
Principle and compromise in the dictionary. Interfaces of theory and application in lexicography
254
DOKTORI DISSZERTÁCIÓ INTERFACES OF THEORY AND APPLICATION IN LEXICOGRAPHY PRINCIPLE AND COMPROMISE IN THE DICTIONARY LÁZÁR A. PÉTER 2010
Transcript of Principle and compromise in the dictionary. Interfaces of theory and application in lexicography

DOKTORI DISSZERTÁCIÓ
INTERFACES OF THEORY AND APPLICATION
IN LEXICOGRAPHY
PRINCIPLE AND COMPROMISE IN THE DICTIONARY
LÁZÁR A. PÉTER
2010

Conventions used
Quoted material is italicized and boldface (Hungarian in italics; English in bold; other languagesbold) amid normal text, even if the original has some other highlighting. Consecutive stretches ofquoted language may not be set off typographically.
Italics is also used for emphasis.
Senses are enclosed between single quotes. The same concerns quoted material where senses areoriginally not between single quotes.
Where Hungarian material is between single quotes, an English translation is provided:the H. napirend is used in the sense ‘napirendi pont’ (= ‘item on the agenda’).
The → sign indicates one-way directionality, between languages or dictionaries.
The ↔ sign indicates two-way directionality, between languages or dictionaries, or a two-way reference work: English↔Hungarian dictionary.
E→H, e.g., abbreviates English→Hungarian; E→H stands for English→Hungarian.
H↔E e.g., abbreviates Hungarian↔English; H↔E stands for H→E & E→H.
Hungarian affixed forms with different shapes due to vowel harmony are referred to like this:
-bAn, bÓl, nAk etc. – the capital vowel letter stands for both (or all three) allomorphs.
In whatever format senses may be numbered in a dictionary, in this paper they are given as 1. … 2.… 3. ... etc. (number with full stop).
A adjectiveAP Adjective PhraseAdv adverbAdvP Adverb PhraseC ComplementizerE EnglishH HungarianN nounNP Noun PhraseO, Obj ObjectP PrepositionPoS part of speech / word class / syntactic categoryPP Prepositional PhraseS, Subj SubjectV verbVP Verb Phrase

2
Material quoted from reference works (unless it is the exact original formatting that is relevant) is10 pt Sans Serif, with the original type (boldface, italics) preserved.
The same font is used for quoting non-existent but recommended entries. Irrelevant parts of quotedentries are signalled like this: […].
es·pres·so n., pl. -sos. 1. a strong coffee […]
In material from reference works, any of the following may have been ignored when not relevant:(a) grammatical information; (b) the original centred dots for word division; (c) pronunciationinformation. Entries have usually been condensed into one paragraph, i.e. senses do not beginon a new line:
espresso 1. a strong coffee prepared by forcing live steam under pressure, or boil-ing water, through ground dark-roast coffee beans. 2. a cup of this coffee.
For a gender-neutral generic third person English pronoun, all the possible versions are used: s/he,(s)he, etc., sometimes they, as appropriate.

Contents
CHAPTER ONE: DICTIONARIES FROM LINGUISTS’ AND USERS’ PERSPECTIVES________ 9
1.1 Background and aims ___________________________________________________________ 9
1.2 Coverage ______________________________________________________________________ 91.2.1 Interfaces: compromise vs. principle ___________________________________________________ 101.2.2 The structure of this study ___________________________________________________________ 11
1.3 Lexicology vs. lexicography ______________________________________________________ 12
1.4 Words and their status in linguistics ______________________________________________ 131.4.1 The lexicon promoted, words demoted? ________________________________________________ 131.4.2 The lexicon seen as gaining prestige ___________________________________________________ 141.4.3 Separation of lexical and grammatical__________________________________________________ 141.4.4 Core vs. periphery _________________________________________________________________ 15
1.5 Lexicon, vocabulary, dictionary __________________________________________________ 15
1.6 The user–dictionary interface ____________________________________________________ 161.6.1 User research (based mainly on Atkins & Rundell 2008)____________________________________ 161.6.2 Problems with user profiling _________________________________________________________ 221.6.3 Word lists: non-homographic, homographic, partially homographic __________________________ 221.6.4 “Encyclopaedic” headwords _________________________________________________________ 251.6.5 Proper names of various types ________________________________________________________ 251.6.6 Productivity and user profiling _______________________________________________________ 29
CHAPTER TWO: WHAT GOES INTO THE DICTIONARY ______________________________ 31
2.1 Hedgehog vs. fox_______________________________________________________________ 312.1.1 Langue linguistics vs. parole linguistics ________________________________________________ 31
2.2 Dichotomies and continua _______________________________________________________ 322.2.1 Rationalism vs. empiricism __________________________________________________________ 332.2.2 E-language vs. I-language ___________________________________________________________ 352.2.3 Spoken vs. written language _________________________________________________________ 38
2.3 Theory into practice ____________________________________________________________ 422.3.1 Rigour vs. user-friendliness __________________________________________________________ 43
2.4 Linguists’ views of lexicography, lexicographers’ views of linguistics ___________________ 452.4.1 Principles of lexicography ___________________________________________________________ 462.4.2 Linguistics and lexicography _________________________________________________________ 472.4.3 Trade-off between anecdotalism and rigour______________________________________________ 602.4.4 Trade-off between coverage and accessibility ____________________________________________ 612.4.5 Linguistics vs. lexicography: linguists’ voices ___________________________________________ 632.4.6 The task of lexicography ____________________________________________________________ 752.4.7 Pre-Saussurean and Saussurean dictionaries _____________________________________________ 82
2.5 Lexicon into dictionary __________________________________________________________ 852.5.1 Checklist for dictionary design: Hudson’s “types of lexical fact” _____________________________ 85
2.6 Lexicon into dictionary: listing in the lexicon vs. the dictionary ________________________ 892.6.1 Listedness and listemes _____________________________________________________________ 892.6.2 Listedness in the lexicon: the traditional rank scale________________________________________ 942.6.3 Below the level of words ____________________________________________________________ 952.6.4 Fine tuning the word level __________________________________________________________ 1012.6.5 “Lexical” items of doubtful status ____________________________________________________ 106

4
2.7 Above the level of words _______________________________________________________ 1252.7.1 Compounds for the linguist and the user________________________________________________ 1252.7.2 Synthetic compounds______________________________________________________________ 1252.7.3 Lexicon vs. lexis _________________________________________________________________ 1262.7.4 Types of lexical items in Atkins & Rundell (2008) _______________________________________ 126
2.8 Lexical unit __________________________________________________________________ 1282.8.1 “Phrasicon” and phraseology________________________________________________________ 1292.8.2 Idiomaticity due to singularity of occurrence in some medium ______________________________ 134
2.9 A catalogue of multiword expressions (MWEs)_____________________________________ 1352.9.1 Cruse (2000) on compositionality ____________________________________________________ 1362.9.2 Multiword expressions in Biber & al. (2000) ___________________________________________ 1422.9.3 Multiwords in McCarthy (2006) _____________________________________________________ 1432.9.4 Multiword expressions in Hanks (2006) _______________________________________________ 1442.9.5 Idiom dictionaries in Dobrovol’skij (2006) _____________________________________________ 1452.9.6 Idioms in Ayto (2006) _____________________________________________________________ 1462.9.7 Corpus approaches to idiom: Moon (2006) _____________________________________________ 1512.9.8 Formulaic language in Wray (2002) __________________________________________________ 1522.9.9 Formulaic speech in Kuiper (2006) ___________________________________________________ 1552.9.10 Multiword expressions in Fazly & Stevenson (2007) _____________________________________ 1562.9.11 “Constructions” in Goldberg & Casenhiser (2007) _______________________________________ 1582.9.12 Multiword units in Abu-Ssaydeh (2005) _______________________________________________ 1592.9.13 Multiword expressions in Sag & al. (2002) _____________________________________________ 1612.9.14 Semantic/syntactic compositionality, statistical idiosyncrasy _______________________________ 1632.9.15 Bundles in Biber & al. (2000) _______________________________________________________ 1652.9.16 Idioms in Nunberg & al. (1994)______________________________________________________ 167
2.10 Implications for lexicography ________________________________________________ 170
CHAPTER THREE: GRAMMAR AND LEXICON ____________________________________ 173
3.1 Grammar in the dictionary _____________________________________________________ 1733.1.1 Grammar in definitions ____________________________________________________________ 1733.1.2 Number and countability ___________________________________________________________ 1743.1.3 One’s vs. smb’s: coreferentiality in MWE “slots” _______________________________________ 1763.1.4 Parts of speech ___________________________________________________________________ 1783.1.5 Prepositions _____________________________________________________________________ 2003.1.6 Small clauses ____________________________________________________________________ 207
3.2 Between grammar and lexicon __________________________________________________ 2093.2.1 Lexico-grammar__________________________________________________________________ 2093.2.2 Productivity: straddling the “words vs. rules” divide______________________________________ 212
CONCLUSIONS AND RESULTS _________________________________________________ 237
POTENTIALITIES FOR FURTHER RESEARCH _____________________________________ 240
SOURCES RELEVANT FOR FURTHER RESEARCH _________________________________ 241

Detailed contents
CHAPTER ONE: DICTIONARIES FROM LINGUISTS’ AND USERS’ PERSPECTIVES.................9
1.1 Background and aims ....................................................................................................................... 9
1.2 Coverage............................................................................................................................................. 91.2.1 Interfaces: compromise vs. principle ........................................................................................................ 101.2.2 The structure of this study........................................................................................................................ 11
1.3 Lexicology vs. lexicography ............................................................................................................ 12
1.4 Words and their status in linguistics ............................................................................................. 131.4.1 The lexicon promoted, words demoted? .................................................................................................. 131.4.2 The lexicon seen as gaining prestige........................................................................................................ 141.4.3 Separation of lexical and grammatical ..................................................................................................... 141.4.4 Core vs. periphery.................................................................................................................................... 15
1.5 Lexicon, vocabulary, dictionary..................................................................................................... 15
1.6 The user–dictionary interface ......................................................................................................... 161.6.1 User research (based mainly on Atkins & Rundell 2008)......................................................................... 16
1.6.1.1 Serving the user with ordering of LUs ................................................................................................ 191.6.1.1.1 Kill bilingually .......................................................................................................................... 191.6.1.1.2 Hungarian rendőr ‘police officer’.............................................................................................. 20
1.6.2 Problems with user profiling.................................................................................................................... 221.6.3 Word lists: non-homographic, homographic, partially homographic ...................................................... 221.6.4 “Encyclopaedic” headwords .................................................................................................................... 251.6.5 Proper names of various types ................................................................................................................. 251.6.6 Productivity and user profiling ................................................................................................................ 29
CHAPTER TWO: WHAT GOES INTO THE DICTIONARY .............................................................31
2.1 Hedgehog vs. fox .............................................................................................................................. 312.1.1 Langue linguistics vs. parole linguistics.................................................................................................. 31
2.2 Dichotomies and continua............................................................................................................... 322.2.1 Rationalism vs. empiricism...................................................................................................................... 332.2.2 E-language vs. I-language........................................................................................................................ 35
2.2.2.1 Portrait dictionaries vs. instrument dictionaries .................................................................................. 362.2.2.2 Lyons and corpora............................................................................................................................... 38
2.2.3 Spoken vs. written language .................................................................................................................... 382.2.3.1 For dictionaries, spelling is very much part of language..................................................................... 382.2.3.2 When orthography hinders lookup ...................................................................................................... 392.2.3.3 User-friendliness, or encouragement of ignorance? ............................................................................ 41
2.3 Theory into practice ........................................................................................................................ 422.3.1 Rigour vs. user-friendliness ..................................................................................................................... 43
2.3.1.1 Frawley on “format vs. form” ............................................................................................................. 442.3.1.2 Murray on prototypicality ................................................................................................................... 45
2.4 Linguists’ views of lexicography, lexicographers’ views of linguistics ....................................... 452.4.1 Principles of lexicography ....................................................................................................................... 462.4.2 Linguistics and lexicography ................................................................................................................... 47
2.4.2.1 Lew (2007) on semantics and lexicography........................................................................................ 472.4.2.2 Dictionaries as ultimate tests of theories? ........................................................................................... 482.4.2.3 Dictionary-making is a craft................................................................................................................ 502.4.2.4 Dictionaries do not change.................................................................................................................. 51
2.4.2.4.1 Tools, not descriptions................................................................................................................ 522.4.2.4.2 Science, empirical and applied ................................................................................................... 532.4.2.4.3 The notion of “explanatory basis” .............................................................................................. 55

6
2.4.2.5 Points of agreement between linguists: Hudson (1981) ...................................................................... 572.4.2.6 Illusions of simplicity: PoS ................................................................................................................. 582.4.2.7 Illusions of simplicity: “abbreviation” as PoS..................................................................................... 60
2.4.3 Trade-off between anecdotalism and rigour............................................................................................. 602.4.4 Trade-off between coverage and accessibility ......................................................................................... 61
2.4.4.1 Market demands beyond users’ demand ............................................................................................. 622.4.4.2 Descriptivism and application............................................................................................................. 63
2.4.5 Linguistics vs. lexicography: linguists’ voices ........................................................................................ 632.4.5.1 Kiefer (1990) on lexicography and theoretical linguistics .................................................................. 632.4.5.2 How theoretical is theoretical? ............................................................................................................ 652.4.5.3 The “real world linguists” of McCawley (1986)................................................................................. 652.4.5.4 The case of budge ............................................................................................................................... 662.4.5.5 Inside an entry: dichotomies in Hudson (1988) .................................................................................. 672.4.5.6 Lexical storage and the lexical entry................................................................................................... 692.4.5.7 Just linguistic or intra-linguistic information? .................................................................................... 712.4.5.8 Written language ................................................................................................................................. 722.4.5.9 Abbreviations as special items for the written medium ...................................................................... 742.4.5.10 The dichotomies of Hudson (1988) in the dictionary..................................................................... 74
2.4.6 The task of lexicography.......................................................................................................................... 752.4.6.1 Defining collocation............................................................................................................................ 752.4.6.2 Sense analysis of defend vs. protect for background......................................................................... 772.4.6.3 Ordering of senses............................................................................................................................... 802.4.6.4 Monitoring lookup for customization.................................................................................................. 81
2.4.7 Pre-Saussurean and Saussurean dictionaries............................................................................................ 822.4.7.1 Országh (1967) sees Saussure’s langue “crowded out of dictionaries” .............................................. 832.4.7.2 Ground for optimism concerning the linguistics/lexicography liaison?.............................................. 84
2.5 Lexicon into dictionary .................................................................................................................... 852.5.1 Checklist for dictionary design: Hudson’s “types of lexical fact” ........................................................... 85
2.5.2. Hudson (1988) tabulated ...................................................................................................................... 87
2.6 Lexicon into dictionary: listing in the lexicon vs. the dictionary................................................. 892.6.1 Listedness and listemes............................................................................................................................ 89
2.6.1.1 “E-lexicon” vs. “I-lexicon” ................................................................................................................. 892.6.1.2 Origins of the term “listing”................................................................................................................ 912.6.1.3 On the mental lexicon ......................................................................................................................... 922.6.1.4 Must or may be listed? ........................................................................................................................ 94
2.6.2 Listedness in the lexicon: the traditional rank scale................................................................................. 942.6.3 Below the level of words ......................................................................................................................... 95
2.6.3.1 Morpheme boundary types.................................................................................................................. 952.6.3.2 The dictionary need only list derived, not inflected forms? ................................................................ 96
2.6.3.2.1 Hungarian nagyot and sokat: straddling inflection and derivation ............................................ 962.6.3.2.2 Adjectival and nominal illustrations: better, best, teeth........................................................... 982.6.3.2.3 Semantics vs. lexicography...................................................................................................... 100
2.6.4 Fine tuning the word level ..................................................................................................................... 1012.6.4.1 Independent words, dependent words and semiwords in Hungarian.................................................. 1022.6.4.2 Listedness of dependent words, semiwords and bound bases ............................................................ 1032.6.4.3 Independent words, semiwords, and bound bases lexicographically ................................................. 104
2.6.4.3.1 Left-hand members................................................................................................................... 1042.6.4.3.2 Right-hand members................................................................................................................. 105
2.6.5 “Lexical” items of doubtful status.......................................................................................................... 1062.6.5.1 Onomatopoeic “words” ..................................................................................................................... 108
2.6.5.1.1 “Inarticulate” onomatopoeic words .......................................................................................... 1082.6.5.1.2 PoS-classifiable onomatopoeics ............................................................................................... 108
2.6.5.2 Interjections........................................................................................................................................ 1092.6.5.3 Sentence words................................................................................................................................... 1112.6.5.4 Expletives: not the four-letter kind..................................................................................................... 112
2.6.5.4.1 Expletives: words?.................................................................................................................... 112

7
2.6.5.5 Interjections: definitions and classification........................................................................................ 1122.6.5.5.1 Exclamations as a PoS label in CALD (2008).......................................................................... 1132.6.5.5.2 Goddam in CALD ................................................................................................................... 115
2.6.5.6 Inserts ................................................................................................................................................. 1162.6.5.7 Lexically bound words....................................................................................................................... 1202.6.5.8 Some lexically bounds words in CEDT and COED.......................................................................... 123
2.7 Above the level of words ............................................................................................................... 1252.7.1 Compounds for the linguist and the user................................................................................................. 1252.7.2 Synthetic compounds ............................................................................................................................. 1252.7.3 Lexicon vs. lexis .................................................................................................................................... 1262.7.4 Types of lexical items in Atkins & Rundell (2008) ............................................................................... 126
2.8 Lexical unit..................................................................................................................................... 1282.8.1 “Phrasicon” and phraseology ................................................................................................................. 129
2.8.1.1 Fixed expressions, phrases, idioms ................................................................................................... 1302.8.1.1.1 Moon (1998) on problems of terminology.................................................................................... 1302.8.1.1.2 Granger (2005) on phraseology .................................................................................................... 131
2.8.1.2 “Phrase” vs. “idiom”: not distinguished in CALD (2008) ................................................................ 1332.8.2 Idiomaticity due to singularity of occurrence in some medium ............................................................. 134
2.9 A catalogue of multiword expressions (MWEs).......................................................................... 1352.9.1 Cruse (2000) on compositionality.......................................................................................................... 136
2.9.1.1 Opacity and dictionary-worthiness.................................................................................................... 1372.9.1.2 Noun binomials lexicographically..................................................................................................... 1372.9.1.3 Whether (irreversible) binomials are nouns ...................................................................................... 1382.9.1.4 “Lumping vs. splitting” of binomials ................................................................................................ 1392.9.1.5 Cruse (2000) on collocation .............................................................................................................. 142
2.9.2 Multiword expressions in Biber & al. (2000) ........................................................................................ 1422.9.3 Multiwords in McCarthy (2006) ............................................................................................................ 1432.9.4 Multiword expressions in Hanks (2006) ................................................................................................ 1442.9.5 Idiom dictionaries in Dobrovol’skij (2006) ........................................................................................... 1452.9.6 Idioms in Ayto (2006)............................................................................................................................ 146
2.9.6.1 The first of Ayto’s three “intersecting spectra”: semantic opacity.................................................... 1472.9.6.2 The second “spectrum”: grammatical/compositional fixity ............................................................... 1472.9.6.3 The third “intersecting spectrum”: syntactic function....................................................................... 148
2.9.6.3.1 Dummy “it” idioms .................................................................................................................. 1482.9.6.3.2 Dummy subject idioms............................................................................................................. 150
2.9.6.4 Ayto’s classification evaluated.......................................................................................................... 1502.9.7 Corpus approaches to idiom: Moon (2006) ........................................................................................... 1512.9.8 Formulaic language in Wray (2002) ...................................................................................................... 1522.9.9 Formulaic speech in Kuiper (2006) ....................................................................................................... 1552.9.10 Multiword expressions in Fazly & Stevenson (2007)............................................................................ 1562.9.11 “Constructions” in Goldberg & Casenhiser (2007)................................................................................ 1582.9.12 Multiword units in Abu-Ssaydeh (2005) ............................................................................................... 1592.9.13 Multiword expressions in Sag & al. (2002) ........................................................................................... 1612.9.14 Semantic/syntactic compositionality, statistical idiosyncrasy................................................................ 1632.9.15 Bundles in Biber & al. (2000)................................................................................................................ 1652.9.16 Idioms in Nunberg & al. (1994)............................................................................................................. 167
2.10 Implications for lexicography ................................................................................................. 170
CHAPTER THREE: GRAMMAR AND LEXICON ..........................................................................173
3.1 Grammar in the dictionary........................................................................................................... 1733.1.1 Grammar in definitions .......................................................................................................................... 1733.1.2 Number and countability........................................................................................................................ 1743.1.3 One’s vs. smb’s: coreferentiality in MWE “slots” ................................................................................ 1763.1.4 Parts of speech ....................................................................................................................................... 178
3.1.4.1 A bird’s eye view .............................................................................................................................. 1783.1.4.1.1 “Lumping vs. splitting” for word classes.................................................................................. 1793.1.4.1.2 Delicacy of analysis: the wood and the trees ............................................................................ 179
3.1.4.2 “Determiner”: lexicographic lip service, no real utility..................................................................... 182

8
3.1.4.2.1 Determiners in GB syntax............................................................................................................. 1833.1.4.2.2 The U turn of many: dormant adjective ................................................................................... 1843.1.4.2.3 The anomaly of such ................................................................................................................ 1873.1.4.2.3 Splitting vs. lumping: determiners............................................................................................ 187
3.1.4.3 “Complementizer” in dictionaries ..................................................................................................... 1883.1.4.4 Parts of speech lexicographically: MED (2002) and (2007) ............................................................. 190
3.1.4.4.1 Part of speech search and grammar search in MED ................................................................. 1903.1.4.4.2 The parts of speech in MED numerically considered ............................................................... 1923.1.4.4.3 Parts of speech in MED: issues of content................................................................................ 193
3.1.4.5 Differing PoS labels for the SL and TL ............................................................................................ 1953.1.4.6 Perspective shift between SL and TL lexical items........................................................................... 197
3.1.5 Prepositions............................................................................................................................................ 2003.1.5.1 Prepositions: a class with two faces .................................................................................................. 200
3.1.5.1.1 Prepositions: one syntactic class lexicographically .................................................................. 2003.1.5.2 The issue of English “complex prepositions” ................................................................................... 201
3.1.5.2.1 Biber & al. (2000) on complex prepositions............................................................................. 2033.1.5.2.2 A mystery word: ago ................................................................................................................ 2043.1.5.2.3 A neologism: gone.................................................................................................................... 206
3.1.6 Small clauses.......................................................................................................................................... 207
3.2 Between grammar and lexicon ..................................................................................................... 2093.2.1 Lexico-grammar..................................................................................................................................... 209
3.2.1.1 The odd thing about it..................................................................................................................... 2103.2.1.2 Grammaticization: end of a lexically bound word ............................................................................ 211
3.2.2 Productivity: straddling the “words vs. rules” divide............................................................................. 2123.2.2.1 Words and rules ................................................................................................................................ 2123.2.2.2 Dictionaries and productivity ............................................................................................................. 213
3.2.2.2.1 Frequency information and its problems ................................................................................. 2133.2.2.2.2 Productively used words........................................................................................................... 2143.2.2.2.3 Combinations with well- .......................................................................................................... 214
3.2.2.3 Combining forms: -proof and -friendly and Hungarian -barát ......................................................... 2183.2.2.3.1 -proof and -friendly ................................................................................................................. 2183.2.2.3.2 Hungarian -barát ..................................................................................................................... 2213.2.2.3.3 “Hyphenated forms” ................................................................................................................. 226
3.2.2.4 Productivity and compounds proper .................................................................................................. 2273.2.2.5 One facet of consistency: number compounds................................................................................... 232
CONCLUSIONS AND RESULTS ....................................................................................................237
POTENTIALITIES FOR FURTHER RESEARCH ...........................................................................240
SOURCES RELEVANT FOR FURTHER RESEARCH....................................................................241

Chapter One:Dictionaries from linguists’ and users’ perspectives
1.1 Background and aims
The study of lexicology and the work with dictionaries has always been empirical and “corpusdriven” for the present author, in terms of being informed by EFL teaching, the teaching of gram-mar and syntax, work on pedagogical English grammars and English↔Hungarian translation. Thestudy draws on the background in these fields, and to the extent that it is possible, it is guided by,and dedicated to, the notion that grammar and lexis are hardly, if at all, separable. Whatever thestance taken on their separability, however, it is probably fair to say that a grammarian’s1 view oflexicography and a lexicographer’s view of grammar will be presented.
1.2 Coverage
Dictionaries are so variegated that it is but small exaggeration that the category “dictionary” itself isone that has been likened to games since Wittgenstein:
“[...] similarities overlapping and criss-crossing: sometimes overall similarities. I canthink of no better expression to characterize these similarities than ‘family resembl-ances’”. Wittgenstein (1953:§66–7)
This study is about lexicology and dictionaries, and has not such an impossible goal as suggested bythe elusive nature of dictionaries, because it narrows down its objective to English lexicography andEnglish ↔ Hungarian dictionary-making.
It is the conviction of this author that the learners’ and users’ need rather than some abstract theo-retical consideration should be the absolute measure in evaluating any work of lexicography. Thisattitude is implicit in the hackneyed phrase “user-friendliness”, which, in a good many cases, is ar-guably no more than hype. Still, this attitude has hardly been present, and certainly has not been inthe limelight, for more than two decades in matters lexicographic.
I examine how this obviously contestable endeavour, the attempt at user-friendliness, manifests it-self; I explore the types of compromises between some principled, often theory-based “scientific-ness” and this user-friendliness in English dictionaries in general. From time to time I exemplify thesuccesses as well as the failures of this endeavour in AM&MASZ (2000/6), an English↔Hungariandictionary for Hungarians.
I also seek answers to such questions as:
• What, if anything, do the insights of linguistic theory and description have to offer for diction-ary-making: (i) where such insights may have left an imprint on the practice of Eng-lish↔Hungarian lexicography; (ii) where there seems to be no room for such insights.
• What are those areas where such insights, even if exist, (would) explicitly jeopardize this user-friendliness: where such approaches would be not just useless but explicitly detrimental. Thereseems to be some, but little, synergy between linguistic theory and lexicography. One wondersif this is a blessing or a curse for both of them.
1 It is readily acknowledged that the term grammarian is somewhat out of context here, but I feel that inverted commas
may destroy the parallelism intended.

Chapter One
10
This study, while it sometimes looks at competing theories or views on an issue, never with a viewto solving them. It offers no theoretical solutions or answers, it does not attempt to clear up prob-lems because it asks no such questions. What these comparisons may present rather is a clearerview of the situation of lexicography: it is in a position to cherry-pick from what theory can offer,always in a position to reject something, to choose whatever it does choose having different, possi-bly conflicting motives, because it is not answerable. It is theory that is applied, and its evaluationcomes from its utility.
The most exacting and demanding pieces of lexicography – so much so that the “dictionary” labelhardly fits them – are the (obviously partial) entries of the lexicons of several languages inspired bythe Meaning↔Text model (originally: Mel'čuk 1974). These entries are so unlike the everyday no-tion of any trade dictionary that they do not have a user in the standard sense: their readership islimited to linguists. The Explanatory Combinatory Dictionaries are formal dictionaries whose aim isthe complete specification of all syntactic, semantic and lexical information for any item. Syntactic:formal representation of all grammatical relationships that it has; semantic: an analytic definitionwhich uniquely differentiates it; lexical: all paradigmatic and syntagmatic associations for the entryin the form of lexical functions that link it to its typical phraseology. In this sense, the notion of theECD as a work of specialized lexicography is an unrivalled piece of scholarship; in the sense of adictionary actually used by even a narrow section of readers, it is less of a dictionary than the OED.
Being pre-theoretical is probably impossible. The most innocent-looking of terms used in the Pref-aces or the “How to” sections of dictionaries – “word”, “word class”, “auxiliary”, “idiom”, “expres-sion”, “meaning”, “combining form”, “sense”, “abbreviation” – present insurmountable difficulty,some perhaps less, some more, and they all assume theories regarding language structure, even ifthis need hardly bother the compilers, and is not realized by the users. Another layer of terms, notmeant for the terminology in the “How to” sections of dictionaries and introductory texts, but inmore technical writing, will contain items such as “regularity”, “productivity”, “listedness”, “poly-semy”, “homonymy” (a random list at the tip of the iceberg), each of which not only assumes anentire sub-theory but one which is interdependent on most of the others. Because in some form orother, dictionaries must cover the entirety of a language, this study must use lexicology as a vantagepoint to touch upon many facets and sub-fields of linguistics, including those just listed. It seemsthat the more general and varied the subject (lexicology, broadly speaking), the more fragmentaryand varied the discussion. Also, it seems evident that the broader the coverage, the shallower thetreatment will be.
1.2.1 Interfaces: compromise vs. principle
The title and subtitle of this study could be reversed. According to the subtitle, in the broadest senseI look at the duality of compromise vs. principle, or aspects of compromise between theoretical ac-curacy and exigencies of application, mostly within one language pair of bilingual lexicography. Assuggested by the title, I explore questions of how linguistics influences lexicography; how insightsfrom linguistics can or should be used in the creating of (English, and English↔Hungarian) dic-tionaries. I examine the issue of how bad this compromise may be, if at all, and whether it meansthe abandonment, as some writers worry, of intellectual exactitude.
The word “interface” in the title is to be read as a non-term, an everyday expression that indicates acommon point or boundary between two things. The title may have been worded thus: Theory meetsapplication, or Theoretical meets applied in lexicography. “Interface” as a verb also means ‘designor adapt the input and output configurations […] so they may work together compatibly’ (CED&T1992). In a discipline that may be roughly defined as lexicology, for theory to inform praxis, as wellas for the practice to feed back into the theory, one had better have a clear notion of how the two arerelated. I will take the standard view that there is a process by which the theory of linguistics is en-

Chapter One
11
acted or practised in and by lexicography; also, the more controversial view that there is a more orless self-contained domain within linguistics that goes by name “lexicology”.
Just as knowledge of language is now supposed to be modular, individual linguists have standardlyspecialized in a particular module. The boundaries of the compartments are variously placed, how-ever, possibly with syntax and phonology enjoying a more central and undisputed status, semanticsand morphology only following suit. Controversies also surround the issue of interfaces betweenthe modules, if indeed there are such modules. It is questionable, then, whether these compartmentsare rigid, or there is overlap between them in whatever form; this can arguably be conceived of in agreat many ways. Not only is the issue of putative intra-modular interfaces, the subject of theirbook, contentious; also, as Ramchand and Reiss (2007:2) point out, the term “interface” can be
“legitimately applied to the connections between the language faculty and other as-pects of cognition […] or between linguistics and other disciplines”.
1.2.2 The structure of this study
Although several facets will be touched upon, some of them only tangentially. Internet-based dic-tionaries, both online and offline, and interactive (open, i.e. publicly edited) dictionaries will not bediscussed at all, or only mentioned inasmuch as they come into play in the treatment of the “dic-tionary–user interface”. It is commonplace that the value of the Internet dictionaries varies, to usean understatement, and the quality of such “open dictionaries” is doubtful. The situation concerningInternet dictionaries, as far as can be judged, changes very rapidly.
Dictionaries in the teaching process in and outside of the classroom will not be dealt with. Manystudies have reported on experiments with dictionary use, mainly for dictionary evaluation andplanning/design purposes, but the use of dictionaries in classroom teaching settings does not seemto be well documented. However important insights for lexicography may come from studies suchas Horváth (2006), which look at possibilities of corpora used in the classroom, issues such as theseare not relevant to the present study.
While some authors always seem rightly thrilled to recognize the usefulness of the Web as a sourceof data and search facility, warnings of the pitfalls of this avenue of research can also be heard. At-kins & Rundell (2008:53) optimistically claim, for example, that if one is not “sure whether a par-ticular usage is still current, a site like Google News will show how recently it has been used (whichusually turns out to be within the last 24 hours)”. [In the footnote:] “One might have imagined, forexample, that the phrase Beam me up, Scotty had fallen into disuse, but web data shows that it isalive and well”. Kilgarriff (2006), on the other hand, reports that an “academic-community alterna-tive” to simple Google-based searching has been developed exactly to avoid “having to be goo-gleologists”, which would indeed require a special branch of science, because: (i) commercialsearch engines do not lemmatise or part-of-speech tag; (ii) their search syntax is limited; (iii) thereare constraints on the numbers of queries and the numbers of hits per query; (iv) search hits are forpages and not for instances; ultimately, search engine counts are arbitrary. The device described inKilgarriff (2006) crawls, downloads, cleans, and de-duplicates, then linguistically annotates andloads the data into a corpus query tool.
All of this, while obviously relevant and exciting for (the future of) dictionary-making, is not dealtwith. I will be mainly concerned with print dictionaries, and few CD-ROM dictionaries, eitherbased on print editions or of a totally new conception, such as the MED (2002). CD-ROM versionsare referred to and used for illustration for convenience of consulting, where they do not differ fromtheir print counterpart.
In a review of Kiefer & Sterkenburg (2003), de Schryver takes the authors to task for ignoring “thecrucial modern backbone” of large dictionary projects, the dictionary compilation software. “Are

Chapter One
12
twenty-first century students of lexicography really supposed to believe that ordinary Office toolsare used for the compilation of real (electronic) dictionaries?” (de Schryver 2004b:14).
This thesis does not concern itself with the actual technology, computerized or otherwise, that isused to produce a dictionary; with whether, and what, software is used in the production. In general,it says little about what is called the first phase of dictionary design, “pre-lexicography”, in the sys-tem of Atkins & Rundell (2008). These aspects, while undeniably the issues in 21st century lexico-graphy, fall outside the scope of this work.
Chapter One, the shortest chapter, which gives a personal background and a description of the aims,discusses the interfaces in terms of which the study explores its object; it gives a rough outline ofhow it uses lexicography and lexicology; it discusses the current status of words as such outsidelexicography; it broadly defines “lexicon”, “vocabulary” and “dictionary” as they are used in thisstudy; and finally it discusses the user–dictionary interface.
Chapter Two is devoted to twin questions of what goes into the dictionary from the lexicon, andwhat goes into the dictionary from the linguistic enterprise, i.e. how this process is seen through theprism of theoretical linguistics and lexicography. It looks at questions of how much theory finds itsway into practice. The bulk of Chapter Two examines the traditional “grammatical rank scale” andidentifies its units as they are catalogued in the dictionary. The most problematic level, that of mul-tiword units in the broadest sense of the word receives special attention in 2.9.
Chapter Three looks at the relationship of the grammatical and the lexical, by exploring, on the onehand, a few aspects of the grammatical information in a dictionary, and on the other, their affinitiesas they are manifested in productivity.
1.3 Lexicology vs. lexicography
The present study is an exploration in lexicography and lexicology. More space will be devoted tomatters lexicological and grammatical in English, and to E → H dictionaries than to Hungarianlexical/grammatical issues and H → E dictionaries: while both English structures and meanings willbe my concern, of and by themselves, Hungarian lexicology will only be explored to the extent thatit is relevant for H ↔ E relation.
One convenient approach to evaluating a piece of lexicography is to check against its practice what-ever claims it makes in the blurb or the front matter. It can also be checked against the accumulatedinsights and judgements of the scholarly community (Jackson 2002). An alternative approach is toestablish a set of criteria that arise from the academic study of lexicography itself. This latter, ambi-tious aim is not what I set out to do even if such broad criteria do not exist for this particular area:English↔Hungarian bilingual print dictionaries (for Hungarians).
To the extent that dictionaries register the existing words of languages, while both their potentialwords and their rules that generate these words are (almost completely) outside their scope, diction-aries are not products of the linguistic enterprise, and lexicography is not part of linguistics, as wesee them today. The present study, because it looks into the questions of what kinds of and howmuch linguistic insight goes into dictionaries, and because linguistics predominantly supplies, or is

Chapter One
13
supposed to supply, grammar-related information whose lexicographic presentation this study ex-plores, it is perhaps more of a lexicological than a lexicographic exploration, and it needs to employnotions – such as that of productivity – used explicitly in morphology.
1.4 Words and their status in linguistics
1.4.1 The lexicon promoted, words demoted?
Paradoxically, while in some parts of the linguistic realm, the study of words and the lexicon seemsto have recently gained more prestige, syntactically oriented work has gone down the other routeand has come to see words more and more of an epiphenomenon. This is the claim made, for exam-ple, in Julien (2007), where she argues that it is syntactic structure that combines with the possibil-ity of particular morphemic collocations to produce a distributional reality. Under this view, thingsthat have traditionally been considered as words
“derive from many possible distinct syntactic head configurations […] where move-ments and lexical access conspire to create linear adjacency and distributional coher-ence”.
And
“constraints on syntactic structure […] can explain the patterns and non-patterns ofso-called word-formation across languages, without invoking morphology-specificmodes of combination” (Julien 2007).
Here, syntax is not just primary; (non-autonomous) morphology is approached syntactically, and alexicalist concept of word is argued for.
In the minimalist approach to syntax in general, pride of place has been given to syntactic features,with languages supposed to differ as to how they combine them into more complex structures, forwhich the usual term is words, and more broadly, lexical items. As Adger (2003:36–53) argues,words are collections of phonological, semantic, and morpho-syntactic features. Not all words, inci-dentally, have all these types. The set of phonological and morpho-syntactic features is part of Uni-versal Grammar (for the individual languages to choose from), while the basic semantic atoms“seem likely to be universal” (Adger 2003:38).
It is ironic that a strain of componential analysis, with its allegedly universal semantic features,which has in the meantime fallen into disfavour, should really be back within this approach. Theyare coupled with (more consensually universal) phonological features, to be interpreted by the syn-tax, along with morpho-syntactic features, which, by contrast, have not previously been termed“features” in the literature.
It is also somewhat of a paradox that, seen from current syntax the lexicon – which in a more tradi-tional and less abstract view should be a repository of listed lexical units with a sound shape and anassociated (lexical) meaning – contains items that are never phonologically “spelt out” as overt lin-guistic objects. Unlike the “light verb” in other – lexical – approaches, the “light verb” of modernsyntax, for example, which is one of the several types of verb here as well, i.e. a lexical class, is de-fined in such a way as to cover (i) objects that surface as affixes or (ii) have no phonological con-tent at all, but it never covers ones at the traditional word level. Verbs, apparently, come in four va-rieties in these frameworks: the lexical ones, the “helping ones”, the affixed ones, and the alwaysinvisible ones. It is obvious that these last two (especially the latter) are never for lexicography toworry about.

Chapter One
14
1.4.2 The lexicon seen as gaining prestige
While mainstream generative grammar has put the most prominent focus on the syntactic compo-nent, some more recent approaches seem to have allowed more play for the lexicon, and/or moreimportantly, have expressly questioned the possibility of a robust separation of the lexicon and thegrammar (which is largely synonymous with syntax in these approaches). Approaches which “con-cur in many respects with many alternative theories of generative syntax” include Head-DrivenPhrase Structure Grammar, Lexical-Functional Grammar, Construction Grammar, AutolexicalSyntax and Role and Reference Grammar (Culicover & Jackendoff 2005:3).
This study does not discuss these, neither does it use their insights. Culicover & Jackendoff (2005),however, has affinities with them: it shares the view that, especially from a lexicographic perspec-tive, the grammar/lexicon borderline appears to be extremely flimsy. This must be contrasted tothose mainstream approaches, whose four aspects have remained constant since 1957:
“The formal technology is derivational; There are “hidden levels” of syntax; Syntax isthe source of all combinatorial complexity; phonology and semantics are “interpret-ive”; Lexicon is separate from grammar.
(Culicover & Jackendoff 2005:14)
Another relevant aspect of this difference between the mainstream and Culicover & Jackendoff’sapproach is that
“Semantics is served by a richly structured representation that is to a great degree in-dependent of language.”
(Culicover & Jackendoff 2005:14)
which has implications for what they take to be the architecture of the mental lexicon, or the se-mantic component.
1.4.3 Separation of lexical and grammatical
Culicover & Jackendoff (2005) provide a neat summary of the issue of the grammar/lexicon dividewhen they discuss the related notions of “the continuum from words to rules” and the“core/periphery” distinction. As they argue
“Mainstream generative grammar makes two divisions among linguistic phenomena,with the goal of identifying those aspects of language where deep generality and richabstract deductive structure are to be expected. The first is the traditional division be-tween grammar – the rules of the language – and the lexicon, which mainstream gen-erative tradition takes to be the locus of all irregularity.
Apparently, in the authors’ assessment, this mainstream view has not changed since the Aspectsmodel, where Chomsky cited Bloomfield’s well-known characterization of the lexicon as “an ap-pendix of the grammar, a list of basic irregularities”. For the purposes of lexicography, of course, aneat separation of the lexicon and the grammar would be ideal; just as ideal as it would be for syn-tax not to have to fiddle with the idiosyncratic, the irregular, the lexical, the random: phenomenaoriginally thought to reside within the lexicon.
Some examples of the relationship between lexical and grammatical are explored in Chapter Three.

Chapter One
15
1.4.4 Core vs. periphery
The second division, Culicover & Jackendoff (2005) claim, was introduced with the GB version ofthe Chomskian theory, and it distinguishes two components within the grammar itself: core and pe-riphery. Thus the core rules are the deep regularities, the ones governed by parameter settings; theperiphery holds the “marked exceptions”, irregular verbs, for example, for which there are no deepregularities. As Culicover & Jackendoff (2005) quote Chomsky:
“The research program idealizes the study of the language faculty to the study of thecore: a reasonable approach would be to focus attention on the core system, puttingaside phenomena that result from historical accident, dialect mixture, personal idio-syncrasies, and the like..”
Chomsky and Lasnik (1993), reprinted in Chomsky (1995:20)
While Culicover & Jackendoff (2005) allow that such idealization is “reasonable”, crucially, theywarn that
“as always, an idealization carries with it an implicit promissory note to make goodon the phenomena it has omitted.”
It has often been found that this “periphery” tends to become a tempting dumping ground for any ir-regularity that a theory cannot explain. The authors admit that they have found themselves
“taking a different track, being attracted over and over again to “peripheral” phenom-ena.” Culicover & Jackendoff (2005:25–26)
1.5 Lexicon, vocabulary, dictionary
To minimize ambiguity, I use “lexicon” to refer to the word stock of individuals (= their mentallexicon/dictionary); “vocabulary” refers to the word stock of a language (= its lexicon); and “dic-tionary” refers to the man-made product, the lexicographer’s dictionary. The expression “lexicon”,accordingly, may be used with or without any qualifying phrase; “vocabulary” is usually followedby the relevant language in an of-phrase; and “dictionary”, along with some premodifier specifyingthe relevant language and/or dictionary type.
In the present study, most occurrences of “the dictionary”, even if without any qualifying expres-sion, refer to English, or specifically E↔H dictionaries. Wherever a statement concerning otherlanguages or any dictionary is made, it is hoped this will be indicated unambiguously.
When the expression “the dictionary” is used, mostly any dictionary is meant. Where claims aboutspecific dictionaries are made, these will be indicated. Where “the English↔Hungarian dictionary”is used with the definite article, it is to be understood that any such dictionary is meant. Whereclaims about specific E↔H dictionaries, or specific E→H or H→E dictionaries are made, these willbe specified.

Chapter One
16
1.6 The user–dictionary interface
1.6.1User research (based mainly on Atkins & Rundell 2008)
The tone of Atkins & Rundell’s (2008), discussing the viability and applicability of user research indictionary design, which is illustrated by the many quotes below, is singularly optimistic. Theauthors’ enthusiasm is only slightly broken at one point where they admit that
“It’s true that some dictionaries have such a wide range of potential users and usesthat it may be difficult to identify information specific enough to be useful.”
They insist, however, that “...even in such cases, the exercise is still worthwhile.” The authors keepemphasizing, recurrently throughout the whole book, that
“The most important single piece of advice we can give to anyone embarking on adictionary project is: know your user. [The Oxford Guide to Practical Lexicography]invokes this mantra in every chapter, and we make no apology for this2. This [...]arises from our conviction that the content and design of every aspect of a dictionarymust, centrally, take account of who the users will be and what they will use the dic-tionary for.” Atkins & Rundell (2008:5)
This is easy to agree with. Also, that
“The [...] user is shown to play a central role in the planning process, and we illustratethe ways in which editorial decisions are influenced by our understanding of theneeds and skills of our dictionary’s typical user.”
Atkins & Rundell (2008:17)
“The marketing department specifies the type of dictionary needed, describes themarket it will sell to and thus the type of user it is destined for, and paints a broad-brush picture of what its contents should be.”
Atkins & Rundell (2008:18)
“For the dictionary planners who will work within this budget to create a dictionaryfor a specific market, the needs of the end-user determine the extent of the book andits content (the number of headwords, the depth of their treatment, the type of mate-rial to be included in the front and back matter, etc.).”
Atkins & Rundell (2008:18)
They also warn that, for each policy decision [...], it is essential to be clear about (a) how muchspace it requires; (b) how this impacts the system as a whole; (c) whether it is in the best interest ofusers to devote so much space to it; (d) what has to be jettisoned to make that possible. The bestway of tackling these complex and challenging issues is to think first and always of the dictionaryuser.
“If you have a clear idea of who your user is and what they want from their diction-ary, you stand a good chance of achieving the right fit between dictionary type anduser need. Atkins & Rundell (2008:23)
They offer a list of the things that someone who is writing, or planning, a trade dictionary [...],needs to be able to think clearly about.
2 In all frankness, the reader does at times feel that they should.

Chapter One
17
[the first 5 of these concern the dictionary; points 6–8 below concern the user]
6. the users’ language(s): is the dictionary meant for...a. a group of users who all speak the same languageb. two specific groups of language-speakersc. learners worldwide of the dictionary’s language
7. the users’ skills: are they...a. linguists and other language professionalsb. literate adultsc. school studentsd. young childrene. language learners
8. what they use the dictionary for: is it for one or both of the following...a. decoding [...]b. encoding [...] Atkins & Rundell (2008:24)
Their message to the effect of “know your user” is repeated over and over:
“There are two ways of finding out about the user: user profiling and user research.The process is never scientific, but the only possible starting point is the targeted usergroup. You need a clear understanding of who will use the dictionary, what they willuse it for, and what kinds of skill they will bring to the task. If you have answers to allthese questions, you have a firm basis for making well-informed decisions about bothcontent and presentation. Know your users: that way, the dictionary will give themwhat they need.” Atkins & Rundell (2008:28)
“A user profile seeks to characterize the typical user of the dictionary, and the uses towhich the dictionary is likely to be put. [...] To build a user profile, you need to thinkcarefully about who your typical users will be, and what they will be using the dic-tionary for. [...]
“[...] ‘User research’ refers to [..] finding out what people do when they consult theirdictionaries, what they like and dislike about them, and what kinds of problem theylook to the dictionary to solve. [..] It is useful to divide the field into market research(carried out by publishers) and academic research [...].
“[...] Dictionary publishers regularly carry out (or claim to carry out) market research.This can take many forms, ranging from detailed questionnaires or surveys to infor-mal conversations with teachers, students, and other users. These are usually ‘inter-nal’ operations and results are rarely made public. On the other hand, publishers arealert to the PR benefits of being seen to be responsive to their customers’ needs, sowill often publicize the fact that they have carried out market research without beingtoo specific about its methods or results. But there is no doubt that good market re-search often has direct and visible consequences for editorial policy [...].”
Atkins & Rundell (2008:30)
“There is a large and growing body of user research by academics and (more rarely)by practising lexicographers, and several books have been devoted to the subject.Academics tend to focus on dictionary use in educational environments. Subjects aresometimes native speakers [...]. More often, they are language-learners of varying de-grees of proficiency [...]. Lexicographers, in their research, have tried to discover howactual users use their actual dictionaries in as near natural settings as possible.”
Atkins & Rundell (2008:32)

Chapter One
18
“[...] it is impossible to predict all the questions that users will ask of their dictionary,so we need to take a pragmatic view about what we can achieve. A realistic goal is tomeet the needs of most users most of the time. And to achieve this, we have to get theclearest possible picture of who these users are and what kinds of question they willask of their dictionary. Creating a user profile and taking careful note of relevant userresearch will help you to make well-informed editorial decisions.”
Atkins & Rundell (2008:32; italics mine)
If user research and market research were as decisive, and the findings from them were as reliableto put into actual practice as it may appear from the multitude of descriptions above, then tagged toall this should come a list of the decisions that are affected by particular user needs, and the waythey inform editorial decisions. Instead of a list of particular policies like that, however, we only getthese generic pieces of content- and metalanguage-related advice:
Content
–Which headwords (and meanings) should be included?Other questions in this area:–How many headwords does the dictionary need to contain?–Will users want to look up literary, dated, or obsolete words?–Should dialect words be included?–Should it cover specialist terms, and if so, which domains are most relevant?–For each headword, which information categories are most important?–Do the users (need to) know about how words combine grammatically?–Do they need information about pronunciation or the stress patterns of phrases?–Do they already know how regular verbs inflect, or will they need to be told?–Do they need to know about typical contexts of the headword?
Atkins & Rundell (2008:32)
Presentation: metalanguage
–What linguistic skills can the users be expected to have? (And, following from this:)–Will definitions need to be written in simplified language?–Can IPA be used to show pronunciations?–Are users familiar with terms relating to transitivity, countability, and collocation?–What reference skills can we assume in your users? Here we ask:–Will they understand ‘standard’ abbreviations (such as adj, phr vb, or AmE)?–Can you use ‘codes’ to indicate syntactic behaviour, or should this information becarefully spelled out?
Presentation: design and layout
–What is the best way to set out the material so that the dictionary is easy to use butstill contains enough information? Atkins & Rundell (2008:34)
On that topic, Atkins & Rundell (2008:253) say, for example, that the
“ordering [the lexical units] in a sensible and coherent manner is a challenge to dic-tionary writers, but we have never met any dictionary users (as opposed to metalexi-cographers and computational linguists) who complained of this aspect of our work.”
To which can be added that again, even ad hoc decisions of ordering including, if need be, ones thatfly in the face of the general arrangement of senses, may serve the user better than rigid consis-tency. If Atkins & Rundell (2008) are right about this ignorance of the user, then all the admoni-tions concerning technical detail will always be futile, and editors “simply can’t go wrong”.

Chapter One
19
1.6.1.1 Serving the user with ordering of LUs
There may always be a good reason in a bilingual dictionary to arrange the senses according to thetranslation side: the user’s immediate needs may be served better on this side. This could be eitherwhen for whatever reason, cultural, pragmatic, or grammatical, the English word has a “pet” trans-lation in the target language in question, which will not always do, which the learners/users are un-willing to let go of, or outright erroneous. This will be illustrated on four examples, the first two ofwhich are briefly covered in this section, while the latter two – kill and Hungarian rendőr ‘policeofficer’ – are elaborated on in some detail in 1.6.1.1.1. and 1.6.1.1.2.
• The word room is so strongly associated with the ‘area within a building/dwelling’ sense,which is translated as szoba, that it may be a good strategy for the E→H dictionary to giveterem rather than szoba as its first equivalent. Terem has a similar sense description as szoba,and the basic difference is in terms of size, but they are not usually interchangeable. Thisplacement then overrides the statistical fact that szoba is commoner.
• For the word morning, giving délelőtt rather than reggel as the first equivalent may sensitizethe learner to the fact that in English there is no separate word for the “ante meridiem” part ofday. While it should be obvious from a particular English text that a later time of day is in-volved, the word reggel is often erroneously used in translations. This may be coupled with theinformation in the entry that early morning is not actually kora reggel but reggel, i.e. the earlypart of the “ante meridiem” period.
1.6.1.1.1 Kill bilingually
It is probably good policy to arrange the entry of kill in such a way as to highlight the fact, put inthe simplest way, that kill does not equal murder. Kill – easily one of the most-analyzed Englishwords, a real semanticists’ pet – is often discussed in its link to the issue of the ambiguity (or justvagueness) of the adverb almost (e.g. Kempson 1977) exactly because of a feature of its meaning.
The important point bilingually is that the E→H dictionary can do justice to the meaning profile ofkill and serve the user at the same time, with preference given to the latter, simply by arranging theequivalents – and the examples, preferably in different grammatical forms – so that the commonestmisconceptions about this verb be avoided.
Two devices may be used to that end in the kill entry:
(a) the ‘megöl’ equivalent of kill – which is the translation of murder – ought to come aslate as possible
(b) the passive form of kill should come as early as possible
The (slightly edited) entry of kill in AMSZ (2000) illustrates this:
kill (1) halált okoz, halálát okozza vkinek, elpusztít, halálos the storm killed three people aviharban hárman meghaltak, a vihar három ember halálát okozta dozens of people werekilled (in the crash) (a balesetben) több tucat ember pusztult el / vesztette életét be killedelesik [háborúban] the weather killed the plants az időjárás elpusztította a növényeket (2)(meg)öl, (meg)gyilkol if looks could kill ha a tekintetével ölni tudott volna... / tudna (3) fájdal-mat okoz my feet/shoes are killing me majd meghalok, úgy fáj (ebben a cipőben) a lábam(4) véget vet, tönkretesz, megszüntet kill the pain megszünteti a fájdalmat […] (5) leszavaz[törvényjavaslatot] (6) agyonüt, üt [szín a másikat] (7) nevettet this guy really kills me meg-halok / meg kell halni ettől a pasastól
KIFEJEZÉSEKBEN: kill two birds with one stone két legyet üt egy csapásra kill time (bydoing smth) vmivel agyonüti/elüti az időt be dressed to kill kicsípte magát, ki van öltözve

Chapter One
20
1.6.1.1.2 Hungarian rendőr ‘police officer’
The English police officer may be translated first as rendőr(tiszt), with tiszt ‘officer’ bracketed, be-cause the average cops in the news may actually be officers in rank, but even if they are, that is ir-relevant – and most likely your average rendőr is not an officer. Splitting even more radically maybe a better solution, with policeman 1. rendőr 2. rendőrtiszt as the alternative order. (This may becloser to semantic reality, assuming that some such exists.)
Splitting police officer for target language purposes obviously does not make the source languagelexeme polysemous. It could very well be that police officer is monosemous to most speakers, andmeans ‘any police person’. As expected, checking police officer in several dictionaries reveals thatit is seen as polysemous in some but not in others.
The checking of English material for the purposes of the present study has been done in electronicdictionaries rather than printed sources. That is only because of their convenience, and usually itcan safely be done since the understanding is that the e-versions contain very much the same infor-mation as the print ones, irrespective of whether the former were produced based on the latter (as inthe case of all electronic products for learners before the MED 2002), or the electronic version gaverise to the print one.
� CED&T (1992) defines police officer thus:‘a member of a police force, esp. a constable; policeman. Often shortened to (esp. as form of address):officer’.This suggests that the word is monosemous.
� NSOED (1997) has this among compounds under police:police officer ‘a. ........ b. a member of a police force’
� RHWUD (1999) has this:1. any policeman or policewoman; patrolman or patrolwoman. 2. a person having officer rank on a po-lice force.This suggests that the word is polysemous between ‘constable’ and ‘officer in rank’.
� Both CALD (2003 and) CALD (2008) have this:‘a male or female member of the police force’
� Both MED (2002) and MED (2007) offer this:‘a member of the police. You can also talk about a policeman or a policewoman, but some people preferto use ‘police officer’, which could be either a man or a woman.’
It is probable that police officer has gained ground owing to its sex neutrality, to replace the non-sex-neutral policeman and policewoman. MED’s explanation actually supports and explicitlyteaches this. NSOED (1997) also has another sex-neutral variant, policeperson right after police of-ficer; this is a rarely used word, not even included in CED&T (1992), RHWUD (1999), and eitherlearner’s dictionary, CALD or MED; this again suggests that police officer is simply another, butmuch more frequent, sex-neutral ‘policeperson’. The fact that the second member of the compound,officer, may also be used (especially as a form of address) in the ‘constable’ sense, as hinted inCED&T (1992), also suggests this.
While justice to these facts can simply be best done in the Hungarian→English part if rendőr isequated with police officer first, and only then with policeman and policewoman (with the appro-priate gender information added), this target-language motivated splitting in the E→H part, coupledwith the tendency towards non-sexist usage, creates unfortunate complications for the police officerentry in the E→H part. Since rendőrnő ‘policewoman’ is a legitimate member of the Hungarianlexicon, without the problems attached to policewoman, it should also be given as an equivalent inthe police officer entry. The entry of a major bilingual dictionary must now recognize and register

Chapter One
21
the fact that the compound either signifies a person of rank or any policeperson (cross-linguistically,this is more important), and also that it either signifies a male or female one. This innocent-lookingword then may end up having an expanded entry like this (indication of the irregular plural has beenignored):
police officer 1. rendőr 2. rendőrtiszt 3. rendőrnő 4. női rendőrtiszt
with tiszt relegated to second place, stressing that ‘policeperson’ is more frequent.
Or, if less space is available:police officer 1. rendőr 2. rendőrnő
with tiszt disappearing altogether, as if ‘policeperson’ were the only meaning.
Or even:police officer rendőras if ‘policeperson’ were the only meaning, and sex were not of high relevance.
Paradoxically, a shorter and simpler entry is not necessarily inferior; it may prove to be more true tosemantic reality.
A few English and Hungarian entries from bilingual (and bilingualized: OAMSZNY and PEHLD)are printed below for illustration in alphabetical order (none of them contains policeperson):
English→Hungarian
AMSZ (2000): police officer – rendőr(tiszt)AMDSZ (2002): police officer – (köz)rendőrEHCD (1998): police officer – rendőrOAMSZNY (2002): police officer (also officer) – rendőr(tiszt); has no H→E Index(PEHLD (2003): word not in; but see PEHLD H→E Index below)
Hungarian→English
HECD (1988): rendőr – policeman, (police-)constable GB, police officer, ......[női] policewoman
MADSZ (2002): rendőr – policeman (női) policewoman, (férfi v. női) police-officer
MASZ (2000): rendőr police officer; [férfi:] policeman, [nő:] policewoman, (police) constable .....MASZNY (2007): rendőr – police officer; (férfi) policeman, BrE (police) constable .......PEHLD (2003): the H→E Index has rendőr – constable; officer; PC; police constable; policeman
The bigger the bilingual dictionary, the more space it will have to provide for all, even rare senses,and compounds or multiword expressions if there are any. A learner’s dictionary may not concernitself with some of these, but must base its decisions in such a way as to explicitly strive to helpavoid known learner pitfalls. Even in the biggest H→E dictionary (HECD 1988 in this case), thislearner-centredness is present without distorting semantic reality. Thus police officer is (a) thecommonest, thus “safest” equivalent, (b) the sex-neutral equivalent, which is partly responsible forits currency, (c) the one whose featuring early on in the entry would also be motivated by thelearner’s needs. This points to the requirement that police officer be placed earlier even in larger –practically all – Hungarian rendőr entries. The other side of the coin is the other direction where itmust be decided whether rendőr or rendőrtiszt should figure in entries for police officer; if both,then in what order; whether the bracketing rendőr(tiszt) solution is adequate. These are more com-plicated issues where size, aim, and user of the dictionary come into play, and there do not seem tobe ready answers available for a uniform kind of readership. The rearrangement of entries for dif-ferent types of readers, on the other hand, is not feasible in the real world of lexicography.

Chapter One
22
1.6.2 Problems with user profiling
One wonders whether Atkins & Rundell’s claim that they have never met a single dictionary userwho complained of the sense ordering aspect of their work (Atkins & Rundell 2008:253) shows thatthey deny the utility of user research and the tailoring of the dictionary to users’ needs. Criticismfrom metalexicographers and increasingly from computational linguists (who also use dictionariesas corpora) as well as other scholars working in the related domains is highly valued in lexicogra-phy partly because all these people including metalexicographers, with practising lexicographersamong them, know a lot about users’ needs. Why bother indeed, if the user just never complains ofaspects of dictionary work which lexicographers find most taxing, and whose products they valuemost highly? If the ordering of senses in a dictionary should prove so haphazard, so faulty, so below(obviously: expert) criticism that all professional critics complain about it but users never notice –can that really be a good dictionary, produced by rigorous application of user profiling?
The problem with the many dozen questions which may be asked in user profiles is (i) that they areextremely varied; (ii) that they cut across one another; (iii) that some demand just a yes/no for ananswer, while some require a whole list; (iv) that the answers to many logically follow from the an-swer to another; (v) that a “yes” to one of the questions and a “no” to another cancel each other out.
Also, and quite generally: while users’ performance in and after using particular dictionaries can in-deed be measured experimentally (and experiments that aim at this are the easiest to administer), aquestionnaire may be able to estimate users’ skills, but it will hardly be capable of calibrating theirneeds. What reference skills, one wonders, can be expected of a prospective user who wants a dic-tionary for crossword puzzles? Why should questionnaires be devised to ascertain, possibly for eachand every dictionary ever planned, whether users are “familiar with terms relating to transitivity,countability, and collocation” – when it is common knowledge that they are not (a fact that Atkins& Rundell 2008 also do not fail to stress)? What kind of user cannot be expected, one wonders, tolearn and remember abbreviations such as adj, phr vb, or AmE? User research indicates that the“List of abbreviations” is just as ignored a part of the dictionary as the “How to use” section; thatusers – all users – feel ill at ease with even this much “technicality”, abbreviation, symbols etc.These have been just a few examples of how the “Know your user” principle is easier said thantranslated into practice. What is the point, after all, in asking this question: “What is the best way toset out the material so that the dictionary is easy to use but still contains enough information?” Thisis no different from asking, for the purposes of a user profile, how to make a good dictionary. Andmost importantly: once we have the answers to most of these question (provided this is possible,and all caveats aside), what next?
1.6.3 Word lists: non-homographic, homographic, partially homographic
Dealing with decisions concerning the planning of the macrostructure, Atkins & Rundell (2008)distinguish three types of word list for dictionaries:
(a) non-homographic, where each headword is a unique orthographic form, and all lexical units withthe same form are considered as constituents of a unique polysemous headword;
(b) totally homographic, where each headword is a unique unity of form and content, and a singleorthographic form may be shared by many headwords, none of which is polysemous; and
(c) partially homographic (used in standard trade dictionaries), where a single form may be sharedby several headwords, each of which may itself be polysemous.
To illustrate the three types of arrangement, the orthographic form can will be used. Two simplifi-cations have to be allowed for here.

Chapter One
23
First: it must be assumed that the abbreviations can. for canon and canto as well as the abbrevia-tions Can. for Canada and Canadian are orthographically different, and do not belong here. Wherethey have their ideal position in relation to their non-capitalized and non-abbreviated counterparts iscontestable.
Second: multiword expressions such as carry the can, which may be listed in the can entry (and –irrelevantly for now – possibly under carry as well) but whose relation to the numbered senses isnot clear and thus present a problem in whichever of the three word list arrangements, have justbeen appended and marked with italics at the end, in the case of all three types.
(a) non-homographic headword list
can1 ability (aux)2 buttocks (n)3 container (n)4 dismiss from a job (v)5 permission (aux)6 preserve in a can (v)
7 prison (n)8 put in prison (v)9 toilet (n)
can of worms (n); in the can (n); carry thecan (v)
In this arrangement, multiword expressions are the least problematic.
In the actual dictionary, a decision would have to be taken concerning the ordering of the senseswithin the single can entry. That, however, is already a microstructural decision, one which is themost difficult in the case of this non-homographic headword arrangement. Nothing in effect beingdecided at the macrostructural level, all decisions have simply been put off until the microstructure.
(b) totally homographic headword list
can buttocks (n)can container (n)can prison (n)can toilet (n)can dismiss from a job (v)can preserve in a can (v)
can put in prison (v)can ability (aux)can permission (aux)
can of worms (n); in the can (n); carry thecan (v)
In this arrangement, multiword expressions are less problematic.
Here, the senses are followed by a PoS label and the number which they were assigned in the non-homographic alphabetical list above. Under this arrangement, the actual dictionary’s ordering of theheadwords is still a macrostructural decision: a decision must be taken anyway concerning the or-dering of the separate can entries. Exactly the same issue, when given different treatments, maysurface as a matter of either microstructural or microstructural policy.

Chapter One
24
(c) partially homographic headword list
Depending on the basic classifying principle (the “first cut”), there are two options:
(c1) With the first cut by meaning:
can–ability (aux)–permission (aux)can–buttocks (n)can–container (n)–preserve in a can (v)
can–dismiss from a job (v)can–prison (n)–put in prisoncan–toilet (n)
can of worms (n); in the can (n); carry thecan (v)
The multiword expressions are problematic in this arrangement too.
(c2) With the first cut is by word class:
can1 aux–ability (aux)–permission (aux)
can2
–dismiss from a job (v)–preserve in a can (v)–put in prison
can3
–container (n)–buttocks (n)–prison (n)–toilet (n)can of worms (n); in the can (n); carry the
can (v)
The multiword expressions are also problematic in this arrangement.
An important and general principle which Atkins stresses and cannot be emphasized enough: if youdo not want to stretch the capabilities of the theory, then any lexicographic decision that puts theleast demands on a theory is a good decision, and of any two solutions, the one should be chosenthat burdens the theory less. This is a very valid general observation.
Atkins & Rundell (2008) warn that when making decisions concerning headword lists and entrystructure, “which affect the whole impact and appearance of the dictionary, it’s as well to do a bit ofmarket research first, to see what your probable readers prefer” (Atkins & Rundell 2008:249). Tothe best of my knowledge, however, there exists no market research project or study which hasyielded a concrete result with regard to a concrete policy that has been followed in the design of adictionary, then subsequently tried with a user group doing a concrete task, such that the whole pro-cess was finally repeated with the same dictionary but with another solution for the same problemcarried through and tried with some other group doing the same task. In short, even in a market sohuge as that of English dictionaries, these kinds of fine-grained studies simply do not exist. Need-less to say that English↔Hungarian dictionary-making in Hungary is not better off. Also, there isno such thing as a user target group that arrangement (a) or (b) or (c) suits better than the any otherarrangement.

Chapter One
25
1.6.4 “Encyclopaedic” headwords
One question to do with headword inclusion in the broadest sense is how much encyclopaedic, orsemi-encyclopaedic, or quasi-encyclopaedic information will be offered, and how much of this willbe entered in the body of the dictionary rather than the back matter. While the first decision maydepend on user group, the latter is completely independent of it.
The encyclopaedic items in the body of the dictionary (as opposed to e.g. the back matter) aremainly words, sometimes phrases. The two marginal expression types, “sentence words” and ency-clopaedic items, differ in an important aspect: the former are typically spoken. This may be accom-panied by a lack of a standardized written form; this makes them marginal in dictionaries, whichhave a bias towards the written language (in addition to the practical difficulty of spelling them) re-sulting in their total omission. Encyclopaedic items – if this distinction is worth making here at all –are more characteristic of the written medium.
Among the (apparently) encyclopaedic headwords in the main A–Z body of general dictionariesmay be found, for example, names that feature in proverbs or idioms. In bilingual dictionaries geo-graphical names are worth entering if they diverge in the two languages and are therefore unpre-dictable in production: sometimes because the original name that is used in English, there being nospecific one, e.g. Hungarian Lipcse is Leipzig; or the simpler case of Hungarian Svájc, which isSwitzerland). Sometimes a term may not even be transparent passively: the Hungarian Genfi tó isLake Constance, and while reading an English text the Hungarian learner has no clue. This is usu-ally a happy hunting grounds for translation howlers.
1.6.5 Proper names of various types
Nicknames for geographical entities belong here: the information that Show Me State stands forMissouri is unlikely to be found in a Hungarian-language encyclopaedia, and when Hungarian us-ers, who typically have no English encyclopaedias at hand, need to make sense of the Englishphrase, the inclusion of such a list seems necessary. Worse than that, no English encyclopaedia islikely to offer these unofficial nicknames as headwords, since these are linguistic, not encyclopae-dic facts.

Chapter One
26
List No1
English nicknames of US states. Source: AMSZ (2000).
Aloha State HawaiiBadger State WisconsinBay State MassachusettsBeaver State OregonBeehive State UtahBluegrass State KentuckyBoomer State OklahomaBowie State ArkansasBuckeye State OhioCentennial State ColoradoConstitution State ConnecticutCornhusker State Nebraska**Cotton State AlabamaCoyote State Dél-DakotaDiamond State Delaware**Empire State New York Állam*Empire State of the South GeorgiaEquality State WyomingEvergreen State WashingtonFirst State Delaware**Flickertail State South DakotaFreestone State Connecticut**Granite State New HampshireGreen Mountain State VermontHawkeye State IowaHoosier State IndianaJayhawker State KansasKeystone State PennsylvaniaLand of Enchantment New Mexico***Land of Opportunity Arkansas***Little Rhody Rhode Island***Lone Star State TexasMountain State MontanaOld Dominion Virginia***Old Line State MarylandPalmetto State South CarolinaPanhandle State West VirginiaPelican State LouisianaPeninsular State FloridaPine Tree State MainePrairie State IllinoisShow Me State MissouriSilver State NevadaSioux State North DakotaSooner State OklahomaSunflower State KansasSunset State Oregon**Sunshine State Florida**Tar Heel State North CarolinaTreasure State Montana**Tree Planters State Nebraska**Volunteer State TennesseeWebfoot State Oregon**Wolverine State Michigan

Chapter One
* In Hungarian, Állam ‘state’ must be added to distinguish it from the city (which is not usuallycalled New York City, just New York.)
** The state has two nicknames.*** State does not feature in the nickname, which makes it even more difficult to guess that astate in the USA is involved here.
There are many subtypes of the names that may warrant inclusion in the H→E dictionary, and thesemay necessitate different types of treatment. Three examples may be singled out:
• of Kafkaesque, Hemingwayesque and Dickensian, probably just the first is general enoughto make it dictionary-worthy, and a Hungarian translation kafkai will be adequate, but it is wiseto include it if only because of the rare affix.
• Adonisz is rightly entered in HECD (1998), but with just the equivalent Adonis; still, becausethis Hungarian word is simply used as a common noun, with an indefinite article (someone maybe nem egy adonisz ‘not an Adonis’), the entry should indeed contain more. CED&T (1992)also suggests this: Adonis 1. Greek myth. […] 2. a handsome young man, while CALD (2008)defines Adonis as ‘a very beautiful or sexually attractive young man’, and exemplifies it withShe walked in on the arm of some blond Adonis.
• Roland and Oliver as names may be included (under both) because of the expression aRoland for an Oliver ‘an effective retort or retaliation’ (CED&T 1992). The expression, how-ever, may seem little used and thus not really worth entering until it is found that e.g. RHWUD(1999) has the definition ‘retaliation or a retort equal to its provocation'; a blow for a blow’ forit, and NSOED (1997) also has the following: ‘an effective retort; an effective retaliatory blow;a quid pro quo’. It seems a good decision then that EHCD (1998) enters a Roland for an Oliverwith the translation szemet szemért, kölcsönkenyér visszajár while give sy a Roland for anOliver is translated as nem marad adósa (vknek).
It is difficult to guess what percentage of names are really usefully entered and will be looked up ina bilingual dictionary. The EHCD (1998), for example, returns 1,184 hits for a “Hungarianheadword: Proper noun” search: these proper names are extremely varied. Of them, men’s andwomen’s names and geographical names with no additional information predominate, and it is dif-ficult to find among these the ones that do contain something special beyond the translation of aname. The correspondences between Hungarian and international names are often impossible togive and sometimes misleading, but can always be argued to be culturally relevant: it may be of realcultural interest that the Hungarian for Adrian or Hadrian is Adorján. It could be objected that theright place for this kind of information is not the bilingual dictionary – but if not that, then what is?
Most of these entries are like that of Zsuzsa → Susan(na), Susannah, Zsuzsi → Susie, Sue, Suke,Suk(e)y. A typically superfluous (because encyclopaedic) one is Zsolnay → Zsolnay porcelán<Hungarian porcelain factory>.
Items like Zsolna, that is, geographical names for one-time historical Hungarian cities (regions, riv-ers, etc.) used in Hungarian, for which the English equivalent should (also) be used, are often veryuseful in H→E translation: Zsolna → Žilina, town in Slovakia. Here, the added encyclopaedic in-formation should not be included. Slightly different is the situation with often used Hungarian geo-graphical terms like Délvidék, Felvidék, Vajdaság and the like, where equivalents such as Up-per/North(ern) Hungary are not adequate, because here, the encyclopaedic information had betterbe built into the translation itself: the one-time North of Hungary [now in Slovakia]; or even:South Slovakia
There are also items whose inclusion (in a dictionary this size) may be justified exactly by their en-cyclopaedic nature: Oliverian → Cromwell-párti: this may (arguably not very frequently) occur inEnglish texts.

Chapter One
28
On the other hand, if geographical names like Zürichi-tó → Lake Zurich and Adirondack-hegység→ the Adirondack Mountains are included, then it is indeed impossible to say what else, and howmany such items, rightly belong here.
The majority of what may be useful as Hungarian (pseudo) proper name entries are not found in anyHungarian→English dictionary: Pató Pál, e.g. probably to be spelt with two lower-case Ps, has aclose equivalent in the English noun do-nothinger; EHCD (1998) actually contains the related do-nothingism.
Mufwene (1988) maintains that:
“proper names are linguistic signs and, just like others denoting lexical units, they arealso carriers of some formal linguistic restrictions […]. They also have some idiosyn-crasies regarding spelling and pronunciation, the kind of information which, like thepreceding, is expected to be found in the dictionary rather than an encyclopaedia.Thus their inclusion in an unabridged dictionary is a must [...].
While it is hard to agree with the view that proper names are linguistic signs just like other lexicalunits, they certainly do have linguistically relevant features that warrant inclusion in dictionaries.Whether proper nouns have meaning or just reference may be a debated issue, but decisions con-cerning it are irrelevant for lexicography. “Idiosyncrasies regarding spelling and pronunciation”, bycontrast, which are undeniable and uncontroversial – so much so that they fall outside the scope oflinguistic disputes – indeed favour their inclusion. Since names may behave strikingly differently indifferent languages, many of the idiosyncrasies in question are displayed in inter-lingual relations,and thus a must indeed for bilingual dictionaries.
In a typical case, adjectives need to be included: the process of Lebanonization or Balkanizationmay make the inclusion of these words necessary, even if the nouns are probably not listed in (thebody) of the dictionary.
Sisyphean is best included with the translation sziszifuszi, and so does sziszifuszi (with no obvioustranslation equivalent); the Hungarian word is actually more important because it is commoner. Theword Sisyphean is not simply the equivalent of sziszifuszi in the phrase sziszifuszi munka: the Hun-garian sziszifuszi means just ‘very difficult’. That is the commoner of its meanings: it means differ-ent things to different people, depending on whether their classical education keeps the original‘actually/seemingly endless and futile’ sense.
The name Tinseltown is not likely to be included in encyclopaedias, which makes it similar to thenicknames for the US states. One Hungarian equivalent could easily be Holivúd, in this rather non-standard spelling. This spelling is not unlike a “pseudo-eye-dialect spelling”, i.e. phonetic respellingof words, “not in order to show a mispronunciation (e.g. Eye-talian), but merely to burlesque thewords or their speaker” (Bolinger (1946: 337). Since /»hçlivu˘d/ is roughly the standard Hungarianpronunciation of Hollywood, the spelling holivúd is eye dialect, a “visual morpheme” according to(Bolinger (1946), which implies some kind of irony. Note that Bolinger’s original examples: licker,vittles, sassiety etc. suggest speaker ignorance rather than irony. Also, because the butt of the ironyis not the speaker but the notion itself, the non-standard spelling suggests pejoration.
A not too large group of such “pseudo-proper” nouns is that of ethnic slurs of one type: pejorativenames for certain groups of people, including nationalities and races. Examples include jim crow or(South African) Jim Fish for a black person; Jerry for a German; Aunt Jemima / Aunt Jane /Aunt Mary / Aunt Sally / Aunt Thomasina (female counterpart of Uncle Tom) ; Mack / Mick /Mickey / Mickey Finn / Paddy for an Irish person; Charlie for Vietnamese (Viet Cong) or blacks.Only one kind of name is meant here, which looks like a normal proper name for a person (excludesthe likes of Geordie, Taffy or Yid on the one hand, and coon, towelhead or jungle bunny on theother – some of which may well be worth registering even in dictionaries larger than just the big-gest). As in most cases of culturally loaded disparaging lexicon, there is simply no corresponding

Chapter One
29
term in another language: thus, while Kike and Yid will be translatable to Hungarian, there existsno such slur, e.g. for Irishmen.
Special “names” are (what are actually marked as) trademarks, and also nouns of intermediatestatus between trademarks and common nouns. Most English native speaker as well as learner’sdictionaries have a warning of the trademark status of certain items, and a legal disclaimer in casethey omit one such.
Such examples include the material Hungarocell (or hungarocell) is polystyrene (foam) or Styro-foam. (Both these spellings are featured, by mistake, in AMSZ 2000, while MASZ 2000 only hasthe capitalized variant.
As this example shows, not only does the editor walk on thin ice because of the legal complications,but often also because of the geographical variation: the Hungarian word xerox 1. [gép:] Xerox ma-chine, (photo-) copier 2. [másolat:] Xerox copy, (photo)copy is unproblematic.
Kleenex, which for some reason is not entered in CALD (2008), is marked trademark and definedin MED (2008) as ‘a small paper handkerchief’ (with no provenance3 given). If someone asks for aKleenex, they should probably be given any papírzsebkendő ‘tissue’ not just this brand. Mean-while, Hungarian cellux (for which there is no natural non-trademark) is sellotape, scotch tape orsticky tape, and the choice will be dialectally determined: sellotape and sticky tape are (supposedto be) British, while scotch tape, US English.
1.6.6 Productivity and user profiling
Atkins & Rundell (2008) group affixes into bound (e.g. im-, -ment) and productive affixes, (e.g.ex-; -gate). Productive affixes are constantly used to create new word forms, so they must beexplained in a native speaker dictionary. Productive prefixes (un-, de-, anti-) usually appear asheadwords, so it’s important to recognize them in the corpus. There are fewer productive suffixes,and Atkins & Rundell (2008:165–166) claim that it’s difficult to believe that users, having failed tofind Zippergate or Italianness, would look up -gate or -ness. For that reason, some dictionariesdecide to omit productive suffixes from the headword list.This wording raises a methodologically relevant point. The authors obviously cannot, as no-onepossibly can, bring empirical support for claims regarding probable or expected user behaviour,such as “it’s difficult to believe that users, having failed to find word X, would (not) look up X”.Empirical support, if at all, comes through market research or academic research. Yet there hardlycould exist a body of empirical research into dictionary use vast enough to yield answers to all as-pects of user strategy in all bilingual pairs for all users and for all dictionary types – to name just themost important parameters.
There exists a huge body of published research on dictionary use by users of all kinds of dictionar-ies worldwide. Atkins & Rundell (2008) – which mentions Miller & Gildea (1985) on Americanpupils understanding of definitions; McCreary (2002) and McCreary and Amacker (2006) on col-lege students’ use of dictionaries; Bogaards (1992, 1998a) on language learners of varying degreesof proficiency – must be the state of the art.
Lexicographers, as pointed out by Atkins & Rundell (2008:32), have tried to discover how actualusers use their actual dictionaries in as near natural settings as possible. Hungary seems to be at adisadvantage. Márkus & Szöllősy (2006) a Hungarian study, which was reported in 2006 but wasconducted earlier, in spring 2004, lists several European studies which the authors say could havebeen the predecessors, but did not inspire them simply because they only came across them whentheir research was well under way. The 2004 project, the only one of its kind (and certainly the only
3 The manufacturer is the Kimberly-Clark Corporation, a USA firm; the object is apparently so international that the
word is not an Americanism.

Chapter One
30
such for English) appears to be the state-of-the-art publication in Hungary (at least for 2006). It israther limited in quantity terms; it cannot build on anything domestic remotely similar in its objec-tives, let alone magnitude; it only covers students at diverse secondary schools but no adult learners.This indicates that in Hungary at the moment, no publisher could possibly base their strategies –their market decisions, much less lexicographic principles – on reliable comprehensive research.
The market for E↔H dictionaries in Hungary is so narrow that the average bilingual dictionary willalways be practically for all learners/users, and for all tasks. More precisely: for the entire range ofusers, literate (young) adults, beginner-to-advanced, with an average, i.e. minimum school-acquiredgrammatical knowledge, using it for encoding and decoding. Learner’s dictionaries and bilingual-ized works may have added to the variety, but Hungarian→English dictionary publishing in Hun-gary has remained – and considering the market, will probably remain – basically monolithic.

Chapter Two:What goes into the dictionary
2.1 Hedgehog vs. fox
2.1.1 Langue linguistics vs. parole linguistics
The old Greek saying about the hedgehog and the fox (Berlin 1953; quoted in Widdowson 2007)tells us that “the hedgehog knows one big thing, while the fox knows many things”. The dualityconcerns the difference between the intellectual and the artistic personality. As argued in Widdow-son (2007:412), Chomsky, with his quest for a universal organizing principle, is the hedgehog oflinguistics par excellence. He knows one big thing. The foxes, on the other hand
“pursue many ends, often unrelated and even contradictory... their thought is scatteredor diffused, moving on many levels, seizing upon the essence of a vast variety of ex-periences and objects for what they are in themselves, without consciously or uncon-sciously seeking to fit them into, or exclude them from, any one unchanging, all-em-bracing, sometimes self-contradictory and incomplete, at times fanatical, unitary innervision.” (Berlin 1953:7–8).
Widdowson likens the second approach to Firth’s (criticizing him, incidentally, for aspiring to be ahedgehog, for not being content to focus on things “for what they are in themselves”, for wanting tofit them into “a unitary inner vision”. Both Chomsky and Firth published a seminal book in 1957,and it was the former, which advocated radical change, and not the latter4 that was to have an enor-mous influence on linguistics for the next half a century: thus 1957 (as Widdowson argues) marksthe beginning of the confrontation of opposing approaches to the study of language.
The present study, then, is guided by the notion that lexicography is a happy hunting ground of,foxes, not hedgehogs; that within this “hedgehogs–foxes” duality, lexicography is closer to beingthe artistic than the intellectual pursuit; that because they are so radically different, little or next tonothing can be hoped to come from the former that may genuinely inform the latter. Worse: becauselexicography is constrained by such starkly extra-linguistic considerations as the requirements – lessmildly put: the dictates – of the market, it cannot be expected to attain even as much as independentart. It is thus popular art at best – and if it comes up to expectations, then paradoxically, this is not asmall thing to say.
The present study takes a hedgehog’s eye view of lexical and/or semantic, some grammatical, andlexicographic phenomena, which, from a modest vista, seem inseparable. To be sure, the hedge-hog’s position commands a low horizon, but it hopefully notices the detail.
4 Firth’s book “is a collection of thematically diverse papers [...] but with no explicit coherent connection between them
at all. It is indeed a motley collection.” (Widdowson 2007)

Chapter Two
32
2.2 Dichotomies and continua
The present study, looking into matters of interest to the fox, is also concerned with dichotomies andclines. At the fox’s level, phenomena are not huge, discrete entities but objects on continua meltinginto one another. Dichotomous phenomena vs. clines – gradiences, continua – will be investigated,and see how they are manifested in lexicography. Many decisions both in the design and evaluationof dictionaries centre around some of these dichotomies. Applied linguistic practice, with whichlexicography may be classified, may either lend support to or question much of linguistic thinkingin such terms.
Most of these dichotomies, although their status as seen from the top – by the fox – may well be un-challenged, turn out to be better analyzed as continua, and work with them is greatly facilitated ifsuch a stance is taken. For the lexicologist and the lexicographer there are few either–or situationsin the empirical realm.
The Longman Grammar of Spoken and Written English (Biber & al. 2000) belongs to the stream ofgrammars (most of which, and mostly, are cognitively-based) that make it an underlying principleto operate with heterogeneous categories. Their basic argumentation is essentially this: if real worldcategories are not (or not exclusively) of discrete organization, then there is no reason for linguisticentities, including word classes, to be otherwise. There must, then, exist (i) more and less(proto)typical exemplars of a class; also, (ii) there must be unclear (“fuzzy”) borderlines betweenthe features of one class and another; (iii) there must be multiple class memberships. We must, then,be “prepared to look for similarities in terms of more-or-less rather than either-or” (Biber & al.2000:60).
The present study embraces the notion that categories are fuzzy rather than discreet, and that thereare prototypical and non-prototypical instances of linguistic entities and phenomena. Lexicography,by contrast, must present crisp categories; moreover, if it is to be effective, it has to work into itsproducts an added level of simplification.
The following dualities will be cropping up in the present study, more or less regularly; some ofthem will only be touched upon:
1 Grammar vs. dictionary & grammar vs. lexicon, as compartments of language2 Words vs. rules as compartments of language3 Langue linguistics vs. parole linguistics
or E(xternal) Linguistics vs. I(nternal) Linguistics, as approaches to language4 Rationalism vs. empiricism, as approaches (to language)5 Descriptivism vs. prescriptivism, as approaches to language6 Idiomatic vs. non-idiomatic use of language/expressions7 Written vs. spoken, as medium of language
8 Free vs. bound forms9 Thematic vs. functional, as syntactic categories10 Open vs. closed classes11 Productive vs. unproductive, as linguistic processes12 Transparency vs. opacity of meaning13 Word vs. affix, as grammatical units
14 Coverage vs. accessibility, as two aims of a dictionary15 Decoding vs. encoding, as types of dictionary16 Portrait dictionary vs. instrument dictionary, as lexicographic types
1—7 are the most general dichotomies, 8—13 represent more traditional grammatical dualities,while 14—16 are specifically dictionary-related ones.

Chapter Two
33
2.2.1 Rationalism vs. empiricism
Although more a practical introduction than a survey of theoretical issues, Atkins & Rundell do notfail to point to the fact that in the rift, if there is one indeed, between rationalism and empiricism,“lexicographers (and corpus linguists generally) are empiricists.” (Atkins & Rundell 2008:49). Thisis an implicit wording of the claim that dictionaries do not model the mental lexicon.
There are two reasons why I do not agree with the authors that
“What we are interested in is describing ‘performance’ (what writers and speakers dowhen they communicate). We do this by observing language in use and – on the basisof this – attempting to make useful generalizations that will account for phenomena inthe language which appear to be recurrent.”
(Atkins & Rundell 2008:49)
For one thing, the aim of lexicography is definitely not the making of “useful generalizations thatwill account for phenomena in the language”. It is not the case that lexicography makes generaliza-tions – neither is it supposed to do so. Dictionaries do not “describe performance” either, any morethan photographs describe their objects: a photo may depict and represent, but for description, moreis needed, and dictionaries do not typically provide that. It is also not easy to decipher who may bemeant by the “we” of the claim “what we are interested in is describing performance)”: after all, thelexicographer may observe (and this is a truism), but not describe or generalize. Also, although thedividing lines are undoubtedly there, lexicography cannot be neatly categorized as either empiricistor rationalist. If having performance as its object makes lexicography empirical, then it is empirical;after all, it represents performance rather than competence.
“Another major tradition in linguistics is represented by the rationalists, whose goal isto describe linguistic ‘competence’: the internalized, but subconscious, knowledge[...] of the rules underlying the production and understanding of our mother tongue.This tradition is associated most obviously with Noam Chomsky. For linguists work-ing in this paradigm, ‘data’ derives from introspection rather than observation.”
(Atkins & Rundell 2008:49)
This reliance on introspection and suspicion of field work has frequently come under criticism, butfew have been as heavily documented and well argued as Wasow & Arnold (2005), who succinctlysummarize their point saying that
“Disciplines differ considerably in the relative emphasis they place on data collectionversus theory construction. In physics, there is a clear division of labor between ex-perimentalists and theorists. Linguistics, too, has subfields (including psycholinguis-tics and sociolinguistics) in which theories tend to be data-driven and others (notablygenerative grammar) that focus almost exclusively on the formulation of elegant theo-ries, with little attention devoted to careful data collection. [...] The theories are con-sequently of questionable relevance to the facts of language.
(Wasow & Arnold 2005:1495).
It is those “facts of language” that lexicography cannot lose sight of.
The mainstream generativists’ suspicion of corpora, data-driven theory and “authentic text” is,however, a fact:
“Until the 1950s, there was a thriving empiricist tradition in American linguistics, but‘in a series of influential publications [Chomsky] changed the direction of linguisticsaway from empiricism and towards rationalism in a remarkably short time’ (McEneryand Wilson 2001:5). It is easy to caricature this major division, and there are livelydebates (for example the CORPRA discussion list) in which Chomskyites are demon-

Chapter Two
34
ized as ‘the enemy’ of corpus-based approaches. As always, the truth is a little morenuanced than this neat, binary characterization implies. Nevertheless, Chomsky is onrecord as being sceptical about the value of corpora, and a recent interview shows thathis stance has not shifted. He says:
“Corpus linguistics doesn’t mean anything. It’s like saying suppose a physicist de-cides… that instead of relying on experiments, what they’re going to do is take video-tapes of things happening in the world and they’ll collect huge videotapes of every-thing that’s happening and from that maybe they’ll come up with some generaliza-tions or insights.” (p 97 in Andor, Jozsef (2004) ‘The Master and his Performance:An Interview with Noam Chomsky’, in Intercultural Pragmatics 1–1:93–111.”
Atkins & Rundell (2008:49)
Stubbs (2002) claims that it is surprising how many approaches to language have dismissed the ideaof observing it in its quantitative aspect:. “as if chemists knew about the different structure of ironand gold but had no idea that iron is pretty common and gold is very rare; or as if geographers knewhow to compare countries in all kinds of ways but had never noticed that Canada is bigger thanLuxembourg” (Stubbs 2002:221, quoting Kennedy 1992: 339, 341). This is indeed no less weirdthan Chomsky’s vision of physicists “taking videotapes of things happening in the world”. If bothpositions are as absurd as this, then probably some golden mean is to be preferred.
It is certainly not for this paper to contribute to an assessment of how pertinent the comparison be-tween the linguist as such and the physicist as such is; incidentally, both physicists and linguistscome in many various persuasions. But if a parallel is indeed to be drawn, and it is between the cor-pus linguist, or lexicographer, on the one hand and some other profession on the other, then itshould be the photographer, or the cameraman, whose job it is not to get at “generalizations or in-sights” but to record, as faithfully as possible the “things happening in the world”.
One thing is certain: lexicography does exactly that, and it cannot be blamed for it. Rather than relyon experimentation, it collects “huge videotapes of everything that’s happening”, and it does noteven aim at “generalizations or insights”.
“With Chomsky’s star in the ascendant, early corpus linguists like the team responsi-ble for the Brown Corpus (…) were working very much against the grain of the pre-vailing orthodoxy. But now that technology can provide us with very large bodies oflinguistic data, the empiricist tradition has moved closer to the mainstream.”
(Atkins & Rundell 2008:49)
It is obvious why the foxes, the “data collectors” should applaud such a surge of data. What is notclear, however, why the hedgehogs, “generalizers”, i.e. mainstream generative school should wel-come corpus linguistics just because it has ever more data. If data are bad things, then lots of it arepresumably very bad.
Whether lexicography is empirical or rationalist, in the final analysis, is probably a misguidedquestion because lexicography, at best applied linguistics, cannot be either. Atkins & Rundell(2008), as we have seen, base their argumentation on the following: linguistics is either empirical orrationalist; corpus linguistics is (a branch of) linguistics; lexicography is (part of) linguistics; lexi-cography shows multiple overlaps with corpus linguistics; consequently, “Lexicographers (and cor-pus linguists generally) are empiricists”. The question of whether lexicography is empiricist or ra-tionalist is probably similar to asking, which of the two traditions the writing of medical books be-longs to. It belongs to neither: a lexicographer asking that question is easily in error concerning theidentity of the profession.
While certain linguistic insights may be unhelpful for lexicography, many lessons not of “theoreti-cal” but of corpus linguistics are readily utilizable, if the willingness and resources are there. Stubbs(2002:16) tells us, for example, that the occurrence of the days of the week greatly differ in corpora.

