
Structural Indexing for Character Recognition
17
COMPUTER VISION AND IMAGE UNDERSTANDING Vol. 66, No. 3, June, pp. 330–346, 1997 ARTICLE NO. IV960518 NOTE Structural Indexing for Character Recognition* Angelo Marcelli² Dipartimento di Informatica e Sistemistica, Universita ´ di Napoli ‘‘Federico II,’’ Via Claudio, 21, 80125 Napoli, Italy Natasha Likhareva Citicorp Securities, Inc., 399 Park Avenue, 11th floor, Zone 12, New York, New York 10043 and Theo Pavlidis Department of Computer Science, Image Analysis Laboratory, SUNY at Stony Brook, Stony Brook, New York 11794-4400 Received June 20, 1994; accepted March 8, 1996 1. INTRODUCTION In this paper we present a structural method to speed up Structural character recognition involves identifying a the character recognition process by reducing the number of correspondence between the pixels of the image represent- the prototypes used during the classification of a given sample. ing the character to be recognized (sample) and the ab- It adopts simplified descriptions of the character shapes and stract definitions of characters (prototypes). In order to uses a rough classification scheme in order to select the prototypes that most likely will match a given sample. The reduce the amount of data to be passed on for further descriptions are stored in a multilevel data structure adopted processing, as well as to remove, at least partially, the noise to represent the character shape. The lowest level of such a introduced by the acquisition and binarization operations, data structure contains the detailed description of the charac- the original representation of the sample is transformed ter in terms of its skeletal features. The intermediate one into a suitable data structure. The prevalent approach to- consists of a list of groups of features, each one representing day is serial; i.e., at each stage information is reduced and a character component. The upper level, eventually, is an only what is considered essential is passed to subsequent index vector, whose dimension equals the different types of stages [1–3]. Modern OCR systems use this approach [4, superfeatures. By using this index vector a fast and reliable 5] and perform very well on high quality text, but their selection of the prototypes to be considered as candidates performance falls drastically on slightly worse quality for the matching can be obtained. Once this subset has been text [5]. obtained, the more detailed description based on the skeletal In order to overcome the intrinsic limitations of the serial features is resorted and the main classifier activated. Experi- approach, a novel method has been proposed recently for ments have proved that the method is efficient and correct, isolated character recognition, which is based on concep- since it allows us to select a small subset of prototypes which tual modeling of both the writing and the reading processes always contains the right one, thus reducing the classification [7–9]. While some decisions are made at each stage, others time without affecting the accuracy of the system. 1997 are postponed. In particular: Academic Press 1. A grey-scale image is adopted to represent the charac- ter. In contrast to the prevailing approach, the scanned images are not binarized; instead features are extracted * This is an expanded version of a paper of the same title appearing in directly from the grey scale image provided by the scanner. Proceedings, 2nd Int. Conference on Document Analysis and Recognition This allows us to label the pixels as background, fore- ICDAR’93, Tsukuba Science City, JAPAN, October 20–22, 1993. ground, or ambiguous pixels, postponing the assignment ² To whom correspondence should be addressed. E-mail: marcelli@ nadis.dis.unina.it. of a definitive label to a subsequent process. 330 1077-3142/97 $25.00 Copyright 1997 by Academic Press All rights of reproduction in any form reserved.
Transcript of Structural Indexing for Character Recognition

COMPUTER VISION AND IMAGE UNDERSTANDING
Vol. 66, No. 3, June, pp. 330–346, 1997ARTICLE NO. IV960518
NOTE
Structural Indexing for Character Recognition*Angelo Marcelli†
Dipartimento di Informatica e Sistemistica, Universita di Napoli ‘‘Federico II,’’ Via Claudio, 21, 80125 Napoli, Italy
Natasha Likhareva
Citicorp Securities, Inc., 399 Park Avenue, 11th floor, Zone 12, New York, New York 10043
and
Theo Pavlidis
Department of Computer Science, Image Analysis Laboratory, SUNY at Stony Brook, Stony Brook, New York 11794-4400
Received June 20, 1994; accepted March 8, 1996
1. INTRODUCTIONIn this paper we present a structural method to speed up
Structural character recognition involves identifying athe character recognition process by reducing the number ofcorrespondence between the pixels of the image represent-the prototypes used during the classification of a given sample.ing the character to be recognized (sample) and the ab-It adopts simplified descriptions of the character shapes andstract definitions of characters (prototypes). In order touses a rough classification scheme in order to select the
prototypes that most likely will match a given sample. The reduce the amount of data to be passed on for furtherdescriptions are stored in a multilevel data structure adopted processing, as well as to remove, at least partially, the noiseto represent the character shape. The lowest level of such a introduced by the acquisition and binarization operations,data structure contains the detailed description of the charac- the original representation of the sample is transformedter in terms of its skeletal features. The intermediate one into a suitable data structure. The prevalent approach to-consists of a list of groups of features, each one representing day is serial; i.e., at each stage information is reduced anda character component. The upper level, eventually, is an only what is considered essential is passed to subsequentindex vector, whose dimension equals the different types of stages [1–3]. Modern OCR systems use this approach [4,superfeatures. By using this index vector a fast and reliable 5] and perform very well on high quality text, but theirselection of the prototypes to be considered as candidates performance falls drastically on slightly worse qualityfor the matching can be obtained. Once this subset has been text [5].obtained, the more detailed description based on the skeletal In order to overcome the intrinsic limitations of the serialfeatures is resorted and the main classifier activated. Experi- approach, a novel method has been proposed recently forments have proved that the method is efficient and correct,
isolated character recognition, which is based on concep-since it allows us to select a small subset of prototypes whichtual modeling of both the writing and the reading processesalways contains the right one, thus reducing the classification[7–9]. While some decisions are made at each stage, otherstime without affecting the accuracy of the system. 1997are postponed. In particular:
Academic Press
1. A grey-scale image is adopted to represent the charac-ter. In contrast to the prevailing approach, the scannedimages are not binarized; instead features are extracted
* This is an expanded version of a paper of the same title appearing in directly from the grey scale image provided by the scanner.Proceedings, 2nd Int. Conference on Document Analysis and Recognition
This allows us to label the pixels as background, fore-ICDAR’93, Tsukuba Science City, JAPAN, October 20–22, 1993.ground, or ambiguous pixels, postponing the assignment† To whom correspondence should be addressed. E-mail: marcelli@
nadis.dis.unina.it. of a definitive label to a subsequent process.
3301077-3142/97 $25.00Copyright 1997 by Academic PressAll rights of reproduction in any form reserved.

