
Indirect text entry using one or two keys
8
Indirect Text Entry Using One or Two Keys Melanie Baljko, Andrew Tam Department of Computer Science and Engineering York University, Toronto, Canada, M3J 1P3 {mb,atam}@cs.yorku.ca 1. ABSTRACT This paper introduces a new descriptive model for indi- rect text composition facilities that is based on the notion of a containment hierarchy. This paper also demonstrates a novel, computer-aided technique for the design of indirect text selection interfaces — one in which Huffman coding is used for the derivation of the containment hierarchy. This approach guarantees the derivation of optimal containment hierarchies, insofar as mean encoding length. This paper de- scribes an empirical study of two two-key indirect text entry variants and compares them to one another and to the pre- dictive model. The intended application of these techniques is the design of improved indirect text entry facilities for the users of AAC systems. Categories and Subject Descriptors D.2.2 [Software Engineering]: Design Tools and Techniques—User Interfaces ; H.5.2 [Information Interfaces and Presentation]: User Interfaces—Evaluation/methodology ; H.1.2 [Models and Princi- ples]: User/Machine Systems—Human factors General Terms Human Factors, Measurement, Design Keywords Augmentative and Alternative Communication (AAC), Voice Output Communication Aids (VOCA), Speech Generating Devices (SGD), Indirect Text Entry, Scanning, Information Theory, Interventions for Communication Disorders, Interface Evaluation 2. INTRODUCTION Augmentative and Alternative Communication (AAC) is an area of research and clinical practice concerned with, among other things, the development of systems that mediate the communication of individuals who have little or no func- tional speech, such as those affected by conditions such as cerebral palsy, amyotrophic lateral sclerosis, or paralysis [2]. A component of many AAC interventions is an AAC de- vice, which, in a large portion of cases, is a laptop, tablet Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. ASSETS’06, October 22–25, 2006, Portland, Oregon, USA. Copyright 2006 ACM 1-59593-290-9/06/0010 ...$5.00. or other similar piece of computational hardware that pro- vides (1) a facility within which text glosses are prepared and (2) a mechanism whereby the text gloss can be passed to a text-to-speech module, so that synthesized speech can be produced from the text gloss. Such devices are often re- ferred to as Voice Output Communication Aids (VOCAs). A variety of techniques have been developed for preparing the text glosses and can be broadly categorized as composition- based or retrieval-based. Composition-based techniques en- tail the selection of symbols (usually orthographic but pos- sibly iconic), one by one, in order to form larger units of text (words, phrases, sentences), whereas the retrieval-based techniques entail navigating and making selections from a database of pre-stored units of text [5]. Each technique has its advantages and disadvantages (a full discussion of which, unfortunately, space does not permit; the interested reader is directed to the work of Alm and colleagues, e.g., [20]). Most commercial AAC devices are hybrids in the sense that they typically implement, to at least some degree, techniques belonging to both classes. Word-prediction and -completion facilities can be viewed as a retrieval-based technique that has been integrated into a composition-based facility. De- spite the utility of the hybrid approach, it remains that retrieval-based techniques are ill-suited to some communica- tive scenarios (e.g., discussions about unanticipated topics or the need to provide information about a topic that has little or no vocabulary coverage in the database). Users of AAC devices must be afforded the possibility to compose text. In previous work [3, 4], we have focused on the utility of information theory as a framework for theoretical models about the relative utility of various text composition designs. We have a particular interest in the use of Huffman coding for automating the design of text composition facilities. In this paper, we discuss a theoretical prediction that re- lates row-column and Huffman-coding-based indirect text selection and present the results of a relevant empirical user study that we conducted. 3. BACKGROUND The users of AAC devices are highly heterogeneous with re- spect to the type and number of input devices that can be reliably operated. By the term input device, we are referring to various specialized mechanisms such as contact switches (buttons) operated by positive or negative mechanical pres- sure, by puffs of breath, by eyebrow raises or threshold sen- sors that incorporate eye tracking or EMG signals (e.g., [8]). Researchers cannot know a priori the type and number of input devices that the members of the target population
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Indirect text entry using one or two keys

Indirect Text Entry Using One or Two Keys
Melanie Baljko, Andrew TamDepartment of Computer Science and Engineering
York University, Toronto, Canada, M3J 1P3
{mb,atam}@cs.yorku.ca
1. ABSTRACTThis paper introduces a new descriptive model for indi-
rect text composition facilities that is based on the notionof a containment hierarchy. This paper also demonstratesa novel, computer-aided technique for the design of indirecttext selection interfaces — one in which Huffman coding isused for the derivation of the containment hierarchy. Thisapproach guarantees the derivation of optimal containmenthierarchies, insofar as mean encoding length. This paper de-scribes an empirical study of two two-key indirect text entryvariants and compares them to one another and to the pre-dictive model. The intended application of these techniquesis the design of improved indirect text entry facilities for theusers of AAC systems.
Categories and Subject DescriptorsD.2.2 [Software Engineering]: Design Tools and Techniques—UserInterfaces; H.5.2 [Information Interfaces and Presentation]: UserInterfaces—Evaluation/methodology; H.1.2 [Models and Princi-ples]: User/Machine Systems—Human factors
General TermsHuman Factors, Measurement, Design
KeywordsAugmentative and Alternative Communication (AAC), Voice OutputCommunication Aids (VOCA), Speech Generating Devices (SGD),Indirect Text Entry, Scanning, Information Theory, Interventions forCommunication Disorders, Interface Evaluation
2. INTRODUCTIONAugmentative and Alternative Communication (AAC) is anarea of research and clinical practice concerned with, amongother things, the development of systems that mediate thecommunication of individuals who have little or no func-tional speech, such as those affected by conditions such ascerebral palsy, amyotrophic lateral sclerosis, or paralysis [2].
