

OpenBLAS:面向深度学习加速的开源软件包 - 中国计算机学会
48
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of OpenBLAS:面向深度学习加速的开源软件包 - 中国计算机学会

提纲
什么是BLAS
为什么BLAS对深度学习如此重要
为什么要做OpenBLAS
OpenBLAS简介
OpenBLAS关键技术:AUGEM自动代码生成框架
OpenBLAS的产业化及其影响
总结

什么是BLAS• 基本线性代数子程序(BLAS)
• BLAS3矩阵和矩阵操作
• BLAS2矩阵和向量操作
• BLAS1向量和向量操作
• 科学工程计算最重要的基础数学库• LINPACK性能测试(TOP500)
• 依赖于BLAS库性能
• 大数据深度学习算法的核心底层依赖库• CPU上89%的算法开销都为BLAS计算
3

主流BLAS软件包
ATLAS
GotoBLAS
Many CPU vendors and HPC researchers have provided high performance BLAS libraries for different CPUs Intel MKL IBM ESSL AMD ACML ATLAS PhiPAC GotoBLAS

为什么要做OpenBLAS
各大CPU厂商都有商业数学库 Intel MKL,AMD ACML,IBM ESSL
开源实现 ATLAS
自适应优化技术,性能一般 GotoBLAS
手工汇编优化,最优实现 开发者Kazushige Goto 2010年离开 已停滞
2011年初发起OpenBLAS 基于GotoBLAS2 1.13 BSD版

OpenBLAS简介
项目主页 http://www.openblas.net/ BSD协议, 当前稳定版本 0.2.15(累计28个版本)
当前开发人员 张先轶, 王茜, Werner Saar 总贡献人数44人
主要进展 龙芯3A 处理器支持和优化 龙芯3B处理器支持(实验) 主流x86 CPUs: Intel SNB, Haswell, AMD Bulldozer, Piledriver 移植ARM平台,针对ARM Cortex-A9、Cortex-A15优化 正在进行ARM V8架构和IBM Power的移植和优化
细节改进 增强Mac OS X, Windows, FreeBSD上的编译、安装和使用

OpenBLAS简介
用户支持 Wiki:文档和FAQ 邮件列表 Issue系统
进入若干Linux发行版的源 Debian, Ubuntu, Gentoo
成为若干开源项目的依赖库之一 MIT Computer Science and Artificial Intelligence Laboratory的
Julia项目 GNU Octave,Deep Learning: Caffe,…
商业化尝试:与旷视科技在深度学习领域的相关合作

Automatically Generate High Performance BLAS Kernels on x86 CPUs

Two ways to generate high performance BLAS• Manually developed, e.g. GotoBLAS
• A collection of fine‐grained optimizations, such as register blocking ,register allocation and assembly instruction scheduling, are carefully orchestrated by domain experts;
• Usually using assembly language, error‐prone; • Non‐acceptable software portability;• Repetitively laborious work on every new generation platform.
• Automatically Tuned, e.g. ATLAS, PhiPAC• Empirical tuning is used to automatically experiment different optimization choices;
• Low‐level C code generation – can’t exploit hardware resources• Time saving but unsatisfied performance portability

Motivations
How to find a way to automatically generate efficient assembly kernels, while still could realize performance portability across different generations of CPUs? Try to find tradeoff between performance and
portability Try to reduce laborious work of manually developing
code for different kinds of CPU architectures

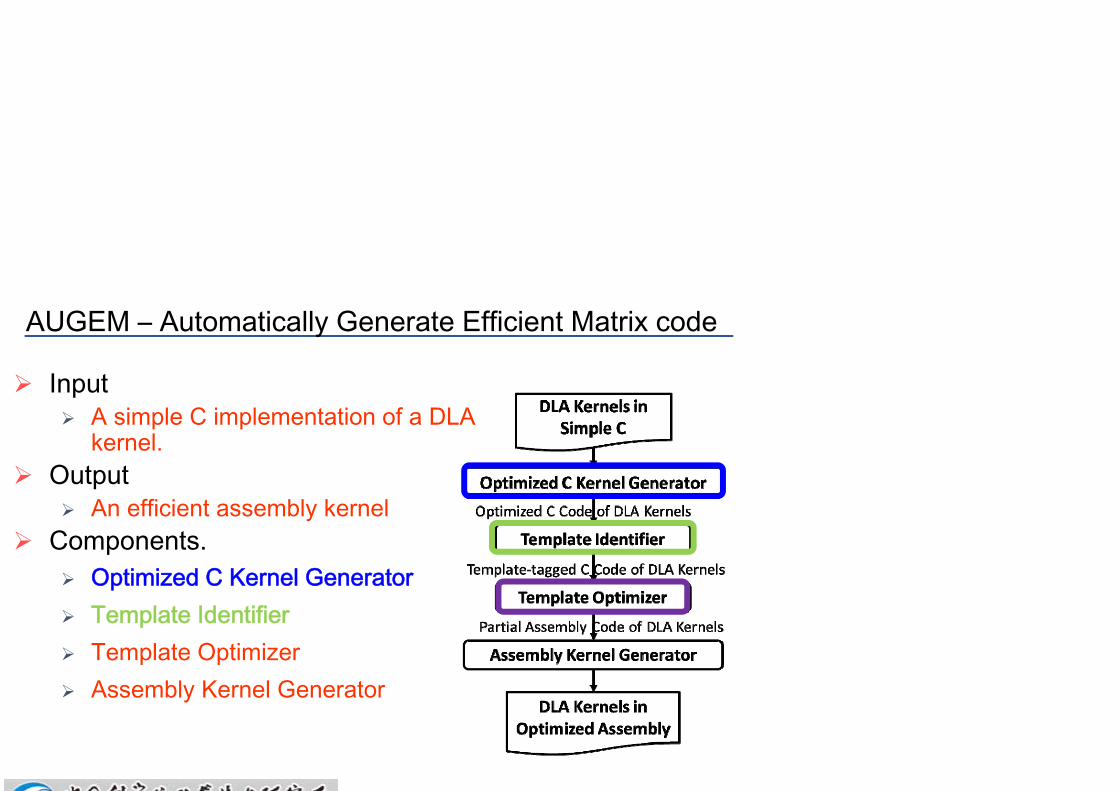
AUGEM – Automatically Generate Efficient Matrix code
Input A simple C implementation of a DLA
kernel. Output
An efficient assembly kernel Components.
Optimized C Kernel Generator Template Identifier Template Optimizer Assembly Kernel Generator

