
DB2 pureScale High Availability: Internals and Customer ...
49
DB2 pureScale High Availability: Internals and Customer Experiences Aamer Sachedina IBM Session Code: C13 Fri, May 3, 2013 (08:00-9:00 AM)| Platform: DB2 for LUW
-
Upload
khangminh22 -
Category
Documents
-
view
4 -
download
0
Transcript of DB2 pureScale High Availability: Internals and Customer ...

DB2 pureScale High Availability:
Internals and Customer Experiences
Aamer Sachedina
IBM
Session Code: C13Fri, May 3, 2013 (08:00-9:00 AM)| Platform: DB2 for LUW

Click to edit Master title style
Agenda
• DB2 pureScale Technology Overview
• DB2 Cluster Services Technology Overview
• DB2 Cluster Services Externals
• DB2 Cluster Services Internals
• High Availability: Customer Experiences
2
Click to edit Master title style
Cluster Interconnect
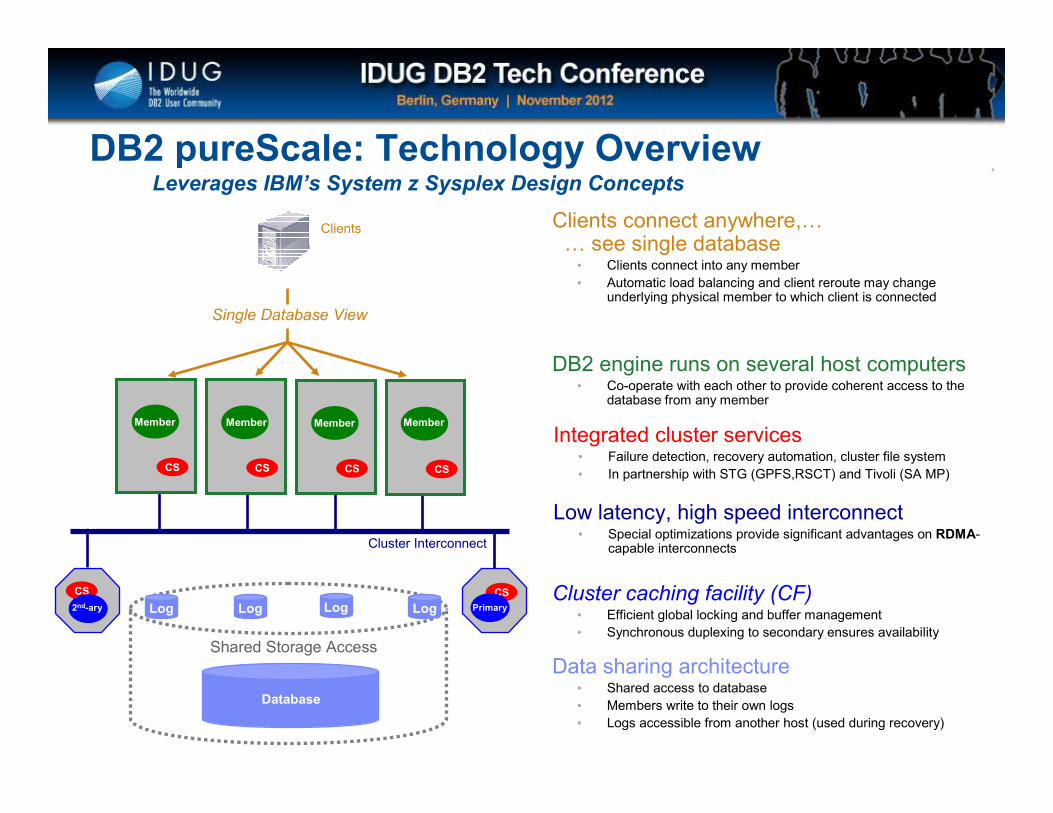
DB2 pureScale: Technology Overview
Single Database View
Clients
Database
Log Log Log Log
Shared Storage Access
CS CS CSCS
CS CS
CS
Member Member Member Member
Primary2nd-ary
DB2 engine runs on several host computers• Co-operate with each other to provide coherent access to the
database from any member
Data sharing architecture • Shared access to database
• Members write to their own logs
• Logs accessible from another host (used during recovery)
Cluster caching facility (CF)• Efficient global locking and buffer management
• Synchronous duplexing to secondary ensures availability
Low latency, high speed interconnect• Special optimizations provide significant advantages on RDMA-
capable interconnects
Clients connect anywhere,77 see single database
• Clients connect into any member
• Automatic load balancing and client reroute may change underlying physical member to which client is connected
Integrated cluster services• Failure detection, recovery automation, cluster file system
• In partnership with STG (GPFS,RSCT) and Tivoli (SA MP)
Leverages IBM’s System z Sysplex Design Concepts

Click to edit Master title style
CF
DB2 Cluster Services
DB2 Cluster Services: Cluster File System
(GPFS)
DB2 Cluster Services: Cluster Manager (RSCT) Cluster Automation (Tivoli SA MP)
DB2DB2 DB2 DB2 DB2
CF
• RSCT, Tivoli SA MP, GPFS and DB2 code that ties these componentstogether in pureScale
• Single install as part of DB2 installation• Upgrades and maintenance through DB2 fixpacks• Designed to interact with DBA
Click to edit Master title style
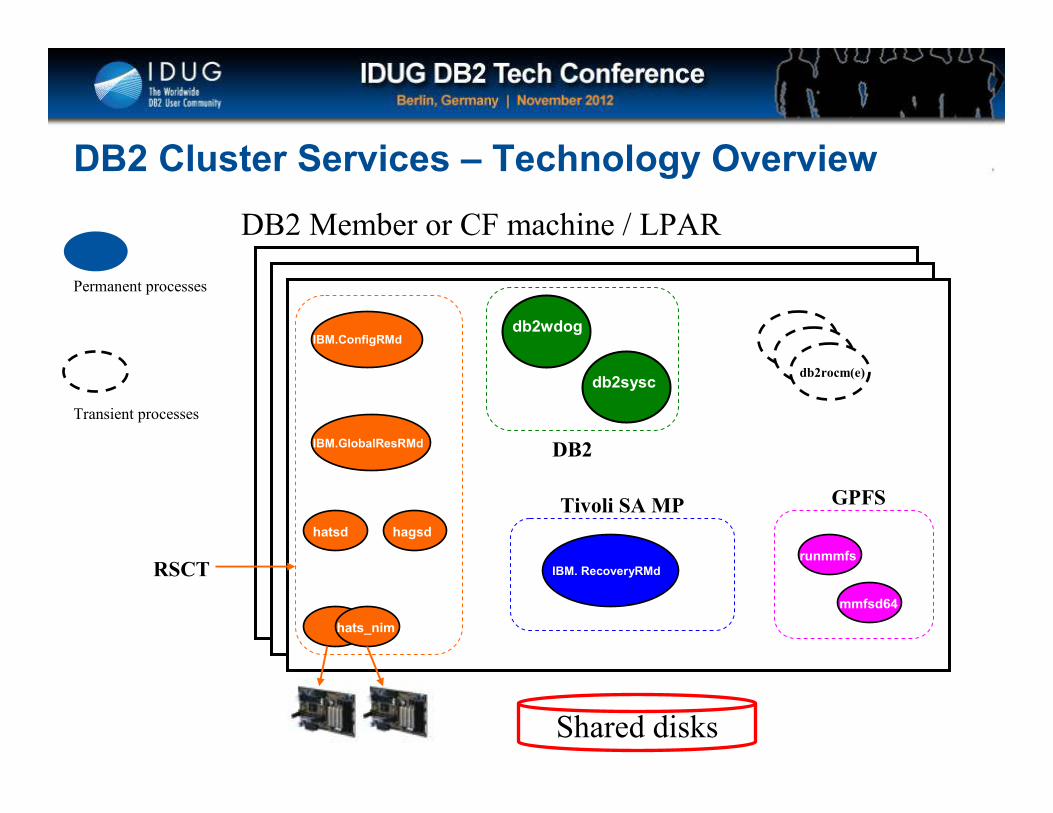
DB2 Cluster Services – Technology Overview
DB2 Member or CF machine / LPAR
db2sysc
Shared disks
db2wdog
Permanent processes
Transient processes
hats_nim
hatsd hagsd
IBM.GlobalResRMd
IBM. RecoveryRMd
IBM.ConfigRMd
runmmfs
mmfsd64
db2rocm(e)
RSCT
Tivoli SA MP
DB2
GPFS

Click to edit Master title style
DB2 cluster services - Externals
$> db2instance –list
ID TYPE STATE HOME_HOST CURRENT_HOST ALERT PART_NUM L_PORT NETNAME
-- ---- ----- --------- ------------ ----- ------- ------ ------------
0 MEMBER STARTED host1 host1 NO 0 0 host1-ib0
1 MEMBER STARTED host2 host2 NO 0 0 host2-ib0
128 CF PRIMARY host3 host3 NO - 0 host3-ib0
129 CF PEER host4 host4 NO - 0 host4-ib0
HOSTNAME STATE INSTANCE_STOPPED ALERT
-------- ----- ---------------- -----
Host1 ACTIVE NO NO
Host2 ACTIVE NO NO
host3 ACTIVE NO NO
host4 ACTIVE NO NO