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 331
2. A flexible matching algorithm is used during the clas- ing time, without affecting the performance of the classifierin complex ones.sification. With respect to other systems using prototypes
described before in the literature (for example [10]), the The general problem of reducing a classifier computa-tional cost has been faced since the early 1970s in theflexible matching algorithm allows a significant reduction
in the number of prototypes, because the features are inter- framework of statistical pattern classification [13]. Themost popular idea adopted since then is that of hierarchi-preted in the context of each prototype: there is no static
labeling of features, but they acquire their meaning ac- cally grouping the input data into disjoint sets and thenreducing the search cost by adopting a branch and boundcording to a priori knowledge. Moreover, great amounts
of noise and shape variations are allowed, since they are algorithm on the resulting tree data structure. This andsimilar approaches proposed to deal with statistical featuremodelled as a series of transformations.
3. Design prototypes by hand. Since the shape of sym- vectors, though, requires a labeling of the features in orderto compute the mean sample of that feature within a givenbols is culturally defined and their number is small, it seems
reasonable to obtain these definitions by a human being class; such a labeling is in contrast with our basic idea ofpostponing any decision about feature interpretation untilmore than by using an automatic inference procedure.the classification step is entered. In the specific framework
The overall result of the method is that any time a difficult of OCR, preclassification techniques have been widely in-case is detected in a certain step, the decision can be post- vestigated in case of handprinted Chinese character recog-poned and left to the following steps, where presumably nition and are still considered the most promising onesmore information will be available. More details about the [14]. The majority of the methods proposed in the literatureclassification method and its performance can be found (a comprehensive review may be found in [15]) belongsin [11]. to one of two groups. The first and wider group includes
While the complex methods involved by this approach methods which adopt as preclassification features a combi-are certainly useful for difficult cases, they are an overkill nation of the features used for the classification, whilefor simple ones; if the input specimen happens to be almost methods belonging to the second one use different classifi-noiseless, and its shape corresponds to the most ‘‘obvious’’ cation strategies on the same set of features used for classi-human perception of a certain character, invoking the com- fication. Although the performance of these methods areplex recognition schemes embedded in the system leads very interesting, especially for the ones belonging to theus to postpone even simple decisions, thus overloading the first group [15], it may be noted that the methods whichclassifier without improving the accuracy. Furthermore, perform better exhibit high computational costs and thatthey require computational efforts proportional to the a slight improvement in the performance results in a con-number of prototypes, and this can be a bottleneck even siderable increase in computing time.when the number of prototypes is rather small (less than In this paper we propose a novel preclassification100 for the English upper and lower case letters, numerals, method which combines an easy-to-compute set of fea-and punctuation symbols). It can be far more serious when tures, arranged into a multilevel data structure, with aone deals with a writing system that contains many more flexible matching scheme to select the prototypes that mostsymbols. The main purpose of this investigation is to find likely will match a given sample. The multilevel data struc-a way to reduce the high cost of the method needed to ture is articulated into three levels. The bottom level con-deal with difficult cases while dealing with simple ones, so tains the complete description of the character, in termsthat the flexibility of the classifier is used only when needed. of the features provided by the feature extractor. The inter-Therefore we have investigated the possibility of using a mediate one consists of subgraphs, extracted from the fea-preclassification procedure to reduce the number of proto- ture graphs, representing the character components. Thetypes to be matched against a given sample. As it has been upper level is an index vector, whose elements, called su-pointed out in [12], such a procedure must satisfy two basic perfeatures, represent the simple shape elements found inrequirements: the specimen. The flexible matching algorithm performs a
rough classification of the sample by comparing its feature(1) the time required to perform both preclassificationvector with those representing the prototypes. Its flexibilityand classification should be less than the time required toallows us to manage systematically the relative distortionperform the classification itself (efficiency);between a candidate shape and its prototype, accomplish-(2) the recognition rate should be the same, or better,ing robustness to noise and shape variations.than the one achieved by the system without using the
The preclassifier includes three main stages: decomposi-preclassifier (accuracy).tion, description, and screening. The decomposition isaimed to group the features around a branch point so thatAccording to these requirements, our main goal was to
design a method to reduce significantly the number of features belonging to the same stroke are kept together.The description stage maps superfeatures onto simple com-candidate prototypes in simple cases, thus saving comput-

332 MARCELLI, LIKHAREVA, AND PAVLIDIS
ponents of the feature graph provided by the decomposi-tion stage and compiles the index vector. The screeninguses such a vector to divide the prototypes into two sets:the first containing prototypes’ candidate to be matchedwith the sample; the second, the remaining ones. The pre-classifier works in two modes, handling in different waysprototype and sample feature graphs. During a preliminaryphase, the multilevel representation for each prototype isbuilt and stored. At run time, after the feature extraction, FIG. 1. Characters can be thought as made of a single self-intersectingthe same representation is computed for a given sample. component (a), as well as two components joining (b) or crossing (c).Thus, the preclassification is carried out by using the high-est description level, where only number and type of super-features are considered in order to divide the prototypeset into the two subsets mentioned above. By using this accomplished by using a set of good continuity criteria to
decide the best way the features joining in a branch pointprocedure we avoid matching every prototype with a givensample; once a few matches with low costs are found within can be grouped together as a part of ‘‘continuous’’ compo-
nents [18, 19]. Such criteria make it possible to recover anthe first subset, the classification for more matches canbe stopped. original self-intersecting character component (Fig. 1a),
the presence of a junction (Fig. 1b) as well as a cross (Fig.The paper is organized as follows: Section 2 describes thedecomposition method, while the description procedure is 1c). Thus, by grouping the features around the branch
point, according to the case, and by connecting them withpresented in Section 3. Section 4 illustrates the flexiblematching algorithm used in the screening stage. Section 5 the remaining ones, the desired decomposition is achieved.
The set of good continuity criteria we have devised de-contains the experimental results, and conclusions aregiven in Section 6. pends on both the length of the features and the angle
between them, such as keeping together features havingequal lengths and forming an angle equal to 1808 has a
2. DECOMPOSITION cost equal to 0. The actual trend of the cost function hasbeen determined experimentally, in a way similar to thatreported in [19], and the total cost is obtained by addingWe assume that the initial representation of a character
in terms of a polygonal approximation of its skeleton has the two contributions, so that it ranges from 0 to 2. Inthe end, the pair with the minimum cost is interpreted asbeen previously obtained, by using an algorithm of the type
described in [9]. Let us note that the method illustrated in belonging to the same component and kept together. Notethat, while computing the angle between features, an arcthe sequel does not depend on the specific skeletonization
algorithm and, therefore, can be applied any time such a is represented by its first polyline segment, assumed torepresent the local direction of the feature. Figure 2 showsrepresentation is made available. Since the characters of
the Latin alphabet are drawn by using conic arcs and the results obtained by applying the decomposition proce-dure to some character skeletons. The set of good continu-straight segments and because it has been shown that the
arc of circle has enough descriptive power to substitute ity criteria we have adopted is an extension of the onessuggested in [18], where only angles were used. By meanscurves of different shapes but with the same semantic value
[16, 17], these two types of lines, straight segments and of this extension, it is possible to deal correctly with caseslike the serifs of the central horizontal stroke of the charac-arcs of circle, have been used as features to describe ribbon-
like shapes as the character ones [7]. Thus, the bottom ter ‘‘E’’ of Fig. 2. In fact, since the angles among thefeatures are equal, any of the three decompositions couldlevel of our representation is a graph, whose arcs represent
the features, and the nodes represent the junctions be obtained, while by looking at the lengths of the featuresthe only possible decomposition is the one reported inamong features.
As mentioned in the Introduction, the decomposition is the figure.The straightforward application of these criteria woulda preliminary stage whose aim is that of partitioning a
graph into a set of subgraphs, each one representing a work well only on a limited number of cases, because ofthe local distortions introduced by the very process ofcharacter component, i.e., one of the basic elements that
have been combined together to form the actual character skeletonization [20]. These distortions may appear in cor-respondence of crossings and junctions. In the first case,shape. Since the branch points represent the locations
where two or more character components join or cross, it both a spurious branch point and a spurious branch aregenerated (Fig. 3a), introducing a spurious junction as wellis necessary to group the features around the branch points
according to the components they belong to. This is often as a spurious feature into the graph, while in the second

