
Phonological consequences of contact with Modern Hebrew on the Palestinian Arabic dialect of Jaffa:...
21
Uri Horesh [email protected] AIMA IV, Atlanta October 14, 2013 Phonological consequences of contact with Modern Hebrew on the Palestinian Arabic dialect of Jaffa: A variationist study http://bit.ly/aimauri
Transcript of Phonological consequences of contact with Modern Hebrew on the Palestinian Arabic dialect of Jaffa:...

Uri Horesh [email protected]
AIMA IV, Atlanta October 14, 2013
Phonological consequences of contact with Modern Hebrew on the Palestinian Arabic
dialect of Jaffa: A variationist study
http://bit.ly/aimauri

Language contact in Palestine – historically
Source: Davis (2011: xxiv)
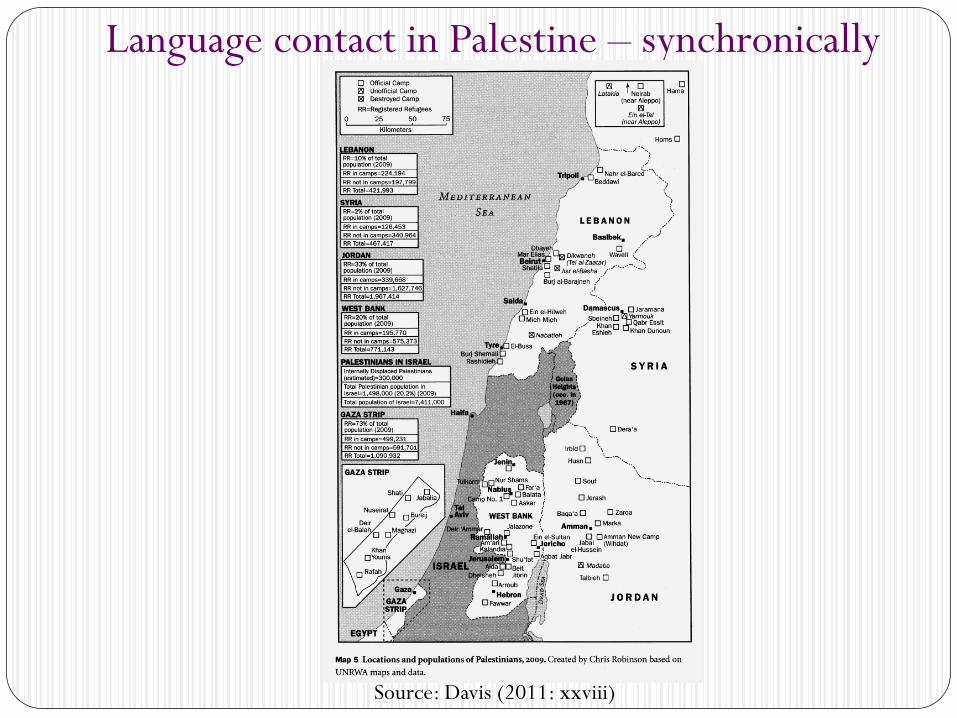
Language contact in Palestine – synchronically
Source: Davis (2011: xxviii)
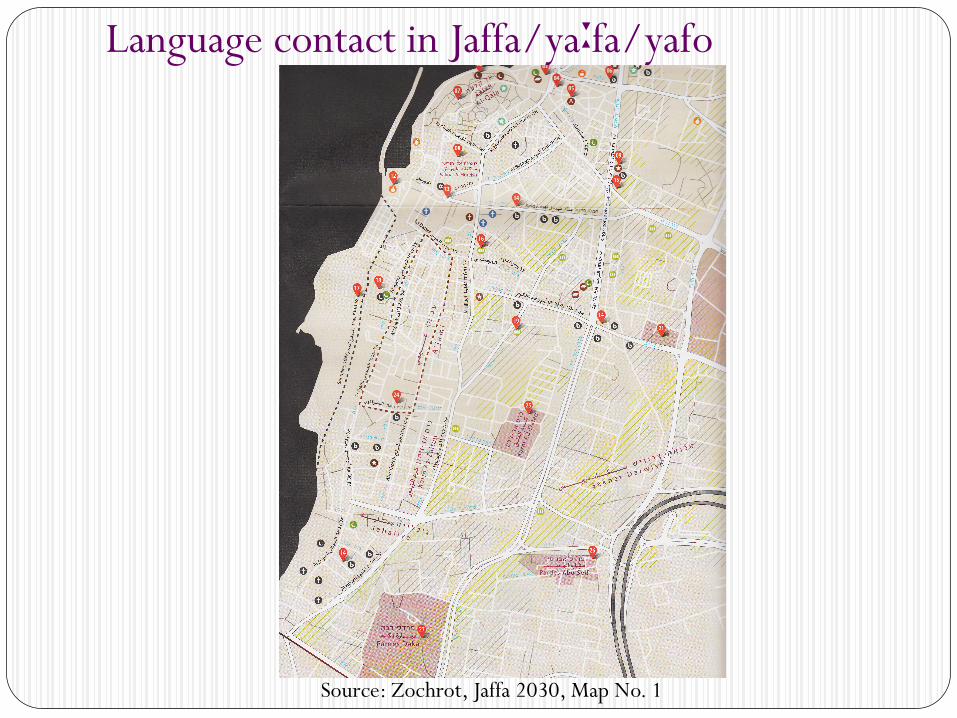
Language contact in Jaffa/yaːfa/yafo
Source: Zochrot, Jaffa 2030, Map No. 1