A component of many AAC interventions is an AAC de-vice, which, in a large portion of cases, is a laptop, tablet
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.ASSETS’06, October 22–25, 2006, Portland, Oregon, USA.Copyright 2006 ACM 1-59593-290-9/06/0010 ...$5.00.
or other similar piece of computational hardware that pro-vides (1) a facility within which text glosses are preparedand (2) a mechanism whereby the text gloss can be passedto a text-to-speech module, so that synthesized speech canbe produced from the text gloss. Such devices are often re-ferred to as Voice Output Communication Aids (VOCAs). Avariety of techniques have been developed for preparing thetext glosses and can be broadly categorized as composition-based or retrieval-based. Composition-based techniques en-tail the selection of symbols (usually orthographic but pos-sibly iconic), one by one, in order to form larger units oftext (words, phrases, sentences), whereas the retrieval-basedtechniques entail navigating and making selections from adatabase of pre-stored units of text [5]. Each technique hasits advantages and disadvantages (a full discussion of which,unfortunately, space does not permit; the interested readeris directed to the work of Alm and colleagues, e.g., [20]).Most commercial AAC devices are hybrids in the sense thatthey typically implement, to at least some degree, techniquesbelonging to both classes. Word-prediction and -completionfacilities can be viewed as a retrieval-based technique thathas been integrated into a composition-based facility. De-spite the utility of the hybrid approach, it remains thatretrieval-based techniques are ill-suited to some communica-tive scenarios (e.g., discussions about unanticipated topicsor the need to provide information about a topic that haslittle or no vocabulary coverage in the database). Users ofAAC devices must be afforded the possibility to composetext.
In previous work [3, 4], we have focused on the utilityof information theory as a framework for theoretical modelsabout the relative utility of various text composition designs.We have a particular interest in the use of Huffman codingfor automating the design of text composition facilities.
In this paper, we discuss a theoretical prediction that re-lates row-column and Huffman-coding-based indirect textselection and present the results of a relevant empirical userstudy that we conducted.
3. BACKGROUNDThe users of AAC devices are highly heterogeneous with re-spect to the type and number of input devices that can bereliably operated. By the term input device, we are referringto various specialized mechanisms such as contact switches(buttons) operated by positive or negative mechanical pres-sure, by puffs of breath, by eyebrow raises or threshold sen-sors that incorporate eye tracking or EMG signals (e.g., [8]).
Researchers cannot know a priori the type and numberof input devices that the members of the target population

Figure 1: A screen shot of a indirect text composi-tion facility that makes use of the row-column vari-ant. The keys are arranged on the basis of un-igram frequencies (rather than the more-familiarQWERTY layout). The on-screen component en-titled “Target Text” has been included for the pur-poses of user experiments (described below).
can reliably operate, other than the fact that this profile willvary widely. The long-term goal of work in this area is toderive text entry techniques that not only are optimal for aparticular user profile, but are parameterized to be optimalin a general way (i.e., for a space of possible user profiles).
In this work, we focus on indirect text composition — atask in which the number of input devices (we will hence-forth use the term key to refer to any such simple button orswitch) that the user can reliably operate is significantlysmaller than the number of selectables. The selectablesare typically alphanumeric and punctuation characters, thespace character and enter. This contrasts with direct textcomposition, such as text can be entered directly, using aone-to-one mapping between selectables and buttons on aphysical or software keyboard.
Indirect text selection — or scanning — uses the notionof “highlighting”. In row-column scanning, a classic variantshown in figure 1, each of the rows of an on-screen keyboardare highlighted one-by-one, each one d seconds. This dura-tion of time is described as the dwell period. The highlight-ing iterates row-by-row. When the user makes a selection,the buttons within the currently-highlighted row are thenhighlighted one-by-one, each for d seconds. When the lastbutton in the row (the last “column”) has been reached andno selection has been made, the button-by-button highlight-ing wraps back to the first column. The effect of user actionis contextualized — a user selection when the “rows” arebeing scanned has the effect of transferring the highlight-ing to the buttons within the in-focus row, whereas whenthe “columns” are being scanned has the effect of select-ing the presently-highlighted button (thereby appending itscorresponding symbol to the text gloss that is under prepa-ration). Below, we focus on the scenario in which only twokeys can be reliably operated by the user: one is dedicatedto error correction (e.g., “undo”) and the other to selec-tion. This scenario falls towards the end of the spectrum ofpossible user profiles.1
1There are user profiles that are more restricted in terms
Figure 2: The containment hierarchy for row-column unigram.
4. DESCRIPTIVE MODEL
4.1 The Containment HierarchyAt this point, we introduce the notion of the containmenthierarchy, which we use to characterize indirect selectiontechniques. We define the containment hierarchy (CH) tobe a directed acyclic graph in which (1) each node is associ-ated with a set of selectables (2) each leaf node’s set containsa single selectable; and (3) each internal node’s set containsprecisely those selectables that are associated with its chil-dren nodes.2 At any point in time, one and only one node ofthe CH can be in focus. When a node is in focus, all of thechildren selectables are highlighted. (Any mode of feedback,and not just visual highlighting, is possible, in principle.)In the indirect selection paradigm, focus advances passively,from one sibling to the next, pausing on each one for d sec-onds (the dwell period). A user’s action corresponds to ei-ther of these two basic operations, depending on the typeof in-focus node: “drill down” (internal in-focus node) and“select” (leaf in-focus node).