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 333
FIG. 4. Because of the skeleton distortions, a branch point corre-sponding to a crossing can be split into two (a), or the feature shapechanged (b).
the character strokes that is not available in our case [21,22], are not adequate to deal with both straight segmentsand curved lines [23, 24], require the use of both the con-tour and the skeleton [25], or are quite complex [26]. In-stead of attempting to recover the distortions, we havedesigned a set of procedures to deal with them. Basically,they are able to detect spurious skeletal branches and toignore them while applying the good continuity criteria,as well as to find the occurrence of special cases, like serifs
FIG. 2. Examples of decomposition provided by the basic algorithm. and symmetries, and to deal with them derogating fromThe character skeletons (a) and the character components found by using
the above-mentioned criteria. Details about the imple-the good continuity criteria (b).mentation of these procedures are given in AppendixA. Let us note that the good continuity criteria we havedesigned to deal with the skeleton distortions are used
case a spurious inflection arises, that can change the type only when there are three features connected to a branchof features associated to the polygonal sides around the point, since in case there are four features none of thebranch point (Fig. 3b). Since the good continuity criteria distortions mentioned above can occur, while cases withuse local information, i.e., information carried by the fea- more than four features are not considered to havetures around the branch point which are the ones affected a simple shape, and therefore the preclassification isby the distortions mentioned above, they might lead to not performed.unreliable decompositions, as shown in Fig. 4. Methods to Once the costs have been computed by using the set ofrecover from these distortions obtaining a faithful skeleton criteria suitable for the specific case, the features aroundhave been proposed in different contexts [21–26], but they the branch points are grouped according to them; the pairrequire the use of information on the local thickness of corresponding to the minimum cost is considered as be-
longing to the same component. Therefore, if there arethree features connected to the branch point, the thirdone is left alone, while if there are four features they aregrouped into two different components. This latter choicedepends on the assumption that such a configuration hasbeen originated by the crossing of two strokes, like inthe character X, rather than by joining three of themin the same point. Once such a grouping has been done,a simple graph traversal algorithm allows us to obtain thedesired decomposition, which is stored in the intermediatelevel of the data structure. Thus, this level is made ofa set of paths on the feature graph, each one representinga character component. Figure 5 shows the results ofthe decomposition on some distorted characters of theFIG. 3. Examples of distortions introduced by the skeletonization
process in correspondence of a crossing (a) and a join (b). data base.

334 MARCELLI, LIKHAREVA, AND PAVLIDIS
FIG. 6. Examples of extended loops.
method to choose such mappings automatically, usably fastand which also improves the performance of the classifierwith respect to simpler fixed mappings has been proposedin [27], where a set of structural shape features are statisti-cally characterized and then mapped into a binary featurevector. In our case, the shape primitives are defined ‘‘apriori’’ on the basis of a writing model and are obtaineddirectly from the set of shape features extracted from theinput image, instead of being derived by means of a statisti-FIG. 5. The results provided by the decomposition procedure. Notecal analysis. As a consequence, we may use a much simplerthe effect of using the features following the short ones (a), the procedure
to deal with crossing (b), the criteria to deal with spurious branch and mapping scheme with respect to the one adopted in [27],serifs (c), the symmetry criterion (d). as it is explained in the sequel.
3.1. Shape Primitives3. DESCRIPTION
As it has been noted in the introduction, printed andhandprinted character shapes can be reliably decomposedThe purpose of the description is that of associating to
each character component a suitable set of simply describ- in terms of sequences of arcs of circle and straight seg-ments. Thus, in order to achieve the goal, we adopt thisable shape primitives, so that any component is trans-
formed into a structure made by the primitives which have type of curves as shape primitives. We call them superfea-tures just to denote the fact that these shape primitives,been found in the specimen. In order that such a descrip-
tion may be used effectively for a model-based approach even being of the same type of the skeletal ones, are moregeneral, since they have been obtained from a more generalto the recognition, it is desirable that each shape primitive
represent a significant feature of the skeleton, so that the decomposition of the character into parts with respect tothat one represented by the skeleton branches. We distin-same description correspond to different shapes belonging
to the same class, thus absorbing part of the variability guish among 13 types of superfeatures, grouped into threefamilies: loops, strokes, and arcs. A loop (L) can be a realexisting among samples of the same character printed with
different fonts or handprinted by different writers. This loop, i.e., a component without branch points or end points,or an extended loop (EL), i.e., a single component self-implies the solution of two problems: the selection of a set
of shape primitives to be mapped onto character compo- touching but not intersecting (see Fig. 6). A stroke can behorizontal (H), vertical (V), or tilted (T) according to thenents, and the design of an algorithm to perform the map-
ping. In this respect, the problem we are facing may be angle it forms with the horizontal axis. An arc faces oneof the eight possible directions in the digital plane: N, NE,seen as a mapping of variable-length, unordered sets of
geometrical features, to fixed-length numerical vectors. A E, SE, S, SW, W, NW.

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 335
3.2. The Mapping Algorithm
The mapping is performed in three steps, one for eachof the families of superfeatures mentioned before.
The aim of the first step is that of searching for loopsand extended loops. This is accomplished by checking thata component does not have end points or branch points(loop), or that it has only one branch point of degree threeand just one end point (extended loop). Actually, sinceloops have been already detected by the feature extraction,the loop detection substep is quite trivial, since it is imple-mented by checking the label of the feature. The use ofextended loops can be explained with reference to Fig. 6; FIG. 7. A former branch point is removed if the segments connected
to it are collinear (a) or if they form a smooth angle (b).the shape of Fig. 6a is not a loop in the topological sense,because there is the small feature on top of it, but it couldbe considered as a loop if we assume that the small featureis negligible. Therefore, we have introduced this type ofsuperfeature; it can be seen as a loop or not, depending
tortion which arises in correspondence to the branch point,on the context of the specific match, as will be explainedthe two segments could be slightly tilted, as in Fig. 7b.in the next section. Furthermore, this allows us to haveTherefore, two segments are merged even if they form athe same description, even if a different grouping of thesmooth angle, which in the current implementation has tofeatures connected to the branch point has been providedbe greater than the threshold TAM . To decide whether aby the decomposition stage. Note that, since this decisionsegment, originally present in the component or obtainedis based only on the topology of the component, indepen-by merging, is long enough to be considered as a stroke,dently of the relative size of the loop with respect to thatits length must be greater than a threshold, whose actualof the other feature, the character of Fig. 6b will be de-value depends on the stroke orientation: TLV for verticalscribed as an extended loop too.strokes; TLH for tilted and horizontal.The second step of the description procedure has the
Once the two substeps have been accomplished, a poly-goal of detecting strokes, and it is implemented in twoline associated to a component may have been split intosubsteps. The first one checks if any one of the segmentsparts, some of which have been already mapped to super-of the component is long enough to be considered a stroke,features, while others have still to be described. In theand then labels it as vertical, horizontal, or tilted accordingsequel, we will use the term component to denote both ato its orientation. Once this substep has been performedcomponent or any of its parts to be described. To completeand the segments satisfying the condition removed fromthe description stage, the third step is entered, whose aimthe component, the second one is entered, in order tois that of mapping arcs to the components. This is accom-merge two successive segments, forming a longer one. Twoplished by using a curve-fitting algorithm, providing us withsegments are candidates for the merge if they form aa reasonable compromise between faithful representationsmooth angle and the resulting segment is long enough toof character shapes and tolerance with respect to insignifi-be considered a stroke. The merge strategy is such thatcant shape variations. The specific method used is de-each segment, except the first and the last of the compo-scribed in Appendix B, but it is worth noticing that anynent, may belong to two different, successive strokes. Onceother method can be used without affecting the perfor-all the candidate strokes have been generated, if two ofmance of the preclassifier.them share a segment, the longest one is chosen, labeled
according to its orientation, and the correspondent seg-3.3. Building the Index Vectorments removed from the component. This substep has been
introduced to deal with cases like the one of Fig. 7a. Since Once the superfeatures have been detected they can bethe polygonal approximation is performed before the arranged into a superfeature vector made up of 13 ele-grouping, a branch point located inside a stroke will split ments, each one representing the number of superfeaturessuch a stroke into two segments, even if they are aligned. of a certain type found in the specimen. During the filling ofAfter the decomposition, the original sequence is recon- such a vector, a check is done to eliminate the superfeaturesstructed but the vertex corresponding to the branch point is that are considered too small to represent a significative
part of the character. This is accomplished by comparingstill there, so that the original stroke could not be detectedwithout such a grouping. Furthermore, because of the dis- the length of the superfeatures with a threshold, expressed