Chapter Two
35
In a corpus of 150 mn which he has investigated, they differ so considerably that Sunday appears17,350 times, Saturday 14,600, Friday 1,065, Monday 9,500, Wednesday 8,150, Thursday6,900 and Tuesday just 6,750 times. Now, in the design of examples and elsewhere, this may berecognized. The fact itself will be recognized anyway, if only because of their collocations: Fridaynight and Saturday night, and Sunday afternoon and Monday morning are typical and thus“useful” collocations, whereas, say Saturday morning or Tuesday night are not.
Any linguist hostile to corpus data could, of course, claim that this juggling with numbers game isexactly what makes corpus linguistics outright harmful: it distorts the “langue”, sacrificing it on thealtar of “parole”. Should such a choice indeed have to be made, lexicography clearly depends on“parole”, not “langue” linguistics, or E-linguistics and not I-linguistics. This is a good illustration,however, of how the concerns of the generative and the corpus approaches – to which broad-brushconcepts we may refer by using, with gross simplification, “langue linguistics” vs. “parole linguis-tics” – differ. It must be added that both may need insights from the other.
2.2.2 E-language vs. I-language
Chomsky either plays down what many see as a growing interest in E-language – sometimes all upto the point of an outright denial of E-language ever having existed, as in Andor (2004:93) – or ap-parently sees it as a return, from the “inner mechanisms that enter into thought and action”, to the“study of behaviour and its products (such as texts)”, as in Chomsky (2000:5). Whatever changesmay have happened to his thought (though not necessarily to syntactic theorizing as a whole) overthe past half century – kernels vs. transforms, transformations themselves appeared and disap-peared; deep vs. surface structure came and went; constructions as such, rules, X bar theory, phrasestructure as such came and went, words as such came to be seen as epiphenomena, just to mention afew shifts – his conviction has remained that E-language, provided that it exists, is not a worthyobject of study:
“the concepts I-language and E-language are not parallel. I-language means some-thing. […] When I introduced the term E-language, it was without any definition; justthat any concept of language other than I-language we’ll call E-language, because itinvolves something external to the person” (Andor 2004:93–4).
Once E-language does not exist, E-language linguistics might as well be equated with “performancelinguistics”, because whatever grounds one may have to deny the existence of E-language, the ex-istence of performance, i.e. language being used to certain (social) purposes cannot be denied – andthis is the way the term is used in this paper.
It cannot be decided generally or in a vacuum – as has been pointed out before – whether lexicogra-phy belongs to either of the empiricist or the rationalist tradition. While it has been long labelled asempiricist, one always suspects that “empiricist” as a modifier often really hides “descriptivist” (asopposed to prescriptivist). Thus, there seems to be a merging of two dichotomies into one another.McGee (1960), for instance, suggests that the following amalgamation might be taking place:
“It is true that dictionary definitions are empirical reports of linguistic usage: the lexi-cographer is an empirical scientist, whose business is the recording of antecedentfacts; and if he glosses ‘bachelor’ as ‘unmarried man’ it is because of his belief thatthere is a relation of synonymy between those forms, implicit in general or preferredusage prior to his own work”. McGee (1960:16), quoting Quine (1953).
Ten Hacken (2009:410) quotes Sterkenburg (2003:8) who makes the claim that the dictionary
“serves as a guardian of the purity of the language, of language standards and ofmoral and ideological values because it makes choices, for instance on the words thatare to be described”

Chapter Two
36
and while such guardianship may indeed be the sometimes deliberate purpose, sometimes just theunwanted fallout of the lexicographer’s pursuits, two things should be borne in mind here. The firstis the aphorism widely known beyond linguistic circuits5 and arguably not (much) less relevant forother languages:
“The problem with defending the purity of the English language is that English isabout as pure as a cribhouse whore. We don’t just borrow words; on occasion, Eng-lish has pursued other languages down alleyways to beat them unconscious and rifletheir pockets for new vocabulary.”
The second, that for much of lexicography, upholding the linguistic standards of language L for thebenefit of the community of speakers of language L makes little sense, if at all. In the case oflearner’s dictionaries, any prescriptivism (not necessarily even so branded) is inevitable and neutral,and it is arguably exactly why the user, who is not sufficiently competent in language L, consultsthe dictionary. The same may be said about bilingual dictionaries in most of their functions. It isonly native speaker dictionaries that can be exploited for the purpose of “upholding the standards”.It seems that the prescriptive bias, in English-language works at least, is carried and fostered bysome kind of inertia that may run counter the compilers’ intentions, or at least motivated by marketconsiderations, manifest in the readers’ perceived insistence on normativeness. If a native speakerfeels that they need to consult a dictionary – the usage “the dictionary” is relevant here – it is in-variably because they judge its competence as being above their own, whether in the domain ofspelling, grammar, meaning, usage – any matter linguistic. In their discussion of what they claim isan undoubted chronological progression from prescriptivism towards descriptivism, of Atkins &Rundell (2008:432) state that
“In the earliest English dictionaries […] defining styles had not yet been standardizedand were quite heterogeneous. […]. In this early period, dictionaries made little claimto ‘authority’, and, for all the ambition that motivated his original Plan of a Diction-ary (1747), Johnson ended up with a realistic appreciation of the limits of lexicogra-phy, and he saw his task as a practical one.”
Later on, dictionaries“aimed […] to cover the whole of the lexicon, not just a subset, and (followingTrench’s characterization of the lexicographer as ‘an historian, not a critic’ […], lexi-cographers increasingly saw themselves as descriptive linguists, rather than prescript-ive ‘authorities’. This didn’t stop dictionary users ascribing ‘authority’ to their dicti-onaries, however, nor dictionary publishers from claiming it.
2.2.2.1 Portrait dictionaries vs. instrument dictionaries
The other problem with a blanket characterization of lexicography as empiricist or rationalist is thatdictionaries are varied. One obvious example, which also ties in with another dichotomy, “portraitdictionary” vs. “instrument dictionary”, is that while a large monolingual, “academic” work thatsets out to catalogue a language, i.e. be a “portrait”, is empirical in that it records “antecedent facts”.Bilingual works as such have no definitions that could be “empirical reports of linguistic usage” ofany language. They invariably are “instrument dictionaries”, and in that capacity always serve asmore than just recorders of facts. Their authors obviously observe, but they do not engage in the de-scription of any language. Because, however, they establish, and present the user with (illusory, oroutright false) translation “equivalents” between (tens of) thousands of lexical items for given pairsof languages, they engage in more than description. The establishment of equivalences is surely notan empirical concern: none of those are to be observed “out there”.
As early as 1983, Pawley & Syder (1983) talk about evidence to the effect that “[...] syntax is notprimary/autonomous; [...] the difference between native and learned commands of English is not as 5 Usually attributed to a certain James D. Nicoll; cf., for example, Kemmer (2002).

Chapter Two
37
fundamental as assumed” and that native speakers do not really use the creative potential to its fullextent that generative grammar credits them with. If they really did so, “they would not be acceptedas exhibiting nativelike competence; merely intuition-based, creative, potentially infinite languageuse of the natives is, at best, only part of the story”.
Most importantly, they argue that
“the largest part of the speaker’s lexicon consists of complex lexical items includingseveral hundred thousand lexicalized sentence stems (collocation patterns), and thispatterned routine is all-pervading in native language use (v) authentic language isused to a large extent in and around patterns (vi) it is not the autonomous knowledgeof grammatical rules which provides the rules for infinite language use, but grammaris a generalization of language use. (Pawley & Syder 1983:16)
If this is indeed the case, then dictionaries are even more harmful, because they distort linguistic re-ality by suggesting that language is made up of words; that knowing a language is knowing the“word stock”; that this word stock can actually be counted and catalogued for each language.
The grouping of dictionaries in terms of whether they are (i) primarily seen as textbooks aidingstudy, or (ii) registers, lists meant to represent the entire lexical system of a language distinguishesthe (i) “instrument dictionary” from (ii) the “portrait dictionary” (originally the notions of Béjoint2000:108). The dictionary-as-instrument is a more slender volume, while the portrait dictionaryaims, to a certain extent, at completeness. Depending on this dominant function, e.g. expressionscontaining what many authors term a light verb (or support verb) and a noun phrase, such as take awalk and give a sigh or H. sétát tesz ‘take a walk’ and H. kivételt tesz ‘make an exception’, or con-taining any frequent collocating verb in an idiom, such as give smb the creeps or H. faképnél hagy‘run out on smb’ (lit. “leave smb at the wooden image”), will differ in headword status assignment.As for the instrument function, it is likely that the average, at least not too under-informed, user willvery sensibly look for these kinds of expression under the nominal rather than the verbal compo-nent. They are best placed in a nominal entry walk and sigh, and H. séta ‘walk’ and H. kivétel ‘ex-ception’, as well as creep(s) and H. fakép in this case6.
It would be impossible even in the largest portrait dictionary to list in the entry for all “light verbs”each and every collocation with that light verb, e.g. provide in the entry of take all the “light verbtake + NP” combinations, or in the entry of tesz all the “light verb tesz + NP” combinations. Togive a full portrait of English, arguably such full listing would be desirable. In electronic dictionar-ies this problem is no longer there.
Similarly, for the representative function it may be important to register what the large set of wordsis with which hagy or give collocates in some idiomatic way or other.
Native speaker dictionaries are obviously closer to the register ideal, while learner’s dictionariesrather to the textbook end of the scale. Importantly, it appears that the overall trend in English dic-tionaries at the beginning of the 21st century, largely due to the enormous demand for learner’s dic-tionaries, is away from portrait dictionaries towards instrument dictionaries. It is probable also thecase that the general trend in the use of reference works in general also favours this turning awayfrom comprehensiveness and the shift towards immediate answers to problems.
6 In this case, incidentally, both the creeps and the fakép expressions are an additional challenge.The word creeps may be faster to access if entered in the plural, although it is hard to guess whether users will look for
this kind of expression under a singular or plural headword.Faképnél hagy contains a lexically bound word, i.e. one not used outside the idiom. It may be decided, in keeping with
the dictionary’s policy, to have the idiom itself as a headword (the less likely solution), or enter the noun as headwordin this form, or alternatively in its citation form, with just this idiom provided in the entry.)

Chapter Two
38
2.2.2.2 Lyons and corpora
Stubbs (2002) remarks that two textbooks by Lyons (Lyons 1968 and Lyons 1977), which wereamong the most influential early discussions of the main concepts of lexical semantics, do not men-tion, let alone use, corpus data. Indeed
“in the two volumes and over 800 pages of Lyons (1977), there is not a single exam-ple of a naturally occurring text” (Stubbs 2002:50).
This may make it appear as though Lyons thinks of meaning as context-independent. This, how-ever, is not the case, and Lyons explicitly says so:
“[When we] inquire about the meaning of words […] we are frequently told that ‘itdepends on the context’. (‘Give me the context in which you met the word; and I’lltell you its meaning.’)”
and
“It is often impossible to give the meaning of the word without ‘putting it in a con-text’…”
More relevantly to lexicography, he adds, very much in defence of the context, that
“dictionaries are useful in proportion to the number and diversity of the ‘contexts’they cite the words” (Lyons 1968:410).
Lyons is decidedly not a fox: he is not what may be termed a “langue” linguist, especially not in thesense of a dedicated generativist, yet apparently it was not impossible (albeit not justified) to criti-cize him for his disinterest in, or neglect of, naturally occurring text. Stubbs makes his remark in re-proach, but the same may well be said appreciatingly: after all, Lyons’ is a seminal book on seman-tics without mentioning texts and corpora, using no naturally occurring text as illustration. If that ispossible, then this feat speaks for itself. Also, the two books by Lyons in question appeared in 1968and 1977, when corpus data as a backdrop to semantic studies were not exactly commonplace.
2.2.3 Spoken vs. written language
2.2.3.1 For dictionaries, spelling is very much part of language
One dichotomy that will be separately considered is that of written/spoken language. While linguis-tically speaking spelling is a non-issue, or at least a very peripheral one, on the lexicographer’s listof priorities the written medium is very high. This, on the dictionary–lexicographer interface, is be-cause of the growing share of written corpora within lexicology, and on the dictionary–user inter-face, because the lay notion of language is predominantly written.
This notwithstanding, because the level of the user’s spelling varies, it is a frequently reported oc-currence that they do not find lexical items because they look in the wrong place.
Many studies of multiword units and idiomaticity, working as they are with (mostly written) cor-pora, apparently take an understandably one-sided, i.e. writing-oriented view of language. Threetypical statements from this recent tradition will be provided:
(a) Sag & al. (2002), e.g. want to develop large-scale, linguistically valid NLP technologies andclassify multiword expressions (MWEs) according to whether they can or cannot be analyzed interms of “words with spaces” (so that syntactic fixedness of an expression guarantees such ana-lyzability).

Chapter Two
39
(b) Poß & van der Wouden (2005) refer as “words with spaces” to any expression whose featureis complete inflexibility.
(c) Even more tellingly Moon (1998:8) goes as far as to say that in delimiting FEIs (i.e. FixedExpressions including Idioms) as her object of study, she has
“made orthography a criterion, in that FEIs should consist of – or be written as – twoor more words.”
although this, as she acknowledges, can be seen
“in computational terms as an indexing problem, perhaps arbitrary, arising from theneed to ascertain the extent of a lexical item.”
also admitting that not all studies use this as a criterion, and that there may be a
“blurring of the boundaries between single-word and multi-word (often hyphenated)cognates: break the ice, ice-breaker, ice-breaking”.
It is odd that the establishment of wordhood (even in lexicography) should be based onspelling conventions: “written as two or more words”. The indexing problem, specific tocomputational linguistics, thus willy-nilly carries over to linguistic analysis in general,where it has absolutely no place, especially not in a brute wording where thus even hyphensdecide, and where apparently ice breaker is two words, but ice-breaker is one.
2.2.3.2 When orthography hinders lookup
The spelling of what are traditionally termed Hungarian verbal prefixes, for example, is notoriouslydifficult: they can be separate (“open”7) or spelt solid with their verbs. The most recent Hungarianvolume on orthography (Laczkó & Mártonfi 2005) devotes seven paragraphs to their spelling.These “prefixes” present a notoriously intractable problem of describing Hungarian syntax. Nativespeaker’s intuition, namely that they form a compound with the verb (not in fact borne out by themost recent syntactic analysis), is reflected in the convention that requires them to be spelt as oneword with their verb: bemegy ‘in.go’, i.e., the verb corresponding to go in.
The verbal prefix, however, is now standardly analyzed as a subtype of a larger class of verb modi-fier, which includes (i) bare nominal complements such as újságot olvas ‘newspaper-ACC read’,i.e. ‘read a paper’ and (ii) oblique complements expressing different things such as goal: iskolábamegy ‘to.school go’ i.e. ‘go to school’ (É. Kiss 2002:55-58). The existence of these verbal modifi-ers, however, is unknown to the average learner (and average school educated adult), but even if itwere, the are not uniformly spelt. Also, because phrases are generally not easy to tell from com-pounds linguistically, native speakers cannot use their linguistic intuition, and must rely on theirmemory when deciding on the spelling. A telling example is the pair of words különír ‘sepa-rately.write’, i.e. ‘write separately’ and külön él ‘separately.live’, i.e. ‘live separately’: there is nocriterion, linguistic or otherwise, that helps decide which of these is one word.
While English multiword verbs do not present at least macrostructural lookup difficulties to anyuser, since both look up and look up to will follow the item look (even if microstructural place-ment decisions may differ), for the Hungarian “verbal modifier + verb” items the user of any dic-tionary must first decide what their spelling is. If users happen to know that különír is one writtenword, they will go to this item and hit it lucky. If they decide that it is two words, they will eitherlook for it under the verb ír ‘write’ – and get it wrong, or they will go (very sensibly) to külön andfind külön ír in its entry. If the user happens to know that külön él is two written words, they willeither go to the él or the külön entry, and hit it lucky either here or there. If they decide that it is one
7 By the use of the term “open” it is not claimed that they are compounds.

Chapter Two
40
word, they will look for it under különél – and miss. This way, knowledge of the right spelling mayactually slow down the lookup process, because a choice must be made halfway.
To this must be added the even more disturbing requirement that some, but not all (!), nominalforms derived from “modifier + verb combinations” are to be spelt as one word, even in caseswhere the verbal form happens to have two words: külön él → különélés ‘separately.living’ (Laczkó& Mártonfi 2005:105). It thus often happens that while the nominal expression for some notion, e.g.“legal separation” is given in one entry, the related verbal expression is in another, alphabeticallyremote, one: különélés under K, but külön él under É.
Another example is provided by the H. ott|ragad, which corresponds to be stuck there, be ma-rooned (the | just signals the place where the spelling may be a problem). Neither the solid nor the“open” variant is in Laczkó & Mártonfi’s spelling guide (2005:1149), so we cannot find outwhether the standard spelling is ott ragad or ottragad. Luckily, if – but only if – a given H→E dic-tionary does contain multiword entries in the blind sense of “word-with-spaces”, and if – but only if– it uses a strict alphabetic ordering of entries, then in this particular case finding the word is not aproblem, because the two – ottragad and ott ragad – would be in the same place anyway. Users willnot even necessarily notice that the dictionary uses a different Hungarian spelling from what theywould have used.
Similar problems arising in connection with the spelling of the prefix ott- do get registered in Lac-zkó & Mártonfi (2005:1149), with verbs such as ott|felejt, ott|fog, ott|hagy, ott|marad and ott|vesz.These are supposed to be spelt as one word in one meaning and two words in the other: e.g. ottfelejtwhen it means ‘lose/forget’ but two words – ott felejt – in the meaning ‘forget smth there’. If thismay indeed be so grave a spelling problem as to justify inclusion in a spelling guide, users of H→Edictionaries ignorant of such niceties of Hungarian spelling will certainly be at a loss trying to findEnglish equivalents. This is no small problem: the number of such prefixed verbs is enormous; thepattern is very productive.
The “one word vs. more words” issue of the orthography, of which the “solid vs. open” spelling ofcompounds is one manifestation, raises a rarely made point: while spelling cannot be but an either–or thing, grammatical judgements, on which spelling is or should be ideally based, are gradational.This is a battery of inherent problems for spellers, especially if they are not native speakers of alanguage.
If one considers the forms of Hungarian -nek ‘to’ in expressions such as neki megy ‘go to him’8 vs.nekimegy [run/bump into], their grammatical difference (and the reason for them to have just thesedifferent spellings), which may be clear to the linguist, is by far not obvious to the lay person. Onedifference is prosodic, which the average Hungarian speaker has practically no explicit knowledgeof: the latter word, nekimegy, is pronounced with one stress. Also, the difference which is seen herewill not easily carry over to similar cases, partly because it is hard to establish what those “similarcases” are. Moreover, because the linguist also finds borderline cases beyond the clear ones that thedistinction is based on, it is not fair to expect lay the user to be always able tell them apart. It isequally or more unfair, and not very reasonable, to expect lay dictionary users to find their wayaround by using information they do not have.
For instance, nekimegy ‘run/bump into’ is spelt as one word in Laczkó & Mártonfi (2005), and isalso given in HECD (1998), also with “solid” spelling. Other personal forms with the -nek prefix(nekem- ‘to me’, neked- ‘to you’ etc) are not given in HECD (1998); neither are any other verbsgiven which are produced with these prefix forms. Since neki- is not separately listed as a verbalprefix in HECD (1998), only as “adv/pron”, forms such as
8 E.g. in the sentence Neki ment a csomag ‘The parcel was (meant) for him / went to him’.

Chapter Two
41
(a) neked|megy and (b) nekem|jön
will not be found anywhere – whatever their meaning, whatever their structure, and whatever theirspelling: either under
(a) neked megy or nekedmegy and (b) either under nekem jön or nekemjön.
Incidentally, besides neki ‘to him/her’, HECD (1998) includes the form nekem ‘to me’, but no otherform (neked, nekünk, nektek, nekik ‘2 Sg and 1/2/3 Pl forms of -nek’).
It is easy to see why the nek-i- forms should be given to the exclusion of the other persons (nek-em-,nek-ed- etc): being “a hidden” 3rd person, neki- is the “dictionary or citation form”. Apparently, inthe practice of Hungarian dictionaries – which, incidentally, is not explained anywhere, not even inthe notoriously unconsulted Prefaces and Introductions – not just nouns and verbs have “citationforms” (nom. sing., and 3rd pers. sing.) but also grammatical forms that do not even have a standardname by which to refer to them. Thus, the nek-i- forms are the quotation forms of all the inflectedforms nek-em- ‘to me’, nek-ünk- ‘to us’ etc. The 3sg form nek-i- is to -nek- as the 3sg megy ‘goes’ isto menni ‘go-Inf’. By including the neki- derivatives (neki|megy, neki|lök, neki|ad etc) as lemmas,however, dictionaries contribute to a situation whereby users encounter significantly more of these3sg variants than any other forms, and will consequently be willing to spell the nek-i- variants butnot e.g. the nek-em- or nek-ik- variants as one word: while nekiad ‘give (smb)’ or nekimegy‘run/bump into’ look perfectly normal, the forms ?nekünkad ‘give us’ or ?nekikmegy ‘run/bumpinto them’ are impossible spellings.
What has been termed the “hidden 3sg forms” of such “prefixes” as the bele- ‘into’ in bele-harap‘bite into’ are thus lexicographic shorthand for all the personal forms: belémharap ‘bite into me’,belédharap ‘bite into you’ etc. Are all of these forms supposed be written as one word? Probablynot: the longer the resulting word, the less likely that this is the case: ?belétekharap ‘bite into you(pl.)’ ?beléjükharap ‘bite into them’ are bad spellings. This suspicion is borne out by the entry ?ne-kiajándékoz ‘give [as a present]’ in Laczkó & Mártonfi (2005:1104): the “quotation form” is spelledas one word; ajándékoz itself is being longer, however, nobody would spell e.g. ?nekedajándékoz‘give you [as a present]’. The point is that no decision concerning such spelling issues can be ar-gued for in a remotely principled way. If users do not know the spelling (and have no knowledge ofthe grammatical machinery behind it), they cannot be expected to do successful lookups.
This is not meant to be criticism of Laczkó & Mártonfi (2005) or HECD (1998), which are not toblame; it is not implied that any guide to Hungarian orthography or H→E dictionary could handlethese issues in a more consistent and theoretically sound, let alone a more consistent and more user-friendly way. Rather, it illustrates the fact that even the vagaries of Hungarian orthography createdifficulties or, as in this case, compound the ones caused, in effect, by Hungarian morpho-syntax. Adictionary is supposed to provide words as translations for words; where derivation produces aword, it will be included; inflectional forms are obviously excluded. The facts, however, may be aspuzzling as in the morpho-syntax of, e.g. nekemjöttetek ‘you bumped into me’ – where a verb in-corporates both subject and complement (NP jön NAK-PP), and where the -NAK affix of the PP (be-side displaying vowel harmony) is inflected (nek-em). Also, grammatical phenomena abound whoseworkings even educated Hungarian speakers know nothing about.
2.2.3.3 User-friendliness, or encouragement of ignorance?
This raises the issue of user-friendliness to the extent of “helping the user at all cost”: if user-friendliness is indeed to be valued above all else, and dictionary editors do not wish to punish usersfor bad spelling but give them every possible help at all costs, then in an electronic dictionary allsuch items may be entered with both types of spelling, right and wrong. In print dictionaries, thereobviously is not enough room for this double entering of the same information. In the case of dic-tionaries of Hungarian, most Hungarian lexicographers would probably judge this to be too muchhelp, opining that ignorance should not be encouraged. (This is true of electronic dictionaries, and

Chapter Two
42
even more so of printed ones.) This device, however, is not an impossible way of improvinglookup, for example, in online or other electronic dictionaries, just as some kind of auto-correctionof the “Did you mean...?” or “Try this alternative spelling” kind are good devices that facilitatelookup in web-based searches as well as existing e-dictionaries.
2.3 Theory into practice
In the widest sense, this study explores the multifarious relations of theory and practice in E↔H bi-lingual and monolingual English lexicography. Looked at from the product, this means trying tofind the imprints of linguistics in dictionaries, identifying ways in which it enriches them with itsnovel features, and searching for traits that betray the difficulties of breaking with tradition. In thetitle of a review of AM&MASZ (2000), a critic (Heltai 2001) actually asks the question if user-friendliness is really above all. While the article generally endorses the novel concepts ofAM&MASZ (2000), the question suggests the need for careful scrutiny. Frawley (1988), for exam-ple, discussing form vs. format in dictionaries, actually wonders
“why we ought to make dictionaries more user-friendly by changing them to be morein accord with users’ needs. No other book caters to its users in such a way – least ofall a reference book – and I’m not yet convinced that such changes will increase the‘usability’ ” (Frawley 1988:208).
I think Frawley is in error on two accounts: there do exist books that cater to readers by being “inaccord with users’ needs”; one is inclined to say that all non-fiction is like that. If, however, noother reference books sought to so please their readers indeed, there is no reason why just diction-aries should not be “user-friendly”. It may, of course, be worth asking whether it is normal for ref-erence works to move towards user-friendliness if this happens at the cost of precision.
In his broad review of lexicography books, Pethő (2004) quotes Landau (2001) as saying that a dis-tinct evolution could be observed in the practical lexicography of the 1990s including such aspectsas the recognition of the importance of user-friendliness. None of the authors involved in the studycomplain that any of these shifts has occurred to the detriment of accuracy.
When setting up the guiding principles of a dictionary, a host of issues await to be decided, in bi-nary or other terms, and most of the solutions given influence one another to the extent of cominginto conflict. The bigger part of those answers – the “philosophy” of the dictionary – are directly,others less directly, visible in the product. The solutions to some, by contrast, are such that they areimpossible to read off the selection, the arrangement of entries, the treatment of senses, i.e. to tracein any other feature of the end product.
There exist aspects of dictionary-making that have turned out to be irrelevant, and yet others whichhave been deliberately ignored in the making of AMSZ (2000/6) and MASZ (2000/6). A commer-cial dictionary is the upshot of linguistic thinking and applied linguistic exploration, but is commis-sioned with entirely non-scientific objectives in mind: before anything else could have a say, thebusiness aspect decides much in the conception of a dictionary.
Many researchers have contended for a long time (one of the earliest being Ilson 1985) that there isa welcome two-way flow of information between the theory of linguistics and lexicography, withnot only linguistic thoughts and insights shaping a lexicography, but the experience of the lexicog-rapher also enriching linguistics. This also will be investigated in this study.

Chapter Two
43
2.3.1 Rigour vs. user-friendliness
The following sections discuss monolingual dictionaries, but their point is valid for bilingual lexi-cography.
In their discussion of dictionary definition, Atkins & Rundell offer what turns out to be animportant discussion of “academic rigour” vs. “intelligibility”.
«Frawley (1988) criticizes Ayto (1983) for “a dubious inclination towards vague-ness”, and “preferring to abandon rigor so as to avoid definitions that are merely‘dumb monuments to arcane speculations’ ” (Ayto’s phrase)”»
(Atkins & Rundell 2008:45)9.
To Frawley, theorists abandoning “rigor” abandon intellectual standards. Ayto, by contrast, has theuser in view, who just attempts to find out what a word means.
«“We do not see the dictionary as a rigorous, exhaustive, theoretically consistent account of a sub-set of the words of a language. (We would have to be mad to believe that such an account can beaccomplished in the confines of one book.) If to be rigorous means to be opaque, then rigor must besacrificed to intelligibility. As Hanks (1979) puts it: “Precision in lexicography is a matter of styleand judgement, not construction by theory.”
Zgusta (1971) is more explicit:
“The lexicographic definition overlaps to some extent with the logical definition, butthere are some striking differences... whereas the logical definition must unequivo-cally identify the defined object... in such a way that it is both put in a definite con-trast against everything else that is definable, and positively and unequivocally char-acterized as a member of the closest class, the lexicographic definition enumeratesonly the most important semantic features of the defined lexical unit, which suffice todifferentiate it from other units”. (252)»
The dictionary, however, is not necessarily to be seen as an account of a (subset of the words ofsome) language. If rigour is not an absolute requirement in the case of these “accounts”, then it iseven less so in the case of those that aspire to be less. Béjoint’s distinction between “portrait dic-tionaries” and “instrument dictionaries” (Béjoint 1994:107) illuminates this fact. It is only the for-mer type, portrait dictionaries, that are supposed to be comprehensive in the sense of “recording andcapturing” a language and being a “treasury of information”. Instrument dictionaries, not necessar-ily but most frequently, aid language learning, or “answer questions about words for users of differ-ent levels of ability”(Béjoint 1994:107).
Hanks (2006:113), discussing the types of dictionaries, distinguishes: (1) scholarly dictionaries ofrecord; (2) practical dictionaries for everyday use; (3) pedagogical dictionaries; (4) dictionaries oflinguistic phenomena such as slang or idioms; and (5) special-subject dictionaries. All of these aremonolingual. To these are added: (6) bilingual dictionaries; (7) onomasiological dictionaries (the-sauruses, synonym dictionaries); and (8) term banks. (There are also hybrid dictionaries, e.g.,monolingual ones for language learners with marginal glosses in a relevant foreign language.)
Hanks’ classification suggests that of all dictionary types only (1) above, for which, significantly,he actually uses the word “record”, may be termed “accounts of the words of a language”. Whetherdictionaries are “accounts” in the first place will, of course, depend on whether “account” is under-stood to contain at least some explanation: if so, then dictionaries are just marginally accounts of alanguage. If, however, “account” merely means “description”, then perhaps more types of the onesgiven by Hanks above qualify.
9 I use « and » signs in the subsequent paragraphs to quote Atkins & Rundell (2008), leaving the original double/single
quotes intact.

Chapter Two
44
Landau (1984:131) goes further to defend practical applicability when he points out that
“[...] if a definition fails in its basic purpose of giving the reader enough immediateinformation to enable him to surmise, at least approximately, its meaning in context,it is of no value whatsoever.”
What this means in this context is that such a definition is of no value even if it is rigorous.
Landau makes the same claim more poignantly when he comments on the lexicographer Gove’s ad-vice to “rigorously avoid the broadening of definitions” that he does not
“think it was the function of a dictionary to rigorously avoid anything that might helpthe reader gasp meaning better.” (Landau 1984:131)
It is, to be sure, not easy to ascertain what exactly corresponds to such good, reasonable practice inthe case of bilingual dictionaries; all the comments in 2.3.1 above concern definitions of monolin-gual works, but the maxim-like advice that is also emphasized in (Atkins & Rundell 2008:212),“Make sure that TL words given as direct translations are general enough to suit most contexts”, isprobably such a guideline.
2.3.1.1 Frawley on “format vs. form”
Frawley (1988) comments that one of the things that can readily be said about lexicographic prac-tice is that it rarely changes:
“alphabetization of entries, choice of entries by frequency, definition by analytic peri-phrastic formula, labeling of usage variation” have been with us for a long time withlittle deviation. Zgusta’s (1971) handbook remains a seminal work […] also becauselittle has changed over the years in lexicographic practice”
(Frawley 1988:189).
This also means, as Frawley observes, that whenever lexicographic practice is scrutinized, “the verydeeply foundational questions are rarely asked”, and that
“A change in form is not the same as a change in format. Format changes are cosmet-ic; form changes are foundational. Changes in the format of a dictionary have oftenbeen attempted, such as in a reverse dictionary or even in a thesaurus. And questionsof adjusting dictionaries to be more user-friendly are also concerned with format, notform” (Frawley 1988:190; italics mine)
This is serious and justified criticism, but it comes in 1988, a period that predates most of thechanges that have happened to English monolingual learner’s dictionaries. It is worthy of note, inci-dentally, that Frawley’s claims do not specify what kinds of dictionary he means. When he quotesHartmann (1983) –mentioning, in all fairness, that other researchers have published “slightly differ-ent findings” – to the effect that
“[..] users access a dictionary for two main reasons: to find synonyms and to findproper spellings”. Not only are such uses NOT things for which one even needs a dic-tionary – all one needs is a thesaurus – but also, if one wants to change dictionaries tomeet such users’ needs, one has only to change the format and do nothing to the dic-tionary form that has been passed on unchanged for centuries.”
then this only concerns native-speaker monolingual English dictionaries. In that narrower domainsuch criticisms may have been right. The reverse dictionary or the thesaurus, however, are hardly

Chapter Two
45
just variations on format, and not form, hardly just minor modifications on “the dictionary”. If onlythose two things – synonyms and spelling – were indeed what users use a dictionary for, thenchanging them into some more user-friendly form(at) would really not make sense.
Some of Frawley’s criticisms aimed at change being slow or not radical enough (in some sections oflexicography) may be well-founded indeed, while others may be contestable. There hardly exists astandard, however, by which the pace of change in lexicography might be measured.
If such change really has been slow, i.e. slower than expected, the present study looks at some ofthe reasons that make it more difficult for theoretical linguistics to have acted as an acceleratingforce.
2.3.1.2 Murray on prototypicality
Discussing the coverage of the term “English language”, Murray (1989) writes:
“The Vocabulary of a [...] language is not a fixed quantity circumscribed by definitelimits. That vast aggregate of words and phrases which constitutes the Vocabulary ofEnglish-speaking men presents [...] the aspect of one of those nebulous masses fa-miliar to the astronomer, in which a clear and unmistakable nucleus shades off on allsides, through zones of decreasing brightness, to a dim marginal film that seems toend nowhere, but to lose itself imperceptibly in the surrounding darkness. In its con-stitution it may be compared to one of those natural groups of the zoologist or botan-ist, wherein typical species forming the characteristic nucleus of the order, are linkedon every side to other species, in which the typical character is less and less distinctlyapparent, till it fades away in an outer fringe of aberrant forms, which merge imper-ceptibly in various surrounding orders, and whose own position is ambiguous and un-certain. For the convenience of classification, the naturalist may draw the line, whichbounds a class or order, outside or inside of a particular form; but Nature has drawnit nowhere.” (Italics are mine)
Presumably all scientific disciplines invariably assume a double task: (i) that of imposing order onthe observed world, i.e., finding fixed entities “circumscribed by definite limits”; and (ii) that of afiner-grained analysis, wherein the limits between these entities will be shown to be rather non-ex-istent. The actual purposes at hand, the dominant methodologies, the changing of “paradigms” andother factors will affect the way in which the pendulum swings. Linguistics employs dozens of cen-tral notions for dozens of phenomena that are intuitively graspable but turn out to be hardly delimit-able with any “scientific precision”. Dictionaries, however, are supposed to represent many of thesephenomena, along with even more that are based on, or otherwise linked to these, as matter-of-fact,without the slightest trace of doubt, and in many cases present them in a pedagogically sound,teachable way.
2.4 Linguists’ views of lexicography, lexicographers’ views of linguistics
This section adds more detail to the question of to what extent, if at all, linguistic theory informslexicography. The answers come from various sources, and it ought to be stated right here that theyare more optimistic than warranted by the facts.

Chapter Two
46
The proponent of a really extreme view, Wierzbicka has argued that
“lexicography has no theoretical foundations, and even the best lexicographers, whenpressed, can never explain what they are doing, or why.”
(Wierzbicka 1985:5; quoted in Atkins & Rundell 2008:8)
This stern observation may be too general: we do not know which those process(es) are that lexi-cographers are so blatantly ignorant of – unless the remark means that this blindness marks diction-ary-making from beginning to end.
2.4.1 Principles of lexicography
Granting that such reproof may have rung more true at the time of writing, it may be admitted (asindeed it is in Atkins & Rundell) that Wierzbicka’s remark has a good deal of truth to it. It is aquestion, however, whether “this absence of theory [is] such a bad thing”, and Atkins & Rundell’sanswer is that as long as there are “principles that guide lexicographers in their work”, this is not aproblem. They offer a summary of such principles:
“Our objective [...] is to create a description of language which is faithful to the avail-able linguistic evidence, and optimized to take account of the specific needs and skillsof those who will use the dictionary. [...] this process entails the exercise of subjectivejudgement – consider, for example, the way that we all (as lexicographers or ordinarylanguage-users) go about the task of finding meaning in texts. But we recognize (andwelcome) the fact that this subjective element can [...] be made more objective, eitherthrough the contribution of intelligent software or through the application of linguistictheory. This interaction between lexicography, linguistics, and language engineeringhas helped to make dictionaries more systematic, more internally consistent, morecomplete, and simply better [...].”
(Atkins & Rundell 2008:9)
This is the description of a kind of lexicography that is not just “optimized” for the user, but alsoallowed to be guided by subjective judgement. Objectivity is desirable, and it is actually supplied byboth linguistics and language engineering. Objectivity and rigour, however, seem to be suspendedwhen the authors acknowledge that in the end they share Johnson’s view that
“»in lexicography, as in other arts, naked science is too delicate for the purposes oflife«. Natural languages are dynamic systems, which tolerate a good deal of invent-iveness, idiosyncrasy, and deviation from »normal« behaviour. Consequently, effortsto make them conform to one particular way of looking at language, efforts – in short– to describe language »scientifically«, have usually foundered when they have comeup against what Landau (1993: 113) refers to as »the stubborn diversity of actualusage«.”
(Atkins & Rundell 2008:9)
Also, they point out, classifying lexicography as applied linguistics, that
“[b]y the nature of the work they do, lexicographers are applied linguists. Yet manypeople working in the field have no formal training in linguistics. Does this matter?Our experience [...] suggests that good lexicographers operate to a large extent on thebasis of instinct, sound judgement, and accumulated expertise. A grounding in lin-guistic theory is not a prerequisite for being a proficient lexicographer – still less aguarantee of success in the field. (Atkins & Rundell 2008:130)

Chapter Two
47
True, in their view there do exist
“certain basic linguistic concepts which are invaluable in preparing people to analysedata and to produce concise, accurate dictionary entries. An awareness of linguistictheory can help lexicographers to do their jobs more effectively and with greater con-fidence. In short, a good lexicographer will become a much better one with an under-standing of relevant theoretical ideas. (Atkins & Rundell 2008:130)
Apparently, then, it is not quite easy to form a clear view of the level of linguistic rigour that can beexpected of lexicography: lexicography is, and needs, no theory but has well-definable principles;dictionaries will be subjective but objectivity must still be aimed at; it is user-centred but must beobservant of basic linguistic concepts and aware of theory; lexicographers need not be linguists butknowledge of a theory is a help.
2.4.2 Linguistics and lexicography
2.4.2.1 Lew (2007) on semantics and lexicography
The dual nature of the terms “semantics” and “lexicography”, and the relation of the two will be ad-dressed, developing the argumentation of Lew (2007) that “the relationship between linguistic sem-antics and lexicography is a troubled one”,
General semantics has concerned itself with the study of how words (and other expressions) meanrather than what they mean. Lexical semantics, by contrast, has concentrated on lexical relationsbetween these expressions, as well as decomposition into primitives. The gap that has resulted israther wide: the description of actual lexical meanings – the question of the what – has been at-tended to less than adequately. Linguists have given up this domain to lexicographers, who havebeen happy to busy themselves with those questions because those are exactly what they see as theirconcern.
Lexicography covers two distinct enterprises: practical lexicography (dictionary-making) and lexi-cographic research (sometimes termed metalexicography). As pointed out by Lew (2007), it is notalways clear in which sense lexicography is claimed to belong within linguistics, although it is usu-ally regarded as part of it. Some see lexicography as an autonomous discipline, which, however,uses insights from linguistics.
Lexicographers have often been censured by semanticists (such as Wierzbicka 1985:5 referred to in2.4 above) for having no theory behind, and an inability, to explain, what they are doing. Howeverharsh this may sound, it says nothing about why lexicography is incapable of benefiting from lin-guistic insight. Wierzbicka also wryly reminds us (eight years later, when lexicography must havemade nearly one decade’s worth of advance) that
“If modern linguistics were to be judged by the contribution it made to lexicography,it would be hard to understand why linguistics is said to have made dramatic advanc-es in recent decades.” (Wierzbicka 1993:45)
However, while semanticists have often provided recommendations for the treatment of meaning indictionaries, these have proved to be less than viable in day-to-day lexicography, so that the seman-ticists rightly come in for even harsher criticism:
“Wierzbicka’s own efforts to offer such a contribution are taken to pieces by Hanks(1993), who systematically demonstrates how very unrealistic and impractical the lin-guists’ view of lexicographic practice may be, if they have not themselves extensivelyengaged in real dictionary writing.” (Lew 2007:7)

Chapter Two
48
Another obstacle in this cooperation may well be what Lew (2007) refers to, illustrating what hecalls “the rift between semanticists’ proposals and real-world lexicography”. He claims that somesemanticists
“give themselves the privilege of abstaining from defining the meaning of [..] seman-tic primitives or undefinables. Now, lexicographers are constrained in their work bythe expectations of dictionary users as well as the restrictions imposed by the publish-ers. Because of this, lexicographers normally cannot afford the convenience of leav-ing out the “troublesome” words from the dictionary.” Lew (2007:7)
2.4.2.2 Dictionaries as ultimate tests of theories?
Atkins makes the following relevant comment:
“most lexicographers would argue that a good dictionary is the ultimate test of anytheory of lexical semantics; they sometimes become impatient with criticisms fromtheorists who have never worked as lexicographers. As one lexicographer has put it,“most of the words one has to deal with when working through the alphabet turn outto be more recalcitrant than those chosen as examples in works on semantic theory”
(Atkins 1993:19; quoted in Lew 2007:7).
This, however, to my mind, is no less than three independent claims: (i) a really weighty one: that“a good dictionary is the ultimate test of any theory of lexical semantics”; (ii) a general but perhapstrivial one: that the practitioner is bound to be suspicious of the aloof theorist, who is to be enviedfor being in a position to make convenient decisions arbitrarily; and (iii) a methodological one: thatthe examples chosen by (introductory?) works on semantics do not by far reflect the level and typesof difficulty presented by most words encountered by the lexicographer on a day-to-day basis.
While (ii) and (iii) are unequivocally true, (i) simply cannot be: there is not a single dictionary thatwere the test of any theory of lexical semantics – or any other theory, for that matter – exactly be-cause of (ii) and all that has been said above about the “troubled relationship” between semanticsand lexicography. (The lexicographic products of the Meaning↔Text project may be exceptions. Itwould be misleading, however, to call these dictionaries, since they are the theory, not produced ortested by one.)
I risk the claim that this is partly why the relationship of lexicography and linguistics as such issuch a troubled one. The best dictionaries are not the tests of any semantic theory, least of all oflexical semantics. Though they can be measured on some scale of success, success will be mostlydetermined by utility, not linguistic merit; and if they may be the test of any theory, then it must beone of methodology, or metalexicography.
Lew claims that if anything, the success of the Meaning↔Text Theory proves the possibility of co-operation between semantics and lexicography. I find this point only valid to the extent that thecomplex descriptions, or even accounts, of particular languages, even language generated withinthe bounds of this theory, can rightly be called dictionaries. These “dictionaries” are lexically ratherthan syntactically based accounts of language, closer to being theories themselves. If they are notlike normal dictionaries, as it should be clear is the case, then this argument of Lew’s also losesweight.
Corpus linguistics, on the other hand, which is usually mentioned as a component of linguistics thathas been beneficial for – and has undoubtedly had a favourable influence on lexicography – is notitself a theory in the sense of a unified theoretical model, rather “a bundle of methodological ap-proaches” (as also pointed out in (Lew 2007:7), and in that sense is not a compartment of linguis-tics.

Chapter Two
49
Moreover, linguists of different persuasions have now turned to corpora, and this suggests that atleast partly, the corpus-driven approaches to linguistic study reflect a contribution of lexicographyto linguistics rather than vice versa.
Atkins & Rundell’s 2008 book, the most comprehensive such volume to date, the authors claim, isnot about theoretical lexicography because they do not believe that such a thing exists. Neverthe-less, they welcome the fact that “there is an enormous body of linguistic theory which has the po-tential to help lexicographers to do their jobs more efficiently and with greater confidence” and re-mind us that lexicographers
“can’t hope to remain fully abreast in every area, but fields of field of particular relev-ance to our work include lexical semantics, cognitive theory, pragmatics, and corpuslinguistics”. (Atkins & Rundell 2008:4)
Syntax, which has dominated the linguistic scene for over fifty years, and is largely associated, ifnot equated with mainstream (theoretical) linguistics, is conspicuous here by its absence.
Atkins & Rundell (2008) keep emphasizing that linguists do not address lexicographic issues di-rectly; they focus on language, not dictionaries. Nor do they tell lexicographers “how to solveproblems”. Rather,
“they show us different ways of looking at language, which we can take and adapt toour needs. Lexicographers have a great deal to learn from linguistic theory, and manyof the recent improvements in dictionaries can be attributed to the intelligent applica-tion of theoretical ideas.”
This is beyond doubt. Just as with the utility of being clear about user profiles and their direct re-flection in dictionaries, however, which latter is missing from Atkins & Rundell (2008), here again,it would be good to see some concrete points that illustrate how these linguistic ideas have been ap-plied, intelligently or otherwise.
Rundell (1998) quotes a typical grumble by a fictitious, but very likely, dictionary user-character:
I have to look in the dictionary to find out what a virgin is. ... The dictionary says,Virgin, ‘woman (usually a young woman) who is and remains in a state of inviolatechastity’. Now I have to look up inviolate and chastity and all I can find here is thatinviolate means not violated and chastity means chaste and that means pure fromunlawful sexual intercourse. Now I have to look up intercourse and that leads tointromission ... I don’t know what that means and I'm too weary going from oneword to another in this heavy dictionary ... […]
Rundell (1998:315)10
This kind of justified criticism, of the circularity fallacy, no longer holds for certain types of dic-tionary. It is also a fact, however, that it has never affected bilingual dictionaries. Also, that it hasalways characterized learner’s dictionaries to a lesser degree than native speaker dictionaries eventhose that do not operate with a simplified (graded, controlled) vocabulary.
So if one is to be realistic – others might say, pessimistic to the point of gloominess – about the“enormous body of linguistic theory” of Atkins & Rundell (2008:4), then perhaps all that can beclaimed about lexicographers being able to do their jobs “more efficiently and with greater confid-ence” is that it is to be thanked to this enormous help that lexicography has succeeded in weedingout a type of perverse definition from one kind of the many types of dictionary. To be sure, evenimprovements such as this may well have come from other quarters than linguistic theory, and theidea of simplified defining vocabularies does indeed stem from H. E. Palmer’s, M. West’s and A. S.Hornby’s work back in the 1920s (Rundell 1998:316). The contributions of these people, who were
10 The book is Irish-American author Frank McCourt’s Angela’s Ashes (1996: 333).The highlight and the “academic” punctuation are mine – the original has no boldface or single quotes.

Chapter Two
50
not (theoretical) linguists in any sense of the term, but pioneers of a modern ELT profession, sig-nificantly predates linguistic science in whatever sense of that term. Controlled vocabulary (in adual sense: (i) a carefully selected subset of the lexicon covered, and (ii) the restricted defining vo-cabulary, which is of relevance here) was seen as central to the creation of any learner’s dictionary(the term “learner’s dictionary” itself is indeed Palmer’s own, cf. Cowie 1999:36). Wierzbicka’sharsh words suggesting the non-existence of theoretical linguistic foundations for lexicography al-low, after all, for the domain of ELT to be foundations.
2.4.2.3 Dictionary-making is a craft
Landau, who is a proponent of dictionaries being practical tools, claims that making dictionaries “isnot a theoretical exercise to increase the sum of human knowledge but practical work to put to-gether text that people can understand” (Landau 2001: 153). Discussing the issue of logical defini-tion vs. lexical definition, for example, Landau (2001:153) claims that
“… lexicographers – all of them – pay a great deal of attention to the needs of theirreaders. For lexicography is a craft, a way of doing something useful. It is not a theo-retical exercise to increase the sum of human knowledge but practical work to put to-gether text that people can understand.”
When Atkins & Rundell (2008) reiterate that “the most important [...] advice we can give to anyoneembarking on a dictionary project is, “ know your user”, they do not simply mean user-friendliness.Rather, they too voice their conviction that “the content and design of every aspect of a dictionarymust, centrally, take account of who the users will be and what they will use the dictionary for.”Atkins & Rundell (2008:5)
That the ultimate measure should be the user was succinctly put by Samuel Johnson 250 years agoin a quote already referred to above. He claims that
“...in lexicography [...] naked science is too delicate for the purposes of life. Thevalue of a work must be estimated by its use”
and that
“it is not enough that a dictionary delights the critick, unless, at the same time, it in-structs the learner; as it is to little purpose that an engine amuses the philosopher bythe subtility of its mechanism, if it requires so much knowledge in its application asto be of no advantage to the common workman.”
which Atkins & Rundell interpret thus: “no amount of theoretical rigour is worth a hill of beans ifthe average user of your dictionary can’t understand the message you are trying to convey”. Thisraises the issue of how certain – semantic, lexicological, and grammatical – notions and terminol-ogy find their way from linguistic science into dictionaries that must “delight the critick” and “in-struct the learner”.
This is far from easy. It is clear that when we assume the existence of down-to-earth or everydaynotions such as Noun, Subject, or Sentence (and even more so if we assume that some consensualview on them may be arrived at), we are moving in a highly theory-laden field. There still is, manylinguists believe and perhaps even more lexicographers hope, a non-theoretical core grammar whichmakes it possible to speak to Johnson’s “common workman” about the linguistic phenomena of theworld, in the same way as there exists a vocabulary that lay people can use to talk about physics,biology, or genetics. There should be a pre-theoretical, or theory-neutral, strain of linguistics thatlexicography should be able to rely on. It seems, however, that even if this grammar exists (whichitself is very doubtful, as is hoped transpires from this study), it does not (always) deliver.
In Chapter Three I look in some detail at some grammatical points where lexicography does notseem to be able to count on the kind of help it ought to be getting from linguistics.

Chapter Two
51
2.4.2.4 Dictionaries do not change
Stark (1995) has the following comment on the previous edition, Béjoint (1994), of Béjoint(2000):
“B[éjoint] investigates the rather limited and sometimes forced reflection of linguistic theory inrecent dictionaries... [he] questions the structures of existing dictionaries, in particular the ob-jective that a dictionary should be representative of the lexis of the language, the relationshipbetween lemmata and meanings, and various approaches to definition. He concludes that, de-spite some progress, dictionaries have really changed very little over the last two centuries andthat insights in linguistics (e.g. Anna Wierzbicka’s and George Lakoff’s work) should be inte-grated into lexicography in order to create substantially new dictionaries.”
Stark (1995:637; italics mine)
Although the point made by Béjoint (1994), that lexicology is not a recognized branch of linguis-tics, may not be true anymore, his claim can be accepted that the dictionary shared in the relativelack of prestige of the lexicon and of semantics within linguistics in the 19th century and first threequarters of the 20th. These, however, are not the point now: the real issue is what Béjoint himselfalso raises, wondering whether the linguistic knowledge of the lexicographer really shapes the dic-tionary. The answer he gives is rather negativistic: he argues that it is a commercial product; that itis without linguistic theory; it is unscientific; an “impure byproduct of linguistics” ( Béjoint2000:169). This is slightly different from the way Atkins & Rundell (2008) phrase the question:lexicographers may be linguists themselves, and may possess nor not possess certain linguisticknowledge, but this does not affect the end product; the reflection of linguistic theory in dictionariesis at best “limited and sometimes forced”.
With the kind of general vagueness that has been mentioned above with reference to Atkins & Run-dell (2008) above, Béjoint (2000:171) also emphasizes that lexicography could benefit from lin-guistics, but he does not quite say how. The controversial relationship between linguistics and lexi-cography is forcefully illustrated by Béjoint accusing linguists, on the one hand, of being disinter-ested in lexicography, and on the other, of being “afraid to see their theories put to the test by thepractical work of compiling a dictionary” Béjoint (2000:171). Here, the notion of “dictionary-as-test-of-theory” emerges again. Linguists’ conviction (even if they were as monolithic from thispoint of view as they likely are not) that lexicography is no test of any of their theories, coupledwith their (surely reasonable) belief that lexicography is not interested in, or capable of absorbing,insights from linguistics, would partly justify their “disinterestedness”.
Béjoint (2000:173) completely divorces lexicography from linguistic tradition when he reminds usthat dictionaries had been produced for centuries while linguistics, certainly not by today’s stand-ards, was not yet practised. After all, Johnson’s fresh-sounding and principled remarks are morevalid today than most of linguistic theory from such a long time ago. If the fact that there has beenno linguist among the authors for centuries has not meant that here has been no linguistic knowl-edge in the dictionary, then this may not be such a grave problem today either. The point, as Béjoint(2000:173) unflatteringly suggests, is that all dictionaries transmit some points of view on language“even if the lexicographers are not aware of any”.
It appears that the only realistic view of their relationship is that theoretical linguistics is not easilyapplied to lexicography, particularly new approaches, which are “ill-fitted for a general-purposedictionary that is meant to be used by the man in the street” Béjoint (2000:173). For some reasonthat he does not explain, he suggests that “lexicographers are wary of jumping on the linguisticbandwagon” Béjoint (2000:173). Even if this were not the case, however, these theories, as theytrickle down, as it were, would be weakened by the time they arrive, and in the final analysis, then,lexicographers would be out of the reach of linguistic doctrines anyway.

Chapter Two
52
2.4.2.4.1 Tools, not descriptions
It is probably widely accepted that dictionaries are tools for solving problems: users consult them toanswer questions they have about vocabulary. Such a view, as ten Hacken argues, is compatiblewith most definitions of dictionaries in theoretical discussions of lexicography (ten Hacken(2009:399).
While lexicographers do not necessarily reject any contribution from linguistics, ten Hacken argues,Chomskyan linguistics is certainly not the first place they turn to. As Béjoint also states,
“The influence of transformational and generative grammar has been even more lim-ited” [i.e. than the influence of Bloomfieldian structuralism]
(Béjoint 2000:175)
When Atkins & Rundell (2008) mention domains of linguistics of potential use to lexicographers,their list includes lexical semantics, prototype theory, pragmatics, and frame semantics. As tenHacken also argues, most linguists working in these are non-Chomskyan; moreover, some of thefields have an obvious anti-Chomskyan general orientation.
Drawing partly on Ten Hacken (2009:409–411), four approaches to lexicography will now besketched out: Zgusta (1971), Hausmann (1985), Sterkenburg (2003), and Atkins & Rundell (2008);the emphasis is mine throughout.
• Zgusta (1971:197) praises the following definition as “one of best definitions I know”:
“A dictionary is a systematically arranged list of socialized linguistic forms compiledfrom the speech-habits of a given speech community (b) and commented on by theauthor in such a way that the qualified reader understands the meaning ... of each sep-arate form, and is informed of the relevant facts concerning the function of this formin its community.
• Hausmann (1985:368–369) explicitly defines lexicography as
“the scientific practice aiming to bring dictionaries into existence”
and about the dictionary, he writes that it is
“a collection of lexical units (mainly words), presented by means of a particular me-dium and giving particular information for the benefit of a particular user. The infor-mation is ordered in such a way that fast retrieval of individual details is possible.”
• Sterkenburg (2003:3) offers a definition of what he considers as the prototypical dictionary(the alphabetical, monolingual general-purpose dictionary), which is the following.
A dictionary is
“a reference work and aims to record the lexicon of a language, in order to providethe user with an instrument with which he can quickly find the information he needsto produce and understand his native language”
• Atkins & Rundell (2008:2) view a dictionary as a
“description of the vocabulary used by members of a speech community (for example,by speakers of English”. And the starting point for this description is evidence ofwhat members of the speech community do when they communicate […]. But be-tween the raw linguistic data and the finished dictionary, a number of other factorscome into play.”
and state that
“All dictionaries are incomplete, and come under the heading ‘work in progress’.”

Chapter Two
53
Apparently, throughout his discussion ten Hacken deems irrelevant the distinction between nativeand non-native users, which, however, is of great importance. It is also worthy of note that only oneof these texts, Sterkenburg (2003), refers explicitly to the type of dictionary that it defines, and yetthe same “prototypical dictionary – the alphabetical, monolingual general-purpose dictionary” – isassumed in all of them.
With the features of lexicography and the dictionary tabulated we get the following scheme:
Language is where? User type Dictionary & its aim LexicographyZgusta social: community qualified;
native??list of forms; com-ments to facilitateunderstanding
—
Hausmann — ? collection of lexicalunits; gives informa-tion ordered for fastretrieval
scientific
Sterkenburg — native reference work;records lexicon oflanguage; gives userinstrument to find in-formation
?
Atkins & Rundell speech community —* description of vo-cabulary
?**
In the boxes, “—“ indicates non-relevance of the given feature, while “?” shows that although thisfeature it would be possible to be included, it nevertheless is not.
*Although this excerpt does not reflect this, Atkins & Rundell keep both types of reader in mind,even if – understandably – non-native users (as well as monolingual dictionaries) are given priority.
**The wording ‘incomplete’, and ‘work in progress’ suggest that they do not consider lexicographyas a science. The fact that “a number of other factors come into play” between the “raw linguisticdata and the finished dictionary” probably also implies that lexicography as (either exact or empiri-cal) science is out of the question. Importantly, the terms science/scientific and lexicography are notused in conjunction in Atkins & Rundell (2008).
2.4.2.4.2 Science, empirical and applied
Whichever way lexicography and the dictionary are defined, ten Hacken claims that lexicography isnot a scientific field “within the scope of Chomskyan linguistics” if we take its object as producingdictionaries that ‘record the lexicon of a language’ or are a description of the vocabulary of a lan-guage: this is the very point of his argument. It is not a science because language (i) cannot be takenas E-language, since there is no empirical object corresponding to E-language; (ii) it cannot betaken as performance, since we need a reference to the competence in order to identify errors; and(iii) it cannot be taken as competence or I-language, since competence is the knowledge of an indi-vidual speaker. (Ten Hacken (2009:411)
“In Chomskyan linguistics, there is no object such that a dictionary can be taken todescribe it. Therefore the idea should be abandoned that a dictionary is the descriptionof an object in order to interpret dictionaries in Chomskyan linguistics.”
Importantly, however, this does not exclude that lexicography is scientific, ten Hacken argues fur-ther. Sciences that require an object in the real world in order to describe it are just one type. As-tronomy and medicine are both sciences, but their statuses are different. Astronomy explains phe-nomena that are treated as given; the purpose is to describe the system underlying them. Medicine,

Chapter Two
54
by contrast, has as its first aim to cure; making observations and constructing theories to describeand explain them only11 serve this goal.
Ten Hacken contrasts empirical to applied science, and the purpose of the former, such as astron-omy, is supposedly understanding; that of the latter, such as medicine, it is solving problems (of amore practical nature). Medicine, unlike many other types of problem solving, is seen as scientificbecause of the basis on which its solutions are founded. Applied science differs from other types ofproblem solving due to its search for explanations, a property that it shares with empirical science.It differs from empirical science, though, in that the focus of the explanations is not the phenomenaas such, but the effectiveness of the problem solution. Given that “the core business” of Chomskyanlinguistics is in empirical science, ten Hacken’s hypothesis is that lexicography should be viewed asan applied science.
The components needed for an applied science are thus
(i) a practical problem,(ii) the solution of this problem, and(iii) an explanation for this solution.
In lexicography, the most immediately observable of these is the solution; this is also reflected inthe definitions above.
Zgusta’s observation that a dictionary must be “commented on by the author in such a way that thequalified reader understands the meaning ... of each separate form" is all-important whether a na-tive or a non-native user is being meant. While the dictionary is the most obvious link in the “prob-lem–solution–explanation” chain, the user is the weakest one. As with any tool, effective solutionsdepend not just on the tool but also on the interaction between it and the user’s experience, althoughfor lexicography this happens in ways different, and ignored by ten Hacken, in the native and non-native user’s case.
Using ten Hacken’s scheme of the “prototypical dictionary use scenario” (ten Hacken2009:415) in slightly modified form, the following can be established:
U(ser) identifies P(roblem); → relates it to some L(exical Item);→ D(ictionary) provides I(nformation) about L;→ U finds I in D and interprets I to solve P.
(Note that this scenario contains no “explanation”, and it would be hard to insert it anywhere.)
If, as has been pointed out above, the Chomskyan – or any other (theoretical) strain of – linguisticsis unhappy with the idea that the dictionary describes a language, or records the lexicon of a lan-guage, or describes the meaning of a word – because these efforts are not compatible with itspremises – and finds that lexicography is not scientific in its terms, it need not be indeed; nothingever done lexicographically has ever stood or fallen by whether lexicography has been regarded as ascience, empirical or otherwise.
Ten Hacken’s scheme does not assume scientificness either. For applied science, his scheme can beused to gauge whether some dictionary is good. True, the quality of information is only partly, andto a lesser extent, determined by how close the dictionary data is to some ostensive (easily non-ex-istent) E-language or I-language. It is rather influenced by (obviously: relative) completeness andtransparency of presentation. Completeness, although just an ideal, is important because it adds tothe number of problems potentially solvable in the final analysis. Transparency, which aids lookupand thus increases efficiency, is the more obvious feature.
11 Ten Hacken tells us how the inventor of the telescope was accused of an unethical attitude because of this exclusive
concentration on diagnosis: despite the inadequacy of available therapies, it was not accepted that observation (of thenatural course of a disease) was good medical practice.

Chapter Two
55
One aspect to the quality of information is undoubtedly authenticity. Here, too, however, acceptingthat quality is determined by the degree to which it contributes to successful use also implies ac-cepting that quality will be measured not (so much) by how true the content of a dictionary is tosome particular language. Rather, it hinges on how efficiently that (ideally complete and transpar-ent) content contributes to solving particular problems. In the perspective advanced in this study,this can be put even more succinctly: adequacy at the dictionary–user interface is more importantthan adequacy at the dictionary–language interface. One of the most obvious manifestations of thisis the moderate use of un-tampered-with authentic examples, whose use ought to be minimized ac-cordingly. Examples, after all, are there to serve problem solving rather than description or expla-nation.
In the case of bilingual dictionaries, authenticity of examples is less of an issue. Here, however, itshould be obvious that being true to the language is not only secondary at best, but that it onlymakes sense in some “oblique” sense. Bilingual dictionaries (i) involve more than one language; (ii)are, and always have been, evidently tools rather than descriptions as far as their function is con-cerned; (iii) cannot possibly be expected to describe both their languages, but especially not the tar-get language, whose data is only represented to the extent that it is elicited, or activated, by thesource language. In short, bilingual works can hardly be true to both languages.
The fact that chronologically (and conceptually), bilingual dictionaries are the precursors of mono-lingual ones and not the other way round (Cowie 2009:31), while both of them obviously predatelearner’s dictionaries, is relevant here12. The first dictionaries were conceived of as practical in-struments in the first place – as instrument, not portrait dictionaries: they have certainly never beenmeant to be descriptions of linguistic systems. All bilingual and learner’s dictionaries are still usedas tools without exception. Just a portion of monolingual dictionaries aspire to do more than that,and be a portrait dictionary, but there is no question of even these being compiled in order to pro-vide a description of the language in question, let alone a coherent theory. Sheer size may suggestcomprehensiveness, but it does not make for description of the language: neither the OED norWebster’s Third can or do make such a claim.
2.4.2.4.3 The notion of “explanatory basis”
Ten Hacken argues that lexicography only achieves the status of an applied science if, in addition toproviding solutions to problems bearing on language, it also explains how these solutions work.This, he states, is the most challenging condition of the three: even in established applied sciences,the bulk of their praxis may not have an explanatory basis that lives up to standards in empiricalscience.
In medicine, ten Hacken (2009:417) claims, explanations are rooted in anatomy, biochemistry andphysics (although some observers consider that medicine is not a science because it does not haveits own explanatory basis). Comparing medicine to lexicography as both applied sciences, tenHacken states that
“it should be a priority to identify the fields and the theories in these fields that canserve as a basis for explanations. The role of Chomskyan linguistics in this effort may
12 Hüllen (2009) writes about these early dictionaries that “Synonyms are used here in the simplest way possible. They
are treated as semantically identical without any reflection on the differences. Earlier Latin–English and English–Latindictionaries had also mainly depended on such simple equations. In the hard-word dictionaries, the interlingualsynonyms of the bilingual (or multilingual) works were replaced by intralingual ones. The two registers of Englishwere, thus, treated as two languages. To that extent, the monolingual hard-word dictionaries can be counted as crypto-bilingual.

Chapter Two
56
perhaps be compared to the role of physics in medicine. It provides knowledge aboutthe reality in the background, matter in medicine, language in lexicography. Howev-er, biochemistry and anatomy are much more important in explaining how diseasesarise and can be cured. It remains to be determined which fields of knowledge cantake this role in lexicography.”
A useful assessment may be made, for the purposes of this study, by tabulating ten Hacken’s trainof thought.
Appliedscience
Aim Related empiricalscience
Own explanatorybasis
Basis of explanations: therelated empirical science
medicine cure par-ticular dis-
eases
anatomy biochem-istry
physics
none ← anatomy ← biochemistry← physics
lexicography help solveparticularproblems
linguistics in gen-eral?
none Chomskyan linguistics?
It is doubtful, and has been repeatedly and rightly questioned, whether of all the possible linguisticschools, the Chomskyan should be singled out as the one that has been, or even simply could be(this is not clear from ten Hacken’s article) the one to (have) serve(d) as the basis for the explana-tions of lexicography. Not only must a question mark be featured after “Linguistics in general” inthe “Related empirical science” box, because, as argued repeatedly in this study, the existence oflinguistic science at large as a backdrop for lexicography is far from taken for granted. Also, be-cause lexicography certainly offers no explanation for “what it is doing” in the aggregate. Evenmore obviously, it does not, and cannot, explain why it has a particular solution for a particularproblem.
The table cannot be filled in adequately exactly because ten Hacken’s use of “explanation” in two,incompatible, ways. Still, interesting conclusions for this study offer themselves, and these will bedrawn below. Explanations of how these solutions provided by the dictionary actually work can bethought of in two ways:
First (ten Hacken 2009:413), claims that the “necessary components of an applied science are apractical problem, the solution of this problem, and an explanation for this solution”; here, the term“explanation” refers to the solution of one particular problem13.
Later, “explanation” is replaced by “basis of explanations”, and this no longer refers to why/howone particular solution is offered to one particular problem, but rather to what the underlying basisof the whole applied science is. Physics and Chomskyan linguistics can only be seen – although Ihardly think they should be – as “explanations” in this latter but not in the former sense.
In no sense may lexicographers be expected to explain why their dictionaries – monolingual or oth-erwise, native-speaker or otherwise – have this or that particular solution for this or that particularproblem. Neither can lexicography in the narrow sense, i.e. the actual production of dictionaries, beoccupied with “why it is doing what” in general: that is the job of metalexicography (whether itconsidered a part of lexicography or a sister science). If ten Hacken compares the role ofChomskyan linguistics to that of physics in medicine because it provides knowledge about the real-ity in the background (“matter in medicine, language in lexicography”), then the only, albeit not
13 The parallel of medicine suggests the following. The problem: scurvy on long sea voyages. The solution: adequate
doses of vitamin C. The explanation: the way vitamin C works on the human body. The selection of the problem is farfrom trivial. In medicine, it consists of identifying which symptoms have to be interpreted as belonging together. Thesolution by itself is not sufficient: the importance of fresh vegetables and fruits was known long before vitamin C wasdiscovered. Only with an explanation does the solution become a part of applied science (the parallel is developed inten Hacken 2009:413).

Chapter Two
57
trivial, question is, why just Chomskyan linguistics, when it is arguably the least suited to be thefosterer of lexicography. More important, however, is the question, ‘What takes the place of bio-chemistry and anatomy for lexicography?’ – what are the analogues of these two for language? Thisis an especially vexing question since, according to ten Hacken, they are much more important inexplaining how diseases arise and can be cured, so there must be some (exactly two?) entities thatcan take this role for the relation of linguistics and lexicography.
The question, of course, must only be answered if the parallel that ten Hacken has developed isreally worth pursuing. There is no disease/cure scenario at all for the linguistics/lexicography di-chotomy, so the analogy may break down right at the outset. Two solutions, then, offer themselves.The first: that ten Hacken’s analogy is inadequate as a whole, though it may be worth going downthe path of some of its useful insights separately. The second: that there indeed are factors, whichmay actually be domains of knowledge, that influence lexicography at least as much as theoretical(in ten Hacken 2009: empirical) linguistics, even if it is not easily placed side by side with eitheranatomy or biochemistry.
Ten Hacken does not finish the task of “determin[ing] which fields of knowledge can take thisrole”. It is highly likely that while there are indeed such factors, there is no such field of knowledge.Lexicography is surely influenced by its contact with reality in dozens of ways: by the perceivedneeds of the user – whether arrived at by profiling, research, or the pressures of the market; by thevagaries of the market, which are influenced by factors quite external to the language teach-ing/learning enterprise; by the extra-linguistically motivated fashions in teaching methods; or evenby dictionary-making fashions; probably even by a need to internalize in some way what are sensedas changes in linguistic theories or linguistic thought at large; but not by some domain of knowl-edge that explores, describes, or explains this reality.
As argued repeatedly in the present study, which looks at how grammatical information and multi-word lexical elements are treated in up-to-date dictionaries, the influence of theoretical linguisticsseems to be negligible. The imprint both of the “grammars” (of whatever hue) on the grammaticalapparatus of dictionaries and of the enormous literature on multiword lexical units is insubstantialfor practice; considering the rapidly changing nature of the potential “theory input” in all areas, it ishardly noticeable in lexicography.
2.4.2.5 Points of agreement between linguists: Hudson (1981)
Hudson (1981), a linguist with a deep concern for lexicography, neatly summarized the points onwhich there seemed, at the time, broad agreement among linguists of different creeds, presentingthem in three large fields, each with many subfields: (1) “The linguistic approach to the study oflanguage”; (2) “Language, society and the individual”; (3) “The structure of language”. (I have noknowledge of this kind of list having been taken seriously to the extent of being repeated at regularintervals; I do not know whether the list would be shorter or longer if one were produced now; Isuspect that it would both lose and gain items, but it would be a leaner one now.)
Of the three, only (3) is relevant for us now, and I have freely used the device of the […] to indicateirrelevant omissions. There is no highlighting in the original, but the claims that are of relevance tous have been italicized. The areas of agreement within (3), “The structure of language”, (where Ihave completely ignored pronunciation and writing) are as follows:
3.3.(a) The relation between meaning and pronunciation (or spelling) is usually arbitrary.(b) Items of vocabulary include not only single words but also idioms […] and other longer struc-
tures [...].

Chapter Two
58
(c) The specification of a lexical item must refer to at least the following: its pronunciation […], itsmeaning, syntactic and semantic contexts […], and how inflectional morphology affects itsform […].
(d) There is no known limit to the amount of detailed information of all such types which may beassociated with a lexical item. Existing dictionaries, even large ones, only specify lexicalitems incompletely.
(e) The syntactic information about a lexical item may be partially given in terms of word-classes[…]. However, a complete syntactic specification of a lexical item needs much more infor-mation than can be given in terms of a small set of mutually exclusive [...] parts of speech.
(f) Many of the boundaries between word-classes are unclear even when defined by linguists.
The importance of (a) and (b) – both hardly controversial for any linguistic school – for the presentstudy will be especially relevant in the sections on idiomaticity and multiword expressions below.Points (c) and (e) need not be separately commented on.
2.4.2.6 Illusions of simplicity: PoS
Point (d) above simply suggests that it is to be expected that dictionaries cannot cope because, toput it simply, the (lexical) facts are too complicated. Point (f) states, without much equivocation, avery important fact: that part-of-speech boundaries are not things that lend themselves to easyanalysis. If so, lexicography will be in a quandary. After all, if linguistic schools will differ on mostof their details (and explanations, and the methodologies of presenting these details), and consensusexists only regarding lack of clarity, then no wonder that lexicographers are left to themselves whenthey try to catalogue words in PoS terms. The dictionary may opt for not labelling parts of speech atall, but it obviously cannot afford the luxury of labelling the odd word, much less whole classes ofwords, as “of uncertain part of speech”. So, as a minimum, tradition dictates that PoS labels must bethere. The user does not want scientific rigour, just the “simple facts”, partly because s/he is used toPoS facts being simple, as this is suggested everywhere that s/he encounters “grammar”. What thenis the problem? This will be illustrated on the example of two prepositions: ago and than.
Two illustrations suffice at this point (a closer look at ago will be taken in 3.1.5.2.2.). The Hungar-ian learner will not be particularly interested in the PoS status of ago. It will not even have to bePoS-labelled unless it has multiple PoS status (which is not the case). Marking it as a preposition isthus no help for anybody. Provided that such words are ever looked up in the first place (and the lit-erature seems to suggest otherwise), users never search for the preposition ago, just the word ago.(If pressed, the learner may be able to guess that this is a preposition; experience shows that the layanswer will be rather “adverb”.) The linguist/lexicographer, on the other hand, if s/he wants to pro-vide grammatical information too, will have a difficult job explaining how/why this is a very way-ward preposition, which fact at least some of the learners intuitively grasp (so the explanation maybe in order). But the practical lexicographer may also be justified in asking, “why not let sleepingdogs lie, and ignore this syntactic quirk, when ago can simply be marked as Prep?”
As another word that may be problematic from the PoS point of view but causing different head-aches for the lexicographer, let us look at than. Most modern schools of syntax, up to some fairlytraditional approaches, now agree that it is always a preposition (with differing complementationpatterns). Some traditional accounts still distinguish a preposition than and a conjunction than;while dictionaries on the market display a wide range of approaches, from the traditional above tosome quite eccentric sets of PoS labels, and obsolete purist advice. No dictionaries, however, noteven the most recent ones, show than to be the syntactic item that probably all contemporary analy-ses claim it to be: preposition requiring either (i) a NP, (ii) some kind of clausal or (iii) zero com-plement.

Chapter Two
59
Four sources – CED&T (1992), RHWUD (1999), COED (2004) and CALD (2008) – have beenselected to illustrate the treatment of than:
• CED&T (1992) uses the quite aberrant set of labels (coordinating) adv., pron, conj., nThey are given indiscriminately at the top of the entry of than. (Which of the four (!) corre-sponds to which sense – and which might be the nominal one – is not made clear.)The three “senses” are illustrated thus:
1. shorter than you; couldn’t do otherwise than love him; he swims faster than I run 2. rather thanbe imprisoned... 3. other than
• RHWUD (1999) distinguishes two PoS’s for than: conj. and prep. It is supposed to be conj. in taller than I am and prep. only “in the old and well-establishedconstruction THAN WHOM: a musician than whom none is more expressive”).The authors, quite perversely for 1999, insist that in “informal, especially uneducated, speechand writing, THAN is usually treated as a preposition and followed by the objective case of thepronoun: younger than me.
• COED (2004) distinguishes two parts of speech, conjunction and preposition. than� conjunction & preposition1 introducing the second element in a comparison. 2 used to introduce an exception or contrast. 3 used in expressions indicating one thing happening immediately after another.
The than entry offers no examples; it is hardly possible to match the senses to the examples pro-vided in the other three dictionaries. It is hardly possible to think of any use that this entry can beput to in a native speaker dictionary, and it would be useless in a learner’s one.
Interestingly, the entry offers a serious and reliable Usage section, the only one of the four sources,which, it must be admitted, would be missing without some (admittedly vague) inspiration frommodern linguistics:
Traditionally, it has been said that personal pronouns following than and as should be in the subjectiverather than the objective case: he is smaller than she rather than he is smaller than her. This is basedon an analysis of than and as by which they are conjunctions and the personal pronoun (in this case,she) is standing in for a full clause: he is smaller than she is. However, it is arguable that than and asare prepositions rather than conjunctions, similar grammatically to words like with or for. By this analysisthe personal pronoun is objective, and constructions such as he is smaller than her are perfectly ac-ceptable in standard English.
• CALD3 (2008) distinguishes two PoS’s: preposition, conjunction.
than 1. [...] taller than my daughter [...] walk faster than I do [...] earlier than usual2. [...] more than I intended to [...] less than I expected
Ironically, then, since the sense breakdown of than here is the same as in any dictionary twenty orthirty years earlier, the only novelty of the CD version of CALD3 (2008) is that the PoS labels arewritten out in full. That advance, however, is to be thanked to technology, again not to linguisticanalysis or methodology.

Chapter Two
60
PoS fact are not simple, but their seemingly unproblematic handling in dictionaries only goes toperpetrate the common perception that clear-cut cases are involved. In this sense, lexicographygreatly hurts the cause of linguistics, suggesting simplicity where there is none. It is also its owngravedigger: users do not mind language being complex and fuzzy; that could remain the worry ofthe linguist. They do, however, insist on dictionaries providing sharp images of its facts.
2.4.2.7 Illusions of simplicity: “abbreviation” as PoS
In MED (2007), a search possibility allows one to find items of the “abbreviation” part of speech.The problem is again manifold: not only is the term “abbreviation” itself highly ambiguous (thismay be a fact the user has no knowledge of), but it is certainly not something that has ever beentermed a part of speech in any descriptive framework. “Abbreviations” (whatever their definition)are certainly not one word class, not even one class: minimally, they comprise two subgroups, ini-tialisms and acronyms.
While abbreviations are by no means a separate class, it is hardly questionable that the inclusion ofall kinds of abbreviations serves the user. This clearly compromises theory: no definition of “abbre-viation”, be it based on distribution, form or semantics, will put them in one class. This is more thansimplification; this is a grave distortion of the facts. It is, however, welcome simplification from alexicographic point of view. Moreover, it is one that may be utilized pedagogically: while nolearner is likely to want to get all the nouns or even all members of a closed class such as preposi-tions listed in a dictionary, it is good to have the possibility of listing all the abbreviations, as theymay deserve a slot of their own in the ESL teaching process. Abbreviations, but not for instancenouns, may be chosen as the topic of a separate session at the appropriate level.
Such a search possibility in an electronic dictionary, then, is a welcome feature. It is the job ofmetalexicographers to scrutinize dictionaries with points like this in mind. Serendipity might bringforth such welcome simplifications as the labelling of abbreviations as one searchable subgroup ofwords even at the cost of losing exactitude.
2.4.3 Trade-off between anecdotalism and rigour
Linguistics has obviously never been a monolith. Reviewing Cruse (1986), Aitchison (1990) de-scribes linguists as belonging to two types: accordingly, and relevantly for us
“... some linguists believe in theory, others in description. Theoreticians tend to getairborne on their own fantasies, and take off towards Never-Never Land. Descriptiv-ists tend to get entangled in the tropical jungle of their own multifarious observa-tions”
and states that Cruse falls into the latter category. Cruse’s 1986 book
“...takes us [...] through the complexities of the lexicon [...] since Cruse ‘does not be-lieve that any currently available formal theory is capable of encompassing all thefacts concerning word-meanings that have a prima facie claim on the attention of lin-guists’ [...]. Faced with a choice between ‘theoretical rigour combined with descript-ive poverty, and descriptive richness combined with a lower degree of theoreticalcontrol’, he has opted for the latter...”
(Aitchison 1990:147; italics mine)
Cruse himself professes his aim in writing the book to have been
“an exploration of the semantic behaviour of words which, methodologically, is lo-cated in the middle reaches of the continuum stretching from mere anecdotalism tofully integrated formal theory.” (Cruse’s 1986:xiii).

Chapter Two
61
Lexicographers may on occasion be “airborne on their own fantasies” but – understandably – theyare constant inhabitants of the “tropical jungle of their own multifarious observations”. Admittedly,rather than being located in the middle reaches of the continuum, they even often engage in “mereanecdotalism”. This “anecdotalism”, or fragmentation, however, which might appear to be lack of aunifying vision, when seen from the user’s point of view, may be just the thing that lexicographyneeds. This stance of Cruse as a theoretician may be simply motivated by his embracing of Geo-the’s anecdotal suspicion of theory: “All theory [...] is grey, but the golden tree of life springs evergreen…”. The attitude, however, surely suggests that he may be one of the linguists that lexicogra-phy can turn to not for the “big picture” provided by “theoretical control”, which it is not in need ofanyway, but for “descriptive richness”.
Wierzbicka’s observation that lexicography has no theoretical foundations, and “even the best lexi-cographers [...] can never explain what they are doing, or why” may have a good deal of truth in it,but in the praxis of lexicography, as has been suggested, this absence of theory is not necessarily abad thing.
As Landau (1933: 113) puts it, efforts to describe language “scientifically” usually miscarry whenthey come up against “the stubborn diversity of actual usage”. It is natural that theoretical linguis-tics, at least of the generativists’ markedly anti-empiricist strain, should have no such bogeyman tocount with as the stubborn diversity of actual usage. This, unfortunately, also makes it harder fortheir more ethereal, intangible stock to be imported into dictionary-making. Lexicographers, bycontrast, are not (or markedly less) constrained by the straitjacket of theoretical rigour, or encum-bered by the shifts in paradigms. This, fortunately, makes it easier for dictionaries to be geared tousers’ real needs.
2.4.4 Trade-off between coverage and accessibility
There is always a trade-off between coverage and accessibility: dictionaries have evolved strategiesto maximize the use of limited space, e.g. by the use of codes, abbreviations, and a special definingstyle (Atkins & Rundell 2008:21). But all this has come at a cost: they have become increasinglyharder to access. Then since the 1970s an offsetting tendency has stressed user-friendliness, and thishas led to a re-evaluation of the packing of large amounts of information into a small space.
Apparently, then, lexicography is torn between the four requirements of provision of richness ofdetail (“anecdotalism” above), attaining theoretical perfection, maximizing coverage, and increasingaccessibility. These interact in all types of dictionaries, but the profile of the users aimed at obvi-ously influences many of the choices along these four axes. This is what Atkins & Rundell(2008:23) give extreme attention to:
“if you have a clear idea of who your user is and what they want from the dictionary, youstand a good chance of achieving the right fit between dictionary type and user need”.
Users’ skills influence the information in the entries; this is true of every type of dictionary, but (asin so many respects, as also recognized in Atkins & Rundell 2008), the bilingual dictionary is “morecomplex, and less amenable to clear explanations, than all but the most scholarly and sophisticatedof the monolinguals” (Atkins & Rundell 2008:43). Bilingual dictionaries are even more obviously“tools”.
Nevertheless, working with Hungarian↔English dictionaries for Hungarian users, one surely is in agood position to know one’s user: the well-delimitable circle of school-educated user/learner withnegligible linguistic knowledge to take for granted. In lexicography for the E↔H relation in thecase of a small market like Hungary, however, there is really not much room for manoeuvre. Thisalso means, paradoxically, that the H↔E lexicographer is in a singularly fortunate position in nothaving much elbow room: less latitude understandably goes with less responsibility. It is obviously

Chapter Two
62
more difficult to compile and continuously update, e.g. French↔English dictionaries for bothFrench and English users than Hungarian↔English ones for only Hungarians.
The mundanely practical flip side of this, unfortunately, is that with this admittedly lighter respon-sibility comes the bad news of a relatively narrow market with the correspondingly meagre re-sources. That, in turn, has an unwelcome impact on profiling as well as user research, market re-search, and academic research budgets.
2.4.4.1 Market demands beyond users’ demand
It is convincingly argued in Coleman (2007) that “most dictionaries are commercial products, andhave to meet market demand. An example of the clash between lexicographic theory and custom-ers’ collective wishes came with the publication of the third edition of Webster’s dictionary ofAmerican English”. These wishes are not to do with individual customers’ needs but are somehowthere en masse. The makers of “Webster’s 3rd”, as now generally, wanted to reflect the way thelanguage was, not how it should be, used. Buyers expected to be told what was right and wrong anddid not want to see usages regarded as wrong legitimized by inclusion in such an authoritative work(Stein 2002:34–35, quoted in Coleman 2007:593).
Although most lexicographers who produce general dictionaries now steer clear of prescriptivism(being in a position to do so partly because many publishers today also cater for this section of themarket by publishing various style manuals, usage guides and dictionaries of hard words and con-fusibles etc), it is still the sentiment that you can turn to a dictionary for information, or actual guid-ance on language. Worded in this more careful way, this is understandable.
There is an even more natural expectation on part of the language learner to turn to bilingual dic-tionaries for information, in which case a moderate amount of prescriptivism is inevitable. The at-titude-related mess that “Webster’s 3rd” created is thus less of a problem for Hungarian↔English,and any other, bilingual lexicography, for source language speakers do not have strong views on thetarget language. Learners are probably not aware of the shock that they would get to find, in theirHungarian explanatory dictionary, the Hungarian equivalents of many of the English forms whichthey are happy to find in their English dictionary, and whose lack there they would complain about.The inclusion of (non-standard) forms such as ain’t and gonna and wanna is justified becausereaders of English texts will encounter them (and they are unpredictable from the standard variants).So is the inclusion in most general dictionaries of slang and taboo terms. The lack of their counter-parts in Hungarian, however, is less of a problem: the learner does not have to use these in Englishbut can always replace them with a stylistically neutral expression. Thus except for some (ostensi-bly rare) translation tasks which must be stylistically true to the original, the lack of vulgarisms,non-standard forms and those of doubtful status (sometimes of even dubious word status) such asthe H. nem t’om ‘dunno’, naná! ‘sure’, ja ‘yep’ and ö-ö ‘unh-unh’ etc. (to provide a very mixed list)may be no problem for the average user, while, e.g. the lack of dunno, unh-unh, nope, yep, youbet! (a similarly motley list, in addition to the grammatically non-standard forms like ain’t men-tioned above) would be regrettable.
The principle of description (as opposed to prescription) paradoxically suffers with every piece ofwarning for offensive vocabulary in learner’s dictionaries. On the one hand, English lexicographerstoday would not like to be seen as prescriptivist, but on the other hand, not indicating style and so-cial connotations or not giving some general warning for “swearwords, racist, sexist, and homopho-bic vocabulary, would be to do a disservice to their buyers” (Stein 2002: 159–68, quoted in Cole-man 2007:594).
In bilingual lexicography, this is no problem at all wherever the translation itself adequately takescare of it, but it must be signalled somehow if no equivalent that matches stylistically can be of-fered. Extreme caution, and constant updating, is obviously needed in this area to avoid instancessuch as meleg in HECD (1998). For the adjectival meleg it offers the translations bent, flit, faggy

Chapter Two
63
(only followed by a warning: “all taboo”) and enters gay only following these. For the nominalmeleg, the following are given: nancy biz [colloq], flit, ginger-beer, [homosexual or effeminateman] Nelly, ponce (again only followed by a warning “all taboo”). Thus, not only are disparagingand offensive words and “derogatory slang” offered for the neutral word, but these dominate: theunabridged RHWUD (1999) does not enter either ginger-beer or Nelly in this sense.
2.4.4.2 Descriptivism and application
Any insight that lexicography may choose to use comes from descriptive (not as opposed to pre-scriptive but to theoretical) linguistics. Explanations supplied by more theoretical, e.g. generativeapproaches being largely irrelevant, the kind of contribution that linguistics may offer is observationand description, and perhaps analysis (part of which, as attested by grammar books of various kinds,come from theory, of course). When, however, not monolingual but bilingual dictionaries are ed-ited, two sets of data from two languages are matched against one another, the result no longer be-ing a descriptive product. It is an applied linguistic product, more than a monolingual dictionary,and it is also prescriptive (if only) in the sense of not finding these matches but rather establishingthem (on the basis of observable correspondences, though). Attempts are constantly made to applyprincipled decisions to link a body of language to another, necessarily singling out, highlighting andplaying down phenomena and establishing the notoriously non-existent “equivalences” betweenlanguages, even to a larger extent than in the case of monolingual works. Obviously, prescriptivismis out of place in the handling of the data of the two “corpuses”; but bilingual dictionary writingwithout intervention would be impossible. That is nothing to worry about: as Crystal (1989) claims,discussing foreign language teaching, but with arguments relevant here:
“what was wrong with traditional pedagogical prescriptivism was that the prescrip-tions bore little relation to the facts of usage, and seemed to fly in the face of thosefacts. That was why the word gained its pejorative overtones. We [...] should now dis-tinguish clearly between ‘old’ and ‘new’ prescriptivism.
It is in this sense that bilingual dictionaries invariably are, monolingual ones may be to a lesser ex-tent, while native speaker dictionaries barely are, prescriptive.
2.4.5 Linguistics vs. lexicography: linguists’ voices
It appears a commonplace that lexicography ought to and (or because) it is in a position to, adoptlinguistic findings. Just what exactly those points might be and how lexicographic practice shouldespouse those ideas, on the other hand, are not usually discussed: lists of such theory-informed de-cisions do not seem to have been published.
It is difficult to identify, and catch in real time, as it were, the points where lexicography has takensome advice of theoretical linguistics, and has acted upon it. It is even harder to identify points, ofwhich there surely must be no fewer, where some lexicographic enterprise, having weighed the prosand cons and the implications that some theoretical discovery would have for lexicography, has de-cided in favour of ignoring, or outright negating.
2.4.5.1 Kiefer (1990) on lexicography and theoretical linguistics
I will examine, with the wisdom of hindsight, some of the claims made in favour of theoretical lin-guistics and lexicography being each other potential helpers. Kiefer (1990) claims that although
“theoretical linguistics and lexicography […] do not seem to show much interest ineach other’s preoccupations and their relationship is far from intimate. [...] The lexi-cographer’s attitude towards language is often a-theoretical and they reproach lin-

Chapter Two
64
guists for producing theories which are not very useful in practical work; theoreticallinguists, on the other hand, blame lexicographers for keeping aloof from theoreticalquestions, for being satisfied with a kind of fiddling job”.
If these claims (not far removed from Wierzbicka’s criticism) were valid almost twenty years ago,they still ring true. “Theoretical linguists construct theories [...]”, the argument in Kiefer (1990)goes on.
“They also construct theories concerning [...] the lexicon of a given language. [..] Anadequate theory of the lexicon has to take into consideration the requirements of othermodules as well. Therefore, a lexical item need not be a word of the language: it canbe a stem morpheme, a phonologically not fully specified sequence of segments oreven an abstract entity with no direct relationship with the actually occurring elem-ents of the language. In most cases the lexicon is not considered to be a simple ag-glomerate of lexical items, it is at least in part rule-governed”. (italics mine)
These exclusions show that lexicography is not concerned with a theory of the lexicon: while bothsuch non-specified or abstract items and rules as such do belong to a theory of the lexicon, none ofthis has a place in traditional dictionaries, and certainly not in most modern general, or trade dic-tionaries. An ECD-type of dictionary, one that is inspired by the Meaning↔Text model, although ithas no room for abstract entities and rules, is much closer to being a model of the lexicon.
Kiefer (1990) goes on to say that in spite of the hostile attitudes of theoretical linguistics and lexi-cography, the two disciplines can be reconciled:
“[...] no theoretical work on the lexicon is possible without appropriate data whichcan, at least to some extent, be supplied by lexicography”
If this was true almost twenty years back, it could be much more so today, with natural languageprocessing and word sense disambiguation heavily relying on dictionaries. To be sure, some strainsof theoretical linguistics simply do not believe in such data being relevant to their enterprise.
Kiefer, then, suggests not only that linguistic science, semantics in particular, has implications forlexicography, while the latter can prove useful for the former by providing empirical material, butalso that the two have a common target. It would be good to have more examples of such synergy,because unfortunately the only example mentioned – “the problem which both the theory of thelexicon and lexicography have to tackle” – is the distinction between linguistic and everydayknowledge, which is a question is for semantics or language philosophy but not the practical pursuitof lexicography. Overall, Kiefer (1990) sounds optimistic that “dictionaries could certainly be mademore adequate by making use of some of the insights gained by theoretical research”. Again, this issurely so in the abstract (as in Béjoint and Atkins & Rundell), but where exactly can we find the re-sults?
It would be hard, or often impossible, to trace back to its ultimate source every single insight of lin-guistics that has ever gone into dictionary-making. One small example may suffice: the realizationthat certain lexical items were predominantly found in negative contexts came a long time both be-fore the advent of modern syntax and corpus linguistics. It is not impossible that the elaboration ofthis suspicion does credit to corpus linguistics even if the suspicion itself was not first articulated,and supported with evidence, by a corpus linguist. If so, is it then the case that theoretical linguisticssupplied material for lexicography here, and many similar cases? If John Sinclair, for example, towhom many such insights can be attributed, is regarded as a semanticist, and his discipline of “em-pirical semantics” (as Stubbs 2009 refers to it) is credited with existence, then the insights of Sin-clair and scholars of a similar persuasion do come from “theoretical” linguistics. The answer is a“yes” only because the internal borderlines of linguistics have (been) moved to fit.

