
Profiling and annotation of human kidney glomerulus proteome
Upload
independentCategory
view
1download
0
AOB-2940; No. of Pages 11
OralCard: A bioinformatic tool for the study of oral proteome
Joel P. Arrais a,*, Nuno Rosa b, Jose Melo a, Edgar D. Coelho a, Diana Amaral b,Maria Jose Correia b, Marlene Barros b,c, Jose Luıs Oliveira a
aDepartment of Electronics, Telecommunications and Informatics (DETI), Institute of Electronics and Telematics Engineering of Aveiro (IEETA),
University of Aveiro, PortugalbDepartment of Health Sciences, Institute of Health Sciences, The Catholic University of Portugal, Viseu, PortugalcCentre for Neurosciences and Cell Biology, University of Coimbra, Portugal
a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x
a r t i c l e i n f o
Article history:
Accepted 30 December 2012
Keywords:
Oral proteome
Microbiome
Diabetes melitus
OralCard
a b s t r a c t
Objectives: The molecular complexity of the human oral cavity can only be clarified through
identification of components that participate within it. However current proteomic tech-
niques produce high volumes of information that are dispersed over several online data-
bases. Collecting all of this data and using an integrative approach capable of identifying
unknown associations is still an unsolved problem. This is the main motivation for this
work.
Results: We present the online bioinformatic tool OralCard, which comprises results from 55
manually curated articles reflecting the oral molecular ecosystem (OralPhysiOme). It com-
prises experimental information available from the oral proteome both of human (OralOme)
and microbial origin (MicroOralOme) structured in protein, disease and organism.
Conclusions: This tool is a key resource for researchers to understand the molecular founda-
tions implicated in biology and disease mechanisms of the oral cavity. The usefulness of this
tool is illustrated with the analysis of the oral proteome associated with diabetes melitus
type 2. OralCard is available at http://bioinformatics.ua.pt/oralcard.
# 2013 Elsevier Ltd. All rights reserved.
Available online at www.sciencedirect.com
journal homepage: http://www.elsevier.com/locate/aob
1. Introduction
The human oral cavity is a complex ecosystem where human,
microbial and environmental factors interact in a dynamic
equilibrium. Understanding the biology of the oral cavity and
disorders that affect it (or systemic diseases that are reflected
in it) depends on the compilation and integration of informa-
tion generated by high-throughput techniques such as
proteomic studies, complemented with targeted studies based
on antibodies techniques. This is of particular relevance in the
oral cavity since it comprises proteins of endogenous (human)
and exogenous (microbiome) origin. Comprehending how
these different sets of proteins relate is of the utmost
* Corresponding author at: Instituto de Engenharia Electronica e TelemaPortugal. Tel.: +351 234 370 500; fax: +351 234 370 545.
E-mail address: [email protected] (J.P. Arrais).
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
0003–9969/$ – see front matter # 2013 Elsevier Ltd. All rights reservehttp://dx.doi.org/10.1016/j.archoralbio.2012.12.012
importance in understanding oral biology and also the
pathogenesis of oral diseases.1
Several sub-compartments contribute to the oral protein
composition, namely secretions from the major salivary
glands: the parotid, submandibular (SM) and sublingual (SL)
glands, making up 90% of the total salivary secretion. The
remaining 10% are contributions of a collection of the minor
salivary glands, the gingival crevicular fluid (GCF), the tongue
and the oral mucosa. Plasma proteins can reach the oral cavity
by several means, the most common being passive diffusion,
ultrafiltration, and as a result of GCF outflow contributing to
the oral protein composition.2 The pool of oral protein is also
enriched by molecules originating from the microbiome which
colonizes the oral surfaces. These microbial metabolites are
tica de Aveiro, Campus Universitario de Santiago, 3810-193 Aveiro,
tool for the study of oral proteome. Archives of Oral Biology (2013), http://
d.

a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x2
AOB-2940; No. of Pages 11
present in the oral cavity as secreted and may act on the
proteins present in the salivary secretions, altering them.3
Considering saliva as the fluid that reflects the protein
composition resulting from the contribution of the above-
mentioned oral sub-compartments and that it is readily
accessible in a non-invasive way, it has long been identified
as a diagnostic sample fluid for a swiftly growing range of
disease and clinical scenarios, as well as a candidate for
biomarker identification.4,5 Over the years there have been
many reviews of the genomics and proteomics of saliva. It has
been highlighted that saliva could be used in oral cancer
diagnosis,6 in the diagnosis of systemic diseases,7 in micro-
biome analysis,8 in psychobiological medicine,9 and in
forensic dentistry.10 The proteomic analysis of saliva, which
was mostly conducted by 2D electrophoresis/mass spectrom-
etry or 2D liquid chromatography/mass spectrometry,11
showed that the salivary proteome consisted of approximately
1.000 distinct protein sequences, by the year 2007.12 By the end
of 2010 this number had more than doubled, with identifica-
tion of 2290 salivary proteins.13 With few exceptions, the
microbial contribution to the oral proteome, although inferred
from the presence of a well-characterized oral microbiome
(e.g., HOMDd and HMPe) has not been the subject of saliva or
oral fluids proteomic analysis.
Biology databases can be focused on particular organisms,
such as Saccharomyces Genome Database (SGD)14 for Saccha-
romyces, or integrative databases, for instance, the Universal
Protein Resource (UniProt).15 Although UniProt is used
worldwide by the scientific community, its data is very broad,
which means researchers on very specific topics will only be
interested in a minuscule portion of each item in the database.
In addition, online data on specific topics is very sparse,
making the researcher’s task burdensome and extremely
time-consuming. These aspects motivate the development of
databases to be used by specific scientific communities
sharing the same research interests.
In previous work we have compiled the OralOme,16 a
collection of specific protein-related biomolecular data col-
lected from UniProt, Protein Data Bank (PDB),17 HUGO Gene
Nomenclature Committee (HGNC),18 Entrez Gene,19
Ensembl,20 Pharmacogenomics Knowledge Database
(PharmGKB),21 BRaunschweig ENzyme Database (BRENDA),22
Online Mendelian Inheritance in Man (OMIM),23 Kyoto
Encyclopaedia of Genes and Genomes (KEGG),24 and Gene
Ontology (GO).25 OralOme comprises experimental data
relative to 3397 non-redundant human oral proteins in healthy
and diseased states (605 altered in pathological conditions and
51 present only in disease), for instance, GO terms, homolo-
gies, pathways involved, and protein structure information.
