
Knowledge discovery with classification rules in a cardiovascular dataset
21
1 Knowledge Discovery with Classification Rules in a Cardiovascular Dataset Vili Podgorelec (1) , Peter Kokol (1) , Milojka Molan Stiglic (2) , Marjan Heričko (1) , Ivan Rozman (1) (1) University of Maribor – FERI, Smetanova 17, SI-2000 Maribor, Slovenia [email protected] (2) Maribor Teaching Hospital, Department of Pediatric Surgery, Maribor, Slovenia Abstract. In the paper we study an evolutionary machine learning approach to data mining and knowledge discovery based on the classification rules induction. A method for automatic rules induction called AREX using evolutionary induction of decision trees and automatic programming is introduced. The proposed algorithm is applied to a cardiovascular dataset consisting of different groups of attributes which should possibly reveal the presence of some specific cardiovascular problems in young patients. A case study is presented that shows the use of AREX for the classification of patients and for discovering possible new medical knowledge from the dataset. The defined knowledge discovery loop comprises a medical expert’s assessment of induced rules to drive the evolution of rule sets towards more appropriate solutions. The final result is the discovery of a possible new medical knowledge in the field of pediatric cardiology. Index terms: machine learning, knowledge discovery, classification rules, pediatric cardiology, medical data mining 1. INTRODUCTION Modern medicine generates huge amounts of data and there is an acute and widening gap between data collection and data comprehension. Obviously it is very difficult for a human to make a use of such amount of information (i.e. hundreds of attributes, thousand of images, several channels of 24 hours of ECG or EEG signals) and to be able to find basic patterns, relations or trends in the data. In such manner data becomes less and less useful, the transformation data ⇒ information harder and harder and the transformation data ⇒ information ⇒ knowledge almost impossible. Thus, there is a great need to find new methods for data analysis to facilitate the creation of knowledge that can be used for clinical decision Citation Reference: V. Podgorelec, P. Kokol, M. Molan Stiglic, M. Heričko, I. Rozman, Knowledge Discovery with Classification Rules in a Cardiovascular Database, Computer Methods and Programs in Biomedicine, Elsevier, vol. 80, suppl. 1, pp. S39-S49, 2005.
Transcript of Knowledge discovery with classification rules in a cardiovascular dataset

1
Knowledge Discovery with Classification Rules
in a Cardiovascular Dataset
Vili Podgorelec(1), Peter Kokol(1), Milojka Molan Stiglic(2), Marjan Heričko(1), Ivan Rozman(1)
(1)University of Maribor – FERI, Smetanova 17, SI-2000 Maribor, Slovenia [email protected]
(2)Maribor Teaching Hospital, Department of Pediatric Surgery, Maribor, Slovenia
Abstract. In the paper we study an evolutionary machine learning approach to data mining and knowledge discovery based on the classification rules induction. A method for automatic rules induction called AREX using evolutionary induction of decision trees and automatic programming is introduced. The proposed algorithm is applied to a cardiovascular dataset consisting of different groups of attributes which should possibly reveal the presence of some specific cardiovascular problems in young patients. A case study is presented that shows the use of AREX for the classification of patients and for discovering possible new medical knowledge from the dataset. The defined knowledge discovery loop comprises a medical expert’s assessment of induced rules to drive the evolution of rule sets towards more appropriate solutions. The final result is the discovery of a possible new medical knowledge in the field of pediatric cardiology. Index terms: machine learning, knowledge discovery, classification rules, pediatric cardiology, medical data mining 1. INTRODUCTION Modern medicine generates huge amounts of data and there is an acute and widening gap
between data collection and data comprehension. Obviously it is very difficult for a human to
make a use of such amount of information (i.e. hundreds of attributes, thousand of images,
several channels of 24 hours of ECG or EEG signals) and to be able to find basic patterns,
relations or trends in the data. In such manner data becomes less and less useful, the
transformation data ⇒ information harder and harder and the transformation data ⇒
information ⇒ knowledge almost impossible. Thus, there is a great need to find new methods
for data analysis to facilitate the creation of knowledge that can be used for clinical decision
Citation Reference: V. Podgorelec, P. Kokol, M. Molan Stiglic, M. Heričko, I. Rozman, Knowledge Discovery with Classification Rules in a Cardiovascular Database, Computer Methods and Programs in Biomedicine, Elsevier, vol. 80, suppl. 1, pp. S39-S49, 2005.

2
making. Intelligent systems for knowledge extraction are the tools that can help in achieving
this goal.
1.1. Objectives and scope of the paper There are two main objectives of this paper. The first objective is to introduce a new
intelligent knowledge extraction paradigm based on evolutionary rule sets induction. We
present a new hybrid classification algorithm based on genetic algorithms (GAs) and genetic
programming (GP) – the AREX approach. AREX (Automatic Rules Extractor) is a general
hybrid method that incorporates two original, independent algorithms that together solve the
problem of automatic classification rules induction. First algorithm is a multi-population self-
adapting genetic algorithm for the induction of decision trees. Second is the system for the
evolution of programs in an arbitrary programming language, which is used to evolve
classification rules. Finally, an optimal set of classification rules is determined with a simple
genetic algorithm.
The second objective is to present a case study of using the developed algorithm to discover
new knowledge in a problem of early and accurate identification of cardiovascular problems
in pediatric patients. It is shown how AREX can be used to extract medical knowledge and
the results obtained in this manner are evaluated by a medical expert. To objectively compare
the developed AREX approach with the existing methods the results are compared to those
obtained with other classification methods.
This paper is organized as follows. Section 2 presents a short overview of data mining and
knowledge discovery with the emphasis on the evolutionary induction of decision trees; it
indicates some reasons for the development of AREX. Section 3 presents the developed
AREX algorithm in detail. Section 4 presents a case study of using AREX upon a
cardiovascular database, where all the obtained results are evaluated and compared with the
existing classification algorithms. Finally, section 5 presents a discussion that concludes the
paper.
2. DATA MINING AND KNOWLEDGE DISCOVERY Although a great deal of time and effort is spent building and maintaining all kinds of
databases, it is nonetheless rare that the full potential of this valuable resource is realised. The
principle reason for this paradox is that the majority of organisations lack the insight and/or