Chapter Two
65
2.4.5.2 How theoretical is theoretical?
As Stubbs (2009:115) also argues, Sinclair’s corpus-assisted search methodology and work hadfound empirical evidence for an innovative model of phraseological units of meaning, which, inturn, provided new findings about the relation between word forms, lemmata, grammar, and phra-seology. If something, then conceptualizing the workings of language in a new light along Sinclair’slines certainly qualifies as theoretical linguistics. Because, however, he also made major contribu-tions to applied linguistics in language education and discourse analysis, Sinclair especially laidhimself and his corpus-assisted lexicographic approach open to criticism from the generativist side.To the extent, then, that the boundaries of linguistics are being moved and redrawn, questions ofhow “theoretical” linguistics informs lexicography become outright elusive.
While the relationship of theoretical linguistics and lexicography was one of hostility as early asaround 1990, twenty years earlier, when A. A. Hill gave a Presidential Address for the LinguisticSociety of America, he had some “suggestions for dictionary-makers”, and he hoped that (para-phrasing President Lincoln) “most linguists would agree with some of them, and some would agreewith all of them”. Yet surely there was a reservation, he argued,
“that must occur to many. Dictionaries are made by publishers and professional com-municators, not by linguists. So how can we make our criticisms felt, presuming thatwe have them? The answer lies in the fact that very many of us are frequently engag-ed in the making of little dictionaries [..]. Or we are called on to produce bilingualdictionaries of various sizes; or we make studies of usage, that is, of speaker–writerattitudes towards words. If these specialized works are made coruscating examples ofimproved methods, we can be sure that eventually, perhaps with glacial slowness, butalso with glacial inevitability, the dictionary-makers will follow.”
Hill (1970:258; italics are mine)
Apparently, in America at least, dictionary-making was not thought of as the business of linguists,not even by philologists, but “publishers and professional communicators”. However, as Hill visu-alizes the scene, linguists critical of dictionary-making, who often had lexicographical jobs “on theside”, were to slowly take over, first by setting an example. Many scholars have followed thosemodels, and many linguists globally have taken an interest in the dictionary on both sides of the di-vide.
2.4.5.3 The “real world linguists” of McCawley (1986)
Two major although by far not recent works by theoretical linguists who have had their criticismfelt and whose work thus has direct relevance for lexicography, are McCawley (1986) and Hudson(1988).
The title of the publication where his work – The real-world linguist – appeared throws some lighton the way lexicography was regarded by McCawley, no lexicographer but predominantly a highlyoriginal syntactician, himself very much a theoretician. Hudson, on the other hand, explicitly ad-dresses many of the more practical issues of the two-way traffic between linguistic theory and dic-tionary-making.
One point made by McCawley (1986) is that “current dictionaries are problematic because they donot indicate the paradigmatic and syntagmatic relations of a word”. This is surely a field whereenormous progress has been made: if there exists an area which is no longer “problematic”, espe-cially in learner’s dictionaries, which have a growing share of the market and whose features areemulated by native-speaker dictionaries, then it is exactly the provision of the paradigmatic andsyntagmatic relations of words. If in 1986 McCawley spoke about this as a lexicographer’s dream

Chapter Two
66
only hoped to be realized in works that were as abstract, and for as narrow a readership, as the ex-planatory combinatorial dictionaries, then today in learner’s dictionaries this is very much reality.Where this is coupled with search possibilities offered by the electronic dictionary, it is probably noexaggeration that this domain of lexicography has achieved the height of its possibilities.
On an optimistic note, Frawley (1988), discussing the Explanatory Combinatorial Dictionary, sug-gests that
“an [Explanatory Combinatorial Dictionary] of English will address almost all ofMcCawley’s (1986) [=McCawley 1986 above] insights into the problems with cur-rent dictionaries, most of which center on vagueness. For instance, the ECD willshow that an entry has negative polarity [...] because this is a critical syntactic andsemantic constraint on the entry. Thus, budge is specified for negative polarity(*Harry budged the desk), unlike in ordinary dictionaries which, by not specifyingthe negative polarity, are vague as to budge, though most certainly lexicographicallyaccurate (see McCawley 1986: 4-5).
2.4.5.4 The case of budge
The case of budge and its handling in three sources will be used to illustrate the impact of a lin-guistic insight upon lexicography, and to show that linguistic analysis is often lost on the user.
When almost ten years on, in a famous case study Sinclair (1998) discusses the verb budge, theauthor no longer has to point to the “negative polarity” feature, which seems to be established bythis time and probably recognized in some dictionaries as well. Sinclair goes beyond this, and looksat how the meaning is created by the construction itself; what the typical subjects are; and what thesemantic preferences of the verb are.
“The whole construction is used to tell a little narrative whose typicality we all recog-nize: the speaker has tried repeatedly to do something, has failed, and is now annoy-ed. This overall evaluative ‘semantic prosody’ is the communicative function of thewhole unit” (Stubbs 2009:124).
One of the difficulties, however, involved in assessing whether a particular dictionary has become“more adequate by making use of some of the insights gained by theoretical research” is that it isnot at all obvious when some linguistic or grammatical insight becomes an unavoidable fact, partand parcel of lexicography. The verb budge has been handled as follows:
� CED&T (1992) explicitly states this:budge (usually used with a negative)
This, however, does not mean that this “usually with neg” feature of budge, the explicit mention ofwhich is no doubt missing from (many, or most) earlier dictionaries, has become common lexico-graphic knowledge by this time.
� In AHD (1994), based on the paper version of 1992, the entry does not explicitly mention thisfeature, only defines and exemplifies the verb:
budge v. [...] --intr. 1. To move or stir slightly: [...] 2. To alter a position or attitude:[...] --tr. 1. To cause to move slightly. 2. To cause to alter a position or attitude: [..]

Chapter Two
67
� CC (2003), a Collins COBUILD dictionary, defines and illustrates budge, explicitly calling at-tention to this syntactic feature. However, it uses a rather cryptic formula which may questionthe point of the whole endeavour:
VERB with brd-neg, V, V n
This overuse of grammatical and other formulae, now commonly regarded as a teething trouble,was a typical early Collins-COBUILD feature, which is supposed to have been removed; apparentlythis 2003 electronic edition still has them. It may take some time indeed to find out that the reallyuser-unfriendly brd-neg “stands for broad negative, that is, a clause which is negative in meaning. Itmay contain a negative element such as ‘no-one’, ‘never’, or ‘hardly’, or may show that it is nega-tive in some other way”: this is the actual text of the Cobuild Help section of the CD’s Help feature(notoriously unconsulted as front matter of this kind usually but also, unfortunately, buried verydeep in Help in this case).
Not only is the formula quite unfriendly. Brd-neg, on the one hand, is not really longer than broadneg would be, so it does not save space even in a print dictionary, but in a CD-ROM dictionary thisspace-saving is quite superfluous. On the other hand, “broad neg” is not more informative thanwould be neg by itself (or the full negative in itself) would be without the modifying “broad”. Themeaning of the qualification “broad” is not easy to work out anyway: it is probably needed to allowfor cases where it is not the element not (or no) that signals negativity but some other element suchas hardly, or the clause is “negative in some other way” – as explained in the Help. The user, how-ever, will not know what these “other ways” may be, so this sounds rather like a small-print dis-claimer, not included for the sake of the user but for the linguistic community, in the worst casescenario, for some gravely ill-conceived and misguided scientific rigour.
These three entries that span over a decade provide substantial proof that there may be lexico-grammatical points of medium or relatively low generality that owe, if not their discovery but theirelaboration, to theory, which are adopted by lexicography where they get handled variously, from(a) being explicitly mentioned in an easy-to-understand way (CED&T 1992); through (b) beingregistered by means of examples only (AHD 1994); all the way to (c) explicit mention in the formof some abbreviation or formula which may be hard or next to impossible to decipher, and thus ofquestionable use (such as CC 2003).
From this point in time onwards, the only potential path of improvement is only made possible bytechnology, not some other advance in linguistics or lexicography. The Cobuild range, e.g. has allthe necessary grammatical information, and making this more user-friendly (e.g. by expanding theabbreviations, which Cobuild have actually been striving to do) may eventually lead to an optimumsolution of such issues.
2.4.5.5 Inside an entry: dichotomies in Hudson (1988)
Writing about linguists traditionally falling into two types, those who think of language as a mentalphenomenon – the mentalists – and those who think it is “out there”, Hudson (1988:288) establishesthat the former have not only taken over, but that all linguists agree now that language is at least amental phenomenon. The question arises, he claims, whether this mental reality is of interest tolexicographers: after all, “historically a great deal of lexicographic work has involved combingthrough written texts where questions of psychological reality appear somewhat remote”.
Hudson also convincingly argues – concurring with Landau (2001) in this respect – that the diction-ary is inevitably prescriptive to some extent because users consult it as an authority. This meansthat a dictionary “takes on a kind of external objectivity that goes beyond the mental structures ofany individual”: the point in having one is to have access to a wider range of linguistic knowledgethan one individual, you, have built up. In that sense, a dictionary is by definition an E-languagerather than an I-language object. Nor should a dictionary limit its capacity “to whatever we think is

Chapter Two
68
the maximum available to a human”: the OED, e.g. obviously has more information on more wordsthan any human could possibly have.
Arguing from a slightly different set of facts, which seem less convincing, Hudson also claims thatlinguists and lexicographers are in pursuit of the same goal: “the truth defined in terms of psycho-logical reality”. This, however, is not relevant for the balance of his argumentation, which runs likethis:
Mainstream linguistics has three general tenets (each concerning an issue of boundary), which arerelevant to lexicography:
(a) the lexicon is a distinct component of the grammar(b) there are discrete lexical entries
(a) and (b) will be covered in this section(c) the lexico-grammar contains only intra-linguistic information
(c) will be discussed in 2.4.5.6.
Hudson, by contrast, argues that there is no boundary between these things: no distinct lexicon andgrammar; no boundary between lexical entries; no separation of language and other kinds of knowl-edge.
Of these, (a) is a distinction that dictionaries strengthen and foster by their very existence, and thushas relevance in the present study. The second, (b) is also supported by the form and format of anylexicographic work, and thus also relevant. The third, (c), which is very much in the focus of cog-nitive linguistics, has no direct relevance (even if some types of dictionaries offer encyclopaedic,i.e., extra-linguistic, information).
(a) Lexicon vs. grammar
Hudson claims that lexicography treats all these boundaries in and ad hoc and atheoretical way.
“If they are unreal, this is both right and inevitable – lexicographers have specificpractical concerns which guide them in their decisions, and they neither need the helpof theoretical linguists in making them nor (in this case) would they benefit from suchhelp if it rested on the main-stream assumptions. If it turns out that lexicography isbetter if dictionaries are separated from grammars and encyclopaedias, or if diction-aries are divided into discrete entries, then so be it; but if not, then lexicographersshould have no theoretical compunctions in jettisoning the boundaries in question.”
Hudson (1988:291)
This passage is a perfect summing up of the issues at hand; the way they may be raised has appar-ently not changed in the past twenty years.
As concerns linguistics, there is no consensus even on issues of this import; neither is it suggestedthat there ought to be, or even can be, such a consensus. Consequently, there is no such thing as aunified view of language that lexicography could adopt for its purposes.
As concerns lexicography: it is to be expected that lexicography treats in ad hoc ways boundarieswhose existence has been called into question, especially given that its “specific practical concernswhich guide them in their decisions” are a serious burden anyway.
As concerns the relation of the two: inevitably, one of those boundaries, which has to do with thestatus of the individual entries themselves, must be kept because of such mundane things e.g. as al-phabetization and the two-dimensional paper and two-dimensional computer display. The lexico-graphic approach to the ostensive boundary of “linguistic knowledge” vs. “encyclopaedic knowl-edge” differs from dictionary to dictionary, as their encyclopaedic nature/content varies. Finally, thegrammar/lexicon boundary is really blurred and, to a growing extent – as the realization that syntaxand meaning are inseparable – this has been duly given a representation in dictionaries.

Chapter Two
69
(b) Discreteness of lexical entries
Hudson (1988:295) sketches an average lexical entry of what he claims to be a mainstream theory,one that is which is standardly supposed to have four kinds of information: phonological, syntactic(sub)categorial, morphological, and semantic. (Some theories will have more complex ones than inGB, such as GPSG or LFG, but this is largely irrelevant here.)
Hudson argues that in the boundary-between-entries system, many problems cannot be handled.The sufficient similarity problem: (i) how similar two meanings ought to be treated as belonging tothe same lexical entry: the polysemy–homonymy issue. (ii) how similar two forms should be to betreated as belonging to the same lexical entry: the issue of irregular, even suppletive forms; and theproblem of the distinction between derived and inflected forms. There do not seem to be clear prin-ciples to which one can point as a guide to making these decisions, which, as Hudson (1988:296)argues, suggests that mental reality is not structured like that. Also, the standard view of lexical en-tries is problematic because it makes no explicit connections among lexical entries: two lexicalitems in two different entries are effectively denied any relatedness, since relatedness is an all-or-none-matter. As has been shown experimentally many times since, the mind is very likely notstructured that way (Martin, Newsome & Vu 2002 offers a synthesis).
2.4.5.6 Lexical storage and the lexical entry
A whole tradition of semantic exploration, which may be given the umbrella term “polysemy re-search”, has grown out of this realization that the mind is not structured in the fashion of the“boundary-between-entries” models. Windisch Brown (2008), besides presenting the author’s ownexperiment, a semantic decision task, also offers a recent summary of these developments fromCruse (1986) and Geeraerts (1993) through Hanks (2000) and Kilgarriff (1997) to Nunberg (1979)and Pustejovsky (1995), makes no secret of it that nothing can be known with any certainty. In gen-eral terms, this is what the author claims about senses:
“The semantic ambiguity of lexical forms is pervasive: Many, if not most, words havemultiple meanings. [...] Despite the frequency of this phenomenon, how human be-ings store and access these meanings is an open question. Do we have a separate rep-resentation in our mental lexicon for each “sense,” or do we store only one very gen-eralized or core meaning for each word? If the latter, do we generate the nuances ofeach separate sense by rule or by accessing subrepresentations? To even speak ofsenses in this way implies that we can clearly identify the separate senses of a word.In this study we [...] investigate the effect of different levels of meaning relatednesson language processing. [...] These results suggest that the distinction between a sin-gle phonological form with unrelated meanings (homonyms) and a single form withrelated meanings (polysemes) may be more one of degree than of kind. They also im-ply that related word “senses” may be part of a continuum or cluster of meaningsrather than discrete entities. In addition, results from specific comparisons betweengroups do not support the theory that each sense of a word has an entirely separatemental representation.” (Windisch Brown 2008:1)
The results of Windisch Brown’s (2008) study refine linguistic understanding of the connectionbetween form and meaning. When a single form is used to represent multiple meanings, these canbe semantically unrelated, or show different degrees of relatedness. Several theories have been pro-posed as to the storage and processing of these meanings. Under one, every sense has a separatesemantic representation in the lexicon. Another theory holds that while related senses share a por-tion of their semantic representation, unrelated ones have separate representations. These theorieshave been primarily tested by comparing differences in processing time between noun homonymsand polysemes. Windisch Brown (2008) uses a semantic judgement task to assess the ease with

Chapter Two
70
which subjects switch between senses that display four degrees of sense relatedness, and used verbs,not nouns because of the greater variability of verb meaning.
Windisch Brown (2008) has not found support for a theory in which each sense connected to someform has a separate mental representation. (Such a theory would predict no difference in processingtime when switching between senses, whether related or unrelated.) Significant differences havebeen found, however, in processing time/accuracy between processing related and unrelated senses.Even distantly related senses were processed faster and more accurately than unrelated ones. Com-patible with Windisch Brown’s findings are theories that postulate separate representations forhomonyms, and single but subdivided representations for polysemes. Moreover, the marked linearprogression through relatedness of sense which was found
“most strongly supports theories in which related meanings share varying portions oftheir semantic representation, or in which related meanings overlap in semantic space.One can imagine varying portions of shared meaning among different degrees of re-latedness. Closely related senses could share a large portion of their semantic repre-sentations, while distantly related senses would have minimally overlapping repres-entations. The sharing of semantic representations may dwindle until no semanticoverlap remains, as in the case of homonyms. [..] This sort of structure is compatiblewith cognitive linguistics theories of family resemblances and fuzzy boundaries inword meaning and concepts (Lakoff 1987; Rosch 1975).”
(Windisch Brown 2008:10)
These theories claim that a category cannot be defined with necessary and sufficient conditions, butthat its members – and polysemes are seen as members of a category – can be more or less proto-typical. Also, the boundaries between categories may be fuzzy.
A structure in which the semantic representations overlap may explain the smooth progression fromsame-sense usages to more and more distantly related usages. It also provides a simple explanationfor semantically underdetermined usages. Although separate senses of a word can be identified indifferent contexts, in some contexts both senses (or a vague one indeterminate between the two)seem to be represented by the same word (as in the now well-known case of newspaper).
“Linguists have attempted to discriminate varying degrees of ambiguity [...and ] todevelop criteria for determining when ambiguity indicates either simple vagueness ordifferent senses. Geeraerts (1993) revealed the inconsistency and unreliability of suchtests, suggesting that a sharp distinction between vagueness and distinct senses maynot exist. A theory of semantic representations that allows for overlapping represen-tations or shared core representations helps explain this phenomenon. When encoun-tering a word, one can simply access the core representation or activate the center ofthe semantic space, and only access further nuances if it is necessary.”
Windisch Brown 2008:11)
The findings of Windisch Brown are not inconsistent with a two-level semantics, or for that matter,with approaches to polysemy in any of the theories of lexical semantics set forth, e.g. in Pethő(2001). It is noteworthy that Pethő also mentions that the experiments which have been carried outwith the aim of learning if speakers have strong intuitions about identities and differences of words(and therefore of senses of words) have not returned conclusive results. Speakers, as argued inPethő (2001:8), where differences between systematic and non-systematic polysemy are also dis-cussed
“have strong intuitions that homophonous instances of words that are prototypicalcases of systematic polysemy are definitely to be considered to belong to the sameword. They also have strong intuitions that homophonous instances of words that areclear cases of homonymy belong to different words. However, there were cases wherespeakers had no clear intuitions about this at all and where their answers were also

Chapter Two
71
statistically very uneven. These cases were homophonous words that would be con-sidered instances of non-systematic polysemy.”These results [..] confirm that there is indeed an intuitive distinction between system-atic polysemy, non-systematic polysemy and homonymy, so it may be assumed thatthese classes are not just artefacts of polysemy research but have some independentmotivation. On the other hand, the results [...] do not allow clear dividing lines to bedrawn between any two of the three phenomena.”
Many decades of linguistic research, then, has not yielded conclusive results concerning boundariesbetween lexical entries; between homonymy and polysemy; between systematic and non-systematicpolysemy; whether senses overlap or are discrete rather; whether grammatical information may beseparate from lexical information; whether linguistic knowledge may be separate from non-linguis-tic, or world knowledge. By contrast, there seems to be a preponderance of prototypicality andfuzziness as opposed to crisp discreteness not just within semantics but visibly in syntax as well.
To all this may be added what is also a problem for polysemy research (Pethő 2001), but may bemuch more general than that – just omit “polysemy” from the argumentation that follows below: thepoor communication between the strands of research.
“The result of this [...] is that different approaches usually concentrate on differentaspects of polysemy without really knowing about those aspects that have been notedand examined by researchers in the other branches. Another further result is that dif-ferent researchers often find sets of data, modes of representation or generalisationsthat they believe to be new but which in fact have already been known for some timeto researchers working in another branch or even in another community within thesame branch. All this leads to a fragmentation of research that is quite pathologicalbecause it hinders both the accumulation of empirical knowledge on the topic at handand the effective discussion of new theoretical proposals.
(Pethő 2001:2)
2.4.5.7 Just linguistic or intra-linguistic information?
Hudson has also argued against the mainstream dogma that the lexico-grammar contains only intra-linguistic information, and that language and other kinds of knowledge are separate. This has beenreferred to as the (c) of Hudson (1988) in 2.4.5.4 above. The mainstream view is that the
(c) Lexico-grammar contains only intra-linguistic information
The issue here is whether there is a boundary between language and other kinds of knowledge.Hudson (1988) claims that it is assumed, without discussion, that the lexicon deals with nothing butphonological, syntactic and semantic, and sometimes morphological, information – that is, strictlylinguistic structures – but not encyclopaedic knowledge. This raises two issues at once: (i) theproblem of why encyclopaedic information should not be referred to in the lexicon, and (ii) that ofhow clear and important is the distinction is between language and other kinds of knowledge.
Hudson’s examples are all relevant from a lexicographic angle. Information concerning contextualrestrictions that have to do with “the kind of person who is speaking”, e.g., is standardly excludedfrom the (traditional) lexicon. Speakers, however, know that sidewalk is used by Americans, anddictionaries too should reflect this. This information, however, cannot be included in the main-stream lexicon, because “American”, even “speaker”, is not a linguistic category. (Hudson1988:299)

Chapter Two
72
What are some of the kinds of information which got thus excluded from the lexicon at the time thatHudson wrote (allowing, of course, that they may no longer quite, or no longer universally, be ex-cluded from more recent approaches)?
Hudson (1988:300) offers a list of such information (his original examples will be given):
(1) Social constraints on the use of words, including restrictions on type of speaker, type ofaddressee (e.g. gee-gee) and formality of social situation (attempt vs. try). These areusually excluded.
(2) Encyclopaedic information about referents.
(3) Etymology, which usually gets excluded because it refers to non-linguistic categories(e.g. names and dates), and because this information is “unevenly distributed throughthe population”.
(4) Spelling: because though phonology is, spelling is not part of language structure.
Importantly, and lending further support Hudson’s claim, it might be added that – although Hudsononly mentions this in connection with (3) – all of the information in (1)–(4) is “unevenly distributedthrough the population”. Although (3) requires special education indeed, education also greatly in-fluences both (1) and (2). For (4), simple literacy is required, but that cannot be taken for grantedeither.
Sure enough: the only linguistic knowledge that is universally recognized to be “evenly distributed”is (morpho)syntactic information: native speakers are in possession of their entire (core) syntax, andthe whole of (regular) and most of irregular morphology.
2.4.5.8 Written language
The “unevenly distributed knowledge” of spelling raises challenging theoretical questions whichhave all to do with “how linguistic” a status that written language is allowed to have within somelinguistic approach. In probably the majority linguistic opinion today the written medium has such asecondary role in the shadow of the more fundamental spoken one that some would actually preferto see dictionaries arranged in some non-alphabetic, vocally-arranged ways (which, incidentally,would facilitate lookups in the case of spelling uncertainties).
It is to be expected that scholars who (also) work with dictionaries will give more prominence to thewritten medium, and ask such questions (and probably answer them in the affirmative) as: Is it pos-sible to know a word which one only has seen, not heard? Is it not the case today that even average-educated English speakers spend more time surrounded, thanks to computers and the internet, bythe written language than ever before? Aren’t the majority of English speakers literate now? Is it notthe case that although the first few years of one’s life, which of course largely overlap with theyears of language acquisition, are spent without visual language, life and language later on will beunimaginable without it?
Hudson’s “liberal” stance is all the more interesting since there is a scholarly tradition, exemplifiedby an early work by Bolinger (1946), which takes a much more careful position on this issue.Bolinger’s is a study devoted to what he terms “Visual morphemes”; it begins with the claim that
“The fact that most writing is the graphic representation of vocal–auditory processestends to obscure the fact that writing can exist as a series of morphemes at its ownlevel, independent of or interacting with the more fundamental (or at least moreprimitive) vocal–auditory morphemes. Recognition of visual morphemes is also ham-pered by the controversy, not yet subsided, over the primacy of the spoken versus the

Chapter Two
73
written; the victory of those who sensibly insist upon language as fundamentally avocal–auditory process has been so hard won that any concession to writing savors ofretreat.” Bolinger (1946:333)
Since, however, for dictionaries the written medium is a fact of life even at an age when the physi-cal medium often is cyberspace, lexicographers do not really have an operative need for supportfrom linguists who are “more permissive towards the written variety”. It is still comforting to findviews such as the following (Bolinger 1946), which “defends the written medium” distinguishingthree types of visible arbitrary signs according to their connection with speech:
“We may distinguish three types of visible arbitrary signs, according to their con-nexion [...] with speech: 1. Signs existing independently of vocal-auditory morph-emes [...]. Such are the [...] death’s-head on bottles of poison, lines [...] to mark thedirection of highways etc. 2. Signs which supplement audible morphemes [...] 3.Signs which, under certain conditions (such as silent reading), to a greater or less ex-tent supplant the audible morphemes [...]. The most important class is obviously thethird, for it embraces the whole of writing. If we grant it, we grant that lose and beatare different visual morphemes just as /lúwz/ and /bijt/ are different vocal-auditorymorphemes.” (Bolinger 1946:334; italics are mine)
Bolinger describes two mini experiments of his own design which (although obviously very lim-ited) demonstrate that the “visual side” may have legitimate existence in a “lexical entry”, whateverthe exact form of such a lexical entry might be. In the first experiment, he offers a set of matchinghomonyms to his subjects, and directs them to fill in any word with identical sound [...].
“Two sample pairs were first presented – bard-barred and sighs-size – and then thefollowing list was distributed to the class: plane, to, vain, gourd, phrase, rein,grate, prey, peak, board, wee, and led. [...] The number of those who did [this] suc-cessfully was, for each word in the order given, 23, 24, 24, 12, 4, 24, 21, 24, 21, 18,17, and 24. The significant result is, of course, that of phrase. Here, despite the exist-tence of TWO homonyms (of identical spelling), frays ‘conflicts’ and frays ‘makes orgrows ragged’, at least one of which everyone knew, almost ninety per cent were dis-tracted by the total dissimilarity in spelling.”
(Bolinger 1946:335)
Bolinger’s daring conclusion (1946:340) is as follows:
“[i]t is probably necessary to revise the dictum that ‘language must always be studiedwithout reference to writing’. This in no way detracts from the value of that dictum asapplied to all languages at some stage of their development and to largely illiteratespeech communities today; it is merely a recognition of a shift that has taken place inthe communicative behavior of some highly literate societies.”
Although around 1946 the issue as such was nowhere near imaginable in linguistic thought, Bolin-ger’s experiments mentioned above involve the problem of storage-and-retrieval. It does not ask thestandard questions of such studies of the late 20th century concerning the intricate ways in whichsound shape and sense may be stored; it adds another dimension – the written medium – and the an-swer which it provides suggests that the “visual shape” also may be separately stored. This, ofcourse, complicates matters even further, but as Hudson himself would argue, if that is what realityis like, then that is the way to look at it.
It also ought to be added at this point that space, including experimental data, is devoted to writtenlanguage in the section of lexical processing in Martin, Newsome & Vu (2002:633).

Chapter Two
74
2.4.5.9 Abbreviations as special items for the written medium
A special function of most types of dictionaries is to provide abbreviations of all kinds. Althoughthe present proliferation of abbreviations is largely due to the spread of IT, and the IT-related oneswill predominantly be needed by people with good access to the Internet, where exactly this kind ofvocabulary can easily be checked, so dictionaries are not needed, abbreviations are still a huge areawhere (especially non-native) users need guidance.
Quite a few have gained currency thanks to IT language but have spread on and become part of eve-ryday language, even imported by other languages in different ways: the English items imho, wrt,rtfm, otoh, wtf, lol and their likes are very much part of communication in many languages, notjust English.
Abbreviations also pose a challenge because many of them often get written, and many exist only inthe written medium. Abbreviations are extremely diverse grammatically (cf., however, the healthyeffort at simplification in MED (2007) by listing abbreviations under the same PoS label “abbrevia-tion”).
2.4.5.10 The dichotomies of Hudson (1988) in the dictionary
How all the information that has been discussed in (a)–(c) above concerning Hudson (1988) can orshould be reflected in “the dictionary”, if the effort is worth at all, is a complex question, one thatrequires a fine-grained approach.
(a) Whether the grammatical aspect of language will be separated from the lexical is no longer anissue in most modern lexicography; rather, it is a given that the two are often inseparable, and theyare presented as such in these dictionaries. Many of these decisions will needs be ad hoc, but this isnot necessarily a bad thing given that the organization of linguistic information is itself far frombeing as neat as some theories may hypothetize.
(b) Information about the mental lexical entries (and the mental lexicon as such) is not somethingthat users of a general dictionary want from any lexicographic work, whatever be the form of thatmental lexical structure. There is no escaping the fact that in a general dictionary the lexical entries(whatever their form within the human mind) will inevitably have to be presented in a fragmentedand atomistic, linear, non-hierarchical, and writing-centred way, very unlike psychological reality,which is probably none of these.
(c) Whether dictionaries should include other knowledge about lexical items than strictly linguisticinformation is a foregone conclusion. Most dictionaries, simply by labelling their words for style,context of use, formality, the temporal dimension etc., have always attempted to be faithful to muchof this information as well, and they have performed rather well. While encyclopaedic informationin the case of monolingual works is willy-nilly part of the definition, from bilingual dictionaries it isalso unavoidably absent. Spelling is an aspect of language that any variety of dictionary could notpossibly avoid providing information about, even if they wanted to. Etymology may or may not bea part of them, but here, decisions will again depend on dictionary type. That the bilingual diction-ary does not, as a rule, offer it, while some monolinguals may clearly shows that when it comes tobeing used as an instrument (of translation), i.e. an instrument (as opposed to portrait) dictionary,etymology is surely irrelevant.

Chapter Two
75
2.4.6 The task of lexicography
Hanks (2006) claims that the “four issues of general principle that must be considered for all serioustypes of dictionaries in any language are: (1) breadth, not depth; (2) consistency; (3) descriptiveversus prescriptive approach to the language; and (4) historical versus synchronic approach.” I can-not agree more with the idea that
“Unlike other kinds of scholarship, lexicography generally aims at breadth rather thandepth. A dictionary does not say everything that could possibly be said about a par-ticular word or linguistic phenomenon. Instead, it tries to present a reasonably com-prehensive inventory of the vocabulary and to state just those facts that are most sali-ent or most relevant about each word. [...] [A]s far as the entries themselves are con-cerned, it is necessary for dictionaries to idealize – and often simplify – word mean-ing and word use. To attempt to account in detail for all possible uses of words wouldbe to attempt the impossible, for usage is open-ended and shades of meaning are de-termined by context. Furthermore, if a dictionary presents too much informationabout a particular word, there is a danger that the user may not be able to see thewoods for the trees. Hanks (2006:113)
Just as (according to Hanks) there are principled as well as practical reasons for dictionaries to beeconomical with space, there are both principled as well as practical reasons for dictionaries not toaim at depth, and be content with breadth. It must also be emphasized that if lexicography has justthis feature – aiming at breadth rather than depth – as opposed to all “other kinds of scholarship”,then this in itself would be enough to exclude it from the realm of scholarship. We will argue thatthe very reasonable “breadth, not depth” slogan characterizes the whole of the lexicographic enter-prise – and does so deservedly – and excludes lexicography from “the sciences”.
Furthermore, although this does not logically follow from a characterization of lexicography such asgiven above, towards the end of this chapter it should be stated that lexicography does not seem tobe able to absorb – or worded more fairly: readily absorb – input from any genuine linguistic disci-pline (the ones sharing borders with lexicography being lexicology, morphology, syntax, semantics,and discourse, provided that these are all recognized), which, unlike lexicography, aim at depth andexplanation but whose insights are too elusive to be put into practice. It will be shown on one smallexample (Apresyan 1980) of English synonym sets including defend and protect how the almostthirty years since the publication of this study are not enough for most up-to-date English diction-aries to register the most relevant differences between the two. The example is undoubtedly typical.
2.4.6.1 Defining collocation
Some of the most often occurring terms in the study of the lexicon are used without definitions, orhave too many senses, of which authors do not specify theirs in a given work. “Collocation” is acase in point. Two standard reference works of linguistic terms, Crystal (2003) and Trask (1993),will first be consulted for the use of “collocation” (and “semantic prosody”).
Crystal (2003) defines collocation as “the habitual co-occurrence of individual lexical items”; e.g.auspicious collocates with occasion, event, sign etc.; [...] letter collocates with alphabet. Thus,collocation is a syntagmatic lexical relation but one that may work at a distance; it is “linguisticallypredictable to a greater or lesser extent: the bond between spick and span is stronger than that be-tween letter and pillar-box” [...] there are many totally predictable restrictions as in eke + outspick + span, and these are usually analyzed as idioms, clichés etc. Collocations are formal, notsemantic statements of co-occurrence: green collocates with jealousy (as opposed to, say, blue orred) even though there is no referential basis for the link. A related notion is “semantic prosody”;collocational restrictions are analogous to “selectional restrictions” in generative grammar (italicsare mine).

Chapter Two
76
Semantic prosody is a term used in corpus-based lexicology to describe a word which typically co-occurs with other words that belong to a particular semantic set. E.g. utterly co-occurs regularlywith words of negative evaluation e.g. utterly appalling (Crystal 2003:410).
There are three problems with the above definition. (i) While it is true that there is a syntagmaticlink between the members of the pairs in both cases, the wording “the bond between spick andspan is stronger than that between letter and pillar-box” blurs the most important difference be-tween them: the former but not the latter may be considered a linguistic, or lexical, unit. If any twolexical items appearing anywhere in the same sentence (same discourse?) are collocates, then theterm becomes vacuous. (ii) Another problem is that, contrary to what the definition suggests, mostcollocations are semantic “statements of co-occurrence”. Green and jealousy, where there is noreferential basis for the link, is a stock example, but – sticking to adjective + noun collocations –most such statistically important pairs obviously do exhibit semantic relatedness (or motivation) aswell. (iii) The third difficulty with the definition is that although this is suggested, “collocation”may by no means be equated with “semantic prosody”, not because the term “semantic prosody” isunfortunate, but because it only makes sense for items with some kind of evaluative aspect.
These three ills of the definition in Crystal (2003) leave one without a guideline as to the real natureof collocation. To this might be added, as Rundell & Atkins (2008) also warns, that Mel'čuk, a lin-guist whose insights lexicography has “benefited hugely”, uses the term collocation differently:“Mel'čuk’s use of the word “collocation” is slightly different from the way we use it [...].” (Rundell& Atkins 2008:150). Ironically, however, the term “collocation”, which occurs 57 times (ignoringthe form “collocational”) in the volume, is not defined. Instead it is claimed, quite appropriately,that “its definition is not stable” (Rundell & Atkins 2008:369).
Stock examples of collocating pairs suggest that in these cases the only difference involved betweentwo items is their chance collocating potential and not their meaning. That is, according to the usualaccount, in pairs such as
V1 N2 as opposed to V3 N4,
it is the V1 that collocates with N2 and not the V3, although the V3 has much the same meaning asthe V1 (or the other way round: V3 collocates with N4 and not V1, although V1 has much the samemeaning as V3). This is in conformity with the aspect of collocations just seen, that they are not se-mantic statements of co-occurrence: thus, e.g. grill is supposed to collocate with meat but not withbread; toast with bread but not with meat. The same is supposed to be true of adjective–nounpairs:
A1 N2 as opposed to A3 N4,
where, under the standard account, A1 collocates with N2 and A3 with N4, though A1 has roughly thesame (cognitive) meaning as A3: e.g. handsome and beautiful supposedly have the same sense‘good-looking’, but while a man would be described as the former, a woman, as the latter.
Other staple collocations (from mixed PoS combinations) include pairs such as high mountain andtall tree, both with the meaning ‘of more than average height’. Get old and get tired are fine collo-cations, but with bald and grey only go collocates, not get: go bald and go grey. It is get that col-locates with sick but fall with ill. Different things are carried out, performed, and conducted, al-though the meanings of these verbs are supposed to be very similar.
Not all of these stock examples, however, are collocations with a chance collocating potential: themeaning of one collocating word in one collocation is often incontestably different from that of thecollocating word in the other. (A weaker version of this statement would be that the difference canbe expressed in terms of meaning). True, in the case of the lexical verb examples above, grill can beparaphrased as ‘cook (meat, fish, etc.) by direct heat, as under a grill or over a hot fire’14, and this isnot much different from toasting (‘brown under a grill or over a fire’) but they collocate with, or 14 The definitions in this paragraph have been modified from CED&T 1992.

Chapter Two
77
select as argument, different things. The same probably goes for tall tree vs. high mountain. Theadjectives handsome and beautiful, however, may be claimed to have different senses becausethey collocate with, or select as their subject, NPs referring to males vs. to females.
The rest of the verbal examples above, which are genuine instances of collocation (with what hasbeen called chance collocating potential) in that get and go as well as fall are used in the “resultingcopula” function here, meaning ‘become’. Thus they are a phenomenon somewhat easier to pindown; which of them is selected with which adjective, however, is a matter of sheer convention,idiosyncratic in the sense of unpredictable: a particular copular verb is used to the exclusion of oth-ers that might do equally well. Similarly, for what may be termed “light verbs” carry out, perform,and conduct: their roughly identical meanings require various collocating objects. In view of thefact that in all probability, “context makes meaning” rather than the other way round, it is but smallwonder that collocation and meaning should shade into one another.
2.4.6.2 Sense analysis of defend vs. protect for background
The verb pair defend and protect has often been quoted as an example of the delicate dividing linebetween collocation and other not-so-easily, or even less easily, definable types of word combina-tion. The difference between them, as in many cases, can be couched in terms of meaning or interms of collocational restriction; this time, they do differ in both. Whether collocational differencesare responsible for the meaning difference or the other way round, however, is a chicken-and-eggissue, as demonstrated by many authors, cf. Hanks (2000); Kilgarriff (1997). What will be showbelow is that although for this pair of verbs, exact and exhausting semantic analyses have beenavailable for almost thirty years, they have not found their way into most lexicographic descrip-tions.
Apresyan (1980), a dictionary of English synonyms containing 400 synonym sets on nearly 500pages, clearly draws the line of semantic distinction between defend and protect15 mainly, but notexclusively, in terms of the real/existing vs. potential danger/harm. This distinction, just one of thepossibly many thousand that can be made between members of synonyms sets, has no sign of beingmade in any of the dictionaries scrutinized below. You can only defend smb against real/existingharm, while you can also protect them against potential danger.
Both the verb protect in the entries for defend, as well as the verb defend in the entries for protecthave been underlined: apparently, the entries for both verbs employ the other one as a synonym, aspart of – or instead of – the definition.
Works consulted have been grouped into native speaker and learner’s dictionaries.
Native speaker dictionaries:
• CED&T (1992)defend 1. to protect (a person, place, etc.) from harm or danger; ward off an attack on 2. support in the
face of criticism, esp. by argument or evidenceprotect defend from trouble, harm, attack, etc
• AHD (1994)defend 1. make or keep safe from danger, attack, or harm. 2. support or maintain, as by argument or
action; justify.protect 1. keep from being damaged, attacked, stolen, or injured; guard. See Synonyms at defend.
15 In an entry including defend and protect as well as guard, shield, and safeguard.

Chapter Two
78
• RHWUD (1999)defend 1. ward off attack from; guard against assault or injury (usually foll. by from or against) [...] 2.
maintain by argument, evidence, etc.; uphold [...] 5. support (an argument, theory, etc.) in the face ofcriticism; prove the validity of (a dissertation, thesis, or the like) by answering arguments and ques-tions put by a committee of specialists.
protect 1. defend or guard from attack, invasion, loss, annoyance, insult, etc.; cover or shield from injuryor danger
• MWUD (2000)defend 1 [...] 2 [...] 3 : drive danger or attack away from : secure against attack : maintain against force
: PROTECT, GUARD often used with from [...] 4 : to maintain against argument or hostile criticism :UPHOLD, JUSTIFY; specifically : to prove valid (as a doctoral thesis) by answering extempore ques-tions asked by experts in an oral examination
protect 1 : cover or shield from that which would injure, destroy, or detrimentally affect : secure or pre-serve usually against attack, disintegration, encroachment, or harm : GUARD [...] Synonyms see de-fend
While the Synonyms sections of two of the native speaker dictionaries involved, AHD (1994) andMWUD (2000), provide several features that help distinguish the synonyms defend and protect(plus: guard, preserve, shield, safeguard), they give no clear indication of the major semantic dif-ference between these two verbs. They do, however, use a wording that makes it possible, if diffic-ult, to identify the major difference.
• AHD (1994), defend entrySYNONYMS: defend, protect, guard, preserve, shield, safeguard.These verbs mean ‘to make or keep safe from danger, attack, or harm’. Defend implies the taking of
measures to repel an attack [...] Protect often suggests providing a cover to repel discomfort, injury, orattack [...] Guard suggests keeping watch [...] To preserve is ‘to take measures to maintain somethingin safety’ [...] Shield suggests protection likened to a piece of defensive armor interposed between thethreat and the threatened [...] Safeguard stresses protection against potential or less imminent dangerand often implies preventive action. [Examples have been cut]
• MWUD (2000), defend entrySynonyms PROTECT, SHIELD, GUARD, SAFEGUARD:DEFEND may imply warding off what actually threatens or repelling what actually attacks or securing
against attack [...] PROTECT is somewhat wider and may imply shielding or guarding, sometimes aswith a cover, from anything that might injure or destroy [...] SHIELD suggests interposition of or as of ashield, screen, or other protective intervention against attack somewhat more imminent and specificthan that suggested by PROTECT [...] GUARD implies protecting with vigilance, force, and strength[...] SAFEGUARD applies to any strong and careful protective measures against potential dangersand threats [...] [Examples have been cut]
It is only MWUD that highlights “actually existing threat” by using the expression “actually threatensor [...] actually attacks”.
Learner’s dictionaries:
• OALD (2005)defend PROTECT AGAINST ATTACK
1. defend (sb / yourself / sth) (from / against sb/sth) to protect sb/sth from attack: SUPPORT2. defend sb / yourself / sth (from / against sb/sth) to say or write sth in support of sb/sth that hasbeen criticized
protect 1. protect (sb/sth) (against / from sth) to make sure that sb/sth is not harmed, injured, damaged,etc. [...]
The Word Finder feature of OALD (2005) provides several clues for distinguishing between thesynonyms defend and protect (plus: keep safe, look after, take care of, save from, shelter

Chapter Two
79
from, guard etc) along with a host of example sentences, but it gives no indication of the majorsemantic difference between those two verbs.
• LDCE (2000) & (2005)defend 1. do something in order to protect someone or something from being attacked : defend sth
against/from [...] 2. do something in order to stop something being taken away or in order to makeit possible for something to continue [...] 3. use arguments to protect something or someone fromcriticism, or to prove that something is right [...]:| defend sb against/from [...] | defend yourself [...]
protect 1. keep someone or something safe from harm, damage, or illness : protect sb/sth from sth[...] protect sth [...]| protect sb/sth against [...] 2. [usu pass] keep something such as an old build-ing or a rare animal safe from harm or destruction, by means of special law
The Activator function of LDCE (2005) specifically says that defend means ‘use physical ormilitary force to protect a person or place that is being attacked’, while protect means ‘preventsomeone or something from being harmed or damaged’ [italics mine].
• CALD (2003)defend 1. protect someone or something against attack or criticism. [...] Compare attack. 2. ‘try to pre-
vent the opposing player or players from scoring points, goals, etc. in a sport’protect 1. keep someone or something safe from injury, damage or loss [...] 2. If a government protects
a part of its country's trade or industry, it helps it by taxing goods from other countries.• CALD3 (2008)
defend verb PROTECT1. protect someone or something against attack or criticism. [...]. Compare attack
protect verb 1. keep someone or something safe from injury, damage or loss
Here, both CALD entries refer the reader to the antonym attack (without being explicit about itsstatus as one) rather than the (quasi)synonym defend.
• MED (2002)defend 1. protect someone or something from attack [...] 2. prevent something from failing, stopping, or
being taken away [...] 3. say things to support someone or something that is being criticized [...]protect 1. keep someone or something safe from harm, injury, damage, or loss [...] 2. if an insurance
policy protects you, it will pay money to you or your relatives if particular bad things happen [...]• MED (2007)
defend 1. protect someone or something from attack [...] 2. prevent something from failing, stopping, orbeing taken away [...] 3. say things to support someone or something that is being criticized [...]
protect 1. keep someone or something safe from harm, injury, damage, or loss [...] 2. if an insurancepolicy protects you, it will pay money to you or your relatives if particular bad things happen [...]
None of the definitions given above seems to substantiate any of the concrete claims of Atkins &Rundell (2008) below, referred to earlier, about the beneficial influence of linguistic theory on lexi-cography.
“There is an enormous body of linguistic theory which has the potential to help lexi-cographers to do their jobs more effectively and with greater confidence. [...] we referto theoretical discussions whenever they illuminate the task in hand and help us toinject more ‘system’ into our work. People whose day job is writing dictionaries can’thope to remain fully abreast in every area, but fields of particular relevance to ourwork include lexical semantics, cognitive theory, pragmatics, and corpus linguistics.[...] lexicography has benefited hugely from the insights of scholars such as CharlesFillmore, Igor Mel'čuk, John Sinclair, Juri Apresjan, Alan Cruse, Eleanor Rosch, BethLevin, Annie Zaenen, George Lakoff, and Douglas Biber (to name just a few).”
This pair of verbs may be a small example, but they are typical of the state of the art: there is notrace of the insights of Apresyan (1980) in the definitions of defend and protect.

Chapter Two
80
It is beyond doubt, as Atkins & Rundell (2008) contend, that these linguists don’t address lexico-graphic issues directly; they focus on language, not dictionaries, and they don’t tell lexicographershow to solve problems; they show different ways of looking at language, which can be adapted tothe needs of lexicographers, who have a great deal to learn from linguistic theory; and “many of therecent improvements in dictionaries can be attributed to the intelligent application of theoreticalideas.” There is reason to believe, however, that the bulk of these (recent) improvements have not,on the one hand, come from “theory” but from quite pragmatic quarters, possibly having to do withmarket demand rather than anything of principle. On the other hand, statements that lexicographyhas benefited (or, with a more careful wording, can benefit) from an interaction with theoretical lin-guistics appear to be no more than exercises in lip service. The treatment of grammar does not seemto have benefited at all. In just one of the most important and fastest developing domains, learner’sdictionaries, new insights for sense elaboration and discrimination can never be applied in practicebecause of the straitjacket of the defining vocabularies.
2.4.6.3 Ordering of senses
One field where insights from theoretical linguistics, in particular psycholinguistics, could indeedbe hoped to shape the philosophy of dictionaries is the structuring of meanings, i.e. ordering ofsenses within entries, of which three
(i) the “(supposed) frequency or commonness of use”;(ii) the (theory-laden) semantic ordering that progresses from ‘core/central’ to marginal;(iii) the “historical”
are distinguished, all of them under several aliases.
As about much else concerning the handling of (psycho)linguistic facts in the dictionary, little isknown about whether e.g. the frequency-based ordering of meanings is a reflection, in any sense, ofthe mental storage of the typical speaker, which would thereby mirror and document a supposedmeaning profile, claiming psychological reality.
It does not seem clear whether the terms frequency-based and “logical” ordering (a designation alsoencountered) are the same thing; it is unlikely, for some would want to capture this “logic” in thechronological progression of meanings down time, others in a strictly synchronic sense. Neither is itobvious whether ranking by “commonness of use” or “ordering by usage” amounts to the samething as either of those previous two. Experience suggests that they may not, although they canprobably be strung on a trio of frequency–familiarity–commonness. One also wonders whethercentrality-of-meaning-based ordering (“centrality” being another term floating around with no sta-ble definition) is the same as “logical” ordering of senses. And, even more importantly, it is a ques-tion whether either of them is to be equated with ordering based on what is “most commonlysought” – which, in the final analysis, is what the dictionary maker is concerned with.
Writing about the often radically differing ordering of senses or lexical units in dictionaries, Stock-well & Minkova (2001) also note that the only order that is “determinate” is the historical one. Thehistorical one, paradoxically, is the one that is farthest removed from speakers’ knowledge of lan-guage and thus not just from the main, or only, concern of modern linguistics but also from the con-cerns of lexicography. For the judgements for the frequency-determined order to be reliable, bycontrast, there are not enough frequency studies. More than that, for this frequency information tobe taken seriously, the counts would have to be continuously updated, and the entries rearrangedaccordingly from time to time – a project very unlikely to be afforded, even if the willingness isthere.
Their ultimate conclusion (Stockwell & Minkova 2001:188) is that “the ordering really depends onthe shrewd guesses of the editors. They will differ”.

Chapter Two
81
Atkins & Rundell go even further when they claim that
“You can’t be too inflexible about this [secondary ordering of dictionary senses]: it’salways better to end up with a sensible entry than a weird one that follows the rulesblindly.” Atkins & Rundell (2008:250)
One wonders whether the problem of the “right” ordering has not been solved with the advent ofcorpora. One look, however, at the frequency information in different learner’s dictionaries con-vinces one that it has not. If that solution were so simple indeed, and also, if differences betweencorpora were negligible and if the statistical findings of one publishing house were acceptable to allparties involved, then there would indeed no longer be a need for new calculations. However, newcounts are required because of language changes; publishers can hardly be expected to agree ontheir statistical findings from different corpora anyway. This means that this would place an impos-sible burden on the editors unless and until software programmes are capable of updating frequencyinformation virtually at a click. It is, of course, hard to say whether some such technology nowsmacking of science fiction becomes reality in a few years’ time. If one reviews the technologicalprogression harnessed in the service of lexicography in recent decades, it will be apparent that the“dreams of lexicographers” yesterday are reality now – cf. for example (de Schryver 2003).
A less developed aspect of the ordering-of-sense issue is that ideally, in different dictionaries, fordifferent purposes, and for different kinds of word different sense orderings may be desirable. Toget a full picture, however, of how these are perceived by users, experiments (which otherwise donot at all guarantee safe and reliable results) would be needed on such a scale that rather makesthem impracticable.
2.4.6.4 Monitoring lookup for customization
There are probably no studies, if at all, of users of paper dictionaries that were as fine-grained as toyield reliable results concerning the lookup strategies of individual words, but there is certainly acomplete lack of such studies concerning grammatical words. It is, to be sure, often mentioned thatgrammatical words and (long and carefully crafted) grammatical entries are seldom searched by us-ers. If so, then there is little point in finding principled ways to motivate the ordering of the mean-ings in these one way or another. Yet it has been suggested, for example, that where the ordering ofsenses is based on frequency, it ought to be exactly the opposite of what has been the consensualone, i.e. from the more to the less frequent (reported by Lew in Pajzs 2008:7). What may motivatesuch a move is that it is just the most typical/frequent meanings of words that users will know bythe time they consult a dictionary.
There may be new solutions to these and other problems approaching soon, but not from the lin-guistic domain. Lew (2009) suggests that in future electronic dictionaries, the user should be able todecide which ordering s/he prefers. He proposes, perhaps futuristically for e-dictionaries but cer-tainly unviably for print ones, that
“we move beyond static ordering in electronic polyfunctional dictionaries of the fu-ture, to dynamically adjust the ordering to the currently dominant function. Anotherfuture possibility that I explore is that Artificial Intelligence systems in electroniclexicographic products could conceivably monitor individual users’ lookup behaviourand thus customize sense ordering on an individual user basis, for example by depri-oritizing senses known to have already been acquired by the user, when in the text re-ception/decoding mode. (Lew 2009:1)
Similar suggestions have been made earlier based on experimental evidence – e.g. de Schryver(2006), which presents an innovative online Swahili–English dictionary project, where “a carefulstudy of some of the log files [...] reveals some hitherto unknown aspects of true dictionary lookupbehaviour, which results in the depreciation of the importance of corpora for dictionary-making”.

Chapter Two
82
De Schryver & Joffe (2004) inform us that proposals to use log files for the improvement of (elec-tronic) dictionaries were circulating as early as 1985. They also remind us that very “few reportshave been published of real-world dictionaries actually making use of this strategy. Notable excep-tions are Löfberg (2002) and Prószéky & Kis (2002)”. Interestingly, “electronic dictionaries cumlog files seem to be more popular in research environments focusing on vocabulary acquisition” (deSchryver & Joffe 2004:187). The kind of context-sensitive search championed in Hungary by theMobiMouse software range may be the solution for the electronic medium (Prószéky & Földes2006).
De Schryver & Joffe (2004) show that “a real-world electronic dictionary can be simultaneouslycompiled and its use studied” and demonstrates that “the results of the dictionary use study may besuccessfully fed back into the compilation”. Their study shows that the analysis of the use “revealshow electronic dictionaries are really used”. They achieve this with an [...] integrated log file [that]tracks every single action of every single user – date and time stamping each lookup, orderingfounds and not-founds, monitoring long-term vocabulary retention, etc. Because the summaries ofthese are presented to the lexicographers, “the parameters of various user profiles could be pin-pointed, with which self-tailoring electronic dictionaries could be built” (De Schryver & Joffe2004:187).
While novel and genuinely revolutionary options like these, and the monitoring of user strategies ingeneral are possible in the electronic medium, this will never become viable with paper dictionaries.It may very well be, as could indeed be anticipated in the 1990’s, that “the advantages of the elec-tronic dictionary and the familiarity of today’s young people with electronic devices will eventuallyrelegate the printed notion of ‘dictionary’ to a secondary sense” (Sharpe 1995: 49).
Monitoring users’ use of print dictionaries is doomed to be a losing battle if only because paperdictionaries themselves may be phased out, and as they become so, it will be less and less worthanyone’s while to investigate their use. One user habit that is certainly much too difficult to track, ina print dictionary at this point in time, is whether at all and how, users search and handle grammati-cal items.
In summary: one can indeed visualize the plight of the dictionary editor standing as s/he is in thecentre of a triangle, with determinate and tangible but irrelevant historical sources at one of itspoints; with hard-to-access (and perhaps lexicographically not even relevant) information on themental lexicon at another point; and “the user”, who in this ideal, unitary form and with homogene-ous needs certainly does not exist, and whose requirements concerning a good dictionary are noteasily detectable, at its third point. More importantly, it again appears that when all is said anddone, shrewd editorial judgement still matters more than “blindly following some rules”.
2.4.7 Pre-Saussurean and Saussurean dictionaries
Béjoint (2000) introduces, albeit implicitly, a distinction between Pre-Saussurean and Saussureandictionaries, which is an insightful remark about the relation of linguistics and lexicography. Hisclaim is that a pre-Saussurean dictionary, e.g. the OED (and the OED2 is not much different), is onethat is centred on the individual word and its existence as a discrete unit, and does not focus on thelexical and linguistic system. Apparently, Saussure’s views left the trade of lexicography unaffectedas they “filtered through, little by little, without causing any great revolution”, and his notion that aword is best seen in the “multi-faceted contexts of its paradigmatic and syntagmatic associations”were not acted upon for a long period of time (Béjoint 2000:173). Béjoint complains that this in-sight is just beginning to be implemented. Of course, this passage and the criticism dates back toBéjoint (1994), when it was more legitimate; it is just during around this time that English lexicog-raphy, learner’s dictionaries in particular, started to prove “truly Saussurean”.

Chapter Two
83
In 1989, Hausmann (1989:342; quoted in Béjoint 2000:174) still had to complain that too manydictionaries “make do with definitions, and neglect verb patterns, collocations, synonyms, and anto-nyms, not to mention morphosemantic paradigms”. Dictionaries, then, were still far from the Saus-surean ideal.
2.4.7.1 Országh (1967) sees Saussure’s langue “crowded out of dictionaries”
More than twenty years before Hausmann, Országh complains (1967) about the same shortcoming.He claims that the broadening of the quantitative scope [of (monolingual) dictionaries]
“has not always gone hand in hand with a corresponding all-round deepening of lin-guistic information. The more frequent and common words of the language have inmost English dictionaries not always and in every respect received that many-sidedtreatment that is due to them in view of their importance [...]. The truly vital compon-ents of a language are its frequent common words and their variable associations insentences. Yet the association-patterns of words, the “social life of words”, the langueof de Saussure has for a long time been almost crowded out of dictionaries by mattersof relatively less importance and seems only now to be gradually coming into its ownin a few modern English lexicographic works. There is still a great danger that evenin the largest monolingual explanatory English dictionaries one may lose sight of thewood for the trees [...].
A new type of an English dictionary is needed, because our conception of the seman-tic role of words has undergone certain changes in the course of the last few decades.We now like to think of words not as independent entities, but rather as coordinatedelements of larger structures, as linked constituents of utterances.
(Országh 1967:485)
Országh provides a list of the principal deficiencies of modern English monolingual dictionarieswhich are responsible for the “hortus siccus of words” that they provide instead of the “linguisticdiorama showing the natural habitat of words in depth”.
A new type of English dictionary, which “need not aim at comprehensiveness in vocabulary”,should include, among other things: phraseology, i.e.:
(i) the smallest group of “idiomatic locutions, or immutable phrases” (such as cut corners);
(ii) the very large group of “standing combinations”, mostly open compounds, “prefabricat-ed constructional elements” (such as command performance);
(iii) “word associations through frequency” (e.g. in the entry for (the ‘apparatus’ kind ofmachine, the adjectives complicated, obsolete; knitting, sewing; verbs of which machineis the subject, such as be out of order, function, go; verbs of which machine is the frequentobject, e.g. adjust, install); (iii) the emotive connotations of the words and their combina-tions (Országh 1967:486–493)
To be sure, the issue of whether infrequent words are indeed “matters of relatively less importance”even in learners’ dictionaries is no easy question. It is often argued that it is just those rare wordsthat users look up most. Országh’s “plea”, outlining some solutions to the shortcomings of existingdictionaries, was a veritable charting of the future for the learner’s dictionary, which was to be richin phraseology, word combinations, and collocations. It thus captured a moment when dictionarieswere beginning to be “truly Saussurean” or (if that would not entirely come before Sinclair’s Co-build project – cf. Sinclair 1990; Sinclair 1991; Sinclair 1998; Sinclair 2004; Moon 2007), then atleast the need was felt for them to be brought in line with Saussurean linguistics. One cannot helpfeeling that this may be the last moment of such, potential rather than actual, synergy between lin-guistics and lexicography.

Chapter Two
84
2.4.7.2 Ground for optimism concerning the linguistics/lexicography liaison?
The currents from generative linguistics, which has aimed at the potentialities of language rather inthe field of the lexicon as well, influenced lexicography even less than structuralism: Hanks (1990)goes as far as to claim that
“the Chomskyan revolution... passed by pretty well unnoticed, at least as far as lexi-cography in English is concerned”
(Hanks 1990:31; quoted in Béjoint 2000:175)
As linguistics grew more and more distant from observed language, it was bound (to be both ableand willing) to offer less and less help to lexicography. A revitalized interest in semantics – proto-types, categorization, polysemy research etc. – may generate a revitalized interest in lexicography,but not necessarily. At the time of Béjoint (2000) – or back in 1994, the time of the first edition – itseemed that modern semantics had not had any impact on practical dictionary-making yet.
It is not at all clear in the light of this (and of many of the claims made above on their relationship)how, after all this, Béjoint reaches the conclusion that “lexicography and linguistics are now inex-tricably mixed”, and that “no modern lexicographer can afford to ignore what linguistics has to of-fer” (Béjoint 2000:177).
Béjoint quotes Geeraerts, who points out that for lexicography, “the principles of language aremerely one among a number of parameters that determine the shape dictionaries take” (Geeraerts1989:287). Béjoint quotes McCawley, who reminds us that the “relationship of linguistic theory tolexicography [...] must be highly indirect if the lexicographer and the pedagogue are to accomplishanything” (McCawley 1986:165); this explicitly sanctions any more direct liaison between the two.
Hudson offers a radical, and indeed unflattering, explanation:
“The basic problem is that any of us linguists is also a citizen, with the same experi-ences as any other typical citizen. We all have dictionaries on our shelves [...]. Thesedictionaries are of course the traditional commercial ones, which have various struc-tural characteristics. One is that they distinguish between ‘the dictionary’ and ‘thegrammar’, the latter being either printed in summary as an appendix, or left out alto-gether. I think it is at least partly because of this institutionalised distinction that somany theoretical linguists are convinced that human language has a similar organisa-tion: it consists of a set of rules plus a lexicon. [...]
What I am suggesting, then, is that folk linguistics contains various ideas about the le-xicon, alias dictionary, which are at least in part founded on the traditional practice oflexicographers. Any linguist brought up in a culture where these folk ideas areprevalent is likely to be infected by them in early life and must beware of buildingthem, without critical examination, into their professional thinking. And forward-looking lexicographers must be even more careful not to mistake ideas which origi-nated in traditional lexicography for carefully considered and researched tenets ofscientific linguistics. I applaud any attempt by a lexicographer to learn from linguis-tics [...] in the hope of being able to move towards radically new and better kinds ofdictionary; but it would be tragic if the effect of this contact with linguistics was justto tie lexicographers even more firmly to their own tradition”.
(Hudson 1988:287; italics are mine)
Béjoint does not exclude the possibility that Hudson’s explanation above is valid: he suggests that ifHudson is right, then “the lexicographers who turn to linguistics for help may actually be givenideas that in fact originated in their own lexicographical traditions” (Béjoint 2000:178).

Chapter Two
85
Although many scholars – Hudson among them – have for some time subscribed to some form ofthe view that language is not so neatly organized into lexicon and grammar, it is unconvincing thatthe traditional rigid compartmentalization should be put down to this naïve world view of ‘folk lin-guistics’ that Hudson suggests. Identifying the root of a scientific evil by claiming that some scien-tific approach has gone wrong because its practitioners did not have enough critical “professionalthinking” to get rid of such naïve “folk ideas” that have simply grown on them is not just a plain in-sult but hardly a probable explanation anyway.
2.5 Lexicon into dictionary
2.5.1 Checklist for dictionary design: Hudson’s “types of lexical fact”
Hudson’s “The Linguistic Foundations for Lexical Research and Dictionary-Design” (1988)16 offersa “check-list of types of lexical fact” in its Appendix, which aims to “cover all the informationwhich could be considered for inclusion in an all-inclusive lexicon”.
“Any attempt to model psychological reality must take account of this broad range ofknowledge-types; but so must any lexicographer whose purpose is to make accessibleall the kinds of knowledge which a typical native speaker has (and which is needed iftypical native speech is to be simulated either by a non-native or by a machine). […]The structure of the list is not meant to have much significance – I have argued else-where that some of the divisions which I exploit here, such as that between syntaxand morphology are inherently vague and should not be made to carry much weight.”
Hudson (1988:310)
A lot more is surely known about psychological reality today, but not as much as to invalidate Hud-son’s claims. It appears that in Hudson’s original conception, the lexicographer’s aims include themaking accessible of the native speaker’s knowledge. This can only mean inclusion in a monolin-gual native speaker dictionary. The typical native speaker’s knowledge may be targeted in the broadcategory of “portrait dictionaries” (Béjoint 1994:107), but certainly not in “instrument dictionaries”;and both monolingual learner’s and bilingual dictionaries belong to the latter type.
It is not clear from this otherwise highly serviceable checklist, nor quite from the article itself, whatHudson means by “making accessible all the kinds of knowledge”: whether this refers to the inclu-sion of pieces of this knowledge as headword, of some as information within entries, possibly in thefront matter, or possibly in some less explicit form, such as the grammatical groundwork of a dic-tionary, which is hardly visible to the user but undoubtedly transpires through most of its policy de-cisions.
Hudson himself, who refers to the paper “What linguists might contribute to dictionary-making ifthey could get their act together” by McCawley (1986), argues that linguists in some of the better-known schools haven’t yet “got their act together” on a number of questions which are of crucialconcern to dictionary making. Hudson says that “most lexicographers are already aware of theseachievements of linguistics”, so he has little to say about them, and that “[i]n case a check-list oflexical knowledge is of interest”, he has included one as an appendix to the paper”. He adds, how-
16 The paper was based on one prepared for a workshop ‘On automating the lexicon’ in 1986, nearly a quarter of a
century ago now.

Chapter Two
86
ever, that “it is much more important to warn lexicographers against taking too seriously some verygeneral claims of linguists that touch on their work” (Hudson 1988:287).
I could not agree more that most of Hudson’s remarks still hold water; the better part of the presentstudy argues just along those lines.
As far as content is concerned, in a few places, Hudson’s explanatory remarks to easily identifiableconcepts as well as his more idiosyncratic notions have been omitted. This has been marked byomission signs.
I have altered the format of the “checklist”. In the table, Hudson’s categories are listed on the left;their lexicographic treatment and notes have added on the right.
Section 4 of Hudson’s list, “Semantics”, contained quite a few items where it was not quite clear tome what he was referring to. Also, since this list mostly concerned information only implicitly fea-tured in dictionaries, I have omitted it altogether (shading marks its original place).
In those (indeed few) cases where unambiguous /+/ or /–/ answers can be given, only these are pro-vided. Wherever a longer comment is needed, numbers are provided and the comments follow be-low the table.
Hudson does not claim universality (although he uses a non-English example at one point). The ta-ble presented here, however, only concerns English dictionaries, but of various types; these are re-ferred to in the Notes.

Chapter Two
87
2.5.2. Hudson (1988) tabulated
Hudson’s label Treated inthe diction-
ary*?
Notes
1. Phonologyunderlying segment structure; or several such structuresif allomorphs are stored rather than computed
+ segmental analysis: transcrip-tion; “storage vs. computation”indifferent
prosodic patterns of word (to the extent that there are norules for computing these) – i.e. mainly word-stress ortone
+ stress: transcription; irresp. ofwhether there are “rules forcomputing these”
2. Morphologystructure in terms of morphemes […] – No information in any form at
all about many different kinds ofword formation
irregular morphological structures linked to particularmorpho-syntactic features (i.e. irregular inflections)
+ for variable word classes: N, V,Adj, (Adverb)
partial similarities to other words(in the case of derived words or compounds)
– 1
cliticizing properties (i.e. whether or not the word con-cerned may be used as a clitic or as host of a clitic)
– 2
3. Syntaxgeneral word-class (e.g. ‘verb’) + see next boxsub-class (e.g. ‘auxiliary’) +/– 3 The class vs. subclass distinction
emerges with nouns and verbsobligatory morpho-syntactic features (e.g. beware) + ideally/mostlyvalency:
deviant position of dependent(e.g. someone etc)
+ ideally/mostly
deviant position of head (e.g. enough) + ideally/mostlyclass of dependent (e.g. object of discuss is a N) +/–class of head (e.g. head of very is an ad-word) – 4
morpho-syntactic features of dependent(e.g. objective of folgen is dative)
+ 5 ideally/mostly
morpho-syntactic features of head (?)**lexical identity of dependent(e.g. high-degree-modifier of drunk is blind)
+/– 6
lexical identity of head (e.g. [ ] … neutralprepositional head of foot is on)
+/– ideally/mostly
semantic identity of dependent(e.g. dependent of herd refers to a set of cows)
+ 7 implied by example/translation
semantic identity of head(e.g. head of each refers to a distributed event)
– 8 implied by example/translation
semantic identity of dependent if optional and absent(e.g. He shaved = ‘He shaved himself’)
– argument structure informationis usually not featured
4. Semantics— — —— — —— — —— — —— — —

Chapter Two
88
5. Contextrestrictions relating to immediate social structure(e.g. power/solidarity markers)
+ usually given by labels
restrictions relating to style (e.g. ‘formal’, ‘slang’) + usually given by labelsrestrictions relating to larger social structure(e.g. speaker classification)
+ usually given by labels
restrictions relating to discourse structure(e.g. topic-change markers)
+ given by (label) / exam-ple / translation
6. Spellingnormal orthography + usual medium; variants
also markedstandard abbreviations or ideographs + have headword statusinflectional irregularities in spelling +/– specially provided7. Etymology and language ? 9
the language to which the word belongs (in a bilingualdictionary)the language from which it is ‘borrowed’the word on which it is ‘based’the date when it was ‘borrowed’8. Usagefrequency and familiarity +/– 10
age of acquisition +/– 11
particular occasions on which the word was used – 12
clichés containing the word +/–13
taboos + if given, by labels (bet-ter placed under 5.Context)
* Unless otherwise indicated, English general dictionaries are meant.*The parenthetical (?) sign is Hudson’s own, with no explanation offered.
1 I do not quite see what Hudson refers to here; certainly nothing like this is done explicitly. The di-verse morphemes themselves, when included as headwords at all, receive diverse treatment.
2 “Cliticization” is not part of the everyday linguistic vocabulary (consisting mainly of standardnames of PoS’s). Phenomena of cliticization will be under the heading “contraction”; con-tracted forms are obviously entered, but the possibility of contraction is not marked in the rele-vant entries.
3 I do not think native speakers have explicit ideas about the classes, let alone the class vs. subclassdistinction. The classes may have some intuitive basis, but certainly not more than that; implic-itly, of course, native speakers know “all” about the finest subclasses as well. Also, I doubt thatany dictionary makes these subclasses explicit anywhere.
4 I find this too abstract/technical to claim that some information like this is in the native grammaron a par with the rest of these items. Implicitly, of course, unlike the learner, the native speakerknows that very does not combine with a non-ad-word (e.g. with a verb, with which it does inHungarian, a potential source of error, cf. nagyon esik ‘rain hard’, lit. ‘very rain’).
5 Interestingly, Hudson never moves outside English throughout the list, just on this point of Ger-man Case.

Chapter Two
89
6 A little of this will necessarily be included in all good native speaker dictionaries; some, in collo-cational dictionaries; this information will be aimed at in its entirety in the Meaning↔Textmodel.
7 This, of course, is not given explicitly in bilingual dictionaries: the supplying of the Hungariancsorda equivalent for herd does not generate this knowledge (as indeed the dependent of herdmay not only refer to cows but sheep as well, while that of csorda may only refer to cows).
8 It is difficult to guess what degree of explicitness Hudson has in mind, but I suspect that a – sign isin order. Also, there will be very different kinds of head with very disparate kinds of semanticspecifications.
9 I do not quite see what Hudson may refer to, especially since none of this is part of the nativespeaker’s knowledge.
10 Frequency information (of headwords, not senses) is often included (and is discussed in severalplaces in the present study). I do not know what is meant by “familiarity”: if it is a statisticalnotion, it is not separable from frequency; if it is a “style” label, it has a better place in 5. Con-text above.
11 This may be, but rarely is in dictionaries, suggested by labels such as “child’s usage”, “caretakerlanguage” or “motherese”.
12 A cultural dictionary, for example, may make a point of illustrating much of its lexicon with a lotof such detail.
13 Clichés may be included in most dictionaries, as may idioms and all sorts of what are referred toas “listemes” in 2.6 below.
2.6 Lexicon into dictionary: listing in the lexicon vs. the dictionary
2.6.1 Listedness and listemes
2.6.1.1 “E-lexicon” vs. “I-lexicon”
Dictionaries (that is, E-lexicons, to use a term based on one of Chomsky’s notions that may havefallen out of favour with himself17, but certainly very helpful for my purposes) are not meant to bemodels of anything, unlike grammars of every hue: descriptive, generative, contrastive or pedagogi-cal. Most of them are certainly not designed to model the lexicon. Since in general, “[a] dictionaryis not a theoretical construct, [...] a list of words, each word being provided with a description serv-ing primarily practical purposes” (Kiefer 1990), monolingual native-speaker dictionaries and bilin-gual ones are certainly not models of the lexicon, and specialized ones even less so. One series ofdictionaries, best referred to using the name of the project under whose umbrella they have beencompiled, the “Meaning↔Text model of language”, may be an exception18. But neither does the“Meaning↔Text” model look to explicitly model the workings of the mental lexicon; rather, it dif-fers from standard E-dictionaries in terms of quantity, quality, and granularity of its data.
17 Cf. Andor (2004).18 Apresyan et al. (1969); Mel’čuk (1984); Mel’čuk & Žolkovskij (1984); Mel’čuk & Žolkovskij (1988); Mackenzie &
Mel’čuk (1988); Mel’čuk (1988); Mel’čuk (1998); Apresjan (2001).

Chapter Two
90
The dissimilarities between the mental dictionary and print dictionaries, as is well-known, are sup-posed to be of both organization and content (Aitchison 1994:10). While the mental lexicon, or “I-lexicon” is in constant flux, dictionaries are by definition conservative due to technical reasons,even with the most advanced technology. Speakers’ lexicons are not static, and not unstructured: thestructure of a lexicon far exceeds that of any dictionary; it is often conceptualized as a network ofsorts, of items displaying phonological, semantic, morphological (and other) similarities. While thelexicon is far richer in information than the dictionary, even general dictionaries often contain ency-clopaedic – both linguistic and non-linguistic – information that, in turn, is not part of linguisticcompetence. Etymology is a case in point. Ironically, the main reasons why average English-speaking users consult their dictionaries are to check spellings, and check “hard words”; if that isso, they deem themselves less competent in spelling, and difficult lexical matters; these are certainlynot at the core of their competence). As Crystal (1987) puts it:
“Dictionaries are traditionally meant to solve our lexical problems – check on spell-ing, or a meaning, or (if you’re a Scrabbler) to establish whether a word exists at all.It is a close encounter of the briefest kind: you open the book, find the word, checkthe point, and close the book” Crystal (1987:vii).
Crystal’s remarks focus on native speaker dictionaries, and since bilingual ones have always servedmore purposes, they are always longer encounters than that. The notion of “the dictionary” hasbeen enormously expanded since by the completely different world of learner’s dictionaries.
The lexicon, unlike most dictionaries, has some (arguably approximate, and never up-to-the-minute)frequency information, which, however, is not encyclopaedic in the sense that the speaker appearsto use it in linguistic production, and, being part of linguistic competence, can be made explicit –e.g. experimentally.
The other lexicon, the entire lexical stock, or “word stock” of a speech community is referred to inthe present study as the vocabulary. Bauer (2004) uses “lexicon” in a rather broad sense when hewrites that the lexicon is either in the heads of speakers or “shared by speakers of a single languagevariety” (Bauer 2004:66).
It is the “social construct”, i.e., the vocabulary that is being meant when the claim is made that
“a dictionary will never provide a full coverage of the lexicon due to practical limita-tions of size and requirements of user-friendliness and because the lexicon is expand-ing and changing daily” (Booij, 2007:18; italics mine)
Since these public word stocks of languages are even more complex phenomena than the individualmental lexicons of their speakers, it must be obvious that contra Booij it is not just the practicalkind of limitation that stops dictionaries from covering them in their entirety.
The dictionary, then, is not meant to model either the lexicon or the vocabulary, but may be seen asa device that documents, represents, or portraits the latter.
An ever more widely held notion must be noted here: that speakers also have an “encyclopaedia”, inaddition to the I-dictionary, at their disposal; Keith (2001:99), for example, contends that this ency-clopaedia contains the mental lexicon. If our world knowledge is seen as containing linguisticknowledge, this is far from implausible. Although it is customary to classify E-dictionaries in termsof more or less encyclopaedic, they characteristically do not represent this encyclopaedic knowl-edge. Besides, a lot – probably most – of the world knowledge that makes human existence possibleis never documented in either encyclopaedias or dictionaries. The relationship between this I-ency-clopaedia and E-encyclopaedias is presumably similar to, and undoubtedly not less challengingthan, that between I-lexicons and E-lexicons.

Chapter Two
91
There is largely agreement on both the lexicon and the dictionary being metaphorically conceptu-alizable as some kind of list; there is not even broad concord about the content or the shape of this.This chapter, which looks at aspects of listedness, takes a rough inventory of the entities stored inthe lexicon and the print dictionary.
Three caveats are in order here. One is that there is much controversy concerning listedness, andrelated problems of storage and retrieval, if one surveys the more relevant psycholinguistic litera-ture. Since the present study has nothing to contribute to that area (and nothing to say about thestructure of mental lexicon entries, their links, the exact nature of information contained in them,including the question of whether the word’s phonetic shape is represented separately from thesyntactic and semantic information), it is to be expected that even the broadest claims made will behighly tentative.
The second is that the present chapter, and presumably the notion of listeme itself, is only relevantin some linear morphological model. Fortunately, Hungarian and English are predominantly likethat.
The third, that a neat, and not necessarily justified, separation of linguistic levels will have to be as-sumed at the outset to make cataloguing possible.
The lexicon is supposed to be a repository of whatever the speaker stores here and retrieves fromhere; it will be stressed, then, that any arbitrary sound–meaning pairings unpredictable for any rea-son are listemes. “Arbitrary”, in this approach is effectively synonymous with “unpredictable”; “ar-bitrary” is usually applied with reference to words and not to other lexical items, but since the termimplies that there is no link between form and meaning, it should be valid at any lexical level, fromcompounds to all multiword units.
When any expression above the morpheme level is unpredictable either semantically or formally, itmay be considered an idiom.
2.6.1.2 Origins of the term “listing”
The concept of “listing”, if not the term itself, is widely believed to have been introduced in Aro-noff (1976:45), where it is claimed that linguistics owes the notion to Zimmer, who was “the firstperson to suggest that productive and unproductive classes could be distinguished by claiming thatonly members of the latter were listed in the lexicon”. The original source, then, is Zimmer (1964).
Under the notion of listedness, if a word had idiosyncratic properties, it was supposed to be listed inthe lexicon. Listedness here, then, only concerned words, and only a subset of words. Whatever wasidiosyncratic was necessarily a listeme; whatever was regular was not. Aronoff’s example were the-ness words, which “must not be listed” unless they were irregular. He did not use “listeme” or“listedness”; the former was first used in Di Sciullo & Williams (1987).
The wording “must not be lexically listed” may seem to only make sense in dictionaries but not inthe lexicon, for which “need not be listed” seems appropriate. The form “must not” does, however,make sense if (i) it is shorthand for “must not be listed in the model of the lexicon”, or (ii) it reallybans the listing of anything redundant in the memory for reasons of economy. Today it appears thatthere is a lot of memorization in the case of regulars as well (Altmann 1998; Martin, Newsome &Vu 2002; Plag 2006; Windisch Brown 2008).

Chapter Two
92
2.6.1.3 On the mental lexicon
Altmann (1998:1ff) 19 warns that
“the history of science is littered with examples that do not work. Often, they aresimply inappropriate, simply wrong, or simply confusing. But even when inappropri-ate, they can prove useful. For instance, it is not unnatural to think of our knowledgeabout the words in our language as residing in some sort of dictionary. The [...] OED,all twenty volumes of it, is as good an example as any – its purpose is to provide, foreach entry, a spelling, a pronunciation, one or more definitions, general knowledgeabout the word itself, and perhaps a quotation or two. Getting to this information isrelatively efficient. [...] on CD-ROM [...] you do not even need to scan down the page[...] just type in the word and, and up pops everything you ever wanted to know aboutit. But [...] the analogy between accessing a written dictionary and accessing themental lexicon is at best fragile. [But] it provides a useful starting point from whichto proceed, using a vocabulary that is easily understood to describe a process (ac-cessing the mental lexicon) that is easily misunderstood. [...]
At least a conventional dictionary can be imagined, and is therefore a useful placefrom which to start our exploration of the mental equivalent. Most importantly of all,the questions one can ask of a dictionary such as the OED, and the questions one canask of the mental lexicon, are remarkably similar. The answers, can be surprisinglydifferent.”
The fact that [the mental lexicon and the OED] are different does not mean that theyare necessarily used any differently – for instance, the OED in book form couldhardly be more different from the OED on CD-ROM, and yet there are aspects oftheir use which are common to both of them.”
While searching the paper dictionary, we do not burden our minds with the “neighbours” of words,that is, when
“accessing the dictionary [..] we will encounter, during the search, other words thatshare certain features with the word we are ultimately interested in finding, whetherthey share their spelling, pronunciation, rhyme, shape, length, or frequency.
(Altmann 1998:4; italics mine)
In the mental lexicon, however, we do access, or activate (the meanings of) the neighbouring wordsthat we encounter. It is far from obvious how all this may happen, but Altmann claims that “it is un-clear how things could possibly happen any other way”. (Altmann 1998:4).
Explaining why “activate” information is better as a term than “access” information, Altmann re-minds us that all the information in the mental lexicon is stored within the neural structures of thebrain.
“[N]othing is accessed; it is activated. And although we might just as well continue torefer to lexical entries, [...] the mental lexicon is in fact a collection of highly complexneural circuits”. (Altmann 1998:6).
Altmann argues that not just words but morphemes also have their own lexical representation.
“the relationship between ‘walking’ and ‘talking’, and between ‘entrapment’ and ‘en-hancement’ can be explained in terms of the words sharing morphemes that eachcontribute to the meaning in a way that is specific to that morpheme.”
(Altmann 1998:18)
19 The page numbers for Altmann (1998) that are given here refer to Ch 6: only this chapter is available.

Chapter Two
93
Words such as apartment and department, however, are not morphologically complex in the sameway that words like enhancement and entrapment are, because enhancement and entrapmentare related to enhance and entrap respectively, but apartment and department are not related toapart and depart, respectively. On hearing the initial sounds of enhance, the mind activates theentry for enhance (i.e. the entry corresponding to the stem, which includes the activation of itsmeaning). Towards the end of the sound sequence it will anticipate a number of possibilities thatwill include the subsequent morpheme -ment. If the subsequent acoustic input matches this mor-pheme, its activation increases. If it does not, then the mismatch decreases the activation. For wordslike apartment, after hearing the sequence ‘apart’, two lexical entries are activated: one corre-sponding to apart, and one corresponding to the still unfolding but unrelated apartment. Crucially,the -ment in apartment is not interpreted as a distinct morpheme (Altmann 1998:18–19).
It could well be that all this linguistic activity really belongs with the happy hunting ground of psy-chology and not linguistics; and theoretical constructs such as “lexical entry” may well be jetti-soned. Lexicography, however, is going to continue needing some – more traditional – foundation.
Altmann (2001) is a review that takes a broad look at how psycholinguistics has developed from theturn of the 20th century through to the turn of the 21st. Of its observations only those concerning“storage and retrieval” and within it, the representation of morphologically complex words, will befocussed on. Altmann’s references, some of which have been left out and marked by [...], are notincluded in the References at the end.
How are morphologically complex words, composed of a root and one or more affixes, representedin the mental lexicon?
“[It has been ] argued that the root word is located (through a process of ‘affix strip-ping’), and then a list of variations on the root word is then searched through [...].[E]xtensive evidence [has been provided] to suggest that polymorphemic words arerepresented in terms of their constituent morphemes [...]. However, the evidence alsosuggests that morphologically complex words which are semantically opaque are rep-resented as if they were monomorphemic (the meaning of ‘casualty’, e.g., is not re-lated to ‘causal’, hence the opaqueness). Thus some morphologically complex wordsare represented in their decomposed form (as distinct and independent morphemes),while others are not.” Altmann (2001:140)
What determines whether a word is represented in decomposed or whole-word form?
“[S]emantic transparency, productivity (whether other inflected forms can also be de-rived), frequency and language [...] In respect of the access of these forms, for pho-nologically transparent forms, such as ‘reviewer’, the system will first activate, onthe basis of ‘review’, the corresponding stem. It will then activate some abstract rep-resentation corresponding to the subsequent suffix ‘er’, and the combination of thesetwo events will cause the activation of the corresponding meaning. For phonologi-cally opaque forms, such as ‘vanity’ (from ‘vain’), the phonetically different forms ofthe same stem would map directly onto (and cause the activation of) that abstract rep-resentation of the stem (making the strong prediction, hitherto untested, that the se-quence /van/ should prime not only ‘lorry’, but also ‘conceit’).
...
“Theories concerning the acquisition, representation and processing of inflectional af-fixes (e.g. ‘review’ + affix ‘ed’ = past tense ‘reviewed’) have been particularly con-troversial.” Altmann (2001:140–141)

Chapter Two
94
2.6.1.4 Must or may be listed?
Most of the psycholinguistic literature seems to suggest that the definition that “whatever is irregu-lar is listed, whatever is regular is not; it is computed on the spot” only holds in one direction. If aform is irregular, or idiosyncratic, it will indeed be stored in the memory, but many – the more fre-quent – regular forms are also stored, since their retrieval can be faster, and their storage more“cost-effective” than generating them online. It is an often neglected aspect of this storage thatwithout such storage of regular forms the general pattern could not emerge in the first place, aspointed up in Taylor (2003:643). Booij (2007) even claims that “a correct model [of morphologicalknowledge] has to allow for the storage of regular inflectional forms” (Booij 2007:244). Dictionar-ies, to be sure, need not be concerned with whether regular forms are or are not listed in the mentallexicon – dictionaries do not, as a rule, list them. The treatment of irregular forms, however, reflectstheir mental listedness.
Since anywhere above the level of morphemes only complex units are found (although whether thiscomplexity is provided by the morphology or the syntax depends on the language in question), inthe study of listedness the basic dichotomy is “constructed ↔ unconstructed”. Simplexes are neces-sarily listemes, while complex units may be – but usually are not. The ratio of listed to unlistedforms will also depend on morphological type. An extreme example that illuminates this is that forwhat is termed a “full listing” of 20,000 nominal and 10,000 verbal roots of the lexicon of Turkish,two hundred billion inflectional forms would have to be stored (according to Hankamer 1989, citedin Katamba 2005:242).
An English learner of Turkish will obviously not want to search for most of these inflected forms ina Turkish–English dictionary, but suppletive forms do have to be listed when their shape is so dif-ferent from the rest of the paradigm that finding them otherwise would be impossible.
2.6.2 Listedness in the lexicon: the traditional rank scale
Traditionally, one of the divisions that may be postulated for linguistics is as follows: phonol-ogy/phonetics; morphology; syntax. It is far from obvious a priori that this division is theoreticallyjustified; it may well be, for example, that the rules for the combination of morphemes are the sameas the rules of combinations for words. If so, no real distinction between morphology and syntax isjustified. It is also conceivable that some such division may be justified, but not this one: e.g. part of“today’s” morphology is “really” part of phonology, but not all of it. The segmentation of speechsignals may be done at various layers and with various levels of “graininess”: of these, lexicographyrepresents all the traditional layers but focuses on the middle ones. Because of this, it is thetraditional picture that is conveniently assumed for the purposes of the present study.
Listedness, in the definition above, applies to the entire scale of meaningful linguistic entities, in asense much broader than originally used by Aronoff (1976). On the traditional “grammatical rankscale” of morphemes, words, phrases and clauses (Halliday 1985/1994), listed must be whichever ofthese are stored in and retrieved from the speaker’s memory rather than generated ab novo. It is ob-vious that in this rank scale all four items do contain listemes. As a rough approximation, it isprobably true that morphemes are necessarily listemes; some, perhaps most, words must be; manyphrases and a small part of clauses are listemes.
This treatment, as has been suggested above, obviously presupposes the separation of these ranksfor expository purposes. These four ranks, along with certain peripheral items which will beemerging as the discussion enfolds, will be explored from the point of view of listedness. In the re-mainder of this chapter, an inventory of these items on the grammatical rank scale will be offered.
The picture is the least controversial within the category of morphemes; the most controversy is ex-pected within the (not always easily separable) categories of words and phrases, and within the

Chapter Two
95
broad category of phraseological, or multiword, expressions. Since there is listedness both belowand at the level of words as well as above the word level, the question must be addressed of whatkinds of morphemes, words, phrases and clauses are characterized most by listing.
The overly simplified picture – ignoring, among other things, (i) the twilight zone around words, (ii)the fact that there exist linguistic elements other than those on the grammatical rank scale, i.e., be-longing within the grammatical system, (iii) the fact that not everything that may be listed must be –is as follows in tabulated form:
listeme?morphemes allwords mostphrases manysentences fewer
2.6.3 Below the level of words
Morphemes, as unpredictable minimal form–meaning units, are all listemes by definition.
This feature of morphemes is independent of the traditional “bound vs. free” and “derivational vs.inflectional” distinction.
Whether meaning components of morphemes exist, i.e. whether morphemes are or are not atomssemantically, is not relevant for us. If these ostensible meaning components do not correspond toformal ones, then for the present analysis they have virtually no existence. Componential analysismay (have) be(en) relevant for semantics, but is surely irrelevant for lexicography.
Morphemes that have no conventional meaning just function, i.e. are not form–meaning units, willbe lexicographically almost non-existent, at least for everyday dictionaries of a more modest cover-age. Thus, while giant portrait dictionaries such as RHUD and MWUD do enter (if without any la-bel) the interfix -o-, average native speaker dictionaries typically do not list such formatives:
• RHUD (1999) -o- the typical ending of the first element of compounds of Greek origin (as -i- is, in compounds of Latinorigin), used regularly in forming new compounds with elements of Greek origin and often used inEnglish as a connective irrespective of etymology: Franco-Italian; geography; seriocomic; speedometer. Cf. -i-. [ME (< OF) < L < Gk]
• MWUD (2000) -o- Etymology: ME, from OFr, from L, from Gk, thematic vowel of many nouns and adjectives in combi-nation used as a connective vowel originally to join two elements of Greek origin and now also tojoin two elements of Latin or other origin and being either identical with <chrysoprase> or analo-gous to <Anglo-Saxon> an original Greek stem vowel or simply inserted <jazzophile> <dramatico-musical> compare -I-
2.6.3.1 Morpheme boundary types
Morphemes are not a unitary group in multiple ways; under one classification, English affixes havebeen claimed to belong to two (phonologically distinct) types from the relevant point of view20:
affixes with a(a) # (cross hatch) boundary: e.g. un#, re# and #s – as in un#natural, re#use, nation#s(b) + (plus sign) boundary: e.g. in+, re+ and +al – as in in+numerable, re+duce, nation+al
20 The original notion behind this classification of morphemes – never embraced by the majority of researchers, and
modified heavily and repeatedly since – is based on Kiparsky (1982), Halle & Mohanan (1985) and Mohanan (1986).