Optimized C kernel Generator
Input simple C code of gemm kernel
Output Optimized C code of gemm kernel
Loop unroll&jam
Loop unrolling
Strength reduction
Data prefetching

POET: Parameterized Optimizations for Empirical Tuning
A scripting language Applying parameterized
program transformations Programmable control of
compiler optimizations Ad-hoc translation between
arbitrary languages

Optimized C Kernel Code
Output Optimized C code of gemm kernel
Load: tmp0 = ptr_A[0];Load: tmp1 = ptr_B[0];Multiply: tmp2 = tmp0 * tmp1;Add: res0 = res0 + tmp2;
Load: tmp0 = C[j*LDC+i];Add: res0 = res0 + tmp0;Store: C[j*LDC+i] = res0;
These computation sequences are commonly appeared within DLA code.What if we identify them and tag them…

Templates
Existing code templates within AUGEM
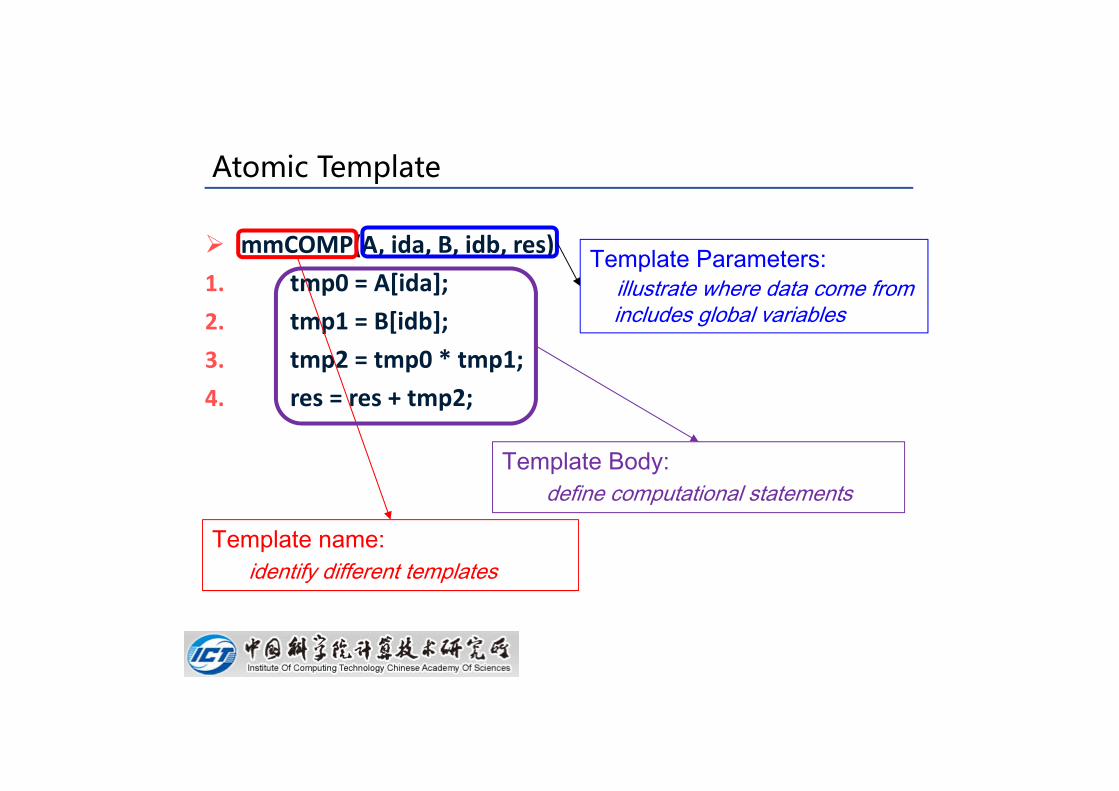
Atomic Template
mmCOMP(A, ida, B, idb, res)1. tmp0 = A[ida];2. tmp1 = B[idb];3. tmp2 = tmp0 * tmp1;4. res = res + tmp2;
Template name:identify different templates
Template Parameters:illustrate where data come fromincludes global variables
Template Body:define computational statements

Complex Template
mmUnrolledCOMP(A, ida, na, B, idb, nb, Res)1. mmCOMP(A, ida, B, idb, res0)2. mmCOMP(A, ida+1, B, idb, res1);3. …4. mmCOMP(A, ida+na‐1, B, idb, resna‐1);5. mmCOMP(A, ida, B, idb+1, resna);6. …7. mmCOMP(A, ida+na‐1, B, idb+nb‐1, res(na‐1)*(nb‐1))
These templates could provide enough information for us to apply fine-grained optimizations
na*nbmmCOMP Templates

