
Independent Dummy Variable
20
Rezzy Eko Caraka Statistika Undip 2011 I. Judul : Independent Dummy Variable II. Tujuan: Setelah mengikuti seluruh kegiatan praktikum ini, mahasiswa diharapkan dapat melakukan analisa regresi dengan variabel bebas dummy dengan menggunakan software E-Views III. Dasar Teori: Variabel Dummy adalah variabel yang merepresentasikan kuantifikasi dari variabel kualitatif. Misal: jenis kelamin, pendidikan, lokasi, situasi, musim, & kualitas. Jika data kualitatif tersebut memiliki m kategori, maka jumlah variabel dummy yang dicantumkan didalam model adalah (m-1). Kesimpulan yang diambil dari keberadaan variabel dummy didalam model adalah perbedaan nilai antar kategori yang bersangkutan. Variabel dummy sering juga disebut variabel boneka, binary, kategorik atau dikotom. Dummy memiliki nilai 1 (D=1) utk salah satu kategori dan nol (D=0) untuk kategori yang lain. Variabel dummy digunakan sebagai upaya untuk melihat bagaimana klasifikasi- klasifikasi dalam sampel berpengaruh terhadap parameter pendugaan. Variabel dummy juga mencoba membuat kuantifikasi dari variabel kualitatif. Berikut model pada variabel dummy: I. Y = a + bX + c D1 (Model Dummy Intersep) II. Y = a + bX + c (D1X) (Model Dummy Slope) III. Y = a + bX + c (D1X) + d D1 (Kombinasi) Uji Statistik Uji t adalah uji parsial untuk melihat pengaruh masing-masing variabel independen atau bebas (x) berpengaruh nyata atau tidak secara parsial terhadap variabel dependen/terikatnya (Y). Untuk menelaah apakah model regresi Y atas X dapat digunakan atau tidak perlu dilakukan uji hipotesis dengan rumusan sebagai berikut: H0 : βi=0 (koefisien tidak signifikan) H1 : βi≠0 (koefisien signifikan) Bentuk statistik yang digunakan untuk uji di atas adalah : Dimana : bi= Sum of square regression Sb1= Sum of square Error dengan derajat bebas (n-2), dimana n = banyaknya pengamatan (ukuran sampel). Untuk taraf nyata α dan derajat bebas (n-2), maka kriteria pengujiannya adalah tolak Ho jika | t hit | ≥ tα/2(n-2) dan terima Ho jika |t hit | < t α/2 (n-2). 1 Sb bi t =
Transcript of Independent Dummy Variable

Rezzy Eko Caraka Statistika Undip 2011
I. Judul :
Independent Dummy Variable
II. Tujuan:
Setelah mengikuti seluruh kegiatan praktikum ini, mahasiswa diharapkan dapat
melakukan analisa regresi dengan variabel bebas dummy dengan menggunakan
software E-Views
III. Dasar Teori:
Variabel Dummy adalah variabel yang merepresentasikan kuantifikasi dari
variabel kualitatif. Misal: jenis kelamin, pendidikan, lokasi, situasi, musim, &
kualitas. Jika data kualitatif tersebut memiliki m kategori, maka jumlah variabel
dummy yang dicantumkan didalam model adalah (m-1). Kesimpulan yang diambil
dari keberadaan variabel dummy didalam model adalah perbedaan nilai antar
kategori yang bersangkutan. Variabel dummy sering juga disebut variabel boneka,
binary, kategorik atau dikotom. Dummy memiliki nilai 1 (D=1) utk salah satu
kategori dan nol (D=0) untuk kategori yang lain.
Variabel dummy digunakan sebagai upaya untuk melihat bagaimana klasifikasi-
klasifikasi dalam sampel berpengaruh terhadap parameter pendugaan. Variabel
dummy juga mencoba membuat kuantifikasi dari variabel kualitatif.
Berikut model pada variabel dummy:
I. Y = a + bX + c D1 (Model Dummy Intersep)
II. Y = a + bX + c (D1X) (Model Dummy Slope)
III. Y = a + bX + c (D1X) + d D1 (Kombinasi)
Uji Statistik
Uji t adalah uji parsial untuk melihat pengaruh masing-masing variabel independen
atau bebas (x) berpengaruh nyata atau tidak secara parsial terhadap variabel
dependen/terikatnya (Y).
Untuk menelaah apakah model regresi Y atas X dapat digunakan atau tidak perlu
dilakukan uji hipotesis dengan rumusan sebagai berikut:
H0 : βi=0 (koefisien tidak signifikan)
H1 : βi≠0 (koefisien signifikan)
Bentuk statistik yang digunakan untuk uji di atas adalah :
Dimana :
bi= Sum of square regression
Sb1= Sum of square Error
dengan derajat bebas (n-2), dimana n = banyaknya pengamatan (ukuran
sampel). Untuk taraf nyata α dan derajat bebas (n-2), maka kriteria
pengujiannya adalah tolak Ho jika | t hit | ≥ tα/2(n-2) dan terima Ho jika |thit | < tα/2
(n-2).
1Sbbit =

