
Neighbor Cache Prefetching for Multimedia Image and Video Processing
15
IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004 539 Neighbor Cache Prefetching for Multimedia Image and Video Processing Rita Cucchiara, Member, IEEE, Massimo Piccardi, Member, IEEE, and Andrea Prati, Member, IEEE Abstract—Cache performance is strongly influenced by the type of locality embodied in programs. In particular, multi- media programs handling images and videos are characterized by a bidimensional spatial locality, which is not adequately exploited by standard caches. In this paper we propose novel cache prefetching techniques for image data, called neighbor prefetching, able to improve exploitation of bidimensional spatial locality. A performance comparison is provided against other assessed prefetching techniques on a multimedia workload (with MPEG-2 and MPEG-4 decoding, image processing, and visual object segmentation), including a detailed evaluation of both the miss rate and the memory access time. Results prove that neighbor prefetching achieves a significant reduction in the time due to delayed memory cycles (more than 97% on MPEG-4 with respect to 75% of the second performing technique). This reduction leads to a substantial speedup on the overall memory access time (up to 140% for MPEG-4). Performance has been measured with the PRIMA trace-driven simulator, specifically devised to support cache prefetching. Index Terms—Cache memories, image processing, multimedia, neighbor prefetching, prefetching. I. INTRODUCTION M ULTIMEDIA workloads are leading the design of modern computers, since high performance in exe- cuting multimedia applications is mandatory. To this aim, memory access performance proves particularly critical, since the speed gap between processors and memories still tends to increase. Cache memories improve memory access performance by al- lowing the exploitation of temporal and spatial data locality. However, spatial locality can actually be exploited only if the storage organization in the cache mirrors the memory access schemes embodied in programs. This requirement is often not satisfied for multimedia data, such as images or videos. In fact, image programs are characterized by a peculiar access locality, that we call two-dimensional (2-D) spatial locality, since im- ages are structured as bidimensional arrays and whenever the CPU accesses a single data item, a high probability exists to ac- cess logically adjacent data items in both vertical and horizontal directions. Manuscript received May 2, 2001; revised November 15, 2002. The associate editor coordinating the review of this manuscript and approving it for publica- tion was Dr. Francky Cathoor. R. Cucchiara and A. Prati are with Dipartimento di Ingegneria dell’Infor- mazione, Università di Modena e Reggio Emilia, 41100 Modena, Italy (e-mail: [email protected]; [email protected]). M. Piccardi is with Department of Computer Systems, Faculty of IT, University of Technology, Sydney, NSW 2007, Australia (e-mail: massimo@ it.uts.edu.au). Digital Object Identifier 10.1109/TMM.2004.830806 Most algorithms for image compression, noise filtering, and image analysis process two-dimensional pixel blocks (e.g., MPEG typically uses 8 8 or 16 16 pixels blocks), thus exhibiting both horizontal and vertical spatial locality. Since standard cache architectures are based on blocks preserving horizontal spatial locality only, in multimedia programs a large amount of compulsory misses in accessing image data has been reported [1]–[3]. Enlarging the cache size is not the right solution, since it decreases only conflict or capacity misses, and even increasing the block size improves exploitation of horizontal locality only. It is possible to alter also the order of memory references in the algorithms in order to achieve a decreased number of misses. However, we aim to describe a general technique that does not require instruction reordering. For enhancing cache performance, prefetching techniques have been deeply explored. Cache data prefetching consists of inserting data into the cache before they are requested by the current instruction, so as to limit or eliminate the waiting time due to compulsory misses. Prefetching can be implemented mainly in either hardware or software. The main advantage of hardware implementations is that prefetching can exploit program information available only to the hardware, such as the fact that a memory reference results in a hit or a miss. The main drawback, instead, is that hardware implementations are more limited than software implementations in terms of timing and computational resources. However, the recent increase of on-chip resources has made hardware prefetching more appealing, and therefore in the scope of this paper we will con- centrate on hardware techniques [4]–[6]. A detailed analysis of hardware implementations of cache prefetching is found in the paper from Tse and Smith [4]. For hardware techniques, two main directions have been explored: static and adaptive (or stride-based). Static techniques are directed toward prefetching one or more blocks, based on a static assumption of probability; adaptive techniques analyze history of strides (the stride is the difference in address between two consecutive accesses made by a same instruction) to predict the most useful blocks to be prefetched. The former approach achieves high performance on vector data, and this results in a good performance improve- ment also on image data, since at least the horizontal locality is used. The latter is good for programs working on data with regular memory access schemes. For this reason they have been proposed for multimedia programs, too [2], [7]–[9]. In fact, many multimedia image and video processing pro- grams are regular in memory access: think for instance of the basic convolution-based filtering, where all the image points are raster scanned and processed by a coefficient mask. Nev- ertheless, some multimedia programs are not regular, since the 1520-9210/04$20.00 © 2004 IEEE Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.
Transcript of Neighbor Cache Prefetching for Multimedia Image and Video Processing

IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004 539
Neighbor Cache Prefetching for MultimediaImage and Video Processing
Rita Cucchiara, Member, IEEE, Massimo Piccardi, Member, IEEE, and Andrea Prati, Member, IEEE
Abstract—Cache performance is strongly influenced by thetype of locality embodied in programs. In particular, multi-media programs handling images and videos are characterizedby a bidimensional spatial locality, which is not adequatelyexploited by standard caches. In this paper we propose novelcache prefetching techniques for image data, called neighborprefetching, able to improve exploitation of bidimensional spatiallocality. A performance comparison is provided against otherassessed prefetching techniques on a multimedia workload (withMPEG-2 and MPEG-4 decoding, image processing, and visualobject segmentation), including a detailed evaluation of both themiss rate and the memory access time. Results prove that neighborprefetching achieves a significant reduction in the time due todelayed memory cycles (more than 97% on MPEG-4 with respectto 75% of the second performing technique). This reduction leadsto a substantial speedup on the overall memory access time (upto 140% for MPEG-4). Performance has been measured with thePRIMA trace-driven simulator, specifically devised to supportcache prefetching.
Index Terms—Cache memories, image processing, multimedia,neighbor prefetching, prefetching.
I. INTRODUCTION
MULTIMEDIA workloads are leading the design ofmodern computers, since high performance in exe-
cuting multimedia applications is mandatory. To this aim,memory access performance proves particularly critical, sincethe speed gap between processors and memories still tends toincrease.
Cache memories improve memory access performance by al-lowing the exploitation of temporal and spatial data locality.However, spatial locality can actually be exploited only if thestorage organization in the cache mirrors the memory accessschemes embodied in programs. This requirement is often notsatisfied for multimedia data, such as images or videos. In fact,image programs are characterized by a peculiar access locality,that we call two-dimensional (2-D) spatial locality, since im-ages are structured as bidimensional arrays and whenever theCPU accesses a single data item, a high probability exists to ac-cess logically adjacent data items in both vertical and horizontaldirections.
Manuscript received May 2, 2001; revised November 15, 2002. The associateeditor coordinating the review of this manuscript and approving it for publica-tion was Dr. Francky Cathoor.
R. Cucchiara and A. Prati are with Dipartimento di Ingegneria dell’Infor-mazione, Università di Modena e Reggio Emilia, 41100 Modena, Italy (e-mail:[email protected]; [email protected]).
M. Piccardi is with Department of Computer Systems, Faculty of IT,University of Technology, Sydney, NSW 2007, Australia (e-mail: [email protected]).
Digital Object Identifier 10.1109/TMM.2004.830806
Most algorithms for image compression, noise filtering, andimage analysis process two-dimensional pixel blocks (e.g.,MPEG typically uses 8 8 or 16 16 pixels blocks), thusexhibiting both horizontal and vertical spatial locality. Sincestandard cache architectures are based on blocks preservinghorizontal spatial locality only, in multimedia programs a largeamount of compulsory misses in accessing image data hasbeen reported [1]–[3]. Enlarging the cache size is not the rightsolution, since it decreases only conflict or capacity misses,and even increasing the block size improves exploitation ofhorizontal locality only. It is possible to alter also the orderof memory references in the algorithms in order to achieve adecreased number of misses. However, we aim to describe ageneral technique that does not require instruction reordering.
