
Learning Decision Trees
29
Aprendizado de Árvores de Decisão Ricardo Prudêncio
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Learning Decision Trees

Aprendizado de Árvores de Decisão
Ricardo Prudêncio

Introdução• Seres humanos manipulam símbolos em alto nível
• Tomamos decisões a partir de regras e modelos que generalizamos
• Realizamos inferências a partir dos dados que temos e do nosso conhecimento explícito

Conhecimento Simbólico• Conhecimento adquirido pode ser representado em linguagens de alto nível– De forma legível e interpretável por humanos
• Motivações– Compreender um problema (mais do que obter modelos precisos)
– Justificar decisões – Incorporar novo conhecimento

Conhecimento Simbólico• Algoritmos de árvores de decisão e regras adquirem conhecimento simbólico a partir de dados de treinamento
• Conhecimento podem ser representado em linguagens com diferentes graus de expressividade

Linguagens de Representação
• Linguagem de Ordem Zero, ou Cálculo Proposicional– Conjunções, disjunções e negações de contantes booleanas • Ex: Fêmea AND Adulta -> Pode_ter_filhos
– Pequeno poder de expressividade e pouco usada na prática

Linguagens de Representação
• Lógica de Atributos– Semelhante ao cálculo proposicional, porém com atributos que recebem valores• Ex: sexo = F AND Idade = A -> Classe = Pode_filhos
– Usado na maioria dos algoritmos de aprendizado de regras e árvores de decisão
– Médio poder de expressividade• Dificuldade de expressar relacionamento entre objetos

Linguagens de Representação
• Lógica de Primeira Ordem– Predicados associados a argumentos
• Ex: IRMAO(X,Y) :- HOMEM(X), PAI(Z,X), PAI(Z,Y)
– Usado em programação em lógica indutiva• Inductive Logic Programming (ILP)
– Alto poder de expressividade, porém algoritmos se tornam mais complexos

Árvores de Decisão• Ampla classe de algoritmos de aprendizado– Exemplo: ID3, C4.5, CART,...
• Conhecimento representado em uma árvore de decisão, em geral, na linguagem da lógica de atributos

Árvores de Decisão• Cada nó interno (não-
terminal) contém um teste sobre os valores de um dado atributo
• Folhas da árvore (nós terminais) são associadas às classes – Comumente, acompanhadas com graus de confiança
• Novas instâncias classificadas percorrendo a árvore a partir da raiz até as folhas
FilmeRuim
(p = 0.7)Gênero
Cores
Não Sim
FilmeRuim
(p = 1.0)
Musical
Ação
Drama
FilmeBom
(p = 0.8)
FilmeRuim
(p = 0.6)

Árvores de Decisão - Construção
• Árvore de decisão construída de forma recursiva da raiz para as folhas (top-down)– A cada nó, é escolhido um teste que separe melhor os exemplos de classes diferentes • Maximização de critério de separação
– Nós terminais são criados ao atingir um critério de parada• Ex.: todos os exemplos do nó pertencem à uma só classe

• AD(Exemplos:D; Atributos:A; Alvo:C)– Crie nó_raiz– SE Critério_de_Parada ENTÃO Crie nó terminal associada à classe
mais freqüente– SENÃO Encontre atributo aj cujo teste de decisão
maximize a separação dos exemplos que atinjem o nó
- PARA CADA valor v do teste adicione nova sub-árvore
- Sub_arvore = AD(D[aj = v], A – {aj}, C)
Árvores de Decisão - Construção

Árvores de Decisão – Critérios de Separação
• Ganho de Informação (Information Gain)– Impureza ou incerteza de um nó pode ser medida através da Entropia
– Propriedades da Entropia: • Se todos os exemplos de D são da mesma classe então entropia assume valor mínimo
– Ent(C,D) = 0• Se todos as classes têm o mesmo número de exemplos em D então entropia assume valor máximo
||log||),( ][2
][
DD
DD
DCEnt i
i
i cC
c
cC

Árvores de Decisão – Critérios de Separação
• Ganho de Informação (Information Gain)– O ganho de um atributo/teste é definido pela redução de Entropia proporcionada após a separação dos exemplos do nó
),(),(),,( ][][
ii
iva
v
va DCEntD
DDCEntDCaInfoGain
Entropia do nó pai Entropia do nó filho ponderada pelo número de exemplos do nó

Árvores de Decisão – Critérios de Separação
• Critério de Gini– Fórmula alternativa para medir impureza
i
i
c
cC
DD
DCGini ][1),(
),(),(),,( ][][
ii
iva
v
va DCGiniD
DDCGiniDCaGiniGain

