
IBM DB2 9.7
183
© Copyright IBM Corporation 2010 0 IBM DB2 On-site Training Course IBM Korea IBM Korea © Copyright IBM Corporation 2010 Software Group Information Management IBM DB2 9.7 On-site Training Course
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of IBM DB2 9.7

© Copyright IBM Corporation 20100
IBM DB2 On-site Training CourseIBM Korea
IBM Korea
© Copyright IBM Corporation 2010
Software Group Information Management
IBM DB2 9.7On-site Training Course

© Copyright IBM Corporation 20101
IBM DB2 On-site Training CourseIBM Korea
Course 소개

© Copyright IBM Corporation 20102
IBM DB2 On-site Training CourseIBM Korea
목차
1. IBM DB2 제품군소개
2.인스턴스및데이터베이스아키텍쳐이해
3.클라이언트접속및쿼리
4.오브텍트비교
5. DDL/DML/DCL6. SQL작성고려사항
7.동시성제어
8.데이터이동
9.마이그레이션

© Copyright IBM Corporation 20103
IBM DB2 On-site Training CourseIBM Korea
IBM DB2 제품군 소개

© Copyright IBM Corporation 20104
IBM DB2 On-site Training CourseIBM Korea
IBM DB2 버전
IBM DB2 for LUW
• RS/6000 기반으로 제품 출시
• 멀티 플랫폼 지원
• 고성능• 확장성• 사용 편의성• SMART (Self management & Resource
Tuning)• 고가용성• 관리의 편의성
• 고가용성 향상 : HADR• 성능 향상• 오라클 마이그레이션 툴
MTK• 각종 advisor 제공• DW 향상
• 스레드기반 아키텍쳐• 워크로드 관리 (WLM)• 오라클 호환성• XML/SQL 향상
• 하이브리드 DBMS-Pure XML• 자율컴퓨팅 항샹• 테이블 파티셔닝• LBAC 보안• Row 압축• SQL 향상
• HADR 조회전용 서버 기능• WLM 향상• 인덱스,임시테이블,LOB 압축• 온라인 테이블 이동• 로컬 인덱스 파티셔닝• 오라클 호환성
1993
1.0 2.0
1995
8.1
2002
8.2
2004
9.1
2006
9.5
2007
9.7
2009
9.8
2010
• 공유디스크 구조• 무한한 확장성• 업무 투명성• 지속적인 가용성

© Copyright IBM Corporation 20105
IBM DB2 On-site Training CourseIBM Korea
IBM DB2 서버 제품군 소개 및 특징
무제한무제한무제한무제한DB Size 제한
무제한4 CPU까지 지원2 CPU까지 지원2 CPU까지 지원CPU 제한
32/64 bit 지원32/64 bit 지원32/64 bit 지원32/64 bit 지원32/64 bit 지원여부
무제한16GB까지 지원4GB까지 지원4GB까지 지원메모리 제한
Linux, Windows,AIX, HP-UX, Solaris
Linux, Windows,AIX, HP-UX, Solaris
Linux, WindowsLinux, Windows지원 운영체제
Enterprise Server Edition (ESE)
Workgroup Server Edition (WSE ) DB2 Express (EXP )DB2 Express-C지원 여부
※ DB2 Express-C• DB2 Express Edition과 동일하나 추가옵션을 구매하실 수 없습니다. • 오라클의 PL/SQL 호환성 기능은 이 제품에서는 지원되지 않습니다. • 무료로 개발/구축/배포할 수 있습니다. • 무료로 다운로드 받아 사용할 수 있습니다. ( http://www.ibm.com/db2/express )

© Copyright IBM Corporation 20106
IBM DB2 On-site Training CourseIBM Korea
IBM DB2 9.7 서버 제품군 특성 요약
●XXXGovernor보안 Advanced Access
Control FeatureXXXLabel Based Access Control
Performance Optimization Feature
XXXWorkload management성능 관리
별도구매별도구매별도구매Performance Manager
●●●●Backup compression
Storage OptimizationFeature XXXRow level compression
XXXXDatabase Partitioning●XXXTable Partitioning
대용량데이터관리
●XXXMQT/MDC/Query Parallelism 고급 튜닝
●●●Online ReorgTivoli System Automation
High Availability Disaster Recovery
Homogenous Q Replication
Homogenous SQL Replication Homogenous Federation
●●●
●●
High Availability Feature ●
고가용서버 구성
Homogeneous Replication FeatureXXX
●●●●
●●●●
시스템통합
Enterprise Server Edition (ESE)
Workgroup Server Edition (WSE ) DB2 Express (EXP )DB2 Express-C주요 지원 기능
※ Database Partitioning : Data Partitioning Feature (DPF)는 DB2 Warehouse Edition Version 9.7를 통해서만 가능합니다.

© Copyright IBM Corporation 20107
IBM DB2 On-site Training CourseIBM Korea
부연설명 : IBM DB2 서버 구성 특징
Federation
nickname
Replication
Table QueueSQL replication
MQ(Send Queue)
MQ (Receive Queue)
Q replication
HADR
primary standby
HADR sync
High Availability Disaster Recovery High Availability system
standby
DPF
Partition 0 Partition 1
Database Partitioning Features
Partition 2 Partition 3 Partition 4
Table
소스 테이블의 변경사항을 로그에서 캡쳐하여 다른 서버에반영하는 테이블 단위 복제 솔루션
모든 하드웨어 리소스가 이중화되어 트랜잭션 레벨로데이터가 동기화 되는 데이터베이스 단위 고가용 솔루션
원격 서버의 테이블을 로컬 테이블과 같이사용하도록 연계 구성하는 솔루션
대용량 DW스템을 구축하기 위하여 단일 시스템의 처리 한계를극복하고 병렬처리를 극대화하기 위해 구성하는 솔루션

© Copyright IBM Corporation 20108
IBM DB2 On-site Training CourseIBM Korea
IBM DB2 클라이언트 제품군
• Java 스토어드 프로시저 및 사용자 정의 함수(UDF)의디폴트 드라이버입니다.
• 이 드라이버는 로컬 또는 리모트 서버에 액세스할 수있도록 JDBC를 사용하여 JAVA로 작성된 클라이언트응용 프로그램 및 애플릿과 JAVA 응용 프로그램의임베디드 정적 SQL용 SQLJ에 대한 지원을 제공합니다.
• ODBC API 또는 CLI API를 사용하여 응용프로그램에대한 런타임 지원을 제공합니다.
• 이 드라이버는 tar 파일로만 사용 가능하며 설치 가능한이미지로 사용할 수 없습니다.
• 메시지는 영어로만 보고됩니다
• Data Server Runtime Client 또는 Data Server Client를 설치할필요 없이 ODBC, CLI, .NET, OLE DB, PHP, Ruby, JDBC 또는SQLJ를 사용하는 응용 프로그램에 대한 런타임 지원을제공하는 솔루션입니다
• 서버를 리모트로 관리하고 응용프로그램을 실행시키는 방법을 제공합니다.
• 데이터베이스 및 서버에 연결하는 데 필요한 정보를저장하는 카탈로그 및 동일 시스템에 여러 개의 사본을설치할 수 있습니다
• Run-Time Client의 기능을 포함하며, 다양한 GUI 도구들을이용한 관리 작업을 가능하게 하는 클라이언트 모듈과ESQL 등의 개발이 가능하도록 하는 프리 컴파일러, 헤더 파일, 라이브러리 등을 제공 합니다.
Comm
unica
tion S
uppo
rt IBM DB2Server
OS/390, AS400
• DB2 Connect Personal Edition은 Linux와 Windows 플랫폼에서 지원되는 단일 사용자용 호스트데이터베이스 액세스 제품입니다
• DB2 Connect Enterprise Edition은 Windows, AIX, HP-UX, Solaris, Linux, Linux/390 플랫폼에서 지원되는다중 사용자용 호스트 데이터베이스 액세스제품입니다
IBM DB2Connect
Data Server Driver for JDBC and SQLJ
Data Server Driver for ODBC and CLI
Data Server Driver Package
Data Server Runtime Client
Data Server Client
© Copyright IBM Corporation 20109
IBM DB2 On-site Training CourseIBM Korea
인스턴스 및 데이터베이스아키텍쳐 이해

© Copyright IBM Corporation 201010
IBM DB2 On-site Training CourseIBM Korea
인스턴스(Instance)
Physical Machine(Hostname or IP Address)DB2 Product
Instance1(Instance username)
DBM Config
Port 1
Instance2(Instance username)
DBM Config
Port 2link
link
인스턴스의개요
• DB2엔진의 기능을 사용할 수 있는 환경을 DB2 인스턴스라고하고 데이터베이스 관리자(Database Manager, DBM)라고 부릅니다.
• UNIX에서 인스턴스명은 해당 인스턴스 관리자의 OS 계정명과동일하고 한 머신에 하나 이상의 인스턴스를 생성할 수 있으며각 인스턴스는 독립된 DB2 엔진으로 운영됩니다.
• 각 인스턴스는 고유의 환경을 구성하는 인스턴스 구성 파일을가지게 됩니다. (Database Manager Configuration File, DBM CFG)
인스턴스시작및중지
• 인스턴스 시작 : db2start• 인스턴스 중지 : db2stop [ force ]
인스턴스구성파일(DBM CFG)관리• DBM CFG는 바이너리 형태의 파일로 관리되므로 직접 편집할 수없고 DB2의 관리 명령어를 통해서만 조회 및 수정이 가능합니다
• 조회 : db2 get dbm cfg• 수정 : db2 update dbm cfg using <변수> <값>
DB2 Registry변수• DB2 인스턴스에만 적용되는 DB2 시스템 환경 변수를 DB2 레지스트리 변수라고 합니다.
• DB2 레지스트리 변수는 인스턴스 관리자가 db2set 명령어를이용하여 관리합니다.
• 조회 : db2set• 설정 : db2set <변수>=<값>• 삭제 : db2set <변수>=
일반사용자의인스턴스지정사용
• DB2INSTANCE 라는 환경 변수를 이용하여 원하는 인스턴스를선택할 수 있습니다. 그리고, DB2 명령을 실행하려면 PATH 등의기본적인 환경 변수의 설정이 필요합니다
export DB2INSTANCE=<인스턴스명>export PATH=$PATH:<인스턴스 사용자 홈디렉토리>/sqllib/bin
• 인스턴스 환경 변수를 간단하게 설정하려면, 인스턴스 홈에생성된 sqllib 서브디렉토리에 있는 db2profile 을 실행하면 됩니다.
. <인스턴스 사용자 홈디렉토리>/sqllib/db2profile

© Copyright IBM Corporation 201011
IBM DB2 On-site Training CourseIBM Korea
데이터베이스
Instance1(Instance username)
Database1 (DB name)
DB Config Log catalog
tablespace1 tablespace2
tablespace3
Database2 (DB name)
DB Config Log catalog
tablespace1 tablespace2
tablespace3
데이터베이스의개요
• 인스턴스 관리 하에 프로세스, 메모리, 물리적인 파일로 구성된데이터 관리 영역으로 하나의 인스턴스에서 독립된 여러 개의데이터베이스를 생성할 수 있습니다.
• 각 데이터베이스는 별도의 트랜잭션 로그와 데이터베이스 구성파일(Database Config, DB CFG)을 가집니다.
• 데이터베이스의 언어 코드셋이나 오라클 PL/SQL호환성 사용여부는 데이터베이스 생성 시점에 결정됩니다.
데이터베이스활성화및비활성화
• 활성화 : db2 activate db <데이터베이스> 또는첫번째 세션 연결시
• 비활성화 : db2 deactivate db <데이터베이스> 또는마지막 세션 종료시
데이터베이스구성파일(DB CFG)관리• DB CFG는 바이너리 형태의 파일로 관리되므로 직접 편집할 수없고 DB2의 관리 명령어를 통해서만 조회 및 수정이 가능합니다
• 조회 : db2 get db cfg [ for <데이터베이스> ]• 수정 : db2 update db cfg [ for <데이터베이스> ] using <변수> <값>

© Copyright IBM Corporation 201012
IBM DB2 On-site Training CourseIBM Korea
네트워크 설정 및 데이터베이스 연결
Physical Machine(Hostname or IP Address)DB2 Product
Instance1(Instance username)
DBM Config
Port 1
Instance2(Instance username)
DBM Config
Port 2
link
link
Database1 (DB name)
DB C
onfig
Log catalog
Database2 (DB name)
DB C
onfig
Log catalog
Database3 (DB name)
DB C
onfig
Log catalog
Client Machine
Node directory
database directory
사용할 Port 설정(DBM CFG)
TCP/IP네트워크사용설정(db2set 레지스트리)
네트워크설정
• 원격 클라이언트로부터의 접속을 허용하기 위해서 인스턴스의네트워크 설정이 필요합니다.
• db2set 레지스트리 변수와 사용할 port를 지정하는 것만으로도네트워크 설정이 되며 인스턴스 엔진 기동 시 별도로 네트워크프로세스를 기동시킬 필요가 없습니다.
• 레지스트리 설정 : db2set DB2COMM=TCPIP• DBM CFG 설정 : db2 update dbm cfg using SVCENAME <port>
port는 /etc/services의 서비스명 또는 포트 번호 중 선택
클라이언트설정
• DB2 클라이언트에서 서버에 접속하기 위해서는 접속 하고자하는 서버의 정보가 필요하며 이러한 서버 정보를 관리하는목록을 디렉토리라 합니다. 디렉토리는 바이너리 파일로 catalog 명령어를 이용하여 제어합니다
• 노드 등록 : db2 catalog tcpip node <임의의 노드명>remote <서버명 또는 IP> server <서비스명 또는 포트>
• 데이터베이스 등록 : db2 catalog db <데이터베이스명> at node <등록한 노드명>
데이터베이스연결
• 데이터베이스 목록 보기 : db2 list db directory• 데이터베이스 연결 : db2 connect to <데이터베이스명>
[ user <OS계정> [ using <OS패스워드> ] ]

© Copyright IBM Corporation 201013
IBM DB2 On-site Training CourseIBM Korea
데이터베이스 연결 인증
DB2 Client
Instance1 DBM ConfigAUTHENTICATION=SERVER
DB2 Client
Instance2 DBM ConfigAUTHENTICATION=CLIENT
DB2 Client
Instance3 DBM ConfigAUTHENTICATION=GSSPLUGINPlug-ins
DB2 Client
Instance4 DBM ConfigAUTHENTICATION=KERBEROS
Kerberos Server
서버인증
• 클라이언트 머신에서 connect 문을 이용하여 데이터베이스 서버머신에 접속을 요청하면, 제공된 사용자ID와 암호가 서버머신으로 전송되어 서버 머신의 OS에 의해 점검됩니다.
• 서버 머신의 OS에 사용자 ID가 존재하고, 암호가 일치하면사용자 인증은 성공하여 데이터베이스에 접속이 허용됩니다
클라이언트인증
• connect 문에서 제공된 사용자ID와 암호는 클라이언트 머신의OS에 의해 점검됩니다.
• 클라이언트 머신에서 사용자 ID와 암호가 일치하면 사용자인증은 성공하여 데이터베이스에 대한 접속이 허용 됩니다.
• 사용자 ID만 서버 머신으로 전송 됩니다
플러그인인증
• 외부 GSSAPI 기반 보안 메커니즘을 사용하여 인증이 수행됨을의미합니다.
Kerberos 인증• 인증을 위해 Kerberos 보안 프로토콜을 사용하여 Kerberos 서버에서 인증이 수행됨을 의미합니다.

© Copyright IBM Corporation 201014
IBM DB2 On-site Training CourseIBM Korea
물리적 저장 모델
DatabaseDatabase
Table spaceTable space
ObjectObject
ExtentExtent
DB2 PageDB2 Page
ContainerContainer
OS PageOS Page
논리적 구조 물리적 단위
테이블스페이스
• 테이블 스페이스는 테이블을 저장하는 논리적 개념 입니다. • 테이블 스페이스를 구성하는 물리적인 개념은 DB2에서는
Container이며 오라클에서는 데이타 파일 입니다.
오브젝트
• 오라클의 세그먼트를 DB2에서는 오브젝트라 명명 합니다.• 물리적 디스크 공간을 차지하는 테이블 혹은 인덱스가 해당됩니다.
익스텐트 (Extent)• Block 또는 페이지가 연속적으로 할당된 공간입니다. • 세그먼트 또는 오브젝트 크기 증가시 Extent 크기로 연속적인공간이 할당됩니다
페이지 (Page)• 가장 작은 저장 공간 단위입니다.(4K,8K,16K,32K)• DB2의 경우 성능 저하를 야기시키는 체인현상 및 마이그레이션현상을 막기 위해 한 행은 반드시 한 페이지에 저장이 되도록설계되었습니다
컨테이너 (Container)• 테이블 스페이스를 구성하는 물리적 파일입니다 .

© Copyright IBM Corporation 201015
IBM DB2 On-site Training CourseIBM Korea
테이블스페이스의 종류
System managed Space (SMS)
Database Managed Space (DMS)
Automatic storage
CREATE TABLESPACE SMS_TSMANAGED BY SYSTEMUSING( ‘/db2/tbs/sms01’ , ‘/db2/tbs/sms02’)
CREATE TABLESPACE DMS_TSMANAGED BY DATABASE USING ( FILE ‘/db2/tbs/dms01’ 10M, FILE /db2/tbs/dms02’ 10M)
CREATE TABLESPACE AS_TS MANAGED BY AUTOMATIC STORAGE
System managed Space (SMS) • 운영체제가 테이블 스페이스를 관리하는 방식입니다.• 컨테이너로 디렉토리가 사용되며 운영체제의 파일시스템이스토리지 할당 및 관리를 제어합니다
• 테이브 스페이스 생성시 크기를 지정할 수 없으며 크기는운영시스템의 파일 시스템 용량에 좌우됩니다.
• 추가 공간이 요구되어질 때마다 한 Page씩 할당됩니다. • 한 테이블은 한 테이블스페이스내에 존재합니다• TEMPORARY 테이블 또는 소형 테이블을 저장하는 데에 주로사용됩니다.
Database Managed Space (DMS) • 데이터베이스가 테이블 스페이스를 관리하는 방식입니다.• Container로 file과 raw device가 이용되어집니다. • 오라클의 Locally Managed Tablespace와 유사합니다.• 공간이 미리 할당되며 하나의 Extent안에 있는 공간은물리적으로 연속적입니다
• 하나의 테이블을 LOB 데이터와 일반 데이터, 인덱스로 테이블스페이스를 분리하여 저장할 수 있습니다.
• SMS보다 성능이 우수합니다.
Automatic storage • DB2가 자동으로 컨테이너를 관리하고 테이블 스페이스의타입에 따라 SMS 또는 DMS로 자동 생성하므로 컨테이너를지정할 필요가 없습니다
• SMS의 편리성과 DMS의 성능을 모두 가질 수 있습니다.
© Copyright IBM Corporation 201016
IBM DB2 On-site Training CourseIBM Korea
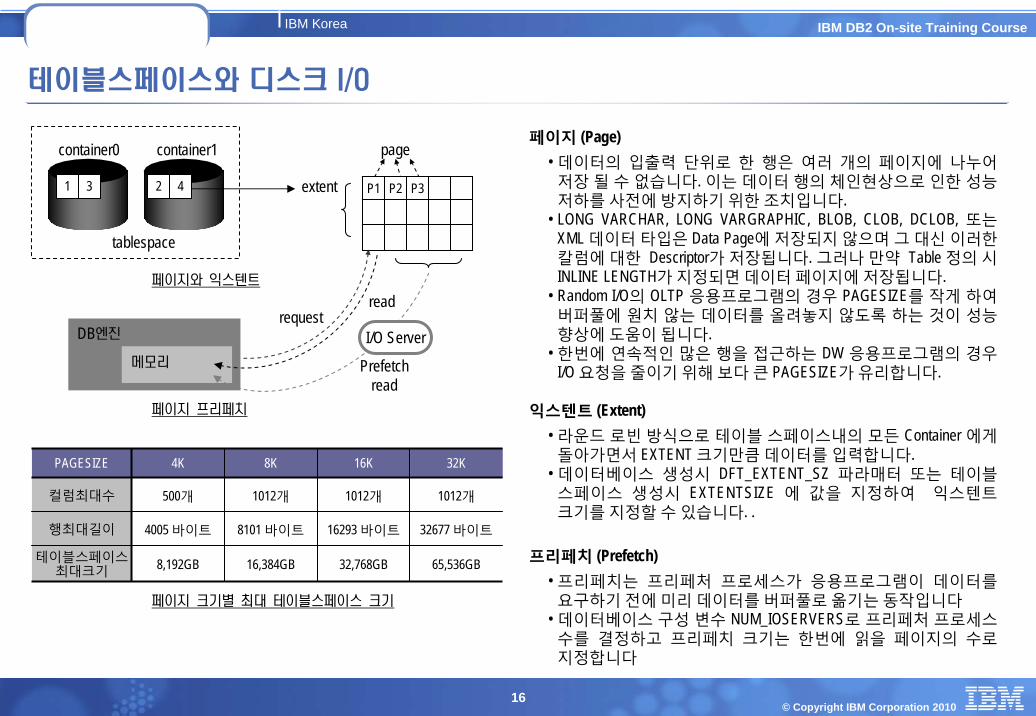
테이블스페이스와 디스크 I/O
extent
tablespace
container0 container1
1 23 4 P1 P2 P3
page
페이지와 익스텐트
페이지 프리페치
DB엔진
메모리
requestread
I/O Server
Prefetchread
65,536GB32,768GB16,384GB8,192GB테이블스페이스최대크기
32677 바이트16293 바이트8101 바이트4005 바이트행최대길이
1012개1012개1012개500개컬럼최대수
32K16K8K4KPAGESIZE
페이지 크기별 최대 테이블스페이스 크기
페이지 (Page)• 데이터의 입출력 단위로 한 행은 여러 개의 페이지에 나누어저장 될 수 없습니다. 이는 데이터 행의 체인현상으로 인한 성능저하를 사전에 방지하기 위한 조치입니다.
• LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DCLOB, 또는XML 데이터 타입은 Data Page에 저장되지 않으며 그 대신 이러한칼럼에 대한 Descriptor가 저장됩니다. 그러나 만약 Table 정의 시INLINE LENGTH가 지정되면 데이터 페이지에 저장됩니다.
• Random I/O의 OLTP 응용프로그램의 경우 PAGESIZE를 작게 하여버퍼풀에 원치 않는 데이터를 올려놓지 않도록 하는 것이 성능향상에 도움이 됩니다.
• 한번에 연속적인 많은 행을 접근하는 DW 응용프로그램의 경우I/O 요청을 줄이기 위해 보다 큰 PAGESIZE가 유리합니다.
익스텐트 (Extent)• 라운드 로빈 방식으로 테이블 스페이스내의 모든 Container 에게돌아가면서 EXTENT 크기만큼 데이터를 입력합니다.
• 데이터베이스 생성시 DFT_EXTENT_SZ 파라매터 또는 테이블스페이스 생성시 EXTENTSIZE 에 값을 지정하여 익스텐트크기를 지정할 수 있습니다. .
프리페치 (Prefetch)• 프리페치는 프리페처 프로세스가 응용프로그램이 데이터를요구하기 전에 미리 데이터를 버퍼풀로 옮기는 동작입니다
• 데이터베이스 구성 변수 NUM_IOSERVERS로 프리페처 프로세스수를 결정하고 프리페치 크기는 한번에 읽을 페이지의 수로지정합니다

© Copyright IBM Corporation 201017
IBM DB2 On-site Training CourseIBM Korea
테이블스페이스와 버퍼풀
IBMDEFAULTBP
SYSCATSPACE
TEMPSPACE1
USERSPACE1
Global Database Memory
default
MYTS1
MYTS2
BP8K1
BP8K2
MYTS4
MYTS3
디폴트로생성되는테이블스페이스
• SYSCATSPACECatalog Table 및 데이터베이스를 관리하기 위한 관리테이블들이 저장됩니다.
• TEMPSPACE1디폴트 Temorary 테이블 스페이스입니다.
• USERSPACE1사용자가 생성한 오브젝트 및 데이타를 저장하는 디폴트테이블 스페이스입니다. 테이블 생성시 테이블 스페이스를지정하지 않을 경우 디폴트로 이 테이블 스페이스를사용합니다
디폴트로생성되는버퍼풀
• 모든 데이터는 버퍼풀을 통하여 검색되므로 데이터베이스에는반드시 한 개 이상의 버퍼풀이 존재해야 합니다. 기본적으로생성되는 버퍼풀은 IBMDEFAULTBP로 4K 페이지 1000개가 할당됩니다.
테이블스페이스와버퍼풀의관계
• 데이터가 저장된 물리적인 저장 영역인 테이블스페이스컨테이너의 페이지 크기와 대응되는 버퍼풀의 페이지 크기는동일해야 합니다 . 여러 개의 테이블스페이스는 한 개의버퍼풀을 공유하여 사용할 수 있습니다.
버퍼풀관리
• 생성 : db2 create bufferpool <버퍼풀> size <갯수> pagesize <크기>• 수정 : db2 alter bufferpool <버퍼풀> size <갯수>• 삭제 : db2 drop bufferpool <버퍼풀>

© Copyright IBM Corporation 201018
IBM DB2 On-site Training CourseIBM Korea
테이블스페이스와 I/O, 버퍼풀 매핑
OptionalBUFFERPOOL 버퍼풀
AUTOMATIC<정수> K or M<페이지수>
OptionalPREFETCH SIZE
Optional<정수> K or M<페이지수>
EXTENTSIZE
AUTOMATIC STORAGE 『크기속성』SYSTEM 『시스템 컨테이너 속성』DATABASE 『데이터베이스 컨테이너 속성』
MANAGED BY
PAGESIZE <정수> K Optional
TABLESPACE 테이블스페이스REGULAR LARGESYSTEM TEMPORARYUSER TEMORARY
CREATE 테이블스페이스의종류
• Regular오브젝트 및 인덱스의 모든 데이터를 저장하는 공간입니다.
• System Temporary정렬 및 조인과 같은 SQL문 및 기타 작업을 실행할 때데이터베이스 엔진이 사용하는 영역입니다.
• User Temporary사용자 세션에서 전역 임시 테이블의 데이터를 임시로저장하는 영역입니다
• LargeRegular처럼 모든 데이터를 저장하나 시스템 관리 유형이
DMS일 경우에만 생성이 가능하며 한 페이지에 저장되는행의 수가 255개를 초과하는 테이블을 저장할 수 있습니다.
• DB2는 UNDO 정보를 로그 버퍼 또는 로그 파일에 저장하므로UNDO 정보를 위한 별도의 UNDO 테이블 스페이스는 존재치않습니다.
테이블스페이스모니터링
• 조회 구문db2 list tablespacesdb2 list tablespace containers for
• 뷰 테이블SYSIBMADM.SNAPTBSPSYSIBMADM.TBSP_UTILIZATIONSYSIBMADM.SNAPCONTAINERSYSIBMADM.CONTAINER_UTILIZATION
• PD tooldb2pd –d <데이터베이스> -tablespaces

© Copyright IBM Corporation 201019
IBM DB2 On-site Training CourseIBM Korea
데이터베이스 로그
Circular Logging
LOG 3
LOG N
LOG 1
LOG 2 LOG 1 LOG MPrimary
Secondary
Archive Logging
LOG 11 LOG 12 LOG 13 LOG 14
Primary
Offline Archive
Online Archive Current Active Log
Circular Logging 개요(기본모드)• 로그 파일이 재사용되므로 추가적인 저장 공간이 필요하지않습니다.
• 백업을 받은 시점까지만 복구가 가능합니다. • 오프라인 백업만 지원되며 온라인 백업이 지원되지 않습니다.• 전체 데이터베이스 백업 및 복구만 가능합니다. • Crash Recovery 에 사용됩니다. • LOGPRIMARY로 지정된 N개의 로그를 모두 사용할 때까지트랜잭션이 완료되지 않으면 LOGSECOND로 지정한 M개의로그까지 추가적으로 생성하여 사용합니다. 이후, 트랜잭션이완료되면 비동기식으로 M개 로그는 제거되고 N개의 로그만남게 됩니다.
Archive Logging 개요• 변경된 트랜잭션의 이력 데이터를 저장하며 Archived 로그를위해 저장 공간이 별도로 필요합니다.
• 온라인 백업이 가능하며 장애가 발생한 시점까지 완전 복구가가능합니다.
• 데이터베이스 및 테이블 스페이스 백업 복구가 가능합니다• 비활성화된 로그는 현재 로그 디렉토리에 아카이브 상태로남거나 지정된 아카이브 매체로 이동하게 됩니다.
• 설정 방법DB CFG의 LOGARCHMETH1으로 아카이브 방법 설정db2 update db cfg using logarchmeth1 DISK:/backup/archive/로깅모드를 변경한 후에는 데이터베이스가 BACKUP
PENDING 상태가 됩니다. 데이터베이스 백업을 수행하여BACKUP PENDING 에서 빠져 나오도록 합니다

© Copyright IBM Corporation 201020
IBM DB2 On-site Training CourseIBM Korea
데이터베이스 백업
tablespace
Offline Backup Online Backup
Disk copy solution
데이터베이스백업개요
• db2 backup 백업 명령어를 이용하여 데이터베이스의 모든데이터와 제어 정보를 저장한 이미지 파일을 생성합니다.
• 백업은 상황에 따라 백업 수준, 백업 범위, 백업 모드를 지정하여백업 전략을 세웁니다.
백업모드
• 오프라인 모드데이터베이스에 접속된 사용자가 없는 상태에서 백업하는모드입니다. 백업이 진행되는 동안 데이터의 변경은 발생하지 않으므로, 백업 이미지 파일만 보관하면 복구에 사용할 수 있습니다. 데이터베이스의 모든 테이블스페이스를 백업합니다
• 온라인 모드사용자가 데이터베이스에 접속하고 있는 상태에서 백업하는 모드입니다. 백업이 진행되는 동안 데이터가 변경 중 일 수도 있으므로백업 이미지 파일과 백업이 진행되는 동안 변경된 데이터에대한 로그 파일을 함께 보관해야 복구에 사용할 수 있습니다. 아카이브 로깅에서만 지원됩니다.지정한 테이블스페이스만 백업할 수 있습니다
• 디스크 솔루션 연계 모드데이터베이스에 쓰기 동작을 정지시켜 일관성을 유지한상태에서 외부 솔루션에 의해 데이터 영역을 모두 복사하는방법을 사용할 수 있습니다백업 중 사용자는 계속 접속되어 있고 읽기 동작이 가능한상태입니다.

