
Intelligent Traffic Management in Next-Generation Networks
36
HAL Id: hal-03546653 https://hal.archives-ouvertes.fr/hal-03546653 Submitted on 28 Jan 2022 HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers. L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés. Intelligent Traffc Management in Next-Generation Networks Ons Aouedi, Kandaraj Piamrat, Benoît Parrein To cite this version: Ons Aouedi, Kandaraj Piamrat, Benoît Parrein. Intelligent Traffc Management in Next-Generation Networks. Future internet, MDPI, 2022, pp.1-35. 10.3390/fi14020044. hal-03546653
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Intelligent Traffic Management in Next-Generation Networks

HAL Id: hal-03546653https://hal.archives-ouvertes.fr/hal-03546653
Submitted on 28 Jan 2022
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
Intelligent Traffic Management in Next-GenerationNetworks
Ons Aouedi, Kandaraj Piamrat, Benoît Parrein
To cite this version:Ons Aouedi, Kandaraj Piamrat, Benoît Parrein. Intelligent Traffic Management in Next-GenerationNetworks. Future internet, MDPI, 2022, pp.1-35. �10.3390/fi14020044�. �hal-03546653�

�����������������
Citation: Aouedi, O.; Piamrat, K.;
Parrein, B. Intelligent Traffic
Management in Next-Generation
Networks. Future Internet 2022, 14, 44.
https://doi.org/10.3390/fi14020044
Academic Editor: Paolo Bellavista
Received: 31 December 2021
Accepted: 21 January 2022
Published: 28 January 2022
Publisher’s Note: MDPI stays neutral
with regard to jurisdictional claims in
published maps and institutional affil-
iations.
Copyright: © 2022 by the authors.
Licensee MDPI, Basel, Switzerland.
This article is an open access article
distributed under the terms and
conditions of the Creative Commons
Attribution (CC BY) license (https://
creativecommons.org/licenses/by/
4.0/).
future internet
Review
Intelligent Traffic Management in Next-Generation Networks
Ons Aouedi * , Kandaraj Piamrat * and Benoît Parrein
LS2N—Laboratoire des Sciences du Numérique de Nantes, Université de Nantes, 44000 Nantes, France;[email protected]* Correspondence: [email protected] (O.A.); [email protected] (K.P.)
Abstract: The recent development of smart devices has lead to an explosion in data generationand heterogeneity. Hence, current networks should evolve to become more intelligent, efficient,and most importantly, scalable in order to deal with the evolution of network traffic. In recentyears, network softwarization has drawn significant attention from both industry and academia,as it is essential for the flexible control of networks. At the same time, machine learning (ML)and especially deep learning (DL) methods have also been deployed to solve complex problemswithout explicit programming. These methods can model and learn network traffic behavior usingtraining data/environments. The research community has advocated the application of ML/DL insoftwarized environments for network traffic management, including traffic classification, prediction,and anomaly detection. In this paper, we survey the state of the art on these topics. We start bypresenting a comprehensive background beginning from conventional ML algorithms and DL andfollow this with a focus on different dimensionality reduction techniques. Afterward, we presentthe study of ML/DL applications in sofwarized environments. Finally, we highlight the issues andchallenges that should be considered.
Keywords: machine learning; deep learning; networking; software-defined networking; resourcemanagement; feature selection; feature extraction; deep neural network; network traffic
1. Introduction
According to the latest Cisco forecast, by 2022, the number of devices connected to mo-bile networks will largely exceed the world’s population, reaching 12.3 billion [1]. This hugenumber of smart devices has made the Internet widely used and has, accordingly, triggereda surge in traffic and applications. This, in turn, has made network architecture highlyresource-hungry and can create significant challenges for network operators. Therefore, itis not possible for network administrators to manage the network manually by processinga large amount of data accurately in a reasonable response time [2]. Consequently, thisrequires ultra-efficient, fast, and autonomous resource management approaches. In thiscontext, machine learning (ML) offers these benefits, since it can find a useful pattern fromdata in a reasonable period of time and eventually allows the network operator to analyzethe traffic and gain knowledge out of it. Network traffic analysis includes network trafficclassification, network traffic prediction using time-series data, and intrusion detectionsystems. Understanding network behavior can improve performance, security, quality ofservice (QoS) and help avoid violation of SLA (service-level agreements). For example,load traffic prediction plays an important role in network management, such as short- andlong-term resource allocation (e.g., bandwidth), anomaly detection, and traffic routing.
To achieve the intelligent management of networks and services in the software-defined networking (SDN) environment, ML methods can be used. A centralized SDNcontroller has a global network view which facilitates the collection of the network traffic.Several researchers argue that, with the introduction of SDN, there is a high potential forcollecting data from forwarding devices, which need to be handled by ML due to theircomplexity [2,3]. Mestres et al. [3] presented a new paradigm that combines ML and SDN
Future Internet 2022, 14, 44. https://doi.org/10.3390/fi14020044 https://www.mdpi.com/journal/futureinternet

Future Internet 2022, 14, 44 2 of 35
which is called knowledge-defined networking (KDN). This architecture consists of knowl-edge, controller, and data planes in order to produce an automatic and intelligent process ofnetwork control. The adoption of ML with SDN for network management is an interestingarea that requires further exploration (i.e., network slicing, traffic prediction). In addition,the availability of low-cost storage from the Cloud, edge computing, and the computer’sevolution provide the high processing capabilities needed for training/testing ML and DLalgorithms. Therefore, the combination of machine learning with SDN creates high-qualityevidence in network traffic management. In this context, we provide a thorough overviewof the research works in this area to gain deep insight into the significant role of ML/DLalgorithms in the SDN environment.
1.1. Related Work
Driven by the recent advances in ML/DL in network traffic management, many stud-ies have been conducted to survey the works on this domain. For example, Xie et al. [4]have provided a comprehensive survey of ML techniques applied to SDN. Different typesof ML/DL algorithms and their applications in the SDN environment are presented. Nev-ertheless, they did not review the traffic prediction application. Additionally, the paperlacks several recent approaches as well as a dataset in the literature review.
Latah and Toker [5] briefly reviewed the application of AI with SDN. Then, in [6], theypresented an extensive overview of AI techniques that have been used in the context ofSDN. Additionally, Zhao et al. [7] surveyed ML/DL algorithms and their applications inthe SDN environment. However, these papers categorized the reviewed contribution basedon the ML model (e.g., supervised, unsupervised) and not by the use case.
A review on the approaches of traffic classification in software-defined wirelesssensor networks (SDWSN) using ML has been presented in [8]. Mohammed et al. [9]briefly surveyed traffic classification and traffic prediction using ML in SDN. Moreover,Boutaba et al. [10] proposed a survey of the ML-based methods applied to fundamentalproblems in networking. In addition, a survey of SDN-based network intrusion detectionsystems using ML/DL approaches is presented in [11]. Nguyen et al. [12] proposed asurvey on different security challenges related to the application of ML/DL in an SDNenvironment. As the main difference, these papers did not cover all the network trafficmanagement applications in one paper. Furthermore, the research challenges in our paperare significantly different than those papers.
Table 1 summarizes existing survey articles with similar topics as ours. We categorizethese papers into (i) overviews of deep learning, (ii) overviews of other machine learningalgorithms, (iii) reviews of dimensionality reduction methods, and (iv) reviews of works atthe intersection between DL/ML and SDN. The previous surveys have focused on ML/DLapproaches in the SDN environment. However, they did not cover the traffic analysisapplications like traffic classification, prediction, and anomaly detection. Additionally,they are lacking some new approaches. such as federated learning. In addition, while DLhas the ability to learn features automatically, conventional ML algorithms try to extractknowledge from a set of features or attributes, but they do not have the capability to extractthese features automatically. Therefore, choosing the appropriate features to be used withML models is a predominant challenge. In this context, one important objective of thispaper is to provide an overview ranging from dimensionality reduction and machinelearning techniques to deep learning used in the SDN environment. Then, we explorethe network traffic management/analysis that has benefited from ML/DL algorithms andSDN architecture.
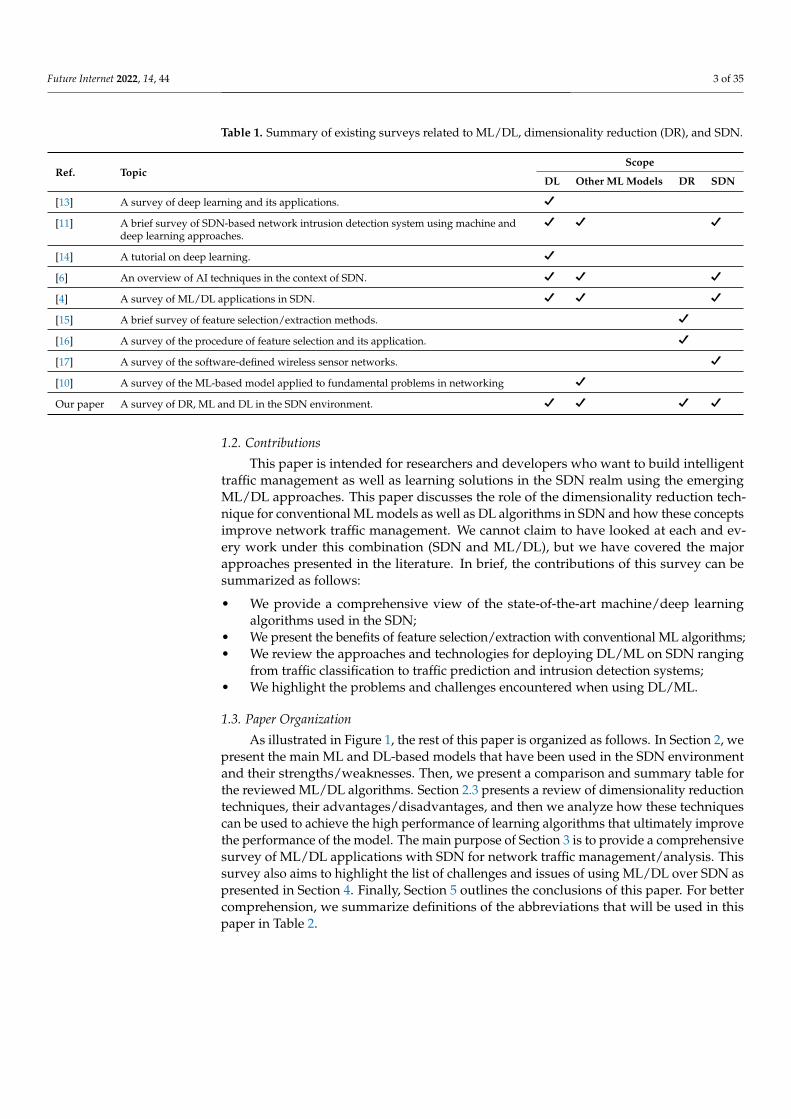
Future Internet 2022, 14, 44 3 of 35
Table 1. Summary of existing surveys related to ML/DL, dimensionality reduction (DR), and SDN.
Ref. TopicScope
DL Other ML Models DR SDN
[13] A survey of deep learning and its applications. D[11] A brief survey of SDN-based network intrusion detection system using machine and
deep learning approaches.D D D
[14] A tutorial on deep learning. D[6] An overview of AI techniques in the context of SDN. D D D[4] A survey of ML/DL applications in SDN. D D D[15] A brief survey of feature selection/extraction methods. D[16] A survey of the procedure of feature selection and its application. D[17] A survey of the software-defined wireless sensor networks. D[10] A survey of the ML-based model applied to fundamental problems in networking DOur paper A survey of DR, ML and DL in the SDN environment. D D D D
1.2. Contributions
This paper is intended for researchers and developers who want to build intelligenttraffic management as well as learning solutions in the SDN realm using the emergingML/DL approaches. This paper discusses the role of the dimensionality reduction tech-nique for conventional ML models as well as DL algorithms in SDN and how these conceptsimprove network traffic management. We cannot claim to have looked at each and ev-ery work under this combination (SDN and ML/DL), but we have covered the majorapproaches presented in the literature. In brief, the contributions of this survey can besummarized as follows:
• We provide a comprehensive view of the state-of-the-art machine/deep learningalgorithms used in the SDN;
• We present the benefits of feature selection/extraction with conventional ML algorithms;• We review the approaches and technologies for deploying DL/ML on SDN ranging
from traffic classification to traffic prediction and intrusion detection systems;• We highlight the problems and challenges encountered when using DL/ML.
1.3. Paper Organization
As illustrated in Figure 1, the rest of this paper is organized as follows. In Section 2, wepresent the main ML and DL-based models that have been used in the SDN environmentand their strengths/weaknesses. Then, we present a comparison and summary table forthe reviewed ML/DL algorithms. Section 2.3 presents a review of dimensionality reductiontechniques, their advantages/disadvantages, and then we analyze how these techniquescan be used to achieve the high performance of learning algorithms that ultimately improvethe performance of the model. The main purpose of Section 3 is to provide a comprehensivesurvey of ML/DL applications with SDN for network traffic management/analysis. Thissurvey also aims to highlight the list of challenges and issues of using ML/DL over SDN aspresented in Section 4. Finally, Section 5 outlines the conclusions of this paper. For bettercomprehension, we summarize definitions of the abbreviations that will be used in thispaper in Table 2.

Future Internet 2022, 14, 44 4 of 35
Figure 1. Conceptual map of survey.
Table 2. List of abbreviations.
Acronym Definition Acronym Definition
SDN Software-defined networking MLP Multi-layer perceptronSDWSN Software-defined wireless sensor networks CNN Convolutional neural networkML Machine learning LSTM Long short-term memoryDL Deep learning MVNO Mobile virtual network operatorKDN Knowledge-defined networking AE AutodncoderAI Artificial intelligence DR Dimensionality reductionQoS Quality of service QoE Quality of experienceANN Artificial neural network RL Reinforcement learningONF Open network foundation OF OpenFlowNFV Network function virtualisation FL Federated learningDBN Deep belief network DRL Deep Reinforcement LearningGRU Gated recurrent units NGMN Next Generation Mobile Networks
2. Machine Learning
ML [18–20] is a branch of artificial intelligence (AI). Arthur Samuel was among the firstresearchers who applied machine learning to teach a computer to improve playing checkersbased on training with a human counterpart in 1959. The increase in the amount of datamade the ML algorithms popular in the 1990s. Nowadays, it is an emerging area that attractsthe attention of academia and industry; Google, Apple, Facebook, Netflix, and Amazonare investing in ML and using it in their products [21]. Its effectiveness has been validatedin different application scenarios, i.e., healthcare, computer vision, autonomous driving,recommendation systems, network traffic management, etc. It addresses the question ofhow to build a computer system that improves automatically through experience [19]. MLalgorithms try to automate the process of knowledge extraction from training data to makepredictions of unseen data. For example, historical traffic data are used to improve trafficclassification and reduce congestion. In other words, ML models generally proceed in twophases: (1) in the training process, a training set is used to construct a model; (2) this modelis then applied to predict or classify the unseen data. Therefore, the main idea of ML is togeneralize beyond the examples in the training set and can be thought of as “programmingby example”. Hence, it is an intelligent method used to automatically improve performancethrough experience. Mitchell [20] defined ML by saying, “A computer program is said to learnfrom experience E with respect to some class of tasks T and performance measure P, if its performanceat tasks in T, as measured by P, improves with experience E”.
The adoption of ML and DL approaches increased thanks to the computer’s evolu-tion, which has provided us with processing capabilities needed for training/testing theirmodels, the availability of large datasets, and the cost-effectiveness of storage capabili-ties. In addition, the availability of open-source libraries and frameworks causes rapiddiffusion within the research community and in our daily life. ML/DL algorithms can