In this paper we present OralCard, a Web Application that
allows mining over an integrative database containing
manually curated information about the oral cavity proteome
with the addition of the experimentally determined oral
proteome of microbial origin. OralCard promptly allows a wide
range of data associations, for instance, whether a protein is
involved in any specific pathological condition, which micro-
bial proteins may be present in the oral cavity, or what the
d www.homd.org/.e http://commonfund.nih.gov/hmp/.
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
annotated functions of any given protein are and in which
pathways it is implicated. Furthermore, for each protein it is
possible to explore the structural and functional details.
OralCard facilitates the interpretation of proteomic data of
the oral cavity and will therefore be a valuable resource for
researchers aiming to understand the physiologies of oral
cavity in health and disease and probing for potential
biomarkers for oral and systemic diseases.
2. Materials and methods
The development of the OralCard database was a combination
of manual and automatic processes. A thorough manual
bibliography review was performed to gather current knowl-
edge about all proteins identified in proteomic studies. The
protein information obtained from data curation was auto-
matically acquired from public biomedical databases and
integrated in the OralCard database. The OralCard was
conceived to allow the end-user to perform queries in a fast
and intuitive way.
The database and user interface were developed using
technologies that are currently state-of-the-art in information
systems, such as linked data, web services, service composi-
tion and interactions network visualization. These tools
helped us build and tune a set of automated processes to
capture information from various biological resources, sim-
plifying the construction of OralCard data warehouse.
Next, we present a general view of the entire process, from
the gathering of biological information to the development of
OralCard presentation layer (Fig. 1).
2.1. Manual data assembly and curation
The assembly of the Human Oralome, i.e. its compilation and
annotation, was performed mostly as described in16 with
several improvements and updates. The following PubMed
query was made: (‘‘proteomics’’ OR ‘‘proteomic’’ OR ‘‘prote-
ome’’) AND (‘‘saliva’’ [Title/Abstract] OR ‘‘oral’’ [Title/Ab-
stract]). The list of articles retrieved was manually inspected
and the identifiers from the proteins found in the various
references were collected. These studies12,26–79 (supplemental
Table 1) collected samples from different sources, i.e. parotid
glands, SM, SL, minor salivary glands, GCF, tongue mucosa and
oral mucosa. From the first publication of oral proteomes,
many of the original identified proteins, catalogued as
different entries in biological databases, have been merged
with others and some were deleted due to misidentification.
Therefore, all information concerning the identified proteins
was manually curated and updated. The update of the IPI
(International Protein Index) entries was carried out with ‘‘IPI
History search’’ online tool.80 All other updates have been
made according to UniProt database.81 Another addition to
OralOme was the inclusion of manually curated data on the
proteins, samples and techniques used. More specifically, for
each protein, the following data were added to the database
when available: the up/down regulation and fold change
regarding normal samples; post translation modifications; and
whether the protein had previously been proposed as a
biomarker. Regarding the sample collection, data such as
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

Fig. 1 – Workflow for manual curation of proteins and automatic annotation.
a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x 3
AOB-2940; No. of Pages 11
stimulation or non-stimulation of saliva and donor data
(health/disease, age, sex and social habits) were also stored. In
studies where there were donors with disease, manual
annotation of the corresponding MeSH term and OMIM code
was also performed. The OMIM code was used to query web
services to retrieve specific information, such as disease name
and description. The usage of MeSH terms provides a widely
used vocabulary for disease annotation including conditions
such as caries or gingivitis which are non Mendelian diseases
and therefore not covered by the OMIM codes. Finally, all of
these data are mapped to the PubMed citation where they
were published.
Supplementary data associated with this article can be
found, in the online version, at http://dx.doi.org/10.1016/
j.archoralbio.2012.12.012.
A further improvement to the previous OralOme database
was the inclusion of microbial proteins experimentally
determined in proteomic studies of oral samples.77–79 Jagtap
et al.78 have made the first deep proteomic analysis of saliva
samples specifically targeting proteins of microbial origin.
This study presents some methodological approaches which
increased microbial protein identification by over one order of
magnitude. However, almost half of the microbial proteins
identified by Jagtap et al.78 were automatically annotated from
the genomic sequences of the Human Oral MicroBiome
Database and were not matched to an UniProt identifier. We
did not include these proteins in OralOme since there is still
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
little information and evidence of the actual existence of these
proteins.
Many of the proteins originally identified in the first
proteomic studies were misclassified as different entries in
the literature and in the biological databases. Some of these
incorrectly allocated proteins were either merged with others
or deleted. Many of the original entries in protein studies had
an International Protein Index (IPI)80 identifier, which ceased
functions in September of 2011. Therefore, the ‘‘IPI History
Search’’ tool was used to update the obsolete IPI entries. From
now on, the database information will be updated after the
UniProt database.
2.2. Automatic data annotation
A key objective of the OralCard project was to collect
information on proteins present in the oral cavity and
integrate that information, providing associations between
proteins, diseases, pathways, gene ontologies and organisms.
To achieve this goal, we carried out a first survey of online
sources where this information would be available.
We begin the information retrieval workflow with a
protein. For this particular case, the data source used was
UniProt, the most complete resource for protein sequence and
functional information. UniProt identifies each protein with
an accession code, which we will refer to as the UniProtKBAC
(UniProt Knowledgebase Accession Code). The UniProt service
tool for the study of oral proteome. Archives of Oral Biology (2013), http://
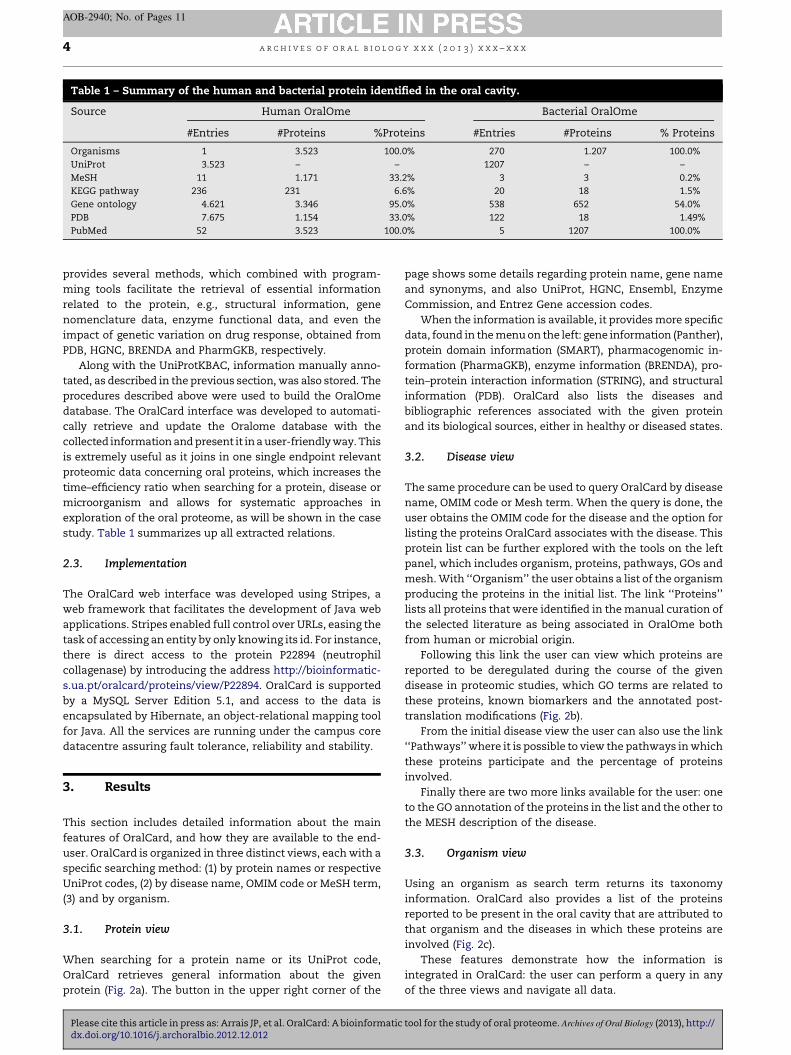
Table 1 – Summary of the human and bacterial protein identified in the oral cavity.