© Copyright IBM Corporation 201021
IBM DB2 On-site Training CourseIBM Korea
버전 복구/크래시 복구
LOG LOG LOGCrash recovery
크래쉬복구
• 시스템 문제시 활성 로그 파일을 이용하여 DB2 가 자동으로복구합니다
• RESTART 명령어는 DB2 장애시 크래쉬 복구를 실행하는명령어입니다. 인스턴스가 비정상적으로 종료되는 경우에크래쉬 복구가 필요합니다. 크래쉬 복구의 자동 실행 여부는AUTORESTART 데이타베이스 구성 변수로 조절합니다
버전복구
• 과거 시점에 생성했던 오프라인 데이터베이스 백업 이미지를이용하여 과거의 시점과 동일한 상태로 복구합니다
• 백업 : db2 backup db <데이터베이스>• 복구 : db2 restore db <데이터베이스>
Offline Backup Offline Backup Offline Backup
restore restore

© Copyright IBM Corporation 201022
IBM DB2 On-site Training CourseIBM Korea
롤포워드 복구
online Backup
restore
LOG LOG LOG
roll forward
롤포워드복구
• 버전 복구를 완료한 후에 로그 파일을 이용하여 복구를 원하는시점까지 로그 파일을 적용합니다.
• 아카이브 로깅 상태에서만 지원됩니다
온라인데이터베이스백업및복구
• 백업 : db2 backup db <데이터베이스> online• 복구 : db2 restore db <데이터베이스>
버전 복구 후 데이터베이스는 rollforward pending 상태db2 rollforward db <데이터베이스> to end of logs and complete
온라인테이블스페이스복구
• 복구 : db2 restore db <데이터베이스> tablespace( <테이블스페이스> ) online
해당 테이블스페이스는 rollforward pending 상태db2 rollforward db <데이터베이스>
to end of logs tablespace( <테이블스페이스> ) online
restoretablespace
roll forward

© Copyright IBM Corporation 201023
IBM DB2 On-site Training CourseIBM Korea
Incremental 백업 및 복구
Full Backup
increment Backup
increment Backup
변경분
delta Backup
변경분
delta Backup
변경분
LOG
LOG
백업의범위
• FULL : 데이터베이스의 모든 데이터와 제어 정보를 백업합니다.• INCREMENTAL : FULL 백업 이후에 변경된 부분만 백업합니다. • DELTA : 이전 백업 이후에 변경된 부분만 백업합니다.
INCREMENTAL /DELTA 백업및복구
• 아카이브 로깅에서만 지원됩니다db2 update db cfg using logarchmeth1 DISK:/backup/archive/
• TRACKMOD 데이터베이스 구성 변수의 값을 "ON"으로 설정하여마지막 백업 이후에 변경된 데이터를 추적할 수 있도록 합니다
db2 update db cfg using trackmod on
데이터베이스백업및복구
• 백업db2 backup db <데이터베이스> onlinedb2 backup db <데이터베이스> online incrementaldb2 backup db <데이터베이스> online incremental delta
• 복구db2 restore db <데이터베이스>
incremental automatic taken at <최근백업파일시간소인>db2 rollforward db <데이터베이스> to end of logs and complete

© Copyright IBM Corporation 201024
IBM DB2 On-site Training CourseIBM Korea
디스크 솔루션 연계 백업 및 복구
roll forward
snapshotLOG LOG LOGmirror
Write suspend Write resume 디스크솔루션연계
• 백업 대상 데이터베이스의 모든 테이블스페이스에 쓰기 동작이허용되지 않는 상태로 만들어 데이터베이스의 일관성을보장하고 데이터가 포함된 디스크를 외부 솔루션에 의해복사합니다.
• 복사가 끝나면 다시 쓰기 동작이 가능하도록 변경합니다.
백업절차
• 쓰기 동작 금지 : db2 set write suspend for database• OS명령에 의해 디스크 복사• 쓰기 동작 재시작 : db2 set write resume for database
복구절차
• 백업시점 복구 : db2inidb <데이터베이스> as snapshot• 완전 복구 : db2inidb <데이터베이스> as mirror
db2 rollforward db <데이터베이스> to end of logs and complete
© Copyright IBM Corporation 201025
IBM DB2 On-site Training CourseIBM Korea
클라이언트 접속 및 쿼리

© Copyright IBM Corporation 201026
IBM DB2 On-site Training CourseIBM Korea
DB2 명령행 처리기 (db2 CLP)
대화식모드
• db2 명령어 프롬프트가 표시된 상태에서 <DB2 명령어> 또는<SQL문>을 실행하는 방식을 대화식 모드의 DB2 세션이라고합니다.
비대화식모드
• db2 명령어를 먼저 입력하고, <DB2 명령어> 또는 <SQL문>을실행하는 방식을 비대화식 모드의 DB2 세션이라고 합니다.
• OS에 따라 특수 문자가 포함되는 경우에는 " (쌍따옴표)가필요할 수도 있습니다.
개요
• db2 명령행 처리기(db2 CLP, Command Line Processor)는 DB2 명령어 또는 SQL문을 실행시키기 위해 기본적으로 제공되는프로그램입니다
• db2 명령어를 실행하면 DB2 세션이 시작되고, 백그라운드프로세스인 db2bp 또는 db2bp.exe가 생성됩니다. quit 명령어는기존의 대화식 모드에서 생성된 db2bp 프로세스를 계속사용하므로, 완전히 새로운 환경의 DB2 세션을 사용하려면, terminate 명령을 입력하고 다시 db2를 입력합니다.
$ db2db2=> <db2 명령어>db2=> <SQL문>db2=> !<OS 명령어>db2=> quit
$ db2 <DB2명령어>$ db2 <SQL문>$ db2 "SQL문"$ <OS 명령어>

© Copyright IBM Corporation 201027
IBM DB2 On-site Training CourseIBM Korea
DB2 세션의 옵션
설정된옵션조회
• 제공되는 옵션의 목록과 현재 상태값은 다음과 같이 확인할 수있습니다. 기본적으로 c,o,p,w 등의 옵션이 적용됩니다. 기본옵션이 적용되지 않게 하려면, +를 이용하여 해당 옵션을비활성화 해야 합니다.
대화식모드에서옵션설정
• 대화식 모드에서 옵션의 상태 전환은 다음 명령어를 이용하여제어합니다 . 대화식 모드를 종료하면 옵션은 기본값으로복귀합니다.
비대화식모드에서옵션설정
• 비대화식 모드에서는 – (마이너스)를 이용하여 옵션을 ON 시키고, +(플러스)를 이용하여 옵션을 OFF 시킵니다. 옵션은실행 당시에만 유효합니다.
$ db2 list command options$ db2set DB2OPTIONS
db2=> UPDATE COMMAND OPTIONS USING <옵션> ONdb2=> <DB2명령어>db2=> UPDATE COMMAND OPTIONS USING <옵션> OFFdb2=> <SQL문>
$ db2 –<옵션> <DB2 명령어>$ db2 +<옵션> <DB2 명령어>
DB2 레지스트리변수로기본옵션설정
• DB2 레지스터리 변수를 이용하여 옵션을 모든 대화식 또는비대화식 세션에 자동적으로 적용되도록 설정할 수 있습니다.
• 레지스터리 변수에서 지정한 옵션은 레지스터리 변수를 제거할때까지 유지됩니다. 대화식 또는 비대화식 모드에서 지정한옵션은 D B 2 O P T I O N S 레지스터리 변수보다 우선적으로적용됩니다.
$ db2set DB2OPTIONS="-a +c"$ db2 <DB2명령어>$ db2 <SQL문>
OFFON OFFOFFOFFOFFOFFOFFOFFON ON OFFOFFOFFOFFOFFON OFFOFF
Display SQLCAAuto-commit Retrieve and display XML declarationsDisplay SQLCODE/SQLSTATE Read from input file Display XML data with indentation Log commands in history file Display the number of rows affected Remove new line character Display output Display db2 interactive prompt Preserve whitespaces and linefeeds Save output report to file Stop execution on command error Set statement termination character Echo current command Display FETCH/SELECT warning messagesSuppress printing of column headings Save all output to output file
acdefil
mnopqrstvwxz
Default SettingDescriptionsOption

© Copyright IBM Corporation 201028
IBM DB2 On-site Training CourseIBM Korea
입력 파일을 이용한 처리 방법
connect to sample ;create table t1 (
col1 char(6), col2 varchar(12), col3 date, col4 dec(9,2)
) ;insert into t1 select empno, lastname, hiredate, bonus
from employee;select * from t1 ;connect reset ;
작성 : script1.txt
실행 : db2 –stvf script1.txt
DB2 세션에서 한 개 이상의 명령문 또는 SQL문을 묶어서실행하려면 비대화식 모드에서 입력 파일을 이용합니다. –svtf옵션을 사용하는 것이 일반적입니다
사용방법개요
• 입력 파일은 OS가 제공하는 에디터로 작성하며, 임의의 파일확장자를 사용할 수 있습니다.
• 각 명령문은 기본적으로 한 줄 단위로 구별되므로, 한 명령문을한 줄 이상에 걸쳐 표현하려면 ; (세미콜론 부호) 등의 명령문구분자가 필요하며, 반드시 –t 옵션을 함께 사용해야 합니다.
• 주석문은 –– (대쉬 부호 2개)를 이용합니다. • SQL문에서 데이터 값을 제외한 부분에서 대소문자는 구별하지않습니다
파일옵션사용법
• 입력 파일명은 –f (file) 옵션을 이용하여 지정• ; (세미콜론)을 명령문 구분자로 사용하면 –t (terminator) 옵션을함께 사용합니다. 구분자를 변경하려면 -td 옵션을 사용합니다.
• –s (stop)는 입력 파일의 실행 도중에 오류가 발생하면 실행을중단하게 합니다
• –v (verify) 옵션은 명령어와 실행 결과를 함께 보여줍니다.• 자동 커미트 옵션이 기본적으로 설정되어 있으므로, 입력파일에 포함된 SQL문은 즉시 커미트됩니다. 입력 파일에서<SQL문> 또는 <DB2 명령어>를 입력하고, +c 옵션을 추가하여실행하면, COMMIT 또는 ROLLBACK문의 실행 직전 시점까지의구간이 한 개의 트랜잭션으로 처리됩니다.
$ db2 +c “delete from t1”$ db2 +c “select * from t1”$ db2 rollback

© Copyright IBM Corporation 201029
IBM DB2 On-site Training CourseIBM Korea
온라인 도움말
DB2 세션에서 ?(물음표)를 사용하여, DB2 명령어에 대한 구문과오류 메시지를 나타내는 SQLCODE, SQLSTATE 값에 대한 텍스트기반의 도움말을 확인할 수 있습니다
$ db2 ? list dbLIST DATABASE DIRECTORY [ON path]LIST DATABASE PARTITION GROUPS [SHOW DETAIL]
온라인도움말사용법
• DB2 세션에서 제공하는 모든 명령어의 목록은 다음과 같이확인합니다. SQL문에 대한 도움말은 제공하지 않습니다
db2 ?• 특정한 DB2 명령어에 대한 구문과 옵션은 다음과 같이확인합니다.
db2 “? <db2명령어일부>”• SQLCODE에 대한 설명은 다음과 같이 확인할 수 있습니다.
SQLCODE는 SQLnnnnx 의 형식으로 표시되며, nnnn은 숫자입니다.db2 "? SQL0100W"
• SQLSTATE에 대한 설명은 다음과 같이 확인할 수 있습니다. SQLSTATE는 nnnnn 형식으로 표시되는 5자리의 문자입니다.
db2 "? 02000"• 대화식 모드에서도 도움말을 사용할 수 있습니다

© Copyright IBM Corporation 201030
IBM DB2 On-site Training CourseIBM Korea
CLPPLUS
결과집합에서 지정된 지점에 페이지 Break 또는 공백을 삽입합니다. SQL> BREAK ON column-name [ SKIP | PAGE | 라인 수 ]
SQLPlus 또는 CLPPlus의 색인 또는 특정 topic에 대한 도움말을 보여줍니다. SQL> [ HELP|?] [ INDEX | topic ]
SQLPlus 또는 CLPPlus에 환경 값을 보여줍니다. SQL> SHOW [ option ]
가장 최근에 실행된 SQL 명령어 또는 SQL 버퍼에 저장된 PL/SQL 블럭을 실행합니다. SQL> R[UN]
단일 PL/SQL 또는 스토어드 프로시저를 수행합니다. SQL> EXEC[UTE]
지정된 스크립트에 있는 SQLPlus 명령어를 수행합니다. SQL> @test.sql
column2를 그룹화하여 column1의 집계함수 값을 보여줍니다. 이 명령어는 BREAK 명령어와 함께 사용됩니다.
각 컬럼의 결과값에 대한 format을 지정합니다.
오브젝트의 컬럼, 데이터 타입 및 길이를 보여줍니다.
명령어 및 결과를 파일에 저장할지를 지정합니다.
SQL 버퍼의 내용을 파일로 저장합니다.
파일을 편집할 수 있습니다.
OS 파일을 SQL Buffer로 읽어옵니다.
가장 최근에 실행된 SQL 명령어 또는 SQL 버퍼에 저장된 PL/SQL 블럭을 실행합니다.
CLPPlus의 세션을 종료합니다.
CLPPlus 세션창에서 DB에 접속합니다.
유사하나 DB2의 경우 인스턴스내에 여러개의 DB가 있으므로 DB Name까지 지정합니다.
설명
SQL> COMPUTE [SUM | MAX | MIN | AVG | COUNT | NUM | STD | VAR][LABEL text OF column1 on column2 ]
SQL> COLUMN [column name] [FORMAT FOR spec | HEA[DING] text]예) COLUMN JOB FORMAT A5예) COLUMN SAL FORMAT $99,999.00
SQL> DESCRIBE [schema.object]
SQL> SPOOL [ output file | OFF ]
SQL> SAVE test.sql
SQL> EDIT plsql.sql
SQL> GET plsql.sql
SQL> /
SQL> QUIT
SQL> CONNECT [<UserID>@<Hostname>:<PortNo>/<DBName> ]
$ clpplus [<UserID>/<Password>@<Hostname>:<PortNo>/<DBName> ]
DB2 CLPPlus
DB2 V9.7에서는 오라클 sql*plus에 익숙한 사용자를 위해 sql*plus와 유사한 clpplus를 새로 지원합니다

© Copyright IBM Corporation 201031
IBM DB2 On-site Training CourseIBM Korea
CLPPLUS
DBMS_OUTPUT의 메세지 버퍼의 내용을 표준 화면에 출력할 것인지를 지정합니다. SET SERVEROUTPUT [ON | OFF]
한 라인에 표시되는 총 글자 수를 지정합니다. SET LIN[ESIZE] [1~32767 : Default : 80]
페이지마다 빈 라인을 얼마나 넣을 것이지를 지정합니다. SET NEWP[AGE]
명령어 및 결과값을 표준출력에 보여줄지를 지정합니다. SET ECHO [ ON | OFF ]
각 SQL 명령이 수행된 시간을 보여줄 것인지를 지정합니다.
화면에 결과값이 표시될 때 각 페이지마다 중지하여 결과값을 보여줄지를 지정합니다. Enter를 치면 다음 페이지를 보여줍니다.
한 페이지를 구성할 라인 수를 지정합니다.
쿼리 결과인 NULL 값을 이 곳에서 지정한 다른 text 값으로 대체하여 표시합니다.
결과화면에 컬럼 이름을 출력할 것인지 여부를 지정합니다.
결과화면에서 컬럼사이에 놓여질 컬럼 구분자 문자를 지정합니다.
COMMIT 을 자동으로 할 것인지 수동으로 할 것인지를 지정합니다.
SQLPlus 또는 CLPPlus가 데이타베이스에서 한번에 fetch 할 row의 수를 설정합니다.
설명
SET TIMI[NG] [ON | OFF ]
SET PAU[SE] [ON | OFF]
SET PAGES[IZE] [2~50000 : default: 14]
SET NULL text 예) SQL> SET NULL ‘—’
SET HEA[DING] [ ON | OFF ]
SET COLSEP [ Column separator ] 예) SQL> SET COLSEP ‘|’
SET AUTO[COMMIT] [ ON | OFF | IMMEIDATE | n ]
SET ARRAYSIZE [ 1 ~ 10000 : default 10]
DB2 CLPPlus
DB2 V9.7에서는 오라클 sql*plus에 익숙한 사용자를 위해 sql*plus와 유사한 clpplus를 새로 지원합니다

© Copyright IBM Corporation 201032
IBM DB2 On-site Training CourseIBM Korea
Data Studio
Data Studio는 포괄적인 데이터관리 솔루션으로써, 데이터 Life Cycle동안 데이터베이스 및 응용프로그램에 대한 디자인, 개발, Deploy, 관리를 지원하는 제품입니다.
Deploy
Manage
Govern
Develop
Design
IBM
Other
Data Governance• Security Access• Security Analysis• Data Auditing• Data Archiving• Data Masking• Data Encryption
Database Administrator
Data Management• Database Administration• Data Management • Change Management• Recovery Management• Storage Management• Performance Management
Security administrator
Data Architect
일관성있고통합된솔루션
Common InterfaceUser
DatabaseDeveloper
Application Developer
Data Design• Logical Modeling• Physical Modeling • Integration Modeling
Data Development• Coding• Debugging• Teaming• Testing• Tuning

© Copyright IBM Corporation 201033
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 데이터베이스 연결

© Copyright IBM Corporation 201034
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 데이터베이스 연결
© Copyright IBM Corporation 201035
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 데이터베이스 연결

© Copyright IBM Corporation 201036
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 테이블 간편 관리

© Copyright IBM Corporation 201037
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 쿼리 작성 및 데이터 조회

© Copyright IBM Corporation 201038
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 쿼리 작성 및 데이터 조회
Ctrl+<space>
Ctrl+<space>

© Copyright IBM Corporation 201039
IBM DB2 On-site Training CourseIBM Korea
Data Studio – 쿼리 작성 및 데이터 조회
© Copyright IBM Corporation 201040
IBM DB2 On-site Training CourseIBM Korea
오브젝트 비교

© Copyright IBM Corporation 201041
IBM DB2 On-site Training CourseIBM Korea
스키마 비교
DB2와 오라클에서 스키마는 특정 사용자가 소유하는 오브젝트의집합입니다. 스키마 오브젝트에는 테이블, 뷰, 인덱스 및 함수, 스토어드 프로시져 등입니다. 오라클에서 스키마는 접속한사용자와 동일한 이름으로 생성해야 합니다. 그러나 DB2에서는일반적으로 접속한 사용자와 동일한 이름으로 생성되지만 다른스키마 이름으로도 생성이 가능합니다.
user1
user1.table1CREATE TABLE table1
user0.table1SELECT * FROM user0.table1
user2.table1
user2
SELECT * FROM user0.table1
SET CURRENT SCHEMA user2SELECT * FROM table1
SELECT * FROM table1
오라클 DB2
스키마설명
사용자를 생성할 경우 동일한 이름을 가진 스키마가 생성되며 그 스키마의 소유자는 사용자가 됩니다 .
스키마 이름이 사용자 이름과 동일할 필요는 없습니다. 스키마를 생성한 사용자가 해당 스키마의 소유자가 됩니다.
기본스키마
데이타베이스 생성시 다음과 같은 기본 스키마가 제공됩니다. SYS: 딕셔너리에 대한 모든 기본 테이블과 뷰의 스키마SYSTEM: 관리정보를 보여주는데 필요한 테이블과 뷰의 스키마SAMPLE 스키마 ( HR, OE, PM, SH)가 존재
데이타베이스 생성시 다음과 같은 기본 스키마가 제공됩니다. SYSIBM: 시스템 카탈로그 테이블의 스키마SYSCAT: 시스템 카탈로그 뷰의 스키마SYSSTAT: 통계자료와 관련된 시스템 카탈로그 뷰의 스키마SYSFUN: 기본적으로 제공되는 사용자 정의 함수의 스키마
스키마생성 구문
CREATE SCHEMA AUTHORIZATION <사용자 명> CREATE TABLE ~ 옵션 설명 :
<사용자 명> : 스키마 명과 사용자 명이 동일하며 스키마에 대한 권한이 사용자에게 부여됩니다.
CREATE SCHEMA <스키마 명> AUTHORIZATION <authorization_name> ~옵션 설명 :
<스키마 명> : 임의의 고유한 이름으로 지정합니다. <authorization_name> : 스키마의 소유자를 지정합니다.
스키마제거구문
스키마 제거 명령어는 존재하지 않으며 사용자를 제거할 경우 자동적으로 스키마도 제거됩니다. DROP SCHEMA <스키마 명> RESTRICT
LIST TABLESLIST TABLES FOR SCHEMA <스키마명>SELECT * FROM SYSCAT.SCHEMATA

© Copyright IBM Corporation 201042
IBM DB2 On-site Training CourseIBM Korea
테이블 비교
오라클 DB2
테이블설명
테이블이 저장되는 테이블 스페이스를 지정하나 물리적인 저장 정보를 테이블 생성시 지정도 가능합니다. 컬럼 삭제 및 컬럼 속성을 변경할 수 있습니다.
테이블이 저장되는 테이블 스페이스를 지정함으로써 물리적인 저장 장소를 선택합니다. 오라클과는 달리 테이블마다 물리적인 저장 옵션을 지정할 수는 없습니다. 일반 데이터와 LOB 데이터, 인덱스 등을 각기 다른 테이블 스페이스에 저장할 수있습니다. 컬럼 삭제 및 컬럼 속성을 변경할 수 있습니다.
테이블종류
일반 테이블 / 전역 임시 테이블 / 파티션 테이블인덱스 구조 테이블
일반 테이블 / 전역 임시 테이블 / 파티션 테이블Multi Dimensional Clustering ( MDC ) 테이블
테이블저장장소지정 방법
지정된 테이블 스페이스에 저장됩니다. PCTFREE 및 스토리지 옵션을 두어 테이블마다 스토리지 값을 변경할수 있으며 옵션 생략시 지정된 테이블 스페이스의 디폴트 값을 적용합니다. 스토리지 옵션을 두는 이유는 오라클은 DB2와는 달리 체이닝과 마이그레이션이 발생되므로 이 현상을 줄이기 위함입니다.
지정된 테이블 스페이스에 저장됩니다. 별도의 스토리지 옵션은 존재하지 않으며 테이블 스페이스에서 지정된 스토리지 옵션 값을 적용합니다. 스토리지 옵션 생략시 지정된 테이블 스페이스의 디폴트 값을 적용합니다. DMS 테이블 스페이스의 경우 한 테이블의 데이터를 여러 개의 테이블 스페이스로 나누어 저장할 수 있습니다.
테이블구문
테이블 생성/변경/제거 구문은 오라클과 DB2 모두 유사합니다. CREATE TABLE ~ / ALTER TABLE ~ / DROP TABLE ~
테이블정보 조회
DBA_TABLES, DBA_TAB_COLUMNS 딕셔너리 테이블을 조회하면 테이블및 컬럼에 대한 정보를 조회할 수 있습니다.
특정 스키마에 속하는 테이블과 뷰를 확인할 경우 “list tables for schema <스키마명>” 명령어를 실행합니다. SYSCAT.TABLES, SYSCAT.COLUMNS 카탈로그 테이블을 조회합니다.DB2 V9.7부터는 DBA_TABLES, DBA_TAB_COLUMNS 딕셔너리 테이블을 이용하여조회할 수 있습니다.
테이블구조 정보
DESC [테이블 명]를 이용하여 테이블 구조를 확인합니다. DESCRIBE [ DESC ] TABLE [테이블 명]을 이용하여 테이블 구조를 확인합니다.
Dummy 테이블
DUAL 테이블 SYSIBM.SYSDUMMY1 DB2 V9.7에서는오라클과동일한 Syntax로조회가가능합니다.
테이블은 데이터를 저장하는 논리적인 저장 장소이며 뷰는 하나이상의 테이블로부터 논리적으로 데이터를 추출한 부분집합으로논리적이고 가상적인 테이블입니다. 오라클과 DB2의 테이블 및 뷰는 거의 동일합니다.

© Copyright IBM Corporation 201043
IBM DB2 On-site Training CourseIBM Korea
데이터 딕셔너리와 카탈로그 테이블 비교
오라클과 DB2는 모두 데이터베이스의 메타 데이터 정보를 저장하는 공간이 존재합니다. 오라클에서는 이를 데이터 딕셔너리라 하고DB2에서는 카탈로그 테이블이라 합니다. 그러나 DB2 V9.7부터는 DB2의 Registry 변수에 오라클 호환성 특성을 지정한 후 데이터베이스를생성할 경우 오라클 딕셔너리를 그대로 사용할 수 있습니다.
오라클 데이터 딕셔너리 DB2 카탈로그 테이블
• DBA_XXX: 모든 사용자의 객체에 대한 정보 제공• USR_XXX: 자신이 소유한 오브젝트에 대한 정보 제공• ALL_XXX: 접근 권한이 가능한 오브젝트에 대한 정보 제공• V$_XXX: 오라클의 성능 분석, 통계 정보 제공
• SYSIBM.XXX: 데이터베이스 내의 모든 객체에 대한 정보 제공.• SYSCAT.XXX: SYSIBM에 속하는 테이블 중 중요 정보만 조합하여 제공.• SYSSTAT.XXX: SYSIBM에 속하는 테이블 중 통계 정보만 조합하여 제공.• SYSFUN.XXXX: 사용자 정의함수에 대한 정보 제공. • SYSIBMADM.XXXX: DB2의 성능 분석 및 관리 정보 제공
• 딕셔너리 테이블의 종류를 확인할 경우 다음과 같은 SQL 문을 이용하여 확인이가능합니다.
SQL> SELECT * FROM DICTIONARY;
• 다음과 같은 명령어를 이용하여 카탈로그 테이블의 종류를 확인합니다. db2=> LIST TABLES FOR SYSTEM
• DB2 V9.7부터는 오라클 딕셔너리 테이블 조회가 가능합니다. 오라클과 동일한 쿼리를 이용하여 딕셔너리 테이블의 종류를 확인하실 수 있습니다.
Db2=> SELECT * FROM DICTONARY
오라클 데이터 딕셔너리 DB2 카탈로그 테이블 DB2 V9.7에서 제공하는 딕셔너리
DBA_TABLES SYSCAT.TABLES DBA_TABLESDBA_TAB_COLUMNS SYSCAT.COLUMNS DBA_TAB_COLUMNSDBA_TABLESPACES SYSCAT.TABLESPACES DBA_TABLESPACESDBA_INDEXES SYSCAT.INDEXES DBA_INDEXESDBA_CONSTRAINSTS SYSCAT.TABCONST DBA_CONSTRAINSTSDBA_CONS_COLUMNS SYSCAT.COLCHECKS,SYSCAT.REFERENCES,SYSCAT.INDEXES DBA_CONS_COLUMNSDBA_VIEWS SYSCAT.VIEWS DBA_VIEWSDBA_SEQUENCES SYSCAT.SEQUENCES DBA_SEQUENCESDBA_TRIGGERS SYSCAT.TRIGGERS DBA_TRIGGERSDBA_USERS OS의 사용자를 사용함으로 해당 정보에 대한 관리가 필요치 않습니다. DBA_USERSDBA_ROLES SYSCAT.ROLES DBA_ROLES
DBA_TAB_PRIVS SYSCAT.TABAUTH,SYSCAT.COLAUTH,SYSCAT.INDEXAUTH 등 각 OBJECT 마다 권한 정보를 담고 있는 테이블이 별도 존재 DBA_TAB_PRIVS

© Copyright IBM Corporation 201044
IBM DB2 On-site Training CourseIBM Korea
DB2 V9.7 이전 데이터 타입 비교
오라클 DB2 범위
CHAR(n) CHAR(n) 1<= n <= 254
VARCHAR2(n) VARCHAR(n) N <= 32672
LONG LONG VARCHAR(n) If n <= 32700 bytes
LONG CLOB ( 2GB) If n < 2GB
NUMBER(p)• SMALLINT • INTEGER• BIGINT
• 1 <= p <= 4일 경우 SMALLINT• 5 <= p <= 9일 경우 INTEGER • 10 <= p <= 18일 경우 BIGINT
NUMBER (p, s) DECIMAL ( p, s) s> 0일 경우
BLOB BLOB(n) n <= 2GB일 경우
CLOB CLOB(n) n <= 2GB일 경우
NCLOB DBCLOB(n) n <= 2GB일 경우 DBCLOB(n/2)를 사용합니다.
DATE• TIMESTAMP• DATE(MM/DD/YYYY)• TIME(HH24:MI:SS)
• DATE 와 TIME이 모두 있을 경우 TIMESTAMP• 날짜만 표현할 경우 DATE(MM/DD/YYYY)가 됩니다.• 시간만 표현할 경우 TIME(HH24:MI:SS)가 됩니다.
TIMESTAMP TIMESTAMP
XMLType XML
RAW ( n) • CHAR(n) FOR BIT DATA • VARCHAR(n) FOR BIT DATA• BLOB(n)
• n <= 254일 경우 CHAR• 254 < n <= 32672일 경우 VARCHAR• 32672 < n <= 2GB일 경우 BLOB
LONG RAW • LONG VARCHAR(n) FOR BIT DATA • BLOB(n)
• n<= 32700일 경우 LONG• 32700 < n <= 2GB일 경우 BLOB
테이블 데이터 타입은 저장되는 데이터에 따라 숫자, 문자, 시간, 날짜 등 다양한 형태의 데이터가 저장됩니다. 오라클과 DB2는 데이터의형태에 따라 타입을 분류합니다. 다음은 오라클과 DB2 데이터 타입을 비교합니다.

© Copyright IBM Corporation 201045
IBM DB2 On-site Training CourseIBM Korea
DB2 V9.7 데이터 타입 비교
Oracle DB2 9.7 범위
VARCHAR2 (n) VARCHAR2 (n)• Varchar2를 사용하려면 데이터베이스를 생성하기 전에 Registry Variable인
DB2_COMPATIBILITY_VECTOR를 0x20 으로 지정하셔야 합니다. • N <= 32672
NUMBER (p) NUMBER (p)
• NUMBER Data 타입을 사용하려면 데이터베이스를 생성하기 전에 Registry Variable인DB2_COMPATIBILITY_VECTOR를 0x10 으로 지정하셔야 합니다.
• P가 지정되지 않는다면 DB2는 내부적으로 DECFLOAT(16)으로 매핑 합니다. 그리고 p가지정된다면 내부적으로 DECIMAL(p)로 매핑 합니다.
• 범위는 p <= 31 로 제약됩니다.
NUMBER (p, s) NUMBER (p,s)
• NUMBER Data 타입을 사용하려면 데이터베이스를 생성하기 전에 Registry Variable인DB2_COMPATIBILITY_VECTOR를 0x10 으로 지정하셔야 합니다.
• 내부적으로 DECIMAL(p,s)로 매핑 합니다.• 범위는 0<p<=31 이며 0<s<=p 입니다.
DATE DATE• Date Data 타입을 사용하려면 데이터베이스를 생성하기 전에 Registry Variable인
DB2_COMPATIBILITY_VECTOR를 0x40 으로 지정하셔야 합니다. • 내부적으로 TIMESTAMP(0)로 변환합니다.
DB2 V9.7 부터는 Registry 변수인 DB2_COMPATIBILITY_VECTOR를 지정하면 오라클의 VARCHAR2와 Date, NUMBER 데이터 타입을 그대로사용하실 수 있습니다. 다음은 DB2 V9.7에서 새로 지원하는 데이터 타입과 오라클의 Data Type을 비교한 표입니다.

© Copyright IBM Corporation 201046
IBM DB2 On-site Training CourseIBM Korea
제약조건 비교
제약조건이란 테이블에 부적절한 자료가 입력되는 것을 방지하기위한 여러 가지 규칙입니다. 간단하게 테이블 안에서 데이터의성격을정의하는것이바로제약조건입니다
• 데이터의 무결성 유지를 위하여 사용자가 지정할 수 있는 성질입니다.
• 모든 CONSTRAINT는 데이터 사전(DICTIONARY)에 저장 됩니다• 의미 있는 이름을 부여했다면 CONSTRAINT를 쉽게 참조할 수있습니다.
• 제약조건은 테이블을 생성할 당시에 지정할 수도 있고, 테이블생성 후 구조변경(ALTER)명령어를 통해서도 추가가 가능합니다.
• NOT NULL 제약조건은 반드시 컬럼 레벨에서만 정의가가능합니다
오라클과 DB2에서제공하는제약조건의종류로는다음과같습니다
• NOT NULL 조건 : 컬럼을 필수 필드화 시킬 때 사용합니다.• UNIQUE 조건 : 데이터의 유일성을 보장 (중복되는 데이터가 존재할 수 없습니다) 자동으로 index가 생성됩니다
• CHECK 조건 : 컬럼의 값을 어떤 특정 범위로 제한할 수 있습니다. • PRIMARY KEY(기본키) 지정 : 기본키는 UNIQUE 와 NOT NULL의결합과 같습니다.
• FOREIGN KEY(외래키)지정 : 기본키를 참조하는 컬럼 또는컬럼들의 집합입니다.
CREATE TABLE EMP ( EMPNO NUMBER CONSTRAINT emp_pk PRIMARY,ENAME VARCHAR2(20),JOB VARCHAR2(40),COMM NUMBER )
PCTFREE 20 PCT USED 50;
CREATE TABLE EMP ( EMPNO INTEGER NOT NULL CONSTRAINT emp_pk PRIMARY KEY, ENAME VARCHAR(20),JOB VARCHAR(40),COMM INTEGER )
IN DMS01;
ORACLE
DB2

© Copyright IBM Corporation 201047
IBM DB2 On-site Training CourseIBM Korea
파티션 테이블 비교
Partitioned 테이블의 특정 컬럼의 데이터를 키 값을 기반으로 파티션이라고 불리는 스토리지 오브젝트에 나뉘어 지도록 하는 기능입니다. 오라클과 DB2는 모두 테이블 파티션을 지원합니다
오라클 DB2
파티션설명
• Range, Hash, List, Composite 등의 파티션 테이블이 존재합니다. • 기존 단일 테이블을 파티션 테이블로 붙일 수 있는 방법은 없습니다. • 파티션 테이블의 파티션을 단일 테이블로 분리할 수 있습니다.
• Range 파티션 테이블이 존재합니다. • ALTER TABLE의 “ATTACH” 옵션을 이용하여 기존 테이블을 파티션 테이블의 파
티션으로 붙일 수 있습니다. • ALTER TABLE의 “DETACH” 옵션을 이용하여 파티션 테이블의 파티션을 단일 테
이블로 분리할 수 있습니다.
파티션정보 조회
• DBA_TAB_PARTITIONS 딕셔너리 테이블에 파티션 정보가 포함됩니다. SYSCAT.DATAPARTITIONS 카탈로그 테이블을 조회하면 파티션 정보를 확인할 수있습니다.
CREATE TABLE ORDER_TRANS ( ORD_NUMBER BIGINT, ORD_DATE DATE, PROD_ID VARCHAR(15), QUANTITY DEC(15,3)
)PARTITION BY RANGE (ORD_DATE) (
PARTITION FY2007Q4 STARTING '10/1/2007' INCLUSIVE ENDING '1/1/2008' EXCLUSIVE IN FY2007Q4
, PARTITION FY2008Q1 STARTING '1/1/2008' INCLUSIVE ENDING '4/1/2008' EXCLUSIVE IN FY2008Q1
) ;ALTER TABLE ORDER_TRANS ADD PARTITION FY2008Q3
STARTING '7/1/2008' INCLUSIVE ENDING '10/1/2008' EXCLUSIVE IN FY2008Q3;ALTER TABLE ORDER_TRANS ATTACH PARTITION FY2008Q2
STARTING '4/1/2008' INCLUSIVE ENDING '7/1/2008' EXCLUSIVE FROM TABLE NEW TRANS;
ALTER TABLE ORDER_TRANS DETACH PARTITION FY2007Q4 INTO FY2007Q4;

© Copyright IBM Corporation 201048
IBM DB2 On-site Training CourseIBM Korea
인덱스 비교
인덱스는 테이블과 결합된 선택적인 구조로 쿼리 속도를 향상시키기 위해 키와 물리적 저장 위치의 정보인 RID 정보가 저장됩니다. 오라클과 DB2는 쿼리 속도를 향상시키기 위해 모두 인덱스를 사용합니다.
오라클 DB2
인덱스
B- Tree 구조를 사용합니다. 최대 32컬럼까지 하나의 인덱스에서 지정할 수 있습니다. UNIQUE 인덱스는 고유값만 저장되나 NULL 값일 경우 하나이상의 NULL 값은 입력이 가능합니다. Clustered index는 clustered Table 만을 위해서만 사용됩니다. IOT는 Index에 모든 데이터가 들어 있는 테이블입니다.
B+ Tree 구조를 사용합니다. 최대 64 컬럼까지 하나의 인덱스에서 지정할 수 있습니다. NULL값이 허용되는 컬럼의 UNIQUE 인덱스는 NULL값 자체를 하나의 데이터로인식하여 한 건의 NULL 값이 입력되는 것만 허용합니다ALTER 명령문은 존재하지 않습니다. 변경할 경우 삭제한 후 재생성합니다.Cluster Index는 테이블당 하나만 사용 가능합니다. Include 옵션을 두어 인덱스 칼럼은 아니지만 자주 액세스하는 컬럼을 인덱스에 포함시켜 인덱스만 조회해도 데이터를 읽을 수 있도록 할 수 있습니다.
인덱스정보조회
DBA_INDEXES 딕셔너리 테이블을 조회합니다. SYSCAT.INDEXES 카탈로그 테이블을 조회합니다. describe indexes for table <테이블 명> show detail 명령어를 이용하여 조회합니다.