For enhancing cache performance, prefetching techniqueshave been deeply explored. Cache data prefetching consists ofinserting data into the cache before they are requested by thecurrent instruction, so as to limit or eliminate the waiting timedue to compulsory misses. Prefetching can be implementedmainly in either hardware or software. The main advantageof hardware implementations is that prefetching can exploitprogram information available only to the hardware, such asthe fact that a memory reference results in a hit or a miss. Themain drawback, instead, is that hardware implementations aremore limited than software implementations in terms of timingand computational resources. However, the recent increaseof on-chip resources has made hardware prefetching moreappealing, and therefore in the scope of this paper we will con-centrate on hardware techniques [4]–[6]. A detailed analysisof hardware implementations of cache prefetching is found inthe paper from Tse and Smith [4]. For hardware techniques,two main directions have been explored: static and adaptive (orstride-based). Static techniques are directed toward prefetchingone or more blocks, based on a static assumption of probability;adaptive techniques analyze history of strides (the stride is thedifference in address between two consecutive accesses madeby a same instruction) to predict the most useful blocks to beprefetched. The former approach achieves high performanceon vector data, and this results in a good performance improve-ment also on image data, since at least the horizontal localityis used. The latter is good for programs working on data withregular memory access schemes. For this reason they have beenproposed for multimedia programs, too [2], [7]–[9].
In fact, many multimedia image and video processing pro-grams are regular in memory access: think for instance of thebasic convolution-based filtering, where all the image pointsare raster scanned and processed by a coefficient mask. Nev-ertheless, some multimedia programs are not regular, since the
1520-9210/04$20.00 © 2004 IEEE
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

540 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
computation is data-dependent. Typical examples are contour-tracing algorithms, region-growing segmenters, or labeling op-erators, used to extract visual objects from images (visual ob-jects are supported by MPEG-4 and MPEG-7). In these cases,even stride-based techniques are not adequate: as we will showin this paper, their performance can be outperformed by somespecific techniques optimized for prefetching image data.
For these reasons, this work aims to analyze performance ofprefetching techniques on a significant multimedia benchmarkwith different access schemes to image and video data. Thegoal is to prove that a significant speedup can be achieved byusing prefetching techniques, and especially by some innova-tive and image-oriented prefetching methods that we present inthis paper. In particular, we propose two new static techniques,called neighbor and eight-step neighbor prefetching that outper-form other prefetching techniques both in terms of miss rate andmemory access time improvement. In [10], we introduced theneighbor prefetching and compared it with other well-assessedprefetching techniques in terms of eliminated cache misses only.In this paper we extend the performance evaluation to temporalanalysis, since the most relevant performance figure in this con-text is the achievable reduction in terms of memory access time.
The paper is structured as follows. Sections II presents re-lated works on cache prefetching, including the main proposalsfor image and multimedia workloads. Section III describesthe prefetching techniques compared in this paper, includingthe novel neighbor prefetching techniques. Section IV outlinesthe multimedia benchmark used for performance evaluation.Section V describes the temporal model used for timing evalu-ation and the simulation environment. Section VI presents theperformance results in terms of cache misses and improvementin memory access time on the benchmark’s programs; theimpact of line size, cache size and miss penalty is shown, too.In the conclusions, the relevant aspects of our work are brieflysketched and the main results achieved commented.
II. RELATED WORKS
In this section, we aim to present a brief overview of themost relevant works addressing cache prefetching. Most papersin the literature address general-purpose workloads, but cacheprefetching techniques have been evaluated also for some multi-media programs; for instance, results are proposed by Zucker etal. in [7], [9] for MPEG-2 decoder and encoder programs and byPimentel et al. in [8] for the median algorithm, used to producenoninterlaced frames from videos with interlaced frames. In thiswork, we extend the analysis to a larger and more complete (inthe sense that it covers different image data access schemes)multimedia benchmark oriented to image and video processing.
In cache prefetching, the two main directions of static andadaptive techniques have been investigated. The basic staticprefetching method is known as One-Block-Lookahead (OBL)[11] (also called always prefetch in a more recent work [4]).With OBL, every time a reference to block is made, a lookupin the cache is issued for block ; if the block is absent,it is prefetched. Many other OBL-based solutions have beenproposed; amongst them we cite those based on stream buffers[7], [12], [13], that prefetch one or more blocks following block
in another level of the memory hierarchy, i.e., the streambuffer. The implicit assumption of all static techniques is that,given the spatial locality, block has a high probabilityto be referenced in the near future, and that scheduling itsprefetching on the first reference to block grants adequatetimeliness. These assumptions are correct, and testified bymany simulations, especially when arrays are accessed. In thispaper we show that they are justifiable for image data too,when pixels of an image or a video frame are evaluated andprocessed one by one in raster-scan mode (i.e., row-by-row).Nevertheless, whenever programs exhibit 2-D spatial locality,we will show that prefetching performance can be improvedwith respect to that of OBL, since it does not exploit locality inthe vertical direction.
The other main direction for prefetching is that of adaptivetechniques. Adaptive techniques take into account some formof adaptivity in order to achieve a better prevision than that rep-resented by block . The idea is to induce block referenceprobability by recent references history, and is promising forprograms with regular memory access schemes. A basic algo-rithm computes the stride, i.e., the address difference betweenthe last two memory references made by a same instruction, andadds it to the address of the last memory reference to obtainblock prevision. Fu and Patel in [14] proposed the use of anassociative memory, called the Stride Prediction Table (SPT),to store stride information. Chen and Baer in [6] proposed theuse of a Reference Prediction Table (RPT), similar to the SPT,but with an added state machine to assert if the prediction canbe trusted (correct) or not (incorrect). Selecting strides usefulfor prefetching is often referred to as stride filtering. Other pro-posals combine static and adaptive techniques in order to receivebenefits from both the approaches: in [15], a stride predictor iscombined with a stream buffer and a voting scheme is used todecide whether the stream buffer or the stride predictor must beused. Finally, other authors propose more complicated forms ofadaptivity (as in [16]), but we expect them to be too demandingin hardware resources to be feasible in hardware, and thereforedid not use them for comparison in this paper.
In this work we consider image data only, i.e., the regulararray-based structure used for referencing pixels in an image orin a video frame. Hence, we evaluate the performance of a pos-sible data cache for image data only. Several studies refer to theperformance improvement that can be achieved by further split-ting the data cache for scalar and vector data types [17] or fortemporal locality and spatial locality [18], [19]. In [9], a streamcache separated from the main cache is used to store data ac-cessed with regular strides. Just as many authors suggest the useof a separate cache for vector data, we suggest the adoption ofa special cache for image data since this choice, together with aspecific cache replacement strategy, reduces cache misses in thevery frequent accesses to image data [20]. Although the additionof a further dedicated cache in modern general-purpose proces-sors is not very likely, this may not be the case for multimediaprocessors which could significantly benefit from the results re-ported in this paper.
The primary metrics typically used in the literature for cacheperformance evaluation are the miss rate and the efficiencyexpressed as the fraction of eliminated misses [6], [7], [9], [10].
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

CUCCHIARA et al.: NEIGHBOR CACHE PREFETCHING 541
TABLE ICOMPARISON OF PREFETCHING TECHNIQUES
These metrics are useful for an initial evaluation of prefetchingtechniques because they focus on cache performance indepen-dently of system parameters. Nevertheless, as clearly stated in[4] and [5], performance analysis must address the executiontime. Tse and Smith in [4] proposed a system-level analysis ofthe impact of prefetching on system performance by way of anaccurate cycle-by-cycle execution simulation. The main metricused is the MCPI, defined as the total memory access penaltydue to delayed memory cycles divided by the total number ofinstructions executed. This figure includes all aspects which canbe influenced by prefetching, while at the same time excludingall those which cannot. To the purpose of comparison, themetric used in [4] is actually the relative MCPI, expressed asthe ratio between the MCPI with and without cache prefetching.Hennessy and Patterson in [5] use instead the average memoryaccess time (AMAT), which includes also the time due tonondelayed memory cycles, and is divided by the number ofmemory references. The AMAT is expressive of the overallimpact of memory access. In this work, we report results withmetrics equivalent to the relative MCPI and AMAT for a widerange of system parameters such as the prefetching technique,cache size, miss penalty, and others.
