
From enterprise models to scheduling models: bridging the gap
12
J Intell Manuf (2010) 21:121–132 DOI 10.1007/s10845-008-0166-5 From enterprise models to scheduling models: bridging the gap Roman Barták · James Little · Oscar Manzano · Con Sheahan Received: 9 August 2008 / Accepted: 14 August 2008 / Published online: 7 November 2008 © Springer Science+Business Media, LLC 2008 Abstract Enterprise models cover all aspects of modern enterprises, from accounting, through management of cus- tom orders and invoicing, to operational data such as records on machines and workers. In other words, all data necessary for running the company are available in enterprise models. However, these data are not in the proper format for some tasks such as scheduling and optimization. Namely, the con- cepts and terminology used in enterprise models are different from what is traditionally used in scheduling and optimiza- tion software. This paper deals with the automated translation of data from the enterprise model to a scheduling model and back. In particular, we describe how to extract data from the enterprise model for solving the scheduling problem using constraint-based solvers. Keywords Enterprise modeling · Optimization · Auto- matic scheduling · Constraint programming R. Barták (B ) Faculty of Mathematics and Physics, Charles University in Prague, Malostranské nám. 2/25, 118 00 Praha 1, Czech Republic e-mail: [email protected]; [email protected] J. Little · O. Manzano Cork Constraint Computation Centre, University College Cork, Cork, Ireland e-mail: [email protected] O. Manzano e-mail: [email protected] C. Sheahan College of Engineering, University of Limerick, Limerick, Ireland e-mail: [email protected] Introduction Manufacturing firms have a requirement for Enterprise Mod- elling and Performance Optimisation tools to enable them to deploy their limited resources for maximum economic yield for their products. Yet, these two areas—modelling and opti- misation—are typically addressed separately. In addition, for Small and Medium Enterprises, describing a scheduling model is a severe challenge in terms of their limited budget, capabilities, and time. We claim that there indeed is enough information within an enterprise model to deduce and automatically generate a scheduling model, which can be run through a scheduler, in order to produce times and resource assignments against the satisfaction of orders. In this way, we are able to com- bine the two models together and provide easy-to-use, entry level scheduling facilities for SME’s. We further claim that the different operating conditions; such as the treatment of lateness for orders and outsourcing options, can also be auto- matically incorporated into the scheduling model in the form of constraints and objectives, within an extended enterprise model. The main innovation here is the development of a set of rules to access information from the extended enterprise model and to create the necessary objects for scheduling. These rules also cover the reverse process of converting the scheduling information back into the enterprise model from which the firm’s key performance indicators (KPI’s) and a schedule of operation can be extracted. The main contribution of this paper is in the area of knowl- edge engineering. We introduce the extended enterprise model, which can be seen as a dictionary for translating the notions and concepts between the enterprise models and scheduling techniques, and the translation rules used to obtain the scheduling model from it. We then present an architec- ture based on Fig. 1, to deliver automatically a schedule and 123
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of From enterprise models to scheduling models: bridging the gap

J Intell Manuf (2010) 21:121–132DOI 10.1007/s10845-008-0166-5
From enterprise models to scheduling models: bridging the gap
Roman Barták · James Little · Oscar Manzano ·Con Sheahan
Received: 9 August 2008 / Accepted: 14 August 2008 / Published online: 7 November 2008© Springer Science+Business Media, LLC 2008
Abstract Enterprise models cover all aspects of modernenterprises, from accounting, through management of cus-tom orders and invoicing, to operational data such as recordson machines and workers. In other words, all data necessaryfor running the company are available in enterprise models.However, these data are not in the proper format for sometasks such as scheduling and optimization. Namely, the con-cepts and terminology used in enterprise models are differentfrom what is traditionally used in scheduling and optimiza-tion software. This paper deals with the automated translationof data from the enterprise model to a scheduling model andback. In particular, we describe how to extract data from theenterprise model for solving the scheduling problem usingconstraint-based solvers.
Keywords Enterprise modeling · Optimization · Auto-matic scheduling · Constraint programming
R. Barták (B)Faculty of Mathematics and Physics, Charles University in Prague,Malostranské nám. 2/25, 118 00 Praha 1, Czech Republice-mail: [email protected]; [email protected]
J. Little · O. ManzanoCork Constraint Computation Centre, University College Cork,Cork, Irelande-mail: [email protected]
O. Manzanoe-mail: [email protected]
C. SheahanCollege of Engineering, University of Limerick, Limerick, Irelande-mail: [email protected]
Introduction
Manufacturing firms have a requirement for Enterprise Mod-elling and Performance Optimisation tools to enable them todeploy their limited resources for maximum economic yieldfor their products. Yet, these two areas—modelling and opti-misation—are typically addressed separately. In addition,for Small and Medium Enterprises, describing a schedulingmodel is a severe challenge in terms of their limited budget,capabilities, and time.
We claim that there indeed is enough information withinan enterprise model to deduce and automatically generatea scheduling model, which can be run through a scheduler,in order to produce times and resource assignments againstthe satisfaction of orders. In this way, we are able to com-bine the two models together and provide easy-to-use, entrylevel scheduling facilities for SME’s. We further claim thatthe different operating conditions; such as the treatment oflateness for orders and outsourcing options, can also be auto-matically incorporated into the scheduling model in the formof constraints and objectives, within an extended enterprisemodel. The main innovation here is the development of a setof rules to access information from the extended enterprisemodel and to create the necessary objects for scheduling.These rules also cover the reverse process of converting thescheduling information back into the enterprise model fromwhich the firm’s key performance indicators (KPI’s) and aschedule of operation can be extracted.