3
expertise to effectively translate information into usable knowledge [1]. In light of these
conditions, there exists a clear need for automated methods and tools to assist in exploiting
the vast amount of available data. This requirement has led to the development of data mining
technology. Data mining is an umbrella term which describes the process of uncovering
patterns, associations, changes, anomalies and statistically significant structures and events in
data. Traditional data analysis is assumption driven in the sense that a hypothesis is manually
formed and validated (by statistical means) against the data. In contrast, data mining is
discovery driven in that useful patterns are automatically extracted from the data [2]. In order
to accomplish this task, data mining systems frequently utilise methods from disciplines such
as artificial intelligence, machine learning and pattern recognition [3].
The data mining algorithms usually operate on data sets composed of vectors (instances) of
independent variables (features, attributes). For example, a database may describe a group of
people in terms of their age, sex, income and occupation. In this case, age is an example of an
attribute and each instance corresponds to a distinct individual.
To discover the hidden patterns in data, it is essential to build a model consisting of
independent variables that can be used to determine a dependent variable (also known as class
or decision). Building such a model therefore consists of identifying the relevant independent
variables (attributes) and minimising the predictive error [4]. It is also highly desirable to find
the simplest possible model that fits the data, since these are typically the most meaningful
and easiest to interpret. This last requirement reflects the principle of Occam's Razor which
tells us to prefer the simplest model that fits the data [5].
Before we proceed further, it is important to distinguish data mining from pattern recognition
as these terms are sometimes confused with each other. Pattern recognition is primarily
concerned with the construction of accurate classifiers. A classifier is fundamentally a
mapping between a set of input variables x1, ..., xn to an output variable y whose value
represents the class label ω1, ..., ωm [5]. In general, representing the knowledge embodied
within the classifier structure is not a priority. Consequently, while there is no shortage of
extremely accurate classifiers, some of the best are akin to a black box; that is, they give little
or no insight into why they make decisions. Neural networks [5, 6] exemplify these types of
systems because its classification rules are embedded in its structure. Since neural networks
components (node activation functions, connection weights, etc.) encode complex
mathematical functions, articulating the rules they represent is a difficult problem [7]. In
contrast, the primary purpose of data mining is not simply classification, but to provide

4
meaningful knowledge to the user regarding the classification process. Thus, the models
produced by data mining algorithms should be in a form that lends itself to analysis by the
user. Decision rule sets which linearly partition the data space into class homogeneous regions
meet this requirement. Examples of techniques that accomplish decision rule induction from
data include decision trees [8, 9, 10, 11] and evolutionary algorithm based classifier systems
[12, 13, 14, 15].
2.1. Evolutionary induction of decision trees Almost since their introduction decision trees (DTs) have been exhaustively used as a
classification method, showing a great potential in several domains. Their efficiency and
classification accuracy have surprised many experts, but their most important advantage is the
transparency of the classification process that one can easily interpret, understand and
criticize. However, the classical induction approach of DTs, that has not changed much since
the introduction, contains several disadvantages, like 1) poor processing of incomplete, noisy
data, 2) inability to build several trees for the same dataset, 3) inability to use the preferred
attributes, etc.
For all those reasons a need for an approach that would preserve the positive aspects of DTs
and avoid their disadvantages emerged. Encouraged by the success of evolutionary algorithms
for optimization tasks a series of attempts occurred to induce a DT-like models with
evolutionary methods [16, 17, 18, 19]. Despite their high classification accuracy, GPs have
proven extremely difficult to interpret – this is a major obstacle to their use in data mining
problems. Nevertheless, many researchers have tried to use the power of GAs/GPs for the
problem of data mining and knowledge discovery [20, 21].
As we learn from the history, the ideal choice for effective, accurate and efficient data mining
algorithm would be to combine the power of GA/GP with the interpretability of DTs (or rule
sets) in a successful way. In this paper we present one such approach that shows a great
potential both in data mining (classification) and knowledge discovery.
2.2. Data and knowledge representation Knowledge discovered with data mining algorithms should ideally give an in-depth
explanation of a problem domain along with a good classification [22]. Experts are
performing exhaustive analyses of the results, which are the output of knowledge discovery
tools, in order to extract the useful knowledge. To make a part of their work as easy as

5
possible the best way is to present the results in a form of a set of classification rules, which
are clear and straightforward to understand, accept or reject. Ideal system would therefore
include:
- accuracy – classification with minimal error rate, - compactness – use of a minimum number of rules, and - simplicity – single rules are not complex.
Data to use as the source for knowledge discovery system are represented with the set of
training objects o1, …, oN. Each training object oi is described with the values of attributes ai1,
…, aik and the accompanied decision ωi from the set of m possible decisions [Ω1, …,Ωm].
Attributes can be either numeric (value is a number from a continues interval) or discrete
(value is one from the discrete set of all possible values). Usually algorithms can work also
with missing values, in this case it is not necessary for all values to be known.
3. THE AREX ALGORITHM Knowledge that is discovered with the help of our algorithm is represented with a set of
classification rules. Each single rule in a set is in the following form:
if <condition> then <decision>, where <condition> := <c1> and … and <cd>, and <decision> := ω, ω ∈ [Ω1, …, Ωm]
In this manner the rules are clear and easy enough for further analyses and in the same time
their functional power is strong enough for successful classification. A set of classification
rules can lose on the understandability if the number of rules in a set is too high. On the other
hand the classification accuracy would decrease if the number of classification rules in a set is
too low. Our algorithm searches for a balanced solution between these two extremes.
The complete rules extracting algorithm has been called AREX (Automatic Rules EXtractor).
AREX uses as the input a training set of objects and based on those objects classification rules
are induced. Algorithm AREX includes a hybrid system of two basic algorithms: 1) an
evolutionary algorithm for the construction of decision trees [23, 19] that is used to build the
initial set of classification rules, and 2) proGenesys system that allows automatic evolution of
programs in an arbitrary programming language and is used for the construction and