Click to edit Master title style7
Member and CF States & Alerts
■The state of a host, a member or a cluster caching facility reflects the current operational capacity of the object in question.
■ HOST state• ACTIVE or INACTIVE – Host is available / unavailable for use
■ CF state•STOPPED - CF has been manually stopped using the db2stop command
•RESTARTING - CF is in the process of starting, either from the db2start command, or after a CF failure.
•BECOMING PRIMARY – CF attempts to take on the role of the primary CF
•PRIMARY – CF is operating as the primary CF
•CATCHUP (% n) – Secondary CF is retrieving information from primary
•PEER – CF is the secondary
•ERROR – An error occurred on the CF
■ Member state•STARTED – Member is started and operating normally
•STOPPED – Member has been manually stopped using the db2stop command
•RESTARTING – Member is restarting, either from the db2start command, or after a member failure
•WAITING_FOR_FAILBACK – Member is waiting to fail back to it's home host
•ERROR – Member could not automatically be restarted
Click to edit Master title style8
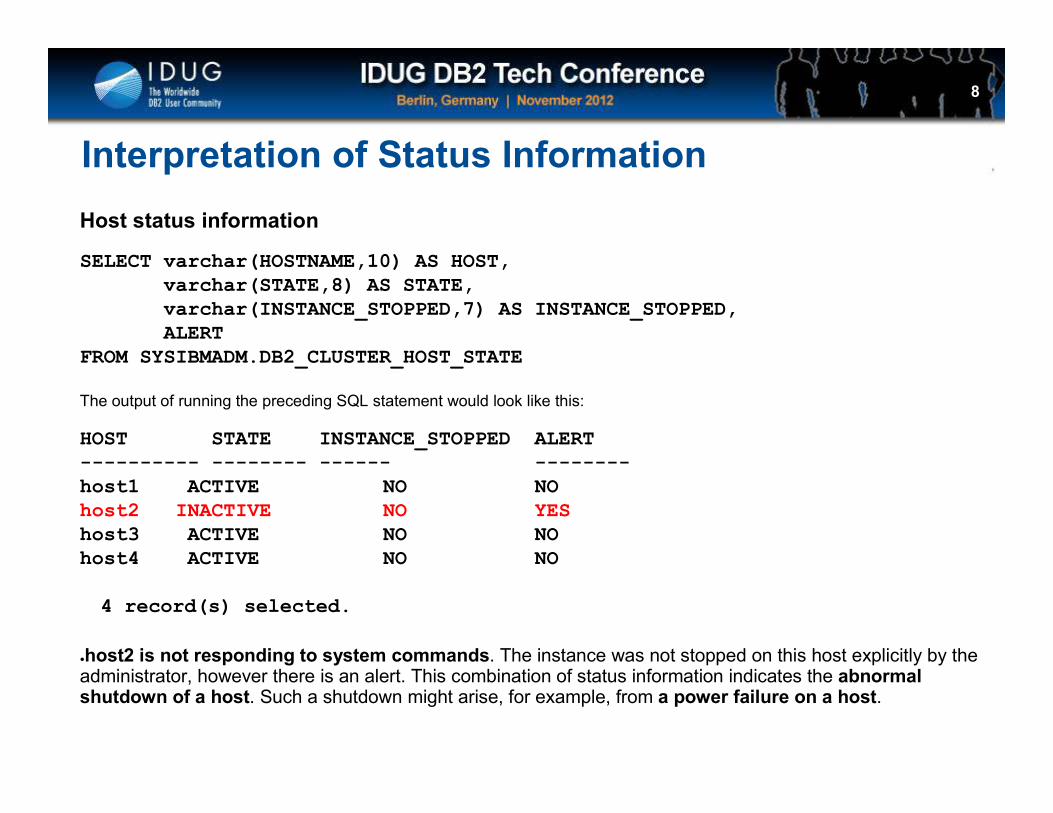
Interpretation of Status Information
Host status information
SELECT varchar(HOSTNAME,10) AS HOST,varchar(STATE,8) AS STATE, varchar(INSTANCE_STOPPED,7) AS INSTANCE_STOPPED, ALERT
FROM SYSIBMADM.DB2_CLUSTER_HOST_STATE
The output of running the preceding SQL statement would look like this:
HOST STATE INSTANCE_STOPPED ALERT---------- -------- ------ --------host1 ACTIVE NO NOhost2 INACTIVE NO YEShost3 ACTIVE NO NOhost4 ACTIVE NO NO
4 record(s) selected.
●host2 is not responding to system commands. The instance was not stopped on this host explicitly by the administrator, however there is an alert. This combination of status information indicates the abnormal shutdown of a host. Such a shutdown might arise, for example, from a power failure on a host.
Click to edit Master title style9
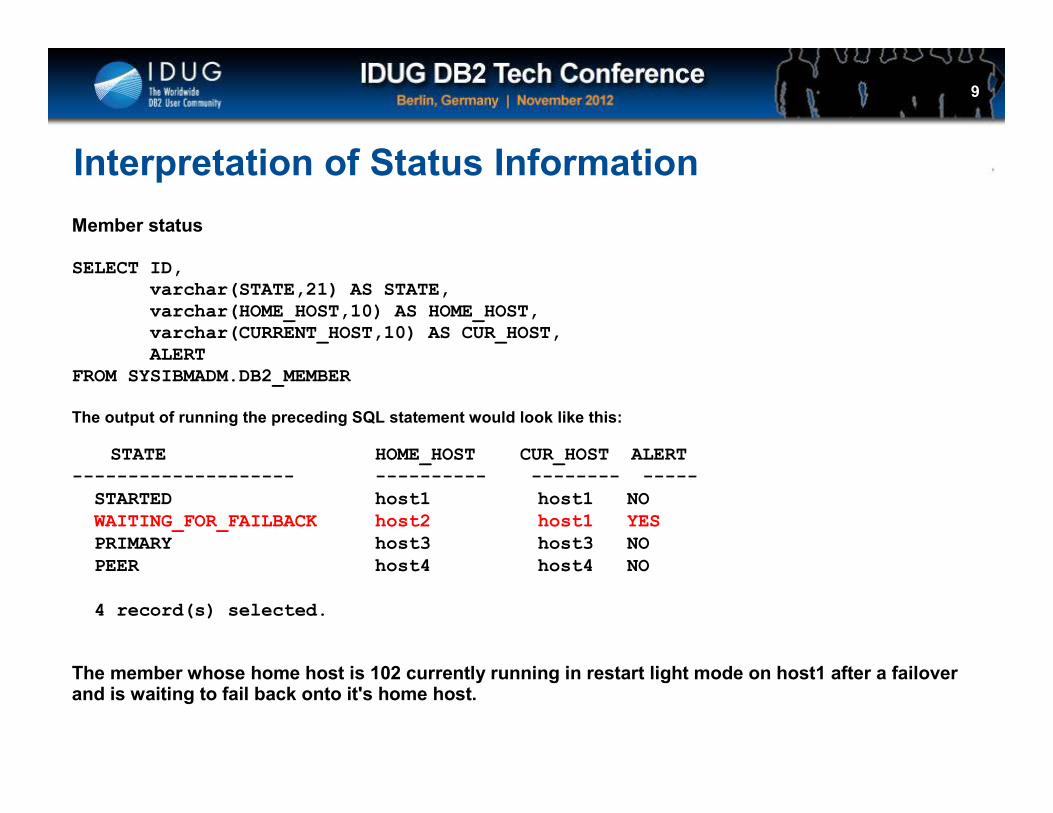
Interpretation of Status Information
Member status
SELECT ID, varchar(STATE,21) AS STATE, varchar(HOME_HOST,10) AS HOME_HOST, varchar(CURRENT_HOST,10) AS CUR_HOST, ALERT
FROM SYSIBMADM.DB2_MEMBER
The output of running the preceding SQL statement would look like this:
STATE HOME_HOST CUR_HOST ALERT-------------------- ---------- -------- -----STARTED host1 host1 NOWAITING_FOR_FAILBACK host2 host1 YESPRIMARY host3 host3 NOPEER host4 host4 NO
4 record(s) selected.
The member whose home host is 102 currently running in restart light mode on host1 after a failover and is waiting to fail back onto it's home host.
Click to edit Master title style10
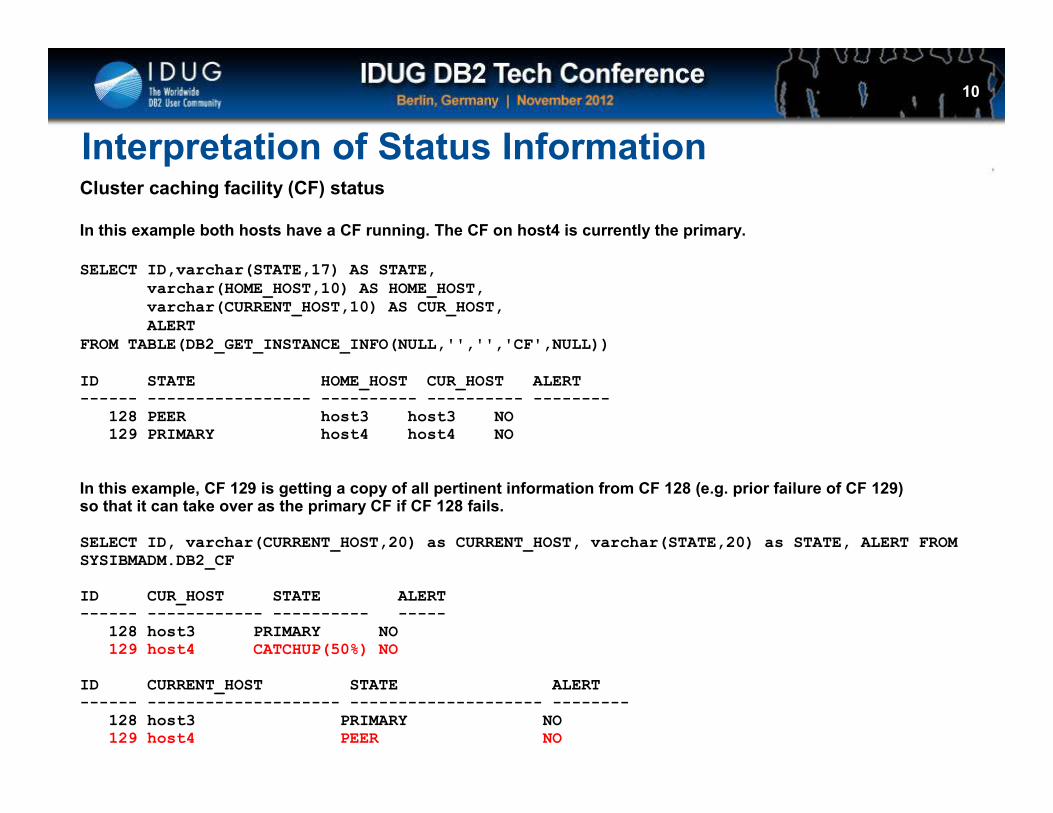
Interpretation of Status InformationCluster caching facility (CF) status
In this example both hosts have a CF running. The CF on host4 is currently the primary.
SELECT ID,varchar(STATE,17) AS STATE,varchar(HOME_HOST,10) AS HOME_HOST,varchar(CURRENT_HOST,10) AS CUR_HOST,ALERT
FROM TABLE(DB2_GET_INSTANCE_INFO(NULL,'','','CF',NULL))
ID STATE HOME_HOST CUR_HOST ALERT------ ----------------- ---------- ---------- --------
128 PEER host3 host3 NO129 PRIMARY host4 host4 NO
In this example, CF 129 is getting a copy of all pertinent information from CF 128 (e.g. prior failure of CF 129) so that it can take over as the primary CF if CF 128 fails.
SELECT ID, varchar(CURRENT_HOST,20) as CURRENT_HOST, varchar(STATE,20) as STATE, ALERT FROM SYSIBMADM.DB2_CF
ID CUR_HOST STATE ALERT------ ------------ ---------- -----
128 host3 PRIMARY NO129 host4 CATCHUP(50%) NO
ID CURRENT_HOST STATE ALERT------ -------------------- -------------------- --------
128 host3 PRIMARY NO129 host4 PEER NO
Click to edit Master title style
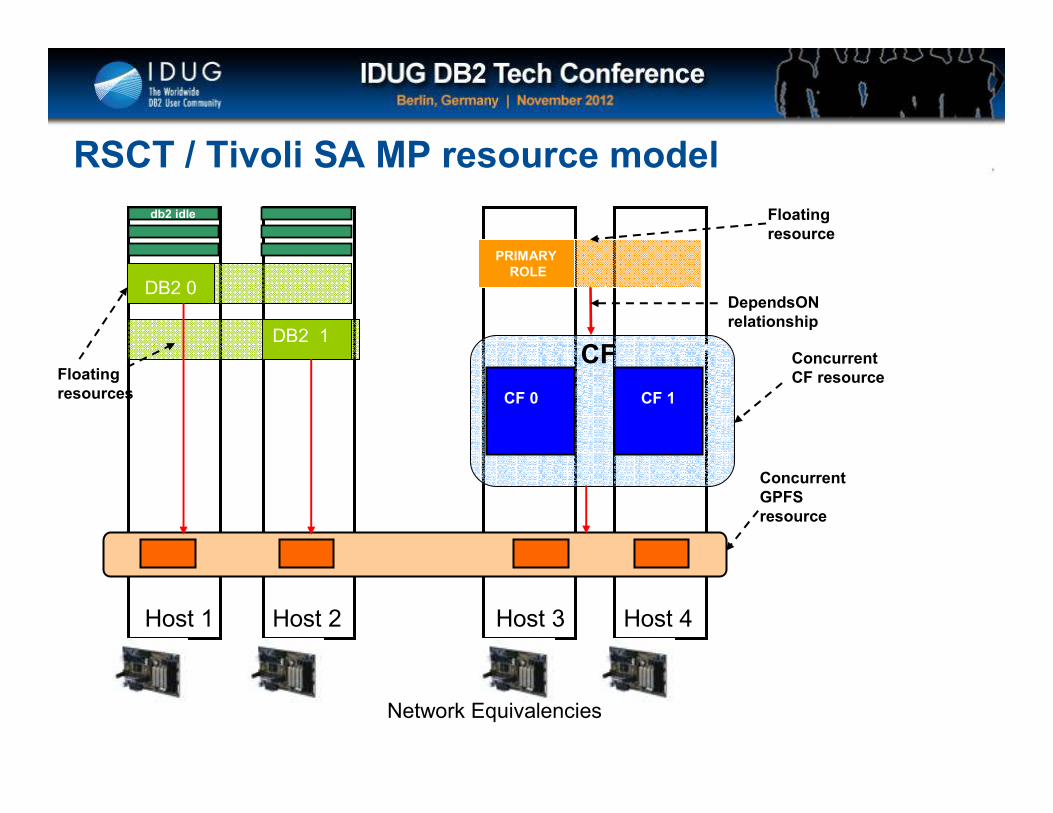
Floating
resources
Host 1 Host 2 Host 3 Host 4
DB2 1
DB2 0
RSCT / Tivoli SA MP resource model
Concurrent
CF resource
PRIMARY
ROLE
Floating
resource
DependsON
relationship
CF
CF 0 CF 1
Network Equivalencies
Concurrent
GPFS
resource
db2 idle