AUGEM – Automatically Generate Efficient Matrix code Input
A simple C implementation of a DLA kernel.
Output An efficient assembly kernel
Components. Optimized C Kernel Generator Template Identifier Template Optimizer Assembly Kernel Generator

Template Identifier
Output Optimized C code of gemm kernel
mm
CO
MP
mm
CO
MP mm
Unr
olle
dCO
MP
mm
STO
RE
mm
Unr
olle
dST
OR
E
Output Optimized C code of gemm kernel
AUGEM – Automatically Generate Efficient Matrix code
Input A simple C implementation of a DLA
kernel. Output
An efficient assembly kernel Components.
Optimized C Kernel Generator Template Identifier Template Optimizer Assembly Kernel Generator
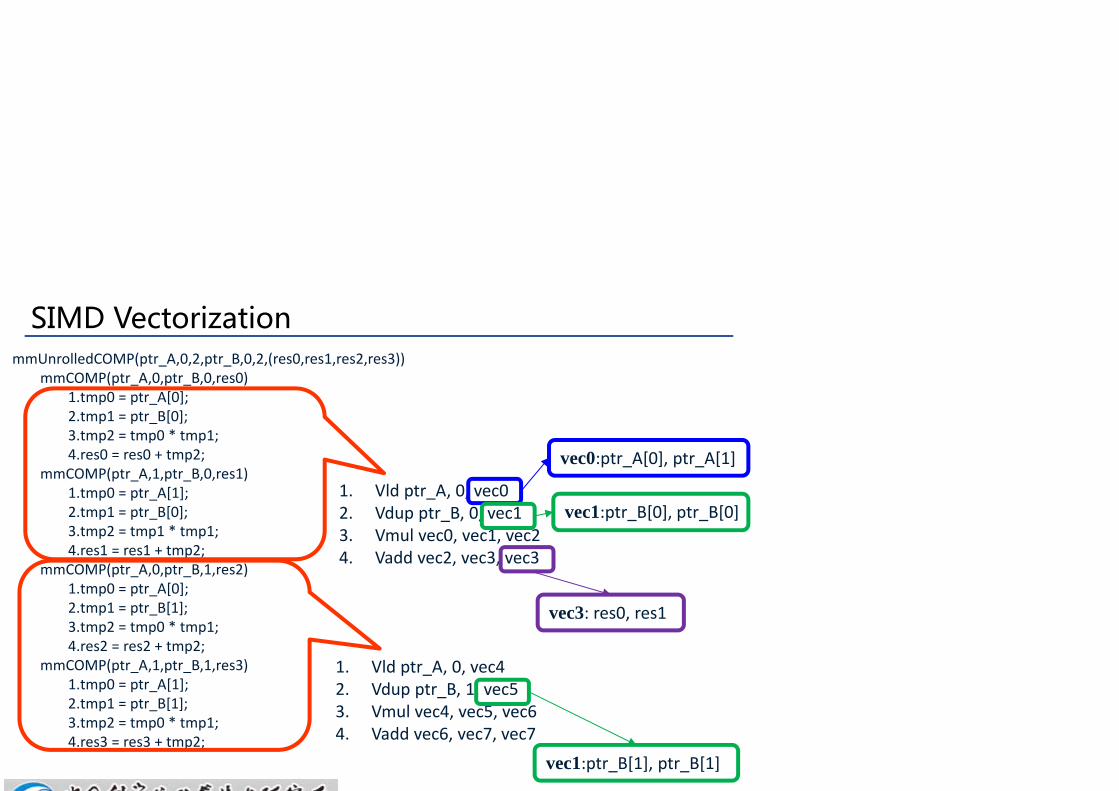
SIMD VectorizationmmUnrolledCOMP(ptr_A,0,2,ptr_B,0,2,(res0,res1,res2,res3))
mmCOMP(ptr_A,0,ptr_B,0,res0)1.tmp0 = ptr_A[0];2.tmp1 = ptr_B[0];3.tmp2 = tmp0 * tmp1;4.res0 = res0 + tmp2;
mmCOMP(ptr_A,1,ptr_B,0,res1)1.tmp0 = ptr_A[1];2.tmp1 = ptr_B[0];3.tmp2 = tmp1 * tmp1;4.res1 = res1 + tmp2;
mmCOMP(ptr_A,0,ptr_B,1,res2)1.tmp0 = ptr_A[0];2.tmp1 = ptr_B[1];3.tmp2 = tmp0 * tmp1;4.res2 = res2 + tmp2;
mmCOMP(ptr_A,1,ptr_B,1,res3)1.tmp0 = ptr_A[1];2.tmp1 = ptr_B[1];3.tmp2 = tmp0 * tmp1;4.res3 = res3 + tmp2;
1. Vld ptr_A, 0, vec02. Vdup ptr_B, 0, vec13. Vmul vec0, vec1, vec24. Vadd vec2, vec3, vec3
vec0:ptr_A[0], ptr_A[1]
vec1:ptr_B[0], ptr_B[0]
