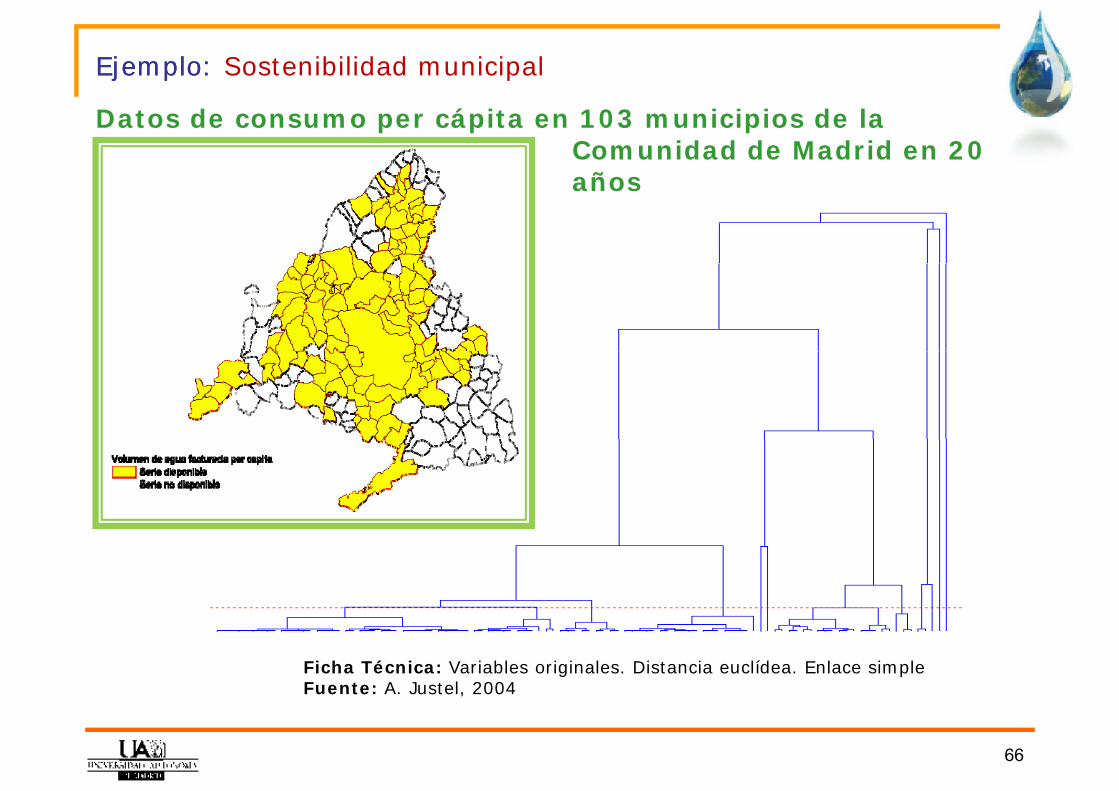
Ejemplo: Ejemplo: Sostenibilidad municipal
Datos de consumo per cápita en 103 municipios de la Comunidad de Madrid en 20 ñaños
Ficha Técnica: Variables originales. Distancia euclídea. Enlace simpleFuente: A. Justel, 2004
66

Ejemplo: Ejemplo: Sostenibilidad municipal
67

Ejemplo: Ejemplo: Sostenibilidad municipalPara interpretar los clusters, se utiliza una variable auxiliar que no se ha empleado en la construcción de los clusters: Porcentaje de segundas viviendas segundas viviendas. (Los habitantes consumen recursos pero no están empadronados y su consume se asigna a los residentes)
Volumenmedio
Existen diferencias significativas entre los porcentajes de segunda vivienda (ANOVA p valor<0 0001) En particular las comparaciones vivienda (ANOVA p-valor<0,0001). En particular, las comparaciones múltiples muestran diferencias entre el cluster de mayor porcentaje de segundas viviendas, “Actividad económica rural” y el resto, excepto el l t “P ó i l i i l í d i ió (t ñ di )”cluster “Próximos a las principales vías de comunicación (tamaño medio)”
69