Selection takes place through a sequence of one or moreof these basic operations (until a leaf has been selected).A particular instance of row-column scanning (with a non-QWERTY keyboard layout, to be discussed in detail later)is represented by the CH that is shown in figure 2.
We denote the number of levels in the tree by n. If theoutdegree is constant over all the internal nodes, we denote itby k; if it outdegree varies from level-to-level (we assume it isconstant within a level), we denote it by {k1, . . . , kn} (whereki is the number of children at level i). The row-columnvariant (figure 2) is characterized by n = 2 and k = {8, 6},where the first level has eight children and the second levelhas six children. The Huffman variant, to be discussed inthe next section, is characterized by {n, k} = {12, 2}, sinceinternal nodes have two children at every level (figure 3).
This containment hierarchy-based representation general-izes those used previously. For example, the three-dimensionalmatrix method described by Abascal et al [1] can be repre-sented as a three-level containment hierarchy with {n, k} ={3, {3, 4, 3}}: the authors’ “D-dimensional matrix” modelencompasses only a subset of the design space covered bythe containment hierarchy model.
of number and type of input devices, such as single binaryswitch activations or even no volitional movement (in whichcase biological or neurological contols — via evoked poten-tials or sensing of the motor or pre-motor cortex — may beused). These scenarios are not considered here.2In the work described here, the DAGs happen to be treessince each selectable is reached by a unique path (but thisis not necessarily always the case in our analyses).

5. RELATED WORKVenkatagiri [21] presented a detailed discussion of severaltext-composition facilities, with a focus on the comparisonof linear vs row-column arrangements (although two more-complex arrangements were also presented) and of lexico-graphic vs unigram-based arrangements. Subsequent to this,the most significant contribution to the design of indirecttext selection has been made by Abascal et al [1], who gener-alized the linear and row-column scanning methods into a hi-erarchical continuum of matrix-dimensional scanning, witha focus on the position of selectables relating to error correc-tion. Their simulation results show that for a selection setof 36 keys, a square layout is optimal for a two dimensionalmatrix, while a 3×4×3 layout yields the best results for athree-dimensional entry scheme. Abascal et al and Venkata-giri were in agreement that keys must be located accordingto their frequencies of use.
The comparison of different text entry methods is com-mon in the area of human-computer interaction, namely inthe context of mobile telephone keypads [9, 10, 11] and softkeyboards [13, 14, 18]. On the basis of models developedby Soukereff and Mackenzie [18] for predicting lower bound(novice user) and upper bound (expert user) soft keyboardtext entry rates, Mackenzie, Zhang and Soukereff [14] eval-uated six different layouts and tested the model predictionswith a low-scale user study. Mackenzie and Zhang [13] de-signed and evaluated OPTI, a soft keyboard design, againsta soft implementation of QWERTY. The comparison wasdone through a longitudinal user study, such that learn-ing effects were characterized while entry speeds predictedthrough modelling can be confirmed without the influenceof users’ familiarity with the QWERTY layout.
Also relevant to this current work is alternative text en-try methods which include necessary time delays as part oftheir design. The half-QWERTY method for one-handedtyping [16] required that the user hold the space bar downfor a timeout value in order for the keys to “flip over” tothe other, mirror half of the QWERTY configuration. Theeye typing methods studied in Majaranta et al [15] featureda “dwell period” for which the typist’s gaze must be fixedon a key before it is selected. Both the timeout and dwellperiod were limiting factors on the upper bound the user’stext entry speed, as is the dwell period that must be usedwhen evaluating the row-column and Huffman methods.
6. TEXT COMPOSITION VARIANTS
6.1 Row-ColumnThe row-column variant features the scanning pattern andcontainment hierarchy as described above in figures 1 and 2.This design provides access to 43 selectables: 26 alphabeticalcharacters, 10 digits, 7 “other” characters (space, punctu-ation, enter, delete). The unigram probability distributionwas derived from a corpus of written English text.
6.2 HuffmanThe Huffman variant has a containment hierarchy that wederived using Huffman coding. Our implementation of thek-ary Huffman coding algorithm takes as its input a setof symbols (the selectables), a probability distribution overthose symbols, and a value k, which indictaed the desiredoutdegree of the coding tree. The algorithm produces a cod-ing tree that has the smallest mean encoding length (MEL)
Figure 3: The containment hierarchy for Huffmank=2.
for each symbol (other techniques can provide more efficientencodings than Huffman for a sequence of symbols, but noton a symbol-by-symbol basis). We use the coding tree as ourcontainment hierarchy. Note that MEL corresponds to themean number of input actions required to select a selectable.
The row-column variant described above has a contain-ment hierarchy with mean outdegree k = 7×6+1×8
8= 5.375
(i.e., 7 internal nodes with outdegree 6 and one internalnode (the root) with outdegree 8) and has a MEL of 1.9994.But the same selectable set with k = 5 and k = 6 Huffmancoding has MELs of 1.8666 and of 1.69229, respectively.