vec3: res0, res1
1. Vld ptr_A, 0, vec42. Vdup ptr_B, 1, vec53. Vmul vec4, vec5, vec64. Vadd vec6, vec7, vec7
vec1:ptr_B[1], ptr_B[1]
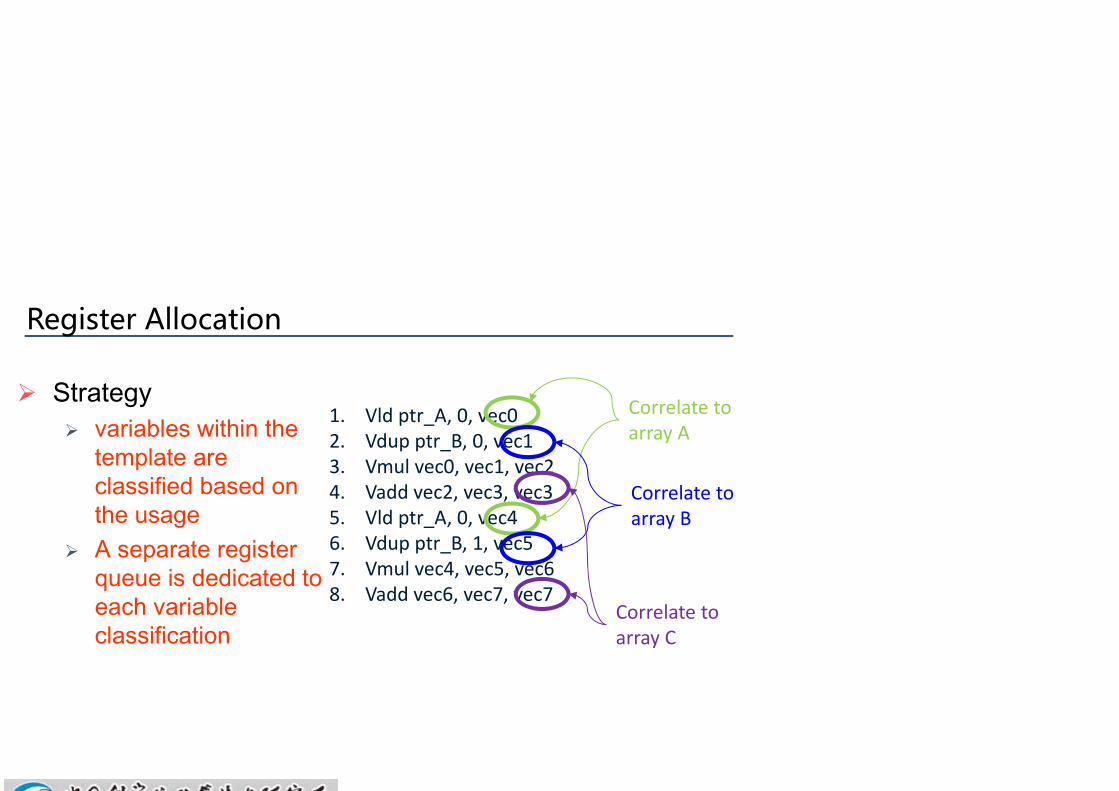
Register Allocation
Strategy variables within the
template are classified based on the usage
A separate register queue is dedicated to each variable classification
1. Vld ptr_A, 0, vec02. Vdup ptr_B, 0, vec13. Vmul vec0, vec1, vec24. Vadd vec2, vec3, vec35. Vld ptr_A, 0, vec46. Vdup ptr_B, 1, vec57. Vmul vec4, vec5, vec68. Vadd vec6, vec7, vec7
Correlate to array A
Correlate to array B
Correlate to array C
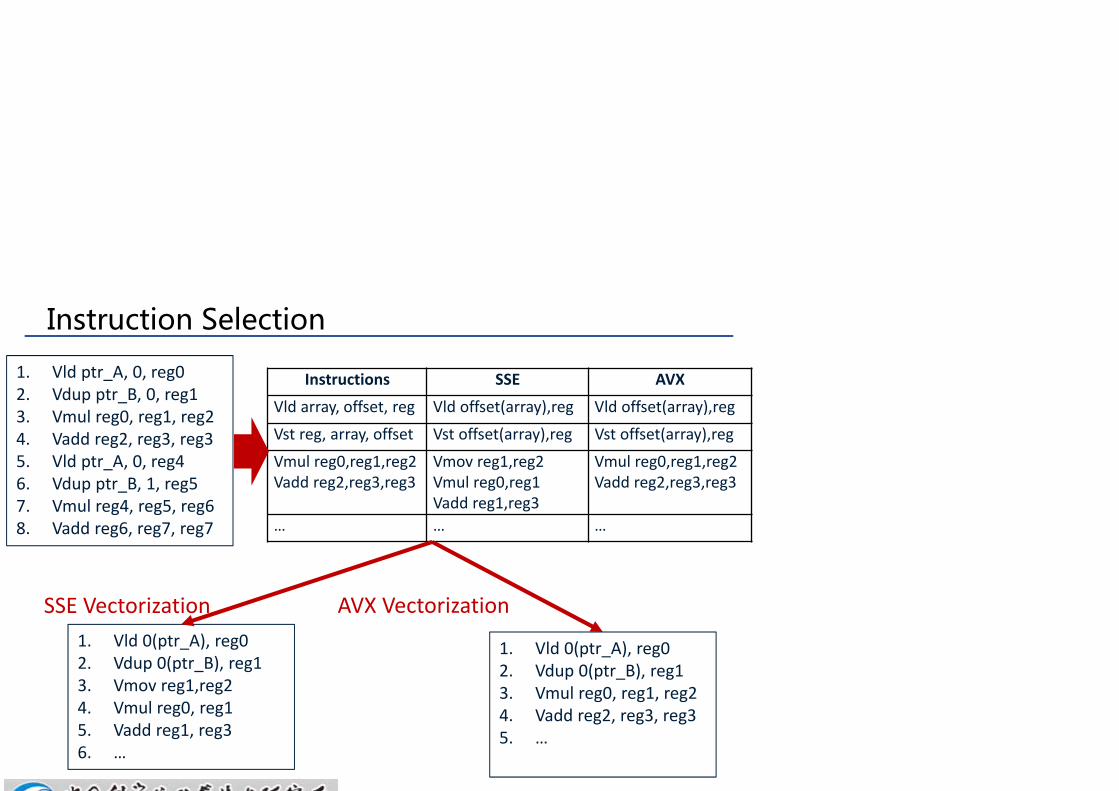
Instruction Selection
1. Vld ptr_A, 0, reg02. Vdup ptr_B, 0, reg13. Vmul reg0, reg1, reg24. Vadd reg2, reg3, reg35. Vld ptr_A, 0, reg46. Vdup ptr_B, 1, reg57. Vmul reg4, reg5, reg68. Vadd reg6, reg7, reg7
Instructions SSE AVX
Vld array, offset, reg Vld offset(array),reg Vld offset(array),reg
Vst reg, array, offset Vst offset(array),reg Vst offset(array),reg
Vmul reg0,reg1,reg2Vadd reg2,reg3,reg3
Vmov reg1,reg2Vmul reg0,reg1Vadd reg1,reg3
Vmul reg0,reg1,reg2Vadd reg2,reg3,reg3
… … …
1. Vld 0(ptr_A), reg02. Vdup 0(ptr_B), reg13. Vmov reg1,reg24. Vmul reg0, reg15. Vadd reg1, reg36. …
1. Vld 0(ptr_A), reg02. Vdup 0(ptr_B), reg13. Vmul reg0, reg1, reg24. Vadd reg2, reg3, reg35. …
SSE Vectorization AVX Vectorization