© Copyright IBM Corporation 201049
IBM DB2 On-site Training CourseIBM Korea
압축 비교
오라클과 DB2는 모두 테이블 압축을 지원합니다. 그러나 중복 데이타의 범위가 오라클과 DB2는 다릅니다. 오라클과 DB2의 압축에 대해비교합니다
여러 개의 알고리즘으로 DBA 개입 없이 DB2가 자동으로 압축 수행단일 알고리즘으로 DBA의 정의가 필요함.압축알고리즘
CREATE TABLE TEST_TAB_1( ID NUMBER(10) NOT NULL, DESCRIPTION VARCHAR2(50) NOT NULL,
CREATED_DATE DATE NOT NULL ) COMPRESS YES;
CREATE TABLE TEST_TAB_1( ID NUMBER(10) NOT NULL, DESCRIPTION VARCHAR2(50) NOT NULL,
CREATED_DATE DATE NOT NULL ) COMPRESS FOR ALL OPERATIONS;
압축방법
전 테이블에 대해 중복된 데이터를 찾아 Compression Dictionary 생성. 각 블럭 Level로 중복되는 데이터를 찾아 Block Header에 저장합니다. 만약 중복되는 데이터가 여러 Block으로 흩어져 있을 경우 압축률이떨어집니다.
압축방식
테이블인덱스Temporary Table
테이블인덱스
압축되는오브젝트
DB2오라클

© Copyright IBM Corporation 201050
IBM DB2 On-site Training CourseIBM Korea
DB2 파티셔닝 기능
대용량 데이터베이스와 테이블은 성능 및 확장에 있어서 많은 제약사항이 따릅니다. DB2는 데이터베이스 파티셔닝, 테이블 파티셔닝 및다차원 클러스터링을 통해 데이터를 분배 및 클러스터함으로써 성능을 향상시킬 수 있습니다
시간에 관련된 컬럼을 선택합니다.
date 컬럼을 포함하여 region 과 product_type과같이 데이터의 종류가 많지 않아 그룹핑하기적합한 컬럼 또는 해당 컬럼의 조합으로선택합니다.
서로 다른 값이 많은 컬럼을 선택합니다.파티션 키 추천컬럼
인덱스는 하나의 테이블 스페이스 또는데이터 파티션 정보와 동일한 규칙에 의해분리되어 저장됩니다.
레코드 기반의 인덱스가 아닌 Block 기반의인덱스가 생성되어 Block 을 가리키는 포인터정보가 들어 있습니다.
인덱스는 테이블이 위치한 데이터베이스파티션에 존재합니다. 인덱스
PARTITION BY RANGEORGANIZE BY DIMENSIONDISTRIBUTE BY HASHCREATE TABLE 구문 절
table partition keyDimensionDistribution Key파티션 키
대량의 레코드가 주기적으로 추가되거나주기적으로 삭제될 경우 적합합니다.
쿼리의 결과값이 동일한 값을 갖는 레코드를반환하는 경우에 적합합니다.
대용량 테이블로 서버의 리소스를 초과하는테이블일 경우 적합합니다.
테이블디자인
쿼리 성능이 좋아지며 데이터 이동이용이합니다. 쿼리 성능이 좋아집니다. 확장성이 좋아집니다. 혜택
지정된 범위 내에 있는 데이터를 그룹핑하여같은 데이터 파티션에 놓습니다.
테이블내의 유사한 값을 갖는 레코드를 Block 이 라 고 하 는 같 은 물 리 적 인 위 치 에다차원적으로 그룹핑하여 저장합니다.
데이터베이스 파티션 전반에 레코드를 분배합니다.설명
다차원 클러스터링 (MDC) 테이블 파티셔닝 ( TP)Database Partitioning Feature

© Copyright IBM Corporation 201051
IBM DB2 On-site Training CourseIBM Korea
DB2 파티셔닝 기능
테이블의 데이터는 3개의 데이터베이스 파티션으로 분배
Database Partition 1 Database Partition 2 Database Partition 3
Tablespace1
Tablespace2
서울 부산
대전 광주
1월
서울 부산
대전 광주
2월
서울 부산
대전 광주
1월
서울 부산
대전 광주
2월
서울 부산
대전 광주
1월
서울 부산
대전 광주
2월
Distribute
데이터 범위에 따라 별도의 테이블스페이스에 저장
Partition
데이터 종류 별로 블록을 만들어 저장
Organize

© Copyright IBM Corporation 201052
IBM DB2 On-site Training CourseIBM Korea
명령어를 이용한 테이블 생성
OptionalCOMPRESS YES
『컬럼정의』LIKE 다른 테이블 또는 뷰
Optional『MDC 지정 옵션』
Optional『데이터베이스 파티션 지정 옵션』
Optional『테이블스페이스 지정 옵션』
TABLE 테이블명CREATE
PRIMARY KEYUNIQUEReference절
제약조건명 OptionalCONSTRAINT
NOT NULL Optional
데이터타입컬럼명컬럼정의
Optional테이블스페이스LONG IN
테이블스페이스INDEX IN Optional
테이블스페이스IN 테이블스페이스
DISTRIBUTE BY HASH ( 컬럼리스트 )데이터베이스파티션
ORGANIZE BY ( 컬럼리스트 )MDC
CREATE TABLE AMJ.SALES(DATE DATE NOT NULL , REGION VARCHAR(15) NOT NULL , PRODUCT_ID BIGINT NOT NULL , REVENUE DECIMAL(15,0) NOT NULL) PARTITION BY RANGE("DATE") (PART FY20081Q STARTING('2008-01-01') IN TBS1Q,PART FY20082Q STARTING('2008-04-01') IN TBS2Q,PART FY20083Q STARTING('2008-07-01') IN TBS3Q,PART FY20084Q STARTING('2008-10-01')
ENDING('2009-01-01') EXCLUSIVE IN TBS4Q) ORGANIZE BY(( "REGION" , "PRODUCT_ID" )) ;

© Copyright IBM Corporation 201053
IBM DB2 On-site Training CourseIBM Korea
시퀀스 비교
오라클과 동일한 딕셔너리 테이블을이용하여 정보를 조회할 수 있습니다.
오라클과 동일하게 사용가능합니다.
DB2 V9.7
PREVAL FOR <시퀀스 이름>과 NEXTVAL FOR <시퀀스 이름> 를이용하여 현재값과 다음 값을 조회합니다.
<시퀀스 이름>.CURRVAL과 <시퀀스이름>.NEXTVAL를 이용하여 현재값과다음 값을 조회합니다.
시퀀스사용 방법
SYSCAT.SEQUENCES 카탈로그 테이블을 조회하면 시퀀스 정보를조회할 수 있습니다.
DBA_SEQUENCES 딕셔너리 테이블을조회하면 시퀀스 정보를 조회할 수있습니다.
시퀀스정보 조회
DB2 V9.7 이전오라클
시퀀스는 자동 생성 일련 번호로써 오라클과 DB2의 시퀀스의 기능은 거의 동일합니다.
CREATE SEQUENCE ORDER_SEQSTART WITH 100INCREMENT BY 1NO MAXVALUE NO CYCLENOCACHE ;
INSERT INTO ORDER_HIS VALUES( NEXTVAL FOR ORDER_SEQ , ’BOOK’, 100 ) ;
SELECT PREVVAL FOR ORDER_SEQ FROM SYSIBM.SYSDUMMY1;DROP SEQUENCE ORDER_SEQ;또는SELECT ORDER_SEQ.PREVVAL FROM SYSIBM.SYSDUMMY1;DROP SEQUENCE ORDER_SEQ;

© Copyright IBM Corporation 201054
IBM DB2 On-site Training CourseIBM Korea
트리거 비교
트리거는 특정 테이블에 대해 INSERT, UPDATE, DELETE 문이 실행될 때 자동으로 실행되는 프로그램입니다.
INSERT, UPDATE, DELETE 입니다.
트 리 거 이 벤 트 의 BEFORE, AFTER 로구분합니다.
PLSQL를 지원함으로써 오라클 문장과유사합니다. REPLACE를 지원합니다.
DB2 V9.7
트리거 이벤트의 BEFORE, AFTER로 구분합니다. 트리거 이벤트의 BEFORE, AFTER로 구분합니다. 트리거발생 시점
INSERT, UPDATE, DELETE 입니다. INSERT, UPDATE, DELETE 입니다. 트리거이벤트
REPLACE 를 지원하지 않으므로 변경 시에는트리거를 제거한 후 다시 생성합니다.
스토리지 옵션을 두어 테이블마다 스토리지를제어할 수 있으며 스토리지 옵션 생략 시 지정된테이블 스페이스의 디폴트 값을 적용합니다.
트리거
DB2 V9.7 이전오라클
CREATE TRIGGER CON_AUDIT_TRGNO CASCADE BEFORE INSERT ON CON_AUDIT REFERENCING NEW AS NFOR EACH ROW MODE DB2SQLBEGIN ATOMIC
SET N.TIMESTAMP = CURRENT TIMESTAMP;END!
CREATE TRIGGER EMP_HISTORY_TRG AFTER DELETE ON EMPLOYEES REFERENCING OLD AS D FOR EACH ROW BEGIN ATOMIC
INSERT INTO EMP_HISTORY ( EMP_ID, FIRST_NAME, LAST_NAME )VALUES ( D.EMP_ID ,D.FIRST_NAME,D.LAST_NAME );
END!

© Copyright IBM Corporation 201055
IBM DB2 On-site Training CourseIBM Korea
함수 비교
함수에는 내장함수와 사용자가 작성하는 함수가 있습니다. 오라클에서는 사용자가 작성하는 함수를 Stored Function 이라 하고 DB2 에서는User Defined Function (UDF)라 합니다. 함수는 프로시저와 달리 리턴 값이 존재합니다.
오라클 DB2
함수리턴 타입
• 테이블 및 Boolean 타입으로 리턴하지 못합니다. • 테이블 타입으로 리턴이 가능합니다.
외부 루틴사용
가능 여부
• JAVA 또는 C 프로그램으로 작성된 외부 루틴을 호출하여 함수를작성할 수 있습니다.
• JAVA 또는 C 프로그램으로 작성된 외부 루틴을 호출하여 함수를 작성할 수 있으며 OLE DB Provider에 등록하여 함수를 작성할 수 있습니다.
함수생성 구문
CREATE [ OR REPLACE ] FUNCTION func_name[ ( 변수명 [ IN | OUT ] datatype [ DEFAULT value] [ , .. ] ) ]
RETURN datatype[ PIPELINED ] { IS | AS } SQL 블럭/
CREATE [ OR REPLACE ] FUNCTION func_name[ ( 변수명 [ IN | OUT ] datatype [ DEFAULT value] [ , .. ] ) ]
RETURN datatype[ PIPELINED ] { IS | AS } SQL 블럭/
에문
sql> CREATE OR REPLACE FUNCTION test01(x number DEFAULT 1000 ) RETURN number IS BEGIN
RETURN ( 0.5 * x * x * 3.14 ) ;END;
/
db2=> CREATE OR REPLACE FUNCTION test01(x number DEFAULT 1000 ) RETURN number IS BEGIN
RETURN ( 0.5 * x * x * 3.14 ) ;END;

© Copyright IBM Corporation 201056
IBM DB2 On-site Training CourseIBM Korea
내장함수 비교 - 숫자
오라클 DB2 V9.5 DB2 V9.7 설명
ABS ABS ABS • 절대값을 리턴합니다. FLOOR FLOOR FLOOR • Argument 값과 같거나 그보다 작은 값을 리턴합니다.
MOD MOD MOD • 첫번째 argument 값을 두번째 argument로 나누었을때 나머지 값을 리턴합니다.
POWER POWER POWER • 첫번째 Argument에 대한 두번째 argument의 승수값을 리턴합니다.
N/A RAND RAND • 무작위 숫자를 리턴합니다. ROUND(arg1,arg2) ROUND(arg1,arg2) ROUND(arg1,arg2) • 반올림값을 리턴합니다.
TRUNC(n[,m]) TRUNC (n[,m]) TRUNC (n[,m]) • 버림값을 리턴합니다. LEAST LEAST LEAST • Argument 집합 중 가장 작은 값을 리턴합니다.
GREATEST GREATEST GREATEST • Argument 집합 중 가장 큰 값을 리턴합니다. CEIL CEIL CEIL • 올림값을 리턴합니다.
db2=> SELECT ABS(-2) FROM SYSIBM.SYSDUMMY12
db2=> VALUES ROUND(45.926,2)45.930
db2=> VALUES TRUNC(45.926) 45.920
db2=> VALUES MOD(1600,300)100
db2=> SELECT CEIL(13.11) FROM SYSIBM.SYSDUMMY114.
db2=> VALUES RAND()+1.25125888851588E-003

© Copyright IBM Corporation 201057
IBM DB2 On-site Training CourseIBM Korea
내장함수 비교 - 문자
오라클 DB2 V9.5 DB2 V9.7 설명
ASCII ASCII ASCII • 문자의 숫자 값을 리턴합니다.
CHR(n) CHR(n) CHR(n) • n을 표시하는 ASCII 코드값을 리턴합니다.
CONCAT CONCAT CONCAT • 두개의 문자열을 붙여 리턴합니다.
N/A GENERATE_UNIQUE GENERATE_UNIQUE • 동일한 함수의 실행내에 유일한 문자열을 리턴합니다.
INITCAP N/A INITCAP • 문자열의 첫문자를 대문자로 나머지 문자는 소문자로 변환합니다.
INSTR POSSTR / POSITIONLOCATE INSTR • 지정된 문자열이 문자열에서 몇번째에 위치하는지 그 위치값을 리턴합니다.
LENGTH LENGTH LENGTH • 문자열 길이를 리턴합니다.
LENGTHB /LENGTHC N/A ( UDF ) N/A ( UDF) • 다른 문자세트에 있는 문자열 길이를 리턴합니다.
LOWER LOWER / LCASE LOWER / LCASE • 문자열의 소문자값을 리턴합니다.
LPAD(arg1,arg2,arg3) N/A ( UDF ) LPAD(arg1,arg2,arg3) • arg1에 arg2의 문자길이가 될때까지 arg3를 왼쪽부터 arg1에 채웁니다 .
RPAD(arg1,arg2,arg3) N/A ( UDF ) RPAD(arg1,arg2,arg3) • arg1에 arg2의 문자길이가 될때까지 arg3 오른쪽부터 arg1에 채웁니다.
LTRIM / RTRIM LTRIM/RTRIM LTRIM / RTRIM • 문자열의 좌측, 우측에 공백이 있을 경우 공백을 제거합니다.
TRIM TRIM/STRIP TRIM/STRIP • 문자열의 좌측, 우측에 공백이 있을 경우 공백을 제거합니다.
REPLACE(arg1,arg2,arg3) REPLACE(arg1,arg2,arg3) REPLACE(arg1,arg2,arg3)• arg1 문자열에서 arg2와 매치되는 문자열을 arg3로 변경합니다. • 오라클은 2개의 인자값도 허용하여 세번째 인자값이 없을 경우 NULL로 인식하
나 DB2는 반드시 3개의 인자값이 있어야 합니다.
SUBSTR SUBSTR/SUBSTRING SUBSTR/SUBSTRING• 문자열의 서브 문자열을 리턴합니다. • 오라클의 경우 2번째 인자값이 0값을 허용하여 1로 인식하나 DB2는 반드시 1부
터 시작합니다.
TRANSLATE TRANSLATE TRANSLATE • 문자열에서 하나이상의 문자를 다른 문자로 변환하여 리턴합니다.
TREAT CAST CAST • 표현식의 선언된 타입을 변경합니다.
UPPER UPPER /UCASE UPPER /UCASE • 모든 문자열을 대문자로 변경하여 리턴합니다.

© Copyright IBM Corporation 201058
IBM DB2 On-site Training CourseIBM Korea
내장함수 비교 – 날짜/시간
오라클 DB2 V9.5 DB2 V9.7 설명
ADD_MONTHS Date 컬럼 + 1 MONTH ADD_MONTHS • Date Argument에 정수로 된 "달"을 더하여 리턴합니다. 즉 2008년 1월 1일 + 1 일 경우 2008년 2월 1일을 리턴합니다.
CURRENT_DATE CURRENT DATE CURRENT_DATE • 현재 날짜를 리턴합니다.
CURRENT_TIMESTAMP CURRENT TIMESTAMP CURRENT_TIMESTAMP • 현재 날짜와 시간을 리턴합니다.
SYSDATE CURRENT DATE SYSDATE • 현재 날짜를 리턴합니다.
SYSTIMESTAMP CURRENT TIMESTAMP+ CURRENT TIMEZONE
CURRENT TIMESTAMP+ CURRENT TIMEZONE • 현재 Timestamp를 리턴합니다.
EXTRACT(datetime)YEAR() / MONTH() / DAY() /
HOUR() / MINUTE() / SECOND()
EXTRACT(datetime) • datetime 시간으로부터 지정된 datetime 필드 값을 추출하여 리턴합니다.
LAST_DAY N/A ( UDF ) LAST_DAY • 주어진 달의 마지막 날을 반환합니다.
NEXT_DAY N/A ( UDF ) NEXT_DAY • 시작 날짜 다음에 지정된 요일이 처음으로 나오는 날짜를 반환합니다.
ROUND N/A ( UDF ) ROUND • 월, 년도, 세기 등과 같이 선택한 날짜 파라미터를 반올림하여 리턴합니다.
TRUNC(date) N/A ( UDF ) TRUNC(date) • 일, 월 등과 같이 지정된 날짜 파라미터를 잘라냅니다.
MONTHS_BETWEEN N/A ( UDF ) MONTHS_BETWEEN • 날짜와 날짜사이의 개월 수를 리턴합니다.
db2=> VALUES ( CURRENT DATE, CURRENT DATE + 1 MONTH) 2008-01-28 2008-02-28
※ DB2 에서는 MONTH,DAY,YEAR,HOUR,MINUTE,SECOND 등 지정된연산자가 존재하여 DATE, TIMESTAMP의 Data Type을 좀 더 용이하게연산을 수행할 수 있습니다. 예를 들면, VALUES CURRENT DATE + 1 DAY 일 경우 현재 날짜값 + 1 day 에 대한 결과값을 리턴 합니다. 마찬가지로 VALUES CURRENT TIME + 1 HOUR 일 경우 현재 시간에1시간을 더한 값을 리턴 합니다.

© Copyright IBM Corporation 201059
IBM DB2 On-site Training CourseIBM Korea
내장함수 비교 –변환
NVL
TO_TIMESTAMP
TO_NUMBER
TO_DATE
TO_CHAR(number)
TO_CHAR(datetime,'MONTHD')
TO_CHAR(datetime,'DAY')
TO_CHAR(datetime)
DB2 V9.7
문자열을 Date 값으로 변환합니다.DATE() /
FORMAT_TIMESTAMP() / TO_DATE ()
TO_DATE
숫자값을 지정된 형태의 문자열로 변환합니다. N/A ( UDF )TO_CHAR(number)
NULL 값을 지정된 값으로 변환합니다. COALESCENVL NVL
TIMESTAMP Data Type의 값을 CHAR Data Type으로 변환합니다.
TO_DATE / TIME / TIMESTAMP /
TIMESTAMP_FORMAT / TIMESTAMP_ISO
TO_TIMESTAMP
달의 이름을 리턴합니다. MONTHNAMETO_CHAR(datetime,'MONTHD')
문자열을 Oracle의 NUMBER 형태로 변환합니다. DB2에서는 숫자를 표현하는데다양한 Data Type 이 존재하므로 해당하는 함수를 선택하여 변환합니다.
BIGINT() / INT() / SMALLINT() /FLOAT() / DOUBLE() / REAL() /
DECIMAL () 등TO_NUMBER
요일을 리턴합니다. DAYNAMETO_CHAR(datetime,'DAY')
Datetime값을 지정된 형태의 문자열로 변환합니다.
설명
TO_CHARTO_CHAR(datetime)
DB2 V9.7 이전오라클
© Copyright IBM Corporation 201060
IBM DB2 On-site Training CourseIBM Korea
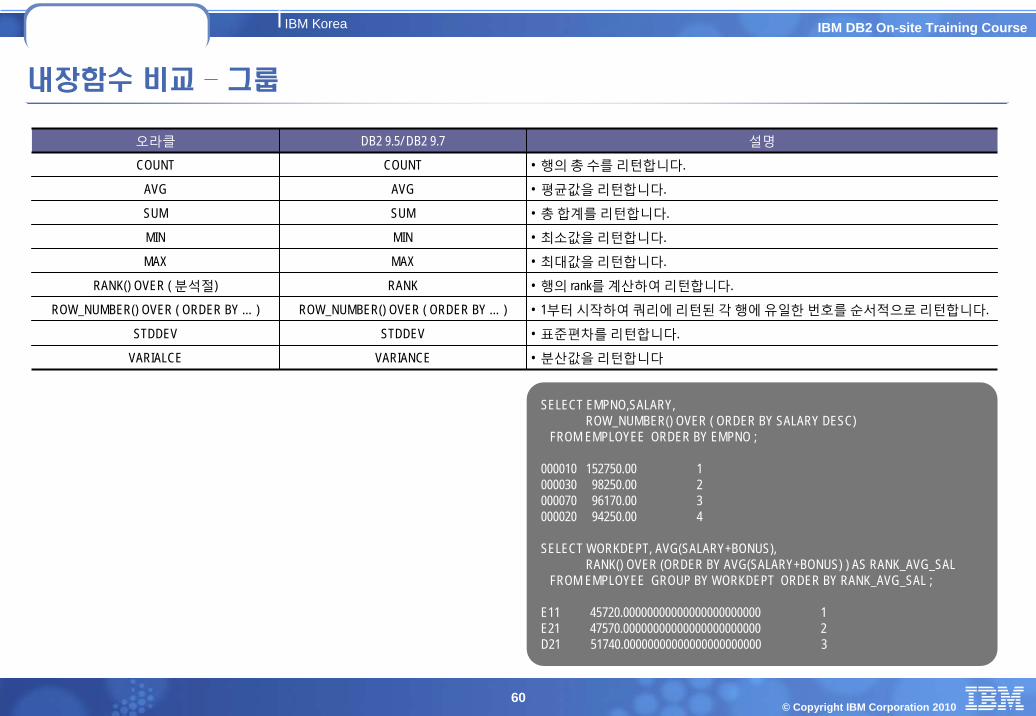
내장함수 비교 – 그룹
오라클 DB2 9.5/ DB2 9.7 설명
COUNT COUNT • 행의 총 수를 리턴합니다.
AVG AVG • 평균값을 리턴합니다.
SUM SUM • 총 합계를 리턴합니다.
MIN MIN • 최소값을 리턴합니다.
MAX MAX • 최대값을 리턴합니다.
RANK() OVER ( 분석절) RANK • 행의 rank를 계산하여 리턴합니다.
ROW_NUMBER() OVER ( ORDER BY … ) ROW_NUMBER() OVER ( ORDER BY … ) • 1부터 시작하여 쿼리에 리턴된 각 행에 유일한 번호를 순서적으로 리턴합니다.
STDDEV STDDEV • 표준편차를 리턴합니다.
VARIALCE VARIANCE • 분산값을 리턴합니다
SELECT EMPNO,SALARY, ROW_NUMBER() OVER ( ORDER BY SALARY DESC)
FROM EMPLOYEE ORDER BY EMPNO ;
000010 152750.00 1000030 98250.00 2000070 96170.00 3000020 94250.00 4
SELECT WORKDEPT, AVG(SALARY+BONUS), RANK() OVER (ORDER BY AVG(SALARY+BONUS) ) AS RANK_AVG_SAL
FROM EMPLOYEE GROUP BY WORKDEPT ORDER BY RANK_AVG_SAL ;
E11 45720.00000000000000000000000 1E21 47570.00000000000000000000000 2D21 51740.00000000000000000000000 3

© Copyright IBM Corporation 201061
IBM DB2 On-site Training CourseIBM Korea
조회쿼리 비교
다음은 조회 쿼리문에서 DECODE 구문을 비교합니다. DB2 9.5 부터는 오라클의 DECODE 구문과 동일한 DECODE 구문을 제공하므로변환하지 않아도 됩니다
SELECT AVG(CASE GRADE WHEN ‘A’ THEN 1WHEN ‘B’ THEN 2WHEN ‘C’ THEN 3
END) INTO v_GradeFROM StudentsWHERE DEPARTMENT = p_Department
AND Course_ID = p_Course_ID;
DB2 9.5 에서 제공하는 DECODE 구문 : SELECT AVG(DECODE( Grade, ’A’,1,’B’,2, ’C’,3 ))
INTO v_GradeFROM StudentsWHERE DEPARTMENT = p_Department
AND Course_ID = p_Course_ID;
SELECT AVG(DECODE( Grade, ’A’,1,’B’,2, ’C’,3 )) INTO v_Grade
FROM StudentsWHERE DEPARTMENT = p_Department
AND Course_ID = p_Course_ID;
CASE conditionWHEN case1 THEN assign 1WHEN case2 THEN assign 2ELSE default
ENDDB2 9.5 에서 제공하는 DECODE 구문 : DECODE(condition,case1,assign1,case2,assign2, default)
DECODE(condition,case1,assign1,case2,assign2., default)
DB2Oracle

© Copyright IBM Corporation 201062
IBM DB2 On-site Training CourseIBM Korea
조회쿼리 비교
다음은 조회 쿼리문에서 ROWNUM 구문을 비교합니다.
9.1의 Fixpak 4 이상 일 경우 : DELETE FROM (SELECT 1 FROM TAB1 FETCH FIRST 100 ROWS ONLY)
DELETE FROM TAB1 WHERE ROWNUM <= 100DELETE
UPDATE TAB1 SET c1 = v1 WHERE c2 = v2 and ROWNUM <= 10
SELECT * FROM TAB1 WHERE ROWNUM < 10
오라클
9.1의 Fixpak 4 이상 일 경우 : UPDATE ( SELECT c1
FROM TAB1 WHERE c2 = v2 FETCH FIRST 10 ROWS ONLY )
SET c1 = V1
UPDATE
SELECT * FROM TAB1FETCH FIRST 9 ROWS ONLY
SELECT
DB2구문

© Copyright IBM Corporation 201063
IBM DB2 On-site Training CourseIBM Korea
JOIN 방법 비교 – Outer Join
JOIN을 통해 여러 테이블에 분산되어 있는 데이터를 한번에 조회할 수 있습니다. 오라클과 DB2는 모두 INNER JOIN, OUTER JOIN을 모두지원합니다. Inner join은 동일하나 Outer join은 아래와 같이 차이점이 있습니다. 그러나 DB2 V9.7부터는 오라클 구문을 지원합니다.
SELECT A.last_name, A.id ,B.nameFROM emp A, Customer BWHERE A.id (+) = B.sales_rep_id (+)
SELECT A.last_name, A.id , B.nameFROM emp A, Customer BWHERE A.id = B.sales_rep_id(+)
SELECT A.last_name, A.id, B.nameFROM emp A, Customer BWHERE A.id (+) = B.sales_rep_id;
Oracle
FULL OUTER JOIN
LEFT OUTER JOIN
RIGHT OUTER JOIN
SELECT A.last_name, A.id, B.nameFROM emp A FULL OUTER JOIN Customer BON A.id = B.sales_rep_id;
SELECT A.last_name, A.id , B.nameFROM emp A LEFT OUTER JOIN Customer BON A.id = B.sales_rep_id;
SELECT A.last_name, A.id , B.nameFROM emp ARIGHT OUTER JOIN customer B ON A.id = B.sales_rep_id;
DB2
SELECT t1.surnameFROM EXAMPLE_TABLE1 t1,
EXAMPLE_TABLE2 t2,EXAMPLE_TABLE3 t3,EXAMPLE_TABLE4 t4
WHERE ((t1.emptype = 1) OR (t1.position = 'Manager'))AND (t1.empid = t2.empid(+)) AND (t2.empid = t3.empid(+))AND (t2.sin = t3.sin(+))AND (t3.jobtype(+) = 'Full-Time')AND (t2.empid = t4.empid(+))AND (t2.sin = t4.sin(+))
ORDER BY t1.emptype, t2.other
SELECT t1.surname,FROM EXAMPLE_TABLE1 t1
LEFT OUTER JOIN EXAMPLE_TABLE2 t2 ON (t2.empid = t1.empid)
LEFT OUTER JOIN EXAMPLE_TABLE3 t3 ON (t3.sin = t2.sin)
AND (t3.empid = t2.empid)AND (t3.jobtype = 'Full-Time')
LEFT OUTER JOIN EXAMPLE_TABLE4 t4 ON (t4.sin = t2.sin)
AND (t4.empid = t2.empid)WHERE ((t1.emptype = 1) OR (t1.position = 'Manager'))ORDER BY t1.emptype, t2.other
ORACLE DB2

© Copyright IBM Corporation 201064
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교 - 변수선언
l_balance NUMBER(10,2) := 0.0;l_balance := 19.99;
Stored Procedure / Function 의 parameter list에서 선언.Stored procedure / Function / Trigger 의 Body에서 선언.Package 선언부 또는 BODY 선언부에서 선언.
오라클 PL/SQL
DECLARE l_balance NUMERIC(10,2) DEFAULT 0.0;SET l_balance = 19.99;SET 구문은 또한 다음과 같이 local 변수에 Table Column 값을 할당할 수있습니다. SET l_balance = (SELECT balance
FROM account_infoWHERE account_no = actNo);
변수 값지정방법
Stored Procedure / Function 의 Parameter list에서 선언.Stored Procedure / Function / Trigger의 Body에서 선언.
변수선언영역
DB2 SQLPL

© Copyright IBM Corporation 201065
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교 – 조건 구문 및 흐름 제어
FOR variable AS cursor_nameCORSOR FOR select_statement DO
statements;END FOR ;
OPEN cursor_variable FOR select_statements;
SET l_count = lower_bound;WHILE l_count <= upper_bound DOstatements;SET l_count = l_count + 1;END WHILE ;
FOR l_count INlower_bound ..upper_boundLOOPstatements;END LOOP;
WHILE condition DO statements;
END WHILE ;
WHILE condition LOOPstatements;
END LOOP;
REPEATstatements;UNTIL condition;END REPEAT;
LOOPstatements;EXIT WHEN condition;END LOOP;
LOOP statements ;
END LOOP;
IF - THEN - END IF ;IF - THEN - ELSE - END IF ;IF - THEN - ELSIF - END IF;
오라클 PL/SQL
[L1:] LOOPstatements;LEAVE L1;
END LOOP [L1];
IF - THEN - END IF ;IF - THEN - ELSE - END IF ;IF - THEN - ELSEIF - END IF ;
DB2 SQLPL

© Copyright IBM Corporation 201066
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교 - 커서
DECLARE cursor_nameCURSOR [WITH HOLD] [ WITH RETURN]
[TO CALLER | TO CLIENT ] FOR Select_statement
CURSOR cursor_name [ ( cursor_parameter(s))]IS select_statement커서 선언
OPEN cursor_name [USING host-variable]OPEN cursor_name [(cursor_parameter(s))]커서 열기
FETCH [from] cursor_name INTO variable(s)FETCH cursor_name INTO variable(s)커서로부터 Fetch
UPDATE table_name SET statements...WHERE CURRENT OF Cursor_name
UPDATE table_name SET statement(s)...WHERE CURRENT OF Cursor_name
Fetch된 행 수정
DELETE FROM table_nameWHERE CURRENT OF cursor_name
DELETE FROM table_nameWHERE CURRENT OF cursor_name;Fetch된 행 삭제
CLOSE cursor_name;CLOSE cursor_name;커서 닫기
오라클 PL/SQL DB2 SQLPL

© Copyright IBM Corporation 201067
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교 - 커서
DECLARE cursor_notopen CONDITION FOR SQLSTATE 24501;DECLARE CONTINUE HANDLER FOR cursor_notopenBEGINopen c1;FETCH c1 int var1;END;...FETCH c1 into var1;
IF c1%ISOPEN THENfetch c1 into var1;
ELSEOPEN c1;
fetch c1 into var1;END IF;
%ISOPEN
DECLARE SQLCODE int DEFAULT 0;……OPEN c1;L1: LOOPFETCH c1 INTO v_var1;IF SQLCODE = 100 THENLEAVE L1;END IF;...END LOOP L1;
OPEN cur1;LOOPFETCH cur1 INTO v_var1;EXIT WHEN cur1%NOTFOUND;
....
END LOOP;
%NOTFOUND
DELETE FROM empWHERE empno = my_empno;IF SQLCODE = 0 THEN -- delete succeededINSERT INTO emp_table
VALUES (my_empno, my_ename);
DELETE FROM empWHERE empno = my_empno;IF SQL%FOUND THEN -- delete succeededINSERT INTO emp_table
VALUES (my_empno, my_ename);
%FOUND
오라클 PL/SQL DB2 SQLPL