Future Internet 2022, 14, 44 5 of 35
be implemented in various platforms and languages such as Weka (does not include DLalgorithms), R, and Python. Python is one of the most popular environments for ML/DL asit provides various libraries to developers. Additionally, its simplicity helps developers tosave more time, as they only require concentrating on solving the ML/DL problems ratherthan focusing on the technicality of language. The most commonly used tool for classicalmachine learning implementation is scikit-learn [22]. Scikit-learn is an open-source MLlibrary (e.g., Matplotlib, Pandas) and is not specific to DL. It covers all data mining stepsfrom preprocessing to classification, regression, and clustering.
Within the field of machine learning, a broad distinction could be made betweensupervised, unsupervised, semi-supervised, and reinforcement learning (RL). The strengthsand weaknesses of these learning approaches are presented in Table 3.
• Supervised learning
This type of learning process is the most commonly used. It operates when an objectneeds to be assigned into a predefined class based on several observed features related tothat object [23]. Therefore, supervised learning tries to find model parameters that bestpredict the data based on a loss function L(y, y). Here, y is our output variable, and yrepresents the output of the model obtained by feeding a data point x (input data) tothe function F that represents the model. Classification and regression are examples ofsupervised learning: in classification, the outputs take discrete values; this is one of themost widely used methods. In regression, a learning function maps the data into a real-value variable (the outputs are continuous values). Binary, multi-class, and multi-labeledclassification are the three approaches of classification [24]. In binary classification, onlytwo possible classes, for example, classify the traffic as “attack” or “normal”. Multi-classclassification implies that the input can be classified into only one class within a pool ofclasses, such as classifying the traffic as “Chat”, “Streaming”, and “Game”. Multi-labeledclassification allows the classification of an input sample into more than one class in the poolof classes, like classifying the traffic as “Skype” and the traffic type as “Video”. Classificationexamples include decision tree, support vector machine (SVM), and neural networks, whilefor regression, we have support vector regression (SVR), linear regression, and neuralnetworks. In addition, an ensemble of different learning algorithms was developed toproduce a superior accuracy than any single algorithm like random forest and boostingmethods [25];
• Unsupervised learning
With the increasing size and complexity of data, unsupervised learning can be onepromising solution. It has the ability to find a relationship between the instances withouthaving any prior knowledge of target features. Specifically, unsupervised learning examinesthe similarity between the instances in order to categorize them into distinctive clusters.The instances within the same cluster have a greater similarity as compared to the instancesin other clusters [26];
• Semi-supervised learning
As the name implies, semi-supervised learning combines both supervised and un-supervised learning to get benefits from both approaches. It attempts to use unlabeleddata as well as labeled data to train the model, contrary to supervised learning (data alllabeled) and unsupervised learning (data all unlabeled). As labeling data (e.g., networktraffic) is difficult, requires human effort, and is time-consuming to obtain, especially fortraffic classification and attack detection, semi-supervised learning tries to minimize theseproblems, as it uses a few labeled examples with a large collection of unlabeled data [27]. Itis an appropriate method when large amounts of labeled data are unavailable. That is why,in the last few years, there has been a growing interest in semi-supervised learning in thescientific community, especially for traffic classification [28];
• Reinforcement learning (RL)

Future Internet 2022, 14, 44 6 of 35
The main idea of reinforcement learning was inspired by biological learning systems.It is different from supervised and unsupervised learning; instead of trying to find a patternor learning from a training set of labeled data, the only source of data for RL is the feedbacka software agent receives from its environment after executing an action [29]. That is why itis considered as a fourth machine learning approach alongside supervised, unsupervised,and semi-supervised learning. In addition, RL is defined by the provision of the trainingdata by the environment. In other words, it is a technique that allows an agent to learnits behavior by interacting with its environment. Three important elements construct thislearning approach, namely observations, reward, and action. Therefore, the software agentmakes observations and executes actions within an environment, and receives rewardsin return. The agent’s job is to maximize cumulative reward. The most well-knownreinforcement learning technique is Q-learning [30], and it is widely used for routing [31,32].Moreover, deep learning has been used to improve the performance of RL algorithms (i.e.,allows reinforcement learning to be applied to larger problems). Therefore, the combinationof DL and RL gives the so-called DRL. DRL began in 2013 with Google Deep Mind [33].A good survey that presents RL and DRL approaches is available in [34] for more details.
Table 3. Comparison of ML approaches.
Method Strengths Weaknesses
Supervisedlearning Low computational cost, fast, scalable
Requires data labeling and datatraining, behaves poorly with highlyimbalanced data
Unsupervisedlearning
Requires only the data samples, can detectunknown patterns, generates labeling data Cannot give precise information
Semi-supervisedlearning
Learns from both labeled andunlabeled data
May lead to worse performance when wechoose the wrong rate of unlabeled data
Reinforcementlearning
Can be used to solve complex problems,efficient when the only way to collectinformation about the environment is tointeract with it
Slow in terms of convergence, needs a lotof data and a lot of computation
In Section 2.1, a synthesis of DL architecture and models is presented, followed byan overview of conventional ML models as well as feature reduction techniques. We onlyfocus on the algorithms that have been used in the SDN environment and that are presentedin Section 3.
2.1. Deep Learning
Deep learning (DL), also known as deep neural networks (DNN) represents one of themost active areas of AI research [13]. It is a branch of ML that evolved from neural network(NNs) which enables an algorithm to make predictions or classifications based on largedatasets without being explicitly programmed. In many domains, DL algorithms are ableto exceed human accuracy. Using conventional ML-based models requires some featureengineering tasks like feature selection [35], which is not the case with DL models, as thesecan hierarchically extract knowledge automatically from raw data by stacked layers [23].
The major benefits of DL over conventional ML models are its superior performancefor large datasets [36] and the integration of feature learning and model training in onearchitecture, as illustrated in Figure 2. Therefore, it helps to avoid human intervention andtime-wasting as maximum as possible. In the literature, DL has also been referred to asdeep structured learning, hierarchical learning, and deep feature learning [37]. This deeparchitecture enables DL to perform better than conventional ML algorithms; accordingly,DL can learn highly complicated patterns. It uses supervised and unsupervised learning tolearn high-level features for the tasks of classification and pattern recognition. Several DLalgorithms are presented in Table 4. The growing popularity of DL inspired several compa-nies, and open-source initiatives have developed powerful DL libraries and frameworks

Future Internet 2022, 14, 44 7 of 35
that can be used to avoid building models from scratch [38]. Many libraries have appeared,and we summarize the most popular ones in Table 5.
DL is capable of learning high-level features better than shallow neural networks.Shallow ANN contains very few hidden layers (i.e., with one hidden layer) while DLcontains many more layers (deep). Each hidden layer comprises a set of learning unitscalled neurons. These neurons are organized in successive layers, and every layer takes asinput the output produced by the previous layer, except for the first layer, which consumesthe input.
Table 4. Summary of different deep learning models used in SDN.
Method Learning Model Description Strengths Weaknesses
MLP Supervised,unsupervised
MLP is a simple artificial neural network (ANN)which consists of three layers. The first layer is theinput layer. The second layer is used to extractfeatures from the input. The last layer is the outputlayer. The layers are composed of several neurons.
Easy to implement.Modest performance, slowconvergence, occupies alarge amount of memory.
AE Unsupervised
Autoencoder consists of three parts: (i) encoder,(ii) code, and (iii) decoder blocks. The encoderconverts the input features into an abstraction,known as a code. Using the code, the decoder triesto reconstruct the input features. It uses somenon-linear hidden layers to reduce theinput features.
Works with big andunlabeled data, suitable forfeature extraction and usedin place of manualengineering.
The quality of featuresdepends model architectureand its hyperparameters,hard to find the codelayer size.
CNN Supervised,Unsupervised
CNN is a class of DL which consists of a numberof convolution and pooling (subsampling) layersfollowed by a fully connected layers. Pooling andconvolution layers are used to reduce thedimensions of features and find useful patterns.Next, fully connected layers are used forclassification. It is widely used for imagerecognition applications.
Weight sharing, extractsrelevant features, highcompetitive performance.
High computational cost,requires large trainingdataset and high number ofhyperparameter tuning toachieve optimal features.
LSTM Supervised
LSTM is an extension of recurrent neural network(RNNs) and was created as the solution toshort-term memory. It has internal mechanismscalled gates (forget gate, input gate, and outputgate) that can learn which data in a sequence isimportant to keep or throw away. Therefore, itchooses which information is relevant toremember or forget during sequence processing.
Good for sequentialinformation, works wellwith long sequences.
High model complexity,high computational cost.
GRU Supervised
GRU was proposed in 2014. It is similar to LSTMbut has fewer parameters. It works well withsequential data, as does LSTM. However, unlikeLSTM, GRU has two gates, which are the updategate and reset gate; hence, it is less complex.
Computationally moreefficient than LSTM.
Less efficient in accuracythan LSTM.
DRL Reinforcement
DRL takes advantage of both DL and RL to beapplied to larger problems. In others word, DLenables RL to scale to decision-making problemsthat were previously intractable.
Scalable (i.e., can learn amore complex environment). Slow in terms of training.
DBN Unsupervised,supervised
DBN is stacked by several restricted Boltzmannmachines. It takes advantage of the greedylearning process to initialize the model parametersand then fine-tunes the whole model usingthe label.
Training is unsupervised,which removes the necessityof labelling data for trainingor properly initializing thenetwork, which can avoidthe local optima, extractingrobust features.
High computational cost.
Future Internet 2022, 14, 44 8 of 35
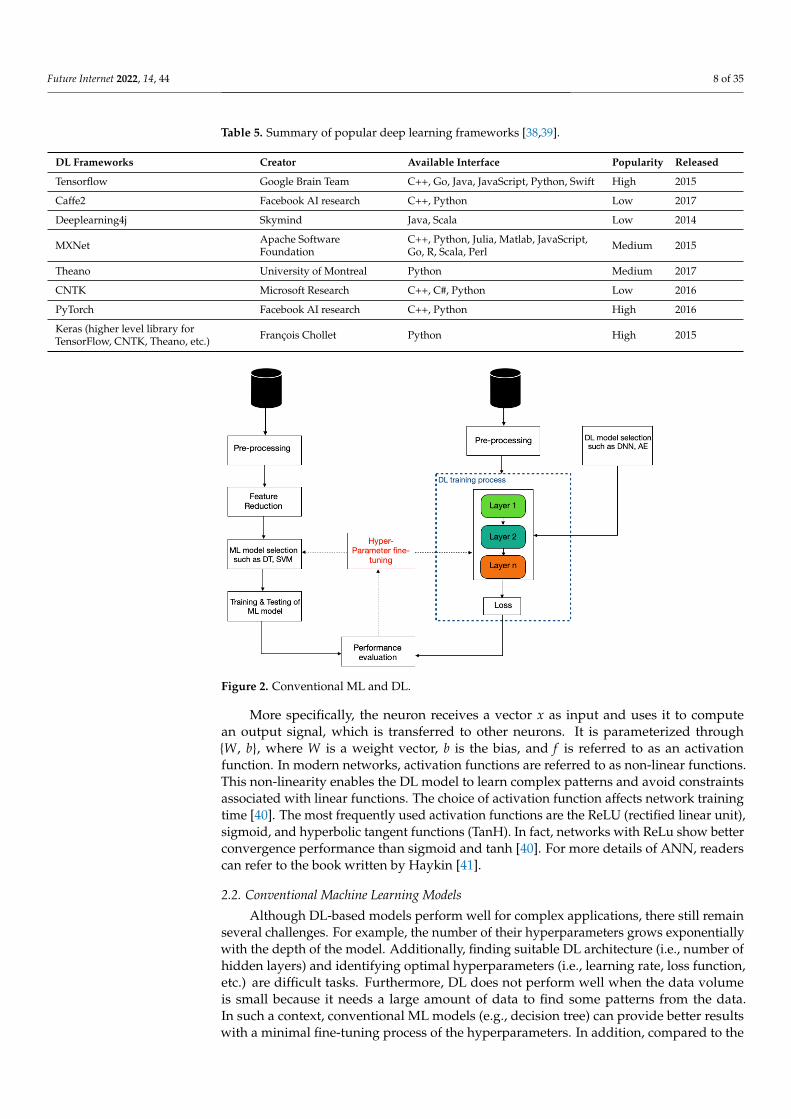
Table 5. Summary of popular deep learning frameworks [38,39].
DL Frameworks Creator Available Interface Popularity Released
Tensorflow Google Brain Team C++, Go, Java, JavaScript, Python, Swift High 2015
Caffe2 Facebook AI research C++, Python Low 2017
Deeplearning4j Skymind Java, Scala Low 2014
MXNet Apache SoftwareFoundation
C++, Python, Julia, Matlab, JavaScript,Go, R, Scala, Perl Medium 2015
Theano University of Montreal Python Medium 2017
CNTK Microsoft Research C++, C#, Python Low 2016
PyTorch Facebook AI research C++, Python High 2016
Keras (higher level library forTensorFlow, CNTK, Theano, etc.) François Chollet Python High 2015
Figure 2. Conventional ML and DL.
More specifically, the neuron receives a vector x as input and uses it to computean output signal, which is transferred to other neurons. It is parameterized through{W, b}, where W is a weight vector, b is the bias, and f is referred to as an activationfunction. In modern networks, activation functions are referred to as non-linear functions.This non-linearity enables the DL model to learn complex patterns and avoid constraintsassociated with linear functions. The choice of activation function affects network trainingtime [40]. The most frequently used activation functions are the ReLU (rectified linear unit),sigmoid, and hyperbolic tangent functions (TanH). In fact, networks with ReLu show betterconvergence performance than sigmoid and tanh [40]. For more details of ANN, readerscan refer to the book written by Haykin [41].
2.2. Conventional Machine Learning Models
Although DL-based models perform well for complex applications, there still remainseveral challenges. For example, the number of their hyperparameters grows exponentiallywith the depth of the model. Additionally, finding suitable DL architecture (i.e., number ofhidden layers) and identifying optimal hyperparameters (i.e., learning rate, loss function,etc.) are difficult tasks. Furthermore, DL does not perform well when the data volumeis small because it needs a large amount of data to find some patterns from the data.In such a context, conventional ML models (e.g., decision tree) can provide better resultswith a minimal fine-tuning process of the hyperparameters. In addition, compared to the

Future Internet 2022, 14, 44 9 of 35
conventional ML models, DL has a higher computational cost, which makes it hard to beused on machines with a simple CPU.
All this makes the conventional ML models still used. They can be broadly dividedinto two categories: (i) simple (i.e., single) machine models and (ii) ensemble models.The commonly used simple models include, for example, SVM, DT, and KNN, whereasensemble models aim to combine heterogeneous or homogeneous simple models in order toobtain a model that outperforms every one of them and overcomes their limitations [42,43].The ensemble methodology imitates our nature to seek several opinions before makinga decision [44]. Bagging, boosting, and stacked generalization (or simply stacking) arethe most popular ensemble models. Similar to single models, there are no best ensemblemethods, as some ensemble methods work better than others in certain conditions (e.g.,data, features). Several conventional ML methods used with SDN are presented in Table 6.
However, the performance of the conventional ML models depends on the amount andthe quality of features. Moreover, extracting a large number of features from the comingflow in the SDN environment is time-consuming and, in turn, can decrease the QoS of thesystem [45]. To solve these issues, effective pre-processing mechanisms can be applied to filterout the unrelated/noisy data that can reduce the dimensionality of the data.
Table 6. Comparison of classical ML approaches used in SDN.
Method Description Strengths Weaknesses
Decisiontree (DT)
Decision tree is a tree-like structure, where every leaf(terminal) corresponds to a class label and each internalnode corresponds to an attribute. The node at the top ofthe tree is called the root node. Tree splitting uses GiniIndex or Information Gain methods [46].
Simple to understand andinterpret, requires little datapreparation, handles many typesof data (numeric, categorical),easily processesdata withhigh dimension
Generates a complex tree withnumeric data, requireslarge storage
Randomforest (RF)
Random forest was developed nearly 20 years ago [47]and is one of the most popular supervised machinelearning algorithms that is capable to be used forregression and classification. As their name wouldsuggest, random forests are constructed from decisiontrees. It uses the bagging method, which enhancesthe performance.
Efficient against over-fittingRequires a large trainingdataset, impractical forreal-time applications
Supportvectormachine(SVM)
SVM is a powerful classification algorithm which can beused for both regression and classification problems.However, it is mostly used as classification technique. Itwas initially developed for binary classification, but itcould be efficiently extended to multiclass problems. Itcan be a linear and non-linear classifier by creating asplitting hyperplane in original input space to separate thedata points.
Scalable, handles complex dataComputationally expensive,there is no theorem to select theright kernel function
K-nearestneighbour(KNN)
KNN is a supervised model reason with the underlyingprincipal “Tell me who are your friends, I will tell youwho are you” [48]. It classifies new instances using theinformation provided by the K nearest neighbors, so thatthe assigned class will be the most common among them(majority vote). Additionally, as it does not build a modeland no work is done until an unlabeled data patternarrives, it is thus considered as a lazy approach.
Easy to implement, has goodperformance with simpleproblems, non-expert users can useit efficiently
Requires large storage space,determining the optimal valueof K is time consuming, Kvalues varies depending on thedataset, testing is slow,and when the training datasetis large, it is not suitable forreal-time classification
K-means
K-means is a well-known unsupervised model. It canpartition the data into K clusters based on a similaritymeasure, and the observations belonging to the samecluster have high similarity as compared to those ofother clusters.
Fast, simple and less complexRequires a number of cluster inadvance, cannot handlethe outliers
Boostingalgorithms
The main idea of boosting is to improve the performanceof any model, even weak learners (i.e., XGBoost,AdaBoost, etc). The base model generates a weakprediction rule, and after several rounds, the boostingalgorithms improve the prediction performance bycombining the weak rules into a single predictionrule [49].
High accuracy, efficient againstunder-fitting
Computationally expensive,hard to find the optimalparameters