Some generalizations re: language contact
“[L]ong-term contact with widespread bilingualism among borrowing-language speakers is a prerequisite for extensive structural borrowing.” (Thomason & Kaufman 1988:67)
“Language contact has traditionally been a subfield of historical linguistics, concentrating on changes in language that are due to ‘external’ influence from other languages, rather than with ‘internal’ change. One concern of language-contact studies that overlaps with the discipline of historical linguistics is the nature of borrowing. ‘Borrowing’ is a technical term for the incorporation of an item from one language into another. These items could be (in terms of decreasing order of frequency) words, grammatical elements or sounds.” (Mesthrie & Leap 2009:243)

Some generalizations re: language contact “Traditional dialectology has mostly concentrated on segmental units of sound (e.g. individual vowels and consonants) rather than continuous prosodic characteristics like rhythm, pitch, intonation and voice quality.” (Mesthrie 2009:68)
“Linguistic investigation shows that [the] Berlin vernacular is apparently a quite heterogenous [sic] phenomenon, composed of many variants, that many of the linguistic features which are generally thought to be constitutive of it appear in other dialects and vernaculars as well, and that its specific flavour may arise from features hardly ever mentioned and surely never carefully studied in the literature, such as speech rate, pause structure or pitch range.” (Klein 1988:147)
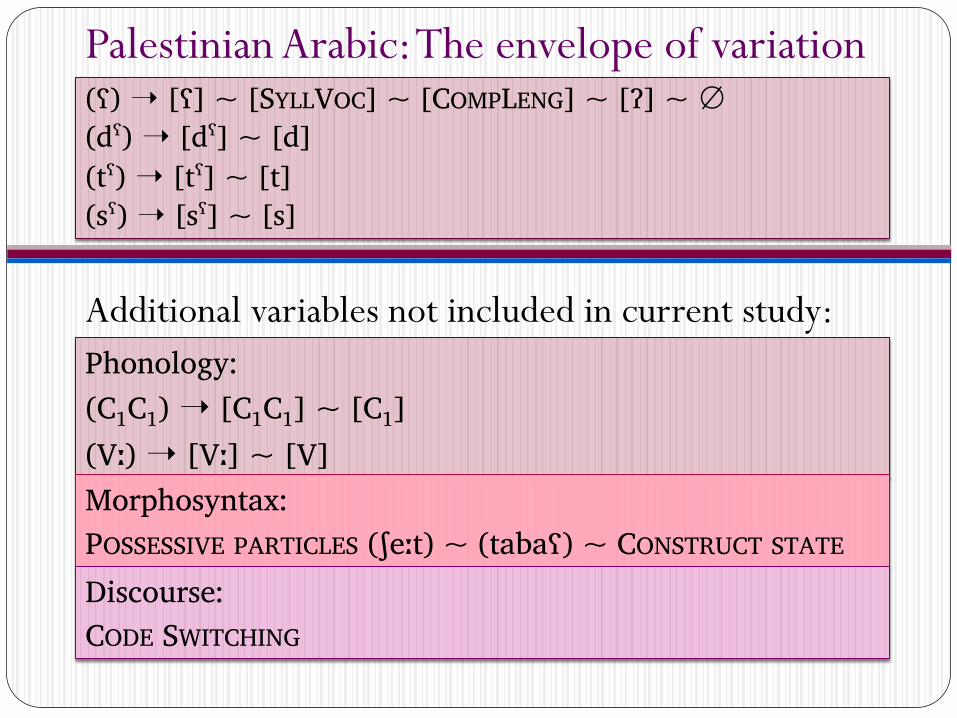