Source Human OralOme Bacterial OralOme
#Entries #Proteins %Proteins #Entries #Proteins % Proteins
Organisms 1 3.523 100.0% 270 1.207 100.0%
UniProt 3.523 – – 1207 – –
MeSH 11 1.171 33.2% 3 3 0.2%
KEGG pathway 236 231 6.6% 20 18 1.5%
Gene ontology 4.621 3.346 95.0% 538 652 54.0%
PDB 7.675 1.154 33.0% 122 18 1.49%
PubMed 52 3.523 100.0% 5 1207 100.0%
a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x4
AOB-2940; No. of Pages 11
provides several methods, which combined with program-
ming tools facilitate the retrieval of essential information
related to the protein, e.g., structural information, gene
nomenclature data, enzyme functional data, and even the
impact of genetic variation on drug response, obtained from
PDB, HGNC, BRENDA and PharmGKB, respectively.
Along with the UniProtKBAC, information manually anno-
tated, as described in the previous section, was also stored. The
procedures described above were used to build the OralOme
database. The OralCard interface was developed to automati-
cally retrieve and update the Oralome database with the
collected information and present it in a user-friendly way. This
is extremely useful as it joins in one single endpoint relevant
proteomic data concerning oral proteins, which increases the
time–efficiency ratio when searching for a protein, disease or
microorganism and allows for systematic approaches in
exploration of the oral proteome, as will be shown in the case
study. Table 1 summarizes up all extracted relations.
2.3. Implementation
The OralCard web interface was developed using Stripes, a
web framework that facilitates the development of Java web
applications. Stripes enabled full control over URLs, easing the
task of accessing an entity by only knowing its id. For instance,
there is direct access to the protein P22894 (neutrophil
collagenase) by introducing the address http://bioinformatic-
s.ua.pt/oralcard/proteins/view/P22894. OralCard is supported
by a MySQL Server Edition 5.1, and access to the data is
encapsulated by Hibernate, an object-relational mapping tool
for Java. All the services are running under the campus core
datacentre assuring fault tolerance, reliability and stability.
3. Results
This section includes detailed information about the main
features of OralCard, and how they are available to the end-
user. OralCard is organized in three distinct views, each with a
specific searching method: (1) by protein names or respective
UniProt codes, (2) by disease name, OMIM code or MeSH term,
(3) and by organism.
3.1. Protein view
When searching for a protein name or its UniProt code,
OralCard retrieves general information about the given
protein (Fig. 2a). The button in the upper right corner of the
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
page shows some details regarding protein name, gene name
and synonyms, and also UniProt, HGNC, Ensembl, Enzyme
Commission, and Entrez Gene accession codes.
When the information is available, it provides more specific
data, found in the menu on the left: gene information (Panther),
protein domain information (SMART), pharmacogenomic in-
formation (PharmaGKB), enzyme information (BRENDA), pro-
tein–protein interaction information (STRING), and structural
information (PDB). OralCard also lists the diseases and
bibliographic references associated with the given protein
and its biological sources, either in healthy or diseased states.
3.2. Disease view
The same procedure can be used to query OralCard by disease
name, OMIM code or Mesh term. When the query is done, the
user obtains the OMIM code for the disease and the option for
listing the proteins OralCard associates with the disease. This
protein list can be further explored with the tools on the left
panel, which includes organism, proteins, pathways, GOs and
mesh. With ‘‘Organism’’ the user obtains a list of the organism
producing the proteins in the initial list. The link ‘‘Proteins’’
lists all proteins that were identified in the manual curation of
the selected literature as being associated in OralOme both
from human or microbial origin.
Following this link the user can view which proteins are
reported to be deregulated during the course of the given
disease in proteomic studies, which GO terms are related to
these proteins, known biomarkers and the annotated post-
translation modifications (Fig. 2b).
From the initial disease view the user can also use the link
‘‘Pathways’’ where it is possible to view the pathways in which
these proteins participate and the percentage of proteins
involved.
Finally there are two more links available for the user: one
to the GO annotation of the proteins in the list and the other to
the MESH description of the disease.
3.3. Organism view
Using an organism as search term returns its taxonomy
information. OralCard also provides a list of the proteins
reported to be present in the oral cavity that are attributed to
that organism and the diseases in which these proteins are
involved (Fig. 2c).
These features demonstrate how the information is
integrated in OralCard: the user can perform a query in any
of the three views and navigate all data.