Rezzy Eko Caraka Statistika Undip 2011
Uji F adalah uji simultan untuk melihat pengaruh variabel-variabel
independen/bebas (x1, x2, x3…) secara serempak terhadap variabel
terikatnya/dependen dengan hipotesisnya yaitu:
H0 : Model regresi tidak cocok
H1 : Model regresi cocok
Bentuk statistik yang digunakan untuk uji di atas adalah :
Kreteria pengujian nilai Fhitung sama seperti pengujian-pengujian di atas,
sehingga kreteria pengujian adalah:
1). Jika Fhit ≤ Ftabel(∝), hal ini berarti bahwa model tidak cocok.
2). Jika Fhit > Ftabel(∝), hal ini berarti bahwa model cocok
1. Regresi dengan variabel independen kualitatif 2 kategori
Untuk memahami Model Regresi dengan Independent Dummy Variable, akan
dilakukan analisis dampak krisis ekonomi terhadap impor di Indonesia pada
periode 1980-2002. Model perilaku impor adalah sebagai berikut:
Yt = β0 +β1Dt + β2Xt + et
Dengan Yt = Impor
Dt = 0 untuk periode sebelum tahun 1997
= 1 untuk periode tahun 1997 dan sesudahnya
Xt= GDP riil
Untuk melakukan analisis model tersebut, dilakukan langkah-langkah berikut
ini:
1. Memasukkan data latihan 5.1 dan simpan dengan nama data3.wf1
2. Buatlah variabel baru dengan nama DUMMY dan diberikan nilai 0 untuk
periode tahun 1997 dan nilai 1 untuk periode tahun 1997 dan sesudahnya.
3. Lakukan estimasi persamaan regresi dengan persamaan
impor c dummy gdp
4. Dari output persamaan regresi yang diperoleh, maka perbedaan impor
sebelum krisis dan sesudah krisis adalah sebagai berikut:
Sebelum krisis: Ŷt = β0 + β2Xt Sesudah krisis : Ŷt = (β0 + β1) + β2Xt
2. Membandingkan dua buah regresi
Untuk membandingkan dua buah regresi model impor sebelum dan sesudah
krisis, digunakan model:
Yt = β0 +β1Dt + β2Xt +β3(DtXt) + et
Langkah-langkah yang dilakukan adalah sebagai berikut:
1. Dengan data3.wf1 dilakukan estimasi persamaan regresi dengan persamaan
impor c dummy gdp dummy*gdp