Palestinian Arabic: The envelope of variation (ʕ) ➝ [ʕ] ~ [SYLLVOC] ~ [COMPLENG] ~ [ʔ] ~ ∅ (dˤ) ➝ [dˤ] ~ [d] (tˤ) ➝ [tˤ] ~ [t] (sˤ) ➝ [sˤ] ~ [s]
Additional variables not included in current study:
Phonology: (C1C1) ➝ [C1C1] ~ [C1] (Vː) ➝ [Vː] ~ [V] Morphosyntax: POSSESSIVE PARTICLES (ʃeːt) ~ (tabaʕ) ~ CONSTRUCT STATE Discourse: CODE SWITCHING

The sample With the exception of two pilot recordings done in 1999, the bulk of the recordings are of sociolinguistic interviews conducted in Palestine in 2004-2005, mostly in Jaffa. A control group was interviewed during two one-day excursions, one to al-Quds (Jerusalem) and one to Ramallah.*
*One of the speakers, a Jaffa native who moved to a village some 35 km away in 1946, was interviewed in her village.

Speech samples for (ʕ)
Nabːil, born 1926, Ja(a, [ʕ]
ʔumm Xaliːl, born 1928, Ja(a⇒Jaljuːlye, [ʕ]
Jamiːl, born 1981, Ja(a, [ʔ] ~ ∅
ʕali, born 1991, Ja(a, [COMPLENG]+[SYLLVOC] – /maʕ l-mawdˤuːʕ/ ➝ [maː.a l-maw.duː.a]

Some quantitative results
% all non-pharyngeal variants for (ʕ) variable by age &
community
Table 2: Rbrul results for total (ʕ) deletion by age
Ages Tokens
N= Factor
weights Log
odds
14-35 625 0.584 0.339
36-60 533 0.564 0.258
61+ 254 0.355 -0.597 0%
10%
20%
30%
40%
50%
60%
70%
80%
16-35 36-60 61+ total
Perc
ent n
on-[ʕ]
Age group
Ja(a West Bank Total
R2=0.34 p<0.005

Table 3: Rbrul results for total (ʕ) deletion by language of primary/ secondary education
Language Tokens N= Factor weights Log odds
(Mostly) Hebrew 228 0.693 0.816
Evenly Mixed 224 0.570 0.282
(Mostly) Arabic 960 0.250 -1.097
R2=0.34; p<10-9
Some quantitative results