Template Optimizer
Optimizer SIMD Register allocation Instruction selection
Build-in Optimizers mmCOMP Optimizer mmSTORE Optimizer mvCOMP Optimizer mmUnrolledCOMP Optimizer mmUnrolledSTORE Optimizer mvUnrolledCOMP Optimizer
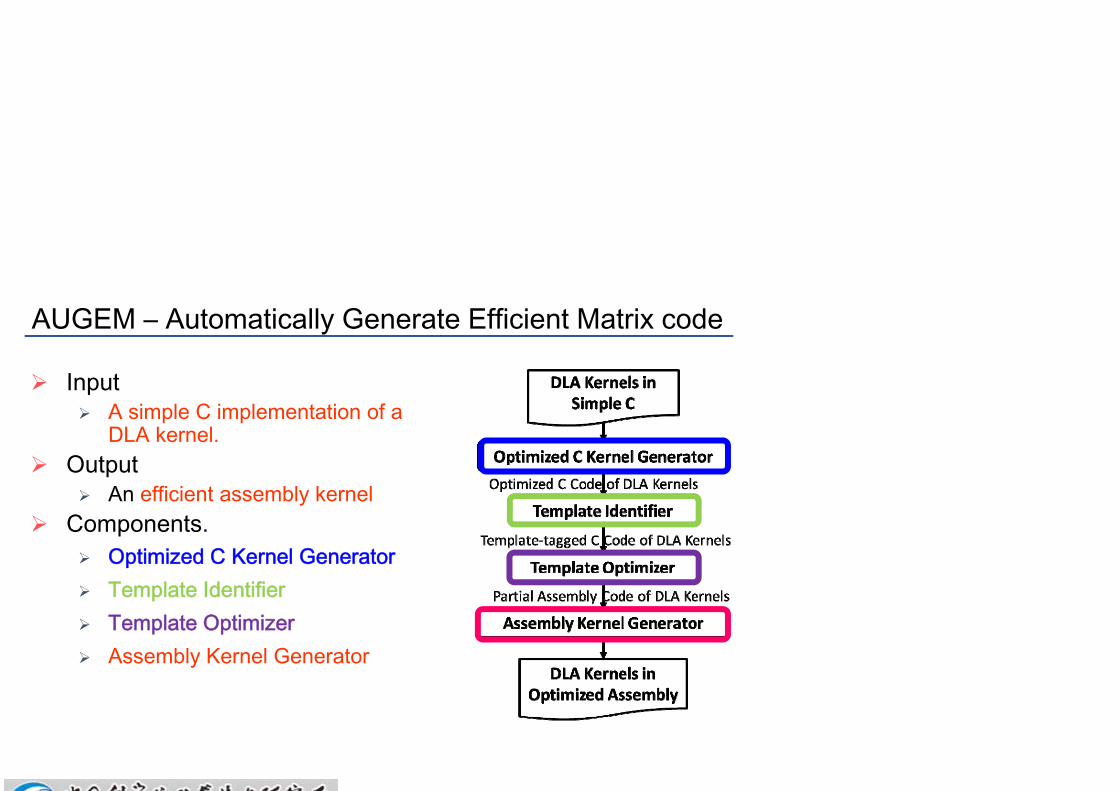
AUGEM – Automatically Generate Efficient Matrix code
Input A simple C implementation of a
DLA kernel. Output
An efficient assembly kernel Components.
Optimized C Kernel Generator Template Identifier Template Optimizer Assembly Kernel Generator

Assembly Kernel Generator
Translate the rest C code to valid machine assembly instructions.
Challenge Keep consistency of register
allocation decisions among different code regions
Algorithm of Template Optimizer

Case Study: DLA Subprograms
• GEMM BLAS 3• C=C+AB
• GEMV BLAS 2• y=y+Ax
• AXPY BLAS 1• y=y+ax
• DOT BLAS 1• y=y+axty