The main contribution of this paper is in the area of knowl-edge engineering. We introduce the extended enterprisemodel, which can be seen as a dictionary for translatingthe notions and concepts between the enterprise models andscheduling techniques, and the translation rules used to obtainthe scheduling model from it. We then present an architec-ture based on Fig. 1, to deliver automatically a schedule and
123

122 J Intell Manuf (2010) 21:121–132
Fig. 1 Integration architecturebetween enterprise model andscheduling model
Enterprise Model Scheduling Model
Translation
Translation
Scheduler
Scheduling data
Schedule
TranslationModel
implement such a system. The outcome demonstrates thepotential for enhancing existing MRP systems to make themmore usable to a wider, non-scheduling proficient,audience.
The enterprise translation model
In this section we describe and justify the requirements on anenterprise model towards providing sufficient information togenerate a scheduling model. Since the extended enterprisemodel describes the company’s operational requirement innon-scheduling terms, we cannot expect to obtain directlysuch scheduling concepts as activities, resource types, tem-poral constraints, etc. Instead, we have to focus on relatedconcepts such as work flow, machine availability, outsourc-ing options and bill of materials. We define the extendedenterprise model as a way for describing a scheduling prob-lem in enterprise terms and call it the translation model. Thismodel covers a subset of enterprise concepts necessary forscheduling, and also extends traditional enterprise modelsto provide more scheduling related information, which weexpect users to have access to. We use an XML format as aninterface language for this translation model. Some examplesin this format will be given in the paper, other examples canbe found in (EMPOSME 2007). This work complements thework done in defining a scheduling model in MaScLib byILOG (Nuijten et al. 2003) and TAEMS formalism (Horlinget al. 1999).
First, it should be said that the translation model expressesa snapshot of the enterprise at some given time. Recall thatthe main motivation for the translation model is to providenecessary data for scheduling. At the first stage, we expectscheduling in batches, where a schedule for some knownperiod is generated. Hence, we expect to know the schedulestart and the schedule end and only data important for thisperiod are included in the translation model. We now describethe essential concepts (objects) of the translation model.
Orders for products are the major input for scheduling;these dictate what needs to be manufactured. Typically, theorder has some identification and it consists of the orderedproduct(s), its quantity, and the delivery date. We assume that
some of this data, such as dates, have been normalised andconverted already by the calendars underlying the enterprisemodel. In particular, the delivery date is specified in someabstract time units from the start of the schedule rather than anabsolute date. At this order level we can also describe the con-sequences of delivering the order late or early by specifyingpenalty for being early or late with the delivery. Again somenormalised cost is used for the penalty. Finally, we can saythat the order can be outsourced (provided that the productis also outsourceable).
Each product can be further described in terms of its com-position and the possibility of it being outsourced. The finalassembly of a product is made up of three stages, the productassembly based on its bill of materials and any additionalprocesses needed before and after that.
The assembly description is effectively a bill of materialsfrom which we can determine how a product is assembledfrom its component parts. At the same time, the descriptionrefers to a manufacturing route which describes a work flowfor each basic part. An example of the manufacturing routeis described below in Fig. 2. This structure brings togetherdifferent route pieces (each made up of pairs of linked pro-cesses) into a single work flow towards making a part. In theexample, we show how two sequential processes MP1 andMP2 need to be carried out, where their temporal relation-ship is defined (MP1 finishes before MP2 can start after aminimum of 1 time unit and a maximum of 100 time units).
The full workflow associated with a product is made ofprocesses before and after the actual product final assem-bly. Processes such as setup, packaging and transportationare important to the final schedule, but are not intrinsic tothe manufacture. These before and after routes are describedsimilarly to the manufacturing processes and hence we omittheir detail description.
For each process, there are one or more machines, tools,operators, etc. which are required to carry it out. Figure 3shows this relationship between a manufacturing processMP1 and various types of resources required to carry it out.In particular, the process MP1 requires machine M1, workerH2 and one of either machine M2 or M3. This process has aduration id DUR1 which is referred to in another part ofthe model. At this stage we do not assume a cost of the
123

J Intell Manuf (2010) 21:121–132 123
Fig. 2 Description of a productwork flow
<Route> <ManufacturingRouteID>MR1</ManufacturingRouteID> <RoutePiece> <ManufacturingProcessID>MP1</ManufacturingProcessID> <SuccessorProcesses> <SuccessorProcess> <ManufacturingProcessID>MP2</ManufacturingProcessID>
<LinkID>L1</LinkID> </SuccessorProcess>
</SuccessorProcesses> </RoutePiece></Route><Links>
<Link><LinkID>L1</LinkID><LinkType>finish-start</LinkType><MinDelay>1</MinDelay><MaxDelay>100</MaxDelay>
</Link></Links>
Fig. 3 Description of machineand labor requirements for aprocess
<Process> <ManufacturingProcessID>MP1</ManufacturingProcessID> <DurationLinkId>DUR1</DurationLinkId> <ResourcesRequired> <RequiredMachineResources>
<MachineResourceID>M1</MachineResourceID> </RequiredMachineResources> <AlternativeMachineResources>
<MachineResourceID>M2</MachineResourceID><MachineResourceID>M3</MachineResourceID>
</AlternativeMachineResources> <RequiredHumanResources>
<HumanResourceID>H2</HumanResourceID> </RequiredHumanResources> </ResourcesRequired></Process>
process (our objectives are described later in the text), but thecost can be added later, for example to differentiate betweenalternative processes.