6
refinement of classification rules. The basic outline of the AREX algorithm is illustrated in
Figure 1 and can be described in the following steps:
Rules construction withproGenesys system.
Input (training) objects -attributes values
vectors
A set of evolutionarydecision trees.
IF ... THEN ... w1IF ... THEN ... w2
...IF ... THEN ... wn
Refined rules.
Simpleobjects.
Complexobjects.
A classification rule set.
if (A3 > split) thenif (INV2 < TRESHOLD2) then
moveTo(3)else
predict(DECISION1)endif
elsemoveTo(1)
endifinc(INV2)
if (A3 > split) thenif (INV2 < TRESHOLD2) then
moveTo(3)else
predict(DECISION1)endif
elsemoveTo(1)
endifinc(INV2)
Initial rules.
Figure 1. The diagram of AREX algorithm.
0. input: a set of training objects S, decision forest size nt, and classification tolerance ct=nt/2
1. build N evolutionary decision trees upon objects from S 2. for all objects oi from S:
a) classify object oi with nt randomly chosen trees from all N trees b) if frequency of the most frequent decision class classified by nt trees > nt-ct: copy oi
from S to a set S* and clear oi from S 3. from all N decision trees create M initial classification rules 4. with the proGenesys system create another ⎣M/2+1⎦ classification rules randomly 5. using the proGenesys system evolve the final set of rules for classifying objects from S* 6. find the optimal final set of rules using simple optimization 7. if S is not empty:
a) add |S| randomly chosen objects from S* to S; b) increase clearness tolerance ct=ct+1; c) repeat the whole procedure from step 1
8. finish if S is empty

7
3.1. Genetic algorithm for the construction of decision trees First step of the genetic algorithm is the creation of the initial population. A random decision
tree is constructed based on the following algorithm, where the input is a randomly chosen
number of attribute nodes that will compose the tree:
0. input: number of attribute nodes M that will be in the tree 1. select an attribute Xi from the set of all possible attributes and set it as a rood node t 2. in accordance with the selected attribute's Xi type (discrete, continuous) define a test for
this node t: 1) for continuous attributes in a form of ƒt(Xi) < φi , where ƒt(Xi) is the attribute value for a data object and φi is a split constant; 2) for discrete attributes two disjunctive sets of all possible attribute values are randomly defined
3. connect empty leaves to both new branches from node t 4. randomly select an empty leaf node t (the probability of selecting an empty leaf is
decreased with the depth of the leaf in a growing tree) 5. randomly select an attribute Xi from the set of all possible attributes (the probability of
choosing an attribute depends on a number of previous uses of that attribute in a tree – in this manner unused attributes have better chances to be selected)
6. replace the selected leaf node t with the attribute Xi and go to step 2 7. finish when M attribute nodes has been created
For each empty leaf the following algorithm determines the appropriate decision class: let S
be the training set of all training objects N with K possible decision classes d1, .., dK and Ni is
the number of objects within S of a class di. Let St be the sample set at node t (an empty leaf
for which we are trying to select a decision class) with Nt objects; Nit is the number of objects
within St of a decision class di. Now we can define a function that measures a potential
percentage of correctly classified objects of a class di:
i
ti
NN
itF =),( (1)
Decision di
t for the leaf node t is then set as a decision di, for which F(t,i) is maximal.
The ranking of an individual DT within a population is based on the local fitness function:
∑ ∑= =
⋅++−⋅=K
i
N
iuiii nuwtcaccwLFF
1 1)()1( (2)
where K is the number of decision classes, N is the number of attribute nodes in a tree, acci is
the accuracy of classification of objects of a specific decision class di, wi is the importance

8
weight for classifying the objects of a decision class di, c(ti) is the cost of using the attribute in
a node ti, nu is number of unused decision (leaf) nodes, i.e. where no object from the training
set fall into, and wu is the weight of the presence of unused decision nodes in a tree.
3.2. System proGenesys for automatic evolution of programs For constructing classification rules we used a system developed for the evolution of
programs in an arbitrary programming language, described with BNF productions –
proGenesys (program generation based on genetic systems) [24]. In our approach an
individual is represented with a syntax tree (a derivation tree), as it is usual for grammar-
based GP [25,26]. To get the final solution this tree (genotype) is transformed into a program
(phenotype) [27].
First step of automatic programming is the initialization of the initial population. For the
successful continuation of the program evolution process the initial programs should be
evenly distributed [28]. Known program initialization procedures are theoretically correct but
are working well only for small problems [29]. The problem is that limitations regarding the
tree size are not considered during the induction. For this reason a lot of built trees have to be
rejected, which is time consuming. An initialization procedure based on dynamic grammar
pruning as proposed in [30] could solve the problem. In the proGenesys system a procedure is
used that allows the induction of a program tree of exactly specified size.
A good classification rule should simultaneously be clear (most of the objects covered by the
rule should fall into the same decision class) and general (it covers many objects – otherwise
it tends to be too specific). Those two criteria can be measured with the following formulas:
num. of classified objects – 1
generality = num. of objects of this decision class ω2 Ω2 ω1 clearness = 1 –
Ω1 where ω1 is number of objects covered by the rule that belong to the most frequent decision
class, ω2 is number of objects covered by the rule that belong to the second most frequent
decision class, Ω1 is number of all objects in the training set that belong to the most frequent
(4)
(3)

9
decision class of the rule, and Ω2 is number of all objects in the training set that belong to the
second most frequent class of the rule. Now a fitness function can be defined as
FF = clearness × generality + ∑
=
N
iitc
1
)( (5)
where the last part represents a cost of the use of specific attributes, the same as in the local
fitness function LFF in building decision trees.
3.3. Finding the optimal set of rules System proGenesys is used to evolve single rules, whereas for the classification of all objects
a set of rules is required. For this purpose between all the evolved rules a set of rules should
be found that together classify all the objects – with high classification accuracy and a small
number of rules. A problem is solved with a simple genetic algorithm that optimizes the
following fitness function:
∑ ∑= =
⋅+⋅++−⋅=K
i
N
iumiii nuwnmwtcaccwFF
1 1)()1( (6)
where the first two parts are the same as in the LFF for building decision trees, and nm is the
number of multiple classified objects, nu is the number of non-classified objects, and wm and
wu are the corresponding weights. The appropriate coverage of the training set is thus
achieved by reducing the number of not classified and multiple classified objects. A more
advanced way to achieve the uniform coverage is discussed in [31].
4. A CASE STUDY The role of classification rules in medical decision making is very important, since they
provide a very important feature – the possibility of explaining the decisions in a way
understandable by humans. But surprisingly this feature somehow shortcut the use of
classification rules from their primary purpose, that is classifying/decision making, to more
explanatory and statistical uses. In our long experience in introducing the classification
models and more generally intelligent systems into real world medical applications we
noticed that rarely they were successful in supporting diagnosing/classifying, but in the case
they were the use was very different. They were read in the opposite way, from decisions