Rezzy Eko Caraka Statistika Undip 2011
2. Dari output persamaan regresi yang diperoleh, maka perbedaan persamaan
regresi impor sebelum krisis dan sesudah krisis adalah sebagai berikut:
Sebelum krisis : Ŷt = β0 + β2Xt
Sesudah krisis : Ŷt = (β0 + β1) + (β2+ β3 )Xt
3. Untuk melihat perbandingan kedua buah regresi, maka diperhatikan nilai t-
statistik atau nilai prob untuk parameter β1 dan β3. Jika parameter β1
signifikan, berarti ada perbedaan intersep pada kedua regresi, sedangkan
jika parameter β3 signifikan, berarti ada perbedaan slope pada kedua regresi.
UJI ASUMSI REGRESI LINIER
1. ASUMSI NORMALITAS
Uji normalitas dilakukan untuk melihat apakah nilai residual berdistribusi normal
atau tidak. Salah satu uji normalitas faktor error adalah Jarque-Berra atau J-B test.
Dengan hipotesis nol yang menyatakan bahwa error berdistribusi normal, maka
kriteria keputusan adalah sebagai berikut:
Membandingkan nilai J-B hitung dengan nilai χ2 (2) tabel dengan aturan:
Bila nilai J-B hitung > nilai χ2 (2) tabel, maka hipotesis yang menyatakan
bahwa error ui berdistribusi normal ditolak.
Bila nilai J-B hitung < nilai χ2 (2) tabel, maka hipotesis yang menyatakan
bahwa error ui berdistribusi normal diterima.
Dengan menggunakan program Eviews, dilakukan langkah-langkah sebagai
berikut:
1. Buka file data3.wf1
2. Buka persamaan regresi estiamsi EQ1, dari output persamaan tersebut, pilih
option:
View Residual Tests Histogram – Normality Test
3. ASUMSI LINEARITAS
Uji linearitas dilakukan untuk mengetahui ada tidaknya hubungan antara harga-
harga prediksi dengan harga residual. Pengujian linearitas dapat dilakukan
dengan Ramsey (RESET) Test. Untuk menerapkan uji ini, harus dibuat suatu
asumsi atau keyakinan bahwa fungsi yang benar adalah fungsi linier. Nilai
statistik F-hitung yang diperoleh dibandingkan dengan statistik F-tabel.
Dengan hipotesa nol menyatakan bahwa fungsi adalah linier, maka kriteria
penolakan Ho adalah:
Ho ditolak jika F-hitung >F-tabel atau Ho ditolak jika Probability <α
Eviews menyediakan fasilitas untuk uji RESET ini, dengan cara:
1. Buka file data3.wf1
2. Buka persamaan regresi estimasi EQ1, dari output persamaan tersebut, pilih
option: View Stability Test ramsey RESET Test..
3. Pada kotak dialog RESET Specification, isikan angka 1 pada Number of
fitted terms. Lalu klik OK.

Rezzy Eko Caraka Statistika Undip 2011
3.ASUMSI HETEROSKEDASTISITAS
Uji heteroskedastisitas digunakan untuk melihat apakah terdapat ketidaksamaan
varian dari residual satu pengamatan ke pengamatan yang lain. Uji ini dilakukan
dengan menentukan nilai χ2 = n.R2. Kriterianya adalah jika χ2-hitung > χ2-tabel
dengan derajat bebasnya sama dengan jumlah koefisien (termasuk konstanta) atau
Obs*R-squared < α, maka hipotesis nol yang menyatakan adanya homoskedastitas
ditolak.
Metode pengujian heteroskedastisitas pada Eviews menggunakan White Test
dengan cara:
1. Buka file data3.wf1
2. Buka persamaan persamaan regresi estimasi EQ1, dari output persamaan
tersebut, pilih option:
View Residual Test white Heteroscedasticity(cross term)
4.ASUMSI MULTIKOLINIERITAS
Uji multikolinieritas dilakukan untuk melihat ada atau tidaknya korelasi yang tinggi
antara variabel-variabel bebas dalam suatu model regresi linier berganda. Salah satu
cara mendeteksi keberadaan multikolinieritas di dalam suatu model adalah dengan
melihat jika nilai R2 yang dihasilkan dari suatu estimasi model empiris sangat
tinggi, tetapi secara individual variabel-variabel independen banyak yang tidak
signifikan mempengaruhi variabel dependen.
Tindakan perbaikan untuk mengatasi keberadaan multikolinieritas adalah dengan
transformasi first difference atau delta. Pengujian ini dilakukan dengan melihat t
statistik yang dihasilkan dengan meregresikan model utama maupun model parsial.
Jika masih ada yang signifikan, berarti masih terdapat multikolinieritas.
Langkah-langkah yang dilakukan dalam transformasi variabel adalah:
1. Buka file data3.wf1
2. Lakukan pembangkitan data dengan cara klik Generate Series, lalu tuliskan
perintah:
Dlimpor=limpor-limpor(-1)
Dlgdp=lgdp-lgdp(-1)
3. Munculkan kotak Estimate equation, lalu pada kotak dialog equation
specification isikan perintah: dlimpor c dlgdp
5.ASUMSI AUTOKORELASI
Pengujian keberadaan autokorelasi dapat dilakukan dengan cara:
1. Durbin-watson (d) Test
Nilai d hitung ini secara langsung ditampilkan Eviews ketika persamaan regresi
ditampilkan. Nilai d hitung tersebut dibandingkan dengan nilai dL dan dU dari
tabel dengan aturan sebagai berikut:
a. Jika hipotesis Ho menyatakan tidak ada serial korelasi positif, maka
d < dL : Ho ditolak
d > dU : Ho diterima