Future Internet 2022, 14, 44 10 of 35
2.3. Feature Reduction
The success of conventional ML algorithms generally depends on the features to whichthey are applied. In other words, their performance depends not only on the parametersbut also on the features, which are used to describe each object to the ML models [50]. Inthis section, we provide an overview of basic concepts as well as the motivation of thedimensionality reduction technique.
In general, the dataset can contain irrelevant (a feature that provides no useful in-formation) and redundant (a feature with predictive ability covered by another) features,which cause an extra computational cost for both storage and processing in an SDN envi-ronment and decreases the model’s performance [51,52]. For example, the time complexityof many ML algorithms is polynomial in the number of dimensions; for example, the timecomplexity of logistic regression is O(mn2 + n3), where n represents the number of featuresand m represents the number of instances [53]. These challenges are referred to as thecurse of dimensionality, which is one of the most important challenges in ML. The curse ofdimensionality was introduced by Bellman in 1961 [18].
In addition, each model is only as good as the given features. Additionally, the modelaccuracy depends not only on the quality of input data but also on the amount features.The model may perform poorly and can overfit if the number of features is larger than thenumber of observations [54]. Moreover, the low-latency applications (e.g., anomaly detec-tion) require fast analysis, especially in the context of the fifth-generation (5G) networks,and feature reduction can help to leverage heavy analysis at network levels. All these makefeature reduction difficult tasks not only because of the higher size of the initial dataset butbecause it needs to meet two challenges, which are to maximize the learning capacity andto reduce the computational cost and delay by reducing the number of features.
In fact, there are many benefits of feature reduction techniques, such as (i) improvingthe performance of learning algorithms either in terms of learning speed or generalizationcapacity and (ii) reducing the storage requirement. It reduces the original data and retainsas much information as possible that is valuable for the learning process. Therefore, in adataset with a high number of features, the data reduction process is a must to produceaccurate ML models in a reasonable time. It can be divided into feature selection (i.e featureelimination) and feature extraction, as shown in Figure 3. The main difference is thatfeature selection selects a subset of original features, while feature extraction creates newfeatures from the original ones. Table 7 presents the advantages and disadvantages ofeach approach.
Figure 3. The classification of dimensionality reduction approaches.
Each approach can be used in isolation or in a combination way with the aim ofimproving performance, such as the accuracy, visualization, and comprehensibility oflearned knowledge [55]. Rangarajan et al. [56] proposed bi-level dimensionality reductionmethods that combine feature selection methods and feature extraction methods to improveclassification performance. Then, they compared the performance of three-dimensionalityreduction techniques with three datasets. Based on their results, these combinationsimprove the precision, recall, and F-measure of the classifier. Additionally, we can findfeature construction, which is different from the feature reduction technique. It is one of the

Future Internet 2022, 14, 44 11 of 35
preprocessing tasks that tries to increase the expressive power of initial features when theinitial features set do not help us classify our data well enough. It is the process of creatingadditional features instead of reducing the features from the initial features set, beginningwith n features f1, f2, f3, . . . , fn. After feature construction, we will have new p featuresfn+1, fn+2, fn+3, . . . , fn+p.
Table 7. Comparison of dimensionality reduction techniques [16,57].
Method Advantages Disadvantages Methods Potential Application in SDN
Filter Low computational cost, fast,scalable
Ignores the interaction with theclassifier CFS, IG, FCBF QoS prediction [58], traffic
classification [59,60].
Wrapper Competitive classification accuracy,interaction with the classifier
Slow, expensive for large featurespace, risk of over-fitting
Forward/backwarddirection
Traffic classification [61], QoSprediction [58].
Featureextraction
Reduces dimension without loss ofinformation
No information about theoriginal features PCA, LDA, AE Traffic classification [59,62,63].
2.3.1. Feature Selection
The feature selection technique has become an indispensable component of the con-ventional machine learning algorithms (e.g., SVM, decision tree, etc.) [64], and it is oneof the simplest ways to reduce data size. It tries to pick a subset of features that “opti-mally” characterize the target variable. Feature selection is the process of selecting the bestfeatures in a given initial set of features that yield a better classification performance [65]and regression as well as finding clusters efficiently [66]. In this section, we will focuson feature selection for classification since there is much more work on feature selectionfor classification than for other ML tasks (e.g., clustering). The best subset contains theleast number of dimensions that improve the accuracy the most. It helps us to identify therelevant features (contribute to the identification of the output) and discard the irrelevantones from the dataset to perform a more focused and faster analysis. The feature selectionprocess consists of four basic steps, which are:
1. Subset generation is a search procedure that generates candidate feature subsets forevaluation based on a search strategy (i.e., start with no feature or with all features);
2. Evaluation of subset tries to measure the discriminating ability of a feature or a subsetto distinguish the target variables;
3. Stopping criteria determines when the feature selection process should stop (i.e., addi-tion or deletion of any feature does not produce a better subset);
4. Result validation tries to test the validity of the selected features.
Many evaluation criteria have been proposed in several research works to determinethe quality of the candidate subset of the features. Based on their dependency on MLalgorithms, evaluation criteria can be categorized into two groups: independent anddependent criteria [16]. For independent measures, we have (1) information measures,(2) consistency measures, (3) correlation measures, (4) and distance measures; for dependentcriteria, we have several measures, such as accuracy. Therefore, feature selection can bedistinguished into two broad categories, which are filters and wrappers, as explained inthe following.
Filter Method: finds the best feature set by using some independent criteria (i.e., infor-mation measures) before applying any classification algorithm. Due to the computationalefficiency, the filter methods are used to select features from high-dimensional data sets.Additionally, it is categorized as a binary or continuous feature selection method dependingon the data type. For example, information gain (IG) can handle both binary and nominaldata, but the Pearson correlation coefficient can only handle continuous data. Moreover, itcan be further categorized into two groups: feature-weighting algorithms and subset searchalgorithms, which evaluate the quality of the features individually or through featuresubsets. Feature-weighting algorithms give weights to all the features individually andrank them based on their weights. These algorithms can be computationally inexpensive

Future Internet 2022, 14, 44 12 of 35
and do not consider feature interactions, which may lead to selecting redundant features.This is why subset search algorithms have become popular. Subset search algorithms searchthrough candidate feature subsets using certain evaluation measures (i.e., correlation) thatcapture the goodness of each subset [67];
Wrapper Method: requires a learning algorithm and uses its performance as theevaluation criterion (i.e., classifier accuracy). It calculates the estimated accuracy of a singlelearning algorithm through a search procedure in the space of possible features in orderto find the best one. The search can be done with various strategies, such as forwardingdirection (the search begins with an empty set and successively adds the most relevantfeatures) and backward direction (the search starts with the full set and successively deletesless relevant features), which is also known as recursive feature elimination. Wrappermethods are also more computationally expensive than the filter methods and featureextraction methods, but they produce feature subsets with very competitive classificationaccuracy [25,52].
2.3.2. Feature Extraction
Feature extraction performs a transformation of the original variables to generate otherfeatures using the mapping function F that preserves most of the relevant information. Thistransformation can be achieved by a linear or non-linear combination of original features.For example, for n features f1, f2, f3, . . . , fn, we extract a new feature set f ′1, f ′2, f ′3, . . . , f ′mwhere m < n and f ′i = F( f1, f2, f3, . . . , fn). With the feature extraction technique, the featurespace can often be decreased without losing a lot of information on the original attributespace. However, one of its limits is that the information about how the initial featurescontribute is often lost [52]. Moreover, it is difficult to find a relationship between theoriginal features and the new features. Therefore, the analysis of the new features is almostimpossible, since no physical meaning for the transformed features is obtained from featureextraction techniques. In this survey, we discuss three of the most frequently used methods.
Principal Component Analysis (PCA) is the oldest technique of multivariate analysisand was introduced by Karl Pearson in 1901. It is an unsupervised (it does not take intoaccount target variable) and non-parametric technique that reduces the dimensionality ofdata from f to p, where p < f , by transforming the initial feature space into a smaller space.However, PCA has some limitations, discussed below:
• It assumes that the relations between variables are linear;• It depends on the scaling of the data (i.e., each variable is normalized to zero mean);• We do not know how many PCs should be retained (the optimal number of principal
components (PCs));• It does not consider the correlation between target outputs and input features [23];
Autoencoder (AE) is an unsupervised learning model which seeks to reconstruct theinput from the hidden layer [68]. During the process, the AE tries to minimize the recon-struction error by improving the quality of the learned feature. It is frequently used to learndiscriminative features of original data. Hence, AE is potentially important for featureextraction, and many researchers use it to generate reduced feature sets (code). In manycases, deep autoencoder (DAE) outperforms conventional feature selection methods andPCA [69] since it consists of several layers with nonlinear activation functions to extractfeatures intelligently;
Linear discriminant analysis (LDA) is a feature extraction method used as a preprocessingstep for ML algorithms and was first proposed in [70]. It is similar to PCA, but LDA is asupervised method. In other words, it takes the target variable into account. It consistsof three main steps, as mentioned in [71]. Firstly, it calculates the between-class varianceusing the distance between the means of the classes. Secondly, it calculates the within-classvariance using the distance between the mean and the observations of each class. Finally, itconstructs the lower dimensional space, which maximizes the between-class variance andminimizes the within-class variance.

Future Internet 2022, 14, 44 13 of 35
2.4. Federated Learning
Federated learning (FL) is a decentralized learning approach used to ensure dataprivacy and decrease the exchange message between the server and clients [72]. As shownin Figure 4, the training process is divided into two steps: (i) local model training and(ii) global aggregation of updated parameters in the FL server. For more details, first,the central server specifies the hyperparameters of the global model and the trainingprocess. Then, it broadcasts the global model to several clients. Based on this model, eachclient trains the global model for a given number of epochs using its own data. Then, theysend back the updated model to the FL server for the global aggregation. These steps arerepeated until the global model is achieved for a selected number of rounds in order toachieve satisfactory performance. As a result, FL helps the final model to take advantageof the different clients without exchanging their data. Additionally, it may decrease thecommunication overhead by exchanging the model parameters instead of the clients’ data.
Since the traffic data has been increased, FL can be a promising solution for trafficmanagement. For example, FL helps to detect the attack without communicating thepacket/flow to a central entity [73]. It keeps the traffic where it was generated. As aresult, FL has started to attract the attention of researchers for intrusion detection [74] andprediction [75].
Central Server
Glo
bal
Model
Local Training
Client 1
Local Training
Client 2
Local Training
Client 3
Local Training
Client 4
Local Training
Client N
Figure 4. General federated learning architecture [73], local model training on the client-side andglobal aggregation of updated parameters in the FL server.
3. DL/ML Applications in Software-Defined Networking
Thanks to the main features of SDN, including the global network view, separationof the data plane from the control plane, and network programmability, SDN provides anew opportunity for ML/DL algorithms to be applied for network traffic management.In this section, we present the different application cases in the SDN environment usingML/DL algorithms in detail. According to the different application scenarios, we dividethe existing application cases into three categories: traffic classification, traffic prediction,and intrusion detection systems.
3.1. Traffic Classification
The explosion in the number of smart devices has resulted in significant growth ofnetwork traffic as well as new traffic types. For example, mobile data traffic will be 77 exabytesper month, which is 7 times that in 2017 [1]. In this context, the purpose of traffic classification isto understand the type of traffic carried on the Internet [76]. It aims to identify the application’sname (YouTube, Netflix, Twitter, etc.) or type of Internet traffic (streaming, web browsing,etc.). Therefore, traffic classification has significance in a variety of network-related activities,from security monitoring (e.g., detecting malicious attacks) and QoS provisioning to providingoperators with useful forecasts for long-term and traffic management. For example, identifyingthe application from the traffic can help us to manage bandwidth resources [24]. Additionally,

Future Internet 2022, 14, 44 14 of 35
network operators need to know what is flowing over their networks promptly so they canreact quickly in support of their various business goals [77]. Thereby, traffic classification hasevolved significantly over time. It tries to separate several applications based on their feature“profile”. Because of its importance, several approaches have been developed over the yearsto accommodate the diverse and changing needs of different application scenarios. There arethree major approaches to achieve application identification and classification: (i) port-based,(ii) payload-based (deep packet inspection), and (iii) ML–based [50]. Since this paper focuseson the application of ML/DL in softwarized networks, we will present only the approachesbased on ML and DL models.
3.1.1. Existing Solutions
In this subsection, we study several works that try to achieve different traffic classificationobjectives. We have divided traffic classification solutions into two broad categories accordingto classification level: (i) coarse-grained and (ii) fine-grained. The coarse-grained level classifiesthe traffic based on the traffic type, while the fine-grained level aims to classify based on theexact application. At the end, we also highlight some other recent approaches.
• Coarse-grained traffic classification
With the intensive growth of online applications, it has become time-consuming andimpractical to identify all the applications manually. Therefore, coarse-grained trafficclassification aims to identify the QoS classes of traffic flows (e.g., streaming, web browsing,chat, etc.). Coarse-grained traffic classification is used to satisfy the QoS requirements ofthe network application at the same time.
Parsaei et al. [78] introduced a network traffic classification in the SDN environmentwhere several variants of neural networks were applied to classify traffic flows into differentQoS classes (instant messaging, video streaming, FTP, HTTP, and P2P). These classifiersprovided 95.6%, 97%, 97%, and 97.6% in terms of accuracy. However, the authors did notmention information on the architecture of the different neural network algorithms.
Xiao et al. [79] proposed a classification framework based on SDN. It consists oftwo modules, which are the flow collector and spectral classifier. First, the flow collectormodule scans the flow tables from SDN controllers to collect traffic flows. Then, the spectralclassifier module receives the flow from the flow collector module to create the clustersthrough spectral clustering. They fixed k = 6 as the number of flow classes (HTTP, SMTP,SSH, P2P, DNS, SSL2). Then, to evaluate their results, a comparative analysis with theK-means method in terms of accuracy, recall, and classification time was done. However,the authors did not mention information on the features and preprocessing methods usedduring their experiments.
Da Silva et al. [59] focused on the identification and selection of flow features toimprove traffic classification in SDN. The authors introduced architecture to computeadditional flow features and select the optimal subset of them to be applied in trafficclassification. This architecture is composed of flow feature manager and flow feature selec-tor. Flow feature manager is responsible for gathering information through the controllerand extending this information to complex flow features. Then, the flow feature selectorfinds the optimal subset of flow features using principal component analysis (PCA) andgenetic algorithm (GA), followed by the classifier (SVM) to evaluate this subset. Basedon the experimental results, we can reveal some conclusions: this feature selection tech-nique can improve traffic classification and the features generated in this paper can givegood accuracy.
In the same direction, Zaki and Chin [80] compared four classifiers, C4.5, KNN, NB,and SVM. Those classifiers were trained with features selected by their proposed hybridfilter wrapper feature selection algorithm named (FWFS). FWFS evaluates the worth ofthe features with respect to the class, and the wrappers use an ML model to measure thefeature subset. The experimental results demonstrate that the selected features throughFWFS improve the performance of the classifiers.