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

Fig. 2 – Interface of the main views provided by OralCard: (a) protein view; (b) disease view; (c) organism view.
a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x 5
AOB-2940; No. of Pages 11
4. Discussion
4.1. Diabetes mellitus type 2 (DMT2) case study
OralCard web tool is to be used in studies related to oral health,
but can also be used in systemic disorders presenting altered
proteins which can be detected in saliva. We chose diabetes
mellitus type 2 (DMT2) as a case study to demonstrate how the
information available on OralCard can be queried, understood
and related to the molecular mechanisms of this particular
disease. DMT2 is an example of a systemic disease of
multifactorial origins, in which different signalling and
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
metabolic pathways are compromised and which also has
implications for oral health, especially the risk of periodonti-
tis.82
One of the most common problems in diabetic patients is
impaired healing, closely related to blood coagulation, which
has a huge impact on oral medical care.83,84 Under normal
conditions, the coagulation system is characterized by a
constant balance between the processes of coagulation and
fibrinolysis. Since OralCard stores all the information on
proteins found in the oral cavity we can verify if there is
molecular evidence of the fibrinolysis/coagulation imbalance
in the oral proteome of these patients. This survey began with
identification of the proteins present in oral samples from type
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

Fig. 3 – OralCard disease view showing the list of pathways related to the proteins identified in diabetes mellitus, type 2. The
list of proteins involved in the complement and coagulation cascades is also showed.
a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x6
AOB-2940; No. of Pages 11
II diabetic patients, using the disease search feature of the
OralCard (search for diabetes and choose ‘‘Diabetes Mellitus,
Type 2’’). This approach led to identification of 445 proteins
(Fig. 2b).
For type II diabetic patients, there are quantitative data,
and therefore it is possible to know which proteins have their
expression level altered (down or up regulated) and even find
the expression level fold change (Fig. 2b, ‘‘Regulation’’
column). This type of information allows the identification
of proteins whose expression is more altered in the disease.
Apart from information directly related to the oral proteins,
OralCard also stores information related to the samples such
as donor (age, gender and social habits), sampling and analysis
methods used.
After identifying the proteins present in saliva that are
altered in DMT2 patients (Fig. 1), we check which pathways
Fig. 4 – OralCard disease view showing a squematic representa
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
these proteins are involved in, allowing verification of the
molecular mechanisms compromised in this disease. To
accomplish that task, in the disease view, we must select
‘‘Pathways’’ from the Menu options (Fig. 3).
From the list of pathways identified as being altered in
DMT2, we can verify that the pathways with the highest
number of modified proteins in DMT2 are those corresponding
to metabolism42 and coagulation/complement cascades
(Fig. 3, #Proteins column).
After identification of proteins in DMT2 already recognized
as altered when compared to healthy donors and that these
proteins are involved in the blood coagulation cascade and
complement response, it is possible, in a next step, to know
exactly which proteins are altered so that their specific role
in the pathways can be identified. Twenty-two proteins
related to coagulation/complement pathway (Fig. 3, column
tion of the complement and coagulation cascades pathway.
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

Fig. 5 – OralCard view showing the molecular network around alpha-2-macroglobulin (minimum score = 900; results per
level = 10; depth = 2).
a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x 7
AOB-2940; No. of Pages 11
‘‘Proteins’’, selecting ‘‘show’’) are altered in the oral cavity of
DMT2 patients.
OralCard can be used to obtain information about the
changes in the expression of these proteins in DMT2 (Fig. 2b,
‘‘Regulation’’ column). It is evident that three of them alpha 1-
antitrypsin (A1AT) (fold change of 3.2�), alpha-2 macroglobu-
lin (A2MG) (2.2�) and complement component C6 (4.8�) are
highly increased.
The disease view can be used to show what are the
molecular functions of the altered proteins. For instance, in
this example we see that alpha 1-antitrypsin and alpha-2
macroglobulin both have ‘‘serine-type endopeptidase inhibi-
tor activity’’ (Fig. 2b, expanding protein information ‘‘+’’).
Considering that blood coagulation is a series of serine
protease cascade reactions, A1AT and A2MG are key points of
regulation in this pathway (Fig. 4).
Fig. 6 – OralCard protein view showing structural information (
(A1AT).
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
The central role of these two proteins in the coagulation
cascade is obvious from analysis of the molecular interaction
networks of A2MG and A1AT, for they interact with several key
molecules like kallikrein (KLKB1), plasminogen (PLMN) or
plasminogen activator inhibitor 1 (PAI1) (Fig. 5), that is,
proteins involved in fibrinolysis, a mechanism closely related
to the regulation of blood coagulation.
At this point it might seem odd that using OralCard it was
possible to identify an increase in the serine protease
inhibitors A1AT and A2MG involved in the regulation of
fibrinolysis/coagulation, for it is known that DMT2 patients are
characterized by hypercoagulable and hypofibrinolysis
states.85 These facts suggest that these two inhibitors,
although in higher quantities in DMT2 patients, may not be
functional. Hyperglycaemia in DMT2 causes non-enzymatic
glycosylation of proteins, leading to various complications like
PDB tab in left menu) for the protein alpha-1-antitrypsin
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x8
AOB-2940; No. of Pages 11
nephropathy, retinopathy, neuropathy and angiopathy.86
Thus, it was important to verify if the inhibitors A1AT and
A2MG have sequences liable to non-enzymatic glycosylation
that may affect their function.
Since OralCard allows exploration of structural informa-
tion relative to oral proteins, it is possible to determine the
existence of non-enzymatic glycosylation sites capable of
influencing the function of A1AT and A2MG. The structure of
the protein complex composed of A1AT and one of the serine
proteases which it inhibits (trypsin) was obtained from
OralCard (in OralCard protein View for A1AT, choose PDB in
left Menu, find the structure corresponding to ‘‘Crystal
Structure of a Serpin:Protease Complex’’ and click ‘‘Down-
load’’) (Fig. 6) and analysed with the PyMOL software.87
We identified several possible sites of non-enzymatic
glycosylation on inhibitor amino acids near the point of
attachment to the active site of the enzyme. These non-
enzymatic glycosylations can prevent serpins inhibitory
function, since the binding of the inhibitor to the serine
enzymes involved in the coagulation cascade is prevented,
allowing the hypercoagulate state characteristic of diabetes,
even in the presence of elevated levels of protease inhibitors of
the coagulation cascade.
OralCard also stores information on proteins from micro-
bial sources. However, experimental studies using oral
samples from DMT2 patients have not been able to identify
any proteins of microbial origin, which precludes any
conclusions as to the role microbial proteins might have in
the molecular mechanisms of oral imbalances in DMT2
patients.
With DMT2 it was possible to illustrate how OralCard can
be used to explore information from different sources,
enabling the user, in a few clicks, to get information on the
proteomic evidence of alterations in the oral cavity of diabetic
patients. In this case, biological processes such as blood
coagulation were known to be altered by clinical evidence/
studies. OralCard, in a simple manner, allowed verification of
the proteomic data available, revealing evidence of which
proteins are really expressed in altered quantities and
identification of the structural reasons for the lack of function
of these specific proteins. This tool allowed the extraction of
biological meaning from the published proteomic results by
revealing the molecular evidence that can explain the
impaired healing of oral tissues in diabetic patients, as well
as key molecules in the process. In other cases, the researcher
might not have clues as to which processes are altered in
pathology, but OralCard can be used in a systematic approach
to search for the proteomic evidence of altered pathways in
the disease and then to analyse the proteins involved therein.