III. PREFETCHING TECHNIQUES
As previously stated, we divide prefetching techniques in thetwo main categories of static and adaptive prefetching. To thepurpose of comparison, in this paper we use OBL as referencefor the static techniques [4], [6], and the stride-based predictiontechnique [9] as the reference for the adaptive class (called SPTfor short in the following). In [10], we explored also more so-phisticated adaptive techniques based on some form of stridefiltering (2-delta filters, [21]), but performance achieved didn’tprove significantly different from that of the basic scheme, andtherefore are not reported in this paper.
In OBL prefetching, every time a memory reference is made,a lookup in the cache is performed for the block that follows thecurrently referenced one in memory. If we call the currentaddress and the current block address, i.e., the memoryaddress without the byte offset field, the block address of thelooked-up block will be (see Table I). If this blockis absent from the cache, its prefetch is issued. Thanks to the
Fig. 1. Eight-connected blocks of an image pixel.
lookup, the actual prefetching of data is performed only if it isnot already in the cache, thus avoiding useless bus occupation.
In adaptive prefetching, every time a memory reference ismade, a lookup in the SPT is performed. If there is a hit, a lookupin the cache is performed at the address (by calling
the computed stride). If this block is absent from the cache,its prefetch is issued.
In this paper, we propose to explicitly explore the 2-Dspatial locality in images by a new approach called neighborprefetching. To this aim, we give definitions of three algo-rithms, called basic, first-reference, and eight-step neighborprefetching, respectively.
Definition 1: The basic neighbor prefetching, at each memoryreference, attempts to prefetch all blocks containing data in thenearest-neighborhood of that currently referenced; we assumea neighborhood of 3 3 blocks that are called 8-connectedblocks; for each block belonging to the 8-connected set that isnot in the cache already, a prefetch is issued.
For the sake of clarity, see the sketch of Fig. 1. Let us assumeimage pixels are stored row-by-row, and divided in blocks ofthe same size of cache blocks; the 8-connected blocks containpixels adjacent in both vertical and horizontal directions.
In basic neighbor prefetching, every prefetching stage con-sists of eight lookups and issued prefetches, with( if all the 8-connected blocks are already present in thecache). The block addresses of the looked-up blocks are shownin Table I, with reference to the address and whereis the number of bytes in an image row. Neighbor prefetchingmirrors the way data are accessed by many image processing al-gorithms, including both raster-scan and data-dependent ones,
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

542 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
and thus promises a general improvement in 2-D spatial localityexploitation. At the same time, potential drawbacks of this ap-proach are evident: i) it carries a substantial increase of thelookup pressure and ii) potentially issues a higher number ofprefetches. The first effect can be limited by an adequate cachearchitecture. We assume a highly efficient lookup mechanism,with a multiple-port tag directory and pipelining with prefetchissuing, so as to consider the lookup time negligible. We alsointroduce two modifications to the basic neighbor prefetching,reducing both the lookup pressure and the number of issuedprefetches.
We consider the sequences of memory references made allto a same block. A sequence starts with the first reference toa block and ends with the first reference to a different block(not included). Therefore, a generic sequence can range fromone reference only up to an unlimited number of references.However, in the tested applications, sequences are typically inthe order of a few units. The idea is to reduce the amount ofprefetching by scheduling the prefetching activity not on allthe references but only on the first reference of each sequence.The rationale of first-reference neighbor prefetching is that if ablock is prefetched at this stage, it will not be substituted in thecache in the sequence access, making it unnecessary to checkfor its presence during next references to the block in the samesequence.
Definition 2: In first-reference neighbor prefetching, theprefetching activities are scheduled at the first reference onlyof each sequence of references.
First-reference neighbor prefetching minimizes lookup costs,accounting for them just once for each block referenced. Nev-ertheless, drawback ii) remains on the first reference, when ahigh number of prefetches could be issued all together, witha potentially long completion time. In order to improve this as-pect we define a modification for distributing the prefetchesover time along the sequence of references to the same memoryblock.
Definition 3: In the eight-step neighbor prefetching, at eachmemory reference of a sequence of references to a same block,at most one prefetch is actually issued.
We can more precisely describe this method with a simplealgorithm. Let us call block one of the 8-connected blocks ofthe currently referenced one, with as in Fig. 1. Ateach memory reference to block the following algorithm isexecuted.
if first_reference ( block) TRUEthen ;else lastdirection ;hit TRUE;while ( AND hit TRUE) do
hit lookup (block );if (hit TRUE) then ;else prefetch ;lastdirection ;
Every time the program changes the referenced block, the di-rection #1 is looked-up. If the data is already present in the cache
the following block within the neighborhood (in the clockwisedirection) is checked. This process continues until either thedata is not present in the cache or the wholeneighborhood has been checked. The next reference to the sameblock will restart the process from the last direction checked.The idea is to more effectively distribute the prefetching activityover time.
Block #1 is used for the first lookup (like in OBL) since it isthat with the highest static probability of access (experimentalevidence is given in Sections IV). The clockwise direction isa heuristic rule tuned in raster scan processing, since data be-longing to block #2 should be absent from the cache and thusits prefetching ought to be scheduled before the others. There-fore, for each reference of a sequence of references to a sameblock, the eight-step neighbor prefetching performs a number
of lookups (with ranging between 0 and 8) until a miss oc-curs; the number of lookups in the same block cannot exceed thenumber of 8, like in first-reference neighbor prefetching. More-over, the eight-step algorithm performs at most one prefetch foreach reference, thus avoiding long prefetching latencies.
In neighbor prefetching, in order to enable the prefetchingmechanism, the memory address must be associated withthe correct image row size in bytes, , by way of a map-ping function. For implementation of the mapping function, werefer to modern programming languages such as C, C++ andJava and we assume that image data are declared as either staticor dynamic 2-D arrays (or objects derived from 2-D arrays).For static variables, the information can be extractedby the compiler from variable declarations and stored in a spe-cial symbol table; the mapping function can then be initialized atrun time from the special symbol table. For dynamic variables,the information can be stored in the mapping functionat allocation time.
In either cases, the extracted information must then be madeavailable to the prefetching unit. In our implementation, theprefetching unit is enabled to query the mapping function to re-trieve from ; in order to improve the efficiency ofthis mechanism, the most recent associations areassumed to be cached in the prefetching unit.
IV. MULTIMEDIA BENCHMARK
Multimedia programs exhibit a different locality in data ac-cess depending on the data type: numerical data and text are ac-cessed with standard spatial/temporal locality schemes, whileaudio is often processed with a stream access showing a strongone–dimensional (1-D) spatial locality. Instead, in image andvideo processing a wide variety of memory access schemes isused, often depending both on programs and data themselves.Unfortunately, no generally accepted benchmark exists for mul-timedia image and video processing yet. Therefore, we selecteda kernel of basic programs that are commonly adopted in imagemultimedia tools, as in other works on multimedia performanceevaluation [7], [22]: the set includes image and video decom-pression programs and common programs for image manipula-tion, characterized by different data access schemes.
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

CUCCHIARA et al.: NEIGHBOR CACHE PREFETCHING 543
TABLE IITHE BENCHMARK’S PROGRAMS
A. The Benchmark’s Programs
Table II summarizes the benchmark’s programs used in thiswork.
Thresholding ( ) is the pure raster-scan data access,since pixels are loaded and processed one by one, row by row. Inparticular, it consists of a simple comparison between the pixelvalue and an assigned threshold.
Image convolution ( for short) is the basic algorithm forimage processing; it consists of processing each image pixel byconvoluting pixels of its bidimensional neighborhood with a co-efficient mask. Examples of programs based on convolution arefiltering for noise cleaning, image enhancement, edge detection,and template matching. Image is evaluated in raster-scan modeand the algorithm execution and data access are not data-depen-dent; a substantial amount of strictly 2-D locality is embeddedin processing each pixel and its neighborhood. In many papersaddressing performance evaluation in image processing [2], [7],[23], convolution is included in the basic benchmark.
Chain code ( ) is included as a typical data-dependentimage processing program characterized by an unpredictable2-D spatial locality. It is a propagative algorithm, since thecomputational flow is propagated along the image, in an apriori unknown direction depending on the data themselves[24]. The program we used is a standard edge tracing algorithmthat scans objects’ contours and can be used for encodingobjects’ geometric properties [24]–[26], including shape en-coding for MPEG-4 [27], [28]. In edge tracing, the direction ofthe next pixel to be used depends on the image and its edges,and therefore the address of the next memory reference isdata-dependent.