Chapter Two
96
Affixes of the “#” type are supposed to typically attach to free roots (#natural, #use, nation#),while “+” affixes may attach to bound roots as well (+numerable, +duce, nation+).
Roots of the “#” type and affixes of the “#” type are probably both listemes. The productivity ofsome “#” type derivational affixes (and concomitantly the transparency of the words produced fromthem) may be as high as that of inflections.
The listedness of bound roots of the “+” type and of “+” type bound affixes, by contrast, cannot besummarily given, but can probably be characterized by a cline. At one extreme of the listednesscontinuum of “+” bound roots, under this assumption, are found those that have an easily recogniz-able free variant, and which thus have a more transparent meaning (e.g. nation+). At the other ex-treme are elements of the +duce, +ceive type, which do not even owe their morpheme status totheir meaning (if indeed they are morphemes), but to their morphological behaviour, i.e. allomor-phic variability.
The “+” type bound affixes are probably not listed. In this sense, they do not have as independent a(psycho)linguistic existence as the listed ones.
2.6.3.2 The dictionary need only list derived, not inflected forms?
2.6.3.2.1 Hungarian nagyot and sokat: straddling inflection and derivation
Forms such as the H. nagyot ‘hard; intensively’ (as e.g. in swallow hard) and sokat ‘a lot; a lot oftimes’, which are considered as marginal exceptions, can be looked upon as lexicalized accusativeforms of the adjectives nagy ‘large’ and sok ‘lot’, respectively. (The H. adverb nagyon ‘very’ is it-self a locative-suffixed form of nagy ‘big’) This obviously results in listing. Because, however, thisprocess involves category change, listing is also inevitable, since this is a derivational not an inflec-tional process. The entries of nagyot and sok below are from MASz (2000); nagyot has its own en-try. The entries are slightly edited:
nagyot – nagyot esik fallRH
heavily, have a bad fall nagyot lép takeRH
a long step nagyot ütstrike
RH heavily nagyot halad make
RH good/great progress
The analogous sokat, unfortunately, has not been accorded headword status in MASz (2000): therelevant meaning of sokat is buried deep within the sok entry (which would be quite a huge onewithout this) with the consequence that is hardly discernible at all. The relevant expression has beenunderlined; the KIFEJEZÉSEKBEN [‘in expressions’] section has been removed.
sok 1. [megszámlálható:] many, a lot of, a large number of, numerous, a host of sok százseveral hundred, hundreds of smth sok ember many people, lots of people, a largenumber of people elég sok quite a lot sokban különbözik differ in many respects/wayssok tekintetben in many respects/ways 2. [nem megszámlálható:] much, a lot of, plentyof, a great deal of sok tej much / a lot of milk sok ideje van have a lot of time nincs sokideje not have a lot of time, haven’t got a lot of time, be pushed/pressed for time elégsok quite a lot sok időt vesz igénybe it takes smb a long time, it’s very time-consumingsok pénze van have a lot of money, have heaps/wads/tons of money sok fáradságbakerül take
RH smb a lot of trouble/effort sokat a lot, a great deal sokat ér be precious/valu-
able tíz fonttal ma nem mész sokra ten pounds goes nowhere now sokat ígérő promisingsokat képzel magáról be full of oneself túl sokat enged meg magának go
RH to liberties,
have the audacity to do smth sokba kerül costRH
a lot sokban hozzájárul contribute agreat deal to smth sokkal jobb be a lot better […]
While inflections are supposed (i) to be highly productive, applying to all (eligible) roots of a wordclass; (ii) to be semantically transparent; (iii) not to change word class, derivation is not necessarilyproductive, does not necessarily produce semantically transparent expressions, and may change

Chapter Two
97
word class21. The simple view is a commonly held one that dictionaries do enter, as headwords, de-rived forms (i.e. different lexemes) but not inflected forms.
This simplistic claim is clearly disproved by many bilingual, including E→H dictionaries. Most ir-regular English forms – past forms, plurals and comparatives – are of course (likely to be) given, asthese have their rightful place in monolingual works, too. The likes of went, men and better willnot be absent in them; these entries, however, will just refer further to the canonical forms.
The H→E part of any larger dictionary, if it is to prove useful to the non-Hungarian user22, mayactually contain a daunting number of such irregular Hungarian forms. However, because irregular-ity is more typical, in addition to the paradigms being much more varied, than in English, the con-sistent registering of all unpredictable forms would be near impossible: the forms mész ‘go 2SG’,menj ‘go SG IMPER.’ and many similar ones, even the infinitive menni itself, are unguessable frommegy ‘go 3SG’, the canonical lemma form. The non-Hungarian user, then, is expected to have justthe right amount of grammatical knowledge to know the (less wayward) verbal, nominal and adjec-tival paradigms. The forms that are usually entered are the irregular/suppletive ones (the distinctionbetween which is but a matter of degree, this proving to be a domain where clines rather than crispeither–or relations hold), even if some of these are not more difficult to guess than the regularly in-flected ones. The form több ‘more’ (comparative of sok ‘many/much’) does indeed differ from sokin each segment, but the form ment ‘went 3sg’, e.g. is not easier to guess from the canonical megy‘go 3SG’ than szebb (comparative of szép ‘beautiful’) is guessable from the canonical szép – and thelatter is not even irregular, let alone suppletive. (There is, incidentally, also a canonical form ment‘save 3SG’; this means that if all such unguessable forms as this one actually were to be included inthe H→E dictionary, then for the string ment two homonymous headwords would be needed –whether in one entry or two; of these, one would just refer to canonical megy.
Focusing now on English: a similar but actually existing, and not too frequent, case is when someform can be assigned to two homophonous word classes (assuming a PoS-first and senses-secondarrangement). Taking the letter sequences broke and worn as examples, there will be one adjectival(e.g. flat/stony broke) and one irregular verb form for broke, with the latter just referring on to theinfinitive break, while with worn, there is one adjectival (‘adversely affected by long use’) and oneverbal entry (the “3rd form”), the latter just referring the user on to wear. This double nature of ad-jectival vs. verbal participle forms, as well as this referring item, is typical in bilingual dictionaries.
Nouns and adjectives are the best illustrations of this phenomenon. With verbs, the situation is dif-ferent: they have irregular past forms whose separate inclusion is generally unwarranted. There isusually little about the past tense abode or wrote that cannot be said in the abide and write entries.Participle forms, however, behave differently: being on the border of inflection and derivation, pastparticiples such as written may have their separate entries; in such cases the pattern is similar to thehomophonous broke headwords, with one referring and one self-contained written. Even idiomscontaining the past and past participle forms of these will be naturally entered in the canonical“plain form” entry.
21 The inflection vs. derivation distinction itself, as is often suggested, may well be trivial, or uninteresting and without
predictive power, for theoretical morphology. It is, however, a relatively stable linguistic notion that is hard to sweepunder the carpet in lexicology.
22 The practice, however, seems to be that they do not wish to cater to non-Hungarian, i.e. mostly English users; theyare unidirectional in this sense.

Chapter Two
98
2.6.3.2.2 Adjectival and nominal illustrations: better, best, teeth
Three (adjectival and nominal) entries are given below to illustrate; the AMSz (2000) entries havebeen slightly edited.
(i) In the case of adjectival better it would probably make no sense to list all of the following ex-pressions in the entry good.
better 1. jobb better and better egyre jobb 2. nagyobb(ik) the better part of smth anagyobbik része vminek 3. jobban van, kevésbé beteg she is better this morning ma dél-előtt már jobban van
KIFEJEZÉSEKBEN: better luck next time! legközelebb több sikert! / sebaj, legközelebb jobbanmegy majd! for better or (for) worse jóban-rosszban, történjék akármi get the better ofsmb legyőz, felülkerekedik vkin better the devil you know a bizonyos rossz is jobb a bizony-talanságnál
Here, even if the clearing or loosening up of the better entry were the purpose of relocating the bet-ter phrases to the entry of good, moving them would not only significantly clutter up the good en-try (sizeable anyway); the relative placement of these better phrases and the good expressionswithin the good entry would also be problematic. The better expressions simply have nothing to dowith the good expressions already in the entry; there is no good expression that each of them mightbe attached to; listing them at the end of the entry practically means listing them separately. Thereis hardly room for the better expressions here:
good, better, best MNÉV 1. jó a good father jó apa […] 2. kellemes, jó have a good time jólmulat, jól érzi magát […] 3. kedves, jó, szíves it was very good of him nagyon kedves volttőle 4. ért vmihez, jó vmiben be good at maths jó matekból […] 5. hasznos, jó, egészséges,célszerű milk is good for you a tej egészséges […] 6. érvényes good for a month […] 7.sikeres make (it) good boldogul, sikerre viszi, befut 8. helyes, jó, erkölcsös […] 9. mennyi-ség-kifejezésekben a good deal of trouble sok / jó nagy baj […]
KIFEJEZÉSEKBEN: very good, sir! hogyne/igenis, uram! no good hasznavehetetlen no goodtalking about it kár a szót vesztegetni rá good for you! gratulálok! […] good on/for him! jóneki! make good jóvátesz, orvosol, pótol as good as szinte, jóformán she as good as re-fused gyakorlatilag nemet mondott as good as new majdnem új, mint újkorában so far sogood eddig/idáig rendben is van/volna all in good time mindent/majd a maga idejében asgood as gold olyan, mint egy angyal be as good as one’s word ura a szavának, szavatartógood and {MNÉV} teljesen, tisztára {MNÉV} I’ll come when I’m good and ready majd jövök, hateljesen kész vagyok good and mad tiszta bolond
(ii) The entries of the four different word classes of the graphic sequence best throw light on otherproblems as well. Let us see one by one what the possible alternatives might be to such a self-con-tained set of four best entries.
If the nominal best were moved from this supposedly inflected-form entry to its “sister” entry, i.e.the supposedly canonical form, which is the nominal entry good in this case, then – whichever ar-rangement within that entry were chosen – it would make it seem that good and best are forms ofthe same noun. If the adjectival best were moved to its “sister” entry, that of the adjectival good,then the problems caused by moving better (discussed above) would only be multiplied: the entrywould thus accommodate all of the good/better/best expressions. If the adverb best were moved toits “sister” entry, that of well (a complicated one without this move), then better would also have tobe moved (above only the adjectival better was targeted.) More importantly, if all of these – nomi-nal, adjectival and adverbial – best expressions were moved and their present entries eliminated,then the only PoS to remain under the form best would be the verbal one, having no “sister entry”to which to be moved. The dictionary would then willy-nilly claim that the only (noteworthy) bestform is a verb, possibly with referring arrows sending the user on to the other three entries.
best FNÉV a legjobb [tudás/eredmény/teljesítmény]KIFEJEZÉSEKBEN: do/try one’s best megtesz/megpróbál minden tőle telhetőt to the best ofone’s knowledge/ability legjobb tudása-képessége szerint look one’s best a legelőnyösebbszínében mutatkozik […]

Chapter Two
99
best MNÉV 1. legjobb all the best minden jót! 2. legnagyobb the best part of smth a nagyob-bik része/fele vminek, vminek a javaKIFEJEZÉSEKBEN: it’s all for the best jól van ez így
best HAT.SZÓ 1. legjobban as best one can amennyire vkitől telik 2. [összetételekben] legin-kább best-loved legjobban szeretett best-hated a legjobban gyűlöltKIFEJEZÉSEKBEN: at best legfeljebb, a legjobb esetben (is) had best [tanács kifejezése] leg-jobban tenné-teszi, ha {MONDAT} you had best go at once legjobb/legokosabb volna azonnalmenned
best IGE legyőz, felülkerekedik vkin
(iii) In the case of teeth, there may be less reason to retain some of the expressions in the teeth en-try. Encountering the plural expression, the learner/user may well check under teeth and be referredto the entry tooth. The problem here is that there are some MWEs containing the singular tooth aswell; this time, size is no problem, but the relative placement of these tooth phrases and the pluralteeth expressions would still be one:
teeth 1. fogak � tooth cut one’s teeth fogzik, jön a foga 2. hatalom, mozgástér we want togive the police more teeth több hatalmat akarunk a rendőrségnek
KIFEJEZÉSEKBEN: get/sink one’s teeth into smth lendülettel/lelkesen / teljes erejéből bele-kezd/belefog / beleveti magát vmibe
tooth TBSZ teeth 1. fog […] I’m going to the dentist to have a tooth out megyek a fogor-voshoz kihúzatni egy fogamat cut a tooth jön egy foga […] 2. fog [fésűn/fűrészen/fogaskeré-ken]
KIFEJEZÉSEKBEN: fight tooth and nail foggal-körömmel harcol have a sweet tooth édesszájúan eye for an eye and a tooth for a tooth szemet szemért, fogat fogért
A similar but by far not marginal case is the (apparent) English plurals such as scales, news, goods,which (may not be derived from anything but) clearly are not regular, predictable inflected (plural)forms.
A problem with such a rule of thumb as the “include as headwords lexemes, not word forms” re-ferred to above is that views in this regard seem to be hugely varied. (Users, of course, are unawareof the bases of these views and are thus ignorant of the motives of such decisions.) The underlyingquestion, as in many cases, can be seen as reducible to a simple one of “meaning vs. form”: howmuch difference of sense and/or possibly distribution must two forms that are only inflectionallydifferent display for these two forms to be regarded as different lexemes? It is not at all clearwhether the word salts will fare better if it is buried (even with the appropriate typographical high-lighting) as just a word form within the salt entry, or whether it deserves an entry of its own. Whensuch an entry is rather long, as seen above in the good–better–best set of examples, then “buried”will unavoidably mean hard-to-find. Is either the meaning or the grammar of plural salts suffi-ciently different from that of the singular salt? These individual expressions may be judged to bedifferent semantically, but quite similar in terms of syntax, or the other way round, whichever thecase may be; both views may be argued for. The problem has often been discussed in the literaturewith all its ramifications: Acquaviva (2008) is a book-length treatment of the relevant phenomenon,which he has termed “lexical plural nouns”. The discussion in the sections below is based on thiswork.
It may be a policy to have plural forms like these entered separately from their singular counterpartswhenever there is a “meaning shift” between them, i.e. the plural meaning is not predictable fromthe singular. As always with such decisions, it is questionable, however, whether users realize thiskind of subtle distinction that is the basis of decisions here, i.e., whether they notice and appreciatethis policy.

Chapter Two
100
A noun can be plural lexically in a variety of ways: the most obvious example (and the least re-vealing one) is the fixed-plural-value noun e.g. scissors. There are lexically idiosyncratic pluralforms, like pence from penny. Plurals that must be learned as whole word forms, like suppletivestems, also involve knowledge about certain words and not just about grammatical morphemes (af-fixed or otherwise). But the empirical domain of lexical plurality is much wider. It includes pluraldoublets and all instances of competing plural alternants, insofar as the choice between them is notautomatically determined by grammar but involves choosing between distinct senses. For those whouse mice for animals and mouses for pointers, the choice between the two plurals is no moregrammatically determined than that between cat and dog. Competing plural alternants often differin form and grammar beside meaning, but even when pluralization does not involve morphologi-cally contrasting alternants, it may affect lexical semantics to such an extent that the questionwhether we are dealing with one noun or two becomes unanswerable. It is not so clear that the plu-ral that appears in she’s got the brains in the family is an inflectional form of the same word thatappears in the singular as brain. After all, if brain refers to an organ, she’s got the brains does notmean that she has many cerebral organs. A plural, likewise, like waters in the river and its watersdoes not refer to a set of waters in the same way as books refers to a set of books. Does that make ita lexical entry distinct from the singular water? Are pence (units of value) and pennies (coins) dis-tinct lexical items? It depends on what is meant by lexical item, and that too is heavily theory-de-pendent.
It seems a worthwhile thought experiment to imagine a situation where all editors of all Englishmonolingual and bilingual dictionaries have a thorough knowledge of Acquaviva (2008). Wouldthey be able to get past this stage and manage to skim just the kind/amount of information that theirparticular dictionary needs? The answer is a definite no. The book, similarly to most such volumesas might be thought to provide guidance for lexicographic use, offers no such knowledge of a di-rectly utilizable kind.
In the absence of such guidance, it might be consoling to think that at least some practical solutionwill be found, but that is not that easy either. It would not be practical, and would not, in the finalanalysis, do a good service to users, if words of the salts (and brains? and waters?) type were in-cluded twice, once in the singular entry and once on their own. In paper dictionaries, this duplica-tion would be a waste of space that is an unforgivable disservice to users. In lexicographic contextswhere space is no problem, this problem of waste would not be there: a double inclusion wouldsimply be an open admission of a semantic–lexicological ignorance. Decisions concerning inclusionof such expressions under the singular, as inflected forms, or under a plural headword of their own,must consequently be ad hoc and remain so. User studies cannot be hoped to provide the answers:they would just show that not only are there widely different users but also that these lexical itemsthemselves come in too many different subclasses for any tendencies to be clearly visible. Fromtheory’s point of view, this may be admission of failure; looked at from utility, ad hoc inclusion isthe only viable option.
On an even more pessimistic note: almost nothing coming from theoretical quarters concerning theinflection–derivation line of demarcation (provided that there is indeed some such) helps the dic-tionary treatment of items such as have been explored above by providing foolproof tests for lexi-cography.
2.6.3.2.3 Semantics vs. lexicography
Lexical semantics only gives tentative and/or relativistic and/or ad hoc answers: after all, the job ofa science is not supposed to be the clearing up of problems once and for all but to handle new onesthat will emerge from the half-solved old. If that is so, lexicography can never hope to get answersto its basically descriptive problems, nor think that getting them would be advantageous. It may

Chapter Two
101
cherry-pick from the (rapidly changing) solutions and theories on offer from time to time, but be-cause whatever input will have to be heavily modified by its own methodological considerations,the treatment of the lexicon that may be hoped to emerge from this large body of input will never be“scientific”.
Kay (2000) argues that his paper has been written
“from the point of view of a semanticist who is also a working lexicographer, and onewho has suffered frustration over the years from a lack of connexion between the twoactivities. These two areas of human endeavour have a natural affinity, yet the degreeof cross-fertilisation between them has been depressingly slight. To semanticists,lexicography often appears largely and lamentably untheorised, uneasily poised be-tween the academic and commercial worlds. To lexicographers, on the other hand,semantics may seem a remote, abstract and even frivolous discipline, with little tocontribute in the way of practical solutions. Dictionaries often merit little more than apassing glance in handbooks on semantics, while semantic theory is rarely mentionedin dictionary prefaces.” (Kay (2000:53)
To this may well be added that most of these observations need not necessarily be phrased in suchwoeful terms. Apparently, those researchers, both on the applied and the theoretical side of the di-vide, who speak of fruitful linkages between lexicography and semantics (thus also implying theo-retical linguistics in general: for if there is a branch of it that qualifies, then it is semantics) onlypractice wishful thinking. In the face of such obvious lack of connection or affinity, it is not deplor-able but very much predictable that there be no “cross-fertilisation”. Lexicography, as has beendemonstrated, is indeed untheorised, but it is not at all clear that this is lamentable. Semantics is in-deed an abstract discipline, and judging by the products of lexicography that may be informed by itsfindings, it is abstract enough to disallow most of its results to be directly utilized. And while dic-tionaries may “merit little more than a passing glance”, they do get a look – maybe not to the extentwarranted by their undoubtedly growing significance – in treatments of semantics, it is hard to seewhy and how anything like semantic theory should be mentioned in dictionary prefaces, uncon-sulted in their present form without being burdened with semantics.
As Kay points out, these attitudes (of and to semantics and lexicography) have historical reasons:she contends that the creation of dictionaries is “an ancient craft” that predates work in semantics bylong centuries, but “a relative newcomer to the pantheon of academic disciplines”, and the method-ology for creating them has developed independently of any direct influences from linguistics (Kay2000:53). One wonders, of course, whether possessing a methodology makes some endeavour intoan “academic discipline”
Meyer (2009) may not be too severe when he claims that “while lexicographers may have devel-oped a methodology for creating dictionaries, their ultimate goal is to sell dictionaries, and theirmethodologies have drawn little upon modern theories of lexical semantics” (Meyer (2009:158);italics mine). As the present study hopefully shows, lexicography has its own not-at-all-academic,reader-oriented concerns, responsibilities that bear on user-friendliness, to use a trite expression;consequently, it has considerations unknown to semanticists.
2.6.4 Fine tuning the word level
Having looked, by and large, at the morpheme level, the level of words will be explored in somedetail in 2.6.4–2.6.5. At the word level, the situation is more straightforward on the one hand, buton the other, the picture is complicated by the fact that a more delicate analysis distinguishes threetypes of wordhood, and affixes also come in two subtypes. This, and the fact that simply put, com-pounds may be argued to be both at, and just above, the level of words lexicographically, the

Chapter Two
102
“around the level of words” may be an appropriate heading for this short section. The argumenta-tion of Atkins & Rundell (2008) when they claim that
“Many dictionaries give specific treatment to compounds and phrasal verbs, but it isnot usual for dictionaries to distinguish many subclasses of phrases. This is becausethe boundaries are so fluid that it has proved impossible to establish watertight crite-ria for lexicographers to apply in dealing with multiword items.”
Atkins & Rundell (2008:166–167)
may be taken to tacitly lump together compounds and multiword expressions.
If this fine-tuning of the “word” category, which will be sketched out in 2.6.4.1 below, were not thecase, the pattern would be as neat as this:
SIMPLEXES
These are monomorphemic, so by definition all listemes: units with unpredictable meanings.
COMPLEX WORDS: (1) derived; (2) inflected; (3) compounded(1) Most of these are listemes, unless their meaning is compositional.(2) – Regular inflected words need not be listemes.
– Irregular inflected words are necessarily listemes23.(3) The majority of compounds are probably listemes.
In a finer analysis, however, words come in several, syntactically definable subtypes. It will beshown that many items at word level may be more adequately termed vocables rather than words.
2.6.4.1 Independent words, dependent words and semiwords in Hungarian
Based on an analysis (Kenesei 2000, 2001, 2006, 2007 and 2008) that seems to suit English24 aswell, three kinds of word-like element will be distinguished for Hungarian.
— Independent words:minimum free forms; occur as utterances; uninterruptible, internally stable, positionally mo-bile in the Bloomfieldian sense25.
— Dependent words:do not occur as utterances; bound forms which, however, allow independent words to occurbetween them and the lexical item to which they are bound: the “word” a in a cat allows,e.g. adjectives to occur between itself and cat, to which a is bound;
include articles, conjunctions, postpositions; particles; clitics.
Lexicographically, dependent words receive exactly the same treatment as independent words. Us-ers would probably be in for a surprise if, by some kind of notational separation of the two types,they were claimed to be different. Nothing in school grammars suggests this separation either.
— Semiwords:initial and final constituents of compounds that can only occur as such;
23 Suppletive forms also belong here. Since they are not different from the rest of irregular forms in that they require
listing, it does make sense to talk about suppletivism in etymological but not lexicological terms.24 Marchand (1969) already distinguishes items “midway between full words and suffixes”, such as -like and –worthy;
some of these only occur as second members of compounds “though their word character is still clearly recognizable”(Marchand 1969:356).
25 A word, then, is a free form which does not consist entirely of […] lesser free forms; […] a word is a minimum freeform” (Bloomfield 1933: 178; italics in the original).

Chapter Two
103
can undergo both forward and backward coordination reduction;(the ellipted element here is represented by a Ø):
forward coordination reduction: monitor-féle vagy Ø-szerű ‘monitor-resembling or Ø-like’
backward coordination reduction: tévé-Ø vagy monitorszerű ‘tv-Ø or monitor-like’.
Below the word level:
— Affixes:these do not tolerate either type of coordination reduction:forward coordination reduction: *feleség-gel vagy Ø-hez ‘wife-with or Ø-to’
backward coordination reduction: *feleség-Ø és anyá-hoz ‘wife and mother-to’
—To these four elements are added the “passive stems”26, which are above the affixes but not nec-essarily below the semiwords. Some of them are themselves semiwords, and some of the semi-words are supposed to be “passive stems”. Since, most importantly, a “passive stem” is bound, it isperhaps best to use “bound base” for this element. Bound bases, then, are semiwords or less-then-semiword items that are not affixes but can take affixes themselves.
As stated in Kenesei (2000, 2006) and elsewhere, bound bases (in his framework, similarly to af-fixes) have no syntactic category. This may be why they cannot be right-hand members of com-pounds (Kenesei 2000:92; 2006:87). In that, but only in that, sense they are outside of the grammar.This ostensive status of extragrammaticality will have further important consequences for the pres-ent study.
Because these bound bases belong to what is usually referred to as stem-based morphology, whilethe majority of Hungarian morphological operations are word-based, Kenesei (2000:92; 2006:87),e.g. argues that passive bases do not fit into the (rest of the) hierarchy, thus they may constitute afifth category but not on a par with the first four.27
2.6.4.2 Listedness of dependent words, semiwords and bound bases
From the point of view of listedness there is nothing to suggest that the different types of word aredifferent. Independent words, dependent words, semiwords on one hand, and bound stems and af-fixes on the other, are listemes to the same degree.
This grouping in the form outlined above is not reflected in dictionaries either, similarly to manysuch more fine-grained approaches. For lexicographic purposes, whether English or Hungarian,autonomous words and dependent words are not different. Semiwords differ from the two otherword types in terms of dictionary-worthiness, but not by being labelled as “semiword” or anythingthat could set them apart from the majority of “standard” words. Even if all the lexical items similarto English -proof and -friendly as well as Hungarian -biztos ‘-proof’ and -barát ‘-friendly’ werelisted as headwords in their respective dictionaries, as many of them surely are in the most reliableones, there would be no label for them28. The much too broad “combining form”, though available,is not universally used, and would cover not just those but all expressions that have been felt to beof a more-than-affixal but less-than-word character.
26 These may simply be referred to as “roots”, and are known by different Hungarian names – “passive stem”, “fictive
stem”, “basic stem”, “phantom stem” (or “root” instead of “stem” in each case).27 Fehér (2007, 2008) criticizes Kenesei’s system of word (sub)types from a more general viewpoint, which is not
relevant here.28 Chapter Three discusses the lexical items -proof, -friendly, -biztos and -barát in some detail.

Chapter Two
104
2.6.4.3 Independent words, semiwords, and bound bases lexicographically
2.6.4.3.1 Left-hand members
A sample is given below of the items resulting from a search on hyphenated headwords of typeXXX- (i.e. where the elements listed are left-hand members of compounds) from MASZ (2000). Asleft-hand members of compounds, these are potential semiwords, i.e. at least semiwords, but canalso be possible independent words as part of compounds.
List No2
agyag-ajak-al-ál-alap-arc-árnyék-atom-barkács-bio-e-elektro-ellen-euro-fa-férfi-fog-foto-fő-giga-gyapjú-gyerek-
gyógy-gyomor-hiper-hold-homlok-hő-idő-kar-kényszer-kiber-konzerv-köb-kölcsön-köz-közép-kripto-kultúr-kvázi-látszat-lumpen-luxus-mag-
magán-makro-mega-méh-mell-mellék-mikro-mini-mirigy-motor-mű-nano-nap-nem-nő-nosztalgia-nyíl-öko-olaj-ön-orr-ős-
össz-össze-panel-papír-petro-pletyka-plusz-pót-próba-prosztata-radio-segéd-sejt-selyem-sí-sport-stílus-száj-szaru-szem-szív-szuper-
társ-táska-techno-tele-tera-terem-terep-többlet-tölgyfa-tömeg-torna-tucat-turbó-turista-ultra-utó-varázs-vas-végbél-vendég-vese-video-
The list comprises different kinds of lexical item:
• Independent words
One of the reasons for including the Hungarian independent words as hyphenated forms in theH→E dictionary is that often what corresponds to the E. adjective is not an adjective but a hyphen-ated form. These items account for the majority of the list.
Such examples include the hyphenated form agyag- for the English earthen; ajak- translating theadjective labial (where both agyag- and ajak- happen to be independent words that may be ad hoccompounded). Some further examples, still from the beginning of the alphabet: arc- (= facial, face);árnyék- (= shadow); atom- (= atomic, nuclear). (Wherever there are homographic items minimallydiffering in the presence of the hyphen, the hyphenated form comes first alphabetically so that itsplacement is more conspicuous: arc- ‘facial’ will be followed by arc ‘face’.)
When these items occur outside compounds, they have their standard PoS labels.
• Semiwords
Another kind of hyphenated forms are the semiwords, i.e. elements that are not more than semi-words:examples include the al- (= vice-, under-, sub-, deputy), ál- (= false, fake, counterfeit, bogus,sham, pseudo-), and alap- (= basic, fundamental) forms.

Chapter Two
105
As compound constituents, these forms can only occur as left-hand members, and thus cannot un-dergo both forward and backward, only backward, coordination reduction (i.e. deletion of the ear-lier conjunct): in al- és főcímek ‘subtitles and main titles’. They clearly must be classified as semi-words rather than bound bases because unlike bound bases, these elements cannot take affixes.
The English equivalents of these Hungarian forms may themselves be independent words vs. com-bining forms: cf. vice-, under-, sub vs. deputy.
• “Latinate” combining forms
Hungarian also has the exact equivalents of what are standardly referred to as English combining orhyphenated forms, i.e. elements of Latin and Greek origin that only occur in compounds (as left orright members thereof). These also belong to the semiword category, even if they have never beenlabelled thus (which shows a certain exclusion from the home-grown Hungarian vocabulary).Examples (for which no gloss is needed) include: bio-, elektro-, euro-, foto-, giga-. The item e- (=e- as e.g. in e-commerce) also belongs here.
These items, being restricted to the status of left-hand member of compounds, do not have syntacticcategories and thus do not have PoS labels.
• Bound bases
A minority of the lexical items in the list are what have been termed bound bases: barkács- (= do-it-yourself, DIY); gyógy- (= curative, medicinal, therapeutic); varázs- (= magic, magical). Thatthese can be affixed is an indication that they are bound bases.
As seen above, some of the bound bases occur as semiwords; Kenesei’s examples, of which gyógy-also features in the list above, include fesz-, gyógy-, tám- and tév- (Kenesei 2000:91).
2.6.4.3.2 Right-hand members
The next list is a sampling of the results from a search on hyphenated headwords of the type -XXX(i.e. the elements in the list are right-hand members of compounds) from the same source as above,MASZ (2000).
The list contains many of what were traditionally considered as derivational affixes (-beli, -féle, -né,-szerű etc) but are actually semiwords.
Since these are right-hand members of compounds, they are PoS-classifiable.
The following classes have been distinguished: A(djective); A(dverb); Num(eral); N(oun). Withinthe Adjective category, the largest number is accounted for by the compounds of the followingtypes:
Num-N-Ú – e.g. -ágú → -branched, -forked, -pointed, -prongedas e.g. in ötágú villa five-pronged fork
A-N-Ú – e.g. -nyomású → -pressureas e.g. in nagy nyomású high-pressure
Num-N-Os – e.g. -soros → -line 12 soros 12-lineas e.g. in 12-soros 12-line

Chapter Two
106
The types being determined by the semantics of the N, some items belong to more than one cate-gory, although not typically. The element -betűs, e.g. may be NumN-Os (e.g. kétbetűs →two-letter) as well as AN-Os (e.g. zöldbetűs → green-lettered).
List No3PoS
-ágú A-ágyas A-ajkú A-árbocos A-barát A-beli A-betűs A-bites A-biztos A-centiméteres A-centis A-centrikus A-egynéhány Num-ellenes A-eres A-eszű A-éves A-félben Adv-felé Adv-féle A-féleképpen A-felől Adv-figyelés N-fogásos A-fokú A-fontos A-hetes A-illatú A-iskolás A-ismeretlenes A-iziglen Adv-jegyű A
-kalóriás A-karátos A-kedélyű A-ként Adv-képpen Adv-kerekű A-kezű A-kilós A-kori A-kötetes A-központú A-külsejű A-lábú A-lakó A-lángú A-lapos A-lelkű A-lépcsős A-lóerős A-lövetű A-megatonnás A-mellű A-menetes A-mentes A-méretű A-mérföldes A-méteres A-milliméteres A-mintájú A-modorú A-nagyságú A-napos A-nauta N
-né N-nélküli A-nként Adv-nyomású A-patájú A-perces A-pontos A-rendező N*-részes A-rét Adv-rétű A-soros A-sorsú A-stÓl Adv-stUl Adv-szájú A-számjegyű A-szavas A-szemű A-szOri A-szerte Adv-szerű A-szintes A-szívű A-szOr Adv-találatos A-tan N-tojásos A-tornyú A-ujjas A-üléses A-valahány Num-wattos A
*= organizer e.g. iratrendező
2.6.5 “Lexical” items of doubtful status
The traditional “grammatical rank scale” was resorted to in 2.6.2 to facilitate an exploration of thoselexical units (many of them probably listemes) that are also featured lexicographically, i.e. whichtend to appear as headwords in dictionaries. In the framework set up above, all morphemes must belistemes; most words are listemes, but more importantly, the category of words has been refined onthe basis of Kenesei (2000, 2006) and similar sources; phrases that are listed are fewer, and sen-tences that are listemes number even less.
In the classification used here, there is, strictly speaking, only place for independent words amongthe morpho-syntactic categories, i.e. only autonomous words have a PoS status29. Dependent wordssubcategorize according to the (lexical or phrasal) class they are dependent on, i.e. bound to, but
29 This is one of the targets of Fehér’s (2007, 2008) justifiable criticism.

Chapter Two
107
have no category themselves. Affixes and semiwords do have some PoS information (since theyproject the category of the complex word of which they are a part), but have no categorial status oftheir own either (both being below word level in this sense).
More importantly for the argumentation in the followings sections, however, excluded from thelexical types with PoS labels are two kinds lexical expression: (i) what are labelled “interjections”and lack a usable definition, and (ii) what are referred to as “sentence words” 30 in traditional Hun-garian descriptions, for which there does not seem to be a workable English term, and which alsohave a semi-legal existence without a proper definition. The (iii) class of lexical items called “(inar-ticulate)31 onomatopoeic words” partly overlap with both. The overlap may be so significant thatrather than positing three separate classes, we may think in terms of just one superclass containingall three types.
The special status of these word types is also recognized in e.g. Biber & al. (2000, 2002), where theterm “insert” is used for a class that is peripheral to grammar and contains “stand-alone” words un-able to enter into syntactic relations with other structures, or “loosely attached to a clause or non-clausal structure” (Biber & al. 2000 passim; Biber & al. 2002:449; Quaglio & Biber 2006:704).Although interjections, sentence words and inarticulate onomatopoeics (and perhaps similar expres-sions) cannot be PoS-classified, they are words syntactically as well: their use in syntax is not lessstrictly governed by rules than that of any other category. This is why, in the framework of Biber &al. (2002), the broad category of “inserts” is used, apparently encompassing the three items (i)–(iii).
Diagramming the three types of lexical item – (“inarticulate”) onomatopoeic word, sentence word,and interjection – is straightforward because due to a lack of proper definitions; the diagram is thusboth informal and tentative. The categories are so volatile that nothing more definitive may be saidthan what the circles suggest: that there will be a common ground between any pair of the three, andthere will be an area shared by all. The semantic clue of onomatopoeics probably makes them easi-est to distinguish from the other two.
The category of “inserts”, as we have seen, is probably best thought of as covering the overall areaof the three terms.
onomatop.
sentence word interj.
In view of the above complexities of the PoS situation, it may be best for the purposes of lexicology(if not for lexicography, which does not need it) to distinguish two types of word: those perfectlyintegrated within the grammar, the grammar-internal ones, which have clear (though obviously the-ory-dependent) morpho-syntactic categories on the one hand, and the extragrammatical, “inarticul-ated” elements, which are non-PoS-classifiable, and thus lie outside of grammar, or of clausalstructure, on the other. A term for the latter will also be used here: vocable will be used for an itemof the lexicon, thus listeme in the obvious sense of an unpredictable form–meaning/function unit,which has no PoS status in frameworks which, for whatever reason, exclude (i), (ii) and (iii) above,
30 The Hungarian term mondatszó ‘sentence word’ suggests, appropriately, that these expressions are “simultaneously
words [...] and utterances” (Ameka 2006:746). This metaphorical usage, although it somewhat blurs the sentence–utterance distinction, is useful since it refers to this duality in the name. The German term “Satzwort” seems to coverthe same domain.
31 As opposed to words of onomatopoeic nature that do have word status, i.e. PoS labels, see 2.6.5.2.

Chapter Two
108
insisting (quite understandably from their syntax-based vantage point) that for something to be aword, it needs to have a syntactic category.
Lexicography (and lexicology), of course, recognizing not merely the existence but the importance(both statistically and pragmatically) of these vocables, must make efforts to represent these as fullyas possible. It is also important that grammars should chart this area, where the pragmatic aspect oflanguage seems to be decisive and the standard categories of syntax less dominant. It goes withoutsaying that it is important to register these vocables in dictionaries. While these kinds of lexicalelements receive ample grammatical treatment in grammatical descriptions such as Biber & al.(2000, 2006), which will also be further explored below, the lexicographic job of covering this sec-tion of the lexicon is excellently handled, e.g. by the Collins-Cobuild line/tradition.
2.6.5.1 Onomatopoeic “words”
2.6.5.1.1 “Inarticulate” onomatopoeic words
It is customary to mention the non-arbitrariness of onomatopoeic words, pointing out in the samebreath that they are, however, language-dependent. This is a contradiction, which provides a goodexample of expressions being motivated but arbitrary; all onomatopoeic expressions are arbitrary,i.e. unpredictable, and thus listemes. These, however, are outside of the grammar, as it were: “inar-ticulate” onomatopoeic words, or IOWs.
2.6.5.1.2 PoS-classifiable onomatopoeics
There is a class of words which has never satisfactorily been set apart from inarticulate onomato-poeic words that can actually be PoS-classified: they are derived or compounded from IOWs. InHungarian, overt verbal or nominal affixes attach to inarticulate onomatopoeics, cf. fúj-ol ‘tophooey’, jaj-gat ‘to moan, wail’, vau-z-ik ‘to bow-wow’ (derivations); jajszó ‘a cry of pain’ (com-pound).
While participation in derivation and compounding processes places “inarticulate” onomatopoeicwords or IOW in the class of bound bases of the fesz- ‘taut-’, röp-‘fly-’, and patt-‘crack-’32 type(Kenesei 2006:99), articulate onomatopoeics, by contrast, have full dependent word status (andtheir speciality of meaning – some degree of sound symbolism – plays no role whatever in theirsyntax).
It is not always obvious, neither synchronically relevant whether a verb such as recseg ‘crack,creak’ is (i) derived from the “inarticulate onomatopoeic”, or (ii) the other way round, or (iii) thetwo were formed together, and the affix is just a pseudo-one. Bárczi & al. (1967) suggests that thislatter, (iii) is the most typical case.
As far as listedness in the dictionary is concerned, generally bound bases (of the fesz- ‘taut-’, röp-‘fly-’, and patt-‘crack-’, i.e. the non-onomatopoeic kind) need not be, and never are, entered in dic-tionaries, since they never occur in text. By contrast, and significantly, onomatopoeics of both of theabove types need to be documented: jaj-gat ‘to moan, wail’ and jajszó ‘a cry of pain’ will be asnatural lexicographically as feszül ‘become taut’ and feszít ‘make taut’, or röpül ‘fly’, röptet ‘flysmth’, all from bound bases.
Besides zero-forms and abstract entities of different types, this is another huge domain where themental lexicon and print dictionaries significantly differ: bound bases of both types are supposed tobe stored in the lexicon, while of these, non-onomatopoeic bound bases are not in the dictionary.
32 The hyphen in the glosses shows the bound nature of the Hungarian “equivalent”; English has no bound forms here.

Chapter Two
109
The rather amorphous realm of ouch, splash, phew, tut-tut, gosh, yuk and their likes in any lan-guage, possibly outside of grammar but surely not outside language has an obvious and legitimateplace in dictionaries. Sadly though, if one considers the EHCD (1998) and HECD (1998), the onlyH↔E dictionaries whose size would make possible their detailed and systematic treatment, they donot seem to be given their due either in quantity or quality terms.
2.6.5.2 Interjections
Expressions of various sorts traditionally labelled as interjections are among what have been termedvocables. Not strictly parts of the grammar, thus technically not words, they are yet listemes, andare included in dictionaries. Which of their subtypes are listed, however, is a point on which dic-tionaries diverge. Items such as H. hess → shoo, juj → ouch, na → come on, sicc → shoo! / scat!typically do get entered in bilingual dictionaries, if the size allows. The problem is that there is justa narrow strip of translatability between “interjections” in H. and E., as presumably in any pair oflanguages.
Items of the inarticulate onomatopoeic kind, which are often classified as interjections as well, suchas nyau → miaow are only sporadically listed in dictionaries. Their articulate, PoS-classifiablecounterparts are not interjections but verbs or nouns; these include verbal nyávog → miaow, nyihog→ neigh, csipog → tweet, and are very much dictionary-worthy.
If one examines the items labelled “interjection” in a typical learner’s dictionary, which, inciden-tally, is very good at representing this area of the English language33, a great number of such itemsis found. It is not suggested that the assignment of an item to this or that PoS in MED 2007, or anyother learner’s dictionary for that matter, reveals their genuine grammatical nature. The word fare-well e.g., is presented as a noun, an interjection, and an adjective MED – this latter e.g. in farewelldinner/party/speech, where the noun farewell is used as a modifier – which clearly shows a confu-sion between category and function. Such a dictionary, in electronic form, is still indispensable withall its obvious faults if a comprehensive list is needed of words of any PoS.
The picture of interjections in MED (2007) is greatly varied, not just from one, but from many in-tersecting points of view.
First, phrases are also featured (and these are heterogeneous themselves: e.g. action stations! /good afternoon! / hey presto! / son of a bitch!); some of these have been italicized in the list be-low. Thus the “interjection” class is not a PoS classifying or subclassifying words, rather, it seems apragmatic-lexical device of any syntactic composition; if this is (if not the definition of, but) the ap-proach to, “interjections”, then they are surely not a word class. It remains to be seen whether theycan at all be placed in a natural class other than one defined by some vague communicative–pragmatic notions.
Second, many items in the list have a straightforward PoS outside of these contexts: nouns, verbs,etc. The word timber, used on its own, is supposed to be an interjection warning people that “a treethat you have cut is going to fall”, or used humorously “when any large object falls over” (MED2007). The word brother on its own, another interjection, is claimed to be “used for showing thatyou are surprised or annoyed”, e.g. Oh brother, what a mess! (MED 2007).
A part of these are simply imperative forms of verbs, i.e. they belong to the verb category no doubt,and the only feature that aligns them with “interjections” is that they are often used on their own asutterances; some of these have been marked with boldface. This feature is what supposedly makesthem “sentence words” or “inserts”.
33 The Collins–COBUILD series excels at providing this information, but the searches in MED were far superior.

Chapter Two
110
It needs to be emphasized that this dual PoS of interjections (the ones that are clearly of word levelsyntactically) is different from the case of conversion, since here the one of the two (or more) osten-sive word classes is grammatical, while the other – the interjections, which are just vocables – is“extragrammatical”. It is not the case that the noun man is converted into an interjection in thesame way in which it is changed into a verb meaning ‘provide with a crew’.
Third, some of the phrasal units seem to have gone through phonological reduction, and as a resultthey may indeed have become words, to the possible extent of unanalyzability by native speakers. Apart of these are such that this reduction or fossilization is not recent: strewth! A subtype of theseare represented by the obscured swearwords, many of which are of deliberately euphemistic origin,e.g. gee whiz! and drat! (cf. 2.6.5.5).
Fourth, the list contains what are straightforward onomatopoeics of the vocable type: atishoo, oinkand (the phonotactically irregular) vroom are such vocables.
Fifth, there are the foreign phrases, oyez, au revoir, gesundheit, plus ça change and touché –mostly French, and a few German expressions – which are as heterogeneous from a formal view-point as their native counterparts, including phrasal units as well. They are less integrated than thevocables within not just the grammar but also within the lexicon of English.
Sixth, the list includes a few items that are not just phonotactically wayward, but phonologicallyanomalous to the extent of containing un-English phonemes, or no vowel: examples include hm /psst / phwoah34 / sh (The item hm has two, equally, if not identically anomalous pronunciations, inMED (2007): /m/ and /hm/.) Some items, by contrast, have spellings that suggest suchphonological anomaly, but are perfectly regular: g'day is an example (it just suggests an abrupt pro-nunciation with a reduced first syllable).
List No4MED (2007): 231 interjections
34 A way of writing a sound that someone makes when they see a sexually attractive person (MED 2007).
1 aah2 aargh3 abracadabra4 achcha5 achoo6 adieu7 adios8 afternoon9 ah10 aha11 ahem12 ahoy13 alas14 aloha15 amen16 atishoo17 aw18 aye19 bah20 bang21 begone22 behold23 bingo24 bless25 blimey
26 bollocks27 boo28 bother29 boy30 bravo31 brother32 brrr33 bye34 cheerio35 cheers36 Christ37 chup38 ciao39 congrats40 cooee41 cor42 crikey43 cripes44 crumbs45 cut46 dammit47 damn48 damnation49 dang50 darn
51 diddums52 d’oh53 done54 drat55 duh56 eek57 eh58 encore59 er60 erm61 eureka62 evening63 farewell64 fiddlesticks65 fuck66 gangway67 gawd68 g’day69 gee70 gesundheit71 God72 goddammit73 golly74 goodbye75 goodness
76 goody77 gosh78 gotcha79 gracious80 ha81 hallelujah82 hallo83 halt84 heck85 heel86 hell87 hello88 help89 here90 hey91 hi92 hiya93 hmm94 ho95 hooray96 hosanna97 howdy98 howzat99 howzit100 huh

Chapter Two
111
101 humph102 hurray103 jeez104 Jesus105 later106 lo107 man108 mm109 morning110 my111 nah112 namaste113 nay114 nuts115 O116 och117 oh118 oho119 oi120 oink121 OK122 ooh123 oops124 ouch125 ow126 oyez127 pah128 pardon129 phew130 phooey131 phwoah132 please133 poof
134 pooh135 presto136 prithee137 pshaw138 psst139 really140 respect141 right142 righto143 roger144 say145 sayonara146 scat147 sh148 shabash149 Shalom150 shh151 shit152 shoo153 shoot154 shucks155 shush156 snap157 ssh158 steady159 strewth160 surprise161 ta162 thanks163 there164 timber165 touché166 tough
167 tut168 ugh169 um170 viva171 voilà172 vroom173 welcome174 well175 wham176 what177 whee178 whew179 whoa180 whoopee181 whoops182 wotcha183 wow184 yahoo185 yikes186 yippee187 yo188 yuck189 yum190 zindabad191 zzz192 action stations193 all right194 au revoir195 big deal196 bon voyage197 boo-hoo198 bow-wow199 bye-bye
200 chop-chop201 code red202 gee whiz203 good afternoon204 good day205 good evening206 good morning207 good night208 ha ha209 hey presto210 ho ho211 ho-hum212 mea culpa213 okey-dokey214 plus ça change215 puh-leeze216 shock horror217 son of a bitch218 ta-ta219 tee hee220 thank you221 tsk tsk222 tut-tut223 uh huh224 uh-oh225 uh-uh226 upsy-daisy227 wakey-wakey228 wham-bam229 yadda, yadda, yadda230 yah-boo231 yoo hoo
Interjections will also be explored in 2.6.5.4.
In 2.6.5.5.1, another list, of the items labelled “exclamations” in CALD (2008), the majority ofwhich feature in the above list of interjections as well, will be given for comparison.
2.6.5.3 Sentence words
Paradoxically, the traditional “sentence words” of Hungarian descriptions do pass the independentwordhood test of being able to form an utterance (see 2.6.4.1 above), but they have been deniedword status since they do not have syntactic links within clauses, and thus have no syntactic cate-gory. Not only do onomatopoeics get no mention either as categories related or unrelated to theseother two, the exact boundaries among sentence words and interjections are not discussed in Kene-sei either. In Kenesei (2000) there is but a single mention of sentence words (Kenesei 2000:91),which thus also leaves this question open.
Traditional Hungarian classifications have a broad category for “sentence words”; this contains(i) interjections (ó → oh, brrr → brrr)(ii) interactional sentence words(helló! → hiya! pá! → ta-ta! amen → amen, hm → hm, nos → well, persze! → sure!pszt → psst)
(iii) “modifiers”35 (talán → perhaps, valószínűleg → probably)(iv) onomatopoeic sentence words (bu → boo, bumm → bang)
35 These probably come closest to sentence adverbs, or disjuncts. They may altogether be missing from the list.

Chapter Two
112
Significantly, the examples offered in such descriptions do not, as a rule, include phrase-level, onlyword-level expressions.
Whatever the term “sentence word” covers, they must be stored in the mental lexicon, even thoughnot marked for a standard syntactic category. Lexicographically they also should be given their due.
2.6.5.4 Expletives: not the four-letter kind
2.6.5.4.1 Expletives: words?
Discussing issues of inclusion and exclusion of lexical material in dictionaries, Hanks (2006:122)claims that expletives ought to be classed as words:
“Are the English expletives er, um, oh, unh-huh, phwoah, etc., words? Should theybe in a dictionary? (The same question applies to expletives in any language.) Theyoccur as types in careful transcriptions of spoken English. To that extent, they may beregarded as words, and indeed, nowadays they often make an appearance in diction-aries.”
Hanks simply does not define the term “expletive”. It is also odd that the appearance of a type ofitem in dictionaries should be taken as proof of that item being a word (in just maybe one,phonological, sense: after all, Hanks refers to “transcriptions of spoken English”). The term “exple-tive” has its own entry in the Encyclopedia of Language and Linguistics (Brown 2006), whereHanks (2006) appears, but it discusses expletives in the “dummy” or “pleonasm” sense, and de-scribes the status of “expletive” as a term that covers a “wide range of disparate phenomena”; it isthus irrelevant to Hank’s claim. “Interjection” does have a substantial and relevant entry (see belowand cf. Ameka 2006) but expectably, that notion has its own problems.
2.6.5.5 Interjections: definitions and classification
Under the definition of Ameka (2006), interjections are
“words that conventionally constitute utterances by themselves and express a speak-er’s current mental state or reaction toward an element in the linguistic or extra-lin-guistic context”.
Interjections are supposed to be definable using (A) formal, (B) semantic and (C) pragmatic criteria.
(A) An interjection is a lexical form that– conventionally constitutes a non-elliptical utterance by itself– does not enter into construction with other word classes– does not take inflectional or derivational affixes, and is monomorphemic.
This definition is claimed to characterize the core members of the class, i.e.(i) words that express emotions: yuk! / ugh! / phew!(ii) words/expressions for greetings, leave-taking, thanking, apologizing etc: hello / thank you(iii) swearwords: shit!(iv) attention-getting signals: pst / hey(v) some particles and response words: yes / no(vi) words directed at animals: whoa!
(vii) onomatopoeic words and what are termed “iconic depictives”

Chapter Two
113
(B) From a semantic point of view, a prototypical interjection is a conventionalized linguistic signthat expresses a speaker’s current mental state, attitude, or reaction towards a situation.
This excludes onomatopoeic words, which are descriptive rather than expressive.
(C) In pragmatics terms, interjections are context-bound linguistic signs, tied to specific situationsand index elements in the extra-linguistic context. It is clear from the above that in the same treat-ment, interjections are supposed to be words, lexical forms, and expressions, i.e. different syntacticobjects, only belonging together pragmatically.
2.6.5.5.1 Exclamations as a PoS label in CALD (2008)
In section 2.6.5.2 a list of the 231 lexical items classified as interjections in MED (2007) was given(List 4). Before the lexical item goddam and its lexicographic treatment in CALD (2008) is ex-plored in detail, a brief look is taken of the items termed exclamations, actually used as a part ofspeech label, in the same dictionary.
List No5
CALD (2008): “exclamations”
Most of the example sentences have been removed, but otherwise just minor changes have beenmade; the definitions have been retained where they may be relevant.
Some of the example sentences have been kept in order to illustrate that some of these ostensibly“sentence words”, which are supposedly not integrated within the clause structure but appear as anutterance, are actually not like that: it would be hard to establish the grammatical status of the com-bination of the noun and ahoy in the expressions below, but the ahoy element certainly does notoccur on its own:
ahoy excl. 2. used, especially on a boat, when you see something, usually something which is inthe distance
Land ahoy! Ship ahoy!
“Exclamation” has been shortened to “excl”; other PoS labels also abbreviated.Although that is not the point now, the list also shows light on many inconsistencies or outright er-rors in PoS labelling, or mistakes of the matching of definitions with examples. The entry for adieu,e.g. contains an example that is clearly not the exclamation but the noun adieu:
adieu excl. literary or old use goodbyeShe bade (= said to) him adieu and left
1 a2 ah excl.3 abracadabra excl.4 achoo excl.5 adieu excl. literary or old use6 adios excl. mainly US infml.7 ah excl. (also aah)8 aha excl.9 ahem excl. mainly humorous10 ahoy excl.11 ahoy excl.12 alleluia excl., n. [C]13 all right (also alright ) excl. GREETING14 all right (also alright ) excl. APPROVAL15 alright adj., adv., excl.16 amen excl. formal
17 April fool excl. UK ( US April fools! )18 Arse! excl. UK offensive19 atishoo excl. (also achoo) UK20 bah excl. old use21 balderdash n. [ U ], excl. old-fash.22 bang excl.23 begone excl. old use or literary24 bingo excl. infml.25 blast excl.26 blimey excl. UK old-fash. infml.27 boo excl.28 boohoo excl.29 bosh excl. , n. [ U ] old-fash.30 bother excl.31 botheration excl. UK old-fash.32 boy excl. ( also oh boy ) mainly US infml.

Chapter Two
114
33 bravo excl.34 brill adj. , excl.35 bugger excl. UK offensive36 bullshit excl. , n. [ U ] offensive37 bye-bye excl. ( also bye )38 champion adj. , excl. mainly Northern infml.39 check excl. US40 cheerio excl. UK old-fash.41 Cheers! excl.42 Cheers! excl.43 Cheers! excl.44 ciao excl. infml.45 congrats excl. , plural n. infml.46 cool adj. , excl. infml.47 cor excl. UK slang48 crikey excl. UK old-fash. infml.49 cripes excl. UK old-fash. infml.50 crumbs excl. UK old-fash. infml.51 damn excl. (also damn it , also dammit) infml.52 darn excl. infml.53 dash excl. UK old-fash. infml.54 dear excl. (also old-fash. dearie) infml.55 diddums! excl. UK humorous56 doggone excl. , adj. [before n.] US infml.57 d'oh , d'uh excl. infml.58 eek excl. infml. mainly humorous59 eh excl. (US usually huh) infml.60 Encore! excl.61 er excl.62 eureka excl. often humorous63 farewell excl. old-fash. or formal64 fiddlesticks excl. (US also fiddle-faddle) old-
fash.65 flip excl. UK old-fash. infml.66 fuck excl. offensive67 Gangway! excl.68 g'day excl. Australian infml.69 geddit? excl. UK infml.70 gee excl. mainly US infml.71 gesundheit excl. mainly US72 goddamn mainly US very infml. , US also God
damn , goddamned , goddam golly excl. old-fash. infml.
73 goodbye excl.74 goodness excl.75 good night , goodnight excl.76 goodo excl. [after verb] , adj. , adv.77 goody excl. (old-fash. goody gumdrops)
infml. or child's word78 gosh excl. infml. slightly old-fash.79 gotcha excl. slang80 gracious excl. old-fash.81 ha, hah excl. mainly humorous82 hah excl.83 ha-ha, ha ha excl.84 hallelujah, alleluia excl., n. [C]85 hallelujah, alleluia excl., n. [C]86 Heavens (above)! excl. (also Good Heavens!)
old-fash.87 heck excl., n. infml.88 heel excl.89 hell excl., n. [U]90 hello excl., n. (UK also hallo, also hullo)
91 hello excl., n. (UK also hallo, also hullo)92 hello excl., n. (UK also hallo, also hullo)93 hello excl., n. (UK also hallo, also hullo)94 hello excl., n. (UK also hallo, also hullo)95 hell's bells excl. (UK also hell's teeth) old-
fash. infml.96 help excl.97 hey excl. infml.98 hey presto excl. (US presto) infml.99 hi excl. infml.100 hip excl.101 hiya excl. infml.102 hm , hmm excl.103 honestly adv. , excl.104 hooray excl. , n.105 hooroo excl.106 hosanna excl.107 howdy excl. US infml.108 huh excl.109 huh excl.110 huh excl.111 hullo excl. , n. [ C ] plural hullos UK112 humph excl. often humorous113 hurray excl. ( also hooray , also hurrah )114 hush excl.115 ick excl. US infml.116 indeed excl.117 jeez excl. US slang118 Jesus (Christ) excl. (also Christ ) infml.119 Knickers! excl. UK slang humorous120 later excl. (also laters) infml.121 lo excl. old use122 look excl. Look here old-fash.123 magic excl. UK old-fash. infml.124 man excl. infml.125 mayday n. [ S ] , excl.126 my excl. old-fash.127 excl. plural O's or Os old use or literary128 oh excl.129 oh excl.130 oh excl.131 OK , okay excl. AGREEING132 OK , okay excl. UNDERSTAND133 OK , okay excl. ACTION134 OK , okay excl. PAUSE135 okey-doke excl. (also okey-dokey)136 ooh excl.137 oops excl. (also whoops ) infml.138 oops-a-daisy excl. (also ups-a-daisy ) infml.139 ouch excl.140 ouch excl.141 ow excl.142 pardon excl.143 pardon excl.144 pfft excl.145 Phew! excl. (also Whew!) infml. mainly humor-
ous146 phooey excl. infml. humorous147 piddle excl. infml.148 please excl.149 please excl.150 please excl.151 please excl.

Chapter Two
115
152 poof excl.153 pooh excl. infml.154 pow excl. infml.155 psst excl.156 quick excl.157 rather excl. mainly UK old-fash.158 really excl.159 rhubarb excl.160 right excl. infml. AGREEMENT161 right excl. infml. AGREEMENT162 right excl. infml. AGREEMENT163 roger excl.164 salaam n. [C], excl.165 say excl.166 scat excl. infml.167 sh , also shh , ssh excl. (also shush)168 shalom excl.169 shame excl.170 shit excl. offensive171 shoo excl.172 shucks excl. US infml.173 shush excl. infml.174 snap excl.175 snap excl.176 sod excl. (also Sod it! ) UK offensive
177 sorry excl. APOLOGY178 sorry excl. POLITE NEGATIVE179 sorry excl. POLITE NEGATIVE180 sorted adj. [after verb] , excl. UK infml.181 ssh excl.182 strewth excl. Australian infml., UK old-fash.183 sugar excl.184 ta excl. UK infml.185 ten-four excl. (also 10-4) mainly US186 thanks excl.187 thank you excl. (infml. thanks)188 thank you excl. (infml. thanks)189 thank you excl. (infml. thanks)190 thank you excl. (infml. thanks)191 there excl.192 timber excl.193 ting-a-ling excl. (mainly US ding-a-ling)194 top adjective , excl. UK infml.195 touché excl.196 tsk excl. (also tsk tsk) old-fash.197 tush excl. old use198 tut excl. (also tut tut)199 ugh excl.
2.6.5.5.2 Goddam in CALD
One example of a lexicographic treatment of an interjection, provided by goddam in CALD (2008),also illustrates that “interjections”, whatever is covered by the term, may have PoS-classifiablehomophones, and that the separation of the two may not be straightforward.
CALD3 (2008):
goddamn also God damn, goddamned, goddam exclamation, adjective, adverbused to add emphasis to what is being saidGoddamn (it), how much longer will it take? Don't drive so goddamn fast!See also damn
The entry, with the three PoS labels given indiscriminately at the beginning, is no help. The paren-thetical notation of first example, goddam (it), confuses two cases: without the it, it may be onephonological word that is polymorphemic, in which case it doubtless qualifies as an interjection.With the it included, it must be a three-word sequence of subject, verb and object, with the verb inthe formulaic subjunctive. CALD (2008), as pointed out above, does not actually use “interjection”,but “exclamation” as a PoS label. Although not a standard PoS label, “exclamation”, very usefullyin a dictionary, singles out the semantic-pragmatic aspect of interjections and uses their “exclama-tory” prosodic feature (which they may not actually have) rather than “interjection”. It would beeven more important to find a better term instead of the Hungarian “indulatszó”, which literallymeans ‘passion/emotion word’.
The item damn, to which the entry goddamn refers the reader, is richer and easier to label becauseit can be broken down into several word classes, most of which obviously not interjection-like: ex-clamation, adverb, (polysemous) verb, adjective, and noun. The register information and some de-tail has been cut; somebody etc. has been replaced with smb etc.
damn exclamation (also damn it, also dammit) an expression of angerDamn, I've spilt coffee down my blouse! See also goddamn

Chapter Two
116
damn adverb1. used, especially when you are annoyed, to mean ‘very’[...] knew damn well [...] he can damn well do it You were damn lucky [...]2. damn all UK informal nothing I know damn all about computers.
(It must be noted that for can damn well do it, the definition ‘very’ is hopelessly inadequate.)
damn verb BLAME1. to blame or strongly criticize smth or smbThe inquiry [...] damns the company for its lack of safety precautions.
damn verb PUNISH2. [...] to force smb to stay in hell and be punished forever [...]
she would be damned for her sins
damn verb3. damn you/them/it, etc. used to express anger with smb or smthYou got the last ticket - damn you, I wanted that!
damn adjective (also damned)used to express anger with smb or smth Damn fool !
damn nounnot give/care a damnused as a way of saying you do not care about smth, especially the annoying things that smb else isdoing or saying He can think what he likes about me – I don't give a damn!
2.6.5.6 Inserts
According to the Longman Grammar of Spoken and Written English (Biber & al. 2000), inserts aresupposed to be a class of words: stand-alone words characterized by their inability to enter intosyntactic relations with other structures. Inserts tend to attach prosodically to a larger structure, andso may be counted as part of that structure. They comprise a class of words that is supposed to beperipheral both in the grammar and in the lexicon of the language. What this means for the syntaxis clear, but why they should be secondary in the lexicon is not obvious.
It may be questioned, Biber & al. (2000) argue, whether some inserts – interjections (ugh, ooh), re-sponse forms (uh huh, mhm), and hesitators (mm, uh) – are words at all.
“Vocable”, which happens to be used just once, as if incidentally, in Biber & al. (2000) with notheoretical significance and repeated nowhere again, has been put to good use in the present study.Vocables, as has been argued, are lexical items whose form–function pairings are undoubtedlystored, i.e. which are listemes but do not pass the syntactic test which would make them eligible tobe assigned to a word class. Many (but not all) of the inserts Biber & al. (2000) are “vocables”.
It should be noted that for Biber & al. (2000) inserts are a words class; from their lexical-basedpoint of view, they are not worried by the syntax-based difference between PoS-classifiable wordsand these “vocables”.
It is not enough to recognize the insert category, Biber & al. (2000) claim, because it is itself bestrepresented as three (or more) concentric circles with central and progressively less central, i.e.more peripheral, members. The more central members:
(1) have the ability to appear on their own (not as part of a larger structure)(2) have the ability to appear prosodically attached to a larger structure
and(3) are not homonyms of words in other word classes(4) have no denotative meaning; their use is defined rather by their pragmatic function.

Chapter Two
117
If one considers the fact that inserts, as long as they behave pragmatically and lexically as unana-lyzable formulae, are supposed to be able to consist of more than one word (e.g. thank you, excuseme, and expletive good God), and the fact that inserts shade into one another and one and the sameinsert can be very versatile (Oh, the commonest interjection, is also a discourse marker and re-sponse form; okay is a discourse marker, response elicitor, and response form), then it is obviousthat inserts are as elusive a category as sentence word and/or interjection, to which their relation isfar from clear.
Turning now to the lexicography of inserts (sentence words, or interjections): however useful it maybe to give all the items in the table below (based on Biber & al. 2000) as elaborate a lexicographictreatment as possible, in both monolingual or bilingual works, three factors will always hinder thiscataloguing:
(i) in many cases there exists no standard/conventionalized orthography for these expressions;
(ii) in the case of bilingual lexicography, lack of standard orthography invariably affects bothlanguages, and the task of matching two basically non-existing representation systems is adaunting one indeed: this is most acute in the case of response forms
(iii) in the majority of cases prosodic information would have to be provided, and to this end, asimple but effective notation and the receptiveness on part of the dictionary user are both ab-sent.

Chapter Two
118
List No6Inserts in Biber (2000)
InsertsFunction-
based subtypeExamples with comments
(Notes to superscripts: inside table)
Interjections
Oh = surprise , unexpectedness, emotive arousal; combines with other insertsOh yeah / Oh yes / Oh no / Oh aye / Oh well / Oh God / Oh I see / Oh right
Ah / wow / oohCor / ahaoops / whoopsugh / ow / ouch / aargh / urghHa! / ha ha ha hayippee / whoopee / wowee / yuck
Greetingsandfarewells
Hi / Hello / Good morning/afternoon/evening/night / Morninghiya / wotcha / hey / howdyhow (are) you doingGood dayBye / see you / Bye bye / Good-bye / See you (later)take careGood nightta ta / tara / cheers / cheerio
Discoursemarkers
well / right / nowI mean / you know / you see / see / look / mind you / now then
Attention sig-nals
hey / yo / say / hey you / oi
Responseelicitors
huh? / eh? / alright? / okay? / right? / see?
Responseforms
yes / no variants: yeah / yep / nope / unh unh – Hung.: “ö-őő” or “e-e” – no real spelling
okay [response to directive]
–POSITIVE:uh huh pron. /´h´/, rising intonation – Hung. ühü(m), öhö(m), aha, ehe
ühüm and aha conventionalizedvariants: mhm pron. /mhm/, rising intonation
mm / hmm–NEGATIVE:
huh uh /m/m/, falling intonation – Hungarian ö-őő or e-e – no spelling convention
unh unh /n/n/ or /N/N/ – ö-őő or e-e
really / I see
TO DIRECTIVES
sure, certainly, okie-dokie, okie-dokehuh? – Hungarian hm? eh? – hm? he? what?
both response forms & response elicitorssorry? / (I) beg your pardon? / excuse me?
Hesitatorsthis is uh pretty heavy stuff / er er, ninety pound, I think
nasalized variants:um, I’ll come over / my erm hairdresser brought those erm kiddies’ chairs – Hung. ööö

Chapter Two
119
Polite speechact formulae
Inserts or formulae conventional speech acts:thanking, apologizing, requesting, congratulating; often elicit a minimizer such as
no problem / you’re welcome / yes pleaseThank you / thank you very much / thanks / thanks a lot / ta / cheersyou’re welcome / no problem
(A. Sorry, …) – B. That’s okay<belch> pardon me
pardon? excuse me? sorry? (I) beg your pardon? pardon me?congratulationsExcuse me! [also attention signal]
Combining with grammatical constructions such as PPs and complement clauses:thank you for having usthank you very very very muchsorry to keep bothering you
Expletives
Taboo expressions, swearwords, semi-taboo expressions in exclamationsMWEs with variable syntactic structures excluded; purely formulaic MWEs included:
my God / bloody hell
Combining with interjections: Oh hellNon-exclamatory taboo expressions excluded (these can/do combine): e.g. bloody
1. Taboo, uncensoredbullshit; balls! bugger! God; my God; Christ! Jesus; Jesus Christ! Hell; Damn!
Shit! Goddamit! Bloody hell! Oh Shit! Fuck!2. Moderated, or self-censored
blimey! crumbs! crikey! dang (it)! Golly! Gosh! (Gosh) darn (it)! Heck! My gosh; Geez; Gees! Gee! Good heavens! Heavens! Good grief! (Good) Lord!
Oh heck! My goodness! Goodness (me)!
It may be interesting that formulae, which also occur in lists of synonymous or quasi-synonymousterms for phrasal expressions of different idiomaticity, should also figure in this list, which drawitems from the border area of genuine words vs. not-quite-words, i.e. words vs. non-PoS-classifiablelexical items termed “vocables” in the present study. There is, apparently, a set of one-word (less-than-phrasal) expressions at the level of words that contains the non-PoS-classifiable vocables.These vocables are either independent utterances, or show no or very little integration within theclauses which they appear in. Moreover, their functions are greatly varied, as shown e.g. in the tableabove. Because these functions are served partly by larger-than-word expressions, which would beconsidered as phrases or even clauses were it not the case that they are made up of vocables andthus fossilized, in this way there seems to be a twilight zone “just above” the word level on the tra-ditional rank scale, which comprises e.g. formulae. These include Oh I see! / Good morning! / Seeyou / mind you / hey you! / excuse me? / you’re welcome / bloody hell – the examples comefrom the various function-based subtypes of inserts above. The transition from words throughvocable/nonwords to multiword units is smoother than often is thought.
This overview of interjections, sentence words, inserts, and formulae in 2.6.5 and 2.6.6 throws lighton the fact that for dictionary making, insisting that (i) a grammatical rank scale-based classificationof what is (not) listed in the lexicon and in the dictionary is as unjustified as insisting that (ii) lexi-cal expressions need to be PoS-classifiable in order to be words. The expressions that will be (a)words with PoS labels for the syntax on the one hand, (b) listemes for the mental lexicon, and (c)dictionary-worthy lexical items are drastically different.

Chapter Two
120
The data suggests that there is an abundance of expressions that are not lexicographically inferiorjust because they cannot be neatly assigned to word classes. For this realization, it is irrelevantwhose fault this may be – the syntacticians, the lexicologists, or someone else’s, or simply languageis just too complex at this juncture.
There is such a wealth of expressions just above the word level on the traditional grammatical rankscale, and within their level, these expressions are so varied semantically, syntactically, lexicallyand functionally/pragmatically that a rank scale-based description pales before this variety.
2.6.5.7 Lexically bound words
The bound nature of morphemes means, in its simplest formulation, that such morphemes only oc-cur together with others. Affixes are bound; most lexical roots are free; independent words are bydefinition free. Dependent words e.g. in the sense of Kenesei (2000) are bound syntactically andphonologically, do not have lexical meanings, and do not occur as utterances.
What are termed lexically bound words in this study are different: together with vocables, interjec-tions, sentence words, inserts, inarticulate onomatopoeics, and bound bases, they inhabit the flexiblezone between the secure position of words and phrases on a grammatical rank scale.
Bound words in another, lexical, sense are words that invariably occur together with other words inmultiword expressions. Just as bound lexical morphemes (e.g. of the “cranberry” type) have neithermeaning nor grammatical function but still distinguish words, such lexically bound words functionsimilarly. Whereas bound lexical morphemes show the inadequacy of a traditional definition of themorpheme under which morphemes need to have meaning, lexically bound words exhibit a traiteven more anomalous: that not all words have meaning. This is certainly so in the eyes of the laydictionary user, who is usually ignorant of, and thus not worried about cranberry morphemes butcannot fail to notice the odd meaningless word: whenever a dictionary cannot provide a one-wordequivalent for such a word, it is a very noticeable phenomenon.
There exist numerous such words, and they are amply registered lexicographically. Although dic-tionaries do not as a rule use a special label, terminology or device to mark them, they do indicatethis feature of theirs variously, but effectively in the following way: “Word W, appears (only) inphrase P”.
Whether dictionaries PoS-label bound words is largely a matter of chance.
In CED&T (1992), lieu, e.g. is marked as a noun with a paraphrasable meaning:
lieu ‘stead; place’ (esp. in the phrases in lieu, in lieu of)
In CALD (2008), lieu is also marked as a noun; a search on lieu returns two items, lieu n and inlieu (of), but here, lieu is entered as a noun without a meaning given, and in lieu (of) with themeaning ‘instead (of)’.
Kuiper & al. (2003) mention that bound words exist in a number of what they term phrasal lexicalitems (presumably the same category as multiword expressions). Examples include take umbrage;take cognisance of; have an inkling; with bated breath; with might and main. The interestingflip side of this argument, of course, is that if an expression contains a (lexically) bound word, itmust be an idiom of sorts. If, under the standard definition, idiomaticity implies that the meaning ofthe whole is not reducible to those of the parts (plus the rules for their combination), this situationclearly holds when the parts have no meaning.

Chapter Two
121
Idioms that owe their existence to lexically bound words, to be sure, are the minority. They, how-ever, count among the “colourful”, conspicuous ones exactly because of the rare or unique, stylisti-cally marked words that they contain.
Lexically bound words have also been called “phraseologically bound”, and may indeed be called“fossil words”: obsolete words which remains in currency because they are contained within an id-iom that is still in currency. An idiom here is seen as some kind of protective structure that pre-serves the form side of some form–meaning duality, although it must be noted that there are lexi-cally bound words that never have had meaning in the first place, e.g. because they are corruptionsof well-known existing words.
It is Trawiński & al. (2008) who call these bound items “cranberry words”, based on Aronoff(1976). This use, however, may be misleading: for a long time, the term “cranberry word” has beenused for items that contain a cranberry morpheme, not for words that are the analogues of thosekind of morpheme. In that sense, cranberry is a cranberry word. If the analogy is to be kept con-sistent, lexically bound words ought to be termed “cran- words”, since they are the fossilized,meaningless parts of the complex. If, however, “cranberry word” is still to be used for lexically, orphraseologically, bound words, then “cranberry expression” is a convenient one for a multiwordexpression that contains (at least) one.
The “cranberry word” examples of Trawiński & al. (2008) include ulterior motives; to and fro;sleight of hand; scantily clad; nook and cranny; days of yore; sticks in one’s craw; in finefettle; kith and kin; spick and span; at loggerheads; in the offing; short shrift; happy as asandboy; play footsie with someone; make headway; the whole caboodle; wend one’s way.
Trawiński & al. (2008) admit that e.g. the verb bate ‘abate’ does exist; indeed, often the allegedlexically bound words are not absolutely non-existent. CED&T (1992) e.g. defines e.g. shrift asfollows:
shrift Archaic. ‘the act or an instance of shriving or being shriven’. See also short shrift.
The phenomenon of lexically bound words is a typical gradience: whether to a person a word isbound, i.e. used outside of some multiword expression, is a matter of education. Just as the personmay know or not know, and adequately use in all circumstances, the idiom itself, they may or maynot have come across the lexically “bound” word contained therein. There seem to be (almost)100% bound and less bound words, and this fact is reflected in the cautious handling of these ex-pressions in dictionaries: instead of the “Word W, appears only in phrase P”, which suggests a fullybound word, other wordings are encountered: CED&T (1992), e.g., sometimes has the qualification“esp. in the phrase”:
cranny ‘narrow opening, as in a wall or rock face; chink; crevice’ (esp. in the phrase every nookand cranny
with the wording “esp.” clearly showing that cranny is less than 100% bound.
Ayto (2006) argues that idioms may contain fossilized words that “have no independent existence”(e.g. pig in a poke). He also recognizes that cranberry expression is often used for the idioms thatcontain such words, the cranberry words. Ayto does not further classify these words, but a dualseparation is useful indeed. Cranberry morphemes really come in two varieties, the cranberry typeand the gooseberry type. Just as the morphemic “cranberry fossils” are either (a) completely non-existent outside the given complex word (as the cran- of cranberry), or (b) exist outside the com-plex word only in some irrelevant meaning (as the goose- of gooseberry), these word-level fossilsin idioms may either (a) be entirely non-existent outside a given pattern, or (b) not exist outside theidiom in one particular, obsolete but etymologically traceable, sense. While, e.g., fro in to and fro,the sleight of the phrase sleight of hand, or the yore of days of yore exemplify the former, abso-

Chapter Two
122
lute cranberry word type. The poke in pig in a poke or root in the phrase root for illustrate thelatter cranberry.
As far as lexicography is concerned, it is expected that dictionaries will also provide conflictingdata on this account. In 2.6.5.7.1, two works will be compared for some lexically bound word items.
• The expressions are in alphabetical order of the ostensible lexically bound words in them.
• The expression “esp. in (the) phrase” has been shortened to “esp. in”.
• Style labels have been cut.
If, based on the wordings in the two dictionaries, a boundness index were to be assigned to the lexi-cally bound words, showing the obviously gradational character of the phenomenon, the task wouldnot be a simple one.
Often the alleged (lexically) bound word has other meanings in which it is freely used outside theostensible cranberry expression, making the form–meaning unit unique, but not the form itself:headway and main are cases in point.
Sometimes the MWE is not even recognized as a cranberry expression in the dictionary, which doesnot enter it at all.
It also happens that the “bound” word is not deemed so unique as to explain the MWE in the entryfor that word; rather, the dictionary has just a referring article to some other word of the ostensiblecranberry expression: e.g. from craw, COED (2004) refers the reader to the entry stick; similarly,from the fro entry to the entry to and fro.
The multiword item may simply not be listed in the dictionary: with might and main and happy asa sandboy, e.g., are not entered in COED (2004).
It even happens that it is not clear which of the components of the cranberry expression is the lexi-cally bound word: the cranny part of nook and cranny is a “normal” word according to COED(2004), which lists every nook and cranny as a phrase under nook and labels it a phrase. By con-trast, CEDT (1992), which uses “esp. in every nook and cranny”, suggests that cranny is thebound word and nook a “normal” one. Thus this multiword expression figures twice below, shadedin both cases.

Chapter Two
123
2.6.5.8 Some lexically bounds words in CEDT and COED
The table takes a look at the treatment of a few bound words in CEDT (1992) and COED (2004).
List No7
Item CEDT (1992) COED (2004)with bated
breath1. bate another word for abate 2. with
bated breath holding one’s breath insuspense or fear
bated(in with bated breath) in great suspense.
the wholecaboodle
caboodle a lot, bunch, or group (esp. inthe whole caboodle, the whole kitand caboodle)
caboodle(in the whole caboodle or the whole kit
and caboodle) informal the wholenumber or quantity of people or thingsin question.
scantily clad clad a past participle of clothe clad1 archaic or literary past participle ofclothe.
1 clothed. 2 provided with cladding.takecognisance
1. knowledge; acknowledgement takecognizance of to take notice of; ac-knowledge, esp. officially 2. therange or scope of knowledge or per-ception
cognizance or cognisance1 formal knowledge or awareness. […] 2 […]PHRASEStake cognizance of formal attend to; take
account of.
nook andcranny
cranny narrow opening, as in a wall orrock face; chink; crevice (esp. inevery nook and cranny
crannya small, narrow space or opening
sticks in one’scraw
craw 1. a less common word for crop(sense 6) 2. the stomach of an animal3. stick in one’s craw or throatInformal. to be difficult, or againstone’s conscience, for one to accept,utter, or believe
crawdated the crop of a bird or insect.PHRASESstick in one’s craw see stick2.
in fine fettle fettle […] 4. state of health, spirits, etc.(esp. in fine fettle)
fettlecondition: the horse remains in fine fettle.
play footsie footsie flirtation involving the touchingtogether of feet, knees, etc. (esp. inplay footsie)
footsie(usually in play footsie) the action of touch-
ing someone’s feet lightly with one’sown feet as a playful expression of ro-mantic interest.
to and fro fro back or from. See to and fro frosee to and fro.
make headway headway 1. motion in a forward direc-tion: the vessel made no headway 2.progress or rate of progress: hemade no headway with the prob-lem 3. another name for headroom 4.the distance or time between con-secutive trains, buses, etc., on thesame route
headway1 forward movement or progress.2 the average interval between trains or
buses on a regular service.
have aninkling
inkling a slight intimation or suggestion;suspicion
inklinga slight suspicion; a hint.
kith and kin kith one’s friends and acquaintances(esp. in kith and kin)
kith(in kith and kin) one’s relations.
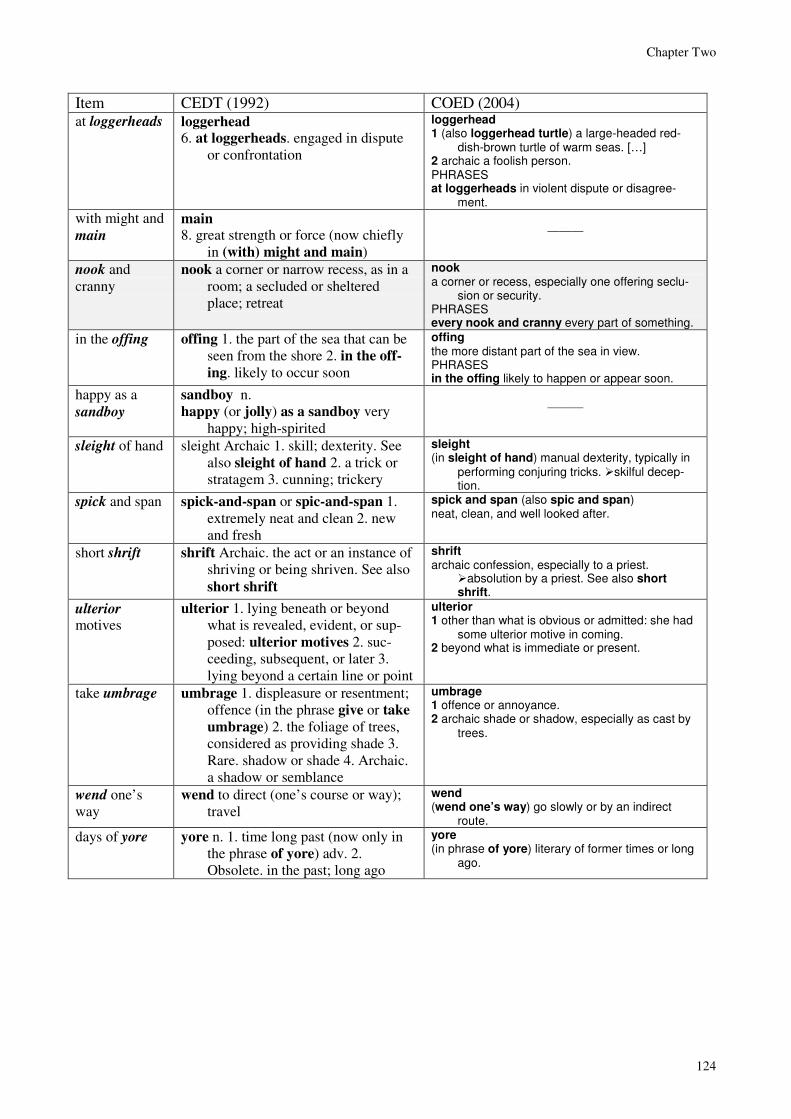
Chapter Two
124
Item CEDT (1992) COED (2004)at loggerheads loggerhead
6. at loggerheads. engaged in disputeor confrontation
loggerhead1 (also loggerhead turtle) a large-headed red-
dish-brown turtle of warm seas. […]2 archaic a foolish person.PHRASESat loggerheads in violent dispute or disagree-
ment.with might andmain
main8. great strength or force (now chiefly
in (with) might and main)
———
nook andcranny
nook a corner or narrow recess, as in aroom; a secluded or shelteredplace; retreat
nooka corner or recess, especially one offering seclu-
sion or security.PHRASESevery nook and cranny every part of something.
in the offing offing 1. the part of the sea that can beseen from the shore 2. in the off-ing. likely to occur soon
offingthe more distant part of the sea in view.PHRASESin the offing likely to happen or appear soon.
happy as asandboy
sandboy n.happy (or jolly) as a sandboy very
happy; high-spirited
———
sleight of hand sleight Archaic 1. skill; dexterity. Seealso sleight of hand 2. a trick orstratagem 3. cunning; trickery
sleight(in sleight of hand) manual dexterity, typically in
performing conjuring tricks. �skilful decep-tion.
spick and span spick-and-span or spic-and-span 1.extremely neat and clean 2. newand fresh
spick and span (also spic and span)neat, clean, and well looked after.
short shrift shrift Archaic. the act or an instance ofshriving or being shriven. See alsoshort shrift
shriftarchaic confession, especially to a priest.
�absolution by a priest. See also shortshrift.
ulteriormotives
ulterior 1. lying beneath or beyondwhat is revealed, evident, or sup-posed: ulterior motives 2. suc-ceeding, subsequent, or later 3.lying beyond a certain line or point
ulterior1 other than what is obvious or admitted: she had
some ulterior motive in coming.2 beyond what is immediate or present.
take umbrage umbrage 1. displeasure or resentment;offence (in the phrase give or takeumbrage) 2. the foliage of trees,considered as providing shade 3.Rare. shadow or shade 4. Archaic.a shadow or semblance
umbrage1 offence or annoyance.2 archaic shade or shadow, especially as cast by
trees.
wend one’sway
wend to direct (one’s course or way);travel
wend(wend one’s way) go slowly or by an indirect
route.days of yore yore n. 1. time long past (now only in
the phrase of yore) adv. 2.Obsolete. in the past; long ago
yore(in phrase of yore) literary of former times or long
ago.

Chapter Two
125
2.7 Above the level of words
2.7.1Compounds for the linguist and the user
One of the clearest clashes between the linguist’s and the layperson-as-dictionary-user’s way oflooking at linguistic expressions is with compounds. While compound words are words in the sys-tem of language (albeit ones that are not easily demarcated either from non-compounds, on the onehand, or from phrases, on the other), compounds will always be naturally seen as multiword items,especially in writing, the happy hunting ground of dictionaries. Whatever the linguistic status of asequence “with a space, or especially more spaces, in the middle”, the user, whose encounters withlanguage are focussed on the written medium, will be quick to establish that they are looking at an“expression”, a “phraseologism”, or an “idiom” of sorts when they see one. Since the status of mul-tiword expressions within what are generally considered as “phraseologisms”, i.e. their relation tothe expressions catalogued in 2.9, is not at all unproblematic, one that notoriously lacks a consen-sual view in the linguists’ community, it is to be expected that a huge portion of linguistic expres-sions that contain more than one (written) word, and are listemes (for the lexicon) will be in an in-determinate twilight zone lexicographically. Sections 2.7 and 2.8 explore this ill-defined zone.Compounds themselves will be discussed in all of those places where they are seen as overlappingwith (other) multiword units.
One central claim in the present study is that the majority of compounds are listemes. The claimheld by many (cf. Katamba 2005; Booij 2007) that they need not be listed since their meanings arecompositional is hard to accept. Booij claims that the
“productivity of compounding in many languages is largely due to its semantic transparencyand versatility” (Booij 2007:75).
While versatility is hard to define and neither is it clear why it should contribute to productivity, thetransparency claim must be mistaken: Booij states that
“the general semantic pattern of a compound of the form XY is that it denotes a Y that hassomething to do with X or vice versa, depending on the language”
(Booij 2007:75).
This may be true, but this does not mean transparency. It may suggest motivatedness in a trivialsense, but not predictability. Just by knowing the meaning of the components of the compounds G.Hausfrau, Du. huis-vrouw, H. házinéni and H. háziasszony (#1: ‘house’ #2: ‘woman’), there is noguessing which is/are the one(s) that mean(s) ‘landlady’ and which means ‘housewife’.
2.7.2 Synthetic compounds
It is only synthetic compounds, a subset of compounds at large, that have predictable meanings in-deed, and display a productivity that otherwise marks the syntax. The operation of their formation isso productive that any verb V and its argument A plus an Affix can be the input to such compoundsas Arg–V–Aff, where Aff may be, e.g. -ing and -er in English (the actual binary structure is irrele-vant now). The outputs range from (a) the established through (b) the potential but unusual along to(c) the bizarre. The most bizarre compounds are exactly of the same (un)acceptability and not lessgrammatical than their related VP with the same verb and argument structure. The expression ?feedthe windows is not a worse syntactic object than ?window-feeding is a morphological one: theusual syntactic creativity, only restricted by semantic anomalies, seems to be involved.

