
Programming Hypothesis on Life Phenomena and the Key Processes Simulation
6
Programming Hypothesis on Life Phenomena and the Key Processes Simulation Jun Ma 1, a , Shuyan Li 2,b and Yide Ma 3,c 1,3 The School of Information Science and Engineering Lanzhou University, Lanzhou, China 2 Lanzhou University Chemistry and Chemical Engineering Lanzhou University,Lanzhou, China a [email protected], b [email protected], c [email protected] Keywords: Programming hypothesis on life phenomena, Program simulation, Gene expression, Cell division and differentiation, Life evolution, P-code, reflection technology Abstract. The formula that life process follows is a major scientific mystery during centuries. Some people put programming thoughts into this field like Gates brought the idea that “Human DNA is like a computer program but far, far more advanced than any software we’ve ever created”[1]. Here we proposed a more specific hypothesis on this topic as that DNA is a set of p-code[2] and the enzymes which control chemical reactions and transport processes in cell metabolism are the basic instructions. Based on this hypothesis, some program models were developed successfully in this work to simulate the key processes of life phenomena: gene expression, cell division and differentiation, and life evolution. The results of these simulations show that there is a high level of similarity between life phenomena and computer programs; the process of cell differentiation and evolution of life can be explained in a programming way. These models also suggest that reflection technology[3, 4] is essential to life process. Besides, C-value paradox, N-value paradox[5] and pseudogene as well as some other biological problems could be also explained by these programming models. These conclusions imply that life phenomena are consistent with the concept of “process” in computer fields. Introduction The coding principle of life information challenges scientists for centuries and variety studies were developed to approaching this goal. Recently, it is noticed that there are similarities between DNA sequences and computer program code and consequently the programming explanation became popular in this field. D'Onofrio viewed a cell “as a complete computational machine in terms that are akin to a multi-core computer cluster, where there is a centralized memory and instruction set, yet computational tasks are distributed among distinct processing elements”[6]. Flynn considered DNA as an example of shared memory in a distributed heterogeneous multiprocessor system with multiple input streams and multiple output streams[7]. In this way, each cell has over 2,000 different enzyme computers that read the shared memory data in DNA, processing that data according to the individual programs, many operating independently[8]. In the last 10 years, at least 20 different natural information codes were discovered in life, each operating according to arbitrary conventions. Such as proteins address codes[9], acetylation codes[10], RNA codes[11], metabolic codes[12], cytoskeleton codes[13], histone codes[14], and alternative splicing codes[15]. All these codes suggested that the complexities of biology are growing by orders of magnitude[16], and the signaling information in cells is organized through networks of information rather than simple discrete pathways which are similar to computer program as well. Whole-cell simulation[17] and the game of life evolving program[18] are performed based on the ideas above. These theories inspired our group to proposed the hypothesis that a DNA chain is an intermediate code sequence, which stores the operation codes and operands in a p-code way. Life is macroscopic showing that is presented by the p-code sequence in running status, as a computer process. The basic instructions of this program are various enzymes, which control chemical reactions and transport processes in cell metabolism. Advanced Materials Research Vol. 647 (2013) pp 258-263 © (2013) Trans Tech Publications, Switzerland doi:10.4028/www.scientific.net/AMR.647.258 All rights reserved. No part of contents of this paper may be reproduced or transmitted in any form or by any means without the written permission of TTP, www.ttp.net. (ID: 117.136.27.202-05/01/13,02:25:01)
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Programming Hypothesis on Life Phenomena and the Key Processes Simulation

Programming Hypothesis on Life Phenomena and the Key Processes Simulation
Jun Ma1, a, Shuyan Li2,b and Yide Ma 3,c 1,3 The School of Information Science and Engineering Lanzhou University, Lanzhou, China
2 Lanzhou University Chemistry and Chemical Engineering Lanzhou University,Lanzhou, China
[email protected], [email protected], [email protected]
Keywords: Programming hypothesis on life phenomena, Program simulation, Gene expression, Cell division and differentiation, Life evolution, P-code, reflection technology
Abstract. The formula that life process follows is a major scientific mystery during centuries. Some
people put programming thoughts into this field like Gates brought the idea that “Human DNA is like
a computer program but far, far more advanced than any software we’ve ever created”[1]. Here we
proposed a more specific hypothesis on this topic as that DNA is a set of p-code[2] and the enzymes
which control chemical reactions and transport processes in cell metabolism are the basic
instructions. Based on this hypothesis, some program models were developed successfully in this
work to simulate the key processes of life phenomena: gene expression, cell division and
differentiation, and life evolution. The results of these simulations show that there is a high level of
similarity between life phenomena and computer programs; the process of cell differentiation and
evolution of life can be explained in a programming way. These models also suggest that reflection
technology[3, 4] is essential to life process. Besides, C-value paradox, N-value paradox[5] and
pseudogene as well as some other biological problems could be also explained by these programming
models. These conclusions imply that life phenomena are consistent with the concept of “process” in
computer fields.