The benchmark includes also standard video decoders.MPEG-2 decode is the typical benchmark for multimediaprocessors, since it is currently the most spread multimediaprogram, both for video streams and files [1], [6], [27]–[30].MPEG frames are of three different types: I (only spatial
compression in JPEG style), P (forward-predicted), and B(forward-backward predicted). Typically MPEG sequences areperiodical repetitions of a same type pattern, like for instancethe standard IPBBPBBPBBPBB (MPEG videos used in thetests); when the pattern is IIIIIII, the decompression (called
in Table II) consists only of JPEG decoding of a sequenceof frames (sometime called also MJPEG or M-JPEG type).MPEG-2 performs a variable-length decoding and inversequantization of Discrete Cosine Transform (DCT) coefficients,Inverse DCT (IDCT) computation, and motion compensation,mostly operating on 8 8 and 16 16 pixel blocks. For thetests we have used different MPEG data, selected from standardmovies with different type pattern, image size and numberof frames (files and address traces are available at http://im-agelab.ing.unimo.it/imagelab/res_cache.html). In particular,the first two (Frisco and Pirates) are MJPEG and are describedin Table III, while the others (Waterski and FlowerG) areMPEG movies with sequence pattern IPBBPBBPBBPBB andare described in Table III.
Finally MPEG-4 decode ( ) has been included as anexample of the recent audio and video compression standard,ISO/IEC 14 496 [27]. MPEG-4 standard defines the basiccoding structure for managing media objects, and among themVisual Objects (VOs) as meaningful individual parts of imagesthat are coded separately. VO decoding requires more imageplanes to be decoded for each VO, one for the shape (or alphaplane) and one for texture information. In this work we usethe MPEG-4 decoder from CSELT, developed according tostandard specifications [27]. Tests are reported for a videoexample, whose features are summarized in Table III; note thatthe trace from only four frames results as being so large as tocontain more than 23.4 million memory references and, forthis reason, we limit our study to few frames. Nevertheless,the behavior of the program and the data access pattern do notchange significantly when considering more frames.
The source code of the programs selected are the following:
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

544 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
TABLE IIIJPEG, MPEG2, AND MPEG4 WORKLOAD
TABLE IVWORKLOAD FEATURES
• as decoder, the free codec developed by theMPEG Software Simulation Group has been used. Thecomplete reference is MPEG-2 Encoder/Decoder, Version1.2, July 19, 1996, Web site http://www.mpeg.org/MSSG/;
• as decoder, the Version 1.0 (August 1999) of theprogram developed for the MPEG-4 Video (ISO/IEC14 496-2) standard within the framework of the EuropeanACTS project MoMuSys was selected. Further informa-tion on the project can be found at http://www.tnt.uni.han-nover.de/project/eu/momusys/ and the software can bedownloaded for example from http://www.ganesh.org/~pmeerw.
Instead, the , and programs are self-written in standard C language.
B. Impact of the Workload on Cache Architecture
In this work, we analyze the impact of cache architecture foraccessing image and video data type (that we call 2-D data) andwe propose new cache prefetching techniques for a dedicated2-D cache, containing only 2-D data. Instead, no improvementis needed for the conventional cache containing other data types(that we call for short, although improperly, scalar data) suchas text, audio, numerical data, and so on. This is due to the fact
that the impact of memory accesses to image data is signifi-cantly more critical than that to other data in multimedia imageprocessing applications. Table IV reports a comparison of thenumber of memory accesses to 2-D and scalar data (and Scalar columns respectively) and the number ofmisses and miss rate without any prefetching approach for a2-D and conventional caches of 32 KB each, two-way set-as-sociative, with 32 bytes/line. Table IV refers to the followingalgorithms: and on a 512 512 image, Chain ona 352 240 frame of the FlowerG Video reported in Table III,
and programs for videos of Table III anddecode.
Table IV shows that the number of scalar references is nor-mally higher than that of 2-D references (apart from ) but,conversely, the scalar miss rate is nearly zero in all cases. Thismeans that the standard locality is already perfectly caught bya conventional cache and that no further effort is justified to re-duce it any more (especially if interference with 2-D referencesis avoided, as we grant by using a separate cache for image data).Instead, the 2-D miss rate is two orders of magnitude greaterthan the scalar one on average. This proves that the locality of2-D references is not caught by conventional caches as accu-rately as other data. Therefore, it could be convenient to exploredifferent prefetching techniques based on a separate cache, in
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

CUCCHIARA et al.: NEIGHBOR CACHE PREFETCHING 545
order to achieve better performance while granting less inter-ference with data exhibiting different locality.
Raster-scan algorithms, such as and , allow forstatic prediction of cache misses, that are mainly of the com-pulsory type (if the convolution mask radius is limited). Thus,cache performance in terms of miss rate could be strongly im-proved with data prefetching techniques. Moreover, convolutionprograms suitably match standard cache architecture in terms oftemporal locality, which arises from the large reuse of pixels in aneighborhood (in fact, Table IV shows that has the lowest2-D miss rate).
Conversely, has been included as an example of imagecomputation that potentially does not benefit from standardcache techniques since it exhibits unusual and nonpredictablespatial locality. From a data access point of view, propagativealgorithms show the same bidimensional spatial locality ofthe raster-scan ones and at the same time the impossibility ofpredicting the data access. Moreover, the temporal locality isdifficult to emphasize, because points involved in the neighborcomputation may be used in the future, but perhaps only afterlong computation and thus capacity misses probably occur.For instance, Fig. 2 shows that when the P pixel is referenced,the other pixels loaded in cache (of the same blocks) could beunused or, as in this case, used after a long processing time;therefore spatial locality is not exploited and the data loaded incache do not have adequate timeliness.
Nevertheless, has an embedded 2-D data locality thatcan be measured: we profile memory accesses to image datastructures based on a simple measure of spatial locality givenby the difference between the current and the following memoryaddress made by a same instruction (i.e., the stride). In the his-togram of Fig. 3(a), a large amount of strides equal to and
testifies the standard 1-D spatial locality (i.e., the pixel ac-cessed is adjacent to that previously accessed in the forward orbackward direction, respectively), but a large number of stridesequal to 352 and 352 indicates that the block of pixels be-longing to the previous and following rows (image is 352 240)is accessed with a 2-D spatial locality.
The and programs are dominated by operationson image blocks (8 8 pixels) or macroblocks (16 16 pixels),thus exhibiting a strong 2-D data locality. MPEG2 decodingtypically carries a high number of cache misses [4]: obviously,a large part are compulsory misses, if no prefetching is used.Moreover, due to the relatively large mask size, the large 2-Dlocality causes a number of cache conflicts as well. The 2-Dmiss rate depends on the image format and compression but isthe same order of magnitude for the same MPEG format: in ourcase is about 2.8% for JPEG videos and 1.4% for MPEG2 (seeTable IV). Contrary to what expected, MPEG2 has a lower missrate than JPEG. This has been confirmed by our former exper-iments in which the locality of the MPEG2 decoder has beenstudied: the results of these experiments are not reported in thispaper, but they demonstrate that MPEG2 shows higher re-use ofthe pixel’s neighborhood and thus achieve lower miss rates.
The performance improvement achievable by reducing the2-D miss ratio depends on the amount of the 2-D referenceswith respect to the overall amount of memory references; in
Fig. 2. Propagative algorithm.
our workload, for the MPEG applications, for instance, the per-centage of 2-D references vary between about 3% and 30%.
Fig. 3(b) reports the stride histogram for the Waterski video.The dominant stride value is 1, which means that the greater partof memory accesses are performed in raster-scan order. How-ever, some other non-negligible stride values are concentratedaround values corresponding to pixels of a same 8 8 (16 16)block belonging to the previous and following rows, thus pro-viding the 2-D data locality.
Finally, the program is more complex since manyimage planes for each VO are processed with a large numberof dynamic image data allocations. It computes the same In-verse DCT as the MPEG-2 programs but it must also decodealpha planes for the VOs’ shape information. decodingexhibits a very high 2-D miss rate that is of 5% in our test (seeTable IV). By assuming that most of the misses are compul-sory, all the benchmark programs should benefit greatly fromadopting aggressive prefetching techniques.