336 MARCELLI, LIKHAREVA, AND PAVLIDIS
(d) in the last row, a pair of spurious branch pointshas been detected; thus, the spurious branch connectingthem has been eliminated, the four remaining featureshave been connected virtually in the middle of the spuriousbranch and then successively split into two crossing compo-nents which, in turn, have been mapped into two tiltedstrokes.
4. SCREENING
Once the character description in terms of superfeatureshas been obtained, the screening stage is entered, whoseaim is that of selecting the prototypes that most likely willmatch the sample. The key idea of the whole process isthat the superfeature vector associated to each prototyperepresents the minimum amount of features that a samplemust have to be a candidate to belong to the class repre-sented by that prototype. If a sample description has lesssuperfeatures than a prototype (in total, over all the com-ponents of the vector), the match is rejected, because thereis not enough evidence that the sample corresponds to thatprototype. It might be noted that this assumption leads us
FIG. 8. The index vectors associated to some of the characters of the very often to select prototypes with simple shapes, i.e.,data base. Note that the vectors result from the combined effects of the
prototypes made of few superfeatures, like I, O, C, sinceoperations performed during both the decomposition and descriptionthey are embedded in more complex shapes. That is cer-stages.tainly true, but this is indeed a desirable effect. Since nointerpretation is attempted during this step, it is reasonableto select one of these simply shaped prototypes each timesuch a simple shape is found in a sample, even if there is
as the ratio between the length of the superfeatures and something else. It will be the main classifier, using thethe height of the character bounding box. original features, as well as their spatial relationships, that
As in the previous case, two thresholds have been used, will establish whether the other features are relevant and,TLSFV for vertical strokes, TLSFH for tilted and horizontal thus, the sample has to be ascribed to another class or not,strokes, as well as for arcs. Figure 8 shows the superfeature thus assigning the character to that class. On the othervector associated to some characters belonging to the data hand, the more complex the shape of the sample, i.e.,base used for the experiment. Note that: the greater the number of superfeatures it has, the more
difficult it is to decide to which class it belongs. Then many(a) in all the characters shown, the superfeatures corre-prototypes have to be selected by the preclassifier to avoidsponding to the serifs have been eliminated by the thresh-missing the right one. This approach also allows us toolding described above;overcome one of the possible drawbacks of the superfea-
(b) in the first row, the skeletal branch on the top ture’s eliminating step performed before building up theof the ‘‘A’’ has been considered spurious and there- superfeature vector; even if one of the negligible superfea-fore eliminated, while the polyline on the left has tures is preserved due to the actual values of the thresholds,been mapped into a single stroke by the curve fitting algo- it does not have any major effect, since the correct class,rithm; having a smallest number of superfeatures, will be selected
in any case. Thus, by using relatively high threshold values,(c) in the third row, the good continuity criteria splitthe ‘‘E’’ into three pieces: the one on the top, the horizontal as the ones reported in the next section, the far more
serious problem of disregarding a relevant superfeaturebar in the middle, and the remaining of the character. Asa consequence, the curve fitting algorithm will map the can be avoided, increasing the robustness of the method.
Although the main goal of the algorithms described infirst into an arc facing South, the second into a horizontalstroke, the third into two arcs, one facing West (corre- the previous sections has been that of absorbing, as much
as possible, the less significant shape variations in ordersponding to the vertical part of the character) and theother facing North; to point out parts, as much as possible, invariant with

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 337
TABLE 1The Semantic Equivalence Among Superfeatures
Family Superfeature Equivalent to
Loop Loop Extended loopStrokes Vertical Tilted stroke
Arc facing EArc facing W
Horizontal Tilted strokeArc facing NArc facing S
FIG. 9. A set of A’s showing that semantically equivalent superfea- Tilted Horizontal stroketures can be interchanged without affecting the possibility of correctly Vertical strokerecognizing the character. Arc facing NE
Arc facing SEArc facing NWArc facing SW
Arcs Arc facing N Arc facing NErespect to the differences existing among the specimen of Arc facing NWa same class, there is still a certain amount of variability Horizontal stroke
Arc facing S Arc facing SEto cope with. This further variability depends partly onArc facing SWthe character shapes and partly on the algorithm we haveHorizontal strokeadopted to fill up the superfeatures vector. Latin characters
Arc facing E Arc facing NE(as well as Cyrillic ones) are drawn by using conic arcs Arc facing SEand straight segments, that in most of the cases can be Vertical stroke
Arc facing W Arc facing NWinterchanged, so that curves of different shapes have theArc facing SWsame semantic value. Figure 9 illustrates a set of A’s inVertical strokewhich straight segments and arcs are mutually inter-
changed without affecting the possibility of recognizing Note. The equivalence is bidirectional; i.e., the superfeatures in therightmost column are equivalent to those in the central one.the character. On the other hand, some of the algorithms
described before are responsible for adding a furtheramount of variability. Figure 10 shows a set of C’s whichshould be described in the same way, as an arc facing to
is required in order to match the superfeature vector ofright (East). Since we compute the direction of the arc asthe sample with that of a prototype. The transformationsthe quantized direction of the normal to the line connectingare based on the concept of semantic equivalence betweenthe two end points of the arc, this parameter is sensitivesuperfeatures: two superfeatures are semantically equiva-to the end points relative location. As a consequence, thelent if they can be interchanged without changing the classthree characters of Fig. 10 would be described by threeto which the specimen belongs. Since the shape of thedifferent superfeatures, arc facing E, NE, and SE, respec-characters is culturally defined, some of these semantictively. The same kinds of variations may be introduced byequivalences depend on the specific alphabet. For example,the curve-fitting algorithm.in the Latin alphabet, a vertical stroke can be changed intoOur solution to the problem is to use a flexible matchingan arc facing E or W, as well as an arc facing N or S canalgorithm. It is based on a set of transformations whichbe changed into a horizontal stroke. These transformationsallow us to change a superfeature into another one if thisare not allowed in the Chinese writing system, where theygenerate confusion between different characters [28].Other semantic equivalences do not depend on the alpha-bet, but have been introduced in order to reduce the vari-ability added by the previous stages. For example, arcsfacing adjacent directions, such as E, NE, and SE, areconsidered semantically equivalent, just to overcome prob-lems introduced by the arc direction quantization. Thecomplete list of semantic equivalences we have devised islisted in Table 1. Similar concepts have been used to modela graph matching algorithm used to classify characterFIG. 10. Due to both the procedure used to compute the arc orienta-shapes [11].tion and the adopted quantization for the direction, the three characters
may be mapped to three different superfeatures. It can be noted that the transformations based on the

338 MARCELLI, LIKHAREVA, AND PAVLIDIS
TABLE 2semantic equivalences may generate confusion even in theThe Actual Values of the Thresholds Usedcase of the Latin alphabet. For instance, changing a vertical
in the Experimentsstroke into an arc facing E could change an I (withoutserifs) into a C (without serifs, too). To avoid these draw- Threshold Actual valuebacks, we embedded the transformations into a context-
TAS 1508dependent flexible matching algorithm: a superfeature canTASB 1708be transformed into one equivalent to it if there is a needTLSB 0.3 p H
for the transformation and the number of superfeatures TDSB 308of that type in the sample is greater than in the prototype. TL 0.75
TA 0.85Let us give an example. Suppose that the sample is madeTAM 1708of a vertical stroke and two arcs, facing N and S, respec-TLV 0.75 p Htively, and that we are matching this sample against aTLH 0.4 p H
prototype made of one vertical stroke and two horizontal TLSFV 0.75ones. Since there are two horizontal strokes unmatched in TLSFH 0.4the prototype and the two arcs in the sample are un-
Note. H represents the height of the character bounding box.matched, both the conditions mentioned above hold. Thus,since the superfeatures in the sample are semanticallyequivalent to those in the prototype, the match conditionis satisfied and the prototype will be passed to the mainclassifier. On the contrary, if a vector associated to a sample ous sections adopted during the experimental work, are
reported in Table 2.matches exactly with the one corresponding to a certainprototype, no transformations will be attempted, since In the first experiment, a test set of 1313 characters from
a data base of printed address label words provided by thenone of the previous conditions holds. Going back to thepair I, C of the previous example, it means that if a vertical U.S. Postal Service was used. Those characters were then
processed by the preclassifier, and two sets associated tostroke is found in the sample and it matches with theprototype of the I, the latter will be the only one passed each of them: the first one containing the prototypes among
which there should be the right one; the second the re-to the main classifier, such as if an arc facing E is found,the prototype of C will be the only one passed on. There- maining ones. It has been found that the method is correct,
since the prototype corresponding to the character class isfore, the flexible matcher first attempts an exact match,i.e., a match element-by-element: if the two vectors are always in the first set. In the same experiment, the number
of prototypes contained in the first set was also recorded,identical, they are successfully matched, and the screeningis terminated. If not, the flexible matching is entered, which as in Table 3. The table shows the number R of prototypes
contained in the second set, i.e., the prototypes screenedtries to find a match between two vectors by using thesemantic similarities between superfeatures. A Pascal-like out (or rejected) by the preclassifier, expressed as the per-
centage of the total number of the prototypes. It showsdescription of the flexible matching algorithm is given inAppendix C.
TABLE 35. EXPERIMENTAL RESULTSThe Number R of Prototypes Screened Out and Its
Two experiments have been done to evaluate the perfor- Distribution among the Samples of the First Experimentmance of the preclassifier. The first one was devoted to
R (in %) No. of samples Percentageascertain the correctness of the proposed method, whilethe second was intended to measure its overall efficiency. ,10 0 0
.10 && ,20 4 0.3Preliminarily, the set of 74 prototypes designed to model
.20 && ,30 0 0both small and capital letters was processed off-line to
.30 && ,40 2 0.2construct the multilevel data structure for each prototype.
.40 && ,50 12 0.9During this processing, different decompositions for a
.50 && ,60 102 7.8given prototype were allowed in order to deal with cases .60 && ,70 201 15.5
.70 && ,80 356 27.1where different groupings of the features around branch
.80 && ,90 322 24.5points with the same cost were proposed by the decomposi-
.90 && ,100 213 16.1tion algorithm. At the end of the processing, 129 superfea-5 100 101 7.6
ture vectors were associated to the original 74 prototypes.Note. For sake of the simplicity, the range of R has been quantized.The actual values of the thresholds mentioned in the previ-