We chose to explore the use of a binary Huffman codingtree (k = 2), shown in figure 3, which yields a MEL of4.2007. The selectable set and the probability distributionwere matched to the row-column variant.
Our conjecture was that the Huffman variant would af-ford higher entry rates than the row-column variant, despitehaving a higher MEL. Our hypothesis was that Huffmanwould entail less time spent in passive focus advancement,which often can be a substantial portion of the total amountof time required to select a selectable (i.e., the time spentwaiting for the selectable to become in-focus, so that it isavailable for selection). Whereas the row-column variantcan be seen as attempting to minimize the total numberof levels in the tree,3 Huffman coding suceeds in minimiz-ing the mean encoding length. Moreover, binary Huffmancoding has the smallest possible number of children, hencerequires the shortest amount of time for complete cycles offocus advancement. We test this hypothesis through modelprediction and experimental results.
3Actually, linear scanning corresponds to a containment hi-erarchy with a single level, but has been shown to be highlyinefficient [21] and is not considered here.

7. PREDICTIONMODELLINGOn the basis of the descriptive containment hierarchy model,a prescriptive entry speed prediction model was derived.
We assumed that the time to compose a given text se-quence C = c1c2 . . . cn is additive over the time required toselect each of the selectables, cj . (All time units are givenin seconds.)
We hypothesized that the process for selecting selectablecj required the user first to locate the target cj on the key-board (the visual scan time or α). Next, the user must waitfor focus to advance to the target (the incremental wait forfocus to reach target or β). Note that the target may havealready been in focus one or more times, in which case theuser must wait for the focus cycle to return to the target(one or more wasted cycles). In particular, when cj is asso-ciated with the first child of the root node, the dwell periodoften elapses before the user locates it. The visual searchmay possibly be completed while the target is in focus, aswell (in which case β = 0). Once focus reaches the target,a certain amount of time is required for the user to reactto this visual event (the visual stimulus time or γ) and togenerate a motor response (the key press time or ζ).
We assume that the time-to-select cj is the sum of thetime-to-select cj at each of the levels of the CH, until theleaf is reached. Thus, time-to-select at the first level (level0 of the CH) can be characterized by:
tts0(cj) = α + β + γ + ζ
We assume that this visual search is done only once atthe beginning, when the focus cycles among the childrenof the root node of the CH, and is not repeated at lowerlevels of the CH. We use EL(cj) to denote the number ofnodes in the path to the leaf node corresponding to cj orthe encoding length of selectable cj . Given a particular leveli in the CH, the time required for focus to reach a particulartarget cj is a function the associated node’s position amongthe level’s children nodes (pos(cj , i)) and the dwell period(d). The levels and sibling positions are indexed by i =0, . . . and s = 0, . . . , respectively. From the start of a givenfocus cycle at level i, the time for focus to reach target cj
is pos(cj , i) · d. Thus, time-to-select at subsequent levels ofthe CH (levels>0) can be characterized by:
tts>0(cj , i) = pos(cj , i) · d + γ + ζ
The total time-to-select selectable cj is thus:
tts(cj) = tts0(Cj) +
EL(cj)Xi=1
tts>0(cj , i)
We constructed a lower bound for tts>0 by assuming thatthe visual stimulation time and the key press time were zero.We constructed an upper bound by assuming that the userperforms the key press at the very end of the dwell period.This is an overestimation, since the last possible point occurs(γ− ζ) seconds before the end of the dwell period (the pointafter which focus will have shifted before the key press willhas been performed, which is one sort of input error). Thus,
Ltts>0(cj , i) = pos(cj , i) · dUtts>0(cj , i) = pos(cj , i) · d + d + γ + ζ
We constructed lower and upper bounds for tts0 by firstconstructing an alternative expression for α+β. We denote
the total time required for a complete focus cycle at leveli by timeCC(i). The amount of time α + β is equal to theamount of time spent in wasted cycles plus the amount oftime for focus to reach the target from the start of a cycle.The time spent in wasted cycles at level i is the product ofthe number of wasted cycles (numWC) and timeCC(i). Thus,
tts0(cj) = α + β + γ + ζ
= pos(cj , i) · d + numWC · timeCC(i) + γ + ζ
For numWC, the following formula was used:
numWC =
(0 if α < pos(cj , 0) · djpos(cj ,0)·d+d−(γ+ζ)
timeCC(0)
kotherwise
Similar to tts>0, we assumed for the lower bound that thevisual stimulation time and the key press time were zero, andfor the upper bound that the user performs the key press atthe very end of the dwell period. Thus,
Ltts0(cj , i) = pos(cj , i) · d + numWC · timeCC(i)
Utts0(cj , i) = pos(cj , i) · d + numWC · timeCC(i) + d + γ + ζ
The visual scan time for 43 characters is α = 1.085s, basedon the Hick-Hyman law [18]. The visual stimulus reactiontime is γ = 0.2s based on literature [7]. The key press timeis ζ = 0.14s based on a key repeat experiment by Card etal [6]. These values have not been established as valid forthe target users of AAC devices (but are applicable for thesubjects in the study described in the next section).
8. EXPERIMENT DESIGNA user study was conducted to compare the two text entryvariants. Twelve people participated in this study, drawnfrom the undergraduate population. There were five femalesand seven males of ages ranging from 19 to 39. All were fa-miliar with the conventional QWERTY text entry method,but none have been exposed to the indirect text entry meth-ods to be compared in the study. None had physical disor-ders.