The machine resources are further described in terms oftheir availability. In particular, each resource has assigned aset of intervals describing the periods of unavailability. Thisinformation is deduced from calendars assigned to resourcesand it is used during scheduling to restrict allocation of activ-ities to a particular resource.
Durations of processes are, where possible, pre-calcu-lated. Durations of processes are determined by the quantityand performance of the resources they require. Therefore, ifthe resources are known a fixed quantity can be included.Where alternative resources with different performances areavailable, then we can enumerate the possibilities. This calcu-lation is tied to an order for a product and associated resourceids involved.
The translation model also holds information on the resultsof the scheduling. This comprises of two parts (Fig. 4). Thefirst is an actual schedule which is used to organize the workthrough the factory. The second type of output is a report onthe implications on the orders; for example, whether the orderis late or not, is being outsourced or will require storage. Forthe schedule, two complementary views are presented; the
task based view and the resource based view. The task basedview consists of a set of tasks, where each task is associatedwith the process id, produced part of a product, an order towhich it belongs, and of course the start time and finish timeexpressed in the same abstract time units as mentioned above.The resource view shows all the tasks using each particularresource. In particular, for each resource there is a set of tasksthat use that particular resource together with the time periodwhen they use the resource.
System architecture
This section describes in more detail the important stagesin building a scheduling model from the enterprise descrip-tion. We initially need to identify the scheduling entities (e.g.activities, unary resources, objectives etc.) from the XMLdescription. After that, some basic checks (pre-processing)can be made on the validity of the data for scheduling andthen additional scheduling information will be added.
Translation rules
The Enterprise model is business centric and so the informa-tion a scheduler needs is not necessary explicit and in addition
123

124 J Intell Manuf (2010) 21:121–132
Fig. 4 Description of an outputschedule
<ScheduleOut><ScheduleInfo>
<ScheduleOutID>schedule_test1</ScheduleOutID><ExpectedDueDate>
<Orders> <OrderID>o1</OrderID>
<Products><ProductID>2ASM</ProductID><Date>65</Date>
<DeliveredOnTime>No</DeliveredOnTime> <LatenessCost>2</LatenessCost>
</Products> </Orders>
</ExpectedDueDate></ScheduleInfo>
<Tasks><Task>
<TaskId>o1_2ASM_ID1s1_SAW1</TaskId> <OrderId>o1</OrderId><ProductId>2ASM</ProductId>
<PartId>ID1s1</PartId> <ProcessId>SAW1</ProcessId> <Start>3</Start>
<End>4</End></Task>
</Tasks>
<Resources><UnaryResources> <ResourceID>CNCH1</ResourceID> <RequiredBy>
<Tasks> <Task>
<TaskId>o1_2ASM_partID1s1_SAW1</TaskId > <Quantity>1</Quantity> <Start>3</Start> <End>4</End>
</Task > </Tasks >
</RequiredBy></UnaryResources>
</Resources></ScheduleOut>
it can be dispersed around the model. The purpose of transla-tion rules is to describe the way a scheduler can examine theenterprise data and realize the different scheduling entitiesand the relationships between them. These rules can then beencoded in the form of an executable parser. We now presenta description of the translation rules necessary for identifyingthe major scheduling entities.
Activities
There are different types of activities found throughout theenterprise model. From the process descriptions (describedin Fig. 3), we can obtain each activity necessary to manufac-ture a part. Equally, from the bill of materials, we can identifythe points at which an assembly of constituent parts needs
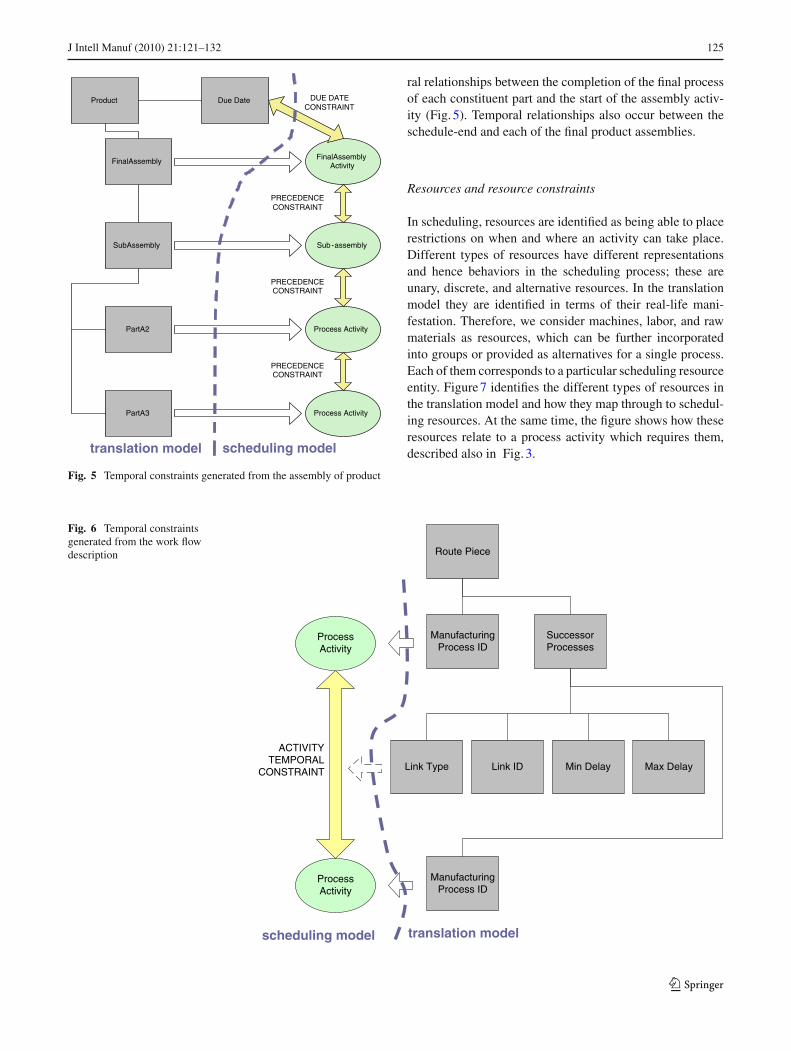
to take place. There are also milestone activities such as theschedule-end or product release, which also need to be rep-resented. Figure 5 shows the access points for identifying theassembly activities.