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 339
representing the character into a set of components, eachof them should represent one of the basic elements ofthe character. The possibility of reliably detecting thesecomponents depends strongly on the quality of the initialrepresentation, i.e., on the shape fidelity of the skeleton.In case of almost noiseless specimen the skeleton distor-tions are mainly those which arise in correspondence ofcrossing and junction, as discussed in Section 2. Moreover,these distortions do not depend on the specific algorithm
FIG. 11. Preclassification errors due to broken (a) and touching char- nor on the metric adopted to compute it, but on the attemptacters (b). The character in (a) was classified as ‘‘H’’ instead of ‘‘B,’’ to implement, more or less directly, in the digital planewhile the other as ‘‘M’’ instead of the sequence ‘‘I-V-I.’’ the definition of skeleton given by Blum in the continuous
plane [29]. As already noticed, the attempt to recover thesedistortions requires complex computations, as well as theavailability of information about the thickness of thestrokes. None of these requirements can be met by ourthat the method is highly efficient, since R ranges from aapproach, since the whole preclassification method isminimum of 50% in the 7.8% of the cases to a maximummeant to be fast, and the skeleton obtained directly by theof 97.5% in 16.1% of the cases, but R comprises betweengrey level input image to overcome some of the inconve-70% and 90% for more than 50% of the characters. It alsoniences associated with the binarization. Therefore, weshows that the preclassifier is effective, since screening ishave proposed a set of simple criteria whose aim is thatreally performed in the 92.4% of the cases, while in theof unfolding the ribbon by using some a priori knowledgeremaining 7.6% of the cases there was no screening at all;about the distortions, rather than using such knowledgei.e., the second set was empty. A further analysis of theseto correct the skeleton. The results of the first experimenterrors has shown that they are related to very difficulthave shown that such simple criteria can manage correctlycases, such as broken characters, characters partially cuta reasonable amount of distortions, as the one that canduring the field segmentation, touching, and merging char-be found in a large population of unconstrained machineacters.printed characters. On the other hand, very preliminaryIn the second experiment, the preclassifier was inte-experiments performed over a few hundred specimens hasgrated in the whole recognition system and a test on theshown that, although the approach works even in casesame data base containing more than 24,000 charactersof handprinted characters, the major challenge is that ofwas performed. The results have shown that the total timedesigning a set of decomposition criteria able to cope withwas reduced to 75% of the time spent without the preclassi-the variability encountered when dealing with a large pop-fier. Since, roughly speaking, 50% of the time is spentulation of handwritten characters produced by differentbefore the classification for skeletonization and featurewriters.extraction and 50% during the classification, the previous
It has already been noticed in Appendix B that the curve-figure means that the preclassifier reduces the classificationfitting procedure we have adopted is not the optimal one,time to 50%. Note that this performance was obtainedsince the latter would require very high computationalon the whole data base containing broken, touching, andcost, in that the problem of finding the curve which is themerging characters, as well as characters produced by dotbest approximation of a given set of segments is an NP-matrix printers, with a textured background, superimposedcomplete problem. Moreover, a too faithful description oflines, etc. Furthermore, even more important, the recogni-the sample is not the purpose of the description stage,tion rate was the same as previously, showing that thewhich, on the contrary, is intended to provide a coarsespeedup was obtained without affecting the recognitiondescription of the specimen in order to select more thanaccuracy. Apparently the preclassifier missed the correctone prototype for the matching. Besides, it does not seemclass in a few cases, but in all such cases the sample wasappropriate to produce a precise description of the charac-misclassified even without the preclassifier. Such samplester components when such a description will be used by acorrespond to cases where the skeleton has been severelymatching algorithm which does not take into account at alldistorted due to broken or touching characters (Fig. 11).the spatial relations among them. It is at least questionablewhether such a precise description would produce any ef-
6. CONCLUSIONS fect, other than increasing the classification time, whenused by a simple classification method. The results of thesecond experiment have confirmed that, by combining theIn conclusion, there are two considerations. One of the
crucial steps of the process is that of unfolding the ribbon a priori knowledge about the writing process with the one

340 MARCELLI, LIKHAREVA, AND PAVLIDIS
relative to the weaknesses of the simple techniquesadopted during the different steps of the process, it ispossible to design a screening algorithm which meets boththe requirements of efficiency and accuracy.
On the basis of the previous considerations and withinthe framework of a novel approach to optical characterrecognition based on a conceptual modeling of both read-ing and writing processes, we have devised a preclassifica-tion method to select the prototypes that most likely willmatch a given sample. It is based on a multilevel represen-tation of the character shape, which uses features to de-scribe the skeleton components and superfeatures todescribe the character components. The highest represen-tation level corresponds to the coarsest description whichis used by the preclassifier to select among the prototypes
FIG. 12. Angles and sides involved while dealing with a crossing.those which are the best candidates to match the sample.The variability of actual character shapes is managed bya flexible matching algorithm and it is modeled by aset of transformations between superfeatures basedon the concept of semantic similarity. These transforma- approach with a higher level of robustness with respect totions are used, depending on the context of the specific segmentation errors.matching.
A.1. Spurious Branch PointsThe experiments have shown that the proposed methodis correct and effective, since it reduces the classification The first criterion aims at dealing with distortions liketime to the 50%, without affecting the recognition accuracy. the one illustrated in Fig. 3a. The presence of such a distor-
tion can be detected by verifying that the following condi-tions hold:
APPENDIX A: DECOMPOSITION CRITERIA(a) there are two branch points connected by a single
straight segment;The decomposition procedures have been designed as-suming that, by moving far enough from the branch point, (b) the other features connected to both the branchthe information carried by the polyline becomes reliable, points are not aligned.because it is less affected by the distortions possibly present
The rationale behind these conditions can be seen intu-in the proximity of the branch points. Thus, good continuityitively by looking at Fig. 12, while an analytical modelcriteria can be more reliably adopted for the groupingbased on the geometry of the crossing has been proposedpurpose. A preliminary test is done to check if the featuresin [26].connected to a branch point are long enough to be consid-
If this is the case, the length of the segment connectingered reliable; if one or both of them are short, they willthe two branch points is compared with a threshold; if it isbe substituted by the following ones, if these are longsmaller, the features are considered connected to a uniqueenough. Of course, it happens if and only if there is justbranch point, located in the center of the spurious branch.one feature following that connected to the joint; i.e., theThen, the good continuity criteria can be applied. Theother joint of the feature is not a branch point nor an endthreshold used to decide if the segment connecting the twopoint. A feature is considered short if its length is smallerbranch points is spurious is given by the formulathan 0.3 p H, where H represents the height of the character
bounding box. A feature following a short one is consid-TLBP 5 H/(1 2 abs(cos s)). (1)ered long if its length is at least 0.6 p H. Here and in the
sequel we have used only the vertical size of the characterbounding box as a parameter in the threshold definition. where H is the character height as defined above and s is
the biggest between the angles a and b formed by theThis has been done because the vertical size of thebounding box is more reliable than its horizontal one, this features connected to the branch points, as illustrated in
Fig. 12. Note that in the ideal case, where a crossing islatter being strongly influenced by the presence of touchingor broken characters. Although we have explicitly stated actually present, the angles a and b should be equal, but
in practice they may be different because of the displace-that this method is intended for isolated characters, byusing only the above-mentioned parameter we provide our ment of the vertices introduced by both the thinning and