Click to edit Master title style
RSCT/Tivoli SA MP resource information
$>lssam• Shows the states of the resources from a RSCT/Tivoli perspective
Online IBM.ResourceGroup:db2_aamer_0-rg Nominal=Online'- Online IBM.Application:db2_aamer_0-rs
|- Online IBM.Application:db2_aamer_0-rs:host1 '- Offline IBM.Application:db2_aamer_0-rs:host2
Online IBM.ResourceGroup:db2_aamer_1-rg Nominal=Online'- Online IBM.Application:db2_aamer_1-rs
|- Offline IBM.Application:db2_aamer_1-rs:host1'- Online IBM.Application:db2_aamer_1-rs:host2
Online IBM.ResourceGroup:primary_aamer_900-rg Nominal=Online'- Online IBM.Application:primary_aamer_900-rs
|- Offline IBM.Application:primary_aamer_900-rs:host3'- Online IBM.Application:primary_aamer_900-rs:host4
Online IBM.ResourceGroup:ca_aamer_0-rg Nominal=Online'- Online IBM.Application:ca_aamer_0-rs
|- Online IBM.Application:ca_aamer_0-rs:host3
'- Online IBM.Application:ca_aamer_0-rs:host4…

Click to edit Master title style
DB2 member resources
$> lssam
Online IBM.ResourceGroup:db2_aamer_0-rg Nominal=Online
'- Online IBM.Application:db2_aamer_0-rs
|- Online IBM.Application:db2_aamer_0-rs:host1
'- Offline IBM.Application:db2_aamer_0-rs:host2
• One resource should always be online
• Resource maps to a db2sysc
• db2_aamer_0-rs is db2 member 0

Click to edit Master title style
CF Resources
• Both resources should always be online• ca_aamer_0-rs is ca-server (CF) process
Online IBM.ResourceGroup:ca_aamer_0-rg Nominal=Online'- Online IBM.Application:ca_aamer_0-rs
|- Online IBM.Application:ca_aamer_0-rs:host3'- Online IBM.Application:ca_aamer_0-rs:host4
• Primary role resource (900) should always have only one resource in the group online
Online IBM.ResourceGroup:primary_aamer_900-rg Nominal=Online'- Online IBM.Application:primary_aamer_900-rs
|- Online IBM.Application:primary_aamer_900-rs:host3'- OfflineIBM.Application:primary_aamer_900-rs:host4
Click to edit Master title style
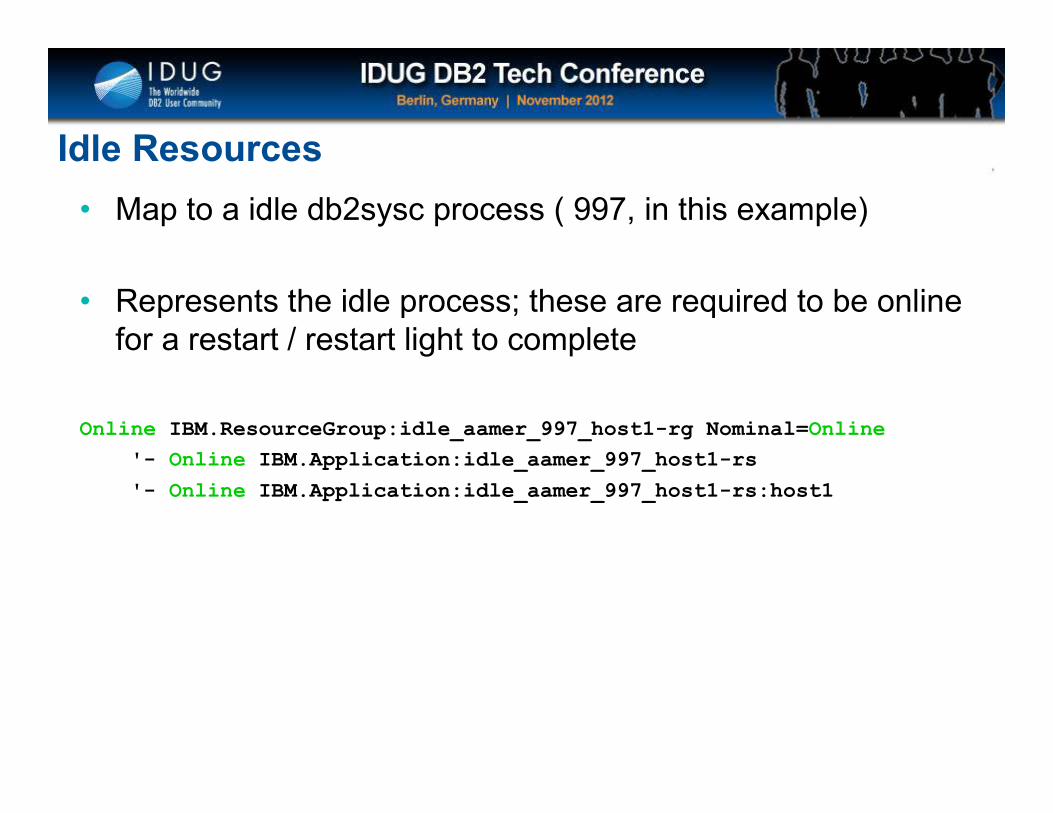
Idle Resources
• Map to a idle db2sysc process ( 997, in this example)
• Represents the idle process; these are required to be online for a restart / restart light to complete
Online IBM.ResourceGroup:idle_aamer_997_host1-rg Nominal=Online
'- Online IBM.Application:idle_aamer_997_host1-rs
'- Online IBM.Application:idle_aamer_997_host1-rs:host1
Click to edit Master title style
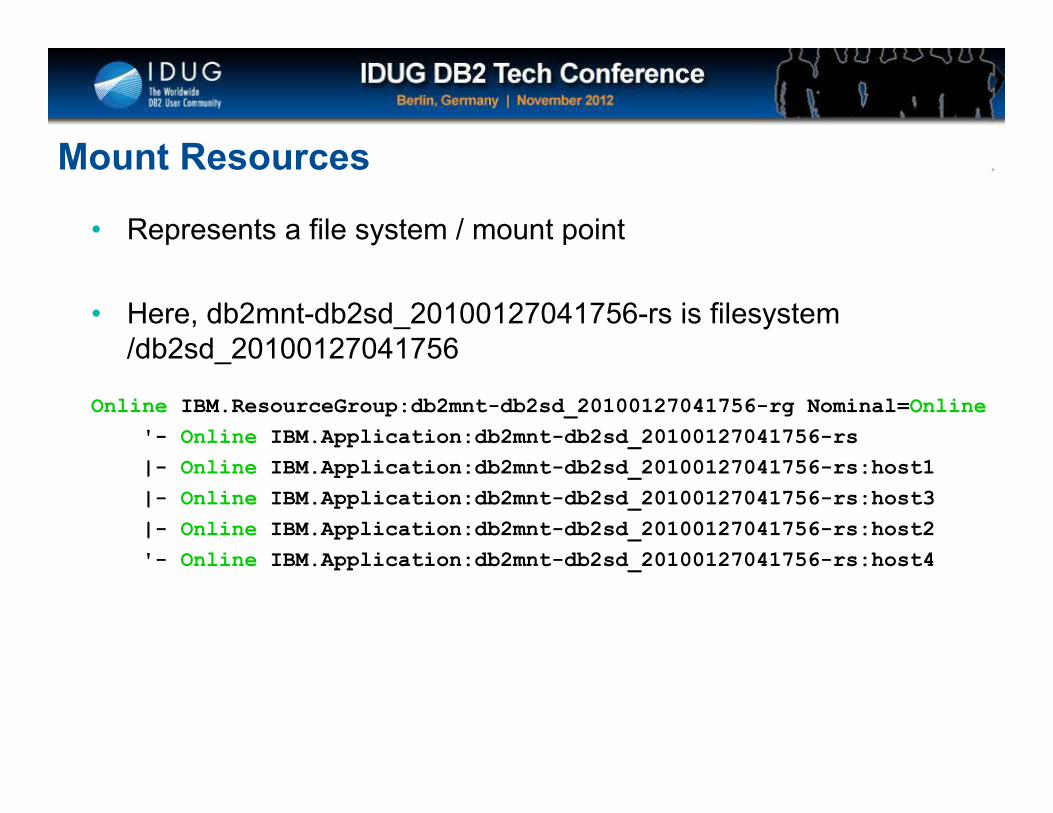
Mount Resources
• Represents a file system / mount point
• Here, db2mnt-db2sd_20100127041756-rs is filesystem/db2sd_20100127041756
Online IBM.ResourceGroup:db2mnt-db2sd_20100127041756-rg Nominal=Online
'- Online IBM.Application:db2mnt-db2sd_20100127041756-rs
|- Online IBM.Application:db2mnt-db2sd_20100127041756-rs:host1
|- Online IBM.Application:db2mnt-db2sd_20100127041756-rs:host3
|- Online IBM.Application:db2mnt-db2sd_20100127041756-rs:host2
'- Online IBM.Application:db2mnt-db2sd_20100127041756-rs:host4

Click to edit Master title style
Member failure detection and restart
• Three scenarios that will result in a member erroneously going down and requiring restart and recovery:
1. Software failure – e.g. kill -9 db2sysc, trap/abend
2. Host hardware or OS failure – e.g. kernel crash, machine power outage
3. Failure of dependant service / hardware (e.g. IB HCA, file system access, etherent adapter)
• These are automatically detected by DB2 cluster services and the member is restarted and crash recovery initiated.