Árvores de Decisão – Critérios de Separação
• Gain Ratio– Valor normalizado do ganho de informação
– Boa alternativa quando os atributos possuem muitos valores • Ex.: E se alguém colocasse o atributo “Data” como preditor?
),(),,(),,(
DaEntropiaDCaInfoGainDCaGainRatio

• Lidando com atributos numéricos: – Testes são da forma: atributo > valor– Procedimento:
• Ordene os valores do atributo observados no conjunto de treinamento
• Considere a média de valores adjacentes como possíveis testes
• Por eficiência, considere apenas os valores onde são observadas mudanças de classe
Árvores de Decisão
Temperatura: 40 48 60 72 80 90 Classe: A A B B B A
54 95 Valores candidatos

• Totalidade (ou alternativamente, a maioria) do exemplos do nó pertencem a mesma classe
• Profundidade máxima para o nó • Número mínimo de exemplos no nó• Ganho pouco significativo no critério de separação
– Obs.: valores definidos como parâmetros do aprendizado
Árvores de Decisão – Critérios de Parada
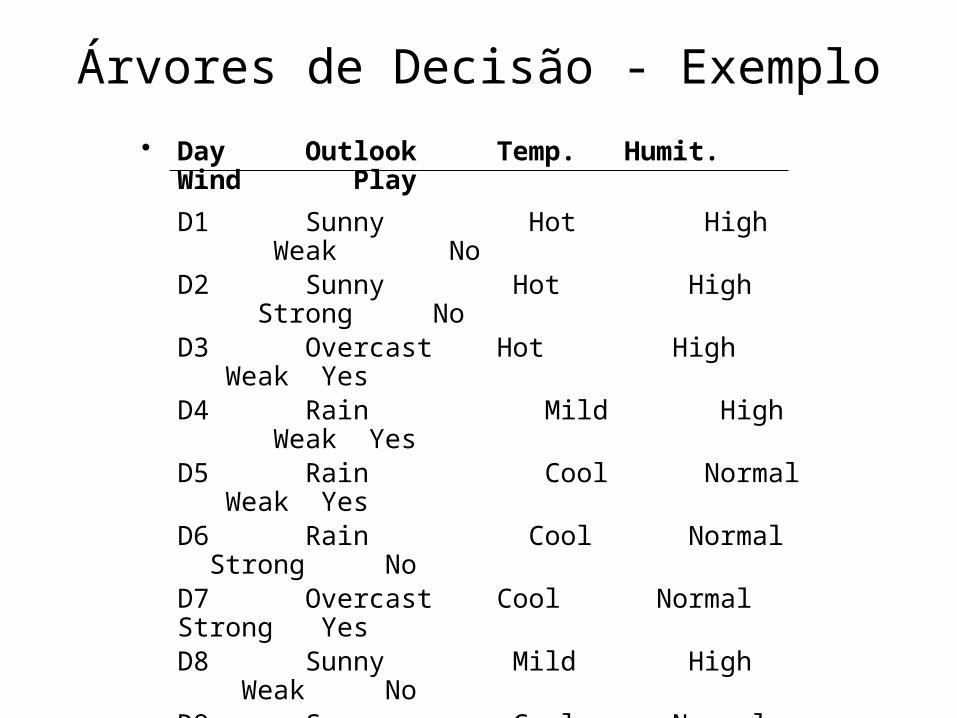
• Day Outlook Temp. Humit. Wind PlayD1 Sunny Hot High Weak No D2 Sunny Hot High Strong NoD3 Overcast Hot High Weak YesD4 Rain Mild High Weak YesD5 Rain Cool Normal Weak YesD6 Rain Cool Normal Strong No D7 Overcast Cool Normal Strong YesD8 Sunny Mild High Weak NoD9 Sunny Cool Normal Weak YesD10 Rain Mild Normal Weak YesD11 Sunny Mild Normal Strong YesD12 Overcast Mild High Strong YesD13 Overcast Hot Normal Weak YesD14 Rain Mild High Strong No
Árvores de Decisão - Exemplo

• Raíz: [9+; 5-]– Entropia = - 9/14*log2(9/14) - 5/14*log2(5/14) = 0.940
• Considerando teste com atributo Outlook– Outlook = Sunny: [2+;3-]
• Entropia = - 2/5*log2(2/5) - 3/5*log2(3/5) = 0.971
– Outlook = Overcast: [4+;0-]• Entropia = - 4/4*log2(4/4) - 0/4*log2(0/4) = 0.0
– Outlook = Rain: [3+;2-] • Entropia = - 3/5*log2(3/5) - 2/5*log2(2/5) = 0.971
– Média: 5/14*0.971 + 4/14*0.0 + 5/14*0.971 = 0.694
– Ganho de Informação: 0.940 - 0.694 = 0.246
Árvores de Decisão - Exemplo