10
towards conditions either in the manner to see the influence/relation of the attributes on the
diagnosis or the influence/relation of the diagnosis and attributes on a specific attribute in the
rule. The auxiliary information like the number of objects covered by the rule suddenly
became very important – the physicians were only interested in rules covering many objects.
Consequently, for us very important information like accuracy, sensitivity, specificity was
normally ignored and the division on training and testing sets disliked, because it reduced the
number of objects. So we changed our attitude and stopped introducing the rule sets for
classifying only but instead we presented to the medical staff additionally their use in
knowledge discovery, hypothesis generation, hypothesis testing, etc. – and suddenly the
approach became much more successful.
Interestingly, another weakness was noticed. In analyzing the rules in the above manner, at
first medical experts expected to find some revolutionary new knowledge, which normally did
not happen. But after the first disappointment they were surprised how well the classification
rules represent their own decision making concepts. And furthermore, they wondered how to
generate rule sets that would teach them something new and unexpected. After some research
we found that the problem is in the classical information content method of decision tree
induction. So we decided to test our AREX method as a new iterative rule generation
approach for new knowledge discovery in data – and the aim of this case study is to present
its application in cardiology.
4.1. The knowledge discovery loop Naturally, as a knowledge discovery system we used AREX, a rule extraction method that is
able to induce a set of classification rules based on the given dataset. For the purpose of
searching for new knowledge in medical datasets, the developed algorithm had to be modified
in some aspects.
In the first run the AREX algorithm generates a set of rules, which are then assessed by
physicians according to medical relevance and originality (see figure 2). The rules, which are
at the same time relevant and represent some new knowledge, are stored in the database of
good rules. In the next runs AREX gives the bonus preference to rules which use the same
attributes and parts of the rules stored in the database. After several runs the quality of the
rules produced by AREX is significantly improved regarding the preference criteria given by
physicians and the process eventually leads to some new knowledge. The outline of the
approach is presented in figure 2.

11
AREX rulesinduction system
Rule assesmentby physicians
The base of good rules
rules
asse
smen
tinduction criteria
rules
Rules assesed goodby physiciansType of rules preferred
by physicians
A set of induced rulesregarding the criteria
Figure 2. The outline of our approach to the discovery of new knowledge.
4.2. The cardiovascular problems of children patients The early and accurate identification of cardiovascular problems in pediatric patients is of
vital importance. In order to help the clinicians in diagnosing the type of the cardiovascular
problems in young patients, computerized data mining and decision support tools are used
which are able to help clinicians to process a huge amount of data available from solving
previous cases and suggest the probable diagnosis based on the values of several important
attributes. Clearly, black-box classification methods (neural networks for example) are not
appropriate for this kind of task, because the clinical experts need to evaluate and validate the
decision making process, induced by those tools, before there is enough trust to use the tools
in practice.
On the other hand, the evaluation of the induced classification rules produced by the
computerized tools by a clinical expert can be an important source of new knowledge on how
to make a diagnosis based on the available attributes. In order to achieve this goal, the
classification process should be easily understandable and straightforward. Different kinds of
knowledge discovery methods are therefore appropriate to do the job, and we decided to use
the developed knowledge discovery method presented above.

12
4.3. A dataset Two cardiovascular datasets have been composed to be used for the knowledge discovery
process. Each of them contains data of 100 patients from Maribor Hospital. A protocol has
been defined to collect the important data. The attributes include general data (age, sex, etc.),
a health status (data from family history and child’s previous illnesses), a general
cardiovascular data (blood pressure, pulse, chest pain, etc.) and more specialized
cardiovascular data – data from child’s cardiac history and clinical examinations (with
findings of ultrasound, ECG, etc.).
In the first dataset three different diagnoses are possible: innocent heart murmur, congenital
heart disease, palpitations with chest pain. In the second dataset five different diagnosis are
possible: innocent heart murmur, congenital heart disease with left to right shunt, aortic valve
disease with aorta coarctation, arrhythmias, and chest pain. Because the first database is
actually the simplified version of the second one, we decided to use in our study only the
second one with five possible decision classes.
4.4. The results The most common measure of efficiency when assessing a classification method is accuracy,
defined as a percentage of correctly classified objects from all objects (correctly classified and
not correctly classified). Accuracy can be thus calculated as:
FTTACC+
= (7)
where T stands for “true” cases (i.e. correctly classified objects) and F stands for “false” cases
(i.e. not correctly classified objects).
The above measure is used to determine the overall accuracy of the classification. In many
cases, especially in medicine, accuracy of each specific decision class is even more important
than the overall accuracy. When there are two decision classes possible (i.e. positive and
negative patients), the common measures in medicine are sensitivity and specificity:
FNTPTPSens+
= (8)
FPTNTNSpec+
= (9)