Rezzy Eko Caraka Statistika Undip 2011
dL ≤ d ≤ dU : pengujian tidak meyakinkan
b. Jika hipotesis Ho menyatakan tidak ada serial korelasi negatif, maka
d > 4-dL : Ho ditolak
d < 4-dU : Ho diterima
4-dU≤ d≤4-dL: pengujian tidak meyakinkan
2. Breusch-Godfrey (BG) Test
Pengujian dengan BG didasrkan pada hipotesa nol: ρ1= ρ2=....= ρp=0
Yang menunjukkan bahwa tidak terjadi autokorelasi pada setiap orde. BG test
ini disediakan oleh Eviews dengan cara:
1. Buka workfile data3.wf1
2. Buka persamaan EQ1
3. Klik ViewResidual TestSerial Correlation LM Test..
4. Masukkan nilai 2 pada kotak dialog Lag Specification
Kriterianya adalah jika Obs*R-squared < α maka hipotesis nol yang
menyatakan tidak adanya autokorelasi ditolak.
IV. Permasalahan:
1. Lakukan analisis regresi dengan variabel independen kulitatif 2 kategori dan
membandingkan dua buah regresi.
2. Lakukan uji asumsi regresi serta analisisnya.
3. Lakukan analisis nilai Ŷd=0 dan Ŷd=1 menggunakan excel dan gambarkan
grafiknya menggunakan minitab.
DATA IMPOR INDONESIA PERIODE 1980-2002
TAHUN IMPOR(MILYAR $) GDP(MILYAR RP)
1980 10834 159343.3
1981 13272 171979.2
1982 16859 175848.7
1983 16352 183216.8
1984 13882 196005.3
1985 10259 200827.0
1986 10718 212615.6
1987 12370 223097.5
1988 13249 235992.5
1989 16360 253597.6
1990 21837 271958.1
1991 25869 290859.1
1992 27280 309648.6
1993 28328 329775.0

Rezzy Eko Caraka Statistika Undip 2011
V. Output:
1. Persamaan regresi dengan variabel independen kulitatif dua kategori
Asumsi normalitas
1994 31983 383792.3
1995 40630 414418.9
1996 42929 413797.9
1997 41694 433245.9
1998 27337 376374.9
1999 24004 379557.7
2000 33515 397666.3
2001 30962 411691.9
2002 31289 426740.6

Rezzy Eko Caraka Statistika Undip 2011
Asumsi linearitas
Asumsi Heteroskedastisitas
Asumsi multikolinieritas
Asumsi autokorelasi