Miss rates of multimedia applications cannot be considerednegligible in general: in our workload the 2-D miss rates varyin a range of 1–5%, but strongly depending on the cache sizeand configuration; miss rates of up to 20% have been reportedby other authors for some cache configurations [3].
V. ARCHITECTURAL AND TIMING MODEL
In this section, we describe the architectural and timingmodel used to evaluate results by means of temporal analysis.We simulate a RISC processor with an ideal single pipelineallowing a standard one clock-per-instruction execution
and a reference memory architecturewith a specific cache for image data (2-D cache) as well as astandard data cache for other data (scalar cache). Simulations arebased on the following assumptions [31]:
• The 2-D and scalar caches can be accessed separately,without interference.
• The size of the 2-D cache is assumed 32 KB (1 K linesof 32 bytes each, two-way set-associative), that is a typ-ical size for an L1 split cache. In addition, we report per-formance also for different cache sizes (both smaller andlarger).
• The 2-D cache is not multiple-ported, i.e., only eitherone miss or one prefetch can be sustained at a time.The hit penalty is assumed null for simplicity, i.e.,
, included in the instruction execution,while miss and prefetch accesses have the same penalty
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

546 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
Fig. 3. Demonstration of 2-D spatial locality. (a) Locality of Chain and (b) locality of MPEG2 on Waterski video.
for the line fill. In addition, wereport performance also assuming higher miss penalties.
• The lookup time, i.e., the time to access the cache tag di-rectory, is assumed null; this is a simplifying assumptionwhich does not affect the significance of simulation re-sults. In particular, for neighbor prefetching we assume amultiple-ported tag directory which can sustain multiplelookups at a time.
• Misses are blocking (or synchronizing) events for execu-tion, meaning that when a miss happens, execution mustwait the miss line fill completion before starting again.Moreover, any prefetching activity scheduled is com-pleted before serving the miss. Hence, if the prefetchingcompletion loads in the cache the data required by themiss, no miss line fill is then issued. This mechanism iscalled lookahead miss inquire, i.e., when a miss occurs,the current prefetching queue is tested and a line fillis performed only if queued prefetches are not alreadyloading the data which caused the miss, thanks to thelookahead miss inquire.
• Instead, prefetches are obviously nonblocking events forexecution, i.e., can be accomplished in parallel with in-struction execution and their penalty could be hidden byexecution of other instructions.
• In our architectural model, we assume in-order execution,since this is the typical execution model of several proces-sors used for multimedia applications such as for instancethe Philips Trimedia and the Texas C6000. Modern gen-eral-purpose processors are based on out-of-order engineswhich can more effectively tolerate the effect of cachemisses.
The total execution time is computed according to thismodel. We account a time (the basic one-clock exe-cution time) for completing each instruction with no memoryreference or with a memory hit access. If an instruction causesa miss, we account an additional execution time of . Ifan instruction causes a prefetch, prefetching is performed inparallel with instruction execution, and no time is accountedfor prefetching in addition to that of instruction execution. In
case instruction execution causes a miss while a prefetch is per-formed, the prefetching activity is completed before serving themiss; for completion of prefetching we account an additionalexecution time , where is the fraction of
covered by overlapping. If further prefetches were alreadyscheduled in the prefetching queue, they are completed anda time is added for each of them to the totalexecution time. The time for the miss line fill is countedonly if the prefetches in the prefetching queue have not alreadyloaded in the cache the data required by the reference whichcaused the miss.
In this work, performance were measured by using trace-driven simulation.
Traces are collected by using the tracer Spy [32] andprocessed using our simulator, called PRIMA (PRefetchingIMproves Multimedia Applications), evolved from ACME [33]simulator: we integrated a support for dealing with prefetchingand 2-D caches; then, we extended it to perform temporalsimulation ([34]).
VI. PERFORMANCE RESULTS
Using the architectural model and the benchmark defined,we measured the performance achieved using caches withoutprefetching, comparing well-known prefetching methods (OBLand SPT) with the new neighbor-based ones.
A. Number of Misses
The number of misses is an important parameter for esti-mating the efficacy of a prefetching method, since an effectiveprefetching method will assess a high miss reduction. In addi-tion to the miss number, an expressive measure to the aim ofcomparison between the different prefetching techniques is thefraction of misses eliminated. We call it miss-based efficiencyof the th prefetching method, , defined as
(1)
where is the number of misses without prefetching.This miss-based efficiency ranges between 0 and 1 (but could
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

CUCCHIARA et al.: NEIGHBOR CACHE PREFETCHING 547
TABLE VNUMBER OF MISSES N
Fig. 4. Miss-based efficiency � (in percentage).
be even negative in case of ineffective prefetching) and tendsto 1 when prefetching achieves the highest performance, thatis its (i.e., the number of noneliminated misses)tends to 0.
Table V and Fig. 4 show, respectively, the number of missesand the efficiency (in percentage) for the four
considered prefetching techniques on the test programs, for a2-way set-associative cache of 32 KB with 32 bytes per line.
Results confirm that exploiting horizontal spatial localityonly (as OBL does) is not an effective solution: in fact thenumber of misses with OBL prefetching remains non-negli-gible and the OBL’s efficiency is only 75% for , 83–87%for , and is 61.9% only for MPEG4 (see Fig. 4). Betterresults are achieved by SPT prefetching ( is greater than 90%for MJPEG video, is 86–87% for MPEG2 videos and in par-ticular is 97.5% for ). However, the best performance isobtained by both the neighbor-based techniques, with efficiencyvery close to 100% for most of the programs. If the prefetchingmechanism did not introduce any time cost, these results wouldsupport the feasibility of including prefetching techniques,especially neighbor-based, in the design of a processor orientedto multimedia image and video processing.
B. Time Analysis
However, the miss number is not sufficient to define executionperformance, since many bus transfers are due to prefetches, andif the prefetch number is too high or if prefetch is not enoughoverlapped with instruction execution, according with the modelpreviously presented, the gain achieved by the miss reductionwould be lost due to the prefetching cost [4].
As a matter of fact, the prefetching techniques issue manyprefetching operations, whose number is reported in Table VI;note however that this number is less than or equal to the originalnumber of misses. For each method the second row of Table VI
denotes the number of prefetch cycles that are not completelyhidden by instruction executions. In many cases this number is0: this mean that all prefetches issued are hidden and do notcause any time penalty. Conversely, in other cases (especiallyfor and ) the number of not completed prefetchesintroduces a non-negligible delay, that depends on the fractionof prefetch cycle that is not completely overlapped (1–OV).
In order to take into account the prefetch cost, we computethe Memory Access Delay Time MADT, as adopted in [4], [35].This figure accounts for the delay caused by the access to thelower level of memory hierarchy. Thus, we define MADT as theratio between the total amount of memory delay and the numberof memory reference instructions executed ( ).
In absence of prefetching, this quantity is
(2)
In the case of the -th prefetching (by assuming), MADT becomes
(3)
In (3), accounts for the actual number of misses(i.e., excluding those attempted but not issued thanks to thelookahead miss inquire mechanism), as shown in Table V.
is the total number of issued prefetches (see Table VI),while is the total amount of time savedthanks to the overlap between prefetches and instruction exe-cution ( being the average of all contributions overthe whole execution). Therefore, MADT is a more significantperformance measure than only the number of misses, since ittakes into account also the number of not completed prefetches,weighted by the fraction of not overlapping with other executedinstructions.
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

548 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
TABLE VITHE NUMBER OF ISSUED PREFETCHES N AND THE NUMBER OF PREFETCHES NOT COMPLETELY OVERLAPPED
TABLE VIITHE TOTAL MEMORY ACCESS DELAY TIME (MADT � N )
The quantity strongly depends on the prefetching tech-nique. As summarized in Table I, the OBL and SPT techniquesschedule a maximum of one prefetch for each reference: there-fore the prefetches issued are less than (or at most equal to)the number of references (note that we are consideringprefetching on reference). Actually, by comparing Tables IV andVI, it is evident that the number of issued prefetches is just a fewpercents of the number of references. Instead, in first-referenceneighbor prefetching, as discussed in Section III, a maximum ofeight prefetches could be issued on the first reference of each se-quence of references to the same block; in the eight-step version,eight prefetches (at most) are distributed along the sequence ofreferences to the same block. Since the length of a sequenceof references is not known a priori, the neighbor-based tech-niques could cause a higher number of prefetches and poten-tially a higher MADT. Instead, by comparing Tables IV and VI,we measured that even for neighbor techniques the number ofprefetches actually issued is much less than the number of ref-erences. This proves that the locality embedded in the programis suitably exploited by the cache prefetching techniques.