Click to edit Master title style
Reliable Scalable Cluster Technology (RSCT)
• Provides concept of a cluster domain with multiple hosts in the domain
• Inter-host ‘heart-beating’ and host liveliness determination
• Provides a single point of truth on which hosts are currently online
• Network adapter livelyness determination
• Quorum determination
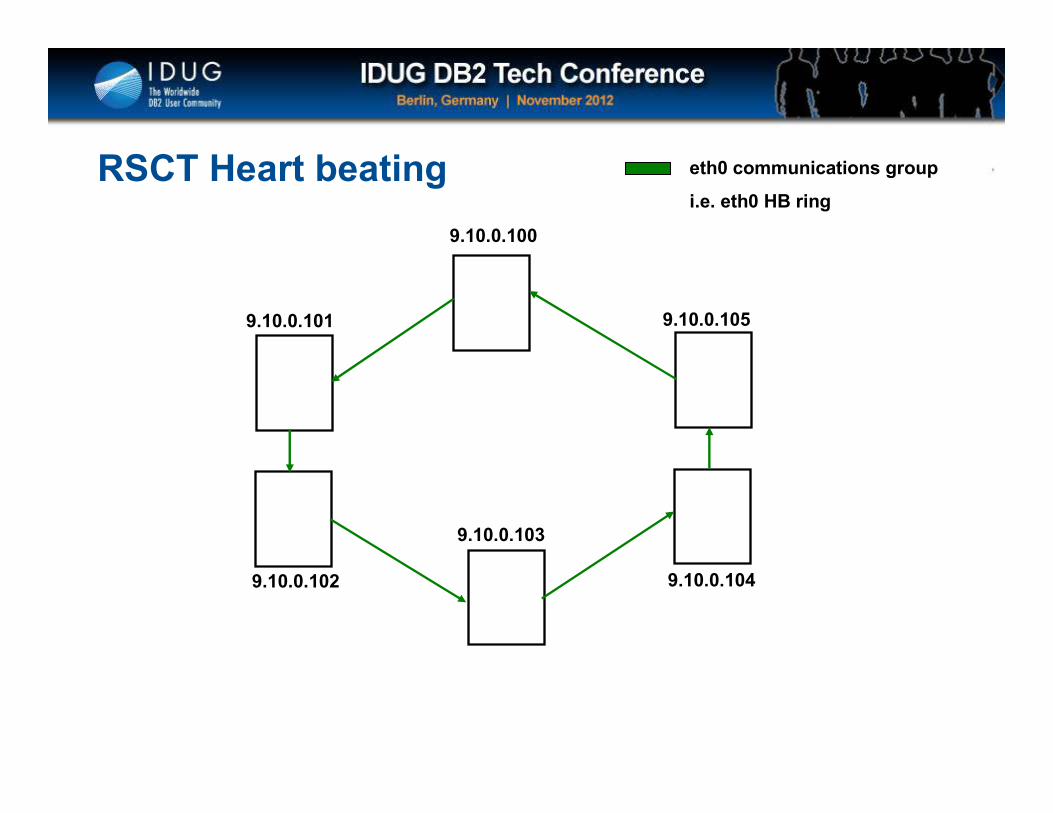
Click to edit Master title style
RSCT Heart beating
9.10.0.100
9.10.0.101
9.10.0.102
9.10.0.103
9.10.0.104
9.10.0.105
eth0 communications group
i.e. eth0 HB ring
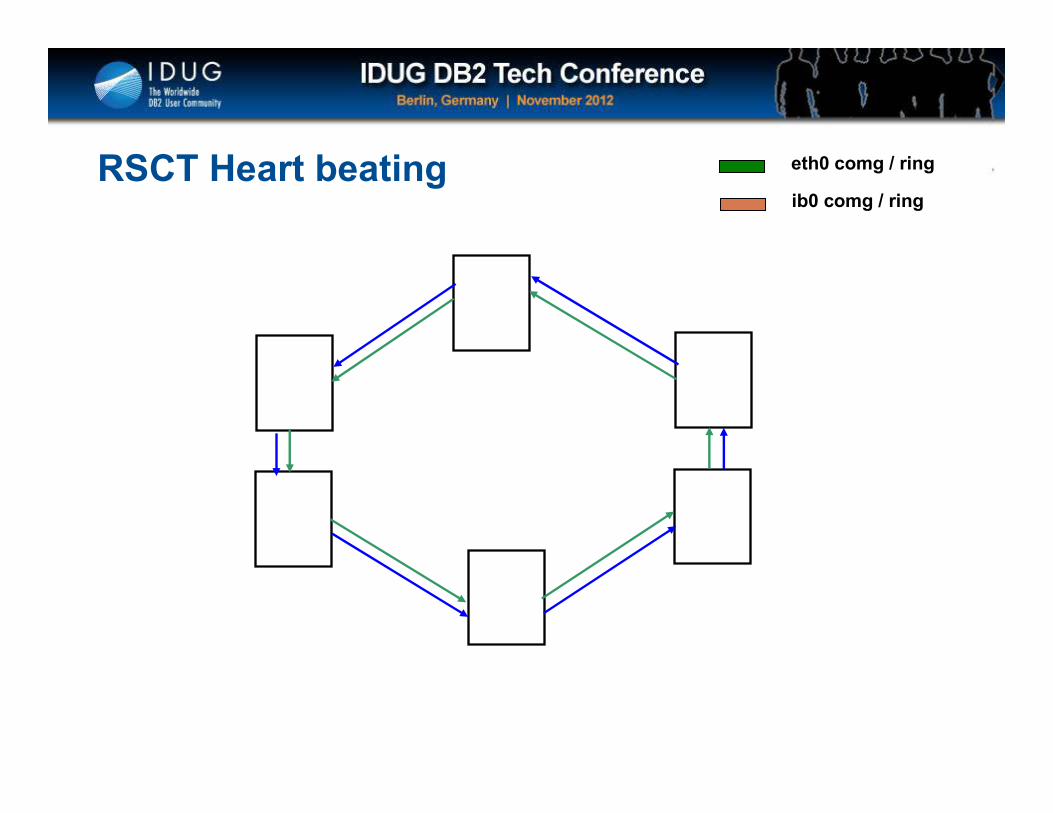
Click to edit Master title style
RSCT Heart beating eth0 comg / ring
ib0 comg / ring
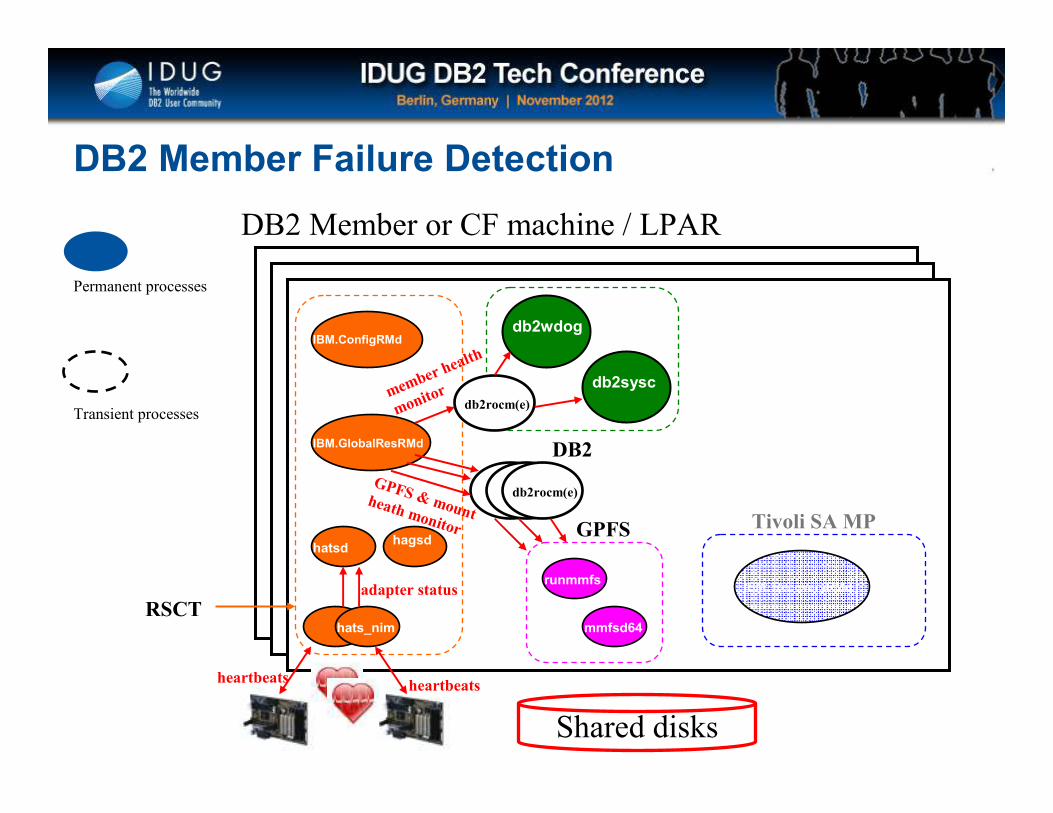
Click to edit Master title style
DB2 Member Failure Detection
DB2 Member or CF machine / LPAR
db2sysc
Shared disks
db2wdog
Permanent processes
Transient processes
hats_nim
hatsdhagsd
IBM.GlobalResRMd
IBM. RecoveryRMd
IBM.ConfigRMd
runmmfs
mmfsd64
RSCT
Tivoli SA MP
DB2
GPFS
heartbeatsheartbeats
adapter status
db2rocm(e)me
mber h
ealth
monitor
db2rocm(e)GPFS & mount heath monitor

Click to edit Master title style
DB2 Member software failure detection
• RSCT (IBM.GlobalResRMd daemon) runs a member health monitor command (db2rocm(e)) configured by DB2 to check the health of the DB2 member periodically.
• Member health monitor command issued by RSCT every 10 seconds bydefault
• Member health monitor command will:
• Send a signal 0 to the db2sysc process
• Send a message on an internal queue and wait for a response
• However, we would like to detect most cases of software failure quicker
than that
• Failure detection time IS loss of application availability
• Stay tuned on how we are able to detect software failures MUCH FASTER.

Click to edit Master title style
Fast software failure detection
• To achieve this:• Software failure of member will case the db2wdog (parent process of db2syc) to receive
a SIGCHLD
• db2wdog will invoke RSCT and ask it to schedule a health monitor command immediately
• Once monitor detects that the DB2 member has failed, the error is reported back to which invokes a DB2 provided ‘cleanup’ command.
db2sysc
db2wdog
IBM.GlobalResRMd
db2rocm(e)
kill -9
SIGCHLD
OS
refereshhealth
monitor
request
FAILE
D!
RSCT

Click to edit Master title style
Dependant resource failure detection
• GPFS sub-system health monitoring (including individual mount points) is done the same way as DB2 member health monitoring.
• RSCT’s IBM.GlobalResRMd process periodically runs a health monitor commands (db2rocm(e)) to check health of GPFS subsystem daemons and individual mount points.
• Attempt will be made to restart the failed service (e.g. restarting failed GPFS daemons, mounting file systems that are not mounted)
• Failure to make the GPFS subsystem available will cascade and result in DB2 member being brought down and restarted in ‘light’ mode on another member’s host.
• Failure of network adapters will result in DB2 member being restarted in “light” mode on another member’s host.

Click to edit Master title style
Host failure detection (1/2)
• The HATS (High Availability Topology services subsystem in RSCT) is responsible for host failure detection
• hats_nim daemons report the status of the heart beats in the cluster to their local hatsd daemon
• HATS uses a ‘group services’ protocol (using hagsddameons) to distribute the status of adapters to all hosts in the cluster.
• A host that is unresponsive (not sending heart-
beat messages) on ALL its network adapters is
considered suspect and declared as having
FAILED after a number of missed heart-beats
hatsd
IBM.GlobalResRMd
IBM.ConfigRMd
RSCT
hagsd
heartbeatsheartbeats
adapter status
hats_nim

Click to edit Master title style
Host failure detection (2/2)
• One IBM.ConfigRMd daemon is designated as the ‘Leader’• Leader is responsible for i) cluster membership ii) quorum iii) I/O
fencing
• To determine which host has the leader:
lssrc -ls IBM.ConfigRM | grep Leader Leader Node Name : host3 (node number = 2)
• Leader reacts to arrival / departure of hosts in the cluster (as informed by its local hatsd)
• In the case of departure (e.g. host failure), it will:1. Run a quorum protocol2. Run an I/O fencing protocol if determined that the sub-cluster
still has quorum3. Distribute information about cluster membership change to the
rest of the cluster including the master IBM.RecoveryRMd
hatsd
IBM.ConfigRMd
Host with master
IBM.ConfigRMd
hagsd
heartbeatsheartbeats
adapter status
hats_nim

Click to edit Master title style
Restart Light
db2sysc 1
db2sysc (idle) db2sysc (idle) db2sysc (idle)
db2wdog 1
db2wdog (idle) db2wdog (idle) db2wdog (idle)
db2sysc (idle)
db2wdog (idle)
‘Animate’ as member 0 to perform MCR
for member 0
db2wdog 0
db2sysc 0
Click to edit Master title style
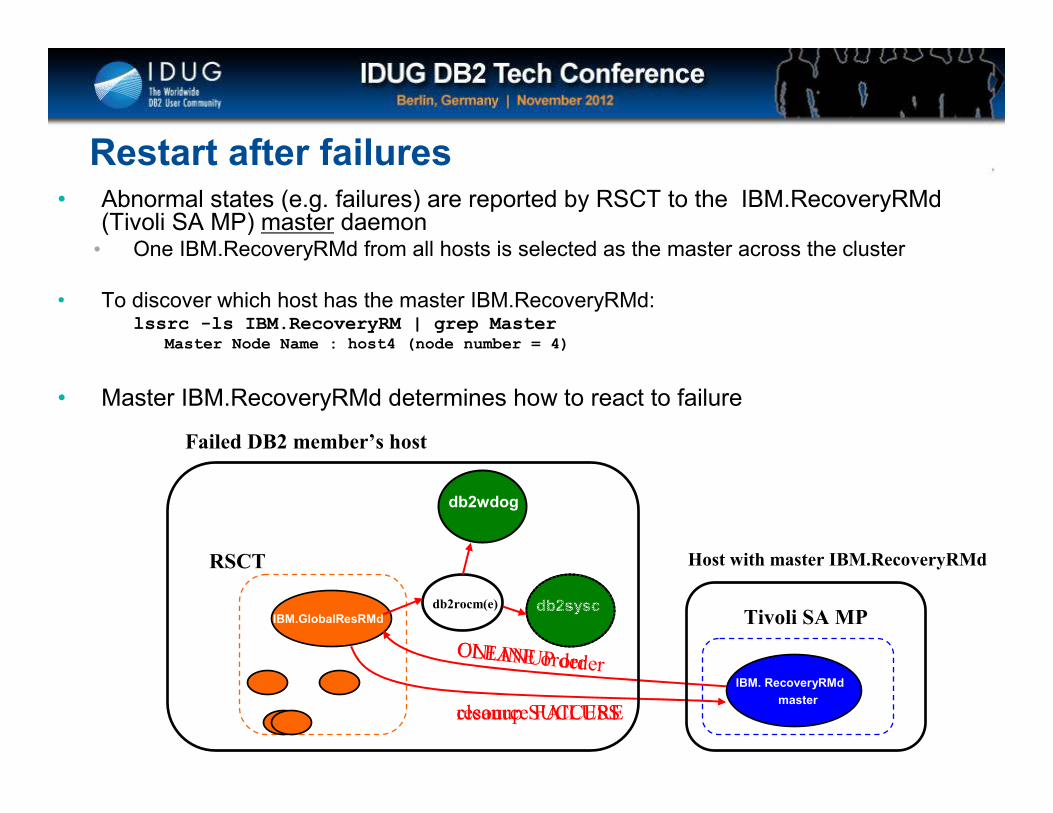
Restart after failures• Abnormal states (e.g. failures) are reported by RSCT to the IBM.RecoveryRMd
(Tivoli SA MP) master daemon • One IBM.RecoveryRMd from all hosts is selected as the master across the cluster
• To discover which host has the master IBM.RecoveryRMd:lssrc -ls IBM.RecoveryRM | grep Master
Master Node Name : host4 (node number = 4)
• Master IBM.RecoveryRMd determines how to react to failure
db2sysc
db2wdog
IBM.GlobalResRMd Tivoli SA MP
IBM. RecoveryRMd
master
RSCT
resource FAILURE
CLEANUP orderONLINE order
cleanup SUCCESS
db2rocm(e)
Failed DB2 member’s host
Host with master IBM.RecoveryRMd