Introduction
The coding principle of life information challenges scientists for centuries and variety studies were
developed to approaching this goal. Recently, it is noticed that there are similarities between DNA
sequences and computer program code and consequently the programming explanation became
popular in this field. D'Onofrio viewed a cell “as a complete computational machine in terms that are
akin to a multi-core computer cluster, where there is a centralized memory and instruction set, yet
computational tasks are distributed among distinct processing elements”[6]. Flynn considered DNA
as an example of shared memory in a distributed heterogeneous multiprocessor system with multiple
input streams and multiple output streams[7]. In this way, each cell has over 2,000 different enzyme
computers that read the shared memory data in DNA, processing that data according to the individual
programs, many operating independently[8]. In the last 10 years, at least 20 different natural
information codes were discovered in life, each operating according to arbitrary conventions. Such as
proteins address codes[9], acetylation codes[10], RNA codes[11], metabolic codes[12], cytoskeleton
codes[13], histone codes[14], and alternative splicing codes[15]. All these codes suggested that the
complexities of biology are growing by orders of magnitude[16], and the signaling information in
cells is organized through networks of information rather than simple discrete pathways which are
similar to computer program as well. Whole-cell simulation[17] and the game of life evolving
program[18] are performed based on the ideas above.
These theories inspired our group to proposed the hypothesis that a DNA chain is an intermediate
code sequence, which stores the operation codes and operands in a p-code way. Life is macroscopic
showing that is presented by the p-code sequence in running status, as a computer process. The basic
instructions of this program are various enzymes, which control chemical reactions and transport
processes in cell metabolism.
Advanced Materials Research Vol. 647 (2013) pp 258-263© (2013) Trans Tech Publications, Switzerlanddoi:10.4028/www.scientific.net/AMR.647.258
All rights reserved. No part of contents of this paper may be reproduced or transmitted in any form or by any means without the written permission of TTP,www.ttp.net. (ID: 117.136.27.202-05/01/13,02:25:01)
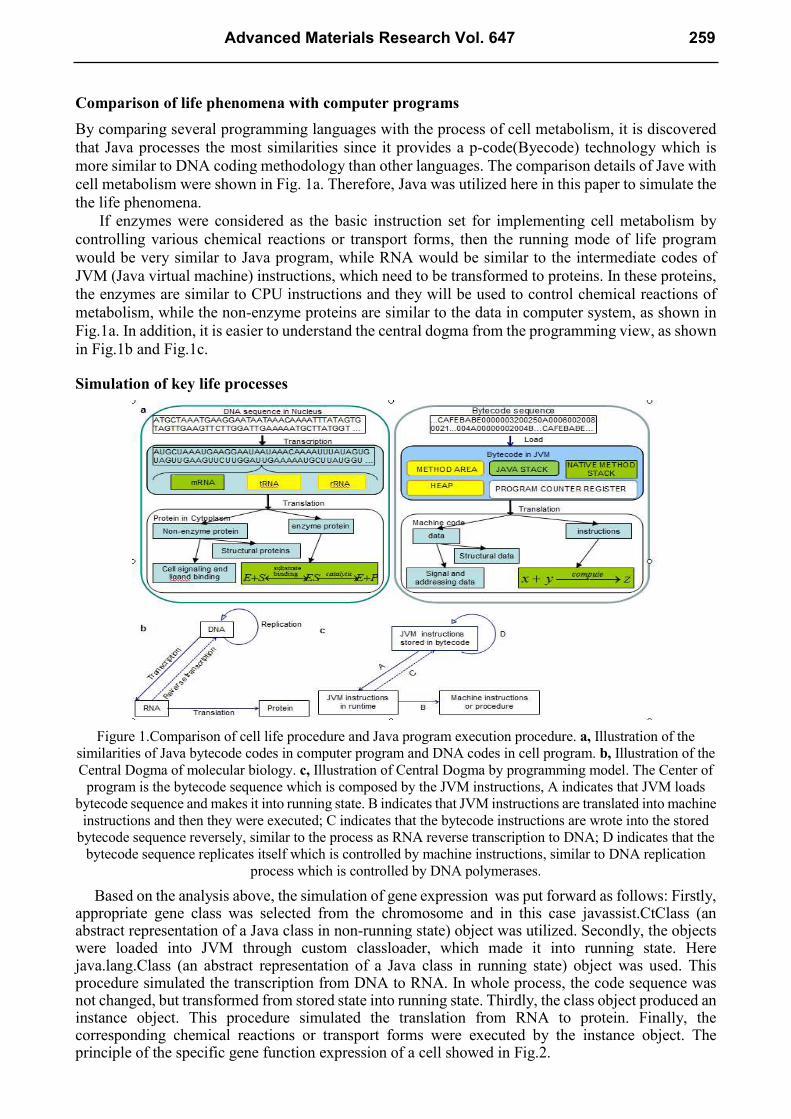
Comparison of life phenomena with computer programs
By comparing several programming languages with the process of cell metabolism, it is discovered
that Java processes the most similarities since it provides a p-code(Byecode) technology which is
more similar to DNA coding methodology than other languages. The comparison details of Jave with
cell metabolism were shown in Fig. 1a. Therefore, Java was utilized here in this paper to simulate the
the life phenomena.