Future Internet 2022, 14, 44 15 of 35
Recently, the pattern of network traffic has become more complex, especially withthe 5G network. This has made simple classifiers unable to provide an accurate model.To solve this issue, researchers in the field of networking started to use ensemble learningfor network traffic classification. One of the main advantages of ensemble learning is itsability to allow the production of better predictive performance compared to a single model.In this context, Eom et al. [81] applied four ensemble algorithms (RF, gradient boostingmachine, XGBoost, LightGBM) and analyzed their classification performance in terms ofaccuracy, precision, recall, FI-score, training time, and classification time. The experimentresults demonstrate that the LightGBM model achieves the best classification performance.
Yang et al. [82] proposed a novel stacking ensemble classifier which combines sevenmodels in two-tier architecture (Figure 5). Specifically, on the first tier, KNN, SVM, RF, Ad-aBoost, and gradient boosting machine are trained independently on the same training set.Then, on the second tier, XGboost uses the prediction of the first-tier classifiers in order toimprove the final prediction results. The comparative analysis against the individual singleclassifier and voting ensemble demonstrates the effectiveness of the proposed ensemble.
Figure 5. Flowchart for the proposed ensemble classifier discussed in Yang et al. [82].
As DL helps to eliminate the manual feature engineering task, Hu et al. [83] proposeda CNN-based deep learning method to address the SDN-based application awarenesscalled CDSA. As shown in Figure 6, CDSA consists of three components, which are trafficcollection, data pre-processing, and application awareness. To evaluate the performance ofthis framework, the open Moore dataset [84] has been used. This dataset was released bythe University of Cambridge.
Figure 6. Framework of CDSA, which consists of traffic collection, data pre-processing and applica-tion awareness [83].
Malik et al. [85] introduced an application-aware classification framework for SDNscalled Deep-SDN. The performance of Deep-SDN was evaluated on the Moore dataset [84],which is real-world traffic. The experimental results demonstrate that the Deep-SDNoutperformed the DL model proposed in [63] by reporting 96% overall accuracy.

Future Internet 2022, 14, 44 16 of 35
As new types of traffic emerge every day (and they are generally not labeled), thisopens a new challenge to be handled. In fact, labeling data is often difficult and time-consuming [28]. Therefore, researchers started to reformulate traffic classification into semi-supervised learning, where both supervised learning (using labeled data) and unsupervisedlearning (no label data) were combined.
In such a context, a framework of a semi-supervised model for network traffic classifi-cation has been proposed in [61]. Specifically, DPI has been used to label a part of trafficflows of known applications. Each labeled application is categorized into four QoS classes(voice/video conference, interactive data, streaming, bulk data transfer). Then, this datais used by Laplacian SVM as a semi-supervised learning model in order to classify thetraffic flows of unknown applications. Here, only “elephant” flows are used in the trafficclassification engine. The proposed framework is fully located in the network controllerand exceeds 90% accuracy. Additionally, the Laplacian SVM approach outperforms aprevious semi-supervised approach based on the K-means classifier. Therefore, based onthe experimental results presented in their paper, we can reveal some conclusions: bycombining the DPI and ML method, traffic flows could be categorized into different QoSclasses with acceptable accuracy. However, the authors did not present any detail aboutthe complexity of the proposed framework.
Similar work is done by Yu et al. [86], where the authors proposed a novel SDN flowclassification framework using DPI and semi-supervised ensemble learning. The significantdifference is the ML algorithm used for the classification. Firstly, they used DPI to generatea partially labeled dataset with the QoS type of flow according to the application type.To train the classifier, they used the heteroid tri-training algorithm. This algorithm is amodified version of tri-training, which is a classic semi-supervised learning mechanismthat uses three identical classifiers to enable iterative training. However, they used threeheterogeneous classifiers (SVM, Bayes classifier, K-NN) instead of three identical classifiersto increase the difference among classifiers. To verify the performance of their framework,they used a real dataset and trained the classifier with different ratios of unlabeled applica-tion flows. However, the authors did not mention information about the feature selectionmethod and the dataset used during the experiments.
In addition, Zhang et al. [63] proposed a DL-based model in the SDN-based envi-ronment to classify the traffic to one of several classes (Bulk, Database, Interactive, Mail,Services, WWW, P2P, Attack, Games, Multimedia). It consists of the stacked autoencoder(SAE) and softmax classifier. SAE was used for feature extraction and softmax was usedas a supervised classifier. The experimental results show that the proposed model outper-forms the SVM. However, the authors proposed only the framework without testing itsperformance in the SDN environment.
Finally, to avoid data labeling, K-means has been proposed by Kuranage et al. [87].In this paper, several supervised learning methods were trained and evaluated individually,including SVM, DT, RF, and KNN. The results demonstrate that SVM has the highestaccuracy with 96.37%. For this paper, the “IP Network Traffic Flows, Labeled with 75 Apps”dataset was used [88]. However, the features used for the models’ training are selectedmanually;
• Fine-grained traffic classification
Fine-grained classification aims to classify the network traffic by application (the exactapplication generating the traffic) and facilitates the operators to understand users’ profilesand hence provide better QoS.
Qazi et al. [89] presented a mobile application detection framework called Atlas.This framework enables fine-grained application classification. The netstat logs from theemployee devices are collected by the agents to collect ground truth data and are sent tothe control plane, which runs the decision tree algorithm (C5.0) to identify the application.Their framework is capable of detecting a mobile application with 94% accuracy for thetop 40 Android applications. However, the authors did not present the features used inthis framework.

Future Internet 2022, 14, 44 17 of 35
Li and Li [90] presented MultiClassifier, an application classifier, by combining bothDPI and ML to do classification in SDN. They try to exploit the advantage of both methodsto achieve a high speed with acceptable accuracy. When a new flow arrives, MultiClassifiergives ML a higher priority to classify because it is much faster than DPI. If the reliabilityof the ML result is larger than a threshold value, its result will be the MultiClassifierresults. If not and if DPI does not return “UNKNOWN”, MultiClassifier will take theDPI result. This combination succeeded in reaching more than 85% accuracy. Based onthe experimental results presented in their paper, we can reveal some conclusions: (i) MLruns four times faster than DPI, and (ii) DPI gives high accuracy. However, the authorsdid not present the features nor the ML algorithm used for the classification. Moreover,the simulations were not scaled, since they used only two hosts, and thus we cannot confirmthe quality of this combination.
Raikar et al. [91] proposed a traffic classification using supervised learning modelsin the SDN environment. Specifically, a brief comparative analysis of SVM, Naïve Bayes,and KNN has been done, where the accuracy of traffic classification is greater than 90% inall the three supervised learning models. However, the authors used only three applications(SMTP, VLC, HTTP), which is therefore not enough to verify the performance of the models.
In addition, Amaral et al. [62] introduced a traffic classification architecture based onan SDN environment deployed in an enterprise network using ML. In this architecture,the controller collected the flow statistics from the switches, and then the preprocessingstep was used, followed by several classifiers individually, including RF, stochastic gradientboosting, and extreme gradient boosting. The accuracy of each application is used as anevaluation metric. However, the study lacks the exploration of the other performancemetrics (e.g., f-measure). Additionally, there is no information on the distribution ofapplications in the dataset. As each application can have several types of flows, likevoice and chat, a fine-grained traffic classiication is needed. To solve this issue, Uddinand Nadeem [92] introduced a traffic classification framework called TrafficVision thatidentifies the applications and their corresponding flow-type in real-time. TrafficVision isdeployed on the controller, and one of the kernel modules of TrafficVision is named TVengine, which has three major tasks: (i) collecting, storing, and extracting flow statisticsand ground-truth training data from end devices; (ii) building the classifiers from thetraining data; and (iii) applying these classifiers to identify the application and flow-typesin real-time and providing this information to the upper layer application. As a proof ofconcept, the authors developed two prototypes of ”network management” services usingthe TrafficVision framework. The classification task of the TV engine has two modules,which are application detection using decision tree (C5.0) and flow-type detection usingKNN with K = 3. Both of these classifiers show more than 90% accuracy. The shortcomingin this paper is the classification of the 40 popular applications and the ignorance of otherapplications; this can cause problems in an enterprise or university network.
Amaral et al. [93] proposed an application-aware SDN architecture, and the experi-mental results demonstrate that the semi-supervised classifier outperforms the supervisedclassifier (random forest classifier) with the same amount of labeled data. This is attributedto the fact that the incorporation of unlabeled data in the semi-supervised training processboosts the performance of the classifiers.
Nakao and Du [94] used deep NN to identify mobile applications. Mobile networktraffic was captured from the mobile virtual network operator (MVNO). Five flow features(i.e., a destination address, destination port, protocol type, TTL, and packet size) were se-lected to train an 8-layer deep NN model. DL achieves 93.5% accuracy for the identificationof 200 mobile applications. The features used for classification are selected filter methodsin order to train and improve the performance of the DL model.
Wang et al. [95] developed an encrypted data classification framework called DataNetwhich is embedded in the SDN home gateway. This classification was achieved throughthe use of several DL techniques, including multilayer perceptron (MLP), stacked au-toencoder (SAE), and convolutional neural networks (CNN). They used the “ISCX VPN-

Future Internet 2022, 14, 44 18 of 35
nonVPN” encrypted traffic dataset [96], which consists of 15 encrypted applications (i.e.,Facebook, Skype, Hangout, etc.) and more than 200,000 data packets. However, theyused only 73,392 flows after adopting the under-sampling method to balance the classes’distribution. This framework helps them to classify the traffic without compromising thesecurity/privacy of services providers or users.
Chang et al. [97] proposed an application for offline and online traffic classification.More specifically, the authors used three DL-based models, including CNN, MLP, and SAEmodels. Using the Tcpreplay tool, the traffic observations are re-produced and analyzed inan SDN testbed to emulate the online traffic service. The experimental results show that theoffline training results have achieved more than 93% accuracy, whereas the online testingprediction achieved 87% accuracy for application-based detection. This may be attributedto the limitation of the processing speed leading to the dropping of statistics packets.
• Other Approaches for Traffic Classification
Video surveillance traffic increased sevenfold between 2016 and 2021 [98]. Due tothese changes, multimedia traffic must be managed as efficiently as possible. SDN and MLcan be promising solutions to manage video surveillance traffic. Therefore, by applyingSDN and ML, we are able to increase efficiency and reduce the cost of management. In thiscontext, Rego et al. [99] proposed an intelligent system for guaranteeing QoS of video trafficin surveillance IoT environments connected through SDN using the AI module, which isintegrated into SDN. The traffic classification that detects whether the incoming flow iscritical or not is based on the packets sent by the SDN controller to the AI system. Thisdetection is performed through the use of SVM as a classifier and is able to detect criticaltraffic with 77% accuracy, which is better than other tested methods (i.e., NN or KNN).
Xiao et al. [60] proposed a real-time elephant flow detection system which includestwo main stages. In the first one, suspicious elephant flows are distinguished from miceflows using head packet measurement. In the second stage, the correlation-based filter(CFS) is used to select the optimal features to build a robust classifier. Then, elephant flowsare used for improving the classification accuracy, and the decision tree (C4.5) classifiesthem as real elephant flows or suspicious flows. To maximize the detection rates andminimize the misclassification costs of elephant flows, they used the cost-sensitive decisiontrees as classifiers.
Indira et al. [100] proposed a traffic classification method using a deep neural network(DNN) which classifies the packets based on the action (accept/reject). As a proof concept,the performance of DNN is compared with two classifiers, which are SVM and KNN.
In addition, Abidi et al. [101] proposed a network slicing classification framework.Given network features, the proposed framework tries to find the network slices, suchas enhanced mobile broadband (eMBB), massive machine-type communication (mMTC),or ultra-reliable low-latency communication (URLLC) by combined deep belief networkand neural network models as well as meta-heuristic algorithms in order to enhance theclassification performance.
3.1.2. Public Datasets
The evaluation and the success of ML/DL models depend on the dataset used. In thissection, we present some well-known datasets used for network traffic classification.
• VPN-nonVPN dataset [96] is a popular encrypted traffic classification dataset. Itcontains only time-related features and regular traffic, as well as traffic captured over avirtual private network (VPN). Specifically, it consists of four scenarios. Scenario A isused for binary classification in order to indicate whether the traffic flow is VPN or not.Both scenario B and scenario C are classification tasks. Scenario B contains only sevennon-VPN traffic services like audio, browsing, etc. Scenario C is similar to ScenarioB, but it contains seven traffic services of the VPN version. Scenario D contains allfourteen classes of scenario B and scenario C to perform the 14-classification task;

Future Internet 2022, 14, 44 19 of 35
• Tor-nonTor dataset[102] contains only time-related features. This dataset has eightdifferent labels, corresponding to the eight different types of traffic captured, which arebrowsing, audio streaming, chat, video streaming, mail, VoIP, P2P, and file transfers;
• QUIC [103] is released by the University of California at Davis. It contains five Googleservices: Google Drive, Youtube, Google Docs, Google Search, and Google Music.
• Dataset-Unicauca [88] is released by the Universidad Del Cauca, Popayán, Colombia.It was collected through packet captures at different hours during the morning and af-ternoon over 6 days in 2017. This dataset consists of 87 features, 3,577,296 observations,and 78 classes (Twitter, Google, Amazon, Dropbox, etc.)
3.1.3. Discussion
This subsection presents several ML-based solutions for traffic classification in SDN,as summarised in Table 8. It has been divided into two tasks: coarse-grained and fine-grained. Nowadays, as new applications emerge every day, it is not possible to have allthe flows labeled in a real-time manner. Therefore, one of the most promising approachesis semi-supervised learning for fine-grained classification, which is closer to reality, as itprofits through the use of labeled and unlabeled data. Moreover, DT-based models are themost frequently used for traffic classification where RF shows a good trade-off betweenperformance and complexity. Furthermore, it requires less hyperparameter tuning [104].Additionally, DL models, as with different domains, verify their effectiveness for networktraffic classification. In addition, most of the researchers used a single classical approachfor traffic classification. However, using ensemble learning by combining several classifiersachieves better accuracy than any single classifier. Nevertheless, multi-classifier approaches(i.e., ensemble learning) can increase the computational complexity of the model and theclassification time. To solve this issue, we can reduce the number of captured packetsper flow in order to reduce the classification time. For example, we can use a set of threepackets instead of five packets as used in some works [62]. Additionally, based on theliterature, each classifier is tested on its environment (i.e., data), and no paper explores allthe classifiers with a deep comparison among them.
3.2. Traffic Prediction
The objective of network traffic prediction is to forecast the amount of traffic expectedbased on historical data in order to avoid future congestion and maintain high networkquality [105]. It helps to keep the over-provisioning of the resources as low as possible,avoid congestion and decrease communication latency [106,107]. Network traffic predic-tion can be formulated as the prediction of the future traffic volume (yt+l) based on thehistorical and current traffic volumes (Xt−J+1, Xt−J+2,. . . , Xt). Therefore, the objective ofthe ML/DL models is to find the parameters that minimize the error between the predictedand observed traffic with respect to Xt−J+1, Xt−J+2,. . . , Xt (Equations (1) and (2)).
W∗ = argminW∗
L(yt+l , yt+l ; W∗) (1)
yt+l = f ([Xt−J+1, Xt−J+2, . . . , Xt]) (2)
where yt+l and yt+l are the observed and predicted value at time t + l, respectively, f (.) isthe activation function, L is the loss function, and W∗ is the optimal set of parameters.