The experiment was a 2×2×4 factorial design. The threefactors were:
1. Indirect text entry variant: {Row-Column, Huffman}2. Dwell period (d): {750ms, 1250ms}3. Repetition: {4 repetitions}The first factor was administered within-subjects with
counterbalancing, such that half the participants startedwith the Row-Column variant and the other half startedwith the Huffman variant. The second factor was adminis-tered between subjects. The third factor was administeredwithin-subjects. Table 1 shows how the 12 participants wereallocated to the factors.
SequenceRow-Col,Huff Huff,Row-Col
Dwell Period750 ms 3 31250 ms 3 3
Table 1: Experiment design: distribution of partic-ipants to the conditions.

The experiment software was developed with Java 5.0.The host system was an Intel Pentium 4, at 3 GHz with1 GB RAM, running Microsoft Windows XP ProfessionalService Pack 2.
The experiment was conducted in a 10-machine lab atYork University’s Computer Science and Engineering Build-ing. To minimize interference from other users, the lab wasbooked for the experiment. The only people present duringthe experiments were the experimenter and the participants.
Each session involved between one to three participantsat their convenience, and featured only one configurationof variant sequence and dwell time. At the beginning ofeach session, the experimenter gave a demonstration of eachvariant, in the order and with the dwell period that theparticipant(s) would be subjected to.
Participants entered a target text four times with one vari-ant, and then did the same with the other variant. Data col-lection for each phrase began when the participant pressed“Enter” on the keyboard . Participants were asked to taketheir time between phrases.
8.1 Choice of Dwell PeriodThe dwell period d must be chosen carefully, and for the de-sign domain of AAC devices, needs to be tailored on an in-dividual basis (as the user population is heterogeneous withrespect to physical capabilities). A dwell period that is tooshort will result in many errors, since the target user willhave a difficult time pressing the key before the dwell pe-riod finishes and the focus moves on. A dwell period thatis too long can result in unnecessarily slow entry speeds. Inorder to see the effect of varying the scanning period, twoperiods are chosen in the experiment design based on visualscan time of humans.
While in the models it is assumed that the slope coef-ficient of the Hick-Hyman law is 200 ms, work by Welfordhas shown that this coefficient can range from 160 ms to 320ms [14]. We use these two coefficient bounds to find visualscan plus repeat key times of 1.0082 s and 1.8764 s. Round-ing to the nearest second for convenience, the dwell periodswere initially chosen to be dfast = 1s and dslow = 2s. Forusers of AAC devices, the derivation of other dwell periodvalues will be necessary.
In a preliminary trial, three participants were asked to en-ter the test phrase four times for each method, with dslow =2s. It became apparent that this dwell period was too long,as participants were seen to be waiting unnecessarily, espe-cially for the row-column method. On the basis of thesepreliminary trials, the scanning periods were reassigned todfast = 750ms and dslow = 1250ms, which correspond to +/-250 ms relative to the visual scan lower bound. The effectof the dwell period is emphasized as the threshold of visualscan time is straddled by the two values.
8.2 Choice of Target TextThe same target text was presented repeatedly to all theparticipants. Our hypothesis was that this would afford afaster learning effect that if the target text varied among thesessions. The effect of learning must be taken into accountwhen evaluating the overall relative effectiveness of one vari-ant over another, rather than localized phenomena. We werenot concerned that this choice would shift the task fromone of skill acquisition to motor memorization, since motormemorization characterizes expert-level text entry anyway.
Figure 4: Screen shot of Huffman variant.
The following character sequence C served as the target text:THE QUICK BROWN FOX JUMPED OVER THE LAZY DOGS
This target text contains at least one instance of eachselectable. The probability distribution over the selectablesin the target text does not resemble that used to derive theHuffman coding. We decided that this was acceptable, giventhat the same target text was used for both of the variants.We assumed that the effect on each of the variants wouldbe approximately the same. Moreover, confounding due todifferences in the probability distributions over the targettext selectables is eliminated. A much larger set of targettexts would be needed for the probability distribution to berepresentative of the one used in the design of the variants.
8.3 Interface DesignScreen shots of the software used in the experiment are
shown in figure 1 for the row-column variant and figure 4for the Huffman variant.
A Huffman coding-based containment hierarchy presentsa challenge for the keyboard layout. At any given stage, thehighlighting alternates between two groups which are oftenof quite different sizes. We fashioned the layout such that nomatter the user’s current position in the containment hier-archy, the groups between which the highlighting alternateswould be adjacent and contiguous. The desired effect wasthat the user would be able to clearly see the scanning al-ternating between two groups of keys, from a group on theleft to one on the right, or from an upper group to a lowerone. The layout can be seen in figure 4.
The “up arrow” key was assigned to the “undo” function.If an incorrect selection is made when focus is on a leafnode, the undo function has the effect of deleting the most-recently appended selectable from the text being composed.If an incorrect selection is made when focus is on an internalnode, the undo function has the effect of shifting the focusup one level in the CH. Without this undo function, if theuser makes an incorrect selection at an internal node, he orshe would be obligated to complete the traversal down theCH until some leaf is chosen. (Then, he or she would need tosubsequently choose the selectable corresponding to delete.)The participants were instructed that if they appended anincorrect character to the composed text, they should ignoreit and continue with the next character of the target text.

9. RESULTS AND DISCUSSION
9.1 Model PredictionsWe used words per minute (wpm) as a normalized unit tocharacterize rate of input (where 5 chars = 1 word). Thelower bound on the time-to-enter text sequence C corre-sponds to the upper bound on its rate of entry, r. Themodel predictions are shown in table 2.