Click to edit Master title style
Database crash recovery after DB2 member restart
• Upon restart the member will automatically perform Member Crash Recovery (MCR) which involves log redo/undo of any transactions that were in-flight on that member.
• The AUTORESTART database configuration parameter governs whether a database is recovered automatically upon crash of members.
• Default: ON
• If AUTORESTART is set to OFF, user needs to issue ‘RESTART
DATABASE’ command or dynamically enable AUTORESTART to ON

Click to edit Master title style
Customer Experiences
Click to edit Master title style
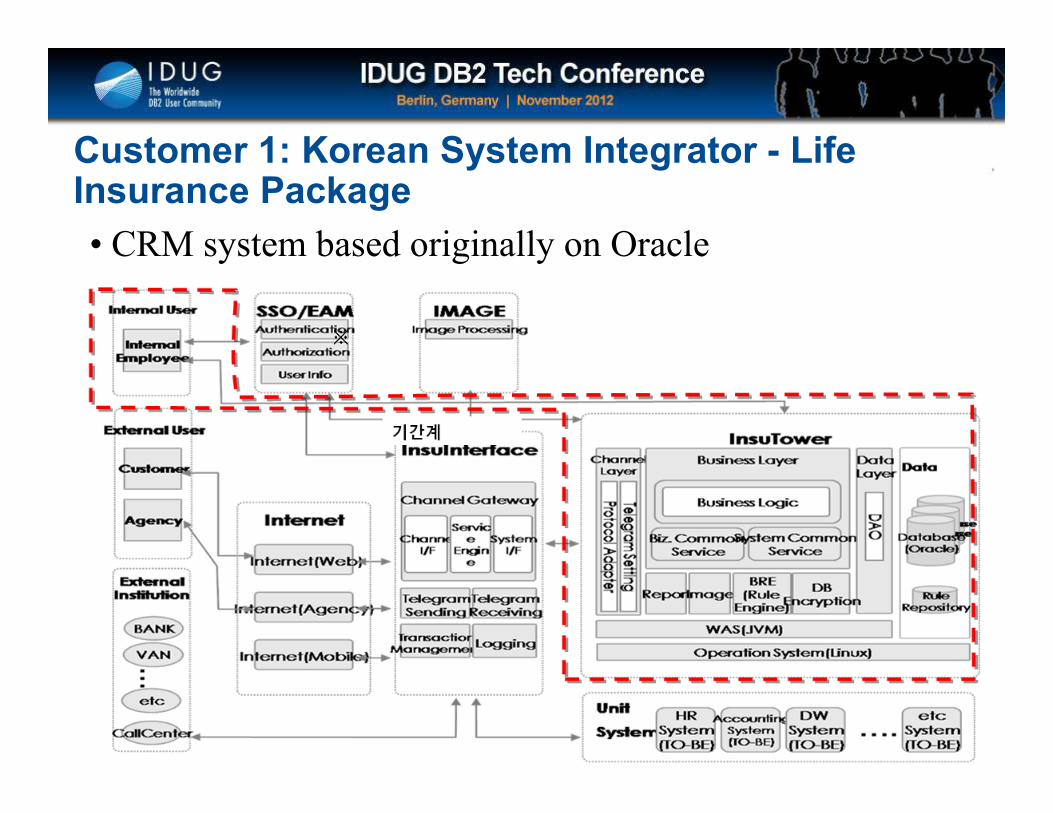
Customer 1: Korean System Integrator - Life Insurance Package
• CRM system based originally on Oracle
Click to edit Master title style
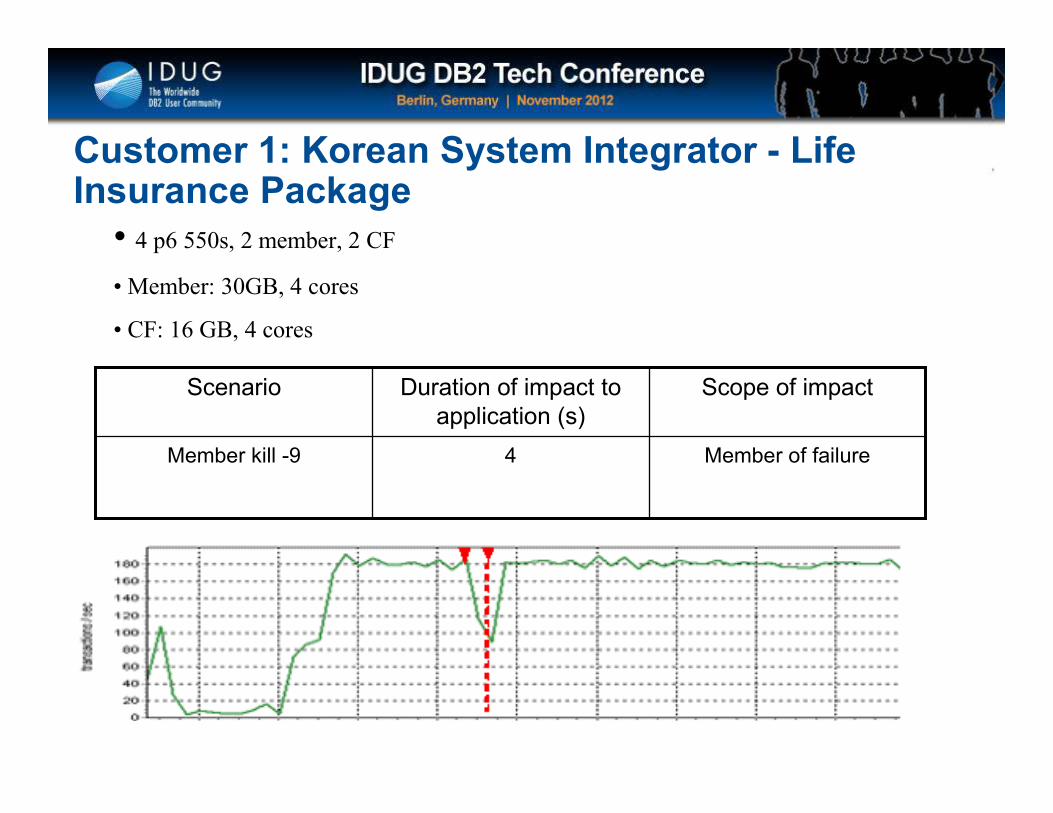
Member of failure4Member kill -9
Scope of impactDuration of impact to application (s)
Scenario
• 4 p6 550s, 2 member, 2 CF
• Member: 30GB, 4 cores
• CF: 16 GB, 4 cores
Customer 1: Korean System Integrator - Life Insurance Package
Click to edit Master title style
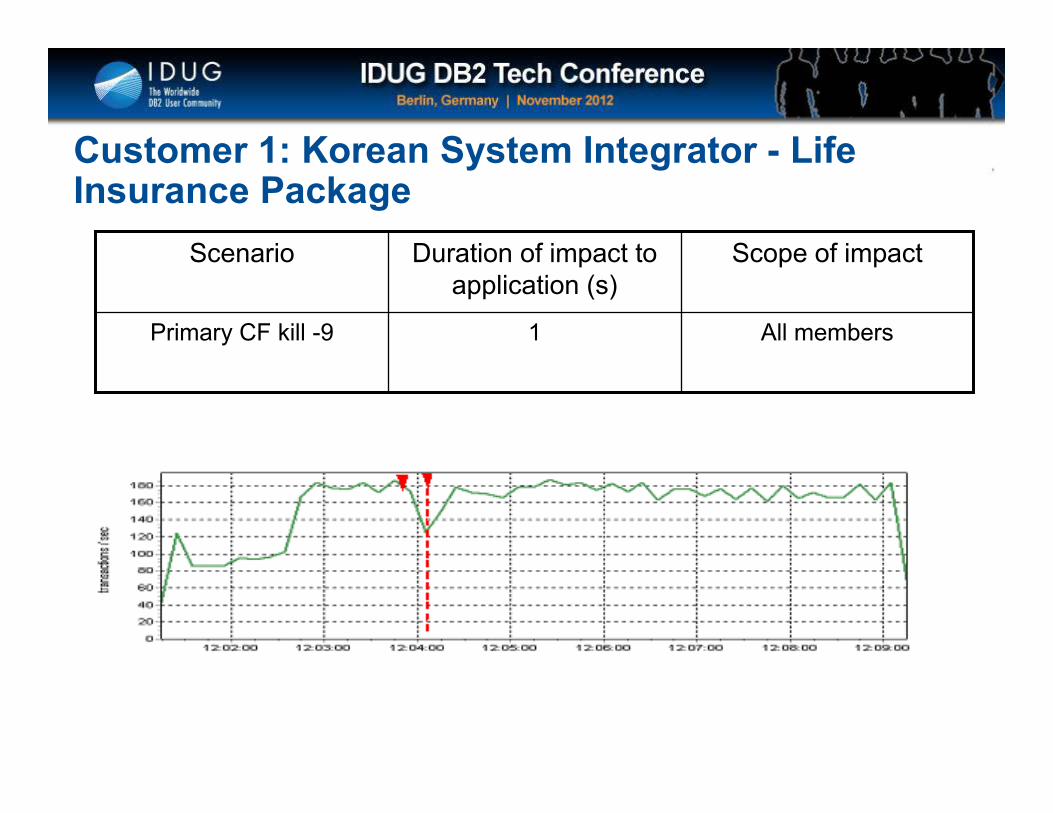
All members1Primary CF kill -9
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package
Click to edit Master title style
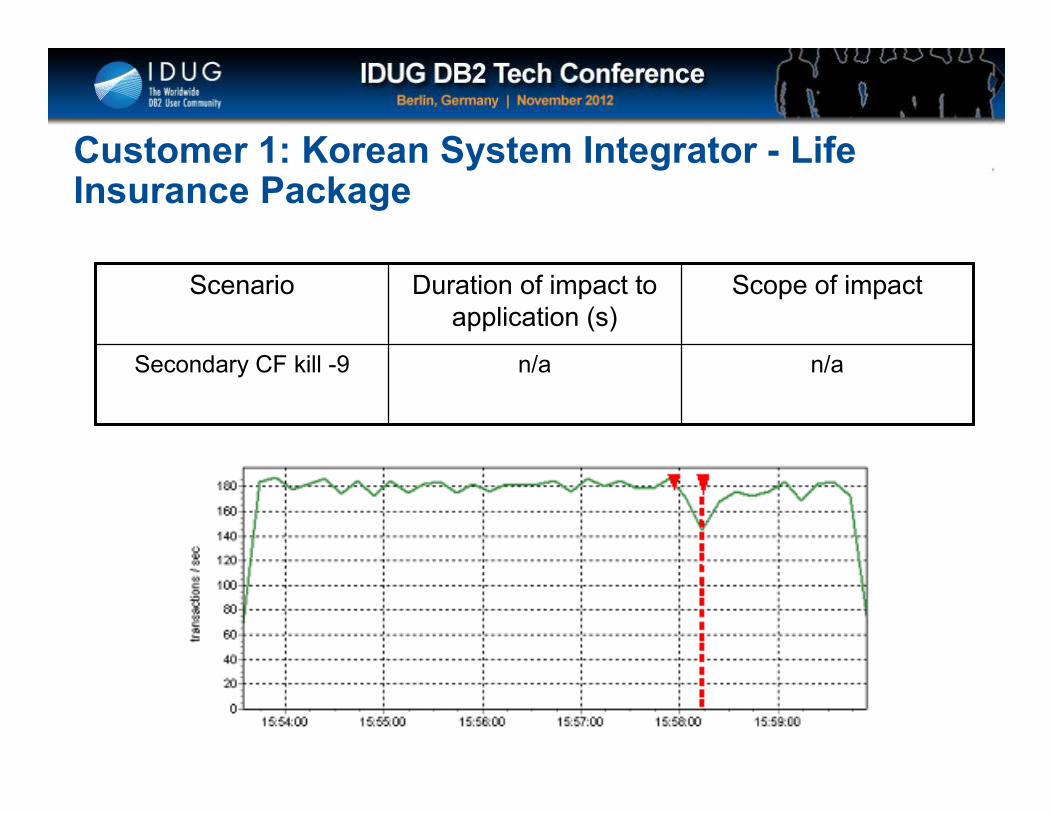
n/an/aSecondary CF kill -9
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package
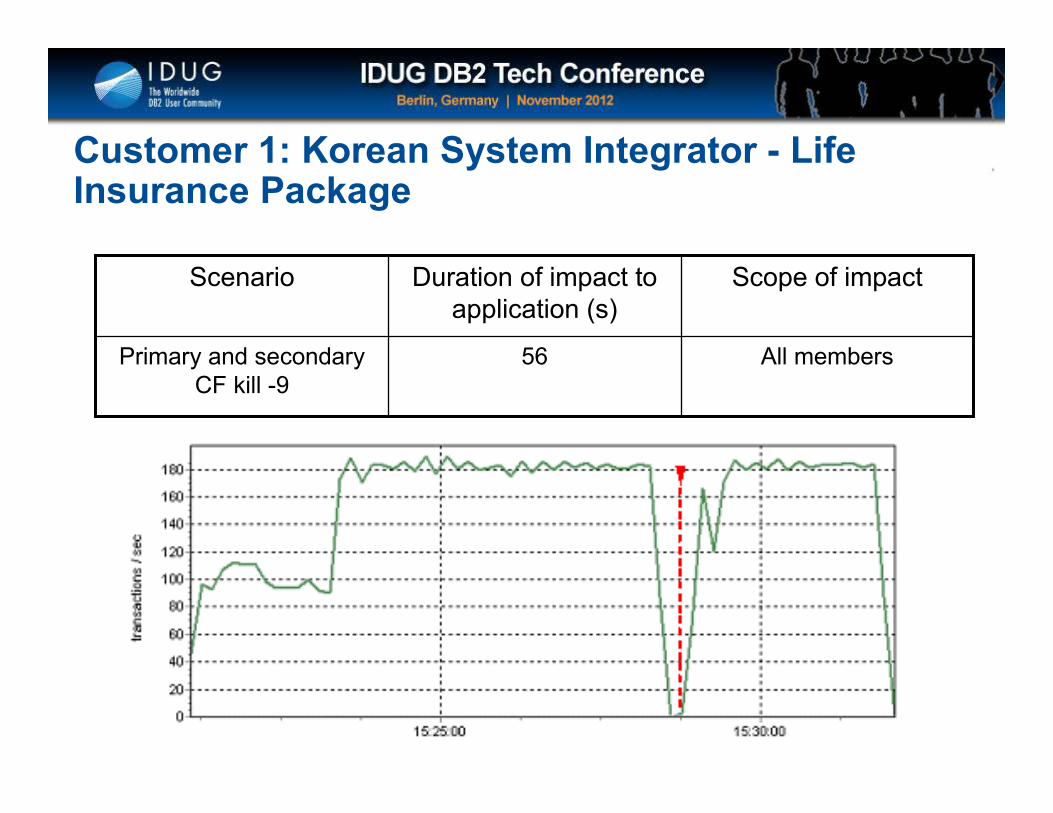
Click to edit Master title style
All members56Primary and secondary CF kill -9
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package
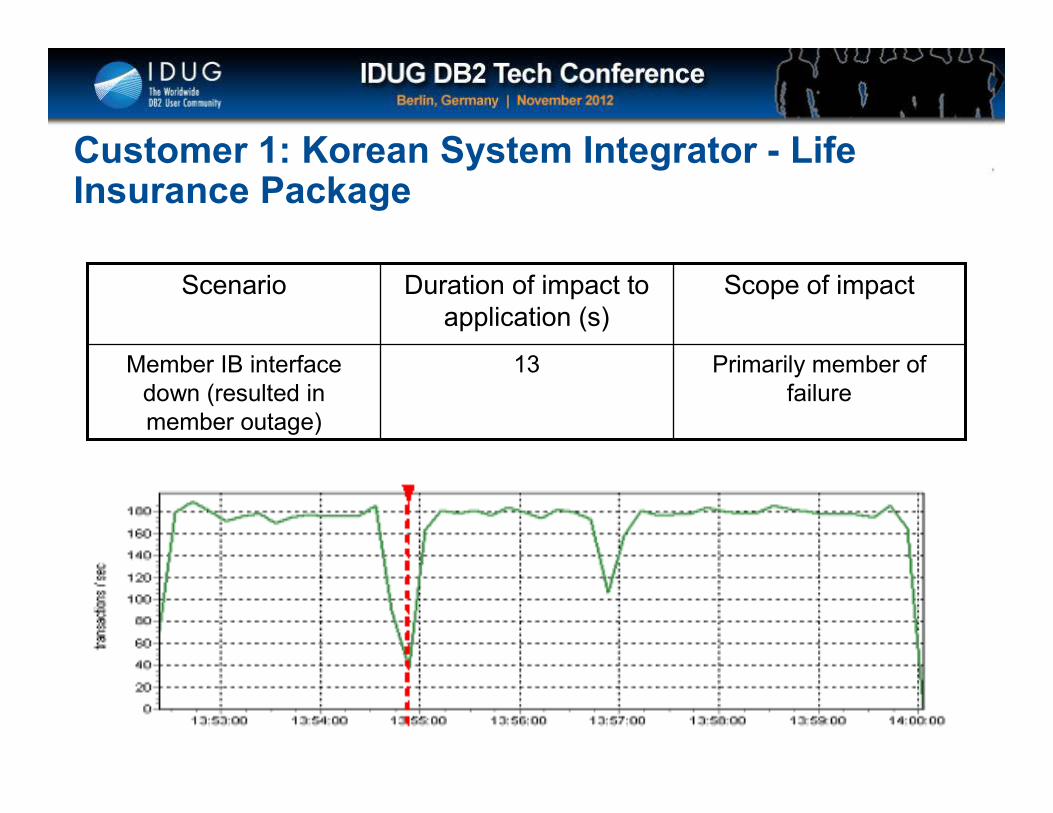
Click to edit Master title style
Primarily member of failure
13Member IB interface down (resulted in member outage)
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package