© Copyright IBM Corporation 201068
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교 - 커서
DECLARE c1 CURSOR FOR SELECT ename, deptno FROM emp_table
FETCH FIRST 10 ROWS ONLY;
DECLARE CONTINUE HANDLER FOR NOT FOUNDBEGIN
SET end-of-fetch = 1;END;L1 : LOOP
FETCH c1 INTO my_ename, my_deptno;IF end-of-fetch = 1 THEN
LEAVE L1;END IF;
..........END LOOP L1;
LOOP FETCH c1 INTO my_ename, my_deptno;IF c1%ROWCOUNT > 10 THEN
EXIT;END IF ;...END LOOP;
%ROWCOUNT( 10행만 처리하는
경우)
DECLARE v_CURCOUNT INT DEFAULT 0;......L1 : LOOP
FETCH c1 INTO my_ename, my_deptno;v_CURCOUNT = v_CURCOUNT + 1;IF v_CURCOUNT > 10 THEN ..... END IF ; ..... END LOOP L1;
LOOP FETCH c1 INTO my_ename, my_deptno;IF c1%ROWCOUNT > 10 THEN
... END IF ;...END LOOP;
%ROWCOUNT(Cursor로부터
처리되어진 Rows 수를계산할때 )
DECLARE rc INT DEFAULT 0;....
DELETE FROM emp_table WHERE ...GET DIAGNOSTICS rc = ROW_COUNT;
IF rc > 10 THEN ...
END IF;
DELETE FROM emp_tableWHERE ....
IF SQL%ROWCOUNT > 10 THEN....
END IF;
%ROWCOUNT( 10개의 row를
삭제한 후수행할 작업이
있을 경우 )
오라클 PL/SQL DB2 SQLPL

© Copyright IBM Corporation 201069
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교 - Collection
DECLARE v_empname varchar(30);DECLARE v_num INT DEFAULT 0;DECLARE GLOBAL TEMPORARY TABLE SESSION.temp_emp_list (num INTEGER, EmpName VARCHAR(30)) WITH REPLACE ON COMMIT PRESERVE ROWS NOT LOGGED;INSERT INTO SESSION.temp_emp_list (SELECT emp_name FROM emp_table WHERE detp = v_dept);
DECLARETYPE EmpList IS TABLE OF emp_table.ename%TYPE ;CURSOR c1 IS SELECT emp_name FROM emp_table WHERE dept = v_dept;BEGIN
OPEN c1;FETCH c1 BULK COLLECT INTO EmpList;CLOSE c1;
END;
DECLARE GLOBAL TEMPORARY TABLE SESSION.temp_emp_list (num integer,EmpName varchar(30)) WITH REPLACEON COMMIT PRESERVE ROWSNOT LOGGED;INSERT INTO session.temp_emp_listSELECT row_number() over(), emp_name FROM emp_table WHERE dept = v_dept;
DECLARETYPE EmpList IS TABLE OF emp_table.ename%TYPE ;CURSOR c1 IS SELECT emp_name FROM emp_table WHERE dept = v_dept;EmpName emp_table.ename%TYPE;empNum NUMBER;BEGINLOOP
FETCH c1 INTO EmpName;WHEN c1%NOTFOUND EXIT;empNum := empNum + 1;EmpList(empNum):= EmpName;
END LOOP;CLOSE c1;END;
오라클 PL/SQL DB2 SQLPL

© Copyright IBM Corporation 201070
IBM DB2 On-site Training CourseIBM Korea
DDL 일반 사항

© Copyright IBM Corporation 201071
IBM DB2 On-site Training CourseIBM Korea
스키마
개요
• 테이블 등의 데이터베이스 오브젝트의 이름을 명시할 때는<스키마명>.<오브젝트명> 형식을 사용하는 것이 원칙입니다.
• <스키마명>을 명시적으로 지정하지 않으면 <기본 스키마명>을사용한 것으로 간주됩니다
• 데이터베이스의 오브젝트를 지정할 때는 개별적인 SQL문에서<스키마명>을 명시적으로 지정하는 것이 권장됩니다.
• <현재 세션의 로그온 사용자명>, <데이터베이스 접속 시에사용된 사용자명>, <CURRENT SCHEMA 특수 레지스터리 변수의현재값> 보다 SQL문에서 명시적으로 지정한 <스키마명>이 가장우선적으로 적용됩니다
CASE1 • SQL문에서 <스키마명> 없이 <테이블명>만 지정하면, <현재세션의 로그온 사용자명>이 <기본 스키마명>으로 인식됩니다.
CASE2 • 데이터베이스에 접속하는 connect 문에서 USER 와 USING 옵션을이용하면, <로그온 사용자명>에 관계 없이 <데이터베이스접속시에 사용된 사용자명>이 <기본스키마명>으로 인식됩니다.
$ login db2inst1$ db2 connect to sample$ db2 "select * from org"
db2inst1.org
$ login db2inst1$ db2 connect to sample user user1 using dkagh$ db2 "select * from org"
user1.org
CASE3• CURRENT SCHEMA 특수 레지스터리 변수는 스키마명을명시적으로 지정하지 않는 경우에 사용되는 <기본스키마명>을저장하고 있습니다. set current schema 문은 데이터베이스에접속한 후에 실행할 수 있으며, 접속이 해제되면 <로그온사용자명>으로 복원됩니다.
• CURRENT SCHEMA 값은 values 문으로 현재 값을 확인할 수있습니다. set current schema 문을 이용하여 CURRENT SCHEMA 특수 레지스터리 변수를 변경하면, <데이터베이스 접속시사용된 사용자명> 보다 우선적으로 적용됩니다
$ login db2inst1$ db2 connect to sample user user1 using dkagh$ db2 values(current schema)$ db2 set current schema group1$ db2 values(current schema)$ db2 "select * from org" group1.org

© Copyright IBM Corporation 201072
IBM DB2 On-site Training CourseIBM Korea
테이블
관리
• CREATE TABLE, ALTER TABLE, DROP TABLE 문으로 관리합니다• CREATE TABLE 문을 이용하여 테이블과 컬럼 정보를 정의하고, 테이블스페이스명을 지정합니다 . IMPLICIT_SCHEMA 특권이있으면, 존재하지 않는 <스키마명>을 이용하여 테이블을 정의할수 있습니다.
• 테이블의 한 행의 총 길이는 지정한 테이블 스페이스의 페이지크기보다 작아야 합니다
• ALTER TABLE 문을 이용하여 컬럼 추가, 고유키 추가 및 제거, 기본키 추가 및 제거, 외부키 추가 및 제거, 점검 제한 조건 추가및 제거 등의 변경 작업이 가능합니다
• TABLE DDL구문의 NOT LOGGED INITIALLY 특성은 ALTER TABLE 문으로 활성화할 때만 적용되고, COMMIT 또는 ROLLBACK시에해제됩니다. NOT LOGGED 모드에서 실행한 SQL이 실패하면, 테이블을 재생성해야 합니다.
테이블정보조회
• LIST TABLES 명령어에서 테이블의 목록을 확인할 수 있습니다.
• 테이블에 대한 정보는 SYSCAT.TABLES 뷰를 이용해서 확인할 수있습니다
• DESCRIBE 문으로 테이블의 컬럼에 대한 정보를 확인합니다.
• db2look 명령어로 테이블에 대한 DDL문을 추출할 수 있습니다.
$ db2 list tables $ db2 list tables for schema <스키마명>$ db2 list tables for system$ db2 list tables for all
$ db2 "select * from syscat.tables"
$ db2 "describe table <스키마명>.<테이블명>"
$ db2look –d <DB명> –e –z <스키마명> –t <테이블명> -o <파일명>

© Copyright IBM Corporation 201073
IBM DB2 On-site Training CourseIBM Korea
데이터 유형
구분 유형 BYTE 수 최대범위
숫 자 SMALLINT 2 -32,768 ~ +-32,767
INT 4 -2,147,483,648 ~ +2,147,483,647
BIGINT 8 -9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807
DEC(p,s) (p+s)/2+1 31 자리
DOUBLE 8 -1.79769E+308 ~ +1.79769E+308
문 자 CHAR(n) n 254 바이트
VARCHAR(n) n + 4 4000 바이트 (4K 페이지인 경우)32672 바이트 (32K 페이지인 경우)
날 짜 DATE 10 0001-01-01 ~ 9999-12-31
TIME 8 00:00:00 ~ 24:00:00
TIMESTAMP 26 0001-01-01-00.00.00.000000 ~ 9999-12-31-24.00.00.000000
Data Types
SMALLINTINTEGERBIGINT
Numeric
Integer
Decimal
Floating Point
DECIMAL
REALDOUBLE
String
Character Single ByteCHARVARCHARLONG VARCHARCLOB
Double Byte GRAPHICVARGRAPHICLONG VARGRAPHICDBCLOBCharacter BLOB
VARCHAR FOR BIT DATA
String DATETIMETIMESTAMP

© Copyright IBM Corporation 201074
IBM DB2 On-site Training CourseIBM Korea
NULL값과 DEFAULT값
개요
• 테이블을 정의할 때, 각 컬럼에 NULL 값과 DEFAULT 값을허용하게 할 수 있습니다.
• DEFUALT 속성을 가지지 않는 컬럼은 INSERT 시에 반드시명시적으로 값을 지정해야 합니다.
• CREATE TABLE 문에서 NOT NULL 옵션과 WITH DEFULAT 옵션을이용합니다.
• NULL 값은 알 수 없는 값을 의미합니다. NULL 값은 0 또는 공백(blank) 또는 empty string 이 아닙니다. empty string은 길이가 0인값을 의미하며, 공백 문자와는 다릅니다. 테이블을 정의할 때, 컬럼에 NULL 값을 허용하지 않으려면 CREATE TABLE 문에서NOT NULL 옵션을 이용합니다.
CREATE TABLE STAFF (ID SMALLINT NOT NULL WITH DEFAULT 10,NAME VARCHAR(9),DEPT SMALLINT NOT NULL,JOB CHAR(5),YEARS SMALLINT,SALARY DECIMAL(7,2),COMM DECIMAL(7,2) WITH DEFAULT
);
사용자가 정의한 기본값10이 사용됩니다
시스템 기본값인 0.00이사용됩니다
시스템기본값
00숫자
길이가 0 인 문자EMPTY STRING문자
현재 시스템 날짜CURRENT DATEDATE
현재 시스템 시간CURRENT TIME TIME
현재 시스템 시간 소인CURRENT TIMESTAMP TIMESTAMP
유형 기본값 설 명
사용자기본값지정예
WITH DEFAULT 10숫자
WITH DEFAULT 'xx'문자
WITH DEFAULT '2006-04-17'DATE
WITH DEFAULT '14:12:30'TIME
WITH DEFAULT '2006-04-17-14.12.30.694001'TIMESTAMP
유형 사용자지정기본값예

© Copyright IBM Corporation 201075
IBM DB2 On-site Training CourseIBM Korea
테이블스페이스 지정
개요
• CREATE TABLE 문에서 IN 키워드를 이용하여 테이블스페이스를지정할 수 있습니다. INDEX IN, LONG IN 키워드로 테이블, 인덱스, LONG 데이터를 개별적인 DMS 테이블스페이스에 저장할 수있습니다. 지정한 테이블스페이스는 변경될 수 없습니다.
• CREATE TABLE 문에서 IN 옵션을 지정하지 않으면, 테이블은기본 사용자 테이블스페이스에 저장됩니다. 기본 사용자테이블스페이스는 사용자가 정의한 테이블스페이스 중에서해당 테이블의 행의 총 길이를 수용할 수 있는 페이지 크기를가진 첫 번째 REGULAR 유형의 테이블스페이스입니다.
• 테이블 스페이스를 drop할 때 한 테이블이 여러 테이블스페이스에 저장되었다면, 테이블스페이스는 함께 drop 되어야합니다.
CREATE TABLE STAFF (ID SMALLINT NOT NULL WITH DEFAULT 10,NAME VARCHAR(9),DEPT SMALLINT NOT NULL,JOB CHAR(5),YEARS SMALLINT,SALARY DECIMAL(7,2),COMM DECIMAL(7,2) WITH DEFAULT
) IN TS01INDEX IN TS02LONG IN TS03;
테이블의 데이터,인덱스, LONG 데이터를 TS01,TS02,TS03에
분리하여 저장합니다
테이블스페이스지정
• C R E A T E T A B L E 문에서 I N 옵션으로 테이블이 저장될테이블스페이스를 지정합니다. 테이블의 모든 데이터와 인덱스데이터는 동일한 테이블스페이스에 저장됩니다.
인덱스스페이스지정
• CREATE TABLE 문에서 INDEX IN 키워드를 이용하여 인덱스를위한 데이터를 별도의 테이블스페이스에 저장할 수 있습니다. IN 옵션과 INDEX IN 옵션에서 지정한 테이블스페이스는 DMS 방식의 REGULAR 유형이어야 합니다. INDEX IN 옵션만 지정할수는 없습니다.
LONG 스페이스지정
• CREATE TABLE 문에서 LONG IN 키워드를 이용하여 LONG 데이터를 별도의 테이블스페이스에 저장할 수 있습니다. IN 옴션에서 지정한 테이블스페이스는 DMS 방식의 REGULAR 유형이고, LONG IN 옵션에서 지정한 테이블스페이스는 DMS 방식의 LARGE 유형이어야 합니다. INDEX IN 옵션은 지정하지않았다면 , 인덱스는 테이블과 동일한 테이블스페이스에저장됩니다. LONG IN 옵션만 지정할 수는 없습니다.

© Copyright IBM Corporation 201076
IBM DB2 On-site Training CourseIBM Korea
고유키
개요
• 고유키는 한 개 이상의 컬럼들로 구성되어 테이블의 각 행을고유하게 구별하는 값입니다. 고유키에 대응하는 인덱스가이미 존재하면, SQL0000W 라는 경고 메시지가 반환되지만, 무시해도 됩니다.
CREATE TABLE STAFF (ID SMALLINT NOT NULL,NAME VARCHAR(9),DEPT SMALLINT NOT NULL,JOB CHAR(5),YEARS SMALLINT,SALARY DECIMAL(7,2),COMM DECIMAL(7,2) WITH DEFAULT,CONSTRAINT STAFF_UK UNIQUE (ID)
) IN TS01INDEX IN TS02LONG IN TS03; ALTER TABLE STAFF DROP CONSTRAINT STAFF_UK ;ALTER TABLE STAFF ADD CONSTRAINT STAFF_UK UNIQUE (ID) ;
NOT NULL로 지정합니다
ID컬럼이 고유키가 됩니다
자동적으로 생성되는고유 인덱스의 이름은
제약조건명과 같습니다
고유키정의및관리
• 고유키 제한 조건을 정의하는 구문은 다음과 같습니다.
• 고유키를 구성하는 각 컬럼은 NOT NULL 속성을 지정해야합니다
• <제한조건명>과 동일한 이름을 가진 고유 인덱스가 자동적으로생성됩니다.
• 고유키는 한 테이블에 여러 개 정의할 수 있습니다. • CONSTRAINT 옵션을 지정하지 않으면, 제한조건명과 인덱스의이름은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다.
• <제한조건명>은 데이터베이스 내에서 고유해야 합니다. • alter table 문을 이용하여 고유키를 추가 및 삭제 할 수 있습니다
( 컬럼리스트 )UNIQUE
CONSTRAINT 제약조건명 Optional고유키정의

© Copyright IBM Corporation 201077
IBM DB2 On-site Training CourseIBM Korea
기본키정의및관리
• 기본키 제한 조건을 정의하는 구문은 다음과 같습니다.
• <제한조건명>과 동일한 이름을 가진 고유 인덱스가 자동적으로생성됩니다. 기본키는 한 테이블에 한 개만 정의할 수 있습니다.
• CONSTRAINT 옵션을 지정하지 않으면, 제한조건명과 인덱스의이름은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다. <제한조건명>은 데이터베이스 내에서 고유해야 합니다.
• alter table 문을 이용하여 기본키를 추가 및 삭제 할 수 있습니다
기본키
개요
• 기본키는 고유 키와 동일한 특성을 갖지만, 한 테이블에 한 개만지정할 수 있습니다.
• 고유키에 대응하는 인덱스가 이미 존재하면, SQL0000W 라는경고 메시지가 반환되지만, 무시해도 됩니다.
• 고유키와 기본키는 기능적으로 동일합니다 . 단 , IMPORT 명령어의 INSERT_UPDATE 옵션을 사용할 때에는 반드시기본키가 필요합니다.
CREATE TABLE STAFF (ID SMALLINT NOT NULL,NAME VARCHAR(9),DEPT SMALLINT NOT NULL,JOB CHAR(5),YEARS SMALLINT,SALARY DECIMAL(7,2),COMM DECIMAL(7,2) WITH DEFAULT,CONSTRAINT STAFF_PK PRIMARY KEY (ID)
) IN TS01INDEX IN TS02LONG IN TS03; ALTER TABLE STAFF DROP CONSTRAINT STAFF_PK ;ALTER TABLE STAFF ADD CONSTRAINT STAFF_PK PRIMARY KEY (ID) ;
NOT NULL로 지정합니다
ID컬럼이 기본키가 됩니다
자동적으로 생성되는고유 인덱스의 이름은
제약조건명과 같습니다
( 컬럼리스트 )PRIMARY KEY
CONSTRAINT 제약조건명 Optional기본키정의

© Copyright IBM Corporation 201078
IBM DB2 On-site Training CourseIBM Korea
외부키
개요
• 외부키는 부모 테이블의 고유키 또는 기본키를 참조하는키입니다.
• 참조하는 고유키 또는 기본키와 호환되는 컬럼들로 구성되어야하며, 각 컬럼은 NULL 값을 허용합니다. RI 관계를 유지하기 위한DELETE규칙과 UPDATE 규칙을 명시합니다.
CREATE TABLE STAFF (ID SMALLINT NOT NULL,NAME VARCHAR(9),DEPT SMALLINT,JOB CHAR(5),YEARS SMALLINT,SALARY DECIMAL(7,2),COMM DECIMAL(7,2) WITH DEFAULT,CONSTRAINT STAFF_FK FOREIGN KEY (DEPT) REFERENCES DEPT
) IN TS01INDEX IN TS02LONG IN TS03; ALTER TABLE STAFF DROP CONSTRAINT STAFF_FK ;ALTER TABLE STAFF ADD CONSTRAINT STAFF_FK
FOREIGN KEY (DEPT) REFERENCES DEPT ON DELETE RESTRICT ON UPDATE RESTRICT ;
외부키는 NULL을 허용합니다
DEPT컬럼이 외부키가 됩니다
RI관계를 유지하기 위한규칙을 지정합니다
외부키정의및관리
• 외부키 제한 조건을 정의하는 구문은 다음과 같습니다.
• 외부키는 한 테이블에 여러 개 정의할 수 있습니다. CONSTRAINT 옵션을 지정하지 않으면, 제한 조건명은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다.
• <제한조건명>은 데이터베이스 내에서 고유해야 합니다. • alter table 문을 이용하여 외부키를 추가 및 삭제 할 수 있습니다
Optional( 컬럼리스트 )
부모테이블REFERENCES
( 컬럼리스트 )FOREIGN KEY
CONSTRAINT 제약조건명 Optional외부키정의

© Copyright IBM Corporation 201079
IBM DB2 On-site Training CourseIBM Korea
참조 무결성
개요
• 두 테이블이 고유키와 외부키로 연결되어 외부키를 가진테이블에 데이터를 추가, 변경하는 경우에 데이터의 참조무결성이 유지됩니다. 고유키를 가진 테이블에 데이터를 변경, 제거하는 경우에는 UPDATE 규칙과 DELETE 규칙이 적용됩니다.
• 외부키를 가진 자손 테이블에 INSERT 문으로 데이터를 추가할때, 제공된 외부키가 부모 테이블의 고유키에 존재하는 값인지점검합니다. 존재하지 않는 값인 경우에는 SQL0530N 오류코드가 반환되고, INSERT 문은 실패합니다. 부모 테이블에INSERT문을 실행할 때, 점검 규칙은 필요하지 않습니다. 자손테이블에 외부키에 입력된 데이터는 부모 테이블의 고유키에존재하는 값이므로 항상 참조가 가능합니다 . 이러한기능을 '참조 무결성 (RI, Refrential Integrity)' 라고 합니다.
DefaultOptional
NO ACTIONRESTRICT
ON UPDATE
NO ACTIONRESTRICTCASCADESET NULL
ON DELETE DefaultOptionalOptionalOptional
참조무결성규칙
UPDATE 규칙• 고유키를 가진 부모 테이블에서 UPDATE 문을 실행할 때는다음과 같이 2 가지의 UPDATE 규칙을 적용받게 할 수 있습니다.
• CREATE TABLE 문에서 외부키를 정의할 때 ON UPDATE 옵션을이용하여 지정합니다.
DELETE 규칙• 고유키를 가진 부모 테이블에서 DELETE 문을 실행할 때는다음과 같이 4 가지의 DELETE 규칙을 적용 받게 할 수 있습니다.
• CREATE TABLE 문에서 외부키를 정의할 때 ON DELETE 옵션을이용하여 지정합니다.
갱신 명령문 완료 시 종속 테이블의 행 중 해당 상위 키가 없는행이 있는 경우(사후 트리거 제외) 갱신 규칙이 NO ACTION이면갱신이 거부됩니다
NO ACTION
종속 테이블의 행 중 키의 원래 값과 일치하는 행이 있는 경우갱신 규칙이 RESTRICT이면 갱신이 거부됩니다
RESTICT
UPDATE 규칙 설명
삭제되는 행의 고유키 값을 참조하고 있는 자손 테이블의 행의외부키의 값을 NULL 값으로 변경합니다. 자손 테이블의 외부키컬럼이 NULL 을 허용하는 컬럼일 때 지정할 수 있습니다.
SET NULL
삭제되는 행의 고유키 값을 참조하고 있는 자손 테이블의 행이존재하면, SQL0532N 오류 코드가 반환되고, DELETE 문이 실패합니다.
NO ACTIONRESTICT
삭제되는 행의 고유키 값을 참조하고 있는 자손 테이블의 행을함께 삭제합니다.
CASCADE
DELETE 규칙 설명

© Copyright IBM Corporation 201080
IBM DB2 On-site Training CourseIBM Korea
점검 제한 조건
개요
• 테이블의 컬럼에 입력되는 값을 제한하는 조건입니다 . INSERT와 UPDATE 문을 실행하면 자동적으로 입력된 값에 대한점검이 실행되어 조건에 맞지 않는 값인 경우에는 오류를반환합니다.
CREATE TABLE STAFF (ID SMALLINT NOT NULL,NAME VARCHAR(9),DEPT SMALLINT,JOB CHAR(5),YEARS SMALLINT,SALARY DECIMAL(7,2),COMM DECIMAL(7,2) WITH DEFAULT,CONSTRAINT STAFF_CK CHECK ( YEARS > 2005 )
) ; ALTER TABLE STAFF DROP CONSTRAINT STAFF_CK ;ALTER TABLE STAFF ADD CONSTRAINT STAFF_CK CHECK ( YEARS > 2005 )
NULL을 허용합니다
표현식은 where절과 동일합니다
점검제한조건정의및관리
• 점검 제한 조건을 정의하는 구문은 다음과 같습니다.
• 점검 제한 조건은 한 테이블에 여러 개 정의할 수 있습니다.• CONSTRAINT 옵션으로 제한 조건명을 지정하지 않으면, 제한조건명은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다.
• <제한조건명>은 데이터베이스 내에서 고유해야 합니다. • alter table 문을 이용하여 점검 제한 조건을 추가 및 삭제 할 수있습니다
• 점검 제한 조건에 포함되는 조건식은 SQL 문의 WHERE 조건절의표현식과 동일합니다.
( 조건문 )CHECK
CONSTRAINT 제약조건명 Optional점검제한조건정의
© Copyright IBM Corporation 201081
IBM DB2 On-site Training CourseIBM Korea
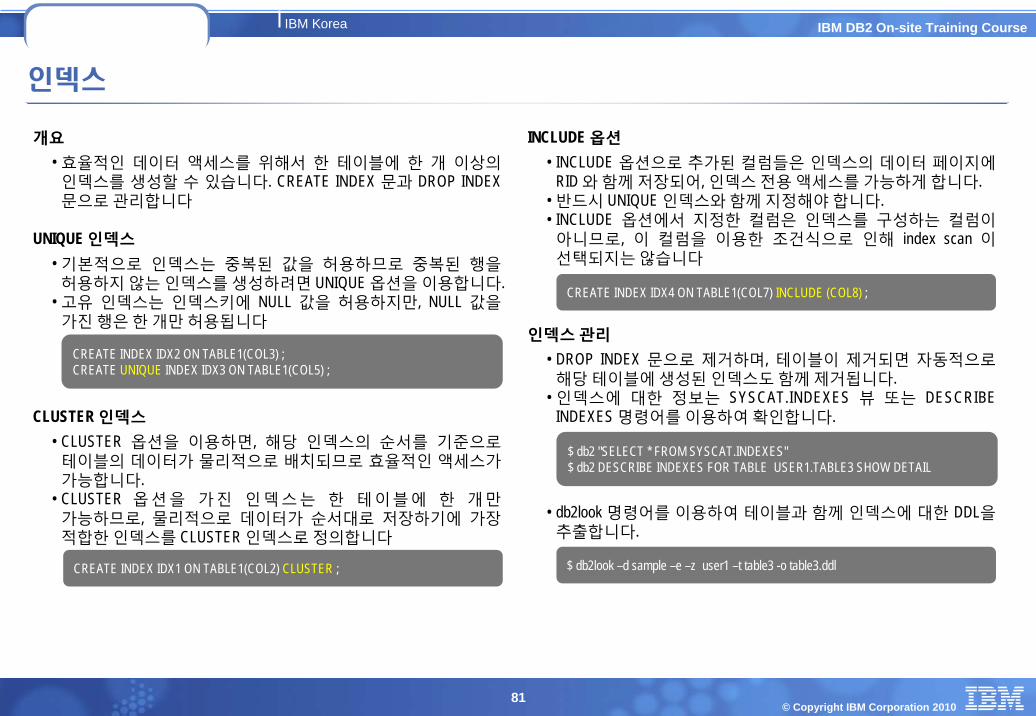
인덱스
개요
• 효율적인 데이터 액세스를 위해서 한 테이블에 한 개 이상의인덱스를 생성할 수 있습니다. CREATE INDEX 문과 DROP INDEX 문으로 관리합니다
UNIQUE 인덱스• 기본적으로 인덱스는 중복된 값을 허용하므로 중복된 행을허용하지 않는 인덱스를 생성하려면 UNIQUE 옵션을 이용합니다.
• 고유 인덱스는 인덱스키에 NULL 값을 허용하지만, NULL 값을가진 행은 한 개만 허용됩니다
CLUSTER 인덱스• CLUSTER 옵션을 이용하면, 해당 인덱스의 순서를 기준으로테이블의 데이터가 물리적으로 배치되므로 효율적인 액세스가가능합니다.
• CLUSTER 옵션을 가진 인덱스는 한 테이블에 한 개만가능하므로, 물리적으로 데이터가 순서대로 저장하기에 가장적합한 인덱스를 CLUSTER 인덱스로 정의합니다
INCLUDE 옵션• INCLUDE 옵션으로 추가된 컬럼들은 인덱스의 데이터 페이지에
RID 와 함께 저장되어, 인덱스 전용 액세스를 가능하게 합니다. • 반드시 UNIQUE 인덱스와 함께 지정해야 합니다. • INCLUDE 옵션에서 지정한 컬럼은 인덱스를 구성하는 컬럼이아니므로, 이 컬럼을 이용한 조건식으로 인해 index scan 이선택되지는 않습니다
인덱스관리
• DROP INDEX 문으로 제거하며, 테이블이 제거되면 자동적으로해당 테이블에 생성된 인덱스도 함께 제거됩니다.
• 인덱스에 대한 정보는 SYSCAT.INDEXES 뷰 또는 DESCRIBE INDEXES 명령어를 이용하여 확인합니다.
• db2look 명령어를 이용하여 테이블과 함께 인덱스에 대한 DDL을추출합니다.
CREATE INDEX IDX2 ON TABLE1(COL3) ;CREATE UNIQUE INDEX IDX3 ON TABLE1(COL5) ;
CREATE INDEX IDX1 ON TABLE1(COL2) CLUSTER ;
CREATE INDEX IDX4 ON TABLE1(COL7) INCLUDE (COL8) ;
$ db2 "SELECT * FROM SYSCAT.INDEXES"$ db2 DESCRIBE INDEXES FOR TABLE USER1.TABLE3 SHOW DETAIL
$ db2look –d sample –e –z user1 –t table3 -o table3.ddl

© Copyright IBM Corporation 201082
IBM DB2 On-site Training CourseIBM Korea
DML 일반 사항

© Copyright IBM Corporation 201083
IBM DB2 On-site Training CourseIBM Korea
시스템 레지스터리
개요
• Special Register 라고 부르며, SQL문에서 직접 참조하여 DBMS 시스템에 관련된 여러 가지 환경 값을 확인할 수 있습니다.
• current date 등의 레지스트리는 참조만 가능하며, current explain mode 등은 변경도 가능합니다
• 제공되는 레지스터리의 목록은 다음과 같습니다• SQL 문에서 참조되므로 , 데이터베이스에 대한 접속이필요합니다. 레지스터리명은 대소문자를 구분하지 않습니다
• 변경하는 방법은 다음과 같습니다. 일부 레지스터리에 대한변경은 현재의 세션에서만 유효합니다
NNNNNNNNNNNNNNNNYNNYNNNNNNNNNNNNNN
NNNNNNNYYYYYYYYYYYYYYYYYYNYNNNNYNY
CURRENT CLIENT_ACCTNG CURRENT CLIENT_APPLNAME CURRENT CLIENT_USERID CURRENT CLIENT_WRKSTNNAME CURRENT DATE CURRENT DBPARTITIONNUM CURRENT DECFLOAT ROUNDING MODE CURRENT DEFAULT TRANSFORM GROUP CURRENT DEGREE CURRENT EXPLAIN MODE CURRENT EXPLAIN SNAPSHOT CURRENT FEDERATED ASYNCHRONY CURRENT IMPLICIT XMLPARSE OPTION CURRENT ISOLATION CURRENT LOCALE LC_MESSAGES CURRENT LOCALE LC_TIME CURRENT LOCK TIMEOUT CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATIONCURRENT MDC ROLLOUT MODE CURRENT OPTIMIZATION PROFILE CURRENT PACKAGE PATH CURRENT PATH CURRENT QUERY OPTIMIZATION CURRENT REFRESH AGE CURRENT SCHEMA CURRENT SERVER CURRENT SQL_CCFLAGS CURRENT TIME CURRENT TIMESTAMP CURRENT TIMEZONE CURRENT USER SESSION_USER SYSTEM_USER USER
특수레지스터 갱신가능
NULL입력가능
$ db2 SET CURRENT EXPLAIN MODE YES

© Copyright IBM Corporation 201084
IBM DB2 On-site Training CourseIBM Korea
INSERT
예제
• 단일 행 입력
• 멀티 행 입력
• SELECT결과로부터 입력
• NULL 및 DEFAULT 키워드를 이용한 데이터 입력
INSERT INTO emp_act_copy VALUES ('100000' ,'ABC' ,10 ,1.4 ,'2003-10-22', '2003-11-24');
INSERT INTO emp_act_copy VALUES('200000' ,'ABC' ,10 ,1.4 ,'2003-10-22', '2003-11-24'),('200000' ,'DEF' ,10 ,1.4 ,'2003-10-22', '2003-11-24'),('200000' ,'IJK' ,10 ,1.4 ,'2003-10-22', '2003-11-24');
INSERT INTO emp_act_copy (empno, actno, projno)SELECT LTRIM(CHAR(id + 700000)) , MINUTE(CURRENT TIME) , 'DEF'FROM staff WHERE id < 40;
INSERT INTO emp_act_copySELECT * FROM emp_act_copy;
• 멀티 테이블 입력
• 서브쿼리 결과가 없을 때 데이터 입력
INSERT INTO(SELECT * FROM us_customerUNION ALLSELECT * FROM intl_customer)
VALUES (111,'Fred','USA'),(222,'Dave','USA'),(333,'Juan','MEX');
INSERT INTO emp_act_copy (empno, actno, projno)SELECT LTRIM(CHAR(id + 920000)) ,id ,'ABC'FROM staffWHERE id < 40AND NOT EXISTS
(SELECT * FROM emp_act_copy WHERE empno LIKE '92%');
INSERT INTO emp_act_copy VALUES('400000' ,'ABC' ,10 ,NULL ,DEFAULT, CURRENT DATE);