Chapter Two
126
There is no need for the listing of synthetic compounds in the mental lexicon: their majority are thusprobably not listemes. A part of them, the more frequent ones, may well be stored, if storage ismore cost-effective than real-time generation. The infinite number of potential synthetic com-pounds, which are generated in a way only characteristic of the maximum productivity of syntax,are per definitionem unlisted.
2.7.3 Lexicon vs. lexis
“Lexis” and “lexicon” both refer to the storage in the mental lexicon of lexical units, i.e. listemes,that are retrieved and combined into meaningful language. They may be used interchangeably, andsometimes are, as in much lexicographic writing. Corpus linguistics – with perhaps a sweeping gen-eralization – is of the view that the old dichotomy between grammar and the lexicon/vocabularydoes not exist, and often opts for lexis rather than lexicon because, as opposed to the lexicon, it fo-cuses on probabilistic, not possible language usage. The concept of lexis is thus supposed to con-trast with mainstream (generative) theoretical accounts of language; grammar is seen as the productof accumulated lexis, rather than an entity that generates it. Research along these lines claims that ithas found grammar to be actually avoided as far as possible, and much of language consists of pre-fabricated pieces of some form or other (Moon 2007).
As a foretaste of sections 2.8 and 2.9, List No8 sketches out the simple but workable overview ofthe various types of lexical item in Atkins & Rundell (2008:164). These lexical items are notclaimed to be either idiomatic or dictionary-worthy, although there may seem to be a link betweenidiomaticity and dictionary-worthiness.
Atkins & Rundell (2008:169–170) argue that because non-idiomatic compounds, e.g. table leg, are(i) spontaneously produced and found in their thousands in corpus data, and (ii) semantically trans-parent, they pose few problems to lexicographer or dictionary user. As the present study arguesthroughout, however, idiomaticity is not best defined in terms of transparency, but rather in terms ofpredictability, and for the purposes of bilingual lexicography predictability is the prime concept.
The kind of predictability that comes even before predictability of meaning is predictability of ex-istence (or existence of some similar form). Carstairs–McCarthy 2002:126 is explicit about thisdouble aspect of predictability: “Unpredictability of existence does not entail unpredictability ofmeaning.” Thus there is no guarantee, e.g. that even a (clearly transparent) compound like table legwill also be a compound in some other language (that language may not use compounds at all), letalone a compound with the same metaphor and of the same form as the English one. The case of theHungarian compound nyílegyenes ‘straight as an arrow’ will illustrate this. English has a simile,while Hungarian a compound for this concept (literally: “arrow-straight”). It is never predictablewhether notions like this are going to be expressed at all, and whether they are expressed by the twotypical devices of (i) similes or (ii) compounds (iii) or possibly in some other way. Any linguisticexpression in either of a pair of languages, especially when looked at from the learner’s point ofview, is thus idiomatic.
2.7.4 Types of lexical items in Atkins & Rundell (2008)
The examples in Atkins & Rundell 2008:169–170 (given below except for the simple words) arenot originally included, but come from Chapter 6:

Chapter Two
127
List No8Types of lexical item
SIMPLE WORDS ABBREVIATIONS PARTIAL WORDS MULTIWORD EXPRESSIONS36
–lexical
–grammatical(function words;closed categoryitems):
5 types: Prep,Conj, Pron,Aux, Det
alphabetisms:
BBC
bound affixes:
im- as inimpossible
-ment as inattainment
fixed & semi-fixed phrases37
–transparent collocations: to risk one’s life–fixed phrases: knives, forks and spoons;
kith and kinSome function as compounds.–similes: white as snow–catchphrases:
if you can’t beat ’em, join ’em–proverbs:
too many cooks (spoil the broth)–quotations:
to be or not to be; an eye for an eyeacronyms:
NATO
productiveaffixes38:
ex- as in ex-wife-gate as in
Zippergate
other phrasal idioms39:
Includes all idiomatic phrases except theother four types in this column.throw in the sponge / towelto get too big for one’s boots etc etc
contractions:
don’t
combining forms:
one-legged,vinyl-covered,flat-leafed
compounds:
idiomatic40 & non-idiomatic–PoS mainly: N, A & V
(within V: commonest = phrasal V)
in spite of = compound P–types:–figurative: lame duck, civil servant–semi-figurative: high school, blind drunk–functional: can opener, police dog
phrasal verbs:consists of V + one or more particle(s)Particle may function as Adverb (away,
out) or Prep (with, to), or both (in,through).
Meaning may be literal and figurative (=metaphorical): run out
support verb (= light / delexical / empty verb) constructions:
make a complaint, take a decision, have
a rest, give a lecture, do a dance
36 Atkins & Rundell (2008:166) mention that of the four principal classes, only MWE‘s pose problems of identification.37 Without specifically mentioning “bundles” or “chunks”, Atkins & Rundell (2008:166) emphasize that many groups
of words, such as she put it in the or immediately below the, co-occur frequently in corpus text but are of no realinterest to lexicography”, adding that “Some theorists call such fragments collocations […]”.
38 Atkins & Rundell (2008:165) include this footnote: “Some dictionaries call these combining forms, but we give thisterm a more specific definition”.
39 In the absence of hard and fast criteria, Atkins & Rundell (2008:166) admit that it is almost impossible to beconsistent here. The phrase must pass the “meaning is more than the sum of the parts” test, and then it may have oneor more defining properties (no idiom has them all).
40 Atkins & Rundell (2008:170) warn that there are no watertight criteria for identifying idiomatic compounds in corpusdata. Then, most confusingly, they say that idiomatic compounds they will call simply compounds.

Chapter Two
128
No claim is made here, or elsewhere in the book, that a list of the types of lexical item covers thewhole lexicon of English, or that a similar one may cover that of another language.
Of the four principal classes – simple words, abbreviations, partial words, and multiword expres-sions – only the members of the first are all traditionally classified into parts of speech (which clas-sification, of course, is a lexicographical problem in its own right).
The only type in the multiword column whose members, being word-level items, are PoS-classifi-able, are compounds. Of these, however, only A and N compounds are a straightforward matter:compound prepositions are claimed not to exist by many authors.
Support verb “constructions” are not verbs as PoS, but VPs.
Phrasal verbs, while (i) they have an uncontested place from both the pedagogical and lexicographicpoint of view, (ii) receive widely differing analyses syntactically, and (iii) are classified differentlyin the lexicological literature. Two extreme approaches in the latter are Atkins & Rundell (2008),who, as seen above, explicitly classify them with compounds – which they are sometimes claimednot to be syntactically: to be compounds, they would have to be left-headed, which is sometimesclaimed to be impossible in English. At the other end, Booij (2007) claims them to be lexical unitsbut not words since they lack lexical integrity: “another way of putting this is to say that look up isa listeme but not a lexeme of English” Booij (2007:23).
A dictionary, then, may contain several types of lexical item whose “word vs. nonword” status re-mains forever unclear, and irrelevant, for the general user. The “simplex word vs. compound” bor-derline is no more clearly defined than the “word vs. phrase” divide.
2.8 Lexical unit
It has been traditional in lexicography to refer to the units catalogued in dictionaries as “lexicalitems”, or “lexical units”, terms which are supposed to include any unit of the lexicon, not justwords, but which sometimes restricted to larger-than-word units. As summarized, e.g., in Kiefer(1990), “a lexical item need not be a word of the language: it can be a stem morpheme, a phonol-ogically not fully specified sequence of segments or even an abstract entity with no direct relation-ship with the actually occurring elements of the language”. Of these, most stem morphemes are not,and certainly no phonologically underspecified elements and abstract entities are, entered in dic-tionaries. This is one of the rarely mentioned differences between the mental dictionary and thelexicographical product. Whether an abstract lexical entity may be a listeme that is stored and re-trieved seems a highly controversial issue that the present study obviously cannot endeavour tosolve, but it may be in order to point the fact out. Essentially, however, “lexical item” may cover thewhole ground both below and above the word.
Since, crucially, the expressions “lexical item” or “lexical unit” were introduced so that they couldalso cover multiword expressions in the first place, “multiword (lexical) unit/item”, or an unquali-fied “multiword unit/item”, more than precisely delimits its object in the phraseological realm: alexical unit consisting of more than one word-level item.
In contrast to this, the term “lexical unit” is used more restrictively e.g. in Atkins & Rundell (2008),where it explicitly means “word sense”: they speak of a “...a methodology for dividing words (or‘lemmas’) into senses (or ‘lexical units’)” (2008:20). They write about “finding the senses, or lexi-

Chapter Two
129
cal units, of the headword [...] and [...] identifying what is worth recording for each of these lexicalunits (2008:114). Lexical units here are thus associations of form and meaning: ball1 ‘sphericalbody’ and ball2 ‘social function for dancing’ are two (of the many) lexical units (with the sameform /bç˘l/).
Similarly, Atkins & Rundell (2008) explicitly warn “that the paradigmatic relationships [..] in thischapter are all between lexical units (LUs), that is to say, word meanings and not words them-selves” (2008:144). They define LUs thus: “a headword in one of its senses is a lexical unit (or LU),and [...] we use the term to denote one sense (either during the analysis process or within a diction-ary entry)” (2008:175).
Discussing word-centred vs. collocation-centred vocabulary teaching, for example, Almela &Sánchez (2007) claim that “recent advances in corpus linguistics mark a departure from the word-centred approach”, because “vocabulary teaching should be inspired by a revised notion of whatconstitutes a lexical unit. [...] The concept of an extended lexical item, or ELI, has implications bothfor the structure of the lexicon and for the scope of the phrasicon”. To put these insights more suc-cinctly, they basically claim that the lexicon is mostly a phrasicon.
2.8.1 “Phrasicon” and phraseology
The term “phrasicon”, signifying the whole inventory of idioms and phrases of a language, does notseem to be universally used, but it does appear in Gläser 2001 (Rosemarie Gläser’s contribution inCowie 2001), one of the most influential volumes on the subject.
It is this term, “extended lexical unit”, used in e.g. Poß & van der Wouden (2004) for what the ma-jority of scholars now seem to label “multiword expression”. Writing about what they term ex-tended lexical units Poß & van der Wouden (2004) claim that
“recent developments in linguistic theory [...] question the traditional picture of thelanguage system consisting of an interesting grammar vis à vis a boring lexicon.Large parts of everyday spoken language are arguably constructed out of “extendedlexical units” (ELUs), which we will use as a pre-theoretical term to refer to all lin-guistic building blocks larger than words, be they compositional or not, that must beassumed to be stored in the lexicon (sometimes also known as “construction”), be-cause they have idiosyncratic properties as regards their phonology, morphology,syntax, semantics, pragmatics, style level, etc. Note that lexical storage of these ELUsdoes not preclude the possibility that they possess various degrees of grammaticalstructure and/or grammatical freedom.”
Poß & van der Wouden (2004:187); italics mine
This significant and densely worded statement will have to be separated into two: (i) more broadly,about the significance of longer-than-word lexical units for syntax, and the changes that their rec-ognition may imply for linguistics, involving a fundamental theme of linguistics: the architecture ofgrammar, and the division of labour between the lexicon and the grammar; (ii) more narrowly, thenature of these longer-than-word, “extended” lexical units: their compositionality, storage, and idio-syncrasies at different linguistic levels; also, their relation to other longer-than-word expressions,e.g. “constructions”.
Whatever one’s view on the overall linguistic significance of these extended, or multiword, lexicalunits may be, and whether one agrees that these units disprove the tenet of an “interesting grammarvis à vis a boring lexicon”, the second part of the statement can hardly be denied: the literature onthe phrasal lexicon, which has always suffered from an embarrassment of riches and a lack of defi-nitions due to the elusive character of its object, contains a host of “pre-theoretical”, mostly unde-fined or rather untidily defined, and obviously cross-cutting terms such as: “multiword expression”,

Chapter Two
130
“lexical phrase”, “polyword”, and “phraseme”. Under the headings of these terms researchers haveinvariably placed widely differing linguistic patterns, and this has resulted in a multitude of differ-ent terms signifying a multitude and partly overlapping phenomena that are impossible to unravel.This unconstrained invention of names and new classification is not the fault of the numerous ana-lysts who either use the existing formidable multitude or, dissatisfied, add their own but – contraoptimistic voices from lexicographic quarters – it is of no use for dictionary-making.
2.8.1.1 Fixed expressions, phrases, idioms
2.8.1.1.1 Moon (1998) on problems of terminology
Moon (1998:2) characterizes this situation as follows:
“Terminology in this field has always been problematic […]. There is no generallyagreed common vocabulary. Different terms are sometimes used to describe identicalor very similar kinds of unit; at the same time, a single term may be used to denotevery different phenomena”
Moon (1998) uses “fixed expression” as a general term to cover several kinds of “phrasal lexeme,phraseological unit, or multi-word lexical item, that is, holistic units of two or more words” (thustreated synonymously). Fixed expressions for Moon (1998) include (among other things) frozencollocations, grammatically ill-formed collocations, proverbs, routine formulae, sayings, andsimiles.
“Fixed expression” also covers idioms. Moon also sets out a more detailed typology, and finds“fixed expression”, like “idiom”, unsatisfactory, since many are not actually fixed. She states thatshe “will retain it for simplicity’s sake”, and refer to fixed expressions (including idioms) as FEIs.
The really difficult question of whether a string is a unit, i.e., a FEI, is decided by taking three fac-tors into account: (i) institutionalization, (ii) lexico-grammatical fixedness, and (iii) non-composition-ality. These “form the criteria by which the holism of a string may be assessed.” (Moon 1998:6).
Institutionalization, in turn is supposed to be
“the process by which a string or formulation becomes recognized and accepted as alexical item of the language. […] In corpus terms, institutionalization is quantitative,and assessed by the frequency with which the string recurs. […] However, […] mostFEIs occur infrequently.” (Moon 1998:7)
FEIs cover only some of the phraseological units in English: Moon claims that she is “deliberatelyavoiding four particular kinds of item”: compound nouns, adjectives, and verbs […]; phrasal verbs[…]; foreign phrases […]; and multi-word inflectional forms of verbs, adjectives, and adverbs suchas had been lying and more careful(ly)”, explaining this by claiming that “the interest in com-pound words seems […] to rest largely in morphology, and multi-word inflectional forms are sim-ply part of the grammar of English”. She is excluding phrasal verbs and foreign phrases becauselimits need to be set; phrasal verbs are easily separable on lexico-grammatical grounds, but other-wise show a similar range of idiomaticity types to FEI s.
“Idiom” itself is fraught with problems, first of all because it is used in a narrower and abroader sense:
“Narrower uses restrict idiom to a […] kind of unit: one that is fixed and semantically

Chapter Two
131
opaque or metaphorical, or, traditionally, ‘not the sum of its parts’ […]. Such unitsare sometimes called pure idioms […]. In broader uses, idiom is a general term for many kinds of multiword item, whethersemantically opaque or not.”
Moon reminds us that Anglo-American dictionaries typically call idioms what she has termed FEIs,making no further typological classification. Idiom is also used for “non-compositional polymor-phemic words” such as blackbird. (This basically equals idiomatic compounds). In Hockett’s vieweven single morphemes are idioms, since “their meanings cannot be deducible” (Hockett 1958:171ff, quoted in Moon 1998:4).
“In some discussions of speech act theory”, the term idiom refers to a conventionalized formulawith an illocutionary function (for example, can you pass the salt?), but that formulae such as thisare rarely recognized as idioms in lexicology.
Moon states that while she uses FEI as a general term, there are others in use, in addition to broaderuses of idiom. Phraseological unit is used in some Slavonic and German linguistic traditions as asuperordinate term for multi-word lexical items. Phraseme is sometimes used as a superordinateterm outside Anglo-American traditions. Even more confusingly, there are other uses for both ofthese terms. Phraseological unit and phraseme can be identified with phrasal lexeme in (Lyons1977: 23; quoted in Moon 1998:5).
2.8.1.1.2 Granger (2005) on phraseology
The different approaches to multiword units and phraseology in general are aptly summarized byGranger (2005:165). Phraseology is supposed to deal with
“the study of word combinations rather than single words. These multi-word units[…] are classified into a range of subtypes in accordance with their degree of seman-tic non-compositionality, syntactic fixedness, lexical restrictions and institutionaliza-tion. As phraseology has strong links but fuzzy borders with several other fields oflinguistics, however, notably morphology, syntax, semantics and discourse, linguistsvary in their opinion as to which subsets of these MWUs should be included in thefield of phraseology. Compounds and grammatical collocations are cases in point.”
And because phraseology has fuzzy borders, opinions also widely vary as to which of these ought tobe included in dictionaries. Opinion is even more widely divided on how they should be included, ifat all, but that is a matter of lexicographic policy rather than lexicological wisdom.
Crucially, “institutionalization”, an expression that sometimes appears in lists of the axes alongwhich multiword units may be placed, is rarely defined. (Moon 1998, quoted 2.8.1.1.1, which is anexception, defines it in basically statistical terms, considering it as one of three factors that makeunits holistic, i.e. fixed expressions.)
...Although there is still some considerable discrepancy between linguists as regardsthe terminology and typology of word combinations [...], there is general agreementthat phraseology constitutes a continuum along which word combinations are situ-ated, with the most opaque and fixed ones at one end and the most transparent andvariable ones at the other.
...One of the main preoccupations of linguists [...] has been to find linguistic criteriato distinguish one type of phraseological unit from another (e.g. collocations vs. idi-oms or full idioms vs. semi-idioms) and especially to distinguish the most variableand transparent multi-word units from free combinations, which [...] are [...] consid-ered as falling outside the realm of phraseology.”

Chapter Two
132
One is tempted to say that if the expression is really “free”, then it has no place in the dictionary. If,however, the border between the grammar and the lexicon is fuzzy – as certainly seems to be thecase from a lexicological angle – then even this much is uncertain.
Granger also argues that by establishing non-compositionality and fixedness as the criteria for wordcombinations, the focus shifted to (or, contra Granger, stayed with) multiword units such as prov-erbs, idioms and phrasal verbs, while the less central, more variable combinations usually get muchless attention. This is reflected in the omnipresence of books on idioms and phrasal verbs on themarket; lip service to what the present study refers to as the “colourful” type of idioms (such as begreen with envy, appropriately using a colour metaphor) has been around for far too long.
More importantly, Granger reminds us that a more recent approach to phraseology, the statistical orfrequency-based approach (as opposed to a top-down one which identifies phraseological units onthe basis of linguistic criteria
uses a bottom-up corpus-driven approach to identify lexical co-occurrences. This in-ductive approach generates a wide range of word combinations, which do not all fitpredefined linguistic categories [...]. It has opened up a ‘huge area of syntagmaticprospection’ (Sinclair 2004: 19) encompassing sequences [...] which are ‘syntacticallyand semantically compositional, but occur with markedly high frequency’ [...]. Suchunits [...] have recently revealed themselves to be pervasive in language, while manyof the most restricted units have proved to be highly infrequent.
Here, “free” is allowed to creep back into the dictionary, as it were, simply provided it is frequentenough.
Word combinations, then, are equated with multiword units, which are classifiable into subtypes byfour criteria. MWUs have fuzzy borders, and no clear definitions: a compound, e.g. may or may notbe considered one. MWUs constitute a continuum with an opaque/fixed extreme and a transpar-ent/variable extreme. Analysts try to find criteria both for separating out types of MWU, and for thedemarcation of the MWU vs. “free combination” border. The new approach to MWUs may notbase itself on linguistic criteria: MWUs may not be grammatical, i.e. linguistically natural, units.Indeed, the notion MWU is open to every and any interpretation.
All this makes it more than unlikely that there ever emerges an all-embracing definition for MWUs,since not only have these been found to have even fuzzier boundaries than most linguistic objects,but also less clear ones than before; and in the absence of at least an initial working definition, theirsphere can be widened arbitrarily. Some of the units that have “recently revealed themselves” areclearly not units of grammar at all, only units in the statistical sense: the “bundles” of Biber & al.2000 and the “clusters” of Carter & McCarthy (2006) are cases in point.
Pawley & Syder (1983) argue that
“fluent and idiomatic control of a language rests to a considerable extent on knowl-edge of a body of ‘sentence stems’ which are institutionalized or lexicalized”.
These are units
“of clause length or longer whose grammatical form and lexical content is wholly orlargely fixed [...]. Although lexicalized in this sense, most such units are not true idi-oms but rather are regular form-meaning pairings. The stock of lexicalized sentencestems known to the ordinary mature speaker of English amounts to hundreds of thou-sands. In addition there are many semi-lexicalized sequences, for just as there is acontinuum between fully productive rules of sentence formation and rules of low pro-ductivity, so there is a cline between fully lexicalized formations on the one hand andnonce forms on the other.”
Pawley & Syder (1983:191; italics mine)

Chapter Two
133
In the light of such (frequently made) realizations, it is odd that when questions concerning the“word stock” of a language are asked, authors (although warning about the problems of definitionand methodology involved) fail to point out: words are not what count. This multiply erroneous laynotion of the “word stock” is in this way partly perpetuated by dictionaries.
Another fact worthy of note is that according to Pawley & Syder (1983) too, lexicalization of sen-tence stems is not an either–or but gradational phenomenon.
2.8.1.2 “Phrase” vs. “idiom”: not distinguished in CALD (2008)
Notwithstanding the volumes of literature on phraseology, the everyday notion of the lexicon issuch that it contains “words and expressions”, or “words and phrases”, where the latter signifies any(memorizable) multiword sequence.
CALD (2008), one of the best learner’s dictionaries in electronic form, offers different sorts of use-ful searches, and even has a system of colour coding for the different types of hit:
dark blue = main entries and variants; green= phrasal verbs; light blue = phrases; red = idioms
While all users will (have to) accept this grouping, which is a given in the dictionary, the termsthemselves are not explained in the Help. Thus the difference between “phrase” and “idiom” willnever be explained; a glance at the list of examples convinces one that there is no such difference.
Not only are phrase and idiom, distinguished by labelling but not kept apart consistently, there isalso no labelling either for compounds (which is not a unique feature of this dictionary: compoundsare not usually marked as such): the boldface items in list (A) below are all compounds (with wordthe head or the modifier), but neither in their entries nor in this list is there indication of their com-pound status. The first group of hits are Main entries and variants, not Main entries and compounds.“Variant” thus remains undefined – and indeed undefinable.
The above is no criticism of CALD (2008): there simply does not exist a workable taxonomy in theliterature on which lexicographic treatments of these and similar examples could be based; the lexi-cal phenomena involved are apparently too complex for that.
List No9Search on word in CALD (2008):
(A) Main entries and variants
word n LANGUAGE UNITword n TALKINGword n NEWSword n PROMISEword n ORDERword vbig word ncomplex word ndirty word nfour-letter word n
function word nthe f-word na good word nguide word nword association nword perfect adjword processing nword processor nthe written word nword class n, at part of speech (n)
(Boldface here signifieswhat are labelled “variants”)
(B) Phrases
not believe a word of itdoubt sb/doubt sb’s wordkeep your promise/word
the printed wordthe f-/c- etc. word

Chapter Two
Three of the phrases are VPs. The two NPs, the f-word and the printed word could also figureamong the “variants”.
(C) Idioms
not have a civil word to say about sb(your) every wordbe as good as your wordwon’t hear a word (said) against sb/sthMany a true word is spoken in jest.not know the meaning of the wordbe the last word in sthWhat’s the magic word?Mum’s the word.the operative wordsay the wordsend wordspread the wordtake my word for it, at take it from meweigh each word, at weigh your wordsbreathe/say a wordby word of mouthfrom the word gogive your word
have a word in sb’s earin a wordman/woman of his/her word(upon) my word!not get a word in edgewaysput in a good word for sbput the word about/around/out/roundtake sb at their wordword for wordword gets about/around/roundword has it(the) word isyour word is your bond(the) word is/gets outnot get a word in edgewise, at not get a
word in edgewaystake sb’s word for it, at take sb at their
word
In (B) and (C), word is boldface – in the dictionary there is no such highlighting.
2.8.2 Idiomaticity due to singularity of occurrence in some medium
It may be difficult to determine whether an expression such as KEY CUT WHILE YOU WAIT is specialowing to its register, field, or medium – because it is really none of these: written language, butmore than that, a typical notice. Corpora are written or spoken, and notices are a subtype of theformer, but while corpora may very well gather linguistic material from notices as subcorpora, inthe dictionary there will be no such standard register as “Notices”.
As any learner of a foreign language will tell, notices use a special language, sometimes withunique grammar or vocabulary, possibly both, and these are largely unpredictable from the “nor-mal” language. They may also vary with dialect, but that in itself does not make them special; thisfeature just adds to unpredictability.
Because they are not genuinely written (and mostly not kept in electronic form) it seems hard to de-vise and collect corpora, e.g. for street signs and all kinds of notices, including official ones. Dis-cussing text types, Stubbs (2002:5) mentions that some whole texts can be very short. Exactly be-cause these are self-contained texts, these are maximal formulas, as it were; it is easy to se that thefollowing equivalences are unguessable from either language:
EnglishPRIVATE WET PAINT CLOSED FOR LUNCH
NO ENTRY
TRESPASSERS WILL BE PROSECUTED
corresponding to
Hungarian(IDEGENEKNEK) TILOS A BEMENET FRISSEN MÁZOLVA EBÉDIDŐ – ZÁRVA
literally‘(for strangers) entry is forbidden’41 ‘freshly painted’ ‘lunchtime – closed’
41 PRIVÁT is not impossible as a notice in Hungarian.

Chapter Two
135
One can indeed appreciate the idiomaticity reading some of the word-for-word glosses. Gettingthem wrong and producing intelligible but still un-English expressions is a fine example of what itmeans to speak “unidiomatic”.
The “thank you for…” type seems to be a recent addition to Hungarian notices, owing to which itis now possible to find – or invent – a Hungarian equivalent for notices such as THANK YOU FOR
NOT LETTING DOGS LOOSE – e.g. Köszönjük, hogy nem vette le a kutyájáról a pórázt.
One ticket office at a Budapest underground station boasts the following English-language notice:AFTER LEAVING YOU CANNOT RECLAIM. It is clear that though removing the false friend, andchanging the you cannot part may improve it a lot, there no simple salvaging the entire phrase ex-cept by replacing it with an authentic one (that will bear the mark of one of the varieties of Englishand, to be sure, may look foreign to speakers of other varieties).
The fact that notices such as this will differ geographically reminds one of another fact related togeographical variation. Paradoxically, reclaim, a false friend in more European languages than not(cf. Hill 1982), is perhaps better understood in “world English” than would be its idiomatic counter-part complain, which will be usually better known worldwide in the sense ‘grumble’, and perhaps be-cause of this, it will not be readily used in this “official” sense by Europeans less proficient in English.
A subtype of this hard-to-translate notice item is when there is no linguistic equivalent of somewritten notice: WALK or GO and DON’T WALK or STOP are standard texts on the red and green light,respectively, but because presumably in several cultures this is not verbalized, either some para-phrase or a translation will have to be given:
WALK ‘zöld; szabad’ (jelzése) [jelzőlámpán] DON’T WALK ‘piros; tilos’ (jelzése) [jelzőlámpán] [i.e. ‘on traffic lights’]STOP ‘piros; tilos’ (jelzése) [jelzőlámpán]
Although neither szabad nor tilos is used in traffic lights, which making them pragmatically unsuit-able as equivalents, from a Hungarian → English point of view, the idiomatic translation of Hunga-rian szabadot/tilosat mutatott a lámpa (lit. ‘the lamp showed allowed / not allowed’) may be justthis: the light/sign said walk/don’t walk.
An added difficulty may be dialectal variation again: this use of (DON’T) WALK seems to be Ameri-can rather; but the inclusion of such information is sure to clutter up an entry completely.
2.9 A catalogue of multiword expressions (MWEs)
Not all authors use the MWE label for the same phenomenon, but if there is to be one such label,multiword expression will be used as a catch-all.
Taking the inevitable risk of misunderstanding or misrepresenting the original conceptions, dia-grams will be provided of each taxonomy of MWEs, to illustrate what Sag & al. (2002) have called“a pain in the neck for NLP”, which apparently causes a pain in the neck for the whole of the studyof the lexicon, if not the whole of the linguistic enterprise.
Listed, scrutinized and tabulated in 2.9 are fifteen different, mostly recent, schemes that can behoped to make a contribution to the cataloguing in dictionaries of expressions larger than the word.(Ayto (2006) and especially Numberg & al. (1994) will be more detailed.) What emerges from thiscatalogue is that, similarly to many, perhaps most, such inventories, it is too fine-grained for use inlexicography.

Chapter Two
136
Each framework is summarized in a Venn diagram, which, though inevitably a simplification, ishoped to be true to the spirit of the discussion in question. Also, such unifying simplification isneeded if the common features of these widely differing frameworks are to be captured.
What brings together these diverse discussions is their claim, mostly explicit, that there is a lot moreto the lexicon than words, and that this realization, although naturally and inescapably acted upon inlexicography, is far from common knowledge in linguistics in general. What will clearly transpirefrom this variety of frameworks, and what must have been plain especially in Moon (1998) above,is that if an editor should need guidelines as to what to include of the larger-than-word expressions,“idiomatic” or otherwise, then there is certainly no single source to turn to, in view of the strikingdisparity of approaches (which most of them themselves recognize and admit). It is even less likelythat they allow for some consensual view to be gleaned.
The following sources have been examined:
2.9.1: Cruse 20002.9.2: Biber & al. 20002.9.3: McCarthy 20062.9.4: Hanks 20062.9.5: Dobrovol’skij 20062.9.6: Ayto 20062.9.7: Moon 20062.9.8: Wray 2002
2.9.9: Kuiper 20062.9.10: Fazly & Stevenson 20072.9.11: Goldberg & Casenhiser 20072.9.12: Abu-Ssaydeh 20052.9.13: Sag & al. 20022.9.14: Biber & al. 20002.9.15: Numberg & al. 1994
2.9.1 Cruse (2000) on compositionality
Cruse (2000:67) defines the principle of compositionality as follows: the meaning of a grammati-cally complex form is a compositional function of the meanings of its grammatical constituents.Since, however, there are expressions not all of whose grammatical constituents contribute an iden-tifiable component of its meaning [= idioms], the principle is reformulated thus:
The meaning of a complex expression is a compositional function of the meanings of its semanticconstituents, that is, those constituents which exhaustively partition the complex, and whose mean-ings, when appropriately compounded, yield the full global meaning.
(While “grammatical constituent” apparently needed no definition, “semantic constituent” has to be,and is defined by means of the recurrent contrast test.)
The type of grammatically complex expression not all of whose grammatical constituents are se-mantic constituents is an idiom. Although “this term is more usually applied to phrasal units”, bythis definition, blackbird is an idiom Cruse (2000:72). Idioms are non-compositional in the sensethat their apparent constituents are not real semantic constituents, and the meanings which suchconstituents have in expressions where they are semantic constituents may not have any relevanceto the meaning of the unit. Cruse’s approach lends support to the view, maintained in the presentstudy, that compounds are typically idiomatic.

Chapter Two
137
2.9.1.1 Opacity and dictionary-worthiness
Different degrees of opacity are distinguished in both Cruse (1986) and (2000), and two compo-nents to this notion are claimed to exist:
(i) the extent to which the constituents of opaque expressions are “full semantic indicators”.
E.g. blackbird has two full indicators, and is thus less opaque than ladybird (which has only onepartial indicator: the element -bird); this, in turn is less opaque than red herring (no indicators atall). The opacity scale is thus:
red herring > ladybird > blackbird (> black bird)
(ii) The other component is the “discrepancy between the combined contribution of the indicators(whether full or partial ones) on the one hand, and the expression’s overall meaning on the other”.
Some irreversible binomials, e.g. fish and chips, are less opaque than, e.g. blackbird, even thoughboth contain only full semantic indicators. (Cruse admits that the objective measuring of such a dis-crepancy is difficult.) The expression fish and chips is not a completely free and transparent syn-tactic phrase; it is opaque because not just any kind of fish or any method of cooking or presentationwill qualify. By contrast, both the phrases chips and fish and chips with fish and the expressionfish with chips are both transparent and free.
The opacity scale then is modified thus:
red herring > ladybird > blackbird > fish and chips (> black bird)
As the degree of opacity diminishes, the transitional zone between opacity and transparency is ap-proached: Cruse admits that some irreversible binomials are indeed hard to categorize as one or theother, e.g. salt and vinegar, soap and water. It may be added that not only some irreversible bi-nomials, but many items of intermediate status are difficult to classify “as one or the other”. Allopaque sequences are obviously minimal lexical units and therefore, in an ideal dictionary, shouldbe listed. This is independent of whether some of the genuinely free/transparent combinations arelistemes in the mental lexicon.
2.9.1.2 Noun binomials lexicographically
Cruse (1986: 2000) cannot be right when he claims that practical lexicographers would draw theline of demarcation at a different place from him and argue that fish and chips or bread and butter(while they are undoubtedly slightly opaque in the technical sense) present few problems of inter-pretation to speakers familiar with the normal constituent meanings of the parts, and are thus notworth listing. What likely happens is that if items like these do not get included, it is not becausethey do not deserve to be included, in the judgement of editors; rather, it may be (partly) because itis not always easy to spot the potentially semi-opaque character of an expression (as Cruse himselfwarns in the case of fish and chips).
Cruse must tacitly have native speaker dictionaries in mind here, although this is not easy to verify.It does seem to be the case that native speaker dictionaries do not usually contain such noun bino-mials as headwords; this will be explored below.
• It is not easy to find dictionaries with search possibilities that can be put to use to prove apoint like this. However, a wildcard search on “? and ?” in CED&T (1992), a native speakerdictionary, shows that there is not one single headword of the “N and N” form, that is, one thatmatches the pattern of bread and butter or soap and water. (Bread and butter, the only ap-parent example of this type, does get listed, but in the ‘livelihood’, not the ‘slices of breadspread with butter’ sense; it is thus a genuine idiom rather than a simple binomial.)

Chapter Two
138
• NSOED (1997), another native speaker dictionary, has no compounds with bread asthe first member as headwords, and has no bread binomials either. It does contain, within thebread entry, the following binomials: bread and butter; bread and circuses; bread and milk;bread and scrape; bread and water; bread and wine. These are all somewhat opaque butonly in the sense that in all of them there is what Cruse calls “discrepancy between the com-bined contribution of the indicators and the expression’s overall meaning”.
Although dictionaries may have a section for compounds in the entry of either42 of the compoundmembers (if the compounds themselves are not made into headwords, like in NSOED 1997), theynever have a separate zone for binomials within these sections for compounds. Binomials are thusnever recognized lexicographically43.
• MED (2002), a learner’s dictionary, allows this kind of search: a smart search on nounheadwords containing the word and yields 84 results, of which the relevant ones (with the likesof the expression bring and buy sale having been removed) are listed below:
List No10
42 It is simplistically assumed here that compounds have two members.43 The linguistic sense of binomial is not contained the NSOED (1997) at all.
arts and craftsassault and batteryB and Sbed and boardbed and breakfastblock and tackleboom and bustbread and butterbreaking and enteringbricks and mortarbubble and squeakcash and carrycat and mousechecks and balancescomings and goingscountry and westernCustoms and Excisecut and pasteD and Cdown-and-outdribs and drabsfish and chips
five and dimeflesh and bloodgoods and chattelshammer and sicklehealth and safetyhide-and-seekhook and eyehue and cryhundreds and thousandsins and outsJekyll and Hydekith and kinlaw and orderlost and foundmeet and greetmover and shakernoughts and crossesodds and endsodds and sodspainter and decoratorpark and ridepay and display
pins and needlespros and consR and DR and Rrank and filerhythm and bluesrock and rollroom and boardrough and tumblesearch and rescueshow and tellskull and crossbonesslap and ticklesnakes and laddersso-and-sosupply and demandto and frotoing and froingtongue and groovetrack and fieldwear and tearyin and yang
Here, too, the item bread and butter (marked “Uncount Noun”) happens to be listed in the ‘liveli-hood’ sense, not the ‘slice of bread spread with butter’ sense.
2.9.1.3 Whether (irreversible) binomials are nouns
The above list of binomials contains quite dissimilar items. “Binomial noun”, if regarded as a sub-class of nouns, is a “word (sub)class”. Some are marked “singular” in MED, presumably meaningthat they unpredictably take singular rather than plural concord (hue and cry); others are marked“plural”: hundreds and thousands; kith and kin; yet others are marked “Uncount”: law and or-der, lost and found. (Count, Uncount, Singular, and Plural are the four grammar labels in MEDthat make sense with nouns.)

Chapter Two
139
There are also abbreviations among the binomials: e.g. B and S; D and C; R and D; and R and R,which MED 2002 – very pragmatically and very much in the face of all descriptive (and other) tra-dition – regards as word classes. Paradoxically, however, although you can search on abbreviations,these four items – B and S, D and C, R and D, and R and R – are not labelled as abbreviations butas nouns.
One may expect there to be also “plural only” and “singular only” nouns; however, pins and nee-dles and yin and yang e.g. are not “plural-only” but “Uncount”. This information is of little use anddeceptive at the same time: yin and yang e.g. is used with a plural, not singular verb.
Some of the items in the list are nouns in the sense that they have nominal distribution, but do nothave obvious noun members. In this they resemble (non-binomial) compounds that are exocentric:cash and carry; lost and found; so-and-so are cases in point. Arguably, if one criterion is used tothe exclusion of the others, then these exocentric nouns are not binomials at all: a noun that is notfrom two conjoined nouns, i.e., not a “like-category conjoined” item, cannot be a genuine noun bi-nomial. Also, if unpredictability is the determining factor in idiomaticity, then these, being formallyunpredictable, will qualify as idioms.
Labelling these as NPs rather than nouns may solve the problem syntactically, but it certainly is noway out in lexicographically: all of these items above are listemes, and will have to feature in dic-tionaries accordingly. There is nothing against listing NPs as headwords if they are listemes.
Even a semi-formal examination of items like those above suggests that: (1) the criteria for estab-lishing classes cross-cut one another, adding to a basic arbitrariness of grouping; (2) in a fine-enough analysis, all lexical items that appear to constitute a group can be shown to behave – that is,pattern, distribute, collocate, govern, be governed, or show some other property – differently; (3)(partly as a consequence): there is no real difference between class and subclass. Taking (a smallnumber of, traditional-like) word classes as basis, the set can always be analyzed into smallergroups with still common uniting features, and these in turn (4) (partly as a consequence): into yetsmaller ones. Any classification may be adequate for a given purpose, as has just been the case with“binomials”.
This must be understood so radically as to also imply that either “noun” is seen as a subclass of “bi-nomial”, or the other way round – even if the set of nouns is significantly larger than that of the bi-nomials. There are non-nominal (typically: adjectival and verbal) binomials, so the binomial classmay be argued to include the class of nouns; on the other hand, only some of the nouns are binomi-als, so nouns include binomials.
2.9.1.4 “Lumping vs. splitting” of binomials
To summarize an important conclusion: the variety of grammatical phenomena even in this verynarrow segment of English (into which some insights are constantly supplied by theoretical linguis-tics) is so great that finding ideal balances between the “theoretically” sensible and the lexico-graphically justified is impossible.
Classification problems for this set of phenomena (as for many similar observations) can be ap-proached with a broadbrush strategy or with more fine-tuned instruments. The former, in which allof these expressions will be seen as belonging to the same broad category, can be nicknamed“lumping” (to use an informal term from sense analysis) ; the latter, which is sensitive to manysubtypes, is “splitting”. It is obvious that no a priori answer can be given, once and for all, to thequestion of which of these two strategies is ideal for lexicography at large.
If a minimum amount of “splitting” is done, with all the N and N types of MWEs in the list above“lumped" together, i.e. considered as one type of phenomenon, then this unitary MWE phenomenoncan be termed several things: (i) special compound nouns; (ii) special coordinated noun phrases;

Chapter Two
140
(iii) binomial expressions (most of which are irreversible). Descriptively, this would do (and thequalification “special” is there in both cases to warn us that these are not the standard type of nouncompound or coordinate NP).
For lexicographic purposes, however, they cannot simply be termed compound nouns because theyare quite unlike the standard compound nouns (without a coordinating word) that the dictionary userwill be familiar with; that is, they are too special. Compound nouns are never specially indicated assuch in dictionaries anyway. “Coordinated noun phrase” is not an option, because – although usersmay be more or less familiar with both the notions “phrase” and “coordinated”, this label is too spe-cial. NP as a “word class” would be too unique a label anyway. Finally, “binomial” is too exotic aterm, and not one that most dictionary users suspect has a linguistic sense. If a term did indeed haveto be introduced for all of these, as a unified group, then fixed “and” compound would capture whatis happening in them. This, however, would be an innovation that no dictionary likes to experimentwith unless absolutely necessary – and, as has been often claimed, it is never so.
If, by contrast, more “splitting” is done (subcategorizing these items is necessary, since they are farfrom homogeneous), then subclassification may be based on several features, including
(a) countability: whether the noun is C or U(b) concord: whether the noun is used with a singular or plural verb(c) morphology: whether the noun is formally singular or plural(d) exocentricity: whether the resulting N is not made up of two nouns but still functions as one
The resulting taxonomy, based on all these, would surely be so complicated as to be quite uselessfor lexicographic use. In its present state, the MED grammatical apparatus already clearly confusescountability and concord.
The expression bread and butter is special in that it would have to be labelled two different lin-guistic categories, depending on its sense: it is both an idiom [= one’s livelihood] and a binomial[‘slice of bread spread with butter’]. It is far too little emphasized that while single words are typi-cally and expectably polysemous, and the more frequent they are, the more so, the situation withMWEs (in the broadest sense of the term) is different: they are typically monosemous, and fre-quency does not typically alter this. That bread and butter behaves in this dual fashion is an ex-ceptional example of a MWE having multiple meanings. MWEs come in many varieties, and whilesome, e.g. the genuine, “colourful” idioms are infrequent (contra expectations); others are muchmore frequent; binomials are probably heterogeneous from this point of view. All types of MWEs,however, from binomials to “core/genuine” idioms, are typically monosemous; and with MWEs,higher frequency (of the “other kinds of phraseological item”, cf. Moon 2006) does not contributeto (more) polysemy.
Learner’s dictionaries had best include this type of not-so-opaque and not-so-transparent expression(in this case, if only because of the irreversibility problem in the syntax). Even more (and more ob-viously) so the editor of bilingual works: the Hungarian user e.g. does not suspect that soap andwater should (or at least can44) be translated as szappanos víz ‘soapy water’, because they do notsuspect any degree of opacity here. Fish and chips, even more “culturally laden”, is even moredictionary-worthy. Szappanos víz, then, cannot simply be translated by putting together the parts ofthis expression, soapy and water; this is 100% idiomatic behaviour.
The above list also convinces one that wherever a foreign-language equivalent of an English bino-mial is not likewise a binomial, a bilingual dictionary is very well advised to enter it.
The expressions bread and butter, soap and water, fish and chips and salt and vinegar havebeen summed up in the following table:
44 If soap and water is indeed ambiguous (as potentially all such expressions that have a homonymous irreversible
binomial and a normal reading, in the former construed as singular, and in the latter construed as plural.).

Chapter Two
141
1 2 3 4 5 6 7 8 9
StatusMayhaveothermng?
Listed inMED w/relevantmng?
Discrepancybetween indic-ators’ combin-ed contribu-tion & idiom’soverall mng
Cultur-allymarked(in E→Hrelation)?
StandardHung.transla-tion ex-ists?
StandardHung.transla-tion pre-dictable?
Hung.transla-tion syn-tacticallydiffer-ent?
Inclusionin H→Ediction-ary war-ranted?
salt andvinegar
+ – 1 + – +
fish andchips
+ +* 4 + – +
soap andwater
+ – 2 – + – + +
breadandbutter
irrev-ersi-ble
bino-mial
+ –** 3 – + – + +
*The definition is ‘a meal consisting of fish and long thin pieces of potato, both cooked in very hot oil’.**Listed only with the ‘smth that provides the main income’ sense.
The columns one by one:
(1) If a common label must be found for these four items (and most of the ones in the list above),this is perhaps the best that fits their status.
(2) All of the four expressions have a non-binomial, standard coordinate NP sense, in which theyobviously take plural concord, e.g. salt and vinegar are both inexpensive.
(3) MED, the learner’s dictionary selected, only enters the culture-specific fish and chips (and onlythe genuine idiom bread and butter ‘livelihood’.
(4) According to their idiomaticity, both tentatively and subjectively measured as the discrepancybetween the combined contribution of the indicators and the overall meaning of the idiom, thefour items have been placed on a scale of four, with 4 signifying the largest.
(5) Being “culturally marked" is meaningful in an English–Hungarian relation: thus, bread andbutter would be culturally marked for speakers whose culture does not have the institution ofbread and butter, but it is not a problem for Hungarians.
(6)–(8) “Standard” Hungarian translations exist for the third/fourth, but not for the first two items.The English pattern in these four is “N1 and N2”. Corresponding to the English “N1 and N2”pattern, the standard Hungarian expression has “N1y N2” (szappanos víz ‘soapy water’) or “N2yN1” (vajas kenyér ‘buttery bread’). These patterns, however, cannot be always used for “non-standard cases”; as this small sample of four items shows, the Hungarian for fish and chips canindeed use the “N2y N1” but not the “N1y N2” pattern, while salt and vinegar cannot be trans-lated with either. The fact, then, that the English “N1 and N2” pattern sometimes corresponds to the Hungarian“N1y N2” (szappanos víz) and sometimes to “N2y N1” (vajas kenyér), while sometimes neitherpattern translates them, demonstrates that these binomials are fundamentally idiomatic in themost relevant sense for a bilingual dictionary, by virtue of being unpredictable.
(9) Consequently, these binomials are no less dictionary-worthy than “genuine”, central idioms.
Not one of the above ideas concerning the handling and analysis of these expressions, in terms ofbinomials or otherwise, either “lumped” or “split”, has any trace whatever in dictionaries. Binomi-als, which are strictly irreversible/frozen, but whose most important idiosyncrasy is not this restric-tion on syntactic mobility, are highly idiom-like and should be marked as such. They, however,never receive their lexicographic due.

Chapter Two
142
2.9.1.5 Cruse (2000) on collocation
Cruse (2000) distinguishes frozen metaphors, and discusses collocations without including themwithin idioms. We are not told this explicitly, but collocation must be a type of idiom; and in the fi-nal analysis, all of them – from noun compounds through “standard” idioms of the paint the townred type, and his “frozen metaphors” and collocations – all involve gradation.
The sheer quantity of treatment may be nothing to go by, but Cruse has little to say about colloca-tion, which is supposed to do with compositionality from the point of view of the speaker: colloca-tions are idioms of encoding from the speaker’s viewpoint. Like the more familiar kind of idioms,they must be individually learned.
Non-compositional expressions
clichéscollocations
frozen metaphors
idioms
Cruse (2000) does not use any of “multiword expression”, “multiword”, “phraseological unit” or“phraseme”. His approach is not “phraseological”; based on compositionality, this framework sup-plies the two major classes of expressions, “complex vs. simplex”, and “compositional vs. non-compositional”. With simplexes, the issue of compositionality does not occur; with non-composi-tionality, everything is a gradience; there are no rigid boundaries.
Quite idiosyncratic is his handling of collocations (idioms of encoding, as opposed to idioms of de-coding, i.e. idioms from the hearer’s viewpoint). It is not clear that this distinction is meaningful,and Cruse himself does not pursue this further. No other framework except Nunberg & al. (1994)makes this distinction. They, however, use it in a way that is different from Cruse’s and also, highlyimportant for the purposes of this study.
2.9.2 Multiword expressions in Biber & al. (2000)
According to Biber & al. (2000:987), a MWEs function as structural or semantic units, the mostcommon types of which are phrasal and prepositional verbs. MWEs are distinguished according toidiomaticity and invariability. At one end are idioms, relatively invariable, and with meanings thatcannot be predicted from the meanings of the parts. Collocations, on the other hand, are associationsbetween lexical words, so that the words co-occur more frequently than expected by chance.
Phrasal/prep’l verbsMultiword Exprs
Idioms Collocations

Chapter Two
143
“Idiomatic phrase” and “idiom” are used interchangeably.
Idiomatic phrases (defined as expressions with meanings not entirely derivable from those of theirparts) represent many different kinds of structural units, such as wh-Q, NP, PP, VP:
• wh-Q – how do you do? / what on earth...? / what’s up? / what in the world...?• NP – a piece of cake• PP – as a matter of fact, for the time being, not on your life, out of order• V PP – bear __ in mind, beat around the bush, fall in love, take __ into account
V NP – change one’s mind, miss the boat, keep an eye on __, kick the bucket
Though they are a separate category, the verbs in V NP combinations with have, make, and takeare not termed “light verbs” (or any such, often synonymous label, as e.g. “support verb”) in Biber& al. (2000). This suggests that any VPs containing these verbs are light verb VPs – which isclearly not the case. Importantly, though, the expressions that result from a few especially produc-tive verbs combining with NPs to form idioms are claimed to form a cline of idiomaticity (Biber &al. 2000:1026):
– At one extreme of this cline are have a look, make a killing, take time– In between: relatively idiomatic:have a chance, have a bath, make a deal
– At the other end of the scale are the ones that retain the core meaning:make a sandwich; take a snack in your pocket
This idiomaticity scale, then, is not within the category of light verbs but all productive verbs suchas have, make and take.
Many, as they argue, could be replaced by a single verb (have dinner – dine; make provision for– provide for; take part – participate); this, however, is clearly no operational criterion, and onehopes indeed that this is not one of the features that are supposed to make this class intermediate,since replaceability of an XP by a single X, be it a verb phrase or any other phrase, occurs at bothends of the cline, and in between the extremes.
2.9.3 Multiwords in McCarthy (2006)
McCarthy (2006:66) explains that
“Lexemes can have more than one word stem, for example, post office […] referredto as ‘multiwords’ […] phrases where the meaning is not compositional, that is, themeaning of the phrase is not simply a sum of the meaning of component words. [...]There are a variety of multiword types including idioms, specific constructions suchas phrasal verbs and collocations, i.e., words which occur together by convention”(Sag & al. 2002).
The wording “more than one word stem” suggests compounds; indeed, the first example of multi-words offered is not an idiom, a phrasal verb, or a collocation, but a straightforward compound,post office. Under this definition, a multiword is a noncompositional phrase – the usual definingfeature of idioms. On the other hand, multiwords are just said to include idioms, along with phrasalverbs, and collocations. This suggests the following scheme:

Chapter Two
144
Idioms Multiwords
Phrasal Vs Collocations
Compounds
Compounds of the nominal type include verbal (synthetic) compounds, which is quite a productiveclass with syntax-like regularities. They have an internal argument structure, which, in computer-based approaches (where they are typically termed “compound nominalizations”, cf., for example,Nicholson & Baldwin 2008), has recently been amply explored. Thus, when the head noun is de-verbal, the non-head corresponds to the subject, the direct object, or to the prepositional object – i.e.some argument – of the base verb. These may be extremely productive, suggesting that there is noneed for their lexicographic inclusion; but a good number of them are so frequent and what is oftenreferred to as “institutionalized” that they need to be included in virtually all general dictionaries.
2.9.4 Multiword expressions in Hanks (2006)
Hanks (2006:121) asserts that“the number of multiword expressions in a language is unimaginably vast”.
Then, switching to lexicography right away:
“They could not possibly all go into a dictionary, even one that was unconstrained by thephysical limitations of printed books45. Nevertheless, some [MWEs] receive entries in dic-tionaries.”
Hanks’s typology of MWEs is as follows: MWEs include idioms, whose “meaning is not recover-able from the analysis of the parts”. Other subcategories within MWEs are not mentioned. All thatcan be derived from this textual information to be tabulated is as follows:
Multiwords Idioms
According to Hanks (2006:121), those MWEs that do find their way into dictionaries are selectednot on the basis of frequency, but on semantic grounds: when their meaning is not recoverable fromthe analysis of the parts. (What type of dictionary is meant is not specified; nor is it made clearwhich MWE types are meant.) It is difficult to agree with this especially in the light of the need toenter a great many frequent (albeit) transparent/recoverable compounds (e.g. in bilingual dictionar-ies). Hanks claims that “there is no point in putting a frequent collocation into a dictionary if it is
45 It is odd that the author should have no such worries about simple words. It may be true that the number of MWEs,
simply by combination, is orders of magnitude higher, but the “physical limitations of printed books” is surely not re-stricted to MWEs.

Chapter Two
145
perfectly obvious what it means” [...]. (Collocation is undefined here; it is loosely identical toMWE.) This suggests that only idioms are (though obviously not all of them), and all other MWEsare not, included as entries. This is much too simplistic: observing this “rule” would be problematicin all dictionaries, and obviously so in bilingual ones.
Discussing bilingual lexicography, Corréard (2006) e.g. asks the (rhetorical) question, “How shouldmultiword expressions be dealt with? Should they be treated as separate entries, or nested under oneof the elements and, if so, which?” Two problems with this wording must be ignored before ourmain point can be made: (i) that this is only an issue in print dictionaries; and (ii) that entering aMWE “separately” necessarily involves entering it under one of its elements, in alphabetical terms.The real difficulty is that, in bilingual lexicography or elsewhere, there can be no summary solu-tions to placement decisions or any treatment of MWEs, because by consensus “multiword” seemsto be the largest category of the units in question, coming in dozens of varieties, as acknowledgedby all researchers. There cannot possibly be a best placement strategy for what are so widely dif-fering expressions.
The dictionary user may disfavour solutions based on solid linguistic grounds. The MWE by andlarge, for example, is both 100% noncompositional and 100% immobile. In addition, it is syntacti-cally anomalous, coordinating as it does different types of category, P and A, which is why it issometimes classified as anomalous, or “extragrammatical”, The function of the complex is adver-bial/adjunctive; its category is problematic. This fixedness is still no guarantee that users will look itup under the first component. They may think it a better guess to first check it under large, which isat least an open-class item. (That users generally have no explicit knowledge of open vs. closedclasses does not mean that they cannot have an intuitive grasp of the distinction.)
2.9.5 Idiom dictionaries in Dobrovol’skij (2006)
Dobrovol’skij (2006:514) uses ‘phraseme’ as a hypernym for “all kinds of phrasal lexical items,figurative as well as non-figurative”. He argues that notwithstanding the terminological chaos
“there is a consensus about the main features of phrasemes” [which] are conventionalmultiword units of the lexicon showing various kinds of formal and/or semantic ir-regularities. Phrasemes are stable by definition: as soon as an expression has becomeconventionalized, it will be reproduced in discourse as a prefabricated unit of lan-guage.”
Phrasemes, then, are MWUs of the lexicon, which, like all lexical units, are relatively stable in formand meaning. They are claimed to have long been classified into classes: restricted collocations,phrasal verbs, routine formulas, idioms, proverbs, etc. The central group is that of idioms, whichare supposed to share a crucial property: semantic irregularity, i.e. idiomaticity. Crucially, however,
“there is no general consensus about where to draw the line between idioms and otherphraseme types. The differences between various linguistic schools concerning theextension of idiom class are [also] due to different terminological traditions in differ-ent languages” Dobrovol’skij (2006:514)
Thus, “idiom” is often understood as an umbrella term for all fixed expressions. Dobrovol’skij(2006:515) claims that this use is uncommon in Russian or German, where “idiom” exclusivelycovers idioms in the narrower sense. Idioms are the most irregular category among phrasemes;since irregularity manifests itself in idiomaticity and stability, these features must be more salient inidioms than in other phrasemes.

Chapter Two
146
“Idiomaticity is understood as a semantic reinterpretation and/or opacity, while stabil-ity is understood as frozenness or lack of combinatorial freedom of a certain expres-sion. Idioms can be thus defined as phrasemes with a high degree of idiomaticity andstability. [...] Idioms must be fixed in their lexical structure (however, this does notexclude a certain variation), and they must be [...] semantically reinterpreted units [...]and/or semantically opaque.”“Current approaches to phraseology also distinguish proverbs and idioms with sent-ence structure (sentence idioms, or speech formulas), e.g. the coast is clear or the dieis cast.”
The following important equations, some explicitly, some implicitly given, can be established basedon the text:
Phraseme = conventional multiword unit = fixed expression = prefabricated unit.
The information may be presented in diagram form:
IdiomsPhrasemes
Proverbs Sentence idioms
Phrsl Vs
Restricted coll’s Routine formulae
2.9.6 Idioms in Ayto (2006)
“Multiword expression” (MWE), “multiword unit” (MWU), and “multiword construction” (MWC)all seem to be used synonymously in the literature, and Ayto also uses “multiword construction” asa cover term for all kinds of idioms and related (more or less) fixed expressions.
Compounds are MWEs in the sense of being composed of more than one free stem; also, their com-positional “fixedness”, or “fixity”, is greater than that of most “phraseological units” (an expressionthat Ayto also uses). The class of compounds, to be sure, is open at both ends of the spectrum. Atone end, compounds are hard to distinguish from free phrases: the phonological criterion, usuallytouted as the safest, is far from reliable (this is summarized e.g. in Bauer 2007). At the other end ofthe spectrum, since compounding may be hard to differentiate from derivation (the issue of neo-classicals being just one case in point), compounds may not be easy to tell from non-compoundwords.
Ayto defines idiom as an
“institutionalized multiword construction, the meaning of which cannot be fully de-duced from the meaning of its constituent words, and which may be regarded as aself-contained lexical item” (Ayto 2006:518)
arguing also that “beneath this broad definition are grouped a large number of different construc-tions that inhabit intersecting spectra of (i) semantic opacity, (ii) compositional fixity, and (iii) syn-tactic function.”

Chapter Two
147
These three axes are discussed below. The examples show that there is indeed a gradience in allthree areas.
The taxonomy of Ayto (2006) may be presented in the following diagram. Idioms have a“core” as well as peripheral members that overlap with other MWE expressions.
Idioms MW Constr (Expr/Unit)
“Idioms proper” Clichés Institutionalized phrs
Sayings Freezes Collocations
Proverbs Compound Ns Constr’l idioms
Allusions Opaque similes
In Ayto’s lists of idioms, broken down by syntactic function and type of derivation, some of thenouns and adjectives are claimed to be produced “by premodification”: salad days, monkey busi-ness; brand new, dirt poor. That these are prototypical examples of nominal and adjectival com-pounding can again be taken as suggesting that the line between compound and noncompound idi-oms is a flimsy one indeed.
2.9.6.1 The first of Ayto’s three “intersecting spectra”: semantic opacity
At one extreme, each word defies literal understanding: eat crow. Some fixed phrases contain ele-ments used in their literal sense: in get down to brass tacks, the expression get down to is used asit would be in a range of other collocations [...]. Such literal elements may be variable: know theropes, show someone the ropes (where the ropes could be seen as meaning ‘special methods orprocedures’). In some cases, all the main words have literal meanings; it is only their combinationthat lends a meaning beyond the sum of the parts: bread and butter.
The closer to the opaque end of the spectrum a MWC is, Ayto argues, the more likely it is to be re-garded as a fully fledged idiom. Many compound nouns satisfy the criteria of opacity appliedabove. However, such compounds are generally not regarded as idioms unless the complete lexicalitem is metaphorized, e.g. dark horse. The referent of green room, e.g. is a type of room, so theterm does not qualify as an idiom. It must be mentioned that “metaphorization” or “metaphor” havenot been defined even informally.
2.9.6.2 The second “spectrum”: grammatical/compositional fixity
Most idioms participate in the inflectional variations of person/tense; however, manyare subject to a range of grammatical restrictions, and are capable to a greater or less degree of be-ing altered.

Chapter Two
148
Transitive verbal idioms may have a vacant slot for a variable: a direct object (sweep X off theirfeet, an indirect object (give X a piece of one’s mind), or a prepositional object (clap eyes on X).
“Constructions”, such as what is X doing Y? and V + obj + away such as in dance the nightaway, are supposed to occupy the most “fluid” end of the spectrum. Here the overall meaning isclaimed to be determined more by the syntactic structure than by any semantic properties of theelements; these have been termed “constructional idioms”. Ayto claims that idioms of this sort,midway between completely fixed idioms, which have to be interpreted as indivisible units and or-dinary non-idiomatic combinations, which are interpreted according to productive grammaticalrules, actually require a new type of grammar. An approach termed ‘construction grammar’ (Kayand Fillmore 1999; Jackendoff 2002: 181) has been proposed, he argues, which “deploys a set ofextra, bolt-on rules, beyond the general grammar of the language, to deal with these semi-idioms”.Whether a separate grammar is indeed warranted by the existence of idioms like these is question-able, but these kinds of MWEs are another example of how the linguistic separation of lexicon andgrammar is challenged.
2.9.6.3 The third “intersecting spectrum”: syntactic function
No other of the authors mentioned in 2.9 but Ayto (2006) classifies MWEs, or idioms, according totheir detailed syntactic function. Some ignore this altogether, while most simply note that they oc-cur in all functions. Ayto’s breakdown of idioms by function is useful for classification as well asfor the problems that it raises in connection with MWEs in general.
• Verbs
Idiomatic verb phrases function syntactically as verbs.46 Their internal structure is commonlyV + O, with or without further elements: change hands, stick one’s neck out, clap eyes on. Idio-matic combinations of verb + particle (phrasal verbs) are usually also categorized as idioms: shutup, take in ‘deceive’, back down. Combinations with other adverbials are also frequent: go some-one’s way, cut both ways, go west. Other frequent patterns are a verb with the dummy object it:lump it; and combinations of two or more verbs with a conjunctive: pick and choose.
2.9.6.3.1 Dummy “it” idioms
A surprisingly huge collection of idioms containing the “dummy” object pronoun it, optionally ac-companied by some other constituent is found in CALD 200847.
This object-expletive it can indeed be argued to be a dummy in most of the cases; however, thereare again no clear boundaries. (Not only is the “meteorology” type subject it, with its restricted butpalpable semantic content48, different from the genuinely dummy (pleonastic, non-referring) it;there also seem to be intermediate cases, with the object it idioms. At one end of the scale, the ob-ject it in these idioms can be attributed some notional content. Accordingly, expressions such as (i)spit it out, (ii) grin and bear it and (iii) be coining it, none of which contains the clearly, or 100%dummy it, may well be excluded from the list below: in (i) the it refers (presumably backwards) tosome proposition; in (ii) the understood object is “life”, “fate”, or something similar; in (iii), evenmore restrictively, it is unquestionably money. The it, to be sure, while referential – perhaps deictic– in (i), is not referential in (ii) and (iii) in the sense of being anaphoric or cataphoric; it is just “un- 46 Ayto uses V(erb) as a function symbol (= Predicate).47 An idiom search for it yields all words containing it; results have been filtered so that only the object type remains.48 The expressions it’s 10 miles to London; it’s raining; it’s two o’clock; it’s nice to be here differ in terms of the
semantic emptiness of the it.

Chapter Two
149
derstood”. The idiom be rolling in it, which is synonymous with be coining it, actually alternateswith the phrase rolling in money, providing support for the referentiality of this it. (There happensto be no *be coining money.)
Both the sheer number of the “verb with dummy object it” idioms and their lexical makeup (theyuse the most frequent words in addition to the item it) causes most of them to be absolutely unpre-dictable, and makes them highly dictionary-worthy. Because, however, they are never entered underthe it itself (which, from the system’s point of view, would be a highly logical decision, althoughone resulting in a hardly manageable it entry), but under the verb (or some other component), theirgrammatical nature practically goes unnoticed. In this sense it is true that out of sight is out of mind:if it is not in the dictionary, it is more difficult to take notice of.
List No11Verbs with dummy object idioms in CALD (2008)
beat it
bring it on
bugger it
button it!
be coining it
clinch it
do it
end it all
get it on
get it together
go for it
go it alone
have had it
have had it (up to here) with
have it in you
have it in for smb
have it off
have it away (with smb)
hightail it
hit it off
hold it
hoof it
hotfoot it
knock it off
be larging it
lay it on a bit thick
leave it at that
Leave it out! [sentential] leg it
let sb have it
let it lie
live it up
lord it over smb
be losing it
lose it
lump it
make it
make it up to smb
make it with smb
mix it
move it
you name it [sentential?] get it in the neck
pack it in
pile it on
push it
put it about
put it there [sentential] give it a rest
rolling in it
rough it
shove it
slug it out
slum it
snuff it
step on it
stick with it
be stretching it
strike it lucky
strike it rich
suck it and see
sweat it out
swing for it
take it in turns
take it out of smb
be tipping it
to top it all
try it on
walk it
watch it
wing it
give it a whirl
whoop it up
be with it
be with it

Chapter Two
150
2.9.6.3.2 Dummy subject idioms
The number of expletive object idioms just found is surprisingly great because these types seem tobe rather underrepresented in treatments of idioms in general, and especially because expletives aresupposed to be restricted to subject function and not to occur in object positions. This is noteworthybecause while there are so many expletive object idioms, there are few dummy subject idioms. Thereason is also obvious: expletive object idioms are VPs with an it object; the number of such ex-pressions is expectably large. A subject-plus-predicate idiom, by contrast – whether this subject isexpletive or otherwise – must be clausal. Also, although expletive subject idioms are fewer, it ismore difficult to establish whether it is just expletive for a subject it than for an object it: we arealso up against a gradience here.
Four discreet points have been singled out on this gradience of dummy subject idioms for illustra-tion: (i) expressions such as as it is (‘already; even so’) and as it were have a purely expletive sub-ject; (ii) full clausal structures such as It beats me or It figures (‘I’m not surprised’) clearly havesome kind of concrete linguistic or non-linguistic entity which the it refers to anaphorically; (iii)idioms exemplified with if/when it comes to the crunch have a general kind of “understood” sub-ject easily paraphrasable as ‘the situation’; (iv) idioms of the type it goes without saying are verydifferent: the expletive subject that they have is traditionally termed “anticipatory”, which meansthat they also have another “logical” or “notional” subject, the (bracketed) that-clause: e.g. it goeswithout saying [that you'll be paid for the extra hours you work] (the example is from CALD2008). These are not in effect it idioms: this example is not an it goes without saying idiom but agoes without saying idiom, which has two subjects, a pleonastic (syntactic) and a “logical” (no-tional) one.
2.9.6.4 Ayto’s classification evaluated
• NounsNominal idioms are formed by premodification (salad days, monkey business); postmodification(fish out of water, salt of the earth); or conjunction of more nouns (sy’s pride and joy, meat anddrink).
• Adjectives
Adjectival idioms are formed by premodification: brand new, dirt poor; postmodification: dyed-in-the-wool, wet behind the ears; by conjunction: tired and emotional, spick and span.
Since most of these adjectival examples, but especially the postmodified ones, illustrate syntacti-cally rigid/fixed phrases, two of them – dyed-in-the-wool and holier-than-thou – would have anequally good, if not better, place among compounds. If they are written in this hyphenated form,and there hardly is another option for this type, then they automatically deserve
word status in a (folk/naive) lexicographic sense of the word. Expressions like these are certainlynot marked as idioms, if “idiom” is reserved for multiword expressions.
• Adverbs
Many adverbial idioms are compositionally similar to adjectival idioms: by and large, on and off,once or twice, by the skin of one’s teeth. Other types also occur: all along, ever so, no end.
• Others
In Ayto (2006), idioms can also function as prepositions (in view of, by dint of, to the tune of,over and above)49 and what are termed “conjunctives”: not to mention, as long as. Idioms can
49 Huddleston & Pullum (2002, 2005) call “syntactically largely fossilized” P+N+P sequences such as by means of, in
effect from and in league with prepositional idioms.

Chapter Two
151
also constitute complete utterances or sentences: (Well,) I never. Many are jussive: Never mind,God forbid, or used interjectionally: Big deal! / Not on your life! / So there! Standardized (or cli-chéd) sayings such as Great minds think alike and There’s one born every minute merge intofully-fledged proverbs, e.g. Many hands make light work. “More-or-less buried” literary allusions(e.g. There’s the rub) are important members of this type.
Especially concerning this last, mixed category, a real alphabet soup of structures and functions, butalso in general about Ayto’s remarks, four observations are in order:
(i) The use of the type “adverb” with its “adverbial idioms” is more than an informal use of“adverb”; it is confusion of category and function. In Ayto’s list of types according to syn-tactic function, all the types are categorial, not functional. “Adverb” suggests category again.The examples, however, are PPs, not adverb phrases. Rather than lump the prepositionalidioms with the “others” group, the system might benefit from the adverbial group being re-named “prepositional”, which would then contain the PPs now in the “adverbs” group. It is amatter of taste whether, after this rearrangement, an “adverbs” group shall remain in place.
(ii) The claim that an idiom can be used as an utterance is not restrictive enough, since any nounor verb can be used on its own, as an utterance. It is also impossible to tell these “utteranceidioms” apart from the next type, the ones used “interjectionally”. The wording “typicallyused as an utterance” may be more true to the facts.
(iii) The notion “jussive use” is rather vague and also not sufficiently restrictive; for an expres-sion to be used “jussively”, it need not be, or contain, an idiom.
(iv) Without a suitable definition of “interjection”, the concept “used interjectionally” is notclear either. Since both idioms and interjections can be, and have indeed been, approachedand defined in a confusing variety of ways, “idiom used interjectionally” is at the intersec-tion of two undefinable notions. (The wording “idiom used interjectionally” is non-com-mittal as to whether interjections themselves are a part of speech.)
Points (ii)–(iv) indicate that the closer one gets to idioms of clausal structure, boundaries becomeever fuzzier.
2.9.7 Corpus approaches to idiom: Moon (2006)
Moon (2006), discussing “what corpus evidence demonstrates about English idioms, along withother figurative expressions such as proverbs and similes”, defines idiom as an “institutionalizedmultiword item with a metaphorical meaning”. Under this definition, then, idioms are “figurative”,“institutionalized”, and “metaphorical”. The problem is not just that these terms are not definedthemselves; the relative taxonomic positions of “phraseological item” and “multiword item” is alsonot clarified.
One of the points of Moon (1998), to which she refers in 2006, was to show the (at that time pre-sumably surprising50) infrequency of idioms and proverbs and similes, as opposed to the high fre-quency of “other kinds of phraseological item”, such as take place, in fact and give up.
This is why figurativeness, institutionalization, and metaphorization feature thus high in thisframework. Moon focuses on the “figurative” and “metaphorical” kinds of idioms, referred to as“colourful” in the present study – because it is felt that other features than figuration and metaphor
50 It is to Moon (1998) that idiom study owes the realization that the infrequency of these “colourful” idioms in conver-
sation is counter-intuitive. These are thought of as colloquial, informal, ‘folksy’. Their seeming prominence in use ismisleading, comes from their markedness and salience, which is a result just of their low frequency.

Chapter Two
152
(such as the presence of unique words, i.e. bound or “cranberry” words) also contribute to their“colour”.
Moon (2006:231) also mentions formulae, but where these belong in the scheme of MW items isnot specified again.
Multiword items( = Phraseological items)
Figurativeexpressions
Idioms
Proverbs
Similes
2.9.8 Formulaic language in Wray (2002)
It is not as easy to do justice to the taxonomy of, and approach to, idioms and other related MWEsin Wray (2002) as in the classification of McCarthy (2006), Hanks (2006), Dobrovol’skij (2006),Ayto (2006) or Moon (2006). Wray offers a huge collection of such terms, and her point is just theirfuzzy nature.
“Words and words strings which appear to be processed without recourse to theirlowest level of composition are termed formulaic […]. They are interesting because oftheir widespread existence is an embarrassment for certain modern theories of lin-guistics, which have unashamedly pushed them aside and denied their undoubted sig-nificance.” Wray (2002:4; italics mine)
Wray does not explain how idiomaticity differs from formulaicity. Since under the above definitionnot just word strings but words too can be formulaic, there seems to be no principled reason at thispoint for using the term “formulaic” for these sort of expressions, “processed without recourse totheir lowest level of composition”. The term “idiom” covers much the same types of expression.
Formulaic language, however, is
“[...] more than a static corpus of words and phrases which we have to learn in orderto be fully linguistically competent. Rather, it is a dynamic response to the demandsof language use, and, as such, will manifest differently as those demands vary frommoment to moment and speaker to speaker.”
Wray (2002:5)

Chapter Two
153
“Just as we are creatures of habit in other aspects of our behaviour, so apparently arewe in the ways we come to use language” (Nattinger & DeCarrico 1992:1). DespitePinker’s (1994:90ff) assertion that using prefabricated chunks of language is a peri-pheral pursuit that tells us nothing about real language processing, there is plenty ofevidence to the contrary. [...] in our everyday language, ‘the patterning of words andphrases... manifests far less variability than could be predicted on the basis of gram-mar and lexicon alone’ (Perkins 1999:55–56) [...].
In the context of ‘collocation’ we find that some words seem to belong together in aphrase, while others, that should be equally good, sound odd. [...] Biber, Conrad andReppen (1998) report that, in a 2.7 million word corpus of academic prose, largenumber was more than five times more common than great number [...]”
It is not clear why an expression such as large number would be different from great numberfrom the processing point of view – if indeed this is what the quotation suggests.
“Whether these preferred strings are actually stored and retrieved as a unit or simplyconstructed preferentially, it has been widely proposed that they are handled, effect-ively, like single “big words” (Ellis 1996:111). They are ‘single choices, even thoughthey might appear to be analysable into segments’ (Sinclair 1991:110). Some are fullyfixed in form (e.g. Fancy seeing you here; Nice to see you) and can bypass the entiregrammatical construction process (Bateson 1975:61). Others, termed semi-precon-structed phrases, such as NPi set + TENSE POSSi sights on (V) NPj, require the inser-tion of morphological detail and/or open class items, normally referential ones (giv-ing, for instance, The teacher had set his sight on promotion; I’ve set my sight onwinning that cup).” Wray (2002:5–7; italics mine)
The quotes from Nattinger & DeCarrico, Pinker, Perkins, Biber, Conrad and Reppen, Ellis, Sinclair,and Bateson have been quoted in Wray 2002:5–7.
“Single choices” above seems to be a retrieval-based synonym of the storage-based term “listeme”.
“Modern theories of linguistics” might of course reply to this line of argumentation that these acci-dences are quite irrelevant to their pursuits. For lexicography, however, they are conspicuous: in adictionary, lexical items above the level of words, presumably also in the sense of being listemes,i.e. memorized chunks, are numerous. If a dictionary has n thousand words, there is a fair chancethat it will contain at least as many “idioms”, in the sense of units with meanings not reducible to,or predictable from, the meanings of the elements. On top of those “idioms”, many thousands ofcombinations, although compositional, will be memorized as units.
This “chunky” nature of language, Wray reminds us, was discovered as early as the mid-19th cen-tury by John Hughlings Jackson, the “father of English neurology”. Also, that half century later,Saussure (1916/1966) talked of “synthesizing the elements of [a] syntagm into a new unit... [suchthat] when a compound concept is expressed by a succession of very common significant units, themind gives up analysis – it takes a short cut – and applies the concept to the whole cluster of signs,which then becomes a single unit” (p. 177). Wray also reminds us that Jespersen (1924/1976) ob-served that a ‘language would be a difficult thing to handle if its speakers had the burden imposedon them of remembering every little item separately’ (p. 85). He characterizes formula as follows:
[it] may be a whole sentence or a group of words, or it may be one word, or it may beonly part of a word, – that is not important, but it must always be something which tothe actual speech instinct is a unit which cannot be further analyzed or decomposed inthe way a free combination can. (p. 88)
It is not easy to see how formula is an interesting object at or below the word level, and what ismeant by speech instinct is not less problematic, but above that level formulae seem to be just thelistemes.

Chapter Two
154
Bloomfield (1933) observed that “many forms lie on the border-line between bound forms andwords (p. 181). According to Firth (1937/64), “when we speak ... [we] use a whole sentence ... theunit of actual speech is the holophrase (p. 83) [...] Hymes (1962/68) proposed that “a vast portion ofverbal behaviour ... consists of recurrent patterns, of linguistic routines ... [including] the full rangeof utterances that acquire conventional significance for an individual, group or whole culture” (p.126–127). Bolinger (1976) asserted that “our language does not expect us to build everything start-ing with lumber, nails and blueprint, but provides us with an incredibly large number of prefabs” (p.1); and Charles Fillmore (1979) argued that “a very large portion of a person’s ability to get alongin a language consists in the mastery of formulaic utterances” (p. 92)
Wray (2002:8) adds that
“insofar as these descriptions applied beyond the realm of the noncompositional idi-om, they became increasingly marginalized as Chomsky’s approach to syntactic stru-cture gained prominence. Only with the new generation of grammatical theories,based on performance rather than competence [...], has the idea of holistically man-aged chunks of language been slowly reinstated, and its implications recognized.
(The quotes from Saussure, Jespersen, Bloomfield, Firth,Hymes, Bolinger and Ch. Fillmore are in Wray 2002:7–8.)
All of these observations about the importance of linguistic levels above that of “signs” concernquite disparate phenomena, with some of them hard to assign any immediately relevance to Wray’sline of argument. It is not clear, e.g., how Firth’s insistence on the unit of speech being the “holo-phrase” has to do with these purported chunks of language. Wray offers a long list terms describinga “larger or smaller part of the set of related phenomena” which she looks at (Wray 2002:9). Themost important ones, some of which appear in the present study as well, are as follows (the italics ofthe ones which are adjectives and not nouns are mine):
chunks – clichés – collocations – complex lexemes – fixed expressions – formulaiclanguage – formulaic speech – formulas/formulae – fossilized forms – frozen meta-phors – frozen phrases – holistic – idioms – lexical(ized) phrases – lexicalized sen-tence stems – listemes – multiword items/units – multiword lexical phenomena –noncompositional – noncomputational – petrifications – phrasemes – preassembledspeech – prefabricated routines and patterns – ready-made expressions – ready-madeutterances – recurring utterances – routine formulae – schemata – set phrases –stereotyped phrases – stock utterances – unanalyzed chunks of speech – unanalyzedmultiword chunks
Wray makes two comments of general importance. One, that there is a lot of “conceptual duplica-tion”, where several words are used to describe the same thing [...] while some of the terms sharedacross different fields do not mean entirely the same thing in all instances. The other, that
“a label used by a given commentator may reflect anything from the careless appro-priation of a nontechnical word to denote a specific meaning, to the deliberate selec-tion of a particular technical term along with all its preexisting connotations.”
Thus, not just the labels vary, but it is also hard to know what the individual researcher has in mind:this is a huge list, whose members have been categorized in an intimidating variety of ways.
Ours is not the task of casting fresh light, or imposing order, on the set. What is suggested by thisplethora of terms and the proliferation of approaches to the same phenomenon, that of formulaicity(Wray 2002:9) behind their façade (if indeed there is such a unitary phenomenon) that practicallexicography is in absolutely no position to build on a consensual view of phraseology.
This time, a Venn diagram style summary is not favoured by the nature of Wray’s formulae.

Chapter Two
155
Under various labels, the “chunky” nature of language seems to be so much in the foreground andto have arrived on the scene with such a vengeance, that, as Rundell (1998:318) writes, it spreadalso throughout the language teaching profession:
“The buzzword in the ELT community (repeated almost to the point of tiresomeness)is ‘chunking’: that is, the tendency of writers and speakers to store, retrieve, and pro-cess language very largely in chunks (or pre-assembled multiword units of variouskinds), rather than by stringing together individual words at the point of articulation.”
Rundell (1998:318) is actually of the opinion that in general, the revived concern with phra-seology
“in all its forms dates back, in the UK, to the late 1970s […] And the work of Sinclairand other early corpus linguists (e.g. Sinclair 1991:110ff) has also been very influen-tial here. But of course its roots go much deeper, and can be traced back not only tothe Firthian academic tradition but also to the work done by Palmer and Hornby inthe 1930s on collocations and other multiword expressions […].”
2.9.9 Formulaic speech in Kuiper (2006)
Formulaic speech is simply defined as speech that utilizes formulae. Formulae are phrasal lexicalitems that are indexed for their role in social interaction, or, more narrowly, indexed for specific usein discourse varieties, registers, and genres.
All linguistic performance draws on the lexicon; formulaic speech draws on the phrasal lexicon.As Kuiper argues, I name this ship the... or I now declare you man and wife... are performativeformulae, or formulaic performatives: those who know them know the conditions under which theymay be appropriately uttered. Some single-word lexical items are also claimed to have such usageproperties in Wray (2002): one-word curses, for example, have specific contexts of use (darn!shit!). Some linguists include such one-word items within the definition of formulae, but usuallyformulae are regarded as being phrasal. If “being indexed” for some specific role in social interac-tion or variety is the defining feature of formulae, then of course one-word expressions also qualify.Given a term like “formulaic performative”, however, it is not at all clear what the relationship be-tween performatives and formulae may be.
Formulae exist, Kuiper argues, because performance requires memory and processing resources.Formulae cut down the amount of information a speaker has to keep in memory and to processwhile performing – easing the burden on the syntax – and does not have to construct them ab novo.Apparently, according to some psycholinguists, memorization may be “cheaper” than processing incertain hard-to-define cases.
Kuiper’s phrasal lexical items, or PLIs (which are arguably the same as many other authors’MWEs) have, in some instances, linguistic properties besides associated conditions of use. Theycan, for example, be classified as idioms. E.g. the presale formula going once, going twice does notliterally mean that the lot is sold one, two or three times. In this way it is like tug at NP’s heart-strings or make heavy weather of NP, which are generally taken to be semantically noncomposi-tional phrasal lexical items.
Formulae are a subtype of PLI’s, and the number of PLO’s has been variously estimated: Kuiperreminds us that these figures range from the same order of magnitude as the single-word lexicon(Jackendoff 1995) to an order of magnitude higher (Melčuk 1995), both quoted in Kuiper2006:602). This is a very significant observation. One wonders, however, whether these differentcounts have been based on quite different definitions of the same phenomenon, or the lexicon – os-tensibly, language as such – is really as elusive as this; or indeed both. Moreover, Kuiper adds thatoften those who make such estimates do not indicate whether the numbers are those of PLIs in a

Chapter Two
156
language or in the lexicon of an individual speaker. This is an important dimension, one that isoddly missing from much of educated guesswork on this count. The percentage of formulae withinthis amount is again not normally estimated. One suspects that inadequate definitions would notmake this possible.
Kuiper warns that the although observation that much of naturally occurring speech is formulaic toa degree is sometimes taken as evidence against the Chomskian position that human linguistic ca-pacity is creative, that does not follow. Human linguistic potential, Kuiper states, is fully as Chom-sky regards it; that this potential is
“not fully […] brought into play in some varieties of speech is not counterevidence tothis position. It is counterevidence to the position that every utterance humans utter isa novel creation”.
Then the question is how much of language is based on recall and how much on novel utterances.This, Kuiper claims, is contextually determined: the two factors that govern formulaic speech –psycholinguistic factors to do with memory and processing, and sociocultural factors such as thedegree to which the speech situation is routine – are likely to be the major determinants.
Phrasal Lexical Item = idioms? = MWEs?
Performatives Formulae
2.9.10 Multiword expressions in Fazly & Stevenson (2007)
Multiword Expressions, or MWEs, are claimed to be composed of two or more words that togetherform a single unit of meaning: frying pan, take a stroll, kick the bucket. Most MWEs behave likeany multiword phrase, e.g. their components may be separated, as in She took a relaxing stroll
along the beach. Nevertheless, MWEs are distinct from multiword phrases as they involve somedegree of semantic idiosyncrasy: the meaning of an MWE diverges from the combined contributionof its constituents. Because of their frequency and peculiar behaviour, MWEs are claimed to pose agreat challenge to the creation of natural language processing (NLP) systems.
In this scheme of Fazly & Stevenson (2007), “multi-word expression” is contrasted to “multiwordphrase”: the former, but not the latter, are “semantically idiosyncratic”. This effectively contrasts“expression” with “phrase”, which is hardly desirable. In the present study, at least “free” or “non-idiomatic” is used as a qualification of phrase or expression when it is contrasted with MWE, whichis thus defined as semantically idiosyncratic.
Semantic idiosyncrasy, Fazly & Stevenson (2007) argue, is a matter of degree. The idiom shoot thebreeze is largely idiosyncratic, because its meaning [...] does not have much to do with the meaningof shoot or breeze. MWEs such as give a try […] and make a decision are semantically less idio-syncratic (more predictable). [...] In these, the complement of the verb (here, a noun) determines theprimary meaning of the overall expression. This class of expressions is referred to as light verb con-structions in the literature (Miyamoto 2000; Butt 2003).

Chapter Two
157
Clearly, a computational system should distinguish idioms and light verb constructions, both fromeach other, and from similar-on-the-surface (literal) phrases such as shoot the bird and give a pre-sent. Idioms are largely idiosyncratic; a computational lexicographer thus may list idioms such asshoot the breeze in a lexicon along with their idiomatic meanings. In contrast, the meaning ofMWEs such as make a decision can be largely predicted, given that they are Light Verb Construc-tions.
[...] Many NLP applications also need to distinguish another group of MWEs that are less idiosyn-cratic than idioms and LVCs, but more so than literal combinations. Examples include give confi-dence and make a living. […], where the meaning of the verb is a metaphorical (abstract) extensionof its basic physical semantics. The notion of gradience is also transparent in this approach toMWEs.
From literal phrase to idiom: Fazly & Stevenson (2007) in tabulated formType Example Event structure Institution-
alizationLexico-semanticfixedness
Compo-sitional-
ityLiteralphrase
shoot the bird event: shoot2 arguments
– – FULL
Abstractcombination
make a living event: “earn-money”1 argument
+ ? ?
Light verbconstruction
give [thelasagna] a try
event: try2 arguments; lasagna =Patient/Theme
+ + +/–
Idiomaticcombination
[Jack and Jill ]shoot thebreeze
event: chat1 argument: conjoined J & J
+ + –
Semantically idiosyncratic expressions are supposed to have the following characteristics: (1) in-stitutionalization, (2) lexico-syntactic fixedness (3) non-compositionality.
(1) Institutionalization is a process through which a combination of words becomes recognized andaccepted as a semantic unit involving some degree of semantic idiosyncrasy.
(2) Lexico-syntactic fixedness involves some degree of lexical-syntactic restrictiveness, i.e.:– lexical fixedness: the substitution of a semantically similar word for any of constituents does not
preserve its original meaning– syntactic fixedness: the expression cannot undergo syntactic variations and retain its original in-
terpretation.(3) Non-compositionality means that the meaning of a word combination deviates from the meaning
emerging from a word-by-word interpretation of it.
Multiword Expressions
Idioms
Metaphorical/abstract combinations
Light Verb Constructions

Chapter Two
158
2.9.11 “Constructions” in Goldberg & Casenhiser (2007)
The term “construction”, used without a qualifying word, and apparently showing overlaps withsuch terms as “prefabricated constructional element”, “multiword construction”, “institutionalizedmultiword construction” and “constructional idiom”, has been so variously used in the literature andreceives so unhelpful a treatment in this article specifically devoted to this subject that it does notclarify the debates around the term. It is nevertheless worth examining the heading “construction”because it contains multiword expressions not found elsewhere.
In Goldberg & Casenhiser (2007:343) the traditional use of the term “corresponds to a conventionalpairing of form with (semantic or discourse) function”. They also state that
“linguists vary in their approaches to constructions [but] are willing to apply the term[...] to certain grammatical patterns that have unusual quirks in either their formalproperties or their semantic interpretation (or both) that make them ill-suited for uni-versal status. That is, these cases do not follow completely from any general princi-ples and so their patterns can not [sic] be predicted; they must be learned piecemeal.[...] it is not the case that these are simple idioms to be learned as individual chunks.They are in fact phrasal patterns with identifiable and definable generalizations.”
“...not only are phrasal grammatical patterns constructions, but grammatical patternsthat combine two or more morphemes lexically are also constructions. Still, othertheorists emphasize the parallels between morphemes, words, and idioms and largerphrasal patterns by applying the term “construction” to any conventional pairing ofform and function, including individual morphemes and root words along with idi-oms, partially lexically filled and fully general linguistic patterns”
(Goldberg & Casenhiser 2007:349)
Further examples, from lexical to phrasal, include book, dog, or (“root words”); un-V (“combina-tions of morphemes”); going great guns (“idioms, filled”); jog someone’s memory (“idioms, par-tially filled”); give her a book (“ditransitive construction”); and the house was hit by lightning(“passive”). This definition attempts a taxonomy of things covered by “construction”, but com-pletely fails to state what is common to these extremely diverse linguistic objects.
According to a more inclusive use of “construction”, the authors argue, any linguistic pattern is rec-ognized as one if some aspect of its form or function is not strictly predictable from its componentparts [...]. Psycholinguistic evidence suggests that patterns are stored even if they are fully predict-able provided they occur with sufficient frequency (Bybee 1995; Barlow and Kemmer 2000; Toma-sello 2003, quoted in Goldberg & Casenhiser 2007:349). These highly frequent expressions, even iffully compositional, are also sometimes labelled “constructions”. These are simply listemes in termsof the present study.
Examples, which are claimed by the authors to be especially clear cases of constructions, include(i) the TIME AWAY construction (e.g. danced the night away);(ii) the “incredulity construction” (e.g. Him, trapeze artist?!);(iii) the covariational-conditional construction (e.g. the more..., the more...);(iv) the benefactive ditransitive with non-reflexive pronoun (e.g. I’m gonna make me a sand-
wich);(v) the WHAT’S X DOING Y? construction (e.g. What are your shoes doing on the table?);(vi) the stranded preposition construction (e.g. What did you put it on?);(vii) the NPN construction (e.g. day after day); and(viii) the TO N construction (e.g. to school, to hospital).