Densidad de poblaciónEjemplo: Ejemplo: Sostenibilidad municipal p
70

EjemploEjemplo: : Gastos de las familias por provincias
71

EjemploEjemplo: : Gastos de las familias por provincias
Ficha TécnicaFicha Técnica: Variables originales. Distancia euclídea.
Enlace con Método de Ward
72
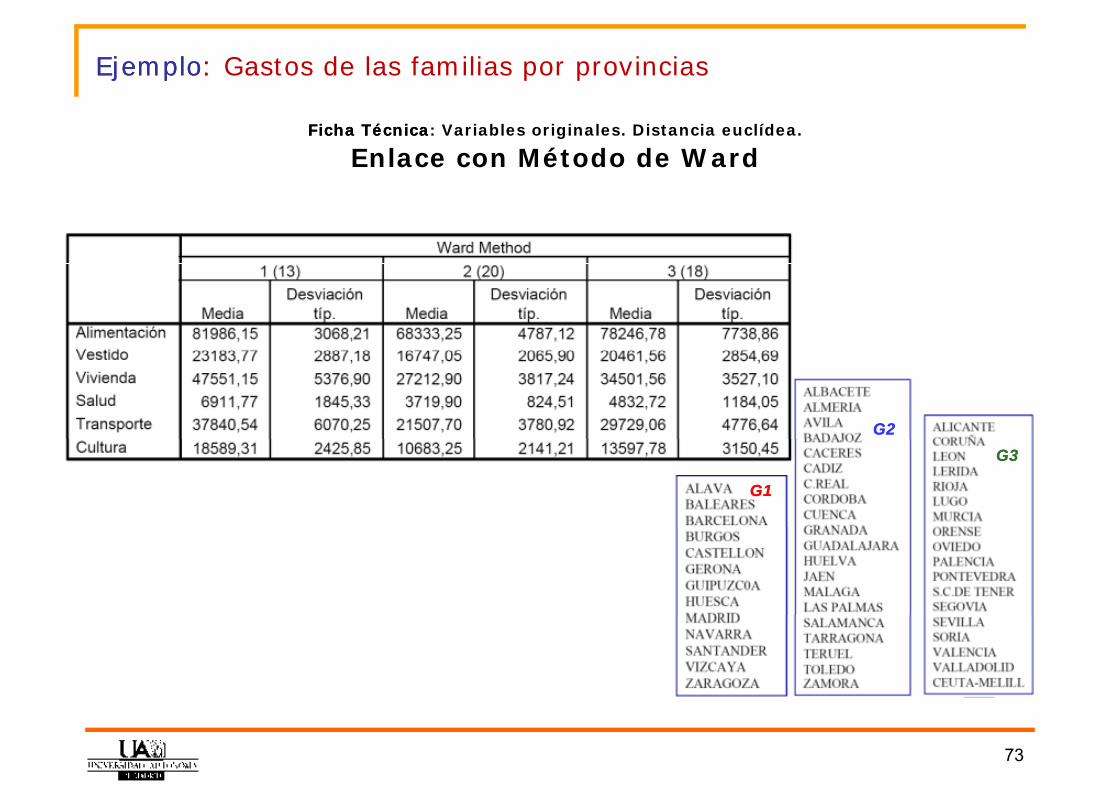
EjemploEjemplo: : Gastos de las familias por provincias
Ficha TécnicaFicha Técnica: Variables originales. Distancia euclídea.
Enlace con Método de Ward
G2G2
G1G1
G3G3
73

EjemploEjemplo: : Gastos de las familias por provincias
G1G1
**G3G3
Clusters con k-medias
G2G2
G2G2**
G1G1
**
G3G3**
****
**
Enlace con Método de WardEnlace con Método de Ward
74









![08 Tema 2 morfologia[1]](https://static.fdokumen.com/doc/165x107/6319d89ab41f9c8c6e09ee54/08-tema-2-morfologia1.jpg)