Temporal relationships
There are many temporal relationships between processesthroughout the enterprise model. The work flow descriptiongives us a clear set of relationships between these processesas shown in Fig. 6. We can see from Fig. 2 how ‘Route Pieces’holds the process id’s of successive pairs of processes. Fromthis, a temporal relationship is known and from their ‘link’information the precise temporal relationship is obtained.From the bill of materials we can also obtain the tempo-
123
J Intell Manuf (2010) 21:121–132 125
PartA2
Product
SubAssembly Sub-assembly
PartA3
Process Activity
Process Activity
PRECEDENCECONSTRAINT
PRECEDENCECONSTRAINT
FinalAssemblyFinalAssembly
Activity
PRECEDENCECONSTRAINT
Due Date DUE DATECONSTRAINT
translation model scheduling model
Fig. 5 Temporal constraints generated from the assembly of product
ral relationships between the completion of the final processof each constituent part and the start of the assembly activ-ity (Fig. 5). Temporal relationships also occur between theschedule-end and each of the final product assemblies.
Resources and resource constraints
In scheduling, resources are identified as being able to placerestrictions on when and where an activity can take place.Different types of resources have different representationsand hence behaviors in the scheduling process; these areunary, discrete, and alternative resources. In the translationmodel they are identified in terms of their real-life mani-festation. Therefore, we consider machines, labor, and rawmaterials as resources, which can be further incorporatedinto groups or provided as alternatives for a single process.Each of them corresponds to a particular scheduling resourceentity. Figure 7 identifies the different types of resources inthe translation model and how they map through to schedul-ing resources. At the same time, the figure shows how theseresources relate to a process activity which requires them,described also in Fig. 3.
Fig. 6 Temporal constraintsgenerated from the work flowdescription Route Piece
Link Type
ProcessActivity
ManufacturingProcess ID
ProcessActivity
SuccessorProcesses
ManufacturingProcess ID
Link ID Min Delay Max Delay
ACTIVITYTEMPORAL
CONSTRAINT
translation modelscheduling model
123

126 J Intell Manuf (2010) 21:121–132
translation model
scheduling model
Manufacturing Process ID
Process Activity
Duration
AC
TIV
ITIE
S R
ES
OU
RC
ES
CO
NS
TR
AIN
T
Unary Resource
Discrete Resource
Human Resources
Machine Resources
Raw Material Rsources
Human Resource
Group
Resources Required
Raw Material Resource
Group
MaxQuantityAvailable
DURATIONCONSTRAINT
DISCRETE RESOURCE CONSTRAINT
Fig. 7 Resource and duration identification and their relationship with an activity
Fig. 8 OPL model forgeneralized outsourced routeselection
// only one resource can be chosen and at different duration forall(os in Outsource) os1[os] + os2[os] = 1; // only one resource can be chosen forall(ta in Two_Alternative_Resource_Constraint_Diff_Durn) { a[ta.act] requires (t1[ta]) res_unary[ta.unary_resource1]; a[ta.act] requires (t2[ta]) res_unary[ta.unary_resource2]; t1[ta] + t2[ta] = 1;
t1[ta] = 1 a[ta.act].duration = ta.unary_resource1_durn; t2[ta] = 1 a[ta.act].duration = ta.unary_resource1_durn; }
Durations
The enterprise model already contains information on thequantities of product for each order needing to be produced.Therefore, the duration of each manufacturing process, in thework flow, can be calculated in advance, provided that themachine/labor resource it uses is known. When the resourceis unknown, as is the special case of alternative resourceswith different performance characteristics, then the set ofpossible durations can be specified and the appropriate dura-tion selected. Figure 7 shows the point at which this dura-tion constraint information is extracted from the translationmodel. Figure 8 shows the relationship between the durationsof the activities and the selected resource within the schedul-ing model as implemented in the OPL language (OPL 2007).In this case, two alternative resources are available and thescheduler chooses exactly one of them.
Due dates
Each product order has a due date associated with it. Anappropriate constraint on the end of the final assembly activ-
ity of each product can be imposed in the scheduling model(Fig. 5). The nature of this constraint will depend on theacceptability of tardiness or earliness of each product order.