13
where TP stands for “true positives” (i.e. correctly classified positive cases), TN stands for
“true negatives” (i.e. correctly classified negative cases), FP stands for “false positives” (i.e.
not correctly classified positive cases) and FN stands for “false negatives” (i.e. not correctly
classified negative cases).
In our case of cardiovascular dataset, as in many other real-world medical datasets, there are
more than two decision classes possible, actually five. In this case the direct calculation of
sensitivity and specificity is not possible. Therefore, the separate class accuracy of i-th single
decision class is calculated as:
ii
iik FT
TACC
+=, (10)
and the average accuracy over all decision classes is calculated as
∑= +
⋅=v
i ii
ik FT
Tv
ACC1
1 (11)
where v represents the number of decision classes.
4.4.1. Classification results
To evaluate the classification results of our method AREX the above mentioned measures of
efficiency were calculated based on 10 independent evolutionary runs. For the comparison
with other classification algorithms we calculated the classification results obtained with
algorithms ID3, See5/C5 [9, 32], Naïve-Bayes (N-B), Naïve-Bayes tree (NB tree), and
instance-based classifier (IB) [33]. Based on 10-fold cross validation for each algorithm we
calculated overall accuracy on a training set (Table 1 and Figure 3) and a testing set (Table 2
and Figure 4), and average accuracy over decision classes on testing set (Table 2 and Figure
5).
Table 1. Average overall accuracy of classification on a training set.
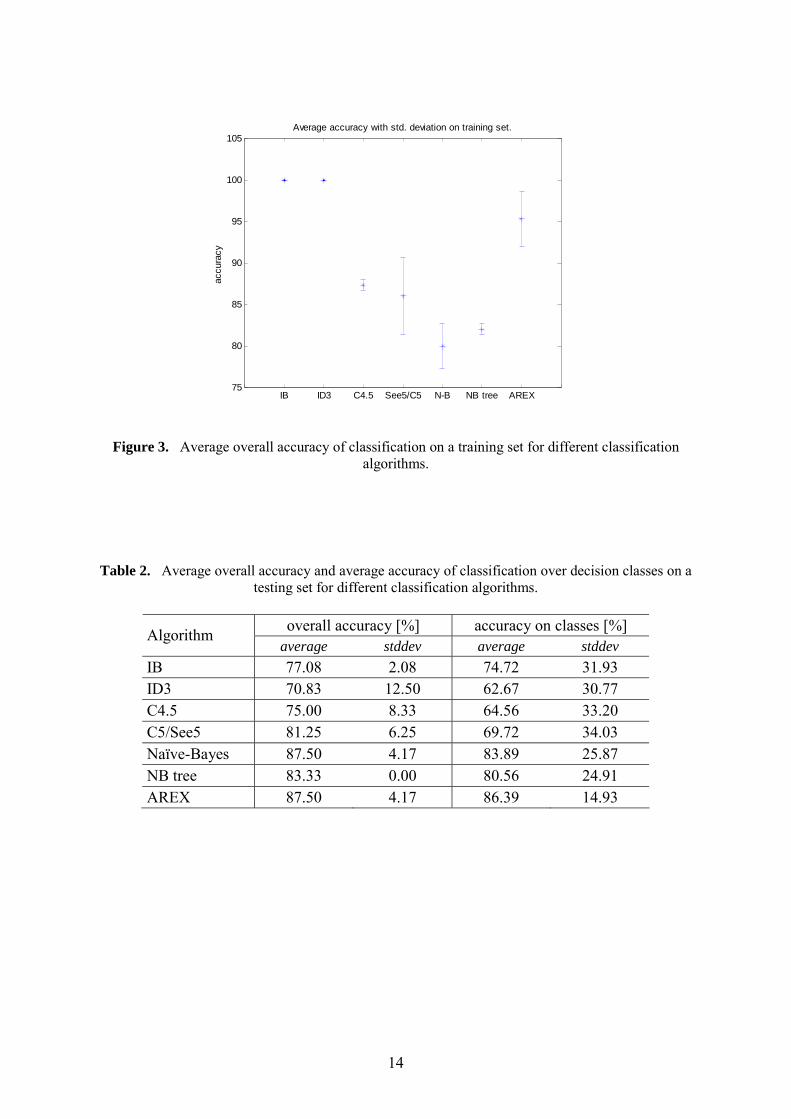
overall accuracy [%] Algorithm
average stddev IB 100.00 0.00 ID3 100.00 0.00 C4.5 87.33 0.67 C5/See5 90.67 4.67 Naïve-Bayes 80.00 2.67 NB tree 82.00 0.67 AREX 95.33 3.33
14
IB ID3 C4.5 See5/C5 N-B NB tree AREX75
80
85
90
95
100
105
accu
racy
Average accuracy with std. deviation on training set.
Figure 3. Average overall accuracy of classification on a training set for different classification algorithms.
Table 2. Average overall accuracy and average accuracy of classification over decision classes on a
testing set for different classification algorithms.
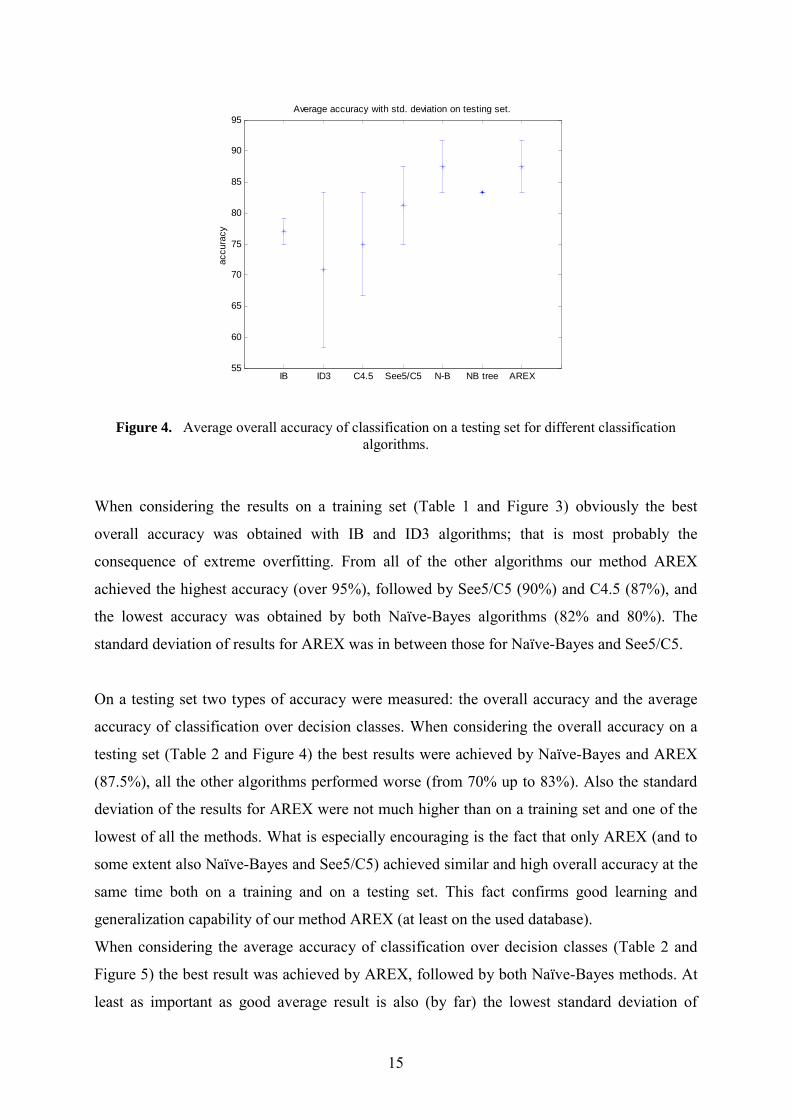
overall accuracy [%] accuracy on classes [%] Algorithm average stddev average stddev
IB 77.08 2.08 74.72 31.93 ID3 70.83 12.50 62.67 30.77 C4.5 75.00 8.33 64.56 33.20 C5/See5 81.25 6.25 69.72 34.03 Naïve-Bayes 87.50 4.17 83.89 25.87 NB tree 83.33 0.00 80.56 24.91 AREX 87.50 4.17 86.39 14.93
15
IB ID3 C4.5 See5/C5 N-B NB tree AREX55
60
65
70
75
80
85
90
95
accu
racy
Average accuracy with std. deviation on testing set.
Figure 4. Average overall accuracy of classification on a testing set for different classification algorithms.
When considering the results on a training set (Table 1 and Figure 3) obviously the best
overall accuracy was obtained with IB and ID3 algorithms; that is most probably the
consequence of extreme overfitting. From all of the other algorithms our method AREX
achieved the highest accuracy (over 95%), followed by See5/C5 (90%) and C4.5 (87%), and
the lowest accuracy was obtained by both Naïve-Bayes algorithms (82% and 80%). The
standard deviation of results for AREX was in between those for Naïve-Bayes and See5/C5.
On a testing set two types of accuracy were measured: the overall accuracy and the average
accuracy of classification over decision classes. When considering the overall accuracy on a
testing set (Table 2 and Figure 4) the best results were achieved by Naïve-Bayes and AREX
(87.5%), all the other algorithms performed worse (from 70% up to 83%). Also the standard
deviation of the results for AREX were not much higher than on a training set and one of the
lowest of all the methods. What is especially encouraging is the fact that only AREX (and to
some extent also Naïve-Bayes and See5/C5) achieved similar and high overall accuracy at the
same time both on a training and on a testing set. This fact confirms good learning and
generalization capability of our method AREX (at least on the used database).
When considering the average accuracy of classification over decision classes (Table 2 and
Figure 5) the best result was achieved by AREX, followed by both Naïve-Bayes methods. At
least as important as good average result is also (by far) the lowest standard deviation of
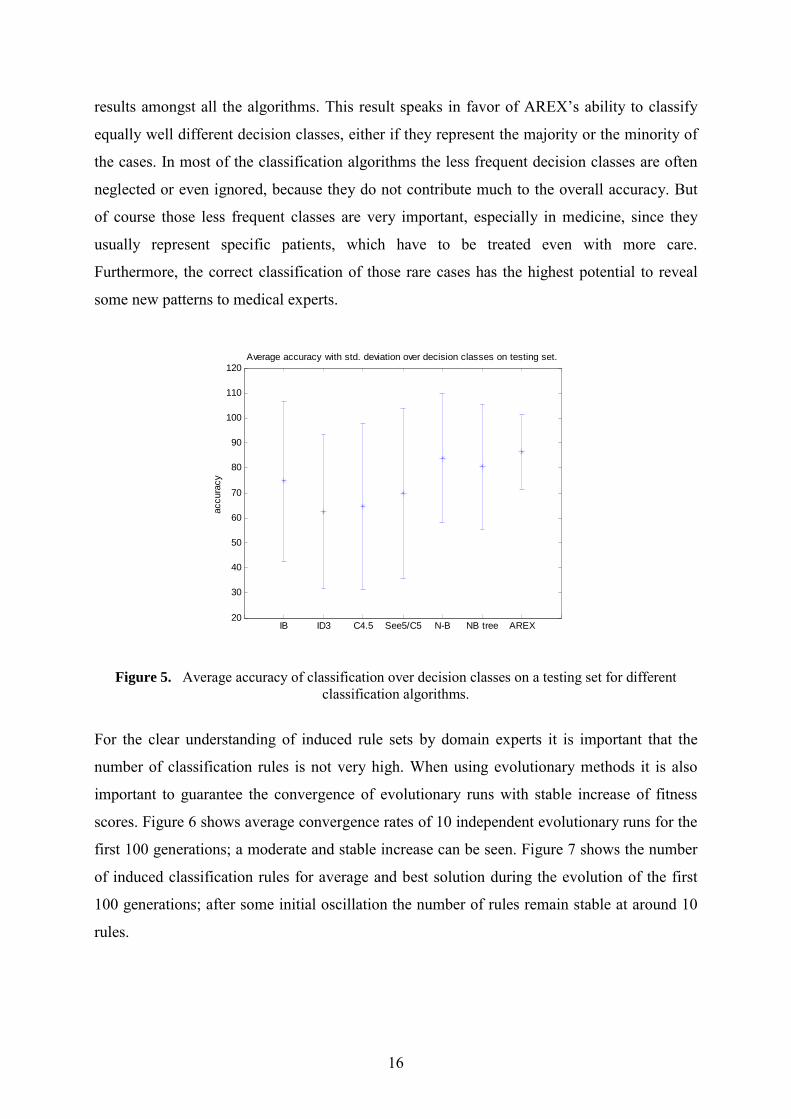
16
results amongst all the algorithms. This result speaks in favor of AREX’s ability to classify
equally well different decision classes, either if they represent the majority or the minority of
the cases. In most of the classification algorithms the less frequent decision classes are often
neglected or even ignored, because they do not contribute much to the overall accuracy. But
of course those less frequent classes are very important, especially in medicine, since they
usually represent specific patients, which have to be treated even with more care.
Furthermore, the correct classification of those rare cases has the highest potential to reveal
some new patterns to medical experts.
IB ID3 C4.5 See5/C5 N-B NB tree AREX20
30
40
50
60
70
80
90
100
110
120
accu
racy
Average accuracy with std. deviation over decision classes on testing set.
Figure 5. Average accuracy of classification over decision classes on a testing set for different classification algorithms.
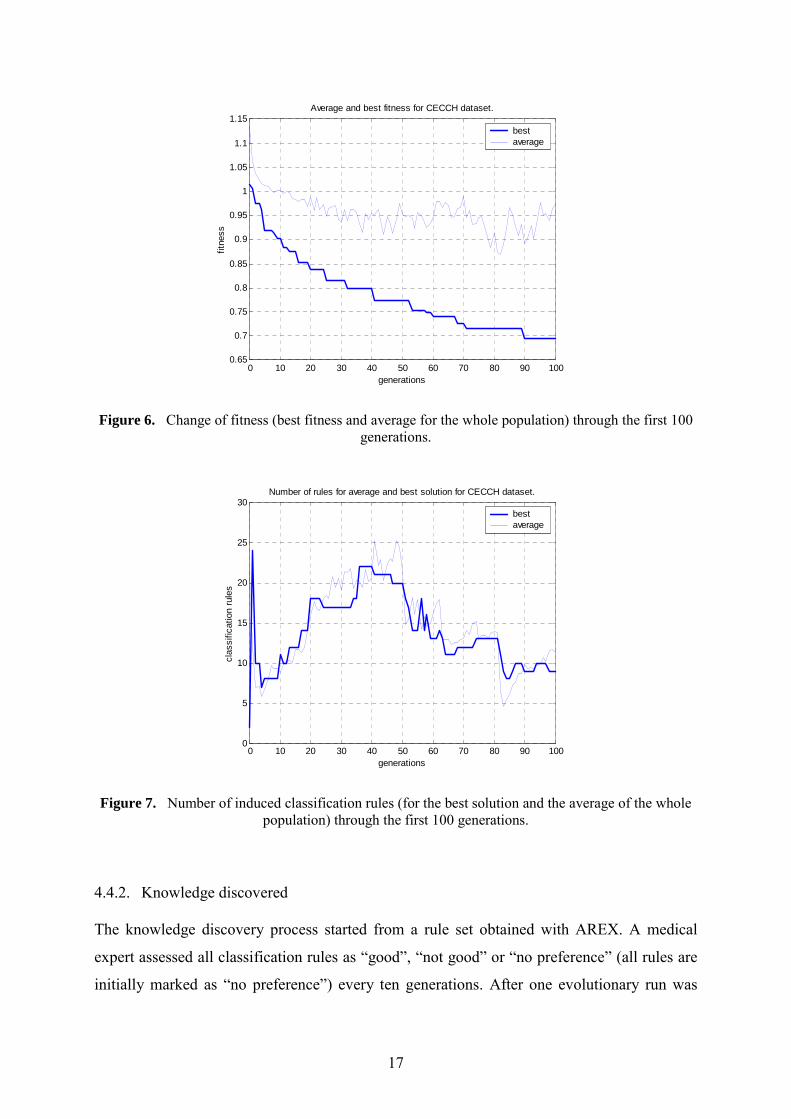
For the clear understanding of induced rule sets by domain experts it is important that the
number of classification rules is not very high. When using evolutionary methods it is also
important to guarantee the convergence of evolutionary runs with stable increase of fitness
scores. Figure 6 shows average convergence rates of 10 independent evolutionary runs for the
first 100 generations; a moderate and stable increase can be seen. Figure 7 shows the number
of induced classification rules for average and best solution during the evolution of the first
100 generations; after some initial oscillation the number of rules remain stable at around 10
rules.
17
0 10 20 30 40 50 60 70 80 90 1000.65
0.7
0.75
0.8
0.85
0.9
0.95
1
1.05
1.1
1.15
generations
fitne
ss
Average and best fitness for CECCH dataset.
bestaverage
Figure 6. Change of fitness (best fitness and average for the whole population) through the first 100
generations.
0 10 20 30 40 50 60 70 80 90 1000
5
10
15
20
25
30
generations
clas
sific
atio
n ru
les
Number of rules for average and best solution for CECCH dataset.
bestaverage
Figure 7. Number of induced classification rules (for the best solution and the average of the whole
population) through the first 100 generations.
4.4.2. Knowledge discovered The knowledge discovery process started from a rule set obtained with AREX. A medical
expert assessed all classification rules as “good”, “not good” or “no preference” (all rules are
initially marked as “no preference”) every ten generations. After one evolutionary run was

