
Start of Lecture: March 21, 2014
29
Kernel Modules 1 Start of Lecture: March 21, 2014
-
Upload
khangminh22 -
Category
Documents
-
view
3 -
download
0
Transcript of Start of Lecture: March 21, 2014

Kernel Modules ���1
Start of Lecture: March 21, 2014

Kernel Modules
Reminders
• Exercise 5 is released and today’s lecture is key for one of the questions about kernel modules
• You will have two absolutely amazing guest lecturers next week; what they talk about is on Exercise 5 and the final
• also, its guaranteed to be interesting and very pertinent for future work
• Bob Beck will talk about exploit mitigation techniques; you must read the smashing the stack paper linked in Weekly Summary for Monday’s lecture
• Jeeva Paudel will talk about advances in parallel programming
• Any questions? About anything whatsoever?
���2

Kernel Modules
Thought Questions
• I fail to grasp why Little’s law is such an important law for scheduling. For instance, on a FCFS system, average wait time for a task is not a very revealing statistic. Turnaround time seems much more appropriate. Or "fairness" or overhead. Wouldn't something like the Poisson process be much more applicable when predicting performance of an task scheduler?
• Is simulation a responsible means to derive conclusions about scheduling algorithms? Simulation is expensive, trace tapes not as detailed. Would the cost of using real machines in a real (maybe even live) environment to produce tests be more profitable in terms of accuracy and time versus simulations?
���3

Kernel Modules and Scheduling
CMPUT 379, Section A1, Winter 2014 March 21

Kernel Modules
Objectives
• With your advanced knowledge of operating systems, we now come back to how to test kernel functionality for important algorithms, such as scheduling
• Demo: simple kernel module to test some simple scheduling functions (code for kernel land rather than user land!)
• Learn how to add kernel modules to the Linux kernel
• Learn about some restrictions on kernel code
���5

Kernel Modules
More scheduling…
• Knowledge of approaches for evaluating scheduling algorithms transfers to other algorithms
• Not just difficult to evaluate scheduling algorithms, but rather, many of the algorithms in operating systems
• One of the most important parts of being a computing scientist is proper testing
���6

Kernel Modules
How can we evaluate scheduling algorithms without directly using them in a system?
• Want to understand behaviour of algorithms before expose to users and real world
• e.g. priority inversion in Mars pathfinder
• Two important aspects to examine
• analytic evaluation with queuing theory or simulation?
• using expert defined distributions/rates
���7

Kernel Modules
Analytic evaluation versus simulation
• Analytic evaluation — given algorithm and estimates of system workload and algorithm rates, produce a (closed form) formula to evaluate performance of the algorithm
• Simulations of a real system — approximate a model of the system and simulate behaviour from that model
���8

Kernel Modules
Simulations are powerful but never perfect
���9
Title text: You can look at practically any part of anything manmade around you and think "some engineer was frustrated while designing this." It's a little human connection.

Kernel Modules
Analytic evaluation gives insight but sometimes limited
���10
Title text: Or the pressure at the Earth's core will rise slightly

Kernel Modules
How to obtain models and rates?
• Use expert knowledge to design a system that is as realistic as possible
• deterministic models
• queuing models, with guessed or approximated rates
• Save and use past process behaviour from real systems
• approximate (non-parametric) distributions using data
• evaluate directly on saved execution behaviour (trace tapes)
• Can use a mixture of expert knowledge (specify parts of the model) and approximation with data
���11

Kernel Modules
Deterministic modeling
• Define a set of fixed problems on which to run the algorithms
• Disadvantages:
• a small set of deterministic problems might not elucidate problems
• hard-coded set may become outdated
• labour-intensive to create set of deterministic problems
• Advantages:
• fast and simple
• can explicitly cover important corner cases (difficult to generate randomly)
• large, often updated set of realistic possibilities could evaluate well
���12
Process Bursts P1 10 P2 29 P3 3 P4 7 P5 12
Process Bursts P1 50 P2 1 P3 75 P4 2 P5 10
. . .