Outsourcing
Some products may be produced externally for a known costand duration. This is an option which many SME manufac-turers use to be able to satisfy all their orders within thepromised time. Within the translation model, each producthas a flag indicating whether it can be outsourced or not. Wechoose to model this as an alternative manufacturing routein the scheduling model (see Fig. 9). For a product with anoutsourcing option, the translation will create an outsourc-ing activity alongside the internal manufacturing activities.A decision variable within the scheduling model allows thesearch to evaluate both possibilities similarly to selectionbetween alternative resources (Fig. 8). The cost and dura-tion calculation are also contained in the translation modelfrom which we can put the appropriate constraints on thevariable durations of all the activities involved (whether theyare selected or not). Currently we assume only additional
123

J Intell Manuf (2010) 21:121–132 127
OutSource
PartMake1 PartMake2
PartMake3
SubAssembly
PartMake4
Final Assembly
Or
Fig. 9 Alternative routes for manufacture using outsourcing
cost for outsourcing (in comparison to on site production)and hence no cost of processes is included. Nevertheless, thetranslation model can be easily extended by assuming thecost of processes which is especially useful when alternativeprocesses are present. To model any type of process alterna-tives, we developed so called Temporal Networks with Alter-natives (Barták et al. 2007) that formally describe alternativeroutes in processes. Note also, that to exploit the full potentialof alternatives one may need a full cost model, where the(weighted) sum of costs is used as the primary objective.
Batching
It is assumed that all batch size calculations have been madefor each product order in advance. Therefore, separate orderswill be introduced and consequently different activities arecreated.
Schedule relaxations and objectives
On time in full is the common requirement for the scheduleby the SME’s in the project. We interpret this initially as try-ing to deliver before all promise dates and to complete thework as quickly as possible, within the given scheduling timewindow. This in turn is reflected in the model having hardconstraints on products being available before the due datesand the objective function being to minimize the end time ofthe final activity (makespan).
However, there are other aspects permissible in the sched-ule and different overall objectives that we need to consider.For example, on time in full may be the goal, but if thedue dates cannot be met, then a model with hard due dateconstraints will return no schedule. If we remove the duedate restrictions, then assuming availability of resources, wewould produce a schedule, but orders would likely be over-due. Therefore, if lateness was allowed, then we should treatit using a goal programming approach, of penalizing lateness
in the objective. Equally, earliness from the schedule mayalso impose a cost and so should be discouraged.
We therefore allow the user to indicate whether to acceptorders being late, early or both, and at the same time, anassociated objective has to be chosen. Together they indicatethe type of model and the set of appropriate constraints werequire to reflect this.
In describing the quality of a schedule the user is look-ing for, there are many factors which can be included. Thepossible criteria are,
1. Minimise lateness2. Minimise earliness3. Minimise lateness and earliness (Just in Time)4. Minimise outsourcing cost5. Minimise makespan
Any combination can be considered if appropriate weightsare given to each. However, we provide in the current systemonly single criteria.
Within the translation model the Performance Indicationvalue identifies the objective criteria which the schedule triesto improve on and the Treatment Of Lateness value indicateswhether the orders can be late or not. Only valid combina-tions of objective and handling of lateness are accepted by thesystem. For example, outsourcing can be selected for consid-eration and made available, but will only be considered whenthe objective is to minimize makespan.
Scheduling preferences
How a schedule looks and feels is quite subjective to the user.Indeed the EMPO system is designed only to give a starting-point schedule for further manual enhancements. However,we can incorporate certain preferences or features into theschedule, if these are required by the user. The preference ofalternative machines is an example which can be incorporatedinto both models. Here, the user prioritizes one machine overanother for reasons of utilization. In the XML description, animplicit priority is assumed through the declared order of thealternative machines. Hence in Fig. 3, machine M2 is prior-itized before machine M3. We reflect this in the schedulingmodel by including an aspect of the search strategy whichconsiders the preferred resource first, and only if improve-ments can be made to the objective of the schedule, a reverseassignment will be considered.
In a similar way, the priority of orders can be incorpo-rated into the search so that those activities associated withthe order of highest priority are scheduled first leaving thelower priority activities to be fitted in later. This means thatif lateness is allowed then equivalent schedules will have thehigher priority orders complete in time, while less priorityorder may be delayed.
123

128 J Intell Manuf (2010) 21:121–132
Fig. 10 Scheduling results intothe translation model
Resources
Schedule Out
Schedule Info
Tasks
Lateness CostProduct
Delivered OnTime
Start Time End Time
Total Cost
DiscreteResource
ProcessActivity
UnaryResource
ActivityDuration
SolverResults
Task IDProcessActivity
Makespan Cost Just In TimeCost
translation modelscheduling model
The schedule and order management
The results of the scheduling are represented within thescheduling model as timed activities with assigned resources.Each activity in the model contains the order and product idswithin its own identifier and so in the reverse translation, wecan present the schedule in terms of the orders. Equally, wecan deliver the schedule for use in managing operations on thefactory floor. Order management issues such as lateness orearliness (for storage) can be calculated from due dates andactual release dates (as indicated by the finish time of thefinal assembly activities). Figure 10 shows how the schedul-ing entities are translated back into the enterprise model thatit can understand and handle.
Pre-processing
Once the scheduling information has been extracted andassembled, simple “schedulability” checks can be made
before proceeding. This is called ‘pre-processing’. Apartfrom type and range errors in the data, there are some sched-uling logic tests which can be applied. This allows us todeduce early whether or not the orders can be possibly sched-uled or not. Indeed, current scheduling systems do not pro-vide explanations as to why a schedule cannot be producedand this is not helpful to users. The current experimentalexplanation techniques can for example explain the failureof a particular scheduling constraint (Vilím 2003) but thismay be too hard to interpret by users that are not profi-cient in scheduling. On the other hand, in many cases thelack of a schedule may be for a very simple reason and thepre-processing module both prevents unnecessary time beingspent going ahead in scheduling and gives early clear feed-back on why a schedule cannot be made. The pre-processingwe have implemented is not exhaustive; there are still caseswhere a schedule is found to be infeasible only after tryingto schedule, but it demonstrates the idea of recognising com-mon scheduling ‘mistakes’. There are currently three types
123

J Intell Manuf (2010) 21:121–132 129
of pre-processing activities carried out within the EMPOsystem.