© Copyright IBM Corporation 201085
IBM DB2 On-site Training CourseIBM Korea
UPDATE
예제
• 테이블 전체 행 수정
• SELECT 결과를 이용한 수정
• SELECT 결과를 이용한 멀티 컬럼 수정
• 첫 n 행에 대한 수정
UPDATE emp_act_copySET actno = actno / 2;
UPDATE emp_act_copySET actno = (SELECT MAX(salary) / 10 FROM staff)WHERE empno = '200000';
UPDATE emp_act_copySET (actno,emstdate,projno)
= (SELECT MAX(salary) / 10 ,CURRENT DATE + 2 DAYS,MIN(CHAR(id))FROM staff
WHERE id <> 33)WHERE empno LIKE '600%' ;
• Correlated 서브 쿼리를 이용한 테이블 수정
• OLAP 함수를 이용한 데이터 수정
UPDATE emp_act_copy ac1SET (actno,emptime)
= (SELECT ac2.actno + 1,ac1.emptime / 2FROM emp_act_copy ac2
WHERE ac2.empno LIKE '60%'AND SUBSTR(ac2.empno,3) = SUBSTR(ac1.empno,3))
WHERE EMPNO LIKE '700%';
UPDATE(SELECT * FROM staffORDER BY salary DESCFETCH FIRST 5 ROWS ONLY) AS xxx
SET comm = 10000;
UPDATE emp_act_copy ea1SET emptime = (SELECT MAX(emptime) FROM emp_act_copy ea2
WHERE ea1.empno = ea2.empno)WHERE empno = '000010‘ AND projno = 'MA2100';
UPDATE (SELECT ea1.*,MAX(emptime) OVER(PARTITION BY empno) AS maxtimeFROM emp_act_copy ea1) AS ea2
SET emptime = maxtimeWHERE empno = '000010‘ AND projno = 'MA2100'; --동일한결과
UPDATE emp_act_copySET emptime = MAX(emptime) OVER(PARTITION BY empno)WHERE empno = '000010‘ AND projno = 'MA2100'; --틀린결과

© Copyright IBM Corporation 201086
IBM DB2 On-site Training CourseIBM Korea
DELETE
예제
• 선택적 삭제
• Correlated 삭제
• 첫 n 행에 대한 삭제
DELETE FROM emp_act_copyWHERE empno LIKE '00%‘ AND projno >= 'MA';
DELETE FROM staff s1WHERE id NOT IN
(SELECT MAX(id) FROM staff s2WHERE s1.dept = s2.dept);
DELETE FROM staff s1WHERE EXISTS
(SELECT * FROM staff s2WHERE s2.dept = s1.dept AND s2.id > s1.id); --동일한결과
DELETE FROM (SELECT * FROM staffORDER BY salary DESCFETCH FIRST 5 ROWS ONLY) AS xxx;

© Copyright IBM Corporation 201087
IBM DB2 On-site Training CourseIBM Korea
DML 처리 결과 조회
예제
• 입력 결과 조회
• 데이터 갱신 이전 값 조회
• 데이터 갱신 이후 값 조회
SELECT empno,projno,actnoFROM FINAL TABLE
(INSERT INTO emp_act_copy VALUES ('200000','ABC',10 ,1,'2003-10-22','2003-11-24'),('200000','DEF',10 ,1,'2003-10-22','2003-11-24')) ;
SELECT empno,projno,emptimeFROM OLD TABLE
(UPDATE emp_act_copySET emptime = emptime * 2
WHERE empno = '200000')ORDER BY projno;
SELECT projno,old_t,emptimeFROM NEW TABLE
(UPDATE emp_act_copy INCLUDE (old_t DECIMAL(5,2)) SET emptime = emptime * RAND(1) * 10, old_t = emptime
WHERE empno = '200000')ORDER BY 1;
• 삭제된 행 조회
SELECT projno,actnoFROM OLD TABLE
(DELETE FROM emp_act_copyWHERE empno = '300000')
ORDER BY 1,2;

© Copyright IBM Corporation 201088
IBM DB2 On-site Training CourseIBM Korea
MERGE
예제
• 수정 또는 입력
• 삭제
MERGE INTO old_staff ooUSING new_staff nn ON oo.id = nn.idWHEN MATCHED THEN
UPDATE SET oo.salary = nn.salaryWHEN NOT MATCHED THEN
INSERT VALUES (nn.id,'?',nn.salary);
MERGE INTO old_staff ooUSING new_staff nn ON oo.id = nn.idWHEN MATCHED THEN
DELETE;
MERGE INTO old_staff ooUSING new_staff nn ON oo.id = nn.idWHEN MATCHED AND oo.salary < 78000 THEN
UPDATE SET oo.salary = nn.salaryWHEN MATCHED AND oo.salary > 78000 THEN
DELETE WHEN NOT MATCHED AND nn.id > 10 THEN
INSERT VALUES (nn.id,'?',nn.salary)WHEN NOT MATCHED THEN
SIGNAL SQLSTATE '70001' SET MESSAGE_TEXT = 'New ID <= 10';
• 복합 옵션
• Full SELECT 결과를 이용한 머지
MERGE INTO (SELECT * FROM old_staff WHERE id < 40) AS ooUSING (SELECT * FROM new_staff WHERE id < 50) AS nnON oo.id = nn.idWHEN MATCHED THEN
DELETE WHEN NOT MATCHED THEN
INSERT VALUES (nn.id,'?',nn.salary);

© Copyright IBM Corporation 201089
IBM DB2 On-site Training CourseIBM Korea
DCL 일반 사항

© Copyright IBM Corporation 201090
IBM DB2 On-site Training CourseIBM Korea
보안 관련 용어
인증 (authentication)• 데이터베이스에 접속하려는 사용자를 패스워드를 이용하여확인하는 과정입니다
권한 (authorities) 및특권 (privilege)• 데이터베이스 내의 명령문을 실행할 수 있는 능력 및 특정오브젝트 및 데이터에 대한 접근 제어, 리소스 사용을 제어할 수있는 권리를 권한이라 합니다
DCL (Data control Language)• 특권을 특정 사용자 또는 그룹, Role 에 부여하거나 제거하는명령문입니다
Role• 하나 이상의 특권을 그룹화한 데이터베이스 오브젝트로 “grant”명령문으로 사용자 및 그룹, 또는 다른 Role에 부여할 수있습니다
Explicit 및 Implicit 부여차이점
• Explicit는 직접 사용자에게 권한 /특권을 부여하는 것을의미합니다.
• Implicit 는 사용자가 그룹에 속함으로써, 또는 role 을 부여받음으로써 그룹 또는 Role 에 권한/특권이 부여 될때 자동으로동일한 권한/특권을 부여 받는 것을 의미합니다.

© Copyright IBM Corporation 201091
IBM DB2 On-site Training CourseIBM Korea
권한 (AUTHORIZATION)
인스턴스레벨권한
• 인스턴스 레벨 권한을 통해 인스턴스 차원의 기능을 수행 할 수있습니다 (예 : 데이터베이스 작성 및 업그레이드, 테이블스페이스 관리, 인스턴스에서의 활동 및 성능 모니터링)
• 인스턴스 레벨 권한은 데이터베이스 테이블의 데이터에 대한액세스 권한을 제공하지 않습니다.
SYSADM인스턴스 전체를 관리하는 사용자를 위한 권한
SYSCTRL 데이터베이스 관리 프로그램 인스턴스를 관리하는 사용자를 위한권한
SYSMAINT 인스턴스 내에서 데이터베이스를 유지하는 사용자를 위한권한
SYSMON 인스턴스 및 해당 데이터베이스를 모니터링 하는사용자를 위한 권한
인스턴스레벨권한제어방법
• SYSADM 권한을 가진 사용자로 로그인합니다• UPDATE DBM CFG 명 령 어 를 이 용 하 여 SYSADM_GROUP,
SYSCTRL_GROUP, SYSMAINT_GROUP, SYSMON_GROUP 등의 값을OS에 정의된 <그룹명>으로 지정합니다
• UPDATE DBM CFG 명령어를 이용하여 SYSADM_GROUP 등의 값을NULL로 지정하면 기본값으로 복귀하므로, 해당 그룹은 더 이상인스턴스 권한을 가질 수 없습니다
• 각 구성 변수의 변경은 인스턴스를 재시작해야 반영됩니다• GET DBM CFG 명령어를 이용하여 인스턴스 권한과 관련된 구성변수의 값을 확인합니다
$ db2 UPDATE DBM CFG USING SYSCTRL_GROUP <그룹명>
$ db2 GET DBM CFG | grep _GROUPSYSADM group name (SYSADM_GROUP) = ADMGRPSYSCTRL group name (SYSCTRL_GROUP) = CTRLGRPSYSMAINT group name (SYSMAINT_GROUP) =SYSMON group name (SYSMON_GROUP) = MONGRP

© Copyright IBM Corporation 201092
IBM DB2 On-site Training CourseIBM Korea
권한 (AUTHORIZATION)
데이터베이스레벨권한
• 데이터베이스 레벨 권한을 통해 특정 데이터베이스 내에서기능을 수행할 수 있습니다 (예: 특권 부여 및 취소, 데이터 삽입, 선택, 삭제 및 갱신, 워크로드 관리).
SECADM데 이 터 베 이 스 내 에 서 보 안 을관리하는 사용자를 위한 권한
ACCESSCTRL 권한과 특권을 부여 및 취소해야하는 사용자를 위한 권한
DATAACCESS 데이터에 액세스해야 하는사용자를 위한 권한
DBADM데이터베이스를 관리하는사용자를 위한 권한
SQLADM SQL 쿼리를 모니터링하고 조정하는 사용자를위한 권한
EXPLAIN 쿼리 계획을 설명해야 하는 사용자를 위한권한 (EXPLAIN 권한은 데이터 자체에 대한액세스 권한을 부여하지 않음)
WLMADM워크로드를관 리 하 는사 용 자 를위한 권한
데이터베이스레벨권한제어방법
• 데이터베이스 권한은 OS에 정의된 그룹명 또는 사용자계정에게 부여됩니다. 그룹에게 권한이 부여되면, 해당 그룹에속하는 사용자 계정은 모두 동일한 데이터베이스 권한을가지게 됩니다.
• SYSADM 권한을 가진 사용자로 데이터베이스에 접속합니다• GRANT문으로 데이터베이스 권한을 사용자에게 부여합니다.
• DBADM 권한을 부여하면 데이터베이스에 대한 특권인 BINDADD, CONNECT, CREATETAB, CREATE_NOT_FENCED, IMPLICIT_SCHEMA 등이 자동적으로 부여됩니다
• REVOKE 문으로 데이터베이스 권한을 제거할 수 있습니다. DBADM 권한을 제거해도 간접적으로 부여 받은 데이터베이스에대한 특권은 자동적으로 제거되지 않으므로 REVOKE문으로명시적으로 제거합니다.
$ db2 GRANT DBADM ON DATABASE TO USER <사용자명>$ db2 GRANT DBADM ON DATABASE TO GROUP <그룹명>
$ db2 REVOKE DBADM ON DATABASE FROM USER <사용자명>$ db2 REVOKE DBADM ON DATABASE FROM GROUP <그룹명>
CONNECTBINDADD
CREATETABCREATE_EXTERNAL_ROUTINE
CREATE_NOT_FENCED_ROUTINEIMPLICIT_SCHEMA
LOADQUIESCE_CONNECT

© Copyright IBM Corporation 201093
IBM DB2 On-site Training CourseIBM Korea
권한 (AUTHORIZATION) 기능 요약
가능Create / Drop Security Label components, policies 및 labels
가능Quiesce Instance
가능가능가능가능Reorgs & Runstats
가능가능Load Tables가능가능Quiesce database
가능Establish/Change SYSCTRL and SYSMAINT
가능
SYSMON
가능가능Create / Drop Activity or Event Monitors가능
가능가능가능
DBADM
가능READ LOG FILES
가능LBAC rules 및 set USERSESSION
가능가능가능Quiesce Table Space가능가능가능Update / Prune Log History Files가능가능가능Query Table Space states가능가능가능Take Monitor Snapshots가능가능가능Run Trace가능가능가능Restore Table Space가능가능가능Start / Stop Instance가능가능가능Perform roll forward recovery가능가능가능Backup Database / Table Space가능가능가능Update DB CFG
가능가능Restore to new Database가능가능Create / Drop / Alter Table Space가능가능Create / Drop Database가능가능Force users off the Database가능가능Update db / node DPF / dcs Directories
가능Grant / Revoke DBADM
가능Update DBM CFG가능Migrate Database
SECADMSYSMAINTSYSCTRLSYSADM기능

© Copyright IBM Corporation 201094
IBM DB2 On-site Training CourseIBM Korea
특권 (Object Privileges)
특권
• 특권이란 특정 조치 또는 태스크를 수행하는 데 필요한 권한을말합니다. 권한 부여된 사용자는 오브젝트를 작성하고, 자신이소유하는 오브젝트에 액세스하며, GRANT문을 사용하여 자신의오브젝트에 대한 특권을 다른 사용자에게 전달할 수 있습니다.
• 특권은 특정 사용자, 그룹 또는 PUBLIC에 부여될 수 있습니다. PUBLIC은 향후 사용자를 포함하는 모든 사용자로 구성된 특수그룹입니다. 그룹의 구성원인 사용자는 해당 그룹에 권한부여된 특권을 간접적으로 이용합니다.
테이블및뷰 테이블공간
스키마
시퀀스
인덱스
패키지
루틴
USEALTERCONTROLINDEXREFERENCES
BINDCONTROLEXECUTE
USAGEALTER
CONTROL
ALTERINCREATEINDROPIN
EXECUTE
DELETEINSERTSELECTUPDATE
특권제어방법
• 특권은 GRSANT 문과 REVOKE 문을 이용하여 사용자 또는그룹별로 제어합니다. 특정 그룹에 특권을 부여하면, 해당그룹에 속하는 사용자 계정은 동일한 특권을 간접적으로 부여받게 됩니다.
• PUBLIC은 모든 사용자를 의미하는 특별한 키워드입니다.• GROUP과 USER 키워드는 생략할 수 있지만, 동일한 그룹 ID와계정이 존재하는 경우에는 SQLSTATE 56092 가 반환되므로명시하는 것이 좋습니다
ON FUNCTION / PROCEDURE
함수/프로시저EXECUTE
ON SEQUENCE시퀀스
시퀀스특권
OF TABLESPACE테이블스페이스
USE
ON SCHEMA스키마
스키마특권
ON INDEX인덱스
CONTROL
ON TABLE테이블/뷰
테이블/뷰특권
ON PACKAGE패키지
패키지특권
UseridGroupidPUBLIC
USER /GROUP
TO /FROM
ON DATABASE데이터베이스특권
GRANT /REVOKE

© Copyright IBM Corporation 201095
IBM DB2 On-site Training CourseIBM Korea
SQL 작성 고려 사항

© Copyright IBM Corporation 201096
IBM DB2 On-site Training CourseIBM Korea
인덱스 선정 기준
다음과같은 Column으로인덱스를구성하는것이유리합니다. • Where절에서 자주 사용되는 컬럼• "=" 연산자를 사용하며, 5 ~ 10% 이내의 좋은 분포도를 가지는컬럼
• "BETWEEN" , "IN" , "<", ">" 조건절을 사용하는 컬럼• Join에 자주 사용되는 컬럼• Primary Key, Unique Key, Foreign Key로 사용되는 컬럼• ORDER BY, DISTINCT, GROUP BY 구문에 사용되는 정렬에 필요한컬럼
다음과같은 Column은인덱스에적합하지않습니다. • 값의 종류가 많지 않아서 Cardinality가 작은 컬럼• 값이 균등하게 분포되지 않고 특정 값이 심하게 많은 컬럼• 갱신이 빈번한 컬럼• 길이가 40 바이트 이상 되는 컬럼• LOB, LONG VARCHAR, LONG VARGRAPHIC 유형의 컬럼
디자인어드바이저
• 워크로드의 SQL문 세트에 대해 디자인 어드바이저는 다음에대한 권장사항을 생성합니다.
새 인덱스새 클러스터링 인덱스새 MQT MDC(다차원 클러스터링) 테이블로 변환테이블 재분산
• db2advis 명령으로 디자인 어드바이저를 시작합니다

© Copyright IBM Corporation 201097
IBM DB2 On-site Training CourseIBM Korea
인덱스 생성옵션
SQL 문 인덱스생성 DDL 문 설명
SELECT WORKDEPT, LASTNAMEFROM employee
WHERE empno >= 10000AND empno <= 20000
CREATE UNIQUE INDEX ix01ON employee (empno)CLUSTER
WHERE절의 조건식에서 range 검색에 자주 사용되는 칼럼에대해 cluster 인덱스를 생성합니다. 예의 SQL에서는 WHERE 절에 사용된 empno 컬럼에 대해 인덱스를 생성합니다.
SELECT LASTNAMEFROM EMPLOYEE
WHERE WORKDEPT IN ('A00','D11')
CREATE UNIQUE INDEX ix01ON employee (workdept, lastname)
INDEX ONLY ACCESS는 RID를 이용하여 테이블을 Fetch 하지않고, 인덱스만 액세스하여 데이터를 조회할 수 있으므로훨씬 효율적입니다. 예에서는, WORKDEPT와 LASTNAME컬럼으로 복합 인덱스를 생성하여 INDEX ONLY ACCESS를유도했습니다. 단, WORKDEPT 컬럼이 복합 인덱스의 첫 번째컬럼으로 구성되어야 합니다.
SELECT LASTNAMEFROM EMPLOYEE
WHERE WORKDEPT IN ('A00','D11')
CREATE UNIQUE INDEX ix01ON employee (workdept)INCLUDE (lastname)
INCLUDE 옵션을 이용하여 인덱스키가 아닌 컬럼의 값을인덱스에 포함시킬 수 있습니다. 예에서는, WORKDEPT 컬럼으로 UNIQUE 인덱스를 생성하고, LASTNAME 컬럼을INCLUDE COLUMN으로 지정했습니다. LASTNAME 컬럼은인덱스키로 사용될 수는 없지만, 인덱스의 LEAF PAGE에 그값이 저장되어 있으므로, INDEX ONLY ACCESS가 가능합니다.

© Copyright IBM Corporation 201098
IBM DB2 On-site Training CourseIBM Korea
Predicate
개요
• WHERE, HAVING, ON 절에서 AND, OR, NOT 등을 이용하여표현되는 개별적인 조건식을 predicate 라고 하며, 내부적으로처리되는 단계에 따라 stage 1 predicate와 stage 2 predicate로구분됩니다
• RDS (Relational Data Services) 는 문자열 결합, 스칼라 함수 적용, 연산식 판별, 데이터 유형 전환 등의 상대적으로 복잡한 stage 2 predicate를 처리합니다.
• DMS (Data Management Services) 는 동일한 데이터 유형과 길이를가진 상수값과 비교되는 컬럼을 포함한 간단한 stage 1 predicate의 처리를 담당합니다
• IM (Index Manager)는 인덱스 액세스를 담당합니다

© Copyright IBM Corporation 201099
IBM DB2 On-site Training CourseIBM Korea
Predicate
다음과같은경우에 Stage 2 predicates 로분류됩니다
• Stage 1 에서 전달된 데이터 유형 변환, 연산식, 함수 적용 등은Stage 2 에서 처리됩니다.
• Stage 1 에서 전달된 Sort / Join / Correlated subquery / Non-Correlated subquery 등은 Stage 2 에서 처리됩니다.
• 조건식에서 비교되는 컬럼과 변수의 데이터 유형이 다른경우가 해당됩니다. ( 예 : WHERE C1 > 1.1 )
• 컬럼에 대해 연산식 또는 스칼라 함수를 포함한 술어를 사용한경우가 해당됩니다. ( 예 : WHERE C1 * 4 > :H )
• 값이 아닌 표현식을 포함한 I N 절을 사용하는 경우가해당됩니다. ( 예 : WHERE C1 IN (<표현식>) )
• IN, =ALL, =ANY, =SOME 을 포함한 서브 쿼리를 사용한 경우가해당됩니다.
• correlated 서브쿼리, EXISTS 또는 NOT EXISTS 를 포함한 서브쿼리를 사용하는 경우가 해당됩니다.
• 한 개의 컬럼이 두 개 이상의 다른 컬럼과 비교되는 경우가해당됩니다. ( 예 : WHERE C1 BETWEEN C2 AND C3 )
• Data Manager가 일차적으로 처리한 행 또는 컬럼을 전달받은RDS가 Stage 2 predicate를 적용하므로, 더 많은 CPU가 소모됩니다.
다음과같은경우에 Stage 1 predicates 로분류됩니다
• 컬럼과 비교되는 변수의 데이터 유형과 그 길이는 일치하고, 단순 연산자 (=, >, >=, <, <=)로 비교되는 조건식이 해당됩니다.
• 상수값으로 표현되는 IN, BETWEEN, LIKE, IS NULL 등을 이용한조건식도 stage 1 에서 평가됩니다.
• 부정형 연산자인 NOT은 stage 1 에서 평가되기는 하지만, matching index scan 은 사용되지 않습니다.
• AVG, SUM, COUNT 등은 인덱스의 리프 노드 또는 데이터페이지를 액세스하여 평가되며, MIN, MAX는 한 번의 fetch로처리될 수도 있습니다.
• >ALL, >ANY, >SOME 등과 함께 사용되어 단일한 값을 반환하는non-correlated 서브 쿼리는 stage 1 에서 평가될 수 있습니다.
• 일부 서브 쿼리는 옵티마이저에 의해 재작성되어 stage 1 에서평가될 수 있습니다

© Copyright IBM Corporation 2010100
IBM DB2 On-site Training CourseIBM Korea
Predicate
종류
• Predicate는 인덱스 스캔의 가능 여부와 스캔 범위에 따라 "Range delimiting predicates", "Index SARGable predicates", "Data SARGablepredicates", "Residual predicates" 로 분류되며, 각 유형별로 독립된처리 방법 및 cost 를 가지게 됩니다.
• SARGable의 SARG는 Search ARGument의 약자로서 키값을이용하여 검색할 수 있다는 의미입니다.
• employee 테이블에 (name, dept, mgr, salary, years)로 구성된인덱스가 있다고 가정할 때, 다음과 같이 분류할 수 있습니다
종류 설명 예문
Range delimiting predicate Index 검색에 필요한 시작키 값 또는 종료키 값을 명시되면, 인덱스에서 해당 페이지만 검색합니다. 검색할 인덱스의 페이지 수와 테이블의 페이지 수를 모두 줄일 수 있습니다.예문에서 NAME과 DEPT에 대한 조건식은 delimiting predicate 에 해당됩니다.
SELECT name, job, salary FROM employeeWHERE NAME = 'John'AND DEPT = 10 ;
Index SARGable predicate Range 검색이 아니더라도, 조건식의 컬럼이 인덱스키에 포함된 컬럼이라면, 인덱스 leaf page를 모두 스캔하여 조건에 맞는 데이터를 검색할 수 있습니다. NAME과 DEPT 컬럼에 대한 조건식은 range delimiting predicates이지만, YEARS에 대한 조건식은 NAME과DEPT에 의해 결정된 범위의 모든 인덱스 leaf page를 검색해야 하므로, Index SARGable predicates입니다.만약 YEARS >= 5 인 경우라면, range delimiting predicate 가 될 수 있습니다.
Select name, job, salary from employee Where NAME = 'John'And DEPT = 10 And YEARS > 5;
Data SARGable predicate 조건식을 평가하기 위해 인덱스 스캔을 이용할 수 없으므로 테이블을 스캔합니다. SALARY 컬럼에 대한 인덱스가 없으므로 테이블을 스캔하여 조건식을 평가해야 합니다.Data Management Services 에 의해 평가됩니다.
SELECT name, job, salary FROM employee WHERE salary > 1000
Residual predicate 테이블 액세스 후에 추가적인 I/O를 요구하는 predicate로 cost가 가장 높습니다.ANY, ALL, SOME, IN을 사용한 서브 쿼리와 Long Varchar, LOB 데이터의 검색, Index ORing, Index ANDing 이 사용되는 경우에 해당됩니다.Relational Data Services 에 의해 평가됩니다.
SELECT empno, msgFROM employeeWHERE msg like ‘TEST%’

© Copyright IBM Corporation 2010101
IBM DB2 On-site Training CourseIBM Korea
Predicate
유형 Index 사용 Stage 1
COL = :hv1 YES YES
COL IS NULL YES YES
COL op :hv YES YES
COL BETWEEN :hv1 AND :hv2 YES YES
COL LIKE 'char%' YES YES
COL IN (list) YES YES
COL <> value NO YES
COL IS NOT NULL NO YES
COL NOT BETWEEN v1 AND v2 NO YES
COL NOT IN (list) NO YES
COL NOT LIKE 'char%' NO YES
COL LIKE '%char' NO YES
COL LIKE '_char' NO YES
T1.COL = T2.COL YES YES
T1.COL op T2.COL YES YES
T1.COL <> T2.COL NO YES
Stage1 처리여부
유형 Index 사용 Stage 1
T1.COL1 = T1.COL2 NO NO
T1.COL1 op T1.COL2 NO NO
T1.COL1 <> T1.COL2 NO NO
COL op ANY (noncorrelated subquery) YES YES
COL op ALL (noncorrelated subquery) YES YES
COL IN (noncorrelated subquery) NO NO
COL NOT IN (noncorrelated subquery) NO NO
COL = ANY (noncorrelated subquery) NO NO
COL <> ANY (noncorrelated subquery) NO NO
COL = (correlated subquery) NO NO
COL op (correlated subquery) NO NO
COL <> (correlated subquery) NO NO
COL = expression NO NO
expression = value NO NO
expression <> value NO NO
expression op value NO NO

© Copyright IBM Corporation 2010102
IBM DB2 On-site Training CourseIBM Korea
컬럼 함수
SELECT workdept, SUM(salary)FROM empWHERE salary > 100GROUP BY workdeptHAVING SUM(salary) + 10 > 10000;
SELECT workdept, SUM(salary)FROM empWHERE salary > 100GROUP BY workdeptHAVING SUM(salary) > 9990;
WORSE BETTER
• 불필요한 데이터 유형의 변환과 연산은 피해야 합니다.• MIN, MAX, SUM, AVG, COUNT 등의 컬럼 함수는 stage 1 또는 stage 2 에서 처리됩니다.• 정렬 작업을 요구하지 않는 GROUP BY가 사용된 경우에는 stage 1 에서 평가됩니다.• DISTINCT 가 없는 경우에는 stage 1 에서 평가됩니다.• (SUM(C1) + SUM(C2)) 또는 (SUM(C1) + 100) 등과 같은 연산식이 없는 경우에는 stage 1 에서 평가됩니다.• 컬럼에 대한 stage 2 술어가 없는 경우에는 stage 1 에서 평가됩니다.• STDDEV, VAR, 등은 stage 2 에서 평가됩니다.

© Copyright IBM Corporation 2010103
IBM DB2 On-site Training CourseIBM Korea
데이터 유형 변환
SELECT name, job, salary FROM employee e, department dWHERE e.dept_id = d.dept_id
strcpy(v1,"S1 ");SELECT sn, snameFROM sWHERE sn = :v1;
SELECT sn, pnFROM spjWHERE qty > 100.5AND pn = 'P5';
SELECT name, job, salary FROM employee e, project pWHERE e.emp_id = cast(p.emp_id as integer)
strcpy(v1,"S1");SELECT sn, snameFROM sWHERE sn = :v1;
SELECT sn, pnFROM spjWHERE qty > 100.50AND pn = 'P5';
WORSE BETTER
• 불필요한 데이터 유형의 변환은 피해야 합니다. • 유사 유형의 데이터 유형 변환은 내부적으로 발생되며, CAST 함수를 통한 명시적인 유형 변환도 피할 수 있으면 좋습니다. • 유형의 변환이 발생하면 성능은 저하되므로, 조인의 조건으로 사용되는 컬럼들은 테이블 정의시 데이터 유형을 동일하게 하는 것이좋습니다.
• 특히 조인시 숫자 컬럼의 데이터 유형 변환은 성능을 심하게 저하시킬 수 있습니다.• Optimizer가 Matching Index Scan을 사용하게 하려면, 상수 또는 호스트 변수를 사용하여 비교할 때 그 데이터의 유형과 길이가 일치하여야합니다.
• 짧은 길이의 컬럼에는 VARCHAR보다는 CHAR 유형이 유리합니다. • FLOAT 나 DECIMAL 보다는 INTEGER를 사용하는 것이 좋습니다.

© Copyright IBM Corporation 2010104
IBM DB2 On-site Training CourseIBM Korea
부정형 PREDICATE
SELECT sn, snameFROM sWHERE NOT status > 20;
SELECT sn, snameFROM sWHERE status <= 20;
SELECT sn, snameFROM sWHERE status != 20;
SELECT sn, snameFROM sWHERE status < 20OR status > 20 ;
SELECT 'OK'FROM empWHERE empno <> '000000';
SELECT 'OK' FROM empWHERE empno > '000000';
(status) 컬럼으로 인덱스가생성되어 있었다면, INDEX ORING 기능을 이용할 수 있습니다.
만약 empno 의 최소값이 '000000' 인것이 규칙이라면,< > 을 > 으로 변환할 수 있습니다.
• 대부분의 Predicate는 stage1 에서 처리되지만, 부정형 Predicate를 사용한 경우에는 Matching Index Scan을 사용하지 못합니다. • != 보다는 > 또는 <가 유리하며, 등호가 포함된 >= 또는 <= 이 더 유리합니다. • 그러나, 모든 행을 Select 한 후, 프로그램 로직을 통해 불필요한 행을 제거하는 것보다는, 부정형 Predicate를 사용하는 것이 더효과적입니다.
WORSE BETTER

© Copyright IBM Corporation 2010105
IBM DB2 On-site Training CourseIBM Korea
NOT BETWEEN
SELECT SN, PN, JN, QTYFROM SPJWHERE QTY < 100 OR QTY > 800;
SELECT SN, PN, JN, QTYFROM SPJWHERE QTY < 100
UNION ALL
SELECT SN, PN, JN, QTYFROM SPJWHERE QTY > 800;
SELECT SN, PN, JN, QTYFROM SPJWHERE QTY NOT BETWEEN 100 AND 800;
• NOT BETWEEN 문 대신에 OR 문을 사용할 수 있습니다.• UNION ALL을 사용하는 것도 효율적입니다.• 호스트 변수를 이용하여 두 개의 BETWEEN 문으로 구성하면 Range Delimeter Predicate로서 Index Matching Scan을 이용할 수 있습니다
WORSE BETTER
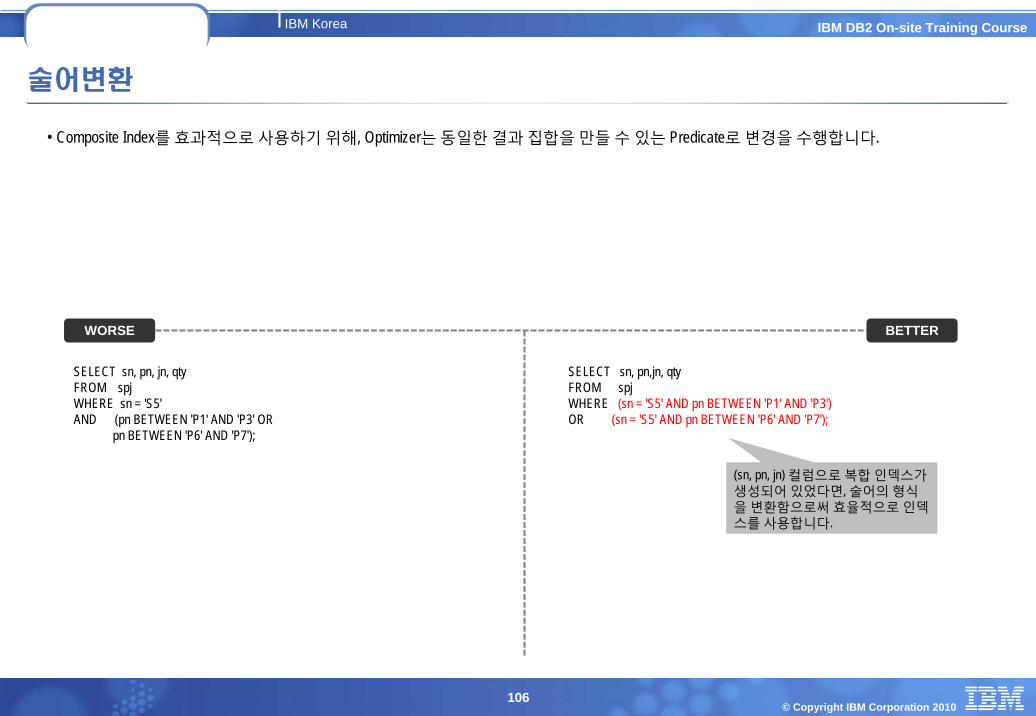
© Copyright IBM Corporation 2010106
IBM DB2 On-site Training CourseIBM Korea
술어변환
SELECT sn, pn, jn, qtyFROM spjWHERE sn = 'S5'AND (pn BETWEEN 'P1' AND 'P3' OR
pn BETWEEN 'P6' AND 'P7');
SELECT sn, pn,jn, qtyFROM spjWHERE (sn = 'S5' AND pn BETWEEN 'P1' AND 'P3')OR (sn = 'S5' AND pn BETWEEN 'P6' AND 'P7');
(sn, pn, jn) 컬럼으로 복합 인덱스가생성되어 있었다면, 술어의 형식을 변환함으로써 효율적으로 인덱스를 사용합니다.
• Composite Index를 효과적으로 사용하기 위해, Optimizer는 동일한 결과 집합을 만들 수 있는 Predicate로 변경을 수행합니다.
WORSE BETTER