Kernel Modules
Queueing models
• Processes on most systems vary day to day, week to week and year to year
• Instead, can try to approximate distributions of CPU and I/O bursts
• Can either know from experience approximately how bursts often look (e.g. exponential distribution) and distribution of arrival time (e.g. Poisson distribution)
• then can approximate means of these distributions using real data
• Can try to learn distributions in a non-parametric way
���13
Kernel Modules
Examples of explicit distributions
���14
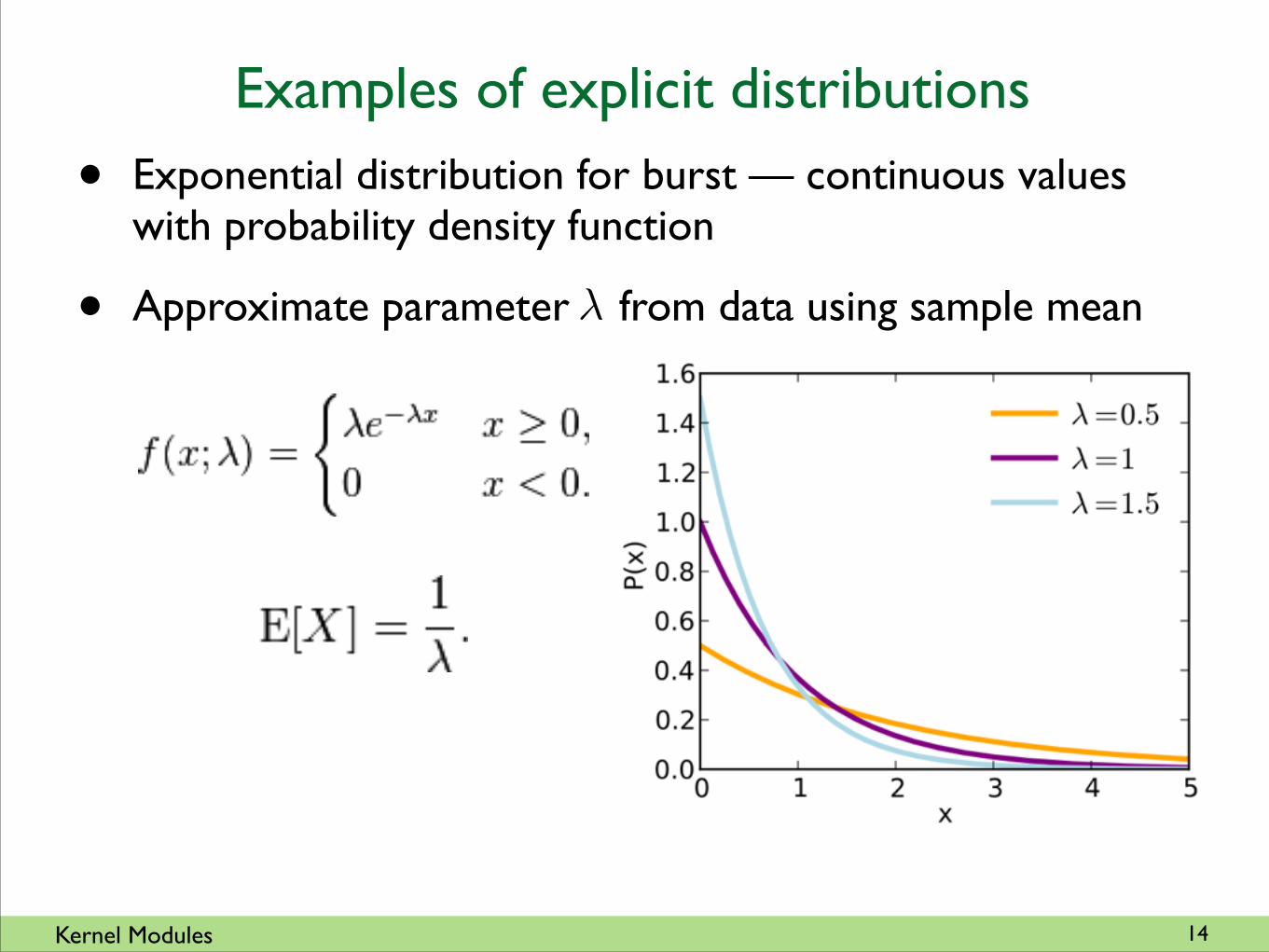
• Exponential distribution for burst — continuous values with probability density function
• Approximate parameter from data using sample mean�
Kernel Modules
Examples of explicit distributions
���15
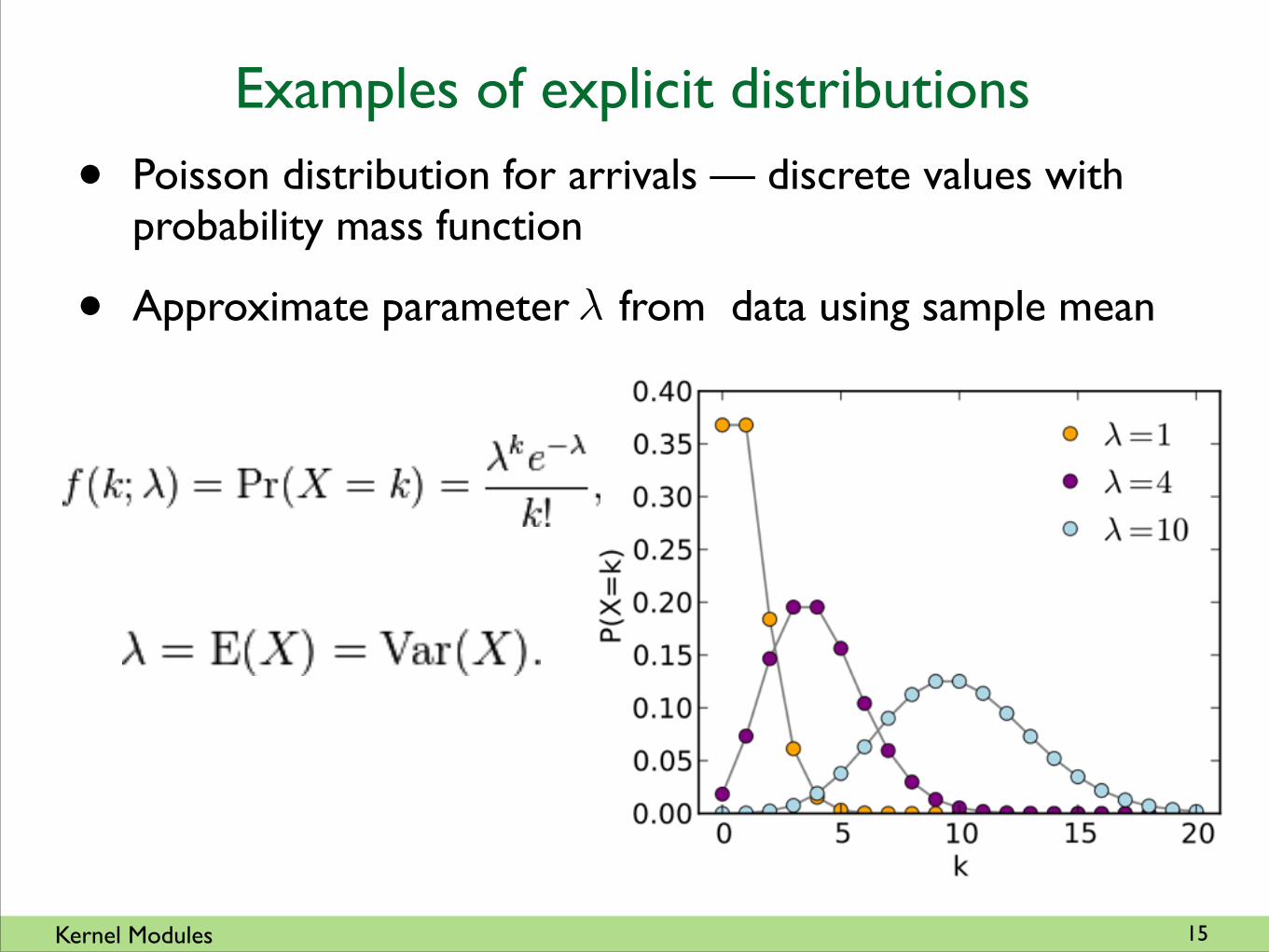