Check for infeasible scheduling data—this covers typeand range discrepancies in the data which would not behandled correctly inside the scheduler. Since the translationmodel is described as an XML file, we are able to generateand use an XML Schema to verify the input structure anddata types as well.
Check for incorrect scheduling data—this is data, whichalthough correct in isolation, is not consistent with other datain the enterprise description from a scheduling point of view.For example, we have implemented tests on the minimumpossible delivery date for a product and compared this againstthe requested release date. If we do not allow lateness, andthe sum of durations is greater than the release date, then noschedule can be obtained. Another test is in comparing theinitial availability of raw material with what will be requiredduring the scheduling period. Assuming no further deliv-ery of raw material during the scheduling period, then if therequirement is greater than what is available no schedule canbe produced. Notice also that in each of these cases an exactreason can be given for the failure of the schedule. It is thenup to the user to correct this.
Reduce problem complexity—the complexity of the result-ing scheduling problem is often a consequence of the num-ber of activities generated. There are opportunities in whichactivities can be aggregated together at the product levelrather than at the part level in order to provide some schedul-ing feedback. It is possible to deduce this information rightbefore the scheduling stage for example by identifying sim-ilar substructures in process networks (Kovács and Váncza2006), but this information is easier to access at the transla-tion stage where original semantics (such as names of prod-ucts) is still present.
Implementation
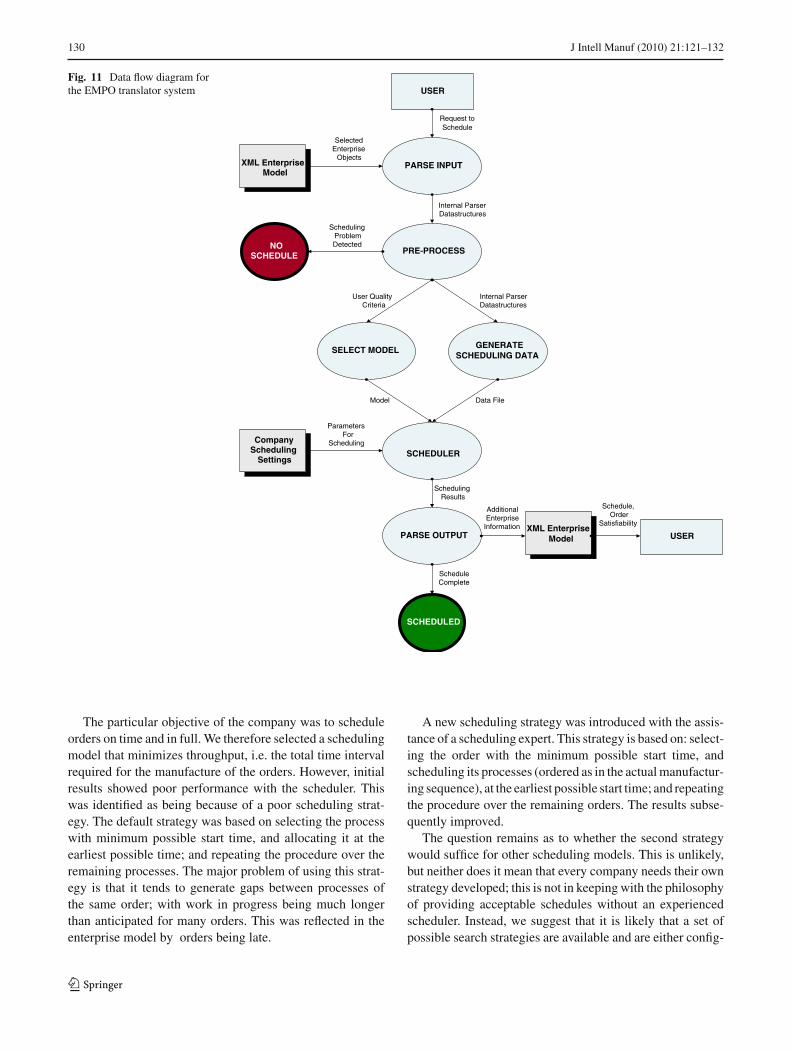
The EMPO system is based on enterprise scheduling infor-mation represented in an XML format. This data is accessedby the translator which generates an instance of a schedulingmodel which in turn is run through a scheduling engine. Thetranslator is written in C#, while the scheduling engine isone of either Ilog OPL 3.7.1 (OPL 2007) or SICStus Prolog4.0.1 (SICS 2007). All are contained with a .NET environ-ment. Each engine has its own characteristics in terms ofperformance and modeling capabilities, and for this projectboth were evaluated. The translator is able to use the samerules to provide the same scheduling information to bothengines; albeit in different formats. In Fig. 11, we illustrateas a data flow, how the various modules of the EMPO systeminteract.