18
finished, the process started again from the induction of an initial rule set, but keeping all the
marks about specific rules (good and not good). The whole process was repeated 7 times
(when the base of good rules remained stable). Some interesting patterns have been
discovered, which should provide some information on how the diagnosis of the
cardiovascular problems can be made. The most important result is the rule, presented on
Figure 8 together with the medical expert’s comment on the rule; it has been assessed by the
expert as “possible rule – potentially containing new knowledge”. The discovering of this rule
speaks in favor of our hypothesis that new patterns can be found in the cardiovascular data
with the use of AREX.
Rule: IF Stenocardy = no RR_Diastolic <= 55 ECHO = Pathological THEN class 1
Possible rule – potentially new knowledge How the hemodynamic changes in patients with congenital heart disease with left to right shunt influence to the possible changes of systemic arterial blood pressure?
Figure 8. The most important rule found by AREX. It has been assessed by a medical expert as
potentially containing new medical knowledge.
5. CONCLUSION
There are some specifics in the classification of medical data. The overall accuracy of
classification is only one of several important aspects that have to be fulfilled in order to
attract the attention of medical experts for further research on the given problem. Regarding
the classification results of our method AREX upon a cardiovascular database, we can say
that it shows a promising base for other real-world medical data analysis. One of the most
evident advantages of AREX is the simultaneous very good generalization (high and similar
overall accuracy on both training and testing set) and specialization capability (high and very
similar accuracy of all decision classes, also the least frequent ones).
Also the knowledge discovery results on cardiovascular data, obtained with the presented
approach to knowledge discovery with the help of physicians’ assessment, turned out to be
very good. The physician’s evaluation of the final solution – a set of rules obtained through an
iterative rule induction process – shows that our method AREX produces mostly correct and
reliable rules. What is especially important is the fact that between the rules in the induced