These predictions confirm our hypothesis that the Huff-man variant affords faster rates of entry, but only for one ofthe variants and not as significantly as one would expect.
Predicted Entry Speeds (wpm)Dwell Period
Variant d = .75s d = 1.25sRow-Column 2.48 < r < 4.5 1.57 < r < 3.32Huffman 1.45 < r < 4.36 0.95 < r < 3.89
Table 2: Predicted rate of entry for the Huffmanand Row-Column variants for two different dwell pe-riods.
9.2 Entry SpeedThe analysis of variance of text entry speed showed signif-icant effects for variant (F1,10 = 101.87, p < .0001), session(F3,30 = 34.11, p < .0001), and variant-by-session interac-tion (F3,30 = 6.01, p < .005).
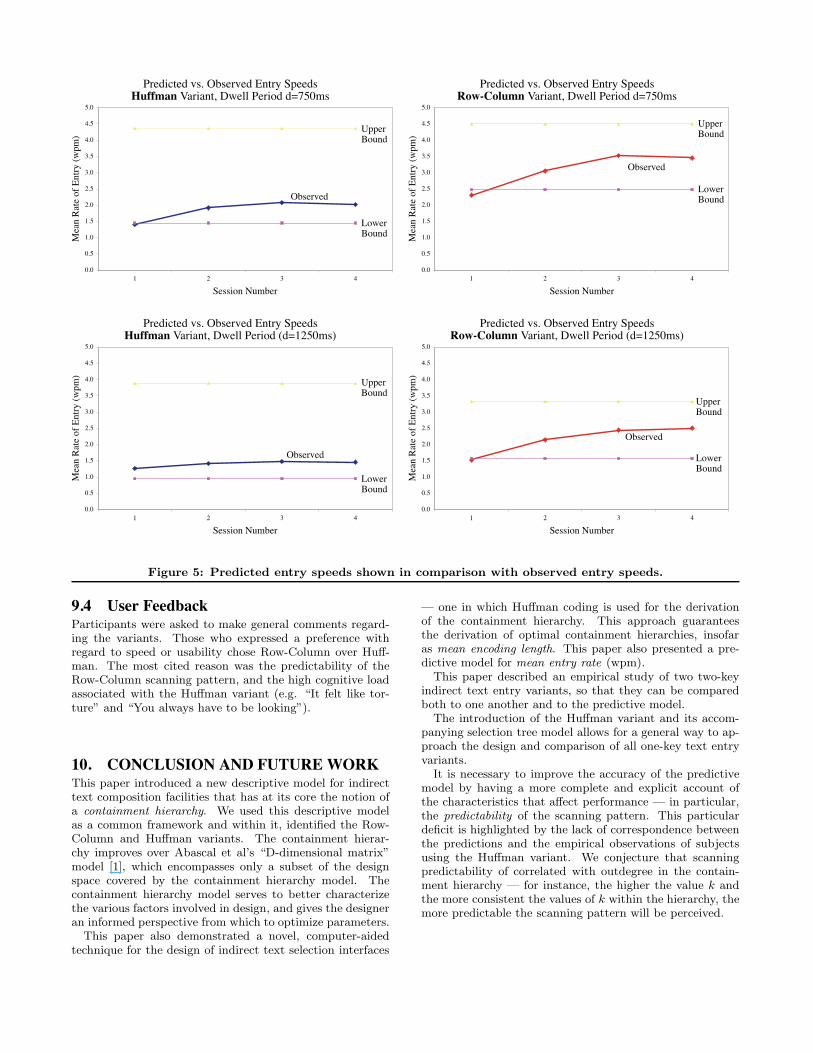
Figure 5 (next page) shows the observed entry speeds rel-ative to the predicted entry speeds. Contrary to the modelpredictions, the Row-Column variant was clearly the fastervariant. According to the variant-by-session means, theRow-Column variant started out at 2.048 wpm and reached3.075 wpm after four sessions, whereas the Huffman variantstarted at 1.445 wpm and ended at 1.809 wpm.
These empirical results suggest that the upper bound es-timation on entry rate (corresponding to the lower boundson time-to-enter) is inaccurate.
The Huffman variant minimizes the encoding length of theselectables and the binary instantiation (k = 2) minimizesthe size of the focus cycle. Our hypothesis was predicatedon the belief that these properties would translate into im-proved rate of entry. However, the Huffman variant carries amuch higher cognitive load. For instance, at any given pointin time, focus is shifting among differently-sized groups ofselectables. We attempted to mediate this through the useof spatial proximity (namely, the groups are always contigu-ous and in either left-right or top-bottom relationship witheach other). However, the high cognitive load manifested it-self in terms of a much larger number of wasted cycles thanpredicted by the model.
Figure 6 illustrative the learning trends for the Huffmanand row-column variants. Not only are the Huffman rates-of-entry well below the upper bounds, but (at R2 = 79%)they do not exhibit the adherence to the power law of learn-ing [6], which was demonstrated by the row-column variant(R2 = 96%). It is possible that after four sessions, users ofthe Huffman variant are still too early in the learning processfor the learning relation to take shape. Adding a parame-ter to the model to reflect scanning pattern familiarity orpredictability may yield a better upper bound prediction.
y = 0.2713Ln(x) + 1.5038
R2 = 0.7929
y = 0.7883Ln(x) + 2.093
R2 = 0.9587
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
1 2 3 4 5 6 7 8 9 10 11 12
Session Number
Mea
n R
ate
of E
ntry
(w
pm) Mean Upper Bound
Mean Lower Bound
Row-Column
Huffman
Rate of Entry Extrapolated to 12th Session
Figure 6: Learning curves by variant, extrapolatedto the 12th session.