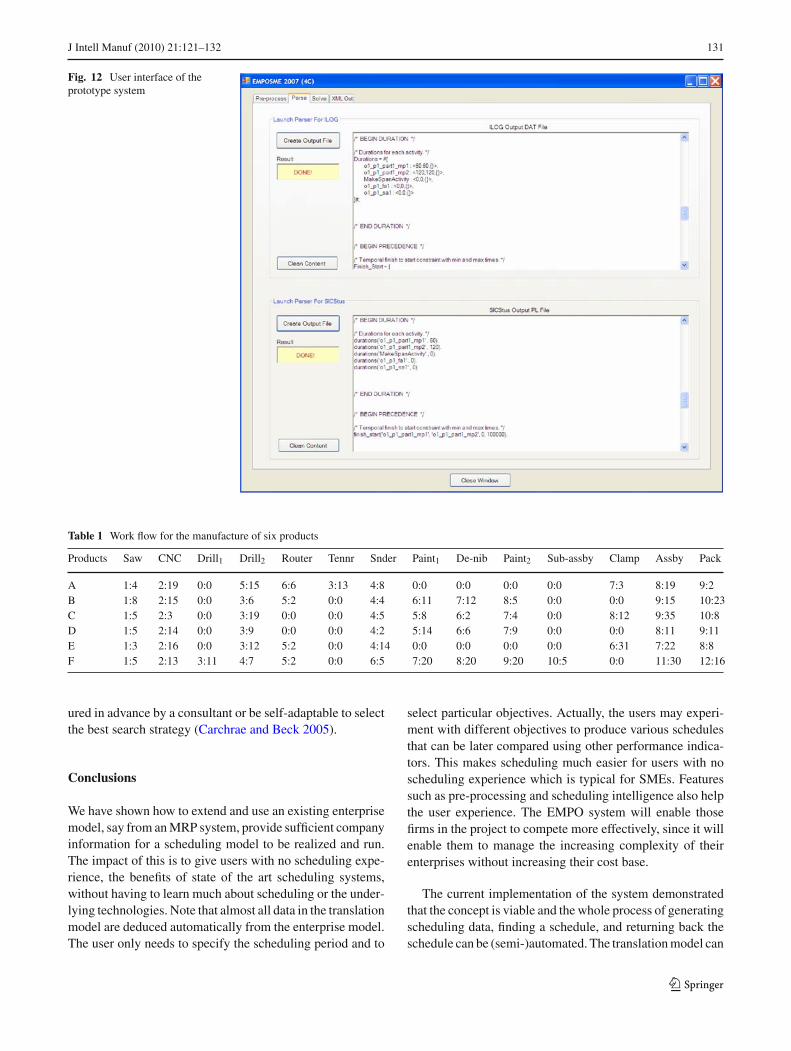
The implemented system uses a simple user interface dem-onstrating the stages of the forward and backward translation(Fig. 12). It gets an XML file with the translation model, pre-processes the model, generates the scheduling model whichis then passed either to Ilog OPL or to SICStus Prolog for pro-ducing a schedule, and finally the schedule is converted backto XML format and presented to the user. The user interfaceis used to control these stages and to display the generatedreports.
Evaluation
The evaluation of the system addresses how well a company’sexisting enterprise model fits with our translation model. Inother words, are we able to represent enough information toallow meaningful scheduling to take place? A second evalu-ation criterion is in how well the translation performs in pro-viding a model which will deliver good scheduling results.
Case study
The company in this study is a manufacturer of nursery fur-niture. The manufacturer supplied an Excel sheet with thedescription of production process for all products (includ-ing machine requirements and process durations). Table 1shows the company’s representation of its workflow for someproducts. Each product requires a number of sequential pro-cesses associated with certain machines (there may be severalinstances of each type). The first number shown in each cellrelates to the process sequence, with a zero indicating thatthe machine is not used for that product. The second numberis the ‘process duration’ per unit of product.
The company’s workflow description provides sufficientinitial information on the manufacturing processes and therelationships between each (assumed and confirmed to befinish to start of zero duration). Potential overlaps were notconsidered by the company as batches were designed to besmall enough for sequential operations. Equally, changeovertimes were incorporated into the duration of each process.Machines are the dominant resources in the factory and aredescribed along with their production rates for each process.In some cases there are identical machines and so these areput into groups. The bill of material is a single level decom-position with each product being viewed as a single part withits own assembly. We generated a reference set of orders fora standard week, including orders for different quantities ofthe six products represented in Table 1. Time horizon andorder due dates were set to 4 weeks, as these are the typicalvalues for their manufacturing planning. The description wasmanually converted to the XML translation model and then afully automated process of parsing, pre-processing, solving,and generating the output was presented to the manufacturer.
123
130 J Intell Manuf (2010) 21:121–132
Fig. 11 Data flow diagram forthe EMPO translator system USER
PARSE INPUT
Request to Schedule
Internal Parser Datastructures
XML Enterprise Model
Selected Enterprise
Objects
PRE-PROCESS
Internal Parser Datastructures
SELECT MODEL GENERATE SCHEDULING DATA
SCHEDULER
User Quality Criteria
Model Data File
Scheduling Results
PARSE OUTPUT
Company Scheduling
Settings
Parameters For
Scheduling
NO SCHEDULE
Scheduling Problem Detected
XML Enterprise Model
Additional Enterprise
Information
SCHEDULED
Schedule Complete
USER
Schedule,Order
Satisfiability
The particular objective of the company was to scheduleorders on time and in full. We therefore selected a schedulingmodel that minimizes throughput, i.e. the total time intervalrequired for the manufacture of the orders. However, initialresults showed poor performance with the scheduler. Thiswas identified as being because of a poor scheduling strat-egy. The default strategy was based on selecting the processwith minimum possible start time, and allocating it at theearliest possible time; and repeating the procedure over theremaining processes. The major problem of using this strat-egy is that it tends to generate gaps between processes ofthe same order; with work in progress being much longerthan anticipated for many orders. This was reflected in theenterprise model by orders being late.