© Copyright IBM Corporation 2010107
IBM DB2 On-site Training CourseIBM Korea
OR 와 IN
SELECT sn, pn, jn, qtyFROM spjWHERE sn = 'S4'AND (pn = 'P1' OR pn = 'P2' OR pn = 'P3' OR pn = 'P4')AND jn > 'J1';
SELECT sn, pn, jn, qtyFROM spjWHERE sn = 'S4'AND pn = IN ('P1','P2','P3','P4')AND jn > 'J1';
(SN, PN, JN) 컬럼으로 복합 인덱스가 생성되어 있었다면, 4회의 Index Scan을 가능하다면 병렬로 수행하여 INDEX ORING을 사용할 수 있습니다.
비교되는 값이 상수이므로 IN으로 표현하는 것이 더 간결합니다.
• Index Scan 을 이용할 수 있다면, Optimizer는 OR 술어를 IN으로 변경합니다.• INDEX ORING 의 기능을 이용할 수 있다면, IN이 OR로 변환될 수도 있습니다.• IN 절에 나열된 값이 표현식이 아닌 상수 값인 경우라면, OR을 이용하는 경우보다 표현이 간결합니다.
WORSE BETTER

© Copyright IBM Corporation 2010108
IBM DB2 On-site Training CourseIBM Korea
LIKE
SELECT PN, PNAMEFROM PWHERE PNAME LIKE '_CH%';
SELECT PN, PNAMEFROM PWHERE PNAME LIKE 'CH%';
SELECT PN, PNAMEFROM PWHERE PNAME LIKE :PNAME;
SELECT PN, PNAMEFROM PWHERE PNAME LIKE '%CH%';
DELETEFROM t1WHERE order_date = :v1 AND substr(obm_name, 1, 1) = 'F'
DELETEFROM t1WHERE order_date = :v1 AND obm_name LIKE 'F%'
SUBSTR을 like로 변환하여 인덱스를 사용할 수 있게 합니다.
% 또는 _ 문자가 앞쪽에 나오는like 연산 처리는 인덱스 전체를scan 하게 됩니다.
앞쪽에 나오는 % 또는 _ 문자를 제거하여 filtering 한 후에 추가적인 로직으로 처리합니다.
(obm_name) 인덱스를 사용할 수없을 수도 있습니다.
• % 또는 _ 문자가 앞쪽에 나오면, Non-Matching Index Scan을 사용하게 됩니다.• % 또는 _ 문자가 뒤쪽에 나오면, Matching Index Scan을 사용할 수 있습니다. • 인덱스 컬럼의 일부 문자열을 비교할 때 substr 함수를 사용하게 되면 인덱스를 사용하지 못하게 됩니다. 이 경우에는 like를 사용하는 것이좋을 수도 있습니다.
• 호스트 변수가 사용된 경우에는 실행 시점에 SCAN 방법이 결정됩니다.
WORSE BETTER

© Copyright IBM Corporation 2010109
IBM DB2 On-site Training CourseIBM Korea
연산식을 포함한 술어
SELECT SN, PN, QTYFROM SPJWHERE QTY * 4 > :v1;
v1 = 200
SELECT SN, SNAMEFROM SWHERE QTY > :v1 / 2;
v1 = 200 / 2;
SELECT SN, SNAMEFROM SWHERE QTY > :v1;
• 컬럼에 수식 연산을 사용한 경우에는 Matching Index Scan을 사용할 수 없습니다. • 컬럼에 적용될 연산식을 비교되는 호스트 변수 쪽에 적용하면 Matching Index Scan을 사용할 수 있습니다.• 컬럼에 적용될 연산식을 미리 실행하여 호스트 변수에 그 값을 저장한 뒤에 비교하면 Matching Index Scan을 사용할 수 있습니다.
WORSE BETTER

© Copyright IBM Corporation 2010110
IBM DB2 On-site Training CourseIBM Korea
스칼라 함수, UDF
SELECT SN, PN, JN, QTYFROM SPJWHERE DECIMAL(QTY) > :CALC_QTY;
SELECT SN, PN, JN, QTYFROM SPJWHERE DECIMAL_QTY > DECIMAL(:CALC_QTY, 7,2);
SELECT PN, DATE_RECEIVEDFROM SHIPMENTSWHERE DATE_RECEIVED < CURRENT DATE - 15 DAYS;
SELECT PN, DATE_RECEIVEDFROM SHIPMENTSWHERE MONTH_REQUIRED = MONTH(:DATE-REQUIRED);
• 스칼라 함수와 UDF는 Stage 2 에서 평가됩니다.• 컬럼에 스칼라 함수를 적용하지 말고, 비교되는 호스트 변수에 스칼라 함수를 적용하는 것이 좋습니다.• 비교되는 값에 Special Register 를 이용하는 것은 Stage 1 에서 평가됩니다.
WORSE BETTER

© Copyright IBM Corporation 2010111
IBM DB2 On-site Training CourseIBM Korea
중복된 테이블 SCAN
SELECT EMPNO, LASTNAME, 'Male' AS GENDERFROM EMPWHERE WORKDEPT = 'D4'AND SEX = 'M'UNION ALLSELECT EMPNO, LASTNAME, 'Female' AS GENDERFROM EMPWHERE WORKDEPT = 'D4'AND SEX = 'F'UNION ALLSELECT EMPNO,LASTNAME,'Unknown' AS GENDERFROM EMPWHERE WORKDEPT = 'D4'AND SEX NOT IN ('M', 'F');
SELECT EMPNO, LASTNAME,CASE SEX
WHEN 'M' THEN 'Male'WHEN 'F' THEN 'Female'ELSE 'UNKNOWN'
END AS GENDERFROM EMPWHERE WORKDEPT = 'D4';
• UNION 을 사용하면, 동일한 테이블에 대한 SCAN 을 여러 번 중복하게 됩니다.• CASE 문을 이용하면 동일한 테이블에 대해 한 번의 SCAN으로 조건을 판별할 수 있으므로 더 효율적입니다.
WORSE BETTER

© Copyright IBM Corporation 2010112
IBM DB2 On-site Training CourseIBM Korea
SELECT *
EXEC SQL DECLARE c1 CURSOR FOR SELECT *FROM projectWHERE deptno = 'D11';
EXEC SQL OPEN c1;
do {EXEC SQL FETCH c1 INTO :v1, :v2. :v3; if (SQLCODE != 0) break;
} while ( 1 );
EXEC SQL CLOSE c1;
EXEC SQL DECLARE c1 CURSOR FOR SELECT projno, prstdate, prendateFROM projectWHERE deptno = 'D11';
EXEC SQL OPEN c1;
do {EXEC SQL FETCH c1 INTO :v1, :v2. :v3; if (SQLCODE != 0) break;EXEC SQL UPDATE project
SET prenddate = CURRENT DATEWHERE projno = :v1;
} while ( 1 );
EXEC SQL CLOSE c1;
• SELECT LIST에는 반드시 필요한 칼럼만 명시합니다.• 테이블의 모든 칼럼의 자료를 선택하고자 하는 경우라도 * 대신에 컬럼명을 일일이 나열하는 것이 바람직합니다. • 불필요한 컬럼까지 fetch 하므로 응답 시간이 증가되어 비효율적입니다.• SELECT 해야 할 컬럼을 모두 가진 인덱스가 존재하더라도 Index Only Access를 할 수 없습니다.• SELECT 에서 * 을 사용하면 칼럼이 추가되는 경우 등 테이블 구조가 변경되면 테이블이 사용된 모든 프로그램에 수정이 필요하게 됩니다.• SELECT 문의 가독성이 향상되며, 향후 운영시에도 도움이 됩니다.
WORSE BETTER

© Copyright IBM Corporation 2010113
IBM DB2 On-site Training CourseIBM Korea
COUNT(*)
EXEC SQL SELECT COUNT(*)INTO :v1FROM projectWHERE deptno = 'D11';
if (v1 > 0) {printf("데이터가 존재합니다");return;
}
EXEC SQL SELECT 1INTO :v1FROM projectWHERE deptno = 'D11';
if (SQLCODE == -811) {printf("데이터가 존재합니다");return;
}
EXEC SQL SELECT deptno, COUNT(*)INTO :v1FROM projectWHERE deptno > 'D11'AND projno IS NOT NULLGROUP BY deptno;
EXEC SQL SELECT deptno, COUNT(projno)INTO :v1FROM projectWHERE deptno > 'D11'GROUP BY deptno;
SELECT 문의 결과가 두 행 이상이면, SQLCODE -811이 반환됩니다.
(deptno, projno) 인덱스가 있고, projno가NULL이 아닌 건수를 확인하는 경우에유리합니다.
• 단순히 테이블에 데이터가 존재하는지를 확인하기 위해 COUNT(*) 을 사용하지 않도록 합니다.• 대신에 상수를 이용한 SELECT문을 실행하여 SQLCODE 값으로 판별합니다. 즉, SQLCODE가 100이면 데이터가 0건, 0이면 1건, -811이면 2건이상인 것으로 판별합니다.
• 인덱스에 있는 특정 컬럼의 값이 NULL 값이 아닌 건수를 확인하려면, COUNT 함수에서 * 대신에 해당 컬럼명을 명시합니다.
WORSE BETTER

© Copyright IBM Corporation 2010114
IBM DB2 On-site Training CourseIBM Korea
MIN, MAX
SELECT salary FROM empWHERE dept = 'DBA' ORDER BY salaryFETCH FIRST 1 ROWS ONLY;
SELECT salary FROM empWHERE dept = 'DBA' ORDER BY salary DESCFETCH FIRST 1 ROWS ONLY;
SELECT MIN(salary) FROM empWHERE dept = 'DBA' ;
SELECT MAX(salary) FROM empWHERE dept = 'DBA' ;
(salary) 컬럼에 대한 ASC 인덱스가 있는경우에는 인덱스에 대한 한 번의 fetch 만으로 MIN 값을 얻을 수 있습니다.
(salary) 컬럼에 대한 DESC 인덱스가 있는경우에는 인덱스에 대한 한 번의 fetch 만으로 MIN 값을 얻을 수 있습니다. ASC 인덱스로 ALLOW REVERSE SCANS 옵션을준 경우에도 동일합니다.
• MIN 또는 MAX 값을 구하기 경우에는 FETCH FIRST 절을 이용하면 유용합니다.• 필요하다면, ALLOW REVERSE SCANS 옵션을 가진 인덱스를 생성하도록 합니다
WORSE BETTER

© Copyright IBM Corporation 2010115
IBM DB2 On-site Training CourseIBM Korea
DISTINCT, GROUP BY, ORDER BY
SELECT DISTINCT cityFROM t1;
SELECT cityFROM t1GROUP BY city;
SELECT DISTINCT empno, lastnameFROM employee;
SELECT empno, lastnameFROM employee;
SELECT issue_code, pos_code, SUM(book_qty)FROM t1WHERE stock_chng_type = :v1 AND book_qty > 0GROUP BY issue_code, pos_codeORDER BY issue_code
SELECT issue_code, pos_code, SUM(book_qty)FROM t1WHERE stock_chng_type = :v1 AND book_qty > 0GROUP BY issue_code, pos_code
DISTINCT 보다는 GROUP BY가효율적입니다.
(empno)로 UNIQUE 인덱스가있다면, DISTINCT는 불필요합니다.
issue_code 순으로 이미 정렬되었으므로OREDER BY를 제거합니다.
• 불필요한 DISTINCT와 ORDER BY, GROUP BY 절은 가급적 배제합니다.• 이 절을 사용하면 SORT 작업이 요구되는데, SORTHEAP이 부족한 경우에는 임시 테이블 등을 통한 정렬 작업이 발생하므로, CPU 사용량이증가하게 됩니다.
• GROUP BY 절은 수행 중에 중복된 값을 제거 하면서 SORT TREE 를 구성합니다. DISTINCT는 모든 값을 정렬한 후 중복된 값을 제거합니다.• 이 절이 사용되면 커서의 OPEN 시점에 RESULT SET이 모두 만들어진 후 FETCH를 하게 됩니다. • 이 절을 사용해야만 한다면, 적합한 인덱스를 생성하고, 인덱스의 컬럼 순서대로 정렬을 지정하여 SORT 작업이 발생하는 것을 방지하는것이 좋습니다.
• 결과 집합에 UNIQUE KEY, PRIMARY KEY, UNIQUE INDEX를 구성하는 컬럼들이 포함되어 있다면 DISTINCT는 불필요합니다.• group by에서 지정한 컬럼을 이용하여 결과 집합을 정렬하고자 한다면, 추가적으로 order by를 사용할 필요가 없습니다.
WORSE BETTER

© Copyright IBM Corporation 2010116
IBM DB2 On-site Training CourseIBM Korea
FETCH FIRST N ROWS ONLY
EXEC SQL DECLARE c1 CURSOR FOR SELECT projno, projname, repempFROM projectWHERE deptno = 'D11'ORDER BY projno DESCFETCH FIRST 10 ROWS ONLY;
EXEC SQL OPEN c1;
do {EXEC SQL FETCH c1 INTO :v1, :v2, :v3; if (SQLCODE != 0) break;
} while ( 1 );
EXEC SQL CLOSE c1;
EXEC SQL DECLARE c1 CURSOR FOR SELECT projno, projname, repempFROM projectWHERE deptno = 'D11'ORDER BY projno DESC;
EXEC SQL OPEN c1;
i = 0;do {
EXEC SQL FETCH c1 INTO :v1, :v2, :v3; if ( SQLCODE != 0 || i>9 ) break;i++;
} while ( 1 );
EXEC SQL CLOSE c1;
• 조건에 맞는 데이터 중에서 최초의 N건만 Fetch 해도 되는 경우에는 Fetch First 절을 사용하여 반환되는 행의 개수를 줄여주는 것이좋습니다.
• 실제 조건에 맞는 데이터 중에서 최초의 N건만 반환됩니다.• 이 절은 FOR UPDATE 절과 함께 사용될 수 없습니다.• 이 절은 데이터베이스 엔진으로부터 검색된 행을 클라이언트 응용프로그램으로 전달시 블럭킹할 행의 건수에 영향을 줍니다. • 한 번의 Fetch 요청으로 N개의 행이 클라이언트로 전송될 수 있으며, 블록에 있는 행이 다 사용될 때까지는 Fetch 요청이 클라이언트머신에서만 처리될 수 있으므로, 서버로의 통신 부하를 줄여줄 수 있습니다.
• 원격 클라이언트인 경우에는 rqrioblk, 지역 클라이언트인 경우에는 aslheapsz 라는 구성 변수가 블럭킹 버퍼의 크기에 영향을 줍니다.
WORSE BETTER

© Copyright IBM Corporation 2010117
IBM DB2 On-site Training CourseIBM Korea
OPTIMIZE FOR K ROWS
EXEC SQL DECLARE c1 CURSOR FOR SELECT projno, projname, repempFROM projectWHERE deptno = 'D11'ORDER BY projno DESCFETCH FIRST 100 ROWS ONLYOPTIMIZE FOR 20 ROWS;
EXEC SQL OPEN c1;
do {EXEC SQL FETCH c1 INTO :v1, :v2, :v3; if (SQLCODE != 0) break;
} while ( 1 );
EXEC SQL CLOSE c1;
EXEC SQL DECLARE c1 CURSOR FOR SELECT projno, projname, repempFROM projectWHERE deptno = 'D11'ORDER BY projno DESC;
EXEC SQL OPEN c1;
i = 0;do {
EXEC SQL FETCH c1 INTO :v1, :v2, :v3; if ( SQLCODE != 0 || i >99 ) break;i++;
} while ( 1 );
EXEC SQL CLOSE c1;
Result set이 100건이라는 것을 안다면, 100번째 fetch 까지만 진행하기 위해 fetch 회수를 기억하는 로직은 불필요합니다.
• OPTIMIZE FOR K ROWS를 지정하므로 옵티마이저는 K행의 검색에 적합한 액세스 플랜을 생성합니다.• N의 값이 너무 작거나, K값보다 작거나, batch 프로그램인 경우에는 OPTIMIZE 절을 사용할 필요가 없습니다.• N과 K, 클라이언트와 서버 측의 qrioblk 또는 aslheapsz 중에서 작은 값이 한 블록 안에 들어갈 행의 개수에 영향을 줍니다.• 조건에 맞는 행의 개수가 많고, 게시판의 첫 페이지처럼 최초의 K건이 빨리 검색되기를 원하는 경우에 주로 사용됩니다. • 조건에 맞는 데이터 중에서 최초의 N건만 Fetch 하면서 K건의 빠른 초기 검색을 원한다면, FETCH FIRST N ROWS와 OPTIMIZE FOR K ROWS 절을 함께 사용합니다.
WORSE BETTER

© Copyright IBM Corporation 2010118
IBM DB2 On-site Training CourseIBM Korea
인덱스 컬럼변형
SELECT *FROM EMPWHERE SUBSTR(DNAME,1,3) = 'ABC'
SELECT *FROM EMPWHERE DNAME LIKE 'ABC%';
SELECT *FROM EMPWHERE DEPTNO = '10'AND JOB = 'SALSMAN';
SELECT *FROM EMPWHERE DEPTNO || JOB = '10SALESMAN';
WORSE BETTER
• 인덱스 컬럼이 조건식의 표현식이나 함수에 의해 수정되는 경우에는 인덱스를 최적의 방법으로 사용할 수 없습니다.• 인덱스 컬럼을 변형시키지 말고, 비교되는 상수값을 변형하여 처리하도록 합니다.

© Copyright IBM Corporation 2010119
IBM DB2 On-site Training CourseIBM Korea
SUBQUERY 와 JOIN
SELECT ISSUE_GB, ISSUE_CODE, VALUE(DIFF_GB,'3'), VALUE(DIFF, 0),VALUE(CURR_PRICE, 0), VALUE(SELL_PRICE, 0), VALUE(BUY_PRICE , 0)
FROM TVJONGCURRWHERE ISSUE_GB = :v1 AND ISSUE_CODE IN
( SELECT ISSUE_CODEFROM TVJONGMAST
WHERE ISSUE_GB = :v1 AND ADMIN_GB = :v2 )
ORDER BY ISSUE_CODE;
SELECT ISSUE_GB, ISSUE_CODE, VALUE(DIFF_GB, '3'), VALUE(DIFF, 0),VALUE(CURR_PRICE, 0), VALUE(SELL_PRICE, 0), VALUE(BUY_PRICE , 0)
FROM TVJONGCURR A,TVJONGMAST B
WHERE A.ISSUE_GB = :v1AND A.ISSUE_GB = B.ISSUE_GB AND A.ISSUE_CODE = B.ISSUE_CODE AND B.ADMIN_GB = :v2
ORDER BY ISSUE_CODE;
• SUBQUERY 보다는 JOIN이 일반적으로 더 효율적입니다.• SUBQUERY와 JOIN 간의 상호 변환은 옵티마이저에 의해 대부분은 자동적으로 조절될 수 있습니다.• Null 을 허용하지 않는 Outer SELECT의 컬럼과 비교하는 Inner SELECT의 컬럼이 Null값인 경우에는 성능이 저하됩니다. • 여러 개의 서브 쿼리가 AND로 연결되어 있다면, Filtering 이 잘 되는 서브 쿼리를 앞쪽에 배치하는 것이 성능에 도움이 됩니다.• Outer SELECT의 컬럼과 Inner SELECT의 비교 컬럼의 데이터 유형이 일치하지 않아서 Outer SELECT의 컬럼에 대한 데이터 유형의 변환이필요한 경우에는 성능이 저하됩니다.
WORSE BETTER

© Copyright IBM Corporation 2010120
IBM DB2 On-site Training CourseIBM Korea
동시성 제어

© Copyright IBM Corporation 2010121
IBM DB2 On-site Training CourseIBM Korea
동시성을 지원할 때 발생하는 현상
Lost update• A와 B가 동일한 데이터를 동시에 조회하고 변경하면, A가변경한 값은 유실되고, B가 변경한 값이 남게 됩니다.
Uncommitted Read• A가 추가 또는 갱신한 후에 COMMIT 하지 않은 데이터를 B가조회할 수 있도록 허용할 때, A가 COMMIT으로 트랜잭션을종료되었다면, B가 조회한 데이터는 정확한 데이터가 되지만, A가 ROLLBACK으로 트랜잭션을 종료한다면, B가 이미 조회한데이터는 잘못된 데이터가 됩니다.
A
100 50B
UPDATE 100 + 50
UPDATE 100 - 50
?
A
100 150 100B
UPDATE 100 + 50ROLLBACK
SELECT : 110?
Non Repeatable Read• A가 SELECT문을 실행하여 결과 집합을 조회하고, 동일한트랜잭션에서 동일한 조건의 SELECT 문을 다시 요청하면이전의 결과 집합이 그대로 반환되지 않습니다.
Phantom Read• A가 SELECT문을 실행하여 10 건의 결과 집합을 조회하고, 동일한 트랜잭션에서 동일한 조건의 SELECT 문을 다시요청하면 이전의 결과 집합인 10건은 그대로 반환되고, B가추가한 1 건의 행이 추가적으로 반환됩니다. B가 새로 추가한행을 팬텀 행이라고 합니다.
A 10B
SELECT DATABETWEEN 10 AND 20
UPDATE 20 + 5
?15
20 25
10,15,20
10,15
A 10B
SELECT DATABETWEEN 10 AND 20
UPDATE 25 - 5
?15
25 20
10,15
10,15, 20

© Copyright IBM Corporation 2010122
IBM DB2 On-site Training CourseIBM Korea
분리 레벨(isolation level)
분리레벨이란
• 비즈니스 업무에 따라 데이터의 무결성및 일관성을 어느수준까지 허용할 것인지를 지정하는 규약입니다
• 분리 레벨에 따라 앞장에서 설명 드렸던 4가지 현상들이 발생할수 있습니다.
Uncommitted Read가 발생할 수 있습니다. Uncommitted Read없음READ UNCOMMITTED
트랜잭션이 시작하는 시점에 commit 된데이터만을 볼 수 있으며 INSERT, UPDATE, DELETE 가 허용되지 않습니다.
없음Read Only없음
Cursor Stability (CS) (DB2 9.7 이전 기본 값)Currently Committed(CC) (DB2 9.7 기본 값)
Read Stability (RS)
Repeatable Read ( RR)
DB2 분리 레벨
non repeatable Read 및 phantom read가 발생할수 있습니다.
READ COMMITTED(기본 값)READ COMMITTED
phantom read가 발생할 수 있습니다. 없음REPEATABLE READ
4가지 현상이 발생하지 않으나 동시성은많이 떨어집니다. SERIALIZABLESERIALIZABLE
Oracle 분리 레벨ISO 분리 레벨 현상

© Copyright IBM Corporation 2010123
IBM DB2 On-site Training CourseIBM Korea
동시성 제어를 위한 Locking 비교
Oracle DB2
Lock 대상Row level Locking (Default입니다.)Table기타 내부 object
Row level Locking (Default입니다.)Table기타 내부 object
Lock의 종류data Locks (DML Locks)Dictionary Locks (DDL Locks)Internal Locks and latches
data Locks (DML Locks)Catalog Table Locks (DDL Locks)Internal Locks and latches
Lock 취득및 해지
해당행이 있는 block에 ITL Entry를 작성하고 해당 행의 Lock byte를 갱신합니다
ITL을 삭제하고 각 행의 Lock byte의 정보를 clear시킵니다
메모리에 있는 locklist에 기록합니다메모리에 있는 locklist로 부터 lock정보를 삭제합니다
Lock관련 현상
ITL entry를 작성할 수 없는 경우• CREATE TABLE INITRANS의 부족• Block내에 free space 부족• 한 block에서 update가 집중되는 경우
현상• TX Enqueue ITL Wait이 발생합니다• 해당 블록을 갱신하려는 트랜잭션은 ITL공간을 확보할때까지 기다려야 합니다
해소 방법• 테이블의 Inittrans크기를 조정 합니다• 한 블록으로의 집중을 막기 위해 freespace확대 및 작은블록 크기로 변경하도록 합니다
메모리의 locklist에 entry를 작성할 수 없는 경우• Locklist 메모리 용량 부족• 동시의 다수의 lock을 보관해야하는 경우• 장기의 commit되지 않은 트랜잭션 발생
현상• row lock에서 table lock으로 lock escalation이발생합니다• table lock 발생 시 동시성이 저하됩니다
해소 방법• Locklist 메모리 크기를 조정합니다• commit 간격을 짧게 합니다

© Copyright IBM Corporation 2010124
IBM DB2 On-site Training CourseIBM Korea
동시성을 위한 분리레벨 동작 방법 비교
Oracle• Read Committed. • Undo Table Space 에서 before 이미지를 읽습니다
DB2 V9.7 이전• Cursor Stability 분리 레벨 동작• Read 는 Update가 끝날 때까지 기다립니다. UR isolation 을 사용할경우 대기 현상은 발생하지 않으나 uncommitted read가 발생할 수있습니다.
DB2 V9.7 • Currently committed • DB2 V9.7은 다른 애플리케이션이 같은 페이지에 Update 수행시
Read Application은 로그에서 Before 이미지를 읽으므로 대기현상이 발생하지 않습니다.
OracleSnapshot isolation
BlockBlock 안함쓰기
Block 안함Block 안함읽기
쓰기읽기Blocks →
Atablespace
UPDATE
Block 2SCN 12
Undo tablespaceBlock 2SCN 11
Read시대기현상발생하지않음
tablespace
UPDATE
Block 2SCN 12
Lock list
Lock entry
Read시대기현상
DB2Cursor Stability
BlockBlock쓰기
BlockBlock 안함읽기
쓰기읽기Blocks →
DB2Currently
committedBlockBlock 안함쓰기
Block 안함Block 안함읽기
쓰기읽기Blocks →
tablespace
UPDATE
Block 2SCN 12
Lock list
Lock entry
Read시대기현상발생하지않음
Log buffer
Log file

© Copyright IBM Corporation 2010125
IBM DB2 On-site Training CourseIBM Korea
DB2 분리 레벨(isolation level)의 종류
한 응용프로그램이 SELECT문을 실행하여 결과 집합이 반환되면, 다른 응용프로그램은 해당 결과 집합에 영향을 주는 액세스를 제한 받게됩니다. 액세스가 제한되는 대상의 범위와 SQL문의 종류는 분리 수준에 의해 조절됩니다.
분리 수준은 SELECT문에 대해서만 적용됩니다. 데이터를 변경시키는INSERT,UPDATE,DELETE 문에 의해 잠금이 적용된 행은 COMMIT 또는ROLLBACK이 될 때까지 액세스가 제한됩니다.
FETCH
12
34
56
12
34
56
NO ROW LOCKS FOR READ-ONLY CURSORS
Commit Point4SOUND61CPU518CABLE415MOUSE33KEYS210DISP1
QTYNameID
유형 설명
CC Currently Committed의 약자입니다. 조회하는 UOW는 동시에 변경하는 다른 사용자에 의해 변경되고 있더라도 수행에 방해를 받지 않고 즉시 결과를리턴 받게 됩니다. DB2 9.7에서 기본 분리 수준입니다.
CSCursor Stability의 약자입니다. 한 UOW 에서 동일한 조건의 SELECT문을 여러 번 실행하면 이전의 결과 집합이 반환되는 것을 보장하지 않습니다. 현재처리 중인 한 개의 행에 대해서만 NS 잠금을 설정합니다. 다른 응용프로그램은 결과 집합의 데이터를 추가, 변경, 삭제할 수 있습니다. DB2 9.5까지기본 분리수준 입니다.
RR Repeatable Read 의 약자입니다. 한 UOW 에서 동일한 조건의 SELECT문을 여러 번 실행하면, 이전의 결과 집합과 항상 동일한 결과 집합이 반환되는것을 보장하므로 반복 읽기가 가능합니다. 반환된 결과 집합의 모든 행과 결과 집합을 추출하기 위해 액세스된 모든 행에 대해 S 잠금을 적용합니다. 다른 응용프로그램은 결과 집합의 데이터를 추가, 변경, 삭제할 수 없습니다.
RSRead Stability의 약자입니다. 한 UOW 에서 동일한 조건의 SELECT문을 여러 번 실행하면, 이전의 결과 집합을 항상 포함하고, 팬텀 행이 추가적으로반환되는 것을 허용합니다. 반환된 결과 집합의 모든 행에 NS 잠금을 적용합니다. 다른 응용프로그램은 결과 집합의 데이터를 추가는 할 수 있지만, 변경과 삭제는 할 수 없습니다.
UR Uncommitted Read의 약자입니다. 한 UOW 에서 동일한 조건의 SELECT문을 여러 번 실행하면 이전의 결과 집합이 반환되는 것을 보장하지 않습니다. 잠금을 전혀 적용하지 않습니다. 다른 응용프로그램은 결과 집합의 데이터를 추가, 변경, 삭제할 수 있습니다. 다른 응용프로그램에서 처리 중인UOW의 COMMIT 되지 않은 데이터를 조회할 수 있고, COMMIT 하지 않은 데이터가 액세스되는 것을 허용합니다.
RR 또는 RS CS UR

© Copyright IBM Corporation 2010126
IBM DB2 On-site Training CourseIBM Korea
DB2 분리 수준 지정 방법
DB2는 다음과 같이 다양한 레벨에서 분리수준을 지정할 수있습니다. 만약 분리 수준이 각 세션, 패키지, CLI 등에서 지정한 후개별 SQL문에서 재지정할 경우 개별 SQL문에서 WITH 옵션으로 분리수준을 지정하는 것이 가장 우선적으로 적용됩니다
SQL문의 마지막에 WITH 옵션을 사용하여 지정합니다. 패키지 수준과 세션 수준의 설정 값보다 우선적으로적용됩니다. SELECT 문, SELECT INTO 문, INSERT 문, FOR 문, searched DELETE 문, searched UPDATE 문, DECLARE CURSOR 문 등은 WITH 옵션을 사용할 수 있습니다.
SQL문
SET CURRENT ISOLATION 문을 이용하여 지정합니다. 패키지에 저장된 동적 SQL문에 대해서 패키지 수준의설정값보다 우선적으로 적용됩니다.
현재세션
PREP 명 령 어 의 ISOLATION 옵 션 , BIND 명 령 어 의ISOLATION 옵션으로 지정하며, 패키지에 포함된 모든SELECT문에 적용됩니다.
패키지
CHANGE ISOLATION LEVEL 명령어, SQLSetConnectAttr 함수, db2cli.ini 파일의 TXNISOLATION 키워드를 이용하여지정하며 , CLI 와 ODBC 드라이버를 통한 실행시에적용됩니다.
DB2 CLI
CHANGE ISOLATION LEVEL 명 령 어 를 이 용 하 며 , 데이터베이스의 재접속시에 반영됩니다. DB2 CLP
$ db2 change isolation level to RS$ db2 connect to sample$ db2 "select * from t1 where c1 = 1"$ db2 set CURRENT ISOLATION = CS$ db2 “select * from t1 where c1 = 1”$ db2 “select * from t1 where c1 = 1 with UR ”
$ db2 bind kes.bnd CURRENT ISOLATION RR $ db2 list packages
$ db2 update cli cfg for section sample using TXNISOLATION 1$ db2 get cli cfg
세션의분리수준을RS로지정합니다.
특수레지스터리의값을CS로지정합니다.
SELECT 문의분리수준을UR 로지정합니다..
패키지의분리수준을RR로지정합니다
CLI 의분리수준을 UR로지정합니다. CLI 구성파일인db2cli.ini 파일에저장되는 TXNISOLATION 키워드의값은1(UR), 2(CS), 4(RS), 8(RR) 중에서한가지로지정합니다.