Future Internet 2022, 14, 44 20 of 35
Table 8. Summary of reviewed papers on ML application for traffic classification in SDN.
Classification Level Ref. ML/DL Algorithm DimensionalityReduction Dataset Output Controller
Coarse-grainedclassification
[61] DPI and Laplacian SVM Wrapper method Voice/video conference, interactive data,streaming, bulk data transfer N/A
[78] Feedforward, MLP - Instant message, stream, P2P, HTTP, FTP Floodlight
[79] Spectral clustering N/A HTTP, SMTP, SSH, P2P, DNS, SSL2 Floodlight
[59] SVM PCA DDoS attacks, FTP, video streaming Floodlight
[63] Stacked Autoencoder AE Bulk, database, interactive, mail, services,WWW, P2P, attack, games, multimedia N/A
[86] Heteroid tri-training (SVM,KNN, and Bayes classifier) N/A Voice, video, bulk data, interactive data N/A
[87] SVM, decision tree,random forest, KNN - N/A RYU
[80] C4.5, KNN, NB, SVM Filter andwrapper method
WWW, mail, bulk, services, P2P, database,multimedia, attack N/A
[83] CNN -WWW, mail, FTP-control, FTP-data, P2P,database, multimedia, services, interactive,games
N/A
[81] DT, RF, GBM, LightGBM N/A Web browsing, email, chat, streaming, filetransfer, VoIP, P2P RYU
[82]Ensemble classifier (KNN,SVM, RF, AdaBoost,Boosting, XGBoost)
- Video, voice, bulk data transfer, music,interactive N/A
Fine-grainedclassification
[85] Deep learning - WWW, mail, FTP-control, FTP-pasv, FTP-data,attack, P2P, database, multimedia, services POX
[90] DPI and classificationalgorithm N/A N/A Floodlight
[89] Decision tree (C5.0) N/A Top 40 Android applications N/A
[62]Random forest, stochasticgradient boosting,XGBoost
PCA Bittorent, Dropbox, Facebook, HTTP, Linkedin,Skype, Vimeo, Youtube HP VAN
[92] Decision tree (C5.0), KNN - The top 40 most popular mobile applications Floodlight
[95] MLP, SAE, CNN AEAIM, email client, Facebook, Gmail, Hangout,ICQ, Netflix, SCP, SFTP, Skype, Spotify, Twitter,Vimeo, Voipbuster, Youtube
N/A
[94] Deep Learning Filter method 200 mobile applications N/A
[93] Random forest - Bittorrent, Dropbox, Facebook, HTTP, Linkedin,Skype, Vimeo, Youtube HPE VAN
[97] MLP, CNN, SAE - Facebook, Gmail, Hangouts, Netflix, Skype,Youtube Ryu
[91] SVM, KNN, Naive Bayes N/A SMTP, HTTP, VLC POX
Others
[99] SVM Video surveillance traffic in IoT environment(critical or non-critical traffic) N/A
[60] Decision tree (C4.5) Filter method Elephant flow, mice flow Floodlight
[100] DNN - Action (accept/reject) N/A
[101] Deep belief network,neural network -
Enhanced mobile broadband slice, massivemachine-type communications slice,ultra-reliable low-latency communication slice
N/A
3.2.1. Existing Solutions
In this section, we present the recent works concerning traffic prediction.Kumari et al. [108] presented a framework for SDN traffic prediction. To do so, two predictionmodels, namely ARIMA and SVR (support vector regression) have been used. The resultsshowed that SVR outperforms the ARIMA method, where the average performance improve-

Future Internet 2022, 14, 44 21 of 35
ment is 48% and 26%. However, the temporal and spatial variation of network traffic made theaccurate prediction of flows challenging. Consequently, learning highly complicated patternsrequires more complicated models, like deep learning-based models.
From the recent literature, we can find representative DL methods that are frequentlyused for network prediction tasks in the SDN environment. For example, Azzouni andPujolle [109] proposed a framework called neuTM to learn the traffic characteristics fromhistorical traffic data and predict the future traffic matrix using LSTM (long short-termmemory). They implemented their framework and deployed it on SDN, then trained iton a real-world dataset using different model configurations. The experimental resultsshow that their model converges quickly and can outperform linear forecasting models andfeed-forward deep neural networks. Alvizu et al. [110] applied a neural network modelto predict network traffic load in a mobile network operator. The prediction results areused to make online routing decisions. The authors in this work train a real dataset formobile network measured during November and December 2013 in Milano, Italy. Similarly,based on ANN, Chen-Xiao and Ya-Bin [111] proposed a solution to keep network loadbalanced using SDN. This solution aims to select the least-loaded path for newcomer dataflow. They take advantage of the global view of SDN architecture to collect four featuresof each path, which are bandwidth utilization ratio, packet loss rate, transmission latency,and transmission hop, and use ANN to calculate the load condition of each path.
In addition, network traffic prediction is even important for the IoT network giventhe huge amount of IoT devices widely used in our daily life. To improve the transmissionquality for such a network, an efficient deep learning-based traffic load prediction algorithmto forecast future traffic load was proposed by Tang et al. [112]. The authors presentedthe performance of their algorithms with three different systems (centralized SDN system,semi-centralized, and a distributed conventional control system without centralized SDN).For the centralized SDN system, the authors used M deep CNN where each deep CNN isonly used to predict the traffic load of one switch. In each switch, the traffic load consists oftwo parts: (i) the relayed traffic flow from other switches, and (ii) the integrated traffic flowcomposed by the sensing data from devices. However, for the semi-centralized SDN system,each switch uses just a deep belief network to predict the traffic generated by connectedsensing devices; then, centralized SDN uses Deep CNN to make the final prediction. Basedon the obtained results, the accuracy with a centralized SDN system is always better thanthe two other systems (more than 90%).
Due to the volatile nature of network traffic in smaller time scales, Lazaris et al. [113]focused on network traffic prediction over short time scales using several variations of theLSTMs model. To evaluate the performance of their solution, the authors used real-lifetraffic (CAIDA Anonymized Internet Traces 2016 Dataset) [114]. The experimental resultsdemonstrate that the LSTM models perform much better than the ARIMA models in allscenarios (e.g., various short time scales).
Le et al. [115] proposed a DL-based prediction application for an SDN network. Specifi-cally, the authors have used three RNN variants models, which are long short-term memory(LSTM), gated recurrent units (GRU), and BiLSTM. Their experiments show that all threemodels, especially the GRU model, perform well but still produce significant predictingerrors when the traffic is suddenly shot. However, BiLSTM consumes the most resources intraining and predicting.
Additionally, to ensure dynamic optimization of the allocation of network resourcesin a proactive way, Alvizu et al. [106] proposed machine-learning-based traffic prediction.Specifically, the GRU model was used in order to predict the mobile network traffic matrixin the next hour.
Moreover, with the scale and complexity expected for the networks, it is essential topredict the required resources in a proactive way. To do so, network traffic forecasting isthe need of the hour. In this context, Ferreira et al. [116] used both linear and non-linearforecasting methods, including machine learning, deep learning, and neural networks,to improve management in 5G networks. Through these forecasting models, a multi-slice

Future Internet 2022, 14, 44 22 of 35
resource management approach has been proposed, and the experimental results showthat it is possible to forecast the slices’ needs and congestion probability efficiently and,accordingly, maintain the QoS of the slice and the entire network.
Last but not least, since the ML/DL-based models need continuous training becausethe network situation changes quickly, sending all raw data to a central entity can slow theconvergence of the models as well as introduce network congestion. To solve these issues,Sacco et al. [75] used the LSTM model in a collaborative way in order to predict the futureload to optimize routing decisions (i.e., select the best path). More specifically, the authorsused federated architecture with a multi-agent control plane, where each controller trainsthe LSTM model locally then sends only its model parameters to the Cloud for globalaggregation (Figure 7).
Figure 7. A federated learning approach with SDN-enabled edge networks [75].
3.2.2. Public Datasets
The dataset is an important component in the process of traffic prediction, as it has adirect impact on the accuracy and applicability of the model. Here, we identify some publicdatasets that can be used for network traffic prediction.
• Abilene dataset [117] contains the real trace data from the backbone network located inNorth America consisting of 12 nodes and 30 unidirectional links. The volume of trafficis aggregated over slots of 5 min starting from 1 March 2004 to 10 September 2004;
• GEANT [118] has 23 nodes and 36 links. A traffic matrix (TM) is summarized every15 min starting from 8 January 2005 for 16 weeks (10,772 TMs in total);
• Telecom Italia [119] is part of the “Big Data challenge”. The traffic was collected from1 November 2013 to 1 January 2014 using 10 min as a temporal interval over Milan.The area of Milan is divided into a grid of 100 × 100 squares, and the size of each squareis about 235 × 235 m. This dataset contains three types of cellular traffic: SMS, call,and Internet traffic. Additionally, it has 300 million records, which comes to about 19 GB.
3.2.3. Discussion
In the above subsection, several ML-based solutions for traffic prediction in SDN havebeen presented, as summarized in Table 9. Mobile communication faces many challengeswhen the number of smart devices increases, and hence, the load in the network can lead tonetwork congestion. In this context, ML models can be used to predict the network situationand help the operator to anticipate exceptional resource demand or reduce resources whenno longer needed. Traffic prediction is considered a regression problem (i.e., dataset outputshave continuous values). Therefore, supervised learning can be used for traffic prediction.Based on the literature, DL algorithms, especially LSTM, are widely adopted and can beconsidered a promising solution for network traffic prediction. However, building an LSTM
Future Internet 2022, 14, 44 23 of 35
model does not mean successful results, since several factors can affect the performanceof the model, such as the model hyperparameters and the size of the dataset used duringthe training process. Additionally, the model needs continuous training, since the networksituation changes quickly. Moreover, the exchange of information between the controllerand the forwarding devices can overload the system and can pose security and data privacyproblems. Therefore, federated learning seems to be an efficient solution. This methodcan optimize the communication between SDN and the involved forwarding devices bykeeping the data where it was generated. This leads to preserving the bandwidth for theapplication traffic, reducing costs of data communication, and ensuring data security. Thus,more attention should be given to this research direction.
Table 9. Summary of reviewed papers on ML applications for network traffic prediction in SDN.
Ref. ML/DL Model Controller Contribution
[109] LSTM POX The authors proposed a traffic prediction framework and deployed it on SDN using areal-world dataset under different model configurations.
[110] ANN N/A The authors used the prediction results to make online routing decisions.
[111] ANN Floodlight
The proposed system tries to benefit from the global view of SDN controller in order tocollect the bandwidth utilization ratio, packet loss rate, transmission latency,and transmission hop of each path. Then, using the ANN model, it predicts the loadcondition of each path.
[112] Deep CNN N/AThe authors presented the performance of their systems with three different systems,which are a centralized SDN system, a semi-centralized SDN system, and a distributedconventional control system without centralized SDN.
[106] GRU-RNN N/A The authors used (GRU-RNN) in order to predict the mobile network traffic matrix in thenext hour.
[108] SVR N/A The authors demonstrate that SVR outperforms the ARIMA method; the averageperformance improvement is 48% and 26%.
[113] LSTM N/A The authors focused on network traffic prediction for short time scales using severalvariations of the LSTM model.
[75] LSTM+FL FloodlightThe authors used an LSTM model and federated learning in order to predict the futureload to optimize routing decisions and at the same ensure data privacy as well decreasethe exchange message between the SDN controller.
[115] LSTM, BiLSTM, GRU POX The authors proposed a comparative analysis between three RNN-based models: LSTM,GRU, and BiLSTM.
[116] Shallow ML models, DLmodels, ensemble learning N/A The authors take advantage of the forecasting results in order to manage the network slice
resource.
3.3. Network Security
Despite the advantages of SDN, its security remains a challenge. More specifically,the centralized control plane of SDN can be a point of vulnerability [120]. An intrusiondetection system (IDS) is one of the most important network security tools due to itspotential in detecting novel attacks [121]. According to Base and Mell [122], intrusions aredefined as “attempts to compromise the confidentiality, integrity, or availability of a computer ornetwork, or to bypass the security mechanisms of a computer or network”.
3.3.1. Existing Solutions
Recently, ML/DL based models have been widely used for intrusion and attackdetection. In this section, we present a literature review of these models for IDS (Table 10).
ML-based models are widely applied for network IDS. For example, Latah et al. [123]proposed a comparative analysis between different conventional ML-based models for theintrusion detection task using a benchmark dataset (NSL-KDD dataset). The features usedby these classifiers were extracted and reduced after the application of the PCA method.The results demonstrate that using PCA enhances the detection rate of the classifiers, as wellas the DT approach, showing the best performance in terms of all the evaluation metrics.

Future Internet 2022, 14, 44 24 of 35
Additionally, as SDN and ML-based models are considered the enablers of the realiza-tion of the 5G network, Li et al. [124] proposed an intelligent attack classification systemin an SD-5G network using RF for feature selection and AdaBoost for attack classificationwith the selected features. The 10% of the KDD Cup 1999 dataset was used to evaluate theproposed system. The results demonstrate that, using the selected features, the classifiercan better differentiate the attack traffic and produce a low overhead system. Similarly,Li et al. [125] proposed a two-stage intrusion detection and attack classification system inan SD-IoT network. In the first stage, they selected the relevant features, which were usedin the second stage for attack anomaly detection. The experiments on the KDD Cup 1999dataset show that random forest achieved a higher accuracy with an acceptable complexitytime compared to the existing approaches.
However, as conventional ML models have difficulties detecting attacks in large-scale network environments [126], DL models have been used. They can give betterperformance for intrusion detection, as with network traffic classification and prediction(Sections 3.1 and 3.2) without the need to extract the features manually. In this context,Tang et al. [45] proposed a DNN model for anomaly detection using only six features thatcan be easily obtained in an SDN environment. The experimental results on the NSL-KDDdataset show that the deep learning approach outperforms the conventional ML models.Then, Tang et al. [127,128] proposed, for the first time, the GRU-RNN model for anomalydetection in SDN, which is an extension of their previous work [45]. This model has theability to learn the relationship between current and previous events. Using the NSL-KDDdataset, the GRU-RNN model achieved 89% accuracy using the 6 features. Additionally,the experimental results demonstrate that the GRU-RNN model outperforms VanilaRNN,SVM, and DNN.
To also improve the detection rate of the attack or the intrusion, some researchershave started to combine DL-based models and conventional or classical ML models. Morespecifically, they take advantage of the benefits of the deep features extracted throughdeep learning, which can be used with conventional models for classification or attackdetection. In this context, Elsayed et al. [129] combined CNN architecture with conventionalML-based models, including SVM, KNN, and RF. Specifically, CNN extracts the deeperrepresentations from the initial features, while the classification task is performed throughSVM, KNN, and RF. To evaluate the performance of their approach, the authors useda novel dataset, called InSDN, which is specific to an SDN network [130], along withUNSW-NB15, and CIC-IDS2018 datasets. The results demonstrate the potential of CNN foranomaly detection even with a few amount of features (9 features). Also, the combinationof CNN and SVM, KNN, and especially the RF algorithm provide higher performancecompared to a single CNN.
Unlike the centralized architecture, distributed SDN can deploy multiple IDS for theactive detection of attacks. In contrast to the other IDS approaches, Shu et al. [131] proposeda collaborative IDS based on distributed SDN in VANETs, called CIDS. In other words,CIDS enables all the distributed SDN controllers to collaboratively train a stronger detectionmodel based on the whole network flow. To do so, generative adversarial networks (GAN)have been used, wherein a single discriminator is trained on the Cloud server and severalgenerators are trained on the SDN controllers. Using the KDD99 and NSL-KDD datasets,the evaluation results show that the proposed method achieves better performance ascompared to centralized detection methods.
Although distributed SDNs are trained on richer data, they are limited in terms ofcollaboration. Consequently, the FL started to attract researchers since there is a needfor collaboration among the domain. In this context, Thapa et al. [74] proposed an FLmodel for the detection and mitigation of ransomware attacks in the healthcare systemcalled FedDICE. Specifically, FedDICE integrates FL in an SDN environment to enablecollaborative learning without data exchange. The performance of the FedDICE frameworkis similar to the performance achieved by centralized learning. Similarly, Qin et al. [132]used FL for intrusion detection in the SDN environment. They combined FL and binarized