9.3 Dwell Period and Error RateSignificant effects were found for dwell period (F1,10 = 9.57, p <.05), and dwell period-by-variant interaction (F1,10 = 8.37, p <.05). On average, users entered text faster when the dwellperiod was slower (2.62 wpm at 750 ms, 1.82 wpm at 1250ms). However, no significant effect was found for dwellperiod-by-session (F3,30 = 1.26, p > .05). Learning occurredjust as quickly for variants with a short dwell period as thosewith a longer dwell period.
A better measure of adeptness with session may be er-ror rate, since rate of entry may increase for both dwellperiods simply with the confidence that comes with famil-iarity. However it was found that there were no significanteffects with respect to errors for scanning period (F1,10 =3.91, p > .05), for period-by-session (F3,30 = 0.179, ns), norfor period-by-variant (F1,10 = 0.667, ns).
There was a significant difference between the error ratesfor each variant (F1,10 = 14.58, p < .005), with the means byvariant being 18.50% for Huffman and 6.60% for Venkata-giri. This is demonstrated in figure 7.
0%
5%
10%
15%
20%
25%
1 2 3 4
Session Number
Err
or R
ate
(%)
Huffman
Row-Column
Error Rates
Figure 7: Error rates by variant and session.
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
1 2 3 4
Session Number
Mea
n R
ate
of E
ntry
(w
pm)
Predicted vs. Observed Entry SpeedsHuffman Variant, Dwell Period d=750ms
UpperBound
LowerBound
Observed
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
1 2 3 4
Session Number
Mea
n R
ate
of E
ntry
(w
pm)
Predicted vs. Observed Entry SpeedsRow-Column Variant, Dwell Period d=750ms
UpperBound
LowerBound
Observed
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
1 2 3 4
Session Number
Mea
n R
ate
of E
ntry
(w
pm)
Predicted vs. Observed Entry SpeedsHuffman Variant, Dwell Period (d=1250ms)
UpperBound
LowerBound
Observed
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
1 2 3 4
Session Number
Mea
n R
ate
of E
ntry
(w
pm)
UpperBound
LowerBound
Observed
Predicted vs. Observed Entry SpeedsRow-Column Variant, Dwell Period (d=1250ms)
Figure 5: Predicted entry speeds shown in comparison with observed entry speeds.
9.4 User FeedbackParticipants were asked to make general comments regard-ing the variants. Those who expressed a preference withregard to speed or usability chose Row-Column over Huff-man. The most cited reason was the predictability of theRow-Column scanning pattern, and the high cognitive loadassociated with the Huffman variant (e.g. “It felt like tor-ture” and “You always have to be looking”).
10. CONCLUSION AND FUTURE WORKThis paper introduced a new descriptive model for indirecttext composition facilities that has at its core the notion ofa containment hierarchy. We used this descriptive modelas a common framework and within it, identified the Row-Column and Huffman variants. The containment hierar-chy improves over Abascal et al’s “D-dimensional matrix”model [1], which encompasses only a subset of the designspace covered by the containment hierarchy model. Thecontainment hierarchy model serves to better characterizethe various factors involved in design, and gives the designeran informed perspective from which to optimize parameters.
This paper also demonstrated a novel, computer-aidedtechnique for the design of indirect text selection interfaces
— one in which Huffman coding is used for the derivationof the containment hierarchy. This approach guaranteesthe derivation of optimal containment hierarchies, insofaras mean encoding length. This paper also presented a pre-dictive model for mean entry rate (wpm).
This paper described an empirical study of two two-keyindirect text entry variants, so that they can be comparedboth to one another and to the predictive model.
The introduction of the Huffman variant and its accom-panying selection tree model allows for a general way to ap-proach the design and comparison of all one-key text entryvariants.
It is necessary to improve the accuracy of the predictivemodel by having a more complete and explicit account ofthe characteristics that affect performance — in particular,the predictability of the scanning pattern. This particulardeficit is highlighted by the lack of correspondence betweenthe predictions and the empirical observations of subjectsusing the Huffman variant. We conjecture that scanningpredictability of correlated with outdegree in the contain-ment hierarchy — for instance, the higher the value k andthe more consistent the values of k within the hierarchy, themore predictable the scanning pattern will be perceived.

Figure 8 shows a hybrid between Row-Column and Huff-man that may serve as a successful compromise between thepredictability of the Row-Column variant and the selection-over-wait advantage of Huffman (outdegree of k = 7 is theceiling of the outdegree of the row-column variant, but theencoding is based on Huffman). The method is character-ized by {n, k} = {4, 7}.
Figure 8: Containment hierarchy of the hybrid ofthe Row-Column and Huffman variants.