• Considerando os outros atributos:– Ganho(Outlook, D) = 0.246– Ganho(Humit., D) = 0.151 – Ganho(Wind, D) = 0.048– Ganho(Temp., D) = 0.029
– Atributo Outlook é o escolhido na raíz
Árvores de Decisão - Exemplo
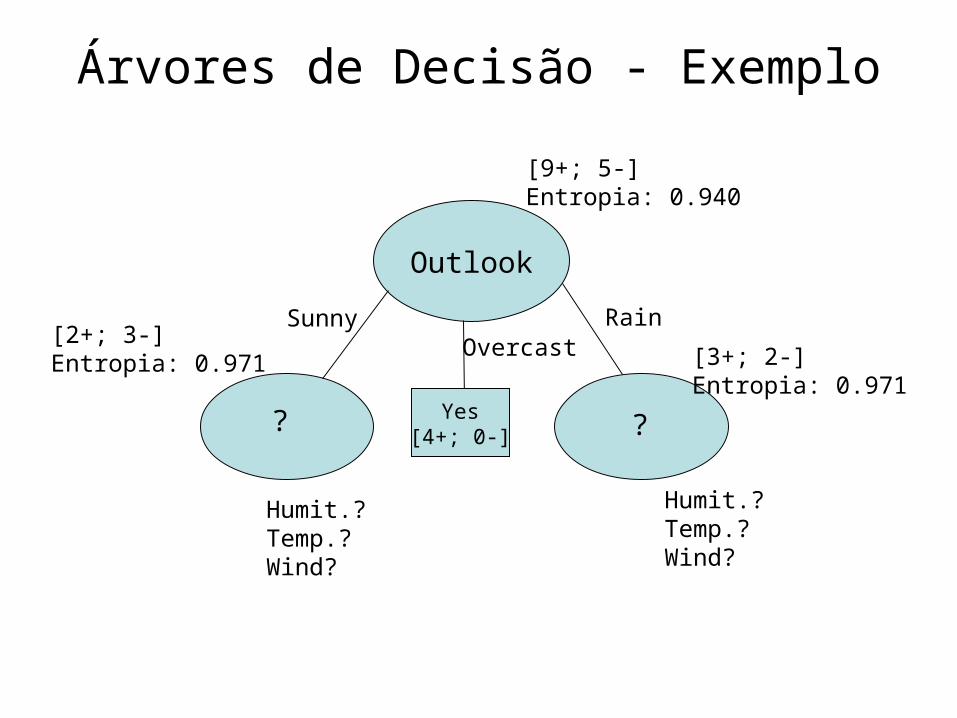
Árvores de Decisão - Exemplo
Outlook
Overcast
Rain
Yes[4+; 0-] ?
[3+; 2-]Entropia: 0.971
[2+; 3-]Entropia: 0.971
?
Sunny
[9+; 5-]Entropia: 0.940
Humit.?Temp.?Wind?
Humit.?Temp.?Wind?

• Árvores de decisão podem super-ajustar os dados de treinamento (overfitting) – Sempre é possível crescer a árvore de forma a classificar corretamente todos os dados
• Ná prática, a árvore é podada, i.e., nós desnecessários são cortados
Árvores de Decisão - Poda

• Procedimento:– Passo 1: Separe um conjunto de validação diferente do conjunto de treinamento
– Passo 2: Gere a árvore de decisão completa usando o conjunto de treinamento
– Passo 3: Para cada nó da árvore: • Passo 3.1: Computar o erro no conjunto de validação obtido se a sub-árvore do nó fosse cortada da árvore
• Passo 3.2: Efetue a eliminação da sub-árvore, caso o erro de validação se mantenha ou diminua
Árvores de Decisão - Poda

• Vantagens:– Geram modelos dos dados (i.e., método eager)
– Conhecimento interpretável– Pouca sensibilidade a atributos irrelevantes• Uma vez que implementam seleção de atributos
• Desvantagens:– Em geral, menos precisos comparados com algoritmos como redes neurais e SVMs
Árvores de Decisão - Discussão