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 341
i.e., serifs whose features have a length comparable withone of the third features representing the character body,like the serifs on the bottom of the character M in Fig. 13.Furthermore, there might be cases of characters havingsome parts of their skeletons not corresponding to serifsbut satisfying the conditions stated above. In case of a‘‘single serif,’’ there is not a branch point, therefore itspresence does not influence the decomposition, but ratherFIG. 13. A ‘‘single serif ’’ is present on top of the character ‘‘F,’’ while
‘‘long serifs’’ are on the bottom of the character ‘‘M.’’ it could affect the description and the screening, since itchanges the shape of the component to which it is con-nected. This case is managed later on in the process, bythe screening stage, as has been illustrated in Section 4.The case of a ‘‘long serif ’’ is one of those complex casesthe polygonal approximation. By adopting for s the biggestthat have to be managed within the context of the matchingvalue between a and b, we guarantee that the conditionwith each prototype. In fact, the appearance of this typeon the length of the spurious branch holds on both theof serif is very similar to that of a stroke that, in anotherbranch points.context, could be considered as a meaningful component;any static labeling may produce a misleading indication.A.2. SerifsBesides, the purpose of the algorithm is not one of de-
If the previous case does not occur, i.e., the branch points tecting serifs in order to exclude them for further pro-are not considered spurious, for any of them, as well as cessing, but rather one of attempting a meaningful andfor any other of degree three, a check is done in order to stable grouping of the features around the branch point,establish if two of the features joining at the branch point by using some a priori knowledge about the charactercan be considered as serifs. If such a case occurs, the cost shape and the distortions due to the thinning. Thus, a ‘‘longto keep the features belonging to a serif together is set to serif ’’ does not fall in the model we have adopted for serifs0. The serifs are detected by checking that the following and, therefore, will be dealt by using the good continu-conditions hold: ity criteria.
(a9) the features which are supposed to represent a serif
A.3. Spurious Branchare terminated by end points, while the third one is not;
(b9) the two features are of the same type, segmentsIf no serifs are detected, a further check is performed,or arcs;
whose aim is that of establishing if one of the features can(c9) they are both short in comparison with the third be interpreted as a spurious branch of the skeleton and
one; then left apart, keeping the other two features together.This is implemented by checking that:(d9) there is a wide angle between them or none of the
two features satisfying the previous conditions is aligned(a0) the two features which are not supposed to be spuri-with the third one.
ous are not aligned;These conditions implement some a priori knowledge (b0) the feature representing the spurious branch isabout the appearance of a serif; its shape is relatively simple short with respect to the other ones;in comparison with the character main body (condition a9) (c0) the angles it forms with the other two featuresand made of a single, small component (conditions b9–c9). are similar.Eventually, condition (d9) states that it has to be separablefrom the character main body by using simple good-conti- Condition (a0) is obvious, since, if the two features are
aligned, the branch does not appear because of the thinningnuity criteria. In condition (c9), the features which aresupposed to represent the serifs are considered short if algorithm, and therefore it will be properly managed by
the good continuity criteria reported above. Condition (b0)they are shorter than half the length of the third one, whilecondition (d9) has been implemented by comparing the is obvious, too, since the length of the spurious branch
depends on the thickness of the character stroke, as re-angles between the features with the threshold TAS .It could be argued that these conditions do not cover ported, for instance, in [22], which in the case of ribbon-
like shapes is small with respect to the length. Eventually,all the appearances of serifs; for instance, they do not covera ‘‘single serif,’’ i.e., a serif which is not symmetric with condition (c0) has aims to avoid labeling as a spurious
branch, and thus splitting, a short feature aligned withrespect to the character main body, like the one on thetop of the character F of Fig. 13, as well as ‘‘long serif,’’ one of the others connected to the branch point, as could

342 MARCELLI, LIKHAREVA, AND PAVLIDIS
A.4. Searching for Symmetries
If none of the cases mentioned above occurs, a symmetrycriterion is used, which ascertains if two of the featurescan be considered symmetric with respect to the third one,and then grouped together. Of course, the symmetry crite-rion can be used if, among the features there is at leastone straight segment which represents the hypotheticalsymmetry axis and the two features are both arcs or seg-ments. This further criterion has been introduced for theFIG. 14. A sample of the character ‘‘T’’ where the branch point is
displaced toward the left ending of the horizontal bar. sake of stability of the decompositions. In fact, if we con-sider a shape like the one of Fig. 16a, the good continuitycriteria might provide the decomposition shown in Fig.16b, as well as the one of Fig. 16c, depending on very smallvariations in the lengths of the features and/or in the angles
happen, for instance, when a branch point which is sup- between them. On the contrary, the symmetry criterionposed to lie around the center of a feature joining or cross- provides the decomposition of Fig. 16d, which is still mean-ing another one has been moved toward one of the ending, ingful from a perceptive point of view, while being, at theas illustrated in Fig. 14. Without this further constraint, same time, much more stable.the character of the figure would be decomposed into two Two features, f1 and f2, are considered symmetric withcomponents, one made of the short branch and the other respect to the third one if both their lengths and the anglesof two straight segments forming a right angle. To deal they form with the third one are similar. These similaritieswith the variability introduced by the previous processing, are measured by using the ratioscondition (a0) has been implemented by assuming that thefeatures are not aligned if they form an angle smaller than
Rl 5 min length/max length (2)the threshold TASB , condition (b0) by requiring that thelength of the spurious branch is shorter than TLSB , and Ra 5 min angle/max angle, (3)condition (c0) by allowing a difference between the anglesno greater than TDSB . Once a spurious branch is detected,the cost to keep it together with any of the other features where min length (max length) is the length of the short-is set to 2, while the cost to group the other features is set est (longest) between the features f1 and f2 and min angleto 0. (max angle) is the narrowest (widest) angle between the
The results obtained by applying the criteria to deal with angles a and b of Fig. 17. In the ideal case of a perfectlyserifs and spurious branches can be observed, respectively, symmetric shape, both these ratios should be equal to 1.on the bottom and on the top of the character of Fig. 15a, To allow a more flexible definition of symmetry, neededwhile Fig. 15b shows the results that would have been to manage practical cases, two thresholds, TL and TA , haveobtained by using only the good continuity criteria. been introduced: Rl must be greater than TL , while Ra
must be greater than TA . The higher the values assignedto the thresholds, the higher will be the similarity thestrokes have to show to be considered symmetric withrespect to the third one. Of course, none of the featurescan be aligned with the symmetry axis, this condition beingdetected by the occurrence of a 1808 angle between thefeatures and the symmetry axis. If the two conditions hold,a further test is performed to be sure that the two features,f1 and f2, beside being almost similar to each other, are,at the same time, different from the third one. For thispurpose, two ratios are computed,
R9l 5 5max length/a length if max length # a length
a length/min length if min length . a lengthFIG. 15. The decomposition obtained by using the criteria to deal
with spurious branch and serifs (a) and that one which would be obtainedby using only the good continuity criteria (b). (4)