The intended application of these techniques is the designof indirect text entry facilities for the users of AAC sys-tems. The evaluation of such facilities must be conductedby the actual intended users — namely, those individualswho have physical disorders. Since such evaluations are se-rious undertakings, it is prudent to first perform a prelim-inary evaluation with subjects who are more readily avail-able. The generalizability of the evaluation results may belimited, but the exercise is invaluable for honing in on salientexperimental questions, thus giving us the best possible useof experimental trials with more-representative users. Fromthis particular empirical study, we have learned that a largernumber of sessions need to be conducted, over a longer pe-riod of time, which will allow any learning effects to becomesalient. Future experimental conditions will also include theuse of other experimental stimulus (e.g., include punctua-tion) [12] and may include other design variants based onthose from the domain of mobile device and soft-keyboardtext entry (which are also concerned with few-key text entryand thus also belongs to the domain of AAC [17]. Futureanalysis will also include the used of more sophisticated errormetric [19] than the metric error rate that was used here.
11. ACKNOWLEDGMENTSThis research was supported by the Natural Sciences and En-
gineering Research Council of Canada. Dr.Horabail Venkatagiri
kindly provided the evaluation materials from his 1999 study (the
“V260 corpus”), from which we were able to extract the proba-
bility distribution that was used in this study. The anonymous
reviewers provided much valuable feedback, for which we are sin-
cerely thankful.
12. REFERENCES[1] J. Abascal, L. Gardeazabal, and N. Garay. Optimisation of
the selection set features for scanning text input. InProceedings of the 9th International Conference onComputers Helping People with Special Needs (ICCHP2004), pages 788–795, Paris, France, 2004.
[2] A. ASHA. Competencies for speech-language pathologistsproviding services in augmentative communication. ASHA,31(3):107–110, 1989.
[3] M. Baljko. The contrastive evaluation of unimodal andmultimodal interfaces for voice output communication aids.
Proceedings of the Seventh International Conference onMultimodal Interfaces ICMI’05, 2005.
[4] M. Baljko. The information-theoretic analysis of unimodalinterfaces and their multimodal counterparts. Proceedingsof the Seventh International ACM Conference on AssistiveTechnologies – ASSETS’05, 2005.
[5] D. R. Beukelman and P. Mirenda. Augmentative andalternative communication: Supporting children & adultswith Complex Communication Needs. Paul H. Brookes,Baltimore, MD, third edition, 2005.
[6] S. Card, T. Moran, and A. Newell. The Psychology ofHuman–Computer Interaction. Lawrence ErlbaumAssociates, Hillsdale, NJ, 1983.
[7] A. Dix, J. Finlay, G. Abowd, and R. Beale.Human–Computer Interaction. Pearson, third edition, 2004.
[8] T. Felzer and R. Nordmann. How to operate a PC withoutusing the hands. In Proceedings of the SeventhInternational ACM Conference on Assistive Technologies,ASSETS’05, pages 198–199, Baltimore, MA, October 9–122005.
[9] I. S. MacKenzie. Mobile text entry using three keys. InProceedings of the Second Nordic Conference onHuman–Computer Interaction NordiCHI 2002, pages27–34, 2002.
[10] I. S. MacKenzie, H. Kober, D. Smith, T. Jones, andE. Skepner. Letterwise: Prefix-based disambiguation formobile text input. In Proceedings of the ACM Symposiumon User Interface Software and Technology UIST 2001,pages 111–120, 2001.
[11] I. S. MacKenzie and R. W. Soukoreff. Text entry for mobilecomputing: Models and methods, theory and practice.Human–Computer Interaction, 17:147–198, 2002.
[12] I. S. MacKenzie and R. W. Soukoreff. Phrase sets forevaluating text entry techniques. In Extended Abstracts ofthe ACM Symposium on Human Factors in ComputingSystems CHI 2003, pages 754–755, 2003.
[13] I. S. MacKenzie and S. X. Zhang. The design andevaluation of a high-performance soft keyboard. InProceedings of the 1999 Conference on Human Factors inComputing Systems CHI’99, pages 25–31, May 1999.
[14] I. S. MacKenzie, S. X. Zhang, and R. W. Soukoreff. Textentry using soft keyboards. Behaviour & InformationTechnology, 18:235–244, 1999.
[15] P. Majaranta, I. S. MacKenzie, A. Aula, and K.-J. Raiha.Auditory and visual feedback during eye typing. InExtended Abstracts of the ACM Symposium on HumanFactors in Computing Systems CHI 2003, pages 766–767,2003.
[16] E. Matais, I. S. MacKenzie, and W. Buxton. One-handedtouch-typing on a qwerty keyboard. Human–ComputerInteraction, 11(2–3):1–27, 1996.
[17] K. F. McCoy, C. A. Pennington, and A. L. Badman.Compansion: From research prototype to practicalintegration. Natural Language Engineering, 4(1):73–95,March 1998.
[18] R. W. Soukoreff and I. S. MacKenzie. Theoretical upperand lower bounds on typing speed using a stylus and softkeyboard. Behaviour & Information Technology,14:370–379, 1995.
[19] R. W. Soukoreff and I. S. MacKenzie. Metrics for text entryresearch: an evaluation of MSD and KSPC, and a newunified error metric. In Proceedings of SIGCHI Conferenceon Human Factors in Computing Systems, CHI 2003,pages 113–120. ACM Press, 2003.
[20] J. Todman and N. Alm. Modelling conversationalpragmatics in communication aids. Journal of Pragmatics,35(4):523–538, April 2003.
[21] H. S. Venkatagiri. Efficient keyboard layouts for sequentialaccess in augmentative and alternative communication.Augmentative and Alternative Communication,15(2):126–134, June 1998.




