Table VII reports the total memory access delay time (MADT) for each tested program, or in other words the number
of clocks spent for accessing the lower level of memory hi-erarchy; without prefetching (first row), it measures the misspenalty only and, in the case of a prefetch technique, the sum ofboth miss and prefetch penalties.
Just as in Section VI-A we defined the miss-based efficiency(1), we can define the MADT efficiency in terms of MADT as
(4)
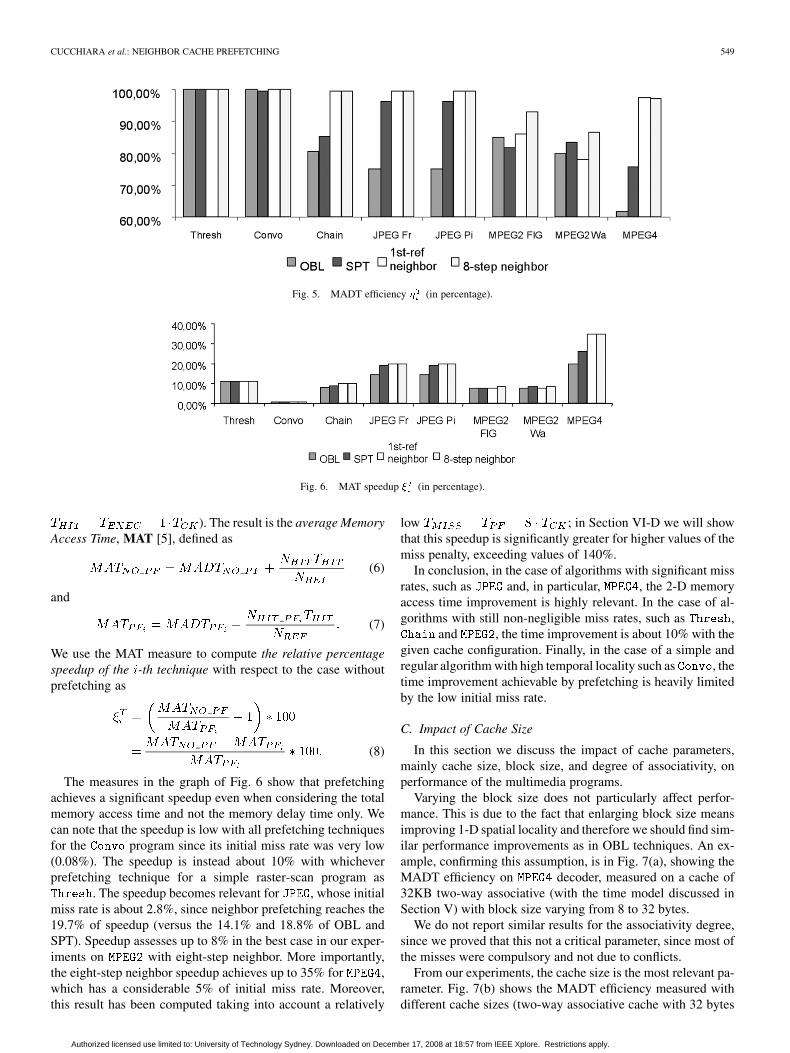
This measure has the characteristics of an efficiency, but atthe same time is a relative measure equivalent to the relativeMCPI of [4] . The measures of ,reported in the histogram of Fig. 5, are similar to the ones ofFig. 4, but differ for the cost of the noncompletely-overlapped
prefetching. In fact, by substituting the definition of (2) and (3)in (4), we have that
(5)
The second term is the cost of prefetching for the noncom-pletely overlapped memory accesses. By comparing the graphsof Figs. 4 and 5 we can note that prefetches are totally hidden(and thus ), for , while in other cases ( ,
, ) this cost is not negligible. The prefetchingcosts particularly affect the OBL and SPT methods and farless the neighbor methods. On average, the eight-step neighborprefetching exhibits the best performance: the explicit exploita-tion of the 2-D data locality allows a better prediction of thedata to be prefetched, together with a good distribution overtime of the prefetching activity.
An important consideration is that, observing the time mea-sures for , not only OBL but also SPT prefetching ex-hibits a relatively low efficiency ( is 61.8% and 75.6% re-spectively). Instead the adoption of neighbor prefetching revealsitself to be extremely beneficial for MPEG-4, proving an effi-ciency of 97%.
Prefetching actually improves performance in terms ofmemory access time. This result is not obvious, sinceprefetching could even worsen the memory access time, inthe case where the prefetching activity cannot be completelyaccomplished in overlap with execution and the number ofprefetches is high. The amount of execution time actually savedcan be easily deduced from Table VII, if the number of spentclock cycles with a given prefetching method is compared withthat of the first row, assessed without prefetching.
Another relevant measure takes into account how muchthe improvement obtained by prefetching influences thememory access time: this can be obtained by adding up theMADT (which is the average memory access delay time)with the normal memory access time without delay (equal to
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.
CUCCHIARA et al.: NEIGHBOR CACHE PREFETCHING 549
Fig. 5. MADT efficiency � (in percentage).
Fig. 6. MAT speedup � (in percentage).
). The result is the average MemoryAccess Time, MAT [5], defined as
(6)
and
(7)
We use the MAT measure to compute the relative percentagespeedup of the -th technique with respect to the case withoutprefetching as
(8)
The measures in the graph of Fig. 6 show that prefetchingachieves a significant speedup even when considering the totalmemory access time and not the memory delay time only. Wecan note that the speedup is low with all prefetching techniquesfor the program since its initial miss rate was very low(0.08%). The speedup is instead about 10% with whicheverprefetching technique for a simple raster-scan program as
. The speedup becomes relevant for , whose initialmiss rate is about 2.8%, since neighbor prefetching reaches the19.7% of speedup (versus the 14.1% and 18.8% of OBL andSPT). Speedup assesses up to 8% in the best case in our exper-iments on with eight-step neighbor. More importantly,the eight-step neighbor speedup achieves up to 35% for ,which has a considerable 5% of initial miss rate. Moreover,this result has been computed taking into account a relatively
low ; in Section VI-D we will showthat this speedup is significantly greater for higher values of themiss penalty, exceeding values of 140%.
In conclusion, in the case of algorithms with significant missrates, such as and, in particular, , the 2-D memoryaccess time improvement is highly relevant. In the case of al-gorithms with still non-negligible miss rates, such as ,
and , the time improvement is about 10% with thegiven cache configuration. Finally, in the case of a simple andregular algorithm with high temporal locality such as , thetime improvement achievable by prefetching is heavily limitedby the low initial miss rate.
C. Impact of Cache Size
In this section we discuss the impact of cache parameters,mainly cache size, block size, and degree of associativity, onperformance of the multimedia programs.
Varying the block size does not particularly affect perfor-mance. This is due to the fact that enlarging block size meansimproving 1-D spatial locality and therefore we should find sim-ilar performance improvements as in OBL techniques. An ex-ample, confirming this assumption, is in Fig. 7(a), showing theMADT efficiency on decoder, measured on a cache of32KB two-way associative (with the time model discussed inSection V) with block size varying from 8 to 32 bytes.
We do not report similar results for the associativity degree,since we proved that this not a critical parameter, since most ofthe misses were compulsory and not due to conflicts.
From our experiments, the cache size is the most relevant pa-rameter. Fig. 7(b) shows the MADT efficiency measured withdifferent cache sizes (two-way associative cache with 32 bytes
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

550 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
Fig. 7. (a) MADT efficiency for MPEG4 with variable block size (T = 8 � T ; 32KB size). (b) MADT efficiency for MPEG4 with variable cache size(T = 8 � T ; 32 bytes/line).