Chapter Two
159
Neither the three quasi-definitions in three different places of Goldberg & Casenhiser (2007), northe examples above provide a remotely clear picture of what “construction” is; if one were to inventexamples based on these definitions, the examples would not at all be similar to (i)–(vii) above. Ifone were to devise a definition based on these examples, that would also be doomed to failure.
The first definition above, “conventional pairing of form with (semantic or discourse) function”, isso broad as to be the definition of any linguistic object. The second – “patterns that have unusualquirks in either their formal properties or their semantic interpretation (or both) that make them illsuited for universal status” – classes any inflectionally irregular word with “constructions”.
In addition, the exemplifying items are extremely heterogeneous:(i) is probably better regarded as a “partially filled” verbal idiom, i.e. one with a slot in it;(ii) is a syntactically well-definable object, a small clause51, which just happens to have the typi-
cal function of expressing incredulity (but also has other functions, or modal shades);(iii) is really unique in that it is an idiosyncratic combination of a form and a function (one that
cannot be expressed in any other way);(iv) is simply a heavily marked usage of personal for reflexive pronoun;(v) is simply a special meaning of do, mainly or exclusively found in this pattern, which may be
simply translatable (e.g. into Hungarian with the verb keres ‘look for’ – literally ‘What areyour shoes looking for on the table?’);
(vi) is a most productive syntactic object, obviously generated “on the fly” without regard even tothe kind of preposition involved;
(vii) and (viii) are simply prepositional phrase idioms (and this is what their label would be in allother standard frameworks).
One part of the above definition, which uses “unusual formal or semantic quirks”, may be salvagedby claiming that these patterns have a specific combination of the formal and the semantic, or func-tional/pragmatic aspects, and it is this combination that is idiosyncratic rather than either the formor the function. That definition, while jettisoning (i), (ii), (iv), (v), (vi), (vii) and (viii), would saveonly one of the above as a construction: the one that is called the “covariational-conditional” themore..., the more... pattern.
The most explicit definition of a construction of the three, the one that uses predictability – “someaspect of the construction’s form or function from its component not strictly predictable” – effec-tively classifies it with “idiom” without specifying what the difference would then be. Also, andmore importantly for the notion of listedness, it claims that patterns (which themselves are not de-fined here or anywhere else in the article) are stored even if fully predictable, provided they are fre-quent enough. This claim of storage amounts to labelling them listemes.
There is no way, however, that items such as the “incredulity construction”, the “stranded preposi-tion construction”, and “the passive” can be considered as stored patterns, whatever “pattern” mightmean; if these are to be included among constructions, then the term effectively ceases to be of anyuse.
2.9.12 Multiword units in Abu-Ssaydeh (2005)
MWUs are “lexical phenomena [...] which are conventionalized form/function composites that oc-cur more frequently and have more idiomatically determined meaning than the language that is puttogether every time” (Nattinger & DeCarrico 1992:1, quoted in Abu-Ssaydeh 2005:125).
Abu-Ssaydeh (2005) also note that MWUs have been studied under various labels: “lexical phrases,multi-word units, fixed phrases, formulaic phrases, chunks, preassembled chunks, prefabricated
51 The “small clause”, a typical example of the rift between theory and (lexicographic) practice, is explored in 3.1.6.

Chapter Two
160
chunks, holophrases, and so on” (Willis 1997, quoted in Abu-Ssaydeh (2005:125). MWUs straddlelexicon and syntax, ranging from a single phrase (pipe dream, green thumb) to compound sen-tences (look after the pennies and the pounds will look after themselves); from binomial fixedphrases (beck and call; knife and fork) to “slot-and-filler frames” (as ...-er, ...-er as e.g. in themore, the merrier); even proverbs. They are claimed to interact with textuality and serve a multi-tude of pragmatic and social functions. MWUs represent “probably close to half the lexis of theEnglish language”.
Abu-Ssaydeh (2005) classifies MWUs into the following categories (four plus two that they add be-cause they are claimed to have been overlooked by most researchers):
(a) Fixed phrases (Lewis 1997 polywords)
It only confuses matters that “polyword”, which does not seem to be used in any other framework,is equated here with “fixed phrase”.Abu-Ssaydeh (2005) takes his definition from Sag & al. (2003) [= Sag & al. (2002) in the Refer-ences of the present study]): “fully lexicalized and undergo neither morpho-syntactic variation... norinternal modification”; preassembled, extremely stable language chunks that cover a fairly hetero-geneous group of MWUs including binomials [...]. They also include conventionalized discourseformulae (on the one hand, last but not least), and Latin and Greek borrowings such as ad hoc, adinfinitum, ipso facto, persona non grata, post mortem, carpe diem etc. To this can be addedmany French phrases such as joie de vivre, bon appetit, crème de la crème.
(b) Institutionalized utterances
These are complete sentences or fragments thereof which have been lexicalized and serve as con-versational routines or social formulae such as greetings [...] etc: nice to meet you, so long, how doyou do, have a nice weekend, take care now, come off it.
“Institutionalized” and “lexicalized” are also among those fuzzy notions that are “perhaps definedostensibly” or “by implicit opposition to related categories” (an euphemistic wording of Nunberg &al. (1994) for not defined).
(c) Lexicalized sentence stems
“Units of clause length or longer whose grammatical form and lexical content is wholly or largelyfixed”. Their fixed elements “form a standard label for a culturally recognized concept, a term in thelanguage”. Lexicalized sentence stems include sentence heads: (if I were you, would you mind if,that’s ... for you); sentence tails: as it were, and what have you, and so on); and sentence slots:...-er, ...-er
(d) Idioms
Abu-Ssaydeh (2005) remind us of the disagreement as to what counts as an idiom (although it is notclear why idioms should be singled out when this disagreement is not greater than any concerningwhat constitutes any other MWE). Some researchers, he goes on, include similes and proverbs, oth-ers list single words (blarney, ergo), even acronyms (WASP, VIP, UFO) and Latin phrases bor-rowed into English (magnum opus, de facto). The Oxford Idioms Dictionary for Learners of Eng-lish (OIDLE 2001), the author tells us, considers as idioms almost all the categories listed here asMWUs, but despite the confusion, there is general consensus that idioms are semantically opaqueand syntactically fixed (or frozen, or fossilized) MWUs. Examples include light at the end of thetunnel, ball and chain, hold your horses, clear the decks, lock stock and barrel.

Chapter Two
161
It is difficult to visualize remotely general consensus on the semantic opacity, syntactic fixity, orany trait of idioms, for that matter, when such disparate terms as similes, single words, acronymsand foreignisms are included within this category.
(e) Similes
There are claimed to be either (i) lexicalized (as clean as a whistle, stubborn as a mule, as drunkas a skunk / a lord / a judge / a newt / fiddler), or (ii) created by the language user on the basis ofactual similarity (behave/sweat like a pig; work like a Trojan/hell/automaton/a madman/a bea-ver/a slave).
It is hard to see how this distinction helps a better understanding of similes, let alone any broadercategory, such as MWEs, that they may be part of.
(f) Proverbs
In an oft-encountered non-linguistic quasi-definition of “proverb”, Abu-Ssaydeh (2005) describesthem as “sentence-long encapsulations of popular wisdom”.
The thrust of Abu-Ssaydeh (2005), however, is that the variation of MWUs is not adequately repre-sented either in general or specialized dictionaries. That is certainly a valid observation, but thisproblem is dwarfed by the well-known hardships of the classification of MWUs.
2.9.13 Multiword expressions in Sag & al. (2002)
Sag & al. (2002) is a classic example of how, in current linguistic research, computational concernssuch as NLP and lexicographic endeavours apparently merge into one another52. Multiword expres-sions, according to Sag & al. (2002), are not a problem for lexicology, lexical semantics or lexicog-raphy, as they always have been, but “a pain in the neck for NLP”.
Sag & al. define MWEs “very roughly as idiosyncratic interpretations that cross word boundaries(or spaces)” – a semantically-based definition (which, incidentally, ignores the spoken language va-riety).
Writing about the significance of the MWE issue, Jackendoff (1997:156, quoted in Sag & al.2002:2) also claims that their role is far greater than has traditionally been realized within linguis-tics, and puts the number of MWEs in a speaker’s lexicon at the same order of magnitude as that ofsingle words. Sag & al. think this is an underestimate, since “specialized domain vocabulary, suchas terminology, overwhelmingly consists of MWEs”. They claim that “the theory of MWEs is un-derdeveloped, and the importance of the problem is under-appreciated” (Sag & al. 2002:2).
In the Conclusion, they argue that MWEs are far more diverse and interesting than is standardly ap-preciated.
Linked in obvious ways to the apparent gradual shifting of such problems as MWEs from tradi-tional to computational lexicography is the coming into the foreground of the written medium: thisis seen in definitions like the “or spaces” part of the above definition: “idiosyncratic interpretationsthat cross word boundaries (or spaces)”. The framework of Sag & al. (2002) describes how thetreatment of MWEs ranges from simply analyzing them as words-with-spaces, through “restrictedcombinatoric rules, to simple statistical affinity”. Crucially, the spoken variety – as everywhere incorpus linguistics – is relegated to second place.
52 Kilgarriff (1999), for example, remarks that “computer scientists [understand] formalism, mark-up, inheritance rela-
tions, maybe syntax codes, so it is these aspects they consider when considering dictionaries”.

Chapter Two
162
Sag & al. (2002:2ff) offer a taxonomy of MWEs exactly in terms of the analytic techniques that canbe used for dealing with them. MWEs are thus neatly classified into (i) lexicalized phrases; (ii) in-stitutionalized phrases.
(i) Lexicalized phrases have at least partially idiosyncratic syntax or semantics, or contain wordswhich do not occur in isolation [referred to as “lexically bound words” in the present study];they can be further broken down into:(i/a) fixed expressions (by and large, in short, kingdom come, ad hoc, ad hominem)(i/b) semi-fixed expressions (spill the beans, car park, part of speech)(i/c) syntactically flexible expressions (look up, sweep under the rug, make a mistake) – in
(roughly) decreasing order of lexical rigidity.
(ii) Institutionalized phrases are syntactically/semantically compositional but occur with markedlyhigh frequency (in a given context).
(i/a) Fixed expressions are “immutable expressions in English that defy conventions of grammarand compositional interpretation”; they are fully lexicalized and show no morpho-syntacticvariation (cf. *in shorter) or internal modification (cf. *in very short). The truly fixed expres-sions, such as ad hoc and of course can be dealt with as words-with-spaces.
(i/b) Semi-fixed expressions “adhere to strict constraints on word order and composition, but un-dergo some degree of lexical variation, e.g. in the form of inflection, variation in reflexive form,and determiner selection. This makes it possible to treat them as a word complexes with a sin-gle part of speech […]”.
Subtypes:(i/b 1) non-decomposable idioms: no internal modification; no passivization; possible in-
flection; variation in reflexive form (kick the bucket, trip the light fantastic);(i/b 2) certain compound nominals: syntactically unalterable but inflect for number – some
left-headed, some right-headed (car park, attorney general, part of speech);(i/b 3) proper names: syntactically highly idiosyncratic (e.g. US sports teams)
(i/c) Syntactically-flexible expressionsSubtypes:
(i/c 1) Verb–particle constructions: idiosyncratic or compositional (look up, brush up on)(i/c 2) Decomposable idioms: syntactically flexible (let the cat out of the bag)(i/c 3) Light verb constructions: highly idiosyncratic (give a demonstration).
The most important insight for lexicography, and for the present study, comes from (ii) in Sag & al.(2002:2ff):
(ii) Institutionalized phrases are semantically/syntactically fully compositional but statistically idio-syncratic. In traffic light, both traffic and light are supposed to retain simplex senses andcombine to produce a compositional reading. If such strict compositionality obtains, the samebasic concept could be expected to be expressed in other ways, e.g. *traffic director or*intersection regulator. No such alternate forms exist because traffic light has been conven-tionalized: its idiosyncrasy is thus statistical rather than linguistic, in that it is observed withmuch higher relative frequency than any alternative lexicalization of the same concept.
Other examples include telephone booth (or telephone box in British/Australian English), freshair and kindle excitement. One subtle effect observed with institutionalized phrases, the authorsclaim, is that association with the concept denoted by that expression can become so strong as todiminish decomposability. Traffic light, for example, could conceivably be interpreted as a devicefor communicating intended actions to surrounding traffic. However, partly because for that device

Chapter Two
163
institutionalized terms (turning signal or turn signal) exist, and partly because of the convention-alization of traffic light to denote a stoplight, this reading is not readily available.
This observation usefully broadens the domain of idiomaticity. The “statistical idiosyncrasy” of anexpression involves that it is unpredictable, whatever its degree of compositionality. It is doubtfulthat, as the authors claim, it is decomposability that gets diminished in processes like this: once oneknows the meaning of the expression, it will remain decomposable. What is relevant is that abso-lutely decomposable phrases can be unpredictable, which is the valid measure of idiomaticity.
2.9.14 Semantic/syntactic compositionality, statistical idiosyncrasy
Institutionalized phrases in Sag & al. (2002) are both semantically and syntactically compositional,but statistically idiosyncratic. Such information, with the Hungarian translations added, is presentedin the following table:
Meaning Hunga-rian equi-valent
Other meaning Could just aswell mean
Meaning couldjust as well be ex-pressed by
traffic light — device for in-dicating turn
traffic signal — device for in-dicating turn
stoplight brakelighttraffic controlsignal
—
light
‘colouredlights atcrossroads’
közleke-dési(jel-ző)lámpa,
lámpaillumination,
lamp, aspect, viewdevice for in-dicating turn
traffic director,
traffic regulator,
intersectionregulator,
signal light ...
turn(ing) signal —turning sign —turn indicator —indicator any instrument/
measureblinker smth blinking; eyewinker smth winking; eyetrafficator
‘device forindicatingturn’
index,
irányjelző
—
coloured lightsat crossroadsfor turningtraffic
traffic signal,
traffic sign,
traffic indicator,
direction indica-tor ...
Note: Singular has been used for all the items expressing the concept ‘traffic light’ throughout, although allitems, with the exception of trafficator, are typically used in the plural. The items expressing the notion‘turn signal’, of which always one (the right or the left one) is used, seem to prefer the singular.
Five variants for traffic light, and eight for turn signal have been given. Three Hungarian equiva-lents my be assigned to the former, and two (one of them rather formal) to the latter. Typically, justas English variant light as in at the lights, is used most often, in Hungarian this corresponds tolámpa as a lámpánál ‘at the lights’ as the most frequent one.
As quasi-synonyms of ‘traffic lights’, the obsolete Hungarian villanyrendőr (lit. “electric police-man”) as well as the (strictly official/written) phrase forgalomirányító fényjelző készülék, which is“marked as formal”, appears in EHCD (1998).
The border between statistical idiosyncrasy (institutionalized phrases) and idiomatic idiosyncrasy(lexicalized phrases) is a flimsy one. As is acknowledged by Sag & al. themselves: “associationwith the concept denoted by [the institutionalized phrase] can become so strong as to diminishdecomposability”. This is what they claim, but especially in the light of Nunberg & al. (1994), themost important single source for the present study, this is not so: it must be stressed again that it isnot decomposability but predictability that diminishes.

Chapter Two
164
The system of MWEs in Sag & al. (2002), a neat taxonomy, is much clearer in tabulated form; thisis given below with just one example for each type.
MWEs
Lexicalized phrasesInstitutionalized
phrases:traffic light
Fixed ex-pressions:of course
Semi-fixed expressions Syntactically flexible expressions
Non-decompos-
able idi-oms:
shoot thebreeze
Com-pound
nominals:car park
(Propernames:
the49ers)
Verb–par-ticle con-structions:look up
Decompos-able idi-
oms: sweepunder the
rug
Lightverb con-structions:
make ademo
Summarizing Sag & al. (2002) in diagram form:
Lexicalized phrases Fixed expressions
Non- decomposable Compound idioms nominals
Semi-fixed expr’sMWEs
(Proper names)
Syntactically flexible expr’s
Verb–particle constr’s Decomposable
idiomsLight VConstr’s
Institutionalized phrases

Chapter Two
165
2.9.15 Bundles in Biber & al. (2000)
Biber & al. (2000) focus on the “lexical end of grammar, describing systematic patterns of use thatcan only be identified through large-scale corpus studies”. This approach is supposed to show lan-guage in its aspects often ignored. Grammar, they claim, is not just a study of abstract classes andstructures, but of particular words and their particular functions within these. Biber & al. (2000)state that such information is also important for the learner, which is why they are relevant to bilin-gual lexicography too: producing natural, idiomatic English is evidently not just a matter of con-structing well-formed sentences but also of “using well-tried lexical expressions in appropriateplaces” (2000:989).
Biber & al. (2000) recognize bundles as a type of MWE in addition to idioms. MWEs, as definedhere, are structural and semantic units, the most common type of which are phrasal verbs in thebroad sense. Different MWEs can be distinguished according to idiomaticity/invariability, at oneextreme being (the relatively invariable) idioms, and at the other collocations (associations betweenlexical words such that the words co-occur more frequently than expected by chance).
The longer sequences in which words co-occur are called lexical bundles, and these can thus be re-garded as extended collocations. Statistically, the authors claim, idioms are not necessarily commonexpressions; lexical bundles, by contrast, are the sequences that most commonly co-occur in someregister. Usually they are not fixed; it is impossible to substitute a single word for the sequence;most importantly, the majority are not structurally complete at all.
Lexical bundles are recurrent expressions, regardless of their idiomaticity and structural status: theyare simply sequences of word forms that commonly go together in natural discourse. They are sup-posed to be “identified empirically, as combinations of words that recur most commonly in a givenregister”.
The same expressions that are called “bundles” in the Longman Grammar of Spoken and WrittenEnglish (Biber & al. 2000) are termed clusters in the Cambridge Grammar of English (Carter &McCarthy 2006). Here, clusters are “unitary or fragmentary and grammatically incomplete struc-tures, usually in patterns of two, three or more words, that repeatedly occur”. Significantly, while nosuch claim is specifically made in Biber & al. (2000), clusters are claimed to be “usually retrievedfrom memory as whole units and contribute to fluency”. Examples include the in the in I’ll see youin the morning, the string you know what I mean? and the linking but I mean.
This purely statistical approach to clusters, or bundles simply ignores whether the objects that it in-vestigates are structural units or not, and thus effectively shows a total neglect of syntax/structure assuch. Also, at least in Carter & McCarthy (2006), this approach considers its objects as psycholin-guistically real in the sense of stored items. It is small wonder if, in view of these, the “rationalist”tradition regards this kind of approach to language as an abuse of the corpus, a veritable lunaticfringe of the “empiricist”.
Discussing MWEs, Atkins & Rundell (2008:166–7) also claim that this term covers different typesof phrases that have some degree of idiomatic meaning/behaviour, and that “[m]any groups ofwords, such as she put it in the or immediately below the, co-occur frequently in corpus text butare of no real interest to lexicography”. In the Footnote they remind us that some theorists call suchfragments “collocations”. This is so confusing that it is hard to believe that their authors actuallymean this. These are exactly the “bundles” or “chunks” or “clusters” mentioned in Biber & al.(2000).
This neglect of syntax is barely excusable, but the taxonomy that it provides delivers useful itemsthat are best included in, for example, a learner’s dictionary. The judgement of Atkins & Rundell(2008:166) concerning the uselessness of such “groups of words” for lexicography may be too re-

Chapter Two
166
strictive. Contra Atkins & Rundell (2008), some of these “groups” (at one end of the gradience) domerit inclusion because they are idiomatic in the sense of being unpredictable; some (at the otherend of the scale) may be usefully listed as illustrative material in the entry of some of their compo-nents. The former type includes I mean..., a couple of, at the time, as well as, you now and youknow what I mean. If one considers their translation into another language, this receives furthersupport: in idiomatic Hungarian, e.g. there may be several ways to express the meaning, or ratherpragmatic content, expressed by I mean.…: these include úgy értem..., szóval... and akarom mon-dani..., none of which is predictable. The latter type includes to be honest with you and I knowwhat you mean. To be sure, these are not 100% predictable either: to be honest with you, e.g.could easily be in all honesty (cf. in all fairness), and it is not an impossible variant.
Biber & al. 2000 argue that some of the most frequently repeated word clusters reveal grammaticalregularities. It is hard to see how this could be if, as they claim, “the most frequently repeated onesoften are not complete phrases or clauses” (italics mine). It is also not clear why it might be gram-matically revealing to identify as recurrent chunks the differently underlined sequences in the sen-tence I mean I don’t know, you know. It is even less obvious how it may be significant that wecan identify the cluster I don’t on the one hand, and the chunk don’t know on the other hand, in thesame sequence, when they overlap. It is hardly useful to identify all or most two-word, three-word,even four-word sequences as significant e.g. in the sentence Do you think I don’t know? repeatedbelow, especially if most of them are not units of grammar in the first place. This is what this identi-fication of all such clusters would involve:
— do you; I don’tDo you think I don’t know?
— you think; don’t know
— do you think; I don’t know
— do you think I
However, the misgivings and scepticism of this general kind notwithstanding, the resulting listsmay be of good use to lexicography. What makes clusters relevant for the whole of the presentstudy is that they are retrieved from memory as whole units; and (obviously linked to this claim insome form) that “they are formulaic, and very possibly not assembled afresh each time”.
A sample of clusters is given below; clusters of more than two words in written, mainly academic,English have been ignored; nevertheless, the 2-word examples are given for illustration.
List No12
2-word clusters in spoken texts1. you know2. I mean3. I think4. in the5. it was
6. I don't7. of the8. and I9. sort of10. do you
11. I was12. on the13. and then14. to be15. if you
16. don't know17. to the18. at the19. have to20. you can
2-word clusters in written texts1. of the2. he was3. in the4. in a5. to the
6. with the7. on the8. of a9. it was10. by the
11. at the12. was a13. and the14. she was15. to be
16. I was17. for the18. had been19. from the20. with

Chapter Two
3-word clusters in spoken texts:1. I don't know2. you want to3. a lot of4. you know what5. I mean I
6. do you know7. I don't think8. a bit of9. do you think10. I think it's
11. do you want12. but I mean13. one of the14. and it was15. you have to
16. a couple of17. it was a18. you know the19. you know I20. what do you
4-word clusters in spoken texts1. you know what I2. I thought it was3. know what I mean4. I don't want to5. I don't know what6. you know I mean7. do you want to
8. that sort of thing9. do you know what10. I don't know how11. I don't know if12. if you want to13. a bit of a14. well I don't know
15. I think it was16. I was going to17. I don't know whether18. have a look at19. what do you think20. you don't have to
5-word clusters in spoken texts1. you know what I mean2. and all that sort of3. at the end of the4. I was going to say5. do you know what I6. and all the rest of7. the end of the day
8. and that sort of thing9. do you want me to10. I don't know what it11. in the middle of the12. all that sort of thing13. I mean I don't know14. do you want to go
15. this that and the other16. to be honest with you17. I know what you mean18. an hour and a half19. all the rest of it20. it's a bit of
2.9.16 Idioms in Nunberg & al. (1994)
Most importantly for the present study, Numberg, Sag & Wasow’s massive study in Languageclaims that in both linguistic discourse and lexicographic practice “idiom” is a fuzzy category, usu-ally defined by
(i) ostension of prototypical examples, such as kick the bucket(ii) implicit opposition to related categories:
to formulae, fixed phrases, collocations, clichés, saying, proverbs, allusions,
and these terms also “inhabit the ungoverned country between lay metalanguage and the theoreticalterminology of linguistics” (Numberg & al. 1994:492).
It is exactly this fuzziness that is true of all the various types of MWE in the other frameworks ex-plored so far in the present study.
Idioms are claimed to occupy a multidimensional lexical space, and have distinct properties: se-mantic, syntactic, discursive, poetical and rhetorical. For kick the bucket to be a/the prototypicalidiom, it probably needs to display the following “more or less orthogonal” properties, including:
1. conventionality 2. inflexibility 3. figuration 4. proverbiality 5. informality 6. affect

Chapter Two
168
1. Conventionality: “the meaning or use of an expression cannot be (entirely) predicted on the basisof a knowledge of the independent conventions that determine the use of their constituentswhen they appear in isolation from one another”. A footnote clarifies “conventionality” itself53.
Conventionality, then, amounts to (or is explained in terms of) unpredictability, which in turn istantamount to a definition from arbitrariness.
2. Inflexibility: idioms appear only in a limited number of syntactic frames/constructions, unlikefreely composed expressions (e.g. *the breeze was shot, *the breeze is hard to shoot).
3. Figuration: idioms typically involve metaphors (take the bull by the horns), metonymies (lenda hand), hyperboles (not worth the paper it’s printed on) or other kinds of figuration. Speak-ers may not perceive the motive for the figure, e.g. why shoot the breeze should be used tomean ‘chat’; they do, however, usually perceive the (fact of the) figuration – at least they canassign a ‘literal meaning’ to the idiom.
“Figurative”, then, opposes “literal”, and not all idioms need to be figurative; this is why e.g.shoot the breeze is seen as prototypical.
4. Proverbiality: idioms typically describe recurrent situations of particular social interest in virtueof their relation to a scenario involving homey, concrete things and relations.
5. Informality: idioms are typically associated with relatively informal/colloquial registers and withpopular speech and oral culture.
6. Affect: idioms typically imply a certain evaluation or affective stance toward they denotata.
It may be noted right here that some of the most obvious idioms of certain structural types arenot like this: the PP idiom by and large e.g. implies no “evaluation or affective stance”.
Apart from conventionality, none of these properties is obligatory. Property 1 is the decisiveone. Property 2 is syntactic. Properties 3–6 are the ones usually associated with the kind of“colourfulness”, which is so characteristic of the lay view of idioms and idiomaticity.
For any collocation, conventionality (a) is a matter of degree, and (b) depends on the interpreta-tion of “meaning” and “predictability”.
Predictability itself might, in principle, be defined more broadly and more narrowly.
• More broadly:If a native speaker who knows the meaning of the idiom’s constituents but has no knowledge ofany conventions governing the use of the collocation as a whole can generate it in appropriatecircumstances (and with the regularity with which it is used in the language), then the idiom ispredictable. This definition, then, uses production or encoding. Under this definition, manytransparent and literal phrases like industrial revolution and center divider (Nunberg & al.’sexamples) are idioms. Center divider, though transparent/literal, is idiomatic because it is usedto the exclusion of other expressions that might do as well if there were no convention involved.E.g. middle separator would do just as well. The conventions that mandate how a MWE isused vary across space and time.
• More restrictively, predictability might be defined as follows:If a native speaker can recover the sense of an idiom on hearing it in an “uninformative con-
53 The original footnote: “Conventionality is a relation among a linguistic regularity, a situation of use, and a population
that has implicitly agreed to conform to that regularity in that situation out of a preference for general uniformityrather than because there is some obvious and compelling reason to conform to that regularity instead of some other;that is what it means to say that conventions are necessarily arbitrary to some degree.” [italics mine]

Chapter Two
169
text”, it is predictable. Under this definition spill the beans is an idiom because it is unpredict-able (while industrial revolution is not, or is less prototypically one). This definition uses re-covery or decoding.
It must be noted that while users consult dictionaries during tasks which usually do involve con-texts, the dictionary itself is a most uninformative context.
Numberg & al. (1994) argue that this latter, narrower definition is quite unnatural, because it isnever in uninformative contexts that idioms are typically learned: you do not ask explicitly whatidioms mean; learning takes place in context. For native speakers, we should add, the “recoverytask” is simpler than for the language learner.
The main point of Numberg & al. (1994) is that when the idiom’s meaning is known (e.g. from aninformative-enough context), it can often be devolved on (or: transferred on to; distributed over;“spread out” over) the constituents of the expression. Numberg & al. (1994) argue that on hearingJohn was able to pull strings to get the job, since he had a lot of contacts in the industry, it maybe concluded that pull strings means (something like) ‘exploit personal connections’ – and theycould not have guessed this meaning hearing it in isolation. The thrust of the argumentation is justthis: it is possible to establish correspondences between the parts of the structured denotation of anexpression and its parts, in such a way that each constituent will be seen to refer metaphorically toan element of the interpretation. The idiom will be given a compositional, albeit idiosyncratic,analysis. Conventionality, of course, is there: by convention, strings can metaphorically mean ‘per-sonal connections’ when it is the object of pull; and pull can be used metaphorically to refer to ex-ploitation when its object is strings.
Importantly, idioms that are compositional in this sense are not the same as transparent expres-sions: speakers need not wholly recover the rationale for the figuration that it involves. Some idi-oms are transparent without being compositional: it is obvious why both to saw logs and mean ‘tosleep’. But sleeping is not decomposed into elements that correspond to the meanings of the parts ofthe expression. This contrasts e.g. with the Hungarian húzza a lóbőrt ‘saw logs’, which uses a dif-ferent metaphor – literally, it is draw the horse’s hide: this is neither transparent nor composi-tional. (Since the etymology is obscured, it is not completely evident what the meaning of húz is,but most likely the metaphor has to do with sound.)
Decomposition is thus also a semantic–syntactic notion in that it has to do with argument structure.Whether an expression is decomposable, i.e. compositional, in this way is easy to see in the case ofVPs, whose argument structure is straightforward. Sleeping is not a situation involving two, just oneargument, so the two-argument saw logs cannot possibly be mapped onto it. This holds for theHungarian expression húzza a lóbőrt as well. Other phrases, such as noun phrases, that have apoorer argument structure do not show this compositionality, and it is doubtful whether e.g. aprepositional phrase may ever be decomposable along those lines. Numberg & al. (1994), who onlyuse VP examples, are silent on this point.
A compositional expression need not be one for which speakers can explain the figural interpreta-tion. Spill the beans means ‘divulge the information’; we can assume that spill denotes the divulg-ing and beans the information, even if it is unclear why beans should have been used in this expres-sion. Spill does not mean ‘divulge’ when it does not co-occur with the beans; beans does not mean‘information’ without spill: the availability of these meanings for each constituent depends on thepresence of another. The meaning ‘divulge the information’ need not attach to the phrase as a

Chapter Two
170
whole: rather, it comes about through a convention that assigns meanings to its parts when they oc-cur together. Clearly, not all idioms are compositional: the idiomatic interpretations of numerousexpressions cannot be spread over their parts: e.g. saw logs, kick the bucket, and shoot the breeze.
Crucially, this conventionality is why “compositional” expressions must be entered in the lexicon;these compositional expressions also have to be lexically stored because they are unpredictable.Moreover, for the non-native speaker, learner or dictionary user, it is the predictability criterion thatis relevant, and compositionality, as well as transparency, is of minimum relevance.
Although the thrust of Nunberg & al. (1994) is the rethinking of compositionality, they compare thethree features of MWEs: conventionality, transparency, and compositionality. Of these three, how-ever, it is the first one that is really relevant for – especially bilingual – lexicography.
2.10 Implications for lexicography
The Nunberg & al. (1994) framework discussed above is summarized below, and the mostimportant conclusions for lexicography are drawn, which also provides a summing-up for the wholeof section 2.9.
• Conventionality involves predictability, which is roughly the same as arbitrariness. The mean-ing of simplexes, whether morphemes or words, cannot be guessed/predicted, i.e. it is arbitrary,i.e. governed by convention. The meaning of complexes, whether derivations, compounds orMWEs, can also be unpredictable.
What also transpires from Nunberg & al. (1994) for bilingual lexicography, even it is not explicitlyclaimed, is that because the existence in a language of an expression itself, or the fact that a lan-guage uses one type of expression to the exclusion of some other, is also unpredictable, the domainof idiomaticity is much larger than usually thought.
Prediction is to be interpreted productively/generatively/actively, not passively: an expression ispredictable only if native speakers (or learners) can reliably guess the form that belongs to somemeaning (or content or function) that they wish to express: “How is this in English?” – or any otherlanguage. The passive kind of “prediction”, i.e. the guessing of the meaning of existing expressionsis thus not prediction – it is recovery, not production; an after-the-fact phenomenon.
Conventionality (or predictability, or arbitrariness) shows both variation and gradation.
• Opacity (or its counterpart: transparency) contrasts with predictability since it is interpreted pas-sively: it refers to the inability of a native speaker (or learner) to see the motivation, or recoverthe rationale, for the makeup of existing complex expressions, reliably or unreliably; the guessneed not be (etymologically) correct.
• Compositionality is again interpreted passively: it refers to the ability of native speakers (or lan-guage learners) to “spread” the meaning of the whole existing complex expression over its parts.An expression is thus compositional if its holistic meaning is distributable over the individualconstituents.

Chapter Two
171
Opaque[non-transparent;badly motivated]
Non-composi-tional [non-analyzable]
Conventional[unpredictable]
– see a bird– H. lát egy madarat ‘see a bird’ – – –
– center divider– H. elválasztósáv ‘centre reservation’ – – +– saw logs– H. húzza a lóbőrt ‘saw logs’ [=snore] – + +– spill the beans– H. otthagyja a fogát ‘bite the dust’ [= die] + + +
When a bilingual dictionary such as an English↔Hungarian dictionary is being used in either di-rection, the three types (i) conventional, (ii) conventional plus non-compositional (but not opaque),and (iii) conventional plus opaque (but not compositional) present exactly the same difficulty, sincethey are unpredictable.
“Guessing” the English (i) center reservation, (ii) spill the beans, and (iii) saw logs on the basis ofthese Hungarian expressions, on the one hand, and guessing (i) elválasztósáv, (ii) húzza a lóbőrtand (iii) otthagyja a fogát on the basis of these English phrases, on the other hand, will be equallyimpossible. Guessing see a bird from see, a, and bird is possible; the same is true of the Hungarianversion of this sentence.
True, an idiom such as wash one’s hands, which happens to use the same metaphor as in Hungar-ian, may therefore be easier to remember than take the cake or spill the beans; and even if it didnot, the metaphor would help memorization for the learner as it does for the native speaker. Butspill the beans is not at all easier just because it is “compositional” than saw logs, which is not.
In summary, three examples illustrating the transparency—predictability cline will be offered. Thefirst, a simple case of an English compound with no compound equivalent in Hungarian; the sec-ond, a formal compound–compound coincidence between the two languages with a very differentmeaning; and the third, an entire set of Hungarian compounds, many of which are transparent butnevertheless unpredictable.
• The English eye chart is rather at the transparent end of the spectrum, but completely unpre-dictable: in Hungarian no compound can be used to translate it; szemorvosi tábla ‘opticians ta-ble/chart’, látásvizsgáló táblázat ‘vision examination table’, and snellen tábla ‘snellen54 table’.
• The Hungarian pápaszem (lit. ‘pope eye’, i.e. pope’s eye) is a two-edged example of compoundunpredictability, a. While the Hungarian compound has the – quite transparent and motivated –meaning ‘spectacles’, pope’s eye is used in two senses:
1. (in sheep and cows) a gland in the middle of the thigh surrounded by fat2. (in Scotland) denoting a cut of steak CED&T (1992)
• If a random Hungarian animal name is taken, and is combined with another randomly selectednoun, the chances are fair that an existing compound results. The meaning of these nominal
54An obviously completely unmotivated expression, from Dutch opthalmologist Hermann Snellen’ name. (The
compound snellen chart is also used in English.)

Chapter Two
172
compounds may range from the totally opaque to the fully transparent, but none will be predict-able. Transparency, in the cases illustrated below, ranges from egérút and farkastorok (0%) tobárányfelhő and maybe csigalépcső (100%): English speakers may well be unable to guess themeaning of many these Hungarian expressions even on being shown the “literal” gloss. Totalunpredictability in both directions will guarantee total idiomaticity.
Examples from the beginning of the alphabet include:bárányfelhő [lit. ‘sheep cloud’], mackerel skycicamosdás [lit. ‘kitten wash’], (a lick and a promise)csigalépcső [lit. ‘snail stairs’], spiral staircasedisznósajt [lit. ‘pig cheese’], brawn55
egérút [lit. ‘mouseway’], escape routefarkastorok [lit. ‘wolf’s throat’], cleft palate
55 The word brawn is not an idiom because it is a simplex.

Chapter Three:Grammar and lexicon
3.1 Grammar in the dictionary
In this section several grammar-related issues will be touched upon. Explored in more or less detailwill be the role of grammar in definitions in monolingual dictionaries; the issue of countability asmanifested lexicographically; and the use of grammatical devices one’s and oneself (vs. smb andsmb’s). General issues of parts of speech are explored in a more bulky section; this is followed bysections focussing on determiners (with a case study of many and such, and a case study of ago andgone), on complementizers and on prepositions. Small clauses will demonstrate one of the centralclaims of the present study, that dictionaries seem to do without input from theoretical syntax.These sections either flesh out claims in Chapters Two and Three, or introduce phenomena thus farnot touched upon. The focus is on the potential input from theory; lexicographic aspect of gram-matical points will be illustrated.
3.1.1 Grammar in definitions
Though irrelevant for bilingual lexicography, finding a suitable level of complexity for the grammarof definitions is a challenge for monolingual works, the extent of which often goes unnoticed. Theexample of prepositional phrases will be picked out for illustration.
The expression bottom drawer is defined in CALD (2008) as follows:‘clothes, sheets, etc. that a young woman traditionally collects for use after she is married’
Owing to the structure of English (this must be established if it is to be clear that this is neither theuser’s nor the editor’s fault) a prepositional phrase, after she is married in this case, can syntacti-cally relate to different earlier parts of a structure. The relative clause is thus structurally ambigu-ous: the relevant part can be construed as
(a) collects for [use [after she is married]], i.e. the use is in the marriage,or as
(b) collects for use [after she is married] i.e. the collecting is in the marriage
Given that the understanding of bottom drawer (a compound nominal idiom that is opaque partlybecause it involves a “container/object” metonymy) hinges on the syntactic parsing of the PPstructure, understanding of the definition is thus both syntactically and semantically hindered.
Relative clauses are an indispensable element of definitions, and this type of PP-related ambiguityis a highly typical stubbing block in monolingual dictionaries. A careful rephrasing, possibly at thecost of losing precious space, could make them much easier to understand.
In the above case, if (b) were the intended meaning, this rephrasing could be done by moving thePP, and separating it on either side by commas, to the right of the verb: ‘...that a young woman tra-ditionally collects, after she is married, for use’. Since, however, not (b) but (a) is the intendedmeaning, movement is no solution; collects can only be separated by a comma (that is otherwise notneeded): ‘...that a young woman traditionally collects, for use after she is married’.

Chapter Three
174
The use of the relative which instead of that in definitions, while it may make the defining stylesless colloquial or natural-sounding, achieves the aim of removing another ambiguity. Apparently,these are among the aims that will always be at cross purposes, a constant source of clash.
Even if it were easy to compile a list of such potential ambiguities that the editors agreed on, revis-ing all the definitions accordingly would present insurmountable difficulty.
3.1.2 Number and countability
Landau (2001) reminds us that
“there is good reason to include countability information in ESL and bilingual dic-tionaries, especially when the translation in the target language is a count noun,whereas the source-language term is a mass noun, or vice versa”
(Landau 2001:114)He does not consider a situation where the target language is without such a category, as Hungarianis commonly assumed to be, or where it has a really intricate, barely noticeably, and not widely rec-ognized system of countability, one that Hungarian arguably has. He argues, however, that nativespeaker dictionaries should not contain such information. Native speakers do not need this, becausethe “distinction is given to many exceptions” among them. (McCawley disagrees when he missesthe countability information in Crystal’s A Dictionary of Linguistics and Phonetics (4th edition),which is obviously not just for native speakers but specialist natives. In his review of it, he says thatthe “definitions often leave unclear whether the word being defined is a count noun or a mass noun”(McCawley 1999:67). Landau claims that we must
“therefore be weary of presuming that practical guidelines for the foreign-born stu-dent have any theoretical basis or practical utility for the native speaker...”
Landau 2001:115).
Without assuming that he is right, this is a clear example of how “localization” considerations over-ride “theoretical” uniformity.
It will be noted that from the outset, the bilingual dictionaries in the gradually developing Országhrange, which have grown into EHCD (1998) and HECD (1998), have not included such informa-tion. This was reasonably claimed to be notoriously difficult, partly because this information wasunavailable in the then current native speaker dictionaries.
Three approaches will be outlined here that yield drastically different classifications of Englishnouns in terms of countability. They are given chronologically, from 1973 to 2005, spanning thirtyyears. If there is such a thing as progress in linguistics (no positive answer is implied), or if one be-lieves in some kind of continuous improvement of methodological and analytical tools (a tentativeyes may be risked), then these approaches should reflect this.
They are presented in a table each: first, Quirk & associates, summarized on the basis of Quirk &Greenbaum (1973); second, the one to most radically depart from the tradition, Varga (1993); andthird, the simplest and most elegant, which is thus the most suited to lexicographic applications,Huddleston & Pullum’s, economically summarized in Huddleston & Pullum (2005):

Chapter Three
175
Quirk & Greenbaum (1973)Nouns
1 2 3 4Countable Uncountable can be both C &U
bottle furniture cake go by car, be in bed, have lunch, arm in arm,news, the true, scissors, thanks, cattle, the
rich, the Dutch, measles, the classics, lyrics,darts, maths, Naples, pains, the army, the
clergy, the KremlinColumn 4 contains various “hard cases” which have no label; these differ from all the other col-umns. The fact that in this way the system probably has too many “exceptions”, i.e. Column 4 typesof noun, does not seem to worry the authors.
Varga (1993)Nouns
+Count –Count xCountbottle furniture
measles, darts, maths, news;
trousers, scissors, thanks, arms, lyricsthe Dutch, the rich
family, clergypeople, cattle, police, vermin
The system is one with three values: count, non-count, and “neutral”, i.e. “xCount”.Some nouns occur in more than one group:
The people support you is xCount vs. The people supports you is +Count.
Huddleston & Pullum (2005):Nouns
Invariable/Fixed numberVariable number:contrasting sg and pl sg only pl only
crockery, footwear, harm,nonsense, indebtedness
alms, auspices, belongings, clothes,genitals, scissors, spoils, trousers
cat vs. cats
(s =/= plural marker:)italics, linguistics, news, mumps
(no inflectional marking of plurality:)cattle, police, vermin
Count and noncountDefinition: Count nouns take cardinal numerals; Noncount nouns do not.
Importantly, no mention is made of the indefinite article.
Noncount nouns that are singular onlyusu invariably singular – furniture, clothing, equipment, footwear; eagerness, perseverance
sg with Det the sg w/ Numeral one pl with numeralsCount the chair one chair two chairsNoncount the furniture *one furniture *two furnitures
Noncount nouns that are plural onlyinvariably singular: few in number – credentials, genitals, proceeds
pl with Det the sg w/ Numeral one pl with numeralscount the corpses one corpse two corpsesnoncount the remains *one remain *two remains
Note: nouns that have only a count or only a noncount interpretation are a minority.

Chapter Three
176
Dictionaries show no sign of change in the treatment of countability. Any countability informationthat is given is exactly in the same time-honoured (?) binary terms: this means being marked for [C]vs. [U], with an indication that the odd noun – or many, depending on how systematically it is done– can be used as both. If indicated before sense breakdown, as is often done, then information onthis twin usage is practically useless. The user will have to guess which sense is the U and which isthe C one.
• Native speaker dictionaries characteristically do not use these labels.• In learner’s dictionaries, it is usually not just the “hard ones” (cf. Landau’s reference to SL–TL
pairs that differ in this respect) that are marked for countability, but all nouns that can conven-iently be handled in such binary terms. Marking just the Top 50 or 100 of these would belearner-friendly and space-saving, and it would make it possible both for editors and users to fo-cus on the real problems (and would unnoticeably sweep under the carpet all the “non-binary”cases). Providing linguistically adequate labels for all of them, be these to the tastes of any de-scriptive framework, including the three above, is apparently something that (mono- and bilin-gual) dictionaries are neither capable nor willing to do. If they lack the capacity, i.e. the extragrammatical apparatus, then the reason is clear. If the willingness is missing, it can be a sign ofseveral things, from lack of expertise to simple inertia that has famously guided so many(non)decisions in lexicography.
Giving lexicography the benefit of the doubt: while native speaker dictionaries do well not to optfor completeness in this area, learner’s dictionaries may be excused for not providing enough ofcountability information if this is motivated by user-friendliness. Giving a near-complete picture ofthis aspect of grammar would hardly be imaginable without a lot of technical detail.Learner’s dictionaries should nevertheless provide more countability information on all nouns,preferably not just in the binary terms above. The problem is how the balance between complete-ness and usability/clarity is found. Bilingual dictionaries should ideally contain the Top 50, or Top100, depending on size, meaning by this the ones that involve the most pitfalls.
3.1.3 One’s vs. smb’s: coreferentiality in MWE “slots”
It is a commonly accepted claim about multiword units (or as, e.g. Kuiper & al. (2003)56 calls them,phrasal lexical items) that they can have slots, i.e. unfilled positions within them, which behave asvariables. Some of these are empty argument positions, e.g. the NP complement in take NP totask; some are not, e.g. the NP in get NP’s goat.
Some non-argument slots have coindexing restrictions. In the MWE get NP’s goat, the genitive NPcannot be coreferential with the MWEs subject; it must be coreferential with a non-subject, whichmay be a lexical NP. A simple way of wording this, in accessible grammar book style, is that suchMWEs are “really” of the form “get smb’s goat”, where the item smb’s is simply shorthand for“somebody else’s, i.e. “someone else than the subject’s”, i.e. not the subject’s. In a MWE like loseone’s way, by contrast, the relatively easy way of indicating this is that one’s effectively means“one’s own”, i.e. “the subject’s own”, so:
smb’s = “somebody else’s, whileone’s = “one’s own”
Because smb’s may be expressed by a pronoun or a lexical NP (This really got his goat vs. Thisreally got Jack’s goat), whereas a syntactic restriction (that the second “copy” of subject must bepronominalized and cannot remain lexical) requires that one’s be always expressed by a pronoun
56 The examples in this section are from Kuiper & al. (2003), hence reference to their use of PLIs.

Chapter Three
177
(Tom lost his way vs. *Tom lost Tom’s way), one cannot capitalize on their (partial) similarity andwrite the two formulas identically: it does make sense to use “NP” for get NP’s goat, but not forlose NP’s way: NP suggests lexical nominals not pronominal ones. This is why get smb’s goat butlose one’s way are used. The MWE lose one’s way, accidentally, is very much of an idiom for aHungarian speaker, since Hungarian expresses this with the single word eltéved. By contrast, e.g.lose one’s voice, which is expressed in the same “analytic” way in Hungarian as in English (elvesztia hangját ‘lose one’s way’), is not perceived as an idiom but a standard literal expression.
The status of oneself vs. somebody parallels that of one’s and somebody’s both in descriptive andlexicographic terms, but these will not be examined. (The form oneself, unlike one, shows nohomonymy, and is more clearly a non-subject pronoun, just like its Hungarian equivalent.)
It is not easy to judge how complicated this tiny portion of English syntax seems to a linguisticallyunsophisticated non-English user, but one thing is certain: the editors of some English learner’sdictionaries (including LDCE 2005, CALD 2008 and MED 2008) have seen it fit to radically breakwith the tradition of presenting this information in this dual way, as has always been done, see e.g.the smb’s vs. one’s contrast in COED 2004.
This decision creates unexpected problems.
CALD (2008) now uses the general pronoun your instead of one’s in its definitions:lose your way (in the entry of lose) is defined as ‘to become lost’
MED (2008) opts for the same:lose your way 1. ‘to not know where you are or how to get to where you want to go’ 2. […]
In the entry of best, the expression to the best of your ability is included, and defined as ‘as wellas you can’ (do the job to the best of your ability). Users will never suspect that you(r) is not theonly person with which this MWE can be used, i.e. that this is not a grammatical restriction, but thatyou(r) is really lexicographic shorthand. The pronouns you and your generically may be useful inexample sentences, but here their use is more than doubtful.
More seriously, MED (2008) has the same MWE entered twice. In the entry of ability it has:PHRASESto the best of your ability ‘as well as you can’Just try to do the job to the best of your ability
while in the entry for best it has:to the best of someone’s ability used for saying that someone does something as well as they canI promise to carry out my duties to the best of my ability
This is a double error:
(i) the same expression is worded in two different ways, and thereby different grammatical expla-nations are used for the same thing – the MED-type generic your and the traditional one.
(ii) Instead of someone’s, the form one’s ought to be given: to the best of ONE’S ability. This maysimply be an oversight, but it would not be there, were it not for this experimenting.
From the user-unfriendly to the more accessible is a welcome tendency. It is always a question,however, whether a (general, e.g. grammar-related) decision actually helps along those lines orhurts the logic of the system. It is appreciated that learner’s dictionaries go for simplicity when theyuse the generic you/your instead of one/one’s. An advantage may be that this also avoids the

Chapter Three
178
homonymy of one (numeral vs. pronoun), but whether the homonymy between genuine 2nd personand “general subject” that is created instead is potentially less or more dangerous is difficult to say.
3.1.4 Parts of speech
3.1.4.1 A bird’s eye view
“Partes orationis quot sunt? Octo. Quae? Nomen, pronomen, verbum, adverbium, participium, co-niunctio, praepositio, interiectio”. Thus speaks Aelius Donatus of the partes orationis in his Arsgrammatica more than sixteen hundred years ago. The same parts of speech, with adjective in placeof the participle, still serve much of English lexicography and everyday discourse about language.
The likes of this would surely have been unthinkable already fifty years ago in the most oversimpli-fying popularizing brochure of any other science, and would be even more so today. In dictionaries,this is still a fact of life, and as far as the lay public is concerned, the same situation obtains in lin-guistics. How is it possible that today’s lists do not significantly differ; that they do not, as far ascan be known, significantly vary with language; that they do not, as far as can be judged, very muchvary from author to author?
It may be as difficult as it ever was to find points of agreement between linguists. Yet except forauthors whose purpose is expressly the shaking of such traditional foundations of linguistic thoughtas the framework of word classes, everyone working in any area of linguistics takes for granted theexistence of a grammatical system of (more or less firmly identifiable) “parts of speech”. RichardHudson in an article that also lists eighty-three points on which he has found agreement among lin-guists of different persuasions, claims that
“The analysis of syntactic structure takes account of at least the following factors: theorder in which words occur, how they combine to form larger units (phrases, clauses,sentences etc.), [and] the syntactic classes to which the words belong (including thosemarked by inflectional morphology) [...]”. Hudson (1981)
Hudson (1994) refutes the claim that “linguists can’t agree among themselves”. He reminds theLinguist List of the list of the 83 points on which he found that about fifty of his UK colleaguesagreed (i.e., Hudson 1981). He claims that
“When we’re talking about school-level linguistics, most of the things we disagreeabout are out of sight”.
Since dictionaries represent, and one might say promote, just this domain of “school level linguis-tics”, they might as well agree as to word classes. Agreement does exist to the extent that syntaxmust consider “syntactic classes to which the words belong (including those marked by inflectionalmorphology)”, but there never has been consensus on what these classes might be. This is reminis-cent of the situation of semantic/thematic roles in the previous decades: while there has beenagreement that some version of these probably enjoy some kind of existence, the size and member-ship of the category has been considered irrelevant and even asking such questions has been re-garded with suspicion. The difference is that dictionaries never have to work with thematic roles:they never have to present them in a watered-down way.

Chapter Three
179
3.1.4.1.1 “Lumping vs. splitting” for word classes
As has long been recognized, “the near-universal use of a small number of PoS labels has obscuredthe existence of deep problems” (Crystal 1967:24). Also, “the terminological vagueness is en-demic”, and people can rarely be sure that their use of a term is not significantly distinct from an-other’s.
Word classes are things that either theoretical linguistics or teaching grammars and, more relevantlyfor us, lexicography cannot do without. The public are convinced that there is one real classificationout there which must be, or has long been, captured by science. Little is it realized that PoS frame-works may be legitimately different depending on theoretical and pragmatic considerations. Themisconception stems from the idea that PoS’s are an end for themselves. They actually are not: theyare just instruments of grammatical description and analysis.
As Crystal (1967:25) puts it, “word classes should not be taken as being in some way part of a ter-minological preamble to grammar”. This notion, however, is fostered by the simplification in dic-tionaries.
Simplification as such, of course, is not necessarily a bad thing; that is exactly what word classesare for, to simplify work with language. Consequently, if this work is the kind of didactically ori-ented lexicographic description that is expected of an instrument dictionary, especially a learner’sdictionary, a different kind of simplification is needed than in the case of a portrait dictionary. Thepractice, however, has been that while the lexical contents of these two kinds of work obviously dif-fer, their grammatical apparatus is largely the same. This is a contradiction that mostly gets lostsight of.
For linguistics in general, explicating the word classes involves explicating the grammar; the wordclasses, therefore, must be a system set up by an ideal application of an ideally established set ofcriteria. The end result will depend on the selection of criteria. The attention of structural linguisticshas been on form: as many classes are set up as words of different formal behaviour are found.
3.1.4.1.2 Delicacy of analysis: the wood and the trees
The aim must be a system of PoS’s characterized by
“maximum homogeneity within the classes57; ‘a class of forms which have similar priv-ileges of occurrence in building larger forms is a form class’ ... ‘a part of speech is aform class of stems which show similar behaviour in inflection, in syntax, or both’58;form classes are treated as separate when they show ‘enough difference’ from otherclasses59. […] such statements only postpone the central issue, namely, How can no-tions of […] ‘maximum homogeneity’, ‘similarity of behaviour’ and ‘enough difference’be precisely defined? This question does not seem to have been answered. If the decisionis arbitrary, […] then perhaps there is no one answer – but people should at least beaware of this weakness and limitation of the word class concept, and note the extent towhich decisions become little more than a matter of linguistically sophisticated taste[…].
(Crystal 1967:28–29; references are to the works in the footnotes below).
As Crystal (1967:29) argues, the ideal situation for linguistic science is to
“assign all words of a language to a very few classes by applying a very few generalcriteria – a balance between the number of classes, and the number and degree of
57 Gleason (1965:130)58 Hockett (1958:162, 221)59 Hall (1964:163)

Chapter Three
180
complexity of the criteria; […] the more criteria […] the more classes […]. The cur-rent tendency is towards a more delicate or refined subclassification […]”.
In this scheme, it becomes clear that the difference between class and subclass is one of degree.
“[T]hat the more subclassification one allows, the more points of general similaritybecome less clear: one begins to see some new trees […], but one also begins to losesight of the wood. And […] there is the danger of finding oneself with such smallclasses if items that general statement becomes impossible […]. On the other hand,too few criteria produce […] under-classification – major classes, e.g. bipartite (e.g.noun vs. non-noun), tripartite, with a very uncertain and miscellaneous constitution,lacking any readily perceivable homogeneity.”
Crystal (1967:30)
Crystal speaks for linguistics at large, not for applied linguistics, and certainly not for lexicography.In linguistics, “splitting vs. lumping” trends may and do change, i.e. perceptions as to whether moreor less delicate subclassifications are ideal do vary. Dictionary editors, on the other hand, need nothave a stand on over- vs. under-classification, i.e. whether the one or the other is the greater danger.In their daily work it is the most natural thing that they constantly find new trees, and since theirwork is basically lexical, i.e. just the opposite of the general, there is never the danger of losingsight of the wood.
If there is one area where lexicography might use the insight of linguistic thought, then it is here:not by slavishly following theoretical trends, but by realizing that because word classes are notGod-given products but have always been manufactured with a particular purpose and sphere of ap-plication in mind, there might be one set of PoS’s for one application, and a different one for an-other. To be sure, changes in the approach to the part-of-speech treatment in dictionaries have oc-curred, but these are often unnoticeable, and often really unnecessary. If they are small and piece-meal, it is not necessarily a criticism of lexicography, since drastic changes for whole readerships ofdictionaries can only be introduced in tandem with the general sentiment for change, e.g. in gram-mar teaching – and that sentiment is certainly not there.
Quirk & al. (1985:67–68), the most comprehensive and reliable descriptive grammar for decades,recognizes the most commonly used parts of speech for pedagogical purposes, and thus found indictionaries:
(a) the closed classes: Prepositions, Pronouns, Determiners, Conjunctions, Modal Verbs, Pri-mary Verbs
(b) the open classes: Nouns, Adjectives, Full Verbs, Adverbs(c) the “lesser category” of Numerals(d) the “marginal and anomalous class of Interjections(e) “a small number of words of unique function, which do not easily fit into any of these
classes: e.g. the negative particle not and the infinitive marker to.
Importantly, Quirk & al. add that “there is nothing sacrosanct about the traditional part-of-speechclassification”, and that they have also deviated from it when they subsumed the Article under thelarger heading of Determiner, and when they divided the traditional “Verb” group into three catego-ries. They state that these adjustments are well-motivated for modern English (Quirk & al.1985:73). These two changes are there to be seen in almost all of English lexicography.
In another tripartite split that Crystal cannot possibly have had in mind in 1967, the LongmanGrammar of Spoken and Written English distinguishes three “major word classes”, three super-categories that have not been recognized before:
“Words can be broadly grouped into three classes according to their main functionsand their grammatical behaviour: lexical words, function words, and inserts.”
(Biber & al. 2000:55)

Chapter Three
181
Setting up a third major category of inserts in addition to the standard groups of lexical words andfunction words, the approach of Biber & al. (2000), which is both corpus-driven and discourse-based, apparently claims that, looked at from the living spoken language, the “real word classes” arecompletely different from the standard assumptions. Lexical words have the usual features: (i) lowfrequency; (ii) heading of phrases; (iii) length: yes; (iv) lexical meaning; (v) variable morphology;(vi) open class; (vii) large number; (viii) strong stress. The characteristics of function words are:(i’) high frequency; (ii’) non-heads of phrases; (iii’) length: no; (iv’) no lexical meaning; (v’) in-variable morphology; (vi’) closed class; (vii’) small number; (viii’) weak stress. (The four mainclasses of lexical words here are: Nouns, Verbs, Adjectives, and Adverbs.)
More relevantly, the third group, that of inserts, is “a relatively newly recognized category ofword”; these words are claimed “not to form an integral part of a syntactic structure, but are insertedrather freely in the text”. (This of course is another way of saying that they are not word classes inthe strict sense.)
This may remind one of the bifurcation between “competence grammar” and “competence linguis-tics” vs. “performance grammar” and “performance linguistics”. Thus, beside the “traditionally”recognized syntactic word classes, there exist “text word classes”. This may be a legitimate distinc-tion, even if the claim that these types of words are not part of syntactic structure but “insertedrather freely in the text” raises the question of speaker knowledge of the obviously rigorous syntac-tic, certainly not only pragmatic, rules that govern their use. Both their intonational features anddistributional facts show their integration within the grammar – even if not in the sense of beingable to form phrases with members of either of the lexical or the functional categories.
Predominantly spoken and morphologically simple, inserts include such (still diverse) items asyeah; hm hm; Bye. Cheers man. Inserts are more marginal than lexical and function words, and
“it can indeed be debated whether some [of them] should be recognized as words atall. But there is no doubt that they play an important role in communication. If we areto describe spoken language adequately, we need to pay more attention to them thanhas traditionally been done” (Biber & al. 2000:56).
This group of lexical items were termed vocables in 2.6.4–5.
That the old phenomenon with the new term – insert – is by far not insignificant is shown by thestatistics in Biber & al. (2000), who claim that the distribution of word types in the spoken registeris as follows: lexical words – 41 %; function words – 44 %; inserts – 15 %. This is a huge quantityof lexical items, not to be taken lightly.
Of inserts, interjections seem to be the only type that have always had a place in most grammars(and consequently in dictionaries). The variety of forms of inserts, however, shows that there is justa slight overlap between the two categories; interjections are at best a subcategory of inserts. Thereis reason to believe that what have been termed interjections for centuries have been a really mixedbag.
Lexicographically, it seems that the recent relatively generous treatment of interjections, e.g. in bothMED (2002) and (2007) reflects this relatively new interest in the pragmatic aspect of language andthe spoken medium in general, as well as the “newly-discovered” category of inserts. Most of whatare called interjections in MED, to be sure, are not members of the narrower class of “genuine” in-terjections but inserts of various kinds; this also may explain their high number.

Chapter Three
182
3.1.4.2 “Determiner”: lexicographic lip service, no real utility
Lexicographically, “determiner” is a recognized word class of high generality, above the level ofthe members of the traditional systems.
It is hard enough for applied linguistics to work with a hard-to-delimit class like that of determinersin an Anglo-Saxon setting where determiners have long been part of linguistic discourse. It is im-possible where they have never been: “determiner” is an unheard-of category in Hungarian laygrammatical discourse. But the missing notion of determiner is absolutely no problem: the Országhrange of dictionaries, which dominated the bilingual scene for decades, have never used this term.In a Hungarian setting, there is very little to be gained from the knowledge that articles and “posses-sive” pronouns (and some other “little words”, the full list of which is never given and is muchcontroversial anyway) belong to some hitherto unheard-of supercategory with the baffling name“determináns”. This is why AMSZ (2000) also does not use the category “determiner”. It is, ofcourse, fortunate that my has no homonym in another word class and thus need not be PoS-labelled.Unfortunately mine, however, which has both a verb and a noun homonym, must be PoS-labelled;and within the standard Hungarian system, it can only be labelled a pronoun – which it clearly isnot. But a dictionary will never be able to change the whole school grammar tradition, where bothmy and (possessive) mine are just that: pronouns.
It would be a welcome feature, then, of EHCD (1998) that it does not recognize determiners as aclass. On the other hand, it does serious disservice to users on several accounts, of which three willbe singled out. (a) It labels the independent/pronominal this as nm, i.e. pron, while it classifies theprenominal/determiner this as mn, i.e. adj – going back half a century lexicographi-cally/grammatically. (b) It labels both my and mine pronouns – the former is not one by any stan-dard today; (c) moreover, it labels as an adjective the mine in mine ears and in mine host (whichare, in addition, stylistically labelled as vál, i.e. “literary” style, in an abuse of the “literary” label).
Interestingly, Kenesei (2008), who also distinguishes articles for Hungarian (among the word-levelfunctional categories, along with auxiliaries, complementizers, negative words, the “interrogativeparticle”60), specifically equates “article” with “determiner”. Moreover, only the definite article isrecognized as an article (= determiner). This yields a perverse, although not unheard-of, situationwhereby (i) the general public’s list of articles contains two, definite and indefinite; (ii) a state-of-the art syntactic framework recognizes just one; (iii) Hungarian learners working with Englishmonolingual dictionaries may encounter Determiner but never Article (even if the list of determin-ers does include the articles); and (iv) Hungarian learners working with English↔Hungarian dic-tionaries will find Article but not Determiner.
Just because a dictionary does not use the PoS label Determiner, it may contain that term as aheadword. EHCD (1998) does not use “determiner”, but in its entry for determiner, the followingmisleading information is given:
determiner fn 1. meghatározó / eldöntő / megállapító személy / dolog 2. nyelv determináns [névelő,névmás stb.]
While some of the determiners are indeed what are called pronouns in very traditional systems, thisis misleading. The Hungarian equivalent without the explanation part would be sufficient in a non-specialized dictionary and thus avoid the problem. In Hungarian school grammatical terminology,the prototypical pronoun is the personal pronoun; and those are obviously definitely not included inthe determiner class.
The treatment of grammatical terms is a very uncertain area for (especially bilingual) lexicography,because what is involved here is the ever-changing terminology of a discipline; bilingually thismeans having to juxtapose two never-identical systems.
60 Somewhat below the level of words: Hungarian -e is dependent word in Kenesei (2000), (2001), (2006), (2008).

Chapter Three
183
3.1.4.2.1 Determiners in GB syntax
As an up-to-date introduction to syntax (roughly after GB and before or simultaneously with mini-malism), Newson & al. (2006) recognizes eight basic syntactic categories, which fall into two types:thematic – V, N, A, P – and functional – inflection (I), determiner (D), degree adverb (Deg), com-plementizer (C). The thematic vs. functional divide seems to feature high in current syntacticthinking (this is the basis of distinguishing, e.g. lexical verbs from auxiliaries in Kenesei (2008).Similarities and differences between word categories can be captured using binary features: [±] dis-tinguishes between thematic and functional categories: e.g. nouns are [–F, +N, –V], while verbs are[–F, –N, +V].
Crystal (1967) argues that the standard three or sometimes four bipartite divisions of words into (i)full vs. empty, (ii) open-class vs. closed-class, (iii) variable vs. invariable and (iv) lexical vs. gram-matical, although they are often used synonymously, or at least without an explanation of the differ-ences, do not yield the same sets of words. To these four have been added, as (v), the grouping intothematic vs. non-thematic. This expansion makes the equivalences even less complete and the pic-ture even more elaborate.
Determiners have something in common with nouns, and modal auxiliary verbs with verbs, and thiscan be captured by establishing that determiners are the functional equivalents of nouns, and mo-dals, the [+F] equivalents of verbs. This kind of attempt at achieving a high degree of generality is akind of information that is never to be included in a dictionary.
A further refinement, one that nevertheless retains the binarity and high generality of the system, isintroduced in Newson & al. (2006) with the notion of underspecification. With all these [±F] cate-gories (the categories underspecified for the Functional feature) also in place, Newson & al. (2006)now has 3×4 rather than 2×4 members in the following arrangement:
V N A P
thematic, T see her a cup of tea fond of her on the desk
functional, F can see this cup so fond for me to go
underspecified, T/F aspectuals;light verbs:
have (it)seen
measure/groupnouns: cup oftea
“post-determiners”:many/more /few desks
picture of Mary
seen by her
traditionally:all verbs ofdifferentkinds
traditionally: [T]
and [T/F] are
nouns; [T] is
Pron or Det
traditionally: [T]
and[ T/F] are
adjectives;
[F] is Adv?
traditionally: allprepositions(with norefinementgroup-internally)
The following table, simplified from the one above, containing the four times three word classes inthis framework, highlights the differences between e.g. Newson & al. (2006) and what may be con-sidered as the most widely used traditional “Quirkian” classification. The smaller/italicized termsbelow are the classes of Quirk & al. (1985):

Chapter Three
184
V N A P
thematic, T see her a cup of tea fond of her on the desk
Full Verbs Nouns Adjectives Prepositions
functional, F can see this cup so fond for me to go
Modal Verbs Determiners —— ——
underspecified,T/F
aspectuals; lightverbs: have (it)seen
measure/groupNs: cup of tea
“postdetermin-ers”: many etc.
picture of Maryseen by her
(Primary Verbs) —— PostDeterminers ——
Missing from this table (because missing from Newson & al. 2006) but included in (Quirk & al.1985) are the following: Adverbs, Pronouns, Conjunctions, Numerals, and Interjections. Because ofthe partial overlaps and the functional non-identity of identical terms, the two systems – as expected– are not be compared in this simple way. As can be seen, English dictionaries are true, if not toDonatus’ (3.1.4.1) system, but to the Quirkian taxonomy, and take no notice of these developments.
3.1.4.2.2 The U turn of many: dormant adjective
The word many used to be generally treated as an adjective in school grammars of English, and acombined internet search on “many” and “adjective” still returns dozens of amateurish sites wheremany is classified as one. This claim often comes accompanied by such statements as “some adjec-tives modify nouns by telling HOW MANY (several, few, many, one, all, seven)” and “the indefi-nite adjective many modifies the noun people” and “adjectives of quantity tell how much or howmany”.
In the descriptive tradition, many is classed with the determinatives (or determiners61), which aresometimes supposed to come in three distributional classes (predeterminers, central and postdeter-miners), with sequences of different determiner types possible. Thus all the many problems willbe a string of PreDet, CentrDet and PostDet. The existence e.g. of many a big problem, however,would classify many with the predeterminers. Many has been analyzed variously in the literature:Huddleston, Pullum & al. (2002:539ff) treat it as a determiner, similarly to Quirk & al. (1985), ar-guing from the existence of many of the books and the impossibility of e.g. *nice of the books: theposition before the of cannot be adjectival.
In the generative framework, it has been treated as adjectival. Kayne resorts to movement to explainthe determiner-like features of many: it is claimed to move to a determiner position (Kayne 2002,quoted in Aarts & Haegeman (2007:121).
Under the analysis of Newson & al. (2006), which uses binary features for N, V, A and P as well as“F[unctional]” and “T[hematic]” and underspecification for the “F” feature, the “postdeterminer”many is an adjectival element, although a special one: a non-thematic/non-functional adjective. It is
61 The Quirk et al. range of grammars (e.g. Quirk et al. 1985) use determiner as a form label and determinative as a
function label, while Huddleston, Pullum et al. (2002) recognize determinative as a formal and determiner as a func-tional category.

Chapter Three
185
not thematic (cannot even be a predicate62), but inflectionally it patterns with adjectives (cf. more,most). It is a +N, +V, ±F item.
The analysis of Newson & al.(2006) solves the problem of many of the books by claiming manyto be in Specifier position of a NP headed by an empty noun (the slot of the [e]mpty symbol may bethought of as being taken by books):
DP g
D’ 3
D NP e 3
AP N’ g 3
A’ N PP g g g
A e P’ g 3
many P DP g 6
of the books
While the above analysis does offer a solution to the issue of multiple determiners, it offers none tothe many a book problem.
It is ironic that having come full circle many is an adjective again (albeit a semi-functional or semi-thematic one), this time solidly based on strict distributional principles of a fairly recent syntax ofGB-cum-X-bar theory and also on morphological behaviour, because more and most are forms ofmany that prove its adjectival rather than determiner status.
How does all this, one wonders, translate into dictionary practice? In a sample of electronic diction-aries63 listed below chronologically, this “mainstream” many, seen in e.g. all the many (prob-lems), is labelled as (i) adjective, (ii) determiner, (iii) determiner, pronoun [with no hint as to whichexample is which]. LDCE (2000) simply uses the label quantifier. NSOED (1997) even explicitlypoints out that what is generally termed an a(djective) goes by the “modern” term determiner.LDCE only uses the determiner label for many in all of its uses and functions. All American dic-tionaries use the adjective label; all British publications use determiner, sometimes in combinationwith pronoun (with none of them distinguishing which example is which of determiner and pro-noun).
Crucially, although the word much, the noncount counterpart of many, does not have the problemsassociated with the distribution of many (there is no *much a big difficulty, for example, on theanalogy of many a big problem), the issue of PoS labelling is contentious here as well. The prob-lem of the existence of much of the information is not less grave than many of the books.
62 This is claimed in Newson (2006), although e.g. His faults were many is grammatical.63 As usual, there is no reason to think that their print versions have used a different classification.

Chapter Three
186
Native speaker dictionaries:
CED&T (1992)–determiner as in: many coaches; many are seated; many a man; too many clouds–noun as in: the many ‘the majority of mankind’
AHD (1994)–adjective as in: many a child, many another day, many friends–noun as in: a good many of the workers, the many fail–pronoun as in: for many are called
NSOED (1997)–a. (in mod. usage also classed as a determiner) as in: many things, many a year, many isthe time–pron. & n as in: many of his ideas, many served, a good many were
RHWUD (1999)–adjective as in: many people; for many a day–noun as in: a good many of the beggars; the many the greater part of mankind–pronoun as in: many of the beggars; many were unable to attend
MWUD (2000)–adjective as in: many people; the many advantages; many a man–pronoun as in: many are called; many of the statements–noun as in: a good many of the books; contempt for the many
MWCD (2003)–adjective as in: many years; many a man–pronoun as in: many are called–noun as in: a good many of them; the many
Learner’s dictionaries:
LDCE (2000)–quantifier as in: many people, many of our staff, many a person, many a time, many’sthe day, the many
CALD (2003)–determiner, pronoun as in: many clothes, as many, many a time, many’s the
OALD (2005)determiner, pronounas in: many copies, for the many, many a good man
LDCE (2005)–determiner as in: many people, many of our staff, a great many, many a parent/time,the many
CALD3 (2008)–determiner, pronoun as in: many clothes, as many, many a time, many’s the
The Macmillan English Dictionary (MED 2002 and MED 2007) is unique not only in (i) distin-guishing four different many types/functions, but also (ii) in separating determiner from predeter-miner, as well as (iii) in providing examples and explanations for each of these.64 The illustrativeexamples are full sentences but have been edited to make them conform to the examples of theother dictionaries.
64 In the very first line, adverb, determiner, predeterminer, pronoun are given, but this is a misprint: the boxed summary
at the top of the entry is correctly printed.

Chapter Three
187
MED (2002) & (2007)65
The first line specifies many as a function word and quantifier (without explaining what thesetwo things mean)
–determiner: many years–pronoun: not many (followed by of): many of you–predeterminer (foll. by the indefinite article a and a singular noun): many a long day–adjective (after a word such as the, his, or these, and foll. by a noun): his many friends–noun in the phrase the many: the enjoyment of the many
EHCD (1998), the only bilingual English→Hungarian dictionary checked for comparison, distin-guishes just two word classes for many: adjective and noun.
–adjective as in: many a time, many times, a good many people, many have seen it–noun as in: the many, a great/good many
While the syntactic treatment of determiners, exemplified here in detail by many, has been variedand in constant change, from this random sample it will be apparent that dictionaries have not sim-ply been lagging behind these developments but most of them have ignored most of them com-pletely. Quite a few still use the largely pre-structuralist label, Adjective; some just label the itemmany as a twin class of determiner/pronoun without the distinction either made clear or exempli-fied anywhere; just one (LDCE 2005) gives determiner for all of many’s diverse uses; some distin-guish a separate noun use (the many in the ‘mankind’ sense); one is so explicit as to distinguishfive different classes (warranted by distribution, not by meaning); and one actually calls attention toan instance of relabelling, thereby explicitly teaching a bit of syntax: that for this function, “modernusage” has determiner. Finally, one learner’s dictionary, LDCE (2000), uses the intuitive meaning-based label quantifier, grouping many with other items that it clearly does not belong with syntacti-cally/distributionally.
3.1.4.2.3 The anomaly of such
The word such is at least as anomalous as many: it has also been regarded either as an adjective oras a determiner. As pointed out in Aarts & Haegeman (2007:122), if one wants to treat it as a de-terminer, it will either have to be a pre- or a postdeterminer: predeterminer in such a nice day,where it precedes a; postdeterminer in no such thing, following no; postdeterminer (possibly ad-jective), in the next such event, where it follows next, which is another postdeterminer (possiblyadjective). At this point one is overwhelmed by the notion that the dictionary user in general wouldreally be better off without grammatical labels altogether. If such is regarded as an adjective, prob-lems only arise with such a nice day, where some kind of fronting movement has to be hypothe-sized to get such before the article – but of course any reference to movement is unthinkable in adescriptive grammar or a dictionary. Biber & al. (2000) invent the term “semi-determiner” for theword such, which shows its intermediate status but further messes up the system.
3.1.4.2.3 Splitting vs. lumping: determiners
It would, of course, be also conceivable that for the syntax, there are two different words many (andsuch, and much and the like): one a predeterminer, the other a postdeterminer. (No such alternativehas been outlined above.) The introduction of indeterminate, or intermediate, categories, such as“semi-determiner”, along the lines of Biber & al. (2000) is also a theoretically viable solution.(These, however, should not be on an ad hoc basis, and ideally should also be independently moti-vated.) A neat theoretical framework such as GB syntax and/or X-bar theory may clearly show that
65 No change between the two editions.

Chapter Three
188
there are no separate pre-, central and postdeterminers, and their existence has been an optical illu-sion. In pedagogical grammars, and even more relevantly in dictionaries, however, one gains verylittle indeed either by “splitting” or “limping”. By “splitting”, that is, claiming. e.g. that many be-longs to different determiner categories in view of some highly abstract syntactic pattern that it dis-plays. By “lumping”, which is intuitively even more problematic, and amounts to claiming, in thisparticular instance, that the items all, the and many – which three can occur in exactly this order –are really the same kind of syntactic object. Current practice is just this: the three items are all De-terminers”. Their observable behaviour and visible distribution – predeterminers precede and post-determiners follow centrals is no less of a fact than that they all precede their nouns – must be ac-counted for somehow. Blurring the distinction may be wholesome for the theory but harmful forany practical application. Because in traditional Hungarian school grammar determiners are un-heard-of anyway, for the Hungarian user the Determiner label is not too helpful in the first place.
Nothing can be a bit of noun and a bit of something else in a dictionary. It is not unimaginable thatthere may be new, intermediate classes established, but this will never happen first in, and spreadfrom, a practical tool such as a dictionary. On the other hand, theoretical linguistics of one denomi-nation will tend to aim at simplification and generality, thereby reducing the numbers of categories;another may prefer a more delicate analysis, which results in the growth of categories. Crucially,however, because – understandably – neither has lexicography in mind, no advances in linguisticthought will have a bearing on this aspect of dictionary-making.
The limits of what dictionaries can do to make clearer the classification and exposition of wordclasses and facilitate the user’s orientation, among other things, however, also depend on the nativelanguage and metalanguage of the prospective user. It is arguable, for example, that auxiliaries, andmodals among them, have less in common with lexical verbs than would justify a common name.Yet since the Hungarian term is segédige i.e., ‘helping verb’ for “auxiliary”, and modális segédige,i.e., ‘modal helping verb’ for “modal”, all of these are clearly looked upon as kinds of ige ‘verb’:this is the way the average user thinks of them. Auxiliaries may well be less prototypical than lexi-cal verbs, and modals even less so (most of them being even inflectionally irregular), with the worddo (sometimes, but not always considered as a modal) being even more deviant than the rest. (Thisis a clear case of subsective (as opposed to intersective) gradience in the well-defined sense, for ex-ample, of Aarts 2007 and Aarts 2008:254-256). It is a lot easier to keep the three of them consis-tently apart in a language such as English where they also have distinct names: verbs; auxiliaries;modals.
3.1.4.3 “Complementizer” in dictionaries
One minor grammatical issue is whether dictionaries show signs of the syntactic category “com-plementizer” (once standardly abbreviated to COMP, and further to C), which has been around inlinguistic argumentation since the early 1970s, and hardly an unavoidable term in syntax today.
A learner’s dictionary (CALD 2008), a native speaker dictionary (AHD 2004) and two bilingualones (AMSZ 2000 and EHCD 1998) have been examined for information on the complementizersof English: (1) that, (2) for, (3) if and (4) whether66. They are all recent enough to recognize thesesomehow.
66 These three are currently listed in standard theoretical syntax; whether has been removed from the initial list and
classed with wh- items. The point, however, is that it has never featured as a complementizer in dictionaries evenwhen it was still looked upon as one.

Chapter Three
189
First of all, it turns out that “complementizer” as a term is not used in any of these four dictionar-ies. If that is so, there is obviously no way the user/learner can see them as types of the same lin-guistic object. What remains to be examined, then, is whether the sources contain examples of thephenomenon in question at all.
The words that, if and whether receive standard treatment as conjunctions; the complementizerfor, however, is missing from all but one.
that for if whetherCALD (2008) conjunction ——1,2 conjunction conjunctionAHD (2004) conj. ——1 conj. ‘whether’ conj.AMSZ (2000) kötőszó [conj.] kötőszó [conj.]5 ——4 ——4
EHCD (1998) ksz [conj.] ——3 ksz [conj.] ksz. [conj.]
1 There is not one sentence exemplifying the COMP for in the entry of for itself: this use is not rec-ognized. (The term “use” is used because the other three words are adequately covered by thelabel conjunction, and it would not do to introduce a new word class for the sake of for.
2 To be sure, CALD (2008) does contain sentences that illustrate the COMP for, just these are not inthe for entry. The examples below, which are hits on a search for the sequence “for him to”,are exactly like that. COMP is followed by the subject him; the clauses below have been brack-eted:
delinquency n: His past delinquencies have made it difficult [for him to get a job]go ahead phrasal v: I got so fed up with waiting [for him to do it] that I went ahead and did it myselflag v: He's lagging behind a bit - I think we'd better wait [for him to catch us up]night after night: She stayed in night after night, waiting [for him to call]plug v: That interview was just a way [for him to plug his new book]referral n: The doctor gave him a referral to (= arranged [for him to see) the consultant]reject v: The prime minister rejected the suggestion that it was time [for him to resign]struggle n: It was a terrible struggle [for him to accept her death]
3 EHCD (1998) lists all of the following sentences, which contain clearly different types of for, inthe preposition section of for (the entry has been slightly edited):
vk / vm részéről / szempontjából, esetén; as for him ami őt illeti; as for that ami azt illeti; […] it is diffi-cult for him to come nehéz eljönnie; it is not for him to blame us nem hivatott minket bírálni; […] it isusual for the mother to accompany her daughter az anya el szokta kísérni lányát; you are gazing toolong for politeness at her az már nem nevezhető jó modornak, hogy ön ennyi ideje bámul rá […].
Still, even if the equivalents that are offered – vk / vm részéről / szempontjából, esetén – do notwork in the case of one single example, the example sentences at least are given.
4 Since AHD (2004) only provides PoS labels where there are word class homonyms, if is not PoS-labelled. To be sure, the noun if (e.g. …a big if hanging over the project; CALD 2008).
5 In addition to the ‘seeing that; because’ for, AMSZ (2000) enters the COMP for before the otherone to highlight its importance. This is the entry (slightly edited):
for kötőszó 1. hogy, ha wait for her to speak várja, hogy megszólaljon […] I think it important forher to go to college fontosnak tartom, hogy egyetemre menjen she spoke too softly for us to hear túlhalkan beszélt ahhoz, hogy halljuk 2. mivel, mert […]
This is an illustration of how an insight from theory may be lexicographically utilized without theterminological apparatus also used. In the Hungarian grammatical tradition, conjunctions are of twotypes, subordinating and coordinating; the difference is obvious. It is of course questionablewhether users will simply believe that for is a conjunction here.

Chapter Three
190
The opposite of this – introduction of a more recent term for an old category that remains to be usedin the traditional way – may also happen, but there is probably less need for this than for introduc-ing some genuinely new notion.
3.1.4.4 Parts of speech lexicographically: MED (2002) and (2007)
The most obvious way that a dictionary presents syntactic information is the treatment of wordclasses, and it is here that insights from theories of syntax, if there are any, may be captured.
A part of speech (PoS) count was done with two versions of the Macmillan English Dictionary,MED (2007) and MED (2002), both carefully designed and up-to-date works with vocabularies ofclose on 100,000 words, which can safely and rightly be regarded the ultimate in dictionary design.These two e-dictionaries were chosen because of the very easy access they offer to all types ofgrammatical information. (MED happens to be the first learner’s dictionary in whose case the elec-tronic form preceded the print product.) It was also hoped that potential differences between theversions would reveal facts, possibly motives behind syntactic decisions that are otherwise impossi-ble to get at67.
Some of the findings below may only be relevant just to these versions of the same dictionary; someonly for English monolingual lexicography; most, however, will characterize any mono- or bilin-gual English dictionary that does, and even some that do not, offer PoS labels with every headword.
Any other grammatical but non-part-of-speech information has been ignored. It was not the aim toassess MED’s treatment of grammar in general. MED (2007) on CD-ROM has been laboriously re-viewed from several points of view, albeit grammar has not featured high in them, e.g. in Rizo-Ro-dríguez (2008), which praises MED (2007) because it lets the results obtained with the advancedsearch be exported to a word processor. While the copy and print functions will certainly be appre-ciated by EFL teachers and language researchers, it must be stressed that studies like the presentone would also be virtually impossible without such search/copy facilities.
It was also found that a few bugs, which may be editing lapses or software faults, easily distort thefindings. When these have been noticed and found significant, note has been taken of them.
It was found that the PoS lists itself and the treatments of its items significantly differ in the twoeditions, and both these differences and the lists themselves may be very instructive.
The first two tables (alphabetically ordered for easy reference) show the PoS’s of the 2007 and the2002 version. Empty boxes have been marked conspicuously. MED (2002) has “function word”,“linking verb”, “phrasal verb” and “quantifier”, which are missing from the newer version; MED(2007) has “predeterminer”, which was not featured in the older one.
3.1.4.4.1 Part of speech search and grammar search in MED
Although they are not treated as a PoS in MED (2007) – and cannot be searched as such – “auxil-iary” is included in the CD’s Grammar search options. The search finds three such items: be, doand have (the “primary” auxiliaries of Quirk & al. (1985) and the “Quirkian” tradition generally).Included in the Grammar search option are also “linking verb” (the search finds 19), as well as“transitive” (4 412 hits), and “intransitive” (2 604 hits). These have also been appended to the table.
Similarly not treated as a PoS in MED (2002) but included in the Grammar search are “transitive”,“intransitive”, and “linking verb” . These have been numbered and appended to the table.
67 While the MED 2002 version does not at all allow copying of hits lists, the 2007 version only allows copying or sav-
ing/printing of the first 200 items on any search. The user can manually work with them, copy them out individually,but not retrieve all of them at one go.