Rezzy Eko Caraka Statistika Undip 2011
2. Persamaan regresi dengan membandingkan dua buah regresi
Asumsi normalitas
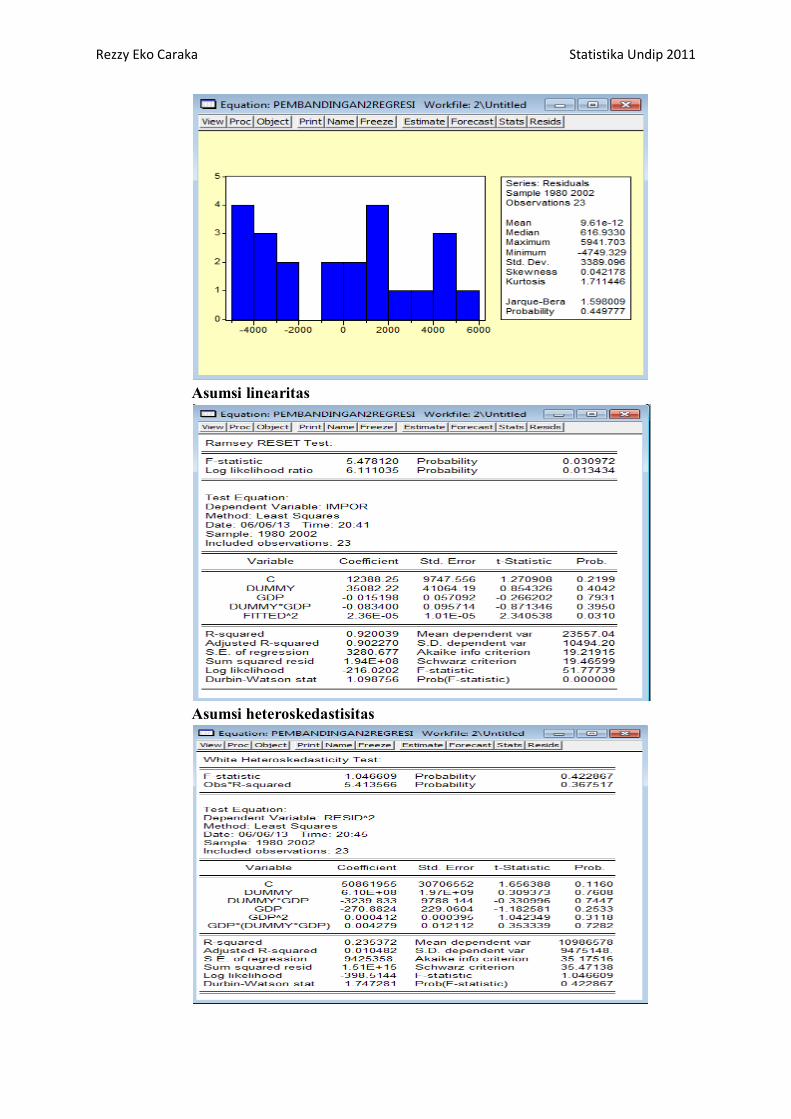
Rezzy Eko Caraka Statistika Undip 2011
Asumsi linearitas
Asumsi heteroskedastisitas

Rezzy Eko Caraka Statistika Undip 2011
Asumsi multikolinieritas
Asumsi autokorelasi

Rezzy Eko Caraka Statistika Undip 2011
3. Perhitungan nilai Ŷd pada excel
4. Grafik pada minitab

Rezzy Eko Caraka Statistika Undip 2011
VI. Analisis dan Pembahasan:
A. Regresi dengan variabel independen kualitatif 2 kategori
1. Model awal
Impor = -10110.97 – 6351.086*D + 0.118573*GDP
Untuk D=0 (sebelum krisis / sebelum tahun 1997)
Impor = -10110.97 + 0.118573*GDP
Untuk D=1 (sesudah krisis / tahun 1997-2002)
Impor = -16462,056 + 0,118573*GDP
2. Uji F ( Kecocokan Model)
Hipotesis:
Ho : Model regresi tidak cocok
H1 : Model regresi cocok
Taraf signifikansi:
α = 5%
Statistik Uji:
F-statistic = 78.63625
Prob(F-statistic) = 0.000000
Daerah kritis:
Ho ditolak jika Prob ( F-statistic ) < α
Keputusan:
Karena Prob ( F-statistic ) = 0.000000 < α = 0.05 maka Ho ditolak
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa model regresi
cocok
3. Uji t
i) Variabel DUMMY
Hipotesis:
Ho : βi=0 (variabel dummy tidak signifikan)
H1 : βi≠0 (variabel dummy signifikan)
Taraf signifikansi:
α = 5%
Statistik Uji:
t-statistic = -2.707421
Prob = 0.0136
Daerah kritis:
Ho ditolak jika Prob < α
Keputusan:
Karena Prob = 0.0136 < α = 0.05 maka Ho ditolak
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa variabel
dummy signifikan