Click to edit Master title style
All members1Primary CF IB adapter interface down (resulted
in primary failover to secondary)
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package
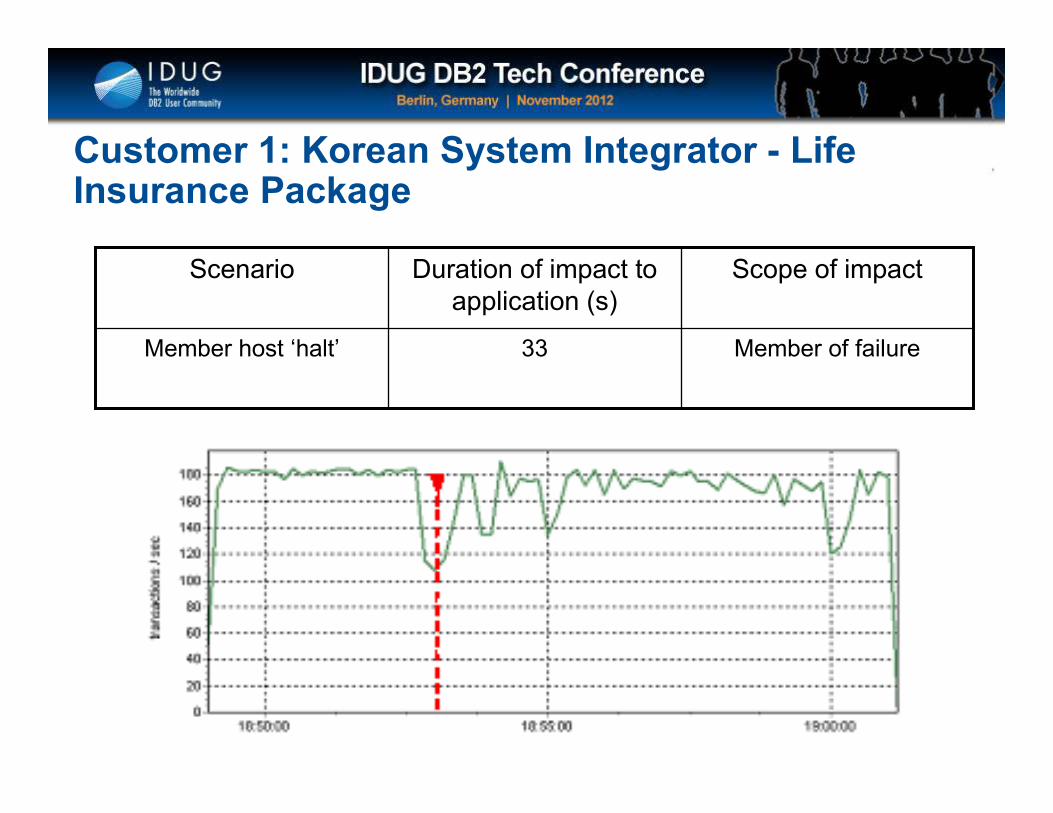
Click to edit Master title style
Member of failure33Member host ‘halt’
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package
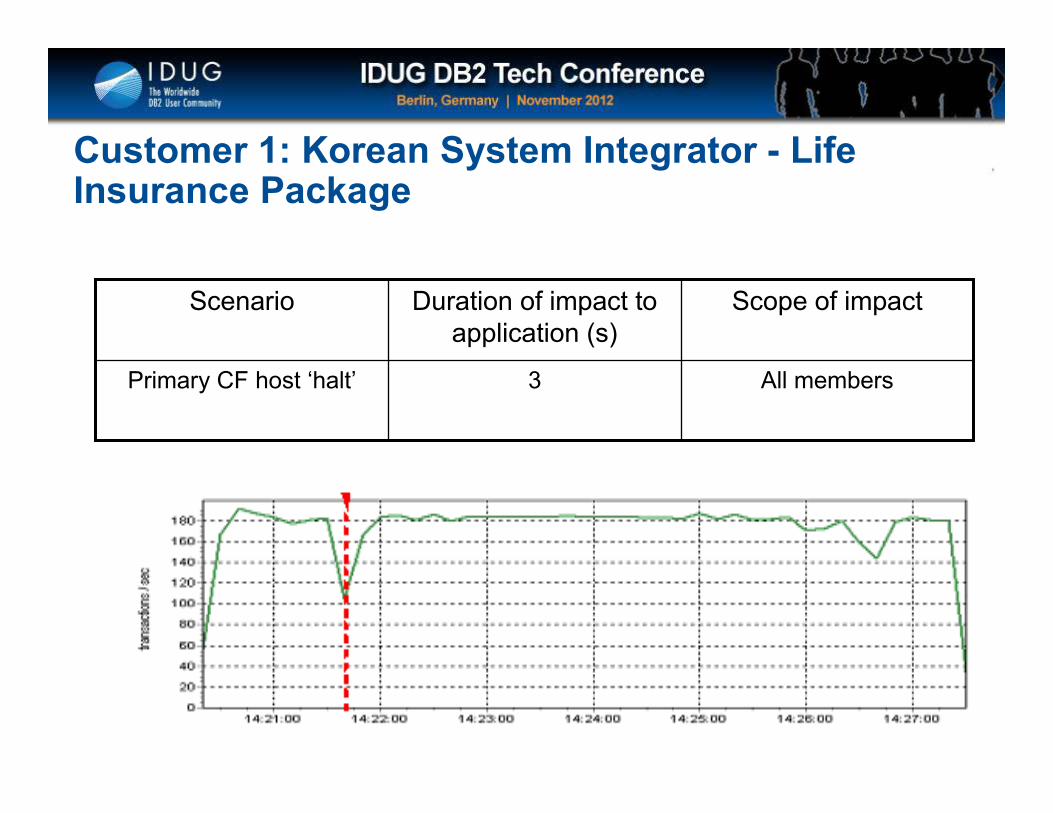
Click to edit Master title style
All members3Primary CF host ‘halt’
Scope of impactDuration of impact to application (s)
Scenario
Customer 1: Korean System Integrator - Life Insurance Package
Click to edit Master title style
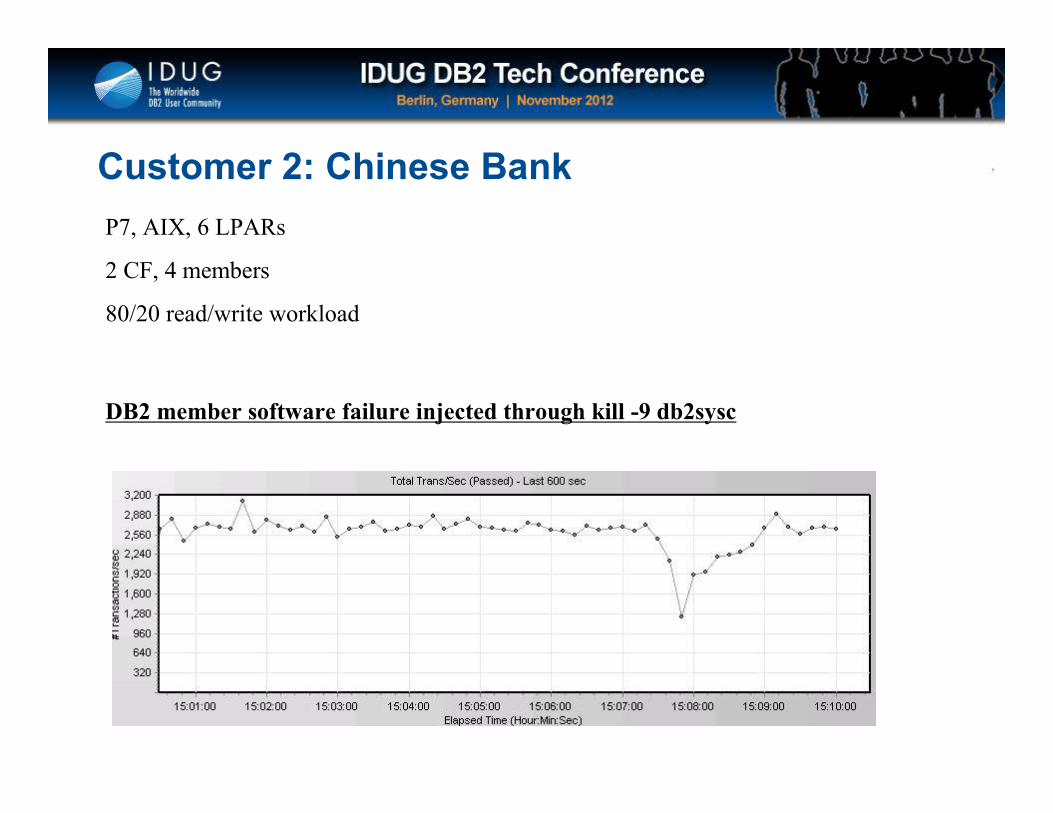
Customer 2: Chinese Bank
DB2 member software failure injected through kill -9 db2sysc
P7, AIX, 6 LPARs
2 CF, 4 members
80/20 read/write workload
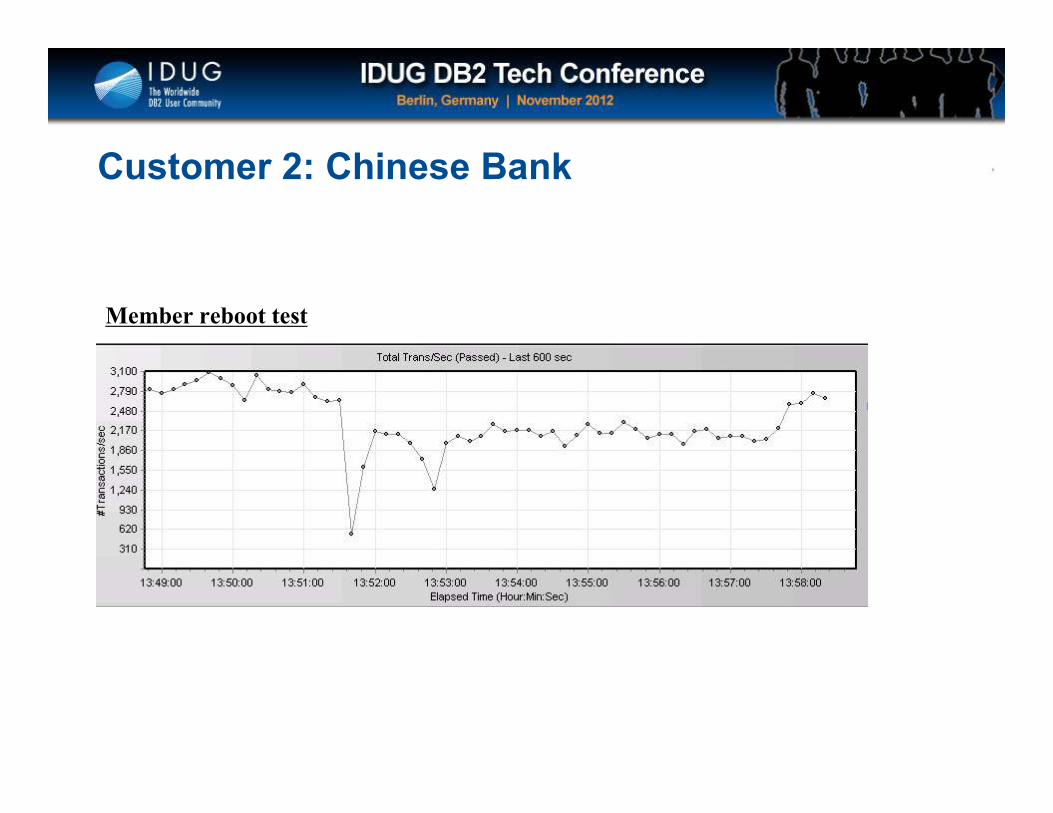
Click to edit Master title style
Customer 2: Chinese Bank
Member reboot test
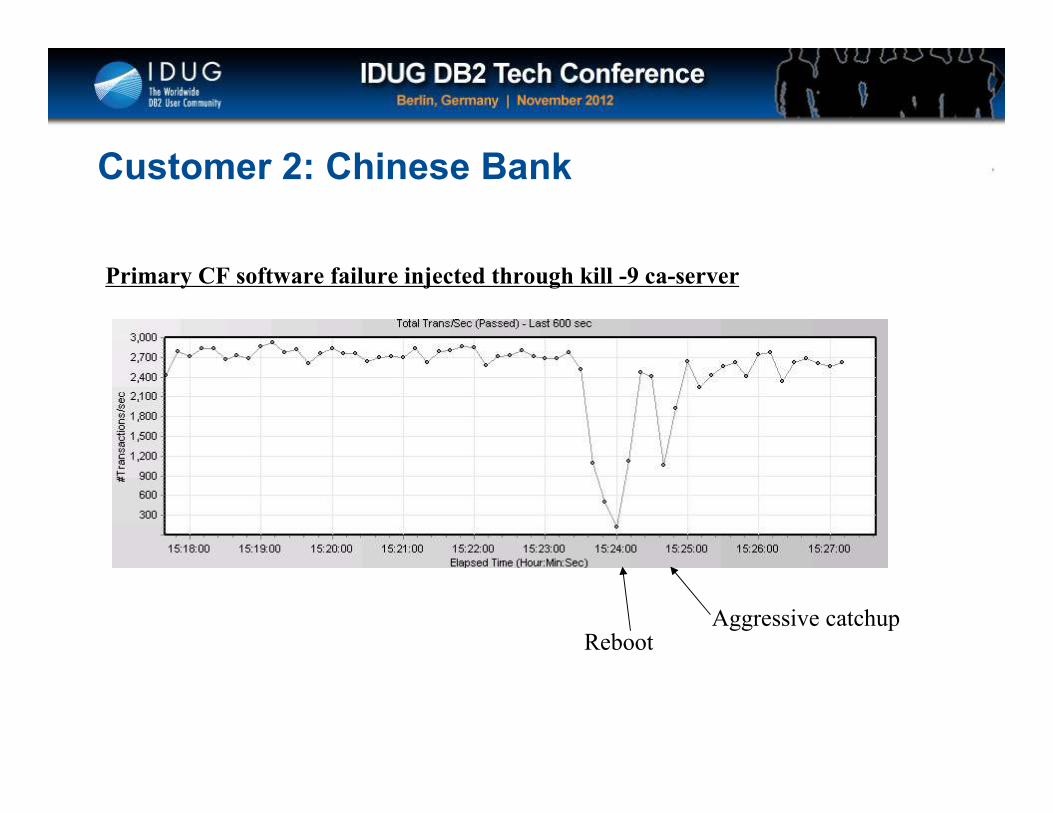
Click to edit Master title style