Chapter Three
191
The more recent state is the left-hand column:
List No13
MED (2007), ABC MED (2002), ABC
The set of PoS’s
Some boxes contain numbers that are conspicuous in themselves. What the part of speech labelsprecisely cover is something that we do not have to bother now; users are known to have widelyvarying notions about these anyway, and some of them will turn out to be much too heterogeneous,or not word classes at all. The facts (ignoring numbers for the moment) that can most immediatelybe read off the tables are as follows:
1. Both MED (2007) and MED (2002) list “ABBREVIATION” as a PoS.
2. MED (2002) had a general term: “FUNCTION WORD”; it is now gone.
3. MED (2002) had LINKING VERBS; they have vanished.
4. There is no “PHRASAL VERB” in MED (2007).
5. “PREDETERMINER” is now an independent category.
6. Both MED versions contain two kinds of item below word level: PREFIXES and SUFFIXES, appar-ently considered as PoS’s.
7. QUANTIFIERS are gone.
8. “SHORT FORM” was and is considered to be a PoS.
9. Virtually nothing has happened to “MODAL VERBS”, “PREFIXES”, “SHORT FORMS”, and“SUFFIXES”.
1 abbreviation 4062 adjective 8 9873 adverb 1 0404 conjunction 325 determiner 226 function word 1337 interjection 2448 linking verb 99 modal verb 1310 noun 25 51011 number 6112 phrasal verb 11 98013 predeterminer ——14 prefix 10115 preposition 6616 pronoun 6117 quantifier 2318 short form 6919 suffix 11120 verb 5 408
21 auxiliary verb ——22 linking verb 023 transitive 3 13124 intransitive 1 379
1 abbreviation 4312 adjective 9 7183 adverb 2 7964 conjunction 675 determiner 606 function word ——7 interjection 2318 linking verb ——9 modal verb 1310 noun 28 00411 number 6512 phrasal verb ——13 predeterminer 714 prefix 11015 preposition 11516 pronoun 10717 quantifier ——18 short form 6919 suffix 11120 verb 5 235
21 auxiliary verb 322 linking verb 1923 transitive 4 41224 intransitive 2 604

Chapter Three
192
10. “AUXILIARY VERB” has appeared in MED (2007).
11. MED (2002) offers Grammar search on “LINKING VERB”, but then finds no results: this is appar-ently a bug, whose status can never be ascertained. There is, however, a PoS search, which re-turns 9 linking verbs. The “linking verbs” thus yielded by the MED (2002) Grammar Search arenot marked as “linking verbs” in MED (2002). Did the editors, one wonders, really want such acategory, just the software fails to find its exemplars? Did the change their minds, and the pro-gram failed to follow up?
12. There is, in both versions, a huge class of “TRANSITIVES” and “INTRANSITIVES” (presumablywithin that of verbs).
3.1.4.4.2 The parts of speech in MED numerically considered
The two “quantity” tables below, rearranged by number of items in the individual PoS classes,contain the same information as above the same empty boxes have been marked. In both tables, thePoS’s returned by the Grammar searches have been added to their relevant places according tonumber, and have been italicized. This arrangement will permit number comparisons between theindividual PoS’s.
The more recent state is the left-hand column:
List No14
MED (2007), quantity MED (2002), quantity
The boxes containing numbers that are conspicuous in themselves, as well as the numerical differ-ences that are most immediately visible, will be commented on.
1 noun 25 5102 phrasal verb 11 9803 adjective 8 9874 verb 5 4085 adverb 1 0406 transitive 3 131
7 intransitive 1 379
8 abbreviation 4069 interjection 24410 function word 13311 suffix 11112 prefix 10113 short form 6914 preposition 6615 number 6116 pronoun 6117 conjunction 3218 quantifier 2319 determiner 2220 modal verb 1321 linking verb 922 predeterminer23 auxiliary verb
24 linking verb 0
25 noun 28 00426 phrasal verb ——27 adjective 9 71828 verb 5 23529 transitive 4 412
30 adverb 2 79631 intransitive 2 604
32 abbreviation 43133 interjection 23134 function word ——35 preposition 11536 suffix 11137 prefix 11038 pronoun 10739 short form 6940 conjunction 6741 number 6542 determiner 6043 linking verb 19
44 quantifier ——45 modal verb 1346 linking verb ——47 predeterminer 748 auxiliary verb 3

Chapter Three
193
1. The number of NOUNS has gone up from around 25 000 to around 28 000, a both expectable andwelcome change from 2002.
2. PHRASAL VERBS, of which there were close on 12 000, have disappeared.
3. ADJECTIVES have grown in number, which is also explicable with the five-year span betweenthe two editions.
4. There are fewer VERBS than in 2002; this decrease is odd in itself, and would alert the user tosome serious discrepancy.
5. The fact that there are slightly over 5 000 VERBS altogether (and roughly the same number werethere in 2002) shows that the data for verbs cannot be used for our purposes. The number forverbs is smaller than for adjectives. Even with modals, linking verbs, and auxiliaries added, thisis not a real figure in either version.
6. In 2002, the joint number of VERBS (5408) and “phrasal verbs” (11980) was 17 388; the addednumber of “transitives” (3131) and “intransitives” (1379) was 4510. If verbs and “phrasals”were counted separately, then “transitives” and “intransitives” added should yield the number ofverbs, but they do not. The verb zoom is marked as “verb” (without transitivity label), zone isgiven as “transitive”, while ad lib is marked as “transitive or intransitive”, which means that forverbs, these categories criss-cross in ways that make reliable calculations impossible. In the2007 version the situation is worse: while there are no phrasals, transitives and intransitives addup to 7016, which is significantly more than the figure for verbs.
7. There are more than twice as many ADVERBS in the new edition: this is an unexpected rate ofgrowth. It is not clear why this has happened.
8. Both the “TRANSITIVES” and the “INTRANSITIVES” category have grown more than 30 percent.
9. “ABBREVIATION” shows a slight increase, while INTERJECTIONS have grown smaller in number.
10. Figures for “SUFFIX”, “PREFIX”, “SHORT FORM” and “MODAL VERB” have remained practicallyunchanged. (The numbers may of course hide different items.)
11. The more drastic changes (ignoring now “zero” in either version) include “PREPOSITION”(doubled); “PRONOUN” (almost doubled); “CONJUNCTION” (almost doubled); “DETERMINER”(trebled).
3.1.4.4.3 Parts of speech in MED: issues of content
Some of the PoS’s listed in MED have never been treated as separate parts of speech, although theymay have their own labels in dictionaries (as PoS’s or other entities): “abbreviation”, “functionword”, “linking verb”, “number”, “short form”, “suffix” are such classes. The inclusion of these,however, is not motivated by any novel idea from the theory of syntax: some are (probably wel-come) upshots of a classification which may be inconsistent with standard theory and also fly in theface of classifications in other dictionaries, but which may actually well serve the user.
In this section the PoS’s that are unique to MED, or are traditionally not treated as PoS categoriesare examined, again alphabetically.
“ABBREVIATIONS” are not a unique word class; moreover, the term itself is highly loaded function-ally. It may refer to at least two kinds of thing, initialism, and acronym, but these two are not clearlyseparable to the average user. Also, an “abbreviation” may be a written-only form that is never saidaloud (Mass. for Massachusetts); it may be a truncated form like pram for (the almost extinct

Chapter Three
194
perambulator); it may be a spoken form not usually expanded, such as BBC or CIA. Before usersstart a search, it cannot be taken for granted that they have exact knowledge of what sense “abbre-viation” is used in; that problem, however, is there with any term listed, used and explained in anydictionary.
Three sources will be quoted here which may give an idea of the lay notion of “abbreviation”; it isprobably even hazier than these definitions suggest. Only the Britannica (EBURS 2009; includedbecause the wide currency of the term outside linguistics) seems to appreciate the complexity of theterm. (Just the relevant senses have been printed.)
AHD (1994)has one undifferentiated entry for the two senses of
abbreviation: “shortened form of a word or phrase used chiefly in writing to repres-ent the complete form, such as Mass. for Massachusetts or USMC for United StatesMarine Corps.“Acronym” is defined thus:‘a word formed from the initial letters of a name, such as WAC for Women's ArmyCorps, or by combining initial letters or parts of a series of words, such as radar forradio detecting and ranging’. The term “initialism” is not listed in AHD (1994).
MWCD (2003)is more refined: it defines abbreviation as
‘a shortened form of a written word or phrase used in place of the whole <amt is anabbreviation for amount>; for acronym it has ‘a word (as NATO, radar, or snafu)formed from the initial letter or letters of each of the successive parts or major partsof a compound term; also: an abbreviation (as FBI) formed from initial letters :INITIALISM; and initialism is explained thus (but not exemplified): ‘an abbreviationformed from initial letters’.
The Encyclopaedia Britannica (typography modified) has:
There are several important forms of abbreviation. One form entails representing asingle word either by its first letter or first few letters (as n for noun or Co. for Com-pany), by its most important letters (as Ltd. for Limited), or by its first and last let-ters (as Rd. for Road). These abbreviations are usually spoken as the whole wordthey represent (though Ltd. is sometimes spoken as “el-tee-dee”). Truncation is espe-cially common in popular speech, as, for example, Mets for Metropolitans.The combination of the first syllables or letters of component words within phrases orwithin names having more than one word is common and often produces acronyms,which are pronounced as words and which often cease to be considered abbreviations.An example of this type of abbreviation is the word flak [...] Other popular acronymsare the well-known radar [...] and snafu [...].Acronyms are to be distinguished from initialisms such as U.S.A. and NCAA, whichare spoken by reciting their letters.
(abbreviation EBURS 2009)
Atkins & Rundell’s 2008 lexicography textbook does not at all clear up the situation when it classi-fies abbreviations into alphabetisms, acronyms, and contractions (Atkins & Rundell 2008:165). It isnot at all helpful to include contractions as well; “abbreviation” is functionally loaded enough with-out it.

Chapter Three
195
To summarize the parts of speech in MED (the boxes of unproblematic cases have been left empty):
List No15
1 It is ironic that the adverb class, which is by far the most problematic – to the point of non-exist-ence in several frameworks – seems problem-free, and has (consequently?) not been experi-mented with in dictionaries.
2 The syntactic innovation that many lexical items such as after are not separately an adverb, apreposition, and a conjunction, but the preposition in all their uses only distinguished by theircomplementation (zero vs. NP vs. clause) has no reflection whatever in dictionaries. Some re-cent descriptive grammars (e.g. Huddleston, Pullum & al. 2002 and 2005) do experiment withthis novelty.
3.1.4.5 Differing PoS labels for the SL and TL
For the Hungarian dictionary user, such niceties as the part-of-speech details of the source languageare largely irrelevant when they are not needed for lookup. It is sufficient, to give the source-lan-guage PoS on the tacit assumption that an item of PoS X in the source language will have anequivalent of the same PoS X in the target language. The part of speech of the target language wordis never specified; the source language PoS is assumed to be simply carried over to the target lan-guage PoS. One does not fond the most fleeting, even implicit, mention either of this strategy in allbilingual dictionaries, or indeed of the possibility of some kind of loosening of this “requirement”.If bőrbarát, e.g. is marked as an adjective, then it will be taken for granted that skin-friendly is alsoone. This is usually a legitimate expectation and strategy, but the correspondence does not alwayshold.
1 abbreviation not a PoS: all abbreviations belong to some PoS2 adjective3 adverb1
4 conjunction no distinction between subordinating and coordinating5 determiner does the user need it?
Article, Demonstrative etc. arguably better6 function word not a PoS; supercategory: content =?7 interjection has no word status?8 linking verb subcategory of verb9 modal verb subcategory of verb10 noun unproblematic but see Countability11 number not a PoS12 phrasal verb subcategory of verb13 predeterminer traditionally subcat of Det14 prefix not a word – no PoS15 preposition2
16 pronoun what is the content =? personal? all?17 quantifier what exactly does it cross-cut with?18 short form not a PoS19 suffix not a word – no PoS20 verb
21 auxiliary verb subcategory of verb; cross-cuts with linking verb?22 linking verb subcategory of verb; cross-cuts with aux?23 transitive subcategory of (non-aux, non-linking, non-modal) verb24 intransitive subcategory of (non-aux, non-linking, non-modal) verb

Chapter Three
196
This aspect of bilingual dictionaries, the incidental non-correspondence between the part of speechof the SL and the TL will be briefly explored in this section.
First, most Hungarian↔English dictionaries do use PoS labels for all source language (SL) items:this apparently has always seemed an obvious and unavoidable feature of bilingual works. To thebest of my knowledge, no dictionaries except AM&MASZ (2000) dispense with this traditional la-belling. In bilingual works (which are instrument dictionaries) perhaps not less than 90% of the totalcases for English and Hungarian, a situation holds where either (i) the obvious meaning/form of thetranslations (in the E→H part) or (ii) the easily identifiable form of the source expression (in theH→E part), or both (i) and (ii), adequately inform about the word class of the SL item. It seems,therefore, that uniform PoS labels are not needed, and they must standardly have been included onlybecause both the English and Hungarian sources on which they have been based – quite legitimatelyfor portrait dictionaries, which they have necessarily been – always include PoS labels.
In respect of the SL–TL part-of-speech (non)correspondences, a dictionary that uses PoS labels uni-formly, e.g. EHCD (1998) or HECD (1998), is no different from one that employs them only incases where neither (i) nor (ii) above obtains. In both types there will be cases that present a specialdifficulty: (a) where the above assumption of “always equate item of PoS X with item of PoS X”does not hold – where no such translation exists for an entire syntactic category due to typologicaldifferences between languages (which is not relevant for E↔H); (b) where simply no PoS-for-PoSequivalent exists for some individual item (this situation does, of course, occur in E↔H relation);and (c) where a source-language expression may not be outright “translation-resistant” but still, ex-pressions of a different PoS in the TL are also possible or even better “equivalents”68. (This proba-bly holds for any language pair.) The only (partly technical) problem for both types of dictionariesis that there exist no conspicuous devices employed systematically and uniformly, to mark those TLequivalents whose PoS is different from that of the SL. Such simple, straightforward non-equiva-lence between SL and TL part-of-speech labels does not seem to be a widely appreciated lexico-graphic problem. Paradoxically, while the lack of semantic equivalences between lexical items is awidely recognized fact, and is indeed one of the truisms in dictionary production, cf. e.g.
“The perfect translation – where an SL word exactly matches a TL word – is rare ingeneral language […]. The equivalence relationship between a pair of words, SL andTL, varies from exact to very approximate, from perfect to just-adequate […]”
(Atkins & Rundell 2008:467–468)there is no accepted convention for the marking of just those cases where this match unavoidablyand necessarily, moreover, quite visibly breaks down: right at the grammatical level.
Discussing types of translations and sense indicators in bilingual dictionaries, Atkins & Rundell(2008: 211–218; 501–506), e.g. mention two types of translation: (i) direct, i.e. given without con-text and often with sense indicators, and (ii) contextual, i.e. attached to an idiom or example phrase.Where no translation exists, a (iii) near-equivalent, or a (iv) TL gloss, or both can be used. Whilethese are supposed to, and largely do, cater for all kinds of translation non-equivalence, none ofthem covers the “no PoS-for-PoS equivalent” situation at hand.
That said, there nevertheless are two strategies for a bilingual dictionary to follow to handle the PoSnon-equivalence situation:(a) using a (type of) contextual translation; this, to be sure, is not exactly what contextual transla-tions are usually used for
(b) using the device of sense indicators, e.g. between square brackets.
68 The term “equivalent”, to be sure, may only be legitimately used between quotation marks in lexicography in general,
but here the word rings even more obviously untrue.

Chapter Three
197
Slang expressions, the Hungarian gáz / gázos ‘sucks’ ciki / cikis ‘sucks’, will be used as illustration.With both pairs, the latter is an adjective (also formally marked with -s) derived from the former,which is a noun. Both of the nouns, gáz and ciki, however, are often predicatively used (maybe ac-tually adjectives), synonymously and interchangeably with the adjectives derived from them. Ifsomething, e.g., is naff, it can be referred to as gáz or gázos, ciki or cikis. A somewhat similar casemay be made for the more Hungarian slang expressions király ‘rocks69, rules, rulez’ and királyság‘rocks, rules, rulez’, which are both nouns. The former is a noun literally/originally meaning ‘king’,and the latter, also a noun that means ‘kingdom’.
(a) MASZ (2000) uses “contextual translation” in the ciki VAGY cikis entry, offering crusty, naff,tacky, ropey, crummy as well as the example tök ciki ez a ruha this dress sucks big time. Thisdoes not explicitly say that suck is a verb, that consequently this is a verb-based MWE, and thatsucks is almost exclusively used in this, Sg 3 Pres form; at least the former, however, can be in-ferred. Nothing points to a grammatical difference between the SL and the TL expression.
(b) Square brackets or some other type of bracketing may call attention to cases where a differentword class from that of the SL expression is offered; such bracketing does get used, e.g. in CEHD(1976) and CHED (1977). In the same entry of MASZ (2000) for the item ciki VAGY cikis, we thusfind:
1. [nehéz*:] dodgy, risky, dicey cikis helyzet dicey/ticklish situation 2. [kínos/vacak**:]crusty, naff, tacky, ropey, crummy, [igével***:] sucks tök ciki ez a ruha this dress sucks bigtime
(* = hard; ** embarrassing, naff; *** = with verb)In this case, too, an example with contextual translation is still in order, which effectively meanscombining methods (a) and (b) above.
3.1.4.6 Perspective shift between SL and TL lexical items
A special type or grammatical non-correspondences between SL and TL equivalents involves whatmay be called perspective shifts. The prototypical perspective shift is one where in both languagesthe same PoS, mainly verb, is featured, but the arguments which describe the same state of affairsget arranged differently, as e.g. in the commonest case of the possessive verb in different languages.Hungarian uses ‘essere’ where English uses ‘habere’:
X-nek van Y-ja corresponds to X has Y‘for X there is Y’
This case is (i) so general, i.e., so much part of grammar as opposed to the lexicon, thus moving theproblem so evidently outside the realm of lexicography, and (ii) involves no major word class shift(it is a case of a verb translating a verb) that it would be hard to imagine a dictionary even with theheaviest didactic bias that uses some devices to call the user’s attention to this change of perspec-tive. While it is true that few, if any, users will turn to the dictionary to check the meaning of theEnglish possessive have, failure to accord proper grammatical treatment to have may result in seri-ously distorted profiles of verbs. This will not harm the utility of this particular dictionary as an in-strument, but it does offer a false picture of have. The entry of have in EHCD (1998), e.g. begins asfollows:
have 1. van (vknek vmje), vmt bír; have a cold megfázott; have faith in sy bízik / hiszvkben; have an idea van / támadt egy ötlete« have no idea/notion of sg fogalma / sejtelmesincs vmről; have measles kanyarója van; have a name to lose van veszítenivalója; haveneed of sg szüksége van vmre; have a right to sg joga van vmhez; have a taste for sg ér-zéke van vmhez; have sy in one's power hatalmában tart vkt; have to deal with sy dolgavan vkvel; have to do with sg köze van vmhez, dolga / kapcsolata van vmvel; have to dowith sy kapcsolata / dolga van vkvel, köze van vkhez; have nothing to do nincs semmi dol-
69 It is interesting that rocks, also a verb, itself has no verbal equivalent just adjectival and nominal ones in Hungarian.

Chapter Three
198
ga; have nothing to do with semmi köze sincs (vkhez / vmhez); have nothing to gain by… semmit sem nyerhet azzal, ha / hogy …; have no place to go (to) nincs hova mennie,nem tud hova menni; we don't have many visitors nem sok látogatónk van, van, nem sokvendég jár hozzánk; he had only himself to thank for it csak magának köszönhette; all Ihave mindenem, amim csak van; which one will you have? melyiket óhajtja / választja? […]
The entry exemplifies two faults, one of which has to do with inadequate emphasis on grammaticalinformation. One, that under the first sense, which is translated in two ways, with both the ‘essere’verb, i.e. van, and a bookish-sounding transitive verb (with the wrong complement: vmit bír insteadof vmvel bír), a genuine possessive example does not come before have a right (Line 4), but eventhis is not a prototypical context for possessive have. The expressions have no idea/notion docome before that, but because they are negated, the equivalent verb van must be replaced with theformally unrelated nincs ‘is not’. The majority of the examples, beginning with have a cold, are notrelated to possessive have, and though a dictionary of such impressive size may list them underhave, they have a much better place under their nominal elements.
The second shortcoming, more relevant to the issue under scrutiny, is that although van is obviouslythe first equivalent offered, apparently the need was still felt to use a transitive verb as Hungarianequivalent, as if to suggest transitivity of the English SL verb to the user in this way, i.e. by pro-viding a transitive TL item. This produces the unnatural example with bír.
One consequence (or subtype) of this particular “habere–essere” perspective shift is that Hungarianigaza van (lit. ‘have right’) is be right in English. Paradoxically, this is not usually seen as con-forming to the above pattern, rather as an isolated “idiom”. More often than not, in school teachingpractice all of the English equivalents below are taught as exactly that: phrasal expressions, or idi-oms. Given the general ambivalent feeling of awe before idioms and “expressions”, this suggests tothe learner an additional layer of difficulty of English – which it naturally does not have in excess ofany other language.
Some of the most salient shift-of-perspective scenarios in H→E include the following (where, un-like above, a major PoS shift does occur: here, Hungarian verbs are translated with be + Adjective):
csalódik → be disappointed csodálkozik → be amazed/surprised fázik → be coldfél → be afraid/scared késik → be late megdöbben → be astonishedmegijed → be frightened meglepődik → be surprised örül →be happy/pleased/gladsajnál→ be sorry téved → be wrong/mistaken vigyáz→ be careful
Similar points of clash from E→H are provided by “passive perception” verbs such as feel, look,smell, sound, taste, followed by an Adjective Phrase (X feels Q; X smells Q), where the expressionencodes that
X has some K kind of Quality; Q is perceivable; Q is encoded in the verb itselfwhile Hungarian expresses this state of affairs with (i) an Adjective for K; (ii) Q expressed by anoun; (iii) possession (which itself, as seen above, is expressed with ‘essere’ rather than ‘habere’:
a levesnek furcsa íze van → the soup tastes strangelit. ‘there is a strange taste for the soup’
There are many examples of similar minor shifts, some containing more and some fewer members,which are well worth exploring in grammars of English for Hungarians with any contrastive bias.There also exist what are quite idiosyncratic cases such as wear perfume or wear a smile → mo-soly van az arcán in E→H direction, which cannot be translated with a transitive verb and keepingas the subject the wearer of the perfume or the smile. Neither perfumes nor smiles are worn inHungarian. Thus when actual rather than usual situations are to be described (in the latter casehasznál ‘use’ being a suitable equivalent for wear), the perfume will have to become subject, andthe only possible verb is van ‘be’: what perfume is she wearing? is milyen parfüm van rajta?‘what perfume is on her?’.

Chapter Three
199
There is, in conclusion, just one kind of – negative – uniformity across possible types of dictionaryin the lexicographic treatment of these shifts of perspective (involving a shift in the thematic con-figuration, in the more difficult cases): that there is no dedicated device used to show this syntacticpeculiarity. Most of the time the examples will have to take care of the problem.
A typical and inevitable but partial-only correspondence between PoS labels in bilingual dictionar-ies involves the case of a language having a complex verbal–nominal expression (e.g. with a lightverb) which is translatable only, or fares much better if translated, in verbal-only form. The equiva-lence kárt okoz/tesz vmiben → damage smth, cause damage to smth is a case in point. This senseof ‘damage’ cannot be expressed in Hungarian differently (the single-verb károsít ‘wrong; harm;hurt’ is not suitable), so the verbal–nominal form must be used. This phenomenon is rather perva-sive: the non-match is only partial, and perspective change is not involved; this results in even lessnoticeability than with the other types discussed above. As concerns the consequences of this forlexicography, no special device showing this is necessary.
Failure to recognize this PoS non-equivalence as a general grammatical problem may result in, or atleast massively contribute to, heavily skewed presentation of entries, such as the one quoted belowfrom EHCD (1998). Here, several obsolete “equivalents” are placed at the top of the entry as ifthese were the (tacitly more frequent and) natural ones. While the most natural/neutral translation oförül [vminek] is (and no doubt was at the time of EHCD’s publication) the English be + Adj se-quence be happy [about], this be-construction only emerges as the 7th option, and even here aspart of a colloquial idiom70, seriously distorting the equivalences.
örül […] 1.(vmnek) rejoice (at/in sg), be glad (of sg), be delighted (of sg), glory (in sg), bepleased (with sg), exalt (at/in sg); örül, mint majom a farkának biz szl be happy as a clam /lark, be pleased as punch; előre örül vmnek look forward to sg, be delighted at the prospectof sg; örül a mások boldogságának rejoice (v. be happy) in the happiness of others; igenörülök neki I am very happy about it; örülj neki, hogy otthon maradtál you should be gladthat you stayed at home, you are lucky you did not go; csak örülhet neki he can only con-gratulate himself (upon having done sg); még örülhet neki, ha he can consider himself lucky/ fortunate if; örül a szerencséjének he blesses his stars; mindennek örül he is happy /pleased with everything; nem örül semminek he does not find pleasure in anything; nagyonörül be overjoyed, be very happy / glad; örülnénk, ha elfogadná we would be glad if youaccepted v. would accept it; tudom, hogy örülnének neki I know they would be glad (ifsg…); 2. örül, hogy be delighted / pleased (to); örülök, hogy láthatom I am glad / pleased /happy to see you; örülök, hogy megismerhettem it was a pleasure to meet you, [bemuta-tásnál] how do you do, pleased / glad to meet you biz; nagyon örülök, hogy beleegyezik Iam very glad that you consent; örülhet, hogy ilyen olcsón szabadult he is lucky to havegotten off so easily
There are altogether seventeen equivalents offered for örül in the entry above in its two (not easilyjustifiable) sense sections, out of which seven are verbs. Worse, the first translation for örül is re-joice at/in, No4 is glory in, and No7 is exalt at/in; even the first be + Adjective variant is not onewith happy but with glad (of sg).
70 Translated, quite unfortunately and further distorting the picture, with three literary phrases: be happy as a clam/lark,
be pleased as punch.

Chapter Three
200
3.1.5 Prepositions
3.1.5.1 Prepositions: a class with two faces
One clear manifestation of the flimsy line between grammar and lexicon is the no man’s land, orrather “two men’s land”, of prepositions. The class of prepositions is as heterogeneous as to includeboth lexical and functional members. While prepositions are functional items for traditional andstructuralist grammar, they are a lexical/thematic class for Government and Binding, or Principlesand Parameters theory. Their heterogeneity is effectively acknowledged with the recognition of aclass – albeit not of, but related to, the prepositions – which is underspecified for the Functionalfeature (as mentioned in 3.1.4.2.1 based on Newson & al. 2006 passim). Crucially, however, prepo-sitions are thematic (i.e. non-functional) in feature terms.
The claim that different subtypes of preposition exist is current: in Huddleston & Pullum (2005),e.g. what are termed grammaticized prepositions are not supposed to “express spatial relations, asprepositions often do”, but mark certain grammatical functions; “where they are placed in sentencesdoes not depend on what the mean but entirely on rules of the grammar” (Huddleston & Pullum2005:136).
3.1.5.1.1 Prepositions: one syntactic class lexicographically
These two preposition types, whether subordinated types or placed beside each other, never showany difference in terms of lexicographic treatment. Keeping them apart by reserving a con-stant/separate zone in the entry for “grammaticized” prepositions would perhaps add to consistency,maybe elegance, of the PoS system in a portrait dictionary. Spatial senses could be followed bytemporal and these in turn by other senses, so that the “grammaticized” prepositions go to the end ofthe entry. (The ordering of senses within the entries may, of course, be based on totally differentconsiderations.) Alternatively, the “grammaticized” ones could be placed first, better to draw atten-tion to them. What actually characterizes dictionaries depends on type: these are surveyed in thefollowing sections.
(i) Native speaker dictionaries
These, especially the larger ones, list each and every “meaning” of every preposition, which meansthat they will have as many meanings for a P as there are governing heads, i.e. mostly verbs, thatrequire that P: in RHWUD (1999), e.g. with is entered with 21 meanings, No. 10 being ‘(of separa-tion) from’: to part with a thing. It is obvious that this sense does not come from the preposition(which could well be from), but the verb, and the P is a “blind” syntactic complement. In a biggerdictionary, this can assume absurd proportions: MWUD (2000) has just 13 senses for with becausemost senses have subsenses such that No 4 looks like this:
with […] 4 a used as a function word to indicate one that shares in an action, transaction,or arrangement *[…] worked with them […]* *[…] business […] is now done with Americans[…]* b used as a function word to indicate the object of attention, behavior, or feeling *[…]satisfaction with the institution* *get tough with him* *angry with her* *in love with her* c : inrespect to : so far as concerns *on friendly terms with[…]* *expressed agreement with hisviews* *[…] be all right with her […]* d used to indicate the object of an adverbial expres-sion of imperative force *off with his head* *away with him* e : as the doer, giver, or victim of*charged with murder* *threatened with tuberculosis* f : OVER, UPON *no longer has anyinfluence with him* g : in the performance, operation, or use of *prospering with their dairyindustry […]* *the trouble with this machine* *something went wrong with the radio*

Chapter Three
201
(ii) Learner’s dictionaries:
If they have a sense breakdown by means of some kind of signposting, layout considerations willalways force them to aim at economy with these signposts, and not with the senses themselves. Thismeans that a danger is there that identical senses will be spread under different signposts.CALD (2008) e.g. has 18 such “meanings” plus the usual idiom/phrase etc hits (which are ex-tremely useful but irrelevant and so not copied here):
List No16
1. with prep COMPANY2. with prep METHOD3. with prep DESCRIPTION4. with prep RELATIONSHIP5. with prep CONTAINING /
COVERING6. with prep CAUSE
7. with prep OPPOSITION8. with prep SEPARATION9. with prep AND10. with prep COMPARISON11. with prep SUPPORT12. with prep DIRECTION13. with prep TIME
14. with prep UNDERSTANDING15. with prep DESPITE16. with prep EXPRESSIONS17. with it adj FASHION18. with it adj MIND
There are far too few labels even in this way, and arguably not just same-sense shades but differentsenses have been lumped together under one of these signposts: this is shown e.g. by work with
[smb] and Ice cream with your apple pie and left my coat with the cloakroom attendant, whichare all supposed to illustrate the COMPANY sense.
At the same time, the examples […] make a clean break with the past and […] part with my cashare all supposed to illustrate the SEPARATION sense; this suggests that there may be just too manylabels, MWUD (2000) style: the meaning of with in these two is not that of the P itself but thenoun/verb governing it.
3.1.5.2 The issue of English “complex prepositions”
Paradoxically, while prepositions (traditionally supposed to express “relations”) were considered as“grammatical”, they had to be recognized as an open class. (The paradox is still there: in frame-works where prepositions are thematic, which aligns them with the open classes, their closed naturemay be seen as a problem.) This was necessitated by the recognition of the class of “complexprepositions”, i.e. consisting of two to four words, including at least one simple preposition.
The following is a list of the ostensible “complex preposition” types71 (based on Huddleston1984:341) broken down by number of elements:
71 Some other types of what may equally be considered as “complex prepositions” have never been controversial. The
units from below and from behind, e.g., can be analyzed lexically as complex and syntactically as prepositionsgoverning a PP, but this has never seemed to be a clash.

Chapter Three
202
A B C2 elements: X–P
2 of 6 contain of3 elements: P–N–P
11 of 16 contain of4 elements: P–D–N–P
6 of 7 contain ofAPART from in ACCORDANCE with in the CASE ofASIDE from on ACCOUNT of in the COURSE ofBECAUSE of in ADDITION to to the DETRIMENT ofDUE to on BEHALF of in the RANGE ofINSTEAD of in CASE of for the SAKE ofOWING to in COMPARISON with on the STRENGTH of
by DINT of with a VIEW toin FRONT ofin LIEU ofby MEANS ofwith REFERENCE toon TOP ofin SPITE ofin VIEW ofby VIRTUE ofin RELATION to
Both their distributions and meanings (in front of e.g. opposes behind both distributionally andsemantically) have been used as proof that they are not simply sequences of P1 + lexical N + P2,where P1–N–P2 do not form a constituent – as in (b) – but one complex P – as in (a).
(a) Complex preposition recognized (b) No complex preposition recognized PP PP
3 3
P NP P NP fgh 4 1
P N P N PP 1
P NP4
Thus, in front of could be a complex P, as in (a), while just a sequence of P–N–P–NP, as in (b):
(a) (b) PP PP
3 3
P NP P NP fgh 5 in 2
P N P the building N PPin front of front 2
P NP of 5
the building
A simple compromise is to claim that a sequence of P–N–P, or even P–D–N–P, may exhibit lexi-calization (= forming lexical items), i.e. lexical listing. These larger items are idioms, and it is thenexpected that there will be conflict between what counts as a unit from the lexical and the gram-

Chapter Three
203
matical point of view. Such a mismatch between lexicon and grammar may be argued to be found inthese sequences. Lexically, and perhaps psycholinguistically, there do appear to exist complexprepositions. Just as there is nothing against treating a sequence as S in the syntax and M in themorphology, there is nothing against treating a sequence as S in the syntax and L in the lexicon.While psychological considerations of storage and retrieval, listing vs. ad hoc generation, may beconsidered irrelevant for syntax, they certainly are relevant for semantics and for studies of thelexicon in general. The lexicon may include elements such as the by dint of in the expression by
dint of hard work, while the expressions themselves have the same syntactic structure as after
years of hard work, where no such complex preposition is posited. The lexical entry for dint indictionaries will just have to specify, suitably for idioms, that this dint is unique (possibly to theextent of not being a noun at all; this, however, would not have to be worried about in the entry ifthe sequence is an idiom). Under such an analysis, “complex preposition” may, of course, be said tobe a misnomer: by dint of is no syntactic constituent but rather a (preposition-based) idiom. Didac-tically, “prepositional idiom” or “preposition-based idiom” is no better than “complex preposition”,but if these two do not distort the syntactic facts as much as “complex preposition”, then one ofthose two may be a better term. If so, dint ought to have its own entry, unspecified for word class,and left undefined/untranslated (depending on dictionary), since only the prepositional idiom whichit is part of can have a definition/translation.
This still does not answer the question whether by dint of should have a PoS label. Should it be de-cided that labelling it as a P is both superfluous and misleading (because syntactically inaccurate),then no PoS label will be offered.
The actual strategies for this situation are different:• COED (2004)
has a nominal dint entry, followed by a verb dint, and then a PHRASES section, which has by dintof by means of. No PoS label is given either for dint or by dint of. The place in the entry, though,suggests that this dint is not the noun dint – but the user probably does not notice this anyway.
• CALD3 (2008) enters dint as a noun, with two senses: 1. (formal) by dint of sth as a result of sth 2. [C] a smallhollow mark in the surface of something, caused by pressure or by being hit. Here, a PoS labelis given for dint but none for by dint of.
• EHCD (1998) is similar to CALD: though the dint entry has both a nominal and a verbal section (predictablyunlike the smaller CALD), but by dint of is listed in the nominal section, with four translations,without a PoS label of its own.
3.1.5.2.1 Biber & al. (2000) on complex prepositions
The Longman Grammar of Spoken and Written English (Biber & al. 2000) classifies prepositionswith function words, which, however (in its highly odd wording), are “links which introduce prepo-sitional phrases”.
Now uniquely among the new comprehensive English grammars72, Biber & al. (2000) recognizecomplex prepositions, which “function semantically and syntactically as single prepositions”. While 72 Biber et al. (2000): Longman grammar of spoken and written English; Carter & McCarthy (2006): Cambridge
grammar of English; Huddleston & Pullum (2002): The Cambridge Grammar of the English Language. This wasonce accepted in the descriptive tradition up until Quirk et al (1985): A comprehensive grammar of the Englishlanguage.

Chapter Three
204
semantically, this is certainly true and probably warrants unique lexical memorization/retrieval, i.e.these are listemes, syntactically they are clearly not units: it is no accident that because of this,complex prepositions are not recognized in modern grammars.
Symptomatically, on one hand Biber & al. (2000) recognize four-word prepositions (which are sup-posed to be variants of three-word ones, augmented, so to speak, by the determiner the or a, andwhich usually end in of: as a result of; at the expense of; for the sake of; in the event of; withthe exception of); on the other hand, in the case of these four-word sequences they still note thatsome of these can be considered “free combinations”, adding even that the distinction betweencomplex prepositions and free combinations is a matter of degree. They fail to add, however,whether this concerns their syntactic analysis (where this is less likely) or a lexical approach.
The distinction between “complex prepositions” and “free combinations”, to be sure, may be amatter of degree, but this may hold true even if syntactically they belong to the same class. Theremay still be analyzability and/or predictability and/or storage-related differences between them thatplace them on a gradience. It is difficult to prove a point like this, but sequences such as by virtueof, by dint of and in spite of, which are completely opaque, are more likely to be stored/retrievedas wholes than e.g. on top of, in line with and in the light of; and these in turn are more likely tobe so than e.g. in conformity with, in comparison with, at the back of, and at the centre of.
Lexicographically, for the sake of and similar P–D–N–P sequences must be registered one way oranother, whatever be the dominant syntactic view of handling them. With many other phenomena,changing syntactic views may, and often do, affect lexicographic treatment, but not in this case: forthe sake of always has to be entered under SAKE, the noun member, and so do all similar se-quences. These noun “cores” under which all of them will have to be entered are in small caps incolumns B and C in the table in 3.1.5.2 above where they were first introduced. They will have tobe entered as idioms, or MWEs cf. COED (2004), CALD (2008) and EHCD (1998) above – and itwill not matter to the user which of (1) or (2) is more adequate syntactically, the complex P in (a) orthe “free combination” in (b):
(a) [P on ACCOUNT of [NP me] ] (b) [PP on [NP account of me] ]
3.1.5.2.2 A mystery word: ago
Huddleston & Pullum (2005) call ago “the exceptional preposition”, suggesting thereby that this isthe way a preposition can be exceptional (Huddleston & Pullum 2005:141). They offer a descriptionand an explanation of the deviance. The nature of the deviation is that the head–complement rela-tion is inverted, i.e. the head ago comes on the right and its complement on the left, uniquely amongall prepositions. Even the idea of this kind of exception – understandably – would be impossible inmainstream theoretical syntax, since heads and complements are not supposed to be reversed likethis in isolated instances, and it is not very fortunate in a descriptive but heavily theoretically ori-ented framework either.
The explanation of the deviation that Huddleston & Pullum (2005:141) provide is a historical one:ago is supposed to derive from agone, a participle (of ago, cf. OED 2002). This could well be whathas happened, but it would be even diachronically more convincing if prepositions of a similar deri-vation, which obviously exist, showed similar kinds of deviance, which they do not. Many preposi-tions originate as participles: past, e.g. is still marked as prep. and adv. in the OED (2002), and the“prepositional use appears to have arisen out of the perfect tenses of pass v.”. The word gone, forexample (see 3.1.5.2.3), also functions as a preposition in the sense ‘past’. It is also entered inAMSz (2000) with the Hungarian equivalent után, később vminél, e.g. she's gone eighty nyolcvanéves is elmúlt.

Chapter Three
205
Huddleston & Pullum just use part of the information of the OED’s entry for their description. Theyuse the etymological information to explain the exceptional phenomenon, but not the PoS classifi-cation of ago: the OED does not classify ago as a preposition but a “ppl. a. and adv.”. Gone is alsoa preposition, and though it is hard not to see its connection with go, which could explain any simi-lar wayward behaviour, it does not show the same distribution as ago, i.e. does not behave like a“postposition”.
Huddleston & Pullum (2002, 2005) claim that “dictionaries classify ago as an adverb”, which is toomuch of a generalization: both learner’s and native speaker dictionaries label it as adverb, adjectiveor both. It is hard, of course, to see how it could be either of those.
Native speaker dictionaries:
• CED&T (1992) marks it as adv.• COED (2004) labels it as adv.• NSOED (1997) labels it as adj. and adv.• MWCD (2003), RHWUD (1999) and MWUD (2000) label it adjective or adverb;• AHD (1994) quite inadequately labels it adj. at the head of the entry, but then adv. in the exam-
ple two years ago.
The word ago does not fare better in learner’s dictionaries either; these also fail to do justice to itsgrammar:• LDCE (2000) labels ago as adjective• OALD (2005) labels ago as adverb• CC (2003) does not label it anything; it gives a sentential definition, examples and, at the end of
the entry, the following unhelpful grammatical information: ADV ADV with v, n ADV, longADV.73
• CALD (2003) and CALD (2008) both label ago as adverb.• MED (2002) and (2007) both label ago as adverb.• CCAD (2009) labels ago as follows: ADV [ADV with v, n ADV]74
Not one of these recognizes that for ago in the phrase five days ago to be an adjective, the wholeexpression would have to be a NP and have nominal distribution – which it evidently is not anddoes not. This means that all of the dictionaries above offer an erroneous, and hardly defensible,PoS label – adverb, adjective, or both.
Dictionaries may be rather unreliable when it comes to grammar as basic as word classes.In all fairness to dictionaries, the issue of ago as a descriptive point is so difficult that, e.g., Carter& McCarthy’s grammar (2006) avoids it altogether; it is hard to find another explanation, since theydo not even list it among the simple prepositions, and do not alert the reader to its deviant behav-iour.
The question is whether ago is a preposition that is somehow exceptional, or not a preposition. If itwere indeed an adverb or an adjective, it would still be exceptional – not less, even more so; this,however, does not bother any of the editors above, who actually think that it is. This has rarely, ifever, bothered users, who do not need PoS information after they have, basing themselves on theexamples, located the sense needed.
73 This source is so user-unfriendly that one always has to go back to check the abbreviations; this time, the search for
the items ADV with v, n ADV, long ADVERB has failed.74 CCAD (2009) offers no explanation whatever for these grammatical symbols, once the forte of the Collins
COBUILD series.

Chapter Three
206
3.1.5.2.3 A neologism: gone
The word gone shows an area where derivation and inflection, or put more generally, lexicon andgrammar, are hard to separate – and even more difficult to find both an adequate linguistic and lexi-cographic presentation for; to find a balance, if not the balance, between description and presenta-tion.
If gone were just the past participle of go, an E→H dictionary could easily do justice to it by pro-viding some sign of referral, as in the case of all irregulars, from it to go. Gone, however, is also apreposition, and labelling it as such hardly causes difficulty for the user: “rigour” will not lead toconfusion. More interestingly, the same string gone is also an adjective (and CED&T 1992 printsten adjectival senses of gone).
It is obvious that out of the gone types in (i) he had gone back and (ii) he was gone (in any of the‘dead’ or ‘faint’ or ‘missing’ senses) and (iii) he was gone ninety, only (i) is an participial form,which will be adequately covered by a referring � sign. It should also be obvious that (ii) and (iii)do not exemplify the same kind of gone, and that the gone in (iii) distributes exactly as a preposi-tion (e.g. the preposition past – contra CED&T 1992, e.g., which claims that this gone is an adverbmeaning ‘past’ in it’s gone midnight). Then the details may be argued, but gone ought to receivethree entries:
AMSz (2000)gone adj
1. elveszett, reménytelen, [betegségben] előrehaladott he was too far gone to understandwhat we were saying túl volt már azon, hogy felfoghatta volna, amit mondunk 2. eltűnt it'sgone eltűnt, elveszett 3. be gone elvan, távol van I won't be gone long nem maradok /nem leszek el sokáig here today, gone tomorrow ma itt, holnap ott/sehol / ma még itt van,holnap már nyoma sincs 4. terhes she is six months gone hat hónapos terhes 5. be goneon smb bele van esve vkibe 6. be gone el van varázsolva, be van lőve
gone prepután, később vminél she's gone eighty nyolcvan éves is elmúlt they didn't come until gonemidnight / four o'clock csak éjfél/négy után jöttek
gone verb � go
The adjectival function of gone is widely recognized, but the preposition function of gone is not.This is not a problem word (as is ago), since the preposition PoS of gone is not universally recog-nized: of the native speaker dictionaries, it is not mentioned in CED&T (1992), NSOED (1997),MWCD (2003), RHWUD (1999), MWUD (2000) and AHD (1994); it is only featured (as a British-only preposition) in COED (2004). This use of gone is featured in all the five learner’s dictionaries:as prep. in informal British usage in the LDCE (2000); prep. in informal British usage in the OALD(2005); prep. Brit/informal in CC (2003); prep. UK in the CALD (2003) and CALD (2008); asBritish informal in MED (2002) and (2007)75.
75 It is telling that the definition is the inadequate ‘after a particular time’ (a whole PP): it shows that gone itself is
regarded as some kind of time expression, even if it is apparently acknowledged that its grammatical status ispreposition. If this indeed were what gone meant, it could never appear in the MED (2007) example: It was gone teno’clock by the time they arrived.

Chapter Three
207
3.1.6 Small clauses
Small clauses, which never have existed for lexicography, are a good illustration of how dictionar-ies can do without input from (theoretical) syntax.
Over the past over thirty years, since the publication of Stowell (1981), the construction called“small clause” has been analyzed in many different ways, depending on the dominant framework.Small clauses, in one syntactic framework, are supposed to be one of the three major clause typesbesides standard/ordinary clauses (CPs) and exceptional clauses (IPs). In the GB strain of genera-tive grammar, there are supposed to be verbless small clause types (universally recognized) andverbal small clause types (which some sources ignore). They come in different shapes, from theones functioning as complements of verbs to complements of with and what with76; they may alsobe independent main clauses77. The only constant feature they share is their minimal predicativestructure (usually contrasted to both ordinary and exceptional, clauses).
Radford (1988) defines the small clause as [NP XP], where XP = AP or PP or NP or VP, and ac-cordingly recognizes such types as the following:
(1) believe [him incapable]; make [him sick](2) want [him out of the team]; let [him into the house](3) find [him a drag](4) let [him go] modified from Radford (1988:324ff)
The verbal type, exemplified by (4) above, is often further classified into bare infinitival, gerundive(-ing), and participial (-en):
(4a) saw [him go](4b) imagine [him singing](4c) imagine [him shot]
Of these structures (1) and (3), which contain AP and NP predicates in the clause and (4), the verbaltypes, have long figured in descriptions of English grammar under the traditional label “Accusativewith the Infinitive”. They were also singled out for Hornby’s Verb Patterns (e.g. Hornby & al.1948) and figured prominently in many editions of the first two learner’s dictionaries, the OALDand LDOCE, until they proved – or rather were assumed to be – both too technical and notmnemonic enough to use.
Some of the relevant structures are as follows:want him to stay –
Hornby’s No. 17, characterized as S + vt + (pro)noun + to Infinitive;feel the house shake –
Hornby’s No. 18a, characterized as S + vt + (pro)noun + Infinitive;consider him (to be) clever –
Hornby’s No. 25, characterized as S + vt + (pro)noun + DO + (to be) + adj/n.
Importantly, the to-infinitival variant of this last No. 25 does not illustrate a Small Clause, while theversion without it does.The three examples with the Small Clauses bracketed look like this:
want [SC him to stay]; feel [SC the house shake]; consider [SC him innocent]
76 I can’t sleep with [him snoring]; What with [it raining all day], I didn’t get a chance to hang the washing out77 The so-called Mad Magazine sentences: Me worry? or Max a doctor?

Chapter Three
208
The verbal SC structures in (4), illustrated above, have also figured among the Verb Patterns undersuch labels as “Accusative with the Participle”. These, however, as we have seen, are not consid-ered as Small Clauses by all analysts.
Variations on many of the small clauses – e.g. (1), (2), (3), (4a) – above, with to infinitives ratherthan plain/bare infinitives, are labelled “exceptional clauses”, never small clauses:
• want [him to be on the team]• believe [him to be incapable]
The relation between “Accusative with Infinitive”, the “Accusative with Participle”, the “Excep-tional Clause”, and the “Small Clause” itself, in one possible framework, can be sketched out asfollows:
Small ClauseAcc w/ Infin.
Exceptional ClAcc w/ Pple
Just as a detailed summary than this may not be hoped to be given here of the various syntactic ap-proaches to small clauses, so no overview will be attempted of the different lexicographic treat-ments, following in the wake of Hornby and associates, of all of the phenomena which the notion“small clause” covers. Both the phenomena themselves and the analyses offered for them are far tooheterogeneous, as evidenced by the vast literature – too complex indeed for the “small clause” toever have been used in lexicography.
If just the most important syntactic developments and U turns in the analysis of the most importantobjects that have been termed “small clause” were to be followed up in lexicography, and diction-aries genuinely were to shape their presentation of those phenomena that might come under the la-bel “small clause”, then dictionary-making would be impossible. Each new edition would have tobe updated accordingly; and the lexical updating of a dictionary, whether print or electronic, is dif-ficult, time-consuming, and costly enough without impossible grammar-related tasks like that. Try-ing to absorb into lexicography the most recent syntactic insights (and possibly also use the giventerminology) would be a constant race against time – provided, of course, that whatever new infor-mation emerges can be used, and is worth using.
The question naturally emerges, who and what is to decide which those areas are that may serve asworthy inputs for lexicography. It has turned out that even the little that was once imported fromgrammatical analysis – the millennia-old notion of Accusative with Infinitive and the Accusativewith Participle with its subtypes – and was carefully adopted to be accommodated in learner’sdictionaries had come to be jettisoned for fear that it might be user-unfriendly. That was amethodological, pedagogical decision, by no means one to do with linguistics. Meanwhile, most ofthe insights from the new approaches to syntax have never found their way into dictionaries. Thetheoretical approaches, where explanation is obviously foremost, radically differ. Descriptively, orpre-theoretically, however, there is no disagreement as to the handling of the phenomenon at hand,and nothing indeed warrants a different lexicographic treatment since the first versions of the VerbPatterns. In the dictionary, where explanation has no place, description counts most – and that is

Chapter Three
209
probably best at its simplest. In the case of the Small Clause, it is safe to say that for lexicography,it does not exist. If (a very big if that has not been answered uniformly) that kind of syntacticinformation is needed at all, the time-honoured approach to the structures grouped under the “SmallClauses” label suits the user better, is more intuitive, and seems to be a point where tradition oughtto prevail.
3.2 Between grammar and lexicon
3.2.1 Lexico-grammar
Discussing a variety of languages, Halliday & Yallop (2007) deals with notions of “'word” in Eng-lish and, arguing from the differences between languages, introduces the notion of “lexico-gram-mar”. The term, first used in systemic functional linguistics (Halliday 1978; Halliday 1985/1994;Halliday & Matthiessen 2004; Hasan 1987), suggests that there may be “no exact point where thelexicologist stops and the grammarian takes over” (Halliday & Yallop 2007:3–4). The view of cor-pus linguistics is sceptical of separating the levels of lexicon, syntax, semantics and pragmatics. Acentral claim is that ‘there is a strong tendency for sense and syntax to be associated’ (Sinclair1991: 65).
At different stages of twentieth-century linguistics, the lexicon, semantics and pragmatics seem tohave been variously ignored, or seen as an unsystematic remainder, as opposed to syntax, whichwas seen as highly structured and rule-governed. Stubbs (2002:216) however claims that “a disci-pline progresses by turning chaos into order, and linguists and philosophers have had considerablesuccess in showing that all of these areas are internally highly organized, and related to each otherin principled ways”. Chaos, however, need not be turned into order if lexicon, semantics and prag-matics are both non-discrete, probabilistic, have fuzzy internal as well as external boundaries. Thisis not chaos then but the natural order of things, and the “order” that this could be turned into wouldunnatural and false. If fuzziness is inherent indeed in language, then corpus linguistics need not beseen as saving the (study of the) lexicon from chaos, but can rather be welcomed as an approachshowing the true nature of language – “lexi-grammar”.
Dictionaries, especially bilingual ones, where grammar is less conspicuous, inevitably suggest theseparation of lexicon and grammar. With the notable exception of some learner’s dictionaries (e.g.Thompson & al. 1991) and coursebook-cum-workbooks and vocabulary builders that began to showthe influence of English learner’s dictionaries in the 1990s (cf. Salamon & Zalotay 1993, 1994;Dörnyei & al. 1986), Hungarian↔English dictionaries have always contained very little grammati-cal information, apart from such details as part of speech labels (which are probably not perceivedto be grammatical information as much lookup aids) and transitivity (which is usually clear fromthe translations, so superfluous). What little grammatical information the Hungarian→English partof the comprehensive HECD (1998) has contained, for example, was morphological; and becausesuch information was mainly featured for irregulars, its inclusion fosters the impression that it wasreally words’ individual, lexical characterization that mattered.
Syntactic information is not specially targeted; it is hidden in the examples. Even when a Hungarianexplanatory dictionary offers a special feature, this will not be collocational information, but syno-nyms and antonyms, for example; this further augments the feeling that useful information can befound, and ought to be sought, on the paradigmatic and not the syntagmatic axis. Everything above

Chapter Three
210
the word level tends to be considered a matter of “idiom” of sorts. It is possible that “idiom” is agood term to designate some or all of these above-the-word chunks of language, but “idiom” alsospells trouble: it issues a false warning of a terra incognita where no man, especially not movingabout in a foreign language, should venture. The scanty results available from empirical Hungarianresearch into dictionary use (e.g. Márkus & Szöllősy 2006) do not at all justify optimism.
Hudson (1988) discusses several notions that are relevant for an exploration into dichotomies. Heuses “grammar” narrowly, to include just the rules (‘the grammar proper’) of language, and “lexico-grammar” for the combination of the general rules plus the lexicon (Hudson 1988:291). Hudson at-tacks the (then, or still?) standard assumption that a rule is always classified as either lexical or non-lexical, and he invokes the notion of prototype, claiming that all linguistic concepts are prototypes –a proposition with which it is very easy to identify. A lexical rule is such a prototype, “organizedaround clear cases but with deviation permitted in its instances”. As an example that is non-canoni-cal because it does not fit into any normal pattern (and not derivable from any fuller structure) heprovides questions of the type What about a drink? and Down with the government! A rule isthus needed to “generate the pattern found in each such case; but these rules are tied just to a fewlexical items” (what can be replaced by how).
I totally concur with Hudson’s claim that
“any lexicographer must agree with […] what I have said about the distinction be-tween the lexicon and the grammar. In practice they must often be faced with unan-swerable questions about what information to include in their dictionary and what toleave out on the grounds that it belongs rightly in a grammar.
The word order facts that Hudson uses as illustration are even more instructive. The two extremes,“100% lexical” and “100% grammatical”, are sufficiently clear: enough is exceptional because itfollows its head (sufficiently big vs. big enough); it belongs in a dictionary. The subject precedesthe verb: this belongs in the grammar. However, there are a presumably huge number of intermedi-ate cases. The some-, any- and no- pronoun series, e.g. have their modifier adjective followingrather than preceding them (someone nice, not *nice someone). A rather small list of auxiliariesallow inversion in conditional clauses, turning e.g. If I had known... into the inverted Had Iknown… (Hudson 1988:294).
Hudson applauds the tendency for trade dictionaries (he mentions the LDCE) to include a good dealof grammatical information (besides such grammars, e.g. as Quirk & al. 1972 including vastamounts of lexical information, i.e. on particular words). It is difficult again to see how he arrives atthe following dual conclusion:
“...if there is in fact no natural boundary between the lexicon and the grammar, theprofessional linguists should develop theories which reflect this fact. Such theoriesare bound to be of more interest to lexicographers than the current main-stream ones”
Hudson 1988:295)These are two quite independent claims. While theories should obviously reflect what they think islinguistic reality even it is one without rigid internal boundaries, it is not clear why and how thiswould or should bear on the daily business of lexicographers. As has been pointed out, the two arefarther removed than is usually supposed.
3.2.1.1 The odd thing about it
Grammatical information is most often so general that it is indeed impossible, and unnecessary, topresent it within individual dictionary entries or across similar entries. One small example of thiswill be provided in this section.
The information, e.g. that regular nouns have -s in the plural is a matter of pure grammar and neednot be placed in any entry (unless a special zone such as a Study section with such general informa-

Chapter Three
211
tion is included, which is not really part of the dictionary proper). The fact is still tacitly, or nega-tively, registered in all the thousands of entries where the headwords themselves or the exampleshave this form. The user is expected to know that “if it is not marked as irregular, it is regular”.(The fact that this plural is variously pronounced as dictated by the relevant rules of phonology isnot usually indicated; one exception is CC (2003), which provides all the verbal and nominal regu-lar pronunciations.)
How can less general facts be presented, such as the valency or government related information thatabout corresponds to the Hungarian suffix -bAn ‘in [position]’ wherever adjectives like odd,strange and a handful of others are used? This kind of structure is involved: Az benne a furcsa,hogy… – which is translatable as The odd thing about it is that… . One reply might be that thisshould be left to a pedagogical English grammar that should take care of it. But where in the gram-mar should this be? A thematically arranged grammar book may call attention to this, but such in-formation will be a deeply buried lexical point within its (sub)chapter on Complementation (underthis or any other label). In an alphabetical collection of difficult “grammar” points, on the otherhand, the same information would have to be repeated under several adjectives where this is typicalusage (odd, strange, good, nice etc) – because this is really a lexical point. That there is no sepa-rate section in such a grammar for the individual Hungarian affixes is obvious.
az benne a különös, hogy… → the strange thing about it is that…a megoldásban az a szép, hogy… → the nice thing about the solution is that…az újdonság benne az, hogy… → the novel thing / novelty about it is that…
The only way for such information to be conveyed lexicographically is an indirect one, via the ex-amples in the entry of such adjectives, since dictionaries, similarly to grammars, do not as a rulecontain affix entries.
This seemingly innocent structure – the Adj thing about smth is/was that… actually contains an-other pitfall: a typical learner error is not to use thing: *the odd was… That may be coupled withwrong preposition use: *the odd in it was…
The only reference to the omission of thing in the pedagogically oriented Carter & McCarthy(2006), with a strong contrastive bias, is the following explanation:
“In cleft constructions which involve comparison, thing is needed:The most obvious thing to do is to keep out of the rain.(The most obvious to do is to keep out of the rain.)”
(Carter & McCarthy 2006:74a)
where the example, incidentally, is neither a comparison nor a cleft sentence.Even ignoring this serious error it must be clear that dictionaries can hope to do even less thangrammars for the avoidance of such a mistake.
3.2.1.2 Grammaticization: end of a lexically bound word
A minor illustration from the grammar–lexicon border will be provided by the lexical item amok.Stubbs (2002:32) mentions that amok is almost always preceded by run, but he also discusses twounique examples, however, with go. The standard collocation, then, is run amok, but in these twoexamples of his go amok is used: an era gone amok; journalism gone amok.
The item amok, which is not used outside of the phrase run amok (and perhaps go amok), behaveslike a lexically bound word with indeterminate morpho-syntactic class.
Stubbs offers no explanation for his idiosyncratic examples; one will be provided here. What mustbe happening here is the following. First, go comes to be used as a variant of run, since it is a syno-nym of run as a verb of motion. The verb run is then reinterpreted as copulative (as in run dry),

Chapter Three
212
and because amok has both a vague meaning ’crazy’, and an equally vague PoS status (or no PoSstatus within these expressions), it will be able to collocate with go, yielding the combination goamok. At this point the word amok, which now does have a PoS status as an adjective, stands agood chance of coupling with other resulting copulas. (The flip-side diagnostic test of this is that ifit does collocate with other copulas, then it is an adjective.)
Google searches on all common result copulas plus amok actually return authentic78 hits withgrow, get and become (which, unlike the other two verbs, is always copulative):
GROW: tumour cells to grow amok in the host body79
GET: They will feel very uncomfortable and start to get amok]80
BECOME: This just makes my blood boil....starting to become amok81
This, then, is a type of grammaticization, a verb of motion (go, run) being reinterpreted as a copula.It is noteworthy because the grammaticization of one element, the verb, goes hand in hand with therevitalization of another, the non-PoS-classifiable amok. These phrases simultaneously illustraterun and go being reclassified as copulas from verbs of motion and amok “coming back” from fos-silization, i.e. gaining (adjectival) PoS of its own. At the end of the process, run amok joins theV+A pattern and parallels a number of combinations that have no lexically bound word. The proc-ess as a whole provides a challenging case of the grammar–lexicon indeterminacy.
The (now largely corpus-aided) task of lexicographic capturing developments such as these, ofcourse, is a challenge for the hedgehog, not the fox, to use the metaphor developed in 2.1.
3.2.2 Productivity: straddling the “words vs. rules” divide
3.2.2.1 Words and rules
With elegant and often refuted but probably insightful simplification, Pinker (1999) distinguisheswords and rules as the ingredients of language, and argues for their relative separation: this roughlycorresponds with the distinction between the lexicon and the grammar (as well as inevitably sweepsunder the rug such questions as how the grammar itself is compartmentalized. An ideal lexical itemis individual, unpredictable; governed by nothing rule-like; an ideal rule is general and predictable.
With a similar simplification, grammatical rules may accordingly be said to be rationalistic, and thelexicon, empiricist. While rules qua rules obviously cannot be observed, only their effect can, mostpeople see in language the observable, and see it as words (perhaps their combinations). To mostpeople, the existence of a word is an empirical issue, which can be verified by looking at specimensof E-language. Dictionaries are notorious, and innocent, suppliers of ammunition for this way ofseeing things linguistic.
Productivity, which has many faces and analyses in linguistics, straddles exactly this divide. Contrathe lay view, knowing whether some word is really a word in a language does not mean knowingwhether it has been put to use (this would be impossible to detect in the speech of speakers any-way), but knowing whether it has that potential. In that sense this is a more interesting question forlinguistics. Lexicology, exploring as it does that which has been recorded, only has the happyhunting ground of E-language. Lexicography, which records it, has even less elbowroom.
78 I.e. from (presumably) English-language sites.79 http://linkinghub.elsevier.com/retrieve/pii/S095980490900053780 http://uk.answers.yahoo.com/question/index?qid=20090716072632AABqmj781 http://rockybru.com.my/2007/08/son-in-law-in-port-klang-ftzs-fiasco.html

Chapter Three
213
Productivity straddles the words/rules divide, the lexicon/grammar divide, the actual/potential andthe empirical/rationalist divide: this much may be risked without taking a stand on whether thesereally amount to the same dichotomy. It is unfortunate, therefore, that the dictionary, which alsospans the often wide-seeming grammar/lexicon span, is so badly suited to record – or even suggestto its users anything about the nature and products of productivity in language. The “more Saus-surean”, i.e., systemic, one’s way of thinking about it, the more it is evident that the better the dic-tionary, the more integration between the lexicon and the grammar it presents in every feature, i.e.,the more blurred the lexical and syntactic information is shown to be. Moreover, because the dic-tionary, which for most lay people (perhaps even more so in an Anglo-Saxon than a Hungarian set-ting) is the only interface between them and language at large, conveys just this picture of clearseparation of linguistic facts, the words/grammar dichotomy constantly gets reinforced.
3.2.2.2 Dictionaries and productivity
Productivity is variously taken to characterize either morphological processes (or word formationrules), or the affixes themselves involved in these. It is variously considered to be a qualitative (ei-ther–or, all-or-nothing) notion, or a scalar (quantitative) phenomenon, ranging from (perhaps) 100%unproductive to (perhaps) 100% productive. Productivity in the former, qualitative, sense is oftentermed availability: a process is either available or not. In the latter, quantitative sense, it is calledprofitability: the question is how profitable a process is (Bauer 2001; Chung 2003; Plag 2006:122).
The basic opposition presupposed in the notion “degree of productivity” is that between possiblewords and actual words (Booij 2007:68). The claim that “all words are equal” is indeed too sim-plistic to ever have been made by any analyst, this opposition explicitly says that some words aremore, and some less, “equal”, i.e. actual, existing, than others. This sounds like an irreparable con-tradiction in the case of entities of many other sciences; in linguistics, thanks to the workings ofproductivity, lexical items have a gradation of realness; of all that, dictionaries show one degree.The dictionary can do nothing to suggest that some process or form is productive; what little it maydo will usually go unnoticed.
3.2.2.2.1 Frequency information and its problems
The closest that a dictionary comes to indicating productivity is that it suggests the central, impor-tant nature of some pattern by a richer-than-average exemplification, or the explicit signalling of thestatistical frequency of an item – but these do not actually involve productivity. Worse even, fre-quency data fall short of expectations also because they remain at the level of the lemma and arenever given broken down by sense.
Frequency information is also not something that may be used uncritically. Jackson (2009), explor-ing the origins and the methodologies of frequency information, looks at the usefulness of such in-formation in various learner’s dictionaries. His findings suggest that dictionaries present this inways that are far too different and hard (or impossible) to compare, based on criteria much too di-verse and often not publicly accessible. Most importantly for the present study, however, he hasfound that the modifications (sometimes welcome, sometimes for the worse) from one dictionary tothe other, and from one edition to the next, have been guided not so much by a more sophisticateduse of more powerful and huge corpora, but on the contrary: it now seems to be realized that otherfactors beside frequency influence dictionary-worthiness. MED (2002), for example, already basedits choice of words not just on frequency but also on their “usefulness to learners in production,their own speaking and writing” (Jackson 2009:173). Jackson (2009) investigates usefulness of fre-quency information from the learner’s, not the lexicographer’s point of view. If, however, the 4thedition of the Cobuild dictionary (Sinclair 2003) e.g. removes from the top frequency band suchthings as all the months of the year and the days of the week and the titles Mr, Mrs, Ms and Miss

Chapter Three
214
(Jackson 2009:172), then this information is probably unreliable and irrelevant. These words mustbe included anyway: at the top of the frequency table, which they inhabit, inclusion decisions arenot influenced by frequency, just their marking is – by stars, diamonds, and/or indications ofS(poken) vs W(ritten).
This again proves what are two important points about lexicography at large. The more general one,on which there largely seems to be agreement is that the importance of human intervention in dic-tionary making will not diminish with technological advances. And the other, specifically related tothe linguistics–lexicography relationship which the present study focuses on: that most editorialmodification and improvement both from one dictionary to its newer competitor, and from an olderedition to the next, is not induced – not even helped along – by linguistic considerations; rather bymethodological aspects internal not to lexicography but metalexicography at best. Althoughlearner’s dictionaries seem somewhat exceptional in this respect, few of the features of dictionarieschange, and fewer do so consistently, but what change there is comes mostly from considerationsconcerning the side of the user.
Another domain where traces of productivity can be hoped to be captured in dictionaries isstyle/usage labels with information on lexical items’ obsolete, or slangish/informal/colloquial char-acter, with the tacit implication, of course, that obsolete is less frequent, whereas infor-mal/colloquial more frequent. Expressed in productivity terms, the former label effectively says:beware – this is no more “productive”! The latter one is often taken (but obviously not meant) to beas encouragement to the user: “go ahead: “productive”! The effectiveness of these, however, isdoubtful: labels like old use or obsolete tend to be ignored even if offered, while colloquialism, in-formal words and especially slang expressions, will be happily used.
3.2.2.2.2 Productively used words
The use of “productive” may be loosened82 so that it makes sense to talk about words that have pro-ductive derivational affixes or have been formed by such a productive process. This is not unique:Biber & al. use “productive” in a similar informal fashion, stating that “Despite the general rarity ofmost idioms, a few verbs are especially productive in combining with NPs to form idioms.” Biber& al. 2000:987; italics are mine.
In this informal but serviceable sense, items like watchable, clickable or saltable, and most transi-tive verbs thus coined with productive -able, will themselves be productive. The deverbal locativenoun bakery is not productive, because it has been produced by a process that applies to few lexe-mes and cannot apply to new ones. The wording “bakery is not productive” is thus effectivelyshorthand for “not generated by a productive process”, or “not containing a productive affix”.
3.2.2.2.3 Combinations with well-
The twin notions “predictability/productivity” will be illustrated on well- combinations (not all ofwhich are genuine compounds, or at least are hardly classifiable as either that or phrasal adverb +adjective combinations) in CED&T (1992).
For “standalone” well as adverb, CED&T (1992) distinguishes 10 senses of standard usage, and itexplicitly mentions that some of these are “also used in combination”. Though the point of such a
82 The many approaches to productivity include Aronoff & Anshen (1998) as well as the more recent Bauer (2001) and
Plag (2006).

Chapter Three
215
remark would probably be lost on a non-native speaker (and is not certain to be much clearer to thenative ones), it does suggest that the well- combinations “inherit” these but presumably not theother senses of the “standalone” well. Note also that well, being, among other things, the adverbialvariant of good, is notoriously hard to split/lump for senses.
The 10 senses are:1. (often used in combination) in a satisfactory manner: the party went very well2. (often used in combination) in a good, skilful, or pleasing manner: she plays the violin well3. in a correct or careful manner: listen well to my words4. in a comfortable or prosperous manner: to live well5. (usually used with auxiliaries) suitably; fittingly: you can't very well say that6. intimately: I knew him well7. in a kind or favourable manner: she speaks well of you8. to a great or considerable extent; fully: to be well informed9. by a considerable margin: let me know well in advance10. (preceded by could, might, or may) indeed: you may well have to do it yourself
Items 5. and 10., which always combine with modals, can be clearly separated. This shows that toomuch splitting has been done here, and in actual fact not more than just two basic senses are in-volved. These are:
(a) a qualitative sense: ‘positive’, seen in 1., 2., 4., and 7(b) a quantitative sense: “intensity”, seen in 3., 6., 8., 9.
(Alternatively, 5. and 10. can be seen as manifestations of the “intensity” sense, as modifiers of themodal auxiliary.)
List No18
Well-combinations in CEDT (1992)
well-acceptedwell-accomplishedwell-accustomedwell-acknowledgedwell-acquaintedwell-actedwell-adaptedwell-adjustedwell-administeredwell-advertisedwell-aimedwell-airedwell-appliedwell-arguedwell-armedwell-arrangedwell-assortedwell-assuredwell-attendedwell-attestedwell-attiredwell-authenticatedwell-awarewell-behavedwell-belovedwell-blessed
well-builtwell-calculatedwell-clothedwell-coachedwell-compensatedwell-concealedwell-conditionedwell-conductedwell-confirmedwell-consideredwell-constructedwell-contentedwell-controlledwell-cookedwell-coveredwell-cultivatedwell-defendedwell-definedwell-demonstratedwell-describedwell-deservedwell-developedwell-devisedwell-digestedwell-disciplinedwell-documented
well-dressedwell-earnedwell-educatedwell-employedwell-endowedwell-equippedwell-establishedwell-esteemedwell-financedwell-finishedwell-fittedwell-fortifiedwell-foughtwell-furnishedwell-governedwell-guardedwell-handledwell-hiddenwell-housedwell-illustratedwell-inclinedwell-judgedwell-justifiedwell-keptwell-likedwell-loved
well-madewell-managedwell-markedwell-matchedwell-meritedwell-mixedwell-motivatedwell-notedwell-organized orwell-organisedwell-paidwell-phrasedwell-placedwell-plannedwell-playedwell-pleasedwell-practisedwell-preparedwell-proportionedwell-protectedwell-providedwell-qualifiedwell-reasonedwell-receivedwell-recommendedwell-regarded

Chapter Three
216
well-regulatedwell-rehearsedwell-rememberedwell-representedwell-respectedwell-reviewedwell-ripenedwell-satisfiedwell-schooledwell-seasoned
well-securedwell-shapedwell-situatedwell-spentwell-statedwell-stockedwell-suitedwell-suppliedwell-supportedwell-sustained
well-taughtwell-timedwell-trainedwell-travelledwell-treatedwell-triedwell-troddenwell-understoodwell-usedwell-verified
well-woodedwell-wordedwell-writtenwell-wrought
(137 items)
The way these are handled is extremely unhelpful. The list in its present form, with its undefineditems, does not tell the user which meaning is involved: well-advertised, for example, couldequally mean and be synonymous with properly advertised (= quality) and much-advertised (=quantity). It is probably still true that these two (rather than ten) meanings are discernible in thewell- combinations: “quantity” and “quality” sense.
The opposite of “qualitative” well is badly, while that of “quantitative” well is little or rarely. It islikely that within the two broad senses these 137 items contain well in slightly different or indeter-minate senses, and it is not impossible that some will be totally unrelated to these two senses. Thus,although native speakers may have quite clear intuitions in most cases, well-advertised e.g. couldhave the antonym badly-advertised or (ill-advertised?) in one, and little-advertised; the list pro-vides no help there. (In all fairness, learner’s dictionaries typically do not contain undefined listssuch as these).
CALD3 (2008) yields the following list on a search on well-X-en83 adjectives: most of the items inthe list have their own entries themselves and are defined, although (as the example of well-keptshows) some do not get a proper definition.
• In this list, the adjective well-kept actually appears with two senses given: 1. ‘clean, tidy andcared for’ and 2. ‘carefully kept’ (e.g. A well-kept secret has not been told or shown to any-one (CALD3 2008)
• Well-intentioned and well-mannered ill fit with the rest because here the -en attaches to nounbases. The expected default forms would thus be good-intentioned and good-mannered, whichalso happen to exist. The forms well-intentioned and well-mannered are thus exceptional, notgenerated by productive processes.
• Other items found that can be thought of as idiomatic in the sense of unpredictable includewell-rounded ‘involving or having experience in a wide range of ideas or activities’. While thishas the base -round-, it is impossible to say which PoS of round, and which meaning, is in-volved here. This word is not generated by the rules of the grammar; it is also at the zero end ofthe transparency scale.
• Well-thumbed ‘[of a book] having damaged appearance because used many times’ [definitionmodified from CALD3 2008], by contrast, is grammatically analyzable: it contains a verbalbase, thumb. It is not less opaque, since the meaning of well- is not obvious.
The words at the completely productive end include well-adjusted, well-documented, well-bal-anced, well-done and well-timed, i.e., with a general formula, well-V-en: these are no less pro-ductive/regular/predictable/transparent than their corresponding verb phrases of the V NP well type.These are fully productive in that they (i) contain well- in the “qualitative” sense; (ii) have a verbalbase; (iii) their verb is transitive.
The productive well-combinations are close to being syntactic objects. The unproductive ones, tothe extent that they are indeed words, are complexes such that the meanings of their components do
83 I.e., well-V-ed, where -ed stands for past participle.

Chapter Three
217
not add up to the meaning of the whole; they also often have unpredictable grammar between theconstituents. This is the perfectly regular behaviour of idioms – and in the light of this, the unde-fined listing is an especially user-unfriendly strategy. For the learner, the problem is exactly thatwords do not show whether they are productively formed: well-used could be (a productive/freecombination meaning ‘used well’, or an unproductive lexicalized item meaning ‘used a lot’. Justbecause such an item can be used in the lexicalized sense does not mean that it cannot occur withthe free meaning (in the terminology of productivity: there is no blocking of the productive pattern).Unfortunately, not all dictionaries contain all these items in all their meanings, focusing on both the“phrasal” and the “lexical” pattern. Unless and until they do, however, the dictionary is no betterplace for this information than the grammar book.
It would be reassuring to know, at least, that the inclusion in the dictionary of these well- items, andall the similar combining forms of which they are symptomatic, is justified by frequency. This isprobably not so: similar (non-corpus-based, CED&T 1992; and corpus-based, MED 2007) listsyield slightly different items; the lists have not been reproduced here. There are many items in othersources that are missing from CED&T (1992), but LDCE (2005), e.g., has well-hung, well-stacked, well-turned-out, and well-worn that neither CED&T (1992) nor CALD3 (2008) offers.OALD (2005)
List No19
CALD3 (2008) hits: well-X-en
well-adjustedwell-advisedwell-appointedwell-arguedwell-attendedwell-balancedwell-behavedwell-bredwell-brought-upwell-builtwell-chosenwell-connectedwell-definedwell-developedwell-disposedwell-documentedwell-donewell-dressedwell-earned
well-educatedwell-endowedwell establishedwell-fedwell-foundedwell-groomedwell-groundedwell-heeledwell-heeledwell-informedwell-intentionedwell-keptwell knownwell-likedwell-manneredwell-matchedwell-meaningwell-meantwell-oiled
well-oiledwell-preservedwell-qualifiedwell-readwell-roundedwell-spokenwell-thought-ofwell thought outwell-thumbedwell-timedwell-triedwell-troddenwell-turnedwell-versedwell-wornwell-orderedwell-matched/ill-matched

Chapter Three
218
3.2.2.3 Combining forms: -proof and -friendly and Hungarian -barát
3.2.2.3.1 -proof and -friendly
A manifestation of the blurred boundary between grammar and lexicon, and of how hard it may beto adequately provide the related information in the dictionary, is the productivity of derivational af-fixes or combining forms (which two may be difficult separate).
A highly productive pattern is the combining of bases with -proof. It is widespread in English; theHungarian equivalents of the -proof words are heterogeneous: there is no comparable set of -biztos‘-proof’ words, i.e. words containing the equivalent of -proof. There is no productive Hungarian af-fix or combining form, in other words, that corresponds to English -proof.
The productivity of the combining form -friendly, by contrast, is closely paralleled by that of theHungarian -barát ‘-friendly’. They will be discussed separately, under the Hungarian -barát head-ing.
English dictionaries cannot explicitly “teach” such productivity facts, i.e., make users aware of thisproductive element just by entering the headword -proof. If a user chances to look into an entry thatis productive in some sense, they may notice the large number of examples and thus have a clear, ifintuitive, idea of the frequency, or availability, of a pattern, but not of its productivity itself. Be-cause there is no single across-the-board item that translates it, the English→Hungarian dictionarycan only register one or two equivalents for -proof, e.g. -biztos and -álló. The list of Hungarianlexical units translating the various words with hyphenated -proof, however, contains not just thesebut quite a lot different of suffixes and combining forms, including -mentes, -biztos, -álló, -hatlan,and more importantly, various unsystematic, individual translations.
• MASZ (2000) offers this entry for -proof:-proof -biztos, -álló bullet-proof golyóálló water-proof vízálló, vízhatlan
while AMSZ (2000) has this to say about -biztos:-biztos -proof tűzbiztos fireproof
Unfortunately, while hyphenated -proof and -biztos are featured, neither hyphenated -friendly nor-barát is given in these two dictionaries. They actually deserve to be registered even more than-proof and -biztos, since they could simply mutually serve as convenient equivalents in each other’sentries.• In HECD (1998) and EHCD (1998) the picture is different.
While HECD (1998) does not contain either an entry for -barát or -biztos, EHCD (1998) does giveboth -friendly and -proof, but without indication at the headword level that these are combiningforms, i.e., no self-contained entry with a PoS for -friendly and -proof. They are out of place withintheir entries, where their labels (“összet”84), are way too deep in their entries for users to notice.More seriously, they are not exemplified, which may make it hard to appreciate what is involved in-barát below.
The case of -proof is different: -mentes, -biztos, -álló and -hatlan are all given, which are the mostfrequent translations.
friendly I. mn 1. barátságos, kedves, nyájas, szívélyes [........], baráti, barátságos [..............]2. a) jóindulatú, jóakaratú, segíteni kész; [...........................] b) kedvező, előnyös, alkalmas[körülmények stb.]; friendly winds kedvező szelek c) összet -barát
84 I.e., “comb.”

Chapter Three
219
proof I. fn 1. bizonyíték, bizonyság, tanújel; jog [...............] 2. a) próba(tétel), teszt, mat bizo-nyítás, kipróbálás; [.................] b) (előírt) szesztartalom, szeszfok; US c) vegy kémcső, epru-vetta d) kat kipróbálás [lőszeré stb.]; tört [...............................] 3. a) nyomd kefelevonat, kor-rektúra;[.....................................] b) műv lenyomat [rézmetszeté] 4. proof coin próbaveret[érméé] II. mn 1. a) proof against sg vmnek ellenálló, vm ellen védő [.........................] b)összet -mentes, -biztos, -álló, -hatlan
The long [.........] omissions indicate that a substantial portion of the entry has been cut out; this un-fortunately makes it hard to see how deep the relevant PoS label is buried within the entries.
A pedagogical grammar can say very little about -proof beyond sensitizing users to the productiveitem by mentioning it in the word formation section, labelling it “combining form” – a term thatwill surely be used differently in other sources – and list some of the words in which it appears. Insuch a practical grammar, use of the label “productive” to state that -proof is productive may be ahelpful and safe idea, since the term is being used in its everyday sense: ‘creative, fertile, fruitful,prolific, rich’. “Productive” will be intuitively felt to be effectively anything that can be abundantlyexemplified; this is no problem even if this just one aspect, and the linguistically less important one,of productivity. Grammar books for learners, however, do not as a rule mark either processes orpatterns (let alone words) as productive. If they were not productive, they would not be in thegrammar – this is how the argument tacitly goes.
A search on word-final -proof in RHWUD (1999), after careful selection (i.e. removal of the itemsburden of proof, cosmological proof, disproof, foundry proof, high-proof etc., which containdifferent kinds of -proof) yields almost sixty hits.MWUD (2000), the electronic version of “Webster’s Third”, supposed to be around 50% larger thanRHWUD (1999), has even more than this: items found in MWUD (2000) but not in RHWUD(1999) include mouse-proof, musket-proof, splinter-proof, termite-proof and vapor-proof.These are so much alive that their list has probably grown ten years on.
List No20
RHWUD (1999) -proof combinations:
1. actor-proof2. airproof3. baby-proof4. bombproof5. bulletproof6. burglarproof7. childproof8. chipproof9. crashproof10. crushproof11. dampproof12. dishwasherproof13. drownproof14. dustproof
15. fireproof16. flameproof17. foolproof18. germproof19. greaseproof20. holeproof21. idiot-proof22. jamproof23. leakproof24. lightproof25. mildewproof26. mothproof27. noiseproof28. nonfireproof
29. ovenproof30. pickproof31. quakeproof32. quasi-fireproof33. rainproof34. recession-proof35. rotproof36. runproof37. rustproof38. shatterproof39. shellproof40. shockproof41. showerproof42. skidproof
43. smokeproof44. soundproof45. spillproof46. spinproof47. stormproof48. sunproof49. tamperproof50. theftproof51. troubleproof52. waterproof53. wearproof54. weatherproof55. wetproof56. windproof
Most of these have Hungarian translations other that combinations with -biztos (plus -mentes, -állóand -hatlan). Checking nine items from the beginning and nine from the end of the above list inEHCD (1998) and MASZ (2000) yields the following table:
The superscripts are explained below.*The asterisks are my own grammaticality judgements for Hungarian.

Chapter Three
220
List No21EHCD (1998) MASZ (2000) -biztos /-mentes / -álló /
/-hatlan possible WHETHER
EXISTENT OR NOT
actor-proof1 — — színészi játékkal el serontható?*színészbiztos
air-proof — — légmentes? hermetikus?baby-proof — — baba által nem hozzáférhető /
tönkretehetőbullet-proof golyóálló adjective/verb:
golyóálló(vá tesz)golyóbiztos
child-proof gyermekbiztos,gyerekek számárabiztonságos
gyerek által nem hoz-záférhető / tönk-retehető
gyerekbiztos?
crash-proof lökésmentes,rázkódásmentes,rázkódásnak ellenálló
— törésálló, ütközésbiztos2
fool-proof igen egyszerű,könnyen kezelhető
(1) könnyen kezelhető,elronthatatlan,kétbalkezesnek is való(2) tévedhetetlen,biztos(ra menő)
bolondbiztos, hülyebiztos3
frost-proof fagyálló fagyállógrease-proof — zsírálló, zsírt át nem
eresztő*zsírbiztos
storm-proof — (1) viharálló(2) bevehetetlen
tamper-proof biztonságosan csoma-golt, záróvédjeggyelellátott4
hamisíthatatlan
theft-proof lopás / betörés ellenvédő
ellophatatlan
trouble-proof üzembiztos,hibamentes
—
water-proof vízhatlan, vízáthatlan,vízátnembocsátó,vízálló, impregnált,vízhatlanított
verb: vízhatlanít,impregnál, víz ellenszigetel, vízhatlanszigeteléssel lát el
vízhatlan, vízálló
verb:vízhatlanít, impregnál
wear-proof kopásállóweather-proof időjárásnak ellenálló,
viharálló, időálló,vízálló, vízhatlan, szél-mentes, vízmentes, szél(v. rossz időjárás)ellen védett, hézagzáró
viharálló, vízhatlan,szél ellen védő
verb:viharállóvá / vízhat-lanná tesz
wet-proof — — vízhatlan, vízállówind-proof — — széltől védő, szélnek
ellenálló, szélálló?

Chapter Three
221
1 All items have been spelled with a hyphen; no claim is thereby made that this is the right/typicalspelling.
2 AMMTSZ (1996)3 A Google search (18/07/2009 14:37) returns 25 400 hits for bolondbiztos ‘foolproof’ and 13 000
for hülyebiztos ‘foolproof’. These are apparently mirror translations for the English foolproof;this, of course, does not automatically preclude their dictionary-worthiness, but they may notcatch on. What these expressions do show is the high productivity – or at least the high tokenfrequency – of this -proof element.
It is worthy of note that the element -proof itself is rather unnoticeably polysemous: the meaningcontribution of -proof to childproof is different to that of -proof to babyproof or childproof, andthis, predictably, carries over to the verbs as well. Childproofing or babyproofing one’s home in-volves making it safe, i.e. childproof/babyproof for children/babies, while in all the rest of thecases X-proofing does not mean making something safe for X but protecting it, i.e. making it safeagainst X. This difference, interestingly, is not tied to the [+Human] vs. [–Human] feature of thefirst element (even if most of them are [–Human]), as shown by actor-proof. This adjective, used tomodify play/part/script, means ‘effective no matter how badly acted’, i.e. ‘[so good as to be]safe/proofed against bad acting’, and actor is [+Human].
The productivity of English -proof is also displayed by the possibility of further conversion: theverb damp-proof is readily available once the adjectival damp-proof exists. Any ‘X-proof’ adjec-tive A can thus become a verb meaning ‘make A’, provided that the result makes semantic andpragmatic sense. That this possibility owes its existence to this across-the-board word-formationaldevice, conversion, is shown by the fact that the addition of a verbalizer to the relevant Hungariansuffixes (e.g. to -hatlan) does not necessarily yield such verbs meaning ‘make A’; if you cannot vi-harállósít ‘weather-proof’, ellophatatlanít ‘theft-proof’ or zsírállósít ‘grease-proof’ something, it isnot because of semantic or pragmatic constraints. The verb vízhatlan-ít ‘water-proof’ from the ad-jective vízhatlan ‘water-proof’ is an exception rather.
3.2.2.3.2 Hungarian -barát
Phenomena of productivity, which inhabit on the lexicon–grammar border, will be illustrated withanother Hungarian example, the -barát combining form, which, in some of its senses at least, israther productive. Its productivity argues for a self-contained -barát headword (or perhaps several-barát headwords). Another, perhaps just as weighty consideration, however, is that few users willbe looking for the -barát ‘-friendly’ member of the expressions
bőrbarát ‘skin-friendly’ [e.g. cream], gyerekbarát ‘kid-friendly’ [district], vakbarát ‘blind-friendly [webpage]’, zsebbarát ‘pocket-friendly’ [price], szívbarát ‘heart-friendly’ [margarine], zsebpénzbarát ‘pocket money friendly’ [price],utasbarát ‘passenger-friendly’ [railway timetable], melegbarát ‘gay-friendly’ [place]
in a separate Hungarian -barát entry (and these examples are all supposed to illustrate the highlyproductive end of -barát). To be sure, if one wants to have reliable access to this kind of informa-tion on user behaviour, user studies are needed; on the basis of the existing ones it is neverthelesslikely that it is the whole expression that is searched, not the right-hand member.
If a particular combining form is not included, it is also unlikely that the user will try a search forthe second element after the lookup failure. Whether this search policy is equally true of genuinecompounds is another issue, which is not easy to ascertain since, as many other lookup strategies, itdepends on the combined effect of the users’ knowledge of things grammatical, on their generalproficiency in dictionary use, as well as their knowledge of the particular dictionary. There is, of

Chapter Three
222
course, no reason even to posit the same single uniform search policy for the same kind of linguisticexpression; it was assumed above that there may be such a uniform policy.
To be sure, the inclusion in the H→E dictionary of -barát ‘-friendly’ as a headword does not meanthat the individual -barát combinations themselves cannot be also included. By the inclusion of-barát, the dictionary registers the productivity of (some of the meanings of) this combining form.This, however, is not supposed to be the job of an “instrument” dictionary, such as a H→E diction-ary; it is a (major) “portrait” dictionary that may be expected to provide such “dynamic” informa-tion that verges on the grammatical. It is thus not surprising if only the individual -barát expres-sions will be entered, alphabetically under their left-hand members, in instrument dictionaries suchas bilingual E→H ones.
One problem, however, with entering the (right-hand, hyphenated) elements of such expressions isthat when they are polysemous, their entry becomes too complicated. Such an entry can be providedin a monolingual portrait dictionary (e.g. -barát in a Hungarian explanatory dictionary) but hardlyin a bilingual (instrument) one. Another pitfall is that some combinations given as illustrative ex-amples in such an entry must be included individually anyway, as we have seen. A third, most seri-ous problem, which actually strongly militates against the inclusion of such combining forms asheadwords in bilingual dictionaries, is that often no equivalent can be given (similarly to deriva-tional affixes, which may be similarly productive but on their own similarly untranslatable).
This lexicographic dilemma will be illustrated with the examples of the Hungarian
(1) bőrbarát ‘skin-friendly’,(2) németbarát ‘pro-German’(3) kertbarát ‘lover of gardens’, and(4) kebelbarát ‘bosom friend’.
They all contain as their right-hand member the combining form -barát, but crucially, they are dif-ferent types both grammatically and semantically. When items like these are entered separately, inwhatever dictionary, the superficial lexical sameness – in the face of the grammatical and semanticunrelatedness – of their -barát component will pass unnoticed: nothing, understandably, refers thereader from, e.g. kertbarát to bőrbarát. When, however, the hyphenated form -barát has an entry ofits own with a separate meaning profile, then at least the above four types/senses must be distin-guished, resulting in an entry that is rather too complex even for a monolingual dictionary, butclearly much too inflated for a bilingual instrument dictionary. (Because two of the items (1)–(4)above are adjectival and two nominal, in a dictionary with a PoS-first macrostructural arrangement,two entries rather than one may have to be provided: the adj. and the n. entries will then have twosections each.)
In the following sections the above four Hungarian -barát combinations will be presented:� in individual entries in an E→H dictionary;� -barát as a self-contained entry in a Hungarian dictionary;� -barát as a self-contained entry for a bilingual H→E dictionary.
� As separate/self-contained entries in the E↔H dictionary (which is the most straightforwardcase of the four), the expressions (1)–(4) get their PoS label (plus any other information ignoredhere). The first two are adjectives; the second and third are nouns:
(1) bőrbarát adj skin-friendly(2) németbarát adj / (noun) pro-German(3) kertbarát noun lover of gardening/gardens, amateur gardener(4) kebelbarát noun bosom friend

Chapter Three
223
The PoS status of -barát, the right-hand member of the complexes, is irrelevant. Their word classmay pose a problem for approaches to morphology that subscribe to the right-hand-rule, which isapparently violated here, but not for lexicography. Thus, type (1) may be argued to present such amorphological problem. The likes of bőrbarát must be either compounds, or derivations, or “com-bining forms”, which may be just in between; in any case, by the right-hand-head rule of morphol-ogy, for bőrbarát to be an adjective, its right-hand member must either also be an adjective or anadjective-forming suffix – as its PoS is supposed to percolate up to the complex form. It is not easyto decide whether barát here is an adjective or a derivational suffix. Either way, (1) will be an ad-jective by percolation. If, on the other hand, barát is a noun here as well as everywhere, then both(1) and (2) are problematic: bőrbarát is, and németbarát may be, an adjective that is not headed byone. To be sure, it may also be that the adjective/noun divide is not so obviously marked morpho-syntactically in Hungarian in general: in that case all the PoS-related questions, including thoseconcerning the rule of the right-hand head seen in (1)–(4), cease to be relevant.
There is at least one environment, though, where the Hungarian nominal -barát forms do showmorphological distinctions from their adjectival counterparts: the plural form, which is marked inboth, but may differ. Some, but not all, Hungarian adjectives take either the vowel -A- or the -O-,while the homonymous nominals only take the vowel -O- before the plural termination. Such vac-illation thus characterizes adjectives but not nouns (the grammaticality judgements are mine):
(1) bőrbarátok = bőrbarátak ‘skin-friendly-ADJ-PL’← both forms are possible as adjectives
(2) németbarátok = németbarátak ‘pro-German-ADJ-PL’← both forms are possible as adjectives, but németbarátok would likely be felt
to be a noun: this is why the PoS of németbarát adj / (noun) above is given in this way
(3) kertbarátok ‘lovers of gardening’ – cf. *kertbarátak← only one form is possible as noun
(4) kebelbarátok ‘bosom friends’ – cf. *kebelbarátak← only one form is possible as noun
Lexicographically, a solution to these PoS niceties is simply not needed. For the complex bőrbarátthe traditional label “adj.” will do, whatever its internal structure. The element -barát itself, whichis of intermediate status, a semi-word, will have an ill-fitting label whichever of “adjective” or“derivational suffix” is opted for – if such labelling is used at all. This is simply no problem forlexicography, and certainly not one that concerns the dictionary user.
Of the -barát examples above, (1), which is an obvious adjective in both the SL and the TL, and (3)and (4), which are not less obviously nouns in both, pose no such labelling problem; (2) however israther idiosyncratic:
(1) bőrbarát skin-friendly:– the Hungarian user will (ideally) know that this SL word is an adjective (whichever form ofplural they might employ in Hungarian), and will thus use the equivalent skin-friendlyadjectivally without any syntactic indication of this fact in the dictionary;
(3) kertbarát lover of gardening – the Hungarian user will know that this is a noun, and will thus use lover of gardening(or whatever translation) without any syntactic indication of this fact in the dictionary
(4) kebelbarát bosom friend shows the same behaviour (as (3))
(2) németbarát pro-German
This is truly, bi-directionally, and multiply problematic. Although both the Hungarian word is bothadjective and noun (and could be marked accordingly) and its equivalent can also be used bothadjectivally and nominally, from a practical viewpoint, having two entries for words such as this is

Chapter Three
224
surely a waste of space. This will be perceived as such by the dictionary users; more importantly,the significance of the finer-grained analysis gained by this waste of space may be lost on them.This is what such doubling of this entry would involve:
németbarát n. pro-Germannémetbarát adj. pro-German
HECD (1998) employs such doubling, offering the following not very helpful entry, with indicationof the dual SL word class but with no separation of the PoS in the TL85:
németbarát mn/fn86 pro-German, Germanophile, Germanophilist87
A bilingual dictionary can only do justice to such a word by providing grammatically adequate in-formation if it adequately represents both the SL and the TL word classes. This space-saving inHECD (1998), especially since it is basically an H→E dictionary for Hungarians rather than theother way round, is a luxury that cannot be afforded: it is not the SL but the TL where more gram-matical information should be offered. With PoS information adequately on both sides, the entryought to look something like this:
németbarát n. pro-German, Germanophilenémetbarát adj. pro-German
or even, with a bit of (perhaps tolerable) simplification:
németbarát n. Germanophilenémetbarát adj. pro-German
� As a self-contained hyphenated entry, the item -barát will be very, indeed too, complex. Thedifficulty of its lexicographic presentation is mainly caused by the diverging degrees of produc-tivity of this element. This means, among other things, that a general formula containing a vari-able X will be adequate for (1) and perhaps (2) but much less for (3), and certainly not for (4).This time not (2) but (4) presents a problem.
A sketchy monolingual Hungarian entry might thus look something like this88:(1) X-barát adj. = helpful, easy, advantageous for X
(X = thing or person)e.g. bőrbarát ‘skin-friendly’, zsebbarát ‘pocket-friendly’89, ózonbarát ‘ozone-friendly’
(2) Y-barát adj. = in favour of / supporting / friendly towards Y (Y = group of people)
e.g. németbarát ‘pro-German’, emberbarát ‘philanthropic’This Hungarian sense is relatively still easy to define, but it is different inthat it is usually, but not uniformly (as also shown by emberbarát)translatable with the pro- prefix.
(3) Z-barát n. = lover/friend/admirer of Z(Z = thing/activity)
e.g. kertbarát ‘lover of gardening’, zenebarát ‘music lover’(4) Q-barát n. = ?
(Q = ?)e.g. kebelbarát ‘bosom friend’, felebarát ‘brother, neighbour’, szürkebarát ‘pinot gris’
(lit. “grey monk”), elvbarát ‘comrade’ (lit. “principle friend”), házibarát ‘friend of the family’ (lit. “house friend”).
85 This is adequate for English users of the dictionary, who are thus informed about the Hungarian word, but not for
Hungarians, who do not need information.86 Mn/fn translates into English as adj./n.87 Of these, Germanophilist is contained in OED (2009) but not even in MWUD (2000), and so will be ignored.88 It would be pointless to give Hungarian definitions and abbreviations, so all of them are provided in English.89 The word pocket-friendly has another meaning: ‘suited for one’s pocket’, i.e. ‘(conveniently) pocket-sized’.