The main limitation of these approaches is that most
proteomic studies of oral samples in several diseases report
only the presence or absence of a protein without protein level
quantification. This fact makes the search for altered targets
more time-consuming for there is no indication as to which of
the possible altered proteins varies the most. As more
quantitative proteomics studies are published, they will be
included in OralCard and interpretation of proteomics data
from the oral cavity will become progressively easier and more
accurate. For all the reasons presented, OralCard is a key tool for
the design of experimental work in quantitative proteomics.
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
One other aspect we became aware of during manual
curation of the information present in OralCard, is that there is
still some variability of the proteomic data generated by the
sampling methods and the proteomic techniques used. These
aspects have been identified by other authors,88,89 who
reported the need for standardization in saliva and oral tissue
sampling, processing and proteomic analysis. Recently,
studies have been published on the rational for protocol
standardization90 and it is our expectation that these studies
will result in more reproducibility in proteomic experiments
performed in different laboratories.
Funding
This work was supported by the European Community’s
Seventh Framework Programme (FP7/2007–2013), under grant
agreement no. 200754 (GEN2PHEN project), and from Funda-
cao para a Ciencia e Tecnologia, FCT, under grant agreement
PTDC/EIA-CCO/100541/2008. Joel P. Arrais is funded by FCT
grant SFRH/BPD/79044/2011.
Competing interests
None declared.
Ethical approval
Not required.
Authors’ contribution
All authors contributed extensively to the work presented in
this paper. NR, DA and MJC were the main responsible for the
bibliographical review and testing. JPA and JM contributed to
the modelling and development. MB and JLO were responsible
for the work supervision. All authors discussed the results and
implications and contributed to the manuscript.
r e f e r e n c e s
1. Rouabhia M. Interactions between host and oral commensalmicroorganisms are key events in health and disease status.Canadian Journal of Infectious Diseases 2002;13(1):47–51. [Epub2007/12/27].
2. Kaufman E, Lamster IB. The diagnostic applications ofsaliva—a review. Critical Reviews in Oral Biology and Medicine2002;13(2):197–212. [Epub 2002/07/05].
3. Imamura T, Travis J, Potempa J. The biphasic virulenceactivities of gingipains: activation and inactivation of hostproteins. Current Protein and Peptide Science 2003;4(6):443–50.[Epub 2003/12/20].
4. Mandel ID. The diagnostic uses of saliva. Journal of OralPathology and Medicine 1990;19(3):119–25. [Epub 1990/03/01].
5. Lee YH, Wong DT. Saliva: an emerging biofluid for earlydetection of diseases. American Journal of Dentistry2009;22(4):241–8. [Epub 2009/10/15].
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x 9
AOB-2940; No. of Pages 11
6. Westra WH, Califano J. Toward early oral cancer detectionusing gene expression profiling of saliva: a thoroughfare ordead end? Clinical Cancer Research 2004;10(24):8130–1. [Epub2004/12/30].
7. Lawrence HP. Salivary markers of systemic disease:noninvasive diagnosis of disease and monitoring of generalhealth. Journal (Canadian Dental Association) Journal de lAssociation Dentaire Canadienne 2002;68(3):170–4. [Epub 2002/03/26].
8. Smoot LM, Smoot JC, Smidt H, Noble PA, Konneke M,McMurry ZA, et al. DNA microarrays as salivary diagnostictools for characterizing the oral cavity’s microbialcommunity. Advances in Dental Research 2005;18(1):6–11.[Epub 2005/07/07].
9. Chiappelli F, Iribarren FJ, Prolo P. Salivary biomarkers inpsychobiological medicine. Bioinformation 2006;1(8):331–4.[Epub 2007/06/29].
10. Lijnen I, Willems G. DNA research in forensic dentistry.Methods and Findings in Experimental and Clinical Pharmacology2001;23(9):511–7. [Epub 2002/03/06].
11. Amado FM, Vitorino RM, Domingues PM, Lobo MJ, Duarte JA.Analysis of the human saliva proteome. Expert Review ofProteomics 2005;2(4):521–39. [Epub 2005/08/16].
12. Hu S, Wang J, Meijer J, Ieong S, Xie Y, Yu T, et al. Salivaryproteomic and genomic biomarkers for primary Sjogren’ssyndrome. Arthritis and Rheumatism 2007;56(11):3588–600.[Epub 2007/10/31].
13. Loo JA, Yan W, Ramachandran P, Wong DT. Comparativehuman salivary and plasma proteomes. Journal of DentalResearch 2010;89(10):1016–23.
14. Cherry JM, Hong EL, Amundsen C, Balakrishnan R, BinkleyG, Chan ET, et al. Saccharomyces genome database: thegenomics resource of budding yeast. Nucleic Acids Research2012;40(database issue):D700–5. [Epub 2011/11/24].
15. Consortium TU. Reorganizing the protein space at theUniversal Protein Resource (UniProt). Nucleic Acids Research2012;40(D1):D71–5.
16. Rosa N, Correia MJ, Arrais JP, Lopes P, Melo J, Oliveira JL,et al. From the salivary proteome to the OralOme:comprehensive molecular oral biology. Archives of OralBiology 2012. [Epub 2012/01/31].
17. Bernstein FC, Koetzle TF, Williams GJ, Meyer Jr EF, Brice MD,Rodgers JR, et al. The Protein Data Bank: a computer-basedarchival file for macromolecular structures. Journal ofMolecular Biology 1977;112(3):535–42. [Epub 1977/05/25].
18. Seal RL, Gordon SM, Lush MJ, Wright MW, Bruford EA.genenames.org: the HGNC resources in 2011. NucleicAcidsResearch 2011;39(database issue):D514–9. [Epub 2010/10/12].
19. Maglott D, Ostell J, Pruitt KD, Tatusova T. Entrez Gene: gene-centered information at NCBI. Nucleic Acids Research2005;33(database issue):D54–8. [Epub 2004/12/21].
20. Flicek P, Amode MR, Barrell D, Beal K, Brent S, Chen Y, et al.Ensembl 2011. Nucleic Acids Research 2011;39(Suppl. 1):D800–6.
21. McDonagh EM, Whirl-Carrillo M, Garten Y, Altman RB, KleinTE. From pharmacogenomic knowledge acquisition toclinical applications: the PharmGKB as a clinicalpharmacogenomic biomarker resource. Biomarkers inMedicine 2011;5(6):795–806. [Epub 2011/11/23].