Future Internet 2022, 14, 44 25 of 35
neural networks for intrusion detection using programmable network switches (e.g., the P4language). Using programmable switches and FL enables the incoming packet to beclassified directly in the gateway instead of forwarded to the edge controller or Cloudserver. The results demonstrate that FL leads to more accurate intrusion detection comparedwith training each gateway independently.
• DDoS attack detection/classification
A DDoS attack is a complex form of denial of service attack (DoS). It generates a hugeamount of source IP address and destination IP address packets, and in turn, the switchessend a large number of packets to the controller. This may exhaust the networking, storage,and computing resources of the controller [133]. Therefore, detection and mitigation ofDDoS attacks in real-time is necessary. As a result, several ML models have been usedfor DDoS attack detection in the SDN environment. In this context, Ahmad et al. [134]evaluated different well-known models, including SVM, naive Bayes, DT, and logisticregression. The results show that the SVM performed better than other algorithms, sincethe classifiers were used for the binary classification scenarios.
Chen et al. [135] used XGBoost as a detection method in a SDN-based Cloud network.Then, they evaluated the efficiency of XGBoost through the Knowledge Discovery andData mining (KDD) Cup 1999 dataset. The evaluation was done considering a binaryclassification scenario (DDoS/benign traffic). A final comparison was made betweenXGBoost, Random Forest, and SVM. Additionally, to detect the anomaly in the data planelevel and to minimize the load on the control plane, Da el al. [107] proposed a frameworkfor the detection, classification, and mitigation of traffic anomalies in the SDN environmentcalled ATLANTIC. It consists of two phases, which are (i) the lightweight phase and(ii) the heavyweight phase. The lightweight phase is responsible for anomaly detectionby calculating the deviation in the entropy of flow tables, whereas the heavyweight phaseuses the SVM model for anomaly classification.
Recently, like the other domains, DL models have been used for DDoS attack detection.For example, Niyaz et al. [136] proposed a DL-based system for DDoS attack detection in anSDN environment. Specifically, SAE has been used for feature reduction in an unsupervisedmanner. Then, the traffic classification was performed with the softmax layer in the scenarioof two classes (DDoS/benign traffic) and the eight classes, which included normal trafficand seven kinds of DDoS attacks. The experimental results show that the SAE modelachieved higher performance compared to the neural network model using their ownprivate dataset.
Other DL models have been used for DDoS attack detection like CNN, RNN, and LSTM.For example, Li et al. [137] used CNN, RNN, and LSTM as neural network models to real-ize the detection of DDoS attacks in the SDN environment. The evaluation and trainingtasks of the used models were done on the ISCX2012 dataset. Similarly, Haider et al. [138]used the same DL-based model for DDoS attack detection using a benchmark dataset (CI-CIDS2017 dataset). More specifically, four DL-based models were applied in an ensemble(RNN+RNN, LSTM+LSTM, CNN+CNN) or in a hybrid way (e.g., RNN+LSTM). The resultsshow the capability of DL models and especially the ensemble CNN model in detectingDDoS very well. Ensemble CNN provides high detection accuracy (99.45%); however, ittakes more time for the training and classification tasks.
Moreover, Novaes et al. [120] proposed a detection and mitigation framework againstDDoS attacks in SDN environments. To do so, they used the generative adversarial Net-work (GAN) model in order to make the proposed framework less sensitive to adversarialattacks. The experiments were conducted on emulated data and the public dataset CICD-DoS 2019, where the GAN obtained superior performance compared to the CNN, MLP,and LSTM models.
Although the DL-based models are efficient for the DDoS attack detection/classification,combining deep and conventional ML models can take advantage of both techniques andhence further improve the performance of the security system. Krishnan et al. [139] proposeda hybrid ML approach by combining DL and conventional ML models called VARMAN. AE

Future Internet 2022, 14, 44 26 of 35
was used to generate 50 new reduced features from the CICIDS2017 dataset as well as tooptimize the computation and memory usage. Then, random forest acts as the main DDoSclassifier. The experiments demonstrate that VARMAN outperforms the deep belief networksmodel, and this is attributed to the combination of different models.
3.3.2. Public Datasets
As the performance of the IDS techniques relies on the quality of the training datasets,in this subsection, we review the publicly widely used datasets to evaluate the performanceof the ML/DL-based model for intrusion detection.
• KDD’99 [140] is one of the most well-known datasets for validating IDS. It consistsof 41 traffic features and 4 attack categories besides benign traffic. The attack traf-fic is categorized into denial of service (DoS), remote to local (R2L), user to root(U2R), or probe attacks. This dataset contains redundant observations, and therefore,the trained model can be biased towards the more frequent observations;
• The NSL-KDD dataset [141] is the updated version of the KDD’99 dataset. It solves theissues of the duplicate observations. It contains two subsets, a training set and testing set,where the distribution of attack in the testing set is higher than the training set;
• The ISCX dataset [121] was released by the Canadian Institute for Cybersecurity,University of New Brunswick. It consists of benign traffic and four types of attack,which are brute force attack, DDoS, HttpDoS, and infiltrating attack;
• Gas pipeline and water storage tank [142] is a dataset released by a lab at MississippiState University in 2014. They proposed two datasets: the first is with a gas pipeline,and the second is for a water storage tank. These datasets consist of 26 features and1 label. The label contains eight possible values, benign and seven different types ofattacks, which are naive malicious response injection, complex malicious responseinjection, malicious state command injection, malicious parameter command injection,malicious function command injection, reconnaissance, and DoS attacks;
• The UNSW-NB15 dataset [143] is one of the recent datasets; it includes a simulatedperiod of data which was 16 h on 22 January 2015 and 15 h on 17 February 2015. Thisdataset has nine types of attacks: fuzzers, analysis, backdoors, DoS, exploits, generic,reconnaissance, shellcode, and worms. It contains two subsets, a training set with175,341 observations and a testing set with 82,332 observations and 49 features;
• The CICDS2017 dataset [144] is one of the recent intrusion detection datasets releasedby the Canadian Institute for Cybersecurity, University of New Brunswick. It contains80 features and 7 types of attack network flows: brute force attack, heartbleed attack,botnet, DoS Attack, DDoS Attack, web attack, infiltration attack;
• The DS2OS dataset [145] was generated through the distributed smart space orches-tration system (DS2OS) in a virtual IoT environment. This dataset contains benigntraffic and seven types of attacks, including DoS, data type probing, malicious control,malicious operation, scan, spying, and wrong setup. It consists of 357,952 observationsand 13 features;
• The ToN-IoT dataset [146] was put forward by the IoT Lab of the UNSW CanberraCyber, the School of Engineering and Information Technology (SEIT), and UNSWCanberra at the Australian Defence Force Academy (ADFA). It contains traffic collectedfrom the Internet of Things (IoT) and industrial IoT devices. It contains benign trafficand 9 different types of attacks (backdoor, DDoS, DoS, injection, MITM, password,ransomware, scanning, and XSS) with 49 features;
• The IoT Botnet dataset [147] uses the MQTT protocol as a communication proto-col. It contains 83 features and 4 different types of attacks, including DDoS, DoS,reconnaissance, and theft, along with benign traffic;
• The InSDN dataset [130] is a recent dataset and the first one generated directly fromSDN networks. It consists of 80 features and 361,317 observations for both normal andattack traffic. It covers different types of attack types, including DoS, DDoS, probe,
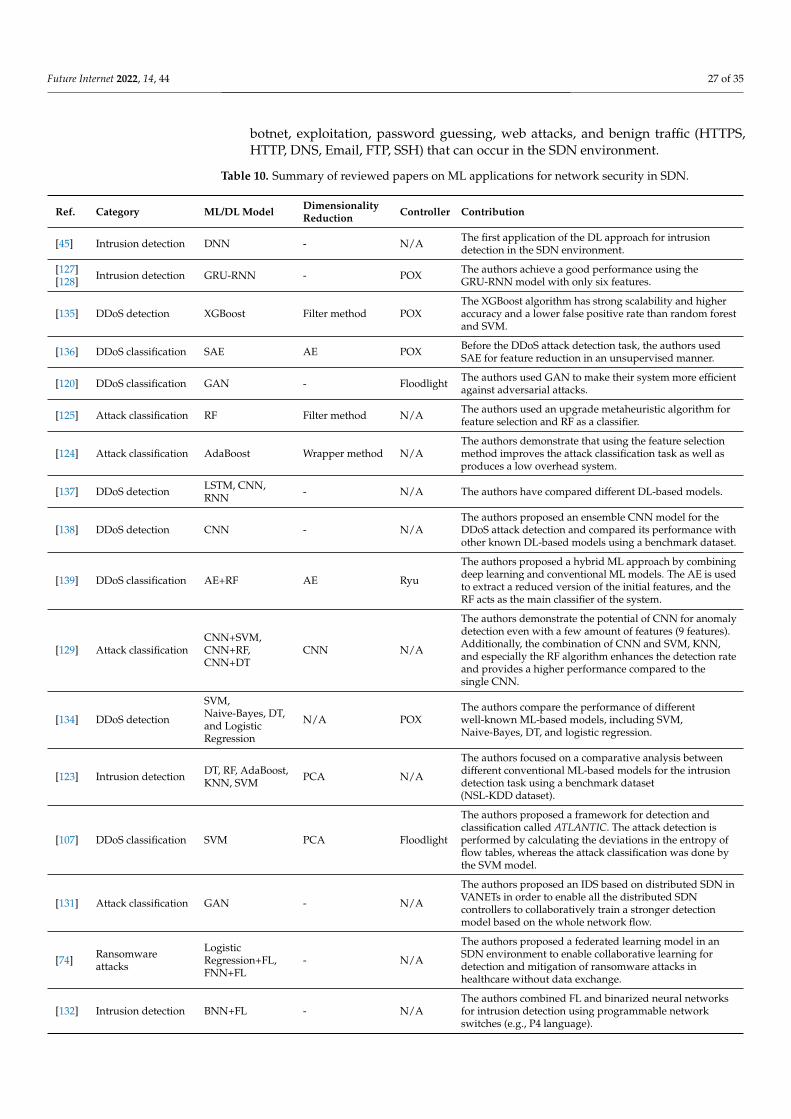
Future Internet 2022, 14, 44 27 of 35
botnet, exploitation, password guessing, web attacks, and benign traffic (HTTPS,HTTP, DNS, Email, FTP, SSH) that can occur in the SDN environment.
Table 10. Summary of reviewed papers on ML applications for network security in SDN.
Ref. Category ML/DL Model DimensionalityReduction Controller Contribution
[45] Intrusion detection DNN - N/A The first application of the DL approach for intrusiondetection in the SDN environment.
[127][128] Intrusion detection GRU-RNN - POX The authors achieve a good performance using the
GRU-RNN model with only six features.
[135] DDoS detection XGBoost Filter method POXThe XGBoost algorithm has strong scalability and higheraccuracy and a lower false positive rate than random forestand SVM.
[136] DDoS classification SAE AE POX Before the DDoS attack detection task, the authors usedSAE for feature reduction in an unsupervised manner.
[120] DDoS classification GAN - Floodlight The authors used GAN to make their system more efficientagainst adversarial attacks.
[125] Attack classification RF Filter method N/A The authors used an upgrade metaheuristic algorithm forfeature selection and RF as a classifier.
[124] Attack classification AdaBoost Wrapper method N/AThe authors demonstrate that using the feature selectionmethod improves the attack classification task as well asproduces a low overhead system.
[137] DDoS detection LSTM, CNN,RNN - N/A The authors have compared different DL-based models.
[138] DDoS detection CNN - N/AThe authors proposed an ensemble CNN model for theDDoS attack detection and compared its performance withother known DL-based models using a benchmark dataset.
[139] DDoS classification AE+RF AE Ryu
The authors proposed a hybrid ML approach by combiningdeep learning and conventional ML models. The AE is usedto extract a reduced version of the initial features, and theRF acts as the main classifier of the system.
[129] Attack classificationCNN+SVM,CNN+RF,CNN+DT
CNN N/A
The authors demonstrate the potential of CNN for anomalydetection even with a few amount of features (9 features).Additionally, the combination of CNN and SVM, KNN,and especially the RF algorithm enhances the detection rateand provides a higher performance compared to thesingle CNN.
[134] DDoS detection
SVM,Naive-Bayes, DT,and LogisticRegression
N/A POXThe authors compare the performance of differentwell-known ML-based models, including SVM,Naive-Bayes, DT, and logistic regression.
[123] Intrusion detection DT, RF, AdaBoost,KNN, SVM PCA N/A
The authors focused on a comparative analysis betweendifferent conventional ML-based models for the intrusiondetection task using a benchmark dataset(NSL-KDD dataset).
[107] DDoS classification SVM PCA Floodlight
The authors proposed a framework for detection andclassification called ATLANTIC. The attack detection isperformed by calculating the deviations in the entropy offlow tables, whereas the attack classification was done bythe SVM model.
[131] Attack classification GAN - N/A
The authors proposed an IDS based on distributed SDN inVANETs in order to enable all the distributed SDNcontrollers to collaboratively train a stronger detectionmodel based on the whole network flow.
[74] Ransomwareattacks
LogisticRegression+FL,FNN+FL
- N/A
The authors proposed a federated learning model in anSDN environment to enable collaborative learning fordetection and mitigation of ransomware attacks inhealthcare without data exchange.
[132] Intrusion detection BNN+FL - N/AThe authors combined FL and binarized neural networksfor intrusion detection using programmable networkswitches (e.g., P4 language).

Future Internet 2022, 14, 44 28 of 35
3.3.3. Discussion
Different ML/DL-based models have been used for intrusion detection/classification.Despite the performance of DL models, many solutions use conventional ML models(shown from Table 10) due to their simplicity. However, these models are usually accom-panied by some dimensionality reduction methods. Additionally, as seen in the literaturereview, the detection of DDoS attacks has attracted many researchers. In other words, sincethe SDN controller represents the central brain of the network that stores and processesthe data from all forwarding devices, it can be targeted by DDoS attacks. Moreover, FLcan be used to improve the security and privacy of the end-users by keeping the traffic atthe level of the data plane without damaging the controller. It is able to involve a massivenumber of forwarding devices which are important for training DL models. Therefore,by only sharing the local update of the global model between the forwarding devices andthe controller, the communication overhead may be reduced, hence speeding up the attackdetection/classification.
4. Research Challenges and Future Directions
Research works on the use of ML techniques with networks have produced a multitudeof novel approaches. The application of ML/DL models to networking brings several usecases and solutions. However, these solutions suffer from some issues and challengesin practice [50,148]. Many important factors should be considered when designing anML-based system in an SDN environment. In this context, this section discusses the keychallenges and the issues of using ML/DL algorithms for network management in the SDNenvironment. Then, we present some research opportunities in related areas.
Imbalanced data samples: Class imbalances are one of the critical problems in trafficclassification/intrusion detection. For example, most of the time, the samples of theanomaly are rare, and there is a great imbalance between the amount of several applications’traffic (i.e., Google, Facebook, Skype) compared to other traffic. A two-class dataset is saidto be imbalanced if one of the classes (the minority one) is represented by a very smallnumber of instances in comparison to the other (majority) class. The classifier tends to bebiased toward the larger groups that have more observations in the training sample [149].Therefore, ignoring the unequal misclassification risk for different groups may have asignificant impact on the practical use of the classification [23]. Several methods have beenproposed as solutions to imbalance class problems, such as under-sampling, over-sampling,synthetic minority over-sampling techniques (SMOTE), or using boosting methods [150].
Identifying DL architecture: Engineering the right set of features for a given scenariois often key to the success of a machine-learning project and is not an easy-to-solve question.Therefore, one of the challenges of ML is to automate more and more of the featureengineering process. DL is currently the most active topic of ML. It can process raw dataand generate relevant features autonomously. These features are automatically extractedfrom the training data by DL. However, it is computationally demanding, especially ifcomputing resources are limited. DL has many hyperparameters and their number growsexponentially with the depth of the model. Therefore, it requires a lot of tuning, and thereis no clear mathematical proof to interpret its architecture. Finding suitable architecture(i.e., number of hidden layers) and identifying optimal hyperparameters (i.e., learning rate,loss function, etc.) are difficult tasks and can influence the model performance.
Available datasets: Note that the model training performance is highly dependent onthe dataset. Therefore, it is one important component for ML/DL models training, as it hasa direct impact on the accuracy and applicability of classifiers [86]. Although there are afew recent public datasets available for traffic classification [88,96], there is no commonlyagreed-upon dataset for most traffic-related classification problems. Additionally, choosingthe right dataset is difficult because ML models can only identify applications based onwhat it has known (existing in the training set). ML algorithms, and especially DL models,can further benefit from training data augmentation. This is indeed an opportunity forusing ML/DL algorithms to improve QoS, as the networks generate tremendous amounts