Chapter Three
225
For (3) a variety of paraphrases are needed in the definition, just a few of which have been givenhere. For (4),however, it is just impossible to offer a formula with a variable. The examples in (4),although homogeneous grammatically, are semantically so varied that they can simply not be en-tered under -barát but will obviously have a better place under the individual complex expressions.In is in this sense that combining forms behave as polysemous derivations. While the affix -mente.g. means state, condition, or quality (e.g. enjoyment), the result or product of action (e.g. em-bankment), process or action (e.g. management)90, and this is as much as a monolingual portraitdictionary can register, just by providing this much it has not helped the user much. In the light ofthis it is all the more odd that even some learner’s dictionaries contain derivational suffixes. MED(2007) has no -ment entry, but
CALD3 (2008) has this:-ment used to form nouns which refer to an action or process or its result
a great achievement, successful management, a disappointment
OALD (2005) offers this:-ment suffix (in nouns) the action or result of: bombardment, development;
LDCE (2005) has the following:-ment [in nouns] used to form a noun from a verb to show actions, the people who do them,or their results:
the government (= the people who govern a country)the replacement of something (= the action of replacing something)some interesting new developments
While the CALD (2008) entry specifies that the output is a noun, it does not say whether verbs(most typically) or other categories may also be inputs; in this sense, it fails to supply grammaticaldetail that would be expected of a portrait dictionary. The OALD (2005) entry, while it specifies -ment as a suffix, specifies only the category of the output, and gives a meagre definition. Interest-ingly, LDCE (2005), which comes closest to also meeting the demands of a portrait dictionary inthat it offers etymology, certainly not a necessity for the learner, provides both a full grammaticaldescription and a full definition. Of the really productive meanings, CALD (2008) gives all three:action, process, result; OALD (2005) just two: action and result; LDCE (2005) omits process butincludes a rather unproductive use of -ment: “the people who do them”.
The item -barát is easy to define in its more productive senses, but further down the productivityscale such defining becomes difficult. The items in (4) appear to be real (non-verbal) compoundswith a genuine noun as their right-hand member. Such compounds are notoriously opaque for de-coding, and unpredictable from the encoding point of view. If a formula were to be found, for allitems under (4), it might only be “Q friend”, and here Q may indeed be anything both grammati-cally and semantically, from the noun kebel ‘bosom’ to the adjective szürke ‘grey’ and fele91).
90 The source of the -ment definitions is CED&T (1992).91 Of obscure meaning and etymology; may have to do with fél ‘half’.

Chapter Three
226
� A Hungarian→English entry for the same -barát might be represented like this:
-barát
(1) -friendly X-barát X-friendly[exx:] bőrbarát skin-friendly, zsebbarát pocket-friendly
(2) pro- pro-Y pro-Y[exx:] németbarát pro-German, emberbarát philanthropic
The prefix pro- does not always feature in the translation; thus, a formula may begiven, but the examples do not all conform to this formula.
(3) lover of Z(s) / friend of Z(s)/ admirer of Z(s) / connoisseur of Z(s)[exx:] kertbarát lover of gardening, amateur gardener zenebarát music lover
borbarát wine connoisseur természetbarát lover of nature
A single formula cannot be given; the variety of structures testify to this.
(4) friend[exx:] kebelbarát bosom friend, felebarát brother, neighbour, szürkebarát pinot gris,
elvbarát comrade, fellow, házibarát 1. friend of the family 2. lover [of a married woman]
The items in (4) appear to be real compounds with a genuine noun as their right-hand member,which regularly yields a noun compound. Also, in (1) and (2), hyphenated English forms, while for(3 and (4) free phrases and compounds can be provided as equivalents.
3.2.2.3.3 “Hyphenated forms”
As has been mentioned in 2.7.2.1., in the system of Atkins & Rundell (2008:165), “partial words”include (i) bound affixes (e.g. the prefixes un-, de- and anti-; the prefix ex- in ex-wife, and the suf-fix the -gate in Monicagate), (ii) productive affixes (e.g. the im- in impossible, the -ment in at-tainment), and (iii) combining forms, i.e. first or second elements of hyphenated compounds (e.g.one-legged; vinyl-covered; flat-topped, flat-leafed, broad-leafed). They argue that the ones withnumerals as the first element are numerous, but not at all problematic. The ones with nouns and ad-jectives as their first member may either be self-contained headwords, or the entries of these firstmembers may refer to the fact that they are frequently first elements in hyphenated compounds. De-cisions as to the second element of these compounds (-covered, -leafed) are more difficult: they areeither given headword status or treated within the entry for cover and leaf.
This attempt at classification is a very unhelpful one, but the problems of the placement of suchitems are very real. This editor’s task is more difficult for the Hungarian→English part of the dic-tionary because, although combining forms abound, they are rarely actually hyphenated. An E→Hdictionary may conveniently opt to list the hyphenated words -legged, -covered, -topped and-leafed (i.e., the items above) and e.g. -eared, -footed, -haired, -handed, -headed, -legged and-roofed, and then the hyphens will adequately call attention to their compound status even withoutlabelling them as such (cf. the hyphenated English equivalents in HECD (1998) below).
In the case of the English second members, AMSZ (2000) places such hyphenated combining formsbefore their non-hyphenated homographs, thus:
-armed -karú before the adjective armed;-borne (vmi által) szállított/hordott, vmiben lévő before the verb form borne-bound vhová tartó before adjectival bound-buster -törő, -romboló, -irtó before nominal buster

Chapter Three
227
In the case of the Hungarian second members, MASZ (2000) places these hyphenated combiningforms in their proper alphabetical place. It is rare for them to have non-hyphenated homographs:
-fejű -headed, HÁTRAVETVE92: having/with a {MNÉV93} head-fülű -eared elálló fülű jug-eared-kezű -handed-hajú is unfortunately not included (and neither does the entry for haj ‘hair’ contain such informa-
tion)-lábú (1) [vmilyen lábszárú:] -legged, HÁTRAVETVE: with {MNÉV} legs gyors lábú swift-footed
(2) [vmilyen lábfejű:] -footed, HÁTRAVETVE: with {MNÉV} feet feltört lábú footsore
If in a H→E direction nothing is used to indicate that these are second members of compounds, theresult is that these compound-second-member headwords will be labelled as mn, i.e. adjectives(non-existent in isolation, or at least of doubtful status), and look like this (HECD 1998):
fejű mn -headed; deresedő fejű grey-headed; hosszú fejű long-headed [...] kerek fejű round-headed; kes-keny fejű long-headed [...] nagy fejű large / big-headed [...] rövid fejű short-headed [...] világosfejű clear-headed; zavaros fejű scatter-brained [...]
fülű mn -eared; elálló fülű jug-eared; hosszú fülű long-eared; jó fülű quick-eared; lelógó fülű lop-eared;nagy fülű long / flop-eared; rövid fülű short-eared; vágott fülű crop-eared
hajú mn -haired; hosszú hajú long-haired; rövid hajú short-haired; vörös hajú red-haired / head
kezű mn -handed; erős kezű strong-armed; fürge / gyors kezű quick / swift-handed; hosszú kezű long-armed / handed; könnyű / ügyes kezű light-fingered / handed; nagy kezű large / big-handed, big-limbed, large of limb ut94, having big hands ut, [...] rövid kezű short-handed; tiszta kezű átv95
white-handed
lábú mn with legs / feet ut, of foot ut, -legged, -footed, [...] csámpás lábú club-footed; having crooked /bow legs ut; [..] fájós / feltört lábú footsore; fürge lábú nimble / swift / fleet-footed, swift / quick /fleet of foot ut; görbe lábú bow / bandy-legged; hosszú lábú long-legged / shanked, leggy; [...]könnyű lábú light-foot(ed) / heeled; nagy lábú big-footed, having large feet ut, large of limb ut;párnás lábú with padded feet ut; rövid lábú short-footed / legged, short in the legs ut; szép lábúwith shapely legs ut; vastag lábú thick-legged
orrú mn -nosed; görbe orrú beak-nosed; hosszú orrú long-nosed; jó orrú átv sharp-nosed; nagy orrú big-nosed, nosy biz, conky szl; pisze / fitos orrú snub-nosed
szemű ‘-eyed’ is not includedtetejű mn roofed
The majority of the examples within the entries, one suspects, would have a better place as head-words on their own: these have been underlined.
3.2.2.4 Productivity and compounds proper
The domain of compounds and their lexicographic presentation is a rich topic that may be used asillustration of the lexicon–grammar interface as well as the problem of productivity. Productivity, inturn, a matter of cline rather than crisp boundaries, also raises the issue of “dichotomy vs. gradi-ence”. Compounds point up a difficulty that may be created by inadequate knowledge of spelling onthe part of the user, or by the vagaries of spelling and/or orthographic conventions of Hungarian.These will be illustrated below with English and Hungarian examples.
92 HÁTRAVETVE = in postposition93 MNÉV = adjective94 ut = in postposition95 átv = metaphorically/figuratively

Chapter Three
228
As the number of grammatical sentences (in English or any other language) is unlimited, so it hasbeen claimed that the same is true of verbal compounds96, cf. Bauer 2003) of the fox hunt-ing/hunter type; such a claim has been made in e.g. (Katamba 2005:70). Compounds, not just ver-bal ones, do generally feature high in a dictionary of any (pair of) language(s) whose type allowsthis, constituting as they do a sizeable part of many a vocabulary. Which compounds to include asheadwords and which are the ones whose members but not the wholes justify inclusion, however, isa difficult question of inclusion/exclusion, obviously also dependent on size and purpose of the dic-tionary.
If a pattern, e.g. verbal compounds, is productive, then it is completely rule-governed, predictable,and general wisdom places it within the grammar rather than the lexicon. This, however, does notautomatically mean that its product should not be included in the dictionary. While the products ofa typical ruled-governed process such as the regular past and participle forms of verbs are usuallynot registered, i.e. are conspicuous by their absence, the productive process itself that generatesverbal compounds is totally unobservable.
This concerns print versions; in electronic dictionaries, where unlimited space is available, predict-able verb forms may also be supplied. This is seen, for instance, in CC (2003), where the line of theheadword, with frequency diamonds (and GB and US pronunciation icons but no transcription) pro-vided, may look like this:
cat ♦◊◊ cat � cats �This, incidentally, may prove too much information technically to be squeezed into one line:in the entry for dog, e.g. the missing word class discrimination plus the presence of regular formsplus the absence of transcription results in the following:
dog ♦♦◊ dog � dogs � dogging � dogged �
where dog � can be both N and V; dogs � can still be both N and V; and dogging � can be Vonly. The fact that this dogged � is not a past V form does not become clear until one clicks on thespeaker icon and hears the pronunciation / »dÅgId/ – hardly excusably, since this is another lexeme,the adjective dogged; this is probably a programming error that indiscriminately assigns the /»dÅgId/ string to the written dogged string.
It would be ideal to be able to state that the more productive a pattern, the less dictionary-worthy itis. Many of the institutionalized verbal compounds, however, must also be included even if they are100% productive syntactically. The focus will first be on verbal compounds of the N V-ing pattern.First, weight watching and tojásfestés ‘egg painting’ will illustrate.The verbal compound weight watching is perfectly productive, but it has an idiosyncratic, specificmeaning (‘[trying to lose weight, esp. by] dieting’) which is largely from its constituents, whichjustifies its inclusion. If it is not, the compound may remain perfectly opaque to the user. EHCD(1998), e.g., does not contain weight watching, it only includes weight watcher:
weight watcher <fölös kilói miatt a súlyára ügyelő személy> ‘person concerned about his/her weightbecause of surplus weight’)
Nor can the entry for watching be expected to make the meaning of weight watcher clear:
watching fn 1. őrködés, megfigyelés 2. [...].
Similarly, the Hungarian noun tojásfestés ‘egg painting/dyeing’, a 100% productive verbal com-pound, has a specific meaning (‘decorating an Easter egg’), which is why it must be entered.
96 Or synthetic, or verbal-nexus, or secondary compounds. None of these terms, unfortunately, is helpful in indicating
what it is about. “Verbal”, which at least points to a verb being a necessary component in them, is used in this study.

Chapter Three
229
To take another example: there is undoubtedly a difference in statistical frequency (and/or institu-tionalization, and/or lexicalization) between the Hungarian verbal compounds névsorolvasás ‘takingthe roll call’ (more frequent) and névsorkészítés ‘making a list of names’ (less frequent) on the onehand, and névsorolvasás and novellaolvasás ‘reading short stories’ (less frequent), on the otherhand. If the Hungarian compound expression is established/frequent but its compound equivalentwould not be, a gerundial verb phrase or a verbal-noun-headed noun phrase may be given as trans-lation. Whereas for névsorolvasás – an established concept that is culturally salient, if not inde-pendently of language but surely so in English and Hungarian – there is an even more idiosyncratic(completely opaque, perfectly unpredictable, thus idiomatic) English expression, roll call, this is nottrue of névsorkészítés or novellaolvasás: here it is not possible to offer a compound, just gerundiveforms reading short stories or (the) reading of short stories. This illustrates how the “lexicon–grammar” boundary has been crossed.
Similarly productive syntactic patterns are displayed e.g. by the far less frequent, non-institutional-ized word faltisztítás ‘cleaning the/a wall’ (which will obviously not be included in dictionaries).One of the difficulties shown here lies in the fact that the differences between the variants may in-volve grammatical features (mostly aspects of referentiality), which are manifest in the choice of (i)English singular vs. plural; (ii) definite vs. indefinite article; and (iii) VP vs. NP vs. Noun. It is ob-viously not just words as translations for words that a dictionary is supposed to provide. In the caseof verbal compounds, although these exist in both English and Hungarian and are supposed to sharethe same characteristics, equivalence is volatile and erratic. Wherever such equivalences are neededto be given bilingually, the alternatives, spelt out and labelled, are like the ones that follow:
• (nonfinite) VP structuresgerundial VP w/ O: cleaning a wall (Det & number cleaning the wall usage in O varies) cleaning the walls
cleaning walls
• (definite) NP structuresverbal-N-headed97 NP: the cleaning of a wall
(Det & number usage the cleaning of the wall in of-PP varies) the cleaning of the walls
the cleaning of walls(cleaning of walls)
• Nounverbal compound wall cleaning
(with three possible punctuation forms, which have been ignored here.)
These patterns may all be adequate translations, in a given (pragmatic) situation, of the nounfaltisztítás, and there is no amount of grammatical labelling (in the form of codes or otherwise) andthere is no amount of sense distinguishers of any kind, that could guide the user to the requiredequivalent for a given situation. Sense indicators (as understood, e.g. by Atkins & Rundell2008:214, 511), as navigation aids, are supposed to distinguish between senses. This is just oneHungarian word: there are no senses between which to distinguish; the problem exactly is that thesenses of these ten or so expressions do not differ. Usage notes also serve a different purpose: theycannot be expected to guide to the right version either.
Even if it were somehow possible (with a set of sense indicators of a different kind, or “grammaticalsignposts” if such were recognized) a bilingual entry that contained all of the above for just a singleHungarian compound would have to be accompanied by examples, without which even the richest
97 “Verbal noun” is the convenient standard label for the -ing form in the pattern the V-ing of NP labelled as NP (as
opposed to the pattern V-ing NP labelled as nonfinite VP).

Chapter Three
230
signposting of sense indicators would not work; the length of that entry would run to half a page onaverage. This, then, cannot be the task of the dictionary: this is a grammatical problem which theuser should ideally be familiar with without consulting a dictionary.
The problem is compounded by the fact that Hungarian verbal compound nouns of the novellaol-vasás, névsorkészítés, faltisztítás type, although nouns, may be argued to have an associated subjectslot, since (in some form or other) they are compact “predicate + argument” skeletons. The transla-tion of novellaolvasás közben may well be just reading the/a story, i.e. the nonfinite structurewithout the probably expected prepositions (*during and while). Worse than that, adequate transla-tions can include a finite subclause with an overt subject and (possibly) another overt subject in themain clause, while the covert subject – PRO – of the Hungarian structure is controlled by a (possi-bly also covert, pro) NP subject in the main clause:
[PRO Novellaolvasás közben] ‘lit. during story reading’ gyakran álmodozikwill be more idiomatically translated as
[When/While he’s reading stories], he often indulges in fancies[When/While he’s reading stories], his mind often wanders off
The definiteness and specificity parameter will have to be adjusted to the situation. The averageHungarian user will have no idea about these grammatical notions, similarly to the difference be-tween event and result nominals, which knowledge would also be indispensable for adequatelytranslating such Hungarian -Ás verbal nouns into English.
The phenomena illustrated above indicate that in an unpredictably large percentage of cases, nonoun (phrase) or even nonfinite structure can be made to correspond to a Hungarian verbal com-pound, only a finite structure: this brings the number of possibilities listed above to (around) ten.Thus, instead of the “ideal” situation of registering for any Hungarian X-V-Ás ‘X-V-ing’ compounda similar English verbal compound of the N-V-ing template, we are left with a dozen different syn-tactic ways of expressing this idea. There is no “default” form available, and the dictionary entry isby far not an ideal place to represent or “teach” the variety of means that a given sense can be ex-pressed by.
A Hungarian compound noun does not readily show either whether it is of the (i) verbal type – e.g..portörlő ‘dust cloth’, literally: ‘dust wiper’; lábtörlő ‘door mat’, lit. ‘foot wiper’ ablaktörlő ‘wind-screen wiper’, lit. ‘window wiper’; or (ii) a root/primary98 compound – e.g. papírtörlő ‘kitchen pa-per’, lit. ‘paper wiper’.
Hungarian compounds of the type csonttörés ‘fracture’; lit. ‘bone breaking’ can be construed in twoways: with the first member, csont ‘bone’ here as (a) patient/object (b) patient/subject. The mean-ings, correspondingly, are: (a) ‘breaking a bone’ (b) ‘the breaking (= intransitive V) of a bone’, i.e.‘fracture’. Both of these are productive in the sense that any new NV-Ás pattern is only constrainedby its semantics: provided that the N is “Patient”, such a compound is possible both with this Pa-tient N as object and subject. (An “Agent” or a “Theme”, e.g. cannot be the first member as subject:*gyereksétálás ‘child walking’; *időmúlás ‘time passing’.)
It is not clear that csonttörés ‘bone breaking’ and csőrepedés lit. ‘pipe cracking’, whose first mem-ber is not object but subject, are regarded as verbal compounds in the literature. If the left-handmember is defined as an argument of the verb and if subjects count as arguments, then the likes ofthese two words are indeed verbal compounds; if the definition differs, then csonttörés and csőre-pedés will not be.
98 “Root” and “primary” (not unlike “verbal”, “synthetic” and “verbal-nexus”) say very little of essence. Worse than
that, “root” and “primary” also fail to visibly oppose any of these three. Therefore, where such an opposition isneeded, “verbal vs nonverbal” will be used.

Chapter Three
231
The table shows some correspondences between Hungarian -Ó and -Ás verbal compounds and theirEnglish equivalents (rókavadászat is formally different):
Hungarian EnglishNoun Non-compound
(= phrase)verbal compound -ing or -er
verbalcompound
other than -ingor -er verbalcompound
non-verbalcompound
simplex(often Latinetc)
ablaktörlő windscreenwiper (!)
csőbevezetés intubation,cannulation
csőrepedés burst pipecsonttörés fracture breaking a bonefaltisztítás cleaning the/a wall
(etc.)kutyasétáltatás walking the/a (etc.)
doglábtörlő door matnévsorolvasás roll call, calling
the rollreading aloud the/alist of names (etc.)
névsorkészítés making/preparinga/the (etc.) list ofnames
novellaolvasás short storyreading
reading short stories
rókavadászat fox hunting fox huntportörlő dust clothtojásfestés egg painting decorating/painting
eggs (etc.)
Not verbalcompoundcsőberendezés pipework piping ,
tubingsystem of pipes
No amount of knowledge of productive compounding enables the learner/user to pick the rightequivalent.
Whether the English equivalent of a Hungarian -ing verbal compound will also be an -ing verbalcompound, a verbal compound other than -ing, a nonverbal compound, or a non-compound, in-cluding simplex words and phrases, the equivalents must be provided as though all of them wereidiosyncratic. This is partly because the source-language user has no precise notions about the se-mantics of compounds, and partly because of lexicalization, which may distort the otherwise neatlyproductive patterns.
If the user does not come to the translation task equipped with this grammatical (including seman-tic/ pragmatic) knowledge, then the consultation of the dictionary entry will never yield an idio-matic result.
For the user working with the dictionary, the grammatical PoS status of the source language word is(mostly) obvious, especially if it is a noun. The question, however, of whether it is a process or a re-sult noun which may prove important for translation, will not be known: most Hungarian users willhave never heard of this distinction either in their mother tongue instruction or language learning

Chapter Three
232
careers. The difference between compounds and non-compounds may be easily appreciated, but thatbetween verbal and non-verbal compound will also be unknown. The next impediment is the noto-riously uncertain intuitions and the oft-cited ignorance of users concerning sense breakdown. Thenotion of productivity also being unknown, users cannot be expected to know that the meaning ofverbal compounds is predictable. Whether a compound is a verbal one does not become obviousfrom its form (cf. the example papírtörlő ‘kitchen paper’ above, which, since its structure is ‘paperwiper’, could equally be a root or a verbal compound). And, of course, the otherwise productivepattern of ablaktörlő (a verbal compound) does not guarantee the existence of *window wiper – thecompounding syntax is predictable, but the lexical items to be compounded themselves, which aresimplexes, are not (windscreen). Guessing the English equivalent of csőrepedés is even less likely,since both lexicon and syntax contrive to make this impossible: the verb to be used is not crack (orbreak or fragment or crackle or split or chink or splinter or tear or gap or rupture or fissure, allof which translate notions related to reped), but burst. The syntax of the expression will also be un-predictable: the pattern being burst pipe, a past participle as modifier of the noun involved, Englishuses not a process but a result nominal, the result of pipes bursting. Syntactically, of course, pipesbursting or bursting pipes are no less acceptable.
The claim made here is, of course, not that learners will never be able to produce acceptable trans-lations of source language texts containing compounds, but that the dictionary cannot be expectedto supply the missing knowledge. Even if this information could be given, it could not possibly berepeated in the entries of all the relevant compounds. This, coupled with the decreasing importanceof formal/explicit grammatical instruction, makes it hard to imagine how anything but heavy expo-sure to idiomaticity can produce acceptable expressions.
3.2.2.5 One facet of consistency: number compounds
Internal consistency in a dictionary can be captured in many ways: in the most general sense, edito-rial consistency means uniformity, i.e. that answers to problems of type X in one (type of) entryshould not be different from answers to the same (kind of) problems other (types of) entries. This isthe requirement of generality, of the need to observe rule-like behaviour and present the informationaccordingly. This is the sense in which it has to do with the lexicon/grammar boundary: statementsabout language of very high generality are grammatical statements, while statements of low gener-ality or outright isolated ones are lexical ones.
Atkins (2008) mentions that in an explanatory dictionary, ideally, identical/similar senses would re-quire identical/similar definitions. Consistency is easiest to achieve in the case of closed classes;standard examples of this type of consistency include: days of the week; months; flowers; metal.
This semantic, lexical field-related consistency can be opposed to lexical consistency, which coversthe case of words lexically similar but semantically distinct. The case of the number “compounds”in MASZ (2000) illustrates this.
The precise status of the number component of these “compounds”, and the type of word thus cre-ated, is now irrelevant. Not all of them are actually compounds (egyesével ‘one by one’ e.g. is not acompound, but a derivation of egy); for the present purposes they will still be labelled that.
What lexical similarity, i.e. partial semantic overlap, means will be illustrated on the example ofHungarian egyesével ‘one by one’ and hatlövetű ‘six-shooter’: the only meaning component that iscommon to these two is the presence of the number – which is not enough to relegate them to thesame semantic field: these are not one lexical set, or semantic field.
The task involved in the compiling of MASZ (2000) was to ensure that all words that contain thenumbers egy ‘one’, két ‘two’, etc. etc. (predominantly adjectives, and some forms derived from

Chapter Three
233
them) be uniformly included. (The item kettő, a variant of két, does not occur in such combinations:két- is the combining variant.) The aim was to have a system that was consistent in the sense that, ifegylovas ‘one-horse’ was included, then kétlovas ‘two-horse’, and preferably as many similar com-pounds as are typical should also be. Only those number “compounds” were relevant that showed,and were recurrent in, that “number opposition”. The complexes egyhamar ‘soon’ (e.g. egyhamarnem látod ‘it’ll take some time before you see her’) or egyhangú (1) ‘monotonous’ (2) ‘unanimous’,egycsapásra ‘at one fell swoop’ were obviously not to be included. Recurrence as a requirementwas important because although e.g. egynejű ‘monogamous’ (lit. “one-wifed”) and egynejűség ‘mo-nogamy’ (lit. “one-wifed-ness”) do have to do with “one-ness” and do oppose “more-than-one-ness”, they only contrast with többnejű (lit. “more-wifed”) and többnejűség (lit. “more-wifed”) andnot with any other number “compound”. The forms kétnejű and kétnejűség do not seem to exist.
Most such items are adjectival, and some are secondary derivatives from adjectives e.g. the adjec-tive tízcentes ‘ten-cent’ yields the noun tízcentes ‘ten cent coin’.
It must be noted that this is a typical unidirectional task: perhaps most of the items included therebywould never be headwords in a English→Hungarian dictionary.
Making the list meant finding the relevant words beginning with egy ‘one’, két ‘two’, etc. and fill-ing them in a grid. The grid, so supplied, proved to be full of holes indeed, but fortunately verylarge. Partly because of this original vast quantity, careful selection was needed: (i) what percentageof these potential “number compounds” was to be included? And (ii) how far should one go for aparticular number?
A list like this is expected to include such items (with approximate equivalents given) as: egyéves‘one-year’, kétcsövű ‘double-barrelled’, háromhetes ‘three-week’, négyoldalas ‘four-page’, ötszögű‘pentagonal’, hatlövetű ‘six-shooter’, hétféle ‘seven different types of’, nyolclábú ‘eight-legged’,kilencesztendős ‘nine-year’, tízcentes ‘ten-cent’.
This sample illustrates that what is involved here is the fuzzy border area between the grammaticaland the lexical: in a grammar book, rules and subrules for these lexical items could be given, and ahost of exceptions listed; lexicographically, the dictionary-worthy ones, but only those, will have tobe entered. The generality, i.e. the common pattern to them, will be there only for the editors to see,because they will be scattered, individual items.
For illustration, the second members of a sample of the compounds from the A–L range (X-ablakosto X-lövetű) have been gathered in the grid below, a small portion of the original grid.
For the purpose of the actual dictionary entries, where a ceiling had to be set at some number, notthe entire combination, just the second constituent has been included as combining form above thislimit:
-féleképpen VAGY -féleképp in {SZMNÉV} (different) ways hatféleképp(en) in six (different) ways

Chapter Three
234
List No22
A sample of number compounds as documented in MASZ (2000)
1 2 3 4 5 6 7 8 9 10 20 100 Typical collocate*
-ablakos + BUILDING-ágú + + + + + 1 fork; star
-ágyas + 2 2 + + + + room
-ajtós + + + + + vehicle; room
-árbocos + + + + + 3 3 3 vessel
-centes4 + + + coin
-centis5 + + line
-csillagos + + + + + brandy
-csövű + + gun
-éves + + + + + + + + + + + + child
-felé + + + + (adverb)**
-féle6 + + + + + + + + + 7
-hetes + + + + + + + + + period; baby
-heti + + + + + + + + + period
-kamarás + + parliament
-kerekű + + + + vehicle
-lábú + + + + + + living thing; furntiture
-lovas + + + + + cart
-lövetű + + revolver
* It is not necessarily the case that just one item collocates: depending on the noun base of thecompound’s right-hand member, there may be several.
** No collocate is given for adverbs.
1 Hatágú ‘six-pointed’ is sadly missing.2 Kétágyas and háromágyas are not given, but kétágyas szoba and háromágyas szoba are included
as a headword.3 Google returns lots of hits for határbocos ‘six-masted’, hétárbocos ‘seven-masted’ and even
nyolcárbocos ‘eight-masted’. This will never be learned from this dictionary.4 These are all nouns, and tízcentes ‘ten-cent’ is also included an adjective.
5 Any collocate that is semantically suitable.6 Only these two are included; the combining form, however, is given as a headword:
-centis -centimetre két centis vonal two-centimetre line.7 The combining form -féle itself is also entered: -féle 1. [fajta:] kind/sort ilyenféle of this sort 2.
[vki nevéhez fűződő:] smb’s a Kovács-féle {FNÉV} Kovács’s {FNÉV}.

Chapter Three
235
List No23
A sample of the actual compound entries with egy- ‘one-’ in MASZ (2000):
egyajtós one-dooregycentes one-cent piece/coinegycentis one-centimetreegycsillagos single-star, one-staregydolláros one-dollar noteegyemeletes two-storey(ed), two-story AM, two-
storied AMegyéves 1. one-year-old, one year old egyéves
gyerek one-year-old child egyéves bevásár-lóközpont one-year-old shopping mall Freddyegyéves Freddy is one year old 2. [egy évigtartó:] one-year
egyévi 1. [egy évre szóló, pl. fizetés:] yearly, ayear's, annual 2. [egy évig tartó:] HÁTRAVETVE:for/lasting one year
egyfázisú single-phase, monophaseegyfedelű repülőgép monoplaneegyfelé in the same directionegyféle 1. [azonos:] HÁTRAVETVE: of the same
kind 2. [egy fajta:] one kind/sort (amiből: of),HÁTRAVETVE: of one kind/sort 3. [vmiféle:] cer-tain, HÁTRAVETVE: of a certain/special sort/kind
egyfelől (1) [azonos irányból:] from the same di-rection (2) egyfelől {MONDAT}, másfelől{MONDAT} on the one hand {MONDAT}, on theother (hand) {MONDAT}
egyfelvonásos MNÉV/FNÉV one-act (play)egyfogatú one-horseegyfokozatú single-phase, single-stageegyfontos one-pound piec/coinegyfordulós single-roundegyforintos one-forint piece/coinegyfős VAGY egyfőnyi one-person, one-manegygyerekes VAGY egygyermekes single-child,
one-child, HÁTRAVETVE: with one childegyhetes (1) [időtartam:] one-week, one/a week's,
HÁTRAVETVE: lasting a/one week, HÁTRAVETVE:of one week (2) [kor:] (one-) week-old, one weekold
egyheti one-week, one/a week'segyhónapos (1) [egy hónapig tartó:] one-month,
one month's, HÁTRAVETVE: lasting a/one month,HÁTRAVETVE: of one month (2) [kor:] one-month-old, one month old
egyjegyű single-digitegykamarás unicameral, single-chamberegykerekű one-wheel(ed), single-wheel(ed)egykulcsos adó flat taxegylábú one-leggedegylépcsős single-step, single-stage, single-phaseegylovas one-horseegylövetű single-shotegynapi one-day, one/a day's, HÁTRAVETVE:
lasting/of one/a dayegynapos 1. [korú:] one-day-old, one day old 2.
[egy napig tartó:] one-day, one/a day's,HÁTRAVETVE: lasting/of one/a day
egynapos kirándulás day trip
egyoldalas 1. one-page, single-page 2. [másolat:]single-sided
egyoldali one-sided, unilateralegyoldalú 1. [pl. felfogás:] one-sided, bias(s)ed,
partial, predisposed 2. [szerelem:] unrequited 3.[pl. felmondás:] unilateral
egyórai 1. [időtartam:] one-hour, an hour’s,HÁTRAVETVE: lasting-for-of an hour 2. [időpont:]az egyórai vonat the one-o’clock train
egyórás [időtartam:] one-hour, an hour’s,HÁTRAVETVE: lasting-for-of an hour
egyöntetű 1. uniform, identical, like, similar,unanimous 2. [következetes:] consistent
egyösszegű lump sum, flat feeegypályás [út:] single-laneegypárevezős FNÉV single scullegypártrendszer one-party systemegypennys one-penny piece-coinegyperces one-minute, a minute’s, HÁTRAVETVE:
of-lasting a minuteegypetéjű uniovular, one eggegypetéjű uniovular, one eggegypetéjű ikrek identical twinsegypólusú unipolaregypúpú one-humpedegypúpú teve dromedaryegyrendbeli on one countegyrészes one-piece szorosan simuló egyrészes
női ruha bodysuitegyrétegű single-layer(ed)egysávos single-laneegysíkú 1. two-dimensional 2. [unalmas:] unso-
phisticated, simple, uncomplicatedegyszakos [képzés:] single honoursegyszámjegyű single-digit, one-digitegyszárnyú ajtó single dooregyszarvú FNÉV unicornegyszemélyes one-person, one-man,
HÁTRAVETVE: for one personegyszemélyi one-person egyszemélyi felelősség
one-person responsibility egyszemélyi vezetésone-person leadership-management
egyszemű one-eyedegyszeres 1. simple, single, one-time, one-off 2.
[könyvvitel:] single-entryegyszeri 1. [egyszer történő:] single, one-off, one-
time, HÁTRAVETVE: done-happening-occurringonce 2. [egykori:] former, one-time, ex- 3. [törté-netbeli:] this az egyszeri ember this man/guy
egyszikű monocotyledonousegyszintes single-storey(ed), single-story AM,
single-storied AMegyszínű 1. [egyetlen színű:] single-coloured, uni-
coloured, HÁTRAVETVE: of one colour 2. [pl.monitor:] monochrome
egyszobás lakás bedsit, bedsitter, studio flat, one-room flat

Chapter Three
236
egyszólamú unison, unisonous, unisonant, mono-phonic
egyszótagú monosyllabic, one-syllableegytagú 1. one-member 2. [egy részből álló:]
HÁTRAVETVE: having-with-of one part 3.[egyszótagú:] monosyllabic 4. [matematikai kife-jezés:] monomial, single term
egyterű [autó:] people carrier, minivan, multipur-pose vehicle, MPV
egyujjas kesztyű mitten(s)együléses single-seateregyvágányú single-track

Conclusions and results
By contrasting lexicological and metalexicographic ideals to existing dictionary entries, the disser-tation has investigated interfaces of lexicography and lexicology, and lexicography and linguistics,to identify aspects where principled rigour can, or indeed must, be sacrificed to practical utility.
The dissertation substantiates the claim that compromise is to be sought between theory andpractice. Lexicographic decisions are indeed more usefully made with users in mind than based onscraps of ill-fitting theory, even where such are available. This is in the spirit of Landau’sadmonition99 that intelligibility must not be “sacrificed to a purity of style bordering on lunacy”.
One finding, however, has been that such readily usable insights from linguistics are not available.If, however, most linguistic insights have little relevance for dictionary making (a gloomy view notuniversally shared), and/or they would be well nigh impossible to accommodate within lexico-graphic praxis (a form of pessimism that many analysts would subscribe to), and/or most of theseinsights would be lost on most users anyway (an almost consensual claim), then editors’ familiaritywith theory can at least help identify where those areas of compromise exactly are.
1. In charting the correspondences between “lists” in the mental lexicon vs. lists in dictionaries,only tentative hypotheses seem to be available as to the former. Based on the little that is available,the dissertation has proved that the printed lists produced by lexicographical wisdom are farremoved indeed from the “lists” of the mental lexicon. Next to nothing that is assumed, howevertentatively, about the mental lexicon can be reflected by means of lexicography.
2. The dissertation assumes that the mental lexicon is a system of multiword units rather than aset of isolated words. Unfortunately for dictionary-making, however, these are so varied andelusive, and as a consequence, their linguistic treatment is so chaotic, as to promise very little forpractitioners of lexicography. A novelty of the dissertation is a lexico-semantic and grammaticalexamination of such lexical units of diverse types above the traditional word level, and contrastingthese with potential and existing dictionary entries.
3. The dissertation claims, and proves on a variety of examaples, that very few findings oflinguistics have made their way into lexicography; to show the little that has been utilized, entriesfrom several dictionaries of different types have been explored. More recent dictionaries that havebeen under scrutiny include: RHWUD 1999 (Random House Webster’s Unabridged Dictionary);MWUD 2000 (Merriam–Webster’s Unabridged Dictionary); CC 2003 (Collins COBUILD on CD-ROM); AHD 2004 (American Heritage© Dictionary of the English Language); LDCE 2005(Longman Dictionary of Contemporary English); OALD 2005 (Oxford Advanced Learner’sDictionary); MED 2002 & 2007 (Macmillan English Dictionary); CALD 2003 & 2008(Cambridge Advanced Learner’s Dictionary; CCAD 2009 (Collins COBUILD Advanced Dictionary).
4. Several claims of the dissertation are best couched in terms of – not just lexicographic and lexi-cological – paradoxes. It has been found and illustrated throughout that notions of gradience orcline are better suited to many phenomena than discreteness, both in and outside of lexicology.This, the present author thinks but has not argued here, probably carries over to linguistics at large.
99 Landau (2001) .

238
(By the recognition of prototypicality and the indeterminacy of linguistic facts, the dissertation doesnot automatically argue for prototypes in the realm of things “out there”, and thus assumes nospecifically cognitive framework.)
4. 1 Perhaps the gravest paradox of lexicography is this: almost nothing of the analogue natureof the lexicon, and possibly language at large, can be represented in the inevitably black-and-white,two-dimensional world of lexicography, which, in addition to this crispness, must add a goodmeasure of inevitable simplification for the sake of users. This amounts to the claim that although inlexical phenomena the probabilistic nature of language clearly transpires, lexical patterns aredifficult to capture in the static world of dictionaries. Also, it seems that what users expect areexactly hard-and-fast rules and rigid boundaries supplied by dictionaries that change as little aspossible.
4.2 Idiomaticity itself has been found to be gradational, especially that of multiword expres-sions, which show a strong centre–periphery pattern in other respects as well. I have tried to showthat this adds to the difficulty of their lexicographic treatment, whose inadequacy is quite clear inthe most recent monolingual native speaker dictionaries, and less so in the didactically otherwisesuccessful learner’s dictionaries. This edge of learner’s over native speaker dictionaries is a paradoxspecifically in English lexicography: the mundane considerations and motives of the ELT industryhave apparently left on it a deeper impact than has theoretical linguistics.
4.3 The dissertation has separated the notions of idiomaticity, transparency, and compositional-ity100. Idiomaticity is best seen as defined in terms of unpredictability. In that framework, allmultiwords – including compounds, combining forms, binomials, and what are referred to in thedissertation as traditional “colourful” idioms, are idiomatic since they are unpredictable across anytwo languages, which is the only true measure of idiomaticity.
4.4 One type of gradience is inherent in the notion of productivity: the status of lexical unitsranging from frequent/existing through rare/existing and potential all the way to the ungrammaticalbut existing. The dissertation (especially in 3.2) captures another paradox of dictionary-making: thatproductivity is also impossible to capture in the static world of dictionaries, where, due to theinevitable limitations, “all words are equal”.
4.5 Another paradox identified in the dissertation is that while not just idiomaticity but many(perhaps most) lexical phenomena inhabit continua, this ill suits the purposes of lexicography.Dictionaries, especially “instrument dictionaries”, where clear-cut advice is expected, produce toolsfor the layperson. Aggravating this problem are the efforts at simplification, motivated by users’perceived needs and general poor levels of grammatical informedness.
5. Numerous examples support the claim that linguistic “theory”, more and more aloof with itserratic changes and spectacular fragmentation, proves less and less adequate for a provision ofguidelines for lexicographic practice, especially as regards the narrower field of grammar. It seemsevident that most linguistic advances are lost on lexicography. At the linguistic input is a collectionof arcane, mostly incompatible and ever-shifting findings never meant for lexicographic end use inthe first place. At the output, in the dictionaries, which under user pressure to change as little aspossible anyway, is a hardly noticeable imprint of linguistic science, with the gap between it andlexicography ever widening.
6. If users’ needs rather than theoretical considerations can be the real measure of evaluating worksof lexicography, then the inadequacy of linguistic theory as model or theoretical basis, serving as astable source of inspiration, is less damaging than might be supposed. Users’ needs, however, aremuch harder to assess than is usually thought. There are too many different users, and indeed too 100 Drawing on Nunberg & al. (1994).

239
widely differing tasks in any bilingual relation. And while the need for user research is over-emphasized in the literature, what this injunction precisely means for the praxis is unclear.Moreover, the “know your user” requirement, unfortunately, is unhelpful for small markets, andespecially so for bilingual Hungarian↔English lexicography, where dictionaries are produced forHungarians using English rather than vice versa, and thus will never have a chance of being asdiverse as to justify large-scale user studies.
This means that even if users’ needs can indeed be found out, dictionaries cannot be easily tailoredaccording to the findings. This suggests that although dictionaries will evidently be different, veryfew, if any, of their differences in design and editorial policy will come from user/market research.The dissertation arrives at the indeed unfortunate conclusion that because input from linguistics isinsufficient and user research sparse, perhaps inevitably dictionaries will be bound to continue ontheir path of inertia.

Potentialities for further research
The dissertation, “a lexicographer’s view of linguistics”, has brought to the surface quite a fewfurther issues which are of paramount importance. A most worthwhile path of further study is to ex-plore and chart, in a consistent and unified framework101, the gradience of various types of lexicalphenomena.
A list of sources pointing to further areas of exploration and thus relevant have become availableafter closing the manuscript is provided below. One of them102, a study that claims that “the stand-ard word class framework becomes just a convenient labelling system, primarily for such everydaypurposes as teaching as well as dictionary and grammar writing but without any theoreticalbackground”, is thus a pointed illustration of an even more radical rift between linguistic theory andlexicography.
The dissertation refers to Bauer (2003)103, according to which some processes are more while someless (centrally) morphological and more syntactic than others, and thus may be argued to exhibit acontinuum of major significance. Prefixation has affinities with (neo-classical) compounding aswell as back-formation; suffixation is borders on neo-classical compounding, conversion, and back-formation; the latter shows similarities with both conversion and clipping; neo-classical compound-ing has affinities with blending, which is similar to acronym formation. Crucially, compoundingborders on syntax. Within the theory, this may necessitate redrawing on a major scale of the boun-daries of morphology and consequently of the compartments of language. The aim of lexicographicpractice, by contrast, will be to capture as many as possible and represent as many as can be use-fully represented, of these potential changes.
101 In the spirit of Aarts (2007).102 Kenesei (2010); my translation.103 Bauer (2003:122–125).

241
Sources relevant for further research
Booij (2009): Geert Booij “Compound construction: schemas or analogy? A construction morphol-ogy perspective”. To appear in: Sergio Scalise & Irene Vogel eds. Compounding. Benjamins.
Geeraerts (2010): Dirk Geeraerts Theories of lexical semantics. OUP.
Kastovsky (2009): Dieter Kastovsky “Astronaut, astrology, astrophysics: About Combining Forms,Classical Compounds and Affixoids”. In: R. W. McConchie, A. Honkapohja & J. Tyrkkö eds. Sel-ected Proceedings of the 2008 Symposium on New Approaches in English Historical Lexis, 1–13.Somerville.
Kenesei (2010): “Vannak-e szófajok? És ha igen, mennyi?” [Whether word classes exist, and if yes,how many?] Presentation at the Research institute for Linguistics of the Hungarian Academy ofSciences, 17/06/2010, http://www.nytud.hu/kenesei/szofajokea100617.pdf, accessed 27/06/2010.
Lieber & Štekauer (2009): Rochelle Lieber & Pavol Štekauer The Oxford Handbook of Compound-ing. OUP.


References*
[1] Aarts (2007): Bas Aarts Syntactic Gradience. The Nature of Grammatical Indeterminacy. OUP.
[2] Aarts (2008): Bas Aarts English Syntax and Argumentation 3rd ed. Palgrave Macmillan.
[3] Aarts & McMahon (2007): Bas Aarts & April McMahon eds. The handbook of English linguis-tics. Blackwell.
[4] Aarts & Haegeman (2007): Bas Aarts & Liliane Haegeman “English word classes and phrases”.In: Aarts & McMahon (2007).
[5] Abu-Ssaydeh (2005): Abdul-Fattah Abu-Ssaydeh “Variation in multi-word units: the absent di-mension”. In: Studia Anglica Posnaniensia: International Review of English Studies 41. AdamMickiewicz University, Poznan, Poland.
[6] Acquaviva (2008): Paolo Acquaviva Lexical Plurals: A Morphosemantic Approach. OUP.
[7] Adger (2003): David Adger Core syntax. A minimalist approach. OUP.
[8] AHD (1994): The American Heritage Electronic Dictionary 3rd ed. Version 3.5. Houghton Mifflin.
[9] AHD (2004): American Heritage© Dictionary of the English Language, 4th ed. Houghton Mif-flin Company. Software by Kanda Software, Inc. Copyright © 1999-2004.
[10] Aitchison (1990): Jean Aitchison “Cruse, D. 1986. ‘Lexical Semantics’. CUP. In: InternationalJournal of Lexicography 1990 3(2):147-149. OUP.
[11] Aitchison (1994): Jean Aitchison Words in the mind. An introduction to the mental lexicon. 2nded. Blackwell.
[12] Almela & Sánchez (2007): Moisés Almela & Aquilino Sánchez “Words as ‘Lexical Units’ inLearning/Teaching Vocabulary”. In: International Journal of English Studies. University ofMurcia, Spain. Vol. 7, No 2. 21–40.
[13] Altmann (1998): Gerry T. M. Altmann The ascent of Babel. 2nd ed. (in preparation).http://homepage.mac.com/gerry_altmann/babel/assets/Chapter-6.pdf, accessed 30/07/2008.
[14] Altmann (2001): Gerry T. M. Altmann “The language machine: Psycholinguistics in review”.In: British Journal of Psychology 92, 129–170
[15] AMDSZ (2002): Tamás Magay & László Kiss eds. Angol–magyar diákszótár [English–Hungarian student’s dictionary]. 2nd ed. Akadémiai, Budapest.
[16] Ameka (2006): F. K. Ameka “Interjections”. In: Brown (2006)
[17] AMSZ (2000): Péter A. Lázár & György Varga Angol–magyar szótár. Aquila, Budapest. 8th,enlarged ed. 2006.
[18] AM&MASZ (2000) = AMSZ (2000) and MASZ (2000) referred to together.
[19] AMMTSZ (1996): Tamás Magay & László Kiss Angol-magyar műszaki és tudományos szótár[English–Hungarian Technical Dictionary] Vol. 1–2. Akadémiai Publishers. Electronic version.Scriptum Kft. 1996.
[20] Andor (2004): József Andor “The master and his performance: An interview with NoamChomsky”. In: Intercultural Pragmatics 1–1 (2004), 93–111. Walter de Gruyter.
[21] Apresyan & al. (1980): Yuriy Apresyan & al. Anglo–russkij sinonimicheskij slovar’ [English–Russian Dictionary of Synonyms]. Russkij jazyk, Moscow.
* Cited dictionaries (both print and electronic) are listed together with other literature, in strict alphabetical order. They
are easily distinguishable, however, because initialisms (a standard letter code, if available) refer to them, rather thanbeing listed by author/editor.
With major, internationally know publishing houses, the place of publication is not given; Hungarian publishers alwaysappear like this: Publisher, City, Hungary.
Non-English names may occur in different transliterations, with the original retained.

244
[22] Apresyan & al. (1969): Yuriy Apresyan, I. A. Mel'čuk & A. Žolkovskij “Semantics and lexi-cography: Towards a new type of unilingual dictionary”. In: Ferenc Kiefer ed. Studies in syntaxand semantics. Reidel.
[23] Apresjan (2001): Juri Apresjan [transl. Kevin Windle] Systematic Lexicography. OUP.
[24] Aronoff (1976): Mark Aronoff Word formation in generative grammar. MIT Press.
[25] Aronoff & Anshen (1998): Mark Aronoff & Frank Anshen “Morphology and the lexicon: lexi-calization and productivity”. In: Spencer & Zwicky (1998)
[26] Atkins (1993) Beryl T. Sue Atkins “Theoretical lexicography and its relation to dictionary-making”. In: Dictionaries: The Journal of the Dictionary Society of North America 14: 4–43.
[27] Atkins (2008): Sue Atkins “Theoretical lexicography and dictionary-making” [orig. publ.1992/93]. In: Fontenelle (2008).
[28] Atkins & Rundell (2008): B. T. Sue Atkins & Michael Rundell The Oxford Guide to practicallexicography. OUP.
[29] Ayto (1980): John R. Ayto “When is a meaning not a meaning?” In: Times Educational Sup-plement, 25 April.
[30] Ayto (1983): John R. Ayto “On specifying meaning: semantic analysis and dictionary defini-tions”. In: Hartmann (1983).
[31] Ayto (2006): John Ayto “Idioms”. In: Keith Brown (2006).
[32] Bárczi & al. (1967): G. Bárczi, L. Benkő & J. Berrár A magyar nyelv története [A history ofthe Hungarian language]. Budapest.
[33] Barlow & Kemmer (2000): M. Barlow & S. Kemmer Usage based models of grammar. Stan-ford, CA. CSLI Publications.
[34] Bauer (2001): Laurie Bauer Morphological productivity. CUP.
[35] Bauer (2003): Laurie Bauer Introducing linguistic morphology. Edinburgh University Press.
[36] Bauer (2004): Laurie Bauer A glossary of morphology. Edinburgh University Press.
[37] Bauer (2007): “Compounds and minor word-formation types”. In: Aarts & McMahon (2007)
[38] Béjoint (1994): Henri Béjoint Tradition and innovation in modem English dictionaries. (Ox-ford studies in lexicography and lexicology). Clarendon Press.
[39] Béjoint (2000): Henri Béjoint Modern lexicography: An introduction. OUP. [updated paper-back version of Béjoint (1994)]
[40] Berlin (1953): Isaiah Berlin The hedgehog and the fox. An essay on Tolstoy’s view of history.Widenfeld & Nicolson. London.
[41] Biber & al. (2000): Douglas Biber, Stig Johansson, Geoffrey Leech, Susan Conrad & EdwardFinegan Longman grammar of spoken and written English. 3rd impression. Longman
[42] Biber & al. (2002): Douglas Biber, Susan Conrad & Geoffrey Leech Longman student gram-mar of spoken and written English. 2nd impression, 2003. Longman.
[43] Bloomfield (1933): Leonard Bloomfield Language. New York: Holt.
[44] Bolinger (1946): Dwight L. Bolinger “Visual Morphemes” In: Language, Vol. 22, No. 4. 333–340.
[45] Booij (2007): Geert Booij The grammar of words. An introduction to morphology. 2nd ed. OUP.
[46] Brown (2006): Keith Brown ed. Encyclopedia of Language and Linguistics. Elsevier.
[47] Bybee (1995): J. L. Bybee “Regular morphology and the lexicon”. In: Language and cognitiveprocesses 10, 425–55.
[48] CALD (2003): Cambridge Advanced Learner’s Dictionary. CD-ROM Version 1.0 CUP. Basedon the printed edition of Cambridge Advanced Learner’s Dictionary.
[49] CALD3 (2008): Cambridge Advanced Learner’s Dictionary. CD-ROM Version 3.0 CUP.Based on the Cambridge International Dictionary of English, editor-in-chief Paul Procter.

245
[50] Carter & McCarthy (2006): Ronald Carter & Michael McCarthy Cambridge grammar of Eng-lish. CD-ROM Version 1.0.
[51] Carstairs–McCarthy (2002): Andrew Carstairs–McCarthy An Introduction to English Mor-phology. Words and Their Structure. Edinburgh University Press.
[52] CC (2003): Collins COBUILD on CD-ROM. Resource Pack. HarperCollins Publishers. Soft-ware: Lingea Lexicon, Brno.
[53] CCAD (2009): Collins COBUILD Advanced Dictionary. Heinle Cengage Learning. DictionaryText © HarperCollins 2008.
[54] CCED (1995): Collins COBUILD English Dictionary, 2nd ed. HarperCollins.
[55] CED&T (1992): Collins English Dictionary and Thesaurus. Electronic Version 1.0. Harper Collins.
[56] CEHD (1976): László Országh A Comprehensive English–Hungarian dictionary. In two vol-umes. 5th edition. Akadémiai, Budapest.
[57] CHED (1977): László Országh A Comprehensive Hungarian–English dictionary. In two vol-umes. 5th edition. Akadémiai, Budapest.
[58] Chomsky (2000): New horizons in the study of language and mind. CUP.
[59] Chung (2003): Karen Steffen Chung, Review of Laurie Bauer’s Morphological productivity[= Bauer (2001)]. In: Canadian Journal of Linguistics 48(1/2) 2003.
[60] COED (2004): Catherine Soanes & Angus Stevenson eds. Concise Oxford English Dictionary.11th ed. OUP.
[61] Coleman (2007): Julie Coleman “Lexicography”. In: Aarts & McMahon (2007).
[62] Cowie (1999): Anthony P. Cowie English dictionaries for foreign learners. A history. OUP.
[63] Cowie (2001): Anthony P. Cowie ed. Phraseology: Theory, Analysis, and Applications. OUP.
[64] Cowie (2006): Anthony P. Cowie “Lexicology: Overview”. In: Brown (2006).
[65] Cowie (2009): Anthony P. Cowie ed. The Oxford History of English Lexicography. Oxford:Clarendon Press.
[66] Corréard (2006): M-H. Corréard “Bilingual lexicography”. In: Brown (2006).
[67] Cruse (1986): D. A. Cruse Lexical semantics. CUP.
[68] Cruse (2000): D. A. Cruse Meaning in language. An introduction to semantics and pragmatics. OUP.
[69] Culicover & Jackendoff (2005): Peter W. Culicover & Ray Jackendoff. Simpler Syntax. OUP.
[70] Crystal (1967): David Crystal “English”. In: Word classes (special volume of Lingua) 17. 24–56.
[71] Crystal (1980): David Crystal A first dictionary of linguistics & phonetics. Andre Deutsch.
[72] Crystal (1987): David Crystal “Preface”. In: M. Manser & N. Turton The Penguin WordmasterDictionary. Harmondsworth: Penguin.
[73] Crystal (1989): David Crystal “Little need to worry”. In: English Today 18. 12–13.
[74] Crystal (2003): David Crystal A dictionary of linguistics & phonetics. 5th ed. Blackwell.
[75] de Schryver (2003): Gilles-Maurice de Schryver “Lexicographers’ dreams in the electronic-dictionary age”. In: International Journal of Lexicography, Vol.16 No2
[76] de Schryver (2004a): Gilles-Maurice de Schryver, Review of A practical guide to lexicographyed. by Piet van Sterkenburg (2003). In: International Journal of Lexicography 17.3: 327–334.
[77] de Schryver (2004b): Gilles-Maurice de Schryver, Review of Piet van Sterkenburg, ed. 2003.A Practical Guide to Lexicography. TshwaneDJe Online Publications.http://tshwanedje.com/publinguisticcations/PracLexUnabridged.pdf, accessed 30/07/2008.
[78] de Schryver (2006): Gilles-Maurice de Schryver “Do Dictionary Users Really Look Up Fre-quent Words? – On the Overestimation of the Value of Corpus-based Lexicography”. In:Lexikos 16 (AFRILEX-reeks/series 16: 2006): 67-83

246
[79] de Schryver & Joffe (2004): Gilles-Maurice de Schryver & David Joffe “On How ElectronicDictionaries are Really Used”. In: EURALEX 2004 Proceedings, http://tshwanedje.com/publications/euralex2004-LOGS.pdf, accessed 26/02/2009.
[80] Di Sciullo & Williams (1987): A. M. Di Sciullo & E. Williams “On the Definition of Word”.In: Linguistic Inquiry Monograph 14, MIT Press.
[81] Dobrovolskij (2006): Dmitrij Dobrovolskij “Idiom dictionaries”. In: Brown (2006).
[82] Dörnyei & al. (1986): Zoltán Dörnyei, M. Salamon, M. Szesztay & Tábori Words on YourOwn. A vocabulary building course for (post)intermediate students of English. InternationalHouse, Budapest.
[83] EBURS (2009): Encyclopædia Britannica. Ultimate Reference Suite. Encyclopedia Britannica.Chicago.
[84] EHCD (1998): László Országh & Tamás Magay English–Hungarian comprehensive diction-ary. AND Complex electronic edition. Akadémiai, Budapest.
[85] É. Kiss (2002): Katalin É. Kiss The syntax of Hungarian. CUP.
[86] Everaert & al. (1995): M. Everaert, E-J. van der Linden, A. Schenk & R. Schroeder eds. Idi-oms: structural and psychological perspectives. Lawrence Erlbaum Associates. 167–232.
[87] Fazly & Stevenson (2007): Afsaneh Fazly & Suzanne Stevenson “Distinguishing subtypes ofmultiword expression using linguistically-motivated statistical measures”. In: Proceedings ofthe Workshop on a broader perspective on multiword expressions, Prague, June 2007. Associa-tion for Computational Linguistics.
[88] Fehér (2007, 2008): Krisztina Fehér “A szó problémája I & II [Problems of wordhood]”. In:Magyar Nyelvjárások [Hungarian dialects] Vol. 45, 2007, pp 5–26. & Vol. 46, 2008, pp 55–70.
[89] Fontenelle (2008): Thierry Fontenelle ed. Practical lexicography. A reader. OUP.
[90] Frawley (1988): William Frawley “New forms of specialized dictionaries”. In: InternationalJournal of Lexicography, Vol. 1. No. 3.
[91] Geeraerts (1989): Dirk Geeraerts “Principles of monolingual lexicography”. In: Hausmann (1989).
[92] Geeraerts (1993): Dirk Geeraerts “Vagueness’s Puzzles, Polysemy’s Vagaries”. In: CognitiveLinguistics 4: 223-272.
[93] Gläser (2001): Rosemarie Gläser “The Stylistic potential of phraseological units in the light ofgenre analysis”. In: Cowie (2001).
[94] Gleason (1965): H.A. Gleason Jr. Linguistics and English grammar. Holt, Rinehart & Winston.
[95] Goldberg & Casenhiser (2007): Adele E. Goldberg & Devin Casenhiser “English construc-tions”. In: Aarts & McMahon (2007)
[96] Granger (2005): “Pushing back the limits of phraseology: How far can we go?” In: C. Cosme,C. Gouverneur, F. Meunier & M. Paquot eds. Proceedings of phraseology 2005. An interdisci-plinary conference, 165–168. Nouvain-la-Neuve: Université Catholique de Louvain.
[97] ten Hacken (2009): Pius ten Hacken “What is a dictionary? A view from Chomskyan linguis-tics.” In: International Journal of Lexicography, Vol. 22 No.4. Advance access publication 4September 2009. OUP.
[98] Hall (1964): R. A. Hall Jr. Introductory linguistics. New York: Chilton Books.
[99] Halliday (1978) M. A. K. Halliday Language as a Social Semiotic. Edward Arnold.
[100] Halliday (1985/1994) M. A. K. Halliday An Introduction to Functional Grammar. 1st. edi-tion. [2nd ed. 1994] Edward Arnold.
[101] Halliday & Matthiessen (2004) M. A. K. Halliday & Christian M. I. M. Matthiessen An Intro-duction to Functional Grammar, 3rd edition. Edward Arnold.
[102] Halliday & Yallop (2007): Michael A. K. Halliday & Colin Yallop Lexicology. A short intro-duction Continuum International Publishing Group Ltd.

247
[103] Hankamer (1989): J. Hankamer “Morphological parsing and the lexicon”. In: W. D. Marslen-Wilson ed. Lexical representation and process. MIT Press.
[104] Hanks (1979): Patrick Hanks “To what extent does a dictionary definition define?” In: Hart-mann (1979).
[105] Hanks (1990): Patrick Hanks “Evidence and intuition in lexicography”. In: Tomaszczyk &Lewandowska-Tomaszczyk (1990) 31–41.
[106] Hanks (1993): Patrick Hanks “Lexicography: Theory and practice” In: Dictionaries: TheJournal of the Dictionary Society of North America 14: 97–112.
[107] Hanks (2000): Patrick Hanks “Do Word Meanings Exist?” Computers and the HumanitiesKluwer Academic Publishers, 34: 205–215.
[108] Hanks (2006): Patrick Hanks “Lexicography: Overview”. In: Brown (2006)
[109] Hartmann (1979): R. R. K. Hartmann ed. Dictionaries and their users. Exeter.
[110] Hartmann (1983): R. R. K. Hartmann ed. Lexicography: Principles and practice. Academic Press.
[111] Hasan (1987): R. Hasan “The Grammarian’s Dream: Lexis as More Delicate Grammar”. In:M. A. K Halliday & R. P. Fawcett eds. New Developments in Systemic Linguistics, Vol 1: The-ory and Description. Pinter, 184–211.
[112] Hausmann (1985): Franz Josef Hausmann “Lexikographie”. In: Cristoph Schwarze & DieterWunderlich Handbuch der Lexikologie. Königstein/Ts.: Athenäum, 367–411.
[113] Hausmann (1989): Franz Josef Hausmann “Component parts and structures of general mono-lingual dictionaries: a survey”. In: Hausmann & al. eds. International Encyclopedia of Lexico-graphy. Vol. 1. Walter de Gruyter. 328–360.
[114] HECD (1998): László Országh, Dezső Futász & Zoltán Kövecses Hungarian–English com-prehensive dictionary. AND Complex electronic edition. Akadémiai, Budapest.
[115] Heltai (2001): Pál Heltai “User-friendliness: next to godliness?”. In: novELTy Vol. 8, No. 1.ELTE SEAS, Budapest.
[116] Hill (1970): Archibald A. Hill “Laymen, lexicographers and linguists”. In: Language Vol. 46, No. 2.
[117] Hill (1982): Robert J. Hill A dictionary of false friends. The Macmillan Press Ltd.
[118] Hockett (1958): C. F. Hockett A course in modern linguistics. New York. The Macmillan Co.
[119] Hornby & al. (1984): A. S. Hornby, A. V. Gatenby & H. Wakefield A learner’s dictionaryof current English. OUP.
[120] Horváth (2006): József Horváth, “Review of Patterns and meanings: using corpora for Eng-lish language research and teaching by Alan Partington”. In: Language learning & technologyVol. 10. No1. pp 24–27.
[121] Huddleston (1984): Rodney Huddleston Introduction to the grammar of English. Reprinted1989. CUP.
[122] Huddleston, Pullum & al. (2002): Rodney Huddleston, Geoffrey K. Pullum & al. The Cam-bridge Grammar of the English Language. CUP.
[123] Huddleston & Pullum (2005): Rodney Huddleston, Geoffrey K. Pullum A student’s introduc-tion to English grammar. CUP.
[124] Hudson (1981): Richard Hudson “83 things linguists can agree about”. In: Journal of Lin-guistics 17, 1981, 333–344.
[125] Hudson (1988): Richard Hudson “The linguistic foundations for lexical research and diction-ary design”. In: International Journal of Lexicography, Vol. 1 No. 4. OUP.
[126] Hudson (1994): Richard Hudson’s contribution to The Linguist List, 13 June 1994. http://www.linguistlist.org/issues/5/5-690.html accessed 25/02/2009.
[127] Hüllen (2009): Werner Hüllen “Glosses, Glossaries, and Dictionaries in the Medieval Period”.In: Cowie ed. The Oxford History of English Lexicography. Vol II, Part I.

248
[128] Ilson (1985): Robert Ilson “The linguistic significance of some lexicographic conventions”.In: Applied linguistics, Vol. 6, No. 2.
[129] Jackendoff (1995): R. Jackendoff “The boundaries of the lexicon”. In: Everaert & al. (1995).
[130] Jackendoff (1997): R. Jackendoff The architecture of the language faculty. MIT Press.
[131] Jackson (2002): Howard Jackson Lexicography. An introduction. Routledge.
[132] Jackson (2009): Howard Jackson “Does frequency matter?” In: Zsolt Lengyel & Judit Navra-csics eds. Tanulmányok a mentális lexikonról. Segédkönyvek a nyelvészet tanulmányozásához 92[Studies on the mental lexicon. Papers for the study of linguistics]. Tinta Publishers, Budapest.
[133] Johnson (1747): Samuel Johnson The Plan of an English Dictionary. ed. by Jack Lynch.http://andromeda.rutgers.edu/~jlynch/Texts/plan.html, accessed 26/07/2008.
[134] Julien (2007): Marit Julien “On the relation between morphology and syntax”. In: Ramchand& Reiss (2007).
[135] Katamba (2005): Francis Katamba English words. Structure, history, usage. 2nd ed. Routledge.
[136] Kay (2000): Christian J. Kay “Historical semantics and historical lexicography: will the twainever meet?” In: Julie Coleman & Christian J. Kay ed. Lexicology, semantics and lexicography.John Benjamins Publishing Co.
[137] Keith (2001): Allan Keith Natural language semantics. Blackwell.
[138] Kemmer (2002): Suzanne Kemmer (Message 1:) “James D. Nicoll quote – mystery solved”.The Linguist List. http://linguistlist.org/issues/13/13-499.html, accessed 04/04/2009.
[139] Kempson (1977): Ruth Kempson Semantic theory. Reprinted 1987. OUP
[140] Kenesei (2000): István Kenesei “Szavak, szófajok, toldalékok”. In: F. Kiefer ed. Strukturálismagyar nyelvtan [A structural grammar of Hungarian] Vol. 3. Morfológia. Akadémiai, Budapest.
[141] Kenesei (2001): I. Kenesei: “Criteria for auxiliaries in Hungarian”. In: I. Kenesei ed. Argu-ment structure in Hungarian, Akadémiai, Budapest, 2001, 73–106. Downloaded 11/03/2009 athttp://www.nytud.hu/kenesei/publ/auxil.pdf.
[142] Kenesei (2006): I. Kenesei: “Szófajok” [Word classes]. In: Ferenc Kiefer ed. Magyar nyelv[The Hungarian language]. Akadémiai, Budapest.
[143] Kenesei (2007): I. Kenesei “Semiwords and affixoids. The territory between word and affix”.In: Acta Linguistica Hungarica 54: 263-293.
[144] Kenesei (2008): István Kenesei “Funkcionális kategóriák”. In: Kiefer (2008).
[145] Kennedy (1992): G. Kennedy “Preferred ways of putting things with implications for languageteaching”. In: J. Svartvik ed. Directions in corpus linguistics. Berlin: Mouton. 335–373.
[146] Kiefer (1990): Ferenc Kiefer “Linguistic, conceptual and encyclopedic knowledge: some im-plications for lexicography”. In: T. Magay & J. Zigány eds. BudaLEX ‘88 proceedings. Papersfrom the 3rd International EURALEX Congress Budapest, 4–9 September 1988.
[147] Kiefer (2003): Ferenc Kiefer “How much information do adjectives need in the lexicon?” In:Igék, főnevek, melléknevek. Előtanulmámyok a mentális szótár szerkezetéről [Verb, nouns andadjectives. Preliminary studies of the structure of the lexicon]. Tinta Publishers, Budapest.
[148] Kiefer (2008): Ferenc Kiefer ed. Strukturális magyar nyelvtan [A structural grammar of Hun-garian] Vol. 4. A szótár szerkezete [The structure of the lexicon]. Akadémiai, Budapest.
[149] Kiefer & Sterkenburg (2003): Ferenc Kiefer & Piet Sterkenburg “Design and production ofmonolingual dictionaries”. In: Sterkenburg (2003).
[150] Kilgarriff (1997): Adam Kilgarriff “I Don’t Believe in Word Senses”. In: Computers and theHumanities Kluwer Academic Publishers, 31: 91–113.
[151] Kilgarriff (1999): Adam Kilgarriff “Don’t Be a Dictionary Dentist”. In: ELSNEWS 8.2 (June 1999)
[152] Kilgarriff (2006): Adam Kilgarriff “Googleology is Bad Science”. In: Computational Lin-guistics 33 (1): 147-151.

249
[153] Kiparsky (1982): Paul Kiparsky “From cyclic phonology to lexical phonology”. In: H.van derHulst & N. Smith eds. The structure of phonological representations, Part I. Dordrecht: Foris.
[154] Kuiper (2006): K. Kuiper “Formulaic speech”. In: Brown (2006).
[155] Kuiper & al. (2003): K Kuiper, H. McCann, H. Quinn, Th. Aitchison & K. van der Veer “Asyntactically annotated Idiom Database (SAID)” v.1 http://www.ldc.upenn.edu/Catalog/docs/LDC2003T10/readme.doc., accessed 26/04/2009.
[156] Laczkó & Mártonfi (2005): Krisztina Laczkó & Attila Mártonfi Helyesírás. [(Hungarian) or-thography]. Osiris, Budapest.
[157] Landau (1984): S. I. Landau Dictionaries. The art and craft of lexicography. The Scribner Press.
[158] Landau (1993): S. I. Landau “Wierzbicka’s Theory and the Practice of Lexicography”. In: W.Frawley ed. Dictionaries: the Journal of the Dictionary Society of North America. Cleveland, OH:DSNA.113–119.
[159] Landau (2001): S. I. Landau Dictionaries. The art and craft of lexicography. 2nd ed. CUP.
[160] LDCE (2000): Longman Dictionary of Contemporary English CD-ROM 3rd ed. PearsonEducation Limited
[161] LDCE (2005): Della Summers Longman Dictionary of Contemporary English Writing Assis-tant Edition CD-ROM. Pearson Education Limited.
[162] LDOPV (1983): Rosemary Courtney Longman Dictionary of Phrasal Verbs. Longman.
[163] Lew (2007): Robert Lew “Linguistic semantics and lexicography: A troubled relationship”.In: M. Fabiszak ed., Language and meaning. Cognitive and functional perpectives, 217–224.Franfurt am Main: Peter Lang.
[164] Lew (2009): “Towards variable function-dependent sense ordering in future dictionaries”. In:Henning Bergenholtz, Sandro Nielsen & Sven Tarp eds. Lexicography at a crossroads: Dic-tionaries and encyclopedias today, lexicographical tools tomorrow. (Linguistic insights -studies in language and communication, Vol. 90.). 237–264. Bern: Peter Lang.
[165] Lyons (1968): John Lyons Introduction to theoretical linguistics. CUP. Reprinted 1992.
[166] Lyons (1977): John Lyons Semantics. 2 vols. CUP. Reprinted 1978.
[167] Mackenzie & Mel'čuk (1988): Ian Mackenzie & Igor Mel'čuk “Crossroads of obstetrics andlexicography: A case study (The lexicographic definition of the English adjective PREGNANT)”.In: International Journal of Lexicography, Vol. 1 No. 2. OUP.
[168] MADSZ (2002): Tamás Magay & László Kiss eds. Magyar–angol diákszótár [Hungarian–English student’s dictionary]. 2nd ed. Akadémiai, Budapest.
[169] Magay & al. (1990): Tamás Magay & Judit Zigány eds. BudaLEX ’88 Proceedings. Papersfrom the EURALEX Third International Congress. Akadémiai, Budapest.
[170] Martin, Newsome & Vu (2002): R. C. Martin, M. R. Newsome & H. Vu “Language and LexicalProcessing”. In: V. S. Ramachandran Encyclopedia of the human brain. Elsevier. Academic Press.
[171] Márkus & Szöllősy (2006): Katalin Márkus & Éva Szöllősy “Angolul tanuló középiskolása-ink szótárhasználati szokásairól (Egy vizsgálat első eredményei)” [Dictionary use by Hungariansecondary school students of English (First results of a research project)]. In: Magay (2006).
[172] MASZ (2000): György Varga & Péter A. Lázár Magyar–angol szótár. Aquila, Budapest. 8th,enlarged ed. 2006.
[173] MASZNY (2007): Eszter M. Magay & Katalin P. Márkus Magyar–angol szótár nyelvtanu-lóknak [Hungarian–English dictionary for learners (of English)]. Grimm, Budapest.
[174] Marchand (1969): Hans Marchand Categories and types of present-day English word-forma-tion. Verlag C. H. Beck, Munich.
[175] McCarthy (2006): Diana McCarthy “Lexical Acquisition”. In: Brown (2006).

250
[176] McCawley (1986): James McCawley “What linguists might contribute to dictionary-makingif they could get their act together”. In: The real-world linguist, ed. P. Bjarkman & V. Raskin,1–18, Ablex, Norwood, NJ.
[177] McCawley (1999): James McCawley “David Crystal. A Dictionary of Linguistics and Phone-tics (Fourth edition). In: International Journal of Lexicography, Vol. 12. No. 1. OUP.
[178] McEnery & Wilson (2001): Tony McEnery & Andrew Wilson Corpus linguistics – An intro-duction. 2nd ed. Edinburgh University Press.
[179] McGee (1960): C. Douglas McGee “A Word for Dictionaries”. In: Mind, New Series, Vol.69, No. 273, pp. 14–30.
[180] MED (2002): Macmillan English Dictionary CD-ROM Ver 1.1. Based on the MacmillanEnglish Dictionary. Macmillan.
[181] MED (2007): Macmillan English Dictionary for Advanced Learners CD-ROM, 2nd Edition,Ver. 2.1, Macmillan.
[182] MÉK (2003): Ferenc Pusztai ed. Magyar értelmező kéziszótár. [Explanatory Dictionary ofHungarian] Program version 1.1. Akadémiai, Budapest.
[183] Mel'čuk (1974): “���� ������ ���� ���� ��� ������ «��� ↔ ��� �»”[Opyt teorii lingvisticheskikh modelej “Smysl↔Tekst”]. Nauka, Moscow.
[184] Mel'čuk (1988): Igor Mel'čuk “Semantic description of lexical units in an explanatory combi-natorial dictionary: Basic principles and heuristic criteria”. In: International Journal of Lexico-graphy, Vol. 1 No. 3. OUP.
[185] Mel'čuk (1998): Igor Mel'čuk “Collocations and Lexical Functions”. In: Anthony P. Cowieed. Phraseology. Theory, Analysis and Applications. 23–53. Clarendon Press.
[186] Mel'čuk (1995): I. Mel'čuk “Phrasemes in language and phraseology in linguistics”. In:Everaert (1995).
[187] Mel'čuk & al. (1984): I. Mel'čuk Dictionnaire explicatif et combinatoire du francais contem-porain. Recherches lexico-semantiques I. Université de Montréal. (Vol. II: 1988; Vol. III: 1992).
[188] Mel'čuk & Žolkovskij (1984): I. A. Mel'čuk and A. K. Žolkovskij Tolkovo-kombinatornyj slo-var' sovremennogo russkogo jazyka. Wiener slawistischer Almanach Sonderband 14. Vienna.
[189] Mel'čuk & Žolkovskij (1988): I. A. Mel'čuk and A. K. Žolkovskij “The Explanatory Combi-natorial Dictionary”. In: Evens ed. Relational Models of the Lexicon, 41–74. CUP.
[190] Meyer (2009): Charles Meyer Introducing English linguistics. CUP.
[191] Mohanan (1986): K. Mohanan The theory of lexical phonology. Reidel: Dordrecht.
[192] Moon (1998): Rosamund Moon Fixed Expressions and Idioms in English: A Corpus-BasedApproach. Oxford Studies in Lexicography and Lexicology. Oxford: Clarendon Pres
[193] Moon (2006): Rosamund Moon “Corpus approaches to idiom”. In: Brown (2006)
[194] Moon (2007): Rosamund Moon “Sinclair, lexicography, and the Cobuild Project. The appli-cation of theory”. In: International Journal of Corpus Linguistics 12:2, 159–181.
[195] Mufwene (1988): Salikoko S. Mufwene “Dictionaries and Proper Names”. In: InternationalJournal of Lexicography, Vol. 1, No. 3, OUP.
[196] Murray (1989): James A. H. Murray Introduction 1st vol. of the OED; Preface, 2nd Edition:General explanations. OUP.
[197] MWCD (2003): Merriam–Webster’s 11th Collegiate Dictionary. CD-ROM. Ver. 3.0. Mer-riam–Webster Inc.
[198] MWUD (2000): Merriam–Webster’s Unabridged Dictionary. CD-ROM. Ver. 2.5. Merriam–Webster Inc.
[199] Nattinger & DeCarrico (1992): James R. Nattinger & Jeanette S. DeCarrico Lexical phrasesand language teaching. OUP.

251
[200] Newson & al. (2006): Mark Newson & al. Basic English Syntax with Exercises. 2006. BasicEnglish Syntax with Exercises. Bölcsész Konzorcium, ELTE.
[201] Nicholson & Baldwin (2008) Jeremy Nicholson & Timothy Baldwin “Interpreting compoundnominalizatons”. In: N. Grégoire, S. Evert & B. Krenn eds Proceedings of the LREC Workshop“Towards a Shared Task for Multiword Expressions”. LREC, Marrakech, Morocco. pp. 43–45.
[202] NSOED (1997): New Shorter Oxford English Dictionary. CD-ROM Version 1.0.03. OUP.
[203] Nunberg & al. (1994): Geoffrey Nunberg, Ivan Sag & Thomas Wasow “Idioms”. In: Lan-guage, 70:3.
[204] OALD (2005): Oxford Advanced Learner’s Dictionary. 7th edition. Oxford AdvancedLearner's Compass CD-ROM. OUP.
[205] OALDCE (1984): A. S. Hornby & al. Oxford Advanced Learner’s Dictionary of Current Eng-lish. OUP.
[206] OAMSZNY (2002): Janet Phillips ed. OXFORD angol–magyar szótár nyelvtanulóknak [Hun-garian–English dictionary for learners (of English)]. OUP.
[207] ODOCIE (1983): Anthony P. Cowie, R. Mackin & I. R. McCaig Oxford Dictionary of Cur-rent Idiomatic English. Volume 2: Phrase, clause and sentence idioms. OUP.
[208] OED (2002): Oxford English Dictionary 2nd ed. CD-ROM Version 3.00. OUP.
[209] OED (2009): Oxford English Dictionary Second Edition on CD-ROM (V. 4.0). OUP.
[210] OIDLE (2001): James R. Nattinger & Jeanette S. DeCarrico eds. Oxford Idioms. Dictionaryfor Learners of English. OUP.
[211] Országh (1967): László Országh “A plea for a dictionary of modern idiomatic English”. In:Virágos (2007). [originally in Volume III of Hungarian Studies in English 1967, 71–81]
[212] Pawley & Syder (1983): Andrew Pawley & Frances H. Syder “Two puzzles for linguistic the-ory: nativelike selection and nativelike fluency”. In: J. C. Richards & R.W. Schmidt eds. Lan-guage and Communication. Longman. 191–226.
[213] Peeters (2000): Bert Peeters The lexicon-encyclopedia interface. Elsevier.
[214] PEHLD (2003): Tamás Magay ed. PASSWORD. English–Hungarian learner’s dictionary.Nemzeti Tankönyvkiadó, Budapest.
[215] Pethő (2001): Gergely Pethő “What is polysemy? – A survey of current resarch and results”. In:K. Bibok & E. Németh T. eds. Pragmatics and the flexibility of word meaning. Elsevier, 175–224.
[216] Pethő (2004): Gergely Pethő “A survey of recent textbooks on lexicography”. In:Sprachtheorie und Germanistische Linguistik. Vol. 14. No.2. pp 171–194. Debrecen/Münster.
[217] Pinker (1999): Steven Pinker Words and rules: The ingredients of language. Basic Books.
[218] Plag (2006): Ingo Plag “Productivity”. In: Brown (2006)
[219] Poß & van der Wouden (2005): Michaela Poß & Ton van der Wouden “Extended LexicalUnits in Dutch”. In: Ton van der Wouden, Michaela Poß, Hilke Reckman & Crit Cremers eds.Computational Linguistics in the Netherlands 2004, Selected Papers from the Fifteenth CLINMeeting, Dec. 17, Leiden Centre for Linguistics. LOT Utrecht.
[220] Prószéky & Kis (2002): G. Prószéky & B. Kis “Development of a Context-Sensitive Elec-tronic Dictionary”. In: A. Braasch & C. Povlsen eds., EURALEX 2002 Proceedings. Copenha-gen: Center for Sprogteknologi.
[221] Prószéky & Földes (2006): Gábor Prószéky & András Földes: “An Intelligent, Context-Sen-sitive Dictionary: A Polish–English Comprehension Tool”. In: Z. Vetulani ed. Human Lan-guage Technologies as a Challenge for Computer Science and Linguistics, 386–389.Mickiewicz University, Poznan, Poland (2005).
[222] Quaglio & Biber (2006): Paolo Quaglio & Douglas Biber “The grammar of conversation”. In:Aarts & McMahon (2007).
[223] Quine (1953): W. V. Quine From a Logical Point of View Harvard University Press.

252
[224] Quirk & al. (1985): R. Quirk, S. Greenbaum, G. Leech & J. Svartvik A comprehensive gram-mar of the English language. Longman.
[225] Radford (1988): Andrew Radford Transformational grammar. A first course. CUP.
[226] Ramchand & Reiss (2007): Gilliam Ramchand – Charles Reiss eds. The Oxford handbook oflinguistic interfaces. OUP.
[227] RHWUD (1999): Random House Webster’s Unabridged Dictionary. CD-ROM version 3.0.Random House Inc.
[228] Rizo-Rodríguez (2008): Alfonso Rizo-Rodríguez, Review of English learners’ dictionaries onCD-ROM. In: Language Learning & Technology Febr 2008, Vol. 12, No. 1, 23-42
[229] Rundell (1998): Michael Rundell “Recent trends in English pedagogical lexicography”. In:International Journal of Lexicography, Vol. 11, No. 2.
[230] Rundell (2002): Michael Rundell “Good Old-fashioned Lexicography: Human Judgment andthe Limits of Automation”. In: Marie–Hélène Corréard ed. Lexicography and Natural LanguageProcessing: A Festschrift in Honour of B. T. S. Atkins. Euralex, 138–155.
[231] Sag & al. (2002): Ivan A. Sag, Timothy Baldwin, Francis Bond, Ann Copestake & DanFlickinger “Multiword Expressions: A Pain in the Neck for NLP”. In: Proceedings of the ThirdInternational Conference on Intelligent Text Processing and Computational Linguistics(CICLING 2002), Mexico City. 1–15.
[232] Salamon & Zalotay (1993): G. Salamon & M. Zalotay Huron’s Check Book 6000 Biográf,Hungary.
[233] Salamon & Zalotay (1994): G. Salamon & M. Zalotay Huron’s Wordy Dictionary 150–1500.Biográf, Hungary.
[234] Saussure (1916/1966): Ferdinand de Saussure Course in general linguistics. Transl. WadeBaskin. McGraw-Hill.
[235] Sharpe (1995): P. A. Sharpe “Electronic Dictionaries with Particular Reference to the Designof an Electronic Bilingual Dictionary for English-speaking Learners of Japanese”. In: Interna-tional Journal of Lexicography Vol. 8. No. 1.
[236] Sinclair (1990): John Sinclair Collins–Cobuild English grammar. Reprinted 1992. HarperCollins.
[237] Sinclair (1991): John Sinclair Corpus, concordance, collocation. OUP.
[238] Sinclair (1998): John Sinclair “The lexical item”. In: E. Weigand ed. Contrastive Lexical Se-mantics. Benjamins, 1–24.
[239] Sinclair (2003): John Sinclair ed. Collins COBUILD English Dictionary. 4th ed. HarperCollins.
[240] Sinclair (2004): John Sinclair Trust the Text – Language, corpus and discourse. Routledge.
[241] Spencer & Zwicky (1998): Andrew Spencer & Arnold Zwicky eds. The handbook of mor-phology. Blackwell.
[242] Stark (1995): Detlef Stark, Review of “Tradition and Innovation in Modern English Diction-aries” by Henri Béjoint. In: Language, Vol. 71, No. 3, 636–637.
[243] Stein (2002): G. Stein Better words: evaluating EFL dictionaries. University of Exeter Press.
[244] Sterkenburg (2003): Piet van Sterkenburg ed. A practical guide to lexicography. John Benjamins.
[245] Stockwell & Minkova (2001): Robert Stockwell & Donka Minkova English words: historyand structure. Reprinted 2002. CUP.
[246] Stowell (1981): Tim Stowell Origins of Phrase Structure. Doctoral dissertation, MIT.
[247] Stubbs (2002): Michael Stubbs Words and phrases. Corpus studies of lexical semantics.Blackwell.
[248] Stubbs (2009): Michael Stubbs “The Search for Units of Meaning: Sinclair on Empirical Se-mantics”. In: Applied Linguistics 30/1: 115–137, OUP. doi:10.1093/applin/amn052 AdvanceAccess publ. 28 January 2009.

253
[249] Taylor (2003): John R.Taylor “Polysemy’s paradoxes”. In: Language sciences 25, 2003.www.elsevier.com/locate/langsci, accessed 11/03/2009.
[250] Thompson & al. (1991): Geoffrey Thompson & al. Thompson’s Dictionary for HungarianLearners of English Közgazdasági és Jogi Könyvkiadó, Budapest.
[251] Tomaszczyk & Lewandowska-Tomaszczyk (1990): J. Tomaszczyk & B. Lewandowska-To-maszczyk eds. Meaning and lexicography. Benjamins.
[252] Tomasello (2003): Constructing a language: a usage-based theory of language acquisition.Harvard University Press.
[253] Trask (1993): R. Larry Trask A dictionary of grammatical terms in linguistics. Routledge.
[254] Trawiński & al. (2008) B. Trawiński, M. Sailer, J-Ph. Soehn, L. Lemnitzer & F. Richter“Cranberry expressions in English and German”. In: N. Grégoire, S. Evert & B. Krenn eds.Proceedings of the LREC Workshop “Towards a Shared Task for Multiword Expressions”.LREC, Marrakech, Morocco. pp. 35–38.
[255] Van de Meer (2004): “The learner’s dictionaries and grammar. A comparison”. In: HenrikGottlieb & Jens Erik Mogensen eds. Dictionary visions, research and practice. selected papersfrom the 12th International symposium on Lexicography, Copenhagen 2004. Benjamins.
[256] Varga (1993): László Varga “On common nouns that are neither count nor mass”. In: ZoltánKövecses ed. Voices of Friendship (Linguistic Essays in Honor of László T. András 1930-1993).ELTE Budapest. 91–101.
[257] Virágos (2007): Zsolt Virágos ed. Országh László válogatott írásai. [Selected writings ofLászló Országh] Kossuth Press, Debrecen University, Hungary.
[258] Wasow & Arnold (2005): Thomas Wasow & Jennifer Arnold “Intuitions in linguistic argu-mentation”. In: Lingua 115 (2005) 1481–1496
[259] Widdowson (2007): Henry Widdowson “J. R. Firth, 1957, Papers in linguistics 1934–51”. In:International Journal of Applied Linguistics Vol. 17, No 3.
[260] Wierzbicka (1985): Anna Wierzbicka Lexicography and Conceptual Analysis. AnnArbor, MI:Karoma.
[261] Wierzbicka (1993): Anna Wierzbicka “What are the uses of theoretical lexicography?” In:Dictionaries: The Journal of the Dictionary Society of North America 14: 44–78.
[262] Windisch Brown (2008): Susan Windisch Brown “Polysemy in the Mental Lexicon”. In:Colorado Research in Linguistics. June 2008. Vol. 21. University of Colorado.
[263] Wittgenstein (1953/2001): Ludwig Wittgenstein Philosophical Investigations. Blackwell Pub-lishing.
[264] Wray (2002): Alison Wray Formulaic language and the lexicon. CUP.
[265] Wray (2006): Alison Wray “Formulaic language”. In: Brown (2006)
[266] Zimmer (1964): K. Zimmer Affixal negation in English and other languages: an investigationof restricted productivity. Supplement to Word, Monograph 5, New York.
[267] Zgusta (1971): Ladislav Zgusta (in cooperation with V. Černy). Manual of lexicography.Mouton.




