Customer 2: Chinese Bank
Primary CF software failure injected through kill -9 ca-server
RebootAggressive catchup
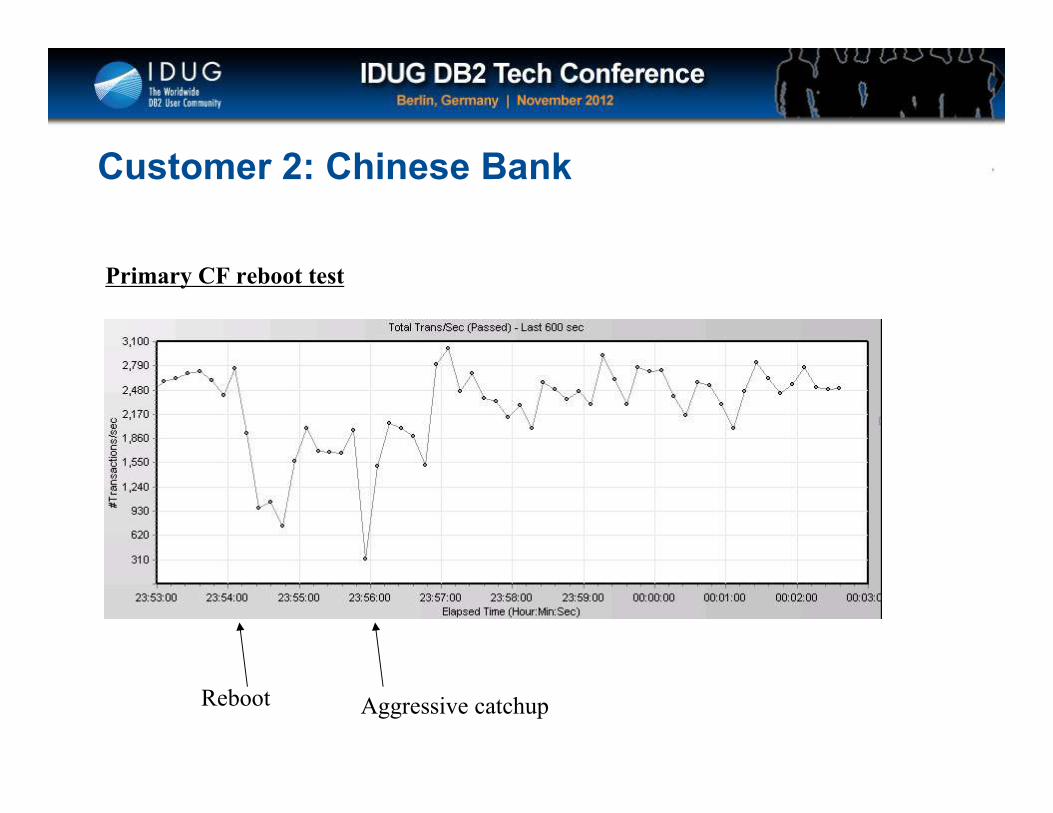
Click to edit Master title style
Customer 2: Chinese Bank
Primary CF reboot test
Reboot Aggressive catchup
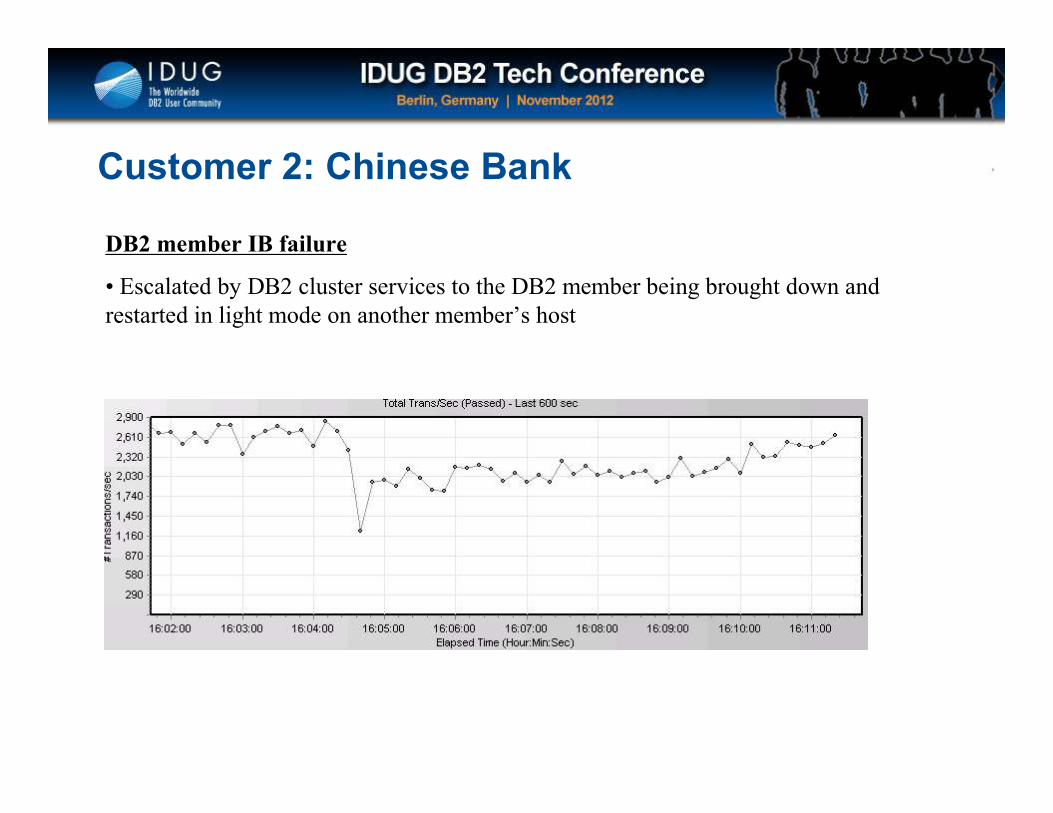
Click to edit Master title style
Customer 2: Chinese Bank
DB2 member IB failure
• Escalated by DB2 cluster services to the DB2 member being brought down and
restarted in light mode on another member’s host
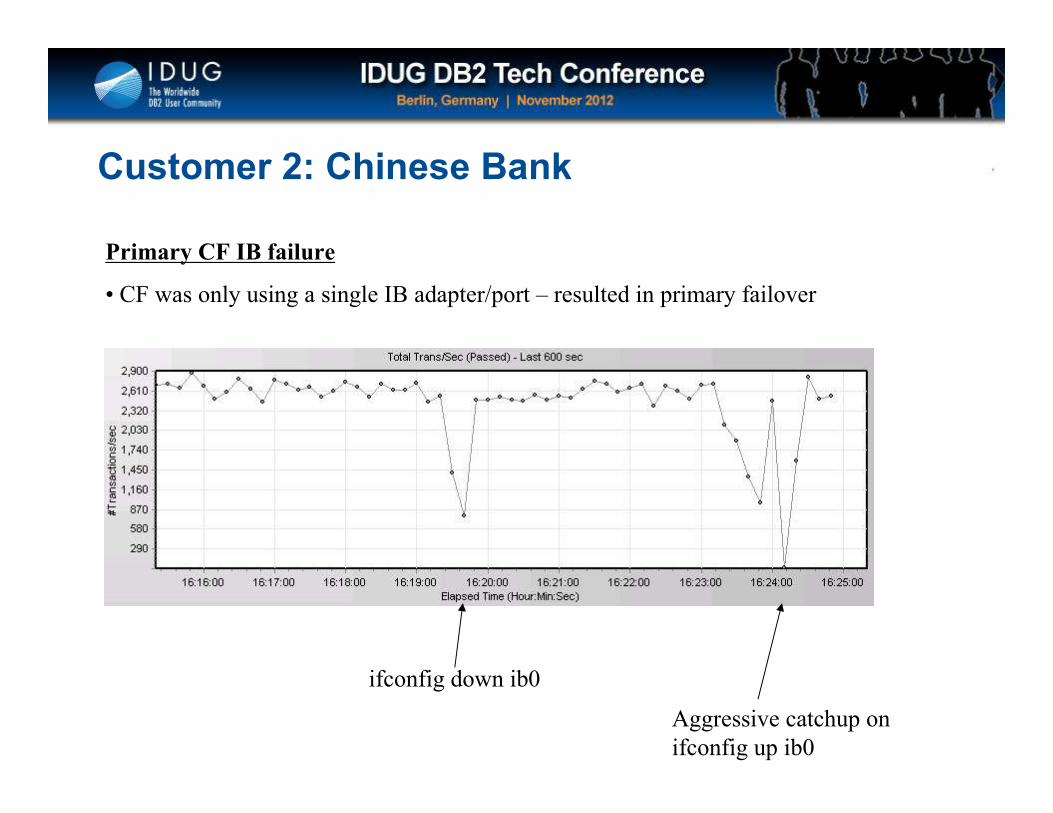
Click to edit Master title style
Customer 2: Chinese Bank
Primary CF IB failure
• CF was only using a single IB adapter/port – resulted in primary failover
Aggressive catchup on
ifconfig up ib0
ifconfig down ib0
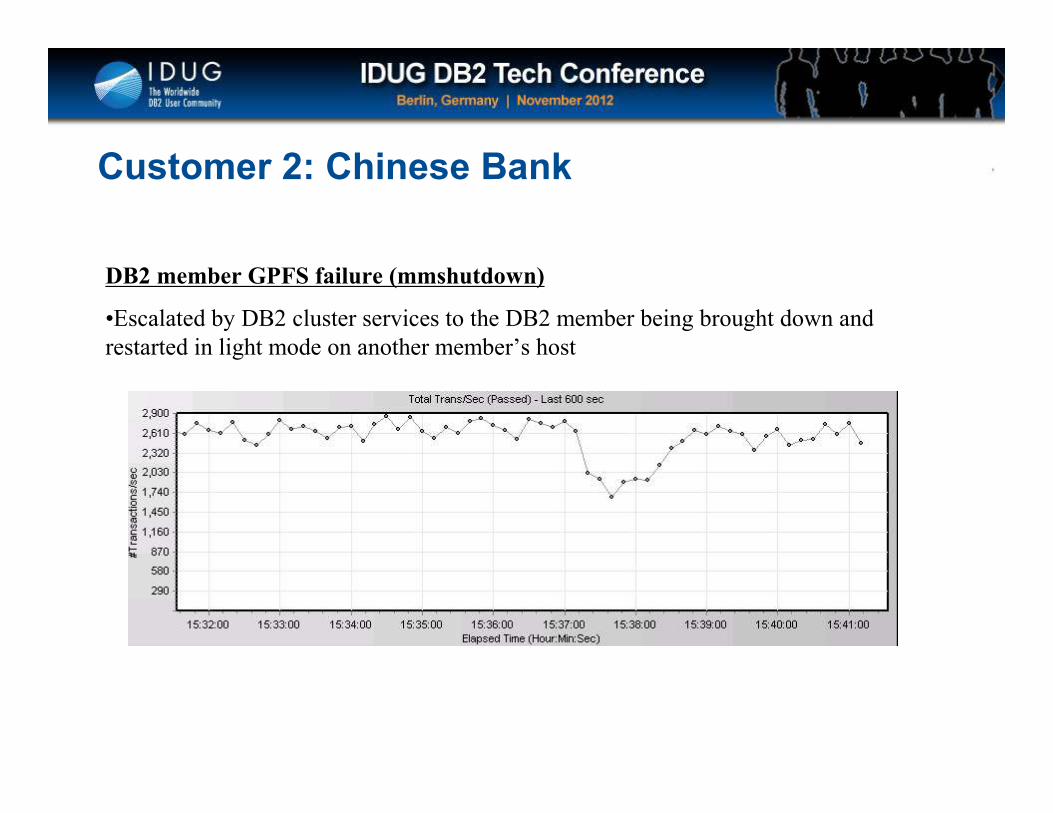
Click to edit Master title style
Customer 2: Chinese Bank
DB2 member GPFS failure (mmshutdown)
•Escalated by DB2 cluster services to the DB2 member being brought down and
restarted in light mode on another member’s host