Fig. 8. (a) MADT efficiency for MPEG4with variable T (32 bytes/line; 32KB size). (b) MAT speedup for MPEG4with variable T (32 bytes/line; 32KBsize).
per block) for the program. Enlarging the cache size, theperformance improves from very small cache (8KB) to mediumsize cache (32KB); then, a further cache enlargement does notimprove performance anymore. However, a significant result isthat eight-step neighbor prefetching is able to completely elimi-nate misses even with caches of small size. This measure can bevery useful in cache design for low-cost, multimedia processors,which cannot be endowed with large data caches (for instance,like the Philips TriMedia TM1100 processor, with 16 KB datacache).
D. Impact of the Miss Penalty
The following test analyzes the impact of the miss penaltytime on the total memory access time: the higher the penalty,the larger the impact of misses and noncompletely overlappedprefetches. Therefore, the benefit achievable with a prefetchingstrategy able to nullify almost all misses while at the same timeoverlapping prefetches will accordingly be higher. Since theratio between memory and cache access times is increasing withcurrent technologies, large miss penalties are expected to be-come common.
In all the previous tests the miss penalty considered was. Now, let us suppose we modify
the architecture, by incrementing the number of clocks neededto access to the lower level of hierarchy. What could happen ifthe memory miss penalty increases? Considering the memoryaccess delay time, not only the miss costs but also prefetchingcosts will increase. Moreover, this increase is not proportional,
since the number of noncompletely overlapped prefetcheschanges, together with the amount of fraction overlapped. Wereport the simulations provided for the decoder withdifferent miss penalties. Results with other programs of thebenchmark are similar and are omitted for brevity. Fig. 8(a)shows the MADT efficiency for on a 32KB 32Bcache with , 16, 24 and .
With the assumption previously introduced of, the efficiency of neighbor methods was higher than that of
all standard techniques (see Fig. 5). Increasing the time latency,the prefetching efficiency varies differently for each method: inparticular the SPT technique is very sensitive to this change,while OBL is almost insensitive: when SPTexhibits an efficiency of 59.7% only with respect to 62.14% ofOBL. Nevertheless, efficiency of neighbor techniques remainsclose to 100%; in particular, the eight-step neighbor prefetchinghas an efficiency of 97.42% with and 97.3% with
.Results for the speedup on the overall memory access time
(MAT) are even more significant. Fig. 8(b) reports the MATspeedup for for the same 32KB 32B cache with
, 16, 24, and 32 . The speedupachievable with OBL and SPT prefetching grows modestlywith the miss penalty, proving that the noneliminated missesand non-overlapped prefetches heavily limit prefetching per-formance. Instead, the speedup obtained with neighbor-basedprefetching techniques grows linearly with the miss penalty,exceeding 110% for a miss penalty of and 140% for a
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

CUCCHIARA et al.: NEIGHBOR CACHE PREFETCHING 551
miss penalty of . This means that the memory accesstime can be more than halved by neighbor prefetching for theseconfigurations.
VII. CONCLUSION
This paper has presented a detailed performance analysis ofdifferent cache prefetching techniques on a multimedia bench-mark. The benchmark consists of a set of standard image andvideo decompression programs (JPEG, MPEG-2, MPEG-4)and some common image processing programs characterizedby different memory access schemes to 2-D data, includingboth raster-scan and data-dependent accesses.
We proposed two new techniques of cache prefetching,namely first-reference and eight-step neighbor prefetching,whose results outperform standard techniques both in terms ofmiss rate and memory access delay time. The most importantresults can be summarized as follows.
1) Prefetching should be adopted by multimedia orientedprocessors since all programs working on images andvideo have a high initial miss rate, and misses are es-sentially of compulsory type. All prefetching methodsimprove performance considerably.
2) The standard One-Block Lookahead prefetching tech-nique that exploits classic (1-D) spatial locality isinteresting for raster-scan programs but is not particularlyefficient for programs working on macroblocks such asMPEG-2 and MPEG-4.
3) Stride-based techniques (such as the Stride PredictionTable) achieve better results in terms of eliminatedmisses, but if a time analysis is performed by taking intoaccount also the cost of prefetching, it shows limitedefficiency (81–83% for MPEG-2 and 75% for MPEG-4with the reference cache architecture). Moreover, theSPT technique decreases its performance as the latencytime increases (see Section VI).
4) The new prefetching techniques proposed in this paper,namely the neighbor and the eight-step neighborprefetching, show high efficiency both in terms ofmiss rate and memory access delay time, and an impres-sive speedup of the overall memory access time. Theyoutperform the other techniques in the test provided onthe multimedia workload. On average, the eight-stepneighbor performs slightly better than first-referenceneighbor, thanks to a better distribution of the prefetchingactivity.
5) A specific consideration must be addressed regarding theMPEG-4 program. MPEG-4 decoding exhibits a signifi-cant miss rate (about 5% in the reference 2-D cache) sinceit is characterized by a data access sequence which isnot well caught by standard caches. With this workload,neighbor techniques are very interesting: for instance,with a two-way set-associative 32 KB cache with 32bytes/line, the miss rate becomes about 0.11–0.14% and
the speedup in the average memory access time rangesfrom 35% to 140% assuming increasing miss penalty.
6) A detailed analysis of implementation costs was out of thescope of the present paper. However, the area and powercosts of a split data cache can be considered in first ap-proximation proportional to its size. In this paper, resultswere reported with a reference cache size of 32 KB whichis fairly large and correspondingly costly, but results seemto be very good also for smaller sizes such as for instance8 KB, as shown in Fig. 7(b) Therefore, the technique couldbe used even for small caches which imply far more lim-ited implementation costs.
These results qualify neighbor prefetching as an effective so-lution for prefetching of 2-D data such as images and videosprocessed in the most common multimedia applications.
REFERENCES
[1] I. Kuroda and T. Niscitani, “Multimedia processors,” Proc. IEEE, vol.86, pp. 1203–1221, 1998.
[2] R. Cucchiara, M. Piccardi, and A. Prati, “Exploiting cache in multi-media,” in Proc. IEEE Int. Conf. Multimedia Computing and Systems(ICMCS), vol. 1, 1999, pp. 345–350.
[3] Z. Wu and W. Wolf, “Study of cache system in video signal processors,”in Proc. IEEE Workshop on Signal Processing Systems (SiPS), Oct 1998,pp. 23–32.
[4] J. Tse and A. J. Smith, “Cpu cache prefetching: Timing evaluation ofhardware implementation,” IEEE Trans. Comput., vol. 47, pp. 509–526,1998.
[5] J. Hennessy and D. Patterson, Computer Architecture: A QuantitativeApproach, 2 ed: Morgan Kaufmann, 1996.
[6] T. F. Chen and J. L. Baer, “A performance study of hardware and soft-ware data prefetching schemes,” in Proc. 21th Int. Symp. on ComputerArchitecture (ISCA), 1996, pp. 223–232.
[7] D. Zucker, M. J. Flynn, and R. Lee, “A comparison of hardwareprefetching techniques for multimedia benchmark,” Proc. IEEE Mul-timedia, pp. 236–244, 1996.
[8] A. D. Pimentel, L. O. Hertberger, P. Struik, and P. Van Der Wolf,“Hardware versus hybrid data prefetching in multimedia processors,” inProc. IEEE Int. Performance, Computing and Communications Conf.(IPCCC), 1999, pp. 525–531.
[9] D. B. Zucker, R. B. Lee, and M. J. Flynn, “Hardware and software cacheprefetching techniques for MPEG benchmarks,” IEEE Trans. CircuitsSyst. Video Technology, vol. 10, pp. 782–796, Aug. 1995.
[10] R. Cucchiara, M. Piccardi, and A. Prati, “Improving data prefetchingefficacy in multimedia applications,” Multimedia Tools Applicat., vol.20, no. 3, pp. 159–178, 2003.
[11] A. J. Smith, “Cache memories,” ACM Comput. Surv., vol. 14, no. 3, pp.473–530, 1982.
[12] N. P. Jouppi, “Improving direct-mapped cache performance by the ad-dition of a small fully-associative cache and prefetch buffers,” in Proc.IEEE/ACM Int. Symp. Computer Architecture (ISCA), May 1990, pp.364–373.