22. Sohngen C, Chang A, Schomburg D. Development of aclassification scheme for disease-related enzymeinformation. BMC Bioinformatics 2011;12:329. [Epub 2011/08/11].
23. Hamosh A, Scott AF, Amberger JS, Bocchini CA, McKusickVA. Online Mendelian inheritance in man (OMIM), aknowledgebase of human genes and genetic disorders.Nucleic Acids Research 2005;33(database issue):D514–7. [Epub2004/12/21].
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
24. Kanehisa M, Goto S, Sato Y, Furumichi M, Tanabe M. KEGGfor integration and interpretation of large-scale moleculardata sets. Nucleic Acids Research 2012;40(databaseissue):D109–14. [Epub 2011/11/15].
25. Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, CherryJM, et al. Gene ontology: tool for the unification of biology.The Gene Ontology Consortium. Nature Genetics2000;25(1):25–9. [Epub 2000/05/10].
26. Bandhakavi S, Van Riper SK, Tawfik PN, Stone MD, HaddadT, Rhodus NL, et al. Hexapeptide libraries for enhancedprotein PTM identification and relative abundance profilingin whole human saliva. Journal of Proteome Research2011;10(3):1052–61. [Epub 2010/12/15].
27. Bostanci N, Heywood W, Mills K, Parkar M, Nibali L, DonosN. Application of label-free absolute quantitativeproteomics in human gingival crevicular fluid by LC/MS E(gingival exudatome). Journal of Proteome Research2010;9(5):2191–9. [Epub 2010/03/09].
28. Brinkmann O, Kastratovic DA, Dimitrijevic MV,Konstantinovic VS, Jelovac DB, Antic J, et al. Oral squamouscell carcinoma detection by salivary biomarkers in aSerbian population. Oral Oncology 2011;47(1):51–5. [Epub2010/11/27].
29. Cabras T, Pisano E, Mastinu A, Denotti G, Pusceddu PP,Inzitari R, et al. Alterations of the salivary secretorypeptidome profile in children affected by type 1 diabetes.Molecular and Cellular Proteomics 2010;9(10):2099–108. [Epub2010/06/30].
30. Castagnola M, Inzitari R, Fanali C, Iavarone F, Vitali A,Desiderio C, et al. The surprising composition of the salivaryproteome of preterm human newborn. Molecular and CellularProteomics 2011;10(1). [M110.003467. Epub 2010/10/15].
31. Chi LM, Lee CW, Chang KP, Hao SP, Lee HM, Liang Y, et al.Enhanced interferon signaling pathway in oral cancerrevealed by quantitative proteome analysis ofmicrodissected specimens using 16O/18O labeling andintegrated two-dimensional LC-ESI-MALDI tandem MS.Molecular and Cellular Proteomics 2009;8(7):1453–74. [Epub2009/03/20].
32. Choi YJ, Heo SH, Lee JM, Cho JY. Identification of azurocidinas a potential periodontitis biomarker by a proteomicanalysis of gingival crevicular fluid. Proteome Science2011;9:42. [Epub 2011/07/29].
33. Costa PP, Trevisan GL, Macedo GO, Palioto DB, Souza SL,Grisi MF, et al. Salivary interleukin-6, matrixmetalloproteinase-8, and osteoprotegerin in patients withperiodontitis and diabetes. Journal of Periodontology2010;81(3):384–91. [Epub 2010/03/03].
34. Denny P, Hagen FK, Hardt M, Liao L, Yan W, Arellanno M,et al. The proteomes of human parotid and submandibular/sublingual gland salivas collected as the ductal secretions.Journal of Proteome Research 2008;7(5):1994–2006. [Epub 2008/03/26].
35. Dowling P, Wormald R, Meleady P, Henry M, Curran A,Clynes M. Analysis of the saliva proteome from patientswith head and neck squamous cell carcinoma revealsdifferences in abundance levels of proteins associated withtumour progression and metastasis. Journal of Proteomics2008;71(2):168–75. [Epub 2008/07/12].
36. Fang X, Yang L, Wang W, Song T, Lee CS, DeVoe DL, et al.Comparison of electrokinetics-based multidimensionalseparations coupled with electrospray ionization–tandemmass spectrometry for characterization of human salivaryproteins. Analytical Chemistry 2007;79(15):5785–92. [Epub2007/07/07].
37. Fleissig Y, Deutsch O, Reichenberg E, Redlich M, Zaks B,Palmon A, et al. Different proteomic protein patterns insaliva of Sjogren’s syndrome patients. Oral Diseases2009;15(1):61–8. [Epub 2008/10/23].
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x10
AOB-2940; No. of Pages 11
38. Giusti L, Baldini C, Bazzichi L, Ciregia F, Tonazzini I, MasciaG, et al. Proteome analysis of whole saliva: a new tool forrheumatic diseases—the example of Sjogren’s syndrome.Proteomics 2007;7(10):1634–43. [Epub 2007/04/17].
39. Giusti L, Bazzichi L, Baldini C, Ciregia F, Mascia G,Giannaccini G, et al. Specific proteins identified in wholesaliva from patients with diffuse systemic sclerosis. Journalof Rheumatology 2007;34(10):2063–9. [Epub 2007/08/28].
40. Goncalves Lda R, Soares MR, Nogueira FC, Garcia C,Camisasca DR, Domont G, et al. Comparative proteomicanalysis of whole saliva from chronic periodontitispatients. Journal of Proteomics 2010;73(7):1334–41. [Epub2010/03/11].
41. Gonzalez-Begne M, Lu B, Han X, Hagen FK, Hand AR, MelvinJE, et al. Proteomic analysis of human parotid glandexosomes by multidimensional protein identificationtechnology (MudPIT). Journal of Proteome Research2009;8(3):1304–14. [Epub 2009/02/10].
42. Gonzalez-Begne M, Lu B, Liao L, Xu T, Bedi G, Melvin JE, et al.Characterization of the human submandibular/sublingualsaliva glycoproteome using lectin affinity chromatographycoupled to multidimensional protein identificationtechnology. Journal of Proteome Research 2011;10(11):5031–46.[Epub 2011/09/23].
43. Grant MM, Creese AJ, Barr G, Ling MR, Scott AE, Matthews JB,et al. Proteomic analysis of a noninvasive human model ofacute inflammation and its resolution: the twenty-one daygingivitis model. Journal of Proteome Research 2010;9(9):4732–44. [Epub 2010/07/29].
44. Haigh BJ, Stewart KW, Whelan JR, Barnett MP, SmolenskiGA, Wheeler TT. Alterations in the salivary proteomeassociated with periodontitis. Journal of Clinical Periodontology2010;37(3):241–7. [Epub 2010/02/13].