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 343
FIG. 16. In case of a shape like the one in (a), the algorithm would provide the decomposition in (b) if a , b, that in (c) otherwise. The onedepicted in (d) has been obtained by using the symmetry criterion.
a symmetry between them. Of course, this last test is notperformed if the two features, f1 and f2, are arcs.R9a 5 5max angle/a angle if max angle # a angle
min angle/f angle if min angle . a angle, (5) When a symmetry is detected, the cost to keep the sym-metric features together is given by the formula
where a length is the length of symmetry axis and a angleC 5 (1 2 Rl) 1 (1 2 Ra)is the angle s between the two features, f1 and f2 (Fig.
17). The features, f1 and f2, are not considered similar tothe third one if the ratios given by the formulas (4) and so that in the case of perfectly symmetric shape this cost(5) are smaller than the thresholds is 0, while it tends to 2 as far as the two features become
less symmetric.T 9L 5 TL 2 (1 2 Rl) (6)
APPENDIX B: A CURVE-FITTING ALGORITHMT 9A 5 TA 2 (1 2 Ra). (7)
As pointed out in [30], curve fitting implies two prob-lems: how to fit a given curve to a set of data; and how toIn this way, the more the two features are similar, thedecide that the fitting is satisfactory. To face the formersmaller are Rl and Ra ; thus, the bigger are the thresholdsproblem, we adopt an arclength representation of eachT 9L and T 9A , used to establish that f1 and f2 are dissimilarcharacter component, by transforming the polyline in thefrom the third one and, thus, to recognize the existence of(x, y) plane into a stepwise function into the (l, a) plane,where l is the curvilinear abscissa of the points along theskeleton component, starting from a reference point, anda is the angle between each polyline side and a startingsegment. By adopting this transformation, the problem offinding the arc of a circle that better approximates a se-quence of polyline sides is transformed into that of approxi-mating a stepwise function by a straight line. Note thatthis transform is position and rotation invariant. Moreover,the representation has been normalized by expressing thelength of the segments as a percentage of the total lengthof the component, in order to be size invariant. Such prop-erties are highly desirable, since they are necessary bothto apply correctly the acceptance criterion and to achieverobustness to actual character size. In our implementation,each segment is represented by its middle point, the start-
FIG. 17. Angles and features involved by the symmetry criterion. ing point is one of the end points of the component, and
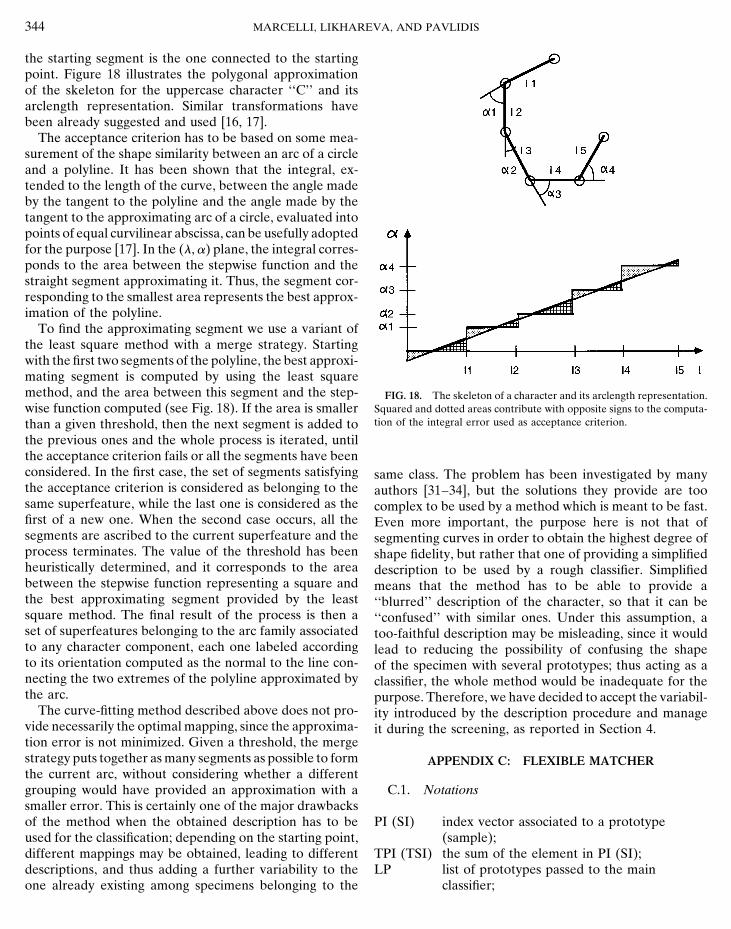
344 MARCELLI, LIKHAREVA, AND PAVLIDIS
the starting segment is the one connected to the startingpoint. Figure 18 illustrates the polygonal approximationof the skeleton for the uppercase character ‘‘C’’ and itsarclength representation. Similar transformations havebeen already suggested and used [16, 17].
The acceptance criterion has to be based on some mea-surement of the shape similarity between an arc of a circleand a polyline. It has been shown that the integral, ex-tended to the length of the curve, between the angle madeby the tangent to the polyline and the angle made by thetangent to the approximating arc of a circle, evaluated intopoints of equal curvilinear abscissa, can be usefully adoptedfor the purpose [17]. In the (l, a) plane, the integral corres-ponds to the area between the stepwise function and thestraight segment approximating it. Thus, the segment cor-responding to the smallest area represents the best approx-imation of the polyline.
To find the approximating segment we use a variant ofthe least square method with a merge strategy. Startingwith the first two segments of the polyline, the best approxi-mating segment is computed by using the least squaremethod, and the area between this segment and the step- FIG. 18. The skeleton of a character and its arclength representation.
Squared and dotted areas contribute with opposite signs to the computa-wise function computed (see Fig. 18). If the area is smallertion of the integral error used as acceptance criterion.than a given threshold, then the next segment is added to
the previous ones and the whole process is iterated, untilthe acceptance criterion fails or all the segments have beenconsidered. In the first case, the set of segments satisfying same class. The problem has been investigated by manythe acceptance criterion is considered as belonging to the authors [31–34], but the solutions they provide are toosame superfeature, while the last one is considered as the complex to be used by a method which is meant to be fast.first of a new one. When the second case occurs, all the Even more important, the purpose here is not that ofsegments are ascribed to the current superfeature and the segmenting curves in order to obtain the highest degree ofprocess terminates. The value of the threshold has been shape fidelity, but rather that one of providing a simplifiedheuristically determined, and it corresponds to the area description to be used by a rough classifier. Simplifiedbetween the stepwise function representing a square and means that the method has to be able to provide athe best approximating segment provided by the least ‘‘blurred’’ description of the character, so that it can besquare method. The final result of the process is then a ‘‘confused’’ with similar ones. Under this assumption, aset of superfeatures belonging to the arc family associated too-faithful description may be misleading, since it wouldto any character component, each one labeled according lead to reducing the possibility of confusing the shapeto its orientation computed as the normal to the line con- of the specimen with several prototypes; thus acting as anecting the two extremes of the polyline approximated by classifier, the whole method would be inadequate for thethe arc. purpose. Therefore, we have decided to accept the variabil-
The curve-fitting method described above does not pro- ity introduced by the description procedure and managevide necessarily the optimal mapping, since the approxima- it during the screening, as reported in Section 4.tion error is not minimized. Given a threshold, the mergestrategy puts together as many segments as possible to form APPENDIX C: FLEXIBLE MATCHERthe current arc, without considering whether a differentgrouping would have provided an approximation with a C.1. Notationssmaller error. This is certainly one of the major drawbacksof the method when the obtained description has to be PI (SI) index vector associated to a prototype
(sample);used for the classification; depending on the starting point,different mappings may be obtained, leading to different TPI (TSI) the sum of the element in PI (SI);
LP list of prototypes passed to the maindescriptions, and thus adding a further variability to theone already existing among specimens belonging to the classifier;