• Diferentes versões de algoritmos podem ser encontradas na literatura– Algoritmo ID3 – versão básica de AD para atributos categóricos, com InfoGain
– Algoritmo C4.5 – extensão do ID3 para atributos categóricos e numéricos, com GainRatio
Árvores de Decisão
Árvores de Decisão - no WEKA
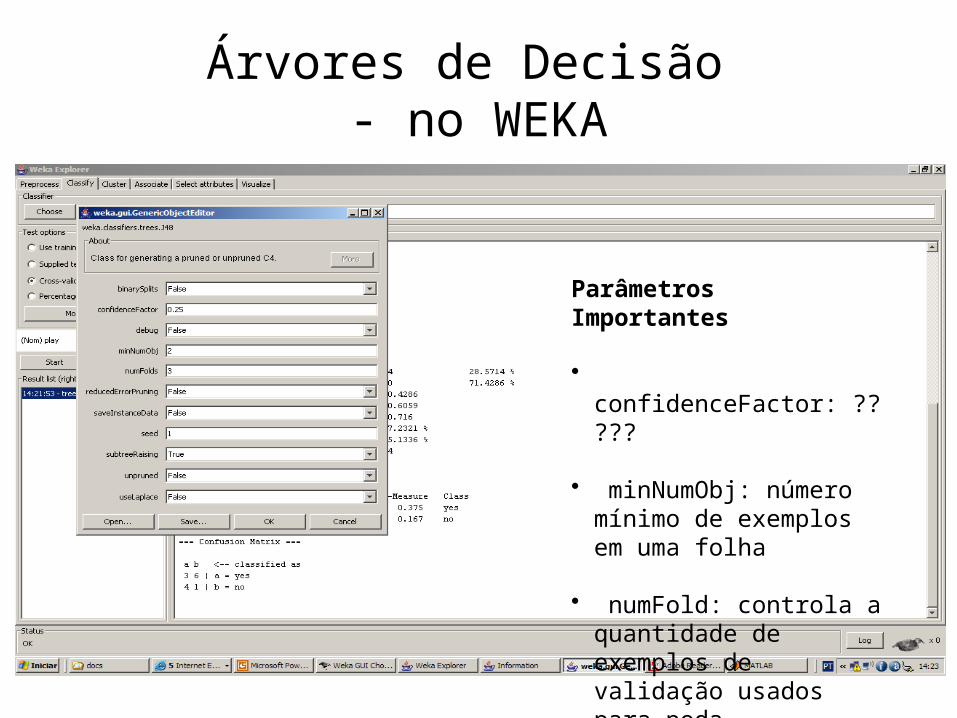
Árvores de Decisão - no WEKA
Parâmetros Importantes
• confidenceFactor: ?????
• minNumObj: número mínimo de exemplos em uma folha
• numFold: controla a quantidade de exemplos de validação usados para poda
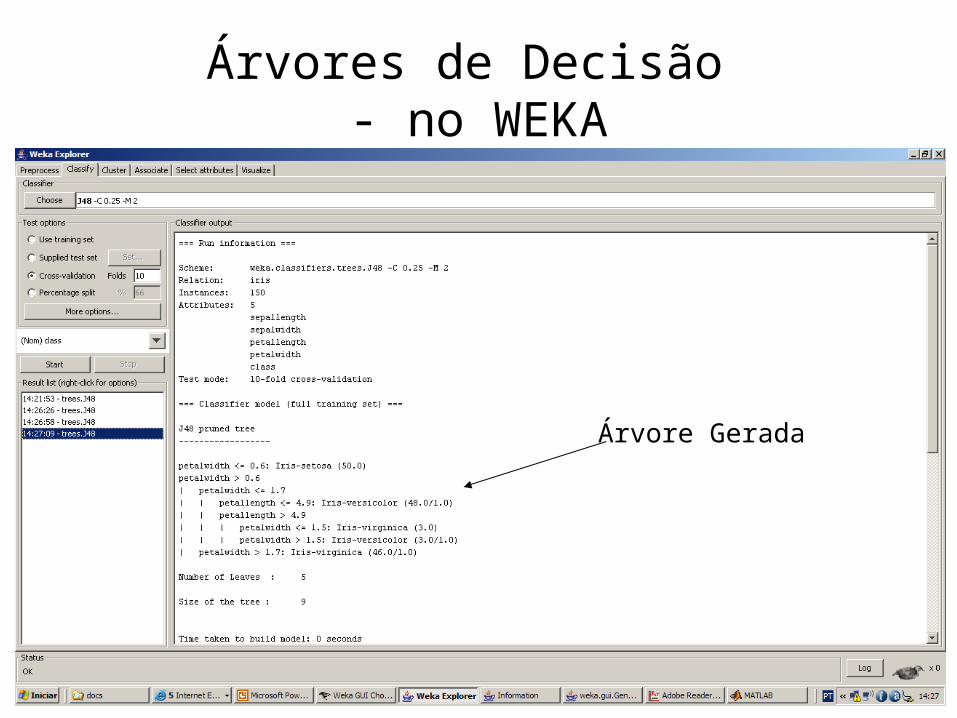
Árvores de Decisão - no WEKA
Árvore Gerada

• T. Mitchell, Machine Learning, Cap. 3, 1997.
• M. Monard, J. Baranauskas, Indução de Regras e Árvores de Decisão, Sistemas Inteligentes, Cap. 5, 2005.
• J. R. Quinlan, Induction of Decision Trees, Machine Learning, Vol.1, N.1, 1986.
Referências




