Rezzy Eko Caraka Statistika Undip 2011
ii) Variabel GDP
Hipotesis:
Ho : βi=0 (variabel GDP tidak signifikan)
H1 : βi≠0 (variabel GDP signifikan)
Taraf signifikansi:
α = 5%
Statistik Uji:
t-statistic = 10.95957
Prob = 0.0000
Daerah kritis:
Ho ditolak jika Prob < α
Keputusan:
Karena Prob = 0.0000 < α = 0.05 maka Ho ditolak
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa variabel
GDP signifikan
4. Model akhir
Impor = -10110.97 – 6351.086*D + 0.118573*GDP
Untuk D=0 (sebelum krisis / sebelum tahun 1997)
Impor = -10110.97 + 0.118573*GDP
Untuk D=1 (sesudah krisis / tahun 1997-2002)
Impor = -16462,056 + 0,118573*GDP
B. Membandingkan dua buah regresi
1. Model awal
Impor = -9564.941 – 40994.19*D + 0.116476*GDP + 0.086451*(D*GDP)
Untuk D=0 (sebelum krisis / sebelum tahun 1997)
Impor = -9564.941 + 0.116476*GDP
Untuk D=1 (sesudah krisis / tahun 1997-2002)
Impor = -50559,131 + 0,202927 GDP
2. Uji F (Kecocokan Model)
Hipotesis:
Ho : Model regresi tidak cocok

Rezzy Eko Caraka Statistika Undip 2011
H1 : Model regresi cocok
Taraf signifikansi:
α = 5%
Statistik Uji:
F-statistic = 54.39103
Prob(F-statistic) = 0.000000
Daerah kritis:
Ho ditolak jika Prob ( F-statistic ) < α
Keputusan:
Karena Prob ( F-statistic ) = 0.000000 < α = 0.05 maka Ho ditolak
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa model regresi
cocok
3. Uji t
i) Variabel DUMMY
Hipotesis:
Ho : βi=0 (variabel dummy tidak signifikan)
H1 : βi≠0 (variabel dummy signifikan)
Taraf signifikansi:
α = 5%
Statistik Uji:
t-statistic = -1.469523
Prob = 0.1581
Daerah kritis:
Ho ditolak jika Prob < α
Keputusan:
Karena Prob = 0.1581 > α = 0.05 maka Ho diterima
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa variabel
dummy tidak signifikan
ii) Variabel GDP
Hipotesis:
Ho : βi=0 (variabel GDP tidak signifikan)
H1 : βi≠0 (variabel GDP signifikan)
Taraf signifikansi:
α = 5%
Statistik Uji:
t-statistic = 10.78038
Prob = 0.0000
Daerah kritis:

Rezzy Eko Caraka Statistika Undip 2011
Ho ditolak jika Prob < α
Keputusan:
Karena Prob = 0.0000 < α = 0.05 maka Ho ditolak
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa variabel
GDP signifikan
iii) Variabel DUMMY*GDP
Hipotesis:
Ho : βi=0 (variabel DUMMY*GDP tidak signifikan)
H1 : βi≠0 (variabel DUMMY*GDP signifikan)
Taraf signifikansi:
α = 5%
Statistik Uji:
t-statistic = 1.246149
Prob = 0.2279
Daerah kritis:
Ho ditolak jika Prob < α
Keputusan:
Karena Prob = 0.2279 > α = 0.05 maka Ho diterima
Kesimpulan:
Jadi pada taraf signifikansi 5% dapat disimpulkan bahwa variabel
DUMMY*GDP tidak signifikan
4. Model akhir
Impor = -9564.941 + 0.116476*GDP
Untuk D=0 (sebelum krisis / sebelum tahun 1997)
Impor = -9564.941 + 0.116476*GDP
Untuk D=1 (sesudah krisis / tahun 1997-2002)
Impor = -9564.941 + 0.116476*GDP
Parameter 𝛽1 (DUMMY) dan 𝛽3 (DUMMY*GDP) tidak signifikan
sehingga dapat disimpulkan bahwa tidak terdapat perbedaan intersep dan
slope pada persamaan regresi tersebut.
C. Uji Asumsi
1. Regresi dengan variabel independen kualitatif 2 kategori
a. Asumsi Normalitas
Hipotesis:
Ho : residual berdistribusi normal
H1 : residual tidak berdistribusi nornal
Taraf signifikansi :
α=5%
Statistik Uji :
Jarque-Berra = 1,327116 dengan probability= 0,515016
Daerah Kritis:

Rezzy Eko Caraka Statistika Undip 2011
Ho ditolak jika probability < α
Keputusan :
Ho diterima karena probability > α yaitu (0,515016 > 0.05)
Kesimpulan
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa residual
berdistribusi normal (asumsi normalitas terpenuhi).
b. Asumsi Linearitas
Hipotesis:
Ho : fungsi linier
H1 : fungsi tidak linier
Taraf signifikansi :
α=5%
Statistik Uji :
F-statistic = 6,976899 dengan probability= 0.016096
Daerah Kritis
Ho ditolak jika probability < α
Keputusan :
Ho ditolak karena probability < α yaitu (0.016096 < 0.05)
Kesimpulan
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa fungsi
tidak linier (asumsi linieritas tidak terpenuhi).
c. Asumsi Heteroskedastisitas
Hipotesis:
Ho : varian residual homogen
H1 : varian residual tidak homogen
Taraf signifikansi :
α=5%
Statistik Uji :
Obs*R-squared = 1.184354 dengan probability= 0.309299
Daerah Kritis
Ho ditolak jika probability < α
Keputusan :
Ho diterima karena probability > α yaitu (0.309299 > 0.05)
Kesimpulan
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa varian
residual homogen (tidak terjadi heteroskedastisitas)
d. Asumsi Autokorelasi
Breusch-Godfrey (BG) Test
Hipotesis:
Ho : tidak terjadi autokorelasi

Rezzy Eko Caraka Statistika Undip 2011
H1 : terjadi autokorelasi
Taraf signifikansi :
α=5%
Statistik Uji :
Obs*R-squared = 7.737923 dengan probability= 0,020880
Daerah Kritis
Ho ditolak jika probability < α
Keputusan :
Ho ditolak karena probability < α yaitu (0,020880 < 0.05)
Kesimpulan:
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa terjadi
autokorelasi.
2. Membandingkan dua buah regresi
a. Asumsi Normalitas
Hipotesis:
Ho : residual berdistribusi normal
H1 : residual tidak berdistribusi nornal
Taraf signifikansi :
α=5%
Statistik Uji :
Jarque-Berra = 1,598009 dengan probability= 0,449777
Daerah Kritis:
Ho ditolak jika probability < α
Keputusan :
Ho diterima karena probability > α yaitu (0,449777 > 0.05)
Kesimpulan
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa residual
berdistribusi normal (asumsi normalitas terpenuhi).
b. Asumsi Linearitas
Hipotesis:
Ho : fungsi linier
H1 : fungsi tidak linier
Taraf signifikansi :
α=5%
Statistik Uji :
F-statistic = 5,478120 dengan probability= 0.030972
Daerah Kritis
Ho ditolak jika probability < α
Keputusan :
Ho ditolak karena probability < α yaitu (0.030972 < 0.05)
Kesimpulan

Rezzy Eko Caraka Statistika Undip 2011
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa fungsi
tidak linier (asumsi linieritas tidak terpenuhi).
c. Asumsi Heteroskedastisitas
Hipotesis:
Ho : varian residual homogen
H1 : varian residual tidak homogen
Taraf signifikansi :
α=5%
Statistik Uji :
Obs*R-squared = 5.413566 dengan probability= 0.367517
Daerah Kritis
Ho ditolak jika probability < α
Keputusan :
Ho diterima karena probability > α yaitu (0.367517 > 0.05)
Kesimpulan
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa varian
residual homogen (tidak terjadi heteroskedastisitas)
d. Asumsi Multikolinieritas
Nilai R2 = 0.895704, namun secara individual variabel-variabel
independen banyak yang tidak signifikan sehingga dapat
diasumsikan bahwa model tersebut terdapat multikolinieritas.
e. Asumsi Autokorelasi
Breusch-Godfrey (BG) Test
Hipotesis:
Ho : tidak terjadi autokorelasi
H1 : terjadi autokorelasi
Taraf signifikansi :
α=5%
Statistik Uji :
Obs*R-squared = 9.400827 dengan probability= 0,009092
Daerah Kritis
Ho ditolak jika probability < α
Keputusan :
Ho ditolak karena probability < α yaitu (0,009092 < 0.05)
Kesimpulan:
Jadi, pada taraf signifikansi α=5% didapatkan hasil bahwa terjadi
autokorelasi.
D. Analisis pada excel
Berdasarkan output diperoleh persamaan regresi pada variabel independen
kualitatif 2 kategori yaitu : Impor = -10110.97 – 6351.086*D + 0.118573*GDP