[13] P. Ranganathan, S. Adve, and N. P. Jouppi, “Performance of image andvideo processing with general-purpose processors and media ISA exten-sions,” in Proc. of IEEE/ACM Int. Symp. Computer Architecture (ISCA),1999, pp. 124–135.
[14] J. W. C. Fu and J. H. Patel, “Data prefetching in multiprocessor vectorcache memories,” in Proc. IEEE/ACM Int. Symp. Computer Architecture(ISCA), May 1991, pp. 54–63.
[15] G. S. Manku, M. R. Prasad, and D. A. Patterson, “A new voting basedhardware data prefetch scheme,” in Proc. of IEEE Int. Conf. High-Per-formance Computing, 1997, pp. 100–105.
[16] D. Joseph and D. Grunwald, “Prefetching using markov predictors,”IEEE Trans. Comput., Special Issue on Cache Memory and RelatedProblems, vol. 48, pp. 121–134, Feb 1999.
[17] M. Tomasko, S. Hadjiyiannis, and W. A. Najjar, “Experimental evalua-tion of array caches,” IEEE TCCA Newslett., pp. 11–16, Mar. 1997.
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

552 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 6, NO. 4, AUGUST 2004
[18] A. Gonzalez, C. Aliagas, and M. Valero, “A data cache with multiplecaching strategies tuned to different types of locality,” in Proc. ACM Int.Conf. Supercomputing, 1995, pp. 338–347.
[19] V. Milutinovic, B. Markovic, M. Tomasevic, and M. Tremblay, “Thesplit temporal/spatial cache: Initial performance analysis,” in Proc.SCIzzL-5, Santa Clara, CA, 1996.
[20] R. Cucchiara and M. Piccardi, “Exploiting image processing localityin cache pre-fetching,” in Proc. of IEEE Int. Conf. High-PerformanceComputing, Dec 1998, pp. 466–472.
[21] R. J. Eickemeyer and S. Vassiliadis, “A load instruction unit forpipelined processor,” IBM J. Res. Develop., vol. 37, pp. 547–564, July1993.
[22] C. Lee, M. Potkonjak, and W. Mangione-Smith, “Mediabench: Atool for evaluating multimedia and communications systems,” inProc. IEEE/ACM Int. Symp. Microarchitecture (MICRO), 1997, pp.330–335.
[23] P. Baglietto, M. Maresca, M. Migliardi, and N. Zingirian, “Image pro-cessing on high performance RISC systems,” Proc. IEEE, vol. 84, pp.917–925, 1996.
[24] H. Freeman, “On the encoding of arbitrary geometric configurations,”IRE Trans. Electron. Comput., vol. EC-10, pp. 260–268, 1961.
[25] J. Koplowitz, “On the performance of chain codes for quantization ofline drawings,” IEEE Trans. Pattern Anal. Machine Intell., vol. 3, pp.180–185, 1981.
[26] T. Kanedo and M. Okudaira, “Encoding of arbitrary curves based on thechain code representation,” IEEE Trans. Commun., vol. COM-33, pp.697–707, 1985.
[27] Coding of Audio-Visual Objects—Part 2: Visual, ISO/IEC DIS 14 496-2Information Technology.
[28] A. K. Katsaggelos, P. K. Lisimachos, F. W. Meier, J. Ostermann, andG. M. Schuster, “MPEG-4 and rate-distortion-based shape-coding tech-niques,” Proc. IEEE, vol. 86, pp. 1126–1154, June 1998.
[29] D. Gall, “MPEG: A video compression standard for multimedia appli-cation,” Commun. ACM, vol. 34, no. 4, pp. 46–58, 1991.
[30] T. F. Chen and J. L. Baer, “Effective hardware-based data prefetchingfor high-performance processors,” IEEE Trans. Comput., vol. 44, pp.609–623, 1995.
[31] R. Cucchiara, M. Piccardi, and A. Prati, “Temporal analysis of cacheprefetching strategies for multimedia applications,” in Proc. IEEE Int.Performance, Computing and Communications Conf. (IPCCC), 2001.
[32] G. Irlam. (1991) SPA—SPARC Analyzer Tool Set. [Online]. Available:http://www.base.com/gordoni/spa/spa-1.0.tar.Z
[33] ACME Cache Simulator. [Online]. Available: http://atana-soff.nmsu.edu/~acme/acs.html.
[34] PRIMA Web Site. [Online]. Available: http://imagelab.ing.unimo.it/im-agelab/prima.html
[35] G. Park, O. Kwon, T. Han, A. Kim, and S. Yang, “An improved looka-head instruction prefetching,” Proc. High-Performance Computing onthe Information Superhighway (HPC-Asia), pp. 712–715, 1997.
Rita Cucchiara (M’92) graduated (magna cumlaude) in 1989 with the Laurea degree in electronicengineering from the University of Bologna, Italy,the Ph.D. degree in computer engineering from theUniversity of Bologna in 1993.
She was Assistant Professor, University of Fer-rara, Italy, and is currently Associate Professor ofcomputer engineering, Faculty of Engineering ofModena, University of Modena and Reggio Emilia,Italy, since 1998. Her current interests include com-puter vision and pattern recognition and in particular
motion analysis for video-surveillance and color analysis for medical imaging.She is currently involved in research projects of video-surveillance, domotics,video analysis, and transcoding for high performance video servers
Massimo Piccardi (M’92) is with the Faculty ofInformation Technology at the University of Tech-nology (UTS), Sydney, Australia. Until 2001, hewas a Senior Lecturer (ricercatore confermato) withthe Faculty of Engineering, University of Ferrara,Italy. He currently coordinates the activity of theComputer Vision group at the Faculty of InformationTechnology, UTS. His major research interests arein the areas of computer vision,pattern recognition,image analysis and processing, video processing formultimedia, and computer architecture for computer
vision and multimedia application. He is the author of more than 40 scientificpapers on international journals and conferences, and a book chapter.
Dr. Piccardi is a member of the IEEE Computer Society and the InternationalAssociation for Pattern Recognition.
Andrea Prati (M’98) received the Laurea degree(magna cum laude) computer engineering fromthe University of Modena, Italy, in 1998 and thePh.D. degree in computer enginering from the sameuniversity in 2001, discussing a Ph.D. thesis onreal-time architecture for video and image analysis.
During the last year of his Ph.D. studies, he spentsix months as Visiting Scholar at the Computer Vi-sion and Robotics Research (CVRR) Lab, Universityof California at San Diego (UCSD), La Jolla, workingon a research project for traffic monitoring and man-
agement through computer vision. His research interests are mainly on motiondetection and analysis, shadow removal techniques, video transcoding and anal-ysis, computer architecture for multimedia and high performance video servers,video-surveillance, and domotics.
Dr. Prati is a member of the ACM, IAPR, and IAPR-GIRPR.
Authorized licensed use limited to: University of Technology Sydney. Downloaded on December 17, 2008 at 18:57 from IEEE Xplore. Restrictions apply.

Thomson lSI - Journal Search Results
THOMSON•••
ilr;;::::~~~~~~~~~_._._.._.._-ill Business Websites._:t..llll
Disclaimer I Terms of UsePrivacy Policy
lof2
• Hom • ABOUT UI • PREll R()Oll • CAREER\ • COtHAClIJI • THOMSOIl COM
Thomson Scientific Master Journal ListSEARCH RESULTS
Search Terms: 1520-9210Total journals found: 1
The following title(s) matched your request:
Journals 1-1 (of 1) ,., FORMAT 'FOR PRINT ,
IEEE TRANSACTIONS ON MULTIMEDIA•.,.
Highlight
QuarterlyISSN: 1520-9210iEEE ..INST ELECTF~IO;'\L. ~LE.Cm()NICS ENGINEE.RS INC445 HOES LANE. PISCATAWAY. USA, NJ. 08855
Journals 1-1 (of 1) ,. FORMAT FOR PRINT
t.earn more
Home I Site Map I About Us I Press Room I Careers I Contact Us I Thomsen.comSupport I Journal Lists IISI Links IISI Essays I HOI flesearcl1
http://www.isinet.com/cgi-bin/jrnlst/jlresults.cgi?PC=MASTER&ISSN= 1520-921 C
3/16/2005 2:40 PM




