• Poisson distribution for arrivals — discrete values with probability mass function
• Approximate parameter from data using sample mean�
Kernel Modules
Example of non-parametric distribution
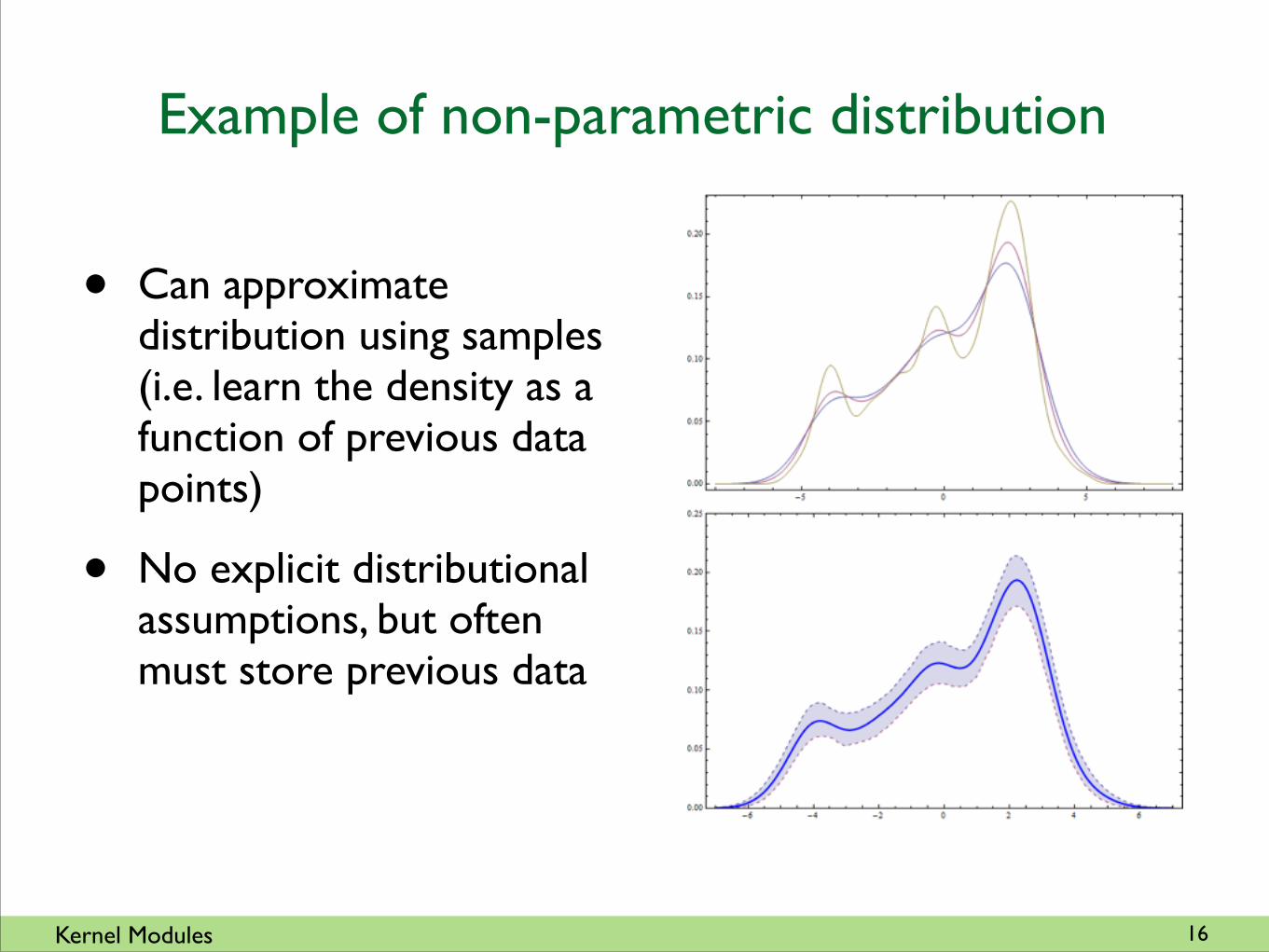
• Can approximate distribution using samples (i.e. learn the density as a function of previous data points)
• No explicit distributional assumptions, but often must store previous data
���16