Rezzy Eko Caraka Statistika Undip 2011
Dengan β0 = -10110.97 ; β1 = -6351.086 ; β2 = 0.118573
Untuk YD=0 (sebelum krisis / sebelum tahun 1997)
Impor = -10110.97 + 0.118573*GDP
Misal untuk GDP pada tahun 1980:
Impor = -10110.97 + 0.118573*159343.3= 8782.843111
Berarti nilai penduga impor untuk gdp pada tahun 1980 sebelum krisis
yaitu sebesar 8782.84311
Untuk YD=1 (sesudah krisis / tahun 1997-2002)
Impor = (-10110.97 – 6351.086) + 0.118573*GDP
Impor = -16462.056 + 0.118573*GDP
Misal untuk GDP pada tahun 1980:
Impor = -16462.056 + 0.118573*159343.3= 2431.757111
Berarti nilai penduga impor untuk gdp pada tahun 1980 setelah krisis
yaitu sebesar 2431.757111
E. Analisis pada scatterplot
Nilai impor sebelum krisis (tahun 1980-1996) yang digambarkan pada garis
berwarna hitam lebih tinggi dibandingkan setelah krisis (tahun 1997-2002) yang
digambarkan pada garis berwarna merah. Hal ini berarti bahwa krisis
mempengaruhi nilai impor.
VII. Kesimpulan :
1. Variabel dummy digunakan sebagai upaya untuk melihat bagaimana klasifikasi-
klasifikasi dalam sampel berpengaruh terhadap parameter pendugaan.
2. Model persamaan regresi untuk variabel independen kualitatif dua kategori
yaitu: Impor = -10110.97 – 6351.086*D + 0.118573*GDP
Untuk D=0 (sebelum krisis / sebelum tahun 1997)
Impor = -10110.97 + 0.118573*GDP
Untuk D=1 (sesudah krisis / tahun 1997-2002)
Impor = -16462,056 + 0,118573*GDP
3. Berdasarkan uji F diperoleh model regresi untuk variabel independen kualitatif
dua kategori tersebut cocok dan pada uji t, variabel dummy dan variabel gdp
tersebut signifikan.
4. Pada uji asumsi persamaan regresi untuk variabel independen kualitatif dua
kategori diperoleh bahwa asumsi normalitas terpenuhi, asumsi linieritas tidak
terpenuhi, tidak terjadi heteroskedastisitas, dan terjadi autokorelasi.
5. Model akhir membandingkan dua buah regresi yaitu:
Impor = -9564.941 + 0.116476*GDP
Untuk D=0 (sebelum krisis / sebelum tahun 1997)
Impor = -9564.941 + 0.116476*GDP
Untuk D=1 (sesudah krisis / tahun 1997-2002)
Impor = -9564.941 + 0.116476*GDP

Rezzy Eko Caraka Statistika Undip 2011
6. Berdasarkan uji F diperoleh model regresi untuk membandingkan dua buah
regresi cocok, namun pada uji t untuk variabel DUMMY dan DUMMY*GDP
tidak signifikan.
7. Pada uji asumsi persamaan membandingkan dua buah regresi diperoleh bahwa
asumsi normalitas terpenuhi, asumsi linieritas tidak terpenuhi, tidak terjadi
heteroskedastisitas, tidak terdapat multikolinieritas, dan terjadi autokorelasi.
8. Berdasarkan grafik pada scatterplot diperoleh nilai impor sebelum krisis (tahun
1980-1996) yang digambarkan pada garis berwarna hitam lebih tinggi
dibandingkan setelah krisis (tahun 1997-2002) yang digambarkan pada garis
berwarna merah. Hal ini berarti bahwa krisis mempengaruhi nilai impor.





![Cover [Dummy] - Sartorius AG](https://static.fdokumen.com/doc/165x107/6337856da5ba10dda7019c32/cover-dummy-sartorius-ag.jpg)