Treating the dependent variable as a continuous variable! #linguadork
One of the novel features of Rbrul is that it allows to view all variables, including the dependent variable, as continuous, provided they are coded as consecutive integers.
I have recoded the variants on the following scale: 0 = ∅ 1 = COMPLENG 2 = SYLLVOC 3 = [ʔ] 4 = [ʕ]

Continuous variable – continued !BEST STEP-DOWN MODEL IS WITH School.Lang (9e-10) + Education (5.71e-07) + Position (0.000215) + Age (0.000557) + Heb.Contact (0.00241) + Sex (0.00308) [p-values dropping from full model]!
!$Age! factor coef tokens mean! 61+ 0.445 254 3.323! 14-35 -0.147 732 2.251! 36-60 -0.298 666 2.847! !$Sex! factor coef tokens mean! M 0.146 825 2.919! F -0.146 827 2.394! !$Education! factor coef tokens mean! uni 0.566 1081 2.712! high 0.285 246 2.618! pupil -0.165 270 2.444! elem -0.686 55 2.764! !
!

Continuous variable – continued $School.Lang!
factor coef tokens mean!
Ara 0.597 1151 2.975!
Mix -0.027 224 2.161!
Heb -0.570 277 1.733!
!
$Heb.Contact!
factor coef tokens mean!
1 0.353 213 3.099!
0 -0.067 376 3.128!
2 -0.286 1063 2.401!
!
$Position!
factor coef tokens mean!
cluster 0.218 59 2.983!
onset 0.092 1153 2.755!
coda -0.310 440 2.355 !

Continuous variable – continued $misc! deviance df intercept grand mean R2! 5192.611 13 2.258 2.656 0.119!
It is probably best to think in terms of prediction. In your model, the predicted value is given by computing the sum of the intercept and all of the coefficients, rounded to the nearest integer. For example, imagine an onset pharyngeal (target) spoken by a low-Hebrew-contact, Arabic-language-schooled, university educated, female young adult and see what it predicts. In fact, I can do this by hand by adding the coefficients (and the intercept, which is under the "$misc" header). !round(2.258 + -0.147 + -0.146 + 0.566 + 0.597 + -0.067 + 0.092) = 3!
!So your best guess for this person (assuming I didn't make any errors: this should be automated rather than done by hand) is a glottal stop.
(Kyle Gorman, via email, 8 June 2013)

The story of the “emphatics:” Are they headed toward a merger?
Historically, both Arabic and Hebrew had pharyngealized stops and sibilants, paired with non-pharyngealized counterparts:
PROTO-SEMITIC CLASSICAL ARABIC JAFFA ARABIC BIBLICAL HEBREW MODERN HEBREW
ðʼ ðˤ dˤ ~ d sˤ ʦ
ɮʼ / ɬʼ dˤ dˤ ~ d sˤ ʦ
sʼ sˤ sˤ ~ s sˤ ʦ
tʼ tˤ tˤ ~ t tˤ t
s ʃ ʃ s s
ʃ s s ʃ ʃ
ɬ s ~ ʃ s ~ ʃ ś s
t t t t t

� li-l-ʔasaf bi-zzamanaːt, li-l-ʔasaf bi-zzamanaːt, ma kaːnʃ * wah ̠ad jʔul “haːda mislim” u-“haːda masiːħi.” kunna kullna nʔuːl “iħna ʕarab.” ja waħad jisʔal it-taːni “eːʃ inte?” willa jsaː*r “eːʃ inte?” – walla “ana -astˤiːni!”
� ‘Unfortunately, back in the day, unfortunately,
back in the day, no one would say, “this guy’s a Muslim,” and “that guy’s a Christian.” We’d all say, “We are Arabs.” Nor would anyone ask anyone else, “what are you?” Or [while] traveling, “what are you?” – by God, “I’m a Palestinian!”’
!
Beyond the numbers: 1. Nabiːl