Kernel Modules
Simpler queueing models
• If know the distributions for bursts and arrival, can compute average throughput, utilization, waiting time, etc. including variance on those values
• Can avoid explicit distributions and just use rates
• Queueing network analysis: if know the service rate and arrival rate for each component (CPU, I/O system, etc.), then can compute utilization, average queue length, average wait time, etc.
• Simple and useful queueing analysis: Little’s formula
���17

Kernel Modules
Little’s Formula
• Let n be the average queue length
• Let W be the average waiting time
• Let be the average arrival rate for new processes in the queue
• If a process waits W time, then W new processes will have arrived during that time
• If system is in a steady state (neither growing nor shrinking), then # processes leaving queue must equal to the number of process that arrive: n = W
���18
�
�
�

Kernel Modules
Why is this simple queueing model useful?
• Since it only requires a rate, applies to any arrival distribution and scheduling algorithm
• Enables calculation of a missing rate given the other two
• given that = 7 processes arrive every second on average, with n = 14 processes in the queue on average, then W = 2 seconds
• Reasonable way to approximate parameters for system to ensure that remain in stable state
���19
�

Kernel Modules
Issues with queuing models
• Distributional assumptions are generally unrealistic
• even if compute mean of Gaussian from data, might be erroneous to assume distribution Gaussian when could really be some complicated distribution
• More interesting distributions can result in computationally intensive simulations and are mathematically intractable
• To simplify computation, often need to make various independence assumptions that are also unrealistic
• Using only rates give little insight into variance, worst-case
���20
Kernel Modules
Driving simulations with trace tapes
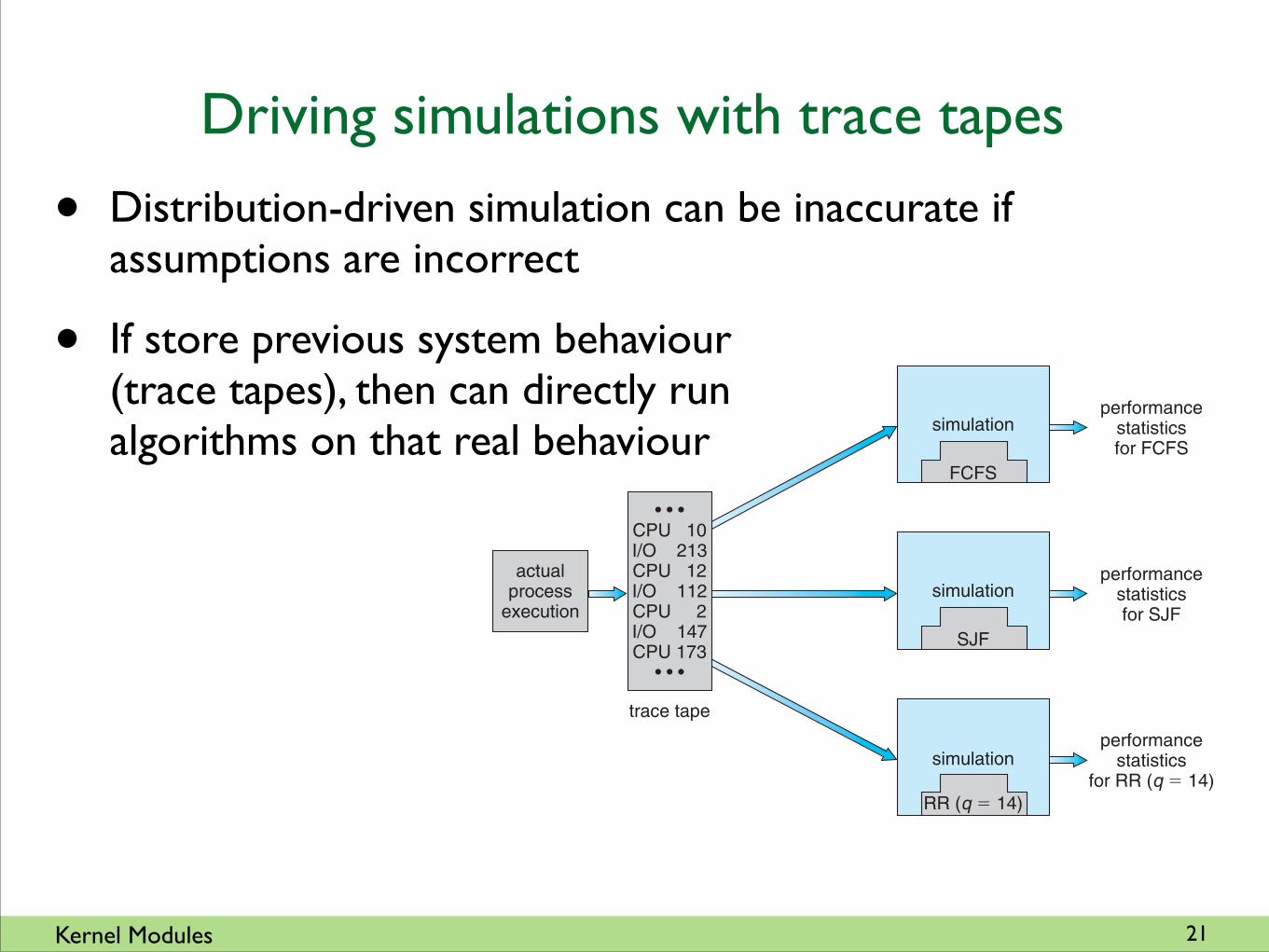
• Distribution-driven simulation can be inaccurate if assumptions are incorrect
• If store previous system behaviour (trace tapes), then can directly run algorithms on that real behaviour
���21
actualprocess
execution
performancestatisticsfor FCFS
simulation
FCFS
performancestatisticsfor SJF
performancestatistics
for RR (q ! 14)
trace tape
simulation
SJF
simulation
RR (q ! 14)
• • •CPU 10I/O 213 CPU 12 I/O 112 CPU 2 I/O 147 CPU 173
• • •