45. Hardt M, Thomas LR, Dixon SE, Newport G, Agabian N,Prakobphol A, et al. Toward defining the human parotidgland salivary proteome and peptidome: identification andcharacterization using 2D SDS-PAGE, ultrafiltration, HPLC,and mass spectrometry. Biochemistry 2005;44(8):2885–99.[Epub 2005/02/23].
46. Hardt M, Witkowska HE, Webb S, Thomas LR, Dixon SE, HallSC, et al. Assessing the effects of diurnal variation on thecomposition of human parotid saliva: quantitative analysisof native peptides using iTRAQ reagents. AnalyticalChemistry 2005;77(15):4947–54. [Epub 2005/08/02].
47. He QY, Chen J, Kung HF, Yuen AP, Chiu JF. Identification oftumor-associated proteins in oral tongue squamous cellcarcinoma by proteomics. Proteomics 2004;4(1):271–8. [Epub2004/01/20].
48. Hjelmervik TO, Jonsson R, Bolstad AI. The minor salivarygland proteome in Sjogren’s syndrome. Oral Diseases2009;15(5):342–53. [Epub 2009/04/15].
49. Hu S, Arellano M, Boontheung P, Wang J, Zhou H, Jiang J,et al. Salivary proteomics for oral cancer biomarkerdiscovery. Clinical Cancer Research 2008;14(19):6246–52. [Epub2008/10/03].
50. Hu S, Xie Y, Ramachandran P, Ogorzalek Loo RR, Li Y, Loo JA,et al. Large-scale identification of proteins in humansalivary proteome by liquid chromatography/massspectrometry and two-dimensional gel electrophoresis–mass spectrometry. Proteomics 2005;5(6):1714–28. [Epub2005/04/01].
51. Huang CM. Comparative proteomic analysis of humanwhole saliva. Archives of Oral Biology 2004;49(12):951–62.[Epub 2004/10/16].
52. Ito K, Funayama S, Hitomi Y, Nomura S, Katsura K, Saito M,et al. Proteome analysis of gelatin-bound salivary proteinsin patients with primary Sjogren’s syndrome: identificationof matrix metalloproteinase-9. Clinica Chimica Acta2009;403(1–2):269–71. [Epub 2009/03/24].
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
53. Jou YJ, Lin CD, Lai CH, Chen CH, Kao JY, Chen SY, et al.Proteomic identification of salivary transferrin as abiomarker for early detection of oral cancer. AnalyticaChimica Acta 2010;681(1–2):41–8. [Epub 2010/11/03].
54. Larsen MR, Jensen SS, Jakobsen LA, Heegaard NH. Exploringthe sialiome using titanium dioxide chromatography andmass spectrometry. Molecular and Cellular Proteomics2007;6(10):1778–87. [Epub 2007/07/12].
55. Lawler JM, Kwak HB, Kim JH, Suk MH. Exercise traininginducibility of MnSOD protein expression and activity isretained while reducing prooxidant signaling in the heart ofsenescent rats. American Journal of Physiology RegulatoryIntegrative and Comparative Physiology 2009;296(5):R1496–502.[Epub 2009/03/20].
56. Lo WY, Tsai MH, Tsai Y, Hua CH, Tsai FJ, Huang SY, et al.Identification of over-expressed proteins in oral squamouscell carcinoma (OSCC) patients by clinical proteomicanalysis. Clinica Chimica Acta 2007;376(1–2):101–7. [Epub2006/08/08].
57. Messana I, Cabras T, Inzitari R, Lupi A, Zuppi C, Olmi C, et al.Characterization of the human salivary basic proline-richprotein complex by a proteomic approach. Journal ofProteome Research 2004;3(4):792–800. [Epub 2004/09/14].
58. Negishi A, Masuda M, Ono M, Honda K, Shitashige M, SatowR, et al. Quantitative proteomics using formalin-fixedparaffin-embedded tissues of oral squamous cellcarcinoma. Cancer Science 2009;100(9):1605–11. [Epub 2009/06/16].
59. Preza D, Thiede B, Olsen I, Grinde B. The proteome of thehuman parotid gland secretion in elderly with and withoutroot caries. Acta Odontologica Scandinavica 2009;67(3):161–9.[Epub 2009/03/03].
60. Quintana M, Palicki O, Lucchi G, Ducoroy P, Chambon C,Salles C, et al. Inter-individual variability of protein patternsin saliva of healthy adults. Journal of Proteomics2009;72(5):822–30. [Epub 2009/05/28].
61. Ramachandran P, Boontheung P, Pang E, Yan W, Wong DT,Loo JA. Comparison of N-linked glycoproteins in humanwhole saliva, parotid, submandibular, and sublingualglandular secretions identified using hydrazide chemistryand mass spectrometry. Clinical Proteomics 2008;4(3–4):80–104. [Epub 2008/12/01].
62. Ramachandran P, Boontheung P, Xie Y, Sondej M, Wong DT,Loo JA. Identification of N-linked glycoproteins in humansaliva by glycoprotein capture and mass spectrometry.Journal of Proteome Research 2006;5(6):1493–503. [Epub 2006/06/03].
63. Rao PV, Reddy AP, Lu X, Dasari S, Krishnaprasad A, Biggs E,et al. Proteomic identification of salivary biomarkers oftype-2 diabetes. Journal of Proteome Research 2009;8(1):239–45.[Epub 2009/01/03].
64. Ryu OH, Atkinson JC, Hoehn GT, Illei GG, Hart TC.Identification of parotid salivary biomarkers in Sjogren’ssyndrome by surface-enhanced laser desorption/ionizationtime-of-flight mass spectrometry and two-dimensionaldifference gel electrophoresis. Rheumatology2006;45(9):1077–86. [Epub 2006/03/09].
65. Siqueira WL, Salih E, Wan DL, Helmerhorst EJ, Oppenheim FG.Proteome of human minor salivary gland secretion. Journal ofDental Research 2008;87(5):445–50. [Epub 2008/04/25].
66. Stone MD, Chen X, McGowan T, Bandhakavi S, Cheng B,Rhodus NL, et al. Large-scale phosphoproteomics analysisof whole saliva reveals a distinct phosphorylation pattern.Journal of Proteome Research 2011;10(4):1728–36. [Epub 2011/02/09].