Future Internet 2022, 14, 44 29 of 35
of data and the intensive growth of applications on the Internet. However, due to privacyand lack of shareable data, there is difficulty in progressing on traffic classification. To solvethese issues, distributed learning and, especially, FL have started to attract more andmore researchers for network traffic management. Moreover, due to the huge number ofapplications on the Internet, the dataset cannot contain all of them. Therefore, the amountof available data could still be insufficient to train ML algorithms effectively, especiallyDL algorithms. For these reasons, many researchers try to use old datasets to test theirsolutions. However, this solution is inefficient, as the behaviors of modern applicationschange, and their complexity increases every day. Furthermore, most network data areunlabeled; hence, fine-grained classification becomes impractical, and it is unrealistic toachieve low complexity classification based on unsupervised learning.
Selection of ML models: ML/DL models are constructed and tested in their environ-ment (i.e., dataset, features). However, average high performance does not guarantee highperformance with other problems. Additionally, the choice of the appropriate model isa daunting task, since it depends on many parameters such as the types of data, the sizeof the data samples/features, the time, and computing resource constraints, as well asthe type of prediction outcomes. Therefore, in light of the diversity of ML/DL models,choosing the appropriate one is a difficult task because a single wrong decision can beextremely costly.
Selection of flow features: Besides the selection of the suitable ML model, the per-formance of this model relies on the collection of features used for the flow classification.Thus, one of the most challenging aspects of flow-based techniques is how to select theappropriate flow of statistical features. Researchers try to only use features which are easyto be obtained with the SDN controller to train the model, but this solution can decreasethe performance of ML models [45]. Additionally, some features can have a continuous ordiscrete value. However, several ML models cannot learn with two types of features at thesame time, such as SVM and XGBoost.
Scalable traffic classification: In recent years, we have observed enormous growth inInternet traffic. Increased traffic volume makes traffic classification tasks computationallyintensive and imposes several challenges to implement in real-time. Distributed architecturecan solve this issue and rapidly query, analyze, and transform data at scale. Spark performs100x faster computation than Hadoop [151]. It also provides a fast machine learning library,MLib, that leverages high-quality learning algorithms. However, based on Table 8, nostudy has carried out an experimental evaluation on the scalability of ML-based trafficclassification in SDN. Moreover, FL can be used in order to take advantage of the end-userand edge devices by training the model locally in a distributed way on such devices.
Variance and bias: The most important evaluation criterion for a learner is its abilityto generalize. Generalization error can be divided into two components, which are varianceand bias. Variance defines the consistency of a learner’s ability to predict random things(over-fitting), and bias describes the ability of a learner to learn the wrong thing (under-fitting) [18]. A learner with the lowest bias, however, is not necessarily the optimal solution,because the ability to generalize from training data is also assessed by a second parametertermed variance. A major challenge for ML/DL models is to optimize the trade-off betweenbias and variance. Therefore, to prevent this problem, we can split our data into threesubsets, which are training, validation, and testing. The training set is used for the learningtask, validation helps to find the parameters of the learner, and then the testing set is used toevaluate the performance of the constructed model. Additionally, another method namedK-fold cross-validation can be used to avoid the problem of over-fitting. In this method,the data is divided into k folds; then, k − 1 folds are used as the training set, and theremaining fold is used as the test set. However, it is expensive in terms of training timeand computation.
Network Slicing: As presented in the literature, the definition of a slice is based onthe QoS requirement proposed by NGMN, and no intelligence has been applied in thiscontext. Currently, new online applications are emerging every day, and network behavior

Future Internet 2022, 14, 44 30 of 35
is constantly changing. Additionally, the explosion of smart devices and the surge in trafficwill need different requirements for their performance. Therefore, the ML concepts canhelp to find more behaviors and better slices even with a single network infrastructure.
Knowledge transfer in multiple SDN controllers: The model trained by some SDNcontrollers can capture common features with other SDN controllers (e.g., domain). Thismeans the data can be transferable between the domain and hence can provide a moregeneral model. For this purpose, transfer learning can be used in order to transfer theknowledge between the different SDN controllers. It helps the model to avoid beingtrained from scratch, thus accelerating the model convergence and solving the problem ofinsufficient training data [152].
Privacy: In recent years, privacy has been one of the most important concerns inthe network domain. ML models, especially DL models, may benefit from training dataaugmentation. However, the end-users or clients refuse to provide their data due to therisk of data misuse or inspection by external devices. To solve this issue and guaranteethat training data remains on its owners, a distributed learning technique like FL can be apromising solution. It enables the operators to benefit through the data of clients withoutsacrificing their privacy. In this context, FL can be the appropriate approach for networktraffic management, especially with SDN architecture, as it reduces the data exchangebetween the data plane and SDN controller. Therefore, it guarantees data confidentiality,minimizes costs of data communication, and relieves the burden on the SDN controller.Additionally, it can be used with network slicing for user prediction for each slice to enablethe local data training without the need of sharing the data between the slices.
5. Conclusions
In this survey, we examined the integration of machine and deep learning in nextgeneration networks, which is becoming a promising topic and enables intelligent networktraffic management. We first provide an overview of ML and DL along with SDN in whichthe basic background and motivation of these technologies were detailed. More specifically,we have presented that SDN can benefit from ML and DL approaches. Furthermore,we have summarized basic concepts and advanced principles of several ML and DLmodels, as well as their strengths and weaknesses. We have also presented dimensionalityreduction techniques (i.e., feature selection and extraction) and their benefits with theconventional ML models. In addition, we have shown how ML/DL models could helpvarious aspects of network traffic management, including network traffic classification,prediction, and network security. However, the combination of SDN and ML can suffer fromvarious issues and challenges. Therefore, we discussed those which need the researcher’sattention both in industry and academia. In summary, research on the integrated SDN andML for intelligent traffic network management in next-generation networks is promising,and several challenges lay ahead. This survey attempts to explore essential ingredientsrelated to the integration of ML in SDN and aims to become a reference point for the futureefforts of researchers who would like to delve into the field of intelligent traffic networksand their applications.
Funding: This research received no external funding.
Data Availability Statement: Not Applicable. The study does not report any data.
Conflicts of Interest: The authors declare no conflict of interest.
References1. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2017–2022 White Paper; Cisco: San Jose, CA, USA, 2019.2. Ayoubi, S.; Limam, N.; Salahuddin, M.A.; Shahriar, N.; Boutaba, R.; Estrada-Solano, F.; Caicedo, O.M. Machine learning for
cognitive network management. IEEE Commun. Mag. 2018, 56, 158–165.3. Mestres, A.; Rodriguez-Natal, A.; Carner, J.; Barlet-Ros, P.; Alarcón, E.; Solé, M.; Muntés-Mulero, V.; Meyer, D.; Barkai, S.;
Hibbett, M.J.; et al. Knowledge-defined networking. ACM SIGCOMM Comput. Commun. Rev. 2017, 47, 2–10.

Future Internet 2022, 14, 44 31 of 35
4. Xie, J.; Yu, F.R.; Huang, T.; Xie, R.; Liu, J.; Wang, C.; Liu, Y. A survey of machine learning techniques applied to software definednetworking (SDN): Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 21, 393–430.
5. Latah, M.; Toker, L. Application of Artificial Intelligence to Software Defined Networking: A survey. Indian J. Sci. Technol. 2016,9, 1–7.
6. Latah, M.; Toker, L. Artificial Intelligence enabled Software-Defined Networking: A comprehensive overview. IET Netw. 2018,8, 79–99.
7. Zhao, Y.; Li, Y.; Zhang, X.; Geng, G.; Zhang, W.; Sun, Y. A survey of networking applications applying the Software DefinedNetworking concept based on machine learning. IEEE Access 2019, 7, 95397–95417.
8. Thupae, R.; Isong, B.; Gasela, N.; Abu-Mahfouz, A.M. Machine learning techniques for traffic identification and classification inSDWSN: A survey. In Proceedings of the 44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC,USA, 21–23 October 2018; pp. 4645–4650.
9. Mohammed, A.R.; Mohammed, S.A.; Shirmohammadi, S. Machine Learning and Deep Learning based traffic classificationand prediction in Software Defined Networking. In Proceedings of the IEEE International Symposium on Measurements &Networking (M&N), Catania, Italy, 8–10 July 2019; pp. 1–6.
10. Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive surveyon machine learning for networking: Evolution, applications and research opportunities. J. Internet Serv. Appl. 2018, 9, 1–99.
11. Sultana, N.; Chilamkurti, N.; Peng, W.; Alhadad, R. Survey on SDN based network intrusion detection system using machinelearning approaches. Peer- Netw. Appl. 2019, 12, 493–501.
12. Nguyen, T.N. The challenges in SDN/ML based network security: A survey. arXiv 2018, arXiv:1804.03539.13. Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S. A survey on deep learning:
Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36.14. Deng, L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process.
2014, 3, e2.15. Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In
Proceedings of the Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378.16. Liu, H.; Yu, L. Toward Integrating Feature Selection Algorithms for Classification and Clustering. IEEE Trans. Knowl. Data Eng.
2005, 17, 491–502.17. Kobo, H.I.; Abu-Mahfouz, A.M.; Hancke, G.P. A survey on Software-Defined Wireless Sensor Networks: Challenges and design
requirements. IEEE Access 2017, 5, 1872–1899.18. Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87.19. Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260.20. Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997.21. Bengio, Y.; Lee, H. Editorial introduction to the neural networks special issue on deep learning of representations. Neural Netw.
2015, 64, 1–3.22. Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.;
Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830.23. Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Man, Cybern. 2000, 30, 451–462.24. Pacheco, F.; Exposito, E.; Gineste, M.; Baudoin, C.; Aguilar, J. Towards the deployment of machine learning solutions in network
traffic classification: A systematic survey. IEEE Commun. Surv. Tutor. 2019, 21, 1988–2014.25. Aouedi, O.; Piamrat, K.; Parrein, B. Performance evaluation of feature selection and tree-based algorithms for traffic classification.
In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC,Canada 14–23 June 2021.
26. Tomar, D.; Agarwal, S. A survey on Data Mining approaches for Healthcare. Int. J. Bio-Sci. Bio-Technol. 2013, 5, 241–266.27. Zhu, X.J. Semi-Supervised Learning Literature Survey; Technical Report; University of Wisconsin-Madison Department of Computer
Sciences: Madison, WI, USA, 2005.28. Aouedi, O.; Piamrat, K.; Bagadthey, D. A semi-supervised stacked autoencoder approach for network traffic classification. In
Proceedings of the 2020 IEEE 28th International Conference on Network Protocols (ICNP); Madrid, Spain, 13–16 October 2020.29. Sutton, R.S.; Barto, A.G.; others. Introduction to Reinforcement Learning, MIT Press: Cambridge, UK, 1998; Volume 135.30. Watkins, C.J.; Dayan, P. Q-learning. Machine Learn. 1992, 8, 279–292.31. Boyan, J.A.; Littman, M.L. Packet routing in dynamically changing networks: A reinforcement learning approach. In Advances in
Neural Information Processing Systems. Available online: https://proceedings.neurips.cc/paper/1993/hash/4ea06fbc83cdd0a06020c35d50e1e89a-Abstract.html (accessed on 15 January 2022) .
32. Bitaillou, A.; Parrein, B.; Andrieux, G. Q-routing: From the algorithm to the routing protocol. In Proceedings of the InternationalConference on Machine Learning for Networking, Paris, France, 3–5 December 2019; pp. 58–69.
33. Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deepreinforcement learning. arXiv 2013, arXiv:1312.5602.
34. Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274.35. Ketkar, N.; Santana, E. Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; Volume 1.36. Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157.

Future Internet 2022, 14, 44 32 of 35
37. Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach.Intell. 2013, 35, 1798–1828.
38. Mayer, R.; Jacobsen, H.A. Scalable deep learning on distributed infrastructures: Challenges, techniques, and tools. ACM Comput.Surv. (CSUR) 2020, 53, 1–37.
39. Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065.40. Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf.
Process. Syst. 2012, 25, 1097–1105.41. Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice-Hall: Hoboken, NJ, USA, 2007.42. Wozniak, M.; Grana, M.; Corchado, E. A survey of multiple classifier systems as hybrid systems. Inf. Fusion 2014, 16, 3–17.43. Li, Y.; Pan, Y. A novel ensemble deep learning model for stock prediction based on stock prices and news. Int. J. Data Sci. Anal.
2021, 1–11, doi:10.1007/s41060-021-00279-9.44. Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45.45. Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep learning approach for network intrusion detection
in Software Defined Networking. In Proceedings of the 2016 International Conference on Wireless Networks and MobileCommunications (WINCOM), Fez, Morocco, 26–29 October 2016; pp. 258–263.
46. Freund, Y.; Mason, L. The alternating decision tree learning algorithm. In Proceedings of the 16th International Conference onMachine Learning (ICML), Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 124–133.
47. Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32.48. Abar, T.; Letaifa, A.B.; El Asmi, S. Machine learning based QoE prediction in SDN networks. In Proceedings of the 13th Interna-
tional Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 1395–1400.49. Schapire, R.E. The boosting approach to machine learning: An overview. In Nonlinear Estimation and Classification; Springer:
New York, NY, USA, 2003; pp. 149–171.50. Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40.51. L’heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A. Machine learning with big data: Challenges and approaches. IEEE
Access 2017, 5, 7776–7797.52. Janecek, A.; Gansterer, W.; Demel, M.; Ecker, G. On the relationship between feature selection and classification accuracy.
In Proceedings of the New Challenges for Feature Selection in Data Mining and Knowledge Discovery, Antwerp, Belgium,15 September 2008; Volume 4, pp. 90–105.
53. Chu, C.T.; Kim, S.K.; Lin, Y.A.; Yu, Y.; Bradski, G.; Olukotun, K.; Ng, A.Y. Map-reduce for machine learning on multicore. Adv.Neural Inf. Process. Syst. 2007, 19, 281–288.
54. Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn.2002, 46, 389–422.
55. Motoda, H.; Liu, H. Feature selection, extraction and construction. Commun. IICM (Institute Inf. Comput. Mach. Taiwan) 2002, 5, 2.56. Rangarajan, L.; others. Bi-level dimensionality reduction methods using feature selection and feature extraction. Int. J. Comput.
Appl. 2010, 4, 33–38.57. Pal, M.; Foody, G.M. Feature selection for classification of hyperspectral data by SVM. IEEE Trans. Geosci. Remote Sens. 2010,
48, 2297–2307.58. Stadler, R.; Pasquini, R.; Fodor, V. Learning from network device statistics. J. Netw. Syst. Manag. 2017, 25, 672–698.59. Da Silva, A.S.; Machado, C.C.; Bisol, R.V.; Granville, L.Z.; Schaeffer-Filho, A. Identification and selection of flow features
for accurate traffic classification in SDN. In Proceedings of the 14th International Symposium on Network Computing andApplications,Cambridge, MA, USA, 28–30 September 2015; pp. 134–141.
60. Xiao, P.; Qu, W.; Qi, H.; Xu, Y.; Li, Z. An efficient elephant flow detection with cost-sensitive in SDN. In Proceedings of the 1stInternational Conference on Industrial Networks and Intelligent Systems (INISCom), Tokyo, Japan, 2–4 March 2015; pp. 24–28.
61. Wang, P.; Lin, S.C.; Luo, M. A framework for QoS-aware traffic classification using semi-supervised machine learning in SDNs.In Proceedings of the IEEE International Conference on Services Computing (SCC), San Francisco, CA, USA, 27 June–2 July 2016;pp. 760–765.
62. Amaral, P.; Dinis, J.; Pinto, P.; Bernardo, L.; Tavares, J.; Mamede, H.S. Machine learning in software defined networks: Datacollection and traffic classification. In Proceedings of the 24th International Conference on Network Protocols (ICNP), Singapore,8–11 November 2016; pp. 1–5.
63. Zhang, C.; Wang, X.; Li, F.; He, Q.; Huang, M. Deep learning-based network application classification for SDN. Trans. Emerg.Telecommun. Technol. 2018, 29, e3302.
64. Kalousis, A.; Prados, J.; Hilario, M. Stability of Feature Selection Algorithms: A Study on High-Dimensional Spaces. Knowl. Inf.Syst. 2007, 12, 95–116.
65. Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156.66. Dash, M.; Liu, H. Feature selection for clustering. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and
Data Mining, Kyoto, Japan, April 18–20 2000; pp. 110–121.67. Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th
International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 856–863.