Kernel Modules
Issues with trace tapes
• Must store lots of data, rather than more compact model
• Smooth interpolation in models might be more useful than discrete events if algorithms do not behave smoothly
• e.g. smooth change in CPU bursts between two logged events might cause SJF to “jump” in average wait time, throughput, etc.
���22

Kernel Modules
Video Break: brought to you by another super duper classmate!
���23
https://www.youtube.com/watch?v=tGvHNNOLnCk

Kernel Modules
How do we actually write schedulers in the Linux kernel?
• Generally, the scheduler is a core component of the kernel, and not added as a kernel module
• But, maybe you think that you can write a better scheduler, and you want it to be written in kernel code
• So, you want to write a kernel module to prototype your new algorithms and simulate some behaviour
���24

Kernel Modules
Available functionality restricted in the kernel
• Knowledge of the C library not always helpful for writing kernel code, because they are different
• I want to generate random numbers, can I use rand()?
• Nope, must use get_random_bytes to fill bytes randomly
• I want to use qsort(), can I use that?
• Nope, must use sort(), which uses heap sort
• I want to use malloc and printf, can I use that?
• must use kernel versions, kmalloc and printk
���25

Kernel Modules
Why is the functionality restricted?
• Why can’t we just have the useful C library? Its fast, right? It’s not like I’m running Python
• kernel limited to a small amount of stack space
• kernel lacks memory protection afforded to user-space and is not pageable — cannot write larger code that is very infrequently used with the assumption that it will not be loaded until needed
• written in GNU C, with precise control of memory layout, etc., whereas C standard defines behaviour, not implementation
• Kernel about portability, not simplicity in compiling it or writing it; has to behave similarly on different hardware
���26

Kernel Modules
Baby gorilla & baby human == hardware Linux kernel == cold stethoscope.
���27
http://imgur.com/MMrYXxd

Kernel Modules
References for kernel modules
• http://kernelnewbies.org/FAQ/
• http://www.tldp.org/LDP/lkmpg/2.6/html/
• http://kernelbook.sourceforge.net/kernel-hacking.pdf
• Read the source code
���28

Kernel Modules
Example: writing a simple module
• Very simple test_schedulers.c module that computes the total wait time for tasks of randomly generated length in milliseconds
• Compile module into test_schedulers.ko
• Display modules with: lsmod
• Insert module with: sudo insmod test_schedulers.ko
• Display output with: sudo dmesg
• Remove module: sudo rmmod test_schedulers
���29




