Platforms Configurations

Performance Evaluation Intel Sandy Bridge AMD Piledriver
dgemm dgemm
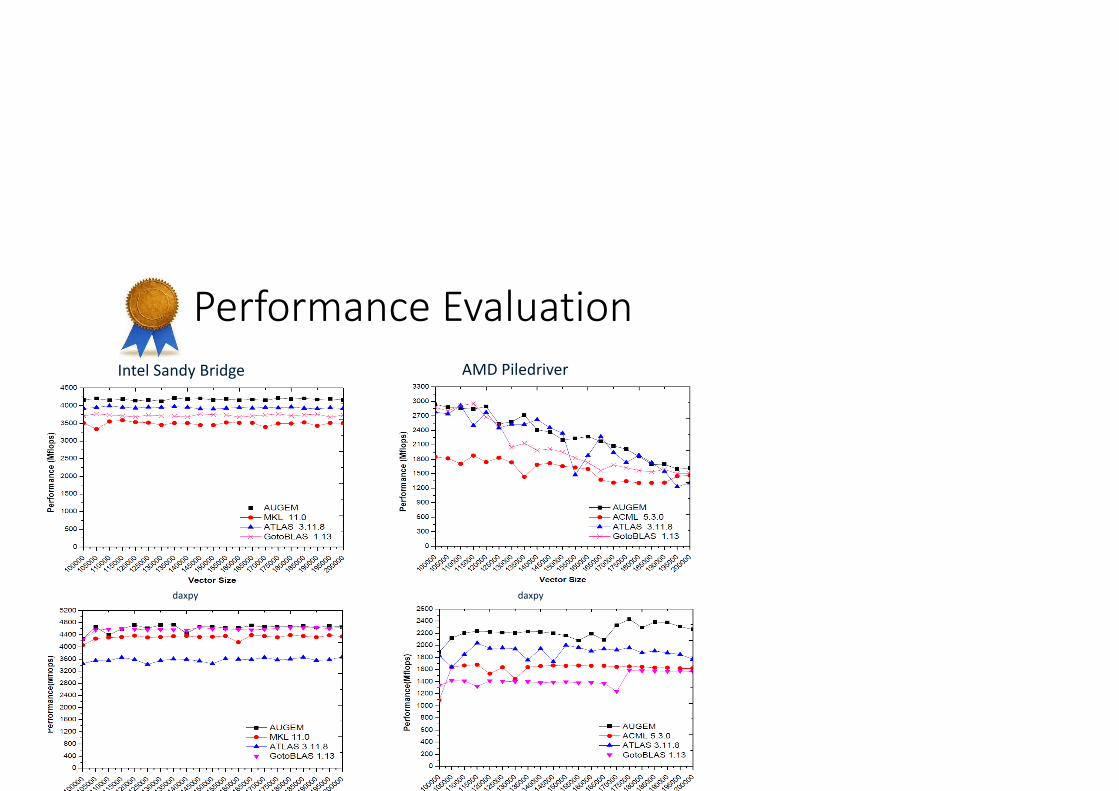
Performance Evaluation Intel Sandy Bridge AMD Piledriver
daxpy daxpy

Performance Evaluation The performance of other DLA routines within the BLAS library,
which invokes the four above DLA kernels.

OpenBLAS性能结果• 龙芯3A CPU
• BLAS3级 4线程,OpenBLAS超过GotoBLAS 120%,ATLAS 73%
Zhang Xianyi, Wang Qian, Zhang Yunquan, Model‐driven Level 3 BLAS Performance Optimization on Loongson 3A Processor, 2012 IEEE 18th International Conference on Parallel and Distributed Systems (ICPADS), 17‐19 Dec. 2012