67. Streckfus CF, Storthz KA, Bigler L, Dubinsky WP. Acomparison of the proteomic expression in pooled salivaspecimens from individuals diagnosed with ductalcarcinoma of the breast with and without lymph node
tool for the study of oral proteome. Archives of Oral Biology (2013), http://

a r c h i v e s o f o r a l b i o l o g y x x x ( 2 0 1 3 ) x x x – x x x 11
AOB-2940; No. of Pages 11
involvement. Journla of Oncology 2009;2009:737619. [Epub2010/01/07].
68. Turhani D, Krapfenbauer K, Thurnher D, Langen H,Fountoulakis M. Identification of differentially expressed,tumor-associated proteins in oral squamous cell carcinomaby proteomic analysis. Electrophoresis 2006;27(7):1417–23.[Epub 2006/03/29].
69. Vitorino R, Lobo MJ, Duarte JA, Ferrer-Correia AJ, DominguesPM, Amado FM. Analysis of salivary peptides using HPLC-electrospray mass spectrometry. Biomedical Chromatography2004;18(8):570–5. [Epub 2004/09/24].
70. Walz A, Stuhler K, Wattenberg A, Hawranke E, Meyer HE,Schmalz G, et al. Proteome analysis of glandular parotid andsubmandibular–sublingual saliva in comparison to wholehuman saliva by two-dimensional gel electrophoresis.Proteomics 2006;6(5):1631–9. [Epub 2006/01/13].
71. Wilmarth PA, Riviere MA, Rustvold DL, Lauten JD, MaddenTE, David LL. Two-dimensional liquid chromatographystudy of the human whole saliva proteome. Journal ofProteome Research 2004;3(5):1017–23. [Epub 2004/10/12].
72. Wu Y, Shu R, Liu H. Comparison of proteomic profiles ofwhole unstimulated saliva obtained from generalizedaggressive periodontitis patients and healthy controls. HuaXi Kou Qiang Yi Xue Za ZhiHuaxi Kouqiang Yixue ZazhiWestChina Journal of Stomatology 2011;29(5):519–2125. [Epub 2011/12/15].
73. Wu Y, Shu R, Luo LJ, Ge LH, Xie YF. Initial comparison ofproteomic profiles of whole unstimulated saliva obtainedfrom generalized aggressive periodontitis patients andhealthy control subjects. Journal of Periodontal Research2009;44(5):636–44. [Epub 2009/05/21].
74. Xie H, Rhodus NL, Griffin RJ, Carlis JV, Griffin TJ. A catalogueof human saliva proteins identified by free flowelectrophoresis-based peptide separation and tandem massspectrometry. Molecular and Cellular Proteomics2005;4(11):1826–30. [Epub 2005/08/17].
75. Yan W, Apweiler R, Balgley BM, Boontheung P, Bundy JL,Cargile BJ, et al. Systematic comparison of the human salivaand plasma proteomes. Proteomics Clinical Applications2009;3(1):116–34. [Epub 2009/11/10].
76. Yang LL, Liu XQ, Liu W, Cheng B, Li MT. Comparativeanalysis of whole saliva proteomes for the screening ofbiomarkers for oral lichen planus. Inflammation Research2006;55(10):405–7. [Epub 2006/07/20].
77. Esser D, Alvarez-Llamas G, de Vries MP, Weening D, Vonk RJ,Roelofsen H. Sample stability and protein composition ofsaliva: implications for its use as a diagnostic fluid.Biomarker Insights 2008;3:25–7. [Epub 2008/01/01].
Please cite this article in press as: Arrais JP, et al. OralCard: A bioinformaticdx.doi.org/10.1016/j.archoralbio.2012.12.012
78. Jagtap P, McGowan T, Bandhakavi S, Tu ZJ, Seymour S, GriffinTJ, et al. Deep metaproteomic analysis of human salivarysupernatant. Proteomics 2012;12(7):992–1001. [Epub 2012/04/24].
79. Xie H, Onsongo G, Popko J, de Jong EP, Cao J, Carlis JV, et al.Proteomics analysis of cells in whole saliva from oral cancerpatients via value-added three-dimensional peptidefractionation and tandem mass spectrometry. Molecular andCellular Proteomics 2008;7(3):486–98. [Epub 2007/11/30].
80. Kersey PJ, Duarte J, Williams A, Karavidopoulou Y, Birney E,Apweiler R. The International Protein Index: an integrateddatabase for proteomics experiments. Proteomics2004;4(7):1985–8. [Epub 2004/06/29].
81. Reorganizing the protein space at the Universal ProteinResource (UniProt). Nucleic Acids Research 2012;40(databaseissue):D71–5. [Epub 2011/11/22].
82. Lakschevitz F, Aboodi G, Tenenbaum H, Glogauer M.Diabetes and periodontal diseases: interplay and links.Current Diabetes Reviews 2011;7(6):433–9. [Epub 2011/11/19].
83. Abiko Y, Selimovic D. The mechanism of protracted woundhealing on oral mucosa in diabetes. Review. Bosnian Journalof Basic Medical Sciences 2010;10(3):186–91. [Epub 2010/09/18].
84. Lamster IB, Lalla E, Borgnakke WS, Taylor GW. Therelationship between oral health and diabetes mellitus.Journal of the American Dental Association2008;139(Suppl.):19S–24S. [Epub 2008/11/01].
85. Mafrici A, Proietti R. Aterotrombosi e diabete mellito di tipo2: analisi dei principali meccanismi fisiopatogenetici[Atherothrombosis in patients with type 2 diabetes mellitus:an overview of pathophysiology]. Giornale Italiano diCardiologia 2010;11(6):467–77. [Epub 2010/10/07].
86. Nawale RB, Mourya VK, Bhise SB. Non-enzymatic glycationof proteins: a cause for complications in diabetes. IndianJournal of Biochemistry and Biophysics 2006;43(6):337–44. [Epub2007/02/09].
87. Schrodinger, LLC. The PyMOL molecular graphics system,version 1.3r1, 2010.
88. Al-Tarawneh SK, Border MB, Dibble CF, Bencharit S.Defining salivary biomarkers using mass spectrometry-based proteomics: a systematic review. Omics A Journal ofIntegrative Biology 2011;15(6):353–61. [Epub 2011/05/17].
89. Castagnola M, Cabras T, Iavarone F, Fanali C, Nemolato S,Peluso G, et al. The human salivary proteome: a criticaloverview of the results obtained by different proteomicplatforms. Expert Review of Proteomics 2012;9(1):33–46. [Epub2012/02/02].
90. Xiao H, Wong DT. Method development for proteomestabilization in human saliva. Analytica Chimica Acta2012;722:63–9. [Epub 2012/03/27].
tool for the study of oral proteome. Archives of Oral Biology (2013), http://
Copyright © 2022 FDOKUMEN




