� ma kaːn-ʃ wa-la aʃjaː taːnje li-ʕanno haːda aʃjaː ɣariːbe, ʔudχilat baʕdeːn. ħasab əs-səjaːse – farroq tasud.
� ‘There were no other things, because these are
foreign things, which were inserted later on, according to the policy of “divide and conquer.”’!
Beyond the numbers: 1. Nabiːl

� əl-joːm sˤaːr ʕin-na, ʔabel bi-zam-, sˤaːr ʕin-na ʕarab u-jahuːd. baʕdeːn l-ʕarab sˤaru jʔuːlu ʕan, sˤaːrat yaʕni, ʔeː, wasaːil iʕlaːm hoːn, ta-, taʃʒiːʕ min əs-sulutˤaːt, sˤar mislim u-masiːħi, l-ʕarabi sˤar julu an-o “mislim u-masiːħi.” baʕdeːn sˤaːr juːlu “mislim u-masiːħi u-durzi.” u-, ha, b-, baʕd ə-ʃwaj “mislim u-masiːħi u-durzi u-, u-badawi.”
� ‘Today we have, first of all, we had Arabs and Jews. Then the
Arabs became, because of mass media and encouragement from the authorities, [we] became Muslims and Christians. [Instead of] Arab we started saying, “Muslim and Christian.” Later on they started saying, “Muslim and Christian and Druze.” And after a little bit, “Muslim and Christian and Druze and Bedouin.”’
Beyond the numbers: 1. Nabiːl

ʔAriːʒ: ismaʕi, inti, inti bitʔuli “ʃeːt.” ana marra ma baʔul “ʃeːt.” ‘Listen, [grandma,] you, you do say “ʃeːt.” I never say “ʃeːt.”’ UX: ana baʔulɪʃ “ʃeːt-i.” kan ʕind-i lli bɪʔulu “ʃeːt-i,” bi-ʒʒiːl l-ʒdid. ‘I don't say “ʃeːt-i.” We did have those who said “ʃeːt-i.” The new generation.’ ʔAriːʒ: jɪmkɪn inti nsiːti kalimat kanu staʔmaluː-ha b-jaːfa ‘You may have forgotten some words that had been used in Ja,a.’ UX: ʕaːrɪf miːn illi kanu jʕulu z-zamaːn “ʃet-i, ʃeːt-i?” l-masiħijje. ‘You know who used to say “ʃeːt-i, ʃeːt-i” back in the day? The Christians.’
Beyond the numbers: 2. Umm Xaliːl

References Davis, Rochelle.2011. Palestinian Village Histories. Stanford: Stanford University
Press. Gorman, Kyle and Daniel Ezra Johnson. 2013. “Quantitative analysis”. In:
Bayley, Robert, Richard Cameron, and Ceil Lucas (eds.). The Oxford Handbook of Sociolinguistics. 214-240. Oxford: Oxford University Press.
Klein, Wolfgang. 1988. “The unity of a vernacular: some remarks on ‘Berliner Stadtsprache.’” In: Dittmar, Norbert and Peter Schlobinski (eds,). The Sociolinguistics of Urban Vernaculars: Case Studies and their Evaluation. Berlin: de Gruyter. 147–153.
Mesthrie, Rajend and William L. Leap. 2009. “Language contact 1: Maintenance, shift and death.” In: Mesthrie et al. 2009. 242-270.
Mesthrie, Rajend, Joan Swann, Ana Deumert and William L. Leap. 2009. Introducing Sociolinguistics. Edinburgh: Edinburgh University Press.
Mesthrie, Rajend. 2009. “Regional dialectology.” In: Mesthrie et al. 2009. 42-73.
Thomason, Sarah Grey and Terrence Kaufman. 1988. Language Contact, Creolization, and Genetic Linguistics. Berkeley: University of California Press.











![Староаккадский (саргоновский) диалект [Old Akkadian (Sargonic) dialect]](https://static.fdokumen.com/doc/165x107/631fc76415f75c9c2e0d0e7f/staroakkadskiy-sargonovskiy-dialekt-old-akkadian.jpg)