© Copyright IBM Corporation 2010127
IBM DB2 On-site Training CourseIBM Korea
DB2 잠금의 대상
QUIESCE 명령어, CONNECT 명령어, LOCK TABLE문으로 인스턴스, 데이터베이스, 테이블스페이스, 테이블에 사용자가 명시적으로잠금을 적용할 수 있습니다. SQL문을 실행하면 엔진에 의해테이블과 인덱스의 행에 자동으로 잠금이 적용됩니다.
잠금이적용되는데이터베이스오브젝트는다음과같습니다
• 인스턴스 , 데이터베이스 , 테이블스페이스에 대한 잠금은데이터베이스 관리 차원의 잠금입니다.
• 일반적인 응용프로그램에서 SQL문으로 데이터를 액세스하므로테이블, 행, 인덱스에 대한 잠금이 적용됩니다.
Table Space
Table
Row
Index
잠금을적용하는방법은다음과같습니다
SQL문을 이용하여 데이터를 액세스할 때 , 특정한인덱스를 이용하여 액세스하게 되면, 해당 인덱스의 행에잠금이 적용됩니다.
인덱스
QUIESCE INSTANCE 명령어를 실행하면, SYSADM / SYSCTRL / SYSMAINT 권한을 가진 사용자와 액세스가 허용된사용자만 인스턴스와 데이터베이스를 액세스할 수있습니다.
인스턴스
CONNECT 문을 이용하여 데이터베이스에 접속할 때배타적 모드의 접속이 가능합니다. 기본 접속 모드는공유적 모드이므로 여러 사용자가 동시에 접속할 수있습니다 . QUIESCE DATABASE 명령어를 실행하면 , SYSADM / SYSCTRL / SYSMAINT / DBADM 권한을 가진사용자와 액세스가 허용된 사용자만 데이터베이스를액세스할 수 있습니다.
데이터베이스
QUIESCE TABLESPACES FOR TABLE 명령어를 실행하면, LOAD 명령어를 실행하는 동안 해당 테이블스페이스에잠금을 적용합니다.
테이블스페이스
LOCK TABLE 문을 이용하여 배타적 또는 공유적 모드로테이블 전체에 잠금을 설정할 수 있습니다. 한 테이블의 행잠금의 비율이 지정한 기준을 초과하면, 내부적으로 행잠금이 테이블 잠금으로 변환될 수도 있습니다.
테이블
SQL문을 이용하여 데이터를 액세스하면 기본적으로 행수준의 잠금이 적용됩니다. 행

© Copyright IBM Corporation 2010128
IBM DB2 On-site Training CourseIBM Korea
잠금 상승 현상 (Lock Escalation)
행 잠금이 테이블 잠금으로 전환되는 현상을 잠금 상승 현상이라고 합니다. 잠금 상승 현상은 교착 상태를 유발시킬 수 있으며, 동시성을저하시키므로, 가급적이면 발생하지 않도록 데이터베이스 구성 변수인 LOCKLIST와 MAXLOCKS을 조절합니다.
LOCKLIST 초과시 Table Lock 으로잠금상승
• 잠금 정보는 데이터베이스 별로 공유 메모리에 있는 LOCKLIST 영역에 저장됩니다.
• 잠금 정보의 양이 LOCKLIST의 크기를 초과하게 되면, 가장 많은행 잠금을 가진 테이블을 식별하여 그 테이블에 대한 행 잠금을모두 취소하고 테이블 잠금을 적용합니다.
LOCKLIST 설정방법• update db cfg 명령어로 데이터베이스 구성 변수인 LOCKLIST 구성변수를 이용하여 잠금 정보를 저장하는 메모리 영역의 크기를조절합니다. <크기>는 4K 페이지 단위로 지정합니다.
• LOCKLIST 는 '온라인 구성 가능 변수' 이므로 동적으로 변경할 수있습니다.
• LOCKLIST를 AUTOMATIC으로 설정하면 자동으로 DBMS가 크기를조정합니다.
db2 update db cfg for <데이터베이스> using LOCKLIST <크기>
LOCKLIST
Table1Row lock
Table2Row lock
Table2 Row lock
Table1 table lock
MAXLOCkS초과시 Table Lock 으로잠금상승
• 한 응용프로그램에 대한 잠금 정보의 양이 MAXLOCKS의 비율을초과하게 되면, 해당 응용프로그램에서 가장 많은 행 잠금을가진 테이블을 식별하여 그 테이블에 대한 행 잠금을 모두취소하고, 테이블 잠금을 적용합니다.
MAXLOCKS설정방법• MAXLOCKS 구성 변수는 LOCKLIST 구성 변수가 지정한 크기에서한 응용프로그램이 사용할 수 있는 최대 비율을 지정합니다. <비율>은 백분율로 표시합니다.
• MAXLOCKS는 '온라인 구성 가능 변수' 이므로 동적으로 변경할수 있습니다.
db2 update db cfg for <데이터베이스> using MAXLOCKS <비율>
MAXLOCKS APP1
APP2
table lockAPP1
APP2

© Copyright IBM Corporation 2010129
IBM DB2 On-site Training CourseIBM Korea
잠금 대기 현상
응용프로그램이 잠금을 적용한 행을 다른 응용프로그램에서 액세스하려면, 그 잠금이 해제될 때까지 대기해야 합니다
LOCKTIMEOUT 데이터베이스구성변수
• LOCKTIMEOUT 데이터베이스 구성 변수를 이용하여 잠금 대기현상을 관리합니다.
• 이 데이터베이스 구성 변수의 기본값은 -1로서 무한대로대기하는 것을 의미합니다.
• 값을 0 으로 설정하면, SQL문 요청 시점에서 잠금을 획득하지못하면 즉시 중단되게 합니다.
• 일반적인 OLTP 환경에서는 잠금 대기 시간을 30초 이내로 설정합니다.
• 잠금 대기 시간 이내에 필요한 잠금을 획득하면 , 응용프로그램은 작업을 계속할 수 있습니다.
LOCKTIMEOUT 데이터베이스구성변수설정방법
• update db cfg 명령어로 LOCKTIMEOUT 데이터베이스 구성 변수를설정합니다. <잠금 대기 시간>은 1초 단위로 표시합니다.
db2 update db cfg for <데이터베이스> using LOCKTIMEOUT <잠금 대기 시간>
db2 +c "update t1 set c2 = c2 + 100 where c1= 2"
LOCKTIMEOUT
db2 "select * from t1 where c1 = 2"
SQL0911N The current transaction has been rolled back because of a deadlock or timeout. Reason code “68". SQLSTATE=40001

© Copyright IBM Corporation 2010130
IBM DB2 On-site Training CourseIBM Korea
교착 상태
두 개의 응용프로그램이 서로 잠금 대기 상태가 되는 것을 교착 상태라고 합니다
DLCHKTIME 데이터베이스구성변수
• 데이터베이스 구성 변수인 DLCHKTIME을 이용하여 이파라미터에 설정된 값을 주기로 교착 상태에 있는 응용프로그램을 파악하고, 한 응용프로그램을 강제로 종료시키면, 다른 응용 프로그램은 작업을 계속합니다.
• 교착 상태를 해결하기 위해 희생자 프로세스를 선택하는기준은 엔진 내부의 알고리즘으로 사용자가 조절할 수없습니다.
DLCHKTIME데이터베이스구성변수설정방법
• DLCHKTIME 은 '온라인 구성 가능 변수' 이므로 attach 명령어를이용하여 인스턴스에 접속한 후 변경하면 즉시 반영될 수있습니다.
• update db cfg 명령어로 DLCHKTIME 데이터베이스 구성 변수를설정합니다. <점검 간격>은 밀리초(1000분의 1초) 단위로표시하며 수의 기본값은 10000 ms로 10초 간격으로 교착 상태가점검됩니다.
db2 update db cfg for <데이터베이스> using DLCHKTIME <점검간격>
db2 +c "select * from t1 where c1 = 1 with rs"
DLCHKTIMESQL0911N The current transaction has been rolled back because of a deadlock or timeout. Reason code “2". SQLSTATE=40001
db2 +c "select * from t1 where c1 = 2 with rs"
db2 +c "update t1 set c2 = c2 + 100 where c1= 2"
db2 +c "update t1 set c2 = c2 + 100 where c1= 1"

© Copyright IBM Corporation 2010131
IBM DB2 On-site Training CourseIBM Korea
데이터 이동

© Copyright IBM Corporation 2010132
IBM DB2 On-site Training CourseIBM Korea
데이터 이동 방법
데이터베이스 내에 존재하는 데이터를 다른 플랫폼 또는 다른 데이터베이스로 이동하는 방법에는 Import , Export 및 Load 유틸리티, 백업 및복구, 복제 등이 있습니다
오라클의 IMPORT와 EXPORT 유틸리티와 DB2의 IMPORT/EXPORT는기능상 유사합니다. 그러나 오라클의 IMPORT/EXPORT 는 오라클 전용포맷인 DUMP 파일 형태로 데이터를 이동하는 것으로 이기종데이터베이스간에 데이터를 이동시킬 수 없습니다. DB2는 전용 포맷인IXF 파일형태뿐 아니라 ASCII 파일 형태로 데이터를 이동할 수 있으므로이기종 데이터베이스간에 데이터 이동이 가능합니다.
Source DB Target DB
IMPORT / EXPORT
BACKUP / RESTORE
LOAD
Replication Tool
Relocate Database
IMPORT/EXPORT 툴을이용한데이터이동
• IMPORT/EXPORT 유틸리티를 이용해 특정 테이블에 대한데이터를 이동합니다.
• 표준 데이터 형식인 ASC,DEL 형식 또는 DB2 전용 형식인 IXF 를지원합니다.
BACKUP / RESTORE 를이용한데이터이동
• 백업 및 복구를 이용하여 데이터를 이동합니다
LOAD 유틸리티를이용한데이터이동
• LOAD 유틸리티를 이용하여 특정 테이블, 특정 스키마에 대한데이터를 적재할 수 있습니다.
• HPU ( High Performance Unload ) 제품을 이용하여 데이터베이스의데이터를 고속으로 빠르게 적재합니다.
복제솔루션을이용한데이터이동
• 복제 솔루션을 이용하여 데이터베이스를 복제합니다.
reloatedb를이용한데이타베이스이동
• 데이터베이스를 같은 시스템 또는 다른 시스템에 재배치하여이동시킬 수 있습니다.

© Copyright IBM Corporation 2010133
IBM DB2 On-site Training CourseIBM Korea
다양한 DB2 데이터 이동 유틸리티
IMPORT 는 다음과 같은 경우일 경우 LOAD를 대신합니다타겟 테이블이 뷰일 경우타겟 테이블에 제약조건이 존재하여 Load시 "Set Integrity Pending" 상태를 원하지않을 경우타겟 테이블에 트리거가 존재하며 트리거가 수행되기를 원할 경우
가능외부 파일로부터 데이터를 읽어 테이블, 뷰 , 닉 네 임 에 삽 입 하 고자 할 경우사용됩니다.
IMPORT
가능
가능
가능
가능
Cross platform 호환여부
목적 Best Practice
EXPORT데이터베이스로부터 데이터를 다양한형태의 외부 파일로 추출해 내고자 할경우 사용됩니다..
외부 파일로 데이터를 저장하여 향후 다른 테이블에 데이터를 이동하고자 할 경우사용합니다. High Performance Unload ( HPU) 는 고성능 유틸리티이나 별도로 구매해야 합니다. EXPORT 유틸리티는 XML 칼럼을 지원합니다
LOAD 대용량 데이터를 새 테이블 또는 기존테이블로 효율적으로 이동할 수 있습니다
성능이 가장 최우선될 경우
db2move
IMPORT/EXPORT 옵션과 함께 사용할경우 DB2 데이터베이스간에 대량의테이블을 편리하게 이동할 수 있습니다. COPY 옵션과 함께 사용할 경우 소스DB에서 타겟 DB로 스키마 템플릿을복사할 수 있습니다.
cross platform 에 대한 백업 및 복구를 지원하지 않을 경우 IMPORT, EXPORT 옵션을이용하여 데이타베이스를 복제할 수 있습니다
ADMIN_COPY_SCHEMA 프로시저
단일 스키마내의 모든 오브젝트의복사본을 생성하여 새로운 스키마에속하는 오브젝트로 재 생성 할 수있습니다. copy 옵션을 이용하여 데이터와 함께복사할 것인지 아닐지를 지정할 수있습니다.
스키마 템플릿을 생성하여 기존 소스 스키마에 영향을 주지 않은채 새로 인덱스를만들어 테스트를 수행할 수 있습니다.

© Copyright IBM Corporation 2010134
IBM DB2 On-site Training CourseIBM Korea
다양한 DB2 데이터 이동 유틸리티
백업 또는 복구작업이 오래 걸릴 경우 이용될 수 있습니다. 백업 및 복구의 대안으로 데이터베이스의 복사본을 생성하거나 이동할 수있습니다. 테스트 환경을 구성할 경우 빨리 데이터베이스의 복제 본을 생성할 수 있습니다. 테이블 스페이스 컨테이너를 새로운 스토리지 디바이스 그룹으로 이동시킬 수있습니다.
불가능
데이터베이스 이름 재정의, 데이터베이스위치 변경, 데이터베이스의 일부분을 같은시스템 또는 다른 시스템에 위치시키고자할 경우 사용합니다.
db2reloatedb
불가능
제한적
Cross platform 호환여부
목적 Best Practice
RESTORE
기존 백업 이미지로부터 스크립트를이용하여 한 시스템에서 다른 시스템으로전체 데이터베이스를 복사할 경우사용됩니다
REDIRECT, GENERATE SCRIPT 옵션과 함께 사용합니다백업 이미지가 존재할 경우 가장 적합합니다
Split Mirror 복제본, Standby 또는 백업 데이터베이스를생성하는데 사용됩니다
down time을 최소화 하기위해 primary 서버가 down 되었을 경우 standby 시스템을생성합니다. 테스트 환경을 구성할 경우 데이터베이스의 복제본을 가장 빠른 방법으로 생성할수 있습니다.

© Copyright IBM Corporation 2010135
IBM DB2 On-site Training CourseIBM Korea
EXPORT / IMPORT
DB2의 EXPORT 와 IMPORT 는 데이터를 이기종 간에 이동하기 위한 가장 간편한 방법입니다
Source DB
EXPORTMessage파일
db2look
데이터파일
DDL 파일
IMPORTMessage파일
Target DB
EXPORTMessage파일
IXF 파일 IMPORTMessage파일
EXPORT• DEL / IXF / WSF 형태로 데이터 파일을 추출합니다. • IXF 형태의 경우 DDL 정보가 들어 있어 IMPORT 시 테이블 생성정보 없이도 테이블 생성 및 데이터 적재가 가능합니다.
EXPORT TO <filename> OF <file_type> SELECT * FROM <tablename>
IMPORT• ASC / DEL / WSF / IXF 형태를 지원합니다. • IXF 형태를 제외하고는 Target 테이블이 존재해야 합니다. • INSERT 구문을 이용하 데이터를 적재합니다. • 데이터베이스 로그가 사용됩니다.
IMPORT FROM <filename> OF <file_type> INSERT INTO <tablename>
db2look• DDL 파일 및 통계자료를 추출해 냅니다.
db2look -d SAMPLE -a –e -l -x -m -f
Non-Delimited ASCII 파일로, IMPORT / LOAD 시 사용됩니다. ASC
Delimited ASCII 파일로, EXPORT/IMPORT/LOAD 시 사용됩니다. DEL
Work Sheet Format 으로 Lotus 1-2-3, Symphony 등에 사용됩니다WSF
Integrated eXchange Format 으로 EXPORT/ IMPORT/ LOAD 시에사용되며 데이터를 삽입할 테이블이 존재하지 않아도 IXF 파일에 저장된 테이블 구조를 읽어 테이블을 생성한 후데이터를 적재합니다.
IXF
SELECT 문의 결과 집합을 저장한 구조체로 LOAD 에서사용됩니다. CURSOR

© Copyright IBM Corporation 2010136
IBM DB2 On-site Training CourseIBM Korea
DB2 LOAD 유틸리티
DB2의 LOAD 는 IMPORT 와 유사한 툴로 파일로부터 대량의 데이터를 기존의 테이블에 고속으로 저장하는 유틸리티입니다. LOAD 명령어와SET INTEGRITY 명령어가 사용됩니다
단계
• 파일을 읽어 데이터를 목표 테이블에 로드 합니다. 3단계 과정인LOAD, BUILD, DELETE 과정을 수행합니다
LOAD : 입력파일의 데이터를 테이블 스페이스 컨테이너로직접 복사합니다.BUILD : 수집한 인덱스 정보를 이용하여 기존 인덱스를갱신하거나 재생성 합니다. DELETE : 고유 인덱스를 위반한 데이터를 점검하여 미리정의된 예외 테이블에 입력합니다. LOAD FROM <filename> OF <filetype> INSERT INTO <table-name>
• LOAD QUERY 명령어를 이용하여 테이블의 상태를 확인합니다LOAD QUERY TABLE <table-name>
• LOAD 명령어가 완료되면 목표 테이블은 점검 보류 ( CHECK PENDING) 상태가 됩니다. 예외(Exception) 테이블을 이용하여SET INTEGRITY 문으로 점검 보류 상태를 해지합니다
SET INTEGRITY FOR <테이블 명> IMMEDIATE CHECKED FOR EXCEPTION IN <목표 테이블 명> USE <예외 테이블 명>
특징
• 많은 양의 데이타를 빨리 효과적으로 적재할 수 있습니다. format 된 페이지를 직접 데이타베이스내에 기록합니다. 트리거를 일으키지 않습니다. referential checking 을 수행하지 않습니다.
• Online load 가 가능합니다. 기존 테이블 데이타를 LOAD 시에도 읽을 수 있습니다.
• 통계자료를 생성할 수 있습니다. • exception 데이타를 별도의 테이블로 복사할 수 있습니다 . • INPUT 값으로 PIPE 또는 CURSOR 를 이용할 수 있습니다. • LOB 데이타 및 UDT를 다룰 수 있습니다. • ASC,DEL, IXF 파일 형태를 모두 지원합니다.

© Copyright IBM Corporation 2010137
IBM DB2 On-site Training CourseIBM Korea
IMPORT와 LOAD 의 차이점
"GENERATED ALWAYS"로 선언된 컬럼을 덮어 쓸 수 있습니다. "GENERATED ALWAYS"로 선언된 컬럼을 덮어 쓸 수 없습니다. Load 연 산 동 안 에 는 Uniqueness 만 이 검 증 되 며 모 든 다 른제약조건들은 "SET INTEGRITY"를 통해 체크됩니다. Import 시에 모든 제약조건이 검증됩니다.
데이터가 모두 적재된 후에 Key 값이 정렬되어 인덱스가생성됩니다. import시에 Key 값이 Index 테이블에 한번에 하나씩 삽입됩니다.
테이블내의 모든 데이터가 교체되면 LOAD 연산 동안 통계자료가수집됩니다.
통계자료의 변경을 요구할 경우 RUNSTATS 유틸리티가 Import 후에수행되어야 합니다.
host (mainframe) 데이터베이스로 Load할 수 없습니다. DB2 Connect 를 이용하여 host (mainframe) 데이터베이스로 import 가가능합니다.
테이블만 Load 작업이 가능합니다. 테이블, 뷰, 닉네임 등으로 Import 가 가능합니다.
최소한의 로깅이 수행됩니다. 모든 행이 로그 됩니다. 트리거가 지원되지 않습니다. 트리거가 지원됩니다.
BINARYNUMERICS / PACKEDDECIMAL / ZONEDDECIMAL 지원됩니다. BINARYNUMERICS/PACKEDDECIMAL/ZONEDDECIMAL 미지원
WSF 형식이 지원되지 않습니다. WSF 형식이 지원됩니다. Support for loading into summary tablesImporting 을 Summary Table로 지원하지 않습니다. 테이블 및 인덱스는 형태에 상관없이 존재해야 합니다. IXF 형태일 경우 테이블, 계층, 인덱스가 자동 생성됩니다. 계층적 데이터를 지원하지 않습니다. 계층적 데이터를 지원합니다. 항상 intra-partition 병렬성을 이용합니다.제한된 intra-partition 병렬성을 이용합니다. 많은 양의 데이터를 적재할 때 IMPORT 보다 빠릅니다. 많은 양의 데이터를 적재할 때 LOAD 보다 느립니다.
LoadImport

© Copyright IBM Corporation 2010138
IBM DB2 On-site Training CourseIBM Korea
db2move 유틸리티
db2move 유틸리티를 이용하여 테이블 별, 테이블 스페이스 별, 스키마 별 또는 전체 데이터베이스에 대한 IMPORT, EXPORT, LOAD 작업을수행할 수 있습니다.
필요파일및자동생성되는파일
• EXPORT시input파일은 필요치 않으며 db2move.lst 파일 , tabnnn.ixf, tabnnn.msg, tabnnnc.yyy 파일이 자동으로 생성됩니다.
• IMPORT시입력 파일로 db2move.lst, tabnnn.ixf, tabnnn.msg, tabnnnc.yyy파일이 필요하며 IMPORT.out 파일과 tabnnn.msg 파일이자동 생성됩니다.
$ db2move sample export $ db2move sample export –tc us*rid2 –tn tbname1, *tbname2
$ db2move sample import –io replace –u inst95 –p **** $ db2move DBSRC COPY –sn AMJ –co TARGET_DB dbtgt USER inst95 using ****
Sample DB의모든테이블 export
us로시작하여 rid2 로끝나는모든사용자가생성한테이블과테이블이름이 tbname1 과tb로시작하여 name2로끝나는테이블들을
EXPORT 합니다
Sample DB의모든테이블을replace 모드로 IMPORT
Source 데이터베이스의 AMJ 스키마를Target 데이터베이스로복사합니다

© Copyright IBM Corporation 2010139
IBM DB2 On-site Training CourseIBM Korea
Migration

© Copyright IBM Corporation 2010140
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차
준비단계 변환 단계 적용단계검증단계분석평가단계
마이그레이션대상이되는자원 (프로그램, 데이터베이스등) 선정
선정된자원을분석하여마이그레이션공수및기간을평가
시스템변환규칙을정의하고, 이를자동/수동으로변환
변환된어플리케이션을테스트과정
마이그레이션결과를기반으로, 실업무에적용방안수립
준비 분석 변환 검증
DB Object 및 Data 변환
Application 변환
마이그레이션결과분석
테스트DB2 물리적구성정의
표준데이터유형정의
변환유형분류및표준작성
목표및전략수립
대상범위검토
수행계획수립
환경구축
적용
적용/운영방안수립
실업무적용
• IBM 포팅설문서• IBM 포팅평가툴 (MEET)• IBM 포팅평가보고서
• DB 마이그레이션작업내역• APP마이그레이션작업내역
• 테스트시나리오및결과• 마이그레이션체크리스트

© Copyright IBM Corporation 2010141
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차 : 분석 평가 단계
목적목적
• 마이그레이션 작업을 위한 환경 이해 및 공수 산정
분석평가내용분석평가내용
• 마이그레이션 대상 어플리케이션과 데이터베이스 정보 수집DB interface (JDBC, ADO.NET, etc) 정보수집DB 오브젝트 확인 및 PL/SQL 지원 제한 여부 확인환경 평가 보고서 작성
평가툴평가툴
• IBM 포팅 설문서• IBM 평가툴 :MEET DB2
상세 분석방법상세 분석방법
• 1단계: 소스 DB DDL문을 가지고 테스트 Oracle DB 작성• 2단계: 테스트 Oracle에서 타겟 DB2 코드 변환 스크립트 추출• 3단계: 타겟DB2에 추출 DDL문을 적용하면서 소스 패턴 분석• 4단계: 점검 항목 산출

© Copyright IBM Corporation 2010142
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차 : 분석 평가 단계 > 평가툴
IBM 포팅 설문서
• Porting Assessment Questionnaire (PAQ)• 어플리케이션과 데이터베이스 환경에 대한 자세한 정보 수집
MEET DB2
• Migration Enablement Evaluation Tool• DB2 9.7에서 지원가능 여부 사전 식별• Windows 환경에서만 기동.• IBMer 및 BP에서만 사용 가능 (http://tinyurl.com/meetdb2)• HTML 보고서 출력
96.6% of PL/SQL statements immediately transferable to IBM DB2

© Copyright IBM Corporation 2010143
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차 : 변환 단계
오브젝트이관오브젝트이관
• 오라클 오브젝트의 DDL과 데이터 추출• DB2 데이터베이스에 해당 DDL 스크립트 적용• DB2에 추출된 데이터 적재
오브젝트이관툴오브젝트이관툴
• IBM Data Movement Tool데이터와 DB 오브젝트 분리 작업 가능IBM Migration ToolKit (MTK)의 새로운 버전
• Optim Development Studio• 데이터 적재를 위해 InfoSphere Federation Server 활용 가능
어플리케이션마이그레이션
어플리케이션마이그레이션
• DB2 연결인터페이스 환경 설정표준 인터페이스: JDBC, ADO.NET, PDO, etc.Oracle's OCI 관련 인터페이스그 외 다양한 인터페이스: Pro*C, Tuxedo , IBATIS…
• 오라클 소스를 DB2에 적용오라클 호환성 사용필요시 SQL 변환어플리케이션 특성에 따른 수정 필요

© Copyright IBM Corporation 2010144
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차 : 변환 단계 > 어플리케이션 마이그레이션
DB2 연결 구성
• 표준 인터페이스: JDBC, ADO.NET, PDO, 등• Connection String 수정은 필수
Class.forName(“com.ibm.db2.jcc.DB2Driver”)DriverManager.getConnection(“jdbc:oracle:thin:@server.com:5000:db1”)
Class.forName(“com.ibm.db2.jcc.DB2Driver”)DriverManager.getConnection(“jdbc:db2://server.com:5000/db1”)
.NET 변경 예
• 대부분의 경우 Oracle .NET Data Provider에서 제공하는 클래스를기능적으로 상응하는 DB2 .NET Data Provider의 클래스로 변경하는일이 수반
Dim conn As New OracleConnection(con_str)
Dim conn As New DB2Connection(db1)
Dim cmd As New OracleCommandcmd.Connection = conn cmd.CommandText
= “select * from employees where dept_code = ‘IT’”
Dim cmd As New DB2Commandcmd.Connection = conn cmd.CommandText
= “select * from employees where dept_code = ‘IT’”
Dim dr as OracleDataReader = cmd.ExecuteReader()
Dim dr as DB2DataReader = cmd.ExecuteReader()

© Copyright IBM Corporation 2010145
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차 : 변환 단계 > 어플리케이션 마이그레이션
사용 툴
• IBM Optim Series: Optim Data Studio, Design Studio, Query Tunner..• 3rd 툴 이용 – Toad for DB2, Orange for DB2, Aqua Studio• IBM DataStudio
무료의 통합 개발 환경 제공(Integrated Development Environment ,IDE)개발자와 DBA 통합 기능 제공Eclipse기반으로 툴 습득시간 최소화 가능다운로드: http://www.ibm.com/software/data/studio
Project Explorer
View
Data Source Explorer
View
Main View
Miscellaneous View
OutlineView
CLPPlus
• 오라클 sql*plus에 익숙한 사용자를 위한 command line processor
clpplus db2admin/password@localhost:50000/sample
User IDDB name
Port #Password
host

© Copyright IBM Corporation 2010146
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 절차 : 검증 단계
기능테스트기능테스트
• 뷰, 트리거 및 저장 프로시저 기능 테스트컴파일 시 이상 유무 상세 확인 및 로직 에러 점검오브젝트 내역확인: 프로시저 별 수행 순서 또는 테스트, 백업 여부확인1차 컴파일 이상 유무 확인(Error 및 Warning) 후 로직 확인준비사항: SP별 테스트용 데이터 준비 및 디버깅 인력
• 화면 테스트화면에서 호출하는 소스 쿼리 / SP문 이상 유무 점검1차 컴파일 이상 유무 확인 (Error 및 Warning) 테스트 파라매터 적용준비사항: 테스트데이터, 테스트 시나리오, 디버깅 인력

© Copyright IBM Corporation 2010147
IBM DB2 On-site Training CourseIBM Korea
DB2 9.7의 오라클 호환성 기능 사용
DB2 V9.7은 오라클 애플리케이션을 변경 없이 그대로 DB2에서 운영할 수 있도록 오라클 호환성을 위한 기능을 포함하였습니다. DB2 V9.5부터 지원되는 기능에 추가적으로 오라클에서 많이 사용되는 데이터 타입, 오라클 Stored Procedure, Function을 거의 변경없이 그대로사용하실 수 있습니다.
데이타베이스의 데타 데이터 정보를 볼 수 있는 오라클 Data Dictionary 를 그대로 사용 가능. 데이터 베이스 생성 전 변수 설정DB2 V9.7 이상0x400Data Dictionary
오라클의 PL/SQL 프로그램을 거의 변경없이 그대로 사용 가능. 데이터 베이스 생성 전 변수 설정DB2 V9.7 이상0x800PL/SQL Compilation
Array 에 대한 연산을 편리하게 수행할 수 있도록 지원. 데이타베이스 생성후 적용 가능DB2 V9.7 이상0x200Collection 방법
계층 쿼리인 Connect by 사용 가능데이타베이스 생성후 적용 가능DB2 V9.5 이상0x08CONNECT BY
데이터 베이스 생성 전 변수 설정DB2 V9.7 이상0x10NUMBER Data Type
데이터 베이스 생성 전 변수 설정DB2 V9.7 이상0x20VARCHAR2 Data Type
데이터 베이스 생성 전 변수 설정DB2 V9.7 이상0x40DATE Data Type
문자 상수의 길이가 254보다 작을 경우 상수를 CHAR 또는 GRAPHIC 데이터 타입으로 설정.데이타베이스 생성후 적용 가능DB2 V9.7 이상0x100Character 상수
데이타베이스 생성후 적용 가능
데이타베이스 생성후 적용 가능
데이타베이스 생성후 적용 가능
적용 시점
Outer 연산자인 + 기호 사용 가능
SYSIBM.DUAL을 DUAL로 Public Synonym으로 생성했으므로 SYSIBM.DUAL 및 DUAL 모두 사용 가능.
ROW_NUMBER() OVER () 의 Synonym으로 WHERE 절에서도 ROWNUM을사용할 수 있습니다.
설명
DB2 V9.5 이상
DB2 V9.5 이상
DB2 V9.5 이상
지원 버전
0x04+ ( outer 조인 연산자 )
0x02DUAL
0x01ROWNUM
HEX 값오라클 / DB2

© Copyright IBM Corporation 2010148
IBM DB2 On-site Training CourseIBM Korea
DB2 9.7의 오라클 호환성 기능 사용
오라클 데이터 타입 및 연산자를 DB2 V9.7에서 사용하기 위해서는DB2 Registry 변수인 DB2_COMPATIBILITY_VECTOR를 설정해야합니다. 몇가지 특성은 데이타베이스를 생성하기 전에 반드시Registry 변수를 설정해야 합니다.
설정방법
• 오라클 기능을 그대로 사용하기 위해서는 DB2 Registry 변수인D B 2 _ C O M P A T I B I L I T Y _ V E C T O R에 활성화하는 H e x 값을설정합니다.
• Hex 값은 앞의 표를 참고하시기 바랍니다. • DB2 Instance를 재시작합니다
• 모든 오라클 호환 기능을 포함하는 DB2_COMPATIBILITY_VECTOR 는 0xFFF 또는 ORA로 설정합니다
$ db2stop$ db2set DB2_COMPATIBILITY_VECTOR=0x800$ db2start$ db2 create db <DB Name>
$ db2stop$ db2set DB2_COMPATIBILITY_VECTOR=0x03$ db2start$ db2 connect to <DB Name>

© Copyright IBM Corporation 2010149
IBM DB2 On-site Training CourseIBM Korea
DB2 9.5 이상에서 제공하는 오라클 기능
DB2 9.5와 9.7 에서는 오라클에서 가장 많이 사용되는 함수 및 연산자 등을 DB2 에서 그대로 사용할 수 있는 기능을 제공합니다. 다음 함수와 연산자는 DB2 Registry 변수인 DB2_COMPATIBILITY_VECTOR를 설정해야 사용 가능합니다.
db2set DB2_COMPATIBILITY_VECTOR=08
SELECT name, LEVEL, salary, CONNECT_BY_ROOT name AS root, SUBSTR(SYS_CONNECT_BY_PATH(name, ':'), 1, 25) AS chain
FROM emp1 START WITH name = 'Goyal' CONNECT BY PRIOR empid = mgridORDER SIBLINGS BY salary;
SELECT name, LEVEL, salary, CONNECT_BY_ROOT name AS root, SUBSTR(SYS_CONNECT_BY_PATH(name, ':'), 1, 25) AS chain
FROM emp1 START WITH name = 'Goyal' CONNECT BY PRIOR empid = mgridORDER SIBLINGS BY salary;
db2set DB2_COMPATIBILITY_VECTOR=04
SELECT empname, deptnameFROM emp, dept WHERE emp.deptid = dept.deptid (+);
SELECT emp.empname, mgr.empname AS mgrnameFROM emp, dept, emp as mgrWHERE emp.deptid = dept.deptid (+)AND dept.mgrid = mgr.empid (+);
SELECT empname, deptnameFROM emp, dept WHERE emp.deptid = dept.deptid (+) ;
SELECT emp.empname, mgr.empname AS mgrnameFROM emp, dept, emp as mgrWHERE emp.deptid = dept.deptid (+)AND dept.mgrid = mgr.empid (+);
db2set DB2_COMPATIBILITY_VECTOR=02
SELECT * FROM DUAL;SELECT * FROM DUAL;
db2set DB2_COMPATIBILITY_VECTOR=01
SELECT * FROM TAB1 WHERE ROWNUM < 10 SELECT * FROM TAB1 WHERE ROWNUM < 10
DB2오라클

© Copyright IBM Corporation 2010150
IBM DB2 On-site Training CourseIBM Korea
DB2 9.5 이상에서 제공하는 오라클 함수
다음은 DB2 Registry 변수인 DB2_COMPATIBILITY_VECTOR 설정 없이도 그대로 사용 가능한 오라클 함수 또는 연산자의 예 입니다
SELECT SEQ.CURRVAL FROM SYSIBM.SYSDUMMY1;SELECT SEQ.NEXTVAL FROM SYSIBM.SYSDUMMY1;
SELECT SEQ.CURRVAL FROM DUAL;SELECT SEQ.NEXTVAL FROM DUAL;
SELECT * FROM T1 MINUS SELECT * FROM T2;SELECT * FROM T1 MINUS SELECT * FROM T2;
SELECT TO_DATE('2007/07/12','YYYY/MM/DD')FROM SYSIBM.SYSDUMMY1;
SELECT TO_DATE('2007/07/12','YYYY/MM/DD')FROM DUAL;
SELECT TO_CHAR(CURRENT TIMESTAMP,'MM/DD/YYYY')FROM SYSIBM.SYSDUMMY1;
SELECT TO_CHAR(sysdate,’MM/DD/YYYY’)FROM DUAL;
DB2오라클