19
rule set there is a rule showing a potential to be new knowledge. We may say that the
obtained results satisfy our intentions and, more importantly, equip the physicians with a
powerful technique to 1) confirm their existing knowledge about some medical problem, and
2) enable searching for new facts, which should reveal some new interesting patterns and
possibly improve the existing medical knowledge.
One of the patterns we were able to discover with the combination of AREX and MtDeciT, a
tool for the induction of decision trees developed in our laboratory [34], showed the possible
relation between the operation under a general anesthesia and arrhythmias even months after
the operation. At the 37th Annual Scientific Meeting of the AEPC (Association for Pediatric
Cardiology in Europe) professor Marie-Christine Seghaye in her state of the art lecture [35]
presented almost the same conclusion, as the result of a very comprehensive and expensive
European Union founded research project.
REFERENCES [1] S.R. Hedberg, The Data Gold Rush, Byte, (October 1995).
[2] R.L. Grossman, Data Mining: Challenges and Opportunities for Data Mining During the Next Decade, Technical Report, (Laboratory for Advanced Computing, University of Illinois at Chicago, 1997).
[3] S.M. Weiss and N. Indurkhya, Predictive Data Mining: A Practical Guide, (Morgan-Kaufmann, 1998).
[4] R.D. Small, H.A. Edelstein, Building, Using and Managing the Data Warehouse, chapter Scalable Data Mining, pp. 151-172 (Prentice Hall, 1997).
[5] C.M. Bishop, Neural Network for Pattern Recognition (Oxford University Press, 1995).
[6] R.B. Macy, A.S. Pandya, Pattern Recognition with Neural Networks in C++, (CRC Press, 1996).
[7] H. Lu, et al., NeuroRule: A Connectionist Approach to Data Mining, in Proceedings of the 21st Very Large Data Base Conference (1995).
[8] L. Breiman, J.H. Friedman, R.A. Olsen, C.J. Stone, Classification and regression trees, (Wadsworth, USA, 1984).
[9] J.R. Quinlan, C4.5: Programs for Machine Learning, (Morgan Kaufmann, 1993).
[10] K.V.S. Murthy, On Growing Better Decision Trees from Data, PhD dissertation, (Johns Hopkins University, Baltimore, MD, 1997).
[11] V. Podgorelec, P. Kokol, B. Stiglic, I. Rozman, Decision trees: an overview and their use in medicine, Journal of Medical Systems, 26(5), pp. 445-463 (2002).
[12] D.E. Goldberg, Genetic algorithms in search, optimization and machine learning, (Addison Wesley, 1989).