If enzymes were considered as the basic instruction set for implementing cell metabolism by
controlling various chemical reactions or transport forms, then the running mode of life program
would be very similar to Java program, while RNA would be similar to the intermediate codes of
JVM (Java virtual machine) instructions, which need to be transformed to proteins. In these proteins,
the enzymes are similar to CPU instructions and they will be used to control chemical reactions of
metabolism, while the non-enzyme proteins are similar to the data in computer system, as shown in
Fig.1a. In addition, it is easier to understand the central dogma from the programming view, as shown
in Fig.1b and Fig.1c.
Simulation of key life processes
Figure 1.Comparison of cell life procedure and Java program execution procedure. a, Illustration of the
similarities of Java bytecode codes in computer program and DNA codes in cell program. b, Illustration of the
Central Dogma of molecular biology. c, Illustration of Central Dogma by programming model. The Center of
program is the bytecode sequence which is composed by the JVM instructions, A indicates that JVM loads
bytecode sequence and makes it into running state. B indicates that JVM instructions are translated into machine
instructions and then they were executed; C indicates that the bytecode instructions are wrote into the stored
bytecode sequence reversely, similar to the process as RNA reverse transcription to DNA; D indicates that the
bytecode sequence replicates itself which is controlled by machine instructions, similar to DNA replication
process which is controlled by DNA polymerases.
Based on the analysis above, the simulation of gene expression was put forward as follows: Firstly, appropriate gene class was selected from the chromosome and in this case javassist.CtClass (an abstract representation of a Java class in non-running state) object was utilized. Secondly, the objects were loaded into JVM through custom classloader, which made it into running state. Here java.lang.Class (an abstract representation of a Java class in running state) object was used. This procedure simulated the transcription from DNA to RNA. In whole process, the code sequence was not changed, but transformed from stored state into running state. Thirdly, the class object produced an instance object. This procedure simulated the translation from RNA to protein. Finally, the corresponding chemical reactions or transport forms were executed by the instance object. The principle of the specific gene function expression of a cell showed in Fig.2.
Advanced Materials Research Vol. 647 259

Figure 2.Abstracted gene expression process. a, a gene was simulated using a Java class, which contains three
subparts: cell function expression, regulation of cell division and other auxiliary code. b, A chromosome is a
combination of a group of genes. c, Shows a gene expression process.
In addition, combining with Reflection technology[19] and Bytecode engineering technology[20],
another two programming models were constructed in this paper for the other two key life processes:
Cell division and differentiation l and life evolution [21].
In a life cycle of cell division, the first step is related to DNA replication and separation. The
second stage related to the products of gene expression which involves transcription and translation of
DNA segments, and tries to decode and express the new gene. From the perspective of programming,
the growth of life is a process that organism loading and decoding DNA codes and also is the process
of cell division and differentiation which controlled by the DNA codes and the internal and external
environment of the cell. Since one type of cell is determined by a group of genes, k types of cells will
be determined by m genes. Let xi represents the code part of cell function expression and yi represents
the code part of regulation of cell division, then the vector X (xk1, xk2, xk3 ...) and Y (yk1, yk2, yk3 ...) will
determine the expression of cell function and regulation function. The principle of cell division and
differentiation showed in Fig.3.
Figure 3.Abstracted process of cell division. a, Division process of a cell. Decoded x will generate productions
for implementing specific function, and decoded y will generate productions for regulating gene expression.