OpenBLAS性能结果• 申威1600
• 950MHz,1.7GB内存
• OpenBLAS单线程DGEMM是GotoBLAS 6倍
01000200030004000500060007000
1000
1500
2000
2500
3000
3500
4000
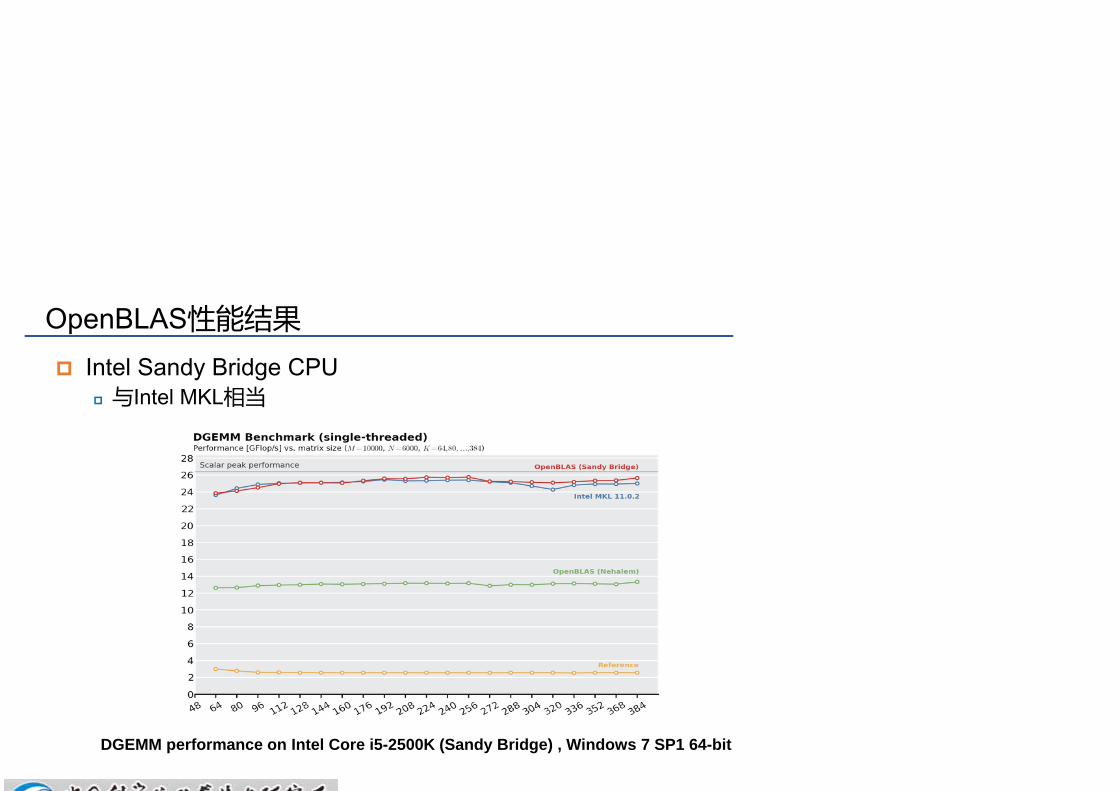
OpenBLAS性能结果
Intel Sandy Bridge CPU 与Intel MKL相当
DGEMM performance on Intel Core i5-2500K (Sandy Bridge) , Windows 7 SP1 64-bit
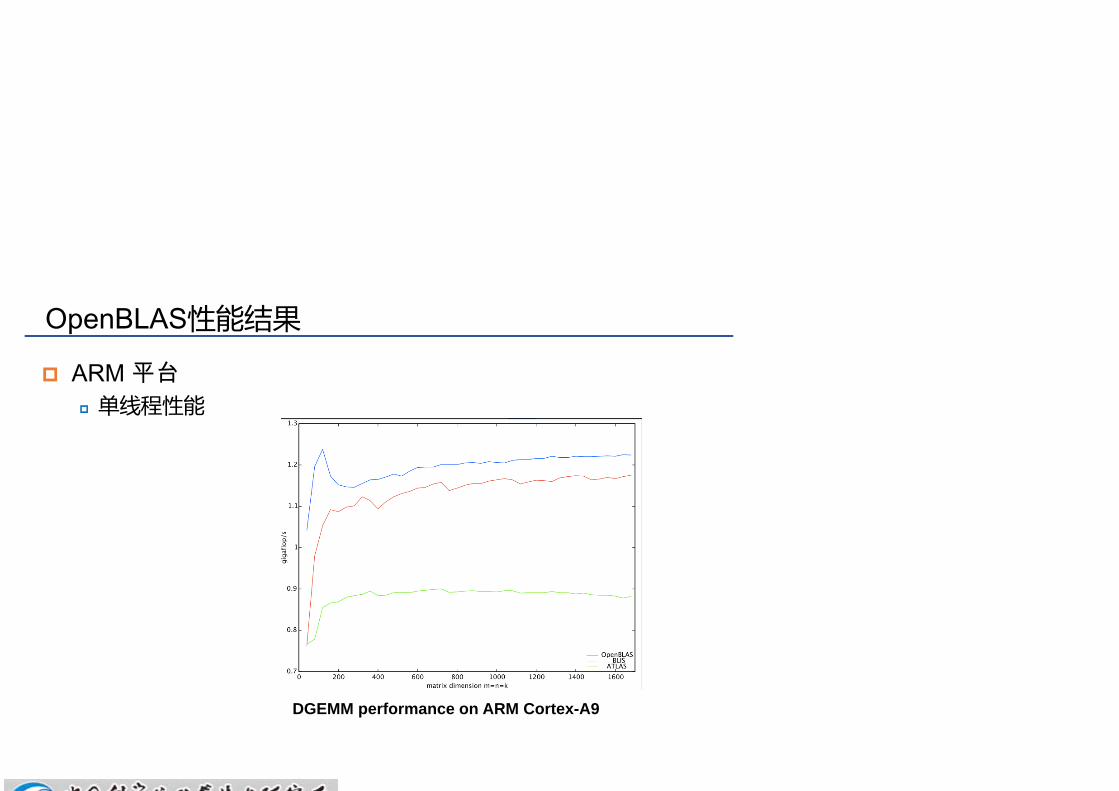
OpenBLAS性能结果
ARM 平台 单线程性能
DGEMM performance on ARM Cortex-A9

OpenBLAS相关文章
• Wang Qian, Zhang Xianyi, Zhang Yunquan, Qing Yi, AUGEM: AutomaticallyGenerate High Performance Dense Linear Algebra Kernels on x86 CPUs, Inthe International Conference for High Performance Computing,Networking, Storage and Analysis (SC‘13), Denver CO, November 2013.(CCF B类)
• Zhang Xianyi, Wang Qian, Zhang Yunquan, Model‐driven Level 3 BLAS Performance Optimization on Loongson 3A Processor, 2012 IEEE 18th International Conference on Parallel and Distributed Systems (ICPADS), 17‐19 Dec. 2012.(CCF C类)
• 引用16次• UT Austin大学的Robert van der Geijn教授
• BLIS• 将OpenBLAS作为多种平台的性能对比组
• 张先轶, 王茜, 张云泉. OpenBLAS:龙芯3A CPU的高性能BLAS库.软件学报.第39卷增刊2. 2011年12月.