20
[13] J.H. Holland, J.S. Reitman, Cognitive systems based on adaptive algorithms, Pattern-directed inference systems, (Academic Press, New York, 1978).
[14] S.F. Smith, Flexible learning of problem solving heuristics through adaptive search, in Proceedings of the 8th International Joint Conference on Artificial Intelligence, pp. 422-425 (1983).
[15] P.L. Lanzi, W. Stolzmann, S.W. Wilson (eds.), Learning Classifier Systems: From Foundations to Applications, Lecture Notes in Artificial Intelligence, vol. 1813, (Springer-Verlag, 2000).
[16] K.A. DeJong, et al., Hybrid learning using genetic algorithms and decision trees for pattern classification, in Proceedings of the IJCAI Conference (1995).
[17] P.D. Turney, Cost-sensitive classification: empirical evaluation of a hybrid genetic decision tree induction algorithm, Journal of Artificial Intelligence Research, 2, pp. 369-409 (1995).
[18] A. Papagelis, D. Kalles, Breeding decision trees using evolutionary techniques, in Proceedings of the ICML’01 (2001).
[19] V. Podgorelec, P. Kokol, Evolutionary induced decision trees for dangerous software modules prediction, Information Processing Letters, 82(1), pp. 31-38 (2002).
[20] V. Podgorelec, P. Kokol, Towards more optimal medical diagnosing with evolutionary algorithms, Journal of Medical Systems, 25(3), pp. 195-220 (2001).
[21] A.A. Freitas, A survey of evolutionary algorithms for data mining and knowledge discovery, in Advances in Evolutionary Computation , eds. A. Ghosh and S. Tsutsui, pp. 819-845, (Springer-Verlag, 2002).
[22] J. Han and M. Kamber, Data Mining: Concepts and Techniques, (Morgan Kaufmann Publishers, 2000).
[23] V. Podgorelec and P. Kokol, Evolutionary decision forests – decision making with multiple evolutionary constructed decision trees, in Problems in Applied Mathematics and Computational Intelligence, pp. 97-103 (WSES Press, 2001).
[24] V. Podgorelec, ProGenesys – program generation tool based on genetic systems, in Proceedings of the ICAI’99, pp. 299-302 (1999).
[25] F. Gruau, On using syntactic constraints with genetic programming, in Advances in Genetic Programming II, pp. 377-394, (MIT Press, 1996).
[26] P.A. Whigham, Inductive Bias and Genetic Programming, in IEE Conference Proceedings 414, pp. 461-466 (1995).
[27] C. Ryan, Shades – a polygenic inheritance scheme, in Proceedings of Mendel'97 Conference, pp. 140-147 (1997).
[28] A. Geyer-Schulz and W. Böhm, Exact uniform initialization for genetic programming, Foundations of Genetic Algorithms 4 (1996).
[29] H. Hörner, A C++ class library for genetic programming, M.Sc. thesis, (Vienna University of Economics, 1996).
[30] A. Rattle, M. Sebag, Genetic programming and domain knowledge: beyond the limitations od grammar-guided machine discovery, in Parallel Problem Solving from Nature VI, pp. 211-220, (Springer Verlag, 2000).

21
[31] C. Anglano, A. Giordana, G. Lo Bello, L. Saitta, An experimental evaluation of coevolutive concept learning, in Proceedings of the International Conference on Machine Learning ICML98, pp. 19-27 (1998).
[32] −, RuleQuest Research Data Mining Tools, http://www.rulequest.com, (2001).
[33] ⎯, Machine Learning in C++, MLC++ library, http://www.sgi.com/tech/mlc, (2001). [34] M. Zorman, S. Hleb, M. Sprogar, Advanced tool for building decision trees MtDeciT
2.0, in Proceedings of the ICAI’99, pp. 315-318 (1999).
[35] M.-C. Seghaye, Impact of the inflammatory reaction on organ dysfunction after cardiac surgery, in Cardiology for the young, (Association for European Paediatric Cardiology, XXXVII Annual Meeting, 2002).




