These productions are used to activate the subsequent genes according to the reflection of current environment
condition. Then, the cell will generate a new type of cell. If the activation conditions are not met, the cell will
make regeneration division. b, Schematic diagram of process that how a set of gene groups determine various
type of cells from a global view, in which, F(X) and G(Y) respectively represent the decoding operation for X
and Y.
260 Biomaterial and Bioengineering

When program starts, it generates an embryonic stem cell object first, then continuously decodes
DNA coding sequences and generates various cells that have different functions. These cells will do
their own works, and then die randomly. If all the cells are dead, the organism will be over. The cell
function expression and regulation of cell differentiation are implemented through the reflection to
environment conditions. This model performed properly to simulate the processes of cell division and
differentiation, function expression and death degradation. It indicated that reflection mechanism is
crucial in life process.
Relative to cell division, Life evolution process is more abstract and complex. From a long time
span, life evolution can be seemed as an evolving process of life-program p-code sequence (DNA
molecular chains). An Evolutionary Programming Model[22] is utilized here to simulate the process.
In order to get a concise model, the gene function expressions in cell level were ignored and the genes
here in this process are only used to simulate macro behavior.
Assume a single-sex breeding dog, having a virtual genome as Fig.4a, is abstracted to simulating
this process. As shown in Fig.4b, firstly, several dog objects are generated by the same genome, and
then some of these dogs generate gene mutations randomly or through reflection. The dogs, which are
adapted to the environment, will generate offspring, and the others will die. Hence, the instance object
of the offspring has new abilities as shown in Fig.4c, which is as same as breeding phenomena in
biological world. This showed our program model can simulate the life evolution process in some
degree.
Figure 4.Abstracted process of evolutionary program. a, Genome of abstracted dog in parent generation. b,
Schematic diagram of the evolutionary program. c, Genome of offspring, in which the code sequence of gene0
has been changed, and a new gene (genex) which can properly adapt the environment has been appended.
Results and discussions
The models performed properly to simulate the processes of gene expression, cell division and
differentiation, function expression, death degradation and life evolution. The result showed that these
program models were able to simulate the life phenomena perfectly in a macro-scale way Thus it
concluded that if DNA coding sequences were regarded as a set of programming p-codes, the life
phenomena would be fully consistent with the concept of computer processes. This implies that life
phenomena are macroscopic presentations of static program-coding sequence in running status and the
codes were stored in DNA chain by a special p-code way. Besides, the simulating model for cell
division and differentiation suggested that reflection mechanism is crucial in life process.
Advanced Materials Research Vol. 647 261

When life program is running, a cell can be seemed as a microprocessor. Its signal channel[23] is
similar to the integrated circuit of computer chip, but the instruction set is more complex than
computer instruction set. Different from computer instructions that merely consume energy, the
instructions of a cell do not only consume energy, but also release or store energy. For life program
and computer program, although the complexity of their instruction sets is different, the essence of
them are the same from a procedural point of view: both are ordered instruction sequence, and both
can continuously run when there is enough amount of energy supply, and then perform the outcomes
as macro life phenomena by the organism or processing results by the computer. Based on this
modeling idea, it is discovered that many other pathways of metabolism, such as carbohydrate
metabolism, lipid metabolism, amino acids, nucleic acid metabolism and the citric acid cycle, are all
consistent with the work principle of sub-program.
Through program modeling and simulation, we are more convinced that the life phenomenon is a
process (which is the instructions continuously executing). The code of life program is stored in the
DNA in a p-code way. Chromosome is the compressed structure for the storage of these codes. And
we believe that the difference between chemical structures of deoxyribonucleotide and ribonucleotide
is just the difference of this p-code in stored status and running status.
In this p-code programming theory about DNA sequence, some exploratory explanation can be
provided for certain biological phenomena:
Exons and introns. Exons may be the codes that can be expressed as protein, while introns may be
the code that can indicate the position mark, regulation mark and temporary carrier.
Pseudogene. Maybe pseudogene is the outdated genes, which are not used at current growing
environment of organisms, but still have biological activities and positioning functions. They cannot
be removed because that cell differentiation process needs them to locate the follow-up gene.
Otherwise, it will cause inaccurate positioning, and then influencing the life process.
C-value paradox and N-value paradox. Since it is well known in the computer world that there are
no necessary connections between the complexity and code size of a computer program, the C-value
paradox and N-value paradox problem could be easily solved by considering a DNA coding sequence
as a program code.