高性能数学库:二十年的坚持• 国内高性能数学库领域领军研究团队
• 1995年开始为日立超级计算机研制高性能数学库
• 20多年坚持为国产曙光、龙芯、申威等处理器研制国产高性能数学库
• 在核高基支持下,为龙芯3处理器研制多核版数学库CleXML• 十多年坚持为国产申威系列处理器研制串行、多核、众核版数学库WeXML• 部署在国家超算济南中心神威蓝光和无锡中心神威太湖之光
• 支撑软件所团队获得中国首个戈登贝尔奖(超算的诺贝尔奖)• 数学库为其获奖的三大核心技术之一
• 核心技术AUGEM发表在国际顶级会议SC 2013• 针对自适应优化的性能不高和手工调优的性能可移植性差的问题
• 创新性提出采用模板法对核心计算片段参数化的新思路
• 开创了国际高性能代码自动生成的新方向
• 研制国际性能最优的开源数学库OpenBLAS
CPU
计
型
计算模型
BLAS FFT
自适应优
水。。。
自适应优化
汇编指令重排
预取、软件流
水。。。
LAPACK
任务并行
稀疏线性解法器
自适
并行
自适应优化
多核并行
37

国内影响力• 主持课题,总经费超过2500万元!
• 江南所国防军工课题,高性能扩展数学库合作研发, 2006.1‐208.6,280万• 江南所国防军工课题,多核版高性能扩展数学库研发,2009.1‐2011.6,420万• 江南所国防军工课题,众核版高性能扩展数学库,2012.10‐2016.12, 500万• 核高基《支持国产CPU的编译系统及工具链》第三课题,2009.01‐2011.12, 573万• 旷世科技横向项目、CPU和GPU上深度学习算法库开发、2015/5‐2017/4、500万• 华为横向项目、MAL高性能BLAS和FFT库合作项目、 2016.07~2017.12、260万
• 2000年度国家科技进步奖二等奖
• 2009年中科院软件所首届杰出青年基金
• 2012年度中科院科技创新交叉与合作团队成员
• 2016年中国计算机学会科学技术二等奖,排名第一
• 2017年度中科院科学与技术杰出成就奖
38

国际影响力
• 支持主流Intel和AMD处理器,ARM和Power处理器等
• 与ATLAS一起成为BLAS两大主要开源实现,性能优于ATLAS• 2013年7月,开源软件包下载量14万余次
• 用户分布在美、中、德、日、韩等90多个国家
• 主流Linux发行版采用,进入OpenHPC套件
39

国际影响力
• 十多个开源项目的依赖库• MIT的Julia,UCB的Caffe,Amazon的MXNet,Stanford的S4等
• 工业界广泛应用• IBM,搜狗,360,地平线,出门问问,NVIDIA,Ceemple,Bright Computing等
• 十多家超算中心广泛部署• 瑞典HPC2N,美国犹他大学CHPC,德国康斯坦茨大学SCCKN,国家超算济南中心、中科院超算中
心,美国马里兰大学信息中心等
40

OpenBLAS国际评价和应用
• 核心技术AUGEM发表在CCF A类SC 2013• “I think it is an advance over current practice ‐‐ both in terms of the
technology as well as the actual performance results.”• 审稿人认为该工作无论是方法创新性还是性能结果,都比现有技术更为
先进
• 国际著名高性能数学库PLAPACK,BLIS等的发起人,美国UT Austin大学Robert A. van de Geijn教授
• SIAM J. Sci. Comput. 2014、ACM TOMS 2016• 全面评价和对比了OpenBLAS, ATLAS与BLIS• 结论:性能上BLIS仍然无法超过OpenBLAS!
• 澳大利亚新南威尔士州立大学薛京灵教授在CGO 2017的论文进一步发展了我们提出的技术路线;
• 国际学术界大量科学计算应用的研究使用了OpenBLAS作为其底层高性能数学库。
41

OpenBLAS的产业化:澎峰科技
• AI领域的性能优化解决方案提供商;
• 以博士毕业生张先轶为主创办的澎峰(北京)科技有限公司,已完成天使轮融资,申请人为公司首席科学家;
• 2016年9月紫牛基金、明势资本和猎豹资本等联合投资550万元,估值3500万元人民币
• 合作伙伴包括华为、360、猎豹、中科视拓、阅面科技、水滴等,一年实现盈亏平衡,马上进入Pre‐A ;
• 2016年CCF科学技术二等奖;
• 17年新智元创业大赛TOP10酷炫AI创业公司
• 计算所三大老牌硬件公司(联想、曙光、龙芯)
• 计算所三大深度学习公司(寒武纪,theta,澎峰)
42

PerfBLAS on ARM
单精度SGEMM Neon SIMD指令 与IEEE 754标准不一致 Round mode (Flush to Zero) 不影响深度学习的精度
AUGEM生成汇编代码 支持ARM特殊指令
• vmla.f32 c, a, b[d]

PerfBLAS on ARM
ARM Cortex A15 (2.32GHz) 单线程SGEMM 性能3倍
0.562000.564000.566000.568000.5610000.5612000.5614000.5616000.5618000.56
40 240
440
640
840
1040
1240
1440
1640
1840
MFlop
s
Sqaure Matrices
OpenBLAS
PerfSGEMM

PerfBLAS on ARM
10层卷积模型 Inference 速度提高1倍
0
20
40
60
80
100
120
OpenBLAS PerfSGEMM
Time(ms)
Time(ms)

总结 OpenBLAS
最好的开源BLAS实现
AUGEM 自动生成高效汇编 与手工汇编性能可比
PerfBLAS ARM 深度学习

总结
OpenBLAS:国产高性能BLAS库,在科学计算和人工智能领域得到
了广泛的应用
OpenBLAS目标:国际最快的开源BLAS库之一
AUGEM: 高性能DLA代码自动生成方法,简化开发难度
PerfBLAS: 商业版本,比OpenBLAS性能更快
期待合作,欢迎使用!





