Future Internet 2022, 14, 44 33 of 35
68. Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing2016, 187, 27–48.
69. Aouedi, O.; Tobji, M.A.B.; Abraham, A. An Ensemble of Deep Auto-Encoders for Healthcare Monitoring. In Proceedings of theInternational Conference on Hybrid Intelligent Systems, Porto, Portugal, 13–15 December 2018; pp. 96–105.
70. Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188.71. Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear discriminant analysis: A detailed tutorial. AI Commun. 2017,
30, 169–190.72. Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated Learning for Wireless Communications: Motivation, Opportunities, and
Challenges. IEEE Commun. Mag. 2020, 58, 46–51.73. Agrawal, S.; Sarkar, S.; Aouedi, O.; Yenduri, G.; Piamrat, K.; Bhattacharya, S.; Maddikunta, P.K.R.; Gadekallu, T.R. Federated
Learning for Intrusion Detection System: Concepts, Challenges and Future Directions. arXiv 2021, arXiv:2106.09527.74. Thapa, C.; Karmakar, K.K.; Celdran, A.H.; Camtepe, S.; Varadharajan, V.; Nepal, S. FedDICE: A ransomware spread detection in a
distributed integrated clinical environment using federated learning and SDN based mitigation. arXiv 2021, arXiv:2106.05434.75. Sacco, A.; Esposito, F.; Marchetto, G. A Federated Learning Approach to Routing in Challenged SDN-Enabled Edge Networks. In
Proceedings of the 6th IEEE Conference on Network Softwarization (NetSoft), Ghent, Belgium, 29 June–3 July 2020; pp. 150–154.76. Zhang, M.; John, W.; Claffy, K.C.; Brownlee, N. State of the Art in Traffic Classification: A Research Review. In Proceedings of the
PAM Student Workshop, Seoul, Korea, 1–3 April 2009; pp. 3–4.77. Nguyen, T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv.
Tutor. 2008, 10, 56–76.78. Parsaei, M.R.; Sobouti, M.J.; Khayami, S.R.; Javidan, R. Network traffic classification using machine learning techniques over
software defined networks. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 220–225.79. Xiao, P.; Liu, N.; Li, Y.; Lu, Y.; Tang, X.j.; Wang, H.W.; Li, M.X. A traffic classification method with spectral clustering in SDN.
In Proceedings of the 17th International Conference on Parallel and Distributed Computing, Applications and Technologies(PDCAT), Guangzhou, China, 16–18 December 2016; pp. 391–394.
80. Zaki, F.A.M.; Chin, T.S. FWFS: Selecting robust features towards reliable and stable traffic classifier in SDN. IEEE Access 2019,7, 166011–166020.
81. Eom, W.J.; Song, Y.J.; Park, C.H.; Kim, J.K.; Kim, G.H.; Cho, Y.Z. Network Traffic Classification Using Ensemble Learning inSoftware-Defined Networks. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information andCommunication (ICAIIC), Jeju Island, Korea, 20–23 April 2021; pp. 89–92.
82. Yang, T.; Vural, S.; Qian, P.; Rahulan, Y.; Wang, N.; Tafazolli, R. Achieving Robust Performance for Traffic Classification UsingEnsemble Learning in SDN Networks. In Proceedings of the IEEE International Conference on Communications, 14–23 June 2021,virtual.
83. Hu, N.; Luan, F.; Tian, X.; Wu, C. A Novel SDN-Based Application-Awareness Mechanism by Using Deep Learning. IEEE Access2020, 8, 160921–160930.
84. Moore, A.; Zuev, D.; Crogan, M. Discriminators for Use in Flow-Based Classification. Available online: https://www.cl.cam.ac.uk/~awm22/publication/moore2005discriminators.pdf (accessed on 15 January 2022).
85. Malik, A.; de Fréin, R.; Al-Zeyadi, M.; Andreu-Perez, J. Intelligent SDN traffic classification using deep learning: Deep-SDN. InProceedings of the 2020 2nd International Conference on Computer Communication and the Internet (ICCCI), Nagoya, Japan,26–29 June 2020; pp. 184–189.
86. Yu, C.; Lan, J.; Xie, J.; Hu, Y. QoS-aware traffic classification architecture using machine learning and deep packet inspection inSDNs. Procedia Comput. Sci. 2018, 131, 1209–1216.
87. Kuranage, M.P.J.; Piamrat, K.; Hamma, S. Network Traffic Classification Using Machine Learning for Software Defined Networks.In Proceedings of the International Conference on Machine Learning for Networking, Paris, France, 3–5 December 2019; pp. 28–39.
88. Rojas, J.S.; Gallón, Á.R.; Corrales, J.C. Personalized service degradation policies on OTT applications based on the consumptionbehavior of users. In Proceedings of the International Conference on Computational Science and Its Applications, Melbourne,Australia, 2–5 July 2018; pp. 543–557.
89. Qazi, Z.A.; Lee, J.; Jin, T.; Bellala, G.; Arndt, M.; Noubir, G. Application-awareness in SDN. In Proceedings of the ACM SIGCOMMconference on SIGCOMM, Hong Kong, China, 12–16 August 2013; pp. 487–488.
90. Li, Y.; Li, J. MultiClassifier: A combination of DPI and ML for application-layer classification in SDN. In Proceedings of the 2ndInternational Conference on Systems and Informatics (ICSAI), Shanghai, China, 15–17 November 2014; pp. 682–686.
91. Raikar, M.M.; Meena, S.; Mulla, M.M.; Shetti, N.S.; Karanandi, M. Data traffic classification in Software Defined Networks (SDN)using supervised-learning. Procedia Comput. Sci. 2020, 171, 2750–2759.
92. Uddin, M.; Nadeem, T. TrafficVision: A case for pushing software defined networks to wireless edges. In Proceedings of the 13thInternational Conference on Mobile Ad Hoc and Sensor Systems (MASS), Brasilia, Brazil, 10–13 October 2016; pp. 37–46.
93. Amaral, P.; Pinto, P.F.; Bernardo, L.; Mazandarani, A. Application aware SDN architecture using semi-supervised trafficclassification. In Proceedings of the 2018 IEEE Conference on Network Function Virtualization and Software Defined Networks(NFV-SDN), Verona, Italy, 27–29 November 2018; pp. 1–6.
94. Nakao, A.; Du, P. Toward in-network deep machine learning for identifying mobile applications and enabling application specificnetwork slicing. IEICE Trans. Commun. 2018, E101.B, 1536–1543.

Future Internet 2022, 14, 44 34 of 35
95. Wang, P.; Ye, F.; Chen, X.; Qian, Y. Datanet: Deep learning based encrypted network traffic classification in sdn home gateway.IEEE Access 2018, 6, 55380–55391.
96. Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy,19–21 February 2016; pp. 407–414.
97. Chang, L.H.; Lee, T.H.; Chu, H.C.; Su, C. Application-based online traffic classification with deep learning models on SDNnetworks. Adv. Technol. Innov. 2020, 5, 216–229.
98. Cisco Visual Networking Index: Forecast and Methodology, 2016–2021. Available online: https://www.reinvention.be/webhdfs/v1/docs/complete-white-paper-c11-481360.pdf (accessed on 15 January 2022).
99. Rego, A.; Canovas, A.; Jiménez, J.M.; Lloret, J. An intelligent system for video surveillance in IoT environments. IEEE Access2018, 6, 31580–31598.
100. Indira, B.; Valarmathi, K.; Devaraj, D. An approach to enhance packet classification performance of software-defined networkusing deep learning. Soft Comput. 2019, 23, 8609–8619.
101. Abidi, M.H.; Alkhalefah, H.; Moiduddin, K.; Alazab, M.; Mohammed, M.K.; Ameen, W.; Gadekallu, T.R. Optimal 5G networkslicing using machine learning and deep learning concepts. Comput. Stand. Interfaces 2021, 76, 103518.
102. Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features.In Proceedings of the 3rd International Conference on Information System Security and Privacy (ICISSP), Porto, Portugal,19–21 February 2017; pp. 253–262.
103. Tong, V.; Tran, H.A.; Souihi, S.; Mellouk, A. A novel QUIC traffic classifier based on convolutional neural networks. InProceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6.
104. Bentéjac, C.; Csørgo, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021,54, 1937–1967.
105. López-Raventós, Á.; Wilhelmi, F.; Barrachina-Muñoz, S.; Bellalta, B. Machine learning and software defined networks forhigh-density wlans. arXiv 2018, arXiv:1804.05534 .
106. Alvizu, R.; Troia, S.; Maier, G.; Pattavina, A. Machine-learning-based prediction and optimization of mobile metro-core networks.In Proceedings of the 2018 IEEE Photonics Society Summer Topical Meeting Series (SUM), Waikoloa, HI, USA , 9–11 July 2018;pp. 155–156.
107. Silva, A.; Wickboldt, J.; Granville, L.; Schaeffer-Filho, A. ATLANTIC: A framework for anomaly traffic detection, classification,and mitigation in SDN. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium (NOMS), Istanbul,Turkey, 25–29 April 2016; pp. 27–35.
108. Kumari, A.; Chandra, J.; Sairam, A.S. Predictive Flow Modeling in Software Defined Network. In Proceedings of the TENCON2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 1494–1498.
109. Azzouni, A.; Pujolle, G. NeuTM: A neural network-based framework for traffic matrix prediction in SDN. In Proceedings of theIEEE/IFIP Network Operations and Management Symposium (NOMS), Taipei, Taiwan, 23–27 April 2018; pp. 1–5.
110. Alvizu, R.; Troia, S.; Maier, G.; Pattavina, A. Matheuristic with machine-learning-based prediction for software-defined mobilemetro-core networks. J. Opt. Commun. Netw. 2017, 9, 19–30.
111. Chen-Xiao, C.; Ya-Bin, X. Research on load balance method in SDN. Int. J. Grid Distrib. Comput. 2016, 9, 25–36.112. Tang, F.; Fadlullah, Z.M.; Mao, B.; Kato, N. An intelligent traffic load prediction-based adaptive channel assignment algorithm in
SDN-IoT: A deep learning approach. IEEE Internet Things J. 2018, 5, 5141–5154.113. Lazaris, A.; Prasanna, V.K. Deep learning models for aggregated network traffic prediction. In Proceedings of the 2019 15th
International Conference on Network and Service Management (CNSM), Halifax, NS, Canada, 21–25 October 2019; pp. 1–5.114. CAIDA Anonymized Internet Traces 2016. 2016. Available online: https://www.youtube.com/watch?v=u8OKjyKqcV8&list=
RDqyvwOSHOpT8&index=4 (accessed on 15 January 2022).115. Le, D.H.; Tran, H.A.; Souihi, S.; Mellouk, A. An AI-based Traffic Matrix Prediction Solution for Software-Defined Network. In
Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6.116. Ferreira, D.; Reis, A.B.; Senna, C.; Sargento, S. A Forecasting Approach to Improve Control and Management for 5G Networks.
IEEE Trans. Netw. Serv. Manag. 2021, 18, 1817–1831.117. Available online: http://www.cs.utexas.edu/~yzhang/research/AbileneTM/ (accessed on 15 January 2021).118. Uhlig, S.; Quoitin, B.; Lepropre, J.; Balon, S. Providing public intradomain traffic matrices to the research community. ACM
SIGCOMM Comput. Commun. Rev. 2006, 36, 83–86.119. Barlacchi, G.; De Nadai, M.; Larcher, R.; Casella, A.; Chitic, C.; Torrisi, G.; Antonelli, F.; Vespignani, A.; Pentland, A.; Lepri, B. A
multi-source dataset of urban life in the city of Milan and the Province of Trentino. Sci. Data 2015, 2, 1–15.120. Novaes, M.P.; Carvalho, L.F.; Lloret, J.; Proença, M.L., Jr. Adversarial Deep Learning approach detection and defense against
DDoS attacks in SDN environments. Future Gener. Comput. Syst. 2021, 125, 156–167.121. Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets
for intrusion detection. Comput. Secur. 2012, 31, 357–374.122. Base, R.; Mell, P. Special Publication on Intrusion Detection Systems; NIST Infidel, Inc., National Institute of Standards and
Technology: Scotts Valley, CA, USA, 2001.

Future Internet 2022, 14, 44 35 of 35
123. Latah, M.; Toker, L. Towards an efficient anomaly-based intrusion detection for software-defined networks. IET Netw. 2018,7, 453–459.
124. Li, J.; Zhao, Z.; Li, R. Machine learning-based IDS for Software-Defined 5G network. IET Netw. 2018, 7, 53–60.125. Li, J.; Zhao, Z.; Li, R.; Zhang, H. AI-based two-stage intrusion detection for Software Defined IoT networks. IEEE Internet Things
J. 2018, 6, 2093–2102.126. Elsayed, M.S.; Le-Khac, N.A.; Dev, S.; Jurcut, A.D. Machine-learning techniques for detecting attacks in SDN. arXiv 2019,
arXiv:1910.00817.127. Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep recurrent neural network for intrusion detection in
sdn-based networks. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft),Montreal, QC, Canada, 25–29 June 2018; pp. 202–206.
128. Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M.; El Moussa, F. DeepIDS: Deep learning approach for intrusiondetection in Software Defined Networking. Electronics 2020, 9, 1533.
129. ElSayed, M.S.; Le-Khac, N.A.; Albahar, M.A.; Jurcut, A. A novel hybrid model for intrusion detection systems in SDNs based onCNN and a new regularization technique. J. Netw. Comput. Appl. 2021, 191, 103160.
130. Elsayed, M.S.; Le-Khac, N.A.; Jurcut, A.D. InSDN: A novel SDN intrusion dataset. IEEE Access 2020, 8, 165263–165284.131. Shu, J.; Zhou, L.; Zhang, W.; Du, X.; Guizani, M. Collaborative intrusion detection for VANETs: A deep learning-based distributed
SDN approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4519–4530.132. Qin, Q.; Poularakis, K.; Leung, K.K.; Tassiulas, L. Line-speed and scalable intrusion detection at the network edge via federated
learning. In Proceedings of the 2020 IFIP Networking Conference (Networking), Paris, France, 22–26 June 2020; pp. 352–360.133. Singh, J.; Behal, S. Detection and mitigation of DDoS attacks in SDN: A comprehensive review, research challenges and future
directions. Comput. Sci. Rev. 2020, 37, 100279.134. Ahmad, A.; Harjula, E.; Ylianttila, M.; Ahmad, I. Evaluation of machine learning techniques for security in SDN. In Proceedings
of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6.135. Chen, Z.; Jiang, F.; Cheng, Y.; Gu, X.; Liu, W.; Peng, J. XGBoost classifier for DDoS attack detection and analysis in SDN-based
cloud. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing (BIGCOMP), Shanghai,China, 15–17 January 2018; pp. 251–256.
136. Niyaz, Q.; Sun, W.; Javaid, A.Y. A deep learning based DDoS detection system in software-defined networking (SDN). arXiv2016, arXiv:1611.07400.
137. Li, C.; Wu, Y.; Yuan, X.; Sun, Z.; Wang, W.; Li, X.; Gong, L. Detection and defense of DDoS attack–based on deep learning inOpenFlow-based SDN. Int. J. Commun. Syst. 2018, 31, e3497.
138. Haider, S.; Akhunzada, A.; Mustafa, I.; Patel, T.B.; Fernandez, A.; Choo, K.K.R.; Iqbal, J. A deep CNN ensemble framework forefficient DDoS attack detection in software defined networks. IEEE Access 2020, 8, 53972–53983.
139. Krishnan, P.; Duttagupta, S.; Achuthan, K. VARMAN: Multi-plane security framework for software defined networks. Comput.Commun. 2019, 148, 215–239.
140. KDD Cup 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99 (accessed on 7 November 2021).141. Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009
IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009;pp. 1–6.
142. Morris, T.; Gao, W. Industrial control system traffic data sets for intrusion detection research. In International Conference on CriticalInfrastructure Protection; Springer: Berlin/Heidelberg, Germany, 2014; pp. 65–78.
143. Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 networkdata set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT,Australia, 10–12 November 2015; pp. 1–6.
144. Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion trafficcharacterization.. Int. Confer-Ence Inf. Syst. Secur. Priv. (ICISSP) 2018, 1, 108–116.
145. Pahl, M.O.; Aubet, F.X. All eyes on you: Distributed Multi-Dimensional IoT microservice anomaly detection. In Proceedingsof the 2018 14th International Conference on Network and Service Management (CNSM), Rome, Italy, 5–9 November 2018;pp. 72–80.
146. Moustafa, N. New Generations of Internet of Things Datasets for Cybersecurity Applications based Machine Learning: TON_IoTDatasets. In Proceedings of the eResearch Australasia Conference, Brisbane, Australia, 21–25 October 2019; pp. 21–25.
147. Ullah, I.; Mahmoud, Q.H. A two-level flow-based anomalous activity detection system for IoT networks. Electronics 2020, 9, 530.148. Casas, P. Two Decades of AI4NETS-AI/ML for Data Networks: Challenges & Research Directions. In Proceedings of the
IEEE/IFIP Network Operations and Management Symposium (NOMS), Budapest, Hungary, 20–24 April 2020; pp. 1–6.149. García, V.; Sánchez, J.; Mollineda, R. On the effectiveness of preprocessing methods when dealing with different levels of class
imbalance. Knowl.-Based Syst. 2012, 25, 13–21.150. Abd Elrahman, S.M.; Abraham, A. A review of class imbalance problem. J. Netw. Innov. Comput. 2013, 1, 332–340.151. Apache Spark. Available online: http://spark.apache.org/ (accessed on 15 January 2022).152. Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial
Neural Networks; Springer: Cham, Switzerland, 2018; pp. 270–279.




