Conclusions and methods summary
Inspired by the previous outstanding works, this paper puts forward a hypothesis: a DNA chain is a set
of intermediate programming codes which stores instructions and data, similar to Java bytecode
program in storing state; an mRNA chain is the programming codes in running state, similar to Java
bytecode program in running state. Life phenomena are the macroscopic performances of life program
when it starts running, which bases on cooperation of two related instruction, as RNA instruction set
and protease instruction set. These two sets are similar to JVM bytecode instructions and CPU
machine code instructions. In addition, based on this hypothesis, some computer program models were
developed in this work to simulate some key procedures of life phenomena: gene expression,
cell–division cycle and life evolution. These simulations show us that there is a high level of similarity
between life phenomena and computer process.
First, a gene is abstracted as a java class. Consequently, a chromosome can be composed of a series
of java classes. Then gene expression process and cell division and differentiation process can be
simulated. In this process we created many cell objects. Each object will activate or restrain the
corresponding genes according to various conditions and decode the activated genes. Decoding
process consists of two sub-processes. The first one is to locate and obtain the activated gene class in
chromosome, and uses a custom classloader to load it into JVM. This process is similar to the
transcription from DNA to RNA and RNA modification process. The second one is that JVM
translates the bytecode instructions in gene class into computer instructions, and executes these
instructions under appointed conditions. This process is similar to the translation from RNA to protein
and protein function expression. Cell division and differentiation is a continuous process of obtaining
and decoding genes.
262 Biomaterial and Bioengineering

Second, Evolutionary Programming Model is utilized here to simulate life evolution process. After
loaded and run the program which is designed by using EPM, the program's code sequence may be
changed. If the design is very exquisite, the program can perceive the environment and make
adaptive changes each time it runs, and then the program will have the ability to evolve. In our
program model only macro behaviors of organism were simulated while the gene function
expressions in cell level were ignored here in order to get a concise model.
References
[1] B. Gates, N. Myhrvold, and P. Rinearson, The road ahead: Penguin Books; Revised edition
(1996), 332.
[2] K.V. Nori, U. Ammann, Jensen, and H. Nageli, The Pascal P Compiler Implementation Notes.
Zurich: Eidgen1975).
[3] B.C. Smith, Reflection and semantics in a procedural language. Technical Report: MIT
Laboratory of Computer Science(1982), 272.
[4] P. Maes, ACM SIGPLAN Notices,Vol. 22(1987), 147-155.
[5] B. Lewin, Genes. Genes, New York: John Wiley and Sons, Inc(1983).
[6] D.J. D'Onofrio and G. An, Theor. Biol. Med. Model,Vol. 7(2010), 3.
[7] M.J. Flynn, IEEE trans. Comput.,Vol. C-21(1972), 948-960.
[8] D.E. Johnson, Programming of Life, Alabama: Big Mac Publishers(2010), 136.
[9] P. Barry, Science News,Vol. 173(2008).
[10] C.D. Knights, J. Catania, et al., J. Cell. Biol.,Vol. 173(2006), 533-544.
[11] M. Faria, RNA As Code Makers: A Biosemiotic View Of RNAi And Cell Immunity, in Introduction
to Biosemiotics, Springer-verlag New York Inc.2007), p. 347-364.
[12] M. Barbieri, Genetics as a communication process involving error-correcting codes, in
Biosemiotics: Information, Codes and Signs in Living Systems, Nova Science Publisher,
Inc.2007), p. 103.
[13] M. Gimona, Biosemiotics,Vol. 1(2008), 189-206.
[14] J.K. Sims, S.I. Houston, T. Magazinnik, and J.C. Rice, J. Biol. Chem.,Vol. 281(2006), 12760-6
[15] Y. Barash, J.A. Calarco, et al., Nature,Vol. 465(2010), 53-59.
[16] E.c. Hayden, Nature,Vol. 464(2010), 664-667.
[17] M. Tomita, Trends. Biotechnol.,Vol. 19(2001), 205-210.
[18] Information on http://www.spore.com/.
[19] I.R. Forman and N. Forman, Java reflection in action: Manning Publications Co.(2004), 273.
[20] Information on http://www.jboss.org/javassist/.
[21] J.H. Postlethwait and J.L. Hopson, Modern Biology: Holt McDougal(2006), 1130.
[22] J. Ma, M. Fan, and Y. Ma. Research on Evolutionary Programming Model based on Reflection
and Bytecode Engineering. in The 3rd International Conference on Information Science and
Engineering Yangzhou, China(2011).
[23] E.H. Davidson, J.P. Rast, et al., Science,Vol. 295(2002), 1669-1678.
Advanced Materials Research Vol. 647 263




