© Copyright IBM Corporation 2010151
IBM DB2 On-site Training CourseIBM Korea
PL/SQL과 SQL PL 비교
오라클과 DB2는 모두 구조화 데이터베이스 프로그래밍 언어를 사용하여 서버 프로그램을 작성합니다. 오라클에서 사용되는 이러한언어를 PL/SQL이라 하며 DB2에서는 SQLPL이라 합니다.
설명
명령문
표준
정의
Oracle PL/SQL과 DB2 SQLPL은 모두 서버 프로그램 작성을 위한 언어로 Oracle PL/SQL 작성한 서버 프로그램을 DB2 SQLPL로 변환시킬수 있습니다. 그러나 DB2 SQLPL이 표준 SQL/PSM 을 따르는 방면 Oracle PL/SQL은 3세대 언어의 일부기능을 포함해 독자적으로 SQL 언어를 확장하였기 때문에 DB2 SQL PL 와 Oracle PL/SQL의 구문상 차이가 있습니다.
변수 관련 명령문조건문반복문제어 전달문오류 관리문결과 세트 조작문
모든 SQL문변수 및 상수 등의 선언문대입문조건 판단문제어 흐름문반복 처리문
표준 SQL/PSM(SQL Persistent Stored Modules) 언어의 서브세트표준 SQL과 표준 3세대 언어의 일부 기능을 포함한 SQL의 확장언어.
SQL PL(SQL Procedural Language)은 프로시저 및 함수를 작성하기 위해 SQL 과함께 사용하는 구조화 프로그래밍 언어로 복합 SQL문 및 프로시저를 작성하는기능을 개발자에게 제공합니다.
PL/SQL(Procedural Language/SQL)의 약어로 오라클 DB 환경에서실행되는 절차적인 데이터베이스 프로그래밍 언어입니다. 표준 SQL과 3세대 언어의 일부 기능을 포함한 SQL의 확장 언어로프로시저 및 함수 등 애플리케이션 로직을 작성합니다.
DB2 SQL PL오라클 PL/SQL
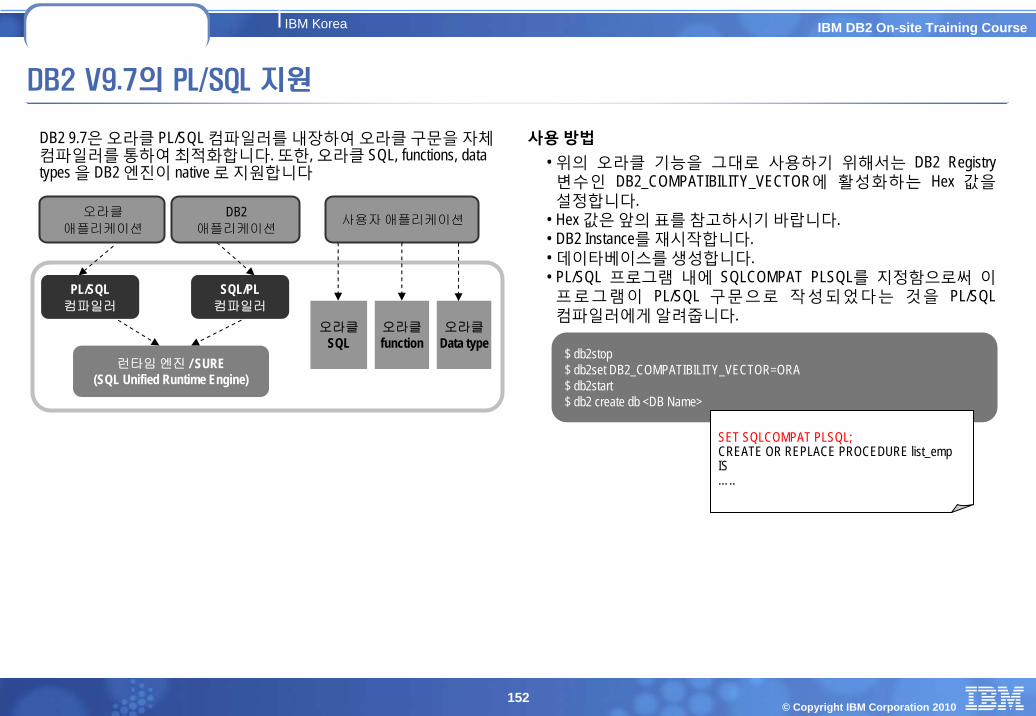
© Copyright IBM Corporation 2010152
IBM DB2 On-site Training CourseIBM Korea
DB2 V9.7의 PL/SQL 지원
DB2 9.7은 오라클 PL/SQL 컴파일러를 내장하여 오라클 구문을 자체컴파일러를 통하여 최적화합니다. 또한, 오라클 SQL, functions, data types 을 DB2 엔진이 native 로 지원합니다
오라클SQL
오라클function
오라클Data type
PL/SQL 컴파일러
SQL/PL 컴파일러
런타임엔진 / SURE(SQL Unified Runtime Engine)
오라클애플리케이션
DB2 애플리케이션
사용자애플리케이션
사용방법
• 위의 오라클 기능을 그대로 사용하기 위해서는 DB2 Registry 변수인 DB2_COMPATIBILITY_VECTOR에 활성화하는 Hex 값을설정합니다.
• Hex 값은 앞의 표를 참고하시기 바랍니다. • DB2 Instance를 재시작합니다. • 데이타베이스를 생성합니다. • PL/SQL 프로그램 내에 SQLCOMPAT PLSQL를 지정함으로써 이프로그램이 PL/SQL 구문으로 작성되었다는 것을 PL/SQL 컴파일러에게 알려줍니다.
$ db2stop$ db2set DB2_COMPATIBILITY_VECTOR=ORA$ db2start$ db2 create db <DB Name>
SET SQLCOMPAT PLSQL;CREATE OR REPLACE PROCEDURE list_empIS …..

© Copyright IBM Corporation 2010153
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 방법
• DDL변환 / Data 이관IBM Data Movement ToolOptim Development StudioInfosphere Federation Server
• 소스 변환원본 수정 없이 사용단순한 에러 수정로직 변경

© Copyright IBM Corporation 2010154
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 방법 : IDMT (IBM Data Movement Tool)
초기 화면
1. Connection Parameters
2. Connect
3. Select Source Schema
4. Indicates if Compatibility Features are ON
5. Output dir
7 Items to extract
6. Limit # of rows to extract

© Copyright IBM Corporation 2010155
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 방법 : IDMT (IBM Data Movement Tool)
DDL및 Data 추출
Check progress at the “View File” tab
DDL for objects using DB2 syntax *
DDL for objects using PL/SQL syntax
Script files Directories

© Copyright IBM Corporation 2010156
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 방법 : IDMT (IBM Data Movement Tool)
Deploy using the GUI
Extracted objects organized by type
Deploy ALL or SELECTED objects
Use the editor to make adjustments
Check deployment results
Deploy using the command line
• “db2gen.sh” (or “db2gen.cmd”) 스크립트 수행DDL생성 : 테이블,기본값,체크조건,PK,인덱스,시퀀스 등데이터로드 : 추출된 텍스트 파일로부터 로드무결성 검사: SET INTEGRITY 명령 실행제약조건 생성: Unique 또는 FK 생성
• “db2gen.log” 파일 검사데이터로드 중 발생한 에러가 있는지 메시지 파일, 덤프파일등을 확인
• PL/SQL 오브젝트 생성DDL 및 데이터 이관이 완료된 후“db2plsql_*.db2” 파일 실행PL/SQL코드 중 호환이 되지 않는 부분 수정
db2 –tvf db2plsql_type.db2db2 –tvf db2plsql_type_body.db2db2 –tvf db2plsql_package.db2db2 –tvf db2plsql_package_body.db2db2 –tvf db2plsql_function.db2db2 –tvf db2plsql_views.db2db2 –tvf db2plsql_procedures.db2db2 –tvf db2plsql_triggers.db2

© Copyright IBM Corporation 2010157
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 방법 : Optim Development Studio (ODS)
개요
• 데이터베이스 오브젝트, 쿼리, 데이터베이스 로직 등을 개발하고테스트하는 개발환경 제공
• 오라클 마이그레이션을 위한 기능 제공DDL과 데이터 이동IBM과 오라클 이기종간 마이그레이션 개발 환경PL/SQL 지원 (개발 및 디버깅)
• IBM의 통합 데이터 관리 참조www.ibm.com/developerworks/spaces/optim
간편한 오브젝트 마이그레이션
• Copy & Paste로 간편하게 오브젝트 마이그레이션ODS 2.2 : 테이블,인덱스,뷰,제약조건,PL/SQL(프로시저,함수)ODS 2.2.0.1 : 트리거,사용자정의타입,시쿼스,동의어(synonyms)DB2 ⇔ DB2, Oracle ⇔ Oracle, Oracle ⇔ DB2
Copy objects from source connection
Paste to target connection

© Copyright IBM Corporation 2010158
IBM DB2 On-site Training CourseIBM Korea
마이그레이션 방법 : Infosphere Federation Server 사용
IFS를 이용한 마이그레이션
• DDL생성Federation으로 연결된 Oracle테이블의 컬럼 정보를 수집하여DB2의 DDL로 작성 후 수행
• 데이터 이관Federation으로 연결된 Oracle테이블에서 직접 select하여 데이터파일 생성 없이 바로 DB2 테이블로 로드
매뉴얼 마이그레이션
• DDL생성Oracle에서 생성된 DDL을 DB2에서 직접 수행
• 데이터 이관Oracle에서 테이블 별로 데이터를 추출하여 파일로 저장저장된 파일을 DB2서버로 전송하여 데이터 로드
DB2 서버
DB2 instanceFederation
Server
OracleClient Oracle서버
table
database
nickname
Wrapper
Server
User mapping
table
create wrapper net8 ;create server pcsserver type oracle version 10 wrapper net8
authorization pcscar password db2igrp1 options (NODE 'db2_test2',varchar_no_trailing_blanks 'Y') ;
create user mapping for db2inst1 server pcsserveroptions (remote_authid 'pcscar', remote_password 'db2igrp1') ;
create nickname db2inst1.T_PK_N for pcsserver.pcscar.T_PK;

© Copyright IBM Corporation 2010159
IBM DB2 On-site Training CourseIBM Korea
소스변환 : Native support
New DB2 Types
• NUMBER / VARCHAR2 / Oracle DATE / TIMESTAMP(n) / BOOLEAN• VARRAY / INDEX BY / ROW TYPE / Reference Cursor Type
New Functions
• Conversion and FormattingTO_CHAR,TO_DATE,TO_TIMESTAMP,TO_NUMBER,TO_CLOB, …
• Date/Time ArithmeticEXTRACT,ADD_MONTHS,MONTHS_BETWEEN,NEXTDAY, …
• String ManipulationINITCAP,RPAD,LPAD,INSTR,REVERSE,SUBSTR extensions, …
• MiscellaneousDECODE,NVL,LEAST,GREATEST,BITAND, …
New Dialect
• CONNECT BY / (+) Join Syntax / DUAL Table / ROWNUM Pseudo column• ROWID Pseudo Column / NEXTVAL, CURVAL / MINUS operator• PUBLIC Synonym / CREATE TEMPORARY TABLE / TRUNCATE statement• Relaxed Name Resolution
Common Built-in Oracle Packages
• DBMS_OUTPUT, UTL_FILE, UTL_MAIL, UTL_SMTP, DBMS_ALERT• DBMS_SQL, DBMS_PIPE, DBMS_JOB, DBMS_LOB, DBMS_UTILITY
PL/SQL compatibility
• 별도의 Oracle PL/SQL 컴파일러 사용기존 Oracle 소스를 DB2에서 수행하기 위해 소스의 첫 라인에SQL 호환성을 위한 지시문을 지정set sqlcompat plsql
• CREATE PACKAGE / Package Body / Variable / Cursor / Exception, …
set sqlcompat plsql@create or replace procedure IOHistoryBatchIS
v_err_code t_procedure_error.SQL_CODE%type;v_sql_errm t_procedure_error.SQL_ERRM%type;v_predate number := 4;v_out_cnt number := 0;v_out_cursor number;v_realout_time T_IO_HISTORY.OUTTIME%TYPE;
--중략 --
EXCEPTIONWHEN OTHERS THEN
v_err_code := TO_CHAR(SQLCODE);v_sql_errm := SQLERRM;INSERT INTO T_PROCEDURE_ERROR
VALUES ((SELECT NVL(MAX(ERRID), 0)+1 FROM T_PROCEDURE_ERROR),
'IOHistory', v_err_code, v_sql_errm, SYSDATE);COMMIT;
END@

© Copyright IBM Corporation 2010160
IBM DB2 On-site Training CourseIBM Korea
소스변환 : 변환
• 에러 유형 파악에러 코드 분석 후 에러 로그 유형을 파악한다.
• 에러 유형원하는 업무를 구현하기 위해 SQL 문법의 사소한 변경이 필요
- PK key 지정 (not null 명시)원하는 업무를 구현하기 위해 SQL 문법의 변경이 필요하나로직 변경은 필요하지 않는 경우
- 외부 함수 활용원하는 업무를 구현하기 위해 SQL 로직 변경이 필요한 경우
- 배열 처리 사용 등

© Copyright IBM Corporation 2010161
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
테이블 변환
• DB2에서 DEFAULT절에 FUNCTION 사용 불가하여 Trigger 등을 이용하여 구현 필요
CREATE TABLE TBOARD (NO NUMBER NOT NULL,SUBJECT VARCHAR2(80 BYTE) NOT NULL,BOARD_GROUP VARCHAR2(2 BYTE),EMAIL VARCHAR2(30 BYTE),REGDATE VARCHAR2(8 BYTE) NOT NULL,
CREATE TABLE TBOARD (NO NUMBER NOT NULL,SUBJECT VARCHAR2(80 BYTE) NOT NULL,BOARD_GROUP VARCHAR2(2 BYTE),EMAIL VARCHAR2(30 BYTE),REGDATE VARCHAR2(8 BYTE)
DEFAULT TO_CHAR(SYSDATE,'YYYYMMDD') NOT NULL,
Oracle DB2

© Copyright IBM Corporation 2010162
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
뷰 변환
• DB2에서는 뷰 생성시 order by 문을 제거하고 실제 뷰 호출시 order by문을 사용
CREATE OR VIEW [XI_LHJ_PROGRAM_V AS……
SQL> SELECT * FROM [XI_LHJ_PROGRAM_VORDER BY JOB_FG,
PGM_ORDER,P2.PGM_ORDER,P3.PGM_ORDER,P4.PGM_ORDER;
CREATE OR VIEW XI_LHJ_PROGRAM_V …ORDER BY P1.JOB_FG,
P1.PGM_ORDER,P2.PGM_ORDER,P3.PGM_ORDER,P4.PGM_ORDER;
SQL> SELECT * FROM XI_LHJ_PROGRAM_V
Oracle DB2

© Copyright IBM Corporation 2010163
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
트리거 변환
• 멀티 액션 트리거는 Oracle이나 DB2에서 단일 액션 트리거로 변경
SQL> SELECT TRIGGER_TYPE,TRIGGERING_EVENT, TABLE_NAME FROM DBA_TRIGGERS WHERE OWNER='MARTNIS' AND TRIGGER_NAME LIKE 'SUMA_PROD_CD_MAP%'
TRIGGER_TYPE TRIGGERING_EVENT TABLE_NAME --------------- ------------------- ----------------AFTER ROW DML SUMA_PROD_CD_MAP AFTER ROW DML SUMA_PROD_CD_MAP
SQL> SELECT TRIGGER_TYPE,TRIGGERING_EVENT, TABLE_NAME FROM DBA_TRIGGERS WHERE TRIGGER_NAME LIKE 'SUMA_PROD_CD_MAP%'
TRIGGER_TYPE TRIGGERING_EVENT TABLE_NAME --------------- ------------------- ----------------AFTER EACH ROW UPDATE OR DELETE SUMA_PROD_CD_MAP
--트리거분할작업후생성한단일액션트리거
AFTER EACH ROW DELETE SUMA_PROD_CD_MAP AFTER EACH ROW UPDATE SUMA_PROD_CD_MAP
Oracle DB2

© Copyright IBM Corporation 2010164
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
프로시저
• 커서 파라매터 처리
CURSOR C_LGCTMP (GEGOCNT number, AS_STORECD varchar2, AS_STDDT varchar2, AS_FRRDT varchar2) IS
SELECT AS_STORECD,AS_STDDT, a.TJAJAECD,BJAJAECD,SUM(INQTY1)/ b.SINUNIT ,SUM(OUTQTY1)/ b.SINUNIT,(SUM(TOTQTY) + SUM(INQTY1) - SUM(OUTQTY1)) / b.SINUNIT,SUM(INQTY2) / b.SINUNIT ,SUM(OUTQTY2)/ b.SINUNIT,
CURSOR C_LGCTMP(GEGOCNT number ) ISSELECT AS_STORECD,
AS_STDDT, a.TJAJAECD,BJAJAECD,SUM(INQTY1)/ b.SINUNIT ,SUM(OUTQTY1)/ b.SINUNIT,(SUM(TOTQTY) + SUM(INQTY1) - SUM(OUTQTY1)) / b.SINUNIT,SUM(INQTY2) / b.SINUNIT ,SUM(OUTQTY2)/ b.SINUNIT, …
Oracle DB2

© Copyright IBM Corporation 2010165
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
프로시저
• 배열 선언
--외부에서패키지로선언CREATE OR REPLACE PACKAGE PSERVER.PKG_TYPEISTYPE ARR_MATECODE IS TABLE OF CHAR(2) INDEX BY BINARY_INTEGER;TYPE ARR_ATIME IS TABLE OF CHAR(6) INDEX BY BINARY_INTEGER;TYPE ARR_BTIME IS TABLE OF CHAR(6) INDEX BY BINARY_INTEGER;TYPE ARR_CTIME IS TABLE OF CHAR(6) INDEX BY BINARY_INTEGER;TYPE ARR_BOGUNSUDANG IS TABLE OF NUMBER(8) INDEX BY BINARY_INTEGER;
END pkg_type
--소스안에포함TYPE ARR_MATECODE IS TABLE OF CHAR(2) INDEX BY BINARY_INTEGER;TYPE ARR_ATIME IS TABLE OF CHAR(6) INDEX BY BINARY_INTEGER;TYPE ARR_BTIME IS TABLE OF CHAR(6) INDEX BY BINARY_INTEGER;TYPE ARR_CTIME IS TABLE OF CHAR(6) INDEX BY BINARY_INTEGER;TYPE ARR_BOGUNSUDANG IS TABLE OF NUMBER(8) INDEX BY BINARY_INTEGER;
Oracle DB2

© Copyright IBM Corporation 2010166
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• JOIN UPDATE문을 MERGE INTO문으로 로직 재작성
MERGE INTO LGC209 A USING ( SELECT YOGUDATE, CLSDATE FROM COM830 ) B
ON A.YOGUDATE = B.YOGUDATE AND B.CLSDATE = TO_CHAR(SYSDATE, 'YYYYMMDD')AND A.CHKFLG = '0'AND A.ORDGBN IN ('01', '02')
WHEN MATCHED THEN UPDATE SET A.CHKFLG ='1';
UPDATE --(
SELECT A.YOGUDATE AS A_YOGUDATE, A.STORECD AS A_STORECD, A.JAJAECD AS A_JAJAECD, A.CHKFLG AS A_CHKFLG
FROM LGC209 A, COM830 B
WHERE A.YOGUDATE = B.YOGUDATEAND B.CLSDATE = TO_CHAR(SYSDATE, 'YYYYMMDD')AND A.CHKFLG = '0'AND A.ORDGBN IN ('01', '02')
)SET A_CHKFLG = '1';
Oracle DB2

© Copyright IBM Corporation 2010167
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• Nvl(decode(sum())) 문장 수정
SELECT SUM(C1) AS C1, SUM(C2) AS C2, SUM(C3) AS C3
FROM ( SELECT
DECODE(KEY_TRAN_ID,'01',COUNT(KEY_TRAN_ID),COUNT(KEY_TRAN_ID)*-1) C1,DECODE(KEY_TRAN_ID,'01',SUM(SALE_AMT1),'02',SUM(SALE_AMT1)*-1) C2,DECODE(KEY_TRAN_ID,'01',SUM(SALE_AMT2),'02',SUM(SALE_AMT2)*-1) C3
FROM PTRLOG.T_LOG_CARDWHERE KEY_BUSINESS_DATE = AS_APPLYDT
AND KEY_STORE_CODE = AS_SHOPCDAND CARD_GBN = '01'
GROUP BY KEY_TRAN_ID)) C,
(SELECT NVL ( SUM ( DECODE ( KEY_TRAN_ID,'01',COUNT(KEY_TRAN_ID),COUNT(KEY_TRAN_ID)*-1)
), 0 ) C1, NVL ( SUM ( DECODE ( KEY_TRAN_ID,'01',SUM(SALE_AMT1),'02',SUM(SALE_AMT1)*-1)
) ,0) C2,NVL ( SUM ( DECODE (KEY_TRAN_ID,'01',SUM(SALE_AMT2),'02',SUM(SALE_AMT2)*-1)
),0) C3FROM T_LOG_CARD@PTRLOGWHERE KEY_BUSINESS_DATE = AS_APPLYDT
AND KEY_STORE_CODE = AS_SHOPCDAND CARD_GBN = '01'
GROUP BY KEY_TRAN_ID) C,
Oracle DB2

© Copyright IBM Corporation 2010168
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• Null 입력 방법
SELECT ... FOOTNM4,’’,...INTO I_IP2, I_IP3, I_IP4,I_COMGBN
FROM COM110WHERE STORECD = AS_SHOPCD;
SELECT ... FOOTNM4,NULL,...INTO I_IP2, I_IP3, I_IP4,I_COMGBN
FROM COM110WHERE STORECD = AS_SHOPCD;
Oracle DB2

© Copyright IBM Corporation 2010169
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• BETWEEN 혹은 비교 연산자 사용 시 비교 대상 DATA TYPE을 명시적으로 동일하게 정의
SELECT MAX(HistoryNo)INTO lCountFROM TReceiptHistoryWHERE WCode = pWCode AND Lot = lLot AND Qty > 0 AND AddTime BETWEEN DATE((SYSDATE - lMethodTermDay1))
AND DATE((SYSDATE - lMethodTermDay2));
SELECT MAX(HistoryNo)INTO lCountFROM TReceiptHistoryWHERE WCode = pWCode AND Lot = lLot AND Qty > 0 AND AddTime BETWEEN (SYSDATE - lMethodTermDay1))
AND (SYSDATE - lMethodTermDay2);
Oracle DB2

© Copyright IBM Corporation 2010170
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• JOIN UPDATE문을 MERGE INTO문으로 로직 재작성
MERGE INTO LGC209 A USING ( SELECT YOGUDATE, CLSDATE FROM COM830 ) B
ON A.YOGUDATE = B.YOGUDATE AND B.CLSDATE = TO_CHAR(SYSDATE, 'YYYYMMDD')AND A.CHKFLG = '0'AND A.ORDGBN IN ('01', '02')
WHEN MATCHED THEN UPDATE SET A.CHKFLG ='1';
UPDATE --(
SELECT A.YOGUDATE AS A_YOGUDATE, A.STORECD AS A_STORECD, A.JAJAECD AS A_JAJAECD, A.CHKFLG AS A_CHKFLG
FROM LGC209 A, COM830 B
WHERE A.YOGUDATE = B.YOGUDATEAND B.CLSDATE = TO_CHAR(SYSDATE, 'YYYYMMDD')AND A.CHKFLG = '0'AND A.ORDGBN IN ('01', '02')
)SET A_CHKFLG = '1';
Oracle DB2

© Copyright IBM Corporation 2010171
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• inline view 안에서는 order by 구문은 생략
SELECT ...FROM DY_FWD_STK E,
(SELECT ...FROM STR_ORG A,PART_CAT B
WHERE A.STR_ORG1_CD = :INPUT.A_STR_CD…
) C,DY_STK F,CATEGORY G,…
SELECT /*+ORDERED USE_HASH(E C F G) INDEX(E DY_FWD_STK_PK) */...FROM DY_FWD_STK E,
(SELECT ... FROM STR_ORG A,PART_CAT B
WHERE A.STR_ORG1_CD = :INPUT.A_STR_CD…
ORDER BY B.CAT_CD) C,DY_STK F,CATEGORY G,…
Oracle DB2

© Copyright IBM Corporation 2010172
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• 문법 변경
SELECT R.DETAIL_VAL1FROM ALL_CD R
WHERE R.GRP_CD = 'VMI01'AND SUBSTR(R.DETAIL_CD,1,LENGTH(A.STR_CD)= A.STR_CD
SELECT R.DETAIL_VAL1FROM ALL_CD R
WHERE R.GRP_CD = 'VMI01'AND R.DETAIL_CD LIKE A.STR_CD||'%'
Oracle DB2

© Copyright IBM Corporation 2010173
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• Decode 조건 문 에서 첫 파라매터 값을 사용자 정의 함수로 사용하는 경우에는 case문으로 변경
SELECT CASE WHEN COOPER_EVT_CODE_FNC(A.STR_CD, DECODE(A.CANCEL_FG,'0',A.SALE_DY,
A.ORGIN_SALE_DY),A.CRED_CARD_NO, A.DIV_PAY_MM) = '000000' THEN 'OK'
ELSE 'STOP' END FROM CARD_SALE A
SELECT DECODE (COOPER_EVT_CODE_FNC(A.STR_CD,DECODE(A.CANCEL_FG,'0',A.SALE_DY,
A.ORGIN_SALE_DY),A.CRED_CARD_NO, A.DIV_PAY_MM) , '000000','OK','STOP')
FROM CARD_SALE A
Oracle DB2

© Copyright IBM Corporation 2010174
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• 단순화 : Connect by문 사용시 단순히 1-99999 숫자를 불러오는 경우에는 해당 작업용 테이블을 먼저 생성 후 사용
SELECT SUBSTR('20100429',4,1) || MIN(EVT_SEQ) EVT_CDFROM ( SELECT LPAD(B.SEQ, 5, '0') EVT_SEQ
FROM (SELECT * FROM DUAL ) A,(SELECT VNO SEQ FROM MAN1) BMINUSSELECT SUBSTR(EVT_CD, 2)
FROM PST_EVT
SELECT SUBSTR('20100429',4,1) || MIN(EVT_SEQ) EVT_CDFROM ( SELECT LPAD(B.SEQ, 5, '0') EVT_SEQ
FROM (SELECT * FROM DUAL ) A,(SELECT ROWNUM SEQ FROM DUAL
CONNECT BY LEVEL < 100000) BMINUSSELECT SUBSTR(EVT_CD, 2)FROM PST_EVT
SQL>SELECT ROWNUM CNT FROM DUAL CONNECT BY LEVEL <= 2
CNT ------1 2
Oracle DB2

© Copyright IBM Corporation 2010175
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• Min(rownum) 는 DB2에서는 인라인 뷰로 SQL문을 재구성
SELECT PROD_CD,SUM(EXPT_SALE ) AS EXPT_SALE ,SUM(PREPARE_QTY) AS PREPARE_QTY, MIN(PROD_SEQ)
FROM ( SELECT PROD_CD,EXPT_SALE AS EXPT_SALE ,PREPARE_QTY AS PREPARE_QTY,ROWNUM AS PROD_SEQ
FROM PST_EVT_PRODWHERE EVT_CD = '050064‘)
GROUP BY PROD_CD
SELECT PROD_CD,SUM(EXPT_SALE) AS EXPT_SALE ,SUM(PREPARE_QTY) AS PREPARE_QTY,MIN(ROWNUM) AS PROD_SEQ
FROM PST_EVT_PRODWHERE EVT_CD = '050064' -- :A_EVT_CDGROUP BY PROD_CD
Oracle DB2

© Copyright IBM Corporation 2010176
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• Group by 에서 사용자 함수 사용시 에러발생 한 경우에는 Inline view를 활용
SELECT AA.EVT_CD, MAX(M1) FROM (
SELECT COOPER_EVT_CODE_FNC(A.STR_CD, DECODE(A.CANCEL_FG,'0',A.SALE_DY,
A.ORGIN_SALE_DY),A.CRED_CARD_NO, A.DIV_PAY_MM) EVT_CD,
A.DIV_PAY_MM M1FROM CARD_SALE A ) AA
GROUP BY AA.EVT_CD
SELECT COOPER_EVT_CODE_FNC(A.STR_CD, DECODE(A.CANCEL_FG,'0',A.SALE_DY,
A.ORGIN_SALE_DY),A.CRED_CARD_NO, A.DIV_PAY_MM) EVT_CD,
MAX(A.DIV_PAY_MM) M1FROM CARD_SALE A
GROUP BY COOPER_EVT_CODE_FNC(A.STR_CD, DECODE(A.CANCEL_FG,'0',A.SALE_DY,
A.ORGIN_SALE_DY),A.CRED_CARD_NO, A.DIV_PAY_MM)
Oracle DB2

© Copyright IBM Corporation 2010177
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
Query 변환
• Lengthb 함수는 length함수로 대체
SELECT 'ALL11', B.STR_CD||SUBSTR(A.DETAIL_CD,4,2) AS DETAIL_CD, SUBSTR(B.IP,1,LENGTH(B.IP)-1)|| DECODE(A.DETAIL_VAL2,'G','1','2') || '|DIST|DIST' AS DETAIL_NM, DECODE(A.DETAIL_VAL2,'G',B.STR_NM||'메인',B.STR_NM) AS DETAIL_VAL1, A.DETAIL_VAL2 - (G-SERVER), SYSDATE, '999999999',SYSDATE,'999999999','I'
FROM ALL_CD A,
SELECT 'ALL11', B.STR_CD||SUBSTR(A.DETAIL_CD,4,2) AS DETAIL_CD, SUBSTR(B.IP,1,LENGTHB(B.IP)-1)|| DECODE(A.DETAIL_VAL2,'G','1','2') || '|DIST|DIST' AS DETAIL_NM, DECODE(A.DETAIL_VAL2,'G',B.STR_NM||'메인',B.STR_NM) AS DETAIL_VAL1, A.DETAIL_VAL2 - (G-SERVER), SYSDATE, '999999999',SYSDATE,'999999999','I'
FROM ALL_CD A,
Oracle DB2

© Copyright IBM Corporation 2010178
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
트리거 변환
• 멀티 이벤트 트리거는 단일 이벤트 트리거로 변경 하시면 됩니다
CREATE TRIGGER "PSERVER"."TR_ACC150_INS"AFTER INSERT ON PSERVER.ACC150FOR EACH ROWDECLAREBEGIN
….….
END TR_ACC150;
CREATE TRIGGER PSERVER.TR_ACC150_DELAFTER DELETE ON PSERVER.ACC150FOR EACH ROWDECLAREBEGIN
….….
END ;
CREATE TRIGGER PSERVER.TR_ACC150AFTER INSERT OR DELETE OR UPDATE ON ACC150FOR EACH ROWDECLAREBEGIN
IF INSERTING OR UPDATING THEN….….END IF;
END TR_ACC150;
Oracle DB2

© Copyright IBM Corporation 2010179
IBM DB2 On-site Training CourseIBM Korea
소스 마이그레이션 예제
DB Link변환
• Inforsphere Federation Server 활용으로 구현 가능
SQL> CREATE NICKNAME MARTLIS.UNSUPPLY FOR ORACLE.MARTLIS.ORD_PROD_REG --닉네임생성
SQL> SELECT COUNT(*) FROM MARTLIS. GET_LOGI_ORD_QTY_FNC
SQL> SELECT COUNT(*) FROM UNSUPPLY@MARTNIS
Oracle DB2

© Copyright IBM Corporation 2010180
IBM DB2 On-site Training CourseIBM Korea
샘플 소스
modules.db2매개변수로 데이터 유형과 커서를 프로시저 및 함수에 전달하는방법
모듈 (오라클의 패키지)
datecompat.db2날짜 호환 모드에서의 DATE 형식, DATE 더하기 및 빼기, 스칼라함수 및 DATE 데이터 유형(예: TIMESTAMP(0)
날짜 호환성 기능
defaultparam.db2CREATE PROCEDURE 및 CALL문에서 DEFAULT 키워드 사용디폴트 매개변수
public_alias.db2테이블 및 모듈과 같은 데이터베이스 오브젝트에 공용 별명 사용공용 별명
제한된 데이터에 액세스하려 할 때 이벤트를 추적하는 방법
중간 결과를 저장하는 방법과, 작성된 임시 테이블을 프로시저, 함수, 트리거 및 뷰에 사용하는 방법
데이터 유형 지정, 비교 및 널(NULL) 값에 내재된 캐스팅을 사용
사용자 정의 함수(UDF)를 사용
잠금 대기 및 교착 상태 시나리오를 방지하는 방법
설명
cgtt.db2 및 Cgtt.java임시 테이블 작성
%DB2PATH%\sqllib\samples\java\Websphere향상된 동시성에 대한
현재 커미트된 시멘틱
autonomous_transaction.db2자율 트랜잭션
implicitcasting.db2 및 ImplicitCasting.java내재된 캐스팅
개선된 스칼라 함수
DB2 9.7 지원 사항 샘플(FixPack 2 포함)
scalarfunction.db2 및 ScalarFunctions.java
Remark (별첨 제공)

© Copyright IBM Corporation 2010181
IBM DB2 On-site Training CourseIBM Korea
부록
1. IBM Movement Tool : www.ibm.com/developerworks/data/library/techarticle/dm-0906datamovement/index.html
2. Optim Development Studio 2.2 www.ibm.com/developerworks/spaces/optim
3. DB2 9.7 FixPack2 www-01.ibm.com/support/docview.wss?uid=swg27007053
4. DB2 9.7 FixPack2 추가된 기능 설명publib.boulder.ibm.com/infocenter/db2luw/v9r7/index.jsp?topic=/com.ibm.db2.luw.wn.doc/doc/c0056050.html

© Copyright IBM Corporation 2010182
IBM DB2 On-site Training CourseIBM Korea
End of Document




