A new scheduling strategy was introduced with the assis-tance of a scheduling expert. This strategy is based on: select-ing the order with the minimum possible start time, andscheduling its processes (ordered as in the actual manufactur-ing sequence), at the earliest possible start time; and repeatingthe procedure over the remaining orders. The results subse-quently improved.
The question remains as to whether the second strategywould suffice for other scheduling models. This is unlikely,but neither does it mean that every company needs their ownstrategy developed; this is not in keeping with the philosophyof providing acceptable schedules without an experiencedscheduler. Instead, we suggest that it is likely that a set ofpossible search strategies are available and are either config-
123
J Intell Manuf (2010) 21:121–132 131
Fig. 12 User interface of theprototype system
Table 1 Work flow for the manufacture of six products
Products Saw CNC Drill1 Drill2 Router Tennr Snder Paint1 De-nib Paint2 Sub-assby Clamp Assby Pack
A 1:4 2:19 0:0 5:15 6:6 3:13 4:8 0:0 0:0 0:0 0:0 7:3 8:19 9:2B 1:8 2:15 0:0 3:6 5:2 0:0 4:4 6:11 7:12 8:5 0:0 0:0 9:15 10:23C 1:5 2:3 0:0 3:19 0:0 0:0 4:5 5:8 6:2 7:4 0:0 8:12 9:35 10:8D 1:5 2:14 0:0 3:9 0:0 0:0 4:2 5:14 6:6 7:9 0:0 0:0 8:11 9:11E 1:3 2:16 0:0 3:12 5:2 0:0 4:14 0:0 0:0 0:0 0:0 6:31 7:22 8:8F 1:5 2:13 3:11 4:7 5:2 0:0 6:5 7:20 8:20 9:20 10:5 0:0 11:30 12:16
ured in advance by a consultant or be self-adaptable to selectthe best search strategy (Carchrae and Beck 2005).
Conclusions
We have shown how to extend and use an existing enterprisemodel, say from an MRP system, provide sufficient companyinformation for a scheduling model to be realized and run.The impact of this is to give users with no scheduling expe-rience, the benefits of state of the art scheduling systems,without having to learn much about scheduling or the under-lying technologies. Note that almost all data in the translationmodel are deduced automatically from the enterprise model.The user only needs to specify the scheduling period and to
select particular objectives. Actually, the users may experi-ment with different objectives to produce various schedulesthat can be later compared using other performance indica-tors. This makes scheduling much easier for users with noscheduling experience which is typical for SMEs. Featuressuch as pre-processing and scheduling intelligence also helpthe user experience. The EMPO system will enable thosefirms in the project to compete more effectively, since it willenable them to manage the increasing complexity of theirenterprises without increasing their cost base.
The current implementation of the system demonstratedthat the concept is viable and the whole process of generatingscheduling data, finding a schedule, and returning back theschedule can be (semi-)automated. The translation model can
123

132 J Intell Manuf (2010) 21:121–132
be further extended to cover features like cost of processesand similarly new checks can be added to the pre-process-ing step. Automatically choosing the right scheduling modelremains a challenge, although we believe many cases can behandled through a finite set of good scheduling strategies.
Acknowledgements This work has been supported by EU FP6CRAFT Programme under the project No. 018071 EMPOSME.
References
Barták, R., Cepek, O., & Surynek, P. (2007). Modelling alternativesin temporal networks. In Proceedings of the 2007 IEEE Symposiumon Computational Intelligence in Scheduling, CI-Sched 2007 (pp.129–136). IEEE Press.
Carchrae, T., & Beck, J. C. (2005). Applying machine learning to lowknowledge control of optimization algorithms. Computational Intel-ligence, 21(4), 372–387.
EMPOSME Translation Model, 4C. (2007). Retrieved February 27,2008 from http://4c.ucc.ie/web/projects/empo/.
Horling, B., Leader, V., Vincent, R., Wagner, T., Raja, A., Zhang, S.,et al. (1999). The TAEMS white paper, University of Massachu-setts. Retrieved February 27, 2008 from http://mas.cs.umass.edu/pub/paper_detail.php/182.
ILOG OPL Studio, ILOG. (2007). Retrieved February 27, 2008 fromhttp://www.ilog.com/products/oplstudio/.
Kovács, A., & Váncza, J. (2006). Progressive solutions: A simple butefficient dominance rule for practical RCPSP. In Proceedings of CPA-IOR 2006, the 3rd International Conference on Integration of AI andOR Techniques in Constraint Programming for Combinatorial Opti-mization Problems (pp. 139–151). LNCS 3990, Springer Verlag.
Nuijten, W., Bousonville, T., Focacci, F., Godard, D., & Le Pape, C.(2003). MaScLib: Problem description and test bed design. RetrievedFebruary 27, 2008 from http://www2.ilog.com/masclib/.
SICStus Prolog 4.0.2, SICS. (2007). Retrieved Februaly 27, 2008 fromhttp://www.sics.se/sicstus.
Vilím, P. (2003). Computing explanations for global scheduling con-straints. In Principles and Practice of Constraint Programming,CP2003 (p. 1000). LNCS 2833, Springer Verlag.
123




