STRUCTURAL INDEXING FOR CHARACTER RECOGNITION 345
C.2. Algorithm Description
compute TPI and TSI;if TSI $ TPI then
exact match5true;for i51 to 13 do begin
if PIi.SIi then unmatchedi5true;exact match5false;
end;if exact match then
add the prototype to LPelse
flexible match5true;for i51 to 13 do begin
if unmatchedi then beginj51;while j?i and j # 13 and unmatchedi do begin
while SIj . PIj and unmatchedi beginif SIj semantically equivalent to PIi then begin
SIi 5 SIi11;SI; 5 SI; 2 1;
end;if SIi 5 PIi then unmatchedi5false;
end;j5j11;
end;end;
end;i51while i#13 and flexible match do begin
if unmatchedi thenflexible match5false;
elsei5i11;
end;end;if flexible match then add the prototype to LP;
end;end.
2. S. Mori, K. Yamamoto, and M. Yasuda, Research on Machine Recog-ACKNOWLEDGMENTSnition of Handprinted Character, IEEE Trans. Patt. Anal. Mach.Intell. PAMI-6, 1984, 386–405.The authors thank Bill Sakoda, Jairo Rocha, and Sophie Zhou for
many helpful discussions and the anonymous reviewers for their valuable 3. K. S. Fu, Syntactic Pattern Recognition, Addison–Wesley, Newremarks. The investigation reported in the paper was conducted while York, 1977.A. Marcelli and N. Likhareva were at the Department of Computer 4. S. V. Rice, J. Kanai, and T. A. Nartker, An evaluation of OCRScience, Image Analysis Lab, SUNY at Stony Brook. It was partially accuracy, UNLV ISRI Annual Report, Las Vegas, 1993, pp. 9–34.supported by European Community ESPRIT Project No. 5203-IN-
5. G. Nagy, At the Frontiers of OCR, Proc. IEEE 80, 1992, 1093–1100.TREPID, by U.S. Postal Service Contract 1042309-1C3770 and by NSF
6. T. Pavlidis and S. Mori (Eds.), Special issue on OCR, Proc. IEEEGrant IRI9209057.80, 1992.
7. W. J. S. Sakoda, J. Zhou, T. Pavlidis, and E. Joseph, Address-recogni-REFERENCEStion system based on feature extraction from gray scale, in Proc.IS&T, SPIE International Symposium on Electronic Imaging: Science1. S. Mori, C. Y. Suen, and K. Yamamoto, Historical review of OCR
research and development, Proc. IEEE 80, 1992, 1029–1058. and Technology, San Jose, CA, Jan. 31–Feb. 4, 1993.

346 MARCELLI, LIKHAREVA, AND PAVLIDIS
8. J. Rocha and T. Pavlidis, A shape analysis model with application hensive survey, IEEE Trans. on Patt. Anal. and Mach. Intell., PAMI-14, 1992, pp. 869–887.to a character recognition system, in Proc. IEEE Workshop on Appli-
cations of Computer Vision, Palm Springs, CA, Nov. 30–Dec. 2, 1992, 21. G. Boccignone, A. Chianese, L. P. Cordella, and A. Marcelli, Usingpp. 182–189. skeletons for OCR, in Progress in Image Analysis and Processing
(L. P. Cordella et al., Eds.), pp. 275–282, World Scientific, Singa-9. L. Wang and T. Pavlidis, A geometric approach to machine-printedpore, 1989.character recognition, in Proc. IEEE Comp. Soc. Conf. on Computer
Vision and Pattern Recognition, Champaign, IL, June 15–18, 1992, 22. S. Lee and J. C. Pan, Offline tracing and representation of signatures,pp. 665–668. IEEE Trans. Syst. Man Cybern., SMC-22, 1992, 755–771.
10. L. Lam and C. Y. Suen, Structural classification and relaxation match- 23. R. O. Duda and P. E. Hart, Use of Hough transform to detect linesand curves in pictures, Commun. ACM 15, 1972, 11–15.ing of totally unconstrained handwritten zip-code numbers, Pattern
Recog. 21, 1988, 19–31. 24. P. Kultanen, E. Oja, and L. Xu, Randomized Hough transform (RHT)in engineering drawing vectorization systems, in Proc. MVA, 1990,11. J. Rocha and T. Pavlidis, A shape analysis model with applicationspp. 173–176.to a character recognition system, IEEE Trans. Pattern Anal. Mach.
Intell. PAMI-16, 1994, 408–419. 25. O. Hori and S. Tanigawa, Raster-to-Vector conversion by line fittingbased on contours and skeletons, Proc. 2nd Int. Conf. on Document12. T. Kumamoto et al., On speeding candidate selection in handprintedAnalysis and Recognition ICDAR’93, Tsukuba Science City, Japan,Chinese character recognition, Pattern Recognit. 24, 1991, 793–799.October 20–22, 1993, pp. 353–358.
13. K. Fukunaga and P. M. Narendra, A branch and bound algorithm26. S. W. Lu and H. Xe, False stroke detection and elimination forfor computing k-nearest neighbors, IEEE Trans. Comput. C-24,
character recognition, Pattern Recognition Letters 13, 1992, pp.1975, 750–753.745–755.
14. M. Ohkura, Y. Shimada, M. Shiono, and R. Hashimoto, On discrimi-27. H. Baird, Feature identification for hybrid structural/statistical pat-nation of handwritten similar kanji characters by subspace method
tern classification, Comput. Vision Graphics Image Process. 42,using several features, in Proc. 2nd Int. Conf. on Document Analysis
1988, 318–333.and Recognition ICDAR’93, Tsukuba Science City, Japan, October
28. J. Zhou, personal communication, 1993.20–22, 1993, pp. 589–592.29. H. Blum, A transformation for extracting new descriptors of shape,15. S. Mori, K. Yamamoto, and M. Yasuda, Research on Machine Recog-
in Models for the Perception of Speech and Visual Form (W. Wathen-nition of Handprinted Characters, IEEE Trans. on Patt. Anal. andDunn, Ed.), pp. 362–380, MIT Press, Cambridge, MA, 1967.Mach. Intell., PAMI-6, 1984, pp. 386–405.
30. T. Pavlidis, Curve fitting as a pattern recognition problem, in Proc.16. W. A. Perkins, A Model-based Vision System for Industrial Parts, 6th Int. Conf. on Pattern Recognition, Munich, October 19–22, 1982,
IEEE Trans. on Computers, C-27, 1978, pp. 126–143. pp. 853–859.17. A. Chianese, L. P. Cordella, M. De Santo, and M. Vento, Decomposi- 31. T. Pavlidis and S. L. Horowitz, Segmentation of plane curves, IEEE
tion of ribbon-like shapes, Proc. 6th SCIA, Oulu (FINLAND) June Trans. Comput. C-23, 1974, 860–870.19–22, 1989, pp. 416–423.
32. D. G. Lowe, Three-dimensional object recognition from single two-18. H. Nishida and S. Mori, Algebraic Description of Curve Structure, dimensional images, Artif. Intell. 31, 1987, 355–395.
IEEE Trans. on Patt. Anal. and Mach. Intell. PAMI-14, 1992, pp. 33. A. Albano, Representation of digitized contours in terms of conic516–533. arcs and straight-line segments, Comput. Vision Graphics Image Pro-
19. G. Boccignone, A. Chianese, L. P. Cordella, and A. Marcelli, Recov- cess. 3, 1974, 23–33.ering dynamic information from static handwriting, Pattern Recogni- 34. G. A. W. West and P. L. Rosin, Techniques for segmenting imagetion 26, 1993, pp. 409–418. curves into meaningful descriptions, Pattern Recognit. 24, 1991,
643–652.20. L. Lam, S. Lee, and C. Y. Suen, Thinning Methodologies—A compre-




