Click to edit Master title style
BACKUP SLIDES
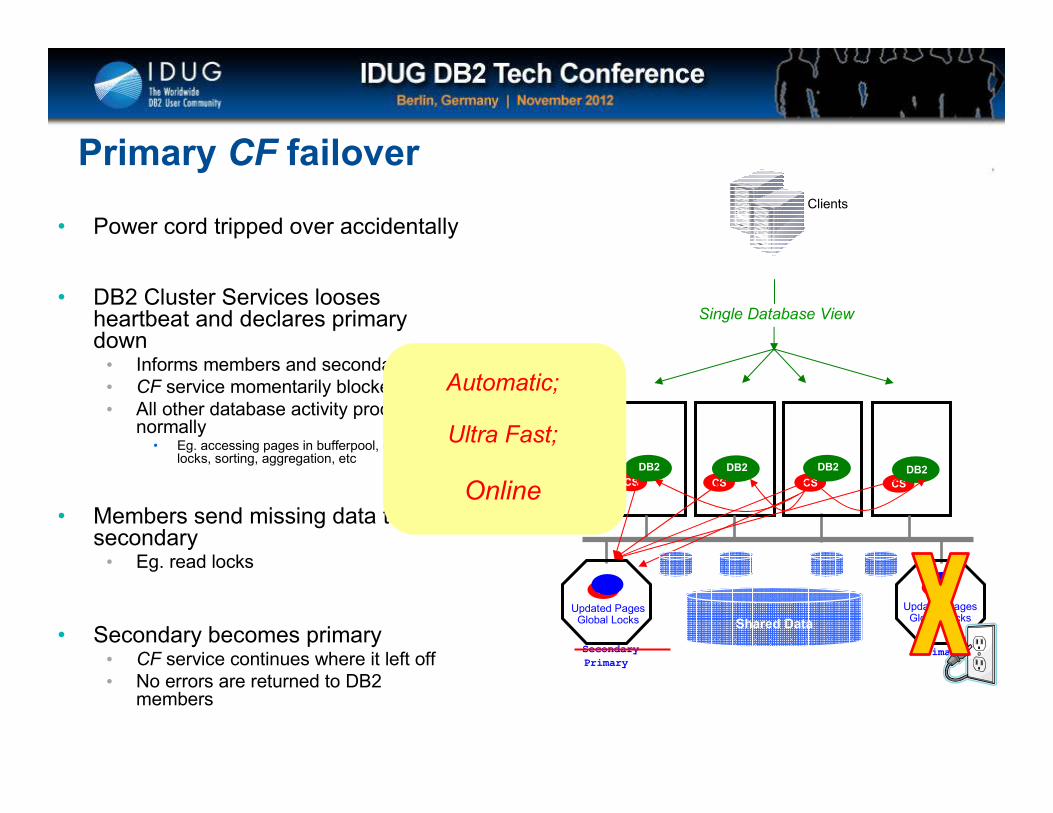
Click to edit Master title style
CS
CS
DB2
Primary CF failover
Shared Data
• Power cord tripped over accidentally
• DB2 Cluster Services looses heartbeat and declares primary down
• Informs members and secondary• CF service momentarily blocked• All other database activity proceeds
normally• Eg. accessing pages in bufferpool, existing
locks, sorting, aggregation, etc
• Members send missing data to secondary
• Eg. read locks
• Secondary becomes primary• CF service continues where it left off• No errors are returned to DB2
members
CS
DB2
CS
DB2
CS
Updated Pages Global Locks
PrimarySecondary
Updated Pages Global Locks
CS
DB2
Single Database View
Primary
Automatic;
Ultra Fast;
Online
Clients

Aamer Sachedina
Session C13DB2 pureScale High Availability: Internals and Customer Experiences




















